5695 lines
6.2 MiB
5695 lines
6.2 MiB
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: windres module doesn't flatten arguments ```meson import('windows').compile_resources('file.rc', args : [[-DFOO'], '-DBAR]) ``` results in ``` ERROR: List item must be one of <class 'str'> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: timeline_drawer measurement bugs There are some bugs drawing measurements in the circuit timeline drawer. Taking a simple circuit and a backend to schedule on: ```py from qiskit import QuantumCircuit, transpile from qiskit.test.mock import FakeParis from qiskit.visualization import timeline_drawer qc = QuantumCircuit(2, 2) qc.cx(0, 1) backend = FakeParis() ``` The following scenarios have various errors... 1- One measurement with show_clbits=False ```py qc.measure(0, 0) new_qc = transpile(qc, backend, scheduling_method='alap') timeline_drawer(new_qc, show_clbits=False) ``` `KeyError: Clbit(ClassicalRegister(2, 'c'), 0)` 2- One measurement with show_clbits=True ```py qc.measure(0, 0) new_qc = transpile(qc, backend, initial_layout=[25, 26], scheduling_method='alap') timeline_drawer(new_qc, show_clbits=True) ``` The clbit measure seems off and starts earlier than the qubit measure.  3- Two measurement with show_clbits=False ```py qc.measure(0, 0) qc.measure(1, 1) new_qc = transpile(qc, backend, initial_layout=[25, 26], scheduling_method='alap') timeline_drawer(new_qc, show_clbits=False) ``` `TypeError: '<=' not supported between instances of 'float' and 'NoneType'` 4- Two measurements with show_clbits=True ```py qc.measure(0, 0) qc.measure(1, 1) new_qc = transpile(qc, backend, initial_layout=[25, 26], scheduling_method='alap') timeline_drawer(new_qc, show_clbits=True) ``` `AttributeError: 'list' object has no attribute 'repeat'` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Entity.reload does not work We should make sure to fix the tests as well as the [code](https://github.com/GoogleCloudPlatform/gcloud-python/blob/b343acf4ade6dfc659f71a981eb51b62d22e33a0/gcloud/datastore/entity.py#L215): ``` python key = self._must_key dataset = self._must_dataset entity = dataset.get_entity(key.to_protobuf()) ``` (the `key` should be re-loaded, not the key protobuf). Example failure: ``` python >>> entity.reload() Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"gcloud/datastore/entity.py\", line 215, in reload entity = dataset.get_entity(key.to_protobuf()) File \"gcloud/datastore/dataset.py\", line 139, in get_entity key = Key.from_path(*key_or_path) TypeError: from_path() argument after * must be a sequence, not Key ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Error in NL API, 'Sentiment' object has no attribute 'score' Upon executing the following code on GCE & locally I'm getting 'score' not found error locally while it works on GCE. ``` def analyze_text(text): language_client = language.Client() document = language_client.document_from_text(text) annotations = document.annotate_text(include_sentiment=True) print(annotations.sentiment.score) print (annotations.sentiment.magnitude) ``` Only difference I can find is on GCE, the gcloud version is different than the local **GCE gcloud** gcloud --version Google Cloud SDK 145.0.0 alpha 2017.02.21 app-engine-python 1.9.50 beta 2017.02.21 bq 2.0.24 bq-nix 2.0.24 core 2017.02.21 core-nix 2017.02.21 gcloud gcloud-deps 2017.02.21 gcloud-deps-linux-x86_64 2017.02.21 gsutil 4.22 gsutil-nix 4.22 **Local gcloud** gcloud --version Google Cloud SDK 148.0.1 bq 2.0.24 bq-nix 2.0.24 core 2017.03.24 core-nix 2016.11.07 gcloud gcloud-deps 2017.03.17 gcloud-deps-darwin-x86_64 2017.02.21 gsutil 4.23 gsutil-nix 4.19 Debugging locally, the response from NL API consist of polarity property and not score. <img width=\"761\" alt=\"image\" src=\"https://cloud.githubusercontent.com/assets/1888535/24331449/62cbdbee-1252-11e7-9d29-8699df078fcf.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: cython magic failing to work with openmp. Specifically I'm referring to the notebook. Apparently if any python function calls an openmp function, it fails. This example works fine in normal cython use, with the args put into setup.py and the extension imported into IPython manually. Cell 1: ``` %load_ext cythonmagic import Cython.Compiler.Options as CO CO.extra_compile_args = ['-fopenmp'] CO.extra_link_args = ['-fopenmp'] ``` Cell 2: ``` %%cython cimport openmp import cython.parallel as cp def ompfunc(): openmp.omp_set_dynamic(1) with nogil, cp.parallel(): with gil: print cp.threadid() ``` It will build if you change `ompfunc` to a `cdef`, but of course the kernel then gives the following error: ``` /home/john/.ipython/cython/_cython_magic_1fbf0dc97ef57476220c1cdf9c600a49.c:1252:18: warning: ‘__pyx_f_46_cython_magic_1fbf0dc97ef57476220c1cdf9c600a49_ompfunc’ defined but not used [-Wunused-function] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: cppstd as a subsetting We considered better to have the cppstd as a subsetting of every compiler: - If you don't specify the -s compiler.cppstd=XXX it won't change anything, because will come with a None default value. - We won't break anything, the global setting will be kept, but deprecated (comment at settings.yml and docs). - So any recipe could receive the subsetting and compile with a different version of the language automatically. - The reasons to do a first level setting was to not generate new binary IDS for C libraries that doesn't remove the subsetting. We consider more important to be \"injectable\" at any recipe. - Conan will fail if both are specified. - Conan will try internally to manage the value of the new one, copying from the old one if possible (to ease the code and future deprecation of the global setting) - Each compiler will have their own values, it has a lot of sense. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: DAGs imported from networkx cannot be drawn <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit version**: 0.19.2 - **Python version**: 3.8.12 - **Operating system**: Windows 10 ### What is the current behavior? I can successfully create `DAGCircuit` objects by importing them from networkx graphs. Those objects seem to behave correctly, but whenever I try to draw them using the `dag_drawer` function, I get an error. I verified that the error only occurs for DAGCircuit objects imported from networkx graphs - in fact, I can draw a dag correctly, but if I convert it to networkx and back (`new_dag = from_networkx(dag.to_networkx())`), then new_dag can no longer be drawn. ### Steps to reproduce the problem ``` import qiskit from qiskit.circuit.random import random_circuit from qiskit.converters import circuit_to_dag, dag_to_circuit from qiskit.tools.visualization import dag_drawer from qiskit.dagcircuit import DAGCircuit in_circ = random_circuit(1,1) in_dag = circuit_to_dag(in_circ) # dag_drawer(in_dag) # if uncommented, draws the DAG correctly graph = in_dag.to_networkx() out_dag = DAGCircuit.from_networkx(graph) dag_drawer(out_dag) # throws an error ``` outputs ``` KeyError Traceback (most recent call last) ---> [12]() dag_drawer(out_dag) --> [224]() dot_str = dag._multi_graph.to_dot(node_attr_func, edge_attr_func, graph_attrs) --> [206]() n[\"label\"] = bit_labels[node.wire] KeyError: Qubit(QuantumRegister(1, 'q'), 0) ``` ### What is the expected behavior? That DAG objects created from networkx graphs have the same properties as those created from quantum circuits. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: resolve web ui views warning re DISTINCT ON ### Body Got this warning in webserver output when loading home page ``` /Users/dstandish/code/airflow/airflow/www/views.py:710 SADeprecationWarning: DISTINCT ON is currently supported only by the PostgreSQL dialect. Use of DISTINCT ON for other backends is currently silently ignored, however this usage is deprecated, and will raise CompileError in a future release for all backends that do not support this syntax. ``` looks like it's this line ``` dagtags = session.query(DagTag.name).distinct(DagTag.name).all() ``` may be able to change to `func.distinct` ### Committer - [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Support 'blob_value' / 'blob_key_value' in datastore protobufs In addition to the scalar types we already support, there are the following value types we don't yet support: - 'entity_value' (PR #232) - 'list_value' (issue #223) - 'blob_value' (see https://github.com/GoogleCloudPlatform/google-cloud-datastore/blob/6073e01540264db58ee50c30a1e9f006677eb794/proto/datastore_v1.proto#L115) - 'blob_key_value' (see https://github.com/GoogleCloudPlatform/google-cloud-datastore/blob/6073e01540264db58ee50c30a1e9f006677eb794/proto/datastore_v1.proto#L111) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Python extension_module does not install in site_packages In the *python* module documentation is claimed that `extension_module` install per default in `site_packages`: > `subdir`: By default, meson will install the extension module in the relevant top-level location for the python installation, eg `/usr/lib/site-packages`. When subdir is passed to this method, it will be appended to that location. This keyword argument is mutually exclusive with `install_dir` However, this does not work. When set `install: true` the modules are installed to `$prefix/lib64` on my system. One workaround is to specify the target like: ``` py3_mod = import('python') py3_inst = py3_mod.find_installation('python3') foo = py3_inst.extension_module('foo', <source_target>, install: true, subdir: get_option('prefix') + py3_inst.get_path('purelib'), dependencies: [py3_inst.dependency()] ) ``` It would be nice, if the subdir is set autotically to the `site-packages` folder. This bug is btw similar to #2859. However, this talks about the now deprecated *python3* module. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %page stops working due to OInfo change `import pandas as pd df = pd.DataFrame(data={'a':[1,2,3],'b':list('abc')}) %page df File lib/python3.11/site-packages/IPython/core/interactiveshell.py:2414, in InteractiveShell.run_line_magic(self, magic_name, line, _stack_depth) 2412 kwargs['local_ns'] = self.get_local_scope(stack_depth) 2413 with self.builtin_trap: -> 2414 result = fn(*args, **kwargs) 2416 # The code below prevents the output from being displayed 2417 # when using magics with decodator @output_can_be_silenced 2418 # when the last Python token in the expression is a ';'. 2419 if getattr(fn, magic.MAGIC_OUTPUT_CAN_BE_SILENCED, False): File lib/python3.11/site-packages/IPython/core/magics/basic.py:300, in BasicMagics.page(self, parameter_s) 298 info = self.shell._ofind(oname) 299 print(info) --> 300 if info['found']: 301 if raw: 302 txt = str(info[\"obj\"]) TypeError: 'OInfo' object is not subscriptable` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUILD: what is generate_mtrand_c.py ? xref #13163 Does anyone know what is ['numpy/random/mtrand/generate_mtrand_c.py'](https://github.com/numpy/numpy/blob/v1.16.2/numpy/random/mtrand/generate_mtrand_c.py) and why it is in ['MANIFEST.in'](https://github.com/numpy/numpy/blob/v1.16.2/MANIFEST.in#L11) ? Is it used by some downstream package? It does not seem to be used in [creating the wheels](https://github.com/MacPython/numpy-wheels) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Fig port with index not working with fig scale Running `fig scale api=2` creates the following with output from `fig ps`: ``` Name Command State Ports --------------------------------------------------------------------------------------------- testcom_api_1 pm2 start /app/app.js --wa ... Up 0.0.0.0:49153->80/tcp testcom_api_2 pm2 start /app/app.js --wa ... Up 0.0.0.0:49154->80/tcp ``` Running `fig port api 80` only returns the first container when we expected it to return both, is this intended? Trying to use the `fig port --index=1 api 80` or `fig port --index=2 api 80` returns \"No container found for api_1\" and \"No container found for api_2\" respectively Handle docopt options and defaults correctly for #667 Fixes #667 Replaces PR #733 Signed-off-by: Udo Spallek udono@virtual-things.biz Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: jupyter lab build ignores Yarn exit codes Environment: `jupyterlab==0.34.12` Example command: ``` $ jupyter lab build ``` Example stdout+stderr: ``` ... <REDACTED> ... yarn run v1.9.4 $ webpack /bin/sh: 1: webpack: not found error Command failed with exit code 127. info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command. ``` Regardless of that error in stdout,`jupyter lab build` returns an exit code of 0. I briefly looked at the code and the issue may lie In [_AppHandler.build()](https://github.com/jupyterlab/jupyterlab/blob/master/jupyterlab/commands.py#L429), it appears that the _AppHandler._run() returns the exit code of the two yarn commands executed, but these exit codes are ignored. ```python def build(self, name=None, version=None, public_url=None, command='build:prod', clean_staging=False): \"\"\"Build the application. \"\"\" # Set up the build directory. app_dir = self.app_dir self._populate_staging( name=name, version=version, public_url=public_url, clean=clean_staging ) staging = pjoin(app_dir, 'staging') # Make sure packages are installed. # exit code ignored? self._run(['node', YARN_PATH, 'install'], cwd=staging) # Build the app. # exit code ignored? self._run(['node', YARN_PATH, 'run', command], cwd=staging) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Missing `libselinux` dependency on Arch swaywm/wlroots#1477 provides more context Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Warning tells you you will get indexing errors in T5 for going beyond max length ### System Info ```shell - `transformers` version: 4.16.2 - Python version: 3.8.12 ``` ### Who can help? @patrickvonplaten @saul ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction To reproduce: ```python >>> from transformers import AutoTokenizer >>> tokenizer = AutoTokenizer.from_pretrained(\"t5-base\") >>> inputs = tokenizer(\"foo \" * 2000, return_tensors=\"pt\") Outputs `Token indices sequence length is longer than the specified maximum sequence length for this model (4001 > 512). Running this sequence through the model will result in indexing errors` ``` ```python >>> from transformers import AutoModelForSeq2SeqLM >>> model = AutoModelForSeq2SeqLM.from_pretrained(\"t5-base\") >>> model.generate(**inputs) tensor([[ 0, 5575, 32, 5575, 32, 5575, 32, 5575, 32, 5575, 32, 5575, 32, 5575, 32, 5575, 32, 5575, 32, 5575]]) ``` No indexing errors ### Expected behavior The warning is wrong for T5 since it uses relative positional embeddings. I would expect no warning, or otherwise, a warning about memory usage I suppose this issue should apply to all models that do no have fixed length postional encodings Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Strange output when find_program() fails meson.build: ``` project('example') foo = find_program('asd12343', required: false) ``` output: ``` $ meson build The Meson build system Version: 0.44.0 Source dir: /mem/test Build dir: /mem/test/build Build type: native build Project name: example Build machine cpu family: x86_64 Build machine cpu: x86_64 Program asd12343 found: NO Program nonexistingprogram found: NO <- bug Build targets in project: 0 Found ninja-1.8.2 at /usr/bin/ninja ``` I've highlighted the strange line. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Checkpoint detected info log in run_clm.py I think # Setup logging should above the # Detecting last checkpoint. so it can show warning Checkpoint detected, resuming training at... in examples of pytorch's language-modeling run_clm.py @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: test_parse_date as originally discussed in #216 and now moved outside I am a bit uncertain if the test rests on correct assumptions: ``` 99 rfc = (\"Thu, 07 Apr 2005 22:13:11 +0000\", 0) 100 iso = (\"2005-04-07T22:13:11 -0200\", 7200) 101 iso2 = (\"2005-04-07 22:13:11 +0400\", -14400) 102 iso3 = (\"2005.04.07 22:13:11 -0000\", 0) 103 alt = (\"04/07/2005 22:13:11\", 0) 104 alt2 = (\"07.04.2005 22:13:11\", 0) 105 veri_time = 1112904791 # the time this represents (Pdb) 106 for date, offset in (rfc, iso, iso2, iso3, alt, alt2): 107 -> assert_rval(parse_date(date), veri_time, offset) ``` while date says it was 20 not 22 hours at UTC ``` $> date -u --date='@1112904791' Thu Apr 7 20:13:11 UTC 2005 ``` changing to 1112911991 (prev + 2 hours) doesn't resolve the problem though Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow running Grover without `is_good_state` if the number of iterations is provided <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Allow running Grover without `is_good_state` if the number of iterations is provided and just return the most likely state in that case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose.yml merge broken when i want to merge two docker-compose.yml i get following error with the current beta 1.12.3-beta29.3 (619507e) docker-compose -f ../docker-compose.yml -f docker-compose.yml up myService ``` Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"compose/cli/main.py\", line 65, in main File \"compose/cli/main.py\", line 114, in perform_command File \"compose/cli/command.py\", line 36, in project_from_options File \"compose/cli/command.py\", line 103, in get_project File \"compose/config/config.py\", line 323, in load File \"compose/config/config.py\", line 414, in load_services File \"compose/config/config.py\", line 405, in merge_services File \"compose/config/config.py\", line 405, in <dictcomp> File \"compose/config/config.py\", line 704, in merge_service_dicts_from_files File \"compose/config/config.py\", line 774, in merge_service_dicts File \"compose/config/config.py\", line 728, in merge_field File \"compose/config/config.py\", line 807, in merge_logging File \"compose/config/config.py\", line 749, in merge_scalar File \"compose/config/config.py\", line 720, in needs_merge TypeError: argument of type 'NoneType' is not iterable docker-compose returned -1 ``` diagnostic id: E9B25A88-ABE3-46AF-B578-39A426964940 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add documentation on how to setup the dag drawer for different OSs _For reference, this was originally posted by @jaygambetta in https://github.com/Qiskit/qiskit-terra/issues/2281#issuecomment-489417445_ > @ajavadia and @mtreinish it has been lost where to find how to add this dependencies outside pip. It is in the doc for the function https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/visualization/dag_visualization.py but I think we need to make this clearer in the documentation in the Qiskit repo. > > I would split this into two issues -- > 1. In terra add better error messaging. If you call drag_drawer and you don't have graphviz give that this dependency needs to be installed on your system. > 2. in qiskit add a documentation on how to setup the dag drawer for different operating systems. This is issue is about the second item. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ERROR: Cannot find frameworks with non-clang compiler Building [ots](https://github.com/khaledhosny/ots) with meson 0.50.0 is failing with non-clang compilers, giving the following error: ``` meson.build:29:0: ERROR: Cannot find frameworks with non-clang compiler ``` The respective `meson.build` line has this: ``` coretext = dependency('appleframeworks', modules: 'applicationservices', required: false) ``` which used to work before with non-clang compilers (not find anything of course, which is fine). I don’t know why this was changed, but it looks like a breaking change to me. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose run command continuously restarting ##### Description of problem: An unexpected behaviour is encountered when using `docker-compose run` with services defining `restart: always`. `docker version`: ``` Client version: 1.5.0 Client API version: 1.17 Go version (client): go1.4.1 Git commit (client): a8a31ef OS/Arch (client): linux/amd64 Server version: 1.5.0 Server API version: 1.17 Go version (server): go1.4.1 Git commit (server): a8a31ef ``` `uname -a`: Linux docker01 3.13.0-45-generic #74-Ubuntu SMP Tue Jan 13 19:36:28 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux ##### Environment details : Host running inside a VMWare VM. ##### How reproducible: Use this docker-compose file : ``` yaml db: image: mysql restart: always environment: MYSQL_ROOT_PASSWORD: mypass ``` ##### Steps to Reproduce: 1. ``` Shell $ docker-compose up -d Creating mysql_db_1... ``` 2. ``` $ docker-compose run --rm db sh -c 'exec mysql -h db -uroot -p\"$DB_ENV_MYSQL_ROOT_PASSWORD\"' mysql> exit Removing mysql_db_run_1... Conflict, You cannot remove a running container. Stop the container before attempting removal or use -f ``` ##### Actual Results: `mysql_db_run_1` is still running. ##### Expected Results: mysql_db_run_1 stopped and removed. ##### Additional info: If I don't specify the '--rm' option, the result is the same but without the conflict message. It looks like `docker-compose run` started the container with 'restart: always' option. I did not find a way to override this behavior from the `docker-compose run` command. Maybe `docker-compose run` shall ignore `restart: always` in docker-compose.yml (at least since the `--rm` flag has been specified) or provide a way to override this ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CMake generator creates invalid CMake files if cflags/linker flags have backslashes To help us debug your issue please explain: - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Conan 1.2.0-dev Generated CMake files are not properly escaped if c(pp)flags/linkflags contain backslashes. This results in a CMake error when a flag requires this inside of it. The package cannot perform the escape itself because it cannot assume the consumer will use CMake (a non-CMake consumer would need to un-escape the flags, in that case). This is similar to the problem already fixed in #1640 but in a different place. I already have a fix for this issue; I will create an appropriate PR. However, this change is possibly breaking because packages running into this issue may have assumed their consumers use CMake and worked around it by manually escaping inside of cpp_info. However, I have made a cursory check on conan-center and my sample did not encounter any packages running into this problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: dtype control for corrcoef ## Feature I am computing a cross-correlation matrix of 150K * 150K matrix of float32. Numpy insists on making the results dtype be float64. This causes the amount of memory to be \"too much\". I would debate that default, but changing it would probably be too disruptive (not backward compatible). However, how about a dtype parameter for corrcoef? In general I would have liked to see a dtype parameter \"everywhere\" to override the float64 default... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: nomkl tests running on Windows fail Appears some `nomkl` feature tests are being run on Windows and [failing on CI]( https://ci.appveyor.com/project/ContinuumAnalyticsFOSS/conda/builds/20408292/job/q40u301c397wpyji?fullLog=true#L1181 ). IIUC `nomkl` does not exist on Windows. So this is as expected. Should these tests be marked as known fails, skipped, or similar? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: making plot_hinton look nicer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? - [ ] add axes to the image part - [ ] replace rho with the latex rho. - [ ] Use standard format for real and imag parts of rho - [ ] add a color bar for the height of element. <img width=\"606\" alt=\"image\" src=\"https://user-images.githubusercontent.com/15731369/57204407-a6b93580-6f85-11e9-9195-59b589bcfbd5.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Split common/platform module on conda to common/os/<os> This is a refactor of the code to split utilities that refer to specific operating systems https://github.com/conda/conda/blob/master/conda/common/platform.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Remove vendored tqdm and add it as a real dependency ### Checklist - [X] I added a descriptive title - [X] I searched for other feature requests and couldn't find a duplicate (including also the ``type-feature`` tag) - [X] I confirmed that it's not related to another project (see the above section) ### What is the idea? The last upgrade the vendored `tqdm` appears to have happened in PR ( https://github.com/conda/conda/pull/10721 ). This bumped `tqdm` to version `4.61.1`. However since then several more versions of `tqdm` have been released. The latest being `4.64.0`. ### Why is this needed We would like to do a better job of staying up to date with the latest `tqdm`, so we are going to see what adding it as a regular dependency looks like. ### What should happen? We will create a pull request demonstrating what this looks like and then discuss it with others to see if it is the right way forward. ### Additional Context Note in PR ( https://github.com/tqdm/tqdm/pull/1302 ) included in version `4.63.0`, `tqdm` replaced `pkg_resources` with `importlib.resources`. So this would also allow dropping `setuptools` as a requirement. ### Tasks - [x] Spike to investigate whether it is possible to use a dependency instead of a vendored dependency. (timebox = 1/2 day) - [x] Create a pull request demonstrating how this can be done: - [x] Add `tqdm` to our `setup.py` and conda repcipe `meta.yml` and version pin it to the latest using `>=` - [x] Find all the locations in conda where we used the vendored `tqdm` and replace it with the dependency version - [x] delete /_vendor/tqdm - [x] Run all the tests (submit a pull request to do this) - [x] See what broke (if anything) and fix it Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Should 'topics.testIamPermissions' be wrapped as 'check_iam_permissions'? See: https://github.com/GoogleCloudPlatform/gcloud-python/pull/1642#discussion_r57048424 and ff. Likewise `subscriptions.testIamPermission`. @jgeewax if you decide so, please assign the issue to me; otherwise, just close it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inconsistent ordering of marginal counts <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.24.1 - **Python version**: - **Operating system**: ### What is the current behavior? `marginal_counts` ordering does not obey a standard convention when returning its output. For example, consider the counts: ``` counts = {'10011':1, '01100':1} ``` using `indices = [0,1,2,3,4]` give the identity mapping, suggesting that the 0th index in the indices list maps the input counts bit to the least significant bit in the new marginal counts, the next least significant is set by the 1st index value etc. However, this does not hold true in general. Namely `indices = [0,1,2,4,3]` does not follow the prescribed convention and returns: ``` {'10011': 1, '01100': 1} ``` whereas one would expect the following: ``` {'01011': 1, '10100': 1} ``` i.e. the output bits are in the order q3q4q2q1q0 I believe it is due to the line: https://github.com/Qiskit/qiskit-terra/blob/40ffd2b07c03e220a174b2bfd0bf8c23aa021c5f/qiskit/result/utils.py#L111 that implicitly reorders any permutation of indices. This is mentioned no where in the docs, and is confusing ### Steps to reproduce the problem ### What is the expected behavior? I would expect the order of indices given to have a one to one mapping to those in the output. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: labapp.py # AttributeError: 'LabApp' object has no attribute 'quit_button' update jupyterlab with pip - after that i get this error. After removing the line 206 - the app runs normaly ``` Traceback (most recent call last): File \"/home/rened/anaconda3/bin/jupyter-lab\", line 11, in <module> sys.exit(main()) File \"/home/rened/anaconda3/lib/python3.6/site-packages/jupyter_core/application.py\", line 266, in launch_instance return super(JupyterApp, cls).launch_instance(argv=argv, **kwargs) File \"/home/rened/anaconda3/lib/python3.6/site-packages/traitlets/config/application.py\", line 657, in launch_instance app.initialize(argv) File \"<decorator-gen-7>\", line 2, in initialize File \"/home/rened/anaconda3/lib/python3.6/site-packages/traitlets/config/application.py\", line 87, in catch_config_error return method(app, *args, **kwargs) File \"/home/rened/anaconda3/lib/python3.6/site-packages/notebook/notebookapp.py\", line 1296, in initialize self.init_webapp() File \"/home/rened/anaconda3/lib/python3.6/site-packages/jupyterlab/labapp.py\", line 206, in init_webapp *settings['page_config_data']['quit_button'] = self.quit_button* AttributeError: 'LabApp' object has no attribute 'quit_button' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: string: Add missing FeatureNew tags to methods There are some new(er) methods that have not version reference, so add the missing ones in order to be properly notified when targetting older meson versions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Trainer] Why not use `tqdm`'s `dynamic_ncols=True` option? ### Feature request # Problem Tqdm progress bar is getting ugly when the width of the terminal is shrunk!  It progress bar makes the new line on every update! It is very ugly... # Solution Simply add the `dynamic_ncols=True` option to `tqdm`. It is located in `trainer_callbacks.ProgressCallback`.  You can check the progress bar is now dynamically resized when the terminal size is updated. ### Motivation When I connect `tmux` session with different widths of the terminal, then the `tqdm` printing is getting ugly. ### Your contribution Please check the PR #24101 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Explore complex schedules - `UnionSchedule`: combines multiple schedules into 1 - `BusinessDaySchedule`: runs an IntervalSchedule but only on weekdays - replace schedules entirely with the Python `schedule` library -- this would require serialization? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: follow #948 update the python examples <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: schema built when creating a view in bigquery Calling create on a table with view_query set fails, as _build_resource sets the schema. Running ``` python new_table = dataset.table('test_view') table.view_query = query_string new_table.create() ``` gives the following error: ``` BadRequest: 400 { \"error\": { \"errors\": [ { \"domain\": \"global\", \"reason\": \"invalid\", \"message\": \"Schema field shouldn't be used as input with a view\" } ], \"code\": 400, \"message\": \"Schema field shouldn't be used as input with a view\" } } ``` One fix that works is only setting `schema` if `view_query` is `None` in `_build_resource` in [`gcloud/bigquery/table.py`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/188515f192e3823ce21a47df2d4742995d08f109/gcloud/bigquery/table.py#L397), e.g.: ``` python def _build_resource(self): \"\"\"Generate a resource for ``create`` or ``update``.\"\"\" resource = { 'tableReference': { 'projectId': self._dataset.project, 'datasetId': self._dataset.name, 'tableId': self.name}, } if self.description is not None: resource['description'] = self.description if self.expires is not None: value = _millis_from_datetime(self.expires) resource['expirationTime'] = value if self.friendly_name is not None: resource['friendlyName'] = self.friendly_name if self.location is not None: resource['location'] = self.location if self.view_query is not None: view = resource['view'] = {} view['query'] = self.view_query else: resource['schema'] = {'fields': _build_schema_resource(self._schema)} return resource ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: task.set_upstream() and task.set_downstream() should have a `flow` argument `task.set_upstream()` and `task.set_downstream()` should have a `flow` argument (which would be passed to `task.set_dependencies()`) so they can be used outside a flow context. They actually reference a passed \"flow\" in their docstring error message. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: add boto3 to conda's s3 adapter Fix prefix data cache with rm_rf for conda-build on windows As reported by @mingwandroid: conda-build uses rd on Windows to remove the prefix before calling `rm_rf`, so we need conda to forget about the installed packages. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: ConcreteArray has no attribute copy I wanted to use `.copy()` on arrays to avoid working on views and corrupting values elsewhere. During tracing jax called my function with a `ConcreteArray` and threw an error since these don't support `.copy()`. Is there a different way i should have done this or should `ConcreteArray`s support a dummy `.copy()` that just returns `self`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: LayoutLM wrong shape for bbox in docs ## Environment info (Colab, 09 december 2020, CPU runtime) - `transformers` version: 4.0.1 - Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.6.9 - PyTorch version (GPU?): 1.7.0+cu101 (False) - Tensorflow version (GPU?): 2.3.0 (False) - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ### Who can help documentation: @sgugger ## Information LayoutLM documentation indicates that the shape for the bbox input is [B, seq_len]:  However, from the code (https://github.com/huggingface/transformers/blob/master/src/transformers/models/layoutlm/modeling_layoutlm.py#L103) bounding boxes are encoded in the form [tl_col, tl_row, br_col, br_row]. Therefore the accepted shape is [B, seq_len, 4]. ## To reproduce Reproduced on this colab: https://colab.research.google.com/drive/1ZRPKlX8-C41nYq3o6QVS68h1JAj1nQMI?usp=sharing ## Expected behavior Better explanation in docs Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub: System test failures on Python 2.7 (invalid syntax) https://source.cloud.google.com/results/invocations/e8706e96-9a37-40d5-8411-7cd62206b4aa/targets/cloud-devrel%2Fclient-libraries%2Fgoogle-cloud-python%2Fpresubmit%2Fpubsub/log ``` tests/unit/pubsub_v1/subscriber/test_subscriber_client.py:18: in <module> from google.cloud.pubsub_v1 import subscriber google/cloud/pubsub_v1/__init__.py:19: in <module> from google.cloud.pubsub_v1 import subscriber google/cloud/pubsub_v1/subscriber/__init__.py:17: in <module> from google.cloud.pubsub_v1.subscriber.client import Client google/cloud/pubsub_v1/subscriber/client.py:30: in <module> from google.cloud.pubsub_v1.subscriber._protocol import streaming_pull_manager E File \"/tmpfs/src/github/google-cloud-python/pubsub/google/cloud/pubsub_v1/subscriber/_protocol/streaming_pull_manager.py\", line 198 E print(f\"{messages_percent}, {bytes_percent}\") E ^ E SyntaxError: invalid syntax ``` Looks like `streaming_pull_manager.py` is using a format string, which isn't valid Python 2.7 syntax. Needs to use `\"{}, {}\".format(...)`, instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Coefficients in Opflow Expectations are handled inconsistently <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? In opflow, states, operators, and expectation value can have coefficients. For example the following expression has a coefficient of 2 for the state and a the measurement operator a coefficient of 3: ```python exp = 3 * ~StateFn(Z) @ (2 * One) ``` which should evaluate to ```python exp = <2 * One | 3 * Z | 2 * One> = 12 * <One | Z | One> = 12 * -1 = -12 ``` Depending on which expectation value converter is used, opflow gives 3 different results for the above expression, see the code example below. **Note:** This bug prevents the usage of `AerPauliExpectation` for gradients and the QFI and is related to Qiskit/qiskit-machine-learning#59. ### Steps to reproduce the problem ```python from qiskit.providers.aer import QasmSimulator from qiskit.opflow import * exp = 3 * ~StateFn(Z) @ (2 * One) result = exp.eval() print('Plain eval:', result) # -12 (correct) result = PauliExpectation().convert(exp).eval() print('PauliExpectation:', result) # -4 (global factor 3 missing) result = MatrixExpectation().convert(exp).eval() print('MatrixExpectation:', result) # -12 (correct) sampler = CircuitSampler(QasmSimulator()) result = sampler.convert(AerPauliExpectation().convert(exp)).eval() print('AerPauliExpectation:', result) # -1 (both factors, 2 and 3, missing) ``` ### What is the expected behavior? All should give -12. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] passwords with special characters not properly encoded when checking out sources from SCM Authentication started failing after upgrading to 1.32.0 ### Environment Details (include every applicable attribute) * Operating System+version: * Compiler+version: * Conan version: 1.32.0 * Python version: ### Logs (Executed commands with output) (Include/Attach if Applicable) command: ``` conan install my_package/1.0.0@user/channel#f6c6506327598117fef706344bbf6bb11bcb8f3c --build=my_package/1.0.0@user/channel#f6c6506327598117fef706344bbf6bb11bcb8f3c --build=missing --lockfile=conan.lock --lockfile-out=updated_conan.lock ``` output: ``` my_package/1.0.0@user/channel: SCM: Getting sources from url: 'https://my/repo/' ERROR: Couldn't checkout SCM: Command 'git -c http.sslVerify=true clone \"https://****:****@my/repo/\" . ' returned non-zero exit status 128. Cloning into '.'... remote: Unauthorized fatal: Authentication failed for 'https://my/repo/' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: pyarrow warning about schema argument samples/tests/test_query_to_arrow.py::test_query_to_arrow /tmpfs/src/github/google-cloud-python/bigquery/google/cloud/bigquery/_pandas_helpers.py:383: FutureWarning: Schema passed to names= option, please pass schema= explicitly. Will raise exception in future return pyarrow.RecordBatch.from_arrays(arrays, column_names) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: LLVM dependency LLVM has it's own special tool for configuration, `llvm-config`. It would be nice for `dependency` to wrap llvm config. I'm planning to write such a class (tomorrow at this point), but I wanted to make sure that there was interest and no one had already done so and just never created a PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: max_qa_length is needed for funetune on multiple-choice problems # 🚀 Feature request In examples/multiple-choice/run_multiple_choice.py, the max_qa_length is not implemented as that in google/Albert, which would cause trouble when funetuning RACE. This should be easy becauce there are similar codes in codes for run_squad.py. ### Your contribution I have done the script and get similar RACE performance compared to google/Albert. # Current Bug In examples/multiple-choice/utils_multiple_choice.py ```python # From 537 lines: # It should be => # inputs = tokenizer.encode_plus( # text_a, text_b, add_special_tokens=True, max_length=max_length, pad_to_max_length=True, return_overflowing_tokens=True # ) # Or the log info below would never be activated. inputs = tokenizer.encode_plus( text_a, text_b, add_special_tokens=True, max_length=max_length, pad_to_max_length=True, ) if \"num_truncated_tokens\" in inputs and inputs[\"num_truncated_tokens\"] > 0: logger.info( \"Attention! you are cropping tokens (swag task is ok). \" \"If you are training ARC and RACE and you are poping question + options,\" \"you need to try to use a bigger max seq length!\" ) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Support `raw_input` returning unicode Hello, I'm trying to port my package https://github.com/Drekin/win-unicode-console to Python 2 and I'd like to be compatible with IPython. My code monkeypatches builtin function `raw_input`, which afterwards returns a unicode object rather than str. Unfortunatelly, IPython is not compatible with this under Python 2: `IPython.terminal.interactiveshell.TerminalInteractiveShell.raw_input` calls `IPython.utils.py3compat.str_to_unicode` (which is mapped to `.decode`) on the result of original `raw_input`. But when `raw_input` returns a unicode object, trying to decode it leads to encoding it first, and if it contains a non-ascii character, the extra encoding step leads to `UnicodeEncodeError` since ascii encoding is assumed. The exception leads to `\"You or a %run:ed script called sys.stdin.close() or sys.stdout.close()!\\nExiting IPython!\\n\"` warning and IPython REPL exit. It would be nice if a unicode object was left alone rather then tried to be decoded, i.e. if for example `IPython.utils.py3compat.cast_unicode` was used instead of `.str_to_unicode`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Detect replication DR secondary mode and skip Prometheus metric collection ### What does this PR do? When vault is in replication dr secondary mode, the prometheus metrics endpoint is not available. This PR detects when vault is in replication DR mode and allows the check to continue running while logging a debug message ### Motivation Resolves https://github.com/DataDog/integrations-core/issues/7819/s ### Additional Notes <!-- Anything else we should know when reviewing? --> ### Review checklist (to be filled by reviewers) - [ ] Feature or bugfix MUST have appropriate tests (unit, integration, e2e) - [ ] PR title must be written as a CHANGELOG entry [(see why)](https://github.com/DataDog/integrations-core/blob/master/CONTRIBUTING.md#pull-request-title) - [ ] Files changes must correspond to the primary purpose of the PR as described in the title (small unrelated changes should have their own PR) - [ ] PR must have `changelog/` and `integration/` labels attached Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Misleading gearman.workers metric The gearmand check is using `get_status()` to get the number of workers. The code is getting the number of workers for each task and adding all together to get the number of workers. The problem is that a single worker can be registered for multiple tasks. Unless you have all your workers dedicated to a single task the result will be much higher than reality. To get the correct number of workers it should use the `get_workers()` function, possibly discarding any entry with no tasks. Rough solution: ```python workers_list = client.get_workers() workers = len([w for w in workers_list if w['tasks']]) self.gauge(\"gearman.workers\", workers, tags=tags) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Do not accept an ipython_dir that's not writeable As reported by Eric Jones, a colleague found himself with this problem: Pylab failed to start after an EPD install, and he was dead in the water. After poking around, he has a HOMESHARE variable that is set to some strange directory he doesn't know about and also that he does not have write access to. As a result, ipython will not start up. This is a show stopper. We should add a patch that checks if the get_ipython_dir() is writable. If it isn't, we should use the temp dir or something, or we should not try to write the ipythonrc file, or something. We want to ensure that file permissions don't result in the inabliity to start using the app. Jason reported progress on the issue: Ilan and I just looked at it and it appears to be a simple fix. path.py get_home_dir() checks a bunch of environment variables on different platforms looking for a home directory. It checks that the directory exists, but not that it's writable. We can just add check to issue a warning if a given directory isn't writable and move on to the next option. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Manual for TGate is missing ## Did you find a doc bug or broken link that needs to be fixed? - What is the file name(s) where you found the bug? https://qiskit.org/documentation/apidoc/circuit_library.html#standard-gates - What is the current text that needs to be fixed or removed? (You can copy and paste) There is no page for TGate, while SGate and TdgGate are available. - What should the documentation say instead? TGate should be included in the page. - Are there other related issues or pull requests about this bug? No. ## Does existing documentation need to be updated with new content? - Which files need to be updated? https://qiskit.org/documentation/apidoc/circuit_library.html#standard-gates - What content needs to be updated or replaced? (You can copy and paste) - What new content needs to be added? Page for TGate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Avoid dependencies duplicity <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently, when you want to add or update a dependency, you need to do that in the `requirements.txt` and `setup.py` files. That is really error-prone. It would be nice to avoid that situation and make changes only in one of the files when a dependency is added or updated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: The equality check in ControlledGate is not strong enough The equality check in ControlledGate may not be strong enough for this test. For instance it doesn't check that ctrl_state matches (bug) and doesn't check that the definitions match. _Originally posted by @ewinston in https://github.com/Qiskit/qiskit-terra/pull/4025_ Notice, for example: ``` XGate().control(1, ctrl_state=1) == XGate().control(1, ctrl_state=0) ``` ``` True ``` The expected result is `False`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: download_as_string documentation says that it downloads a string, instead of bytes For google-cloud-storage, in the documentation for [`download_as_string()`](https://github.com/googleapis/google-cloud-python/blob/53d692517345979b2b4621872d76c1184c987b92/storage/google/cloud/storage/blob.py#L714) method on blobs, it says [on line 715](https://github.com/googleapis/google-cloud-python/blob/53d692517345979b2b4621872d76c1184c987b92/storage/google/cloud/storage/blob.py#L715): \"\"\"Download the contents of this blob as a string. This is not true. The confusingly named method downloads the content as bytes, not string. On [line 731](https://github.com/googleapis/google-cloud-python/blob/53d692517345979b2b4621872d76c1184c987b92/storage/google/cloud/storage/blob.py#L731), the return type is correctly declared as bytes, but reading the documentation, you are still presented with conflicting information. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: fig restart Maybe this should exist. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: add registry modifications to conda init * enable long paths * also consider symlinks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: JupyterLab assets not detected in \"/usr/local/share/jupyter/lab/static\" Related to #3105. In my case, I install jupyter (and jupyter-lab) in my user directory, not system-wide. It works using the flag --core-mode. In ENV_JUPYTER_PATH I get this: `['/usr/share/jupyter']` If I use jupyter_path() I get this instead: `['/home/darkxhunter/.local/share/jupyter', '/usr/local/share/jupyter', '/usr/share/jupyter']` So **jupyter_path()[0]** would work for me (and I guess it should work in other cases too). Is there any reason for not using this? Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Using multiple loggers **Describe the solution you'd like** Trainer could receive a list of loggers instead of only one, all loggers would be called at the appropriate times. **Describe alternatives you've considered** Alternatively could create a customLogger that logged the information to all relevant destinations (eg. tensorboard AND mlflow) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qiskit.tools needs module level docstring and underlying functions need examples <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? This does not apply to functions in `qiskit.tools.jupyter` which already done. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Using print_nan_grads in the Trainer results in an error **Describe the bug** When using ``` print_nan_grads=True ``` in the Trainer, I am getting the error below. trainer.fit(lstm_model) File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/trainer.py\", line 364, in fit self.run_pretrain_routine(model) File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/trainer.py\", line 471, in run_pretrain_routine self.train() File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/train_loop_mixin.py\", line 60, in train self.run_training_epoch() File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/train_loop_mixin.py\", line 99, in run_training_epoch output = self.run_training_batch(batch, batch_nb) File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/train_loop_mixin.py\", line 219, in run_training_batch self.print_nan_gradients() File \"/Users/anaconda3/envs/snorkel/lib/python3.6/site-packages/pytorch_lightning/trainer/training_tricks_mixin.py\", line 16, in print_nan_gradients if torch.isnan(param.grad.float()).any(): AttributeError: 'NoneType' object has no attribute 'float' **To Reproduce** Steps to reproduce the behavior: If some param object, does not have **.grad**, then that object should not be checked for nans Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: dag_drawer should check the existence of filename extension ### Information - **Qiskit Terra version**: 0.10.0.dev0+831d942 - **Python version**: 3.7 - **Operating system**: Mac ### What is the current behavior? If a filename without extension is passed to the function `dag_drawer`, this [line](https://github.com/Qiskit/qiskit-terra/blob/d090eca91dc1afdb68f563885c4ccf13b31de20e/qiskit/visualization/dag_visualization.py#L91) reports two errors: ``` nxpd.pydot.InvocationException: Program terminated with status: 1. stderr follows: Format: \"XXXXX\" not recognized. Use one of: ...... During handling of the above exception, another exception occurred: qiskit.visualization.exceptions.VisualizationError: 'dag_drawer requires GraphViz installed in the system. Check https://www.graphviz.org/download/ for details on how to install GraphViz in your system.' ``` This is confusing because the second error thrown by Qiskit is not the cause of the problem. ### Steps to reproduce the problem Try `dag_drawer(dag, filename='abc')` ### What is the expected behavior? Make the error catching better. ### Suggested solutions We could either catch this error by reading and filtering the error message, or we could check the existence of the filename's extension, and provide a default one. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: create an \"initialize\" command for conda With the new shell capabilities in conda 4.4, shell configuration has gotten a lot more nuanced. This is a tracking ticket for creating a `conda initialize` command. Capabilities: 1. Help ensure users have properly configured shells. 2. Enable `pip install conda`, in a way that will actually work. 3. For conda developers and contributors, facilitate a more stream-lined dev mode. Somewhat related to #107. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Task output does not seem to be cached (despite `cache_for` argument being present) _(I'm using prefect version `0.5.5`.)_ Here is a simple flow containing a single task that has the `cache_for` argument set. I would expect this flow to take ~2s the first time it runs and then pretty much complete instantaneously on subsequent runs. ```python from prefect import task, Flow from datetime import timedelta import time @task(cache_for=timedelta(hours=1)) def return_the_answer(): time.sleep(2) return 42 with Flow(\"answer\") as flow: return_the_answer() flow.run() ``` Here is the output from running in a Jupyter notebook using `%%time`, which confirms that the flow takes ~2s to complete. ``` [2019-07-10 20:45:09,227] INFO - prefect.FlowRunner | Beginning Flow run for 'answer' [2019-07-10 20:45:09,229] INFO - prefect.FlowRunner | Starting flow run. [2019-07-10 20:45:09,235] INFO - prefect.TaskRunner | Task 'return_the_answer': Starting task run... [2019-07-10 20:45:11,240] INFO - prefect.TaskRunner | Task 'return_the_answer': finished task run for task with final state: 'Cached' [2019-07-10 20:45:11,241] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded CPU times: user 14.6 ms, sys: 4.24 ms, total: 18.8 ms Wall time: 2.02 s <Success: \"All reference tasks succeeded.\"> ``` The strange thing is that subsequent runs take exactly the same amount of time but I'd expect the result to be cached so they should complete much more quickly. It's quite possible that this is a misunderstanding on my part rather than a bug. Am I supplying the `cache_for` argument in the wrong place? (I couldn't find an example in the docs which applies it to tasks defined via the `@task` decorator.) Any clarifications would be appreciated. Many thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Documentation error in GPT2Tokenizer Documentation page: https://huggingface.co/transformers/model_doc/gpt2.html#transformers.GPT2Tokenizer Code place: https://github.com/huggingface/transformers/blob/d7d36181fdefdabadc53adf51bed4a2680f5880a/transformers/tokenization_gpt2.py#L112-L113 This phrase: > Otherwise, this tokenizer encode and decode method will not conserve the absence of a space at the beginning of a string: tokenizer.decode(tokenizer.encode(“Hello”)) = ” Hello” is **NOT** correct. Actually: > tokenizer.decode(tokenizer.encode(“Hello”)) = ”Hello” Try this example: ``` from transformers import GPT2Tokenizer tokenizer = GPT2Tokenizer.from_pretrained('gpt2') print(\"'\" + tokenizer.decode(tokenizer.encode(\"Hello\")) + \"'\") ``` Output: ``` 'Hello' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Bug in plot_state_city <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.7.0 - **Python version**: 3.6.4 - **Operating system**: Windows 10 64-bit ### What is the current behavior? qiskit.tools.visualization.plot_state_city() gives incorrectly aligned plots for some input states ### Steps to reproduce the problem Create the state psi = np.array([1, 1]) / np.sqrt(2). Plot plot_state_city(psi). ### What is the expected behavior? Correctly aligned bars. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Enhance graph dependency resolution speed Hello, I have a big dependency graph that is managed in our CI system. About a hundred packages are handled and depends on each other by using version range like `[^1.66.0]` to keep, according to semver, the last backward compatible package. The fact is that as all packages requirements are expressed that way. I observed that conan, for each package, make a query to resolve the range and that can take a lot of time. Observed times are with conan <= 1.4 a `conan info . -bo ... -bo ... [...]` on the graph would take about fifteen minutes (depending on the number of `-bo` that are passed). On conan 1.6, it is twice as before. As a way to enhance the resolution, can conan create a cache so they are resolved only once and future calls to the same range will be answered quickly ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.einsum support support for generic tensor contractions would cover a large class of computations and also provide a foundation for higher order operations. Perhaps jax could then also be added as a `opt_einsum` backend? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Bigquery client doesn't implement list_projects Seems weird, but the bigquery client should also be able to list projects: https://cloud.google.com/bigquery/docs/managing_jobs_datasets_projects#projects Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add Ability to overwrite task settings when calling a task in Functional API Currently, a common pattern is: ```python t = MyTask(name=\"test task\", tags=[\"A\"]) with Flow() as f: res1 = t(1) res2 = t(2) ... ``` and each individual copied instance of the task will appear with the same name `\"test task\"` in the UI and any other place that information is surfaced. To allow for more nuanced control of the copying of tasks, we should add a reserved kwarg `_task_args` to task call signatures which allow for overriding things (such as `name`) when calling / copying the task. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Graph DSL docs references deprecated DependencyDefinition ## What content is missing Hi there! I've been looking at the Graph DSL example (https://docs.dagster.io/concepts/ops-jobs-graphs/jobs-graphs#graph-dsl) and I'm just curious if this is something actively supported by Dagster. If so, I see a reference to [DependencyDefinition](https://docs.dagster.io/_apidocs/pipeline#dagster.DependencyDefinition) which seems deprecated since the whole Pipelines page is deprecated. (Also, it'd be nice to have a bit more examples of the Graph DSL if it's actively maintained, it seems super helpful for my project!) ## Type of the content - Best Practices Guide Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Updated SubscriberClient docs `subscribe_experimental` was promoted to `subscribe` but the docs for the `SubscriberClient` still suggested using `subscribe_experimental` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG?: 1.14 printing requires gc run to clean up all references to printed array Dear NumPy devs, one of our NumPy integration doctests in Cython has been failing on travis for a couple of weeks. I checked the changelog of CPython and Cython from the time when it started, but neither showed anything remotely related. However, the failing travis nodes use NumPy 1.14, and since there were PyPy related changes in that release, I suspect that this could be the cause. I only see the failures in Py3.5+, and they started in the CPython-dev integration test runs for py3.6-dev and py3.7-dev on travis, however those are built (NumPy is pre-installed in them). Here's an example of a [failing run](https://travis-ci.org/cython/cython/builds/342548198). The now failing [test](https://github.com/cython/cython/blob/2e1066dcfc1c4ccbfaa0babf3cbe9f58640431fd/tests/memoryview/numpy_memoryview.pyx#L415-L423) is simply this: ``` cdef int[:, :] array = create_array((4, 5), mode=\"c\", use_callback=True) print(np.asarray(array)[::2, ::2]) ``` Meaning, there is a buffer provider (not NumPy), we take a Cython memory view from it, and then wrap that with `numpy.asarray()` to print it. The difference is when the buffer provider will be deallocated. Previously, it was cleaned up immediately at function exit (and we print a confirmation in a cleanup callback when that happens). With the new NumPy version, it is no longer cleaned up immediately, but only at the next GC run. I added a conditional GC call to the test to trigger that and keep the test from failing (we didn't need a GC run before), but I thought I'd at least bring this change to your attention, in case it's unintentional. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Container: needs 'synth.py' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: build_by_default:false is ignored by mesontest. I have many targets, all flagged as \"build_by_default: false\". When I do ninja <target_name> it correctly builds only what is required for that target. But if I do mesontest <test_name> it seems to build everything. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Open a notebook from the command line `ipython notebook Somefile.ipynb` should start the notebook server, and open a browser tab to that notebook, rather than the dashboard. This should make it possible to double click an ipynb file and have it open in the browser, ready to run. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: ModelCheckpoint instance to JSON ## 🚀 Feature Have a `to_json(path)` function that writes the `best_k_models` to a json file in `path`. ### Motivation Why having a JSON is good? Then you don't need to load the checkpoints to know the metrics and things like a posteriori stochastic weight averaging gets easier. It used to be easier in 0.6, but loss values are now tensors, so it's not directly serializable. This is currently needed: ```python best_k = {k: v.item() for k, v in checkpoint.best_k_models.items()} with open(json_path, \"w\") as f: json.dump(best_k, f, indent=0) ``` Instead, we could have ```python checkpoint.to_json(json_path) ``` I'm ready to make a PR for it. Just tell me if this would be useful for you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Log console toolbar style issue Running JupyterLab from [master](f3550a540b5beeaf750ac5badb42b61bf4efdf3e), it looks like the log console toolbar has some styling issues with the alignment of the items and the clear icon:  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] 1.8.0 uses --sbin instead --sbindir After updating to conan 1.8.0, I ran into an issue building a [librdkafka/0.11.4-1](https://github.com/ess-dmsc/conan-librdkafka) package on CentOS due to the ./configure statement using `--sbin` as a parameter instead of `--sbindir`: ``` librdkafka/0.11.4-1@<asdf>/stable: Calling: ./configure '--prefix=' '--disable-sasl' '--diable-lz4' '--disable-optimization' '--bindir=${prefix}/bin' '--sbin=${prefix}/bin' '--libexec=${prefix}/bin' '--libdir=${prefix}/lib' '--includedir=${prefix}/include' Unknown option sbin=${prefix}/bin ``` The GNU Coding Standard states that the variable for the [`sbin` installation directory is `sbindir`](https://www.gnu.org/prep/standards/html_node/Directory-Variables.html). It looks like the issue came from #3599 and the [librdkafka/0.11.4-1](https://github.com/ess-dmsc/conan-librdkafka) package builds fine on conan 1.6.1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Parameters needs examples in the documentation ### What is the expected enhancement? Many users land in https://qiskit.org/documentation/stubs/qiskit.circuit.Parameter.html when search on how to parametrize circuits. @Cryoris did a good jobs at explaining them in https://quantumcomputing.stackexchange.com/questions/13558/how-to-add-several-parameters-in-qiskit-circuit . I think the Parameter docstring needs a short example. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: datastore: default to empty dataset When working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending \"s~\" to dataset ids as that is not always a valid operation. datastore: default to empty dataset When working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending \"s~\" to dataset ids as that is not always a valid operation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Response file needed for Fortran project on Linux Inspired by #7212. A project with lots of Fortran source: ```sh #!/bin/sh set -eu work_dir=meson_toolong build_dir=b n=12000 mkdir -p ${work_dir} cd ${work_dir} rm -rf ${build_dir} { echo \"project('toolong', 'fortran')\" echo \"srcs = [\" } > meson.build for i in $(seq -w ${n}) do src_file=f${i}.f90 { echo \"Subroutine s${i}\" echo \"End\" } > \"${src_file}\" echo \" '${src_file}',\" >> meson.build done { echo \"]\" echo \"library('toolong', srcs)\" } >> meson.build meson . ${build_dir} cd ${build_dir} ninja -v ``` gives ``` The Meson build system Version: 0.59.0 Source dir: /home/mat_cross/documents/Meson/resp/meson_toolong Build dir: /home/mat_cross/documents/Meson/resp/meson_toolong/b Build type: native build Project name: toolong Project version: undefined Fortran compiler for the host machine: gfortran (gcc 11.2.1 \"GNU Fortran (GCC) 11.2.1 20210728 (Red Hat 11.2.1-1)\") Fortran linker for the host machine: gfortran ld.bfd 2.35.2-4 Host machine cpu family: x86_64 Host machine cpu: x86_64 Build targets in project: 1 Found ninja-1.10.2 at /usr/bin/ninja ninja: fatal: posix_spawn: Argument list too long ``` (Python is 3.9.6). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] authentication error is handled incorrectly in client.rest.uploader_downloader.FileDownloader When installing a Conan package I've got this error message: ``` tools.get(**self.conan_data[\"sources\"][self.version]) AttributeError: 'NoneType' object has no attribute 'token' ``` Obviously, the message isn't very helpful as it implies that there's a problem with the package recipe (there wasn't). After some investigation I found out that the error ultimately happens in `client.rest.uploader_downloader.FileDownloader` when the download fails with a 403. The method does the following check: `auth.token is None`. The issue is, `auth` is an optional parameter. Also it is effectively allowed to be a tuple according to documentation for `tools.get`. So, I assume the check should have been `not auth or not hasattr(auth, \"token\") or auth.token is None`. Conan version: 1.21.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Unexpected behavior of nlp.has_pipe(\"sentencizer\") ## How to reproduce the behaviour Basically following the tutorial in https://spacy.io/usage/linguistic-features#sbd-component with the addition of calling has_pipe() in a loop: ``` import spacy from spacy.lang.en import English nlp = English() # just the language with no model for i in range(2): if not nlp.has_pipe('sentencizer'): sbd = nlp.create_pipe('sentencizer') # or: nlp.create_pipe('sbd') nlp.add_pipe(sbd) doc = nlp(u\"This is a sentence. This is another sentence.\") for sent in doc.sents: print(sent.text) ``` Leads to following error: ` ValueError: [E007] 'sbd' already exists in pipeline. Existing names: ['sbd']` I noticed that, while it is possible to create a pipeline with the \"sentencizer\" string, calling has_pipe(\"sentencizer\") will not return True for the pipeline afterwards. Replacing \"sentencizer\" with \"sbd\" in the code resolves the error. ## Your Environment python 3.6, spacy 2.0.12 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: System library dependencies could be specified in the wrong order Attached is a case which reproduces my issue, just issue conan create . test/test Description: So hidapi depends on libusb and it adds it in cpp_info. The problem however is, that cmake does not really know that hidapi depends on libusb as they are just added using cpp_info.libs=[\"hidapi\", \"usb-1.0\"]. This information is lost. Now, like this, the libs are specified in correct order so everything is fine. But as soon as a user of hidapi itself links against usb-1.0, cmake changes the link order causing undefined references. So, if the pkgconfig block in test_package/CMakeLists.txt is commented out, the package builds fine. With the pkgconfig block, the lib fails to compile here on Ubuntu LTS 16.04 with undefined references to libusb because cmake links in reverse order (-lusb-1.0 -lhidapi). See https://stackoverflow.com/questions/11893996/why-does-the-order-of-l-option-in-gcc-matter for why this matters Attached below is a reproducible case [hidapi.zip](https://github.com/conan-io/conan/files/1664450/hidapi.zip) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: scipy minimal required version does not have unitary_group <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations The changes included in #760 require a `scipy` version that provides `scipy.stats.unitary_group`, which is not available in the minimal version currently required for scipy: ``` scipy>=0.19 ``` We should look for the minimal version of `scipy` that includes that function (seems to be 1.0) and update the dependencies accordingly - otherwise we risk installations with broken `qiskit.tools.qi.qi` in some cases. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Fix all the `None`s in CondaHTTPError ``` CondaHTTPError: HTTP None None for url https://repo.continuum.io/pkgs/free/win-64/repodata.json.bz2 Elapsed: None ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: recfromtext bytes delimiter I had existing code that uses BytesIO and a byte delimiter. It worked in <=1.13 and breaks after. The code works if the delimiter is switched to a string. All tests were performed with Python 3.6.5 from Anaconda. The failure can be reproduced using the excerpt below. Fails using 1.14.0, 1.14.1, and 1.14.2 ``` python -c \"import numpy as np; import io; print(np.version.version); data = np.recfromtxt(io.BytesIO(b'SPC:MW\\nNO:30\\nNO2:36'), delimiter=b':', dtype = ['S3', 'f4']); print(data)\" 1.14.2 Traceback (most recent call last): File \"<string>\", line 1, in <module> File \"/work/ROMO/anaconda3/envs/testnp113/lib/python3.6/site-packages/numpy/lib/npyio.py\", line 2230, in recfromtxt output = genfromtxt(fname, **kwargs) File \"/work/ROMO/anaconda3/envs/testnp113/lib/python3.6/site-packages/numpy/lib/npyio.py\", line 2116, in genfromtxt rows = np.array(data, dtype=[('', _) for _ in dtype_flat]) ValueError: could not assign tuple of length 1 to structure with 2 fields. ``` Passes with 1.13.3 ``` python -c \"import numpy as np; import io; print(np.version.version); data = np.recfromtxt(io.BytesIO(b'SPC:MW\\nNO:30\\nNO2:36'), delimiter=b':', dtype = ['S3', 'f4']); print(data)\" 1.13.3 [(b'SPC', nan) (b'NO', 30.) (b'NO2', 36.)] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Metrics: Base Metric ## 🚀 Feature Add a base class for proper metric implementation Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: initial_state=False is not honored by latex drawer in the classical wires When latex drawer is called with `initial_state=False` the initial state of the classical wires is still there at it should be removed, as the other drawers. ```python from qiskit import * qr = QuantumRegister(3, 'q') cr = ClassicalRegister(3, 'c') circuit = QuantumCircuit(qr, cr) circuit.measure(qr, cr) circuit.draw('latex', initial_state=False) ``` 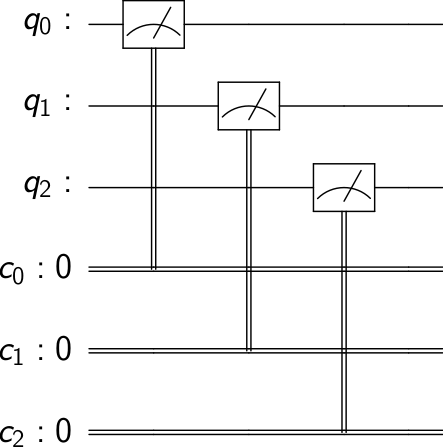 The expected result would be <img width=\"427\" alt=\"Screen Shot 2020-04-27 at 3 10 31 PM\" src=\"https://user-images.githubusercontent.com/766693/80411454-3abc9500-889a-11ea-9e9b-b445c96dda01.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda update icu (54.1-0 --> 56.1-4 conda-forge) In a new installation, it appears that going from icu 54 to 56 will fail unless the following is done (at least on linux): bash Anaconda2-4.2.0-Linux-x86_64.sh conda remove icu rm -r $HOME/anaconda2/lib/icu conda install -c conda-forge icu=56.1 In other words, using the first and fourth lines alone fails with: CondaOSError: OS error: failed to link (src=u'/home/anaconda2/pkgs/icu-56.1-4/lib/icu/current', dst='/home/anaconda2/lib/icu/current', type=3, error=OSError(17, 'File exists')) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: ConfigurableResource does not work with sensor since version 1.3.8 ### Dagster version 1.3.8 ### What's the issue? Does not accept ConfigurableResource parameter in sensor. like: class MongoResource(ConfigurableResource): pass @sensor(job=simple_job) def is_job_created( context: SensorEvaluationContext, mongo: MongoResource, ) ### What did you expect to happen? Expected behavior: sensor definition accpets ConfigurableResource parameter and work like in earlier Dagster version ### How to reproduce? _No response_ ### Deployment type Local ### Deployment details _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [SCM] SCM feature + recipe in a repo subfolder leads to \"same computer clone\" bug Getting back to our Conan recipe, conan `1.7.1` solves the problem described #3322 thus (re)allowing a recipe living in subfolder of the repository to use the `scm` feature. Sadly, another bug, initially described in #3069 (under the name _same computer optimization problem_) is still present: when `conan create`ing the recipe, in this situation, the creation fails, complaining there are no files in the `build` folder (and indeed, there are none). It seems the analysis made in #3069 is still relevant: Basically, when calling `conan create`, an optimization described in the [tip box of this documentation section](https://docs.conan.io/en/latest/creating_packages/package_repo.html#capturing-the-remote-and-commit-from-git-scm-experimental) creates an `scm_folder.txt` file in the conan package. When this file is present, conan tries to clone the repo from the path in this file instead of the git url stored in the exported recipe. Sadly, this file contains the path to the folder containing the recipe, instead of the path to the root of the repository. So, when the recipe is at the root of the repository, the behaviour appears correct. But if the recipe is stored in a subfolder, then it seems nothing is cloned over to the build folder, failing the process. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Windows module fails on multiple resource files with same name I have a project with multiple subfolders that contain resource scripts named 'rsrc.rc', this worked with at least 0.44.0, but fails with current master: > meson.build:7:0: ERROR: Tried to create target \"Windows resource for file 'rsrc.rc'\", but a target of that name already exists. Here is a small testcase: [rsrcbug.zip](https://github.com/mesonbuild/meson/files/2007861/rsrcbug.zip) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Deprecate automatic schema conversion in `load_table_from_dataframe` After discussion around https://github.com/googleapis/google-cloud-python/issues/9024, I'm coming to realize that there are a lot of inconsistencies with the pandas DataFrame serialization when we have to autodetect the schema. I propose that we warn when we are given a DataFrame but can't determine the correct schema. I realize this will be a step backwards in terms of usability. I think the following feature requests are needed to be prioritized if we proceed with this deprecation: - [x] https://github.com/googleapis/google-cloud-python/issues/8140 Allow partial schemas, so that someone can just override certain `object` dtype columns, for example. - [x] https://github.com/googleapis/google-cloud-python/issues/8142 Get table schema if not supplied. This covers the case when appending rows to an existing table. - [x] https://github.com/googleapis/google-cloud-python/issues/9044 Generate a (partial) schema for known dtypes, and merge with the provided schema. - [x] https://github.com/googleapis/google-cloud-python/issues/5572#issuecomment-524012299 Add index(es) to serialized file if specified in `job_config.schema`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Improvements to the IPython.display.Image object It should: - be more friendly to the first argument being a local or remote path to any valid image format (right now it seems to work with png but not jpeg, on simple testing). - support width/height keywords and emit the corresponding html. - we should consider whether the return value should wrap the result in a jquery resizeable container, to match how the other image objects that are returned from plots behave. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Unify pulse Commands and Instructions <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Pulse `Command`s were initially created to allow the pulse to be only defined once as a `SamplePulse` and then have its usage tracked based on the pulse instance. Every `Instruction` instance was then defined as containing a `Command` and its `Channel` operands that the command is applied to. This change may result in some breaking changes, but I have a couple of ideas to make this mostly backward compatible. Requirements for closure of this issue include: - [x] [Approved RFC](https://github.com/Qiskit/rfcs/pull/12) - [x] Implementation ### Background and Ideas I believe this has resulted in a confusing API with many statements that look like ```python PulseCommand(...)(channel1, channel2, ...) ``` which yields an instruction. Or called more explicitly: ```python PulseInstruction(PulseCommand(...), channel1, channel2, ...) ``` If we were to unify commands with instructions a generic instruction would accept a list of operands that could be either a numeric parameter like a complex or a channel to operate on, eg.: ```python PulseInstruction(operand1, operand2, ...) ``` For example, a frame change would go from, ```python FrameChange(0.0)(DriveChannel(0)) ``` or explicitly, ```python FrameChangeInstruction(FrameChange(0.0), DriveChannel(0)) ``` to ```python ShiftPhase(0.0, DriveChannel(0)) ``` where `ShiftPhase` is of type `Instruction`. The current behavior of pulses could be fixed by redefining `Pulse` as a `Type` and defining a `Play` instruction: ```python random_pulse = SamplePulse(np.random.random(10)) Play(random_pulse, DriveChannel(0) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Move failure of providing parameters into the parameter Task itself Currently, if a Flow is constructed with parameters, and those parameter are not provided at run time, the `FlowRunner` itself raises a `FAIL` signal. Proposal: Have the Parameter task itself raise the FAIL signal; this would allow for a clearer error message (_which_ parameter was not provided) and would allow the `BokehRunner` tool to consistently handle this situation. Move failure of providing parameters into the parameter Task itself Currently, if a Flow is constructed with parameters, and those parameter are not provided at run time, the `FlowRunner` itself raises a `FAIL` signal. Proposal: Have the Parameter task itself raise the FAIL signal; this would allow for a clearer error message (_which_ parameter was not provided) and would allow the `BokehRunner` tool to consistently handle this situation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Tracking namespace change Here's a place we can track updates to the future changing of the `gcloud-python` namespace. This change could break things in the future. --- Sub-projects already partially created: - [`google-cloud`](https://pypi.python.org/pypi/google-cloud) - [`google-cloud-core`](https://pypi/.python.org/pypi/google-cloud-core) - [`google-cloud-datastore`](https://pypi.python.org/pypi/google-cloud-datastore) - [`google-cloud-storage`](https://pypi.python.org/pypi/google-cloud-storage) - [`google-cloud-pubsub`](https://pypi.python.org/pypi/google-cloud-pubsub) - [`google-cloud-bigquery`](https://pypi.python.org/pypi/google-cloud-bigquery) - [`google-cloud-bigtable`](https://pypi.python.org/pypi/google-cloud-bigtable) - [`google-cloud-happybase`](https://pypi.python.org/pypi/google-cloud-happybase) - [`google-cloud-logging`](https://pypi.python.org/pypi/google-cloud-logging) - [`google-cloud-vision`](https://pypi.python.org/pypi/google-cloud-vision) - [`google-cloud-speech`](https://pypi.python.org/pypi/google-cloud-speech) - [`google-cloud-language`](https://pypi.python.org/pypi/google-cloud-language) (and the alias [`google-cloud-natural-language`](https://pypi.python.org/pypi/google-cloud-natural-language)) - [`google-cloud-resource-manager`](https://pypi.python.org/pypi/google-cloud-resource-manager) - [`google-cloud-translate`](https://pypi.python.org/pypi/google-cloud-translate) - [`google-cloud-dns`](https://pypi.python.org/pypi/google-cloud-dns) - [`google-cloud-monitoring`](https://pypi.python.org/pypi/google-cloud-monitoring) - [`google-cloud-error-reporting`](https://pypi.python.org/pypi/google-cloud-error-reporting) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: print in multiprocess does not work until a newline is sent, even after a flush In the notebook: `print('blah',end='')` (print without a newline) in a process created with the `multiprocess` module does not appear in the output cell even after `sys.stdout.flush()` is called. If a new line is printed it works fine and it appears immediately. This makes writing progress bars for parallel code quite inconvenient. It works fine in the terminal. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] pkg_config generator has wrong casing in the requires section coming from https://github.com/conan-io/conan-center-index/pull/471#issuecomment-565057342 Seems that there is a missing conditional to make the default name `.lower()` here: https://github.com/conan-io/conan/blob/5336a31744bb114f419ad91310bc3e50dc2eb1cd/conans/client/generators/pkg_config.py#L90 As it was done previously for the file name here: https://github.com/conan-io/conan/blob/5336a31744bb114f419ad91310bc3e50dc2eb1cd/conans/client/generators/pkg_config.py#L43 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Bug: groups and tags don't set correctly after changing to _private context variables Missed these attributes when changing context to use a private attribute -- need to fix + add tests. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: CondaError: Cannot link a source that does not exist. C:\\Users\\...\\Anaconda3\\Scripts\\conda.exe I get this error when trying to conda install tqdm. Pip install works fine. However, when trying conda install spacy, I still get the same error because the conda installation for spacy attempts to conda install tqdm. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Add ability to inject a partitions_def in dynamic_partitioned_config decorator ### What's the use case? I want to declare a DynamicPartitionsDefinition object, using name param, and inject it to my software defined assets and jobs. Then, I want to build a PartitionedConfig using dynamic_partitioned_config but this will build a new DynamicPartitionsDefinition object, using partition_fn param. So I can't use my own. ### Ideas of implementation ```python def dynamic_partitioned_config( partition_fn: Callable[[Optional[datetime]], Sequence[str]], partitions_def: Optional[DynamicPartitionsDefinition[Any]] = None, tags_for_partition_fn: Optional[Callable[[str], Mapping[str, str]]] = None, ) -> Callable[[Callable[[str], Mapping[str, Any]]], PartitionedConfig]: check.callable_param(partition_fn, \"partition_fn\") def inner(fn: Callable[[str], Mapping[str, Any]]) -> PartitionedConfig: def _run_config_wrapper(partition: Partition) -> Mapping[str, Any]: return fn(partition.name) def _tag_wrapper(partition: Partition) -> Mapping[str, str]: return tags_for_partition_fn(partition.name) if tags_for_partition_fn else {} return PartitionedConfig( partitions_def=partitions_def if partitions_def is not None else DynamicPartitionsDefinition(partition_fn), run_config_for_partition_fn=_run_config_wrapper, decorated_fn=fn, tags_for_partition_fn=_tag_wrapper, ) return inner ``` ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Seems like `optimization=0` does nothing **Describe the bug** It seems that `optimization=0` does not have any effect. i.e. `-O0` does not appear in the compiling command when using `optimization=0`. **To Reproduce** With the following code: ```C // meson.build project('hello', 'c') executable('hello', 'hello.c') // hello.c #include <stdio.h> int main(void) { puts(\"Hello world\"); return 0; } ``` And using the following commands: ```C meson setup buildir -Doptimization=0 cd buildir meson compile -v ``` I obtain: ``` ninja: Entering directory `.' [1/2] gcc -Ihello.p -I. -I.. -fdiagnostics-color=always -pipe -D_FILE_OFFSET_BITS=64 -Wall -Winvalid-pch -g -MD -MQ hello.p/hello.c.o -MF hello.p/hello.c.o.d -o hello.p/hello.c.o -c ../hello.c [2/2] gcc -o hello hello.p/hello.c.o -Wl,--as-needed -Wl,--no-undefined ``` **Expected behavior** I expected to see `-O0` to be passed as an option to GCC. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)?: **native** * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.): **NixOS** * what Python version are you using e.g. 3.8.0 * what `meson --version`: **0.57.1** * what `ninja --version` if it's a Ninja build: **1.10.2** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: imports/copy question Suppose I have ``` x86 vc15 bin opencv_core310.dll ... ``` directory structure in my package. Is it possible to import `opencv_core310.dll` and friends to project's `bin` folder forgetting all the directory structure? I tried ```python def imports(self): self.copy(\"*.dll\", \"\", \"bin\") ``` but it creates `x86/vc15/bin/opencv_core310.dll` while I would like to get `bin/opencv_core310.dll` Probably import/copy should have `keep_path` parameter like package/copy does? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Conan should recognize elementaryOS as a distro that uses apt elementaryOS is a Linux distro based on Ubuntu. So, it uses `apt`. However, Conan, via the `conans` module, disagrees and says that it does not use `apt` when calling `tools.os_info.with_apt`. ``` Python 3.7.4 (default, Oct 9 2019, 00:16:19) [GCC 7.4.0] on linux Type \"help\", \"copyright\", \"credits\" or \"license\" for more information. >>> from conans import tools >>> tools.os_info.with_apt False ``` Letting Conan know that elementaryOS uses `apt` is important since recipes that have to know whether or not the distro they are running in uses `apt` may have to resort to doing something less than ideal when ran under elementaryOS. For example, using `opengl/system` in a project under elementaryOS will fail (just like [this](https://github.com/bincrafters/community/issues/1216#issuecomment-653540067) in bincrafters/community#1216) because the recipe, as [it is currently is](https://github.com/conan-io/conan-center-index/blob/97d32ad939ce0acebe681201ef95896736ce1946/recipes/opengl/all/conanfile.py#L60) (and supported by conan-io/conan-center-index#2114), fails hard when being used in an unrecognized distro. As such, Conan should be updated to recognize elementaryOS as a distro that uses `apt`. Based on my quick skim of the `conans` module code, it seems that a change in [`client/tools/oss.py:181`](https://github.com/conan-io/conan/blob/d40f2a9f644c390bfaf202a573d7fb999a30949f/conans/client/tools/oss.py#L181) to: ``` # ... apt_distros = (\"debian\", \"ubuntu\", \"knoppix\", \"linuxmint\", \"raspbian\", \"neon\", \"pop\", \"elementary\") # ... ```` should do the trick. Note: `import distro; distro.id()` returns `'elementary'`. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: `toolz.functoolz` is not vendored ### What happened? The following import from the vendored toolz is wrong https://github.com/conda/conda/blob/b9792e1bbb33346b16c89b6e1a39ae678156f331/conda/models/version.py#L8-L11 The `excepts` wrapper is just reimplemented in `conda/_vendor/toolz/__init__.py`. ### Tasks - [x] #12016 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Ernie-M ### Model description Ernie-M looks pretty good in multilingual benchmarks, beating XLM-Roberta. Paddlepaddle recently added ernie-m to the huggingface repo, we can use it with paddlenlp.transformers. Would be nice to have the model supported in huggingface transformer as well. ### Open source status - [X] The model implementation is available - [X] The model weights are available ### Provide useful links for the implementation https://huggingface.co/PaddlePaddle/ernie-m-base https://huggingface.co/PaddlePaddle/ernie-m-large Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: crash of ipython when alias is used with %s and echo This bug is present in alias of magic commands In [1]: alias parts echo first %s second %s In [2]: parts A After executing the first line of command when we give command as parts A instead of printing \"Incorrect number of arguments: 2 expected.\" ipython automatically crashes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: --collaborative flag is not correctly interpreted when jupyter-collaboration package is installed The `--collaborative` flag aims to indicate if JupyterLab should run or not with RTC. When you use use flag without `jupyter-collaboration` package, the server stops with \"To enable real-time collaboration, you must install the extension jupyter_collaboration You can install it using pip for example: python -m pip install jupyter_collaboration\" which is the expected behavior. When `jupyter-collaboration` is installed, the RTC mode is enabled even if you start without the `--collaborative` flag. RTC should be enabled only if you give `--collaborative` (see also https://github.com/jupyterlab/jupyterlab/issues/14715#issuecomment-1615172289) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [UWP] Could not determine vs dep dependency prefix string **Describe the bug** thorvg fails to configure with: `ERROR: Could not determine vs dep dependency prefix string. output: b\"Microsoft (R) C/C++ Optimizing Compiler Version 19.34.31937 for x64\\r\\nCopyright (C) Microsoft Corporation. All rights reserved.\\r\\n\\r\\ncl : Command line error D8048 : cannot compile C file 'incdetect.c' with the /ZW option\\r\\n\" b''` cross file: [meson-x64-uwp-dbg.log](https://github.com/mesonbuild/meson/files/10368128/meson-x64-uwp-dbg.log) (due to #11143 all flags are passed via the compiler) configure log: [config-x64-uwp-dbg-out.log](https://github.com/mesonbuild/meson/files/10368132/config-x64-uwp-dbg-out.log) meson log: [config-x64-uwp-dbg-meson-log.txt.log](https://github.com/mesonbuild/meson/files/10368133/config-x64-uwp-dbg-meson-log.txt.log) pixman for example works fine with the cross file so what is going on here? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: [Primitive-ize API] SchemaField Consistent with the recent work to allow the API to accept some primitives as well as specific objects, the schema argument to `LoadJobConfig`* could accept a list of dicts. Currently it requires constructing a bunch of `SchemaField` objects: ```python schema = [ # could be just column_dicts bigquery.schema.SchemaField.from_api_repr(column_dict) for column_dict in column_dicts ] with open(empty_path, \"rb\") as source_file: job_config = bigquery.job.LoadJobConfig( schema=schema, write_disposition=\"WRITE_TRUNCATE\" ) job = gbq_client.load_table_from_file( source_file, table_ref, location=\"US\", job_config=job_config, ) ``` We're trying to move to using the BQ Python API rather than subprocessing out to a shell with `bq`; it's got much better but it's still a bit Java-esque, and these are examples of times it's a tougher sell than constructing a string a sending it to bash. As ever, lmk if the API isn't designed for these cases and you'd encourage users to use bash. *this could also be a dict, though less of an imperative. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython beta: interactive matplotlib magic breaks terminal (Windows) When activating interactive figures with `%matplotlib`, and after plotting the first figure, the terminal does not capture any keyboard input anymore ``` In [6]: %matplotlib Using matplotlib backend: Qt4Agg In [7]: plt.plot([1,2,3]) Out[7]: [<matplotlib.lines.Line2D at 0xad116a0>] ``` After that, I cannot type or paste anything anymore, also not when the figure is closed. Something with the event loop? I am working on Windows 7, and should be on master for both ipython and prompt toolkit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Up arrow key history search gets stuck in QTConsole With the ipython installed with with commit 50a583890fd0640492fcd76d6ecc97b5c3f23ae0, going through history with up arrow key in qtconsole works without any problem. But in current commit 48b63c19a53f9e26dc4f64150641c730cb6a2305, in qtconsole, it gets \"stuck\" after several items - pressing up arrow key does not do anything. It seems to be happening when the currently showing history is longer than the qtconsole width. Since there are more than 120 commits in between, I haven't tried to identify what was the commit which caused this. Also, in terminal this does not happen. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Docs: More Detail to the Executors Page. Hello! I've found an issue here:`The DaskExecutor is a completely asynchronous engine that can run functions in a distributed Dask cluster. This is the recommended engine for production.` Page reference: https://docs.prefect.io/core/concepts/engine.html#executors What's the difference between the `LocalDaskExecutor` and the `DaskExecutor`? Which should I use if I want to run a local Dask cluster on the machine I deploy with Docker/Kubernetes? We could expand this section a bit more and add an example `RemoteEnvironment` with a an executor. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ccache cannot work on dist builds Due to how the dist build is implemented in Meson, it will always result in ccache being unable to work. The reason for this is the forced use of `mkdtemp` for directories within the `check_dist` function (in `dist.py`). The source is unpacked into `$tmpdir/tmp$string` which is random and thus unable to produce cache hits for subsequent builds. If I am trying to do e.g., a CI dist build, this is not ideal since it makes the build very long. There are two possible solutions I've come up with which could solve the issue: * Add a `DISTBUILDDIR` (or similar) environment variable which is used instead of `mkdtemp` during a dist build; this directory would take the place of the `mkdtemp` directories and would not be deleted when the build stopped * Add a `TMPBUILDSTRING` (or similar) environment variable which is used in place of the random part of the tempdir string (resulting in e.g., /tmp/tmp$string); this directory can still be created and deleted normally, or even deleted if it already exists since we can assume this should only be used for meson dist builds Other solutions would be great too, as long as ccache becomes usable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: SIMD module doesn't respect include_directories This snippet that I'm trying to use in PulseAudio is failing because `topinc` isn't actually added to the list of includes. ``` simd = import('unstable-simd') libpulsecore_simd = simd.check('libpulsecore_simd', sse : ['remap_sse.c', 'sconv_sse.c', 'svolume_sse.c'], neon : ['remap_neon.c', 'sconv_neon.c', 'svolume_neon.c'], include_directories : topinc, compiler : cc) cdata.merge_from(libpulsecore_simd[1]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Fix large constants in activations This fixes an issue where using the elu, selu, or tanh activation results in a constant as big as the input being created. This PR also switches the use of np.where to lax.select for activation functions to avoid accidental broadcasting of scalars in the future. I added a test that verifies that making the jaxpr does not produce constants that scale in size with the input. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: override_options cpp_std does not work for vs backend **Describe the bug** override_options cpp_std is broken with the vs backend while it is ok with the ninja backend. It fails to override **To Reproduce** main.cpp: ```c++ #include <any> int main(int, char *[]) { std::any ret = 0; return std::any_cast<int>(ret); } ``` meson.build : ``` project('vsbackend-override-options', 'cpp', version : '1.0', default_options : ['cpp_std=c++11',]) executable('override-options', 'main.cpp', override_options: 'cpp_std=c++17') ``` ```shell meson --vsenv --backend=vs2017 builddir meson compile -C builddir ``` **Expected behavior** Compiles with vs2017 (and others) backend. **system parameters** * plain native build * Windows 10 * Python 3.10.3 * Meson 0.62.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax missing scipy.special.expit Would be possible to add gradients for `expit` and `logit`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] components versions and generators When using a recipe declaring components, the global version of the recipe does not seem to be propagated to the components, which can be seen when using `pkg_config` generator This is a problem, because some libraries check their requirements' version via pkg-config, eg https://gitlab.gnome.org/GNOME/atk/-/blob/master/meson.build#L98, so currently they fail to use conan generated pkg-config files ### Environment Details (include every applicable attribute) * Conan version: 1.28.0 ### Steps to reproduce (Include if Applicable) checkout https://github.com/conan-io/conan-center-index/tree/dedc63dc32ca949f0b6448b72fce3efeb1212a3f/recipes/glib/all `conan create . glib/2.65.0@` ### Logs (Executed commands with output) (Include/Attach if Applicable) generated `glib.pc` (the package-wide file) has `Version: 2.65.0` generated `gio-2.0.pc` (component file) has `Version: None` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: default_package_id_mode is not in the default conan.conf The config should be there when a fresh `conan.conf` is created. I would like it to be non-commented and using the default value `semver_direct_mode`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Pass output from all val dataloaders to `validation_end` **Is your feature request related to a problem? Please describe.** I'm working on a retrieval problem. To compute validation scores, I'd like to compute feature vectors for a query set and a catalog set, then measure information retrieval metrics (precision, recall, etc) of the query set against the catalog set. To do this, I'd like to return the two datasets from `val_dataloader` (already possible), then use `validation_step` to accumulate all the feature vectors for each dataset (already possible). Once I have all the feature vectors, I need some way to bring the vectors from the two datasets together so that I can compute retrieval metrics. Right now, `validation_end` processes the outputs of multiple validation dataloaders separately. **Describe the solution you'd like** Change the behavior of `validation_end` in cases where there are multiple validation dataloaders. I propose that it only be called once, but that it be passed a list of outputs dicts, one from each dataloader. Using it would look something like this: ```python def validation_end(self, outputs): query_output, catalog_output = outputs query_vectors = torch.cat([o['vectors'] for o in query_output]) query_labels = torch.cat([o['labels'] for o in query_output]) catalog_vectors = torch.cat([o['vectors'] for o in catalog_output]) catalog_labels = torch.cat([o['labels'] for o in catalog_output]) return retrieval_metrics( query_vectors, query_labels, catalog_vectors, catalog_labels ) ``` **Describe alternatives you've considered** * Breaking outside of lightning entirely to do validation * Concatenating query and catalog datasets, and somehow adding a flag to indicate which dataset a given example came from Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for variable width operations to Target ### What should we add? Right now the target class doesn't have proper support for modelling instructions that have variable width. If you have a gate that can use more than a single number of qubits and the backend supports all variants of that instruction (or at least more than one). We don't have a way to express that. The target currently requires a 1:1 mapping of operation name to a `Operation` instance and that instance is used for type checking and parameter checking at different points in the transpiler. However this requirement won't work for variable width instructions because a single instance of the instructions can only have a single number of qubits. To be able to accurately model these instructions being supported on a target backend we need to come up with an interface to model this in the target, which might mean introducing a `TargetV2`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: composite gates do not have definition when qasm()'d # Information - **Qiskit Terra version**: master - **Python version**: 3.7 ### What is the current behavior? ```python from qiskit import QuantumCircuit, QuantumRegister rinv_q = QuantumRegister(1, name='q') rinv_gate = QuantumCircuit(rinv_q, name='rinv') rinv_gate.sdg(rinv_q) rinv_gate.h(rinv_q) rinv_gate.sdg(rinv_q) rinv_gate.h(rinv_q) rinv = rinv_gate.to_instruction() qr = QuantumRegister(1, name='qr') circuit = QuantumCircuit(qr, name='circuit') circuit.append(rinv, [qr[0]]) print(circuit.qasm()) ``` ``` OPENQASM 2.0; include \"qelib1.inc\"; qreg qr[1]; rinv qr[0]; ``` ### What is the expected behavior? ``` OPENQASM 2.0; include \"qelib1.inc\"; gate rinv q {sdg q; h q; sdg q; h q; } # <--- the definition of rinv qreg qr[1]; rinv qr[0]; ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Possible pickle issues https://github.com/huggingface/transformers/blob/af2aac51fc1c59237ff7228908ace2cd8fc0d9a6/src/transformers/optimization.py#L49 When attempting to pickle this function, there is a potential for an error to occur due to the lambda function that cannot be pickled. I suggest the following solution for this problem. ``` def get_constant_lambda(_): return 1 def get_constant_schedule(optimizer: Optimizer, last_epoch: int = -1): \"\"\" Create a schedule with a constant learning rate, using the learning rate set in optimizer. Args: optimizer ([`~torch.optim.Optimizer`]): The optimizer for which to schedule the learning rate. last_epoch (`int`, *optional*, defaults to -1): The index of the last epoch when resuming training. Return: `torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule. \"\"\" return LambdaLR(optimizer, get_constant_lambda, last_epoch=last_epoch) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Operator task behavior is unintuitive/misleading The docstrings for the various logical `Operator` tasks suggest that they just call the corresponding Python operator. So I would expect `Or(x, y)` to return `x or y` instead of `bool(x or y)`: https://github.com/PrefectHQ/prefect/blob/07cb6c20342c4053a3eaaaf885670ae5dfd6e74d/src/prefect/tasks/core/operators.py#L233-L254. If there's a specific reason why these have to return boolean results, then at least the docstrings should probably be updated to reflect that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: 1.3 regression: AutoToolsBuildEnvironment now aborts on self-defined architectures With 1.3 our AutoTools packages started to fail on architectures that we define ourselves in settings.yml, these includes: `aarch64`, `armv7hf-sysv` etc. The error message we get is: `conans.errors.ConanException: Unknown 'armv7hf-sysv' machine. Conan doesn't know how to translate it to the GNU triplet, please report at https://github.com/conan-io/conan/issues` This is a breaking change and while the warning is probably good it breaks our current packages without changes to conan. Ideally this warning should be not an error but a warning to not break current packages and maybe make it configurable in the future. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: TST: Add the first test using hypothesis This pull request adds the first test that uses hypothesis and hence brings in hypothesis as an additional test dependency. @mattip Could you take a look at this please? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Q-sphere phase colors does not match IQX phase colors <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? As pointed out by @HwajungKang, it is a bit tricky to figure out that the color wheels are more or less rotated by pi. It is even harder to decode due to the implicit phase re-normalization in the Qiskit Q-sphere that is not mentioned anywhere: https://github.com/Qiskit/qiskit-terra/blob/dc3a2a667b8dc22512ca409ecae347d8dbdd944c/qiskit/visualization/state_visualization.py#L761 Qiskit: <img width=\"128\" alt=\"Screen Shot 2020-10-01 at 13 21 55\" src=\"https://user-images.githubusercontent.com/1249193/94842179-159ff580-03e9-11eb-912f-02376c352362.png\"> IQX: <img width=\"193\" alt=\"Screen Shot 2020-10-01 at 13 18 43\" src=\"https://user-images.githubusercontent.com/1249193/94842190-19337c80-03e9-11eb-867d-50d48288c6e7.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Provide a method to convert ndb Key's urlsafe format to/from datastore.Key In GAE standard, ndb has the concept of the urlsafe string version of a Key. e.g. `url_string = sandy_key.urlsafe()` produces a result like `agVoZWxsb3IPCxIHQWNjb3VudBiZiwIM`. However, I cannot find a way to use this format with the google.cloud.datastore library for code running outside GAE standard. Please add a method to the Key class to create urlsafe strings and a method to generate Keys from urlsafe strings. Alternatively, provide some documentation on how to decode/encode them with the existing library. NB, the [console support page](https://support.google.com/cloud/answer/6365503?hl=en) says \"The encoding method is available in any Cloud Datastore client library.\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Renaming repo qiskit-core <!--- Provide a general summary of the issue in the Title above --> Not saying to do now l. Just want to make an issue to remind us and inform the community. ## Expected Behavior <!--- If you're describing a bug, tell us what should happen --> <!--- If you're suggesting a change/improvement, tell us how it should work --> ## Current Behavior <!--- If describing a bug, tell us what happens instead of the expected behavior --> <!--- If suggesting a change/improvement, explain the difference from current behavior --> ## Possible Solution <!--- Not obligatory, but suggest a fix/reason for the bug, --> <!--- or ideas how to implement the addition or change --> ## Steps to Reproduce (for bugs) <!--- Provide a link to a live example, or an unambiguous set of steps to --> <!--- reproduce this bug. Include code to reproduce, if relevant --> 1. 2. 3. 4. ## Context <!--- How has this issue affected you? What are you trying to accomplish? --> <!--- Providing context helps us come up with a solution that is most useful in the real world --> ## Your Environment <!--- Include as many relevant details about the environment you experienced the bug in --> * Version used: * Environment name and version (e.g. Python 3.6.1): * Operating System and version: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: bigquery.ArrayQueryParameter should be able to accept structs as elements of the array I [commented](https://github.com/GoogleCloudPlatform/google-cloud-python/pull/2901#discussion_r94066868) that setting the types on array query parameters needs to be recursive since the array could contain structs. Note that [arrays cannot contain arrays](https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#array-type) (the workaround is to contain a struct which can then contain an array). It's not clear how one would do this with the current `ArrayQueryParameter` constructor. ``` bigquery.ArrayQueryParameter( name='myarray', type='STRUCT', # Note: this isn't enough information to construct the type object. values=? # What would go here? Dictionaries? That doesn't match other uses of StructQueryParameter. ) ``` Maybe we need to change how array query parameters are constructed? Maybe it should look more like the StructQueryParameter constructor? ``` bigquery.ArrayQueryParameter(name, *sub_params) ``` It'd be a pain for scalar values and the names would have to be ignored on the `sub_params` if provided, but it's more flexible. *An aside* *I'd actually love if we could get rid of all the `XQueryParameter` classes and use lists, dicts, and ints, floats, etc. But I see that it might be ambiguous for [some types](https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types) especially `DATETIME` (no time zone) vs `TIMESTAMP` (stored as UTC time).* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Solver plugin hook incompatible with user_agent feature ### Checklist - [X] I added a descriptive title - [X] I searched open reports and couldn't find a duplicate ### What happened? When trying to use the conda solver plugin hook, the `user_agent` method is called on an instance of the backend, even though the API requires it to be called on the backend class itself, since it's a staticmethod. Exception: ``` Traceback (most recent call last): File \"/opt/conda-src/conda/base/context.py\", line 849, in user_agent user_agent_str += f\" {solver_backend().user_agent()}\" TypeError: __init__() missing 2 required positional arguments: 'prefix' and 'channels' ``` ### Conda Info _No response_ ### Conda Config _No response_ ### Conda list _No response_ ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Create 0.6 release notes <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? As this is a \"major\" release, we should prepare some release notes for 0.6, ideally starting working in them sooner rather than later for the benefit of early adopters and similar cases. 0.5 was the first release where we included the release notes - the plan is that they include: * a summary of the noteworthy changes (keeping in mind that the full changelog will also be automatically available for finer details) * a `Upgrading to 0.6` section, with instructions on how to make us of the new features and cope with the breaking changes (basically a \"helper for a smooth transition\") #### References https://qiskit.org/documentation/releases.html#qiskit-sdk-0-5-0 https://github.com/Qiskit/qiskit-terra/blob/0.5.7/doc/releases.rst Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: dagster-slack apidoc still refers to solids and pipelines https://docs.dagster.io/_apidocs/libraries/dagster-slack Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: namedtuple support in arguments to transformed functions It would be great if `xla.abstractify` would also accept namedtuples. Loop state's can consist of quite a lot of values and organizing them in a namedtuple rather than a tuple would make things nicer. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: enable getting upstream asset PartitionsDefinition from InputContext Potential wrinkle: what if the input is a fan-in that's fed by multiple upstream outputs? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Markdown with Mathjax fails during HTML export This Markdown block is failing for us. (extra `<em>` inserted due to `_`) ``` Water that is stored in $t$, $s_t$, must equal the storage content of the previous stage, $s_{t-1}$, plus a stochastic inflow, $I_t$, minus what is being released in $t$, $r_t$. With $s_0$ defined as the initial storage content in $t=1$, we have ``` Is this an issue with #6028 or is the inline Mathjax wrong? I checked the Regex and they are OK. Maybe the problem is at another place? Any pointers? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Scale attribute ignored when set to 0 ## Description of the issue I want some containers scaled down completely by default and only scaled up when needed. I can't set a container to scale 0 via the `docker-compose.yml` file, but I _can_ do this by passing `--scale busybox=0` to the up command. ## Context information (for bug reports) **Output of `docker-compose version`** ``` docker-compose version 1.24.0-rc1, build 0f3d4dda docker-py version: 3.7.0 CPython version: 3.6.6 OpenSSL version: OpenSSL 1.1.0h 27 Mar 2018 ``` **Output of `docker version`** ``` Client: Docker Engine - Community Version: 18.09.2 API version: 1.39 Go version: go1.10.8 Git commit: 6247962 Built: Sun Feb 10 04:12:39 2019 OS/Arch: darwin/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 18.09.2 API version: 1.39 (minimum version 1.12) Go version: go1.10.6 Git commit: 6247962 Built: Sun Feb 10 04:13:06 2019 OS/Arch: linux/amd64 Experimental: true ``` **Output of `docker-compose config`** (Make sure to add the relevant `-f` and other flags) ``` services: busybox: command: sleep 10000 image: busybox scale: 0 version: '2.4' ``` ## Steps to reproduce the issue 1. Create a docker-compose.yml with the following contents ``` version: \"2.4\" services: busybox: image: busybox cmd: sleep 10000 scale: 0 ``` 2. Run `docker-compose up -d` ### Observed result Docker compose creates and starts a single container. ### Expected result Docker compose should output nothing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Contents Manager does not get passed config ? I can't seem to have my custom contents manager receive a config. In sessionmanager we seem to have `contents_manager = Instance('IPython.html.services.contents.manager.ContentsManager', args=())` but nowhere is it passed parent or config. Is that normal ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Policy Type Missing Hi Team, In google-bigquerydatapolicy we have only 3 data policy types defined in [1]. But in google documentation[2] there are 7 types can we add it to the SDK [1] https://cloud.google.com/python/docs/reference/bigquerydatapolicy/latest/google.cloud.bigquery.datapolicies_v1.types.DataMaskingPolicy.PredefinedExpression [2] https://cloud.google.com/bigquery/docs/column-data-masking-intro#masking_options Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: Using offset greater than 1000 on a query doesn't work #### Environment details macOS Mojave 10.14.1 Python 3.6 google-cloud-firestore==0.30.0 #### Steps to reproduce 1. Create a query to get a large collection (over 1000 documents) 2. Add an offset greater than 1000 to the query 3. Get the query and iterate over the documents 4. You should get an exception about having no documents #### Code example ```python from google.cloud import firestore client = firestore.Client() documents = client.collection('Collection').order_by('field').offset(1001).get() for document in documents: pass ``` #### Stack trace ``` ValueError: Unexpected server response. All responses other than the first must contain a document. The response at index 1 was read_time { seconds: 1544736718 nanos: 109409000 } skipped_results: 1 . ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: BUG: (Unintended?) Interaction between -n and -i arguments to %run The documentation states that `-i` would run the script in the present notebook's namespace while `-n` would prevent the `__name__` in the script from being set to `__main__`, thereby preventing execution of code hidden behind the `if __name__ == '__main__':` check. However, [the code](https://github.com/ipython/ipython/blob/master/IPython/core/magics/execution.py#L665) only takes the `-n` into account only if `-i` is NOT passed to the `%run` (i.e. in the `else` branch). Shouldn't it be handled before checking for `-i`? Or is it necessary to change the `__name__` of the program set to `__main__` to run it in the namespace of the notebook? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: tarball install windows @msarahan @mingwandroid What _should_ the `file://` url format be on Windows? ``` ________________________ IntegrationTests.test_python3 ________________________ Traceback (most recent call last): File \"C:\\projects\\conda\\tests\\test_create.py\", line 146, in test_python3 run_command(Commands.INSTALL, prefix, flask_tar_file) File \"C:\\projects\\conda\\tests\\test_create.py\", line 104, in run_command args.func(args, p) File \"C:\\projects\\conda\\conda\\cli\\main_install.py\", line 62, in execute install(args, parser, 'install') File \"C:\\projects\\conda\\conda\\cli\\install.py\", line 195, in install explicit(args.packages, prefix, verbose=not args.quiet) File \"C:\\projects\\conda\\conda\\misc.py\", line 111, in explicit index.update(fetch_index(channels, **fetch_args)) File \"C:\\projects\\conda\\conda\\fetch.py\", line 266, in fetch_index for url in iterkeys(channel_urls)] File \"C:\\projects\\conda\\conda\\fetch.py\", line 67, in func res = f(*args, **kwargs) File \"C:\\projects\\conda\\conda\\fetch.py\", line 149, in fetch_repodata raise RuntimeError(msg) RuntimeError: Could not find URL: file:///C|/projects/conda/ ---------------------------- Captured stdout call ----------------------------- ``` The relevant lines to look at here are line 64 in `conda/misc.py` ``` url_p = utils_url_path(url_p).rstrip('/') ``` and line 147 in `conda/utils.py` ``` def url_path(path): path = abspath(path) if sys.platform == 'win32': path = '/' + path.replace(':', '|').replace('\\\\', '/') return 'file://%s' % path ``` Help here is definitely appreciated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: mpl drawer modifies instruction params <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? ```python import numpy as np from qiskit.circuit import QuantumCircuit, QuantumRegister from qiskit.quantum_info.random import random_unitary q = QuantumRegister(2) qv = QuantumCircuit(q) U = random_unitary(4) qv.append(U, [q[0], q[1]]) print(qv.data[0][0].params) qv.draw(output='mpl') print(qv.data[0][0].params) ``` Before the drawer, it is a numpy array, after, it becomes a string. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: collecting \".bc\" files in collect_libs() for emscripten packages collect_libs currently collects only .lib,.so,.a,.dylib files. emscripten generates ```.bc``` files for libraries. It would be nice to have that too, or provide a parameter for pattern apart from default patterns. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: enable multiple calls to `add_output_metadata` inside an IOManager to combine metadata Currently, successive calls to `add_output_metadata` will overwrite each other. It would be helpful to merge them. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Min (max) conan version checks from conan.conf Companies would like to introduce a check to guarantee that everyone is using the same version of conan. That should be an easy check with a config in conan.conf. Possibilities?: - A min-version check - A max-version check - An exact version check - A range The modes could be raise or warn. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Unable to use nested lists in DAG markdown documentation **Apache Airflow version**: 2.0.2 **What happened**: Tried to use the following markdown as a `doc_md` string passed to a DAG ```markdown - Example - Nested List ``` It was rendered in the web UI as a single list with no nesting or indentation. **What you expected to happen**: I expected the list to display as a nested list with visible indentation. **How to reproduce it**: Try and pass a DAG a `doc_md` string of the above nested list. I think the bug will affect any markdown that relies on meaningful indentation (tabs or spaces) doc_md code block collapsing lines **Apache Airflow version**: 2.0.0 - 2.1.0 **Kubernetes version**: N/A **Environment**: - **Cloud provider or hardware configuration**: Docker on MacOS (but also AWS ECS deployed) - **OS** (e.g. from /etc/os-release): MacOS Big Sur 11.3.1 - **Kernel** (e.g. `uname -a`): Darwin Kernel Version 20.4.0 - **Install tools**: - **Others**: **What happened**: When a code block is a part of a DAG's `doc_md`, it does not render correctly in the Web UI, but collapses all the lines into one line instead. **What you expected to happen**: The multi line code block be rendered with line breaks preserved. **How to reproduce it**: Create a DAG with `doc_md` containing a code block: ````python from airflow import DAG DOC_MD = \"\"\"\\ # Markdown code block Inline `code` works well. ``` Code block does not respect newlines ``` \"\"\" dag = DAG( dag_id='test', doc_md=DOC_MD ) ```` The rendered documentation looks like this: <img src=\"https://user-images.githubusercontent.com/11132999/119981579-19a70600-bfbe-11eb-8036-7d981ae1f232.png\" width=\"50%\"/> **Anything else we need to know**: N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Code to compute concurrence is wrong <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.10.0 - **Python version**: 3.7 - **Operating system**: Linux ### What is the current behavior? The routine 'concurrence' in qiskit/tools/qi/qi.py is wrong, the matrix A = rho.dot(YY).dot(rho.conj()).dot(YY) is not necessarily Hermitian but the Hermitian eigensolver is used to get it's eigenvalues. This can produce negative eigenvalues even though the matrix A is positive semidefinte. ### Steps to reproduce the problem It is sufficient to use an entangled density matrix like array([[0.20194612+0.j, 0.25967063+0.j, 0.27702504+0.j, 0.13035404+0.j], [0.25967063+0.j, 0.33389518+0.j, 0.3562102 +0.j, 0.16761458+0.j], [0.27702504+0.j, 0.3562102 +0.j, 0.38001657+0.j, 0.17881667+0.j], [0.13035404+0.j, 0.16761458+0.j, 0.17881667+0.j, 0.08414212+0.j]]) and check that the eigenvalues returned by the hermitian eigensolver are [-0.0971868 -0.08020192 -0.0104574 0.39189013] ### What is the expected behavior? For the density matrix above the correct eigenvalues are [0.00000000e+00 0.00000000e+00 6.45239207e-09 4.51712320e-01] ### Suggested solutions Replace the following 2 lines of the concurrence routine w = la.eigh(A, eigvals_only=True) w = np.sqrt(np.maximum(w, 0)) with the correct ones w = la.eigvals(A).real isort = np.argsort(w) w = np.sqrt(np.maximum(w[isort[:]],0.)) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make mpl colors and other styles fully configurable by users with a json load <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In #5063, the IQX color scheme was added as an option to the mpl drawer. The style dict entry, 'displaycolor' was expanded to include new gates and to allow for entering both gate and text color for each gate type. This expands color choices to include dark gate colors with light text. This first phase was done by creating 3 classes in qcstyle.py. In this next phase, this can be reduced to 1 default class and the additional styles would be read in from json files. I don't believe users should be allowed to edit these 3 json files - default, iqx, and bw - directly, but they can copy these and create new styles of their own. This issue proposes to make default, iqx, and bw json style files part of qiskit, perhaps in a styles directory under the visualization directory. User json files should go in a fixed place, perhaps in a styles directory under ~/.qiskit. The code for reading in the json files already exists, though there is only minimal error checking currently. Deciding on the locations for the files is the main issue. We might want to look at any possible special cases, like the controlled classical gates in iqx and see if any of these can be addressed in a generic way. Right now all a user can do with color is change the colors of the specific gate names in 'displaycolor'. Any of the other documented style dict items can be set in the user json file. The user can create a partial style dict in the file, and only those elements entered will be changed for that style. The user interface is simple - `qc.draw('mpl', style='user_style1.json')` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Longformer global attention mask, 2 or 1? This example in the LongFormer documentation (https://huggingface.co/transformers/model_doc/longformer.html ) ``` attention_mask[:, [1, 4, 21,]] = 2 # Set global attention based on the task. For example, ... # classification: the <s> token ... # QA: question tokens ... # LM: potentially on the beginning of sentences and paragraphs ``` seems to mislead the user to put a 2 as the global attention mask instead of a 1 this is described in the actual documentation. I'm guessing this is a mistake because (a) the example is directly copied from the AllenAI (https://github.com/allenai/longformer#how-to-use), and (b) the source code actually adds a +1 to the attention mask in the function `_merge_to_attention_mask` (https://huggingface.co/transformers/_modules/transformers/modeling_longformer.html#LongformerModel.forward). Could the documentation please be fixed or clarified? Thanks! Also what is the 1, 4, 21 in that example? ### Who can help Longformer/Reformer: @patrickvonplaten ## Information Model I am using (Bert, XLNet ...): LongFormer Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: remove dist from resolve.py Dist is no longer needed, and it's time to remove it from the code base. The first step is to remove all `dist` references from `resolve.py`, in a way that `py.test tests/test_resolve.py` passes. Once that's done, we can extract `dist` from the remainder of the code base. CC @mcg1969 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda config --get throws a traceback ``` (/root/dev) [root@21ca1df2ceaa conda]# conda config --set verbosity 1 (/root/dev) [root@21ca1df2ceaa conda]# conda config --get verbosity # >>>>>>>>>>>>>>>>>>>>>> ERROR REPORT <<<<<<<<<<<<<<<<<<<<<< Traceback (most recent call last): File \"/root/dev/lib/python3.6/site-packages/conda/exceptions.py\", line 1001, in __call__ return func(*args, **kwargs) File \"/root/dev/lib/python3.6/site-packages/conda/cli/main.py\", line 84, in _main exit_code = do_call(args, p) File \"/root/dev/lib/python3.6/site-packages/conda/cli/conda_argparse.py\", line 81, in do_call exit_code = getattr(module, func_name)(args, parser) File \"/root/dev/lib/python3.6/site-packages/conda/cli/main_config.py\", line 28, in execute execute_config(args, parser) File \"/root/dev/lib/python3.6/site-packages/conda/cli/main_config.py\", line 255, in execute_config numitems = len(items) TypeError: object of type 'int' has no len() `$ /root/dev/bin/conda config --get verbosity` ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cmake module does not sanitize variable names when generating meson.build **Describe the bug** If a subproject that uses CMake names a library with something outside of alphanumeric and underscore characters, the meson module does not sanitize the name, resulting in a failed build. For example if the `CMakeLists.txt` file contains: ``` ... add_library(grpc++ src/cpp/client/insecure_credentials.cc ... src/cpp/codegen/codegen_init.cc ) set_target_properties(grpc++ PROPERTIES VERSION ${gRPC_CPP_VERSION} SOVERSION ${gRPC_CPP_SOVERSION} ) ... ``` **To Reproduce** Encountered this with gRPC: ``` $ cd subprojects $ git submodule add https://github.com/grpc/grpc.git $ git submodule sync --recursive $ git submodule update --init --recursive -- grpc $ meson out $ ninja -C out ... subprojects/grpc/meson.build:0:0: ERROR: Invalid variable name: cm_grpc++_dir A full log can be found at /mnt/data/extra/achang/src/chillfs/out/meson-logs/meson-log.txt FAILED: build.ninja ``` Here's a snippet of `meson.build` to include it: ``` cmake = import('cmake') grpc_proj = cmake_native.subproject('grpc') grpc_dep = grpc_proj.dependency('grpc_dep') deps += grpc_dep executable( 'myprogram', dependencies : deps, install : true ) ``` **Expected behavior** Can build the library and use it as a subproject. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? **plain native build** * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.): **Archlinux, but likely an issue everywhere** * what Python version are you using? **3.8.1** * what `meson --version`? **0.53.0** * what `ninja --version` if it's a Ninja build? **1.9.0** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda 4.2 branch doesn't support CIO_TEST. In config.py in `conda 4.1.x` I see: ``` def get_channel_urls(platform=None): if os.getenv('CIO_TEST'): import cio_test base_urls = cio_test.base_urls ``` cio_test is not imported anywhere in 4.2. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: public_url returning quoted_name with '/' i'm adding my files inside folders, so i give the blob name as `\"UUID/file.ext\"`, but when i request the [public_url()](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/d0cfeb772fd612179984a191be1d8189b369a2c5/storage/google/cloud/storage/blob.py#L224) i get the fullname as [quoted](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/d0cfeb772fd612179984a191be1d8189b369a2c5/storage/google/cloud/storage/blob.py#L233) example: `\".../MYBUCKET/UUID%2Ffile.ext\"` both `\"%2F\"` and `\"/\"` in the link downloads the same file, but with different names Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: log_driver: none causes \" Failed to get logging factory: logger: no log driver named 'none' is registered\" message I'm using docker and docker-compose from homebrew (with boot2docker/docker-machine): ``` $ docker -v Docker version 1.8.1, build d12ea79 ``` ``` $ docker-compose --version docker-compose version: 1.4.0 ``` The docker daemon version is: ``` $ boot2docker ssh docker -v Docker version 1.8.0, build 0d03096 ``` I'm specifying my `log_driver` in the `docker-compose.yml` file as per https://docs.docker.com/compose/yml/#log-driver, and setting it to `none`: `docker-compose.yml`: ``` helloworld: image: busybox command: echo \"Hello World!\" log_driver: none ``` I'm getting the following error when I 'docker-compose up`: ``` ~/dockercompose-test ❯❯❯ docker-compose up Starting dockercomposetest_helloworld_1... Attaching to dockercomposetest_helloworld_1 helloworld_1 | taching: Failed to get logging factory: logger: no log driver named 'none' is registered dockercomposetest_helloworld_1 exited with code 0 Gracefully stopping... (press Ctrl+C again to force) ``` The weird thing is this worked in lower versions of docker-compose and docker. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [autoformatters] wrapping destroying items/lists # 🚀 Feature request Would it be possible to make the auto-wrappers respect items/lists? e.g. ended up with: ``` \"\"\" number of training steps is either 1. args.max_steps if --max_steps > 1 2. else derive from dataset if we can get its size \"\"\" ``` not only it's broken, it's unreadable. The original was: ``` \"\"\" number of training steps is either 1. args.max_steps if --max_steps > 1 2. else derive from dataset if we can get its size \"\"\" ``` Ideally it should not remove new lines before bullets */- and numbers 1. I also am not sure why there is a need to merge lines when the writer meant them to be shorter. I get the shortening, but why can't short lines be left alone. Which would be the case in this example. It looks like the only way I can enforce readable content is to inject paragraphs. Thank you! @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Spurious '-find' argument to XCRun <!-- Please don't forget to update the issue title. Include all applicable information to help us reproduce your problem. To help us debug your issue please explain: --> ### Environment Details (include every applicable attribute) * Operating System+version: Linux / Mac OS X * Compiler+version: clang 10.0 * Conan version: 1.32.1 * Python version: 3.8.5 ### Steps to reproduce (Include if Applicable) Attempt to cross-compile boost with `compiler=apple-clang` in the profile on Linux using the [osxcross](https://github.com/tpoechtrager/osxcross) toolchain. ### Logs (Executed commands with output) (Include/Attach if Applicable) ``` ERROR: boost/1.75.0: Error in build() method, line 649 self._create_user_config_jam(self._boost_build_dir) while calling '_create_user_config_jam', line 1003 contents += \" -isysroot %s\" % tools.XCRun(self.settings).sdk_path CalledProcessErrorWithStderr: Command 'xcrun -find -sdk macosx --show-sdk-path' returned non-zero exit status 1. ``` The Boost recipe attempts to run `xcrun -find -sdk macosx --show-sdk-path` which is an illegal command line. Tthe original Apple `xcrun` tool just ignores the superfluous `-find`, but the osxcross one silently errors out with return code 1. To fix this, the `-find` argument should be removed from ```python def _invoke(self, args): def cmd_output(cmd): return check_output_runner(cmd).strip() command = ['xcrun', '-find'] if self.sdk: command.extend(['-sdk', self.sdk]) command.extend(args) return cmd_output(command) ``` in the `apple.py` file. The `find` function already adds the `--find` argument when finding tools. I'll submit a PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: pprint methods for collections use hard-wired class names The pprint methods for collections classes (`_defaultdict_pprint`, _`ordereddict_pprint`, `_deque_pprint`, and `_counter_pprint`) have explicit class names in the function. This gives inconsistent results when using subclasses of these classes. For example `nltk.FreqDist` is a subclass of `collections.Counter`: ``` python In [60]: pprint() Pretty printing has been turned ON In [61]: x = nltk.FreqDist(['a','b','a']) In [62]: x Out[62]: Counter({'a': 2, 'b': 1}) In [63]: pprint() Pretty printing has been turned OFF In [64]: x Out[64]: FreqDist({'a': 2, 'b': 1}) ``` I can't say I fully understand how the pretty printing dispatch works, but I think the fix is to replace this: ``` python def _counter_pprint(obj, p, cycle): name = 'Counter' with p.group(len(name) + 1, name + '(', ')'): if cycle: p.text('...') elif len(obj): p.pretty(dict(obj)) ``` with something like: ``` python def _counter_pprint(obj, p, cycle): name = obj.__class__.__name__ with p.group(len(name) + 1, name + '(', ')'): if cycle: p.text('...') elif len(obj): p.pretty(dict(obj)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add one time warning when calling dt that it has changed from ns to s <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Recently `dt` in the pulse configuration has changed from `ns` to `s`. A warning that is emitted once per-call should be added. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.left_shift and np.right_shift should infer types from second arg <!-- Please describe the issue in detail here, and fill in the fields below --> `np.left_shift` and `np.right_shift` shouldn't change the dtype of the first argument to match that of the second argument. It took me a few hours to relearn bit shifting before realizing that it was NumPy's fault and why there was such behavior. <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np np.left_shift(np.uint8(255), 1) # 510 - incorrect np.left_shift(np.uint8(255), np.uint8(1)) # 254 - correct ``` <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> 1.15.1 3.7.0 (default, Jun 28 2018, 07:39:16) [Clang 4.0.1 (tags/RELEASE_401/final)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add RESUME state Following some discussion on reacting to states, we will implement a `Resume` state that subclasses `Scheduled` (and should have a default `start_time` of `pendulum.now('utc')`) When the `TaskRunner` sees a `Resume` state, it should set the task context appropriately and then run the task. This will make pause/resume super clean: want to pause a task? Put it in a pause state! Want to resume the task? Put it in a resume state! *NB: some relevance to #88, in that we no longer need dedicated endpoints -- resuming is just a state change mutation. However we may still want ways to easily generate the API calls.* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: AsyncResult.wait(0) can hang waiting for the client to get results? I have some code that runs multiple maps on a load balanced view. I run the code on a remote ipengine that I'm connected to via ssh; the client is running locally in an ipython notebook. The individual tasks take some time to run, perhaps a minute or two each. It appears that AsyncResult instances can end up in a situation where all outstanding jobs for the are finished, but where the outputs are not actually ready for the client yet. Thus _ready is not set, and somehow wait(0) ends up at self._wait_for_outputs(10) (line 161 of asyncresult.py). This hangs for ten seconds owing to the ten second timeout. As a result, any function which uses wait(0) will hang for ten seconds before returning, including AsyncResult.progress. While I'm not exactly sure _why_ this is happening, it seems like it can be solved reasonably easily by changing 10 to timeout, thus causing the timeout there to honor the timeout given to wait. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add a --timeout parameter to `docker-compose scale` AFAIK, when you scale down a service, the excess containers get an stop command. However, they can get killed prematurely if the stop is not quick enough. Allowing for a stop timeout as it's done in 'docker stop' would solve this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Unexpected behaviour for 'env_reader.get_env' Behaviour for `env_reader.get_env` ([link](https://github.com/conan-io/conan/blob/e018e0ff0e7f6addf76cf589f471edc23569939d/conans/util/env_reader.py#L12)): ```python def get_env(env_key, default=None, environment=None): if environment is None: environment = os.environ env_var = environment.get(env_key, default) if env_var != default: if isinstance(default, str): ... elif isinstance(default, list): return [var.strip() for var in env_var.split(\",\")] return env_var ``` From my point of view the following is unexpected: ```bash >>> from conans.util.env_reader import get_env >>> env = {'CONAN_HOOKS': ''} >>> get_env('CONAN_HOOKS', default=list(), environment=env) [''] ``` IMO, it should return an empty list. ---- I found this making some trials with hooks, once you deactivate all the hooks you have a `conan.conf` file with an empty section: ```ini [hooks] ``` and then, when executing any command, it gives me the following warning: `WARN: Hook '.py' not found in /Users/jgsogo/.conan/hooks folder. Please remove hook from conan.conf or include it inside the hooks folder.` So, if you don't consider the previous behavior as unexpected, then an additional check should be added to the `HookManager` to avoid the warning. cc/ @conan-io/barbarians Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore fetch needs to encapsulate all gRPC errors This code: ``` python try: start_date = datetime.datetime(1990, 1, 1) query = client.query(kind='Task') query.add_filter( 'created', '>', start_date) query.add_filter( 'priority', '>', 3) return list(query.fetch()) except google.cloud.exceptions.BadRequest: pass ``` Raises a `grpc._channel._Rendezvous` exception instead of an expected subclass of `google.cloud.exceptions.BadRequest` (I'd also accept `google.cloud.exceptions.GoogleCloudError`): ``` grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with (StatusCode.INVALID_ARGUMENT, Cannot have inequality filters on multiple properties: [created, priority])> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Crash Ultratraceback/ session history ``` print(\"\\x\") ``` In Notebook make ultratraceback not behave : ``` Traceback (most recent call last): File \"/Users/matthiasbussonnier/ipython/IPython/kernel/zmq/ipkernel.py\", line 378, in execute_request shell.run_cell(code, store_history=store_history, silent=silent) File \"/Users/matthiasbussonnier/ipython/IPython/core/interactiveshell.py\", line 2676, in run_cell self.showsyntaxerror() File \"/Users/matthiasbussonnier/ipython/IPython/core/interactiveshell.py\", line 1774, in showsyntaxerror stb = self.SyntaxTB.structured_traceback(etype, value, []) File \"/Users/matthiasbussonnier/ipython/IPython/core/ultratb.py\", line 1205, in structured_traceback if isinstance(value.filename, py3compat.string_types) \\ AttributeError: 'exceptions.ValueError' object has no attribute 'filename' ERROR! Session/line number was not unique in database. History logging moved to new session 13867 ``` Of course not hightlighted, kernel does not dies, but no prompt number returned. (that's not master as I merged a few branch in it, but it shoudln't have any effect, and I can't test on master now) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: vmap of pmap gives wrong shape When I do a batched pmap (vmap over pmap), I can access the batch dimension inside the vmap (and it hides another dim of the array). See repro below: ``` from jax import lax, pmap, vmap, map def vv(x, y): \"\"\"Vector-vector multiply\"\"\" return np.vdot(x, y) def distributed_matrix_vector(x, y, distributed=True): \"\"\"Matrix vector multiply. First batch it and then row by row\"\"\" fv = lambda z: lax.map(lambda j: vv(j, y), z) if distributed: res = pmap(fv)(x.reshape((jax.device_count(), -1) + tuple(x.shape[1:]))) else: res = fv(x) print(\"Inside matrix vector code %s (should be %s)\" % (res.shape, (x.shape[0], 1))) return res print(\"Not vmapped\") key = random.PRNGKey(1) x = random.normal(key, (800, 50)) y = random.normal(key, (50, 1)) result = distributed_matrix_vector(x, y) print(\"Outside matrix vector code\", result.shape) print(\"Vmapped\") batched_mvm = vmap(lambda b: distributed_matrix_vector(x, b, True), in_axes=(0,)) y = random.normal(key, (10, 50)) result = batched_mvm(y) print(\"Outside matrix vector code\", result.shape) # Not vmapped # Inside matrix vector code (8, 100) (should be (800, 1)) # Outside matrix vector code (8, 100) # Vmapped # Inside matrix vector code (8, 10) (should be (800, 1)) # Outside matrix vector code (100, 8, 10)``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add image-guided object detection support to OWL-ViT Hi, The [OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit) model is an open-vocabulary model that can be used for both zero-shot text-guided (supported) and one-shot image-guided (not supported) object detection. It'd be great to add support for one-shot object detection to `OwlViTForObjectDetection` such that users can query images with an image of the target object instead of using text queries - e.g. using an image of a butterfly to search for all butterfly instances in the target image. See an example below. <img width=\"989\" alt=\"Screenshot 2022-08-24 at 17 16 28\" src=\"https://user-images.githubusercontent.com/8944735/186441941-7278676e-aecb-4c7d-b1d5-df4fb444becb.png\"> To do this, we would just need to compute and use the `OwlViTModel` (alias to CLIP) embeddings of the query images instead of the text query embeddings within `OwlViTForObjectDetection.forward()`, which would take the target image + either text queries or image queries as input. Similarly, `OwlViTProcessor` would be updated to preprocess sets of (image, text) and (image, query_image). @sgugger @NielsRogge @amyeroberts @LysandreJik what do you think about this? Would this be something we would like to support? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: enable_pylab(import_all=False) still imports np In SymPy, we use `ip.enable_pylab(import_all=False)`. But it seems that it still imports `np`. I didn't check if any other names are accidentally imported as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: numpy array printing regression for ndarray subclasses in NumPy 1.14 It looks like some of the array printing changes in NumPy 1.14 are causing issues in yt. Specifically, printing yt's object that represents a scalar with units is triggering a recursion error. Here is a simplified example that is sufficient to trigger the same error: ```python import numpy as np class MyArray(np.ndarray): def __new__(cls, inp): obj = np.asarray(inp).view(cls) return obj def __str__(self): return super(MyArray, self).__str__() def __getitem__(self, item): ret = super(MyArray, self).__getitem__(item) return MyArray(ret) if __name__ == \"__main__\": a = MyArray(1) print(a) ``` This script triggers an infinite recursion error on NumPy 1.14.0 and prints `1` on NumPy 1.13.3. Is there any chance that this can be fixed on NumPy's side for a 1.14.1 release? I'm honestly not sure how to fix this on the yt side without making major changes to our ndarray subclasses. Ping @mhvk Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: get_define should raise a better Error if compiler does not support it. If one calls `get_define` for the rust compiler the result is a backtrace. We should check if the compiler has `get_define` defined and raise a better error message if not. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Integration list synchronization with airflow-site Hello friends. Today I am coming to you with another ticket. This time, while working on the website, I discovered that we have some information that is slightly outdated. [`landing-pages/site/static/integrations.json`](https://github.com/apache/airflow-site/blob/master/landing-pages/site/static/integrations.json ) file have lists all the integrations that have been added to Airflow, but unfortunately it is updated manually. Recently, new services were added there on Oct 2019 We can think of a tool that will update this list more automatically by reading the integration list from [provider.yaml](https://github.com/apache/airflow/find/master) files, and then creating an integration.json file that can be published to the airflow-site. For now, we need a manual run script, but in the future, we can also run it on Github Action or during updates and documentation. CC: @ryw Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [suggestion] [workspaces] Support yaml list as workspace root Using yaml list for setting the workspace root variable makes it easier to manage the yaml file, when the workspace has multiple roots. I would like to contribute to this feature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: emit error message and exit if the repo has uncommitted changes I just wanted to suggest putting this warning at the bottom of the `meson dist` output >WARNING: Repository has uncommitted changes that will not be included in the dist tarball I had a bit of trouble because I hadn't read the paragraph in the docs about [how `meson dist` works](https://mesonbuild.com/Creating-releases.html#autotools-dist-vs-meson-dist), and I feel that it's an important warning that could be easily missed (especially by nubs like myself) after it's scrolled away. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Clang via Visual Studio results in error To help us debug your issue please explain: - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Conan 0.30.3 When using the `compiler` to `Visual Studio` and `compiler.toolset` setting set to `LLVM-vs2014` (and possibly others), the CMake generator's generated file creates an error condition: ``` -- Selecting Windows SDK version 10.0.15063.0 to target Windows 6.1.7601. -- The C compiler identification is Clang 5.0.1 -- The CXX compiler identification is Clang 5.0.1 -- Check for working C compiler: C:/Program Files/LLVM/msbuild-bin/cl.exe -- Check for working C compiler: C:/Program Files/LLVM/msbuild-bin/cl.exe -- works ... -- Conan: called by CMake conan helper CMake Error at D:/conan-cache/.../conanbuildinfo.cmake:416 (message): Incorrect 'Visual Studio', is not the one detected by CMake: 'Clang' Call Stack (most recent call first): D:/conan-cache/.../conanbuildinfo.cmake:115 (conan_check_compiler) CMakeLists.txt:6 (conan_basic_setup) ``` Since this compiler.toolset option is present in the default settings.yml, I presume this is supposed to work. My guess at the right way to approach this is to teach the CMake generator about compiler.toolset, which it is currently blissfully ignorant of. The downside is that it also means teaching the generator about this setup (and would potentially not work for custom toolsets). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Implement Depth-First Execution with Mapping Currently each \"level\" of a mapped pipeline is executed before proceeding to the next level. This is undesirable especially for pipelines where it's important that each \"branch\" of the pipeline finish as quickly as possible. To implement DFE, we'll need to rearrange two things: - how mapped work gets submitted (it should start being submitted from the Flow Runner not the Task Runner) - in order to submit work to Dask and let Dask handle the DFE scheduling, we'll want to refactor how we walk the DAG and wait to determine the width of a pipeline before we submit it (because mapping is fully dynamic we can only ascertain this width at runtime) We'll need to be vigilant about: - performance - retries - result handling Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Using \"pid: host\" with override files no longer works in 1.9 I'm setting `pid: host` for one of the services in my docker-compose.yml file. This works as expected if I just use this file -- however, if I apply an override file, this option no longer works and the container will have its own PID namespace. This was working in 1.8, so this appears to be a regression. Adding `pid: host` to the override file does not appear to resolve the problem. There may be other settings that are also being overridden incorrectly as a result of this regression. The example below demonstrates this -- the PID printed by the container's entrypoint.sh script is a very low number because it is running in its own PID namespace. If I don't use the override file, the PID printed is a much higher number because it is in the host's namespace. I'll poke around in a few days if I get a chance to see what recent changes could have caused this. For the moment I've reverted to 1.8. ``` $ docker-compose -f docker-compose.yml -f docker-compose-prod.yml up --build Building netconfig ... Attaching to dockercomposeerror_netconfig_1 netconfig_1 | My PID = 6 ``` ``` $ docker-compose -f docker-compose.yml up --build Building netconfig ... Attaching to dockercomposeerror_netconfig_1 netconfig_1 | My PID = 22083 ``` Example files: **docker-compose.yml** ``` version: '2' services: netconfig: build: . privileged: true pid: host ``` **docker-compose-prod.yml** ``` version: '2' services: netconfig: ports: - \"179:179/tcp\" - \"1194:1194/udp\" ``` **Dockerfile** ``` FROM debian:stable ADD entrypoint.sh /test/entrypoint.sh CMD bash /test/entrypoint.sh ``` **entrypoint.sh** ``` #!/bin/bash echo \"My PID = $$\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Nbconvert, default_preprocessors to list of dotted name not list of obj in some places in nbconvert we have default that are list of object. they should be list of `DottedObject` (strings). Which is probably easier to configure, and does not lead to the following in config files ... ``` # List of preprocessors available by default, by name, namespace, instance, or # type. # c.TemplateExporter.default_preprocessors = [<function wrappedfunc at 0x106d86d70>, <class 'IPython.nbconvert.preprocessors.svg2pdf.SVG2PDFPreprocessor'>, <class 'IPython.nbconvert.preprocessors.extractoutput.ExtractOutputPreprocessor'>, <class 'IPython.nbconvert.preprocessors.csshtmlheader.CSSHTMLHeaderPreprocessor'>, <class 'IPython.nbconvert.preprocessors.revealhelp.RevealHelpPreprocessor'>, <class 'IPython.nbconvert.preprocessors.latex.LatexPreprocessor'>, <class 'IPython.nbconvert.preprocessors.highlightmagics.HighlightMagicsPreprocessor'>] ``` nothing prevent us from also supporting directly object/fucntions ... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: basis_gates not being passed to JSON unroller Currently there the `basis_gates` argument of the `compile` function is ignored when compiling circuits to JSON. This fix simply passes the value of basis gates to the dag2json compiler so that the JSON can be compiled in a user specified set of basis_gates as intended. ## Expected Behavior When you run `QuantumProgram.compile('circuit', basis_gates='a,b,c,d')` the resulting qobj should compile using the basis gates `a,b,c,d`. ## Current Behavior When you run `QuantumProgram.compile('circuit', basis_gates='a,b,c,d')` the JSON unroller is always passed `basis_gates='u1,u2,u3,cx,id` instead. ## Possible Solution Will add pull request to fix this by adding basis_gates argument to the `dag2json` function in `_openquantumcompiler.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: SparsePauliOp causes bugs in e.g. commutators. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18 - **Python version**: 3.8 - **Operating system**: MacOS ### What is the current behavior? The `SparsePauliOp` does not handle coefficients correctly or is used against its specification in opflow. With the help of @Cryoris we noticed the following: ``` >>> SparsePauliOp(Pauli('iZ')) == SparsePauliOp(Pauli('-iZ')) True >>> SparsePauliOp(Pauli('iZ')) == SparsePauliOp(Pauli('Z')) True ``` which is probably the root of the problem with, e.g., the commutator below. ### Steps to reproduce the problem ``` X Out[189]: PauliOp(Pauli('X'), coeff=1.0) Y Out[190]: PauliOp(Pauli('Y'), coeff=1.0) v = commutator(X,Y) v Out[192]: PauliSumOp(SparsePauliOp([[False, False]], coeffs=[0.+0.j]), coeff=1.0) v.equals(2j*Z) Out[193]: False ``` The same problem occurs by a direct calculation: ``` w = X@Y - Y@X w Out[205]: PauliSumOp(SparsePauliOp([[False, True], [False, True]], coeffs=[ 1.+0.j, -1.+0.j]), coeff=1.0) w.equals(2j*Z) Out[206]: False ``` ### What is the expected behavior? ``` >>> SparsePauliOp(Pauli('iZ')) == SparsePauliOp(Pauli('-iZ')) False >>> SparsePauliOp(Pauli('iZ')) == SparsePauliOp(Pauli('Z')) False ``` Or handling it differently in opflow. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Mismatch between CLIP fast and non-fast tokenizers ### System Info - `transformers` version: 4.26.1 - Platform: Windows-10-10.0.22621-SP0 - Python version: 3.8.1 - Huggingface_hub version: 0.11.0 - PyTorch version (GPU?): 1.12.1+cu116 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ### Who can help? @ArthurZucker @younesbelkada @sgugger ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Here is a minimal working example to show the mismatch: ```python from transformers import AutoTokenizer tokenizer_fast = AutoTokenizer.from_pretrained('openai/clip-vit-base-patch16', use_fast=True) tokenizer = AutoTokenizer.from_pretrained('openai/clip-vit-base-patch16', use_fast=False) text = \"You should've done this\" print(tokenizer(text)) print(tokenizer_fast(text)) print(tokenizer(text) == tokenizer_fast(text)) # Outputs: # {'input_ids': [49406, 592, 1535, 262, 563, 1700, 589, 49407], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]} # {'input_ids': [49406, 592, 1535, 1200, 1700, 589, 49407], 'attention_mask': [1, 1, 1, 1, 1, 1, 1]} # False ``` It appears to stem from the `'ve` token. ### Expected behavior The non-fast tokenization should match the fast tokenization (https://github.com/huggingface/tokenizers) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Improperly-formatted docstring for numpy.lib.format.descr_to_dtype The docstring for `numpy.lib.format.descr_to_dtype` does not conform to the `numpydoc` standard. Currently the docstring is not included in the documentation generated by sphinx. ### Numpy/Python version information: 1.20.0.dev0+e7adb14 3.8.3 (default, May 17 2020, 18:15:42) [GCC 10.1.0] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [BUG] Conan Tools does not export detected_os To help us debug your issue please explain: When I was updating cmake_installer, I just found that `detected_os` is not exported by conans.tools Conan Version 1.15.0 ```python from conans import tools if __name__ == \"__main__\": tools.detected_os() ``` **ERROR**: ``` Traceback (most recent call last): File \"conanfile.py\", line 4, in <module> tools.detected_os() AttributeError: module 'conans.tools' has no attribute 'detected_os' ``` - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Working with multiple Windows containers: The semaphore timeout period has expired. Starting twelve containers with docker-compose 1.9.0-rc2 still shows a problem. Follow up of #4082 ``` PS C:\\xxxxx> docker-compose up -d Creating xxxxx_consul_1 Creating xxxxx_db_1 Creating xxxxx_service1_1 Creating xxxxx_service2_1 Creating xxxxx_service3_1 Creating xxxxx_service4_1 Creating xxxxx_service5_1 Creating xxxxx_cli_1 ERROR: for service6 (121, 'WaitNamedPipe', 'The semaphore timeout period has expired.') ERROR: for service7 (121, 'WaitNamedPipe', 'The semaphore timeout period has expired.') ERROR: for service8 (121, 'WaitNamedPipe', 'The semaphore timeout period has expired.') ERROR: for service9 (121, 'WaitNamedPipe', 'The semaphore timeout period has expired.') ERROR: for service3 (121, 'WaitNamedPipe', 'The semaphore timeout period has expired.') Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"compose\\cli\\main.py\", line 65, in main File \"compose\\cli\\main.py\", line 117, in perform_command File \"compose\\cli\\main.py\", line 849, in up File \"compose\\project.py\", line 400, in up File \"compose\\parallel.py\", line 64, in parallel_execute pywintypes.error: (121, 'WaitNamedPipe', 'The semaphore timeout period has expired.') docker-compose returned -1 PS C:\\xxxxx> docker-compose --version docker-compose version 1.9.0-rc2, build d41f869 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Problem: conda-build doesn't clean up temporary files @gabm commented on [Thu Aug 17 2017](https://github.com/conda/conda-build/issues/2289) It seems conda-build doesn't clean up temporary files located under `/tmp/tmpxxxxxx` or `User/../AppData/Local/tmpxxxxxx` on windows. After the build these folders contain the decompressed packages that I suppose have been installed as dependencies during the build. Maybe its also a conda problem?! Anyway, on our Windows build machine we accumulated 25Gb within some weeks .... --- @gabm commented on [Thu Aug 17 2017](https://github.com/conda/conda-build/issues/2289#issuecomment-323134590) .. the same files are located again in `miniconda3/pkgs`... --- @msarahan commented on [Thu Aug 17 2017](https://github.com/conda/conda-build/issues/2289#issuecomment-323158750) Conda-build uses this functionality in conda for temporary folders: https://github.com/conda/conda/blob/dbe99de1d45206c5d6f2e19017a9e2466f81dc6d/conda/compat.py#L23-L67 When we get files from packages, we do so with the package_has_file function: https://github.com/conda/conda-build/blob/master/conda_build/utils.py#L714-L730 package_has_file does not ever extract the whole package. This seems like a conda issue. Sorry, I don't currently have time to investigate this more. I can move this issue to the conda repo if you'd like. --- @gabm commented on [Thu Aug 17 2017](https://github.com/conda/conda-build/issues/2289#issuecomment-323170508) ok, then please move it there... If I find time, I'll have a further look. I realised some strange folders `/tmp/tmpxxxxxxx` some weeks ago, so could be easy to reproduce... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: /parallel/apps/launcher.py error IPython 1.1.0 starting at line 956: def write_job_file(self, n): job = IPEngineSetJob(parent=self) ``` for i in range(n): t = IPEngineTask(parent=self) ``` get keyword errors because IPEngineSetJob and PEngineTask do not have 'parent' in winhpcjob.py: Also, winhpcjob.py uses regEx and tries to pass unicode when run under python 3. This results in error Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda search should do partial name searches (regression) The behavior of `conda search` used to be that `conda search X` would show all packages whose name contained the string `X`. There was a `-f` flag to search for full names. Now it seems you have to explicitly add `*` to either side of the string to do a partial name search. I get that search now accepts a general package spec, but adding stars is annoying and unintuitive to beginner users. The most common desired behavior is to search for substrings. This is how the search functionality for every other package manager that I've used works (`pip search`, `apt-cache search`, `yum search`, `brew search`, `fink list`, `cabal list`, I'm sure you could find and try others) I would suggest making search do a partial match search by default, as long as the search string doesn't include characters that would indicate it's a more general package spec. It can also use the `-f` flag, which was apparently kept but hidden from the help, to override this behavior. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: New field `network_mode` for v2 format Currently we support `host`, `bridge` and `none` as special cases in the list of networks, and we don't support `net: container:...` or `net: service:...`. The new `network_mode` field would be a single scalar string value which supports any of the above, and we would remove this support from the `networks` field. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: ModelCheckpoint Filepath Doesn't Use Logger Save Dir # 🐛 Bug Not sure if this is intended, but the model checkpoint isn't using the same directory as the logger, even if the logger exists. I would have expected this line [here](https://github.com/PyTorchLightning/pytorch-lightning/blob/588ad8377167c0b7d29cf4f362dbf42015f7568d/pytorch_lightning/trainer/callback_config.py#L28) to be `self.logger.save_dir` instead of `self.default_save_path`. Thank you, -Collin Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: using `DaskExecutor` is noisy `dask.distributed` is very verbose with its logging, which is a good thing; however, for newer users (especially those unfamiliar with dask distributed), this can be scary. We could potentially silence all logs that are not \"CRITICAL\" level by default, with a kwarg that allows this to be toggled during development. Another set of logs come from dangling connections / streams and tend to look like: ```python-traceback tornado.iostream.StreamClosedError: Stream is closed ... distributed.comm.core.CommClosedError: in <closed TCP>: ConnectionResetError: [Errno 54] Connection reset by peer ... ``` [these are innocuous](https://github.com/dask/distributed/issues/2220#issuecomment-417075131) but annoying; it would be a good research task to dig into this and see if we can find the source, for our own peace of mind that we clean up our processes appropriately. **cc:** @joshmeek Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: 'ExtractJob.destination_uri_file_counts' docstring copy pasta In #5241, @yiga2 reported: > BTW, there is also an issue with the documentation - see discrepancy @ > https://google-cloud-python.readthedocs.io/en/latest/bigquery/reference.html#google.cloud.bigquery.job.ExtractJob.destination_uri_file_counts and elaborated later: > For the doc, it seems `Returns: number of DML rows affected by the job, or None if job is not yet complete.` is from another property. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Lemmatizer exceptions: `lemma_strings` get sorted anyway Lemmatization exceptions have been working inconsistently, even when they are added directly in `corpora/en/wordnet/dict/verb.exc` The minimal test case of `coping` at https://github.com/explosion/spaCy/issues/389 reveals that, at https://github.com/explosion/spaCy/blob/master/spacy/lemmatizer.py#L94, the lemmatizer's list of potential forms (where the thing in lemmatizer.exceptions is item [0]) is cast to a `set` (and so loses ordering); then in https://github.com/explosion/spaCy/blob/master/spacy/morphology.pyx#L149, that `set` gets sorted. So lemmatizer exceptions only work if they also come first alphabetically! I've implemented the fix for this, but I need this issue in order to submit the PR! One question, though, for @honnibal: this can be fixed either as I did it locally -- return the whole list, with exceptions and then anything that comes back from the lemmatizer's `rules` -- or skip the rules altogether if we used an exception. I think it's more useful downstream if we keep all lemma candidates, even if we're not using them in the default pipeline. But it also seems only destructive to do `sorted(set())` on them! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: No Mass Delete Option for Task Instances Similar to What DAGRuns Have in UI ### Apache Airflow version 2.1.3 (latest released) ### Operating System macOS Big Sur 11.3.1 ### Versions of Apache Airflow Providers n/a ### Deployment Astronomer ### Deployment details default Astronomer deployment with some test DAGs ### What happened In the UI for DAGRuns there are checkboxes that allow multiple DAGRuns to be selected.  Within the Actions menu on this same view, there is a Delete option which allows multiple DAGRuns to be deleted at the same time.  Task instance view on the UI does not offer the same option, even though Task Instances can be individually deleted with the trash can button.  ### What you expected to happen I expect that the Task Instances can also be bulk deleted, in the same way that DAGRuns can be. ### How to reproduce Open up Task Instance and DAGRun views from the Browse tab and compare the options in the Actions dropdown menus. ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: [ENH] Compare environments I find I am often in a situation where I want to know if my current Conda environment matches the environment specification of an `environment.yml` file or a `requirements.txt` file or some other specification of Conda packages. Why? Because as much as I love Conda environments, sometimes I'd like to know: *\"Can I just run this in my current environment without changing anything? Because if so, then I know others can also run this thing in this same environment that I know they have access to, rather than having to complicate my life and theirs with instructions on how to augment their current environment appropriately.\"* So off the top of my head this would mean the ability to do something like: ``` conda compare environment.yml # report on delta between current environment and environment.yml conda compare foo bar # where foo and bar are two named environments ``` But as it stands I end up writing some complicated `conda list -e | grep` statements by hand, after doing `cat environment.yml`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: When COMPOSE_HTTP_TIMEOUT is reached the exit code should be non-zero We often run into timeout issues when using `docker-compose` in [circleci](https://circleci.com/) to run unit tests, for example: ``` $docker-compose run yiic create_unit_test_db ERROR: An HTTP request took too long to complete. Retry with --verbose to obtain debug information. If you encounter this issue regularly because of slow network conditions, consider setting COMPOSE_HTTP_TIMEOUT to a higher value (current value: 60). ``` The problem is that the exit code that `docker-compose` returns is zero, meaning the build continues, whereas it should be stopped. --- compose v1.5.0. It was installed with `sudo pip install --upgrade docker-compose` as part of the `circle.yml` file. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: save_pretrained crashes when torch_dtype is passed If you have the following code ``` p = pipeline(... torch_dtype=torch.bfloat16) p.save_pretrained() ``` you get a crash because `torch.bfloat16` is not json serializable in the `tokenizer.save_pretrained()` method. This PR fixes this. @Narsil @ArthurZucker Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Drop Python 3.5 support Dask (and Dask Distributed) are core dependencies of Prefect and [have dropped Python 3.5](https://github.com/dask/dask/issues/5478) support. This means that all Prefect users are effectively stuck on old versions of dask with Prefect. Given that, and given the occasional frustration of supporting Python 3.5 (typing, dict ordering, etc.) I'd like to open up a discussion for whether we should continue supporting 3.5 or not. To be clear, if users are not using dask executors or hooks, then they might not care. If you are a user who requires 3.5 support please chime in here so we can assess this decision! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: logger does not reload ``` import logging; import sys logging.basicConfig(stream=sys.stdout, level=logging.DEBUG) transpile(circuit, coupling_map=coupling_map, optimization_level=0) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda config --set show_channel_urls yes doesn't work anymore This is happening since the latest conda update: ``` bat λ conda config --set show_channel_urls yes Error: Key: show_channel_urls; yes is not a YAML boolean. ``` It happens with both conda 4.1.1 (local windows py 3.5) and 4.1.0 (appveyor, https://ci.appveyor.com/project/mdboom/matplotlib/build/1.0.1774) and it worked with 4.0.8 (https://ci.appveyor.com/project/mdboom/matplotlib/build/1.0.1765/job/bkldg98f8p087xmf) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Clean up methods which return self See https://github.com/GoogleCloudPlatform/gcloud-python/pull/770/files#r27422508 `return self` is a JavaScript-y method chaining construct. In Python ``` python foo = Foo() foo2 = foo.update() ``` indicates that `foo2` is indeed a `Foo` object, but that `foo.update()` has applied the changes without mutating `foo`. Using `return self` breaks that expectation. For example on `list` ``` python >>> a = [3, -4, 1, 0] >>> b = a.sort() >>> b is None True >>> a [-4, 0, 1, 3] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: The extract_objects() method warns unconditionally Starting from 0.36.0, this code: solver_objects = libemeus.extract_objects(solver_sources) where `solver_sources` is an array with a subset of sources used by a library, generates a warning when running Meson: ```` Single object files can not be extracted in Unity builds. You can only extract all the object files at once. ```` This happens regardless of whether I pass `--unity` or not, and even if I wrap the `extract_objects()` call under a: if not meson.is_unity() ... endif This does not happen with Meson < 0.36.0, and being able to extract a subset of objects is useful when writing tests for a specific internal API. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: [Metrics] Bleu ## 🚀 Feature Implement BLEU Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Dependency for generators I was having a look at the port of protobuf-c to meson and one issue they build an executable that is passed as a command line param to the generator in this format: ``` gen_protobuf_c = generator(protoc, output : ['@BASENAME@.pb-c.c', '@BASENAME@.pb-c.h'], arguments : ['--proto_path=@CURRENT_SOURCE_DIR@', '--plugin=protoc-gen-c=@0@'.format(protoc_gen_c.full_path()), '--cpp_out=@BUILD_DIR@', @INPUT@']) ``` When I try to use the generator it does not find the protoc_gen_c yet, I think we need a way to tell the generator that the executable has to be ready before calling it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Adapt the`Result` API to the new backend result format after the introduction of Qobj. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The format of the results is going to need some changes due to the introduction of `Qobj` in 0.6. The `Result` class needs to be updated to be able to cope with the changes - actually, it will need to understand both the new format and the old format during the transition. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.broadcast_to regression in the latest JAX version The new version 0.1.47 introduces a regression where `np.broadcast_to(1, (3, 2))` throws the error `AttributeError: 'int' object has no attribute 'ndim'`. cc @mattjj @neerajprad Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: reduce test warnings ## What does this PR do? Try to ignore all these warnings... ``` tests/models/test_cpu.py::test_early_stopping_cpu_model | 318s -- | -- 1700 | /drone/src/pytorch_lightning/utilities/distributed.py:23: RuntimeWarning: 2.5854711532592773 is supposed to be a torch.Tensor. Saving checkpoint may not work correctly. HINT: check the value of val_loss in your validation loop | 318s 1701 | warnings.warn(*args, **kwargs) ``` but it would be better to fix them instead ## PR review Anyone in the community is free to review the PR once the tests have passed. If we didn't discuss your PR in Github issues there's a high chance it will not be merged. ## Did you have fun? Make sure you had fun coding 🙃 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: CLI \"Login successful\" should print green `prefect auth login` should print a green `\"Login successful\"` confirmation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: String literals cannot contain literal '\\n' At the moment, `\\\\` is replaced by `\\` before handling of `\\n`. This means string literals cannot be made with the sequence `\\n` in them. For instance, ~~~Meson message('c:\\\\fun\\\\name') ~~~ results in a string where there is a newline between 'fun' and 'ame'. Perhaps something along the lines of: ~~~diff diff --git a/mesonbuild/mparser.py b/mesonbuild/mparser.py index 8400a1ac..5a91a3b9 100644 --- a/mesonbuild/mparser.py +++ b/mesonbuild/mparser.py @@ -111,6 +111,7 @@ class Lexer: par_count = 0 bracket_count = 0 col = 0 + newline_rx = re.compile(r'(?<!\\\\)(\\\\\\\\)*\\\\n') while loc < len(self.code): matched = False value = None @@ -139,10 +140,9 @@ class Lexer: elif tid == 'dblquote': raise ParseException('Double quotes are not supported. Use single quotes.', self.getline(line_start), lineno, col) elif tid == 'string': - value = match_text[1:-1]\\ - .replace(r\"\\'\", \"'\")\\ - .replace(r\" \\\\ \".strip(), r\" \\ \".strip())\\ - .replace(\"\\\\n\", \"\\n\") + value = match_text[1:-1].replace(r\"\\'\", \"'\") + value = newline_rx.sub(r'\\1\\n', value) + value = value.replace(r\" \\\\ \".strip(), r\" \\ \".strip()) elif tid == 'multiline_string': tid = 'string' value = match_text[3:-3] ~~~ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Minor documentation error in np.take_along_axis There is a minor mistake in the documentation of [`np.take_along_axis`](https://docs.scipy.org/doc/numpy/reference/generated/numpy.take_along_axis.html). In the \"Notes\" section there is a snippet functionally equivalent to the function that begins with: ```python Ni, M, Nk = a.shape[:axis], a.shape[axis], a.shape[axis+1:] J = indices.shape[axis] # Need not equal M out = np.empty(Nk + (J,) + Nk) ``` As I understand it, the definition of `out` should be: ````python out = np.empty(Ni + (J,) + Nk) ```` With the initial `Nk` replaced by `Ni`. ### Reproducing code example NA ### Error message NA ### Numpy/Python version information: 1.16.1 Minor documentation error in np.take_along_axis There is a minor mistake in the documentation of [`np.take_along_axis`](https://docs.scipy.org/doc/numpy/reference/generated/numpy.take_along_axis.html). In the \"Notes\" section there is a snippet functionally equivalent to the function that begins with: ```python Ni, M, Nk = a.shape[:axis], a.shape[axis], a.shape[axis+1:] J = indices.shape[axis] # Need not equal M out = np.empty(Nk + (J,) + Nk) ``` As I understand it, the definition of `out` should be: ````python out = np.empty(Ni + (J,) + Nk) ```` With the initial `Nk` replaced by `Ni`. ### Reproducing code example NA ### Error message NA ### Numpy/Python version information: 1.16.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: hdf5.py fails with exception if the project is not set up for C **Describe the bug** what it says in the title. If you have, e.g. a c++ project, trying to call ```dependency('hdf5', language: 'cpp', method: 'config-tool')``` will cause an exception ``` <...> File \"/usr/lib/python3.11/site-packages/mesonbuild/dependencies/hdf5.py\", line 119, in __init__ compiler = environment.coredata.compilers[for_machine][language] ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^ KeyError: 'c' ``` hdf5.py always tries to configure ```c``` language, which is a problem whan it's not set in the project **To Reproduce** ``` project('test', 'cpp') dependency('hdf5', language: 'cpp', method: 'config-tool') ``` **Expected behavior** no exception. If C is always needed for HDF5 - make a special error for this case. **system parameters** meson 1.0.1 ninja 1.11.1 fedora 38 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inverse U gate parameter ordering issue To whom it may concern, It came to my attention that the inverse of U gate doesn't have the right order of parameters as the math notation and understanding. Though it is working as expected in the simulation, the user needs to swap the orders, which is mathematically incorrect. Please look at the order of parameters and mathematical order. https://qiskit.org/documentation/_modules/qiskit/circuit/library/standard_gates/u.html#UGate.inverse math:`U(\\theta,\\phi,\\lambda)^{\\dagger} =U3(-\\theta,-\\phi,-\\lambda)`) \"\"\" return UGate(-self.params[0], **-**self.params[2], -self.params[1]****) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Mismatch of transaction IDs in 'g.datastore.connection.Connecction.rollback_transaction()' The method first checks that a transaction exists for the connection, and that it has a truthy ID[1], but then does not use that ID when setting up the API request: instead, it uses a passed-in ID[2]. This is not the same behavior as in 'g.datastore.connection.Connecction.commit()', where the ID is used from the connection's transaction (if present)[3]. Is there a usecase for using a connection to rollback any transaction ID other than the one bound to the connection? [1] https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/connection.py#L176 [2] https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/connection.py#L180 [3] https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/connection.py#L300 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support `--log-driver` Docker 1.6 adds support for the `--log-driver` option. It'd be great to be able to set this in the `docker-compose.yml` file. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add tree search swap mapper ### What is the expected behavior? Add a new tree search based swap mapper as a possible pass in the transpiler. The algorithm was submitted to the 2018 Qiskit Developer Challange and is described at https://medium.com/qiskit/improving-a-quantum-compiler-48410d7a7084 . Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: convert integer for `static_argnums` to tuple automatically I've made the same mistake a few times on `static_argnums` on `jit` function, by not using a tuple e.g., `jit(f, static_argnums=1)` would it be possible / reasonable to add a simple `if` statement to convert it to tuple? where the correct way is `jit(f, static_argnums=(1,) )` also note `(1)` is not a tuple, but `(1,)` is Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: unused variables should be removed if not needed <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Follow-up to #2396: some variables are unused. If there's really no reason for them to be there, remove them entirely. - [ ] qiskit/qasm/node/binaryop.py - [ ] qiskit/qasm/node/binaryoperator.py - [ ] qiskit/qasm/node/external.py - [ ] qiskit/qasm/node/format.py - [ ] qiskit/qasm/node/id.py - [ ] qiskit/qasm/node/indexedid.py - [ ] qiskit/qasm/node/intnode.py - [ ] qiskit/qasm/node/prefix.py - [ ] qiskit/qasm/node/real.py - [ ] qiskit/qasm/node/unaryoperator.py - [ ] qiskit/qasm/qasmlexer.py - [ ] qiskit/qasm/qasmparser.py - [ ] qiskit/quantum_info/operators/channel/transformations.py - [ ] qiskit/test/mock.py - [ ] qiskit/tools/jupyter/backend_monitor.py - [ ] qiskit/tools/jupyter/backend_overview.py - [ ] qiskit/visualization/latex.py - [ ] qiskit/visualization/matplotlib.py - [ ] test/python/test_util.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: typing should not be a dependency for python>=3.5 https://github.com/ipython/ipython/commit/3ff1be2ea8ef180a6f17a6a03a3f8452303b9abe added `typing` as an `install_requires`. This package is builtin for python>=3.5, so it should be protected by an environment marker (just like `pathlib2`) in setup.py. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] `cmake.test()` cannot execute ### Environment Details (include every applicable attribute) * Operating System+version: Ubuntu 22.04 on WSL * Compiler+version: CMake 3.23.1 * Conan version: 1.49.0 * Python version: 3.10.4 ### Steps to reproduce (Include if Applicable) Put `cmake.test()` and run `conan build .` with `Ninja Multi-Config` as a generator. ### Logs (Executed commands with output) (Include/Attach if Applicable) ``` conanfile.py (mp-units/0.8.0): CMake command: cmake --build \"/home/mpusz/repos/units/build-gcc-11\" --config Release '--' '-j12' [308/308] Linking CXX executable test/unit_test/runtime/Release/unit_tests_runtime conanfile.py (mp-units/0.8.0): CMake command: cmake --build \"/home/mpusz/repos/units/build-gcc-11\" --config Release '--target' 'RUN_TESTS' '--' '-j12' ninja: error: unknown target 'RUN_TESTS' ERROR: conanfile.py (mp-units/0.8.0): Error in build() method, line 172 cmake.test() ConanException: Error 1 while executing cmake --build \"/home/mpusz/repos/units/build-gcc-11\" --config Release '--target' 'RUN_TESTS' '--' '-j12' ``` CMake target `RUN_TESTS` is not available. `test` target works correctly but Conan does not use it for some reason. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: DAGs imported from networkx cannot be drawn <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit version**: 0.19.2 - **Python version**: 3.8.12 - **Operating system**: Windows 10 ### What is the current behavior? I can successfully create `DAGCircuit` objects by importing them from networkx graphs. Those objects seem to behave correctly, but whenever I try to draw them using the `dag_drawer` function, I get an error. I verified that the error only occurs for DAGCircuit objects imported from networkx graphs - in fact, I can draw a dag correctly, but if I convert it to networkx and back (`new_dag = from_networkx(dag.to_networkx())`), then new_dag can no longer be drawn. ### Steps to reproduce the problem ``` import qiskit from qiskit.circuit.random import random_circuit from qiskit.converters import circuit_to_dag, dag_to_circuit from qiskit.tools.visualization import dag_drawer from qiskit.dagcircuit import DAGCircuit in_circ = random_circuit(1,1) in_dag = circuit_to_dag(in_circ) # dag_drawer(in_dag) # if uncommented, draws the DAG correctly graph = in_dag.to_networkx() out_dag = DAGCircuit.from_networkx(graph) dag_drawer(out_dag) # throws an error ``` outputs ``` KeyError Traceback (most recent call last) ---> [12]() dag_drawer(out_dag) --> [224]() dot_str = dag._multi_graph.to_dot(node_attr_func, edge_attr_func, graph_attrs) --> [206]() n[\"label\"] = bit_labels[node.wire] KeyError: Qubit(QuantumRegister(1, 'q'), 0) ``` ### What is the expected behavior? That DAG objects created from networkx graphs have the same properties as those created from quantum circuits. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Ability to yield a RunRequest from a run status sensor User says: \"While working with sensors, we came to the conclusion that you cannot yield a RunRequest from a run_status_sensor . This forces us to have a generic sensor which queries runs and assets with RunsFilter and EventRecordsFilter , then yield a run request for a downstream graph. This works well enough, but it would be much simpler to have run_status_sensor able to yield run requests as it would have the job run and the assets it produced in the sensor context, which means we don’t need to go against the storage API\". Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rename DirectionMapper <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? I would like to rename the DirectionMapper to GateDirection or SwapDirection or DirectionSelection or just CXDirection. I think it is important to separate it from mapper pass. This allows us to define the mapper problem as working for any two qubit gate and it just connects with swaps. This way it is clear that this is not an alternative mapper pass Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Clean up activate.py using proper OO inheritence See * https://github.com/conda/conda/pull/6585#issuecomment-354178822 * https://github.com/conda/conda/pull/6585#issuecomment-354303897 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: config appears to not pick up conda_build/matrix_base_dir in 4.6.0b1 In my .condarc: ``` conda_build: matrix_base_dir: ~/code/automated-build/c3i_configurations/anaconda_public ``` This is for c3i. Somehow this isn't getting loaded properly: ``` c3i one-off py36_win python-3.6-feedstock -p \"win*\" Traceback (most recent call last): File \"/Users/msarahan/miniconda3/bin/c3i\", line 11, in <module> load_entry_point('conda-concourse-ci', 'console_scripts', 'c3i')() File \"/Users/msarahan/code/conda-concourse-ci/conda_concourse_ci/cli.py\", line 240, in main execute.submit_one_off(pass_throughs=pass_throughs, **args.__dict__) File \"/Users/msarahan/code/conda-concourse-ci/conda_concourse_ci/execute.py\", line 802, in submit_one_off config_root_dir = os.path.expanduser(config_root_dir) File \"/Users/msarahan/miniconda3/lib/python3.6/posixpath.py\", line 235, in expanduser path = os.fspath(path) TypeError: expected str, bytes or os.PathLike object, not NoneType ``` The code that loads this setting is at https://github.com/conda/conda-concourse-ci/blob/master/conda_concourse_ci/cli.py#L43 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: os.rename throws exception when renaming directories on lower overlayfs layers OS: CentOS Linux release 7.2.1511 (Core) docker version: 1.12.6 docker storage driver: overlayfs Docker Image has existing conda environment baked into layer ``` During handling of the above exception, another exception occurred: Traceback (most recent call last): File \"/opt/continuum/anaconda/lib/python3.6/site-packages/conda/exceptions.py\", line 640, in conda_exception_handler return_value = func(*args, **kwargs) File \"/opt/continuum/anaconda/lib/python3.6/site-packages/conda/cli/main.py\", line 140, in _main exit_code = args.func(args, p) File \"/opt/continuum/anaconda/lib/python3.6/site-packages/conda/cli/main_install.py\", line 80, in execute install(args, parser, 'install') File \"/opt/continuum/anaconda/lib/python3.6/site-packages/conda/cli/install.py\", line 326, in install execute_actions(actions, index, verbose=not context.quiet) File \"/opt/continuum/anaconda/lib/python3.6/site-packages/conda/plan.py\", line 830, in execute_actions execute_instructions(plan, index, verbose) File \"/opt/continuum/anaconda/lib/python3.6/site-packages/conda/instructions.py\", line 247, in execute_instructions cmd(state, arg) File \"/opt/continuum/anaconda/lib/python3.6/site-packages/conda/instructions.py\", line 108, in UNLINKLINKTRANSACTION_CMD txn.execute() File \"/opt/continuum/anaconda/lib/python3.6/site-packages/conda/core/link.py\", line 297, in execute rollback_excs, conda.CondaMultiError: [Errno 22] Invalid argument: '/opt/continuum/anaconda/envs/anaconda44_py35/lib/python3.5/version.txt' -> '/opt/continuum/anaconda/envs/anaconda44_py35/lib/python3.5/version.txt.c~' ``` cc @msarahan @kalefranz @mmarchetti @dsludwig Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add pulse channels to `FakeBackendV2` ### What is the expected enhancement? https://github.com/Qiskit/qiskit-terra/pull/7643 implemented mocked IBM Quantum Systems backends using the new BackendV2 interface. The BackendV2 class contains [pulse channels](https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/providers/backend.py#L484-L549) (`drive_channel`, `measure_channel`, `acquire_channel`, `control_channel`) that were not implemented by #7643. It's unclear to me whether these channels are useful for fake backends. If they are useful, we should add them. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Batching rule for `dyanmic_slice` not defined If you use indexing , e.g. `x[0]` in a function you `vmap`, it fails. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: wandLogger().name is None in DDP mode If you remove [line 54](https://github.com/PyTorchLightning/pytorch-lightning/blob/8ca8336ce52ee7379f4d399520636143eb31018b/pytorch_lightning/trainer/callback_config.py#L54), everything works. When you're not in ddp mode, this is not an issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: rename op_version to code_version Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub: correctly decrement the byte counter in drop() I'm looking at this 2 files: - https://github.com/GoogleCloudPlatform/google-cloud-python/blob/5c010e3790c9067e6d7bf8ba37724ee5121eadb7/pubsub/google/cloud/pubsub_v1/subscriber/policy/base.py#L215 - https://github.com/GoogleCloudPlatform/google-cloud-python/blob/5c010e3790c9067e6d7bf8ba37724ee5121eadb7/pubsub/tests/unit/pubsub_v1/subscriber/test_policy_base.py Should the code in `base.py` line 215 be `max` instead of `min`? ``` self._bytes = min([self._bytes, 0]) ``` Current code: 1. current state `self._bytes = 50` 2. then we call `self._bytes -= 20` 3. now `self._bytes == 30` 4. but then we do `self._bytes = min([30, 0])` -> `self._bytes = 0` Should be: 1. current state `self._bytes = 50` 2. then we call `self._bytes -= 20` 3. now `self._bytes == 30` 4. but then we do `self._bytes = max([30, 0])` -> `self._bytes = 30` even if we drop it below 0, we should use `max`: 1. `self._bytes = 10` 2. `self._bytes -= 20` 3. `self._bytes == -10` 4. `min([-10, 0]) == -10` should be `max([-10, 0]) == 0` Or is there something I miss? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: print name for IPython Notebooks has become uninformative In versions prior to 0.13, the web page containing a print view would have the notebook name as the title. This meant that when printing the notebook to a PDF printer, the resulting PDF file would have the name of the notebook as the file name. In version 0.13, the print view has the name \"Notebook\" regardless of the name of the worksheet. This is very inconvenient, and I don't see any reason for the change. Could you please change back to using the worksheet name for the title of the print view? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `post_execute` and `post_run_cell` hooks not always triggered Due to various early returns in the code below, `post_execute` and `post_run_cell` hooks are not triggered in some cases. Since the pre hooks are always called, this is either a bug or the [docs](http://ipython.readthedocs.io/en/stable/config/callbacks.html#post-run-cell) should mention that post hooks are not guaranteed to be triggered. https://github.com/ipython/ipython/blob/ca86b79bfd5cdd633ea6cb9c18bb2c1c493402a1/IPython/core/interactiveshell.py#L2694-L2739 /cc @craigcitro Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Multiple %%%% in tab-completion after pdb ``` [carlos@carlos ~]$ ipython Python 3.4.3 (default, Feb 26 2015, 23:01:07) Type \"copyright\", \"credits\" or \"license\" for more information. IPython 3.0.0 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: %pdb Automatic pdb calling has been turned ON In [2]: 1/0 --------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) <ipython-input-2-05c9758a9c21> in <module>() ----> 1 1/0 ZeroDivisionError: division by zero > <ipython-input-2-05c9758a9c21>(1)<module>() ----> 1 1/0 ipdb> q In [3]: %<Tab><Tab><Tab><Tab>... ``` Each succesive tab press adds a new %. Multiple %%%% in tab-completion after pdb ``` [carlos@carlos ~]$ ipython Python 3.4.3 (default, Feb 26 2015, 23:01:07) Type \"copyright\", \"credits\" or \"license\" for more information. IPython 3.0.0 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: %pdb Automatic pdb calling has been turned ON In [2]: 1/0 --------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) <ipython-input-2-05c9758a9c21> in <module>() ----> 1 1/0 ZeroDivisionError: division by zero > <ipython-input-2-05c9758a9c21>(1)<module>() ----> 1 1/0 ipdb> q In [3]: %<Tab><Tab><Tab><Tab>... ``` Each succesive tab press adds a new %. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Move collaboration features to a separate package ### Problem Once the implementation of RTC through IDrive is done. We can extract every specific RTC UI elements to a separate extension. So RTC is a opt-in through extension installation. And we are able to keep iterating faster on the UI elements. The elements that need to be in core for RTC are: - Document model stored in RTC compatible object (= Yjs document) - Getting user identity and permission (Jupyter Server Identity & Authorization API) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Restarting celery issues and better supervisord config file I use supervisord config file based on the example in celery repository and have some issues when celeryd restart is occured: sometimes task processing silently stops after restarting celery without any error messages in logs. Processes remains visible in process list. Finally I figured out that sometimes when processes are restarted celery spawns additional process that is not managed by supervisord and this leads to these bugs. So I started to watch `ps` output carefully after each restart and kill extra processes manually via kill <id>. After killing these processes tasks begin to be executed properly. This is sort of hack that solve a problem for a week or so. And today I think the real reason is found. The default supervisord value for 'stopwaitsecs' option is 10s. This means that after 10s celery process will be killed with KILL signal instead of TERM. It seems that celery don't like being killed and try to spawn additional process in that case. So I think it'll be good to add something like 'stopwaitsecs=600' to all supervisord example config files (from faq: \"You should never stop celeryd with the KILL signal (-9), unless you’ve tried TERM a few times and waited a few minutes to let it get a chance to shut down.\") and investigate celeryd behaviour on KILL signal: it is mentioned in docs that tasks will be lost (and it is tolerably in many cases) but the issue with spawned process is a bit weird. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [DO NOT MERGE] Logging: failed to blacken after synth This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Executing /tmpfs/src/git/autosynth/working_repo/logging/synth.py. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:8b45fae963557c3299921037ecbb86f0689f41b1b4aea73408ebc50562cb2857 Status: Image is up to date for googleapis/artman:latest synthtool > Cloning googleapis. synthtool > Running generator for google/logging/artman_logging.yaml. synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/logging-v2. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/logging_v2/proto/logging_pb2.py. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/logging_v2/proto/logging_metrics_pb2.py. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/logging_v2/proto/log_entry_pb2.py. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/logging_v2/proto/logging_config_pb2.py. .coveragerc .flake8 MANIFEST.in noxfile.py.j2 setup.cfg Running session blacken Session blacken skipped: Python interpreter 3.7 not found. synthtool > Cleaned up 2 temporary directories. synthtool > Wrote metadata to synth.metadata. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove legacy `VariationalForm` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? When the `algorithms` module from Qiskit Aqua got migrated to Terra, the `VariationalForm` was included (possibly by accident). Before the next release, this class will no longer be needed because all variational forms will have been refactored into `BlueprintCircuit`s (see also https://github.com/Qiskit/qiskit-nature/pull/66 for an example). Thus, it would be good to remove the `VariationalForm` class. Furthermore, the `preferred_init_points` argument, which is checked for in [`VariationalAlgorithm`](https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/algorithms/variational_algorithm.py#L204) and set to a dummy value in [`NLocal`](https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/circuit/library/n_local/n_local.py#L509) will no longer be needed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: prioritize channels within multi-channels Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Batchsize and learning rate scheduler I was wondering if I need to adjust the batch size when using TPUs. I had a memory error when trying to run a (image 256x256x3) batch of size 128, which works perfectly fine on GPUs. Furthermore, do I need to adjust my custom learning rate scheduler which on GPUs run every batch (not just epoch): ``` def configure_optimizers(self): optimizer = get_optimizer(self) one_cycle_scheduler = OneCycleScheduler(optimizer, EPOCHS * steps_per_epoch // GRAD_ACCUMULATE) scheduler = {'scheduler': one_cycle_scheduler, \"interval\": \"step\"} return [optimizer], [scheduler] ``` pl version: 0.8.5 system: kaggle Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add support for build-time extra_hosts I'm having an issue with extra_hosts on compose. ```bash $> docker -v Docker version 17.06.0-ce, build 02c1d87 ``` ```bash $> docker-compose -v docker-compose version 1.16.1, build 6d1ac219 ``` The `--add-host` option works correctly with `docker build` but the `extra_hosts` of `docker-compose` doesn't. I'm using a 3.3 version ok Compose file, here is a sample ```Dockerfile version: '3.3' services: my_service: build: context: ./some_folder args: ARG1: $ARG1 ARG2: $ARG2 extra_hosts: - \"my.local.network.url:XXX.XXX.XXX.XXX\" environment: SOME_VAR: $SOME_VAR volumes: - ./folder1:/folder1 ``` My volumes are not interfering with /etc/hosts or anything like that. Can anyone tell me if I'm doing anything wrong ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: AutoConfig.from_pretrained(\"model\", return_unused_kwargs=True) returns `\"_from_auto\": True` field against specification ### System Info ```shell - `transformers` version: 4.17.0 - Platform: Linux-5.13.0-40-generic-x86_64-with-glibc2.34 - Python version: 3.9.7 - PyTorch version (GPU?): 1.11.0+cu102 (False) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed ``` ### Who can help? @sgugger Small bug in which for some cases `{\"_from_auto\": True}` is returned [against specification](https://github.com/huggingface/transformers/blob/31ec2cb2badfbdd4c1ac9c6c9b8a74e974984206/src/transformers/models/auto/configuration_auto.py#L646). Seems to originate [here](https://github.com/huggingface/transformers/blob/31ec2cb2badfbdd4c1ac9c6c9b8a74e974984206/src/transformers/models/auto/configuration_auto.py#L671) and/or [here](https://github.com/huggingface/transformers/blob/31ec2cb2badfbdd4c1ac9c6c9b8a74e974984206/src/transformers/configuration_utils.py#L659) ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction Replicable with ```py >>> from transformers import AutoConfig >>> config, kwargs = AutoConfig.from_pretrained(\"bert-base-uncased\", return_unused_kwargs=True) >>> kwargs {'_from_auto': True} ``` ### Expected behavior There should be no `\"_from_auto\": True` field in returned dict. ```py >>> from transformers import AutoConfig >>> config, kwargs = AutoConfig.from_pretrained(\"bert-base-uncased\", return_unused_kwargs=True) >>> kwargs {} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: In examples, complete steps not correct when load from checkpoint ### System Info https://github.com/huggingface/transformers/blob/8f093fb799246f7dd9104ff44728da0c53a9f67a/examples/pytorch/language-modeling/run_clm_no_trainer.py#L575 Should be: ```python completed_steps = resume_step // args.gradient_accumulation_steps ``` ### Who can help? @sgugger ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction 1. Enable grad acc. 1. Save the checkpoint. 1. Load from it. ### Expected behavior The `completed_steps` should be divided by grad acc steps. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Menu item schema extraction in documentation is off See \"Item must follow this definition:\" in https://jupyterlab.readthedocs.io/en/stable/extension/extension_points.html#context-menu being shifted off by several lines. It is trivial to updated, but opening the issue to get any suggestions on how to handle it better. This also affects the toolbar item definitions: https://jupyterlab.readthedocs.io/en/latest/extension/extension_points.html#toolbar-registry (after \"Add the toolbar item must follow this definition:\") Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: CmdDef always returns positive FC phase. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When we `.get` u1, u2 or u3 from `CmdDef`, all FrameChange phases become positive value. ### Steps to reproduce the problem ``` cmd_def = pulse.CmdDef.from_defaults(defaults.cmd_def, defaults.pulse_library) cmd_def.get('u1', 0, P0=-pi) ``` this returns a schedule consisting of FrameChange of +pi (because P0 is negated in cmd_def). ``` cmd_def = pulse.CmdDef.from_defaults(defaults.cmd_def, defaults.pulse_library) cmd_def.get('u1', 0, P0=pi) ``` this returns a schedule consisting of FrameChange of +pi, but this should be -pi. ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: In the PTK terminal, control-o should indent the newly created line Suppose I have: ``` In [5]: def f(): ...: [CURSOR]a = 1 ``` If I press control-O to open up a new line, I get: ``` In [5]: def f(): ...: [CURSOR] ...: a = 1 ``` I would prefer to get: ``` In [5]: def f(): ...: [CURSOR] ...: a = 1 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: UserWarning: __floordiv__ is deprecated Dear All, I am trying to Fine-tune XLSR for Speech Recognition \"facebook/wav2vec2-base\" model for Urdu Language. However when I run the trainer, I am getting the following warning: ``` /home/e-team/anaconda3/lib/python3.9/site-packages/transformers/models/wav2vec2/modeling_wav2vec2.py:704: UserWarning: __floordiv__ is deprecated, and its behavior will change in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values. To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor'). return (input_length - kernel_size) // stride + 1 ``` Also Consequently my WER is 1.00 which means training is not being done correctly. Can anyone guide ? What changes to make and where? Torch Version: 1.10.1+cu102 Python Version: 3.9.7 CUDA Version: 11.2 Tensorflow Version: 2.7.0  Best regards, Yasir Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Missing 8.3 version of gcc Hi, [conan 1.15.0] is this possible to add the 8.3 version of gcc into the default settings.yml generated ? Regards, Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub JSON Double base64 Encode We recently upgraded from 0.18.1 to 0.21.0 and we do *not* use gRPC/GAX/Protobuf fun times, but we use the JSONPublisherApi. Maybe we are using the topic.Batch().Commit() method wrong, but we have been using it in our retry strategy to just simply call Commit() again. With the change in #2577 it seems that Commit() will double encode *if* you just call Commit() again on a network failure. Is this the intended design? Are we supposed to keep another copy of the message batch or create another message batch? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for variable width operations to Target ### What should we add? Right now the target class doesn't have proper support for modelling instructions that have variable width. If you have a gate that can use more than a single number of qubits and the backend supports all variants of that instruction (or at least more than one). We don't have a way to express that. The target currently requires a 1:1 mapping of operation name to a `Operation` instance and that instance is used for type checking and parameter checking at different points in the transpiler. However this requirement won't work for variable width instructions because a single instance of the instructions can only have a single number of qubits. To be able to accurately model these instructions being supported on a target backend we need to come up with an interface to model this in the target, which might mean introducing a `TargetV2`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: [AIP-31] Create XComArg model **Description** XComArg is a class that references an XCom entry from an operator. Can be used to explicitly set XCom dependencies and explictly pass results between operators. _Class attributes:_ - `operator: BaseOperator`: Origin operator instance. - `key: str`: Stores key for XCom value. Defaults to `airflow.models.xcom. XCOM_RETURN_KEY` _Class methods_ - `get(context: dict)-> Any`: Resolves XCom value given `operator` and `key`. - `__getitem__(key, str) -> XComArg`: Easy method to create new XComArg using the same operator but a different key. - `add_downstream_dependent(operator: BaseOperator)->None`: Add an operator as a downstream dependency of `operator`. [Optional] Makes this task simpler. Proposed implementation: https://github.com/casassg/corrent/blob/master/corrent/xcom_arg.py **Use case / motivation** - Explicit way to pass around results between operators. - This object is a reference to an XCom value that has not been created and will need to be resolved in the future. - It can generate new XComArgs that point to the same operator but has a different key by using the key accessor. E.g: output['train']. - To do so, it includes as class attributes both the originating operator instance and a key (both needed to pull the XCom). - Has a property op that allows access to the origin operator. **Stretch goal** - Store type class for the XCom and lie to MyPy when trying to check class signature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Mask2Former ImageProcessor produces different results on Mac vs Windows. ### System Info >>> transformers.__version__ '4.27.0.dev0' >>> Python 3.10.6 Windows vs Mac ### Who can help? @amyeroberts ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction ``` import torch from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation processor = AutoImageProcessor.from_pretrained(\"facebook/mask2former-swin-large-cityscapes-instance\", reduce_labels=False, ignore_index=255, do_resize=True, size=dict(width=500, height=500), do_normalize=True, image_mean=[0.485, 0.456, 0.406], image_std=[0.229, 0.224, 0.225]) device = torch.device(\"cpu\") image = Image.open(filename1) image = image.convert('RGB') image = np.array(image) image = image.astype(np.float32) image = image.transpose(2,0,1) print(image.dtype, image.shape, image.mean((1, 2))) # float32 (3, 1000, 1000) [156.41327 149.47672 137.97989] ret = processor([image], return_tensors=\"pt\") pixel_values = ret[\"pixel_values\"].to(device) print(pixel_values.dtype, pixel_values.shape, pixel_values[0].mean((1, 2)), pixel_values[0].std((1, 2))) ``` Windows ``` float32 (3, 1000, 1000) [156.41327 149.47672 137.97989] mean = [-0.4228946 -0.17078026 0.25235963] std = [0.81622934 0.699496 0.71027416] ``` Mac ``` float32 (3, 1000, 1000) [156.41327 149.47672 137.97989] mean = [-1.229962 -1.1720737 -0.6407509] std = [1.5912648 1.5453817 1.7506045] ``` ### Expected behavior Same result on Windows and Mac Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove legacy simulators This i think should be done in two parts. I will remove the python code and fix the test that applies. @atilag can you do the removing of the source code and the updating of the install instructions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Build Recommend Dialog always pops up ### From Gitter: ### > I'm on the latest released jupyterlab and have also installed the ipywidgets and jupyterlab-hub extensions. When I start jupyterlab I get a Build Recommended dialog suggesting I run jupyter lab build from the command line. When I do so nothing much seems to happen and I still get the dialog when I relaunch jupyterlab. ``` C:\\>jupyter lab build > npm install > npm run build C:\\> ``` > @dhirschfeld, that sounds like a bug, what does jupyter labextension list give? and also npm -v Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Use new URL format for Q network registration <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The registration for the Q network needs to use the new URL format. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose up prints out \"stty: standard input: Inappropriate ioctl for device\" I have created a docker image using ubuntu trusty as the base. The image is configured to run a Ruby application locally using the Ruby web server Thin. Whenever I run docker-compose up I get the message in the subject constantly printing out along with stdout from the Ruby process. This does not happen when I run a container from the save image using 'docker run' Anyone got any ideas to fix this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: DotDict doesn't accept non-string keys Trying to set a non-string key results in `TypeError: hasattr(): attribute name must be string` because of [this line](https://github.com/PrefectHQ/prefect/blob/dcf0cdb2b27fc1434ad433afe9beb0720eb192db/src/prefect/utilities/collections.py#L62). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit.extend produces empty circuit.qubits <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master@9e78907d2 - **Python version**: 3.7.7 - **Operating system**: macOS ### What is the current behavior? The `QuantumCircuit.extend` operation extends an existing circuit with another circuit. If the second circuit contains registers that are not in the first one, the register is added to the first. This operation can therefore add quantum registers. Before #4766 this was not a problem because the `QuantumCircuit.qubits` attribute was generated from the registers, but now that the qubits are cached, calling extend causes a mismatch between the registers and qubits, because the qubits attribute is not properly updated. ### Steps to reproduce the problem ```python from qiskit import QuantumCircuit empty = QuantumCircuit() other = QuantumCircuit(1) other.x(0) empty.extend(other) print(empty) print(empty.qubits) ``` Before #4766 (1db0340eb): ``` ┌───┐ q_0: ┤ X ├ └───┘ [Qubit(QuantumRegister(1, 'q'), 0)] ``` After: ``` ┌───┐ q_0: ┤ X ├ └───┘ [] ``` ### Suggested solutions Update `self.qubits` upon calling `self.extend`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose cannot handle unicode file paths on Windows I've just hit this error: ``` Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"compose\\cli\\main.py\", line 61, in main File \"compose\\cli\\main.py\", line 113, in perform_command File \"compose\\cli\\main.py\", line 219, in build File \"compose\\project.py\", line 300, in build File \"compose\\service.py\", line 727, in build File \"site-packages\\docker\\api\\build.py\", line 54, in build File \"site-packages\\docker\\utils\\utils.py\", line 103, in tar File \"tarfile.py\", line 2006, in add File \"tarfile.py\", line 1878, in gettarinfo WindowsError: [Error 123] The filename, directory name, or volume label syntax is incorrect: 'C:\\\\[redacted]\\\\?.jpg' ``` The actual file name is `∆.jpg` (don't ask why). This looks like the same issue in http://stackoverflow.com/questions/11545185/handling-utf-filenames-in-python Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: AutotoolsBuildEnvironment adjusting gnueabi in triplet for x86 To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. https://twitter.com/DEGoodmanWilson/status/968797501447917568 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [QoL] Allow `conan remove -t *` In the CI with the cache, it's needed to reinstall system requirements when the machine has been changed. Currently, it's only supported with a full reference. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Compose 1.20.0 crashes while building image from Dockerfile I have a setup with Compose 1.20.0 installed inside a virtualenv. When building an image using a local Dockerfile, it crashes. I can confirm the same behavior in 3 different Linux environments - Fedora 27 x86_64 (dev machine) - Debian Jessie x86_64 (different dev machine) - Ubuntu 14.04 (Travis CI) ``` Building cassandra ERROR: Error processing tar file(exit status 1): open /venv/include/python2.7/Python-ast.h: no such file or directory ``` It seems to me for some reason an absolute path is being used, and my virtualenv obviously does not reside inside my system root. Compose 1.19.0 does not seem to show the same problem. The Dockerfile and Compose config follow. ```dockerfile FROM cassandra:3.11.1 RUN sed -e 's/authorizer: AllowAllAuthorizer/authorizer: CassandraAuthorizer/' -e 's/authenticator: AllowAllAuthenticator/authenticator: PasswordAuthenticator/' -i /etc/cassandra/cassandra.yaml ``` ```yaml version: '2.3' services: cassandra: build: context: . dockerfile: Dockerfile-cassandra environment: MAX_HEAP_SIZE: 250M HEAP_NEWSIZE: 50M ports: - \"9042:9042\" - \"7199:7199\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: 2 RAG test failures The two failures here look related to recent tokenizer changes: https://github.com/huggingface/transformers/runs/1236753957?check_suite_focus=true ``` =========================== short test summary info ============================ FAILED tests/test_modeling_rag.py::RagModelIntegrationTests::test_rag_sequence_generate_batch FAILED tests/test_modeling_rag.py::RagModelIntegrationTests::test_rag_token_generate_batch ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Implement checkpointing for data Currently tasks have a dummy \"checkpoint\" attribute which needs to be handled Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Provider dependencies do not work well with alphas. The dependencies in Alphas are currently >= 2.0.0 and should be >=2.0.0a0 in order to work with Alphas in cases which are not PEP 440-compliant. According to https://www.python.org/dev/peps/pep-0440/, >= 2.0.0 should also work with alpha/beta releases (a1/a2) but in some cases it does not (https://apache-airflow.slack.com/archives/C0146STM600/p1602774750041800) Changing to \">=2.0.0a0\" should help. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: MAML Gradients + Convnets don't work The attached python code snippet implements a MAML gradient update on 1) an MLP and 2) a CNN. When MODEL_TYPE = 'mlp', everything works. When MODEL_TYPE = 'conv', I get the following error: RuntimeError: Invalid argument: Expected LHS feature dimension (value 1) to be a multiple of feature_group_count (value 1), and LHS feature dimension / feature_group_count = RHS feature dimension (value 40); got <conv>(f32[1,1,40,40], f32[10,1,1,40]) Dimension numbers: {kernel_input_feature_dimension: 3 kernel_spatial_dimensions: 1 kernel_spatial_dimensions: 2 input_batch_dimension: 3 output_batch_dimension: 2 output_feature_dimension: 3 input_spatial_dimensions: 1 input_spatial_dimensions: 2 output_spatial_dimensions: 0 [maml-cnn.txt](https://github.com/google/jax/files/2867892/maml-cnn.txt) output_spatial_dimensions: 1 }.: @ 0x7ff2befc9214 xla::XlaBuilder::ReportErrorOrReturn() @ 0x7ff2befd6eaa xla::ConvGeneralDilated() @ 0x7ff2b82e4cb8 xla::swig::LocalComputationBuilder::ConvGeneralDilated() @ 0x7ff029565901 _wrap_LocalComputationBuilder_ConvGeneralDilated() @ 0x4bc454 PyEval_EvalFrameEx Note that for both model architectures, the maml objective loss can be computed. It's only in the case of attempting to take a gradient of the CNN-based loss, things break. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Pretty test result with pprint ## 🚀 Feature ### Motivation Test results are shown at the end of test loops since v0.7.0. The content of the indication is `prog_bar_metrics`, which is basically inputted as a `dict`. By default, this part uses built-in `print` function:  This way cannot display the pretty results so I suggest using `pprint`:  ### Pitch - Substitute `print` at the end of the test loop with `pprint` . ### Alternatives Modify [here ](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/trainer/evaluation_loop.py#L375)like: ```python if test_mode: if self.proc_rank == 0: from pprint import pprint print('-' * 100) print('TEST RESULTS') pprint(prog_bar_metrics) print('-' * 100) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Optim level 2 and 3 modifiy circuits that match topology <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? The following circuit fits Vigo-like topologies exactly: <img width=\"643\" alt=\"Screen Shot 2019-11-04 at 2 35 42 PM\" src=\"https://user-images.githubusercontent.com/1249193/68160328-cae3d800-ff10-11e9-9446-232118c072ca.png\"> But optimization level 3 gives: <img width=\"972\" alt=\"Screen Shot 2019-11-04 at 2 35 56 PM\" src=\"https://user-images.githubusercontent.com/1249193/68160344-d46d4000-ff10-11e9-9bc0-f90048e73747.png\"> Where as the default gives the expected original circuit (save for H -> U2): <img width=\"764\" alt=\"Screen Shot 2019-11-04 at 2 36 13 PM\" src=\"https://user-images.githubusercontent.com/1249193/68160364-e222c580-ff10-11e9-93f9-be059c76cead.png\"> ### Steps to reproduce the problem ```python qc = QuantumCircuit(5) qc.h(3) qc.cx([3, 3, 1, 1], [1, 4, 2, 0]) qc.measure_all() new_qc = transpile(qc, backend, optimization_level=3) new_qc.draw(output='mpl') ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson_options.txt don't allow splitting long strings nicely Currently `meson_options.txt` don't provide a way to split long strings in multiple lines. If I try to use the `+` operator, the syntax is rejected. My use case is the `description` value. Descriptions can be long to be useful, but I don't like writing anything beyond the 80-column barrier and would rather break this long line. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: transpile() always returns a circuit not in a list whether or not the input is a circuit in a list <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When you run transpile function with a circuit list of only one circuit, then the output is the circuit, not the circuit in a list. ### Steps to reproduce the problem from qiskit import * new_qc = transpile([qc], backend) #for some circuit qc and backend new_qc ### What is the expected behavior? Right now, new_qc would produce a circuit not in a list, but I think it would be helpful if it would result as a list. ### Suggested solutions One suggested solution is to make a new variable in the transpile function called list_boolean, or something else, which would keep track of whether the input is a list or not, and in the conditional where the input list is length 1, one can check the value of list_boolean and if it is true, it returns the transpiled circuit in a list, and if false, it just returns the circuit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Timeout handlers \"timeout\" when certain objects are returned The timeout handlers in `prefect.utilities.executors` generally work well. However, I've stumbled across an edge case in which they _incorrectly_ signify a timeout occurred, when clearly one didn't occur: ```python import prefect from prefect.utilities.executors import multiprocessing_timeout multiprocessing_timeout(lambda: prefect.context, timeout=2) # >> TimeoutError: Execution timed out. ``` The timeout handlers work by placing objects into Queues, so _for some reason_ it seems that certain objects disappear from the Queue. This is almost certainly related to the fact that `context` is `thread.local` as seen by the following example: ```python import prefect from prefect.utilities.executors import multiprocessing_timeout multiprocessing_timeout(lambda: prefect.context.to_dict(), timeout=2) # returns a dictionary ``` I think returning objects from context is a reasonable enough thing that we should either find a way to detect this or raise a more informative error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Including some environment variables in `conda info` At the Conda community call yesterday, we discussed adding a few environment variables to `conda info` to make it easier to catch issues related to these while debugging. chenghlee suggested `LD_LIBRARY_PATH`. Maybe it would be worth including a few others. Making a list below. Feel free to suggest others (or edit directly if you can) * `LD_LIBRARY_PATH` * `LD_PRELOAD` * `PYTHONPATH` * `PYTHONHOME` ### Tasks - [x] Add `LD_PRELOAD` - [ ] Spike to investigate whether it would add value to make this list of variables configurable. (timebox = 1/2 day) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Multiprocessing executor appears to be broken on Windows https://dev.azure.com/elementl/dagster/_build/results?buildId=1498 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Key word arguments breaks pmap This code ```python def f(index1, index2): return np.arange(36).reshape(6, 6)[index1, index2] g = jax.jit(jax.pmap(f)) g(index1=onp.asarray([1]), index2=onp.asarray([2])) ``` Causes this error. ``` google3/third_party/py/jax/api.py in _pmap_axis_size(args) 724 return next(_axis_size(leaf) for arg in args for leaf in tree_leaves(arg)) 725 except StopIteration: --> 726 raise ValueError(\"pmap requires a leading axis to map over.\") 727 728 def _axis_size(x): ValueError: pmap requires a leading axis to map over. ``` Whereas the exact same code without the kwargs works correctly. ```python def f(index1, index2): return np.arange(36).reshape(6, 6)[index1, index2] g = jax.jit(jax.pmap(f)) g(onp.asarray([1]), onp.asarray([2])) ``` Which nicely prints ``` DeviceArray([8], dtype=int32) ``` as expected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Buitlin `input` doesn't work over zmq Typing into any client with a remote kernel: ``` python input('a') ``` produces ``` python --------------------------------------------------------------------------- EOFError Traceback (most recent call last) <ipython-input-3-138401a29eba> in <module>() ----> 1 input('a') EOFError: EOF when reading a line a ``` This should be a simple matter of handling `input` calls just like we do `raw_input`, since in the end they are both doing the same `stdin.read()`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Improve handling of ``params`` argument in ``Gradient.convert`` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The `convert` method of the gradients takes a `params` argument specifying for which parameters the gradient should be computed. The error messages and supported input types of that argument vary between `Gradient`, `NaturalGradient`, `QFI` etc. For instance, `Gradient.convert` supports `ParameterVector`s but for the others the parameter vector must explicitly be unpacked in a list. Also the error messages if the argument is missing can be improved. E.g. not passing the argument for the `QFI` merely raises ```python KeyError: None ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: noarch python entry points created by conda differ than those created by conda-build The entry point scripts which are created by conda for `noarch: python` packages differ slightly from those created for standard packages by conda-build. The templates for the scripts are: [conda](https://github.com/conda/conda/blob/master/conda/gateways/disk/create.py#L37-L43): ``` python python_entry_point_template = dals(\"\"\" # -*- coding: utf-8 -*- if __name__ == '__main__': from sys import exit from %(module)s import %(func)s exit(%(func)s()) \"\"\") ``` [conda-build](https://github.com/conda/conda-build/blob/master/conda_build/utils.py#L61-L67): ``` python PY_TMPL = \"\"\"\\ if __name__ == '__main__': import sys import %(module)s sys.exit(%(module)s.%(func)s()) \"\"\" ``` I've found at least one example where the template used by conda produces a script which does not work but when used with the conda-build template the script run fine. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: `np.rec.fromrecords` looks broken since 1.14.0 ```python >>> dt = [('a', int), ('b', float)] >>> np.rec.fromrecords([ [1, 1.5], [2, 2.5] ], dtype=dt) rec.array([[(1, 1. ), (1, 1.5)], [(2, 2. ), (2, 2.5)]], dtype=[('a', '<i8'), ('b', '<f8')]) ``` while in 1.13.3 that would be: ```python rec.array([(1, 1.5), (2, 2.5)], dtype=[('a', '<i8'), ('b', '<f8')]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Delete source folder after conan export command If you export a modified conanfile.py, maybe adding sources, etc, the source folder which is created from a copy of the \"export\" folder + executing the conanfile.py `source()` method is not deleted. If not deleted, build uses the old source folder. Thus, the user has to remember to `conan remove` the local storage before each `conan export` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Move validations out of ConanFileReference class. - [x] Conan 1.7.3 Each time a ConanFileReference is instantiated, all validations are performed (several regex and type checking), even though they have been already validated: internal data, response from APIs,... and this happens a lot of times while evaluating the dependencies graph. So these validations can be moved to Conan inputs when the reference string is first read into the Conan ecosystem. This can contribute to performance. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Support components on cmake_find_package generator Changelog: Feature: Support ``cpp_info.components`` on ``cmake_find_package`` generator. Docs: missing This implementation preserves `CONAN_LIB::XXXXX` per library targets - [x] Refer to the issue that supports this Pull Request: closes #6718 - [x] If the issue has missing info, explain the purpose/use case/pain/need that covers this Pull Request. - [x] I've read the [Contributing guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've followed the PEP8 style guides for Python code. - [x] I've opened another PR in the Conan docs repo to the ``develop`` branch, documenting this one. <sup>**Note:** By default this PR will skip the slower tests and will use a limited set of python versions. Check [here](https://github.com/conan-io/conan/blob/develop/.github/PR_INCREASE_TESTING.md) how to increase the testing level by writing some tags in the current PR body text.</sup> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Remove underscores from context values set by Prefect A number of values are automatically set in `prefect.context` when flows run. Currently, those keys are prefixed with an underscore, which was an early design decision to avoid collisions with user keys. However, as we better understand usage (and prepare to fill the context with lots more information), it appears that those underscores are not helpful -- if anything they create greater confusion. Offhand, some of them include: ``` _task_run_id _task_name _flow_run_id _map_index (should be task_map_index anyway?) _tags ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: If gevent is used, it causes any error to be a gevent.FileObjectClosed(IOError) `gevent.monkey.patch_all()` patches stderr to be `gevent._fileobjectcommon._ClosedIO` object, which raises its own `FileObjectClosed(IOError)`. ``` class _ClosedIO(object): ... def __getattr__(self, name): if name == 'name': # We didn't set it in __init__ because there wasn't one raise AttributeError raise FileObjectClosed ``` GitPython only catches ValueError in [read_all_from_possibly_closed_stream](https://github.com/gitpython-developers/GitPython/blob/5da76e8b4466459a3b6a400c4750a622879acce8/git/cmd.py#L441) ``` def read_all_from_possibly_closed_stream(stream: Union[IO[bytes], None]) -> bytes: if stream: try: return stderr_b + force_bytes(stream.read()) except ValueError: return stderr_b or b'' else: return stderr_b or b'' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Preserve previous exit semantics and behavior Prior to docker-compose 1.5.x, if a single container exited, the entire set of compose's running containers exited as well. (This is actually a rather major semantic change for 1.4.2 -> 1.5.x IMO.) There are still cases where the previous behavior is more desirable. For one example: running an integration test suite using [dockerized Selenium container(s)](https://github.com/SeleniumHQ/docker-selenium) -- ideally when the integration tests exit, the entire docker compose process would exit as well. Is there any way to enable this prior behavior through a flag or other mechanism? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: missing references when using -n in sphinx-build Started in #13104, turned into a tracking issue here. Turning on -n in sphinx-build results in over 1000 warnings about bad references in docs. Trying to break these down with various grep statements, it seems about 200 are from numpy.ma, about 150 from polynomial and about 150 from c:type. That is under half of the WARNINGS. ~My workflow is to cd to the `doc` directory, modify the `ALLSPHINXOPTS` in the `Makefile and add `-n`~, My workflow is to set an environment variable SPHINXOPTS='-n' then run ``` (cd ..; pip install .); make clean; make html 2>&1 |tee /tmp/build.txt less /tmp/build.txt ``` and look for the most common lines. Unfortunately this takes quite a while. Anyone who wishes to contribute can issue PRs, preferably in chunks that address one class of failure. #13104 gives an idea of the changes needed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Make tracebacks from %paste show the code If I just paste code into IPython and there is a traceback, it shows me where in the code the exception was raised. But if I use %paste (which is apparently more recommended), it does not do this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Prevent conda from scheduling downgrades of conda when no version is explicitly given To go along with https://github.com/conda/conda/pull/7517. See https://groups.google.com/a/anaconda.com/forum/?utm_medium=email&utm_source=footer#!msg/conda-builders/ydua189zWcg/rz3I99JzAgAJ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Fix docs pointers for DeepSpeed In this [section](https://huggingface.co/docs/transformers/master/en/main_classes/trainer#deepspeed), the reader is pointed to several links that are broken: * https://huggingface.co/docs/transformers/master/en/main_classes/trainer#deepspeed-trainer-integration * https://huggingface.co/docs/transformers/master/en/main_classes/trainer#deepspeed-installation * https://huggingface.co/docs/transformers/master/en/main_classes/trainer#deepspeed-multi-gpu * https://huggingface.co/docs/transformers/master/en/main_classes/trainer#deepspeed-one-gpu *https://huggingface.co/docs/transformers/master/en/main_classes/trainer#deepspeed-config-passing * etc All of them should be changed like this: `https://huggingface.co/docs/transformers/master/en/main_classes/trainer#(.*)` --> `https://huggingface.co/docs/transformers/master/en/main_classes/deepspeed#(.*)` I would do it myself, but I see that the code uses e.g. `:ref:`deepspeed-notebook` and not sure how to point to a section in another page 🤷♂️ It looks like a trivial change though Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Incorrect tokenization for MarianNMT models in example script. ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 3.0.2 - Platform: Linux-4.4.0-1110-aws-x86_64-with-Ubuntu-16.04-xenial - Python version: 3.7.8 - PyTorch version (GPU?): 1.5.1+cu101 (True) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: yes - Using distributed or parallel set-up in script?: no ### Who can help Marian: @sshleifer ## Information Model I am using (Bert, XLNet ...): Marian (Helsinki-NLP/opus-mt-nl-fr) The problem arises when using: * [x] the official example scripts: (give details below) * [ ] my own modified scripts: (give details below) The tasks I am working on is: * [ ] an official GLUE/SQUaD task: (give the name) * [x] my own task or dataset: (give details below) I'm trying to finetune a MarianMT model (Helsinki-NLP/opus-mt-nl-fr), using the example finetuning script `examples/seq2seq/finetune.py`. Marian models have different sentencepiece models for the encoder and decoder, but it appears the script does not take this into account, as the source line and the target line are tokenized in exactly the same way (in `utils.py`, lines 115-116): ``` source_inputs = encode_line(self.tokenizer, source_line, self.max_source_length) target_inputs = encode_line(self.tokenizer, tgt_line, self.max_target_length) ``` I suggest checking whether the tokenizer is a Marian tokenizer and if so, encoding with the tokenizer's `prepare_translation_batch` method. Doing this improves BLEU score on my validation data by >3 points. ## To reproduce Steps to reproduce the behavior: 1. Simply run the `examples/seq2seq/finetune.sh` with a MarianModel. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: standard extension API inconsistency? The standard extensions provides API for creating `u1`, `u2`, `u3`, and `U` gates. ``` q = QuantumRegister(\"q\", 3) c = ClassicalRegister(\"c\", 3) qc = QuantumCircuit(q, c) qc.u2(pi/2, 0.3*pi, q[1]) # <- two real parameters, one qubit. ``` Similarly with `u3`: ``` qc.u3(pi,pi/2, 0.3*pi, q[1]) # <- three real parameters, one qubit. ``` But the way to interact with `U` is different: ``` qc.u_base([pi, pi/2, 0.3*pi], q[1]) # <- one array, one qubit. ``` Is this intended? ## Expected Behavior I would expect to create a`U` gate the same way that a `u3` gate is created: ``` qc.u_base(pi,pi/2, 0.3*pi, q[1]) # <- three real parameters, one qubit. ``` ## Possible Solution Changing an API is something to avoid when possible. On the other hand, if this was not the intention, better fix it now :) standard extension API inconsistency? The standard extensions provides API for creating `u1`, `u2`, `u3`, and `U` gates. ``` q = QuantumRegister(\"q\", 3) c = ClassicalRegister(\"c\", 3) qc = QuantumCircuit(q, c) qc.u2(pi/2, 0.3*pi, q[1]) # <- two real parameters, one qubit. ``` Similarly with `u3`: ``` qc.u3(pi,pi/2, 0.3*pi, q[1]) # <- three real parameters, one qubit. ``` But the way to interact with `U` is different: ``` qc.u_base([pi, pi/2, 0.3*pi], q[1]) # <- one array, one qubit. ``` Is this intended? ## Expected Behavior I would expect to create a`U` gate the same way that a `u3` gate is created: ``` qc.u_base(pi,pi/2, 0.3*pi, q[1]) # <- three real parameters, one qubit. ``` ## Possible Solution Changing an API is something to avoid when possible. On the other hand, if this was not the intention, better fix it now :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Sort and uniq available objects for config ``` In [1]: config Available objects for config: TerminalInteractiveShell HistoryManager PrefilterManager IPCompleter DisplayFormatter MagicsManager ScriptMagics AliasManager TerminalIPythonApp StoreMagics StoreMagics ``` The result is not sorted, and StoreMagics shows up twice. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Calling IBMQ.load_accounts() twice should give warning, not exception <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: latest master - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? Calling `IBMQ.load_accounts()` twice gives an Exception. However, in notebooks, it is common to just run multiple cells (or whole notebooks) repeatedly. Raising an exception breaks this convenient workflow. A similar issue, #673 , was raised and corrected, previously. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Make repeated calls to `IBMQ.load_accounts()` give a warning instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: LocalReadoutMitigator.quasi_probabilities incorrectly handles the shots argument ### Environment - **Qiskit Terra version**: 0.22.2 - **Python version**: 3.10 - **Operating system**: Windows ### What is happening? 1. The `LocalReadoutMitigator.quasi_probabilities` method has an argument `shots` which is not used in the method (it is overwritten by the output of `counts_probability_vector`) 2. The method returns an object of type `QuasiDistribution`. It would be good to set the number of shots on that method 3. The documentation on the return type of `counts_probability_vector` is incomplete ### How can we reproduce the issue? - ### What should happen? The number of shots argument should be used, or removed, or documented to be unused. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Few variables was changed globally by mistake in runtime <!--- Please provide a summary in the title and describe your issue here. Is this a bug or feature request? If a bug, include all the steps that led to the issue. If you're looking for help with your code, consider posting a question on StackOverflow instead: http://stackoverflow.com/questions/tagged/spacy --> `spacy.lang.zh.ChineseDefaults.use_jieba` should be `True` by default (default value). But actually it is `False` which is changed by `spacy.cli.ud_train` in runtime (when loading spacy). `spacy.cli.ud_train` also make few other changes by accident, for example: `lang.ja.Japanese.Defaults.use_janome = False`, `random.seed(0)` and `numpy.random.seed(0)`. This will cause bugs which is very difficult to find. **I will make a PR to fix this bug later.** ## Your Environment <!-- Include details of your environment. If you're using spaCy 1.7+, you can also type `python -m spacy info --markdown` and copy-paste the result here.--> * Operating System: Any * Python Version Used: Any * spaCy Version Used: 2.1.0.dev4 * Environment Information: Any Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cmake module: support include_type for dependencies With meson 0.52 the `include_type` argument for `dependency()` was introduced. It seems, that the cmake subproject module does not support it. It would be nice to write meson code like: ``` cmake = import('cmake') some_proj = cmake.subproject('some_project')) some_proj_dep = some_proj.dependency('some_target', include_type: 'system') ``` Currently, meson seems not to be respecting the `include_type` argument. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: apple clang does not have visibility \"protected\" This results in the attribute check function returning false on apple clang, but symbol visibility otherwise working. so something like: ```meson args = [] if cc.has_function_attribute('visibility') args += '-DEXPORT=__attribute__((visibility(\"default\"))) endif library( 'foo.c', c_args : args, gnu_symbol_visibility : 'hidden', ) ``` will fail with missing symbols because args is `[]` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Can't access partition key context attributes for assets outside of job Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Returning n-best hypotheses from Wav2Vec2ProcessorWithLM decoder ### Feature request Currently, the [Wav2Vec2ProcessorWithLM](https://github.com/huggingface/transformers/blob/ae54e3c3b18bac0832ad62ea9b896dfd52a09850/src/transformers/models/wav2vec2_with_lm/processing_wav2vec2_with_lm.py#L67) decode function returns [only the best hypothesis](https://github.com/huggingface/transformers/blob/ae54e3c3b18bac0832ad62ea9b896dfd52a09850/src/transformers/models/wav2vec2_with_lm/processing_wav2vec2_with_lm.py#L572). Shall we extend its functionality and make it return n-best hypotheses, logit_scores, lm_scores, word_offsets so that people could rescore these hypotheses with a larger LM. For example, take a look at [NeMo article](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/asr_language_modeling.html#neural-rescoring) regarding the rescoring of n-best hypotheses. ### Motivation I suppose many people use n-gram models during the shallow fusion stage, the n-grams models are a good fit during the beam search because they are fast. People perform the rescoring of the n-best hypotheses with a larger LM (using them during the decoding is too slow so it makes sense to apply them during the rescoring of n-best hypotheses that come out of the ASR system). They fuse the score which comes out of the ASR with the perplexity-like score from the LM. If this external model is trained on the domain data it will drastically improve the WER of the resulting model. ### Your contribution If it sounds like a good feature to you, that can be potentially adopted let me know and I'll prepare the PR 😃 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumCircuit.draw triggers warning with default arguments for single bits ### Environment - **Qiskit Terra version**: main @ 6927a8d - **Python version**: any - **Operating system**: any ### What is happening? The text circuit visualiser raises a warning when using its default arguments if called on a circuit that has an opaque (to the drawer) instruction that operates on a single clbit out of a register. ### How can we reproduce the issue? ```python import qiskit inner = qiskit.QuantumCircuit(1, 1) inner.measure(0, 0) qc = qiskit.QuantumCircuit(2, 2) qc.append(inner, [0], [0]) qc.draw() ``` gives ```text /Users/jake/code/qiskit/terra/qiskit/visualization/text.py:717: RuntimeWarning: The parameter \"cregbundle\" was disabled, since an instruction needs to refer to individual classical wires return \"\\n\".join(self.lines()).encode(self.encoding).decode(self.encoding) ┌─────────────┐ q_0: ┤0 ├ │ │ q_1: ┤ circuit-85 ├ │ │ c_0: ╡0 ╞ └─────────────┘ c_1: ═══════════════ ``` ### What should happen? No warning for using the defaults with a regular circuit. ### Any suggestions? The drawer sets `cregbundle=True` by default, but really it wants to infer the best value in this case. We probably want three-level logic, so the default is set to `None`. This can still default to `True` at a suitable point of the drawer, but should cause no warnings to be emitted if it is inferred to be `False` instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: container_name directive doesn't affect entries in docker-compose logs When using the container_name directive in the docker-compose.yml file, entries in docker-compose logs still show up with the container_name_1 naming scheme. It's non-critical, but a little inconsistent. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: \"Asset is defined multiple times\" error does not show key ``` dagster.core.errors.DagsterInvalidDefinitionError: Asset key {key} is defined multiple times. Definitions in module hacker_news_assets.assets.activity_analytics and hacker_news_assets.assets.activity_analytics. ``` I think the string is missing an \"f\". Separte, but noticed it when looking at this error - when the module is the same in both cases, it would be clearer to just include it once. \"Asset is defined multiple times\" error does not show key ``` dagster.core.errors.DagsterInvalidDefinitionError: Asset key {key} is defined multiple times. Definitions in module hacker_news_assets.assets.activity_analytics and hacker_news_assets.assets.activity_analytics. ``` I think the string is missing an \"f\". Separte, but noticed it when looking at this error - when the module is the same in both cases, it would be clearer to just include it once. \"Asset is defined multiple times\" error does not show key ``` dagster.core.errors.DagsterInvalidDefinitionError: Asset key {key} is defined multiple times. Definitions in module hacker_news_assets.assets.activity_analytics and hacker_news_assets.assets.activity_analytics. ``` I think the string is missing an \"f\". Separte, but noticed it when looking at this error - when the module is the same in both cases, it would be clearer to just include it once. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: min_new_tokens option in generate() implementation ### Feature request Similarly to the `max_new_tokens`, a `min_new_tokens` option would count only the newly generated tokens, ignoring the tokens of the input sequence (prompt) in decoder only models. ### Motivation The option `min_length` of the `generate()` method might be ambiguous for decoder only models. It is not clear if decoder only models consider the length of the input (prompt) for the `min_length` condition or only the newly generated tokens. In Encoder Decoder (seq2seq) it is clear though. ### Your contribution Not that I remember. But I could test it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: hf_argparser doesn't set the required flag on non-defaulted enums ## Environment info - `transformers` version: 3.0.0-4.3.3 - Platform: macOS - Python version: 3.9 - PyTorch version (GPU?): n/a - Tensorflow version (GPU?): n/a - Using GPU in script?: n/a - Using distributed or parallel set-up in script?: n/a ### Who can help I'm not sure who the owner is of hf_argparser. ## Information We're using hf_argparser to parse our experiment config into dataclasses before training. ## To reproduce Steps to reproduce the behavior: 1. Add an enum argument without a default to a dataclass 2. Parse the command line arguments without supplying the enum argument 3. Should have raised an exception and printed the usage, instead defaults the value to `None`. ## Expected behavior It should raise an exception. The issue is on https://github.com/huggingface/transformers/blob/master/src/transformers/hf_argparser.py#L100, the if statement should have an else which sets `kwargs[\"required\"]=True`, the same way line [134](https://github.com/huggingface/transformers/blob/master/src/transformers/hf_argparser.py#L134) does. I can work up a patch if you agree this is an issue. I think it will also occur with anything that falls into [this branch](https://github.com/huggingface/transformers/blob/master/src/transformers/hf_argparser.py#L118) of the if too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: `--net-alias` support in v2 Compose File I am unsure if I am missing this in the docs or not, but I'm not seeing any way in Compose 1.6.0 that implements the new `--net-alias` support in Docker-Engine. Here's the relevant add from the Docker Engine release notes: https://github.com/docker/docker/pull/19242 My specific end-user ask is a way to define multiple aliases for a container on a network. Something like this, perhaps? ``` yml networks: example services: www: image: apache:2.4.18 networks: example: aliases: - localweb - www.localaddress.com ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Move Kubernetes tests and kind setup out of the container to host **Description** We should move kind setup out of the container for CI to the host environment **Use case / motivation** Makes CI image smaller and setup easier for local testing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: pi_check does not convert param containing ParameterExpression of a float <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: current main - **Python version**: 3.8 - **Operating system**: Ubuntu ### What is the current behavior? Running this code with main from June 29th, ``` from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, transpile from qiskit.test.mock import FakeTenerife circuit = QuantumCircuit(3) circuit.h(1) transpiled = transpile(circuit, backend=FakeTenerife(), optimization_level=0, initial_layout=[1, 2, 0], basis_gates=[\"id\", \"cx\", \"rz\", \"sx\", \"x\"], seed_transpiler=0) transpiled.draw('mpl') ``` produces  and using current main produces  All other gates with params seem to properly display pi. ### Steps to reproduce the problem ### What is the expected behavior? Should see pi/2. ### Suggested solutions Not sure what changed. The param in this case is a ParameterExpression which follows a different path in pi_check. For some reason, either a change in tolerances or a change in sympy perhaps, a trailing zero was being added to the sympy expression. This meant the param would not match the sympy expression and the pi string was not substituted. Should be fixable by a str(float(sym)), but it might be good to know what changed in case there are hidden issues. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Selenium Check Broken for Consumers cf https://travis-ci.org/jupyterlab/extension-cookiecutter-ts/builds/408922606#L1217, \"Error: Cannot find module 'puppeteer'\" cc @saulshanabrook Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: export-dyamic repeated for static libraries with deps of other static libraries I've been working on an app that has a lot of static libraries for all the subsystems and plugins, and links them together at the end. However, due to how meson is duplicating export-dynamic in the build commands, I'm hitting the 128kb argv limit. ``` [1/365] Generating ide-build-ident.h with a custom command. fatal: No names found, cannot describe anything. [1/4] Linking target src/gnome-builder.ninja: fatal: posix_spawn: Argument list too long ``` [build.ninja.snip.txt](https://github.com/mesonbuild/meson/files/2632112/build.ninja.snip.txt) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: unknown cpu family 'mips64el' Sent here by a configure message on OpenBSD running on a loongson. $ uname -a OpenBSD hackbookpro.attlocal.net 6.6 GENERIC#18 loongson $ machine -a mips64el Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Whisper generation support for passing acronym to language arg ### System Info - `transformers` version: 4.29.0.dev0 - Platform: macOS-13.0-arm64-arm-64bit - Python version: 3.9.16 - Huggingface_hub version: 0.12.0 - Safetensors version: 0.2.8 - PyTorch version (GPU?): 1.13.1 (False) - Tensorflow version (GPU?): 2.11.0 (False) - Flax version (CPU?/GPU?/TPU?): 0.5.3 (cpu) - Jax version: 0.3.6 - JaxLib version: 0.3.5 - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help? @hollance @gante ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction ```py processor = WhisperProcessor.from_pretrained(\"openai/whisper-tiny\") model = WhisperForConditionalGeneration.from_pretrained(\"openai/whisper-tiny\") ds = load_dataset(\"hf-internal-testing/librispeech_asr_dummy\", \"clean\", split=\"validation\") sample = ds[0][\"audio\"][\"array\"] input_features = processor.feature_extractor(sample, return_tensors=\"pt\").input_features pred_ids = model.generate(input_features, language=\"de\") ``` Throws this error: <img width=\"778\" alt=\"Screenshot 2023-05-03 at 6 29 38 PM\" src=\"https://user-images.githubusercontent.com/78612354/236067028-ee7ab371-e9a2-44eb-9895-b5c8f3a2fcdd.png\"> Then this error when that's fixed: <img width=\"1198\" alt=\"Screenshot 2023-05-03 at 6 30 34 PM\" src=\"https://user-images.githubusercontent.com/78612354/236067052-8f1ae574-db51-44e4-800c-aa4f38b0200e.png\"> ### Expected behavior Should recognize and use language passed in acronym format as per the docstring Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC,BLD: Switch to `xelatex` engine for latex docs? When building the latex/pdf version of the documentation, sphinx is currently configured to use `pdflatex` (the default) to build the pdfs of the user/reference manuals. There are several places in the documentation where the use of unicode characters causes `inputenc` warnings when building the pdf. In some cases these can be resolved by ensuring that extra latex packages are installed (e.g. `texlive-langgreek` adds the necessary mappings for some Greek Unicode characters), but in other cases (e.g. U+22EE vertical dots) it is more difficult to find an appropriate package (or the mapping can be done manually via `\\DeclareUnicodeCharacter`). In addition, there seem to be some URL ref problems that are avoided by `xelatex` (see sphinx-doc/sphinx#7723). Please share any thoughts and possible pros/cons of switching to `xelatex` for the NumPy latex/pdf docs. Note that sphinx provides a `latex_engine` configuration option that makes this simple to try. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Doubtful about Flow creation time I have 4 tasks implemented as classes inheriting Task class. The tasks will be added to a flow dynamically. i am using 'bind' to bind tasks with inputs. but it takes much time to create a flow for larger inputs. Tried using 'map' but time taken is same . Is this an expected behaviour ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Move manifest capture and checking to hooks This is a very rarely used feature, and a bit orthogonal to conan core functionality. Furthermore it is likely that custom logic is to be written by different users, so seems that a hook could be the right place for this functionality. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: T5 special tokens not mapped to unique indices in vocabulary The docs recommend adding the special eos_token `<\\s>` to the end of each string when encoding/decoding with `T5Tokenizer`. However, this (and the other special tokens e.g. `unk_token`, `pad_token` aren't assigned unique ids in the lookup vocabulary (they are mapped to `{0,1,2}`, which are indices for other common words in the vocab). In practice, I find my model fails to properly produce the `eos_token` since it is associated with blank spaces, so the model produces run-ons during generation ## To reproduce ``` >>> from transformers import T5Tokenizer >>> tokenizer = T5Tokenizer.from_pretrained('t5-base') >>> tokenizer.pad_token '<pad>' >>> tokenizer.pad_token_id 0 >>> tokenizer.eos_token '</s>' >>> tokenizer.eos_token_id 1 >>> tokenizer.unk_token '<unk>' >>> tokenizer.unk_token_id 2 ``` ``` >>> tokenizer.decode([0]) '' >>> tokenizer.decode([1]) '' >>> tokenizer.decode([2]) ' ⁇ ' ``` ## Expected behavior ``` >>> tokenizer.decode([0]) '<pad>' >>> tokenizer.decode([1]) '</s>' >>> tokenizer.decode([2]) '<unk>' ``` ## Environment info - `transformers` version: 2.9.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: \"RuntimeError: Address already in use\" when running multiple multi-gpu training (DDP). **Describe the bug** I see \"RuntimeError: Address already in use\" error message if I try to run two multi-gpu training session (using ddp) at the same time. **To Reproduce** Run two multi-gpu training session at the same time. **Expected behavior** Able to run two multi-gpu training session at the same time. **Screenshots**  **Desktop (please complete the following information):** - OS: Ubuntu 18.04 - Pytorch 1.3.0 - CUDA 10.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Move all datetime handling into a shared core module See https://github.com/GoogleCloudPlatform/gcloud-python/pull/1021#discussion_r35710351 We have (essentially) a novel approach to `datetime` in every sub-package, so we should get unified. - From https://github.com/GoogleCloudPlatform/gcloud-python/pull/1044/files#r36545736: Hmm, maybe `_EPOCH` should be moved up to `gcloud._helpers`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Thread dependency failure when building code mixed with Vala Building a Vala executable, which has a transitive dependency on threads results in the following error: ``` Traceback (most recent call last): File \"/usr/lib/python3.6/site-packages/mesonbuild/mesonmain.py\", line 352, in run app.generate() File \"/usr/lib/python3.6/site-packages/mesonbuild/mesonmain.py\", line 147, in generate self._generate(env) File \"/usr/lib/python3.6/site-packages/mesonbuild/mesonmain.py\", line 197, in _generate g.generate(intr) File \"/usr/lib/python3.6/site-packages/mesonbuild/backend/ninjabackend.py\", line 210, in generate self.generate_target(t, outfile) File \"/usr/lib/python3.6/site-packages/mesonbuild/backend/ninjabackend.py\", line 347, in generate_target vala_generated_sources = self.generate_vala_compile(target, outfile) File \"/usr/lib/python3.6/site-packages/mesonbuild/backend/ninjabackend.py\", line 1146, in generate_vala_compile args = self.generate_basic_compiler_args(target, valac) File \"/usr/lib/python3.6/site-packages/mesonbuild/backend/backends.py\", line 510, in generate_basic_compiler_args commands += compiler.thread_flags() AttributeError: 'ValaCompiler' object has no attribute 'thread_flags' ``` I encountered this while trying to port gnome-sudoku. It uses a helper library, which has some C++ code in it and needs to be linked with pthreads. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Unexpected and new conflict between PyFileConfigLoader and IPythonQtConsoleApp Up to IPython 1.2.1, I was able to add coloring to embedded, in-process Qt consoles essentially by adding the following patch to `examples/inprocess/embedded_qtconsole.py`: ``` from IPython.config.loader import PyFileConfigLoader from IPython.qt.console.qtconsoleapp import IPythonQtConsoleApp config = PyFileConfigLoader(\"/path/to/ipython_qtconsole_config.py\").load_config() IPythonQtConsoleApp.instance(config=config).init_colors(control) ``` (after instantiating the `control` widget). When I tried the same with 2.0.0b1, the instantiation of `IPythonQtConsoleApp` failed with the following exception: ``` IPython.config.configurable.MultipleInstanceError: Multiple incompatible subclass instances of IPythonQtConsoleApp are being created. ``` Interestingly, not loading `config` (i.e., removing the 3rd line and `config=config` in the 4th line) gets rid of the error (although it gets rid of the ability of loading a config file too...). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Theme extension documentation needs clarification Hi, I am aiming to create new jupyterlab theme extension and to this end did following steps - copied and modified existing theme extension, JupyterLab Light Theme - removed existing ./node_modules folder - from within extension folder (theme-new-extension) run following $ npm install # runs OK $ jupyter labextension link . // generates following missing directory /style Could you advise what I might be doing wrong or workaround for the note, npm --version 5.4.2 Thanks in advance -Alex > @jupyterlab/application-top@0.12.0 clean ~anaconda3/envs/jupyterlab-theme/share/jupyter/lab/staging > rimraf build > npm run build:prod > @jupyterlab/application-top@0.12.0 build:prod ~anaconda3/envs/jupyterlab-theme/share/jupyter/lab/staging > webpack --define process.env.NODE_ENV=\"'production'\" fs.js:950 binding.stat(pathModule._makeLong(path)); ^ Error: ENOENT: no such file or directory, stat '~/anaconda3/envs/jupyterlab-theme/share/jupyter/lab/staging/node_modules/@jupyterlab/theme-new-extension/style' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] conan.patch incorrectly applied initial issue: https://github.com/conan-io/conan-center-index/issues/214 it turns out conan's `tools.patch` method applies patches incorrectly after the switch to `patch_ng` package. e.g. its behavior significantly differs from the `patch` command, or `git apply` / `git am` test case to reproduce: https://github.com/conan-io/conan/compare/develop...SSE4:patch_issue?expand=1#diff-11632e511bcb65a506566fb2157b051eR27 reduced (short) test case: https://github.com/conan-io/conan/compare/develop...SSE4:patch_issue?expand=1#diff-11632e511bcb65a506566fb2157b051eR409 in terminal: ``` git clone git@github.com:boostorg/boost.git cd boost git checkout boost-1.70.0 curl https://raw.githubusercontent.com/conan-io/conan-center-index/5d3a76231eeab86d24dda08cb0ee92fa307ef50f/recipes/boost/all/patches/bcp_namespace_issues.patch > 1.patch patch -p1 < 1.patch cat Jamroot | grep \"1\\.70\\.0\" cat Jamroot | grep \"1\\.71\\.0\" ``` there is no `1.71.0` in the output (but in case of conan, it is) <!-- Please don't forget to update the issue title. Include all applicable information to help us reproduce your problem. To help us debug your issue please explain: --> ### Environment Details (include every applicable attribute) * Operating System+version: Windows 10 Enterprise * Compiler+version: N/A * Conan version: 1.19.2 * Python version: 3.7.3 ### Steps to reproduce (Include if Applicable) ### Logs (Executed commands with output) (Include/Attach if Applicable) <!-- Your log content should be related to the bug description, it can be: - Conan command output - Server output (Artifactory, conan_server) --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: \"test\" prefix for rewrite_logs() function of WandbCallback # 🚀 Feature request I would like it if the function `rewrite_logs()` of WandbCallback() would be compatible with the trainers `.predict()` function. ## Motivation Currently the `rewrite_logs()` function looks like this: ```python def rewrite_logs(d): new_d = {} eval_prefix = \"eval_\" eval_prefix_len = len(eval_prefix) for k, v in d.items(): if k.startswith(eval_prefix): new_d[\"eval/\" + k[eval_prefix_len:]] = v else: new_d[\"train/\" + k] = v return new_d ``` but `.predict()` has an argument which is called `metric_key_prefix: str = \"test\"` and sets the prefix to `test`, This leads to the kind of ugly metric name `train/test_f1` in wandb. Better would be `test/f1` ## Your contribution This should do the trick? ```python def rewrite_logs(d): new_d = {} eval_prefix = \"eval_\" eval_prefix_len = len(eval_prefix) test_prefix = \"test_\" test_prefix_len = len(test_prefix) for k, v in d.items(): if k.startswith(eval_prefix): new_d[\"eval/\" + k[eval_prefix_len:]] = v elif k.startswith(test_prefix): new_d[\"test/\" + k[test_prefix_len:]] = v else: new_d[\"train/\" + k] = v return new_d ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Allow specifying default options as a dictionary To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Hello, Looking at the structure of the conanfile.py, I always found it weird why the options were specified as a dictionary, but the default_options as a list of tuples. This is not an issue for packages that have a small amount of options, but it gets ugly for projects with a lot of options. I always end up doing the following: ```python _default_options = { \"shared\": True, \"tools\": True, ... } default_options = [(k, str(v)) for k, v in _default_options.items()] ``` In my opinion, it would be a great enhancement if the default_options would allow specifying values as a dictionary and would make the style of the conanfile.py more uniform. Software information: I'm currently using ```Conan version 1.2.0``` on ``` ProductName: Mac OS X ProductVersion: 10.13.3 BuildVersion: 17D102 ``` with ``` Xcode 9.2 Build version 9C40b ``` and ```Python 3.6.4``` installed from brew Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: nbconvert: Ability to specify name of output file Brought up in a conversation between @Carreau and I. Maybe add a traitlet to the `FilesWriter` and add a convenience flag to the `nbconvertapp.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Containers should be discoverable from their container id Containers currently join networks using the container name (default), and with their service name. We'd like to change or deprecate the container name (#1516), so we should provide a second alias that allows a user to uniquely identify a container (when multiple containers have the same service name, when they are scaled). We could either use the short container id, or `service-<short container id>`. I think just container id might be better. It's already possible to query for this id from within the container (`$(hostname)`), but it's not possible to query for the service name. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Raise ConanInvalidConfiguration from recipes constraining settings From here: https://github.com/conan-io/conan/issues/6534 When a recipe is constraining the settings, it should raise a `ConanInvalidConfiguration` if the value provided doesn't satisfy the values allowed by the recipe: ```python class Recipes(ConanFile): ... settings = {\"os\" : [\"Windows\"]} ``` Right now the output is a regular error that is pointing to a misleading Q&A ``` ERROR: Error while initializing settings. Invalid setting 'Macos' is not a valid 'settings.os' value. Possible values are ['Windows'] Read \"http://docs.conan.io/en/latest/faq/troubleshooting.html#error-invalid-setting\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Use jupyter-packaging <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description Use `jupyter-packaging@0.5.0` using `pyproject.toml`. Note: we still need `setup.cfg` until `pytest` supports [`pyproject.toml`](https://github.com/pytest-dev/pytest/issues/1556). We can also update the CONTRIBUTING notes to take advantage of the fact that `data_files` are installed in `develop` mode when using the new version of `jupyter-packaging`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Document better graph_builder code The graph code is far from being trivial. We have to increase the documentation, maybe each relevant portion of code, like the introduced by #4737 should go with a comment block, even \"graphic\" like: ``` This is because when A-->B and B--->C bla bla bla ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `meson_options.txt` cannot be used to specify negative integer values *Actual:* When trying to specify a negative number in `meson_options.txt`, I get the error `Arguments may only be string, int, bool, or array of those.`. *Expected:* No error is raised, and negative values are accepted. *Rationale:* These options are ideal for setting defaults for build configuration via `#mesondefine`. It's fairly common for integer options to treat zero and negative values as having special meanings. And even if not, sometimes you'd like to have negative values as options. *Workaround:* - Add a second option for the special meaning (ugh!) - Pass the option as a string, and use `#define` instead of `#mesondefine` (ugh!) *Details:* The error is raised here: https://github.com/mesonbuild/meson/blob/6e865fc08d0d13b3846d00e80c9f3ea090645fb8/mesonbuild/optinterpreter.py#L170 The culprit looks like it may be here: https://github.com/mesonbuild/meson/blob/6e865fc08d0d13b3846d00e80c9f3ea090645fb8/mesonbuild/mparser.py#L107 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Scheduler needs to shutdown in a way compatible with SimpleQueue and Queue types for worker queue. Currently one test is failing for the scheduler. The issue is Py3.7 changed the _worker_queue to be a SimpleQueue. Traceback (most recent call last): File \"/Users/crwilcox/workspace/google-cloud-python/pubsub/tests/unit/pubsub_v1/subscriber/test_scheduler.py\", line 51, in test_schedule scheduler_.shutdown() File \"/Users/crwilcox/workspace/google-cloud-python/pubsub/google/cloud/pubsub_v1/subscriber/scheduler.py\", line 121, in shutdown self._executor._work_queue. AttributeError: '_queue.SimpleQueue' object has no attribute 'queue' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [build system] [MSBuild] Abilty to set WindowsSDKVersion when using MSBuild build helper To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. It would be nice to be able to use `/p:WindowsTargetPlatformVersion` (WindowsSDKVersion ) when using the msbuild build helper (similar functionality to the tools.vcvars_command()). Unless there is a way to pass arbitrary property flags to the msbuild build command call? ``` if winsdk_version: command.append(\"/p:WindowsTargetPlatformVersion=%s\" % winsdk_version) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Docker-compose not able to get into bash if using entrypoint I have a simple docker-compose.yml file ``` yml version: '2' services: test: image: centos:6.7 entrypoint: echo command: echo From compose ``` Now below is the command i execute ``` bash [root@localhost test-compose]# docker-compose run test echo From compose [root@localhost test-compose]# docker-compose run test this is best this is best [root@localhost test-compose]# docker-compose run --entrypoint \"\" test /bin/bash /bin/bash [root@localhost test-compose]# docker-compose run --entrypoint /bin/bash test /bin/echo: /bin/echo: cannot execute binary file [root@localhost test-compose]# docker-compose run --entrypoint /bin/bash test \"\" /bin/echo: /bin/echo: cannot execute binary file ``` As you can see I am not able to get into bash any how. I am using Docker 1.11.1. If any more is needed please let me know Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: `list(np.arange(10001))` is slow. We should improve this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Read the Docs build failing https://readthedocs.org/projects/gcloud-python/builds/4108022/ https://readthedocs.org/projects/gcloud-python/builds/4108027/ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: repeated request to rebuild with lab I'm getting repeated \"build recommended\" requests 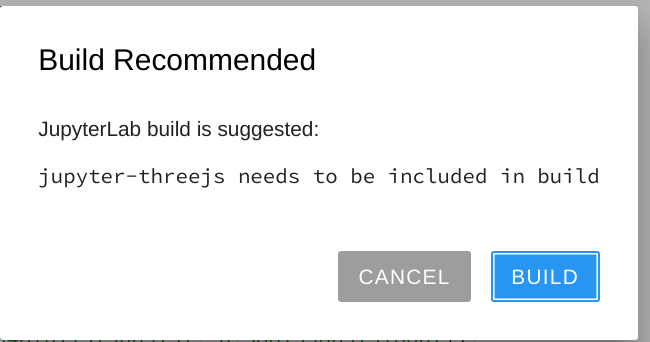 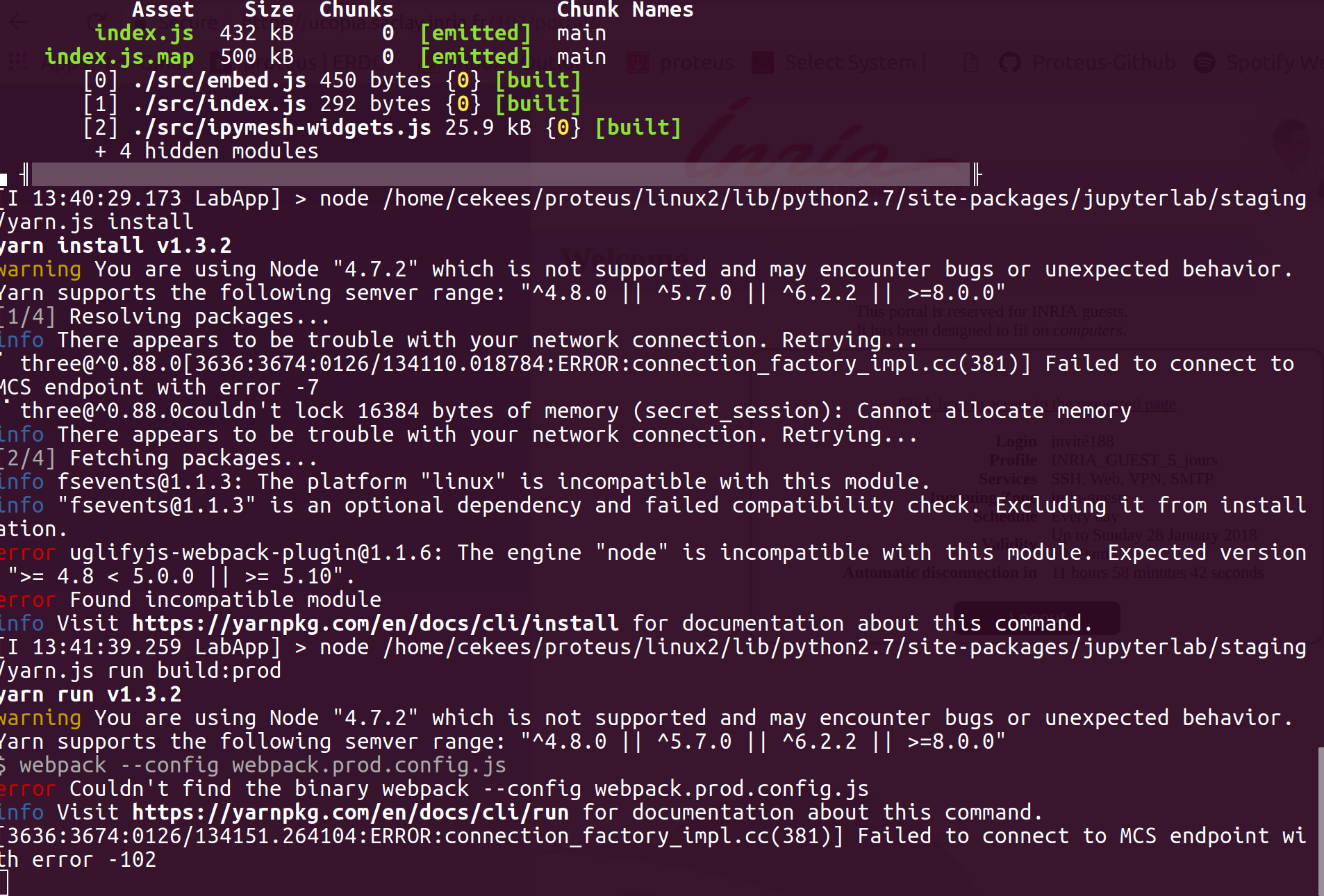 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Custom gates are not extending circuit.definitions This is some sort of follow up from #875. It seems that, at some point, we broke `circuit.definitions`: ``` >>> from qiskit import QuantumCircuit >>> qasm_string = \"\"\"OPENQASM 2.0; >>> gate id a { U(0,0,0) a; } >>> \"\"\" >>> circuit = QuantumCircuit.from_qasm_str(qasm_string) >>> circuit.definitions.keys() odict_keys([]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Comments typo https://github.com/huggingface/transformers/blob/3187228206cce052c5df0a8643fe85d2fd50e6a0/src/transformers/models/gpt2/modeling_gpt2.py#L811 Ou -> or Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Unhandled Python exception on meson test --no-rebuild when test executable not built **Describe the bug** Unhandled Python exception when running `meson test --no-rebuild` when the test executable is not up to date. **To Reproduce** ``` echo \"project('x','c')\" > meson.build echo \"test('t', executable('missing'))\" >> meson.build meson build meson test -C build --no-rebuild ....long stack trace.... FileNotFoundError: [Errno 2] No such file or directory: '..../build/missing' ERROR: Unhandled python exception This is a Meson bug and should be reported! ``` **Expected behavior** Either skip the test with the missing executable, or abort with a tidier error message. **system parameters** * Ubuntu 21.10 * Python 3.9.10 * `meson --version 0.61.2` Check if test executable exists Resolve #10006 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Backward pass error during OWL-ViT finetuning ### System Info Google Colab ### Who can help? @ArthurZucker @amyeroberts ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction https://colab.research.google.com/drive/1GfspAHLGTMmzfNShAVebzM04s32q1LKb?usp=sharing ### Expected behavior I was trying to finetune Owl-ViT, and I came across this backward pass error. I investigated and found out that the error is the operator \"/=\" which does an inplace operation. At lines: - https://github.com/huggingface/transformers/blob/4e8929dcbb9040f54f52d898a600260f338ef54f/src/transformers/models/owlvit/modeling_owlvit.py#L1296 - https://github.com/huggingface/transformers/blob/4e8929dcbb9040f54f52d898a600260f338ef54f/src/transformers/models/owlvit/modeling_owlvit.py#L1297 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"ERROR: name is reserved\" with docker 1.10rc1 Any idea why I keep getting this error trying to bring up a service? Had to upgrade to docker 1.10rc1 to try to workaround a bug. Did clean builds on a new 1.10rc1 server. ``` docker-compose version 1.5.2, build 7240ff3 Server Version: 1.10.0-rc1 ``` ``` socat_foo_console: image: bobrik/socat mem_limit: 50m links: - foo:foo1 command: TCP-LISTEN:80,fork,reuseaddr TCP:foo1:90 ports: - \"7190:80\" ``` ``` docker-compose up -d ... Creating example71_socat_foo_console_1 ERROR: name is reserved ``` ``` systemctl status docker Jan 18 10:30:23 docker110 docker[17741]: time=\"2016-01-18T10:30:23.228078648-05:00\" level=warning msg=\"Your kernel does not support swap limit capabilities, memory limited without swap.\" Jan 18 10:30:23 docker110 docker[17741]: time=\"2016-01-18T10:30:23.270394958-05:00\" level=error msg=\"Handler for POST /v1.19/containers/create returned error: name is reserved\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: The output from the command is not logged out. I noticed the output from commands (set either in a Dockerfile, or in fig.yml) does not currentlf log out. Here is a simple example that might demonstrate what I mean more clearly. For a simple fig.yml file ``` echo: image: ubuntu command: echo hello ``` The result from running `fig up` is ``` Creating FigExperiment_echo_1... Attaching to FigExperiment_echo_1 ``` But I think it would be incredibly useful if the command from the container is also outputted, e.g. ``` Creating FigExperiment_echo_1... Attaching to FigExperiment_echo_1 hello ``` I noticed that docker-py's client start and create_container don't support the attach option currently, so I'm not to sure how involved a fix this might be. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `%matplotlib` is not showing when pressing tab for autocompletation after `%pylab` The issue appears in IPython 6.1, but not in 6.0 I first realize about it using Spyder: spyder-ide/spyder#5020 Nevertheless, even if it is not shown, `%matplotlib`can be executed and it works. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Lower default progress_bar_refresh_rate ## 🚀 Feature From a conversation in Slack. In v0.7.1, the default value of `progress_bar_refresh_rate` is 50, which I think too high. It is a measure to prevent notebook freezing, however, I believe most users run PL on CLI. In addition, the high default value confuses the users in `fast_dev_run` because it has only 2 iterations. So, I suggest the following: - Set the default value as `1` or `2`. (I think `1` is better.) - Add doc for notebook users like \"you should raise `progress_bar_refresh_rate` to prevent freezing!\" for participants of the conversation: @williamFalcon @Borda @jeremyjordan Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Hook new python package types into solver Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: Merge together DISTUTILS.rst.txt#template-files\" and distutils.rst#conversion-of-src-files A follow-up to #11689. These two sections describe the same distutils feature, but in different ways. It would be good to unify them. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: mesonintrospect: Expose install_dir for targets Mentioned on the [gnome-builder issue](https://bugzilla.gnome.org/show_bug.cgi?id=743280) this would be useful information. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Define a better displayFormatter of function and methods I think it should be possible to define a default formatter for functions that would be better than the defautl one. The following is not really useful: ``` In [1]: from inspect import signature In [2]: signature Out[2]: <function inspect.signature> ``` Something that would display less than `signature?` or `signature??`, but still a bit better than plain function/methods REPR. ``` In [1]: from inspect import signature In [2]: signature Out[2]: <function inspect.signature(obj, *, follow_wrapped=True)> ``` Seem like a nice standalone project that could be useful. Thoughts ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Labels being created multiple times ## How to reproduce the behaviour Created a custom NER model the cfg file is showing my entities multiple times \"extra_labels\":[ \"PAY\", \"PAY\", \"PAY\", \"PAY\", \"CPTI\", \"CPTI\", \"CPTI\", \"CPTI\", \"CHG_Amts\", \"CHG_Amts\", \"CHG_Amts\", \"CHG_Amts\" ], ## Your Environment * Operating System: Windows 7 * Python Version Used: 3.6 * spaCy Version Used: 2.0.18 * Environment Information: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Early stopping conditioned on metric `val_loss` isn't recognised when setting the val_check_interval **Describe the bug** Training stops when setting `val_check_interval`<1.0 in the Trainer class as it doesn't recognise `val_loss`. I get the following warning at the end of the 3rd epoch: ``` Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,train_loss ``` **To Reproduce** Steps to reproduce the behavior: 1. Run the CoolModel example but change the `trainer` line to trainer = Trainer(val_check_interval=0.5,default_save_path=\"test\") 2. Training will stop at the end of the third epoch and the above warning will show. **Expected behavior** Training shouldn't stop and `val_loss` should be recognised. **Desktop (please complete the following information):** - VM: Google Colab - Version 0.5.3.2 **Additional context** This doesn't happen with 0.5.2.1 although it looks like something has changed with model saving mechanism since it only seems to save the best model in 0.5.3.2. EDIT: Also seems to happen when setting `train_percent_check`<1.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Uninformative error message when trying to install using python<3.6 Because `setup.py` (lines [182](https://github.com/numpy/numpy/blob/master/setup.py#L182), [191](https://github.com/numpy/numpy/blob/master/setup.py#L191)) uses f-strings introduced in python 3.6, anyone using lower version of python would get a syntax error message. The [code checking if version>=3.6](https://github.com/numpy/numpy/blob/master/setup.py#L29) and producing an informative error message for the user would not be executed. Possible solutions include but are not limited to: 1. Putting the f-strings in try-catch block, e.g. ``` try: eval(\"raise ValueError(f'Submodule {p} missing')\") except SyntaxError: raise RuntimeError('Support for f-strings required') ``` 2. Removing f-strings and using \"traditional\" string formatting methods for backward compatibility AFAIK using `from __future__ import` would be troublesome here https://stackoverflow.com/questions/42097052/can-i-import-pythons-3-6s-formatted-string-literals-f-strings-into-older-3-x If a decision is made to address this non-critical issue and change `setup.py` in any way, I will be glad to submit a PR. ### Reproducing code example: e.g. `python setup.py build_ext -i` ### Error message: ``` File \"setup.py\", line 182 raise ValueError(f'Submodule {p} missing') ^ SyntaxError: invalid syntax ``` ### Numpy/Python version information: `1.16.3 3.5.2` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Minor documentation errors in `execute` > I think this too can be fixed: > >  > > https://github.com/Qiskit/qiskit-terra/blob/186c807877e4af573f1ad8ae6d77bac7a3688e33/qiskit/execute_function.py#L232 > > ``` > :math:`m \\times n` > ``` true @prakharb10 , also m and n could already be written in the same math environment upon definition. wanna open a new issue/PR since this one is already merged? _Originally posted by @johannesgreiner in https://github.com/Qiskit/qiskit-terra/issues/8181#issuecomment-1160522309_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Package download retry. (conan.io ECONNRESET error) Hello! Server sometimes responds with: ('Connection broken: error(\"(104, \\'ECONNRESET\\')\",)', error(\"(104, 'ECONNRESET')\",)). [Remote: conan.io]. It is reproduced in Travis jobs. E.g. https://travis-ci.org/theirix/conan-libssh2/jobs/222844602 : ``` zlib/1.2.11@lasote/stable: Looking for package 8767e89412729a395e7a478e291eeb99291fe27b in remote 'conan.io' Downloading conanmanifest.txt [==================================================] Downloading conaninfo.txt [==================================================] Downloading conan_package.tgz ERROR: Download failed, check server, possibly try again ('Connection broken: error(\"(104, \\'ECONNRESET\\')\",)', error(\"(104, 'ECONNRESET')\",)). [Remote: conan.io] Error while executing: conan test_package . -s arch=\"x86\" -s build_type=\"Release\" -s compiler=\"gcc\" -s compiler.version=\"5.4\" -o libssh2:shared=\"True\" -o OpenSSL:no_electric_fence=\"True\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Need Consistent Layout Representations During Transpile There are a few bug reports recently with how Layout is applied. The source of confusion is that different passes do slightly different thigns with the layout. After internal discussions with @itoko @kdk @1ucian0, here is the plan: - [x] Clean up the ApplyLayout pass (#2050) and merge it. This pass should be dumb, and just consume a virtual circuit + Layout object, and output a register-less circuit (for now, a flat register). This involves updating the dag nodes as well as they contain register pointers. @itoko - [x] Change BasicSwap and StochasticSwap to consume physical circuits (register-less where each index literally corresponds to the physical qubit). @1ucian0 - [x] Change LookaheadSwap to remove the logic for flattening register. @kdk - [x] Remove LegacySwap and replace by StochasticSwap (after some more testing). @ajavadia - [x] Update the other passes that currently consume a Layout (e.g. CXDirection, CXCheck, ..) to just assume that the layout has been applied, so just consult the (physical) circuit. @ajavadia - [x] Add a circuit.layout property, so that the selected layout can be queried by the user later. This property will be populated by the layout selection pass (NoiseAdaptiveLayout, DenseLayout, TrivialLayout, SetLayout). So then, remove this from `pass_manager.property_set`. @1ucian0 Fixing these should close #1831, #2066, #2405, #2503, #2532. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] CMakeToolchain.cache_variables should parse boolean values It's related to #11848. It would be great for users, if don't need to parse boolean values when using `cache_variables`. For instance: ```python default_options = {\"enable_foobar\": True} def layout(self): cmake_layout(self) def generate(self): tc = CMakeToolchain(self) tc.variables[\"DISABLE_FOOBAR\"] = self.options.enable_foobar tc.cache_variables[\"ENABLE_FOOBAR\"] = str(self.options.enable_foobar) tc.generate() ``` You can see a mixed flow, where you need parse or not the option value, because `cache_variables` throws `Object of type PackageOption is not JSON serializable` when receiving a boolean. (It does not matter re-using the option, it's just an exemplification). I would like to ask to follow the same behavior for both `variables` and `cache_variables`: Parse boolean values automatically, just like `variables` does right now. The documentation can be clear about it, but for who is developing a new recipe and is not an expert, it's a confusing behavior. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Revert interfaces for key-value features Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CMake build wrapper should set PKG_CONFIG_PATH - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. conan version 1.0.4 or master A lot of cmake scripts use both `find_package` (`FindFoo.cmake`-based) and `pkg_check_modules` (`pkg-config`-based). CMake build wrapper should automatically provide `PKG_CONFIG_PATH` env var set to build directory or to recipe-provided paths. Exact same behavior is seen in `AutoToolsBuildEnviroment` or `Meson`. `CMake` should not be an exception. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Figure out way to get rid of need for path manipulations to fix include issues See sys.path.insert(0, os.path.abspath(script_relative_path('.'))) in example/toys/repo.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson mistakenly reports executable keyword name_suffix as unknown When using the following code: `executable('hello-world', 'main.c', name_suffix:'js')` Meson reports: `WARNING: Unknown keyword argument(s) in target hello-world: name_suffix.` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Bug in GAN example Bug in https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pl_examples/domain_templates/generative_adversarial_net.py When I run `python generative_adversarial_net.py ` I get ``` Traceback (most recent call last): File \"generative_adversarial_net.py\", line 218, in <module> main(hparams) File \"generative_adversarial_net.py\", line 192, in main model = GAN(hparams) File \"generative_adversarial_net.py\", line 90, in __init__ self.generator = Generator(latent_dim=self.latent_dim, img_shape=mnist_shape) File \"generative_adversarial_net.py\", line 39, in __init__ *block(latent_dim, 128, normalize=False), File \"generative_adversarial_net.py\", line 32, in block layers = [nn.Linear(in_feat, out_feat)] File \"/home/vladimir/anaconda3/lib/python3.7/site-packages/torch/nn/modules/linear.py\", line 72, in __init__ self.weight = Parameter(torch.Tensor(out_features, in_features)) TypeError: new(): argument 'size' must be tuple of ints, but found element of type Namespace at pos 2 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: needs_exe_wrapper = false ignored in tests In meson 0.50.x and earlier one could set the `needs_exe_wrapper` property of the cross file to false to tell meson that the cross binaries could be run natively, without a wrapper (such as when compiling x86 binaries on x86_64 platforms). In 0.51 this stopped working. This is likely related to (and perhaps the corollary to #5818 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: MPL drawer CU1 gate is inconsistent with other drawers <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.11.0 - **Python version**: 3.7 - **Operating system**: Mac OS 10.15.1 ### What is the current behavior? ``` circuit = QuantumCircuit(2) theta = numpy.pi/2 circuit.cu1(theta,0,1) circuit.draw() ``` Output- ``` q_0: |0>─■───── │pi/2 q_1: |0>─■───── ``` However, mpl shows fine-  ### Steps to reproduce the problem Paste the above code in Jupyter notebook and run. ### What is the expected behavior? The text drawer should show up like this- ``` q_0: |0>─────■────── ┌────┴─────┐ q_1: |0>┤ U1(pi/2) ├ └──────────┘ ``` ### Suggested solutions Fix is provided below in the PR by making changes in qiskit/visualization/text.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Classical conditioning on single classical bits <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? As far as I understand, classical conditional statements are done using `c_if` to check whether a classical register holds the binary string for a given integer. It would be useful to be able to do this for individual bits. This can be done by declaring each bit as an individual classical register. But if there is not a better way in the current version of Terra, there probably should be. Note that this has previously been discussed in [issue 356 of the qiskit-tutorial](https://github.com/Qiskit/qiskit-tutorial/issues/356) and on the [Quantum Computing Stack Exchange](https://quantumcomputing.stackexchange.com/questions/4260/how-to-create-a-condition-on-only-one-classical-bit-when-we-have-a-total-of-2-cl). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Allow custom email backends The current `send_email` helper uses SMTP, but sometimes it's useful to be able to send mail without SMTP--for example when using API-based services like Sendgrid, Mailgun, etc. It would be useful to include a hook for overriding `send_email`--maybe a Django-style override like `email_backend = path.to.plugin:send_email`. If folks would be interested, I'm happy to send in a patch for this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: update docs to recommend __call__ for forward passes ## 📚 Documentation We should update the docs to recommend usage of `self(x)` for calculating the forward pass rather than `self.forward(x)`. Calling `forward()` directly can cause issues when you're using PyTorch model hooks (eg. see the additional logic in [`nn.Module.__call__`](https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/module.py#L540)). Although most people don't play around with hooks and using `self.forward()` will work fine for them, we should probably follow the best practice (as I understand) of using `__call__` for calculating forward passes. Related issues: #632 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Better way to set retain_graph Is there a better way to set `retain_graph`, especially when using two optimizers? I have read the issue #356 and the corresponding fix, to set it by overriding the `backward` function. However, this becomes messy especially when more than 1 optimizers are used, as the function doesn't have the `optimizer_idx` as an argument. There are workarounds like naming the optimizer object and using that to set/reset the `retain graph`, but passing `optimizer_idx` would be great. This shouldn't be difficult as the `opt_idx` variable is [available](https://github.com/PyTorchLightning/pytorch-lightning/blob/1030c4a79c2f106e22db02acc11ef2cc1bde068b/pytorch_lightning/trainer/train_loop_mixin.py#L179) inside the loop in which the `backward` function is called - Version [0.6.0] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Flax XLM-RoBERTa # 🌟 New model addition: Flax XLM-RoBERTa ## Model description The Flax version of RoBERTa and PyTorch and TF XLM-RoBERTa have been there for a while, but some pieces were missing that prevented us from doing pre-training and other tasks on Flask XLM-RoBERTa. In this PR #15900, I am adding those parts that were necessary to support XLM-RoBERTa in Flax based on the existing XLM-RoBERTa and Flax RoBERTa implementations. ## Open source status * [x] the model implementation is available: it is based off the existing implementation of XLM-RoBERTa and Flax RoBERTa in HuggingFace. * [x] the model weights are available: not as Flax, but loading from PyTorch seems to work. * [x] who are the authors: @aconneau I think, but not sure who ported it to HF. Maybe @sgugger, @patrickvonplaten? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Tokenizer Batch decoding of predictions obtained from model.generate in t5 How to do batch decoding of sequences obtained from model.generate in t5? Is there a function available for batch decoding in tokenizer `tokenizer.batch_decode_plus` similar to batch enocding `tokenizer.batch_encode_plus`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circ.measure_all gives a creg the name \"measure\" that is a reserved qasm word. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is the current behavior? `circ.measure_all()` attaches a creg with the name 'measure'. However this is a reserved keyword in qasm, and causes conflicts ``` QasmError: \"Expected an ID, received 'measure'\" ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pkgconfig: Include libdir in .pc files if referenced Some packages define variables in their .pc files and those variables may depend on the value of the libdir variable even if no public or private libraries are referenced in the .pc file. Walk the list of variables and check if any of them reference ${libdir} and if so, make sure to include the libdir definition as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Visualizations should allow for passing a Matplotlib axes instance <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Being able to pass an axes instance allows for easily using the visualzations in subplots and other types of figures where the figure instance is already generated Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: compose does not make use of config.json for \"events\" daemon command. Due to https://github.com/docker/docker-py/issues/1472, compose 1.11.1 is unable to propagate the HttpHeaders from config.json on \"events\" commands. Compose looks for containers events when performing \"docker-compose up\". Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: methods for developing quantum channels Go with pr #1191 Also @chriseclectic can you make an issue for all the other future PR that you list there. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose up --timeout does not appear to work ## Version Docker version 17.09.0-ce, build afdb6d4 docker-compose version 1.17.0-rc1, build a0f95af ## Problem Setting timeout on `docker-compose up` does not affect the shutdown timeout `docker-compose.yml` file ```yaml version: \"3.3\" services: test2: image: debian:9 command: nohup sleep 1000 ``` (Also tried with version 2.0, and 2.3) ``` $ docker-compose up -d --timeout 123 test2 $ docker inspect issue_test2_1 # Shows no StopTimeout set at all $ time docker-compose stop Stopping issue_test2_1 ... done real 0m11.473s user 0m0.908s sys 0m0.144s ``` (Also tried `down`) ## Expected behavior ``` $ docker run -it --rm --stop-timeout=121 --name test1 debian:9 nohup sleep 1000 $ docker inspect test1 # Show a StopTimeout of 121 set in the \"Config\" section $ docker stop test1 # takes the ~121 seconds ``` ## Other Using `stop_grace_period` does work when using docker-compose commands, but not docker commands, as it appears that `docker-compose stop` or `down` just re-reads the `docker-compose.yml` file at stop time, and has nothing to do with how the container was started ## Objective I am trying to set the StopTimeout in the actual container, so the daemon knows what to respect when it is shutdown (for example during a full system shutdown). Something like `stop_grace_period` doesn't help me, as that only tells `docker-compose` how long to wait, not the docker daemon. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: typo in bigquery solids.py Typo calls `biquery` instead of `bigquery`: https://github.com/dagster-io/dagster/blob/4a91c9d09b50db93e9174c93a4ada0e138e3a046/python_modules/libraries/dagster-gcp/dagster_gcp/bigquery/solids.py#L136 This causes this solid to fail when it can't find the resource. Fails with the following error: ``` dagster.core.errors.DagsterUnknownResourceError: Unknown resource `biquery. Specify `biquery` as a required resource on the compute / config function that accessed it. ``` I will make a PR to fix it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Open ControlledGates not marked equivalent I think #4444 broke circuit equivalence with controlled gates: ```python from qiskit import QuantumCircuit from qiskit.circuit.library.standard_gates import XGate circuit = QuantumCircuit(5) circuit.append(XGate().control(4, ctrl_state='0101'), [0, 1, 2, 3, 4]) expected = QuantumCircuit(5) expected.append(XGate().control(4, ctrl_state='0101'), [0, 1, 2, 3, 4]) assert circuit == expected ``` ``` --------------------------------------------------------------------------- AssertionError Traceback (most recent call last) <ipython-input-1-27d881d6a5be> in <module> 8 expected.append(XGate().control(4, ctrl_state='0101'), [0, 1, 2, 3, 4]) 9 ---> 10 assert circuit == expected AssertionError: ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Avoid showing tracebacks in CLI We should not be showing the user full tracebacks in CLI. - It could extend beyond the scroll limit of their terminal - It can be overwhelming I think we should follow the lead of `npm` and `yarn` and create an error file that can be easily copied into an issue or given to an administrator. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 'clean' target fails when custom_target's output is a directory I can reproduce it with this test case: `test cases/common/131 custom target directory install` It gives the following error: ``` [1/1] 'Cleaning' FAILED: clean 'ninja' '-t' 'clean' ninja: error: remove(html): Directory not empty Cleaning... 0 files. ninja: build stopped: subcommand failed. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Invalid keywords warning does not say which target, meson.build file, or line/col number > WARNING: Passed invalid keyword argument \"install\". This will become a hard error in the future. > WARNING: Passed invalid keyword argument \"install_dir\". This will become a hard error in the future. These warnings are quite useless because you have no idea what targets they are talking about. We should not release with this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support unicode characters in -f paths On Ubuntu 16.04: ``` $ docker-compose -f 就吃饭/docker-compose.yml config/home/joffrey/work/compose/compose/config/config.py:234: UnicodeWarning: Unicode equal comparison failed to convert both arguments to Unicode - interpreting them as being unequal if filenames == ['-']: Traceback (most recent call last): File \"/home/joffrey/.envs/compose/bin/docker-compose\", line 9, in <module> load_entry_point('docker-compose==1.11.0.dev0', 'console_scripts', 'docker-compose')() File \"/home/joffrey/work/compose/compose/cli/main.py\", line 64, in main command() File \"/home/joffrey/work/compose/compose/cli/main.py\", line 110, in perform_command handler(command, options, command_options) File \"/home/joffrey/work/compose/compose/cli/main.py\", line 305, in config compose_config = get_config_from_options(self.project_dir, config_options) File \"/home/joffrey/work/compose/compose/cli/command.py\", line 46, in get_config_from_options config.find(base_dir, config_path, environment) File \"/home/joffrey/work/compose/compose/config/config.py\", line 242, in find filenames = [os.path.join(base_dir, f) for f in filenames] File \"/home/joffrey/.envs/compose/lib/python2.7/posixpath.py\", line 73, in join path += '/' + b UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 1: ordinal not in range(128) ``` On Windows: ``` docker-compose -f \"C:\\Users\\husun\\documents\\visual studio 2017\\Projects\\测试中文\\docker-compose.yml\" up -d --build ERROR: compose.cli.main.main: .IOError: [Errno 22] invalid mode ('r') or filename: 'C:\\\\Users\\\\husun\\\\documents\\\\visual studio 2017\\\\Projects\\\\????\\\\docker-compose.yml' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Allow nocache option for building docker storage ## Opened from the [Prefect Public Slack Community](https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU) **will**: is there anyway to force prefect to not use docker cache when building flows using docker storage? **zachary**: Hi <@U012VDP6V3N>! It doesn't look like we support that at the moment, but it definitely looks doable! Let me open an issue for that. **zachary**: <@ULVA73B9P> open \"Allow nocache option for building docker storage\" Original thread can be found [here](https://prefect-community.slack.com/archives/CL09KU1K7/p1590510689004100?thread_ts=1590510689.004100&cid=CL09KU1K7). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: `fig help $cmd` fails without fig.yml file Basically… ``` $ ls -a . .. $ fig help up Can't find fig.yml. Are you in the right directory? ``` …I think `fig help $cmd` should not care if there's a `fig.yml` file in the current directory to give you help. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Vertical offsets in LaTeX output for nbconvert The following is an example of the kind of output I'm seeing:  The input is systematically a few points too high, while the output is much too low. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Trainer is using DataParallel on parallelized models ## Environment info - `transformers` version: 4.2.0 - Platform: Ubuntu 20.04 - Python version: 3.8.5 - PyTorch version (GPU?): 1.7.1 / CUDA 11.2 - Using GPU in script?: - Using distributed or parallel set-up in script?: ### Who can help @sgugger @stas00 ## Information I'm trying out the 4.2.0 release with a training script that had been working in 4.1.1. I'm parallelizing my model over two GPUs, and I had been using the `--model_parallel` training arg in the previous version. Now that it's no longer used, I removed the arg from my training command, but I'm getting an error as though the DataParallel is being used and the model isn't being detected as parallelized: `RuntimeError: module must have its parameters and buffers on device cuda:0 (device_ids[0]) but found one of them on device: cuda:1` I did some debugging, and everything seems okay with my model (`trainer. is_model_parallel` returns True). But the `trainer. args.n_gpu` is still 2. I admit that I don't totally understand what's happening in the trainer code, but it might be an error on line 289? [`self.args._n_gpu = 1`](https://github.com/huggingface/transformers/blob/126fd281bc309ec29caef99e982640265c8a4fba/src/transformers/trainer.py#L289) Should that be `self.args.n_gpu = 1`, without the leading underscore? ## To reproduce Steps to reproduce the behavior: 1. Parallelize a model 2. Train on a machine with multiple GPUs Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: incorrect run on the test set with overwritten validation_end and test_epoch_end ## 🐛 Bug If I override validation_end and test_epoch_end, TrainerEvaluationLoopMixin.evaluate works incorrectly on the test set Suppose we override `validation_epoch_end` and `test_end`, but not `validation_end` and `test_epoch_end`. (I actually did this since I am a newbie and haven't yet figured out how everything works; also it seems `validation_end` is the same as `validation_epoch_end`, and `test_end` seems to be the same as `test_epoch_end`). Suppose I run `trainer.test(model)`. Consider lines 300-312 in [evaluation_loop.py](https://github.com/PyTorchLightning/pytorch-lightning/blob/6a0b171be4c08982a7a8b45ddffe04a726265323/pytorch_lightning/trainer/evaluation_loop.py#L300). Then we have `(test_mode and self.is_overriden('test_end', model=model)) == True`, so the first `if` block is executed, that is `eval_results = model.test_end(outputs)`. But look at the second `if` and its `elif`. We have `(test_mode and self.is_overriden('test_epoch_end', model=model)) == False`, hence the `elif` of the second `if` will also be executed, that is `eval_results = model.validation_epoch_end(outputs)`. And we will have validation results recorder as test results, which is a mistake. This problem is present in the commit 60b8246. And the inverse problem (which happens if we override only `test_epoch_end` and `validation_end` is present in 0.7.1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: test_compiler breaks AerJob status check <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? When running the tests, the following does not work when run *after* the `test_compiler` module: ```python backend = Aer.get_backend('qasm_simulator') job_sim = execute(qc, backend) job_sim.status() ``` ``` Traceback (most recent call last): File \"/Users/paul/Desktop/Github_repos/qiskit-core/test/python/test_cpp.py\", line 34, in test_aer_status job_sim.status() File \"/Users/paul/Desktop/Github_repos/qiskit-core/qiskit/backends/aer/aerjob.py\", line 37, in _wrapper return func(self, *args, **kwargs) File \"/Users/paul/Desktop/Github_repos/qiskit-core/qiskit/backends/aer/aerjob.py\", line 118, in status self.__class__.__name__)) qiskit.backends.joberror.JobError: 'Unexpected behavior of AerJob' ``` However, if run *before* that module, it works fine. This is true both when running locally and on Travis. This is blocking #975. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: jupyter [build/labextension] install --dev-build cannot be set to false via CLI #### Describe the bug A few months ago, in #5099 the default value for the flag --dev-build was changed to True. Unfortunately, (as far as I can tell) there's no way to unset this flag via the CLI now! #### To Reproduce Steps to reproduce the behavior: 1. install jupyterlab 2. run `jupyter labextension install <any extension> --dev-build=false` 3. jupyter complains with an error:  #### Expected behavior Jupyter installs the extension and rebuilds in production. #### Additional context This might be a separate conversation, but I was a little surprised that the default behaviour of installing an extension was to leave me with a development build. I'm happy to leave that decision with the team though, as long as opting out is possible! Follow-up question: Is it possible to opt-out via config file? I haven't been able to work out what setting to set, or where to create a config file. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Remove removal of \"sh\" from path for MinGW in CMake New conan.tools.cmake CMake helper contains: ```python if is_windows_mingw: with tools.remove_from_path(\"sh\"): self._conanfile.run(command) ``` This is no longer necessary, can be replaced by ``set(DCMAKE_SH=\"CMAKE_SH-NOTFOUND\")``. Please remove it and add a red/green test for it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: DataprocCreateBatchOperator in deferrable mode doesn't reattach with deferment. ### Apache Airflow version main (development) ### What happened The DataprocCreateBatchOperator (Google provider) handles the case when a batch_id already exists in the Dataproc API by 'reattaching' to a potentially running job. Current reattachment logic uses the non-deferrable method even when the operator is in deferrable mode. ### What you think should happen instead The operator should reattach in deferrable mode. ### How to reproduce Create a DAG with a task of DataprocCreateBatchOperator that is long running. Make DataprocCreateBatchOperator deferrable in the constructor. Restart local Airflow to simulate having to 'reattach' to a running job in Google Cloud Dataproc. The operator resumes using the running job but in the code path for the non-derferrable logic. ### Operating System macOS 13.4.1 (22F82) ### Versions of Apache Airflow Providers Current main. ### Deployment Official Apache Airflow Helm Chart ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: interactiveshell.py misses urllib and io_open imports cf15c8f0ed4493492b50e8fccb72175157afac7c seems to have accidentally removed them. used in line 2957 and 2973 also affects 0.13.1 branch Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Clarify deprecation of Inspector.info() method In its docstring, the [IPython.core.oinspect.Inspector.info()](https://github.com/ipython/ipython/blob/355c5f3774cdfd8320505046973aa5032c93df35/IPython/core/oinspect.py#L705) method states that it was deprecated. When the text was [originally added](https://github.com/ipython/ipython/commit/3c1ce318117e6b2630f7c5d2379e6d269f98a124), the warning applied to the whole method, but in the [same PR](), it was [modified](https://github.com/ipython/ipython/commit/9412553b1d12e84ea7155044e775432bbee164b7) to only warn when the unused `formatter` argument was passed. However, the deprecation notice was not updated, and remained unclear as to what was deprecated, why, and what to replace it with. Of note, the deprecation was done in one of the original PRs that added Docrepr/Sphixify to IPython. As the current de-facto maintainer of Docrepr, which is now being revitalized and heavily used in Jupyter Notebook, I was surprised to see that the `Inspector.info()` heavily used in the Docrepr test suite, with no indicated replacement, and unlike the internal-only method it wraps, it was not documented. This led me on a wild goose chase to figure out what was going on. It looks like only the `formatter` arg should be deprecated, and the docstring clarified to reflect that (and perhaps the much more useful `_info` docstring merged? If not, the docstring should ideally be clarified as to the scope and reason for the deprecation, and what users should replace it with. Happy to submit a PR if/when there is clear indication of what this should say. Thanks! Created as a new issue per request of @carreau _Originally posted by @CAM-Gerlach in https://github.com/ipython/ipython/issues/10511#issuecomment-995437839_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support CMake Interface libraries [Some](https://github.com/skypjack/entt) header-only C++ projects use CMake [interface libraries](https://cmake.org/cmake/help/latest/command/add_library.html#interface-libraries), which [do not currently appear to be supported by meson](https://github.com/mesonbuild/meson/blob/5bd21a96b89efc5fe96025398151dcbce34345ac/mesonbuild/cmake/interpreter.py#L71). It would be nice if they were supported. Adding `'INTERFACE_LIBRARY': 'static_library',` to `target_type_map` works, but creates an extra empty library. `build_target` or `declare_dependency` seem like better choices than `static_library`, but neither work as just a one-line edit. `build_target` requires `target_type`, which is some effort to plumb in and doesn't have a `none` option, and `declare_dependency` gets passed the normal name and (empty) sources, which it can't use. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: NBconvert fails with unicode errors when `--stdout` and file redirection is specified and HTML entities are present I'm not sure if this is a bug, but we just got caught by this in:https://github.com/swcarpentry/bc/pull/163 To reproduce, create an IPython Notebook with any HTML entity such as: `×` Then try running nbconvert with --stdout with output to a file. ``` ipython nbconvert --stdout test.ipynb > test.html ``` This will break, although: ``` ipython nbconvert --stdout test.ipynb ``` and ``` ipython nbconvert test.ipynb ``` both work. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose create Possibility to just create but not run containers. This would be a useful feature for systemd based startups. Using gelf log driver and lose the ability to `fig run <container> bash` Im using `gelf` logging in my docker-compose file and I lose the ability to use `fig run <container> bash` because it gives the error \"Error attaching: configured logging reader does not support reading\". An example config is: ``` my_container: image: link-to-image log_driver: \"gelf\" log_opt: gelf-address: udp://0.0.0.0:12201 gelf-tag: my_container ``` I understand that I lose the ability to use `docker-compose logs` or `docker-compose logs my_container` but I would expect `docker-compose run my_container bash` to let me into the container as I am overriding the CMD line manually. ``` docker-compose version: 1.5.1 Docker version 1.9.0, build 76d6bc9 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: '_' makes matplotlib to render the following character as subscript ### Environment - **Qiskit Terra version**: 0.19.1 - **Python version**: 3.9.9 - **Operating system**: Linux(Fedora 34) ### What is happening? The '_' in the name of QuantumRegister forces the following character to be rendered as subscript In this example see the 'r' is rendered as a subscript.  The problem vanishes when the number of qubits is increased to 2 or more.  ### How can we reproduce the issue? from qiskit import QuantumRegister, QuantumCircuit num_of_qubits=1 q_reg=QuantumRegister(num_of_qubits, 'q_reg') qc=QuantumCircuit(q_reg) qc.draw(output='mpl') ### What should happen? This should be the output:  ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: Non-existing Documents Calls to `DocumentSnapshot.to_dict()` for non-existing documents should return `None` and not an empty dictionary. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Qtconsole - nonstandard \\a and \\b Issue #1089 reported lack of support for \\b (backspace) and \\r (return) PR #629 purported to fix these, and did fix \\r, but it mapped \\b to bell rather than to backspace. The standard mapping for bell is \\a. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: [4.6.0b0] MalformedVersionError Since 4.6.0b0 didn't seem to work with my conda build I attempted to downgrade to the latest stable but got an error! ``` λ conda install conda=4.5.11 Collecting package metadata: failed MalformedVersionError: Malformed version string '~': invalid character(s) ``` conda 4.6.0b0 spec containing != ``` >>> h = History(\"/Users/kfranz/continuum/conda/devenv\") >>> print(yaml_dump(sorted(str(s) for s in h.get_requested_specs_map().values()))) ... - pytest==!=3.7.3 ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: `&` and `|` operators don't work for `float32` arguments Example: ```python a = jnp.array([0.0, 1.0]) b = a | a ``` results in ` RuntimeError: Invalid argument: Expected pred or integral type in argument to and/or operation; got F32.` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Do not package js sourcemaps by default In https://github.com/conda-forge/jupyterlab-feedstock/issues/155, @jcrist suggested not packaging the js sourcemap files since they are quite large. I agree. It would be great if we could delete those files from the stock package. If people want them back, they can install node and do a simple `jupyter lab build`. Deleting the map files from the 1.0.6 wheel seemed to shrink the wheel from about 16M to about 6.5M, so it is a huge savings. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Fully functional “Cloud Flow” example ## Proposed behavior *Please describe your proposed change to the current behavior* * Welcome flow example * More complex example with retries ## Example *Please give an example of how the enhancement would be useful* This would be useful for users new to Prefect Cloud. These would be some good flows to deploy to their Team for testing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Issue when MPL drawing circuits - scale issue <!-- ⚠️ If you do not respect this template, your issue may be be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.8.0 - **Python version**: 3.7.3 - **Operating system**: OS X - Version 10.9.5 ### What is the current behavior? By default if you have large names within the circuit, some of them will be out of the resultant diagram. ### Steps to reproduce the problem You need to put large names to the circuit elements. For example this code https://github.com/Morcu/q-means/blob/master/visualizer.py style = {'backgroundcolor': '#DFEAEC', 'showindex': False, 'displaycolor': { 'id': 'red', 'meas':'#0066DA', 'h': '#00DAA7', 'u3': '#EFFF1B'} } qc.draw(output='mpl', style=style, reverse_bits= False,filename=circuit_file) An example of the resultant circuit https://github.com/Morcu/q-means/blob/master/circuit-without-scale.png ### What is the expected behavior? We think that by default the scale parameter should be set to include large name of the circuit elements. style = {'backgroundcolor': '#DFEAEC', 'showindex': False, 'displaycolor': { 'id': 'red', 'meas':'#0066DA', 'h': '#00DAA7', 'u3': '#EFFF1B'} } qc.draw(output='mpl', style=style, reverse_bits= False,filename=circuit_file,scale=1.2) The resultant circuit should be like this https://github.com/Morcu/q-means/blob/master/circuit-with-scale.png ### Suggested solutions By default the scale should be calculated according to the circuit larger names. --- ### What is the expected behavior? --- ### What is the expected enhancement? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Explore transforming State into a class instead of a String + Data attribute Instead of the current State class that has a string `state` and Any `data` attribute, as well as a bunch of `is_finished()` methods that check the state string against a list of valid strings, consider building a hierarchy of State classes: ```python # Base class class State: # class attribute for example; set in __init__ data = None # ------------------------------------------- # Finished classes - Success, Failed, Skipped class Finished(State): pass class Success(Finished): pass class Failed(Finished): # class attribute for example; set in __init__ message = None class Skipped(Finished): pass # ------------------------------------------- # Pending classes - Retry and Scheduled (and Pending itself) class Pending(State): pass class Retry(Pending): # class attribute for example; set in __init__ retry_time = None class Scheduled(Pending): # class attribute for example; set in __init__ scheduled_time = None ``` Then checking and working with states is easier than the current system of checking the string attribute and hoping the data attribute matches an expected schema: ```python s = Success(100) f = Failed('Division by zero error') assert isinstance(s, Finished) assert isinstance(f, Finished) r = Retry(datetime(2018, 12, 31)) assert isinstance(r, Pending) assert isinstance(r.retry_time datetime) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add stability to speech API results. This was excluded originally to keep the responses simple. For streaming the interim_results have stability information for each response. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Multiple versions of same build_requires package in lockfile? Hello, we are facing the issue that we are generatng a lockfile and in this lockfile we have seen that the same build_requires package is listed twice (with different versions). After analysing this we have found out that one version is provided by the profile and one by the recipe itself. Is that supposed to be allowed? I would have expected this to be forbidden. Also when installing using the lockfile which version is then installed? BTW. We are using Conan 1.59. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Switch to lumino We have continued the Phosphor project code base as a new project, [lumino](https://github.com/jupyterlab/lumino). We have released all of the `lumino` packages at the same version as they were previously in Phosphor. The plan is for 2.0 to depend on `lumino`, and resolve any `@phosphor` libraries to `lumino` using `yarn` resolutions. - [x] Migrate code to point to `@lumino` packages - [x] Add yarn resolution for `@phosphor` -> `@lumino` - [x] Update documentation Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: assemble ignores backend option <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 'qiskit-terra': '0.18.0.dev0+8c19253', 'qiskit-aer': '0.9.0', - **Python version**:3.8 - **Operating system**: macOS ### What is the current behavior? assemble ignores backend option ### Steps to reproduce the problem ```python from qiskit import QuantumCircuit, assemble from qiskit.providers.aer import AerSimulator, FakeMontreal qc = QuantumCircuit(5) qc.measure_all() backend = FakeMontreal() backend.set_options(shots=3000) # backend = AerSimulator(shots=3000) print(assemble(qc, backend).config.shots) ``` The code outputs 1024. ### What is the expected behavior? But it should be 3000. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Don't import dreload by default. `core/builtin_trap.py` ``` python from IPython.lib import deepreload if self.shell.deep_reload: self.auto_builtins['reload'] = deepreload.reload else: self.auto_builtins['dreload']= deepreload.reload ``` Does it make sens to stop doing that by default ? Warn message say it will be removed in 6.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose --rm always returns 1 It doesn't matter how I kick it, it always returns 1 and my ansible task fails! However, without `--rm` it returns 0. docker-compose.yml ``` test: image: debian:wheezy ``` Ubuntu 14.04.2 LTS Docker version 1.6.2, build 7c8fca2 docker-compose 1.2.0 ``` root@megabox:~# docker-compose run --rm test true root@megabox:~# echo $? 1 ``` I believe the exit code comes from `compose/cli/main.py:346`, however, `--rm` doesn't seem to affect the exit code so this doesn't make much sense... ``` ¦ ¦ exit_code = container.wait() ¦ ¦ if options['--rm']: ¦ ¦ ¦ log.info(\"Removing %s...\" % container.name) ¦ ¦ ¦ project.client.remove_container(container.id) ¦ ¦ sys.exit(exit_code) ``` How come it's always 1? It should also be noted that the containers still show up in `docker ps -a` despite using `--rm`, so I'm guessing something is wrong. I thought it might be apparmor at first so I disabled it `service apparmor teardown` but no change. Any ideas? Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: version '==' interpreted differently in 4.3 and 4.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Cannot compose circuits with different numbers of measurements <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.17.4 - **Python version**: - **Operating system**: ### What is the current behavior? Compose fails when combining circuits with no measurements together with those that do, e.g. ```python ansatz = TwoLocal(2, rotation_blocks='ry', entanglement_blocks='cx') qc = QuantumCircuit(2) qc.measure_all() ansatz.compose(qc) ``` gives: CircuitError: \"Trying to compose with another QuantumCircuit which has more 'in' edges.\" while `+` works, but is deprecated in favor of `compose`. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: DataCollator problem # ❓ Questions & Help <!-- The GitHub issue tracker is primarly intended for bugs, feature requests, new models and benchmarks, and migration questions. For all other questions, we direct you to Stack Overflow (SO) where a whole community of PyTorch and Tensorflow enthusiast can help you out. Make sure to tag your question with the right deep learning framework as well as the huggingface-transformers tag: https://stackoverflow.com/questions/tagged/huggingface-transformers If your question wasn't answered after a period of time on Stack Overflow, you can always open a question on GitHub. You should then link to the SO question that you posted. --> ## Details <!-- Description of your issue --> Hi everybody I found an error in the following Colab: https://colab.research.google.com/drive/1jwXgtOXE8v8_qkiOCbjFQRFC5semK8T7?usp=sharing Specifically, As far I understand something changed with the implementation of the following snippet: class T2TDataCollator(DataCollator): def collate_batch(self, batch: List) -> Dict[str, torch.Tensor]: .......... <br> I got the following error: **TypeError: function() argument 1 must be code, not str** Can you suggest any workarounds? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Error while listing submodules GitPython has a problem while listing submodules. As '.gitmodules' contains all the modules have ever been registered, it becomes problematic when some of them are removed. 'repo.submodules' will fail to work in this situation, though, 'repo.iter_submodules()' still works. But when 'repo' itself is a submodule, 'repo.iter_submodules()' does not yield any result. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Indented command hits error We previously allowed entered code to be indented, for convenient pasting from editors, web pages, etc. This no longer works in 0.11rc1: `<space><space>a=1` gives an IndentationError. I think previously we solved this by prepending `if True:\\n` if the first line was indented, although I don't know if there's a neater solution. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Refactor OpsgenieAlertHook to official python sdk ### Body Currently [OpsgenieAlertHook](https://github.com/apache/airflow/blob/d79f506213297dc0dc034d6df3226361b6f95d7a/airflow/providers/opsgenie/hooks/opsgenie_alert.py#L29) works with HTTP. We should change the hook to work with the [official python sdk](https://github.com/opsgenie/opsgenie-python-sdk) This will allow also to easily integrate to airflow the various methods and options the SDK has to offer https://github.com/opsgenie/opsgenie-python-sdk#documentation-for-api-endpoints ### Committer - [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: MSI Installer: Support upgrade I just attempted to upgrade from meson `0.42.1` to `0.43` and was presented with this screen using the MSI installer  At the very least, that error message should be a bit more clear. Besides that - a huge :+1: for having a windows installer! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: add visualization of open controlled gates [text drawer] In PR #3739, open controlled gates were implemented. With that PR a new keyword argument was added to specify the control state, `XGate().control(3, ctrl_state=6)` This creates a 4 qubit gate where the first three qubits are controls and the fourth qubit is the target where the x-gate may be applied. A `ctrl_state` may alternatively be expressed as an integer string, `XGate().control(3, ctrl_state='110')` where it is more apparent which qubits are open and closed. In this case when q[0] is open and q[1] and q[2] are closed the x-gate will be applied to q[4]. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Multivariate Normal Hi all, I noticed that sampling from predefined distributions works a bit different in jax than it does in numpy. Is it possible to use the jax.random module to sample from a multivariate normal distribution (with dense covariance matrix)? If not, is there any other way? So far I only managed to sample from one with a unit variance, using jax.random.normal. Cheers, Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Issues with proxies I've started Conan server in my organization's local network. For external sites (like github) proxy must be used, but not for computers in local network. So, I have there env variables: ``` HTTP_PROXY=http://proxy.domain:3128 HTTP_PROXY=https://proxy.domain:3128 NO_PROXY=localhost,127.0.0.1,*.domain,192.168.* ``` With these variables I can create packages with recipes in my local cache (and this recipes can download external sources), but cannot download recipes and prebuilt packages from organization's Conan server. I've tried to set same settings in conan.conf, but had no luck. Also I've tried to use Conan server domain name and/or IP address in NO_PROXY with same result: ``` > conan search -r <remotename> \"OpenCV*\" ERROR: Permission denied for user: '<username>'. [Remote: <remotename>] ``` But if I disable all proxies (comment in conan.conf and unset env variables), it works just fine: ``` Existing package recipes: OpenCV/3.3.1@lukyanets/testing ``` Conan v. 1.0.1, OS: Arch Linux, CentOS 6, Windows 10. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Support the progress bar to another stream handler <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? ProgressBar is a good visualization tool when you have tons of jobs running in the background. Now, the progress bar will be printed in `sys.stdout`, I wonder that is it possible to add an argument to `TextProgressBar` to print the progress on `sys.stderr` or the other handler? Then, users can control when the progress bar is displayed. (I know that users can always write the wrapper to wrap `sys.stdout` to the logger but it seems to be a workaround.) Thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Bug handling errors while downloading a file If an error happens while downloading a file (signed URL), the client is failing to print an output message because of a None output object. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: is_vision_available() fails when using pillow-simd ### System Info - `transformers` version: 4.30.2 - Platform: Linux-5.11.0-1022-aws-x86_64-with-glibc2.29 - Python version: 3.8.10 - Huggingface_hub version: 0.15.1 - Safetensors version: 0.3.1 - PyTorch version (GPU?): 2.0.0+cu118 (True) - Tensorflow version (GPU?): 2.8.0 (True) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ### Who can help? @sgugger @apbard - additional checks introduced in https://github.com/huggingface/transformers/pull/23163 are failing on my environment. This is because I'm using [pillow-simd](https://github.com/uploadcare/pillow-simd) and not the vanilla pillow package. Is this drop-in pillow replacement not supported or is it possible to introduce additional logic to support this? ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction First install pillow-simd (`pip install pillow-simd`) Run the following code: ``` import PIL print(PIL.__version__) import transformers print(transformers.utils.import_utils.is_vision_available()) ``` ### Expected behavior Previous versions (before 4.30.*) return `True` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Compiling extensions without source map files ### Problem JLab 3.0 extensions are built with .map files, even in production mode, which take a huge amount of space. ### Proposed Solution We should make it possible (and possibly recommended/default) to build the new extensions without .map files. For example, for the ipywidgets jupyterlab manager, the static folder went from 2240K (with source maps) to 488K (without source maps). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Add support for creation of parallel task when no engine is running IPython-0.11 complains when I try to create a parallel task when no engines are running. This makes sense for users who need results directly after they create a task. But there are also users who would like to create tasks in advance, before any engines are started. These tasks could have been stored in ipcontroller/backend database. When the first engine connects to ipcontroller it could start processing those tasks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Make sure datastore.entity.Entity.__repr__ agrees with internal logic of Entity class From TODO: ``` python # TODO: Make sure that this makes sense. # An entity should have a key all the time (even if it's partial). ``` See [`datastore.entity.Entity.__repr__`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/entity.py#L210) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 210) # TODO: Make sure that this makes sense. ``` Make sure datastore.entity.Entity.__repr__ agrees with internal logic of Entity class From TODO: ``` python # TODO: Make sure that this makes sense. # An entity should have a key all the time (even if it's partial). ``` See [`datastore.entity.Entity.__repr__`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/entity.py#L210) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 210) # TODO: Make sure that this makes sense. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Create `backend.properties` method in API and Terra <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? - [x] Update methods in API `backend.parameters`, `backend.calibration` -> `backend.properties` - [x] Update these methods accordingly in Terra. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython qtconsole (0.12) can't export to html with external png This error looks a bit like that in issue #1087 but the details are different. I create a qtconsole session with some embedded figures. Export to HTML with inline PNG works fine. Export to XHTML/SVG 'works' (with missing images). Export to HTML with external PNG creates a folder with the PNG files correctly but fails to write the HTML (leaving a zero size .html file) with the following error: ``` Error exporting HTML to /Users/claumann/Desktop/test/test.html 'ascii' codec can't decode byte 0xc2 in position 2287: ordinal not in range(128) ``` I have an html (with embedded PNG) that constitutes a minimal session reproducing this but I don't know how to attach it to this issue. The (non-graphical) content: ``` In [1]: figure() scatter(r_[0,1,2], r_[0,1,2], marker='x') display(gcf()) <embedded image> In [2]: !uname -a Darwin blackbear.local 11.2.0 Darwin Kernel Version 11.2.0: Tue Aug 9 20:54:00 PDT 2011; root:xnu-1699.24.8~1/RELEASE_X86_64 x86_64 In [3]: np.__version__ Out[3]: '2.0.0.dev-26aa3cf' In [4]: pylab.__version__ Out[4]: '2.0.0.dev-26aa3cf' In [5]: matplotlib.__version__ Out[5]: '1.2.x' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Project description in Pip should pull in contents of README.md The [Project description in Pip](https://pypi.org/project/GitPython/) should pull in the [`README.md`](https://github.com/gitpython-developers/GitPython/blob/main/README.md) by moving the `long_description` in [`setup.py`](https://github.com/gitpython-developers/GitPython/blob/main/setup.py#L98) to `setup.cfg` like: Example `setup.cfg` ``` [metadata] long_description = file: README.md long_description_content_type = text/markdown ``` It probably also makes sense to remove the language from the [`README.md`](https://github.com/gitpython-developers/GitPython/blob/main/README.md) that suggests GitPython is not actively developed anymore since that does not seem to be the case. Alternatively, there could be a Pip Product Description specific markdown file to use instead of the default `README.md` but I think cleaning up and improve the existing `README.md` a bit and using that for the pip product description makes the most sense. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Purge persistent Ninja state when doing a full reconfigure. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Can't invert gate created from QuantumCircuit.to_gate <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When inverting a gate created from QuantumCircuit.to_gate the following exception is raised: `ValueError: not enough values to unpack (expected 3, got 2)` ### Steps to reproduce the problem ``` qc = QuantumCircuit(1) qc.x(0) gate = qc.to_gate() gate.inverse() ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: `docs` check is failing on CI <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue. Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description The `docs` check now seems to be failing on CI. ## Reproduce Example run: https://github.com/jupyterlab/jupyterlab/runs/5184872690?check_suite_focus=true Failing with:  ## Expected behavior We should get it back to green. <!--Describe what you expected to happen--> ## Context Also noticed on other PRs, for example: https://github.com/jupyterlab/jupyterlab/pull/12046 `docs` check is failing on CI <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue. Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description The `docs` check now seems to be failing on CI. ## Reproduce Example run: https://github.com/jupyterlab/jupyterlab/runs/5184872690?check_suite_focus=true Failing with:  ## Expected behavior We should get it back to green. <!--Describe what you expected to happen--> ## Context Also noticed on other PRs, for example: https://github.com/jupyterlab/jupyterlab/pull/12046 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Make --parallel the default for pull #4428 added the `--parallel` flag to the `pull` command. What needs to be done to get that to the point where it's the default? Off the top of my head: - [ ] Some experience with `--parallel` to gather feedback. - [ ] Better, more detailed output. I have some ideas here. Do we need anything else? Is there any reason that parallel pulling should *never* become the default? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Comments should be AST nodes Consider the following program: ``` from qiskit.qasm import Qasm qasm_string = \"\"\"//this is a comment OPENQASM 2.0; qreg q[2]; // This is another comment \"\"\" node_circuit = Qasm(data=qasm_string).parse() print(node_circuit.qasm()) print([ type(i) for i in node_circuit.children]) ``` The output is: ``` OPENQASM 2.0; qreg q[2]; [<class 'qiskit.qasm._node._format.Format'>, <class 'qiskit.qasm._node._qreg.Qreg'>] ``` ### What is the expected enhancement? The following output: ``` //this is a comment OPENQASM 2.0; qreg q[2]; // This is another comment [<class 'qiskit.qasm._node._comment.Comment'>, <class 'qiskit.qasm._node._format.Format'>, <class 'qiskit.qasm._node._qreg.Qreg'>, <class 'qiskit.qasm._node._comment.Comment'>] ``` The current parser ignores comments. There is room for discussion if a parser should create an AST with this information (a Full Syntax Tree). I think in our context is a handy thing to have. For example, to add annotations or metainformation, which might be handy in such experimental field. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Unable to create container with label With the following container we are getting an error creating the container: ``` dynamodb: image: instructure/dynamo-local-admin labels: - \"com.acuris.service.group=companyhub\" ports: - \"8000:8000\" ``` When we run the command: ``` docker-compose run dynamodb ``` We get the error: ``` Traceback (most recent call last): File \"/bin/docker-compose\", line 11, in <module> sys.exit(main()) File \"/usr/lib/python2.7/site-packages/compose/cli/main.py\", line 68, in main command() File \"/usr/lib/python2.7/site-packages/compose/cli/main.py\", line 121, in perform_command handler(command, command_options) File \"/usr/lib/python2.7/site-packages/compose/cli/main.py\", line 768, in run run_one_off_container(container_options, self.project, service, options) File \"/usr/lib/python2.7/site-packages/compose/cli/main.py\", line 1178, in run_one_off_container **container_options) File \"/usr/lib/python2.7/site-packages/compose/service.py\", line 288, in create_container previous_container=previous_container, File \"/usr/lib/python2.7/site-packages/compose/service.py\", line 795, in _get_container_create_options self.config_hash if add_config_hash else None) File \"/usr/lib/python2.7/site-packages/compose/service.py\", line 1338, in build_container_labels labels = dict(label_options or {}) ValueError: dictionary update sequence element #0 has length 35; 2 is required ``` However, if we change the container definition to the following then it works: ``` dynamodb: image: instructure/dynamo-local-admin labels: com.acuris.service.group: companyhub ports: - \"8000:8000\" ``` This has only started failing since we upgraded to docker-compose version 1.17.0, build ac53b73. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Embed \"git-describe\" in bundle. I'm regularly unsure of whether the bundles have been built correctly after I pull, could we embed the value of `git describe` in the bundle and `console.log` it ? Thoughts ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: GNU Make generator https://github.com/solvingj/conan-make_generator/blob/master/conanfile.py by @solvingj is almost it. I agree it could be built-in. Can use conditional: ``` ifneq ($(USE_CONAN),) INC_PATHS += $(CONAN_INC_PATHS) LD_PATHS += $(CONAN_LIB_PATHS) LD_LIBS += $(CONAN_LIBS) CXXFLAGS += $(CONAN_CPP_FLAGS) CFLAGS += $(CONAN_CFLAGS) DEFINES += $(CONAN_DEFINES) LDFLAGS_SHARED += $(CONAN_SHAREDLINKFLAGS) LDFLAGS_EXE += $(CONAN_EXELINKFLAGS) C_SRCS += $(CONAN_C_SRCS) CXX_SRCS += $(CONAN_CXX_SRCS) endif ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qasm3 exporter fails if circuits have delays ### Environment - **Qiskit Terra version**: 20.0 - **Python version**: 3.8.5 - **Operating system**: linux ### What is happening? Using the qasm3 exporter, if your circuit has a delay instruction in it, the export fails complaining about opaque gates: ``` ~/venv/qiskit/lib/python3.8/site-packages/qiskit/qasm3/exporter.py in build_opaque_definition(self, instruction) 568 \"\"\"Builds an Opaque gate definition as a CalibrationDefinition\"\"\" 569 # We can't do anything sensible with this yet, so it's better to loudly say that. --> 570 raise QASM3ExporterError( 571 \"Exporting opaque instructions with pulse-level calibrations is not yet supported by\" 572 \" the OpenQASM 3 exporter. Received this instruction, which appears opaque:\" QASM3ExporterError: 'Exporting opaque instructions with pulse-level calibrations is not yet supported by the OpenQASM 3 exporter. Received this instruction, which appears opaque:\\nDelay(duration=50[unit=dt])' ``` ### How can we reproduce the issue? The following code demonstrates the error ``` from qiskit.qasm3 import Exporter from qiskit import QuantumCircuit circuit = QuantumCircuit(2) circuit.delay(50) circuit.h(1) circuit.measure_all() circuit.draw() Exporter().dumps(circuit) ``` ### What should happen? A proper qasm3 string should be generated. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Cross-compiling warning even when consuming package Conan 1.12.3 I'm trying to package a compiler (gcc) as a tool to be used as a build requirement. Since it's a compiler for native code it must have both `os_build` (where it runs on, in my case it can be Linux, Windows or MacOS) and `os` (which is a target os for compilation output, only Linux in my case). Something like ```python class GccConan(ConanFile): name = \"gcc_installer\" settings = \"os\", \"arch\", \"os_build\" ``` When I build it I get warning: ``` gcc_installer/6.3.1@external/master: ************************************************************ gcc_installer/6.3.1@external/master: This package defines both 'os' and 'os_build' gcc_installer/6.3.1@external/master: Please use 'os' for libraries and 'os_build' gcc_installer/6.3.1@external/master: only for build-requires used for cross-building gcc_installer/6.3.1@external/master: ************************************************************ ``` Which may be fine for general case and I can even put into README a note to ignore it. However same warning appears even when I try to consume it, basically for every package I build and this is not fine (from usability perspective). I would suggest moving this warning from initialization of `ConanFile` class to somewhere where we actually build package. Or maybe make it a part of linter / hook. To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Inconsistent PreTrainedTokenizerBase.pad argument default value & docstring The docstring states the argument `padding` has a default of `False` but its default is `True` docstring: https://github.com/huggingface/transformers/blob/d5b3e56de5376aa85ef46e7f0325139d9e299a41/src/transformers/tokenization_utils_base.py#L2469-L2470 arg: https://github.com/huggingface/transformers/blob/d5b3e56de5376aa85ef46e7f0325139d9e299a41/src/transformers/tokenization_utils_base.py#L2431-L2472 This causes issues when using `DataCollatorForLanguageModeling` with an already padded dataset as it resets the attention mask. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Multiple calls to Pub/Sub Policy.open() can \"interact\" [E.g.][1] if you call `Policy.open()` a second time then it will overwrite the callback attached to the `Policy`. ISTM that we should \"tombstone\" a `Policy` so that it can't be `open()`-ed more than once. [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/cc7da65b4a31d7a33055afe0bd6dc9855c3d6493/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py#L150 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson 0.43 module java.py class JavaCompiler is missing needed methods The JavaCompiler class appears to have fallen behind the times, so that some needed methods are missing. I have not done any kind of through review of what it would take to get JavaCompiler up to date. By simply working the failure symptoms, I found that for my project, adding the following methods, along with the changes from Issue #2569 and Issue #2570, was sufficient to build a simple Java 9 project with Meson 0.43 and Ninja: > def get_warn_args(self, level): > return ['-Xlint:all'] > > def get_no_warn_args(self): > return ['-Xlint:none'] > > def depfile_for_object(self, objfile): > return objfile + '.' + self.get_depfile_suffix() > > def get_depfile_suffix(self): > return 'd' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Progressbars not spawned unless execute or compile are called first <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? The following no longer spawns a progress bar\" ``` HTMLProgressBar() ans = parallel_map(func, list(range(100))) ``` unless `compile` or `execute` have been run first. ### Steps to reproduce the problem uncomment the line below: ``` import time from qiskit import * from qiskit.transpiler._parallel import parallel_map from qiskit.tools.jupyter import * q = QuantumRegister(2) c = ClassicalRegister(2) qc = QuantumCircuit(q, c) qc.h(q[0]) qc.cx(q[0], q[1]) qc.measure(q, c) backend = Aer.get_backend('qasm_simulator') #qobj = compile([qc], backend) def func(t): time.sleep(0.1) return 0 TextProgressBar() parallel_map(func, list(range(100))) ``` ### What is the expected behavior? You should not have to call `execute` or `compile` before a progressbar can be displayed. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Page jumping when output from widget interaction replaced Testing Fernando's [demo notebook](http://t.co/Ef1Ar6jmxN), I see odd jumping when I drag the slider: <iframe width=\"420\" height=\"315\" src=\"//www.youtube.com/embed/qiFbzvCclBs?rel=0\" frameborder=\"0\" allowfullscreen></iframe> www.youtube.com/watch?v=qiFbzvCclBs Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Python 3.7 installation fails due to PyYAML 3.12 - [x] Conan version: 1.6 - [x] Python version: 3.7 - Issue: Installation of Conan fails when using Python 3.7 fails due to a [bug with PyYAML](https://github.com/yaml/pyyaml/issues/126) - Reproduce: - [x] Install Python 3.7 including pip3 - [x] pip3 install conan - [x] Error out `Command \"/usr/local/opt/python/bin/python3.7 -u -c \"import setuptools, tokenize;__file__='/private/tmp/pip-install-7qbn6h01/PyYAML/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\\r\\n', '\\n');f.close();exec(compile(code, __file__, 'exec'))\" install --record /private/tmp/pip-record-obq_96in/install-record.txt --single-version-externally-managed --compile\" failed with error code 1 in /private/tmp/pip-install-7qbn6h01/PyYAML/` - Solution - [ ] Change dependency version to 3.13. Submodules updated before revision checkout Conan version: 1.6.1 Platform/Settings: All Description: When specifying submodules to be updated after cloning from git with the `scm` attribute, the submodules are pulled from the state of the repo's current HEAD rather than the referenced revision. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Individual acquires are created in Qobj to Instruction converter when joined acquires should be <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behaviour? When a marshmallow acquire `PulseQobjInstruction` is converted to a pulse schedule `AcquireInstruction`, an individual `AcquireInstruction` is being created for each qubit, memory_slot pair. See: https://github.com/Qiskit/qiskit-terra/blob/b155373a30c5c1d6550ffb7df9c6a4d660e6dd62/qiskit/qobj/converters/pulse_instruction.py#L428 ### Steps to reproduce the problem Attempt to convert this acquire command ```python PulseQobjInstruction(duration=1200, memory_slot=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19], name='acquire', qubits=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19], t0=0) ``` ### What is the expected behavior? A single `AcquireInstruction` should be created for all of the qubits involved with the acquire. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Resurrect Prefect Client The old `client.py` file which was removed needs to be reimplemented to handle communication with an execution cluster Needs to talk to server with get/post/gql Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Remove dynamic flow / task fields - [x] remove description, version and project - [x] ~flow.name -> flow.slug~ - [x] promoting an id on the tasks (?) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Failed runs do not expose the exit code in Kubernetes ## Summary When a dagster run running as a Kubernetes job fails, the exit code is still 0. This results in not being able to track metrics/configure alerts based on the deployed Kubernetes monitoring infrastructure, e.g. prometheus. Exposing the status as failed will help track statuses, filter logs and other metadata, etc. ## Reproduction Create a run which errors out. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question][suggestion] Listing profile should be recursive Hello, I use multiple profiles, and those are organized in subdirectories: + `~/.conan/profiles/application/x64_gcc6_app1` + `~/.conan/profiles/application/x64_msvc_app1` + `~/.conan/profiles/compilers/x64_gcc6` + `~/.conan/profiles/compilers/x64_msvc` The \"applications\" profile include other profiles etc. This works pretty well, so I assume using subdirectory in profiles is supported and is not a problem. However, the `conan profile list` command does not list profiles contained in subdirectories. I believe it should recursively search for profile files rather than only list the files available directly in the `~/.conan/profiles` directory. I'm wondering if there is a particular reason why the search is limited to the `~/.conan/profiles` directory and if you'd be open to changing this behavior. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add unittests for GCSTaskHandler **Description** The `GCSTaskHandler` from `airflow.utils.log.gcs_task_handler` does not have a unit test. **Use case / motivation** The test is necessary so that we can be able to move the `GCSTaskHandler` to its providers package(`google`) **Related Issues** #9386 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Download models from a private hub In the context of a private hub deployment, customers would like to use from_pretrained() to load models from their hub, not from the public hub. This doesn't seem to be configurable at the moment and it would be nice to add this feature. The obvious workaround is to clone the repo first and then load it from local storage, but this adds an extra step. It'd be great to have the same experience regardless of where the hub is hosted. The same issue exists with the datasets library and the CLI. I'm going to create issues there as well, and I'll reference them below. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Update ShimWarnings to include version numbers. Updating ShimWarnings to include since when the modules have been moved would be helpful to indicate people to transition, or at least to inform better when they can stop using old import versions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub: wrong inherited documentation for StreamingPullFuture The [documentation](https://googleapis.github.io/google-cloud-python/latest/pubsub/subscriber/api/futures.html) for `StreamingPullFuture`'s methods like [`result()`](https://googleapis.github.io/google-cloud-python/latest/pubsub/subscriber/api/futures.html#google.cloud.pubsub_v1.subscriber.futures.StreamingPullFuture.result) and [`exception()`](https://googleapis.github.io/google-cloud-python/latest/pubsub/subscriber/api/futures.html#google.cloud.pubsub_v1.subscriber.futures.StreamingPullFuture.exception) doesn't make sense because it describes Publish futures not streaming pull futures. [`StreamingPullFuture`](https://github.com/googleapis/google-cloud-python/blob/a42b0f1abe83ce981c9573f4c56acc72e4344a2f/pubsub/google/cloud/pubsub_v1/subscriber/futures.py#L20) inherits [`futures.Future`](https://github.com/googleapis/google-cloud-python/blob/a42b0f1abe83ce981c9573f4c56acc72e4344a2f/pubsub/google/cloud/pubsub_v1/futures.py#L24), that's where the \"wrong\" documentation got carried over. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: scan+pmap shape bug @JasperSnoek reported this one: ```python import jax.numpy as np from jax import lax, random from jax import pmap from jax.lib import xla_bridge nrep = xla_bridge.device_count() key = random.PRNGKey(0) n = 80 a_in = np.linspace(0, 1, n)[:, None] a = np.dot(a_in, a_in.T) + np.eye(n) * 0.1 b = random.normal(key, (n,)).flatten() def pmvm(a, b): a = a.reshape((nrep, -1, a.shape[1])) func = pmap(lambda z: np.dot(z, b)) return func(a).reshape(b.shape) for i in range(10): b = pmvm(a, b) # Ok iters = np.arange(10) def body(carry, i): return pmvm(a, carry), i res = lax.scan(body, b, iters) ``` It results in some kind of shape error (the exact one depends on how many replicas there are). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: no string.replace method Currently the only way to perform an operation similar to pythons `str.replace(old, new)` is with `new.join(str.split(old))` which feels clunky. A `str.replace(old, new)` method would be a welcome addition. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add an AWS operator for Create RDS Database ### Description @eladkal suggested we add the operator and then incorporate it into https://github.com/apache/airflow/pull/23681. I have a little bit of a backlog right now trying to get the System Tests up and running for AWS, but if someone wants to get to it before me, it should be a pretty easy first contribution. The required API call is documented [here](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/rds.html#RDS.Client.create_db_instance) and I'm happy to help with any questions and./or help review it if someone wants to take a stab at it before I get the time. ### Use case/motivation _No response_ ### Related issues Could be used to simplify https://github.com/apache/airflow/pull/23681 ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub doc: missing definition for `max_lease_duration` in FlowControl The ref doc for [`max_lease_duration`](https://googleapis.github.io/google-cloud-python/latest/pubsub/types.html#google.cloud.pubsub_v1.types.FlowControl.max_lease_duration) does not describe what it is or how it is used, especially about how it interacts with ack deadlines. Given that this is an important config setting for long-running tasks, we may want to provide more documentation here by showing its default value (is it 2 hours), and explaining whether max lease duration restrains ack deadline modification or ack deadline modification overwrites max lease duration when one configures both flow control settings and ack deadlines. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Dag equality <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? A method to check if two dags are the same. #1363 and #1349 are holding this up Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add support for hierarchical dict ## 🚀 Feature ### Motivation Since v0.7.0, LightningModule accepts dict hparams, however, still TensorBoardLogger raises an error with hierarchical dict. Considering the compatibility of the other package, especially Hydra #807, hierarchical dict should be accepted by any loggers. ### Pitch - Flatten hierarchical dict before hparam logging ### Alternatives The function `_convert_params` in [loggers/base.py](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/loggers/base.py#L45) will be changed like: ```python def _convert_params(self, params: Union[Dict[str, Any], Namespace]) -> Dict[str, Any]: # in case converting from namespace if isinstance(params, Namespace): params = vars(params) # added part params = flatten_dict(params) # convert {'a': {'b': 'c'}} -> {'a/b': 'c'} if params is None: params = {} return params ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Release 'api_core-1.6.0a2'? or 'api_core-1.5.1'? I'd like to use the changes from https://github.com/googleapis/google-cloud-python/pull/6310 in the library I'm working on. Not sure about the version number for that one, since: - I don't know what else has been released since 1.6.0a1 - I don't know what is intended by 1.6.0a1 in https://github.com/googleapis/google-cloud-python/pull/6267 (is it a pre-release?) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Detect should show a warning about libcxx compatibility To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Read: https://github.com/bincrafters/conan-boost_generator/pull/1#issuecomment-362856847 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: build_requirements is ignored I have A package, which build_requires B package. And C package requires A, build_requires B. When I execute \"conan install\" for C, conan will skip B. If I remove requires A, conan will not skip B. What I want is conan will install A and B. Any help you can provide would be great. Thanks To help us debug your issue please explain: To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Aqua GUI interface crashes for default OSX matplotlib backend. @nonhermitian noted in #903: ### What is the current behavior? Aqua GUI interface crashes for default OSX matplotlib backend. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: 'Query.order_by(\"__name__\")' implies converting field values to extended paths. Per the `query-cursor-vals-docid` conformance test. ```python query = collection.order_by('__name__').start_at(['a']).end_at(['z']) ``` The `'a'` should be converted to `/projects/<project-id>/databases/<database>/<collection_path>/a`; likewise the `z`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Saving the output of `flow.visualize` Prefect currently generates a random filename in order to save the state of the flow. It's more useful to store the visualization to a know location so that we can consume the file downstream (either upload it to S3 or push it to a monitoring service, etc.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: [logs] Piped commands are not colored anymore I made a terminal dashboard which is using `docker-compose logs` command to display logs of some services. With the `colorama.init()` (`compose/compose/cli/colors.py`) introduced in version 1.10 for Windows terminal coloration, piped commands seem not being able to display colors. **NodeJS example** ```javascript 'use strict'; let spawn = require('child_process').spawn; const CWD=\"YOUR_COMPOSE_PROJECT_DIR\"; function appendToBox(data) { if (data instanceof Buffer) { data = data.toString(); } data = data.replace(/\\n$/, ''); // Avoid double new line console.log(data); } let tail = spawn( 'docker-compose', ['logs', '--tail=1'], {cwd: CWD} ); tail.stdout.on('data', appendToBox); tail.stderr.on('data', appendToBox); tail.on('exit', (code) => { appendToBox('child process exited with code ' + code); }); ``` **Command line example** ``` docker-compose logs --tail=1 | tee ``` **Manual workaround** Comment the line `colorama.init()` in file `/usr/lib/python3.6/site-packages/compose/cli/colors.py`. Tested on Archlinux, I suppose your install dir may eventually vary depending on your distribution. **Issue resolution** If colorama is for Windows only could it be possible to run the `colorama.init()` only with that OS context ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Materialise an asset with a run config and partition key ### What's the use case? Minimum example: ``` @asset(config_schema={\"value\": str}) def configured(context): return context.op_config[\"value\"] @asset(partitions_def=StaticPartitionsDefinition([\"1\", \"2\"])) def partitioned(context, configured): return context.partition_key + configured materialize_to_memory([partitioned, configured], partition_key=\"1\", run_config={\"ops\":{\"configred\":{\"config\":{\"value\":\"a\"}}}}) ``` This raises \"dagster._check.CheckError: Invariant failed. Description: Cannot provide both run_config and partition_key arguments to `execute_in_process`\" ### Ideas of implementation _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: transitive extract_all_objects no longer works There is new error added by commit 809f01833336be63eb07441e120de2e4f8c4b3c4: \"extract_all_objects: Also extract generated sources\". ERROR: Cannot extract objects from a target that itself has extracted objects There are many cases where this might be needed, and it seemed to work fine in previous versions of meson. This is breaking the build of the DPDK project where we are compiling for older x86_64 targets without AVX2 instruction set support. In that case, we compile the AVX2 code separately as a static lib, extact it and then merge with the rest of the code into the official library static lib. That lib in turn is converted to a shared lib again by extract_all_objects(). [Yes, I have a TODO to look at SIMD module and \"both_library\" support for this, but it is what it is now.] Please fix before next release. This used to work and is a regression IMHO. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: A bug in modeling_tf_marian.py and modeling_tf_pegasus.py SinusoidalPositionalEmbedding _init_weight ## Information should create a new np.array and then store np.sin&np.cos result in it ```python table = np.zeros_like(position_enc) # index 0 is all zero table[:, 0 : dim // 2] = np.sin(position_enc[:, 0::2]) table[:, dim // 2 :] = np.cos(position_enc[:, 1::2]) # convert to tensor table = tf.convert_to_tensor(table) tf.stop_gradient(table) ``` https://github.com/huggingface/transformers/blob/bd3b599c12cfcf5ef517c5ffe526afbdbaa92539/src/transformers/models/marian/modeling_tf_marian.py#L147-L157 https://github.com/huggingface/transformers/blob/8d43c71a1ca3ad322cc45008eb66a5611f1e017e/src/transformers/models/pegasus/modeling_tf_pegasus.py#L148-L158 A bug in modeling_tf_marian.py and modeling_tf_pegasus.py SinusoidalPositionalEmbedding _init_weight ## Information should create a new np.array and then store np.sin&np.cos result in it ```python table = np.zeros_like(position_enc) # index 0 is all zero table[:, 0 : dim // 2] = np.sin(position_enc[:, 0::2]) table[:, dim // 2 :] = np.cos(position_enc[:, 1::2]) # convert to tensor table = tf.convert_to_tensor(table) tf.stop_gradient(table) ``` https://github.com/huggingface/transformers/blob/bd3b599c12cfcf5ef517c5ffe526afbdbaa92539/src/transformers/models/marian/modeling_tf_marian.py#L147-L157 https://github.com/huggingface/transformers/blob/8d43c71a1ca3ad322cc45008eb66a5611f1e017e/src/transformers/models/pegasus/modeling_tf_pegasus.py#L148-L158 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Performance regressions in NoiseAdaptiveLayout <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master with 7972d6c95de41dbffb06594a27b88ddd2c108ec8 - **Python version**: 3.6 - **Operating system**: Linux Since https://github.com/Qiskit/qiskit-terra/commit/7972d6c9 merged a few regressions have been tagged by the benchmark suite. These are both runtime such as: https://qiskit.github.io/qiskit/#transpiler_qualitative.TranspilerQualitativeBench.time_transpile_time_qft_16?machine=dedicated-benchmarking-softlayer-baremetal&os=Linux%204.15.0-46-generic&ram=16GB&p-optimization%20level=3&p-routing%20method='sabre'&p-layout%20method='noise_adaptive'&commits=7972d6c9 as well as depth of the output: https://qiskit.github.io/qiskit/#transpiler_qualitative.TranspilerQualitativeBench.track_depth_transpile_4gt10_v1_81?machine=qiskit-benchmarking&os=Ubuntu%2018.04&ram=16%20GB&p-optimization%20level=2&p-routing%20method='stochastic'&p-layout%20method='noise_adaptive'&commits=7972d6c9 This is unexpected both because `retworkx.PyDiGraph.neighbors()` should be faster than `retworkx.PyDiGraph.adj` so a runtime regression is the opposite of what's expected. But, what's more concerning is the depth regression because the output should be identical between the two methods since they're using the same internal methods in retworkx, it's just a difference in return format. Before we release 0.17.0 we should get to the bottom of these or revert https://github.com/Qiskit/qiskit-terra/commit/7972d6c9 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Disable automatic checkpoint loading **Is your feature request related to a problem? Please describe.** The last checkpoint is being automatically restored when a checkpoint exists. This is an issue for me when the model has previously been trained with different settings or I want to train a network from scratch. If I want to use a checkpoint I would prefer to explicitly pass the checkpoint that should be used. **Describe the solution you'd like** Provide an option to disable the automatic loading of checkpoints to the trainer. **Describe alternatives you've considered** An alternative would be to modify `ModelCheckpoint` class and add that option there so that only that class is responsible for checkpoint creation and loading. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: remove pylatexenc as required dependency <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? pylatexenc is used in a relatively minor place for formatting latex_drawer's strings. Given that everything associated with latex drawing is optional itself, this part should also be optional and not a core dependency of terra. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: wigner functions not supported anymore We are no longer supporting the Wigner function methods correctly. There are four functions - [ ] plot_wigner_function -> supported as a method in plot_state(rho, method=\"wigner\") but broken from plot_winger_data. - [ ] plot_wigner_data --> this was a function to plot the date as: plaquette, function and curve - [ ] plot_wigner_plaquette -> option called from plot_wigner_data - [ ] plot_wigner_curve -> option called from plot_wigner_data We need to think about what we want to do here and make it clearer for the tutorial. tutorial pr : https://github.com/Qiskit/qiskit-tutorial/pull/341 tutorial issue: https://github.com/Qiskit/qiskit-tutorial/issues/339 Questions do we want wigner in terra? If so, should they be all from the plot_wigner_data or is it just an option of the plot_state? If we keep plot_wigner_data should this be in the visualization `__init__`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda 4.3.4 seems to be broken ``` bag@bag ~ % conda --version conda 4.3.4 bag@bag ~ % conda install -y --file https://raw.githubusercontent.com/bioconda/bioconda-utils/master/bioconda_utils/bioconda_utils-requirements.txt CondaError: Downloaded bytes did not match Content-Length url: https://raw.githubusercontent.com/bioconda/bioconda-utils/master/bioconda_utils/bioconda_utils-requirements.txt target_path: /tmp/tmpUp36pQ/bioconda_utils-requirements.txt Content-Length: 195 downloaded bytes: 310 bag@bag ~ % ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add representation of types and expressions for initial classical expressions ### What should we add? This is tracking the work labelled \"PR 1\" in the [initial classical-expression RFC](https://github.com/Qiskit/RFCs/blob/master/0010-simple-classical-representations.md). Brief overview: - write representation of `Expr` and `Type` - test that these objects can be constructed and handle type checking correctly Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add DagProcessor status to health endpoint. ### Description Add DagProcessor status including latest heartbeat to health endpoint similar to Triggerer status added recently. Related PRs. https://github.com/apache/airflow/pull/31529 https://github.com/apache/airflow/pull/27755 ### Use case/motivation It helps in dag processor monitoring ### Related issues _No response_ ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: 2.1.3/4 queued dag runs changes catchup=False behaviour ### Apache Airflow version 2.1.4 (latest released) ### Operating System Amazon Linux 2 ### Versions of Apache Airflow Providers _No response_ ### Deployment Docker-Compose ### Deployment details _No response_ ### What happened Say, for example, you have a DAG that has a sensor. This DAG is set to run every minute, with max_active_runs=1, and catchup=False. This sensor may pass 1 or more times per day. Previously, when this sensor is satisfied once per day, there is 1 DAG run for that given day. When the sensor is satisfied twice per day, there are 2 DAG runs for that given day. With the new queued dag run state, new dag runs will be queued for each minute (up to AIRFLOW__CORE__MAX_QUEUED_RUNS_PER_DAG), this seems to be against the spirit of catchup=False. This means that if a dag run is waiting on a sensor for longer than the schedule_interval, it will still in effect 'catchup' due to the queued dag runs. ### What you expected to happen _No response_ ### How to reproduce _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: AttributeError: 'NoneType' object has no attribute 'keys' hey, i want to install mailcow-dockerized on my debian jessie machine and after `docker pull` I need to run `docker-compose up -d` but it throws following error: ```sh Traceback (most recent call last): File \"bin/docker-compose\", line 3, in <module> File \"compose/cli/main.py\", line 68, in main File \"compose/cli/main.py\", line 118, in perform_command File \"compose/cli/main.py\", line 924, in up File \"compose/project.py\", line 389, in up File \"compose/project.py\", line 437, in initialize File \"compose/network.py\", line 252, in initialize File \"compose/network.py\", line 60, in ensure File \"compose/network.py\", line 180, in check_remote_network_config File \"compose/network.py\", line 163, in check_remote_ipam_config AttributeError: 'NoneType' object has no attribute 'keys' Failed to execute script docker-compose ``` since I dont know python I dont know wheres the problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: .dockerignore \"last-line\" precedence not respected Docker compose doesn't seem to respect the \"last-line\" precedence of `.dockerignore` files. This is described [here in the `.dockerignore` docs](https://docs.docker.com/engine/reference/builder/#/dockerignore-file). For example, even the simple example provided in the doc section above doesn't seem to work when using Docker compose: ``` *.md !README*.md README-secret.md ``` The file `README-secret.md` gets included -- not excluded. I'm using the following: ``` docker-compose version 1.8.0, build 94f7016 Docker version 1.11.1, build 5604cbe Mac OS X 10.11.6 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: parameterized circuits raise exception at optimization_level>=2 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When a parameterized circuit is passed to the compiler with optimization_level>=2 one gets the exception > ParameterExpression with unbound parameters ({Parameter(x)}) cannot be cast to a float. This seems to be due to the commutation analysis pass attempting to convert the rx to a matrix. ### Steps to reproduce the problem ``` qc = QuantumCircuit(1) theta = qiskit.circuit.parameter('theta') qc.rx(theta, 0) qc,x(0) qiskit.compiler.transpile(qc, optimization_level=3) ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Make sure old versions of serializers ignore new fields To avoid issues such as `Failed to set flow state with error: ClientError(\"{0: {'metadata': ['Unknown field.']}}\")` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: RPATH is prefixed with a colon I'm using `build_rpath : '$ORIGIN/lib'` and it works fine but objdump shows `RUNPATH :$ORIGIN/lib` The colon should not be there. Also, lddtree from pax-utils says: `scanelf: rpath_security_checks(): Security problem NULL DT_RUNPATH in ./binary` (where binary is my program name) Probably worth a fix [here](https://github.com/mesonbuild/meson/blob/6d85e10df921c0399adfc01507a76f04c684245c/mesonbuild/compilers/compilers.py#L836). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: infinite exception handling loop in case of corrupt SQLite3 db Traceback here: https://gist.github.com/dwf/c659fdd50285b5a4885c10acc34b77e7 Version 4.1.2 installed via conda. ~~If anyone has a workaround it would be much appreciated.~~ I've worked around it by setting `IPYTHONDIR`, but it seems like this could be handled a bit more gracefully somehow. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add `&` and `^` overloads for QuantumCircuit.compose and .tensor <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Following #5834 and #4208, `QuantumCircuit` should have similar shorthand for `.compose` and `.tensor`, following quantum_info. Should be released in 0.17 so users can transition directly from `+`/`+=`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: `conda.sh` has incorrect paths on Windows ### What happened? Previously, our recipe included a `sed` statement: https://github.com/conda/conda/blob/ca036ed747d955d23fd0abd83295d96ddf74cc40/recipe/build.sh#L8-L10 This was removed for a simpler recipe implementation in #12603 (which in turn was prompted by issues with packaging conda for Python 3.11, see #12256). Removing `sed` resulted in the `conda.sh` breaking on Windows + MSYS2. The issue is evident in the first few lines of `conda.sh`: #### Before Recipe Change (`defaults::conda=23.3.1`) ```bash export CONDA_EXE='C:/Users/kodegard/.conda/miniconda\\Scripts\\conda.exe' export _CE_M='' export _CE_CONDA='' export CONDA_PYTHON_EXE='C:/Users/kodegard/.conda/miniconda\\python.exe' ``` #### After Recipe Change (`conda-canary/label/dev::conda=23.3.1+23`) ```bash export CONDA_EXE='/d/a/conda/conda/pkgs/conda_1682642894222/_h_env/Scripts/conda.exe' export _CE_M='' export _CE_CONDA='' export CONDA_PYTHON_EXE='C:/Users/kodegard/.conda/miniconda\\python.exe' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Allow for volume mounts on Docker storage and / or Docker agent We should allow for volume mounts to flows running with Docker storage. I believe this needs to be an option on the Docker _agent_ (not the storage class), as it won't make sense in other environments (e.g., K8s). This will allow for users to use e.g., `LocalResultHandler` within Docker storage and still write to local disk. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Incorrect global declaration breaks iPython error display ``` Python 2.7.6 |Anaconda 1.9.0 (32-bit)| (default, Nov 11 2013, 10:50:31) [MSC v.1500 32 bit (Intel)] Type \"copyright\", \"credits\" or \"license\" for more information. IPython 1.1.0 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: def a(): ...: x = 11 ...: global x <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration ...: **I hit enter again here** <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <input>:3: SyntaxWarning: name 'x' is assigned to before global declaration <ipython-input-1-25742883ea0e>:3: SyntaxWarning: name 'x' is assigned to before global declaration global x In [2]: ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Adapt file headers to Lint specifications ### What is the expected enhancement? When running the test suite, specifically 'lint' tests for code quality, the same message is displayed for every file in the project: `************* Module qiskit.tools.visualization qiskit\\tools\\visualization.py:1:0: C5001: File header should match regex \"(?:(?:#[^\\n]*)?\\n)*# This code is part of Qiskit.\\n#\\n# \\(C\\) Copyright IBM [0-9, -]*.\\n#\\n# This code is licensed under the Apache License, Version 2.0. You may\\n# obtain a copy of this license in the LICENSE.txt file in the root directory\\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\\n#\\n# Any modifications or derivative works of this code must retain this\\n# copyright notice, and modified files need to carry a notice indicating\\n# that they have been altered from the originals.\\n\" (invalid-file-header)` This message, with some variations, appears hundreds of times in the log. That makes it a bit difficult to keep track of the other code smells that should be fixed. Setting a new format for the headers, or making Lint ignore this issue, would remove hundreds of log entries in one go. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: implement scatter batching rule when indices are batched and updates are not Implement _scatter_batching_rule when `scatter_indices_bdim is not None and updates_bdim is None`. See https://colab.corp.google.com/drive/1VBna662Pcz8zOL3SlzSJ6eETrN2x90FF#scrollTo=vLHx5BcHPykw (internal only) for the source code + context. When input_embeddings and unc_target do not have a batch dimension, `total_loss, grads = inner_loss_value_and_grad(net_params, input_embeddings, unc_target)` works fine. Adding a batch dimension to input_embeddings and unc_target and changing the line to `total_loss, grads = vmap(lambda args: inner_loss_value_and_grad(net_params, args[0], args[1]))([input_embeddings, unc_target])` gives this NotImplementedError error: \"\"\" ~/virtualenvs/_3/lib/python3.7/site-packages/jax/lax/lax.py in _scatter_batching_rule(***failed resolving arguments***) 2842 2843 if scatter_indices_bdim is not None and updates_bdim is None: -> 2844 raise NotImplementedError # TODO(mattjj,phawkins) 2845 elif scatter_indices_bdim is None and updates_bdim is not None: 2846 updates = batching.move_dim_to_front(updates, updates_bdim) NotImplementedError: \"\"\" Full stacktrace https://paste.googleplex.com/4748794925154304. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: MySQL Replication Lag doesn't tag by channel name MySQL 5.7 introduces \"replication channels\", which means a slave can replicate from multiple masters (\"sources\") at any given time. To measure replication lag across `n` channels, it'd be great if DataDog could tag the `mysql.replication.seconds_behind_master` metric with `channel:<CHANNEL_NAME>`. That way users could get an average across the channels, or have monitors alert when one of the channels falls behind. Currently, the check fetches only the _first_ replication channel (https://github.com/DataDog/integrations-core/blob/master/mysql/check.py#L855) [Zookeeper] metadata.csv is missing many metrics emitted by the check Per the [`check.py` docstring](https://github.com/jeffwidman/integrations-core/blob/patch-2/zk/check.py#L10-L15): Duplicate information is being reported by both `mntr` and `stat` to keep backwards compatability. Example: `stat` reports: zookeeper.latency.avg `mntr` reports: zookeeper.avg.latency If available, make use of the data reported by `mntr` not `stat`. The duplicate `stat` reports are only kept for backward compatability. I noticed this in our Datadog account because we have multiple zookeeper installations so I see both metrics myself... Yet in the zookeeper check's `metadata.csv`, I only see the `stat` metrics, not the `mntr` metrics... for example, the `zookeeper.avg.latency` is missing. Since these metrics are missing from `metadata.csv`, are they billed as custom metrics rather than standard metrics? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.numpy.tanh(2) works but jax.grad(tanh)(2) fails- int32 not liked by grad Hi this may be a little churlish to bring up but ints are acceptable for some calls in jax but not for others. I assume this is not by design. example `jax.version.__version__ == '0.1.62'` ``` import jax.numpy as np from jax import grad aval =2 print(\"aval=\" +str(aval)) print(\"np.tanh(aval)=\" + str(np.tanh(aval))) try: grad(np.tanh)(aval) except TypeError as e: print(e) print (\"sadness - grad(np.tanh)(aval) failed \") ``` Output aval=2 np.tanh(aval)=0.9640276 Primal inputs to reverse-mode differentiation must be of float or complex type, got type int32 sadness - grad(np.tanh)(aval) failed Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda configuration documentation mislabeled 'default config' http://docs.continuum.io/conda/intro.html#configuration Says its the default runtime configuration, but it's not: ``` # This is the default conda runtime configuration # channel locations. These override conda defaults, i.e., conda will # search *only* the channels listed here, in the order given. channels: - http://repo.continuum.io/pkgs/dev - http://repo.continuum.io/pkgs/gpl - http://repo.continuum.io/pkgs/free # environment locations. These locations are in *addition* to the system # location at $ROOT_DIR/envs. #locations: - ~/envs ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Data Catalog: add quickstart sample for creating fileset entry. We already have samples for createEntry and createEntryGroup, but the docs use a tutorial quickstart approach, with integrated samples: https://cloud.google.com/data-catalog/docs/how-to/filesets#data-catalog-fileset-java A new quickstart Sample is now required, to update the official docs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Change checkpoint filename without overwriting full filepath ## 🚀 Feature By default, the checkpoint path resolves to `lightning_logs/{version}/checkpoints/{epoch}.ckpt`. It is currently not possible to change the checkpoint filename without replacing the full path. ### Motivation The full path is replacable with the `ModelCheckpoint.filepath` argument. This feature is undisirable because I want to use the default path resolver that uses the options from `Trainer` instead of hardcoding a path. A satisfying path construction workaraound based on values in `Trainer` is not possible because the `Trainer` is constructed *after* the `ModelCheckpoint`. ### Pitch I would like to add a `filename` parameter to the `ModelCheckpoint` constructor. This parameter is complementary to `filepath` and `filepath` will keep working like it does for backward compatibility. - If only `filepath` is provided, the original behaviour is used. - If both `filepath` and `filename` are provided, the checkpoint path will resolve to `filepath`/`filename`. - If only `filename` is provided, the checkpoint path will resolve to `resolved directory`/`filename` (instead of `resolved directory`/`epoch`). Add filename parameter to ModelCheckpoint ## What does this PR do? Adds filename parameter to ModelCheckpoint. See issue #2583. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: plot_coupling_map appears to incorrectly plot in docs example ### Environment the qiskit.org website ### What is happening? The map does not look like what is expected based on the input:  ### How can we reproduce the issue? view the doc page here: https://qiskit.org/documentation/stubs/qiskit.visualization.plot_coupling_map.html ### What should happen? In the example, the displayed image and the input should agree. In the image only the first two edges are displayed, but it looks like there are 8 edges in the `coupling_map` list. Possibly the `qubit_coordinates` are being processed incorrectly as well, not sure. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Can't extract objects form custom_target() While trying to add a custom_target() to a plugin in qemu, I reached the following error: ERROR: Object extraction arguments must be strings or Files. Here is a small example: ``` project('object extraction', 'c') ct = custom_target('custom target', output: ['test.c'], command: ['echo', ''], capture: true) lib1 = shared_library('somelib', ct) obj1 = lib1.extract_objects(ct) ``` help welcome! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Allow boolean flags to work without passing True We tried to fix this but it's still broken This fails when adding args to argparse automatically... ``` --auto_lr_find ``` Instead we have to do: ``` --auto_lr_find True ``` which is not great Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson rejects version numbers ending with a dot From https://github.com/systemd/systemd/pull/5704#issuecomment-291959683 ```sh # Ubuntu Zesty Zapus (development branch) Meson encountered an error in file meson.build, line 536, column 0: Invalid version to compare against: '2.29.'; only numeric digits separated by \".\" are allowed: invalid literal for int() with base 10: '' $ find /usr/lib -name '*.pc' | xargs grep -E 2.29 /usr/lib/x86_64-linux-gnu/pkgconfig/blkid.pc:Version: 2.29. /usr/lib/x86_64-linux-gnu/pkgconfig/mount.pc:Version: 2.29. /usr/lib/x86_64-linux-gnu/pkgconfig/uuid.pc:Version: 2.29. ``` @nirbheek wrote > This is a mistake in util-linux, but it is also a valid pkg-config version, which follows the rpm version comparison rules. Meson barfs on this because we don't implement rpm version comparison bug-for-bug. Arguably, we should, or at least we should be a bit more resilient. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Dropout Layer in OpenAIGPTMultipleChoiceHead not used [OpenAIGPTMultipleChoiceHead](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/pytorch_pretrained_bert/modeling_openai.py#L363) defines an additional dropout layer, which is not used in `forward`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Spurious Exception: Tracer can't be used with raw numpy functions? I cannot seem to make this minimum working example any smaller. It seems like some combination of factors is causing this error, but I have no idea where to start. ``` import jax import jax.scipy.special as jss from jax import numpy as jnp @jax.custom_jvp def log_normalizer(q): return jnp.logaddexp(q[0], 0.0) def nat_to_exp(q): return jss.expit(q) @log_normalizer.defjvp def ln_jvp(primals, tangents): x, = primals x_dot, = tangents y = log_normalizer(x) y_dot = nat_to_exp(x) * x_dot return y, y_dot def cross_entropy_loss(p, q): # Bernoulli cross_entropy(p, q) p_dot_q = jnp.sum(p * q) ln = log_normalizer(q) return -p_dot_q + ln - jnp.zeros(()) # p are expectation parameters of a Bernoulli distribution corresponding to # probability 0.4. p = jnp.array([0.4]) # q are natural parameters of a Bernoulli distribution corresponding to # log-odds 0, which is probability 0.5. q = jnp.array([0.0]) print(jax.grad(cross_entropy_loss, 1)(p, q)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Implement frequency changes for pulse ### What is the expected enhancement? `PulseChannel`s create the control fields `Re[exp(i 2pi j dt f + phi)d_j]`. There should be a `Command` to change the frequency `f` of the `PulseChannel`. This instruction will be implemented by `class SetChannelFrequency(Command)`. It will have * one attribute, the new frequency of the channel, i.e. `self._frequency`, * the prefix `scf`, * and will result in the command_dict {'name': 'scf', 't0': ..., 'ch': ..., 'frequency': ... } Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit.repeat duplicates global phase <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master @ 4d3ed6a3 - **Python version**: 3.7.9 - **Operating system**: macOS catalina ### What is the current behavior? Calling `circuit.repeat(1)` on a circuit with global phase seems to duplicate the global phase. ### Steps to reproduce the problem If `u` is a circuit with only a Z gate and `u_with_phase` the same circuit but with a global phase of pi, then ```python In [75]: u.draw() Out[75]: ┌───┐ q_0: ┤ Z ├ └───┘ In [79]: u_with_phase.draw() Out[79]: global phase: π ┌───┐ q_0: ┤ Z ├ └───┘ In [80]: Operator(u) == Operator(u_with_phase) # should be False since the matrices are not the same Out[80]: False In [81]: Operator(u) == Operator(u_with_phase.power(1)) # should still be False Out[81]: True ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Support references without user/channel The idea would be to declare a \"default user and default channel\" so, for all the input references and all the output references (stdout) won't use the @user/channel. Here is a POC (not valid) where the user and channel is evaluated internally as `None`: https://github.com/lasote/conan/tree/feature/reference_default The task for the 1.17 would be to define the behavior: - How to specify the default values, - What are the default \"default values\" for the central repository) - How to disambiguate the input references when can mean a path (lib/1.0@?) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: flow.visualize(flow_state) with double layer mapping it appears that `flow.visualize()` with the flow_state kwarg and a flow with two sequential mapping layers provides a bad picture; I think the graph node ID isn't being looked up correctly somewhere flow.visualize(flow_state) with double layer mapping it appears that `flow.visualize()` with the flow_state kwarg and a flow with two sequential mapping layers provides a bad picture; I think the graph node ID isn't being looked up correctly somewhere Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: No parameter which is presented in documentation Documentation web page: https://huggingface.co/pytorch-transformers/model_doc/gpt2.html#pytorch_transformers.GPT2Model See `Inputs -> attention_mask`. There is actually no parameter `attention_mask` in `GPT2Model.forward` method (see https://github.com/huggingface/pytorch-transformers/blob/master/pytorch_transformers/modeling_gpt2.py#L473) Of course trying to provide `attention_mask` parameter to model raises an exception: > TypeError: forward() got an unexpected keyword argument 'attention_mask' Please either add parameter `attention_mask` to `GPT2Model.forward` or delete it from documentation. Same for https://huggingface.co/pytorch-transformers/model_doc/gpt2.html#pytorch_transformers.GPT2LMHeadModel and for https://huggingface.co/pytorch-transformers/model_doc/gpt2.html#pytorch_transformers.GPT2DoubleHeadsModel I've created #1116 in case you want just delete it from documentation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Add armv8 support to MSBuildDeps generator Map `armv8` arch to MSBuild `ARM64` platform PR to follow. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Passing `-g MSBuildDeps -s arch=armv8` to `conan install` results in errors of the form: ```log conanfile.txt: ERROR: Traceback (most recent call last): File \"xxx\\venv\\lib\\site-packages\\conans\\client\\generators\\__init__.py\", line 177, in write_generators generator.generate() File \"xxx\\venv\\lib\\site-packages\\conan\\tools\\microsoft\\msbuilddeps.py\", line 128, in generate raise ConanException(\"MSBuildDeps.platform is None, it should have a value\") conans.errors.ConanException: MSBuildDeps.platform is None, it should have a value ERROR: Error in generator 'MSBuildDeps': MSBuildDeps.platform is None, it should have a value ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: jupyter labextension uninstall --all? Similar to `jupyter labextension update --all`, it would be useful to be able to uninstall all the extensions at once without recreating a conda environment. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: RFE: add new `install_symlink` command I have to create a bunch of symlinks, e.g. for alternate binary names. I do by with something like this: ```meson meson.add_install_script('sh', '-c', 'ln -s systemd-mount $DESTDIR@0@/systemd-umount'.format(bindir)) ``` This has the following shortcomings: - requires explicit manipulation of paths and $DESTDIR - the symlink is not removed on `uninstall` (#371 is about that part too). I'd be great to have something like ```meson systemd_mount = executable(..., install : true) install_symlink(systemd_mount, bindir + '/alternate-name') # or install_symlink('systemd-mount', bindir + '/alternate-name') ``` where a symlink from arg2 to arg1 would be created, underneath $DESTDIR. In case an argument like `systemd_mount` which holds a reference to an executable, the install path of that executable would be used. `install_symlink` should take a boolean keyword arg `relative`, `true` by default, to create relative symlinks (like `ln -s --relative`), even if an absolute path is specified. The symlink should be removed on uninstallation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Can't create a library from link_whole static libraries and without any source files I have a project that is designed with several subprojects that are built into static libraries, then a larger library which is linked from all of them like so: ```meson lib_wlr = library('wlroots', [], link_whole: [ lib_wl_protos, lib_wlr_backend, lib_wlr_render, lib_wlr_types, lib_wlr_util, lib_wlr_xcursor, ], dependencies: _wlr_deps, include_directories: wlr_inc) ``` This fails: \"Build target wlroots has no sources\" This commit includes our workaround: https://git.io/v7HNX Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: regression in adding machine info to a dictionary ``` $ git clone https://github.com/mesonbuild/wrapdb $ cd wrapdb $ meson setup builddir/ -Dwraps=cmocka [...] subprojects/cmocka-1.1.5/meson.build:54:2: ERROR: Object <MachineInfo: linux x86_64 (x86_64)> of type MachineInfo is neither in self.holder_map nor self.bound_holder_map. This is a Meson bug and should be reported! ``` Offending code: ``` cc_dict = { 'compiler': meson.get_compiler('c'), 'machine': host_machine, 'config_h_subdir': 'private', 'native': false } cc_native_dict = { 'compiler': meson.get_compiler('c', native: true), 'machine': build_machine, 'config_h_subdir': 'private_native', 'native': true } configurations = [cc_dict, cc_native_dict] foreach entry : configurations compiler = entry.get('compiler') is_native = entry.get('native') machine = entry.get('machine') # <<<<<< meson bug ``` This is fallout from commit af0587cb490dfa2c2a00c2426c10d1de11d34fdd Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug][2.0] patches cannot be applied when using cmake_layout Hello, It seems that `files.patch` and `cmake_layout` do not get along very well. The former does not find the patch files, even when specifying `base_path=self.build_folder`, although they are inside the build folder. I've joined a 2.0 version of `docopt.cpp` that shows the issue. ### Environment Details (include every applicable attribute) * Conan version: 2.0.0a2 ### Steps to reproduce (Include if Applicable) * create the package * uncomment the `layout` method * it should go to the `test_package` step ~(which breaks because `cmake_layout` is commented)~ ### Logs (Executed commands with output) (Include/Attach if Applicable) ``` ERROR: docopt.cpp/0.6.2-r1: Error in build() method, line 35 files.patch(self, **patch, base_path=self.build_folder) FileNotFoundError: [Errno 2] No such file or directory: 'patches/include-stdexcept.patch' ``` [docopt.cpp.zip](https://github.com/conan-io/conan/files/7897313/docopt.cpp.zip) EDIT: The test_package fails because I forgot to add `cmake_layout` there. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: tensordot raises TypeError: exceptions must derive from BaseException Setup: ```python import jax.numpy as jnp import numpy as np shp_a = (3, 2, 2) shp_c = (2,) a = np.random.random(shp_a) c = np.random.random(shp_c) ``` Obviously, `jax.numpy.tensordot(a, c, axis=2)` should not work, but it raises a wrong error (logically, this should be something like dimension mismatch or index error): ```console $ jnp.tensordot(a, c) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-48-e1d9970c866f> in <module> ----> 1 jnp.tensordot(a, c) /usr/lib/python3.8/site-packages/jax/numpy/lax_numpy.py in tensordot(a, b, axes, precision) 2309 if axes > _min(a_ndim, b_ndim): 2310 msg = \"Number of tensordot axes (axes {}) exceeds input ranks ({} and {})\" -> 2311 raise msg.format(axes, a.shape, b.shape) 2312 contracting_dims = tuple(range(a_ndim - axes, a_ndim)), tuple(range(axes)) 2313 elif type(axes) in (list, tuple) and len(axes) == 2: TypeError: exceptions must derive from BaseException ``` while in NumPy ```console $ np.tensordot(a, c) --------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-46-3f592bfd2cd1> in <module> ----> 1 np.tensordot(a, c) <__array_function__ internals> in tensordot(*args, **kwargs) /usr/lib/python3.8/site-packages/numpy/core/numeric.py in tensordot(a, b, axes) 1070 else: 1071 for k in range(na): -> 1072 if as_[axes_a[k]] != bs[axes_b[k]]: 1073 equal = False 1074 break IndexError: tuple index out of range ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Why is the `conda initialize` block placed in `.bashrc` on Linux, but in `.bash_profile` on macOS + Windows? ### Checklist - [X] I added a descriptive title - [X] I searched open requests and couldn't find a duplicate ### What is the idea? I don't really understand why the `conda initialize` section is placed in the `.bashrc` when using conda on Linux and in the `.bash_profile` when initialising conda on macOS or Windows (see [here](https://github.com/conda/conda/blob/0dbf85e0546e0b0dc060c8265ec936591ccbe980/conda/core/initialize.py#L439)). I created a small git blame timeline [here](https://github.com/mamba-org/mamba/issues/1913#issuecomment-1242991342). @kalefranz you were responsible for adding the conda initialize block to the `.bash_profile` instead of `.bashrc` on macOS. Is there a reason for it? This seems weird to me, especially since the macOS terminal sources the `.bashrc` by default when executing `bash` in the command line. `bash` sources the `.bashrc` when executed in the interactive mode (i.e. `bash -i`) and the `.bash_profile` when using the login mode (i.e. `bash -l`). In a regular terminal, the interactive mode is the default. See the [bash man page](https://man7.org/linux/man-pages/man1/bash.1.html#INVOCATION). Here is a small list when which rcfile gets sourced (this is the same for Ubuntu and macOS, haven't tested Windows but I suppose it's the same...): * `.bashrc` gets sourced when executing `bash` or `bash -i` in the terminal. * `.bash_profile` gets sourced when executing `bash -l` in the terminal. * *Only* `.bash_profile` gets sourced when executing `bash -il` ### Why is this needed? _No response_ ### What should happen? This can be confusing; therefore, we should have better documentation surrounding this behavior. Please update the documentation for this repository accordingly. ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Trainer hyperparameter_search only returns the best trial config ### Feature request Allow `hyperparameter_search` method of `Trainer` to return the entire `ExperimentAnalysis` object instead of a single `best_run`. ### Motivation The `hyperparameter_search` method of the `Trainer` currently only returns the best configuration `best_run`, instead of the more comprehensive `ExperimentAnalysis` object `analysis`. However, I believe that `analysis` would be more valuable than just the single best run configuration since it offers additional attributes and methods that can provide more useful information about tuning (see [doc](https://docs.ray.io/en/releases-1.11.0/tune/api_docs/analysis.html#analysis-tune-analysis)). Therefore, I suggest modifying the`hyperparameter_search` method to return the `ExperimentAnalysis` object so that users can do more analysis. ```python analysis = ray.tune.run( dynamic_modules_import_trainable, config=trainer.hp_space(None), num_samples=n_trials, **kwargs, ) best_trial = analysis.get_best_trial(metric=\"objective\", mode=direction[:3], scope=trainer.args.ray_scope) best_run = BestRun(best_trial.trial_id, best_trial.last_result[\"objective\"], best_trial.config) if _tb_writer is not None: trainer.add_callback(_tb_writer) return best_run ``` ### Your contribution I can submit a PR for this feature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: The llvm test fails if static llvm libraries are not provided On Gentoo Linux at least, and maybe other distros, the static llvm libraries are not provided by default. This means that the test suite fails because it is unable to statically link llvm. The issue is in the following file: test cases/frameworks/15 llvm/meson.build In this file, the foreach loop currently reads: ``` foreach static : [true, false] ``` We patch it like this to get passed the failure: ``` foreach static : [false] ``` I'm thinking we should dynamically generate this list based on what is on the system and use that to control the loop instead of hard coding the list. Any thoughts? @floppym Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: LlamaForCausalLM generate() runtime error when top_p=0 ### System Info - `transformers` version: 4.29.2 - Platform: Linux-4.4.0-210-generic-x86_64-with-debian-stretch-sid - Python version: 3.7.3 - Huggingface_hub version: 0.14.1 - Safetensors version: not installed - PyTorch version (GPU?): 1.13.1+cu117 (True) - Tensorflow version (GPU?): 2.5.0 (True) ### Who can help? _No response_ ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction This example follows and modifies the LLaMA documentation at: https://huggingface.co/docs/transformers/v4.29.1/model_doc/llama. ```python from transformers import AutoTokenizer, LlamaForCausalLM model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS).cuda() tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER) prompt = \"Hey, are you conscious? Can you talk to me?\" inputs = tokenizer(prompt, return_tensors=\"pt\").cuda() # Generate generate_ids = model.generate( inputs.input_ids, max_length=1024, do_sample=True, temperature=0.6, top_k=1000, top_p=0.0, # cause error repetition_penalty=(1.0 / 0.85), ) tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0] ``` >RuntimeError: probability tensor contains either `inf`, `nan` or element < 0 ### Expected behavior `generate()` should check if `top_p==0` and disables it to avoid numerical error. This behavior is the same as when `top_p==1` and consistent with the documentation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: grad and vmap do not composable with gamma sampler Here is a repro code, which triggers error `NotImplementedError: Forward-mode differentiation rule for 'while' not implemented` when trying to take gradient of `g`. ``` import jax import jax.numpy as np jax.config.update('jax_platform_name', 'cpu') def f(a): return jax.random.gamma(jax.random.PRNGKey(0), a) def g(x): return np.sum(jax.vmap(f)(x)) print(g(np.ones(3))) print(jax.grad(g)(np.ones(3))) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: add explicit checkpointing (rematerialization) control Analogous to [`checkpoint` in Autograd](https://github.com/HIPS/autograd/blob/c6f630a5ec18bd30f1485bc0dbbccb8664c77510/autograd/differential_operators.py#L192-L202) (but handling closed-over tracers). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: run_command('git') fails when using MSYS2: 'utf-8' codec can't decode byte 0x90 in position 2: invalid start byte **Describe the bug** meson run_command('git') fails when using MSYS2 MINGW64 on Windows: 'utf-8' codec can't decode byte 0x90 in position 2: invalid start byte ``` sebas@ASUS-i7 MINGW64 /c/Users/sebas/workspace/siril $ meson _build/ The Meson build system Version: 0.54.3 Source dir: /c/Users/sebas/workspace/siril Build dir: /c/Users/sebas/workspace/siril/_build Build type: native build Using 'PKG_CONFIG_PATH' from environment with value: '/mingw64/lib/pkgconfig:/mingw64/share/pkgconfig' Using 'PKG_CONFIG_PATH' from environment with value: '/mingw64/lib/pkgconfig:/mingw64/share/pkgconfig' Project name: siril Project version: 0.99.3 C compiler for the host machine: cc (gcc 10.2.0 \"cc.exe (Rev1, Built by MSYS2 project) 10.2.0\") C linker for the host machine: cc ld.bfd 2.34 C++ compiler for the host machine: c++ (gcc 10.2.0 \"c++.exe (Rev1, Built by MSYS2 project) 10.2.0\") C++ linker for the host machine: c++ ld.bfd 2.34 Host machine cpu family: x86_64 Host machine cpu: x86_64 meson.build:53:0: ERROR: Program or command 'git' not found or not executable ``` I think it's a return of the bug that was fixed 2 years ago https://github.com/mesonbuild/meson/pull/3399 Fix encoding bug on Windows And/or the same as reported here https://code.videolan.org/videolan/dav1d/-/issues/267 Build fails on Windows when using MSYS2 **To Reproduce** Follow the steps from my bug report on Siril: https://gitlab.com/free-astro/siril/-/issues/519 Meson fails on Windows: ../meson.build:53:0: ERROR: Program or command 'git' not found or not executable **system parameters** * plain native build (for the same computer) but using MSYS2 MINGW64 * Windows 10 * Python 3.8.5 * meson 0.54.3 * (ninja 1.10.0) Best regards, Sébastien Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Secrets are not secret within the Flow context manager, they should throw an error While trying to figure out the best way to get some data into a deployed flow, I decided to use a secret. I thought it would be good to put my secret into the flow context manager so that I could pass it to my first task as a parameter: ```python from prefect import Flow from prefect.client import Secret @task(name=\"example task\") def example_task(email, token): # does something with Flow(\"Example Flow\") as flow: email = Secret(\"email\").get() token = Secret(\"token\").get() example_task(email, token) ``` This is not secret at all, because the secrets simply become constants and can be easily seen in other parts of the system. So, prefect should throw an error if someone tries this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: tools/github_stats fails on 2fa. ``` $ python tools/github_stats.py --milestone 4.1 --since-tag 4.0.0 no cache fetching GitHub stats since 2015-08-12 00:00:00 (tag: 4.0.0, milestone: 4.1) Please enter your github username and password. These are not stored, only used to get an oAuth token. You can revoke this at any time on Github. Username: ***** Password:***** Traceback (most recent call last): File \"github_stats.py\", line 165, in <module> auth=True) File \"/Users/bussonniermatthias/dev/ipython/tools/gh_api.py\", line 175, in get_milestone_id milestones = get_milestones(project, auth=auth, **params) File \"/Users/bussonniermatthias/dev/ipython/tools/gh_api.py\", line 168, in get_milestones headers = make_auth_header() File \"/Users/bussonniermatthias/dev/ipython/tools/gh_api.py\", line 73, in make_auth_header return {'Authorization': 'token ' + get_auth_token()} File \"/Users/bussonniermatthias/dev/ipython/tools/gh_api.py\", line 67, in get_auth_token response.raise_for_status() File \"/Users/bussonniermatthias/anaconda3/lib/python3.5/site-packages/requests/models.py\", line 840, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 401 Client Error: Unauthorized for url: https://api.github.com/authorizations ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: add_test_setup - new environment behavior ? The behavior of environment for `add_test_setup()` seems to have changed between 0.44.1 and 0.45.0 Our code using ```meson add_test_setup('valgrind', exe_wrapper : ['valgrind', '--error-exitcode=1', '--leak-check=full'], timeout_multiplier : 100) ``` does not work anymore, seems like `os.environ` is not available Patching like ```meson e = environment() e.append('PATH', '', separator : '') e.append('SHELL', '', separator : '') e.append('DBUS_SESSION_BUS_ADDRESS', '', separator : '') add_test_setup('valgrind', env : e, exe_wrapper : ['valgrind', '--error-exitcode=1', '--leak-check=full'], timeout_multiplier : 100) ``` makes all tests pass again (our code uses sd_bus) I run like: `meson test --setup valgrind` If we just do meson test, it seems that the full os.environ is available during test Surely it cannot be correct that test_setup has a different environment ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: gptj doc tied weights mistake? https://github.com/huggingface/transformers/blob/5f1918a4a8ed893822aa7dd2b75acf83f255ad79/src/transformers/models/gptj/modeling_gptj.py#L686 ``` The GPT-J Model transformer with a language modeling head on top (linear layer with weights tied to the input embeddings). ``` The lm head isn't tied to the input embeddings for gpt-j Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: repr_html exception warning on qtconsole with pandas #4745 #4745 - warn on failed formatter calls since qtconsole html output is limited, pandas choses to provide an html repr on ipnb only and raise an exception from `_repr_html_` when in qtconsole to fallback to a text repr. This used to work fine, but #4745 now results in a warning message constantly being emitted about the exception being raised. @minrk, how about supressing a `NotImplementedError` as a form of contract? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Cloud Spanner client incorrectly handles NOT_FOUND error returned by create database While creating a database, is the backend returns NOT_FOUND error, the client assumes it to indicate that instance is not found and thus returns \"Instance not found\" error message: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/spanner/google/cloud/spanner_v1/database.py#L213 This is not always the case as cloud spanner can return NOT_FOUND in other scenarios. For eg in the \"CREATE INDEX ... \" ddl statement that table that the index is being created on does not exist it would return a NOT_FOUND. I think the fix would be to just pass the error message returned by the rpc to the user. This can be reproduced using: ```python from google.cloud import spanner \"\"\"Creates a database and tables for pattern 1 sample data.\"\"\" spanner_client = spanner.Client() instance = spanner_client.instance(\"test-instance\") database = instance.database(\"bitemporal_pattern1\", ddl_statements=[ \"\"\"CREATE TABLE MyTable ( Id String(36) NOT NULL, Field1 STRING(36) NOT NULL ) PRIMARY KEY (Id)\"\"\" , \"\"\"CREATE INDEX IDX ON yTable (Field1)\"\"\" ]) operation = database.create() print('Waiting for operation to complete...') operation.result() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: internal error from optimize_1q_gates from conditional cy gate ``` >>> qc = qk.QuantumCircuit(2,2) >>> qc.cy(0,1).c_if(qc.cregs[0], 0) <qiskit.circuit.instructionset.InstructionSet object at 0x12c540160> >>> qk.transpile(qc, backend=FakeTenerife()) Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/compiler/transpile.py\", line 147, in transpile circuits = parallel_map(_transpile_circuit, list(zip(circuits, transpile_configs))) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/tools/parallel.py\", line 100, in parallel_map return [task(values[0], *task_args, **task_kwargs)] File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/compiler/transpile.py\", line 168, in _transpile_circuit return transpile_circuit(circuit, transpile_config) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/transpiler/transpile_circuit.py\", line 62, in transpile_circuit return pass_manager.run(circuit) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/transpiler/passmanager.py\", line 147, in run dag = self._do_pass(pass_, dag, passset.options) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/transpiler/passmanager.py\", line 180, in _do_pass new_dag = pass_.run(dag) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/transpiler/passes/optimize_1q_gates.py\", line 53, in run raise TranspilerError(\"internal error\") qiskit.transpiler.exceptions.TranspilerError: 'internal error' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Print values inside a vmap function How to print values with a vmapped function even without any jit? From advi.py example, def elbo(logprob, rng, mean, log_std): **sample** = diag_gaussian_sample(rng, mean, log_std) return logprob(sample) - diag_gaussian_logpdf(sample, mean, log_std) def batch_elbo(logprob, rng, params, num_samples): rngs = random.split(rng, num_samples) vectorized_elbo = vmap(partial(elbo, logprob), in_axes=(0, None, None)) return np.mean(vectorized_elbo(rngs, *params)) print(sample) in VS Code debug mode returns the below message None Traced<ShapedArray(float32[2])>with<BatchTrace(level=2/0)> This seems to related to #1396. Even if I disabled all the jit, still I can't print values with the vmapp function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] conan upload --list errors on empty recipe list ### Environment details * Operating System+version: Manjaro Linux 23.0.0 * Compiler+version: N/A * Conan version: Conan version 2.0.7 * Python version: Python 3.11.3 ### Steps to reproduce 1. Create a list file as follows (can be generated from something like `conan list --graph install_graph.json --graph-binaries build --format json`) ```json { \"Local Cache\": {} } ``` 2. conan upload --remote foo --list list.json 3. Conditional check fails: https://github.com/conan-io/conan/blob/release/2.0/conan/cli/commands/upload.py#L84-L85 Note that I believe this should work since some automation workflows in CI may result in an empty list if a specific package was just cached and `--graph-binaries build` is set in the list command. I think the conditional check listed below should probably only error if the `--list` argument was not provided. ### Logs ``` $> conan upload --remote foo --list list.json ERROR: No recipes found matching pattern 'None' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: command package compulsory args `conan package MyLib/0.1@user/channel` raises an error: ``` Packaging Generating the package Package folder C:\\Users\\memsharded\\.conan\\data\\Protobuf\\2.6.1\\memsharded\\testing\\package ERROR: conaninfo.txt does not exist inside of your C:\\Users\\memsharded\\.conan\\data\\Protobuf\\2.6.1\\memsharded\\testing\\build folder. Try to re-build it again to solve it. ``` It requires a package_id or --all flag. It is confusing that not providing either, the error is not very informative. Maybe adding a check that either input is defined? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/mxnet codebase. Here's the problem: improve the sematic of lr_scheduler the current lr_scheduler is based on epoch, it is not flexible, and it has problem with the distributed training, where the optimizer runs on the server nodes. a server node neither can get the current epoch number, nor there is a clear definition of epoch for async sgd. i suggest to turn to a `batch` based lr scheduler implemented in python/mxnet, while provide an epoch like interface to users, say ``` new_lr = .8 * old_lr for every .5 epoch ``` we then set a correct batch value for lr_scheduler. but for a correct implementation, `batch` is not a good term. it means reading a data batch, while not necessary a weight updating: 1. we can sum the gradient for several batches and then apply one weight updating. often useful if the model is huge, while gpu mem is little, especially on the distributed setting. 2. on distributed training, assume n machines and b batches, there are n*b weight updatings for async_sgd while only b updatings for sync_sgd so i suggest to pass `num_updates` to the lr_scheduler. but there there are still two issues 1. we may update layer 1 (conv layer) for each batch, while layer 2 (big fullc layer) for every 2 batches. 2. assume there are two workers, on async_sgd, the possible updating order on the server node could be ``` layer_1_worker_1, layer_2_worker_2, layer_1_worker_2, layer_2_worker_1 ``` to simplify the thing, we pass \"the maximal number of updates applied to a weight\" to the lr_scheduler, for the above example, the values are ``` 1, 1, 2, 2 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan_api incorrect caching. Create fresh instances for every call. There are some components that are caching things: ConanFileLoader, Cache, PythonRequires. These components are instanced once in ConanAPI, but the api can be reused for multiple calls. Consider: - Invalidating mechanism, as in: https://github.com/conan-io/conan/pull/4362 - Creating fresh instances of all collaborators for every call. Related to this: we might want to re-think how functional collaborators are passed around conan codebase. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan qmake generator uses invalid characters in variable names conan version: 1.6.1 Conan allows package names to contain hyphens. If you do have a hyphen in your package name, then so will all the related variables in conanbuildinfo.pri, as generated by the qmake generator. Hyphens are not valid in qmake variable names. I suggest that the generator should change hyphens to underscores. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Small Typo in Docs GenerationMixin for use_cache parameter ### System Info In the text_generation docs (https://huggingface.co/docs/transformers/main_classes/text_generation), `use_cache` does not show up as its own line in the list of parameters. <img width=\"973\" alt=\"Screen Shot 2022-09-16 at 6 09 30 PM\" src=\"https://user-images.githubusercontent.com/565363/190812185-35c6eb4d-fbbf-4d17-ad86-6c1d2083c0e0.png\"> I think this is a small typo due to an extra `:` in the code. Happy to fix. ### Who can help? @LysandreJik ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction The website link ### Expected behavior `use_cache` should be on its own line Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: default value of `optimize` in `numpy.einsum` <!-- Please describe the issue in detail here, and fill in the fields below --> In the documentation page https://docs.scipy.org/doc/numpy-1.15.1/reference/generated/numpy.einsum.html, the default value of `optimize` is correctly stated to be `False` in the function signature, but erroneously stated to be `True` in the parameter description: > optimize : {False, True, ‘greedy’, ‘optimal’}, optional > Controls if intermediate optimization should occur. No optimization will occur if False and True will default to the ‘greedy’ algorithm. Also accepts an explicit contraction list from the np.einsum_path function. See np.einsum_path for more details. **Default is True**. ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import timeit print(timeit.timeit(\"np.einsum('ea,fb,abcd,gc,hd->efgh', C, C, I, C, C, optimize = True)\", 'import numpy as np; I = np.random.rand(10, 10, 10, 10); C = np.random.rand(10, 10)', number = 10)) print(timeit.timeit(\"np.einsum('ea,fb,abcd,gc,hd->efgh', C, C, I, C, C)\", 'import numpy as np; I = np.random.rand(10, 10, 10, 10); C = np.random.rand(10, 10)', number = 10)) ``` The second line should run much slower than the first line. ### Numpy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> 1.15.1 3.7.0 (v3.7.0:1bf9cc5093, Jun 26 2018, 23:26:24) [Clang 6.0 (clang-600.0.57)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: WandbLogger cannot be used with 'ddp' <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug wandb modifies `init` such that a child process calling init returns None if the master process has called init. This seems to cause a bug with ddp, and results in rank zero having experiment = None, which crashes the program. ### To Reproduce Can be reproduced with the basic MNIST gpu template, simply add a WandbLogger and pass 'ddp' as the distributed backend. ``` -- Process 0 terminated with the following error: Traceback (most recent call last): File \"/home/rmrao/anaconda3/lib/python3.6/site-packages/torch/multiprocessing/spawn.py\", line 19, in _wrap fn(i, *args) File \"/home/rmrao/anaconda3/lib/python3.6/site-packages/pytorch_lightning/trainer/distrib_data_parallel.py\", line 331, in ddp_train self.run_pretrain_routine(model) File \"/home/rmrao/anaconda3/lib/python3.6/site-packages/pytorch_lightning/trainer/trainer.py\", line 757, in run_pretrain_routine self.logger.log_hyperparams(ref_model.hparams) File \"/home/rmrao/anaconda3/lib/python3.6/site-packages/pytorch_lightning/logging/base.py\", line 14, in wrapped_fn fn(self, *args, **kwargs) File \"/home/rmrao/anaconda3/lib/python3.6/site-packages/pytorch_lightning/logging/wandb.py\", line 79, in log_hyperparams self.experiment.config.update(params) AttributeError: 'NoneType' object has no attribute 'config' ``` This occurs with the latest wandb version and with pytorch-lightning 0.6. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Listing package content Maybe a stupid question, but is there a quick way to list all the files (artifacts: binaries and header files) contained in a package (i.e. files added through the package method)? TIA Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Import time regression after #5358 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: after 300e9507 - **Python version**: 3.6 - **Operating system**: Linux ### What is the current behavior? After #5358 merged a significant import time performance was introduced: https://qiskit.github.io/qiskit/#import.QiskitImport.time_qiskit_import?commits=300e9507 ### Steps to reproduce the problem Run `import qiskit` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: mcry mode='basic' does not use ancillas <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **0.14.2**: - **3**: - **Ubuntu**: ### What is the current behavior? The mcry gate (implemented in https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py) has a 'basic' mode that expects ancillas, but calls mct in its default 'noancilla' mode. (so both mcry(mode = 'noancilla') and mcry(mode='basic') use no ancillas and a lot of gates). ### Steps to reproduce the problem ### What is the expected behavior? mcry in mode='basic' should call mct with mode='basic' ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: test_scale_with_api_returns_unexpected_exception fails frequently on jenkins `tests/integration/service_test.py ServiceTest.test_scale_with_api_returns_unexpected_exception` aka `Test that when scaling if the API returns an error, that is not of type` fails in many of our jenkins run - https://jenkins.dockerproject.org/job/Compose-PRs/1213/console with error: ``` Traceback (most recent call last): File \"/code/tests/integration/testcases.py\", line 22, in tearDown self.client.remove_container(c['Id']) File \"/code/.tox/py27/lib/python2.7/site-packages/docker/utils/decorators.py\", line 20, in wrapped return f(self, resource_id, *args, **kwargs) File \"/code/.tox/py27/lib/python2.7/site-packages/docker/client.py\", line 696, in remove_container self._raise_for_status(res) File \"/code/.tox/py27/lib/python2.7/site-packages/docker/clientbase.py\", line 103, in _raise_for_status raise errors.NotFound(e, response, explanation=explanation) NotFound: 404 Client Error: Not Found (\"Cannot destroy container faeacc68496793312980e36e20be6c7ae2a04a9b5f98c12f815a2235963ae834: Driver overlay failed to remove root filesystem faeacc68496793312980e36e20be6c7ae2a04a9b5f98c12f815a2235963ae834: stat /var/lib/docker/overlay/faeacc68496793312980e36e20be6c7ae2a04a9b5f98c12f815a2235963ae834: no such file or directory\") ``` This is a docker engine bug, but something about this specific test triggers it frequently. Looking at the test, I can't really tell what it might be. The failure is coming from `tearDown()`. We could wrap this cleanup in a try/except, which would have the added benefit of completing the rest of the cleanup. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Compilation error when using include_directories() object in subdirectory In the setup, which uses '-Wmissing-include-dirs' together with '-Werror' treating all warnings as errors gcc compiler returns an error. Here is the simplified example: git@bitbucket.org:adel-mamin/meson-test.git If I compile it with gcc I get the following error: > ninja [1/5] Compiling c object 'subdir/liba@sha/a.c.o' FAILED: subdir/liba@sha/a.c.o cc '-Isubdir/liba@sha' '-Isubdir' '-I../subdir' '-Iinclude' '-I../include' '-pipe' '-Wall' '-Winvalid-pch' '-Wmissing-include-dirs' '-Werror' '-O0' '-g' '-fPIC' '-MMD' '-MQ' 'subdir/liba@sha/a.c.o' '-MF' 'subdir/liba@sha/a.c.o.d' -o 'subdir/liba@sha/a.c.o' -c ../subdir/a.c cc1: error: include: No such file or directory [-Werror] cc1: all warnings being treated as errors [2/5] Compiling c object 'mytest@exe/main.c.o' ninja: build stopped: subcommand failed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Remove \"`optional`, defaults to :obj:`None`\" There are some docstrings with \"`optional`, defaults to :obj:`None`\" arguments. According to @sgugger this should be avoided: https://github.com/huggingface/transformers/pull/11417#discussion_r629320375 PS: I can provide a PR if wanted... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Initializer should use at most 2^(n+1)-2n cnots <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Initializer should use at most 2^(n+1)-2n cnots (arXiv:quant-ph/0406176). Cost to initialize a 4 qubits state uses Number of cnots (optimization_level=0): 44 Number of cnots (optimization_level=3): 26 max number of cnots: 24 ```python num_qubits = 4 _optimization_level = 3 vector = -1 * np.random.rand(2 ** num_qubits) vector[0] = 0 vector = vector / np.linalg.norm(vector) qr = QuantumRegister(num_qubits, 'qr') circuit = QuantumCircuit(qr) circuit.initialize(vector, qr) b = transpile(circuit, basis_gates=['u1', 'u2', 'u3', 'cx'], optimization_level=_optimization_level) print('Number of cnots: ', b.count_ops()['cx']) print('max number of cnots: ', 2 ** (num_qubits + 1) - 2 * num_qubits) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Gradient shape error. Consider the following code, ```python def pairwise_displacement(Ra, Rb): return Ra - Rb def periodic_displacement(side, dR): return np.mod(dR + side * f32(0.5), side) - f32(0.5) * side def square_distance(dR): return np.sum(dR ** 2, axis=-1) def distance(dR): return np.sqrt(square_distance(dR)) def periodic(side): def displacement_fn(Ra, Rb): return periodic_displacement(side, pairwise_displacement(Ra, Rb)) return displacement_fn def get_samples(sigma): particle_count = 10 key = random.PRNGKey(0) N_2 = particle_count // 2 particle_volume = N_2 * np.pi * (sigma ** 2 + 1.) / 4. box_size = np.sqrt(particle_volume / 0.96) displacement = periodic(box_size) R = box_size * random.uniform(key, (particle_count, 2), dtype=f64) displacement = vmap(vmap(displacement, (None, 0)), (0, None)) return np.sum(displacement(R, R)) print('Got shape {} but expected a scalar!!'.format( grad(get_samples)(1.0).shape)) ``` The function `grad(get_samples)(s)` should return a scalar. However, we get something of shape `[particle_count, particle_count, 2]`. It seems like the issue is most likely coming from tracing through `periodic(box_size)` since without that line the shapes work out as expected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Broken meson after 60969d9 `meson` is totally broken after https://github.com/mesonbuild/meson/commit/60969d99d33001317c569a9b37d3b9efae08d387: every meson call triggers the following error https://paste.ofcode.org/yFytL9HLtXJQEKz8WYfVKN meson.sh: ```bash #!/bin/bash /usr/bin/python3 /home/theqwertiest/meson_trunk/meson.py \"$@\" ``` Python version: ``` > python3 --version > Python 3.5.2 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Firestore] higher precision timestamps The Python SDK timestamps are lossy. The SDK doesn’t expose a way to retrieve timestamps with higher precision. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Please provide docker-compose alternative for docker run --runtime=some-runtime argument I inspected docker-compose reference and did not find any means to provide \"--runtime=some-runtime\" argument for starting containers. Please provide some documentation or add a new feature if it's currently impossible. Main motivation: nvidia-docker 2.0 default usage is: ```bash docker run --runtime=nvidia ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cmake: cmake subproject does not configure with `ERROR: Arguments must be strings.` **Describe the bug** When running meson build with a cmake subproject, the command fails with ``` Element not a string: [None] meson.build:14:0: ERROR: Arguments must be strings. ``` Similar behaviour to https://github.com/mesonbuild/meson/issues/7715 **To Reproduce** Relevant section of the meson.build file: ``` # telnet client cmake = import('cmake') telnetclient_proj = cmake.subproject('SimpleTelnetClient') telnetclient_dep = telnetclient_proj.dependency('SimpleTelnetClient') ``` **Expected behavior** The project configures everything correctly. **system parameters** Fedora 33 meson --version: 0.57.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Jupyterlab not starting after upgrade to > 2. <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description when I upgrade to any version > 2. the JupyterLab notebook does not start. Until 1.2.16 it worked fine, I am using `jupyter-labhub` within `Jupyterhub`. This is error I see: ``` from jupyterlab.labhubapp import main ModuleNotFoundError: No module named 'jupyterlab.labhubapp' ``` <!--Describe the bug clearly and concisely. Include screenshots if possible--> ## Context <!--Complete the following for context, and add any other relevant context--> - Jupyterhub 1.1.0: - JupyterLab version: 2.2.2 (I tried all 2.xxx) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: specifying the tpu_core speed-up TPU training <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug 1. I am getting a huge time difference between training a model on a specific tpu core tpu_cores=[1] and training a model on just 1 tpu core tpu_cores=1. What's the reason for that? Aren't both the conditions the same with just the difference that I am assigning a specific tpu_core in the first case and assigning the number of tpu_cores I want to use in the second case. Also in the second case, I am getting an error. When training with tpu_cores=[1] epoch time is 17 seconds with tpu_cores=1 epoch time is just 5 seconds. 2. Running on colab gives me an error but no error on Kaggle kernels. But the time difference issue is the same on both the platforms. <!-- A clear and concise description of what the bug is. --> ### To Reproduce #### Code sample [Colab Notebook](https://colab.research.google.com/drive/1jPen-P-e4njk_vHUQPsNWrcJ87P5UFxr?usp=sharing) ### Expected behavior As far as I know in both cases, the training time should be the same regardless of training on a single core or training on a specific core. ### Environment - PyTorch Version (e.g., 1.0): 1.5.0 - OS (e.g., Linux): Linux - How you installed PyTorch (`conda`, `pip`, source): pip - Build command you used (if compiling from source): - Python version: 3.7 - CUDA/cuDNN version: 10.1 - GPU models and configuration: Tesla P100-PCIE-16GB - Any other relevant information: ### Additional context <!-- Add any other context about the problem here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Incorrect lld.ld argument check for --allow-shlib-undefined The LLVM lld.ld linker in linkers.py checks if `--allow-shlib-undefined` is an argument, but the check has been incorrect since LLVM version 9 released. The unknown option is now quoted (`'`) in later versions. Opening this in order to track it so it is not forgotten. Originally discussed between myself and @eli-schwartz on IRC. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Load from 2d array within vmap results in two gathers rather than just one ``` import jax import jax.numpy as np import numpy as onp def test(arr, x, y): return arr[x, y] rand_x = onp.random.randint(0, 200, size=1024) rand_y = onp.random.randint(0, 200, size=1024) rand_arr = onp.random.uniform(0, 1, size=(200,200)) test_vmap = jax.vmap(test, in_axes=(None, 0, 0)) jax.jit(test_vmap)(rand_arr, rand_x, rand_y) ``` The `jax.jit` results in an XLA computation with two gathers, but the expression can be implemented with just one. Two gathers is quite bad, because unnecessarily it materializes out a large array; you really don't want to do this. I am not blocked on this, because I've worked around it by flattening the array and doing `x * width + y`. But this is not ideal because it forces a layout upon XLA. Also this is something that nobody other than an XLA expert is going to notice and work around in their code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: nbconvert: add logging for the different steps of nbconvert Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Allow EU dataset ID prefix This PR adds support for datasets located in EU datacenters. EU apps are prefixed with `e~`. Without this patch EU users will most likely see one of the following errors: `Exception: Request failed. Error was: app e~dataset cannot access app dataset's data` or `Exception: Request failed. Error was: Application Id (app) format is invalid: 's~e~dataset'` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Allow scrolling with j, k on IPython's qtconsole's pager System/version details: ``` {'commit_hash': 'be0cc2b', 'commit_source': 'installation', 'default_encoding': 'UTF-8', 'ipython_path': '/usr/local/lib/python2.7/dist-packages/IPython', 'ipython_version': '2.3.0', 'os_name': 'posix', 'platform': 'Linux-3.2.0-65-generic-x86_64-with-Ubuntu-12.04-precise', 'sys_executable': '/usr/bin/python', 'sys_platform': 'linux2', 'sys_version': '2.7.3 (default, Feb 27 2014, 19:58:35) \\n[GCC 4.6.3]'} ``` IPython has a pager, which comes when I type `?<CR>`, for example, or check for a long docstring. On my standard IPython, the pager allows scrolling with j and k (this is the `LESS` pager). On `qtconsole`, it is not calling that pager, but instead present a page with a side scroller, and I can scroll with the keys, but not with j and k, which is a little bit annoying (only a little bit, but enough to make me report an issue!) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: [Notebook] Ipython Kernel does not start if disconnected from internet(/network?) Hi, If I am not connected to the internet, I cannot execute \"ipython notebook\". sucessfully. I get the following error. gaierror: [Errno -9] Address family for hostname not supported (full traceback here: http://pastebin.com/sfEgXay8) If I am connected to the internet, everything works as expected. I do not have a network available that is not connected to the internet, to test if a network connection or internet is required. (I suspect its just a network connection that is required) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [error] Error when calling conanfile.info.clone() I am trying to achieve VS downward compatibility by using the new feature in package info. I have the following method: ``` def enable_visual_studio_downward_compatibility(conanfile): if conanfile.settings.compiler == \"Visual Studio\" and conanfile.settings.compiler.version == \"16\": for version in (\"15\", \"14\"): compatible_pkg = conanfile.info.clone() compatible_pkg.settings.compiler.version = version conanfile.compatible_packages.append(compatible_pkg) if conanfile.settings.compiler == \"Visual Studio\" and conanfile.settings.compiler.version == \"15\": for version in (\"14\"): compatible_pkg = conanfile.info.clone() compatible_pkg.settings.compiler.version = version conanfile.compatible_packages.append(compatible_pkg) ``` And the package uses: ``` def package_id(self): enable_visual_studio_downward_compatibility(self) ``` From my understanding and reading the documentation, this is the right way to enable compatibility. However, when a VS2019 consumer tries to consume a VS2015 package, I get the following error: ``` ERROR: package/version@user/stable: Error in package_id() method, line 53 enable_visual_studio_downward_compatibility(self) while calling 'enable_visual_studio_downward_compatibility', line 8 compatible_pkg = conanfile.info.clone() ConanException: 'minor_mode' is not a known package_id_mode ``` Is this a bug or am I doing something wrong here? (I am using Conan 1.22.2) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Support storing hparams as a dict ## 🚀 Feature Right now, we assume `model.hparams` is an `argparse.Namespace`. We've had a number of requests to support `hparams` as a simple `dict`. Let's do it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: ShellTask docs say it returns string instead of bytes Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan detects ARM architecture, but not defined in settings Initial auto detection of system conf (to load in conan.conf), fails, as it creates old \"arm\" arch, while \"armv7\", etc is what is defined. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Library search path needs to query the linker The get_library_dirs() function in mesonlib hard-codes paths, and that's completely wrong. The search path for C/C++ libraries is decided by the linker. Specifically, the output of: `gcc -Xlinker --verbose | grep SEARCH_DIR` Gives the list of search directories in order of priority. I don't have a patch for this because I'm not sure how this ties in with the compiler detected/selected during configuration; especially cross-compilation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add a way to specify a 'default' test setup Currently, there are two ways to specify a test setup (specifically, a test env) to a build file: 1. `add_test_setup('foo', env: ...)` 2. `test(..., env: ...)` Let's say a specific env var is set by `add_test_setup` to one value, and the same var is set by `test()` to a different value. If you run `meson test` the per-test env vars are used. Sounds good. If you run `meson test --setup=foo`, the per-test env vars are used again! This makes sense, but also leaves a feature gap where you want a 'default' test env that is overriden by either per-test or by a selected test setup. The workaround is to define a `default` setup with `add_test_setup('default', env:...)` and never call `meson test` without a `--setup` argument. Meson should support something like `add_test_setup_default()` which is used by default for all tests when no setup is specified. Everything else stays the same, i.e., per-test env vars override the default setup, and also override any env vars set by the currently-selected test setup. CCing @havardgraff @stianse Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: doc unclear for np.interp https://docs.scipy.org/doc/numpy/reference/generated/numpy.interp.html \"Returns the one-dimensional piecewise linear interpolant to a function\" doesn't look right - I think it should be \"Returns the one-dimensional piecewise linear interpolant to a function, evaluated at x\". Also, \"The x-coordinates of the interpolated values\" should be \"The x-coordinates of the points at which to calculate the interpolated values\". Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Reuse storage HTTP status code -> exception type mapping in datastore [Existing implementation](https://github.com/GoogleCloudPlatform/gcloud-python/blob/56daf8c248be400f69e8c292743a897ea83c34cb/gcloud/storage/exceptions.py#L158) [where we would use it](https://github.com/GoogleCloudPlatform/gcloud-python/pull/506#discussion_r22629787) Reuse storage HTTP status code -> exception type mapping in datastore [Existing implementation](https://github.com/GoogleCloudPlatform/gcloud-python/blob/56daf8c248be400f69e8c292743a897ea83c34cb/gcloud/storage/exceptions.py#L158) [where we would use it](https://github.com/GoogleCloudPlatform/gcloud-python/pull/506#discussion_r22629787) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Inspect requests inside a function call should be smarter about what they inspect. Previously, `func(a, b, <shift-tab>` would give information on `func`, now it gives information on `b`, which is not especially helpful. This is because we removed logic from the frontend to make it more language agnostic, and we have not yet reimplemented that on the frontend. For 3.1, we should make it at least as smart as 2.x was. The quicky and dirty approach would be a regex; the proper way is tokenising the code. Ping @mwaskom who brought this up on the mailing list. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: add 'conda search --envs' As root, running conda search --envs 'openssl<1.0.2n' would list the location of every known environment containing an outdated version of openssl. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Removal of handle_proxy_407 breaks conda-build Elevating as issue from https://github.com/conda/conda/commit/b993816b39a48d807e7a9659246266f6035c3dcd#commitcomment-19452072 so that it does not get lost. Removal of handle_proxy_407 breaks conda-build (it is used in pypi skeleton code for some reason.) Is there an alternative that I can use instead? Please provide example code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Potential regression: incorrect selinux context after install **Describe the bug** Potential regression of https://github.com/mesonbuild/meson/issues/1967 The selinux context is wrong after a ninja install. **To Reproduce** ``` # meson.build project('test', 'c', version : '0') systemd = dependency('systemd') systemd_unit_dir = systemd.get_variable(pkgconfig: 'systemdsystemunitdir') install_data( 'test.service', install_dir: systemd_unit_dir # /usr/lib/systemd/system ) ``` ``` $ touch test.service $ meson --prefix=/usr build # ninja -C build install ``` **Current behaviour** ``` $ ls -lZ /usr/lib/systemd/system | grep test -rw-r--r--. 1 root root unconfined_u:object_r:user_home_t:s0 0 Jul 19 04:38 test.service ``` As shown here, the selinux context is `unconfined_u:object_r:user_home_t:s0`. **Expected behavior** Ideally the installed file should have `system_u:object_r:systemd_unit_file_t:s0` (this is what is set if using `/usr/bin/install` or `restorecon -F` afterwards). Otherwise, at least `unconfined_u:object_r:systemd_unit_file_t:s0` (using `restorecon` afterwards) **system parameters** Fedora 36 with default selinux settings Python 3.10.5 Meson 0.62.2 Ninja 1.10.2 ``` $ selinuxenabled $ which restorecon /usr/sbin/restorecon ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Big overhead in parallel transpile for large target systems ### Environment - **Qiskit Terra version**: `0.19.2` - **Python version**: 3.8 - **Operating system**: Linux ### What is happening? There is a large overhead when doing parallel transpilation for circuits targeting larger systems. In the case below they are targeting the 127Q system, but the circuits themselves consist of only `x` gates and are already the correct width. Thus transpilation should just be a pass-through. However, in parallel mode (quad-core machine) it takes 330sec to transpile. If I turn off parallel transpile it takes 3sec. ```python from qiskit import * from mthree.circuits import balanced_cal_strings, balanced_cal_circuits b_strs = balanced_cal_strings(127) cal_circs = balanced_cal_circuits(b_strs) backend = provider.backend.ibm_washington trans_circs = transpile(cal_circs, backend, optimization_level=0) ``` ### How can we reproduce the issue? Run above ### What should happen? Parallel should not give 100x overhead. ### Any suggestions? I am guessing this is copying overhead from forking when the systems are large. Seed transpiler takes list but it is not in the docstrings ### Environment - **Qiskit Terra version**: 0.20 - **Python version**: - **Operating system**: ### What is happening? In order to seed transpiler for a list of circuits a list of seeds is required. This is supported, but not mentioned anywhere: https://github.com/Qiskit/qiskit-terra/blob/a296ca009bf440b5a2cb00f61b8221c6ce9aa044/qiskit/compiler/transpiler.py#L65 ### How can we reproduce the issue? See the docstring ### What should happen? It should be listed as an option because I originally assumed having all processes set with a single int seed was a bug. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Issues with Ellipsis literal in Python 3 There seem to be some differences between the way the Ellipsis literal (`...`) from Python 3 is handled in python vs. ipython: ``` py >>> ... Ellipsis >>> ....__class__ <class 'ellipsis'> ``` ``` py In [1]: ... In [2]: ....__class__ File \"<ipython-input-2-f022736bb488>\", line 1 .__class__ ^ SyntaxError: invalid syntax ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC, TST: matplotlib backends in doctests As [noted](https://github.com/numpy/numpy/pull/12253#discussion_r239262077) we probably shouldn't have things like `matplotlib.use('agg')` in our docs. I added several such cases in #12253 -- I think my main reason was related to issues of: 1) having matplotlib plots showing (popping) up on my screen locally during doctests because of backend settings / whatever defaults get used with our original docstrings 2) Actual doctest errors, at least locally, without using a fixed backend I'm not sure if the issues are less severe after the doctest->refguide transition now. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: np.random: Use log1p to improve precision This reduces the number of cases when floating point precision makes the argument to `log` become `0` Fixes #17007, probably <!-- Please be sure you are following the instructions in the dev guidelines http://www.numpy.org/devdocs/dev/development_workflow.html --> <!-- We'd appreciate it if your commit message is properly formatted http://www.numpy.org/devdocs/dev/development_workflow.html#writing-the-commit-message --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Introspection API: missing info about `install_subdir` `meson-info/intro-installed.json` does not contain any information about files/directories installed via `install_subdir`. PS: `meson-logs/install-log.txt` contains such info, so it probably could be used as a reference. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Extension manager should be as helpful as labextension for prebuilt extensions Currently, `jupyter labextension uninstall` and `jupyter labextension list` give extra information for packages with an `install.json`, namely listing the package manager and package name, and also the uninstall instructions. The extension manager should give similar information for those just using the UX. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: restorecon called with empty input **Describe the bug** If there is nothing to install, `ninja install` shows a slightly misleading restorecon error **To Reproduce** Basically empty `meson.build` ``` project('empty') ``` and then: ``` meson build cd build ninja install ``` yields: ``` [0/1] Installing files. Failed to restore SELinux context of installed files... Standard output: Standard error: restorecon: SELinux: Could not get canonical path for restorecon: No such file or directory. Nothing to install. ``` **Expected behavior** No error message. **System parameters** Seen with the Fedora 31 Meson package (meson-0.52.1-1.fc31.noarch). **Note** Note the extra space before restorecon in the message. What happens is that restorecon is called with an empty input in `restore_selinux_contexts()` ``` out, err = proc.communicate(input=b'\\0'.join(os.fsencode(f) for f in selinux_updates) + b'\\0') ``` telling it to process a file with name '', where it shouldn't be called at all, because `selinux_updates` is empty. Should be easily fixable with a `if not selinux_updates: return`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: abort-on-container-exit does not work as expected ``` > uname -a Linux mycomputername 3.13.0-77-generic #121-Ubuntu SMP Wed Jan 20 10:50:42 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux > docker -v Docker version 1.10.1, build 9e83765 > docker-compose -v docker-compose version 1.6.0, build d99cad6 ``` According to the docs https://docs.docker.com/compose/reference/up/, `--abort-on-container-exit` should > Stop all containers if any container was stopped. docker-compose.yml: ``` version: \"2\" services: loop1: image: ubuntu:latest command: bash -c 'for i in {1..5}; do echo $$i && sleep 1; done' stop_signal: SIGKILL loop2: image: ubuntu:latest command: bash -c 'for i in {1..10}; do echo $$i && sleep 1; done' stop_signal: SIGKILL ``` After `docker-compose up --abort-on-container-exit` both containers start sending log messages. When `loop1` exits, documentation suggests that `loop2` will also be stopped. This does not happen, which can be confirmed by executing `docker-compose ps` shortly after `loop1` exits. An other issue which may be related: When hitting `Ctrl-C` after `docker-compose up` I would expect this: ``` ^CGracefully stopping... (press Ctrl+C again to force) Stopping dockercompose_loop1_1 ... done Stopping dockercompose_loop2_1 ... done ``` This is only happening occasionally, most of the time I get this instead: ``` ^CERROR: Aborting. ``` Also, the containers remain up. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: No autodiff on linalg.solve Dear jax team, after recent improvements to `linalg.solve` (thanks again!) I found that it has some issues with being autodiff'ed. I have not yet digged into the error messages, but they rather sound like a minute error in handling the shapes than some fundamental limitation. ```python import jax import jax.numpy as np import numpy as onp @jax.jit def solve(A, b): return np.linalg.solve(A, b) def to_gpu(arr): return jax.device_put(arr.astype(onp.float32)) A = to_gpu(onp.random.rand(100, 3, 3)) b = to_gpu(onp.random.rand(100, 3)) x = solve(A, b) assert onp.allclose(jax.vmap(np.dot)(A, x), b, atol=1e-4, rtol=1e-4) print(\"# BATCHED\") try: jac0 = jax.jacobian(solve, argnums=0)(A, b) # error except Exception as e: print(e) # triangular_solve requires both arguments to have the same number of dimensions and equal batch dimensions, got (100, 3, 3) and (100, 100, 3, 3) try: jac1 = jax.jacobian(solve, argnums=1)(A, b) # error except Exception as e: print(e) # 'Zero' object is not subscriptable print(\"# SINGLE\") try: jac0 = jax.jacobian(solve, argnums=0)(A[0], b[0]) # fine except Exception as e: print(e) try: jac1 = jax.jacobian(solve, argnums=1)(A[0], b[0]) # error except Exception as e: print(e) # 'Zero' object is not subscriptable ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Rename CMAKE_SHARED_LINK_FLAGS I couldn't find any CMake documentation for CMAKE_SHARED_LINK_FLAGS which shows up when generating conanbuildinfo.cmake. Is this a typo that should be [CMAKE_SHARED_LINKER_FLAGS](https://cmake.org/cmake/help/v3.0/variable/CMAKE_SHARED_LINKER_FLAGS.html)? I'm not currently conan with CMake myself, so I haven't tested if it causes any errors at the moment. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: Support Azure authentication for pipeline ops Pipeline authors can currently authenticate against GCP by adding a \".apply(gcp.use_gcp_secret('user-gcp-sa'))\" suffix to their ops. This makes the GCP secret provisioned during kubeflow setup available to the op container. However there is no way to do this on Azure Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Default pipelines] Add a revision tag to all pipelines ### Feature request Continuing the discussion here: https://github.com/huggingface/transformers/pull/17286#discussion_r893716733 To make sure that the default pipelines models - some of which - are community contributed models and thus somewhat \"out-of-control\" for transformers, it'd be important to add a `revision` tag to those default models (maybe actually to all pipeline models). ### Motivation To ensure that changing checkpoints don't break transformers ### Your contribution Can open a quick PR Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Zsh.exe not supported on MSYS2 The following error is reported in a MSYS2 zsh shell: ``` ➜ dotfiles git:(master) ✗ source activate py35_32 Traceback (most recent call last): File \"C:\\Miniconda3\\Scripts\\conda-script.py\", line 5, in <module> sys.exit(main()) File \"C:\\Miniconda3\\lib\\site-packages\\conda\\cli\\main.py\", line 48, in main activate.main() File \"C:\\Miniconda3\\lib\\site-packages\\conda\\cli\\activate.py\", line 105, in main shelldict = shells[shell] KeyError: 'zsh.exe' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Agent trying to load remote tools when being offline ### System Info Transformers 4.31 Python 3.11.4 Windows 10 ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Code: ``` import os os.environ['TRANSFORMERS_OFFLINE'] = '1' from transformers import LocalAgent, AutoModelForCausalLM, AutoTokenizer model = AutoModelForCausalLM.from_pretrained(\"tiiuae/falcon-7b-instruct\", trust_remote_code=True) tokenizer = AutoTokenizer.from_pretrained(\"tiiuae/falcon-7b-instruct\") agent = LocalAgent(model=model, tokenizer=tokenizer) # Error here agent.run(\"my query\"); ``` Error: ``` Max retries exceeded with url: /api/spaces?author=huggingface-tools ``` ### Expected behavior To not access the remote tools. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: 'Table.insert_data' does not support Datetime values Seems like the python api library does not support native python datetime objects for inserting BigQuery DateTime-values. ``` INFO:root:Sending load request [(1L, 'as', datetime.datetime(2014, 2, 1, 0, 0), 'asdasd'), (2L, 'ds', datetime.datetime(2014, 2, 2, 0, 0), 'asdsad')] Traceback (most recent call last): ... File \"/home/chris/.local/lib/python2.7/site-packages/google/cloud/bigquery/table.py\", line 770, in insert_data data=data) File \"/home/chris/.local/lib/python2.7/site-packages/google/cloud/_http.py\", line 326, in api_request data = json.dumps(data) File \"/usr/lib/python2.7/json/__init__.py\", line 244, in dumps return _default_encoder.encode(obj) File \"/usr/lib/python2.7/json/encoder.py\", line 207, in encode chunks = self.iterencode(o, _one_shot=True) File \"/usr/lib/python2.7/json/encoder.py\", line 270, in iterencode return _iterencode(o, 0) File \"/usr/lib/python2.7/json/encoder.py\", line 184, in default raise TypeError(repr(o) + \" is not JSON serializable\") TypeError: datetime.datetime(2014, 2, 1, 0, 0) is not JSON serializable ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `install_plan` metadata has full path in destination instead of being based on a placeholder **Describe the bug** Introduced in 0.63.0. Discovered in https://github.com/FFY00/meson-python/issues/95. **To Reproduce** Package: https://github.com/FFY00/meson-python/tree/main/tests/packages/purelib-and-platlib Generated metadata: ```json { \"targets\": { \"/home/anubis/git/mesonpy/tests/packages/purelib-and-platlib/builddir/plat.cpython-310-x86_64-linux-gnu.so\": { \"destination\": \"/usr/lib/python3.10/site-packages/plat.cpython-310-x86_64-linux-gnu.so\", \"tag\": \"runtime\" } }, \"python\": { \"/home/anubis/git/mesonpy/tests/packages/purelib-and-platlib/pure.py\": { \"destination\": \"{py_purelib}/pure.py\", \"tag\": \"runtime\" } } } ``` **Expected behavior** It should generate the following metadata instead ```json { \"targets\": { \"/home/anubis/git/mesonpy/tests/packages/purelib-and-platlib/builddir/plat.cpython-310-x86_64-linux-gnu.so\": { \"destination\": \"{moduledir_shared}/plat.cpython-310-x86_64-linux-gnu.so\", \"tag\": \"runtime\" } }, \"python\": { \"/home/anubis/git/mesonpy/tests/packages/purelib-and-platlib/pure.py\": { \"destination\": \"{py_purelib}/pure.py\", \"tag\": \"runtime\" } } } ``` **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? No * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.): Reproduced on many Linux distros at least * what Python version are you using e.g. 3.8.0: 3.10.5 * what `meson --version`: 0.63.0 * what `ninja --version` if it's a Ninja build: 1.10.2.git.kitware.jobserver-1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Support for gcc 6.1 and clang 3.8 I've tried building the sample project in the Getting started section, but at first I ran into connan not finding any compiler on my system (arch linux with both gcc 6.1 and clang 3.8 installed) ``` $ conan It seems to be the first time you run conan Auto detecting your dev setup to initialize conan.conf ERROR: Unable to find a working compiler Default conan.conf settings os=Linux arch=x86_64 build_type=Release *** You can change them in ~/.conan/conan.conf *** *** Or override with -s compiler='other' -s ...s*** ``` I tried fixing this by specifying the settings manually as the error message suggests, but it wouldn't let me use a newer version of both GCC and Clang than the ones conan knows about. ``` $ conan install .. -s compiler=gcc -s compiler.libcxx=libstdc++11 -s compiler.version=6.1 --build ERROR: '6.1' is not a valid 'settings.compiler.version' value. Possible values are ['4.4', '4.5', '4.6', '4.7', '4.8', '4.9', '5.1', '5.2', '5.3'] ``` and ``` $ conan install .. -s compiler=clang -s compiler.libcxx=libc++ -s compiler.version=3.8 --build ERROR: '3.8' is not a valid 'settings.compiler.version' value. Possible values are ['3.3', '3.4', '3.5', '3.6', '3.7'] ``` Is there a way to work around this? It seems reasonable to use any compiler/version I want, no? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Checkpointing with SLURM #### What is your question? I have a pytorch-lightning code with checkpointing that runs well on my desktop. But when I run it on our cluster with SLURM, the checkpoints do not get saved. #### Code ```python model = Predictor(args) check = ModelCheckpoint(save_top_k=1, verbose=True, monitor='val_acc', mode='max', filepath='checks/{epoch}) trainer = pl.Trainer(checkpoint_callback=check, max_epochs=100, gpus=1) trainer.fit(model) ``` #### What have you tried? I run it in the cluster with the following code: ```bash salloc -G 1 srun python main.py ``` #### What's your environment? - OS: Linux - Packaging conda Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Doc] Something wrong in description of 'DistilBertForSequenceClassification' in doc I think the description of input_ids (one of the parameters) of [DistilBertForSequenceClassification](https://huggingface.co/transformers/model_doc/distilbert.html#distilbertforsequenceclassification) is not correct. I think the input_ids should be `torch.LongTensor of shape (batch_size, sequence_length)`, rather than `torch.LongTensor of shape (batch_size, num_choices)`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: python.find_installation() fails on Windows The following meson.build file fails to build on Windows using a meson MSI installed package: ``` project('foo') python = import('python').find_installation() ``` Same with both meson 0.60.0 and 0.61.1 Complete output: ``` The Meson build system Version: 0.61.1 Source dir: C:\\temp Build dir: C:\\temp\\build Build type: native build Project name: foo Project version: undefined Host machine cpu family: x86_64 Host machine cpu: x86_64 Program python3 found: YES (C:\\Program Files\\Meson\\meson.exe runpython) meson.build:3:0: ERROR: <PythonExternalProgram 'python3' -> ['C:\\\\Program Files\\\\Meson\\\\meson.exe', 'runpython']> is not a valid python or it is missing distutils A full log can be found at C:\\temp\\build\\meson-logs\\meson-log.txt ``` This appears to be a regression of #5217 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: MPL drawer does not handle unitaries well <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? <img width=\"1003\" alt=\"Screen Shot 2019-06-25 at 12 51 45 PM\" src=\"https://user-images.githubusercontent.com/1249193/60117470-1eb30900-9748-11e9-9d12-1451d8cea41d.png\"> vs <img width=\"368\" alt=\"Screen Shot 2019-06-25 at 12 52 13 PM\" src=\"https://user-images.githubusercontent.com/1249193/60117475-21156300-9748-11e9-98d2-f6f80a89f0fe.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Oslogin: needs 'synth.py' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Plot_hinton imaginary section displays incorrect elements ### Environment - **Qiskit Terra version**: 0.19.1 - **Python version**: 3.7.9 - **Operating system**: ios  ### What is happening? In the Visualization section: plot_hinton It displays 2 plots : one for real and one for imaginary There are 2 issues: 1. The imaginary elements displays the elements incorrect for real and negative numbers. 2. The size of the square of the elements are not equal for the imaginary plot ### How can we reproduce the issue?  ### What should happen? We expect the following plot_hinton  ### Any suggestions? We make few simple changes in the state_visualizaton.py file and we can obtain the correct plot for the imaginary section in the plot_hinton. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Remove outdated version compatibility check for extensions This [check](https://github.com/jupyterlab/jupyterlab/blob/53a60f7016a96787765ba40851a4200d8cd5a463/jupyterlab/labextensions.py#L502) needs to be removed in light of the big split until we have a replacement system. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: collection_group query with start_after passing a snapshot Problem: start_after() does not work for collection group queries when passing a document snapshot. #### Environment details python 3.7 google-cloud-firestore version 1.2 #### Steps to reproduce 1. Setup a Google Cloud project with Firestore in Native Mode. #### Code example ``` parent_ref = db.collection('parents').document('parent') parent_ref.set({}) child_data = {'name': 'Tom'} child_ref = parent_ref.collection('children').document('child') child_ref.set(child_data) # works db.collection_group('children').where('name', '==', 'Tom').stream() # works db.collection_group('children').where('name', '==', 'Tom').start_after(child_data).stream() # does not work child_snapshot = child_ref.get() db.collection_group('children').where('name', '==', 'Tom').end_before(child_snapshot).stream() ``` #### Stack trace ``` Traceback (most recent call last): File \"C:/Users/tombr/Documents/GitHub/trader-python/scripts/gcloud/firestore/test.py\", line 22, in <module> db.collection_group('children').where('name', '==', 'Tom').end_before(child_snapshot).stream() File \"C:\\Users\\tombr\\Documents\\GitHub\\trader-python\\venv\\lib\\site-packages\\google\\cloud\\firestore_v1\\query.py\", line 529, in end_before return self._cursor_helper(document_fields, before=True, start=False) File \"C:\\Users\\tombr\\Documents\\GitHub\\trader-python\\venv\\lib\\site-packages\\google\\cloud\\firestore_v1\\query.py\", line 420, in _cursor_helper \"Cannot use snapshot from another collection as a cursor.\" ValueError: Cannot use snapshot from another collection as a cursor. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Support multiple profiles on command-line for composition Profiles support static composition today via `include(other_profile)` directive. Where this mechanism breaks down is when users want to combine partial profiles with completely unrelated information, and to do that today you need an intermediate profile which `includes()` both of the things you really want. So for example, I can't have four special ffmpeg-related profiles defining `ffmpeg` options in the `ffmpeg` project directory, and compose them with profiles that define the common settings of my organization: I want to be able to do: `conan create . bincrafters/testing -pr msvc_15_x64_release_mt -pr ffmpeg_with_options0` and then: `conan create bincrafters/testing -pr gcc_8_x86_debug -pr ffmpeg_with_options3` To do this today, the only feasible approach is to use one profile or the other, and then pass the rest of the items on the CLI manually. Alternatively, you would have to create a bunch of \"intermediate\" profiles for every possible combination, which is clearly nonsensical. Obviously, this feature would require conflict resolution, but something like the order they appear on the command-line should suffice. I am sure conflict resolution was a factor with `include()`, so this is not a new problem. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Run failure sensors don't inject pythonic resources ### Dagster version 1.3.6 ### What's the issue? When creating a sensor, I can declare constructor parameters to have pythonic resources injected when that sensor runs. However when creating a run failure sensor, I get an error trying to do the same. For example, I have a pythonic resource class called ```DbConnection```. If I declare this run failure sensor: ```python @run_failure_sensor( name=\"project_processing_failed_sensor\" ) def project_processing_failed_sensor( context: RunFailureSensorContext, db_connection: DbConnectionResource): ``` I can enable the sensor, however when a job fails and initiates it - I get this error: _TypeError: project_processing_failed_sensor() missing 1 required positional argument: 'db_connection_ ### What did you expect to happen? I would expect a run failure sensor to support pythonic resources in the constructor. ### How to reproduce? 1. Create any job that will throw an error and fail when started. 1. Create a pythonic resource class. 1. Create a run failure sensor that takes that pythonic resource class as a parameter. 1. Start dagster (I was testing in dev though my prod environment is on k8). 1. Start the new run failure sensor in the \"sensors\" area of the UI so it is enabled. 1. Start the job that will fail and wait for it to fail. 1. You should see an error in the logs: _TypeError: project_processing_failed_sensor() missing 1 required positional argument: [name of your pythonic resource variable]_ ### Deployment type Local ### Deployment details _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: No module named 'vcr': requirement is missing (vcrpy) <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.10.1 - **Python version**: 3.7.3 - **Operating system**: windows 10 ### What is the current behavior? Fresh qiskit installation inside a new environment on windows 10. In one of the terra tutorial (using_the_transpiler) `from qiskit.test.mock import FakeTokyo` is failing 'ModuleNotFoundError: No module named vcr' ### Suggested solutions 'pip install vcrpy' 'vcrpy' needs to be added in requirements. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: How to remove `v_num` from the progress bar ? Version: 0.7.3 The `v_num` is automatically added to progress_bar when some logger is used It is not much a problem for tensorboard when v_num is just a simple number But v_num for mlfow takes a lot of space Traning step ``` def training_step(self, batch, batch_nb): .... log = { \"trn_loss\": 0.1, \"lr\": 0.001 } return {\"loss\": loss, \"log\": log, \"progress_bar\": log} ``` Progress bar when using with mlflow logger ``` [00:33<00:46, 1.62s/it, loss=0.740, lr=8e-6, trn_loss=0.659, v_num=18_28bc973b1f0e42e8b4d664d1ef7812f6] ``` Also, `loss` is automatically added to `progress_bar` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Optional dependencies are required for deprecated logging module 🐛 Bug There is a backwards compatibility issues coming from PR #767. Notably, if a user doesn't have any of the extra logging dependencies then they'll be an import error. ### To Reproduce 1. Remove all logging dependencies from your environment (E.g. comet) 2. Depend on the deprecated pytorch_lightning.logging package and run ### Expected behavior We expect to maintain backwards compatibility here so optional dependencies shouldn't be required. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: wrap-git's clone-recursive does not lead to submodules being updated to specified revision When adding a subproject and specifying `clone-recursive = true` as well as `revision = somebranch`, meson will clone the git repository recursively and then checkout `somebranch`. It will however not call `git submodule update` (or it would probably best to call `git submodule update --checkout --init --recursive`), leaving submodules of the cloned repository in the revision that `master` references them in. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Xcode 14.2 with macos sdk 13.1 not working ### Environment details * Operating System+version: MacOS 13.2 * Compiler+version: Xcode 14.2 * Conan version: 1.59.0 * Python version: 3.8 ### Steps to reproduce Setting macos sdk to 13.0 and building cmake on a default install of xcode 14.2 fails ### Logs _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: RFC: remove `return_failed` kwarg from FlowRunner.run()? The more that we run Flows in distributed contexts, and use helpers like `raise_on_exception`, the less useful I think the `return_failed` kwarg is for `FlowRunner.run()`. In particular, it requires some messy code because it can only be satisfied by gathering every single task state to the FlowRunner process, then filtering. If people are finding it useful, then I retract this, but IMO it is not as useful as it used to be. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Latex drawer does not support controlled gates ### Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: MacOS ### What is the current behavior? The latex drawer does not print controlled gates correctly. ### Steps to reproduce the problem ``` qr = QuantumRegister(3, 'q') circuit = QuantumCircuit(qr) circuit.append(HGate().control(2), [qr[0], qr[1], qr[2]]) circuit.draw('latex') ```  ### What is the expected behavior? Something along the text drawer: ``` q_0: |0>──■── │ q_1: |0>──■── ┌─┴─┐ q_2: |0>┤ H ├ └───┘ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Change how we use mypy in CI Currently we use `mypy` as part of our CI process. This frequently leads to extra work trying to appease the type checker for code that is definitely correct (see e.g. https://github.com/PrefectHQ/prefect/pull/2406). We *do* want mypy to check that the type signatures of public methods actually match their implementation, but we *don't* want mypy to error for internal type checking that it thinks is invalid (internal errors can be caught by tests, and frequently the type checker is more of a burden than an aid). Perhaps there's a mypy configuration setting we can change to get this behavior? We also currently run the mypy tests in two locations: - As part of the `Check code style and docs` build - As part of a test in `tests/test_formatting.py`, in the `Run tests` build These two CI builds have different environments (in particular, prefect (and dependencies) aren't installed in the former but are in the latter). This difference can lead to mypy tests passing in one environment and failing in the other. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: If more kwargs/args than required are supplied to `CmdDef` and error is not raised <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**:OSX ### What is the current behavior? If additional kwargs/args are supplied to `cmd_def.get` no error is raised and a result is still returned if the required parameters are present. ### Steps to reproduce the problem ```python from qiskit.test.mock import FakeOpenPulse2Q from qiskit.pulse import CmdDef backend = FakeOpenPulse2Q() config = backend.configuration() defaults = backend.defaults() cmd_def = CmdDef.from_defaults(defaults.cmd_def, defaults.pulse_library) print(cmd_def.get_parameters('u1', 0)) print(cmd_def.get('u1', 0, 0)) print(cmd_def.get('u1', 0, P1=0, P2=1, P3=2)) ``` ### What is the expected behaviour? An error should be raised if unnecessary args/kwargs are supplied. Similarly for an insufficient number of args/kwargs if partial binding is not supported. ### Suggested solutions Add error checks. @nkanazawa1989 could you check if your PR #2493 fixes this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Abort a DAG Run **Description** It would be great having a option to abort a DAG Runs through the REST API. **Use case / motivation** The proposed input params would be: - DAG_ID - DAG_RUN_ID The DAG Run should abort all its tasks running and mark them as \"failed\". **Are you willing to submit a PR?** **Related Issues** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: The read_rows method in the bigtable client does not provide an interface to specify open/closed key ranges The read_rows method of the Table class in the bigtable client is designed such that the results are inclusive of the start key but exclusive of the end key. That seems a reasonable choice, until one considers that keys may be designed to accumulate in reverse order (as recommended in the docs: https://cloud.google.com/bigtable/docs/schema-design-time-series). In that case, it is necessary to flip the natural order of the keys to process a query -i.e. if I query from time t0 to t1, I will create two corresponding keys k0 and k1, but k1 will be the start key and k0 the end key in the call to read_rows. Currently, the specification of open and closed for the start and end key is hard-coded in the _create_row_request method, and that makes it difficult for an end user of the library to alter the default behavior. Consider adding an option to the read_rows method, or better yet, an attribute of a Table instance, such that queries can implement different behaviors with respect to the start and end keys. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Remote URL cannot be accessed for git < 2.7 if SSH isn't working If the system git is < 2.7, and the URL is one that git expects to use SSH access on, but SSH isn't working for any reason, then `self.repo.git.remote(\"show\", self.name)` [here](https://github.com/gitpython-developers/GitPython/blob/master/git/remote.py#L539) in remote.py will fail with: ```python GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git remote show origin stderr: 'Permission denied (publickey). fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists.' ``` or related errors if SSH is not installed or on the path. This can be fixed by falling back to `git config --get remote.%s.url' % self.name` which just reads the URL directly from the configuration. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] `provide` conflict is not informative ### Environment details * Operating System+version: Ubuntu 22.04 * Compiler+version: gcc 12.0.1 * Conan version: 2.0.2 * Python version: 3.10.6 ### Steps to reproduce Create a conanfile with for example requirements to `libjpeg` & `libjpeg-turbo` (the later has `provides = \"libjpeg\"`) Call conan install against this conanfile ### Logs ``` ERROR: provide conflict ``` This message doesn't show the list of conflicted recipes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: link_error tasks not run eagerly when using apply() ## Checklist - [x] I have included the output of ``celery -A proj report`` in the issue. (if you are not able to do this, then at least specify the Celery version affected). - [x] I have verified that the issue exists against the `master` branch of Celery. Tested using the included docker setup ``` $ celery -A tasks report No handlers could be found for logger \"vagrant\" software -> celery:4.2.0 (windowlicker) kombu:4.2.1 py:2.7.14 billiard:3.5.0.4 py-amqp:2.3.2 platform -> system:Linux arch:64bit imp:CPython loader -> celery.loaders.app.AppLoader settings -> transport:pyamqp results:redis://redis/ broker_url: u'amqp://guest:********@rabbit:5672//' result_backend: u'redis://redis/' ``` ## Steps to reproduce Add `tasks.py`: ```python # tasks.py @app.task def on_failure(): print 'from on_failure' @app.task def error(): raise ValueError('oh no!') ``` Run the tasks: ```python >>> from tasks import error, on_failure >>> error.apply(link_error=on_failure.si()).get() ``` ## Expected behavior Both `error` and `on_failure` to be executed eagerly. ## Actual behavior `error` is executed eagerly and `on_failure` is executed on a worker. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Remove SLURM warning when in interactive mode No need to show the \"we launched processes for you\" warning when in interactive SLURM mode. Suggested by @adefazio Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Explicitly depend on setuptools Context: #3295 We should explicitly depend on a minimum version of setuptools to get around problems installing our packages if setuptools is too old. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: nomkl tests running on Windows fail Appears some `nomkl` feature tests are being run on Windows and [failing on CI]( https://ci.appveyor.com/project/ContinuumAnalyticsFOSS/conda/builds/20408292/job/q40u301c397wpyji?fullLog=true#L1181 ). IIUC `nomkl` does not exist on Windows. So this is as expected. Should these tests be marked as known fails, skipped, or similar? Conda Init (v4.6.0b1 ) --system cmd.exe chokes ``` # >>>>>>>>>>>>>>>>>>>>>> ERROR REPORT <<<<<<<<<<<<<<<<<<<<<< Traceback (most recent call last): File \"c:\\users\\wani\\downloads\\repos\\conda\\conda\\exceptions.py\", line 1001, in __call__ return func(*args, **kwargs) File \"c:\\users\\wani\\downloads\\repos\\conda\\conda\\cli\\main.py\", line 84, in _main exit_code = do_call(args, p) File \"c:\\users\\wani\\downloads\\repos\\conda\\conda\\cli\\conda_argparse.py\", line 81, in do_call exit_code = getattr(module, func_name)(args, parser) File \"c:\\users\\wani\\downloads\\repos\\conda\\conda\\cli\\main_init.py\", line 52, in execute anaconda_prompt) File \"c:\\users\\wani\\downloads\\repos\\conda\\conda\\core\\initialize.py\", line 106, in initialize run_plan(plan2) File \"c:\\users\\wani\\downloads\\repos\\conda\\conda\\core\\initialize.py\", line 552, in run_plan result = globals()[step['function']](*step.get('args', ()), **step.get('kwargs', {})) File \"c:\\users\\wani\\downloads\\repos\\conda\\conda\\core\\initialize.py\", line 1196, in init_long_path _write_windows_registry(target_path, \"1\", winreg.REG_DWORD) File \"c:\\users\\wani\\downloads\\repos\\conda\\conda\\core\\initialize.py\", line 1143, in _write_windows_registry winreg.SetValueEx(key, value_name, 0, value_type, value_value) ValueError: Could not convert the data to the specified type. `$ C:\\ProgramData\\MinicondaX\\Scripts\\conda-script.py init --system cmd.exe` ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: atomic write umask Reported on gitter.im/ipython/ipython by @bigzachattack Sadly no one was on the chat at that time, too busy with a big bearded men dressed in red trying to smuggle things in our houses through the cheminee. ``` I noticed today working in master, that any new notebook I create or copy has permissions 0o600 and ignores my umask. In IPython.utils.io.atomic_writing() uses mkstemp() to create a temporary file for the atomic write. According to the python docs, mkstemp creates files as 0o600. After the write succeeds to the tmp file, _copy_metadata is called to copy the metadata from the original file to destination file. It will throw an exception if there is no source file. Thus when the notebook is copied into the notebook dir, it has permissions 0o600. Is this desired behavior, temporary, or a bug? I work in an environment where are default permissions are 0o660 to allow for users to easily share information, so defaulting new notebooks to 0o600 seriously inhibits this ability. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Feature Request: Test Groups Hi, It would be really nice to somehow specify a different set of tests to run. I have some fast running and some really slow running tests and it would be really nice to somehow switch between the two. I can somewhat do this currently by changing a flag via mesonconf, but adding a new target like `ninja test group1` or `ninja test-group1` would be more ideal. UPDATE: Also, the ability to run a single test by itself would also be hepful. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson 0.52.1 breaking shared linking with D **Describe the bug** Since meson 0.52.1 building my project does succeed, but running the resulting binary doesn't work. See the following ldd output: ``` /lib/ld-musl-x86_64.so.1 (0x7f1f79f0c000) Error loading shared library source/corecollector/libcorecollector.so.0.0.1: No such file or directory (needed by /usr/bin/corectl) libhunt.so.0 => /usr/local/lib/libhunt.so.0 (0x7f1f7999e000) libphobos2-ldc-shared.so.88 => /usr/lib/libphobos2-ldc-shared.so.88 (0x7f1f7952e000) libdruntime-ldc-shared.so.88 => /usr/lib/libdruntime-ldc-shared.so.88 (0x7f1f79419000) libgcc_s.so.1 => /usr/lib/libgcc_s.so.1 (0x7f1f79405000) libc.musl-x86_64.so.1 => /lib/ld-musl-x86_64.so.1 (0x7f1f79f0c000) ``` With meson 0.51.2 this works: ``` ldd /usr/bin/corectl /lib/ld-musl-x86_64.so.1 (0x7fe1af538000) libcorecollector.so.0 => /usr/lib/libcorecollector.so.0 (0x7fe1af409000) libhunt.so.0 => /usr/local/lib/libhunt.so.0 (0x7fe1aef15000) libphobos2-ldc-shared.so.88 => /usr/lib/libphobos2-ldc-shared.so.88 (0x7fe1aeaa5000) libdruntime-ldc-shared.so.88 => /usr/lib/libdruntime-ldc-shared.so.88 (0x7fe1ae990000) libgcc_s.so.1 => /usr/lib/libgcc_s.so.1 (0x7fe1ae97c000) libc.musl-x86_64.so.1 => /lib/ld-musl-x86_64.so.1 (0x7fe1af538000) ``` **To Reproduce** Build https://github.com/Cogitri/corecollector **system parameters** Native build on Alpine Linux Edge with meson 0.52.1. Tested with latest scm (being 585ccfc78922393a375160ee3d994ddfcd716f6a) too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QasmError when parsing quantum volume qc.qasm() <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.9.0.dev0+de3f909 - **Python version**: 3.7.4 - **Operating system**: Windows Subsystem for Linux ### What is the current behavior? If you pass a quantum volume circuit's qc.qasm() into qc.from_qasm_str, which calls qiskit's qasm parser, throws a QasmError. The same error occurs for other circuits besides quantum volume. ### Steps to reproduce the problem import qiskit.ignis.verification.quantum_volume as qv qcs = qv.qv_circuits(qubit_lists=[[0,1]]) qc = qcs[0][0][0] print(qc.qasm() + \"\\n\") new_qc = qc.from_qasm_str(qc.qasm()) ### What is the expected behavior? Not throwing an error and parsing correctly. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] Are there environment difference between the \"developer workflow\" and `conan create`? While moving one of our _fat_ dependencies from prebuilt binaries (packaged through Conan ; ) to a recipe actually building the thing, we are encountering a complication we never encountered for our other recipes: We wrote the recipe, following the recommendend [Package Development Flow](https://docs.conan.io/en/latest/developing_packages/package_dev_flow.html#package-development-flow). The end to end flow works without any error, notably `conan build` command. Yet, when moving to the final step of calling `conan create` on the exact same recipe, the process fails during the `build()` step. Are there known difference between the environments used by the \"developer workflow\" and `conan create` command that we could investigate to find the source of this failure? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Environment variable to set [general]default_profile To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [ ] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. This idea was initially proposed at https://github.com/conan-io/conan/issues/1221#issuecomment-403961457 It would be nice if there was an environment variable (perhaps `CONAN_DEFAULT_PROFILE`?) which, if set, would override `[general]default_profile` from `conan.conf `. In an IDE workflow, a project file might be set up to obtain its own dependencies by calling `conan install` (e.g. https://github.com/conan-io/cmake-conan), but it feels wrong to hard-code a desired profile into the call to conan install. Most project systems like this support multiple configurations (e.g. Qt Creator has [kits](http://doc.qt.io/qtcreator/creator-configuring-projects.html), MSVC supports setting up multiple configurations. conan_cmake_settings(...) makes an effort to reverse-engineer the settings from the compiler detection variables, but it's not particularly complete, and in any case a sophisticated profile might have content (e.g. build_requires for toolchains) arguably could never get in this fashion. IDE features to define a build template like this usually have a mechanism to add environment variables to the build invocation, and a way to set the default profile through the environment seems consistent with the existing ability to override specific settings from it using [CONAN_ENV_XXXX_YYYY](https://docs.conan.io/en/latest/reference/env_vars.html#conan-env-xxxx-yyyy). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] How to specify 'includedirs'? This refers to Windows and Visual Studio. I try to change default includedirs of a components on Windows, in package_info() method I say self.cpp_info.components[\"BASE\"].includedirs = ['include/Release', 'include'] and get in CONAN_INCLUDE_DIRS: ['include', 'include/Release'] - reverse order! in conanbuildinfo.cmake, I mean I say self.cpp_info.components[\"BASE\"].includedirs = ['include', 'include/Release'] and get in CONAN_INCLUDE_DIRS: ['include', 'include/Release'] - correct, but not what I want What I really want is self.cpp_info.components[\"BASE\"].includedirs = ['include/$(Configuration)', 'include'] but in this case I get CONAN_INCLUDE_DIRS: ['include'] - which is totally wrong Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: AIP-56 - FAB AM - Permissions view Move permissions view to FAB Auth manager Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Inconsistent behavior between FileContentsManager and Contents Manager API docs Discrepancies with [IPEP-27](https://github.com/ipython/ipython/wiki/IPEP-27:-Contents-Service#contents-api) noted while working on a custom subclass of `ContentsManager`: - Where IPEP-27 lists `'modified'` as an expected dictionary key, `FileContentsManager` uses `'last_modified'` instead. - IPEP-27 specifies that all three of `'contents'`, `'format'`, and `'mimetype'` will be null if `contents` is null. In many (possibly all?) cases however, `'mimetype'` is non-null when `'contents` is null. Cf. https://github.com/ipython/ipython/pull/7140. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ParameterTable expects Instructions to be used only once within a circuit See the bug reported in #3008 . The implementation of `ParameterTable` and the associated binding machinery operate under the assumption that a given `Instruction` instance will appear in only one gate in a circuit, but this isn't guaranteed. e.g. a user could write: ``` >>> import qiskit as qk >>> p = qk.circuit.Parameter('p') >>> qc = qk.QuantumCircuit(2) >>> rz = qk.extensions.standard.RZGate(p) >>> qc.append(rz, [0], []) >>> qc.append(rz, [1], []) >>> print(qc) ┌───────┐ q_0: |0>┤ Rz(p) ├ ├───────┤ q_1: |0>┤ Rz(p) ├ └───────┘ >>> qc.bind_parameters({p: 3}) Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/circuit/quantumcircuit.py\", line 875, in bind_parameters new_circuit._bind_parameter(parameter, value) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/circuit/quantumcircuit.py\", line 897, in _bind_parameter instr.params[param_index] = instr.params[param_index].bind({parameter: value}) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/circuit/parameterexpression.py\", line 68, in bind self._raise_if_passed_unknown_parameters(parameter_values.keys()) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/circuit/parameterexpression.py\", line 136, in _raise_if_passed_unknown_parameters [str(p) for p in unknown_parameters])) qiskit.exceptions.QiskitError: \"Cannot bind Parameters (['p']) not present in expression.\" ``` Users of `Instruction.repeat` would see the same problem. #3013 worked around this by forcing deepcopies of instructions when broadcasting, but this doesn't resolve the general problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Simple Latex typo in u3 gate matrix definition <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Under the u3 gate definition, the 2nd row of the matrix is written (line 48 of u3.py): e^{i\\phi}\\sin(\\th) & e^{i(\\phi+\\lambda)\\cos(\\th)} Notice the code(\\th) is in the exponent. ### Steps to reproduce the problem The cos(\\th) term should be taken out of the exponent. ### What is the expected behavior? ### Suggested solutions It should be written e^{i\\phi}\\sin(\\th) & e^{i(\\phi+\\lambda)}\\cos(\\th) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Undocumented behaviour of `np.concatenate` with `axis=None` ``` >>> a = np.array([[1,2,],[3,4]]) >>> b = a + 10 >>> np.concatenate((a, b), axis=0) array([[ 1, 2], [ 3, 4], [11, 12], [13, 14]]) >>> np.concatenate((a, b), axis=1) array([[ 1, 2, 11, 12], [ 3, 4, 13, 14]]) >>> np.concatenate((a, b), axis=None) array([ 1, 2, 3, 4, 11, 12, 13, 14]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Move manifest calculation after 'post_export' hook One of the provided hooks is the `post_export` one, it allows the user to affect the conanfile and the export folder, but it is being executed after computing an storing the digest/manifest, so those changes will break the computed hashes. Hash must be computed after returning from the `post_export` hook. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [envoy] Missing Envoy metrics Agent (v7.26.0) A number of statistics from Envoyproxy are not exposed in Datadog. Amongst others these include the following: https://www.envoyproxy.io/docs/envoy/latest/configuration/security/secret#statistics https://www.envoyproxy.io/docs/envoy/latest/configuration/overview/extension#discovery-service **Steps to reproduce the issue:** 1. Run Envoy with extension_config_discovery configuration 2. Enable Envoy integration in Datadog Agent 3. Double check in Envoy admin page that the following metrics are exposed: ``` http.*.extension_config_discovery.*.update_time http.*.extension_config_discovery.*.version sds.*.key_rotation_failed ``` **Describe the results you received:** The above metrics are not available in any form in Datadog. **Describe the results you expected:** The above metrics are available, preferably with a tag for the specific `sds` name and `extension_config_discovery` name. **Additional information you deem important (e.g. issue happens only occasionally):** Would it be possible to interpret these metrics generically, so that with every new version of Envoy it would pick up such new metrics as well? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: [dagster-dbt] load_assets_from_dbt_* should support an exclude parameter, in addition to select ### What's the use case? Both of these parameters are useful for describing subsets of a dbt project, so it'd be nice if both were supported ### Ideas of implementation _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Abstract Editor Revisit I noticed a problem while writing tests for the `CodeMirrorEditor`, which implements `CodeEditor.IEditor`. We can't share `CodeMirror.Doc` instances between editors, because the `CodeMirror.Doc` itself includes selections and markers, meaning you can't have different primary selections on each editor. I propose an alternative: `CodeMirrorEditor` accepts a `CodeEditor.IModel` object in its constructor, which is distilled down to `mimeType`, `value`, and `selections`. We move the other parts of `CodeEditor.IModel` onto `CodeEditor.IEditor`. Then, `ICellModel` and `IDocumentModel` *implement* `CodeEditor.IModel` and can be passed directly to editor factories. cc @akosyakov @ian-r-rose @jasongrout @afshin Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.einsum support support for generic tensor contractions would cover a large class of computations and also provide a foundation for higher order operations. Perhaps jax could then also be added as a `opt_einsum` backend? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ParameterExpression throws an error for gradients with complex coefficients. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18 - **Python version**: 3.8 - **Operating system**: MacOS ### What is the current behavior? When having a `ParameterExpression` with an imaginary unit, taking a gradient w.r.t. a parameter existing in a `ParameterExpression` results in an error. ### Steps to reproduce the problem ``` p = Parameter(\"theta\") p2 = 1j*p p2 Out[27]: ParameterExpression(1.0*I*theta) p2.gradient(p) Traceback (most recent call last): File \"/qiskit-terra/venv/lib/python3.8/site-packages/IPython/core/interactiveshell.py\", line 3437, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File \"<ipython-input-28-058190e5d73e>\", line 1, in <module> p2.gradient(p) File \"/qiskit-terra/qiskit/circuit/parameterexpression.py\", line 303, in gradient return float(expr_grad) File \"symengine_wrapper.pyx\", line 1133, in symengine.lib.symengine_wrapper.Basic.__float__ File \"symengine_wrapper.pyx\", line 958, in symengine.lib.symengine_wrapper.Basic.n File \"symengine_wrapper.pyx\", line 4194, in symengine.lib.symengine_wrapper.evalf RuntimeError: Not Implemented ``` ### What is the expected behavior? Calculating a gradient with a complex coefficient. ### Suggested solutions Perhaps ``` File \"/qiskit-terra/qiskit/circuit/parameterexpression.py\", line 303, in gradient return float(expr_grad) ``` should be changed to ``` File \"/qiskit-terra/qiskit/circuit/parameterexpression.py\", line 303, in gradient return complex(expr_grad) ``` ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: broadcast_to docs are unhelpful Right now the docs state \"Like Numpy’s broadcast_to but doesn’t necessarily return views.\" A few suggestions 1. Link to numpy's docs 2. Copy their docs in some way 3. Write our own version Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DO NOT MERGE: asset synth This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/cloud/asset/artman_cloudasset_v1beta1.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/asset-v1beta1. synthtool > No replacements made in google/cloud/asset_v1beta1/gapic/asset_service_client.py for pattern 'google-cloud-cloudasset', \\).version, maybe replacement is not longer needed? synthtool > Replaced 'from google.iam.v1 import policy_pb2 as' in google/cloud/asset_v1beta1/proto/assets_pb2.py. synthtool > Replaced 'from google.iam.v1 import iam_policy_pb2_grpc as google_dot_iam_dot_v1_dot_policy__pb2' in google/cloud/asset_v1beta1/proto/assets_pb2.py. synthtool > Replaced \"_ASSET.fields_by_name\\\\['iam_policy'\\\\].message_type = google_dot_iam_dot_v1_dot_policy__pb2._POLICY\" in google/cloud/asset_v1beta1/proto/assets_pb2.py. synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Convert DAGNode.name attribute to property An unrelated thing here is I think maybe we need a similar property lookup as to DAGNode.condtion so for op nodes we just pull the name directly from the op node. something like: ```python3 @property def name(self): if self._name: return self._name return self.op.name ``` just because it seems like there is a lot of mixing of node.name and node.op.name and while they should always be the same thing, it's probably good to actually enforce that. _Originally posted by @mtreinish in https://github.com/Qiskit/qiskit-terra/pull/6187#discussion_r610764534_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Expose a magic to control config of the inline pylab backend We should provide a magic to provide easy, user-level control of certain features of the inline backend. Something like ``` %inline_backend close_figures=True %inline_backend figure_format = 'svg' ``` would allow easy runtime control of the points discussed in #638 and #781. In the long run, ideally we'd fold this into a richer `%pylab` magic that allows initializing pylab mode in the qtconsole/notebooks (like it does in the terminal), toggling of floating/inline figures _and_ inline configuration. But since that's a larger job, as discussed at the end of #892, it's probably best left for a separate task. Marking this as high priority for 0.12 in case we manage to pull it off, as it would be great to have out of the gate when we release the notebook. But I'm not willing to make it a blocker as we're getting close to the wire, so it may slip to 0.13. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"Missing mandatory value\" error is imprecise/bloated When specifying a required environment variables, the error messages are imprecise/bloated. I have a service defined like the following: ```yml api: environment: NODE_ENV: development DB_USERNAME: ${DB_USERNAME} DB_PASSWORD: ${DB_PASSWORD} API_SESSION_KEY: ${API_SESSION_KEY:?} API_HTTP_PORT: ${API_HTTP_PORT:?} API_HTTPS_PORT: ${API_HTTPS_PORT:?} WEB_HTTP_PORT: ${WEB_HTTP_PORT:?} WEB_HTTPS_PORT: ${WEB_HTTPS_PORT:?} DB_PORT: ${DB_PORT:?} # ... ``` Let's say I forget to set the variable `$API_SESSION_KEY`. This is the error I receive: ``` ERROR: Missing mandatory value for \"environment\" option interpolating {'NODE_ENV ': 'development', 'DB_USERNAME': '${DB_USERNAME}', 'DB_PASSWORD': '${DB_PASSWORD }', 'API_SESSION_KEY': '${API_SESSION_KEY:?API_SESSION_KEY}', 'API_HTTP_PORT': ' ${API_HTTP_PORT:?API_HTTP_PORT}', 'API_HTTPS_PORT': '${API_HTTPS_PORT:?API_HTTPS _PORT}', 'WEB_HTTP_PORT': '${WEB_HTTP_PORT:?WEB_HTTP_PORT}', 'WEB_HTTPS_PORT': ' ${WEB_HTTPS_PORT:?WEB_HTTPS_PORT}', 'DB_PORT': '${DB_PORT:?DB_PORT}'} in service \"api\": ``` It doesn't say which variable is missing, it just lists all the environment variables specified in `docker-compose.yml`. It would be much easier to understand with an error like the following: ``` ERROR: Missing mandatory environment variable \"API_SESSION_KEY\" for option \"environment\" in service \"api\" ``` Related: #6587 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Include things from [context] subsection in config into context Including subsections (e.g., `[secrets]`) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Running `meson` in the source dir without any arguments takes the parent directory as the build dir This is a major regression over 0.46. The parent dir implicit selection should only be for finding the source directory, not the build directory. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inconsistency in gate names with matplotlib and text drawer backends <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.23.0 - **Python version**: 3.8.6 - **Operating system**: Artix Linux ### What is the current behavior? When drawing the complete circuit with a user-defined name, say \"gate\", then when drawing with the `text` backend, the circuit renders the name \"gate\" on the relevant portion of the circuit. However, when drawing with `matplotlib`, the particular portion of the circuit shows \"Gate\" i.e. it capitalizes the first character of the name. ### Steps to reproduce the problem For example, ```python from qiskit import * import matplotlib.pyplot as plt sub = QuantumCircuit(2, name='gate') sub.h(0) sub.cx(0,1) sub.cz(1,0) sub_inst = sub.to_instruction() qc = QuantumCircuit(3) qc.x(0) qc.append(sub_inst, [1,2]) qc.draw('text') ``` **Output**: ``` ┌───┐ q_0: ──┤ X ├── ┌─┴───┴─┐ q_1: ┤0 ├ │ gate │ q_2: ┤1 ├ └───────┘ ``` Doing the same with `matplotlib` ```python qc = QuantumCircuit(3) qc.x(0) qc.append(sub_inst, [1,2]) qc.draw('mpl') ``` **Output**:  ### What is the expected behavior? Both the backends must either render the name of the gate as defined by the user i.e. case-sensitive or both must capitalize the name. In my opinion, the former seems reasonable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Special-case secrets from environment Right now, setting ``` PREFECT__CONTEXT__SECRETS__MY_API_KEY=hello ``` creates a local secret called `my_api_key` (lowercase), and the only way to create a local secret called `MY_API_KEY` is by setting the value directly in your user config. Ideally we should allow both secret setting mechanisms to work smoothly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: sh.py and ipython for python 3.3 Someone using sh.py with ipython ran into the following issue, and I was hoping someone with better working knowledge of ipython's internals could shed some light on what's happening: amoffat/sh/issues/97 sh.py has some magic going on internally, where any attribute access on the module can resolve dynamically to a specific object. This issue only seems to be in ipython for python 3.3, python 2.7 works fine. Anyone have an idea of what could be happening? Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: build.py specifies bazel 0.24 but uses repo_env which is new in bazel 0.26 https://github.com/google/jax/blob/master/build/build.py#L310 specifies that the minimum allowed bazel version is 0.24, but https://github.com/google/jax/blob/master/build/build.py#L167-L169 uses `--repo_env` (as opposed to `--action_env`), which was added in bazel 0.26 (in https://github.com/bazelbuild/bazel/commit/d7702b1 ). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: `Trainer.train(resume_from_checkpoint=False)` is causing an exception Since `resume_from_checkpoint` can be `str` and `bool` it should be possible to pass `False` to it. But when `resume_from_checkpoint` is `False` it causes an exception here: https://github.com/huggingface/transformers/blob/3d4b3bc3fd77e0e48e2364464ea90379f13bcf37/src/transformers/trainer.py#L1049-L1050 ```text E TypeError: expected str, bytes or os.PathLike object, not bool ``` The most simple solution would be to do this at the beginning of the `train` function: ```python resume_from_checkpoint = None if not resume_from_checkpoint else resume_from_checkpoint ``` If wanted I can provide a PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add \"epoch\" options to basic templates ## 🚀 Feature <!-- A clear and concise description of the feature proposal --> Add \"epochs\" option to parser of 'basic_examples/lightning_module_template.py' ### Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too --> Thanks to 'basic_examples/lightning_module_template.py', I could build my deep learning model. Some beginners like me might build their model from this basic template. However, there are no options to manipulate epochs. I just thought that what people use often should be included in the basic template, so I uploaded my issue. ### Pitch <!-- A clear and concise description of what you want to happen. --> I suggest that the basic template includes \"epoch\" option in the basic template. ### Alternatives <!-- A clear and concise description of any alternative solutions or features you've considered, if any. --> Add \"epoch\" options to parser of 'basic_examples/lightning_module_template.py' ```python parser.add_argument('--epochs', default=10, type=int, metavar='N', help='number of total epochs to run') trainer = pl.Trainer(max_epochs=hparams.epochs) ``` ### Additional context <!-- Add any other context or screenshots about the feature request here. --> I am really enjoying PytorchLightning framework. Thanks 😄 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: celery worker has --quiet to suppress banner output but celery beat does not Sorry for leaving out the issue template but I believe this is fairly trivial and straight-forward. In master, there is code to enable the suppressing of printing the banner when running `celery worker` with `--quiet`: https://github.com/celery/celery/blob/9773eba837982c84380c93bd3788470273e7674d/celery/apps/worker.py#L138-L139 This conditional is not present in the code that runs `celery beat`: https://github.com/celery/celery/blob/9773eba837982c84380c93bd3788470273e7674d/celery/apps/beat.py#L77-L78 https://github.com/celery/celery/blob/9773eba837982c84380c93bd3788470273e7674d/celery/apps/beat.py#L100 This causes a few issues for us because we expect all our services to only emit JSON. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: TensorBoardLogger not saving hparams without metrics ## 🐛 Bug `log_hyperparams` for `TensorBoardLogger` saves no data with default `metrics=None`, only hparam entries/names show up in sidebar ### To Reproduce Steps to reproduce the behavior: ``` import pytorch_lightning as pl logger = pl.loggers.TensorBoardLogger(\"./test_logs\") test_dict = {\"test\":0} logger.log_hyperparams(test_dict) ## no data saved logger.log_hyperparams(test_dict, test_dict) ## works logger.log_metrics(test_dict) ## works logger.experiment.add_hparams(test_dict, test_dict) ## works but saves in a different events file ``` <!-- If you have a code sample, error messages, stack traces, please provide it here as well --> ### Expected behavior hparams data is saved and viewable via tensorboard with default args ### Proposed solution For default hparams logging without metrics, add a placeholder metric? I can do a PR if this is appropriate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: InstructionScheduleMap parameters should be ParameterExpressions <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The input parameters into the InstructionScheduleMap should be expected to be `ParameterExpression`s. Types and tests should be updated accordingly. This is a follow on to #3385. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: W&B: Allow for passing experiment into the WandbLogger (and logging semantics) Currently, the WandbLogger will automatically create a new internal experiment (run) whenever you create a new WandbLogger. # Issue If I instantiate a wandb experiment outside of the logger, then I will have two experiments when I train my model since there is no way to set the internal experiment of the WandbLogger to my current external experiment. # Potential Solution Allow for passing an experiment into the WandbLogger: ``` class WandbLogger(LightningLoggerBase): def __init__(self, name=None, save_dir=None, offline=False, id=None, anonymous=False, version=None, project=None, tags=None, experiment=None): . . . self._experiment = experiment ``` Then I can do this: ``` experiment = wandb.init(.......) wandb_logger = WandbLogger(experiment=experiment) ``` I made this change locally, however, I wasn't sure if this was something you also wanted to implement as well. It works for me. # Another small note In the `WandbLogger.log_metrics` function, I would change: `self.experiment.history.add(metrics)` --> `self.experiment.log(metrics)` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Consistent patch handling in conan.tools When using `apply_conandata_patches`: - the `base_path` is set relative to source_folder, but only if the patches are versioned. - the patch can be specified as a patch_string if the patches are not versioned, but trying to do so on versioned patches raises an exception Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Creating Layout from a list of [int] or a map of {int: int} ### What should we add? A Layout object can only be instantiated from the `Qubit`s of a particular circuit. i.e. if the intention is to lay the i'th qubit of the circuit on the j'th qubit of a coupling_map, this would be written as `qr[i] -> j` However the qubits in a circuit are completely ordered (regardless of how many registers there are). So the Layout should not necessarily depend on the Qubit within that circuit --- just an integer should exactly specify that qubit. The reason this is important is that the SetLayout transpiler pass takes a Layout which in turn requires the circuit Qubits. So a PassManager cannot be created independent of the circuit. This is against the design principle of PassManager which is supposed to be created once and run on many circuits. Instead one should be able to create SetLayout like this: ```py SetLayout(Layout([4, 3, 8, 6, 0])) # this means a 5-qubit circuit would be laid out as `0: 4, 1: 3, 2: 8, 3: 6, 4: 0` SetLayout(Layout({4: 0, 3: 1, 8: 2, 6: 3, 0: 4])) # this means the same. Should also work if key/value are reversed. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda Fails with create_default_packages When using `create_default_packages`, `conda create...` fails. ## Sample condarc: ``` channels: - defaults create_default_packages: - python - pip ``` ## Command `conda create -n test_conda_update python=2 numpy` ## Error ``` Traceback (most recent call last): File \"/opt/a/b/c/muunitnoc/anaconda/lib/python2.7/site-packages/conda/exceptions.py\", line 472, in conda_exception_handler return_value = func(*args, **kwargs) File \"/opt/a/b/c/muunitnoc/anaconda/lib/python2.7/site-packages/conda/cli/main.py\", line 144, in _main exit_code = args.func(args, p) File \"/opt/a/b/c/muunitnoc/anaconda/lib/python2.7/site-packages/conda/cli/main_create.py\", line 68, in execute install(args, parser, 'create') File \"/opt/a/b/c/muunitnoc/anaconda/lib/python2.7/site-packages/conda/cli/install.py\", line 171, in install default_packages.remove(default_pkg) AttributeError: 'tuple' object has no attribute 'remove' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Enable python 3.7 in CI At least for Linux Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Regression : %kill_embedded does not work (broken by #6840 ) The Magic [`%kill_embedded`](http://ipython.readthedocs.org/en/stable/api/generated/IPython.terminal.embed.html?highlight=kill_embedded#IPython.terminal.embed.EmbeddedMagics.kill_embedded) flags the embedded shell instance so that it is not started on subsequent calls of `IPython.embed()`. However, fo this to work, we need to keep the instance in memory otherwise, we'll be flagging new instances all the time and never read the flags we've set. In [`IPython/terminal/embed.py`](https://github.com/ipython/ipython/blob/master/IPython/terminal/embed.py#L262), we do several things : - We save the instance that might be the current singleton instance of the `InteractiveShell` class - We remove it from the singleton - We get `InteractiveShellEmbed`'s instance (created if existing) and launch the shell - As soon as it's ended, we delete the instance - We replace the original shell instance as the singleton instance. All these things were done by #6840 in an effort to make embed nestable (but then it broke `%kill_embeded`) It's clear that the current behaviour makes it completely impossible for `%kill_embedded` to work as expected. What would be preferred for a PR : to store the flag elsewhere or to improve #6840 to not destroy instances ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Error in stream_output during ADD command in Dockerfile ``` Step 5 : ADD https://rtdata.dtcc.com/payload.tgz /tmp/ Traceback (most recent call last): File \"/usr/local/bin/fig\", line 9, in <module> load_entry_point('fig==0.5.2', 'console_scripts', 'fig')() File \"/home/vagrant/src/fig/fig/cli/main.py\", line 31, in main command.sys_dispatch() File \"/home/vagrant/src/fig/fig/cli/docopt_command.py\", line 21, in sys_dispatch self.dispatch(sys.argv[1:], None) File \"/home/vagrant/src/fig/fig/cli/command.py\", line 28, in dispatch super(Command, self).dispatch(*args, **kwargs) File \"/home/vagrant/src/fig/fig/cli/docopt_command.py\", line 24, in dispatch self.perform_command(*self.parse(argv, global_options)) File \"/home/vagrant/src/fig/fig/cli/command.py\", line 49, in perform_command handler(project, command_options) File \"/home/vagrant/src/fig/fig/cli/main.py\", line 119, in build project.build(service_names=options['SERVICE'], no_cache=no_cache) File \"/home/vagrant/src/fig/fig/project.py\", line 166, in build service.build(no_cache) File \"/home/vagrant/src/fig/fig/service.py\", line 404, in build all_events = stream_output(build_output, sys.stdout) File \"/home/vagrant/src/fig/fig/progress_stream.py\", line 22, in stream_output image_id = event['id'] KeyError: 'id' ``` branch master More details available or forthcoming (still investigating). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: pubsub fails if data key is not present If a message is published with a string of 0 length (`topic.publish( '', url=url, title=title)`) when the message is received there is no data field in the message and a key error is thrown when trying to transform the message from the PubSub API representation. https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/pubsub/message.py#L74 ``` Traceback (most recent call last): File \"/en_notifications/en_notifications.py\", line 51, in <module> received = PS_SUBSCRIPTION.pull(max_messages=PULL_COUNT) File \"/usr/local/lib/python2.7/dist-packages/gcloud/pubsub/subscription.py\", line 212, in pull File \"/usr/local/lib/python2.7/dist-packages/gcloud/pubsub/message.py\", line 74, in from_api_repr for info in response.get('receivedMessages', ())] data = base64.b64decode(api_repr['data']) KeyError: 'data' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: `stax.BatchNorm` incorrect normalization jax.experimental.stax on current master, line 140 ( `BatchNorm` function): ```python z = (x - mean) / (var + epsilon)**2 ``` The square in the denominator should probably be a square root. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Negative padding in pad_transpose This is a request to support negative padding in the gradient of `lax.pad`, see: https://github.com/google/jax/blob/5592a063375a8feb4439e35edd8c335264dc1e6c/jax/lax.py#L2360 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Parameterized traitlets and default value validation When using a List traitlet with validated elements, the default value of the elements is validated, like in this example: ``` Python from IPython.utils.traitlets import * class Bar(): pass class Foo(HasTraits): bars = List(Instance(Bar, allow_none=False)) foo = Foo() ``` which yields a `TraitError` because the default value, None, is invalid. A fix would be to do `bars = List(Instance(Bar, tuple(), allow_none=False))`, i.e. to create a default value. But somehow, I think that there should not be a need to instantiate a default value that is never going to be used! @minrk should the default value be validated when the traitlet is to be used in a \"template\" trait like List? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Question: Can I set airflow configuration parameters from the environment? I am running airflow under a heroku-like PaaS. Can I somehow use environment variables to specify configuration like the `sql_alchemy_conn` and `broker_url` variables? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Feature Request: compiler.compute_int() Need the ability to extract the int values of certain defines that can be determined at compile time, basically a more generic variant of what the compiler.sizeof() check does. If we're not cross-compiling, the code is pretty much exactly the same. If we're cross-compiling we'd have to do something slightly different, but it should still be possible. The current code just tries to compile code with values from 1 to 1024 in a loop in such a way that compilation will fail if it's not the value, but it's probably not a good idea to try all values from 0 to MAXINT. It should be possible to bisect though by using code such as ``` #if FOO > 144 #error \"larger\" #endif ``` One could check what AC_COMPUTE_INT() does if one can find the actual implementation. Feature Request: compiler.compute_int() Need the ability to extract the int values of certain defines that can be determined at compile time, basically a more generic variant of what the compiler.sizeof() check does. If we're not cross-compiling, the code is pretty much exactly the same. If we're cross-compiling we'd have to do something slightly different, but it should still be possible. The current code just tries to compile code with values from 1 to 1024 in a loop in such a way that compilation will fail if it's not the value, but it's probably not a good idea to try all values from 0 to MAXINT. It should be possible to bisect though by using code such as ``` #if FOO > 144 #error \"larger\" #endif ``` One could check what AC_COMPUTE_INT() does if one can find the actual implementation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Breaking change in 0.6.0 Hi team, We were using release 0.5.5 and when trying to upgrade to 0.6.0 we are faced with a breaking change: prefect forces us to use all lowercase letters for keys in the config.toml file. This creates a problem for us because we have several keys who are different only in their letter-casing by design, so that if we try to lowercase both, we are faced with a duplicate key. Is there a good reason for this change or is it something that may be fixed? Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Binder: \"could not start lab-dev in time\" ... when using this link: https://mybinder.org/v2/gh/jupyterlab/jupyterlab/master?urlpath=lab-dev Is this a temporary glitch or is there a deeper problem?  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: MAINT: Add a RuntimeError to prove _typestr` is unused Follow up will be to remove the preceding lines of code, once CI proves this is never hit on any platform. This dates way back to 668950285c407593a368336ff2e737c5da84af7d, so probably has just been made redundant by one of the ~10 other loops in this file that try to assign names to types. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: add support for signing URLs using IAM / tokens. /cc @frankyn. Follow-on from PR #7460; see also issue #922. Currently, `Blob.generate_signed_url` can only be used where the blob's client has tokens which support signing (i.e., service accounts, GAE accounts). Although such credentials are widespread, they are not ubiquitous: in particular, the default credentials available on GCE do not support signing. An alternate implementation is available using the `IAM` service and access tokens. For an outline, see the [Ruby PoC for V4 signing](https://gist.github.com/frankyn/1a537900c0689903f157740a0a9e36aa#file-v4_signed_urls-rb-L56-L68). For this issue, please adapt that implementation for both V2 and V4 signed URLs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Removing config section via API not effective during subsequent calls Environment: * Windows 7/10 Enterprise 64 Bit * Python 3.6.3 * Conan 1.0.4 (installed from PyPI) I am using the API class and noticed that the sequence of the following call leads to inconsistent behavior: ```python conan, _, _ = conan_api.ConanAPIV1.factory() conan.config_rm('proxies') # this still prints the proxies section, but it probably should not: _logger.info(conan._client_cache._conan_config._sections) # this fails due to incorrect setting of proxies: conan.user(name=..., password=..., remote=...) ``` On disk the section is actually already gone, but apparently the internal cache is not properly refreshed. As a workaround I can simply re-instantiate the API object right after the ``config_rm`` call. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson can't find glbinding via CMake in MSYS2 **Describe the bug** Meson can't find glbinding via CMake in MSYS2. **To Reproduce** This `meson.build` can't find glbinding: ``` project('test', 'cpp') glbinding_dep = dependency('glbinding') ``` But this `CMakeLists.txt` can: ``` project(\"test\") find_package(glbinding REQUIRED) ``` **Expected behavior** Meson should find glbinding. **System parameters** * This is a simple native build via MSYS2 on Windows 10. * Meson is 0.56.0. * Python is 3.8.6. * CMake is 3.19.1. * Ninja is 1.10.2. * glbinding is 3.1.0. Note that in my actual `meson.build`, I'm using a number of other libraries, some of them which seem to be found via CMake, like Boost and GLFW. Everything is installed via `mingw-w64-x86_64_*` packages. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Discussion: `SqliteTask` I am currently working on a simple implementation of a `SqliteTask` for interacting with `sqlite3` databases. What I'd like to support: - executing single statements and returning the values of `fetchall()` (or some prespecified number of return rows) - executing full sql scripts (either as a string or read from a file); note that if you execute a script only, there is nothing to return My current sketch design idea: ```python class SqliteTask(Task): def __init__(self, statement: str = None, script: str = None, db: str = \":memory:\", return_rows: int = 0, **kwargs): ... ``` Moreover, if you provide _both_ `script` and `statement`, the `script` will be executed first and the `statement` last, in case it's a `SELECT` statement to query what just happened in the script. I'm opening this issue for discussion in case this is overloading the task with too many parameters / options / possibilities. I want to make sure it's still clear as a single `Task`. **cc**: @jlowin @joshmeek Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Linter of deploy() self.copy_deps When using `copy_deps` in deploy, exporting: ``` Linter warnings WARN: Linter. Line 122: Instance of 'MyConan' has no 'copy_deps' member ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: \"Naming\" releases ? As discussed on dinner, do we want to add names to releases ? Yes, I know we never did it, but this is 1.0. time to start. I vote for : IPython 1.0 - aka \"I'll spend an afternoon on this\". if a shorter name is needed, I propose \"Finally\" :-) Assigning @fperez to decide. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Trainer.train argument resume_from_last_checkpoint # 🚀 Feature request <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> `Trainer.train` accepts `resume_from_checkpoint` argument, which requires the user to explicitly provide the checkpoint location to continue training from. `resume_from_last_checkpoint` can be useful to resume training by picking the latest checkpoint from `output_dir` of the `TrainingArguments` passed. ## Motivation 1. The checkpoint directory is created by the library, so user needs to navigate to the directory to find the value to provide for `resume_from_checkpoint` 2. User may just want to resume from the last valid checkpoint since their training got disrupted previously (a common scenario for someone to want to resume training). All they know is the `output_dir` they provided initially This motivates to provide a `resume_from_last_checkpoint=True` to the `Trainer.train(...)` call, which will pick the latest checkpoint from `args.output_dir`. FYI `get_last_checkpoint` function from `trainer_utils` can be used to do exactly the same. <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. --> ## Your contribution <!-- Is there any way that you could help, e.g. by submitting a PR? Make sure to read the CONTRIBUTING.MD readme: https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md --> I can raise a PR if it is a useful feature to have! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: BatchNorm breaks for non-default axis values The current BatchNorm implementation breaks if the `axis` argument takes values where the missing axis is not the last one, e.g. `axis=(0, 2, 3)`, because the axes are dropped for `gamma` and `beta` and not restored later. I guess this can be fixed by removing this line: https://github.com/google/jax/blob/7e93bff2b95e6f49be7e2cd310e8953bbbdcdc9d/jax/experimental/stax.py#L134 (and adding `tuple` in the line before) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [12, 4096, 1]], which is output 0 of ViewBackward, is at version 1; expected version 0 instead. When I run trainer to fine-tune pertained long former for sequence classification I get the following error: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.HalfTensor [12, 4096, 1]], which is output 0 of ViewBackward, is at version 1; expected version 0 instead. I'm not sure how to debug this as the error points me to internal processes handled by the trainer: Traceback (most recent call last): File \"finetune_longformer_3.py\", line 126, in <module> trainer.train() File \"/......./conda/envs/diss/lib/python3.8/site-packages/transformers/trainer.py\", line 1269, in train tr_loss += self.training_step(model, inputs) File \"/....../conda/envs/diss/lib/python3.8/site-packages/transformers/trainer.py\", line 1772, in training_step self.scaler.scale(loss).backward() File \"/......../conda/envs/diss/lib/python3.8/site-packages/torch/_tensor.py\", line 255, in backward torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs) File \"/........./conda/envs/diss/lib/python3.8/site-packages/torch/autograd/__init__.py\", line 147, in backward Variable._execution_engine.run_backward( any help would be much appreciated! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Merge multi-value options properly when extending Currently, `environment` and `volumes` are merged when a service `extends` another. With other multi-value options, however, no merging is done - instead, the new list completely replaces the old. The following need to be fixed: - `external_links` - `ports` - `expose` - `labels` (do this in #1139) - `dns` - `dns_search` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] do not save username and password in exported scm object We are used the scm object as bellow: ``` scm = { 'type': 'git', 'url': 'auto', 'revision': 'auto', 'username': tools.get_env(\"GIT_USERNAME\", None), 'password': tools.get_env(\"GIT_PASSWORD\", None) } ``` In CI we set the env var GIT_USERNAME and GIT_PASSWORD, however we noticed that the actual username and password got replaced and exported as part of the recipe. This is not convenient at all as everyone now have access to the CI git credentials. Any suggestion on how to deal with this ? Ideally, username and password should be only read from env var if defined. Thanks, Walid - [ ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: 7.10 breaking tests with exception in publish The new 7.10 release is breaking Bokeh unit tests with an exception coming from within ipython: ``` self = <IPython.core.displaypub.DisplayPublisher object at 0x11883d7f0> data = {'text/html': '\\n <div class=\"bk-root\">\\n <a href=\"https://bokeh.org\" target=\"_blank\" class=\"bk-logo bk-logo...version \\'1.0\\' from Bokeh development version \\'1.0-1-abc\\'. This configuration is unsupported and may not work!</p>'} metadata = None, source = None, transient = None, update = False, kwargs = {} handlers = {} << omitted >> handlers = {} if self.shell is not None: > handlers = self.shell.mime_renderers E AttributeError: 'InteractiveShell' object has no attribute 'mime_renderers' ../miniconda/envs/testenv/lib/python3.6/site-packages/IPython/core/displaypub.py:108: AttributeError ``` Is this an intentional change (documented anwhere?) or a regression/bug? cc @Carreau Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Problem in drawing circuit for conditional measurement using multiple classical registers ### Information The `qc.draw()` function does not draw the quantum circuit properly if we change the order of classical registers while initializing the `QuantumCircuit()` instance if there is a measurement in the circuit that is conditioned on the output of some other classical register. - **Qiskit Terra version**: ``` {'qiskit-terra': '0.17.4', 'qiskit-aer': '0.8.2', 'qiskit-ignis': '0.6.0', 'qiskit-ibmq-provider': '0.14.0', 'qiskit-aqua': '0.9.2', 'qiskit': '0.27.0', 'qiskit-nature': '0.1.3', 'qiskit-finance': None, 'qiskit-optimization': None, 'qiskit-machine-learning': None} ``` - **Python version**: 3.8.6 - **Operating system**: MacOS ### What is the current behavior (and how to reproduce the problem)?  Notice that in the above code, we initialize the quantum circuit as: ```py qc = QuantumCircuit(q_a, q_b, c_a, c_b) ``` However, if we exchange the classical registers while initializing, like so: ```py qc = QuantumCircuit(q_a, q_b, c_b, c_a) ``` we get this, which is the correct circuit...  ### What is the expected behavior? The circuit in the first image should have the arrows going to the classical register `c_b` and the dots going to `c_a`, but here both of them go to `c_a`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Show schedule_interval/timetable description for schedule cron expression in Airflow UI <!-- Welcome to Apache Airflow! For a smooth issue process, try to answer the following questions. Don't worry if they're not all applicable; just try to include what you can :-) If you need to include code snippets or logs, please put them in fenced code blocks. If they're super-long, please use the details tag like <details><summary>super-long log</summary> lots of stuff </details> Please delete these comment blocks before submitting the issue. --> **Description** <!-- A short description of your feature --> Users should be able to see a short description of the cron expression when hovering over the expression in a tooltip.  In the above case, the user should see description like **At 09:30 PM, only on Friday** **Use case / motivation** It will be really easy to get schedule information for the users who are not really great at reading CRON, even for the experience users CRON can be really complicated at times. We will create a tooltip component which will evaluate underlying cron and show the description. **Are you willing to submit a PR?** YES **Related Issues** NONE Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add support for configuring Hive partitioning options As a BigQuery client user, I would like to have an easy way of configuring Hive partitioning options. I would like a new `HivePartitioningOptions` class for setting the tables' [external data config](https://cloud.google.com/bigquery/docs/reference/rest/v2/tables#ExternalDataConfiguration) as defined by the API. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [Feature request] Add `meson compile` command Proposal: Backend-agnostic build command `meson compile` - counterpart of `cmake --build`. Reasoning: - Simplifies `meson` usage and integration: the same `meson` commands could be invoked for all backends. - Reduces the amount of knowledge required to use `meson` out-of-the-box (i.e. with default `ninja` backend). Since user won't have to know anything about ninja (apart from the fact that it's needed). Proposed interface (based on `cmake --build): ``` usage: meson compile [-h] [-C WD] [--clean] [--backend-args ARGS] [args [args ...]] positional arguments: args optional list of targets to build optional arguments: -h, --help show this help message and exit -C WD directory to cd into before running --clean invokes clean command of the native tool. --backend-args ARGS arguments to pass to the native tool. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda should take config information from --file and stdin conda should take config information from --file and stdin Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Implement allocate_ids for datastore I discovered this when checking out the `gcloud-node` [regression tests](https://github.com/GoogleCloudPlatform/gcloud-node/blob/5865e36491ff6cbe2a47a91e576ab92a71dec7b1/regression/datastore.js#L31). Implement allocate_ids for datastore I discovered this when checking out the `gcloud-node` [regression tests](https://github.com/GoogleCloudPlatform/gcloud-node/blob/5865e36491ff6cbe2a47a91e576ab92a71dec7b1/regression/datastore.js#L31). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: [PIN-3] Create DaskOnKubernetes Environment [PIN-3](https://docs.prefect.io/PINs/PIN-3-Agent-Environment.html) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: \"return to editor to correct syntax error\" is annoying When I type a syntax error in the IPython console, like `def test()` without the colon, I get a prompt ``` In [1]: def test File \"<ipython-input-1-50eadd3e41eb>\", line 1 def test ^ SyntaxError: invalid syntax Return to editor to correct syntax error? [Y/n] ``` This is annoying, and seems completely unnecessary, since with prompt_toolkit you now can reasonable edit the input in the console. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Cannot make multi-line code blocks in ipython I just did a `pip install ipython` while teaching a class today and typed an if statement and then hit enter after the first line and the code executed. This seems like a bug. I did a `pip install ipython==6.5.0` and hitting Enter in a code block properly showed me the next indented line to type out. I'm on Ubuntu 18.04 running ipython within tmux, though I doubt tmux is the issue here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Unnecessary result insertion into ran qobj When running a qobj in qiskit there is a side effect of adding the results class to the input qobj. If run is called multiple times this happens recursively. ## Expected Behavior The input qobj to the `QuantumProgram.run` function should not be modified. ## Current Behavior The qobj is modified by inserting a `'result'` field containing a circular reference to the original qobj with `qobj['result']._qobj`. ## Possible Solution I traced this problem to the `_jobprocessor.JobProcessor._job_done_callback` function: Line 106 `self.futures[future]['result'] = result` should be removed. All current tests pass after removing this line. ## Steps to Reproduce (for bugs) Here is an example ```python import qiskit as qk qr = qk.QuantumRegister('qr', 1) cr = qk.ClassicalRegister('cr', 1) c = qk.QuantumCircuit(qr, cr) c.x(qr) c.measure(qr, cr) qp = qk.QuantumProgram() qp.add_circuit('test', c) ``` Executing this example circuit we have ```python qobj = qp.compile('test', backend='local_qasm_simulator') result = qp.run(qobj) # Following prints True print(qobj['id'] == result._qobj['id']) # Following prints True, False print('result' in qobj, 'result' in result._qobj) ``` To see recursion: ```python qobj = qp.compile('test', backend='local_qasm_simulator') result = qp.run(qobj) result = qp.run(qobj) # Following prints True, True print(qobj['id'] == result._qobj['id'], qobj['id'] == result._qobj['result']._qobj['id']) # Following prints True, True, False print('result' in qobj, 'result' in result._qobj, 'result' in result._qobj['result']._qobj) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook menu File -> Download as -> PDF title should be notebook title If you select File -> Download as -> PDF then every notebook has the title of \"Notebook\":  This is very confusing when making handouts for students... they all have the title \"Notebook\"! The PDF should get the title of the notebook, whatever it is. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Tweak colors to match new IQX colors From https://github.com/Qiskit/qiskit-terra/pull/3196#issue-324844793, @nonhermitian says: > Match the upcoming changes to IQX circuit composer styling. The closed PR #3196 suggests a new set of colors the the MPL circuit drawer. However, the PR got out-of-sync. Please, use PR #3196 as a reference to set the new colors and run binder (see https://github.com/Qiskit/qiskit-terra/pull/4544 as reference) to create the new reference images. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: parameter `ignore_keys` of `trainer.predict` not accessible in `Trainer` or `TrainingArguments` # 🚀 Feature request The [`predict`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.Trainer.predict) and [`evaluate`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.Trainer.evaluate) methods of the Trainer class provide an excellent option of `ignore_keys`. Here is a small example: ```python trainer.predict(dataset, ignore_keys=[\"ner_loss\", \"cls_loss\", \"ner_logits\", \"cls_logits\"]) ``` @sgugger This option is however, not accessible during the normal setup of defining `TrainingArguments` class nor the `Trainer` class so the a call to `trainer.train()` leads to errors during the mid-training evaluation. ## Motivation I am unable to evaluate the model metrics on the validation set **during** the training to see if makes sense to continue. ## Your contribution I am happy to make a PR if this is seen as a genuine problem. Like always, may be I am missing something. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: _margv for macros seems to be missing At one point in time, arguments to macro's could be obtained from _margv , but this seems to be missing now ( https://github.com/ipython/ipython/wiki/Cookbook:-Macro-arguments ). I searched the entire ipython folder and only found _margv in the documentation in the macro.py file. Just wondering if this is still supported. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuits_to_qobj does not work <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? ``` q = QuantumRegister(2,'q') c = ClassicalRegister(2,'c') qc = QuantumCircuit(q,c) qc.h(q[0]) qc.cx(q[0], q[1]) qc.measure(q[0],c[0]) qc.measure(q[1],c[1]) qobj = circuits_to_qobj(qc) ``` ``` ModelValidationError: {'header': [\"Value 'RunConfig()' is not the expected type <class 'qiskit.qobj.models.QobjHeader'>\"]} ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Duplicate Version comparison unittests ### Environment details I've noticed there is a large overlap between `/conans/test/unittests/model/version_test.py` and `conans/test/unittests/model/version/test_version_comparison.py`. I can make the changes and create a pull request? ### Steps to reproduce _No response_ ### Logs _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson 0.47.1 breaks cross builds using Boost Python I've bisected between master and 0.46.1 and found that the changeset in #3792 has broken cross builds that utilize [Boost Python](https://www.boost.org/doc/libs/1_67_0/libs/python/doc/html/index.html). The issue is that there is an additional link dependency (libpythonX.Y) that is required to successfully link with `--whole-archive`. Meson ends up cycling through all of the cross binaries, failing along the way and then falls back and ends up incorrectly picking the host libboost_python.so which causes link errors later on in the build after dependency resolution is complete. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Support multiple extension passed using --ext command line option traitlets 5.0 now can accept multiple values for single command line option. It makes sense to allow adding more than one extension using `--ext` option. See related thread here: https://github.com/ipython/traitlets/issues/614 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker config output format is not compatible when compose yml version >= 3.2 the scenario : config.yaml version >=3.2 which contains service port like: ports: - \"127.0.0.1:3306:3306\" Run of the following commands fails in the second command `docker-compose config > config.yaml` `docker-compose -f config.yaml up` The error I got in the `docker-compose up` line is: services.mysql.ports contains unsupported option: 'external_ip' The issue: The output of docker-compose for version >= 3.2 Contain service ports in the following format: ports: - external_ip: 127.0.0.1 published: 3306 target: 3306 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: stderr not used by Conan At least, the exception messages printed in the `command.py` should go to stderr. This is important to improve the CI automation feedback on errors. Maybe we should have the stderr stream on the conan output and print there also the .error messages Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: change results from conda update --all I run my conda update commands in a script and have to wade through the entire list of installed packages to see results. Is it possible to default the results from the update command to `# All requested packages already installed.` without the list? Thanks change results from conda update --all I run my conda update commands in a script and have to wade through the entire list of installed packages to see results. Is it possible to default the results from the update command to `# All requested packages already installed.` without the list? Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: Bad URL in Error Message from 'ensure_signed_credentials\". https://github.com/googleapis/google-cloud-python/blob/5a81ea3b1a2de36e8f2cc33d8cca6cc82ff4f994/storage/google/cloud/storage/_signing.py#L34 The URL shown in the AttributionError that is thrown from `ensure_signed_credentials` when the credentials are unsigned is invalid and takes you to a \"Sorry this page does not exist yet.\" page. Here is the URL from the attribution error for easy reference: https://google-cloud-python.readthedocs.io/en/latest/core/auth.html?highlight=authentication#setting-up-a-service-account Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: DeviceArray.reshape(*shape) does not work NumPy supports both `.reshape(*shape)` and `.reshape(shape)`, but only the later works with jax.numpy: ``` >>> import jax.numpy as jnp >>> jnp.arange(12).reshape(3, 4) --------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-27-144a56eb5cb3> in <module>() ----> 1 jnp.arange(12).reshape(3, 4) /usr/local/lib/python3.6/dist-packages/jax/numpy/lax_numpy.py in _reshape(a, newshape, order) 638 def _reshape(a, newshape, order=\"C\"): 639 dummy_val = onp.broadcast_to(0, shape(a)) # zero strides --> 640 computed_newshape = onp.reshape(dummy_val, newshape).shape 641 642 if order == \"C\": /usr/local/lib/python3.6/dist-packages/numpy/core/fromnumeric.py in reshape(a, newshape, order) 290 [5, 6]]) 291 \"\"\" --> 292 return _wrapfunc(a, 'reshape', newshape, order=order) 293 294 /usr/local/lib/python3.6/dist-packages/numpy/core/fromnumeric.py in _wrapfunc(obj, method, *args, **kwds) 54 def _wrapfunc(obj, method, *args, **kwds): 55 try: ---> 56 return getattr(obj, method)(*args, **kwds) 57 58 # An AttributeError occurs if the object does not have ValueError: cannot reshape array of size 12 into shape (3,) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] Is there a way to skip specific packages from build when calling install --build? I've built a package separately and it took a lot of time. I want to rebuild other main project's dependencies but pass a specific package. Is it possible? **UPD**: Or even better, an option that will force build packages fetched from remote but skip build if the package has already been built in local cache. Example: I build qt from sources which takes a lot of time, then it is built and ready in my cache. I run `conan install` in my application project and it fetches another packages and builds it from sources skipping the qt - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/mxnet codebase. Here's the problem: Running Adam optimizer error Hi, When I change the optimizer to Adam. For example, ``` python model = mx.model.FeedForward( ctx = [mx.gpu(0)], num_epoch = 60, symbol = network, optimizer = 'adam', initializer = mx.init.Xavier(factor_type=\"in\", magnitude=2.34)) model.fit(X= data_train) ``` I get the following error message: ``` python File \"<ipython-input-6-3732cc3a7cd0>\", line 2, in <module> X = data_train) File \"/home/rick/anaconda/lib/python2.7/site-packages/mxnet-0.5.0-py2.7.egg/mxnet/model.py\", line 641, in fit **(self.kwargs)) File \"/home/rick/anaconda/lib/python2.7/site-packages/mxnet-0.5.0-py2.7.egg/mxnet/optimizer.py\", line 52, in create_optimizer **kwargs) TypeError: __init__() got an unexpected keyword argument 'arg_names' ``` Isn't this the correct way of setting the optimizer? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Docker buildimage intermittently builds image Hello, I am playing around with prefect and trying to use the buildimage for docker ``` from prefect import task, Flow from prefect.tasks.docker import images @task def build_image(): images.BuildImage(path='.').run() with Flow(\"ETL\") as flow: e = build_image() flow.run() ``` ``` [2019-07-16 19:36:37,341] INFO - prefect.FlowRunner | Beginning Flow run for 'ETL' [2019-07-16 19:36:37,341] INFO - prefect.FlowRunner | Starting flow run. [2019-07-16 19:36:37,342] INFO - prefect.TaskRunner | Task 'build_image': Starting task run... [2019-07-16 19:36:41,274] INFO - prefect.TaskRunner | Task 'build_image': finished task run for task with final state: 'Success' [2019-07-16 19:36:41,275] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded ``` I noticed that this intermittently builds an image once about ever 4-5 times I run it. Anyone have an idea what is going on? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Branch `master` is failing <!-- commit 9134634f43bc858a32b4d6a9c3edf352e2f58873@master --> Trying to build `master` at commit 9134634f43bc858a32b4d6a9c3edf352e2f58873 failed. More info at: https://travis-ci.com/Qiskit/qiskit-terra/jobs/253757284 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: np.unique(a, axis=0) sorted incorrectly when values cross 255 This is a weird one I noticed while calling `unique(a, axis=0)` for a 2D array `a`. If some values in the first column of `a` are `<= 255` and others are `>255`, the output is incorrectly sorted. Maybe something somewhere is making an assumption about single bytes and causing an overflow. ```python >>> # broken: ... a = np.array([[255, 256], ... [256, 257]]) >>> np.unique(a, axis=0) array([[256, 257], [255, 256]]) >>> # row order doesn't matter, also broken: ... a = np.array([[256, 257], ... [255, 256]]) >>> np.unique(a, axis=0) array([[256, 257], [255, 256]]) >>> # works: ... a = np.array([[254, 255], ... [255, 256]]) >>> np.unique(a, axis=0) array([[254, 255], [255, 256]]) >>> # works: ... a = np.array([[256, 257], ... [257, 258]]) >>> np.unique(a, axis=0) array([[256, 257], [257, 258]]) >>> a.dtype dtype('int64') >>> a.flags C_CONTIGUOUS : True F_CONTIGUOUS : False OWNDATA : True WRITEABLE : True ALIGNED : True WRITEBACKIFCOPY : False UPDATEIFCOPY : False ``` I just noticed this also happens for 1D arrays when the axis kwarg is used: ```python >>> a = np.array([255, 256]) >>> np.unique(a, axis=0) array([256, 255]) >>> np.unique(a) array([255, 256]) ``` It seems the `axis` kwarg is a relatively new feature for `np.unique`. This is in Xubuntu 16.04 amd64. ``` Python 3.5.2 (default, Nov 23 2017, 16:37:01) [GCC 5.4.0 20160609] on linux >>> np.version.version '1.14.0' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub subscriber should batch requests Presently, the pub/sub subscriber only batches modacks, other actions are sent in the stream as single requests. This can lead to the request backlog growing (though this is less concerning with #4892). Other clients (Go, for instance) actually batch the other actions. We should attempt to do so as well. We have two options that I can see right now: 1. Make `QueueCallbackThread` use a variant of `_get_many` to pull multiple items off the queue and then modify `dispatch_callback` to combine actions. We'd have to make the action functions (`ack`, `nack`, etc.) accept multiple items instead of just a single item. 2. Make `dispatch_callback` keep a list of items and occasionally submit them to the appropriate action functions. We'd still need to modify the action functions to accept multiple items. We'd have to have yet another thread to deal with submitting the items on a cadence or modify `QueueCallbackThread` to do so. I'm leaning towards (1). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Ability to copy / add files from local to ContainerEnvironments I'm currently struggling with a Local Secrets issue involving a large JSON blob (specifically, a Google service account key). Moreover, many other services rely on config files being in known locations. Instead of wrangling with this, it would be convenient to allow ContainerEnvironments to COPY / ADD local files from the deploying machine to the container. This could be implemented via simple dictionary: ```python ContainerEnvironment(files={\"/absolute/local/path/filename.ext\": \"/absolute/container/path/filename.ext\"}) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: _get_default_service_project_id() fails in appveyor ``` python ====================================================================== FAIL: test_read_from_cli_info (gcloud.test__helpers.Test__get_default_service_project_id) ---------------------------------------------------------------------- Traceback (most recent call last): File \"C:\\projects\\gcloud-python\\gcloud\\test__helpers.py\", line 223, in test_read_from_cli_info self.assertEqual('test-project-id', project_id) AssertionError: 'test-project-id' != None ``` See also #1973 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: run_command should be able to fail if it doesn't succeed The example on how to use external commands: http://mesonbuild.com/External-commands.html as well as my personal experience with them is rather error prone. I think that in practice one has to always check for the return code, and >90% percent of the time, you want to fail the build if it is not zero. It is cumbersome having to do this manually every time (and making sure that e.g. the stdout is not used before the test). To give a concrete example, a line like this: ``` applgrid_libs = run_command(applgrid_config, '--ldflags').stdout().strip() ``` that I find convenient and clear in reality needs to be separated into the result of `run_command` captured in an intermediate variable, a test for the return code, and finally the result I am interested in. Python's [subprocess.run()](https://docs.python.org/3.5/library/subprocess.html#subprocess.run) has a `check` argument that raises an exception on failure. I think something like that would improve ergonomics sensibly. Even better if it was the default, but that's perhaps asking too much. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add license headers to source files. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Return integer or None from 'Query.total_rows' Split out from #3001, where @amirshavit reported: > It would be 'nicer' if the `total_rows property` return an integer (or None) rather than a string. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Unknown CPU family 's390' building with meson on an s390 (*not* s390x) yields a warning: ``` WARNING: Unknown CPU family 's390', please report this at https://github.com/mesonbuild/meson/issues/new with theoutput of `uname -a` and `cat /proc/cpuinfo` ``` s390 is 32-bit whereas s390x is 64-bit. meson seems to work fine otherwise. ```sh $ uname -a Linux lgentoo3 4.14.12 #1 SMP Tue Jan 9 18:32:25 EST 2018 s390 8561 IBM GNU/Linux $ cat /proc/cpuinfo vendor_id : IBM/S390 # processors : 2 bogomips per cpu: 3241.00 max thread id : 0 features : esan3 zarch stfle msa ldisp eimm dfp edat etf3eh highgprs te vx vxd vxe gs sie facilities : 0 1 2 3 4 6 7 8 9 10 12 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 30 31 32 33 34 35 36 37 38 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 57 58 59 60 61 73 74 75 76 77 80 81 82 128 129 130 131 133 134 135 146 147 148 150 151 152 155 156 168 cache0 : level=1 type=Data scope=Private size=128K line_size=256 associativity=8 cache1 : level=1 type=Instruction scope=Private size=128K line_size=256 associativity=8 cache2 : level=2 type=Data scope=Private size=4096K line_size=256 associativity=8 cache3 : level=2 type=Instruction scope=Private size=4096K line_size=256 associativity=8 cache4 : level=3 type=Unified scope=Shared size=262144K line_size=256 associativity=32 cache5 : level=4 type=Unified scope=Shared size=983040K line_size=256 associativity=60 processor 0: version = FF, identification = 100003, machine = 8561 processor 1: version = FF, identification = 200003, machine = 8561 cpu number : 0 cpu MHz dynamic : 5200 cpu MHz static : 5200 cpu number : 1 cpu MHz dynamic : 5200 cpu MHz static : 5200 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: failing test_introspect_json_dump on new OS (=Solaris) I get a rare issue concerning the test_introspect_json_dump: > >====================================================================== FAIL: test_introspect_json_dump (__main__.AllPlatformTests) >---------------------------------------------------------------------- >Traceback (most recent call last): > File \"./run_unittests.py\", line 3319, in test_introspect_json_dump > self.assertPathListEqual(res['buildsystem_files'], bs_files) > File \"./run_unittests.py\", line 1256, in assertPathListEqual > self.assertPathEqual(i[0], i[1]) > File \"./run_unittests.py\", line 1247, in assertPathEqual > self.assertEqual(PurePath(path1), PurePath(path2)) >AssertionError: PureP[37 chars]on.git/test cases/unit/52 introspection/staticlib/meson.build') != PureP[37 chars]on.git/test cases/unit/52 introspection/sharedlib/meson.build') > > Looking into the respective lines of code show that in the assertPathListEqual test there is an element change. All three elements are there and the same, but the parts with \"sharedlib\" and \"staticlib\" are vice versa. Meaning ('pseudo code for simplicity'): > bs_files = ['meson.build', 'sharedlib/meson.build', 'staticlib/meson.build'] > buildysystem_files = ['meson.build', 'staticlib/meson.build', 'sharedlib/meson.build'] The content in buildsystem_files is as it is extracted by the test, inside the respective meson-info-file the order of the paths is \"['meson.build', 'staticlib/meson.build', 'sharedlib/meson.build']\". So the paths seems to be scrambled on their way into that file. As I do not know what the test shall to since it did not pass yet (is the order needed or not) I would appreciate to get some help on this. When this is done I am a way further on running meson on Solaris. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: `runtest.py` fails with a `KeyError` Since the merging of https://github.com/numpy/numpy/pull/19628 the `python ./runtest.py` fails with a `KeyError`. Based on the traceback it seems that `sysconfig.get_path('platlib', expand=False)` returns an incorrect formattable string. ### Error message: ``` >>> python .\\runtests.py Traceback (most recent call last): File \"C:\\Users\\hardd\\Documents\\GitHub\\numpy\\runtests.py\", line 695, in <module> main(argv=sys.argv[1:]) File \"C:\\Users\\hardd\\Documents\\GitHub\\numpy\\runtests.py\", line 192, in main site_dir, site_dir_noarch = build_project(args) File \"C:\\Users\\hardd\\Documents\\GitHub\\numpy\\runtests.py\", line 480, in build_project site_dir = site_dir_template.format(platbase=dst_dir, KeyError: 'base' ``` And the content of the offending `site_dir_template` formattable string: ``` python >>> print(site_dir_template) {base}/Lib/site-packages ``` ### NumPy/Python version information: 1.22.0.dev0+696.g334428c4d 3.9.4 | packaged by conda-forge | (default, May 10 2021, 22:10:34) [MSC v.1916 64 bit (AMD64)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Formatter class should have staticmethods **Is your feature request related to a problem? Please describe.** When using the `Formatter` in a wrapper script to format a table like compose, it's frustrating to have to create an instance of the class just to call the `table` method. **Describe the solution you'd like** I presume the `Formatter` class is intended to be a container for multiple formatters, even if only one exists currently. Accordingly, it should be made a static method so no object has to be init-ed. **Describe alternatives you've considered** The method could be taken out of the class altogether but this would be a dramatic API change. The proposed change does not break the existing API. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Parameters which are dictionaries are incorrectly cast as `GraphQLResult` objects Parameters whose values are standard dictionaries are incorrectly cast as `GraphQLResult` objects in Cloud. This causes their associated tasks to fail because Parameters are automatically check-pointed with the `JSONResultHandler`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: windows.compile_resources() can't be used with custom targets ```meson rc_target = custom_target('Windows resource file', command : [preprocess_command, rcdefs, '@INPUT@', '@OUTPUT@'], build_always : true, input : 'taisei.rc.in', output : 'taisei.rc', ) version_deps += winmod.compile_resources(rc_target) ``` ``` Meson encountered an error in file src/meson.build, line 59, column 4: Windows resource arguments must be strings or files not <CustomTargetHolder Windows resource file@cus: ['/data/git/taisei/scripts/configure-file.py', '--rootdir', '/data/git/taisei', '--fallback-version', 'v1.1.0-9999', '-DMESON_BUILD_TYPE=release', '-DICONS_DIR=/data/git/taisei/misc/icons', '-DBUILDTYPE_DEFINE=#define RELEASE_BUILD', '@INPUT@', '@OUTPUT@']> ``` This bug makes it impossible to reliably regenerate the `.rc` source on every rebuild. Add something like depend_files to windows.compile_resources() Resource script can include various other files (bitmap, cursor, font, html, icon, message table, binary data, manifest), it would be nice if it were possible to declare the resource script depends on these. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Separate IBMQ from Qiskit Terra I would like to build a separate repo for IBMQ much like JKU. I think the name should be ``` qiskit_ibmq_provider ``` This would make terra not depend on the API. We can not do this until the API has the correct format. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Jupyter Services Example appears broken **Describe the bug** The example found at https://github.com/jupyterlab/jupyterlab/tree/master/packages/services/examples/typescript-browser-with-output doesn't appear to work as advertised any longer. **To Reproduce** Follow the steps within https://github.com/jupyterlab/jupyterlab/blob/master/packages/services/examples/typescript-browser-with-output/README.md **Expected behavior** Expect the example to work with current version of jupyterlab packages Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Get value and gradient simultaneously In Autograd I was used to have `value_and_grad` to return both the gradient and the value of a function simultaneously. Is there any similar functionality in JAX? That would be incredibly useful for, e.g., plotting the loss while training a neural network. This is an example in Autograd: ``` grad_and_value = grad_and_value(np.tanh) v, g = grad_and_value(0.0) # v=0.0, g=1.0 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: VS generator not exporting for <Lib> tag in vcxproj Need to add Conan-handled lib to be referenced in .vcxproj in <Lib> tags. Conan VS-generator is exporting only in <Link> tag. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add `on_failure_callback` kwarg to tasks This kwarg would accept a list or a single function with call signature `fn(state: State) -> None` (the return value is not important, but will be ignored) and be called anytime a task goes into a `Failed` state (including if a Task goes into a `Failed` state prior to a retry). These callback functions would then be converted to state handlers under the hood, and called at the appropriate times. Note: if the callback fails, we should trap the error and log it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Computation of mask indices in Wav2vec2Model fails with low probabilities ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.12.2 - Platform: Linux - Python version: 3.8 - PyTorch version (GPU?): 1.10 ### Who can help @patrickvonplaten ## Information I'm trying to reproduce fine-tuning with Wav2vec2 on Librispeech, however using feature mask probability 0.0012 as in the paper makes the code crash at some point (after ~3_000 steps). ## To reproduce ``` from transformers.models.wav2vec2.modeling_wav2vec2 import _compute_mask_indices mask = _compute_mask_indices( shape=(10, 500), mask_prob=0.0012, # or even lower mask_length=10, ) print(mask) ``` raises ``` Traceback (most recent call last): File \"/home/nik/workspace/phd/repo/w2v2-mt-learning/playground/buggy_mask.py\", line 3, in <module> mask = _compute_mask_indices( File \"/home/nik/workspace/phd/repo/w2v2-mt-learning/.venv/lib/python3.8/site-packages/transformers/models/wav2vec2/modeling_wav2vec2.py\", line 201, in _compute_mask_indices dummy_mask_idx = spec_aug_mask_idx[0] IndexError: index 0 is out of bounds for axis 0 with size 0 ``` Note that using `min_mask=1` prevents this issue as well. ## Expected behavior If the probability is so low that no features are masked, the method shouldn't raise an `IndexError`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Define Conan hooks management Following the feature of Conan Plugins #3555 we should define the following points: - Installation of plugins: `conan config install` with custom plugins parameter or normal? - Merge strategy for plugins with same name or same subfolders. - Automatic activation/desactivation of plugins in *conan.conf*? - What should be the strategy to for plugin versioning? - Should we think about a way to detect compatibility of plugins in respect to the Conan client version? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Handle `manual_only` triggers more elegantly Per [discussion w/ @jlowin](https://github.com/PrefectHQ/prefect/pull/78#discussion_r206279090), we should consider implementing a new signal for `manual_only` triggers which prevents a task from running while also creating a `Pending()` state with `cached_inputs`. The current implementation within `task_runner` feels brittle. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda info to show a bit more about operating system There is some general architecture and bit-width information in the `conda info` output but it would be really handy for debugging if we provided a few more hints that would allow someone looking at the output to make a good guess as to: * Windows version (7, 8, 10, etc) * Linux variant and version (CentOS, RHEL, SUSE, etc.) * Special privileges of user running `conda` command (root, Administrator) * Variations in ownership between \"root\" Conda environment and user executing `conda info` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: equality of instruction initialize does not work ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When compare two circuits with `initialize`, equality fails when it should not. ```python from qiskit import QuantumRegister, QuantumCircuit init_vector = [0.5, 0.5, 0.5, 0.5] qreg = QuantumRegister(2) circuit1 = QuantumCircuit(qreg, name='circuit') circuit1.initialize(init_vector, [qreg[0], qreg[1]]) circuit2 = QuantumCircuit(qreg, name='circuit') circuit2.initialize(init_vector, [qreg[0], qreg[1]]) print(circuit1) print(circuit2) assert circuit1 == circuit2 ``` ### What is the expected behavior? Same as other gates, `initialize` should support equality as other gates. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: svn scm bug when using a tag conan 1.14.3 We have a component that has a recipe called 'conanfile_policy.py' in a sub directory called 'policy'. See:  As part of our test build process this component gets tagged at the component root level ie above the policy dir, after the recipe was changed so a build can be done from the tag. The SVN revision graph showing this is:  As part of our build process, Jenkins checks out the policy subdir using the tag and exports the recipe, this is preparation for doing a `conan create` on our 'product' recipe to build our entire product. The url gets deduced incorrectly by scm auto in this export, which means Jenkins can’t `conan create` from the recipe for this component breaking the build. The exported recipe looks like: ``` scm = {\"revision\": \"126\", \"type\": \"svn\", \"url\": \"svn+ssh://svnserver/svncmake/sophosmanager/tags/CONAN_REL_3.0.0-2/policy@125\"} ``` The `conan create` fails because the tag does not exist at rev 125, only 126. I think the issue might be how scm auto deduces the svn revision to create the url, it appears to use Last Changed Rev rather than the Revision attribute from the svn info. With a subdir under the tag, the Last Changed Rev doesn’t include the tag, as the tag didn’t occur in the subdir, but at the level above it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [workspaces] No out-of-source builds are possible after upgrading to 1.13.2 Most recent edition of Workspace feature is designed in the way that build folder of sub-libraries are relative to location of the libraries, and thus always pollutes source folder. With previous edition of Workspace feature we were able keep build artifacts of sub-libraries, participating in workspace, in workspace build dir, as sub-folders. That was convenient - sources of the libraries were unaffected, and one was able to have multiple workspaces active, with the same libraries used in it. Right now such a setup is impossible - new layouts are imposing relative-to-library pathes only. It would be nice if we can have optional ability to use old logic for build artifacts location, out-of-sources workspace building was one of the key features of Conan for us. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error while implementing RZGate with single open control <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.14.0.dev0+09240bb - **Python version**: 3.6 - **Operating system**: Ubuntu 18.04 ### What is the current behavior? Receiving CircuitError: \"Register size must be positive (int '0' was provided)\" error while trying to append RZGate to a quantum circuit with a single open control. ### Steps to reproduce the problem ``` qc = QuantumCircuit(2) qc.append(RZGate(pi/6).control(ctrl_state='0'),[0,1]) ``` ### What is the expected behavior? The implementation should not raise an error. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Properties of unset special tokens return the string 'None' in non verbose Tokenizers ### System Info ```shell - `transformers` version: 4.20.0 - Platform: Linux-5.4.0-120-generic-x86_64-with-glibc2.27 - Python version: 3.8.0 - Huggingface_hub version: 0.7.0 - PyTorch version (GPU?): 1.11.0+cu102 (False) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ``` ### Who can help? @SaulLu ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction For example, `MarianTokenizer` does not set `bos_token`. The corresponding property returns the string `'None'`: ```python >>> import transformers >>> tokenizer = transformers.MarianTokenizer.from_pretrained(\"Helsinki-NLP/opus-mt-en-de\", verbose=False) >>> tokenizer.bos_token 'None' ``` ### Expected behavior ```shell The property should return None, not the string 'None'. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda env create gives confusing message if environment file does not exist and name is given ### Checklist - [X] I added a descriptive title - [X] I searched open reports and couldn't find a duplicate ### What happened? Related to #5681. `conda env create` gives a confusing error message if a non existing env file *and* a name are given. * `conda env create -f missing.yml`: `EnvironmentFileNotFound: '/Users/adrian/missing.yml' file not found` * `conda env create -f missing.yml -n test`: `SpecNotFound: Invalid name, try the format: user/package` The reason for this behaviour is in https://github.com/conda/conda/blob/main/conda_env/specs/__init__.py#L20 and I'm currently looking into fixing it. ### Conda Info _No response_ ### Conda Config _No response_ ### Conda list _No response_ ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Comm messages aren't handled in ExecutePreprocessor The `ExecutePreprocessor` in nbconvert doesn't properly handle comm messages, resulting in a bunch of errors like this when using widgets or the `nbagg` matplotlib backend: ``` unhandled iopub msg: comm_open unhandled iopub msg: comm_msg unhandled iopub msg: comm_msg ... ``` The fix is pretty trivial; it just involves adding another if clause to the if statement that checks the message type: ``` elif msg_type.startswith('comm'): continue ``` I feel like this is something that should probably be fixed in 3.x, but since nbconvert has already been moved I'm not sure where I should submit the fix. Should I submit it against master, and whoever backports it will handle making the same changes on 3.x? Should I submit two PRs? Should I just wait until the split is done? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: add destinationTableProperties to LoadJobConfig To catch up with https://issuetracker.google.com/issues/70117381 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Parameterized circuits yield incorrect QASM output <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? For example: ```python from qiskit import * from qiskit.circuit import Parameter alpha = Parameter('alpha') qc = QuantumCircuit(1) qc.p(alpha, 0) qc.qasm(True) ``` gives ``` OPENQASM 2.0; include \"qelib1.inc\"; qreg q[1]; p(alpha) q[0]; ``` but alpha is not defined. This leads to errors when importing the QASM. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions I am guessing that this is a QASM2 issue that is to be fixed in QASM3. However there is no exception raised here to indicate that the QASM is invalid for a parameterized circuit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: sentencepiece version need upgrade ## Environment info - `transformers` version: 4.11.0.dev0 - Platform: Debian Gnu/Linux - Python version: 3.9 - PyTorch version (GPU?): - Tensorflow version (GPU?): - Using GPU in script?: - Using distributed or parallel set-up in script?: ### Who can help - setup: @LysandreJik may be ? ## Information sentencepiece==0.1.91 does not exist anymore pip install fails: ``` ERROR: Could not find a version that satisfies the requirement sentencepiece==0.1.91 ERROR: No matching distribution found for sentencepiece==0.1.91 ``` ## To reproduce Steps to reproduce the behavior: 1. create a new venv 2. pip install -e . ## Expected behavior - Need to bump to the latest but minor version change 0.1.96 for transformer's install to work Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Local agent health check ## Use Case The local agent parent process should support external healthchecks We are trying to use prefect as our task manager, where each compute resource has a docker-compose-based service with a prefect local agent in it, and do standard docker / docker-compose administration over it. While we can monitor the health of the docker process itself, there is no clear way for docker to ask the prefect local agent if it is ok, which prevents 2000-era monitoring, auto-restart, etc. ## Solution * the prefect local agent exposes an HTTP status check route * the status check route does whatever consistency checks make sense, even if just a quick \"hello!\", and returns a 200 status if OK. (Unclear what those are, we're ok with \"i'm up\" for starters.) * fancy: config vars to control this further That is enough that `supervisord`, `docker`, etc. healthcheck frameworks can hook in ## Alternatives * Prefect handles all observability & reliability operations internally, including executor monitoring & restart stack, in some unexposed + non-standard way * Prefect does not support health checks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Circuit.decompose doesn't decompose XXPlusYYGate ### Environment - **Qiskit Terra version**: dfbc738be57619b503b931a2d0741433a1bbe21b - **Python version**: 3.10.8 - **Operating system**: Arch Linux ### What is happening? See title. ### How can we reproduce the issue? ```python from qiskit.circuit import QuantumCircuit from qiskit.circuit.library import XXPlusYYGate circuit = QuantumCircuit(2) circuit.append(XXPlusYYGate(0.1, 0.1), [0, 1]) print(circuit.decompose([\"xx_plus_yy\"])) ``` ``` ┌───────────────────┐ q_0: ┤0 ├ │ {XX+YY}(0.1,0.1) │ q_1: ┤1 ├ └───────────────────┘ ``` ### What should happen? It should decompose. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook saving fails on smb share I'm trying to use the ipython notebook on a mounted smb share, but I can’t use it since ipython uses `shutil.copy2` which fails (due to the use of `os.chmod`). A solution would probably be to use `shutil.copyfile` as a fallback, but I haven't tested it. ## Traceback `Traceback (most recent call last): File \"/home/me/Enthought/Canopy_64bit/User/lib/python2.7/site-packages/tornado/web.py\", line 1141, in _when_complete callback() File \"/home/me/Enthought/Canopy_64bit/User/lib/python2.7/site-packages/tornado/web.py\", line 1162, in _execute_method self._when_complete(method(*self.path_args, **self.path_kwargs), File \"/home/me/Enthought/Canopy_64bit/User/lib/python2.7/site-packages/tornado/web.py\", line 2297, in wrapper return method(self, *args, **kwargs) File \"/home/me/Enthought/Canopy_64bit/User/lib/python2.7/site-packages/IPython/html/services/notebooks/handlers.py\", line 107, in post checkpoint = nbm.create_checkpoint(notebook_id) File \"/home/me/Enthought/Canopy_64bit/User/lib/python2.7/site-packages/IPython/html/services/notebooks/filenbmanager.py\", line 315, in create_checkpoint shutil.copy2(nb_path, cp_path) File \"/home/me/Canopy/appdata/canopy-1.3.0.1715.rh5-x86_64/lib/python2.7/shutil.py\", line 131, in copy2 copystat(src, dst) File \"/home/me/Canopy/appdata/canopy-1.3.0.1715.rh5-x86_64/lib/python2.7/shutil.py\", line 100, in copystat os.chmod(dst, mode) OSError: [Errno 95] Operation not supported: '/run/user/1000/gvfs/smb-share/calculations/dipoleTrap/.ipynb_checkpoints/dipole-checkpoint.ipynb'` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: if pkgconfig dep not found - printed twice from `find_external_dependency()` and from cunstructor of `PkgConfigDependency` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Release version 4.3 of Celery @thedrow @georgepsarakis It would be great if we can release the beta version of 4.3 by December 1st. before that, we need to release py-amqp. kombu and other dependencies first though. it's a soft reminder ### If you'd like to contribute, here is a [list of blockers](https://github.com/celery/celery/issues/5180#issuecomment-472043723). ### If you are using Celery to create a commercial product, please consider becoming our [backer](https://opencollective.com/celery#backer) or our [sponsor](https://opencollective.com/celery#sponsor) to ensure Celery's future. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda info in 4.3.17 has a spacing offset problem ``` $ ❯ /conda4/bin/conda info Current conda install: platform : osx-64 conda version : 4.3.17 conda is private : False conda-env version : 4.3.17 conda-build version : 2.1.9 python version : 2.7.13.final.0 requests version : 2.12.4 root environment : /conda4 (writable) default environment : /conda4 envs directories : /conda4/envs /Users/kfranz/.conda/envs package cache : /conda4/pkgs /Users/kfranz/.conda/pkgs channel URLs : https://repo.continuum.io/pkgs/free/osx-64 https://repo.continuum.io/pkgs/free/noarch https://repo.continuum.io/pkgs/r/osx-64 https://repo.continuum.io/pkgs/r/noarch https://repo.continuum.io/pkgs/pro/osx-64 https://repo.continuum.io/pkgs/pro/noarch config file : /Users/kfranz/.condarc offline mode : False user-agent : conda/4.3.17 requests/2.12.4 CPython/2.7.13 Darwin/16.5.0 OSX/10.12.4 UID:GID : 502:20 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Potentially more Pythonic options for the API? I _thought_ I'd discussed this with @tswast, and he'd even generously added a PR; but after ten mins of searching GH I've come up empty on both issues and PRs, so posting here. @tswast lmk if my memory is correct and we have discussed this! I appreciate API design is difficult and there are tradeoffs between verbosity vs explicitness, and consistency within a product vs language-specific adjustments. The bar should be high for people offering criticism when they can only see a subset of the relevant information. But I do frequently use the BQ python API and find it fairly awkward and un-pythonic, as though I were writing Java. Here's an example, straight from the docs: ``` from google.cloud import bigquery client = bigquery.Client() dataset_id = 'my_dataset' # replace with your dataset ID table_id = 'my_table' # replace with your table ID table_ref = client.dataset(dataset_id).table(table_id) table = client.get_table(table_ref) # API request ``` I would love to be able to write this, and receive a table object. ``` client = bigquery.Client() client.table(dataset='ds', table='tbl') ``` There are some points a level down (the `.table` object doesn't return a `Table` object while a dataset object does return a `Dataset` object / do we need a `TableReference` class in place of a string, etc), but they all center around the ergonomics of the API, particularly in respect to Python. Thank you as ever for a wonderful product, and appreciate any thoughts on whether I'm making mistakes here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Can't break exception chaining with 'from None' In plain Python: ``` >>> try: ... 1/0 ... except ZeroDivisionError: ... raise ValueError(\"foo\") from None ... Traceback (most recent call last): File \"<stdin>\", line 4, in <module> ValueError: foo ``` Same code in IPython produces: ``` --------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) <ipython-input-2-68918cb585bc> in <module>() 1 try: ----> 2 1/0 3 except ZeroDivisionError: ZeroDivisionError: division by zero During handling of the above exception, another exception occurred: ValueError Traceback (most recent call last) <ipython-input-2-68918cb585bc> in <module>() 2 1/0 3 except ZeroDivisionError: ----> 4 raise ValueError(\"Noooo\") from None ValueError: Noooo ``` Thanks @jhamrick for pointing this out Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: BeeGFS hard-links [BeeGFS](http://www.beegfs.com), a parallel cluster file system, [does not support](https://groups.google.com/forum/#!topic/fhgfs-user/cTJcqGZceVA) `hard-links` between files in differents directories. Depending on the [configuration](https://groups.google.com/forum/#!topic/fhgfs-user/pvQSo0QWicw), either an error is issued, or a `symbolic-link` is created. If a `symbolic-link` is created instead of a `hard-link`, it can cause problem, for example: ``` pkgs/bin/mpicc pkgs/lib/libopen-pal.so envs/bin/mpicc envs/lib/libopen-pal.so ``` Here, when `envs/bin/mpicc` is executed, it is actually `pkgs/bin/mpicc` that is executed, and the library `$PREFIX/../lib/libopen-pal.so` actually loaded is `pkgs/lib/libopen-pal.so,` which is different from `envs/lib/libopen-pal.so` for which conda has fixed hard-coded prefix path, and as a final consequence `mpicc` fails to find its configuration file. #805 is another (closed) related to `BeeGFS`. Would we need a new conda options to turn hard-link into copy? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: llvm dependency fails to locate llvm-config on fedora 30 ``` llvm-config found: NO need '>= 3.5' Dependency LLVM found: NO (tried config-tool) src/plugins/clang/meson.build:47:0: ERROR: Dependency \"llvm\" not found, tried config-tool ``` Apparently, the tool has been named something rather odd now, 'llvm-config-64', which seems to differ from other naming schemes in `dependencies.py`. ``` rpm -q --whatprovides /usr/bin/llvm-config-64 llvm-devel-8.0.0-0.4.rc3.fc30.x86_64 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Line magic function `%R` not found. (Rmagic) The documentation page could quickly remind that \"%load_ext rmagic\" is required before anything. http://ipython.org/ipython-doc/dev/config/extensions/rmagic.html (it is the case on the page for the extension autoreload) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: llvm: Allow using cmake for dependency We know have a cmake dependency finder, and LLVM can be found using cmake. It should be possible to find LLVM using cmake, for mesa there are some caveats for it's use but this should be investigated and turned on. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda env update : does not support --prefix The `conda env update` does not support the `--prefix` / `-p` argument. ``` $ conda info | grep version conda version : 4.2.12 conda-env version : 4.2.12 conda-build version : 1.20.3 python version : 2.7.11.final.0 requests version : 2.10.0 $ conda env update -p ./conda-env usage: conda-env [-h] {attach,create,export,list,remove,upload,update} ... conda-env: error: unrecognized arguments: -p ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: qt5 module generates broken target if moc-qt5 is not installed When building `gst-plugins-base` while `moc-qt5` is not installed on the system I get: ``` Traceback (most recent call last): File \"/home/jenkins/workspace/meson/mesonbuild/mesonmain.py\", line 282, in run app.generate() File \"/home/jenkins/workspace/meson/mesonbuild/mesonmain.py\", line 169, in generate g.generate(intr) File \"/home/jenkins/workspace/meson/mesonbuild/backend/ninjabackend.py\", line 184, in generate self.generate_target(t, outfile) File \"/home/jenkins/workspace/meson/mesonbuild/backend/ninjabackend.py\", line 257, in generate_target self.generate_custom_generator_rules(target, outfile) File \"/home/jenkins/workspace/meson/mesonbuild/backend/ninjabackend.py\", line 1360, in generate_custom_generator_rules self.generate_genlist_for_target(genlist, target, outfile) File \"/home/jenkins/workspace/meson/mesonbuild/backend/ninjabackend.py\", line 1406, in generate_genlist_for_target elem.write(outfile) File \"/home/jenkins/workspace/meson/mesonbuild/backend/ninjabackend.py\", line 116, in write if quote_char == '\"': File \"/home/jenkins/workspace/meson/mesonbuild/backend/ninjabackend.py\", line 35, in ninja_quote return text.replace(' ', '$ ').replace(':', '$:') AttributeError: 'NoneType' object has no attribute 'replace' ``` basically because the target genrated [here](https://phabricator.freedesktop.org/diffusion/GSTBASE/browse/master/tests/examples/overlay/meson.build;c8c834e4a1361149b373694c502279a3a39dbb2a$21) is broken with `None` as first argument Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Task mapping against 'params' ### Apache Airflow version 2.3.1 (latest released) ### What happened Importing a DAG using `PostgresOperator` with `expand(params=[...])` fails, claiming `params` was already specified as a partial argument, even though it wasn't. ### What you think should happen instead The DAG imports successfully. ### How to reproduce ```python from pathlib import Path import pendulum from airflow.providers.postgres.operators.postgres import PostgresOperator from airflow.decorators import dag, task @dag( start_date=pendulum.datetime(2021, 11, 19, tz=\"UTC\"), schedule_interval=\"@daily\", catchup=False, ) def test(): query_values = [{\"a\": 1}, {\"a\": 2}] PostgresOperator.partial( task_id=\"simple_select\", sql=\"SELECT {{ params.a }}\", ).expand(params=query_values) test_dag = test() ``` Exception during import: ``` Broken DAG: [/usr/local/airflow/dags/test_dag.py] Traceback (most recent call last): File \"/usr/local/lib/python3.9/site-packages/airflow/models/mappedoperator.py\", line 199, in expand prevent_duplicates(self.kwargs, mapped_kwargs, fail_reason=\"mapping already partial\") File \"/usr/local/lib/python3.9/site-packages/airflow/models/mappedoperator.py\", line 139, in prevent_duplicates raise TypeError(f\"{fail_reason} argument: {duplicated_keys.pop()}\") TypeError: mapping already partial argument: params ``` ### Operating System macOS 12.4 ### Versions of Apache Airflow Providers ```apache-airflow-providers-postgres==4.1.0``` ### Deployment Astronomer ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: run_circuits is using a hardcoded sleep when checking job status ### Environment - **Qiskit Terra version**: `main` branch - **Python version**: n/a - **Operating system**: n/a ### What is happening? The qiskit `run_circuits` utility is using a hard-coded sleep when it waits to check the job status here https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/utils/run_circuits.py#L219. ### How can we reproduce the issue? _The issue has to do with using a hard-coded value when there is a configured value that can be used instead._ ### What should happen? The code should instead use `qjob_config[\"wait\"]` which comes from the `QuantumInstance` [constructor](https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/utils/quantum_instance.py#L168) and which can be made available to the code in run_circuits. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add depth estimation pipeline ### Feature request We currently have 2 monocular depth estimation models in the library, namely [DPT](https://huggingface.co/docs/transformers/model_doc/dpt) and [GLPN](https://huggingface.co/docs/transformers/model_doc/glpn). It would be great to have a pipeline for this task, with the following API: ``` from transformers import pipeline pipe = pipeline(\"depth-estimation\") pipe(\"cats.png\") ``` This pipeline could default to the https://huggingface.co/Intel/dpt-large checkpoint. Also check out the [Space](https://huggingface.co/spaces/nielsr/dpt-depth-estimation) that showcases the model. This can be implemented similar to [other pipelines](https://github.com/huggingface/transformers/tree/main/src/transformers/pipelines). For an example PR that added a pipeline, see https://github.com/huggingface/transformers/pull/11598. ### Motivation Pipelines are a great way to quickly perform inference with a model for a given task, abstracting away all the complexity. ### Your contribution I can assist with this, together with @Narsil. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: check.is_str is problematic The issue here is that every other check method throws on failure, and `is_str` returns true or false. Note the different in behavior between `is_str` and `is_list`. I believe the the best fix would be to move `is_str` to dagster.utils, where the is prefix can more credibly mean returns True or False. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: END key inserts autosuggestion in the middle of a line Hitting END in the middle of a line inserts an autosuggestion at the cursor instead of the end of the line. From a new IPython profile (hence ensuring no history), type these keystrokes: ``` 123456789<Enter> 123456<End><Enter> 123456<Left arrow><Left arrow><Left arrow><End><Enter> ``` This produces the transcript: ``` In [1]: 123456789 Out[1]: 123456789 In [2]: 123456789 Out[2]: 123456789 In [3]: 123789456 Out[3]: 123789456 ``` Actual behavior: The final input is \"123789456\", which wasn't present in the history before. Expected behavior: Hitting END when the cursor is in the middle of \"123456\" should either leave the input as-is, or transform it to \"123456789\". @meeseeksdev autosuggestions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: transpile() hung up when running with multiple circuits and custom pass manager <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### What is the current behavior? On Mac OS machine, `transpile()` hung up in `parallel_map` when it runs with multiple circuits and custom pass manager. ### Steps to reproduce the problem ``` from qiskit import QuantumCircuit, Aer, transpile from qiskit.transpiler.coupling import CouplingMap from qiskit.transpiler.pass_manager_config import PassManagerConfig from qiskit.transpiler.preset_passmanagers import level_0_pass_manager qc = QuantumCircuit(2, 2) qc.h(0) qc.cx(0, 1) backend = Aer.get_backend('qasm_simulator') pm_conf = PassManagerConfig( initial_layout=None, basis_gates=['u1', 'u2', 'u3', 'cx'], coupling_map=CouplingMap([[0, 1]]), backend_properties=None, seed_transpiler=1 ) pm = level_0_pass_manager(pm_conf) transpiled = transpile([qc, qc], backend=backend, pass_manager=pm) ``` Note: No problem in the single circuit case `transpile(qc, backend=backend, pass_manager=pm)` or when specifying the same preset pass manager via optimization_level `transpile([qc, qc], backend=backend, optimizaton_level=0)`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: QTConsole tooltip logic chooses wrong object to print infomation about Moved from #6726 as requested The tooltip shifts to display info about the argument rather then the function (^ denotes the cursor) once an argument is provided: ``` python In [14]: s='foo' In [15]: s.split(^ # shows info about str.split In [15]: s.split(^s # shows info about string 's' In [15]: s.split(^x # no tooltip because x does not exist ``` In older version you always saw the function signature and specifically the names of the keyword arguments. and again: The tooltip updates depending on where you are within the parens (maybe intentional, but different than it used to be) and the tooltip looks at what's right in front of the cursor rather than just behind it when just to the right of the parens. @takluyver suggests looking at: https://github.com/ipython/ipython/blob/master/IPython/qt/console/frontend_widget.py#L718 but any language-specific parts should go in the kernel and not the frontend if possible. continues QTConsole regressions from #6726 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Better hyperparameter tensorboard logging in Trainer. # 🚀 Feature request `Trainer` should write `train_batch_size` and `eval_batch_size` to tensorboard. Currently only `per_device_` batch sizes are logged as hyperparamters, which means unless you know how many gpus you trained on (which is also not logged), you can't know the actual batch sizes used in training. ## Your contribution Submitted a PR: [Adds train_batch_size, eval_batch_size, and n_gpu to to_sanitized_dict output for logging.](https://github.com/huggingface/transformers/pull/5331#issue-440857548) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Remove 'conda env attach' and 'conda env upload' For conda 4.6, as a follow-on to #5842. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Trainer._load_rng_state() misbehavior Resuming from checkpoints have been giving me a warning I did not expect. ``` Didn't find an RNG file, if you are resuming a training that was launched in a distributed fashion, reproducibility is not guaranteed. ``` even though I do see a `rng_state.pth` file in the checkpoint directory. A little digging turned up https://github.com/huggingface/transformers/blob/3892d09f4f55607399ac6b9df14dbe9b3e92a3f7/src/transformers/trainer.py#L1513-L1514 which seems to prepend the checkpoint path to the filename twice for the `isfile()` check. I think this was a typo. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Testing this is a test Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Make platform version as independent parameter of ECSOperator Currently `ECSOperator` propagates `platform_version` parameter either in case `launch_type` is `FARGATE` or there is `capacity_provider_strategy` parameter provided. The case with `capacity_provider_strategy` is wrong. Capacity provider strategy can contain a reference on EC2 capacity provider. If it's an EC2 capacity provider, then `platform_version` should not be propagated to the `boto3` api call. And it's not possible to do so with the current logic of `ECSOperator` because `platform_version` is always propagated in such case and `boto3` doesn't accept `platform_version` as `None`. So in order to fix that `platform_version` should be an independent parameter and propagated only when it's specified, regardless which `launch_type` or `capacity_provider_strategy` is specified. That should also simplify the logic of `ECSOperator`. I will prepare a PR to fix that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: memory leak of jax.random in GPU @ziatdinovmax was observing a phenomenon that memory keeps increasing until crashing for some NumPyro models (specifically, the issue https://github.com/pyro-ppl/numpyro/issues/447) when they are run in GPU. Here is an isolated repro code, which only uses JAX ops: ``` from jax import random, lax def model(key): D_X, D_H, D_Y = 3, 5, 1 # sample first layer (we put unit normal priors on all weights) key, subkey = random.split(key) w1 = random.normal(subkey, shape=(D_X, D_H)) key, subkey = random.split(key) w1 = random.uniform(subkey, shape=w1.shape, minval=-2, maxval=2) # sample second layer key, subkey = random.split(key) w2 = random.normal(subkey, shape=(D_H, D_H)) key, subkey = random.split(key) w2 = random.uniform(subkey, shape=w2.shape, minval=-2, maxval=2) # sample final layer of weights and neural network output key, subkey = random.split(key) w3 = random.normal(subkey, shape=(D_H, D_Y)) key, subkey = random.split(key) w3 = random.uniform(subkey, shape=w3.shape, minval=-2, maxval=2) # we put a prior on the observation noise key, subkey = random.split(key) prec_obs = random.normal(subkey) key, subkey = random.split(key) prec_obs = random.uniform(subkey, shape=prec_obs.shape, minval=-2, maxval=2) return w1, w2, w3, prec_obs def cond_fn(state): return state[0] < 100 def body_fn(state): i, key, _ = state key, subkey = random.split(key) return i + 1, key, model(subkey) init_state = (0, random.PRNGKey(0), model(random.PRNGKey(2019))) i, key, params = lax.while_loop(cond_fn, body_fn, init_state) ``` Interesting, if I use [rolled loop in threefry_2x32](https://github.com/google/jax/blob/master/jax/random.py#L138), the issue does not happen. Could it be a hint? cc @mattjj :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Enable serialization of Optimizers <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Enable serialization and de-serialization of the `Optimizer`s such that they can be sent to Qiskit Runtime as algorithm settings. This is easily done by adding `to_dict` and `from_dict` methods and agree on a common structure, such as ```python {'name': 'SPSA', # required key 'maxiter': 100, # other settings } ``` It's probably best to wait after #6319 is merged and then add it to the `SciPyMinimizer` base class. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Only Windows BuildTools installed Here in package tools there is an issue related with an installation of only the buildtools, but not the whole visual studio, investigate how the vcvars command is working (or failing) and how vswhere.exe could help: https://github.com/conan-io/conan-package-tools/pull/137 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add optional argument to pull dependencies on docker-compose pull. This adds the `--include-deps` argument to `docker-compose pull` to additionally pull all dependencies/links images for the specified SERVICE. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: under Windows, \"ipython3 nbconvert \"C:/blabla/first_try.ipynb\" --to latex\" write \"\\\" instead of \"/\" to reference file path in the .tex file Hello, I tried the new nbconvert feature of IPython1.0.0rc1 this morning on a Windows Vista PC. The .TEX generated file is perfect EXCEPT the directory separator character, which is unfortunately written as \"\\\" instead of \"/\". Example (abstract) : ***\\* instruction used to create the .TEX file **** ipython3 nbconvert \"C:/blabla/bla/first_try.ipynb\" --to latex gives (First 5 lines) : ***_(begining of abstract) ***_* % Header, overrides base % Make sure that the sphinx doc style knows who it inherits from. \\def\\sphinxdocclass{article} % Declare the document class \\documentclass[letterpaper,10pt,english]{C:\\blabla\\winpython\\WinPython-32bit-3.3.2.1rc1\\python-3.3.2\\lib\\site-packages\\sphinx\\texinputs/sphinxhowto} **\\* (..., then a reference to another document, also with a \"\\\" instead of a \"/\") *** \\begin{center} \\includegraphics[max size={\\textwidth}{\\textheight}]{first_try_files\\first_try_3_0.png} \\par \\end{center} **\\* (end of abstract) ***** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Metrics: Confusion Matrix ## 🚀 Feature Implement Confusion Matrix Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson_exe: Don't assert that we need an exe_wrapper when we say we do… …n't need one Fixes cross compiling mesa from x86_64 -> x86 on an x86_64 system. Fixes #5567 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Always checkpoint al least once ? When downloading notebook directly to hard drive, we should probably do a checkpoint on first open, always. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: functions marked with NPY_NO_EXPORT still are exported Steps to reproduce (on linux): - git checkout - `python setup.py build_ext` - choose a random function marked with the `NPY_NO_EXPORT` macro, for instance [`datetime_metadata_divides`](https://github.com/numpy/numpy/blob/v1.15.4/numpy/core/src/multiarray/_datetime.h#L108) and ~call `nm build/lib*/numpy/core/_multiarray_umath*.so |grep datetime_metadata_divides`~ check that the function is not exported: ``` import ctypes, numpy as np dll = ctypes.CDLL(np.core._multiarray_umath.__file__) print(getattr(dll, `datetime_metadata_divides`, None) ``` Note that the function appears in the result. It should not. I think the problem is in the `visibility_define` [function](https://github.com/numpy/numpy/blob/v1.15.4/numpy/core/setup.py#L379) which only hides the functions for gcc 4. Edit: use ctypes to check for export Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Port range like 8000-8010:80 PR #4649 says that it fixes #4378, which is the usage of port range in docker-compose. But it does not work (or I'm missing something). I've made a very simple docker-compose to test it ``` version: '3.3' services: nginx: image: nginx ports: - 4200-4500:80 ``` with docker-compose version : 1.17.0dev (same result with 1.16.1) and docker : 17.06.0-ce I've checked the source code, and it seems that there is no test for this use case. The docker-compose.yml in the test/fixtures/ports-composefile miss an case with port range. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Improve error message for type mismatch <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In `qiskit/validation/base.py`, function `check_types`: if type does not match, the error message currently prints the expected type. It would help if it also prints the actual type. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pkgconfig: accept another PkgConfigDependency as requires argument Something like: ```meson pkgg = import('pkgconfig') openssl = dependency('openssl') foo_pc = pkgg.generate(name : 'foo', requires : openssl) bar_pc = pkgg.generate(name : 'bar', requires: foo_pc) ``` Which would create `foo.pc` with `Requires: openssl` and `bar.pc` with `Requires: foo`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: indicate global phase in circuit drawer If a circuit has the global_phase property (introduced in #4565 ) set to something non-zero, then the circuit drawer should show that somewhere. I don't know where, somewhere that looks good (bottom or upper-right maybe). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Assertion error when using libm from find_library() Running Meson fails with Nautilus, as we do explicit linking with libm. ``` Traceback (most recent call last): File \"/home/ernestas/Development/github.com/mesonbuild/meson/mesonbuild/mesonmain.py\", line 353, in run app.generate() File \"/home/ernestas/Development/github.com/mesonbuild/meson/mesonbuild/mesonmain.py\", line 152, in generate self._generate(env) File \"/home/ernestas/Development/github.com/mesonbuild/meson/mesonbuild/mesonmain.py\", line 209, in _generate g.generate(intr) File \"/home/ernestas/Development/github.com/mesonbuild/meson/mesonbuild/backend/ninjabackend.py\", line 210, in generate self.generate_target(t, outfile) File \"/home/ernestas/Development/github.com/mesonbuild/meson/mesonbuild/backend/ninjabackend.py\", line 461, in generate_target elem = self.generate_link(target, outfile, outname, obj_list, linker, pch_objects) File \"/home/ernestas/Development/github.com/mesonbuild/meson/mesonbuild/backend/ninjabackend.py\", line 2465, in generate_link self.determine_rpath_dirs(target), File \"/home/ernestas/Development/github.com/mesonbuild/meson/mesonbuild/backend/backends.py\", line 337, in determine_rpath_dirs for rp in self.rpaths_for_bundled_shared_libraries(target): File \"/home/ernestas/Development/github.com/mesonbuild/meson/mesonbuild/backend/backends.py\", line 326, in rpaths_for_bundled_shared_libraries assert(not os.path.isabs(rel_to_src)) AssertionError ``` The code in Meson checks if the path is a system path by looking at its prefix, but on my machine it seems to be a bit more exotic: `/usr/bin/../lib/gcc/x86_64-redhat-linux/7/../../../../lib64/libm.so`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Define sys.ps{1,2} See https://bugs.launchpad.net/ipython/+bug/512826 for prior history. Summary: we should define sys.ps{1,2} to make it easier for scripts to detect if they are being loaded interactively or not, and without ipython-specific checks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Consider exposing value of wrap-mode I have a dependency (libetpan) which uses a config-tool rather then pkg-config. I can implement this fine with find_program() and run_command() to extract the cflags, libs etc and create the dependency using declare_dependency(). However I can not make this behave correctly in the face of `--wrap-mode=forcefallback` since I do not have access to the wrap mode being used. Would it be possible to expose this somehow? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: empty -D flag passed to g++ causes build to fail meson 0.51.0 generates this compile command and the resulting error: ``` c++ -Imeson-out/25a6634@@alphabot@exe -Isrc -I../src -I/usr/include/libdrm -I/usr/include -I/usr/include/SDL2 -I/usr/include/freetype2 -I/usr/include/libpng16 -I/usr/include/harfbuzz -I/usr/include/glib-2.0 -I/usr/lib/glib-2.0/include -fdiagnostics-color=always -pipe -D_FILE_OFFSET_BITS=64 -Wall -Winvalid-pch -Wnon-virtual-dtor -std=c++17 -g -D_REENTRANT -D -MD -MQ 'meson-out/25a6634@@alphabot@exe/main.cpp.o' -MF 'meson-out/25a6634@@alphabot@exe/main.cpp.o.d' -o 'meson-out/25a6634@@alphabot@exe/main.cpp.o' -c ../src/main.cpp cc1plus: error: to generate dependencies you must specify either ‘-M’ or ‘-MM’ ``` The error is caused by the empty -D after -D_REENTRANT which confuses g++ 9.1.0. the meson.build file looks like this: ``` libgl = dependency('GL') libpng = dependency('PNG') libsdl2 = dependency('SDL2') libsdl2_mixer = dependency('SDL2_mixer') libfreetype2 = dependency('freetype2') executable('alphabot', 'main.cpp', implicit_include_directories: true, dependencies: [libgl, libpng, libsdl2, libsdl2_mixer, libfreetype2], #cpp_args : '-DTEST', install: true) ``` Uncommenting #cpp_args : '-DTEST' will result in \"-D_REENTRANT -D -DTEST\" and allow the compilation to succeed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Documentation on how to vmap on dictionary entries I have a related question to #2367: Is it possible to use `vmap` on an array that is in a dictionary? And if yes, how? To stick with the example given in #2367, how to `vmap` 'b', which is an array within a dictionary: ``` import jax.numpy as np from jax import vmap dictionary = {'a': 5., 'b': np.arange(5)} c = 1. d = 2. def f(dct, c, d): return dct['a'] + dct['b'] + c + d result = vmap(f, magic)(dictionary, c, d) ``` I don't understand how I would have to create the magic axes tuple for this example or if it is even possible? I think it would be great if there would be a related example in the [documentation of vmap](https://jax.readthedocs.io/en/latest/jax.html?highlight=vmap#jax.vmap). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Revert \"Display parameter values from serialized dag in trigger dag view. (#27482) This reverts commit 9409293514cef574179a5320ed3ed50881064423. @tirkarthi we can't view grid view of a dag if the Param type is boolean ```python int1 = randint(20, 200) bool1 = [] bools = bool1.append(True) if int1 % 2 == 0 else bool1.append(False) @task def fail_if_invalid(val): print(val) assert type(val[0]) == bool @dag( start_date=datetime(1970, 1, 1), schedule_interval=timedelta(days=365 * 30), params={\"val\": Param(False, type=\"boolean\")}, doc_md=docs, tags=[\"core\", \"taskflow-api\", \"dag-params\"], ) def bool_taskflow_test(bool_val): # val is a DagParam object # print(val) # <airflow.models.param.DagParam object at 0x103360b50> # the task dereferences it fail_if_invalid(bool_val) the_dag = bool_taskflow_test(bool1) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: pubsub should have a default flow controller re: https://github.com/GoogleCloudPlatform/google-cloud-python/issues/5058#issuecomment-378412550 PubSub should come configured with a default flow controller and some arbitrary default max messages (several other languages use 1000 as the number), with documentation around tuning it for higher-throughput workloads (which requires more memory). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Qt5 module complains when the (previously) optional lrelease program isn't found New behavior in 0.49.0: `meson.build:47:0: ERROR: Program(s) ['lrelease'] not found or not executable` On quite many distributions the `lrelease` tool is only in the `qt5-tools` (or similarly named) package while the base parts of Qt are in `qt5-base` (which was previously enough to use Qt5 with meson). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Longformer] Output both local attentions and global attentions when `output_attentions=True` -> Good Second Issue # 🚀 Feature request **Good Second Issue** - A more advanced issue for contributors who want to dive more into Longformer's attention mechanism. Longformer currently only outputs global attentions, which is suboptimal because users might be interested in the local attentions as well. I propose to change the \"output_attention\" logic as follows in longformer: `attentions` should correspond to the \"local\" attentions and then we'll add a new output type `global_attention` that contains the global_attentions. This is consistent with the naming of `attention_mask` and `global_attention_mask` IMO and the cleanest way to implement the feature. Implementing this feature would mean to that Longformer will require its own `ModelOutput` class => `BaseModelOutput,` => `LongformerBaseModelOutput` or `BaseModelOutputWithGlobalAttention` (prefer the first name though) `BaseModelOutputWithPooling,` => ... Also some tests will have to be adapted. This is a slightly more difficult issue, so I'm happy to help on it. One should understand the difference between local and global attention and how Longformer's attention is different to *e.g.* Bert's attention in general. For more detail check out discussion here: https://github.com/huggingface/transformers/issues/5646 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: find_cmd test failure on Windows I think this is caused by #3301. The [Windows implementation of find_cmd](https://github.com/ipython/ipython/blob/master/IPython/utils/_process_win32.py#L74) expects a command name without an extension, but the test now uses 'python.exe'. I think that 'python.exe' is a valid command on Windows, so I think we should modify `find_cmd` to allow passing a command with an extension. Alternatively, we could modify the test to strip the extension. ``` ====================================================================== ERROR: Make sure we find sys.exectable for python. ---------------------------------------------------------------------- Traceback (most recent call last): File \"S:\\Users\\slave\\Jenkins\\shiningpanda\\jobs\\d5f643a2\\virtualenvs\\ff035a1d\\lib\\site-packages\\nose\\case.py\", line 197, in runTest self.test(*self.arg) File \"S:\\Users\\slave\\Jenkins\\shiningpanda\\jobs\\d5f643a2\\virtualenvs\\ff035a1d\\lib\\site-packages\\ipython-1.0.dev-py2.7.egg\\IPython\\utils\\tests\\test_process.py\", line 36, in test_find_cmd_python nt.assert_equal(find_cmd(python), sys.executable) File \"S:\\Users\\slave\\Jenkins\\shiningpanda\\jobs\\d5f643a2\\virtualenvs\\ff035a1d\\lib\\site-packages\\ipython-1.0.dev-py2.7.egg\\IPython\\utils\\process.py\", line 67, in find_cmd raise FindCmdError('command could not be found: %s' % cmd) FindCmdError: command could not be found: python.exe ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: scheduler gets stuck without a trace **Apache Airflow version**: **Kubernetes version (if you are using kubernetes)** (use `kubectl version`): **Environment**: - **Cloud provider or hardware configuration**: - **OS** (e.g. from /etc/os-release): - **Kernel** (e.g. `uname -a`): - **Install tools**: - **Others**: **What happened**: The scheduler gets stuck without a trace or error. When this happens, the CPU usage of scheduler service is at 100%. No jobs get submitted and everything comes to a halt. Looks it goes into some kind of infinite loop. The only way I could make it run again is by manually restarting the scheduler service. But again, after running some tasks it gets stuck. I've tried with both Celery and Local executors but same issue occurs. I am using the -n 3 parameter while starting scheduler. Scheduler configs, job_heartbeat_sec = 5 scheduler_heartbeat_sec = 5 executor = LocalExecutor parallelism = 32 Please help. I would be happy to provide any other information needed **What you expected to happen**: **How to reproduce it**: **Anything else we need to know**: Moved here from https://issues.apache.org/jira/browse/AIRFLOW-401 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.50.0: test target: AttributeError: Can't get attribute 'ConfigData' on <module 'mesonbuild.coredata' from '/usr/lib/python3.7/site-packages/mesonbuild/coredata.py'> <pre>+ /usr/bin/ninja test -v -j4 -C x86_64-redhat-linux-gnu ninja: Entering directory `x86_64-redhat-linux-gnu' [0/1] /usr/bin/meson test --no-rebuild --print-errorlogs Traceback (most recent call last): File "/usr/lib/python3.7/site-packages/mesonbuild/mesonmain.py", line 122, in run return options.run_func(options) File "/usr/lib/python3.7/site-packages/mesonbuild/mtest.py", line 1002, in run return th.doit() File "/usr/lib/python3.7/site-packages/mesonbuild/mtest.py", line 753, in doit self.run_tests(tests) File "/usr/lib/python3.7/site-packages/mesonbuild/mtest.py", line 888, in run_tests self.build_data = build.load(os.getcwd()) File "/usr/lib/python3.7/site-packages/mesonbuild/build.py", line 2307, in load obj = pickle.load(f) AttributeError: Can't get attribute 'ConfigData' on <module 'mesonbuild.coredata' from '/usr/lib/python3.7/site-packages/mesonbuild/coredata.py'> FAILED: meson-test /usr/bin/meson test --no-rebuild --print-errorlogs ninja: build stopped: subcommand failed. error: Bad exit status from /var/tmp/rpm-tmp.GduYpo (%check) </pre> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan suddenly requires user authentication for accessing conan server conan client: 1.14.0 (Windows) conan server: 1.0.2 (Windows) For over a year, we have a conan server 1.0.2 running without any changes to its configuration. It has the following read permissions, i.e. everybody should be able to download packages: [read_permissions] # opencv/1.2.3@lasote/testing: default_user default_user2 # By default all users can read all blocks */*@*/*: * Since installing conan 1.14.0 (or maybe 1.13.x), the client suddenly starts asking for credentials to access the server when using ``conan install``. To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: The pulse drawer should not override Matplotlib RCparams <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? The pulse drawer inherits its styling [from](https://qiskit.org/documentation/stubs/qiskit.visualization.pulse.qcstyle.html). This overrides the default [Matplotlib rcparams](https://matplotlib.org/tutorials/introductory/customizing.html) which should determine the default parameters. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose run --rm does not remove volumes Running one-off commands with docker-compose does not delete volumes used by the container. This is different than `docker run --rm` which does remove volumes after the container is deleted. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.conj vs np.conjugate Both ``numpy.conj`` and ``numpy.conjugate`` exist, and in fact the docs for ``conj`` show examples that use ``conjugate``: https://docs.scipy.org/doc/numpy-1.12.0/reference/generated/numpy.conj.html Furthermore, the page for numpy.conjugate doesn't exist. It would be nice to make this more consistent, e.g. change the examples in for the ``conj`` page to use ``conjugate``, or add a note to the ``conj`` docs that either can be used. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Can't pickle UFuncTypeError numpy 1.18.4-py38h8854b6b_0 (conda-forge) Linux x64 ```python import pickle import numpy try: numpy.ones(1) * \"foo\" except Exception as e: pickle.dumps(e) ``` Output: ``` Traceback (most recent call last): File \"ufunctypeerror.py\", line 6, in <module> numpy.ones(1) * \"foo\" numpy.core._exceptions.UFuncTypeError: ufunc 'multiply' did not contain a loop with signature matching types (dtype('<U32'), dtype('<U32')) -> dtype('<U32') During handling of the above exception, another exception occurred: Traceback (most recent call last): File \"ufunctypeerror.py\", line 8, in <module> pickle.dumps(e) _pickle.PicklingError: Can't pickle <class 'numpy.core._exceptions.UFuncTypeError'>: it's not the same object as numpy.core._exceptions.UFuncTypeError ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Move gax functionality into google.api.core - [x] [retry](https://github.com/googleapis/gax-python/blob/baa1c13545c642d461c44e6d5f71d6ec446be5f5/google/gax/retry.py) - [x] [timeout](https://github.com/googleapis/gax-python/blob/baa1c13545c642d461c44e6d5f71d6ec446be5f5/google/gax/retry.py) - [x] [path template](https://github.com/googleapis/gax-python/blob/baa1c13545c642d461c44e6d5f71d6ec446be5f5/google/gax/path_template.py) [(context)](https://github.com/googleapis/googleapis/blob/master/google/api/http.proto#L212) - [x] [api callable](https://github.com/googleapis/gax-python/blob/baa1c13545c642d461c44e6d5f71d6ec446be5f5/google/gax/api_callable.py) - [x] loading gapic config - [x] grpc error wrapping - [x] plain methods - [x] paged methods - [x] LRO client & methods - [x] [utils](https://github.com/googleapis/gax-python/tree/baa1c13545c642d461c44e6d5f71d6ec446be5f5/google/gax/utils) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Backport 10361 Not sure how you keep track of these things, @charris, but let's not let backporting #10361 slip off the radar. Backport 10361 Not sure how you keep track of these things, @charris, but let's not let backporting #10361 slip off the radar. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Package revisions Most package managers have a concept of package revision, i.e. additional version number that reflects changes in packaging scripts or applied patches when \"main\" version number of packaged software remains the same. It would be great if Conan added support for revisions too. This will make package updates more trasparent (\"updated from vX.Y.Z-r1 to vX.Y.Z-r2\"). Also there could be a policy that \"stable\" channel can never change conanfile and binaries without bumping revision, to prevent accidental changes in packages used in CI with manifest verification. It would be great if it was possible to keep binary packages for previous revisions so that CI system with manifests checking does not get broken in case new revision is uploaded without committing new reference manifests. It was previously briefly discussed at https://github.com/conan-io/conan/issues/480#issuecomment-247545547 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Bug when constructing a selection widget with both values and labels Length validation causes selection widgets constructed with both values and labels to fail. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: `ERROR: Cannot get the latest package without RREV` from `conan graph build-order` when all packages are cached Conan version: **1.18.2** I'm designing our new CI buid process based on lockfiles and revisions. If I have all packages built in the local cache and rerun the build, I'm getting the error mentioned in the the title. This is the invocation: ``` ❯ ./conan-bin graph build-order --build cascade --build outdated conan.lock Using lockfile: '/home/tamas/work/conan/conan.lock' bzip2/1.0.6: Package is up to date iconv/1.15: Package is up to date zlib/1.2.8: Package is up to date boost/1.69.0: Package is up to date ERROR: Cannot get the latest package without RREV. [Remote: toolchain] ``` If I remove at least one of the packages that were built (via `conan remove`) I'm not getting an error. I have no idea what this means, any clues? What can I do to avoid it? Also, I think `CONAN_VERBOSE_TRACEBACK` is broken as I'm not able to get a traceback for this error. EDIT: I created a minimal(-ish) repro [here](https://github.com/sztomi/cannot_get_latest_package). See the README in that repo for instructions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error in documentation for QuantumCircuit.rz() ### Environment - **Qiskit Terra version**: 0.19.1 - **Python version**: 3.8.10 - **Operating system**: n/a ### What is happening? Documentation description of `QuantumCircuit.rz()` says \"Apply `RYGate`\". Should be \"Apply `RZGate`\". ### How can we reproduce the issue? n/a ### What should happen? Change documentation to \"Apply `RZGate`\". ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Move ShellTask out of prefect.tasks.core `prefect.tasks.core` is intended for tasks that are used by Prefect in some way -- for example, operators and `FunctionTask` (and, arguably, `Parameters`?) I suggest moving `shell_task.py` to `src/prefect/tasks/shell_task.py` Move ShellTask out of prefect.tasks.core `prefect.tasks.core` is intended for tasks that are used by Prefect in some way -- for example, operators and `FunctionTask` (and, arguably, `Parameters`?) I suggest moving `shell_task.py` to `src/prefect/tasks/shell_task.py` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Using multiple SamplePulses with the same name overwritten in Qobj pulse library <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? In the Qobj specification, pulse are identified by their name. In the pulse module pulses are identified by their object instance and when assembled are stored in the Qobj pulse library by name. If two `SamplePulse`s of the same name exist, the second will overwrite the first, causing undesired behaviour. ### Steps to reproduce the problem Create a pulse schedule with two different pulses of the same name and assemble into a Qobj. ### What is the expected behavior? Unique pulses should be stored uniquely in the Qobj pulse library. ### Suggested solutions If a name collision occurs when building the pulse library. Modify the name of the sample pulse in some consistent manner, and adjust the commands that refer to this pulse. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qc.qasm() does not include params of composited gates ### Information - **Qiskit Terra version**: 0.15.2 - **Python version**: 3.7.7 - **Operating system**: macOS 10.15.6 ### What is the current behavior? When you create a `QuantumCircuit` from a qasm string including composited gates, ```python from qiskit.circuit import QuantumCircuit qasm_str = ( 'OPENQASM 2.0;' 'include \"qelib1.inc\";' 'gate nG0 (param0) q0 { h q0; }' 'qreg q[3];' 'creg c[3];' 'nG0 (pi) q[0];' ) qc = QuantumCircuit.from_qasm_str(qasm_str) ``` the circuit is correctly created. But if you get qasm from the already created circuit ```python qc.qasm(formatted=True) ``` ```qasm OPENQASM 2.0; include \"qelib1.inc\"; gate nG0 q0 {h q0; } // it should be: gate nG0 (param0) q0 { h q0; } qreg q[3]; creg c[3]; nG0(pi) q[0]; ``` the composited gates params are not present, so the qasm is incorrect. Any attempt of creating a new quantum circuit from this qasm will fail: ```python qc2 = QuantumCircuit.from_qasm_str(qc.qasm()) ``` ```python QasmError: \"Gate or opaque call to 'nG0' uses 1 qubits but is declared for 0 qubits line 6 file \" ``` ### What is the expected behavior? The qasm of the created quantum circuit should include the params of the composited gate. ```python qc.qasm(formatted=True) ``` ```qasm OPENQASM 2.0; include \"qelib1.inc\"; gate nG0 (param0) q0 {h q0; } qreg q[3]; creg c[3]; nG0(pi) q[0]; ``` ### Suggested solutions Take into account `Instruction` params when creating qasm in `qc.qasm()`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Fix Failing BigTable System tests https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/6646 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: bucket.list_blobs(max_results=n) has no effect passing `max_results=5` to `bucket.list_blobs()` appears to have no effect; all blobs are returned in the `BlobIterator` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: stale_refs failing due to unhandled \"xxxxxx will become dangling!\" message With a repo set up in way that `git remote prune --dry-run origin`returns the following: ``` URL: .... my repo utl... * [would prune] origin/some-branch * [would prune] origin/some-more-branches * [would prune] origin/main refs/remotes/origin/HEAD will become dangling! ``` **stale_refs** throws `ValueError: Could not parse git-remote prune result: ' refs/remotes/origin/HEAD will become dangling!'` I suppose this warning message should just silently be skipped at https://github.com/gitpython-developers/GitPython/blob/main/git/remote.py#L614 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: displacy RTL support Unfortunately, it seems that displacy doesn't support LTR. It scrambles the text when I tried to visualize a doc in Persian using `style=ner` or `style=dep`. ## My Environment * Operating System: Mac OS X * Python Version Used: 3.6 * spaCy Version Used: 2.0.7 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ERROR: Internal Python error in the inspect module. Looks like this is related to issue #53. I just got the following in the notebook: ``` In [33]: # Switch to NumPy pw.prtparam = p ``` ``` Traceback (most recent call last): File \"C:\\Python27\\lib\\site-packages\\ipython-0.13.dev-py2.7.egg\\IPython\\core\\ultratb.py\", line 756, in structured_traceback records = _fixed_getinnerframes(etb, context, tb_offset) File \"C:\\Python27\\lib\\site-packages\\ipython-0.13.dev-py2.7.egg\\IPython\\core\\ultratb.py\", line 242, in _fixed_getinnerframes records = fix_frame_records_filenames(inspect.getinnerframes(etb, context)) File \"C:\\Python27\\lib\\inspect.py\", line 1041, in getinnerframes framelist.append((tb.tb_frame,) + getframeinfo(tb, context)) File \"C:\\Python27\\lib\\inspect.py\", line 1005, in getframeinfo lines, lnum = findsource(frame) File \"C:\\Python27\\lib\\inspect.py\", line 578, in findsource if pat.match(lines[lnum]): break IndexError: list index out of range ERROR: Internal Python error in the inspect module. Below is the traceback from this internal error. Unfortunately, your original traceback can not be constructed. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Fortran 2008 submodule Fortran 2008 added `submodule`, which is quite useful for good structure and fast builds of Fortran programs. The present lack of `submodule` support in Meson is a key blocker for Fortran use. Meson does not appear to understand the `submodule` statement. A self-contained single `.f90` file will of course compile correctly, but almost all use cases for `submodule` are where the submodule is in a different `.f90` file from the `module` containing the `submodule`. Here is a simple example consisting of two files. file `basic.f90` ```fortran module demo real, parameter :: pi = 4.*atan(1.) real :: tau interface module subroutine hello(pi,tau) real, intent(in) :: pi real, intent(out) :: tau end subroutine hello end interface contains end module demo program sm use demo call hello(pi, tau) print *,'pi=',pi, 'tau=', tau end program ``` file `basic_sub.f90` ```fortran submodule (demo) hi contains module procedure hello tau = 2*pi end procedure hello end submodule hi ``` file `meson.build` ```meson executable('basic', ['basic.f90', 'basic_sub.f90']) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Support for `Parameter`s with complex values <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Parameters are now used in schedules. Schedules have pulses which may have complex amplitudes. I'd like to be able to do this: ``` from qiskit import pulse from qiskit.circuit import Parameter amp = Parameter('amp') sched = pulse.Schedule() sched += pulse.Play(pulse.Gaussian(duration=128, sigma=16, amp=amp), pulse.DriveChannel(0)) sched.assign_parameters({amp: 0.2j}) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Preprocess/transform logits before gathering them for computing metrics. ### Feature request In `trainer.evaluation_loop`, `preprocess_logits_for_metrics` should be executed before `_nested_gather` to avoid GPU OOM. ### Motivation `preprocess_logits_for_metrics` processes logits after gathering them when do distributed learning. When training with large batch_size, token_length or vocab_size, gathering all logits to 1 node will cause to out of GPU memory. This preprocessing should be executed before `_nested_gather`. ### Your contribution The main modification would be this in `trainer.evaluation_loop`: ``` if logits is not None: logits = self._pad_across_processes(logits) if self.preprocess_logits_for_metrics is not None: logits = self.preprocess_logits_for_metrics(logits, labels) logits = self._nested_gather(logits) preds_host = logits if preds_host is None else nested_concat(preds_host, logits, padding_index=-100) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Smaller last batch skews Train/EvalResult ## 🚀 Feature Supported weighted average for Result ### Motivation The last batch of dataloader is usually smaller than a regular batch. Hence simply average the statistic of all batches will skew the epoch statistic. _For example_ ``` result.log('accuracy', 0.7) # batch size 256 result.log('accuracy', 0.8) # batch size 256 result.log('accuracy', 0.9) # batch size 10 (last batch) ``` Wrong epoch accuracy =` (0.7 + 0.8 + 0.9) / 3` Correct epoch accuracy = `(256 * 0.7 + 256 * 0.8 + 10 * 0.9) / ( 256 + 256 + 10)` ### Pitch Support input for weight, or batch size in Result `result.log('accuracy', 0.7, batch_size) ` ### Alternatives I don't see any alternatives other than switch back the the old way of using training/validation_epoch_end and do the weighted average manually there. ### Additional context <!-- Add any other context or screenshots about the feature request here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: a.size and np.prod(a.shape) are not equivalent The documentation of `ndarray.size` claims that `a.size` is equivalent to `np.prod(a.shape)`. While they do return the same value, they return different types and therefore are not equivalent. ```python a = np.zeros((2, 2)) type(a.size) # returns <class 'int'> type(np.prod(a.shape)) # returns <class 'numpy.int64'> ``` Continuing the calculations using `np.prod(a.shape)` can therefore lead to integer overflows. I guess `np.prod(a.shape)` cannot be changed to return a `<class 'int'>` instance, and `a.size` should certainly not be changed to return a `<class 'numpy.int64'>` instance, so probably the only solution is to update the documentation to reflect that these two are not fully equivalent. I'd be happy to make pull-request to update the documentation accordingly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: ImportError: cannot import name 'BloomTokenizer' from 'transformers' ### System Info transformers==4.20.1 torch==1.12.0 Python 3.9.13 GPU: yes (running on GCP) ### Who can help? @SaulLu ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ``` from transformers import BloomTokenizer, BloomModel ``` I was following https://huggingface.co/docs/transformers/model_doc/bloom Specifically ``` from transformers import BloomTokenizer, BloomModel import torch tokenizer = BloomTokenizer.from_pretrained(\"bigscience/Bloom\") model = BloomModel.from_pretrained(\"bigscience/Bloom\") inputs = tokenizer(\"Hello, my dog is cute\", return_tensors=\"pt\") outputs = model(**inputs) last_hidden_states = outputs.last_hidden_state ``` ### Expected behavior No import error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Provide 'tools.rename' utility in the new tools namespace A new function to rename files/folders that uses current implementation (_robocopy_ for Windows), but will accept the `conanfile` so we can control behavior in the future if needed ```python def rename(conanfile, src, dst): # Mostly copied from current conans.tools.rename ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: `fs_io_manager` wrong documentation ## What content is missing I found a small issue in the documentation about the `fs_io_manager`: ``` dagster.core.errors.DagsterInvalidConfigError: Error in config for resource io_manager Error 1: Received unexpected config entry \"base_path\" at path root:config. Expected: \"{ base_dir?: (String | { env: String }) }\". ``` ## Type of the content The configuration for `fs_io_manager` should be: ``` @job( resource_defs={ \"io_manager\": fs_io_manager.configured({**\"base_dir\"**: \"/my/base/path\"}) } ) ``` instead of ``` @job( resource_defs={ \"io_manager\": fs_io_manager.configured({\"base_path\": \"/my/base/path\"}) } ) ``` from documentation here: https://docs.dagster.io/_apidocs/io-managers#dagster.fs_io_manager --- #### Message from the maintainers: Are you looking for the same documentation content? Give it a :thumbsup:. We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: canary: mkdir option removed from conda create on a minor bump On conda 4.5 ```bash $ conda create -n testmkdir --mkdir ``` It works On 4.6 on canary ```bash $ conda create -n testmkdir --mkdir ``` It fails. Removing an option from the CLI in a minor version sounds like a no no. Could we instead deprecate (even if the option does not do anything?) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Make the documentation the root of the GH page. Also - how would this work when it comes to moving to the GoogleCloudPlatform page...? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan search <reference> for recipe without binary packages In case there is a recipe without binary packages in the local cache, `conan search` with a full reference just prints `There are no packages for pattern '<ref>'` - \"pattern\" is wrong, should be \"reference\" - Something like \"Package recipe found\" would be nice. - The same command with a suffixed \"*\" gives more information, although the request is less specific. This happens mainly when `conan create` fails between export and package. I was confused about the inconsistent outputs with pattern and reference. Steps to reproduce: ``` > conan search zlib* There are no packages matching the zlib* pattern > conan info zlib/1.2.11@conan/stable ...downloads the recipe > conan search zlib* Existing package recipes: zlib/1.2.11@conan/stable > conan search zlib/1.2.11@conan/stable* Existing package recipes: zlib/1.2.11@conan/stable > conan search zlib/1.2.11@conan/stable There are no packages for pattern 'zlib/1.2.11@conan/stable' ``` Conan 1.0.1, Windows - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: add qiskit.backend methods for getting parameter and calibration data Add methods to qiskit.backends for getting parameters and calibration data. ## Expected Behavior <!--- If you're describing a bug, tell us what should happen --> <!--- If you're suggesting a change/improvement, tell us how it should work --> ## Current Behavior Currently the way to obtain backend parameters and calibration is through QuantumProgram methods. These could be moved to qiskit.backends. ## Possible Solution <!--- Not obligatory, but suggest a fix/reason for the bug, --> <!--- or ideas how to implement the addition or change --> ## Steps to Reproduce (for bugs) <!--- Provide a link to a live example, or an unambiguous set of steps to --> <!--- reproduce this bug. Include code to reproduce, if relevant --> 1. 2. 3. 4. ## Context <!--- How has this issue affected you? What are you trying to accomplish? --> <!--- Providing context helps us come up with a solution that is most useful in the real world --> ## Your Environment <!--- Include as many relevant details about the environment you experienced the bug in --> * Version used: * Environment name and version (e.g. Python 3.6.1): * Operating System and version: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: dagster-ge great_expectations pin It looks like dagster-ge should have a bottom pin of `0.11.9`: ``` import: 'dagster_ge' Traceback (most recent call last): File \"/home/conda/feedstock_root/build_artifacts/dagster_1598270757893/test_tmp/run_test.py\", line 2, in <module> import dagster_ge File \"/home/conda/feedstock_root/build_artifacts/dagster_1598270757893/_test_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehol/lib/python3.7/site-packages/dagster_ge/__init__.py\", line 1, in <module> from .factory import ge_validation_solid_factory File \"/home/conda/feedstock_root/build_artifacts/dagster_1598270757893/_test_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehol/lib/python3.7/site-packages/dagster_ge/factory.py\", line 6, in <module> from great_expectations.render.page_renderer_util import ( ModuleNotFoundError: No module named 'great_expectations.render.page_renderer_util' ``` This file is present in 0.11.9, but not in 0.11.8: - https://github.com/great-expectations/great_expectations/tree/0.11.8/great_expectations/render - https://github.com/great-expectations/great_expectations/tree/0.11.9/great_expectations/render Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: UFunc benchmarks complaining lack of coverage of matmul and _arg When running benchmarks, a warning appears (see https://github.com/numpy/numpy/pull/12666#issuecomment-451790069) that ``` [ 0.00%] ···· Missing ufunc '_arg' Missing ufunc 'matmul' ``` This originates on https://github.com/numpy/numpy/blob/master/benchmarks/benchmarks/bench_ufunc.py#L25 I think `matmul` may well be tested elsewhere, so can be excluded here. `np.core.umath_arg.__doc__` suggests `_arg` is for testing purposes only; am not sure why it is exported. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Fix #67 - Added check to install python-dev. Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add optional pull to local agent If the image is present locally we don't want to attempt a pull from a registry Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: When our debugger class is used standalone `_oh` key errors are thrown See [this bug report](https://github.com/inducer/pudb/issues/30) for an example... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Spanner Unit Test b0rken on AppVeyor https://ci.appveyor.com/project/GoogleCloudPlatform/google-cloud-python/build/1.0.1072.master/job/qvj0q69feleskbpu Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython 1.1.0 Qtconsole syntax highlighting highlights python 2 only built-ins when using python 3 I used IPython 1.1.0 with Python 3.3.2 on 64bit windows to test this. IPython 1.1.0 Qtconsole highlights deprecated python2 built in functions. This includes : unicode, reload, execfile, cmp, apply, file, intern, basestring, xrange, buffer, long, unichr, raw_input, coerce, reduce I don't think they should be highlighted as they are deprecated. (IDLE doesn't highlight them.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: text drawer: gap between gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? This circuit ``` OPENQASM 2.0; include \"qelib1.inc\"; qreg q[7]; h q[0]; swap q[0],q[1]; cx q[2],q[3]; rz(0.100000000000000) q[2]; swap q[1],q[2]; swap q[2],q[3]; cx q[3],q[4]; swap q[5],q[4]; cx q[4],q[3]; cx q[4],q[3]; swap q[6],q[5]; swap q[5],q[4]; swap q[4],q[3]; swap q[3],q[2]; swap q[2],q[1]; cx q[1],q[0]; ``` draws as ``` ┌───┐ ┌───┐ q_0: |0>┤ H ├ ─X─ ────────────────────────────────────┤ X ├ └───┘ │ └─┬─┘ q_1: |0>───── ─X─ ─X────────────────────────────────X───■── ┌─────────┐ │ │ q_2: |0>──■──┤ Rz(0.1) ├─X──X──────────────────────────X──X────── ┌─┴─┐└─────────┘ │ ┌───┐┌───┐ │ q_3: |0>┤ X ├───────────────X───■─────┤ X ├┤ X ├────X──X───────── └───┘ ┌─┴─┐ └─┬─┘└─┬─┘ │ q_4: |0>──────────────────────┤ X ├─X───■────■───X──X──────────── └───┘ │ │ q_5: |0>────────────────────────────X─ ─X─ ──────X─────────────── │ q_6: |0>────────────────────────────── ─X─ ────────────────────── ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: logaddexp and logsumexp do not handle -inf correctly, don't match numpy/scipy logaddexp(-inf, -inf) should be -inf, is nan in jax implementations. numpy.logaddexp(np.NINF, np.NINF) => -inf jax.numpy.logaddexp(np.NINF, np.NINF) => nan Same issue for special.logsumexp Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Update NDArrayOperatorsMixin to implement __matmul__ using np.matmul `np.matmul` is now a ufunc (thanks to #12219), so we can support it with NDArrayOperatorsMixin now -- these lines in the docstring are now out of date! https://github.com/numpy/numpy/blob/82428bb72589c6fd781689feb1f501a6a29c6fdc/numpy/lib/mixins.py#L72-L73 This isn't a strict blocker for 1.16 but it would be good to get it in if possible. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: stax neural network initializers default to 32bit floats even in 64 bit mode I need/want to try out my code with 64 bit wide floats. My code uses neural networks setup with stax, the initializers for which default to 32 bit floats (and there is no useable API to change this in user facing code). Using the thus initialized (`float32`) parameters (and `float64` data batches) in an update `fori_loop` (taking the gradients with `value_and_grad` and updating parameters with any optimizer) results in either one of two faulty behaviors (depending on the exact nature of computation): 1. the gradients come out as `float32`, thus thwarting my intention of computing with `float64` values 2. the gradients come out as `float64`, which results in a type-mismatch exception thrown by `fori_loop` since the initial value argument passed to it was of type `float32` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `install_mode` in `custom_target` does not process integer values for uid/gid **Describe the bug** The `install_mode` kwarg for a `custom_target` cannot process integer values for `owner` and `group`. For instance, adding `install_mode: [false, 10000, 10000]` will not change the `uid` and `gid` to `10000` on installation. Replacing these integers with strings does not work either, as it then expects these to be actual user or group names. **To Reproduce** Sample `meson.build`: ```meson project('testproject') custom_target( 'target', build_by_default: true, output: 'test_output', command: [ 'touch', '@OUTPUT@', ], install: true, install_mode: [false, 10000, 10000], install_dir: meson.current_source_dir(), ) ``` Then, run: ```bash meson setup build sudo meson install -C build ``` On Linux, this will create a file in the `build` directory, before installing that file in the current directory. At the same time, it should change the `uid` and `gid` values to `10000`, but it does not. Looking at the code, I believe this comes from `mesonbuild/interpreter/typechecking.py`. The `_install_mode_convertor` function replaces all non string values with `None`: https://github.com/mesonbuild/meson/blob/84c412a921497432cc6884befddd0b29c3a389cd/mesonbuild/interpreter/type_checking.py#L97-L106 **Expected behavior** As written in the [docs](https://mesonbuild.com/Reference-manual_functions.html#custom_target), the `install_mode` kwarg should process correctly integer values for owner and group for a `custom_target`. **system parameters** Ubuntu 22.04.1 Python 3.10.6 meson 1.0.0 ninja 1.10.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: set_custom_exc exception handlers don't catch SyntaxError ``` In [6]: ipython = get_ipython() In [7]: def exc_handler(self, etype, value, tb, tb_offset=None): ...: print(etype) ...: return self.showtraceback() ...: In [9]: ipython.set_custom_exc((BaseException,), exc_handler) In [10]: bad <class 'NameError'> --------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-10-df207dc9143c> in <module>() ----> 1 bad NameError: name 'bad' is not defined In [11]: 1f File \"<ipython-input-11-0cd11c36f170>\", line 1 1f ^ SyntaxError: invalid syntax ``` (notice no `<class 'SyntaxError'>`) I vaguely remember noticing this before in the code because syntax errors are handled specially. This causes my [iTerm2 extension](https://iterm2-tools.readthedocs.org/en/latest/ipython.html) to not register syntax errors as \"failed\" prompts. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore: Ability to override base URL Seee https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/datastore/google/cloud/datastore/client.py. It is currently only possible to override the base URL: `_DATASTORE_BASE_URL = 'https://datastore.googleapis.com'` by setting the `GCD_HOST` environment variable: ``` try: host = os.environ[GCD_HOST] self._base_url = 'http://' + host except KeyError: self._base_url = _DATASTORE_BASE_URL ``` but this is meant to be used with the emulator and so does not use SSL. It would be helpful to be able to override base_url to an https address. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.loadtxt no longer loads bz2 files in python2 I have been using `np.loadtxt()` to happily load `txt.bz2` files for many years. I recently upgraded to numpy 1.14.2, and I noticed that it no longer seems possible to load a `txt.bz2` file using python2. Was this intensional, or some sort of bug? ``` Traceback (most recent call last): File \"/Users/danhickstein/Documents/GitHub/PyAbel-DH/examples/example_all_O2.py\", line 41, in <module> IM = np.loadtxt('data/O2-ANU1024.txt.bz2') File \"/anaconda2/lib/python2.7/site-packages/numpy/lib/npyio.py\", line 917, in loadtxt fh = np.lib._datasource.open(fname, 'rt', encoding=encoding) File \"/anaconda2/lib/python2.7/site-packages/numpy/lib/_datasource.py\", line 260, in open return ds.open(path, mode, encoding=encoding, newline=newline) File \"/anaconda2/lib/python2.7/site-packages/numpy/lib/_datasource.py\", line 614, in open encoding=encoding, newline=newline) File \"/anaconda2/lib/python2.7/site-packages/numpy/lib/_datasource.py\", line 88, in _python2_bz2open raise ValueError(\"bz2 text files not supported in python2\") ValueError: bz2 text files not supported in python2 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Better way to limit output cache size As discussed on #712 (tagging @stefanv): At present, if the output cache fills up (default 1000 items), it will be automatically flushed, leaving you with just the last three outputs in `_`, `__` and `___`. This could be annoying if you wanted to refer to something that's just been lost, and you're only warned about this when it's already happening. I propose that we drop the oldest 20% (say) of items when we hit the cache limit. This is a little more computationally intensive (sort 1000 integers, delete 200 keys from a dictionary), but it means that we always have at least the last 800 pyout objects stored. I think this should either be silent, or with a brief message the first time it happens (e.g. \"Starting to delete oldest cached output. The latest %d outputs at any point will still be available.\"). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: AttributeError: 'PushInfo' object has no attribute 'name' A simple call to: result = self._client.remotes.origin.push(**args) print(result.summary) results in: Traceback (most recent call last): File \"C:\\Users\\jsmith\\Envs\\halpy\\lib\\site-packages\\halpy\\cms.py\", line 623, in checkin_files print(result.summary) File \"C:\\Users\\jsmith\\Envs\\halpy\\lib\\site-packages\\git\\util.py\", line 883, in __getattr__ if getattr(item, self._id_attr) == attr: AttributeError: 'PushInfo' object has no attribute 'name' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: as*array functions incorrectly describe the order kwarg All of the functions such as `np.asanyarray`, `np.ascontiguousarray`, etc. simply forward to `np.array`, which supports `K` and `A` order. However, these do not document it correctly. Since all of those functions use `copy=False`, the can probably just list `K` and `A` and say that the value has no effect, unless a copy has to be made (in which case they can refer to `np.array`?) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: All agents with default labels are not registering their labels Currently, all agents that have default labels (e.g., `LocalAgent`) are not registering their labels when first registering with Prefect Cloud. This is because the cloud registration step occurs in the `__init__` of the base agent class, which is being called _before_ `self.labels` is fully realized. To be clear, the only consequence of this is that labels are not properly being displayed in the UI - because the agent queries for work using its labels, all work is being properly directed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: The settings compiler, compiler.version and cppstd can't be used for a custom compiler Using a custom compiler with a compiler version and cppstd will always raise an error. ```ERROR: The specified 'cppstd=14' is not available for 'compiler compiler.version'. Possible values are []'``` Steps to reproduce: 1. Add a new compiler with a version to the settings.yml 2. Create a profile using this compiler, the compiler version and the cppstd 3. Call conan install with this profile From looking at the code it looks like using a compiler with a version and cppstd is only possible for gcc, clang, apple-clang and Visual Studio. I would expect that the cppstd is not checked for an unknown compiler. Conan version: 1.8.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: nbconvert can't handle Heading with Chinese characters on Japanese Windows OS. Convert following notebook by `ipython nbconvert test.ipynb` will raise Exception: ``` File \"C:\\Python27\\lib\\site-packages\\ipython-1.0.0_dev-py2.7.egg\\IPython\\nbconv ert\\filters\\strings.py\", line 83, in add_anchor h = ElementTree.fromstring(py3compat.cast_bytes_py2(html)) File \"C:\\Python27\\lib\\xml\\etree\\ElementTree.py\", line 1301, in XML parser.feed(text) File \"C:\\Python27\\lib\\xml\\etree\\ElementTree.py\", line 1643, in feed self._raiseerror(v) File \"C:\\Python27\\lib\\xml\\etree\\ElementTree.py\", line 1507, in _raiseerror raise err ParseError: not well-formed (invalid token): line 1, column 9 ``` Here is the content of the notebook. I am using a Japanese Windows, the default encoding is: ``` In [1]: from IPython.utils import encoding In [2]: encoding.DEFAULT_ENCODING Out[2]: 'cp932' ``` When call `py3compat.cast_bytes_py2(html)` it can't convert the Chinese characters correctly. ``` { \"metadata\": { \"name\": \"\" }, \"nbformat\": 3, \"nbformat_minor\": 0, \"worksheets\": [ { \"cells\": [ { \"cell_type\": \"heading\", \"level\": 1, \"metadata\": {}, \"source\": [ \"\\u6269\\u5c55\\u7c7b\\u578b(cdef\\u7c7b)\" ] }, { \"cell_type\": \"code\", \"collapsed\": false, \"input\": [ \"\\n\" ], \"language\": \"python\", \"metadata\": {}, \"outputs\": [] } ], \"metadata\": {} } ] } ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Feature/#2439 prefect server telemetry **Thanks for contributing to Prefect!** Please describe your work and make sure your PR: - [x] adds new tests (if appropriate) - [x] updates `CHANGELOG.md` (if appropriate) - [x] updates docstrings for any new functions or function arguments, including `docs/outline.toml` for API reference docs (if appropriate) Note that your PR will not be reviewed unless all three boxes are checked. ## What does this PR change? This PR closes #2467 and adds some minimal telemetry to Prefect Server. ## Why is this PR important? This is the first step into collecting usage information that can help the Prefect team understand how Prefect Server is being used and how we can make it better. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Non plain-tensor batches Hello! I have been trying to use Lightning to train a graph neural network built with [torch_geometric](http://github.com/rusty1s/pytorch_geometric/) package using a GPU. This is the error I get when I try to fit the model: ```python3 ~/miniconda3/envs/pyg/lib/python3.7/site-packages/torch_geometric/nn/conv/gcn_conv.py in forward(self, x, edge_index, edge_weight) 83 def forward(self, x, edge_index, edge_weight=None): 84 \"\"\"\"\"\" ---> 85 x = torch.matmul(x, self.weight) 86 87 if self.cached and self.cached_result is not None: RuntimeError: Expected object of backend CPU but got backend CUDA for argument #2 'mat2' ``` I investigated the code of Lightning for a probable cause and found that `transfer_batch_to_gpu` causes this error. The current behavior of this function considers a batch to be either a 'plain' `torch.Tensor` or some simple collection of such objects (a list, a dict or a tuple). The problem is that torch_geometric uses a custom aggregate type `Data` ([docs](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Data)) which itself implements `to` method (and does not implement `cuda`, I believe). It would be nice if you could make the code more flexible to process this case (and similar cases in general) correctly. I believe, the best solution is to replace `isinstance(batch, torch.Tensor)` by a condition of `batch` object having either `to` or `cuda` method implemented. This should solve the problem in general. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: logging usage docs for list_entries method incorrect for both v1 and v2 library #### Environment details 1. Logging API 2. OSX Mojave 3. Python version: 3.7.3 4. google-cloud-logging version: ``` pip show google-cloud-logging Name: google-cloud-logging Version: 1.10.0 ``` #### Steps to reproduce 1. Navigate to the [usage start docs](https://googleapis.github.io/google-cloud-python/latest/logging/usage.html#retrieving-log-entries). 2. Check out the example code `client.list_entries(project_ids=PROJECT_IDS)` 3. Confirm that this is the [method name of the V1 library](https://github.com/googleapis/google-cloud-python/blob/master/logging/google/cloud/logging/client.py#L184-L186) mixed with the [renamed parameter of the v2 library](https://github.com/googleapis/google-cloud-python/blob/master/logging/google/cloud/logging_v2/gapic/logging_service_v2_client.py#L416-L419). I would have just cut a PR to fix it but it is unclear from that page whether the examples are for the v1 or v2 library. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: Update fill_diagonal docstring The current parameter description for `fill_diagonal` states that the fill value `val` must be a scalar. However, no input-checking is done on `val` and it turns out that array-likes with the same first dimension as `a` will also work, for example:: ```python >>> a = np.zeros((4, 5)) array([[0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.]]) >>> np.fill_diagonal(a, np.arange(a.shape[0])) >>> a array([[0., 0., 0., 0., 0.], [0., 1., 0., 0., 0.], [0., 0., 2., 0., 0.], [0., 0., 0., 3., 0.]]) ``` There are also already some examples in the docstring that use lists to fill the diagonal. DOC: Update fill_diagonal docstring The current parameter description for `fill_diagonal` states that the fill value `val` must be a scalar. However, no input-checking is done on `val` and it turns out that array-likes with the same first dimension as `a` will also work, for example:: ```python >>> a = np.zeros((4, 5)) array([[0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.]]) >>> np.fill_diagonal(a, np.arange(a.shape[0])) >>> a array([[0., 0., 0., 0., 0.], [0., 1., 0., 0., 0.], [0., 0., 2., 0., 0.], [0., 0., 0., 3., 0.]]) ``` There are also already some examples in the docstring that use lists to fill the diagonal. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan client crash with CMake and removed settings When I have a conanfile where I remove some settings: ``` settings = {\"os\": [\"Linux\", \"Macos\"], \"compiler\": None, \"arch\": None} ``` If I use the \"CMake\" class in build...: ``` cmake = CMake(self.settings) ``` It crashes because CMake class makes comparations with settings that I don't have, and its checked that this setting exists: ``` if self._settings.os == \"Windows\": ``` I think we should \"cast\" to str the settings in this case or something like that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add additional FlowRunner schedule check Similar to the `TaskRunner` check which determines if a scheduled task is running after its scheduled time, we should add a scheduling check to the `FlowRunner` to ensure the flow run doesn't begin until on or after its scheduled time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Unhandled exception when passing a program object that wasn't found to run_target ```meson project('bad_run_target', 'c') bad_program = find_program('xxxdoesnotexistxxx', required : false) run_target('bad target', command : [bad_program]) ``` ``` The Meson build system Version: 0.47.0.dev1 Source dir: /tmp/mesontest/bad_run_target Build dir: /tmp/mesontest/bad_run_target/builddir Build type: native build Project name: bad_run_target Project version: undefined Native C compiler: ccache cc (gcc 8.1.1 \"cc (SUSE Linux) 8.1.1 20180523 [gcc-8-branch revision 260570]\") Build machine cpu family: x86_64 Build machine cpu: x86_64 Program xxxdoesnotexistxxx found: NO Build targets in project: 1 Found ninja-1.8.2 at /usr/bin/ninja Traceback (most recent call last): File \"/data/git/meson/mesonbuild/mesonmain.py\", line 339, in run app.generate() File \"/data/git/meson/mesonbuild/mesonmain.py\", line 114, in generate self._generate(env) File \"/data/git/meson/mesonbuild/mesonmain.py\", line 163, in _generate intr.backend.generate(intr) File \"/data/git/meson/mesonbuild/backend/ninjabackend.py\", line 220, in generate self.generate_target(t, outfile) File \"/data/git/meson/mesonbuild/backend/ninjabackend.py\", line 323, in generate_target self.generate_run_target(target, outfile) File \"/data/git/meson/mesonbuild/backend/ninjabackend.py\", line 616, in generate_run_target cmd = self.replace_paths(target, cmd) File \"/data/git/meson/mesonbuild/backend/ninjabackend.py\", line 1880, in replace_paths for x in args] File \"/data/git/meson/mesonbuild/backend/ninjabackend.py\", line 1880, in <listcomp> for x in args] AttributeError: 'NoneType' object has no attribute 'replace' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Increased output when running f2py (possibly due to SIMD detection code) In NumPy 1.20, when compiling extensions with f2py, there is a lot of compiler options/testing output that is not there in 1.19: ### Reproducing code example: Saving `fib1.f` from [the documentation](https://numpy.org/devdocs/f2py/f2py.getting-started.html) and running ```bash f2py -c -m fib1 fib1.f ``` results in several blocks similar to ``` compile options: '-I/opt/miniconda3/envs/numpy-dev/include/python3.8 -c' extra options: '-msse2' CCompilerOpt.feature_test[1448] : testing feature 'SSE' with flags (-msse -msse2) C compiler: gcc -pthread -B /opt/miniconda3/envs/numpy-dev/compiler_compat -Wl,--sysroot=/ -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -fPIC ``` [Full output in a pastebin](https://pastebin.com/HrJgK9Km) This also increases the compilation time as several of those tests are apparently executed during compilation. ### Numpy/Python version information: ```python >>> import sys, numpy; print(numpy.__version__, sys.version) 1.20.0.dev0+087ad5e 3.8.3 | packaged by conda-forge | (default, Jun 1 2020, 17:43:00) [GCC 7.5.0] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Version(\"6\") < Version(\"6.0\") == True Version model has a bug. Version(\"6\") is considered lower than \"6.0\". It introduced a bug (fixed in #2885) with the default`std`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Use volumes_from with a container doesn't work https://github.com/orchardup/fig/blob/master/fig/project.py#L138-L139 It's missing a test and clearly doesn't work (`client` isn't defined). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %history documentation out of date? In IPython/core/history.py:722 ``` \"\"\"Print input history (_i<n> variables), with most recent last. %history -> print at most 40 inputs (some may be multi-line)\\\\ %history n -> print at most n inputs\\\\ %history n1 n2 -> print inputs between n1 and n2 (n2 not included)\\\\ ``` ... ``` Ranges of history can be indicated using the syntax: 4 : Line 4, current session 4-6 : Lines 4-6, current session ``` ... Does the range syntax supercede the original syntax for history? Should these lines be removed? ``` %history n -> print at most n inputs\\\\ %history n1 n2 -> print inputs between n1 and n2 (n2 not included)\\\\ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: small issue: wrong printout The ipython notebook proclaims: \"WARNING: the notebook server is listening on all IP addresses but not using any encryption or authentication\" although it is using authentication (but it doesn't use encryption). That should be changed to: \"WARNING: the notebook server is listening on all IP addresses but is not using BOTH encryption and authentication\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Train loss vs loss on progress bar ## ❓ Questions and Help <!-- If you still can't find what you need: --> #### What is your question? I don't understand why `train_loss` is different than `loss` even though I assign the same value. Perhaps one loss is calculated over the whole dataset and the other one is only for a recent batch? But if that's the case, which one is which? ``` Epoch 1: 79%|███████▉ | 691/870 [00:07<00:01, 100.85batch/s, accuracy=0.7, batch_idx=690, gpu=0, loss=0.442, train_loss=0.535, v_num=2] ``` #### Code ``` def training_step(self, batch, batch_idx): ... loss = self.loss(...) tqdm_dict = {'train_loss': loss} outputs = { 'loss': loss, 'progress_bar': tqdm_dict, 'log': tqdm_dict } ``` #### What's your environment? - OS: Ubuntu - Packaging: pip - Version: 0.6.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: happybase emulation docs mention private api the page at https://googlecloudplatform.github.io/gcloud-python/latest/happybase-package.html mentions `make_row()` and `make_ordered_row()`, both of which are _not_ public api. please don't mention those at all. :) (fyi: i'm the happybase author) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Linking when using the cross-compile llvm-mingw toolchain fails Using the (very recent and probably bleeding-edge) [llvm-mingw](https://github.com/mstorsjo/llvm-mingw) toolchain to cross-compile with meson, linking will fail as meson tries to use `-soname` which is (currently?) not supported by `lld` when I cross compile for Windows. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ERROR: xxxxx does not implement rsp format ? I get this error on two of my builds for xc16 and c2000 targets, I'm not sure why? \"ERROR: ar2000 does no implemnt rsp format, this shouldn't be called\" \"ERROR: xc16-ar does no implemnt rsp format, this shouldn't be called\" Both projects had been working on Meson 0.57.1. I have just upgraded to meson 0.58.0 and its the first error I get I seem to have found this spot in the code, mentioning it's not implemented? Is that the case? ` If `self.can_linker_accept_rsp()` returns True, then this needs to be implemented \"\"\" assert not self.can_linker_accept_rsp(), f'{self.id} linker accepts RSP, but doesn\\' provide a supported format, this is a bug' raise mesonlib.EnvironmentException(f'{self.id} does no implemnt rsp format, this shouldn\\'t be called') ` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: notebook.start_kernel is undefined Hi, in notificationarea.js, when we need to restart a kernel we call `notebook.start_kernel` which doesn't exist. Not sure how you guys were planning to handle this, but I took a stab at it. thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: New interactive visualizations <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Include a new set of visualizations that enrich the existing visualizations in `_state_visualization.py` and allow for a more informative experience for the users. ### Details As per @ismaelfaro , while this feature was initially marked as one of the defining features of 0.7, seems like we will be able to include it in 0.6. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add healthcheck for Environments ## Current behavior Currently we have deferred imports for environments which hide python dependencies ## Proposed behavior Fail healthcheck if environment specific libraries are not included ## Example Fail when using the `FargateTaskEnvironment` if boto3 is not installed Note: This will allow us to remove the `kubernetes` dependency on all Docker storages Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Error using lockfiles with conanfile.txt Using: Windows and conan version 1.17.1 I get `ERROR: Unspecified reference in graph-lock, please specify` when trying to use lockfiles in a package that has `conanfile.txt` instead of `conanfile.py` To reproduce: ``` git clone https://github.com/conan-io/examples.git cd examples/libraries/poco/md5 mkdir build && cd build conan install .. conan install .. --lockfile ``` Output: ``` Using lockfile: 'C:\\temp\\examples\\libraries\\poco\\md5\\build\\conan.lock' Configuration: [settings] arch=x86_64 arch_build=x86_64 build_type=Release compiler=Visual Studio compiler.runtime=MD compiler.version=15 os=Windows os_build=Windows [options] [build_requires] [env] ERROR: Unspecified reference in graph-lock, please specify ``` - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: datastore: default to empty dataset When working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending \"s~\" to dataset ids as that is not always a valid operation. datastore: default to empty dataset When working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending \"s~\" to dataset ids as that is not always a valid operation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: TypeError: not all arguments converted during string formatting \"command\": \"C:\\\\Users\\\\court\\\\Anaconda3\\\\Scripts\\\\conda install matplotlib\" \"user_agent\": \"conda/4.4.1 requests/2.18.4 CPython/3.6.3 Windows/10 Windows/10.0.16299\" ``` Traceback (most recent call last): File \\\"C:\\\\Users\\\\court\\\\Anaconda3\\\\lib\\\\site-packages\\\\conda\\\\exceptions.py\\\", line 721, in __call__ return func(*args, **kwargs) File \\\"C:\\\\Users\\\\court\\\\Anaconda3\\\\lib\\\\site-packages\\\\conda\\\\cli\\\\main.py\\\", line 78, in _main exit_code = do_call(args, p) File \\\"C:\\\\Users\\\\court\\\\Anaconda3\\\\lib\\\\site-packages\\\\conda\\\\cli\\\\conda_argparse.py\\\", line 75, in do_call exit_code = getattr(module, func_name)(args, parser) File \\\"C:\\\\Users\\\\court\\\\Anaconda3\\\\lib\\\\site-packages\\\\conda\\\\cli\\\\main_install.py\\\", line 11, in execute install(args, parser, 'install') File \\\"C:\\\\Users\\\\court\\\\Anaconda3\\\\lib\\\\site-packages\\\\conda\\\\cli\\\\install.py\\\", line 220, in install force_reinstall=context.force, File \\\"C:\\\\Users\\\\court\\\\Anaconda3\\\\lib\\\\site-packages\\\\conda\\\\core\\\\solve.py\\\", line 503, in solve_for_transaction force_remove, force_reinstall) File \\\"C:\\\\Users\\\\court\\\\Anaconda3\\\\lib\\\\site-packages\\\\conda\\\\core\\\\solve.py\\\", line 436, in solve_for_diff final_precs = self.solve_final_state(deps_modifier, prune, ignore_pinned, force_remove) File \\\"C:\\\\Users\\\\court\\\\Anaconda3\\\\lib\\\\site-packages\\\\conda\\\\core\\\\solve.py\\\", line 244, in solve_final_state \\\"\\\"\\\") % matches_for_spec) TypeError: not all arguments converted during string formatting ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Batching rules for pad and concatenate primitives not implemented I'm interested in using JAX to compute Jacobians for functions which involve iteratively applying operations to generate a sequence. When using Autograd for this, in order to avoid indexed assignment I would create a list which is iteratively populated with the sequence values and then create an array from the list using `np.array` or `np.stack`. Attempting the same in JAX (built from source with fc4afb409b) raises a `NotImplementedError` when trying to compute the Jacobian of such a function with either `jacrev` or `jacfwd` as batching rules are not implemented for the `pad` and `concatenate` primitives respectively. As a minimal example ```Python import jax.numpy as np from jax import jacrev, jacfwd def func(xs): return np.array([x for x in xs]) jacrev_func = jacrev(func) jacfwd_func = jacfwd(func) xs = np.ones((5, 1)) jacrev_func(xs) # raises NotImplementedError: Batching rule for 'pad' not implemented jacfwd_func(xs) # raises NotImplementedError: Batching rule for 'concatenate' not implemented ``` The same errors are raised when replacing `np.array` in the defnition of `func` with `np.stack`, `np.hstack`, `np.vstack` or `np.concatenate`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: SubDagOperators report success when BackfillJobs deadlock As discussed with @syvineckruyk, follow up from #1225. The `BackfillJob` is deadlocking as expected but it doesn't raise an error, so the `SubDagOperator` thinks it succeeded. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: the AST nodes are not always nodes ## Expected Behavior When parsing QASM, an AST is obtained where the nodes and their children are `Node` objects: ```python import qiskit.qasm as Qasm def f(node): for child in node.children: f(child) qasm = Qasm.Qasm(QASM_FILE_PATH) f(qasm.parse()) ``` It would be expected to call a recursive function `f` over that tree, expecting nodes of the `Node` type. ## Current Behavior When parsing a binary operation `qiskit.qasm._node._binaryop.BinaryOp`, (such as `3.141592653589793/2` from `qelib1.inc`) the `node.children` has three elements: ``` 0 = {str} '/' 1 = {Real} <qiskit.qasm._node._real.Real> 2 = {Int} <qiskit.qasm._node._intnode.Int> ``` The item 0 should from a Node subclass, not a str. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: invalid jaxpr from composition of soft_pmap, _papply, jit, and jit The following: ``` @jit def f(x): y = 2 * x @jit def g(z): h, axis_name =_papply(lambda x: x * y) return soft_pmap(h, axis_name)(z) return g(x) f(onp.arange(4.).reshape((2, 2))) ``` results in the following invalid jaxpr: ``` { lambda b ; ; a. let c = reshape[ new_sizes=(1, 2, 2) dimensions=None old_sizes=(2, 2) ] a d = mul e 2.0 f = xla_pmap[ axis_size=1 axis_name=<axis 0x7fa985eaa890> ] b c { lambda ; b ; c a. let d = gather[ operand_shape=(2, 2) slice_sizes=(1, 2) dimension_numbers=GatherDimensionNumbers(offset_dims=(1, 2), collapsed_slice_dims=(), start_index_map=(0, 1)) ] b c e = reshape[ new_sizes=(2, 2) dimensions=None old_sizes=(2, 1, 2) ] d f = mul a e in f } [ ; d ] g = reshape[ new_sizes=(2, 2) dimensions=None old_sizes=(1L, 2, 2) ] f in g } ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub: Default thread-based subscriber Policy's on_response() implementation degenerates into series of synchronous calls because of debug statement https://github.com/GoogleCloudPlatform/google-cloud-python/blob/4e17158c0f14e0e91cbeb74c3e8483c5a231e9ac/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py#L147 While testing out the new PubSub API (v 0.28.3), I noticed that the default thread-based `Policy`, which uses a `ThreadPoolExecutor(max_workers=10)` seemed to be executing the subscriber callbacks sequentially, instead of asynchronously. Upon introspection of the source, it looks like the above referenced code: ``` ... future = self._executor.submit(self._callback, message) logger.debug('Result: %s' % future.result()) ``` will block until `self._callback` completes, because of the call to `future.result()`. Or am I losing my mind? Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `c_compiler.get_define()` returns a string containing a whitespace even though the define is not defined **Describe the bug** `cc.get_define()` is expected to return an empty string if the define is not defined. However, using specific MSVC version this doesn't seem to be guaranteed. This issue is based on the findings in https://github.com/mesonbuild/wrapdb/pull/350 MSVC seems to print random spaces. I think instead of using the current code: ```c #ifndef DEFINE # define DEFINE #endif \"MESON_GET_DEFINE_DELIMITER\" DEFINE ``` ```c #ifndef DEFINE \"MESON_GET_DEFINE_NDEFINE\" #endif \"MESON_GET_DEFINE_DELIMITER\" DEFINE ``` may be more robust? (This is just something I noticed while reading logs.) **To Reproduce** Build the libpng wrap using msvc via the x64 native tools command prompt for VS 2019. **Expected behavior** `c_compiler.get_define()` should return an empty string if the define is not defined. **system parameters** * Native Build * Windows 10 * Py: 3.10.2 * 0.61.2 I have to leave my computer now but I wanted to post this issue beforehand. I am happy to provide more info and improve the ticket when I am back. Fix `c_compiler`.get_define parsing unintentional whitespace as defined variable This is my attempt to fix https://github.com/mesonbuild/meson/issues/10179 I don't use python often and I had trouble setting up my dev environment for meson. I feel like using this more explicit path should be robuster against wrong whitespaces. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Warn if no files were copied by self.copy It should be nice to receive a warning (or maybe an error) when no files were copied by self.copy inside a package() method. I think that this situation means that something goes wrong in the most cases and will help to address many issues. The message should contain value of pattern and src arguments. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython-8 warns about virtualenv created by pyenv Hi, is there a way to disable the virtualenv warning? I use pyenv, and every time IPython-8.0 starts from a virtual environment that's based on pyenv's miniconda, it shows this warning: ```bash # Activate virtualenv via 'pyenv activate my_project_env' or 'pyenv activate my_base_python_env/envs/my_project_env'. ... # Then, start ipython (installed in that virtual env). $ ipython /Users/xxx/.pyenv/versions/rubix-mds/lib/python3.9/site-packages/IPython/core/interactiveshell.py:802: UserWarning: Attempting to work in a virtualenv. If you encounter problems, please install IPython inside the virtualenv. warn( Python 3.9.7 (default, Sep 16 2021, 08:50:36) Type 'copyright', 'credits' or 'license' for more information IPython 8.0.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: import sys ...: ...: sys.executable Out[1]: '/Users/xxx/.pyenv/versions/rubix-mds/bin/python' In [2]: import os ...: ...: os.environ[\"VIRTUAL_ENV\"] Out[2]: '/Users/xxx/.pyenv/versions/miniconda3-latest/envs/rubix-mds' ``` This only happens for virtualenv based on another pyenv's miniconda3-latest. No warning shown with virtualenv based on another pyenv's \"python version\". ```bash $HOME `-- versions |-- miniconda3-latest | `-- envs | `-- rubix-mds `-- rubix-mds -> $HOME/.pyenv/versions/miniconda3-latest/envs/rubix-mds ``` I'd like to know if there's a way to silent this particular warning? Thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Unknown CPU family 'parisc64' The HP PA-RISC processors can do 64 bit for ages. However many of the \"smaller\" (e.g. my C3600) machines are usually operated with a 32 bit kernel if they have less than 4GB RAM: ``` Linux voyager 4.16.0 #1 Tue Apr 3 23:20:04 CEST 2018 parisc PA8600 (PCX-W+) 9000/785/C3600 GNU/Linux ``` Machines with more RAM or certain types of machines require a 64 bit kernel: ``` Linux pioneer 4.19.9 #2 SMP Fri Dec 14 18:57:12 CET 2018 parisc64 PA8800 (Mako) 9000/785/C8000 GNU/Linux ``` The twist is: there is no 64 bit userspace on these machines, so regardless of what the kernel says, the userspace is always 32 bit. cpuinfo of my C8000 (only first processor): ``` processor : 0 cpu family : PA-RISC 2.0 cpu : PA8800 (Mako) cpu MHz : 1000.000000 physical id : 0 siblings : 2 core id : 0 capabilities : os64 iopdir_fdc needs_equivalent_aliasing (0x35) model : 9000/785/C8000 model name : Crestone Peak Fast? hversion : 0x000088b0 sversion : 0x00000491 I-cache : 32768 KB D-cache : 32768 KB (WB, direct mapped) ITLB entries : 240 DTLB entries : 240 - shared with ITLB bogomips : 1988.60 software id : 6266852346624179925 ``` For reference, this is my single-core C3600 running a 32 bit kernel: ``` processor : 0 cpu family : PA-RISC 2.0 cpu : PA8600 (PCX-W+) cpu MHz : 552.000000 capabilities : os32 os64 nva_supported (0x03) model : 9000/785/C3600 model name : Allegro W+ hversion : 0x00005cf0 sversion : 0x00000481 I-cache : 512 KB D-cache : 1024 KB (WB, direct mapped) ITLB entries : 160 DTLB entries : 160 - shared with ITLB bogomips : 1099.77 software id : 2001234816 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Error in Notebook-Generated latex (nbconvert) When there are `...` in the python output (like in long `__repr__`s), they seem to be replaced with `\\ldots` in latex. However, this command is not protected with `{}`. So the command will stick to whatever follows. If that is not a whitespace, you get `\\ldotsnextword` and a latex error. I checked this with master (actually a week ago master). and the last release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Require parallel tools when depending on HDF5 I have an application that specifically requires the availability of `h5pcc` instead of `h5cc`: https://github.com/mesonbuild/meson/blob/39ceb677744e1f959a0db6406d51a26d78f0ab68/mesonbuild/dependencies/hdf5.py#L97-L99 In my case HDF5 is only build with parallel compatibility and therefore `h5cc` is not available. My current workaround is to simple edit this line and specify the other tool directly. It there a more appropriate workaround for this issue? Alternatively: Is it possible to add an optional parameter to `hdf5_dep = dependency('hdf5')` e.g. `dependency('hdf5', parallel: true)` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cc.has_header_symbol() not working reliable for strlcat cc.has_header_symbol() is not working for strlcat with my setup (reports it found the symbol in the header although it's not defined there). I'm using clang 12 with gcc 11 libs on CentOS 8 Stream. I guess this happens because the command calls the compiler which may not have -Werror=implicit-function-declaration set and thus only gives a warning but does not fail with an error code? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add section on Task auto-generation to Anatomy of a Prefect Task A common question we hear concerns large JSON objects being auto-converted to Tasks, and how to prevent that. (Answer: wrap the object in a `Constant` task or a `Parameter`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: MSBuild verbosity level When building Visual Studio projects via CMake.build() or build_sln_command() default MSBuild verbosity level (normal) is used. It's quite noisy and for big libraries quickly exceeds any CI log size limits. I would like to have a way to control it. Right now I use (not very elegant) ```python if \"Visual Studio\" in cmake.command_line: # Make CI logs manageable args = [\"--\", \"/verbosity:quiet\"] else: args = [] cmake.build(args=args) ``` but I think it's worth conan support. Something like `cmake = CMake(self, verbosity=\"quiet\")` which adds `-- /verbosity:quiet` to cmake command line. BTW, `/verbosity:minimal` seems to be more appropriate default value for CMake build helper (at least Visual Studio IDE thinks so) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: test_dataloader called during check_testing_model_configuration ## 🐛 Bug When testing a model that has been loaded using the `resume_from_checkpoint` Trainer flag (note: `.fit()` has **not** been called yet in this case), the `check_testing_model_configuration` method [calls](https://github.com/PyTorchLightning/pytorch-lightning/blob/c1c6e3b6c988c690f9e2cd5726da4ab3402dbd03/pytorch_lightning/trainer/trainer.py#L1026) `test_dataloader()`, which results in undefined attribute errors if the test dataloader depends on stuff set during `prepare_data` (which is called at the beginning of `fit`) ### To Reproduce Steps to reproduce the behavior: 1. Initialize a Trainer like `trainer = Trainer(model, resume_from_checkpoint=\"...\", ...)` (make sure `.fit` is not called yet) 2. Run `trainer.test()` 3. If test dataloader depends on prepare_data, errors will be thrown that trace back to `check_testing_model_configuration` ### Additional context This seems like It could be fixed with a simple change--remove the `model.test_dataloader()` call from this [line](https://github.com/PyTorchLightning/pytorch-lightning/blob/c1c6e3b6c988c690f9e2cd5726da4ab3402dbd03/pytorch_lightning/trainer/trainer.py#L1026) and replace `hasattr` with `is_overriden` call . I can submit a PR if this solution is acceptable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Loading config file bug Hi guys. I have released a new (XLNet based) transformer model for low-resource language Tigrinya [(TigXLNet)](https://github.com/abryeemessi/Transferring-Monolingual-Model-to-Low-Resource-Language) and found a bug when loading a pre-trained config file: My config file looks like: https://s3.amazonaws.com/models.huggingface.co/bert/abryee/TigXLNet/config.json config = AutoConfig.from_pretrained(\"abryee/TigXLNet\") print(config.d_head) #prints 48 even though d_head in the given config file is 64. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: 0.12.0 Task Names not inferred from function name ## Opened from the [Prefect Public Slack Community](https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU) **jmaxfieldbrown**: Just curious. After updating to the most recent version of prefect `0.12.0` , all tasks on `dask` / `bokeh` are labeled as \"run_task\" instead of the function name. Did the `0.12.0` update make it so I need to explicitly attach a name to each task? `bokeh==2.0.2` `dask==2.18.1` `distributed==2.18.0` **dylan**: Hey <@URRN7598X>! You’ve found a bug :tada: Thank you for taking the time to tell us about it. We really appreciate it! **dylan**: <@ULVA73B9P> open “0.12.0 Task Names not inferred from function name” Original thread can be found [here](https://prefect-community.slack.com/archives/CL09KU1K7/p1592496831014500?thread_ts=1592496831.014500&cid=CL09KU1K7). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: add prefix arg to storage.bucket.get_all_keys Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Typo in docstring for MCX gate The docstring for the ```mcx``` method in [```QuantumCircuit.py```](https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/circuit/quantumcircuit.py#L2532) has a typo regarding the ```mode``` kwarg (```no-ancilla``` rather than ```noancilla```). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] version is not set correctly when using layout When layout is being used, recipe version is not set correctly somehow using json generator, it seems that version is not being fetched from package metadata when running conan install command! ### Environment Details * Operating System+version: macos * Compiler+version: apple-clang 12.0 * Conan version: Conan version 1.47.0 * Python version: 3.9 ### Steps to reproduce * create a conan demo project using `conan new demo/1.0.0 --template=cmake_lib` * create a local conan package `conan create .` * generate deps using json generator `conan install demo/1.0.0@ -g json` * inspect conanbuildinfo.json, version is set to null, however it should be 1.0.0 * remove the layout method from the conanfile.py and try again * now version is set correctly btw, it seems to be the same issue for the description attribute, maybe other attributes as well  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: diable val and test shuffling Fixes part of #1551 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: regression/clear_datastore no longer works As of b343acf4ade6dfc659f71a981eb51b62d22e33a0 running ``` $ python regression/clear_datastore.py ``` fails because the backend returns ``` Exception: Request failed. Error was: queries inside transactions must have ancestors ``` To see an example query, [insert](https://github.com/GoogleCloudPlatform/gcloud-python/blob/b343acf4ade6dfc659f71a981eb51b62d22e33a0/regression/clear_datastore.py#L41) the following: ``` python >>> print query._pb projection { property { name: \"__key__\" } } kind { name: \"Character\" } limit: 20 ``` I'm fairly certain the backend has changed, but I'm not 100% sure. Either way, this isn't super pressing right now since there are lot's of ways to delete entities that were accidentally created. regression/clear_datastore no longer works As of b343acf4ade6dfc659f71a981eb51b62d22e33a0 running ``` $ python regression/clear_datastore.py ``` fails because the backend returns ``` Exception: Request failed. Error was: queries inside transactions must have ancestors ``` To see an example query, [insert](https://github.com/GoogleCloudPlatform/gcloud-python/blob/b343acf4ade6dfc659f71a981eb51b62d22e33a0/regression/clear_datastore.py#L41) the following: ``` python >>> print query._pb projection { property { name: \"__key__\" } } kind { name: \"Character\" } limit: 20 ``` I'm fairly certain the backend has changed, but I'm not 100% sure. Either way, this isn't super pressing right now since there are lot's of ways to delete entities that were accidentally created. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Drop intermediate container and use renaming instead With the merging of https://github.com/docker/docker/pull/8570, Docker 1.5 will support container renaming. This means we can stop creating an \"intermediate container\" when recreating containers - their only purpose is to free up the container name while preserving volumes. This will stop Compose working on Docker <1.5, but I think it's worth it: as well as generally reducing complexity, it'll remove the problem that #516 and #517 attempt to solve. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Consider `jupyter labextension update <extension>` command Consider `jupyter labextension update <extension>` command Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: What's the difference between `fig up -d` and `fig restart`? `fig up` should build but I noticed it does some kind of build only in some cases, not sure when. So in practice as said for #734 on has to: ``` $ fig build $ fig up -d ``` but why not just run then `fig restart` (which should do a `fig start` and stop if there is any existing). `fig start` is actually lot faster than `fig up -d`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Celery class based task is not retrying I defined a class-based celery task defined as follows: ```python class MyTask(Task): name = \"MY_TASK\" autoretry_for = (Exception, ) retry_kwargs = {'max_retries': 5} retry_backoff = True retry_backoff_max = 700 retry_jitter = False def run(self, *args, **kwargs): pass # do something # return some value def on_failure(self, exc, task_id, args, kwargs, einfo): # can extend failure method if needed super().on_failure(exc, task_id, args, kwargs, einfo) app.tasks.register(MyTask()) ``` ###### celery version: 4.4.2 ###### python version: 3.8.2 ### Issue My task is executing perfectly. But when an exception occurs, the task is not retried ### Expected behaviour The task should retry Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] `build_modules` in 2.0 fails with error instead of a nice migration warnings <!-- What is your suggestion? Please be as specific as possible! --> deprecated `build_modules` causes 2.0 to fail where it should output a warnings -- This can be see with the `cpp_info.names` and `cpp_info.user_info` attributes but not this one. Post-op from playing with #12555 ``` json-schema-validator/2.1.0: Full package reference: json-schema-validator/2.1.0#986a89f6a3344cc556dca7c0b062b212:158b7151fbfbfa9ccd829110c8d4cfff48dad2b3#748e6457403877ef605821d6b2a42d17 json-schema-validator/2.1.0: Package folder /Users/christopherm/user-management/backend/.conan2_home/p/2f777ef816571596/p WARN: The use of 'cpp_info.names' is deprecated in Conan 2.0 and will be removed in Conan 2.X. Please, update your recipes unless you are maintaining compatibility with Conan 1.X WARN: The use of 'cpp_info.names' is deprecated in Conan 2.0 and will be removed in Conan 2.X. Please, update your recipes unless you are maintaining compatibility with Conan 1.X ERROR: json-schema-validator/2.1.0: Error in package_info() method, line 128 self.cpp_info.build_modules[\"cmake_find_package\"] = [self._module_file_rel_path] AttributeError: '_Component' object has no attribute 'build_modules' ``` - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: import tab-complete fail with ipython 2.0 shell In the shell, when trying to tab-complete a module name for import, the propose completion is not modules names. with ipython 2.0 ``` >>> import co<tab> coerce( compile( complex( continue copyright( ``` That the same list as when tab-complete without anything instead of what ipython 1.1 give ``` >>> import co<tab> code codeop commands configparser contextlib copy_reg code_erreur collections compileall constantes cookielib copyreg codecs colorsys compiler constantes_vivaldi copy coverage ``` I'm on fedora 17, with python 2.7 in a virtualenv Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Optional dependency added to generated pkgconfig file even when not found If I have an optional dependency `foo`: ```meson foo_dep = dependency('foo', required: false) ``` and I use `foo_dep` to build a shared library that will then be fed to `pkgconfig.generate()`, the dependency on `foo` will be added to the `Requires.private` field, regardless of whether `foo_dep` was found or not. This behaviour changed between Meson 0.44.0 and 0.44.0-176-g81100f06. As a real world issue: building libdrm with `-Dvalgrind=false`, and without Valgrind installed, with Meson 0.44 will generate a libdrm.pc file that does not depend on `valgrind`, whereas doing the same with Meson master will generate a libdrm.pc file that adds a dependency on `valgrind`: ``` --- /home/ebassi/Junk/libdrm-meson-stable.pc 2018-01-13 14:13:20.247204072 +0000 +++ /home/ebassi/Junk/libdrm-meson-master.pc 2018-01-13 14:17:00.365290492 +0000 @@ -5,5 +5,7 @@ includedir=${prefix}/include Name: libdrm Description: Userspace interface to kernel DRM services Version: 2.4.89 +Requires.private: valgrind Libs: -L${libdir} -ldrm +Libs.private: -lm Cflags: -I${includedir} -I${includedir}/libdrm ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: More helpful error message if node isn't installed I tried installing a labextension without having node installed, and got this error message: `FileNotFoundError: [Errno 2] No such file or directory: 'node'` I think it'd be more helpful for users (especially those not familiar with the node/npm world, which is probably most users) if we added a check for the existence of node, and a helpful error message pointing people in the rigt direction if it doesn't exist. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery Time Values May Be Incorrect On the [`_datetime_from_json` function](https://github.com/GoogleCloudPlatform/gcloud-python/blob/62fd8310259bc9761a6eb3ceb0d2db9677814f6a/gcloud/bigquery/table.py#L764), @arterrey [commented](https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#commitcomment-13104217) that > I'm getting values out of BigQuery in seconds. So \\* 1000.0 is not enough - it needs to be \\* 1000000.0 to work. However, I'm not sure if that is a bug in the BigQuery API or a bug in this client library. This contradicts the note in the code that > Field value will be in milliseconds. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: job.py in bigquery does unnecessary client-side validation of data formats The BigQuery engineering team may decide to expand the allowed formats for import and export, but the allowed values are hard-coded client side. Imports are limited to CSV, DATASTORE_BACKUP, NEWLINE_DELIMITED_JSON, AVRO, for example. This means that if the BigQuery starts to allow other formats, users will be unable to use those new formats without updating their client. Moreover, there is no way for BigQuery to roll out new formats to a whitelisted set of users. (note this is not mere idle speculation and is currently impacting real users alpha testing a new format) See code here: [https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/bigquery/google/cloud/bigquery/job.py#L116][1] and [https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/bigquery/google/cloud/bigquery/job.py#L139][2] [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/6d7fae96d25a0a468683a5ab25a2f48014a16378/bigquery/google/cloud/bigquery/job.py#L116 [2]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/6d7fae96d25a0a468683a5ab25a2f48014a16378/bigquery/google/cloud/bigquery/job.py#L139 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Allow for specification of cipher in SftpHook <!-- Welcome to Apache Airflow! For a smooth issue process, try to answer the following questions. Don't worry if they're not all applicable; just try to include what you can :-) If you need to include code snippets or logs, please put them in fenced code blocks. If they're super-long, please use the details tag like <details><summary>super-long log</summary> lots of stuff </details> Please delete these comment blocks before submitting the issue. --> **Description** I want to specify the cipher to use when creating a SftpHook. Currently this is not possible because there is not a way to propagate the value to CnOpts. https://github.com/apache/airflow/blob/master/airflow/providers/sftp/hooks/sftp.py https://pysftp.readthedocs.io/en/release_0.2.9/pysftp.html?#pysftp.CnOpts https://pysftp.readthedocs.io/en/release_0.2.9/cookbook.html **Use case / motivation** <!-- What do you want to happen? Rather than telling us how you might implement this solution, try to take a step back and describe what you are trying to achieve. --> I want to be able to access SFTP servers that have disabled access from connection with weak ciphers. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add documentation on how to delete a property from a datastore entity Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %paste and %cpaste not removing \"...\" lines Pasting doctest code that contains \"...\" lines raises a syntax error. Adding a space to replace such lines with \"... \" fixes the problem. This makes pasting some code snippets very cumbersome (e.g. http://docs.sqlalchemy.org/en/rel_0_8/orm/tutorial.html#declare-a-mapping), as they have to be fixed before being pasted. It would be nice if this were fixed. (Observed with version 0.13.1 on Mac OS X). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Cloning to Path from pathlib no longer work Since version 2.1.7 using `Path` from `pathlib` to declare path in `Repo.clone_from` doesn't work anymore - it was working fine on 2.1.6 and before. How to reproduce: ``` pip install gitpython==2.1.7 ``` Run ``` from pathlib import Path from git import Repo path = Path(\"test1\").resolve() repo = Repo.clone_from(\"https://github.com/gitpython-developers/async.git\", path) ``` On 2.1.7 it raises `TypeError` ``` Traceback (most recent call last): File \"script.py\", line 6, in <module> repo = Repo.clone_from(\"https://github.com/gitpython-developers/async.git\", path) File \"/home/miki/.pyenv/versions/test_gitpython/lib/python3.6/site-packages/git/repo/base.py\", line 972, in clone_from return cls._clone(git, url, to_path, GitCmdObjectDB, progress, **kwargs) File \"/home/miki/.pyenv/versions/test_gitpython/lib/python3.6/site-packages/git/repo/base.py\", line 939, in _clone repo = cls(path, odbt=odbt) File \"/home/miki/.pyenv/versions/test_gitpython/lib/python3.6/site-packages/git/repo/base.py\", line 125, in __init__ if expand_vars and (\"%\" in epath or \"$\" in epath): TypeError: argument of type 'PosixPath' is not iterable ``` I am running this on python 3.6.2. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: deprecate 'conda help' in favor of --help CLI flag With the install on Windows 10: _platform : win-64 conda version : 4.3.30 conda is private : False conda-env version : 4.3.30 conda-build version : 3.0.22 python version : 3.6.3.final.0 requests version : 2.18.4 root environment : C:\\Anaconda3 (writable)_ the command: `conda help install` (or other similar, say, conda help create, etc.) produces the message `C:\\Anaconda3\\python.exe: can't open file 'C:\\Anaconda3\\Scripts\\conda': [Errno 2] No such file or directory` This syntax works under Linux (Ubuntu), but of course, there is no just \"conda\" file in Windows Anaconda Scripts. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Check decorator order As @stas00 pointed out, the slow decorator is ignore if it's not put last. To make sure we don't make the mistake unintentionally and to fix the places where this si not the case, I wrote a script to check the decorators order and fail on `make quality` if there is a wrong order somewhere. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Optional dependencies are required for deprecated logging module 🐛 Bug There is a backwards compatibility issues coming from PR #767. Notably, if a user doesn't have any of the extra logging dependencies then they'll be an import error. ### To Reproduce 1. Remove all logging dependencies from your environment (E.g. comet) 2. Depend on the deprecated pytorch_lightning.logging package and run ### Expected behavior We expect to maintain backwards compatibility here so optional dependencies shouldn't be required. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: deprecate `client.dataset()` See: https://github.com/googleapis/google-cloud-python/pull/7753 We should recommend the simpler \"use a string instead of a reference object\" in most cases. We still call `.dataset()` 96 times in our samples at `docs/snippets.py`. I would feel better about adding the deprecation notice after we update the rest of our samples. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Incorrect Implementation for Accumulating Batch Gradients in Trainer Current Behavior: If accumulate_grad_batches > default of 1, the Trainer will proceed to take the loss from each batch and run loss.backward() for each batch accumulated, running the optimizer.step() once the desired number of batches has undergone backprop. Loss averaging is only done for batch_loss_value. Correct Behavior: The loss from the output needs to be divided by accumulate_grad_batches before loss.backward() is run, otherwise the overall magnitude of the gradient could be up to N times greater for a simulated batch size N times bigger than the actual. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PassManagerConfig.from_backend fails with AerSimulator ### Environment - **Qiskit Terra version**: 088f600be1914bfd2bc3c43d0a171ff08ccba9bf - **Python version**: 3.10.8 - **Operating system**: Fedora 36 - **Qiskit Aer version**: 0.11.2 ### What is happening? See repro. ### How can we reproduce the issue? ```python from qiskit.transpiler.passmanager_config import PassManagerConfig from qiskit_aer import AerSimulator backend = AerSimulator() pass_manager_config = PassManagerConfig.from_backend(backend) ``` ``` --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) Cell In [1], line 5 2 from qiskit_aer import AerSimulator 4 backend = AerSimulator() ----> 5 pass_manager_config = PassManagerConfig.from_backend(backend) File ~/projects/qiskit-terra/qiskit/transpiler/passmanager_config.py:139, in PassManagerConfig.from_backend(cls, backend, **pass_manager_options) 137 if backend_version < 2: 138 if hasattr(backend, \"defaults\"): --> 139 res.inst_map = backend.defaults().instruction_schedule_map 140 else: 141 res.inst_map = backend.instruction_schedule_map AttributeError: 'NoneType' object has no attribute 'instruction_schedule_map' ``` ### What should happen? It should work. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Metrics: Confusion Matrix ## 🚀 Feature Implement Confusion Matrix Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gettext() does not allow keywords to be specified If one uses helpers or wrappers for gettext library, one needs to tell `xgettext` about the keywords. For example, if i use glib gettext helpers, i need to pass `--keyword=_', '--keyword=N_', '--keyword=C_:1c,2', '--keyword=NC_:1c,2', '--keyword=g_dngettext:2,3'` (`intltoolize` adds appropriate magic to autotools-based buildsystem, so with autotools you don't need to add these yourself) to `xgettext` for it to be able to find all the macro and function invocations. One should probably read [xgettext man](https://www.gnu.org/software/gettext/manual/html_node/xgettext-Invocation.html) and see which commandline arguments should be supported by `gettext()` in meson. Or maybe it's easier to just allow flags to be passed to `xgettext` as-is (the same way CFLAGS are passed to C compiler). Note that `xgettext` is not a compiler- or platform-specific tool (AFAIK; though its counterpart gettext _library_ _can_ be part of libc, IIRC; Wikipedia mentions Sun gettext, but i don't know whether anyone uses its tools anymore, if it had any; it might not have supported .pot/.po/.mo at all and used different file formats altogether, for all i know), so abstracting away all of its arguments doesn't make much sense, not for portability reasons (i.e. there's no MSVC- or Windows-specific gettext program that expects `/kw foo` instead of `--keyword=foo`). IMHO. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [POC] Check tqdm progress bars In order to provide feedback for #3536 related to tqdm, we may include a progress bar somewhere to check that it plays well with User interface, CI systems,... As [@memsharded suggested](https://github.com/conan-io/conan/issues/3536#issuecomment-420934410), the decompress job could be a good point to test it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Redis backend does not support SSL? From looking at the code and documentation, it appears that SSL is only supported for redis as a broker, but not as a result backend. Is that right? Currently we do some yucky monkey-patching of the code in our tasks file: ```python import celery.backends.redis import redis import ssl original = celery.backends.redis.RedisBackend._params_from_url def patched(*args, **kwargs): result = original(*args, **kwargs) result.update({ 'connection_class': redis.SSLConnection, 'ssl_cert_reqs': ssl.CERT_NONE, }) return result celery.backends.redis.RedisBackend._params_from_url = patched ``` The code change in celery to support SSL for redis backends would be small. Would you accept a patch for that? It should probably use a different config name than `broker_use_ssl`. Maybe `backend_use_ssl`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Support list values in entities Right now, we support timestamps, keys, booleans, doubles, integers, and strings, but not lists. I think it'd be nice if we could figure out how to support saving lists in a nice way. Ref: https://cloud.google.com/datastore/docs/apis/v1beta2/entity Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Remove `migrate-to-labels` Migrate to labels was added in 1.3 to upgrade from 1.2. I think we can probably drop it for the 1.6 release. What do you think? If someone still needs to migrate, they can always use 1.5. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: loadtxt documentation https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.loadtxt.html says \"converters : dict, optional A dictionary mapping column number to a function that will convert that column to a float. \" Should it not be a function converting to whatever the target dtype is (e.g. it might be complex)? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [build system] AutoToolsBuildEnvironment on linux distros with default \"lib64\" libdir To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. On some linux distributions (for example, suse & derivatives), the default libdir for installations is \"lib64\" on x64 systems, rather than \"lib\". This prevents nearly every package that uses AutoToolsBuildEnvironment and tools.collect_libs(), because they mostly assume the directory for libraries is \"lib\". This could be fixed in many cases, for example, by adding the \"--libdir\" flag with an appropriate value to \"./configure\", when we call AutoToolsBuildEnvironment.configure(). I realise this might be controversial, since it might break existing packages that _do_ assume \"/lib64\" directory. However, my experience in installing conan packages is that essentially none of them currently do this, and I have to patch in the \"lib64\" directory to the folder= argument in tools.collect_libs on most recipes I use that use autotools. Note the similar problem doesn't occur in (most) cmake build systems because we do pass -DCMAKE_INSTALL_LIBDIR=lib to the cmake configuration command. So in the spirit of that behaviour, I would see doing it for autotools as well to be simply a matter of consistency. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Emacs completion produces duplicate prefixes when Jedi is disabled In an IPython session started with `ipython --quick` at 4f98f10 ```python ip = get_ipython() c = ip.Completer ip.ex(\"class TestClass():\\n\\ta=1\\n\\ta1=2\") ip.Completer.use_jedi = False c.all_completions(\"TestClass.a\") ``` yields ```python ['TestClass.TestClass.a', 'TestClass.TestClass.a1'] ``` The expected output is `['TestClass.a', 'TestClass.a1']`. The current output ruins Emacs completion when `jedi` is disabled. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery .exist method in new version 0.28.0 Hello, I used to use the following condition in version 0.26.0 of google-cloud-bigquery: `if dataset.table(my_table_name).exists(): ` I get the following error message when running it with the newer version 0.28.0: > AttributeError: 'TableReference' object has no attribute 'exists' What is the equivalent of the .exist() method in version 0.28.0 ? Environment: Python 2.7.10, macOS Sierra 10.12.6, google-cloud 0.31.0 Many thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: detect_c_or_cpp_compiler cl compiler check return wrong result on non-english windows detect_c_or_cpp_compiler cl compiler check return wrong result on non-english windows https://github.com/mesonbuild/meson/blob/fa431dddbc45fa539373c932dec650e1e26a9a5c/mesonbuild/environment.py#L779 hardcode ' for (.*)$', in non-english windows,its depend system lcid(1033,2052). For example, in zh-CHS chinese env,it is \"用于 x64 的 Microsoft (R) C/C++ 优化编译器 19.16.27030.1 版\". So we can't compile x86_64,because it force return \"x86\" if can't find ' for (.*)$' string. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: VirtualEnvGenerator doesn't call super __init__ A custom generator based on the `VirtualEnvGenerator` does not have the `_deps_build_info`, `_deps_env_info`, `_env_info`, and `_deps_user_info` set since the base constructor is not called. Proposed fix: Call the super constructor as all the other generators do, if they implement `__init__`. Conan version 1.16.1 Operating system: Ubuntu 18.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow `TransformationPass` to write to property set The property set is used to communicate information about the transpilation process \"out-of-band\" from one pass to the next. We originally disallowed `TransformationPass`es from writing it, with the idea that `AnalysisPass`es would exclusively collect information and `TransformationPass`es would exclusively modify circuits. I think the latter assumption is hard to maintain going forward. For example a TransformationPass may have internal state that is useful to a future pass (the example I have is the \"final_layout\" that is computed from a routing pass). We would need to communicate this information somehow. Within the current architecture, the only way to do this is to write an AnalysisPass that does the exact same thing as the routing pass, but does not actually transform the circuit and only returns the \"final_layout\". This is clearly expensive. So I think the solution is to either allow a `TransformationPass` to modify property set, or to declare the routing pass as inheriting from both `AnalysisPass` *and* `TransformationPass`. I couldn't get the latter to actually work though. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse: seconds_to_samples() fails when passed an array <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.16.1 - **Python version**: 3.7 - **Operating system**: Linux (under WSL) ### What is the current behavior? Passing a numpy array to ``qiskit.pulse.seconds_to_samples()`` raises an error: ``TypeError: only size-1 arrays can be converted to Python scalars``. ### Steps to reproduce the problem Run the following test script: ```python import numpy as np import qiskit.pulse as qp import qiskit.test.mock.fake_openpulse_2q as be with qp.build(be.FakeOpenPulse2Q()) as test: times_s = np.array([1e-6, 1e-5]) time_dt = qp.seconds_to_samples(times_s) ``` Traceback: ``` $ python ./test_qp_seconds_to_samples.py Traceback (most recent call last): File \"./test_qp_seconds_to_samples.py\", line 7, in <module> time_dt = qp.seconds_to_samples(times_s) File \"/nix/store/0wf80vpsyn5jmnarclzmdblwyaanhpw0-python3.7-qiskit-terra-0.16.1/lib/python3.7/site-packages/qiskit/pulse/builder.py\", line 665, in seconds_to_samples return int(seconds / active_backend().configuration().dt) TypeError: only size-1 arrays can be converted to Python scalars ``` ### What is the expected behavior? Based on the function signature, this should convert a list of numpy values from seconds to \"dt\". https://github.com/Qiskit/qiskit-terra/blob/ce15f8a5522ff2be865b6520659171288cbae43d/qiskit/pulse/builder.py#L731-L742 ### Suggested solutions Either change the function signature, or have conditional logic based on the type of the input argument ``seconds``: i.e. only apply ``int(result)`` if ``not isinstance(seconds, np.ndarray))`` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `exclude_files` argument to `install_subdir()` should be recorded in `intro-install_plan.json` The expectation is that `intro-install_plan.json` maps source or build artifacts file paths to installation paths containing destination path placeholders. When `install_subdir()` is used without the `exclude_files` or `exclude_dirs` arguments, the files are copied from the source tree to the installation path, thus `intro-install_plan.json` should contain an entry for the subdirectory path in the source tree. However, when either `exclude_files` or `exclude_dirs` are used, a copy of the subdirectory minus the excluded items is created in the build directory and the installation proceeds from there. Therefore, intro-install_plan.json` should contain an entry for the subdirectory path in the build directory. EDIT: my understanding was very wrong. I updated the issue's title to point to what is really missing. See below for details. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [Feature request] Add ability to specify target(/s) to `meson compile` Proposal: Add ability to specify target(/s) to `meson compile`. Reasoning: - Removes most of the cases where direct invocation of `ninja`/`msbuild` is needed. - (relative) Feature parity with `cmake --build`. Proposed interface: ``` usage: meson compile [args [args...]] positional arguments: args optional list of targets to build ``` Extracted from #6670. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Deduplicate notebook from jupyter/notebook See https://github.com/ipython/ipython/pull/8777 and https://github.com/jupyter/notebook/pull/363 among other, notebooks should not be in 2 places. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: No dependency if comment follows fortran module statement Meson 0.51.0. If there is a comment after the fortran module declaration like ``` module nice ! ``` this module is not added as a dependency for another source-file with `use nice`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: When no condarc is found \"no path!\" is printed Why was https://github.com/conda/conda/blob/master/conda/config.py#L115 added? Is this a debug statement which never got removed? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Add impl of `scipy.linalg.lu_solve` This is used by the Glow generative model to parameterize an invertible 1x1 convolution. A TF implementation in terms of triangular solve is here: https://github.com/tensorflow/probability/blob/master/tensorflow_probability/python/math/linalg.py#L306 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support c_std=c11 for newer MSVC 2019 Although I haven't found any mention of this in the [16.7 release notes](https://docs.microsoft.com/en-us/visualstudio/releases/2019/release-notes#16.7.0) `/std:c11` (and only `c11`) is supported for this version, this enables C11 _Generic support which has been a [preview feature](https://developercommunity.visualstudio.com/comments/1039772/view.html) for a while. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Missing whitespaces at RuntimeError message Trailing whitespaces are missing, https://github.com/huggingface/transformers/blob/31ec2cb2badfbdd4c1ac9c6c9b8a74e974984206/src/transformers/pipelines/__init__.py#L494-L499 so the error message is a little hard to read. ```python >>> from transformers import pipeline >>> pipeline(task=None, model=None) Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/.../venv/lib/python3.9/site-packages/transformers/pipelines/__init__.py\", line 495, in pipeline raise RuntimeError( RuntimeError: Impossible to instantiate a pipeline without either a task or a modelbeing specified.Please provide a task class or a model ``` - Python 3.9.4 - transformers 4.18.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: IBMQ Provider Documentation is unclear/incorrect <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**:0.6.1 - **Python version**: - **Operating system**: ### What is the current behavior? - [enable_account documentation](https://qiskit.org/documentation/_autodoc/qiskit.backends.ibmq.ibmqprovider.html?highlight=enable_account#qiskit.backends.ibmq.ibmqprovider.IBMQProvider.enable_account) is unclear. ``` Authenticate and use one IBMQ account during this session. Login into Quantum Experience or IBMQ using the provided credentials, adding the account to the current session. The account is not stored in disk. ``` The first and second sentence can be interpreted as contradictory. - [save_account](https://qiskit.org/documentation/_autodoc/qiskit.backends.ibmq.ibmqprovider.html?highlight=save_account#qiskit.backends.ibmq.ibmqprovider.IBMQProvider.save_account) does not authenticate but claims to. ### Steps to reproduce the problem ### What is the expected behavior? Clear, concise and correct descriptions of the methods. ### Suggested solutions See (#1053). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: mingw: has_function() MSYS2 workaround no longer works with gcc 10 **Describe the bug** has_function for stpcpy and posix_memalign now return true on Windows with gcc 10 My guess is that this is because the workaround here: https://github.com/mesonbuild/meson/blob/39ca178d21a72a8f7560b657b517fb73f81b4a89/mesonbuild/compilers/mixins/clike.py#L738 no longer works because gcc 10 now supports __has_builtin. **To Reproduce** ```meson project('glib', 'c', 'cpp', version : '2.65.0', ) cc = meson.get_compiler('c') cc.has_function('posix_memalign', prefix : '#include <stdlib.h>') ``` ```meson The Meson build system Version: 0.54.1 Source dir: C:/msys64/home/user/foo Build dir: C:/msys64/home/user/foo/_build Build type: native build Using 'PKG_CONFIG_PATH' from environment with value: 'C:\\\\msys64\\\\mingw64\\\\lib\\\\pkgconfig;C:\\\\msys64\\\\mingw64\\\\share\\\\pkgconfig' Using 'PKG_CONFIG_PATH' from environment with value: 'C:\\\\msys64\\\\mingw64\\\\lib\\\\pkgconfig;C:\\\\msys64\\\\mingw64\\\\share\\\\pkgconfig' Project name: glib Project version: 2.65.0 C compiler for the host machine: ccache cc (gcc 10.1.0 \"cc (Rev1, Built by MSYS2 project) 10.1.0\") C linker for the host machine: cc ld.bfd 2.34 C++ compiler for the host machine: ccache c++ (gcc 10.1.0 \"c++ (Rev1, Built by MSYS2 project) 10.1.0\") C++ linker for the host machine: c++ ld.bfd 2.34 Host machine cpu family: x86_64 Host machine cpu: x86_64 Checking for function \"posix_memalign\" : YES Build targets in project: 0 Found ninja.EXE-1.10.0 at C:\\msys64\\mingw64\\bin/ninja.EXE ``` **Expected behavior** ```meson Checking for function \"posix_memalign\" : NO ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: cython magic fail if cache dir is deleted while in session ``` In [1]: %load_ext cythonmagic In [2]: %%cython cimport cython ...: In [3]: rm -rf /home/jtaylor/.config/ipython/cython/ In [4]: %%cython cimport cython CompileError: command 'x86_64-linux-gnu-gcc' failed with exit status 1 ``` the command issued is: ``` x86_64-linux-gnu-gcc -pthread -fno-strict-aliasing -DNDEBUG -g -fwrapv -O2 -Wall -Wstrict-prototypes -fPIC -I/usr/include/python2.7 -I/usr/include/x86_64-linux-gnu/python2.7 -c /home/jtaylor/.config/ipython/cython/_cython_magic_d37c0b24f28dfb69270e82105a4c2e8e.c -o /home/jtaylor/.config/ipython/cython/home/jtaylor/.config/ipython/cython/_cython_magic_d37c0b24f28dfb69270e82105a4c2e8e.o Fatal error: can't create /home/jtaylor/.config/ipython/cython/home/jtaylor/.config/ipython/cython/_cython_magic_d37c0b24f28dfb69270e82105a4c2e8e.o: No such file or directory ``` the problematic part is this long path which is not recreated before trying to compile into it: ``` /home/jtaylor/.config/ipython/cython/home/jtaylor/.config/ipython/cython/ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Transaction is left open when error happens in Datastore API This one is hard to reproduce, but I noticed that when using a transaction with a **with** statement and an error happens inside the transaction itself (a 500 error for example), it appears that the transaction is left open. ``` python with self.client.transaction(): # do stuff # create entities, put, put_multi, etc ``` Exception: ``` python Traceback (most recent call last): File \"my_client.py\", line 190, in do_stuff with self.client.transaction(): File \"site-packages/gcloud/datastore/batch.py\", line 275, in __enter__ self.begin() File \"site-packages/gcloud/datastore/transaction.py\", line 131, in begin self._id = self.connection.begin_transaction(self.project) File \"site-packages/gcloud/datastore/connection.py\", line 307, in begin_transaction _datastore_pb2.BeginTransactionResponse) File \"site-packages/gcloud/datastore/connection.py\", line 124, in _rpc data=request_pb.SerializeToString()) File \"site-packages/gcloud/datastore/connection.py\", line 98, in _request raise make_exception(headers, error_status.message, use_json=False) InternalServerError: 500 internal error. ``` After the exception, any operations to the Datastore using the same client have no effect, and no error is reported. So my guess is that for some reason the transaction was left open and the changes are never committed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Values for logging are not merged while using \"extends\" - common.yml ``` version: '2' services: common: network_mode: \"mynetwork\" environment: - PRODUCTION=true restart: on-failure:5 logging: driver: \"awslogs\" options: awslogs-region: \"eu-central-1\" awslogs-group: \"MY_LOGGING\" ``` - docker-compose.yml ``` webapp: extends: file: common.yml service: common image: some/image:latest container_name: webapp ports: - \"80:80\" - \"443:443\" logging: options: awslogs-stream: \"webapp\" ``` After running `docker-compose up -d` I get: ``` Creating webapp ERROR: for webapp Cannot create container for service webapp: unknown log opt 'awslogs-stream' for json-file log driver ``` All other values are inherited correctly (i.e. network_mode, environment and restart). Is this expected behaviour? In real `docker-compose.yml` I have ~10 services, all of them have common logging driver (awslogs), the same region and logging group. The only difference is this \"awslogs-stream\". Do I really have to repeat the same section (logging) for every service? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Use a folder for linked packages We currently use `npm install <folder>` for linked packages that are not extensions, but in `npm@5` those are handled as symlinks instead of a folder copy. We should used a `linked` folder in `app_dir` and `npm pack` these extensions. This is blocked by #2697. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Easy api for custom primitives and vjps JAX supports custom primitives and vjps, just like Autograd did. Improvements: 1) add this to documentation 2) add a minimal example of this in the examples section 3) add a wrapper function if appropriate? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: SyntaxError display broken in Python 3 With python 2.7 ipython responds to a syntax error with a traceback like this: In [1]: ''. File \"<ipython-input-1-c1607516cd6c>\", line 1 ''. ^ SyntaxError: invalid syntax But with Python 3.2 you only get this: In [1]: ''. SyntaxError: invalid syntax (<ipython-input-1-c1607516cd6c>, line 1) There is no pointer showing where the error is. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qiskit.__qiskit_version__ does not return correct info <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is the current behavior? ```python qiskit.__qiskit_version__ {'qiskit': None, 'qiskit-terra': '0.8.0', 'qiskit-ignis': '0.1.1', 'qiskit-aer': '0.2.1', 'qiskit-ibmq-provider': '0.2.2', 'qiskit-aqua': '0.5.0'} ``` but: ``` qiskit.__version__ '0.9.0' ``` Also, the versioning looks for the packages via pip, but this does not mean that terra can find them. I have run into this before where I update terra (e.g. 0.8 -> 0.9) only to find that I must reinstall the ibmq-provider, aer, etc. even though the identical packages are in the site packages. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: argmax instantiates global constants The culprit is this line: https://github.com/google/jax/blob/22afc8cea1b9b5a0dca0cdfe8a0ce51df94cf9e0/jax/numpy/lax_numpy.py#L2234 I'm attempting to do argmax on large tensors and am running out of memory due to the size of the globally-allocated range object. A `tie_in` might workaround might address the memory issue, but perhaps the better approach is to implement what the TODO says? https://github.com/google/jax/blob/22afc8cea1b9b5a0dca0cdfe8a0ce51df94cf9e0/jax/numpy/lax_numpy.py#L2230-L2237 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Improve CI speed by using more GitHub actions jobs There are a number of pytest plugins to better distribute the tests, e.g.: - https://github.com/jerry-git/pytest-split - https://github.com/mark-adams/pytest-test-groups Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: define LinearFunction class and collect blocks of gates that make a LinearFunction A generalization of #7236: collect all blocks of gates consisting of CX and SWAP ~(and multi-controlled X)~. Then this n-qubit block can efficiently be represented by an `nxn` matrix, which encodes a \"linear function\". There are then known ways of synthesizing this linear function (one of them is in qiskit under the patel-markov-hayes algorithm). (See fig 2 here and the matrix A above it for an example: https://web.eecs.umich.edu/~imarkov/pubs/jour/qic08-cnot.pdf) We need: a) a new class that represents such `nxn` linear functions and can be inserted into the circuit as an Operation (#7087 ) b) a compiler pass that can collect occurences of above gates and replace them by a LinearFunction We will add a few different synthesis methods for the LinearFunctions later. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Remove conan-transit as default remote Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: No module named sphinx.util.compat error using `IPython.sphinxext` with Sphinx pre1.7 master branch Trying out `IPython.sphinxext` 6.1.0 with ``Sphinx==1.7.dev20170617`` I get the following error on a Sphinx project: ``` Extension error: Could not import extension IPython.sphinxext.ipython_directive (exception: No module named 'sphinx.util.compat') ``` Indeed, the `sphinx.util.compat` is deprecated at 1.6 and will be [removed at Sphinx 1.7](https://github.com/sphinx-doc/sphinx/blob/3d5e0c5d7/CHANGES#L45). To reproduce, in a virtual env with IPython 6.1.0 run pip install git+https://github.com/sphinx-doc/sphinx and then ``` mkdir /tmp/IPython-test cd /tmp/IPython-test yes \"n\" | sphinx-quickstart --dot _ --project IPython-test --author \"Example\" -v 0 --release 0 --language en --suffix .rst --master index --makefile --batchfile . echo ' extensions = [ \"IPython.sphinxext.ipython_directive\", ] ' >> conf.py make html ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Function name printing should use __qualname__ instead of __name__ (Python 3) There is a bug in the formatting of functions belonging to a class in IPython 2.0.0 running in Python3. ``` In [1]: class A: ...: def f(self): ...: pass ...: In [2]: A.f Out[2]: <function __main__.f> In [3]: str(A.f) Out[3]: '<function A.f at 0x10b283840>' ``` The function name formatting is using the `__name__` attribute of the function instead of `__qualname__`, which results in incorrectly showing the function `f` here in our example belongs to `__main__` instead of `__main__.A`. A quick fix would be a one line change in https://github.com/ipython/ipython/blob/master/IPython/lib/pretty.py#L749 to use `__qualname__` instead, but will break in Python 2.x as there is no `__qualname__` support. ``` def _function_pprint(obj, p, cycle): \"\"\"Base pprint for all functions and builtin functions.\"\"\" if obj.__module__ in ('__builtin__', 'builtins', 'exceptions') or not obj.__module__: name = obj.__name__ else: name = obj.__module__ + '.' + obj.__name__ # use obj.__qualname__ p.text('<function %s>' % name) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Add help string for xmode When an exception occurs, IPython displays it with its own fancy traceback formatter. I don't mind the coloured output, but the visually expanded display feels much more cumbersome to me with long tracebacks. I would therefore like to revert to the standard Python excepthook Unfortunately, setting `__excepthook__` from the console doesn't work (IPython overrides the newly-set value), therefore it would be nice to get a configuration option for it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/mxnet codebase. Here's the problem: python doc error in KVstore example in the KVstore example: ``` python >>> def update(key, input, stored): >>> print \"update on key: %d\" % key >>> stored += input * 2 >>> kv.set_updater(update) ``` where `kv.set_updater` should be `kv._set_updater(update)` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gnome.marshal() accept files in addition to strings for the sources Hello! Since meson > 0.61 the method [gnome.marshal()](https://mesonbuild.com/Gnome-module.html#gnomegenmarshal) doesn't accept anymore a list of files for the parameter `sources`. According to the documentation this is correct: ``` sources []str required: List of string sources to consume sources: the list of sources to use as inputs ``` I assume a more strict and therefore better type checking. The maintainers of gnome-terminal [prefer](https://gitlab.gnome.org/GNOME/gnome-terminal/-/issues/7886#note_1355184) to keep passing files. Is it possible to extend the API? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add DINOv2 to Transformers ### Feature request Add DINOv2 to the transformers library. Weights are available in [DINOv2 repo](https://github.com/facebookresearch/dinov2) ### Motivation Currently, DINOv2 can be used through `torch.hub.load`, but having it ported to transformers directly would be nice to have, and since DINOv1 is already in the library it might not be that difficult to do ### Your contribution I would love to do a PR to make this addition in the case that it's actually not something hard to do and someone could point me the way that I should look at. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Kernel Adapter might append too late Found out with julia, if I aggressively ask for completion before kernel fully started I got : ``` KERNEL EXCEPTION key not found: \"inspect_request\" in eventloop at /Users/bussonniermatthias/.julia/v0.4/IJulia/src/IJulia.jl:123 in anonymous at task.jl:340 ``` Which adapter should have translated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Environment QA check prior to push Prior to pushing docker based environments, we should do a quick health check to ensure the container can at least get the flow to a Running state. This will require executing a few basic commands in the container which deserialize the flow and report any errors that arise in the process; otherwise, the image is pushed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add option --rm to `fig run` Most of the time, I clean up containers create with `fig run`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Lemmatization errors when text contains contracted forms of 'be' I've noticed some inconsistent behavior here: nlp = spacy_nlp(u\"I'm hungry. You're hungry. He's hungry. It's hungry. We're hungry. They're hungry.\") for tok in nlp: print tok, tok.lemma_ Gives output: I i 'm be hungry hungry . . You you 're 're hungry hungry . . He he 's ' hungry hungry . . It it 's ' hungry hungry . . We we 're 're hungry hungry . . They they 're 're hungry hungry . . A related error is for \"won't\" (and for the much rarer \"shan't\"): nlp = spacy_nlp(u\"They won't move.\") for tok in nlp: print tok, tok.lemma_ They they wo wo n't not move move . . I think I once even saw a similar lemmatization error for \"can't\", but I am not able to recreate this error. ## Your Environment <!-- Include details of your environment --> OSX 10.11.6 Spyder 3.0.0 spaCy 1.2.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Don't completely fail when failing to parse an error See #1438 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add docker:stable to your build matrix It seems like installing Compose on docker:stable inside a GitLab CI build is a pretty popular workflow (see #6617). In this issue, @ulyssessouza said: > This is related to the new SSH support which added some new dependencies. On our test systems these dependencies are already available once pip is installed. https://github.com/docker/compose/issues/6617#issuecomment-477974325 **Should you add this configuration to your build matrix?** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook.ipynb CR+LF turned into CR+CR+LF Loading a Notebook created with IPython 2.2 under Windows  when saved with IPython 2.3 results in  Similar to #3819 and #4122 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Validate input when setting the QuantumCircuit data attribute directly Similar to #2170 , but for `QuantumCircuit`. The possibility of arbitrary data in `circuit.data` makes modifying or replacing the internals of `QuantumCircuit` difficult and error prone (see discussion around `circuit._append` in #2824 ). We should: - Move `circuit.data` to `circuit._data` - Add a getter for `circuit.data` and document it as a ordered list of `(Instruction, qargs, cargs)`. It's an open question whether or not we should commit to preserving user-insertion order. - Add a setter for `circuit.data` with a `DeprecationWarning`, directing users to e.g. `QuantumCircuit.append` and the rest of the circuit API. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Is the addition of the 'OPTforSequenceClassification' class scheduled? ### Feature request Is the addition of the 'OPTforSequenceClassification' class scheduled? Is someone handling it? When adding these functions, I wonder if it is possible to PR one by one, or if I have to PR all classes supported by other models. ### Motivation Added function of OPT class, which is being actively discussed recently ### Your contribution I personally use the forSequenceClassification \bclass because I need it for my experiments, but I would like to inquire if I can contribute to the addition of the function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: `jax.jit` should report an error immediately for uncallable arguments `jax.jit(3)` silently succeeds (although `jax.jit(3)(4)` returns the expected error). The `callable` builtin seems applicable here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: LocalExecutor leads to multi-thread run This one is related to issue #1145 . In the latest version 0.7.0, the default executor is already set to LocalExecutor. According to the [document](https://docs.prefect.io/api/unreleased/engine/executors.html#executor) , LocalExecutor is not capable of parallelism and runs all functions synchronously and immediately in the main thread. So I expect this would fix #1145 naturally. But it turned out that the tasks were still running in \"parallel\". Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Different meanings set on values when reading null Hey, we have a list in our datastore with ids and sometimes nulls in it. Like here: ``` [\"null\",\"null\",\"a953c730fc2e4647b3a5b4e88fa4f0ce\",\"59ce754ddf03401eb09abd50c977cf67\",\"null\"] ``` When we try to fetch them, we get the \"Different meanings set on values within a list_value\" Exception. Is this a bug, that the method does not handles null? [`_get_meaning` Method](https://github.com/GoogleCloudPlatform/gcloud-python/blob/efc1d41d230330fdd2f3c5c8df493b1ffb654be5/gcloud/datastore/helpers.py#L73): ``` python def _get_meaning(value_pb, is_list=False): meaning = None if is_list: # An empty list will have no values, hence no shared meaning # set among them. if len(value_pb.list_value) == 0: return None # We check among all the meanings, some of which may be None, # the rest which may be enum/int values. all_meanings = set(_get_meaning(sub_value_pb) for sub_value_pb in value_pb.list_value) meaning = all_meanings.pop() # The value we popped off should have been unique. If not # then we can't handle a list with values that have more # than one meaning. if all_meanings: raise ValueError('Different meanings set on values ' 'within a list_value') elif value_pb.meaning: # Simple field (int32) meaning = value_pb.meaning return meaning ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda 4.3.4 seems to be broken ``` bag@bag ~ % conda --version conda 4.3.4 bag@bag ~ % conda install -y --file https://raw.githubusercontent.com/bioconda/bioconda-utils/master/bioconda_utils/bioconda_utils-requirements.txt CondaError: Downloaded bytes did not match Content-Length url: https://raw.githubusercontent.com/bioconda/bioconda-utils/master/bioconda_utils/bioconda_utils-requirements.txt target_path: /tmp/tmpUp36pQ/bioconda_utils-requirements.txt Content-Length: 195 downloaded bytes: 310 bag@bag ~ % ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [couch] error \"local variable 'db_stats' referenced before assignment\" I just started using datadog and have an issue getting the couch integration to run (on MacOS Sierra). `/usr/local/bin/datadog-agent info` reports this: ```` Checks ====== ntp --- - Collected 0 metrics, 0 events & 1 service check disk ---- - instance #0 [OK] - Collected 44 metrics, 0 events & 1 service check network ------- - instance #0 [OK] - Collected 27 metrics, 0 events & 1 service check couch ----- - instance #0 [ERROR]: \"local variable 'db_stats' referenced before assignment\" - Collected 0 metrics, 0 events & 2 service checks Emitters ======== - http_emitter [OK] =================== Dogstatsd (v 5.8.0) =================== Status date: 2017-02-22 17:11:34 (8s ago) Pid: 85989 Platform: Darwin-16.4.0-x86_64-i386-64bit Python Version: 2.7.11, 64bit ```` To me, `local variable 'db_stats' referenced before assignment` looks like an error in the couchdb integration library. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"docker-compose config\" produces invalid content When generating docker-compose config from a combination of `docker-compose.yml` and a `docker-compose.override.yml`, compose might leave behind empty properties. Consider we have these two config files: ```yml # docker-compose.yml version: '2.2' services: test: logging: driver: gelf options: gelf-address: localhost image: busybox ``` and ```yml # docker-compose.override.yml version: '2.2' services: test: logging: driver: json-file ``` Let's generate a new config out of these: ```bash $ docker-compose config > test.yml ``` Here's the result: ```yml # test.yml services: test: image: busybox logging: driver: json-file options: null # <- The problem version: '2.2' ``` Now if we try to use the generated config we'll get the following: ```bash $ docker-compose -f test.yml config ERROR: The Compose file './test.yml' is invalid because: services.test.logging.options contains an invalid type, it should be an object ``` Versions: ```bash $ docker-compose version docker-compose version 1.15.0, build e12f3b9 docker-py version: 2.4.2 CPython version: 2.7.12 OpenSSL version: OpenSSL 1.0.2j 26 Sep 2016 ``` ``` $ docker version Client: Version: 17.07.0-ce-rc1 API version: 1.31 Go version: go1.8.3 Git commit: 8c4be39 Built: Wed Jul 26 05:20:09 2017 OS/Arch: darwin/amd64 Server: Version: 17.07.0-ce-rc1 API version: 1.31 (minimum version 1.12) Go version: go1.8.3 Git commit: 8c4be39 Built: Wed Jul 26 05:25:01 2017 OS/Arch: linux/amd64 Experimental: true ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Connections import and export should also support \".yml\" file extensions ### Apache Airflow version 2.2.4 (latest released) ### What happened Trying to export or import a yaml formatted connections file with \".yml\" extension fails. ### What you think should happen instead While the \"official recommended extension\" for YAML files is .yaml, many pipeline are built around using the .yml file extension. Importing and exporting of .yml files should also be supported. ### How to reproduce Running airflow connections import or export with a file having a .yml file extension errors with: `Unsupported file format. The file must have the extension .env or .json or .yaml` ### Operating System debian 10 buster ### Versions of Apache Airflow Providers _No response_ ### Deployment Docker-Compose ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Plot_state_city origin axis not centered <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.9.0 - **Python version**: 3.7.3 - **Operating system**: MacOS ### What is the current behavior? When creating a real or imaginary plot with both positive and negative values, the origin axis is not centered. <img width=\"1405\" alt=\"Screen Shot 2019-09-23 at 9 45 25 AM\" src=\"https://user-images.githubusercontent.com/54714046/65779051-04a51000-e115-11e9-8d79-7edb5d73d717.png\"> ### Steps to reproduce the problem Create a plot_state_city plot that has both positive and negative values. ### What is the expected behavior? On a previous version of plot_state_city (#1540), the origin axis does not appear to have an offset. <img width=\"966\" alt=\"50148613-f0c7a600-0286-11e9-9734-baeab0a059bf\" src=\"https://user-images.githubusercontent.com/54714046/65779450-c52af380-e115-11e9-9bfd-cf741e2fd1b5.png\"> ### Suggested solutions Currently looking through the older version to try and identify the source of change. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Int64 CheckValue in datastore.helpers returns None instead of the value. We current do \"return INT64(val)\", however INT64 returns nothing. We need to run this method, and _then_ return the value. See: https://code.google.com/p/protobuf/source/browse/trunk/python/google/protobuf/internal/type_checkers.py?r=163#100 returns None. We need to _check_ and then return \"val\". and https://github.com/GoogleCloudPlatform/gcloud-python/blob/1779aeccdea1f2557e5e2cf80e448d0b64f48527/gcloud/datastore/helpers.py#L59 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Turning off Verbosity on QA model using Pipeline Hi, I am looking for a way to turn off the logs warnings. Please refer to the screenshot.  This is currently what I am doing.  Is there any way? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: How do I make commits with a specified date? I can't seem to find out how to make commit with specifying `author_date` and `commit_date`, but it did not really work: ``` import git ... repo = git.Repo.init(repo_path) repo.index.add(['some_file']) repo.index.commit(message, authored_date=commit_date, committed_date=commit_date) ``` throws: ``` TypeError: commit() got an unexpected keyword argument 'authored_date' ``` Then I looked at the [source](https://github.com/gitpython-developers/GitPython/blob/master/git/objects/commit.py#L269) and found out it does not really have parameters for commit datetime. (or am I missing something? Would you be interested in a PR which adds these parameters? I am interested to learn and make contribution :smile: ) So, I either I have to create a commit then change dates (using [`Commit`](http://gitpython.readthedocs.org/en/stable/tutorial.html#the-commit-object) object) or use [git directly](http://gitpython.readthedocs.org/en/stable/tutorial.html#using-git-directly). or set OS envs before commit call: ``` ... os.environ['GIT_AUTHOR_DATE'] = date_in_iso os.environ['GIT_COMMITTER_DATE'] = date_in_iso repo.index.commit(message) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Release spanner 1.2.0 Batch query support is merged. Note that `development_status` is still showing beta. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: barriers are ignored in QuantumCircuit.depth() The depth method on QuantumCircuit ignores barriers: ```python from qiskit import QuantumCircuit circ_serial = QuantumCircuit(4) circ_serial.h(0) circ_serial.cx(0, 1) circ_serial.barrier() circ_serial.h(2) circ_serial.cx(2, 3) print(circ_serial) print('depth: ', circ_serial.depth()) circ_parallel = QuantumCircuit(4) circ_parallel.h(0) circ_parallel.cx(0, 1) circ_parallel.h(2) circ_parallel.cx(2, 3) print(circ_parallel) print('depth: ', circ_parallel.depth()) ``` ``` ┌───┐ ░ q_0: |0>┤ H ├──■───░─────────── └───┘┌─┴─┐ ░ q_1: |0>─────┤ X ├─░─────────── └───┘ ░ ┌───┐ q_2: |0>───────────░─┤ H ├──■── ░ └───┘┌─┴─┐ q_3: |0>───────────░──────┤ X ├ ░ └───┘ depth: 2 ┌───┐ q_0: |0>┤ H ├──■── └───┘┌─┴─┐ q_1: |0>─────┤ X ├ ┌───┐└───┘ q_2: |0>┤ H ├──■── └───┘┌─┴─┐ q_3: |0>─────┤ X ├ └───┘ depth: 2 ``` The depth method on DAGCircuit is correct however: ```python from qiskit.converters import circuit_to_dag circuit_to_dag(circ_serial).depth() ``` ``` 5 ``` Note: `snapshot` should also behave similarly to `barrier` and extend the depth. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: distributed eval cleanup - [x] local_rank 0 logging - [x] local_rank 0 tqdm - [x] same scores as `run_eval.py` - [x] deeper investigation of non-determinism. Gens the same. Labels different? - [x] save json to one line. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Mapping w/ SKIP signals doesn't work as intended Consider the following flow: ```python from prefect import * @task def my_list(): return [1, 2, 3] @task def add(x): if x == 1: raise engine.signals.SKIP(\"One is no good\") else: return x + 1 with Flow() as f: res = add.map(add.map(my_list)) flow_state = f.run(return_tasks=f.tasks) ``` We expect `flow_state.result[res]` to be a list with 1 Skipped state and 2 success states with result values 4 and 5. However, instead, the entire second mapping is skipped: ```python flow_state.result {<Task: add>: [Skipped(\"One is no good\"), Success(\"Task run succeeded.\"), Success(\"Task run succeeded.\")], <Task: my_list>: Success(\"Task run succeeded.\"), <Task: add>: Skipped(\"Upstream task was skipped; if this was not the intended behavior, consider changing `skip_on_upstream_skip=False` for this task.\")} ``` **cc:** @jlowin Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Support stepping options for lr scheduler Currently schedulers get called every epoch. Sometimes though, we want them to be called every step. Proposal 1: Allow configure_optimizers to return this: ```python return Adam, {'scheduler': LRScheduler, 'interval': 'batch|epoch'} ``` @ethanwharris @Borda thoughts? any simpler more general way of doing this? i think this dict can eventually have more options if we need to. @srush Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Compatibility shims for future releases * filter loaded repodata on repodata_version * split matchspec on `\" if \"` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Using multiple SamplePulses with the same name overwritten in Qobj pulse library <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? In the Qobj specification, pulse are identified by their name. In the pulse module pulses are identified by their object instance and when assembled are stored in the Qobj pulse library by name. If two `SamplePulse`s of the same name exist, the second will overwrite the first, causing undesired behaviour. ### Steps to reproduce the problem Create a pulse schedule with two different pulses of the same name and assemble into a Qobj. ### What is the expected behavior? Unique pulses should be stored uniquely in the Qobj pulse library. ### Suggested solutions If a name collision occurs when building the pulse library. Modify the name of the sample pulse in some consistent manner, and adjust the commands that refer to this pulse. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Move Hadoop distro out of CI image **Description** Hadoop distro is unnecessarily part of the CI image. It should be moved out and used separately **Use case / motivation** Download and install Hadoop image only when needed not as part of the CI image (as separate integration). This will make the image smaller and the whole process smoother. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Make ctypes completely optional on Windows There are a couple of places where `ctypes` is presumed to be available, which means `numpy` cannot be imported on systems/distributions that do not include it. These are [`_dtype_ctypes.py`](https://github.com/numpy/numpy/blob/master/numpy/core/_dtype_ctypes.py), and the [`_distributor_init.py`](https://github.com/numpy/numpy/blob/bfb156741a92f77c13c50d82fc5a1f4d6177a9f5/tools/openblas_support.py#L197) generated for `libopenblas`. The `_dtype_ctypes` module seems easy enough to update to match the other ctypes-using modules (or simply delay the [eager import](https://github.com/numpy/numpy/blob/master/numpy/core/__init__.py#L100) or handle it failing). I can't find any uses in numpy itself though, so I have no idea what its compatibility constraints are. The `_distributor_init.py` file is somewhat redundant with the [generated `__config__.py`](https://github.com/numpy/numpy/blob/8087e1de04d011f7ce66bf80dbef4a0599b14f7a/numpy/distutils/misc_util.py#L2289), but could also just do nothing when ctypes fails to import. I'm happy to send a PR, but it's not obvious which fixes would be preferred. If I were going to keep it simple, I'd defer the `import ctypes` in `_dtype_ctypes` into the function(s) that use it, and add an early exit from the `_distributor_init.py` when ctypes is unavailable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson doesn't automatically call ldconfig We received an issue in fwupd (https://github.com/hughsie/fwupd/issues/914) that indicated that an application wasn't working properly after installed. The issue ended up being that libraries were installed into `/usr/local/lib/$(triplet)` which was referred to in a file in `/etc/ld.so.conf.d` however since `ldconfig` wasn't run `/etc/ld.so.cache` wasn't refreshed and the application was failing to run. So I wanted to see what thoughts were on setting default behavior of `ninja install` to call `ldconfig`, but let distros such as those using deb or rpm with delayed callbacks turn this behavior off. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Add pxla.ShardedDeviceArray to jaxval_zeros_likers This is a one-line fix at https://github.com/google/jax/blob/master/jax/lax/lax.py#L1503 Just adding this as an issue as a reminder for @mattjj Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: API Endpoint - Health - Spec and impelementataion **Description** There is no endpoint to check if the instance is in good condition We need to prepare the change to the API specification and then implement this change. More information about API Endpoints: https://github.com/apache/airflow/issues/8118 **Use case / motivation** N/A **Related Issues** N/a Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Remove SLURM warning when in interactive mode No need to show the \"we launched processes for you\" warning when in interactive SLURM mode. Suggested by @adefazio Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Simplify back CheckMap pass The goal of `CheckMap` pass is to check that the swapper fulfilled its promise. No more than that. Therefore, `is_swap_mapped` should also be renamed to `requires_swap` (and inverted). The direction checked can be done by a different pass `CheckCnotDirection`, so the property `is_direction_mapped` should be removed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Consider a --force-recreate-volumes flag If I have an image that defines a volume, the container ends up with an anonymous docker volume. This leads to issues like #4476 where I can't add `volumes_from:` if I've previously forgotten it. Another use case I've encountered is when you have an image that populates a volume: ``` FROM base/almost_empty:1.0.0 ENV AIRFLOW_HOME /usr/local/airflow COPY ./foo ${AIRFLOW_HOME}/stuff/foo/ VOLUME ${AIRFLOW_HOME}/stuff ``` In this case, when I update to a newer version of my image, I want a new volume with the latest version of `foo`. At the moment, I can do `docker-compose down && docker-compose up`, but this recreates every single container in my docker-compose.yml. Alternatively, I can do `docker-compose rm xyz && docker-compose up`. However assumes that I know which containers to run `docker-compose rm` on. Would you be willing to add a `--force-recreate-volumes` argument? This would be a huge help for these use cases. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Consider depending on `azure-keyvault-secrets` instead of `azure-keyvault` metapackage ### Description It appears that the `microsoft-azure` provider only depends on `azure-keyvault-secrets`: https://github.com/apache/airflow/blob/388723950de9ca519108e0a8f6818f0fc0dd91d4/airflow/providers/microsoft/azure/secrets/key_vault.py#L24 and not the other 2 packages in the `azure-keyvault` metapackage. ### Use case/motivation I am the maintainer of the `apache-airflow-providers-*` packages on `conda-forge` and I'm running into small issues with the way `azure-keyvault` is maintained as a metapackage on `conda-forge`. I think depending on `azure-keyvault-secrets` explicitly would solve my problem and also provide better clarity for the `microsoft-azure` provider in general. ### Related issues https://github.com/conda-forge/azure-keyvault-feedstock/issues/6 https://github.com/conda-forge/apache-airflow-providers-microsoft-azure-feedstock/pull/13 ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Review the messages encouraging the use of slower Python simulators alternatives ### What is the expected enhancement? After #1484 Python and C++ simulators no longer live under the same `Aer` provider but they are split between `Simulators` and `LegacySimulators` providers respectively. `Simulators` make it clear they are the built-in simulators coming with the foundational Terra element but now, strings such as: > The 'qasm_simulator' backend is not installed in your system. Consider using a slower backend alternative: 'qasm_simulator_py' Does not make sense. What should we do? Using `LegacySimulators.get_backend()` prints a deprecated warning. Should we simply remove these messages? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Continuous memory leak There is a memory leak in the parent process of Celery's worker. It is not a child process executing a task. It happens suddenly every few days. Unless you stop Celery, it consumes server memory in tens of hours. This problem happens at least in Celery 4.1, and it also occurs in Celery 4.2. Celery is running on Ubuntu 16 and brokers use RabbitMQ.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Consider to add Macos.version sub-setting In order to manage `-mmacosx-version-min` especially important if you are buildings apps for OSX we would need a `version` subsetting similar to the Ios, watchos, tvos, etc. It could be added with a None default to not break current packages. Our current `apple_deployment_target_flag` tool, introduced in `1.4` needs a `os_version` but we don't have a model nor detection mechanism to provide it. Looks like the subsetting is needed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Evolution gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Implement an evolution gate that can get synthesized into Pauli-evolution gates (or for a simulator backend just with direct matrix exponentiation) such that the compiler can perform optimizations on blocks of evolved Pauli operators before further decomposing into basis gates. Here's a preliminary design doc: https://gist.github.com/Cryoris/abc9753fd7dfb0cc3b3a83aa58a182e3 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda env giving strange non-blocking behavior on Windows Using conda 4.4.4, this is happening in both the Anaconda prompt and Git Bash. To reproduce, simply run `conda env -h`. The prompt will return and it seems like conda is run in the background, producing output a few seconds later. Strangely enough, this doesn't happen when running `conda-env -h`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Refactor secret-dependent tasks to use new secrets API ## Current behavior *Please describe how the feature works today* Currently, many tasks in the task library expect a secret name, which they load to access credentials. ## Proposed behavior *Please describe your proposed change to the current behavior* With the new secrets API introduced in https://github.com/PrefectHQ/prefect/pull/1664, these tasks should actually accept a secret *value* at run time. We can leave the secret-name behavior in place, raising a deprecation warning, and simply prefer a secret value if provided. ## Example *Please give an example of how the enhancement would be useful* #### Old Way ```python with Flow(\"example\") as flow: bigquery_download = BigQueryTask(credentials_secret='gcs_creds') ``` #### New Way ```python with Flow(\"example\") as flow: gcs_creds = Secret('gcs_creds') bigquery_download = BigQueryTask(credentials=gcs_creds) ``` Though it adds a line, the advantage of the new way is that the secret mechanism is exposed, pluggable, and introspectable. The old way required whatever secret API was embedded in the task (currently, Prefect Cloud / local secrets) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Weird behavior of structured_to_unstructured on non-trivial dtypes With the following helpers: ```python import numpy.lib.recfunctions as rfn def subarray(dt, shape): return np.dtype((dt, shape)) def structured(*dts): return np.dtype([('x{}'.format(i), dt) for i, dt in enumerate(dts)]) def inspect(dt): arr = np.zeros((), dt) ret = rfn.structured_to_unstructured(arr) print(ret.shape, ret.dtype) ``` We can try a bunch of uses of `structured_to_unstructured` (added in #11526): ```python >>> inspect(structured(int, int)) (2,) int32 # obviously ok >>> inspect(structured(int, structured(int, int))) (3,) int32 # nested types are flattened, ok >>> inspect(structured(int, subarray(int, 2))) (3,) int32 # ok: 1 + 2 >>> inspect(structured(int, subarray(int, (2, 2)))) (5,) int32 # ok: 1 + 2*2 ``` Here's where things start to go bad: ```python >>> inspect(structured(subarray(structured(int, int), 3))) (3,) [('x0', '<i4'), ('x1', '<i4')] # bug? ``` ```python >>> inspect(structured(subarray(subarray(int, 2), 2))) (2, 2) int32 # bug ``` ```python >>> inspect(structured(int)) () int32 # bug ``` (#13334) ```python >>> inspect(structured(int, subarray(subarray(int, 2), 2))) TypeError: invalid type promotion ``` ```python >>> inspect(structured()) dts, counts, offsets = zip(*fields) ValueError: not enough values to unpack (expected 3, got 0) ``` A lot of this behavior looks undesirable to me. @ahaldane, which cases were actually intended to be supported? Rather than locking ourselve into some of these weird constucts, we might want to raise an error for anything non-trivial. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add code examples to Result Handler concept docs The docs for results and result handlers could use some code examples either in the concept doc itself or linking to other tutorials/examples around using results https://docs.prefect.io/core/concepts/results.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Chain exceptions where appropriate Picking up from #15731, there are many places in numpy where we do something like: ```python try: something_which_throws_typeError except TypeError: raise ValueError(\"a clearer explanation of what went wrong\") ``` It would produce a marginally clearer error if we could change these to use traceback chaining. Our two options are either: 1. The inner error provides valuable information that is not present in the outer error. We should use `from e`. ```python try: something_which_throws_typeError except TypeError as e: raise ValueError(\"a clearer explanation of what went wrong\") from e ``` 2. The inner error provides no valuable information that is not present in the outer error. We should use `from None`: ```python try: some_dict[name] except KeyError: raise ValueError(\"The name %s is not supported\" % name) from None ``` In that example all the information from the `KeyError` is already in the message of the new error, so there is no point chaining An example of such a change would be [this line](https://github.com/numpy/numpy/pull/15731/files#diff-e55dc29434893b7f529192a2e77e9b07R7070) of this otherwise-discarded patch. For now, I would recommend we only apply this to cases where the exception is thrown unconditionally, as other cases can be more nuanced. --- ### Please see [this list](https://github.com/numpy/numpy/issues/15986#issuecomment-660762674) for potential places to contribute. Special thanks to @nkleinbaer for compiling the list! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] CMakeToolchain support for linker scripts When building an ELF executable for bare-metal targets it is normal to include a linker script to define the memory layout of the specific target microcontroller. It is possible to use multiple linker scripts, too. Each one is passed with the `-T` flag when using GCC. I don't think this actually needs to be applied to dependencies, only the final executable that will be loaded on the microcontroller. It would be great if there was an easy way to configure this for the CMakeToolchain generator. If it only needs to be applied to the consumer, perhaps the CMakeToolchain generator could define a dedicated block for this. I'm not sure if there should be additional ways to configure linker scripts, but there might be some good ideas out there. - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Incorrectly detected arch on aarch64 As per the title, conda currently only knows about the usual x86, x86_64 and armv7l architectures. Since aarch64 systems are compatible with armhf binaries, conda just needs to alias 'aarch64' to 'armv7l'. The only hitch involved in approaching the problem via such an alias is that the armhf linker (ld-linux-armhf) may not be installed - its a rare situation currently, since most ARM systems opt for a 64bit kernel/32 bit userspace due to the rarity of 64 bit ARM binaries. The user (with sudo privileges) would need to install the linker in such a situation. See [PR 4809](https://github.com/conda/conda/pull/4809) for implementation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Latex drawer should prioritize instruction label over name # Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: MacOS ### What is the current behavior? When an instruction has a label, the label should be used. If a no-boxing instruction has a label, a box should be used. ### Steps to reproduce the problem ```python from qiskit import QuantumRegister, QuantumCircuit from qiskit.extensions import XGate, UnitaryGate, CzGate import numpy qr = QuantumRegister(2) circ = QuantumCircuit(qr) circ.append(XGate(), [qr[0]]) circ.append(XGate(label='alt-X'), [qr[0]]) circ.append(UnitaryGate(numpy.eye(4)), [qr[0], qr[1]]) circ.append(UnitaryGate(numpy.eye(4), label=\"iswap\"), [qr[0], qr[1]]) circ.append(CzGate(), [qr[0], qr[1]]) circ.append(CzGate(label='cz label'), [qr[0], qr[1]]) circ.draw('latex') ```  ### What is the expected behavior? Something like the text drawer: ``` ┌───┐┌───────┐┌──────────┐┌────────┐ ┌───────────┐ q2_0: |0>┤ X ├┤ alt-X ├┤0 ├┤0 ├─■─┤0 ├ └───┘└───────┘│ Unitary ││ iswap │ │ │ cz label │ q2_1: |0>──────────────┤1 ├┤1 ├─■─┤1 ├ └──────────┘└────────┘ └───────────┘ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Synchronous query API hides job Under the covers, the resources returned by [synchronous `jobs/query` API](https://cloud.google.com/bigquery/docs/reference/v2/jobs/query) and the [follow-on `jobs/getQueryResults` API](https://cloud.google.com/bigquery/docs/reference/v2/jobs/getQueryResults) obscure most information found in the underlying [`jobs` resource](https://cloud.google.com/bigquery/docs/reference/v2/jobs#resource) for the query job. I'm up against this issue while trying to implement `Client.list_jobs`, which calls the [`jobs/list` API](https://cloud.google.com/bigquery/docs/reference/v2/jobs/list) and tries to return instances of the appropriate job class. That API call returns job resources for synchronous queries which are effectively indistinguishable from those created for asynchronous queries (I've only been able to tell them apart by checking that the `datasetId` of the `destinationTable` does not match any of the \"public\" datasets for the project). Because of this discrepancy, I believe that the current `jobs.RunSyncQueryJob` class is misnamed: instead, it should be called something like `query.QueryResults`: this new/renamed class would not pretend to be a job, but instead would have a `job` accessor which created/returned a `jobs.QueryJob` instance (which would be renamed from the current `jobs.RunAsyncQueryJob`). `Client.list_jobs` would then always return instances of `jobs.QueryJob`, even for synchronous queries. @dhermes, @jgeewax please comment if you disagree with this conclusion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: `auth login` CLI check needs token required query ## Description `prefect auth login` runs a graphql query to verify the token provided is valid. The current query is `query { hello }` and this query does not require authentication. This query needs to be updated to one which requires authentication (which is every other query, let's just find the smallest one) ## Expected Behavior If the token is invalid it should elevate an error to the user ## Reproduction Query the API with `query { hello }` without a token and it will still work. ## Environment N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda does not prompt for proxy username and password ``` [ COMPLETE ] |#################################################| 100% The batch file cannot be found. C:\\Code>conda update conda Fetching package metadata: .Error: HTTPError: 407 Client Error: Proxy Authentication Required: http://repo.continuum.io/pkgs/pro/win-64/ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: remove cast_unicode from the %save magic. This needs to find wether in `code.py` line 336 cmds is always str, if not cast upstream, and repeat. ``` cmds = self.shell.find_user_code(codefrom,raw) ``` - [x] Does find_user_code(codefrom,raw) always return a string ? (interactiveshell.py:3568) - [x] `self.extract_input_lines(target, raw=raw)` str ? - [x] `openpy.read_py_url(target, skip_encoding_cookie=skip_encoding_cookie)` str ? - [x] `source_to_unicode` str ? - [x] `return response.read().decode('latin1')` str ? yes. - [x] `return object_info['source']` str ? - [x] `type self.object_inspect(target, detail_level=1)` ? Dict[str, str| None] - [x] `self.inspector.info` return type ? Dict[str, str| None] - [x] `oinspect.object_info` return type ? Dict[str, str| None] - [x] `return Macro.value` str ? yes - [x] `return f.read()` str ? Yes open file latin 1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `subprojects purge` should not follow symbolic links **Describe the bug** `meson subprojects purge` currently follows symbolic links. That is, if `subprojects/foo` is a symbolic link to `/home/reimu/git/foo`, then `meson subprojects purge` will offer to delete the actual `/home/reimu/git/foo` directory instead of the symbolic link. This is dangerous and makes no sense; I sometimes use symbolic links like that to replace a wrap dependency with my own version locally, and I wouldn't like it to get wiped. **To Reproduce** Setup: ```bash cd /tmp mkdir foreignproj mkdir myproj cd myproj meson init mkdir subprojects ln -s ../../foreignproj subprojects/foo cat <<EOF > subprojects/foo.wrap [wrap-git] directory=foo url=https://example.com/foo.git EOF ``` Purge: ``` $ pwd /tmp/myproj $ file /tmp/foreignproj /tmp/foreignproj: directory $ file subprojects/foo subprojects/foo: symbolic link to ../../foreignproj $ meson subprojects purge --confirm Deleting /tmp/foreignproj $ file /tmp/foreignproj /tmp/foreignproj: cannot open `/tmp/foreignproj' (No such file or directory) $ file subprojects/foo subprojects/foo: broken symbolic link to ../../foreignproj ``` **Expected behavior** `meson subprojects purge` should remove the symbolic link and not touch the real directory. **system parameters** * what operating system: openSUSE Tumbleweed * what Python version are you using: 3.8.10 * what `meson --version`: 0.58.999 (6fb2f8637) * what `ninja --version`: 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Markdown in header cells is not rendered You cannot have italics, etc. in a header cell in master, because the header is not rendered. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DEP: deprecate np.bool, np.int, np.float, np.long, np.str, np.unicode, and np.complex, which are misleading aliases for builtin types This isn't ready yet -- it causes hundreds of test failures due to our own internal usage of `np.bool` etc., plus it is missing new tests of its own -- but posting now as an RFC. --- For reasons which are lost in the mists of time, numpy has always re-exported a bunch of built-in types like `int` as `np.int`, `bool` as `np.bool`, etc. We can't possibly remove these exports anytime in the near future, because they are widely used -- people write things like ``` np.asarray(obj, dtype=np.int) ``` These people are confused, and would be better off writing either ``` np.asarray(obj, dtype=int) ``` or ``` np.asarray(obj, dtype=np.int_) ``` depending on what they actually want, but their code does work (and is equivalent to the `dtype=int` version), so we can't break it. But, thanks to a new feature added in 3.5, plus some glue and sealing back for previous versions, it is finally at least possible to deprecate these attributes! This adds a dependency on the `metamodule` package, which is a tiny pure-Python package that supports every version of Python that numpy supports. This will Just Work for pip and other sensible installation tools, but the alternative would be to just vendor our own copy of `metamodule.py` into the numpy/ directory instead. Personally I am kinda inclined to try going with the explicit dependency route and see how far we can get, because maintaining vendored libraries is a huge pain, and because c'mon it's 2015, and because sooner or later we are probably going to want to add an external dependency or two (e.g. [sempervirens](https://github.com/njsmith/sempervirens)) and so we might as well find out what the pain points are now. But I can see the arguments either way... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Improve column alignment of NaT within repr of datetime64 arrays Another repr change to get into 1.14, filing separately for visibility. See https://github.com/numpy/numpy/pull/10097#discussion_r153120208. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: An unrelated warning when transpiling an empty set of circuits ### Environment - **Qiskit Terra version**: a60374091 - **Python version**: 3.9.5 - **Operating system**: Linux ### What is happening? Transpilation of an empty set of circuits issues a warning about schedule transpilation. ### How can we reproduce the issue? ``` from qiskit import transpile, IBMQ backend = IBMQ.load_account().backend.ibmq_belem # can be any backend transpile([], backend) ``` Output: ``` qiskit/compiler/transpiler.py:246: UserWarning: Transpiling schedules is not supported yet. warnings.warn(\"Transpiling schedules is not supported yet.\", UserWarning) ``` ### What should happen? No warning ### Any suggestions? Just write ``` if len(circuits) > 0: ``` Write before the line ``` warnings.warn(\"Transpiling schedules is not supported yet.\", UserWarning) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: UnboundLocalError when using VisualStudioBuildEnvironment I keep getting the following python error when using `VisualStudioBuildEnvironment` with conan 1.3.1. ```python env_build = VisualStudioBuildEnvironment(self) UnboundLocalError: local variable 'flags' referenced before assignment ``` I think I found the problem in [conans/client/build/compiler_flags.py Line 99](https://github.com/conan-io/conan/blob/develop/conans/client/build/compiler_flags.py#L99) It looks like ```python elif not vs_toolset: ``` should just be an `else` or `flags` should be initialized to something in the ```python if str(compiler) == 'Visual Studio': ``` block. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Enable dynamic?federated extensions in dev mode ### Problem For now, the dynamic?federated extensions are forced-disabled in dev_mode https://github.com/jupyterlab/jupyterlab/blob/f7cb7b5e208d732c8d841ae84d219cbebc97b22a/jupyterlab/labapp.py#L618-L619 Sometimes, like the work done in https://github.com/jupyterlab/jupyterlab/issues/8804, we need those extensions enabled in dev mode ### Proposed Solution Add a setting/flag like `--extensions-dev-mode` to keep the extensions enable in dev mode,. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Auto-Converted Fast Tokenizer Producing Incorrect Results ### System Info - `transformers` version: 4.30.1 - Platform: Linux-5.15.107+-x86_64-with-glibc2.31 - Python version: 3.10.12 - Huggingface_hub version: 0.15.1 - Safetensors version: 0.3.1 - PyTorch version (GPU?): 2.0.1+cu118 (False) - Tensorflow version (GPU?): 2.12.0 (False) - Flax version (CPU?/GPU?/TPU?): 0.6.9 (cpu) - Jax version: 0.4.10 - JaxLib version: 0.4.10 - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help? @ArthurZucker ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction The auto-converted fast tokenizer for the LLaMA model sometimes does not produce the same tokenization results as the original sentence piece tokenizer. This is affecting the OpenLLaMA models. Here's the code to reproduce it: ```python from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('openlm-research/open_llama_7b', use_fast=False) fast_tokenizer = AutoTokenizer.from_pretrained('openlm-research/open_llama_7b') text = 'thermal' print(tokenizer.encode(text)) print(fast_tokenizer.encode(text)) ``` The code produces the following output: ``` [1, 14412] [1, 31822, 496, 12719] ``` ### Expected behavior The auto-converted fast tokenizer should produce the exact same tokens as the original sentencepiece tokenizer. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: PATH manipulation problems with conda.bat activate on Windows With conda 4.4.5: ``` C:\\Users\\builder>echo %PATH% C:\\WINDOWS\\system32;C:\\WINDOWS;C:\\WINDOWS\\System32\\Wbem;C:\\WINDOWS\\System32\\WindowsPowerShell\\v1.0\\;C:\\Program Files (x86)\\Windows Kits\\8.1\\Windows Performance Toolkit\\;C:\\Program Files (x86)\\PuTTY\\;C:\\Program Files\\MiKTeX 2.9\\miktex\\bin\\x64\\;C:\\Program Files (x86)\\Windows Kits\\10\\Windows Performance Toolkit\\;C:\\Program Files\\dotnet\\;C:\\Users\\builder\\AppData\\Local\\Microsoft\\WindowsApps; c:/Users/builder/m64/Library/bin/conda.bat activate 'chcp' is not recognized as an internal or external command, operable program or batch file. (base) C:\\Users\\builder>(base) C:\\Users\\builder>echo %PATH% c:\\Users\\builder\\m64;c:\\Users\\builder\\m64\\Library\\mingw-w64\\bin;c:\\Users\\builder\\m64\\Library\\usr\\bin;c:\\Users\\builder\\m64\\Library\\bin;c:\\Users\\builder\\m64\\Scripts;c:\\Users\\builder\\m64\\bin;C:\\WINDOWS;C:\\WINDOWS\\System32\\Wbem;C:\\WINDOWS\\System32\\WindowsPowerShell\\v1.0\\;C:\\Program Files (x86)\\Windows Kits\\8.1\\Windows Performance Toolkit\\;C:\\Program Files (x86)\\PuTTY\\;C:\\Program Files\\MiKTeX 2.9\\miktex\\bin\\x64\\;C:\\Program Files (x86)\\Windows Kits\\10\\Windows Performance Toolkit\\;C:\\Program Files\\dotnet\\;C:\\Users\\builder\\AppData\\Local\\Microsoft\\WindowsApps; ``` Notice that `C:\\WINDOWS\\system32` got dropped which is why `chcp` isn't found (this folder contains lots of important programs too). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Binder bot dev mode does not redirect to JupyterLab ## Description Looks like the Binder link posted by the bot on new PRs does not redirect to the dev mode lab anymore:  ## Reproduce Go to an open PR and click on the Binder link:  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Improvements to Versioning There are two remaining items from #6312: - If you bump a js package by a major version, we also bump all of its dependencies by a major version, recursively. - If you bump the python package by major and it is not in final, do not bump the js versions, but make them match the release value. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Checkpoint saving isn't atomic ## 🐛 Bug Saving checkpoints happens non-atomically. In some cases, this causes an incomplete write of a checkpoint (for example when receiving a SIGKILL during writing), causing any subsequent loading to fail with `RuntimeError: unexpected EOF, expected 8 more bytes. The file might be corrupted.` ### To Reproduce This is difficult to reproduce, since it relies on timing outside of code. For me, it happens with fast-running models that run at ~1-4 seconds per epoch. ### Expected behavior Checkpointing should be resistant to such issues, and instead simply continue as-is. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: plot_circuit_layout output seems to be dependent on the layout order The function `plot_circuit_layout` (in `qiskit/visualization/gate_map.py`) calls `plot_gate_map` with `qubit_labels`. The `qubit_labels` variable seems to be dependent of the `Layout` \"order\". In my local machine: ``` Layout({ 0: Qubit(QuantumRegister(10, 'qr'), 0), 2: Qubit(QuantumRegister(10, 'qr'), 1), 4: Qubit(QuantumRegister(10, 'qr'), 2), 6: Qubit(QuantumRegister(10, 'qr'), 3), 8: Qubit(QuantumRegister(10, 'qr'), 4), 10: Qubit(QuantumRegister(10, 'qr'), 5), 12: Qubit(QuantumRegister(10, 'qr'), 6), 14: Qubit(QuantumRegister(10, 'qr'), 7), 16: Qubit(QuantumRegister(10, 'qr'), 8), 18: Qubit(QuantumRegister(10, 'qr'), 9) }) qubit_labels = [0, None, 1, None, 2, None, 3, None, 4, None, 5, None, 6, None, 7, None, 8, None, 9, None] ```  While in the CI (see [output here](https://dev.azure.com/qiskit-ci/qiskit-terra/_build/results?buildId=1578&view=logs&jobId=8494c7a7-fba7-5345-1d98-c01d59819600&taskId=39a01fa0-e074-53f1-ec0d-d58f2c66d95b&lineStart=13&lineEnd=25&colStart=90&colEnd=91)): ``` Layout({ 0: Qubit(QuantumRegister(10, 'qr'), 0), 16: Qubit(QuantumRegister(10, 'qr'), 8), 2: Qubit(QuantumRegister(10, 'qr'), 1), 4: Qubit(QuantumRegister(10, 'qr'), 2), 6: Qubit(QuantumRegister(10, 'qr'), 3), 8: Qubit(QuantumRegister(10, 'qr'), 4), 10: Qubit(QuantumRegister(10, 'qr'), 5), 12: Qubit(QuantumRegister(10, 'qr'), 6), 18: Qubit(QuantumRegister(10, 'qr'), 9), 14: Qubit(QuantumRegister(10, 'qr'), 7) }) qubit_labels = [4, None, 3, None, 1, None, 8, None, 2, None, 0, None, 7, None, 5, None, 9, None, 6, None] ```  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: [Content Gap] Document op level retries ## What content is missing See \"Easy Solid-Level Retries\" in https://dagster.io/blog/dagster-0-12-0-into-the-groove This feature was introduced in 0.12.0 but has no documentation available (besides the blog post) ## Type of the content Concepts --- #### Message from the maintainers: Are you looking for the same documentation content? Give it a :thumbsup:. We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Learning rate scheduler should step after each optimizer step ## 🐛 Bug I'm not sure that this is a bug or if it is a deliberate design decision, but right now the learning rate schedule gets updated at every \"step\" which actually corresponds to every forward pass. I think a more standard implementation would have the learning rate scheduler \"step\" interval correspond to being updated every backwards pass. This has caused me a lot of problems with instability as I did not realize that using standard learning rate warmups of say 16000 steps would actually only warm up for 1000 steps if I set `accumulate_grad_batches=16`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: pyin/pyout message type names should be language-agnostic A few suggestions minrk and me came up with on irc: (abridged) < minrk> the obvious generic name is \"**output**\", but that's too ambiguous with side effect output < minrk> **eval_result**, or **result_output**, or just **result** < minrk> and **eval_result** technically isn't accurate < minrk> what about **displayhook**? It's in reference to a name used in Python, but it's a generic concept < timotimo> **result_value**? < timotimo> i wouldn't be against calling it something with displayhook < timotimo> maybe **exec_value** or **exec_result** would be more fitting, though? < minrk> trouble is, _there's also execute_reply_, which is different < minrk> it is essentially a _display_data message with a different name_ < minrk> so perhaps that is the key < timotimo> hm, isn't the connection with the in[N]/out[N] the most interesting part of it? < minrk> well, the most interesting part is the actual thing to display < minrk> the only difference between a _pyout_ message and a _display_data_ message is whether a prompt is drawn to its left < minrk> but they are still both associated with a given input Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Parameterized gate definitions built with incomplete ParameterTable <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master @ d8b5f0f - **Python version**: 3.5 - **Operating system**: osx ### What is the current behavior? As reported by @georgios-ts in the Qiskit slack, `definition`s of parameterized gates are being generated with an incomplete `ParameterTable` . Introduced by #4745 . ### Steps to reproduce the problem ``` x = Parameter('x') rx = RXGate(x) print(rx.params) print(rx.definition.parameters) >> [Parameter(x)] >> set() ``` ### What is the expected behavior? ### Suggested solutions ``` for instr, _, _ in rules: qc._update_parameter_table(instr) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Improve performance of `two_qubits_kak` As per noted by @nonhermitian at #774 ### What is the expected enhancement? A reduction in the number of matrix operations can speed up the overall running time of the functions. It would be also better to verify the function in a test rather than always it is invoked. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Progress bar changes/issues In `conda` 4.3+ the progress bar looks something like this... ``` pycrypto-2.6.1 100% |################################| Time: 0:00:00 6.79 MB/s pytz-2018.4-py 100% |################################| Time: 0:00:00 9.22 MB/s ``` ...it has a nice tabular view and separates out package name, percentage, time, and download speed. In `conda` 4.5+, the progress bar looks like this... ``` ndg-httpsclient 0.4.4################################################### | 100% libffi 3.2.1############################################################ | 100% ``` Here the progress bar starts right near where the version ends. Making it a little hard to read. Also this start point varies depending on package name and the like, which is a bit distracting. Now I'm not sure if this is an intentional change or if I'm running into a bug. Would be great to know either way. If it is an intentional change, would encourage reconsidering. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Avoid importing from IPython.parallel in core IPython.core.interactiveshell imports an error class from IPython.parallel: https://github.com/ipython/ipython/blob/master/IPython/core/interactiveshell.py#L89 This pulls in the parallel machinery, zmq, numpy, paramiko, and so on, so it adds significantly to startup time and memory use. The comment in the file suggests a better way of handling it - move the error class into IPython.core.errors, and have IPython.parallel import it from there. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Refactor `Z2Symmetries` ### What should we add? The [`Z2Symmetries`](https://github.com/Qiskit/qiskit-terra/blob/548dae2/qiskit/opflow/primitive_ops/tapered_pauli_sum_op.py#L83) are the last piece of code coupling the algorithms and application modules to `qiskit.opflow` instead of `qiskit.quantum_info`. Refactoring that class to be based on `SparsePauliOp` instead of `PauliSumOp` will allow us to remove this final dependence and, thus, will clear the path towards deprecating `qiskit.opflow`. To solve this, we need to do the following: - [ ] refactor `Z2Symmetries` based on `SparsePauliOp` instead of `PauliSumOp` (should be fairly trivial) - [ ] move it to a location outside of `qiskit.opflow`. I am open for suggestions on where to put this. Maybe even `qiskit.utils`? - [ ] I vote for the deprecation/removal of `TaperedPauliSumOp` without a replacement. This class merely combines the operator with its identified symmetries in one object, but this is actually never used in neither Qiskit Terra nor Qiskit Nature. And since this will rather become a utility explicitly called by an end-user to find certain symmetries, they can manage the storage of these symmetries themselves anyways, without artificially nesting them in some operator subclass. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Create a single clean script for the top level The clean script is exec-ing each package just to remove a directory: we can do this in a single script. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Snowflake python connector monkeypatches urllib and makes many services unusable. Curreently wnen you run snowflke provider, it monkeypatches urlllb in a way that is not compatible with other libraries (for example presto SSL with kerberos, google, amazon, qubole and many others). This is not critical (as in 2.0 we have provider separation and snowflake code will not even be there until you choose [snowflake] extra or install provider manually, For now we decided to release but immediately yank the snowflake provider! Additional links: * Issue: https://github.com/snowflakedb/snowflake-connector-python/issues/324 Offending code: * https://github.com/snowflakedb/snowflake-connector-python/blob/133d6215f7920d304c5f2d466bae38127c1b836d/src/snowflake/connector/network.py#L89-L92 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gtkdoc-scangobj fails to find the shared library it scans (W32) For example: `Error in gtkdoc helper script:` `'mingw\\\\bin\\\\python.EXE' failed with status 3221225781` `WARNING:root:Running scanner failed: -1073741515, command: ./gtk4-scan.exe` This is because the shared library being scanned is not in library search path. On *nix that is handled by adjusting `LD_LIBRARY_PATH`, but on W32 the variable that needs adjustment is `PATH`, and meson doesn't change it. Here's a patch to fix that. [0001-gtk-doc-Use-LD_LIBRARY_PATH-to-modify-PATH-on-W32.patch.txt](https://github.com/mesonbuild/meson/files/1843401/0001-gtk-doc-Use-LD_LIBRARY_PATH-to-modify-PATH-on-W32.patch.txt) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: remove tools.file_io <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? What is the point of this tool. As we clean up tools I want to try and make sure the tools are extensions to qiskit that don't affect the core but make it simpler to use. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add instructions for pre-push black hook This would be extremely useful to have in the dev instructions. Also, I'd love to know how to do it myself :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: 1.0.3: project_fully_featured: Attempting to access partitions def for asset AssetKey(['snowflake', 'recommender', 'comment_stories']), but it is not partitioned ### Dagster version 1.0.3 ### What's the issue? trying to run the `project_fully_featured` - i've successfully materialized the `core` asset group. I next tried materializing the `recommender.comment_stories` (which works) but when I try the `user_story_matrix` that fails with the errors below ``` dagster._core.errors.DagsterInvariantViolationError: Attempting to access partitions def for asset AssetKey(['snowflake', 'recommender', 'comment_stories']), but it is not partitioned ``` ``` Dependencies for step snowflake__recommender__component_top_stories failed: ['s3__recommender__user_story_matrix'] were not executed: ['s3__recommender__recommender_model']. Not executing. ``` ``` Dependencies for step snowflake__recommender__user_top_recommended_stories failed: ['s3__recommender__user_story_matrix'] were not executed: ['s3__recommender__recommender_model']. Not executing. ``` ### What did you expect to happen? the example project to work ### How to reproduce? _No response_ ### Deployment type Local ### Deployment details _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Build RPATHs should not be overrideable with LD_LIBRARY_PATH, affects OSes using DT_RUNPATH such as FreeBSD and Debian Due to #1519. Should we revert or is there a fix? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Multiple bugs in mct <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is the current behavior? The `mct` gate has several issues: 1) For one or two controls, the function calls `cx` or `ccx` respectively but still requires `q_ancilla` to be set. This should default to `None`. 2) For more than two controls the inputs are not consistent with the rest of Qiskit nor `cx` or `ccx`. `cx` and `ccx` allow for int inputs. However `mct` requires registers or `Qubit` class. Yet in the two or one control case ints are accepted because they dispatch to functions that handle them. `mct` should accept int inputs as well. Note that the `Qubit` class is not even exposed to users. Passing an int to `q_target` does not tell the user to pass `qreg` or `Qubit` but instead gives the unhelpful error \"'MCT needs a single qubit as target.\" Also note that in the one or two control case I can pass any value I want with no checking. E.g. this works just fine ```python qc = QuantumCircuit(3) qc.mct([0,1], [2], 1e6) ``` ### Steps to reproduce the problem Try to use the `mct` gate in the same manner as other gates. ### What is the expected behavior? The gate should behave the same as other gates. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Follow ups to DocumentQuestionAnswering Pipeline ### Feature request PR https://github.com/huggingface/transformers/pull/18414 has a number of TODOs left over which we'd like to track as follow up tasks. ## Pipeline - [x] Add support for documents which have more than the tokenizer span (e.g. 512) words - [ ] Add support for multi-page documents (e.g. for Donut, we need to present one image per page) - [x] Rework use of tokenizer to avoid the need for `add_prefix_space=True` - [x] Re-add support for Donut - [ ] Refactor Donut usage in the pipeline or move logic into the tokenizer, so that pipeline does not have as much Donut-specific code ## Testing - [ ] Enable `test_small_model_pt_donut` once `hf-internal-testing/tiny-random-donut` is implemented ## Documentation / Website - [x] Add DocumentQuestionAnswering demo to [Hosted Inference API](https://huggingface.co/impira/layoutlm-document-qa) so that model demos work - [ ] Add tutorial documentation to [Task Summary](https://huggingface.co/docs/transformers/v4.21.3/en/task_summary#question-answering) ### Motivation These are follow ups that we cut from the initial scope of PR #18414. ### Your contribution Happy to contribute many or all of these. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Webserver fails to pull secrets from Hashicorp Vault on start up ### Apache Airflow version 2.3.4 ### What happened Since upgrading to Airflow 2.3.4 our webserver fails on start up to pull secrets from our Vault instance. Setting AIRFLOW__WEBSERVER_WORKERS = 1 allowed the webserver to start up successfully, but reverting the change added here [https://github.com/apache/airflow/pull/25556](url) was the only way we found to fix the issue without adjusting the webserver's worker count. ### What you think should happen instead The airflow webserver should be able to successfully read from Vault with AIRFLOW__WEBSERVERS__WORKERS > 1. ### How to reproduce Star a Webserver instance set to authenticate with Vault using the approle method and AIRFLOW__DATABASE__SQL_ALCHEMY_CONN_SECRET and AIRFLOW__WEBSERVER__SECRET_KEY_SECRET set. The webserver should fail to initialize all of the gunicorn workers and exit. ### Operating System Fedora 29 ### Versions of Apache Airflow Providers apache-airflow-providers-hashicorp==3.1.0 ### Deployment Docker-Compose ### Deployment details Python 3.9.13 Vault 1.9.4 ### Anything else None ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Implement a way to select cmake generator Currently `CMake.command_line` selects `Unix Makefiles` for OSX and Linux in most situations. I would want to override that to use the `Ninja` generator everywhere (yes even on windows) since it performs much better in most cases and is the configuration we test with the most here. I started to look at adding `cmake_generator` to conan.conf but this doesn't seem to be the correct solution since it will affect the binary package and frankly the generator that was used to build the package shouldn't affect downstream dependencies. My current idea is to define a environment variable to override the generator `CONAN_CMAKE_GENERATOR` perhaps? Any other options? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Warning about leaked semaphore under Python 3.8 ### Current Behavior Under Python 3.8, there is a warning printed when running most conda commands: ``` ~/miniconda3/lib/python3.8/multiprocessing/resource_tracker.py:216: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown ``` ### Steps to Reproduce Running more or less any conda command will reproduce it for me, e.g. `conda env list` ## Expected Behavior There should be no warning ## Environment Information `conda-4.8.1-py38_0` and `python-3.8.1-h359304d_1` on MacOS (Catalina) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add from_heavy_hex() and from_heavy_square() generator methods to CouplingMap <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In [retworkx 0.10.0](https://qiskit.org/documentation/retworkx/release_notes.html#relnotes-0-10-0) new generator functions were added for quickly generating heavy hex and heavy square graphs: https://qiskit.org/documentation/retworkx/stubs/retworkx.generators.directed_heavy_hex_graph.html#retworkx.generators.directed_heavy_hex_graph and https://qiskit.org/documentation/retworkx/stubs/retworkx.generators.directed_heavy_square_graph.html#retworkx.generators.directed_heavy_square_graph. We should leverage these fun and add 2 new constructor methods to the `CouplingMap` to easily create coupling maps using a heavy hex and heavy square (similar to the existing `from_grid` and `from_ring` methods) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Move to more recent numpy random generator <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? We make use of a lot of `np.random.RandomState` generators, however these are now legacy code. It has been replaced with `np.random.default_rng` that generates different values. We should move to this new generator. Ideally before the circuit library comes out because the seed values, and the offset, can be (should be) used to uniquely identify the circuits. This makes that identification a bit more future proof. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Typo in error message of Hamiltonian gate QASM function #### Description Possible typo in error message: \"HamiltonianGate **h**as no QASM definition.\" https://github.com/Qiskit/qiskit-terra/blob/57261183f2f49882e24d255b7b9a9ab1e1c6421e/qiskit/extensions/hamiltonian_gate.py#L116 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: irfft/irfft2/irfftn docs are slightly confusing re: input type. As of numpy 1.17, the docs for fft.irfft{,2,n} start with \"Compute the inverse of the n-point DFT for real input.\" / \"Compute the 2-dimensional inverse FFT of a real array.\" / \"Compute the inverse of the N-dimensional FFT of real input.\", which is slightly confusing if you're unfamiliar with fft conventions: a superficial reading would suggest that these functions take a real input, but actually the argument to irfft is complex, and it's the output which is real. (Also, the inconsistency between the use of \"DFT\" and \"FFT\" could be avoided.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: VideoMAE missing CLS tokens in embedding ### System Info I'm not sure if I've missed something in the code, but I can't seem to find where the CLS tokens are added? I have input data of shape (64,45,2,32,32) with tubelet size = 5, patch_size = 4. This results in a sequence length of 576. From my understanding that is the total number of tubelets. I see that after the data is passed through the embedding layer the final embedding shape is (64,576,768) where 768 is the hidden size. However, should the dimensions not be (64,577,768) since we should be adding a CLS token to the sequence? Would be great to get hear back soon because I'm not sure if I'm wrong or if there is something wrong with the code. Thanks! @NielsRogge ### Reproduction pixel_values = torch.randn(1,45, 2, 32, 32) config = VideoMAEConfig() config.num_frames = 45 config.image_size = 32 config.patch_size = 4 config.tubelet_size = 5 config.num_channels = 2 num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2 seq_length = (model.config.num_frames // model.config.tubelet_size) * num_patches_per_frame print(seq_length.shape) videomae = VideoMAEModel(config) output = videomae(pixel_values, output_hidden_states=True) sequence_output = output[0] print(sequence_output.shape) ### Expected behavior seq_length = 576 sequence_output = (1,577,768) The embedding sequence length should be total number of tubelets + 1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Mark Success on a mapped task, reruns other failing mapped tasks ### Apache Airflow version 2.3.0b1 (pre-release) ### What happened Have a DAG with mapped tasks. Mark at least two mapped tasks as failed. Mark one of the failures as success. See the other task(s) switch to `no_status` and rerun.  ### What you think should happen instead Marking a single mapped task as a success probably shouldn't affect other failed mapped tasks. ### How to reproduce _No response_ ### Operating System OSX ### Versions of Apache Airflow Providers _No response_ ### Deployment Docker-Compose ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: post-link scripts are unable to call entrypoints Using the latest combination of conda and conda-build packages fail to execute anything under bin/ (this folder doesn't exist in this phase). See https://github.com/conda-forge/jupyterlab_code_formatter-feedstock/pull/2 with build log https://dev.azure.com/conda-forge/feedstock-builds/_build/results?buildId=49083&view=logs&jobId=1bf226d3-0e2f-52d8-fa93-7d9e633347b3 for example failure. Going through the changelog of both, the only possible PR affecting this could be https://github.com/conda/conda/pull/8833/files `conda-info`: ``` active environment : base active env location : /Users/uwe/miniconda3 shell level : 1 user config file : /Users/uwe/.condarc populated config files : /Users/uwe/.condarc conda version : 4.7.6 conda-build version : 3.18.7 python version : 3.7.3.final.0 virtual packages : base environment : /Users/uwe/miniconda3 (writable) channel URLs : https://conda.anaconda.org/conda-forge/osx-64 https://conda.anaconda.org/conda-forge/noarch https://repo.anaconda.com/pkgs/main/osx-64 https://repo.anaconda.com/pkgs/main/noarch https://repo.anaconda.com/pkgs/r/osx-64 https://repo.anaconda.com/pkgs/r/noarch package cache : /Users/uwe/miniconda3/pkgs /Users/uwe/.conda/pkgs envs directories : /Users/uwe/miniconda3/envs /Users/uwe/.conda/envs platform : osx-64 user-agent : conda/4.7.6 requests/2.22.0 CPython/3.7.3 Darwin/18.6.0 OSX/10.14.5 UID:GID : 501:20 netrc file : None offline mode : False ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Easy api for custom primitives and vjps JAX supports custom primitives and vjps, just like Autograd did. Improvements: 1) add this to documentation 2) add a minimal example of this in the examples section 3) add a wrapper function if appropriate? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Elasticsearch cluster/index health values Hello, I have noticed that in the [Elasticsearch](https://github.com/DataDog/integrations-core/tree/e3368b3ebaa87d37e01be3b1f58e26fa00e8337f/elastic) integration, index health values are reported as: https://github.com/DataDog/integrations-core/blob/e3368b3ebaa87d37e01be3b1f58e26fa00e8337f/elastic/datadog_checks/elastic/elastic.py#L156 whereas cluster health values are reported as: https://github.com/DataDog/integrations-core/blob/e3368b3ebaa87d37e01be3b1f58e26fa00e8337f/elastic/datadog_checks/elastic/metrics.py#L476 Considering that the index level status is controlled by the worst shard status and the cluster status is controlled by the worst index status, shouldn't the reported values be aligned between the two? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Expose a client method for listing jobs See: https://cloud.google.com/bigquery/docs/reference/v2/jobs/list Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax_debug_nans does not work with complex numbers Running with flag --jax_debug_nans: With this this, I get no error (but I do get nans): ``` @jax.jit def fn(x): return (x * 0.) / jnp.zeros_like(x) print(fn(1j * jnp.ones([2, 3]))) ``` but with this, I get an error (as expected): ``` @jax.jit def fn(x): return (x * 0.) / jnp.zeros_like(x) print(fn(jnp.ones([2, 3]))) ``` Could we add support for nan detection on complex numbers? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Elevate `ENDRUN` to `signals` API We've seen multiple situations now (e.g., https://github.com/PrefectHQ/prefect/issues/1184) where users want to aggressively end a run, avoiding the standard checks. Our `ENDRUN` signal satisfies the correct behavior, but isn't exposed publicly. We should move this signal into our public `signals` API for better visibility to users, and document it accordingly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add support for use_avro_logical_types for extract jobs use_avro_logical_types is supported for load jobs: https://github.com/googleapis/google-cloud-python/blob/89eaedb4a40bd1268df134cc40a4063d6cf8b823/bigquery/google/cloud/bigquery/job.py#L1318 We should add the same mapping for extract jobs. BigQuery already supports it in the API backend. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Tokenizers as an optional dependency # 🚀 Feature request <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> Would it be possible to make `tokenizers` an optional dependency? I see this was already attempted here by @thomwolf: https://github.com/huggingface/transformers/pull/2342. ## Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. --> For various reasons we are unable to support Rust in our environment. Given that `tokenizers` is a hard dependency, this means we cannot use `transformers` at all. We would be fine with using the non-fast versions of tokenizers as a workaround. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DISCUSSION: Is there a way for a Transaction to indicate success/failure from __exit__ From #336. Currently, there is no way to determine if this occurs. It's unclear what a way forward would look like but in `ndb` transactions have [retries](https://cloud.google.com/appengine/docs/python/ndb/transactions) and can [create](https://cloud.google.com/appengine/docs/python/ndb/functions) `Future` objects which know about the success or failure. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: KeyError with '--update-deps' ``` error: KeyError(True,) command: /home/jgrnt/miniconda/bin/conda install --update-deps python= numpy nose scipy matplotlib pandas pytest h5py mkl mkl-service user_agent: conda/4.4.7 requests/2.18.4 CPython/3.6.3 Linux/4.14.4-gentoo gentoo/2.4.1 glibc/2.25 _messageid: -9223372036837525416 _messagetime: 1515513689937 / 2018-01-09 10:01:29 Traceback (most recent call last): File \"/home/jgrnt/miniconda/lib/python3.6/site-packages/conda/exceptions.py\", line 743, in __call__ return func(*args, **kwargs) File \"/home/jgrnt/miniconda/lib/python3.6/site-packages/conda/cli/main.py\", line 78, in _main exit_code = do_call(args, p) File \"/home/jgrnt/miniconda/lib/python3.6/site-packages/conda/cli/conda_argparse.py\", line 76, in do_call exit_code = getattr(module, func_name)(args, parser) File \"/home/jgrnt/miniconda/lib/python3.6/site-packages/conda/cli/main_install.py\", line 11, in execute install(args, parser, 'install') File \"/home/jgrnt/miniconda/lib/python3.6/site-packages/conda/cli/install.py\", line 236, in install force_reinstall=context.force, File \"/home/jgrnt/miniconda/lib/python3.6/site-packages/conda/core/solve.py\", line 504, in solve_for_transaction force_remove, force_reinstall) File \"/home/jgrnt/miniconda/lib/python3.6/site-packages/conda/core/solve.py\", line 437, in solve_for_diff final_precs = self.solve_final_state(deps_modifier, prune, ignore_pinned, force_remove) File \"/home/jgrnt/miniconda/lib/python3.6/site-packages/conda/core/solve.py\", line 385, in solve_final_state for spec in grouped_specs[True]) KeyError: True ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: install_sources installs python sources into wrong directory on windows Standard MSVC python: ``` Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)] on win32 Type \"help\", \"copyright\", \"credits\" or \"license\" for more information. >>> from distutils import sysconfig >>> sysconfig.get_python_lib() 'C:\\\\Python36\\\\Lib\\\\site-packages' ``` modules/python.py - INSTALL_PATHS_COMMAND - sets posix_prefix (on windows) ``` print (json.dumps(sysconfig.get_paths(scheme='posix_prefix', vars={'base': '', 'platbase': '', 'installed_base': ''}))) {\"stdlib\": \"\\\\lib\\\\python3.6\", \"platstdlib\": \"\\\\lib\\\\python3.6\", \"purelib\": \"\\\\lib\\\\python3.6\\\\site-packages\", \"platlib\": \"\\\\lib\\\\python3.6\\\\site-packages\", \"include\": \"\\\\include\\\\python3.6\", \"platinclude\": \"C:\\\\Python36\\\\include\\\\python3.6\", \"scripts\": \"\\\\bin\", \"data\": \".\"} ``` syconfig does the right thing when not forced into posix_prefix ``` print (json.dumps(sysconfig.get_paths( vars={'base': '', 'platbase': '', 'installed_base': ''}))) >>> print (json.dumps(sysconfig.get_paths( vars={'base': '', 'platbase': '', 'installed_base': ''}))) {\"stdlib\": \"\\\\Lib\", \"platstdlib\": \"\\\\Lib\", \"purelib\": \"\\\\Lib\\\\site-packages\", \"platlib\": \"\\\\Lib\\\\site-packages\", \"include\": \"\\\\Include\", \"platinclude\": \"\\\\Include\", \"scripts\": \"\\\\Scripts\", \"data\": \".\"} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Composing circuit with a switch statement causes a bug in the QASM3 exporter ### Environment - **Qiskit Terra version**: 0.25.0 - **Python version**: 3.9 - **Operating system**: OSX ### What is happening? When composing a circuit with another circuit containing a switch statement and then exporting to OpenQASM 3. I receive an error ``` KeyError: \"'ClassicalRegister(3, 'random')' is not defined in the current context\" ``` This may be related to #9746. ### How can we reproduce the issue? Run ```python from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister qr = QuantumRegister(3) cr_random = ClassicalRegister(3, \"random\") cr_result = ClassicalRegister(3, \"result\") qc = QuantumCircuit(qr, cr_random, cr_result) # build a random state qc.h(qr) # measure the state qc.measure(qr, cr_random) with qc.switch(cr_random) as case: with case(1): qc.x(qr[0]) with case(2): qc.x(qr[1]) with case(3): qc.x(qr[0]) qc.x(qr[1]) with case(4): qc.x(qr[2]) with case(5): qc.x(qr[0]) qc.x(qr[2]) with case(6): qc.x(qr[1]) qc.x(qr[2]) with case(7): qc.x(qr) with case(case.DEFAULT): pass qc.measure(qr, cr_result) composed = QuantumCircuit(3, 6) composed.compose(qc, inplace=True) from qiskit import qasm3 print(qc_qasm3 := qasm3.dumps(composed, disable_constants=True, experimental=qasm3.ExperimentalFeatures.SWITCH_CASE_V1)) ``` ### What should happen? QASM3 should be exported. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add maximum_bytes_billed option to magics **Background** BigQuery queries can get expensive, but the `maximum_bytes_billed` query option adds a cap to the price billed and rejects queries that could be too expensive. Provide a default value for `maximum_bytes_billed` when constructing a client by specifying a `default_query_job_config`, but this is not possible when using the `%%bigquery` magics. **Feature Request** Add a `--maximum_bytes_billed` option to `%%bigquery`. Possible values: * `UNSPECIFIED` - Use the default value . Set `job_config.maximum_bytes_billed = google.cloud.bigquery.magics.context.maximum_bytes_billed`. * `--maximum_bytes_billed=None` - No maximum value. Set `job_config.maximum_bytes_billed = None`. This allows all queries to run, overriding any value from the global context. * `--maximum_bytes_billed=123456789` - Set maximum to value specified. Set `job_config.maximum_bytes_billed = int(value)`. * `--maximum_bytes_billed=NotAnInteger` - Raise `ValueError`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: wav2vec processor batching logic is too restrictive ### System Info transformers version at the time of writing is `4.26.1` ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ```python # !pip install transformers torch # in jupyter notebook from transformers import Wav2Vec2Processor import torch import numpy as np batch = 4 # create Wav2Vec2Processor processor = Wav2Vec2Processor.from_pretrained(\"facebook/hubert-large-ls960-ft\") # generate random input tensor input_tensor = torch.tensor(np.random.randn(batch, 10, 10)) # pass input tensor through processor output = processor(input_tensor, return_tensors=\"pt\") print(output[\"input_values\"].shape) # 1 x 4 x 10 x 10 ``` ### Expected behavior It seems reasonable that an input could be of shape `batch x d_1 x d_2 ...` and I'd expect the output to have the same shape. However, [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/wav2vec2/feature_extraction_wav2vec2.py#L184) the code has an extra check for type list or tuple that results in it misinterpreting the input as a single example. Side note: I'm unsure what to infer from the type checking logic because it doesn't match the type hints i.e. `tuple` isn't supposed to be possible here anyways, according to the `__call__` type hint. I did check some other examples of `is_batched` appearing in the `src/transformers/models` directory and they look similar but unexpected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Secrets not export via docker-compose config 3.2 Example: ```yml version: '3.2' services: rabbitmq: image: 'Asd' secrets: - source: api-config-v1 target: config.toml secrets: api-config-v1: file: ~/nx_configs/config.toml ``` `docker-compose config` will export: ```yml networks: {} services: rabbitmq: image: Asd secrets: - source: api-config-v1 target: config.toml version: '3.2' volumes: {} ``` It works fine with version 3.1 I may found the problem: https://github.com/docker/compose/blob/master/compose/config/serialize.py#L10 https://github.com/docker/compose/blob/master/compose/config/serialize.py#L12 I think it should be: ``` from compose.const import COMPOSEFILE_V2_2 as V2_2 from compose.const import COMPOSEFILE_V3_2 as V3_2 ``` https://github.com/docker/compose/blob/master/compose/config/serialize.py#L53 because variable `V3_2` contains `3.1` and the version in the config is `3.2` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Test for whether inside virtualenv does not work if directory is symlinked The following test for whether IPython is running inside a virtualenv does not work if the python executable and the VIRTUAL_ENV variable are at the same place but one is at a symlinked path to the other: https://github.com/ipython/ipython/blob/5bf4949fbd30de6211226e4b27e8680c4b199fc9/IPython/core/interactiveshell.py#L719 Discovered when using invewrapper, but problem appears more generic: https://github.com/berdario/invewrapper/issues/8 ``` tcorbettclark@cmed1:~$ python -c \"import IPython; print(IPython.sys_info())\" {'codename': 'An Afternoon Hack', 'commit_hash': '7c2ea3a', 'commit_source': 'installation', 'default_encoding': 'UTF-8', 'ipython_path': '/home/tcorbettclark/.virtualenvs/ice/local/lib/python2.7/site-packages/IPython', 'ipython_version': '1.1.0', 'os_name': 'posix', 'platform': 'Linux-3.5.0-42-generic-x86_64-with-Ubuntu-12.10-quantal', 'sys_executable': '/home/tcorbettclark/.virtualenvs/ice/bin/python', 'sys_platform': 'linux2', 'sys_version': '2.7.3 (default, Sep 26 2013, 16:35:25) \\n[GCC 4.7.2]'} tcorbettclark@cmed1:~$ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Define static IP address for container It would be useful to be able to define a static IP address for a container within the `docker-compose.yml`. I see that `docker run --ip xxx.xxx.xxx.xxx` is now available in [docker 1.10.0-rc2](https://github.com/docker/docker/releases/tag/v1.10.0-rc2). More details in the merged pull request: https://github.com/docker/docker/pull/19001 Example: ``` docker network create --driver=bridge --subnet=192.168.0.0/24 --gateway=192.168.0.1 mynet docker run --ip=192.168.0.10 --net=mynet -ti some_image ``` Define static IP address for container It would be useful to be able to define a static IP address for a container within the `docker-compose.yml`. I see that `docker run --ip xxx.xxx.xxx.xxx` is now available in [docker 1.10.0-rc2](https://github.com/docker/docker/releases/tag/v1.10.0-rc2). More details in the merged pull request: https://github.com/docker/docker/pull/19001 Example: ``` docker network create --driver=bridge --subnet=192.168.0.0/24 --gateway=192.168.0.1 mynet docker run --ip=192.168.0.10 --net=mynet -ti some_image ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: encoding.py missing OGG_OPUS and SPEEX_WITH_HEADER_BYTE encodings The new encodings OGG_OPUS and SPEEX_WITH_HEADER_BYTE are missing. [https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/speech/google/cloud/speech/encoding.py][1] [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/46e417e838001f4d1eb13f5e3fc2a54d390dd5db/speech/google/cloud/speech/encoding.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: fix segmentation demo @akshaykvnit @Borda ``` ERROR collecting pl_examples/full_examples/semantic_segmentation/semseg.py No module named 'torchvision.models.segmentation' oops, looks like this test fails. Need to fix asap ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.numpy.sum behaving funny for non-existent axis When invoking the `sum` operation on a non-existent axis I don't get an error (as would be the expected result), but sums over one of the existing axes. As far as I can tell, for any array `x` with `n` axes, calls to `sum` with axis `j > n` behave as if the provided axis was `j % n`. E.g., if the array `x` has 3 axes, calls to `sum` with `j` being any multiple of three all sum over the first axis (j=0,3,6,9,... all give the same result). This is especially noteworthy for the one-dimensional array (only one axis), where calls to `sum` with any value for `axis` always sums over the whole array. It would be preferable if either an error was raised, or summing over a non-existing axis would be a no-op. Might be related to #278 example code ``` import jax.numpy as np x = np.array([ [ [ 1, 2 ], [ 3, 4 ] ], [ [ 5, 6 ], [ 7, 8] ], [ [ 9, 10 ], [ 11, 12 ] ] ]) assert(np.all(np.sum(x, axis=3) == np.sum(x, axis=0))) assert(np.all(np.sum(x, axis=4) == np.sum(x, axis=1))) assert(np.all(np.sum(x, axis=5) == np.sum(x, axis=2))) assert(np.all(np.sum(x, axis=6) == np.sum(x, axis=0))) # and so on.. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: name 'IProgress' is not defined name 'IProgress' is not defined when running from Jupyter notebook. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: html.py conflict with html module find that html.py is conflict with python `html` module. that is why when execute `IPython.__main__.py`, this error appears: ``` python __main__.py /Users/suoyi/Documents/GitHub/ipython/IPython/html.py:12: ShimWarning: The `IPython.html` package has been deprecated since IPython 4.0. You should import from `notebook` instead. `IPython.html.widgets` has moved to `ipywidgets`. warn(\"The `IPython.html` package has been deprecated since IPython 4.0. \" Traceback (most recent call last): File \"/Users/suoyi/Documents/GitHub/ipython/IPython/__main__.py\", line 12, in <module> from IPython import start_ipython File \"/Users/suoyi/miniconda3/envs/ipython/lib/python3.9/site-packages/IPython/__init__.py\", line 56, in <module> from .terminal.embed import embed File \"/Users/suoyi/miniconda3/envs/ipython/lib/python3.9/site-packages/IPython/terminal/embed.py\", line 15, in <module> from IPython.core.interactiveshell import DummyMod, InteractiveShell File \"/Users/suoyi/miniconda3/envs/ipython/lib/python3.9/site-packages/IPython/core/interactiveshell.py\", line 60, in <module> from IPython.display import display File \"/Users/suoyi/miniconda3/envs/ipython/lib/python3.9/site-packages/IPython/display.py\", line 16, in <module> from IPython.lib.display import * File \"/Users/suoyi/miniconda3/envs/ipython/lib/python3.9/site-packages/IPython/lib/display.py\", line 5, in <module> from html import escape as html_escape ImportError: cannot import name 'escape' from 'html' (/Users/suoyi/Documents/GitHub/ipython/IPython/html.py) ``` when remove html.py, this error disappear. can you fix this by renaming this file? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: HTML vs Iframe I was again the witness of people miss-using HTML to display IFrames, and having issues. Could we detect in HTML the usage of `<iframe>....</iframe>` and warn user that there is an iframe object ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Celerybeat runs periodic tasks every 5 seconds regardless of interval I recently upgraded to celery 3 and have been experiencing some strange behavior with celerybeat, which was acting normally before the upgrade. My environment: python 2.7.3 django 1.4.1 virtualenv django-celery 3.0.6 celery 3.0.6 Regardless of what interval I define for my periodic tasks - which I adjust through the django admin - celerybeat fires off the periodic tasks every 5 seconds. This occurs regardless of the interval. Interestingly, however, when the periodic task is set disabled, celerybeat stops sending tasks, so it must be responsive to the scheduler at some level. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Unify basis_gates parameter handling (using a list) <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? (I have the feeling there is already an issue for this topic but can't seem to find it - apologies if it ends up being a duplicated issue). After #1323, the `basis_gates` for a backend is defined in its configuration as a list: ``` 'basis_gates': ['u1', 'u2', 'u3', 'cx', 'id', 'snapshot'] ``` Traditionally, we have been passing a comma-separated string around for the internal functions (throughout the transpiler layers), which is a tad ackward and cumbersome (specially since the final \"consumers\" of the basis gates end up splitting the string into a list, such as the `DAGBackend`). Actually one of the changes in #1323 was actually to \"stringify\" back the basis gates [at the right point in the transpilation process](https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/transpiler/_transpiler.py#L62), mostly for avoiding modifying the function signatures. It might be a good time to avoid that going back and forth entirely, making it always a list throughout the whole transpilation process. ### Proposed solution Remove the default value for `basis_gates` in the functions involved in the transpilation process, updating the docstrings and ensuring that it is handled properly at the main entry point. A potential drawback is that we might need to change the format of the argument in the public `compile()` method, deprecating or similar (although might not be a concern if we mostly keep the change internal). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.49.0 fails to find Qt5 using qmake My CI fails on both macOS and Windows: https://travis-ci.org/z3ntu/razer_test/jobs/468630035 https://ci.appveyor.com/project/z3ntu/razer-test/builds/21043013/job/5upak41rvyneo2qu `meson.build:20:0: ERROR: Dependency \"qt5\" not found, tried pkgconfig, qmake-qt5 and qmake` On those platforms, meson used the `qmake` detection with earlier versions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub - Error message on subscription.close() Python version: 2.7.14 API Client version: 0.33.0 While closing a subscription, the following message is printed to stderr but no exception is thrown: ``` ERROR:root:Exception serializing message! Traceback (most recent call last): File \"/miniconda/lib/python2.7/site-packages/grpc/_common.py\", line 87, in _transform return transformer(message) TypeError: descriptor 'SerializeToString' requires a 'google.protobuf.pyext._message.CMessage' object but received a 'UUID' ``` Recreated by creating a topic+subscription and running the following script: ``` import google.cloud.pubsub sub_client = google.cloud.pubsub.SubscriberClient() sub_name = sub_client.subscription_path('[PROJECT]', '[SUBSCRIPTION]') sub = sub_client.subscribe(sub_name) sub.open(lambda x: x.ack()) sub.close() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add new example which rewrites Docker Example using functional API By request, so that users can compare the differences. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Qasm3 Exporter needs to export arrays of qubtis for concatenation in alias of OpenQASM3. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently Qasm3 Exporter generates `qubit[2] _q; let q = _q[0] || _q[1];` to generate an array of `qubit`s in OpenQASM 3. https://github.com/Qiskit/qiskit-terra/blob/main/test/python/circuit/test_circuit_qasm3.py#L34-L35 However, I think that the spec allows concatenating of only two arrays. https://qiskit.github.io/openqasm/language/types.html#register-concatenation-and-slicing In the above case, the type of ` _q[0]` and `_q[1]` is `qubit` and not `qubit[1]`. One of quick fixes may be generating `let q = _q[0:0] || _q[1:1];` instead of `let q = _q[0] || _q[1];`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: shared_library vs_modules_defs parameter dies when passed anything but string I'm not sure whether the bug here is that passing a list (particularly an empty one) is not acceptable, or whether generating a giant stacktrace instead of a nice error message is the bug. But either a more helpful error message or accepting the empty list would be good. meson psuedo code: ```meson if cc.get_id() == 'msvc' def = 'foo.def' else def = [] endif libfoo = shared_library( 'libfoo', 'foo.c', vs_modules_def: def, ) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Create a single point for tracking package version Currently version is tracked in both `setup.py` and the `__init__.py`. I would recommend moving to a single location for both to avoid possible headaches in the future. Possible solutions from Python docs: [https://packaging.python.org/guides/single-sourcing-package-version/](https://packaging.python.org/guides/single-sourcing-package-version/) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Edit/cmd mode keyboard toggles not working Esc/Enter should move back and forth between cmd/edit mode, currently not working. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: In %magic help, remove duplicate aliases Certain magics are actually just aliases of another, like %hist and %history. In %magic, we show the full help for both, which can be confusing. We should instead indicate which one is an alias and refer the reader to the original for details. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Modifications to PCH don't trigger rebuild of the target with GCC Modifying the header file only rebuilds the PCH, but doesn't rebuild the target. If a header that is included by the PCH is modified, then only the sources that also `#include` it will be rebuilt, which leads to inconsistencies and surprising bugs. I've only tested this with GCC 8.2.1 and Clang 7.0.1 so far, C only. With clang it works fine: updating the pch rebuilds the whole project. I'm not sure if this might be a GCC bug (omitting command-line includes from the depfile?), but even if it is, I think it's worth working around in Meson anyway. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: follow up from #948 add a remove_all_accounts() command <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? removed many accounts are annoying we need a remove_all command Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: argmin, argmax, argort, etc. should link to `np.take_along_axis` in their documentation In #6075, I wondered whether it might be possible to > to have some simple way to use the output of `np.arg[min|max|sort]` as a proper index (to avoid hackery as in https://github.com/astropy/astropy/blob/master/astropy/time/core.py#L896 -- if there is a simpler way already, let me know!) and @jaimefrio suggested that it might be simpler to have > a `make_me_an_indexing_tuple=False` new keyword argument for the `argxxx` functions? That indeed seems better, so I'm raising this as a separate issue. The code linked to above could be used as a template on how to generate the index tuple. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Recommended Adafactor settings for T5 cause error ## Environment info - `transformers` version: 3.3.1 - Platform: Darwin-19.6.0-x86_64-i386-64bit - Python version: 3.7.7 - PyTorch version (GPU?): 1.6.0 (False) - Tensorflow version (GPU?): 2.2.0 (False) - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help @sshleifer (from activity on Adafactor PRs) ## Information Model I am using (Bert, XLNet ...): T5 The problem arises when using: * [ ] the official example scripts: (give details below) * [X] my own modified scripts: (give details below) The tasks I am working on is: * [ ] an official GLUE/SQUaD task: (give the name) * [X] my own task or dataset: (give details below) ## To reproduce The Adafactor docs recommend the following for T5 : `Adafactor(model.parameters(), lr=1e-3, relative_step=False, warmup_init=True)` However, the init code then has: ``` if lr is not None and relative_step: raise ValueError(\"Cannot combine manual lr and relative_step options\") if warmup_init and not relative_step: raise ValueError(\"warmup_init requires relative_step=True\") ``` which makes this setting impossible (as well as just changing to `relative_step=True`). So something seems to be missing either in the recommendations or in the implementation. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Can't pickle UFuncTypeError numpy 1.18.4-py38h8854b6b_0 (conda-forge) Linux x64 ```python import pickle import numpy try: numpy.ones(1) * \"foo\" except Exception as e: pickle.dumps(e) ``` Output: ``` Traceback (most recent call last): File \"ufunctypeerror.py\", line 6, in <module> numpy.ones(1) * \"foo\" numpy.core._exceptions.UFuncTypeError: ufunc 'multiply' did not contain a loop with signature matching types (dtype('<U32'), dtype('<U32')) -> dtype('<U32') During handling of the above exception, another exception occurred: Traceback (most recent call last): File \"ufunctypeerror.py\", line 8, in <module> pickle.dumps(e) _pickle.PicklingError: Can't pickle <class 'numpy.core._exceptions.UFuncTypeError'>: it's not the same object as numpy.core._exceptions.UFuncTypeError ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Escaping espaces for defines in cmake generator Comes from: https://github.com/conan-io/cmake-conan/issues/82 ```python def package_info(self): self.cpp_info.defines= ['MY_DEF=My string', 'MY_DEF2=My other string'] ``` Fails because of the spaces. Escaping in cmake works. cc/ @atvise Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson configure -Doption=unknown-value fails with a traceback Compare: ```console $ meson configure build -Dman=asdf Traceback (most recent call last): File \"/usr/bin/meson\", line 37, in <module> sys.exit(main()) File \"/usr/bin/meson\", line 34, in main return mesonmain.run(sys.argv[1:], launcher) File \"/usr/lib/python3.6/site-packages/mesonbuild/mesonmain.py\", line 302, in run return mconf.run(remaining_args) File \"/usr/lib/python3.6/site-packages/mesonbuild/mconf.py\", line 279, in run c.set_options(options.sets) File \"/usr/lib/python3.6/site-packages/mesonbuild/mconf.py\", line 130, in set_options tgt.set_value(v) File \"/usr/lib/python3.6/site-packages/mesonbuild/coredata.py\", line 131, in set_value raise MesonException('Value \"%s\" for combo option \"%s\" is not one of the choices. Possible choices are: %s.' % (newvalue, self.name, optionsstring)) mesonbuild.mesonlib.MesonException: Value \"asdf\" for combo option \"man\" is not one of the choices. Possible choices are: \"auto\", \"true\", \"false\". $ meson build-tmp -Dman=asdf The Meson build system Version: 0.43.0 Source dir: /home/zbyszek/src/systemd Build dir: /home/zbyszek/src/systemd/build-tmp Build type: native build Meson encountered an error in file meson_options.txt, line 96, column 0: Value \"asdf\" for combo option \"man\" is not one of the choices. Possible choices are: \"auto\", \"true\", \"false\". A full log can be found at /home/zbyszek/src/systemd/build-tmp/meson-logs/meson-log.txt ``` This is with meson-0.43.0-1.fc27.noarch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: Blob.compose doesn't use default content_type [`Blob.compose`](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/51ba7e148fc76e07018dc60192219fb28ff628b0/storage/google/cloud/storage/blob.py#L1363-L1381) does not use the [`self._get_content_type` method](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/51ba7e148fc76e07018dc60192219fb28ff628b0/storage/google/cloud/storage/blob.py#L605-L633), which means Blob.compose raises an error if the `content_type` is not explicitly specified. This is [documented behavior](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/51ba7e148fc76e07018dc60192219fb28ff628b0/storage/google/cloud/storage/blob.py#L1377-L1381), but is it intended behavior? Should compose use `self._get_content_type` to use the default type, or perhaps infer the type from the blobs being composed? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Make Meson recover from bad download **Describe the bug** When meson encounters an error while downloading a dependency, it might get into inconsistent state with following error: ``` meson.build:147:0: ERROR: Subproject exists but has no meson.build file ``` **To Reproduce** ```meson # meson.build project('test', 'c') executable('main', 'main.c', dependencies: [ subproject('libuv').get_variable('libuv_dep') ] ) ``` ```c // main.c int main(int argc, char **argv) { return 0; } ``` ```ini # subprojects/libuv.wrap [wrap-file] directory = libuv-v1.42.0 source_url = https://dist.libuv.org/dist/v1.42.0/libuv-v1.42.0.tar.gz source_filename = libuv-v1.42.0.tar.gz source_hash = 43129625155a8aed796ebe90b8d4c990a73985ec717de2b2d5d3a23cfe4deb72 patch_filename = libuv_1.42.0-1_patch.zip patch_url = https://bad-wrapdb.mesonbuild.com/v2/libuv_1.42.0-1/get_patch patch_hash = 891698d781bc68379b799e47bc7e100698f03985b6db5d1ddc4eaa9be42a8f35 [provide] libuv = libuv_dep ``` `bad-wrapdb` above will simulate a network error (in practice error might be caused by network timeout, temporary DNS resolution issue, etc.). Now do usual `meson setup build` and you'll get an obvious error. If you replace `bad-wrapdb` with `wrapdb` to simulate the end of intermittent network issues you'll get: ``` meson.build:3:0: ERROR: Subproject exists but has no meson.build file ``` **Expected behavior** Meson shoudn't keep subprojects in inconsistent state when such issues happen and thus should be able to recover without requiring user to go and manually remove directories under `subprojects`. Retries would also be nice to have I think, like 3 attempts with exponential backoff. **system parameters** * Plain native build * Ubuntu 21.04 * Python 3.9.5 * Meson 0.60.2 * Ninja 1.10.2.git.kitware.jobserver-1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Huggingface create_optimizer method not working ## Environment info - `transformers` version: 3.0.2 - Platform: Windows-10-10.0.18362-SP0 - Python version: 3.6.6 - PyTorch version (GPU?): 1.5.0+cpu (False) - Tensorflow version (GPU?): 2.2.0 (False) - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help @sgugger @jplu ## Information Model I am using (Bert, XLNet ...): Roberta The problem arises when using: * [ ] my own modified scripts: (give details below) The tasks I am working on is: * [ ] my own task or dataset: (give details below) ## To reproduce Steps to reproduce the behavior: 1. Run this code: ``` import tensorflow as tf from transformers import RobertaConfig, TFRobertaForMaskedLM, create_optimizer config = RobertaConfig() optimizer,lr = create_optimizer(1e-4,1000000,10000,0.1,1e-6,0.01) training_loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) model = TFRobertaForMaskedLM(config) model.compile(optimizer=optimizer, loss=training_loss) input = tf.random.uniform(shape=[1,25], maxval=100, dtype=tf.int32) hist = model.fit(input, input, epochs=1, steps_per_epoch=1,verbose=0) ``` 2. I am getting an error: > TypeError: apply_gradients() got an unexpected keyword argument 'experimental_aggregate_gradients' ## Expected behavior optimizer should be created Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: @CURRENT_SOURCE_DIR@ expands to ../ instead of .. Using meson 0.42.0. My goals were similar to those in https://github.com/mesonbuild/meson/issues/1622 but my sources are setup as follows: ``` ├── meson.build ├── proto │ ├── myproto.capnp ├── src └── test ├── meson.build ├── proto │ └── testproto.capnp ├── tests-main.cpp ``` and as such, I'd like to create a single `generator` in the top level meson.build: ``` capnproto_gen = generator(capnp, output : ['@PLAINNAME@.c++', '@PLAINNAME@.h'], arguments : ['compile', '--src-prefix=@CURRENT_SOURCE_DIR@/proto', '-oc++:@BUILD_DIR@', '@INPUT@'] ) ``` However, in the top level build file `@CURRENT_SOURCE_DIR@` expands to `../` (as verified w `ninja -v`) instead of `..`, which creates paths like `--src-prefix=..//proto` which the generator does not accept. It actually ends up working in the subdir, as it expands to `../test` which happens to work OK. I tried `arguments : ['compile', '--src-prefix=@0@/proto'.format(meson.current_source_dir()), '-oc++:@BUILD_DIR@', '@INPUT@']` but that doesn't work since the call to `format()` only happens when the top level build file is processed, not at expansion time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Support 'capacityProviderStrategy' option for ECSOperator **Description** [AWS launches Fargate Spot](https://aws.amazon.com/about-aws/whats-new/2019/12/aws-launches-fargate-spot-save-up-to-70-for-fault-tolerant-applications/) on December, 2019. It can be configured in [run_task on boto3 with 'capacityProviderStrategy' option](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/ecs.html#ECS.Client.run_task). It would be nice if we could set this option for ECSOperator. **Use case / motivation** Tasks with Fargate Spot are cheaper than tasks without Fargate Spot. **Related Issues** None found. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Should be able to initialize from an integer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Should be able to do: ```` qc.initialize(int) ```` and have it add x gates where the bit values are one. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Ability to create internal networks missing I cannot find a way to specify in the docker-compose file (even v2) that a network must be internal (as if it was created with `docker network create --internal ...`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: [ldap] section in configuration is not applicable anymore in 2.0 **Apache Airflow version**: 2.0.0b* / master **What happened**: `[ldap]` section in `airflow.cfg` is not applicable anymore in 2.0 and `master`, because the LDAP authentication (for webserver and API) is handled by FAB, and the configuration for this is handled by `webserver_config.py` file.  **What you expected to happen**: The `[ldap]` section should be removed from `airflow/config_templates/default_airflow.cfg` and `airflow/config_templates/config.yml` (and some other applicable files). Otherwise leaving this section there will be a big confusion for users. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: CLI: Add --detach option for up, run and exec commands This contribution allows the usage of --detach option when running: docker-compose run --detach docker-compose exec --detach docker-compose up --detach The behavior is the same as the -d option. I think it would be one item from #363 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan replaces backslashes with forward slashes in env_info variable in activate.bat Conan replaces all backslashes with forward slashes in activate.bat (and activate.ps1 and activate.sh). This means that to use a variable to pass the path to an executable, we have to manually convert the forward slashes back to backslashes. I am using Conan 1.8.4 on Windows on Python 3.6. I have created a conanfile.py which contains the following: ```python from conans import ConanFile import os.path class TestPkgConan(ConanFile): name = \"TestPkg\" version = \"0.0.1\" description = \"A test package\" settings = \"os\", \"arch\" def package_info(self): self.env_info.testpkg_root = self.package_folder self.env_info.testpkg_normalized = os.path.normpath(self.package_folder) self.env_info.testpkg_test = 'AC\\\\DC' ``` and I get the following activate.bat from the virtualenv generator ```cmd @echo off SET PROMPT=(conanenv) %PROMPT% SET testpkg_root=C:/.conan/data/TestPkg/0.0.1/adam/testing/package/ca33edce272a279b24f87dc0d4cf5bbdcffbc187 SET testpkg_normalized=C:/.conan/data/TestPkg/0.0.1/adam/testing/package/ca33edce272a279b24f87dc0d4cf5bbdcffbc187 SET testpkg_test=AC/DC ``` I would expect the environment variable to be set verbatim to the value I chose. And the job of doing path separator conversion to be the packagers, however given that conan seems to do path separator conversion I would at least expect it to output windows native paths for files which are supposed to be consumed by Windows native tools, i.e. activate.bat and activate.ps1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Define package-revision exploration/search in Api V2 How to inspect the different revisions of a package recipe from a server? ``conan search`` only retrieves latest. Same for package binaries too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Remove pre-3.8 codepath. Once https://github.com/ipython/ipython/pull/13315 is merged the master branch will not support 3.7 anymore, this gives opportunities to remove all the pre-3.8 codepath. If you like to contribute, find 1 block of code that is execute only before python 3.8 (look for sys.version_info in the code base), and simplify it. It may be more than just deleting code, as you might be then able to cleanup imports, or simplify more logics. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Bump NPY_API_VERSION for 1.14 I attempted this in my own PR but failed. The version needs to be increased to use WRITEBACKIFCOPY. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Autoreload Enum Error I'm getting a weird error when trying to use autoreload and Enums. I have an Enum class defined in a file as: ```python class MyEnum(Enum): A = 'A' B = 'B' ``` Using `%autoreload 2`, if I try to add `C = 'C'` to `MyEnum`, or remove an existing definition, I get the following error: ``` [autoreload of updates_type failed: Traceback (most recent call last): File \"/home/amarder/anaconda3/lib/python3.5/site-packages/IPython/extensions/autoreload.py\", line 247, in check superreload(m, reload, self.old_objects) RecursionError: maximum recursion depth exceeded ] ``` Sometimes it is a different error: ``` [autoreload of updates_type failed: Traceback (most recent call last): File \"/home/amarder/anaconda3/lib/python3.5/site-packages/IPython/extensions/autoreload.py\", line 247, in check superreload(m, reload, self.old_objects) AttributeError: __abstractmethods__ ] ``` I'm running the code on Debian Linux, using Anaconda with python 3.5. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: SimMIM output num_channels should not be hardcoded ### Feature request In all 3 simmim models, reconstructed images channel is hardcoded as 3. This should be configurable as num_channels ``` deit/modeling_deit.py swin/modeling_swin.py vit/modeling_vit.py nn.Conv2d(in_channels=config.hidden_size, out_channels=config.encoder_stride**2 * 3, kernel_size=1) ``` @NielsRogge ### Motivation I'm training a grayscale model, but the reconstructed image has different dimension as the input image. ### Your contribution None Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Regression: np.ma.masked_values(..., shrink=True) no longer works The [documentation for `np.ma.masked_values()`](https://docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.ma.masked_values.html) explains the role of the `shrink` option (which defaults to True) as follows: > Whether to collapse a mask full of False to nomask. In Numpy <= 1.13.3, this works correctly: ``` $ python -c 'import numpy as np; print(repr(np.ma.masked_values(np.arange(10.0), -1)))' masked_array(data = [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9.], mask = False, fill_value = -1.0) ``` In Numpy >= 1.14.0 and on master, it is broken: ``` $ python -c 'import numpy as np; print(repr(np.ma.masked_values(np.arange(10.0), -1)))' masked_array(data=[0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0], mask=[False, False, False, False, False, False, False, False, False, False], fill_value=-1.0) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: `np.random.permutation` & `np.random.shuffle` are slow. `np.random.permutation(x)` is the same as `x[np.random.permutation(x.shape[0])]` semantically if `x` is an array. Why the latter is so much faster than the former? ```python x = np.random.rand(50000, 2) %timeit x.take(np.random.permutation(x.shape[0]), axis=0) # 1.02 ms %timeit x[np.random.permutation(x.shape[0])] # 1.75 ms %timeit np.random.permutation(x) # 34.1 ms %timeit np.random.shuffle(x) # 34.2 ms ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Multiple v1 config files breaks logging I don't think this is specific to AWS, but this is where I was able to repro. Of the following scenarios, only \"Two v1 config files\" fails to generate the AWS logs output. It does, however, run the command and produce no error messages. The fact that it works with the \"v2\" config files means that it is probably either user error on my part or a Docker Compose bug. ``` gherkin Feature: Docker Compose awslogs driver Background: Given Docker v1.10.1 And Docker Compose v1.6.0 And the Docker daemon is configured correctly for the `awslogs` driver And config file \"a-v1.yml\" like so: \"\"\" a: image: alpine log_driver: awslogs log_opt: awslogs-region: us-west-2 awslogs-group: docker command: date \"\"\" And config file \"b-v1.yml\" like so: \"\"\" b: image: alpine command: date \"\"\" And config file \"a-v2.yml\" like so: \"\"\" version: '2' services: a: image: alpine logging: driver: awslogs options: awslogs-region: us-west-2 awslogs-group: docker command: date \"\"\" And config file \"b-v2.yml\" like so: \"\"\" version: '2' services: b: image: alpine command: date \"\"\" Scenario: Single v1 config file When I run `docker-compose -f a-v1.yml run --rm a` Then I see the output in the AWS logs Scenario: Two v1 config files When I run `docker-compose -f a-v1.yml -f b-v1.yml run --rm a` Then I see the output in the AWS logs Scenario: Single v2 config file When I run `docker-compose -f a-v2.yml run --rm a` Then I see the output in the AWS logs Scenario: Two v2 config files When I run `docker-compose -f a-v2.yml -f b-v2.yml run --rm a` Then I see the output in the AWS logs ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Need documentation for understanding the difference between `7B` and `7Bf` Unclear what the tradeoffs are between using eg `7B` and `7Bf` as an argument for `model_size` in the `convert_llama_weights_to_hf.py` script: https://github.com/huggingface/transformers/blob/f9cc333805c47665c6afee8b5867931e54abe0c6/src/transformers/models/llama/convert_llama_weights_to_hf.py#L65 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Automate docs for `values.yaml` via pre-commit config and break them into logical groups Automate docs for values.yaml via pre-commit config and break them into logical groups like https://github.com/bitnami/charts/tree/master/bitnami/airflow Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Whitespace in error messages I started creating an environment then cancelled it. The error messages for the later commands have some extra vertical whitespace. Also, the \"CondaValueError\" part and \"Value Error\" parts seem like they shouldn't be included in the terminal output. ``` $conda create -n dot2tex python=2.7 CondaValueError: Value error: prefix already exists: /Users/aaronmeurer/anaconda/envs/dot2tex $conda remove -n dot2tex --all Remove all packages in environment /Users/aaronmeurer/anaconda/envs/dot2tex: $conda create -n dot2tex python=2.7 ... ``` Whitespace in error messages I started creating an environment then cancelled it. The error messages for the later commands have some extra vertical whitespace. Also, the \"CondaValueError\" part and \"Value Error\" parts seem like they shouldn't be included in the terminal output. ``` $conda create -n dot2tex python=2.7 CondaValueError: Value error: prefix already exists: /Users/aaronmeurer/anaconda/envs/dot2tex $conda remove -n dot2tex --all Remove all packages in environment /Users/aaronmeurer/anaconda/envs/dot2tex: $conda create -n dot2tex python=2.7 ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: hotdoc module generates broken \"Edit on github\" links - Browse to https://mesonbuild.com/Hotdoc-module.html - Click \"Edit on github\" - Be redirected to https://github.com/mesonbuild/meson//edit/master/docs/builddir/markdown/Hotdoc-module.md - notice \"builddir/\" in the url /cc @thiblahute Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [revisions] Error on search recipe revisions in remote When revisions are NOT enabled in the Conan Client and a remote search or recipe revisions is done, Conan errors with: ``` $ conan search wiringpi/2.46@conan/stable --revisions -r conan-virtual ERROR: The remote doesn't support revisions. [Remote: conan-virtual] ``` H owever, the remote DOES support revisions and the fault is in the client not having them activated and thus not being able to talk via V2 with the remote. There should be raise early in the code saying that revisions are not enabled, then, if the user enables revisions and finally the remote DOES NOT support revisions, the message ``ERROR: The remote doesn't support revisions. [Remote: conan-virtual]`` would be valid ---------------------------------------- There could be also the option of disabling the ``--revisions`` flag even for local search when revisions are not enabled Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: TrainingArguments._n_gpus serialization I'm not sure, but I think that `TrainingArguments._n_gpu` attribute is not supposed to be serialized in `TrainingArguments.to_dict()` . Or even basically all the attributes that are defined as `dataclass.field(init=False...)` should be filtered out while doing `to_dict()`. What do you think? @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: ppermute is returning 0s Tested with TPUs. ```python @partial(jax.pmap, axis_name=\"shard\") def f(a): return jax.lax.ppermute( a, \"shard\", zip(range(8), [1, 0, 2, 3, 4, 5, 6, 7])) a = np.ones((8, 2, 2)) print(f(a)) ``` Prints out ``` [[[0. 0.] [0. 0.]] [[0. 0.] [0. 0.]] [[0. 0.] [0. 0.]] [[0. 0.] [0. 0.]] [[0. 0.] [0. 0.]] [[0. 0.] [0. 0.]] [[0. 0.] [0. 0.]] [[0. 0.] [0. 0.]]] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: BioGPT Token Classification ### Feature request It would be nice to have this available. ### Motivation working on biomedical token classification datasets and I would like to try BioGPT with them. ### Your contribution I could send a PR if you want. I guess it shouldn't be too hard. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add support for lifecycle management in gcloud.storage.bucket Consider allowing storage.bucket.Bucket.delete_key to silently fail if user requests it From TODO: ``` python # TODO: Should we accept a 'silent' param here to not raise an exception? ``` See [`storage.bucket.Bucket.delete_key`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/bucket.py#L158) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 158) # TODO: Should we accept a 'silent' param here to not raise an exception? ``` Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Core: change the default timeout of JSONConnection.api_request() to non-None As discussed offline - a `None` default timeout can cause requests to hang indefinitely, which is especially problematic in libraries that do not provide any reasonable means of overriding that timeout. In order to avoid bugs resulting from that, the current default needs to be changed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Include partition_expr in DuckDB documentation From https://github.com/pybokeh/dagster-partitioning-av: > Furthermore, I was using duckdb IO manager, but I soon learned dagster's documentation for duckdb integration isn't as complete as their Snowflake documenation. It was not until I looked at their Snowflake's [documenation](https://docs.dagster.io/integrations/snowflake/reference#storing-partitioned-assets) did I learn that I need to add the metadata= parameter to add the partition_expr key and it's value. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Test that dataset not updated when task skipped the AIP specifies that when a task is skipped, that we don’t mark the dataset as “updated”. we should simply add a test that verifies that this is what happens (and make changes if necessary) @blag, i tried to make this an issue so i could assign to you but can't. anyway, can reference in PR with `closes` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"name\" is not a valid service config field Example: ``` yaml web: image: \"alpine:edge\" name: \"different name\" ``` This config would be valid, but shouldn't be. I think `name` is included because we modify the config to move the name in as a field, but I think we should validate it separately as part of the \"top level\" validation instead. The example config should raise an error about an unsupported key. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Reconsider an optimization for triggers when there are no upstream states Right now, triggers are skipped if there are no upstream states. This was originally done because it seemed like a simple optimization -- if there are no upstream states, there's no need to compare them to a trigger function. However, `manual_only` should fire regardless, so we should remove this optimization. The one catch is to make sure that all triggers properly handle the (very likely) scenario of receiving an empty set of upstream states. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Consider PackageFolders that abstract layout for cache, workspaces Now, the layout of a conan package is cache is directly obtained from ``ClientCache``, which is hardcoded into many processes and algorithms. It might be useful to create an abstract ``PackageFolders`` or similar, that abstract that. It will have a concrete ``CachePackageFolders`` which will be an indirection over the ``ClientCache``, but it could be replaced by a ``WorkspacePackageFolders``, for workspaces. It could also enable improvements in the local workflow, and allow other cache layouts, and other operations (e.g. ``conan download`` directly to user folder) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Barrier when reversebits circuit drawer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? I saw two problems when using barriers in the latex drawer. 1. When using `'reversebits': True` in the style, the barriers get messed up. The following should have barriers on quantum registers q and v:  2. The style `'plotbarrier': False` is introduced by the mpl drawer, but the latex drawer ignores it. It would be nice if this style affected both drawers. ### Steps to reproduce the problem ``` from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit from qiskit.tools.visualization import circuit_drawer q = QuantumRegister(3, 'q') v = QuantumRegister(2, 'v') c = ClassicalRegister(4, 'c') d = ClassicalRegister(3, 'd') circ = QuantumCircuit(q, v, c, d) circ.x(q[0]) circ.x(q[2]) circ.x(v[1]) circ.barrier(q) circ.barrier(v) circ.measure(q[0], c[1]) circ.measure(q[2], d[2]) circ.measure(v[1], c[0]) circuit_drawer(circ, output='latex', scale=0.5, style={'reversebits': True, 'plotbarrier': False}) ``` ### What is the expected behavior? Barrier on registers `q` and `v` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Source link in doc of `printoptions` goes to contextlib The source link in [the documentation of the new `printoptions` context manager](https://docs.scipy.org/doc/numpy/reference/generated/numpy.printoptions.html?highlight=printoption) has the wrong link target: it goes to the invalid ``` http://github.com/anaconda3/lib/python3.6/contextlib.py#L281-L311 ``` Seems like an issue with the link auto-generation machinery, maybe even with other decorated functions? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Ability to configure project without a language The use case would be something like a Gnome application written purely in a scripting language such as Python. As such it never needs a C compiler to build any libraries but it is still far more useful than setuptools because you have easy access to building GResource files, configuring desktop files, handling translations, and it isn't setuptools which is awful. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Separate out a new builder package <!-- Welcome! Thanks for thinking of a way to improve JupyterLab. If this solves a problem for you, then it probably solves that problem for lots of people! So the whole community will benefit from this request. Before creating a new feature request please search the issues for relevant feature requests. --> ### Problem We are starting to add a lot of dependencies to `buildutils` that aren't needed for simple utilities like `update:dependency`. <!-- Provide a clear and concise description of what problem this feature will solve. For example: * I'm always frustrated when [...] because [...] * I would like it if [...] happened when I [...] because [...] --> ### Proposed Solution Create a new top-level `builder` package (`@jupyterlab/builder`) that has the `webpack` config and the `build-extension` script. <!-- Provide a clear and concise description of a way to accomplish what you want. For example: * Add an option so that when [...] [...] will happen --> ### Additional context Also need to move the `source-map-loader` and `html-loader` out of this package and back into `dev_mode`. <!-- Add any other context or screenshots about the feature request here. You can also include links to examples of other programs that have something similar to your request. For example: * Another project [...] solved this by [...] --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: `slogdet` sign is incorrect In the following, numpy disagrees with JAX ```python mat = np.array([[[-0.01]], [[-0.01]]]) print(np.linalg.slogdet(mat)) print(jnp.linalg.slogdet(jnp.array(mat))) ``` => ``` (array([-1., -1.]), array([-4.60517019, -4.60517019])) (DeviceArray([1., 1.]), DeviceArray([-4.60517019, -4.60517019])) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Recent shape checking changes result in new XLA errors It turns out that PR #2017 breaks the following code: ``` array = np.ones(5) print(array[:10]) ``` should print `[1. 1. 1. 1. 1.]` but instead throws an error ``` Traceback (most recent call last): File \"/Users/necula/Source/jax/jax/interpreters/xla.py\", line 230, in primitive_computation return c.Build() File \"/Users/necula/Source/jax/jax/lib/xla_bridge.py\", line 281, in Build *args, **kwargs) File \"/Users/necula/Source/jax/build/jaxlib/xla_client.py\", line 734, in Build return Computation(self._builder.Build(), backend=backend) RuntimeError: Invalid argument: Slice size at index 0 in gather op is out of range, must be within [0, 6), got 10.: ``` In some sense this error is reasonable, but it is not what JAX used to do before. Before JAX used to sanitize indices, and produce the following JAXPR for the `gather`: ``` { lambda b ; a. let c = gather[ dimension_numbers=GatherDimensionNumbers(offset_dims=(0,), collapsed_slice_dims=(), start_index_map=(0,)) operand_shape=(5,) slice_sizes=(5,) ] a b in c } ``` After this change, the JAXPR is: ``` { lambda b ; a. let c = gather[ dimension_numbers=GatherDimensionNumbers(offset_dims=(0,), collapsed_slice_dims=(), start_index_map=(0,)) operand_shape=(5,) slice_sizes=(10,) ] a b in c } ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: integrate content/images on broadcasting in docs https://scipy.github.io/old-wiki/pages/EricsBroadcastingDoc explains broadcasting well (including useful diagrams) and is linked to from https://docs.scipy.org/doc/numpy/user/basics.broadcasting.html. It is the only link to https://scipy.github.io/old-wiki left. This content should be integrated in the user guide. There's also useful code to draw such diagrams at https://jakevdp.github.io/PythonDataScienceHandbook/02.05-computation-on-arrays-broadcasting.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Drop support for `fig.yml` and FIG_PROJECT_NAME It's been a year and 5 releases, I think 1.6 will be a good time to drop support, since we're introducing a bunch of new conditionals for v1/v2 config. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: Cloudpickle fails to deserialize a function Deserializing a python function during runtime fails in case the function has a default parameter, which uses an argo variable. Here is a simple example: ``` def _test_func( path: str, local_path: str, remote_artifact_name: str, minio_bucket: str = 'mlpipeline', minio_key: str = 'runs/{{workflow.uid}}/{{pod.name}}', minio_ext: str = '.tgz', ): remote_path = f'minio://{minio_bucket}/{minio_key}/{remote_artifact_name}{minio_ext}' print(remote_path) ``` This can be executed fine when compiled with 0.1.19 (latest version in PyPI), but fails with the latest master (which uses cloudpickle). The error message is one of the following: - in case only `{{workflow.uid}}` is used: ``` Traceback (most recent call last): File \"<string>\", line 9, in <module> AttributeError: 'dict' object has no attribute 'append' ``` - in case `{{pod.name}}` is used: ``` Traceback (most recent call last): File \"<string>\", line 9, in <module> _pickle.UnpicklingError: invalid load key, '5'. ``` Using a default value without brackets resolves the issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Packages should include licensing information Some projects cannot operate with specific licenses and having that information would be significantly helpful. An added bonus would be to add restrictions on what licenses can be used/not used for a project. This feature would need to support libraries that have multiple licensing agreements (i.e. Qt with LGPL2 and LGPL3). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: harden 'ArrayQueryParameter.from_api_repr' against missing 'parameterValue'. Closes #7309. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Suggest %pip or %conda when user types !pip or !conda To guide users towards doing things right, could we suggest they use the magics instead of the shell invocations? Possibly with a short explanation why. Was also mentioned in <https://github.com/ipython/ipython/pull/11524#issuecomment-444875270>. Suggest %pip or %conda when user types !pip or !conda To guide users towards doing things right, could we suggest they use the magics instead of the shell invocations? Possibly with a short explanation why. Was also mentioned in <https://github.com/ipython/ipython/pull/11524#issuecomment-444875270>. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: \"visual_studio\" generator support for multi-config variables (N configs -> 1 package) I'm introducing ```conan``` in products of my company. But, I found one limitation and I want improvement of it. http://docs.conan.io/en/latest/creating_packages/package_approaches.html#n-configs-1-package > The automatic conversion of multi-config variables to generators is currently only implemented in the cmake and txt generators. If you want to have support for them in another build system, please open a GitHub issue for it. I found that sentence in above documentation. And I want to have support for them in **Visual Studio**, So I open this issue. Thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: mgrid result sensitive to data type Using `np.mgrid' depends on slice dtype ### Reproducing code example: ```python import numpy as np a = np.mgrid[[slice(np.float32(0.1), np.float32(0.3), np.float32(0.1)) for _ in range(1)]] # returns array([[0, 0, 0]]) b = np.mgrid[[slice(np.float64(0.1), np.float64(0.3), np.float64(0.1)) for _ in range(1)]] # returns array([[0.1, 0.2]]) np.testing.assert_allclose(a, b) ``` ### Numpy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> 1.18.4 3.6.7 (default, Mar 27 2020, 15:56:09) [GCC 6.5.0 20181026] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rewrite Finite Difference/Parameter Shift/Linear Comb. of Unitaries gradients with primitives. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: What is the purpose of the empty \"prefect.flows\" module? What is the purpose of the empty \"prefect.flows\" module? It is also imported here https://github.com/PrefectHQ/prefect/blob/6f1015957019a86bb86a0504555c354cd8f4af6e/src/prefect/__init__.py#L14 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: celery beat: OSError: [WinError 87] Suddenly I started getting this error when I run celery beat ``` celery beat -A proj ``` Funny thing is that celery worker still runs but beat doesn't. I'm running version 4.1 (latest version) btw. ``` celery beat v4.1.0 (latentcall) is starting. OSError: [WinError 87] The parameter is incorrect ... SystemError: <class 'OSError'> returned a result with an error set ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: (Spurious?) RuntimeError: No specified compiler can handle file impl/json/jsmn.c With 0.44.0, I get this error: ``` RuntimeError: No specified compiler can handle file impl/json/jsmn.c ``` This in a project which is mostly C++, but it uses this one `.c` file, defined as: ``` jsmn = declare_dependency( sources: ['impl/json/jsmn.c'], compile_args: [ '-DJSMN_STRICT=1', '-DJSMN_PARENT_LINKS=1' ]) ``` The project statement at the top was: ``` project('name','cpp',default_options : ['cpp_std=c++11','b_pch=false']) ``` Previous versions of Meson didn't report any errors, but I figured I'd have to add `'c'` to the list. I tried: ``` project('name',['cpp','c'],default_options : ['cpp_std=c++11','b_pch=false']) ``` which gave me the error message I quoted at the top of this report. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub API lists the wrong (slightly incompatible) type for Message.attributes When a subscriber receives a message, the API says it has an 'attributes' member that is a dict: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/11e310ab9f63f06252ff2b9ada201fd8c11ce06c/pubsub/google/cloud/pubsub_v1/subscriber/message.py#L36 However, it is not, in fact, a dict; it is a protobuf map. The behaviour is quite different, which the Python protobuf API documentation explains at some length: https://developers.google.com/protocol-buffers/docs/reference/python-generated#map-fields This is not a small difference... the semantic gap is substantial, because using the `.attributes` type in place of a dict breaks code like this: ``` message_rev = None if some_condition: try: message_rev = int(message.attributes['revision']) except KeyError: message_rev = DEFAULT ``` In this case, instead of assigning the value `DEFAULT`, this code simply raises a new exception that doesn't happen with dicts (it's a ValueError, because the try-block will execute `int('')`). This is an incompatible, breaking change. Again, this is a subtle, but important, API difference. At a minimum, it seems like the PubSub API docs should point to the Protobuf docs, instead of simply listing the incorrect type. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: upload --no-overwrite option doesn't work if the package doesn't exists remotely While the new `--no-overwrite` option to upload is great in theory it doesn't work as expected when the package is not available in the remote: ``` conan search -r test zlib/1.2.8-5@plex/stable ERROR: Recipe not found: plex/zlib/1.2.8-5/stable. [Remote: test] conan upload --no all zlib/1.2.8-5@plex/stable -r test Uploading zlib/1.2.8-5@plex/stable ERROR: Local recipe is different from the remote recipe. Forbbiden overwrite. [Remote: test] conan upload zlib/1.2.8-5@plex/stable -r test Uploading zlib/1.2.8-5@plex/stable Uploading conanmanifest.txt [==================================================] 58B/58B Uploading conanfile.py [==================================================] 3.2KB/3.2KB Uploaded conan recipe 'zlib/1.2.8-5@plex/stable' to 'test': https://artifactory.plex.bz/artifactory/api/conan/conan-test conan upload zlib/1.2.8-5@plex/stable -r test -no all Uploading zlib/1.2.8-5@plex/stable Recipe is up to date, upload skipped ``` I'll argue that `upload --no-overwrite all` should work with a package that is not available in the remote. Our remote is a artifactory server running 5.10.3 and I am running conan 1.2.3 locally. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Update default behaviour of `rm` As per the warning message: ``` console $ docker-compose rm WARNING: Not including one-off containers created by `docker-compose run`. To include them, use `docker-compose rm --all`. This will be the default behavior in the next version of Compose. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [regression] String formatting has regressed since 0.60. ERROR: Format placeholder @9@ out of range. **Describe the bug** There is a regression of as yet unknown cause in Meson's string formatting, as discovered by @alex3kov and diagnosed by myself at libsixel/libsixel#50. This regression causes previously building package to no longer build. **To Reproduce** https://github.com/libsixel/libsixel/blob/v1.10.3/meson.build **Expected behavior** Good build **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? Plain build. * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) Arch Linux * what Python version are you using e.g. 3.8.0 Python 3.9.7 * what `meson --version` Versions above 0.59.2 I confirm are affected. * what `ninja --version` if it's a Ninja build We do not get to Ninja step, Meson is the cause. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Enhance appearance and correctness of Q-sphere visualization <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Enhance appearance and correctness of Q-sphere visualization in the following ways: - All complementary basis states are antipodal - Phase is indicated by color of line and marker on sphere's surface - Probability is indicated by translucency of line and volume of marker on sphere's surface @nonhermitian and I have been collaborating on this enhancement, and are satisfied with the results. There is one, perhaps new, required dependency, namely [seaborn color palettes](https://seaborn.pydata.org/tutorial/color_palettes.html) for associating colors to phases in the Q-sphere plot as well as its legend. Here is an example Q-sphere plot with these enhancements: <img width=\"509\" alt=\"example-qsphere-plot\" src=\"https://user-images.githubusercontent.com/9936602/62621482-edeaf580-b8e9-11e9-8373-113f281dd2ca.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson told me report an \"Unhandled python exception\". While defining a cross build file for `Windows`, I wrote a section for `cmake`, ```ini [cmake] CMAKE_C_COMPILER_WORKS = 1 ``` and I forgot to wrap \"1\" in single quotes and it threw this unhandled exception. ```bash ❯ meson setup --cross-file=cross-windows-x86_64.ini build-win Traceback (most recent call last): File \"/usr/lib/python3.10/site-packages/mesonbuild/mesonmain.py\", line 146, in run return options.run_func(options) File \"/usr/lib/python3.10/site-packages/mesonbuild/msetup.py\", line 294, in run app.generate() File \"/usr/lib/python3.10/site-packages/mesonbuild/msetup.py\", line 180, in generate env = environment.Environment(self.source_dir, self.build_dir, self.options) File \"/usr/lib/python3.10/site-packages/mesonbuild/environment.py\", line 536, in __init__ cmakevars.host = CMakeVariables(config.get('cmake', {})) File \"/usr/lib/python3.10/site-packages/mesonbuild/envconfig.py\", line 442, in __init__ assert isinstance(i, str) AssertionError ERROR: Unhandled python exception This is a Meson bug and should be reported! ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] apple frameworks broken with cmake When trying to build static version of conan-glib/2.58.3@bincrafters/stable on macos, the test recipe fails to link because [it uses link flags](https://travis-ci.com/bincrafters/conan-glib/jobs/253077883#L5712) `-framework Foundation -framework Foundation -framework Foundation` instead of `-framework Foundation -framework CoreServices -framework CoreFoundation` [as specified in conanfile.py](https://github.com/bincrafters/conan-glib/blob/stable/2.58.3/conanfile.py#L138) ### Environment Details (include every applicable attribute) * Operating System+version: Mac OS X 10.14.4 * Compiler+version: apple clang 10.0 * Conan version:1.20.2 * Python version: ### Logs (Executed commands with output) (Include/Attach if Applicable) [conan 1.19.1: success](https://gist.github.com/ericLemanissier/5a2fcca7faf51f7c4ef69cec0c92eabb) [conan 1.20.2: failure](https://gist.github.com/ericLemanissier/116fe4d43d642470cdd141508b4ac033) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Can't connect to 2 HTTPS notebook servers on the same host Just discoverd that one can't connect to two notebooks server at the same time if they are (both?) over https. Login to another notebook server make the cookie invalid for the first server, not actually preventing you from executing code but preventing you from dooing stuff like saving. <del> Speeking of saving, could we reopen #883 ? The `saving failed` message in again pretty brief and not very visible, having the pop up back would be cool. </del> <del> Can I add \"listening on http also and redirecting to https dashboard if notebook is password protected\" in the wishlist ? </del> (not expecting answer until pycon is over of course...) Thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Jobs timeouts are wrongly managed. <!--- Provide a general summary of the issue in the Title above --> Timeouts are not working as expected. ## Expected Behavior <!--- If you're describing a bug, tell us what should happen --> <!--- If you're suggesting a change/improvement, tell us how it should work --> When you set a timeout in `QuantumProgram.execute(timeout=<value>)` or `.run(timeout=<value>)` we want this value to be the actual timeout (in secs). ## Current Behavior <!--- If describing a bug, tell us what happens instead of the expected behavior --> <!--- If suggesting a change/improvement, explain the difference from current behavior --> Values passed are not being properly set, so the default 120 secs timeout is always being used. ## Steps to Reproduce (for bugs) <!--- Provide a link to a live example, or an unambiguous set of steps to --> <!--- reproduce this bug. Include code to reproduce, if relevant --> 1. Call `QuantumProgram.execute(timeout=0.01)` surrounded by `try: ... except QSIKitError:` 2. The method call should timeout and entering the `except` block, but it's not. ## Your Environment <!--- Include as many relevant details about the environment you experienced the bug in --> * Version used: 0.4.x (0.3 is not affected) * Environment name and version (e.g. Python 3.6.1): 3.5 & 3.6 * Operating System and version: Linux, Mac and Windows. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Array form of #labels produces unmarshal error Consider the following docker-compose.yml: ``` version: '2.1' services: labels_as_array: build: context: . labels: - \"com.example.description=Description\" - \"com.example.department=Department\" - \"com.example.label-with-empty-value\" ``` which is canonical sample from [reference v2](https://docs.docker.com/compose/compose-file/compose-file-v2/#labels) The Dockerfile for the sample is irrelevalt and is simply ```FROM busybox``` However, running `docker-compose up`, produces: ``` $ docker-compose -v docker-compose version 1.16.0-rc1, build 9bea70a $ docker-compose up Building labels_as_array ERROR: json: cannot unmarshal array into Go value of type map[string]string ``` Note that the same sample is also listed for v3 [here](https://docs.docker.com/compose/compose-file/#labels), but changing the version to `'3.3'` in the sample above does not help. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: `client.set_secret()` method For usability and to mirror UI functionality, we should expose a set_secret method on the Client. Bonus points for implementing encryption from a key provided in `config.toml` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Major assertion bug in test_activate The activation tests were nowehere near as effective as they should have been due to a bug in the assertion code (my bad). I'm working on fixing this now, but 4.1 should not be shipped until this (and the bugs that it exposes) are fixed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan client should implement HTTP/1.1 resumable downloads if the server supports it. Conan version 1.7.3 OS: Mac OS 10.13.6 Artifactory Enterprise 6.1.0 rev 60100900 SUMMARY: Many developers work remotely and need to sync large binaries (for example test files). If the connection times out or drops and the conan client times out, when the conan install command is re-issued, the download starts again from the beginning. Instead it should resume from where it was interrupted. DESCRIPTION: Since HTTP/1.1 resumable downloads can be implemented by using ranges in the HTTP header (if the server supports it). Artifactory has been supporting this feature since version 3.7.0: https://stackoverflow.com/questions/51027395/does-jfrogs-artifactory-support-client-side-download-resume. Since Artifactory is the most used Conan repository server, the client code should be able to handle this as well. This is not a hypothetical scenario: in my company we have large binaries (multiple GB) which we need to sync from time to time and this feature is a must have if we want to adopt Conan on a large scale. STEPS TO REPRO: 1. Create a large binary Conan package and upload to a remote. 2. Remove it from the local repo. 3. Install it again using `conan install`. During download (say about half way through) remove the network cable and wait for the conan client to time out (it will print an error and return). 4. Re-connect the network and re-issue the `conan install` command. Watch the progress bar carefully. It will start downloading again from zero. I expect it should resume from where it was interrupted (approximately, depending on the chunk size). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumInstance.execute mutates circuit list when performing measurement error mitigation ### Environment - **Qiskit Terra version**: 0.19.1 - **Python version**: 3.9.7 ### What is happening? When using a `QuantumInstance` with `CompleteMeasFitter`, the circuits passed to `execute` are mutated on [this](https://github.com/Qiskit/qiskit-terra/blob/2db16853bf6d890e0ccf87509c5b88d198c81838/qiskit/utils/quantum_instance.py#L562) line ```python circuits[0:0] = cal_circuits ``` This becomes problematic when e.g. using `NeuralNetwork` from `qiskit_machine_learning`, see example below. ### How can we reproduce the issue? The following code throws an error due to the bug described above: ```python import numpy as np from qiskit import Aer, QuantumCircuit from qiskit.providers.aer import noise from qiskit.utils import QuantumInstance from qiskit.utils.mitigation import CompleteMeasFitter from qiskit.circuit.library import RealAmplitudes, ZZFeatureMap from qiskit_machine_learning.algorithms import VQC num_qubits = 3 qi = QuantumInstance(Aer.get_backend('qasm_simulator'), shots=4096, measurement_error_mitigation_cls=CompleteMeasFitter) feature_map = ZZFeatureMap(num_qubits, reps=2, entanglement='linear') ansatz = RealAmplitudes(num_qubits, reps=1, entanglement='linear') model = VQC(num_qubits, feature_map, ansatz, quantum_instance=qi) x = np.random.rand(1, num_qubits) weights = np.random.rand(2*num_qubits) model.neural_network.forward(x, weights) ``` ### What should happen? The circuit list should not be mutated. ### Any suggestions? A simple fix is to instead use ```python circuits = cal_circuits + circuits ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: Improve docs for 'Query.get' / 'Collection.get' `Query.get` (which underlies `Collection.get`) could have better documentation strings. Particularly there is no mention that iteration must be completed in the `max_rpc_timeout_millis` as specificed when creating the firestore_client. If iteration is not completed in that time, the iteration will stop at the timeout. This is in response to a customer question on StackOverflow: https://stackoverflow.com/questions/52395736/loop-over-cloud-firestore-docs-ends-unexpectedly-after-20-seconds-when-iterating Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: pulse jobs fail schema validation Every pulse job is failing schema validation. This happened in https://github.com/Qiskit/qiskit-terra/pull/4539. ```py from qiskit import * IBMQ.load_account() p = IBMQ.get_provider(project='......') backend = p.get_backend('ibmq_armonk') c = QuantumCircuit(1, 1) c.measure(0, 0) c = transpile(c, backend) s = schedule(c, backend) qobj = assemble(s, backend=backend, shots=100) job = backend.run(qobj) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Using two compose files with ports leads to \"port already in use\" I was following the guide in https://docs.docker.com/compose/production/ but I had duplicate port lines in both files. This lead to \"address already in use\" erorrs! #### docker-compose.yml: ``` yaml version: '2' services: test: image: alpine:3.3 ports: - \"1234:1234\" command: nc -l 1234 ``` #### docker-compose.prod.yml ``` yaml version: '2' services: test: ports: - \"1234:1234\" ``` #### command and output ``` % docker-compose --project=test -f docker-compose.yml -f docker-compose.prod.yml up Starting test_test_1 ERROR: for test driver failed programming external connectivity on endpoint 4f94d0857d8f_4f94d0857d8f_test_test_1 (3f6b754fd97c08bb5d2fa037b4de805001f16544246e8fe1ccb7e937836dac6a): Bind for 0.0.0.0:1234 failed: port is already allocated Attaching to % ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Strange behavior of np.ma.masked_where When the mask and array shapes do not match and the mask is always false, no exception is thrown, probably a warning could be good. Consider the example ``` x = np.arange(10) y = np.arange(5) z = np.ma.masked_where(y > 6, x) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.storage.connection.Connection.get_bucket takes spurious '*args', '**kw' arguments ... but ignores them: https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/connection.py#L258 Likewise the 'create_bucket': https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/connection.py#L319 and 'delete_bucket': https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/connection.py#L343 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Gracefully recover from version lock errors ## Current behavior *Please describe how the feature works today* When setting a state results in a version-lock error, the attempt is aborted and progress stops. ## Proposed behavior *Please describe your proposed change to the current behavior* Related to #2730, whenever a version-lock error is encountered, the Client should instead query for the latest state and return it so process can continue. This will enable graceful fallbacks from the latest known state. The only exception is if the latest state is one that *requires* a version lock, like RUNNING or SUBMITTED, because version-locked states indicate run-once semantics. ## Example *Please give an example of how the enhancement would be useful* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: 'requests' version conflict docker-compose install the latest `requests` version (2.5.1) but docker-py expects `requests` version lower than 2.5.0. #### docker-compose(fig) https://github.com/docker/fig/blob/master/setup.py ``` install_requires = [ ... 'requests >= 2.2.1, < 3', 'docker-py >= 0.6.0, < 0.8', ... ] ``` #### docker-py https://github.com/docker/docker-py/blob/master/setup.py ``` install_requires = [ ... 'requests >= 2.2.1, < 2.5.0', ... ] ``` Here is the error message: ``` Traceback (most recent call last): File \"/usr/local/bin/docker-compose\", line 5, in <module> from pkg_resources import load_entry_point File \"/usr/local/lib/python2.7/dist-packages/pkg_resources/__init__.py\", line 3018, in <module> working_set = WorkingSet._build_master() File \"/usr/local/lib/python2.7/dist-packages/pkg_resources/__init__.py\", line 614, in _build_master return cls._build_from_requirements(__requires__) File \"/usr/local/lib/python2.7/dist-packages/pkg_resources/__init__.py\", line 627, in _build_from_requirements dists = ws.resolve(reqs, Environment()) File \"/usr/local/lib/python2.7/dist-packages/pkg_resources/__init__.py\", line 810, in resolve raise VersionConflict(dist, req).with_context(dependent_req) pkg_resources.ContextualVersionConflict: (requests 2.5.1 (/usr/local/lib/python2.7/dist-packages), Requirement.parse('requests<2.5.0,>=2.2.1'), set(['docker-py'])) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Support `logging_ratio`, `save_ratio`, and `eval_ratio` (like for `warmup_ratio`) ### Feature request I would love if `TrainingArguments` and the Huggingface `Trainer` would support `logging_ratio`, `save_ratio`, and `eval_ratio` arguments (complementing `logging_steps`, `save_steps`, and `eval_steps`). If the `*_ratio` argument is set to e.g. `0.1`, logging/saving/eval would be done every `0.1 * total_training_steps`. This is already done for `warmup_ratio` and `warmup_steps`. ### Motivation When dealing with many different tasks and datasets, it can be frustrating to have to calculate different appropriate `logging_steps` etc. for each individual dataset. This proposal would enable a unified, simple and concise way to solve this problem. ### Your contribution I realize this might not be trivial to fully integrate, but hopefully, we can take `warmup_steps` and `warmup_ratio` as a reference. Depending on how deep the required changes are, I can also submit a PR (with some pointers on what to look out for). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Docker Agent should pull images in the background ## Current behavior Right now, the docker agent pulls flow images synchronously which, depending on slow connections can take up to 5 minutes for large images. ## Proposed behavior It would be nice if the Docker agent instead pulled these images \"in the background\" (maybe in a background thread if possible which can be cleaned up with each heartbeat?). This would increase the speed at which flows can be submitted in parallel and prevent any edge cases with the proposed new \"agent registration\" hooks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan client say \"Binary for xxxx not in remote:\" when it's a 500 error To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. 1.0.0-beta5 - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. https://travis-ci.org/lasote/conan-openssl/jobs/326398470 It's trying to download zlib and failing with a 500 error, but Conan instead of fail, it's considering that the package is missing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Using == in setup.py from requirements.txt will cause conflicts with other python packages requirements.txt with == operator is meant to be used when you need completely limit the versions of package. fig uses requirements.txt input in setup.py to fill install_requires. If any package installed after fig requires other version or updates the dependency things will break. ``` fig up -d Traceback (most recent call last): File \"/usr/local/bin/fig\", line 5, in <module> from pkg_resources import load_entry_point File \"/usr/lib/python2.7/dist-packages/pkg_resources.py\", line 2749, in <module> working_set = WorkingSet._build_master() File \"/usr/lib/python2.7/dist-packages/pkg_resources.py\", line 446, in _build_master return cls._build_from_requirements(__requires__) File \"/usr/lib/python2.7/dist-packages/pkg_resources.py\", line 459, in _build_from_requirements dists = ws.resolve(reqs, Environment()) File \"/usr/lib/python2.7/dist-packages/pkg_resources.py\", line 628, in resolve raise DistributionNotFound(req) pkg_resources.DistributionNotFound: requests==2.2.1 ``` The latest version of requests package available is 2.3.0 (which was installed in this case) and it's of course backward compatibile. You should either stop relaying on reading requirements.txt or start using >= operator. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: compiler_args generator produced incorrect setting I'm using `compiler_args` generator in one of my projects and suddenly found this at the end of `conanbuildinfo.args`: ``` -D_GLIBCXX_USE_CXX11_ABI=1 - s t d = c + + 1 z ``` This only occured after updating to 1.2 and setting `cppstd`. Some kind of UTF-16 mismatch? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: add error report upload capability for url errors As part of the repo.continuum.io to repo.anaconda.com transition, add HTTP errors to the auto-uploaded error reports so that we have a heads-up on any problems. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: When extending, `build` should replace `image` and vice versa Currently, if a service with `build` is extended by a service that sets `image`, the resulting configuration will have both options, resulting in an error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub: Flow Control does not work as expected. The flow control settings for the Cloud Pub/Sub subscriber should bound the number of unacknowledged messages outstanding to the callback at a time. However, it seems to have no effect on the client, where the number of outstanding messages always ends up being 10. OS type and version: Mac OS X 10.14.3, Debian Linux Python version: Python 2.7.10 on Mac, Python 3.6.5 on Linux google-cloud-pubsub version: 0.40.0 #### Steps to reproduce 1. Create a Cloud Pub/Sub topic and subscription 2. Publish many messages to the topic 3. Update the project name and subscription name in the code below. 4. Run the code. Expected behavior: Since the flow control settings have `max_messages` set to 2, only two \"Received Message\" lines should print at a time, with two \"Acking Message\" lines printing out 20 seconds later. Instead, 10 messages come to the callback at a time. Changing the value of `max_messages` has no impact on the number of messages sent to the callback. #### Code example ```py import time from google.cloud import pubsub_v1 project_name=<insert project name here> subscription_name=<insert subscription name here> subscriber = pubsub_v1.SubscriberClient() subscription_path = subscriber.subscription_path(project_name, subscription_name) def callback(message): print (\"Received Message\") time.sleep(20) print (\"Acking Message\") message.ack() flow_control = pubsub_v1.types.FlowControl(max_messages=2) subscriber.subscribe( subscription_path, callback=callback, flow_control=flow_control) print('Subscriber started for {}'.format(subscription_path)) while True: time.sleep(60) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub: Message publish_time return type unexpected I am working on a PubSub project and was a bit confused about the Message `publish_time`. I expected to get `datetime` per [the docstring](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/1acc8c22664229b6681ff91654932998e611e1c2/pubsub/google/cloud/pubsub_v1/subscriber/message.py#L152) for the method. Instead I got a `Timestamp` that apparently comes from protobuf types. I found there is even a [unit test](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/1acc8c22664229b6681ff91654932998e611e1c2/pubsub/tests/unit/pubsub_v1/subscriber/test_message.py#L49) that verifies that `publish_time` returns a `Timestamp`. Can we return `datetime`? Or should the docs just be updated to explain what is actually being returned? I'd prefer the former but wanted to ask before submitting a PR, given the inconsistency. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: get_*_nodes methods of DAGCircuit return inconsistent types <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> `get_op_nodes` returns a list of node_id integers or a list of tuple of (node_id, data). `get_gate_nodes` returns the same types as `get_op_nodes` `get_named_nodes` returns a list of node_id integers `get_2q_nodes` returns a list of node dictionaries `get_3q_or_more_nodes` returns a list of tuples of (node_id, node dictionary). ### What is the expected enhancement? For consistency perhaps these should all return the same data types. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumCircuit.decompose() should take which gate(s) to decompose <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? If find myself looking at circuits that look like this: <img width=\"928\" alt=\"Screen Shot 2019-08-05 at 6 28 05 AM\" src=\"https://user-images.githubusercontent.com/1249193/62458217-54d1a880-b74a-11e9-89ef-5bf7b2dcca8d.png\"> and I am always interested in seeing what the circuits look like in terms of cx and other gates. However, this requires doing: ```python from qiskit.transpiler import PassManager from qiskit.transpiler.passes import Unroller pass_ = Unroller(['u1', 'u2', 'u3', 'cx']) pm = PassManager(pass_) new_circ = pm.run(circ) ``` It would be nice if there was a `decompose_unitaries(basis)` method that did this for you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Wrong option value for local flow install + build Conan 1.2 ```python options = { \"foo\": [True, False], } default_options = ( \"foo=True\", ) def configure(self): if self.settings.os == \"Windows\" and \"foo\" in self.options: self.output.info(\"REMOVING foo\") del self.options.foo def build(self): self.output.info(\"OPTION: %s\" % self.options.foo) ``` Local flow: ```bash conan install .. conan build .. ``` Then in prints ``OPTION: True``. This needs to be fixed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Mismatch of displayed 'epoch' ## 🐛 Bug The display of epoch's number mismatches between the progress bar and the checkpoint indicator. I wonder this mismatch could confuse users. - progress bar: The number of epochs starts from 1. - checkpoint indicator: The number of epochs starts from 0. - metrics.csv also starts from 0. I think that to change checkpoint and metrics.csv causes a serious problem. So progress bar should be changed in my opinion. What do you think about it? ``` Epoch 32: 100%|██████████| 331/331 [00:05<00:00, 88.73batch/s, batch_idx=17, loss=1.148, train_batch_loss=1.02, v_num=0, val_loss=1.05] AINFO:root: Epoch 00031: val_loss reached 1.04545 (best 1.04545), saving model to /dummy/version_0/checkpoints/_ckpt_epoch_31.ckpt as top 1 {'loss': 1.022357702255249, 'train_batch_loss': 1.022357702255249, 'val_loss': 1.0454469919204712} Epoch 33: 5%|▌ | 18/331 [00:00<00:05, 61.06batch/s, batch_idx=17, loss=1.073, train_batch_loss=1.31, v_num=0, val_loss=1.05] ``` ### Environment - PyTorch Version : 1.3.1 - OS : macOS 10.14.6 - How you installed PyTorch : `pip install git+https://github.com/williamFalcon/pytorch-lightning.git@master --upgrade` - Python version : 3.7.3 - use CPU Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PulseBackendConfiguration cannot return control channels <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### What is the current behavior? There is no link between qubit index and channel index for ibmq backend, but `PulseBackendConfiguration` forces to put identical index to them and it doesn't return control channel with index larger than maximum qubit number. ### Steps to reproduce the problem ```python back_config.control(23) ``` raises `BackendConfigurationError` when 20 qubit backends is loaded. ### What is the expected behavior? It should not raise an error. ### Suggested solutions Replace argument name by `channel` and remove error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.54 test suite does not pass 0.54 introduces new test suite failures. After fixing #6868, the `test_templates` still does not pass because of cuda: ``` Using \"tmpqayyrpfm\" (name of current directory) as project name. Using \"tmpqayyrpfm\" (project name) as name of executable to build. Sample project created. To build it run the following commands: meson builddir ninja -C builddir The Meson build system Version: 0.54.0 Source dir: /tmp/tmpqayyrpfm Build dir: /tmp/tmpqayyrpfm/builddir Build type: native build Project name: tmpqayyrpfm Project version: 0.1 C++ compiler for the host machine: c++ (gcc 9.3.0 \"c++ (Arch Linux 9.3.0-1) 9.3.0\") C++ linker for the host machine: c++ ld.bfd 2.34 Host machine cpu family: x86_64 Host machine cpu: x86_64 meson.build:6:0: ERROR: No host machine compiler for \"tmpqayyrpfm.cu\" ``` The latter cuda test cases succeed, though. ``` Succeeded test: test cases/cuda/1 simple Succeeded test: test cases/cuda/2 split Succeeded test: test cases/cuda/3 cudamodule Succeeded test: test cases/cuda/4 shared Succeeded test: test cases/cuda/5 threads Succeeded test: test cases/cuda/6 std Succeeded test: test cases/cuda/7 static vs runtime Succeeded test: test cases/cuda/8 release Succeeded test: test cases/cuda/9 optimize for space Succeeded test: test cases/cuda/10 cuda dependency Succeeded test: test cases/cuda/11 cuda dependency (nvcc) Succeeded test: test cases/cuda/12 cuda dependency (mixed) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Recursive debugger doesn't restore trace function properly ``` Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.18.1 -- An enhanced Interactive Python. Type '?' for help. In [1]: 1/0 --------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) <ipython-input-1-9e1622b385b6> in <module> ----> 1 1/0 ZeroDivisionError: division by zero In [2]: %debug > <ipython-input-1-9e1622b385b6>(1)<module>() ----> 1 1/0 ipdb> debug print() ENTERING RECURSIVE DEBUGGER > <string>(1)<module>() (ipdb>) q LEAVING RECURSIVE DEBUGGER --Call-- > c:\\users\\quentin.peter\\appdata\\local\\continuum\\anaconda3\\lib\\cmd.py(157)postcmd() 155 return line 156 --> 157 def postcmd(self, stop, line): 158 \"\"\"Hook method executed just after a command dispatch is finished.\"\"\" 159 return stop ipdb> ``` It should go back at ``` > <ipython-input-1-9e1622b385b6>(1)<module>() ----> 1 1/0 ``` Not `postcmd` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Switch back to upstream dockerpty https://github.com/d11wtq/dockerpty/pull/19 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Unable to show logs from just a single service Running the latest build from master branch: When I try to `docker-compose logs MYSERVICE` I get the entire stack of services log output. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: latex drawer support for cregbundle In the spirit of https://github.com/Qiskit/qiskit-terra/issues/2797 it would be great if latex drawer add support for `cregbundle`. Take the following example: ```python from qiskit import * qr = QuantumRegister(3, 'q') cr = ClassicalRegister(3, 'c') circuit = QuantumCircuit(qr, cr) circuit.measure(qr, cr) circuit.draw('latex') ``` <img width=\"427\" alt=\"Screen Shot 2020-04-27 at 3 10 31 PM\" src=\"https://user-images.githubusercontent.com/766693/80410889-43f93200-8899-11ea-9bed-558804fa26c6.png\"> I suggest something like this: ``` circuit.draw('latex', cregbundle=True) ``` <img width=\"451\" alt=\"Screen Shot 2020-04-27 at 3 11 26 PM\" src=\"https://user-images.githubusercontent.com/766693/80410958-612e0080-8899-11ea-9cce-5005f5ef43b1.png\"> The latex code for that figure is: ```latex \\begin{equation*} \\Qcircuit @C=1.0em @R=1.0em @!R { \\lstick{ {q}_{0} : } & \\qw & \\meter & \\qw & \\qw & \\qw & \\qw\\\\ \\lstick{ {q}_{1} : } & \\qw & \\qw & \\meter & \\qw & \\qw & \\qw\\\\ \\lstick{ {q}_{2} : } & \\qw & \\qw & \\qw & \\meter & \\qw & \\qw\\\\ \\lstick{c:} & {/_{_3}} \\cw & \\dstick{0} \\cw \\cwx[-3] & \\dstick{1} \\cw \\cwx[-2] & \\dstick{2} \\cw \\cwx[-1] & \\cw & \\cw\\\\ } \\end{equation*} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Edit user config file programatically It would be great to be able to modify the user config file from Qiskit. Something like `user_config['default']['option'] = True`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DO NOT MERGE: logging synth (enums order only) This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/logging/artman_logging.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/logging-v2. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/logging_v2/proto/logging_pb2.py. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/logging_v2/proto/logging_metrics_pb2.py. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/logging_v2/proto/log_entry_pb2.py. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/logging_v2/proto/logging_config_pb2.py. synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Qt6 on Windows -> QtEntryPoint **Describe the bug** A very simple Qt 6 executable in the windows subsystem requires a WinMain function. Previously, this was provided by the static qtmain.lib, but, it seems, in Qt 6 it is provided by the new QtEntryPoint library. This is not heeded by the \"main\" keyword of the qt dependency(). **To Reproduce** Trivial main.cpp ``` #include <QApplication> #include <QPushButton> auto main(int argc, char * argv[]) -> int { auto Application = QApplication{argc, argv}; auto Button = QPushButton{\"Exit\"}; QObject::connect(&Button, &QAbstractButton::clicked, []() { QApplication::quit(); }); Button.show(); return Application.exec(); } ``` Trivial meson.build: ``` project('bug', 'cpp', default_options: ['cpp_std=c++17']) qt_dep = dependency('qt6', modules: ['Core', 'Widgets'], main: true) app = executable('app', 'main.cpp', dependencies: [qt_dep], win_subsystem: 'windows') ``` **Expected behavior** This should compile successfully. There are two options to solve this: 1. rely on the programmer to supply the 'EntryPoint' module in the dependency, and remove the 'main' argument for qt6 I.e. this works: `qt_dep = dependency('qt6', modules: ['Core', 'EntryPoint', 'Widgets'])` 2. leave the interface as is and improve the Qt6 dependency handling to map from `'main': true` to the 'EntryPoint' module It should be noted, that QtEntryPoint is not available on at least Ubuntu 22.04. So, the second options seems to be more portable, as it doesn't need OS-specific handling in the meson.build file. **system parameters** * no cross-compile * OS: Windows, MSVC and Qt 6.3.2, run inside MSYS2 * meson --version: 0.63.2 * ninja --version: 1.11.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Make sure that local installation works with installing airflow + all providers. We have to double-check that providers work and can be tested locally when installing airflow in a local virtualenv. After we've changed to separate providers and core package, pip install . will not install those packages, but with local -e it will likely work as providers packages are in the same folder. We still need to check how local virtualenv work when we install without -e though. Most likely solution will be dynamic selection of packages in setup.py based on the fact whether you are installing airflow from packages or sources. This is connected with #11464 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Cannot use `execute` with a `PassManager` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.15.1 - **Python version**: 3.8.5 - **Operating system**: Ubuntu 18.04 ### What is the current behavior? Providing any `PassManager` to the `execute` method will throw an exception as it fails the `_check_conflicting_arguments` call - this method fails if a backend (a _required_ argument) is provided. ### Steps to reproduce the problem ``` from qiskit.transpiler import PassManager from qiskit import QuantumCircuit, execute from qiskit.providers.aer import Aer qc = QuantumCircuit(2) qc.h(0) qc.measure_all() b = Aer.get_backend('qasm_simulator') job = execute(qc, b, pass_manager = PassManager()) ``` ``` Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/home/will/miniconda3/envs/dev/lib/python3.8/site-packages/qiskit/execute.py\", line 243, in execute _check_conflicting_argument(optimization_level=optimization_level, File \"/home/will/miniconda3/envs/dev/lib/python3.8/site-packages/qiskit/execute.py\", line 302, in _check_conflicting_argument raise QiskitError(\"The parameters pass_manager conflicts with the following \" qiskit.exceptions.QiskitError: 'The parameters pass_manager conflicts with the following parameter(s): backend.' ``` ### What is the expected behavior? This should not throw an exception since there are no conflicts here. ### Suggested solutions Remove `backend` from the list of arguments checked for conflicts. Or, alternatively, deprecate the use of the `pass_manager` argument (it is currently unusable anyway) to encourage users to use `PassManager.run()` and `assemble` instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Incorrect Properties in FakeBackends <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.11.1 - **Python version**: 3.6 - **Operating system**: Windows 10 ### What is the current behavior? All u2 and u3 gates in FakeYorktown have an error rate of 1.0 or 2.0. This leads to a complete depolarizing channel when used in basic_device_noise_model. FakeTokyo has error rates for some cx gate, that are not defined in the coupling map (and vice versa). FakeRueschlikon has no property file. ### Steps to reproduce the problem Simulate with basic_device_noise_model() or have a look at the .json files in https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/test/mock/backends ### What is the expected behavior? FakeYorktown should not define a complete depolarization after each single-qubit gate. FakeTokyo should have missing cx gates and cx error rates added to the coupling map/property file and/or unused cx gates should be consistently removed from the .json file. FakeRueschlikon should have a property file. ### Suggested solutions Regenerate the .json files. For FakeYorktown, I assume either an unit error (0.0002 becoming 2.0 or similar) or a snapshot of an incorrect calibration. FakeTokyo might have been build from different snapshots for the coupling map and the gate errors, thereby setting error rates for cx gates that are not defined in the coupling map and setting cx gates in the coupling map that have no error rate set. As a side note, historical calibration data for FakeBackends would be nice. :-) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: namespace changes broke `foo.*bar*?` syntax On master we now have: ``` In [2]: sys.*pt*? --------------------------------------------------------------------------- ValueError Traceback (most recent call last) /home/fperez/usr/lib/python2.7/site-packages/IPython/core/oinspect.pyc in psearch(self, pattern, ns_table, ns_search, ignore_case, show_all) 760 if name not in ns_table: 761 raise ValueError('invalid namespace <%s>. Valid names: %s' % --> 762 (name,ns_table.keys())) 763 764 #print 'type_pattern:',type_pattern # dbg ValueError: invalid namespace <user>. Valid names: ['alias', 'user_global', 'builtin', 'user_local'] ``` We should add a test for this form of call before fixing it, so that we're sure the bug doesn't come back. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Super slow ByT5 Tokenizer Hi, The ByT5 Tokenizer seems to be super slow compared to others (T5). See colab link below for example code. T5-small tokenizer:  By-T5-small tokenizer:  See colab code here: https://colab.research.google.com/drive/1nVxCerQon3hVA1RylZz7Be4N8LfjPgth?usp=sharing Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Move `qiskit.test.mock` to `qiskit.providers.fake_provider` and deprecate In #7437 we began the process of moving the features in `qiskit.test.mock` to `qiskit.providers.fake_provider`, by making them accessible at the new name. We can't issue deprecation warnings in Terra 0.20, but between 0.20 and 0.21 we should ensure that all our internal uses point to the new names, and then implement the deprecation warning. This is on hold until after Terra 0.20 has released. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add ECR/iSwap to list of gates handled by `Clifford.from_circuit` ### What should we add? `Clifford.from_circuit` has a list of 1- and 2-qubit Cliffords that it knows how to handle via updating the tableau directly. https://github.com/Qiskit/qiskit-terra/blob/1fb00e628a73f960980648cf9c4db0dfecc936ca/qiskit/quantum_info/operators/symplectic/clifford_circuits.py#L331 This list currently doesn't include some Clifford gates from the standard library like `ECR` and `iSwap`. For `iSwap`, this is not a problem because it's `.definition` is all Clifford, but `ECR` is defined in terms of `RZX` and so can't be converted directly. This partially covered by #9475 but requires falling back to the matrix form to reconstruct the tableau. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Environment values passed to Repo.clone_from() are not kept in the resulting repo r = Repo.clone_from(\"git@github.com:bpiotr/whatever_repo.git\", \"/tmp/repo\", env={\"key\": \"value\"}) r.git.environment() {} This is not what I expected when I called `Repo.clone_from` and documentation does not elaborate on the transient nature of the `env` here so IMHO this is a bug. BTW it costed me quite a while to figure out that `clone_from` actually uses `env` but any subsequent operations on the result needs it to have it set again. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add a not filter for schedules There is a filter for schedules (https://github.com/Qiskit/qiskit-terra/blob/a3ae434326aefbb19a7861518b4a4f1e05528fb1/qiskit/pulse/schedule.py#L232) It would be convenient if that returned the remainder of the schedule that doesn't satisfy the filter. This makes it easier to, e.g., shift a part of a schedule. `filter(schedule, blah) << 100 + filter(schedule, not blah)` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Proposal PIN: Storage & Execution # Status Proposed # Context Our current environments setup contains multiple classes, some of which can be deployed, others which can't. Moreover, the environment classes tightly couple _storage_ of a flow with _execution platform_ details. This leads to an unsatisfactory interface, and a spreading out of documentation. Additionally, it makes it hard to delineate which environments are appropriate for which use cases and also requires a large number of highly specific classes. # Decision Separate out the storage component of an environment into its own module and attach it to the flow as an argument. # Consequences All current environments will need to be reworked or removed and PIN-3 will be partially voided. @cicdw Let's keep this pin proposal here and update as needed Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: BasicAer qasm_simulator missing 'unitary' implementation <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.8 - **Python version**: 3.6 - **Operating system**: MacOS 10.14 ### What is the current behavior? The BasicAer qasm simulator has 'unitary' in its bases gates, but does not have an implementation for arbitrary unitaries leading to an exception for any circuit that contains them. ### Steps to reproduce the problem ```python from qiskit import QuantumCircuit, ClassicalRegister, QuantumRegister from qiskit import execute, BasicAer from qiskit.quantum_info.operators import Operator # Add to a circuit qr = QuantumRegister(1) cr = ClassicalRegister(1) circ = QuantumCircuit(qr, cr) circ.append(Operator([[0, 1], [1, 0]]), [qr[0]]) circ.measure(qr, cr) backend = BasicAer.get_backend('qasm_simulator') job = execute(circ, backend) job.result().get_counts(0) ``` Raises `BasicAerError: 'qasm_simulator encountered unrecognized operation \"unitary\"'` ### What is the expected behavior? Circuit executes ### Suggested solutions I will put in a PR to add an implementation of arbitrary unitaries to the BasicAer simulators. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Issue in develop: \"conan upload zlib/1.2.8#package_id\" doesn't work anymore Caused by https://github.com/conan-io/conan/pull/5817 Add test and fix. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Print URI to HTML coverage report from coverage-html target Once the `coverage-html` target has finished running successfully, it would be useful if it printed a `file:///` URI pointing to the index of the generated coverage report, so that it’s easy to open the report from a terminal window in a browser. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"service\" key in extending should be optional This is unnecessarily verbose: ``` base: ... web: extends: service: base ... ``` You should be able to just do this: ``` base: ... web: extends: base ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: GCSResultHandler deserialization attempts to load Google Client It turns out that _deserializing_ a `GCSResultHandler` (in the sense of marshmallow) attempts to initialize a google client. This results in errors when the deserialization occurs on the backend, causing certain task run states to error out when set. To see this in action, simply open an IPython session with `PREFECT__CLOUD__USE_LOCAL_SECRETS=false ipython` and then: ```python from prefect.serialization.result_handlers import GCSResultHandlerSchema schema = GCSResultHandlerSchema() schema.load({'bucket': 'nasa', '__version__': '0.5.4+113.g9310fc44', 'type': 'GCSResultHandler'}) # ClientError: [...] ``` We should ensure that deserializing these objects doesn't attempt to load clients. In this case, it's as simple as removing the `initialize_client` call from `__init__`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda clean -pt with empty package cache and non-root user I have a root miniconda install at /opt/anaconda. I ran ``` conda clean -pt ``` successfully as root then immediately tried running the same command as a lesser user. I got this error even though the package cache was empty: ``` Cache location: There are no tarballs to remove An unexpected error has occurred, please consider sending the following traceback to the conda GitHub issue tracker at: https://github.com/conda/conda/issues Include the output of the command 'conda info' in your report. Traceback (most recent call last): File \"/opt/anaconda/envs/anaconda.org/bin/conda\", line 5, in <module> sys.exit(main()) File \"/opt/anaconda/lib/python2.7/site-packages/conda/cli/main.py\", line 195, in main args_func(args, p) File \"/opt/anaconda/lib/python2.7/site-packages/conda/cli/main.py\", line 202, in args_func args.func(args, p) File \"/opt/anaconda/lib/python2.7/site-packages/conda/cli/main_clean.py\", line 340, in execute pkgs_dirs, warnings, totalsize, pkgsizes = find_pkgs() File \"/opt/anaconda/lib/python2.7/site-packages/conda/cli/main_clean.py\", line 166, in find_pkgs pkgs = [i for i in listdir(pkgs_dir) if isdir(join(pkgs_dir, i)) and OSError: [Errno 2] No such file or directory: '/home/user5/envs/.pkgs' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Running a service before `up` with networking enabled fails Steps to reproduce (against docker 1.9.0-rc3): 1. Create a new project, or set a new project name 2. Run any service with the new project name `docker-compose --x-networking run service bash` You'll get an error: `Cannot start container b631dcb1feea803af2d06471789fe3646a3b6f59af04bc771f66fd70137a024b: network networking not found` We need to create the network as part of `run` as well as `up` I think. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Installation messages are inconsistent if DESTDIR is present For install subdirectories it does not include DESTDIR in log message, but for files it does. This was tested on released 0.44 version and master. I believe correct behavior would be to show actual destination path, including DESTDIR. ``` $ env DESTDIR=/tmp/root ninja -C bd install -j1 ... [4/5] Installing files. Installing subdir /home/XXX/dev/bacs-project/bunsan/test/include/bunsan to /usr/local/include Installing subdir /home/XXX/dev/bacs-project/bunsan/common/include/bunsan to /usr/local/include Installing subdir /home/XXX/dev/bacs-project/bunsan/crypto/include/bunsan to /usr/local/include Installing bunsan/test/libbunsan_test.so.0.1.0 to /tmp/root/usr/local/lib/libbunsan_test.so.0.1.0 Installing bunsan/common/libbunsan_common.so.0.1.0 to /tmp/root/usr/local/lib/libbunsan_common.so.0.1.0 Installing bunsan/crypto/libbunsan_crypto.so.0.1.0 to /tmp/root/usr/local/lib/libbunsan_crypto.so.0.1.0 ``` Sidenote: I can fix this since I am already working on #2869, pending #2994. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CONAN_RUN_TEST: getenv available in recipes for a checker to run unit tests Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qiskit.converters needs doc examples <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Examples are needed for `circuit_to_dag`, `dag_to_circuit`, `circuit_to_instruction`, and `ast_to_dag` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: DagRuns are created beyond dag end_date To replicate, setup a simple dag as follows ``` python from datetime import datetime, timedelta from airflow import DAG from airflow.operators import DummyOperator delta = timedelta(hours=1) runs = 3 start_date = datetime(2015, 1, 1) end_date = start_date + (runs - 1) * delta dag = DAG( 'test-dag', start_date=start_date, end_date=end_date, schedule_interval=delta, ) task = DummyOperator( task_id='test-operator', owner='someone', dag=dag, ) ``` Refreshing the DagRuns view periodically reveals an endlessly increasing list of DagRuns even though and `end_date` was specified. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: U3 gates expand too wide in MPL drawer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? <img width=\"435\" alt=\"Screen Shot 2019-11-18 at 10 02 35 AM\" src=\"https://user-images.githubusercontent.com/1249193/69063521-a5fc6400-09ea-11ea-84f6-fb14c023b9fe.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: FunctionalPulse should wrap underlying callable <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? FunctionalPulse should wrap its underlying callable with `functools.wraps`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: LoadJobConfig.schema setter should accept None **Is your feature request related to a problem? Please describe.** There is no (public) way to unset a schema after you've set one. Even though the client doesn't distinguish between unset schema and an empty schema, the backend API does. **Describe the solution you'd like** When the set schema is `None`, remove the whole schema property from the underlying `_properties`. **Describe alternatives you've considered** We could always send `None` if a schema is empty, but this wouldn't be right, either. **Additional context** Needed for https://github.com/googleapis/google-cloud-python/pull/9064 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Handle Aer deprecation on AerPauliExpectation <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? AerPauliExpectation shows the following deprecate msg: ``` PendingDeprecationWarning: The `SnapshotExpectationValue` instruction will be deprecated in the future. It has been superseded by the `SaveExpectationValue` and `SaveExpectationValueVariance` instructions. ``` ### Steps to reproduce the problem ### What is the expected behavior? SaveExpectationValue / SaveExpectationValueVariance should be used instead. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: --yes not functioning for \"Clean\" Hi, either `conda clean -y --all` or `conda clean --yes --all` still prompt for a confirmation. conda 4.2.13 macOS 10.12.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse channel independent scaling <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Scaling parameter of pulse visualizer should be able to be independently applied to each pulse channel. Usually pi pulses or pi/2 pulses have small amplitudes, while pulses on control channels, e.g. CR pulses, have larger amplitudes. Independent scaling is convenient for visualizing those pulses simultaneously. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Syntax issues are confusingly attributed to the start of the clause rather than the offending atom's position **Describe the bug** When a syntax issue occurs, the parser is currently billing the start of a semantic structure, instead of the offending atom's position. This causes, for instance, mismatched `elif`s to be billed to the start of the `if` clause instead of the position of the actual broken `elif`. **To Reproduce** meson.build: ```meson project('test', 'c') CMDLINE_SELECT = [ 'help', 'apple', ] IGNORE_MESON_BUILTINS = [ 'help', ] MESON_OPTIONS = [ ] foreach flag: CMDLINE_SELECT if IGNORE_MESON_BUILTINS.contains(flag) continue elif MESON_OPTIONS.contains(flag) value = get_option(flag) if value != 'unset' features.set(flag, value) endif elif error('Unhandled option @0@'.format(flag)) endif endforeach ``` **Expected behavior** Compilation will fail, but it should bill line 24 and not 17: ``` meson.build:17:26: ERROR: Unknown statement. ``` **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? **Native** * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) **Windows 10 21H2** * what Python version are you using e.g. 3.8.0 **3.10.7** * what `meson --version` **1.0.1** * what `ninja --version` if it's a Ninja build **1.10.2.git.kitware.jobserver-1** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Flow default result handler persists on incompatible storage option change ## Description If a Flow is initialized then has its storage option changed the default result handler still persists: ```python @task def task1(): return \"bad\" with Flow(\"my-flow\") as flow: task1() flow.storage = Docker(...) flow.register(...) ``` The default result handler of the flow will remain as the `LocalResultHandler` because the default is only populated at initialization https://github.com/PrefectHQ/prefect/blob/master/src/prefect/core/flow.py#L165 I'm not 100% sure this is classified as a bug but it is definitely undesirable behavior. There is an incompatibility of the default result handler and this storage option. I think a simple check that would either change or raise a warning will suffice. ## Expected Behavior I expect the default result handler to be removed since the Local Result Handler will not work with this storage type. ## Reproduction Register the flow above from the Description section. ## Environment `0.9.0` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] conan_build_info `--skip-env` flag behaves counterintuitively The [`--skip-env` flag is True by default](https://github.com/conan-io/conan/blob/d42ec055d459489c184b160cafbd3f200ceb6d41/conans/build_info/command.py#L83). This means the `--skip-env` arg must be added to **not** skip the capturing of env vars. I think either the default value or the name of the arg should be changed to avoid confusion. ### Environment Details (include every applicable attribute) * Operating System+version: Windows 10 * Compiler+version: n/a * Conan version: 1.20.4 * Python version: 3.7.3 ### Steps to reproduce (Include if Applicable) run `conan_build_info --v2 create buildinfo.json --lockfile=conan.lock` and env info is **not** captured. run `conan_build_info --v2 create buildinfo.json --skip-env --lockfile=conan.lock` and env info is captured Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Implement PyTorch and/or TensorFlow sequence classification architectures for causal language models # 🚀 Feature request The architecture `GPT2ForSequenceClassification` was added in #7501 in PyTorch. It would be great to have it in TensorFlow (cf. issues #7622), but it would also be great to have it for other causal models: ~OpenAI GPT~, ~CTRL~ (PR opened @elk-cloner), ~TransfoXL~ (PR opened @spatil6) Below is a list of items to follow to make sure the integration of such an architecture is complete: - Implement `XXXForSequenceClassification` in `modeling_xxx.py` or `TFXXXForSequenceClassification` in `modeling_tf_xxx.py - Test that architecture in `tests/test_modeling_xxx.py` or `tests/test_modeling_tf_xxx.py` - Add that architecture to `__init__.py` and ` docs/source/model_doc/xxx.rst`. Taking a look at the code changes in #7501 would be a good start. A very good first issue to get acquainted with the library and its architectures! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Import Qiskit gives NumPy error due to misaligned array <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master (NumPy 1.15.1) - **Python version**: - **Operating system**: Pi ### What is the current behavior? Trying `import qiskit` on a fresh install gives the following error: ```python ~/berryconda3/lib/python3.6/site-packages/qiskit_terra-0.9.0-py3.6-linux-armv7l.egg/qiskit/quantum_info/synthesis/two_qubit_decompose.py in decompose_two_qubit_product_gate(special_unitary_matrix) 105 # extract the left component 106 temp = np.kron(np.eye(2), R.T.conj()) --> 107 special_unitary_matrix.dot(temp, temp) 108 L = temp[::2, ::2] 109 detL = L[0, 0]*L[1, 1] - L[0, 1]*L[1, 0] ValueError: output array is not acceptable (must have the right datatype, number of dimensions, and be a C-Array) ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions It appears that the `temp` matrix to be stored is not c-aligned. This is not surprising given that the decomposition routines use eigensolvers that are fortran based and return f-aligned NumPy arrays. The suggestion is to just do something like `temp = special_unitary_matrix.dot(temp)` instead. The matrix is 4x4 so not so worried about a copy here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Extra U3 gates inserted into circuits by ConsolidateBlocks pass <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? These two decompositions should be the same: ```python import numpy as np from qiskit import * q = QuantumRegister(2) c = ClassicalRegister(2) qc = QuantumCircuit(q, c) qc.cz(q[0], q[1]) qc.barrier(q) qc.cu1(np.pi, q[0], q[1]) cz_circ = transpile(qc, None, basis_gates=['u1', 'u2', 'u3', 'id', 'cx']) cz_circ.draw() ``` <img width=\"675\" alt=\"Screen Shot 2019-05-14 at 3 49 57 AM\" src=\"https://user-images.githubusercontent.com/1249193/57680341-64ce6600-75fb-11e9-9f44-beb6159e6490.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Having trouble downloading from osx-64 on Travis CI _From @jakirkham on June 14, 2016 20:46_ Seems we are now having issues downloading on packages on Travis CI. See the snippet below and this [log](https://travis-ci.org/conda-forge/apache-libcloud-feedstock/jobs/137608834#L369-L376). Note none of the packages below are on conda-forge (there is `python`, but not 2.7). So, this seems to be a `defaults` channel issue. Log snippet below. ``` BUILD START: apache-libcloud-0.18.0-py27_1 Using Anaconda Cloud api site https://api.anaconda.org Fetching package metadata ....... WARNING: Could not find any versions of conda-build in the channels Solving package specifications .... Error: Packages missing in current osx-64 channels: - python 2.7* - setuptools ``` Also, see these PRs for examples - https://github.com/conda-forge/apache-libcloud-feedstock/pull/3 - https://github.com/conda-forge/colorlog-feedstock/pull/4 - https://github.com/conda-forge/python-feedstock/pull/20 cc @msarahan @danielfrg @frol @jjhelmus @vamega _Copied from original issue: Anaconda-Platform/support#45_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Using hasattr for trait_names instead of just looking for it directly/using __dir__? This issue just came up with IPython 2.0-dev (appears to not be an issue for IPython 1.0) where our DictWrapper object raised KeyError on bad `__getattr__` (which screws up `hasattr`). It's a badly behaved object, but it's been around for a while. We're going to fix this in 0.13, which we're releasing soonish, but this probably affects a number of versions. https://github.com/pydata/pandas/issues/5182 I'm not clear why defining a `__dir__` method isn't enough, but a simple fix would be to go the EAFP route and just try to do it in try/except rather than doing the `hasattr` check. I'm sure there are other places where this could be an issue cc @d10genes who pointed out the problematic interaction with IPython 2.0-dev. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: utility to build an asset sensor from a software-defined asset * By default, it would trigger whenever the upstream assets are updated. Will need to figure out how this works when there are multiple upstream assets - AND or OR? * If the assets are partitioned, it would trigger the corresponding partition in the downstream assets when the corresponding partitions in the upstream assets are updated. Relevant requests: - https://dagster.slack.com/archives/C01U5LFUZJS/p1659067359346519 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: mesontest isn't flushing stdout? I'm using `ninja test` with a gitlab runner for CI. When the runner builds the code, I see the output get updated live. When the tests run, the output doesn't get flushed to the screen until after they are done - about 30 min worth of tests. My guess is that `mesontest` isn't flushing it's stdout and it's being buffered by the system. When the current test finishes, I'll rerun with `mesontest.py` changed to `#!/usr/bin/env python3 -u` which should force unbuffered stdout. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Bug in SVN is_pristine Conan 1.12.3 The user warning regarding `is_pristine` not being implemented on svn versions prior to 1.9 is a little confused! See below when I use it with svn 1.7.14: ``` UserWarning: SVN::is_pristine for SVN v1.7.14 (less than 1.9) is not implemented, it is returning not-pristine always because it cannot compare with checked out version. \" checked out version.\".format(self.version, SVN.API_CHANGE_VERSION)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add gcc 9.2 to default list of compilers gcc 9.2 is released, so we can add it to the default list of compilers that conan recognizes. Checked vs. conan v1.18.2 on macOS 10.14.6 To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Widgets: skip intermediate callbacks during throttling Suppose you have a slider, with a callback function (`interact`) that takes 2 seconds to display a plot (intensive calculations). If you move the slider for a few seconds, many `on_change` callbacks will be called successively. The throttle queue becomes longer and longer, the widget goes through many changes, and you have to wait dozens of seconds before the widget stops updating. In this case, shouldn't the intermediate steps be killed _before_ they are processed, so that only the most recent callbacks in the queue stay alive? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson setup fails to report relevant pkgconfig error **Describe the bug** When dependency `d1` is found by pkgconfig but its transitive dependency `d2` isn't, meson displays output as if `d1` is missing with no mention to `d2` anywhere. **To Reproduce** Below example is for building `fontconfig` (where `d1` is `freetype2` and `d2` is `zlib`) Setup command `PKG_CONFIG_PATH=<freetype_path> meson setup --wrap-mode=nofallback <fontconfig_src>` outputs: ``` [...] Run-time dependency freetype2 found: NO (tried pkgconfig) [...] ../fontconfig-2.14.1/meson.build:32:2: ERROR: Dependency 'freetype' is required but not found. A full log can be found at meson-logs/meson-log.txt ``` and relevant bits from `meson-log.txt`: ``` [...] Called `/usr/bin/pkg-config --modversion freetype2` -> 1 Run-time dependency freetype2 found: NO (tried pkgconfig) [...] ../fontconfig-2.14.1/meson.build:32:2: ERROR: Dependency 'freetype' is required but not found. ``` Now if you run the command printed on `meson-log.txt` you will see the actual error: ``` $ PKG_CONFIG_PATH=<freetype_path> /usr/bin/pkg-config --modversion freetype2 Package zlib was not found in the pkg-config search path. Perhaps you should add the directory containing `zlib.pc' to the PKG_CONFIG_PATH environment variable Package 'zlib', required by 'freetype2', not found ``` **Expected behavior** Output should include failed pkg-config command output. Actual missing package in this example is `zlib` but it is not present in either `meson setup` output or `meson-log.txt`. Debugging this requires recreating the build environment and executing a pkg-config command just to see an error message that meson could have displayed instead of omitting. **system parameters** `meson --version` is `0.64.0` (latest) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Improve/hide `failed with initial frozen solve. Retrying with flexible solve` ### Checklist - [X] I added a descriptive title - [X] I searched open requests and couldn't find a duplicate ### What is the idea? I often see this message when installing packages with conda: Solving environment: failed with initial frozen solve. Retrying with flexible solve. The message is: - quite difficult to understand: what is a frozen/flexible solve? - seems alarming. While as far as I understand, it indicates that conda couldn't solve my request (e.g. install numpy=1.0.0) with the current package versions available in my environment and that it has to upgrade/downgrade/remove some of them to find a solution. conda anyway lists the changes it has to make, if any, to the users when it asks for confirming the install. I suggest two alternative improvements: - Improving the error message to make it more understandable and not alarming, with e.g. `Solving environment: found that changes to the current set of installed packages are required.` - Or, only show this message in verbose mode Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: non json output on root clone I understand that cloning root env is probably a not very good idea... but even then with the json flag, we get this non json output ``` $ conda create -n rootclone --clone root --json` The following packages cannot be cloned out of the root environment: - conda-build-2.0.2-py35_0 - conda-4.2.13-py35_0 ... (valid Json output) ``` Possible fixes according to @kalefranz - Send that output to stderr - Just eat that output - Please fill in with your suggestion ... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda install --no-deps still installing deps when installing tarball When running the following command: `conda install --no-deps ./matplotlib-1.4.0-np18py27_0.tar.bz2` You would assume that no dependencies are installed, but conda seems to install the dependencies anyway. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Bug in autotokenizer some open source models such as falcon. ### System Info I want to get the sentence difference and use autotokenizer a falcon model 40B and 7B but usually, I receive an attribute error bug: model 'signal' has no attribute 'SIGALRM'.  @younesbelkada @ArthurZucker @Rocketknight1 ### Who can help? _No response_ ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ''' from transformers import AutoModelForCausalLM, AutoTokenizer tokenizer = AutoTokenizer.from_pretrained(\"tiiuae/falcon-40b-instruct\") model = AutoModelForCausalLM.from_pretrained(\"tiiuae/falcon-40b-instruct\") '''  ### Expected behavior Give me a method to get the word embeddings using sentence transformers or autotokenizer open source models such as falcon or LLMA2. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Refresh Airflow UI **Description** As the Airflow 2.0 is coming nearer it would be awesome to **refresh** the Airflow WebUI. By this it mostly means: - using some \"modern colors\" (how about Airflow logo palette?) - fixing some padding/spacing - and other small HTML / CSS touches **Use case / motivation** The main point is to **refresh** the look, not to rewrite the Web UI. **Related Issues** Apache Airflow brand book: https://cwiki.apache.org/confluence/display/AIRFLOW/Brandbook I'm far away from being a frontend expert but removing the \"Airflow green\" gives a good impression I think: <img width=\"2560\" alt=\"Screenshot 2020-09-14 at 10 45 22\" src=\"https://user-images.githubusercontent.com/9528307/93226956-2b1fe900-f774-11ea-9b6a-52579f4109c5.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson CMake dependency lookup ignores CMAKE_PREFIX_PATH after recent changes After upgrading from 0.49.2 to 0.50.1, my build which relies on a CMake dependency lookup started failing to find the dependency. By using `git bisect` on the Meson repo I found that the lookup starts failing with [this PR](https://github.com/mesonbuild/meson/pull/4914), specifically [this commit](https://github.com/mesonbuild/meson/pull/4914/commits/cdc338b74337e29c903bb73b61dc6f22877208e7) (cc @mensinda). I've also tested on 0.51.0 and master and the problem persists. As per that PR, Meson now checks if the expected CMake modules exist before actually invoking CMake, except I believe it fails to consider all the places CMake itself would look. Specifically, as I understand it, CMake looks in the paths of the [`CMAKE_PREFIX_PATH`](https://cmake.org/cmake/help/latest/variable/CMAKE_PREFIX_PATH.html) environment variable, which I believe is automatically set by my dependency handling system and was key to finding the dependencies when I used 0.49.2. In newer versions, Meson bails out and never gives CMake the chance to run and check those paths. I can seemingly work around this by configuring with `-Dcmake_prefix_path=$(echo \"$CMAKE_PREFIX_PATH\" | tr : ,)`, but this feels a bit redundant. It's unclear to me whether it's intended design, given that Meson is happy to read other env vars like CXX/LDFLAGS without passing them through `-D` flags, for example. Previously, Meson's CMake support was really \"plug and play\" and didn't require any thought beyond what would make CMake itself work in the normal way, and I think it would be ideal to preserve that property. Let me know if you need any more specific details. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.storage.bucket.Bucket.upload_file defaults 'key' to None The API cannot do anything useful with the default: either it should be a required argument, or else the method should do something sensible if it is not passed. E.g., one might crack the last element of the filename off and use that as a default key. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Trainer: Support scheduler that reduce LR on loss plateau. # 🚀 Feature request The HuggingFace Trainer currently only supports learning rate schedulers where the learning rate follows a fixed trajectory. Schedulers that adapt the learning rate to the state of the training procedure are (as far as I know) not supported. As en example, take [ `ReduceLROnPlateau`](https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.ReduceLROnPlateau.html) from `torch.optim.lr_scheduler`. This scheduler reduced the learning rate when a given metric is stuck on a plateau. In its `step` method, this scheduler requires an input. This input, typically the validation metric, is used to decide whether or not to decrease the learning rate. This behaviour could be supported by giving the scheduler access to the training/validation metrics. This would most likely involve changing [this piece of code](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/trainer.py#L1468). I believe that [`TrainerState`](https://huggingface.co/docs/transformers/v4.17.0/en/main_classes/callback#transformers.TrainerState) holds the training/validation metrics in its `log_history` attribute. If the scheduler would have access to `TrainerState`, it would be easy to create a 'stateful' scheduler. ## Motivation This change would allow user to easily use more complex learning rate schedulers together with the `Trainer` class. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [REGRESSION] `conan info` does not work correctly with 1.17.0 After upgrading Conan from `1.16.1` to `1.17.0`, `conan info` command stopped working. Here is the output for one package with Conan v1.16.1: ``` $ conan info AndroidNdk/r20@microblink/stable AndroidNdk/r20@microblink/stable ID: 743cf0321be3152777da4d05247a66d1552e70a2 BuildID: None Remote: microblink=http://artifactory.microblink.com/artifactory/api/conan/conan-local URL: https://developer.android.com/ndk/downloads/ Recipe: Cache Binary: Cache Binary remote: microblink Creation date: 2019-06-18 11:00:55 ``` The same command with Conan `v1.17.0` gives the following: ``` conan info AndroidNdk/r20@microblink/stable ERROR: AndroidNdk/r20@microblink/stable: 'options.enable_testing' doesn't exist Possible options are [] ``` I haven't given any option to `conan info`, so where does it get it from? Furthermore, if same command is given from empty folder, then it works. My guess is that it is somehow related to executing this command from folder that contains `conan.lock` for completely different package (which does have `enable_testing` option). Now, why does `conan info` read lockfile even if `--lockfile` option is not given. I've tried removing the `conan.lock` file, and then something even weirder happens: ``` $ rm conan.lock [dodo@knight-rider: Debug]$ conan info AndroidNdk/r20@microblink/stable ERROR: Missing lockfile in: /my/current/folder/containing/cmake/cache/and/conan/installation/for/different/package ``` However, deleting file `graph_info.json` from current folder makes `conan info` work, however I do not want to do that - I am not interested for information about conan package installed in current folder (if I were, I would call `conan info /path/to/conanfile.py`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: BackendConfiguration fails validation if backend supports pulse <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**:0.8.0 - **Python version**3.6.6 - **Operating system**:OSX ### What is the current behavior? If a backend sets `open_pulse=true` in its configuration Qiskit will raise a validation error when creating a `BackendConfigurationSchema` ### Steps to reproduce the problem Create a backend with `open_pulse=true` set in its configuration. ### What is the expected behavior? Should not fail. ### Suggested solutions Allow `open_pulse=true` to be valid. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Convert 12-1 and 6-1 en-de models from AllenNLP https://github.com/jungokasai/deep-shallow#download-trained-deep-shallow-models + These should be FSMT models, so can be part of #6940 or done after. + They should be uploaded to the AllenNLP namespace. If stas takes this, they can start in stas/ and I will move them. + model card(s) should link to the original repo and paper. + I hope same en-de tokenizer already ported. + Would be interesting to compare BLEU to the initial models in that PR. There is no ensemble so we should be able to reported scores pretty well. + **Ideally** this requires 0 lines of checked in python code, besides maybe an integration test. Desired Signature: ```python model = FSMT.from_pretrained('allen_nlp/en-de-12-1') ``` Weights can be downloaded with gdown https://pypi.org/project/gdown/ ```bash pip install gdown gdown https://drive.google.com/uc?id=1x_G2cjvM1nW5hjAB8-vWxRqtQTlmIaQU ``` @stas00 if you are blocked in the late stages of #6940 and have extra cycles, you could give this a whirl. We could also wait for that to be finalized and then either of us can take this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: pyreadline version dependency not correctly checked Installing IPython on windows with `python setup.py install` and pyreadline 1.5: <pre> C:\\code\\dev_trees\\ipython [main-master]> ipython Python 2.6.5 (r265:79096, Mar 19 2010, 21:48:26) [MSC v.1500 32 bit (Intel)] Type \"copyright\", \"credits\" or \"license\" for more information. IPython 0.13.dev -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. Traceback (most recent call last): File \"C:\\Python26\\Scripts\\ipython-script.py\", line 9, in <module> load_entry_point('ipython==0.13.dev', 'console_scripts', 'ipython')() File \"C:\\Python26\\lib\\site-packages\\ipython-0.13.dev-py2.6.egg\\IPython\\frontend\\terminal\\ipapp.py\", line 409, in launch_new_instance app.start() File \"C:\\Python26\\lib\\site-packages\\ipython-0.13.dev-py2.6.egg\\IPython\\frontend\\terminal\\ipapp.py\", line 383, in start self.shell.mainloop() File \"C:\\Python26\\lib\\site-packages\\ipython-0.13.dev-py2.6.egg\\IPython\\frontend\\terminal\\interactiveshell.py\", line 290, in mainloop self.interact(display_banner=display_banner) File \"C:\\Python26\\lib\\site-packages\\ipython-0.13.dev-py2.6.egg\\IPython\\frontend\\terminal\\interactiveshell.py\", line 346, in interact hlen_b4_cell = self.readline.get_current_history_length() AttributeError: 'module' object has no attribute 'get_current_history_length' </pre> I see that `setup.py` `requires` pyreadline >= 1.7.1, iff `setupext.check_for_readline()` returns False. However, in my case, it returns True because the function does not check the version, and I have version 1.5. I wasn't sure how best to put the version dependency into the function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Invalid XML generated in testlog.junit.xml with \\x07 in test output **Describe the bug** I was running tests with meson and the output of one of my tests contains special character `\\x07`. When I run testlog.junit.xml through xmllint, I get an error saying: `testlog.junit.xml:11045: parser error : PCDATA invalid Char value 7` I think we should use the right escape characters so that the output is valid XML. **To Reproduce** I wrote a simple meson.build file to reproduce this issue. The code in the file is: ``` project('tutorial', 'c') test('mytest',find_program('python'), args: ['-c','print(u\"Test\\x07\")']) ``` I then ran `meson setup`, followed by `ninja test` to run it and generate the `testlog.junit.xml` file. Then, running: `xmllint builddir/meson-logs/testlog.junit.xml` outputs an error message: ``` builddir/meson-logs/testlog.junit.xml:2: parser error : PCDATA invalid Char value 7 e name=\"mytest\" classname=\"tutorial\" time=\"0.06694579124450684\"><system-out>Test ``` **Expected behavior** I think the character should be correctly escaped so that the output is valid XML. **system parameters** OS: MacOS Monterey (12.1) meson --version 0.61.1 ninja --version 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: can't configure inline plot in qtconsole This problem exists in ipython 3.0.dev (git master), but not in ipython 2.1. Has the configuration system changed in 3.0? Suppose I have the following lines in my ~/.ipython/profile_default/ipython_qtconsole_config.py ``` python c.IPythonWidget.font_size = 20 c.InlineBackend.rc = {'font.size': 18, 'figure.figsize': (9.0, 6.0)} ``` If I start ipython by $ ipython qtconsole --pylab=inline then IPythonWidget.font_size is correctly handled but InlineBackend.rc is ignored. ipython 3.0 (git master) matplotlib 1.5 (git master) MacOSX 10.8.5 / Python 2.7.2 (Apple) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Feature request: IFFT Hi there! I'm finding Jax to be very useful in my work, but a new project (spectral Gaussian process stuff) requires me to differentiate through both FFT and IFFT operations. It is possible to express IFFT in terms of FFT, but it would be cleaner to just have an IFFT primitive, I think. Thank you! edit: also, vmap support would be very helpful as well. Also for people from the future, here is an implementation using FFT only: ```python from typing import Optional, Sequence def ifftn( a: np.ndarray, s: Sequence[int] = None, axes: Sequence[int] = None, norm: Optional[str] = None, ) -> np.ndarray: \"\"\"Compute the n-dimensional inverse Fourier transform. Args: a: Input array. s: Shape of the output. axes: Axes over which to compute the IFFT. norm: Normalization mode, one of ``None`` or ``\"ortho\"``. Returns: The n-dimensional IFFT of ``a``. \"\"\" if s is not None: raise NotImplementedError if norm is not None: raise NotImplementedError n = np.prod(np.array(a.shape)[axes]) return (1 / n) * np.conj(np.fft.fftn(np.conj(a), axes=axes)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %cpaste doc error: Magics ARE supported `%cpaste?` claims \"IPython statements (magics, shell escapes) are not supported (yet).\" But at least magics apparently are! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PauliExpectation warning given unexpectedly When running the following test https://github.com/Qiskit/qiskit-nature/blob/01ec334a18fbcf2368765dfd2d522e116da9de0e/test/algorithms/ground_state_solvers/test_groundstate_eigensolver.py#L334 it prints this message unexpectedly to me. `Measured Observable is not composed of only Paulis, converting to Pauli representation, which can be expensive.` In looking it seems to be when the expectation is taken of the aux_operators. This is a ListOp of PauliSumOps i.e. a List of a number of different operators like dipole X, num particles etc of which an expectation is computed against the result state of VQE to measure these. Now at the time of writing this test is failing to meet the final result. That's a different problem than the above but in looking at that is when I saw this message appearing Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: 0.8.2 calls backward on '_GeneratorContextManager' ## 🐛 Bug 0.8.2 calls backward on '_GeneratorContextManager' and crashes training. 0.8.1 works correctly. my `training_step` returns `{'loss':loss, 'log':{'learn_rate':self.lr}}` ``` Traceback (most recent call last): File \"/opt/conda/lib/python3.6/site-packages/torch/multiprocessing/spawn.py\", line 20, in _wrap fn(i, *args) File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/distrib_data_parallel.py\", line 538, in ddp_train self.run_pretrain_routine(model) File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/trainer.py\", line 1100, in run_pretrain_routine self.train() File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/training_loop.py\", line 370, in train self.run_training_epoch() File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/training_loop.py\", line 452, in run_training_epoch batch_output = self.run_training_batch(batch, batch_idx) File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/training_loop.py\", line 630, in run_training_batch self.hiddens File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/training_loop.py\", line 804, in optimizer_closure model_ref.backward(self, closure_loss, optimizer, opt_idx) File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/core/hooks.py\", line 189, in backward loss.backward() AttributeError: '_GeneratorContextManager' object has no attribute 'backward' ``` ### Expected behavior backward is called on the loss and training runs correctly Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: document lax.axis_index to get mapped element index from axis name Hello JAX team, First of all, thanks a lot for cool JAX. This is a great tool. This issue contains a question about your plans regarding `pmap` and a feature request. What `pmap`ed function receives as an input, is that a slice of input array or a full array? What happens in case of nested `pmap`s? Guess JAX traces a function and runs copies of it on sharded chunks of an input array. If so, that would super useful to have access to an index of that shard, that would allow encoding more complex algorithms. Otherwise, it still would be great to have an access to the shard index. <details><summary>Example</summary> <p> ```python @partial(pmap, axis_name='rows') @partial(pmap, axis_name='cols') def f(x): # Q: When the code is running, what the `x.shape` actually is? # # Dummy example of how to get shard id: # shard_row_id = __global_axis_name__[\"rows\"] # shard_col_id = __global_axis_name__[\"cols\"] # # Do something smart with it! E.g. process tensor in `chess` like style - blacks are positive, whites are negative. pass ``` </p> </details> Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Difference between `logit_scale` initialisation in Transformers CLIP and the original OpenAI implementation. I tried another training code based on the OpenAI'CLIP version: I found a difference at logit_scale between them. Does it mean temperature parameter? Is it the reason for loss rising? huggingface transformers' CLIP: ``` self.logit_scale = nn.Parameter(torch.ones([])) ``` OpenAI CLIP: ``` self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: fetch_data() should return a core iterator See: [https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/bigquery/google/cloud/bigquery/query.py#L363][1] ```python def fetch_data(...): \"\"\"... :returns: ``(row_data, total_rows, page_token)`` ... \"\"\" ``` I would expect it to return some kind of [Iterator](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/core/google/cloud/iterator.py) to be consistent with the other cloud APIs. [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/2d9c109211331c6cfc59a2a9acbda4c4e3609509/bigquery/google/cloud/bigquery/query.py#L363 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support ulimit options Now that Docker 1.6 supports ulimit options, it would be nice to have this as an option for containers managed by compose, similar to `mem_limit`, `cpu_shares`, etc. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Should meson specifiy -release for DLang projects with the `plain` buildtype? Right now meson doesn't specify `-release` on the compiler command line when compiling with the `plain` buildtype. This is problematic, since the `-release` flag doesn't do unwanted optimizations distros want to avoid, it disables asserts, quoting the LDC docs: `-release | Disables asserts, invariants, contracts and boundscheck` [0]. Since distros usually use the `plain` buildtype, but don't want debug asserts, contracts (input validation for functions, also via asserts) etc. in their binaries it'd make sense to specify `-release` even with the `plain` buildtype IMHO. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] [develop2] Order new hook_ hooks Alphabetically, so at least there is an order defined for all hooks found in the cache. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose $(docker-machine config default) up Fails. docker and docker-compose handle arguments differently. `docker-compose $(docker-machine config default) up`causes an error. (see below) and `docker-compose $(docker-machine config default | xargs) up` works. joe@jsd-mbp ~ $ docker-compose $(docker-machine config default) -f docker-compose.yml up [2.2.3] Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"compose/cli/main.py\", line 58, in main File \"compose/cli/main.py\", line 106, in perform_command File \"compose/cli/command.py\", line 33, in project_from_options File \"compose/cli/docker_client.py\", line 36, in tls_config_from_options File \"site-packages/docker/tls.py\", line 47, in **init** docker.errors.TLSParameterError: Path to a certificate and key files must be provided through the client_config param. TLS configurations should map the Docker CLI client configurations. See https://docs.docker.com/engine/articles/https/ for API details. docker-compose returned -1 joe@jsd-mbp ~ $ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Regression in conda 4.3.33 regarding build features It seems that `conda 4.3.33` installs packages that have a build feature when installing any package that has the same build feature. From a fresh miniconda, with conda pinned at `4.3.32`: ```sh scorlay@mbp ~]$ conda install cryptopp -c QuantStack -c conda-forge Fetching package metadata ............... Solving package specifications: . Package plan for installation in environment /Users/scorlay/miniconda3: The following NEW packages will be INSTALLED: cling-patches: 1-0 QuantStack cryptopp: 5.6.5-cling_0 QuantStack [cling] ``` With `conda 4.3.33` ```sh [scorlay@mbp ~]$ conda install cryptopp -c QuantStack -c conda-forge Fetching package metadata ............... Solving package specifications: . Package plan for installation in environment /Users/scorlay/miniconda3: The following NEW packages will be INSTALLED: clangdev: 5.0.0-cling_1 QuantStack [cling] cling-patches: 1-0 QuantStack cryptopp: 5.6.5-cling_0 QuantStack [cling] icu: 58.2-0 conda-forge libiconv: 1.15-0 conda-forge libxml2: 2.9.7-0 conda-forge llvmdev: 5.0.0-cling_1 QuantStack [cling] ``` The only package tracking the `cling` build feature is `cling-patches`. Notice in the second case that `clangdev` gets installed while it is not a dependency. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Sqrt(X) and C-Sqrt(X) gates We should add these two gates. The first one is the current native hardware gate that is tuned up (a.k.a X90p or RX(pi/2) although I think there's a global phase difference). The second one gives more efficient oracles via better Toffolis. Let's call them SX and CSX for now (although V and CV also appear in the literature). Then we should try to replace all usages of U2 with the SX gate (conjugated by RZ), which would put us on a path towards https://github.com/Qiskit/qiskit-terra/issues/4106. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Tensorboard logging in multi-gpu setting not working properly? Hi there :) I have a question (that may be an issue with the code or just my ignorance). (b.t.w. I am using the latest version, pytorch-lightning==0.4.9) If I set the trainer `trainer = Trainer(experiment=exp, gpus=[0])` I can see the corresponding logging (scalars and hyperparameters) in Tensorboard. If I change it to distributed training (keeping the rest of the code unchanged) : ` trainer = Trainer(experiment=exp, gpus=[0,1], distributed_backend='ddp')` The Tensorboard logging stops working at least for scalars and hyperparameters, I see nothing except the experiment name. In both cases 'exp' is a Experiment instantiated like this: ` exp = Experiment(save_dir=/SOME/PATH, name=NAME, version=VERSION, description=DESCRIPTION)` This picture illustrates the problem.  In the picture the red arrows point to the \"distributed\" experiment, with no drawing in the chart. The other two (the ones that appear in the chart) are the very same, except than the run in single GPU. Am I missing something or do I need to add extra configuration to make the logging work in multi-gpu with the ddp setting? Or is it a bug? Thank you! :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: i18n: allow to use keywords in i18n.merge_file() It needed for libpeas-based plugin systems and another plugin systems, which relies on keyfile-based configs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Extra blank line needed in multi-line Thanks for the all the fast fixes so far. This is really minor, so feel free to punt, but it has been tripping me up a little. In 5.0, if a function contains a return statement, it takes 1 extra line to close the multi-line block compared to previous behavior. Note that if that function (or more realistically, an `if` block) doesn't end in a `return`/`pass`, then the old behavior persists. Let me know if these examples aren't clear. #### 4.x ``` In [3]: def f(a): ...: return 5 ...: ``` #### 5.0b2 ``` In [10]: def f(a): ...: return 4 ...: ...: In [11]: def f(a): ...: a = 5 ...: ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Create UndefinedJinjaVariablesRule to ease upgrade to 2.0 This issue is part of #8765 ## Rule Create `UndefinedJinjaVariablesRule` which corresponds to > Prior to Airflow 2.0 Jinja Templates would permit the use of undefined variables. They would render as an empty string, with no indication to the user an undefined variable was used. With this release, any template rendering involving undefined variables will fail the task, as well as displaying an error in the UI when rendering. entry in UPDATING.md. Introduced in #11016 This rule should check if any of the jinja templates use undefined variables. This might not be always possible, as this might involve the dynamic generation of some context variables, but likely we can at least print some warning or \"double-check this\" statements. ## How to guide To implement a new rule, create a class that inherits from `airflow.upgrade.rules.base_rule.BaseRule`. It will be auto-registered and used by `airflow upgrade-check` command. The custom rule class has to have `title`, `description` properties and should implement `check` method which returns a list of error messages in case of incompatibility. For example: https://github.com/apache/airflow/blob/ea36166961ca35fc51ddc262ec245590c3e236fb/airflow/upgrade/rules/conn_type_is_not_nullable.py#L25-L42 **Remember** to open the PR against `v1-10-test` branch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: HfArgumentParser doesn't recognize new list type hint syntax Since Python 3.9 we can use generic types as type hints (e.g. `list[str]` instead of `typing.List[str]`), see also [PEP 585](https://www.python.org/dev/peps/pep-0585/). Currently this does not seem to work with the `HfArgumentParser`, but using the old `typing.List[str]` works. Minimal example for an arguments data class: ```python @dataclass class Args: my_boring_argument_list: typing.List[str] # works my_cool_argument_list: list[str] # fails ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Allow for different \"Spins\" We should allow for pre-built applications to be distributed that do not depend on the JupyterLab Python package (and its server extension). All that is needed to accommodate this is a separate Python package that exposes a function that takes a notebook app, a config directory and a prefix and adds the appropriate handlers. The package will also include an `index.html` template. An application author would use the main JupyterLab package to build its assets, and the app launcher to launch the application. The main JupyterLab package will use the app launcher in its server extension, and also include its built assets. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Cleanup duplicated \"credentials can not sign\" error Context: https://github.com/GoogleCloudPlatform/google-cloud-python/pull/2998#discussion_r100650121 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for `Expr` to `DAGCircuit.substitute_node_with_dag` Similar to `DAGCircuit.compose`, we need to ensure that the mapping of conditions and targets works with the general `Expr` format of classical values. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Boolean function parser We need a way to express Boolean functions compactly (e.g. f(x1,x2) = x1^x2), without resorting to exponential descriptions. Right now we only do things like truth table descriptions using exponential arrays (in synthesis algorithms like graysynth and libraries like FourierChecking). Some tools for this exist as opensource like RevKit and the Tweedledum library. Then we can also have synthesis algorithms for these that do not rely on synthesis of diagonal operators, and use those for synthesizing FourierChecking, Forrelation, HiddenShift, etc. etc. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Create \"new --template\" for Autotools. Like https://github.com/conan-io/conan/pull/10760/files but for Autotools. Tests using it, even with windows subsystems. Better study if a predefined layout is convenient. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BQML `get_model` snippets tests are failing https://github.com/googleapis/google-cloud-python/pull/8049#issuecomment-494463181 Appears that there's a new field in the response message. I thought protobuf was supposed to ignore unknown fields, but maybe that's not the default. I'll see if I can get a fix today to the Python client. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: \"limit_train_batches\" not receiving float value <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug error: argument --limit_train_batches: invalid int value: '0.3' ### To Reproduce Just put any float value after '--limit_train_batches' or '--val_check_interval' I am using the latest master branch. 0.9.rc14 I think this issue is related to the fix of #2943 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: CmdDef from_defaults does not add buffer to channels. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**:master - **Python version**: - **Operating system**: ### What is the current behavior? Command definition is built with a buffer of 0 for channels. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Add the defaults buffer to the channels when building the CmdDef. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Make ConanApiAuthManager and RestClient concurrent https://github.com/conan-io/conan/pull/5856 is failing. The problem is that the auth-restclient layer is not designed for concurrency, and it has a single instance of user, remote, remote.url, and auth-tokens for all the calls. It is necessary to implement this feature to unblock the concurrent uploads. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add valac.find_library Vala library (`.vapi`) names don't always match the pkg-config name, and sometimes the C library doesn't even have a pkg-config file so we need a `valac.find_library()` to be able to find those. Related to #687. I'm planning on working on this, and I think we should get this in for 0.36, so I thought I'd file an issue for it too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Examples][Flax] AttributeError: 'DataTrainingArguments' object has no attribute 'test_file' ## Description While running run_summarization_flax.py with local files, currently we have only two DataTrainingArguments, one for training and another for validation file still we are validating test_file which is producing an error ``` Traceback (most recent call last): File \"transformers/examples/flax/summarization/run_summarization_flax.py\", line 808, in <module> main() File \"transformers/examples/flax/summarization/run_summarization_flax.py\", line 352, in main if data_args.test_file is not None: AttributeError: 'DataTrainingArguments' object has no attribute 'test_file' ``` ## Environment info - `transformers` version: 4.9.0(master branch) - Platform: TPU VM - Python version: 3.9 - PyTorch version (GPU?): - Tensorflow version (GPU?): - Using GPU in script?: - Using distributed or parallel set-up in script?: ### Who can help @sgugger, @patil-suraj ### Possible Fix: Either we can add test_file argument or remove test file validation section https://github.com/huggingface/transformers/blob/7d6285a921a23c06169e2d90c94faa0d92d00d78/examples/flax/summarization/run_summarization_flax.py#L352-L354 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Add git hooks for updating js @fperez suggested adding a directory of git hooks like in the notebook (https://github.com/jupyter/notebook/tree/master/git-hooks) so that pulling or merging will automatically rebuild the js and update the server extension. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: add 'QueryJob.estimates_bytes_processed' property See [API ref](https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs#statistics.query.estimatedBytesProcessed). Read-only, based on the `statistics.query.estimatedBytesProcessed` field. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG? hstack/vstack/column_stack no longer accept generators As reported by @ilayn over in https://github.com/numpy/numpy/issues/12262: > There are other backwards incompatible changes for hstack and column_stack which were explicitly accepting generator expressions but now they don't. > > Xref : scipy/scipy#9405 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: mpl drawer: unitary gate looks messy for 1 qubit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? If I add unitary gates to the circuit, they show up fine in the `mpl` drawer except for the 1-qubit case. The single-qubit case should also not print the full matrix, and just do a box labeled \"unitary\". ```python from qiskit import QuantumRegister, QuantumCircuit from qiskit.quantum_info.random import random_unitary qr = QuantumRegister(4) qc = QuantumCircuit(qr) U1 = random_unitary(2) U2 = random_unitary(4) U3 = random_unitary(8) U4 = random_unitary(16) qc.append(U1, [qr[0]]) qc.append(U2, [qr[0], qr[1]]) qc.append(U3, [qr[0], qr[1], qr[2]]) qc.append(U4, [qr[0], qr[1], qr[2], qr[3]]) qc.draw(output='mpl') ```  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cross compilation doesn't support the \"--strip\" option cross_file.txt: c = '/opt/br_mips-2013.11/usr/bin/mips-linux-gcc' cpp = '/opt/br_mips-2013.11/usr/bin/mips-linux-g++' ar = '/opt/br_mips-2013.11/usr/bin/mips-linux-ar' strip = '/opt/br_mips-2013.11/usr/bin/mips-linux-strip' [host_machine] system = 'linux' cpu_family = 'mips' cpu = 'mips' endian = 'big' Without the \"-strip\" option it works fine: meson --cross-file ../../../../lte1160/cross_file.txt . $d --prefix=$HOME/tmp/meson ninja-build -C build ninja-build -C build install With the \"-strip\" option it doesn't work: meson --cross-file ../../../../lte1160/cross_file.txt . $d --prefix=$HOME/tmp/meson --strip ninja-build -C build ninja-build -C build install Stripping target 'libkt_dmc_cm-1.0.so' Could not strip file. Stdout: Stderr: strip: Unable to recognise the format of the input file `/home/fabiopo/tmp/meson/lib64/libkt_dmc_cm-1.0.so' FAILED: install '/usr/bin/python3' '/home/fabiopo/packages/meson/meson.py' '--internal' 'install' '/ssd/lte/app-2/tcommon/src/oma-dm/kt_lib/build/meson-private/install.dat' ninja: build stopped: subcommand failed. I'm doing something wrong? It is expected? Any suggestion on how to fix it? Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Fail to send class definitions from interactive session to engines namespaces Here is a [sample notebook](http://nbviewer.ipython.org/4471180/) to demonstrate the issue. Please note that I don't get any unpickling error message when calling: ``` rc[:]['AClass'] = AClass ``` While @minrk is reporting a `DummyModule` `AttributeError` in this [SO question](http://stackoverflow.com/questions/14184621/how-to-work-with-interactively-defined-classes-in-ipython-parallel). I will see if I can come up with a pull request for a `can_class` / `uncan_class` along the lines of [this gist](https://gist.github.com/4470212). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: How to pass include directories / CFlags to gtkdoc-scangobj ? I'm probably not understanding something here, but I need to pass additionnal flags to scangobj: * `include_directories` to specific dirs of the project * `link_with` helper/static libraries of the project It seems that the only way to do that is to `declare_dependency` with those infos and pass this dependency to `gnome.gtkdoc`. Isn't there an easier way ? EDIT: That doesn't work, because `meson.source_root()` is a relative path, and the scanobj call is equivalent to: cd devel-docs/libgimp && gtkdoc-scangobj --cflags=... --ldflags=... That seems to break the path to `meson.source_root() == ../.`. Or am i missing something ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] CMakeToolchain always enables CMAKE_POSITION_INDEPENDENT_CODE ### Steps to reproduce (Include if Applicable) Using the CMakeToolchain generator, run `conan install` and disable `fPIC` option. The generated CMakeToolchain file will contain `CMAKE_POSITION_INDEPENDENT_CODE=ON`. This is obviously due to a typo fixed by #9752 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: up --force-recreate fails with tmpfs on volume you can reproduce this with thoses 2 files: ``` version: '2' services: test: build: . tmpfs: /mnt/tmpfs ``` ``` FROM alpine:3.4 VOLUME /mnt/tmpfs CMD /bin/sh ``` then run: * `docker-compose up -d` this one works * `docker-compose up -d --force-recreate` this one fails with this message: > Recreating tmp_test_1 ERROR: for test Cannot create container for service test: Duplicate mount point '/mnt/tmpfs' ERROR: Encountered errors while bringing up the project. version of Docker : Docker version 1.12.2, build bb80604 and tested with 2 versions of docker compose: * docker-compose version 1.8.0, build f3628c7 * docker-compose version 1.9.0-rc4, build 181a4e9 At first I thought it was the same issue as docker/docker#23301 but if this was still an issue the first `docker-compose up -d` should have failed too. So I'm not sure if this is a problem with docker-compose or with docker itself as I don't really know what docker-compose does on `--force-recreate` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: [hparams] save_hyperparameters doesn't save kwargs ## ❓ Questions and Help when I use hyperparemeters like docs: ``` class LitMNIST(LightningModule): def __init__(self, layer_1_dim=128, learning_rate=1e-2, **kwargs): super().__init__() # call this to save (layer_1_dim=128, learning_rate=1e-4) to the checkpoint self.save_hyperparameters() ``` model checkpoint doesn't save args in kwargs. But kwargs is important. Args such as `num_frames, img_size, img_std ...` must be used in creating `dataloader`, but it will be tedious if writes them in `__init__` explicitly . it can make code clean if hides them in `kwargs`. Before I use `hparams`, it's ok. But now it's not recommended to use `hparams`, is there any good idea to deal with this problem? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: cmake_find_package_generator does not generate guards To help us debug your issue please explain: Ubuntu 16.04, conan 1.5.1, cmake 3.11.4: Using the cmake_find_package generator with a project that calls find_package multiple times on the same library is not safe because the generated find_package script does not guard against being called multiple times. Since the script generates targets, this will cause cmake to fail the build. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: mesonconf and meson should accept same flags `meson` takes `--prefix=/foo` `mesonconf` takes `-Dprefix=/foo` It would be nice for these to be consistent for both users and tools and for unknown ones to error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Task library: add Filter When working with mapped tasks, it's common to have one or more children tasks skip or fail (for any reason). Anticipating these non-success states can complicate users who want to reduce over the result of a map, because they need to set custom trigger settings on the reducing task as well as handle the non-success results (`NoResult` and `Exceptions`). A \"Filter\" task (open to any other name) would essentially be the following: ```python class Filter(Task): def __init__(self, **kwargs): super().__init__(trigger=all_finished, skip_on_upstream_skip=False, **kwargs) def run(self, mapped_result): return [r for r in mapped_result if not isinstance(r, (NoResult, Exception))] ``` And used like this: ```python numbers = [1, '2', 3] numbers_plus_one = plus_one.map(numbers) good_results = Filter()(numbers_plus_one) ``` good_results would return `[1, 3]` -- having filtered the map for only the useful tasks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: MSVC build fails owing to overly long build directory names So I'm building `gst-build` on Windows, with glib as a subproject. The build fails with the following error message: `[1/1857] Compiling C object subprojects/glib/gio/tests/gdbus-object-manager-example/subprojects@glib@gio@tests@gdbus-object-manager-example@@libgdbus-example-objectmanager@sha/meson-generated_.._gdbus-example-objectmanager-generated.c.obj. FAILED: subprojects/glib/gio/tests/gdbus-object-manager-example/subprojects@glib@gio@tests@gdbus-object-manager-example@@libgdbus-example-objectmanager@sha/meson-generated_.._gdbus-example-objectmanager-generated.c.obj cl @subprojects/glib/gio/tests/gdbus-object-manager-example/subprojects@glib@gio@tests@gdbus-object-manager-example@@libgdbus-example-objectmanager@sha/meson-generated_.._gdbus-example-objectmanager-generated.c.obj.rsp subprojects/glib/gio/tests/gdbus-object-manager-example/gdbus-example-objectmanager-generated.c: fatal error C1041: cannot open program database 'subprojects\\\\glib\\\\gio\\\\tests\\\\gdbus-object-manager-example\\\\subprojects@glib@gio@tests@gdbus-object-manager-example@@libgdbus-example-objectmanager@sha\\\\meson-generated_.._gdbus-example-objectmanager-generated.c.pdb'; if multiple CL.EXE write to the same .PDB file, please use /FS ` Turns out the problem is the overly long build directory paths here, exceeding the default 260 path limit. The build works fine if I use `c:\\build` as build directory instead. I understand why these paths might be needed in the flat layout case, but Meson knows that we don't use a flat layout here, so I think it shouldn't be using these long cluttery paths in this case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add a few `flow.visualize()` unit tests We should have a few tests just to make sure the colors work, etc. Adding this as a small, low priority issue for picking up whenever any of us need some added diversity of tasks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Convert `BIPMaping` transpiler pass into an external plugin ### What should we add? The [`BIPMapping` transpiler pass](https://qiskit.org/documentation/stubs/qiskit.transpiler.passes.BIPMapping.html) has been in a weird state since it's introduction. It is a standalone transpiler pass that is used for both the layout and routing stage but we never integrated it into `transpile` because it has an external dependency on `cplex` which is a proprietary software package that most people don't have access too.. Now that we've added an external plugin interface for transpiler stages (which was added in #8305) we have a better option for how to advertise and use the `BipMapping` pass. We can create an external package for the pass that contains the code of the transpiler pass and offers a plugin that cleanly integrates into the `transpile()` function. Basically the workflow for using the bip mapper would change to be `pip install qiskit-bip-mapper` (or whatever the package name we pick is) and then doing `transpile(qc, backend, layout_method=\"bip_mapping\")`. This make it easier for users to run and also separates the dependency on cplex into a separate package where we can more cleanly document the extra requirements around installing and/or purchasing a commercial license depending on the size of the circuits. Steps: - [x] Create a new package for the `BipMapping` pass - [x] Add layout plugin for the pass - [x] Deprecate `BIPMapping` pass in qiskit-terra after release of p Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: '_AsyncQuery.cancel' fails to update from returned resource E.g.: ``` python Traceback (most recent call last): File ... job.cancel() File \".../google/cloud/bigquery/job.py\", line 378, in cancel self._set_properties(api_response) File \".../google/cloud/bigquery/job.py\", line 262, in _set_properties self._scrub_local_properties(cleaned) File \".../google/cloud/bigquery/job.py\", line 1050, in _scrub_local_properties configuration = cleaned['configuration']['query'] KeyError: 'configuration' ``` The [docs for `job.cancel`](https://cloud.google.com/bigquery/docs/reference/v2/jobs/cancel#response) show that the job resource is in a `job` subkey of the response. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Enable ONNX export for `VisionDecoderEncoderModel` # 🚀 Feature request <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> As discussed on the [forums](https://discuss.huggingface.co/t/can-i-export-a-visionencoderdecoder-checkpoint-to-onnx/12885), it would be nice if one could export `VisionDecoderEncoderModel` classes using the `transformers.onnx` package. ## Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. --> It is currently not possible to export `VisionDecoderEncoderModel` classes (or vision models more generally), unless the end user is willing to write their own `OnnxConfig`. It might make sense to first explore what is involved in exporting ViT before tackling this more complex example. Looking at this a bit more closely, I can see that `transformers.onnx` currently has a tight integration with tokenizers (e.g. to generate dummy inputs), so some refactoring will be necessary to support other modalities. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: text drawer bug in drawing conditional multi-qubit gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Conditional versions of 2-qubit or 3-qubit gates are drawn incorrectly in the text drawer. The box is drawn on only one of the qubits, whereas it should be 2 or 3 qubits. ```python qr = QuantumRegister(3, 'qr') cr = ClassicalRegister(2, 'cr') circuit = QuantumCircuit(qr, cr) circuit.cz(qr[0], qr[1]).c_if(cr, 1) circuit.ccx(qr[0], qr[1], qr[2]).c_if(cr, 3) ``` ``` ┌────┐┌─────┐ qr_0: |0>─┤ Cz ├┤ Ccx ├ └─┬──┘└──┬──┘ qr_1: |0>───┼──────┼─── │ │ qr_2: |0>───┼──────┼─── ┌──┴──┐┌──┴──┐ cr_0: 0 ╡ ╞╡ ╞ │ = 1 ││ = 3 │ cr_1: 0 ╡ ╞╡ ╞ └─────┘└─────┘ ``` ### What is the expected behavior? The mpl and latex drawers draw these correctly:   Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: coupling_map.subgraph() creates extra nodes Trying to get a subgraph of this coupling map: ```py from qiskit.test.mock import FakeMumbai from retworkx.visualization import mpl_draw backend = FakeMumbai() cmap = CouplingMap(backend.configuration().coupling_map) mpl_draw(cmap.graph) ``` <img width=\"418\" alt=\"image\" src=\"https://user-images.githubusercontent.com/8622381/125465693-39b6c29f-bf4e-4399-8fac-7fa82acd0a50.png\"> If I use retworkx directly to get the subgraph on 9 nodes, it gives me this which is correct I think: ```py mpl_draw(cmap.graph.subgraph([0, 1, 4, 7, 10, 12, 15, 18, 17])) ```  But if I do the same using the CouplingMap API I get this. There are incorrect nodes added here: ```py cmap.subgraph([0, 1, 4, 7, 10, 12, 15, 18, 17]).draw() ```  @mtreinish says this is due to a difference in how networkx and retworkx implement `.subgraph()`. But I like the retworkx output because it numbers nodes as 0-k, and that is consistent with how coupling maps in qiskit are numbered (i.e. no \"holes\"). So I think something just needs to change here to remove the extra nodes. If we provide an option to keep the original node numberings, I'd be fine with that, but I'm not sure whether Qiskit can actually work with such a coupling map object. The best route I see is to remap the node numbers in the same order (smallest to 0, largest to k). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Setting log_format in config file results in error (and no format changes) Setting c.NotebookApp.log_format results in an error. The culprit is line 168 in config/application.py: ``` python _log_formatter = LevelFormatter(new, datefmt=self._log_datefmt) ``` Which should be: ``` python _log_formatter = LevelFormatter(new, datefmt=self.log_datefmt) ``` with no underscore before \"log_datefmt.\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Commit 1ea3ddc6 breaks the compile command Prior to commit 1ea3ddc6 the *compile_commands.json* output from the config phase looks like this: ``` \"command\": \"cc -Isrc/lib/libast/e416224@@ast@sta -Isrc/lib/libast -I../src/lib/libast -I. -I../ ``` I've omitted the subsequent args because they aren't relevant. With commit 1ea3ddc6 that same command looks like this: ``` \"command\": \"cc -Isrc/lib/libast/e416224@@ast@sta -Isrc/lib/libast -I../src/lib/libast -I -I../ ``` **Notice that `-I.` has become `-I`** This breaks our build because a dynamically constructed header placed in the build root dir is no longer found. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Watch mode to auto-compile extensions in active development First off, congratulations on JupyterLab. It's a great piece of software and I've loved working with it so far! I'm trying to build an extension not too different from https://github.com/jupyterlab/jupyterlab-google-drive. I'm having a hard time finding a good build process for rapid iteration on the extension and I've spend some time looking around for suggestions, but haven't found any. I set up an npm script which does a babel compile whenever my source changes, but I find I have to do the following each time I want to verify a change: 1. Kill `jupyter lab` process 2. Run `jupyter lab build` 3. Start `jupyter lab` process (opens a new tab) At this point, my extension changes are shown. I'm wondering if there is a watch mode I can run or some way to symlink my directory like `npm link` for example to make this process more seamless. Ideally without having to restart `jupyter lab` so I can keep working in my same tab. I'm happy to contribute docs or help set up a watch process if there isn't anything currently in place on either front. Thanks in advance. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Global Gradient calculation is turned off during validation step. If an error occurs during the validation step, the tradition calculation is turned off for the runtime, you have to either specifically enable it or restart runtime! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Issues with man pages I've run into issues with how ipython installs its man pages: - Since 0.13, the man pages are no longer gzipped when installed - I just wanted to check if this is intentional? - When installing ipython with Python 3.2, the man pages are not installed - is this normal? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Progress Bar for large model loading ### Feature request Add progress bars for large model loading from cache files. ### Motivation Most of the time, model loading time will be dominated by download speed. However, for very large models we will often first download the checkpoints, then during runtime simply load them from cache. For models like Bloom however, it can take upwards of 100 minutes to load the model into RAM. During this time, there is no feedback to the user, even with verbosity set to debug. This can be frustrating as the only way to check progress is by checking system utilisation through `top`. ### Your contribution Happy to help if I am pointed to the relevant file or files! I don't think the progress bar would need to be extremely accurate, just some indication that something is happening. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: objc freestanding sanitycheck failed Header stdio.h isn't available on the freestanding environment, https://github.com/mesonbuild/meson/blob/7b9c348102792030859ed0001a51416506a0a092/mesonbuild/compilers/objc.py#L44 https://en.cppreference.com/w/cpp/freestanding Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove underscore prefix from (almost) all files <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? As we are transitioning from relative imports to absolute imports: ```python from ._module import Class ---> from qiskit.module import _module ``` We are introducing code like: ```python circuit = _quantumcircuit.QuantumCircuit() ``` ... this code is telling me that I want a `QuantumCircuit` class from an internal/private `_module`, but QuantumCircuit is not internal nor private. The concept of internal classes has been diffused during all this time, and I don't think we have this concept anymore, at least not in the vast majority of the files. So in order to keep code cleaner, I'd suggest to remove underscore prefix from all the files that we have doubts about its domain and files we know they are meant to be used by other components (I'd say all of them). This is somewhat of a large change, mostly style related so I'm labeling this issue as `discussion` just in case someone has different views. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Merge task responds to a merge trigger ## Current behavior *Please describe how the feature works today* A merge task will run even if all upstream tasks are skipped. ## Proposed behavior *Please describe your proposed change to the current behavior* If there are no tasks proceeding, a merge task should be skipped as well. ## Example *Please give an example of how the enhancement would be useful* If I have an ETL process with 3 conditional Transform tasks that aren't met, the downstream Load dependency should be skipped, since none of its upstream Transform tasks were completed. A merge task with only skipped ancestors should not be run. If I have an upstream conditional that is not met, the downstream dependency should be considered as also not met. Trigger to be implemented (courtesy of @cicdw): ``` def merge_trigger(upstream_states): if all(state.is_skipped() for state in upstream_states): raise signals.SKIP(\"All upstreams skipped\") elif not all(state.is_successful() for state in upstream_states): raise signals.TRIGGERFAIL( 'Trigger was \"all_successful\" but some of the upstream tasks failed.' ) return True ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Uninformative error when saving notebook to HTML w/o pygments If you try to save your Notebook to HTML (or do \"print preview\") and pygments is not installed, you get a very unhelpful 500 error page. When I looked at stdout/err from notebook I see: ``` ERROR:tornado.access:500 GET /nbconvert/html/XXX.ipynb?download=false (XXX) 3.13ms referer=XXX WARNING:tornado.general:500 GET /nbconvert/html/XXX?download=false (XXX): Could not construct Exporter: No module named pygments.formatters ERROR:tornado.access:{ \"Accept-Language\": \"en-US,en;q=0.8\", \"Accept-Encoding\": \"gzip,deflate,sdch\", \"Connection\": \"keep-alive\", \"Accept\": \"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8\", \"User-Agent\": \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36\", \"Host\": \"XXXX:8888\", \"Referer\": \"XXXX.ipynb\", \"Cache-Control\": \"max-age=0\" } ``` The solution was to install `pygments`, but it would be nice if the HTML page said that rather than a 500 error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose up assumes --no-build It seems if I try to run docker-compose up with a yml that uses `build: .` and the image does not already exist, it acts like --no-build is passed. This is on version 1.3.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Option to change Ray's gridsearch scope # 🚀 Feature request It would be great if we can get more control over how Ray is selecting the best trial in a hyperparameter search. Currently, the default value for [`get_best_trial`](https://docs.ray.io/en/latest/tune/api_docs/analysis.html#ray.tune.ExperimentAnalysis.get_best_trial) is used here: https://github.com/huggingface/transformers/blob/7c5d79912a21880ce13d77881940458e90d98917/src/transformers/integrations.py#L299 namely `scope=\"last\"`. So for each trial, it will simply take the _last_ checkpoint of that trial, and use its performance to compare with the other trials. This is not always ideal as it may very well be that some trials converge sooner than other and than overfit, leading to poor evaluation scores in their last checkpoints. Fortunately, Ray allows other options, such as `\"all\"`, which takes the best checkpoint instead of the last, of each trial and compares those. ## Motivation Currently there is no way to pass this through to Ray from within `transformers` as I can tell, yet it is an important aspect of hyperparameter search. ## Your contribution I can work on this if requested, although I am still looking for input how to best tackle this. One could simply add an argument to TrainingArguments, e.g. `ray_scope`, and then change this line https://github.com/huggingface/transformers/blob/7c5d79912a21880ce13d77881940458e90d98917/src/transformers/integrations.py#L299 to ```python best_trial = analysis.get_best_trial(metric=\"objective\", mode=direction[:3], scope=trainer.args.ray_scope) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Deploy Conan develop branch on test.pypi.org To help us debug your issue please explain: Hi! My proposal here is return to use test.pypi.org (used until Conan 0.4.1) when merging a new PR into develop branch. I see no difficult installing Conan on my machine running `pip install .` but for who wants to install the latest version (non-stable) without git, it could be an good option. For example, bincrafters-package-tools is uploaded to test.pypi.org for every new change in master branch (we follow github flow), only tags are uploaded to pypi.org. That flow helped me to find many bugs, including missing files in the package. The version released could be incremental, using the suffix dev as well. Conan Version: ANY OS: ANY - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Audit Log for Connections/Variables update ### Description We have audit logs for major actions in Airflow except for Connection/Variables creation, update, and deletion ### Use case/motivation Connections and variables form the primary component of DAGs. Having a track of who changed what when will come in handy when troubleshooting ### Related issues _No response_ ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add tests and improve behavior for spaces in paths Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Update TaskFlow API example to use `@dag` decorator **Description** Update https://github.com/apache/airflow/blob/master/airflow/example_dags/tutorial_taskflow_api_etl.py tp use `@dag` decorator instead of leveraging context manager to make it more TaskFlow-y. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Cannot import RobertaPreTrainedModel ## Environment info I tried with both transformers 3.5.1 and 4.6.1. ### Who can help Maybe @julien-c since they contributed RoBERTa. ## Information I want to derive my own class from RobertaPreTrainedModel, but I cannot import that class like I can import e.g. BertPreTrainedModel or AlbertPreTrainedModel. More specifically, ```from transformers import BertPreTrainedModel``` and ```from transformers import AlbertPreTrainedModel``` works, but ```from transformers import RobertaPreTrainedModel``` returns `ImportError: cannot import name 'RobertaPreTrainedModel'`. Is this the intended behavior or could it be a bug? ## To reproduce Try `from transformers import RobertaPreTrainedModel` ## Expected behavior The RobertaPreTrainedModel class should be imported like it works for other transformers. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: error reporting still broken at 0.24 After updating to 0.24 to fix https://github.com/GoogleCloudPlatform/google-cloud-python/issues/3167 I'm still unable to report exceptions. Ubuntu xenial w/ Python 3.5.2 ```python client.report_exception(http_context=error_reporting.build_flask_context(flask.request)) ``` On google-cloud-error-reporting <0.23 the above line works fine. At 0.24 I get: ```python Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/cloud/error_reporting/client.py\", line 347, in report_exception Apr 1 15:52:51 user=user) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/cloud/error_reporting/client.py\", line 276, in _send_error_report Apr 1 15:52:51 self.report_errors_api.report_error_event(error_report) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/cloud/error_reporting/_gax.py\", line 75, in report_error_event Apr 1 15:52:51 ParseDict(error_report, error_report_payload) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/protobuf/json_format.py\", line 384, in ParseDict Apr 1 15:52:51 parser.ConvertMessage(js_dict, message) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/protobuf/json_format.py\", line 415, in ConvertMessage Apr 1 15:52:51 self._ConvertFieldValuePair(value, message) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/protobuf/json_format.py\", line 501, in _ConvertFieldValuePair Apr 1 15:52:51 raise ParseError('Failed to parse {0} field: {1}'.format(name, e))\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: virtualenv generator with `set -u` leads to unbound variable failure Conan 1.9.0, ubuntu 16.04 If a package sets env_info to a list (so that [tools.environment_append](https://docs.conan.io/en/latest/reference/tools.html?highlight=environment_append#tools-environment-append) will prepend it with a delimter, the virtualenv generator produces an assignment like: `PYTHONPATH=\".../release/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/python\":$PYTHONPATH` If there is no current value in that variable, and `set -u` is in effect, this will cause the shell to error out with `bash: PYTHONPATH: unbound variable` To fix this, the virtualenv generators should explicitly use a conditional expansion like ${PYTHONPATH:-}, that can substitute to nothing if the variable is unset (even with set -u, since this was explicitly requested). But since I think it would also be nice to not get a junk trailing delimiter when there's nothing to append, I suggest: `val1:val2${NAME+:$NAME}` Despite being a little fancy, `${VAR:-}` and `${VAR+}` are portable posix sh substitutions, not bashisms (see [section 26.2 Parameter Expansion](http://pubs.opengroup.org/onlinepubs/009695399/utilities/xcu_chap02.html#tag_02_06_02)) - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Implement Virtual Package Plugin Hook and Plugins ### Checklist - [X] I added a descriptive title - [X] I searched open requests and couldn't find a duplicate ### Why is this needed? #### Virtual Package Hooks An implementation of virtual packages via the plugin system would be a good use-case for the new plugin infrastructure, since it will enable other virtual packages to be able to be utilized without requiring direct changes to the `conda` codebase; we will need to create hooks for these first. #### Virtual Package Plugins [Virtual packages defined by conda](https://docs.conda.io/projects/conda/en/latest/user-guide/tasks/manage-virtual.html) can be implemented as core plugins under the `conda.plugins.*` namespace and registered directly in `conda.base.context.get_plugin_manager`. The virtual packages plugins will be shipped by default with `conda`, as an initial set of officially `conda`-developed plugins. ### What should happen? Hooks that enable virtual package plugins will be created in the [`plugins/__init__.py` file](https://github.com/conda/conda/blob/feature/plugins/conda/plugins/__init__.py). After that,`index.py` will be refactored to accommodate for usage of plugins (vs hard-coded virtual package detection), and we will develop separate plugin modules for our currently-supported virtual packages (_i.e._, Linux, CUDA, MacOS, Windows) which will live in the [plugins directory](https://github.com/conda/conda/tree/feature/plugins/conda/plugins). These will then get registered directly in `conda.base.context.get_plugin_manager` instead of via entrypoints. ### Additional Context This work is a continuation of the initial plugin implementation [here](https://github.com/conda/conda/pull/11435) (connected to issue https://github.com/conda/conda/issues/11112). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add automatic error report uploads Rather than asking users to report unexpected errors on the github issue tracker, offer to post the error to a private resource accessible by the conda core team. The posted content should be anonymous. It should only include the error stack trace and the contents of `conda info`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: logging basic configuration level: INFO vs. WARNING (usability with W&B) Thanks for the amazing package! I am having a great time using it. # Issue Recently, I have been playing around with the weights and biases (W&B) logging functionality and I noticed that I was getting a lot of logging messages in my jupyter notebook while training my model (every epoch I got new messages). When I looked into `logging.__init__.py`, the logging basic configuration was set with: `logging.basicConfig(level=logging.INFO)` However, that means a lot of INFO messages are being printed from W&B's use of the logger (e.g. when the RunManager modifies files). # Potential Solution To disable this, I switched the logging basic configuration in `logging.__init__.py` to: `logging.basicConfig(level=logging.WARNING)` Would this be a useful addition in general to the package or should I just keep this change local? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: resubmitted tasks doesn't have same session name If I understand correctly, a task gets a new msg_id when you call client.resubmit(msg_id). I noticed that the 'cloned' task seems to have a random session name. I would suggest to take over all cutomizable attributes: session, username, retries, after, ... in order to let the resubmitted task behave like the original one. One side effect for me would be to delete the original task after the resubmitted one took it's place. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Can't pass parameters to a Clock unless they have default values ## Description *A clear description of the bug* I would like to create a flow on a schedule, passing in default parameters. Currently this fails unless all parameters have default values. ## Expected Behavior *What did you expect to happen instead?* Passing parameters should be allowed even if they do not have defaults - we should be able to resolve the following example ## Reproduction *A minimal example that exhibits the behavior.* ```from prefect import task, Parameter, Flow from prefect.schedules import Schedule from prefect.schedules.clocks import CronClock @task def add(a, b): return a + b schedule = Schedule(clocks=[ CronClock( cron=f\"* * * * *\", parameter_defaults={ 'a': 1, } ) ]) with Flow('flow', schedule=schedule) as flow: a = Parameter('a') b = Parameter('b', default=1) result = add(a, b) flow.register() ``` ## Environment *Any additional information about your environment* *Optionally run `prefect diagnostics` from the command line and paste the information here* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add \"keep_permissions\" option to tools.get() A nice enhancement to the tools.get() high level wrapper function would be allowing the user to keep permissions when the unzip process happens. This is really useful when downloading compilers or other tools that need to be marked as executable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] compiler.base.runtime is not set based on build_type when using Visual Studio as the base compiler <!-- Please don't forget to update the issue title. Include all applicable information to help us reproduce your problem. To help us debug your issue please explain: --> Currently, `compiler.runtime` is implicitly set based on the `build_type` being used. When using `compiler=Intel` and Visual Studio for a base compiler, we expect `compiler.base.runtime` to be set based on the build_type as well. This is not the case, though, and it needs to be set explicitly on the command line or conditionally set directly in the recipe (which I do not think is recommended). There are easy workarounds to this, but it makes using the Intel compiler settings not as straight forward. ### Environment Details (include every applicable attribute) * Operating System+version: Windows 10 * Conan version: 1.21.0 * Python version: 3.7.3 ### Steps to reproduce (Include if Applicable) Start from a new bare recipe `conan new test/1.2.3 -b` Create a package from this bare recipe with `compiler=Intel`, `compiler.base=\"Visual Studio\"`, `build_type`, and compiler version settings `conan create . -s compiler=intel -s compiler.version=19 -s compiler.base=\"Visual Studio\" -s compiler.base.version=15 -s build_type=Release` The following error is received `ERROR: test/1.2.3: 'settings.compiler.base.runtime' value not defined` Meanwhile running with `Visual_Studio` as the compiler implicitly sets the runtime and succeeds `conan create . -s compiler=\"Visual Studio\" -s compiler.version=15 -s build_type=Release` > [settings] arch=x86_64 arch_build=x86_64 build_type=Release compiler=Visual Studio compiler.runtime=MD compiler.version=15 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Bloch Sphere Visualization doesn't do anything with non-GUI backends <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: latest master (but should effect released versions too) - **Python version**: 3.7 - **Operating system**: Linux ### What is the current behavior? When calling `qiskit.tools.visualization.plot_bloch_vector()` it unconditionally calls show() on the figure to get an interactive 3d visualization of the bloch sphere for the provided vector. However if you're using a non-GUI matplotlib backend this doesn't have a user visible effect. All that happens is that matplotlib will emit a warning like: `lib/python3.5/site-packages/matplotlib/figure.py:448: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.` This comes up particularly if running on a system that doesn't have X or a graphical interface installed. All that happens is the warning is displayed and the script exits without failure. ### Steps to reproduce the problem Call `qiskit.tools.visualization.plot_bloch_vector()` on a system with matplotlib configured with a non-GUI backend. ### What is the expected behavior? The visualization is saved to disk somewhere, or the function returns the PIL.image object (or something else that represents the visualization) ### Suggested solutions Add a filename flag and/or add a return for the function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: possible mistake in documentation Looking at description of the parameter \"decoder_input_ids\" in \"forward\" method of BartForConditionalGeneration/T5ForConditionalGeneration, I see following: BartForConditionalGeneration: decoder_input_ids - ... For translation and summarization training, decoder_input_ids should be provided. If no decoder_input_ids is provided, the model will create this tensor by shifting the !!INPUT_IDS!! to the right for denoising pretraining following the paper. T5ForConditionalGeneration: decoder_input_ids - ... To know more on how to prepare decoder_input_ids for pretraining take a look at T5 Training. If decoder_input_ids and decoder_inputs_embeds are both unset, decoder_input_ids takes the value of !!INPUT_IDS!!. Looks like there should be LABELS instead of INPUT_IDS. Thanks, @patrickvonplaten, @patil-suraj Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pubsub: clients emit pending deprecation warnings (See [Google Group](https://groups.google.com/forum/?utm_medium=email&utm_source=footer#!msg/cloud-pubsub-discuss/A53nuoc3Eb4/LH6gwaXfDgAJ) ) With the Python pubsub package v 0.39.0, a simple call to pubsub_v1.SubscriberClient() gives warnings from deep in Google code ``` publisher/client.py:89: PendingDeprecationWarning: The `channel` argument is deprecated; use `transport` instead. ... subscriber/client.py:83: PendingDeprecationWarning: The `channel` argument is deprecated; use `transport` instead. ... ``` This apparently incorrect channel is created inside Google code, e.g. `google.cloud.pubsub_v1.subscriber.client.Client#__init__` Although keeping ahead of deprecation can be challenging, Google's _own_ code should avoid warnings and do whatever Google says is the official way. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Cleanup stopped containers in docker agent Currently containers that finish aren't cleaned up, and will build up over time. We should make use of the `AutoRemove` option on `HostConfig` when starting a container to automatically delete containers after they've completed. This requires docker engine api version >= 1.25, which came out in Jan 2017 - given that it's been around for a few years I think we can apply this universally. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inverting a quantum circuit <!--- Provide a general summary of the issue in the Title above --> I can create a circuit for generating arbitrary quantum superposition with `initialize()` function. I know there is a call to `inverse()` function within the `initialize()`. So, it should be easy to do that (just do not execute that call to `inverse()`). But I cannot find a way to inverse a circuit I obtain from the `initialize()` nor for any quantum circuit that I have. ## Expected Behavior <!--- If you're describing a bug, tell us what should happen --> <!--- If you're suggesting a change/improvement, tell us how it should work --> Access to `inverse()` function, or, at least an example of using `CompositeGate` that supports operation to invert the gate. ## Current Behavior <!--- If describing a bug, tell us what happens instead of the expected behavior --> <!--- If suggesting a change/improvement, explain the difference from current behavior --> There seems to be no test case and examples of using `CompositeGate` from the `initialize()`. ## Possible Solution <!--- Not obligatory, but suggest a fix/reason for the bug, --> <!--- or ideas how to implement the addition or change --> ## Steps to Reproduce (for bugs) <!--- Provide a link to a live example, or an unambiguous set of steps to --> <!--- reproduce this bug. Include code to reproduce, if relevant --> 1. 2. 3. 4. ## Context <!--- How has this issue affected you? What are you trying to accomplish? --> <!--- Providing context helps us come up with a solution that is most useful in the real world --> ## Your Environment <!--- Include as many relevant details about the environment you experienced the bug in --> * Version used: 0.5.2 * Environment name and version (e.g. Python 3.6.1): Python 3.6.x * Operating System and version: MacOSX Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: no validity check on Target construction ### Environment - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is happening? It's possible to build a Target where the Instruction does not match the number of qubits it's being added to. ### How can we reproduce the issue? For example here I add a 1-qubit gate to a two-qubit tuple. ```py from qiskit.transpiler import Target, InstructionProperties from qiskit.circuit.library import RZGate from qiskit.circuit import Parameter θ = Parameter('θ') rz_props = { (0, 1): InstructionProperties(duration=0, error=0) } target = Target() target.add_instruction(RZGate(θ), rz_props, name='rz') ``` ### What should happen? raise Error ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Proposal: make upstream inputs have precedance over cached_inputs Currently, the `TaskRunner.get_task_inputs()` method will load upstream inputs, then overwrite that dict with any cached inputs on the task. I'd like to propose reversing that order, so first cached inputs are loaded, then upstream inputs overwrite them. Let's say task A runs and then task B wants to be retried. If I (manually) rerun task A, then my expectation would be that task B would use A's *new* result, not the old one that task B cached. In other words, while it's a useful and important Prefect feature that *B* does the caching of *A's* result, this is a case where that would go against my expectation, since B's cache no longer matches A's result. This isn't a fully baked recommendation, but I'd like to think through the above situation and see if it can/should be addressed. cc @cicdw Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] RuntimeWarning while using python_requires In Conan 1.8, I am getting RuntimeWarning while using python_requires: ``` conan export . demo/test /home/sun/.conan/data/MyBase/1.7/demo/test/export/conanfile.py:1: RuntimeWarning: Parent module 'MyBase/1' not found while handling absolute import from conans import ConanFile, CMake, tools /home/sun/.conan/data/MyBase/1.7/demo/test/export/conanfile.py:2: RuntimeWarning: Parent module 'MyBase/1' not found while handling absolute import import os,sys .. .. ``` My base conan file is: ``` from conans import ConanFile, CMake, tools import os,sys, _scm = { \"type\" : \"git\", \"url\" : \"auto\", \"revision\" : \"auto\" } class MyBase(ConanFile): .. .. ``` To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: initial_layout cannot be used in compile with circuits of differing qubit number <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? You can not use an `initial_layout` when circuits with differing numbers of qubits are input to compile. This is true even the circuits are smaller than the size of the layout passed, i.e. the layout is valid for the subset of qubits in the smaller width circuits. ``` q = QuantumRegister(3,'q') c = ClassicalRegister(3) qc = QuantumCircuit(q, c) qc.h(q[0]) qc.cx(q[0], q[1]) qc.cx(q[1], q[2]) qc.measure(q, c) q = QuantumRegister(2,'q') c = ClassicalRegister(2) qc2 = QuantumCircuit(q, c) qc2.h(q[0]) qc2.cx(q[0], q[1]) qc2.measure(q, c) layout = [None, None, (QuantumRegister(3, 'q'), 0), (QuantumRegister(3, 'q'), 1), (QuantumRegister(3, 'q'), 2)] backend = IBMQ.get_backend('ibmqx4') qobj = compile([qc, qc2], backend, initial_layout = layout) ``` `MapperError: 'initial_layout qubit q[2] not in input DAGCircuit'` ### Steps to reproduce the problem ### What is the expected behavior? Given that we allow compiling circuits with different widths, I would expect that we can supply initial_layouts to these circuits. If we are not allowing this, then terra should throw the proper warning before trying to compile the circuits. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: regression: mesa x86_64 -> x86 compilation broken with meson 0.48 Commit 16fa65730469dacbdb9374858c090fe59c1aa70c adds code that checks that if a compiled file is used as a generator that it is either native to the build_machine or there is an exe wrapper. There are some cases where the build machine can run host machine binaries without an emulation layer, such as when building x86 code on an x86_64 machine of the same OS. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose complains about invalid TLS configuration I am running Docker 1.11.2, and so far, everything is fine. The Docker engine is exposed via TCP, TLS is enabled. The certificate is a self-signed one, but so far it has always been working. E.g., if you run ``` $ docker ps ``` everything is fine and the running processes are shown. Now I tried to use docker-compose to start an application. This failed with the following error message: > TLS configuration is invalid - make sure your DOCKER_TLS_VERIFY and DOCKER_CERT_PATH are set correctly The same error happens if you provide the parameters `--tlscert` and `--tlskey` manually. The certificate contains the host name, so it should not be related to #3365. I have read multiple times that setting `CURL_CA_BUNDLE` to an empty value should help, but it didn't. I have experienced this behavior with docker-compose 1.7.0 and 1.8.0. Any ideas? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson incorrectly detects loop in CMake custom target **Describe the bug** If a CMake subproject contains a custom target in which the basename of the output file is the same as the basename of the input file, importing it into meson will incorrectly generate the following error: ``` meson.build:3:0: ERROR: Cycle in CMake inputs/dependencies detected. ``` Building the same project in CMake works as expected. **To Reproduce** * Clone the example repository at https://github.com/conte91/meson_cmake_cycle_issue * Run `meson build` **Expected behavior** The `test.txt` target is correctly detected to be an output file, depending on the input file at `subprojects/test_cmake/test.txt`. **system parameters** * Native build * Arch Linux * Python 3.8.1 * `meson --version` 0.53.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Release new storage client I need a new version of the storage client containing the IAM bits so I can write some samples. :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan virtualenv on Windows should generate shell script as well as .bat and .ps1 Hi, It's a fairly common usecase in Windows for people to develop software using bash shells such as git-bash, MSYS2, cygwin, etc. Right now, conan only generates environment scripts for CMD and powershell, although these terminals often are not the preferred choice. This means that users have to open a windows command prompt just to execute the programs they've built. It would be far more ideal to just generate the bash script which already gets generated in unix. I don't see this change really breaking anyone's workflow either, it would only make it easier to write software on windows using conan. Many thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Widget TextView Placeholder Mainly also a question to @jdfreder , Is there a way to have placeholder in text widget, especially when default value is empty string, it would be nice. I'm not familiar with widget infrastructure to find how to do it. Any advice appreciated ! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove opflow dependency in `EvolvedOperatorAnsatz` ### What should we add? The `EvolvedOperatorAnsatz` class still depends on opflow expectations, and is not compatible with the new primitive-based workflow. This WIP PR #7275 already proposes an alternative to replace `EvolvedOperatorAnsatz` with `EvolutionGates`, so it might be a good starting point to realize this task. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: formalize gate operands as Qubit objects <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently gates operate on qubits as a `(QuantumRegister, int)` tuple. To improve code clarity this could be formalized into it's own type. A simple solution would be just something like, ```from collections import namedtuple Qubit = namedtuple('Qubit', ['register', 'index']) # then you could do qr = QuantumRegister(5) q1 = Qubit(qr, 1) qc = QuantumCircuit(qr) qc.x(q1) if q1.register == qr and q1.index != 0: qc.h(q1) def my_gate(self, q): assert isinstance(q, Qubit) ``` Something more complex could do type checking. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: segment_sum primitives / advanced indexing in jax.ops.index_add Would it be useful to others (aside from me) to have better support of sorted and unsorted segment_sums? https://www.tensorflow.org/api_docs/python/tf/math/unsorted_segment_sum https://www.tensorflow.org/api_docs/python/tf/math/segment_sum In numpy one way to do unsorted segment sums is to sort then call np.add.reduceat, but this doesn't seem to be in jax or autograd: ``` >>> import jax.numpy as np np.add >>> np.add <function _one_to_one_binop.<locals>.<lambda> at 0x1430cdbf8> >>> np.add.reduceat Traceback (most recent call last): File \"<stdin>\", line 1, in <module> AttributeError: 'function' object has no attribute 'reduceat' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Installing any package fails (on one of my machines) (master) Master (`4.0.7.dev430+2b8b214`) again. I get: ``` Traceback (most recent call last): File \"/home/ilan/minonda/bin/conda\", line 6, in <module> sys.exit(main()) File \"/home/ilan/conda/conda/cli/main.py\", line 120, in main args_func(args, p) File \"/home/ilan/conda/conda/cli/main.py\", line 127, in args_func args.func(args, p) File \"/home/ilan/conda/conda/cli/main_install.py\", line 62, in execute install.install(args, parser, 'install') File \"/home/ilan/conda/conda/cli/install.py\", line 394, in install plan.execute_actions(actions, index, verbose=not args.quiet) File \"/home/ilan/conda/conda/plan.py\", line 555, in execute_actions inst.execute_instructions(plan, index, verbose) File \"/home/ilan/conda/conda/instructions.py\", line 133, in execute_instructions cmd(state, arg) File \"/home/ilan/conda/conda/instructions.py\", line 80, in UNLINK_CMD install.unlink(state['prefix'], arg) File \"/home/ilan/conda/conda/install.py\", line 1075, in unlink mk_menus(prefix, meta['files'], remove=True) TypeError: 'NoneType' object has no attribute '__getitem__' ``` This only happens on one of my machines. CC @kalefranz @mcg1969 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.load() fails to read empty archive created by np.savez() Try this: np.savez('nothing.npz') # OK np.load('nothing.npz') # error Loading fails: OSError: Failed to interpret file 'nothing.npz' as a pickle It should succeed (and give you an object with no arrays inside). Likewise for `savez_compressed()` (which also currently fails). I'm using NumPy 1.13.1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Re-generate library using tasks/synth.py This PR was created by autosynth. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Make GraphViz optional Following up on #101 -- I think GraphViz should be optional. Should we have a \"viz\" `extras` package in `setup.py` that includes bokeh and graphviz? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: support a commutative DAG. Opinions? In #1503, @godott raises, as I see it, a valid point. Many passes, as gate cancelation, could make a good use of commutative set. The question now is how to support it. Ideas? Opinions? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda 4.4.x does not prevent removal of conda dependencies from base environment? Some user tried to remove `pycosat` from within Navigator using conda 4.4.8 as reported on [this issue](https://github.com/ContinuumIO/anaconda-issues/issues/8563) It seems conda 4.4.x is allowing user to remove conda dependencies like `pycosat` which effectively leaves them in a broken state. I checked with 4.4.9 and 4.4.10 and it seems to be that this is still possible. I have tested on Mac, @jjhelmus tested on Linux. Need to check on windows Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: add support for other service account types Not just JWT certificate. Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Move YDocWebSocketHandler to Jupyter Server core ### Problem I think that the [YDocWebSocketHandler](https://github.com/jupyterlab/jupyterlab/blob/055099fa565f3589d8db38588678614fdb286023/jupyterlab/handlers/ydoc_handler.py) is not specific to JupyterLab and deserves to live in [jupyter-server](https://github.com/jupyter-server/jupyter_server) core. It is a generic websocket server that can talk to any websocket provider for the supported Y documents. JupyterLab is just one of them, but I can imagine e.g. a Python web client that would also have a websocket provider, such as [ypy-websocket](https://github.com/y-crdt/ypy-websocket/blob/39252430d79141ec7900cda8c291996da6aaf340/ypy_websocket/websocket_provider.py), to implement a Jupyter client in the terminal. In that case we wouldn't need to run JupyterLab in the back-end but only Jupyter Server. ### Proposed Solution Move [ydoc_handler.py](https://github.com/jupyterlab/jupyterlab/blob/055099fa565f3589d8db38588678614fdb286023/jupyterlab/handlers/ydoc_handler.py) to [jupyter-server](https://github.com/jupyter-server/jupyter_server). ### Additional context This is also needed if we want to implement a [new kernels REST API](https://github.com/jupyter-server/jupyter_server/issues/900) in jupyter-server. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Capturing shell command output after indentation causes SyntaxError in IPython console. To reproduce, type this in console: ```python def test(): for i in range(1): print(i) res =! ls ``` But if something is put above the line, everything will seem to be fine. ```python def test(): for i in range(1): print(i) 'just a separate line' res =! ls ``` Find this in IPython 7.1.0.dev Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: D: strip unsupported -D (and -f) flags for ldc2 Building [tilix](https://github.com/gnunn1/tilix) on FreeBSD, where the x11 pkgconf file contains a define flag: ``` % cat /usr/local/libdata/pkgconfig/x11.pc […] Cflags: -I${includedir} -D_THREAD_SAFE ``` ``` [1/63] ldc2 -I=tilix@exe -I=. -I=.. -I=../source/ -I=data -I/usr/local/include/d/gtkd-3/ -I/usr/local/include -enable-color -wi -release -enable-inlining -Hkeep-all-bodies -O3 -D_THREAD_SAFE -vcolumns -d-version=StdLoggerDisableTrace -of='tilix@exe/source_secretc_secret.d.o' -c ../source/secretc/secret.d FAILED: tilix@exe/source_secretc_secret.d.o ldc2 -I=tilix@exe -I=. -I=.. -I=../source/ -I=data -I/usr/local/include/d/gtkd-3/ -I/usr/local/include -enable-color -wi -release -enable-inlining -Hkeep-all-bodies -O3 -D_THREAD_SAFE -vcolumns -d-version=StdLoggerDisableTrace -of='tilix@exe/source_secretc_secret.d.o' -c ../source/secretc/secret.d ldc2: Unknown command line argument '-D_THREAD_SAFE'. Try: 'ldc2 -help' ldc2: Did you mean '-pre-RA-sched'? ``` I guess such flags should be just removed… Also, FreeBSD Ports sets up `LDFLAGS` for C/C++, and meson ends up passing unsupported flags to ldc2 here as well: ``` ldc2: Unknown command line argument '-fstack-protector-strong'. Try: 'ldc2 -help' ldc2: Did you mean '-stack-symbol-ordering'? ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit.draw(output = 'latex') truncates circuit unexpectedly <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: 0.7.0 - **Python version**: 3.6.5 - **Operating system**: Windows 10 ### What is the current behavior? test.draw(output = 'latex')  ### Steps to reproduce the problem ``` numq = 6 q = QuantumRegister(numq, name='qn') c = ClassicalRegister(numq, name='cn') test = QuantumCircuit(q,c) for i in range(numq): test.h(q[i]) test.barrier(q[i]) for i in range(numq-1): test.h(q[i+1]) test.cx(q[i],q[i+1]) test.h(q[i+1]) test.barrier(q[i+1]) ``` ### What is the expected behavior? test.draw(output = 'mpl')  ### Suggested solutions possibly a issue with latex or windows, might not be terra related Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose pull doesn't work with mixure of official and local images I use my own image build process in my development environment. This process create images localy so I can test them. I also use mose official images (databases) in my `docker-compose.yml`. With this combination `docker-compose pull` command fail when its tries to pull my local only images and if I'm not lucky no database images are pulled. I would like to from time to time pull new images from repository and so far I have to list them all. Is it possible to pass some flag to `pull` that it tries to pull all images and only report those that failed (instead of stop pulling others)? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Revert change to `User-Agent` header From #2223. See https://github.com/GoogleCloudPlatform/gcloud-common/issues/179 for rationale, such as it is and what there is of it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Update to MathJax 3 MathJax 3 was released a few days ago. Perhaps we should upgrade to it in 2.0. PR for our external plugin is at https://github.com/jupyterlab/jupyter-renderers/pull/213 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Recursive declare_dependency() Hi Jussi, This is somewhat related to #304 - should this work? I ran into this the other day. I have a library that depends on another library and there is a `declare_dependency` for both of them. ``` opencl_inc = include_directories('/usr/local/opencl12', '/opt/AMDAPP/include') opencl_dep = declare_dependency( include_directories: opencl_inc, dependencies: find_library('OpenCL', dirs:'/usr/lib64'), ) another_dep = declare_dependency( include_directories: another_inc, dependencies: opencl_dep ) foo = executable('foo', src, dependencies:[another_dep], ) ``` This is the error: ``` Dependencies must be external deps ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Since 1.4, `docker-compose up container` logs all containers, not just those passed as argument `docker-compose up lb wsgi` now also logs other containers, not just those explicitly passed in argument (\"lb\" and \"wsgi\" in this example). So instead of having just the logs I'm interested in like before, I'm now flooded with logs of verbose containers like varnish. Since 1.4, `docker-compose up container` logs all containers, not just those passed as argument `docker-compose up lb wsgi` now also logs other containers, not just those explicitly passed in argument (\"lb\" and \"wsgi\" in this example). So instead of having just the logs I'm interested in like before, I'm now flooded with logs of verbose containers like varnish. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Adding regularizers to Stax Some utilities for regularizing the cost functions would be useful in Stax. I have not seen this mentioned in #137. Is this planned? Also, I was wondering about the best way to implement this in pure JAX. For example considering L2 regularization, with the flattening utility from #190 I could write: ``` w_flat, _ = ravel_pytree(w) reg = np.sum(w_flat ** 2.0) ``` Looking a little bit on the code of tree_util I can also write: ``` reg= tree_reduce(lambda x, y: np.sum(x) + np.sum(y), tree_map(lambda wi: np.sum(wi**2.0), w)) ``` Is there a simpler solution I am missing? More in general it would be useful to document tree utilities in the main doc. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add gcc 10.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Python 3.8 and `python3-config --libs` Quoting https://bugzilla.redhat.com/show_bug.cgi?id=1718290: > The build no longer links to libpython, resulting in undefined references to Python API. Code that embeds Python (rather than building an extension module) needs to pass `--embed` to any `python3-config --libs` invocation to build with Python 3.8. More information: https://docs.python.org/3.8/whatsnew/3.8.html#debug-build-uses-the-same-abi-as-release-build In libratbag, we are using swig to generate a Python library that we link with a dependencies of `dependency('python3')`. I wasn't able to find out how the pkg-config was invoced, so I can not really submit a patch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: `conda.install.update_prefix` is modifying cached pkgs in Windows Since files are hardlinks, it looks like conda's prefix replacement mechanism is breaking its own files. File contents inside package: ``` python x = r'/opt/anaconda1anaconda2anaconda3\\Scripts', ``` File contents after installing in 'env1': ``` python x = r'C:\\Miniconda\\envs\\env1\\Scripts', ``` File contents after installing in 'NOTENV1': ``` python x = r'C:\\Miniconda\\envs\\env1\\Scripts', ``` Note that the second install fails, because the first one modified the cached files in `C:\\Miniconda\\pkgs`. Reading @asmeurer comments in #679, I agree that the correct behavior in this case would be to delete the file being modified and re-create it to avoid this issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Refactor progress bars After the transition to the _tqdm_ library, it would be nice to make consistent the way in that the progress bars are created and used in different places in Conan. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Accurate Control Channels <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: This only applies for OpenPulse enabled backends, for users trying to get data from the backend to build Pulse Schedules. ### What is the current behavior? `backend.configuration().control(qubit: int)` returns a trivial mapping to a `ControlChannel` with index specified by the given int `qubit`. This is not correct. It should be possible to determine the correct channel by inspecting the backend hamiltonian, if it is provided. ### What is the expected behavior? Right now the easiest (and hacky) way to get the correct channel is by reverse engineering the control channel index by inspecting the `cmd_def` of `backend.defaults()`. ### Suggested solutions I think the Pulse simulator does some hamiltonian parsing to figure out the same information that would be required to implement this feature. That is probably a good starting place. It should be implemented in `qiskit.providers.models.PulseBackendConfiguration.control`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: shared_library() kwarg vs_module_defs should trigger rebuild When the visual studio module definitions file is edited, the library that uses it should get re-linked. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Layout source folder when using ``source()`` to ``git clone`` a third-party fails - Layout defines source folder as ``src`` - Conan exports at least ``conanfile.py`` and ``conanmanifests.txt`` into the ``export`` folder in the cache - The ``export`` folder in the cache is automatically copied to ``source/src`` in the cache. - If the package tries to do a ``git clone <url> src`` to put the sources inside the ``src`` folder as the layout specified, it fails with \"folder already exists\". Should we? - Do not copy the ``export`` into the ``source/src`` folder, only the ``exports_sources``? - Document some git gymnastics to do it, like cloning in a different folder? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PrimitiveOp does not handle binding to complex values. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18 - **Python version**: 3.8 - **Operating system**: MacOS ### What is the current behavior? Error when binding a complex coefficient to an operator's parameter. ``` return self.assign_parameters(param_dict) File \"/qiskit-terra/qiskit/opflow/primitive_ops/primitive_op.py\", line 249, in assign_parameters param_value = float(self.coeff.bind(binds)) File \"/qiskit-terra/qiskit/circuit/parameterexpression.py\", line 431, in __float__ return float(self._symbol_expr) File \"symengine_wrapper.pyx\", line 1133, in symengine.lib.symengine_wrapper.Basic.__float__ File \"symengine_wrapper.pyx\", line 958, in symengine.lib.symengine_wrapper.Basic.n File \"symengine_wrapper.pyx\", line 4194, in symengine.lib.symengine_wrapper.evalf RuntimeError: Not Implemented ``` ### Steps to reproduce the problem ``` from qiskit.opflow import X from qiskit.circuit import Parameter th = Parameter('th') (th * X).bind_parameters({th: 1j}) ``` ### What is the expected behavior? No error, handling a potentially complex value. ### Suggested solutions In File \"/qiskit-terra/qiskit/opflow/primitive_ops/primitive_op.py\", line 431, changing `param_value = float(self.coeff.bind(binds))` to `param_value = complex(self.coeff.bind(binds))`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.array named columns and different column types not working Classical numpy arrays allow to specify column names/identifiers and assign different types to columns. From the documentation: > Data-type consisting of more than one element: > > ``` >>>> x = np.array([(1,2),(3,4)],dtype=[('a','<i4'),('b','<i4')]) >>>> x['a'] >array([1, 3]) > ``` The same documentation is given for jax's `np.array` but trying the above example yields a ``` TypeError: unhashable type: 'list' ``` for the `dtype` argument (raised in function `_check_user_dtype_supported`, line 5096, `jax/lax/lax.py`). Is there a chance that this kind of array specifications could be supported? If not, could at least the documentation be clarified? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: CLI `run cloud --logs` needs exit Currently the watch on logs does no exit and should finish on completion of flow run Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: asn1 error in reading credentials on windows Hi, I reckon line 39 in glcoud.credentials should open the private key with read binary on windows: private_key=open(private_key_path, 'rb').read(), cheers, David Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Make redis use of sorted sets for group results opt-out Following up on #6245 - can we make the use of sorted set opt-out for 5.0 as discussed? In particular, this would simply be a change to the default value of the config value, and associated changes to tests and doco merged in #6245. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: IAM: Improve Policy docs It would help the Policy docs if there were an example of how to set bindings. The dunder methods don't have docstrings and so, without looking at the source, it's not very obvious how to assign roles and members to a policy. ``` policy = iam.Policy() policy[role] = [iam.Policy.user(user_email)] ``` This will help people reading the docs for methods that take an `iam.Policy` who follow the link to the class definition and then can't figure out how to build the policy they want--for instance, for a new storage bucket. (I was helping a friend today who also found this confusing.) I'm happy to contribute an example here but not sure how you all would like that done. Edit: [Link to current Policy docs](https://googleapis.github.io/google-cloud-python/latest/core/iam.html#google.cloud.iam.Policy) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Fargate agent warning is too aggressive ## Description This warning can be relaxed because it does not suit all use cases ## Expected Behavior Elevate warning only under certain conditions ## Reproduction Run the fargate agent without ARNs Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add --json flag on conda-env that works! The json flag seems to be there, but it is not working. With a file that looks like ```yaml # environment.yaml name: test_env_1 channels: - defaults dependencies: - python - pytest-cov ``` ``` (root) $ conda-env create --json Using Anaconda API: http s://api.anaconda.org (root) $ ``` So two problems here: 1.) No json output on the create process 2.) `Using Anaconda API: https://api.anaconda.org` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Ignore calls to flow.register when parsing a flow using file based storage ## Current behavior <!-- Please describe how the feature works today --> If a flow script contains a reference to the `.register` method, it'll fail with this error: ``` Failed to load and execute Flow's environment: RuntimeError('Attempting to call `flow.register` during execution of flow file will lead to unexpected results.') ``` ## Proposed behavior <!-- Please describe your proposed change to the current behavior --> Flow runner ignores calls to the `.register` method. ## Example <!-- Please give an example of how the enhancement would be useful --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add ability to resolve image digests without pulling entire images PR #4333 added `--resolve-image-digests` to `docker-compose config`, which resolves image tags to their digest to form stable references. However, this relies on the images being available on the Docker host. It would be useful if Docker Compose could fetch image digests without having to pull the image if the image doesn't exist locally. In CI jobs using Docker-in-Docker, pulling images just for tag digests can be a significant waste of time and network resources. Digests can be obtained using `HEAD` requests against `/v2/<name>/manifests/<reference>` in the [v2 API](https://docs.docker.com/registry/spec/api/#manifest). https://stackoverflow.com/questions/35186693/what-is-the-docker-registry-v2-api-endpoint-to-get-the-digest-for-an-image#35420411 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Console animations printed to the log files as new lines I have a system that execs the `compose`command and that logs the output (stderr/stdout output streams redirected) to a log file. Apparently the `docker up -d` is showing some image pull animations (obviously contains ANSI escape sequences to clear lines or delete chars) and when those get logged to the log file, I just see bunch of empty lines. Not a big deal, mostly a cosmetics issue but wanted to bring up if it's easy to fix. Output: ``` Creating compose307929553_blog_1... Pulling image ghost:latest... latest: Pulling from ghost ghost:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security. Digest: sha256:b415d8cdf5aa809b95def3e122251b80fe6f99c557bd37ba9d7af2523089511a Status: Downloaded newer image for ghost:latest Creating compose307929553_cache_1... Pulling image memcached:latest... latest: Pulling from memcached memcached:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security. Digest: sha256:61a047af4f93bf3750658197594e5145beadf02f1236b411034b9ce6cfa61140 Status: Downloaded newer image for memcached:latest ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.50.0: c_link_args is ignored in compiler sanity checks of cross-builds with exe_wrapper See https://github.com/mesonbuild/meson/pull/5085 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: **gather_all_tensors_if_available** share the same underlying storage for all GPUs <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug <!-- A clear and concise description of what the bug is. --> Hi, one of new features in #2528 `gather_all_tensors_if_available` has a `list` copy bug, and this would lead that tensors in all GPUs are the wrongly same as one GPU, since they share the same storage: https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/metrics/converters.py#L304 ``` gathered_result = world_size * [torch.zeros_like(result)] ``` change into: ``` gathered_result = [torch.zeros_like(result) for _ in range(world_size)] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: Non-standard scaling factor for the covariance matrix in `numpy.polyfit` As discussed on the [mailing list](http://numpy-discussion.10968.n7.nabble.com/Inconsistent-results-for-the-covariance-matrix-between-scipy-optimize-curve-fit-and-numpy-polyfit-td45582.html) recently, and (as @josef-pkt pointed out to me) also already [in a discussion in 2013](https://mail.scipy.org/pipermail/numpy-discussion/2013-February/065664.html), `numpy.polyfit` uses a non-standard factor in the estimated scale of the covariance matrix. Namely, rather than using the standard `chisq/(M-N)`, it scales it with `chisq/(M-N-2)` where `M` is the number of data points and `N` is the number of parameters. Neither my colleague @wummo and I, while researching this, nor @josef-pkt as stated in the subsequent E-Mail conversation has found any reference for this in the literature. There is a comment in the corresponding code here explaining the choice: https://github.com/numpy/numpy/blob/79ec65de3064cbdc687820ab09f20b989028509d/numpy/lib/polynomial.py#L593-L604 But there is no reference given there. As this is non-standard and is inconsistent with other fitting programs (such as e.g. `scipy.optimize.curve_fit`), we feel that this should be changed to avoid surprises when using this library. As a side note, one could use the occasion to add an additional parameter which enables the return of an unscaled covariance matrix (@josef-pkt suggested the name `absolute_weights`, analogous to `curve_fit`'s `absolute_sigma`). This was already suggested in both mailing list discussions. It would be useful in occasions, where the weights are given by `1/sigma` with sigma being the (known) standard errors of (gaussian distributed) data points, in which case the unscaled matrix is already a correct estimate for the covariance matrix. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Adding environments to repository.yml and then supporting in dagit Per discussion at lunch, add the ability to register environments in repository.yml and then surface them nicely in dagit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: ediff1d handles data type errors badly If the `to_end` or `to_begin` argument is an invalid type for the array, you don't get an error message, you just get bad results. For example, if you try to put `np.nan` into an int array: ```Python a = np.array([1, 2, 3]) np.ediff1d(a, np.nan) ``` You get `array([ 1, 1, -9223372036854775808])` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Add base_url to labextension handler cf https://github.com/jupyterlab/jupyterlab/blob/bcf78198f1220257a92ff95523afc86f7af9e816/jupyterlab/labapp.py#L197-L204 From gitter debugging session with @epifanio. The app was trying to load extensions from `/hub/labextension/`, while the correct url should have been `/user/epinux/labextension`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: BSD detect_cmake: _INCLUDED_FILE \"NOTFOUND\" Hi. On at least OpenBSD and FreeBSD, the cmake module fails to determine the compilerpath. This is because it looks at the _INCLUDED_FILE value: ``` $ cmake --system-information -G Ninja | grep _INCLUDED_FILE ``` On BSD, the output is: ``` _INCLUDED_FILE \"NOTFOUND\" ``` On Linux, the output is: ``` _INCLUDED_FILE \"/usr/share/cmake-3.12/Modules/Platform/Linux-GNU-CXX.cmake\" ``` I wonder is we could maybe use something like _INCLUDED_SYSTEM_INFO_FILE which has the following output (according to the OS): ``` /usr/local/share/cmake/Modules/Platform/OpenBSD.cmake /usr/share/cmake-3.12/Modules/Platform/Linux.cmake\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: typo IBERT in `__repr__` should be `quant_mode: {self.quant_mode}` in here https://github.com/huggingface/transformers/blob/71e602725b90f63f404109bae9f72cbdf755477b/src/transformers/models/ibert/quant_modules.py#L150-L155 typo IBERT in `__repr__` should be `quant_mode: {self.quant_mode}` in here https://github.com/huggingface/transformers/blob/71e602725b90f63f404109bae9f72cbdf755477b/src/transformers/models/ibert/quant_modules.py#L150-L155 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CMake for dependencies can't use modules CMake for finding dependencies could easily be further extended with off-the-shelf `Find<foo>.cmake` scripts. The only thing that needs to happen for that is that the invocation of `cmake` needs to point `-DCMAKE_MODULE_PATH=<dir>` at the directory containing these scripts. A good place for this might be here: https://github.com/mesonbuild/meson/blob/90c9b868b20b11bb089fc5e0c634d5ed76fea0cb/mesonbuild/dependencies/base.py#L1422 As a simple suggestion, just redefine all `CMAKE_*` environment variables as CMake variables: ```python for key in env.keys(): if key.startswith('CMAKE_'): args.append('-D%s=%s' % (key, env[key])) ``` That should do the trick (some testing required). As an added benefit, you can influence CMake further with other `CMAKE_*` variables in the environment. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add support for bucket labels See: https://cloud.google.com/storage/docs/json_api/v1/buckets#labels Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore: broken paging next_page_token I want to use `datastore` paging to fetch the query results. Specifically, I upload 11 entities to `datastore` and then want to fetch them (`limit=10`) using following code: ```python query = <google.cloud.datastore.Client>.query(kind='test_kind') query_iter = query.fetch(limit=limit, start_cursor=cursor) page = next(query_iter.pages) next_cursor = query_iter.next_page_token entities = list(page) logging.info('Cursor: %s, Next cursor: %s, Loaded entities: %d.', cursor, next_cursor, len(entities)) ``` (where initially `cursor = None` and then is set to `next_cursor` value) Unfortunately, I am getting not `None` value for the `next_cursor` even there are not any more results to fetch: ``` # First call, everything as expected Cursor: None, Next cursor: foo, Loaded entities: 10. # Second call, expected next_page_token = None Cursor: foo, Next cursor: bar, Loaded entities: 1. # Third call, again expected next_page_token = None Cursor: bar, Next cursor: bar, Loaded entities: 0. ``` It seems that `next_page_token` is always not `None` and moreover, if there is not any result to fetch, `next_cursor == cursor`. Setup: ``` Python 2.7.12 google-cloud-datastore==1.3.0 ``` Is this expected? If yes, how can I recognise that there are not more results to fetch? I've checked the code briefly and it might be related to https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/datastore/google/cloud/datastore/query.py#L457. It seems like `response_pb.batch.end_cursor == b''` does not hold and thus `next_page_token` is not set to `None`, but not sure why this is the case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add functions equivalent to create_rows and create_rows_json that create a table for you using a load job 1. BigQuery API 2. Linux, Ubuntu 16.04.3 LTS running Google Cloud Datalab 1.0.1 3. Python 2.7.12 4. Google cloud v 0.31.0 5. // 6. Create a dataframe or dict list and try to send to an existing table. The first request will raise no errors but nothing will be appended to the table. Running the same command again and rows are added. This will not add rows: ``` from google.cloud import bigquery as bq import time client = bq.Client(project='project-name') dataset = bq.DatasetReference('project-name', 'dataset-name') tableref = bq.table.TableReference(dataset, 'users') schema = [bq.SchemaField('email', 'STRING'), bq.SchemaField('id', 'STRING'), bq.SchemaField('added', 'TIMESTAMP')] table = bq.Table(tableref, schema=schema) create = client.create_table(table) public_members = [{'email': 'testemail@email.com', 'id': '1234', 'added': '2017-12-01 13:13:13 UTC'}] client.create_rows_json(table, public_members) ``` This will add exactly one row: ``` from google.cloud import bigquery as bq import time client = bq.Client(project='project-name') dataset = bq.DatasetReference('project-name', 'dataset-name') tableref = bq.table.TableReference(dataset, 'users') schema = [bq.SchemaField('email', 'STRING'), bq.SchemaField('id', 'STRING'), bq.SchemaField('added', 'TIMESTAMP')] table = bq.Table(tableref, schema=schema) create = client.create_table(table) public_members = [{'email': 'testemail@email.com', 'id': '1234', 'added': '2017-12-01 13:13:13 UTC'}] client.create_rows_json(table, public_members) time.sleep(15) client.create_rows_json(table, public_members) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make python-constraint requirement optional ### What is the expected enhancement? After #7213 we're no longer using the CSP layout pass in preset passmanagers, while I think keeping the pass in terra makes sense since we're not using it by default with `transpile()` anymore I think we can remove `python-constraint` from the requirements list and make it an optional dependency and only require it if people are explicitly using the csplayout pass. This is technically a breaking change but I think one with minimal impact as most users are not going to be explicitly using the pass. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Copying from Qt console appends newline in clipboard IPython 2.1.0 on Windows As title says, for example if I copy single word in clipboard I have the word plus '\\r\\n'. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Name change for S_dg and T_dg not reflected in drawers <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.8 - **Operating system**: Ubuntu 18.04 ### What is the current behavior? Previously the s-dagger and t-dagger gates were named sdg and tdg. This was changed to S_dg and T_dg, which means the drawers no longer display the dagger icon. ### Steps to reproduce the problem ``` qc = QuantumCircuit(1) qc.sdg(0) qc.draw('mpl') ``` ### What is the expected behavior? Both gates should display the dagger icon after S or T. ### Suggested solutions This can be fixed in qcstyle.py. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Wrong suggestion message Version ``` docker-compose -v docker-compose version 1.8.0, build f3628c7 docker -v Docker version 1.12.1, build 23cf638 ``` docker-compose.yml ``` version: '2' services: nginx: image: 'nginx:1.10-alpine' ``` command ``` $ docker-compose bundle ERROR: Some images are missing digests. The following images need to be pulled: nginx:1.10-alpine Use `docker-compose pull nginx:1.10-alpine` to pull them. ``` Clearly, the message should've been `docker pull nginx:1.10-alpine`, without compose. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Internal static library leaks to the ldflags when using gnome.gtkdoc() Similar to #3934: additional uninstalled static libraries end up on the linker flags for shared libraries, causing build failures when running `gtkdoc-scangobj`: ``` ERROR: 'gtkdoc-scangobj' failed with status 1 /usr/bin/ld: cannot find -lgeoclue-public-api collect2: error: ld returned 1 exit status 2018-07-24 18:53:45,120:scangobj.py:execute_command:1196:WARNING:Linking scanner failed: 1, command: ccache cc libgeoclue-scan.o -L/home/ebassi/gnome/source/geoclue/_build/libgeoclue -L/home/ebassi/gnome/install/lib -Wl,-rpath,/home/ebassi/gnome/install/lib -Wl,-rpath,/home/ebassi/gnome/source/geoclue/_build/libgeoclue -lgeoclue-2 -lgeoclue-public-api -lglib-2.0 -lgio-2.0 -lgobject-2.0 -o libgeoclue-scan ``` `geoclue-public-api` is a static library defined as an internal dependency of `geoclue-2`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: AttributeError: 'Trainer' object has no attribute 'is_world_master' ## Environment info - `transformers` version: 4.0.0 - Platform: Linux-4.15.0-96-generic-x86_64-with-debian-buster-sid - Python version: 3.7.8 - PyTorch version (GPU?): 1.7.0 (True) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: Yes - Using distributed or parallel set-up in script?: No - Ray version: 1.0.1.post1 ### Who can help @sgugger — Would you be able to offer any insight? ## Information Model I am using (Bert, XLNet ...): BertForSequenceClassification The problem arises when using: * [ ] the official example scripts: * [ x] my own modified scripts: The tasks I am working on is: * [ ] an official GLUE/SQUaD task: * [ x] my own task or dataset: ## To reproduce The error occurs when I try to run a hyperparameter search for my finetuning step using Ray Tune. I am able to successfully finetune the BertForSequenceClassification model normally — the error only arises when running hyperparameter search. ``` config = BertConfig.from_pretrained(pretrained_model_path, num_labels=num_labels, finetuning_task ='text-classification') def model_init(): return BertForSequenceClassification.from_pretrained(pretrained_model_path, config=config) trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset, eval_dataset=eval_dataset, model_init=model_init ) trainer.hyperparameter_search( direction=\"minimize\", backend=\"ray\", n_trials=20, keep_checkpoints_num=1, resources_per_trial = {'gpu':1, 'cpu':1} ) ``` ## Expected behavior I am trying to run Ray Tune from Huggingface as per these instructions: https://huggingface.co/blog/ray-tune If anyone has any insight as to what could be causing this error, it would be greatly appreciated, thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Swap `eval_delay signs` ### Who can help @sgugger ## Information The signs for the `eval_delay` comparisons need to be switched. This is pretty NB @sgugger as there are a lot of breakages involved here. Greater than sign must be changed to less than sign [here](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer_callback.py#L422) and [here](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer_callback.py#L446). I'll put in a PR if need be. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Unable to find locally built image I have a locally built image (built with `docker build -t project/heroku-base ./project-heroku-base`) that version 1.3 of docker-compose is not finding during the build process for another image. I can build with `docker build app ./app`, and with version 1.2 of docker-compose I can build with `docker-compose build app`. ``` $ docker-compose build app Building app... Step 0 : FROM project/heroku-base:latest Pulling repository project/heroku-base Service 'app' failed to build: Error: image project/heroku-base:latest not found ``` ``` $ docker images REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE project/heroku-base latest ebe895ea759a 10 minutes ago 1.325 GB mysql latest d63d4723d715 2 days ago 283.5 MB debian jessie bf84c1d84a8f 2 days ago 125.2 MB heroku/cedar 14 89fc314a0a6e 4 weeks ago 1.242 GB busybox latest 8c2e06607696 8 weeks ago 2.433 MB ``` ``` $ docker-compose -v docker-compose version: 1.3.0 CPython version: 2.7.9 OpenSSL version: OpenSSL 1.0.1e 11 Feb 2013 $ docker version Client version: 1.7.0 Client API version: 1.19 Go version (client): go1.4.2 Git commit (client): 0baf609 OS/Arch (client): linux/amd64 Server version: 1.7.0 Server API version: 1.19 Go version (server): go1.4.2 Git commit (server): 0baf609 OS/Arch (server): linux/amd64 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: more control over job_monitor output <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Allow the user to control the new line characters that are emitted by job_monitor output. I found myself needing to change this to allow me to use qiskit-terra's tools on my non jupyter notebook environment. I'm already working on a PR for this, which will appear linked here very soon. more control over job_monitor output <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Allow the user to control the new line characters that are emitted by job_monitor output. I found myself needing to change this to allow me to use qiskit-terra's tools on my non jupyter notebook environment. I'm already working on a PR for this, which will appear linked here very soon. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for exporting `Expr` values to OpenQASM 3 ### What should we add? This tracks the work labelled \"PR 3\" in [the initial classical-expression design document](https://github.com/Qiskit/RFCs/blob/master/0010-simple-classical-representations.md). Fully depends on #10223. Work can begin following only that, but to be properly useful, this also depends on #10224. Brief overview: - add support for exporting `Expr` values in the OpenQASM 3 exporter. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Different behavior in DistilBERT when using \"inputs_embeds\" ### System Info - `transformers` version: 4.24.0 - Platform: Linux-3.10.0-1160.80.1.0.1.el7.x86_64-x86_64-with-glibc2.27 - Python version: 3.10.8 - Huggingface_hub version: 0.11.1 - PyTorch version (GPU?): 1.12.1 (True) @ArthurZucker @younesbelkada ### Reproduction Do a forward pass with distilBERT passing \"inputs_embs\" instead of \"input_ids\", where \"inputs_embs\" contains the output of the forward over the word embedding matrix, i.e. just picking the token embeddings. When doing this, one would expect the same behaviour as other popular models like BERT or ROBERTA, but distilBERT skips \"positional embeddings addition + layerNorm + droput\" as it skips the self.embedding() call. I would expect that passing inputs_embs instead of input_ids has a coherent behaviour across diferent architectures, but it is not the case, at least for distilBERT. I am not sure if other models have this issue. ### Expected behavior Properly build the input embedding by adding positional embeddings + layerNorm + droput (as happens in modeling_bert or modeling_roberta). This does not happen as the call to self.embedding() is skipped. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Verbose option for apply_conandata_patches() ### What is your suggestion? I'd like to have this... ```diff -def apply_conandata_patches(conanfile): +def apply_conandata_patches(conanfile, verbose=False): ``` ...which does this when `verbose=True`... ```diff ======== Installing packages ======== zlib/1.2.13: Calling source() in /home/username/.conan2/p/zlibef641b716caf2/s +zlib/1.2.13: Applying: patches/0001-Fix-cmake.patch +zlib/1.2.13: Applying: patches/0002-gzguts-xcode12-compile-fix.patch -------- Installing package zlib/1.2.13 (1 of 1) -------- zlib/1.2.13: Building from source ``` ...so that information on which patches were applied is recorded in the build log. I have this implemented and ready to go. ### Have you read the CONTRIBUTING guide? - [X] I've read the CONTRIBUTING guide Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Celery executor should support custom database backend models Currently, the celery executor imports the `Task` model for the Celery database backend directly: https://github.com/apache/airflow/blob/2dd4e96045d4a7f45cc8c06df3d25c4f1479392c/airflow/executors/celery_executor.py#L38 However, Celery, being highly customisable, uses `self.task_cls` in the backend implementation; this defaults to either `Task` or `TaskExtended` depending on the Celery configuration, see [`celery.backends.database:66`](https://github.com/celery/celery/blob/406f04a082949ac42ec7a4af94fed896c515aaa4/celery/backends/database/__init__.py#L66): > ```python > task_cls = Task > ``` and [`celery.backends.database:76,77`](https://github.com/celery/celery/blob/406f04a082949ac42ec7a4af94fed896c515aaa4/celery/backends/database/__init__.py#L76-L77): > ```python > if self.extended_result: > self.task_cls = TaskExtended > ``` Airflow should support this flexibility, and instead of importing a fixed class just use `backend.task_cls`, so in `_get_many_from_db_backend` just use: ```python Task = app.backend.task_cls with session_cleanup(session): tasks = session.query(Task).filter(Task.task_id.in_(task_ids)).all() ``` I suppose there is one downside to this: `TaskExtended` fetches a few more columns per task, but given that the result of `task.to_dict()` is passed to `backend.meta_from_decoded()`, which could also have been customised to make use of information contained in a custom model, that's neither here nor there. It would be the price anyone using the `result_extended` option would need to pay elsewhere anyway. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DISCUSSION: Implement Key.__eq__ and Entity.__eq__ Currently comparison must be done in an ad-hoc way: ``` python assert dict(arya_entity.items()) == {'name': 'Arya', 'family': 'Stark'}) ``` FWIW `__eq__` is not something that should really be needed outside of the `Key`, and even then not so much. **NOTE**: This was a small part of #336 DISCUSSION: Implement Key.__eq__ and Entity.__eq__ Currently comparison must be done in an ad-hoc way: ``` python assert dict(arya_entity.items()) == {'name': 'Arya', 'family': 'Stark'}) ``` FWIW `__eq__` is not something that should really be needed outside of the `Key`, and even then not so much. **NOTE**: This was a small part of #336 DISCUSSION: Implement Key.__eq__ and Entity.__eq__ Currently comparison must be done in an ad-hoc way: ``` python assert dict(arya_entity.items()) == {'name': 'Arya', 'family': 'Stark'}) ``` FWIW `__eq__` is not something that should really be needed outside of the `Key`, and even then not so much. **NOTE**: This was a small part of #336 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: datastore: default to empty dataset When working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending \"s~\" to dataset ids as that is not always a valid operation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [Suggestion] has_function should accept 'required' keyword has_header_symbol accepts the required keyword so it can error when a symbol is missing. has_function is more robust since it checks that it's able to link, but doesn't accept the required keyword. Since they're similar in purpose and usage, I see no reason has_function shouldn't offer the required keyword for convenience as well. Checked against Meson 0.55 on Debian Bullseye GNU/Linux. ``` project('f', 'c') cc = meson.get_compiler('c') cc.has_function('puts', required : true) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add expansion of environment variables in `channels` config key As per https://github.com/conda/conda/issues/1156#issuecomment-299913430, can we get expansion of environment variables in the `channels` config key? This would be useful for me, as I can then add the following lines to my `.condarc` file: ``` channels: - https://${USERNAME}:${PASSWORD}@my.private.conda.channel ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Improve custom CMakeToolchain blocks extension From https://github.com/conan-io/docs/pull/2312, lets avoid the ``import CMakeToolchainBlock`` altogether, using Python dynamism. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: MongoDB integration should run the `top` command on the admin database. When configuring the agent check for a database != `admin` to gather stats on the collections, the `top` additional metric no longer works: ``` dd.collector[29969]: WARNING (mongo.py:997): Failed to record `top` metrics top may only be run against the admin database. ``` That's because the `top` command can only be run against the admin database: https://docs.mongodb.com/manual/reference/command/top/#dbcmd.top The issue comes from this line: https://github.com/DataDog/integrations-core/blob/master/mongo/datadog_checks/mongo/mongo.py#L962 That should probably be changed to be: ``` dbtop = admindb.command('top') ``` as the `admindb` variable points to the admin database to be able to run commands that only run against the admin database as stated https://github.com/DataDog/integrations-core/blob/master/mongo/datadog_checks/mongo/mongo.py#L734 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: Incorrect listing of `order` parameter in tobytes The docstring for `tobytes` ([link to source](https://github.com/numpy/numpy/blob/e66453568b685dee47d6e6e634b3a47edffcaeed/numpy/core/_add_newdocs.py#L3935-L3969)) lists the options for the order parameter as 'C', 'F', and None but does not include 'A' or 'K' (as in e.g. the copy docstring). 'Any' is also mentioned as a (seemingly) valid input for the `order` argument in the first part of the docstring. ### Numpy/Python version information: 1.19.0.dev0+35d5c2f 3.8.2 (default, Apr 8 2020, 14:31:25) [GCC 9.3.0] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: ExternalTaskSensor logs a poke message that lists the current execution_date, it should show the execution_date it is poking for. The log for ExternalTaskSensor shows a poke for \"dag.task on context[executino_date]\" which is the execution_date of the running task. But it would be more helpful to know what execution date it is actually looking for. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Remove the \"Beta\" release label? I think we are being somewhat ineffective in communicating to users that JupyterLab is ready for use. I propose that we drop the \"Beta\" label on releases, but still keep the pre-1.0 version number. We've had discussions and disagreements about whether we want to release 1.0 or not, and I think this strikes a nice balance of communicating what we want to the different audiences we are addressing. As a huge generalization, users seem to pay attention to the words, while developers seem to pay attention to the more precise and semantically meaningful version numbers. If we want to communicate to users that JLab is ready for use, I think we should drop the \"Beta\" label. If we want to communicate to developers that we are still stabilizing the extension api, and breaking changes are coming every 4-6 weeks with a new 0.x release, we should keep the pre-1.0 version numbers. I think we want to do both, so I propose we call the next release just JupyterLab 0.33. I think we have done a lot of polishing since February, so I think it was still valuable to have a \"beta\" release period up to this point. What do you think? Are there some important polish issues to address before dropping the beta label? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Nose unsupported, doesnt work with Python 3.10 3 months until 3.10 is released (Oct 2021), so i've just tried run the test suite on 3.10.0beta4. Didn't get very far, as Nose does not work on 3.10. The issue was reported during 3.9alpha release, so not going to be fixed or released: https://github.com/nose-devs/nose/issues/1099. Finally time to move to pytest? Then can use all the plugins! Seems is as easy to move to pytest as Nose2. If anyone wants to help with that..... ('ve never used Nose before). https://github.com/pytest-dev/nose2pytest might help? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Incorrect padding error Hi, This is in regards to the pubsub module. When I send a test message with data \"testing 1 2 3\" from the web console to a simple python application it fails to decode the message and throws a ``` binascii.Error: Incorrect padding ``` Error from ``` File \"/python3.5/site-packages/google/cloud/pubsub/message.py\", line 88, in from_api_repr data = base64.b64decode(api_repr.get('data', b'')) File \"/lib/python3.5/base64.py\", line 88, in b64decode ``` I get the same error if I send the same message using the Go libraries. I do not get the error if I send the message using python however. All I'm doing is receiving and printing out the messages. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: USERPROFILE in conanbuildinfo.props Visual Studio files PR https://github.com/conan-io/conan/pull/2936 was reverted due to failing things. cc/ @pawelkami Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Fix conda init \"--no-user\" argument being ignored Currently it is being ignored, because option `no_user` in [https://github.com/conda/conda/blob/master/conda/cli/main_init.py#L46](main_init.py) is marked `False` when `--no-user` option is present. I picked `action=\"store_true\"` instead of `dest=\"user\"` because of existance of the reference to `args.no_user` in the code, probably it is left on intent. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Optimizer initialization with DDP ## ❓ Questions and Help #### What is your question? I would have expected optimizers to always be initialized after parameters have been moved to their destination device. However, some ddp backends such as [ddp_backend](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/accelerators/ddp_backend.py#L174), [ddp_spawn_backend](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/accelerators/ddp_spawn_backend.py#L115), [ddp2_backend](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/accelerators/ddp2_backend.py#L111) initialize the optimizer with the CPU parameters before moving the model to the GPU while others such as [gpu_backend](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/accelerators/gpu_backend.py#L39) pass the GPU parameters. I'm currently trying to understand two things: (1) Where does the linking from the CPU to GPU parameters happen? (2) Is it actually necessary to initialize the optimizer before moving to the specific device or could it be done afterwards? (Most tutorials initialize the optimizer *after* placing the parameters on the corresponding device, e.g. [this one](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html#basic-use-case)) The reason I'm asking is that I did some parameter/gradient bending to be views into other tensors. This does not work with the current implementation as the optimizer keeps the reference to the CPU parameters with these tweaks but works fine when adapting the pytorch_lightning code by moving the optimizer creation after the model has been moved to the correct device. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Linter \"Unable to import\" warning when importing a shared Python Conan package in the build() step - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. --- I followed the instructions on http://docs.conan.io/en/latest/howtos/python_code_reuse.html. When I get to the \"Requiring a python conan package\" step, the linter gives me a warning about importing the shared package: $ git clone https://github.com/smokris/conan-test-library $ cd conan-test-library $ conan export . me/testing $ cd .. $ git clone https://github.com/smokris/conan-test-consumer $ cd conan-test-consumer $ conan create . me/testing HelloPyReuse/1.0@me/testing: Exporting package recipe Linter warnings WARN: Linter. Line 9: Unable to import 'hello' … HelloPyReuse/1.0@me/testing: Calling build() Hello World from Python! … (The imported package works fine; the problem is just that the linter is emitting a warning. I'd prefer that the linter not show this false-positive warning, to improve the linter's signal-to-noise ratio.) I'm able to reproduce this using: - Conan 1.1.1 on my local macOS 10.13.3 system - Conan 1.1.1 on Travis CI's Mac OS 10.10.5 image - Conan 1.1.1 on Travis CI's Ubuntu 14.04.5 image - Conan 1.2.0 on CentOS 7.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Remove `--live-stream` option ### What is the idea? Remove the `--live-stream` option as it isn't useful and it's confusing users (eg. https://github.com/conda/conda/issues/10558). ### Why is this needed `--live-stream` is used (only!) by `subprocess_call` (and is only passed in `conda.cli.main_run`): https://github.com/conda/conda/blob/35cd47952fe694b49375a72bdbaf7834570fdc2d/conda/cli/main_run.py#L30-L37 and has the effect that stdout/stderr are printed as well as captured in the parent process: https://github.com/conda/conda/blob/20622423ace946475ba1680b74ea99c52ed2230e/conda/gateways/subprocess.py#L87-L94 The captured stdout/stderr is attached to the `response` object returned by that function: https://github.com/conda/conda/blob/20622423ace946475ba1680b74ea99c52ed2230e/conda/gateways/subprocess.py#L124 But it is ignored subsequently: https://github.com/conda/conda/blob/35cd47952fe694b49375a72bdbaf7834570fdc2d/conda/cli/main_run.py#L49-L53 Thus it looks like the only effect `--live-stream` does have is that it makes `conda xyz` output appear live on the terminal, the same effect as `--no-capture-output`. ### What should happen? Deprecate `--live-stream` and temporarily make it an alias to `--no-capture-output`, then in the future remove the `--live-stream` option ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: No docs on handling sysroot for pkg-config in cross-builds? Hi, 1. First, my impression is that the recommended way to make pkg-config work when cross-compiling is to set PKG_CONFIG_PATH and PKG_CONFIG_SYSROOT_DIR. Is this accurate? 2. Second, assuming that #1 is at least partially accurate, can we say something about this in the help for doing cross-compilation? I ask because I spent about 5 hours figuring this approach out while doing a cross-compile from linux to windows using gtk2 libs from `repo.msys2.org`. There's nothing about sysroots in here: http://mesonbuild.com/Cross-compilation.html It also looks like setting the sys_root property is (maybe) deprecated and (maybe) doesn't do anything? Maybe this should also be mentioned in the docs. if @nirbheek or @jpakkane can give my an overview I can make a PR with some attempted docs. 3. Third, it looks like there is no way to set the PKG_CONFIG_PATH and PKG_CONFIG_SYSROOT variables in the cross file. is this intentional? My apologies if I'm just overlooking some documentation. Meson is pretty nice overall to use for cross-building. -BenRI Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error in Rz gate There is a bug in this line and the line above it (rz gate): https://github.com/QISKit/qiskit-sdk-py/blob/4f15c99c1dc4b91abd5d54ccc6b94c8e38ac4997/qiskit/extensions/standard/rz.py#L61 It is replicated in rx and ry as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: dir(numpy) returns duplicate \"testing\" <!-- Please describe the issue in detail here, and fill in the fields below --> ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np >>> np.__version__ '1.18.1' >>> len(dir(np)) 620 >>> np.testing <module 'numpy.testing' from 'C:\\\\Python\\\\Python38\\\\lib\\\\site-packages\\\\numpy\\\\testing\\\\__init__.py'> >>> len(dir(np)) 621 >>> [i for i in dir(np) if i == \"testing\"] ['testing', 'testing'] ``` ### Error: \"testing\" appears twice in dir(np) ### Numpy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> Python 3.8.0 (tags/v3.8.0:fa919fd, Oct 14 2019, 19:37:50) [MSC v.1916 64 bit (AMD64)] on win32 >>> np.__version__ '1.18.1' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Pre-processing re-runs for each process ### System Info - `transformers` version: 4.22.0.dev0 - Platform: Linux-4.15.0-180-generic-x86_64-with-glibc2.27 - Python version: 3.10.4 - Huggingface_hub version: 0.8.1 - PyTorch version (GPU?): 1.12.1+cu102 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: yes - Using distributed or parallel set-up in script?: yes ### Who can help? @muellerzr @sgugger @patil-suraj ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction In `examples/summarization_no_trainer.py`, we use the following code to pre-process the data: ``` with accelerator.main_process_first(): processed_datasets = raw_datasets.map( preprocess_function, batched=True, num_proc=args.preprocessing_num_workers, remove_columns=column_names, load_from_cache_file=not args.overwrite_cache, desc=\"Running tokenizer on dataset\", ) ``` In a multi-GPU (process) setup, the main process pre-processes the data first and saves it in the cache. Ideally, the other processes should just pick it up from there. But that's not happening. Every process is re-pre-processing the data. This is a problem when the data is large. I have tried to check if something changes during the run with `Hasher.hash(preprocess_func)`. But the hash remains the same. ### Expected behavior Processes other than the main process should read the processed data from cache.the Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: custom_jvp does not work when first jvp rule is None Here is a repro code ```python from jax import grad, custom_jvp @custom_jvp def f(x, y): return x ** 2 * y f.defjvps(None, lambda x_dot, primal_out, x, y: 2 * x * y * x_dot) print(grad(f, 1)(2., 3.)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.array_repr fails on np.matrix objects Cause of #5875: ```python >>> np.array_repr(np.eye(2).view(np.matrix)) Traceback (most recent call last): File \"<pyshell#52>\", line 1, in <module> np.array_repr(np.matrix(np.eye(2))) File \"C:\\Program Files\\Python 3.5\\lib\\site-packages\\numpy\\core\\numeric.py\", line 1807, in array_repr ', ', \"array(\") File \"C:\\Program Files\\Python 3.5\\lib\\site-packages\\numpy\\core\\arrayprint.py\", line 447, in array2string separator, prefix, formatter=formatter) File \"C:\\Program Files\\Python 3.5\\lib\\site-packages\\numpy\\core\\arrayprint.py\", line 325, in _array2string _summaryEdgeItems, summary_insert)[:-1] File \"C:\\Program Files\\Python 3.5\\lib\\site-packages\\numpy\\core\\arrayprint.py\", line 519, in _formatArray summary_insert) File \"C:\\Program Files\\Python 3.5\\lib\\site-packages\\numpy\\core\\arrayprint.py\", line 496, in _formatArray word = format_function(a[-1]) File \"C:\\Program Files\\Python 3.5\\lib\\site-packages\\numpy\\core\\arrayprint.py\", line 598, in __call__ if isnan(x): ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all() ``` Spot the `x[i].shape == x.shape[1:]` fallacy... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Normalize module docstring patterns From https://github.com/GoogleCloudPlatform/gcloud-python/pull/1164/files#r40942738. ``` $ git grep \"API wrapper\" gcloud/bigquery/__init__.py:\"\"\"Google Cloud BigQuery API wrapper. gcloud/dns/__init__.py:\"\"\"Google Cloud DNS API wrapper. gcloud/pubsub/__init__.py:\"\"\"Google Cloud Pubsub API wrapper. gcloud/resource_manager/__init__.py:\"\"\"Google Cloud Resource Manager API wrapper gcloud/search/__init__.py:\"\"\"Google Cloud Search API wrapper.\"\"\" $ git grep \"interacting with API\" gcloud/bigquery/client.py:\"\"\"gcloud bigquery client for interacting with API.\"\"\" gcloud/client.py:\"\"\"gcloud client base class for interacting with API.\"\"\" gcloud/dns/client.py:\"\"\"gcloud dns client for interacting with API.\"\"\" gcloud/pubsub/client.py:\"\"\"gcloud pubsub client for interacting with API.\"\"\" gcloud/search/client.py:\"\"\"gcloud dns client for interacting with API.\"\"\" gcloud/storage/client.py:\"\"\"gcloud storage client for interacting with API.\"\"\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda install --offline still performs online operations Even `conda` seems to notice that it shouldn't be doing an online operation when the `--offline` flag has been specified: ```bash $ conda install --offline statsmodels Fetching package metadata ........... Solving package specifications: . Package plan for installation in environment C:\\Users\\d53542\\AppData\\Local\\Continuum\\Anaconda2: The following packages will be UPDATED: statsmodels: 0.6.1-np111py27_1 --> 0.8.0-np111py27_0 Proceed ([y]/n)? y CondaError: RuntimeError(u'EnforceUnusedAdapter called with url https://repo.continuum.io/pkgs/free/win-64/statsmodels-0.8.0-np111py27_0.tar.bz2\\nThis command is using a remote connection in offline m ode.\\n',) CondaError: RuntimeError(u'EnforceUnusedAdapter called with url https://repo.continuum.io/pkgs/free/win-64/statsmodels-0.8.0-np111py27_0.tar.bz2\\nThis command is using a remote connection in offline m ode.\\n',) CondaError: RuntimeError(u'EnforceUnusedAdapter called with url https://repo.continuum.io/pkgs/free/win-64/statsmodels-0.8.0-np111py27_0.tar.bz2\\nThis command is using a remote connection in offline m ode.\\n',) C:\\Users\\d53542\\Documents\\GIT\\health_score>conda -V conda 4.3.17 ``` I'm at PyCon and am seeing this on the computer of someone I'm talking to (an Anaconda user) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: TPU Training Issues and Feature Requests TPU training is really cool. A couple issues that came up in training. * There is no longer a call to `optimizer_step` this is needed for setting learning rates that change over each step. Not sure how to fix this except by maybe having another \"post_optimizer\" call, which might be a better place for this style of stepping. * According to this tutorial https://github.com/pytorch/xla/blob/master/TROUBLESHOOTING.md `clip_grad_norm_` is very slow in XLA. The give a suggestion for a replacement function call. It would be nice if lightning just called this instead. * Nice to have: Point to that speed tutorial in the docs so people don't get stuck. * When using DDP, we have been using proc_rank to decide when to print debug statements. Might be nice to have a value that works with DDP and TPU to abstract away from using this term. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Windows: NameError: global name 'ExecOperation' is not defined If I try to run a `docker-compose exec` command it always gives me this error: ``` D:\\Path\\> docker-compose exec some-container some-command Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"compose\\cli\\main.py\", line 57, in main File \"compose\\cli\\main.py\", line 108, in perform_command File \"compose\\cli\\main.py\", line 347, in exec_command NameError: global name 'ExecOperation' is not defined docker-compose returned -1 ``` Is there a known bug on this message? My guess is that this has something to do with this message `Interactive mode is not yet supported on Windows.` when you use `docker-compose run` but I'm not sure.. Thanks for any help in advance! Some more system information: ``` D:\\> docker version Client: Version: 1.11.0 API version: 1.23 Go version: go1.5.4 Git commit: 4dc5990 Built: Wed Apr 13 18:13:28 2016 OS/Arch: windows/amd64 Server: Version: 1.11.0 API version: 1.23 Go version: go1.5.4 Git commit: 4dc5990 Built: Wed Apr 13 19:36:04 2016 OS/Arch: linux/amd64 D:\\> docker-compose version docker-compose version 1.7.0, build 0d7bf73 docker-py version: 1.8.0 CPython version: 2.7.11 OpenSSL version: OpenSSL 1.0.2d 9 Jul 2015 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BLD: Regression: improper double quotes appear in rpath (linux) ### Steps to reproduce the problem: I've observed a regression on RH7 when installing numpy (currently v1.16.0) with ```bash pip install numpy --force-reinstall --ignore-installed --no-binary :all: ``` Until now I had no problem with python 3.6.5 (and previous) and with earlier versions of numpy (v1.14.3), now I observe the following issue (python 3.7.2, and even python 3.6.5) with numpy 1.16.0. I fill `~/site.cfg` with information where to find lapack and blas libraries ```ini [lapack] lapack_libs = lapack language = gfortran library_dirs = /some/path/rh7/lapack/3.6.1/lib runtime_library_dirs = /some/path/rh7/lapack/3.6.1/lib [blas] blas_libs = blas,cblas language = gfortran library_dirs = /some/path/rh7/lapack/3.6.1/lib runtime_library_dirs = /some/path/rh7/lapack/3.6.1/lib ``` ### Observed problem: When I run `ldd` on the produced `numpy/linalg/lapack_lite.cpython-*m-x86_64-linux-gnu.so`, `liblapack.so`, `libblas.so` and `libblas.so` aren't found. When I ask `readelf -d numpy/linalg/lapack_lite.cpython-*m-x86_64-linux-gnu.so | grep rpath`, I see ``` 0x000000000000000f (RPATH) Library rpath: [\"/some/path/rh7/lapack/3.6.1/lib\"] ``` instead of ``` 0x000000000000000f (RPATH) Library rpath: [/some/path/rh7/lapack/3.6.1/lib] ``` that I had with previous versions of numpy. Removing the double-quotes with `chrpath` fixes the issue. ### Numpy/Python version information: Numpy 1.16.0 (according to `pip -v`) Python 1.6.5 and 1.7.2 No trouble with Numpy 1.14.3 (and earlier versions) and Python 1.6.5 (and earlier versions) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Multiple licenses in a single package The Beast library is available under the Boost license (https://github.com/TyRoXx/Beast/blob/17b04b87e05e636db4ea73dfa11f2710cd9aeeb1/LICENSE_1_0.txt), but it also brings the HTTP parser from node.js/NGINX which requires a separate license (MIT, https://github.com/TyRoXx/Beast/blob/17b04b87e05e636db4ea73dfa11f2710cd9aeeb1/src/http-parser/LICENSE-MIT). The following seems to be impossible as of 0.8.6: ``` Python license = \"Boost\", \"MIT\" ``` There should probably be a way to enumerate all licenses required by a package. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: barrier counted as non-local gate <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 14.1 - **Python version**: - **Operating system**: ### What is the current behavior? The `num_nonlocal_gates` method of the `QuantumCircuit` object counts mult-qubit barriers as non-local gates (since the `num_qubits` of the instruction is >1). I don't think users would expect this. ### Steps to reproduce the problem ``` qc = QuantumCircuit(n) qc.h(range(n)) qc.measure_all() qc.num_nonlocal_gates() ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug][2.0] patches cannot be applied when using cmake_layout Hello, It seems that `files.patch` and `cmake_layout` do not get along very well. The former does not find the patch files, even when specifying `base_path=self.build_folder`, although they are inside the build folder. I've joined a 2.0 version of `docopt.cpp` that shows the issue. ### Environment Details (include every applicable attribute) * Conan version: 2.0.0a2 ### Steps to reproduce (Include if Applicable) * create the package * uncomment the `layout` method * it should go to the `test_package` step ~(which breaks because `cmake_layout` is commented)~ ### Logs (Executed commands with output) (Include/Attach if Applicable) ``` ERROR: docopt.cpp/0.6.2-r1: Error in build() method, line 35 files.patch(self, **patch, base_path=self.build_folder) FileNotFoundError: [Errno 2] No such file or directory: 'patches/include-stdexcept.patch' ``` [docopt.cpp.zip](https://github.com/conan-io/conan/files/7897313/docopt.cpp.zip) EDIT: The test_package fails because I forgot to add `cmake_layout` there. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: `start_tasks` kwarg doesn't work The `start_tasks` kwarg appears to not be working: ```python from prefect import * GLOBAL_DICT = {'key': 0} class PrintTask(Task): def run(self): GLOBAL_DICT['key'] += 1 return 1 class ReturnTask(Task): was_called = False def run(self, x): if self.was_called is False: self.was_called = True raise ValueError(\"error\") return x with Flow() as f: t1 = PrintTask() t2 = ReturnTask(max_retries=1) result = t2(t1()) state = f.run(return_tasks=[t2]) state = f.run(return_tasks=[t2], start_tasks=[t2]) ## GLOBAL_DICT['key'] == 2 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add support for pid_mode 'service:name' 1. This would add a feature similar to `network_mode: service:svc_name` for the `pid` field of a service configuration. 2. This feature would be supported for the following formats when using `docker-compose`: 2.1, 2.2, 3.0-3.3 3. Support for this feature when using `docker stack` is out of scope of this proposal. Override: #4643 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Non sensical `fill_value: {var}` in masked array The following thing introduced by 61f9f6d0fb169cadefe35ea2bdd783848aa771f5 (Stefanv 2007), then seem to have spread by copy-past in the file; and is only present there in the numpy codebase. ``` numpy/ma/core.py 5442: fill_value : {var}, optional 5500: fill_value : {var}, optional 5546: fill_value : {var}, optional 5597: fill_value : {var}, optional 5668: fill_value : {var}, optional 5802: fill_value : {var}, optional 5879: fill_value : {var}, optional ``` I'm not sure what this means, and Stefan said: > Probably meant something like 'various', but I don't think that is a notion still used. This make jedi (that is used for tab-completion) choke on the docstrings to infer types. `{...}` is usually used to denotes set of values, like `{True, False}`, `{'C','F'}`, but `{var}` does not make much sense to me. If that has a specific meaning; can it be clarified ? otherwise removed ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: SuzukiTrotter class should not accept odd orders ### Environment - **Qiskit Terra version**: - **Python version**: - **Operating system**: It applies to all environments. ### What is happening? The SuzukiTrotter class in `qiskit.synthesis.evolution` currently accepts any integer as input for the order. However the formula is not defined for odd orders (see definition below) and even though the code works on such input, the results do not make sense when the order is odd.  ### How can we reproduce the issue? ```python from qiskit.opflow import X, Y from qiskit.circuit.library import PauliEvolutionGate from qiskit.synthesis import SuzukiTrotter op = X + Y time = 0.1 reps = 1 evo_gate = PauliEvolutionGate(op, time, synthesis=SuzukiTrotter(order=1, reps=reps)) ``` ### What should happen? It should raise an error message and do not accept odd integers as input for the order. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Unnecessary and deranging override message when using alias packages In a situation with 3 packages CA, CB and CC where CB requires CA (via an alias) and CC requires CB and CA also via aliases, when installing CC with a \"conan install ...\" conan reports a version override while actually the alias is pointing to exaclty the version of the package that conan says overrides the alias: CB/0.0.2@user/testing requirement CA/ALIAS@user/testing overriden by CC/0.0.3@user/testing to CA/0.0.1@user/testing To help us debug your issue please `explain:` - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Move memsharded/hello repository to the conan-io organization When using the ``conan new`` command, the conanfile.py created points to https://github.com/memsharded/hello and it is a bit weird to use an example out of the organization. We should move it to a isolated repo in the conan-io org and give it a better name, like: hello-cpp-lib-example After that, the ``conan new`` command should be updated to use the new repo Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Databricks integration I've been following Dagster for a month or so as we're looking to revamp our data pipelines at $company. We'll be using Spark for the majority of our ETLs, but using Databricks to manage our infrastructure rather than manually managing Spark clusters. I noticed that there was an EMR launcher for launching PySpark solids added a week or so ago. I haven't used EMR much, but think Databricks has a similar workflow where jobs are submitted using their [Jobs API](https://docs.databricks.com/dev-tools/api/latest/jobs.html#runs-submit) (which I've been using in the past through Airflow). Does this sound like a good candidate for a `dagster-databricks` integration library? And if so, are their any plans to support Databricks already, or would you be accepting contributions there? Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Incorrect type hint of \"exponential_decay_length_penalty\" in function \"generate\" Hi, Please check below line, https://github.com/huggingface/transformers/blob/7e7f62bfa72ca03e9f16285dad182f7c57cd8cab/src/transformers/generation_utils.py#L956 According to doc string, \"exponential_decay_length_penalty (`tuple(int, float)`, *optional*, defaults to `model.config.exponential_decay_length_penalty`):\" (https://github.com/huggingface/transformers/blob/main/src/transformers/generation_utils.py#L1114) the correct type hint should be \"Optional[Tuple[int, float]]\", the number of tuple elements should be 2, and must be \"int\" in position 0, and \"float\" in position 1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: increase spacing of parameters in latex drawer QISKit's visualization module is not properly drawing the **cu1** gate. With the following code, ``` from qiskit import QuantumProgram from qiskit.tools.visualization import circuit_drawer qp = QuantumProgram() qr = qp.create_quantum_register('qr', 3) cr = qp.create_classical_register('cr', 1) qc = qp.create_circuit('test', [qr], [cr]) qc.cu1(2.3, qr[0], qr[2]) qc.measure(qr[1], cr[0]) circuit_drawer(qc) ``` The obtained image is,  Which is clearly corrupt. ### Informations - **Qiskit (Python SDK) version**: 0.5.7 - **Python version**: 3.6.6 - **Operating system**: Ubuntu 18.04.1 LTS Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumCircuit.draw() does not draw circuit in terminal <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? Currently returns a `<qiskit.visualization.text.TextDrawing>`. However, it should print to the terminal because it is an explicit command to draw the circuit. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Disable .netrc authentication Anaconda-Server/support#23 When a user has a `~/.netrc` file present, `requests` will use that file to populate the `Authorization` header (using HTTP Basic auth). When authorization fails, conda falls into an infinite loop retrying. To fix this problem in `anaconda-client`, I disabled `.netrc` authorization by adding a `NullAuth` to the `requests.Session`. https://github.com/Anaconda-Server/anaconda-client/pull/298 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda init keeps modifying powershell profile Repeated calls to conda init keep modifying profile.ps1 each time. ``` (base) wani@lenovo ~/h/conda ❯❯❯ conda init --all ... modified /home/wani/.config/powershell/profile.ps1 ... (base) wani@lenovo ~/h/conda ❯❯❯ conda init --all ... modified /home/wani/.config/powershell/profile.ps1 ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: FakeBackendV2 runs noise-less simulation if not touching `target` in advance ### Environment - **Qiskit Terra version**: main branch - **Python version**: 3.8 - **Operating system**: Mac ### What is happening? `FakeBackendV2.run` invokes noise-less simulation if it is called before touching `target` (more precisely, if it is called before the internal `_target` object is populated). ### How can we reproduce the issue? Run the following code. ``` from qiskit.circuit import QuantumCircuit from qiskit.providers.fake_provider.backends import FakeManilaV2 circ = QuantumCircuit(2, 2) circ.cx(0, 1) circ.measure([0, 1], [0, 1]) result = FakeManilaV2().run(circ).result() counts = result.get_counts() print(counts) # -> {'00': 1024} (noise-less result) ``` ### What should happen? Noisy simulation should be run if `qiskit_aer` is installed (as like FakeBackend V1). ### Any suggestions? [This line](https://github.com/Qiskit/qiskit-terra/blob/4a857f61146fb185878abd8634524941d71f1f6b/qiskit/providers/fake_provider/fake_backend.py#L124) should be replaced with `if self.target:` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Call for comments: Python 2.6 support will be dropped August 1, 2016 Anyone who thinks they still need Python 2.6, please speak up here. (Sorry there isn't a better channel.) Relates to #995 /cc @tseaver @jgeewax Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Numpy 1.16.1 fails to run tests Newly released NumPy 1.16.1 built and installed from source fails to run tests: > python3 setup.py build > sudo python3 setup.py install ``` import numpy numpy.test('full') NumPy version 1.16.1 NumPy relaxed strides checking option: True ================================================================================================================== ERRORS =================================================================================================================== _____________________________________________________________________________________________ ERROR collecting core/_multiarray_module_test.py ______________________________________________________________________________________________ import file mismatch: imported module 'numpy.core._multiarray_module_test' has this __file__ attribute: /usr/local/lib/python3.6/dist-packages/numpy-1.16.1-py3.6-linux-x86_64.egg/numpy/core/_multiarray_module_test.cpython-36m-x86_64-linux-gnu.so which is not the same as the test file we want to collect: /usr/local/lib/python3.6/dist-packages/numpy-1.16.1-py3.6-linux-x86_64.egg/numpy/core/_multiarray_module_test.py HINT: remove __pycache__ / .pyc files and/or use a unique basename for your test file modules !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Interrupted: 1 errors during collection !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! 1 error in 4.18 seconds False ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Channels in centrally installed .condarc file are being ignored in conda 4.3.4 Hi, I am testing a centrally installed Anaconda setup with Anaconda installed under `C:\\Program Files\\Anaconda3`. I have a condarc file under `C:\\Program Files\\Anaconda3\\.condarc`. When I run `conda info` it tells me that my config file is under the correct location. config file : C:\\Program Files\\Anaconda3\\.condarc I have configured a few custom channels in this `.condarc` file, e.g.: channels: - http://some.internal/url I can also use `conda config --system --add channels http://some.internal/url` to set this value and conda tells me that channels already contains this value. But when I run `conda config --system --show`, the list of channels is always set to: channels: - defaults It seems that the list of channels in the central `.condarc` file is completely ignored and always replaced by `defaults`. I have also tried to set the list of `default_channels` in the central `.condarc` file but without success. Using conda 4.3.4 on win-64. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: AttributeError: 'Client' object has no attribute 'kill' The kill method on a DirectView throws an attribute error. The following code demonstrates the problem: ``` python import time from IPython.utils.path import locate_profile from IPython.parallel.apps.launcher import LocalControllerLauncher, LocalEngineLauncher from IPython.parallel import Client controller = LocalControllerLauncher(profile_dir=locate_profile()) controller.start() e = LocalEngineLauncher(profile_dir=locate_profile()) e.start() time.sleep(1) rc = Client() time.sleep(5) dv = rc[:] dv.kill() rc.shutdown(hub=True) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: multi-gpu ddp calls validation and testing loops too many times When using ddp with multiple gpus, each validation and test loop is called with the entire validation dataset for each gpu. Expected behavior is that the dataset is divided appropriately across the gpus. I am using current master (cloned Mar 14), Ubuntu 19.10, Cuda 10.1, python 3.7.5, pytorch 1.4, venv environment. The problem appears to be in `auto_add_sampler()` in data_loading.py. It does not create a `DistributedSampler` for validation or test datasets. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: dependency got using find_library is not deduplicated for static library builds Simple test case attached. [Original issue found when porting DPDK project to meson, where we got errors due to too many parameters.] Setup: liba, which depends on libdl, and pthreads. Libb which depends on liba. App which depends on both liba and libb Shared build looks ok, no duplication seen with latest HEAD: ``` $ ninja -v -j1 <snip for brevity> [8/8] ccache cc -o app/app 'app/app@exe/app.c.o' -Wl,--no-undefined -Wl,--as-needed -Wl,--start-group liba/liba.so libb/libb.so -pthread -ldl -Wl,--end-group -ldl '-Wl,-rpath,$ORIGIN/../liba:$ORIGIN/../libb' -Wl,-rpath-link,/home/bruce/temp/meson-test/shared_build/liba:/home/bruce/temp/meson-test/shared_build/libb ``` Static library shows a large amount of duplication for -ldl, but not pthreads, despite both being listed as dependencies in the same places: ``` $ ninja -v -j1 <snip for brevity> [6/6] ccache cc -o app/app 'app/app@exe/app.c.o' -Wl,--no-undefined -Wl,--as-needed -Wl,--start-group liba/liba.a libb/libb.a -pthread -ldl -Wl,--end-group -ldl -ldl -ldl -ldl -ldl ``` [meson-test.zip](https://github.com/mesonbuild/meson/files/1194545/meson-test.zip) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add how-to Guide for Snowflake operators **Description** A guide that describes how to use all the operators for Snowflake (https://github.com/apache/airflow/tree/master/airflow/providers/snowflake/operators) would be useful. Other guides are available: https://airflow.readthedocs.io/en/latest/howto/operator/index.html Source code for those guides are at: https://github.com/apache/airflow/tree/master/docs/howto/operator Are you wondering how to start contributing to this project? Start by reading our [contributor guide](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst) Best regards, Kaxil Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Support list values in entities Right now, we support timestamps, keys, booleans, doubles, integers, and strings, but not lists. I think it'd be nice if we could figure out how to support saving lists in a nice way. Ref: https://cloud.google.com/datastore/docs/apis/v1beta2/entity Support list values in entities Right now, we support timestamps, keys, booleans, doubles, integers, and strings, but not lists. I think it'd be nice if we could figure out how to support saving lists in a nice way. Ref: https://cloud.google.com/datastore/docs/apis/v1beta2/entity Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Investigate size of cloudpickle payloads passed to `executor.submit` Currently, we submit a class method to `executor.submit`. This ultimately has the effect of serializing large portions of the class that could actually be imported. I believe that our unusually large submissions here are partially responsible for eating up Dask Scheduler CPU cycles, but we'll need to investigate further to decide if that's true. Ultimately this ticket is for: - determining the effect of our payload size on the dask scheduler - reducing our payload sizes where possible Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Enable passing different container names from gRPC services to EcsRunLauncher ### What's the use case? The `DAGSTER_CONTAINER_CONTEXT` currently accepts some parameters from the gRPC server the run belongs, such as `task_definition_arn`. This would, however, require all gRPC services to have a container named `run` (or some other arbitrary name). It would be great to vary the container name depending on the gRPC task, such as `'{\"ecs\": \"task_definition_arn\": \"<your arn here>\", \"container_name\": \"my_cool_container\"}'`. ### Ideas of implementation _No response_ ### Additional information See Slack discussion under https://dagster.slack.com/archives/C014UDS8LAV/p1667921690467969 ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Japanese (MeCab): the very first call of `nlp` fails ## How to reproduce the behaviour <!-- Include a code example or the steps that led to the problem. Please try to be as specific as possible. --> The very first call of `nlp` (probably for any string) results in an error: ```python >>> import spacy >>> nlp = spacy.blank('ja') >>> nlp('pythonが大好きです') Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/usr/local/lib/python3.6/site-packages/spacy/language.py\", line 340, in __call__ doc = self.make_doc(text) File \"/usr/local/lib/python3.6/site-packages/spacy/lang/ja/__init__.py\", line 117, in make_doc return self.tokenizer(text) File \"/usr/local/lib/python3.6/site-packages/spacy/lang/ja/__init__.py\", line 81, in __call__ doc = Doc(self.vocab, words=words, spaces=[False]*len(words)) File \"doc.pyx\", line 176, in spacy.tokens.doc.Doc.__init__ File \"doc.pyx\", line 559, in spacy.tokens.doc.Doc.push_back ValueError: [E031] Invalid token: empty string ('') at position 0. >>> nlp('pythonが大好きです') pythonが大好きです >>> ``` MeCab is installed according to https://github.com/SamuraiT/mecab-python3#user-content-installation-and-usage. The example from there works: ```python >>> import MeCab >>> mecab = MeCab.Tagger (\"-Ochasen\") >>> print(mecab.parse(\"pythonが大好きです\")) python python python 名詞-固有名詞-組織 が ガ が 助詞-格助詞-一般 大好き ダイスキ 大好き 名詞-形容動詞語幹 です デス です 助動詞 特殊・デス 基本形 EOS >>> ``` ## Info about spaCy * **spaCy version:** 2.0.16 * **Platform:** Linux-3.16.0-4-amd64-x86_64-with-debian-8.10 * **Python version:** 3.6.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: RuntimeError: can't start new thread ``` error: RuntimeError(\"generator didn't stop after throw()\",) command: /home/mholekev/miniconda3/bin/conda install --yes numpy scipy matplotlib jupyter git pandas user_agent: conda/4.4.4 requests/2.18.4 CPython/3.6.3 Linux/2.6.32-696.10.3.el6.x86_64 centos/6.7 glibc/2.12 _messageid: -9223372036842075552 _messagetime: 1514766990662 / 2017-12-31 18:36:30 Traceback (most recent call last): File \"/home/mholekev/miniconda3/lib/python3.6/site-packages/conda/common/io.py\", line 399, in backdown_thread_pool yield ThreadPoolExecutor(max_workers) File \"/home/mholekev/miniconda3/lib/python3.6/site-packages/conda/core/index.py\", line 214, in get_reduced_index new_records = query_all(spec) File \"/home/mholekev/miniconda3/lib/python3.6/site-packages/conda/core/index.py\", line 187, in query_all return tuple(concat(future.result() for future in as_completed(futures))) File \"/home/mholekev/miniconda3/lib/python3.6/site-packages/conda/core/index.py\", line 187, in <genexpr> return tuple(concat(future.result() for future in as_completed(futures))) File \"/home/mholekev/miniconda3/lib/python3.6/concurrent/futures/_base.py\", line 217, in as_completed fs = set(fs) File \"/home/mholekev/miniconda3/lib/python3.6/site-packages/conda/core/index.py\", line 186, in <genexpr> futures = (executor.submit(sd.query, spec) for sd in subdir_datas) File \"/home/mholekev/miniconda3/lib/python3.6/concurrent/futures/thread.py\", line 123, in submit self._adjust_thread_count() File \"/home/mholekev/miniconda3/lib/python3.6/concurrent/futures/thread.py\", line 142, in _adjust_thread_count t.start() File \"/home/mholekev/miniconda3/lib/python3.6/threading.py\", line 846, in start _start_new_thread(self._bootstrap, ()) RuntimeError: can't start new thread ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: API Endpoint - Dags details/Task **Description** We need to have endpoints that allow us to read information about workflow - DAG, Task. Endpoints should properly support serialization. - GET /dags/{dag_id}/details - GET /dags/{dag_id}/tasks - GET /dags/{dag_id}/tasks/{task_id} More details about API Endpoints: https://github.com/apache/airflow/issues/8118 **Use case / motivation** N/A **Related Issues** N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: qtconsole ipython 0.13.2 - html/xhtml export fails Hi, I'm having problems trying to export qtconsole sessions to html/xhtml on my linux box(Macbook Pro). I'm running python 3.3.2. The html export fails with: ``` 'Traceback (most recent call last): File \"/usr/lib/python3.3/site-packages/IPython/frontend/qt/console/rich_ipython_widget.py\", line 71, in export_html super(RichIPythonWidget, self).export_html() File \"/usr/lib/python3.3/site-packages/IPython/frontend/qt/console/console_widget.py\", line 615, in export_html self._html_exporter.export() File \"/usr/lib/python3.3/site-packages/IPython/frontend/qt/rich_text.py\", line 80, in export if inline is None and IMG_RE.search(html): TypeError: can't use a string pattern on a bytes-like object' ``` The xhtml export fails with : 'Type string doesn't support the buffer API' Am I doing something wrong? Cheers Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Operator.transpose fails for rectangular operators <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? `Operator.transpose` doesn't swap input and output operator dimensions, which causes a failure for non-square operators. ### Steps to reproduce the problem ```python op = Operator([[0, 1, 2, 3]]) op.transpose() `` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub MergeFrom error publish message 🏷 pub/sub SO: Linux/Ubuntu 16.04 api_core_version = 1.3.0 client_library_version = None gapic_version = 0.37.2 grpc_version = 1.14.2 python_version = 3.6.4 ``` client = pubsub.PublisherClient.from_service_account_json('account.json') topic_path = client.topic_path('project_name', 'topic_name') data = b'The rain in Wales falls mainly on the snails.' response = client.publish(topic, data) ``` Version: google-cloud-pubsub==0.37.2 ## Error: ` response = client.publish(topic_path, data) File \"venvpy/lib/python3.6/site-packages/google/cloud/pubsub_v1/gapic/publisher_client.py\", line 393, in publish messages=messages, TypeError: Parameter to MergeFrom() must be instance of same class: expected google.pubsub.v1.PubsubMessage got int.` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Checkpoint saving order The last model save action, [here](https://github.com/PyTorchLightning/pytorch-lightning/blob/1369012bc71f257dcf7423ec65146d055ddc1cc7/pytorch_lightning/callbacks/model_checkpoint.py#L295), should be after saving the top k model because the best model and best score could have changed. Swapping the order allows resuming the training from the last checkpoint, with the last checkpoint having the latest information about the best model path/score. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Bring in more resolution to hivestats Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson 0.46.0 - invalid .pc file written for libgxps This is a sample,other builds can excerpt the same. libgxps.pc generated with meson < 0.46.0 (tested with 0.45.0) contains: ``` Requires: gobject-2.0 >= 2.36.0, gio-2.0 >= 2.36.0, libarchive >= 2.8.0, cairo >= 1.10.0 ``` The same source build using meson 0.46.0 contains: ``` Requires: gobject-2.0 >= 2.36.0,gio-2.0>=2.36.0,libarchive>=2.8.0,cairo>;=1.10.0 ``` which in turn is not understood by pkgconfig: ``` $ pkg-config --libs libgxps Package gio-2.0>=2.36.0 was not found in the pkg-config search path. Perhaps you should add the directory containing `gio-2.0>=2.36.0.pc' to the PKG_CONFIG_PATH environment variable Package 'gio-2.0>=2.36.0', required by 'libgxps', not found ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: tokenizer_bert.py not call _clean_text? for transformers/src/transformers/tokenization_bert.py, there is a function called _clean_text. But seems this function is not be called at all? In google bert(https://github.com/google-research/bert/blob/master/tokenization.py) there exists a same function and that function has been called at the beginning of the tokenization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Remove some more redundant parentheses Removed redundant parentheses in airflow/_vendor/connexion/apis/flask_api.py and in many more Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Support `norm=\"unnormalized\"` for FFT functions? I tried searching in the issue tracker here but didn't find any, so let me know if this is a duplicate. This issue was first brought up in CuPy (cupy/cupy#944) and has regained some interest, and I believe it's better to be implemented/considered first in upstream, which downstream libraries like SciPy and CuPy can follow. The desired effect is to do the normalization opposite to `norm=None`; that is, the backward/inverse transform is unscaled, and the forward transform is scaled by 1/n. For a perfectionist's point of view adding this option makes a lot of sense, as it would cover every possible normalization scheme. In particular, for GPU libraries like CuPy this could be performance critical for certain applications, as kernel launching is more costly in the GPU world. People usually don't do extra work whenever possible, especially if the normalization is of no interest. The name `\"unnormalized\"` can be changed to a more informative one. I don't have any preference (in fact I'm just a messenger bringing this to NumPy...) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: add convenience wrapper for array updating with fancy index expressions We should provide an `update` function that lets users write ```python A = lax.update(A, (slice(1, None, 2), Ellipsis, slice(None, -3)), value) ``` which would behave similarly to this kind of expression in regular NumPy ```python A[1::2, ..., :-3] = value ``` except without the in-place mutation that would update any aliases. This wrapper would be similar to the `lax_numpy._rewriting_take` function we already have for handling complex indexing expressions, and would ultimately call into primitives like `lax.dynamic_update_slice` and `lax.index_untake`. Better name suggestions welcome! This is a separate issue from whether to provide more convenient syntax for this kind of operation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Structured array - Introduction - Doc error On page : http://docs.scipy.org/doc/numpy-1.10.1/user/basics.rec.html Structured array - Introduction In the example : \"Conveniently, one can access any field of the array by indexing using the string that names that field.\" ``` y = x['foo'] should be >>> y = x['bar'] (the actual name of the \"second\" field which is addressed along the example). Additionally, this has to be updated at several places on the page. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Improve TI modal layout on smaller screens Improves the presentation of the Task Instance modal when the browser width is >992px (tablets, mobile). | Before | After | |---|---| | <img width=\"489\" alt=\"Image 2020-11-18 at 12 00 02 PM\" src=\"https://user-images.githubusercontent.com/3267/99562683-69b16a00-2996-11eb-8609-75dabd4be7eb.png\"> | <img width=\"489\" alt=\"Image 2020-11-18 at 11 58 50 AM\" src=\"https://user-images.githubusercontent.com/3267/99562695-6ae29700-2996-11eb-813c-b82666aa666f.png\"> | Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Add support for cloud clusters in Dask resource Add support for creating Dask clusters on AzureML, ECS, and Fargate in the Dask resource. This does not cover the Dask executor. But, the executor should gain the same capabilities when its Dask implementation is merged with the Dask resource (see #2901). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: mpl drawer has inconsistent use of hyphens and math minus signs <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.8 - **Operating system**: Ubuntu 18.04 ### What is the current behavior? The mpl drawer changes leading hyphens in parameters to the math mode minus sign, which is similar in width to the + and about twice the width of a hyphen. There are other places, such as e notation and the imaginary part of complex numbers, where a minus is intended, but a hyphen is used. Note below. ### Steps to reproduce the problem ``` from qiskit import QuantumCircuit qc = QuantumCircuit(1) qc.u1(complex(-1.0, -1.0), 0) qc.u1(-1e-7, 0) qc.draw('mpl') ```  Also note that pi_check returns +- for the imaginary part instead of just -. ### What is the expected behavior? ### Suggested solutions For all parameter expressions in the mpl drawer, convert hyphens to minus signs. Since all parameters go through pi_check, this could be done at the pi_check level. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Start tagging for release versions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: java: install jar files to share/java by default Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Python 3.9 on linux hangs when using multiprocessing <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: Master - **Python version**: 3.9 - **Operating system**: Linux ### What is the current behavior? On the linux 3.9 ci job there have been several jobs recently that fail due to a job timeout after 1 hour. For example: https://dev.azure.com/qiskit-ci/qiskit-terra/_build/results?buildId=26619&view=logs&jobId=53f3e6ef-9cd2-51f8-4c23-ef405deeeb83&j=53f3e6ef-9cd2-51f8-4c23-ef405deeeb83&t=f9e6fb36-fdac-5369-6649-12f2d7a63b5d Looking through the logs there, partway through the job test runner `{1}` stops reporting test status early on in the job. It is only partway through the `test.python.algorithms.test_vqe.TestVQE` test class when it stops reporting test status. This means one of the test methods it has yet to run in the class have likely gotten stuck for some reason and the job just hits the 1 hr timeout and exits. ### Steps to reproduce the problem Run unit tests in the linux 3.9 ci environment. ### What is the expected behavior? Test finish, either success or failure. ### Suggested solutions Figure out the root cause and fix. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: RemoveFinalMeasurement scales superlinearly with gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> The RemoveFinalMeasurement pass scales superlinearly with the number of gates in a circuit. For a randomly generated circuit of equal width and depth this pass scales as width^n where n ~ 2.8 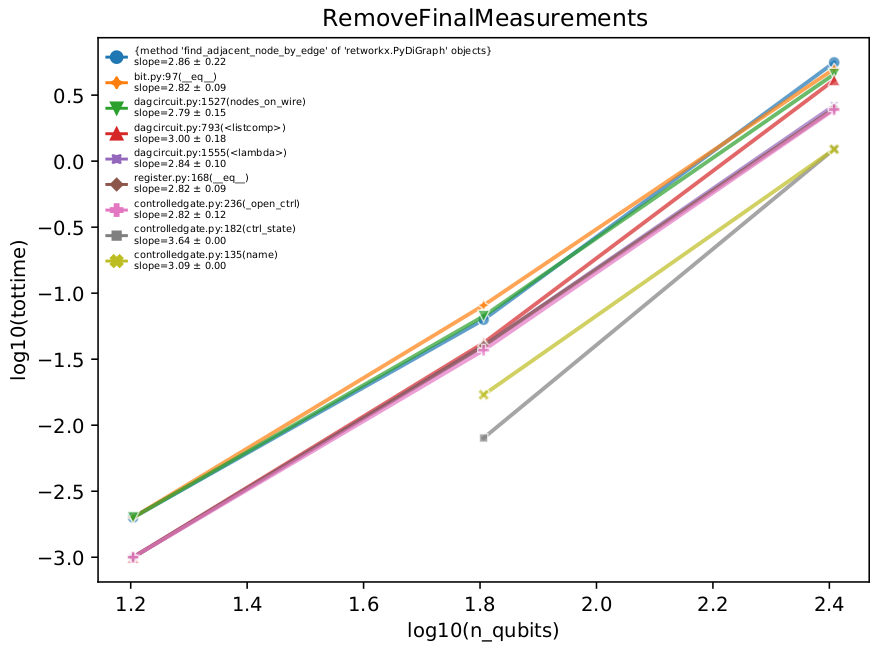 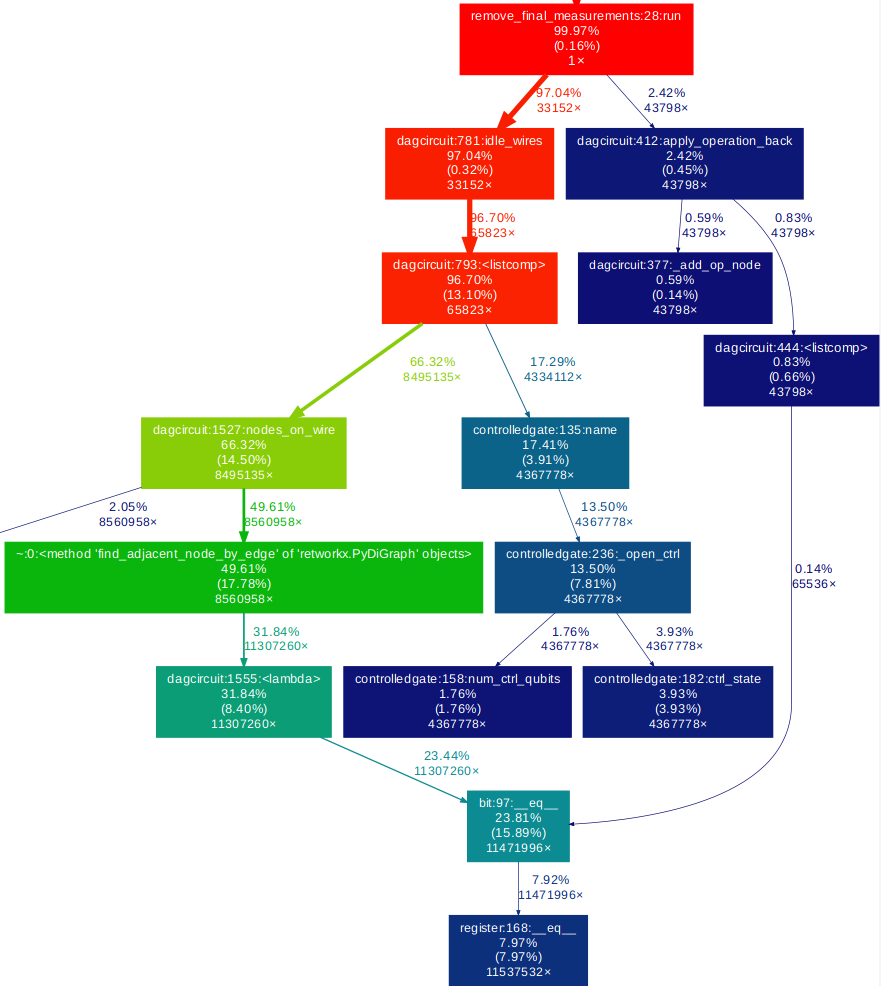 ### What is the expected enhancement? It seems like the scaling could be <= 2. Since the number of final measurements can be at most the number of qubits, this might be closer to 1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Improve callback system Following the [new callback system](https://github.com/PyTorchLightning/pytorch-lightning/pull/889) here are a few things we might want to do proposed by people who participated in #889 and #896. - [ ] Consolidate model hooks and callbacks system. Make the calls at the same moment: https://github.com/PyTorchLightning/pytorch-lightning/pull/889#issuecomment-590634896 - [ ] Fix `on_train_begin()` being called in the early stopping callbacks: https://github.com/PyTorchLightning/pytorch-lightning/pull/889#discussion_r383052267 - [ ] Assert `pl_module` and `trainer` are excepted object instances in the callback system train tests: https://github.com/PyTorchLightning/pytorch-lightning/pull/889#discussion_r383051932 - [ ] Incorporate existing callbacks into the new callback system. - [ ] Edit the changelog ping @Borda @williamFalcon @jeremyjordan @awaelchli Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: error on $DAGSTER_HOME set to \".\" this doesn't fail in any intuitive way - a lot of things sort of work assuming you run most commands from one directory Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: VS 2019 with older toolsets broken since 1.15.0 This is the same as https://github.com/conan-io/conan/issues/5318, but for Visual Studio 2019. With Visual Studio 2019 (16.0), you can also install the Visual Studio 2017 (v141) and 2015 (v140) build tools. This broke with https://github.com/conan-io/conan/commit/6d3282fad34365eeee530e3b69e4eb91ec3e9338, as only the v142 toolset can be used now if you don't have older IDEs installed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Feature request: allow reading the build options line from inside meson.build Hey! I'm working on some enhancements to a wrap, and one of the missing features is storing the configuration line inside the config.h header. Meson already saves this information in the build log, so currently I'm using a hack to extract this information at setup time: ```python import re import os if __name__ == '__main__': with open(f'{os.environ[\"MESON_BUILD_ROOT\"]}/meson-logs/meson-log.txt', encoding=\"utf-8\", mode='r') as f: lines = [line for line in f if 'Build Options' in line] options = re.match(r'Build Options:\\s+(.+)$', lines[-1]) if options is not None: print(options.group(1)) ``` And then in meson.build: ```meson extractor = find_program('capture_build_options.py', required: true) configuration = run_command(extractor) assert(configuration.returncode() == 0, 'Could not extract configuration string from meson!') final_conf = configuration_data() final_conf.set_quoted('CONFIGURATION', configuration.stdout().strip()) configure_file( output: 'config.h', configuration: final_conf, ) ``` Would it be possible to add a read-only variable, perhaps to the `meson` object, to access this information? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: mesonintrospect --dependencies returns list instead of dictionary Reported it breaking completely in #1963 . When I got around to testing the fix just now I noticed that the root object for mesonintrospect --dependencies now is a list instead of an object like it used to be prior to 0.41. Probably not what is wanted. Example output (added newlines to make it easier to read): ```shell $ mesonintrospect --dependencies <build path> [\"threads\", {\"compile_args\": [], \"link_args\": []}, \"libjpeg\", {\"compile_args\": [], \"link_args\": [\"-ljpeg\"]}, \"libpng\", {\"compile_args\": [\"-I/usr/include/libpng16\"], \"link_args\": [\"-lpng16\"]}, \"libwebp\", {\"compile_args\": [], \"link_args\": [\"-lwebp\"]}] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: TypeError: kwargs_from_env() got an unexpected keyword argument 'environment' after 1.7 update Hello! After updating Docker got this error when building: ``` $ docker-compose build Traceback (most recent call last): File \"/usr/bin/docker-compose\", line 9, in <module> load_entry_point('docker-compose==1.7.0', 'console_scripts', 'docker-compose')() File \"/usr/lib/python2.7/site-packages/compose/cli/main.py\", line 57, in main command() File \"/usr/lib/python2.7/site-packages/compose/cli/main.py\", line 105, in perform_command project = project_from_options('.', options) File \"/usr/lib/python2.7/site-packages/compose/cli/command.py\", line 31, in project_from_options environment=environment File \"/usr/lib/python2.7/site-packages/compose/cli/command.py\", line 76, in get_project host=host, environment=environment File \"/usr/lib/python2.7/site-packages/compose/cli/command.py\", line 49, in get_client environment=environment File \"/usr/lib/python2.7/site-packages/compose/cli/docker_client.py\", line 52, in docker_client kwargs = kwargs_from_env(environment=environment) TypeError: kwargs_from_env() got an unexpected keyword argument 'environment' ``` I'm using Fedora 23. Docker from docker repository. ``` $ rpm -qa | grep -i docker docker-compose-1.7.0-1.fc23.noarch python-docker-py-1.7.2-1.fc23.noarch docker-engine-1.11.0-1.fc23.x86_64 python-dockerpty-0.4.1-2.fc23.noarch python3-docker-py-1.7.2-1.fc23.noarch docker-engine-selinux-1.11.0-1.fc23.noarch ``` ``` $ python --version Python 2.7.11 ``` Docker-compose 1.6 still works well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Ancestor's PATH component is repeated in PATH in activate.sh For the `virtualenv` generator, I'm seeing the path that I append to `env_info` in a distant ancestor repeated in the `PATH=` variable set in the generated `activate.sh` a number of times equal to that ancestor's `requires()` distance from the ultimately installed package. If my package requires C that requires B that requires A, then the `PATH` I set up in A is repeated four times in `activate.sh` if I install C. I only append it once in the `package_info(self)` method of the ancestor. Is this known, or is there something I might be doing wrong? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: python3 notebook: TypeError: unorderable types I got this traceback when starting an python3 notebook on current git head: ``` Traceback (most recent call last): File \"/usr/lib/python3/dist-packages/tornado/web.py\", line 954, in _execute getattr(self, self.request.method.lower())(*args, **kwargs) File \"/usr/lib/python3/dist-packages/tornado/web.py\", line 1667, in wrapper return method(self, *args, **kwargs) File \"/usr/lib/python3/dist-packages/IPython/frontend/html/notebook/handlers.py\", line 676, in get self.finish(jsonapi.dumps(cm.list_profiles())) File \"/usr/lib/python3/dist-packages/IPython/frontend/html/notebook/clustermanager.py\", line 95, in list_profiles result.sort() TypeError: unorderable types: dict() < dict() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: clean up cli import in conda 4.3.x clean up cli import in conda 4.3.x Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: not compatible with numpy 1.18 and python 3.7 With numpy 1.18 and python 3.7, `import jax` will raise the error ```python >>> import jax Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/home/fehiepsi/miniconda3/envs/py37/lib/python3.7/site-packages/jax/__init__.py\", line 20, in <module> from jax import nn File \"/home/fehiepsi/miniconda3/envs/py37/lib/python3.7/site-packages/jax/nn/__init__.py\", line 17, in <module> from . import initializers File \"/home/fehiepsi/miniconda3/envs/py37/lib/python3.7/site-packages/jax/nn/initializers.py\", line 28, in <module> from jax import random File \"/home/fehiepsi/miniconda3/envs/py37/lib/python3.7/site-packages/jax/random.py\", line 33, in <module> from . import numpy as np File \"/home/fehiepsi/miniconda3/envs/py37/lib/python3.7/site-packages/jax/numpy/__init__.py\", line 16, in <module> from .lax_numpy import * File \"<frozen importlib._bootstrap>\", line 1019, in _handle_fromlist File \"/home/fehiepsi/miniconda3/envs/py37/lib/python3.7/site-packages/jax/numpy/lax_numpy.py\", line 3211, in wrapped raise NotImplementedError(msg.format(fun)) NotImplementedError: Numpy function <function __getattr__ at 0x7f029e9dd560> not yet implemented ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Early stopping conditioned on metric `val_loss` isn't recognised when setting the val_check_interval **Describe the bug** Training stops when setting `val_check_interval`<1.0 in the Trainer class as it doesn't recognise `val_loss`. I get the following warning at the end of the 3rd epoch: ``` Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,train_loss ``` **To Reproduce** Steps to reproduce the behavior: 1. Run the CoolModel example but change the `trainer` line to trainer = Trainer(val_check_interval=0.5,default_save_path=\"test\") 2. Training will stop at the end of the third epoch and the above warning will show. **Expected behavior** Training shouldn't stop and `val_loss` should be recognised. **Desktop (please complete the following information):** - VM: Google Colab - Version 0.5.3.2 **Additional context** This doesn't happen with 0.5.2.1 although it looks like something has changed with model saving mechanism since it only seems to save the best model in 0.5.3.2. EDIT: Also seems to happen when setting `train_percent_check`<1.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: HMAC Service Account key support (@tseaver) Working from the internal support request / user guide, steps are: - [x] Add class `google.cloud.storage.hmac.HMACKeyMetadata` (representing resource returned from create / get / list operations, and passed to update). Holds reference to a client, and maps resource entities onto properties. (#8041) - [x] Add `Client.create_hmac_key` method, taking `service_account_email` and returning a tuple, `(metadata, secret)`, where `metadata` is an `HMACKeyMetadata` instance and `secret` is the bytes returned by the `hmacKeys.create` API. (#8043) - [x] Add `Client.list_hmac_keys` method, taking optional `service_account_email`, `max_results`, and `show_deleted_keys`, and returning an iterator whose items are `HMACKeyMetadata` instances. (#8043) - [x] Add `HMACKeyMetadata.exists` method. (#8045) - [x] Add `HMACKeyMetadata.reload` method. (#8045) - [x] Add `HMACKeyMetadata.update` method, pushing the current value of the `HMACKeyMetadata.state` property. (#8045) - [x] Add `HMACKeyMetadata.delete` method. (#8045) - [x] Add system tests exercising the CRUD cycle. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: resolve web ui views warning re DISTINCT ON ### Body Got this warning in webserver output when loading home page ``` /Users/dstandish/code/airflow/airflow/www/views.py:710 SADeprecationWarning: DISTINCT ON is currently supported only by the PostgreSQL dialect. Use of DISTINCT ON for other backends is currently silently ignored, however this usage is deprecated, and will raise CompileError in a future release for all backends that do not support this syntax. ``` looks like it's this line ``` dagtags = session.query(DagTag.name).distinct(DagTag.name).all() ``` may be able to change to `func.distinct` ### Committer - [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Job Monitor fails in possible race condition <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.11.0.dev0+cf9c3f8 - **Python version**: Python 3.6.8 - **Operating system**: Linux 4.15.0-66-generic #75-Ubuntu SMP Tue Oct 1 05:24:09 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux ### What is the current behavior? Job monitor fails unrepeatably in a fashion suggesting that if the job has finished right at the instant the job monitor loops it ends up comparing `None` with an `int`. ``` Job Status: job is queuedTraceback (most recent call last): File \"qyq.py\", line 348, in <module> job_monitor(job_exp) File \"/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/tools/monitor/job_monitor.py\", line 84, in job_monitor quiet=quiet, output=output) File \"/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/tools/monitor/job_monitor.py\", line 49, in _text_checker interval = max(job.queue_position(), 2) TypeError: '>' not supported between instances of 'int' and 'NoneType' ``` ### Steps to reproduce the problem Not reproduceable on-demand. This occured on `ibmq_london` ### What is the expected behavior? Job monitor survive any value returned by backend. ### Suggested solutions None at present. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.36.0 test regression test cases/frameworks/13 yelp Hi, after trying to package the new 0.36.0 version i have noticed a test regression in ```test cases/frameworks/13 yelp```. I have used ```MESON_PRINT_TEST_OUTPUT=1``` but not quote sure what the problem is: ``` Failed test: test cases/frameworks/13 yelp Reason: Running install failed. The Meson build system Version: 0.36.0 Source dir: /build/meson/src/meson-0.36.0/test cases/frameworks/13 yelp Build dir: /build/meson/src/meson-0.36.0/b 9cu54r21 Build type: native build Project name: yelp Native c compiler: cc (gcc 6.2.1) Appending CFLAGS from environment: '-march=i686 -mtune=generic -O2 -pipe -fstack-protector-strong' Appending LDFLAGS from environment: '-Wl,-O1,--sort-common,--as-needed,-z,relro' Appending CPPFLAGS from environment: '-D_FORTIFY_SOURCE=2' Build machine cpu family: x86 Build machine cpu: i686 Build targets in project: 2 ninja: no work to do. No tests defined. No benchmarks defined. [0/1] Installing files. Running custom install script /usr/bin/python3 Failed to run install script: /usr/bin/python3 /build/meson/src/meson-0.36.0/meson.py --internal yelphelper install --subdir=help --id=meson --installdir=share/help --sources=index.page --media=media/test.txt --langs=de@@es FAILED: install '/usr/bin/python3' '/build/meson/src/meson-0.36.0/meson.py' '--internal' 'install' '/build/meson/src/meson-0.36.0/b 9cu54r21/meson-private/install.dat' ninja: build stopped: subcommand failed. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: \"Checking out files\" not covered by operation names in RemoteProgress When cloning a repository the following message is printed to stderr repeatedly: \"Operation name u'Checking out files' unknown - skipping line 'Checking out files: 1% (216/11210)'\". 1. Does it makes sense to add the operation 'Checking out files' to the list of operations in the RemoteProgress._parse_progess_line()? (see https://github.com/gitpython-developers/GitPython/blob/master/git/util.py#L162) 2. Shouldn't the error logged by using the logging mechanism and not printed to stderr directly? (https://github.com/gitpython-developers/GitPython/blob/master/git/util.py#L242) (Environment: Windows 7, Python 2.7.10, GitPython 1.0.1) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython should specify pygments entry points for its lexers IPython implements a few pygments lexers - IPyLexer, IPythonTracebackLexer, etc., but does not install pygments entry points, so these lexers cannot be used with the pygmentize command. Having them available to pygmentize will be helpful because pygmentize has some features that are not available from from nbconvert. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Incorrect Inner Product Implementation? I have ran across a circuit called \"InnerProduct\" in the Qiskit documentation, here: https://qiskit.org/documentation/stubs/qiskit.circuit.library.InnerProduct.html According to the documentation, this circuit \"computes the inner product of two registers\". However, I believe this to be blatantly wrong. Is this implementation wrong, or am I missing something? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add agent(s) documentation and setup instructions Docs should include: an overview of what agents are and their implementation pattern, individual agent setup instructions, add relevant info to the [first steps](https://docs.prefect.io/cloud/first-steps.html) cloud doc Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: RuntimeError: expected device cpu but got device cuda:0 I am traing a roberta model and running the script examples/run_language_modeling.py The following error occurs when i am trying to resume training. Traceback (most recent call last): File \"examples/run_language_modeling.py\", line 284, in <module> main() File \"examples/run_language_modeling.py\", line 254, in main trainer.train(model_path=model_path) File \"/home/socian-pc1/anaconda3/envs/XformerEnv/lib/python3.6/site-packages/transformers/trainer.py\", line 326, in train optimizer.step() File \"/home/socian-pc1/anaconda3/envs/XformerEnv/lib/python3.6/site-packages/torch/optim/lr_scheduler.py\", line 67, in wrapper return wrapped(*args, **kwargs) File \"/home/socian-pc1/anaconda3/envs/XformerEnv/lib/python3.6/site-packages/transformers/optimization.py\", line 155, in step exp_avg.mul_(beta1).add_(1.0 - beta1, grad) RuntimeError: expected device cpu but got device cuda:0 My config python examples/run_language_modeling.py \\ --train_data_file $TRAIN_FILE \\ --eval_data_file $TEST_FILE \\ --output_dir ./MyRobertaOutput \\ --model_name_or_path ./MyRoBERTa/checkpoint-570000 \\ --config_name ../xformer_output \\ --tokenizer_name ../xformer_output \\ --mlm \\ --do_train \\ --do_eval \\ --line_by_line \\ --learning_rate 1e-5 \\ --num_train_epochs 2 \\ --save_total_limit 20 \\ --save_steps 5000 \\ --per_gpu_train_batch_size 6 \\ --warmup_steps=10000 \\ --logging_steps=100 \\ --gradient_accumulation_steps=4 \\ --seed 666 --block_size=512 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: autoretry_for and retry_kwargs for class-based tasks python==3.6.4 celery==4.1.0 ## Steps to reproduce ``` from project.celery import app class test_task(celery.Task): autoretry_for = (Exception,) retry_kwargs = { 'max_retries': 5, 'countdown': 10, } def run(self, *args, **kwargs): raise Exception('test') test_task = app.register_task(test_task()) test_task.delay() ``` ## Expected behavior 5 retries of this task with countdown of 10 seconds each. ## Actual behavior No retries at all. So the main question - is there any way for specifying autoretry_for and retry_kwargs for class-based tasks? Just to mention - function-based tasks works properly with shared_task decorator and this arguments for it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython.embed changes color on error `IPython.embed` does something weird when you raise an error: it changes color! In your config, set colors to non-default: ``` c.TerminalInteractiveShell.colors = 'Linux' # or 'LightBG' on Linux ``` Then embed IPython anywhere, and raise an exception (just 1/0 is enough). After the traceback, the color scheme will have reverted to the default (confirmed on both Linux and OS X, with different defaults). I imagine this is due to lacking a `Singleton.instance()` somewhere, which does not exist when IPython is embedded, but does from a normal entry point. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Implement safetensors checkpoint loading for Trainer ### Feature request At the moment, Trainer loads models with `torch.load` method directly onto the cpu: (`Trainer._load_from_checkpoint` method) ```python ... # We load the model state dict on the CPU to avoid an OOM error. state_dict = torch.load(os.path.join(resume_from_checkpoint, WEIGHTS_NAME), map_location=\"cpu\") # workaround for FSDP bug https://github.com/pytorch/pytorch/issues/82963 # which takes *args instead of **kwargs load_result = model.load_state_dict(state_dict, False) # release memory del state_dict self._issue_warnings_after_load(load_result) ... ``` Loading on cpu with safetensors is a lot faster, so this method should (?) be preffered if safetensors library is installed. ### Motivation I care to speed up checkpointing process since I use it to store the best model checkpoint every time the metric is improved (via callback). ### Your contribution The change should be straightforward, but I am not sure if safetensors checkpointing should be defaulted to if safetensors are installed, or configured manually like in `PreTrainedModel.from_pretrained` method. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Support for retain_graph=True **Is your feature request related to a problem? Please describe.** Some models require retain_graph=True, but it's not possible to set it in the .backward() call inside of Trainer.__run_training_batch(...) **Describe the solution you'd like** Add train_graph member function the LightningModule have the trainer read this option and then pass it into the .backward() call. **Describe alternatives you've considered** Driving a version of Trainer to support retain_graph=True is tough because __run_training_batch and other functions are name-mangled. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Running tests locally kills the IBMQ credentials in qiskitrc <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: lastest master - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? Running the test suite resulted in my public IBMQ credentials being removed from my `qiskitrc` file. Note that I also have another account stored that appears to be untouched. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: weights partially missing for CamembertForMaskedLM ## Environment info - `transformers` version: 3.1.0 - Platform: Darwin-18.7.0-x86_64-i386-64bit - Python version: 3.7.5 - PyTorch version (GPU?): 1.6.0 (False) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ### Who can help @louismartin ## Information When loading \"camembert-base\" with `CamembertForMaskedLM` with: from transformers import CamembertForMaskedLM model = CamembertForMaskedLM.from_pretrained(\"camembert-base\") the bias of the LM head decoder is not loaded: Some weights of CamembertForMaskedLM were not initialized from the model checkpoint at camembert-base and are newly initialized: ['lm_head.decoder.bias'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference. As I understand `lm_head.decoder.bias` is therefore initialized randomly. I checked the original `camembert-base` model as published by the author, and the lm_head decoder bias is missing too, which is not discussed in the camembert or roberta publication. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: AIP-56 - FAB AM - Login Create the whole login process: - Move the login form view to auth manager - Move the login logic to auth manager - Return the login URL as part of get_url_login() API Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [suggestion] Support .gz files in tools.get() To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. I suggest that `tools.get()` supports .gz files in the same way as .tar.gz. I want to download a gzipped patch and apply it. https://github.com/nkshigeru/conan-libpng/blob/cdebdf4ae4a7b33871b6080ac13927b1036bdd41/conanfile.py#L45-L53 `tools.get()` is a very useful function but it does not support .gz file. So I need to use low level functions. ``` tools.download(\"http://example.com/example.patch.gz\", \"example.patch.gz\") tools.check_sha1(\"example.patch.gz\", hash) with gzip.open(\"example.patch.gz\", \"rb\") as f: patch = f.read().decode() tools.patch(patch_string=patch) ``` It would be great if I could write as below. ``` tools.get(\"http://example.com/example.patch.gz\", sha1=hash) # we get example.patch tools.patch(patch_file=\"example.path\") ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `plot_state_hinton` doesn't plot all real matrix components <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.13 - **Python version**: 3.7 - **Operating system**: MacOS ### What is the current behavior? `plot_state_hinton` isn't plotting all matrix components for computational basis states. ### Steps to reproduce the problem Plot a computational basis state on any number of qubits ```python from qiskit.quantum_info import DensityMatrix from qiskit.visualization import * rho = DensityMatrix.from_label('11').data plot_state_hinton(rho) ``` returns 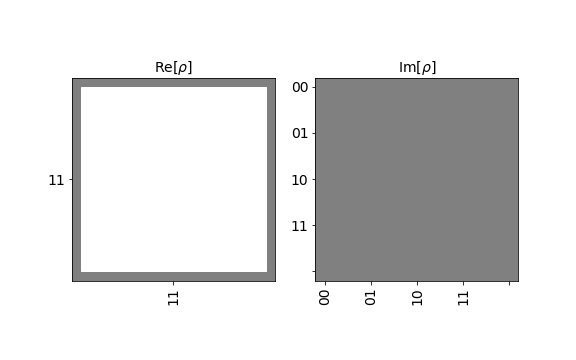 ### What is the expected behavior? It should look like the hinton version of hte city plot, but there are not enough ticks or entrys on the real part of the plot. It is only plotting the one non-zero component. 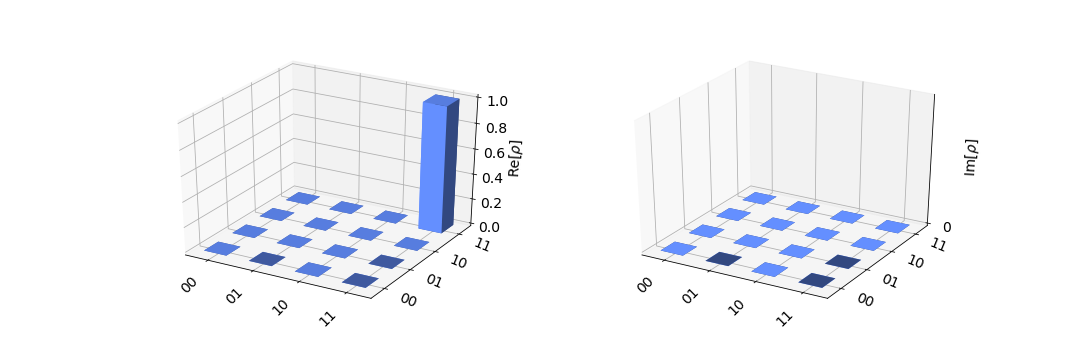 ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: qt4 tool path misdetected In qt5, the tool path is detected from pkg-config using the host_bins variable, as is currently done in the code, but for qt4, the .pc file looks like this: moc_location=${prefix}/lib/x86_64-linux-gnu/qt4/bin/moc uic_location=${prefix}/lib/x86_64-linux-gnu/qt4/bin/uic rcc_location=${prefix}/lib/x86_64-linux-gnu/qt4/bin/rcc lupdate_location=${prefix}/lib/x86_64-linux-gnu/qt4/bin/lupdate lrelease_location=${prefix}/lib/x86_64-linux-gnu/qt4/bin/lrelease So the default path is used to find tools. On debian, at least, this chooses the system default qt which may be qt4, or it may incorrectly be qt5 tools when using the qt4 module. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Some states are not documented in the API docs e.g., `Submitted` states Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Upgraded to meson 0.43.0 and now boost program-options is not a valid boost library ``` boost = dependency ('boost', modules : [ 'thread', 'filesystem', 'program_options', 'log_setup', 'log', 'date_time', 'system' ]) ``` error: ``` Meson encountered an error in file meson.build, line 23, column 0: Dependency program_options not found. It is not a valid boost library. ``` the program no longer links, since it is missing a bunch of references. Boost package list on Arch Linux: https://gist.github.com/gauteh/205bcdf30d7eda628264e4eb8f4a8bd6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cc.has_function fails to detect GCC/Clang __builtin functions **Describe the bug** Calls such as `cc.has_function('__builtin_clz')` return false when the function exists as a builtin compiler intrinsic (gcc and clang). [meson-log.txt for GCC](https://github.com/mesonbuild/meson/files/4418182/meson-log.txt) [meson-log.txt for Clang](https://github.com/mesonbuild/meson/files/4418184/meson-log.txt) **To Reproduce** ```meson project('builtinfail', 'c') cc = meson.get_compiler('c') assert(cc.has_function('__builtin_clz'), '__builtin_clz not found') ``` **Expected behavior** `cc.has_function` should correctly detect support for compiler builtins. **system parameters** * openSUSE Tumbleweed * Python 3.8.2 * meson 0.54.999 (b9b118b267219e6ac8d6f0d5e5c73152e88b8269) * ninja 1.10.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: lint error is left in PR <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? lint error is left in #2027 ### Steps to reproduce the problem ### What is the expected behavior? remove lint error ### Suggested solutions optimize import order in `qiskit.qobj.models.pulse` and `qiskit.qobj.models.qasm` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Probabilities ``>1`` in the sampler (and statevector) ### Environment - **Qiskit Terra version**: main @ 5c49d1400b5ceb75662ebf79d06650ca39449579 - **Python version**: 3.10 - **Operating system**: macOS Ventura ### What is happening? The ``Statevector.probabilities`` method sometimes contains roundoff errors, leading to probabilities larger than 1. This breaks the `Sampler` if shots are emulated, as larger than 1 probabilities are not valid inputs to NumPy's multinomial library. ### How can we reproduce the issue? ```python from qiskit.circuit import QuantumCircuit from qiskit.primitives import Sampler import numpy as np np.random.seed(1) sampler = Sampler(options={\"shots\": 1024}) for _ in range(1000): try: angle = np.random.random(1)[0] # this angle breaks on my laptop for example: # angle = 0.10233442882782584 qc = QuantumCircuit(1) qc.ry(angle, 0) qc.ry(-angle, 0) qc.measure_all() _ = sampler.run(qc).result() except Exception as exc: print(\"Failed on\", angle) ``` The error raised is ``` File \"/Users/jul/Qiskit/qiskit-terra/qiskit/primitives/sampler.py\", line 130, in _call counts = rng.multinomial(shots, np.fromiter(prob_dict.values(), dtype=float)) File \"_generator.pyx\", line 3916, in numpy.random._generator.Generator.multinomial File \"_common.pyx\", line 391, in numpy.random._common.check_array_constraint File \"_common.pyx\", line 377, in numpy.random._common._check_array_cons_bounded_0_1 ValueError: pvals < 0, pvals > 1 or pvals contains NaNs ``` ### What should happen? The probabilities should not exceed 1. ### Any suggestions? Clip the probabilities. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson-0.49.0 Windows installation misses most of the /scripts ```Meson\\lib\\mesonbuild\\scripts``` contains only two files: ``` depfixer.pyc __init__.pyc ``` Every other script is missing. This happens both on x86 and x64 installations. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Detect when people try to run meson from a subdir in the source tree and print a friendly error I think it's hard to understand what \"First statement must be a call to project\" means. I question if the sentence is proper English, but I'm not a native speaker, so it would be nice if someone could confirm this. Whom are you calling upon to project something, and what will you project? Or, if it's not in the context of calling upon someone or projecting something, which function are you calling? `project` is not a function and it's not obvious how `project` should be called. Could the error message be reworded? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: API Endpoint - CRUD - Variable Hello We need to create several endpoints that perform basic CRUD operations on **Variable**. We need the following endpoints: POST /variables DELETE /variables/{variable_key} PATCH /variables/{variable_key} Detailed information is available in the issue: https://github.com/apache/airflow/issues/8118 LOVE, Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add TF implementation of GPT-J model # 🚀 Feature request Add TF implementation of GPT-J model ## Motivation Narrow the gap between PT and TF implementations. ## Your contribution I'd like to work on this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: transpiler error <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> The transpiler is not behaving correctly with optimization_level=2 for some inputs. - **Qiskit Terra version**:0.8.0 - **Python version**:3.7.3 - **Operating system**:MacOsX ### What is the current behavior? Running the transpiler on the circuit Cnot - XI -Cnot returns XI when the optimization level is set to 2. ### Steps to reproduce the problem from qiskit.compiler import transpile from qiskit import (QuantumCircuit, ClassicalRegister, QuantumRegister, execute) q = QuantumRegister(2, name='qn') c = ClassicalRegister(2, name='cn') test = QuantumCircuit(q,c) test.barrier() test.cx(q[0],q[1]) test.x(q[0]) test.cx(q[0],q[1]) test.barrier() print(\"Initial Circuit\") print(test.draw()) test2 = transpile(test,optimization_level=2) print(\"Transpiled Circuit\") print(test2.draw()) ### What is the expected behavior? Expected behavior is probably to do nothing, which is the case in the circuit Cnot - IZ - Cnot. ### Suggested solutions It looks like the transpiler is smart enough to reduce the equivalent ZI and IX circuits and somehow is mistaking XI for IX. Either that or it is not respecting the barriers in this one specific case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: --manifest=[manifest folder] removes information from dependencies Conan 1.5.2 Using the ``--manifest=[manifest folder]`` argument, deletes information from the dependency graph, the ``package_info()`` method information of the dependencies is lost, and the generated files (conanbuildinfo.cmake) doesn't have it, so compilation fails. To reproduce: ``` $ conan new Pkg/0.1 -s -t $ conan create . user/testing --manifests=mymanifests ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Extend an entire Compose file It is a common pattern to define a base Compose file, and then define Compose files for different environments with a few small changes. It is currently possible to extend single services, but it is very verbose to include a large number of services and make a small change to one of them (for example, setting `RAILS_ENV=production`). It should be possible to extend a Compose file with a complete set of services from another Compose file. All of those services will be copied into the Compose file, as if you were extending each of the services individually: - If you don't define a service in the child file, it is copied as-is. - If you do define a service, it should behave as if you've extended that single service. - There is no way of undefining a service (yet) This is an intentionally simple first step, and I am intentionally not defining a syntax so we can discuss. Design questions: - This is the first top-level configuration we have added to Compose. How should we do this? Related issues / suggested designs: https://github.com/docker/compose/issues/318 #1380 [dcao-merge](https://github.com/dnephin/compose-addons#dcao-merge) [(This is part of an initiative to define an app once in a way that can be used across dev, test and prod.)](https://github.com/docker/compose/issues/1784) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Qasm output should look for numbers close to fractions of pi <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? `circuit.qasm()` outputs long float values for many parameters even though many are close to fractions of pi that can be checked with `pi_check`. Also, the number of digits returned is excessive, and should be truncated to a reasonable precision. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Remove Transaction dependency on Dataset Instead imply the dataset ID from the mutations added throughout the transaction. Needed to finish #477 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Future version of gcovr requires updated syntax In testing the gcovr provided solution that was discussed in #4801 I discovered that the syntax for calling gcovr has changed slightly since the last release. I can see that this has happened before since there's handling for different root directory expectations already in coverage.py. Now there's yet another syntax, which is further different from the two already supported. Basically, in order to be compatible with the next version of gcovr we now need to call gcovr like this (note that both the build root and the source root are being passed): `gcovr_base_cmd = [gcovr_exe, '-r', source_root, build_root]` This complicates things as there will be three different ways of handling directories passed to gcovr based on the installed version, with the new version syntax being more of a departure compared to the currently supported versions. Since I've already figured out how the command needs to be updated I would be happy to submit a PR to update the necessary parts once I've figured out a nice way of doing it with via detect_gcovr(). I'm creating this issue though to ensure that people are aware that this will be a problem once the new version of gcovr is released. I don't know exactly when that will happen, but anyone interested can simply follow [this ticket](https://github.com/gcovr/gcovr/issues/297). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: custom_target does not validate that the input actually exists **Describe the bug** ```meson custom_target( 'name', input : 'nonexistant.py' output : 'out.h', command : ['@INPUT@', '@OUTPUT@'] ) ``` Meson will happily configure, then ninja will barf because `nonexistant.py` doesn't actually exist. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add documentation for storage.Blob's special methods (contains, next, etc) Right now it's not really clear how to check for a key's existence (do I need to do if `Key('name') in bucket`? or just `'name' in bucket`? We need to make sure these special methods are documented with examples in the API docs for the Key class. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: np.unique(a, axis=0) sorted incorrectly when values cross 255 This is a weird one I noticed while calling `unique(a, axis=0)` for a 2D array `a`. If some values in the first column of `a` are `<= 255` and others are `>255`, the output is incorrectly sorted. Maybe something somewhere is making an assumption about single bytes and causing an overflow. ```python >>> # broken: ... a = np.array([[255, 256], ... [256, 257]]) >>> np.unique(a, axis=0) array([[256, 257], [255, 256]]) >>> # row order doesn't matter, also broken: ... a = np.array([[256, 257], ... [255, 256]]) >>> np.unique(a, axis=0) array([[256, 257], [255, 256]]) >>> # works: ... a = np.array([[254, 255], ... [255, 256]]) >>> np.unique(a, axis=0) array([[254, 255], [255, 256]]) >>> # works: ... a = np.array([[256, 257], ... [257, 258]]) >>> np.unique(a, axis=0) array([[256, 257], [257, 258]]) >>> a.dtype dtype('int64') >>> a.flags C_CONTIGUOUS : True F_CONTIGUOUS : False OWNDATA : True WRITEABLE : True ALIGNED : True WRITEBACKIFCOPY : False UPDATEIFCOPY : False ``` I just noticed this also happens for 1D arrays when the axis kwarg is used: ```python >>> a = np.array([255, 256]) >>> np.unique(a, axis=0) array([256, 255]) >>> np.unique(a) array([255, 256]) ``` It seems the `axis` kwarg is a relatively new feature for `np.unique`. This is in Xubuntu 16.04 amd64. ``` Python 3.5.2 (default, Nov 23 2017, 16:37:01) [GCC 5.4.0 20160609] on linux >>> np.version.version '1.14.0' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: slow linalg.solve Dear jax team, I'd like to perform a lot (1e5-1e7) `np.linalg.solve` operations on small (3x3) matrices. jax is a lot slower than the numpy version: 17s in jax vs. 382ms in numpy. Is 3x3 too small to be effective on GPU? Or is the `solve` method just not as efficiently implemented for such a task as the numpy version? ```python import jax import jax.numpy as np import numpy as onp def to_gpu(arr): return jax.device_put(arr.astype(np.float32)) num_matrices = int(1e6) sidelen = 3 A = to_gpu(onp.random.normal(size=(num_matrices, sidelen, sidelen))) b = to_gpu(onp.random.normal(size=(num_matrices, sidelen))) solve_jit = jax.jit(np.linalg.solve) solve_vmap = jax.vmap(np.linalg.solve) solve_vmap_jit = jax.jit(jax.vmap(np.linalg.solve)) # run jit'ed versions once _ = solve_jit(A, b) _ = solve_vmap_jit(A, b) %time np.linalg.solve(A, b).block_until_ready() # 16.5 s %time solve_jit(A, b).block_until_ready() # 17.0 s %time solve_vmap(A, b).block_until_ready() # 17.0 s %time solve_vmap_jit(A, b).block_until_ready() # 15.3 s %time onp.linalg.solve(A, b) # 383 ms ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ERROR: Argument gobject/glib-mkenums of type File is not held by an ObjectHolder. **Describe the bug** master branch fails to build glib 2,64.1 ``` gobject/meson.build:99:0: ERROR: Argument gobject/glib-mkenums of type File is not held by an ObjectHolder. This is a Meson bug and should be reported! ``` **To Reproduce** 1. get the source code of glib 2.64.1 (or switch to git tag 2.64.1) 2. run `meson build` using latest meson from master branch 3. above error **Expected behavior** no error **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? native * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) arch linux (parabola) * what Python version are you using e.g. 3.8.0: 3.9.5 * what `meson --version` latest master branch * what `ninja --version` if it's a Ninja build N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] CMakeToolchain boolean variables are cached as strings ### Environment Details * Operating System+version: macos * Compiler+version: clang * Conan version: 1.46.2 * Python version: 3.7 ### Steps to reproduce using this generate method ``` def generate(self): tc = CMakeToolchain(self) tc.variables[\"FOO\"] = True tc.variables[\"BAR\"] = False tc.generate() ``` I got these results the `conan_toolchain.cmake` ``` set(FOO ON CACHE STRING \"Variable FOO conan-toolchain defined\") set(BAR OFF CACHE STRING \"Variable BAR conan-toolchain defined\") ``` However I expect these to be Boolean, something like ``` set(FOO ON CACHE BOOL \"Variable FOO conan-toolchain defined\") set(BAR OFF CACHE BOOL \"Variable BAR conan-toolchain defined\") ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson introspect fails when options.builddir is None In run(args) (mesonbuild/mintro.py, line 202), options.builddir is checked to see if it is None, but cdata.load(options.builddir) is called anyway, resulting in: ```python Traceback (most recent call last): File \"/usr/bin/meson\", line 26, in <module> sys.exit(main()) File \"/usr/bin/meson\", line 23, in main return mesonmain.run(sys.argv[1:], launcher) File \"/usr/lib/python3.6/site-packages/mesonbuild/mesonmain.py\", line 293, in run return mintro.run(remaining_args) File \"/usr/lib/python3.6/site-packages/mesonbuild/mintro.py\", line 212, in run coredata = cdata.load(options.builddir) File \"/usr/lib/python3.6/site-packages/mesonbuild/coredata.py\", line 344, in load filename = os.path.join(build_dir, 'meson-private', 'coredata.dat') ``` I worked around it for now by inserting an else clause: ```python def run(args): datadir = 'meson-private' options = parser.parse_args(args) if options.builddir is not None: datadir = os.path.join(options.builddir, datadir) else: options.builddir='./' ``` I'm using meson 0.45.0, Fedora 28 prerelease, with meson being called from gnome-builder 3.28.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: gate.sqrt() ### What is the expected enhancement? Similar to #2805, a `gate.root(<int>)` is needed. This will allow `gate.power` to support rational numbers as exponent. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Difference of extras Airflow 2.0 vs. Airflow 1.10 **Description** When airflow 2.0 is installed from PyPI, providers are not installed by default. In order to install them, you should add an appropriate extra. While this behavior is identical in Airflow 1.10 for those \"providers\" that required additional packages, there were a few \"providers\" that did not require any extras to function (example http, ftp) - we have \"http\", \"ftp\" extras for them now, but maybe some of those are popular enough to be included by default?. We have to make a decision now: - [x] should all of them (or some of them) be included by default when you install Airflow? - [x] if we decide to exclude only some (or none), we should add them in UPGRADING_to_2_0 and in UPDATING documentation. **Use case / motivation** We want people to get a familiar experience when installing airflow. Why we provide familiar mechanism (with extras) and people will expect a slightly different configurations, installation and we can describe the differences, maybe some of those providers are so popular that we should include them by default? **Related Issues** #12685 - where we discuss which of the extras should be included in the Production Image of 2.0. **Additional info** Here is the list of all \"providers\" that were present in 1.10 and had no additional dependencies - so basically they woudl work out-fhe-box in 1.10, but they need appropriate \"extra\" in 2.0. * \"apache.pig\": [], * \"apache.sqoop\": [], * \"dingding\": [], * \"discord\": [], * \"ftp\": [], * \"http\": [], * \"imap\": [], * \"openfaas\": [], * \"opsgenie\": [], * \"sqlite\": [], Also here I appeal to the wisdom of crowd: @ashb, @dimberman @kaxil, @turbaszek, @mik-laj. @XD-DENG, @feluelle, @eladkal, @ryw, @vikramkoka, @KevinYang21 - let me know WDYT before I bring it to devlist? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: datetime property I not sure is it is a bug but when I have tried save() a entity with a datetime property appear this error. ``` pb_attr, pb_value = helpers.get_protobuf_attribute_and_value(value) File \"/usr/local/lib/python2.7/dist-packages/gcloud/datastore/helpers.py\", line 39, in get_protobuf_attribute_and_value name, value = 'timestamp_microseconds', time.mktime(val.timetuple()) NameError: global name 'time' is not defined ``` datetime property I not sure is it is a bug but when I have tried save() a entity with a datetime property appear this error. ``` pb_attr, pb_value = helpers.get_protobuf_attribute_and_value(value) File \"/usr/local/lib/python2.7/dist-packages/gcloud/datastore/helpers.py\", line 39, in get_protobuf_attribute_and_value name, value = 'timestamp_microseconds', time.mktime(val.timetuple()) NameError: global name 'time' is not defined ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Clean up handling of file browser server errors Right now we get a cryptic \"Server Connection Error\" when the file browser model can't complete an operation. It isn't triggered uniformly for different server error types either. We should clean this up and use an error message more like the one in the classic notebook: ``` A connection to the notebook server could not be established. The notebook will continue trying to reconnect. Check your network connection or notebook server configuration. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: datastore: Query does not allow inequality filter on __key__ property. Datastore query raises a ValueError for inequality(non-equality to be correct) operators on `__key__` property. https://github.com/GoogleCloudPlatform/gcloud-python/blob/3e86aaed3c7e192a17d9b790f90a41cc2b7baa6a/gcloud/datastore/query.py#L223 According to Google Cloud Datastore documentation inquality operators on `__key__` property are supported, and should not raise exception. https://cloud.google.com/datastore/docs/concepts/queries#Datastore_Key_filters It is a critical part of our data-model. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Create Slack task for Task Library It would be awesome to have a task in the Task Library that sent a slack message. Inputs could be for a `channel` or a `user`. Similar installation instructions to https://docs.prefect.io/guide/tutorials/slack-notifications.html#installation-instructions (or just a link to these instructions) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Parameterize unwrap to allow for different ranges (not just -pi, pi) The idea would be to make unwrap a more general function applicable to problems like quantization overflow (uint8 254+1 -> 0) and allow for `min_val` and `max_val` parameters (which would default to give the same behavior as currently implemented). ### Reproducing code example: ```python import numpy as np np.unwrap([0, 1, 2, 0], min_val=0, max_val=3) ``` should give `array([0., 1., 2., 3.])` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: /files/ only serving attachments https://github.com/ipython/ipython/pull/6624 changes the behavior of serving html files from '/files/'. Instead of displaying a html page, I get the option to download it as file. Before I got as a response: ``` Python import requests r = requests.get('http://localhost:8888/files/Untitled10.html') print(r.headers) {'Last-Modified': 'Sat, 23 Aug 2014 16:03:02 GMT', 'Set-Cookie': 'username-localhost-8888=; expires=Thu, 31 Oct 2013 22:14:47 GMT; Path=/', 'Content-Type': 'text/html', 'X-Frame-Options': 'SAMEORIGIN', 'Server': 'TornadoServer/4.0.2', 'Date': 'Fri, 31 Oct 2014 22:14:47 GMT', 'Content-Length': '237903', 'Accept-Ranges': 'bytes'} ``` Now I get ``` Python r = requests.get('http://localhost:8888/files/Untitled10.html') print(r.headers) {'Date': 'Fri, 31 Oct 2014 22:17:27 GMT', 'Transfer-Encoding': 'chunked', 'X-Frame-Options': 'SAMEORIGIN', 'Set-Cookie': 'username-localhost-8888=; expires=Thu, 31 Oct 2013 22:17:27 GMT; Path=/', 'Server': 'TornadoServer/4.0.2', 'Content-Type': 'text/html', 'Content-Disposition': 'attachment; filename=\"Untitled10.html\"'} ``` Is this an intended new behavior ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Rename build files for clarity Some of the build files are causing confusion, and should be renamed. - `jupyterlab/package_list.txt` -> `jupyterlab/released_packages.txt` - `jupyterlab/package.template.json` -> `jupyterlab/package.app.json` - `jupyterlab/index.template.js` -> `jupyterlab/index.app.js` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [Regression] Two dots in lib filename I use conan 1.16.0 on windows 10 and I have a package that has a lib file named `GTEngine.v12.lib`. If I run `conan install` which uses the `visual_studio_multi` generator, it adds the lib filename _without extension_ in `conanbuildinfo_debug_x64_v120.props` (I use x64/msvc2013 which is irrelevant). Version 1.15.0 keeps the `.lib` suffix in the property sheet, but 1.16.0 somehow removes it which results in a build error. Thanks in advance - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: won't install rpm macros ``` Installing RPM macros to /home/brain/rpmbuild/BUILDROOT/meson-0.22.0-7.20150321gita5f30e7.fc23.x86_64/usr/lib/rpm/macros.d. Traceback (most recent call last): File \"./install_meson.py\", line 112, in <module> shutil.copyfile('macros.meson', outfilename) File \"/usr/lib64/python3.4/shutil.py\", line 108, in copyfile with open(dst, 'wb') as fdst: FileNotFoundError: [Errno 2] No such file or directory: '/home/brain/rpmbuild/BUILDROOT/meson-0.22.0-7.20150321gita5f30e7.fc23.x86_64/usr/lib/rpm/macros.d/macros.meson' ``` We need to do mkdir I think and have install option in `OptionParser` instead of check if path exists Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: Use range instead of pin for python dependencies for kfp Currently kfp pins a list of package versions in [sdk/python/setup.py](https://github.com/kubeflow/pipelines/blob/52d7c7bd9e3076d4077d112dbf94211f9e51538c/sdk/python/setup.py). It could be too restrictive if kfp is used with other OSS projects (i.e, tfx). The particularly conflicting one is 'google-auth==1.6.1'. Can we use a range version for kfp dependencies? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: mpl drawer fails with multiple X target Consider the following situation: ``` from qiskit import QuantumCircuit from qiskit.circuit.library import MCXVChain circuit = QuantumCircuit(5) circuit.append(MCXVChain(3, dirty_ancillas=True), range(5), []) ``` When drawn by mpl drawer: ``` circuit.draw('mpl') ```  Compare with the other drawers: ``` q_0: ──■─── │ q_1: ──■─── │ q_2: ──■─── ┌─┴──┐ q_3: ┤0 ├ │ X │ q_4: ┤1 ├ └────┘ ``` 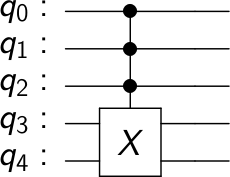 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: auto_scale_batch_size won't reset current_epoch ## 🐛 Bug When `auto_scale_batch_size` is enabled, the model is initially trained with varying batch sizes. When training begins, `trainer.current_epoch` equals 1 instead of 0. ### To Reproduce Either observe the progress bar or use a simple callback to track the epoch number, once with `auto_scale_batch_size` enabled and once with `auto_scale_batch_size` disabled. ``` from pytorch_lightning import Callback class PrintCallback(Callback): def __init__(self): self.observed_epochs = [] def on_train_epoch_start(self, trainer, pl_module): print(f'Current Epoch: {trainer.current_epoch}') self.observed_epochs.append(trainer.current_epoch) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.60 fails to build GNOME components Using the new meson 0.60, either from upstream or Debian, GNOME components started to fail to build Example of the eog snap build https://launchpadlibrarian.net/565502418/buildlog_snap_ubuntu_focal_amd64_eog_BUILDING.txt.gz ``` Configuring org.gnome.eog.desktop.in using configuration ../src/data/meson.build:25:5: ERROR: Function does not take positional arguments. ``` Trying to build the current eog deb in Ubuntu with the new meson 0.60 deb from Debian unstable leads to a similar error Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: numpy.ma.sort and copying behaviour I started out thinking I've found a docbug but I'm becoming less sure. The problem is that [the documentation of `numpy.ma.sort`](https://docs.scipy.org/doc/numpy/reference/generated/numpy.ma.sort.html) ([devdocs version](https://numpy.org/devdocs/reference/generated/numpy.ma.sort.html#numpy.ma.sort)) says > Sort the array, in-place > [...] > Returns: `sorted_array` Whereas the behaviour seems to be the opposite: ```py >>> import numpy as np >>> arr = np.arange(5)[::-1] >>> np.ma.sort(arr) array([0, 1, 2, 3, 4]) >>> arr array([4, 3, 2, 1, 0]) ``` The weird thing is that I've found https://github.com/numpy/numpy/issues/1966 which suggests that until 2010 the docs had mentioned a copy and the behaviour was mutating, and the docstring was subsequently fixed. However looking at the git blame even [in commit 5cb370e923 from 2008](https://github.com/numpy/numpy/blob/5cb370e9234582f62231384c26a426301dad3331/numpy/ma/core.py#L2859) I can see ```py from numpy import array as narray # [...] def sort(...): a = narray(a, copy=True, subok=True) ``` This seems to me that even in 2008 it should have returned a copy, which makes the linked docbug issue very confusing. What am I missing? Ultimately I think this is a docbug, because `np.ma.sort` should match `np.sort` which copies (and is documented as such), whereas the corresponding instance methods should sort in-place. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: firefox 25.0: notebooks report \"Notebook save failed\", .py script save fails, but .ipynb save succeeds Notebooks have recently reported \"Notebook save failed\" when I save (or it autosaves). The .ipnb is updated, but the .py script fails to save. If I don't set NotebookManager.save_script=True, things work as expected. I get this in in the log when I attempt a save is: > [tornado.access] WARNING | 400 PUT /api/notebooks/Untitled0.ipynb (127.0.0.1) 3.94ms The \"Last Checkpoint\" is reported as Ocober 28 or 29 (depending on the notebook) This is presumably just before problems started? Suspiciously, I have this in my apt logs: > Start-Date: 2013-10-30 12:25:13 > Commandline: apt-get upgrade -y --fix-missing > Upgrade: firefox-globalmenu:amd64 (24.0+build1-0ubuntu0.12.04.1, 25.0+build3-0ubuntu0.12.04.1), firefox:amd64 (24.0+build1-0ubuntu0.12.04.1, 25.0+build3-0ubuntu0.12.04.1), firefox-locale-cs:amd64 (24.0+build1-0ub > End-Date: 2013-10-30 12:25:43 That's the most recent firefox update, and is just after the reported \"Last Checkpoint\"s. I'm running in firefox 25.0 (the most recent ubuntu update). My ipython is updated (14625df). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Labextensions not working on starting notebook Hi, So when I start jupyter lab with `jupyter lab` , labextensions seem to work perfectly fine, but they don't work when I start notebook : `jupyter notebook` and redirect to /lab. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Deserializing data mutates the input payload in place ## Description *A clear description of the bug* Loading data mutates the input payload by stripping its version tag. This means that in an (unusual) situation where a serialized payload is deserialized twice in sequence, the first time has an opportunity to look at its version information but the second time does not because the key is deleted. ## Expected Behavior *What did you expect to happen instead?* The input payload should not be mutated. ## Reproduction *A minimal example that exhibits the behavior.* ```python from prefect import Task from prefect.serialization.task import TaskSchema serialized = TaskSchema().dump(Task()) assert '__version__' in serialized deserialized = TaskSchema().load(serialized) assert '__version__' not in serialized # oh no! ``` ## Environment *Any additional information about your environment* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Meson build helper: add test() and install() methods Hello, I created recently a recipe using [Meson](https://docs.conan.io/en/latest/reference/build_helpers/meson.html) and I discovered that the methods `test()` and `install()` are not available alike [CMake helper](https://docs.conan.io/en/latest/reference/build_helpers/cmake.html). What would you think about adding them to Meson build helper ? - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Agent 7.16.0 cannot parse non-semantic nginx version After upgrading DataDog agent to 7.16.0 nginx integration stopped working. Agent Log: ```Dec 18 15:42:50 nginxproxy agent[29323]: 2019-12-18 15:42:50 EST | CORE | ERROR | (pkg/collector/python/datadog_agent.go:116 in LogMessage) | nginx:17d65b5a97c80644 | (core.py:45) | Unable to transform `version` metadata value `nginx`: Version does not adhere to semantic versioning``` nginx -v: `nginx version: nginx/1.13.9 (Ubuntu)` Nothing changed in `nginx.d/conf.yaml` except status url: `- nginx_status_url: http://localhost:8080/stub_status/` datadog-agent version: `Agent 7.16.0 - Commit: 3e13b77 - Serialization version: 4.15.0 - Go version: go1.12.9` Worked fine with version `Agent 6.15.1-1` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: New Etcd preview integration doesn't fully work with default kubernetes etcd versions The etcd integration with `use_preview=true` to use the new v3 specific integration determines leader using `/v3beta` paths https://github.com/DataDog/integrations-core/blob/4400118a16668dd9fc4b1b98e8601ff9cdf74767/etcd/datadog_checks/etcd/etcd.py#L142 Per https://github.com/etcd-io/etcd/blob/master/Documentation/dev-guide/api_grpc_gateway.md#notes , `/v3beta` is added in etcd 3.3+. The default etcd version even as of kubernetes 1.13 is 3.2.24 (https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.13.md#external-dependencies). After configuring the agent to use_preview with a version of etcd <3.3, you are unable to determine the leader from any of the datadog metrics. The new disk, latency, and go metrics are really important for understanding the behavior of etcd. Unfortunately, using the new integration means giving up all the metrics of the old agent (leading to a more difficult upgrade path) AND doesn't work on etcd versions commonly used to run kubernetes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add option in user config file to control `reverse_bits` in `circuit_drawer` ### What should we add? Currently, the user config file supports `circuit_drawer` display options such as `output` (`\"text\"`, \"`mpl`\", etc.). Including the ability to change the `reverse_bits` option would allow users that prefer setting this option to `True` to not have to explicitly set this parameter every time a circuit is drawn. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Output of %magic? is not very helpful The output of `%magic?` (in the qtconsole) is contains some text about magic functions, followed by ``` %2to3: Callable object storing the details of one alias. Instances are registered as magic functions to allow use of aliases. %2to3-27: Callable object storing the details of one alias. Instances are registered as magic functions to allow use of aliases. %2to3-35: Callable object storing the details of one alias. Instances are registered as magic functions to allow use of aliases. %7z: Callable object storing the details of one alias. Instances are registered as magic functions to allow use of aliases. %7za: Callable object storing the details of one alias. Instances are registered as magic functions to allow use of aliases. <elided> ``` which I guess is just the list of all executables in my PATH. After some scrolling I find the actual magics interspersed in between. Arch Linux standard packages ``` Jupyter QtConsole 4.0.1 Python 3.5.0 (default, Sep 20 2015, 11:28:25) Type \"copyright\", \"credits\" or \"license\" for more information. IPython 4.0.0 -- An enhanced Interactive Python. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.arange ignores dtype arange ignores the passed dtype and is always `int*` ```python a = np.arange(4, dtype=np.complex64) print(a.dtype) assert a.dtype == np.complex64 ``` Results in: ``` int64 --------------------------------------------------------------------------- AssertionError Traceback (most recent call last) <ipython-input-12-5b101f76f4c3> in <module>() 1 a = np.arange(4, dtype=np.complex64) 2 print(a.dtype) ----> 3 assert a.dtype is np.complex64 AssertionError: ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Enable control flow in `optimization_level=3` ### What should we add? ### What should we add? Sub-epic of #9417. This is the list of issues needed to support control flow at optimisation level 3 in `transpile`. Depends on: - [x] #9419 - [x] #9421 - [x] #9423 - [x] #9425 - [x] #9426 Once all the dependants are satisfied (add more to the list as they're found), the error-on-control-flow pass in the run initialisation for optimisation level 3 should be dropped to close this issue: https://github.com/Qiskit/qiskit-terra/blob/e981b7e8ba073388edc3544b30d908b731dc6d7d/qiskit/transpiler/preset_passmanagers/level3.py#L177-L179 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: add systests for V4 signed URLs with CSEK headers /cc @frankyn Follow-on from PR #7460. Currently, the GCS back-end has a bug for signed URLs using customer-supplied encryption key headers (`x-goog-encryption-key` and `x-goog-encryption-key-sha256`). Once a fix for that bug is rolled out, add system tests which show using the CSEK headers to build V4 signed upload / download URLs, and exercise them. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [python_requires] objects are overwritten when using multiple python_requires calls in one recipe To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. conan version: 1.7.4 os: Windows 7 Python 3.6.5 We are using multiple python_requires calls in our recipes. It seems that a second python_requires call overwrites objects of the previous python_requires call. Given the following two python modules:   If I import both modules via the python_reuqires I would expect the follwing behavior:  But the behavior is the following:  So the second python_requires overwrites the function and the variable from the first python_requires:  This seems a bit confusing to us. Can you please have a look at this? Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: CONDA_PYTHON_EXE was removed in 4.6.11 The environment variable `CONDA_PYTHON_EXE` was removed in 910a7ee19. I was using this environment variable in the installer for an application, in order to create a shortcut for the application using the cwp script. Here's what I was doing to get the executable and args for the shortcut: ```python def condify(target, arguments): # format is ROOT_PYTHONW ROOT_CWP_SCRIPT ENV_BASE ENV_PYTHONW # Followed by our actual program and args root_pythonw = os.getenv('CONDA_PYTHON_EXE').replace('.exe', 'w.exe') root_cwp_script = root_pythonw.replace('pythonw.exe', 'cwp.py') env_base = os.getenv('CONDA_PREFIX') env_pythonw = target args = [root_cwp_script, env_base, env_pythonw] + arguments return root_pythonw, args ``` I copied this method (not the above code, just the required aguments to call the cwp script to launch a program) of creating application shortcuts from Spyder. I am not sure how spyder does it now, but I am not sure how to go about correctly creating application shortcuts if I don't have a way of figuring out what the conda python executable is. 4.6.11 was a bugfix release and I did not see comments in the release notes regarding this change, so it was surprising. Can the environment variable be added back in, or if not, could someone let me know what the correct way to make a shortcut programmatically using the cwp.py script now is? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython terminal issue with Qt4Agg on XP SP3 If matplotlib backend in 'matplotlibrc' is set to Qt4Agg, terminal console mode slows down on multiple levels: there is pause on every letter entered; if I paste some code I have to wait approx 1sec for every 2-3 characters!; and overall it seems so unnaturally slow. This does not happen however in IPython qtconsole, and I don't remember similar behavior when I used 10.2 on Windows 7. This also does not happen if matplotlib backend is set to WXAgg for example. Noticed on: Windows XP SP3 32 bit Python 2.6.6 (official from python.org) PyQt4 4.8.4 matplotlib 1.0.1 IPython 0.11.dev Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] QCC compiler is missing cppstd The QCC compiler is missing the cppstd setting [feature] Update qcc to latest version Update qcc to support 8.3 and c++17. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add support for ThinLTO when using Clang and LLD **Describe the bug** ThinLTO has significant improvements under the \"Full\" LTO path. It scales incredibly well from a memory consumption point of view and gives incremental and threaded linking to a project. ThinLTO has long been stable with other build systems also supporting it now. https://clang.llvm.org/docs/ThinLTO.html **To Reproduce** Easy enough to reproduce, `CC=clang CC_LD=lld meson -Db_lto=true <remaining options>` Meson will only set `-flto` for the compile args in this instance **Expected behavior** I expect meson to check which version of clang and lld is being used, and if it is above a certain version (ThinLTO was supported back with clang 3.9, but probably shouldn't be enabled there) then by default enable the thin lto option with `-flto=thin` Additionally a nice feature might be an option to set LTO flavour. This way people can still build with `-flto=full` for their final releases but keep thin around for their development and regression testing. `-Db_lto_flavor=full, -Db_lto_flavor=thin` **system parameters** * This isn't a cross-building problem * Linux at the very least effected, MacOS might matter as well, unsure if thinlto is supported under Windows * Python version doesn't matter * `git HEAD` for meson, checked the source tree and it isn't supporting thinlto * Ninja doesn't matter here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: jupyterhub not present in page config data ## Description When I tried to use the jupyterlab==3.0.0rc6 release in my jupyterhub environment, the two items related to jupyterhub (Hub Control Panel, Log Out) in the `File` menu are gone. JL2.x release:  JL3.0rc6 release:  And if I check the `jupyter-config-data` in the page's source file, the `hubHost\": \"\", \"hubPrefix\": \"/hub/\", \"hubServerName\": \"\", \"hubUser\": \"username\"` fields are not present anymore. Also, the `notebookVersion\": \"[6, 1, 4]\"` in the 2.x release becomes `\"notebookVersion\": \"[1, 0, 5, \\\"\\\"]\"`, which refers to `jupyter-server`'s version. So maybe this issue is related to the replacement of notebook server by jupyter-server? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Create a new release of the Bigtable library As of 7 Aug 2018, the [latest version of the Bigtable library on PyPi](https://pypi.org/project/google-cloud-bigtable/) is 0.29.0 from 28 Feb 2018. Would it be possible to release a new version (and release new ones regularly) to pick up the latest updates and ongoing feature additions, please? Thank you! /cc: @sduskis, @ghaisa Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Use the Client's http object when talking to google-resumable-media This is intended to be done after #3674. Currently, in the two places `google-resumable-media` is used: ``` $ git grep -l resumable_media -- '*/google/*' bigquery/google/cloud/bigquery/table.py storage/google/cloud/storage/blob.py ``` we manually create a transport every time the upload/download APIs are invoked ([`storage`][1] and [`bigquery`][2]). [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/6fff098ce998aac90738b32b0ac500c9a8d9fb65/storage/google/cloud/storage/blob.py#L365-L381 [2]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/6fff098ce998aac90738b32b0ac500c9a8d9fb65/bigquery/google/cloud/bigquery/table.py#L828-L842 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: VisualStudioBuildEnvironment uses semicolon as a delimiter `SET CL=-MDd;%CL%` And this is what cl.exe does not like: ``` cl : Command line warning D9002 : ignoring unknown option '-MDd;' ``` delimiter should be a space instead of a semicolon as documented here: https://msdn.microsoft.com/en-us/library/kezkeayy.aspx https://github.com/conan-io/conan/blob/d62ac20f21d73b1d681c3d138034a0d70b9a513e/conans/client/build/visual_environment.py#L55 cc/ @db4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Make version a string It doesn't make sense for `version` to be a number: we likely want the next update to the file format to be `2.1`, not `3`, and we definitely don't want it to be a float. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Robust Speech Challenge Evaluation File does not use entire dataset for metric calculation ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.15.0 - Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.7.12 - PyTorch version (GPU?): 1.10.0+cu111 (True) - Using GPU in script?: Yes ### Who can help @patrickvonplaten, @anton-l ## To reproduce Steps to reproduce the behavior: 1. ~/transformers/examples/research_projects/robust-speech-event/eval.py --model_id ./ --dataset mozilla-foundation/common_voice_7_0 --config sv-SE --split test --log_outputs <!-- If you have code snippets, error messages, stack traces please provide them here as well. Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.--> ## Expected behavior 1. Evaluation is done only on 10 examples [https://github.com/huggingface/transformers/blob/master/examples/research_projects/robust-speech-event/eval.py#L71 ](https://github.com/huggingface/transformers/blob/master/examples/research_projects/robust-speech-event/eval.py#L71 ) It should be done on entire dataset provided 2. To avoid any ambiguity WER and CER are generally reported in percentages but [https://github.com/huggingface/transformers/blob/master/examples/research_projects/robust-speech-event/eval.py#L26](https://github.com/huggingface/transformers/blob/master/examples/research_projects/robust-speech-event/eval.py#L26) will print the results in range of 0-1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Log output from Rails doesn't display when running fig up ``` ± % fig up !73 Recreating myapp_db_1... Recreating myapp_web_1... Attaching to myapp_db_1, myapp_web_1 myapp_db_1 | 140122 13:07:06 [Note] /usr/sbin/mysqld: ready for connections. myapp_db_1 | Version: '5.5.34-0ubuntu0.12.04.1-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 (Ubuntu) myapp_web_1 | myapp_web_1 | myapp_web_1 | myapp_web_1 | myapp_web_1 | myapp_web_1 | ``` `fig logs` works: ``` ± % fig logs web !71 Attaching to myapp_web_1 myapp_web_1 | => Booting Thin myapp_web_1 | => Rails 3.2.16 application starting in development on http://0.0.0.0:3020 myapp_web_1 | => Call with -d to detach myapp_web_1 | => Ctrl-C to shutdown server myapp_web_1 | A server is already running. Check /code/tmp/pids/server.pid. myapp_web_1 | Exiting ``` (Note that this is after I have run `fig up`.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: abort-on-container-exit does not work as expected ``` > uname -a Linux mycomputername 3.13.0-77-generic #121-Ubuntu SMP Wed Jan 20 10:50:42 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux > docker -v Docker version 1.10.1, build 9e83765 > docker-compose -v docker-compose version 1.6.0, build d99cad6 ``` According to the docs https://docs.docker.com/compose/reference/up/, `--abort-on-container-exit` should > Stop all containers if any container was stopped. docker-compose.yml: ``` version: \"2\" services: loop1: image: ubuntu:latest command: bash -c 'for i in {1..5}; do echo $$i && sleep 1; done' stop_signal: SIGKILL loop2: image: ubuntu:latest command: bash -c 'for i in {1..10}; do echo $$i && sleep 1; done' stop_signal: SIGKILL ``` After `docker-compose up --abort-on-container-exit` both containers start sending log messages. When `loop1` exits, documentation suggests that `loop2` will also be stopped. This does not happen, which can be confirmed by executing `docker-compose ps` shortly after `loop1` exits. An other issue which may be related: When hitting `Ctrl-C` after `docker-compose up` I would expect this: ``` ^CGracefully stopping... (press Ctrl+C again to force) Stopping dockercompose_loop1_1 ... done Stopping dockercompose_loop2_1 ... done ``` This is only happening occasionally, most of the time I get this instead: ``` ^CERROR: Aborting. ``` Also, the containers remain up. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Enable anchor links in docs Our docs don't have these links. We need to enable them.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit_with_custom_gates.qasm() does not print the definition of the custom gate _Originally posted by @1ucian0 in https://github.com/Qiskit/qiskit-terra/pull/3393#issuecomment-592720851_ > > 3. Can we write the loaded QASM back as the same QASM (with the custom definitions)? > > You mean `circuit.qasm()`? Let's leave the exporter out of this PR for now... > > As a reference, this is the exporter behavior: > ``` > qasm_string = \"\"\"OPENQASM 2.0; > include \"qelib1.inc\"; > gate my_other_gate(phi,lambda) q > {u3(asin(cos(phi)/2), phi+pi, lambda/2) q;} > gate my_gate(phi) r > {my_other_gate(phi, phi+pi) r;} > qreg qr[1]; > my_gate(pi) qr[0];\"\"\" > circuit = QuantumCircuit.from_qasm_str(qasm_string) > print(circuit.qasm()) > ``` > ``` > OPENQASM 2.0; > include \"qelib1.inc\"; > qreg qr[1]; > my_gate(3.141592653589793) qr[0]; > ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: cmd_def parameter string is incorrectly reported as unsafe <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When parsing the cmd_def provided by the backend, pulse commands may be parameterized (typically phase shifts). These commands are sanitized before being passed to Sympy for parameter and expression extraction. Currently, this sanitization is too conservative and is failing on the string ```\"-(P1)\"```. ### Steps to reproduce the problem Create a cmd_def with a frame change command with the parameter ```\"-(P1)\"```. ### What is the expected behavior? This string should pass sanitization ### Suggested solutions Relax sanitization strictness to allow consecutive special match characters. In the long run, replace with a full math parser. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Use .comet.config file for CometLogger ## 🚀 Feature When creating a CometML experiment normally, the API key will be read from the file `~/.comet.config` or from an environment variable if it isn't passed in directly. It would be nice if the `CometLogger` supported these uses as well. ### Motivation Putting the API key in code is certainly a bad practice, and it's a pain to have to export it as an environment variable and then get its value in Python or else read it from the file manually. Adding this feature makes things more seamless compared to how people use CometML when not using PyTorch Lightning. ### Additional context I have a [patch] written for this already; it only changes a few lines of code. From the template message when I went to create a PR, though, it seemed I should create an issue first. Let me know if you have thoughts about this. (somewhat related - the REST API key is also [deprecated]; the normal API key should be used instead now. I didn't change that code, though, because I'm not sure if older versions of Comet would have any issues with that change.) [patch]: https://github.com/PyTorchLightning/pytorch-lightning/compare/master...neighthan:master [deprecated]: https://www.comet.ml/docs/python-sdk/advanced/#python-configuration Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda 4.1 breaks fish integrations The new version does not work with fish at all. While the .fish script is finally there in the bin directory, it does not seem to kick in, since the new activate.py command is messing with it. How is it supposed to work? This is the error I get: ``` $ conda activate myenv Traceback (most recent call last): File \"/home/jrodriguez/.local/anaconda/bin/conda\", line 6, in <module> sys.exit(main()) File \"/home/jrodriguez/.local/anaconda/lib/python3.5/site-packages/conda/cli/main.py\", line 48, in main activate.main() File \"/home/jrodriguez/.local/anaconda/lib/python3.5/site-packages/conda/cli/activate.py\", line 119, in main shelldict = shells[shell] KeyError: 'myenv' ``` Meanwhile, I had to downgrade to conda 4.0 with `conda install conda=4.0`. Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Slow tokenizers return overflowing tokens in reversed order When implementing the slow tokenizer for LayoutLMv2, I spotted some weird behaviour for slow tokenizers when specifying `return_overflowing_tokens = True`. Namely, in that case, overflowing tokens are returned in reversed order, and no padding is performed, unlike fast tokenizers. Small example: ``` from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\") text = \"hello my name is niels\" encoding = tokenizer(text, padding=True, max_length=6, truncation=True, return_overflowing_tokens=True) ``` When checking out the encoding, it looks as follows: ``` print(tokenizer.decode(encoding.input_ids)) # prints '[CLS] hello my name is [SEP]' print(tokenizer.decode(encoding.overflowing_tokens)) # prints '##els ni' ``` As you can see, the overflowing tokens are returned in reversed order, and they are not padded up to the max length of 6 tokens. In contrast, `BertTokenizerFast` does everything correctly: ``` from transformers import BertTokenizerFast tokenizer = BertTokenizerFast.from_pretrained(\"bert-base-uncased\") text = \"hello my name is niels\" encoding = tokenizer(text, padding=True, max_length=6, truncation=True, return_overflowing_tokens=True) ``` returns ``` print(tokenizer.decode(encoding.input_ids[0])) # prints '[CLS] hello my name is [SEP]' print(tokenizer.decode(encoding.input_ids[1])) # prints '[CLS] niels [SEP] [PAD] [PAD]' ``` So I guess we have some work to do for slow tokenizers to work correctly. cc @LysandreJik @SaulLu @n1t0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CONAN_LOGIN_USERNAME and CONAN_PASSWORD are ignored in non-interactive mode Conan 1.3.2 To reproduce: 1. Run `conan user -c` 2. Set `CONAN_LOGIN_USERNAME`, `CONAN_PASSWORD` and `CONAN_NON_INTERACTIVE` environment variables. 3. Run `conan upload -r staging` to remove which requires authentication. **Expected result**: Conan uses credentials stored in environment variables (as was in Conan 1.2) **Actual result**: Upload fails with message: ``` Please log in to \"staging\" to perform this action. Execute \"conan user\" command. ERROR: Conan interactive mode disabled. [Remote: staging] ``` My best guess is that in `userio.py` ```python def request_login(self, remote_name, username=None): \"\"\"Request user to input their name and password :param username If username is specified it only request password\"\"\" self._raise_if_non_interactive() ``` call to `self._raise_if_non_interactive()` is unnecessary as this check performed by functions called from it (Having prompt printed is not that ugly, or move this check closer to `conan user` command). Option to always require explicit `conan user` is also possible, although feels little bit inconsistent and makes use of credentials variables pointless. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: running ipython on python files adds an extra traceback frame If you make a file `test.py` that throws a trivial error, and then run it with `ipython test.py`, you get an extra frame in the traceback: ``` root@8e0bcc11822a:~# ipython test.py --------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) /usr/lib/python2.7/dist-packages/IPython/utils/py3compat.pyc in execfile(fname, *where) 173 else: 174 filename = fname --> 175 __builtin__.execfile(filename, *where) /home/coderpad/test.py in <module>() 2 while x < 10: 3 x += 1 ----> 4 10 / (5 - x) 5 6 print x ZeroDivisionError: integer division or modulo by zero root@8e0bcc11822a:~# ipython --version 0.12.1 ``` Is there some way to configure the traceback formatted for file runs to drop the topmost frame? I know that the console does this in places, but I have no idea how to achieve that for script runs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: dns option documentation? Can someone give me example of using dns option? Or it haven't supported yet? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Relative imports broken in the notebook (Windows) It seems like relative imports do not work anymore in my notebooks since 6590fa5cce38f9b5020f219433b6821ba318a533. I'm on Windows 8 64 bits, Python 2.7.5. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Convert Hamiltonian variables to Hz <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? All other time-based units are currently defined in terms of seconds/Hertz. The Hamiltonian variables should also be. This may have an effect on the Qiskit-Aer pulse simulator @chriseclectic @DanPuzzuoli. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add `Aborted` state - `Failed` subclass used to indicate that a flow run (or task) was canceled due to user input. Update state colors + doc diagram To match @itsngansense 's awesome new color palette: <img width=\"650\" alt=\"states\" src=\"https://user-images.githubusercontent.com/13255838/56510837-daa14f00-64df-11e9-9295-08eda2d5ae5b.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Cannot pass dictionary config to partitioned asset job ### Dagster version 1.0.13 ### What's the issue? If I define a partitioned asset job using `define_asset_job`, then I cannot pass in a static dictionary as config (only a `PartitionedConfig`). For example: ```python daily_partitions_def = DailyPartitionsDefinition( start_date=\"2022-10-13\", ) @op(config_schema={\"my_config\": str}) def my_op(context): return None my_asset = AssetsDefinition.from_op(op_def=my_op, partitions_def=daily_partitions_def) my_asset_job = define_asset_job( name=\"my_asset_job\", selection=AssetSelection.assets(my_asset), config={ \"ops\": {\"my_op\": {\"config\": {\"my_config\": \"Hello!\"}}}, }, partitions_def=daily_partitions_def ) ``` Executing this job raises ```dagster._check.CheckError: Invariant failed. Description: Can't supply a ConfigMapping for 'config' when 'partitions_def' is supplied.``` When the job is not partitioned this works fine. ### What did you expect to happen? Users should be able to pass static config that will apply to all partitions. ### How to reproduce? _No response_ ### Deployment type _No response_ ### Deployment details _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Language: support mention type in Entity.mentions. [Currently](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/language/google/cloud/language/entity.py#L79) the mentions property of an entity is only a list of strings whereas it should be a list of objects containing the mention text and mention type. Furthermore, this change should add mention_type information to the mention documentation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Regression in wrap support with git Since https://github.com/mesonbuild/meson/commit/0008b326ffc39c86be2ae4352bdddc03f01840cc#diff-b50022e0b6a45e8e8d96225bdce8f92a we have failures with in CI with the CentOS 7 build with a project that uses a wrap with a git upstream. ``` # git --version git version 1.8.3.1 ``` ``` Initialized empty Git repository in /root/toolkit/subprojects/posixsignalmanager/.git/ remote: Counting objects: 68, done. remote: Compressing objects: 100% (68/68), done. remote: Total 68 (delta 41), reused 0 (delta 0) Unpacking objects: 100% (68/68), done. From git.somewhere.de:posixsignalmanager * branch master -> FETCH_HEAD error: pathspec 'master' did not match any file(s) known to git. ``` This is also reproduces with executing the git commands by hand as following: ``` # git init posixsignalmanager # cd posixsignalmanager/ # git remote add origin git@git.somewhere.de:posixsignalmanager # git fetch origin master # git checkout master error: pathspec 'master' did not match any file(s) known to git. ``` This might be related: > git branch -a Does not return anything, so it seems this git version does not create a upstream branch in response to the fetch. CC @WSoptics Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Documentation mistake ## Does existing documentation need to be updated with new content? Yes - Which files need to be updated? https://qiskit.org/documentation/stubs/qiskit.circuit.library.U3Gate.html - What content needs to be updated or replaced? (You can copy and paste) Assuming the given form of U3 is correct, we can clearly see it will NOT factorise to U3(\\theta, \\phi, \\lambda) = RZ(\\phi - \\pi/2) RX(\\pi/2) RZ(\\pi - \\theta) RX(\\pi/2) RZ(\\lambda - \\pi/2) as claimed. We can easily see this by taking eg (\\phi, \\lambda) = (-\\pi/2,\\pi/2) and expanding this expression and noting it does not yield RX(\\theta)$as claimed (and can easily be shown to be true). - What new content needs to be added? One possible correct answer is RZ(\\phi) RX(\\pi/2)RZ(\\pi - \\theta) RX(\\pi/2)RZ(\\lambda+\\pi). Issue originally opened in Qiskit/qiskit but I suspect this is the correct place for it now? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make plot_histogram & iplot_histogram similar <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? 1- Make the function signature the same for both functions 2- Make the `iplot_histogram` default when using jupyter and connected to internet. ### How to do this? In order to easily switch between the `plot_histogram` and `iplot_histogram` functions, both need some changes. 1- The `plot_histogram` function must be able to plot multiple histograms in one figure, just like `iplot_histogram` does. 2- We have to stay backward-compatible. Therefore, the `iplot_histogram(counts)` should work. So I'm thinking we use this function signature? ```python [i]plot_histogram(counts = {'000': 4, '010': 10}) # plot a simple counts histogram [i]plot_histogram(counts = [{'000': 4, '010': 10}, {'000':8, '001': 4, '010': 9}]) # plot 2 histograms in one fig [i]plot_histogram(counts = [{'000': 4, '010': 10}, {'000':8, '001': 4, '010': 9}], legend = ['simulator', 'device']) # plot 2 histograms w legend iplot_histogram(counts, legend, options) # the fancy options of the interactive plotter ``` ### More details *iplot_histogram* In the above, I'm proposing splitting the `executions_results` arg into a `counts` arg and a `legend` arg. I don't think we need the `device` thing at all. *plot_histogram* `plot_histogram` has a `number_to_keep` arg which i think should be absorbed in `options`. It will be a breaking change, but it does not affect as many users as the regular counts arg. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.ma.core.doc_note does not work correctly for indented docstrings Given: ```python class C: def method(self): \"\"\" This docstring Has multiple lines And notes Notes ----- original note \"\"\" ``` `np.ma.core.doc_note` gives: ```python >>> print(np.ma.core.doc_note(Bar.foo.__doc__, \"badly indented note\")) This docstring Has multiple lines And notes Notes ----- badly indented note original note ``` which has bad indents. This isn't public API, but it's possible we're being caught out by this internally somewhere. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Ability to cancel Cloud Bigtable reads Cloud Bigtable scanning reads can be long. In many cases, users want to cancel the request before the read stream is complete. `read_rows` should return a cancelable generator. This is an important feature for a Cloud Bigtable Apache Beam connector. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson 0.51.0 Xcode backend is not working. The backend for Xcode doesn’t work for some reason. I’m using Meson version 0.51.0.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Widget set_css doesn't always work (front-end order of ops.) Scenario: Create a couple of ContainerWidgets, set the CSS such that `margin` = `0px`. Later in the notebook try changing just the `margin-left` to something like `10px`, this works sometimes and fails others. This is because the CSS dict it re-applied in the front-end and the ordering is the order of the dict keys (which has no predictable notion of order since they are hashed) and sometimes during the reapplication of the dict, `margin` will be set after `margin-left` etc... Workaround: Use path independent CSS traits. i.e. first set margin-left, right, top, bottom to 0px. Later set margin-left to 10px. Possible solution: Use a list to store CSS traits so order is preserved between the back-end and front-end. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Conan 1.40 (PR-9361) breaking changes Sorry about the sloppy title. ;) We used to have our own method, but then ported to `apply_conandata_patches()`. This worked fine, but with conan 1.40 _(due https://github.com/conan-io/conan/pull/9361)_ all our recipes are broken. Sure, - this feature is still experimental, so I had to expect something to break during the update. But this PR also removes the possibility to specify a `base_path`. We use this option intensively and it is very useful. We try to take unmodified patches from upstream. But to apply them you often need to set `base_path` (and/or `strip`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: 2 test failures in Python 3.4 in parallel group Not sure where you are on Python 3.4, but I'm getting a couple of test failures. This is on Ubuntu 12.04, and only occurs when I kick off the tests from within an IPython notebook -- even though they're in a totally separate Python process started via `subprocess.call`. Steps: Clone Snake Charmer: https://github.com/andrewclegg/snake-charmer.git Checkout this revision (so as to avoid any confounding factors): 7d5e90e8b8816b0a28b037cf3094cdf4f24bf19f Start up a VM: `vagrant up` ... wait about an hour ... Open notebook browser on VM: [http://localhost:8834/tree](http://localhost:8834/tree) Open \"Snake Charmer QA\" notebook Run the first code cell (under \"Initialization\"), then the second (under \"Serial tests\") The first test to complete should be ``` python3.4 `which iptest3` --all -j ``` with exit code 1. When it completes, check out `log/charmed34/test_output/ipython.out` (inside your `snake-charmer` directory) I see these two errors: https://gist.github.com/andrewclegg/823d005491850d7f66cb One of them is an instance of the error described here -- https://github.com/ipython/ipython/pull/5291 -- the other is in test_elapsed_single and looks maybe unrelated? The interesting thing is that when I ssh into the VM and run the tests from bash, using the exact same command line I passed to `subprocess.call`, those tests pass. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: jupyterlab-hub executable needs to be removed in 2.0.0 ## Description jupyterlab-hub executable still is in 2.0.0 even though the library module has been removed ## Reproduce install jupyterlab, the executable jupyterlab-hub still exists even though it throws an error if run ## Expected behavior Executable should be removed ## Context - Operating System and version: linux - Browser and version: - JupyterLab version: 2.0.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Error finding version of arm gcc When meson tries to recognize the version of arm-none-linux-gnueabi-gcc it finds the wrong version. the output of arm-none-linux-gnueabi-gcc --version is: ``` arm-none-linux-gnueabi-gcc (Sourcery CodeBench Lite 2014.05-29) 4.8.3 20140320 (prerelease) Copyright (C) 2013 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. ``` printing the version within meson outputs: `2014.05-29` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub / Sub `maintain_leases` checks if consumer is active **twice** [Source][1]: ```python if self._consumer.stopped.is_set(): _LOGGER.debug('Consumer inactive, ending lease maintenance.') return ... if ack_ids and not self._consumer.stopped.is_set(): ... ``` I'm not sure if this is on purpose (since a different thread could update `consumer.stoped`) or if this just reflects an old state of the code. [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/235ac559531012474d05e0bc48ca730f3962d655/pubsub/google/cloud/pubsub_v1/subscriber/policy/base.py#L311-L327 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Reverse bit order in latex_circuit_drawer with conditional <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### What is the current behavior? I found a bug in `latex_circuit_drawer` when conditional gate is drawn with `reversebits` option. Index of registers is not correctly handled in `latex_circuit_drawer` when bit order is reversed. ### Steps to reproduce the problem ``` q1 = QuantumRegister(3, 'q1') c1 = ClassicalRegister(3, 'c1') qc = QuantumCircuit(q1, c1) qc.x(q1[0]).c_if(c1, 2) circuit_drawer(qc, style={\"reversebits\": True}) ``` The results: ``` ... ~/testbench/qiskit/tools/visualization/_circuit_visualization.py in _get_image_depth(self, aliases) 611 for i in range(pos_1, pos_2 + self.cregs[if_reg]): 612 if is_occupied[i] is False: --> 613 is_occupied[i] = True 614 else: 615 columns += 1 IndexError: list index out of range ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Handling tag with no prefix for aggregation_strategy in TokenClassificationPipeline # 🚀 Feature request Previously the parameter grouped_entities would handle entity with no prefix (like \"PER\" instead of \"B-PER\") and would correctly group similar entities next to each others. With the new parameter aggregation_strategy, this is not the case anymore. ## Motivation In some simple models, the prefix add some complexity that is not always required. Because of this we are forced to add a prefix to make aggregation works even if not required by the model. ## Your contribution Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] deploy generator doesn't preserve symlinks The [deploy generator](https://docs.conan.io/en/latest/reference/generators/deploy.html) uses [shutil.copy](https://docs.python.org/3/library/shutil.html#shutil.copy) to copy files. By default, shutil.copy follows symlinks rather than preserving them. This means that e.g. libstdc++.so is deployed as a copy of libstdc++.so.6 rather than a symlink to it. Since Python 3.3 shutil.copy can take a follow_symlinks argument. Therefore the fix could be: ```diff diff --git a/conans/client/generators/deploy.py b/conans/client/generators/deploy.py index 44bcf74..5aa2640 100644 --- a/conans/client/generators/deploy.py +++ b/conans/client/generators/deploy.py @@ -41,6 +41,6 @@ class DeployGenerator(Generator): os.path.relpath(root, rootpath), f) dst = os.path.normpath(dst) mkdir(os.path.dirname(dst)) - shutil.copy(src, dst) + shutil.copy(src, dst, follow_symlinks=False) copied_files.append(dst) return self.deploy_manifest_content(copied_files) ``` I'd submit a pull request but getting my head around the tests was taking more time than I can spare, sorry. ### Environment Details (include every applicable attribute) * Operating System+version: Ubuntu 16.04 * Conan version: 1.21.2 * Python version: 3.5.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: clean up CLI imports to improve process startup time Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: table.insert_data should allow for dictionaries [`table.insert_data`][2] currently only accepts tuples/lists in the order of the schema. It'd be a great feature allow lists of dictionaries to be passed. Would expect cases where if the keys in the dictionary do not match the schema, it would return back an error. FWIW, here's an example of how another python library handles it for a typical database connection: [https://github.com/pudo/dataset/blob/master/dataset/persistence/table.py#L62][1] [1]: https://github.com/pudo/dataset/blob/5fd8b3ef3ebc3ed143be8f435d917746d10b0c51/dataset/persistence/table.py#L62 [2]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/ff4f492f04c9b4f5511f8b0b7d2a32df86328306/bigquery/google/cloud/bigquery/table.py#L688-L694 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Reconnect Docker Agent on daemon restart ## Description When a Docker Agent is running and connected to a docker daemon it will raise a broken pipe error when the daemon restarts and a new flow run is found. ## Expected Behavior Docker Agent either gracefully reconnects to the daemon or exits when the pipe is broken. I'm leaning on the side of reconnecting as all it takes is reinstantiating the Docker low level API client Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: [dagit] execute does not stop on certain errors Repro: Run against intro_tutorials Set log_level in the config yaml to an invalid value Execute See error in console but Dagit stays in running state Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add `in_chans` to `DetrModel` # 🚀 Feature request <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> Add `in_chans` parameter to `DetrConfig` and corresponding models ## Motivation I find myself wanting to test DETR on data that have only one channel (it can be grey scale images or spectrograms in my case). But to make it work I have to use hacks, that may eventually work purely. <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. --> ## Your contribution I will be happy to open PR with this if this is as useful as I see it. Maybe some other improvements that can be incorporated? UPADTE: I think this will involve also adding parameters to disable `replace_batch_norm` and very specific part of setting `parameter.requires_grad_(False)` to all parameters in resnet except layer2-4 <!-- Is there any way that you could help, e.g. by submitting a PR? Make sure to read the CONTRIBUTING.MD readme: https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Possible broken documentation in https://qiskit.org/documentation/apidoc/providers.html <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? In the [providers documentation page](https://qiskit.org/documentation/apidoc/providers.html), some documentation redirects seem to be broken. - In the first paragraph _Providers Interface_, `Schedule` and `Backend` link to the respective classes, but `QuantumCircuit` is not linked. - There are references to `BackendV2`, `BackendV34`, `AerBackend` classes, but they are not linked to any class documentation (for example in the paragraph _Version Policy Support_). Should these be linked to appropriate documentation pages? - In the paragraph _Writing a New Provider_, some references to `BackendV1` link to a documentation, but others don't. Similarly, reference to `run()` is linked but `execute()` is not. - In _Transpiler Interface_ (_Custom Basis Gates_), step 2., reference to `HGate` documentation is broken. (In the line \"... and some commonly used single qubit rotation gates like the HGate and UGate that should be sufficient for the transpiler to translate any circuit into the custom basis gates.\") - There may be other such broken docs on this page. Perhaps this entire page should be revisited from the point of view of documentation linking. ### Steps to reproduce the problem Hover with the mouse over the class names - at some places, they don't lead to the documentation. ### What is the expected behavior? All references linked to docs. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Remove local throttling I'm sad to write this, because @cicdw worked extremely hard on this feature, but local throttling has become a very large piece of coordinated machinery which is no longer useful as we move Prefect into distributed settings, since it can only enforce throttling within its local cluster (by sharing queues). We will replace it with a robust, global solution. In the meantime, it should be removed in 0.4.0 to avoid user confusion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: add Softmax layer to stax test in examples/mnist_classifier.py, ```python def accuracy(params, batch): inputs, targets = batch target_class = np.argmax(targets, axis=1) x = predict(params, inputs) print(x[0]) ``` the final layer is LogSoftmax, but the output seems not correct, ```python Starting training... [-2.3113673 -2.6440005 -2.4797316 -1.79847 -1.6207608 -2.931935 -3.303906 -2.7275395 -2.2099946 -2.1403143] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `?` may generate hundreds of cell By mistake I have executed a cell like ``` for i in range(3): x= range? ``` but with ~70 instead of 3 which generated 70 code cell with just `x= range` in it... it was _really_ painfull to clean, it would be nice to prevent something like that Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Qasm3 exporter failing when if branch does not contain all clbits ### Environment - **Qiskit Terra version**: 0.39.0 - **Python version**: 3.10.6 - **Operating system**: MacOs 12.6 (21G115) ### What is happening? In some cases, the qasm3 exporter gives an error if the circuit has more clbits than needed in the if_else statement. ### How can we reproduce the issue? Run the following: ``` backend_wellington = provider.get_backend('ibm_wellington') cr = ClassicalRegister(1) # if >1 breaks cr2 = ClassicalRegister(1) # if this reg exists, breaks qr = QuantumRegister(5) qc = QuantumCircuit(qr, cr, cr2) with qc.if_test((cr[0], 1)) as _: qc.cnot(0,1) qc.cnot(0,2) qc.cnot(0,3) qc.cnot(0,4) qc_trans = transpile(qc, backend=backend_wellington, basis_gates=backend_wellington.configuration().basis_gates+['if_else'], optimization_level=1) print(qasm3.Exporter().dumps(qc)) print(qasm3.Exporter().dumps(qc_trans)) ``` Now, `qc` gets correctly exported, while `qc_trans` provides the following error: ``` QASM3ExporterError: 'Tried to push a scope whose circuit needs 2 clbits, but only provided 1 clbits to create the mapping.' ``` ### What should happen? The QASM3 string should be output for both cases. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: datetime property I not sure is it is a bug but when I have tried save() a entity with a datetime property appear this error. ``` pb_attr, pb_value = helpers.get_protobuf_attribute_and_value(value) File \"/usr/local/lib/python2.7/dist-packages/gcloud/datastore/helpers.py\", line 39, in get_protobuf_attribute_and_value name, value = 'timestamp_microseconds', time.mktime(val.timetuple()) NameError: global name 'time' is not defined ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Enable webagg in %matplotlib magic It seems somehow `%matplotlib webagg` no longer works. ``` File ipy/lib/python3.10/site-packages/IPython/core/pylabtools.py:321, in find_gui_and_backend(gui, gui_select) 317 import matplotlib 319 if gui and gui != 'auto': 320 # select backend based on requested gui --> 321 backend = backends[gui] 322 if gui == 'agg': 323 gui = None KeyError: 'webagg' ``` Could we add webagg backend for selection? It needs just adding the key to the dictionary `backends` in `pylabtools.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add labels to Environments All environments should allow for the setting of multiple \"labels\" (similar to Task tags) that are serialized as metadata. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Remove `Property._CREATION_COUNTER` from `ndb` Stepping into the [original source][1], it's clear it was not used for anything: ``` $ cd datastore-ndb-python/ $ git grep -n '_creation_counter' RELEASE_NOTES:112:- Issue 175: Add _creation_counter. ndb/model.py:888: __creation_counter_global = 0 ndb/model.py:942: Property.__creation_counter_global += 1 ndb/model.py:943: self._creation_counter = Property.__creation_counter_global ndb/model_test.py:1230: self.assertTrue(MyModel.foo._creation_counter < ndb/model_test.py:1231: MyModel.bar._creation_counter < ndb/model_test.py:1232: MyModel.baz._creation_counter) ``` It seems the stated goal in https://github.com/GoogleCloudPlatform/datastore-ndb-python/issues/175 (when this was introduced) was never implemented. @tseaver @chrisrossi WDYT? @theacodes Do we have leeway to get rid of such a feature? [1]: https://github.com/GoogleCloudPlatform/datastore-ndb-python Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC, TST: matmul docstring fails refguide The matmul docstring in `numpy/core/code_generators/ufunc_docstrings.py` fails the refguide check in #12253 for a variety of reasons varying from behavior changes to not even closing brackets in `np.array()` declarations. While I've cleaned up some of the trivial issues, I'm going to mark the rest of the issues in that docstring with the `SKIP` directive and I suggest that they be fixed **after** that PR is merged so that the fixes are properly verified in CI. I'll probably continue with this approach moving forward until the doctest PR is merged -- adding SKIPs and opening bookmark issues--otherwise I end up as the \"human refguide checker\" for doc changes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: align_center() DSL directive This is a follow up to #4174 to add another directive for aligning the pulses that appear within a block at their center. I think this is not that different from the other alignments (left, right). You would just find the longest pulse within that block and reserve a slot of that size. Mark the center point as `c`. Then all other pulses will last from `c-duration/2 - c+duration/2`. Example: ``` d0 -----------------------[20 dt]------------------------ d1 -----[ 180 dt ]----- d2 ------------[ 100 dt ]----------- ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Entity indexed=False not preserved in helpers.entity_from_protobuf In `entity_from_protobuf` a key is [created](https://github.com/GoogleCloudPlatform/gcloud-python/blob/6bde37d1162749eea72a1b177f99750d575739d1/gcloud/datastore/helpers.py#L48) and the values are added via ``` python for property_pb in pb.property: value = _get_value_from_property_pb(property_pb) entity[property_pb.name] = value ``` However, `property_pb.value.indexed` is ignored and `entity` has the default empty tuple for `exclude_from_indexes`. --- To see this, first save with `exclude_from_indexes` non-empty and inspect the protobuf values: ``` python >>> from gcloud import datastore >>> from gcloud.datastore.entity import Entity >>> from gcloud.datastore.key import Key >>> >>> datastore.set_default_connection() >>> datastore.set_default_dataset_id('foo') >>> >>> e = Entity(key=Key('Foo', 1), exclude_from_indexes=('foo', 'bar')) >>> e.update({ ... 'foo': 10, ... 'bar': 11, ... 'baz': 12, ... }) >>> e.save() >>> >>> entity_pb, = datastore.get_connection().lookup( ... dataset_id=e.key.dataset_id, ... key_pbs=[e.key.to_protobuf()], ... ) >>> for p in entity_pb.property: ... print p.value.indexed ... True False False ``` then use the key to `get` (which calls `get_entities` -> `entity_from_protobuf`), save the newly created (supposedly identical) `Entity`. After saving, check the same protobuf values: ``` python >>> e_retrieved = e.key.get() >>> e_retrieved.save() >>> >>> entity_pb, = datastore.get_connection().lookup( ... dataset_id=e_retrieved.key.dataset_id, ... key_pbs=[e_retrieved.key.to_protobuf()], ... ) >>> for p in entity_pb.property: ... print p.value.indexed ... True True True ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Timeslots should have informative representation <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently `Interval`, `Timeslot` and `TimeslotCollection` have the standard python object representation. This should be replaced with an informative implementation of `__repr__`. As `TimeslotCollection` contains `Timeslot`s and `Timeslot`s contain `Interval`s the hierarchal nature of these data structure should be used to derive representations. ### Example A possible representation might look like Interval: `(t0, tf)` eg. `(0, 10)` Timeslot: Is an interval on a channel `(channel, repr(interval))`: `(DriveChannel(0), (0, 10))` TimeslotCollection: Is a dictionary of timeslots. Ie. it groups together intervals on channels. `{channel1: [repr(interval1_c1), repr(interval2_c1), ...]), channel2: [repr(interval1_c2), repr(interval2_c2), ...]}` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Gnome-initial-setup is broken https://build.gnome.org/continuous/buildmaster/builds/2018/10/25/27/build/log-gnome-initial-setup.txt Git bisect says the cause is this: https://github.com/mesonbuild/meson/commit/176af2c8c33 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Expose TLS config on Docker storage ## Opened from the [Prefect Public Slack Community](https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU) **aseev.arsenii**: Hey all! I'm trying to set up a CircleCI job that builds and pushes flows Docker images to AWS ECR. CircleCI provides a remote docker execution environment, and to connect to it I need to pass on TLS configuration to the docker client. Unfortunately Prefect seems to only expose the `base_image` of `docker.APIClient` (<https://github.com/PrefectHQ/prefect/blob/1447982cc63a1f87c4a19cc7be18f2b2693fb883/src/prefect/environments/storage/docker.py#L508>). Any suggestions on how to do this? Thanks! **laura**: Hi <@UR914ST7H>, I’m not sure of a workaround per se but it looks like the signature of exactly where you found the client instantiation could be changed to accept TLS config, configured by the user against an attribute of the `Docker` Storage instance like you can for `base_url` now. Let me get the bot to open an issue off this thread. **laura**: <@ULVA73B9P> open “Expose TLS config on Docker storage” Original thread can be found [here](https://prefect-community.slack.com/archives/CL09KU1K7/p1590055135302100?thread_ts=1590055135.302100&cid=CL09KU1K7). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Search query handles os_build and arch_build as options When searching for the packages of a receipe os_build and arch_build are not take into account correctly. Even if a package matches, it is not included in the resulting list. From what I can see, only specific strings in the query are treated as settings, all others as options. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PauliFeatureMap docs not formatted correctly <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? <img width=\"803\" alt=\"Screen Shot 2020-05-01 at 09 08 00\" src=\"https://user-images.githubusercontent.com/1249193/80807526-6d60d900-8b8b-11ea-9d29-83cb814f2000.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: execute gives depreciation warnings <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? ```python from qiskit import * sim = Aer.get_backend('unitary_simulator') qr = QuantumRegister(2, name='q') qc = QuantumCircuit(qr) execute(qc, sim); ``` gives ```python /Users/paul/Desktop/Github_repos/qiskit-terra/qiskit/validation/base.py:360: DeprecationWarning: The as_dict() method is deprecated, use to_dict(). DeprecationWarning) /Users/paul/Desktop/Github_repos/qiskit-terra/qiskit/validation/base.py:360: DeprecationWarning: The as_dict() method is deprecated, use to_dict(). DeprecationWarning) ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Create contextmanager for set_dirty/clean_dirty functions Consider creating a `contextmanager` for the `set_dirty/clean_dirty` functions, it may have an optional argument to delete the directory if an exception is raised. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Cloud PR references Core See https://github.com/PrefectHQ/cloud/pull/1394 for more details Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: rename or remove %profile magic This is an issue to discuss what we should do with the `%profile` magic. Background: This magic currently returns the name of the active profile. By name, it is easily confused with the functionality found in `%prun` and `%run -p`. Renaming or removing the current implementation of `%profile` opens up the possibility to use `%profile` for code profiling purposes. Here are a few proposals: (please feel free to add others) 1. Rename `%profile` to `%profile_name` to better signify that it does not do code profiling. 2. Deprecate and then remove `%profile` and tell users to use `get_ipython().profile` rename or remove %profile magic This is an issue to discuss what we should do with the `%profile` magic. Background: This magic currently returns the name of the active profile. By name, it is easily confused with the functionality found in `%prun` and `%run -p`. Renaming or removing the current implementation of `%profile` opens up the possibility to use `%profile` for code profiling purposes. Here are a few proposals: (please feel free to add others) 1. Rename `%profile` to `%profile_name` to better signify that it does not do code profiling. 2. Deprecate and then remove `%profile` and tell users to use `get_ipython().profile` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: RemoteEnvironment doesn't use storage.get_flow() in execute() Basically, this: https://github.com/PrefectHQ/prefect/blob/6fe3fc31ce7023403ef0048e7ea1318501391111/src/prefect/environments/execution/remote.py#L68 I thought that an environment would use storage.get_flow() method to retrieve the flow to ensure universal compatibility of different envs/storages. Not opened as a bug because I'm not sure it is, maybe I'm missing something. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Failure to find linker for custom_target Meson failes to determine linker if multiple languages are used and a custom_target is the sole source file of a shared library: == meson.build == project ('Showcase for custom_target source', ['c', 'cpp']) Foo_cc = custom_target ('Foo.cc', command : [ 'touch', '@OUTPUT@' ], output : 'Foo.cc') Somelib = shared_library ('Somelib', [ Foo_cc ]) == build result == File \"/tmp/meson/mesonbuild/backend/backends.py\", line 290, in determine_linker raise RuntimeError('Unreachable code') RuntimeError: Unreachable code Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add MEGA ### Model description MEGA introduces a new attention method which incorporates gating and exponential moving averages to create strong local dependencies, reducing the need for full softmax attention. MEGA set a new SOTA on Long Range Arena, and MEGA-chunk performs nearly as well while achieving linear complexity WRT sequence length. I have seen really promising results from my own experiments with MEGA on long documents -- both in efficiency and model performance. It would be awesome to have MEGA (+ MEGA-chunk) available in the Hugging Face ecosystem! ### Open source status - [X] The model implementation is available - [X] The model weights are available ### Provide useful links for the implementation * [Paper](https://arxiv.org/abs/2209.10655) * [Official implementation](https://github.com/facebookresearch/mega) * [Links to pretrained weights](https://github.com/facebookresearch/mega#models-checkpoints) * I'm only aware of @violet-zct through the official MEGA repo Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add support for -H and TLS flags The `docker-compose` command should support these options from the `docker` command: ``` -H, --host=[] Daemon socket(s) to connect to --tls=false Use TLS; implied by --tlsverify --tlscacert=~/.docker/ca.pem Trust certs signed only by this CA --tlscert=~/.docker/cert.pem Path to TLS certificate file --tlskey=~/.docker/key.pem Path to TLS key file --tlsverify=false Use TLS and verify the remote ``` This will allow you to do `docker-compose $(docker-machine config dev) ...` etc. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [bug] `token` not supported in `AutoModel` I see `use_auth_token` is already deprecated and will be replaced by `token`, https://github.com/huggingface/transformers/blob/b257c46a075419c09e5ce5c5aa39bc346ecdb9a5/src/transformers/modeling_utils.py#L2196-L2204 But `AutoModel` doesn't accept the new argument `token` yet. Especially in https://github.com/huggingface/transformers/blob/b257c46a075419c09e5ce5c5aa39bc346ecdb9a5/src/transformers/configuration_utils.py#L631-L638 Directly call `LlamaForCausalLM` instead of `AutoModelForCausalLM` is a temporary workaround to get rid of the deprecation warning. ### Reproduction ```python3 transformers.AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-chat-hf',use_auth_token='XXX') transformers.LlamaForCausalLM.from_pretrained('meta-llama/Llama-2-7b-chat-hf',token='XXX') ``` ### Expected behavior `AutoModel` should support new `token` argument. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: More incompatibilities of `TaperedPauliSumOp` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master @ 28c543ae - **Python version**: 3.8.8 - **Operating system**: Linux, Fedora 33: `uname -r: 5.11.10-200.fc33.x86_64` ### What is the current behavior? `TaperedPauliSumOp` cannot be multiplied with another `OperatorBase`. ### Steps to reproduce the problem Try the following snippet: ```python from qiskit.circuit import Parameter from qiskit.opflow import PauliSumOp, TwoQubitReduction from qiskit.opflow.evolutions import PauliTrotterEvolution qubit_op = PauliSumOp.from_list([ (\"IIII\", -0.8105479805373266), (\"IIIZ\", 0.17218393261915552), (\"IIZZ\", -0.22575349222402472), (\"IZZI\", 0.1721839326191556), (\"ZZII\", -0.22575349222402466), (\"IIZI\", 0.1209126326177663), (\"IZZZ\", 0.16892753870087912), (\"IXZX\", -0.045232799946057854), (\"ZXIX\", 0.045232799946057854), (\"IXIX\", 0.045232799946057854), (\"ZXZX\", -0.045232799946057854), (\"ZZIZ\", 0.16614543256382414), (\"IZIZ\", 0.16614543256382414), (\"ZZZZ\", 0.17464343068300453), (\"ZIZI\", 0.1209126326177663), ]) tapered_qubit_op = TwoQubitReduction(num_particles=2).convert(qubit_op) param = Parameter('c') param * tapered_qubit_op ``` ### What is the expected behavior? The multiplication should work just fine. ### Suggested solutions Since this is very similar error to #6100 I suggest to find a more general solution which makes `TaperedPauliSumOp` generally compatible. I am quite positive that otherwise more such problems will arise. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose run --rm does not remove volumes Running one-off commands with docker-compose does not delete volumes used by the container. This is different than `docker run --rm` which does remove volumes after the container is deleted. docker-compose config --volumes In addition to ``` $ docker-compose config --services ``` it'd be nice to have ``` $ docker-compose config --volumes ``` listing the named volumes similarly to services. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Documentation missing is_decoder ### System Info Not relevant. Issue is about online documentation. ### Who can help? @sgugger @stevhliu ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction The bert documentation [page](https://huggingface.co/docs/transformers/model_doc/bert) mentions `is_decoder` 5 times but the BertConfig [class documentation](https://huggingface.co/docs/transformers/model_doc/bert) not a single time. This probably affects other models as well. ### Expected behavior BertConfig class documentation should contain an entry for `is_decoder`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Prepend to sys.path in the Django fixup instead of appending. This makes sure that project modules have precedence over system ones. Closes #5347. ## Description This follows @Phyks's suggestion of a fix for #5347, by prepending instead of appending to the system path, to ensure that the project modules are not hidden by system-wide ones. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: docs: compiler.find_library: discourage lib prefix I continue seeing it in the wild. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: How to use ReduceLROnPlateau methon in matster branch version? #### What is your question? I find the log design has changed a lot between version 0.8.5 and master branch [0c26468](https://github.com/PyTorchLightning/pytorch-lightning/tree/0c264689cb566582ac47333d8b7192d656e19440) I got the error message when I follow the [docs logging-from-a-lightningmodule](https://pytorch-lightning.readthedocs.io/en/latest/loggers.html#logging-from-a-lightningmodule) to modify the log code. error message: ``` MisconfigurationException: ReduceLROnPlateau conditioned on metric val_loss which is not available. Available metrics are: val_early_stop_on,val_checkpoint_on,epoch,checkpoint_on. Condition can be set using `monitor` key in lr scheduler dict ``` #### Code ```python def configure_optimizers(self): optimizer = torch.optim.Adam(self.parameters(), lr = 0.01) scheduler = ReduceLROnPlateau(optimizer, patience=10) return [optimizer], [scheduler] def validation_step(self, batch, batch_nb): x, y = batch y_hat = self(x) loss = F.l1_loss(y, y_hat) result = pl.EvalResult() result.log('val_step_loss', loss) return result def validation_epoch_end(self, outputs): avg_loss = outputs.val_step_loss.mean() result = pl.EvalResult() result.log('val_loss', avg_loss) return result ``` I wonder if I should defined `validation_epoch_end` like above, **if there are any example about how to use `ReduceLROnPlateau` in a right way?** #### What's your environment? - OS: Ubuntu 18.04 - Packaging pip - Version 0.9.0 rc 12 master branch [0c26468](https://github.com/PyTorchLightning/pytorch-lightning/tree/0c264689cb566582ac47333d8b7192d656e19440) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Handle serialization of State results We need to put together a new serializer spec for how to handle state results. An edge case that comes to mind is `Failed` states --> should we be storing the caught exceptions in the DB, or not? We have discussed that you can fail a task and _still_ pass data around (which is 💯 ) and makes me think we should avoid ever storing the `.result` attribute Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: tools.patch cant create files To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Hello, I am trying to apply some out-of-tree git patches, some of them create new files. Some of them contain new files, and the tools.patch utility will then compail that absolute filepaths are not allowed (`/dev/null`). Lacking this support, its cumbersome to add bugfixes and git commits in general. Example patch (created with `git format-patch`): ```patch From d0807313143bb35da65c2b858a2d9e17fd3fbf9e Mon Sep 17 00:00:00 2001 From: Norbert Lange <nolange79@gmail.com> Date: Fri, 7 Jun 2019 21:49:19 +0200 Subject: [PATCH] add and remove file --- newfile | 1 + oldfile | 1 - 2 files changed, 1 insertion(+), 1 deletion(-) create mode 100644 newfile delete mode 100644 oldfile diff --git a/newfile b/newfile new file mode 100644 index 0000000..fdedddf --- /dev/null +++ b/newfile @@ -0,0 +1 @@ +Hello mean world diff --git a/oldfile b/oldfile deleted file mode 100644 index 32332e1..0000000 --- a/oldfile +++ /dev/null @@ -1 +0,0 @@ -Old litter -- 2.20.1 ``` My environment is: ``` Debian Buster x64 Conan version 1.16.0 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: RFC: merging __init__() and run() arguments #291 raises the specter of an old discussion we had tabled -- how to handle arguments that are appropriate for both `__init__` and `run`. In short: flows built with the functional API will prefer run() arguments, since the user often isn't instantiating the task explicitly at all. Conversely, flows built with the imperative API are instantiated and then attached to other tasks explicitly, so __init__() seems more appropriate. If we don't provide some way of doing this, then users will end up writing repetitive code which is unpleasant: ```python class MyTask(Task): def __init__(self, a, b): self.a = a self.b = b def run(self, a=None, b=None): a = self.a if a is None else a b = self.b if b is None else b ``` I'll throw out two possible alternatives to get the ball rolling: - This decorator provides default values for any specified run arguments, retrieving those values from instance attributes of the same name. ```python class MyTask(Task): def __init__(self, a, b): self.a = a self.b = b @defaults_from_attrs('a', 'b') def run(self, a, b): ... ``` This indicates the same thing, but uses Python 3 annotations instead. ```python class MyTask(Task): def __init__(self, a, b): self.a = a self.b = b def run(self, a:DefaultFromAttr, b:DefaultFromAttr): ... ``` The annotations approach has the disadvantage of not allowing proper typing of the argument itself. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: DuplicateTaskIdFound when reusing tasks with task_group decorator ### Apache Airflow version 2.2.2 (latest released) ### Operating System MacOS 11.6.1 ### Versions of Apache Airflow Providers $ pip freeze | grep airflow apache-airflow==2.2.2 apache-airflow-providers-celery==2.1.0 apache-airflow-providers-ftp==2.0.1 apache-airflow-providers-http==2.0.1 apache-airflow-providers-imap==2.0.1 apache-airflow-providers-sqlite==2.0.1 ### Deployment Other ### Deployment details `airflow standalone` ### What happened Exception raised : ``` raise DuplicateTaskIdFound(f\"Task id '{key}' has already been added to the DAG\") airflow.exceptions.DuplicateTaskIdFound: Task id 'do_all_things.do_thing__1' has already been added to the DAG ``` ### What you expected to happen _No response_ ### How to reproduce * Add the following python file to the `dags` folder: ```python from datetime import datetime from airflow.decorators import dag, task, task_group @dag(start_date=datetime(2023, 1, 1), schedule_interval=\"@once\") def test_dag_1(): @task def start(): pass @task def do_thing(x): print(x) @task_group def do_all_things(): for i in range(5): do_thing(i) @task def end(): pass start() >> do_all_things() >> end() test_dag_1() ``` * Start airflow by running `airflow standalone` ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Missing LINK_ARGS -framework for OpenCL run-time dependency tries to link a directory Looks like it's attempting to link a directory instead of referencing the framework: ``` ld: can't map file, errno=22 file '/System/Library/Frameworks/OpenCL.framework' for architecture x86_64 ``` In https://github.com/LeelaChessZero/lc0/issues/972 I bisected meson finding two changes that seemed to change the build.ninja line for LINK_ARGS. 0.51.0: ``` -L/usr/local/opt/openssl/lib -Wl,-dead_strip_dylibs /usr/local/Cellar/protobuf/3.10.0/lib/libprotobuf.dylib -lpthread -F/System/Library/Frameworks -framework Accelerate -F/System/Library/Frameworks -framework OpenCL /usr/lib/libz.dylib -Wl,-headerpad_max_install_names -Wl,-rpath,/usr/local/Cellar/protobuf/3.10.0/lib -Wl,-rpath,/usr/lib ``` (Has `-framework OpenCL`) After https://github.com/mesonbuild/meson/commit/5bd21a96b89efc5fe96025398151dcbce34345ac ``` -L/usr/local/opt/openssl/lib -Wl,-dead_strip_dylibs /usr/local/Cellar/protobuf/3.10.0/lib/libprotobuf.dylib -lpthread -F/System/Library/Frameworks -framework Accelerate /usr/lib/libz.dylib -Wl,-headerpad_max_install_names -Wl,-rpath,/usr/local/Cellar/protobuf/3.10.0/lib -Wl,-rpath,/usr/lib ``` (Removes `-framework OpenCL`) After https://github.com/mesonbuild/meson/commit/f097b96883a54868cf98600be23893268b5832f4 ``` -L/usr/local/opt/openssl/lib -Wl,-dead_strip_dylibs -Wl,-undefined,error -Wl,-headerpad_max_install_names /usr/local/Cellar/protobuf/3.10.0/lib/libprotobuf.dylib -lpthread -F/System/Library/Frameworks -framework Accelerate /System/Library/Frameworks/OpenCL.framework /usr/lib/libz.dylib -Wl,-headerpad_max_install_names -Wl,-rpath,/usr/local/Cellar/protobuf/3.10.0/lib -Wl,-rpath,/usr/lib ``` (Adds `/System/Library/Frameworks/OpenCL.framework`) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Programmatic customization of run_id for scheduled DagRuns ### Description Allow DAG authors to control how `run_id`'s are generated for created DagRuns. Currently the only way to specify a DagRun's `run_id` is through the manual trigger workflow either through the CLI or API and passing in `run_id`. It would be great if DAG authors are able to write a custom logic to generate `run_id`'s from scheduled `DagRunInterval`'s. ### Use case/motivation In Airflow 1.x, the semantics of `execution_date` were burdensome enough for users that DAG authors would subclass DAG to override `create_dagrun` so that when new DagRuns were created, they were created with `run_id`'s that provided context into semantics about the DagRun. For example, ``` def create_dagrun(self, **kwargs): kwargs['run_id'] = kwargs['execution_date'] + self.following_schedule(kwargs['execution_date']).date() return super().create_dagrun(kwargs) ``` would result in the UI DagRun dropdown to display the weekday of when the Dag actually ran. <img width=\"528\" alt=\"image001\" src=\"https://user-images.githubusercontent.com/9851473/156280393-e261d7fa-dfe0-41db-9887-941510f4070f.png\"> After upgrading to Airflow 2.0 and with Dag serialization in the scheduler overridden methods are no longer there in the SerializedDAG, so we are back to having `scheduled__<execution_date>` values in the UI dropdown. It would be great if some functionality could be exposed either through the DAG or just in the UI to display meaningful values in the DagRun dropdown. ### Related issues _No response_ ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Use of GIT_REPO env-var for setting Repo path in 2.0.9 [This change](https://github.com/gitpython-developers/GitPython/commit/26bb778b34b93537cfbfd5c556d3810f2cf3f76e) in `2.0.9` is a bit problematic: - Even if a `path` is explicitly provided to the constructor, the `GIT_DIR` environment variable is used instead - For things like git hooks, `GIT_DIR` is set to `.git` by default. This will result in [`self.git_dir`](https://github.com/gitpython-developers/GitPython/blob/master/git/repo/base.py#L156) being set to `.git` (`os.path.abspath` instead of `os.path.normpath` would fix this). Consequently, subsequent commands fails (eg: `repo.git.status()`) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Dummy command argument wasn't removed from auto-link after download Auto-linking of downloaded languages was broken in https://github.com/explosion/spaCy/commit/7f0ab145e95036a55af4802184a4b1c496557d0a. The dummy argument wasn't removed from the `link` call at https://github.com/explosion/spaCy/blob/master/spacy/cli/download.py#L44. I can make a PR for the fix unless it's easier for a maintainer to just fix this quickly. ## Your Environment * Operating System: Docker python:3.6 * Python Version Used: 3.6.2 * spaCy Version Used: Changes made since 2.0.5 * Environment Information: Docker python:3.6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Sampler fails on gates with unhashable parameters ### Environment - **Qiskit Terra version**: fbff44bfe9ebc9d97203929b1bff5483fe06028a - **Python version**: Python 3.10.8 - **Operating system**: Arch Linux ### What is happening? See title. ### How can we reproduce the issue? ```python import numpy as np from qiskit.circuit import QuantumCircuit from qiskit.extensions.unitary import UnitaryGate from qiskit.primitives import Sampler gate = UnitaryGate(np.eye(2)) circuit = QuantumCircuit(1) circuit.append(gate, [0]) circuit.measure_all() sampler = Sampler() sampler_result = sampler.run([circuit]).result() quasi_dists = sampler_result.quasi_dists ``` ``` Traceback (most recent call last): File \"/home/kjs/projects/qiskit-terra/scratch/sampler_hash_bug.py\", line 14, in <module> sampler_result = sampler.run([circuit]).result() File \"/home/kjs/projects/qiskit-terra/qiskit/primitives/base/base_sampler.py\", line 184, in run return self._run( File \"/home/kjs/projects/qiskit-terra/qiskit/primitives/sampler.py\", line 146, in _run index = self._circuit_ids.get(key) TypeError: unhashable type: 'numpy.ndarray' ``` ### What should happen? It should work. ### Any suggestions? It appears the primitives rely on associating a hashable key with each circuit https://github.com/Qiskit/qiskit-terra/blob/514e38394657802e6cf4aefbf65fe3be3b23b783/qiskit/primitives/utils.py#L127. This is not working. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [examples] should all examples support the predict stage? This is part of the ongoing effort to sync the example scripts. In https://github.com/huggingface/transformers/issues/10437#issuecomment-789090858 it was flagged that some scripts have test/predict, whereas others don't. Should we: A. have all scripts have train/eval/predict B. only have predict where it's desired @sgugger, @patil-suraj, @LysandreJik Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Move Galata to the `jupyterlab` repo? Opening a new issue since this was originally brought by @fcollonval during the weekly meeting yesterday: https://github.com/jupyterlab/team-compass/issues/117#issuecomment-867008413 Should we move Galata to the `jupyterlab` repository here? Galata currently lives in its own repo under the `jupyterlab` organization: https://github.com/jupyterlab/galata This would make it easier to iterate on it when core PRs make significant changes to the UI for example. For reference there is already the `testutils` package being developed in core lab, that other third-party extensions can depend on for unit tests: https://github.com/jupyterlab/jupyterlab/tree/master/testutils Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: IterableDataset breaks 1.1 compatibility A recently introduced feature unfortunately breaks compability with Pytorch 1.1.0. **Describe the bug** IterableDataset support, introduced in [issue 323](https://github.com/williamFalcon/pytorch-lightning/issues/323), requires Pytorch 1.2.0+. **To Reproduce** In a python environment with Pytorch 1.1.0 do: import pytorch_lightning **Expected behavior** Compatibility with Pytorch 1.1.0. I'm filing it as a bug report rather than a docs fix since the dependency on 1.2.0+ introduced by [issue 323](https://github.com/williamFalcon/pytorch-lightning/issues/323) doesn't seem to be intentional. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: npm@5 breaks linking to extensions As [discussed on gitter](https://gitter.im/jupyterlab/jupyterlab?at=593fd880d83c50560c03ac5f), npm@5 breaks using `jupyter labextension link path/to/extension` because of the changed semantics when handling paths as package specifiers. Here's the npm pull request implementing these changes: https://github.com/npm/npm/pull/15900 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumCircuit mirror method failure <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.10.0 - **Python version**: 3.6.8 - **Operating system**: MacOS, Ubuntu ### What is the current behavior? The mirror method calls the append method in the circuit passing a tuple while the signature should is: 'append(self, instruction, qargs=None, cargs=None)' causing the append method to fail. This causes Aqua unit test to fail. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions The problem is at line 191 of quantumcircuit.py. I believe it should be: reverse_circ.append(inst.mirror(), qargs, cargs) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add flow run information to Slack notification The built-in [Slack notifier](https://docs.prefect.io/core/advanced_tutorials/slack-notifications.html#slack-notifications) is neat but doesn't convey quite enough information to be useful, especially in a \"production\" context where many users might be running flows simultaneously. Including information about the specific flow *run* (for example, the run name or a link to the flow run in the Cloud UI) would go a long way towards making the notification more informative+actionable. It might also be nice to be able to pass some sort of formatter function to `slack_notifier` that could customize the message at run-time based on information about the task/flow, some variables in the context, things like that. cc @cicdw who it sounds like thinks this would be pretty easy 😁 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumInstance.execute returns the calibration circuits results <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.3 - **Python version**: 3.8.6 - **Operating system**: MacOSX 10.15.7 ### What is the current behavior? When QuantumInstance class uses measurement error mitigation, the `execute` command returns the results of the calibration circuits in addition to the requested circuits. This causes an error in the CircuitSample.sample_circuits command and as a result alters the first iteration of the VQE optimization. ### Steps to reproduce the problem ``` from qiskit import Aer, QuantumCircuit from qiskit.ignis.mitigation import CompleteMeasFitter from qiskit.opflow import CircuitSampler, CircuitStateFn from qiskit.utils import QuantumInstance qc = QuantumCircuit(1) qc.x(0) qc_meas = qc.copy() qc_meas.measure_all() backend = Aer.get_backend('aer_simulator') for idx, is_use_mitigation in enumerate([False, True]): if is_use_mitigation: quantum_instance = QuantumInstance(backend, measurement_error_mitigation_cls=CompleteMeasFitter) else: quantum_instance = QuantumInstance(backend) counts = quantum_instance.execute(qc_meas).get_counts() print(counts) circuit_sampler = CircuitSampler(quantum_instance) sampling = circuit_sampler.sample_circuits(circuit_sfns=[CircuitStateFn(qc)]) print(sampling) ``` ### What is the expected behavior? Should return just the result of the input circuit. ### Suggested solutions It seems like there is a mechanism to skip result in line 641 in utils/quantum_instance.py file. I think it can be utilised to skip the calibration results as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Parameters needs examples in the documentation ### What is the expected enhancement? Many users land in https://qiskit.org/documentation/stubs/qiskit.circuit.Parameter.html when search on how to parametrize circuits. @Cryoris did a good jobs at explaining them in https://quantumcomputing.stackexchange.com/questions/13558/how-to-add-several-parameters-in-qiskit-circuit . I think the Parameter docstring needs a short example. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Remove version_checker from client The checks of the remote versions against client versions are no longer done. So we can remove that extra complexity wrapping the requester in the client. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Forward-mode differentiation rule for 'custom_lin' not implemented Running this code produces the above error. ``` @partial(jax.custom_vjp, nondiff_argnums=(0, 1)) def _clip_gradient(lo, hi, x): return x # identity function def clip_gradient_fwd(lo, hi, x): # return x, None return x, (hi, ) def clip_gradient_bwd(lo, hi, _, g): return (np.clip(g, lo, hi),) _clip_gradient.defvjp(clip_gradient_fwd, clip_gradient_bwd) def clip_gradient(x): lo = -1 hi = x + 1 # causes things to break return _clip_gradient(lo, hi, x) print(jax.grad(clip_gradient)(1.)) ``` Replacing the residual with `None` (see commented out line in `clip_gradient_fwd`) makes the output ``` Traced<ConcreteArray(1.0)>with<JVPTrace(level=1/0)> with primal = DeviceArray(1., dtype=float32) tangent = Traced<ShapedArray(float32[]):JaxprTrace(level=0/0)> ``` I was also able to get a mismatched tracer levels error on a more complex example. To my understanding setting `hi = x + 1` is the issue as it creates a trace of `hi` with `x`. This example may seem a bit contrived, but I originally came across this trying to set an initial step size for `odeint` (see #2604). IIUC we want to make concrete all `JVPTracer` instances that are in static args [here](https://github.com/google/jax/blob/master/jax/custom_derivatives.py#L441). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add resuming from specific checkpoint **Is your feature request related to a problem? Please describe.** In current version, there is no way to resume training from a specific checkpoint (not the last checkpoint). Sometimes (very often in my case), one needs experiment training with different hyperparameters (e.g. dropout rate, augmentation) from a specific checkpoint. **Describe the solution you'd like** Add `resume_from_checkpoint`argument to Trainer class. **Describe alternatives you've considered** I tried to use `restore` from Trainer class, but was not successful because it is meant to be used only when .fit() is called. **Additional context** FYI, I made a PR to demonstrate my idea: https://github.com/williamFalcon/pytorch-lightning/pull/516 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Missing f-string in qasm3 export error ### Environment - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is happening? There is a missing f-string in the following error (L468): https://github.com/Qiskit/qiskit-terra/blob/531e62f3a3c218fee6db116f54ed41ce4e88d9a9/qiskit/qasm3/exporter.py#L466-L469 ### How can we reproduce the issue? Export a circuit with a parametric subroutine. ### What should happen? The name `instruction` should be printed. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda=4.1 no longer respects HTTP_PROXY My proxy variables are properly set: ``` $ set https_proxy HTTPS_PROXY=http://myproxy:8080 ``` `conda=4.0.8` successfully picks up my `%HTTPS_PROXY%` and installs `conda=4.1`: ``` $ conda install conda=4.1 Fetching package metadata: .......... Solving package specifications: ......... The following packages will be UPDATED: conda: 4.0.8-py27_0 defaults --> 4.1.0-py27_0 defaults ``` now trying to revert back to `conda=4.0`: ``` $ conda install conda=4.0 Fetching package metadata ......... Could not connect to https://repo.continuum.io/pkgs/free/win-64/ Connection error: HTTPSConnectionPool(host='repo.continuum.io', port=443): Max retries exceeded with url... ``` proxy settings no longer work. Configuring `proxy_servers` in `.condarc` restores connectivity. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: dagster-airbyte misidentifies destinations which can support normalization ### Dagster version version 1.2.6 ### What's the issue? https://github.com/airbytehq/airbyte/pull/21005 I believe due to the change above in the Airbyte API (which, as far as I can tell is not reflected in the openapi spec) the dagster-airbyte library can no longer correctly configure a connection to `normalize_data=True`. Last I understood, the dagster Ingestion as Code sources/destinations were code-genned from Airbyte documentation, so it seems the two may have gotten out of sync. ### What did you expect to happen? When I set the connection parameter `normalize_data = True` on a destination that supports normalization, such as Snowflake, I do not receive the exception: `Exception: Destination $destination_name does not support normalization` and my connection configuration is a success. ### How to reproduce? Use Airbyte version `0.43.1` and try to configure a connection with `normalize_data = True` in dagster-airbyte Ingestion as Code. ### Deployment type Dagster Cloud ### Deployment details Right now I'm running this command locally to test, before it hits our CICD. ### Additional information There's an open thread in #airbyte-help in the Airbyte Slack about the openapi spec being out of sync, ~2 weeks old. I've asked for an update on that status, and I'll update here when I receive a response ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: compiler object compiles() does not track changes to the files being compiled The compiler object compiles() method does not take into account changes to the file object being compiled. For example, ``` project('foo', 'c') cc = meson.get_compiler('c') test = cc.compiles(files('foo.c')) ``` won't get re-evaluated if `foo.c` changes. I presume the same applies to link() too, but did not try. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Manual for TGate is missing ## Did you find a doc bug or broken link that needs to be fixed? - What is the file name(s) where you found the bug? https://qiskit.org/documentation/apidoc/circuit_library.html#standard-gates - What is the current text that needs to be fixed or removed? (You can copy and paste) There is no page for TGate, while SGate and TdgGate are available. - What should the documentation say instead? TGate should be included in the page. - Are there other related issues or pull requests about this bug? No. ## Does existing documentation need to be updated with new content? - Which files need to be updated? https://qiskit.org/documentation/apidoc/circuit_library.html#standard-gates - What content needs to be updated or replaced? (You can copy and paste) - What new content needs to be added? Page for TGate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan crash if .count-files consist NULL-character conan version 1.8.0, Windows 7 x64 For some reason (maybe a crash), the .count-files in each conan package in the cache were corrupted and contained a unicode NULL character (https://www.fileformat.info/info/unicode/char/0000/index.htm). This led to a conan crash for basically every package action (e.g. conan info). I already prepared a fix (https://github.com/conan-io/conan/compare/develop...pianoslum:develop) which also adds a little bit more verbosity in case there is no number in the .count-file. Is this enough info or should I elaborate? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: make_exception fails when json.loads fails See [report](https://github.com/GoogleCloudPlatform/gcloud-python/issues/616#issuecomment-74173944) from @pdknsk Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: testing: timeout behavior when testing via `meson test mytestcase` on meson 0.42.0, I am seeing 2 issues: * stdout does not appear to be included in `build/meson-logs/testlog.txt` if the test times out. If it passes or fails, it is included as expected, and stderr is included in all cases. * I haven't found a convenient way to kill the test executable when running the meson test harness. ctrl-C kills the `meson test` parent process, but does not appear to kill the test executable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Add `isfinite` support for `datetime64` and `timedelta64` `numpy.isfinite` should support `datetime64` and `timedelta64` objects. It should return `True` for any ordinary value, and `False` for `datetime64('NaT')` and `timedelta64('NaT')`. As a side-effect, this will make `isclose` and `allclose` usable for `datetime64` and `timedelta64` objects. ``` In [97]: numpy.isfinite(numpy.datetime64(10**9, 's')) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-97-8555b18406e5> in <module>() ----> 1 numpy.isfinite(numpy.datetime64(10**9, 's')) TypeError: ufunc 'isfinite' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe'' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub: Release the first GA version If no major issues are discovered during the ongoing bake-in period, the PubSub client should be released as GA. Releasing a new version is done with the help of [releasetool](https://github.com/googleapis/releasetool). Prior to the GA release, the following must be done: - Go through the checklist from the internal GA release doc, make sure everything is in order. - Changes in the client lib files: - Update PubSub Python lib README to indicate semver just like Java library has - Update beta tag in PubSub Python lib README - Update beta tag in Python libs root - Set the release level to `ga` in `.repo-metadata.json` - Change beta label in code samples in clients page in Google Cloud website - Add to release notes (talk to @kir-titievsky) - Update any documentation on Cloudsite Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add PrefixData, SubdirData, and PackageCacheData to conda/api.py https://github.com/conda/conda/commit/69f1b7af939adb783ee284fa952174e8fa447569#diff-aa516f421733d7851d878e08d4bf7464R408 This is used in conda-build at https://github.com/conda/conda-build/blob/master/conda_build/render.py#L210 Please provide an interface (ideally in conda's exports) that I can use to ask Conda to download packages for me. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: CVE-2022-24439: `<gitpython::clone> 'ext::sh -c touch% /tmp/pwned'` for remote code execution This appeared in the CVE feed today: https://security.snyk.io/vuln/SNYK-PYTHON-GITPYTHON-3113858 Not sure if this was reported to you before or not, reporting it here just in case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda-canary ignores CONDA_FORCE_32BIT environment variable Repro: ``` set CONDA_FORCE_32BIT=1 conda create -n test-win32 python=3.5 pywin32 ``` The above command will install a 64bit Python and pywin32 despite `CONDA_FORCE_32BIT` being set to 1. Curiously I can install a 32bit python on its own, but if I then try to install `pywin32` into the same environment it installs the 64bit version which fails (`import win32ui`) with a DLL no a valid win32 application error. **_Aside:**_ It would be nice if the architecture info was shown in the install phase so you would know beforehand that it was attempting to install the wrong architecture version Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: extreme truncating of return values while stepping through a function, when printing return values, ipython truncates them quite a bit - you get things like ``` <Context...ble.txt'> ``` Where in the code is this done? I haven't been able to find it. I want to give it more room - at least 80 chars wide would be fine. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add date attribute to BasicAer job result ### What is the expected enhancement? This is a practical improvement because it aligns the API with AerJob. It is also required according to https://arxiv.org/abs/1809.03452. See https://github.com/Qiskit-Partners/mthree/issues/94 for context. add date to all Result objects - QAMP <!-- ⚠️ If you do not respect this template, your pull request will be closed. ⚠️ Your pull request title should be short detailed and understandable for all. ⚠️ Also, please add a release note file using reno if the change needs to be documented in the release notes. ⚠️ If your pull request fixes an open issue, please link to the issue. - [ ] I have added the tests to cover my changes. - [ ] I have updated the documentation accordingly. - [ ] I have read the CONTRIBUTING document. --> ### Summary Executing the following code gives an error because BasicAer backend job has no attribute date. Fixes #7781 ``` python import numpy as np import mthree from qiskit import BasicAer, QuantumCircuit, Aer backend = BasicAer.get_backend(\"statevector_simulator\") mit = mthree.M3Mitigation(backend) mit.cals_from_system(range(2)) circuit = QuantumCircuit(2) circuit.rx(np.pi / 4, 0) circuit.rx(np.pi / 2, 1) circuit.measure_all() ``` ### Details and comments This error can be solved by putting the attribute`job.result().date = None` as a default parameter. Part of https://github.com/qiskit-advocate/qamp-spring-22/issues/37 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Bug: Finetuning large models resume checkpoint error When finetuning a large model (e.g. Eleuther 6B), you shard the checkpoints upon saving [here](https://github.com/huggingface/transformers/blob/c79bbc3ba54a81dab2eac13d89f264ed64cb2460/src/transformers/modeling_utils.py#L193). However, upon resuming the checkpoint (and loading the best checkpoint after training), you confirm if there is a valid checkpoint assuming weights are no sharded [here](https://github.com/huggingface/transformers/blob/dced262409177586bb510b6b724c762fb89da0e8/src/transformers/trainer.py#L1196). This causes an error upon resuming training. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Compatibility classes for converting BackendV1 to BackendV2 to facilitate migration ### What should we add? For package developers trying to transition to new backends it would be very convenient if terra had wrapper backend classes/functions that can make a backend V1 into a backend V2 and vice versa. Something to this effect was [recently added to qiskit-experiments](https://github.com/Qiskit/qiskit-experiments/blob/main/qiskit_experiments/framework/backend_data.py#L23) to help facilitate handling both types of backends in tests, however it falls a bit short of general use because it uses duck-typing of methods for both backends but wont actually be an instance of a backend so can't be used as a drop-in replacement. It would be convenient having either a backend class or generator function that can take one backend and return an equivalent instance of the other. Eg we could have classes that can be initialized with another backend like: ```python class WrappedBackendV1(BackendV1): def __init__(self, backend: Union[BackendV1, BackendV2]): class WrappedBackendV2(BackendV2): def __init__(self, backend: Union[BackendV1, BackendV2]): ``` An alternative would be a function to generate a backend either V1->V2 or V2->V1 (or trivially V1->V1, V2->V2) ```python # function interface def wrapped_backend( backend: Union[BackendV1, BackendV2], target_cls=BackendV2 ) -> Union[BackendV1, BackendV2] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Issue with f2py in Numpy 1.13 when character arrays appear in a callback function There is an issue with f2py in Numpy 1.13 when character arrays appear in a callback function. The following example works with Numpy 1.12 but not in 1.13: ``` #! /usr/bin/env python from __future__ import print_function import numpy from subprocess import call # # build extension from FORTRAN source # source = \"\"\" subroutine func_with_callback(callBack, cu, lencu) implicit none integer :: lencu character*8 cu(lencu) external callBack print *,'Lencu:', lencu print *,'Calling callback...' call callBack(cu, lencu) print *,'Back in fortran...' end subroutine func_with_callback \"\"\" with open(\"callback.f\", \"w\") as src_file: src_file.write(source) rc = call(\"f2py callback.f -m callback -h callback.pyf\".split()) if rc: quit() rc = call(\"f2py -c callback.pyf callback.f\".split()) if rc: quit() # # define callback function # def callBack(cu, lencu): print ('In callback:', cu) # # call library function with callback # from callback import func_with_callback print(func_with_callback.__doc__) print(\"\\nNumpy Version:\", numpy.__version__, \"\\n\") cu = numpy.zeros((1, 8), 'c') func_with_callback(callBack, cu) ``` ================ Numpy Version: 1.12.1 Lencu: 1 Calling callback... In callback: [['' '' '' '' '' '' '' '']] Back in fortran... ================ Numpy Version: 1.13.3 Lencu: 1 Calling callback... Call-back cb_callback_in_func_with_callback__user__routines failed. Traceback (most recent call last): File \"test_callback.py\", line 57, in <module> func_with_callback(callBack, cu) ValueError: data type must provide an itemsize Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: PIN 16: Add `CustomResult` that will be used to hydrate user Results from cloud states ## Use Case See [PIN 16](https://docs.prefect.io/core/PINs/PIN-16-Results-and-Targets.html) for more motivation on new style Result classes. Today, users may provide their own custom `ResultHandler` subclasses that do not serialize to Cloud; we expect to support the same for custom new style `Result` subclasses. ## Solution Add a `CustomResult` that wraps any custom result handler implementation or Result subclass from the user that we can serialize to Cloud and instantiate in `State._result` for a user when hydrating States from Cloud. The important method to implement is: `CustomResult.hydrate(result: Result) -> Result` This should return an instance of the result arg, since the pipeline will call this a la `state._result.hydrate(result=self.task.result)`. Other methods common to Results like store_safe_value, validate, read, write etc should not be implemented. (Decide if it should raise its own kind of warning or not especially if we miss an edge case and then get the NotImplementedError from tbhe base class.) ## Alternatives *Please describe any alternatives you've considered, even if you've dismissed them* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Save checkpoint for the last epoch How to save the checkpoint only for the last epoch? In the docs: ``` if save_top_k == k, the best k models according to the quantity monitored will be saved. if save_top_k == 0, no models are saved. if save_top_k == -1, all models are saved. Please note that the monitors are checked every period epochs. if save_top_k >= 2 and the callback is called multiple times inside an epoch, the name of the saved file will be appended with a version count starting with v0. ``` * `k = 0` does not save any. * `k > 1` saves only a few the best * `k = -1` saves all of them Currently, I am using k = -1, but it space consuming. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda xontrib xonsh wrapper Make a wrapper for xonsh. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Allow users to choose transaction isolation level? I believe we currently only support the default transaction isolation level for Datastore (`snapshot`). Could we figure out a way to allow people to choose a `serializable` transaction? See https://cloud.google.com/datastore/docs/apis/v1beta2/datasets/beginTransaction Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: PerceiverAudioPreprocessor: forward() missing 1 required positional argument: 'pos' The [`forward()` method implementation of `PerceiverAudioPreprocessor`](https://github.com/huggingface/transformers/blob/38cc35069c10d153e872162265288263bb7394b7/src/transformers/models/perceiver/modeling_perceiver.py#L3267) seems to be problematic because it has an extra required `pos` argument, whereas all other preprocessors do not (or it is optional). In fact, while it is passed to `_build_network_inputs()`, `pos` is not actually used in that method. Hence, I am not sure why it exists. Moreover, it breaks the default `PerceiverModel` operation, because that class assumes that there only one positional argument called `inputs` [when calling the preprocessor](https://github.com/huggingface/transformers/blob/38cc35069c10d153e872162265288263bb7394b7/src/transformers/models/perceiver/modeling_perceiver.py#L865). This seems to be a serious issue in my opinion because it crashes any instantiation of `PerceiverModel` with a `PerceiverAudioPreprocessor` as `input_preprocessor`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Replaced task does not complete when replacement sig is a group (4.0.2) ## Checklist - [x] I have included the output of ``celery -A proj report`` in the issue. ``` software -> celery:4.0.2 (latentcall) kombu:4.0.2 py:2.7.11 billiard:3.5.0.2 py-amqp:2.1.4 platform -> system:Darwin arch:64bit imp:CPython loader -> celery.loaders.app.AppLoader settings -> transport:amqp results:redis://localhost:6379/0 broker_url: u'amqp://guest:********@localhost:5672//' result_backend: u'redis://localhost:6379/0' ``` (The above output is against `master`.) Also: ``` (foo) $ pip freeze | grep redis redis==2.10.5 ``` - [x] I have verified that the issue exists against the `master` branch of Celery. ## Steps to reproduce *foo.py:* ```python from celery import Celery, group app = Celery('foo', broker='amqp://guest:guest@localhost:5672//', backend='redis://localhost:6379/0') @app.task def multiply(a, b): return a * b @app.task(bind=True) def multiply_by_two(self, num): raise self.replace(multiply.s(num, 2)) @app.task(bind=True) def multiply_all_by_two(self, nums): subtasks = [multiply_by_two.s(n) for n in nums] raise self.replace(group(*subtasks)) ``` *bar.py:* ```python from foo import multiply_by_two, multiply_all_by_two if __name__ == '__main__': print multiply_by_two.delay(3).get() # completes in 4.0.1 and 4.0.2 print multiply_all_by_two.delay([1, 2, 3]).get() # completes in 4.0.1; does not complete in 4.0.2 ``` ## Expected behavior A replaced task should complete when the replacement sig is a group (and does in 4.0.1). ## Actual behavior A replaced task does not complete when the replacement sig is a group (in 4.0.2). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Docstring for jax.lax.tie_in `jax.lax.tie_in` seems to have subtle but important properties, but [has no docstring](https://jax.readthedocs.io/en/latest/_autosummary/jax.lax.tie_in.html#jax.lax.tie_in). Could we add one? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rewrite Variational Quantum Deflation with primitives. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support for DMD -makedeps switch A new feature has recently been merged into DMD (see dlang/dmd#12011) to implement emission of dependency file in Makefile format. This should be available in DMD v2.096, and in LDC when it will use the DMD frontend of the same version. Meson can add this switch to the ninja D language rules in order to have correct dependencies and retrigger builds in an appropriate way. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose config --volumes In addition to ``` $ docker-compose config --services ``` it'd be nice to have ``` $ docker-compose config --volumes ``` listing the named volumes similarly to services. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook docs touchup Cleaning up outstanding issues in notebook.rst. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Possible issue with partial gradient application I'm trying to define the derivative of a function at a point, for then compiling it with jit, but either I'm not doing it in the right way (with functools.partial) or there is a problem somewhere. Define a simple function of x and y and its derivative with respect to x: ```python from jax import grad def f(x,y): return x+y df = grad(f, argnums=0) ``` This works: ```python from functools import partial partial(f, x = 0.)(y = 1) # 1.0 ``` This doesn't: ```python from functools import partial partial(df, x = 0.)(y = 1) # IndexError: tuple index out of range ``` why? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: --backend=vs2019 DebugInformationFormat is not set correctly **Describe the bug** DebugInformationFormat is set in the Configuration PropertyGroup, but Visual Studio 2019 only reads it from the ClCompile section. It looks like vs2010backend.py accidentally sets DebugInformationFormat=EditAndContinue in type_config instead of clconf. (Possibly BasicRuntimeChecks too). It's possible that older Visual Studio wants this value outside ClCompile. I didn't check, but it seems unlikely. **To Reproduce** meson --backend=vs2019 --buildtype=debug <any source dir> **Expected behavior** Projects built with the default debug configuration in visual studio (not from ninja) should be built with /ZI (Program Database for Edit and Continue). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: run -d message unclear Prior to 1.0.dev, (0.12.1), I had to hit 'c' to start the script: ``` IPython 0.12.1 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: run -d foo.py ERROR: File `u'foo.py'` not found. In [2]: pwd Out[2]: u'/Users/mhearne/src/python/scipy2013/ipython/ipython-in-depth/notebooks/figs' In [3]: cd /Users/mhearne/src/python /Users/mhearne/src/python In [4]: run -d foo. foo.py foo.pyc In [4]: run -d foo.py *** Blank or comment *** Blank or comment Breakpoint 1 at /Users/mhearne/src/python/foo.py:3 NOTE: Enter 'c' at the ipdb> prompt to start your script. > <string>(1)<module>() ipdb> c > /Users/mhearne/src/python/foo.py(3)<module>() 2 1---> 3 x = 1 4 print 'hello world' ``` With 1.0.dev, it behaves like this ('c' not required): ``` In [1]: !cat foo.py #!/usr/bin/env python x = 1 print 'hello world' In [2]: run -d foo foo.py foo/ foolog.py In [2]: run -d foo.p foo.py foo.pyc In [2]: run -d foo.py *** Blank or comment *** Blank or comment *** Blank or comment NOTE: Enter 'c' at the ipdb> prompt to start your script. > /Users/mhearne/src/python/foo.py(3)<module>() 2 ----> 3 x = 1 4 print 'hello world' ``` If this is the intended behavior, I suggest removing the misleading message. Looks like @tkf implemented this change, @ivanov said to mention him. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Tsconfig references are not being popultated <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description While working on #8747 we noticed that the `tsconfig` references were not being properly updated for `debugger` and `metapackage` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Create dagster-graphql CLI Should replace dagit -q and used in integrations like airflow Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Trait default values are validated even when not ever used ``` Python from IPython.utils.traitlets import * class Foo(HasTraits): bar = Type(allow_none=False) foo = Foo(bar=int) ``` yields `The 'bar' trait of a Foo instance must be a subclass of object, but a value of type 'NoneType' (i.e. None) was specified.` The default value is validated while it is not needed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Templating for ShellTask commands Opening for discussion; we could go for a full-fledge solution like Jinja, _or_ we could do something simple like: ``` echo !param ``` and replace all instances of `!string` with a parameter value (either taken from context or from an actual `Parameter`). [The exclamation point should be a safe character to rely on](https://unix.stackexchange.com/questions/3747/understanding-the-exclamation-mark-in-bash). I'm not really sure how heavily people will use templating, and how intricate their use cases will be. **cc:** @jlowin @joshmeek Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Schedule drawing fails if schedule is empty <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: OsX ### What is the current behavior? Schedule drawing fails if schedule is empty ### Steps to reproduce the problem ```python from qiskit import pulse fc_pi = pulse.FrameChange(np.pi) dc0 = pulse.DriveChannel(0) fc_pi_dc0 = fc_pi.to_instruction(dc0) sched = pulse.Schedule() sched += fc_pi_dc0 sched.draw() ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cannot compile spice when cross compiling **Describe the bug** Worked under 0.56.2. Broke with 0.57 **To Reproduce** https://gitlab.freedesktop.org/spice/spice/-/blob/master/meson.build I guess. **Expected behavior** Compile **system parameters** * cross build * Fedora 33 * Python 3.9.2 * latest master - 0.57.1 tested * 1.10.2 Sample log: https://downloads.openwrt.org/snapshots/faillogs/mips64_octeonplus/packages/spice/compile.txt Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda run doesn't respect the documented \"--\" option ## Current Behavior The documented `--` flag for `conda run` is very useful; lacking it, you can't run programs that share command-line arguments with `conda run`. It doesn't work, though. ### Steps to Reproduce ``` # conda run -n myenv -- echo hello /opt/conda/envs/myenv/.tmp7xhfcesk: line 3: --: command not found ERROR conda.cli.main_run:execute(39): Subprocess for 'conda run ['--', 'echo', 'hello']' comma nd failed. Stderr was: /opt/conda/envs/myenv/.tmp7xhfcesk: line 3: --: command not found ``` ## Expected Behavior I would expect, as per the documentation, that this would run `echo hello` within the environment. ## Environment Information This happens in Conda 4.8.1 as well as earlier versions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: GPU memory show max/min only Instead of logging GPU mem for all GPUs, probably better to just show the min/max usage? Maybe the flag can be modified? ```python # now Trainer(log_gpu_memory=False) # proposed Trainer(log_gpu_memory='min_max') # and for all GPUs Trainer(log_gpu_memory='all') ``` @adefazio Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: put ftp:// back into 4.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking ### Model description LayoutLMV3 is the successor of the LayoutLM models. the models are specialized in multimodal document analysis tasks and achieve SOTA results on them. The current [code](https://github.com/microsoft/unilm/blob/master/layoutlmv3/layoutlmft/models/layoutlmv3/modeling_layoutlmv3.py) for the LayoutLMV3 is implemented in huggingface format. Since the code is already more similar to the Huggingface format, I am not sure whether integrating this model into this repo is necessary, but there will be an ease of use if it is available in the library itself. ### Open source status - [X] The model implementation is available - [X] The model weights are available ### Provide useful links for the implementation Model Implementation: https://github.com/microsoft/unilm/tree/master/layoutlmv3 Model Weights: https://huggingface.co/microsoft/layoutlmv3-base Authors: Yupan Huang,Tengchao Lv, Lei Cui, Yutong Lu ,Furu Wei Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: \"Both `max_new_tokens` and `max_length` have been set but they serve the same purpose\" when only setting max_new_tokens. ### System Info - `transformers` version: 4.27.0.dev0 - Platform: Windows-10-10.0.19044-SP0 - Python version: 3.10.4 - Huggingface_hub version: 0.12.0 - PyTorch version (GPU?): 1.13.1+cpu (False) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help? @gante I believe. ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction 1. Install transformers 2. Run the following script ``` from transformers import pipeline summarizer = pipeline(\"summarization\", max_new_tokens=50) prompt = \"text to summarize\" summary = summarizer(prompt) ``` 3. It crashes with the following error: > ValueError: Both `max_new_tokens` and `max_length` have been set but they serve the same purpose -- setting a limit to the generated output length. Remove one of those arguments. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation) ### Expected behavior Expected behavior is that the script should run. I only set `max_new_tokens` and not `max_length`. This might seem like a duplicate of https://github.com/huggingface/transformers/issues/20894 but the issue persists even after installing the latest version of transformers with the fix for that issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: nditer.__next__ keeps working after `close` is called @mattip. This surprises me a little: ```python >>> it = np.nditer(np.arange(3)) >>> next(it) array(0) >>> it.close() >>> next(it) array(1) >>> next(it) array(2) >>> next(it) StopIteration ``` Compare with ```python >>> def generator(): ... yield from range(3) >>> it = generator() >>> next(it) 0 >>> it.close() >>> next(it) StopIteration ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: UnicodeEncodeError: 'ascii' codec can't encode character u'\\u2023' When trying to install `RUN /bin/bash -l -c 'passenger-install-nginx-module --auto --auto-download --prefix=/opt/nginx'` from Docker, I get: ``` Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.cli.main\", line 39, in main File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.cli.docopt_command\", line 21, in sys_dispatch File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.cli.command\", line 31, in dispatch File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.cli.docopt_command\", line 24, in dispatch File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.cli.command\", line 50, in perform_command File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.cli.docopt_command\", line 27, in perform_command File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.cli.main\", line 108, in build File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.project\", line 123, in build File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.service\", line 313, in build File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.service\", line 374, in stream_output File \"/Users/nonsense/code/fig/build/fig/out00-PYZ.pyz/fig.service\", line 419, in print_output_event UnicodeEncodeError: 'ascii' codec can't encode character u'\\u2023' in position 2: ordinal not in range(128) ``` I guess the reason is that at this point nginx shows a list of languages and there is a unicode character used as a bullet point in front of each language. fig version is: 0.4.1 docker version is: Client version: 0.11.1 Client API version: 1.11 Go version (client): go1.2.1 Git commit (client): fb99f99 Server version: 0.11.1 Server API version: 1.11 Git commit (server): fb99f99 Go version (server): go1.2.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `DensityMatrix.partial_transpose` does not preserve input dimensions ### Environment - **Qiskit Terra version**: to be released in 0.24.0 - **Python version**: 3.10 - **Operating system**: MacOS ### What is happening? The `partial_transpose` should return a density matrix of the same dimensionality as the input `DensityMatrix` object. When the dimensions are for systems different than qubits, the dimensions are currently not preserved. ### How can we reproduce the issue? For in the following example, the dimensions of the output density matrix ρ2 are (9,) but they should be (3,3). ```python >>> import numpy as np >>> from qiskit.quantum_info import Statevector, DensityMatrix >>> ψ = Statevector(np.array([1,0,0,0,1,0,0,0,1])*1/np.sqrt(3),dims=(3,3)) >>> ρ1 = DensityMatrix(ψ) >>> ρ1.dims() (3, 3) >>> ρ2 = ρ1.partial_transpose([0]) >>> ρ2.dims() (9,) ``` ### What should happen? It should be an easy fix. The function should return: ```python return DensityMatrix(rho, dims=self.dims()) ``` instead of just: ```python return DensityMatrix(rho) ``` ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Please cut new release of Cloud Storage Please cut a release to include https://github.com/GoogleCloudPlatform/google-cloud-python/pull/5877 (Object Lifecycle Management) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Switch from print to logging Use logging instead of print. (@Ir1d you brought this up before) Suggested by @adefazio Switch from print to logging Use logging instead of print. (@Ir1d you brought this up before) Suggested by @adefazio Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigTable Row Data cells property not copy **Is your feature request related to a problem? Please describe.** I was profiling the code I wrote that makes use of the BigTable client python API. I realised that it made a lot of calls to `deepcopy` and that these calls were very costly. It's actually because the `cells` property of a [row data](https://googleapis.github.io/google-cloud-python/latest/bigtable/row-data.html#cells) is actually returning a deep copy of the actual private `_cells` property. The fact is that I don't need all the cells information and I am only using it once so I don't really need the copy. **Describe the solution you'd like** I think it would be nice to have the possibility to return the `_cells` property directly without copying. I imagine there are reasons why it has been coded like that, not offering the alternative, but I don't see them. **Describe alternatives you've considered** Of course a hacky solution is to access directly the private property but it doesn't look like the right way to do it (i.e. `row._cells`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Unimplemented: binary integer op 'power' ```python def square(x): return x**2 val = 3 dfn = grad(square) print(dfn(val)) ``` I was surprised this threw an error. Changing it to `val = 3.0` works as expected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Should we compare Entity._meanings in __eq__ /cc @tseaver @pcostell Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Ensure that libraries are designated alpha. As part of the refresh for `core>=0.23.0` and HTTP headers, please also ensure that all client libraries are designated alpha in `setup.py` _except_ the following, which are beta: * BigQuery * Datastore * Logging * Storage This should be altered as part of the umbrella release (should be trivial). Thank you. :-) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython.utils.columnize sometime wrong... ``` python In [1]: import IPython.utils.text as ut ...: len(ut.columnize(['x'*40,'x'*40],displaywidth=80).split('\\n')[0]) Out[1]: 82 # should be < 80 ``` two 40 letters words separated by 2 char could not enter on a 80 char line. should be 2 times 40(+separator size maybe) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Pagination doesn't work with tags filter **Apache Airflow version**: 2.0.1 **Environment**: - **OS**: Linux Mint 19.2 - **Kernel**: 5.5.0-050500-generic #202001262030 SMP Mon Jan 27 01:33:36 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux **What happened**: Seems that pagination doesn't work. I filter DAGs by tags and get too many results to get them at one page. When I click second page I'm redirected to the first one (actually, it doesn't matter if I click second, last or any other - I'm always getting redirected to the first one). **What you expected to happen**: I expect to be redirected to the correct page when I click number on the bottom of the page. **How to reproduce it**: 1. Create a lot of DAGs with the same tag 2. Filter by tag 3. Go to the next page in the pagination bar **Implementation example**: ``` from airflow import DAG from airflow.utils.dates import days_ago for i in range(200): name = 'test_dag_' + str(i) dag = DAG( dag_id=name, schedule_interval=None, start_date=days_ago(2), tags=['example1'], ) globals()[name] = dag ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Option precedence is inconsistent Which of several conflicting options is applied is not consistent. ``` cd \"test cases/common/1 trivial\" meson build --bindir=foo --bindir=bar -Db_sanitize=address -Db_sanitize=thread meson configure build ``` Expected: `bindir=bar` `b_sanitize=thread` Actual: `bindir=bar` `b_sanitize=address` Affected: At least 0.43.0 to 0.46.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: \"Modulus\" refers to normalizing by largest singular value in docs https://github.com/numpy/numpy/blob/33415905e85c51c3348c1def9dfa306fbd358b5e/numpy/linalg/linalg.py#L1903-L1904 ^ This code from master corresponds to the documentation for [numpy.linalg.pinv](https://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.pinv.html?highlight=modulus): > Singular values smaller (in modulus) than _rcond * largest_singular_value_ (again, in modulus) are set to zero. Note that singular values cannot be complex. They are always real and non-negative. And so this is a confusing use of the term \"modulus\" to me. From what I can see, the singular values are normalized by the largest value. For example, if `s = [2. 1. 0.]` and `rcond = 1e-15`, then `cutoff = 2e-15` and so `s > cutoff` is effectively normalizing `s` by the largest singular value (2) before comparing to `rcond` (i.e., by cross-multiplying). https://github.com/numpy/numpy/blob/33415905e85c51c3348c1def9dfa306fbd358b5e/numpy/linalg/linalg.py#L1968-L1969 Perhaps I misunderstand the usage of this term, but I think it would be more appropriate to say something like...? > Singular values smaller than rcond (normalized such that the largest singular value is one) are set to zero. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: f2py with \"associate\" <-> \"end associate\" f2py break with functions/subroutines containing associate construct. my hack ``` diff diff --git a/numpy/f2py/crackfortran.py b/numpy/f2py/crackfortran.py index 5d664e3..009fa3e 100755 --- a/numpy/f2py/crackfortran.py +++ b/numpy/f2py/crackfortran.py @@ -470,7 +470,7 @@ beginpattern90=re.compile(beforethisafter%('',groupbegins90,groupbegins90,'.*'), groupends=r'end|endprogram|endblockdata|endmodule|endpythonmodule|endinterface' endpattern=re.compile(beforethisafter%('',groupends,groupends,'[\\w\\s]*'),re.I),'end' #endifs='end\\s*(if|do|where|select|while|forall)' -endifs='(end\\s*(if|do|where|select|while|forall))|(module\\s*procedure)' +endifs='(end\\s*(if|do|where|select|while|forall|associate))|(module\\s*procedure)' endifpattern=re.compile(beforethisafter%('[\\w]*?',endifs,endifs,'[\\w\\s]*'),re.I),'endif' # implicitpattern=re.compile(beforethisafter%('','implicit','implicit','.*'),re.I),'implicit' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.50.0 regression: ERROR: \"install_dir\" must be a string libwnck3 fails to build with: ``` meson.build:87:2: ERROR: \"install_dir\" must be a string ``` Everything what it does in meson.build seems to be legit: ```meson foreach pc: [PACKAGE_NAME, PACKAGE_NAME + '-uninstalled'] install_path = [] if not pc.contains('-uninstalled') install_path = join_paths(libdir, 'pkgconfig') endif configure_file(input: pc + '.pc.in', output: pc + '.pc', configuration: pc_conf, install_dir: install_path) endforeach ``` Definitely it can be improved to always set install_path, and conditionally setting install: true/false.. But this is either regression or worth mentioning in release-notes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: pulse delay instruction cause error when np.int is given <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? T1 experiment for example: ```python delay_times = np.linspace(0, 200, 21, dtype=int) for delay_time in delay_times: ... sched += Delay(delay_time, d0) ``` This program will cause an error: ``` AttributeError: 'numpy.int64' object has no attribute 'name' ``` np.int should be allowed for the `duration` of Delay instruction. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC : dype attributes docs don't contain examples The documentation for attributes of `dtype` in the `_add_newdocs.py` can be improved by adding examples, which are currently missing for most of the attributes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: BigQuery Load Job Task To complement #685: importing data from GCS feels to me like a pretty critical feature for BigQuery functionality to be useful. cf. https://airflow.apache.org/_api/airflow/contrib/operators/gcs_to_bq/index.html#airflow.contrib.operators.gcs_to_bq.GoogleCloudStorageToBigQueryOperator. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Misleading error message Getting this error in dagit for the airline demo:  The real issue is further up in the logs, an S3 access denied exception:  cc @mgasner Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: dependency('gl') can return an object which claims to be a pkgconfig dependency, but isn't ```meson.build project('gl dependency', 'c') gl_dep = dependency('gl', method: 'pkg-config', required: false) message(gl_dep.type_name()) if gl_dep.found() and gl_dep.type_name() == 'pkgconfig' gl_dep.get_pkgconfig_variable('prefix') endif ``` confusingly fails with: ``` Message: pkgconfig Meson encountered an error in file meson.build, line 6, column 0: 'gl' is not a pkgconfig dependency ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython.parallel tests seem to hang on ShiningPanda I've bumped the time limit up to 25 minutes, but it still gets cut off before the parallel tests complete, and the progress indicator isn't any further along than it was with the 15-minute cut off. See [this log](https://jenkins.shiningpanda-ci.com/ipython/job/ipython-multi/PLATFORM=debian6,PYTHON=CPython-2.7/453/console). On my system, the IPython.parallel suite completes in 90 seconds (195 tests, no skips), so I think something is getting stuck. For now, I've disabled the parallel tests (removed the `--all` flag) so that we can use the rest of the test suite. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error when using size() method on a quantum circuit in terra 0.8.0 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.8.0 (master) - **Python version**: 3.7.3 - **Operating system**: Windows 10 ### What is the current behavior? size() method on a quantum circuit throws error : ```python q = QuantumRegister(6) circuit = QuantumCircuit(q) circuit.h(q[0]) circuit.ccx(q[0], q[1], q[2]) circuit.size() ``` Error: ```python --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-20-18ab26fa2a60> in <module> 7 #circuit.h(q[2]) 8 #circuit.h(q[3]) ----> 9 circuit.size() 10 circuit.draw(output='mpl',style=style) c:\\users\\francoisvarchon\\anaconda3\\envs\\qis09z\\lib\\site-packages\\qiskit_terra-0.8.0-py3.7-win-amd64.egg\\qiskit\\circuit\\quantumcircuit.py in size(self) 436 gate_ops = 0 437 for item in self.data: --> 438 if item.name not in ['barrier', 'snapshot']: 439 gate_ops += 1 440 return gate_ops AttributeError: 'tuple' object has no attribute 'name' ``` ### Steps to reproduce the problem circuit.size() ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Joining to chains loses link_error of least chain https://github.com/celery/celery/blob/cbbf481801079f0e2cfbfe464c9ecfe3ccc7a067/celery/canvas.py#L408-L414 Should be something like ```python link_error_sigs = other._with_list_option('link_error') sig.tasks.extend( reduce( lambda t, s: t.on_error(s), link_error_sigs, t.clone()) for t in other.tasks) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Missing .. versionadded in `prepend` parameter of np.diff There is no versionadded tag for prepend on https://docs.scipy.org/doc/numpy/reference/generated/numpy.diff.html. This is not a huge problem, but I've started using that argument quite a bit more, so it would be nice to know what versions break my code. I would be happy to submit a PR, but am not sure what the correct version is (I think it's 1.16.0, but would prefer to have an expert verify). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: What is the correct way to pass labels to DetrForSegmentation? The [current documentation](https://huggingface.co/transformers/master/model_doc/detr.html#transformers.DetrForSegmentation.forward) for `DetrModelForSegmentation.forward` says the following about `labels` kwarg: > The class labels themselves should be a torch.LongTensor of len (number of bounding boxes in the image,), the boxes a torch.FloatTensor of shape (number of bounding boxes in the image, 4) and the **masks a torch.FloatTensor of shape (number of bounding boxes in the image, 4).** But when I looked at the tests, it seems the shape of `masks` is `torch.rand(self.n_targets, self.min_size, self.max_size)` . https://github.com/huggingface/transformers/blob/d2753dcbec7123500c1a84a7c2143a79e74df48f/tests/test_modeling_detr.py#L87-L103 --- I'm guessing this is a documentation mixup! Anyways, it would be super helpful to include a snippet in the DETR docs that shows how to correctly pass masks/other labels + get the loss/loss dict. 😄 CC: @NielsRogge Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Make classifier backbone dynamic maskformer, mask2former ### Feature request Make classifier backbone dynamic maskformer, mask2former. Currently it only supports swin transformer. link example: https://github.com/huggingface/transformers/blob/main/src/transformers/models/mask2former/modeling_mask2former.py#L1393 ### Motivation If this feature request successful, it will help to benchmark for new clasifier easily. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Option to fall back to old file format The rollout of the new file format has exposed some problems in conda-package-handling. Some/all packages are missing symlinks (at least to folders) which makes conda barf about missing content. We need a way for users to get unstuck if the new format doesn't work for them for whatever reason. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: T5Tokenizer shouldn't add pad token as prefix to labels ## Information `prepare_seq2seq_batch` method in `T5Tokenizer` now prefixes `pad` token to the `labels`. [here](https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_t5.py#L362) But in finetune.py [here](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/finetune.py#L149) we are calling `_shift_right` for T5 , which again adds another `pad` token at the beginning, so now `decoder_input_ids` contain two `pad` tokens. ## To reproduce ```python from transformers import T5Tokenizer, T5Model model = T5Model.from_pretrained(\"t5-small\") tok = T5Tokenizer.from_pretrained(\"t5-small\") enc = tok.prepare_seq2seq_batch(\"src text\", \"target text\", return_tensors=\"pt\") print(enc[\"labels\"]) # tensor([[ 0, 2387, 1499, 1]]) decoder_input_ids = model._shift_right(enc[\"labels\"]) # call _shift_right print(decoder_input_ids) #tensor([[ 0, 0, 2387, 1499]]) ``` <!-- If you have code snippets, error messages, stack traces please provide them here as well. Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.--> ## Expected behavior There should be no special prefix token for T5 `labels` @sshleifer Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: setuptools hard build dependency Here: https://github.com/conda/conda/blob/master/setup.py#L8 @kalefranz I thought we had agreed that setuptools is not going to be a hard build dependency anymore. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Unable to fetch CloudWatch Logs of previous run attempts ### Apache Airflow version 2.7.0 ### What happened After upgrading to `apache-airflow-providers-amazon==8.5.1`, I am no longer able to view logs from previous run attempts. Airflow is able to find the log stream successfully, but there's no content viewable (even though there are logs in the actual streams): ``` REDACTED.us-west-2.compute.internal *** Reading remote log from Cloudwatch log_group: REDACTED log_stream: dag_id=REDACTED/run_id=REDACTED/task_id=REDACTED/attempt=1.log. ``` I believe this issue occurred from #33231 - Looking at the [CloudWatch Logs code](https://github.com/apache/airflow/blob/providers-amazon/8.5.1/airflow/providers/amazon/aws/log/cloudwatch_task_handler.py#L109-L133), I think `task_instance.start_date` and `task_instance.end_date` somehow refer to its __latest__ run, and so the log contents are getting filtered out on previous attempts. ### What you think should happen instead _No response_ ### How to reproduce 1. Configure environment with remote CloudWatch logging 2. Run task 3. Clear task and re-run 4. The logs for the first attempt now no longer show ### Operating System Debian 11 ### Versions of Apache Airflow Providers apache-airflow-providers-amazon==8.5.1 ### Deployment Other ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda config needs --prepend; change behavior of --add to --append referencing https://github.com/conda/conda/issues/2841 - conda config needs `--prepend` - change behavior of `--add` to `--append` - un-reverse order of `conda config --get channels` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: `replace_sampler_ddp` doesn't create a shuffled sampler <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug The `DistributedSampler` created using `replace_sampler_ddp` is not shuffled. Check the `kwargs` [here](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/trainer/data_loading.py#L195) ### Expected behavior If training dataloader, create a shuffled `DistributedSampler`, else create a non-shuffled sampler. Even though the `train` flag is passed to the function [here](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/trainer/data_loading.py#L146), it is ignored. ### Environment pytorch-lightning master Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Tokenizer - Raises wrong \"UserWarning: `max_length` is ignored when `padding`=`True`\" In the newest version of transformers (4.11.2 & 4.12.0.dev0) I get the following warning: ``` C:\\Anaconda3\\envs\\sbert\\lib\\site-packages\\transformers\\tokenization_utils_base.py:2227: UserWarning: `max_length` is ignored when `padding`=`True`. warnings.warn(\"`max_length` is ignored when `padding`=`True`.\") ``` Code to re-produce: ```python from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') texts = [\"Short sentence\", \"A really really really really really long sentence to test max length\"] output = tokenizer(texts, padding=True, truncation=True, max_length=5, return_tensors='pt') print(output['input_ids'].shape) output = tokenizer(texts, padding=True, truncation=True, return_tensors='pt') print(output['input_ids'].shape) ``` Output: ``` C:\\Anaconda3\\envs\\sbert\\lib\\site-packages\\transformers\\tokenization_utils_base.py:2227: UserWarning: `max_length` is ignored when `padding`=`True`. warnings.warn(\"`max_length` is ignored when `padding`=`True`.\") torch.Size([2, 5]) torch.Size([2, 14]) ```` As we see, max_length is not ignored when padding = True. It truncates the text as expected to a max_length of 5. I would say that the warning is incorrect and should not be raised. Should I fix it? Or is it really intended that max_length is ignored when padding=True? This would be horrible, I want to truncate my text to a certain max_length. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumCircuit.remove_final_measurements leaves remnant classical bits? <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.16.3 - **Python version**: - **Operating system**: ### What is the current behavior? `QuantumCircuit.remove_final_measurements()` removes the idle classical registers - just as its docstring states - but not the associated classical bits. ### Steps to reproduce the problem ```python from qiskit import QuantumCircuit qc = QuantumCircuit(1,1) qc.measure(0,0) qc.remove_final_measurements() assert len(qc.cregs)==0, \"idle classical register not removed\" assert len(qc.clbits)==0, f\"idle classical bits not removed: {qc.clbits}\" ``` ### What is the expected behavior? ### Suggested solutions If the above behavior is not intended, `circ.clbits.clear()` before parsing the new circuit DAG for active classical bits? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: combining multiple static libraries into one it's not uncommon to create a static library that is a combination of multiple static libraries. Meaning i have my project dir: -proj -- a -- b -- c they result in liba.a, libb.a, libc.a. I want to create a libproj.a that contains all other static libraries. In autotools it's possible to define a Makefile.am that accomplishes the same task: liba_la_SOURCES = \\ a/a.cxx \\ a/a.h \\ $(NULL) libb_la_SOURCES = \\ b/b.cxx \\ b/b.h \\ $(NULL) libc_la_SOURCES = \\ c/c.h \\ c/c.cxx \\ $(NULL) libcombo_la_LIBADD = \\ liba.la \\ libb.la \\ libc.la \\ $(NULL) I think that an API should be implemented for this target. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Rename cppflags-> cxxflags in conan codebase Conan codebase is using all around the deprecated cppflags. The new cxxflags should be used. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: impossible to exit debugger traces I like to set traces, and from what I understand from the docs, The Right Way is to use `TerminalPdb`. However, I can not find out how to quit the `TerminalPdb` debugger---maybe I'm just daft. Say I set a trace in a long loop: ``` python from IPython.terminal.debugger import TerminalPdb pdb = TerminalPdb() while True: pdb.set_trace() ``` The only way to exit this program that I found is to kill it. My questions are: - Is TerminalPdb the best way to set traces? - Is this expected behavior? - How do I quit? Thanks! (I'm on IPython 5.1.0) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [DO NOT MERGE] Firestore: pick up fixes in GAPIC generator. This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/firestore/artman_firestore.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:90f9d15e9bad675aeecd586725bce48f5667ffe7d5fc4d1e96d51ff34304815b Status: Image is up to date for googleapis/artman:latest synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/firestore-v1beta1. synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Builder runs wrong webpack In the current design of the builder package, it executes the webpack cli as a system command: https://github.com/jupyterlab/jupyterlab/blob/4c82962ee34c7d667d095bca07b249f8b34560aa/builder/src/build-labextension.ts#L50 In the current setup of ipywidgets, I'm trying to use the builder from inside a repo that has a different version of webpack installed. Basically: `ipywidgets/node_modules/webpack` is webpack 4 `ipywidgets/node_modules/@jupyterlab/builder/node_modules/webpack` is webpack 5. When I invoke the builder inside the ipywidgets repo, it correctly runs: ``` node \"[snip]/ipywidgets/node_modules/@jupyterlab/builder/node_modules/webpack-cli/bin/cli.js\" --config \"[snip]/ipywidgets/node_modules/@jupyterlab/builder/lib/webpack.config.ext.js\" ``` However, webpack-cli is using `ipywidgets/node_modules/webpack` instead of `ipywidgets/node_modules/@jupyterlab/builder/node_modules/webpack`. I think this is because we are launching the cli via a shell subprocess, so information about the node resolution and the correct webpack to use is totally lost. Two possible strategies: 1. Launch the cli in the current directory of the builder, or somewhere so that the node resolution algorithm picks up the right webpack. This may mess up webpack - is the pwd of the process where the files are found? But then perhaps there is a webpack configuration to set the directory where the files are found. 2. The strategy above is a bit of a hack to get around the problems that shelling out to a subprocess creates. Instead, use the [webpack node api](https://webpack.js.org/api/node/) directly and not the cli, and just run webpack directly from the builder script. This avoids shelling out to run webpack, and hopefully would preserve the existing node resolution. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Revert “Black by default” Version 8.0 added automatic formatting with Black. This was added in #13397 without much discussion - at least there is none linked. IMO this is not desirable. It is surprising for a REPL to change what you wrote, and it introduces a large dependency (Black). As @rhettinger has pointed out on Twitter it reduces the utility of IPython in educational contexts: https://twitter.com/raymondh/status/1482225220475883522 Additionally the release note read: > If `black` is installed in the same environment as IPython... But this is misleading, implying that it's opt-in by installing Black. The change made IPython depend on Black, so it is always be installed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: build_number comparison not functional in match_spec Version comparisons work. conda search 'python[version=\"<3\"]' Seems that build_number comparisons do not. conda search 'python[build_number=\"<5\"]' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Documentation issue with `make_slack_on_run_failure_sensor` and `make_slack_on_pipeline_failure_sensor` examples ### What's the issue or suggestion? Documentation issue with `make_slack_on_run_failure_sensor` and `make_slack_on_pipeline_failure_sensor ` They expect `text_fn` parameter but the documentation examples have `message_fn` ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose bundle --fetch-digests isn't a communicative name According to one rather alarmed test user, the name of the `--fetch-digests` flag didn't make it clear that images were going to be pushed. We should perhaps come up with a better one. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: _ipython_display_, return value, and output prompt behavior I might have found a strange interaction between `_ipython_display_` the in output prompt system. Given this file: ```python # tst.py from IPython import display class A: def __repr__(self): return \" A\\n0 B\" class B(A): def _ipython_display_(self): data = {'text/plain': repr(self)} display.display(data, raw=True) class C(B): def _ipython_display_(self): super()._ipython_display_() return \"C\" ``` Here's the output: ```python In [1]: from tst import * In [2]: A() Out[2]: A 0 B In [3]: B() Out[3]: A 0 B In [4]: C() Out[4]: A 0 B ``` I think the correct output for `In[3]` is just the `repr(self)`, but no `Out[3]` tag, since nothing is returned? I have no idea what the correct output of `In[4]` is, but maybe ``` A # the super 0 B \"C\" # the return value of C._ipython_display_() ``` but I don't know if / where the `Out[4]` tag would go. For background, we're working on a table schema repr for pandas in https://github.com/pandas-dev/pandas/pull/14904. This is on IPython master from about 3 weeks ago. cc @minrk Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: [Metrics] IOU ## 🚀 Feature Implement (differentiable) IOU Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: exceptions while handling of exceptions it is difficult to trace/debug what is wrong with one service not willing to be brought up because during handling of exceptions other exceptions occured. The latter one can be traced to the first line of[ `log_api_error()`](https://github.com/docker/compose/blob/master/compose/cli/main.py#L89) there `client is newer than server` (str) is not of the same type as `e.explanation` (bytes). I am not sure where the bytestring come from but probably from the failed http request results which IIRC are bytestreams. At least on 3.5.1 (what I am running docker-compose in) you need to do:: ``` def log_api_error(e): expl = e.explanation try: if isinstance(e.explanation, bytes): expl = e.explanation.decode('utf-8') except: pass if 'client is newer than server' in expl: ``` After changing that, I was able to see and address the real problem If you are running under Python 2.7 you will not see this problem and utf-8 encoding should not be necessary. In any case a failed decoding leads to the `in` test to be as good as the original Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: json_splitter fails when leading whitespace is present in buffer. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Make Docs builds fallback in case external docs sources are missing Every now and then our docs builds start to fail because of external dependency (latest example here #14985). And while we are doing caching now of that information, it does not help when the initial retrieval fails. This information does not change often but with the number of dependencies we have it will continue to fail regularly simply because many of those depenencies are not very reliable - they are just a web page hosted somewhere. They are nowhere near the stabilty of even PyPI or Apt sources and we have no mirroring in case of problem. Maybe we could a) see if we can use some kind of mirroring scheme (do those sites have mirrrors ? ) b) if not, simply write a simple script that will dump the cached content for those to S3, refresh it in the CI scheduled (nightly) master builds ad have a fallback mechanism to download that from there in case of any problems in CI? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Dask Distributed Errors are not captured by `handle_signals` Minimal example: ```python from prefect import * import queue from prefect.engine.executors import DaskExecutor q = queue.Queue() @task def put(): q.put(55) f = Flow(tasks=[put]) f.run(executor=DaskExecutor()) ``` results in ```python-traceback --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-1-bc3865b51bd5> in <module>() 10 11 f = Flow(tasks=[put]) ---> 12 f.run(executor=DaskExecutor()) ../prefect/src/prefect/core/flow.py in run(self, parameters, return_tasks, **kwargs) 767 # state always should return a dict of tasks. If it's None (meaning the run was 768 # interrupted before any tasks were executed), we set the dict manually. --> 769 if state.result is None: 770 state.result = {} 771 for task in return_tasks or []: AttributeError: 'NoneType' object has no attribute 'result' ``` If you drop in at the `executor.submit()` step, you'll find that `dask.distributed` is actually raising an error that lock objects are not pickleable, but this doesn't surface through prefect. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumCircuit constructor fails if n_qubits is np.int64 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? ``` Python 3.5.6 |Anaconda, Inc.| (default, Aug 26 2018, 16:30:03) [GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)] on darwin Type \"help\", \"copyright\", \"credits\" or \"license\" for more information. >>> import numpy as np >>> import qiskit as qk >>> n = np.int64(12) >>> qr = qk.QuantumRegister(n) >>> qc = qk.QuantumCircuit(n) Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/circuit/quantumcircuit.py\", line 157, in __init__ self.add_register(*regs) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/circuit/quantumcircuit.py\", line 541, in add_register if register.name in [reg.name for reg in self.qregs + self.cregs]: AttributeError: 'numpy.int64' object has no attribute 'name' ``` Similar to as was added for `Register`s in #2288, the `QuantumCircuit` constructor should test if a provided argument can be cast to an int before it raises an error. For reference, here is where `Register` does the check: https://github.com/Qiskit/qiskit-terra/blob/2ee7a3a/qiskit/circuit/register.py#L39 and where `QuantumCircuit` makes new `Registers` from the provided `int`: https://github.com/Qiskit/qiskit-terra/blob/703c9a3/qiskit/circuit/quantumcircuit.py#L522 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: dag.extend_back() not general and dag.compose_back() hard to use `DAGCircuit.extend_back()` was created as a wrapper around `DAGCircuit.compose_back()`, making the wiring requirements more relaxed (allows partial wiring). But it is not general and only works on physically-embedded circuits (see https://github.com/Qiskit/qiskit-terra/pull/3762#pullrequestreview-350581230). I think we should just remove this method and make `compose_back()` also work with partial wirings. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: i18n.merge_file() + build_by_default = warning Meson 0.49.2 throws the following warnings when building GNOME Settings: ``` tests/interactive-panels/applications/meson.build:14: WARNING: Passed invalid keyword argument \"build_by_default\". WARNING: This will become a hard error in the future. ``` Here's the snippet that triggers it: ``` desktop_files = [ 'dynamic-panel', 'header-widget', 'sidebar-widget', 'static-init', 'toplevel-sidebar-widget', ] foreach desktop_file : desktop_files i18n.merge_file( desktop, type : 'desktop', input : 'gtp-@0@.desktop.in'.format(desktop_file), output : 'gnome-@0@-panel.desktop'.format(desktop_file), po_dir : po_dir, build_by_default : true, install : false, ) endforeach ``` Discussing on IRC, this is a buggy behavior, since i18n actually uses the `build_by_default` value, and yet warns about it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: MAINT, TST: bump OpenBLAS for exotic archs Mostly a reminder to myself to rebuild and generate new link for OpenBLAS binaries on gcc compile farm ppc64le and ARMv8 architectures -- as noted in #14002, currently using `0.3.5` instead of `0.3.7.dev` on those platforms vs. more conventional platforms in our CI. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add ability to serialize / deserialize user-written ResultHandlers Right now, only ResultHandlers which are a part of the Prefect library can be serialized / deserialized (and consequently, used). Possibly using a `FunctionReference`, we should allow for more custom / arbitrary result handlers to be serialized. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rewrite Grover with primitives. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: 'Bad file descriptor' error logged in atexit call back **Issue:** Following log lines are observed in stderr on daemonizing a process with `IPython.utils.io` as an import. > Exception ignored in atexit callback: <built-in method close of _io.TextIOWrapper object at 0x7f19e8aa9b10> > OSError: [Errno 9] Bad file descriptor **Reproducer:** ```python import daemon import sys import IPython.utils.io file_descriptors_to_preserve = [] with daemon.DaemonContext( prevent_core=False, signal_map={}, stderr=sys.stderr, stdout=sys.stdout, files_preserve=file_descriptors_to_preserve, ): pass ``` **Root cause:** This is due to the following lines in I**Python.utils.io module** ```python # setup stdin/stdout/stderr to sys.stdin/sys.stdout/sys.stderr devnull = open(os.devnull, \"w\", encoding=\"utf-8\") atexit.register(devnull.close) ``` After the child process is launched, all the files opened by the parent process are closed(except for stderr, stdout). While closing all the files, devnull opened in the IPython.utils.io module is also closed. On process exit atexit module runs all the functions that were registered. Since devnull close is registered, atexit handler is trying to close the already closed file which is generating ' Bad file descriptor' log in stderr Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Implement interact/interactive for widgets We will implement a high-level interact/interactive API for widgets that have a `value` attribute and produce output. The different APIs we will support are: - [x] `interact(f, *args, **kwargs)` = immediate display - [ ] `@interact(*args, **kwargs)` = immediate display, identity decorator - [x] `@interact` without arguments = used with annotate - [ ] `w = interactive(f, *args, **kwargs)` = delayed display, return Widget We also attach f.widget when appropriate. Initial work done in this branch: https://github.com/ellisonbg/ipython/tree/newinteract Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: i18n: need update-po target that does msgmerge There is currently a `$gettextname-pot` target to update the .pot template file from the input files with translations; and the .po files for the specified languages will be compiled and installed correctly on `ninja install`. What is missing is an `update-po` target that 1. updates the .pot template (i.e. depends on `$gettextname-pot` target) 2. uses msgmerge to update the `*.po` files based on the `.pot` file For bonus points, add something to pass extra arguments to the various tools like this from a typical po/Makevars: ``` XGETTEXT_OPTIONS = --keyword=_ --keyword=N_ ... # Avoid line numbers in *.po, but keep them in *.pot. MSGMERGE = msgmerge --no-location MSGMERGE_UPDATE = msgmerge --no-location --update --backup=off MSGFILTER = msgfilter --no-location ``` Issue #554 added an `args` kwarg but it's too general I think. Note that one would likely want the `*.po` files to be update _in the source directory_, since these are maintained in git. The typical workflow from a maintainer/releaser is: 1. download latest translated version of all the .po files from somewhere (if translators don't work directly on the repository) 2. update pot from source files to pick up any added/removed/changes translation strings 3. update po files based on pot template file, so new strings get added, changed strings marked as fuzzy translation etc. Translators will then be notified when a new release is out (or pending) and can update the .po files as needed (fill in missing translations for new strings; update fuzzy translations, etc.), then the cycle repeats. Note: there might be different workflows or I might be misremembering things, so entirely possible I made up most of the above ;) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: latex drawer: justifying doesn't work for custom gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Boxes get overlapped in the latex drawer. In the example below I have 3 boxes: a 1-qubit unitary, a 2-qubit unitary, and a 2-qubit custom opaque gate. ```python from qiskit.circuit import QuantumRegister, QuantumCircuit from qiskit.circuit import Gate from qiskit.quantum_info.random import random_unitary qr = QuantumRegister(3) qc = QuantumCircuit(qr) U1 = random_unitary(2) U2 = random_unitary(4) opaque_gate = Gate(name='opaque_gate', num_qubits=2, params=[]) qc.append(U1, [qr[1]]) qc.append(U2, [qr[0], qr[1]]) qc.append(opaque_gate, [qr[1], qr[2]]) qc.draw(output='latex', justify='left') ```  Maybe an issue with justification? Though I was not able to fix this by tweaking the `justify` param. PS. The underscore in the opaque_gate name should also render better. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Include service name when printing an error message We've been happily using docker compose for a couple of months in our project (~9 service, moderately complex setup). From time to time, usually when a new team member tries to set up the development environment, there's an issue with bringing up the environment. When this happens, all we get is some cryptic error message: - `No such file or directory` - `Container command not found or does not exist.` At this point, we usually have to dig into the person's machine and check what's wrong. We usually have to: check container logs, check images, inspect containers, try to start them manually using `docker` directly. From time to time, we even have to check docker logs, start stuff with `strace`... It would be so much better if compose printed way more information when an error occurs: service name, engine API call, all arguments... Ideally, engine would do the same by sending more detailed error messages. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: valdation_epoch_end won't log if no logging is done in validation_step ## 🐛 Bug @edenlightning looks like setting both logger=False and prog_bar=False won't do anything. If this is intended, maybe we should add a warning or something. Also saw another issue, if I don't log anything in validation_step then logged values in validation_epoch_end won't be logged too even if we set logger=True. Updated the notebook attatched above for the same to verify. #### Code sample https://colab.research.google.com/drive/1Os9oSPK_rwwutcFdZTDsBaMc2IrqkSrP#scrollTo=3BJmPqHwX6WA ### Environment pl: master env: colab Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Supported meas_levels should be validated on client-side at assembly <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The new `ibmq_armonk` device only supports `meas_levels=[1,2]`. An optional validation error should be raised if a user tries to submit a `meas_level=1` job. This is related to #3606. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add an `install:` kwarg to `configure_file()` Just for consistency with other targets otherwise people get confused by it not existing, even though setting `install_dir:` has the same effect: https://github.com/mesonbuild/meson/issues/860#issuecomment-410086728 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [possible regression in 0.55] New rpath must not be longer than the old one Several projects fail to build with meson with the error from the subject. For example devel/gnome-builder: http://package22.nyi.freebsd.org/data/113amd64-default-PR244008/2020-07-15_21h37m37s/logs/errors/gnome-builder-3.28.4_4.log See the list here: https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=247935#c2 Could you please comment on this? Why did these build before and not with 0.55? FreeBSD 12.1 Thanks, Yuri Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Another clone bug ``` kfranz@0283:~/continuum/conda *master ❯ conda create --clone root -n rootclone Source: '/conda' Destination: '/conda/envs/rootclone' The following packages cannot be cloned out of the root environment: - conda-team::conda-4.1.0rc2-py27_0 - conda-build-1.20.1-py27_0 Error: no URL found for package: <unknown>::gcc-4.8.5-3 ``` But /conda/conda-meta/gcc-4.8.5-3.json has, in part, ``` \"channel\": \"https://repo.continuum.io/pkgs/free/osx-64/\", ``` so the information is there. The logic here is located around line 273 of `conda/misc.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery - filter job list by time window Please add `minCreationTime` and `maxCreationTime` optional parameters to `list_jobs`, which are supported by the API. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pulling subprojects fails if the build directory is outside the source directory I am using meson 0.40.0 To reproduce, git clone git://git.gnome.org/nautilus mkdir build cd build meson --prefix=/usr --buildtype=debug --sysconfdir=/etc --libexecdir=/usr/lib/ -Denable-gtk-doc=false -Denable-exif=true -Denable-xmp=true -Denable-selinux=false ../nautilus This results in the following error: Meson encountered an error in file meson.build, line 107, column 0: Subproject directory 'subprojects/libgd' does not exist and cannot be downloaded: No libgd.wrap found for 'subprojects/libgd' The directory subprojects/libgd exists but is empty. Next I tried: cd nautilus mkdir build cd build meson --prefix=/usr --buildtype=debug --sysconfdir=/etc --libexecdir=/usr/lib/ -Denable-gtk-doc=false -Denable-exif=true -Denable-xmp=true -Denable-selinux=false ../ said: Submodule path 'subprojects/libgd' not initialized Maybe you want to use 'update --init'? A Gnome developer suggested I file a bug report here. Thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose failing to read env_file with UTF8 BOM Hi! I was trying to use the `env_file` feature in docker-compose but the environment variables were not being readed from the file. In this [example project](https://github.com/vtortola/dotnet-docker-env) you will see two files named `config.env` and `config2.env`. They almost contains the same data, but `config.env` starts with the [UTF8 BOM](https://en.wikipedia.org/wiki/Byte_order_mark), causing docker-compose to not read the variables. <img src=\"https://github.com/vtortola/dotnet-docker-env/raw/master/hex.png\" /> Most text editors shows the same content for both files. During the execution, the log shows that something is going wrong with the parsing: config.env: ``` environment: NUGET_FALLBACK_PACKAGES: /root/.nuget/fallbackpackages \"\\uFEFFTEST\": Compose ``` config2.env ``` environment: NUGET_FALLBACK_PACKAGES: /root/.nuget/fallbackpackages TEST: Compose ``` Would it be possible for docker in general to be aware of the UTF8 BOM in configuration files? # How did happen? Well it seems that when you add a text file in Visual Studio, it adds the UTF8 BOM by default. I generated the second file that has to BOM using the Windows Explorer contextual menu \"New File\". Maybe: [StackOverflow: Reading Unicode file data with BOM chars in Python ](https://stackoverflow.com/questions/13590749/reading-unicode-file-data-with-bom-chars-in-python) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Simpler system for running code after InteractiveShell is initialised A very common need for config is to run code after the InteractiveShell is initialised - e.g. to define extra magics or aliases, or to import modules. Currently, the user has to track down `exec_lines` in the config file, and put their code inside a string (i.e. it doesn't get syntax highlighted etc.), or save a file in a suitable place, and add it to exec_files. I propose either: - A file in the profile directory which is automatically run in the shell if it is present, as an addition to the user-specified exec_files. Something like `ipython_startup.py`. - A directory, similar to the `/etc/rcN.d/` folders on Linux, in which any files found are run in a predictable order (i.e. to allow prefixes 00-99 if desired). This would allow customisations to be easily distributed: download a file, drop it in your `IPYTHONDIR/profile_default/startup/` directory, and an extra magic function will be available. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: RST docs are not generated for every module I'm not very familiar with Sphinx but it seems our documentation is incomplete. For example the `gcloud.connection` and `gcloud.credentials` modules are not documented: ``` $ ls docs/_build/html/_modules/gcloud/ datastore/ storage/ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: hparams sometimes don't save in checkpoint hparams sometimes don't save in checkpoint (maybe just a SLURM thing?) checkpoints saved on slurm are missing hparams Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Performance drop when activating gradient clipping Hello all, I experienced a substantial drop in computation time when activating gradient clipping (by passing a non-zero value to the keyword argument `gradient_clip_val` when initializing the Trainer). I noticed that in the current implementation of the `clipping_gradient` method in pytorch-lightning/trainer/training_tricks.py redundant computations are made by first computing the 2-norm and second squaring this result, which could be shortened by computing the sum of squares directly. This saves one square root and squaring operation per parameter set. Best, Jonas ### Environment ``` cuda: GPU: available: False version: None packages: numpy: 1.18.1 pyTorch_debug: False pyTorch_version: 1.4.0 pytorch-lightning: 0.7.4-dev tensorboard: 2.2.1 tqdm: 4.45.0 system: OS: Darwin architecture: 64bit processor: i386 python: 3.8.2 version: Darwin Kernel Version 19.4.0: Wed Mar 4 22:28:40 PST 2020; root:xnu-6153.101.6~15/RELEASE_X86_64 ``` ### Additional context I trained a relatively small (two-layered) MLP on MNIST; perhaps this performance drop does not become that apparent when training on larger network architectures. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: rep_times should be integer and not float in provider models <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Marshmallow provider models expect float as rep_time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Multiprocessing CUDA issues when importing transformers ## Environment info - `transformers` version: 4.2.0dev0 - Platform: Linux-4.15.0-128-generic-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.6.9 - PyTorch version (GPU?): 1.6.0 (True) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: Yes - Using distributed or parallel set-up in script?: Partly ### Who can help @stas00 ## Information When using multiprocessing, importing the transformers package causes `RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method` The problem arises when using: * `import transformers` is used in the main process. This is due to the [following line](https://github.com/huggingface/transformers/blob/master/src/transformers/models/fsmt/modeling_fsmt.py#L268) in `modeling_fsmt.py`, removing `torch.cuda.is_available()` call resolves the issue. ## To reproduce ``` import multiprocessing import transformers # NOQA # You can also call torch.cuda instead of import transformers to get the same error import torch.nn as nn class Net(nn.Module): def __init__(self): super().__init__() self.linear = nn.Linear(10, 10) def forward(self, x): return self.linear(x) def to_cuda(i): net = Net().cuda() print(f'Called {i} process') try: cpus = multiprocessing.cpu_count() except NotImplementedError: cpus = 2 # arbitrary default pool = multiprocessing.Pool(processes=cpus) pool.map(to_cuda, range(10)) ``` ## Expected behavior The code snippet above runs without issues. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: usage documentation: please mention unicode http://google-cloud-python.readthedocs.io/en/latest/datastore/usage.html please add (in the first example) a mention that storing strings should be done with u: entity['name'] = u'Jane' Not using unicode will make the datastore convert them to blobs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: raise a `TypeError` if a dictionary is passed to `insert_rows_json` **Is your feature request related to a problem? Please describe.** If I want to only insert a single row at a time into a table, it's easy to accidentally try something like: ```python json_row = {\"col1\": \"hello\", \"col2\": \"world\"} errors = client.insert_rows_json( table, json_row ) ``` This results in a `400 BadRequest` error from the API, because it expects a list of rows, not a single row. **Describe the solution you'd like** It's difficult to debug this situation from the API response, so it'd be better if we raised a client-side error for passing in the wrong type for `json_rows`. **Describe alternatives you've considered** Leave as-is and request a better server-side message. This may be difficult to do, as the error happens at a level above BigQuery, which translates JSON to Protobuf for internal use. **Additional context** This issue was encountered by a customer engineer, and it took me a bit of debugging to figure out the actual issue. I expect other customers will encounter this problem as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add `insert_rows_from_dataframe` to use the streaming API to append a pandas DataFrame to an existing table **Is your feature request related to a problem? Please describe.** There is a limit on the number of load jobs per day (per table and per project limit of 1,000 load jobs). When a pandas DataFrame is used as part of a data processing pipeline, this limit can easily be reached. See: https://github.com/pydata/pandas-gbq/issues/238 **Describe the solution you'd like** I'd like to see a `insert_rows_from_dataframe` method on the client to complement the `insert_rows` method. It would transform the (column-oriented) DataFrame in to (row-oriented) JSON and upload the rows via calls to tabledata.insert (in batches). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Equivalence library lacks many equivalences in the clifford group Many equivalences in the clifford group are missing from the equivalence library. Some examples: * `sdg == h.z == z.s == s**3` * `sx` == `sdg.h.sdg` * `cy == sdg.cx.s` * `x`,`y`, and `z` in terms of `h` and `s` (for example, `x == h.s.s.h`) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson will fail when use the Chinese version of VS2017 **Describe the bug** 1. install VS2017 with zh_cn 2. make a meson.build 3. exec meson build . when will show: meson.build:1:0: ERROR: Failed to detect MSVC compiler target architecture: 'cl /?' output is ���� x64 �� Microsoft (R) C/C++ �Ż������� 19.16.27035 �� **To Reproduce** \" cl /?\" output : 用于 x64 的 Microsoft (R) C/C++ 优化编译器 19.16.27035 版 there is a bug in environment.py: cl_signature = lookat.split('\\n')[0] match = re.search('.*(x86|x64|ARM|ARM64)$', cl_signature) This expression may fail in a non-english version. **Expected behavior** match = re.search('.*(x86|x64|ARM|ARM64)', cl_signature) **system parameters** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Cannot apply gates to more than 3 qubits <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.6 - **Operating system**: MacOS ### What is the current behavior? If I try and apply a 4-qubit unitary, or define a custom gate that acts on 4 qubits I get an error of `QiskitError: 'This gate cannot handle 4 arguments'` (and similarly for any number of qubits greater than 3). This only occurs in master, seems to work fine in 0.8/stable. ### Steps to reproduce the problem The following circuits will give this error ```python qr = QuantumRegister(4) circ = QuantumCircuit(qr) circ.unitary(np.eye(2 ** 4), [qr[0], qr[1], qr[2], qr[3]]) ``` ```python qr = QuantumRegister(4) circ = QuantumCircuit(qr) circ.append(Gate(\"mcx\", 4, []), [qr[0], qr[1], qr[2], qr[3]]) ``` ### What is the expected behavior? The `Gate` object should work for any number of qubits. ### Suggested solutions The error is being raised by the `Gate.broadcast_arguments` function which looks to be hardcoded to only handle 1,2,3 qubit cases. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Subscribe experimental doesn't appear to be retrying on retryable exceptions, also doesn't surface the error. Full context at https://github.com/GoogleCloudPlatform/google-cloud-python/issues/4841#issuecomment-386988007 downwards. gist with logs: https://gist.github.com/psalaberria002/e91956d94e82d706d65da7111a40ca24 Possible culprits: 1. `send()` and `recv()` expectedly error on `next(self.call)`, but if that was a *retryable* error that somehow re-bubbled, it would not trigger any callbacks. 2. `bidi` uses `rpc._wrapped` because `api_core` doesn't appropriately expose `add_done_callback`. This means that bidi unwraps all of the retry logic. This doesn't explain *why* retrying a perfectly normal looking error somehow still leads us to a broken stream, unless the newly opened stream also has an error. But it's unclear why that wouldn't happen when calling the initial RPC. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: Bucket.list_blobs fields param doc I have google-cloud-storage-1.15.0 and want to user `Bucket.list_blobs` for many objects, so want to limit the fields returned. However, [from the doc](https://googleapis.github.io/google-cloud-python/latest/storage/buckets.html?highlight=list_blobs#google.cloud.storage.bucket.Bucket.list_blobs) it's not clear to me: - If I have to specify `nextPageToken` in the `fileds` param as well or is it obsolete like the `page_token` param? - How to specify multiple fields and what's the proper form: `items(name,size)` or `items/name,items/size`? Please, fill the doc, thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Extract layout from mapping passes Layout should be established during the embed stage of the transpiler, but several mapping passes have logic to establish their own layouts or change the layout provided. These should be extracted into their own passes and mappers should instead rely on the layouts set in the property_set. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PauliOp matmul gives incorrect result with iI ### Environment - **Qiskit Terra version**: 0.21.2 - **Python version**: 3.9 - **Operating system**: WSL Ubuntu 18.04 ### What is happening? In opflow.PauliOp, @ gives incorrect result with iI. Actual problem can be seen with only X, Y, Zs. ### How can we reproduce the issue? ``` from qiskit.opflow import X,Y,Z,I, PauliOp from qiskit.quantum_info import Pauli print(PauliOp(Pauli('iI'))@Z) # Z print(X@Y@Z@X) # X ``` ### What should happen? Output should be iZ, iX respectively. ### Any suggestions? I think the following line is wrong. Not sure how to fix it https://github.com/Qiskit/qiskit-terra/blob/a4cf1483c8ccf711c9b01a70288d1a35affd4693/qiskit/opflow/primitive_ops/pauli_op.py#L158-L159 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: \"conan install\" fails in the root folder The conan install command seems to fail if I am at the root folder (conan 1.9.1, Win7, x64, NTFS, the user is member of the local Administrators group). I don't really understand this because when I am somewhere else, and not in the root folder, then conan will properly download and place the package to my \"home\" or \"profile\" folder, as expected. So why does it try to write to the \"current folder\"?  I gave it a try under Mac (10.13.6, conan 1.8.4) and I have a failure but with a different error code:  I think it is strange ... please consider some more error handling. To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Can not stop \"ipython kernel\" on windows when running the \"ipython kernel\" command on windows I can not stop the kernel process. Ctrl-c does not stop the process like it does when using \"ipython notebook\". I have to kill the process manually using the process explorer. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: On Windows, the cli should connect to a named pipe by default Since Docker 1.11, the docker CLI has been connecting to the daemon on `npipe:////./pipe/docker_engine` named pipe on Windows. Before 1.11, the default behaviour was to connect to `localhost:2375` Compose 1.8RC1 still defaults to `localhost:2375`. I believe we should have the same behaviour. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: TransfoXLLMHead doesn't shift labels internally when called for loss # 🐛 Bug When called with labels to get the language-modeling loss, `TransfoXLLMHead.forward` computes the NLLLoss of the outputs directly against the labels, rather than against the shifted labels like the documentation indicates (and like the other models). This makes it impossible to train with `lm_labels = input_ids` as suggested by the doc. ## Information Model I am using: TransformerXL Language I am using the model on: English The problem arises when using: * [x] my own modified scripts: The task I am working on is: * [x] my own task or dataset: ## To reproduce ``` import torch from transformers import TransfoXLConfig, TransfoXLLMHeadModel config = TransfoXLConfig() lm = TransfoXLLMHeadModel(config) test_tensor = torch.LongTensor([[0]]) print(lm(input_ids=test_tensor, labels=test_tensor)[0]) ``` A 1x1 loss tensor is returned. ## Expected behavior As there is only 1 token in the input tensor, no loss should be returned: there's no next label to compare the output against. For example, running this with GPT2 ``` import torch from transformers import GPT2Config, GPT2LMHeadModel config = GPT2Config() lm = GPT2LMHeadModel(config) test_tensor = torch.LongTensor([[0]]) print(lm(input_ids=test_tensor, labels=test_tensor)[0]) ``` returns `tensor(nan, grad_fn=<NllLossBackward>)`. ## Environment info - `transformers` version: 2.8.0 - Platform: Linux-5.3.0-45-generic-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.6.9 - PyTorch version (GPU?): 1.4.0 (True) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: False - Using distributed or parallel set-up in script?: False Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Inline default values raise an error with volumes After the recent addition of #3108. See the following : ``` version: '2.1' services: test: container_name: test-name image: busybox command: \"true\" privileged: true volumes: - ${DATA_DIR-/home/hadim/test_data_dir}:/data:Z ``` And the error : ``` ERROR: Invalid interpolation format for \"volumes\" option in service \"test\": \"${DATA_DIR-/home/hadim/test_data_dir}:/data:Z\" ``` ``` $ docker version Client: Version: 1.12.2-rc2 API version: 1.24 Go version: go1.6.3 Git commit: ad9538a Built: Tue Oct 4 18:23:48 2016 OS/Arch: linux/amd64 Server: Version: 1.12.2-rc2 API version: 1.24 Go version: go1.6.3 Git commit: ad9538a Built: Tue Oct 4 18:23:48 2016 OS/Arch: linux/amd64 $ docker-compose version docker-compose version 1.9.0dev, build unknown docker-py version: 1.10.3 CPython version: 2.7.12 OpenSSL version: OpenSSL 1.0.2g 1 Mar 2016 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: numpy.deprecate indentation question This code has two functions marked as deprecated with `numpy.deprecate`: ``` import numpy as np @np.deprecate(message=\"foo() is no longer supported.\") def foo(): \"\"\"This is foo. It doesn't do anything. \"\"\" return @np.deprecate(message=\"bar() is no longer supported.\") def bar(): \"\"\" This is bar. It does the same thing as foo(). \"\"\" return ``` The docstrings of `foo` and `bar` end up like this: ``` In [5]: print(foo.__doc__) `foo` is deprecated! foo() is no longer supported. This is foo. It doesn't do anything. In [6]: print(bar.__doc__) `bar` is deprecated! bar() is no longer supported. This is bar. It does the same thing as foo(). ``` Note that the indentation of the added deprecation text doesn't match the indentation of the original docstring. Is this intentional? It messes up the HTML documentation; see, for example, the online documentation for [`scipy.stats.itemfreq`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.itemfreq.html). That gray bar in front of what was originally the first line of the docstring (\"Return a 2-D array...\") shouldn't be there. A related issue was reported in https://github.com/numpy/numpy/issues/8058, which was closed by https://github.com/numpy/numpy/pull/8131. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: resumable uploads should try to send the file in one chunk by default Sending data in one chunk is the recommended approach, documented in a not very clear way [here](https://cloud.google.com/storage/docs/json_api/v1/how-tos/upload#resumable) in the “Uploading the file in chunks” section. We should allow the user to override the chunk size, making sure that the library ends up using a multiple of 256 KB, as expected from the API (except for the final chunk that completes the upload where the size can vary according to the total size of the file). [gsutil code](https://github.com/GoogleCloudPlatform/gsutil/blob/ccca18e64f3f7d87c989675f8673af7bdecae0d1/gslib/util.py#L464) dealing with this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Message with package ID \"Can't find a XXX package for the specified settings\" To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. 1.0.4 It helps if Conan shows the package ID when a package is missing, so you can, for example, search for it in local or remote. UX improvement: show the sha of the missing package When a binary package is not available we could show the SHA. In case we have it in a different repository would be nice to see what is the package missing, not only the settings and options. ``` OpenSSL/1.0.2l@conan/stable: WARN: Can't find a 'OpenSSL/1.0.2l@conan/stable' package for the specified options and settings: - Settings: arch=x86, build_type=Release, compiler=apple-clang, compiler.version=9.0, os=Macos - Options: 386=False, no_asm=False, no_bf=False, no_cast=False, no_des=False, no_dh=False, no_dsa=False, no_hmac=False, no_md2=False, no_md5=False, no_mdc2=False, no_rc2=False, no_rc4=False, no_rc5=False, no_rsa=False, no_sha=False, no_sse2=False, no_threads=False, no_zlib=False, shared=False, zlib:shared=False ERROR: Missing prebuilt package for 'OpenSSL/1.0.2l@conan/stable' Try to build it from sources with \"--build OpenSSL\" Or read \"http://docs.conan.io/en/latest/faq/troubleshooting.html#error-missing-prebuilt-package\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Inadequate total steps shown in progress bar during sanity validation check when number of validation dataloaders >= 2 **Describe the bug** The number of total steps shown in progress bar during validation sanity check is underestimated when multiple validation dataloaders are provided. **To Reproduce** Steps to reproduce the behavior: 1. At def val_dataloader(self), return a list of >= 2 validation dataloaders. e.g. return [val_dataloader1, val_dataloader2] 2. Set nb_sanity_val_steps for trainer to n (default n = 5) 2. Run experiment **Expected behavior** 1. If two validation dataloaders are provided, the total steps shown in progress bar during validation sanity check are n * 2. That is, 10 steps shown progress bar. In current master - trainer.py ``` if self.get_val_dataloaders() is not None and self.num_sanity_val_steps > 0: # init progress bars for validation sanity check pbar = tqdm.tqdm(desc='Validation sanity check', total=self.num_sanity_val_steps, leave=False, position=2 * self.process_position, disable=not self.show_progress_bar, dynamic_ncols=True, unit='batch') ``` Should be modified to ``` if self.get_val_dataloaders() is not None and self.num_sanity_val_steps > 0: # init progress bars for validation sanity check pbar = tqdm.tqdm(desc='Validation sanity check', total=self.num_sanity_val_steps*len(self.get_val_dataloaders()), leave=False, position=2 * self.process_position, disable=not self.show_progress_bar, dynamic_ncols=True, unit='batch') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython 8.0: built in aliases issue warnings: You executed the system command !ls Starting with IPython 8 built in aliases `ll`, `ldir`, `lf`, `lx` etc issue warnings: ``` /Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/IPython/core/interactiveshell.py:2373: UserWarning: You executed the system command !ls which may not work as expected. Try the IPython magic %ls instead. warnings.warn( ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Parallel controller failing with Pymongo 2.2 [Test failure](https://jenkins.shiningpanda.com/ipython/job/ipython-mac/94/testReport/junit/nose.failure/Failure/runTest/) The mongodb backend for the controller tries to import from `pymongo.binary`, but this no longer exists in 2.2; it should import from `bson.binary` instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Runtime Performance Regression in `SabreLayout` ### Environment - **Qiskit Terra version**: 0.25.0 - **Python version**: 3.11 - **Operating system**: Linux ### What is happening? When running `SabreLayout` with 0.25.0 has a large performance regression between 0.24.x and 0.25.0 that is a function of the number of gates in the circuit. The rust computation of the swap map and initial layout is as fast as before, but when we iterate over that to rewrite the `DAGCircuit` using that output from rust the runtime performance is significantly slower. For more modestly sized circuits this isn't super noticeable , but as the number of instructions in a circuit increases this overhead can be significantly higher. ### How can we reproduce the issue? You can parse this qasm file from qasmbench: https://github.com/pnnl/QASMBench/blob/master/medium/bwt_n21/bwt_n21.qasm ```python from qiskit import transpile, QuantumCircuit from qiskit.providers.fake_provider import FakeCairoV2 import time import logging logging.basicConfig(level=\"INFO\") backend = FakeCairoV2() for filename in [\"bwt_n21.qasm\"]: start = time.time() qc = QuantumCircuit.from_qasm_file(filename) parse_stop = time.time() print(f\"parse {filename}: {parse_stop - start}\") tqc = transpile(qc, backend, optimization_level=1) stop = time.time() print(f\"{filename}: {stop - start}\") ``` ### What should happen? The performance should be roughly equivalent to qiskit-terra < 0.25.0. Looking at 0.24.2 the above example `SabreLayout` took `22515.55800 ms` and 0.23.0 took `18759.72962 ms`. But I've been too impatient to wait for 0.25.0 to finish after several minutes. ### Any suggestions? I expect the underlying issue stems from #10366 and specifically the rust<->python boundary doing unnecessary copies or conversions when we access data as we iterate over the circuit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: local install create file: folder Hi, A folder named `file:` is always created if I installed conda package locally. `conda install /local/path/bz2` related to: https://github.com/conda/conda/issues/3770 ```bash $ conda info Current conda install: platform : linux-64 conda version : 4.2.11 conda is private : False conda-env version : 4.2.11 conda-build version : 2.0.7 python version : 3.5.1.final.0 requests version : 2.9.1 root environment : /home/haichit/anaconda3 (writable) default environment : /home/haichit/anaconda3 envs directories : /home/haichit/anaconda3/envs package cache : /home/haichit/anaconda3/pkgs channel URLs : https://conda.anaconda.org/conda-canary/linux-64 https://conda.anaconda.org/conda-canary/noarch https://repo.continuum.io/pkgs/free/linux-64 https://repo.continuum.io/pkgs/free/noarch https://repo.continuum.io/pkgs/pro/linux-64 https://repo.continuum.io/pkgs/pro/noarch https://conda.anaconda.org/conda-forge/linux-64 https://conda.anaconda.org/conda-forge/noarch https://conda.anaconda.org/ambermd/linux-64 https://conda.anaconda.org/ambermd/noarch config file : /home/haichit/.condarc offline mode : False ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Expose serialization/deserialization of Results ## Current behavior Currently when you use a `Result` with a `target` the user does not have any control over how the data is (de)serialized before being (read from)written to the `target`. The default (cloudpickle) allows for I/O of a wide variety of objects, but there are many cases where you might want to use something more specialized, e.g. Pandas's `to_csv`. ## Proposed behavior First I propose coming up with a standard interface for a serializer/deserializer, something like an object with `serialize` and `deserialize` methods. Then I propose that serialization/deserialization be exposed as a kwarg accepting an instance of that object, probably in the instantiation of the `Result`. ## Example You can see discussion of this in #2115. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: ValueError exception when asking for authored_datetime I am receiving a `ValueError` exception when getting the author date of a commit in Rails project. You can replicate it with the following code: ``` > from git import Repo > repo = Repo('rails') > commit = repo.commit('4cf94979c9f4d6683c9338d694d5eb3106a4e734') > commit.authored_datetime Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/dspadini/Documents/pydriller/.venv/lib/python3.6/site-packages/git/objects/commit.py\", line 151, in authored_datetime return from_timestamp(self.authored_date, self.author_tz_offset) File \"/Users/dspadini/Documents/pydriller/.venv/lib/python3.6/site-packages/git/objects/util.py\", line 124, in from_timestamp > local_dt = utc_dt.astimezone(tzoffset(tz_offset)) ValueError: offset must be a timedelta strictly between -timedelta(hours=24) and timedelta(hours=24). ``` Tracing back the error, I got that the timestamp of the commit is 1312735823, while the tz_offset is -1864800. The problem is when creating the tzoffset: I indeed printed the timedelta ``` local_dt = utc_dt.astimezone(tzoffset(tz_offset)) class tzoffset(tzinfo): def __init__(self, secs_west_of_utc, name=None): self._offset = timedelta(seconds=-secs_west_of_utc) print('Timedelta is {}'.format(timedelta(seconds=-secs_west_of_utc))) ``` and it is not in the range of [-24,24] hours, but it is actually 21 days. *EDIT*: looking at the information of the commit, the offset is completely wrong: `Date: Mon Aug 29 06:50:23 2011 +51800` So the problem is not of gitpython. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan config install should accept ca cert for verification Conan version: 1.7.4 Our organization uses an internal CA to issue certificates for services. When running `conan config install` the very first time using an https URL, the user must either pass `--verify-ssl=False` or manually append our root CA certificate to `$CONAN_USER_HOME/cacert.pem`. It would be nice to be able to pass the ca certificate to use as an optional parameter to `conan config install` (e.g. `--cacert=/path/to/cert/bundle.pem` and `Conan.config_install`. ---- To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rewrite Hamiltonian Quantum Phase Estimator with primitives. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson does not support Windows kernel drivers **Describe the bug** Meson assumes a binary state of affairs when building Windows applications based on the `gui_app` kwarg: either you're building a GUI app or you're building a console app. This is translated to either a `/SUBSYSTEM:WINDOWS` or a `/SUBSYSTEM:CONSOLE` in the ninja files respectively. The reality is that `link` supports a variety of different subsystems ranging from kernel drivers to EFI applications and drivers which are not buildable with meson because of this. **To Reproduce** I don't think this requires any specific project files for reproduction as the outlined behavior should be apparent by opening the generated `build.ninja` of any Windows application project. **Expected behavior** Meson features a `subsystem` kwarg in `executable` that allows the user to select between one of the subsystems supported by `link`. **system parameters** * Native build targeting Windows * Windows * Python version 3.8.6 * Meson version 0.55.3 * Ninja version 1.10.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: tools/github_stats.py still fails on two factor auth with app See #9179. I think #9186 fixed it only for SMS codes, not for OTPs generated from a smartphone app. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add pip shadow packages into PrefixData Epic at #7053 Teach PrefixData to recognize when python is installed in an environment, and then scan site-packages to find packages that don't have metadata in conda-meta. Also replace `conda/egg_info.py` and how it influences `conda list`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Celery Import Error <!-- Please use one of our issue templates. We reserve the right to close bug reports or feature requests who don't use our templates. --> Not able to import Celery module when creating simple app. from celery import Celery ImportError: cannot import name 'Celery' from 'celery' Additonal info: This issue doesn't occur when we downgrade importlib-metadata to 4.12.0 Env details  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Circuit widths should be checked before compiling for backend <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Since we allow fior different width circuits in compile / transpile the width of the circuits should be validated to fit on the backend that they are being compiled for BEFORE actually being compiled. This prevents compiling many circuits only to have an exception thrown because a later one is not compatible with the backend. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: No way to disable special dependency lookups, such as 'sdl2' This is hardcoded, and it uses sdl2-config first. But what if I want to use my custom build of sdl2 and not the system's? There should be a way to disable these special dependency classes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda fails if a user's home directory doesn't exist In certain applications that we support, it is possible that a user does not have a home directory within which to create `~/.conda`. This is causing a fatal error in the `append_env` method [here](https://github.com/conda/conda/blob/master/conda/misc.py#L185-L193). Note that this function is already designed to fail silently if there is an `IOError`. However, if the home directory itself does not exist, the `os.mkdir` command fails with an `OSError` instead. I would suggest that this exception type be included in the `except` line as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: PYTHONPATH could be automatically handled Refactoring `tools.environment_append` context manager to manage `PYTHONPATH` variable. That way PYTHONPATH would be set automatically before `source`, `build`, `package` and `imports` from self.env_info objects. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Allow run failure sensor and run status sensor to target unresolved asset jobs Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: backward compatibility broken on vcvars command Since implementing #3157 in conan 1.7, using vcvars with Visual Studio 2015 and architecture 86 uses amd64_x86 as parameter for vcvars, even if arch_build is not specified and not part of the recipes settings. This breaks for example builds where Silverlight is used, as Silverlight cannot be used with 64 bit msbuild commands. Expected behavior: if arch is set to 86 and arch_build is not specified, x86 is used as parameter to vcvars.bat (allowed on 64 bit systems, see https://msdn.microsoft.com/en-us/library/f2ccy3wt.aspx#Anchor_1). - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: More idiomatic definition of dev/production conditional dependencies The current mechanism is to define options for it, then use such options to conditionally require (or not) a certain dependency. It could be easier and more idiomatic if a higher level of abstraction, as specifying a global (dev/production/package) scope for all packages, and packages could use such scope for conditionally defining dependencies. Requested in https://github.com/conan-io/conan/issues/79, but it is not the first time, so I think it is an interesting feature to develop Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Inner class files not included in Jar javac produces separate class files for inner classes. So multiple output files can be generated for one input file. If Foo.class and Foo$Bar.class files are generated form Foo.class, meson only includes Foo.class not Foo$Bar.class. I am not a Java expert (I am just trying to write a binding for my C library); but according to a quick research on the Internet, an easy solution does not seem possible with javac while keeping the support for incremental builds. SCons has a parser for Java files to guess output files. Another solution would be to pass only the output directory to jar command instead of passing each class file. Some info about this: http://blog.ltgt.net/in-quest-of-the-ultimate-build-tool/#internals SCons's parser: https://bitbucket.org/scons/scons/src/3763c12a06be2b44e945bdb03fcc1b5a888e5c96/src/engine/SCons/Tool/JavaCommon.py?at=default&fileviewer=file-view-default Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: matplotlib should only be imported when needed After merging #911, matplotlib is imported when `import qiskit`. Please, see the discussion in #911 . Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Add components to 'pkg_config' generator This PR (https://github.com/conan-io/conan-center-index/pull/1782) is adding components to OpenSSL and overriding the name of those components for `pkg_config` generator: ```python self.cpp_info.components[\"crypto\"].names[\"cmake_find_package\"] = \"Crypto\" self.cpp_info.components[\"crypto\"].names[\"cmake_find_package_multi\"] = \"Crypto\" self.cpp_info.components[\"crypto\"].names['pkg_config'] = 'libcrypto' self.cpp_info.components[\"ssl\"].names[\"cmake_find_package\"] = \"SSL\" self.cpp_info.components[\"ssl\"].names[\"cmake_find_package_multi\"] = \"SSL\" self.cpp_info.components[\"ssl\"].names['pkg_config'] = 'libssl' ``` How do components work with `pkg_config`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Allow partial schema in `load_table_from_dataframe` As discussed in https://github.com/googleapis/google-cloud-python/pull/8105#discussion_r286997609 and implemented in pandas-gbq at https://github.com/pydata/pandas-gbq/issues/218, often times the default schema detection works well enough for pandas -> BQ, and only one or two of many columns need to be overridden. Example: ```python df = pandas.DataFrame({... lots of columns ..., \"needs_manual_schema\": [...]}) job_config = bigquery.LoadJobConfig(schema=[ bigquery.SchemaField(\"needs_manual_schema\", \"BOOLEAN\"), ]) client.load_table_from_dataframe( df, \"my_dataset.my_table\", job_config=job_config, ) # All columns from df are uploaded, but only df[\"needs_manual_schema\"] is # coerced into a specific type (BOOLEAN). ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Allow passing GeneratedList to generator.process Sometimes you want to chain two generators one after the other; for instance while building assembly with MSVC, you need to use `ml.exe` but it doesn't do pre-processing, so you need to call `cl.exe /EP /P /Fi@OUTPUT@ @INPUT@` to do the pre-processing, and then pass it to `ml.exe /Fo @OUTPUT@ /c @INPUT@` to get compiled object code which can be added as sources to an `executable` or `library`. This is not trivial to do (I tried) but shouldn't be too difficult. Also implementing it on the Visual Studio backend has the same problem that is causing the `113 generatorcustom` test to fail there. This is needed for building libffi with Meson without resorting to a wrapper script. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Retry tasks which failed because of SIGKILL Hello, We are currently using celery with Broker=RabbitMQ & Backend=Redis. Our setup runs on Kubernetes with auto-scaling enabled. (Our number of pods scale up / down based on resource utilization). We use the Forked Process mode to run our celery worker. When the size of our cluster increases, everything works great. However, when the pods turn down, the tasks that were running on the pods get marked as FAILED. The sequence of actions is as follows: 1. Resource consumption decreases 2. Kubernetes realizes that pods that were scaled up now need to be turned down 3. Kubernetes sends `SIGKILL` signal to the pods that should turn down 4. Celery intercepts the signals and turns down all the Forked Processes 5. The tasks that were running on the processes return their execution back to the Main Process 6. The main process marks all the running tasks as FAILED When the main process is the one that marks the running operations as FAILED, the `retry` code is never executed. We do want to recover these tasks as they are part of a long running process. Celery should provide a way to recover these tasks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: New Wav2Vec2 padding has slightly backward breaking changes The PR: https://github.com/huggingface/transformers/pull/13650 introduced some quite tricky backwards breaking changes that we should try to fix. The problem is the following: A user might directly use `feature_extractor.pad(...)` instead of `feature_extractor(...)` to just pad already preprocessed inputs in, *e.g.* a data collator. The following code correctly returned `torch.float32` before merging the PR while the new PR returns `torch.float64` which is slighly breaking and can lead to errors in current fine-tuning Wav2Vec2 scripts: ```python from transformers import Wav2Vec2FeatureExtractor import numpy as np extractor = Wav2Vec2FeatureExtractor.from_pretrained(\"facebook/wav2vec2-base-960h\") rand_input = np.ones((100,), dtype=np.float64) out = extractor.pad([{\"input_values\": rand_input}], return_tensors=\"pt\") print(out.dtype) # <- this should be `torch.float32` ``` Here is a colab showing how the \"old\" version works correctly: https://colab.research.google.com/drive/10TlRWvwKx34UORmYdCFAyMWKUU3OtPRf?usp=sharing Here is a colab showing how the \"new\" version works incorrectly: https://colab.research.google.com/drive/1cXGuG4Rnypmivdm-vdE-61BA1f4hC4e8?usp=sharing Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Ensure PKG_CONFIG_PATH persistence Encountered the following issue: ``` $ PKG_CONFIG_PATH=/foo/pkgconfig meson ``` and everything builds fine, _but_ one of the meson.build files has something like this: ``` runcmd = run_command('pkg-config', '--variable=pluginsdir', 'gstreamer-1.0') ``` The problem is now that without an export the environment passed to meson is not inherited by subprocesses (I think that's the issue anyway, although I'm not sure why the dependency() detection via pkg-config works then, since it's also a subprocess), so it returns the pluginsdir of the installed gstreamer here, not the prefix I specified. I think it's unreasonable to expect users to export this var, so I think whatever the issue is it needs to be worked around in meson somehow or we need specific functions to do the equivalent that will do the right thing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: BUG: 8.7.0 removes `code-block:: ipython` pygment lexer support Installed via pip / PyPI -- previously this RST worked: ``` .. code-block:: ipython In [1]: %matplotlib qt ``` but now we get: ``` /home/circleci/project/doc/install/advanced.rst:33: WARNING: Pygments lexer name 'ipython' is not known ``` At least this is what I think is happening in our CircleCI build today (which fails because we treat warnings as errors), we haven't changed the RST lines in question at all recently: https://app.circleci.com/pipelines/github/mne-tools/mne-python/17137/workflows/27c6f253-b7a7-4b67-9c2e-db9aa4e925fc/jobs/50745?invite=true#step-112-532 And 8.7.0 is being installed properly in the env: https://app.circleci.com/pipelines/github/mne-tools/mne-python/17137/workflows/27c6f253-b7a7-4b67-9c2e-db9aa4e925fc/jobs/50745?invite=true#step-112-532 Changing this to `.. code-block:: ipythonconsole` does not seem to help. Is this an intentional change? Or is this lexer meant to be installed a different way? I didn't see anything in these pages at least: - https://ipython.readthedocs.io/en/stable/whatsnew/version8.html#ipython-8-7-0 - https://ipython.readthedocs.io/en/stable/development/lexer.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda run command removed in 4.1.0 After upgrading to 4.1.0: ``` $ conda run ``` outputs: ``` Error: Could not locate 'conda-run' ``` Also, when running `conda --help`, the documentation about the run command is no longer present. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Tab completion does not work with IPython.embed_kernel() When I pause a script with IPython.embed_kernel() and connect to the kernel with qtconsole, whil %whos show all the objects correctly, tab completion does not work. Specifically, tab completion for any names generated by original script does not work, and also, it does not work for new objects generated in the qtconsole either. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Proper error message using conan remote disable/enable if remote doesn't exist Using Conan 1.19 you will be able to enable or disable remotes with `conan remote enable/disable remote_name`. If the remote does not exist there is no error message. There should be one error message in this case. To help us debug your issue please explain: - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Feature Request: multi-format file output in QuantumCircuit.draw(..., filename='...') Qiskit uses PIL for processing image in the Qiskit circuit drawer, which supports several [image file formats](https://pillow.readthedocs.io/en/stable/handbook/image-file-formats.html). However, it always saves in `image/png`: ```python from qiskit import * circuit = QuantumCircuit(2) circuit.h(0) circuit.cx(0, 1) circuit.draw('latex', filename='./file.jpg') !file file.jpg ``` ``` file.jpg: PNG image data, 276 x 90, 8-bit/color RGB, non-interlaced ``` It would be great if the drawer notices the `filename` file extension and saves the image in the correct format. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: multiplex channels over a single websocket Connecting a frontend to a kernel involves 3 zmq connections. There are various message pattern reasons for this. In the HTML notebook, we turn each zmq connection into a websocket connection. The message pattern differences no longer apply, so we could easily have only one websocket connection from client to server, and let the server multiplex zmq channels onto a single websocket. The costs of the multiple websockets start showing up when there is a proxy in front of one or more notebook servers, such as [tmpnb](https://github.com/jupyter/tmpnb) or [JupyterHub](https://github.com/jupyter/jupyterhub), because each open notebook page has **6** persistent sockets in the proxy. Running out of FDs in the proxy seems to be the most common first wall hit when scaling any of these services. If only one websocket connection were open, three times as many notebooks could be open at a time behind a given proxy. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Interactive Qsphere shows black vectors <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### What is the current behavior? The Qsphere vectors can be black becuse phase angle is negative ### What is the expected behavior? All vectors must be on a range of colors according next image:  ### Suggested solutions Modify phase formula to get (always) positive angles. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda info exposing tokens Hi, the conda info command is exposing tokens again. Por ejemplo: ``` Current conda install: platform : win-64 conda version : 4.2.9 conda is private : False conda-env version : 4.2.9 conda-build version : 2.0.2 python version : 2.7.12.final.0 requests version : 2.11.1 root environment : C:\\Anaconda2 (writable) default environment : C:\\Anaconda2 envs directories : C:\\Anaconda2\\envs package cache : C:\\Anaconda2\\pkgs channel URLs : https://conda.anaconda.org/t/**EXPOSED TOKEN**/topper/win-64/ https://conda.anaconda.org/t/**EXPOSED TOKEN**/topper/noarch/ https://repo.continuum.io/pkgs/free/win-64/ https://repo.continuum.io/pkgs/free/noarch/ https://repo.continuum.io/pkgs/pro/win-64/ https://repo.continuum.io/pkgs/pro/noarch/ https://repo.continuum.io/pkgs/msys2/win-64/ https://repo.continuum.io/pkgs/msys2/noarch/ config file : d:\\Usuarios\\108630\\.condarc offline mode : False ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Wrong expression in UGate docs <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.13 - **Python version**: All - **Operating system**: All ### What is the current behavior? The documentation for [`UGate`](https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/circuit/library/standard_gates/u.py) states that: ``` U(\\theta, \\phi, \\lambda) = RZ(\\phi - \\pi/2) RX(\\pi/2) RZ(\\pi - \\theta) RX(\\pi/2) RZ(\\lambda - \\pi/2) ``` ### Steps to reproduce the problem Problem is in the code documentation of [`UGate`](https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/circuit/library/standard_gates/u.py). ### What is the expected behavior? The expression above does not correspond to the matrix form given in the documentation of [`UGate`](https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/circuit/library/standard_gates/u.py), nor to the RX and RY expressions in terms of U. Since the latter are all in line with the behaviour of Qiskit's ideal simulator, the expression itself is incorrect. The correct expression is instead: ``` U(\\theta, \\phi, \\lambda) = RZ(\\phi) RX(\\pi/2) RZ(\\pi - \\theta) RX(\\pi/2) RZ(\\lambda - \\pi) ``` ### Suggested solutions Fix the expression in the documentation. For convenience of the reader, one could also add the following simplified expression, from which the matrix, RX and RY expressions are more readily derived: ``` U(\\theta, \\phi, \\lambda) = RZ(\\phi + \\pi/2) RX(\\theta) RZ(\\lambda - \\pi/2) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Forward-mode differentiation rule for 'select_and_scatter_add' not implemented Ran into a not implemented error when taking second order gradients through a max pool. Repro: ``` import jax.numpy as np from jax.api import jvp from jax import grad import jax.random from jax.experimental import stax import numpy as onp data = np.array(onp.random.normal(size=[1, 4, 4, 1])) model = stax.serial(stax.Conv(1, (1,1), (1,1), 'SAME'), stax.MaxPool((2,2), strides=(2,2))) model_init, model_predict = model key = jax.random.PRNGKey(0) params = model_init(key, list(data.shape))[1] def loss(params, data): return np.sum(model_predict(params, data)) def hvp(loss, params, batch, v): loss_fn = lambda x: loss(x, batch) return jvp(grad(loss_fn), [params], [v])[1] # Raises NotImplementedError: Forward-mode differentiation rule for 'select_and_scatter_add' not implemented hvp(loss, params, data, params) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Raise AttributeError on training deberta models with gradient checkpointing ### System Info ```shell - `transformers` version: 4.20.1 - Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.7.13 - Huggingface_hub version: 0.8.1 - PyTorch version (GPU?): 1.11.0+cu113 (True) - Tensorflow version (GPU?): 2.8.2 (True) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: yes - Using distributed or parallel set-up in script?: no ``` ### Who can help? @LysandreJik ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction - deberta models and `Trainer` with `gradient_checkpointing=True` - `trainer.train()` - raise `AttributeError: module 'torch.utils' has no attribute 'checkpoint'` Refs #9617 ### Expected behavior ```shell nothing raised on training with `gradient_checkpointing=True`. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: enable progress bar = update freq 1 i think we can collapse two args. - remove enable progress bar arg. - disable the progress bar when update freq = 0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: map of pmap IndexError bug Map of pmap seems to fail due to a strange shape bug. See repro below. ``` import jax.numpy as np from jax import lax, pmap, vmap, random def vv(x, y): \"\"\"Vector-vector multiply\"\"\" return np.dot(x, y) def distributed_matrix_vector(x, y, distributed=True): \"\"\"Matrix vector multiply. First batch it and then row by row\"\"\" fv = lambda z: lax.map(lambda j: vv(j, y), z) if distributed: res = pmap(fv)(x.reshape((jax.device_count(), -1) + tuple(x.shape[1:]))).reshape((x.shape[0], 1)) else: res = fv(x) return res print(\"Not batched\") key = random.PRNGKey(1) x = random.normal(key, (800, 50)) y = random.normal(key, (50,)) result = distributed_matrix_vector(x, y, False) print(\"Outside matrix vector code\", result.shape) print(\"Vmap + pmap\") batched_mvm = vmap(lambda b: distributed_matrix_vector(x, b, True)) y = random.normal(key, (10, 50)) result = batched_mvm(y) print(\"Result\", result.shape) print(\"mapped\") y = random.normal(key, (10, 50)) result = lax.map(lambda b: distributed_matrix_vector(x, b, False), y) print(\"Result\", result.shape) print(\"map + pmap\") y = random.normal(key, (10, 50)) result = lax.map(lambda b: distributed_matrix_vector(x, b, True), y) print(\"Result\", result.shape) ``` Output: ``` Not batched Outside matrix vector code (800,) Vmapped Result (10, 800, 1) mapped Result (10, 800) map + pmap IndexError: cannot do a non-empty take from an empty axes. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Relax requirement for DistributedSampler with ddp **Is your feature request related to a problem? Please describe.** I have an application where I'm using a custom `BatchSampler` to construct batches for the N-Pairs metric learning loss. I need all of the data to be available on all processes when using `DistributedDataParallel`, so I wouldn't want to use `DistributedSampler`, even if it was compatible with a custom `BatchSampler`. Right now, I've hit a wall because lightning throws this exception: ``` pytorch_lightning.utilities.debugging.MisconfigurationException: when using multiple gpus and multiple nodes you must pass a DistributedSampler to DataLoader(sampler). ie: this: dataset = myDataset() dataloader = Dataloader(dataset) becomes: dataset = myDataset() dist_sampler = torch.utils.data.distributed.DistributedSampler(dataset) dataloader = Dataloader(dataset, sampler=dist_sampler) ``` **Describe the solution you'd like** Could this exception be turned into a warning? I'm all for letting the user know when they're violating best practices, but throwing an exception removes flexibility for advanced users. **Describe alternatives you've considered** I looked at using the dp backend, but that's not going to work because the n-pairs loss needs the entire batch to compute the loss. Splitting it into chunks breaks things. If I'm understanding correctly, this is actually another limitation introduced by Lightning. In a usual `DataParallel` setting, the batch would be merged back together before computing the loss and everything would be fine. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: nbconvert latex: code highlighting causes error The latex generated from this notebook fails to compile due to the code highlighing: http://nbviewer.ipython.org/2f85ddd8d967795dcb0e and the tex: https://gist.github.com/ihnorton/a86c521d4aa223f9dba9 ``` ! LaTeX Error: Environment Shaded undefined. See the LaTeX manual or LaTeX Companion for explanation. Type H <return> for immediate help. ... l.237 \\begin{Shaded} ? ! Emergency stop. ... l.237 \\begin{Shaded} ``` Ubuntu 13.04, IPython 1.1, pandoc 1.10.1 edit: Confirmed in pandoc 1.12.01 on Windows 7 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: except-shadows-builtin osm.py:687 except ValueError, IOError: should be except (ValueError, IOError): Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Executing a schedule with one instruction raises an error <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? If I make a schedule with only one instruction: ``` sched = pulse.Acquire(20, pulse.AcquireChannel(0), pulse.MemorySlot(0)) ``` then when I `execute` it, it's type is `Instruction` and not `Schedule`, so `execute` wrongly sends it through the `transpiler`, thinking it's a `QuantumCircuit`. Since the transpiler is expecting a circuit, we end up with an attribute error as it tries to access `circuit.qubits`, which isn't a Schedule property. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions The easiest fix is to replace `isinstance(experiments, Schedule)` with `isinstance(experiments, (Schedule, pulse.Instruction)`, or perhaps more correctly: `isinstance(experiments, ScheduleComponent)`. Would have to add tests and make sure there aren't other consequences of taking an `Instruction` as input. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: PSNR metric in metrics ## 🚀 Feature Can we have [PSNR](https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio) metric in the metrics module? ### Motivation This metric is used in Image generative models eg. super-resolution. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add \"raise_on_fail\" context manager Task runners and flow runners trap all errors, which can make debugging difficult. We could create a context manager that would raise errors rather than trapping them. Given a Flow `flow` that contains a task that raises some error: ```python flow.run() # returns State(FAILED) with raise_on_fail(): flow.run() # actually raises an error at the appropriate place ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Add '--strip' option to cmake install ### What is your suggestion? Can you add a parameter to `cmake.install` function in order to be able to strip binaries before install ? install and strip were added to CMake about 4 years ago, and if I got it correctly in version 3.15 https://gitlab.kitware.com/cmake/cmake/-/merge_requests/3069 Strip is very useful to remove debug symbols (actually all DWARF extension) from binaries and especially release binaries. I tried many options to make it work with conan, but without success, so I think adding this option as a parameter to `install` function in `cmake` tool will be the best solution instead of some workarounds. ### Have you read the CONTRIBUTING guide? - [X] I've read the CONTRIBUTING guide Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Bug in drawing conditionals in latex and matplotlib <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations After #1278 and #1276, the latex and matplotlib have a bug in drawing conditional gates: This code: ```python from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit q = QuantumRegister(3, 'q') c = ClassicalRegister(1, 'c') circ = QuantumCircuit(q, c) circ.u2(1.57, 0.7, q[0]) circ.measure(q[0], c[0]) circ.u1(0.1, q[1]).c_if(c, 1) circ.draw(output='latex') ``` was drawn correctly before these 2 recent PR merges: 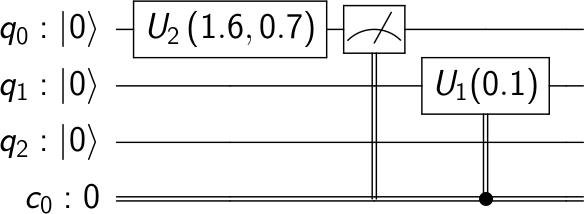 but with this patch the conditional vertical wire is gone:  This is also an issue with the mpl drawer:  But the text drawer is fine: ``` q_2: |0>────────────────────────────── ┌─────────┐ q_1: |0>───────────────────┤ U1(0.1) ├ ┌──────────────┐┌─┐└────┬────┘ q_0: |0>┤ U2(1.57,0.7) ├┤M├─────┼───── └──────────────┘└╥┘┌────┴────┐ c_0: 0 ═════════════════╩═╡ = 1 ╞ └─────────┘ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Example cross entropy loss, wrong scaling The current examples of using a cross entropy loss, e.g. in https://github.com/google/jax/blob/d90993f798ff00404e2d5869f78d3642d99b6a33/examples/mnist_classifier.py#L43 is ```python def loss(params, batch): inputs, targets = batch preds = predict(params, inputs) return -np.mean(preds * targets) ``` Due to `np.mean` this code introduces a scaling of (1/class_count) to the loss computation. I believe the common/correct scaling should be ```python def loss(params, batch): inputs, targets = batch preds = predict(params, inputs) return -np.mean(np.sum(preds * targets, axis=1)) ``` Also, this may be a silly question, but does the multiplication with 0 have the potential to introduce numerical issues upon gradient computation? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Feature: Single-qubit R(v) gate It would be good to have a single-qubit gate parametrized as: ``` R(v) = exp(-i v.sigma) ``` Explicitly if `|v| = sqrt(vx^2+vy^2+vz^2)`: ``` Rv(vx, vy, vz) = Cos(|v|)-i vz Sinc(|v|), -(i vx + vy) Sinc(|v|) -(i vx - vy) Sinc(|v|), Cos(|v|) +i vz Sinc(|v|) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: TwoLocal entangling map does not work for numpy integers <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit version**: 0.17.1 - **Python version**: 3 - **Operating system**: ubuntu 18 ### What is the current behavior? When generating an entangling map by virtue of numpy arrays (e.g. np.arange(num)) it raises a ValueError ```ValueError: Invalid value of entanglement: [[(0, 1), (1, 2), (2, 3), (3, 4), (4, 5)]]``` ### Steps to reproduce the problem Minimal working example ``` import qiskit import numpy as np L = 6 def create_map(L): return [(i,i+1) for i in np.arange(L-1)] map1 = create_map(L) print(map1) map_by_hand1 = [(0, 1), (1, 2), (2, 3), (3, 4), (4, 5)] print(map_by_hand1) print(map1 == map_by_hand1) # returns True ansatz = qiskit.circuit.library.TwoLocal(L,\"ry\",\"cz\",[map_by_hand1],reps=2, insert_barriers=True) ansatz.draw(\"mpl\") # works ansatz = qiskit.circuit.library.TwoLocal(L,\"ry\",\"cz\",[map1],reps=2, insert_barriers=True) ansatz.draw(\"mpl\") # raises ValueError ``` ### What is the expected behavior? Since map1 == map_by_hand1 is the same value, it is expected that both are viable options to pass as entangling maps. ### Suggested solutions change the isinstance() check in n_local Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make non interactive plot_histogram accept the same formatting options as the interactive version <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Both representations, interactive and non-interactive will support the same formatting capabilities. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore Key's reference is missing location identifier in app argument in to_legacy_urlsafe() @dhermes I put this as a new issue because I thought people might have a problem with this too. Please feel free to edit/remove this issue if it is not appropriate to put it here. I was running `pip install --upgrade google-cloud-datastore` to get latest version that has the `key.to_legacy_urlsafe()` implemented in [#3491](https://github.com/GoogleCloudPlatform/google-cloud-python/pull/3491). I tested the method and I found out that the urlsafe generated from the method is still not the same as datastore's urlsafe. I have implemented my own function to generate the urlsafe key before the update was released and so far it worked properly for me (I can share my code if anybody wants). So I compared my function with the to_legacy_urlsafe and I found the problem: ``` reference = _app_engine_key_pb2.Reference( app=self.project, path=_to_legacy_path(self._path), # Avoid the copy. name_space=self.namespace, ) ``` In the app argument, the location identifier is missing unlike in my function where I concatenated the \"s~\" at the beginning of the string. I think this is the cause of the problem why it was not getting the urlsafe correct, although I don't understand why it needs the location identifier in front of the project name in the first place. Do you think I should send a PR to fix this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Incorrect lemma from lemmatizer **Right:** `[w.lemma_ for w in nlp('funnier')]` -> `['funny']` **Wrong:** `[w.lemma_ for w in nlp('faster')]` ->`['faster']` I think for word _faster_ lemma should be _fast_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Convert rep_times to seconds <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? All other time-based units have been converted to seconds/Hz. rep_times should also be converted. This may not be so straightforward because it is currently defined as an integer. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Wrong default argument of DirectView.clear DirectView.clear in parallel/client/view.py line 800 seems to have the wrong default-argument for _block_: def clear(self, targets=None, block=False) It should probably be None instead of False. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore: please support specifying read consistency According to the Cloud Datastore docs, the python client does not support setting the read consistency of a query: https://cloud.google.com/datastore/docs/concepts/structuring_for_strong_consistency#datastore-eventual-consistent-query-python Any chance this could be implemented? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Wrong string in nbconvert.py? I was confused when the shim referred me to import from \"IPython_nbconvert\" but couldn't find any information on such a module or make sense of it. Shouldn't it be \"nbconvert\"? Or is there a detail that I missed? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Newer versions of pytest are failing because of multiple hypothesis imports. The CI tests fail for newer pytest on account of a pytest warning, see https://travis-ci.org/github/numpy/numpy/jobs/730868650 and https://github.com/pytest-dev/pytest/issues/7810. If I comment out hypothesis related code in `numpy/_pytesttester.py` the warning goes away. The other place hypothesis is imported is `numpy/configtest.py`. I seems we need to get rid of one of the imports. <!-- Please describe the issue in detail here, and fill in the fields below --> ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np << your code here >> ``` ### Error message: <!-- If you are reporting a segfault please include a GDB traceback, which you can generate by following https://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging --> <!-- Full error message, if any (starting from line Traceback: ...) --> ### NumPy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson init --name xyz --build doesn't work on Windows - doesn't follow its own advice Pardon the screenshot-as-a-bug-report, I was working on this in a VM as I don't generally use Windows.  It seems when passing the --build flag to meson init, it runs ninja directly rather than the meson compile wrapper, which leads to a failed build as it does not automatically activate the visual studio environment (which is an *excellent* feature, by the way!). Running meson compile -C build works fine, as shown This is on Windows 10, meson 0.64.1, installed with the MSI installer. Native build. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: T5 Conversion from Original Tensorflow Produce rubbish Text ## Environment info - `transformers` version: 3.0.2 - Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.6.9 - PyTorch version (GPU?): 1.6.0+cu101 (False) - Tensorflow version (GPU?): 2.3.0 (False) - Using GPU in script?: yes - Using distributed or parallel set-up in script?: no ### Who can help Text Generation: @TevenLeScao T5: @patrickvonplaten ## Information Model I am using (Bert, XLNet ...): T5 The problem arises when using: * [X] the official example scripts: (give details below) * [ ] my own modified scripts: (give details below) The tasks I am working on is: * [ ] an official GLUE/SQUaD task: (give the name) * [X] my own task or dataset: (give details below) ## To reproduce Steps to reproduce the behavior: https://colab.research.google.com/drive/112Jt7VFwHHT-QmMxFPJ764GNJBn0d5eX?usp=sharing ## Expected behavior We have started a big project for source code tasks (generation, summarisation, documentation, etc.) using language models. Using T5 text to text library, the model can predict the input correctly, However, after we converted the Tensorflow checkpoint to huggingface the output text is rubbish. I am not sure if we are doing something wrong during conversion or there is a problem in loading and converting the weights from the original Tensorflow checkpoint to Pytorch. The above Colab re-produce the issue. Important Note: We are using a copy of \"adapt_t5_for_covid_19_3b\" branch which should fix the conversion problem with only one small modification, setting is_tied to false. Your help is highly appreciated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Improve tools.vs_installation_path with VSXX.0COMNTOOLS env variable To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. Conan version 1.0.0-beta.5 - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Now `vs_installation_path()` tool uses `vswhere` to locate VS installations. However, `vswhere` is not always installed (in case of versions **prior to** Visual Studio 2017 or Build Tools 2017). My suggestion is to search for `VSXX.0COMNTOOLS` variable to locate the installation path of old VS versions. **Note**: `vswhere` is able to locate old versions of both VS and BuildTools installations (`vswhere -legacy`, `vswhere -products *`). This issue focuses in the case when there is no vswhere in the system (vswhere is only installed with 2017 installers). Maybe add a `vs_comntools` helper method, as `os.getenv(\"vs15comntools\")` and similar is used in other places of the codebase. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Imprecise docstring for np.pad Excerpt of the docstring for np.pad ``` constant_values : sequence or int, optional Used in 'constant'. The values to set the padded values for each axis. ((before_1, after_1), ... (before_N, after_N)) unique pad constants for each axis. ((before, after),) yields same before and after constants for each axis. (constant,) or int is a shortcut for before = after = constant for # <---- HERE all axes. Default is 0. end_values : sequence or int, optional Used in 'linear_ramp'. The values used for the ending value of the linear_ramp and that will form the edge of the padded array. ((before_1, after_1), ... (before_N, after_N)) unique end values for each axis. ((before, after),) yields same before and after end values for each axis. (constant,) or int is a shortcut for before = after = end value for # <---- PERHAPS TOO all axes. Default is 0. ``` Since #6026 has been fixed the first \"int\" should be replaced by \"scalar\" or \"constant\". Not sure about the second one. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Delete DAG REST API Functionality ### Description The stable REST API seems to be missing the functionality to delete a DAG. This would mirror clicking the \"Trash Can\" on the UI (and could maybe eventually power it)  ### Use case/motivation _No response_ ### Related issues _No response_ ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Introduce validation against the schemas ### What is the expected enhancement? According to the [robustness principle](https://en.wikipedia.org/wiki/Robustness_principle), Qiskit should validate that the `Qobj` emitted complies with the schemas. If doing this is something that should be done upon a new request or during testing, is open for debate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Getting a datastore.entity by key name is a pain If I know I have a person named Jim, and I want to get Jim, I can't do a look-up by path. What I'd like to do ``` python dataset.get_entity(['Person', 'jim']) ``` or ``` python dataset.entity('Person').get('jim') ``` (or with an ancestor) ``` python dataset.entity('Person').get('jim', parent='parent key name') ``` What I currently have to do ``` python key = Key.from_path(['Person', 'jim']) dataset.get_entity(key) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: We should add an alias to `ssl_verify` -> `verify_ssl` Having this would allow to have parity with anaconda-client configuration and perhaps `verify_ssl` is a better name. Thoughts @kalefranz ? ---- Related to https://github.com/conda/conda/issues/5256 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: numpy.random.sample and numpy.random.random_sample I just noticed in the docs that the page for `numpy.random.sample` indicates that the function should be called as `numpy.random.random_sample`. I understand that this may just indicate that the function may be called as either `sample` or `random_sample`, but it does come across as a mistake when first viewing the page. Perhaps make it more explicit that `random_sample` is an alias of `sample`? Or is this the accepted practice for functions that have aliases? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: SystemPackageTool should call yum update instead of yum check-update To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. conan version 1.5.0 Fedora 28, gcc-8.1.1 from https://github.com/bincrafters/community/issues/345 for instance, attempt to install sdl2/2.0.8@bincrafters/stable recipe on fedora. you'll see that ```yum check-update``` failed with error code 100. this is a legal situation according to the https://access.redhat.com/solutions/2779441. also, as ```yum check-update``` only verifies are updates available, I believe ```yum update``` shall be used instead. see https://www.centos.org/docs/5/html/5.1/Deployment_Guide/s1-yum-useful-commands.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: on_before_zero_grad hook ## 📚 Documentation The documentation report the method `on_before_zero_grad`. Strangely, this method is not shown in the lifecycle for hooks documentation. Moreover, when it is defined in a lightning module it is not called. Hence the question : is it a discontinued hook ? If so we could erase its mention in the docs. Thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Constants for all scalar standard SQL data types Related to https://github.com/googleapis/google-cloud-python/issues/7632 (legacy SQL), it would be useful to have constants for all scalar data types for the new `bigquery_v2.types.StandardSqlDataType` format. Currently, one has to construct an object like ``` bigquery_v2.types.StandardSqlDataType( type_kind=bigquery_v2.enums.StandardSqlDataType.TypeKind.INT64 ) ``` It would be convenient if instead one could just say `bigquery.StandardSqlDataTypes.INT64` and similar for all scalar data types. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: SquadProcessor: Wrong reference name/filename in docstring As the docstring of the function `get_train_examples()` refers to `train-v1.1.json`/`train-v2.0.json`, I guess `get_dev_examples()` should refer to `dev-v1.1.json`/`dev-v2.0.json` (but refers to `train-v1.1.json`/`train-v2.0.json`): https://github.com/huggingface/transformers/blob/aa6c3c14b4ff8fbd5d40b100f4aae71fb359d6ae/src/transformers/data/processors/squad.py#L610-L617 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Allow `meson configure` in an uninitialised build dir Currently, running `meson configure` in an uninitialised builddir (such as the srcdir) results in > Directory /path/to/project/ does not seem to be a Meson build directory. This is an issue when a user clones a project and tries to configure it for the first time, but is missing dependencies for components that can be turned off. They have no way of listing the options to know how to turn one off and make the initial `meson builddir/` command pass, as `meson configure` refuses to list them. IMO the condition should be relaxed, disallowing *setting an option* from the srcdir, but letting users *list options*. I'm happy to give this a stab, I just want a green light first :) (Cc: @imirkin, who raised the issue in the Mesa project) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan install returns wrong example on version 0.10.1 Hi! When I run the line: > $ conan install --help I give the follow output: > usage: conan install [-h] [--package PACKAGE] [--all] [--integrity] > [--file FILE] [--update] [--scope SCOPE] [-r REMOTE] > [--options OPTIONS] [--settings SETTINGS] > [--build [BUILD [BUILD ...]]] > [reference] > > install in the local store the given requirements. > Requirements can be defined in the command line or in a conanfile. > EX: conans install opencv/2.4.10@lasote/testing Look that the example uses _conans_ instead of _conan_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: PIN 16: Implement `ValidationFailed` State ## Use Case See [PIN 16](https://github.com/PrefectHQ/prefect/pull/2134) for background. In particular, this blocks full implementation of `Result.validate`. ## Solution Implement a new State, `ValidationFailed`, similar to [other Prefect states](https://github.com/PrefectHQ/prefect/blob/66703e5f0a2d0d035d4d48af013b87d24a7a2a56/src/prefect/engine/state.py), that can be utilized during Result validation. - [x] add new state - [x] add new signal - [x] update state docs and diagram ## Alternatives *Please describe any alternatives you've considered, even if you've dismissed them* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `'NoneType' object has no attribute 'metadata'` when trying to serialize custom gate on `qiskit-terra==0.21.2` when it used to work on `qiskit-terra==0.21.1` ### Environment - **Qiskit Terra version**: 0.21.2 - **Python version**: 3.8.13 - **Operating system**: Ubuntu ### What is happening? Qsikit errors out when trying to serial a circuit which contains a custom gate, when it used to work before on `qiskit-terra==0.21.1` ### How can we reproduce the issue? Run ```python import io from typing import Optional, Union import numpy as np import qiskit from qiskit.circuit.library import XGate from qiskit.qpy import dump class CustomCXGate(qiskit.circuit.ControlledGate): def __init__( self, label: Optional[str] = None, ctrl_state: Optional[Union[str, int]] = None ) -> None: super().__init__( \"cx\", 2, [], label, num_ctrl_qubits=1, ctrl_state=ctrl_state, base_gate=XGate() ) def _define(self) -> None: qc = qiskit.QuantumCircuit(2, name=self.name) qc.cx(0, 1) self.definition = qc def __array__(self, dtype: Optional[type] = None) -> np.ndarray: mat = qiskit.circuit._utils._compute_control_matrix( self.base_gate.to_matrix(), self.num_ctrl_qubits, ctrl_state=self.ctrl_state ) return np.asarray(mat, dtype=dtype) circuit = qiskit.QuantumCircuit(2) circuit.append(CustomCXGate(),[0, 1]) buf = io.BytesIO() dump(circuit, buf) ``` This will throw an error ``` circuit.metadata, separators=(\",\", \":\"), cls=metadata_serializer AttributeError: 'NoneType' object has no attribute 'metadata' ``` ### What should happen? The above snippet should run with no errors. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: OpenMP dependency explodes if version is not found Using GOMP with the C++ flag `-fdirectives-only` causes Meson to miss a dictionary lookup, and instead of getting an \"not found\" we get a python backtrace. See [upstream issue](https://gitlab.freedesktop.org/mesa/mesa/-/issues/4632). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: simplegeneric is super out of date, vendor the library or take over maintainership of a fork last uploaded in 2012, and no wheel. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: AST: Audio Spectrogram Transformer # 🌟 New model addition ## Model description In the past decade, convolutional neural networks (CNNs) have been widely adopted as the main building block for endto-end audio classification models, which aim to learn a direct mapping from audio spectrograms to corresponding labels. To better capture long-range global context, a recent trend is to add a self-attention mechanism on top of the CNN, forming a CNN-attention hybrid model. However, it is unclear whether the reliance on a CNN is necessary, and if neural networks purely based on attention are sufficient to obtain good performance in audio classification. In this paper, we answer the question by introducing the Audio Spectrogram Transformer (AST), the first convolution-free, purely attention-based model for audio classification. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2. Index Terms: audio classification, self-attention ## Open source status * [x] the model implementation is available: https://github.com/YuanGongND/ast * [x] the model weights are available: https://github.com/YuanGongND/ast#Pretrained-Models * [x] who are the authors: @YuanGongND Happy to supervise anyone interested in porting the model :-) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Add an alias 'stable' for 'mergesort' in sort Currently, numpy supports only one way of performing a stable sort i.e. mergesort. Therefore, it makes sense to add an alias for mergesort which will help in making the code more readable. When I see 'mergesort' written in the code, it is not explicit that this was done to make the sort stable. Therefore having a 'stable' option will fit well with the idea \"explicit is better than implicit\". I would like to give this a try if this issue makes sense and the devs decide to accept this proposal. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Publically expose `QuantumCircuit._layout` and add helper functions for working with embedded layout ### What should we add? As discussed in #8800 the way we're embedding the `Layout` from the transpiler into the output quantum circuit is a bit of a weird place right now. We have a private attribute `_layout` which is used widely across the qiskit code but we provide no public or supported interface for working with this. This came to be an issue for fixing #8800 because to fix the issue we changed what was stored in the `_layout` attribute, and while it is a private layout external users depend on it because it was the only way to reason about the permutation caused by initial layout in the transpiler. To address this gap in 0.23.0 we should introduce a public `QuantumCircuit.layout` attribute and/or also have methods to work with the embedded layout. Like something to return the qargs for the circuit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: cannot import conda.fetch.cache_fn_url I'm using conda 4.3.2, and the function `conda.fetch.cache_fn_url` does not exist anymore. What to do? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: BigQueryLoadFile does not return the response from load_table_from_file ## Description <!-- A clear description of the bug --> For BigQueryLoadFile, the documentation suggests it: ``` Returns: - the response from `load_table_from_file` ``` In the code, however, the google.cloud.bigquery.job.LoadJob is not returned: ``` try: with open(file, \"rb\") as file_obj: load_job = client.load_table_from_file( file_obj, table_ref, rewind, size, num_retries, job_config=job_config, ) except IOError: raise IOError(f\"Can't open and read from {path.as_posix()}.\") load_job.result() # block until job is finished # END OF FUNCTION ``` ## Expected Behavior <!-- What did you expect to happen instead? --> I expected the the load_job object to be returned. I usually inspect this object to identify errors, output_rows, etc. ## Reproduction <!-- A minimal example that exhibits the behavior. --> ``` bq_load_file = gcp.BigQueryLoadFile() load_job = bq_load_file( my_gcs_path, dataset_id=my_dataset, table=my_table, project=my_project, schema=my_schema, create_disposition=google.cloud.bigquery.job.CreateDisposition.CREATE_NEVER, source_format=google.cloud.bigquery.job.SourceFormat.NEWLINE_DELIMITED_JSON, write_disposition=google.cloud.bigquery.job.WriteDisposition.WRITE_APPEND, ) ``` ## Environment <!-- Any additional information about your environment Optionally run `prefect diagnostics` from the command line and paste the information here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose config renders short-form target/published ports as strings in long-form Example `docker-compose.yml` with short-form port mapping: ```yaml version: '3.2' services: jenkins: image: jenkins ports: - \"8080:8080\" ``` Result of `docker-compose config`: ```bash $ docker-compose config networks: {} secrets: {} services: jenkins: image: jenkins ports: - published: '8080' target: '8080' version: '3.2' volumes: {} ``` When using the resulting configuration, an error occurs: ```bash $ docker-compose config | docker-compose -f - up ERROR: The Compose file is invalid because: services.jenkins.ports.published contains \"8080\", which is an invalid type, it should be an integer ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: _has_connection('https://qvisualization.mybluemix.net/', port=443) returns False <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? Interactive visualizations do not work because `_has_connection('https://qvisualization.mybluemix.net/', port=443)` is returning `False`. ### Steps to reproduce the problem Try it. ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Make `name` a required argument for Flows Right now, there is *too little* friction in naming a flow, which leads to unexpected things in the UI (thanks to auto-versioning, it means lots of flows getting versioned / archived) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Missing backward compat warning when passing declare_dependency() to compiler Hi, Starting in 0.57 one can pass declare_dependency() to compiler.has_function() etc: ``` [](https://mesonbuild.com/Release-notes-for-0-57-0.html#passing-internal-dependencies-to-the-compiler-object)Passing internal dependencies to the compiler object Methods on the compiler object (such as compiles, links, has_header) can be passed dependencies returned by declare_dependency, as long as they only specify compiler/linker arguments or other dependencies that satisfy the same requirements. ``` Which is great! However, there is no warning about doing so even when `meson_version: '>=0.54',` or such. It's pretty easy to accidentally break even just slightly older operating systems like Debian Bullseye. Regards, Andres Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Interactive visualizations require internet connection <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: 0.6 - **Python version**: 3.6 - **Operating system**: OSX ### What is the current behavior? The new interactive visualizations, introduced in #765 , require having an internet connection: ```javascript requirejs.config({ paths: { qVisualization: \"https://qvisualization.mybluemix.net/q-visualizations\" } }); ``` when it should be possible to have the required js reside locally. @filemaster and @tansito, is there any overriding issue that prevents having the required js in terra? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Client library incorrectly returns error when FLAC is used with long-running-recognize The client library incorrectly returns an error when anything other than LINEAR16 is used for a long-running recognize request: [https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/speech/google/cloud/speech/sample.py#L173][1] The v1 server support all encodings so this breaks functionality. In general, the client library should almost never do it's own validation; it should always delegate to the server to be sure that that behavior and error messages are consistent across APIs. [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/46e417e838001f4d1eb13f5e3fc2a54d390dd5db/speech/google/cloud/speech/sample.py#L173 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add keyword arguments to batch_encode_plus() to match encode_plus() ## 🚀Consistent Keyword arguments for batch_encode_plus() to match encode_plus() Currently, features such as `return_special_tokens_mask` that are available for the `encode_plus()` method are not available for `batch_encode_plus()`. It would be nice if all keyword arguments worked in a similar fashion. ## Motivation `batch_encode_plus()` is extremely useful to seamlessly tokenize batches, however, the lack of features forces to fall back to encode_plus() and an _uglier_ implementation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add user-agent info to Jupyter magics Client constructor(s). In order to better prioritize jupyter features such as #8342 and #8143, it is important for Google to know how much these features are used to query BigQuery. This is done by populating the user-agent string with the corresponding \"application name\" and version information. I propose we use the IPython version information in this string, as these magics are being used from an IPython kernel. Getting the IPython version string: https://stackoverflow.com/a/56265255/101923 Something like: ``` bigquery.Client( client_info=ClientInfo( user_agent=\"ipython-{}\".format(IPython.__version__) ) ) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QasmQobj includes pulse job information <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? `QasmQobj` includes pulse specific fields (`meas_lo_freq', 'schedule_los`, etc): QasmQobj(config=QasmQobjConfig(initial_layout=[5, 6], meas_level=2, meas_lo_freq=[], meas_lo_range=[], meas_return='avg', memory=False, memory_slot_size=100, memory_slots=2, n_qubits=2, parameter_binds=[], qubit_lo_freq=[], qubit_lo_range=[], schedule_los=[], shots=1024), experiments=[QasmQobjExperiment(config=QasmQobjExperimentConfig(memory_slots=2, n_qubits=2), header=QobjExperimentHeader(clbit_labels=[['c', 0], ['c', 1]], creg_sizes=[['c', 2]], memory_slots=2, n_qubits=2, name='bell', qreg_sizes=[['q', 2]], qubit_labels=[['q', 0], ['q', 1]]), instructions=[QasmQobjInstruction(name='h', qubits=[0]), QasmQobjInstruction(name='cx', qubits=[0, 1]), QasmQobjInstruction(memory=[0], name='measure', qubits=[0]), QasmQobjInstruction(memory=[1], name='measure', qubits=[1])])], header=QobjHeader(backend_name='ibmq_16_melbourne', backend_version='1.0.0'), qobj_id='68127e25-a6b5-4cb6-9c32-3ce16dea9223', schema_version='1.1.0', type='QASM') ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: text drawer in jupyter notebook is not using a fully-monospaced font It seems that the text drawer is not using a monospaced font when in jupyter notebooks (at least, for the black square character). <img width=\"510\" alt=\"Screen Shot 2019-07-07 at 3 52 32 PM\" src=\"https://user-images.githubusercontent.com/766693/60773161-4f435d00-a0cf-11e9-9e68-3ccfd64ffd5c.png\"> vs ``` ┌───┐ ┌───┐ q_0: |0>┤ H ├──■────■────■────■────■─────────■───────┤ H ├ ├───┤ │ │ ┌─┴─┐┌─┴─┐ │ ┌───┐ │ └───┘ q_1: |0>┤ H ├──┼────┼──┤ X ├┤ X ├──┼──┤ H ├──┼──────────── ├───┤ │ ┌─┴─┐└───┘└───┘┌─┴─┐└───┘ │ ┌───┐ q_2: |0>┤ H ├──┼──┤ X ├──────────┤ X ├───────┼──┤ H ├───── ├───┤┌─┴─┐└───┘ └───┘ ┌─┴─┐└───┘┌───┐ q_3: |0>┤ H ├┤ X ├─────────────────────────┤ X ├─────┤ H ├ └───┘└───┘ └───┘ └───┘ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add compiler flags detection method This is especially important for C/C++ compilers, but I assume that other compilers that expose particular flags on the command line would benefit from it. Currently, if I wanted to select a set of compiler arguments to pass to my projects I need to write something like this: ``` test_args = [ '-ffast-math', '-fstrict-aliasing', '-Wpointer-arith', '-Wformat=2', '-Wstrict-prototype', '-Werror=init-self' ] test_args_prog = ''' int someVariableJustForFun; ''' foreach arg: test_args if cc.compiles(c_test_prog, name: 'check for ' + arg, c_args: [ arg ]) common_c_args += arg endif endforeach ``` This does not really work, because `cc.compiles()` does not have a `c_args` argument. (translate to other, non-C languages for other compilers) Since the `compiler` object already has various discovery methods, a `has_flag` or `has_argument` method would allow a more compact syntax: ``` foreach arg: test_args if cc.has_flag(arg) common_c_args += [ arg ] endif endforeach ``` as well as ensuring portability. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: generating RPM spec file fails With this error: ``` Traceback (most recent call last): File \"/tmp/meson/mesonbuild/mesonmain.py\", line 279, in run app.generate() File \"/tmp/meson/mesonbuild/mesonmain.py\", line 167, in generate intr.run() File \"/tmp/meson/mesonbuild/interpreter.py\", line 1314, in run self.evaluate_codeblock(self.ast, start=1) File \"/tmp/meson/mesonbuild/interpreter.py\", line 1336, in evaluate_codeblock raise e File \"/tmp/meson/mesonbuild/interpreter.py\", line 1330, in evaluate_codeblock self.evaluate_statement(cur) File \"/tmp/meson/mesonbuild/interpreter.py\", line 1455, in evaluate_statement return self.method_call(cur) File \"/tmp/meson/mesonbuild/interpreter.py\", line 2608, in method_call return obj.method_call(method_name, self.flatten(args), kwargs) File \"/tmp/meson/mesonbuild/interpreter.py\", line 996, in method_call value = fn(state, args, kwargs) File \"/tmp/meson/mesonbuild/modules/rpm.py\", line 97, in generate_spec_template fn.write('BuildRequires: pkgconfig(%s)\\n' % dep) TypeError: not all arguments converted during string formatting ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [requires} in conanfile.txt gives no error The typo: ``` [requires} ... ``` in `conanfile.txt` does not give any error indication at all when running `conan install ...`. The way to see that something is wrong is that it doesn't do anything, but finding the cause was not as easy as it could've been. This is on 0.9.2 on Ubuntu 15.10. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: completed_count reports only successfully completed tasks Not sure if that's on purpose but it looks like `completed_count` only takes into account the tasks that have completed successfully: https://github.com/celery/celery/blob/3db7c9dde9a4d5aa9c0eda8c43a219de1baa9f02/celery/result.py#L633 Would it make more sense to report: ``` return sum(int(result.ready()) for result in self.results) ``` the task count in the \"ready\" state? Happy to open a PR if that's an acceptable change. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Useless warning when calling conan package Conan version: `1.2.3` With the command: ``` conan package --source-folder /path/to/myProject --build-folder /path/to/myProject/build --package-folder /path/to/myPorject/../../Staging /path/to/myProject ``` And the `package()` in `/path/to/myProject/conanfile.py`: ``` def package(self): self.copy(\"myProject\", src=\"bin\", dst=\"linux64/bin\") self.copy(\"myProject.exe\", src=\"bin\", dst=\"win32/bin\") ``` The following output is produced: ``` PROJECT: Generating the package PROJECT: Package folder /path/to/myPorject/../../Staging PROJECT: Calling package() PROJECT package(): WARN: No files copied! PROJECT package(): Copied 1 '' files: myProject PROJECT: Package 'Pre-release' created ``` The warning: `PROJECT package(): WARN: No files copied!` in this scenario is useless, and even misleading. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add a convenience method to fetch data for a single row @jonparrott would prefer: ```python row = database.read_row(table='Albums', columns=('MarketingBudget',), key=[1, 1])) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Mock devices have not been updated to match new hardware basis gateset <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: N/A - **Operating system**: N/A ### What is the current behavior? Current defined mock (Fake) device configurations in `qiskit.test.mock.backends`, for example yorktown: https://github.com/Qiskit/qiskit-terra/blob/4d3ed6a3e972a79341ebf305f4c4d7f25bb256fb/qiskit/test/mock/backends/yorktown/conf_yorktown.json#L1 Are still using `u1/u2/u3` gates instead of the new basis gates reported in slack: `['id', 'rz', 'sx', 'x', 'cx']` From the slack channel the following backends should be using this new basis gateset: ``` ibmq_5_yorktown ibmq_16_melbourne ibmq_vigo ibmq_ourense ibmq_armonk ibmq_valencia ibmq_athens ibmq_santiago ``` ### Steps to reproduce the problem N/A ### What is the expected behavior? `qiskit/test/mock/backends/conf_yorktown.json` and others listed above should have the correct basis gateset. ### Suggested solutions Update the appropriate json files. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Use `contract_nodes` from retworkx for ConsolidateBlocks pass ### What is the expected enhancement? For improved performance and cleaner code, we should use `PyDiGraph.contract_nodes` to replace a bulk of the logic in `DAGCircuit.replace_block_with_op`, once it becomes available in a future retworkx release. Contract nodes PR: https://github.com/Qiskit/retworkx/pull/487 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: filesensor wildcard matching does not recognize directories **Apache Airflow version**: 2.1.0 **Environment**: - **Cloud provider or hardware configuration**: - **OS** (e.g. from /etc/os-release): - **Kernel** (e.g. `uname -a`): - **Install tools**: - **Others**: **What happened**: FileSensor does not recognize directories with wildcard glob matching. **What you expected to happen**: FileSensor would sense a directory that contains files if it matches with the wild card option. **How to reproduce it**: Create a directory with a pattern that matches a wild card using glob **Anything else we need to know**: Code from FileSensor source that I believe to cause the issue: ``` for path in glob(full_path): if os.path.isfile(path): mod_time = os.path.getmtime(path) mod_time = datetime.datetime.fromtimestamp(mod_time).strftime('%Y%m%d%H%M%S') self.log.info('Found File %s last modified: %s', str(path), str(mod_time)) return True for _, _, files in os.walk(full_path): if len(files) > 0: return True return False ``` I believe to resolve the issue `full_path` in os.walk should be `path` instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Cloud PR references Core See https://github.com/PrefectHQ/cloud/pull/659 for more details Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: AttributeError: 'BlockingKernelClient' object has no attribute 'started_channels' I have an app that is centered around IPython running in qt (https://github.com/neuropy/neuropy/blob/master/neuropy/main.py). Yesterday I updated IPython from git, and have had to change a few things since the refactoring about 3 months ago, which split a kernel client off of the kernel manager (see #3011). In the process, I came across the error in the title. This error only happens when I try to create a normal two-process app, but not when creating an inprocess app, ie, it happens with QtKernelManager, but not with QtInProcessKernelManager. I think a BlockingKernelClient happens to be the default for QtKernelClient, which may be due to #3222. Not sure how to fix this in IPython, but to get around it, I set the client_factory to QtKernelClient, and then calling QtKernelManager.client() works fine. My minimalist example is in this gist: https://gist.github.com/mspacek/6018206 Can this be fixed so that setting up the 2-process app doesn't require the extra step of changing the client_factory? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"extends\" and multiple yml files don't work together I'm currently trying to use the new \"multiple files\" (#2051) feature and got stuck on extends not working anymore when used together. Example: ``` # common.yml baseservice: labels: - \"my.label=my-value\" environment: MY_ENV: \"MY_VALUE\" # base.yml service1: extends: file: common.yml service: baseservice ...more stuff... # dev.yml service2: extends: file: common.yml service: baseservice ...more stuff... ``` When started with: ``` docker-compose -f base.yml -f dev.yml up ``` the services do not include the labels and env vars from \"baseservice\". Just for testing purposes, I tried to use a random name for the extends/file field in dev.yml and it did not complain about not found files, which looks like it doesn't even try to open the file. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Output of 'conan search <ref> --revisions --raw' failure for single result ### Environment Details (include every applicable attribute) * Conan version: Conan version 1.20.3 * Python version: py 3 ### Steps to reproduce (Include if Applicable) Raw argument of `conan search --raw` is not honoured if there is a `@` in the reference. More than one package in the cache: ``` ⇒ conan search dep/0.1 --revisions --raw dep/0.1#f732ec8d19fb3190c01f3df44f48b0e8 dep/0.1@issue/testing#f732ec8d19fb3190c01f3df44f48b0e8 ``` Asking for a specific one (`--raw` is not honoured): ``` ⇒ conan search dep/0.1@ --revisions --raw Revisions for 'dep/0.1': f732ec8d19fb3190c01f3df44f48b0e8 (No time) ⇒ conan search dep/0.1@issue/testing --revisions --raw Revisions for 'dep/0.1@issue/testing': f732ec8d19fb3190c01f3df44f48b0e8 (No time) ``` If there is only one in the cache (wihtout user/channel) it works: ``` ⇒ conan search dep/0.1 --revisions --raw dep/0.1#f732ec8d19fb3190c01f3df44f48b0e8 ``` If there is only one in the cache (with user/chanel) it fails: ``` ⇒ conan search dep/0.1 --revisions --raw dep/0.1@issue/testing#f732ec8d19fb3190c01f3df44f48b0e8 ⇒ conan search dep/0.1@issue/testing --revisions --raw Revisions for 'dep/0.1@issue/testing': f732ec8d19fb3190c01f3df44f48b0e8 (No time) ``` * Something doesn't behave the same when there is a `@` in the query. * And have a look to the JSON output too Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Use `black` for autoformatting [`black`](https://github.com/python/black) has become popular enough for Python formatting that it was officially adopted by the PSF, and is being used to format the standard library. I like it because it makes code that's very consistent to read, which makes development ever so slightly easier for everyone. In case this PR is desired but the actual formatting changes interfere with other current branches, I can rebase to leave out the actual formatting for now. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Bug in masked array boolean comparison in Numpy 1.15.3 An issue was introduced in Numpy 1.15.3 compared to Numpy 1.15.2 which results in comparisons of masked arrays crashing (this has broken some functionality over at astropy - e.g. https://github.com/astropy/astropy/issues/7943) This is likely due to https://github.com/numpy/numpy/pull/12237 ### Reproducing code example: **Expected (Numpy 1.15.2)** ```python >>> (np.ma.array(['A', 'B', 'C'], fill_value='N') == 'A') | (np.ma.array(['A', 'B', 'C'], fill_value='N') == 'A') masked_array(data=[ True, False, False], mask=False, fill_value='N') ``` (arguably this was wrong too since fill_value should have been a bool, but at least it didn't crash) **Actual (Numpy 1.15.3)**: ```python >>> (np.ma.array(['A', 'B', 'C'], fill_value='N') == 'A') | (np.ma.array(['A', 'B', 'C'], fill_value='N') == 'A') Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/tom/miniconda3/envs/np1153/lib/python3.6/site-packages/numpy/ma/core.py\", line 3016, in __array_finalize__ self._fill_value = _check_fill_value(self._fill_value, self.dtype) File \"/Users/tom/miniconda3/envs/np1153/lib/python3.6/site-packages/numpy/ma/core.py\", line 476, in _check_fill_value fill_value = np.array(fill_value, copy=False, dtype=ndtype) ValueError: invalid literal for int() with base 10: 'N' ``` ### Numpy/Python version information: Python 3.6, Numpy 1.15.3 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: check_security_dir() and check_pid_dir() fail on network filesystem For testing purposes and quick setup, I use SSHFS as a simple network filesystem. On Linux and Mac OSX there is FUSE SSHFS available. On Windows there's Dokan SSHFS. I use SSHFS because Samba and NFS share were leading to incorrect uid/gid mapping. At least for Mac OSX and Ubuntu is was possble to avoid these problems by using SSHFS. When starting ipengine on Windows, IPython executes check_security_dir() and check_pid_dir() which both try to set the permissions using chmod to 0700. This fails in my setup. After commenting out the offending lines in core/profiledir.py ipengine works. It would be nice to be able to configure the permission setup. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: DataCollatorForWholeWordMask error persists after fix After quick fix #8379 Tried same flow of #8378 **Gives error:** ``` /usr/local/lib/python3.6/dist-packages/transformers/data/data_collator.py in __call__(self, examples) 321 for e in examples: 322 ref_tokens = [] --> 323 for id in e[\"input_ids\"].tolist(): 324 token = self.tokenizer._convert_id_to_token(id) 325 ref_tokens.append(token) AttributeError: 'list' object has no attribute 'tolist' ``` When I tried with _DataCollatorForLanguageModeling_, trainer works as usual. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Handling old-format jobs (test_get_jobs_filter_job_status) <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information We are experiencing some intermitent failures at `test.python.ibmq.test_ibmqjob.TestIBMQJob.test_get_jobs_filter_job_status` (specifically, seems to happen at premium): https://travis-ci.org/Qiskit/qiskit-terra/jobs/461104008 ``` 1: b'Traceback (most recent call last):' 1: b' File \"/home/travis/build/Qiskit/qiskit-terra/test/python/ibmq/test_ibmqjob.py\", line 283, in test_get_jobs_filter_job_status' 1: b\" self.log.info('match #%d: %s', i, job.result().status)\" 1: b' File \"/home/travis/build/Qiskit/qiskit-terra/qiskit/backends/ibmq/ibmqjob.py\", line 210, in result' 1: b' return self._result_from_job_response(job_response)' 1: b' File \"/home/travis/build/Qiskit/qiskit-terra/qiskit/backends/ibmq/ibmqjob.py\", line 506, in _result_from_job_response' 1: b' _reorder_bits(job_response)' 1: b' File \"/home/travis/build/Qiskit/qiskit-terra/qiskit/backends/ibmq/ibmqjob.py\", line 546, in _reorder_bits' 1: b\" for circuit_result in job_data['qasms']:\" 1: b\"KeyError: 'qasms'\" 1: b'' ``` This seems to be because of the co-existence of different formats currently, and sort of accounted for - by 0.7, all jobs created and stored should have the same format. However, we should provide a cleaner way of dealing with pre-0.7 style jobs, revising the functions that retrieve them from the API (and emitting a warning if an old-style job cannot be parsed or similar). ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add flag to build environment.yml without build strings https://gitter.im/conda/conda?at=59ef54ebe44c43700a70e9a4 https://twitter.com/drvinceknight/status/922837449092542464?ref_src=twsrc%5Etfw > Due to hashes of packages being introduced in `envinronment.yml` I'm getting all sorts of issues with building envs from file. (Very new problem) test.py error \"prefix is not writeable\" While attempting to use \"pyinstaller\" to create a standalone conda-index executable, the resulting binary failed in “conda/gateways/disk/test.py” prefix_is_writable because that method assumes the prefix is a python root directory, and in the case of the standalone, the “prefix” is the executable’s current directory. If I add append sys.executable to the end of the “find_first_existing” call parameter list, then it worked as expected. Of course, this particular writability check seems unnecessary for conda-index, because the only writing is to the target, not the conda-meta directory. Any change that would allow the creation of a standalone conda-index is appreciated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Regenerate client for `google-cloud-deploy` There is an update pending to the client library for `google-cloud-deploy`. An owlbot PR appeared while we were migrating the source code to `google-cloud-python`. See https://github.com/googleapis/python-deploy/pull/168. This issue tracks regenerating the client [here](https://github.com/googleapis/google-cloud-python/tree/main/packages/google-cloud-deploy). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: No method to override use of interactive plot visualizations <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? When running visualizations that have an interactive mode if you're system meets the requirements we unconditionally use the interactive visualizations. We need to provide an option to let users override this and use the non-interactive visualizations. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Make docker-compose fail when an undefined environment variable used in a compose file. Right now, if a compose file references an undefined environment variable, `docker-compose` prints a warning and defaults it's value to an empty string, as described [here](https://docs.docker.com/compose/compose-file/#variable-substitution). This may not always be the desired approach and can mask a failure in continuous deployment environment. I think there are 2 backward compatible ways to address this: 1. Add a option to enable strict config validation. E.g. `docker-compose config --strict` 2. Add support for `${VARIABLE?err_msg}` and `${VARIABLE:?err_msg}` substitution syntax. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inst map in transpile is always ignored with V2 backend ### Environment - **Qiskit Terra version**: 0.23 - **Python version**: any - **Operating system**: any ### What is happening? When we explicitly specify the `inst_map` argument in transpile, this must check the provided inst map and apply pulse gate if available. In #9343 support for `target` argument is added to the pulse gate pass. When both `target` and `inst_map` are provided for the pass, the inst map in the target overrides user provided `inst_map` value. However, even if we don't explicitly specify the target, this parse function implicitly set the target option and the user specified inst map is always ignored with the V2 backend. https://github.com/Qiskit/qiskit-terra/blob/a3b359b899d5d963272a7b424c8a283bc6bd4c0d/qiskit/compiler/transpiler.py#L999-L1003 ### How can we reproduce the issue? ```python from qiskit.providers.fake_provider import FakeHanoi, FakeHanoiV2 from qiskit.pulse import ScheduleBlock, InstructionScheduleMap from qiskit import transpile, QuantumCircuit inst_map = InstructionScheduleMap() inst_map.add(\"x\", (0,), schedule=ScheduleBlock(name=\"custom_x\")) qc = QuantumCircuit(1) qc.x(0) qc1 = transpile(qc, FakeHanoi(), inst_map=inst_map) qc2 = transpile(qc, FakeHanoiV2(), inst_map=inst_map) qc1 == qc2 ``` This results in > False Because ```python >>> qc1.calibrations {'x': {((0,), ()): ScheduleBlock(, name=\"custom_x\", transform=AlignLeft())}} >>> qc2.calibrations {} ``` ### What should happen? Pulse gate should be applied to circuit with V2 backend. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Container: Regional Cluster support for GKE clusters I'm unable to get or create regional clusters using the container_v1 client APIs. The [documentation](https://googleapis.github.io/google-cloud-python/latest/container/gapic/v1/api.html#google.cloud.container_v1.ClusterManagerClient.create_cluster) suggests that this is possible by using the `parent` parameter to describe the project/region to launch the cluster but I get the following errors: ```bash (env) david@ ~ $ which python ~/dev/env/bin/python (env) david@ ~ $ pip freeze ... google-api-core==1.6.0 google-auth==1.6.1 google-cloud==0.34.0 google-cloud-container==0.1.1 googleapis-common-protos==1.5.5 grpcio==1.16.1 ... (env) david@ ~ $ python --version Python 2.7.10 (env) david@ ~ $ python ./get_cluster.py Traceback (most recent call last): File \"./get_cluster.py\", line 6, in <module> cluster = client.get_cluster(project_id=credentials.project_id, parent='projects/<project_id>/locations/us-east1', cluster_id='ha-cluster-1') TypeError: get_cluster() got an unexpected keyword argument 'parent' ``` Is it possible that the API documentation has been updated before the feature was merged or is it more likely an environment issue on my end? Any insight into this would be appreciated I have also looked at using the [google-api-python-client](https://github.com/googleapis/google-api-python-client#google-api-client) to launch regional clusters but I would prefer to use this library if the feature is supported. Are there any known workarounds for this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Missing feature warning < 0.60: concatenating list with custom target Hi, in <0.60 it was not possible to do [list, of, targets] + custom_target. But in 0.60 that is possible. Repro: ``` project('repro', ['c'], version : '0.1' ) foo = custom_target('foo', output: 'foo', command: ['touch', '@OUTPUT@'] ) sometargets = [] + foo ``` HEAD: ``` $ ~/src/meson/meson.py setup build-master --reconfigure The Meson build system Version: 0.60.0.rc1 Source dir: /tmp/repro-meson-src Build dir: /tmp/repro-meson-src/build-master Build type: native build Project name: repro Project version: 0.1 C compiler for the host machine: ccache cc (gcc 11.2.0 \"cc (Debian 11.2.0-9) 11.2.0\") C linker for the host machine: cc ld.bfd 2.37 Host machine cpu family: x86_64 Host machine cpu: x86_64 Program touch found: YES (/usr/bin/touch) Build targets in project: 1 Found ninja-1.10.1 at /usr/bin/ninja ``` 0.59.2: ``` ~/src/meson-0.59/meson.py setup build-0.59 The Meson build system Version: 0.59.2 Source dir: /tmp/repro-meson-src Build dir: /tmp/repro-meson-src/build-0.59 Build type: native build Project name: repro Project version: 0.1 C compiler for the host machine: ccache cc (gcc 11.2.0 \"cc (Debian 11.2.0-10) 11.2.0\") C linker for the host machine: cc ld.bfd 2.37 Host machine cpu family: x86_64 Host machine cpu: x86_64 Program touch found: YES (/usr/bin/touch) meson.build:10:0: ERROR: Invalid use of addition: can only concatenate list (not \"CustomTargetHolder\") to list ``` Regards, Andres Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: python 2 can't read unicode in environments.txt on a conda install operation, during the transaction ``` Traceback (most recent call last): File \"/Users/kfranz/continuum/conda/conda/core/link.py\", line 535, in _execute_actions action.execute() File \"/Users/kfranz/continuum/conda/conda/core/path_actions.py\", line 876, in execute register_env(self.target_prefix) File \"/Users/kfranz/continuum/conda/conda/core/envs_manager.py\", line 28, in register_env if location in yield_lines(USER_ENVIRONMENTS_TXT_FILE): File \"/Users/kfranz/continuum/conda/conda/gateways/disk/read.py\", line 49, in yield_lines if not line or line.startswith('#'): UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 54: ordinal not in range(128) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Extra argument for `get_task_mapped_state`? Question for @cicdw: I think this `state` argument is extraneous: https://github.com/PrefectHQ/prefect/blob/1eedc4413b2e3aa10f672feafa58ad6f79e58078/src/prefect/engine/task_runner.py#L559 My guess is it used to be there to conform to the requirement that methods which are \"state-handled\" have a first argument `state`, but since this method isn't state-handled, can we get rid of it? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Exception logging success function instead of failure https://github.com/apache/airflow/blob/fdd9b6f65b608c516b8a062b058972d9a45ec9e3/airflow/sensors/sql_sensor.py#L97 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Combined command to kill and remove containers Most of the times, during development of a docker-compose.yml file, I found myself killing services and then removing the stopped containers immediately. To do this, I had to execute 2 docker-compose commands , first to kill the services and then to remove the containers and associated volumes. I think It would be very convenient if one command did the complete clean-up , viz., killing AND removing the stopped containers. So, I think it would be a great convenience option to have --rm in the kill command. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Problems when displaying multiple views of ContainerWidget. `ContainerView.render` registers anonymous functions to `this.model.on('displayed')` . This is a problem because when rendering multiple views of the same widget container, multiple instances of this anonymous function get registered to this event. PS: This is also related to #5958 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Schedules should be timezone aware to (optionally) account for DST All schedules; this might require some new initialization kwargs for `CronSchedule`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython.core.page:snip_print seem to be unused. ``` IPython/core/page.py 346:def snip_print(str,width = 75,print_full = 0,header = ''): ``` Should likely be removed. Remove try/except import for Py2 compat Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Compiling QFT circuit on 1k qubits fails ### Environment - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is happening? There is an overflow when converting a Python int to a numerical float ```bash ~/mambaforge/envs/qiskit/lib/python3.8/site-packages/qiskit/circuit/library/basis_change/qft.py in _build(self) 259 num_entanglements = max(0, j - max(0, self.approximation_degree - (num_qubits - j - 1))) 260 for k in reversed(range(j - num_entanglements, j)): --> 261 lam = np.pi / (2 ** (j - k)) 262 circuit.cp(lam, j, k) 263 OverflowError: int too large to convert to float ``` ### How can we reproduce the issue? ```python from qiskit import transpile from qiskit.transpiler.coupling import CouplingMap from qiskit.circuit.library import EfficientSU2, QFT cmap = CouplingMap.from_heavy_hex(21) qc = QFT(cmap.size()) transpile(qc, coupling_map=cmap, optimization_level=0) ``` ### What should happen? It should work ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Drop _helpers.make_secure_channel in favor of google.auth.transports.grpc.secure_authorized_channel Unless there is a compelling reason to keep it @dhermes? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Add JavaScript to nbconvert HTML display priority Right now JavaScript output does not show up in HTML output in nbconvert. We need to add this to the display priority in nbconvert for all HTML output types. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub should send streaming pull requests over unary RPCs Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: dag.depth seems broken It seems that PR #1815 introduced a bug in `depth()`. ``` from qiskit import QuantumRegister, QuantumCircuit from qiskit.converters import circuit_to_dag qr = QuantumRegister(2) circuit = QuantumCircuit(qr) circuit.h(qr[0]) circuit.h(qr[1]) circuit.cx(qr[0], qr[1]) circuit.cx(qr[0], qr[1]) circuit.cx(qr[0], qr[1]) circuit.cx(qr[0], qr[1]) circuit.cx(qr[1], qr[0]) circuit.cx(qr[1], qr[0]) dag = circuit_to_dag(circuit) assert dag.depth() == 7 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Return cross-attention weights in generation function # 🚀 Feature request <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> With v4.2.0 release, generation can now return encoder and decoder self-attention weights but it still doesn't return cross-attention weights. These weights are already computed and returned in model `forward` method, and just need to be returned in `generate` method. ## Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. --> Visualizing cross-attention weights is useful for many applications such as token-alignment. ## Your contribution <!-- Is there any way that you could help, e.g. by submitting a PR? Make sure to read the CONTRIBUTING.MD readme: https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md --> I can submit a PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Better formatting of build errors Right now the build errors are printed as a raw binary string. We should be converting to unicode and handling line breaks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rewrite VQE with primitives. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Bad error message when a repository definition contains a non-pipeline-like object The error message produced when a pipeline contains a non-pipeline-like object is wrong, due to a couple of missing parens in the `_Repository` code: ``` if isinstance(repository_definitions, list): bad_definitions = [] for i, definition in enumerate(repository_definitions): if not ( isinstance(definition, PipelineDefinition) or isinstance(definition, PartitionSetDefinition) or isinstance(definition, ScheduleDefinition) ): > bad_definitions.append(i, type(definition)) E TypeError: append() takes exactly one argument (2 given) ``` It's a simple fix so I'll push a PR with a test. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: fix error due to wrong argument name to Tensor.scatter() The named argument is called \"source\", not \"src\" in the out of place version for some reason, despite it being called \"src\" in the in-place version of the same Pytorch function. This causes an error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Flax] Add Flax implementation of `RoFormer` # 🚀 Feature request Add Flax implementation of `RoFormer` models. ## Motivation Improve the level of Flax/Jax support. ## Your contribution I'll be glad to work on this :] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: import Error from official example caused by fastprogress ## 🐛 Bug <!-- Important information --> Model I am using (Bert, XLNet....): BERT Language I am using the model on (English, Chinese....): ALL The problem arise when using: * [x] the official example scripts: (give details) * [ ] my own modified scripts: (give details) The tasks I am working on is: * [x] an official GLUE/SQUaD task: (give the name) * [ ] my own task or dataset: (give details) ## To Reproduce Steps to reproduce the behavior: V0.2.1 of fastprogress released a couple of days ago seems to cause errors in run_tf_ner.py in the official example. Traceback (most recent call last): File \"run_tf_ner.py\", line 12, in <module> from fastprogress import master_bar, progress_bar ImportError: cannot import name 'master_bar' from 'fastprogress' (/usr/local/lib/python3.7/dist-packages/fastprogress/__init__.py) users need to either downgrade: pip3 install fastprogress==0.1.22 or change the code: ` from fastprogress.fastprogress import master_bar, progress_bar ` ## Expected behavior <!-- A clear and concise description of what you expected to happen. --> ## Environment * OS: * Python version: * PyTorch version: * PyTorch Transformers version (or branch): * Using GPU ? * Distributed of parallel setup ? * Any other relevant information: ## Additional context <!-- Add any other context about the problem here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: CLIPProcessor with CLIPTokenizerFast # 🚀 Feature request Current `CLIPProcessor` doesn't support `CLIPTokenizerFast` requiring `CLIPTokenizer`. In my thinking, there is no reason not to support `CLIPTokenizerFast` for `CLIPProcessor` ## Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. --> ## Your contribution https://github.com/huggingface/transformers/blob/v4.16.2/src/transformers/models/clip/processing_clip.py#L23 it may be easy by modifying upper python code. I think I can contribute. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Handling old-format jobs (test_get_jobs_filter_job_status) <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information We are experiencing some intermitent failures at `test.python.ibmq.test_ibmqjob.TestIBMQJob.test_get_jobs_filter_job_status` (specifically, seems to happen at premium): https://travis-ci.org/Qiskit/qiskit-terra/jobs/461104008 ``` 1: b'Traceback (most recent call last):' 1: b' File \"/home/travis/build/Qiskit/qiskit-terra/test/python/ibmq/test_ibmqjob.py\", line 283, in test_get_jobs_filter_job_status' 1: b\" self.log.info('match #%d: %s', i, job.result().status)\" 1: b' File \"/home/travis/build/Qiskit/qiskit-terra/qiskit/backends/ibmq/ibmqjob.py\", line 210, in result' 1: b' return self._result_from_job_response(job_response)' 1: b' File \"/home/travis/build/Qiskit/qiskit-terra/qiskit/backends/ibmq/ibmqjob.py\", line 506, in _result_from_job_response' 1: b' _reorder_bits(job_response)' 1: b' File \"/home/travis/build/Qiskit/qiskit-terra/qiskit/backends/ibmq/ibmqjob.py\", line 546, in _reorder_bits' 1: b\" for circuit_result in job_data['qasms']:\" 1: b\"KeyError: 'qasms'\" 1: b'' ``` This seems to be because of the co-existence of different formats currently, and sort of accounted for - by 0.7, all jobs created and stored should have the same format. However, we should provide a cleaner way of dealing with pre-0.7 style jobs, revising the functions that retrieve them from the API (and emitting a warning if an old-style job cannot be parsed or similar). ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: RFC: support a dictionary as the configuration parameter of configure_file? I like dictionaries. Any support for the following idea? ``` configure_file(output: 'config.h', configuration: {'version': '1.0'}) ``` Or as a more cluttered alternative (but still better than was is available right now): give the `configuration_data()` constructor an optional dictionary argument: ``` configure_file(output: 'config.h', configuration: configuration_data({'version': '1.0'})) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Trainer] add --max_train_samples --max_val_samples --max_test_samples As we were planning to add `--max_train_samples --max_val_samples --max_test_samples` to all examples https://github.com/huggingface/transformers/issues/10423, I thought is there any reason why we don't expand the Trainer to handle that? It surely would be useful to be able to truncate the dataset at the point of Trainer to enable quick testing. Another plus is that the metrics can then automatically include the actual number of samples run, rather than how it is done at the moment in examples. That way this functionality would be built-in and examples will get it for free. TODO: 1. [ ] port `--max_train_samples --max_val_samples --max_test_samples` to Trainer and remove the then unneeded code in `run_seq2seq.py` 2. [ ] extend metrics to report the number of samples as it's done now in: https://github.com/huggingface/transformers/blob/aca6288ff42cebded5421020f0ff088adeb446dd/examples/seq2seq/run_seq2seq.py#L590 so that all scripts automatically get this metric reported. Most likely it should be done here: https://github.com/huggingface/transformers/blob/aca6288ff42cebded5421020f0ff088adeb446dd/src/transformers/trainer_utils.py#L224 @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Class inheriting nametuple is not treated as a valid JAX Type ``` import collections from jax.lax import scan Point = collections.namedtuple( 'Point', ['x', 'y'] ) class ZeroPoint(Point): def is_zero(self): return (x==0) and (y==0) def loop(in_, idx): return in_ a = ZeroPoint(1., 0.) b = ZeroPoint(1., 1.) scan(loop, [a,b], np.arange(2)) ``` The error was `TypeError: <class '__main__.ZeroPoint'> is not a valid Jax type` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Reading and writing global configuration parameters There is no way to get global configuration parameters without `Repo` object. `config_reader()` **must** be repository independent. So does `config_writer()` and accompanying methods. Simplest (and ugly) hack is to allow `path=None` in `Repo()`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Check for symmetry needed in hidden_linear_function.py for input matrix A <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The input adjacency matrix A for `HiddenLinearFunction` should be required to be a symmetric matrix. A check for the same seems to be missing in `qiskit/circuit/library/hidden_linear_function.py` Please let me know if I'm missing something here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: TAB key does not indent In the git version of IPython, type ``` def foo(a): pass<ENTER> ``` The new line is not correctly indented, and the tab key does not insert 4 spaces. /cc @Carreau @takluyver Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Chained execution of circuit methods in circuit library objects <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior It looks like sub-classing `QuantumCircuit`, as done in the circuit library, causes jupyter execute to re-execute each circuit method, e.g. cx, cy, again as it thinks it is something new. This causes the docs builds to be very slow. For example: ``` executing qiskit.circuit.library.XOR.ccxircuit.library.XOR.ccx executing qiskit.circuit.library.XOR.chcircuit.library.XOR.ch executing qiskit.circuit.library.XOR.cnotrcuit.library.XOR.cnot executing qiskit.circuit.library.XOR.crzircuit.library.XOR.crz executing qiskit.circuit.library.XOR.cswapcuit.library.XOR.cswap executing qiskit.circuit.library.XOR.cu1ircuit.library.XOR.cu1 executing qiskit.circuit.library.XOR.cu3ircuit.library.XOR.cu3 executing qiskit.circuit.library.XOR.cxcircuit.library.XOR.cx executing qiskit.circuit.library.XOR.cycircuit.library.XOR.cy executing qiskit.circuit.library.XOR.czcircuit.library.XOR.cz ``` ### Steps to reproduce the problem ### What is the expected behavior? I would expect that the underlying gate examples do not get executed every time I build the circuit docs. ### Suggested solutions I am not sure how to fix this given that we add gate methods in a unconventional way. Perhaps make the library objects functions rather than sub-classing `QuantumCircuit`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Ternary if Im really want see ternary IF in meson. 1. This is readable 2. This is widespread common operation 3. Reduce size of script I prefer c ternary if form: `variable = (condition) ? true : false` but are be happy with python form `variable = true if condition else false` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Shift operator cycles for int32 and int64 (Trac #1856) _Original ticket http://projects.scipy.org/numpy/ticket/1856 on 2011-06-02 by trac user klasj, assigned to unknown._ The bitshift operations, both right and left cycles when they are shifted more bits than the length of the datatype. This happens for both int32 and int64 but not for int16, unsigned integers works as expected. In the example below version 1.6.1 is used but this is also present in at least 1.5.0. ``` In [1]: import numpy as np In [2]: np.right_shift(np.int32(8),32) Out[2]: 8 In [3]: np.right_shift(np.int64(8),64) Out[3]: 8 In [4]: np.right_shift(np.int16(8),16) Out[4]: 0 In [5]: np.left_shift(np.int32(8),32) Out[5]: 8 In [6]: np.left_shift(np.int64(8),64) Out[6]: 8 In [7]: np.left_shift(np.int16(8),16) Out[7]: 524288 In [8]: np.version.full_version Out[8]: '1.6.1.dev-08953ea' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipdb completely broken in Qt console When starting the debugger via `%debug` in the Qt console, no valid command works: ``` ipdb> l *** SyntaxError: invalid syntax (<stdin>, line 1) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add cli_args argument to cmake.install() > > if self.settings.build_type == 'Release': > > Ok, makes sense, though nowadays, I'd expect that `Release` builds already don't contain any debug information to be stripped, I understand it might not be the case for all platforms and tools, so I am ok with making this a opt-in conf. From https://discourse.cmake.org/t/what-does-strip-do/4302 and if I'm not mistaken, it's not only debug information that gets stripped (if there is any), but also symbols that don't need to be externally visible, so this should have a benefit. PR looks good to me, thanks @sagi-ottopia for your contribution!!! @memsharded one thing I'd consider outside of this PR is adding a `cli_args` argument to `cmake.install()` - to mirror what we have for `cmake.configure()` and `cmake.build()` - while the current setup for install pretty much covers the bases, it may be useful for some advanced users to have the added flexibility _Originally posted by @jcar87 in https://github.com/conan-io/conan/pull/14167#pullrequestreview-1516018103_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Displaying a widget using displayhook produces misaligned Out[N] prompt  This doesn't look right. @jdfreder, can you investigate? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CMake install target fails for capnproto-c++-0.7 cmake subproject **Describe the bug** When you run install and use capnproto in subprojects/, installation will fail. **To Reproduce** Use the attachment (attachment tested under windows) and: 1. meson build 2. ninja -C build install [CapnpCMakeSubprojectInstallFails.zip](https://github.com/mesonbuild/meson/files/4292873/CapnpCMakeSubprojectInstallFails.zip) **Expected behavior** `ninja -C build install` should install correctly the dependencies. **Actual output** The installation step fails, I suspect because it is trying to install a dependency that has not been compiled but has been identified as a target when CMake configuration is done. It seems that version 0.53.0 lazily compiles only needed dependencies for cmake subprojects? I saw some generated meson.build from an AST and CMake server running to gather this information. I guess this was not what version 0.52.0 of Meson did. **system parameters** Tested in Ubuntu 19.10 * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? Native * what operating system -> Ubuntu 19.10, Windows 10 * what Python version are you using e.g. 3.8.0 -> pre-packaged python3 version (no access at this moment) * what `meson --version` 0.53.2 (in fact, this bug does not happen in 0.52.0) * what `ninja --version` if it's a Ninja build -> the one packaged with Ubuntu 19.10 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Text drawer can't draw composite instructions composite gates (i.e. without classical registers) work fine, but with classical registers it cannot be drawn. The logic is here: https://github.com/Qiskit/qiskit-terra/blob/109d8ea562987b9309501b9260c80180216061eb/qiskit/visualization/text.py#L849 latex and mpl can do this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Create `BaseOperator.map` and basic mapping framework We need to create a `map()` method on BaseOperator instance that returns a new object that looks somewhat like BaseOperator, but that gives us a place to add the DAG-authoring mapping API, and that the serializer can understand. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Add all interpolation methods to quantile (and percentile) # Description At the moment, only the \"linear\" interpolation method from [`numpy.quantile`](https://docs.scipy.org/doc/numpy/reference/generated/numpy.quantile.html) and by extension [`numpy.percentile`](https://docs.scipy.org/doc/numpy/reference/generated/numpy.percentile.html) are implemented (as [noted in Issue #70](https://github.com/google/jax/issues/70#issuecomment-509322341)) https://github.com/google/jax/blob/1cf708ea77fae0fc1418e0b944f0115646f7f2ec/jax/numpy/lax_numpy.py#L3446-L3447 It would be useful to also have the \"nearest\" interpolation method, along with the others (\"lower\", \"higher\", \"midpoint\") implemented as well. cc @lukasheinrich @kratsg Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Metric aggragation is broken for LoggerCollection <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug <!-- A clear and concise description of what the bug is. --> After changes in #1278 it is now not possible to log testing metrics after traning while using several loggers. ### To Reproduce Say we want to run a [MINST example](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pl_examples/basic_examples/cpu_template.py) and also want to add a change - log testing metrics after training. For that we define a Callback ``` class TestCallback(Callback): def on_train_end(self, trainer, pl_module): # note that it would crash if you don't pass the `pl_module` trainer.test(pl_module) ``` and pass it to trainer `callbacks` argument. We would also like to use several loggers to track all metrics, say `MLFlowLogger` and `TensorBoardLogger`. For this we create instances of these loggers and pass them into `Trainer` in a list. ### Expected behavior Testing metrics should be logged - but they don't as there's no final aggregation when our logger is a `LoggerCollection` ### Additional context In my opinion, the logic in `agg_and_log_metrics` and `_finalize_agg_metrics` is hard to follow, so I'd be happy if user could choose plain old `log_metrics` which worked nicely. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan updates all my software installed with yum Hi, my system: CentOs7, conan 1.16.0, packet manager yum ```python installer = SystemPackageTool() installer.update() ``` The above code will instuct conan to update ALL installed packets in the system. It was introduced here: https://github.com/conan-io/conan/pull/3181 This contradicts with the docu that states: > update(): Updates the system package manager database. It’s called automatically from the install() method by default. This would be achieved with `yum check-update` instead of `yum update`. In my opinion conan should not touch any installed packets, unless expicitly instructed to do so. So I would like to see the old behavior back, like it is discribed in the docu. Cheers Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.stack raises incorrect exception when given a traced array ```python @jax.jit def foo(x): return np.stack(x) foo(np.zeros(2)) # this fails ``` Raises an exception because of a `if not arrays` check which assumes `arrays` is an object without a `__bool__` method so that the size of arrays would be used instead. Using `len(arrays) == 0` might be sufficient to fix this. This issue might be present in a few other places and might warrant a test. Error message: ```python TypeError: Abstract value passed to `bool`, which requires a concrete value. The function to be transformed can't be traced at the required level of abstraction. If using `jit`, try using `static_argnums` or applying `jit` to smaller subfunctions instead. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Building the documentation throws a variety of warnings ## Checklist - [x] I have verified that the issue exists against the `master` branch of Celery. ## Steps to reproduce On a fresh Ubuntu 18.04 system, clone the repo and follow the steps in CONTRIBUTING.rst to build the documentation files. ## Expected behavior The docs should build without warnings as stipulated in CONTRIBUTING.rst ## Actual behavior Warnings are thrown for a number of things, including: - missing python packages and system packages. - missing and mislabelled toctree entries - ambiguous typehints in docstrings - a link intended to show the `--port` option for `flower` instead links to the options list for the base `celery` command, which has no `--port` option if `flower` is not installed. - there are also a few warnings which cannot be fixed with a PR on this project because they originate in kombu and sphinx_celery. i'm working on issues and PRs for those warnings also. I recognize that this seems really nit-picky; I do think that some of these issues result in the docs being slightly less useful than they would otherwise be. Certainly as a whole they make it feel much more intimidating to try to contribute to the docs, which seems worth avoiding as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Update gcloud-python/datastore to use the v1 API The v1 API is now available. The protos are identical (just a different package name). The only behavioral change is captured in the release notes: https://cloud.google.com/datastore/release-notes Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: After deploying a flow, display a UI link to see it immediately UX improvement: after calling `flow.deploy()`, present a message to the user with a link to viewing the flow in the UI. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: set correct project when using from_service_account_json When instantiating with `bigquery.Client.from_service_account_json('...')` the `project` field in the client should be set to the `project_id` defined in the service account JSON. Right now it is still the one from env. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: HfArgumentParser defaults booleans to on ## Environment info - `transformers` version: 4.9.0.dev0 (initially discovered on 4.8.1) - Platform: macOS-11.4-x86_64-i386-64bit - Python version: 3.9.5 - PyTorch version (GPU?): not installed (NA) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed ### Who can help @sgugger ## Information HfArgumentParser when used on a dataclass with a bool field with no default turns the bool on unless it's supplied with `--<field_name> False` or similar \"false-y\" value. I would expect that as the field has no default it should be false unless `--<field_name>` or `--<field_name> True` is supplied. This is a behaviour change from `v3.0.0` where the booleans are parsed correctly as we're looking at upgrading and this issue hit us. ## To reproduce Steps to reproduce the behavior: 1. Define a dataclass with a boolean field 2. Supply a list of arguments which does not include that field name 3. The field is turned on. Appending this snippet to the bottom of [`test_basic` at line 110](https://github.com/huggingface/transformers/blob/master/tests/test_hf_argparser.py#L110) in `test_hf_argparser.py` fails the test. ```python args = [\"--foo\", \"1\", \"--baz\", \"quux\", \"--bar\", \"0.5\"] example, = parser.parse_args_into_dataclasses(args, look_for_args_file=False) self.assertFalse(example.flag) ``` Extending `args` with `[\"--flag\",\"False\"]` recovers the expected behaviour. ## Expected behavior The boolean should be set to false if the argument is not passed in. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: \\r and \\b in qtconsole don't behave as expected In a normal terminal, the \"\\r\" and \"\\b\" control characters should move to the beginning of the line and back one character, respectively. However, in qtconsole, writing '\\b' to stdout (or \"print '\\b'\") seems to do nothing at all, and '\\r' behaves like '\\n'. Is there any way to get around this and return them to the expected behavior? This is useful for things like download notifiers that shouldn't print a new line to update the percentage downloaded or something like that - I'm not seeing the terminal just fill up with garbage instead of a dynamically updating download notification. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pymod.find_installation with modules is broken on conda Windows since 0.63.0 **Describe the bug** Today I observed while updating the [xraylib conda-forge feedstock](https://github.com/conda-forge/xraylib-feedstock/pull/40) that the build fails while trying to execute `pymod.find_installation(get_option('python'), modules: ['numpy',])` on Windows, when using meson 0.63.x I did a bit of debugging and realised that the command works fine, as long as I do not add the modules kwarg (which is not a realistic option for me though): the python interpreter is found but it fails at loading the requested modules. Since this build works fine for 0.62.x, I had a look at the changes that could have led to this, and realised quickly that https://github.com/mesonbuild/meson/pull/10309 is the culprit: I confirmed this with a custom build of meson 0.63.1 with the patch from that PR reverted. **To Reproduce** You will need to create a Windows conda environment with meson, ninja and numpy installed from the conda-forge channel, and I expect that any `meson.build` file containing: ```meson pymod = import('python') python = pymod.find_installation(get_option('python'), modules: ['numpy',]) ``` will error out. **Expected behavior** I expected the same behaviour from older releases **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? No * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) Windows 10 * what Python version are you using: 3.7, 3.8, 3.9 and 3.10 * what `meson --version`: 0.63.1 * what `ninja --version` if it's a Ninja build: 1.11.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add ability to pull snippets when generating JSON documentation We have a lot of great snippet code that we should be able to include when we generate docs. See: [pubsub_snippets.py](https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/docs/pubsub_snippets.py) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: DAG.width needs to be updated to match QuantumCircuit definition <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? ```python qr = QuantumRegister(5,'qr') cr = ClassicalRegister(5, 'cr') ghz = QuantumCircuit(qr, cr, name='ghz') ghz.h(qr[2]) ghz.cx(qr[2], qr[1]) ghz.cx(qr[1], qr[0]) ghz.cx(qr[2], qr[3]) ghz.cx(qr[3], qr[4]) ghz.draw() ghz_dag = circuit_to_dag(ghz) print(ghz.width(), ghz_dag.width()) ``` gives: `(10, 5)`. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions DAG width needs to count both qubits and cbits for self-consistency. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [docs] TrainingArguments default label_names is not what is described in the documentation ### System Info - `transformers` version: 4.25.1 - Platform: macOS-12.6.1-arm64-arm-64bit - Python version: 3.8.15 - Huggingface_hub version: 0.11.1 - PyTorch version (GPU?): 1.13.1 (False) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: <fill in> - Using distributed or parallel set-up in script?: No ### Who can help? @sgugger, @stevhliu and @MKhalusova ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction 1. Create a model with a `forward` that has more than one label. For example: ``` def forward( self, input_ids, bbox, attention_mask, token_type_ids, labels, reference_labels ) ``` 2. Create a trainer for your model with `trainer = Trainer(model, ...)`. Make sure to not set `label_names` and let it default. 3. Check `trainer.label_names` and see that it returns `[\"labels\", \"reference_labels\"]` ### Expected behavior [The documentation](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Seq2SeqTrainingArguments.label_names) states that: > Will eventually default to [\"labels\"] except if the model used is one of the XxxForQuestionAnswering in which case it will default to [\"start_positions\", \"end_positions\"]. [This PR](https://github.com/huggingface/transformers/pull/16526) changed the behaviour that the documentation describes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: security_opt and seccomp I'd like to make a `docker-compose.yml` containing something like this: ```yaml services: desktop: security_opt: - seccomp:\"./chrome.json\" ``` This would correspond to the `docker run` option `--security-opt seccomp:./chrome.json`, where [`chrome.json` is this seccomp profile](https://raw.githubusercontent.com/jfrazelle/dotfiles/master/etc/docker/seccomp/chrome.json). Is there any way to give the `seccomp` key an arbitrary JSON string? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Firestore] Field Path escaping in python doesn't match other languages There are no FieldPath overloads in the SDK. Instead, there is a field_path() method that returns an encoded string. While the Python SDK expects fully escaped field paths, other SDKS escape user-provided field paths by default and split on dots for this escaping. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Subscriber can effectively deadlock itself when there are pending requests. Due to emergent behavior between three different systems: 1. Re-establishing the stream on error. 2. Pausing the stream when over load. 3. Factoring request queue size in load. The subscriber can deadlock itself if it tries to re-establish a stream while the stream is paused due to request pressure, for example: ``` ===== Subscriber Monitor ===== Messages processed: 1659 Rate: 0.82 Messages/second Run time: 0:33:35.001386 Load: 1.67 p99 ack: 299 seconds Leased Messages: 0 Executor queue size: 0 Callback queue size: 0 Request queue size: 167 ``` The load is `1.67` because there are `167` requests which means the stream is *paused*. Because the stream is paused when the consumer tries to restart the stream the RPC is never started because to *start* the RPC the iterator must at least be started and the request iterator is blocked on the load going down. It won't go down because it *can't* send requests until the RPC is started. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: TestF77Callback::test_all[t] fails: fatal error: threads.h: No such file or directory <!-- Please describe the issue in detail here, and fill in the fields below --> ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ``` pytest -sv numpy/f2py/tests/test_callback.py -k 'test_all[t]' -r s -x ``` ### Error message: <!-- If you are reporting a segfault please include a GDB traceback, which you can generate by following https://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging --> <!-- Full error message, if any (starting from line Traceback: ...) --> ``` E /tmp/tmphz3v9phb/src.linux-x86_64-3.9/_test_ext_module_5403module.c:75:10: fatal error: threads.h: No such file or directory E 75 | #include <threads.h> E | ^~~~~~~~~~~ E compilation terminated. ``` ### NumPy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> ``` >>> import sys, numpy; print(numpy.__version__, sys.version) 1.21.0.dev0+438.gbf4ac1f81 3.9.1 | packaged by conda-forge | (default, Jan 10 2021, 02:55:42) [GCC 9.3.0] ``` ### Additional information ``` $ ldd --version ldd (Ubuntu GLIBC 2.27-3ubuntu1.2) 2.27 Copyright (C) 2018 Free Software Foundation, Inc. ``` C11 threads.h appears to be supported starting from glibc 2.28, see [here](https://sourceware.org/bugzilla/show_bug.cgi?id=14092#c10). Undefining CPP macro F2PY_THREAD_LOCAL_DECL makes the test pass. A solution is not to define F2PY_THREAD_LOCAL_DECL for glibc version < 2.28 in numpy/f2py/cfuncs.py . Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: State Visualizations have inconsistent return types in the docs ### Environment - **Qiskit Terra version**: Current versions of docs as of 2pm ET on June 26, 2023 https://qiskit.org/documentation/apidoc/visualization.html#state-visualizations https://github.com/Qiskit/qiskit-terra/blob/791a45433a21a5604086bfcd96d804433b8aecfe/qiskit/visualization/state_visualization.py ### What is happening? All state visualizations return a matplotlib.Figure. However, some docstrings report this as a `Figure`, some as a `matplotlib.Figure`. ex: https://qiskit.org/documentation/stubs/qiskit.visualization.plot_bloch_vector.html#qiskit.visualization.plot_bloch_vector ex: https://qiskit.org/documentation/stubs/qiskit.visualization.plot_state_hinton.html#qiskit.visualization.plot_state_hinton The inconsistency is a bit confusing (for example, a user might wonder if there's a difference between a Figure and matplotlib.Figure). ### How can we reproduce the issue? Check the docs: https://qiskit.org/documentation/apidoc/visualization.html#state-visualizations https://github.com/Qiskit/qiskit-terra/blob/791a45433a21a5604086bfcd96d804433b8aecfe/qiskit/visualization/state_visualization.py ### What should happen? Ideally, all would list a common return type. ### Any suggestions? I'm happy to submit a PR to update all return types to `matplotlib.Figure` if that's the agreed-upon solution. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Super easy fix: backend_version should be backend_name, Result.__repr__ <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.16.0 - **Python version**: 3.8 - **Operating system**: Linux ### What is the current behavior? When initializing a Result object with argument `(backend_name='backend_name', backend_version=\"0.0.0\"...)` the repr prints backend_name as \"0.0.0\" (whatever the version is) ### Steps to reproduce the problem Initialize a Result object with a backend_name and backend_version argument and print a __repr__ ### What is the expected behavior? Obviously they should be different ### Suggested solutions In https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/result/result.py lines 62-68: ``` def __repr__(self): out = (\"Result(backend_name='%s', backend_version='%s', qobj_id='%s', \" \"job_id='%s', success=%s, results=%s\" % ( self.backend_version, self.backend_version, self.qobj_id, self.job_id, self.success, self.results)) ``` The first `self.backend_version` should be `self.backend_name`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Make prompt_toolkit history search configurable We currently hard-code it on, but people may want to disable it. https://github.com/ipython/ipython/blob/8008eda4a856dd2e8c6dcae21d651d36ce52c683/IPython/terminal/interactiveshell.py#L245 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Functionality to pass first few tokens as input to the decoder in T5 model I am finetuning the T5 model on a downstream sequence to sequence task. I wanted to know if it is possible to pass first few tokens as input to the T5 decoder during inference (like it is done in text generation models) apart from the input provided to the encoder? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Incorrect compiler detection for `clang` with `--gcc-toolchain={}` option When setting e.g. ``` CC=\"clang-9 --gcc-toolchain=/usr/lib/gcc/x86_64-linux-gnu/9\" CXX=\"clang++-9 --gcc-toolchain=/usr/lib/gcc/x86_64-linux-gnu/9\" ``` Conan will autodetect `gcc` as the compiler because of this line: https://github.com/conan-io/conan/blob/0eea418adf86a93ad3a9547be6e16a3c980ffc4b/conans/client/conf/detect.py#L78 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: fix overwriting modes in project like IJulia Current IJulia custom.js works by setting the right option of CodeCell , but do not have (yet) kernelspec. This leads to master not using the mode set by IJulia, and defaulting to 'null' which remove highlight. This seem to do the trick by leaving default highliht mode and/or respecting metadata.language which is set by alot of projects. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: SONAME fails to match library name The shared_library argument name_prefix that can be used to e.g. strip 'lib' from the library name of a dynamic module isn't reflected in the actual SONAME. Linker lookups rely on SONAME to match library file names, so this potentially breaks DSO dependencies. A test case exists already in 'meson/test cases/python3/2 extmodule': test cases/python3/2 extmodule>$ mkdir b && meson.py b && ninja -C b && objdump -p b/ext/tachyon.so | fgrep SONAME [...] [2/2] Linking target ext/tachyon.so SONAME libtachyon.so Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: compose 1.5.0rc1 fails to work on something that works with 1.4.2 see https://github.com/docker/docs.docker.com/tree/hugo-github-linking if you checkout the `hugo-github-linking` branch, and run with 1.5.0rc1 you get: ``` 15:26 $ make clean docker-compose -p docsdockercom rm -fv ; \\ docker rmi $( docker images | grep -E '^docsdockercom_' | awk '{print $1}' ) 2>/dev/null ||: The AWS_S3_BUCKET variable is not set. Substituting a blank string. Invalid interpolation format for \"command\" option in service \"cleanup\": \"/bin/bash -c ' \\ if [[ \"$AWS_S3_BUCKET\" =~ \"/\" ]] ; then BUCKET_PATH=$( echo \"$AWS_S3_BUCKET\" | sed \"s/[^\\/]*\\///\" ) BUCKET_PATH+=\"/\" AWS_S3_BUCKET=$( echo \"$AWS_S3_BUCKET\" | sed \"s/\\/.*//\") else BUCKET_PATH= fi [ -z \"$RM_OLDER_THAN\" ] && exit 1 CUTOFF_UNIX_TS=$( date --date \"$RM_OLDER_THAN\" '+%s' ) aws s3 ls --recursive s3://$AWS_S3_BUCKET/$BUCKET_PATH | while read -a LINE ; do DATE=\"${LINE[0]}\" TIME=\"${LINE[1]}\" SIZE=\"${LINE[2]}\" NAME=\"${LINE[*]:3}\" VERSION_REGEX=\"^${BUCKET_PATH}v[0-9]+\\.[0-9]+/\" UNIX_TS=$( date --date \"$DATE $TIME\" \"+%s\" ) if [[ \"$NAME\" =~ $VERSION_REGEX ]] || [[ \"$CUTOFF_UNIX_TS\" -le \"$UNIX_TS\" ]] ; then echo \"Keeping $NAME\" continue fi echo \"Creating redirect for $NAME\" aws s3 cp \"s3://$AWS_S3_BUCKET/$NAME\" \"s3://$AWS_S3_BUCKET/$NAME\" --website-redirect=\"/${BUCKET_PATH}index.html\" --acl=public-read > /dev/null done ' \" docker rmi -f docsdockercom:latest 2>/dev/null ||: ✔ ~/src/docs.docker.com [hugo-github-linking|…5⚑ 3] ``` when using compose 1.4.2, you get: ``` 15:29 $ make clean docker-compose -p docsdockercom rm -fv ; \\ docker rmi $( docker images | grep -E '^docsdockercom_' | awk '{print $1}' ) 2>/dev/null ||: No stopped containers docker rmi -f docsdockercom:latest 2>/dev/null ||: ✔ ~/src/docs.docker.com [hugo-github-linking|…5⚑ 3] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda install from file fails in version 4.1 I've recently installed linux-32 conda on CentOS 6.2. I confirmed this on linux-64 version as well. If I run: `conda install ./FILE_1.tar.bz2`, I always get the error: `Fetching package metadata ...Error: Could not find URL: file:///root/dir1/ ` If i downgrade to conda 4.0.8, it works fine. Here's the command with the added `--debug` option: ``` $ conda --debug install ./FILE_1.tar.bz2 DEBUG:conda.fetch:channel_urls={'file:///root/dir1/': ('file:///root', 0)} Fetching package metadata ...INFO:stdoutlog:Fetching package metadata ... DEBUG:requests.packages.urllib3.util.retry:Converted retries value: 3 -> Retry(total=3, connect=None, read=None, redirect=None) DEBUG:conda.fetch:Could not find URL: file:///root/dir1/ Error: Could not find URL: file:///root/dir1/ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for `Expr` values to `QuantumCircuit.compose` ### What should we add? Once `Expr` values are allowable in some attributes in `QuantumCircuit` operations, we need to ensure that `QuantumCircuit` methods take them into account. For the minimal set of expressions described in [the initial classical-expression design document](https://github.com/Qiskit/RFCs/blob/master/0010-simple-classical-representations.md), the necessary \"register-mapping\" logic should be _largely_ the same as already exists, but the mapping will need to rebuild the expression tree fully as well. Depends on #10223 and #10224. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: \"setup.py\" does not seem to have been updated for v3.5.1 ## Environment info I try ``` !git clone https://github.com/huggingface/transformers.git %cd transformers/ !pip install -e . ``` on Colaboratory. - `transformers` version: 3.5.0 <- this seems strange. - Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.6.9 - PyTorch version (GPU?): 1.7.0+cu101 (True) - Tensorflow version (GPU?): 2.3.0 (True) - Using GPU in script?: <fill in> - Using distributed or parallel set-up in script?: <fill in> ### Who can help documentation: @sgugger ## Information \"setup.py\" does not seem to have been updated for v3.5.1. When I install transformers by `pip install -e .`, the version of transformers is shown as v3.5.0. ## To reproduce Steps to reproduce the behavior: I try ``` !git clone https://github.com/huggingface/transformers.git %cd transformers/ !pip install -e . ``` on Colaboratory after v3.5.1 release. Then, ``` import transformers transformers.__version__ ``` returns ``` '3.5.0' ``` ## Expected behavior The return of `transformers.__version__` is expected to be '3.5.1' now, if my understanding is not wrong. Maybe, in https://github.com/huggingface/transformers/blob/afb50c663a5d5623906ead1e87481926467d59fa/setup.py#L120 '3.5.0' should be changed to '3.5.1'. Is my understanding correct? Sorry if I misunderstand your intension. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Fallback frontend for console when connecting pylab=inlnie -enabled kernel? Hi, I recently updated from 0.10 to 0.12 and I have been enjoying ipython a lot! One thing I couln't find in the IPython manual is the way to display figure when I call plot function in the ipython console which is connected to the notebook server. Isn't it good to have a fallback frontend, for example using TkAgg in the console when the kernel is started with pylab=inline? Or if it is not an easy solution, maybe jsut write the data into a temp file and call some external viewer? Actually, this is better soltion for me if uer can configure the viewer because I can view the image in Emacs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Pruning function in T5Attention doesnt affect _relative_position_bucket ### Who can help? @patrickvonplaten ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Run pruning function in t5 model, then run inference. ### Expected behavior Relative position head should be pruned too. Here it is https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py#L355 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: Repr of 0d timedelta fails ```python >>> np.array(np.timedelta64('NaT')) ~\\Repos\\numpy\\build\\testenv\\Lib\\site-packages\\numpy\\core\\arrayprint.py in __init__(self, data) 1086 else: 1087 max_str_len = 0 -> 1088 if len(v) < len(data): 1089 # data contains a NaT 1090 max_str_len = max(max_str_len, 5) TypeError: len() of unsized object ``` Replacing with `data.size` should do the trick. We could also probably use `isnat` in this function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Eager Application Synchronous Subtask Guard Blocks Canvas ## Checklist - [x] I have included the output of ``celery -A proj report`` in the issue. (if you are not able to do this, then at least specify the Celery version affected). - [x] I have verified that the issue exists against the `master` branch of Celery. ## Steps to reproduce ``` celery -A minimal_eager_chain report software -> celery:4.2.0 (latentcall) kombu:4.1.0 py:2.7.13 billiard:3.5.0.3 py-amqp:2.2.2 platform -> system:Linux arch:64bit imp:CPython loader -> celery.loaders.app.AppLoader settings -> transport:amqp results:disabled ``` Minimal script to reproduce: https://gist.github.com/npilon/9f3c8469a615081fc8454359945eebd7 ## Expected behavior - No error occurs ## Actual behavior - We trip the synchronous subtask alarm: ``` >>> test.delay().get() Traceback (most recent call last): File \"<console>\", line 1, in <module> File \"/home/npilon/Documents/celery/celery/result.py\", line 949, in get raise self.result RuntimeError: Never call result.get() within a task! See http://docs.celeryq.org/en/latest/userguide/tasks.html#task-synchronous-subtasks ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: CLI Cloud Preparation The `prefect` CLI needs some enhancements to handle communication with the execution cluster (all which route through the client). - [x] Build environment from flow env - [x] Serialized flow from serialized registry - [x] Container shipment to registry - [x] Configuration / Access permissions - [x] Flow running / execution Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [cmake][clang] compiler version check fails when `compiler.version` is different as `major.minor` Conan Version 1.5.2 Compiler: Clang-based The compiler version check in the generated `conanbuildinfo.cmake` file (`check_compiler_version` function) extracts the major and minor version components from `CMAKE_CXX_COMPILER_VERSION` and compares them against `CONAN_COMPILER_VERSION`. This works fine when the `compiler.version` also consists of exactly `major.minor`. However, as soon as, for example, a more specific version like `major.minor.patch` is specified the check incorrectly fails even though the versions do actually match exactly. In the specific case where I encountered this error a custom llvm/clang compiler with the version `6.99.1` has been used. CMake correctly recognises the version and provides `6.99.1` in `CMAKE_CXX_COMPILER_VERSION`. However, when `compiler.version = 6.99.1` is specified in the associated profile (and white-listed in the `settings.yml`), configuring the project fails with the following error: ~~~ Incorrect 'clang' version 'compiler.version=6.99.1' is not the one detected by CMake: 'Clang=6.99 ~~~ Of course, as workaround, I can specify `compiler.version=6.99` to match conan's expectations that `compiler.version` adheres to `major.minor`. However, it is clearly a bug to report a version mismatch when the versions actually match perfectly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ConsolidateBlocks pass drops classical conditionals From https://travis-ci.com/Qiskit/qiskit-terra/jobs/213175981#L4994 : ``` >>> import qiskit as qk >>> qc = qk.QuantumCircuit(1,1) >>> qc.h(0).c_if(qc.cregs[0], 1) >>> qc.measure(0, 0) >>> print(qc) ┌───┐ ┌─┐ q_0: |0>─┤ H ├─┤M├ └─┬─┘ └╥┘ ┌──┴──┐ ║ c_0: 0 ╡ = 1 ╞═╩═ └─────┘ >>> print(qk.transpile(qc, optimization_level=3)) ┌───┐┌─┐ q_0: |0>┤ H ├┤M├ └───┘└╥┘ c_0: 0 ══════╩═ >>> print(qk.transpile(qc, optimization_level=2)) ┌───┐ ┌─┐ q_0: |0>─┤ H ├─┤M├ └─┬─┘ └╥┘ ┌──┴──┐ ║ c_0: 0 ╡ = 1 ╞═╩═ └─────┘ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigTable: google-cloud-bigtable 0.30.0 throws InvalidChunk error while iterating through a large collection Python version: 3.6.3 google-cloud-bigtable 0.30.0 After switching to 0.30.0 and adapting my code to use the newly integrated iter function of PartialRowsData, I can't iterate through a large collection without the InvalidChunk error being thrown. Sample code: ``` rows = table.read_rows() for r in row: ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Neptune logger with a validation epoch end conflict due to the 'epoch' key added on the fly. Hi everybody! First thanks for this lib, it is very handy! ## 🐛 Bug When using pytorch lightning in conjunction with the neptune logger, one can see this kind of error popping every time an epoch ends: ` neptune.api_exceptions.ChannelsValuesSendBatchError: Received batch errors sending channels' values to experiment SOC-114. Cause: Error(code=400, message='X-coordinates must be strictly increasing for channel: e4e2635d-b707-46fa-9a1b-996dd009790f. Invalid point: InputChannelValue(timestamp=2020-08-13T11:55:38.422Z, x=5.0, numericValue=2.0, textValue=null, image', type=None) (metricId: 'e4e2635d-b707-46fa-9a1b-996dd009790f', x: 5.0) Skipping 1 values. ` the import part in this error is the following line: `X-coordinates must be strictly increasing` This is because, in `trainer/logging.py`, the `epoch` key is added on the fly on line 69: ```python scalar_metrics['epoch'] = self.current_epoch ``` But why does Neptune complains? If you log all the timesteps (using `row_log_interval = 1`), at the end of an epoch, 2 calls are emitted to the logger: One to log the training logs and one for the validation logs. Both of those have the same `step` value which is the current training `step` value. Since the key `epoch` is duplicated in both those calls, Neptune receives the key `epoch` twice with the same `step` value leading to the exception. ### To Reproduce launch training with: - Neptune logger - training logs - validation logs - row_log_interval=1 ### Expected behaviour Don't add the `epoch` key on the fly which force the logger to log it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: CTRL backslash sends QUIT signal but freezes the terminal A convenient way to quit Ipython and kill the debugged process is to press CTRL \\ (backslash). Once pressed, the two exit but the terminal freezes. I can type commands, press enter and see the result but I can't see the command I'm typing. Is there any problem with STD OUT redirection after the signal is sent? I tested on gnome-terminal and xterm with bash Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: Add method(s) to parse `gs://bucket_name` and `gs://bucket_name/path/to/blob` URIs It would be very convenient if we could take a string such as `gs://bucket_name/path/to/blob` and download the content for it. I propose we add a `Blob.from_string` classmethod, similar to BigQuery's [`TableReference.from_string` method](https://googleapis.github.io/google-cloud-python/latest/bigquery/generated/google.cloud.bigquery.table.TableReference.html#google.cloud.bigquery.table.TableReference.from_string). Since the `Blob` class requires a client object (via Bucket) to support downloads, I suggest both `path` and `client` are required arguments for `Blob.from_string(path, client)`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Return the new Key/Blob from gcloud.storage.bucket.upload_file_obj() Right now it doesn't appear that [gcloud.storage.bucket.upload_file_object()](https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/storage/bucket.py#L415) returns anything. This is in contrast to [gcloud.storage.bucket.upload_file()](https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/storage/bucket.py#L375), which does return the new blob. It would be much handier if the newly created Key/Blob was returned instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Disentangle import cycles Some local non-testing imports are explicitly marked as related to cycles: ``` $ git grep -n circular gcloud/datastore/dataset.py:125: # This import is here to avoid circular gcloud/datastore/entity.py:157: # This is here to avoid circular imports. ``` Others are not so marked: ``` gcloud/datastore/__init__.py:64: from gcloud import credentials gcloud/datastore/__init__.py:65: from gcloud.datastore.connection import Connection gcloud/datastore/dataset.py:73: from gcloud.datastore.query import Query gcloud/datastore/dataset.py:86: from gcloud.datastore.entity import Entity gcloud/datastore/dataset.py:99: from gcloud.datastore.transaction import Transaction gcloud/storage/__init__.py:65: from gcloud import credentials gcloud/storage/__init__.py:66: from gcloud.storage.connection import Connection gcloud/storage/iterator.py:158: from gcloud.storage.bucket import Bucket gcloud/storage/iterator.py:186: from gcloud.storage.key import Key ``` We should refactor to fix the cycles, allowing us to normalize those imports. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Environment Variables in volumes trigger named volume warning Warning added in #1833 is triggered by volumes starting with environment variables (e.g. `${VOLUME_DIR}:/var/stuff`). How would we know whether the env-var was a name or a path? Is there a way to wait to test for `.~/` until after env-vars are evaluated? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] Unclear how to use transitive python_requires The documentation at https://docs.conan.io/en/latest/extending/python_requires.html#resolution-of-python-requires states that: > python-requires can python-require other recipes too, but this should probably be limited to very few cases, we recommend to use the simplest possible structure. But it is unclear how that should work. I made an example where I define a base class in a python_requires module. This base class uses a helper function from another python_requires module. How can I transitively define that the base class has another python_requires? At the moment I can only get it to work by specifying all python_requires explicitly in the consumer. Example: [transitive-python_requires.tar.gz](https://github.com/conan-io/conan/files/6035128/transitive-python_requires.tar.gz) To run the example: - `conan export shared-function` - `conan export base-class` - `conan create consumer` It will fail with: ``` ERROR: consumer/1.0.0: Error in requirements() method, line 8 assert self.python_requires[\"shared-function\"].module.helper(1, 2) == 3 ConanException: 'shared-function' is not a python_require ``` Alternatively, using the old python_requires method results in a crash. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: bug in latex drawer barrier <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When drawing this circuit, the barrier on the last qubit is not respected. ```python from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit from qiskit.tools.visualization import circuit_drawer q = QuantumRegister(3, 'q') c = ClassicalRegister(3, 'c') circ = QuantumCircuit(q, c) circ.x(q[0]) circ.x(q[1]) circ.barrier(q) circ.measure(q, c) circuit_drawer(circ, output='latex') ```  The `mpl` drawer works fine. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Update `qiskit.utils.wrap_method` for Python 3.11 (backport #9310) This is an automatic backport of pull request #9310 done by [Mergify](https://mergify.com). --- <details> <summary>Mergify commands and options</summary> <br /> More conditions and actions can be found in the [documentation](https://docs.mergify.com/). You can also trigger Mergify actions by commenting on this pull request: - `@Mergifyio refresh` will re-evaluate the rules - `@Mergifyio rebase` will rebase this PR on its base branch - `@Mergifyio update` will merge the base branch into this PR - `@Mergifyio backport <destination>` will backport this PR on `<destination>` branch Additionally, on Mergify [dashboard](https://dashboard.mergify.com/) you can: - look at your merge queues - generate the Mergify configuration with the config editor. Finally, you can contact us on https://mergify.com </details> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Lockfiles of packages without user/channel have _ The lockfile contains: ``` \"graph_lock\": { \"nodes\": { \"3e78db6e-de3d-11e9-bfb7-84fdd15e6b30\": { \"pref\": \"test4/0.1@_/_:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9\", \"options\": \"\" } } ``` Should it drop the user/channel with _? Should that be used exclusively for paths and folders? Right now it seems there is no support for something that is able to dump ``PackageReference`` including the revisions but dropping None user/channel. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Make use of KenLM's pypi version ### Feature request Use PyPi version of KenLM instead of installing archieve file from Github. ### Motivation Now that kenlm is on pypi: https://github.com/kpu/kenlm/issues/363#issuecomment-1280050903 let's use it :-) ### Your contribution @sanchit-gandhi would you give this a try as an exercise to see how we deal with soft dependencies in Transformers maybe? :-) I think we can now update the `setup.py` file to include the pypi version of `kenlm` and remove all those `pip install https://github.com/kpu/kenlm/archive/master.zip` statements e.g. in https://github.com/huggingface/transformers/blob/c7edde1a692012eda23bc2b837588557b97ad729/docker/transformers-all-latest-gpu/Dockerfile#L44 I'd also advocate to add a `is_kenlm_available` flag to give a nice error message and update warnings / errors here: https://github.com/huggingface/transformers/blob/c7edde1a692012eda23bc2b837588557b97ad729/src/transformers/pipelines/__init__.py#L839 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose exec -d (detached) doesn't return control of terminal According to the documentation `docker-compose exec -d` should run in detached mode, but after running with -d the control of the terminal is not returned. Am I missing something? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: What is IPython.utils.upgradedir ? Can we delete `IPython.utils.upgradedir`? It doesn't appear to be used by anything except one import test: ``` py def test_import_upgradedir(): from IPython.utils import upgradedir ``` ``` $ egrep -rl upgradedir * IPython/utils/tests/test_imports.py ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Remove cyclic imports or just stop worrying and love the bomb See #477 for context. Relevant [code](https://github.com/GoogleCloudPlatform/gcloud-python/blob/2b4f52f9991348f262ca6d9fa1d987012ad2b087/gcloud/datastore/key.py#L231) and pylint [config](https://github.com/GoogleCloudPlatform/gcloud-python/blob/2b4f52f9991348f262ca6d9fa1d987012ad2b087/pylintrc_default#L76-L85). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: config` includes python objects instead of string `PS C:\\Users\\Administrator\\test> docker-compose version docker-compose version 1.6.0dev, build 304a44a docker-py version: 1.6.0 CPython version: 2.7.11 OpenSSL version: OpenSSL 1.0.2d 9 Jul 2015` Given the docker-compose.yml: ``` my_nginx: build: . ports: - 8080:80 volumes: - \".\\testdir:\\foo\" ``` docker-compose config ``` PS C:\\Users\\Administrator\\test> docker-compose config my_nginx: build: !!python/unicode 'C:\\Users\\Administrator\\test' ports: - 8080:80 volumes: - !!python/object/new:compose.config.types.VolumeSpec - !!python/unicode '/c/Users/Administrator/test/testdir' - !!python/unicode '/foo' - !!python/unicode 'rw' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose failed if is in path what contains dir starting on `_` ## Description of the issue docker-compose failed if is in path what contains dir starting on `_` ## Context information (for bug reports) can run docker-compose build if `docker-compose.yml` is in `_docker` dir as in before version getting ERROR: invalid reference format when I rename dir `_docker` to `docker` everything run good ``` docker-compose version 1.21.1, build 5a3f1a3 docker-py version: 3.3.0 CPython version: 3.6.4 OpenSSL version: OpenSSL 1.0.2o 27 Mar 2018 ``` ``` Client: Version: 18.03.1-ce API version: 1.37 Go version: go1.9.5 Git commit: 9ee9f40 Built: Thu Apr 26 07:13:02 2018 OS/Arch: darwin/amd64 Experimental: false Orchestrator: swarm Server: Engine: Version: 18.03.1-ce API version: 1.37 (minimum version 1.12) Go version: go1.9.5 Git commit: 9ee9f40 Built: Thu Apr 26 07:22:38 2018 OS/Arch: linux/amd64 Experimental: true ``` ## Steps to reproduce the issue 1. move docker-compose.yml (contains service: build: .... ) to _docker dir 2. run docker-compose build ## Additional information Docker for Mac: version: 18.03.1-ce-mac65 (dd2831d4b7421cf559a0881cc7a5fdebeb8c2b98) macOS: version 10.13.4 (build: 17E202) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Disabling validation with val_percent_check=0.0 not working <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug I am trying to train on a small subset of data by settting `train_percent_check` and `val_percent_check` flags. I am not able to disable validation by setting `ver_percent_check=0.0`. Despite it being set to 0, `validation_epoch_end` is executed. <!-- A clear and concise description of what the bug is. --> ### To Reproduce Steps to reproduce the behavior: Running the MNIST model on the Google Colab link <!-- If you have a code sample, error messages, stack traces, please provide it here as well --> <img width=\"1068\" alt=\"Screen Shot 2020-03-26 at 11 06 16 AM\" src=\"https://user-images.githubusercontent.com/4838833/77662280-0c256480-6f52-11ea-873c-7a9d41bf347c.png\"> #### Code sample <!-- Ideally attach a minimal code sample to reproduce the decried issue. Minimal means having the shortest code but still preserving the bug. --> ``` mnist_model = MNISTModel() # most basic trainer, uses good defaults (1 gpu) trainer = pl.Trainer(gpus=1, val_percent_check=0.0, train_percent_check=0.1) trainer.fit(mnist_model) ``` ### Expected behavior <!-- A clear and concise description of what you expected to happen. --> I expected the `validation_epoch_end` to not be invoked but it is. ### Environment Running on Google Colab with the sample MNIST tutorial Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Fix broken references to old auth doc See #3517 and https://github.com/GoogleCloudPlatform/google-cloud-python/commit/7cb86b47acea2339c6c18cb70189d2b0c347ec5e#commitcomment-22758235 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: error when adding nvbench as subproject Hello, I'm just getting started with meson and would like to add [nvbench](https://github.com/NVIDIA/nvbench) as a subproject in my meson project using the `cmake` module. Following the examples in the documentation, I cloned the `nvbench` repo under `subprojects` and added the following lines to my top-level meson.build file. ```python cmake = import('cmake') opt_var = cmake.subproject_options() opt_var.add_cmake_defines({'CMAKE_CUDA_ARCHITECTURE': 70}) nvbench_proj = cmake.subproject('nvbench', options: opt_var) ``` However, when running `meson setup`, we seem to get through the cmake configure process just fine and fail with the following error: ```txt subprojects/nvbench/meson.build:0:0: ERROR: File nvbench does not exist ``` I can see the generated meson.build file under `builddir/subprojects/nvbench`, but I'm not sure what the next steps are from there. Any help would be appreciated! OS: Ubuntu 20.04 Meson version: 0.62.0 cmake version: 3.22.3 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Statevector.evolve works incorrectly for subsystem evolution on mixed-dimension subsystems ### Environment - **Qiskit Terra version**: 0.21 - **Python version**: All - **Operating system**: All ### What is happening? `Statevector.evolve` returns the incorrect answer when evolving certain subsystems if the statevector has mixed dimension subsystems. This is due to it incorrectly reshaping the temporary transposed tensors during the evolution contraction when flattening back to a returned statevector. ### How can we reproduce the issue? ```python import qiskit.quantum_info as qi import numpy as np # Mixed dimension statevector dims = (3, 4, 5) state = qi.random_statevector(dims, seed=123) # Evolve subsystem zero by an operator op = qi.random_unitary(dims[:1], seed=123) evo = state.evolve(op, [0]) # Compare to full system evolution mat = op.expand(np.eye(np.prod(dims[1:]))).data target = qi.Statevector(np.dot(mat, state.data), dims) # Fidelity should be 1 qi.state_fidelity(evo, target) 0.011873940293697585 ``` ### What should happen? If things were working correctly the above code snippet should return a fidelity of 1 ### Any suggestions? The error is in the `Statevector._evolve_operator` method where one of the `np.reshape` instructions is given an incorrect dimension specification in certain cases where there are >= 2 non-evolved subsystems with different dimensions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: FeaturesManager assumes only one of Torch or TensorFlow is installed ## Environment info - `transformers` version: 4.12.5 - Platform: macOS-10.16-x86_64-i386-64bit - Python version: 3.9.10 - PyTorch version (GPU?): 1.10.0 (False) - Tensorflow version (GPU?): 2.8.0 (False) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help @michaelbenayoun @Albertobegue ## Information When both Torch and TensorFlow are installed, `FeaturesManager` defaults to using `AutoModel`, so the model returned by `get_model_from_feature` is always Torch. ## To reproduce Steps to reproduce the behavior: 1. Install Torch and TF 2. Call `FeatureManager.get_model_from_feature` with arbitrary but supported `features` and `model_name` arguments 3. The resulting model is always a Torch model ```python features = \"default\" # randomly chosen, supported feature model_name = \"bert\" # randomly chosen, supported model model = FeaturesManager.get_model_from_feature(features, model_name) ``` ## Expected behavior Some test environments have both Torch and TensorFlow installed, because the immediate task is to ensure functionality is the same regardless of the framework. I would expect `FeaturesManager.get_model_from_feature` to allow TensorFlow to be used even when Torch is installed. This could be implemented by e.g. a keyword argument to `get_model_from_feature` with a default value of `None`. When the keyword argument is `None`, and both Torch and TensorFlow are installed, `FeatureManager` would default to Torch, as it does now. Otherwise, it would use the specified framework. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Local simulators return n_qubits that is supported by local memory <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently the simulator backends do not have a `n_qubits` key in their configuration (#1047), whereas the spec says that `n_qubits=-1` for a simulator. Would it not make sense to have local simulators return `n_qubits=N_max`, where `N_max` is the max number of qubits supported by the local memory? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [pipeline] Explicitly set framework is ignored ### System Info - `transformers` version: 4.30.2 Omitting the rest because they aren't really relevant. Can submit later if needed. ### Who can help? @Narsil ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ``` from transformers import pipeline from transformers import WhisperProcessor, WhisperForConditionalGeneration processor = WhisperProcessor.from_pretrained(\"openai/whisper-tiny\") model = WhisperForConditionalGeneration.from_pretrained(\"openai/whisper-tiny\") # Using this just to make sure an error if thrown if pipeline tries to check using module instead of specified framework. class FakeWhisper: def __getattr__(self, item): return model.__getattr__(item) pipe = pipeline( \"automatic-speech-recognition\", model=FakeWhisper(), tokenizer=processor.tokenizer, feature_extractor=processor.feature_extractor, chunk_length_s=30, device=model.device, framework=\"pt\", ) ``` The above code raises this error: ``` TypeError: Could not infer framework from class <class '__main__.FakeWhisper'>. ``` ### Expected behavior When specifying the framework explicitely, there is no need to infer it from the module of the model class, as mentioned here: https://github.com/huggingface/transformers/blob/main/src/transformers/pipelines/__init__.py#L784-L796 But then, inside `infer_framework_load_model`, `infer_framework` is called regardless of the value of the `framework` parameter: https://github.com/huggingface/transformers/blob/main/src/transformers/pipelines/base.py#L280 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: ReadOptions support for 'Connection.lookup', 'Connection.run_query' The protobuf specs for the [lookup RPC](https://github.com/GoogleCloudPlatform/google-cloud-datastore/blob/v1beta2-rev1-2.1.0/proto/datastore_v1.proto#L439) and the [runQuery RPC](https://github.com/GoogleCloudPlatform/google-cloud-datastore/blob/v1beta2-rev1-2.1.0/proto/datastore_v1.proto#L465) show an optional 'read_options' field, which denominate the consistency level and optional transaction to be used. Do we need to support this field? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: cmake_find_package generator do not include system libraries If the library is not found (with find_library()) is not adding it to the target (nor the global lib list) so it fails linking if the package is declaring system libs (as ws2_32 or pthread) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: tf.matrix_band_part have been deprecated https://github.com/huggingface/transformers/blob/fae0b9faefc371977d139b60202a63dcedbd8ea8/src/transformers/models/xlnet/modeling_tf_xlnet.py#L500 This should be replaced by `tf.linalg.band_part` here? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Documentation related to token_type_ids for RoBERTa needs to be updated ### System Info This is about online documentation at https://huggingface.co/docs/transformers/v4.23.1/en/model_doc/roberta#transformers.RobertaModel.forward.token_type_ids ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction RoBERTa has no token type embeddings by default, while the documentation, indicates: ``` token_type_ids (torch.LongTensor of shape (batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in [0, 1]: * 0 corresponds to a sentence A token, * 1 corresponds to a sentence B token. ``` ### Expected behavior The documentation should reflect that the default RoBERTa model has no token type embeddings. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: pubsub: add support for dead letter topics Add fields necessary to create/update subscriptions with a [dead letter policy](https://github.com/googleapis/googleapis/blob/master/google/pubsub/v1/pubsub.proto#L627-L658). This allows messages to be redelivered to a separate dead letter topic after a configured number of delivery attempts have failed (nack/ack_deadline expired). In addition to adding `DeadLetterPolicy` to a Subscription, we need to properly expose the [`delivery_attempt` field](https://github.com/googleapis/googleapis/blob/0735b4b096872960568d1f366bfa75b7b0e1f1a3/google/pubsub/v1/pubsub.proto#L757) in the client. This is done one of two ways, so for detailed implementation details, please consult the detailed information guide that Prad wrote. Feel free to ping me if you need a link to this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add executor kwargs to `KubernetesJobEnvironment` I recently realized that to configure a `KubernetesJobEnvironment` to use a non-default executor requires knowledge of the appropriate environment variables. We should expose a better interface for this (similar to the `RemoteEnvironment`) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Online help utility broken in QtConsole Whatever I type in online help utility (started in QtConsole), I get help on unicode object, ``` Python 2.7.2 (default, Nov 21 2011, 17:25:27) Type \"copyright\", \"credits\" or \"license\" for more information. IPython 0.12.beta -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. %guiref -> A brief reference about the graphical user interface. In [1]: help() Welcome to Python 2.7! This is the online help utility. If this is your first time using Python, you should definitely check out the tutorial on the Internet at http://docs.python.org/tutorial/. Enter the name of any module, keyword, or topic to get help on writing Python programs and using Python modules. To quit this help utility and return to the interpreter, just type \"quit\". To get a list of available modules, keywords, or topics, type \"modules\", \"keywords\", or \"topics\". Each module also comes with a one-line summary of what it does; to list the modules whose summaries contain a given word such as \"spam\", type \"modules spam\". help> topics Help on unicode object: class unicode(basestring) | unicode(string [, encoding[, errors]]) -> object | | Create a new Unicode object from the given encoded string. | encoding defaults to the current default string encoding. | errors can be 'strict', 'replace' or 'ignore' and defaults to 'strict'. | | Method resolution order: | unicode | basestring | object | | Methods defined here: | | __add__(...) | x.__add__(y) <==> x+y | | __contains__(...) | x.__contains__(y) <==> y in x etc ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support build --rm=false (reopen ticket) Hi I use circleci, and currently circleci v1 has trouble deleting old containers, as such I would like to use --rm=false Same as [4325](https://github.com/docker/compose/issues/4325) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Inconsistency in how compose handles empty environment variables If you want to use the value of an environment variable that is available in the host you can: ``` bash $ HOST_ENV=value docker run -e HOST_ENV ubuntu:14.04 env PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=acb280b6edd9 HOST_ENV=value HOME=/root ``` But, if the variable is not defined in the host, then it also doesn't get created in the container: ``` bash $ docker run -e HOST_ENV ubuntu:14.04 env PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=29a464f43ecb HOME=/root ``` But, given the following `docker-compose.yml`: ``` yaml banana: image: ubuntu:14.04 command: env environment: HOST_ENV: ``` We get an empty variable: ``` bash $ docker-compose run banana PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=9841adaf229b TERM=xterm HOST_ENV= HOME=/root ``` Should this be considered a bug? I would expect the same behavior from both tools. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [0.60.2] import('cmake') cannot handle cmake not being on path. Meson just says it cannot find cmake although it has been passed via a native/cross file as: ``` [binaries] ... cmake = 'E:/vcpkg_cache/downloads/tools/cmake-3.21.1-windows/cmake-3.21.1-windows-i386/bin/cmake.exe' .... ``` CI run (https://dev.azure.com/vcpkg/public/_build/results?buildId=64620&view=logs&jobId=7922e5c4-0103-5f8f-ad17-45ce9bb98e80&j=878666d5-db33-5b27-9e7d-b0c7ee352005) The fact that meson assumes stuff to be on path although full paths are passed seems to be a consistent error...... (same goes for ninja) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: LHS circuit calibration lost when combining with another circuit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**:0.17.0 - **Python version**:3.9.1 - **Operating system**:macOS Catalina ### What is the current behavior? Calibration information is lost when using \"+\"(extend) for a lhs calibrated circuit. ### Steps to reproduce the problem from qiskit import QuantumCircuit from qiskit.circuit.library import RZXGate from qiskit.pulse import Schedule qc_cal = QuantumCircuit(2) qc_cal.rzx(0.5, 0, 1) qc_cal.add_calibration(RZXGate, (0, 1), params=[0.5], schedule=Schedule()) # qc_cal = transpile(qc_cal,backend) print(qc_cal.calibrations) qc = QuantumCircuit(2) qc.h(0) new_circ_cal_on_lhs = qc_cal + qc print(new_circ_cal_on_lhs.calibrations) #calibration information is lost new_circ_cal_on_rhs = qc +qc_cal print(new_circ_cal_on_rhs.calibrations) #calibration information is kept ### What is the expected behavior? For the calibrations information to be maintained when making new circuit from \"calibrated_circuit+uncalibrated_circuit\" ### Suggested solutions Modify extend function to check and add calibrations from lhs circuit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Some magics seems broken Following the merge of cell magic it seems like some of the magics are broken. At 6cb2026f76d00422b9daa55ed590c9ab16f71ec6 the %qtconsole magic from the notebook and the list of all magics in the qtconsole works. In current master 89c23370cacc3bdee12af9a199656e83a387df5b they are broken. Could this be an issue with the merge of the merge kernel branch and the cell magic branch? The list of all magics is now: ``` %ERROR %AttributeError %ZMQInteractiveShell %object %has %no %attribute %lsmagic ``` where lsmagic is the only genuine one. It seems like an error message leaks into the list. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: [1.27.0+] docker-compose config truncates version ('3' instead of '3.x') <!-- Welcome to the docker-compose issue tracker! Before creating an issue, please heed the following: 1. This tracker should only be used to report bugs and request features / enhancements to docker-compose - For questions and general support, use https://forums.docker.com - For documentation issues, use https://github.com/docker/docker.github.io - For issues with the `docker stack` commands and the version 3 of the Compose file, use https://github.com/docker/cli 2. Use the search function before creating a new issue. Duplicates will be closed and directed to the original discussion. 3. When making a bug report, make sure you provide all required information. The easier it is for maintainers to reproduce, the faster it'll be fixed. --> ## Description of the issue Not sure if it's a bug or a new feature, but ... Since `1.27.0+`, `docker-compose config` returns only the major digit from version field. ## Context information (for bug reports) **Output of `docker-compose version`** ``` docker-compose version 1.27.0, build unknown docker-py version: 4.3.1 CPython version: 3.7.9 OpenSSL version: OpenSSL 1.1.1 11 Sep 2018 ``` **Output of `docker version`** ``` Docker version 19.03.12, build 48a66213fe ``` ## Steps to reproduce the issue 1. Create a docker-compose.yml file with the following content. ```yaml version: '3.7' ``` 2. Run `docker-compose config`. 3. Check the output. ### Observed result ```yaml services: {} version: '3' ``` ### Expected result ```yaml services: {} version: '3.7' ``` ### Stacktrace / full error message *No error* ## Additional information Ubuntu 18.04, docker-compose 1.27.0 installed from pip on Python 3.7.9. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: TableauRefreshWorkbookOperator fails when using personal access token (Tableau authentication method) **Apache Airflow version**: 2.0.1 **What happened**: The operator fails at the last step, after successfully refreshing the workbook with this error: ``` tableauserverclient.server.endpoint.exceptions.ServerResponseError: 401002: Unauthorized Access Invalid authentication credentials were provided. ``` **What you expected to happen**: It should not fail, like when we use the username/password authentication method (instead of personal_access_token) <!-- What do you think went wrong? --> Tableau server does not allow concurrent connections when using personal_access_token https://github.com/tableau/server-client-python/issues/717 The solution would be redesigning completely the operator to only call the hook once. My quick fix was to edit this in TableauHook: ``` def __exit__(self, exc_type: Any, exc_val: Any, exc_tb: Any) -> None: pass ``` **How to reproduce it**: Run this operator TableauRefreshWorkbookOperator using Tableau personal_access_token authentication (token_name, personal_access_token). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: 'properties' parameter in google.cloud.bigquery.client.Client.update_table is not documented 'properties' parameter in google.cloud.bigquery.client.Client.update_table is not documented. The body of the description is also inaccurate as it always does a PATCH request. See: https://googlecloudplatform.github.io/google-cloud-python/latest/bigquery/reference.html#google.cloud.bigquery.client.Client.update_table Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Coverage regression on macOS Catalina On macOS Mojave, enabling `b_coverage=true` resulted in successfully instrumented test executables generating .gcno files. On Catalina, I instead get ``` ERROR: Linker APPLE ld doesn't implement coverage data generation. ``` The following patch seems to fix coverage generation on Catalina for me: ```diff diff --git a/mesonbuild/linkers.py b/mesonbuild/linkers.py index 84bfceb4..371220bf 100644 --- a/mesonbuild/linkers.py +++ b/mesonbuild/linkers.py @@ -580,6 +580,9 @@ class AppleDynamicLinker(PosixDynamicLinkerMixin, DynamicLinker): result.append(a) return result + def get_coverage_args(self) -> typing.List[str]: + return ['--coverage'] + def sanitizer_args(self, value: str) -> typing.List[str]: if value == 'none': return [] ``` #6160 may be relevant here, as it suggests that clang coverage shouldn't be working at all with meson. I didn't investigate further to figure out why the above patch wasn't necessary on Mojave but now is. If desired, I can open a PR with the above patch, but at this point I'm not confident I know what the root issue is. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Make ctypes completely optional on Windows There are a couple of places where `ctypes` is presumed to be available, which means `numpy` cannot be imported on systems/distributions that do not include it. These are [`_dtype_ctypes.py`](https://github.com/numpy/numpy/blob/master/numpy/core/_dtype_ctypes.py), and the [`_distributor_init.py`](https://github.com/numpy/numpy/blob/bfb156741a92f77c13c50d82fc5a1f4d6177a9f5/tools/openblas_support.py#L197) generated for `libopenblas`. The `_dtype_ctypes` module seems easy enough to update to match the other ctypes-using modules (or simply delay the [eager import](https://github.com/numpy/numpy/blob/master/numpy/core/__init__.py#L100) or handle it failing). I can't find any uses in numpy itself though, so I have no idea what its compatibility constraints are. The `_distributor_init.py` file is somewhat redundant with the [generated `__config__.py`](https://github.com/numpy/numpy/blob/8087e1de04d011f7ce66bf80dbef4a0599b14f7a/numpy/distutils/misc_util.py#L2289), but could also just do nothing when ctypes fails to import. I'm happy to send a PR, but it's not obvious which fixes would be preferred. If I were going to keep it simple, I'd defer the `import ctypes` in `_dtype_ctypes` into the function(s) that use it, and add an early exit from the `_distributor_init.py` when ctypes is unavailable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Think of adding a project_URL for 7.0 see for example : https://github.com/jupyter/nbconvert/pull/869/commits/c66d65262567fa0e9d9834f3524a0056d2a38f9e Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow formatting in names of custom gates ### What is the expected enhancement? Allow formatting of custom gate names in circuit diagrams. The names of custom gates are shown as plain text. It would be nice to format these as latex or html. For example the following code generates a circuit diagram with a custom gate ``` from qiskit import QuantumCircuit from qiskit.circuit import Gate qc = QuantumCircuit(1, 1) qc.append(Gate(name=r'X_t', num_qubits=1, params=[]), [0]) qc.measure([0, ], [0,]) qc.draw(output='latex', interactive=False, filename='test.png') ``` The custom gate is labelled as `X_t`, but I want the name to be formatted as an `X` with subscript `t`. The custom gate name is transformed by `utf8tolatex`, but it is escaping the `_`. Also variations as `qc.append(Gate(name=r'$X_t$', num_qubits=1, params=[]), [0])` do not work. Note: here is also a discussion on stack exchange on this: https://quantumcomputing.stackexchange.com/questions/8329/how-to-plot-custom-gate-labels-in-qiskit Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: add custom_jvp / vjp, delete custom_transforms fixes #116, #1097, #1249, #1275, #1366, #1723, #1670, #1875, #1938, #2345, #2346 See the [design doc](https://github.com/google/jax/blob/custom-transforms3/design_notes/custom_derivatives.md) and [user tutorial](https://github.com/google/jax/blob/custom-transforms3/docs/notebooks/Custom_derivative_rules_for_Python_code.ipynb) for details. TODO: - [x] improve error messages - [x] write a PR message / design doc - [x] add docstrings and reference docs - [ ] fix user code (Google code, NumPyro, jaxnet, anything else we think of...) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Output of `conan install` displays `Install finished succesfully` instead of `Install finished successfully` ### Environment details * Operating System+version: MacOS Ventura 13.2.1 * Compiler+version: NA * Conan version: 2.0.2 * Python version: 3.9.6 After a successful call of `conan install .`, the final message which is displayed is `Install finished succesfully`. I suggest to use `successfully` instead of `succesfully`. I can create a PR if necessary. ### Steps to reproduce _No response_ ### Logs _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Regression: CustomTarget no longer allowed for qt.preprocess in 0.59 Hi! A project I am working on currently fails to build with Meson 0.59 because output of the Qt DBus generator / Qt Remote Object compiler is passed to `qt.preprocess`, resulting in this new error: ``` ERROR: qt.preprocess keyword argument \"moc_headers\" contained a value of type \"CustomTarget\" but should have been one of: \"File\", \"str\" ``` This has worked fine before (Meson <= 0.58), and is probably a sideeffect of the Qt refactoring that has happened - maybe it's just a matter of allowing `CustomTarget` as a parameter, I will have a look at the code later :-) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Documentation for the Pulse module: `Command` linking <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Locally, `Command` API cross references are not working. With the Azure docs artifact, neither Channels nor Commands works, but Channels works for me locally! :( ### Steps to reproduce the problem Build this locally https://github.com/Qiskit/qiskit-terra/pull/3849 ### What is the expected behavior? Clicking `Command` and `commands` should lead to another API page ### Suggested solutions Just need to update `:mod:~qiskit.pulse.commands` probably. It should work though, so unclear! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Wav2Vec2 Conformer Encoder # 🚀 Feature request <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> Implementing Conformer version of context encoder for [Wav2Vec2](https://github.com/pytorch/fairseq/blob/main/fairseq/models/wav2vec/wav2vec2.py#L390). ## Motivation Fairseq has recently updated their Wav2Vec2 codebase, incorporating [Conformer-based](https://github.com/pytorch/fairseq/blob/main/examples/wav2vec/config/pretraining/wav2vec2_conformer_large_librivox.yaml) encoder as an option with already existing Transformer-based version. As long as a decent number of the new SOTA-matching papers are utilizing Conformers for either of ctc or transducer models, it would be a great addition to Transformers library to have an option of using transformer or conformer based encoder for [Wav2Vec2ForCTC](https://github.com/huggingface/transformers/blob/main/src/transformers/models/wav2vec2/modeling_wav2vec2.py#L1647) Some of the papers: [JUST](https://arxiv.org/pdf/2111.08137v1.pdf), [Pushing the Limits of Semi-Supervised Learning for ASR](https://arxiv.org/pdf/2010.10504.pdf) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: bizarre repr of empty dtype I doubt anyone is using this, but multiple parts of this repr are bizarre: ``` >>> np.zeros(10, np.dtype([])) array([), ), ), ), ), ), ), ), ), )], dtype='[]') ``` Thankfully not a 1.14 regression - was there in 1.13 too Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Make External Data Source formats into constants As suggested in PR #5491 Make constants for external data source formats to avoid directly using strings like 'CSV' and 'GOOGLE_SHEETS' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Learning rate is given as tensor, cannot serialize TrainerState in order to save checkpoint. ### System Info - `transformers` version: 4.21.1 - Platform: Linux-5.15.0-46-generic-x86_64-with-glibc2.35 - Python version: 3.10.5 - Huggingface_hub version: 0.8.1 - PyTorch version (GPU?): 1.12.1.post200 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: yes - Using distributed or parallel set-up in script?: no ### Who can help? @sgugger ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction 1. use Adafactor optimizer and schedule ``` optimizer = Adafactor( model.parameters(), relative_step=True, warmup_init=True, ) lr_scheduler = AdafactorSchedule(optimizer) ``` 2. save a checkpoint ### Expected behavior When using an `AdafactorSchedule` I can't use the `Trainer` class to save a checkpoint. It breaks [here](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer_callback.py#L97) since the learning rate attached to the `TrainerState` is given by a tensor and tensors are not JSON serializable. I dropped a breakpoint at this line and took a look at my `TrainerState`: ``` In [4]: self.log_history[0]['learning_rate'] Out[4]: tensor(0.0001, device='cuda:0') ``` Expected behavior is that the learning rate attached to the log history would be given by a float and would therefore be JSON serializable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: File not found with rules calling meson --internal Commit d882b6fbd466940d452cfaa890bd9270e10a93b4 introduced a regression caught by the GNOME Continuous integration builder. While building a project, in this case libinput, after that commit, the process would stop with this error: ``` FAILED: input@sha/libinput.so.10.13.0.symbols /usr/bin/python3 /usr/lib/python3.5/site-packages/mesonbuild/../meson.py --internal symbolextractor libinput.so.10.13.0 'input@sha/libinput.so.10.13.0.symbols' /usr/bin/python3: can't open file '/usr/lib/python3.5/site-packages/mesonbuild/../meson.py': [Errno 2] No such file or directory ninja: build stopped: subcommand failed. ``` Full build log available [here](http://build.gnome.org/continuous/buildmaster/builds/2017/11/21/60/build/log-libinput.txt). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: RedshiftDataOperator: Add support for Redshift serverless clusters ### Description This feature adds support for Redshift Serverless clusters for the given operator. ### Use case/motivation RedshiftDataOperator currently only supports provisioned clusters since it has the capability of adding `ClusterIdentifier` as a parameter but not `WorkgroupName`. The addition of this feature would help users to use this operator for their serverless cluster as well. ### Related issues None ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: description keyword for interactive widget When I use the keyword description with interact ``` python from IPython.html import widgets def simpleFunction(a): print a i = interact(simpleFunction, a=widgets.FloatSliderWidget(values=(0,10), description='A label for my widget')) ``` I get this error ``` --------------------------------------------------------------------------- TypeError Traceback (most recent call last) TypeError: simpleFunction() got an unexpected keyword argument 'A label for my widget' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Typo in documentation. Under parameters for `GenerationMixin.generate()` there is no new bullet point for `prefix_allowed_tokens_fn`, and the content for it is under [`diversity_penalty`](https://huggingface.co/docs/transformers/v4.13.0/en/main_classes/model#transformers.generation_utils.GenerationMixin.generate.diversity_penalty). This typo only exists for versions after the document UI update(>= 4.13.0). @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Expose parameter_prefix to ZZFeatureMap ### What is the expected enhancement? Currently, the `ZZFeatureMap` class inherits from `PauliFeatureMap` but the `parameter_prefix` cannot be set in the constructor. https://github.com/Qiskit/qiskit-terra/blob/fe5acd4d15355a566a32ee63fb4a50771e5994d4/qiskit/circuit/library/data_preparation/zz_feature_map.py#L60-L68 Thus, when one wants to include more than one `ZZFeatureMap`s per quantum circuit, one needs to rebind the parameters by doing: ``` params_a = ParamVector(...) params_b = ParamVector(...) qc_a = fm.bind_parameters(params_a) qc_b = fm.bind_parameters(params_b) ``` Circuits with multiple feature maps are often used when employing data reuploading. If `parameter_prefix` would be exposed to `ZZFeatureMap`, the user could just initialise the different feature maps with distinct parameter prefixes and append them to the larger circuit without having to define/rebind additional parameter vectors. Furthermore, `parameter_prefix` is already exposed to other forms such as `TwoLocal`, so by adding this feature, the code would become more consistent. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: links in docs, static code analysis and autocompletion in PyCharm are broken Due to docstrings formatted like this, static code analysis and autocomplete in PyCharm and the links in the [online Sphinx docs](https://googleapis.github.io/google-cloud-python/latest/firestore/client.html#google.cloud.firestore_v1beta1.client.Client.document) are broken: https://github.com/googleapis/google-cloud-python/blob/de0103cedaf9fb9f03ddca9be801ac64635d7b74/firestore/google/cloud/firestore_v1/client.py#L250-L252 This should result in the same short name with a working link in the Sphinx docs and would not kill autocomplete etc: ``` Returns: :class:`~google.cloud.firestore_v1.document.DocumentReference`: A reference to a document in a collection. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Static library may contain stale object files If a meson build script removes files from a static library, they may still reside in the resulting library after rebuilding. For example, if the following is built: ``` project('test', 'c') lib = static_library('foo', 'file1.c') executable('a.out', 'main.c', link_with: lib) ``` libfoo.a will include file1.c.o. However, if meson.build is changed so file2.c is used instead, libfoo.a will include both file1.c.o and file2.c.o: ``` $ nm libfoo.a file1.c.o: ... file2.c.o: ... ``` At least on gcc, linking the final executable will link in file1.o (most likely because it precedes file2.o), which would result in a broken executable if at all. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Script to generate contributor list for release note should pick up co-authors Example commit: https://github.com/numpy/numpy/pull/18956/commits/eb231979b90cfe7f434bd598aefe4196df74b32e It looks like the script does not pick up co-authors. The PRs at today's sprint mostly came from pairs of contributors, so we should ensure we fix this before the next release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: MSBuild helper useEnv option causes missing include paths in some casess In using MSBuild helper for the first time, I received a number of errors about headers that could not be found. After spending significant time validating that the project works normally when running msbuild manually, I determined that the breaking flag was `/useEnv:True`. I briefly looked at the implementation and it was not immediately obvious to me where the problem might be. I have worked around it by using the `get_command` method from the MSBuild helper, which returns a command where the default of `useEnv` is `False`. It's mysterious why it causes this problem, but if everything is correct, then the requested change would be to simply expose `useEnv` as a parameter in the `build` method of the `MSBuild` helper rather than forcing it to `True`. I will try to provide a way to reproduce the error, but it's a private project and I don't know if I have time to isolate the problem any time soon. I spent to much time just identifying it. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Use of `ravel` in `intersect1d` breaks compatibility with xarray See https://github.com/pydata/xarray/issues/2371 ### Numpy/Python version information: ``` 1.15.0 3.6.6 |Anaconda, Inc.| (default, Jun 28 2018, 17:14:51) [GCC 7.2.0] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: BertGenerationTokenizer provides an unexpected value for BertGenerationModel - `transformers` version: 4.2.2 - PyTorch version (GPU?): 1.7.0+cu101 - tokenizers: @n1t0, @LysandreJik ## Information in both models BertGenerationEncoder, BertGenerationDecoder, there's no need for `token_type_ids` however the BertGenerationTokenizer provides it, this issue will be raised if you want to input the tokenizer results directly with `**`, and if it meant to be like this, and the user should be aware of this behaviour, I think a change should be in the documentation. Note: Another issue with BertGenerationTokenizer is the necessity of sentencepiece module, do you prefer that it should for the user to install it separately or it should be included in transformers dependencies. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan install causes conanbuildinfo.cmake to be re-generated even if it hasn't changed I've written my own buildscript that attempts to build my entire project including all dependencies in a single step. On every build, my script calls `conan install` to install the dependencies and then runs `cmake` and `ninja` to build my own source files. I'm calling `conan install` before every build, because otherwise the build process won't pick up any changes in the consumer `conanfile.py` (for example a version update of a dependency). Unfortunately, every time I call `conan install`, conan will re-generate the `conanbuildinfo.cmake`, even when its contents haven't changed. Now the cmake/ninja step will cause a full rebuild of my own sources, because the timestamp on `conanbuildinfo.cmake` was updated. This rebuild is unnecessary (and takes a long time), since nothing has actually changed. Wouldn't it be better if conan only generated that file if it doesn't yet exist or if any changes were made? Or am I missing something? I'm running conan 1.3.3 on macOS and my build system is CMake+ninja. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Transactions are commited in CommitRequest.NON_TRANSACTIONAL mode We have just been bitten by this using the latest `0.5.0`. We had the following piece of code, run in two different threads: ``` python with dataset.transaction as t: entity = dataset.get(entity_key) archived_entity = _move_to_archive_key(entity) t.delete(entity.key) t.put(archived_entity) return archived_entity ``` We've seen two copies of the `archived_entity` for the same `entity`. We've managed to reproduce it with two threads performing this concurrently (running separate Connections each, because httplib2 is not thread safe). Having used Datastore's underlying technology before, I expected to get a `ConcurrentModificationException` on delete, and one of the threads throwing it, similar to what the Java API for AppEngine describes: https://cloud.google.com/appengine/docs/java/datastore/transactions#Java_Uses_for_transactions However, both of them succeed creating two copies of `archived_entity`, and there's no `ConcurrentModificationException` anywhere in `gcloud-python` code. We've tracked down to the following: - `Transaction#commit` calls the `Batch#commit` https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/transaction.py#L177 - `Batch#commit` is unaware of the `Transaction#id`, calls `Connection#commit` without the `transaction_id` parameter https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/batch.py#L214 - `Connection#commit`gets `transaction_id`, and sets the REST request's mode to `datastore_pb.CommitRequest.NON_TRANSACTIONAL` in https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/connection.py#L321 _Impact_: This means that **all** transactions made through `python-gcloud` are **non-transactional**. Please treat it as a P0 bug. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson crashes when calling dependency with no specified languages if a C toolchain is not installed **Describe the bug** If your system doesn't have a C toolchain installed and you have a project with no specified languages, and try to call the dependency function, meson will encounter an uncaught exception and crash. I encountered this while installing meson as an overlay package on fedora silverblue. **To Reproduce** - have no C toolchain installed - place the following in `meson.build`: ```meson project('foo', version: '0.1.0', meson_version: '>= 0.59.0', default_options: [ 'warning_level=2', 'werror=false' ]) dependency('openssl', version: '>= 3.0', required: false) ``` - `meson build` **Expected behavior** No crash, possibly an error telling the user that no C toolchain is installed. **System Parameters** * Native build * Fedora Silverblue 36 * Python 3.10.5 * Meson 0.62.2 * Ninja 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython 5.1 sporadically freezes when matplotlib plots are active I've using ipython 5.1 with matplotlib 1.5.1 with the Qt4Agg backend on Mac OS X 10.9.5. There have now been 3 occasions when the ipython terminal froze entirely - it would not accept control-c, control-z, or any command I tried. Quitting the Qt plot windows re-activated the python terminal. This so far has *not* affected me the first or second time I've made a plot window, but eventually it seems to affect every ipython session I've started with a plot window. I upgraded to matplotlib 2.0, and the same thing happened, but this time (now with Qt5Agg as a backend), I get a message: ``` QEventDispatcherMac::unregisterSocketNotifier: Tried to unregister a not registered notifier ``` After that notification, the entire terminal containing ipython became unresponsive. I think the same message was issued under ipython + matplotlib 1.5.1, but the message only appeared after closing ipython entirely, i.e.: ``` In [11]: Do you really want to exit ([y]/n)? QEventDispatcherMac::unregisterSocketNotifier: Tried to unregister a not registered notifier ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DO NOT MERGE: Error Reporting: fix client_info bug, update docstrings. This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/devtools/clouderrorreporting/artman_errorreporting.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/error-reporting-v1beta1. synthtool > Replaced 'from google.devtools.clouderrorreporting_v1beta1.proto import ' in google/cloud/errorreporting_v1beta1/proto/error_group_service_pb2.py. synthtool > Replaced 'from google.devtools.clouderrorreporting_v1beta1.proto import ' in google/cloud/errorreporting_v1beta1/proto/report_errors_service_pb2.py. synthtool > Replaced 'from google.devtools.clouderrorreporting_v1beta1.proto import ' in google/cloud/errorreporting_v1beta1/proto/error_group_service_pb2_grpc.py. synthtool > Replaced 'from google.devtools.clouderrorreporting_v1beta1.proto import ' in google/cloud/errorreporting_v1beta1/proto/error_stats_service_pb2_grpc.py. synthtool > Replaced 'from google.devtools.clouderrorreporting_v1beta1.proto import ' in google/cloud/errorreporting_v1beta1/proto/report_errors_service_pb2_grpc.py. synthtool > Replaced 'from google.devtools.clouderrorreporting_v1beta1.proto import ' in google/cloud/errorreporting_v1beta1/proto/error_stats_service_pb2.py. synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: shift_tokens_right function missing for mt5 models ## Environment info - `transformers` version: 4.17.0.dev0 - Platform: Linux-5.11.0-1028-gcp-x86_64-with-glibc2.29 - Python version: 3.8.10 - PyTorch version (GPU?): 1.11.0a0+git06838ce (False) - Tensorflow version (GPU?): 2.9.0-dev20220221 (False) - Flax version (CPU?/GPU?/TPU?): 0.4.0 (cpu) - Jax version: 0.3.1 - JaxLib version: 0.3.0 ### Who can help @patil-suraj ## Information Hello I am trying to finetune with Flax on TPU a mt5-small model on a summarization task, using the examples/flax/summarization/run_summarization_flax.py script. When I run the script, I get an error about the fact that shift_tokens_right is not defined for mt5 models: `` File \"/home/prod/transformers/examples/flax/summarization/run_summarization_flax.py\", line 521, in main # shift_tokens_right_fn = getattr(model_module, \"shift_tokens_right\") AttributeError: module 'transformers.models.mt5.modeling_flax_mt5' has no attribute 'shift_tokens_right' `` Moreover, the current flax summarization script has a typo line 516 : See https://github.com/huggingface/transformers/blob/master/examples/flax/summarization/run_summarization_flax.py#L516 : `` model_module = __import__(model.__module__, fromlist=[\"shift_tokens_tight\"]) `` (tight should be right !) I have been able to fix the issue by copying the function shift_tokens_right defined in `src/transformers/models/t5/modeling_flax_mt5.py` into the file `src/transformers/models/mt5/modeling_flax_mt5.py` . Now the Flax summarization script works fine. Hope you can fix the mt5 code accordingly ! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow for setting qobj header description in execute and propagate to job <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The Qobj accepts a description in the header that allows the user to label the qobj with whatever message they want, e.g. `'cool_exp_v1'`. However, this can not be set unless one first does `compile` and then manually sets the description. Because the user never sees the qobj (and perhaps never should since it is just a fancy box) when using `execute` it is impossible to save this info. In addition, if I try to grab a job by the description (see #1710), or some substring in description, to the best of my knowledge I need to load all the jobs, and then make another API call for each job to load the qobj and then search the header description. It would be nice if the qobj header description could be set in execute, and then this description gets added to the resulting job, e.g. `job.description` so that I can search jobs by this value without needing to load qobjs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Cloud spanner client does not seem to be retrying broken streams [Documentation](http://google-cloud-python.readthedocs.io/en/latest/spanner/snapshot-usage.html) for snapshot transactions mentions: ``` If streaming a chunk fails due to a “resumable” error, Session.read() retries the StreamingRead API reqeust, passing the resume_token from the last partial result streamed. ``` This is the correct thing to do but the client actually does not seem to be doing this. I looked around a little bit in the code and I could find anyplace where it is retrying the read with the resume token. This is the place where the stream would throw an error if it broke: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/9d9b6c0708ae6553458ad6107e5ad8efb23762e8/spanner/google/cloud/spanner/streamed.py#L132 I dont see any exception handling happening here and it looks like that the error would just be propagated back to the user. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: scatter_add requires dimension numbers, default value invalid ```python3 jax.lax.scatter_add(np.zeros(10), np.asarray([3, 1]), np.asarray([5., 7.])) ``` fails with `AssertionError` because of `assert type(dimension_numbers) is ScatterDimensionNumbers` The following works, but there is no documentation on these parameters, so I inferred them from the tests. ```python3 dnums = jax.lax.ScatterDimensionNumbers(update_window_dims=(), inserted_window_dims=(0,), scatter_dims_to_operand_dims=(0,), index_vector_dim=1) jax.lax.scatter_add(np.zeros(10), np.asarray([3, 1]), np.asarray([5., 7.]), dnums) ``` Also, it might be worth adding `jax.lax.scatter` with the first argument set to zeros. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Speed up gradient norm clipping. ## 🚀 Feature Improve the speed of gradient clipping. ### Motivation I've noticed that clipping the gradients is quite slow, e.g., for a ResNet50 model (with some minor extensions) gradient clipping takes ~207 ms. The major bottlenecks are the `torch.where` computation within a loop and the manual norm computation. ### Pitch With slight modifications that don't hurt readability and work well on TPU, grad_norm can be computed in ~75ms, i.e., 2.7x as fast. For implementation details see the PR I'm going to link in a second. Reproduce: Train any model you've got lying around with gradient_clip_val=0.1 and take a look at the trace timeline ;) As a reference, here's a before and after comparison for my model (trace after 40 warmup steps): Current:  With speed improvements:  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: marginal_distribution raises for NumPy array indices ### Environment - **Qiskit Terra version**: 0.21 - **Python version**: 3.10 - **Operating system**: osx ### What is happening? `marginal_distribution` raises error when passes a NumPy array of indices: ```python marginal_distribution(counts, np.asarray([0, 2])) ``` --> 225 if indices is not None and (not indices or not set(indices).issubset(range(num_clbits))): 226 raise QiskitError(f\"indices must be in range [0, {num_clbits - 1}].\") 228 if isinstance(counts, Counts): ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all() ### How can we reproduce the issue? Try above ### What should happen? It should work for both lists and arrays. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Using gelf log driver and lose the ability to `fig run <container> bash` Im using `gelf` logging in my docker-compose file and I lose the ability to use `fig run <container> bash` because it gives the error \"Error attaching: configured logging reader does not support reading\". An example config is: ``` my_container: image: link-to-image log_driver: \"gelf\" log_opt: gelf-address: udp://0.0.0.0:12201 gelf-tag: my_container ``` I understand that I lose the ability to use `docker-compose logs` or `docker-compose logs my_container` but I would expect `docker-compose run my_container bash` to let me into the container as I am overriding the CMD line manually. ``` docker-compose version: 1.5.1 Docker version 1.9.0, build 76d6bc9 ``` Using gelf log driver and lose the ability to `fig run <container> bash` Im using `gelf` logging in my docker-compose file and I lose the ability to use `fig run <container> bash` because it gives the error \"Error attaching: configured logging reader does not support reading\". An example config is: ``` my_container: image: link-to-image log_driver: \"gelf\" log_opt: gelf-address: udp://0.0.0.0:12201 gelf-tag: my_container ``` I understand that I lose the ability to use `docker-compose logs` or `docker-compose logs my_container` but I would expect `docker-compose run my_container bash` to let me into the container as I am overriding the CMD line manually. ``` docker-compose version: 1.5.1 Docker version 1.9.0, build 76d6bc9 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: cached-property dep unnecessary for py3.8+ ## Description of the issue The dependency on `cached-property` package is unnecessary for Python 3.8 and newer. These versions of Python provide it via `functools.cached_property`. ## Context information (for bug reports) **Output of `docker-compose version`** n/a **Output of `docker version`** n/a **Output of `docker-compose config`** n/a ## Steps to reproduce the issue 1. Install the package on py3.8+ ### Observed result `cached-property` is installed. ### Expected result `cached-property` not installed. ### Stacktrace / full error message n/a ## Additional information n/a Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: custom lookup dependencies have broken .type_name() As discussed on IRC, I was trying to create a new custom lookup dependency and in the process (message() debugging in meson.build) discovered this is a giant pile of fail. Ordinarily, we set e.g. pkg-config lookups as pkg-config types etc. but mesonbuild.dependencies.* is handling this... bizarrely. https://github.com/mesonbuild/meson/blob/15fb6a407f06eae35b9d1ab72953bfdf7d9aa5ed/mesonbuild/dependencies/base.py#L309-L313 But Dependency treats type_name as type_name. And everywhere we create an ExternalDependency, we give it the .name() of the dependency in the type_name position. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse simulator QobjConfig <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Pulse simulator configuration needs additional fields: `hamiltonian`, `dt`, `noise`, `ode_options`. These values should be validated and added to `PulseQobjConfig`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: completer latex_matches no respecting API It return matched text even if it return no completions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: module 'torch.nn' has no attribute 'Identity' Traceback (most recent call last): File \"trainer.py\", line 17, in <module> model = XLMForSequenceClassification(config) File \"/home/ankit/anaconda3/lib/python3.6/site-packages/pytorch_transformers/modeling_xlm.py\", line 823, in __init__ self.sequence_summary = SequenceSummary(config) File \"/home/ankit/anaconda3/lib/python3.6/site-packages/pytorch_transformers/modeling_utils.py\", line 734, in __init__ self.summary = nn.Identity() AttributeError: module 'torch.nn' has no attribute 'Identity' https://github.com/huggingface/pytorch-transformers/blob/2f869dc6651f9cf9253f4c5a43279027a0eccfc5/pytorch_transformers/modeling_utils.py#L734 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: `tokenizer.special_tokens_map` has stringified list for \"additional_special_tokens\" value. ## Environment info - `transformers` version: 4.8.2 - Platform: macOS-10.15.7-x86_64-i386-64bit - Python version: 3.8.10 - PyTorch version (GPU?): 1.9.0 (False) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help @LysandreJik maybe? ## Information Model I am using (Bert, XLNet ...): XLMRoberta The problem arises when using: * [ ] the official example scripts: (give details below) * [X] my own modified scripts: (give details below) The tasks I am working on is: * [ ] an official GLUE/SQUaD task: (give the name) * [ ] my own task or dataset: (give details below) ## To reproduce Steps to reproduce the behavior: 1. `>>> from transformers import XLMRobertaTokenizer` 2. `>>> m = XLMRobertaTokenizer.from_pretrained('xlm-roberta-base')` 3. `>>> m.add_special_tokens({\"additional_special_tokens\": [\"<space>\"]})` 4. `>>> m.special_tokens_map['additional_special_tokens'] == \"['<space>']\" # True` ## Expected behavior The value should be a list containing the special characters. :-) The work-around is to use the `additional_special_tokens` attribute directly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add deprecation warnings for conda 4.6 deprecated modules: * `conda.cli.activate` * `conda.compat` * `conda.install` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: latex_to_mpl_png relies on deprectated functionality in matplotlib 3.4 Short repro: ``` In [1]: from IPython.lib import latextools In [2]: png = latextools.latex_to_png_mpl('f(x) = y', True) /lib/python3.8/site-packages/IPython/lib/latextools.py:126: MatplotlibDeprecationWarning: The to_png function was deprecated in Matplotlib 3.4 and will be removed two minor releases later. Use mathtext.math_to_image instead. mt.to_png(f, s, fontsize=12, dpi=dpi, color=color) /lib/python3.8/site-packages/IPython/lib/latextools.py:126: MatplotlibDeprecationWarning: The to_rgba function was deprecated in Matplotlib 3.4 and will be removed two minor releases later. Use mathtext.math_to_image instead. mt.to_png(f, s, fontsize=12, dpi=dpi, color=color) /lib/python3.8/site-packages/IPython/lib/latextools.py:126: MatplotlibDeprecationWarning: The to_mask function was deprecated in Matplotlib 3.4 and will be removed two minor releases later. Use mathtext.math_to_image instead. mt.to_png(f, s, fontsize=12, dpi=dpi, color=color) /lib/python3.8/site-packages/IPython/lib/latextools.py:126: MatplotlibDeprecationWarning: The MathtextBackendBitmap class was deprecated in Matplotlib 3.4 and will be removed two minor releases later. Use mathtext.math_to_image instead. mt.to_png(f, s, fontsize=12, dpi=dpi, color=color) ``` Deprecation info: https://matplotlib.org/stable/api/api_changes.html#mathtextparser-bitmap-is-deprecated `math_to_image` has been around since the beginning, so it hopefully has no version compatibility issues: https://github.com/matplotlib/matplotlib/blame/e904fa3b1e5455cf741017268dae7c94b6caa5d6/lib/matplotlib/mathtext.py#L587 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: LayoutXLMProcessor applies the english Tesseract model # 🚀 Feature request LayoutXLMProcessor.\\_\\_call\\_\\_ should support a language argument for Tesseract OCR ## Motivation LayoutXLM is a multilingual version of the successful LayoutLMv2 model. The main reason to use it over LayoutLMV2 is to handle different languages, yet the current API does not allow specifying the language to be used in apply_tesseract. ## Your contribution I could submit a PR but I am not that familiar with the Transformers library to suggest the best place to add the lang argument. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Require for Geometric Distribution It seems that `jax` does not have geometric distribution in its random module like `scipy.stats`. Will it be added? I really need it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Don't set hostname to service name when using --x-networking Using the new networking features, when you start a container. The name is correctly `<folder>_<service>_1` but the hostname is `<service>` It's impossible the scale the containers in some case because all the containers get the same hostname. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Missing \"if __name__ == '__main__':\" check in /usr/bin/ipython When executed, the top level ipython script always launches a new instance, even if the module is not being executed as `__main__`. This is currently being worked around in the standard library (by special casing IPython), but the correct fix is for IPython to not launch a new instance when the module is being run as anything other than `__main__`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: add prefix arg to storage.bucket.get_all_keys add prefix arg to storage.bucket.get_all_keys Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: XLNetLMHeadModel has no attribute 'from_config' ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.8.0 - Platform: Linux-4.15.0-20-generic-x86_64-with-LinuxMint-19-tara - Python version: 3.6.9 - PyTorch version (GPU?): 1.8.0+cu111 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: yes ### Who can help @patrickvonplaten ## Information Model I am trying to train a XLNet model from scratch to portuguese but when i run this script: https://github.com/huggingface/transformers/blob/v4.8.2-release/examples/pytorch/language-modeling/run_plm.py i get this error: Traceback (most recent call last): File \"run_plm.py\", line 498, in <module> main() File \"run_plm.py\", line 330, in main model = XLNetLMHeadModel.from_config(config) AttributeError: type object 'XLNetLMHeadModel' has no attribute 'from_config' The problem arises when using: * [x] the official example scripts: (give details below) The tasks I am working on is: * [x] my own task or dataset: (give details below) portuguese wikipedia dataset Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: cmake_find_package generator not usable with CMake multi-config generators like VS * conan 1.12.3 * CMake 3.13.4 * Windows 10 When using the cmake_find_package generator conan generates FindXXX.cmake modules for consumption. However these find modules only contain one build_type. When using these find modules with a CMake multi configuration build system, like Visual Studio, this does not work, because we need information for all configurations in the find module. Example: Running `conan install -g cmake_find_package zlib/1.2.11@conan/stable` produces a `Findzlib.cmake` file that will contain all relevant information about using zlib in Release configuration. Specifically only the link library name `zlib` is provided. When running `conan install -g cmake_find_package -s build_type=Debug zlib/1.2.11@conan/stable` the find module `Findzlib.cmake` now contains all relevant information for using the debug build of zlib, specifically the link library name now correctly is `zlibd`. Because the find modules only contain one build_type at a time they cannot correctly be used with a multi configuration build system like Visual Studio. However find modules can contain multiple configuration they \"only\" need to be written accordingly by conan. I stumbled upon this while using the conan cmake wrapper. This script installs all build types when used by a multi configuration generator and then only the find module of the last installed build_type survives. Also I think it is not feasible to have both find modules available (e.g. by using different names or directories) as only one can be used at a time because targets are generated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: PTK completion: Close completion drop-down box Completion drop-down box can not be closed with <kbd>Escape</kbd>. User will need to type something to close it, or move cursor back. Suggestion: <kbd>Escape</kbd> should close completion drop-down box Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add back `environment.yml` file I realized why we might want to maintain an `environment.yml` file in parallel with our `requirements.txt` file: `requirements.txt` will be installed via `pip`, whereas if you create an environment via `conda`, the packages will be installed / maintained via `conda`. This can be useful for those who try to `conda install` everything (since it has different package version logic + handles non-python dependencies). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: ParamsDict represents the class object itself, not keys and values on Task Instance Details ### Apache Airflow version 2.3.3 (latest released) ### What happened ParamsDict's printable presentation shows the class object itself like `<airflow.models.param.ParamsDict object at 0x7fd0eba9bb80>` on the page of Task Instance Detail because it does not have `__repr__` method in its class. <img width=\"791\" alt=\"image\" src=\"https://user-images.githubusercontent.com/16971553/180902761-88b9dd9f-7102-4e49-b8b8-0282b31dda56.png\"> It used to be `dict` object and what keys and values Params include are shown on UI before replacing Params with the advanced Params by #17100. ### What you think should happen instead It was originally shown below when it was `dict` object.  I think it can be fixed by adding `__repr__` method to the class like below. ```python class ParamsDict(dict): ... def __repr__(self): return f\"{self.dump()}\" ``` ### How to reproduce I guess it all happens on Airflow using 2.2.0+ ### Operating System Linux, but it's not depending on OS ### Versions of Apache Airflow Providers _No response_ ### Deployment Other ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Error compiling while_of_pmap The test is lax_control_flow_tests.py:test_while_loop_of_pmap. It fails on CPU, GPU, and TPU. For GPU the failure seems to be ``` F0331 01:03:30.304149 7266 ir_emitter_unnested.cc:1766] Non-OK-status: body->Accept(&ir_emitter_body) status: Unimplemented: Requested AllReduce not implemented on GPU; replica_count: 8; operand_count: 1; IsCrossReplicaAllReduce: 1; NCCL support: 0; first operand array element-type: F64 ``` For TPU the failure is perhaps related but shows up elsewhere: ``` File \"/build/work/c62b4eb2372c3477aa8032626244c507067f/google3/runfiles/google3/third_party/py/jax/interpreters/xla.py\", line 169, in apply_primitive compiled_fun = xla_primitive_callable(prim, *map(arg_spec, args), **params) File \"/build/work/c62b4eb2372c3477aa8032626244c507067f/google3/runfiles/google3/third_party/py/jax/interpreters/xla.py\", line 194, in xla_primitive_callable compiled = built_c.Compile(compile_options=options, backend=backend) File \"/build/work/c62b4eb2372c3477aa8032626244c507067f/google3/runfiles/google3/third_party/tensorflow/compiler/xla/python/xla_client.py\", line 571, in Compile return backend.compile(self.computation, compile_options) File \"/build/work/c62b4eb2372c3477aa8032626244c507067f/google3/runfiles/google3/third_party/tensorflow/compiler/xla/python/xla_client.py\", line 151, in compile compile_options.tuple_arguments) RuntimeError: Invalid argument: Invalid (replica_count,computation_count) pair: (8,1) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Support both seconds from epoch and timestamp string If someone already has a timestamp string, we shouldn't force them to convert it to `datetime.datetime` so that we can in turn [convert that](https://github.com/GoogleCloudPlatform/gcloud-python/blob/0c74a599b6aa0a16e21575998e1770182c05e12c/gcloud/bigquery/table.py#L665-L669) into seconds. (Inspired by #1381.) From [the docs](https://cloud.google.com/bigquery/preparing-data-for-bigquery#datatype) > TIMESTAMP data types can be described in two ways: UNIX timestamps or calendar datetimes. BigQuery stores TIMESTAMP data internally as a UNIX timestamp with microsecond precision. so we could allow the user to just pass a string and we \"take their word for it\" that it's a valid datetime. Since `Table.insert_data` returns a list of errors anyhow, we wouldn't have to do much/anything to enforce this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: get table schema if not supplied (and have pyarrow) in `load_table_from_dataframe` Follow-up to https://github.com/googleapis/google-cloud-python/pull/8105#discussion_r286998303 When a table schema isn't supplied in `load_table_from_dataframe`, try to get the existing table schema. This will prevent errors due to ambiguous pandas types (#7370) without having to explicitly provide a schema. Note: this behavior is similar to that of pandas-gbq, which always fetches the table schema and then compares to make sure it's compatible with the dataframe schema. https://github.com/pydata/pandas-gbq/blob/59228d9c20cee12b24caa5cc41d3f2e6c0337932/pandas_gbq/gbq.py#L1115-L1121 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: TypeError: startswith first arg must be bytes or a tuple of bytes, not str when installing on python3 As stated in the description, this error occurs when installing on python3. ``` Collecting conan-0.9.0 from http://github.com/conan-io/conan/archive/release/0.9.0.tar.gz#egg=conan-0.9.0 Downloading http://github.com/conan-io/conan/archive/release/0.9.0.tar.gz (350kB) Complete output from command python setup.py egg_info: Traceback (most recent call last): File \"<string>\", line 1, in <module> File \"/tmp/pip-build-_afor1qa/conan-0.9.0/setup.py\", line 27, in <module> project_requirements = get_requires(\"conans/requirements.txt\") File \"/tmp/pip-build-_afor1qa/conan-0.9.0/setup.py\", line 23, in get_requires if not line.strip().startswith(\"#\"): ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `transpile` is always serial on windows `qiskit.tools.parallel_map` defaults to running jobs serially whenever the user is running on windows (since the default behavior of `multiprocess.Pool` under windows is considerably different from than that of mac/linux.) However, there are still some cases (like transpiling for RB) where there may be potential benefit to being able to parallelize jobs under windows. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: add IN and ARRAY_CONTAINS_ANY query operators With an upcoming backend up date Firestore will have support for two new query operators `IN` and `ARRAY_CONTAINS_ANY`. In order for these new operators to be used, they need to be wired up to the high level query system. These new operators allow queries like the following: ```js // IN query firestore.collection('cities') .where(\"country\", 'in', ['USA', 'Japan']) // ARRAY_CONTAINS_ANY firestore.collection('cities') .where('regions', 'array-contains-any', ['west_coast', 'east_coast']) ``` Both operators expect an ArrayValue to match against. #### Additional context * New operators added to protos in https://github.com/googleapis/googleapis/commit/10f91fa12f70e8e0209a45fc10807ed1f77c7e4e * NodeJS reference implementation: https://github.com/googleapis/nodejs-firestore/pull/715 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Check double retrieval of manifest pre-upload, and remove progress bars. Right now, the ``self._check_recipe_date(conan_ref, upload_remote)`` done in the upload retrieves the manifest first, and then the RestApi class do it again. It is also a bit weird to show progress bars on the download of the manifest prior to start uploading. This already happens in 1.7.3, but need to check it once the manifest comparison is done instead of the md5, merged in develop for 1.8 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Default compile config seed is not random The default seed in `qiskit._compiler.COMPILE_CONFIG_DEFAULT` is set to 1. By default this should be `None` and result in a random seed being generated by simulator backends. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse-optimized SU4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: psum of complex64 not supported for multi GPU. Complex numbers are not supported for AllReduce. I found this bug when trying to do psum across 4 GPUs with complex64 as the dtype. ``` RuntimeError: Unimplemented: Requested AllReduce not implemented on GPU; replica_count: 4; operand_count: 1; IsCrossReplicaAllReduce: 1; NCCL support: 1; first operand array element-type: C64 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Implement discoverability for [conf] items Some usages of the new `[conf]` construct are starting to be instrumented throughout the codebase. Currently, it's primarily in generators and other experimental places. While it's still early for `conf`, I think we should consider providing a good experience for users to print out all available `conf` items , current values, etc. Also, I think we should do something different from `conan config get`, which prints the config file and doesn't reflect environment variables, and doesn't show a comprehensive list of settings which can be set. Instead, I suggest doing something similar to `argparse`, where every possible `conf` item within the codebase is declared very early on in the main setup. Such a strategy presents some significant challenges. For example, the actual values of the variables are reconciled as \"instances\" per-package during various different times. Still, perhaps it's possible. Another strategy might be annotations. While I don't know all the options for implementing, I still want to suggest the feature be considered and looked into. We keep adding new `[conf]` items in each new release of Conan. I feel that as users get used to adding `conf` items to profiles, it will become increasingly annoying for users to figure out what all the possible `conf` items are. They'll have to check their Conan version, then go to the specific version of the docs, and then search the docs to find out what `conf` items are available. Exposing them at the CLI for discovery similar to `conan --help` and `conan install --help` seems a much better pattern if it can be implemented. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Feature Request: Deal with upgrades better Hi Jussi, I just upgraded from .27-research to .28-research and got an error message - which I expected. Is there a flag or target that could be added to force this upgrade to happen? And by upgrade, I mean delete the old stuff and regenerate. It's awkward to tell people to `rm -rf build; mkdir build; <cc flags> meson build` when I upgrade meson on the systems and their build breaks. I'm trying to replace our crusty make based build and this, IMO, is a wart. (meson is still awesome, though!) ``` [1/1] Regenerating build files Traceback (most recent call last): File \"/opt/meson/share/meson/meson.py\", line 211, in run app.generate() File \"/opt/meson/share/meson/meson.py\", line 126, in generate env = environment.Environment(self.source_dir, self.build_dir, self.meson_script_file, self.options) File \"/opt/meson/share/meson/environment.py\", line 69, in __init__ self.coredata = coredata.load(cdf) File \"/opt/meson/share/meson/coredata.py\", line 199, in load (obj.version, version)) RuntimeError: Build tree has been generated with Meson version 0.27.0-research, which is incompatible with current version 0.28.0-research. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Owlvit's Image Guided Detection Broken ### System Info Colab env. for better reproducibility (transformers==4.32.0.dev0) I ran the example for several times but it still give wrong results. https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb Dear @amyeroberts , @ArthurZucker ### Who can help? _No response_ ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Reproduction is easy, 1) Just run the following Colab Notebook to the bottom (https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb) The last cell of the notebook, it is now showing one bounding box ```python results = processor.post_process_image_guided_detection(outputs=outputs, threshold=0.6, nms_threshold=0.3, target_sizes=target_sizes) boxes, scores = results[0][\"boxes\"], results[0][\"scores\"] print(scores) ``` The above code shows weird output, tensor([1.0000]) 2) Interestingly, if I change the query image to something irrelevant, like ```python skimg = skimage.data.astronaut() query_image = Image.fromarray(np.uint8(skimg)).convert(\"RGB\") # ... omiited lines print(scores) ``` The above shows tensor([1.0000]) as well with a giant bbox. ### Expected behavior The last cell of the notebook, it should show two bounding boxes for each cat in the image. (finding two cat bboxes according to the query image) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Determine desired/expected return value(s) of storage.bucket.Bucket.delete_keys From TODO: ``` python # TODO: What should be the return value here? ``` See [`storage.bucket.Bucket.delete_keys`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/bucket.py#L192) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 192) # TODO: What should be the return value here? ``` Determine desired/expected return value(s) of storage.bucket.Bucket.delete_keys From TODO: ``` python # TODO: What should be the return value here? ``` See [`storage.bucket.Bucket.delete_keys`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/bucket.py#L192) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 192) # TODO: What should be the return value here? ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: GPTNeoXAttention does not deal with odd numbers of attention heads ### System Info transformers 4.29, HEAD Linux (not relevant, reproducible on e.g. Mac OS) python 3.10.11 (not relevant, reproducible on e.g. python 3.9.13) ### Who can help? @ArthurZucker @younesbelkada ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction When the hidden size is not evenly divisible by the number of attention heads, GPTNeoXAttention throws an exception while trying to reshape its state. Here is a minimal example to reproduce: ``` from transformers import pipeline p=pipeline(model=\"Isotonic/gpt_neox_225M\",task=\"text-generation\") p(\"I like to eat \") ``` The exception is the following: ``` /home/jps/anaconda3/envs/transformers/lib/python3.10/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py:133 in forward â RuntimeError: shape '[1, 5, 12, 255]' is invalid for input of size 15360 ``` ### Expected behavior What happens here is that the model has 12 attention heads and a hidden size of 1024. Thus, head_size is calculated as 1024 // 12 == 85. Then, 3 * head-size is not 256 but 255, giving the issue here. I am not quite sure how this is supposed to work. In https://github.com/EleutherAI/gpt-neox, the code checks that the hidden size is evenly divisible by the number of heads. This would not enable the use of this model, but it might give a better error message. Is there any chance to run such a model? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Refactor the `Optimizer` interface <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Mimic the common structure of minimization routines (like SciPy or scikit-quant) and change the \"main\" method of `Optimizer.optimize` to ```python minimize(f, x0=None, jac=None, hess=None, callback=None) ``` This also makes clear that our optimizers _minimize_ something instead of just saying they _optimize_. Since we don't use the same function name as before we can gracefully deprecate the old \"main\" method. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Support Pydantic V2 and/or peg it to V1 for now ### What's the use case? Pydantic is beta testing a V2 version, which replaces the core of the library with Rust and overhauls the API. I'd like to use it as a dependency in a pre-release project to validate my own data, however, Dagster now bundles Pydantic V1 and hasn't yet capped the version. This is what I get when I try to upgrade: ``` Traceback (most recent call last): File \"/Users/admin/Desktop/hello-dagster/venv/bin/dagster\", line 5, in <module> from dagster.cli import main File \"/Users/admin/Desktop/hello-dagster/venv/lib/python3.10/site-packages/dagster/__init__.py\", line 100, in <module> from dagster._config.pythonic_config import ( File \"/Users/admin/Desktop/hello-dagster/venv/lib/python3.10/site-packages/dagster/_config/pythonic_config/__init__.py\", line 22, in <module> from pydantic import ConstrainedFloat, ConstrainedInt, ConstrainedStr File \"/Users/admin/Desktop/hello-dagster/venv/lib/python3.10/site-packages/pydantic/_migration.py\", line 279, in wrapper raise PydanticImportError(f'`{import_path}` has been removed in V2.') pydantic.errors.PydanticImportError: `pydantic:ConstrainedFloat` has been removed in V2. For further information visit https://errors.pydantic.dev/2.0b2/u/import-error ``` ### Ideas of implementation I think as a pre-release this won't cause problems for anyone except people like me who want to use the new version, but a) Dagster should probably change requirements.text to reflect `pydantic<2` and b) maybe support it when it's no longer a pre-release. The V2 does include some V1 shims, so it shouldn't be too bad, but some parts of the API did change in breaking ways. ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Remove duplicate line of code for configuration copy This is code improvement PR to remove a duplicate line. The code copies config in either cases of IF statement hence duplicate call. Moving that before IF makes it unique and sufficient for the purpose. I have moved first call above IF and removed ELSE block --- **^ Add meaningful description above** Read the **[Pull Request Guidelines](https://github.com/apache/airflow/blob/main/CONTRIBUTING.rst#pull-request-guidelines)** for more information. In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/main/UPDATING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Update Docker Compose installation for Toolbox Should mention users on Mac should install Compose with Toolbox. Fig port with index not working with fig scale Running `fig scale api=2` creates the following with output from `fig ps`: ``` Name Command State Ports --------------------------------------------------------------------------------------------- testcom_api_1 pm2 start /app/app.js --wa ... Up 0.0.0.0:49153->80/tcp testcom_api_2 pm2 start /app/app.js --wa ... Up 0.0.0.0:49154->80/tcp ``` Running `fig port api 80` only returns the first container when we expected it to return both, is this intended? Trying to use the `fig port --index=1 api 80` or `fig port --index=2 api 80` returns \"No container found for api_1\" and \"No container found for api_2\" respectively Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support `dist` In #823 there is some work to make meson executable like one file. After all it would be nice to have target which will bundle current meson to the zip app, run all generators and make archive with all that stuff. In the beginning I was thinking that it's completely useless, but advantages are (for some cases): - No need to have meson installed (and have it with some updated version), only python - No need to have generators installed (like swig, cython), it will be prepared during dist This will require some work, but will be nice to have. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: How to resolve DeprecationWarning Version: 0.7.3 My trainer ``` trainer = pl.Trainer( max_epochs=19 ) ``` Warnings: ``` pytorch_lightning/utilities/warnings.py:18: DeprecationWarning: Argument `show_progress_bar` is now set by `progress_bar_refresh_rate` since v0.7.2 and this method will be removed in v0.9.0 ``` ``` DeprecationWarning: Epochs indexing of `scheduling` starts from \"1\" until v0.6.x, but will start from \"0\" in v0.8.0. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: dependency not_found_message prints multiple times ``` Run-time dependency gpgme found: NO (tried pkgconfig and config-tool) Message: gpgme >=1.3.0 is needed for GPG signature support Message: gpgme >=1.3.0 is needed for GPG signature support ``` I can get it to print only once, if I add `methods:` to the dependency() call, it seems to be printing once per method it tries. Even if it doesn't try them due to being disabled, in this case it ignores `methods:`: ``` Dependency gpgme skipped: feature gpgme disabled Message: gpgme >=1.3.0 is needed for GPG signature support Message: gpgme >=1.3.0 is needed for GPG signature support ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan install unexpectedly reports invalid version range i have this requirement in my `conanfile.py`: `foo/[>16.5.0 <17.0.0]@bar/stable` `conan install` aborts with this error: `ERROR: version range expression '>16.5.0<17.0.0' is not valid` note: using the deprecated comma-based syntax works fine * Python 3.6 on CentOS 7.5 * Conan 1.11.2 * node-semver 0.6.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Plotting of instruction schedule from mock backend fails <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: '0.17.0.dev0+6f0eca6' - **Python version**: 3.8.6 - **Operating system**: Windows 10 The output of `qiskit.version.QiskitVersion()` is ``` {'qiskit-terra': '0.17.0.dev0+6f0eca6', 'qiskit-aer': '0.7.3', 'qiskit-ignis': '0.5.1', 'qiskit-ibmq-provider': '0.11.1', 'qiskit-aqua': '0.8.1', 'qiskit': '0.23.4'} ``` ### What is the current behavior? When importing the `FakeAthens`, gettting the schedule for the `u3` instruction and plotting an exception is generated. Depending on this qiskit version I get different error messages. The version reported above yields: ``` ... File \"c:\\projects\\qiskit-terra\\qiskit\\visualization\\pulse_v2\\generators\\frame.py\", line 318, in gen_frame_symbol program.append('{}({})'.format(inst.__class__.__name__, inst.phase.name)) AttributeError: 'ParameterExpression' object has no attribute 'name' ``` ### Steps to reproduce the problem A minimal example is: ``` from qiskit.test.mock import FakeAthens backend = FakeAthens() defaults = backend.defaults() inst_map = defaults.instruction_schedule_map schedule=inst_map.get('u3', [0]) schedule.draw() ``` print(qiskit.version.QiskitVersion()) ### What is the expected behavior? The schedule should be plotted ### Suggested solutions None Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: note new dependencies in docs / setup.py nbconvert introduces a bunch of new optional dependencies. - ~~markdown~~ - pandoc - sphinx - pygments (already needed for qtconsole, but should be on the nbconvert list as well) And make sure everything else is up to date as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: _matches_coupling_map seems to check single qubit ops too and fails <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: 0.6.0 - **Python version**: 3.6 - **Operating system**: macos ### What is the current behavior? Using _matches_coupling_map breaks and returns false at first single qubit op as single qubits are not in the coupling map ### Steps to reproduce the problem Run the function on a dag ### What is the expected behavior? Ignore single qubits ops ### Suggested solutions Check no of qubits. Have fixed and pull request ready to go if ok. 👍 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Bug - MSBuild helper should not force compiler flags such as `/o` It seems that the `.props` file used to inject a few things implicitly into the build sometimes results in conflicts as seen here: ``` 2>cl : Command line warning D9025: overriding '/O2' with '/Od' [path_to_my_project.vcxproj] 2>cl : Command line warning D9025: overriding '/Od' with '/O2' [path_to_my_project.vcxproj] <..... above pair of message seen dozens of times.> 2>cl : Command line error D8016: '/RTC1' and '/O2' command-line options are incompatible ``` This can happen in very common circumstances, including any projects that have \"Runtime checks\" enabled, which I believe is the default for DLL projects. Eventually, would be good to validate whatever flags are being injected. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Redis connection timeouts are not coerced correctly Found using celery 4.1.0. ## Steps to reproduce Configure with redis as a backend with timeouts set in the url: ``` result_backend = 'redis://127.0.0.1:6379?socket_timeout=30&socket_connect_timeout=5' ``` ## Expected behavior Timeouts are applied and celery works normally. ## Actual behavior Errors are raised by the socket library that the timeout needs to be a float. Pull request incoming. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: TestF77Callback::test_all[t] fails: fatal error: threads.h: No such file or directory <!-- Please describe the issue in detail here, and fill in the fields below --> ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ``` pytest -sv numpy/f2py/tests/test_callback.py -k 'test_all[t]' -r s -x ``` ### Error message: <!-- If you are reporting a segfault please include a GDB traceback, which you can generate by following https://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging --> <!-- Full error message, if any (starting from line Traceback: ...) --> ``` E /tmp/tmphz3v9phb/src.linux-x86_64-3.9/_test_ext_module_5403module.c:75:10: fatal error: threads.h: No such file or directory E 75 | #include <threads.h> E | ^~~~~~~~~~~ E compilation terminated. ``` ### NumPy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> ``` >>> import sys, numpy; print(numpy.__version__, sys.version) 1.21.0.dev0+438.gbf4ac1f81 3.9.1 | packaged by conda-forge | (default, Jan 10 2021, 02:55:42) [GCC 9.3.0] ``` ### Additional information ``` $ ldd --version ldd (Ubuntu GLIBC 2.27-3ubuntu1.2) 2.27 Copyright (C) 2018 Free Software Foundation, Inc. ``` C11 threads.h appears to be supported starting from glibc 2.28, see [here](https://sourceware.org/bugzilla/show_bug.cgi?id=14092#c10). Undefining CPP macro F2PY_THREAD_LOCAL_DECL makes the test pass. A solution is not to define F2PY_THREAD_LOCAL_DECL for glibc version < 2.28 in numpy/f2py/cfuncs.py . Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Unknown CPU family ft32 I'm currently compiling a project for an embedded device usint a bridgetek FT902 (FT32 architecture in GCC), as I expected this is not a supported target on meson, I'm not sure what this target variable implies, but compiling with the unsupported ``` cpu_family = 'ft32' cpu = 'ft900' ``` doesnt seem to produce any issues for me. If there is something I can do about this let me know I'm open to contribute. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Feature Request] Add 3D attention mask for T5Model ## Environment info - `transformers` version: 4.2.1 - Platform: Linux - Python version: 3.6.9 - PyTorch version (GPU?): 1.7.0+cuda11.0 ### Who can help T5: @patrickvonplaten ## Information The `get_extended_attention_mask()` does not sufficiently address the case with 3D attention mask. The problem emerges for T5Model as `input_ids` and `decoder_input_ids` are of different length and the `attention_mask` is of shape [Batch_size, Seq_length, Seq_length]. The decoder uses `attention_mask` directly for `encoder_attention_mask` in cross-attention, which is of incorrect shape and the error message does give any information about why it happens. ## To reproduce As described above. I can add code later if needed. ## Expected behavior I propose to add a sanity check for attention masks or improve the `get_extended_attention_mask()` method. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Matplotlib circuit drawer is unconditionally using latex mode for gate names <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: Master - **Python version**: Any - **Operating system**: Any ### What is the current behavior? The matplotlib circuit drawer is unconditionally using latex mode for all gate names. This is a change in behavior from previous releases and can lead to weird results. For example, having a gate named `my_gate^22` will result in this being drawn:  but the string should `my_gate^22` like:  but obviously without the rendering bug (I used an older qiskit version to show the previous behavior which had other bugs) ### Steps to reproduce the problem Run: ``` from qiskit.circuit import QuantumCircuit from qiskit.circuit import Instruction qc = QuantumCircuit(2) qc.append(Instruction('my_gate^22', 1, 0, []), [0], []) qc.draw('mpl', filename='/tmp/latex_mode.png') ``` ### What is the expected behavior? The gate title text is not in latex mode by default anymore, the documented behavior is to use `$` around the latex portions of the string. ### Suggested solutions Fix the default change. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: install_headers(preserve_path) ```meson # proj/kola.h -> /usr/include/myproj/kola.h install_headers('proj/kola.h', subdir : 'myproj') # proj/kola.h -> /usr/include/myproj/proj/kola.h install_headers('proj/kola.h', subdir : 'myproj', preserve_path : true) ``` ```meson # you can write install_headers( 'foo/bar.h', 'baz/bob.h', subdir : 'proj', preserve_path : true, ) # instead of install_headers('foo/bar.h', subdir : 'proj/foo') install_headers('baz/bob.h', subdir : 'proj/baz') ``` One possible alternative to consider is `preserve_path_from : directory`, but it introduces invalid uses of API and by calling `install_headers` from subdirectory the same behavior can be achieved with proposal above, so I don't think it's worth implementing. @textshell also mentioned: My usecase was a list of headers to install. Where the headers might not be all in one directory. Allowing that usecase is esp. important for an IDE integration that can modify file lists, but is not smart enough to actually write and auto maintain more general elements in a meson.build file. And i belive editing file lists should be the primary write interaction of an IDE with the meson.build files. Because meson files are really not easy to auto maintain because they allow all kinds of different styles and usages. Also i think IDEs automatically editing target definitions to add files is not what most projects expect. I think most somewhat bigger projects have lists of files instead of a list in the target definition call. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: celery multi ignores FQNs and subscribes to incorrect queue. The following does not work: `celery multi start celery1@turing.lan celery2@turing.lan -A tserver.app -Q:1 celery,hq1 -Q:2 celery,high,hq1 -c 4 -l info` Output: ``` celery multi v3.1.23 (Cipater) > Starting nodes... > celery1@turing.lan: OK > celery2@turing.lan: OK ``` In this case both workers subscribe only to the `celery` queue. However, the following works: `celery multi start 2 -A tserver.app -Q:1 celery,hq1 -Q:2 celery,high,hq1 -c 4 -l info` In this case, both workers subscribe to correct queues. Output: ``` celery multi v3.1.23 (Cipater) > Starting nodes... > celery1@turing.lan: OK > celery2@turing.lan: OK ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: BeitForMaskedImageModeling forward not using bool_masked_pos ### Who can help @NielsRogge ## Information I am reading the code of BEIT, trying to use the `BeitForMaskedImageModeling`, while I found the `bool_masked_pos` is defined but not used in `BeitForMaskedImageModeling`'s forward. In my understanding, `bool_masked_pos` is used to mask out the input image tokens, thus should be passed to the `self.beit` forward here. https://github.com/huggingface/transformers/blob/5c6eca71a983bae2589eed01e5c04fcf88ba5690/src/transformers/models/beit/modeling_beit.py#L723 Furthermore, the documentation of the `BeitForMaskedImageModeling`'s `forward` lack the description of the `bool_masked_pos`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.datastore.key.Key.from_path is undocumented, untested I'm not sure what its contract is, either: ``` >>> from gcloud.datastore.key import Key >>> Key.from_path().path() [{'kind': ''}] >>> Key.from_path('abc').path() [{'kind': ''}] >>> Key.from_path('abc', 'def').path() [{'kind': 'abc', 'name': 'def'}] >>> Key.from_path('abc', 'def', 'ghi').path() [{'kind': 'abc', 'name': 'def'}] >>> Key.from_path('abc', 'def', 'ghi', 123).path() [{'kind': 'abc', 'name': 'def'}, {'kind': 'ghi', 'id': 123}] ``` Dropping the odd last element doesn't seem correct. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Results gathering with varying tensor shapes (e.g. last batch) <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug Results object reduction when batch sizes are different won't work because torch.stack get's different input shapes. This can happen if your dataloader returns a smaller batch for the last iteration, for example. ```python def recursive_stack(result: MutableMapping): for k, v in result.items(): if isinstance(v, dict): recursive_stack(v) if isinstance(v, list) and len(v) > 0 and isinstance(v[0], torch.Tensor): v = torch.stack(v) result[k] = v ``` Context From slack discussion by @artgor https://pytorch-lightning.slack.com/archives/CRBLFHY79/p1597604494424600 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Provide a converter that outputs the old schema, for the transition ### What is the expected enhancement? Currently, IBM-Q backends consume a proprietary version of `Qobj`. Make it compatible with the proper `Qobj` implementation by providing a translator in a separated component. Remove when the backends fully support the `Qobj` format. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: xla in pmap fails (i.e. jit-of-pmap or lax.scan with collectives) The parallel xla interpreter currently doesn't properly support nested jit compilation. A practical example of this issue is when trying to use psum from within scan: ``` pmap( partial(lax.scan, lambda c, x: (c + lax.psum(x, \"i\") , c), 0.), axis_name=\"i\" )(np.ones((8, 4))) ``` Scan need to compiles the body of the loop using xla which fails because psum is only defined in the context of the pxla interpreter. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Respecting topological sorting for environment removal Not sure if this is implemented in newer versions of `conda`, but it would be nice if environment removal performed a topological sort and uninstalled packages based on this sorting. Namely only removing packages that are not required for anything else first. For the most part this doesn't matter, but when `pre-unlink` scripts are involved it does. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] conan profile update not working for env section When trying to update a value for an existing key in a profile's `env` section, the command returns without an error but the key still has its old value. Updating values for existing keys in other sections, e.g. `options`, `scopes` and `settings`, works as expected. Example: 1. `conan profile show default` -> `env.foo` does not exist 2. `conan profile update env.foo=bar default` 3. `conan profile show default` -> `env.foo` with value `bar` exists 5. `conan profile update env.foo=baz default` 6. `conan profile show default` -> `env.foo` still has old value `bar` instead of expected value `baz` Conan 1.0.0 (bug persists at least since version 0.28.1) Python 2.7.6 64-bit Linux Mint 17.3 64-bit and Conan 0.30.3 Python 3.6.4 64-bit Windows 10 64-bit Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Document ndindex(shape) This usage of `ndindex`: ``` >>> list(np.ndindex((3,2))) [(0, 0), (0, 1), (1, 0), (1, 1), (2, 0), (2, 1)] ``` seems to work with ``` >>> np.__version__ '1.18.4' ``` but it's not [documented](https://numpy.org/doc/stable/reference/generated/numpy.ndindex.html). Is this usage intended to be allowed? (I'd like it to be, because if `shape == 5` then `np.index(shape)` works while `np.ndindex(*shape)` does not.) If it is, could it be added to the docs? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Consider allowing for conda compression that uses deflate rather than bzip2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Find a better name for Row.commit_modifications() or fold the behavior into See discussion in #1547 for context. The name `modifications` is intended to map to the RPC method name `ReadModifyWriteRow` but the word modification is a synonym of mutation, so this method is poorly named. The method actually sends changes that - increment an int (stored in BT as 8 bytes) - append bytes to a cell value so we should either - Fold it into `Row.commit()` as `commit(append_only=True)` - Rename it to something like `Row.commit_cell_updates` (or a better name than that) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: IoT: needs 'synth.py' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Equality of `SparsePauliOp`s with different orders ### What is the expected enhancement? Two `SparsePauliOp`s with different orders are judges as \"not equal\" as follows. ```python from qiskit.quantum_info import SparsePauliOp a = SparsePauliOp.from_list([('X', 1), ('Y', 2)]) b = SparsePauliOp.from_list([('Y', 2), ('X', 1)]) print(a == b) ``` output ``` False ``` Is it better to return `True` for this comparison or mention the order dependency in the docsting of `__eq__`? @ikkoham also told me another case as follow. A redundant operator (coeff is 0) makes the comparison \"not equal\". ```python from qiskit.quantum_info import SparsePauliOp a = SparsePauliOp.from_list([('X', 1)]) b = SparsePauliOp.from_list([('X', 1), ('Y', 0)]) print(a == b) ``` ``` False ``` If we need to compare two operator with different order and/or redundant operators, I think we need to call as follows. Is there any simple alternatives? ```python np.allclose((a - b).simplify().coeffs, [0]) ``` ### Update I updated `SparsePauliOp` in #7656 as follows. - Leave `__eq__` as is (elementary-wise comparison) - Add `equiv` for equivalence check Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: OrderedDict output differs in ipython from python (and official documentation) [collections — Container datatypes](https://docs.python.org/3/library/collections.html#collections.OrderedDict) An ordered dictionary can be combined with the Counter class so that the counter remembers the order elements are first encountered: ``` from collections import Counter, OrderedDict class OrderedCounter(Counter, OrderedDict): 'Counter that remembers the order elements are first encountered' def __repr__(self): return '%s(%r)' % (self.__class__.__name__, OrderedDict(self)) def __reduce__(self): return self.__class__, (OrderedDict(self),) ``` This is based off a Raymond Hettinger - Super considered super! - PyCon 2015, and his blog post [Python’s super() considered super!](https://rhettinger.wordpress.com/2011/05/26/super-considered-super/). My confusion is IPython returns a result that differs from the Python it's built on. The ordering of the output is important and the recipe in Hettinger's blog and the official documentation preserves the insertion order but IPython 6.1.0 built on Python 3.6.3 does not. However if I execute directly in Python 3.6.3 I receive the expected desired result. `oc = OrderedCounter('abracadabra')` output in Python 3.6.3 (and Python 2.7.14) `OrderedCounter(OrderedDict([('a', 5), ('b', 2), ('r', 2), ('c', 1), ('d', 1)]))` output in IPython 6.1.0 on Python 3.6.3 Anaconda `OrderedCounter({'a': 5, 'b': 2, 'c': 1, 'd': 1, 'r': 2})` //ordering is not preserved, seems sorted by key Would someone kindly explain why the output is different in IPython 6.1.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Trainer track_grad_norm always results in 0 **Describe the bug** The Trainer has a flag `track_grad_norm` which allows us to log the gradient norms to Tensorboard. This flag is checked in the `run_tng_epoch` function after the training step and validation step. However, the training step (`__run_tng_batch`) calls `model.optimizer_step()`, which, in the default implementation, calls `optimizer.zero_grad()`. This results in the tracked gradient norms to be always zero. Moreover, there is an optional `__run_evaluation` call in the validatin_step. This results in a call to `model.zero_grad()`, which I assume will also result in zero gradient norms. **To Reproduce** Steps to reproduce the behavior: 1. Train a model with the `track_grad_norm` flag set to True and Tensorboard logging enabled 2. Go to Tensorboard 3. Check the gradient_norms **Expected behavior** The gradient norms should not always be zero. **Desktop (please complete the following information):** - OS: Windows - Version 0.4.9 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Tool: is_msvc helper Our friend and great contributor SpaceIm is using a new detection which I believe could be part of the mainstream: ```python @property def _is_msvc(self): return str(self.settings.compiler) in [\"Visual Studio\", \"msvc\"] ``` This property can be largely re-used, when checking on `validate()` or any other condition. - [ ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: In datastore.connection.Connection.delete_entities, make return values consistent with one another From TODO: ``` python # TODO: Make this return value be a True/False (or something more useful). ``` See [`datastore.connection.Connection.delete_entities`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/connection.py#L380) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 380) # TODO: Make this return value be a True/False (or something more useful). ``` In datastore.connection.Connection.delete_entities, make return values consistent with one another From TODO: ``` python # TODO: Make this return value be a True/False (or something more useful). ``` See [`datastore.connection.Connection.delete_entities`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/connection.py#L380) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 380) # TODO: Make this return value be a True/False (or something more useful). ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan config install polutes the installation dir To help us debug your issue please explain: Hi! Since `conan config install` is able to install our hooks (that's great), it also can pollute the installation dirirectory (~/.conan) when more files are versioned together. For example: conan config install https://github.com/conan-io/hooks.git I want to install all official hooks, and this command works fine. However, more files are included there, as README, LICENSE and tests/. I think `config install` could be optimized for hooks, only installing the hooks, or we could add some `--query` argument, where we could filter and install the folder `hooks/` only. Regards! Conan Version: 1.12.3 - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Improve coverage of the documentation Currently, some public classes are not documented anywhere because we didn't create the corresponding doc pages. Those missing pages are: - Benchmark classes - Bert Japanese - Data collators If someone feels like working on one of those, please tag yourself with a comment on this issue. Once the objects are properly documented, they can be removed from the `SHOULD_BE_DOCUMENTED` constant in [this file](https://github.com/huggingface/transformers/blob/1310e1a758edc8e89ec363db76863c771fbeb1de/utils/check_repo.py#L374). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan Create (scm) copy source removing folder symlink To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. ``` Conan version 1.14.3 Distributor ID: Ubuntu Description: Ubuntu 16.04.6 LTS Release: 16.04 Codename: xenial ``` Hi there, It appears when running `conan create` locally or remotely, folder symlinks are removed when source is copied to the build folder. This is not true for file symlinks. We are using the `scm` feature. After running `conan create` and going to the build directory: ``` Changes not staged for commit: (use \"git add/rm <file>...\" to update what will be committed) (use \"git checkout -- <file>...\" to discard changes in working directory) deleted: Libs/prebuilt/Debug ``` ``` lrwxrwxrwx 1 mh70023 bluetooth 8 Feb 21 14:14 Debug -> Release/ ``` All other file symlinks are working as intended and are not deleted. I have checked my .gitignore as well for errors. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Easy way to recreate current configuration Sometimes the build can get messed up and the best way forward is to just recreate a new build with the same configuration as now. For examples I just upgraded from Fedora 27 to Fedora 28 and build is now broken for my gst-build setup: ``` $ ninja -C build/ ninja: Entering directory `build/' ninja: error: '/usr/lib64/libdl-2.26.so', needed by 'subprojects/gstreamer/gst/libgstreamer-1.0.so.0.1500.0', missing and no known rule to make it ``` In the autotools worlds, you just get the last run configure commandline from `head config.log`. Would be good for meson to provide something very similar. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Docker API v1.23 has broke IPv6 in docker-compose defined networks As @gaertner-mike noticed in #2804, and due to this change in Docker API v1.23 : > POST /networks/create now supports enabling ipv6 on the network by setting the EnableIPv6 field (doing this with a label will no longer work). IPv6 custom networks doesn't work anymore with docker-compose, which uses a label so far to enable IPv6 (`com.docker.network.enable_ipv6: \"true\"`) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Wrong parameter name in documentation Documentation web page: https://huggingface.co/pytorch-transformers/model_doc/gpt2.html#pytorch_transformers.GPT2DoubleHeadsModel See `Inputs -> multiple_choice_labels`. There is actually no such parameter in `GPT2DoubleHeadsModel.forward` method. It was renamed to `mc_labels`. Also it is presented two times in documentation which seems to be just a copy past error. Please change `multiple_choice_labels` to `mc_labels` and delete second occurrence of this parameter in documentation. Created #1118 to fix documentation. Also you may squash it with fix of #1115 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Run cmake wrapped with scan-build I would like to be able to run cmake wrapped with clang's scan-build to perform a static analysis while building. However the CMake class hard-codes the name of the executable to be 'cmake'. It would be great if it were possible to override this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Fixes #2942 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `meson configure` output formatting unreadable In meson version 0.54.0 the output of `meson configure` (in build dir) to the terminal became unreadable due to seemingly broken spacing between columns and description text does not staying in it's column if more than one line is required to display it. Here are a screenshots of how it looks for me currently:   I believe that in earlier versions there was no such problem, and the formatting started to change since 0.53, but was still readable until now. So if nothing else, it would be nice if it could be rolled back to pre-0.53 state. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Better error messages when screwing up dep dictionaries e.g.: <img width=\"1208\" alt=\"Screenshot 2019-04-08 14 32 05\" src=\"https://user-images.githubusercontent.com/28738937/55758283-25649680-5a0b-11e9-83ac-a6184b6ad134.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Wrong conan graph build-order in package_revision_mode ### Environment Details * Operating System: Red Hat Enterprise Linux 7.4 * Compiler: GCC 4.8.5 * Conan version: 1.21.0 * Python version: 3.7.1 ### Steps to reproduce Assumptions: - Cache is clean; no binary packages exist so the expectation is a full build on the CI server will be necessary. - libA depends on libC - libB has no dependencies - libC has no dependencies - appX depends on libA and libB Steps: 1. conan export libA ... 2. conan export libB ... 3. conan export libC ... 4. conan export appX ... 5. conan graph lock appX --lockfile appX.lock 6. conan build-order --build missing appX.lock Package libA shows up as Unknown Package libB shows up as Missing Package libC shows up as Missing Package appX shows up as Unknown The problem is that the conan graph build-order output excludes libA since it is \"Unknown\". I expect that of appX, I suppose, since it's the application whose dependencies I'm trying to determine need building - but not of libA. Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: bigquery dataset should not always take project argument from client The project in which a dataset resides is not necessarily the project in which jobs involving the dataset will be executed. For example, if querying the bigquery public data hacker news dataset the following will error ``` client = bigquery.Client(project='bigquery-public-data') dataset = client.dataset('hacker_news') client.extract_table_storage(..., dataset.table('comments')) ``` Because the user can't create a job in the project 'bigquery-public-data'. Instead the fairly convoluted: ``` client = bigquery.Client(project='my-project') client.extract_table_storage(..., bigquery.Client(project='bigquery-public-data').dataset('hacker_news').table('comments')) ``` Despite the fact that the client involved will never be used. The proposed fix is to add a kwarg `project` to the Dataset class which overrides the originating project. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: User defined context in print_stack_entry When using `ipdb`'s `set_trace()`, `print_stack_entry` sets the [default context to 3 lines](https://github.com/ipython/ipython/blob/master/IPython/core/debugger.py#L335). While this does preserve space, it can be very helpful to have a user defined context size, rather than continuously hitting `l` (list) to display more lines. It would be great to add a keyword to `ipdb's`'s `set_trace` (such as `context` or even `c`) that passes a context value to [Pdb](https://github.com/ipython/ipython/blob/master/IPython/core/debugger.py#L201). The change to ipython would be minimal: Adding a `context` keyword to `Pdb` and `print_stack_entry`. Not sure if there is a cleaner way to integrate this (perhaps into [Tracer's set_trace](https://github.com/ipython/ipython/blob/master/IPython/core/debugger.py#L170)?) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Doc request: Alphabetical sorting of parameters in QuantumCircuit ### Environment qiskit-terra: 0.20.0 ### What is happening? `QuantumCircuit` objects sort their list of parameters alphabetically by the parameter names, and AFAICT this is not documented. I think it would help to point it out on the `assign_parameters` and `bind_parameters` documentation, and maybe on the `QuantumCircuit` page. ### How can we reproduce the issue? https://qiskit.org/documentation/stubs/qiskit.circuit.QuantumCircuit.assign_parameters.html ### What should happen? I'm bringing this up because the behavior seems surprising given that `circuit.parameters` kind of looks like a list, but does not preserve order of insertion like a list. Clueless users like me then assume `assign_parameters()` will, when given a list of values, bind those values to the parameters in order of insertion. This assumption leads to trouble that's tricky to notice, diagnose, and fix. (E.g., `ParameterVector('angles_11')` gets bound with the values intended for `ParameterVector('angles_2')` ) ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Update CHANGELOG for 0.7.x ## 🐛 Bug <!-- A clear and concise description of what the bug is. --> Updated CHANGELOG according to the reset changes (about last two weeks) especially deprecated items like `data_loader` or `xxxxx_end` ### Additional context <!-- Add any other context about the problem here. --> https://github.com/PyTorchLightning/pytorch-lightning/milestone/4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Build on Launch Sketch for a service that builds on demand: - Checks for should_build - different version, different extensions, etc. - Set metadata in page config - Add a build service tornado handler that gives back the build data - New plugin in apputils-extension - checks for page_config, then runs the build service - When it completes we get the option to reload - If it fails we get some indication Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Cannot train model from scratch using `run_mlm.py`. Looks like the trainer does not like when it gets a `None`, so when we train from scratch, there is a `None` in this `if` and crashes: https://github.com/huggingface/transformers/blob/a6cf9ca00b74a8b2244421a6101b83d8cf43cd6b/examples/language-modeling/run_mlm.py#L357 I solved it by deleting that line, but I guess it could affect to other use cases. To reproduce, call `run_mlm` this way (I guess it is easier to reproduce, but this might be enough): ``` python run_mlm.py \\ --model_type bert \\ --train_file ./data/oscar_1000.txt \\ --validation_file ./data/oscar_1000_valid.txt \\ --output_dir testing_model \\ --tokenizer_name bert-base-spanish-wwm-cased \\ --overwrite_output_dir \\ --do_train \\ --do_eval \\ --evaluation_strategy steps \\ --per_device_train_batch_size 16 \\ --per_device_eval_batch_size 16 \\ --max_steps 500 \\ --save_steps 2000 \\ --save_total_limit 15 \\ --overwrite_cache \\ --max_seq_length 512 \\ --eval_accumulation_steps 10 \\ --logging_steps 1000 \\ ``` The dataset I'm using I guess that isn't relevant so any corpus will do. @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: python setup.py failed vs git submodule update worked Hi, I am following master and just pulled to get the navigation feature. I'm using IPython from the git repo by issuing ``` python setup.py develop ``` after pulling. This time it told me to update the submodules. Issuing ``` python setup.py submodule ``` threw an error. While ``` git submodule update ``` worked. Not sure whether this problem is with my local installation or with some changes in master. I'm not even sure how to debug this. If you want me to test anything please feel free to ask. Here is the full shell session including the traceback ``` shell markus@zurich:~/python-dev/ipython$ python setup.py develop Cannot build / install IPython with unclean submodules Please update submodules with python setup.py submodule or git submodule update or commit any submodule changes you have made. markus@zurich:~/python-dev/ipython$ python setup.py submodule Traceback (most recent call last): File \"setup.py\", line 193, in <module> package_data = find_package_data() File \"/home/markus/python-dev/ipython/setupbase.py\", line 197, in find_package_data assert len(glob(path)) > 0, \"No files match pattern %s\" % path AssertionError: No files match pattern IPython/html/static/components/font-awesome/font/*.* markus@zurich:~/python-dev/ipython$ git submodule update Submodule path 'IPython/html/static/components': checked out 'bf1ac7f0df7207b26775089c5ac788ce11c23be5' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Avoid potential import cycles from Aer and IBMQ <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Right now the effort to remove namespace packaging in #5089 is blocked on the modules level imports of `Aer` and `IBMQ`. This is because this causes an import cycle when those factory objects are no longer in the qiskit namespace. Basically, `qiskit_aer` imports `qiskit` whichi imports `qiskit_aer.Aer` which can't be resolved by python. To move forward on this we need to make these objects lazily load `qiskit.providers.aer`/`qiskit_aer` and `qiskit.providers.ibmq`/`qiskit_ibmq_provider`. The easiest way to handle this is to wait for python 3.7 to be the minimum python version and then we can just use a module level `__getattr__` and import when `Aer` or `IBMQ` are accessed. But that is likely 6+ months away since 0.17.0 will start the deprecation timer on Python 3.6 support. In the meantime we should be able do something like: ```python3 class _AerWrapper: def __init__(self): self.aer = None def __getattr__(self, attr): if self._aer is None: try: from qiskit.providers.aer import Aer except ImportError: raise ImportError(\"useful message\") self.aer = Aer return getattr(self.aer, attr) ``` (note this is completely untested, just my rough idea). This should hopefully enable us to remove the import cycle at the module level. It would also have a noticeable benefit for #5100 as we're not unconditionally importing ibmq and aer all the time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Drag target very small if IPython Dashboard has no notebooks When importing a notebook into the dashboard, the table of existing notebooks is the drag target. This is quite a small area. If the drag target is missed, the browser merely loads the ipynb file as plain text. Consider making the drag target larger, especially if the existing notebook list is empty. Drag target very small if IPython Dashboard has no notebooks When importing a notebook into the dashboard, the table of existing notebooks is the drag target. This is quite a small area. If the drag target is missed, the browser merely loads the ipynb file as plain text. Consider making the drag target larger, especially if the existing notebook list is empty. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: no include directories with precompiled headers ? Hi, i have a project structure tree that looks like: lib/ inc lib lib.h src pch stdafx.h app/ inc src pch stdafx.h what i do (maybe it's a bad idead?), is that I include all the headers in my lib inside lib.h. that way, any app using that needs lib can just include lib/lib.h. i'm trying to use precompiled headers so that lib/pch/stdafx.h contains lib.h app/pch/stdafx.h also contains lib.h meson.build for the app is setup like this: executable( 'app' , src , include_directories : [lib_inc] , link_with : lib_lib , cpp_pch : ['pch/stdafx.h', 'pch/stdafx.cpp']) problem is when i'm compiling, i have this error: Precompiling header ../app/pch/stdafx.h FAILED: app/app@exe/stdafx.h.pch clang++ \"-Wall\" \"-Winvalid-pch\" \"-Wnon-virtual-dtor\" \"-std=c++11\" \"-DWINDOWS\" \"-DIX_DEBUG\" \"-O0\" \"-g\" \"-MMD\" \"-MQ\" app/app@exe/stdafx.h.pch \"-MF\" \"app\\\\app@exe\\\\stdafx.h.pch.d\" -o app/app@exe/stdafx.h.pch -c ../app/pch/stdafx.h clang++.exe: warning: treating 'c-header' input as 'c++-header' when in C++ mode, this behavior is deprecated ../app/pch/stdafx.h:5:10: fatal error: 'lib/lib.h' file not found #include <lib/lib.h> seems to me that the include_directories doesnt apply to precompiled headers. is it expected? bonus: how can i get rid of the warning? note that i'm running a meson.build script from the root directory, with subdir for lib and app. thanks a lot in advance, best regards, Uj Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add validate parameter to gcloud.storage.connection.get_bucket() But make it default to False (http://www.appneta.com/blog/s3-list-get-bucket-default/) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Unnecessary performance bottleneck in Statevector.evolve <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Aer version**: 0.5.0 - **Python version**: 3.8 - **Operating system**: linux (ubuntu 18.04) ### What is the current behavior? Statevector.evolve is slow, because it recreates Statevector objects, which itself is a slow operation. ### Steps to reproduce the problem Throw a line profiler on a code segment that calls Statevector.evolve repeatedly. ### What is the expected behavior? Creating a Statevector should have little to no overhead. ### Suggested solutions I profiled some code that uses Statevector.evolve repeatedly, and identified the bottleneck: ``` # qiskit/quantum_info/states/statevector.py in Statevector.evolve return Statevector(np.reshape(tensor, np.product(new_dims)), dims=new_dims) # same file, Statevector.__init__ super().__init__(...) # qiskit/quantum_info/states/quantum_state.py in QuantumState.__init__ self._rng = np.random.RandomState() ``` Now, creating a RandomState object seems to have tremendous overhead; indeed, the np.reshape operation of tensor is much quicker. Workaround: after loading qiskit and numpy, run ``` def _global_rng_fix(): return _global_rng_fix._random_state _global_rng_fix._random_state = np.random.RandomState() np.random.RandomState = _global_rng_fix ``` This is not a fix! A true fix would be to use a newer rng object that doesn't have massive overhead (note that RandomState is legacy code anyhow - and since there's no seed set, it's unclear what the benefit of a separate RandomState object should be within a Statevector anyhow). Thanks for your great work! ~ Johannes Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add MSN checkpoints to ViT ### Feature request It's been a while Meta released the [MSN](https://github.com/facebookresearch/msn) (Masked Siamese Networks) checkpoints. MSN is known to perform pretty well in few-shot settings. Few-shot regime is important for real-world applications. They have only released the encoder weights. I have worked on a [Colab Notebook](https://colab.research.google.com/gist/sayakpaul/51556ce57facea02041cf0c0f1c3fed3/scratchpad.ipynb) that converts the released MSN checkpoints into HF format and performs assertions to ensure the converted weights can be loaded into HF's ViT classes. This issue proposes adding the MSN checkpoints to be compatible with HF's ViT classes. ### Motivation MSN is particularly useful in few-shot learning regimes. ### Your contribution Can contribute to the checkpoints and other related utilities. @NielsRogge could you assign this issue to me? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: bug in permutation circuits The permutation circuits from the circuit library do not implement some permutation correctly. For example: ```py from qiskit.circuit.library import Permutation Permutation(8, [5,4,1,7,6,3,0,2]).decompose().draw() ``` here the 5th qubit has to end up in the 0th location, but it ends up in the 6th location because two swaps act on it. ``` q_0: ────X─────X─ │ │ q_1: ─X──┼──X──┼─ │ │ │ │ q_2: ─┼──┼──X──┼─ │ │ │ q_3: ─┼──┼──X──┼─ │ │ │ │ q_4: ─X──┼──┼──┼─ │ │ │ q_5: ────X──┼──┼─ │ │ q_6: ───────┼──X─ │ q_7: ───────X──── ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumCircuit __eq__ fails when comparing with None ## Information Qiskit Terra version: 0.15.1 Python version: 3.7.7 Operating system: MacOS v10.15.6 ## What is the current behavior? When two `QuantumCircuit` objects are compared with `==` and one of them is `None`, an error is thrown. ## Steps to reproduce the problem ``` from qiskit import QuantumCircuit qc1 = QuantumCircuit() qc2 = None qc1 == qc2 --> error ``` ## What is the expected behavior? The `qc1 == qc2` comparison should always return `True` or `False`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Virtualbuildenv generator should setup Visual Studio paths I believe Virtualbuildenv generator should generate `activate_build.bat` that setup the whole Visual Studio environment like `tools.vcvars()` does. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Circuit drawers do not respect classical conditional ordering <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.16.0 - **Python version**: - **Operating system**: ### What is the current behavior? Having gates conditioned on measurements performed earlier are moved before the measurements in the circuit drawing eg ``` qr = QuantumRegister(3) cr = ClassicalRegister(2) qc = QuantumCircuit(qr,cr) qc.reset(range(3)) qc.h(1) qc.cx([1,0],[2,1]) qc.h(0) qc.measure([0,1], [0,1]) qc.z(2).c_if(cr, 1) qc.x(2).c_if(cr, 2) ``` ``` ┌───┐┌─┐ q6_0: ─|0>──────────────■───┤ H ├┤M├─────── ┌───┐ ┌─┴─┐ └┬─┬┘└╥┘ q6_1: ─|0>─┤ H ├──■───┤ X ├──┤M├──╫──────── └───┘┌─┴─┐ ├───┤ └╥┘ ║ ┌───┐ q6_2: ─|0>──────┤ X ├─┤ Z ├───╫───╫──┤ X ├─ └───┘ └─┬─┘ ║ ║ └─┬─┘ ┌──┴──┐ ║ ║ ┌──┴──┐ c9: 2/═══════════════╡ = 1 ╞══╩═══╩═╡ = 2 ╞ └─────┘ 1 0 └─────┘ ``` <img width=\"467\" alt=\"Screen Shot 2020-11-11 at 19 14 01\" src=\"https://user-images.githubusercontent.com/1249193/98878880-1305d680-2452-11eb-9d5e-2c2900babe1e.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: macOS: LD version detection not working with Xcode 15.0 beta 3 The linker version detection happens here: https://github.com/mesonbuild/meson/blob/master/mesonbuild/linkers/detect.py#L197C6-L197C6 ```python for line in newerr.split('\\n'): if 'PROJECT:ld' in line: v = line.split('-')[1] break ``` However, the latest Xcode 15.0 beta 3 outputs this: ``` @(#)PROGRAM:ld PROJECT:dyld-1009.5 BUILD 20:45:24 Jun 29 2023 configured to support archs: i386 x86_64 x86_64h armv6 armv7 armv7s armv7m armv7k arm64 arm64e arm64_32 LTO support using: LLVM version 15.0.0 (static support for 29, runtime is 29) TAPI support using: Apple TAPI version 15.0.0 (tapi-1500.0.12) Library search paths: Framework search paths: ld: Undefined symbols: _main, referenced from: clang: error: linker command failed with exit code 1 (use -v to see invocation) ``` Compare this with Xcode 14.3.1: ``` @(#)PROGRAM:ld PROJECT:ld64-857.1 BUILD 23:13:29 May 7 2023 configured to support archs: armv6 armv7 armv7s arm64 arm64e arm64_32 i386 x86_64 x86_64h armv6m armv7k armv7m armv7em Library search paths: Framework search paths: Undefined symbols for architecture arm64: \"_main\", referenced from: implicit entry/start for main executable ld: symbol(s) not found for architecture arm64 clang: error: linker command failed with exit code 1 (use -v to see invocation) ``` As you can see, the project name changed from `PROJECT:ld` to `PROJECT:dyld` and the detection code no longer works. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: `max_results` is ignored if `bqstorage_client` is used in `to_dataframe` or `to_arrow` #### Steps to reproduce 1. Call `list_rows` with `max_results` set. 2. Call `to_dataframe` or `to_arrow`. 3. Observe that more rows were returned than were requested. #### Code example ```python from google.cloud import bigquery from google.cloud import bigquery_storage bqclient = bigquery.Client() bqstorage_client = bigquery_storage.BigQueryStorageClient() df_tabledata_list = bqclient.list_rows( \"bigquery-public-data.utility_us.country_code_iso\", selected_fields=[bigquery.SchemaField(\"country_name\", \"STRING\")], max_results=100, ).to_dataframe() print(\"tabledata.list: {} rows\".format(len(df_tabledata_list.index))) df_bqstorage = bqclient.list_rows( \"bigquery-public-data.utility_us.country_code_iso\", selected_fields=[bigquery.SchemaField(\"country_name\", \"STRING\")], max_results=100, ).to_dataframe(bqstorage_client=bqstorage_client) print(\"bqstorage: {} rows\".format(len(df_bqstorage.index))) ``` #### Output ``` tabledata.list: 100 rows bqstorage: 278 rows ``` #### Possible fixes 1. (Harder) Keep track of how many rows you've downloaded in a BQ Storage session so far. Once you've downloaded enough rows, close all streams (is this even possible?). 2. (Easier, but acceptable) If `max_results` is set, always download data with tabledata.list. I think we should implement the fix with (2) because if `max_results` is set, it's unlikely that we are downloading all that many rows where using the BQ Storage API makes sense. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Cloud PR references Core See https://github.com/PrefectHQ/cloud/pull/546 for more details Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: update PyPI classifiers to not install with unsupported Python versions Right now if you do `pip-3.9 install numpy`, it will try to build NumPy for a version that does not support Python 3.9 yet (as stated in the release notes, and in `numpy/__init__.py`). We should see if we can fix the PyPI classifiers for this. EDIT: or it's `python_requires='>=3.6'` in `setup.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DLP Synth.py will not generate buildable docs The current synth.py for DLP will not build docs correctly. Add replacement patterns to adjust docstrings Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add support for query parameters The CLI command `bq query` now supports query parameters for Standard SQL queries and the API does as well (https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#request-body). It would be great to be able to provide these via google.cloud. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: add TPU tests ## 🚀 Feature we shall also cover TPU usage as we are supporting it ### Motivation now all changes are tested for GPUs and CPU but we do not have a check for TPU yet ### Pitch getting coverage back to ~99% Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Path expansion in virtualrunenv generator adds extra colon for empty path ### Environment Details * Operating System+version: Debian GNU/Linux 10 * Conan version: 1.34.0-dev * Python version: 3.7.0 * Shell: GNU bash, version 5.0.3(1)-release (x86_64-pc-linux-gnu) ### Steps to reproduce (Include if Applicable) ~~~bash export LD_LIBRARY_PATH= # install a recipe with \"-g virtualrunenv\" source activate.sh echo $LD_LIBRARY_PATH ~~~ The last echo prints path with extra \":\" at the end. ### Explanation According to [Bash expansion](https://www.gnu.org/software/bash/manual/html_node/Shell-Parameter-Expansion.html): > **${parameter:+word}** > If parameter is null or unset, nothing is substituted, otherwise the expansion of word is substituted. Conan uses: ~~~bash PATH=\"...\"${PATH+:$PATH} ~~~ Using `${var+:$var}`: ~~~bash export DEFINED_EMPTY_VAR= echo \"xxx\"${DEFINED_EMPTY_VAR+:$DEFINED_EMPTY_VAR} echo \"xxx\"${UNDEFINED_VAR+:$UNDEFINED_VAR} ~~~ Results ~~~ xxx: xxx ~~~ Correct form `${var:+:$var}`: ~~~bash export DEFINED_EMPTY_VAR= echo \"xxx\"${DEFINED_EMPTY_VAR:+:$DEFINED_EMPTY_VAR} echo \"xxx\"${UNDEFINED_VAR:+:$UNDEFINED_VAR} ~~~ Results ~~~ xxx xxx ~~~ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qpy not recognizing complex number as a parameter for Initialize <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.0 - **Python version**: - **Operating system**: ### What is the current behavior? When trying to serialize a QuantumCircuit using qpy, I got ``` ~/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py in _write_instruction(file_obj, instruction_tuple, custom_instructions, index_map) 722 size = len(data) 723 else: --> 724 raise TypeError( 725 f\"Invalid parameter type {instruction_tuple[0]} for gate {type(param)},\" 726 ) TypeError: Invalid parameter type <qiskit.extensions.quantum_initializer.initializer.Initialize object at 0x103fd6dc0> for gate <class 'complex'>, ``` ### Steps to reproduce the problem The circuit I used: ``` import io import numpy as np from qiskit.circuit import QuantumCircuit, qpy_serialization from qiskit.circuit.library import QFT from qiskit.quantum_info import Statevector k = 5 state = (1/np.sqrt(8))*np.array([np.exp(-1j*2*np.pi*k*(0)/8),np.exp(-1j*2*np.pi*k*(1)/8), np.exp(-1j*2*np.pi*k*(2)/8), np.exp(-1j*2*np.pi*k*3/8),np.exp(-1j*2*np.pi*k*4/8),np.exp(-1j*2*np.pi*k*5/8), np.exp(-1j*2*np.pi*k*6/8), np.exp(-1j*2*np.pi*k*7/8)]) qubits = 3 circuit = QuantumCircuit(qubits, qubits) circuit.initialize(state) circuit.append(QFT(qubits),range(qubits)) circuit.measure(range(qubits),range(qubits)) buffer = io.BytesIO() qpy_serialization.dump(circuit, buffer) ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Reconnecting error messages with master(-ish) Version: ee6223ab74eb My situation is that I set up a remote notebook on a server that I only can reach when in a VPN. Now, my Wifi is shaky for some reason, that's possibly how my VPN get's shaky. So I needed to close my notebook after a VPN reconnect and the dashboard still reported it as 'running'. When I clicked on the 'running' notebook, I got this error in the console: ``` python RunTimeError: Method not supported by Web Sockets ``` Full error log here: https://gist.github.com/23ed2e252897d96804a5 Working on OSX 10.9.5 using conda and Python 3.4 Reconnecting error messages with master(-ish) Version: ee6223ab74eb My situation is that I set up a remote notebook on a server that I only can reach when in a VPN. Now, my Wifi is shaky for some reason, that's possibly how my VPN get's shaky. So I needed to close my notebook after a VPN reconnect and the dashboard still reported it as 'running'. When I clicked on the 'running' notebook, I got this error in the console: ``` python RunTimeError: Method not supported by Web Sockets ``` Full error log here: https://gist.github.com/23ed2e252897d96804a5 Working on OSX 10.9.5 using conda and Python 3.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Trying to set c_std to 18 and got an error I am trying to set ‘c_std’ to version 18 and it printed an error about that version not being valid. The document on built-in options states that it is. However the value “c17” is working. Would this be fixed at some point? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: ImportError: cannot import name 'ciient_info' `i != l`: https://github.com/googleapis/google-cloud-python/blame/a9bcc2755248d41b7610ceff80cd9357ad7fd04a/error_reporting/google/cloud/error_reporting/client.py#L25 Who reports the error reporter? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Text circuits in Jupyter misaligned <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? Following #2769 my text circuits are not aligned in Jupyter: <img width=\"400\" alt=\"Screen Shot 2019-07-18 at 9 17 11 AM\" src=\"https://user-images.githubusercontent.com/1249193/61460581-02684d80-a93d-11e9-843b-a6ea0a344ac8.png\"> verses the old way: <img width=\"395\" alt=\"Screen Shot 2019-07-18 at 9 16 59 AM\" src=\"https://user-images.githubusercontent.com/1249193/61460604-0a27f200-a93d-11e9-86c4-761b4b73012b.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: distutils deprecation in Python 3.12 ### What is the idea? [PEP 0632](https://www.python.org/dev/peps/pep-0632/) announced the deprecation of the `distutils` package in Python 3.10 and the removal of said package in Python 3.12. `conda` should be prepared for when this happens. ### Why is this needed conda will likely break with Python 3.12 if no updates are made. (That or a `distutils` shim package will need to be added as a dependency.) ### What should happen? Use of `distutils` should be replaced (or supplemented) with non-distutils equivalents; as of the latest `master` @ [commit fb5c95f1f](https://github.com/conda/conda/tree/fb5c95f1f), it's being used in the following places: ``` $ egrep -rnIH '(from|import) distutils' conda conda/common/path.py:17:from distutils.spawn import find_executable conda/auxlib/packaging.py:70:from distutils.command.build_py import build_py conda/auxlib/packaging.py:71:from distutils.command.sdist import sdist conda/auxlib/packaging.py:72:from distutils.util import convert_path conda/auxlib/path.py:3:from distutils.sysconfig import get_python_lib ``` ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: `Flow.visualize()` should be able to display inline in a Jupyter notebook Whether by user-provided `kwarg` or by magic, `Flow.visualize()` should be able to render inline in IPython notebooks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: parallel.client.client references undefined error.EngineError parallel/client/client.py, line 712 tries to instantiate the undefined class error.EngineError It seems to me that it should be defined in parallel/error.py I'm using IPython 1.0.0 In the current master trunk, error.EngineError is referenced on line 718, and is still undefined. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Potential type promotion bug. Since the latest jax type promotion changes I'm seeing the following strange type promotion behavior (x64, CPU at head): ```python import jax.numpy as np from jax.config import config config.update('jax_enable_x64', True) xs = np.array([1., 2.], np.float32) sigma = np.float32(1.0) print(np.exp(xs / sigma ** 2).dtype) # Float64 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: BaseOperator type hints for retry_delay and max_retry_delay should reveal float option ### Describe the issue with documentation `BaseOperator` type hints for `retry_delay` and `max_retry_delay` shows `timedelta` only, however the params also accept `float` seconds values. Also, type hint for `dag` param is missing. More precise type hints and params descriptions in the docs can help to understand the code behavior easier. ### How to solve the problem _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: add list of packages to conanbuildinfo.cmake Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: CI test to simulate JupyterLab usage without NodeJS > Would it be easy to set a case in the CI to simulate the installation and execution of JupyterLab with no NodeJS available ? @blink1073 and I both thought that we already were testing this. It's possible that the move to the Microsoft CI somehow accidentally deleted this test. It's also possible that both of us were misremembering what we currently test, which is that we test that we can build even without a global yarn: https://github.com/jupyterlab/jupyterlab/blob/c27318d64f84dc85f04a10fd00c577bcb037f137/scripts/ci_install.sh#L8-L11 We definitely *should* test it somehow, though. _Originally posted by @jasongrout in https://github.com/jupyterlab/jupyterlab/pull/7461#issuecomment-549037943_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: MLflowCallback to log run_name argument # 🚀 Feature request When using the MLflowCallback (set as default for Trainer), I would like to log the `run_name` argument passed to TrainingArguments as the Run Name on the MLflow dashboard. Currently runs are being logged as nameless. E.g. see below.  ## Motivation Trainer makes training 🤗 models so easy and MLflow is great for organising experiments/caching artifacts. I would like to make it easier to organise experimental runs and make research easier, particularly for larger teams. This feature would be a very simple patch on the original PR #8016 example usage ``` training_args = TrainingArguments( label_names=['labels_t1', 'labels_t2'], output_dir='./runs, # output directory run_name='multitask_clf_<run_name>', ) trainer = Trainer( model=model, # the instantiated 🤗 Transformers model to be trained args=training_args, # training arguments, defined above train_dataset=train_dataset, # training dataset ) ``` ## Your contribution I can submit a PR Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson 0.43 module build.py fix to known_kwargs for jar targets When the jar() function is used to create a Java target, build.py issues a warning message: 'WARNING: Unknown keyword argument(s) in target <your_target>: target_type.' This occurs because class Jar in build.py doesn't known about the target_type argument passed to it. In build.py, top level, just after setting known_exe_kwargs, add these two lines: known_jar_kwargs = known_basic_kwargs.copy() known_jar_kwargs.update({'target_type': 'jar', }) In the definition of class Jar in build.py, override the check_unknown_kwargs() method inherited from class BuildTarget with: def check_unknown_kwargs(self, kwargs): self.check_unknown_kwargs_int(kwargs, known_jar_kwargs) That should eliminate the warning message . Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Attachable flag brakes compatibility mode and requires local swarm cluster Hello; When using compatibility mode, if there is an attachable flag declared in networks It is expected to run as a regular docker-compose stack. Example as follows: ``` networks: foonetwork: - driver: overlay - attachable: true ``` However, this config asks for local swarm cluster. When I run the ```docker-compose --compatibility config``` command, I can still see the ```attachable: true``` flag, which requires a version 3.2v compose file. It seems like a conversion bug in ```docker-compose config``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: \"conan install .. \" broken for Wrong package recipe reference (1.12.0) - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. If a launch 'conan install ..' in my build director, where .. has a conanfile.py file. I got an exeption \"Wrong package recipe reference\". I have add a display and it seems that conan tries to parse \"..\" as a recipe. the same happens if I use \"conan install ../conanfile.py\" Regards, Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: With RTC enabled, large notebooks to fail on save and whole UI becomes extremely sluggish. ## Description When Lab is started with `--collaborative`, certain large notebooks fail to save or take inordinately long to do so. ## Reproduce [This Gist](https://gist.github.com/06cc8cab195a7ebaa97bf42ff77dd141.git) contains a notebook that illustrates the problem. To reproduce, clone the gist and run side-by-side JupyterLab with and without `--collaborative`. I tested on a Mac Mini with Big Sur, Python 3.9, 64GB of RAM and JupyterLab 3.1.10. The version with `--collaborative` on will either not save at all, or take easily 10 minutes to do a save. In addition, the whole UI gets very sluggish, and the browser occasionally pops warnings about the page consuming too many resources (seen on Firefox, Chrome and Safari). ## Additional context We spent some time tracking down this problem [over at the Jupyter meets the Earth repo](https://github.com/pangeo-data/jupyter-earth/issues/78). Flagging that thread for reference, but all relevant info is here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Make classifier backbone dynamic maskformer, mask2former ### Feature request Make classifier backbone dynamic maskformer, mask2former. Currently it only supports swin transformer. link example: https://github.com/huggingface/transformers/blob/main/src/transformers/models/mask2former/modeling_mask2former.py#L1393 ### Motivation If this feature request successful, it will help to benchmark for new clasifier easily. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Promote 'TimestampWithNanos' from 'spanner' to 'api_core' It would be useful for other services as they begin to render nanosecond-resolution timestamps. See: #4807 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: ResultHandlers should be serializable to JSON From PIN2 (https://github.com/PrefectHQ/prefect/pull/570): In order to attach information to `state.metadata` about how each attribute should be handled, all `ResultHandler`s need to be serializable with an associated versioned schema. Currently there are only three result handlers - Local, Cloud, and GCS but soon there will be more. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Converting masked array from float to uint8 does not convert dtype of fill_value When a masked array of dtype float32 is converted to uint8, the dtype of the fill_value persists. When setting the fill_value to a uint8 value, the value is converted to float. Filling such an array yields an array of dtype object. This was working in numpy==1.14. ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np foo = np.ma.masked_equal(np.arange(10, dtype=\"float32\"), 5) foo.fill_value = -1.0 bar = foo.astype(\"uint8\") print(bar.fill_value) bar.fill_value = 255 print(bar.fill_value) print(bar.filled().dtype) ``` ### Error message: with numpy==1.14.2 this yields: ``` 255 255 uint8 ``` with numpy==1.15.2 this yields: ``` -1.0 255.0 object ``` ### Numpy/Python version information: Tested with python 2.7 and 3.5.2 numpy==1.15 <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Option to suppress progress There should be an option that still shows the build steps, but not the actual progress bars which spray a huge amount of output on CI servers since the docker commands expect that your using a terminal that has the control codes to write over previous lines. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: forward-mode eigh derivatives return NaN's First off, thanks for developing JAX, it's awesome! I recently noticed that when one computes higher order derivatives of expressions involving eigenvectors obtained from `jax.numpy.eigh` or `jax.scipy.eigh`, NaNs are returned. However, it only appears to be a problem with forward-mode autodiff. This is unfortunate, since forward-mode tends to be more efficient for higher order derivatives. A minimal example: ```python import jax import jax.numpy as np # Create a random symmetric matrix seed = jax.random.PRNGKey(0) tmp = jax.random.uniform(seed, (2,2)) a = np.dot(tmp, tmp.T) def test(inp): val, vec = np.linalg.eigh(inp) return np.dot(np.dot(vec, inp), vec.T) def test_deriv(func, inp): grad_func = jax.jacfwd(func) hess_func = jax.jacfwd(grad_func) cube_func = jax.jacfwd(hess_func) # This derivative returns NaN, but jax.jacrev works! print(grad_func(inp)) print(hess_func(inp)) print(cube_func(inp)) test_deriv(test, a) ``` Additional notes: - Expressions involving eigenvalues do not appear to have this issue - Any array contractions involving eigenvectors and other arrays (`dot`, `einsum`, etc) also exhibit similar behavior: `jacfwd` fails, while `jacrev` works. - I'm using CPU - JAX version 0.1.46 Thanks for your time! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: MismatchCAPIWarning during build Something we might want to deal with before 1.16: > numpy\\core\\setup.py:400: MismatchCAPIWarning: API mismatch detected, the C API version numbers have to be updated. Current C api version is 13, with checksum 5b0e8bbded00b166125974fc71e80a33, but recorded checksum for C API version 13 in codegen_dir/cversions.txt is a1bc756c5782853ec2e3616cf66869d8. If functions were added in the C API, you have to update C_API_VERSION in numpy\\core\\setup_common.py. The build continues despite this warning, so it's possible we just didn't notice it. This is likely my fault as part of #8955 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: improve deprecation warnings in IPython/terminal/interactiveshell.py warn on import, and add version since deprecation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython 5 shell does not react to SIGQUIT (CTRL + \\) In previous IPython versions it was possible to terminate an IPython session quickly by sending an `SIGQUIT`, i.e., by pressing <kbd>CTRL</kbd>+<kbd> \\ </kbd>. This is useful when having an `embed()` in a loop with a large number of iterations. Pressing <kbd>CTRL</kbd>+<kbd>d</kbd> followed by <kbd>y</kbd> is not practical. Since `%kill_embedded` is currently also broken there is no convenient way to terminate the process. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Invalid formatting of libdir/includedir in pkg_config generator [bug] Version: conan-1.2.3 OS: Linux https://github.com/conan-io/conan/blob/ac25c8994878706bac23efd009ae74bc294c1add/conans/client/generators/pkg_config.py#L28-L36 `pkg_config` generator doesn't check if libdir or includedir are absolute paths which leads to the following (invalid) `.pc` being generated for `boost_math/1.66.0@bincrafters/stable`: ``` prefix=/home/user/.conan/data/boost_math/1.66.0/bincrafters/stable/package/937af278b1c9d86290dddaf1322dc99fb7d75862 libdir=${prefix}//home/user/.conan/data/boost_level8group/1.66.0/bincrafters/stable/package/afc149253b16bde7d64e527e0dbfa27b203330c8/math/lib includedir=${prefix}//home/user/.conan/data/boost_level8group/1.66.0/bincrafters/stable/package/afc149253b16bde7d64e527e0dbfa27b203330c8/math/include ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [feature request] a tool to clone existing models to make new models with small changes # 🚀 Feature request So we have great templates for creating a new model. ### Can you think of a way to create full clones of existing models? Practically for BigScience needs we will have to create something like GPTMeg which is 99.9% identical to GPT2 with 2-3 tiny changes. And then we will need another GPT2 variant that replaces Positional Embeddings with ALiBi. And there will be more variants. Using templates would be quite expensive, when always everything is really identical. So ideally a user will do: ``` transformers-clone-model GPT2 GPTMeg ``` and voila it'd replicate model's files, tests and docs. If all source files could be easily identified this perhaps could be done in a few perl one liners. Here is a very rough outline: 1. find the pertinent source files grep -Irl GPT2 . 2. rename files/dirs while copying s/gpt2/gpt_meg/ 3. rename internals to s/GPT2/GPTMeg/g The hard to automate part is the index files as they is only one of each I think I can work it out, but I'm afraid that the end result would be a set of Perl one-liners only Stas will know what to do with. So perhaps long term this is not a good solution. Here is the Issue where we need to implement this: https://github.com/bigscience-workshop/Megatron-DeepSpeed/issues/138 and 2 more will be coming soon. @LysandreJik, @patrickvonplaten, @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Error when using default_options as tuple with equals sign (=) in value To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Similar to #1296, specifying a tuple for `default_options` with an option that has an `=` in the value part fails. ```python from conans import ConanFile class ReproConan(ConanFile): name = \"repro\" version = \"0.1.0\" options = {\"opt\": \"ANY\"} default_options = (\"opt=a=b\",) ``` ``` $ conan install . ERROR: /path/to/conanfile.py: Error while initializing options. too many values to unpack (expected 2) ``` This happens on latest on the `develop` branch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Validate input when setting the QuantumCircuit data attribute directly Similar to #2170 , but for `QuantumCircuit`. The possibility of arbitrary data in `circuit.data` makes modifying or replacing the internals of `QuantumCircuit` difficult and error prone (see discussion around `circuit._append` in #2824 ). We should: - Move `circuit.data` to `circuit._data` - Add a getter for `circuit.data` and document it as a ordered list of `(Instruction, qargs, cargs)`. It's an open question whether or not we should commit to preserving user-insertion order. - Add a setter for `circuit.data` with a `DeprecationWarning`, directing users to e.g. `QuantumCircuit.append` and the rest of the circuit API. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Accept list of AssetsDefinitions directly on repo I've seen a few users get tripped up on this (including myself) Right now you can do this: ``` assets: Sequence[AssetsDefinition, SourceAsset] = ... @repository def repo(): return [*assets] ``` but this fails: ``` assets: Sequence[AssetsDefinition, SourceAsset] = ... @repository def repo(): return [assets] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub: Got unbound method error when calling the class method from_service_account_json I am using the service account for authentication. By following the example in [here](https://googlecloudplatform.github.io/google-cloud-python/latest/core/auth.html#service-accounts) , I create the following code: ``` from google.cloud import pubsub logging.debug(dir(pubsub.PublisherClient)) pubsub_publisher_client = pubsub.PublisherClient.from_service_account_json(key_path) ``` The output: ``` DEBUG:root:['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'batch', 'create_topic', 'delete_topic', 'from_service_account_file', 'from_service_account_json', 'get_iam_policy', 'get_topic', 'list_topic_subscriptions', 'list_topics', 'project_path', 'publish', 'set_iam_policy', 'target', 'test_iam_permissions', 'topic_path', 'update_topic'] Traceback (most recent call last): File \"main.py\", line 81, in <module> pubsub_publisher_client = pubsub.PublisherClient.from_service_account_json(key_path) TypeError: unbound method from_service_account_file() must be called with PublisherClient instance as first argument (got str instance instead) ``` However, when I use similar code to create datastore client with the service account JSON file, it works. E.g. ``` from google.cloud import datastore datastore_client = datastore.Client.from_service_account_json(key_path) ``` After checking the source code, perhaps the decorator in `pubsub/google/cloud pubsub_v1/_gapic.py` failed to create the class method properly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add FLAN-UL2 ### Model description UL2 is a unified framework for pretraining models that are universally effective across datasets and setups. UL2 uses Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. UL2 introduces a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. FLAN-UL2 has the same configuration as the original UL2 20B model, except that it has been instruction tuned with Flan. ### Open source status - [X] The model implementation is available - [X] The model weights are available ### Provide useful links for the implementation The model architecture (UL2) is already in Huggingface Transformers. The 20B model weights are here: https://github.com/google-research/google-research/tree/master/ul2#checkpoints Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: distutils/misc_util.py Configuration settings lead to ImportError DLL load failed When building NumPy from the source on Windows 10, the resulting `.libs` folder is not added to the path. ### Reproducing code example: The regular ```bash python setup.py build python setup.py install ``` machinery succeeds however afterwards numpy import fails with the recently reported `ImportError`s elsewhere, say, #14896 and others. This happens also on SciPy builds which were successfully working until I switched to Python 3.8. This is also reported on SciPy https://github.com/scipy/scipy/issues/11062 It seems like the generated `__config__.py` has the lines https://github.com/numpy/numpy/blob/6e75b9ab7888e2d807893a8237811f97f605547e/numpy/distutils/misc_util.py#L2324-L2335 Somehow, .libs folder is not present on the `src.win-amd64-3.8` but it is created in `lib.win-amd64-3.8` and for reasons I have not yet understood, this if branch is not entered. On the linked SciPy issue, the file is modified manually to add the libs to the path. Hence I am under the impression that it is not necessarily an Anaconda issue but something has changed along the way, that is maybe, Python3.8 related. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Two link objects with name conflicts Right now we have two things called `link`: - One in `traitlets` that links attributes of any `HasTraits` subclass. - One in `widgets` that does a JS based link of any `Widget` subclass. Their API is nearly identical and it is very common to import both at the same time. I spent about 2 hours tracking down a super subtle bug because I had both imported and didn't realize which one I was using. I think we should consider naming the JS one to `jslink`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: 720x runtime performance regression in `QuantumCircuit.depth()` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: main (after 7c30a6e7) - **Python version**: 3.8 - **Operating system**: Linux ### What is the current behavior? The nightly benchmark runs flagged a regression in the QUEKO transpiler benchmarks caused by https://github.com/Qiskit/qiskit-terra/pull/6998: https://qiskit.github.io/qiskit/#queko.QUEKOTranspilerBench.time_transpile_bigd?cpu=Intel(R)%20Xeon(R)%20E-2174G%20CPU%20%40%203.80GHz&machine=qiskit-benchmarking01&num_cpu=8&os=Ubuntu%2020.04&ram=64GB&python=3.8&p-optimization%20level=0&p-routing%2Flayout%20method=None&commits=7c30a6e7 It is showing a 720x runtime performance slowdown (from 35.824ms to 25.810s). At first I was surprised because a transpiler benchmark shouldn't be using `QuantumCircuit.depth()` but looking at the benchmark code calling `.depth()` on the output circuit is part of the timed function: https://github.com/Qiskit/qiskit/blob/master/test/benchmarks/queko.py#L235 This is arguably a benchmark bug, but it did catch the regression in this case so it's useful for that. The regression wasn't quite as bad on other variants so my guess is the regression scales with number of instructions in the circuit (probably because the filter function runs over circuit.data). ### Steps to reproduce the problem Run `QuantumCircuit.depth()` ### What is the expected behavior? depth() doesn't scale so poorly Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Plan for Extension Handling After several attempts, we have finally come to the conclusion that it is not feasible to handle extensions without using node to build the assets on the server. Our latest attempt, #1973, was to use a WebPack extension to build individual bundles, and then assemble the bundles on the server, using semver to deduplicate packages. What we soon realized is it is impossible to know for sure which modules from an upstream npm package will be consumed, so we cannot effectively deduplicate packages at the package level without having the entire package. The proposed solution is to bundle the entire `node_modules` tree with an extension, and then merge the trees and build the final WebPack bundle on the server. We rely on `npm` to deduplicate the packages in their entirety, and WebPack to bundle the assets. Note that the above are only required to add new extensions to the system. Bundles can be distributed that contain a preconfigured set of extensions, and the user can be given the opportunity to enable or disable individual extensions in the bundle (cf #1523). The requirement to have `node` installed on the user's machine can be alleviated by using the `node` package from `conda`, or we could use a standalone node executable builder such as [nexe](https://github.com/nexe/nexe) that could be distributed as a Python wheel. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Regression in Ninja link flags generation in 0.52.0 Meson version: **0.52.0** OS: **Linux** Compiler toolchain: **LLVM/Clang** I believe the change introduced in 0.52.0 wrt link flag generation caused a regression. Not sure what the minimal working example would look like but in my case the error appears when using Boost with `BOOST_ROOT` defined. After successfully running `meson` followed by `ninja` the linker errors out with: ``` [2/2] Linking target test_app. FAILED: test_app clang++ -o test_app ... /opt/boost/lib -L ... ld.lld: error: cannot open /opt/boost/lib: Is a directory ``` Ninja generator puts `-L` after the path instead of the other way around. I've found a probable cause: In 0.51.2: https://github.com/mesonbuild/meson/blob/6857936c592d6f9608add5a74a51ee405aaddc0d/mesonbuild/compilers/clike.py#L270-L271 In 0.52.0: https://github.com/mesonbuild/meson/blob/2779603c689c6347809255a5aa3bd59b46b18b81/mesonbuild/linkers.py#L414-L415 Here: https://github.com/mesonbuild/meson/blob/ba1367b588388ebe9e37057cee9639e2ea2046fb/mesonbuild/backend/ninjabackend.py#L2517 `extend_preserving_lflags` receives an argument that looks like this: ```python # In 0.52.0 linker.get_dependency_link_args(dep) # ['-L', '/boost/root/lib'] # In 0.51.2 dep.get_link_args() # ['-L/boost/root/lib'] ``` And `extend_preserving_lflags` reorders the args here: https://github.com/mesonbuild/meson/blob/ba1367b588388ebe9e37057cee9639e2ea2046fb/mesonbuild/compilers/compilers.py#L589-L598 `-L` goes into `lflags` and `/opt/boost/lib` goes into `normal_flags` then `normal_flags` gets appended first resulting in `[ ..., '/opt/boost/lib', '-L', ...]`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add missing generation arguments for bucket and blob methods. Allow setting generation for getting and deleting blobs, and respect generation for rewriting. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: #RREV in conanfile.txt Hello! I try to pin revision for some recipes in conanfile.txt. Conan 1.16.1 What i do: I've added hashtag and number of revision like https://docs.conan.io/en/latest/mastering/revisions.html#package-revisions. [requires] gtest/1.8.1@bincrafters/stable#0 But # - is a comment symbol and \"#0\" is ignored by Conan. Help please and tell me what i do wrong. PS: on command line it is works normal. conan install gtest/1.8.1@bincrafters/stable#0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: GPT2TokenizerFast raises pad_token error even if not used # 🐛 Bug ## Information Model: GPT2 Language: English Encoding with the `GPT2TokenizerFast` causes a `pad_token` error to be sent to stderr, despite not attempting to access that property. ## To reproduce ```import transformers from transformers import GPT2TokenizerFast tokenizer = GPT2TokenizerFast.from_pretrained('gpt2') res = tokenizer.encode(\"This is a sentence\") print(transformers.__version__) ``` Output: ``` Using pad_token, but it is not set yet. 2.11.0 ``` ## Expected behavior I'm aware that GPT-2 doesn't include a pad token (#2630) - I haven't tried to use it. I would expect no error to be displayed until I try to access that property. ## Environment info - `transformers` version: 2.11.0 - Platform: Ubuntu - Python version: 3.6.9 - PyTorch version (GPU?): 1.5.0 with CUDA - Tensorflow version (GPU?): n/a - Using GPU in script?: yes - Using distributed or parallel set-up in script?: no Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Avoid the Windows file lock An idea to avoid the file lock is to move files (which I believe Windows allows) that can't be deleted into some trash directory, which is deleted on future runs of conda. We could do this automatically on a file-by-file basis. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Labextensions not working on starting notebook Hi, So when I start jupyter lab with `jupyter lab` , labextensions seem to work perfectly fine, but they don't work when I start notebook : `jupyter notebook` and redirect to /lab. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda should exec to non-conda subcommands, not subprocess Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Using the rzz gate yields an error on circuit drawing <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: qiskit version 0.7.0 - **Python version**: python 3.6.6 - **Operating system**: Red Hat Entreprise Server 7.4 ### Current behavior At circuit draw I get the following error ```bash Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/usr/local/lib/python3.6/site-packages/qiskit/circuit/quantumcircuit.py\", line 83, in __str__ return str(self.draw(output='text')) File \"/usr/local/lib/python3.6/site-packages/qiskit/tools/visualization/_text.py\", line 413, in __str__ return self.single_string() File \"/usr/local/lib/python3.6/site-packages/qiskit/tools/visualization/_text.py\", line 438, in single_string return \"\\n\".join(self.lines()) File \"/usr/local/lib/python3.6/site-packages/qiskit/tools/visualization/_text.py\", line 472, in lines layers = self.build_layers() File \"/usr/local/lib/python3.6/site-packages/qiskit/tools/visualization/_text.py\", line 758, in build_layers elif len(instruction['qubits']) >= 2 and not instruction['cargs']: KeyError: 'qubits' ``` ### Steps to reproduce the problem ```python from qiskit import * q = QuantumRegister(2) qc = QuantumCircuit(q); qc.rzz(0, q[0], q[1]) print(qc) ``` ### What is the expected behavior? It should draw the circuit with no problem, but here it gives a KeyError on \"qubits\" ### Suggested solutions Maybe it is expecting \"qargs\" instead of \"qubits\"? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore query offsets are not working as it supposed to This is a weird behaviour when setting the offset parameter so I have 9825 entities and ```python len(list(client.query(kind=\"Foo\").fetch())) ``` Will yield 9825, but ```python len(list(client.query(kind=\"Foo\").fetch(offset=1))) ``` will yield 9808 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: try falling back to pip-vendored requests if no requests available Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Open source tests We'd like contributors to be able to make sure their code isn't breaking anything, and that they add tests that cover their own contributions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: barrier allows qubit reordering <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.7.0 - **Python version**: 3.7.1 - **Operating system**: Windows 10 ### What is the current behavior? An inserted barrier allows system to reorder, or act the circuit on different qubits than those declared. ### Steps to reproduce the problem Even without cnots to avoid the possibility of mapping issues, place single qubit rotations on n qubits, then a barrier, then a final single qubit rotation on an (n+1)th qubit. ### What is the expected behavior? Barrier is expected to keep gates on either side of the barrier, not allowing a compiler to modify ordering across this point of the circuit. Barrier is expected to play no role in determining which qubits the circuit is acted upon. ### Suggested solutions Clarify definition of barrier in optimization software for hardware implementation Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Deepcopy of control flow with standalone clbit results in invalid circuit ### Environment - **Qiskit Terra version**: 0.24.1 (but also on main) - **Python version**: 3.11 - **Operating system**: Linux ### What is happening? When running a deepcopy of a circuit object using a clbit as a standalone bit as the condition for a control flow operation results in the deepcopied circuit being invalid so that qasm3 or qpy serialization, and visualization will fail because the internal state of the circuit is corrupted and not valid in the copy. ### How can we reproduce the issue? ```python import copy from qiskit.circuit import QuantumCircuit, Qubit, Clbit, ClassicalRegister, QuantumRegister, Gate, Parameter bits = [Qubit(), Qubit(), Clbit()] qc = QuantumCircuit(bits) with qc.if_test((qc.clbits[0], 1)): qc.x(0) copy_qc = copy.deepcopy(qc) print(copy_qc) ``` ### What should happen? It should print the visualization of the circuit. This will stack trace though during the circuit to dag conversion. You can also replace `print(copy_qc)` with something like: ``` import io from qiskit.qpy import dump with io.BytesIO() as fd: dump(copy_qc, fd) ``` this will also fail on a lookup of the clbit. ### Any suggestions? I think the special `__deepcopy__` handling in the `qiskit.circuit.Instruction` class is not valid for the `ControlFlowOp` when the `.condition` attribute is a clbit. It might just be simplest to revert to the default deepcopy behavior for `ControlFlowOp`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: [test] Add hydra tests Use hydra in one of the plain lightning tests. omri yadan can review. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda run is not preserving exit code ## Current Behavior `conda run` used to return the correct exit status of the target process, but it doesn't anymore. This was apparently working correctly in conda 4.8.0 but it seems broken since version 4.8.1. `conda run` now erroneously always return the exit status of 0. This is a serious problem as jobs fail silently now. ### Steps to Reproduce ``` $ conda -V conda 4.8.1 $ conda run -n myenv /usr/bin/true; echo $? 0 $ conda run -n myenv /usr/bin/false; echo $? ERROR conda.cli.main_run:execute(30): Subprocess for 'conda run ['/usr/bin/false']' command failed. (See above for error) 0 ``` ## Expected Behavior `conda run` should preserve the exit status of the target process, whether the target is `python` or otherwise. It worked correctly with the previous version: ``` $ conda -V conda 4.8.0 $ conda run -n base /usr/bin/true; echo $? 0 $ conda run -n base /usr/bin/false; echo $? ERROR conda.cli.main_run:execute(39): Subprocess for 'conda run ['/usr/bin/false']' command failed. Stderr was: 1 ``` ## Environment Information This issue really is independent of the environment as it happens both in various dockerfiles and on MacOS too. --- @msarahan Please fix this bug considering I see a commit from 25 days that may have introduced it! Adding unit tests would also be wise. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Alternate example for plot_bloch_multivector ### Environment - **Qiskit Terra version**: 0.19.1 ### What is happening? The example for the plot_bloch_multivector doc looks broken - https://qiskit.org/documentation/stubs/qiskit.visualization.plot_bloch_multivector.html#qiskit.visualization.plot_bloch_multivector The example is trying to visualize a bell state and the entanglement isn't clearly visualizable with bloch sphere and hence there are 2 blank bloch spheres that may not depict the idea of the function clearly!  ### How can we reproduce the issue? The issue can be checked out here! https://qiskit.org/documentation/stubs/qiskit.visualization.plot_bloch_multivector.html#qiskit.visualization.plot_bloch_multivector LIne in docs - https://github.com/Qiskit/qiskit-terra/blob/4301fc47c73507e489dbafc7bae490ab29736daa/qiskit/visualization/state_visualization.py#L263-L277 ### What should happen? An example that clearly depicts a use case for the `plot_bloch_multivector` for people checking out the documentation ### Any suggestions? Since the examples are uniform across all the sections of https://qiskit.org/documentation/apidoc/visualization.html#counts-and-state-visualizations, contributor may have to take into consideration that if at all this example is to be modified, the subsection docs `plot_histogram` , `plot_state_city`, `plot_state_hinton`, `plot_state_paulivec` and `plot_state_qsphere `may have to be similarly accommodated since currently all seem to be using the same example across to depict the visualisation ideas uniformly in their respective sections. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Move nested 'storage.acl.ACL.Entity' to module scope Nested classes don't feel right, here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Channel pins in \"environment.yaml\" files are not saved to package specs Channel pins specified in environment files are not respected. For example,run ```conda env create``` with this environment file: ```yaml name: channel-not-written-to-user-specs dependencies: - defaults::six ``` If we look at conda-meta/six*.json we can see that the channel pin has not been added to specs. Where we should read ```\"requested_spec\": \"defaults::six\"```, we only find ```\"requested_spec\": \"six\"```. This is with conda 4.4.0rc2. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Icons loading on demand slows their rendering I confirmed what @ian-r-rose observed this morning that our SVG icons are being loaded from the server on demand. When working on remote JupyterLab instances, this can take a long enough that various icons being to be glitchy. Is there a way to ship these inline? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Llama2 models not loading (Using main branch) ### System Info Error when loading the model \"meta-llama/Llama-2-7b-chat-hf\" using the following code: ```python from transformers import AutoModelForCausalLM chk = 'meta-llama/Llama-2-7b-chat-hf' if __name__ == '__main__': model = AutoModelForCausalLM.from_pretrained(chk, load_in_4bit=True, device_map='auto') print(\"Loaded Ok\") ``` The error message was: ```shell `do_sample` is set to `False`. However, temperature is set to 0.9 -- this flag is only used in sample-based generation modes. Set `do_sample=True` or unset temperature to continue. ``` This is because the method GenerationConfig.validate() raises a ValueError and that Error is not controlled in modeling_utils.py file. One possible solution is to add the the ValueError to the except clause in that file:  ### Who can help? @gante ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Using the main branch (install from source code) ```python from transformers import AutoModelForCausalLM chk = 'meta-llama/Llama-2-7b-chat-hf' if __name__ == '__main__': model = AutoModelForCausalLM.from_pretrained(chk, load_in_4bit=True, device_map='auto') print(\"Loaded Ok\") ``` ### Expected behavior To be able to load the model Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: container_name syntax breaks docker-compose run When using the container_name syntax added in #1711 \"docker-compose run\" fails with a message like the following: ``` Conflict. The name \"myservice\" is already in use by container bc5601faea86. You have to delete (or rename) that container to be able to reuse that name. ``` Example docker-compose.yml: ``` myservice: container_name: myservice_name image: ubuntu:latest command: tail -f /dev/null ``` Commands run: ``` docker-compose up -d docker-compose run --rm myservice /bin/sleep 3 ``` \"docker-compose run\" is using the same directive to name its container, as can be verified by changing the container_name in docker-compose.yml after starting the service, and running: ``` docker-compose run -d myservice tail -f /dev/null ``` I changed the service name to \"myservice_name_another\", which became the instantiated container's name. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: fix multiple deprecation warnings in 4.4.x Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: The \"ldap\" extra misses libldap dependency The 'ldap' provider misses 'ldap' extra dep (which adds ldap3 pip dependency). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Building ContainerEnvironments should be more verbose Right now no output is piped to the user when building a container environment, which can be a little stressful when it takes a long time to build. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: AIP-44 Migrate DagModel.get_paused_dag_ids to Internal API Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Ensure all tests that create TaskInstances in DB also create DagRuns As part of the work on AIP-39 we want to make it so that _every_ TaskInstance in the DB has DagRun. Now at \"run time\" this is already the case (baring the case where someone might delete a DagRun. Rare, now only possible by direct DB? I can't remember if Browse -> DagRuns allows deleting anymore or not) but in our tests this is far from the case There are countless examples of where the tests just directly create TaskInstances, without a matching DagRun. We need to fix that so that the tests reflect reality. - [x] https://github.com/apache/airflow/pull/16889 is part of this -- creating a pytest fixture to reduce amount of duplication in tests - [x] #17556 - [ ] We probably also want to enforce foreign key constraints between DagRun and TaskInstance once we've done this (see also https://github.com/apache/airflow/pull/17030) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: 'Table.location' should be read-only From https://github.com/GoogleCloudPlatform/google-cloud-python/pull/5678#issuecomment-407830285 Currently, the `Table.location` property is [settable](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/814e75bdff73c8c298eb90f828cc4f8a36f5cc3e/bigquery/google/cloud/bigquery/table.py#L603), but the [API reference](https://cloud.google.com/bigquery/docs/reference/rest/v2/tables#location) marks it as `[Output-only]`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Allow configuration_file() without config.h.meson (or input file) It would be great if we could make it so that we can write config.h files without manually maintaining a config.h.meson input file, which is error prone. Also, autoconf doesn't make us do that ;) Case in point: defines that determined symbol visibility weren't written into config.h because the config.h.meson file wasn't fully up-to-date, and meson users then wondered what went wrong during linking of some tests that symbols didn't show up etc. But usually such things fail in much more subtle ways. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan running on ARM device: detected arch issues When running conan in an ARM device the `detected_architecture` is not detecting the arm, eventually, the main problem was that it was considering cross-building and adjusting a wrong triplet in Autotools causing the build to fail. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] win_bash new approach The current win_bash and run_in_windows_bash needs some improvements. This ticket would be the first iteration for improving that, to better serve the new build system integrations and for Conan 2.0. Important points: - It should have strictly 0 auto-detection. All information that it would need should be extracted from settings or new [conf] - It should have a simple ``win_bash=True`` syntax, not necessary to do ugly checks in recipes about the platform. Internally, it should do nothing if not in Windows. - It should use strictly the 2 profiles approach. - Consider skipping using the WSL as a win_bash, as that would be a Linux environment, not a Windows one? - ``tools.run_in_windows_bash()`` can probably be dropped if nicely supported in ``self.run(..., win_bash=True)`` - No need to integrate it with the existing build integrations, or to be backwards compatible, it can be treated as a completely new feature to replace the previous one. Start simple, probably just the ``bash`` wrapper itself, but not necessarily handling all the possible environment and path (cygwin, and the like) variants. Related issue: https://github.com/conan-io/conan/issues/8883, difficult to solve without breaking... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for classical expressions to `SwitchCaseOp`, `WhileLoopOp` and `IfElseOp` ### What should we add? This tracks the work labelled \"PR 2\" in [the initial classical-expression design document](https://github.com/Qiskit/RFCs/blob/master/0010-simple-classical-representations.md). Depends on #10223. Brief overview: - relax the type checking to permit `WhileLoopOp.condition` and `IfElseOp.condition` to be `Expr` values with type `Bool`, and `SwitchCaseOp.target` to be an `Expr` value with type `Bool` or `Uint[n]`. Closing this issue _does not_ require adding support for the builder interface. That's tracked in a follow-up: #10228. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: AIP-56 - FAB AM - Move profile view into auth manager The profile view (`/users/userinfo/`) needs to be moved to FAB auth manager. The profile URL needs to be returned as part of `get_url_account()` as specified in the AIP Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Make Bucket.delete() in storage more restricted / opinionated UPDATED 1/26/14 by @dhermes After discussion with @jgeewax the approach will be - Cap at 512 object deletes (or similar number) and cowardly refuse if more objects exist - Don't try to deal with retries or 409s, just raise the error and give info - RE: eventual consistency, just ignore (maybe log?) 404s for object deletes --- See @thobrla [comment](https://github.com/GoogleCloudPlatform/gcloud-python/pull/535#issuecomment-71094336): > ...If you provide this functionality, it must be made extremely clear that this is a > non-atomic operation that is not expected to succeed if there are concurrent writers to > the bucket. The danger here is providing the illusion of atomicity to the client, especially > because that illusion is likely to work at small scale and then fail cryptically at large scale. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: sync_imports() fails in python 3.3 builtins.**import** no longer seems to use level=-1, view.py, line 481: if level == -1 and key not in modules: This if never get executed and nothing is imported on engines because level defaults to 0 for python 3.3 I changed to: if level == 0 and key not in modules: Which works for me, but is probably not a good fix. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Aliases not documented We have a page documenting magic functions now, but nothing describing the available aliases. From discussion on #8762 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add support for logging in gcloud.storage Described here: https://developers.google.com/storage/docs/accesslogs Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Allow custom signature while saving TF models ### Feature request Currently, when we use the [save_pretrained](https://github.com/huggingface/transformers/blob/ca485e562b675341409e3e27724072fb11e10af7/src/transformers/modeling_tf_utils.py#L2085) function from this library the model signature used to save the model is the default one that only calls the model on the inputs, I would like to be able to provide a custom signature while using the `save_pretrained` function. ### Motivation Persisting models with custom signatures is quite important for models that target production setups, especially if they are going to be served with TF Serving. I might be wrong but it seems that currently, the only way to save a `Transformer` model with a custom signature is by saving it using functions from the TF library, it would be very nice if the HF ecosystem could also support this feature. ### Your contribution I think this might be simple to implement and I would be happy to draft a PR if you think this could be a helpful feature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.histogram erroneously emit warning when density=False As seen in https://travis-ci.org/ejeschke/ginga/jobs/395720074 . The actual code in Ginga calling histogram is: ```python # get image histogram hist, bins = numpy.histogram(some_array, hashsize, density=False) ``` Note that `normed` was not used. However, it caused this warning in Numpy ~~dev~~ prerelease: ```python else: if normed is not None: # 2018-06-13, numpy 1.15.0 (this was not noisily deprecated in 1.6) warnings.warn( \"Passing normed=False is deprecated, and has no effect. \" \"Consider passing the density argument instead.\", > DeprecationWarning, stacklevel=2) E DeprecationWarning: Passing normed=False is deprecated, and has no effect. Consider passing the density argument instead. ``` I think this is caused by #11352 . When `density=False`, it goes into the logic block that forces `normed=False`, which resulted in it going into this logic block in `np.histogram()`: ```python else: if normed is not None: ... ``` cc @ejeschke Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Document constants for things like NEWLINE_DELIMITED_JSON and move to bigquery module See: https://github.com/GoogleCloudPlatform/google-cloud-python/pull/4790#discussion_r164172094 I think we used to have constants / enum-like classes for some of these things, but maybe they got lost in the rewrite. I can't find NEWLINE_DELIMITED_JSON in the [reference docs for the BigQuery client](https://googlecloudplatform.github.io/google-cloud-python/latest/bigquery/reference.html ). **Feature request:** Add constants for commonly-used strings such as the source formats. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Entities loaded in gcloud.datastore don't have a dataset ``` python >>> dataset = demo.get_dataset() >>> query = dataset.query() >>> entity = query.fetch()[0] >>> entity.delete() ... Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"gcloud/datastore/entity.py\", line 206, in delete self.dataset().connection().delete_entity( AttributeError: 'NoneType' object has no attribute 'delete_entity' ``` This is because we're creating entities from the protobufs, with the proper `dataset_id` but not a true reference to the Dataset object (which has a pointer to the connection). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %aimport autocompletion Currently %aimport autocompletes on variable names, rather than on module names, which is obviously not very useful. I didn't check whether other magics could likewise benefit from a better autocompleter. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: test_qobj_to_circuits_multiple is ocassionally failing <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: latest master - **Python version**: any - **Operating system**: any ### What is the current behavior? When running test_qobj_to_circuits_mutiple we're seeing occasional sporadic failures, like: https://travis-ci.org/Qiskit/qiskit-terra/jobs/451515130#L2711 It looks like something is getting out of order and that's causing the tests to fail because the lists don't match 100%. We're seeing this mostly in CI, although I was able to reproduce after running `tox -epy37 -- --until-failure` (you can replace 'py37' with the version of python you have installed locally and it will work the same) which ran the tests in a loop until it encountered the failure. I've attached the subunit file from the failed run for reference too: [failure.subunit.gz](https://github.com/Qiskit/qiskit-terra/files/2555411/failure.subunit.gz) This leads me to believe there is some non-deterministic behavior in the test or function itself. Or there is a cross interaction with another test in the suite (which by switching to running in parallel in #737 would trigger). ### Steps to reproduce the problem It's not a 100% failure so either run the tests in the loop until it fails, or look at one of the referenced CI failures. ### What is the expected behavior? The test passes 100% of the time ### Suggested solutions Figure out what is causing the failure and address it Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Make sure our 2 years old license headers are in line with Came up because of #2370. Related to #2371. To paraphrase @rimey: The Apache license header given in our internal instructions differs from the one used in this project. /cc @rimey @jgeewax Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Adding external secrets results in invalid yml produced by config This is the same issue as #4348 and #3429, but for secrets. Running `docker-compose config` with this yml: ``` version: \"3.1\" services: s1: image: someimage secrets: - secret1 - secret2 secrets: secret1: external: true secret2: external: true ``` produces this: ``` networks: {} secrets: secret1: external: true external_name: secret1 secret2: external: true external_name: secret2 services: s1: image: someimage secrets: - source: secret1 - source: secret2 version: '3.1' volumes: {} ``` Trying to use this with `docker stack deploy` then produces this error: > external_name Additional property external_name is not allowed I tried this with docker 1.12.0 and 1.13.0-rc1 with the same result. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Can not combine the Result object from the same backend (statevector) <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: the master branch - **Python version**: 3.6.5 - **Operating system**: macOS 10.13 ### What is the current behavior? raise error ``` Traceback (most recent call last): File \"/Users/rchen/Developer/Quantum/qiskit-terra/qiskit/result/_result.py\", line 125, in __add__ copy_of_self += other File \"/Users/rchen/Developer/Quantum/qiskit-terra/qiskit/result/_result.py\", line 108, in __iadd__ raise QISKitError('Result objects from different backends cannot be combined.') qiskit._qiskiterror.QISKitError: 'Result objects from different backends cannot be combined.' ``` ### Steps to reproduce the problem Code ```python from qiskit import QuantumRegister, QuantumCircuit, ClassicalRegister import qiskit as qk import numpy as np num_qubits = 2 q = QuantumRegister(num_qubits, name='q') c = ClassicalRegister(num_qubits, name='c') circuits = QuantumCircuit(q, c) param_idx = 0 for qubit in range(num_qubits): circuits.u3(0.0, 0.0, 0.0, q[qubit]) circuits.u1(3.0, q[qubit]) # circuits.measure(q, c) my_backend = qk.Aer.get_backend('statevector_simulator') qobj = qk.compile(circuits=circuits, backend=my_backend) job = my_backend.run(qobj) result_a = job.result() qobj = qk.compile(circuits=circuits, backend=my_backend) job = my_backend.run(qobj) result_b = job.result() result = result_a + result_b ``` ### What is the expected behavior? Result objects are combined without error ### Suggested solutions None Note: If I change the backend to `qasm_simulator`, there is no error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Flush log buffer when printing logs ``` bash $ docker-compose up -d && docker-compose logs &> composer.log ``` Someone correct me if I am wrong here, but what happens in the above is that nothing gets written to `composer.log` until `docker-compose logs` is killed, at which time stdout/stderr are unbuffered and written to `composer.log`? \"name\" is not a valid service config field Example: ``` yaml web: image: \"alpine:edge\" name: \"different name\" ``` This config would be valid, but shouldn't be. I think `name` is included because we modify the config to move the name in as a field, but I think we should validate it separately as part of the \"top level\" validation instead. The example config should raise an error about an unsupported key. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Consider and add common sensitive names **Description** Since sensitive informations in the connection object (specifically the extras field) are now being masked based on sensitive key names, we should consider adding some common sensitive key names. `private_key` from [ssh connection](https://airflow.apache.org/docs/apache-airflow-providers-ssh/stable/connections/ssh.html) is an examples. **Use case / motivation** Extras field used to be blocked out entirely before the sensitive value masking feature (#15599). [Before in 2.0.2](https://github.com/apache/airflow/blob/2.0.2/airflow/hooks/base.py#L78 ) and [after in 2.1.0](https://github.com/apache/airflow/blob/2.1.0/airflow/hooks/base.py#L78 ). Extras field containing sensitive information now shown unless the key contains sensitive names. **Are you willing to submit a PR?** @ashb has expressed interest in adding this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Loading aligned dtype error (Trac #1619) _Original ticket http://projects.scipy.org/numpy/ticket/1619 on 2010-09-24 by trac user Ihor.Melnyk, assigned to unknown._ ``` import numpy as np t = np.dtype('i1, i4, i1', align=True) d = np.zeros(1, t) np.save(\"test.npy\", d) data = np.load(\"test.npy\") Traceback (most recent call last): File \"D:\\Projects\\Cuda\\Cuda_Git\\pathwise\\liinc\\model\\feeds\\numpy_bug.py\", line 8, in <module> data = np.load(\"test.npy\") File \"D:\\Projects\\Cuda\\Cuda_Git\\pathwise\\pathwise\\vendors\\lib64\\x64\\python\\numpy\\lib\\npyio.py\", line 314, in load return format.read_array(fid) File \"D:\\Projects\\Cuda\\Cuda_Git\\pathwise\\pathwise\\vendors\\lib64\\x64\\python\\numpy\\lib\\format.py\", line 440, in read_array shape, fortran_order, dtype = read_array_header_1_0(fp) File \"D:\\Projects\\Cuda\\Cuda_Git\\pathwise\\pathwise\\vendors\\lib64\\x64\\python\\numpy\\lib\\format.py\", line 358, in read_array_header_1_0 dtype = numpy.dtype(d['descr']) ValueError: two fields with the same name ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CMake helper requires compiler during package To help us debug your issue please explain: Hi everyone! I'm trying give some support to taocpp/PEGTL and I would like to use CMake helper to install the project. The project is header-only, thus it installs the license, headers and pegtl-config.cmake. However, when the package method runs over Windows, I receive the follow message: conans.errors.ConanExceptionInUserConanfileMethod: pegtl/2.5.2@taocpp/testing: Error in package() method, line 22 cmake = CMake(self) ConanException: You must specify compiler, compiler.version and arch in your settings to use a CMake generator. You can also declare the env variable CONAN_CMAKE_GENERATOR. When I run the same recipe on Linux (Travis CI), I have no problems. Appveyor error log: https://ci.appveyor.com/project/uilianries/pegtl/build/feature/conan-9/job/tnwvkd69gvkgsb6x#L250 The current PR uses just self.copy, but my intention is revert to follow state, using CMake: https://github.com/uilianries/PEGTL/blob/dc4011991624faedf67fd390e8f53737f562a897/conanfile.py Current PR for PEGTL: https://github.com/taocpp/PEGTL/pull/112 I'm curious if CONAN_CMAKE_GENERATOR is required by Conan or is just a CMake limitation. Conan Version: 1.4.3 - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Drop `experimental_solver` context key and replace with a new one named `solver`, aliasing the former to the latter for a couple releases Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: AttributeError: 'CustomTargetIndex' object has no attribute 'is_internal' **Describe the bug** meson crashes with the error in the title **To Reproduce** ```meson project('bug', 'c') t = custom_target('dummy', output: [ 'libdummy.a' ], command: [ 'echo', 'dummy' ]) dep = declare_dependency(link_with: t[0]) l = static_library('l', 'src/empty.c', dependencies: dep, install: true) ``` **system parameters** * ArchLinux * Python: 3.8.0 * meson: 0.52.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: ValueError: could not broadcast input array from shape (2816,384) into shape (2698,384) the command to reproduce: cd huggingface-transformers/examples/pytorch/question-answering python -m torch.distributed.launch --nproc_per_node=8 ./run_qa.py \\ --model_name_or_path roberta-large \\ --dataset_name squad \\ --do_train --do_eval \\ --per_device_train_batch_size 16 \\ --per_device_eval_batch_size 256 \\ --learning_rate 3e-5 \\ --num_train_epochs 2 \\ --max_seq_length 384 \\ --doc_stride 128 \\ --output_dir test_result2/$trials --overwrite_output_dir \\ --logging_dir test_result2/$trials/tensorboard --logging_first_step --logging_steps 50 \\ --fp16 i tried add \"--max_eval_samples 10240\", this will fix the error, while the AUC result is quite low(exact_match = 4.9414, f1 = 8.9784). and when i ran with 1gpu, the above command can succeed(exact_match = 88.5336, f1 = 94.3266) the full error is \"File \"./transformers/src/transformers/trainer_pt_utils.py\", line 410, in _nested_set_tensors i * slice_len : (i + 1) * slice_len i * slice_len : (i + 1) * slice_len ValueError: could not broadcast input array from shape (2816,384) into shape (2698,384)\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: chord_unlock isn't using the same queue as chord I've created a tasks_queue and priority_task_queue. in addition to that i've set the tasks_queue to be used as default queue. Now every time i would like a task to be perfrom right away i use priority_queue which is generally empty most of the time. now, the problem araise whenever i'm using chord. i noticed that chords are unable to complete their task because their chord_unlock counterpart always run on the default tasks queue(tasks_queue) ## Steps to reproduce - Ubnutu 16 server - celery==4.1.0 - kombu==4.1.0 - boto==2.48.0 - boto3==1.4.7 - botocore==1.7.31 - Using SQS for as broker. ## Expected behavior I expected the chord_unlock to be performed in the same queue the chord was executed. This causes a major problem for me. Since SQS does not support priority tasks. I'm forced to use two queues to enable the effect of tasks priority. but since chord_unlock will always use the same default queue. priority_tasks using chords, will never be able to finish whenever the default queue is packed. ## Actual behavior the chord was consumed from priority_task_queue and the chord_unlock got stuck in line on the regular tasks_queue Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Running on statevector_simulator alters the qobj <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When a qobj is run on a statevector_simulator, it implicitly inserts a snapshot at the end, sets `shots=1`, then runs it on the qasm_simulator. The added instruction makes the qobj not pass validation if run again. ```python statevector_simulator = Aer.get_backend('statevector_simulator') qobj = compile(circ, statevector_simulator, shots=1) statevector_simulator.run(qobj).result().get_statevector() # this works fine statevector_simulator.run(qobj).result().get_statevector() # the second time, SchemaValidationError is raised ``` ### Suggested solution: Move this logic to the transpiler, and make Qobj immutable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: New-line handling in if statements is silently dangerous. Consider the following `if` statement: ``` if get_option('enable_alsa') == 'true' or (get_option('enable_alsa') == 'auto' and meson.get_compiler('cpp').has_header('alsa/asoundlib.h')) ``` The entire `or` clause is silently ignored. No errors or warnings, it just ignores it. If I put it all one one line is fine, but that's kind of ugly. Does meson not support multi-line statements? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cross compiler ignored when build and host architectures are identical I'm trying to compile for Android x86_64 on Linux x86_64. Unfortunately, Meson selects the native compiler instead of the one provided by the cross-file. The setup is the same as described in #5097. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda config --describe reports elements types as str for everything Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Make sure list_extensions and should_build can run without sudo As reported by @Mou5e on gitter: ``` INFO:root:JupyterLab v0.25.1 INFO:root:Known labextensions: INFO:root: app dir: /opt/test/services/.396762/var/public/conda/share/jupyter/lab INFO:root: jupyterlab-extension ^[[32m enabled ^[[0m ^[[32mOK^[[0m [W 2017-07-16 19:15:42.912 admin notebookapp:1054] Error loading server extension jupyterlab Traceback (most recent call last): File \"/opt/test/services/.396762/var/public/conda/lib/python3.5/site-packages/notebook/notebookapp.py\", line 1049, in init_server_extensions func(self) File \"/opt/test/services/.396762/var/public/conda/lib/python3.5/site-packages/jupyterlab/extension.py\", line 72, in load_jupyter_server_extension build_needed, msg = should_build(app_dir) File \"/opt/test/services/.396762/var/public/conda/lib/python3.5/site-packages/jupyterlab/commands.py\", line 263, in should_build _ensure_package(app_dir, logger=logger) File \"/opt/test/services/.396762/var/public/conda/lib/python3.5/site-packages/jupyterlab/commands.py\", line 673, in _ensure_package shutil.copy(pjoin(here, fname), dest) File \"/opt/test/services/.396762/var/public/conda/lib/python3.5/shutil.py\", line 241, in copy copyfile(src, dst, follow_symlinks=follow_symlinks) File \"/opt/test/services/.396762/var/public/conda/lib/python3.5/shutil.py\", line 121, in copyfile with open(dst, 'wb') as fdst: PermissionError: [Errno 13] Permission denied: '/opt/test/services/.396762/var/public/conda/share/jupyter/lab/staging/index.js' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Know who is requiring a missing dependency When the command ``conan info`` or ``conan install`` fails, because there is a missing dependency, it is not possible to know who required it, and that can be specially difficult for complex dependency graphs, using version ranges, etc. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: [AIRFLOW-4438] Add Gzip compression to S3_hook - Added bool parameter gzip to load_file to s3_hook - Tested the load_file with load_file_gzip unittest - Updated the load_file docstring to reflect the extra parameter --- Issue link: [AIRFLOW-4438](https://issues.apache.org/jira/browse/AIRFLOW-4438) Make sure to mark the boxes below before creating PR: [x] - [x] Description above provides context of the change - [x] Commit message/PR title starts with `[AIRFLOW-NNNN]`. AIRFLOW-NNNN = JIRA ID<sup>*</sup> - [x] Unit tests coverage for changes (not needed for documentation changes) - [x] Commits follow \"[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)\" - [x] Relevant documentation is updated including usage instructions. - [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). <sup>*</sup> For document-only changes commit message can start with `[AIRFLOW-XXXX]`. --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Regression: Error in GStreamer configuration I get this error during gst-build configuration, I believe it's ObjectHolder refactoring: `subprojects/gstreamer/gst/meson.build:275:2: ERROR: Gir target must be an executable or library`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Small inconsistency in the mpl drawer There is a small inconsistency how the parameters of a gate are showed in the matplotlib, with and without '(...)'. ```python qr = QuantumRegister(2, 'q') circuit_all = QuantumCircuit(qr) circuit_all.u3(pi, pi, pi, qr[0]) circuit_all.cu3(pi, pi, pi, qr[0], qr[1]) circuit_all.draw(output='mpl') ```  ### What is the expected enhancement? If I have to choose, I would go with removing the parenthesis everywhere. But, for sure, it should be everywhere the same... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Numpy failing to install with python3.5 The new release of numpy fails to install when using python3.5. It seems clear the problem is the use of f string formatting in the setup.py file that is only supported in python 3.6 and higher. ### Reproducing code example: ``` docker run python:3.5.2-alpine pip install numpy==1.19.0rc1 ``` <!-- Remove these sections for a feature request --> ### Error message: File \"/tmp/pip-build-gg798dty/numpy/setup.py\", line 182 raise ValueError(f'Submodule {p} missing') ^ SyntaxError: invalid syntax ### Numpy/Python version information: Fails installing `numpy==1.19.0rc1` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose super slow on macOS Catalina when i do docker-compose up -d, it takes a while to start the process, same when i do docker-compose restart. in other words, there's a delay of few seconds before it begins to restart containers or stopping containers. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Error fetching results from a BigQuery asynchronous call in 0.19.0 Referring to the [doc](https://googlecloudplatform.github.io/google-cloud-python/stable/bigquery-usage.html#querying-data-asynchronous), calling `QueryResults.fetch_data` raises an exception since `self.name` is `None`: ``` python if self.name is None: raise ValueError(\"Query not yet executed: call 'run()'\") ``` However, if `QueryResults.run` is called, an exception is also raised since `self._job` already exists: ``` python if self._job is not None: raise ValueError(\"Query job is already running.\") ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: expose numDmlAffectedRows in query results See: https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs/query#numDmlAffectedRows It is marked as experimental. This is because DML statements are currently in beta for BigQuery. This will be needed to correctly implement [cursor.rowcount](https://www.python.org/dev/peps/pep-0249/#rowcount) for DB-API support https://github.com/GoogleCloudPlatform/google-cloud-python/issues/2434 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pkgconfig module should allow nullification of some default variables. Not all projects require the prefix, libdir, and includedir variables in their pkgconfig files. In addition, it should be possbile to remove the `Cflags: -I${includedir}` line either entirely or in order to have your own variables there, minus the `-I${includedir}` addition. For example's sake, this is the entireity of the xorg-libinput.pc file: ``` sdkdir=/usr/include/xorg Name: xorg-libinput Description: X.Org libinput input driver. Version: 0.28.0 Cflags: -I${sdkdir} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Regression in 1.5.2 re: hitting Control-C when running `up` It looks like there is a regression in docker-compose 1.5.2 when compared with 1.5.1. Previously, after running `docker-compose up` in a terminal window, pressing `Control-C` (i.e. sending SIGINT from the same shell window) caused services to enter the \"Stopping\" phase. However, when I upgraded to 1.5.2, services now immediately go to \"Killing.\" Note that if I go to a _different_ terminal window and send a SIGINT or SIGTERM to that process using `kill`, then the services _do_ go to the \"Stopping\" phase. So the issue looks like it is restricted to hitting `Control-C` from the same shell window. I'm observing this on Mac OS X 10.11 using Python 3.5.1. One more thing. I did notice one improvement with 1.5.2. Previously, sending a SIGTERM to `docker-compose up` from a different window didn't seem to work and stop services like SIGINT. With 1.5.2, it now does, and behaves the same as sending SIGINT from a different window. So the issue now is with hitting Control-C from the same window. My guess is that this might have to do with the fact that hitting Control-C in a terminal window sends a SIGINT not just to the parent process, but also to all child processes (and there is at least one child with docker-compose). So maybe docker-compose is treating that as receiving two distinct SIGINT signals, causing it to go immediately into the \"Killing\" phase (as if the user hit Control-C twice). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Allow for Markup in UI page title ### Description A custom page title can be set on the UI with the `instance_name` variable in `airflow.cfg`. It would be nice to have the option to include Markup text in that variable for further customization of the title, similar to how dashboard alerts introduced in #18284 allow for `html=True`. ### Use case/motivation It would be useful to be able to use formatting like underline, bold, color, etc, in the UI title. For example, color-coded environments to minimize chances of a developer triggering a DAG in the wrong environment:  ### Related issues _No response_ ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: compiler's rsp syntax should be a Compiler method This is mostly just to help me remember to do this. See: #8500 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Improve the `run_xlni` example to use the Datasets library The [`run_xlni`](https://github.com/huggingface/transformers/blob/master/examples/text-classification/run_xnli.py) example should be improved (following the model of [`run_glue`](https://github.com/huggingface/transformers/blob/master/examples/text-classification/run_glue.py)) to use the Datasets library to download and preprocess the datasets. Ideally, copying the `run_glue` example and adapting the relevant parts should be the way to go. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: misleading description in https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.linalg.lstsq.html This starts by saying \"Solves the equation a x = b\", which (except in special cases) it does not do. Perhaps better is to start with \"Computes a vector x that minimizes the Euclidean 2-norm || b - a x ||^2. If the minimal 2-norm is zero, then we have ax=b.\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: plot_coupling_map() and plot_gate_map() needs snapshot testing Now we have snapshot testing for other graphs besides circuits (thanks to #6672), it should be extended with other graphing functions, like `plot_coupling_map` and `plot_gate_map` (introduced in #6751). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Make the extension metadata in package.json take a module for the plugin Up to now, the extension metadata in the package.json only allows a plugin to export the plugin data as the default export of the package: ```json \"jupyterlab\": { \"extension\": true }, ``` This means that any libraries the plugin imports must be available to npm. This is onerous if we are wrapping a small private dependency, or a dependency version we don't want to push to npm (a dev version, for example). In these cases, it would be much simpler to include the lab extension in the package itself - but that is impossible if the default export of the package *must* be the plugin data. ## Proposal The `extension` attribute in package.json is either a boolean or a string. If it is `true`, look in the default exports of the package for the plugins as we do now. If it is a string, look in that file of the package for the plugins: ```json \"jupyterlab\": { \"extension\": \"some/entry/point/that/exports/plugins\" }, ``` This makes it possible for a package to export some api *in addition* to providing a lab extension. Another possibility is to make the string the *export* of the package to use (i.e., the export key name), but I think having a separate entry point may make more sense, as you may not want to export the lab plugin data in the public interface of the package. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: repo.index.add() first argument type accepts os.PathLike but code raises TypeError In the docs and in the code types, the first argument for `repo.index.add()` is `Sequence[Union[str, os.PathLike, git.objects.blob.Blob, git.index.typ.BaseIndexEntry, Submodule]]`. However, actually trying to submit a list of Paths to this argument results in a TypeError, as it seems the code inside `_preprocess_add_items` does not handle Paths. I think this could be fixed by changing line 611 inside of `_preprocess_add_items` in `base.py` to: ``` if isinstance(item, str) or isinstance(item, os.PathLike): ``` https://github.com/gitpython-developers/GitPython/blob/fe54118ec07a68d5dc6f6108510cffc55dfca643/git/index/base.py#L611 Since `_to_relative_path()` already accepts pathlike arguments. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose config interpolation type mapping issue with services whose name contains dot ## Description of the issue Usages of PATH_JOKER regex in docker-compose config interpolation [logic](https://github.com/docker/compose/blob/master/compose/config/interpolation.py#L163) are in conflict with services whose name contains dot. ## Context information (for bug reports) ``` Output of \"docker-compose version\" ``` docker-compose version 1.22.0, build f46880f docker-py version: 3.5.0 CPython version: 3.4.6 OpenSSL version: OpenSSL 1.0.2j-fips 26 Sep 2016 ## Steps to reproduce the issue 1. Given the sample docker-compose.yaml file with a service named **app.0**: ``` version: \"3\" services: app.0: image: redis ulimits: nofile: soft: ${APP_NOFILE} hard: ${APP_NOFILE} ``` 2. Given the sample .env file: ``` APP_NOFILE=10000 ``` 3. Call `docker-compose config` ### Observed result ``` ERROR: The Compose file './docker-compose.yaml' is invalid because: services.app.0.ulimits.nofile.soft contains \"10000\", which is an invalid type, it should be an integer ``` ### Expected result ``` services: app.0: image: redis ulimits: nofile: hard: 10000 soft: 10000 version: '3.0' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add a `chdir` kwarg to `ShellTask` Maybe named something more explicit, but I believe a common pattern with `ShellTask`s will be: ``` cd $DIR && do_something ``` so being able to write ```python bash = ShellTask(chdir='/usr/tmp') ``` would be helpful. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: transpile unrolls even when basis_gates=None The intention in the transpile() function was that if `basis_gates` is not specified, all gates are fair game and no explicit unrolling will be done (see docstring) This behavior broke in #2357 when u3 and cx were added to all basis. This means that some explicit unrollings could happen. This can be fixed in 2 ways: - Set the basis gates as the full set of gates in the original circuit. If any pass happens to add to this set, enlarge the basis gates (so basis_gates has to be stored in property set and Unroller read from there) - Modify the unroller to not do anything when basis_gates=None. This will be faster, as the Unroller won't even pass through the circuit once. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: The Python BigQuery client fails on creating a view in standardSQL ```python from google.cloud import bigquery bigquery_client = bigquery.Client(project=\"my-project\") dataset = bigquery_client.dataset(\"my-dataset\") table = dataset.table(\"v_test\") #Fails on Standard SQL #table._properties['view'] = {'query': \"select * from `my-project.my.dataset.test_table`\",'useLegacySql':False} #Works on Legacy SQL table._properties['view'] = {'query': \"select * from [my-project:my-dataset.test_table]\",'useLegacySql':True} try: table.create() except Exception as err: print(err) ``` The https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/bigquery/google/cloud/bigquery/table.py#L355 should also take in another property for useLegacySql Example payload at http://stackoverflow.com/questions/33243427/how-can-i-create-a-new-view-in-bigquery-using-the-python-api Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Update Noxfiles to use new Nox Nox recently made a [big change](https://github.com/theacodes/nox/blob/master/CHANGELOG.md#2018823) from declarative to imperative and broke the Noxfile API. We need to update our Noxfiles to work with the new API and update our test scripts to install `nox` (instead of `nox-automation`) and invoke `python3 -m nox {args}`. Most projects just need to do a few steps: 1. Remove usage of `session_{name}` sessions and use `@nox.session` instead. 2. Don't use `session.interpreter`, use `@nox.session(py='...')` 3. Don't use `nox.parametrize` for multiple Pythons, use `@nox.session(py=['..', '..'])`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: 'Blob.reload' does not pass encryption headers Per the [docs on customer-supplied encryption keys](https://cloud.google.com/storage/docs/encryption/customer-supplied-keys#encrypted-elements), the `X-Goog-Encryption-Key` header applies not only the the blob / object's payload, but also to its CRC32c checksum and MD5 hash fields. `Blob.reload` (inherited from `_helpers._PropertyMixin` does not pass those headers, and thus the returned resource will not have the `crc32c` or `md5Hash` fields set. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: high-level documentation for __array_function__ missing This was noted in the tracking issue (gh-12028) but didn't have its own issue. I wanted to refer to these docs today and found them missing. Documentation is needed in two places: - [x] https://www.numpy.org/devdocs/reference/arrays.classes.html#special-attributes-and-methods - [x] https://www.numpy.org/devdocs/user/basics.subclassing.html A bigger-picture issue is that the subclassing doc nor other docs really discuss the issues with subclassing, and when it would be more appropriate to implement a duck array instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Cannot build using Conan and Visual Studio 2017 in Japanese Environment Tests are with conan 1.4.4, Python 2.7.10, Windows 7 When trying to build a package in the local cache (conan install MyPackage/1.0.0@user/channel --build=missing) I get the following error vcvars = tools.vcvars_command(self.settings) ValueError: Invalid \\escape: line 12 column 54 (char 597) This occurred after installing Visual Studio 2017. The environment is Japanese Windows 7, but set to English environment. This sets the UI to English but many system strings still appear in Japanese. Tracing through conan source shows the problem to be in the line return json.loads(vswhere_out) of vswhere in win.py. The output of vswhere.exe for VS2017 contains the line \"description\": \"生産性向上と、さまざまな規模のチーム間の調整のための Microsoft DevOps ソリューション\", (This is line 12 of the vswhere.exe output) Adding the code output = '\\n'.join(line for line in output.split('\\n') if 'description' not in line) to strip out this line from the vshwere.exe output before the line vswhere_out = decode_text(output).strip() in vswhere in win.py allows the build to proceed normally. So it seems the Japanese message in the json from vswhere is causing the loading of the json to fail. When running vshwere.exe directly, the output is in utf-8 but this bug https://github.com/Microsoft/vswhere/issues/146 suggests that sometimes the output is not in utf-8. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: argsort/sort with O(n) algorithms: counting-sort, radix-sort You can already sort with [couting-sort](https://en.wikipedia.org/wiki/Counting_sort) using numpy: as stated in an [SO answer](http://stackoverflow.com/a/18502321/2399799), it is simply: ``` python np.repeat(np.arange(1+x.max()), np.bincount(x)) ``` But there is no way (as far as I can tell) to do an argsort. I think it would be fairly easy to implement and slot into the argsort/sort documentation. The benefit of counting sort is that it's O(n), although it only works for not-too-large non-negative integers...however those are actually quite common in the real world! Pandas uses it behind the scenes [apparently](http://wesmckinney.com/blog/tag/pandas/). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: partially revert no default shortcuts Closes https://github.com/ContinuumIO/navigator/issues/570 This changes shortcuts to again be installed by default, but adds a condarc setting \"shortcuts\" that can be set to False to disable shortcut installation. CC @joelhullcio @csoja @multicastmatt Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Implement PEP-440 compatible release operator https://www.python.org/dev/peps/pep-0440/#compatible-release xref: https://github.com/conda/conda/issues/7776 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: qtconsole does not accept --gui switch As suggested by Min, as \"silly oversight that `--gui=foo` is not available at the command-line for the qtconsole\", I'm opening this issue for \"tiny fix\" ;) Cheers Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan remote update command error in 1.15 With the Conan 1.15 release it is no longer possible to use the `conan remote update` command to ensure an existing remote is configured to be at the specified index. Reverting to Conan 1.14 sees the command work as expected. conan remote update ci-conan https://my-artifactory-instance.com/artifactory/api/conan/ci-conan --insert=0 ERROR: Remote 'ci-conan' already exists with same URL Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: storage: bucket management > Buckets are the basic containers that hold your data Details at [/storage/docs/concepts-techniques](https://developers.google.com/storage/docs/concepts-techniques). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Allow GroupResult.join timeout to be configurable in celery.chord_unlock # Checklist - [x] I have checked the issues list for similar or identical enhancement to an existing feature. - [x] I have checked the commit log to find out if a the same enhancement was already implemented in master. # Brief Summary Pull request: #5348 Previously the timeout passed down to `GroupResult.join` in `celery.chord_unlock` was hardcoded to 3.0 seconds. This introduces the new configuration option `result_chord_join_timeout` which allows users to configure the timeout. The default value remains as 3.0. This change will solve the issue of unwanted timeouts caused when there's a moderate latency between the Celery workers and the configured backend or the result set to join is relatively large (5000+ task results to join). # Design ## Architectural Considerations <!-- If more components other than Celery are involved, describe them here and the effect it would have on Celery. --> None ## Proposed Behavior See summary. ## Proposed UI/UX The introduced configuration can be applied as follows: ```python app.conf.result_chord_join_timeout = 3.0 # default timeout app.conf.result_chord_join_timeout = 10.0 # 10 second timeout app.conf.result_chord_join_timeout = None # No timeout ``` ## Diagrams <!-- Please include any diagrams that might be relevant to the implementation of this enhancement such as: * Class Diagrams * Sequence Diagrams * Activity Diagrams You can drag and drop images into the text box to attach them to this issue. --> N/A ## Alternatives <!-- If you have considered any alternative implementations describe them in detail below. --> None Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ExecutionInfo _repr_'s missing selfs ``` class ExecutionInfo(object): \"\"\"The arguments used for a call to :meth:`InteractiveShell.run_cell` Stores information about what is going to happen. \"\"\" raw_cell = None store_history = False silent = False shell_futures = True def __init__(self, raw_cell, store_history, silent, shell_futures): self.raw_cell = raw_cell self.store_history = store_history self.silent = silent self.shell_futures = shell_futures def __repr__(self): name = self.__class__.__qualname__ raw_cell = ((self.raw_cell[:50] + '..') if len(self.raw_cell) > 50 else self.raw_cell) return '<%s object at %x, raw_cell=\"%s\" store_history=%s silent=%s shell_futures=%s result=%s>' %\\ (name, id(self), raw_cell, store_history, silent, shell_futures, repr(self.result)) ``` `(name, id(self), raw_cell, store_history, silent, shell_futures, repr(self.result))` <- selfs are missing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: creating network with defined ipam subnet is slow Whenever I define a subnet for a network, `docker-compose up` is really slow, and seems to wait for ± 15 seconds on creating the network. example config: ``` networks: default: ipam: config: - subnet: 172.17.0.0/28 ``` It doesn't matter what the network is called, or what the subnet actually is, and it doesn't conflict with anything. If I define multiple networks, creating each network takes about 15 seconds. PoC: https://github.com/ComaVN/docker-compose-network-slow ``` $ docker-compose --version docker-compose version 1.11.2, build dfed245 ``` ``` $ docker version Client: Version: 17.09.0-ce API version: 1.32 Go version: go1.8.3 Git commit: afdb6d4 Built: Tue Sep 26 22:42:18 2017 OS/Arch: linux/amd64 Server: Version: 17.09.0-ce API version: 1.32 (minimum version 1.12) Go version: go1.8.3 Git commit: afdb6d4 Built: Tue Sep 26 22:40:56 2017 OS/Arch: linux/amd64 Experimental: false ``` ``` $ lsb_release -a LSB Version: core-9.20160110ubuntu0.2-amd64:core-9.20160110ubuntu0.2-noarch:security-9.20160110ubuntu0.2-amd64:security-9.20160110ubuntu0.2-noarch Distributor ID: Ubuntu Description: Ubuntu 16.04.3 LTS Release: 16.04 Codename: xenial ``` docker-compose up should not allow -d and --timeout together As mentioned in #5310, --timeout on docker-compose is meant to be used for interactive mode so it doesn't make sense to use in combination with -d. If a user provides both options it should result in an error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Use an Enum for meas_level and meas_return <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? `meas_level` seems to be the perfect candidate for an `Enum` class. The change would improve readability and clarity around raw numbers in the code. For instance: `meas_level=MeasLevel.CLASSIFY` is more suggestive of turning readout results into classified {0,1} bits than `meas_level=2`. This also fits with most other leveling systems in python, such as logging levels (https://docs.python.org/3/library/logging.html#levels). This could also apply for `meas_return`. My proposal: ``` class MeasLevel(Enum): RAW = 0 KERNELED = 1 CLASSIFIED = 2 class MeasReturn(Enum): SINGLE = \"single\" AVG = \"avg\" ``` I'd love any recommendations for the meas_level names. Likely this would induce another change further down the line to pull `.value` out. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: New unix2dos tool #2605 - [x] Refer to the issue that supports this Pull Request: - This PR references the issue #2605. - [x] If the issue has missing info, explain the purpose/use case/pain/need that covers this Pull Request. - No missing information. - [x] I've read the [Contributing guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've followed the PEP8 style guides for #Python code. - [x] I've opened another PR in the Conan docs repo to the ``develop`` branch, documenting this one. Also adding a description of the changes in the ``changelog.rst`` file. https://github.com/conan-io/docs - PR [#596](https://github.com/conan-io/docs/pull/596) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DISCUSSION: Switch to `apitools` as a dependency This was an issue before `apitools` was on PyPI and before it's dependencies were Py3 compatible. Now neither of these are blockers. See #754 for context. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPC transport option not taking effect ? Haven't been able to set IPC as transport neither from `--transport` option or `c.IPKernelApp.transport` python config file, as `tcp` is always used. Been able to force the value on the call stack and use it successfully. Took a look at the code with latest master and ran it through a debugger but wasn't able to figure the configuration system completely or i would had gladly send a patch after confirmation of the issue. Suspect i can be an issue around the kernel manager factory around: https://github.com/ipython/ipython/blob/master/IPython/frontend/html/notebook/kernelmanager.py#L84 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Change default scheduler on `LocalDaskExecutor` Right now, our `LocalDaskExecutor` defaults to using the `\"synchronous\"` dask scheduler which doesn't allow for any parallelism. The original reason for this was to provide a smooth transition `LocalExecutor` -> `LocalDaskExecutor` -> `LocalDaskExecutor` w/ parallelism but I think more often than not users are confused when `LocalDaskExecutor` doesn't provide parallelism. We should update the default scheduler to `\"threads\"` (or `\"processes\"`, @jcrist you might have an opinion about which is best in this case). @kingsleyb I'll assign this to you as a good first issue but feel free to unassign yourself if you decide not to pick it up. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Start Date in main DAG view shows redundant information This is shows:  For all DAGs it shows the same YYYY-MM-DD HH:MM as we see on the main view. the (i) tooltip simply doesn't give any more information. As far as I remember it wasn't like this before. It used to show the timestamp which the dag started to run. So in the above image the main DAG was: 2020-07-19 07:00 but the (i) was 2020-07-19 **08:00** as 08:00 is the end of the interval of hourly dag so the DAG started to run on 08:00 I don't know why this logic was changed on the UI but if that's stays like that there is no need for the tooltip. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Visual Studio Generator: PATH variable not correct Hi I am using the visual studio generator to generate a 'conanbuildinfo.props' file. The PATH variable in props file has the wrong directory separator char. In Windows CMD paths with '/' aren't supported in the PATH variable. Since the PATH variable isnt correct, the executables aren't be found if i am using ShellExecute in the code. An example of a generated props file is: `<LocalDebuggerEnvironment>PATH=%PATH%;$(USERPROFILE)/.conan/data/xx/0.6.0/3rdparty/release/package/c85f9b4041181d7a/bin;</LocalDebuggerEnvironment> <DebuggerFlavor>WindowsLocalDebugger</DebuggerFlavor>` It is supposed to looks like: `<LocalDebuggerEnvironment>PATH=%PATH%;$(USERPROFILE)\\.conan\\data\\xx\\0.6.0\\3rdparty\\release\\package\\c85f9b4041181d7a\\bin;</LocalDebuggerEnvironment> <DebuggerFlavor>WindowsLocalDebugger</DebuggerFlavor>` Version info: Conan 1.14 Visual Studio 2015 Windows 10 Pro The issue is in the file: conans/client/generators/visualstudio.py: Line 25: <LocalDebuggerEnvironment>PATH=%PATH%;{bin_dirs}</LocalDebuggerEnvironment> Line 70: 'bin_dirs': \"\".join(\"%s;\" % p for p in build_info.bin_paths).replace(\"\\\\\", \"/\"),' To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/mxnet codebase. Here's the problem: [example] train_model.py AttributeError: 'Namespace' object has no attribute 'clip_gradient' # ../../tools/launch.py -n 2 python train_mnist.py 2015-11-26 10:03:21,152 Node[0] start with arguments Namespace(batch_size=128, data_dir='mnist/', gpus=None, kv_store='local', load_epoch=None, lr=0.1, lr_factor=1, lr_factor_epoch=1, model_prefix=None, network='mlp', num_epochs=10, num_examples=60000) 2015-11-26 10:03:21,153 Node[0] start with arguments Namespace(batch_size=128, data_dir='mnist/', gpus=None, kv_store='local', load_epoch=None, lr=0.1, lr_factor=1, lr_factor_epoch=1, model_prefix=None, network='mlp', num_epochs=10, num_examples=60000) [10:03:22] src/io/iter_mnist.cc:91: MNISTIter: load 60000 images, shuffle=1, shape=(128,784) [10:03:22] src/io/iter_mnist.cc:91: MNISTIter: load 60000 images, shuffle=1, shape=(128,784) [10:03:22] src/io/iter_mnist.cc:91: MNISTIter: load 10000 images, shuffle=1, shape=(128,784) Traceback (most recent call last): File \"train_mnist.py\", line 122, in <module> train_model.fit(args, net, get_iterator) File \"/search/data/user/qhj/github/mxnet/example/image-classification/train_model.py\", line 51, in fit clip_gradient = args.clip_gradient, AttributeError: 'Namespace' object has no attribute 'clip_gradient' [10:03:22] src/io/iter_mnist.cc:91: MNISTIter: load 10000 images, shuffle=1, shape=(128,784) Traceback (most recent call last): File \"train_mnist.py\", line 122, in <module> train_model.fit(args, net, get_iterator) File \"/search/data/user/qhj/github/mxnet/example/image-classification/train_model.py\", line 51, in fit clip_gradient = args.clip_gradient, AttributeError: 'Namespace' object has no attribute 'clip_gradient' 2015-11-26 10:03:22,423 DEBUG Thread %d exit with 0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: pmap static_broadcasted_argnums does not respect keyword arguments. Tested on internal TPU donut. This code ```python import jax def f(a, b): return a + b g = jax.pmap(f, static_broadcasted_argnums=(1,)) g(jnp.ones((8, 1)), b=1) ``` Crashse with ``` 5 return a + b 6 g = jax.pmap(f, static_broadcasted_argnums=(1,)) ----> 7 g(jnp.ones((8, 1)), b=1) 3 frames google3/third_party/py/jax/api.py in _get_axis_size(i, shape, axis) 775 return shape[axis] 776 except (IndexError, TypeError) as e: --> 777 raise ValueError(f\"vmap got arg {i} of rank {len(shape)} but axis to be mapped {axis}\") from e 778 779 def _mapped_axis_size(tree, vals, dims, name): ValueError: vmap got arg 1 of rank 0 but axis to be mapped 0 ``` However, changing the last line to ```python g(jnp.ones((8, 1)), 1) # No keyword args! ``` works as expected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: When underlying process is killed during dagit execution the button keeps on spinning  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: reverting json setting to use json_encoder despite warnings closes: [26527](https://github.com/apache/airflow/issues/26527) The `flask_app.json_provider_class` does not take a JsonEncoder as an argument. Reverting the setting to `flask_app.json_encoder` despite deprecation warnings until a provider can be written. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: add complex128 support (and match NumPy behavior) In the following example, the inputs to `jax.numpy.exp` are float64, but the output is complex64. ```python import numpy as onp import jax.numpy as np from jax import jacrev, jit R = onp.random.RandomState(0).randn x = R(128) arg_dtype = x.dtype def np_fn(x): assert x.dtype == arg_dtype return onp.exp(x + 1j) def jax_fn(x): assert x.dtype == arg_dtype return np.exp(x + 1j) assert x.dtype == np.float64 assert np_fn(x).dtype == np.complex128 result = jax_fn(x) assert result.dtype == np.complex128, result.dtype ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: OUTPUT: search should be able to output json data similar to install/create I would love to have similar information from `search` as `install` with the `--json` parameter. There are several automation aspects that this could this help. In my current case I would like to be able to run `conan upload` on all the packages in my local cache that matches certain settings or options. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: JupyterLab assets not detected in \"/usr/share/jupyter/lab/static\" I just upgraded to latest version using pip, and now I cant use, and just get this error, whether I start with 'jupyter notebook' or 'jupyter lab' This directory does not exist. Any ideas? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: investigate os.scandir Starting with Python 3.5 os.scandir is available and is faster than listdir. It is also availlable on PyPI there : https://pypi.python.org/pypi/scandir Looking as the various usage of listdir and os.walk on our codebase and seeing whether we can replace their usage by scandir/scandir walk should be a relatively simple task that might lead to some performance improvements and maybe even code simplification. We should also investigate this on jupyter/notebook and jupyter/nbconvert likely (cc @michaelpacer) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: [feature request] random permutation It would be nice if we could get `jax.random` functions analogous to `np.random.permutation` and `np.random.shuffle`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: in 0.3.2 executing git commands using environment variables breaks Recent release 0.3.2 contains a change to set the LC_MESSAGES=C for all git commands to ensure the error messages are consistent across systems. this breaks commands that use the environment to allow users to control behaviour. To reproduce, clone the GitPython repo, checkout the current 0.3 branch and within execute the following command ``` shell PYTHONPATH=. python -c 'import os import git test = git.Git(\".\") os.environ[\"GIT_EDITOR\"] = \"cat\" test.var(\"GIT_EDITOR\")' ``` Output will be: ``` Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"git/cmd.py\", line 240, in <lambda> return lambda *args, **kwargs: self._call_process(name, *args, **kwargs) File \"git/cmd.py\", line 536, in _call_process return self.execute(make_call(), **_kwargs) File \"git/cmd.py\", line 399, in execute raise GitCommandError(command, status, stderr_value) git.exc.GitCommandError: 'git var GIT_EDITOR' returned exit status 128: fatal: Terminal is dumb, but EDITOR unset ``` This breaks https://github.com/stackforge/git-upstream usage of GitPython. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Memory-related spec changes for 0.7 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? After recent discussion, the specs needs further tweaks before 0.7: * `BackendConfiguration`: * `BackendConfiguration.memory` (boolean): new **required** field, indicates if the backend supports `memory` * `BackendConfiguration.max_shots` (int): new **required** field, contains the maximum number of shots supported * `Qobj`: * `config.memory` (boolean): new **optional** field, indicates if the job is going to use `memory` This changes need to be reflected as well in #1047, for tracking purposes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Remote lookup in offline mode Hello, Following up the small issue that I had during my demo at swampUP: I was trying to create a package for which I had every build requirement recipe already exported and thus available. I was expecting to get an error: >no such package with current options/settings: **build requirement package** However, it seems that Conan did try to check this package in remotes (with no internet access, it failed). The expected behavior would be for Conan to check the local cache after remotes. Passing `--build missing` to `conan create` did not fix the issue. Using Conan v1.3.3 - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add an eASCII/Unicode drawer ### What is the expected behavior? Something along these lines, with minimal or non dependencies. ``` ┌───┐ q[0] ──┤ H ├──·───m └───┘ │ ║ q[1] ─────────┼───╫──m │ ║ ║ q[2] ────────(+)──╫──╫──m ║ ║ ║ c[0] ─────────────╨──╫──╫── ║ ║ c[1] ────────────────╨──╫── ║ c[2] ───────────────────╨── ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Databricks SQL fails on Python 3.10 ### Apache Airflow Provider(s) databricks ### Versions of Apache Airflow Providers The databricks SQL does not work on Python 3.10 due to \"from collections import Iterable\" in the `databricks-sql-connector` * https://pypi.org/project/databricks-sql-connector/ Details of this issue dicussed in https://github.com/apache/airflow/pull/22050 For now we will likely just exclude the tests (and mark databricks provider as non-python 3.10 compatible). But once this is fixed (in either 1.0.2 or upcoming 2.0.0 version of the library, we wil restore it back). ### Apache Airflow version main (development) ### Operating System All ### Deployment Other ### Deployment details Just Breeze with Python 3.10 ### What happened The tests are failing: ``` self = <databricks.sql.common.ParamEscaper object at 0x7fe81c6dd6c0> item = ['file1', 'file2', 'file3'] def escape_item(self, item): if item is None: return 'NULL' elif isinstance(item, (int, float)): return self.escape_number(item) elif isinstance(item, basestring): return self.escape_string(item) > elif isinstance(item, collections.Iterable): E AttributeError: module 'collections' has no attribute 'Iterable' ``` https://github.com/apache/airflow/runs/5523057543?check_suite_focus=true#step:8:16781 ### What you expected to happen Test succeed :) ### How to reproduce Run `TestDatabricksSqlCopyIntoOperator` in Python 3.10 environment. ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: modules/gnome: parametrize includes for g-ir-scanner https://github.com/jpakkane/meson/blob/master/modules/gnome.py#L61 there can be not only `GObject-2.0`. Most of introspected libs contains much more includes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Windows : ImportError: No module named pwd on util.py When i try to build gitpython on Windows Server i have this error message. ``` powershell File \"C:\\project\\.tox\\back\\lib\\site-packages\\git\\objects\\commit.py\", line 318, in create_from_tree committer = committer or Actor.committer(cr) File \"C:\\project\\.tox\\back\\lib\\site-packages\\git\\util.py\", line 416, in committer return cls._main_actor(cls.env_committer_name, cls.env_committer_email, config_reader) File \"C:\\project\\.tox\\back\\lib\\site-packages\\git\\util.py\", line 386, in _main_actor default_email = get_user_id() File \"C:\\project\\.tox\\back\\lib\\site-packages\\git\\util.py\", line 152, in get_user_id return \"%s@%s\" % (getpass.getuser(), platform.node()) File \"c:\\python27\\Lib\\getpass.py\", line 157, in getuser import pwd ImportError: No module named pwd ``` After search, the only solution is try [this hack](https://t37.net/on-getting-the-running-process-user-under-python-and-supervisord.html) on [utiy.py](https://github.com/gitpython-developers/GitPython/blob/master/git/util.py#L14) file. Then use this : ``` python try: import pwd except ImportError: import winpwd as pwd import os def get_user_id(): \"\"\":return: string identifying the currently active system user as name@node\"\"\" return \"%s@%s\" % (pwd.getpwuid(os.getuid()).pw_name, platform.node()) ``` instead of ``` python import getpass def get_user_id(): \"\"\":return: string identifying the currently active system user as name@node\"\"\" return \"%s@%s\" % (getpass.getuser(), platform.node()) ``` What do you think about that ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Make missing solid error better # STR 1. make a solid have a dependency on a solid not listed in the pipeline instantiation. 2. Run and watch for this: ``` dagster.check.CheckError: Invariant failed. Description: dep must exist got: <<your_missing_solid>> and set {'<<solids>>'} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Determine what values can come back as BQ access roles See #1046 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Virtualenv activate scripts cause infinite loop in Powershell when multiple are activated To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. ## Environment OS: Windows 10 Conan version: 1.17.0 Python: 3.7.4 Powershell: 5.1 ## Problem Running multiple virtualenv scripts in Powershell causes an infinite loop where it repeatedly prints the prompt. ## Reproducing the problem ``` > conan install cmake_installer/3.15.0@conan/stable -g virtualenv -g virtualbuildenv > ./activate_build.ps1 > ./activate.ps1 ``` Output: ``` (conanenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) (conanbuildenv) ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Grid view details shows `_PythonDecoratedOperator` instead of `@task.python` ### Apache Airflow version main (development) ### What happened I ran a dag and navigated to the details drawer in the grid view. Saw this: <img width=\"358\" alt=\"Screen Shot 2022-04-05 at 12 49 03 PM\" src=\"https://user-images.githubusercontent.com/5834582/161830203-60b79ff7-3984-4c8b-b010-efd0bd6470d3.png\"> ### What you think should happen instead The class name was descriptive enough, but it's not a class I had ever directly referenced. It would be easier for me to correlate this detail with my code if `@task` showed up somewhere in whatever is displayed. ### How to reproduce Run any dag with task decorators, view details about those task instances ### Operating System Mac OS 12.3.1 ### Versions of Apache Airflow Providers _No response_ ### Deployment Virtualenv installation ### Deployment details installed via `pip install ~/src/airflow` cloned at 34154803a ran via `airflow webserver` ### Anything else I'm under the impression that a new endpoint might be needed to expose friendlier operator descriptions. ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: AttributeError: url on Storage Exception when key not found When attempting to get a key that does not exist the exception for the `NotFoundError` is trying to reference `request.url` which does not exist. ``` py Traceback (most recent call last): [...] file_key = self.bucket.get_key(path) File \"gcloud/storage/bucket.py\", line 83, in get_key response = self.connection.api_request(method='GET', path=key.path) File \"gcloud/storage/connection.py\", line 212, in api_request raise exceptions.NotFoundError(response, content) File \"gcloud/storage/exceptions.py\", line 17, in __init__ self.message = 'GET %s returned a 404.' % (response.url) File \"httplib2/__init__.py\", line 1680, in __getattr__ raise AttributeError, name AttributeError: url ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: get_python_version_for_prefix in prefix_data.py doesn't handle two digit minor version The function `get_python_version_for_prefix` silently truncates two digit minor version numbers. For example, if the Python version number is 3.10, it will return \"3.1\", which can cause some packages to be installed in the incorrect location. Of course, there isn't a Python 3.10 yet -- I ran into this while experimenting. FWIW, the accepted [PEP 602](https://www.python.org/dev/peps/pep-0602/) suggests that 3.10 will be the version after 3.9 (as opposed to 4.0). https://github.com/conda/conda/blob/2cdd7ab052c2b96c088137f52dc40c613e99ce33/conda/core/prefix_data.py#L370-L380 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: qt preprocess calls individual functions, triggering incorrect FeatureNew calls Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: remove transpile_dag <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Once we have pass_manager fully integrated we should remove the function transpile_dag from the transpiler. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Output for semicolon-terminated lines with comments cf https://github.com/JuliaLang/IJulia.jl/issues/109 The output of a semicolon-terminated line with comment is not suppressed in IPython. ``` b = 1 b; # foo ``` give `Out[13]: 1` ``` b = 1 b; ``` does not. Havent found such and issue on our tracker. @takluyver you are the best with the input machinery and coroutines; Thoughts ? (Because of the comment @stevengj in sus-cited issue, marking as prio-high, but won't mind if priority decreased later, or not fixed) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Int num_sanity_val_steps is always replaced by float limit_val_batches The type annotations of `num_sanity_val_steps:` and `limit_val_batches` are `int` and `Union[int, float]` for _percent_ or _`num_batches`_. The minimum of _percent_ and _`num_batches`_ will be _percent_. (except when `num_batches==0`) https://github.com/PyTorchLightning/pytorch-lightning/blob/a59e140ee814d8818d121405582133cf6b767e1a/pytorch_lightning/trainer/trainer.py#L461 Maybe we can remove the dependency of `limit_val_batches` from `num_sanity_val_steps` and revert to https://github.com/PyTorchLightning/pytorch-lightning/blob/1e68968ed7fb9b8f73df148dd48194d469655ea3/pytorch_lightning/trainer/trainer.py#L491 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Left over U1 gates at optimization level 2 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? ```python import numpy as np from qiskit import * qc = QuantumCircuit(3) qc.h(0) qc.h(1) qc.cp(np.pi/8,0,1) qc.cp(np.pi/4,0,2) trans_qc = transpile(qc, basis_gates=['id', 'rz', 'sx', 'x', 'cx'], optimization_level=2) trans_qc.draw() ``` gives ``` global phase: -26.4090132442392 ┌─────────┐┌────┐┌────────────┐ » q_0: ┤ RZ(π/2) ├┤ √X ├┤ U1(11π/16) ├──■──────────────────■────────────────■──» ├─────────┤├────┤└┬─────────┬─┘┌─┴─┐┌────────────┐┌─┴─┐┌──────────┐ │ » q_1: ┤ RZ(π/2) ├┤ √X ├─┤ RZ(π/2) ├──┤ X ├┤ RZ(6.0868) ├┤ X ├┤ RZ(π/16) ├──┼──» └─────────┘└────┘ └─────────┘ └───┘└────────────┘└───┘└──────────┘┌─┴─┐» q_2: ───────────────────────────────────────────────────────────────────┤ X ├» └───┘» « «q_0: ───────────────■───────────── « │ «q_1: ───────────────┼───────────── « ┌───────────┐┌─┴─┐┌─────────┐ «q_2: ┤ RZ(15π/8) ├┤ X ├┤ RZ(π/8) ├ « └───────────┘└───┘└─────────┘ ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: IndexError in SVN.excluded_files() To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Conan version: 1.8.2 Python 3.6.5 SVN: 1.9.5 (r1770682) compiled Nov 26 2016, 14:22:31 on x86-microsoft-windows When I use the new SCM Feature for SVN I get the following error: ``` > ERROR: Traceback (most recent call last): > File \"D:\\CWS\\Tools\\Python3\\lib\\site-packages\\conans\\errors.py\", line 24, in conanfile_exception_formatter > yield > File \"D:\\CWS\\Tools\\Python3\\lib\\site-packages\\conans\\client\\source.py\", line 139, in config_source > _fetch_scm(scm_data, dest_dir, local_sources_path, output) > File \"D:\\CWS\\Tools\\Python3\\lib\\site-packages\\conans\\client\\source.py\", line 195, in _fetch_scm > excluded = SCM(scm_data, local_sources_path).excluded_files > File \"D:\\CWS\\Tools\\Python3\\lib\\site-packages\\conans\\model\\scm.py\", line 57, in excluded_files > return self.repo.excluded_files() > File \"D:\\CWS\\Tools\\Python3\\lib\\site-packages\\conans\\client\\tools\\scm.py\", line 231, in excluded_files > if it[0] == 'I': # Only ignored files > IndexError: string index out of range ``` Output of svn client: ``` 'M Modules\\trunk\\conanfile.py' 'I Modules\\trunk\\include\\Filter\\properties.h' '? SDKs\\base\\trunk\\bin' 'X Scripts\\trunk\\Windows\\Network' '' ``` There seems to be an empty line at the end which leads to the error in scm.py line 231 Could you please have a look at this? Thank You! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Task.throws cannot be a list, misleading documentation The check at https://github.com/celery/celery/blob/b35569090c5cabfa784b00a68b55c7628fee813d/celery/worker/job.py#L456 throws this error when the `Task.throws` is a list: ``` shell TypeError: isinstance() arg 2 must be a class, type, or tuple of classes and types ``` Documentation on `Task.throws` is misleading by mentioning that `throws` can be a `List/tuple`: https://github.com/celery/celery/blob/b35569090c5cabfa784b00a68b55c7628fee813d/celery/app/task.py#L316-L322 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython==8.8.0 has weird tab completion bug <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories. If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org. If you are unsure, it's ok to post here, though, there are few maintainer so you might not get a fast response. --> self.my_attr.my_method(self.f<tab> Becomes: self.my_attr.my_method(self.my_attr.my_method(self.foo It looks like it would grab and prepend the front part of the line. ## Workaround Rolling back to 8.7.0 solves it. ## Repro Unfortunately, I failed to reproduce it with simple setup with a simple class and method and attribute. But I easily reproduce this bug at my work projects (which are huge... and have so much complicated dependencies). I think this bug wouldn't manifest itself unless the code base is complicated enough. I've confirmed 8.7.0 doesn't have this issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: [Request] - Implement -t | --timeout option for `docker-compose down There is the `-t | --timeout` option that can be passed to `docker-compose stop`, it would be nice to add this option to `docker-compose down`. As `down` destroys a containers, it means we won't be using it again, so we should be allowed \"not to care if it exits correctly. Alternatively it could be a `-k | --kill` flag so that instead of \"stopping and removing container\" it would \"kill and remove container\". I understand that it should not be the default behavior because some linked containers can still prefer if the present container is stopped correctly, but there are such cases where it could speed things up. For instance, I do a lot of debugging on an application that _unfortunately_ doesn't handle `SIGTERM` signal, and it is a pain to wait 10 seconds after running `down`, so I usually `kill` it first, then `down` it. It's just a suggestion, what do you think? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: full works on lists but with very bad performance When you pass a python list to full, it actually works as expected but with bad performance. The documentation says that only a scalar is accepted, but because it does the right thing, it's very easy for people to end up with code like this that's correct but inefficient. ``` import numpy x = numpy.full(100, range(100)) ``` The reason it's inefficient is because the source looks like this: ``` if dtype is None: dtype = array(fill_value).dtype a = empty(shape, dtype, order) multiarray.copyto(a, fill_value, casting='unsafe') return a ``` If the dtype is not specified, the branch actually creates a copy of the whole array, throws it away, and then does it again. I would suggest either explicitly supporting this use case, and improving performance and docs to match. Or, try to do some kind of basic check to reject this input as unacceptable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: pubsub Message class does not set timestamp `pubsub.Message` timestamps are not set. There are two object properties, neither of them is set. What's even more confusing is that attempting to access an attribute of an instance throws an error. To reproduce: ``` python from gcloud import pubsub t = pubsub.Client(project='...').topic('${TOPIC}') # MAY NEED t.create() s = t.subscription('${SUBSCRIPTION}') # MAY NEED s.create() t.publish('test data') # RETURNS A MSG ID ack_id, m = s.pull() # WAS t.pull() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: ENH: add --force option to conda env create Both conda env create and conda create need a --force option that will overwrite the environment if it already exists. conda could warn the user and prompt for confirmation but must also allow for --yes option to not prompt so conda can be used effectively in automation scripts that won't have human interaction. ENH: add --force option to conda env create Both conda env create and conda create need a --force option that will overwrite the environment if it already exists. conda could warn the user and prompt for confirmation but must also allow for --yes option to not prompt so conda can be used effectively in automation scripts that won't have human interaction. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Extension manager does not display \"update\" when updates are available As noticed by @sho-87 in #5053 the extension manager does not seem to display the \"Update\" button when new versions of extensions are available on npm. Despite the code for the update functionality being there, it does not work as expected. After the big update to 1.0 version the manager did not propose to update a single extension (and I had to manually update them from the command line - successfully!). Delving into the technical details the `latest_version` of entry model seems to always equal the `installed_version` (see screenshot). **To Reproduce** Steps to reproduce the behavior: 1. Install an old version of jupyterlab_go_to_definition extension or any other extension: ``` jupyter labextension install @krassowski/jupyterlab_go_to_definition@0.3.0 ``` 2. Start JupyterLab 3. Go to extension manager and click \"referesh\" 4. See that there is no \"Update\" button despite the latest extension version being 0.5.2 **Expected behavior** The update button is displayed when the extension has a new version available. **Screenshots** No update button:  Relevant code:  What happend to 0.5.2? Why is it not here?  **Desktop** - OS: Ubuntu 19.04 - Browser Chrome 70+ - JupyterLab 1.0.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Need a Qobj2Circuits method <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? There is a need to be able to reconstruct a QuantumCircuit (or list of QuantumCircuits) from a compiled Qobj. This is to be able to inspect the circuit after it has been compiled. We need a wrapper method for this. Currently this is doable by this long nested call: ```python circuits = [load_qasm_string(exp.header.compiled_circuit_qasm) for exp in qobj.experiments] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Why do we have Angular vendor deps checked in? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: \"ninja -C builddir test\" fails on appveyor with 0.48.0 ``` ninja -C builddir test ninja: Entering directory `builddir' [0/1] Running all tests. usage: meson [-h] [--buildtype {plain,debug,debugoptimized,release,minsize,custom}] [--strip] [--unity {on,off,subprojects}] [--prefix PREFIX] [--libdir LIBDIR] [--libexecdir LIBEXECDIR] [--bindir BINDIR] [--sbindir SBINDIR] [--includedir INCLUDEDIR] [--datadir DATADIR] [--mandir MANDIR] [--infodir INFODIR] [--localedir LOCALEDIR] [--sysconfdir SYSCONFDIR] [--localstatedir LOCALSTATEDIR] [--sharedstatedir SHAREDSTATEDIR] [--werror] [--warnlevel {1,2,3}] [--layout {mirror,flat}] [--default-library {shared,static,both}] [--backend {ninja,vs,vs2010,vs2015,vs2017,xcode}] [--stdsplit] [--errorlogs] [--install-umask INSTALL_UMASK] [--auto-features {enabled,disabled,auto}] [--optimization {0,g,1,2,3,s}] [--debug] [-D option] [--cross-file CROSS_FILE] [-v] [--wrap-mode {default,nofallback,nodownload,forcefallback}] [--fatal-meson-warnings] [--reconfigure] [builddir] [sourcedir] meson: error: unrecognized arguments: -u --no-rebuild --print-errorlogs FAILED: meson-test \"C:\\\\python37\\\\Scripts\\\\meson\" \"-u\" \"test\" \"--no-rebuild\" \"--print-errorlogs\" ninja: build stopped: subcommand failed. Command exited with code 1 ``` The same configuration worked in 0.47.2. Full build log at https://ci.appveyor.com/project/z3ntu/razer-test/build/job/8ak33l51nayn4a92 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: import error in version 3.3.0, conflict with local directory \"datasets\" ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 3.3.0 - Platform: Google Colab Model I am using :Bert ## To reproduce Steps to reproduce the behavior: Traceback (most recent call last): File \"train.py\", line 19, in <module> from mydataset import load_data,dist_load_data,load_data2 File \"/content/drive/My Drive/mrc4ner/mydataset.py\", line 5, in <module> from transformers import BertTokenizer File \"/usr/local/lib/python3.6/dist-packages/transformers/__init__.py\", line 22, in <module> from .integrations import ( # isort:skip File \"/usr/local/lib/python3.6/dist-packages/transformers/integrations.py\", line 42, in <module> from .trainer_utils import PREFIX_CHECKPOINT_DIR, BestRun # isort:skip File \"/usr/local/lib/python3.6/dist-packages/transformers/trainer_utils.py\", line 6, in <module> from .file_utils import is_tf_available, is_torch_available, is_torch_tpu_available File \"/usr/local/lib/python3.6/dist-packages/transformers/file_utils.py\", line 72, in <module> logger.debug(f\"Succesfully imported datasets version {datasets.__version__}\") AttributeError: module 'datasets' has no attribute '__version__' ## Expected behavior <!-- A clear and concise description of what you would expect to happen. --> My code works well before, and there is a \"datasets\" folder in my working directory. When my transformers version upgraded to 3.3.0, I get this error. If I change the name of the folder \"datasets\" or downgrade transformers to version 3.2.0, the error is get fixed. Is this a bug? Because it doesn't allow me to use \"datasets\" as a folder name. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `TimeUnitConversion` runs even if not using `scheduling_method`, `Delay` or pulse gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The transpiler pass `TimeUnitConversion` is included in the preset pass managers and will unconditionally copy all `Instruction`s in a circuit, which can become expense for larger circuits, even if not running any subsequent passes which would make use of `Instruction.duration`. It would be good to either exit early (without modifying the dag) if `InstructionDuration`s is empty, or skip the pass entirely when it is known the durations are not needed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: [qtconsole] Namespace not empty at startup in qtconsole, namespace already contain `IPython.core.usage` as usage , instead of beeing empty. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: non-ascii in __doc__ string crashes qtconsole kernel when showing tooltip If there is a regular str object with non-ascii characers in a **doc** string. Then the kernel crashes when showing a tooltip for that object. Using master ee9e1d9. Example run the script in https://gist.github.com/1198484 typing a( at a prompt will show the tooltip typing b( at a prompt will crash the kernel Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support .netrc when fetching subprojects using wrap files **Describe the bug** Currently, the only way to fetch urls with authentication is `source_url = ftp://user123:pass123@foo.com/some/file.zip` However, critical information like passwords should be ideally hidden. **To Reproduce** Create a ~/.netrc with the following information: ``` machine foo.com login user123 password pass123 ``` Meson ignores the ~/.netrc file, and the following error appears when fetching the subproject: ``` <urlopen error ftp error: error_perm('530 Login incorrect.')> WARNING: failed to download with error: could not get ftp://foo.com/some/file.zip is the internet available?. Trying after a delay... ``` **Expected behavior** Defining a wrap file with `source_url = ftp://foo.com/some/file.zip` and fetch from it should not give any error, and should authenticate with data from the ~/.netrc file. **system parameters** ``` $ meson --version 0.63.0 ``` I write in representation of [Fluendo](https://fluendo.com). We want to implement it. Do you wish this feature? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: refactor the handoff between FlowRunner and TaskRunner Currently FlowRunners provide to the individual TaskRunners a dictionary of upstream tasks which is keyed by the keyword argument the task represents, along with a special `None` key for upstream, non-keyed dependencies. TaskRunners are then responsible for inferring various information about whether upstream dependencies are mapped or not, keyed or not, etc. We should instead have FlowRunner provide a dictionary whose keys are actual Edge objects, and whose values are the states (as it currently is). This will help us simplify the FlowRunner execution logic (which is starting to look complicated) and provide strictly _more_ information to the TaskRunner that will be useful for handling mapped tasks and possibly other situations in the future. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Tab display of docstring in function args failing with multiline statement above My setup: - IPython 3.2.1 - Clean profile (no local configuration) - Python 2.7.10 - Mac OS X 10.10.3 I've noticed some strange autocomplete issues since updating to V3 and I think I isolated the root of the problem (or at least one problem...). It seems that tab-display of a function docstring shows the wrong docstring if there is a multi-line statement above the object you are trying to inspect. For example: ``` python a = (1, 2, 3) int() map() ``` If you put the cursor in the parens in `int()` and Shift+Tab, the docstring for `map` pops up instead. See video of behavior here: https://www.youtube.com/watch?v=Zevyejt37Qk&feature=youtu.be Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Standard pulse function library <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? A library of standard `AnalyticPulses` (#1934) for quantum computing should be provided for users. Pulses: - [x] drag - [x] gaussian - [x] gaussian square - [x] cosine - [x] sine - [x] delay - [x] square - [x] sawtooth - [x] gaussian derivative Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Data Catalog: add sample for creating a fileset entry Fileset operations were added to Data Catalog's API and the client library supports them since 2019-10-23 (https://googleapis.dev/python/datacatalog/0.4.0/changelog.html#id1). Samples are now required, to update the official docs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Return explicit error when you specify in memory storage and reexecution Multiprocessing case (i.e. dagit case) has some subtleties here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Trainer add args doesn't add default root dir ## 🐛 Bug 1. When using `parser = Trainer.add_argparse_args(parser)`, it's supposed to put all Trainer's arguments in the argparse with default values. Though currently it doesn't add `default_root_dir` and you get the error: ``` 'Namespace' object has no attribute 'default_root_dir' ``` It does add `default_save_path` which is deprecated. ### To Reproduce #### Code Sample ```python import argparse from pytorch_lightning import Trainer parser = argparse.ArgumentParser(description='demo') parser = Trainer.add_argparse_args(parser) args = parser.parse_args() print(args.default_root_dir) ``` A similar unit test could also be made, if not there already. ### Environment ``` * CUDA: - GPU: - GeForce RTX 2080 Ti - GeForce RTX 2080 Ti - GeForce RTX 2080 Ti - GeForce RTX 2080 Ti - GeForce RTX 2080 Ti - GeForce RTX 2080 Ti - GeForce RTX 2080 Ti - GeForce RTX 2080 Ti - available: True - version: 10.1 * Packages: - numpy: 1.18.1 - pyTorch_debug: False - pyTorch_version: 1.4.0 - pytorch-lightning: 0.7.3 - tensorboard: 2.2.0 - tqdm: 4.45.0 * System: - OS: Linux - architecture: - 64bit - - processor: x86_64 - python: 3.6.7 - version: #75-Ubuntu SMP Tue Oct 1 05:24:09 UTC 2019 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Metrics: MSE, RMSE, MAE, RMSLE ## 🚀 Feature Implement the following as metrics (grouped due to similarity): - [ ] MSE - [ ] RMSE - [ ] MAE - [ ] RMSLE > Note: Probably it suffices for some of them to derive a new class from the loss variant in `torch.nn` and the `BaseMetric` class Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: (TF) model.generate with beam search to an exportable tf.function ### Feature request It would be good if we could export the `tf.function` `model.generate` with beam search, so it is servable with TF Serving. ### Motivation When we try to export a `model.generate` with `do_sample=True` to a `tf.function` and save it, we get an error due to Transformers and Tensorflow Internals. It would be good if, such as what is done in #18372, we could do for beam search: ```python import tensorflow as tf from transformers import TFAutoModelForSeq2SeqLM class MyOwnModel(tf.Module): def __init__(self, model_path=\"t5-small\"): super(MyOwnModel, self).__init__() self.model = TFAutoModelForSeq2SeqLM.from_pretrained(model_path) @tf.function(input_signature=(tf.TensorSpec((None, 32), tf.int32, name=\"input_ids\"), tf.TensorSpec((None, 32), tf.int32, name=\"attention_mask\")), jit_compile=True) def serving(self, input_ids, attention_mask): outputs = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, max_new_tokens=32, return_dict_in_generate=True, do_sample=True) return {\"sequences\": outputs[\"sequences\"]} model = MyOwnModel() export_dir = \"./t5-example\" tf.saved_model.save( model, export_dir, signatures={ \"serving_default\": model.serving }) ``` That way, we would be able to serve TF text to text models with beam search in TF Serving, which would be a blast. Otherwise we would have to implement our own servers which is not ideal. ### Your contribution I can try submitting a PR, but would be glad if I could get some guidance because this one seems harsh. It seems like we would have to remove lots of `shape` related operations. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Start only resumable sessions to do browser-based uploading Start a resumable upload in the server and then send the URL to the client to finish the upload. Documentation: https://cloud.google.com/storage/docs/json_api/v1/how-tos/upload#resumable Related issue in gcloud-node: https://github.com/GoogleCloudPlatform/gcloud-node/issues/641 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: cache_from gets ignored when using multiple compose files Simplified example: docker-compose.yml: ```yaml version: '3.2' services: test: build: context: / cache_from: - some-registry.com/image:tag ``` additions.yml: ```yaml version: '3.2' services: test: # Contains some unrelated settings environment: SOME_VAR: some-value ``` ```shell $ docker-compose config networks: {} secrets: {} services: test: build: cache_from: - some-registry.com/image:tag context: / version: '3.2' volumes: {} $ docker-compose -f docker-compose.yml -f additions.yml config networks: {} secrets: {} services: test: build: context: / environment: SOME_VAR: some-value version: '3.2' volumes: {} ``` In the second command, the `cache_from` directive is missing from the merged service configuration. ```shell $ docker-compose --version docker-compose version 1.13.0, build 1719ceb $ docker --version Docker version 17.05.0-ce, build 89658be ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Access to Transformers example Pytorch link broken . Impact on navigation as well Hello there! 👋 ## Context Exploring Pytorch translation example ## Issue There seems to be a broken link in Pytorch example in the Translation example, similar to what happened in #24497 https://github.com/huggingface/transformers/blob/347001237a8ff845fc23f678107fc505361f9f13/examples/pytorch/translation/run_translation.py#L381 When I follow the link , the following message appears. And when I click the here link <img width=\"1154\" alt=\"Captura de pantalla 2023-08-10 a las 18 19 10\" src=\"https://github.com/huggingface/transformers/assets/24204714/9cc8450f-85bc-4be2-934b-b687dcb8c4f9\"> It redirects me to https://huggingface.co/docs/transformers/main/en/examples with an 404 error. ## Potential fix 1. Is that ok if I submit a quick fix as in #24594 ? 2. Would it be hard to try to submit a contrib of something like this? ... > specify doc redirects using a `redirects.yml` like in datasets and other libraries: https://github.com/huggingface/datasets/blob/main/docs/source/_redirects.yml Do you know if this entails more than create than source folder and .yaml file? Would I have to study [this](https://github.com/huggingface/datasets/tree/main/docs#generating-the-documentation)? @sgugger Keep up the good work! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: SamplePulse should clip approximately unit norm pulses to unit norm <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? The qobj specification does not specify a datatype for pulse samples datatypes. This is because JSON does not have a floating point datatypes. Backends that create a pulse_library may not emit sufficient precision to JSON and this may cause `SamplePulse`s to have a norm greater than one when cast to `np.complex128` even if it should be exactly unit norm. ### Example ```python import cmath import numpy as np from qiskit.pulse import SamplePulse pulse = np.array([cmath.exp(2*np.pi*i*1j) for i in np.linspace(0, 1, 1000)], dtype=np.complex64) samples = np.stack(np.transpose([np.real(pulse), np.imag(pulse)])) samples_list = samples.tolist() samples = [sample[0]+sample[1]*1j for sample in samples_list] samples = np.asarray(samples, dtype=np.complex128) SamplePulse(samples) ``` ### What is the expected behavior? Should not fail ### Suggested solutions Samples that have a norm of almost but greater than 1. should have their norm scaled to 1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: find_program('python3', version: '>=3.5') fails on Windows With meson 0.62 (tested with 0.61 as well), on Windows \"VsDevCmd\" shell environment ``` find_program('python3', version: '>=3.5') ``` Fails with ``` ..\\meson.build:3:0: ERROR: Command \"C:\\Program Files\\Meson\\meson.exe runpython --version\" failed with status 2. ``` ``` Running command: C:\\Program Files\\Meson\\meson.exe runpython --version --- stdout --- --- stderr --- usage: meson runpython [-h] [-c] script_file ... meson runpython: error: the following arguments are required: script_file, script_args ``` NOTE: without `version: '>=3.5'`, works as expected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Regression: array2string breaks for some subclasses EDIT: the below may not be complete; there seems to be other breakage for structured dtypes. The guard against infinite recursion in array2string done in #10544 causes problems for subclasses that count on user-defined formatters to have access to items of their own class; see https://github.com/astropy/astropy/issues/7214. In particular, astropy's `Angle` class assumed that inside array2print, any item selection would be done using its `__getitem__`, so that even scalars would be returned as array scalars with all the appropriate methods. This assumption broke by the introduction of an `asarray` in #10544. As noted in https://github.com/numpy/numpy/pull/10544#discussion_r170435274, it may be possible to solve this by doing `asarray` inside the numpy formatters, rather than upon entry in `array2print`. Here's a minimal testcase: ``` import numpy as np class DuckCounter(np.ndarray): def __getitem__(self, item): result = super(DuckCounter, self).__getitem__(item) if not isinstance(result, DuckCounter): result = result[...].view(DuckCounter) return result def to_string(self): # only on scalers in this example... return {0: 'zero', 1: 'one', 2: 'two'}.get(self.item(), 'many') def __str__(self): if self.shape == (): return self.to_string() else: return np.array2string(self, formatter={'all': lambda x: x.to_string()}) dc = np.arange(5).view(DuckCounter) print(dc) # [zero one two many many] ``` On numpy 1.14.1, this gives ``` AttributeError: 'numpy.int64' object has no attribute 'to_string' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: mangled ASCII color codes(?) in __init__ signatures IPython 5.0b3, PTK master, empty `ipython_config.py`. ``` In [6]: class C: ...: def __init__(self): pass ...: ...: In [7]: C?? Init signature: [0mC[0m[1;33m([0m[1;33m)[0m[1;33m[0m[0m *** ERROR: EOF in multi-line statement Type: type ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: Client.download_blob_to_file fails. `Client.download_blob_to_file()` does not work properly when passing a URI because the parsed path which is passed as a blob name has the initial `/` . https://github.com/googleapis/google-cloud-python/blob/master/storage/google/cloud/storage/client.py#L389-L395 It should be removed from the path before passing into a Blob constructor. ``` scheme, netloc, path, query, frag = urlsplit(blob_or_uri) if scheme != \"gs\": raise ValueError(\"URI scheme must be gs\") blob_name = path[1:] bucket = Bucket(self, name=netloc) blob_or_uri = Blob(blob_name, bucket) blob_or_uri.download_to_file(file_obj, client=self, start=start, end=end) ``` BTW: I tried to create a pull request to fix it but I was not allowed to push my commit into this repo. How can I contribute? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Suppress full stack trace for UnicodeEncodeError and UnicodeDecodeError in python 2 Decline to handle UnicodeEncodeError and UnicodeDecodeError when python2 is the interpreter under which conda is running. If you encounter this problem, consider downloading Miniconda3 or Anaconda3. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.isnan doesn't work on CPU in fast-math mode as a result np.nan_to_num, np.nanmean, etc all don't work ``` import jax.numpy as np a = np.zeros(1) / np.zeros(1) print(a.__array__()) print(np.isnan(a).__array__()) ``` `[nan]` `[False]` This bug only happens with the CPU-only build of JAX, when I see this warning: \"warnings.warn('No GPU found, falling back to CPU.')\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook save failure I can't save my notebook on master branch, if it contains this cell: ``` Python from IPython.display import Latex display(Latex([1])) ``` I know Latex() should not be called like this, still this probably should not lead to a failure in saving the notebook. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Implement check_pid for .NET This is a reminder - I added an `IPython.utils.process.check_pid` function to check if a process exists with a given PID. However, we have a `_process_cli` module containing .NET implementations of these things, and I didn't write the check_pid implementation for .NET. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: didn't write code at first line in %%writefile ``` python %%writefile test.py # coding: utf-8 print('안녕하세요') %run test.py File \"~/test.py\", line 2 print('안녕하세요') ^ SyntaxError: Non-ASCII character '\\xec' in file ~/test.py on line 2, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details ``` first line is ignored in %%writefile. But is ok. Add one new line ``` python %%writefile test.py # coding: utf-8 print('안녕하세요') %run test.py # 안녕하세요 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Airflow doesn't re-use a secrets backend instance when loading configuration values ### Apache Airflow version main (development) ### What happened When airflow is loading its configuration, it creates a new secrets backend instance for each configuration backend it loads from secrets and then additionally creates a global secrets backend instance that is used in `ensure_secrets_loaded` which code outside of the configuration file uses. This can cause issues with the vault backend (and possibly others, not sure) since logging in to vault can be an expensive operation server-side and each instance of the vault secrets backend needs to re-login to use its internal client. ### What you think should happen instead Ideally, airflow would attempt to create a single secrets backend instance and re-use this. This can possibly be patched in the vault secrets backend, but instead I think updating the `configuration` module to cache the secrets backend would be preferable since it would then apply to any secrets backend. ### How to reproduce Use the hashicorp vault secrets backend and store some configuration in `X_secret` values. See that it logs in more than you'd expect. ### Operating System Ubuntu 18.04 ### Versions of Apache Airflow Providers ``` apache-airflow==2.3.0 apache-airflow-providers-hashicorp==2.2.0 hvac==0.11.2 ``` ### Deployment Official Apache Airflow Helm Chart ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Bring in more resolution to hivestats Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Bump supported mysqlclient to <1.5 **Description** version 1.4.X introduced in Jan 2019 we should support it if we can. **Use case / motivation** pin of <1.4 was done in https://github.com/apache/airflow/pull/4558 due to lack of Python 2 compatibility. Since Master doesn't support Python 2 anymore there is no need for that restriction **Related Issues** Moved from https://issues.apache.org/jira/browse/AIRFLOW-4810 I tried to fix it in https://github.com/apache/airflow/pull/5430 but didn't get help with the tests so if any one wants to pick it up be my guest. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add option on agent install to set flow run environment variables Currently we can set environment variables for all runs deployed by an agent either through the `env_vars` kwarg or the `--env, -e` CLI options to the `prefect agent start` command. However there is no way to set it when using something like `prefect agent install`. I propose we add an option for these environment variables and then on start the agent will read some information out of config for them. e.g. ```toml [cloud.agent] [cloud.agent.env] my_var = \"test\" ``` could be set as ```bash prefect agent install kubernetes -e PREFECT__CLOUD__AGENT__ENV__MY_VAR=test ``` Then the agent would read all env vars set in `config.cloud.agent.env` and load them into runs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: DATETIME columns invalid when uploaded with `load_table_from_dataframe` https://github.com/googleapis/google-cloud-python/issues/9920#issuecomment-566642042 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: 15MB upload limit Trying to upload big files returns the error: ``` Upload Error Cannot upload file (>15 MB) \"1gb.zip\" ``` Is such a small size intentional? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: `SchemaField.to_standard_sql` and `SchemaField.from_standard_sql` methods Some BigQuery APIs (Models, Routines) use a new standard SQL format `bigquery_v2.types.StandardSqlDataType` for schemas, while Tables still use the legacy SQL format. It would be desirable to be able to convert easily between these formats. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: BokehRunner not compatible with maps This is a tricky one; I think ideally, since the `BokehRunner` isn't a production tool anyway, we can introspect the flow state and expand out any `mapped` tasks into the appropriate number of individual tasks for the visualization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Option to display hidden files in the file browser side panel I couldn't find another issue that mentioned this, so I'll open it here: It would be nice to be able to view hidden files in the file browser. Perhaps it could be in the `File` dropdown, although I don't see any other configuration options that it would group naturally with. Maybe a standalone command in the `Commands` tab would be most appropriate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: What causes error message: ERROR: <pkg-name> 'settings.arch' value not defined? Conan 1.6.1 Hi, We have a structure like the following (simplified): PkgA requires PkgB PkgB requires PkgC PkgA has no settings attribute PkgB has _settings = \"os\", \"compiler\", \"build_type\", \"arch\"_ PkgC has no settings attribute if we run (for PkgA): ``` conan install PkgA-recipe -if <build dir> conan build PkgA-recipe -bf <build dir> -sf <src folder> conan export-pkg PkgA-recipe dev/test -bf <build dir> ``` we get the error _ERROR: PkgB 'settings.arch' value not defined_. The output from conan suggests that the _conan export-pkg_ command successfully exporting the package, but failed before the package() method is called. if we run (for PkgA): `conan create PkgA-recipe dev/test` it works fine. To stop the error for the local build we added _settings = \"os\", \"compiler\", \"build_type\", \"arch\"_ to PkgA but we don't understand why this was required. Any guidance on what we may have done wrong? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add Latex Formatting for Arrays <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> It has been requested that I add the `array_to_latex` tool from the textbook package to qiskit. I will need some assistance with how / where is best to add this, as well as bringing to code up to qiskit's standard before I make a pull request. [Here is a link to the tool in its current form.](https://github.com/Qiskit/qiskit-textbook/blob/536835ee1e355bb8e9cb9fff00722e968bc6dc79/qiskit-textbook-src/qiskit_textbook/tools/__init__.py#L163) Thank you! ### What is the expected behavior? There is a way to neatly convert numpy arrays (such as the output of `.get_statevector()` and `.get_unitary()`) into readable latex. Example of current output: ``` [[1. +0.j 0. +0.j 0. +0.j 0. +0.j ] [0. +0.j 1. +0.j 0. +0.j 0. +0.j ] [0. +0.j 0. +0.j 1. +0.j 0. +0.j ] [0. +0.j 0. +0.j 0. +0.j 0.70710678+0.70710678j]] ``` Example of `array_to_latex` output for same matrix: <img width=\"548\" alt=\"Screenshot 2020-04-23 at 08 40 17\" src=\"https://user-images.githubusercontent.com/36071638/80072563-53e1e080-853e-11ea-8fc6-a060ce01db98.png\"> [more usage examples can be found here](https://qiskit.org/textbook/ch-gates/phase-kickback.html) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Logging system-calls? Would there be value in a command-line flag to force Meson to log all `Popen_safe()` system calls, for debugging? (Of course, I can use `strace` in a pinch.) For reference: * https://github.com/mesonbuild/meson/blob/fc5e8dfcdae11d23469fd01d878c7c9c30d67d30/mesonbuild/dependencies/base.py -- `class Dependency`, which runs **pkg-config** invisibly * https://github.com/mesonbuild/meson/blob/fc5e8dfcdae11d23469fd01d878c7c9c30d67d30/mesonbuild/mesonlib.py -- `Popen_safe()` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CMake subproject fails with \"Tried to form an absolute path to a source dir\" **Describe the bug** I have a simple Meson project that uses a CMake subproject. I pass an additional CMake option in using `cmake_options`, specifying `BOOST_ROOT`. When configuring, I see the subproject getting configured with CMake correctly, but as soon as the configuration succeeds, Meson quits with an error: > subprojects/mySubproject/meson.build:0:0: ERROR: Tried to form an absolute path to a source dir. You should not do that but use relative paths instead. (The error message is followed by an explanation on how to use `include_directories`.) Note that the error message points to a nonexistent file `subprojects/mySubproject/meson.build` in line 0. **To Reproduce** Here's my `meson.build`: ``` project( 'myApp', 'cpp', version : '0.0.1' ) cmake = import('cmake') boost_root = meson.source_root() + '/myBoost' message('Configuring mySubproject with BOOST_ROOT = ' + boost_root) proj = cmake.subproject('mySubproject', cmake_options : [ '-DBOOST_ROOT=' + boost_root ]) ``` **Expected behavior** It should either provide better diagnostics, or not fail. **system parameters** * Native build * OS: Oracle Linux 7.7 (based on CentOS) * Python: 3.7.4 * Meson version: 0.53.1 * Ninja version: 1.9.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Transpile Performance Regression <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: >=0.14.0 - **Python version**: Any - **Operating system**: Any ### What is the current behavior? https://github.com/Qiskit/qiskit-terra/commit/529a22b6 made some changes to how we reorder bits in stochastic swap and basic swap. These change slow down these passes about [2x slower for basic swap ](https://qiskit.github.io/qiskit/#mapping_passes.PassBenchmarks.time_basic_swap?machine=dedicated-benchmarking-softlayer-baremetal&os=Linux%204.15.0-46-generic&ram=16GB&p-n_qubits=5&p-depth=1024&commits=529a22b6)and [10-30% for stochastic swap](https://qiskit.github.io/qiskit/#mapping_passes.PassBenchmarks.time_stochastic_swap?machine=qiskit-benchmarking&os=Ubuntu%2018.04&ram=16%20GB&p-n_qubits=5&p-depth=1024&commits=529a22b6). You can also see the impact of stochastic swap for transpiles with the preset pass managers (because of stochastic swap) here: https://qiskit.github.io/qiskit/#transpiler_levels.TranspilerLevelBenchmarks.time_quantum_volume_transpile_50_x_20?machine=qiskit-benchmarking&os=Ubuntu%2018.04&ram=16%20GB&p-transpiler%20optimization%20level=1&commits=529a22b6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Error when parsing fortran code with abstract interface f2py appears to be missing support for abstract interfaces. Attempting to parse code containing an abstract interface produces an error. ### Reproducing code example: ```python from numpy.f2py.crackfortran import crackfortran crackfortran('test_interface.F90') ``` test_interface.F90: ```fortran module test abstract interface end interface end module test ``` ### Error message: ``` Traceback (most recent call last): File \"/Users/jhaiduce/Development/lightda/test_interface_crackfortran.py\", line 3, in <module> crackfortran('test_interface.F90') File \"/usr/local/lib/python3.9/site-packages/numpy/f2py/crackfortran.py\", line 3310, in crackfortran readfortrancode(files, crackline) File \"/usr/local/lib/python3.9/site-packages/numpy/f2py/crackfortran.py\", line 526, in readfortrancode dowithline(finalline) File \"/usr/local/lib/python3.9/site-packages/numpy/f2py/crackfortran.py\", line 759, in crackline raise Exception('crackline: groupcounter(=%s) is nonpositive. ' Exception: crackline: groupcounter(=0) is nonpositive. Check the blocks. ``` ### NumPy/Python version information: 1.20.1 3.9.1 (default, Feb 3 2021, 07:04:48) [Clang 11.0.0 (clang-1100.0.33.17)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: take_along_axis inconsistent with numpy Stumbled upon this while migrating some code for selecting a batch of main eigenvectors to jax: ```python import numpy as onp import jax.numpy as jnp B, M, N = 2, 3, 5 v, m = onp.random.rand(B, N), onp.random.rand(B, M, N) def foo(np=None): i = np.argmax(v, axis=-1)[..., None, None] return np.take_along_axis(m, i, axis=-1) print(foo(np=onp).shape) # => (2, 3, 1) print(foo(np=jnp).shape) # => (2, 1, 1) ``` Jax returns something of a different shape. I also found that I could omit one of the dummy axes on `i`, which numpy does not accept (`m` and `i` must have the same ndim and compatible shapes) but jax does. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Context docs are broken For some reason the actual `context` class signature is not being documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add support for --health-start-period Docker CE 17.06 will contain support for --health-start-period, compose should add a matching capability and updates to the corresponding v3.x & v2.x compose formats to support this option. Originally mentioned in docker/cli#116 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Coupling maps is about wires, not qubits The `Coupling` object talks about \"qubits\" instead of \"wires\". In the context of layouts and wire maps, that's confusing. The `Layout` object denotates wires with numbers. I think the same should happen in `Coupling`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: GroupResult.as_tuple forget serialize group parent ``` celery -A ct report software -> celery:4.0.2 (latentcall) kombu:4.0.2 py:2.7.9 billiard:3.5.0.2 py-amqp:2.1.4 platform -> system:Linux arch:64bit, ELF imp:CPython loader -> celery.loaders.app.AppLoader settings -> transport:amqp results:cache+memcached://127.0.0.1:11211/ broker_url: u'amqp://guest:********@localhost:5672//' result_backend: u'cache+memcached://127.0.0.1:11211/' ``` **Steps to reproduce** ``` # ct.py # ct.py from __future__ import absolute_import, unicode_literals from celery import Celery app = Celery( 'ct', broker='amqp://guest@localhost//', backend='cache+memcached://127.0.0.1:11211/' ) @app.task def nothing(*args): return args if __name__ == '__main__': app.start() ``` Start worker `python ct.py worker -l INFO` In `python` console ``` >>> from celery import chain, group >>> from celery.result import result_from_tuple >>> from ct import nothing >>> c = nothing.s() | group(nothing.s(), nothing.s()) >>> r = c.delay() >>> r <GroupResult: f46d7bcc-3140-40e8-9e21-d2f74eef6f28 [4854af6e-8e4a-48d8-98e9-d5f0eefcce20, 5c8d4ec1-84ff-4845-a9b2-9f07fd9bed19]> >>> r.parent <AsyncResult: a359ae60-ed18-4876-a67b-fc8cd83759a2> >>> t = r.as_tuple() >>> r2 = result_from_tuple(t) >>> r2 <GroupResult: f46d7bcc-3140-40e8-9e21-d2f74eef6f28 [4854af6e-8e4a-48d8-98e9-d5f0eefcce20, 5c8d4ec1-84ff-4845-a9b2-9f07fd9bed19]> >>> r2.parent >>> r2.parent is None True ``` **Expected behavior** ``` >>> r2 = result_from_tuple(t) >>> r2.parent <AsyncResult: a359ae60-ed18-4876-a67b-fc8cd83759a2> >>> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: SqueezBert link gives a 404 error The main Readme.md file (https://github.com/huggingface/transformers/blob/master/README.md), the SqueezeBert link (https://huggingface.co/transformers/model_doc/squeezebert.html) gives a \"404 - Not Found\" Error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add user-agent info to Jupyter magics Client constructor(s). In order to better prioritize jupyter features such as #8342 and #8143, it is important for Google to know how much these features are used to query BigQuery. This is done by populating the user-agent string with the corresponding \"application name\" and version information. I propose we use the IPython version information in this string, as these magics are being used from an IPython kernel. Getting the IPython version string: https://stackoverflow.com/a/56265255/101923 Something like: ``` bigquery.Client( client_info=ClientInfo( user_agent=\"ipython-{}\".format(IPython.__version__) ) ) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [workspaces] Use conanws.yml by default if no workspace file given From the documentation it appears that the intention is for different workspace configs to be used under different settings, however I will use only one workspace config and use layout placeholders to make it work under different settings. For this use case I think it would be good to have `conan workspace install` look for a `conanws.yml` file in the current directory and use that if no file is explicitly provided. This implies the need for #4777 as I don't think it's a good idea to recurse up the directory hierarchy to look for this file. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython setup darwin/CPython error Hi on some alternative project, ipython is failing to build on a linux system: <pre> Searching for ipython>=3.0.0 Reading https://pypi.python.org/simple/ipython/ Best match: ipython 4.1.1 Downloading https://pypi.python.org/packages/source/i/ipython/ipython-4.1.1.zip#md5=445ff597cccb7818c23c988010f62838 Processing ipython-4.1.1.zip Writing /tmp/easy_install-gDd17B/ipython-4.1.1/setup.cfg Running ipython-4.1.1/setup.py -q bdist_egg --dist-dir /tmp/easy_install-gDd17B/ipython-4.1.1/egg-dist-tmp-QzsqPK error: Setup script exited with error in ipython setup command: Invalid environment marker: sys_platform == \"darwin\" and platform_python_implementation == \"CPython\" </pre> fixing the `requirements.txt` like this solves the problem: <pre> diff --git a/requirements.txt b/requirements.txt index 2b00519..1a20c72 100644 --- a/requirements.txt +++ b/requirements.txt @@ -8,7 +8,7 @@ decorator wheel pyyaml werkzeug -ipython>=3.0.0 +ipython==4.0.0 statistics requests rlp>=0.4.4 </pre> In short, ipython 4.1.1 is automatically choosen and fails, while 4.0.0 is fine, and it seems related to the following line in `setup.py`: `207: ':sys_platform == \"darwin\" and platform_python_implementation == \"CPython\"': ['gnureadline'],` Cheers Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Include `timeout` attribute (related to DDP) to TrainingArguments ### Feature request Would it be possible to include a `timeout` attribute to the `TrainingArguments` dataclass, such as it will be used as an argument of the `torch.distributed.init_process_group` calls? Reference: https://pytorch.org/docs/stable/distributed.html#torch.distributed.init_process_group ### Motivation Essentially, if a process uses DDP and performs a set of operations prior to using the GPUs, such as tokenization/mapping, for more than `timeout` seconds (defaults to 30 minutes), the process will stop and get killed due to a `Socket Timeout`. (issue #17106). By adding a `timeout` argument to the `TrainingArguments` class, we will be able to let users decide in overriding the default timeout defined by PyTorch and hopefully introduce a way to prevent `Socket Timeouts` when mapping large datasets. ### Your contribution I could definitely submit a PR, seems to be pretty straightforward to add a new attribute to the `TrainingArguments` class. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Initial layout does not support some types of list <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? This fails: ```python lay = QuantumCircuit(5, 5) lay.h(2) lay.cx(2, 1) lay.cx(1, 0) lay.cx(2, 3) lay.cx(3, 4) lay.barrier() lay.measure(range(5), range(5)) layout = list(np.random.permutation(5)) job6 = execute(lay, backend, initial_layout=layout) ``` with error: ` AttributeError: 'list' object has no attribute 'get_physical_bits'` but inputting the resulting list by hand works. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: up should not add 3 dots after container name. Makes slow to copy/paste There are added 3 dots after the container name when doing `up` ``` # docker-compose up Starting dockercomposetest_helloworld_1... Attaching to dockercomposetest_helloworld_1 ``` which makes copy/pasing the name on Linux slow, as you can't just double click on the name without also getting the 3 dots. So one would have to drag the mouse cursor over the name and make sure not to get any of the dots included. **Proposal** Don't add the 3 dots. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: CSRF token should be expire with session ### Apache Airflow version 2.5.0 ### What happened In the default configuration, the CSRF token [expires in one hour](https://pythonhosted.org/Flask-WTF/config.html#forms-and-csrf). This setting leads to frequent errors in the UI – for no good reason. ### What you think should happen instead A short expiration date for the CSRF token is not the right value in my view and I [agree with this answer](https://security.stackexchange.com/a/56520/22108) that the CSRF token should basically never expire, instead pegging itself to the current session. That is, the CSRF token should last as long as the current session. The easiest way to accomplish this is by generating the CSRF token from the session id. ### How to reproduce _No response_ ### Operating System Linux ### Versions of Apache Airflow Providers _No response_ ### Deployment Official Apache Airflow Helm Chart ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Artifactory without enabled \"anonymous access\" doesn't use revisions If the \"anonymous access\" is not enabled in Artifactory, the \"ping\" Conan endpoint returns a 401 if no authentication is sent, so the capabilities are never read, but the 401 is currently ignored by the client, storing an empty set of capabilities for the remote. To fix this, we have to raise an exception if we receive a 401 in the \"ping\" endpoint so we force the authentication process in the client. But there is another issue to solve: the authenticating process in the client is trying to get the capabilities to know if it should use v1 or v2 so it is like a snake biting its own tail. It can be fixed by using always \"v1\" to authenticate and not hiding the 401 in the ping endpoint. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: network: collect TCPRetransFail metric Nothing additional to add, this is just a metric that we'd like to collect. We had a host that was hitting a high number of these that was causing some network instability. The closest metric we had was `system.net.tcp.retrans_segs` but this just indicates that a segment was retransmitted, which is normal TCP behaviors. The problem is when they fail to retransmit, but this metric isn't tracked by dd-agent today. This can be seen from `netstat -s -p tcp` the same way the other stats are collected. I will likely submit a PR, but I don't know how to collect this on Solaris system to cover that case, but I can do the BSD case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Dealing with images in multidirectory environment I am playing with this and I found this behaviour: My directory have the following structure: /Desarrollos ---/damian_blog ---/pyconar2013_talks ---/etc... I started the notebook in `Desarrollos` using: `ipython notebook pyconar2013_talks/IPython_fu_talk.ipynb` Then if I load an image in markdown cell, `<img src=\"figs/logo.png\" />` the files prepend is no longer necessary, which is great... But if I try to load the image in a code cell, ``` from IPython.display import Image Image(filename='pyconar2013_talks/figs/logo.png') ``` I have to preppend with the `pyconar2013_talks` to make it render in the code cell... and if a preppend the src in the markdown cell `<img src=\"pyconar2013_talks/figs/logo.png\" />`, it is not rendered... This is the intended behaviour? Because we have a lack of consistency? Or a I missing something? Dami]an. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: LGTM alerts . I notice that there are still a fair number LGTM alerts, many of which look pretty simple. I wonder if they would be a good source of issues for the next NumPy sprint? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Fortran reshape order runs but gives wrong behaviour Hi there, Big fan of Jax, thanks for making this! I believe there is a problem with specifying the reshaping order: ```python a = np.arange(6) + 1 np.reshape(a, (3, 2), order='F') ``` Should give: ``` array([[1, 4], [2, 5], [3, 6]]) ``` But instead gives: ``` array([[1, 2], [3, 4], [5, 6]], dtype=int32) ``` Basically, it is ignored and always does column-major reordering. If unsupported, it would be nice for it to just fail rather than silently carry on. Fortran reshape order runs but gives wrong behaviour Hi there, Big fan of Jax, thanks for making this! I believe there is a problem with specifying the reshaping order: ```python a = np.arange(6) + 1 np.reshape(a, (3, 2), order='F') ``` Should give: ``` array([[1, 4], [2, 5], [3, 6]]) ``` But instead gives: ``` array([[1, 2], [3, 4], [5, 6]], dtype=int32) ``` Basically, it is ignored and always does column-major reordering. If unsupported, it would be nice for it to just fail rather than silently carry on. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: `numpy.dtype()` issue warning when run python3 with `-b` switch See [here](https://github.com/pandas-dev/pandas/issues/16776) 1. Run Python using `python3 -b` 2. Run ``` import numpy as np np.dtype('int32') ``` I get output ``` >>> import numpy as np >>> np.dtype('int32') __main__:1: BytesWarning: Comparison between bytes and string dtype('int32') >>> print(sys.version) 3.5.3 |Continuum Analytics, Inc.| (default, Mar 6 2017, 12:15:08) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] >>> np.version.version '1.13.0' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan upload should print the remote it is using ``` conan upload \"*\" Are you sure you want to upload 'XXX@XXX/XXXX'? (yes/no): ```` It should be `Are you sure you want to upload 'XXX@XXX/XXXX' to remote 'conan-center'? (yes/no): Or print first: ``` > conan upload \"*\" Uploading to remote 'conan-center': Are you sure you want to upload 'XXX@XXX/XXXX'? (yes/no): ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: improve scaling of append method of QuantumCircuit for wide circuits <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> Creating a circuit of fixed depth and variable width scales superlinearly with increasing width. This seems to be due to the issubset method of python sets. Other circuit methods which use append are likely also affected such as `inverse`, `reverse_ops`, `combine`, and `extend`.  Looking at the call graph this seems to be due to the `issubset` call in `_check_qargs`. Probably a similar issue would exist for `_check_cargs` 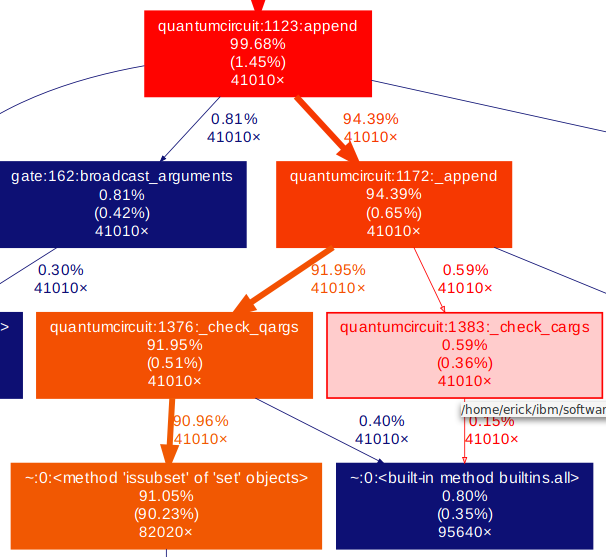 qiskit version: 0.19.0.dev0+ccb9a6c ### What is the expected enhancement? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: introspection: Add version information to 'meson introspect --scan-dependencies' @mensinda Add ability to display required version for dependencies discovered via 'meson introspect --scan-dependencies' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: threading.setDaemon has been deprecated in favor of setting daemon attribute directly in Python 3.10 Ref : python/cpython#25174 ``` /root/checked_repos_clone/GitPython/git/cmd.py:106: DeprecationWarning: setDaemon() is deprecated, set the daemon attribute instead t.setDaemon(True) Iterated 1 Commits in 0.005753278732299805 [s] ( 173.813932 commits/s ) ./root/checked_repos_clone/GitPython/git/cmd.py:106: DeprecationWarning: setDaemon() is deprecated, set the daemon attribute instead t.setDaemon(True) E/root/checked_repos_clone/GitPython/git/cmd.py:106: DeprecationWarning: setDaemon() is deprecated, set the daemon attribute instead t.setDaemon(True) E/root/checked_repos_clone/GitPython/git/cmd.py:106: DeprecationWarning: setDaemon() is deprecated, set the daemon attribute instead t.setDaemon(True) EE/root/checked_repos_clone/GitPython/git/cmd.py:106: DeprecationWarning: setDaemon() is deprecated, set the daemon attribute instead t.setDaemon(True) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Using a numpy integer type as an index for a QuantumRegister fails ### Information - **Qiskit Terra version**: 0.11.1 - **Python version**: 3.7.6 - **Operating system**: Ubuntu 18.04.4 LTS ### What is the current behavior? An error is raised: ``` File \"/lib/python3.7/site-packages/qiskit/circuit/register.py\", line 90, in __getitem__ raise CircuitError(\"expected integer or slice index into register\") qiskit.circuit.exceptions.CircuitError: 'expected integer or slice index into register' ``` ### Steps to reproduce the problem ```python from qiskit import QuantumRegister import numpy as np qr = QuantumRegister(3) qubit_index = np.int64(0) qubit = qr[qubit_index] ``` ### What is the expected behavior? Since numpy is used extensively in scientific programming, the type checking should not be as strict. ### Suggested solutions Change line 89 of register.py from: ```python if not isinstance(key, (int, slice, list)): ``` to ```python if not isinstance(key, (int, slice, list, np.integer)): ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for `Expr` and `Type` values in QPY serialisation Part of #10239. As part of the push for classical rvalue expressions for conditions in Terra, we need to support serialisation/deserialisation of these within QPY. This is necessary for initial support. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add GAE/GCE support for datastore.set_default_dataset and add exception on failure See discussion in #444 for comments on exception. Something like [`oauth2client.client._get_environment`](https://github.com/google/oauth2client/blob/481b4b6310e5872fbd5ed6c7aa336938e564d729/oauth2client/client.py#L953) could be good to detect GAE/GCE dataset ID's but `_detect_gce_environment` should be better as discussed in google/oauth2client#93 Not blocking for M1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: GlueOperator: iam_role_arn as a parameter ### Description Hi, There is mandatory parameter iam_role_name parameter for GlueJobOperator/GlueJobHook. It adds additional step of translating it to the arn, which needs connectivity to the global iam AWS endpoint (no privatelink availabale). For private setups it needs opening connectivity + proxy configuration to make it working. It would be great to have also possibility to just pass directly iam_role_arn and avoid this additional step. ### Use case/motivation Role assignation does not need external connectivity, possibility of adding arn instead of the name. ### Related issues _No response_ ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: fPIC auto-managed in autotools build helper The same we did with CMake here https://github.com/conan-io/conan/pull/2818/files Take into account that there is already a flag fPIC. So, act when the parameter is not specified. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Wrong argument to `Path` in ipython in version 8.0.0a1 <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories. If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org. If you are unsure, it's ok to post here, though, there are few maintainer so you might not get a fast response. --> I have pre-release tests on my package and I got such error (only on windows https://github.com/4DNucleome/PartSeg/runs/4559230495?check_suite_focus=true) : ``` D:\\tmp\\tox\\py38-PyQt5-all\\lib\\site-packages\\PartSeg\\common_gui\\qt_console.py:9: in <module> from ipykernel.inprocess.ipkernel import InProcessInteractiveShell D:\\tmp\\tox\\py38-PyQt5-all\\lib\\site-packages\\ipykernel\\inprocess\\ipkernel.py:10: in <module> from IPython.core.interactiveshell import InteractiveShellABC D:\\tmp\\tox\\py38-PyQt5-all\\lib\\site-packages\\IPython\\__init__.py:51: in <module> from .core.application import Application D:\\tmp\\tox\\py38-PyQt5-all\\lib\\site-packages\\IPython\\core\\application.py:37: in <module> programdata = Path(os.environ.get(\"PROGRAMDATA\", None)) c:\\hostedtoolcache\\windows\\python\\3.8.10\\x64\\lib\\pathlib.py:1042: in __new__ self = cls._from_parts(args, init=False) c:\\hostedtoolcache\\windows\\python\\3.8.10\\x64\\lib\\pathlib.py:683: in _from_parts drv, root, parts = self._parse_args(args) c:\\hostedtoolcache\\windows\\python\\3.8.10\\x64\\lib\\pathlib.py:667: in _parse_args a = os.fspath(a) E TypeError: expected str, bytes or os.PathLike object, not NoneType ERROR: InvocationError for command 'D:\\tmp\\tox\\py38-PyQt5-all\\Scripts\\pytest.EXE' package/tests --no-cov (exited with code 4) ``` It looks like wrong default value is provided here `os.environ.get(\"PROGRAMDATA\", None)` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Spanner docs are outdated Spanner docs still talk about [checking out a session](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/docs/spanner/snapshot-usage.rst) and then doing operations on that such as `session.snapshot` and `session.batch`. We changed the API long time back where such operations can be done directly on the database object and that is the API we want to promote. Please audit all the docs to scrub out all the calls directly made on session object and replace those with calls on Database object. This should be doe before Beta since we expect an uptick in usage once we mark the client as Beta and we want to people to use the preferred API. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Calling run_in_transaction twice causes the second call to fail It seems that the `_transaction` object in Session is not being reset once the transaction commits. This leads to a \"Transaction is already committed\" error. Here is a simple code to demonstrate this: ```python def run_txn(): from google.cloud import spanner spanner_client = spanner.Client() instance_id = 'your-instance' instance = spanner_client.instance(instance_id) database_id = 'example-db' database = instance.database(database_id) def f(t): t.insert_or_update( table=\"Singers\", columns=('SingerId', 'FirstName'), values = [(6, \"A\"),]) database.run_in_transaction(f) database.run_in_transaction(f) if __name__ == '__main__': run_txn() ``` The error that is raised is: ```python Traceback (most recent call last): File \"txn.py\", line 17, in <module> run_txn() File \"txn.py\", line 14, in run_txn database.run_in_transaction(f) File \"/usr/local/google/home/vikask/venvs/pythonq/local/lib/python2.7/site-packages/google/cloud/spanner/database.py\", line 379, in run_in_transaction return session.run_in_transaction(func, *args, **kw) File \"/usr/local/google/home/vikask/venvs/pythonq/local/lib/python2.7/site-packages/google/cloud/spanner/session.py\", line 309, in run_in_transaction txn.commit() File \"/usr/local/google/home/vikask/venvs/pythonq/local/lib/python2.7/site-packages/google/cloud/spanner/transaction.py\", line 104, in commit self._check_state() File \"/usr/local/google/home/vikask/venvs/pythonq/local/lib/python2.7/site-packages/google/cloud/spanner/transaction.py\", line 46, in _check_state raise ValueError(\"Transaction is already committed\") ValueError: Transaction is already committed ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Support for \"headers\" configuration in haproxy.yaml? Hi all, I'm interested in passing a custom header to my HAProxy integration in `haproxy.yaml`, like this: ``` instances: - name: haproxy url: http://localhost:3000 headers: service-route: haproxy-stats ``` However, that [doesn't appear to be supported](https://github.com/DataDog/integrations-core/blob/master/haproxy/check.py#L160). Any chance something like this could be added, or ideas for a workaround? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: S3ToSnowflakeTransfer enforces usage of schema parameter Unlike all other Snowflake operators, S3ToSnowflakeTransfer requires the usage of schema instead of letting it be an optional variable that when passed would be used, and if not, then connection metadata is used. I can be assigned on this if needed. Keeping this up here so this doesn't go unnoticed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: qtconsole drag target? Having recently switched from IPython on osx terminal to qtconsole, I miss the \"drag a file from finder to get full path in terminal\" feature. Is something along these lines planned? More generally is some kind of drag and drop from/to qtconsole planned? Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: [mpl and latex circuit drawer] The box needs to extend over the classical registers as well when an instruction has classical parameters _Originally posted by @ajavadia in https://github.com/Qiskit/qiskit-terra/issues/2973#issuecomment-521635150_ > No mpl and latex also need to be fixed. The box needs to extend over the classical registers as well. But at least they draw something. I would say text is priority since that's the default drawer. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Add the ability to disable/enable extensions The `ignorePlugins` approach is not as effective as disabling, since the plugin will still be loaded if it is required by another plugin. We can add the ability to disable plugins, where a plugin is considered enabled if it is installed and does not have `disabled: false` metadata. These will be handled by not registering the plugin in the `index.js` if the plugin is in the list of disabled plugins. The plugin itself will still be in the bundle, so this will not require a rebuild. cc @minrk who asked for this feature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Spelling Error (_medical_likeliehood) _medical_likeliehood -> _medical_likelihood https://github.com/GoogleCloudPlatform/google-cloud-python/blob/b28a4eb667ae08c3f4dcf9af891ed4931884989c/vision/google/cloud/vision/safe_search.py#L43 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Link to \"coverage\" directly from API sidebar This vuepress enhancement will allow it, but depends on #770: https://github.com/vuejs/vuepress/pull/1534 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Changing contents of a wrap file doesn't trigger a rebuild of the subproject. **Describe the bug** If I have a project with a wrap file and I change some information in the file (such as version), that isn't picked up by ninja to make meson run configure again. **To Reproduce** I don't think a reproducer is needed, but if one is, I can cook it up on request. **Expected behavior** ninja will trigger a meson reconfiguration, which will pick up differences in the wrap file. **system parameters** * Native build * Ubuntu 20.04 * python 3.8 * meson master * samurai In case this is intended behavior, I think it should be documented (or I missed it in the docs :c ) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: Crate VolumeOP from k8s_resource error **What happened:** when I run ``` dsl.VolumeOP(k8s_resource=my_vpc) ``` ``` Raises: ValueError: if k8s_resource is provided along with other arguments ``` I think the reason is : ``` if \"k8s_resource\" in kwargs: if resource_name or size or storage_class or modes or annotations: raise ValueError(\"You cannot provide k8s_resource along with \" \"other arguments.\") ``` ``` def __init__(self, resource_name: str = None, size: str = None, storage_class: str = None, modes: List[str] = VOLUME_MODE_RWM, annotations: Dict[str, str] = None, data_source=None, **kwargs): ``` but the mode has a default value sdk/python/kfp/dsl/_volume_op.py **What did you expect to happen:** I think, I should only put k8s_resource and name in it. **What steps did you take:** [A clear and concise description of what the bug is.] **Anything else you would like to add:** [Miscellaneous information that will assist in solving the issue.] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Client.queue_status info gets confused by retried tasks The Hub doesn't get notified of tasks that fail on an engine but are awaiting resubmission, so it thinks the task is perpetually pending on the engine on which it failed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Allow passing a list of File objects to custom_target Currently the following code fails with a python assertion about unknown type: ```meson foo = custom_target( 'foo', input : [files('foo'), files('bar')], output : 'foo.h', command : [my_prog, '@INPUT0@', '@INTPUT1@', '-o', '@OUTPUT@'], ) ``` However, replacing `[files('foo'), files('bar')]` with `files('foo') + files('bar')` does work. So this is probably pretty trivial to fix. I'll have a look at it soon if on one else gets to it before then. link_with: isn't flattened extracted from xserver meson.build, with the maze of conditionals removed for clarity: ```meson project('test', 'c') libxserver_dri3 = [] libxserver = [ libxserver_dri3 ] executable('Xephyr', 'xephyr.c', link_with: [ libxserver ]) ```` fails with ``` Meson encountered an error in file meson.build, line 6, column 0: Link target [] is not library. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan server can't be setup in the subdirectory of a domain I want to run Conan at, say, `https://example.com/conan` behind Apache. Currently, there is no way to do this. If I set `host_name` to `example.com/conan` and `port` to `443`, the Conan client will try to upload to `https://example.com/conan:443/v1/...` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson test --suite SUITE does not work? Hi, I cannot find the way to use the option `--suite` of `meson test` I have defined some tests in this way ``` test('test_name', executable, suite: '1D') ``` everything works fine if I run ``` meson test ``` or ``` ninja test ``` but if I run ``` meson test --suite '1D' ``` it tells me ``` No suitable tests defined. ``` is the option `--suite` still working? how can I select just a subset of tests to be executed? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Remove `DateSchedule` and `NoSchedule` Prefect currently supports two schedule classes that are probably not useful: `DateSchedule` (a list of datetimes) and `NoSchedule` (no schedule at all). In Prefect's original design, schedules were created when the flow was created and was therefore impossible to change, so it was desirable to have 1. a uniform interface for accessing the schedule's information, even if there wasn't a schedule 1. a way to specify that the flow should run on a few (off-schedule) dates Now, with @dylanbhughes's great observation that schedules should/can be modified after the flow is created, we may do schedule examination and validation at any time. `NoSchedule` can simply be replaced by `None` and `DatesSchedule` can be replaced by using Prefect's API to simply schedule flow runs by hand on the appropriate dates. Therefore, the only built-in schedule classes should handle ongoing, regular schedules. Currently we have `CronSchedule` and `IntervalSchedule` and I can imagine more complex versions (like `BusinessDaySchedule`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Switch build_type with python api On our build server we usually do something like ``` pip install --upgrade conan ``` ```python api, _, _ = ConanAPIV1.factory() api.create(..., settings=...+[\"build_type=Release\"]) api.upload... api.create(..., settings=...+[\"build_type=Debug\"]) api.upload... ``` That worked well until Dec 19, 2018 (conan 1.10.2). Since the following conan update (must be 1.11.0), the second ```api.create()``` always failed. It prints ``` Configuration: [settings] arch=x86_64 arch_build=x86_64 build_type=Debug compiler=Visual Studio compiler.runtime=MD compiler.version=15 ... ``` ```compiler.runtime=MD``` is wrong, should be ```MDd```. It should be automatically set by conan based on the ```build_type```. It only happens when the debug build is invoked after the release build. Workaround: Recreate the api before switching ```build_type```. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Separate out tableau provider from salesforce **Description** Tableau provider is currently embedded into Salesforce, but it should be removed to a separate 'tableau' provider.. This should lead to: * 1.0.1 version of the Salesforce provider * 1.0.0 version of the Tableau provider Seems that Salesforce provider might be backwards-compatible with deprecation warnings: * The Tableau classes from the Salesforce provider should be moved to Tableau * The old Tableau classes in the Salesforce provider should get a deprecation warning and import the classes from the Tableau one * The Salesforce provider should have a \"hard\" dependency on \"tableau\" provider (no extra needed) **Use case / motivation** Dicussion [here](https://lists.apache.org/thread.html/rb1828485df78df7649000ff586a749ab685635f606b394386e1be808%40%3Cdev.airflow.apache.org%3E) has shown that the tableau provider is really independent from Salesforce and we have already similar examples (slack for example). Also it makes sense not to change provider structure when ownership of a service changes. **Related Issues** #13595 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: In storage.connection.Connection.api_request, make response checking more robust From TODO: ``` python # TODO: Add better error handling. # TODO: Better checking on this header for JSON. ``` See [`storage.connection.Connection.api_request`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/connection.py#L220) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 220) # TODO: Add better error handling. b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 227) # TODO: Better checking on this header for JSON. ``` In storage.connection.Connection.api_request, make response checking more robust From TODO: ``` python # TODO: Add better error handling. # TODO: Better checking on this header for JSON. ``` See [`storage.connection.Connection.api_request`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/connection.py#L220) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 220) # TODO: Add better error handling. b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 227) # TODO: Better checking on this header for JSON. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Implement fast tokenizer for Big Bird models This issue is similar to #10498 ## Your contribution I can help with the implementation. Can someone provide me the high-level steps ? @stefan-it Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: set_custom_completer seems to be a no-op In [interactive_shell.py](https://github.com/ipython/ipython/blob/a2685d78f2403f84e6cb915ae11a4f6033ccc5f6/IPython/core/interactiveshell.py#L2034), `set_custom_completer` does self.Completer.matchers.insert(pos,newcomp) Looking at the source code of IPCompleter, though, [matchers](https://github.com/ipython/ipython/blob/eed56ba34aa3856b5726d60eedfe60a17e1c26c5/IPython/core/completer.py#L1114) seems to be a property returning an ephemeral list, so the insert is a no-op. To reproduce: import IPython def foo(*args, **kwargs): pass print(len(IPython.get_ipython().Completer.matchers)) IPython.get_ipython().set_custom_completer(foo, 0) print(len(IPython.get_ipython().Completer.matchers)) This should print the same number twice (in my version, 5, 5) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Remove newline_with_copy_margin. It has been deprecated for at least 2 versions. We can remove this. _Originally posted by @Carreau in https://github.com/ipython/ipython/pull/13888#discussion_r1071293652_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Slow tokenizers return overflowing tokens in reversed order When implementing the slow tokenizer for LayoutLMv2, I spotted some weird behaviour for slow tokenizers when specifying `return_overflowing_tokens = True`. Namely, in that case, overflowing tokens are returned in reversed order, and no padding is performed, unlike fast tokenizers. Small example: ``` from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\") text = \"hello my name is niels\" encoding = tokenizer(text, padding=True, max_length=6, truncation=True, return_overflowing_tokens=True) ``` When checking out the encoding, it looks as follows: ``` print(tokenizer.decode(encoding.input_ids)) # prints '[CLS] hello my name is [SEP]' print(tokenizer.decode(encoding.overflowing_tokens)) # prints '##els ni' ``` As you can see, the overflowing tokens are returned in reversed order, and they are not padded up to the max length of 6 tokens. In contrast, `BertTokenizerFast` does everything correctly: ``` from transformers import BertTokenizerFast tokenizer = BertTokenizerFast.from_pretrained(\"bert-base-uncased\") text = \"hello my name is niels\" encoding = tokenizer(text, padding=True, max_length=6, truncation=True, return_overflowing_tokens=True) ``` returns ``` print(tokenizer.decode(encoding.input_ids[0])) # prints '[CLS] hello my name is [SEP]' print(tokenizer.decode(encoding.input_ids[1])) # prints '[CLS] niels [SEP] [PAD] [PAD]' ``` So I guess we have some work to do for slow tokenizers to work correctly. cc @LysandreJik @SaulLu @n1t0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: todo: enable CI to run torchdynamo/tensorrt tests @ydshieh, let's talk about instrumenting one of the jobs to run tests for torchdynamo/tensorrt It's quite a handful of things to build, the instructions are in the OP: https://github.com/huggingface/transformers/pull/17765 I installed the environment locally, the tests work. I didn't want to get in the way of the PR, so doing it in a separate task. thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Passing a dummy dependency to library() doesn't work Trying to pass a dummy dependency to library() I saw that it is suggested in the dependency() docs that one creates a dependency with name \"\" and required: false. ``` project('glib', 'c', 'cpp', version : '2.55.0', meson_version : '>= 0.44.0', ) thread_dep = dependency('', required : false) library('glib-2.0', dependencies: [thread_dep]) ``` but this results in the following error: ``` Meson encountered an error in file meson.build, line 6, column 0: Argument is of an unacceptable type 'Dependency'. Must be either an external dependency (returned by find_library() or dependency()) or an internal dependency (returned by declare_dependency()). ``` What am I doing wrong? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Measurement instruction create qobj with wrong memory slot number <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? All pulse jobs including measurement instruction fail. ### Steps to reproduce the problem ### What is the expected behavior? `max_memory_slot` in qobj should be configured properly. ### Suggested solutions https://github.com/Qiskit/qiskit-terra/blob/01bdfe88c15a93fa7548edc0db0e33b287cc8c98/qiskit/assembler/assemble_schedules.py#L73-L74 here the assembler estimates `max_memory_slot` smaller than the actual configuration because `slot.index` starts from zero and maximum index is smaller than number of `mem_slots`. using `slot.index + 1` or `len(instruction.mem_slots)` will solve the problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Refactor `EquivalenceLibrary` to internally be a graph ### What should we add? In #7211 we refactored the search algorithm in the `BasisTranslator` transpiler pass to perform a dijkstra search using retworkx. To accomplish this the pass had to generate a retworkx graph object from the `EquivalenceLibrary` on demand and then perform the dijkstra search over that graph. However, it would be better if the equivalence library itself just internally wrapped a graph object. The data in the `EquivalenceLibrary` is inherently a graph and using a graph representation for the internal data model makes sense and will also improve the performance of the basis translator because there will be no overhead for constructing the graph object. The output of this issue should be to change the internal `_map` attribute of the `EquivalenceLibrary` with a `retworkx.PyDiGraph` object built as the basis translator does during it's basis search: https://github.com/Qiskit/qiskit-terra/blob/8a3e760ffaf6dcd06c0a0e04f13612fdefd9ab3c/qiskit/transpiler/passes/basis/basis_translator.py#L470-L502 We should maintain the same public API that exists on the class, but just change the internal data model (and likely add helper functions to access the graph object). Then after we update the `EquivalenceLibrary` in a second pull request we can update the `BasisTranslator` to leverage the internal graph object instead of creating it on demand for each search. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Small typo https://github.com/huggingface/transformers/blob/4475f1dc2aa7153adb5e66b361c48aed1321fe3d/examples/pytorch/question-answering/run_qa.py#L423 On this line, the word 'agument' has a typo. I believe it should be argument. While we are at it, I think changing it to 'the argument' would be better as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Indicate attempted allocation size when constructing an array gives a MemoryError I've seen multiple questions now of the form \"why does this give a MemoryError\" when the reason is the user ended up allocating a bigger array than expected. It would be helpful to include the shape and dtype in the error message. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Trace: needs 'synth.py' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Object returned by executable() does not expand to full path when used as argument in test() http://mesonbuild.com/Reference-manual.html#build-target-object says > full_path() returns a full path pointing to the result target file. NOTE: In most cases using the object itself will do the same job as this and will also allow Meson to setup inter-target dependencies correctly. Please file a bug if that doesn't work for you. ... so I'm filling this. ```meson exe = executable('systemd-tmpfiles', 'src/tmpfiles/tmpfiles.c', include_directories : includes, link_with : [libshared], dependencies : [libacl], install_rpath : rootlibexecdir, install : true, install_dir : rootbindir) public_programs += [exe] test('test-systemd-tmpfiles', test_systemd_tmpfiles_py, args : exe) ``` this expands to ``` --- command --- /home/zbyszek/src/systemd-work/src/test/test-systemd-tmpfiles.py systemd-tmpfiles ``` i.e. it runs the system-installed binary instead of the one I want to test. Using `exe.full_path()` works fine, but it will break dependency calculation when #1704 is resolved. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson is failing to detect boost libraries suffixed with '-mt' on mac On macports boost library names look like '/opt/local/lib/libboost_program_options-mt.dylib'. Boost builds are finding boost, but then saying that the modules are not found. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Whether instantiation is premature? https://github.com/huggingface/transformers/blob/515ed3ad2a11a6b0cd9800b2ad4d3b313fdaea8c/src/transformers/feature_extraction_utils.py#L429 For example my code is: ```python3 processor = LayoutXLMProcessor.from_pretrained('microsoft/layoutxlm-base', apply_ocr=False) ``` I don't need to use OCR, but pytesseract still has to be installed. Would it be a good solution to this kind of problem if the parameters were updated with kwargs before instantiation? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Make sure deep copy is correctly performed in datastore.query.Query._clone From TODO: ``` python # TODO(jjg): Double check that this makes sense... ``` See [`datastore.query.Query._clone`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/query.py#L63) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 63) # TODO(jjg): Double check that this makes sense... ``` Make sure deep copy is correctly performed in datastore.query.Query._clone From TODO: ``` python # TODO(jjg): Double check that this makes sense... ``` See [`datastore.query.Query._clone`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/query.py#L63) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 63) # TODO(jjg): Double check that this makes sense... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Can't downgrade python: \"No module named 'distutils.spawn'\" Issue (conda-forge issue: https://github.com/conda-forge/conda-forge.github.io/issues/805) I'm not sure whether it is a CF or conda issue, but it only occurs after running conda update --all with conda-forge channel added. Here is a Dockerfile to reproduce: ``` FROM continuumio/miniconda3 RUN conda config --add channels conda-forge && \\ conda config --set channel_priority strict && \\ conda update --all RUN conda install python=2.7 ``` Fails with: ``` Preparing transaction: ...working... done Verifying transaction: ...working... done Executing transaction: ...working... done ERROR conda.core.link:_execute(637): An error occurred while installing package 'conda-forge::ipaddress-1.0.22-py_1'. ModuleNotFoundError(\"No module named 'distutils.spawn'\") Attempting to roll back. Rolling back transaction: ...working... done ModuleNotFoundError(\"No module named 'distutils.spawn'\") () ``` The failing package varies based on the python version downgraded to, with python=3.6: ``` ERROR conda.core.link:_execute(637): An error occurred while installing package 'conda-forge::tqdm-4.32.2-py_0'. ModuleNotFoundError(\"No module named 'distutils.spawn'\") Attempting to roll back. Rolling back transaction: ...working... done ModuleNotFoundError(\"No module named 'distutils.spawn'\") () ``` Tried both with and without conda config --set channel_priority strict, same outcome. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CPT won't work with Conan 1.14.0-dev To help us debug your issue please explain: Conan Version: 1.14.0-dev Hi! After to merge the PR #4713 and exclude the test module from Conan installer, CPT will not be able to run its tests because we re-use many of Conan test tools there. How could we install the test module only when required? I've searched some options, and found some possible solutions in the internet: - Create multiple eggs. One for Conan, One for test. Very complex IMO - Use setuptools namespaces. I only read that is support on python +3.3. - Package all things as before, and remove only the test folder after to install. Most simple solution I think. I made this workaround some time ago: https://github.com/uilianries/conan-ldap-authentication/blob/master/setup.py#L55 To install the test_folder, we can use extra. For now `conan[test]` only installs the development requirements, but we could change to skip the folder deletion. You can check the log [here]( https://travis-ci.org/conan-io/conan-package-tools/jobs/506451807#L684). Regards! - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [ ] I've specified the Conan version, operating system version and any tool that can be relevant. - [ ] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Combining default_options : ['cpp_std=c++2a', 'cuda_std=c++17'] breaks nvcc I'm trying to compile a project where the host code (*.cpp) uses c++20, but the device code (*.cu) uses c++17, since that is the latest version currently supported by nvcc. **Describe the bug** In `meson.build`, I tried this: ``` project('C++ std', 'cpp', 'cuda', version : '1.0.0', default_options : ['cpp_std=c++2a', 'cuda_std=c++17']) ``` but `nvcc` fails because it was called with `--std=c++17 -std=c++2a`: ``` meson compile -v ninja: Entering directory `.' [1/2] nvcc -Xcompiler=-Wall -Xcompiler=-Winvalid-pch -Xcompiler=-Wnon-virtual-dtor --std=c++17 -std=c++2a -g -G -g -I.. -I. -Iprog.p -Iprog.p -o prog.p/main.cu.o -c ../main.cu FAILED: prog.p/main.cu.o nvcc -Xcompiler=-Wall -Xcompiler=-Winvalid-pch -Xcompiler=-Wnon-virtual-dtor --std=c++17 -std=c++2a -g -G -g -I.. -I. -Iprog.p -Iprog.p -o prog.p/main.cu.o -c ../main.cu nvcc fatal : Value 'c++2a' is not defined for option 'std' ninja: build stopped: subcommand failed. ``` **To Reproduce** Start with cuda example [6 std](https://github.com/mesonbuild/meson/tree/master/test%20cases/cuda/6%20std), but use this: ```project('C++ std', 'cpp', 'cuda', version : '1.0.0', default_options : ['cpp_std=c++2a', 'cuda_std=c++17'])``` **Expected behavior** I expected that `gcc` would be invoked with c++2a and `nvcc` would be invoked with c++17. If I manually remove the spurious `-std=c++2a` then `nvcc` succeeds. **system parameters** This is a native build on 5.4.101-1-MANJARO with Meson 0.57.1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: [FR] support batching rule for np.cumprod It is strange to me that we have batching rule for `reduce_window` but `np.cumprod` raises `NotImplementedError: Batching rule for 'reduce_window' not implemented`. Here is a simple repro code ```python from jax import vmap import jax.numpy as np def f(x): return np.cumprod(x, axis=-1) vmap(f)(np.ones((3, 3))) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery client.list_datasets() fails when the project has no datasets Found while doing clean-up of a project after reproducing #1419 Reproduce: ``` python In [11]: client.list_datasets() --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-11-fed4650eba20> in <module>() ----> 1 client.list_datasets() gcloud-python/gcloud/bigquery/client.pyc in list_datasets(self, include_all, max_results, page_token) 89 query_params=params) 90 datasets = [Dataset.from_api_repr(resource, self) ---> 91 for resource in resp['datasets']] 92 return datasets, resp.get('nextPageToken') 93 KeyError: 'datasets'`` ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: unhide .git_commit_info.ini .git_commit_info is installed into system paths by setup.py some security audit tools do not like this. I see no reason why this file should be hidden, can the dot be removed? see http://bugs.debian.org/cgi-bin/bugreport.cgi?bug=663256 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC,BLD: Switch to `xelatex` engine for latex docs? When building the latex/pdf version of the documentation, sphinx is currently configured to use `pdflatex` (the default) to build the pdfs of the user/reference manuals. There are several places in the documentation where the use of unicode characters causes `inputenc` warnings when building the pdf. In some cases these can be resolved by ensuring that extra latex packages are installed (e.g. `texlive-langgreek` adds the necessary mappings for some Greek Unicode characters), but in other cases (e.g. U+22EE vertical dots) it is more difficult to find an appropriate package (or the mapping can be done manually via `\\DeclareUnicodeCharacter`). In addition, there seem to be some URL ref problems that are avoided by `xelatex` (see sphinx-doc/sphinx#7723). Please share any thoughts and possible pros/cons of switching to `xelatex` for the NumPy latex/pdf docs. Note that sphinx provides a `latex_engine` configuration option that makes this simple to try. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: transpile(..., initial_layout=...) is ignored if there is no coupling map <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: all - **Operating system**: all ### What is the current behavior? ```python from qiskit import QuantumCircuit from qiskit.compiler import transpile from qiskit.transpiler import CouplingMap circ = QuantumCircuit(2) circ.h(0) circ.cx(0,1) transpile(circ, routing_method='basic', initial_layout=[1, 0]).draw() ``` ``` ┌───┐ q_0: ┤ H ├──■── └───┘┌─┴─┐ q_1: ─────┤ X ├ └───┘ ``` Notice that, when a coupling map is provided, the output is: ```python transpile(circ, routing_method='basic', initial_layout=[1, 0], coupling_map=[[1,0], [0,1]]).draw() ``` ``` ┌───┐ q_1 -> 0 ─────┤ X ├ ┌───┐└─┬─┘ q_0 -> 1 ┤ H ├──■── └───┘ ``` ### What is the expected behavior? `transpile` should apply the layout, even when there is no coupling map. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: compiler.has_argument doesn't work with clang for warnings Try this meson.build (github wouldn't let me upload directly here) https://gist.github.com/iainlane/2935fba6bdd02214eb2de4212573aa3b with `CC=gcc` and then `CC=clang`. The option is unknown, and yet the test passes with clang. In `meson-log.txt` we can see why: ``` Running compile: Command line: clang /tmp/tmph4afoz0x.c -Wzzzzzzzz -c· Code: int i; Compiler stdout: warning: unknown warning option '-Wzzzzzzzz' [-Wunknown-warning-option] 1 warning generated. Compiler stderr: · Compiler for c supports argument -Wzzzzzzzz: YES Meson encountered an error in file meson.build, line 6, column 8: Error encountered: buggy ``` clang is only outputting this as a warning. There's a clang-specific flag `-Werror=unknown-warning-option`, which meson could pass. It's clang-specific because it makes gcc error. Or meson could pass `-Werror` for `has_argument`, which I hope works for all compilers, but maybe it's less safe to do so for `has_argument` for some reason I haven't thought of yet - like a value a user could pass that generates a warning but is actually okay (deprecations?). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: storage: some acl methods fail on empty (private) acl Easiest to set this up with `gsutil`. Please notice the verbose message. ``` $ gsutil defacl set private gs://bucket Setting default object ACL on gs://bucket/... $ gsutil defacl get gs://bucket No default object ACL present for gs://bucket. This could occur if the default object ACL is private, in which case objects created in this bucket will be readable only by their creators. [] ``` In particular `acl.reload` and `acl.save` don't work, probably others too. ``` Python >>> acl = storage.acl.DefaultObjectACL(bucket) >>> acl.get_entities() Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/home/user/.local/lib/python2.7/site-packages/gcloud/storage/acl.py\", line 358, in get_entities self._ensure_loaded() File \"/home/user/.local/lib/python2.7/site-packages/gcloud/storage/acl.py\", line 192, in _ensure_loaded self.reload() File \"/home/user/.local/lib/python2.7/site-packages/gcloud/storage/acl.py\", line 409, in reload for entry in found['items']: KeyError: 'items' >>> acl.get_entities() [] >>> acl.reload() Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/home/user/.local/lib/python2.7/site-packages/gcloud/storage/acl.py\", line 409, in reload for entry in found['items']: KeyError: 'items' >>> acl.save() Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/home/user/.local/lib/python2.7/site-packages/gcloud/storage/acl.py\", line 453, in save for entry in result[self._URL_PATH_ELEM]: KeyError: 'defaultObjectAcl' ``` This works fine if the default ACL is set to `project-private` rather than `private`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: regression: nuisance warning for gfortran @mensinda git bisect reveals b1b8a7a7e356297741c3c8e5996928ff244578c8 is the first bad commit that introduced spurious warning: ``` WARNING: No include directory found parsing \"gfortran -xfortran -E -v -\" output ``` This occurs with Linux and Windows (at least) with at least Gfortran 7 and 9. This occurs for any trivial Fortran target. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gnome.generate_gir() is failing with address sanitizer. Compiling fwupd with: meson .. -Db_sanitize=address ...completes until it gets to the `g-ir-scanner` calls. This returns: [1/4] 'Generating Fwupd-1.0.gir with a custom command.' FAILED: libfwupd/Fwupd-1.0.gir '/usr/bin/g-ir-scanner' '../libfwupd/fwupd-client.c' '../libfwupd/fwupd-enums.c' '../libfwupd/fwupd-enums.h' '../libfwupd/fwupd-error.c' '../libfwupd/fwupd-remote.c' '../libfwupd/fwupd-result.c' '-I/usr/include/gobject-introspection-1.0' '-I/usr/include/glib-2.0' '-I/usr/lib64/glib-2.0/include' '-pthread' '--no-libtool' '--namespace=Fwupd' '--nsversion=1.0' '--warn-all' '--output' 'libfwupd/Fwupd-1.0.gir' '-I/home/hughsie/Code/fwupd/libfwupd' '-I/home/hughsie/Code/fwupd/build/libfwupd' '-I./libfwupd/..' '-I../libfwupd/..' '--include=GObject-2.0' '--cflags-begin' '-fstack-protector-strong' '-Wwrite-strings' '--cflags-end' '--symbol-prefix=fwupd' '--identifier-prefix=Fwupd' '--pkg-export=fwupd' '..' '-I/usr/include/gio-unix-2.0/' '-I/usr/include/glib-2.0' '-I/usr/lib64/glib-2.0/include' '-pthread' '-I/usr/include/libsoup-2.4' '-I/usr/include/libxml2' '-L/home/hughsie/Code/fwupd/build/libfwupd' '--extra-library=gio-2.0' '--extra-library=gobject-2.0' '--extra-library=glib-2.0' '--extra-library=soup-2.4' '--library' 'fwupd' ==6599==ASan runtime does not come first in initial library list; you should either link runtime to your application or manually preload it with LD_PRELOAD. Command '[u'/home/hughsie/Code/fwupd/build/tmp-introspectKke532/Fwupd-1.0', u'--introspect-dump=/home/hughsie/Code/fwupd/build/tmp-introspectKke532/functions.txt,/home/hughsie/Code/fwupd/build/tmp-introspectKke532/dump.xml']' returned non-zero exit status 1 I think the gnome module needs to remove the address sanitization flags before passing them to `/usr/bin/g-ir-scanner` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: unable to complete remote connections for two-process steps to reproduce: ``` ipython console --ip=0 ``` and then, try to connect to it from another window: ``` ipython console --exiting ``` and it will stall. If you don't specify --ip, everything works, because the local code goes through a slightly different code path. Just opening this now so @minrk has a thing to reference as he submits the fix Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CUDA lacks support for external flags and especially for -ccbin (aka --compiler-bindir) flag **Describe the bug** A clear and concise description of what the bug is. **To Reproduce** Please include your `meson.build` files, preferably as a minimal toy example showing the issue. You may need to create simple source code files (don't include private/proprietary code). **Expected behavior** A clear and concise description of what you expected to happen. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) * what Python version are you using e.g. 3.8.0 * what `meson --version` * what `ninja --version` if it's a Ninja build Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Mention new dev requirements somewhere in the docs (or make more prominent) While trying to build the master branch of ipython, I noted the following warning: ``` Failed to build css sourcemaps: [Errno 2] No such file or directory ``` Tracking this down in the source code, I eventually realized that this is because I don't have `lessc` or `invoke`. I figured out what LESS is in this context, but still am not sure what `invoke` is supposed to be. So it would be helpful if this were mentioned somewhere quite prominent in the dev docs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Can't use None (anymore) in checkpoint_callback ## 🐛 Bug using None in checkpoint_callback now errors out ``` -- Process 0 terminated with the following error: Traceback (most recent call last): File \"/opt/conda/lib/python3.6/site-packages/torch/multiprocessing/spawn.py\", line 20, in _wrap fn(i, *args) File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/distrib_data_parallel.py\", line 562, in ddp_train q.put(self.checkpoint_callback.best_model_path) AttributeError: 'NoneType' object has no attribute 'best_model_path' ``` ### To Reproduce `trainer = Trainer(checkpoint_callback=None)` Ran into this issue from upgrading to masters, was using masters from a few commits ago before Edit: `False` casuses the same error as well Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub 0.37.1 Subscription Client is Broken Hi, I encountered the following error. ``` File \"/******/PubsubAccessor.py\", line 129, in create_subscriber_client credentials=credentials, File \"/******/lib/python2.7/site-packages/google/cloud/pubsub_v1/gapic/subscriber_client.py\", line 188, in __init__ self.iam_policy_stub = (iam_policy_pb2.IAMPolicyStub(channel)) File \"/******/lib/python2.7/site-packages/google/iam/v1/iam_policy_pb2.py\", line 344, in __init__ self.SetIamPolicy = channel.unary_unary( AttributeError: 'NoneType' object has no attribute 'unary_unary' ``` This problem did not occur in 0.35.4. I checked the commit log and found a strange part. https://github.com/GoogleCloudPlatform/google-cloud-python/commit/371333a51165e99d4d02876b1ef133618485b6fc#diff-e221f62050dd418b49b113c7909d0ea2L129 Channel initialization processing has been deleted. https://github.com/GoogleCloudPlatform/google-cloud-python/commit/371333a51165e99d4d02876b1ef133618485b6fc#diff-e221f62050dd418b49b113c7909d0ea2R188 However, implementations using channel remain. Thanks, Kazutomo Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG?: 1.14 printing requires gc run to clean up all references to printed array Dear NumPy devs, one of our NumPy integration doctests in Cython has been failing on travis for a couple of weeks. I checked the changelog of CPython and Cython from the time when it started, but neither showed anything remotely related. However, the failing travis nodes use NumPy 1.14, and since there were PyPy related changes in that release, I suspect that this could be the cause. I only see the failures in Py3.5+, and they started in the CPython-dev integration test runs for py3.6-dev and py3.7-dev on travis, however those are built (NumPy is pre-installed in them). Here's an example of a [failing run](https://travis-ci.org/cython/cython/builds/342548198). The now failing [test](https://github.com/cython/cython/blob/2e1066dcfc1c4ccbfaa0babf3cbe9f58640431fd/tests/memoryview/numpy_memoryview.pyx#L415-L423) is simply this: ``` cdef int[:, :] array = create_array((4, 5), mode=\"c\", use_callback=True) print(np.asarray(array)[::2, ::2]) ``` Meaning, there is a buffer provider (not NumPy), we take a Cython memory view from it, and then wrap that with `numpy.asarray()` to print it. The difference is when the buffer provider will be deallocated. Previously, it was cleaned up immediately at function exit (and we print a confirmation in a cleanup callback when that happens). With the new NumPy version, it is no longer cleaned up immediately, but only at the next GC run. I added a conditional GC call to the test to trigger that and keep the test from failing (we didn't need a GC run before), but I thought I'd at least bring this change to your attention, in case it's unintentional. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: tensorboard logger should support remote directories ## 🚀 Feature Tensorboard allows you to write to gc, s3, hdfs, etc by specifying paths with the right prefix e.g. `logDir='hdfs://path/to/logs/` However the lightning logger breaks this. see [tensorboard.py#L99](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/loggers/tensorboard.py#L99) ### Motivation Training often occurs on remote clusters which don't persist the local disk at the time the job ends. The local disk is also not accessible from outside tools so tensorboard can not access the results while training is in progress. ### Pitch Replace all directory operations with some remote-aware tool. tensorboard itself provides a [gfile compatible handle .](https://github.com/tensorflow/tensorboard/blob/master/tensorboard/compat/tensorflow_stub/io/gfile.py) There are other options as well. tensorboard itself supports these things natively so maybe we can just get around doing any local file operations and leverage tensorboard lib to write remotely. ### Alternatives Some other option would be to write locally but add hooks to sync the logs to a remote storage. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Coverage report link is broken A 404 status code is returned when you try to navigate to the coverage report link. Most likely caused by the changes in https://github.com/PrefectHQ/prefect/pull/805 **cc:** @jlowin Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: 1D ``np.linalg.norm`` not preserving input dtype? I saw the [v1.14.0 release note](https://github.com/numpy/numpy/blob/master/doc/release/1.14.0-notes.rst#1d-nplinalgnorm-preserves-float-input-types-even-for-arbitrary-orders) saying: > 1D np.linalg.norm preserves float input types, even for arbitrary orders However, when I try the code on the release note, it does not behave as it says. ```py >>> import numpy as np >>> np.__version__ '1.14.0' >>> f32 = np.float32([1, 2]) >>> np.linalg.norm(f32, 2.0).dtype dtype('float32') >>> np.linalg.norm(f32, 2.0001).dtype dtype('float64') # it should be float32 on numpy 1.14? ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Refactor apitools legacy 'handle_http_exceptions' for sanity. The [apitools code which handles the various errors being raised when making a request](https://github.com/tseaver/gcloud-python/blob/streaming-strip_unused_features/gcloud/streaming/http_wrapper.py#L225-L276) is seriously awkward, and likely a bug magnet. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: SAM: Notebook example not working ### System Info - `transformers` version: 4.29.0.dev0 - Platform: macOS-13.2-arm64-arm-64bit - Python version: 3.10.6 - Huggingface_hub version: 0.13.4 - Safetensors version: 0.3.0 - PyTorch version (GPU?): 1.13.0 (False) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): 0.6.9 (cpu) - Jax version: 0.4.8 - JaxLib version: 0.4.7 - Using GPU in script?: NO - Using distributed or parallel set-up in script?: NO Dependencies - torch = 1.13.0 - numpy = 1.23.4 ### Who can help? _No response_ ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction 1. Pull [SAM Notebook example](https://github.com/huggingface/notebooks/blob/main/examples/segment_anything.ipynb) 2. Run notebook up until ``` masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs[\"original_sizes\"].cpu(), inputs[\"reshaped_input_sizes\"].cpu()) ``` 3. Get error ``` TypeError: upsample_bilinear2d() received an invalid combination of arguments - got (Tensor, list, bool, NoneType), but expected one of: * (Tensor input, tuple of SymInts output_size, bool align_corners, tuple of floats scale_factors) didn't match because some of the arguments have invalid types: (Tensor, !list!, bool, !NoneType!) * (Tensor input, tuple of SymInts output_size, bool align_corners, float scales_h, float scales_w, *, Tensor out) ``` ### Expected behavior original_sizes/output_sizes to be of the expected type, is this a dependency issue? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [BigQuery] Can't insert correct TIMESTAMP. In my environment, I can't insert correct data to the `TIMESTAMP` column. - gcloud 0.8.0 - Python 2.7.10 - MacOS X 10.10.5 The following snippet is the smallest reproducible example. Please let me know that it's a bug or my mistake. ``` python import os from datetime import datetime from gcloud import bigquery GCP_KEY_PATH = os.path.join(os.path.dirname(__file__), './gcpkey.json') project_id = 'my_project' dataset = 'tmp' table_name = 'test' bq = bigquery.Client.from_service_account_json(GCP_KEY_PATH, project=project_id) table = bq.dataset(dataset).table(name=table_name) if not table.exists(): table.schema = [bigquery.SchemaField('time', 'TIMESTAMP')] table.create() table.reload() rows = [[datetime.now()]] table.insert_data(rows) ``` <img width=\"339\" alt=\"2015-11-28 15 47 08\" src=\"https://cloud.githubusercontent.com/assets/899217/11450553/58c48c1a-95e7-11e5-8cf5-c4ca55a77026.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda-4.5.12 does not work after downgrading from conda-4.6rc1 after conda update -c conda-canary conda and later (because conda-4.6rc1 kept wanting to upgrade to python-3.7) conda install conda=4.5 python=3.6 conda-4.5.12 now refuses to work ``` (base) $ conda install -c conda-forge conda=4.6 Solving environment: failed CondaUpgradeError: This environment has previously been operated on by a conda version that's newer than the conda currently being used. A newer version of conda is required. target environment location: /home/dm/anaconda3 current conda version: 4.5.12 minimum conda version: 4.6 (base) $ conda update -c conda-forge conda Solving environment: failed CondaUpgradeError: This environment has previously been operated on by a conda version that's newer than the conda currently being used. A newer version of conda is required. target environment location: /home/dm/anaconda3 current conda version: 4.5.12 minimum conda version: 4.6 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cmake config generator doesn't support `check_and_set` According to https://cmake.org/cmake/help/v3.2/module/CMakePackageConfigHelpers.html?highlight=set_and_check, it's a best practice to use `set_and_check` instead of plain `set`. `set_and_check` is of course not normally defined, but is generated as part of the replacement of @PACKAGE_INIT@. I would like to share a single .in file between a legacy cmake build system and a new meson build system, without giving up cmake best practice in the mean time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Undefined variable x I'm hitting this line in `pxla.py` which doesn't seem to be tested right now: https://github.com/google/jax/blob/505b47c1fcef45534aa0cc90509ce146f9939c15/jax/interpreters/pxla.py#L80 The variable `x` isn't defined anywhere. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: [v3.4] Volume name field See https://github.com/docker/cli/pull/306 Additionally, consider support in v2? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Use exec instead of subprocess for webserver command Stopping the webserver using systemd only kills the parent process but leaves the gunicorn master and workers around, similar to what was reported with [gunicorn+supervisor](https://github.com/benoitc/gunicorn/issues/520). It appears the problem is related to running gunicorn with subprocess.Popen in cli.py instead of os.exec which would replace the process under control by systemd. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda Init Bug in v4.6.0b1 While exploring #7881 , I found a small bug in the regex pattern matching at: https://github.com/conda/conda/blob/7a93664267488adc5052efef38614fab537da446/conda/core/initialize.py#L1157-L1166 The regex pattern assumes that I would not have quotes in my already existing value in the registry key. For example, if I have the current value set as... ``` \"\\path\\to\\custom\\startup.bat\" & \"\\path\\to\\prev_installation\\condabin\\conda_hook.bat\" ``` ... upon `conda init`, it will change the value to: ``` \"\\path\\to\\new_installation\\condabin\\conda_hook.bat\" ``` Instead of: ``` \"\\path\\to\\custom\\startup.bat\" & \"\\path\\to\\new_installation\\condabin\\conda_hook.bat\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Move speech methods to `Sample`. Speech API calls should be from the `Sample` object instead of directly from the client. ``` python # Before client.sync_recognize(sample) # After sample.sync_recognize() ``` See: https://github.com/GoogleCloudPlatform/google-cloud-python/pull/2483#discussion_r82463142 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Increment threadsafety on BigQuery DB-API interface when httplib2 is removed From https://github.com/GoogleCloudPlatform/google-cloud-python/pull/2921/files/5b29a9e42a40f7c74ced0b7a7e9db0add52a20a1#r123596828 Blocked by https://github.com/GoogleCloudPlatform/google-cloud-python/issues/1998 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Cannot start services when ports are mentioned For some reason I cannot bind the port correctly. When I remove the port, it works. If i change the port to any other number, it still does not work ``` version: '3' services: rtorrent: container_name: rtorrent image: yusufali/rtorrent privileged: true web_nginx: container_name: web_nginx image: marvambass/nginx-ssl-secure links: - rtorrent:rtorrent ports: - \"8800:80\" ``` However, run I run docker-com up -d, this does not work ``` Creating network \"docker_default\" with the default driver Creating rtorrent Creating web_nginx ERROR: for web_nginx Cannot create container for service web_nginx: invalid port specification: \"None\" ERROR: Encountered errors while bringing up the project. ``` Useful info: ``` # docker-compose --version docker-compose version 1.12.0, build b31ff33 # docker --version Docker version 17.04.0-ce, build 4845c56 # uname -a Linux gsad 4.4.30-mod-std-ipv6-64 #9 SMP Tue Nov 1 17:58:26 CET 2016 x86_64 GNU/Linux ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Incorrect docs in metrics ## 📚 Documentation Here https://github.com/PyTorchLightning/pytorch-lightning/blob/a5f45787eabddfec4559983f8e6ba1c8317f62f1/pytorch_lightning/metrics/functional/classification.py#L137 the argument is `num_classes` but in docs it is `class_index` https://github.com/PyTorchLightning/pytorch-lightning/blob/a5f45787eabddfec4559983f8e6ba1c8317f62f1/pytorch_lightning/metrics/functional/classification.py#L148 Also, it returns 5 values but only 4 are mentioned. https://github.com/PyTorchLightning/pytorch-lightning/blob/a5f45787eabddfec4559983f8e6ba1c8317f62f1/pytorch_lightning/metrics/functional/classification.py#L152-L153 **Also, some more typos and docs needed to be fixed in the metrics module.** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda env create giving ImportError for yaml package `conda env create` suddenly started giving `\"ImportError: No module named 'yaml'\"` with latest miniconda on my TravisCI builbs: https://travis-ci.org/leouieda/website/builds/170917743 I changed nothing significant in my code. Tried rebuilding previous passing builds and started getting the same error. Is this something from a recent release? conda env create giving ImportError for yaml package `conda env create` suddenly started giving `\"ImportError: No module named 'yaml'\"` with latest miniconda on my TravisCI builbs: https://travis-ci.org/leouieda/website/builds/170917743 I changed nothing significant in my code. Tried rebuilding previous passing builds and started getting the same error. Is this something from a recent release? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Test priorities/ordering Right now, the order of tests during `ninja -C build test` is the order they were defined in `meson.build`. In my case, some tests take forever, others are very quick. I know that if one of the quick tests fails, the test suite fill fail so there's no point waiting an hour for the rest of the tests to finish. Moving the quick tests up in the meson.build file means moving them outside their logical scope. e.g. if I build a helper library that's used by the main code, I want the tests for that helper library defined right there, not in some other part of `meson.build`. So what I'd like is some way to influence the test order, e.g. by assigning a numerical priority to the test. Tests will then be executed in decreasing priority, with all the tests defaulting to 0. Is this something worth implementing? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Strip excess custom exceptions from 'gcloud.streaming' Many (all, maybe) of the custom exception types in `gcloud.streaming.exceptions` are providing no value, and could be replaced with either standard exceptions (`ValueError`, `TypeError`, etc.), or one of our existing types mapping particular HTTP response codes. Strip out as many of the custom types as seems feasible, and move the remainder to `gcloud.exceptions`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.linalg.svd with hermitian=True does not properly sort singular values ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> `svd` with `hermitian=True` (introduced by @eric-wieser in https://github.com/numpy/numpy/pull/12693) has a bug with the order of singular values: ```python import numpy as np a = np.array([[0, 1, 0], [1, 0, 1], [0, 1, 0]]) u, s, v = np.linalg.svd(a, hermitian=True) print(s) ``` Outputs: `[1.41421356e+00 6.07153217e-18 1.41421356e+00]` <!-- Remove these sections for a feature request --> Per the contract of `svd`, the singular values should be sorted in descending order, but they aren't here. That's because we simply reverse the order of eigenvalues than sorting, which only suffices if all eigenvalues happen to be positive. ### Numpy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> 1.17.5 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Consider setting optimize=True as default for einsum We should consider changing the default of einsum to be optimized, as the search for the best contraction order will generally be faster than compilation anyway. The contraction order calculation tends to only be slow when there are >10 tensors, which doesn't happen very often. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Two compile methods are redundant <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently we have: 1. wrapper.compile() ```python def compile(circuits, backend, config=None, basis_gates=None, coupling_map=None, initial_layout=None, shots=1024, max_credits=10, seed=None, qobj_id=None, hpc=None, skip_transpiler=False) ``` 2. transpiler.compile() ```python def compile(circuits, backend, config=None, basis_gates=None, coupling_map=None, initial_layout=None, shots=1024, max_credits=10, seed=None, qobj_id=None, hpc=None, pass_manager=None) ``` The latter should just be removed. The first will have a `pass_manager` option. Also see #978 about other simplifications to these function signatures. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook prints classes without regard to __repr__ Displaying a class that is an instance of a metaclass is done with no regard to the metaclass's **repr**. This is much unexpected and different from what the Python REPL would do. See [example notebook](http://nbviewer.ipython.org/gist/remram44/11389cfe653eeceddc0f) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Cannot make multi-line code blocks in ipython I just did a `pip install ipython` while teaching a class today and typed an if statement and then hit enter after the first line and the code executed. This seems like a bug. I did a `pip install ipython==6.5.0` and hitting Enter in a code block properly showed me the next indented line to type out. I'm on Ubuntu 18.04 running ipython within tmux, though I doubt tmux is the issue here. Cannot make multi-line code blocks in ipython I just did a `pip install ipython` while teaching a class today and typed an if statement and then hit enter after the first line and the code executed. This seems like a bug. I did a `pip install ipython==6.5.0` and hitting Enter in a code block properly showed me the next indented line to type out. I'm on Ubuntu 18.04 running ipython within tmux, though I doubt tmux is the issue here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Python documentation missing examples, etc It seems to have disappeared: https://googlecloudplatform.github.io/gcloud-python/#/docs/master/gcloud/datastore/client/client Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Cmake build helper + Intel Fortran This is similar to #2747, but there isn't as elegant a workaround, so I thought it was worth opening an issue. Intel fortran doesn't understand the verbosity command, and it causes the build to fail. The workaround I came up with is this: cmake = CMake(self, parallel=False) command_line = cmake.command_line command_line.replace(\"/verbosity:%s\" % cmake.msbuild_verbosity, \"\", 1) self.run('cmake \"%s\" %s' % (self.source_folder, command_line)) self.run('cmake --build . %s' % cmake.build_config)` Unlike #2747, no value that I pass to the msbuild_verbosity argument in the CMake constructor will prevent the command from being issued. It would be nice if there was some way to just remove the \"/verbosity: ... \" command from being issued at all. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Copyright “The SciPy community” ## Documentation 1. the copyright refers to the \"SciPy\" community and should be changed to \"NumPy\". 2. Should the start date be changed according to the numpy.org webpage? On numpy.org the copyright starts 2019, on the numpy documentation pages it starts 2008 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [SVN] Export of readonly conanfile.py results in permission denied error To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. I am using Conan 1.8.0-dev, Win10 & Python3.6. When having an readonly `conanfile.py` file (SVN locking mechanism make them readonly), we get the follwing error message: `ERROR: [Errno 13] Permission denied: 'C:\\\\...\\\\user\\\\svn25\\\\export\\\\conanfile.py'` Because `_export_conanfile` function uses `shutil.copy2` all stat info including readonly are taken. May be add an option, to ignore readonly flag. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Support multi-line docstrings for asset descriptions Better support for multi-line docstrings. This request makes a ton of sense to me - we should at least do better to support the first line of a description in the asset node. Maybe we always render the first line, and add a \"Show more\" button to expand it in other views? **Reported in Slack [here](https://dagster.slack.com/archives/C01U5LFUZJS/p1684071307688029)** > Any plans to support multi-line docstrings for assets? (summary line, followed by empty line, followed by detailed description). At the moment Dagit drops all the newlines and displays the entire docstring as one long line in the description. I'd expect it to just use the first line of the docstring so it appears neatly in the UI. And maybe expose the rest somewhere else in the UI. Or at least not drop all the newlines! :slightly_smiling_face: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Fix \"Attempt 2 out of 1\" messages It's possible to get strange \"Attempt 2 out of 1\" status messages when Airflow forces a task to run after it's completed or previously run. For example, this unit test in CoreTests prints such a message (https://github.com/airbnb/airflow/blob/aee3cacb1042dbdc26d9ba06d481c81948f418ec/tests/core.py#L467): ``` python def test_raw_job(self): TI = models.TaskInstance ti = TI( task=self.runme_0, execution_date=DEFAULT_DATE) ti.dag = self.dag_bash ti.run(force=True) ``` The \"Attempt\" message is built as ``` python tot_tries = task.retries + 1 msg = \"Attempt {} out of {}\".format(self.try_number+1, tot_tries) self.try_number += 1 ``` So every time the task gets loaded, the number of attempts is incremented. If the task is run an unexpected number of times, either due to prior failures or `force` runs, then this message becomes nonsensical. I think this is straightforward to fix by resetting self.try_number any time the task is run that ISN'T a retry. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Use Hash / SHA to compare Serialized DAGs <!-- Welcome to Apache Airflow! For a smooth issue process, try to answer the following questions. Don't worry if they're not all applicable; just try to include what you can :-) If you need to include code snippets or logs, please put them in fenced code blocks. If they're super-long, please use the details tag like <details><summary>super-long log</summary> lots of stuff </details> Please delete these comment blocks before submitting the issue. --> **Description** <!-- A short description of your feature --> Currently, we compare entire Serialized blobs to determine if the DAG changed or not before we write the Serialized DAGs to the Database which can be expensive. Instead, we will store the HASH / SHA of the Serialized JSON and store that in a separate column in the serialized_dag table. And before writing the Serialized Blob, we will compare the SHA to decide if DAG changed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: forward-mode differentiation of lax.scan suddenly not working When running a piece of code that was working earlier today, I am suddenly getting the following error ` NotImplementedError: Forward-mode differentiation rule for 'while' not implemented ` If necessary I can try to create a minimal repo, but I will say that if I replace a lax.scan call with a for loop then this error goes away. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `RecursionError` when calling `SummedOp.to_pauli_op()` This ```python from qiskit.opflow import I, X, Z op = ((Z + I) ^ Z) + (Z ^ X) op.to_pauli_op() ``` fails with `RecursionError: maximum recursion depth exceeded while calling a Python object` The error occurs in this method https://github.com/Qiskit/qiskit-terra/blob/0c8bb3dbf8d688590431ca79a83ba8aede84ed20/qiskit/opflow/list_ops/summed_op.py#L174-L187 In this case, one can see that `pauli_sum` is `==` to `self`, so the last line calls the method again with the same (implicit) argument. See also #5733 * Terra version 0c8bb3db `RecursionError` when calling `SummedOp.to_pauli_op()` This ```python from qiskit.opflow import I, X, Z op = ((Z + I) ^ Z) + (Z ^ X) op.to_pauli_op() ``` fails with `RecursionError: maximum recursion depth exceeded while calling a Python object` The error occurs in this method https://github.com/Qiskit/qiskit-terra/blob/0c8bb3dbf8d688590431ca79a83ba8aede84ed20/qiskit/opflow/list_ops/summed_op.py#L174-L187 In this case, one can see that `pauli_sum` is `==` to `self`, so the last line calls the method again with the same (implicit) argument. See also #5733 * Terra version 0c8bb3db Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Regression in .embed() As reported by @certik in the IPython-dev mailing list: Before this commit: ``` b70ac127e2c3698ea643b15af7d6bb5783ff3e7e is the first bad commit commit b70ac127e2c3698ea643b15af7d6bb5783ff3e7e Author: Bradley M. Froehle <brad.froehle@gmail.com> Date: Wed Jul 4 15:02:21 2012 -0700 embed(): Default to the future compile flags of the calling frame. ``` This is how things used to work in Qsnake (http://qsnake.com/): ``` $ qsnake ---------------------------------------------------------------------- | Qsnake Version 0.9.12, Release Date: May 7, 2011 | | Type lab() for the GUI. | ---------------------------------------------------------------------- In [1]: 4 / 3. Out[1]: 1.3333333333333333 ``` After that commit, this is how it works now: ``` $ qsnake ---------------------------------------------------------------------- | Qsnake Version 0.9.12, Release Date: May 7, 2011 | | Type lab() for the GUI. | ---------------------------------------------------------------------- In [1]: 4 / 3. TypeError: unsupported operand type(s) for |: 'NoneType' and 'int' ``` Here is how I call .embed(): ``` banner = \"...\" namespace = {\"lab\": run_lab} c = IPython.config.loader.Config() c.InteractiveShell.confirm_exit = False IPython.frontend.terminal.embed.InteractiveShellEmbed(config=c, user_ns=namespace, banner1=banner).mainloop(local_ns={}) ``` Would anyone know what the problem is? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Use the Sphinx option which causes an error if any warning occurs see @takluyver 's comment in #10895 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: run_training_batch breaks on None batch or -1 response from on_batch_start (in new 0.7.2 release) ## 🐛 Bug run_training_batch now is supposed to return a 4-tuple in 0.7.2 however, there are two places where it still returns a 3-tuple, which will cause the program to crash, saying \"ValueError: not enough values to unpack (expected 4, got 3)\" (training_loop.py:533) ``` if batch is None: return 0, grad_norm_dic, {} ``` (training_loop.py:543) ``` if response == -1: return -1, grad_norm_dic, {} ``` vs. the standard return `return 0, grad_norm_dic, all_log_metrics, batch_output` ### To reproduce just return -1 from on_batch_start Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gnome: gdbus_codegen includes outdir in include So what I mean by that is if you have the tree: - meson.build - src - meson.build (calling `gnome.gdbus_codegen`) The output source file will include `#include \"src/foo.h\"` Our [test](https://github.com/mesonbuild/meson/blob/7144b03fd412e9a441d9abaa615d90af348a9137/test%20cases/frameworks/7%20gnome/gdbus/meson.build#L7) even relies upon this behavior which I'd argue is simply wrong. The problem seems to be that `gdbus-codgen` gets the include line based upon the `--generate-c-code` flag. So either we need to run the command in the correct subdir or add a new flag to `gdbus-codgen` to specify the output directory. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Make `RowIterator._to_dataframe_iterable` public Follow-up to https://github.com/googleapis/google-cloud-python/issues/7293 There are use cases where it's not ideal to download a whole table at once, but a pandas DataFrame is still desired. Potential solution: Make the `pages` member of `RowIterator` return a generator of a subclass of `google.api_core.page_iterator.Page` with a `to_dataframe()` method. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Numpy FFTs return data types don't match input data types <!-- Please describe the issue in detail here, and fill in the fields below --> Unlike other functions, the NumPy FFT functions do not return arrays whose data types match the input arrays. Instead, `complex64` is promoted to `complex128`. ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import sys import numpy as np print(np.__version__, sys.version) input = np.ones((5, 5), dtype='complex64') output = np.square(input) assert output.dtype == 'complex64', f\"{output.dtype} square\" # assert passes output = np.fft.fft2(input) assert output.dtype == 'complex64', f\"{output.dtype} fft\" # assert fails ``` ### Numpy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> 1.17.3 3.8.0 | packaged by conda-forge | (default, Nov 6 2019, 23:20:36) [GCC 7.3.0] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: More Comprehensive Auth CLI commands ## Use Case Currently `prefect auth` only contains a `login` command and we need to support all the new hooks in #1410 ## Solution `prefect auth logout` (logout tenant, delete token) w/ confirm prompt `prefect auth list` (list available tenants) `prefect auth switch` (switch tenant) `prefect auth create-token` (create token scoped to a role) `prefect auth revoke-token` (revoke an API token) login w/ user token -> verify user show list of tenants -> choose tenant ## Alternatives N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Proposal: discard autosuggestion with `delete` key Auto-suggestions can be discarded using <kbd>Esc</kbd> key (which works slow as there is a time delay allowing to press a combination of <kbd>Esc</kbd> with another key):  When an auto-suggestion is partially accepted e.g. using <kbd>Ctrl</kbd> + <kbd>Right</kbd> it would appear intuitive to use <kbd>delete</kbd> key to clear the remaining part of the suggestion, but currently this does not work:  the proposed behaviour is depicted on the GIF below:  IPython 3.11 users can opt-in for the proposed behaviour by defining a custom shortcut: ```python custom_shortcuts = [ { \"command\": \"IPython:auto_suggest.discard\", \"new_keys\": [\"delete\"], \"new_filter\": \"navigable_suggestions & has_suggestion & default_buffer_focused\" } ] %config TerminalInteractiveShell.shortcuts = custom_shortcuts ``` but there may be a value in making this a default behaviour (opt-out rather than opt-in). Can I ask anyone interested to indicate if they would be happy with an addition of such a shortcut by default (:+1: or :-1: )? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: mesontest: tests should be namespaced by subproject When running `mesontest` in a top project, it would be good if tests were automatically namespaced by subproject. This would make things clearer for users as they would know right away which component is to blame if a test is failing (without having to dig in logs). It would also prevent naming clashes. At the moment, if two subproject have tests with the same name, running `mesontest $TEST-NAME` will run all of these and it's impossible to pick the one we actually care about. We are hitting those two issues in GStreamer: https://bugzilla.gnome.org/show_bug.cgi?id=776718 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: resource manager CAN be used with service account credentials Not implemented errors on constructing clients from service accounts are inaccurate. Cloud Resource Manager CAN be called with service accounts. Those methods should be implemented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Custom folder name in conan test command When people integrates Conan inside the project the name \"test\" is commonly overlapped with project tests folder. Make conan test command use the subfolders layout So the test code and files is not copied to every build/sha folder, but referenced instead. The build folder will live under the test folder, not the root one. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: use_auth_token deprecation in pipeline ### System Info I noticed that `pipeline` uses `use_auth_token` argument which raises `FutureWarning: The use_auth_token argument is deprecated and will be removed in v5 of Transformers.`. Replacing `use_auth_token=True` with `token=True` argument does not yet work in `pipeline` (will raise an error). Sys Info ``` - `transformers` version: 4.31.0 - Platform: Linux-5.15.0-78-generic-x86_64-with-glibc2.31 - Python version: 3.10.12 - Huggingface_hub version: 0.14.1 - Safetensors version: 0.3.1 - Accelerate version: 0.20.3 - Accelerate config: not found - PyTorch version (GPU?): 2.0.0+cu117 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: Yes - Using distributed or parallel set-up in script?: No ``` ### Who can help? @narsil ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ``` import torch from transformers import pipeline model_name = \"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v3\" generate_text = pipeline( model=model_name, torch_dtype=\"auto\", trust_remote_code=True, use_fast=True, device_map={\"\": \"cuda:0\"}, use_auth_token=True) res = generate_text( \"Why is drinking water so healthy?\", min_new_tokens=2, max_new_tokens=256, do_sample=False, num_beams=1, temperature=float(0.3), repetition_penalty=float(1.2), renormalize_logits=True ) print(res[0][\"generated_text\"]) ``` ### Expected behavior pipeline handles `token=True` argument. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Release google-cloud-storage Hi @tseaver, could you help cut a release for google-cloud-storage? cc: @JesseLovelace Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: PIN 16: deprecate Task kwargs that are moving to `Result` ## Use Case See PIN 16 (PR #2134) for background. ## Solution Raise DeprecationWarnings upon use of cache_for, cache_validator, cache_key and result_handler kwargs on task initialization. (These are either directly or effectively being moved to the `Result` class during this PIN.) ## Alternatives *Please describe any alternatives you've considered, even if you've dismissed them* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Question: \"Python module\" vs \"Python 3 module\" From the documentation, I can't tell when I should use the \"Python module\" (which supports both Python 2 and Python 3) vs. the \"Python 3 module\". It looks like the \"Python module\" is much newer. They both have very similar methods and descriptions. Is the \"Python 3\" module deprecated? If so, should it be removed in favor of the more generic \"Python module\"? Links to the relevant documentation here: https://mesonbuild.com/Python-module.html https://mesonbuild.com/Python-3-module.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Remove dataset from Entity constructor and allow a key See comment near end of a previous [comment](https://github.com/GoogleCloudPlatform/gcloud-python/issues/451#issue-52524401). This will be required to successfully finish #477 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Logging: grace_period & batch_size needs to get passed to _Worker in BackgroundThreadTransport grace_period & batch_size needs to get passed to _Worker: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/6c602823e7101b40dfe5bfc614da633beb8accfb/logging/google/cloud/logging/handlers/transports/background_thread.py#L258 Ran into this issue because we're using BackgroundThreadTransport and I'm trying to override the default grace period on shutdown. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PauliSumOp for opflow based on SparsePauliOp Add a dedicated SummedPauliOp class to opflow, for efficiency and functionality, based on quantum_info SparsePauliOp. The new operator class should be part of opflow and respect the pratice, design of opflow etc. Have operator math, and other operations commensurate with the rest of opflow. In order to allow legacy operators to be deprecated and internal logic moved fully over to opflow addition function, presently supported by the legacy operators is required. This should includes such methods to check commutation - [x] commutes - [x] anti-commutes ideally also methods for truncation, rounding etc., based on a supplied tolerance value in the method, like are currently in the legacy operators. Also Z2 Symmetry support see Qiskit/qiskit-aqua#1029 - [x] Z2 symmetry support Plus here is an nice to have Qiskit/qiskit-aqua#1425 - I will link it but it could be considered separately later as an enhancement once the basics are in place. ======== Update by @ikkoham TODO - [x] Add PauliSumOp Qiskit/qiskit-aqua#1440 - [ ] Support Z2 symmetry and deprecate legacy WeightedPauliOperator (https://github.com/Qiskit/qiskit-terra/pull/5537) - [ ] Optimize AbelianGrouper, CircuitSampler, Expectation, and Evolution for PauliSumOp (https://github.com/Qiskit/qiskit-terra/pull/5623) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Moving Constructor definition to the top like a Function definition I would like to know if there is any specific reason for displaying the constructor definition at the bottom unlike a normal function definition. Currently it is less user-friendly to check up the default values of the arguments in the constructor. For example : https://github.com/scikit-image/scikit-image/issues/885#issuecomment-34863149 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Test DataLoader never uses multiple workers ### Feature request / Bug Fix I realized that in the `get_test_dataloader` method of the `Trainer` class, for datasets that are not instances of `torch.utils.data.IterableDataset`, the `num_workers` argument is not given to the `DataLoader` init call. https://github.com/huggingface/transformers/blob/edb672ac5edcd92fadb15d3172a115eb5fe6f663/src/transformers/trainer.py#L936-L943 Whereas it is the case juste above if `test_dataset` is an instance of `torch.utils.data.IterableDataset`: https://github.com/huggingface/transformers/blob/edb672ac5edcd92fadb15d3172a115eb5fe6f663/src/transformers/trainer.py#L925-L931 Moreover, the DataLoader outputted in `get_eval_dataloader` is initialized with the num_workers argument https://github.com/huggingface/transformers/blob/edb672ac5edcd92fadb15d3172a115eb5fe6f663/src/transformers/trainer.py#L888-L896 I know this is not really a feature request, but I do not think it is not a bug either, sorry if I have posted at the wrong place. I read that when talking about the trainer class, @sgugger was generally the one to ping. ### Motivation Adding a line with `num_workers=self.args.dataloader_num_workers,` in the `DataLoader` init call of the `get_test_dataloader` method could fasten the prediction steps by using multiple workers to load the data. https://github.com/huggingface/transformers/blob/edb672ac5edcd92fadb15d3172a115eb5fe6f663/src/transformers/trainer.py#L936-L943 ### Your contribution I have submitted #17751 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Make conn_id unique in Connections table s we discussed in the thread on Spec thread for our new API, the idea came up of making conn_id unique in Airflow <https://lists.apache.org/thread.html/rfb6f7d95b2754fda9dd09b08444214dfad12d10f143d32de0fcf4104%40%3Cdev.airflow.apache.org%3E> The people in that thread seemed to be in favour of it: - It is often confusing to users (there have been a few bug reports about it over the years) - It's questionable if it actually works well or not - There are better/smarter tools for loadbalancing connections to a DB than picking one of a random list - For Hive at least it has been implemented another way - allowing two host's in a single connection string https://github.com/apache/airflow/pull/4708 (available in 1.10.6) - It makes the HTTP API confusing (needing a integer connection ID, and a string conn_id field) Given the downsides/work arounds, and the confusion this causes we should remove this (mis)feature from Airflow 2.0. We should take some care in the migration that does this to capture the unique constraint error and report it a a meaninful way to the user. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: duplicated code: Arrow3D classs The class `Arrow3D` seems to be duplicated in `qiskit/visualization/state_visualization.py` and in `qiskit/visualization/bloch.py`. Maybe a faulty merge? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: localstatedir defaults to /usr/var This is discussed somewhat in #68, which correctly identifies this is the default in the [GNU Coding Standards](https://www.gnu.org/prep/standards/html_node/Directory-Variables.html), but that this directory doesn't exist... FHS-conforming systems appear to have a `/usr/share/config.site` (as documented [here](https://www.gnu.org/software/autoconf/manual/autoconf-2.69/html_node/Site-Defaults.html)), to override the autoconf defaults to FHS-conforming values, if the prefix is /usr. e.g if prefix=/usr then default sysconfdir=/etc, sharedstatedir=/var and localstatedir=/var. Then again, the current default might be right on Hurd. :smile: (If the default is an absolute path, there's probably also a documentation issue here that the correct way to use this option in a meson.build is `join_paths(get_option('prefix'), get_option('localstatedir')))` so the correct path is used if localstatedir is an absolute path or relative to prefix.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Failure while indexing across both dimensions of a 2D jax.lax.FilledConstant array The same indexing works when applied to a numpy.ndarray. According to the README, all NumPy indexing (excepting indexed assignments) should work. Screenshots: Indexing works in original numpy but fails with jax's numpy https://drive.google.com/file/d/1bpj4RWV9_oFajeEDAN43IdiN9VHeRHJE/view?usp=sharing Indexing over one dimension works, but not over two: https://drive.google.com/file/d/10nCNyIIj2Gr9vOcSKV0p203hfKqEuQd_/view?usp=sharing Any idea why this is happening? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [T5] Unused `n_positions` and `max_position_embeddings`. The T5Config has the parameter `n_positions` set to 512 and `max_position_embeddigs` referring to `n_positions`. However, neither `max_position_embeddigs` nor `n_positions` is used in the `T5Model` and T5 is not limited to `max_position_embeddings`. *E.g.*: ```python from transformers import T5Model model = T5Model.from_pretrained(\"t5-small\") model.config.max_position_embeddings # shows 512 input_ids = torch.tensor([600 * [0]]) # input of size > 512 model(input_ids, decoder_input_ids=input_ids) # works fine ``` I think we should delete the parameter. @thomwolf - do you remember why we added `max_position_embeddigs` and `n_positions` to T5? The model does not seem to use these params and also should not be limited to 512 due to its relative position embeddings. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: 'Query.where' needs to raise for sentinels / transforms The following conformance tests assert that attempting to use `DELETE_FIELD`, `SERVER_TIMESTAMP`, `ArrayRemove`, or `ArrayUnion` as the value of a `Query.where` must raise an exception, which the current implementation does not do: - `query-arrayremove-where.textproto` - `query-arrayunion-where.textproto` - `query-del-where.textproto` - `query-st-where.textproto` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: hive ldap with auth=noSasl bug i have a little troube with CDH 5 cluster: with ``` <property> <name>hive.server2.authentication</name> <value>LDAP</value> </property> ``` this change useful for properly working: ``` diff diff --git a/airflow/hooks/hive_hooks.py b/airflow/hooks/hive_hooks.py index 794c78a..ca15a64 100644 --- a/airflow/hooks/hive_hooks.py +++ b/airflow/hooks/hive_hooks.py @@ -86,7 +86,7 @@ class HiveCliHook(BaseHook): jdbc_url = ( \"jdbc:hive2://\" \"{0}:{1}/{2}\" - \";auth=noSasl\" + #\";auth=noSasl\" ).format(conn.host, conn.port, conn.schema) cmd_extra += ['-u', jdbc_url] ``` i.e. NO sasl parameter need in this case, can u fix it? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython 5 won't install on python 2.7 The latest release (2.6.x) of the pygments dependency is python >=3.5 only. As the pygment version is unbounded by ipython, this breaks the installation of ipython 5.9.0 on python 2.7 (this is last version supporting python 2). If you wish to maintain the support of ipython on python 2.7, then you need to pin pygments to <2.6. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: ExternalTaskSensor does not fail when failed_states is set along with a execution_date_fn **Apache Airflow version**: 2.x including main **What happened**: I am using an `execution_date_fn` in an `ExternalTaskSensor` that also sets `allowed_states=['success']` and `failed_states=['failed']`. When one of the N upstream tasks fails, the sensor will hang forever in the `poke` method because there is a bug in checking for failed_states. **What you expected to happen**: I would expect the `ExternalTaskSensor` to fail. I think this is due to a bug in the `poke` method where it should check if `count_failed > 0` as opposed to checking `count_failed == len(dttm_filter)`. I've created a fix locally that works for my case and have submitted a PR #16205 for it as reference. **How to reproduce it**: Create any `ExternalTaskSensor` that checks for `failed_states` and have one of the external DAGs tasks fail while others succeed. E.g. ``` ExternalTaskSensor( task_id='check_external_dag', external_dag_id='external_dag', external_task_id=None, execution_date_fn=dependent_date_fn, allowed_states=['success'], failed_states=['failed'], check_existence=True) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gRPC pubsub missing scope error It appears that something changed in gRPC. ``` Exception google.auth.exceptions.RefreshError: RefreshError('invalid_scope: Empty or missing scope not allowed.', u'{\\n \"error\" : \"invalid_scope\",\\n \"error_description\" : \"Empty or missing scope not allowed.\"\\n}') in 'grpc._cython.cygrpc.plugin_get_metadata' ignored ``` Reference: https://travis-ci.org/GoogleCloudPlatform/google-cloud-python/builds/187483537#L2101 Running `$ tox -e system-tests -- pubsub` yields the same results. However running `$ GOOGLE_CLOUD_DISABLE_GRPC=true tox -e system-tests -- pubsub` allows the tests to pass. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Bug in drawing barriers in matplotlib circuit drawer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: master - **Python version**: 3.6 - **Operating system**: mac ### What is the current behavior? Drawing barriers (or barrier like instructions such as snapshot) sometimes fails in matplotlib drawer. ### Steps to reproduce the problem ```python from qiskit import QuantumCircuit qasm = \"\"\" OPENQASM 2.0; include \"qelib1.inc\"; qreg q[1]; qreg r[1]; creg c[1]; cz q, r; barrier q, r; x q; y q; measure q -> c; z q; if (c==1) z r; \"\"\" circ = QuantumCircuit.from_qasm_str(qasm) circ.draw(output='mpl') ```  ### What is the expected behavior? Barrier should extend across all qubits. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Trainer.add_argparse_args bool type ## 🐛 Bug The boolean arguments added using `Trainer.add_argparse_args` always evaluate to True. This is caused by the following lines of the add_argparse_args fucntion: ```python if isinstance(allowed_type, bool): def allowed_type(x): return bool(distutils.util.strtobool(x)) ``` Because `allowed_type` is the actual data type and not an instance of bool. `isinstance(bool, bool)` is equal to `False`. `bool is bool` is equal True Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Why is Marian to Torch converter hardcoded for tied vocab ? I see the following condition: https://github.com/huggingface/transformers/blob/16f0b7d72c6d4e122957392c342b074aa2c5c519/src/transformers/models/marian/convert_marian_to_pytorch.py#L462 While training my Marian model, I do not want to tie my source and target embeddings. How do I convert such a model? (This is a very common thing in NMT) I see that in `MarianConfig` itself, this is not supported: https://github.com/huggingface/transformers/blob/16f0b7d72c6d4e122957392c342b074aa2c5c519/src/transformers/models/marian/configuration_marian.py#L46-L49 Can this be considered a **feature request** to make it generic? --- Also, why is the `hidden-dim` required to be `512` in the converter? https://github.com/huggingface/transformers/blob/16f0b7d72c6d4e122957392c342b074aa2c5c519/src/transformers/models/marian/convert_marian_to_pytorch.py#L478 What if I train transformer-big models? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Problems with the new auto suggestion keybindings in #13888 I'm using a git build of IPython and found two problems with autosuggestion related to #13888. 1. In Vi mode, when there is a suggestion displayed, `escape` will only discard the suggestion, but will not enter the Vi normal mode like it usually does. I find it more reasonable if both actions are performed. 2. If I type some words so a suggestion pops up, and then press `left` followed by `right`, there will be one spurious character from the suggestion inserted at the wrong position. Example (using `|` to indicate cursor position) ``` (\"123\" is the suggestion) In [1]: a=|123 (after pressing left, the suggestion disappears) In [1]: a|= (after pressing right, an extra character 1 is inserted) In [1]: a1|= ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: TimeSlotCollection is_mergeable_with method causes channels to be added to instruction <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.8.1 - **Python version**: 3.7 - **Operating system**: Osx ### What is the current behavior? The calling TimeslotCollection is being extended when this method is called. ### Steps to reproduce the problem ```python from qiskit.pulse.channels import DriveChannel, AcquireChannel, MemorySlot from qiskit.pulse.commands import SamplePulse, Acquire drive_ch0 = DriveChannel(0) acquire_ch0 = AcquireChannel(0) memory_slot0 = MemorySlot(0) acquire = Acquire(100) sine_pulse = SamplePulse([0, 1]) sine_instr = sine_pulse.to_instruction(drive_ch0) acquire_instr = acquire(acquire_ch0, memory_slot0) print(sine_instr.channels) sine_instr.timeslots.is_mergeable_with(acquire_instr.timeslots) print(sine_instr.channels) print(acquire_instr.channels) ``` Output ```python (DriveChannel(0),) (DriveChannel(0), AcquireChannel(0), MemorySlot(0)) (AcquireChannel(0), MemorySlot(0)) ``` ### What is the expected behavior? The TimeslotCollection should not be mutated and only `True`/`False` should be returned. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Validation errors should specify the file they originate from Right now, validation errors don't include the filename, which will make problems hard to track down if you're using multiple files. Of course, we can't validate files in isolation because override files aren't required to be valid standalone Compose files, which makes this complicated. Perhaps we could do something like this (pseudocode): ``` python config = load_config(filenames[0]) # on failure, will output an error message specifying the name of the first file validate_config(config, filenames[0]) for filename in filenames[1:]: config = merge_config(config, filename) # on failure, will output an error message specifying the name of the current file validate_config(config, filename) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Instead of just printing a warning, Meson should abort and exit with an error code if an unknown build option is used **Describe the bug** Meson currently only prints an easy to miss, especially in CI builds, warning if an unknown build option has been passed via `-D<option-name>=<value>`. It may not be that easy to miss if `meson configure` is used, but it is certainly easy to miss if `meson` is used to create a `build/` directory. **To Reproduce** Invoke meson with an argument that configured an unknown build option. For example. ``` $ meson -Dfoo=bar build-foo/ The Meson build system Version: 0.52.1 Source dir: /home/user/code/barproject Build dir: /home/user/code/barproject/build-foo Build type: native build WARNING: Unknown options: \"foo\" Project name: barproject Project version: 0.1 C compiler for the host machine: ccache cc (gcc 9.3.0 \"cc (Gentoo 9.3.0 p2) 9.3.0\") C linker for the host machine: GNU ld.bfd 2.33.1 C++ compiler for the host machine: ccache c++ (gcc 9.3.0 \"c++ (Gentoo 9.3.0 p2) 9.3.0\") C++ linker for the host machine: GNU ld.bfd 2.33.1 Host machine cpu family: x86_64 Host machine cpu: x86_64 Run-time dependency threads found: YES Configuring barproject_config.h using configuration Found pkg-config: /usr/bin/pkg-config (0.29.2) Run-time dependency GTest found: YES 1.9.0 Dependency threads found: YES (cached) Build targets in project: 9 Found ninja-1.9.0.git.kitware.dyndep-1.jobserver-1 at /usr/bin/ninja ``` **Expected behavior** The meson command should abort with an error code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Agents Should not Fail flow runs due to version mismatches Suppose I have two agents running, and they both pick up the same flow run. Whichever one submits _second_ will experience an error like: ``` [{'message': 'State update failed for flow run ID 5073a4ea-61dd-400c-892a-294b93ac3633: provided version 1 but current version is 2.', 'locations': [{'line': 4, 'column': 13}], 'path': ['setFlowRunStates', 'states', 0, 'id'], 'extensions': {'code': 'INTERNAL_SERVER_ERROR'}}] ``` and then [mark the Flow Run as Failed](https://github.com/PrefectHQ/prefect/blob/master/src/prefect/agent/agent.py#L209-L228). This is incorrect behavior though, because another agent did in fact successfully submit the flow run for work, which will then proceed shortly. We should do a check on the exception to match against `\"State update failed\"` and in that case, _not_ update the state at all. **cc:** @jlowin @zdhughes Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: MIssing parenthesis in call to is_fsdp_enabled? ### System Info - `transformers` version: 4.32.0.dev0 - Platform: Linux-5.15.0-1028-nvidia-x86_64-with-glibc2.10 - Python version: 3.8.13 - Huggingface_hub version: 0.16.4 - Safetensors version: 0.3.2 - Accelerate version: 0.21.0 - Accelerate config: not found - PyTorch version (GPU?): 1.12.0a0+8a1a93a (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: <fill in> - Using distributed or parallel set-up in script?: <fill in> ### Who can help? @ArthurZucker @younesbelkada ### Information - [ ] My own modified scripts - [ ] The official example scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction I do not have an example, but rather I found this when debugging another issue. Therefore I do not have a testcase and I am *assuming* that the following is an error. ``` if ( (is_deepspeed_zero3_enabled() or is_fsdp_enabled) # <----- HERE and torch.distributed.is_initialized() and torch.distributed.get_rank() > 0 ): map_location = \"meta\" else: map_location = \"cpu\" ``` ### Expected behavior I expect is_fsdp_enabled is intended to be called rather than tested if None Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: \"'JVPTrace' object is not callable\" while taking grad of function with matrix trace operator You can not take a gradient of a function that uses the method `trace`. It will give you an error `TypeError: 'JVPTrace' object is not callable` Code example: ```python import jax import numpy as np def foo(x): return x.trace() print(foo(np.random.randn(3, 3))) print(jax.grad(foo)(np.random.randn(3, 3))) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Set the default CondaSession.verify default from the config setting Currently, the .condarc config setting must be explicitly used when making a request with a CondaSession object. This means that anyone who wants to use CondaSession must check the .condarc ssl_verify value and appropriately interpret it, etc. (For example, see https://github.com/conda/conda/blob/47e300b0e2cd5aad1dfe18d26eada5995b058004/conda/fetch.py#L101) I think it would be much cleaner for CondaSession itself to set the default verify value in its **init**: `self.verify = <code to get the .condarc ssl_verify setting`. See https://github.com/kennethreitz/requests/blob/8b5e457b756b2ab4c02473f7a42c2e0201ecc7e9/requests/sessions.py#L314 to see that this is correct. This change would mean that we don't need the verify argument here: https://github.com/conda/conda/blob/47e300b0e2cd5aad1dfe18d26eada5995b058004/conda/fetch.py#L101, and would also solve this issue: https://github.com/conda/conda-build/issues/523 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: BLIP-2 batch generate error ### System Info `transformers` version: 4.27.0.dev0 ### Who can help? @NielsRogge ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction The following error happens when running BLIP-2 model's generate() with num_beams>1 and input batch_size>1 <img width=\"892\" alt=\"Screenshot 2023-02-13 at 6 53 28 pm\" src=\"https://user-images.githubusercontent.com/13638455/218443029-8bc45f00-4884-4785-95a9-228aa08d1266.png\"> ### Expected behavior The model should be able to do batch generate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Zero-Shot-Classification: multi_class or multi_label? https://github.com/huggingface/transformers/blob/068df740bd73b95e9a1e233e47608df942fda9da/src/transformers/pipelines.py#L1048 Since we're allowing multiple labels to be true, shouldn't this be called `multi_label` instead of `multi_class`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: RST_STREAM error from grpc via Bidi in Firestore Client Library Implementing a watch/listen in Firestore, waiting a while (some reports of 30, 60, and 120 minutes) results in an unhandled RST_STREAM error. We should investigate if this can be handled. Related to https://github.com/firebase/firebase-admin-python/issues/282 ``` google-api-core==1.14.3 google-auth==1.7.1 google-cloud-core==1.0.3 google-cloud-firestore==1.6.0 googleapis-common-protos==1.6.0 grpcio==1.25.0 ``` Output and repro code at: https://gist.github.com/crwilcox/0ed944c7afa70a6a78dd8e8e76ebf1fd Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: configure_file(): be more strict with missing variables in the configuration Given a template file and a configuration it would be nice it meson would warn, or have a flag to make it more strict and error out, in case a \"@foo@\" does not have a corresponding \"foo\" variable in the configuration. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Make KernelSpecManager configurable I would like to be able to write a custom subclass of `KernelSpecManager` to automatically list all the venvs in my system. I started to try and do this: https://github.com/Cadair/ipython/blob/custom_kernel_manager/IPython/html/notebookapp.py#L614 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Wrong message about \"conan link\" remover.py, line 103, the message when you try to remove a package being an editable is: `WARN: Package 'zlib/1.2.11@conan/stable' is installed as editable, unlink it first using command 'conan link zlib/1.2.11@conan/stable --remove'` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: DAGCircuitError: 'bit mapping invalid ### Informations - **Qiskit: 0.39.2**: - **Python: 3.10.9**: - **Mac**: ### What is the current behavior? I'm implementing quantum half adder on Jupyter Notebook. When I try running my circuit on the simulator \"qasm_simulator\", Jupyter said DAGCircuitError: 'bit mapping invalid: expected 4, got 8' here is the code I've written. The error occurs on the last line of the third code. ``` from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, execute, Aer #SUM X = QuantumRegister(1, \"in |X⟩\") Y = QuantumRegister(1, \"in |Y⟩\") sum_out = QuantumRegister(1, \"out SUM |0⟩\") SUM = QuantumCircuit(X, Y, sum_out, name='SUM') SUM.cx(1, 2) SUM.cx(0, 2) fig = SUM.draw('mpl', True) SUM = SUM.to_instruction() fig ``` ``` #half_adder cout = QuantumRegister(1, 'out Carry |0⟩') c = ClassicalRegister(4) hadder = QuantumCircuit(X,Y,sum_out,cout,c) hadder.ccx(X,Y,cout) hadder.append(SUM,[0,1,2]) show = hadder.draw(\"mpl\",True) hadder = hadder.to_instruction() show ``` ``` #testing half_adder qu = QuantumRegister(4) cl = ClassicalRegister(4) circ = QuantumCircuit(qu,cl) circ.x(qu[0]) circ.x(qu[1]) circ.append(hadder,[0,1,2,3]) for i in range(0,4): circ.measure(qu[i],cl[i]) circ.draw(\"mpl\",True) print(execute(circ,Aer.get_backend('qasm_simulator'), shots = 1).result().get_counts()) ``` ### What is the expected behavior? I don't totally understand the error. I hope to troubleshoot to see the result. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: How to use metrics classes of 0.8.0 ## ❓ Questions and Help 0.8.0 has new Metric class which can auto_reduce in ddp. But no examples of them. Can you give some examples about how to use it? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Rename main storage/datastore/etc. docs since captions now have the name We end up just repeating the names. See http://googlecloudplatform.github.io/gcloud-python/latest/  and http://gcloud-python.readthedocs.org/en/latest/  And notice that \"Datastore\" is both the heading name and the name of the first document in the heading. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose pull --parallel crash with \"expected a bytes-like object, str found\" ## Description of the issue When running `docker-compose pull --parallel` with a compose file version 2.1 or higher, docker-compose will fail with error message `TypeError: sequence item 0: expected a bytes-like object, str found`. ## Context information (for bug reports) ``` docker-compose version 1.20.1, build 5d8c71b docker-py version: 3.1.4 CPython version: 3.6.4 OpenSSL version: OpenSSL 1.0.1t 3 May 2016 ``` ``` Client: Version: 17.12.1-ce API version: 1.35 Go version: go1.9.4 Git commit: 7390fc6 Built: Tue Feb 27 22:15:20 2018 OS/Arch: linux/amd64 Server: Engine: Version: 17.12.1-ce API version: 1.35 (minimum version 1.12) Go version: go1.9.4 Git commit: 7390fc6 Built: Tue Feb 27 22:17:54 2018 OS/Arch: linux/amd64 Experimental: false ``` ``` version: '2.1' services: test: image: alpine:does-not-exist ``` ## Steps to reproduce the issue 1. Copy the above docker-compose.yaml file 2. Run `docker-compose pull --parallel` ### Observed result Exception with string-operations-related traceback. ### Expected result No misleading exception, just clean error message. ### Stacktrace / full error message ``` Traceback (most recent call last): File \"bin/docker-compose\", line 6, in <module> File \"compose/cli/main.py\", line 71, in main File \"compose/cli/main.py\", line 127, in perform_command File \"compose/cli/main.py\", line 716, in pull File \"compose/project.py\", line 558, in pull TypeError: sequence item 0: expected a bytes-like object, str found ``` ## Additional information RedHat, docker-compose installed by downloading https://github.com/docker/compose/releases/download/1.20.1/docker-compose-Linux-x86_64. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: DockerEnvironment push/pull needs newline Can print nothing to just move the cursor down a single line so output doesn't overwrite push/pull progress bar Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Not passing --coverage for clang + meson coverage? I get lots of weird errors like `error: undefined reference to 'llvm_gcda_start_file'` or `error: undefined reference to 'llvm_gcov_init'` when trying to build a coverage target with `CXX=clang++`, but as soon as I pass `LDFLAGS=--coverage`, those errors appear to be solved. GCC(g++) builds and produces coverage fine. There is however another error probably caused by mismatch of gcov version - ``` build ci/travis ア ninja coverage-html [1/1] Generating HTML coverage report. FAILED: /home/agauniyal/projects/termdb/build/meson-logs/coveragereport/index.html 'lcov' '--directory' '/home/agauniyal/projects/termdb/build' '--capture' '--output-file' '/home/agauniyal/projects/termdb/build/meson-logs/coverage.info' '--no-checksum' && 'genhtml' '--prefix' '/home/agauniyal/projects/termdb/build' '--output-directory' '/home/agauniyal/projects/termdb/build/meson-logs/coveragereport' '--title' 'Code coverage' '--legend' '--show-details' '/home/agauniyal/projects/termdb/build/meson-logs/coverage.info' Capturing coverage data from /home/agauniyal/projects/termdb/build Found gcov version: 6.3.1 Scanning /home/agauniyal/projects/termdb/build for .gcda files ... Out of memory! Found 1 data files in /home/agauniyal/projects/termdb/build Processing test.cpp.gcda ninja: build stopped: subcommand failed. ``` but atleast the first error gets solved.. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Numpy logo in new theme links to an undesirable page It goes to https://numpy.org/devdocs/contents.html instead of the index. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make API calls consistent <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? After #686, job properties were changed to methods (`job.id()` and `job.status()` instead of `job.id` and `job.status`). But for backends, the user still has to write `backend.status`, etc. These should be made consistent to avoid confusion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cannot create shared libraries from D sources on OSX (and macOS) Using the `library` function in a 'meson.build' to create a shared library on Debian Sid and Fedora Rawhide works fine. For example: ``` tinyendian_lib = library( meson.project_name(), [tinyendian_src], include_directories: [src_dir], version: meson.project_version(), pic: true, install: true, ) ``` correctly builds the '.so' file and it all installs fine. However on OSX (I am on El Capitan) and I assume macOS, the option `-L-soname` is passed to the 'ldc2' command line, and whilst this works for Linux, it does not work for OSX: ``` FAILED: libtinyendian.0.dylib ldc2 -of libtinyendian.0.dylib 'tinyendian@sha/source_tinyendian.d.o' -shared -relocation-model=pic -L-soname -Llibtinyendian.dylib.0 ld: unknown option: -soname clang: error: linker command failed with exit code 1 (use -v to see invocation) Error: /usr/bin/gcc failed with status: 1 ``` I believe this to be an error in the D tooling for Meson. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: --remove-orphans is ignored when using up --no-start Given the following configuration: ```yaml # cat two_containers.yml version: '2.1' services: foo: image: my-web-service bar: image: my-web-service # cat one_container.yml version: '2.1' services: foo: image: my-web-service ``` `--remove-orphans` removes the `bar` container when I do `up -d`: ```bash # /apps/research/tools/docker-compose/1.17.1_no_cert_warnings/bin/docker-compose -f two_containers.yml up -d Creating mytest_bar_1 ... Creating mytest_foo_1 ... Creating mytest_foo_1 Creating mytest_bar_1 ... done # /apps/research/tools/docker-compose/1.17.1_no_cert_warnings/bin/docker-compose -f one_container.yml up -d --remove-orphans Removing orphan container \"mytest_bar_1\" mytest_foo_1 is up-to-date ``` However, `--remove-orphans` seems to be ignored with `up --no-start`: ```bash # docker-compose -f two_containers.yml up --no-start Creating network \"mytest_default\" with the default driver Creating mytest_bar_1 ... Creating mytest_foo_1 ... Creating mytest_bar_1 Creating mytest_bar_1 ... done # docker-compose -f one_container.yml up --no-start --remove-orphans ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: NumPy 1.16.0 causes warnings ```jax/lax.py:769: FutureWarning: Conversion of the second argument of issubdtype from complex to np.complexfloating is deprecated. In future, it will be treated as np.complex128 == np.dtype(complex).type.``` (I don't have code to reproduce it right now, because any attempt to create a minimal example makes the warning disappear even though it doesn't make any sense.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit.initialize has no documentation <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Have more than this: ``` Docstring: Apply initialize to circuit. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add an option to disable Trainer.detect_nan_tensors ## 🚀 Feature Add an option to disable `Trainer.detect_nan_tensors` ### Motivation This function tends to be pretty slow when your network has got a lot of parameters, especially in small tensors. For example in my case it took ~0.5s per training iteration. ### Pitch Add an option to the `Trainer` class that disables calling `detect_nan_tensors` every epoch. ### Alternatives Remove it all together. Bad idea. ### Additional context Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] MesonToolchain: improve cross-compilation workflow on Apple systems unlike CMake, meson is dumb and doesn't attempt to guess a path to the compiler in case of cross-compiling mode. it has to be explicitly specified within cross-file we probably can deduce required things in the conan client, but it's kinda auto-magic... OTH it makes recipes easier we may try to populate the contents of the cross-file similar to the examples meson provides: https://github.com/mesonbuild/meson/blob/master/cross/iphone.txt https://github.com/mesonbuild/meson/blob/master/cross/tvos.txt see also: https://github.com/conan-io/conan-center-index/pull/7360 https://github.com/conan-io/conan-center-index/pull/6678 /cc @ericLemanissier @madebr @SpaceIm - [ ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: [question] detecting resources using \"legacy\" naming convetion > > In 1.21.0, we introduced a change to how project names are sanitized for > internal use in resource names. This caused issues when manipulating an > existing, deployed application whose name had changed as a result. > This release properly detects resources using \"legacy\" naming conventions. How does exactly compose detect resources using legacy naming conventions? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: get_option('b_xxx') inconsistent on reconfigure `get_option('b_xxx')` returns the provided value on initial configure, but the default one on reconfigure (when `meson.build` has been modified). The option affects the build in both cases. ```patch +++ a/mesonbuild/interpreter.py --- b/mesonbuild/interpreter.py @@ -1669,11 +1669,11 @@ raise InterpreterException('Argument required for get_option.') optname = args[0] try: - return compilers.base_options[optname].value + return self.environment.get_coredata().base_options[optname].value except KeyError: pass try: - return self.environment.get_coredata().get_builtin_option(optname) + return self.environment.coredata.get_builtin_option(optname) except RuntimeError: pass try: ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: AutoTools PKG_CONFIG_PATH value should be a list Hi, Currently, AutoTools is able to generate `PKG_CONFIG_PATH` automatically. However, the value set is not a list. See: https://github.com/conan-io/conan/blob/develop/conans/client/build/autotools_environment.py#L134 (L135 and L141) As a consequence, every previous value(s) set or \"append\" to `PKG_CONFIG_PATH` in dependencies are destroyed by `environment_append`. As `PKG_CONFIG_PATH ` is supposed to be a list of paths, it should be a list. It should have the same behaviour as `PATH`. Validated locally: declare as a list in lines quoted before solves the issue. Thus, `environment_append` does not overwrite previous value(s). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose build on Windows fails with stacktrace if API version < 1.24 See original comment: https://github.com/docker/compose/issues/4106#issuecomment-266105765 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Request to release GCS Python library Hi, Is it possible to release the Storage client library for Python? I'd like the new method `get_service_account_email` to be available. Unless there exist concerns. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Native Amp Support Native automatic mixed precision support (`torch.cuda.amp`) is finally merged: https://pytorch.org/docs/master/amp.html https://pytorch.org/docs/master/notes/amp_examples.html Apex Amp has many known pain points (extension builds, forward/backward compatibilty, DataParallel support, flaky checkpointing, i don’t even know if it can be hacked to handle double backward/gradient penalty, others…). `torch.cuda.amp` fixes all these, the interface is more flexible and intuitive, and the tighter integration brings more future performance optimizations into scope. If you want to talk about adding `torch.cuda.amp` to Lightning, with an eye towards it becoming the true source of mixed precision and replacing Apex, message me on Pytorch slack anytime. I pinged you there as well, but I’m not sure if you monitor it habitually. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Add a utility method to pretty printer for common Class(a, b, c=d) style output It'd be nice if common boring _repr_pretty_ methods could just be written like: ``` def _repr_pretty_(self, p, cycle): assert not cycle p.pretty_constructor(self, [self.a, self.b], [(\"c\", self.c)]) ``` Something like this (extracted from the patsy source): https://gist.github.com/3113186 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Don't allow float indices and shapes Numpy is throwing an error when using a float index or or shape, e.g. `np.zeros(0.5)` . Jax.numpy on the other hand silently converts to integer: ``` > jnp.zeros(1.5) _FilledConstant([ 0.], dtype=float32) ``` Jax.numpy should probably enforce the same type strictness here to prevent silent bugs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: New in NumPy 1.14: failures in PyTables In the following snippet: ```python import numpy as np data_proper = [(456, b'dbe', 1.2), (2, b'ded', 1.3)] data_improper = [[456, b'dbe', 1.2], [2, b'ded', 1.3]] descr = [('f0', '<i4'), ('f1', 'S3'), ('f2', '<f8')] dtype = np.dtype((np.record, descr)) np.array(data_improper, dtype=dtype) ``` Execution of the last line in 1.13 used to raise: ``` TypeError: a bytes-like object is required, not 'int' ``` which allowed the logic in [numpy/core/records.py#L676](https://github.com/numpy/numpy/blob/master/numpy/core/records.py#L676) to recover and reinterpret the line as `np.array(data_proper, dtype=dtype)`. The trouble is that in NumPy 1.14 ``` ValueError: invalid literal for int() with base 10: b'dbe' ``` is being raised instead, which results in the failure. This is a gist of the issue behind numerous test failures in pyTables when used with NumPy 1.14. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Added retry on internal error Added retry on internal error as suggested by the internal error message: '500 Error encountered during execution. Retrying may solve the problem.'. Rationalised the conditions structure so it would simplify addition of other retry conditions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the JohnSnowLabs/spark-nlp codebase. Here's the problem: DocumentAssembler on array<string> ### Is there an existing issue for this? - [X] I have searched the existing issues and did not find a match. ### Who can help? _No response_ ### What are you working on? I don't know why but my question was deleted. Therefore, I will repeat again. I am working with a dataframe that I need to lemmatize. There, the input is an array of strings. I am trying to use DocumentAssembler for array of strings. The documentation says: \"The DocumentAssembler can read either a String column or an Array[String])\". But it doesn't work like that for me. Can you explain what I'm doing wrong? Or is the documentation out of date? ### Current Behavior I am getting an error ``` AnalysisException: [CANNOT_UP_CAST_DATATYPE] Cannot up cast input from \"ARRAY<STRING>\" to \"STRING\". The type path of the target object is: - root class: \"java.lang.String\" You can either add an explicit cast to the input data or choose a higher precision type of the field in the target object ``` ### Expected Behavior - ### Steps To Reproduce When I do a simple example: ``` data = spark.createDataFrame([[[\"Spark NLP is an open-source text processing library.\"]]]).toDF(\"text\") documentAssembler = DocumentAssembler().setInputCol(\"text\").setOutputCol(\"document\") result = documentAssembler.transform(data) result.select(\"document\").show(truncate=False ``` ### Spark NLP version and Apache Spark sparknlp.version() == '4.4.0' spark.version == '3.4.0' ### Type of Spark Application _No response_ ### Java Version _No response_ ### Java Home Directory _No response_ ### Setup and installation _No response_ ### Operating System and Version _No response_ ### Link to your project (if available) _No response_ ### Additional Information _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Pipeline “zero-shot-classification” gives “TypeError: __call__() takes 2 positional arguments but 3 were given.” - `transformers` version: 4.11.0.dev0 - Platform: Linux-4.9.253-rt168-tegra-aarch64-with-debian-buster-sid - Python version: 3.6.13 - PyTorch version (GPU?): 1.9.0 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: (True) - Using distributed or parallel set-up in script?: (False) @LysandreJik ## Information Model I am using (‘facebook/bart-large-mnli’): The problem arises when using: the official example scripts: (basically) ```python from transformers import pipeline classify=pipeline('zero-shot-classification') text=(\"Give me a weather report\") tags=[\"request_weather\", \"catch_fire\"] classify(text, tags) ``` The tasks I am working on is: my own task or dataset: It’s a bunch of ugly hacks on each other’s shoulders, in a trench coat, masquerading as a Python script. ## To reproduce Steps to reproduce the behavior: 1. Run script Result: ```bash Traceback (most recent call last): File \"test.py\", line 8, in <module> classify(text, tags) TypeError: __call__() takes 2 positional arguments but 3 were given ``` ## Expected behavior Literally anything but this. I am very confused. Please help, very much appreciated, getting gray hairs from this, thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Unnecessary warnings during airflow pods starts ### Apache Airflow version 2.2.2 (latest released) ### What happened Warnings `{providers_manager.py:156} WARNING - Exception when importing 'airflow.providers.google.leveldb.hooks.leveldb.LevelDBHook' from 'apache-airflow-providers-google' package: No module named 'plyvel'` appear in `wait-for-airflow-migrations` init containers and during webserver pod start. ### What you expected to happen No such warnings, they were not present in 2.1.3 version. ### How to reproduce Install Airflow using airflow helm chart with 2.2.2 airflow docker image and check `wait-for-airflow-migrations` init containers logs. Warnings can also be seen in webserver container. ### Operating System Debian “buster” ### Versions of Apache Airflow Providers Providers that come with the official Airflow docker image. ### Deployment Official Apache Airflow Helm Chart ### Deployment details _No response_ ### Anything else Looking at commit history, isn't this supposed to be a debug level log as per https://github.com/apache/airflow/commit/2f32df7b711cf63d18efd5e0023b22a79040cc86#diff-c56df299b30e60d690494057a4e8721d36406c0cca266961ff2ae6504993c8cb ? Seems like this logic was changed in https://github.com/apache/airflow/commit/29aab6434ffe0fb8c83b6fd6c9e44310966d496a#diff-c56df299b30e60d690494057a4e8721d36406c0cca266961ff2ae6504993c8cbL288 since `_sanity_check` doesn't handle `ImportError`s as debug messages . Should these warnings be ignored for now? ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Warning on `ifelse`/`merge` use ## Description I can't seem to find any combination of `ifelse`/`merge` usage that doesn't give me the `UserWarning: Tasks were created but not added to the flow` warning. ## Expected Behavior No warning ## Reproduction ```python from prefect import Flow, task from prefect.tasks.control_flow.conditional import ifelse, merge @task def a(x): return x + 1 @task def b(x): return x * 2 with Flow('f') as flow: x = 2 t1 = a(x) t2 = b(x) ifelse(x > 1, t1, t2) y = merge(t1, t2) flow.run() # UserWarning: Tasks were created but not added to the flow ``` Is there something going on in the example above I may be misunderstanding? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Put parameters into context inside of a flow run When a flow runner is in a cloud context it makes a call to the client's `get_flow_run_info` function. That call queries for the parameters, version, and current_state. The parameters however are not used. Inside the flow runner it can take those parameters (from its `flow_run_info` object that it creates) and set it in the context here -> https://github.com/PrefectHQ/prefect/blob/master/src/prefect/engine/flow_runner.py#L189 if there are no other parameters passed into the runner. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: deepsource.io issue analysis Maybe useful to start improving the codebase. https://deepsource.io/gh/jaipradeesh/GitPython/issues/ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Option to disable printing logstate on log activation /usr/lib/python2.7/site-packages/IPython/core/magics/logging.py Line 135 printing the log state everytime shell is opened is annoying, please make it configurable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan hooks exceptions show not useful stack trace Having a hook raising an ``Exception`` produces something like: ```bash ERROR: [HOOK - name_conventions.py] pre_export(): Reference Hello/0.1@user/testing should be all lowercase Traceback (most recent call last): File \"c:\\users\\memsharded\\envs\\conanpip\\lib\\site-packages\\conans\\client\\hook_manager.py\", line 56, in execute method(output=output, **kwargs) File \"C:\\Users\\memsharded\\.conan\\hooks\\name_conventions.py\", line 4, in pre_export raise Exception(\"Reference %s should be all lowercase\" % ref) Exception: Reference Hello/0.1@user/testing should be all lowercase ``` As this is not very useful, I suggest removing it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Serialize State in New Triggers With #947 merged, we now have triggers (and have always had `cache_validators`) which carry _state_. However, when we serialize them to Cloud, we only carry their names for display in the UI. It would be a very nice-to-have if we could serialize the state as well, i.e., serialize the bounds in the triggers and the validation lists in the curried cache validators for display in the UI. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: display.FileLinks should work in the exported html verion of a notebook It would be nice to have the output of FileLinks work in the exported html version of a notebook. Would this be as simple as using relative file-paths? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support mapping specific ports in \"docker-compose run\" It should be possible to pass the `-p` option to expose ports when doing `docker-compose run`. It should probably be not be possible to use this option in combination with the `--service-ports` option. This is part of #363. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: function to calculate 2-qubit gate depth <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Currently `circuit.depth()` considers all gates in the circuit. In the context of present experiments 2-qubit gates are often much longer than 1-qubit gates, so a function `circuit.depth_2q_gates()` would be useful. This would be a better estimate of true depth cost. Of course the most accurate would be to schedule the circuit with the gate durations and look at `circuit.duration`, but that requires further compilation and is not a pure analysis of the circuit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Bigtable: docs Snippet only includes half of documentation Small problem with `snippets_table.py` for `google.cloud.bigtable.row.DirectRow.clear` [documentation](https://googleapis.github.io/google-cloud-python/latest/bigtable/row.html#google.cloud.bigtable.row.DirectRow.clear) only showing half the example code (e.g. not actually showing the running of the clear command)  This is because the test has two parts and the snippit is only including the first. ``` def test_bigtable_row_clear(): # [START bigtable_row_clear] from google.cloud.bigtable import Client client = Client(admin=True) instance = client.instance(INSTANCE_ID) table = instance.table(TABLE_ID) row_key = b\"row_key_1\" row_obj = table.row(row_key) row_obj.set_cell(COLUMN_FAMILY_ID, COL_NAME1, b\"cell-val\") # [END bigtable_row_clear] mutation_size = row_obj.get_mutations_size() assert mutation_size > 0 # [START bigtable_row_clear] row_obj.clear() # [END bigtable_row_clear] mutation_size = row_obj.get_mutations_size() assert mutation_size == 0 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Handle TODO: .first() is not None can be changed to .scalar() ### Body The TODO part of: https://github.com/apache/airflow/blob/d67ac5932dabbf06ae733fc57b48491a8029b8c2/airflow/models/serialized_dag.py#L156-L158 can now be addressed since we are on sqlalchemy 1.4+ and https://github.com/sqlalchemy/sqlalchemy/issues/5481 is resolved ### Committer - [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: MPL circuit drawer does not draw CCZ properly Take the following example: ```python from qiskit import QuantumCircuit from qiskit.circuit.library import ZGate qc = QuantumCircuit(3) qc.append(ZGate().control(2, ctrl_state='01'), range(3)) ``` The `text` and `latex` drawer outputs are the following: ```python qc.draw('text') q_0: ─■─ │ q_1: ─o─ │ q_2: ─■─ ``` ```python qc.draw('latex') ```  However, here is the `mpl` output: ```python qc.draw('mpl') ```  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: channel UNC path encoding errors on windows I have some channel specifications for UNC file paths on windows that stopped working in conda 4.2.11, but did work in 4.2.9 and earlier The conda command with channel specification followed this style conda install -c file://\\\\machine\\shared_folder\\path\\conda my_package Channels specified in condarc were also affected and caused a bug when parsing the condarc file (via calling a conda command). Is there another preferred style for UNC paths on windows? I see some new channel decoding code in the channel model that is likely the culprit. if value.startswith('file:') and on_win: value = value.replace('\\\\', '/') return Channel.from_url(value) channel UNC path encoding errors on windows I have some channel specifications for UNC file paths on windows that stopped working in conda 4.2.11, but did work in 4.2.9 and earlier The conda command with channel specification followed this style conda install -c file://\\\\machine\\shared_folder\\path\\conda my_package Channels specified in condarc were also affected and caused a bug when parsing the condarc file (via calling a conda command). Is there another preferred style for UNC paths on windows? I see some new channel decoding code in the channel model that is likely the culprit. if value.startswith('file:') and on_win: value = value.replace('\\\\', '/') return Channel.from_url(value) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Argmax on empty array returns 2147483647 How to reproduce: ``` >>> jnp.argmax(jnp.array([])) DeviceArray(2147483647, dtype=int32) ``` Confirmed to occur on CPU and TPU. For reference, in numpy an exception is returned: \"ValueError: attempt to get argmax of an empty sequence\". Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Upgrade style setting in upgrade_extension <!-- Welcome! Thanks for thinking of a way to improve JupyterLab. If this solves a problem for you, then it probably solves that problem for lots of people! So the whole community will benefit from this request. Before creating a new feature request please search the issues for relevant feature requests. --> ### Problem <!-- Provide a clear and concise description of what problem this feature will solve. For example: * I'm always frustrated when [...] because [...] * I would like it if [...] happened when I [...] because [...] --> The upgrade script is great. But it is missing a late complex point about style setting in `package.json` ### Proposed Solution <!-- Provide a clear and concise description of a way to accomplish what you want. For example: * Add an option so that when [...] [...] will happen --> The script should update the `package.json` file to add `style/index.js` where needed. ### Additional context <!-- Add any other context or screenshots about the feature request here. You can also include links to examples of other programs that have something similar to your request. For example: * Another project [...] solved this by [...] --> It took me some times to figure out what was wrong when replacing the official launcher when porting that alternative launcher: https://github.com/fcollonval/jlab-enhanced-launcher Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: newparallel on Windows IPython.parallel has various issues on Windows, some of which may actually be pyzmq or libzmq issues. One issue that comes up is that the Windows select does not allow events==0 (causing a crash in libzmq). This is fixed in pyzmq, with PR95: https://github.com/zeromq/pyzmq/pull/95 There also appear to be some process launching issues that result from the use of multiprocessing, which is not well behaved on Windows. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Tracebacks should be logged When unexpected errors occur, we currently only log the repr of the caught exception. I propose that we should begin logging tracebacks for better visibility into issues. To do so requires two steps: - begin logging caught exceptions with `logger.exception(msg)` (this will require a full audit; some caught exceptions are currently being logged as \"INFO\", others as \"DEBUG\") - in the `CloudHandler` itself, include traceback text by: ```python if record.exc_text is not None: record.message += \"\\n\" + record.exc_text ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add backoff for agent when pulling runs from Cloud In order to interface better with the `Submitted` state bottleneck, we'll implement the backoff logic for agents. As long as the agent is receiving work, it'll continue to request more work rapidly. Once work stops being delivered (either because there is no work, or there's a bottleneck), the agent will back-off requests until it reaches a 5-second steady-state interval. Note: I would recommend that we go to 10 or even 15 seconds as the steady state. That would be the maximum delay for new work to begin, but once work arrives, subsequent work would happen rapidly. ```python intervals = { 0: 0 1: 0.25, 2: 0.5, 3: 1.0, 4: 2.0, 5: 4.0 6: 8.0, 7: 15.0, } def backoff_example(): t = 0 while True: runs = get_runs_from_queue() if runs: t = 0 elif t < max(intervals): t += 1 sleep(intervals[t]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add `--api` Flag Documentation to Prefect CLI and Docs ## Current behavior *Please describe how the feature works today* The `prefect agent start`/`prefect agent install` commands have an `--api` flag that a user can pass to specify the endpoint the agent should poll for Flow Runs. This flag used to be for internal use only, but now that Prefect Server has been open-sourced, our users find it useful as well! ## Proposed behavior *Please describe your proposed change to the current behavior* We should document this flag both in: - [ ] Our Documentation - [ ] The CLI help commands for `prefect agent start` and `prefect agent install` ## Example *Please give an example of how the enhancement would be useful* Addressed above. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Default ``cmake_layout()`` source folder This layout is assuming that the main library ``CMakeLists.txt`` is inside a ``src`` subfolder in the repo. This is probably not the most common user layout, in which they will have a CMakeLists.txt in the root of the folder: - How to model this? - Should we change the ``cmake_layout()`` default to ``folders.source = \".\"``? - Check implications of defining the root as source folder. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Introduce max-polls flag on all Agents ## Current behavior Currently calling `prefect agent start ...` will create a long-running process that will only stop after a kill signal is sent to the process. This is great for 99% of use cases, especially in production environments. However, there are two situations in which I'd like to specify a max number of polls that an agent will make: - **local development / short-lived agents**: sometimes when quickly iterating users spin up a local agent with many labels just to test a single run of a Flow. Doing something like `prefect agent start --max-polls 5` would allow users to kick off a single run and know the agent won't stay live - **mixed schedulers / serverless setups**: there are some situations in which we don't want to have a 24/7 process for scheduling work and instead rely on an internal-infra scheduler to check whether there's anything to do. For example, users might want to run a flow once a day within a Heroku instance, and use the Heroku scheduler to schedule a short-lived Prefect agent to run right around the time a Flow run is scheduled in Prefect Cloud. The Heroku scheduler would spin up an agent with e.g., `--max-polls 20` and their work could still be tracked via Cloud. For the latter, I fully recognize that this introduces \"gotchas\" but until we offer a fully serverless agent it at least exposes the pattern to users. ## Proposed behavior `prefect agent start $AGENT_TYPE --max-polls N` would only poll Prefect Cloud `N` times before gracefully exiting. For some agents, immediate exit is possible (e.g., k8s) and for others we would need to wait for submitted work to reach completion (e.g., the `LocalAgent`). Open for discussion to see what others think. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Update pylint to a more recent version <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The version of `pylint` we are using is a bit outdated, and more recent version are available which support enhanced checks and better compatibility with recent Python versions. Updating will involve taking care of the new warnings raised and making sensible choices related to them (and might involve re-generating the .pylintrc file to take advantage of new options). See also: #1588 , #1179 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: google.cloud.logging.handlers: send messages to stderr Would it be ok if we do the print at https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/logging/google/cloud/logging/handlers/transports/background_thread.py#L222 to stderr instead? So it doesn't disturb the output of the software? Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qiskit/mapper/_coupling.py needs more testing ### What is the expected enhancement? The coupling graph structure in `qiskit/mapper/_coupling.py` is currently not very well tested. Please, add more tests. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.datastore.helpers.get_value_from_protobuf() returns naive datetimes Naive datetimes (without timezones) are explicitly coerced to UTC by 'get_protobuf_attribute_and_value': ``` >>> import calendar >>> import datetime >>> import pytz >>> from gcloud.datastore.helpers import get_protobuf_attribute_and_value >>> naive = datetime.datetime(2014, 9, 16, 10, 19, 32, 4375) # no zone >>> utc = datetime.datetime(2014, 9, 16, 10, 19, 32, 4375, pytz.utc) >>> _, naive_micros = get_protobuf_attribute_and_value(naive) >>> _, utc_micros = get_protobuf_attribute_and_value(utc) >>> naive_micros == utc_micros True ``` But the datetimes returned by 'get_value_from_protobuf' do not set the UTC timezone: ``` >>> from gcloud.datastore.helpers import get_value_from_protobuf >>> from gcloud.datastore.datastore_v1_pb2 import Property >>> pb = Property() >>> pb.value.timestamp_microseconds_value = utc_micros >>> get_value_from_protobuf(pb) == utc TypeError: can't compare offset-naive and offset-aware datetimes >>> get_value_from_protobuf(pb) == naive True ``` Leaving them naive when we know they are UTC seens wrong: is there a policy in place which says we will keep in-memory timestamps around as naive-but-UTC-by-convention? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] CMakeToolchain + Android POC Implement a proof of concept of using the new CMakeToolchain feature for building: - Android projects (from Linux/OSX) - From Windows Notes: - Android NDK can be assumed installed - Focused on creating/building 1 package, both local flow (conan install + native cmake) and ``conan create`` flow. - Integration test. - Test can be skipped for CI, but should work locally, annotate assumptions and installation details - No env-var configuration at all - All code must be private and local to the toolchains package - New cross-build model with contexts must be used if necessary, not the old os_build, arch_build - If enough time to implement reuse of a package, the ``cmake_find_package_multi`` generator must be used Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Hide sensitive data in UI **Description** I'm using Airflow for 2 years now and I have a plugin that get password for a specific account in a Vault and then push it through a XCOM to reuse it on another tasks. The fact is that if the value is sensitive like a password, I can't hide it in the UI except for XCOM if I add an underscore in the prefix name of the key value. Eg: **kwargs['ti'].xcom_push('key':'_password', 'value':'my_value')** But for rendered template UI page, I didn't find anything similar, so if I try to pull a XCOM, it will show the value in the UI and I want to avoid it. Maybe is it possible to add a condition in **https://github.com/apache/airflow/blob/master/airflow/www/views.py** after line **635** ```python elif template_field.startswith('_'): html_dict[template_field] = (\"<pre><code>sensitive data will not be exposed here</pre></code>\") ``` **Use case / motivation** I know that I can use connections but in my case, and due to security politic in my company, we have to store it in a dedicated Vault. **Related Issues** N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: \"TypeError: decode() takes no keyword arguments\" on Python 2.6 The change in commit 79c99c0 specifies the `errors` argument of `decode()` as a keyword argument. Support for keyword arguments in `decode()` was added only in Python 2.7. This causes this code to raise: ``` TypeError: decode() takes no keyword arguments ``` on Python 2.6. This occurs for example on line 2297 of [this Travis run](https://travis-ci.org/pywbem/pywbem/jobs/134314959). Specifying the `errors` argument in the `decode()` invocations in `git/objects/commit.py` as a positional argument resolves this. For example, line 504 is currently: ``` parse_actor_and_date(author_line.decode(self.encoding, errors='replace')) ``` and should be, to resolve this: ``` parse_actor_and_date(author_line.decode(self.encoding, 'replace')) ``` This applies to the three places that were changed by commit 79c99c0. I verified that the proposed change works on Python 2.6, 2.7, 3.4, 3.5. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: pytorch_pretrained_bert/convert_tf_checkpoint_to_pytorch.py error attributeError: 'BertForPreTraining' object has no attribute 'global_step' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: drawing `unitary` gates in mpl messed up There are huge gaps when drawing \"unitary\" gates. Also the box should say \"unitary\" (which is the `gate.name`), exactly like what latex and text drawers do. The fix should be patched on stable. ``` from qiskit import QuantumCircuit from qiskit.quantum_info.random import random_unitary circ = QuantumCircuit(2) circ.unitary(random_unitary(4), [0,1]) circ.unitary(random_unitary(4), [0,1]) circ.draw(output='mpl') ```  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Allow skipping NPM download / hash checks when doing build check. ### Problem When launching a jupyterlab instance in our JupyterHub cluster, the `build_check` request can take as much as a minute despite the fact that the image that we have built is in a known-good state. ### Proposed Solution Add an option to `AppOptions` named something like `fast_build_check` (or something else; this is just a first proposal) that a user or admin can set to default to using fast build-checks (with the option at any location that calls `build_check` to override this default). I have a first cut of a solution here: https://github.com/TileDB-Inc/jupyterlab/commit/068b8e41f091e6d3a0334f1e60aeb99ee4a9ee87 but am open to changes or other approaches. Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit -> schedule raises exception <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? ```python ghz = QuantumCircuit(5, 5) ghz.h(0) ghz.cx(range(4), range(1,5)) ghz.barrier() ghz.measure(range(5), range(5)) sch = schedule(ghz, backend) ``` gives: AttributeError: 'NoneType' object has no attribute 'instruction_schedule_map' This works on older versions. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Schedule plot has final duration of final schedule duration even if channels are not plotted <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? The domain is not adjusted if channel is dropped. ### Steps to reproduce the problem ```python import qiskit.pulse as pulse import qiskit.pulse.pulse_lib as pulse_lib sched = pulse.Schedule() sched += pulse_lib.square(1000, 1.0)(pulse.DriveChannel(0)) sched += pulse_lib.square(10, 1.0)(pulse.DriveChannel(1)) sched.draw(channels_to_plot=[pulse.DriveChannel(1)]) ```  ### What is the expected behavior? Adjust the domain of plot if the channel is dropped. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Extension compatibility check We need to implement a compatibility check for extensions. An idea here is to mark the packages that we depend on that should be singletons, along with the associated semver. We can then check the top level dependencies of an extension to see if they are compatible with this list, and mark it as invalid if the semver range does not overlap on any of these packages. This check requires us to vendor the Python implementation of node semver that we had previously used. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson doesn't link libgfortran when linking Fortran together with C++ I get the following linker error: cschwan@cschwan-laptop ~/projects/mwe-cpp-fortran-meson/build $ ninja -v [1/3] gfortran -Iexe@exe -I. -I.. -pipe -Wall -O0 -g -Jexe@exe -o 'exe@exe/fortran.f.o' -c ../fortran.f [2/3] c++ -Iexe@exe -I. -I.. -fdiagnostics-color=always -pipe -D_FILE_OFFSET_BITS=64 -Wall -Winvalid-pch -Wnon-virtual-dtor -O0 -g -MMD -MQ 'exe@exe/main.cpp.o' -MF 'exe@exe/main.cpp.o.d' -o 'exe@exe/main.cpp.o' -c ../main.cpp [3/3] c++ -o exe 'exe@exe/main.cpp.o' 'exe@exe/fortran.f.o' -Wl,--no-undefined -Wl,--as-needed FAILED: exe c++ -o exe 'exe@exe/main.cpp.o' 'exe@exe/fortran.f.o' -Wl,--no-undefined -Wl,--as-needed exe@exe/fortran.f.o: In function `fortran': /home/cschwan/projects/mwe-cpp-fortran-meson/build/../fortran.f:4: undefined reference to `_gfortran_rand' collect2: error: ld returned 1 exit status ninja: build stopped: subcommand failed. with this minimal working example: [mwe-cpp-fortran-meson.tar.gz](https://github.com/mesonbuild/meson/files/1502664/mwe-cpp-fortran-meson.tar.gz) The program is basically the following callchain: `main` (written in C++) calls `fortran` (written in Fortran) calls `rand` (in the Fortran runtime library). Because the C++ linker is used to link everything together, `libgfortran` is not linked which leads to the linker error. Manually linking `libgfortran` circumvents the problem, but this specific to GCC, of course. Meson should figure out all the runtime libraries and link against them. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Problems due to adding IPython profile dir (~/.ipython) to sys.path When starting IPython, the profile directory gets added to sys.path. This means any `import` statement will also look for modules in that folder and in some cases allow you to import packages that aren't installed. For instance, after using the Cython magic, I can import cython even when cython is not installed in my environment. This causes issues when using packages/modules that rely on ImportError exceptions to check for optional features, for instance. We have a package that uses `cython.compiled` to check if one is using a plain-code or compiled version of a package. Due to IPython's behaviour regarding the profile directory, we cannot rely on the ImportError anymore - because `import cython` will just work. I guess IPython uses the addition to sys.path to discover extensions and such. But giving the interference with module discovery, I think different ways for this should be found. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Convert vendored `boltons` to a dependency ### What is the idea? `boltons 21.0.0` is now available on `pkgs/main` (and has been available on `conda-forge`). Deprecate the vendored `boltons` in favor of the latest available packages. ### Why is this needed? No need to vendor `boltons`. ### What should happen? Deprecate vendored `boltons`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Patching sources tool This has been reported a few times, at least 2 publicly: - @mcraveiro: https://github.com/conan-io/conan/issues/56 - @Klaim: http://boost.2283326.n4.nabble.com/Feedback-boost-conan-binary-packages-td4682377.html I think this is a common use-case, maybe some helpers can be done to ease this task. Patching sources tool This has been reported a few times, at least 2 publicly: - @mcraveiro: https://github.com/conan-io/conan/issues/56 - @Klaim: http://boost.2283326.n4.nabble.com/Feedback-boost-conan-binary-packages-td4682377.html I think this is a common use-case, maybe some helpers can be done to ease this task. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add support for c++2b and gnu++2b cpp_stds Add support for the work in progress C++23 support in GCC and Clang Signed-off-by: Joshua Ashton <joshua@froggi.es> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Restructure the files under algorithms.gradients. ### What should we add? Currently the files under under `algorithms.gradients` are messy. It's better to restructure the files. Grouping files by gradient type seems like a good idea. The files related to qgt and qfi are a bit tricky though. ``` gradients/ ├──base/ │ ├── base_estimator_gradient.py │ └── base_sampler_gradient.py ├── finite_diff/ │ ├── finite_diff_estimator_gradient.py │ └── finite_diff_sampler_gradient.py ├── lin_comb/ │ ├── lin_comb_estimator_gradient.py │ └── lin_comb_sampler_gradient.py ├── param_shift/ │ ├── param_shift_estimator_gradient.py │ └── param_shift_sampler_gradient.py ├── qgt/ │ ├── base_qgt.py │ ├── lin_comb_qgt.py │ └── reverse_qgt.py ├── qfi/ │ └── qfi.py └── reverse/ └── reverse_gradient.py ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub: AttributeError: 'NoneType' object has no attribute 'received_messages' #### Environment details OS: OS X and Linux Python 3.8.1rc1 google-cloud-pubsub==1.1.0 PubSub Emulator running out of the `google/cloud-sdk:latest` docker image #### Steps to reproduce I'm working on getting an isolated reproduction of this, but at current it's \"run my integration tests against the PubSub emulator\" (closed source, unfortunately) and see that on 1.1.0 the stack trace listed below gets written to stdout/stderr as it's seemingly occurring in another thread (not in my logs), and the test suite continues on normally and eventually passes. When pinned on 1.0.2, the stack trace below does not occur. For whatever it's worth, our code using PubSub via a streaming pull future has not changed recently. I get that this isn't very helpful by itself but I wanted to get report this sooner than later, instead of just pinning to 1.0.2 and forgetting about it. #### Stack trace ```python ERROR:google.api_core.bidi:Thread-ConsumeBidirectionalStream caught unexpected exception 'NoneType' object has no attribute 'received_messages' and will exit. Traceback (most recent call last): File \"/Users/briancurtin/elastic/cloud/python-services-v3/.tox/integration/lib/python3.8/site-packages/google/api_core/bidi.py\", line 657, in _thread_main self._on_response(response) File \"/Users/briancurtin/elastic/cloud/python-services-v3/.tox/integration/lib/python3.8/site-packages/google/cloud/pubsub_v1/subscriber/_protocol/streaming_pull_manager.py\", line 547, in _on_response len(response.received_messages), AttributeError: 'NoneType' object has no attribute 'received_messages' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose run should allow unsetting an entrypoint `docker-compose run --entrypoint='' blah` The above command should allow you to unset the entrypoint for the container, but has no effect. The corresponding behavior was added to the docker client in https://github.com/moby/moby/pull/23718 Allow unsetting an entrypoint (resolves #5582) When an empty string is passed to the 'entrypoint' parameter, for example `docker-compose run --entrypoint='' ...` OR `docker-compose run --entrypoint '' ...` It allows the default entrypoint to be overriden by empty value. Signed-off-by: Ganesh Satpute <ghsatpute@gmail.com> docker-compose run should allow unsetting an entrypoint `docker-compose run --entrypoint='' blah` The above command should allow you to unset the entrypoint for the container, but has no effect. The corresponding behavior was added to the docker client in https://github.com/moby/moby/pull/23718 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson instrospect without configured directory broken by b72b5365afe319e576e254f12437aeff899eb03e Before said commit `meson introspect --buildoptions meson.build` would return something, now it returns nothing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: core.call_bind aggressively raises args to top trace ``` def f(a_bool, y): if a_bool: return y + 1 else: return y jax.jit(jax.remat(f), static_argnums=0)(True, 1) ``` Results in: ``` ConcretizationTypeError: Abstract tracer value encountered where concrete value is expected (in `bool`). Use transformation parameters such as `static_argnums` for `jit` to avoid tracing input values. See `https://jax.readthedocs.io/en/latest/faq.html#abstract-tracer-value-encountered-where-concrete-value-is-expected-error`. Encountered value: Traced<ShapedArray(bool[], weak_type=True):JaxprTrace(level=-1/2)> ``` I think this arises from the full_raise occurring here when processing `remat_call_p` - which raise to the JaxprTrace when we told JIT we don't want to! https://github.com/google/jax/blob/77901e9fa71f5b23066c70132a983ae57f655b39/jax/core.py#L1001 This also applies to user-defined call primitives using `core.call_bind`, resulting in unnecessary workarounds like this one in Haiku: https://github.com/deepmind/dm-haiku/blob/49b21f7192dfdb3dc0a49cc097c8d3b0ccabb107/haiku/_src/named_call.py#L101-L109 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Do JAX jit'd Python loops run faster than jit'd LAX loop constructs? Please see the GIST [Minimal repro](https://gist.github.com/sussillo/76e191ba07bf2e75a4d4945f749549fe) where I tried to implement a recurrent computation (an echostate network) both in JAX and LAX. Using the lax.fori_loop resulted in a roughly 3x slow-down over jax jit'd naive python for loop. ``` JAX speed Params seed 100001 JAX run 0.0160 sec LAX speed LAX run 0.0418 sec ``` This is not blocking me, but I was surprised by it and I cannot find anything I did wrong, though I may have misused the APIs in some way. JAX versions are listed as comment in the gist. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: bug in scan higher-order autodiff The test added in cf99673 shows a failing autodiff test for scan. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Unable to pass arguments to modules with run -m I am working with the git master branch. The following: `In [1]: %run -m my_packages.my_module -verbosity 20` returns: `UsageError: option -v not recognized ( allowed: \"nidtN:b:pD:l:rs:T:em:G\" )` Even though the following works: `$ python -m my_packages.my_module -verbosity 20` I am using `argparse` as follows: ``` parser = argparse.ArgumentParser(description='my_program) parser.add_argument('-verbosity', help='Verbosity', required=True); ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: load checkpoint from URL Let's enable loading weights from a URL directly ## Option 1: Automate it with our current API ```python Trainer.load_from_checkpoint('http://') ``` ## Option 2: Have a separate method ```python Trainer.load_from_checkpoint_at_url('http://') ``` ## Resources We can use this under the hood: (https://pytorch.org/docs/stable/hub.html#torch.hub.load_state_dict_from_url) Any thoughts on which one is better? @PyTorchLightning/core-contributors Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: New Standard SQL Data Types Not Supported in gcloud._helpers._rows_from_json() / _CELLDATA_FROM_JSON() Standard SQL dialect support was added in 0.18.0, but current release does not support queries that return results that include data types that are not supported by Legacy SQL. E.g. executing the following query using Standard SQL: ``` SELECT PARSE_DATE('%Y%m%d', '20160810') AS table_date; ``` results in ``` rows = query.rows File \"/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/gcloud/bigquery/query.py\", line 204, in rows return _rows_from_json(self._properties.get('rows', ()), self.schema) File \"/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/gcloud/bigquery/_helpers.py\", line 85, in _rows_ from_json converter = _CELLDATA_FROM_JSON[field.field_type] KeyError: u'DATE' ``` Not a significant issue since the Legacy SQL Data types will work for my needs, but wanted to report it all the same. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Data parameter from Operator class does not show properly in API reference ### Environment - **Qiskit Terra version**: N/A - **Python version**: N/A - **Operating system**: N/A ### What is happening? The part of the `Operator` class [API reference page](https://qiskit.org/documentation/stubs/qiskit.quantum_info.Operator.html) from `qiskit.quantum_info` in which the parameters are listed does not show properly. In particular, where the data argument is supposed to be the page reads: > Parameters or (data ([QuantumCircuit](https://qiskit.org/documentation/stubs/qiskit.circuit.QuantumCircuit.html#qiskit.circuit.QuantumCircuit)) – Instruction or BaseOperator or matrix): data to initialize operator. Instead of > Parameters data ([QuantumCircuit](https://qiskit.org/documentation/stubs/qiskit.circuit.QuantumCircuit.html#qiskit.circuit.QuantumCircuit) or Instruction or BaseOperator or matrix): data to initialize operator. However I don't see any problem with the source code: ``` def __init__(self, data, input_dims=None, output_dims=None): \"\"\"Initialize an operator object. Args: data (QuantumCircuit or Instruction or BaseOperator or matrix): data to initialize operator. input_dims (tuple): the input subsystem dimensions. [Default: None] output_dims (tuple): the output subsystem dimensions. [Default: None] ``` ### How can we reproduce the issue? * Open the `Operator` class [API reference page](https://qiskit.org/documentation/stubs/qiskit.quantum_info.Operator.html). * Check the parameters section ### What should happen? You should see the aforementioned error. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Cyclic references could lead to memory leaks Cyclic references (for example, in graph data structures) don't get garbage collected by python immediately. This can cause tensors to not be deallocated when all references are removed, causing memory leaks on device and possible OOM crashes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Reattach ECS Task when Airflow restarts **Description** In similar fashion to https://github.com/apache/airflow/pull/4083, it would be helpful for Airflow to reattach itself to the ECS Task rather than letting another instance to start. However, instead of making this the default behavior, it would be better to use a `reattach` flag. **Use case / motivation** Allow Airflow the option to reattach to an existing ECS task when a restart happens, which would avoid having \"rogue\" tasks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery snippets have started failing \"consistently\" See the 3 most recent BigQuery builds on `master`: - https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/4382 - https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/4388 - https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/4390 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: nbconvert does not process SVGs into PDFs nbconvert does not manage to take the final step to transform SVGs into PDFs and hence breaks figure inclusion in the final `pdflatex` call to generate PDF files using, for example, the --format=\"latex\" and --format=\"sphinx_howto\" options. This is despite the technology being ready and waiting in `IPython/nbconvert/transformers/svg2pdf.py`. (Requires `inkscape` to do the conversion.) Crucial for 1.0. By the way, I am on Mac OS but installed `inkscape` with `brew`, so the logic to choose the `Mac OS` version of `inkscape` will fail in my case. It should check if the command line `inkscape` is not already available. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: pretty print list too slow It seems ipython's behaviour is very different if I say: ``` print range(10**6) # case 1, fraction of a second, output in ONE line range(10**6) # case 2, ten seconds, 10^6 lines ``` and the difference is not due to the actual output, but presumably the formatting of the one-value-per-line output. As this is a factor of about 10x (not counting the actual output), and growing with list size, there appears to be a problem because this is unexpected by the user. It was only through debugging, then web search, and a stackoverflow comment that I found the %pprint magic which is nowhere documented. So even if you dismiss this as bug or enhancement, this ticket should add helpful documentation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Missing None verification in the CLM language modeling example Here: https://github.com/huggingface/transformers/blob/1682804ebd504d3381523116773583a52f35afd1/examples/language-modeling/run_clm.py#L230, data_args.train_file can be None (as it is checked some lines above). Therefore, there should be a check to see if it is the case or not. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython slow in os x mavericks? I updated to mac os x mavericks yesterday and now realized that while working in ipython, it is sometimes irresponsive, i.e. I type something, but it takes ~5 seconds until it suddenly appears on the console. This issue happens more or less randomly, however more frequently when coming back to the console from another application. It seems to happen in the terminal \"ipython --pylab\" as well as in the qtconsole. In the normal python console it seems to be no problem. Did anyone else experience this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: NLLB MoE router_state referenced before assignment ### System Info - `transformers` version: 4.29.2 - Platform: Linux-5.15.0-69-generic-x86_64-with-glibc2.17 - Python version: 3.8.17 - Huggingface_hub version: 0.15.1 - Safetensors version: not installed - PyTorch version (GPU?): 2.0.1 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: <fill in> - Using distributed or parallel set-up in script?: <fill in> ### Who can help? @ArthurZucker @youn ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ```python model = AutoModelForSeq2SeqLM.from_pretrained(\"facebook/nllb-moe-54b\") model( input_ids=input_ids, attention_mask=attenstion_mask, decoder_input_ids=decoder_input_ids, decoder_attention_mask=decoder_attention_mask, output_router_logits=True, return_dict=True, ) ``` ```bash transformers/models/nllb_moe/modeling_nllb_moe.py\", line 720, in forward outputs += (router_states,) UnboundLocalError: local variable 'router_states' referenced before assignment ``` ### Expected behavior return encoder_router_logits and decoder_router_logits rather than error. The error happens on the dense layers where no router_state is returned. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Improve validation schema for list_or_dict fields Right now `extra_hosts` and `labels` use \"one of: object or array\", but no validation is done on the contents of the `object`. I think this can be improved by creating a schema for the object that uses `patternProperties`, so that it will fail if someone uses nested objects, or arrays within the object. ``` json { \"type\": \"object\", \"patternProperties\": {\"type\": \"string\"}, } ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Better error message for installing JupyterLab extensions ## Description I got the following error message when installing a JupyterLab extension. It was hard for me to figure out which JupyterLab extension had caused the issue since I was building a Docker image. It would be much clearer if the name of the JupyterLab extension is included in the error message.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: add retry policy to @asset Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: bug in np.full / lax.full for DeviceArray wrapped scalars If you pass in a jax-wrapped scalar as the fill-constant value to np.fill, it breaks, e.g.: ```python np.full((1,1), np.array([1])[0]) ``` this hits the condition in lax.full: ```python elif isinstance(fill_value, xla.DeviceValue): return FilledConstant(convert_element_type(fill_value, dtype), shape) ``` no matter what dtype is, the convert_element_type result is still a DeviceArray, then this line in lax.FillConstant: ```python class FilledConstant(xla.DeviceConstant): __slots__ = [\"fill_value\"] def __init__(self, fill_value, shape): assert type(fill_value) is onp.ndarray ``` wants the fill value to be an onp ndarray instead. I'm not too certain about the type logic here to make a PR confidently. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Circuit drawers do not handle complex values <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? ```python ket = np.array([0.7071067811865476, 0, 0, 1j*0.7071067811865476]) qc = QuantumCircuit(2) qc.initialize(ket, [0, 1]) qc.draw() ``` ``` ┌────────────────────────────┐ q_0: |0>┤0 ├ │ initialize(0.70711,0,0,0) │ q_1: |0>┤1 ├ └────────────────────────────┘ ``` same for MPL <img width=\"221\" alt=\"Screen Shot 2019-12-19 at 5 15 36 PM\" src=\"https://user-images.githubusercontent.com/1249193/71214390-2da3ef80-2283-11ea-945f-6c8bc5786e96.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add defined phases to the PassManager <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The typical (and all the preset) pass managers have fixed stages, typically something like: ``` Layout -> Routing -> Basis Translation -> Optimization Loop -> scheduling ``` We should formalize these stages, we can expand the set over time (but probably not remove) and some are obviously optional depending on runtime conditions and options and enable people to compose pass managers by constructing the phases individually and not have to worry about control flow. This also provides us the option of including hook points for backends to add customization which are backend specific before and after each transpile stage (which is something I'd like to include in #5885 ). For example, if we have a backend with all custom gate definitions our 1q optimization pass will not be able to simplify anything. But, the provider/backend author can write their own pass that runs a custom post optimization loop to do this and we update `transpile()`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Function checking fails on newest sid Here's the log: ``` Running compile: Command line: ccache cc /tmp/tmp8lpdrvql.c -o /tmp/tmpnp00uh46 Code: #define lchmod meson_disable_define_of_lchmod #include <sys/stat.h> #include <unistd.h> #undef lchmod #ifdef __cplusplus extern \"C\" #endif char lchmod (); #if defined __stub_lchmod || defined __stub___lchmod fail fail fail this function is not going to work #endif int main () { return lchmod (); } Compiler stdout: /tmp/tmp8lpdrvql.c:13:9: error: unknown type name ‘fail’ fail fail fail this function is not going to work ^ /tmp/tmp8lpdrvql.c:13:19: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘fail’ fail fail fail this function is not going to work ^ /tmp/tmp8lpdrvql.c:13:19: error: unknown type name ‘fail’ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub doc: missing/broken link for FlowControl type definition The parameter `FlowControl` in the `subscribe()` method in the ref [doc](https://googleapis.github.io/google-cloud-python/latest/pubsub/subscriber/api/client.html) doesn't have a link to its definition. We should add a link to make the doc easy to use. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: compose should not unroll (by default) when using the circuit library <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? The idea of having a circuit library is to build up larger circuits and have simple visualizations that we can recognize when using them. I am fine having a non default option to unroll circuit when you compose it but by default the combined circuit should look like building blocks of the libraries. As an example see this figure <img width=\"796\" alt=\"Screen Shot 2021-04-03 at 11 07 27 AM\" src=\"https://user-images.githubusercontent.com/15731369/113482441-c789ae80-946c-11eb-9fb1-6261b562e021.png\"> It should make output (by default) <img width=\"750\" alt=\"Screen Shot 2021-04-03 at 11 08 06 AM\" src=\"https://user-images.githubusercontent.com/15731369/113482475-eab45e00-946c-11eb-9f72-6064e9e4143b.png\"> @ajavadia I know we talked about this but just making issue so we remember. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Given inexistent file X, \"%run X\" reports that it's unable to open \"X.py\" ... which confuses users. See #13542. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Change --volume behavior to add instead of replace mounts Potential solution to #4728. When using the `docker-compose run` command, rather than replacing all mount when using the `-v/--volume`, this will add to the list of mounts (potentially overriding mounts already in the `docker-compose.yml` file). - [ ] Need to add unit tests `run --volumes` replaces volume configuration rather than adding Using [`run --volumes`](https://github.com/docker/compose/pull/4566) replaces all volumes in the docker-compose config. It would be more useful to me to be able to specify the volumes to mount in addition to the ones in config. Perhaps `--append-volumes` or `--add-volumes`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: API Endpoints - Read-only - Import errors **Description** Hello We need to create several endpoints that perform basic read-only operations on **Import error** . We need the following endpoints: - GET /importErrors - GET /importErrors/{import_error_id} For now, we focus only on read-only operations, but others will also be implemented as the next step. Detailed information is available in the issue: https://github.com/apache/airflow/issues/8118 **Use case / motivation** N/A **Related Issues** N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Commit without executing hooks If I do `index.commit(msg)` it will execute [`pre-commit`](https://github.com/gitpython-developers/GitPython/blob/d5739cd466f77a60425bd2860895799f7c9359d9/git/index/base.py#L941) and [`post-commit`](https://github.com/gitpython-developers/GitPython/blob/d5739cd466f77a60425bd2860895799f7c9359d9/git/index/base.py#L946) That makes it very hard to do the equivalent of `git commit -m \"msg\" --no-verify` (same as `git commit -m \"msg\" -n`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Documentation build drops a file in the working directory ### Environment - **Qiskit Terra version**: main @ 686ba34 - **Python version**: any - **Operating system**: any ### What is happening? Running the documentation build (such as by `tox -e docs`) causes a file `new_hist.png` to be dropped in the working directory. This came from #8569, which added a `jupyter-execute` block to the `qiskit.visualization` documentation that leads a `savefig` command. ### How can we reproduce the issue? Run the documentation build. ### What should happen? No files outside the documentation build directory should be created. ### Any suggestions? The offending `.. jupter-execute` block can just be replaced by a `.. code-block` one, since it doesn't actually output anything visually, or execute code in the IPython kernel that needs persisting to later cells. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: `--build <pattern>` seems not to work When calling `conan help install` it states the following regarding the --build parameter: ``` --build=[pattern] Build always these packages from source, but never build the others. [...] 'pattern' is a fnmatch file pattern of a package name. ``` I would like to install a package and rebuild all of my own packages with it. All of my packages are within the `@monsdar/release` channel. The following seems not to work though: `conan install ... --build *monsdar*`. Conan gives me the message `ERROR: No package matching '*monsdar*' pattern`. Do I do something wrong? Or is this feature not working correctly? This happens with Conan 1.13.0 installed via Pip. Python 3.6.1 on a Windows 10 Professional with 64bit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Circuit drawer reverse_bits does not reverse registerless bits ### Environment - **Qiskit Terra version**: Current main - **Python version**: 3.8 - **Operating system**: Ubuntu ### What is happening? When using classical registers only with `reverse_bits`, the registers and the bits in the registers are reversed before display. However, bits without registers are reversed in terms of usage, but are not reversed when displayed. ``` bits = [Qubit(), Qubit(), Clbit(), Clbit()] bits1 = [Clbit()] cr = ClassicalRegister(2, \"cr\") crx = ClassicalRegister(2, \"crx\") qc = QuantumCircuit(bits, cr, [Clbit()], crx, bits1) qc.x(0).c_if(crx[1], 0) qc.measure(0, bits[3]) qc.draw('mpl', cregbundle=False, reverse_bits=True) ```  ### How can we reproduce the issue? --- ### What should happen? Registerless bits should show in descending order.  ### Any suggestions? This will require the merge of #7285 before the above circuit will work. @javabster Can you assign this to me? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Learning Rate Schedulers' default dictionary parameters should be set via the Trainer ## 🚀 Feature The default Learning Rate Schedulers (LRS) dictionary parameters should be settable from the Trainer constructor. ### Motivation The documentation doesn't seem to be clear that the LRS have the following additional parameters available to be set when you configure the optimizers: ``` 'interval': 'epoch', # default every epoch 'frequency': 1, # default every epoch/batch 'reduce_on_plateau': False, # most often not ReduceLROnPlateau scheduler 'monitor': 'val_loss' ``` ### Pitch Set those defaults in the constructor of the Trainer and the user can set them themselves. ### Alternatives Force the return type of the function LightningModule.configure_optimizers() to be List[Optimizer], List[Dict] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: EmailTask is outdated In `prefect.tasks.notifications`, the `EmailTask` encourages users to store usernames / passwords as Task attributes; we should be using secrets. Also, the docstring is incomplete. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: GPT2 is not fully torch.jit.trace-able # 🐛 Bug ## Information I'm trying to use PyTorch's tracing on a pre-trained GPT2 model and running into the following warning emitted from torch.jit.trace: ``` /opt/miniconda3/envs/py3/lib/python3.6/site-packages/transformers/modeling_gpt2.py:144: TracerWarning: Converting a tensor to a Python float might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! w = w / math.sqrt(v.size(-1)) ``` Additionally, if I inspect the graph generated from the trace, I can see that the denominator in that division expression is a constant value, not one determined by the size of the tensor. ## To reproduce The following snippet can be used to repro the problem (based on the example in the Quickstart guide) ```python tokenizer = GPT2Tokenizer.from_pretrained('gpt2') model = GPT2LMHeadModel.from_pretrained('gpt2').eval() example_input = torch.tensor([ tokenizer.encode(\"The Manhattan bridge\")]) traced_model = torch.jit.trace(model, example_input) ``` ## Environment info - `transformers` version: 2.8.0 - Python version: 3.6.10 - PyTorch version (GPU?): 1.4.0 (False) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Feature Request to Add C17/C18/ISO-9899:2018 Support ISO-9899:2018 (C17/C18) came out last year. Although it's a non-feature corrections release, folks are going to be wanting to specify it in compiler options. As a first shot at scoping the issue, I simply hacked a local copy of mesonbuild/compilers/c.py to add 'c17', 'c18', 'gnu17', and 'gnu18' to the list of the supported standards in class GnuCCompiler, and added 'c17' and 'gnu17' in class ClangCCompiler. Passing c_std=c17 to project(), my test compiles using GCC 8 and Clang 7 were successful. There's a lot more to it than that, but maybe it won't be too tough. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.config doesn't report command-line flags correctly Another one from @jmgilmer and I - I don't think the jax config is parsing command line flags correctly. I don't know if this is functionally important or just a reporting error - but it is certainly important for user scripts knowing what flags have been set. If I run this script: ``` from absl import app, flags from jax.config import config FLAGS = flags.FLAGS def main(_): print(\"FLAGS.jax_enable_x64\", FLAGS.jax_enable_x64) print(\"FLAGS.jax_debug_nans\", FLAGS.jax_debug_nans) print(config.values) if __name__ == \"__main__\": config.config_with_absl() app.run(main) ``` I get the following problem: jax.config doesn't report the correct flag settings. ``` > python jaxtest.py --jax_enable_x64=1 --jax_debug_nans=1 FLAGS.jax_enable_x64 True FLAGS.jax_debug_nans True {'jax_enable_x64': 0, 'jax_xla_backend': 'xla', 'jax_backend_target': 'local', 'jax_platform_name': '', 'jax_device_values': 1, 'jax_debug_nans': 0, 'jax_disable_jit': 0} ``` if I run the same with envvars instead it works: ``` JAX_ENABLE_X64=1 JAX_DEBUG_NANS=1 python jaxtest.py FLAGS.jax_enable_x64 True FLAGS.jax_debug_nans True {'jax_enable_x64': 1, 'jax_xla_backend': 'xla', 'jax_backend_target': 'local', 'jax_platform_name': '', 'jax_device_values': 1, 'jax_debug_nans': 1, 'jax_disable_jit': 0} ``` I've tried parsing the flags in different ways but nothing seems to fix the issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: apex gradient clipping #🐛 Bug It seems when apex + gradient clipping is not handled explicitly. I see note here https://nvidia.github.io/apex/advanced.html#gradient-clipping. where amp.master_params needs to be used. Is what's in this repo correct or not? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Unable to set conda-build.root-dir with config Not sure the right way to do this, but it looks like there might not be any right way ATM. I would like to be able to use `conda config` to get the following added to my `.condarc` file. ```yaml conda-build: root-dir: /tmp ``` If I try to set `conda-build.root-dir` with `conda config`, I get this error. ```bash $ conda config --set \"conda-build.root-dir\" \"/tmp\" CondaValueError: Value error: Error key must be one of add_anaconda_token, shortcuts, add_pip_as_python_dependency, ssl_verify, client_tls_cert, binstar_upload, use_pip, add_binstar_token, always_copy, always_yes, client_tls_cert_key, channel_alias, changeps1, channel_priority, show_channel_urls, update_dependencies, allow_softlinks, anaconda_upload, offline, allow_other_channels, auto_update_conda, not conda-build.root-dir ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Suppress documentation logging For some reason, this line is printed many times by `generate_docs.py` when building docs: `(https://github.com/PrefectHQ/prefect/commit/7fd54f656c76aa6571939dd9b330f2a4c6867140)*</sub> 11:32:22 AM: <sub>*This documentation was auto-generated from [7fd54f6]` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: celery worker -q --quiet seems not working with 4.4.7 Running celery 4.4.7 [not woking] Running celery 4.4.6 [ok] Running celery 4.4.1 [ok] commands : > celery -A proj worker --loglevel=info -P eventlet --quiet > celery -A proj worker --loglevel=info -P eventlet -q Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pylint not applied to tools directory Pylint is not applied to tools directory. Some of the tools are non-compliant with project style. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: It should be easier to modify pass managers. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently, if you want to use a default pass manager with only a single pass changed, e.g. for example the swap mapper changed, you need to go and create a whole new pass manager. It should be possible to simply replace one pass in a pass manger with another. Something like: ```python pm = default_pass_manager() pm.replace(6, LookaheadSwap) # where 6 is the index of the pass in the pm ``` An index is used here since you could have multiple passes of the same type. It would also be nice to be able to slice a pm and get a new pm, e.g. `pm2 = pm[:5]` which would save people from having to rewrite things like this: ```python pass_manager = PassManager() pass_manager.property_set['layout'] = initial_layout pass_manager.append(Unroller(basis_gates)) pass_manager.append(TrivialLayout(coupling_map), condition=lambda property_set: not property_set['layout']) pass_manager.append(CheckMap(coupling_map)) pass_manager.append(DenseLayout(coupling_map), condition=lambda property_set: not property_set['is_swap_mapped']) pass_manager.append(FullAncillaAllocation(coupling_map)) pass_manager.append(EnlargeWithAncilla()) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Figure out and documents exceptions thrown in storage.connection.Connection.create_bucket From TODO: ``` python # TODO: Which exceptions will this raise? ``` See [`storage.connection.Connection.create_bucket`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/connection.py#L320) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 320) # TODO: Which exceptions will this raise? ``` Figure out and documents exceptions thrown in storage.connection.Connection.create_bucket From TODO: ``` python # TODO: Which exceptions will this raise? ``` See [`storage.connection.Connection.create_bucket`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/connection.py#L320) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 320) # TODO: Which exceptions will this raise? ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: UnboundLocalError: local variable 'seq_length' referenced before assignment ### System Info Hi, I am using the `ConvBertForTokenClassification` model in models.convbert and encountered the bug when passing only `input_embeds` to `forward()`. The traceback says that at line 833 in modeling_convbert.py ``` if token_type_ids is None: if hasattr(self.embeddings, \"token_type_ids\"): buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length] ``` The seq_length is unassigned. I noticed just above this piece of code in ``` elif input_ids is not None: input_shape = input_ids.size() batch_size, seq_length = input_shape elif inputs_embeds is not None: input_shape = inputs_embeds.size()[:-1] ``` seq_length is not assigned if the program enters `elif inputs_embeds is not None`. Not sure if it is the `batch_size, seq_length = input_shape` missing for `inputs_embeds` or I am not using the model correctly? ### Who can help? text models: @ArthurZucker and @younesbelkada ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction passing only `inputs_embeds` and `attention_mask` to `ConvBertForTokenClassification` model. ### Expected behavior There should be no error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Extension metadata for replacement <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description Add extension metadata for replacing an extension. The system will read this metadata and disable that extension automatically. Currently extensions that replace core extensions have to tell their users to disable the core extension. This would enable that to work automatically. <!--Describe the bug clearly and concisely. Include screenshots if possible--> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Restrict allowed characters in connection ids ### Description I bumped into a bug where a connection id was suffixed with a whitespace e.g. \"myconn \". When referencing the connection id \"myconn\" (without whitespace), you get a connection not found error. To avoid such human errors, I suggest restricting the characters allowed for connection ids. Some suggestions: - There's an `airflow.utils.helpers.validate_key` function for validating the DAG id. Probably a good idea to reuse this. - I believe variable ids are also not validated, would be good to check those too. ### Use case/motivation _No response_ ### Related issues _No response_ ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Create NoAdditionalArgsInOperatorsRule to ease upgrade to Airflow 2.0 This issue is part of #8765 ## Rule Create `NoAdditionalArgsInOperatorsRule` which corresponds to > Additional arguments passed to BaseOperator cause an exception entry in UPDATING.md. This rule should allow users to check if their current configuration needs any adjusting before migration to Airflow 2.0. ## How to guide To implement a new rule, create a class that inherits from `airflow.upgrade.rules.base_rule.BaseRule`. It will be auto-registered and used by `airflow upgrade-check` command. The custom rule class has to have `title`, `description` properties and should implement `check` method which returns a list of error messages in case of incompatibility. For example: https://github.com/apache/airflow/blob/ea36166961ca35fc51ddc262ec245590c3e236fb/airflow/upgrade/rules/conn_type_is_not_nullable.py#L25-L42 **Remember** to open the PR against `v1-10-test` branch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: provide option to omit 'insertId' for 'insert_rows' and 'insert_rows_json'. Streaming inserts to BigQuery can achieve [1GB per second](https://cloud.google.com/bigquery/quotas#streaming_inserts) but only when insertId is omitted. Currently both methods from the google-cloud-bigquery [client](https://github.com/googleapis/google-cloud-python/blob/master/bigquery/google/cloud/bigquery/client.py) that implement the BigQuery insertAll REST API method, **insert_rows** and **insert_rows_json**, automatically add insertId preventing anyone from making use of the higher throughput limits. Proposing that an argument be added to one or both of these methods like \"insertId=True\" (defaulting to true). When false, uuid is not used to add insert IDs. Furthermore, documentation is updated to clearly articulate that omitting insertId can result in duplicate records upon retry of failed API calls according to [this guide](https://cloud.google.com/bigquery/streaming-data-into-bigquery#dataconsistency). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Cloud Assets: Autosynth fails to find the generated output ```bash cd asset python3 synth.py ``` Output: ``` synthtool > Ensuring dependencies. synthtool > Pulling artman image. synthtool > Cloning googleapis. synthtool > Running generator for google/cloud/asset/artman_cloudasset_v1beta1.yaml. Traceback (most recent call last): File \"synth.py\", line 36, in <module> artman_output_name=f\"cloudasset-{version}\", File \"[removed]/.local/lib/python3.6/site-packages/synthtool/gcp/gapic_generator.py\", line 100, in py_library return self._generate_code(service, version, \"python\", **kwargs) File \"[removed]/.local/lib/python3.6/site-packages/synthtool/gcp/gapic_generator.py\", line 183, in _generate_code f\"Unable to find generated output of artman: {genfiles}.\" FileNotFoundError: Unable to find generated output of artman: [removed]/.cache/synthtool/googleapis/artman-genfiles/python/cloudasset-v1beta1. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: while_loop vmap error This one is reported by @fehiepsi in [another thread](https://github.com/google/jax/pull/486#issuecomment-471140362). Quoting the repro from there: ``` # generate a random number in the interval [0, 0.5] def f(key): def body_fn(uk): key = uk[1] u = random.uniform(key, ()) key, _ = random.split(key) return u, key u, _ = lax.while_loop(lambda uk: uk[0] > 0.5, body_fn, (1., key)) #u = random.uniform(key, ()) # this is fine return u print(f(random.PRNGKey(0))) # no error print(vmap(f)(random.split(random.PRNGKey(0), 2))) # TypeError: 'NoneType' object cannot be interpreted as an integer ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: logging options Since fig is talking to docker, having some way of seeing what commands it is running sending would be really great for debugging purposes. Perhaps something like: ``` DEBUG=true fig up ``` Or: ``` fig up --debug ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Downscaling should remove containers If one scales down an app, containers will be stopped in order to achive that. If one restarts everything, the app starts all existing containers, and therefore the downscaling has no effect. At least is doesn't survive a restart, whereas an upscaling a restart survives. Suggestion: The scaling function should not only stop the containers, but also remove them. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Message spec changes related to `clear_output` This is a reminder for @minrk to: - Increment the minor version of the message spec to reflect the changes to `clear_output`. - Add handling in the JS code to gracefully handle the old `clear_output` messages. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda 4.4 incorrect activate message I updated to conda 4.4.0b2 from conda v4.3. I created a new environment and it recommended the following - which I ran and got an error: To activate this environment, use $ conda activate anaconda2 To deactivate an active environment, use $ conda deactivate 0288-csoja:scripts csoja$ conda activate anaconda2 Traceback (most recent call last): File \"/Users/csoja/Desktop/anaconda/lib/python3.5/site-packages/conda/cli/main.py\", line 176, in main raise CommandNotFoundError(argv1) conda.exceptions.CommandNotFoundError: 'activate is not a conda command. Did you mean 'source activate'? During handling of the above exception, another exception occurred: Traceback (most recent call last): File \"/Users/csoja/Desktop/anaconda/bin/conda\", line 6, in <module> sys.exit(conda.cli.main()) File \"/Users/csoja/Desktop/anaconda/lib/python3.5/site-packages/conda/cli/main.py\", line 178, in main from ..exceptions import handle_exception ImportError: cannot import name 'handle_exception' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Merge release notes and changelog ### Problem: There seems to have been a historic seperation between the release notes in the docs folder and the changelog in the root directory of the repo. I double-checked the content and despite it being differently formatted with Restructured Text and Markdown, there isn't enough difference to warrant maintaining two files. ### Expectation: One file to record development changes that can also be used in user facing documentation. ### Solution: One option: 1. Move content of `docs/source/release-notes.rst` to `./CHANGELOG.rst` 2. Update `docs/source/release-notes.rst` to use an rST include() to load `CHANGELOG.rst` 3. Delete `./CHANGELOG.md` There are other options available like: - setting a symlink from `CHANGELOG.rst` to `docs/source/release-notes.rst` but that is not well-rendered on GitHub. - switching to [towncrier](https://pypi.org/project/towncrier/) - switching to [MyST](https://myst-parser.readthedocs.io/) for using Markdown in Sphinx projects (even in parallel to rST files). ### Links Refs #10715. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: distutils/misc_util.py Configuration settings lead to ImportError DLL load failed When building NumPy from the source on Windows 10, the resulting `.libs` folder is not added to the path. ### Reproducing code example: The regular ```bash python setup.py build python setup.py install ``` machinery succeeds however afterwards numpy import fails with the recently reported `ImportError`s elsewhere, say, #14896 and others. This happens also on SciPy builds which were successfully working until I switched to Python 3.8. This is also reported on SciPy https://github.com/scipy/scipy/issues/11062 It seems like the generated `__config__.py` has the lines https://github.com/numpy/numpy/blob/6e75b9ab7888e2d807893a8237811f97f605547e/numpy/distutils/misc_util.py#L2324-L2335 Somehow, .libs folder is not present on the `src.win-amd64-3.8` but it is created in `lib.win-amd64-3.8` and for reasons I have not yet understood, this if branch is not entered. On the linked SciPy issue, the file is modified manually to add the libs to the path. Hence I am under the impression that it is not necessarily an Anaconda issue but something has changed along the way, that is maybe, Python3.8 related. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %matplotlib notebook broken with current matplotlib master With current matplotlib master, executing %matplotlib notebook fails with an `AttributeError: module 'matplotlib.backends' has no attribute 'backend'` Please find a notebook demonstrating this problem here: https://gist.github.com/ericdill/1bfdc12692aec09047bb matplotlib/matplotlib#6013 is the PR that broke this. Cross-posted at matplotlib/matplotlib#6092. cc @tacaswell Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Adding python 3.9, release prior to dropping 3.4. #1131 Hi, When running the tests after dropping 3.4, I also tested against 3.9 on Linux. All tests passed, so I was thinking to add simply add 3.9. But will probably want final 3.4 release cutting before either are merged? Dropping 3.4 allows the use of function type hints and async/await coroutines. Note: According to https://pypistats.org/packages/gitpython python 3.4 downloads are at 0.04% and 3.5 is still at 3.38% Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Shutdown qtconsole problem? The following from the windows console, after starting, then stopping a qtconsole session with cntrl-D, C:\\Users\\burnett>ipython qtconsole --pylab [IPKernelApp] To connect another client to this kernel, use: [IPKernelApp] --existing kernel-5140.json Traceback (most recent call last): File \"c:\\python27\\lib\\site-packages\\IPython\\frontend\\qt\\console\\mainwindow.py\", line 853, in update_restart_checkbox self.confirm_restart_kernel_action.setChecked(widget.confirm_restart) AttributeError: 'NoneType' object has no attribute 'confirm_restart' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jnp.asarray does not copy when copy=True This can be a problem now that we have donate_argnums. It took me a while to realize this, before I smartened up and just used x.copy() in the example below. ``` import functools import jax import jax.numpy as jnp @functools.partial(jax.jit, donate_argnums=(0,)) def _test(array: jnp.ndarray): return array.at[0].set(77) x = jnp.asarray([0, 1]) x_copy = jnp.array(x, copy=True) new_x = _test(x) # Gives: RuntimeError: Invalid argument: CopyToHostAsync() called on invalid buffer. print(x_copy) ``` @tomhennigan Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Hooks: post_package_info To receive the adjusted `conanfile.cpp_info` and perform some checks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: fig service name ``` my-symfony: image: docker.ukwm.local:5000/ukwm/my-symfony ``` `Invalid name: my-symfony` It seems - & _ are invalid characters for use in a service name. However I can't see this documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Create a class method in `DAGCircuit` which returns its disconnected components JUSTIFICATION: Circuit cutting requires breaking a quantum circuit up into smaller, disconnected subcircuits and potentially running those subcircuits on different qubit partitions in parallel. There is currently no easy way to retrieve all of the disconnected subsets of qubits in a given circuit, even though this information is easily accessible in the graph representation of a quantum circuit. TASK: Create a class method, `DAGCircuit.separable_circuits`, that returns a list of DAGCircuits -- one for each set of disconnected qubits in the quantum circuit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Previous volume setting overrides new changes I've been using a host directory as my data volume for a postgresql container. My docker-compose.yml reads something like this. ``` postgresql: image: postgres ports: - \"5432:5432\" container_name: postgresql networks: - mynet volumes: - pg-data:/var/lib/postgresql/data volumes: pg-data: driver_opts: type: none device: /volumes/pgdata o: bind ``` As we wanted to consolidate all data into a single encrypted volume, I decided to remap the volume for this container. ``` volumes: pg-data: driver_opts: type: none device: /volumes/data/pgdata o: bind ``` I know that I need to remove the containers of this image and recreate the image. I removed all containers and images. It appears that docker-compose is still remembering my old setting somewhere when I try to rebuild (docker-compose up --build postgresql) the image. I get the following error. `ERROR: for postgresql Cannot create container for service postgresql: error while mounting volume with options: type='none' device='/volumes/pgdata' o='bind': no such file or directory` Its still trying to access the old volume definition where as my new docker-compose.yml has no reference to this directory. I tried to start a container using this image directly `docker run -p 5432:5432 --name postgresql -v /volumes/data/pgdata:/var/lib/postgresql/data postgres` And this brings up the image with changed volume path. Why is `docker-compose` not changing the path? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Improve filtering for invalid schemas in Hive hook ### Description #27647 has introduced filtering for invalid schemas in Hive hook based on the characters `;` and `!`. I'm wondering if a more generic filtering could be introduced, e.g. one that adheres to the regex `[^a-z0-9_]`, since Hive schemas (and table names) can only contain alphanumeric characters and the character `_`. Note: since the Hive metastore [stores schemas and tables in lowercase](https://stackoverflow.com/questions/57181316/how-to-keep-column-names-in-camel-case-in-hive/57183048#57183048), checking against `[^a-z0-9_]` is probably better than `[^a-zA-Z0-9_]`. ### Use case/motivation Ensure that Hive schemas used in `apache-airflow-providers-apache-hive` hooks contain no invalid characters. ### Related issues _No response_ ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rename `pulse_lib` to `library` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Let's deprecate the `pulse_lib` path and move everything to `library` instead. This 1) matches the circuit style (`circuits.library` and `pulse.library`) and 2) looks nice, and less redundant by using the namespacing (`pulse.pulse_lib` vs `pulse.library`) If a user imports from `pulse.pulse_lib`, the code should still work, but a `DeprecationWarning` should be printed, explaining that `pulse.pulse_lib` should be replaced by `pulse.library`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: [1.6.0] Extra volumes are created when using new compose file format I have **docker-compose.yml** file in folder **nowsd**: ``` yml version: 2 volumes: data: driver: local ugc: driver: local services: web: image: busybox volumes: - data:/var/log - ugc:/var/ugc ``` _$_ **docker-compose up** ``` Starting nowsd_web_1 Attaching to nowsd_web_1 nowsd_web_1 exited with code 0 ``` _$_ **docker volume ls** ``` DRIVER VOLUME NAME local nowsd_data local data local ugc local nowsd_ugc ``` You can see that two extra unscoped volumes has been created. When I inspect container nowsd_web_1 i can see that volumes _data_ and _ugc_ are attached to container instead of _nowsd_data_ and _nowsd_ugc_ respectively. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: In conda 4.3, look at basename usage in core/package_cache.py Probably need to memoize something a level or two up from the basename call. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: sourceGeneration in copy_blob Hi, I need that the copy_blob function of Bucket object in Cloud Storage library manage the \"sourceGeneration\" parameter to copy the archived version of an object. Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: SSHOperator - Allow specific command timeout ### Description Following #29282, command timeout is set at the `SSHHook` level while it used to be able to set at the `SSHOperator` level. I will work on a PR as soon as i can. ### Use case/motivation Ideally, i think we could have a default value set on `SSHHook`, but with the possibility of overriding it at the `SSHOperator` level. ### Related issues #29282 ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Pipeline Loading Models and Tokenizers # ❓ Questions & Help <!-- The GitHub issue tracker is primarly intended for bugs, feature requests, new models and benchmarks, and migration questions. For all other questions, we direct you to Stack Overflow (SO) where a whole community of PyTorch and Tensorflow enthusiast can help you out. Make sure to tag your question with the right deep learning framework as well as the huggingface-transformers tag: https://stackoverflow.com/questions/tagged/huggingface-transformers If your question wasn't answered after a period of time on Stack Overflow, you can always open a question on GitHub. You should then link to the SO question that you posted. --> ## Details <!-- Description of your issue --> Hi I'm trying to use 'fmikaelian/flaubert-base-uncased-squad' for question answering. I understand that I should load the model and the tokenizers. I'm not sure how should I do this. My code is basically far ` from transformers import pipeline, BertTokenizer nlp = pipeline('question-answering', \\ model='fmikaelian/flaubert-base-uncased-squad', \\ tokenizer='fmikaelian/flaubert-base-uncased-squad')` Most probably this can be solve with a two liner. Many thanks <!-- You should first ask your question on SO, and only if you didn't get an answer ask it here on GitHub. --> **A link to original question on Stack Overflow**: https://stackoverflow.com/questions/60287465/pipeline-loading-models-and-tokenizers Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Large memory needed in gathering operations [Here][1] is a simplified example of my problem. While I can compute the gradients of a single input, I quickly run out of memory. Is there a way to make it more memory efficient? With a batch size of 6 I need 2157 MiB, but the gradients are of shapes (6, 50, 21) and (6, 50, 50, 21, 21), which are 25 MiB, but I am incurring in a 100x overhead. Am I doing something wrong? Can we help jax be smarter? Can I profile or inspect the graph to figure out which operations are taking the space? [1]: https://gist.github.com/Dapid/e980a26e063838d472f46db1b7df59bd Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cuda fail when building shared_library When building a shared_library containing cuda code, the build configuration checks fail with the following error: ```sh File \"/usr/local/lib/python3.6/dist-packages/meson-0.49.999-py3.6.egg/mesonbuild/backend/ninjabackend.py\", line 2372, in get_target_type_link_args commands += linker.get_soname_args(target.prefix, target.name, target.suffix, AttributeError: 'CudaCompiler' object has no attribute 'get_soname_args' ``` This can be demonstrated in the `test cases/cuda/2 split/static` test case by changing to use a `shared_library`. I am running off `627d0d1f3e`. Thanks. Let me know if you need more details or a hand fixing this if you can point me in the preferred direction. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Facebook Ads Provider uses a deprecated version of the API ### Apache Airflow Provider(s) facebook ### Versions of Apache Airflow Providers 2.0.1 ### Apache Airflow version 2.1.1 ### Operating System Ubuntu 20.04 ### Deployment Docker-Compose ### Deployment details _No response_ ### What happened Task fails because the hook uses a deprecated Facebook API version. The hook is calling v6.0 which is longer supported. ### What you expected to happen I expected this task to connected to the Facebook API and fetch the requested data. My log files for the failed task output the following message: ``` facebook_business.exceptions.FacebookRequestError: Message: Call was not successful Method: POST Path: https://graph.facebook.com/v6.0/act_1210763848963620/insights Params: {'level': 'ad', 'date_preset': 'yesterday', 'fields': '[\"campaign_name\",\"campaign_id\",\"ad_id\",\"clicks\",\"impressions\"]'} Status: 400 Response: { \"error\": { \"message\": \"(#2635) You are calling a deprecated version of the Ads API. Please update to the latest version: v11.0.\", \"type\": \"OAuthException\", \"code\": 2635, \"fbtrace_id\": \"AGRidwR5VhjU3kAJVUSkvuz\" } } ``` Line 69 of https://github.com/apache/airflow/blob/main/airflow/providers/facebook/ads/hooks/ads.py should be changed to a newer API version. ### How to reproduce Run the sample DAG posted here: https://airflow.apache.org/docs/apache-airflow-providers-google/stable/_modules/airflow/providers/google/cloud/example_dags/example_facebook_ads_to_gcs.html ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Warning from qtconsole when %autocall enabled If autocall is enabled (1 or 2), ipython gives this warning whenever a function is called without parens: ``` Warning: received unknown payload of type u'IPython.zmq.zmqshell.ZMQInteractiveShell.auto_rewrite_input' ``` To reproduce: start ipython with ``` ipython qtconsole --pylab=inline ``` In the qtconsole, type ``` autocall 2 len 'test' ``` The terminal ipython was started in will show the above warning. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [fixup/style] requires TF but doesn't say that cleanly It looks like `make fixup` et al, require tf (and pt), but fail in unexpected way when the requirements are missing: ``` python utils/check_repo.py Checking all models are properly tested. Checking all objects are properly documented. Checking all models are in at least one auto class. Traceback (most recent call last): File \"/home/michael/projects/transformers/utils/check_repo.py\", line 481, in <module> check_repo_quality() File \"/home/michael/projects/transformers/utils/check_repo.py\", line 477, in check_repo_quality check_all_models_are_auto_configured() File \"/home/michael/projects/transformers/utils/check_repo.py\", line 290, in check_all_models_are_auto_configured all_auto_models = get_all_auto_configured_models() File \"/home/michael/projects/transformers/utils/check_repo.py\", line 253, in get_all_auto_configured_models for attr_name in dir(transformers.models.auto.modeling_tf_auto): File \"/home/michael/projects/transformers/src/transformers/file_utils.py\", line 1690, in __getattr__ raise AttributeError(f\"module {self.__name__} has no attribute {name}\") AttributeError: module transformers.models.auto has no attribute modeling_tf_auto make: *** [Makefile:35 : extra_quality_checks] Erreur 1 ``` Thank you, @michaelbenayoun for flagging this Should we add a small script first that checks all the requirements so that the error is not misleading, but something like: \"need to install `pip install -e .[dev]` to develop `transformers`\"? @sgugger, @LysandreJik Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Allow passing input metadata to Definitions.load_asset_value ### What's the use case? I have a huge parquet file asset. I don't need it all, I only need to load certain columns from it. My IOManager can do it by accessing the `\"columns\"` field in the `AssetIn` metadata. However, I can't pass it to `Definitions.load_asset_value`. ### Ideas of implementation _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: add batching (vmap) rule for eigh Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Return errorcode 6 when settings are constrained to not support the current environment There are two approaches to restrict the environment a recipe is working for: [Constrain Settings and Options](https://docs.conan.io/en/latest/mastering/conditional.html?highlight=conaninvalidconfiguration#constrain-settings-and-options) When using the first approach and raising a `ConanInvalidConfiguration` Conan returns with errorcode 6. This could be further processed by scripts/CI perfectly. However the second approach with constraining the settings does not return with errorcode 6, but results in an [error](http://docs.conan.io/en/latest/faq/troubleshooting.html#error-invalid-setting) and errorcode 1 instead. Is there a reason why both return with different behaviour? It would be perfect if both would return with errorcode 6, so developers could use both methods and scripts/CI can react on that in the same way. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Broken link Hello, I found that the link at [https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/core/google/cloud/client.py#L33][1] is broken. https://google-cloud-python.readthedocs.io/en/latest/google-cloud-auth.html [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/661816540f1387bcc6e08b0fd722f4abae585b37/core/google/cloud/client.py#L33 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: there is no way to remove labels from a bucket Attempting to remove a label from a bucket does not appear to work: ```python # {'example': 'label'} labels = bucket.labels if 'example' in labels: del labels['example'] # {} bucket.labels = labels bucket.patch() # Still {'example': 'label'} pprint.pprint(bucket.labels) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: depscan.dd is not found with Fortran preprocessing **Describe the bug** I have an error if I use Fortran prepropressing with Meson. ``` meson compile -C builddir4 INFO: autodetecting backend as ninja INFO: calculating backend command to run: /usr/bin/ninja -C /home/alexis/Bureau/git/hsl/juliahsl/builddir4 ninja: Entering directory `/home/alexis/Bureau/git/hsl/juliahsl/builddir4' ninja: error: loading 'preprocessor.p/depscan.dd': No such file or directory ``` **To Reproduce** ``` fc = meson.get_compiler('fortran') libhsl_src = [] libhsl_src += files(file1.f, file2.f, file3.f90) pp_libhsl_src = fc.preprocess(libhsl_src, compile_args : ['-Dmetis_nodend=juliahsl_metis', '-DMETIS_NODEND=juliahsl_metis'], output: '@PLAINNAME@') ``` **Expected behavior** I expect to not have an error. it's working fine with `cc.preprocess(...)` where `cc=meson.get_compiler('c')`. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? No * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) Ubuntu 22.04 * what Python version are you using e.g. 3.8.0 3.10 * what `meson --version` 1.0.1 * what `ninja --version` if it's a Ninja build 1.10.1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: NotImplementedError: Forward-mode differentiation rule for 'digamma' not implemented I'm running into the following error using jax 0.1.57 and numpyro 0.2.4 while trying to model a GammaPoisson distribution with SVI: NotImplementedError: Forward-mode differentiation rule for 'digamma' not implemented. This issue can be replicated by running the following: ```python import jax jax.hessian(jax.scipy.special.gammaln)(jax.numpy.ones(3)) jax.grad(jax.scipy.special.digamma)(jax.numpy.ones(3)) ``` It sounds like the ideal case would be an implementation of [scipy.special.polygamma](https://docs.scipy.org/doc/scipy/reference/generated/scipy.special.polygamma.html). This way numpyro could handle taking the derivative of any polygamma. For more information, please look here: https://github.com/pyro-ppl/numpyro/issues/621#issuecomment-640892756. The GammaPoisson distribution is critical for modeling in my industry, so it would be awesome to get it working. Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Remove Recursion from CloudTaskRunner run method Just to be safe. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Monitoring TimeSeries.Query docs: broken links Today (9 March), I received a notice from a link checker that the file at [http://gcloud-python.readthedocs.io/en/latest/monitoring/query.html](http://gcloud-python.readthedocs.io/en/latest/monitoring/query.html) had two bad links to the Stackdriver Monitoring API reference. Here are two warnings I found: W,https://cloud.google.com/monitoring/api/ref_v3/rest/v3/projects.timeSeries/list#Aligner,http://gcloud-python.readthedocs.io/en/latest/monitoring/query.html,Anchor: Aligner not found. W,https://cloud.google.com/monitoring/api/ref_v3/rest/v3/projects.timeSeries/list#Reducer,http://gcloud-python.readthedocs.io/en/latest/monitoring/query.html,Anchor: Reducer not found. The Aligner and Reducer tags are no longer in the monitoring/api/ref_v3/rest/v3/projects.timeSeries/list.html file. This is a generated file, and in the most recent regeneration of the API (published on 8 March), these two tags and the content associated with them was moved (by the generating tool) to monitoring/api/ref_v3/rest/v3/projects.alertPolicies.html. Here's the [alertPolicies](https://cloud.google.com/monitoring/api/ref_v3/rest/v3/projects.alertPolicies) page. I apologize for this. I was able to pre-emptively fix the links in my own docs that this change would break, but I had no way to know from where else these anchors might be linked to. And I cannot \"fix\" this with the usual URL redirects mechanism we use when pages move. This is content in a page. I have filed a bug against the generator for this behavior. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: OSX wxPython (osx_cocoa, 64bit) command \"%gui wx\" blocks the interpreter On mac os x trying to use ipython with wxPython in interactive mode as soon as I type the command ``` %gui wx ``` completely block the python interpreter and the only way to stop it is to kill it. If I try to use an old version of wxpython (wxPython2.8-osx-unicode-2.8.12.1-universal-py2.7.dmg) I should start ipython in 32 bit mode and it works. The versions used in the blocking mode are: - OSX 10.7.5 - python 2.7.2 (and even 2.7.3) binary version from python.org - ipython 0.13.1 (pip install and local install from sources) - wxPython 2.9.4.0 (locally compiled and binary version from wxpython.org) Here the console example ``` $ ipython Python 2.7.2 (v2.7.2:8527427914a2, Jun 11 2011, 15:22:34) Type \"copyright\", \"credits\" or \"license\" for more information. IPython 0.13.1 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: gui wx Out[1]: <wx._core.App; proxy of <Swig Object of type 'wxPyApp *' at 0x102936fd0> > In [2]: **[here completely blocked]** ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inconsistent coloring in controlled Hadamard <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.12.0 - **Python version**: 3.7.6 - **Operating system**: MacOS Catalina 10.15.3 ### What is the current behavior? When drawing a circuit containing a controlled Hadamard gate (output='mpl'), the coloring it displays is blue for the box and purple for the control line. ### Steps to reproduce the problem Draw a circuit containing a controlled Hadamard gate. ### What is the expected behavior? Consistent coloring. ### Suggested solutions I would suggest using blue everywhere so that it is consistent with two qubit control gates such as CNOT. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: celery.schedules.crontab.__reduce__ does not return kwargs. ## Checklist - [x] I have included the output of ``celery -A proj report`` in the issue. (if you are not able to do this, then at least specify the Celery version affected). - [X] I have verified that the issue exists against the `master` branch of Celery. ``` software -> celery:4.0.2 (latentcall) kombu:4.0.2 py:3.5.2 billiard:3.5.0.2 py-amqp:2.1.4 platform -> system:Linux arch:64bit, ELF imp:CPython loader -> celery.loaders.app.AppLoader settings -> transport:amqp results:disabled timezone: 'UTC' beat_schedule: { 'test task': { 'args': ('hello',), 'schedule': <crontab: 35 18 * * * (m/h/d/dM/MY)>, 'task': 'test.test'}, 'test task2': { 'args': ('world',), 'schedule': <crontab: 35 15 * * * (m/h/d/dM/MY)>, 'task': 'test.test'}} accept_content: ['json'] task_serializer: 'json' result_serializer: 'json' ``` ## Steps to reproduce Set a nowfun. The nowfun will not be restored. When starting up celery beat, I never get a working nowfun back. ## Expected behavior relevant kwargs should be returned instead of `None` here: https://github.com/celery/celery/blob/master/celery/schedules.py#L532. An appropriate `__setstate__` may also be necessary to cope with this (as `app` doesn't get stored in `__dict__` as `app`, but rather `_app`). ## Actual behavior Only the constructor elements are returned from `__reduce__`, dropping all kwargs passed to the original `crontab.__init__` when pickling. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: logs command quits if one container uses syslog. If you run «`docker-compose logs`» and one container's logging driver is set to syslog, compose has an unexpected behaviour. It may show logs from some of the containers that use default json-file logging driver, but exits as soon as it reaches a container using syslog. Sometimes it shows no logs at all. docker-compose test file: ``` version: '2' services: serviceA: image: ubuntu:16.04 command: echo serviceA logging: driver: syslog options: syslog-address: \"tcp://localhost:514\" serviceB: image: ubuntu:16.04 command: echo serviceB ``` Tests: ``` $ docker-compose logs Attaching to testlogs_serviceB_1, testlogs_serviceA_1 ERROR: configured logging reader does not support reading $ docker-compose logs Attaching to testlogs_serviceB_1, testlogs_serviceA_1 serviceB_1 | serviceB ERROR: configured logging reader does not support reading $ ``` I guess it should consistently show logs from containerA and containerB, like when logging driver is set to «none»: ``` $ docker-compose logs Attaching to testlogs_serviceA_1, testlogs_serviceB_1 serviceA_1 | WARNING: no logs are available with the 'none' log driver serviceB_1 | serviceB $ ``` Please note that I did not test how it behaves with other drivers. Versions used: Docker version 1.12.1, build 23cf638 docker-compose version 1.8.0, build f3628c7 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: bug(logger): wandb fails on sweep ## 🐛 Bug When using `wandb` sweeps for hyperparameters search, I get this error: > wandb: ERROR Attempted to change value of key \"dropout_std\" from 0.030424838979365657 to 0.030424838979365654 The reason is I ran: ```python wandb_logger.log_hyperparams(params) ``` Which I guess has some problem with floating-point numbers in high accuracy? bug(logger): wandb fails on sweep ## 🐛 Bug When using `wandb` sweeps for hyperparameters search, I get this error: > wandb: ERROR Attempted to change value of key \"dropout_std\" from 0.030424838979365657 to 0.030424838979365654 The reason is I ran: ```python wandb_logger.log_hyperparams(params) ``` Which I guess has some problem with floating-point numbers in high accuracy? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: run_in_windows_bash runs commands inside bash --login, which clobbers the environment When msys2 commands are run inside `run_in_windows_bash`, they are run inside `bash --login`, which overrides many environment variables e.g. `PKG_CONFIG_PATH`: https://github.com/conan-io/conan/blob/develop/conans/client/tools/win.py#L611 This prevents the `PKG_CONFIG_PATH` functionality of `AutoToolsEnvironment.configure()` working correctly. Why `--login` used here? It seems incorrect. @lasote - I believe you introduced this originally? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %run -m doesn't support relative imports I'm trying to use `%run -m` to run modules within some packages, but it doesn't work quite like `python -m`: it doesn't support relative imports. For example, I have the following two files: - ./foo/**init**.py ``` x = 1 ``` - ./foo/bar.py ``` from . import x print x ``` With `python -m foo.bar` or `ipython -m foo.bar` the output is `x`. With `%run`, however: ``` >>> run -m test.bar Traceback (most recent call last): File \"/Library/Python/2.7/site-packages/IPython/utils/py3compat.py\", line 179, in execfile __builtin__.execfile(filename, *where) File \"/private/tmp/test/bar.py\", line 1, in <module> from . import x ValueError: Attempted relative import in non-package ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add support for generating storage upload policies and signatures [Details](https://cloud.google.com/storage/docs/xml-api/post-object#policydocument) A policy (and its associated signature) allows a web application to create a form that allows user agents to *directly upload* to Google Cloud Storage. This is a pretty useful feature and it would be great if this client library could make that easier. A rough idea: ```python storage = google.cloud.storage.Client() policy = storage.policy( bucket='my-bucket', acl='bucket-owner-read', succes_action_redirection=url_for('upload_success'), content_type='image/jpeg', content_length_range=(0, 1024*10)) encoded = policy.encoded signature = policy.signature for field_name, field_value in policy: # HTML field names and values ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: speech api with sample content bytes is not encoded to ASCII string before being sent over the wire When using the package as under with python3.5 - ``` with open('linear.wav', 'rb') as f: data = f.read() s = client.sample(data, None, encoding=Encoding.LINEAR16, sample_rate=16000) texts = client.sync_recognize(s) ``` Throws an error that it is not possible to convert the byte stream to JSON. In `speech/google/cloud/speech/client.py#240` the following line encodes the bytes in base64 but the return type of b64encode is still bytes. ``` audio = {'content': b64encode(_to_bytes(sample.content))} ``` If this is changed to the following, the API behaves as expected - ``` audio = {'content': b64encode(_to_bytes(sample.content)).decode('ascii')} ``` speech api with sample content bytes is not encoded to ASCII string before being sent over the wire When using the package as under with python3.5 - ``` with open('linear.wav', 'rb') as f: data = f.read() s = client.sample(data, None, encoding=Encoding.LINEAR16, sample_rate=16000) texts = client.sync_recognize(s) ``` Throws an error that it is not possible to convert the byte stream to JSON. In `speech/google/cloud/speech/client.py#240` the following line encodes the bytes in base64 but the return type of b64encode is still bytes. ``` audio = {'content': b64encode(_to_bytes(sample.content))} ``` If this is changed to the following, the API behaves as expected - ``` audio = {'content': b64encode(_to_bytes(sample.content)).decode('ascii')} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: ndarray.T does not return self as doc says <!-- Please describe the issue in detail here, and fill in the fields below --> `x.T` seems returning *a view of* `x` if `x.ndim < 2`, while the documentation (https://www.numpy.org/devdocs/reference/generated/numpy.ndarray.T.html) says it returns \"self\". To me it's not clear what is different between `x.T` and `x.transpose()` except for performance. ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np x = np.array([3, 4]) print(x.T is x) # => False print(x.T.base is x) # => True ``` ### Numpy/Python version information: I checked two sets of versions: ``` >>> print(numpy.__version__, sys.version) 1.16.1 3.6.5 (default, Jun 21 2018, 17:25:32) [GCC 5.4.0 20160609] ``` and ``` >>> print(numpy.__version__, sys.version) ('1.9.3', '2.7.15 (default, Nov 7 2018, 12:21:05) \\n[GCC 4.2.1 Compatible Apple LLVM 10.0.0 (clang-1000.10.44.4)]') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Compose trying to attach to dead container after error reported? Just noticed that there is an error from the `compose up` command but still says that it's trying to attach. What's it trying to attach to here? ``` docker-compose up --build Recreating poc_1 ERROR: for poc Container command './entrypoint.sh' not found or does not exist. Attaching to ``` Might be just erroneous output. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Performance of graph_builder got worse since 1.13.2 In our company we have decided to upgrade to the newest version of Conan (1.15.1). What was a surprise for me was that conan install took way more time than before. So I did some tracing with debug and found out that graph_builder is running 550 seconds instead of previous 8. This happends on libraries which have large count of dependencies (full_requires item count in conan_info.txt > 60) and some of the dependencies have also large count of dependencies. The very dependent libraries are probably making problem there. From log I can see that in 1.13.1 took graph_builder less than second to run for the very dependent dependency (its full_requires item count = 64), in 1.13.2 it takes 78 seconds. I was able to detect version where this started and it is 1.13.2. With 1.13.1 I do not have such problem. Unfortunately I cannot provide you a packages for reproducing because they are company asset. Is it known bug or is this happening just to me? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Strange behavior with `unknown` and `offline` As reported by @frol in #1797: ``` conda create -n test python --offline --unknown ``` Causes a maximum recursion error. In master, it causes a traceback of a different sort. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Elasticsearch - Snapshots metrics Hello, we would like to monitor Elasticsearch snapshotting handled by https://www.elastic.co/guide/en/elasticsearch/reference/current/snapshot-lifecycle-management-api.html and be alerted in case there aren't new snapshots sucessfully created for whatever reason. SLM provides stats https://www.elastic.co/guide/en/elasticsearch/reference/current/slm-api-get-policy.html#slm-api-get-example which provides useful information about snapshotting and would be great to have these as a metrics in datadog. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: recarray fromfile doesn't support file like objects (Trac #1911) _Original ticket http://projects.scipy.org/numpy/ticket/1911 on 2011-07-18 by trac user sbreuss, assigned to unknown._ The current implementation of the record array fromfile method doesn't support file like objects (e.g. StringIO, io.BytesIO, ...) By two minor changes in the source this would be possible: 1) change the get_remaining_size method to use seek 2) not using the readinto method of the file object I'm open to any suggestions, a patch for the current master version showing my changes is attached. Cheers, Simon Breuss Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for `Expr` values to `DAGCircuit.__eq__` The semantic equality checkers of `DAGCircuit.__eq__` should continue to work with the remapping `Clbit` instances into indices. This currently won't work, because `DAGNode.semantic_eq` converts the `.condition` field into a simple Python list for comparison, but this doesn't translate well to the general `Expr` tree. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Investigate latest mypy release It appears https://github.com/python/mypy/releases/tag/v0.730 breaks our mypy tests in unexpected ways. Currently bounding mypy above, but we should investigate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: tools.os_info.detect_windows_subsystem() should not raise To help us debug your issue please explain: *conanfile.py* ``` ... def build(self): ... if tools.os_info.detect_windows_subsystem(): make = \"make\" use_win_bash = True ``` commnad: ``` $ conan create . danitmb/testing ... ERROR: TBB/4.4.4@danimtb/testing: Error in build() method, line 42 if tools.os_info.detect_windows_subsystem(): ConanException: bash is not in the path ``` Using `cygwin_installer/2.9.0@bincrafters/stable` and `msys2_installer/20161025@bincrafters/stable` bash is in path and `tools.os_info.detect_windows_subsystem()` behaves well. So it would be better to not raise in case you want to check if you are in a windows subsystem and just return `None`. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant: conan 1.2.3 - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: LightningTemplateModel is broken <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug `LightningTemplateModel` has no implemented `validation_step_end` method. See [here](https://github.com/PyTorchLightning/pytorch-lightning/blob/8035c10f379dd0c00dcf00bd3fdee3f66fb074a2/pl_examples/models/lightning_template.py#L245) ### To Reproduce Just try to run test evaluation on MNIST example ### Expected behavoir It should not crash Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Provide a Jupyter magic function to get the status of running jobs <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Get a way of inspecting the state of executed jobs by using a Jupyter magic function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Masking passwords with empty connection passwords make some logs unreadable in 2.1.0 Discovered in this [Slack conversation](https://apache-airflow.slack.com/archives/CCQ7EGB1P/p1621752408213700). When you have connections with empty passwords masking logs masks all the character breaks: ``` [2021-05-23 04:00:23,309] {{logging_mixin.py:104}} WARNING - ***-***-***-*** ***L***o***g***g***i***n***g*** ***e***r***r***o***r*** ***-***-***-*** [2021-05-23 04:00:23,309] {{logging_mixin.py:104}} WARNING - ***T***r***a***c***e***b***a***c***k*** ***(***m***o***s***t*** ***r***e***c***e***n***t*** ***c***a***l***l*** ***l***a***s***t***)***:*** [2021-05-23 04:00:23,309] {{logging_mixin.py:104}} WARNING - *** *** ***F***i***l***e*** ***\"***/***u***s***r***/***l***o***c***a***l***/***l***i***b***/***p***y***t***h***o***n***3***.***8***/***l***o***g***g***i***n***g***/***_***_***i***n***i***t***_***_***.***p***y***\"***,*** ***l***i***n***e*** ***1***0***8***1***,*** ***i***n*** ***e***m***i***t*** *** *** *** *** ***m***s***g*** ***=*** ***s***e***l***f***.***f***o***r***m***a***t***(***r***e***c***o***r***d***)*** ``` Until this is fixed, an easy workaround is to disable masking via disabling sensitive connection masking in configuration: ``` [core] hide_sensitive_var_conn_fields = False ``` or vial env variable: ``` AIRFLOW__CORE__HIDE_SENSITIVE_VAR_CONN_FIELDS=\"False\" ``` This is only happening if the task accesses the connection that has empty password. However there are a number of cases where such an empty password might be \"legitimate\" - for example in `google` provider you might authenticate using env variable or workload identity and connection will contain an empty password then. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Not auto add DistributedSampler for DDP training ## 🐛 Bug <!-- A clear and concise description of what the bug is. --> in 0.72, even if we don't set sampler, pytorch_lightning will not add DistributedSampler for us. ### To Reproduce the reason is in pytorch, if we don't set sampler, pytorch will add a sampler for us. in pytorch's dataloader.py: ``` if sampler is None: # give default samplers if self._dataset_kind == _DatasetKind.Iterable: # See NOTE [ Custom Samplers and IterableDataset ] sampler = _InfiniteConstantSampler() else: # map-style if shuffle: sampler = RandomSampler(dataset) else: sampler = SequentialSampler(dataset) ``` but in pytorch_lightning we check whether sampler is None to decide to add sampler in data_loading.py funciton auto_add_sampler: ``` no_sampler_added = dataloader.sampler is None ``` because pytorch have default sampler for us, which is not None, pytorch_lighting will not automatically add sampler. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Add ability to schedule a static partition job ## Use Case <!-- Help us to understand your request in context --> Currently the only schedule decorators and functions that support partitions only support temporal partitions. In addition, a standard (non-partition) schedule fails when attempting to use in conjunction with a static partition job (`dagster.core.errors.DagsterInvalidSubsetError: No qualified ops to execute for op_selection=['']`) ## Ideas of Implementation <!-- Your ideal solution --> Provide functionality to either execute all partitions or explicitly define a partition to be ran with a cron schedule ## Additional Info <!-- (Optional)--> --- #### Message from the maintainers: Excited about this feature? Give it a :thumbsup:. We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: is_required on @asset Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Config not passed down to subcommands Debugging a complex issue at Scipy, we ran into the fact that config manually passed in to `TerminalIPythonApp` doesn't get passed down to subcommands. The use case was overriding KernelManager.kernel_cmd to start notebook kernels in a Python interpreter running under Mono. Adding a `config=self.config` to [this call](https://github.com/ipython/ipython/blob/master/IPython/config/application.py#L398) solved it for us - is that the right way to do it? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Using \"?\" in a tools.get() URL will fail, while using it in a tools.download() will succeed. To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Example: ``` from conans import ConanFile, tools class LibraryConan(ConanFile): name = \"Library\" version = \"1.0\" license = \"\" url = \"<Package recipe repository url here, for issues about the package>\" description = \"\" settings = \"os\", \"compiler\", \"build_type\", \"arch\" def source(self): tools.get(\"http://example.com/?file=1\") ``` ``` conan create . Company/beta ERROR: Library/1.0@Company/beta: Error in source() method, line 12 tools.get(\"http://example.com/?file=1\") ConanConnectionError: Download failed, check server, possibly try again [Errno 22] Invalid argument: 'C:\\\\Users\\\\User\\\\.conan\\\\data\\\\Library\\\\1.0\\\\Company\\\\beta\\\\source\\\\?file=1' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose up not attaching to container I cant seam to run anything with docker-compose now that I am using the development version. ``` $ docker-compose --version docker-compose version: 1.5.0dev $ git log --oneline --decorate 83c514f (origin/master, origin/HEAD) Merge pull request #1933 from dnephin/fix_scale_test_flakes 235fe21 Prevent flaky test by changing container names. ``` Trying to run `up` spins up the container, then immediately closes it: ``` $ docker-compose up Recreating smeservice_web_1... Attaching to Gracefully stopping... (press Ctrl+C again to force) Stopping smeservice_web_1... ``` running docker run -it busybox /bin/sh -c \"while true; do /bin/echo 'hello'; sleep 5; done;\" works fine. Here is my docker-compose.yml ``` web: image: busybox command: /bin/sh -c \"while true; do /bin/echo 'hello'; sleep 5; done;\" ``` Running on version 1.4.0 gives me the following: ``` $ docker-compose up Starting smeservice_web_1... Attaching to smeservice_web_1 web_1 | hello web_1 | hello ``` Other info: ``` $ python --version Python 3.4.0 ``` Running Ubuntu 14.10 ``` $ uname -r 3.19.0-26-generic ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: remove `Configurable.created` ? What is the point of `Configurable.created` ? it does not seem to be use anywhere : ``` $ ack '\\.created' **/*.py IPython/config/configurable.py 105: self.created = datetime.datetime.now() IPython/nbformat/v2/nbbase.py 159: metadata.created = unicode_type(created) IPython/nbformat/v2/tests/test_nbbase.py 109: self.assertEqual(md.created, u'today') IPython/nbformat/v3/nbbase.py 195: metadata.created = cast_unicode(created) IPython/nbformat/v3/tests/test_nbbase.py 139: self.assertEqual(md.created, u'today') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: add base_url to notebook configuration options Hi, (Apologies if this is already possible - I didn't find it anywhere.) I'd like to serve my notebook behind a proxy server. For example, comsider nginx running on http://somewhere.com and serving all URLS matching the regex http://somewhere.com/ipython/astraw/(.*) by proxying them to http://localhost:8888/ipython/astraw/$1. In particular, this is proxying without URL rewriting. To do this, I think two changes need to be made to the source: 1) change the handlers specified to tornado.web.Application so that they specify a base_url before their current name. 2) have all URL emitters (e.g. \"/static/blah/blah\") also have the base_url (e.g. emit base_url+\"/static/blah/blah\" instead). Does this make sense? Is there a way to do it already? If so, I missed it after looking for some time, but apologies nevertheless. Thanks for the notebook interface. I am dreaming big with this... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Unpin jinja2 / flask / werkzeug See: https://dagster.phacility.com/D7879 which added the pins And user-reported issue here that demonstrates the symptoms of upgrading to flask2 (dagit unable to serve any requests): https://github.com/dagster-io/dagster/issues/4166 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Disable ClearML automatic model uploading ### Feature request Allow users of `transformers` to disable the automatic model uploading of ClearML. Perhaps we can also allow users to write their own integration callbacks in case they want to configure some more stuff. The place where the saving happens is `src/transformers/integrations.py`: ``` def on_save(self, args, state, control, **kwargs): if self._clearml_task and state.is_world_process_zero: ckpt_dir = f\"checkpoint-{state.global_step}\" artifact_path = os.path.join(args.output_dir, ckpt_dir) logger.info(f\"Logging checkpoint artifacts in {ckpt_dir}. This may take time.\") self._clearml_task.update_output_model(artifact_path, iteration=state.global_step, auto_delete_file=False) ``` We should add a condition to the main `if`, similar to what `NeptuneCallback` or `MLflowCallback` is doing. ### Motivation Several experiments that I ran were interrupted because I reached the max limit of model uploading. However, I was not interested in uploading my models in the first place. Hence, a configuration would be appropriate in this case. ### Your contribution I can submit a PR if the contributors would help figure out the correct way of handling it :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: scm query Is there a reason the .git folder is excluded from the copy that occurs? Would it be possible to ensure that it isn't ignored? I've got a tool I'm using in parts of my conanfile that requires being able to query the git repo. I think it would make sense for the .git folder to be included in the copy to make the export from source closer to what happens on a machine that pulls the recipe and tries to build a non-existant hash. https://github.com/conan-io/conan/blob/94222228824c90f482cd56769667d1f5c42cca8e/conans/client/tools/scm.py#L99 Thanks! Matt Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: `resize_token_embeddings` not taken into account in `save_pretrained` for `EncoderDecoderModel` ## Environment info - `transformers` version: 4.5.0 - Platform: Darwin-17.7.0-x86_64-i386-64bit - Python version: 3.7.2 - PyTorch version (GPU?): 1.4.0 (False) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ### Who can help @patrickvonplaten, @patil-suraj ## Information I am extending the embeddings of the decoder of an `EncoderDecoderModel` model. When I save it, the config does not reflect the new size. However, it works fine when I try doing the same for non `EncoderDecoderModel` models. ## To reproduce ``` In [1]: model = t.EncoderDecoderModel.from_encoder_decoder_pretrained('bert-base-uncased', 'bert-base-uncased') In [2]: model.decoder.bert.embeddings.word_embeddings Out[2]: Embedding(30522, 768, padding_idx=0) In [3]: model.decoder.resize_token_embeddings(30522+100) Out[3]: Embedding(30622, 768) In [4]: model.save_pretrained('test-bert') ``` ## Expected behavior The updated embedding size should be saved in `config.json` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add features/track_features support for MatchSpec Resolve cleanup following new MatchSpec implementation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Envs need to be activated before post-link scripts run In Python 3.7, we removed a patch to Python that put Library/bin on PATH. This was done because putting that on PATH broke the new conda activate stuff somehow. A side effect of this change is that packages with post-link scripts may fail to run (see https://github.com/ContinuumIO/anaconda-issues/issues/10082 for one example). At a minimum, we should be activating environments before we run post-link scripts. We should think about pre-unlink and pre-link, too, I guess. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: Backend Docker build fails with python error in resnet-train-pipeline.py Ran on master branch (`086d4763d9f163acdeb423bc2bc49ab470442a92`) with `--no-cache` arg and got the following the error: ``` Step 20/31 : RUN find . -maxdepth 2 -name '*.py' -type f | while read pipeline; do dsl-compile --py \"$pipeline\" --output \"$pipeline.tar.gz\"; done ---> Running in 3205bef0c5cb Traceback (most recent call last): File \"/usr/local/bin/dsl-compile\", line 10, in <module> sys.exit(main()) File \"/usr/local/lib/python3.5/site-packages/kfp/compiler/main.py\", line 103, in main compile_pyfile(args.py, args.function, args.output, not args.disable_type_check) File \"/usr/local/lib/python3.5/site-packages/kfp/compiler/main.py\", line 92, in compile_pyfile _compile_pipeline_function(function_name, output_path, type_check) File \"/usr/local/lib/python3.5/site-packages/kfp/compiler/main.py\", line 72, in _compile_pipeline_function kfp.compiler.Compiler().compile(pipeline_func, output_path, type_check) File \"/usr/local/lib/python3.5/site-packages/kfp/compiler/compiler.py\", line 644, in compile workflow = self._compile(pipeline_func) File \"/usr/local/lib/python3.5/site-packages/kfp/compiler/compiler.py\", line 596, in _compile pipeline_func(*args_list) File \"./resnet-cmle/resnet-train-pipeline.py\", line 127, in resnet_train export_output = os.path.join(str(train.outputs['job-dir']), 'export') KeyError: 'job-dir' The command '/bin/sh -c find . -maxdepth 2 -name '*.py' -type f | while read pipeline; do dsl-compile --py \"$pipeline\" --output \"$pipeline.tar.gz\"; done' returned a non-zero code: 1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Clean up the Clean Logic We need to improve the logic around cleaning. We should follow the lead of `git clean` and support flags for the `jupyter lab clean` command [here](https://github.com/jupyterlab/jupyterlab/blob/e2fd4c8841a7393f9131fb6b6e8252864a8bd351/jupyterlab/labapp.py#L87). The current logic only cleans the staging directory: https://github.com/jupyterlab/jupyterlab/blob/e2fd4c8841a7393f9131fb6b6e8252864a8bd351/jupyterlab/commands.py#L357 in the app directory. I think we should add flags for cleaning: - The static directory - The settings directory (for recovery - warn if there are local linked extensions) - The extensions directory (for recovery) - The entire app directory (for recovery) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: GCC Link order Hi Sorry about the weak problem description, but I have yet to find out what is really causing it. Tools: GCC, CMake, Linux (and MingW-64 on Windows), using conan BASIC and not TARGET. When I moved from conan 1.3.3 to conan 1.4.2 (also tried with 1.4.0 and 1.4.3) my builds where unable to link. The ordering of the libraries to link has changed. I have a project A that depends on B and C and where project B also depends on C. B and C are both static libraries where A is a shared library. When linking A, I get an undefined reference from project B to project C. When looking at the generated link.txt file I can see that the order of the libraries in the file have changed from 1.3.3 to 1.4.x. In version 1.3.3 I had library C twice in the link.txt file, in version 1.4.x it is only listed once, and unfortunately not after library B. I have tried to establish a small test project to see if I could recreate it in a way where you could see the problem, but I have not been able to so far. Do you have any thoughts about changes in the link ordering determination that might help me locate my issue. And possibly provide you with a working example (or rather not working) Regards Lau Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: qtconsole truncates help The Ipython shell opened with `qtconsole` option (i.e `ipython qtconsole`) truncates the help message obtained by the `??` magic. i.e ``` In [1]: import string In [2]: string?? ``` Gives: ``` lineno = len(lines) raise ValueError('Invalid placeholder in string: line %d, col %d' % (lineno, colno)) def substitute(self, *args, **kws): if len(args) > 1: raise TypeError('Too many positional arguments') if not args: mapping = kws elif kws: mapping = _multimap(kws, args[0]) else: mapping = args[0] # Helper function for .sub() def convert(mo): # Check the most common path first. named = mo.group('named') or mo.group('braced') if named is not None: val = mapping[named] # We use this idiom instead of str() because the latter will # fail if val is a Unicode containing non-ASCII characters. ... ``` This bug is observed on Win32 and OSX. IPython itself (without `qtconsole`) does not exhibit this problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: DockerEnvironment prefect version Currently, `DockerEnvironment`s pull the bleeding edge version of Prefect from git, which might not agree with a user's local version, or might not be stable. I think we should have a \"prefect_version\" init kwarg that (optionally) specifies a specific Prefect version to pull (defaults to pulling bleeding edge). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: graph --table=file.html does not show outdated packages They were previously shown in colors. I guess adding a column \"outdated\" will resolve this issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: config does not validate broken subnets docker-compose 1.11.2 Broken config, due to missing variable - no error during `config` ``` networks: default: ipam: config: - subnet: '' driver: default ``` On `docker-compose up` ``` ERROR: Invalid subnet : invalid CIDR address: ``` Should be thrown already during validation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add intel compiler to default settings.yml Suggested: ``` intel: version: [\"17.0.0\", \"17.0.1\", \"17.0.2\", \"17.0.3\", \"17.0.4\", \"17.0.5\", \"17.0.6\", \"17.0.7\", \"17.0.8\", \"18.0.0\", \"18.0.1\", \"18.0.2\", \"18.0.3\", \"18.0.4\", \"19.0.0\", \"19.0.1\", \"19.0.2\", \"19.0.3\"] libcxx: [libstdc++, libstdc++11] # Linux only runtime: [MD, MT, MTd, MDd] # Windows only cppstd: [None, 98, gnu98, 11, gnu11, 14, gnu14, 17, gnu17, 20, gnu20] ``` To investigate: - Binary compatibility of update/patches: reported erorrs on 17.0.4->17.0.6 - Intel compiler also includes fortran, check if it makes sense regarding cppstd/libcxx - libcxx/runtime in different OS, how to manage? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: celery.utils.time.maybe_make_aware docstring incorrect The docstring for [celery.utils.time.maybe_make_aware](https://github.com/celery/celery/blob/master/celery/utils/time.py#L321) claims that it doesn't do anything if dt is already timezone-aware, but this is incorrect, as it will try to convert to the localtime or utc instead. This doesn't look like correct behavior, and doesn't allow timezones to work correctly in the crontab scheduler. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: generate_docs.py fails with functools.partial functions In `prefect.utilities.json`, there's a `dumps` function that is generated by applying `functools.partial` to `json.dumps`. It creates an error if you try to add it to `generate_docs.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: _repr_svg_ needs better documentation `_repr_svg_` has additional return options as mentioned by @takluyver here: https://github.com/igraph/python-igraph/issues/145#issuecomment-344283193 I couldn't find the fact that `_repr_svg_` could return a tuple mentioned anywhere. Specifically, this could be mentioned here: * http://ipython.readthedocs.io/en/stable/api/generated/IPython.display.html * http://ipython.readthedocs.io/en/stable/api/generated/IPython.core.formatters.html Perhaps there are other `_repr_` functions that are also under-documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %%writefile can't handle white space in file path/filename It is as the title suggests. In ipython, I have tried `%%writefile \"test out.txt\"` `%%writefile 'test out.txt'` `%%writefile test out.txt` `%%writefile test\\ out.txt` and none gives me the expected behavior. The first one leads to creating a file literally named \"test out.txt\" (yes, with quotes). The third one just leads to > unrecognized arguments: out.txt Is this a bug or am I just missing something obvious? Using IPython 6.5.0 with Python 3.6.5. %%writefile can't handle white space in file path/filename It is as the title suggests. In ipython, I have tried `%%writefile \"test out.txt\"` `%%writefile 'test out.txt'` `%%writefile test out.txt` `%%writefile test\\ out.txt` and none gives me the expected behavior. The first one leads to creating a file literally named \"test out.txt\" (yes, with quotes). The third one just leads to > unrecognized arguments: out.txt Is this a bug or am I just missing something obvious? Using IPython 6.5.0 with Python 3.6.5. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: volumes: absolute path becomes relative if it is in an environment variable This used to work with `fig`, but no longer seems to work in `docker-compose==1.2.0rc3`: ``` myservice: volumes: - ${DOCKER_CERT_PATH}:/certs ``` `DOCKER_CERT_PATH` contains an absolute path to a directory (e.g `/Users/me/.boot2docker/certs/boot2docker-vm`). Instead of mounting that, it will make it relative to the directory of the `docker-compose.yml` file. Probably the code checks somewhere if it starts with `/` before expanding the variable, since setting it to `- /${DOCKER_CERT_PATH}:/certs` works. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit.draw(output='mpl) does not draw qubit labels correctly. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: osx ### What is the current behavior? Using Latex: <img width=\"603\" alt=\"screen shot 2018-12-07 at 11 49 43 am\" src=\"https://user-images.githubusercontent.com/1249193/49661112-39c16400-fa16-11e8-8610-70a1d89474e6.png\"> Using MPL: <img width=\"496\" alt=\"screen shot 2018-12-07 at 11 50 21 am\" src=\"https://user-images.githubusercontent.com/1249193/49661148-4fcf2480-fa16-11e8-8f52-ad065c35d815.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add tensorboard logger **Is your feature request related to a problem? Please describe.** A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] **Describe the solution you'd like** A clear and concise description of what you want to happen. **Describe alternatives you've considered** A clear and concise description of any alternative solutions or features you've considered. **Additional context** Add any other context or screenshots about the feature request here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan config install and \"LICENSE.txt\" and \"README.md\" To help us debug your issue please explain: - [x ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [ ] I've specified the Conan version, operating system version and any tool that can be relevant. - [ x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. If you install the conan config via **conan config install ....** like (conan config install https://github.com/bincrafters/conan-config.git) All files will be copied in the ~/.conan folder. So far so good, but files like the famous \"LICENSE.txt\" and \"README.md\" are also copied to ~/.conan. This somehow pollutes the .conan folder. I think its better to filter out this special files during the installation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Logical error in transpiler.py ### Environment - **Qiskit Terra version**: 7ae670a8e74d5a98dd516f696530c74e95f73885 - **Python version**: n/a - **Operating system**: n/a ### What is happening? While debugging other issues with the coupling_map, I noticed a puzzling section in the code: https://github.com/Qiskit/qiskit-terra/blob/1282a04d528dd56d8e401dccc388a32178e9c6cc/qiskit/compiler/transpiler.py#L358-L361 At this point, `coupling_map` is either a `CouplingMap`, a list of lists of integers, or `None` and `unique_transpile_args` is a list of dicts with these keys: https://github.com/Qiskit/qiskit-terra/blob/1282a04d528dd56d8e401dccc388a32178e9c6cc/qiskit/compiler/transpiler.py#L757-L763 So I don't see how this condition could ever be true. ### How can we reproduce the issue? Here is some code that can raise an exception because of the problem with the code: ``` from qiskit import QuantumCircuit, transpile qc = QuantumCircuit(1) transpile([qc] * 2, coupling_map=[None, None]) ``` ### What should happen? No error for the above code. ### Any suggestions? I think code needs to check if `\"coupling_map\"` is in the shared dict, pull the coupling maps out of the unique dicts if not. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Wasb connection to Azure Fileshareservice Hook not working **Apache Airflow version**: Version: v2.1.0 Git Version: .release:2.1.0+304e174674ff6921cb7ed79c0158949b50eff8fe **What happened**: INFO - __init__() got an unexpected keyword argument 'extra__wasb__connection_string' **What you expected to happen**: We have used the extra field and populated the SAS token according to the documents on how to use wasb connection for fileshare and we should be able to login in using the SAS token. This has been working in 2.0.0 <img width=\"416\" alt=\"airflow_bug\" src=\"https://user-images.githubusercontent.com/1429314/120696017-a85dcc00-c471-11eb-925d-05794e33d40b.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Enhancement: configuration summary printing Many configure scripts have something like this at the end: ``` echo $PACKAGE configuration summary: echo echo Installation Prefix .............. : ${prefix} echo GStreamer API version ............ : $GST_VERSION echo VA-API version ................... : $VA_VERSION_STR echo Video encoding ................... : $(yesno $USE_ENCODERS) echo Video outputs .................... : $VIDEO_OUTPUTS ``` It would be nice if we had dedicated API for this in Meson. It would provide two features: - booleans printed as yes|no by default, though possibility to pass alternative strings would be nice to have too - formatting the output so that it's nicely in two columns (so would have to collect all config summary statements to figure out width first) API-wise it could be something like: ``` summary_message('Foo', value) summary_message('Bar', other_value) ``` or ``` print_summary([ ['Foo', value], ['Bar', value], ]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: the default decimals in get_statevector is too small <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The original statevector simulator will return decimals as many as possible; however, the new terra clips it to 8-digits by default, which results in many chemistry simulations fails because the returned statevector is not enough. For example, 8-digits is not accurate enough for me to reach ground state energy of H2 since the optimizer can not build accurate gradient with such precision. I imagine that some users will result in the same situation and it is not easy to find this issue. Could we make the default to as many as possible and then if users would like to truncate that they can pass the parameters. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: 1.18.0-rc1 - Container run error - mount path must be absolute After updating **docker compose** from version 1.17.1 to version 1.18.0-rc1 has been appeared error: ``` ERROR: for php_php72_1 Cannot create container for service php72: invalid mount config for type \"bind\": invalid mount path: 'web' mount path must be absolute ERROR: for php72 Cannot create container for service php72: invalid mount config for type \"bind\": invalid mount path: 'web' mount path must be absolute ERROR: Encountered errors while bringing up the project. ``` I use [long syntax for bind mounts](https://docs.docker.com/compose/compose-file/#long-syntax-3). If this change to short syntax everything works well My docker-compose.yml file contents: ``` version: '3.4' services: php72: image: php:alpine ports: - \"80:8080\" volumes: - type: bind source: ./web target: /var/www/html/ command: [\"php\", \"-S\", \"0.0.0.0:8080\", \"-t\", \"/var/www/html\"] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Toggling logger verbosity causes issues for test suite ### What happened? Ran into into some funky verbosity/logging issues because of our mixed usage of what `--verbose` means (both `conda clean` and `conda doctor` expose this). Historically `--verbose` was exclusively used to indicate increasing the logging verbosity but recently we’ve also used it to print out more detailed info (compare for example, `conda info --all` versus `conda info --verbose`). To replicate this today on main run the following, note the test order is important: ``` pytest \\ tests/plugins/subcommands/doctor/test_cli.py::test_conda_doctor_happy_path_verbose \\ tests/cli/test_main_run.py::test_run_returns_nonzero_errorlevel ``` The issue is caused by `--verbose` being treated as an alias for `context.verbosity` which sets the logging verbosity in `conda.cli.main::main_subshell` (see `init_loggers`) and toggling the verbosity/logging in our test suite results in stream closed errors as the old handlers are replaced with new ones (I think this happens [here](https://github.com/conda/conda/blob/c691f729a942ab0a3303424a31d0e1e5b07143d9/conda/common/io.py#L320-L341)): ``` Traceback (most recent call last): File \"/Users/kodegard/.conda/devenv/Darwin/arm64/envs/devenv-3.10-c/lib/python3.10/logging/__init__.py\", line 1103, in emit stream.write(msg + self.terminator) ValueError: I/O operation on closed file. ``` I believe there are two possible fixes: 1. don’t replace logging handlers, rather mutate them in place (not 100% sure if this is safe to do) 2. don’t use `--verbose` to print more info, introduce a new argument like `--detailed` ### Prior Discussions - https://github.com/conda/conda/issues/12420 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Improve the server printed traces I have a user configured for Conan server: ```ini [users] test: test ``` But when I try to check if this works it fails: ```bash % curl -s --basic -u test:test localhost:9300/v2/users/authenticate Wrong user or password ``` Same goes for the `conan` command: ```bash % conan user --password test --remote my-repo test ERROR: Wrong user or password. [Remote: my-repo] ``` Am I doing something wrong here? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Expose `Environment::get_build_command()` to meson.build Hi, As part of the build generation I would like to generate tests / scripts that in invoke meson. One example is generating a script that runs `DESTDIR=/sometemp meson install` and then runs tests against that temporary installation. I can't just use `find_program('meson')` because meson may not be on `PATH` or the meson on `PATH` isn't the same as used in a build directory. I obviously can just invoke `ninja install ` in such scripts / tests, but that will not work in case a different backend is used. Hence the desire to expose `get_build_command()`. Would a patch adding that feature have a decent chance of getting accepted? A second, less crucial, use-case for this is that I would like to generate a script that uses meson introspect + knowledge of the source-tree to compares - and optionally resyncs - the list of tests existing in the source tree and the tests that the corresponding meson.build knows about. `get_build_command()` effectively already is exposed via `MESONINTROSPECT` (including inside `run_command` and `add_postconf_script`, which doesn't seem to be documented). Exposing just the meson invocation as an array to meson.build seems a lot cleaner however than needing to do shell-splitting inside commands. Regards, Andres Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Empty COMPOSE_PROJECT_NAME treated differently in 1.6.0rc2 In docker-compose 1.5.x an empty env variable for the project name is okay, it uses the default of the directory name. In 1.6 behavior has changed and this is now an error. I prefer the 1.5 behavior but if this is intentional seems like it's good for a release note. ``` $ env COMPOSE_PROJECT_NAME= docker-compose up -d Creating _npmlazy_1 ERROR: Invalid container name (_npmlazy_1), only [a-zA-Z0-9][a-zA-Z0-9_.-] are allowed ``` ``` $ docker-compose --version docker-compose version 1.6.0rc2, build 695c692 $ docker info Containers: 81 Images: 1904 Server Version: 1.9.1 Storage Driver: aufs Root Dir: /mnt/sda1/var/lib/docker/aufs Backing Filesystem: extfs Dirs: 2066 Dirperm1 Supported: true Execution Driver: native-0.2 Logging Driver: json-file Kernel Version: 4.1.12-boot2docker Operating System: Boot2Docker 1.9.0 (TCL 6.4.1); HEAD : 16e4a2a - Thu Dec 10 06:53:38 UTC 2015 CPUs: 4 Total Memory: 4.719 GiB Name: dev ID: VHZ6:63LX:AV4M:RCLR:562Q:EXOS:S5SL:5REP:AOET:6ZZE:YZUU:FQMV Debug mode (server): true File Descriptors: 177 Goroutines: 323 System Time: 2016-01-28T18:24:24.322889587Z EventsListeners: 1 Init SHA1: Init Path: /usr/local/bin/docker Docker Root Dir: /mnt/sda1/var/lib/docker Labels: ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: gatefacecolor key has no effect on circuit diagrams ### Information - **Qiskit Terra version**: 0.9.0 - **Python version**: 3.7.4 - **Operating system**: Ubuntu 18.04.3 ### What is the current behavior? When plotting circuit diagrams, the `gatefacecolor` key has no effect. ### Steps to reproduce the problem ```python from qiskit import QuantumRegister, QuantumCircuit, ClassicalRegister qr = QuantumRegister(3) cr = ClassicalRegister(1) qc1 = QuantumCircuit(qr) qc1.x(qr[1]) qc1.h(range(3)) qc1.cx(qr[1], qr[2]) qc1.cx(qr[0], qr[1]) style = {'gatefacecolor': '#hhhhhh'} qc1.draw(output='mpl', style=style).show() ``` Produces this image: 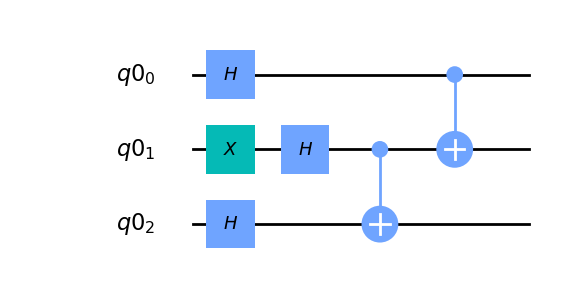 The same image is produced using any hex colour code or by removing the gatefacecolor key. ### What is the expected behavior? The gate faces should be white in this example. ### Suggested solutions A suggested solution was to use `style=False`, which overrides the default styling and produces a black and white diagram. However, this would not allow the use of other desired style keys such as `'usepiformat': 'true'`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Update local Python simulators to use Qobj internally <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? After #655, the local Python simulators accept a `Qobj` instance (with the new schema) during `.run()`, but internally they still use the old schema (for example, in `.run_circuit()`). Ideally they should also make use of the new schema and the instances directly instead of performing that conversion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Deprecate 'conda env attach' and 'conda env upload' These two commands are outside the scope and spirit of conda. The first requires knowledge of a \"notebook,\" which is not one of conda's fundamental units of work. The second requires knowledge of the Anaconda API, which is the purview of anaconda-client, not conda. Deprecation warnings will be given in conda 4.4, with the command scheduled for removal in conda 4.5. Deprecate 'conda env attach' and 'conda env upload' These two commands are outside the scope and spirit of conda. The first requires knowledge of a \"notebook,\" which is not one of conda's fundamental units of work. The second requires knowledge of the Anaconda API, which is the purview of anaconda-client, not conda. Deprecation warnings will be given in conda 4.4, with the command scheduled for removal in conda 4.5. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Migrate MySQL example DAGs to new design There is a new design of system tests that was introduced by the [AIP-47](https://cwiki.apache.org/confluence/display/AIRFLOW/AIP-47+New+design+of+Airflow+System+Tests). All current example dags need to be migrated and converted into system tests, so they can be run in the CI process automatically before releases. This is an aggregated issue for all example DAGs related to `MySQL` provider. It is created to track progress of their migration. List of paths to example DAGs: - [x] airflow/providers/mysql/example_dags/example_mysql.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Empty classpath in java. I'm trying to generate java project with meson. The `meson.build` is: <pre> project('Calculator', 'java') src = files('calculator/Tokens.java', 'calculator/Tokenizer.java', 'calculator/Calculator.java') jar = jar(meson.project_name(), src, main_class : 'calculator/Calculator') test('test', jar) </pre> The meson generates ninja targets with empty -cp options. <pre> # Build rules for targets build Calculator@jar/calculator/Tokens.class: java_COMPILER ../calculator/Tokens.java ARGS = -g -d Calculator@jar -s Calculator@jar -cp '' -sourcepath ../:.: </pre> And I get a bunch of 'cannot find symbol' errors. I'm noob in java, but I believe the classpath should be `Calculator@jar`. When I set it manually in build.ninja all compiles fine. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: XY gate ### What is the expected enhancement? It would be useful if the `XY` gate could be added to the existing circuit library https://qiskit.org/documentation/apidoc/circuit_library.html The use case is for a basis gate for the qiskit transpiler. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Bug in network check On this line: https://github.com/DataDog/integrations-core/blob/master/network/check.py#L438 This should be `self.log` rather than `self.logger`. As it is, this raises ``` AttributeError: 'Network' object has no attribute 'logger' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: How to get meson to not add the -pipe option to my cpp compilation steps I have declared my project settings as such. `project('MyProject', 'cpp', 'c', default_options: ['buildtype=plain', 'b_staticpic=false', 'b_asneeded=false', 'b_lundef=false']` The project requires cross-compilation and neither my c _args or my cpp_args that come under the properties section of my crossfile include the '-pipe' option. However, the build.ninja that meson generates for my build directories shows that the '-pipe' has been added as a compiler argument in all my c/cpp compilation steps. Not sure if I missed it, but I'm unable to find a way to not enable meson to do this from the documentation. Is there a default option that I can set to not allow meson to insert compilation arguments other than the ones listed in my crossfile? System parameters: OS: Debian stretch Python version: 3.5.3 Meson version: 0.56.0 Ninja version; 1.7.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add a way to operate on all outputs from training_step I realized the ddp2 implementation i put together doesn't allow the user to operate on the ouputs of all DP processes. For instance, you calculate some logits on each process and current ddp2 forces the loss to be calculated in each process individually. However, if you wanted to say normalize across all examples in the batch you'd need to somehow share the output of each process. Currently: ```python total_loss = [] for process: # training step out = model(x) loss = loss(out) total_loss.append(loss) loss = total_loss.mean() ``` Proposed: ```python outs = [] for process: # training step out = model(x) outs.append(out) # allow training_end to (softmax for instance) using ALL outputs loss = model.training_end(outs) loss.backward() ``` The implication is adding an optional: ```python def training_end(...): ``` To model which when defines gives you all the outputs of training_step. If you don't need anything advanced like this, you return a loss from training_step and don't implement training_end. If you need more advanced control, you implement ```training_end```. @tullie @neggert Any thoughts on this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: cmd_def parameter string is incorrectly reported as unsafe <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When parsing the cmd_def provided by the backend, pulse commands may be parameterized (typically phase shifts). These commands are sanitized before being passed to Sympy for parameter and expression extraction. Currently, this sanitization is too conservative and is failing on the string ```\"-(P1)\"```. ### Steps to reproduce the problem Create a cmd_def with a frame change command with the parameter ```\"-(P1)\"```. ### What is the expected behavior? This string should pass sanitization ### Suggested solutions Relax sanitization strictness to allow consecutive special match characters. In the long run, replace with a full math parser. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Standalone WX GUI support is broken The example in `docs/lib/gui-wx.py` doesn't currently work, and I've failed in all simple attempts at fixing it. Since we can't hold the 0.11 release for any longer, I'm marking this as a known bug in the release notes, but we should get to the bottom of it. The other three examples (Qt, GTK, Tk) do run fine. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add creationTime and expirationTime properties to TableListItem API reference: https://cloud.google.com/bigquery/docs/reference/rest/v2/tables/list The properties `creationTime` and `expirationTime` now appear in the API results for `list_tables()`. The `creationTime` properties is exposed as `Table.created`. A similar property needs to appear on `TableListItem`. https://github.com/GoogleCloudPlatform/google-cloud-python/blob/62740078538ea84167705c15bf109c1a2737c648/bigquery/google/cloud/bigquery/table.py#L387-L397 Likewise `Table.expires` needs a corresponding property. https://github.com/GoogleCloudPlatform/google-cloud-python/blob/62740078538ea84167705c15bf109c1a2737c648/bigquery/google/cloud/bigquery/table.py#L546-L556 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Batch upload fails when messages exceed API limit 1. OS type and version All OS and all versions supporting topic.Batch 2. Steps to reproduce Create a batch context & publish messages to it On batch commit an API failure occurs due to batch size being too large Suggestion: In the publish function check the serialised size of the message does not exceed 10MB and that the number of messages doesn't exceed 1000. If it does then commit the batch prematurely and clear the batch queue. I've crudely implemented it in my own project (just for size, not quantity): ``` class SizedBatch(topic.Batch): def __init__(self, topic, client): super(SizedBatch, self).__init__(topic, client) self.messages_size = 0 def publish(self, message, **attrs): self.topic._timestamp_message(attrs) item = {'data': message, 'attributes': attrs} self.messages.append(item) self.messages_size += len(base64.b64encode(json.dumps(item, ensure_ascii=False).encode('utf-8'))) if self.messages_size > 95e5: self.commit() self.messages_size = 0 ``` Of course this adds the published message to the queue before checking, allowing a case in which the message creates the API violation but from my own observations the API accepts messages of 15MB and sometimes of 20MB. This also does not take into account the other aspects of the message (which are largely insignificant compared to the message content). Another issue with this snippet is that self.messages_size is not reset if performing a manual commit() on the batch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add destination_table to %%bigquery magic to allow materializing query results Discussed with @tswast over email, suggestion is: We should not reuse the destination_var parameter. Also bq:// is not really something I've seen used in any other official BigQuery docs / libraries, and I don't think it's necessary. Instead, I recommend adding a --destination_table argument which sets QueryJobConfig.destination. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Implement PyTorch and/or TensorFlow sequence classification architectures for causal language models # 🚀 Feature request The architecture `GPT2ForSequenceClassification` was added in #7501 in PyTorch. It would be great to have it in TensorFlow (cf. issues #7622), but it would also be great to have it for other causal models: ~OpenAI GPT~, ~CTRL~ (PR opened @elk-cloner), ~TransfoXL~ (PR opened @spatil6) Below is a list of items to follow to make sure the integration of such an architecture is complete: - Implement `XXXForSequenceClassification` in `modeling_xxx.py` or `TFXXXForSequenceClassification` in `modeling_tf_xxx.py - Test that architecture in `tests/test_modeling_xxx.py` or `tests/test_modeling_tf_xxx.py` - Add that architecture to `__init__.py` and ` docs/source/model_doc/xxx.rst`. Taking a look at the code changes in #7501 would be a good start. A very good first issue to get acquainted with the library and its architectures! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda does not respect --quiet flag Loggers have been a little off since 4.3.18 or so. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Add line number to error messages As suggested in #13169, it adds line number to error messages, in order to make them more friendly.  That was the file used in the test  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Trainer's create_model_card creates an invalid yaml metadata `datasets: - null` ## Environment info - any env ### Who can help - discussed with @julien-c @sgugger and @LysandreJik ## Information - The hub will soon reject push with invalid model card metadata, - **only when `datasets`, `model-index` or `license` are present**, their content need to follow the specification cf. https://github.com/huggingface/huggingface_hub/pull/342 ## To reproduce Steps to reproduce the behavior: 1. Train a model 2. Do not association any datasets 3. The trained model and the model card are rejected by the server ## Expected behavior trainer.py git push should be successfull, even with the coming patch https://github.com/huggingface/transformers/pull/13514 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: to support data section in qobj to run the same circuits multiple times with different input data <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? I expect that with the same circuits, I can run it multiple times with different input data. In this case, I don't need to recompile the circuits multiple times. Every time when I want to run on new data, I just need to update the data section without updating other parts. For example, in this qasm below, I had one operation \"u3(data:input_magic1,0,pi) q1[0]\" and a data section with foreach. So if it will execute all circuits for every different input_magic1, it will be very great. OPENQASM 2.0;\\ninclude \\\"qelib1.inc\\\";\\nqreg q0[2];\\nqreg q1[2];\\ncreg c0[2];\\ncreg c1[2];\\nmeasure q1[1] -> c1[1];\\nu3(data:input_magic1,0,pi) q1[0];\\nmeasure q1[0] -> c1[0];\\nu3(pi,0,pi) q0[1];\\nmeasure q0[1] -> c0[1];\\nu2(localinputvar1,0) q0[0];\\nmeasure q0[0] -> c0[0]; section data: foreach (input_magic1: pi; input_magic1: 0.1; input_magic1: 0.2, input_magic1: 0.3) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Visualize pi-values as pi in parameter expressions <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? If the rotation angles are close to pi, `pi` will be displayed instead of the numeric value. This should also be the case for more complex `ParameterExpression`s. The `pi_check` function in `qiskit.visualization.tools` already recognizes if the angle is a `ParameterExpression` and calls the `__str__` method of this class. We probably can update this method to replace numerical values close to pi with the string literal `pi`. Here's an example: ```python >>> from qiskit.circuit import QuantumCircuit, Parameter >>> from qiskit.qasm import pi >>> x, y = Parameter('x'), Parameter('y') >>> circuit = QuantumCircuit(1) >>> circuit.rx((pi - x) * (pi - y), 0) >>> circuit.draw() ┌───────────────────────────────────────────────────┐ q_0: ┤ Rx((3.14159265358979 - x)*(3.14159265358979 - y)) ├ └───────────────────────────────────────────────────┘ ``` should produce ``` ┌───────────────────────┐ q_0: ┤ Rx((pi - x)*(pi - y)) ├ └───────────────────────┘ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Warning e-mails are sent without the Date header The warning e-mails don't have the \"Date\" header. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: WARNING: Unknown CPU family 'sun4u' While building glib2 on a Solaris 11.3 sun4u system (using pkgsrc) the following warning is issued: WARNING: Unknown CPU family 'sun4u', please report this at https://github.com/mesonbuild/meson/issues/new with theoutput of `uname -a` and `cat /proc/cpuinfo` Output from 'uname -a': SunOS gcc-solaris11 5.11 11.3 sun4u sparc SUNW,SPARC-Enterprise Output from /proc/cpuinfo is not possible since this is not available on a Solaris 11 system. Output from the Solaris isainfo command: sparcv9 sparc Output from the Solaris isalist command: sparcv9+fmuladd sparcv9+vis2 sparcv9+vis sparcv9 sparcv8plus+vis2 sparcv8plus+vis sparcv8plus sparcv8 sparcv8-fsmuld sparcv7 sparc Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: An error occurs when displaying multiple Qbits with subscript names set in QuantumRegister using the QuantumCircuit draw method <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.10.0 - **Python version**: 3.7.4 - **Operating system**: Win10 ### What is the current behavior? Hi Team, There is no problem when displaying 1Qbit with the subscript name set in QuantumRegister with the draw method of QuantumCircuit.  However, An error ( ParseFatalException ) occurs when displaying multiple Qbits with subscript names set in QuantumRegister using the QuantumCircuit draw method  By the way, if {} is not added, it will be displayed as follows:  ### Steps to reproduce the problem As I wrote above ### What is the expected behavior? I would like to be able to display multiple Qbits using the QuantumCircuit draw method for the subscript name set by the user in QuantumRegister. When displaying multiple Qbits with the QuantumCircuit draw method, a subscript of the number is added, so I would like the subscript specified by the user to be displayed even before the number ### Suggested solutions Please let me know if there are any method at this time Thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Saving TFVisionEncoderDecoderModel as SavedModel: `The following keyword arguments are not supported by this model: ['attention_mask', 'token_type_ids'].` ### System Info - `transformers` version: 4.27.4 - Platform: Linux-6.2.6-76060206-generic-x86_64-with-debian-bookworm-sid - Python version: 3.7.16 - Huggingface_hub version: 0.13.4 - PyTorch version (GPU?): 1.13.1 (False) - Tensorflow version (GPU?): 2.11.0 (False) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: False - Using distributed or parallel set-up in script?: False ### Who can help? @gante Could be related to #16400? ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction Hello, I am trying to save a TFVisionEncoderDecoderModel in a SavedModel format. Specifically, I am using the `nlpconnect/vit-gpt2-image-captioning` pretrained model. It seems like the model is able to be intiallised from the PyTorch checkpoint. However, when trying to save it as a SavedModel, it fails with the error. ``` ValueError: The following keyword arguments are not supported by this model: ['attention_mask', 'token_type_ids']. ``` Link to Google Colab Reproduction: https://colab.research.google.com/drive/1N2TVejxiBT5S7bRJ2LSmJ8IIR45folGA#scrollTo=aIL92KqPDDjf Thanks for your time! ### Expected behavior The model should be saved as a SavedModel without problems, similarly to other pretrained models. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: incorrect index mode for files which have a mode not in (0644, 0755) A recent [bug report](https://bugzilla.redhat.com/1963954) in Fedora revealed an issue where GitPython creates incorrect index modes for a file added which had mode `0700`. This is similar to issue #430 which was addressed in commit bebc4f56 (Use correct mode for executable files, 2016-05-19). I'll push a fix for this momentarily. This area could certainly use some tests. The previous commit did not add any tests for me to copy and extend. I'm happy to try to add some tests, but I'm not sure that I have enough time to bring myself up to speed. Any help would be more appreciated if we want tests to go along with this change. A very simple example of the issue is: ``` $ git init -q /tmp/git-test; cd /tmp/git-test ; touch foo ; chmod 700 foo $ python -c 'import git; repo = git.Repo(); repo.index.add([\"foo\"])' $ git ls-files -s 100744 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 0 foo ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Allow users to register local flows without autogenerated labels ## Current behavior *Please describe how the feature works today* As it exists today, flows registered with local storage are auto-labeled with information related to their local machines, and there's no way to opt out. ## Proposed behavior *Please describe your proposed change to the current behavior* Auto-labeling provides a sensible default, but we should also provide a way to opt out of labels for local flows. ## Example *Please give an example of how the enhancement would be useful* As it stands today, it's cumbersome for users to run local flows registered on one machine on a different machine. While that's a pretty rare use case, we have had some folks opt to use Prefect in that way. Allowing users to toggle auto-generated labels would help remove some of that friction. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add a warning for files skipped in 'tar_extract' In the [`tar_extract` function](https://github.com/conan-io/conan/blob/556e2043e11bc53d6ad797519385b9b34dfdbb2d/conans/util/files.py#L293) we are skipping non-safe members: ```python def tar_extract(fileobj, destination_dir): \"\"\"Extract tar file controlling not absolute paths and fixing the routes if the tar was zipped in windows\"\"\" def badpath(path, base): # joinpath will ignore base if path is absolute return not realpath(abspath(joinpath(base, path))).startswith(base) def safemembers(members): base = realpath(abspath(\".\")) for finfo in members: if badpath(finfo.name, base) or finfo.islnk(): continue else: ... ``` we should warn the user about those files. After #4965 this should be an exceptional behaviour, so a warning should be fine. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove legacy operators in opflow <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In #5460 we migrated the opflow module from qiskit-aqua into terra as part of the migration it included a legacy submodule. This was left intact for ease of migration since there are still some dependencies on it. Before we release 0.17 we should remove this legacy operators. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Documentation Request: ResultHandler ## Use Case *Please provide a use case to help us understand your request in context* I'm trying to create a custom ResultHandler for use with Prefect Cloud. I've noticed that the API Docs for the result handler ([here](https://docs.prefect.io/api/unreleased/engine/result_handlers.html#jsonresulthandler)) don't describe the interface of the ResultHandler class in sufficient detail for me to understand what I need to implement in a child class. ## Solution *Please describe your ideal solution* Please add more detail to the docs =] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Early Stopping behavior Hi there, thanks for the great library (I am using 0.7.5.). I am not following the bug report template as I'm not sure this is indeed a bug, or simply I cannot understand how early stopping is implemented. My code looks as follows: early_stop_callback = EarlyStopping( monitor='val_acc', min_delta=0.0, patience=80, verbose=True, mode=self.mode ) trainer = Trainer( early_stop_callback=early_stop_callback, auto_select_gpus=True, max_epochs=200, terminate_on_nan=True, show_progress_bar=True, fast_dev_run=False, gpus=1 ) As I understand it, the model should perform early stopping after AT LEAST 80 epochs have passed without improvement on the validation accuracy. However, in my case, early stopping happened at epoch 75. Is this how it should be? As I said, I am not sure this is actually a bug or a choice (perhaps early stopping is implemented at the batch level?). If it is indeed a bug, I will work a reproducible example. Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: grad bug: Forward-mode differentiation rule for 'reduce' not implemented I implemented the transformer in jax and got the following mysterious exception ``` File \"jax_transformer.py\", line 92, in _attn W_bhtt = stax.softmax(W_bhtt, axis=-1) File \"/Users/joschu/Src/jax/jax/experimental/stax.py\", line 52, in softmax unnormalized = np.exp(x - x.max(axis, keepdims=True)) File \"/Users/joschu/Src/jax/jax/numpy/lax_numpy.py\", line 771, in reduction result = lax.reduce(a, _reduction_init_val(a, init_val), op, dims) File \"/Users/joschu/Src/jax/jax/lax.py\", line 293, in reduce jaxpr=jaxpr, consts=consts, dimensions=tuple(dimensions)) File \"/Users/joschu/Src/jax/jax/core.py\", line 74, in bind out_tracer = top_trace.process_primitive(self, tracers, kwargs) File \"/Users/joschu/Src/jax/jax/interpreters/ad.py\", line 178, in process_primitive .format(primitive)) NotImplementedError: Forward-mode differentiation rule for 'reduce' not implemented ``` However, after replacing `stax.softmax` with my own softmax implementation that doesn't subtract out the max, the code runs just fine. (See `unstable_softmax` in the code linked below). To reproduce the bug, run bug=1 python jax_transformer.py alice.txt using https://github.com/joschu/jax-exp The code runs without error when `bug=1` is removed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: interact doesn't work with instance methods This code: ``` python from IPython.html.widgets import interact class Foo(object): def show(self, x): print x f = Foo() interact(f.show, x=(1,10)) ``` produces this exception: ``` --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-58-b03b8685dfc0> in <module>() 7 f = Foo() 8 ----> 9 interact(f.show, x=(1,10)) /home/fperez/usr/lib/python2.7/site-packages/IPython/html/widgets/interaction.pyc in interact(__interact_f, **kwargs) 235 f = __interact_f 236 w = interactive(f, **kwargs) --> 237 f.widget = w 238 display(w) 239 return f AttributeError: 'instancemethod' object has no attribute 'widget' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove `deepcopy` from `circuit_to_dag` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? It's very slow. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Cannot convert boolean arrays to ctypes with ctypeslib ctypeslib seems to be unable to convert Boolean numpy arrays to ctypes. ``` python import numpy as np a = np.empty(10, dtype=np.bool_) b = np.ctypeslib.as_ctypes(a) ``` Leads to: ``` KeyError Traceback (most recent call last) <ipython-input-3-e5712fdde6f3> in <module>() ----> 1 b = np.ctypeslib.as_ctypes(a) /home/chug/.local/lib/python2.7/site-packages/numpy/ctypeslib.py in as_ctypes(obj) 419 if readonly: 420 raise TypeError(\"readonly arrays unsupported\") --> 421 tp = _typecodes[ai[\"typestr\"]] 422 for dim in ai[\"shape\"][::-1]: 423 tp = tp * dim KeyError: '|b1' ``` This is using Python 2.7.10 and numpy 1.9.2 on Scientific Linux release 6.6 (Carbon). My naive fix (I don't know much about the numpy internals and if this will break anything elsewhere) was adding the bool type to the type list in ctypeslib.py: ``` python simple_types = [ ((ct.c_byte, ct.c_short, ct.c_int, ct.c_long, ct.c_longlong), \"i\"), ((ct.c_ubyte, ct.c_ushort, ct.c_uint, ct.c_ulong, ct.c_ulonglong), \"u\"), ((ct.c_float, ct.c_double), \"f\"), ((ct.c_bool, ), \"b\"), ] ``` Now this works: ``` python In [1]: import numpy as np In [2]: a = np.empty(10, dtype=np.bool_) In [3]: b = np.ctypeslib.as_ctypes(a) In [4]: print(b) Out[4]: <numpy.ctypeslib.c_bool_Array_10 object at 0x7fd449652f80> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Parameters are not tracked from within ControlFlowOp blocks ### Environment - **Qiskit Terra version**: 0.19.0dev @ 271a82f - **Python version**: any - **Operating system**: any ### What is happening? When adding a `ControlFlowOp` to `QuantumCircuit`, the parameter table is not updated with any of the parameters that occur in the bodies of the control-flow operators. ### How can we reproduce the issue? ```python In [1]: from qiskit.circuit import Parameter, QuantumCircuit ...: ...: x = Parameter(\"x\") ...: y = Parameter(\"y\") ...: ...: body = QuantumCircuit(1, 1) ...: body.rx(x, 0) ...: ...: main = QuantumCircuit(1, 1) ...: main.for_loop(y, range(1), body, [0], [0]) ...: ...: set(main.parameters) Out[1]: {Parameter(y)} ``` ### What should happen? The inner parameter `Parameter(x)` should have been tracked as well. ### Any suggestions? Likely update `QuantumCircuit._update_parameter_table` to pull parameters out of `ControlFlowOp` instances as well. With the way they store the bodies of the instructions in the `params` field, it's probably best just to teach `_update_parameter_table` to pull things out of `QuantumCircuit` instances as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: add support for linux on s390/s390x https://en.wikipedia.org/wiki/Linux_on_z_Systems In our CI we are running \"normal\" Linux distributions like Ubuntu and Red Hat on s390/s390x. To publish and fetch packages, we would need support for s390 (31bit, yes, gcc will need -m31) and s390x (64bit). ``` >>> import platform >>> platform.system() 'Linux' >>> platform.machine() 's390x' >>> platform.processor() 's390x' >>> ``` add support for linux on s390/s390x https://en.wikipedia.org/wiki/Linux_on_z_Systems In our CI we are running \"normal\" Linux distributions like Ubuntu and Red Hat on s390/s390x. To publish and fetch packages, we would need support for s390 (31bit, yes, gcc will need -m31) and s390x (64bit). ``` >>> import platform >>> platform.system() 'Linux' >>> platform.machine() 's390x' >>> platform.processor() 's390x' >>> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Subscription.pull() fails with KeyError Hi, My code below fails with a KeyError coming from the library: ``` python sub = Subscription(SUBSCRIPTION_NAME, Topic(INCOMING_TOPIC_NAME)) while True: try: msgs = sub.pull() ... except: msg = 'poll %s: %s' % (SUBSCRIPTION_NAME, traceback.format_exc()) print msg ``` Fails with the message: ``` poll extractors: Traceback (most recent call last): File \"main.py\", line 46, in main msgs = sub.pull() File \"/usr/local/lib/python2.7/dist-packages/gcloud/pubsub/subscription.py\", line 176, in pull for info in response['receivedMessages']] KeyError: 'receivedMessages' ``` This seems like a bug on the pubsub library code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Missing secrets file creates a directory? When docker-compose up with the config below, if the **file mypass.txt** is missing, docker-compose creates an empty **directory mypass.txt**. Is that expected behaviour? ``` version: '3.1' services: app: image: alpine secrets: - mypass secrets: mypass: file: ./mypass.txt ``` macOS 10.13.1 Docker version 17.11.0-ce-rc3, build 5b4af4f docker-compose version 1.17.0, build ac53b73 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Default transpiler pipeline <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? This is part of cleaning up the transpiler. Currently we have preserved backwards compatibility by following the old code path of circuit transformations when no pass manager is used in `compile()`. That old path is a bunch of hardcoded transformations. To fully complete the transition to the transpiler architecture, we need to remove that old path, and create a default pipeline of passes that gets used when `pass_manager=None`. Note that a PR that closes this issue must also close #157. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Incorrect drawing of composite gates with qubits and classical bits when using text drawer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.0.dev0+2ecf45d - **Python version**: 3.7 ### What is the current behavior? Text drawer incorrectly draws composite gates that contain both qubits and classical bits. This error seems to arise only when appending the composite gate and the qreg_list or the creg_list provided to the qc.append() is not in ascending order. For instance consider the following code: ```python from qiskit import QuantumCircuit inst = QuantumCircuit(3, 2, name='inst').to_instruction() inst2 = QuantumCircuit(3,name='inst2').to_instruction() qc = QuantumCircuit(4,2) qc.append(inst,[2,1,0],[0,1]) qc.append(inst,[0,1,2],[1,0]) qc.append(inst2,[2,1,0]) qc.draw() ``` The text circuit drawn is as below:  Also, the numbering of the active wires is incorrect. ### Suggested solutions The error seems to be caused due to drawing the gate components in the incorrect ordering. Have a look at the following function will help. https://github.com/Qiskit/qiskit-terra/blob/2ecf45d90d47b430493e218b218d6639cabf7ff1/qiskit/visualization/text.py#L1211 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Xformers is not installed correctly. ### System Info - `transformers` version: 4.30.2 - Platform: Linux-5.15.0-76-generic-x86_64-with-glibc2.35 - Python version: 3.10.6 - Huggingface_hub version: 0.16.4 - Safetensors version: 0.3.1 - PyTorch version (GPU?): 2.0.1+cu117 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: yes - Using distributed or parallel set-up in script?: no ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ``` python from transformers import pipeline pipe = pipeline(\"text-classification\", model=\"roberta-base\", device=0) ``` Edit: I know this model isn't trained for the \"text-classification\" task, I get the same problem with a private model I fine tuned. Results in the message ``` ... Xformers is not installed correctly. If you want to use memory_efficient_attention to accelerate training use the following command to install Xformers pip install xformers. ``` But I'm using torch==2.0.1 and [memory-efficient-attention](https://huggingface.co/docs/diffusers/optimization/fp16#memory-efficient-attention ) states \"If you have PyTorch 2.0 installed, you shouldn’t use xFormers!\" The message is confusing - I have torch 2.0 installed and pipeline is for inference. This message doesn't occur if I use `AutoModelForSequenceClassification.from_pretrained` ### Expected behavior The documentation or the warning message are inconsistent. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Duplicate kwargs warning doesn't print filename or lineno ```meson project('duplicate kwarg', 'c') a = library('liba', 'a.c') b = library('libb', 'b.c') executable('main', 'main.c', link_with: a, link_with: b) ``` Only the last` link_with:` has effect. I guess this should be reported as an error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Documentation Issue] Page Name: pubsub-subscription Release: 0.12.0 The reference link for modify_ack_deadline points to the acknowledge method. \"See: https://cloud.google.com/pubsub/reference/rest/v1/projects.subscriptions/acknowledge\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Do not configure python logging ## 🐛 Bug pytorch-lightning right now configures the python logging module ([here](https://github.com/PyTorchLightning/pytorch-lightning/blob/8322f1b039c890b8ccdbfe29bf42056e5273d74f/pytorch_lightning/__init__.py#L16)). This is generally not recommended when writing a library as it makes it difficult for users to modify logging format (see [python docs](https://docs.python.org/3/howto/logging.html#configuring-logging-for-a-library), Stack Overflow [post](https://stackoverflow.com/questions/27016870/how-should-logging-be-used-in-a-python-package)). I would suggest deleting the configuration line. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Tab completion for method arguments shows other functions args. With the below example class the args list that shows up when tab completing has arguments from other methods on the class that share the same root name. ```python class Test: def meth(self, meth_arg1): print(\"meth\") def meth_1(self, meth1_arg1, meth1_arg2): print(\"meth1\") def meth_2(self, meth2_arg1, meth2_arg2): print(\"meth2\") ```  Using jupyter==1.0.0, ipython==7.0.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Clarifying -n vs -p \"error\" messages New(ish) users don't always use the right flags. `-n` instead of `-p` is a pretty common failure mode. A recent interaction with a novice-ish conda user produced the following: > The error message is perplexing given that the supplied path is a legal Windows path. (I also tried enclosing the path in double quotes, to no avail). and the terminal output: ``` (base) C:\\>conda create --clone base -n C:\\ProgramData\\Anaconda3\\envs\\py37 CondaValueError: Invalid environment name: 'C:\\ProgramData\\Anaconda3\\envs\\py37' Characters not allowed: ('/', ' ', ':', '#') ``` Suggested resolution would be to check if the argument passed to `-n` is a full path and, if so, suggest to the user that they may be meaning to use `-p` instead Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: WARNING: Unknown CPU family 'rl78' I was trying to setup a meson cross build environment for the RL78 microprocessor family from Renesas. Technically it comes in 3 variants RL78-S1, RL78-S2, RL78-S3 that differ somewhat in their instruction set (e.g. hardware multiply support in S3) but the GCC compiler generally refers to it as RL78. Actual implementations of these cores are like: RL78-S1 core: RL78/G10 RL78-S2 core: RL78/G12, RL78/G13, RL78/G1A, RL78/G1E, RL78/G1C, RL78/I1A, RL78/F12, RL78/D1A, RL78/L12, and RL78/L13 RL78-S3 core: RL78/G14 In GCC again, these processors are selected with -mcpu=g13 or -mg13 Recognised options in GCC are g10, g13 and g14 for each of the 3 cores with option rl78 a synonym for g14 which is also the default. See also https://en.wikipedia.org/wiki/RL78 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: -u option does not exist ## Steps to reproduce Start -> celery -A application worker -l info ## Actual behavior RuntimeWarning: You're running the worker with superuser privileges: this is absolutely not recommended! Please specify a different user using the -u option. User information: uid=0 euid=0 gid=0 egid=0 uid=uid, euid=euid, gid=gid, egid=egid ## Fixes When displaying the help menu -> celery -A application worker -l info -h There is currently no longer a -u option and the warning should be changed to use --uid / --gid options Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add Parameter Specification to run CLI command ## Current behavior Currently the CLI command doesn't allow for the specification of parameters for a flow run ## Proposed behavior Couple options we could take here: Multiple --parameter NAME=VALUE options (e.g. each --parameter similar to how docker build does --build-arg) Single --parameters {name: value} that takes a dictionary Also we should have a file option where you can provide a json file Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: bad message when %pylab fails due import *other* than matplotlib this is just to capture an issue that was sent to IPython-User by @michaelaye: > I know you guys are busy getting a release on 1.0 done, so here's some > feedback trying to use git master: > > In version > rel-0.13-3590-gadb77e3 > matplotlib is not found, even so it is importable, so when using pylab > mode I get an error message: > > Python 2.7.3 |EPD 7.3-2 (64-bit)| (default, Apr 12 2012, 11:14:05) > Type \"copyright\", \"credits\" or \"license\" for more information. > > IPython 1.0.dev -- An enhanced Interactive Python. > ? -> Introduction and overview of IPython's features. > %quickref -> Quick reference. > help -> Python's own help system. > object? -> Details about 'object', use 'object??' for extra details. > > In [1]: import matplotlib > > In [2]: pylab > ERROR: pylab mode doesn't work as matplotlib could not be found. > Is it installed on the system? > > And since version ((rel-0.13-3681-g123ae5a)) up to now I get an import > error for the sip module (using --pylab=qt) > > ImportError: No module named sip > > Michael Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Configuration of dagster CLI command options with environment variables ### Problem to solve The `dagit` CLI allows command options to be set via environment variables using the `DAGIT` prefix, implemented with Click's [auto_envvar_prefix](https://click.palletsprojects.com/en/7.x/options/?highlight=auto_envvar_prefix#values-from-environment-variables) feature. I would like to be able to do the same with the `dagster` CLI. ### Intended users * DevOps Engineer ### User experience goal It should be possible to configure `dagster` CLI options in the same way as `dagit` CLI options. ### Proposal **Current state**: When running the Dagster gRPC server, for example, the values for module name, host, and port have to be passed as direct CLI arguments. ``` dagster api grpc --module-name sa_pipelines --host 0.0.0.0 --port 4266 ``` **Proposed state**: It would be nice to be able to set the arguments as environment variables. If Dagster's Click config had `auto_envvar_prefix=\"DAGSTER\"` set, it would be possible to do something like this. ``` export DAGSTER_API_GRPC_MODULE_NAME=sa_pipelines export DAGSTER_API_GRPC_HOST=0.0.0.0 export DAGSTER_API_GRPC_PORT=4266 dagster api grpc ``` The values for `--module-name`, `--host`, and `--port` are picked up from the environment variables. ### Further details I would like to use environment variables mostly for containerization purposes. * [Dagit's auto_envvar_prefix declaration](https://github.com/dagster-io/dagster/blob/7f323b76be9aef19fadf55c7d3578be4aae7431e/python_modules/dagit/dagit/cli.py#L198) * [Click's auto_envvar_prefix docs](https://click.palletsprojects.com/en/7.x/options/?highlight=auto_envvar_prefix#values-from-environment-variables) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Do we use JSON lines or JSON only for run_translation.py in PyTorch? ### Who can help Models: - maintained examples (not research project or legacy): @sgugger, @patil-suraj ## Information The run_translation.py file requires that we pass `train_file` and `validation_file` as **json** file only, see: https://github.com/huggingface/transformers/blob/master/examples/pytorch/translation/run_translation.py#L219 However, the [README](https://github.com/huggingface/transformers/tree/master/examples/pytorch/translation) states that > The task of translation supports only custom JSONLINES files, with each line being a dictionary with a key \"translation\" and its value another dictionary whose keys is the language pair Also in the example just above this line, it references jsonlines: ```bash python examples/pytorch/translation/run_translation.py \\ --model_name_or_path t5-small \\ ... --train_file path_to_jsonlines_file \\ --validation_file path_to_jsonlines_file \\ ... ``` Similarly, from the argument description: https://github.com/huggingface/transformers/blob/master/examples/pytorch/translation/run_translation.py#L115 I have made a merge request to address, what I believe, is an issue. Please correct me if I'm wrong. Thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Support PauliGate in qpy <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Serializing a circuit with a PauliGate fails with ``` File \"/Users/jessieyu/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py\", line 824, in dump _write_circuit(file_obj, circuit) File \"/Users/jessieyu/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py\", line 867, in _write_circuit _write_instruction(instruction_buffer, instruction, custom_instructions, index_map) File \"/Users/jessieyu/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py\", line 724, in _write_instruction raise TypeError( TypeError: Invalid parameter type <qiskit.circuit.library.generalized_gates.pauli.PauliGate object at 0x13bde8730> for gate <class 'str'>, ``` ### Steps to reproduce the problem ``` circ = (X ^ Y ^ Z).to_circuit_op().to_circuit() qpy_serialization.dump(buff, circ) ``` ### What is the expected behavior? The circuit can be serialized. Also the error message seems backwards - should have said `Invalid parameter type 'str' for gate 'PauliGate'` instead. ### Suggested solutions Allow string as a valid parameter for gates. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Allow activating multiple environments Hi, I'm trying to configure conda to use it on a computing cluster with command line access for multiple users (~300 accounts). The idea is that we will provide to users some preinstalled conda environments that they can use as they need. Some people will want to activate several of these environments to perform their compute task. The problem is that the `activate` script calls `deactivate` before doing the activation job, so users can only have 1 environment loaded. I know that activating multiple environments could be a problem as some incompatibility could arise depending on the packages installed in each env. But in our case, in many situations, it would work perfectly well (and if it's not, users would be able to take care of it). So I'm wondering if you think this feature could be added to conda somehow? Maybe with a special option for the activate script, and a modification to deactivate to allow it to deactivate _all_ the loaded env. I can work on a PR if you are ok with the idea. The other option would be to force them to adopt the proper conda way (they create their own environments), but it would make the transition too hard for most of them... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Release spanner 1.4.0 This pull request was generated using releasetool. Fixes #5466 5465 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support compilation of LLVM-IR .ll => .o This can be accomplished through either llc or clang. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: python crashes when importing matplotlib in terminal mode on m1 mac Hello community, I am experiencing the following crash when trying to plot from the command line on my M1 mac: ``` (base) ➜ ~ ipython Python 3.9.1 | packaged by conda-forge | (default, Jan 26 2021, 01:30:54) Type 'copyright', 'credits' or 'license' for more information IPython 7.20.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: import matplotlib In [2]: matplotlib.get_backend() Out[2]: 'MacOSX' In [3]: [1] 2797 bus error ipython ``` Even more weird, if I try to set any value of `c.InteractiveShellApp.matplotlib` in the `ipython_config.py`, the crash occurs instantly (that is, when ipython starts). In \"vanilla\" python REPL, everything works as expected. My ipython (7.20.0) and matplotlib (3.3.4) are installed through conda and this is otherwise a \"fresh\" install. Any help is appreciated! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: cuda runtime error (101) : invalid device ordinal CUDA_VISIBLE_DEVICES and ddp are not compatible. https://github.com/PyTorchLightning/pytorch-lightning/blob/25ee51bc570503f331dceecc610d0eb355e22327/pytorch_lightning/trainer/distrib_data_parallel.py#L504 the pytorch respects the CUDA_VISIBLE_DEVICES. gpu_idx should be the same as local_rank. If I set CUDA_VISIBLE_DEVICES to be 1. It will break. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython/utils/py3compat.py unused `with_metaclass` function. The function `with_metaclass` seem to be unused; we should : check if it is used, if not remove the function . Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Command line \"ipython trust\" option does not work I'm working with a slideshow template I found on Fernando's github account: https://github.com/fperez/nb-slideshow-template When I open the notebook, IPython complains that it isn't trusted. When I close the notebook, kill the server, run `ipython trust my_notebook.ipynb`, and then restart the notebook, I get the same warning about the notebook not being trusted. I was able to work around this issue using the \"Trust this notebook\" option in the File dropdown menu on the notebook web interface. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Automatically create build directory if it does not exist Currently, invoking meson in a project root folder with a non created build folder leads to: ``` % meson build Error during basic setup: [Errno 2] No such file or directory: '/some/path/build' ``` Since meson can find that the current folder contains a `meson.build` file, and that it probably also knows that `build` is my expected build directory. Should not it create it itself? I personally don't see any value invoking `mkdir build && meson build` while `meson build` could do the trick. I can submit a PR for that if wished but I'd like to know your opinion on that first. (in a second time I would also love to have some `meson --build` argument which would invoke backend automatically, so that you finally simply type `meson --build <buildfolder>`; bypassing always-the-same `mkdir` and `cd` commands). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Transitive python_requires does no longer work since Conan 1.17 (in combination with lockfile) Hi @memsharded, @lasote and @jgsogo, since Conan 1.17 there is an issue with transitive python_requires references. To reproduce you just need the following: 1. define a simple conan file which can be used as python_requires. Let's call it \"base_helper\". ```python from conans import ConanFile def hello_world(): message = \"Hello World\" print(message) return message class MyBaseConan(ConanFile): name = \"base_helper\" version = \"1.2.3\" # .. ``` 2. create another simple conan file which can be used as python_requires. Let's call it \"impl_helper\" ```python from conans import ConanFile, tools from conans import python_requires #@UnresolvedImport my_base= python_requires(\"base_helper/1.2.3@user/channel\") test = my_base.hello_world() class ImplConan(ConanFile): name = \"impl_helper\" version = \"2.3.4\" ``` 3. create a \"normal\" package recipe which python_requires \"impl_helper\" ```python from conans import ConanFile, tools from conans import python_requires #@UnresolvedImport python_requires(\"impl_helper/2.3.4@user/channel\") class DummyexampleConan(ConanFile): name = \"DummyExample\" version = \"0.0.1\" settings = \"os\", \"compiler\", \"build_type\", \"arch\" ``` If you now call ```conan install DummyExample/0.0.1@user/channel``` and after that ```conan source``` (or something else) it will end in an error. Also ```conan graph lock DummyExample/0.0.1@test/testing``` shows the same result. Best Aalmann Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: b2 generator doesn't specify transitive dependencies Boost.Build targets created by files produced by b2 generator don't list their dependencies. As a result of that, if you `require` package `A` which depends on package `B`, and then you use a target for package `A`, you are likely to encounter a build error, because the build system is not aware of dependency between `A` and `B`. Example project: ```python # conanfile.py from conans import ConanFile class FoobarConan(ConanFile): name = 'foobar' version = '0.0.1' settings = 'arch', 'os', 'compiler' requires = 'boost_core/[>=1.68]@bincrafters/stable' build_requires = 'b2/4.0.0' generators = \"b2\" exports_sources = \"jamroot.jam\", \"*.cpp\" def build(self): self.run('b2') ``` ```jam # jamroot.jam project foobar ; # Boost.Core actually depends on Boost.Config lib foobar : foobar.cpp /boost_core//libs ; ``` ```c++ // foobar.cpp #include <boost/core/null_deleter.hpp> ``` Relevant Conan version: 1.18.5 - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Allow defining settings for a downstream consumer (different than upstream dependencies) Continuation from https://github.com/conan-io/conan/pull/9129 The command ``conan install . -s pkg:build_type=Debug -s build_type=Release``, to have all dependencies in Release, but build your current project as Debug has some limitations: - It requires a conanfile.py, that defines the ``name = \"pkg\"`` - conanfile.txt will not allow this - conanfile.py without a name will not allow this The solution could be some kind of placeholder that means \"current consumer\", something like ``conan install . -s $:build_type=Debug -s build_type=Release`` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Prevent conan alias from overwriting existing packages When creating an alias package with `conan alias` it is easy to mix up the order of parameters: * Correct: `conan alias boost/ALIAS@conan/stable boost/1.69.0@conan/stable` * Wrong: `conan alias boost/1.69.0@conan/stable boost/ALIAS@conan/stable` In case you're accidentally calling the wrong order you're overwriting the package you initially wanted to reference. If this happens you render your original package useless and need to remove it. Then you can start all over again. It would be perfect to have a built-in check that tells the user that the existing package `boost/1.69.0@conan/stable` already exists and will be overwritten by an alias package - and if the user is really sure this is what he wants to do. Happens to me with Conan 1.11.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Change reloading feature to watchman or similar process-based mechanism I think it is time to rip out the reloader and rely on a process-based reloading mechanism. This is the second time it has caused difficult-to-diagnose bugs. In the hands of the general public this will be a pretty serious. @Aylr has a watchman-based workflow I believe. How can we make this happen automatically. This would also allow us to remove the RepositoryContainer nonsense which is maybe the hairiest and most difficult-to-understand part of the codebase. @Aylr was using the watchman-based workflow a serious regression? Reloading time in between file saves was likely longer. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Model.load_from_checkpoint tries to open file path as URL and fail ## 🐛 Bug load_from_checkpoint tries to classify if the input is a file path or an URL and detects the hard drive letter as a scheme and then classify wrongly the input because of this. urllib.error.URLError: \\<urlopen error unknown url type: d\\> My input: D:\\Prog\\Projects\\AceriNet\\research_seed\\checkpoints\\acerinet\\bnacerinet0_target=OVA_OK_penalized=None_loss_fn=ce_normalized=True_balanced=FalseFalse_seed=42_val_loss=0.374_val_auroc=0.9041_v0.ckpt ### To Reproduce Steps to reproduce the behavior: Use any path with a hard drive letter at the start (windows formatting) for pl.LightningModule().load_from_checkpoint(path) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Add API documentation for np.distutils.core.Extension class [The f2py docs mention](https://docs.scipy.org/doc/numpy/f2py/distutils.html) that the `numpy.distutils.core.Extension` class can be used, but as far as I can tell there is no documentation of this class either in the main numpy documentation or in the f2py documentation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: move initializer optimizations to transpiler <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The arbitrary state initializer is based on https://arxiv.org/abs/quant-ph/0406176v5, and it implements some of the optimizations that the paper talks about to reduce the depth. But the optimizations are ad-hoc, and they don't fully capture all optimization opportunities. We should make the synthesizer dumb, and relegate the optimizations to the transpiler. For example, consider the circuit for initializing `[1/math.sqrt(2), 0, 0, 0, 0, 0, 0, 1/math.sqrt(2)]`. The non-optimized/canonical synthesis is:  The optimized version as implemented currently is:  Note that this manual optimization misses the fact that the last 4 CNOTs can be removed also. If we just relegate all optimizations to the transpiler, then optimizing this circuit is fairly straightforward. It involves removing zero rotations, removing adjacent CNOTs, and commuting CNOTs that share a target but are on different qubits (these passes have to be done repetitively until converging to a fixed-point). I'm removing these optimizations from the initializer as part of the refactoring in #1816. This issue should be fixed through the construction of a default pass manager that addresses the above. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Several GNU directory options are not available I see several [predefined directory options](https://github.com/mesonbuild/meson/blob/master/mesonbuild/coredata.py#L202), but several of the [GNU Coding Standard directories](https://www.gnu.org/prep/standards/html_node/Directory-Variables.html) are missing, notably `sysconfdir` being the main one. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Specifying app/backend in GroupResult.restore is slightly awkward In Celery 3.x I used `GroupResult.restore('some-id')` and it somehow found my app and figured out the backend (not sure how, but it worked). In Celery 4.x this does not work (it does not find the backend and crashes). That makes sense to me (I like the idea of explicit apps a lot!). `GroupResult.restore()` does not accept a `app` argument which would be convenient. It does however support a `backend` argument, so I changed my code to use `GroupResult.restore('my-id', backend=app.backend)` and everything is fine. However, to me this is not that super-intuitive, my suggestion is that we should add an `app` kwarg to `restore()` that can be used like: ```py GroupResult.restore('someid', app=app) ``` Do you think this makes sense? Then I'd be happy to work on a PR to add the argument! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Error in workspace graph with several build_requires consuming same package Changelog: (Feature | Fix | Bugfix): Describe here your pull request Docs: https://github.com/conan-io/docs/pull/XXXX Reproduce issue in #5612 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: ddp_backend in 0.9.0rc12 fails if no CUDA_VISIBLE_DEVICES found ## 🐛 Bug In ddp_backend, training immediately fails if the environment variable CUDA_VISIBLE_DEVICES isn't set. This line should handle the None case gracefully: https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/accelerators/ddp_backend.py#L90 ### To Reproduce Start a run using ddp on CPU. This was discovered using torchelastic to launch #### Code sample <!-- Ideally attach a minimal code sample to reproduce the decried issue. Minimal means having the shortest code but still preserving the bug. --> ### Expected behavior This shouldn't crash if the environment variable isn't set. We could default to `num_gpus = 0` in this case. Replacing the line above with something like this could work: `num_gpus = os.environ.get('CUDA_VISIBLE_DEVICES', []).split(',').__len__() ` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: pastebin magic does not work: github requires authentication to create gists Github now [requires authentication](https://developer.github.com/v3/gists/#authentication) to create gists: > You can read public gists anonymously, but you must be signed into GitHub to create gists. `%pastebin` does not work anymore and returns 401: HTTPError: HTTP Error 401: Unauthorized Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Big overhead in parallel transpile for large target systems ### Environment - **Qiskit Terra version**: `0.19.2` - **Python version**: 3.8 - **Operating system**: Linux ### What is happening? There is a large overhead when doing parallel transpilation for circuits targeting larger systems. In the case below they are targeting the 127Q system, but the circuits themselves consist of only `x` gates and are already the correct width. Thus transpilation should just be a pass-through. However, in parallel mode (quad-core machine) it takes 330sec to transpile. If I turn off parallel transpile it takes 3sec. ```python from qiskit import * from mthree.circuits import balanced_cal_strings, balanced_cal_circuits b_strs = balanced_cal_strings(127) cal_circs = balanced_cal_circuits(b_strs) backend = provider.backend.ibm_washington trans_circs = transpile(cal_circs, backend, optimization_level=0) ``` ### How can we reproduce the issue? Run above ### What should happen? Parallel should not give 100x overhead. ### Any suggestions? I am guessing this is copying overhead from forking when the systems are large. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add additional default LLVM toolsets Add to the default settings: ``` LLVM-vs2012, LLVM-vs2012_xp, LLVM-vs2013, LLVM-vs2013_xp, LLVM-vs2017, LLVM-vs2017_xp ``` Should it be possible to add wildcard settings? Like `LLVM-vs*`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Please use `sys.exit()` or flush STDERR if failed on `platform.check_privileges` https://github.com/celery/celery/blob/a3c377474ab1109a26de5169066a4fae0d30524b/celery/platforms.py#L794:24 The way it is now, the message could be lost because `os._exit()` does not flushes STDERR. Why are we using `os._exit()` instead of the recommended `sys.exit()`? I can provide a PR if asked, but please clarify why the `os._exit()` before the patch is written. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: `@deprecated` doesn't render on properties in the API docs ### What's the issue or suggestion? Making this render a deprecated badge should require a small tweak to `autodoc_dagster`. ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Grad should raise an error for non-inexact types Continuation of https://github.com/google/jax/issues/48 . `grad` should report an error for integer/bool types (i.e., non-inexact types): e.g., this example should report an error: ``` def square(x): return x**2 val = 3 dfn = grad(square) print(dfn(val)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: --backend=vs2019 EntryPointSymbol incorrect for 'UNICODE' projects **Describe the bug** vcxproj files generated by meson have an incorrect EntryPointSymbol for UNICODE applications (ie. those that have an entry point of wmain (console) or wWinMain (gui)). ``` 2>MSVCRTD.lib(exe_main.obj) : error LNK2019: unresolved external symbol main referenced in function \"int __cdecl invoke_main(void)\" (?invoke_main@@YAHXZ) 2>.\\main.exe : fatal error LNK1120: 1 unresolved externals ``` Removing EntryPointSymbol from all generated .vcxproj files works around the issue. Ninja builds do not have this issue. **To Reproduce** meson.build: ``` meson project('wmain', 'c') executable('main', 'wmain.c') ``` wmain.c: ``` c #include <stdio.h> int wmain(int argc, wchar_t *argv[]) { printf(\"Hello, World!\\n\"); } ``` **Expected behavior** main.exe should be generated instead of a link error. **system parameters** This is a native build, with Visual Studio 2019, on Windows 10, with meson and ninja from the official 0.53.1 MSI (I looked at the code, and it's still the same in master on github). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [Enhancement] Output of `conan config install` exposes preconfigured URL (which may include a password) To help us debug your issue please explain: - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. On our CI system, the first build step is to run `conan config install` (with no arguments) to ensure the latest configuration is installed on the agent. No parameters are used because the initial configuration of that build agent already set up the URL. This is convenient because during initial configuration, we can load the HTTP password (i.e., http://foo:bar@artifactory/...) and it's not available anywhere within the build script. However, the first output of the command is to output the exact URL, including the password. As a result, the password is exposed on the CI system's build log. It would be nice if the `conan config install` hid the password from the URL. Alternatively, perhaps a command line switch could be offered to put it into a \"quiet mode\" so that the URL is not output. This way, the password is not exposed in the build log. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Limit disk space : Set storage driver options per container Hello, would it be possible to add the limits for disk space per container with docker compose. Like: https://github.com/docker/docker/blob/master/docs/reference/commandline/run.md#set-storage-driver-options-per-container BR Stefan Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: add progress bar to the sharded model download status ### Feature request `from_pretrained('bigscience/bloom')` is taking forever the first time until it's cached (~350GB) - I thought that perhaps with 72 shards it'd be awesome to have an overall progress bar (in addition to the each shard download progress bar) to know where things stand and how many hours the coffee break should last. Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Resurrect ONNX -> jaxpr compatibility This worked in a demo at one point. Would be great to be able to load all models in the [ONNX model zoo](https://github.com/onnx/models) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan info graph output to html should include local versions of vis library Conan version: 1.7.4 When running `conan info -g foo.html .` to generate a dependency graph, the generated HTML includes hard-coded links to cdnjs for `vis.min.js` and `vis.min.css`: ```html <head> <script type=\"text/javascript\" src=\"https://cdnjs.cloudflare.com/ajax/libs/vis/4.18.1/vis.min.js\"></script> <link href=\"https://cdnjs.cloudflare.com/ajax/libs/vis/4.18.1/vis.min.css\" rel=\"stylesheet\" type=\"text/css\" /> </head> ``` In a corporate environment users may not have access to these URLs so the generated file is not useful. It would be nice if we could package these files in conan itself and output them alongside the generated html file if requested (via command-line flag, for example). --- To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add a way to configure timeout for downloading files from a remote We had a few jobs get stuck in downloading the package from the remote because of a wrongly configured network. These would then get stuck for hours and we wouldn't notice in the CI until someone manually checked. I would like to be able to set a sane default timeout for the download to requests. Via environment or conan.conf. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC,DISCUSS: Reorganizing documentation development and contribution docs We have multiple documents for documentation development- [How to contribute to the NumPy documentation](https://numpy.org/devdocs/dev/howto-docs.html), [NumPy’s Documentation](https://numpy.org/devdocs/docs/index.html), [Documentation conventions](https://numpy.org/devdocs/doc_conventions.html). This issue is to discuss ways to merge these documents if possible and figure out where they should live. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/mxnet codebase. Here's the problem: Issue in amalgamation ~/mxnet/amalgamation$ make g++ -std=c++11 -Wno-unknown-pragmas -Wall -I/opt/OpenBLAS -fPIC -o mxnet_predict-all.o -c mxnet_predict-all.cc mxnet_predict-all.cc:31:18: fatal error: cuda.h: No such file or directory #include <cuda.h> ^ compilation terminated. make: **\\* [mxnet_predict-all.o] Error 1 I have built OpenBlas 0.2.16 . OpenBLAS root: /opt/OpenBLAS Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Support user-overridable dtypes in `to_dataframe` method. With pandas 0.24.0 (unreleased), a new dtype is available to support nullable integer columns. http://pandas-docs.github.io/pandas-docs-travis/integer_na.html#integer-na The default behavior is to convert to float, but this can result in data loss (#6177). This new dtype extension avoids that. I propose we allow the user to provide a map from column names to dtypes for any columns for which they'd like to override the default behavior. This argument could be called `dtype_overrides`. This would also be useful for other extension dtypes in the future, such as for GEOGRAPHY columns. See https://github.com/pydata/pandas-gbq/issues/242 for additional discussion. **Alternatives** - Make the new dtype for nullable integer the default for integer columns. - Con: Not compatible with older versions of pandas. - Con: Inconsistent with pandas's default behavior. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %run magic on ipynb continues after a cell has an exception When you run an .ipynb file with the %run magic, and a cell generates an exception, the remaining cells continue to run. This can have unexpected outcomes as subsequent cells typically rely on results from the cell that generated the exception. It is also inconsistent with the behaviour of 'run all' when viewing a notebook and with the behaviour when running a .py file (probably .ipy also..). It would be good at least to have the option to halt when an exception is thrown, but ihmo it'd probably be best to simply stop execution of the remaining cells if an exception is thrown. I'm working on ipython 2.0.0 (the tag in the repo with that name) as I need the --script functionality (which at last check had been disabled in the head version), so apologies if this is resolved in the head version. For the record, this is related to #4452 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Ensure that gRPC metrics headers are in the order requested by the spec. The present order in `api.core` is: ``` core/0.27.1 gl-python/3.6.0 grpc/0.27.1 gapic/0.27.2 ``` The order per spec should be: ``` gl-python/2.7.12 gccl/0.21.0 gapic/0.1.0 core/0.14.1 grpc/1.0.1 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Wrong parameter name used in find_library() function in cmakedeps_macros.cmake When using the cmake function find_library() it accepts a parameter named \"NAMES\" but in cmakedeps_macro.cmake, generated by conan/tools/cmake/cmakedeps/templates/macros.py , the parameter name \"NAME\" is used by mistake. See also: https://cmake.org/cmake/help/latest/command/find_library.html As the NAMES parameter name is kind of optional, it currently works as it is but the find_library() function not only searches for the actual library by its name, but it also looks for a library called NAME. This can bee seen, when cmake is run with the --debug-find argument. I will provide a pull request for the fix. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: install_man() does not take files ```meson foo = configure_file(...) install_man(foo) ```` results in ```` Meson encountered an error in file meson.build, line 212, column 0: Arguments must be strings. ```` The output of `configure_file` is a file, so one would expect this to work. This would be the easiest fix to resolve #2025 too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: sys_info missing git hash in sdists #1538 changed how sys_info works, but the way it is done it puts no info in sdists. This should be fixed, though it is not critical as most sdist installs are from releases. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Generation of build files takes very long time **Describe the bug** The generation of build files in our project takes 2 minutes in meson 0.60.2 compared to 3 seconds in meson 0.60.1. Using git bisect, the the performance regression was introduced in commit 73bac14c8fe7279037433b15b6c15bc93e9156a1. **To Reproduce** Cannot include any meson.build files since it is proprietary project. However, by debugging the involved meson code in the Backend class, the following characteristics was found: * Number of calls to Backend.determine_rpath_dirs with a build.BuildTarget: 206 * Number of calls to Backend.rpaths_for_bundled_shared_libraries with a build.BuildTarget: 2434034 **Expected behavior** The time to generate build files takes about the same as in meson 0.60.1. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? Native build * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.): Arch Linux (updated 2021-12-02) * what Python version are you using e.g. 3.8.0: Python 3.9.9 * what `meson --version`: Meson 0.60.2 * what `ninja --version` if it's a Ninja build; Ninja 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Loading model microsoft/tapex-base-finetuned-wtq failed with error No module named 'transformers.models.tapex' ### System Info OS: Ubuntu 22.04 Python 3.9 Packages installed: ``` pip install git+https://github.com/huggingface/transformers pip install datasets huggingface_hub torch torchvision tensorflow accelerate librosa ffmpeg ``` ### Who can help? _No response_ ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction Code ``` import transformers transformers.pipeline( task=\"table-question-answering\", model=\"microsoft/tapex-base-finetuned-wtq\" ) ``` raises error: ``` ModuleNotFoundError: No module named 'transformers.models.tapex' ``` ### Expected behavior Returns `transformers.pipelines.table_question_answering.TableQuestionAnsweringPipeline` object Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Integer limit_val_batches does not work with infinite DataLoader. ## 🐛 Bug Documentation states that you can use limit_val_batches=100 (with integer value) to limit number of batches. However, when using IterableDataset I get the following error: pytorch_lightning.utilities.exceptions.MisconfigurationException: When using an infinite DataLoader (e.g. with an IterableDataset or when DataLoader does not implement `__len__`) for `limit_val_batches`, `Trainer(limit_val_batches)` must be `0.0` or `1.0`. ### To Reproduce Just use: pl.Trainer(val_check_interval=10, limit_val_batches=100) with infinite DataLoader. ### Expected behavior Do only N (100 in this case) validation steps. ### Environment * CUDA: - GPU: - GeForce GTX 1080 Ti - available: True - version: 10.0.130 * Packages: - numpy: 1.17.4 - pyTorch_debug: False - pyTorch_version: 1.3.1 - pytorch-lightning: 0.8.5 - tensorboard: 2.2.2 - tqdm: 4.46.1 * System: - OS: Linux - architecture: - 64bit - - processor: x86_64 - python: 3.7.4 - version: #1 SMP Wed Mar 7 19:03:37 UTC 2018 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Tool for running binaries in test() Conan 1.1 It is typical in packages in conan center to see in test_package: ```python def test(self): with tools.environment_append(RunEnvironment(self).vars): bin_path = os.path.join(\"bin\", \"test_package\") if self.settings.os == \"Windows\": self.run(bin_path) elif self.settings.os == \"Macos\": self.run(\"DYLD_LIBRARY_PATH=%s %s\" % (os.environ.get('DYLD_LIBRARY_PATH', ''), bin_path)) else: self.run(\"LD_LIBRARY_PATH=%s %s\" % (os.environ.get('LD_LIBRARY_PATH', ''), bin_path)) ``` As this seems very easy to automate, I'd suggest creating a tool for running test binaries with this code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Enable option to use Apex when PyTorch 1.6 is installed ## 🚀 Feature <!-- A clear and concise description of the feature proposal --> Currently, if PyTorch 1.6 is installed, PyTorch Lightning will use native AMP by default. It would be useful to have an option to force PL to use Apex if needed, which is not currently possible ### Motivation Native AMP is great but under certain conditions may perform differently to Apex. For debugging purposes and backwards compatibility, having the option to still use Apex might be useful. In my particular problem, I needed to roll back to PT 1.5 since I was seeing different behaviour between the two. Having the option to switch between the two AMP methods would make it easier to diagnose my issue. <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too --> ### Pitch Have a flag to force the Trainer to use Apex over native AMP <!-- A clear and concise description of what you want to happen. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: page_token parameter documentation is misleading The `page_token` parameter to several api functions such as `list_projects` and `list_jobs` is documented as follows: > opaque marker for the next \"page\" of projects. If not passed, the API will return the first page of projects. This is very misleading, as these functions return an `HTTPIterator` which if iterated on will seamlessly return multiple pages of results. Only though experimentation did I determine that multiple pages of results are returned and that if I did want to make use of `page_token` I'd need to access it at the `next_page_token` of the `HTTPIterator`. I think the documentation should be updated to better reflect that multiple pages can be fetched without touching the `page_token` and possibly include where to access `page_token` if someone does need to use it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Support Alpine Linux system package manager ### What is your suggestion? Hi, The system manager support in conan is really handy and already covers a large list of distributions/tools. It would be very nice though if it could also support [`apk`](https://wiki.alpinelinux.org/wiki/Alpine_Package_Keeper) for the Alpine Linux distribution. ### Have you read the CONTRIBUTING guide? - [X] I've read the CONTRIBUTING guide Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Static URLs are not auto-versioned In master, static URLs are not auto-versioned; Ej: ``` html <script src=\"/static/components/requirejs/require.js\" type=\"text/javascript\" charset=\"utf-8\"></script> ``` on #ipython@freenode, _minrk_ sayd > I think it's a regression from when we switched to jinja templates thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: End of multiline string that contains a backslash-terminated line is not recognized IPython 5.0/PTK1.0.5 does not recognize that ``` \"\"\" foo\\ bar \"\"\" ``` is a full string and that it should execute the typed-in string after that point. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Bigtable: systests leaking instances Similar to #4935. We have a bunch of leaked instances, and are now seeing systest failures due to quota exhaustion. With the labels, it is possible to see that several different \"kinds\" of instances are leaked from systests: - `dif-####` (leaked from `test_create_instance_w_two_clusters`). - `g-c-p-###` w/ display name \"Foo Bar Baz\" (the default instance in `tests/system.py`, mutated by `test_update_display_name_and_labels` and not restored) - `g-c-p-###` w/o display name (the default instance in `tests/system.py`) - `new-###` (leaked from `test_create_instance` systest) and from snippets: - `inst-my-###` (leaked one of two snippets: `test_bigtable_create_instance` or `test_bigtable_delete_instance`) - `snippet-###` w/ display name \"My new instance\" (default instance for snippets; display name set by 'test_bigtable_update_instance`) - `snippet-###` w/o display name (default instance for snippets) I ~~will delete~~ have deleted all but the most recent example of each kind. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: building local dockerfile from compose, hits windows max path length error I can build and run containers on windows just fine. But when including the `build: .` in my `docker-compose.yml`, the build step fails as it hits the max path error that was fixed in `docker`. Anyone else encounter the same issue have any workarounds? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow ### System Info System Info nvidia CUDA Version: 12.1, Driver Version: 525.105.17 transformers-cli env is - `transformers` version: 4.29.2 - Platform: Linux-4.19.87-netease6-1-x86_64-with-glibc2.29 - Python version: 3.8.10 - Huggingface_hub version: 0.14.1 - Safetensors version: not installed - PyTorch version (GPU?): 2.1.0a0+fe05266 (True) ### Who can help? _No response_ ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction when i use tokenizer(...,padding=True), i will get a warnning : \"UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor.\" and this function latency is 0.744675874710083 if query_list over 800 words . ``` st = time.time() inputs = tokenizer(query_list, return_tensors=\"pt\" ,padding=True) print(time.time() - st) ``` ### Expected behavior Reduce latency and fix the UserWarning. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Converting masked array from float to uint8 does not convert dtype of fill_value When a masked array of dtype float32 is converted to uint8, the dtype of the fill_value persists. When setting the fill_value to a uint8 value, the value is converted to float. Filling such an array yields an array of dtype object. This was working in numpy==1.14. ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np foo = np.ma.masked_equal(np.arange(10, dtype=\"float32\"), 5) foo.fill_value = -1.0 bar = foo.astype(\"uint8\") print(bar.fill_value) bar.fill_value = 255 print(bar.fill_value) print(bar.filled().dtype) ``` ### Error message: with numpy==1.14.2 this yields: ``` 255 255 uint8 ``` with numpy==1.15.2 this yields: ``` -1.0 255.0 object ``` ### Numpy/Python version information: Tested with python 2.7 and 3.5.2 numpy==1.15 <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ? should look at __signature__ I was watching http://pyvideo.org/video/1716/python-3-metaprogramming (intersting talk btw) and it was mentioned that Python 3 has this new feature `__signature__`, which lets you redefine what the signature of an object should be, which is used by things like inspect.signature. It is pointed out that `help` doesn't support this, but it would be great if IPython's `?` does. I checked however, and it doesn't (this is Python 3): ``` py In [2]: import inspect In [3]: from inspect import Signature, Parameter In [4]: a = Signature([Parameter('test', Parameter.POSITIONAL_OR_KEYWORD)]) In [5]: class Test: __signature__ = a ...: In [11]: print(inspect.signature(Test)) (test) In [12]: Test? Type: type String Form:<class '__main__.Test'> Docstring: <no docstring> In [18]: def f(*args): ....: pass ....: In [20]: f? Type: function String Form:<function f at 0x1026ac0e0> File: /Users/aaronmeurer/Documents/ipython/<ipython-input-18-446f067045b6> Definition: f(*args) Docstring: <no docstring> In [21]: f.__signature__ = a In [22]: f? Type: function String Form:<function f at 0x1026ac0e0> File: /Users/aaronmeurer/Documents/ipython/<ipython-input-18-446f067045b6> Definition: f(*args) Docstring: <no docstring> In [24]: print(inspect.signature(f)) (test) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Every error that is not catchable by the user should be logged via the logging module Currently, at the very least helper threads for pubsub seem to not and they let the exception bubble up and get printed to stderr. I think this is bad form, there's nothing _I_ can do to catch this error, but it'd be nice if I could get it logged in the format I want. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: accessing f_locals in debugger resets namespace This is the pendant of https://github.com/deshaw/pyflyby/pull/144, see there for a longer explanation. We do access `current_frame.f_locals` in a couple of place which reset the namespace changes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Entities created in datastore snippets should use a namespace This is useful for debugging build failures. This is [already done][1] for the rest of the entities created in the datastore system test. [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/e63ddc384e4a54a6a085595d779a399ed449c26c/datastore/tests/system/test_system.py#L52-L64 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: InputContext for loading assets at the root of a job missing resource dependencies Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Unknown CPU family 'powerpc' I'm using meson to build a program. I'm getting this warning: `WARNING: Unknown CPU family 'powerpc', please report this at https://github.com/mesonbuild/meson/issues/new with theoutput of `uname -a` and `cat /proc/cpuinfo`` uname -a: `FreeBSD XXX 12.0-BETA1 FreeBSD 12.0-BETA1 #7 r339445M: Sat Oct 20 02:36:21 CEST 2018 root@:/usr/obj/usr/src/powerpc.powerpc64/sys/GENERIC64 powerpc` Since this is FreeBSD, there's no `/proc/cpuinfo`. Excerpt from dmesg: ``` cpu0: IBM POWER9 revision 2.2, 2700.00 MHz cpu0: Features dc007182<PPC32,PPC64,ALTIVEC,FPU,MMU,SMT,ISNOOP,ARCH205,ARCH206,VSX,TRUELE> cpu0: Features2 eee00000<ARCH207,HTM,DSCR,ISEL,TAR,VCRYPTO,ARCH300,IEEE128,DARN> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: Document ma.filled behavior with non-scalar fill_value The ma.filled function and equivalent MaskedArray method are documented as follows: ``` filled(self, fill_value=None) .. Parameters ---------- fill_value : scalar, optional ``` However, the current implementation (using np.copyto(.., where=mask)) allows any shape that can be broadcast to the shape of self for fill_value. This is a useful property and should be documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: CLI help output: avoid click text rewrapping # Checklist - [x] I have checked the [issues list](https://github.com/celery/celery/issues?q=is%3Aissue+label%3A%22Issue+Type%3A+Enhancement%22+-label%3A%22Category%3A+Documentation%22) for similar or identical enhancement to an existing feature. - [x] I have checked the [pull requests list](https://github.com/celery/celery/pulls?q=is%3Apr+label%3A%22Issue+Type%3A+Enhancement%22+-label%3A%22Category%3A+Documentation%22) for existing proposed enhancements. - [x] I have checked the [commit log](https://github.com/celery/celery/commits/main) to find out if the if the same enhancement was already implemented in the main branch. - [x] I have included all related issues and possible duplicate issues in this issue (If there are none, check this box anyway). # Brief Summary The command `celery worker --help` gives ```bash Usage: celery worker [OPTIONS] Start worker instance. Examples -------- $ celery --app=proj worker -l INFO $ celery -A proj worker -l INFO -Q hipri,lopri $ celery -A proj worker --concurrency=4 $ celery -A proj worker --concurrency=1000 -P eventlet $ celery worker --autoscale=10,0 ``` This is caused by the [text rewrapping of `click`](https://click.palletsprojects.com/en/8.1.x/documentation/#preventing-rewrapping). The solution is to add `\\b` before every paragraph which results in ```bash Usage: celery worker [OPTIONS] Start worker instance. Examples -------- $ celery --app=proj worker -l INFO $ celery -A proj worker -l INFO -Q hipri,lopri $ celery -A proj worker --concurrency=4 $ celery -A proj worker --concurrency=1000 -P eventlet $ celery worker --autoscale=10,0 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: Python test fails with bunch of errors. URL: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/CONTRIBUTING.rst#running-system-tests Steps: 1. git clone https://github.com/GoogleCloudPlatform/google-cloud-python 2. Create JSON key on developer console 3. Set GOOGLE_APPLICATION_CREDENTIALS: The path to a JSON key file 4. Change directory to google-cloud-python 5. Run Storage system test ex: ~/.local/bin/nox -f storage/nox.py -s \"system(py='2.7')\" Attached is the error log from test output. Error: [Errors.docx](https://github.com/GoogleCloudPlatform/google-cloud-python/files/2308110/Errors.docx) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Include osx loadable modules support (-bundle) Please include a loadable module target (-bundle flag without -shared and -install_name flag) for OS X (mac os) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Better error message for when `conda activate` isn't a command Tell users how to get `conda activate` as a command in 4.4 through a better error message. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: cmake project generator incorrect order `project(PackageTest CXX) cmake_minimum_required(VERSION 2.8.12)` test package cmake projects get generated in this order. the order should be `cmake_minimum_required(VERSION 2.8.12) project(PackageTest CXX)` see cmake documentation : https://cmake.org/cmake/help/v3.6/command/cmake_minimum_required.html > Call the cmake_minimum_required() command at the beginning of the top-level CMakeLists.txt file even before calling the project() command. It is important to establish version and policy settings before invoking other commands whose behavior they may affect. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add mathematical definition of pulses in pulse_lib documentation <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Mathematical definitions of pulses should be added in the `pulse_lib` documentation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: An Error report about pipeline # 🐛 Bug ## Information This may be an easy question, but it has been bothering me all day. When I run the code: nlp = pipeline(\"question-answering\") It always tells me: Couldn't reach server at 'https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-cased-distilled-squad-modelcard.json' to download model card file. Creating an empty model card. If I ignore it and continue to run the rest of the code: nlp({ 'question': 'What is the name of the repository ?', 'context': 'Pipeline have been included in the huggingface/transformers repository' }) The error will appear: KeyError: 'token_type_ids' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: CI: Force docs compilation warnings to be raised as errors ## 📚 Documentation We frequently have the issue that a part of the code is changed but the documentation gets broken. Since most doc breaking changes only raise warnings, they are often overlooked. Let's fix all the warnings and force the build to raise future warnings as errors such that we see it in CI. Possible way to raise errors suggested [here]( https://stackoverflow.com/questions/38048945/how-to-turn-warnings-into-errors-when-building-sphinx-documentation-with-setupto/42426616#42426616) on stackoverflow: `make html SPHINXOPTS=\"-W\"` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add `.draw()` method to `quantum_info.Operator` class ### What should we add? It would be very convenient to have a `draw` method for the `Operator` class similar to what is available for the `Statevector` and `DensityMatrix` classes. A good start would be to just add text representations (`repr`, `text`, `latex_source` and `latex`), but more could be added later if needed, like a visual representation of Pauli decompositions, cityscape plot of the op matrix, etc. (I believe the state visualizations work for operators as well, so some of these will be minimal work too). Having this feature will also allow the user to set a predefine way of displaying things locally in the user config file. Not sure if this would have to be a separate PR since it will require its own testing, release notes, etc. I can implement this if there is any interest. I would just need some guidance on what would be the best way to organize the code. In the case of the `Statevector` class, the `draw` method calls the `state_drawer` function which lives under `visualization.state_visualization`. Not sure if for `Operator` something similar would have to be done, or if everything could just be defined under the `draw` method itself since a `__repr__` method already exists, and `latex_source` and `latex` only need to call the `array_to_latex` function. The only representation remaining would be `text`, which ideally could be implemented just by reusing the `visualization.state_visualization.TextMatrix` class, but currently this does not support operators. [This line](https://github.com/Qiskit/qiskit-terra/blob/02502b5d98796dcc2c8b80ac5d0f2af85e978e5c/qiskit/visualization/state_visualization.py#L1406) errors out because the `Operator` class does not have a `.dims` attribute, so either that would need to be modified, or a `__str__` method could be defined for `Operator` and simply use that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: configuration_data: assignment to new variable does not make a copy The way this seems to work currently seems counterintuitive to me, I don't know if it's intentional or a bug, so I filed an issue. In short, I think this should work: ``` a = configuration_data() a.set('HELLO', 1) b = a configure_file(output : 'a.h', configuration : b) # This should still work, as we didn't use the original above but a copy! a.set('WORLD', 1) ``` But it results in a `Can not set values on configuration object that has been used.` error. I'd attach a patch for the unit tests, but github won't let me (\"We don't support that file type.\")! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ImportError: No module named shutil_get_terminal_size Update from @carreau : Reopening, tagging 5.4 we should vendor shutil_get_terminal_size. --- After installing ipython `sudo apt-get install ipython-notebook` , `ipython` it appears a error, as follows: jiangyuping@Lenovo:~$ ipython Traceback (most recent call last): File \"/usr/local/bin/ipython\", line 4, in <module> from IPython import start_ipython File \"/usr/local/lib/python2.7/dist-packages/IPython/**init**.py\", line 48, in <module> from .core.application import Application File \"/usr/local/lib/python2.7/dist-packages/IPython/core/application.py\", line 25, in <module> from IPython.core import release, crashhandler File \"/usr/local/lib/python2.7/dist-packages/IPython/core/crashhandler.py\", line 28, in <module> from IPython.core import ultratb File \"/usr/local/lib/python2.7/dist-packages/IPython/core/ultratb.py\", line 128, in <module> from IPython.utils.terminal import get_terminal_size File \"/usr/local/lib/python2.7/dist-packages/IPython/utils/terminal.py\", line 22, in <module> from backports.shutil_get_terminal_size import get_terminal_size as _get_terminal_size ImportError: No module named shutil_get_terminal_size Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Hacker news example uses old schedule API https://github.com/dagster-io/dagster/blob/master/examples/hacker_news/hacker_news/schedules/hourly_hn_download_schedule.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: add telemetry for use of IO managers Some of these might be more difficult to determine than others, but it would be helpful to understand the adoption of: * Each of the built-in integration IO managers, i.e. s3, snowflake, gcs, duckdb, etc. * Custom user-authored IO managers Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: `rm` reports that it will delete services that aren't defined in the current file Hello, I have a `data.yml` that declares various data containers that should not be deleted in normal circumstances. In the main `docker-compose.yml` these containers are referenced by name in `volumes_from`. With this setup under 1.2 `docker-compose rm` deletes only containers from `docker-compose.yml`. Since 1.3 it tries to delete also the data containers, and this breaks my deploy. I think that the yml file should be used to restrict the containers found by the label lookup, unless some specific command line option is given. As a workaround, is there another way to prevent deletion of data containers? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Migrat `sphinx-panels` to `sphinx-design` extension in documentation ### What should we add? `sphinx-panels` extension is not actively maintained and the maintainer recommends migrating to `sphinx-design` extension: https://github.com/executablebooks/sphinx-panels#sphinx-panels A migration guide can be found here: https://sphinx-design.readthedocs.io/en/latest/get_started.html#migrating-from-sphinx-panels See related discussions here: https://github.com/Qiskit/qiskit-terra/pull/8124#issuecomment-1143704773 and the comments below. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Can no longer take powers of matrices with dtype object I am using numpy in python 3.6.5 where the code ``` >>> import numpy as np >>> M = np.matrix([[2,1],[1,1]], dtype=object) >>> M**3 ``` Runs fine in numpy 1.14.x but raises a `TypeError: Object arrays are not currently supported` in numpy 1.15.0. I looked in the 1.15.0 release notes but couldn't see anything about matrix multiplication / powers being depreciated for objects. Is there a way around this? Currently I need to make matrices of python integers in order to be able to support doing large powers without overflow. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Installing packages from files broken in master ``` ((p35)) Z:\\msarahan\\code\\conda>conda install --force z:\\msarahan\\Downloads\\numexpr-2.6.0-np110py35_0.tar.bz2 Could not parse explicit URL: z:\\msarahan\\Downloads\\numexpr-2.6.0-np110py35_0.tar.bz2 ((p35)) Z:\\msarahan\\code\\conda>conda install --offline z:\\msarahan\\Downloads\\numexpr-2.6.0-np110py35_0.tar.bz2 Could not parse explicit URL: z:\\msarahan\\Downloads\\numexpr-2.6.0-np110py35_0.tar.bz2 ((p35)) Z:\\msarahan\\code\\conda>conda install --force ..\\..\\Downloads\\numexpr-2.6.0-np110py35_0.tar.bz2 Could not parse explicit URL: ..\\..\\Downloads\\numexpr-2.6.0-np110py35_0.tar.bz2 ``` z: is a mapped network drive - not sure if that makes any difference. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: AttributeError: 'NoneType' object has no attribute 'seek' I happened to still install meson master in pygobject CI, which just broke: The result of executing `xvfb-run -a meson test -C _build -v` on a gitlab runner: ``` Traceback (most recent call last): File \"/home/user/.local/lib/python3.6/site-packages/mesonbuild/mesonmain.py\", line 109, in run return options.run_func(options) File \"/home/user/.local/lib/python3.6/site-packages/mesonbuild/mtest.py\", line 783, in run return th.doit() File \"/home/user/.local/lib/python3.6/site-packages/mesonbuild/mtest.py\", line 533, in doit self.run_tests(tests) File \"/home/user/.local/lib/python3.6/site-packages/mesonbuild/mtest.py\", line 693, in run_tests self.drain_futures(futures) File \"/home/user/.local/lib/python3.6/site-packages/mesonbuild/mtest.py\", line 708, in drain_futures result.result() File \"/usr/lib/python3.6/concurrent/futures/_base.py\", line 432, in result return self.__get_result() File \"/usr/lib/python3.6/concurrent/futures/_base.py\", line 384, in __get_result raise self._exception File \"/usr/lib/python3.6/concurrent/futures/thread.py\", line 56, in run result = self.fn(*self.args, **self.kwargs) File \"/home/user/.local/lib/python3.6/site-packages/mesonbuild/mtest.py\", line 265, in run return self._run_cmd(wrap + cmd + self.test.cmd_args + self.options.test_args) File \"/home/user/.local/lib/python3.6/site-packages/mesonbuild/mtest.py\", line 374, in _run_cmd stdout.seek(0) AttributeError: 'NoneType' object has no attribute 'seek' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: data_collator.py:131: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow ### System Info - `transformers` version: 4.23.1 - Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35 - Python version: 3.10.6 - Huggingface_hub version: 0.10.1 - PyTorch version (GPU?): 1.12.1+cu116 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: yes - Using distributed or parallel set-up in script?: no ### Who can help? @sgugger ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction https://colab.research.google.com/drive/1gK9iXBiIEmmt2OMq6wmxwcpslkchHJh-?usp=sharing See the output of `trainer.train()` ### Expected behavior The warning should not occur. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose slow on docker for mac os beta docker-compose is slow with docker for mac os beta on my home network. Here is my workaround for now: - docker-compose up (take ages) - shut down wifi - docker-compose up (really fast) - re-enable wifi I do not reproduce the issue on another network than mine, my work network for instance do not make it slow. I already had a potentially related issue with the docker client itself which couldn't pull any image (going to bizarre local ips instead of the docker hub registry) but it has been fixed since one of the latest docker for mac os beta update. The issue is not reproduced against the docker-toolbox, only the \"native\" docker for mac. My version of docker-compose is : `docker-compose version 1.7.0, build 0d7bf73` My version of docker for mac is: `Version 1.11.1-beta10 (build: 6662)` The docker-compose file I'm trying to run is: ``` #docker-compose.yml sync-engine: build: nylas-sync-engine ports: - 5555:5555 links: - mysql:mysql - redis:redis hostname: sync-engine log_opt: max-size: \"10m\" max-file: \"10\" mysql: image: mysql environment: - MYSQL_ROOT_PASSWORD=whateverpassword volumes: - nylas_mysql:/var/lib/mysql log_opt: max-size: \"10m\" max-file: \"10\" redis: image: redis volumes: - nylas_redis:/data log_opt: max-size: \"10m\" max-file: \"10\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose restart ought to exit with non-zero if it didn't actually restart If you have no containers running and you do `docker-compose restart` it exits with 0. It failed to restart so it should exit with non-zero. This will let you do something like: ``` docker-compose restart || docker-compose up -d ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: link_language has no effect A patch from issue 1534 introduced link_language, but I believe that it is not working and the introduced test case does not test link_language, see https://github.com/mesonbuild/meson/issues/1534 The introduced patch does not seem to work and the supplied test case does not seem to be a proper test of the functionality. This is because the C component is only supplied as a library and it will therefore select the Fortran compiler for linking. From a discussion in #mesonbuild we figured out that \"as far as executable() can tell, it is fortran-exclusive code, and shared libraries don't have a language type.\" A minimal example is: project('tproj', ['fortran','cpp']) executable('run', ['test.f90','test.cpp'], link_language: 'fortran') then it generates rule cpp_LINKER with the gcc command instead of gfortran Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Selection of wrong IMPORTED_LOCATION_<CONFIG> **Describe the bug** ``` if 'IMPORTED_CONFIGURATIONS' in tgt.properties: cfgs = [x for x in tgt.properties['IMPORTED_CONFIGURATIONS'] if x] cfg = cfgs[0] if 'RELEASE' in cfgs: cfg = 'RELEASE' if 'IMPORTED_IMPLIB_{}'.format(cfg) in tgt.properties: libraries += [x for x in tgt.properties['IMPORTED_IMPLIB_{}'.format(cfg)] if x] ``` Always selects RELEASE configuration. (which breaks every native debug build on windows.....) **To Reproduce** Have a CMake config which includes IMPORTED_LOCATION_DEBUG and IMPORTED_LOCATION_RELEASE and see the build break in debug builds due to mismatching ITERATOR_DEBUG_LEVELS since meson always links the RELEASE library. **Expected behavior** Selecting the correct CMake library configuration depending on some variable (maybe debug option or buildtype or another variable like CXXFLAGS if /MTd or /MDd is set) **system parameters** doesn't matter Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: implement defaultEncryptionConfiguration on datasets This feature request is to ensure the client library supports default encryption settings on BigQuery dataset resources. On a dataset, defaultEncryptionConfiguration (an instance of EncryptionConfiguration) can be used to indicate a default CMEK key that will apply to all new tables or ML models created within the dataset. Existing models are not affected, and this can be overridden when a (table or model) is created by specifying the settings explicitly. For libraries that expose underlying discovery types directly, this request may be a no-op. For more information, please contact @shollyman Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Metas MMS speech recognition ### Feature request Our request a simpler and more convenient inference process for a speech recognition model based on MMS just like wav2vec 2.0 in Transformers. ### Motivation We aim to encapsulate the various subroutines called by Facebook’s official model into a direct speech recognition model that is as easy to use as other transformer-based models like wav2vec 2.0. But we also know that the Hugging face team has been among the industry leaders in this area of work. ### Your contribution We recognize that it may not be feasible for us to directly assist the Hugging Face technical team in this task. We believe that such an effort would be forward-looking given the popularity of MMS in current speech recognition research. The resulting model would be ideal for quickly transcribing our meeting notes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Unroll before noise aware layout assignment <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Noise aware layouts look at the number of cx gates, and which edges they act on, to determine a good initial layout. Therefore unrolling should be done before these passes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: -Wnon-virtual-dtor is a dumb option, don't use it The default warnings for C++ (and Obj-C++) appear to include `-Wnon-virtual-dtor`. This is a very strange choice. That warning is pretty much broken by design, and doesn't warn about the right thing anyway. Why is it enabled by default? https://github.com/mesonbuild/meson/blob/master/mesonbuild/compilers/cpp.py#L359 I added `-Wdelete-non-virtual-dtor` to GCC in [2011](https://gcc.gnu.org/g:014ab419efc12a59efebd2720d79e1c055675c85), copying it from Clang which has had it for even longer. That warns when you try to `delete` a polymorphic object with a non-virtual destructor, which is the real problem case that matters. Simply *having* a non-virtual dtor is not bug (and GCC has numerous false positives where it warns even if the dtor is protected, or deleted, or otherwise unable to lead to the problems the warning tries to prevent). The `-Wdelete-non-virtual-dtor` has no false positives, it only warns about code that actually has a problem, not about classes that might have a potential problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Issue with logging and google-auth The following code: ``` import google.cloud.logging import logging from google.cloud.logging.handlers import CloudLoggingHandler client = google.cloud.logging.Client() handler = CloudLoggingHandler(client) cloud_logger = logging.getLogger() cloud_logger.setLevel(logging.INFO) cloud_logger.addHandler(handler) cloud_logger.addHandler(logging.StreamHandler()) cloud_logger.info('hello') ``` works fine with google-cloud-logging==1.1.0 but fails with newer versions (1.2.0 or 1.3.0) : ``` Failed to submit 1 logs. Traceback (most recent call last): File \"/usr/local/lib/python2.7/dist-packages/google/cloud/logging/handlers/transports/background_thread.py\", line 99, in _safely_commit_batch batch.commit() File \"/usr/local/lib/python2.7/dist-packages/google/cloud/logging/logger.py\", line 549, in commit client.logging_api.write_entries(entries, **kwargs) File \"/usr/local/lib/python2.7/dist-packages/google/cloud/logging/_http.py\", line 163, in write_entries self.api_request(method='POST', path='/entries:write', data=data) File \"/usr/local/lib/python2.7/dist-packages/google/cloud/_http.py\", line 290, in api_request headers=headers, target_object=_target_object) File \"/usr/local/lib/python2.7/dist-packages/google/cloud/_http.py\", line 183, in _make_request return self._do_request(method, url, headers, data, target_object) File \"/usr/local/lib/python2.7/dist-packages/google/cloud/_http.py\", line 212, in _do_request url=url, method=method, headers=headers, data=data) File \"/usr/local/lib/python2.7/dist-packages/google/auth/transport/requests.py\", line 175, in request self.credentials.before_request( AttributeError: 'AuthorizedSession' object has no attribute 'credentials' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make local and online simulator accept the new `bfunc` instruction ### What is the expected enhancement? The new Qobj format changes the way in which conditionals are treated. Before, a `conditional` object was embedded inside the gate instruction, in the form: ```json { \"conditional\": { \"mask\": \"0x4\", \"type\": \"equals\", \"val\": \"0x1\" }, \"name\": \"u1\", \"params\": [ 1.5707963267948966 ], \"qubits\": [ 3 ], \"texparams\": [ \"0.5 \\\\pi\" ] } ``` Now, you use the `bfunc` instruction to set a classical register (referred by its index in the `register` property) and then refer that register in the instruction gate to make it depends on it: ```json { \"name\": \"bfunc\", \"mask\": \"0x4\", \"relation\": \"==\", \"val\": \"0x1\", \"register\": 1 }, { \"name\": \"u1\", \"conditional\": 1, \"params\": [ 1.5707963267948966 ], \"qubits\": [ 3 ], \"texparams\": [ \"0.5 \\\\pi\" ] } ``` No local nor online simulators currently accept the `bfunc`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] cmake_find_package support Standard Variable Names <!-- What is your suggestion? Please be as specific as possible! --> `cmake_find_package` generator should set standard variable names as per https://cmake.org/cmake/help/v3.20/manual/cmake-developer.7.html#standard-variable-names: - [ ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add TF implementation of XGLM model # 🚀 Feature request Add TF implementation of XGLM model ## Motivation Narrow the gap between PT and TF implementations. ## Your contribution I'd like to work on this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: `BatchFeature` performance improvement: convert `List[np.ndarray]` to `np.ndarray` before converting to pytorch tensors # 🚀 Feature request @NielsRogge, @sgugger When using a `FeatureExtractor` for images and passing `List[np.ndarray]` with `return_tensors=\"pt\"`, the following warning is outputted: ``` .../lib/python3.8/site-packages/transformers/feature_extraction_utils.py:158: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:201.) ``` As reported in https://github.com/pytorch/pytorch/issues/13918, a significant performance improvement can be obtained by using `torch.tensor` on a `numpy.ndarray` instead of on `List[numpy.ndarray]`. I think a possible solution would be https://github.com/huggingface/transformers/pull/14306: https://github.com/huggingface/transformers/blob/05fed8bf19547161707aec882e081023378608a7/src/transformers/feature_extraction_utils.py#L136-L144 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Support n-way conditionals XLA supports an n-way conditional form of `Cond`, which will perform better on GPU in particular. We should support it in JAX also. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Allow returning values from transactional functions Somebody asks in the Slack: > Question about spanner python APIs, specifically transactions. > In a read-write transaction, is it possible to return the updated > value without hitting the database again? > > let's say I have the following transaction (pretty much the example from the docs) > ```def f(transaction): > second_album_result = transaction.read( > table='Albums', columns=('MarketingBudget',), > keyset=second_album_keyset, limit=1) > second_album_row = list(second_album_result)[0] > second_album_budget = second_album_row[0] > second_album_budget += 10000000 > transaction.update(table=mytable, columns=('MarketingBudget'), > keyset=second_album_keyset, values=[(second_album_budget)] > ) > return second_album_budget > database.run_in_transaction(f) > ``` > is the `return` at all possible? I believe that this is currently not possible in the Python library, because when you pass a closure to `run_in_transaction`, the return value always gets ignored, and it just returns the commit timestamp. However this _is_ possible in the Cloud Spanner Java library, and being be able to return whatever you want from the body of a transactional function in the case that a transaction successfully commits is extremely useful. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pass arguments to install_script based on installing headers I need to make compatible symlinks for them in $includedir, so I can't have one script, because it doesn't know anything about meson options. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Cloud speech veneer should not provide a default sample rate Default sample rates should be removed. For audio types with a header the server can automatically determine the sample rate. (We are implementing this for V1.) For audio types without a header the default causes more harm than good because if it is incorrect the results could be empty or wildly inaccurate, which causes user confusion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support to PassManager drawer to display stages ### What should we add? In #6403 we added the concept of a staged passmanger where the different sections of a pass manager are organized into named stages. However, when calling the `draw()` method the additional metadata for the stages are missed. We should modify the drawer for the `StagedPassManager` class to annotate the output diagram with the stages. The idea I had in mind was putting each stage as an outer box around the passes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: kak decomposition is needed A kak decomposition pass is needed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Allow SUCCESS signals to carry results Currently, tasks can `raise signals.SUCCESS()` but not provide a result. It would be great if a result could be passed and applied to the resulting state. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Docker Compose \"images\" prints the registry port in the wrong column If I have a Docker image reference including a full registry host name and port ``` example.com:8443/example ``` It's not displayed properly in the images table ``` $ docker-compose images Container Repository Tag Image Id Size ---------------------------------------------------------------------- example_example_1 example.com 8443/example abcdef123456 173 MB ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Upgrade script is broken following copier 8.0.0 release <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue. Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description <!--Describe the bug clearly and concisely. Include screenshots if possible--> Error [seen on CI](https://github.com/jupyterlab/jupyterlab/actions/runs/5174471636/jobs/9320833877) when executing `python -m jupyterlab.upgrade_extension` ``` copier.run_auto(template, output_dir, vcs_ref=vcs_ref, data=extra_context, defaults=True) ^^^^^^^^^^^^^^^ AttributeError: module 'copier' has no attribute 'run_auto' ``` ## Expected behavior <!--Describe what you expected to happen--> no error Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Pull in improvements from namespaces PR for 4.6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add pop2piano ### Model description - Introduce a large amount of paired and synchronised {pop, piano cover} data using an automated pipeline. - Pop2Piano, a Transformer network that generates piano covers given waveforms of pop music. - First model to directly generate a piano cover from pop audio without melody and chord extraction modules. - Uses a T5 model so should be straightforward. ### Open source status - [X] The model implementation is available - [X] The model weights are available ### Provide useful links for the implementation - Weights : https://github.com/sweetcocoa/pop2piano/releases/download/dpi_2k_epoch/model-1999-val_0.67311615.ckpt - Code : https://github.com/sweetcocoa/pop2piano/ - Paper : https://arxiv.org/abs/2211.00895 - Colab : https://colab.research.google.com/drive/1rBAs2TkryDnnQOhcM-mtlrgtL2h3ekml?usp=sharing Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Feature request: meson test: Add --fail-fast or --stop-after-failures When enough tests fail it often isn't useful to continue running - something fairly fundamental may be broken. Sometimes that may even mean that every test segfaults and produces core files. Especially for CI it'd be useful to abort meson test after a few failures. I can probably prototype something, but I thought I'd collect some input first. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Enable retries for Fargate Agent ## Current behavior We invoked `client.create_flow_run` in a for loop with 365 different parameter values. This caused 258 of them to fail with one of two different errors. In each case there was only run log message for the whole flow run. ``` March 17th 2020 at 2:32:51am | agent ERROR An error occurred (ThrottlingException) when calling the RunTask operation (reached max retries: 4): Rate exceeded. ``` ``` March 17th 2020 at 2:32:59am | agent ERROR list index out of rangeMarch 17th 2020 at 2:32:59am | agent ERROR list index out of range ``` Apparently, for the flow runs that the FargateAgent received an error from the AWS API, the FargateAgent quit and sent the error back to Prefect Cloud. ## Proposed behavior When the FargateAgent receives a throttling error response from AWS, it could retry the request (perhaps using backoff). It appears that botocore already has retry functionality: https://github.com/boto/botocore/pull/1260 ## Example If this were implemented, it would cover the case when a team is running a backfill workflow for every day in a given year, all at once. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Auto-refresh doesn't take into account the selected date ### Apache Airflow version 2.1.3 ### Operating System Debian GNU/Linux 9 (stretch) ### Versions of Apache Airflow Providers _No response_ ### Deployment Other Docker-based deployment ### Deployment details _No response_ ### What happened In the DAG tree view, if I select a custom date in the date filter (top left corner) and press \"update\", DAG runs are correctly filtered to the selected date and number of runs. However, if the \"auto-refresh\" toggle is on, when the next tick refresh happens, the date filter is no longer taken into account and the UI displays the actual **latest** x DAG runs status. However, neither the header dates (45° angle) nor the date filter reflect this new time window I investigated in the network inspector and it seems that the xhr request that fetches dag runs status doesn't contain a date parameter and thus always fetch the latest DAG run data ### What you expected to happen I expect that the auto-refresh feature preserves the selected time window ### How to reproduce Open a DAG with at least 20 dag runs Make sure autorefresh is disabled Select a filter date earlier than the 10th dag run start date and a \"number of runs\" value of 10, press \"update\" The DAG tree view should now be focused on the 10 first dag runs Now toggle autorefresh and wait for next tick The DAG tree view will now display status of the latest 10 runs but the header dates will still reflect the old start dates ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Update Noxfiles to use new Nox Nox recently made a [big change](https://github.com/theacodes/nox/blob/master/CHANGELOG.md#2018823) from declarative to imperative and broke the Noxfile API. We need to update our Noxfiles to work with the new API and update our test scripts to install `nox` (instead of `nox-automation`) and invoke `python3 -m nox {args}`. Most projects just need to do a few steps: 1. Remove usage of `session_{name}` sessions and use `@nox.session` instead. 2. Don't use `session.interpreter`, use `@nox.session(py='...')` 3. Don't use `nox.parametrize` for multiple Pythons, use `@nox.session(py=['..', '..'])`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: TFSequenceClassifierOutput can't return loss batch_size when num_labels=1 ### System Info [**Colab Env**](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb) - `transformers` version: 4.22.2 - Platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.7.14 - Huggingface_hub version: 0.10.0 - PyTorch version (GPU?): 1.12.1+cu113 (False) - Tensorflow version (GPU?): 2.8.2 (False) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: <fill in> - Using distributed or parallel set-up in script?: No ### Who can help? @Rocketknight1 @sgugger @stevhliu ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction https://colab.research.google.com/drive/1lTxUPTa0XPRXJRV1NDYzwvzcMOY-fqJf?usp=sharing ### Expected behavior `STS-B` task can train with `model.fit()` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Use CMAKE_FIND_ROOT_PATH_MODE_INCLUDE in CMakeToolchain instead of XXX_DIR solution for OSX > I don't see the new toolchain setting CMAKE_FIND_ROOT_PATH_MODE_INCLUDE, am I missing something? Why this feature in the legacy generators but not the new ones? `find_package()` doesn't need `CMAKE_FIND_ROOT_PATH_MODE_PACKAGE BOTH` in `CMakeDeps` (see https://github.com/conan-io/conan/issues/9202#issuecomment-878363451, but it could be replaced by `CMAKE_FIND_ROOT_PATH_MODE_PACKAGE BOTH` instead). `find_library()`, `find_path()` and `find_file()` would also need https://github.com/conan-io/conan/issues/9427, `CMAKE_FIND_ROOT_PATH_MODE_* BOTH` is not sufficient. _Originally posted by @SpaceIm in https://github.com/conan-io/conan/issues/9437#issuecomment-902808812_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Reject comparison between boolean & string (or any incompatible combinations) While reviewing libdrm's meson port I found such construction (which is typo, but anyway). `if get_option('foo') != 'false'` To be honest, I want meson to fail hard on this... Or at least show noisy warning. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: custom_target: install: true always enables build_by_default even when explicitly disabled With Meson 0.47.2 it seems a custom_target with install set to true will always override build_by_default. Which means it's not possible to have an optional target that can also be installed. Minimal repro: ``` project('test') custom_target('test_bug', command: ['echo', 'executed'], output: '.', install: true, install_dir: '/tmp', build_by_default: false) ``` ``` $ ninja -C build ninja: Entering directory `build' [1/1] Generating test_bug with a custom command. executed ``` with install: false: ``` $ ninja -C build ninja: Entering directory `build' ninja: no work to do. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Classically efficient gradients and QFI ### What should we add? For statevector simulations we can use faster classical evaluation schemes for the gradients, as proposed in https://arxiv.org/abs/2009.02823 and https://arxiv.org/abs/2011.02991. These methods are significantly faster than the current ones as they (1) asymptotically scale with one less power (linear for gradients, quadratic for natural gradients) and (2) have no overhead from constructing circuits and going via primitives. The code for these methods is implemented using Qiskit in https://github.com/Cryoris/surfer. The gradient version works for any circuit, but the QFI code doesn't currently support repeated parameters. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Disabler in nested arrays not working fine See #5658 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Environment variable to set [general]default_profile To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [ ] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. This idea was initially proposed at https://github.com/conan-io/conan/issues/1221#issuecomment-403961457 It would be nice if there was an environment variable (perhaps `CONAN_DEFAULT_PROFILE`?) which, if set, would override `[general]default_profile` from `conan.conf `. In an IDE workflow, a project file might be set up to obtain its own dependencies by calling `conan install` (e.g. https://github.com/conan-io/cmake-conan), but it feels wrong to hard-code a desired profile into the call to conan install. Most project systems like this support multiple configurations (e.g. Qt Creator has [kits](http://doc.qt.io/qtcreator/creator-configuring-projects.html), MSVC supports setting up multiple configurations. conan_cmake_settings(...) makes an effort to reverse-engineer the settings from the compiler detection variables, but it's not particularly complete, and in any case a sophisticated profile might have content (e.g. build_requires for toolchains) arguably could never get in this fashion. IDE features to define a build template like this usually have a mechanism to add environment variables to the build invocation, and a way to set the default profile through the environment seems consistent with the existing ability to override specific settings from it using [CONAN_ENV_XXXX_YYYY](https://docs.conan.io/en/latest/reference/env_vars.html#conan-env-xxxx-yyyy). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda package update error Hi, I am having this error while trying to upgrade scikit-learn package: ``` $ conda update scikit-learn Fetching package metadata ......... Solving package specifications: . Package plan for installation in environment /Users/ivan/anaconda: The following packages will be UPDATED: conda: 4.3.4-py27_0 --> 4.3.9-py27_0 mkl: 11.3.3-0 --> 2017.0.1-0 numexpr: 2.5.2-np110py27_1 --> 2.6.1-np111py27_2 numpy: 1.10.4-py27_2 --> 1.11.3-py27_0 scikit-learn: 0.17.1-np110py27_2 --> 0.18.1-np111py27_1 scipy: 0.17.1-np110py27_1 --> 0.18.1-np111py27_1 Proceed ([y]/n)? y CondaError: dist_name is not a valid conda package: rfoo ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: populate RowIterator.total_rows after running a query job Request to have `total_rows` property public, under `QueryJob()` along with other stats Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QASM version of a controlled gate <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.16.0 - **Python version**: 3.8.5 - **Operating system**: MacOS 10.15.7 ### What is the current behavior? Consider the following code snippet. Both gates have the same qasm representation. ``` from qiskit.circuit.library import RYGate gate_ctrl_0 = RYGate(1).control(num_ctrl_qubits=1, ctrl_state='0') gate_ctrl_1 = RYGate(1).control(num_ctrl_qubits=1, ctrl_state='1') print(gate_ctrl_0.qasm()) print(gate_ctrl_1.qasm()) ``` ``` cry(1) cry(1) ``` ### Steps to reproduce the problem ### What is the expected behavior? A controlled gate, with control state equals to 0 will be represented with additional X gates. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda.install imports other conda modules I just noted https://github.com/conda/conda/blob/master/conda/install.py#L47, however, it has always been a policy that `conda.install` has to be standalone, see: https://github.com/conda/conda/blob/master/conda/install.py#L22 The problem is that all our installers depend on this, that is, they use `conda.install` as a module for bootstrapping. This means that currently (even though we can build installers) they are broken. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Use rmtree workaround for write-protected files on Windows See https://stackoverflow.com/questions/1889597/deleting-directory-in-python/1889686#1889686. Alternately we can use rd /s. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson-options.txt allows upper case characters in array but setting them is imposible meson version is 0.44.1 I have an array in meson-options.txt similar to below which is title case. However when I set it with ```-Dplugins=PlugTwo``` it is set with lower case. ``` option('plugins', type: 'array', choices: ['PlugOne', 'PlugTwo'], value: ['PlugOne', 'PlugTwo'], description: 'Select plugins') ``` The output of meson configure looks like below then ``` plugins ['plugtwo'] ['PlugOne', 'PlugTwo'] Select plugins ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Python 3.10 support In [this PR about PEP-6222](https://github.com/gvanrossum/patma/pull/117) I created an experimental build of Python 3.10 that is available [at this binder link](https://mybinder.org/v2/gh/fperez/patma/master?urlpath=lab). However if I install IPython using `py10 -m pip install IPython` and then try to use it, eventually I get a crash. I'll post the details in a comment below so we keep the top-level issue description simple. It would be great to track 3.10 compatibility, if possible, so we can use IPython for testing/experimenting with new features and ideas (though I realize that may be a big lift in that it's tracking quite a moving target). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Consolidate parsing of RFC 3339 datetime strings See: https://github.com/GoogleCloudPlatform/gcloud-python/pull/1145/files#r40020506 `gcloud._helpers._RFC3339_MICROS` is used to parse datetime strings in: - `gcloud.dns.changes` (after #1145 lands) - `gcloud.pubsub.message` - `gcloud.storage.bucket` - `gcloud.storage.blob` (twice) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: How to enable default notebook toolbar with all default buttons in the notebook 4.0.0 As now in 4.0.0 default notebook toolbar is empty, how to get all the default buttons in the toolbar? https://jupyterlab.readthedocs.io/en/latest/extension/extension_migration.html#deprecated-code-removed We are using notebook example ( https://github.com/jupyterlab/jupyterlab/tree/main/examples/notebook ) in our application. Is there any option to get the default toolbar with all the default buttons ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Bigtable Python Client Max Row size is 4mb On the big table documents, it says the max cell size is 100mb. However, when I try to read a row with a cell of size 10mb using the Bigtable Python client, I get the following error: ``` Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/usr/local/lib/python2.7/dist-packages/google/cloud/happybase/table.py\", line 190, in row row, filter_=filter_) File \"/usr/local/lib/python2.7/dist-packages/google/cloud/bigtable/table.py\", line 234, in read_row rows_data.consume_all() File \"/usr/local/lib/python2.7/dist-packages/google/cloud/bigtable/row_data.py\", line 323, in consume_all self.consume_next() File \"/usr/local/lib/python2.7/dist-packages/google/cloud/bigtable/row_data.py\", line 261, in consume_next response = six.next(self._response_iterator) File \"/usr/local/lib/python2.7/dist-packages/grpc/_channel.py\", line 344, in next return self._next() File \"/usr/local/lib/python2.7/dist-packages/grpc/_channel.py\", line 335, in _next raise self grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with (StatusCode.INTERNAL, Max message size exceeded)> ``` This max size seems to be hard coded in the grpc library. Has anybody been able to read large rows using the Bigtable Python client? Any idea for workarounds or how I can set the max size? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: In datastore.query, figure out how to properly handle namespaces From TODO: ``` python # TODO: Figure out how to properly handle namespaces. ``` See [`datastore.query`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/query.py#L9) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 9) # TODO: Figure out how to properly handle namespaces. ``` In datastore.query, figure out how to properly handle namespaces From TODO: ``` python # TODO: Figure out how to properly handle namespaces. ``` See [`datastore.query`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/query.py#L9) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 9) # TODO: Figure out how to properly handle namespaces. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Parameter is_real seems not correct ### Environment - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is happening? `Parameter.is_real()` seems not correct. ### How can we reproduce the issue? ```python >>> from qiskit.circuit import Parameter >>> Parameter(\"a\").is_real() True >>> (1j * Parameter(\"a\")).is_real() True ``` ### What should happen? Both should return `False` since we don't know whether `a` is real or not. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [scm] Rework SVN is_pristine() function To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). The actual implementation of SVN `is_pristine` function could fail by the following two cases: * When using externals there will be X in the first column and also the output will come for the main project and all externals libs, so that output.splitlines()[:-1] will not work. * When using the -u parameter, there will be shown files that are updated on the server with an * . Because we want also to be able to checkout an specific revision, I think this column must also not be used. May be we should use the --xml option, to better parse the files. To get the SVN #3192 pull request into the develop branch, we postponed this issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Zero-shot classification pipeline change in 4.11.2 The latest version of the ZSL classification pipeline appears to give slightly different output for the following test code: ```python from transformers import pipeline nlp = pipeline(\"zero-shot-classification\") print(nlp([\"I am happy\", \"I am sad\"], [\"negative\", \"positive\"])) ``` Version 4.10.2 output ``` [{'sequence': 'I am happy', 'labels': ['positive', 'negative'], 'scores': [0.9984542727470398, 0.0015457083936780691]}, {'sequence': 'I am sad', 'labels': ['negative', 'positive'], 'scores': [0.9985381364822388, 0.0014618091518059373]}] ``` Version 4.11.2 output ``` [[{'sequence': 'I am happy', 'labels': ['positive', 'negative'], 'scores': [0.9984542727470398, 0.0015457083936780691]}], [{'sequence': 'I am sad', 'labels': ['negative', 'positive'], 'scores': [0.9985381364822388, 0.00146180868614465]}]] ``` It appears that 4.11.2 is adding an extra list around each element. This can be manually processed out but I also wanted to pass this along in case this wasn't expected new behavior. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [Commands] Validate remote URL Conan version: 1.7.3 Testing conan behind a proxy let me to an error when I specified a wrong URL for my conan remote. I simply forgot to specify the protocol in the remote configuration: `conan remote update localhost 127.0.0.1:9300` Should have been: `conan remote update localhost http://127.0.0.1:9300` The wrong remote specification together with the no_proxy information: `echo $no_proxy` `localhost,127.0.0.1,localaddress` or in conan.conf below `[proxies]` `no_proxy_match = localhost,127.0.0.1,localaddress` I got the error: `conan upload <test_package> -r=localhost` `ERROR: inet_aton() argument 1 must be string, not None` It took me a while to track down the issue to `requests.utils.should_bypass_proxies(...)` where the url `127.0.0.1:9300/v1/ping` is parsed. Of course, if the request package handles this kind of url better, there is still an error from conan: `ERROR: No connection adapters were found for 127.0.0.1:9300/v1/ping` The error still is not clear enough IMHO. I think it would be more user friendly if the remote url is validated when added or the error message should be more clear what's wrong. (In addition to the package request, which should not fail that way ;-)) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Wrong capitalization on bitgenerator MT19937 Wrong capitalization of MT19937 in default argument values of functions in numpy.random._pickle.py ### Reproducing code example: ```python import numpy as np np.random._pickle.__randomstate_ctor() # => error np.random._pickle.__randomstate_ctor('mt19937') # => error np.random._pickle.__randomstate_ctor('MT19937') # => works ``` ### Error message: *** ValueError: mt19937 is not a known BitGenerator module. ### Numpy/Python version information: 1.17.0 3.6.8 (default, Jan 14 2019, 11:02:34) [GCC 8.0.1 20180414 (experimental) [trunk revision 259383]] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add clang 9 to default list of compilers LLVM 9 is released, so we can add it to the default list of compilers that conan recognizes. Checked vs. conan v1.18.2 on macOS 10.14.6 To help us debug your issue please explain: - [x ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x ] I've specified the Conan version, operating system version and any tool that can be relevant. - [x ] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Problem with indentation in the `run_cell` method Hi, When using the InteractiveShell method `run_cell`, there is a problem when the string to execute begins with a line that contains only 4 spaces. It then does not handle properly the indentations of the subsequent loops.  Tested on JupyterNotebook, JupyterLab and the Ipython interactive shell in the terminal. Config: - jupyter --version 4.4.0 - ipython --version 7.0.1 - python3 --version Python 3.6.7 - Ubuntu 18.04.1 LTS Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Entity creation type safety Right now, if you create an entity like: ``` e = datastore.entity.Entity(key, ('data')) ``` The unindexable properties will be 'd', 'a', or 't'. Obviously in this case the user meant to specify: ``` e = datastore.entity.Entity(key, ('data',)) ``` Perhaps the Entity constructor should verify that exclude_from_indexes is a list or tuple. Here is the discussion where the user ran into this: https://groups.google.com/forum/#!topic/gcd-discuss/rqwF8CRdTAY Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Consider setting for C++ std Compiling the same source code, with the same compiler and version, activating or deactivating C++ std features might lead to different native code (type sizes, etc). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Wandb logger doesn't upload saved model checkpoint for final epoch ## 🐛 Bug When training a model on the TPU and using the wandb logger, the checkpoint for the last epoch trained doesn't get uploaded to wandb. ### To Reproduce Colab notebook: https://colab.research.google.com/drive/1oPaRWGZcz6YEol012xFADN42LV-jowtT Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Add Redis + TLS connections to result_backend setting Component issue of #2833. Users should be able to configure a connection to Redis over TLS using a url with protocol [`rediss://`](https://www.iana.org/assignments/uri-schemes/prov/rediss): `result_backend = 'rediss://...` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] ContextualVersionConflict due to Pylint -> Astroid -> Six Conan depends on pylint: pylint>=2.0,!=2.3.0; python_version >= '3' Pylint version 2.4.3 depends on astroid: \"astroid>=2.3.0,<2.4\" astroid 2.3.3 depends on six~=1.12 (minimum 1.12, so will take 1.13 if available) conan requires six < 1.13 Result: > pkg_resources.ContextualVersionConflict: (six 1.13.0 (c:\\python36\\lib\\site-packages), Requirement.parse('six<1.13,>=1.10.0'), {'conan'}) ### Environment Details (include every applicable attribute) * Operating System+version: Windows 10 * Compiler+version: * Conan version: 1.19.4 * Python version: 3.6.7 ### Steps to reproduce (Include if Applicable) Install conan in python As an aside, I'm curious as to why Conan requires Pylint to build conan packages. [bug] [windows] Path added to virtualenv is not considered when looking for a program Although there is a major refactor related to Conan virtualenvs (https://github.com/conan-io/conan/issues/5821) this issue can be addressed first: 1. Something wrong with the path for CMD: https://github.com/conan-io/conan/blob/4217bb326e02e14c8168b080ef1e7a07c18795c8/conans/test/functional/generators/virtualenv_test.py#L263 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] SCM and not using \"--ignore_dirty\" copies wrong folder to source / build folder ### Environment Details (include every applicable attribute) * Operating System+version: Win10 * Compiler+version: VC15 * Conan version: 1.20.3 vs 1.19.2 * Python version: 3.7 ### Steps to reproduce (Include if Applicable) I have a `conanfile.py` located in a subfolder `test/main` of my git repository. The repository is in `dirty` state. When I use 'conan create ....` with changes in my repository with Conan 1.19.2 all files (starting from repository root) are copied to the source / build folder of the local cache. **Ok** When I use 'conan create .... --ignore_dirty` with changes in my repository with Conan 1.20.3 all files (starting from repository root) are copied to the source / build folder of the local cache. **Ok** When I use 'conan create .... ` with changes in my repository with Conan 1.20.3 only files loacated in 'test/main' are copied to the source / build folder of the local cache. The following build process fails, because the files are in other location. **Failed** Should conan try to copy the files from the same root as the git repository, when `--ignore_dirty` is not selected? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.load() \"invalid shape in fixed-type tuple\" in NumPy 1.16.0 In NumPy 1.16.0, `np.load()` fails to load some files created by `np.save()`, saying \"ValueError: invalid shape in fixed-type tuple.\" The problem seems to be that #12358 changed `np.lib.format._read_array_header()`. It used to pass the descr to `np.dtype()`, but now it uses a new function `descr_to_dtype()` which fails for some valid inputs. We have significant amounts of data stored on disk with formats which NumPy 1.16.0 cannot load, so this is a showstopper for upgrading beyond 1.15. ### Reproducing code example: This fails in NumPy 1.16.0, but works in all prior versions: ```python import numpy as np a = np.zeros(1, np.dtype([('c', ('<f8', (5,)), (2,))])) np.save('a.npy', a) np.load('a.npy') ``` ### Error message: ``` Traceback (most recent call last): File \"numpy/lib/npyio.py\", line 440, in load pickle_kwargs=pickle_kwargs) File \"numpy/lib/format.py\", line 678, in read_array shape, fortran_order, dtype = _read_array_header(fp, version) File \"numpy/lib/format.py\", line 563, in _read_array_header dtype = descr_to_dtype(d['descr']) File \"numpy/lib/format.py\", line 282, in descr_to_dtype dt = numpy.dtype((descr_to_dtype(descr_str), shape)) File \"numpy/lib/format.py\", line 282, in descr_to_dtype dt = numpy.dtype((descr_to_dtype(descr_str), shape)) ValueError: invalid shape in fixed-type tuple. ``` ### Numpy/Python version information: NumPy 1.16.0 Python 3.6.6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DNS doesn't parse creationTime field I know DNS is not oficially supported yet, but I'm reporting it anyway. I'm using the master `gcloud-python` repo with this code: ``` python client = dns.Client.from_service_account_json( 'service-account.json', project='xyz-eu') zones = client.list_zones() ``` This is the error I get: ``` python Traceback (most recent call last): .. zones = client.list_zones() File \"/app/src/gcloud/gcloud/dns/client.py\", line 94, in list_zones for resource in resp['managedZones']] File \"/app/src/gcloud/gcloud/dns/zone.py\", line 67, in from_api_repr zone._set_properties(resource) File \"/app/src/gcloud/gcloud/dns/zone.py\", line 218, in _set_properties cleaned['creationTime'] = float(cleaned['creationTime']) ValueError: invalid literal for float(): 2015-04-02T13:21:24.943Z ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Document that MetadataEntry static initializers are deprecated Caused some confusion here: https://github.com/dagster-io/dagster/pull/8732#issuecomment-1175564089 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Number of experiments in primitive results ### What should we add? In the current specification of `SamplerResult` and `EstimatorResult` there is no unified way of retrieving the the total number of experiments that are comprised within one result object. It would be great to add a property `result.num_experiments` that would retrieve it. Additionally, when one of these objects is instantiated, no checks are performed to verify that the number of experiments is consistent across all data fields. This should be performed as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Input parsing issue with %prun ``` In [5]: %prun grouped.agg({'value1' : 'mean', 'value2' : 'var', 'value3' : 'sum'}) File \"<string>\", line 1 'value1' : 'mean', 'value2' : 'var', 'value3' : 'sum' ^ SyntaxError: invalid syntax ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: lsmagic causes invalid Notebook JSON This is happening in master. Steps to reproduce: - create a new notebook - type `lsmagic` - save the notebook A message pops up \"Notebook validation failed\" and the a console output shows: ``` [E 11:34:22.498 NotebookApp] Notebook JSON is invalid: '{\"line\": {\"xmode\": \"Basi cMagics\", \"load_ext\": \"ExtensionMagics\", \"alias\": \"OSMagics\", \"logon\": \"LoggingM agics\", \"notebook\": \"BasicMagics\", \"killbgscripts\": \"ScriptMagics\", \"rehashx\": \" OSMagics\", \"pinfo\": \"NamespaceMagics\", \"pinfo2\": \"NamespaceMagics\", \"macro\": \"Ex ecutionMagics\", ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Possible incompatibility with Visual Studio 2019 Preview (releasing in April) After installing Visual Studio 2019 Preview, which (I suppose) upgraded the MSVC compiler, it appears that the executables produced by Meson debug builds no longer have debugging information. It also appears that they aren't debug executables, actually, because my unit tests seem to be running much too fast for debug. I wanted to investigate what options are passed to the compiler, but on Windows the arguments are passed in a `@file`, and after ninja finishes, these files are gone. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: The specified 'cppstd=20' is not available for 'gcc 8'. Using Conan 1.4.0, I've manually added `20` and `gnu20` to `cppstd` in `settings.yml`. But when trying to build a package I get: ERROR: The specified 'cppstd=20' is not available for 'gcc 8'. Possible values are ['98', 'gnu98', '11', 'gnu11', '14', 'gnu14', '17', 'gnu17']' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Implement throttling for tasks, by tags Proposal: allow for throttling the number of tasks that can be executed in parallel simultaneously, by `tags`. Basically this would be implemented as a queue within the `FlowRunner`, so that calls to the `Executor` would occur in groups of `group_size` / `pool_size` (whatever we decide to name it). Example: ```python from prefect import task, Flow @task(tags=[\"scrape\"]) def scrape(url): pass @task(tags=[\"db\"]) def save(data): pass with Flow('webscraper') as f: for url in LIST_OF_URLS: site = scrape(url) final = save(site) # no more than 15 scrape tasks will be simultaneously running # no more than 5 db tasks will be simultaneously running f.run(throttle=dict(scrape=15, db=5)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Inconsistent behaviour of arange I have installed JAX on Colab as in the QuickStart notebook. Then I run this instruction: ``` import jax.numpy as np print(np.arange(0.0, 1.0, 0.1)) ``` And I get an array with a single value [0], which is different from: ``` import numpy as np print(np.arange(0.0, 1.0, 0.1)) ``` Where I (correctly) get an array with 11 values 0, 0.1, ..., 0.9, 1.0. Is this intended? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: [5.0.0] Celery does NOT start with both -D and -E options enabled Hi, I've just installed Celery 5.0.0 and noticed that it doesn't start when both `-D` and `-E` options enabled: Only `-E` options works fine: ``` $ celery -A sample.celery worker -E -------------- celery@MacBook-Pro.local v5.0.0 (singularity) --- ***** ----- -- ******* ---- Darwin-19.6.0-x86_64-i386-64bit 2020-09-24 15:59:59 - *** --- * --- - ** ---------- [config] - ** ---------- .> app: sample:0x7fc944afebd0 - ** ---------- .> transport: amqp://guest:**@192.168.0.101:5672// - ** ---------- .> results: disabled:// - *** --- * --- .> concurrency: 4 (prefork) -- ******* ---- .> task events: ON --- ***** ----- -------------- [queues] .> celery exchange=celery(direct) key=celery ``` But both `-D` and `-E` options doesn't work. It exits with exit code 0 and nothing happens... ``` $ celery -A sample.celery worker -D -E ``` **Info:** Python 3.7.9 Celery 5.0.0 on macOS 10.15 Catalina. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Account for existing objects in bucket when using storage.bucket.Bucket.upload_file From TODO: ``` python # TODO: What do we do about overwriting data? ``` See [`storage.bucket.Bucket.upload_file`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/bucket.py#L201) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 201) # TODO: What do we do about overwriting data? ``` Account for existing objects in bucket when using storage.bucket.Bucket.upload_file From TODO: ``` python # TODO: What do we do about overwriting data? ``` See [`storage.bucket.Bucket.upload_file`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/bucket.py#L201) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 201) # TODO: What do we do about overwriting data? ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: \"num_examples\" incorrect when using IterableDataset When using ```torch.utils.data.IterableDataset```, logging ```num_examlpes``` (as in https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L1518) is not the actual num_examples, but the number of examples processed on a single process. For example, when I have 2000 training samples and 2 gpus, with and IterableDataset, current output be like: ``` [INFO|trainer.py:1519] 2022-06-28 12:51:44,666 >> ***** Running training ***** [INFO|trainer.py:1520] 2022-06-28 12:51:44,666 >> Num examples = 1000 [INFO|trainer.py:1521] 2022-06-28 12:51:44,666 >> Num Epochs = 1 [INFO|trainer.py:1522] 2022-06-28 12:51:44,666 >> Instantaneous batch size per device = 8 [INFO|trainer.py:1523] 2022-06-28 12:51:44,666 >> Total train batch size (w. parallel, distributed & accumulation) = 16 [INFO|trainer.py:1524] 2022-06-28 12:51:44,666 >> Gradient Accumulation steps = 1 [INFO|trainer.py:1525] 2022-06-28 12:51:44,666 >> Total optimization steps = 125 ``` Here's the possible cause I've found: as defined in https://github.com/huggingface/transformers/blob/e02037b3524686b57c5a861ea49ac751f15568af/src/transformers/trainer.py#L1085 ```num_examples``` is equal to ``` len(dataloader.dataset)```. However, when ```isinstance(dataset, torch.utils.data.IterableDataset)```, the```dataloader.dataset``` is an instance of ```IterableDatasetShard```, which \"generate samples for one of the processes only\", whose ```__len__``` is the length of dataset on a single process, not the entire project. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: DetrAttention `is_decoder` is not defined https://github.com/huggingface/transformers/blob/fe861e578f50dc9c06de33cd361d2f625017e624/src/transformers/models/detr/modeling_detr.py#LL502C9-L502C19 The `is_decoder` parameter is in the init function, but it is not reference in the body. While in `DetrDecoderLayer`, this parameter is initialized as `True`. Very confused, not sure whether there's something missing in `DetrAttention`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Request for better error message when pmap and psum don't match on axis_name. ``` a = np.arange(4)[np.newaxis,:] print(a.shape) def test(x): return jax.lax.psum(x, axis_name='batch') jax.pmap(test)(a) ``` Gives an error message of `AttributeError: 'str' object has no attribute 'obj'`. It took me forever to figure out that the issue was the pmap needed axis_name='batch'. It would be helpful if this gave a better error message here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Overloading `@` for `Operator` class ### What should we add? ## Proposition Overloading the `@` operator for class `qiskit.quantum_info.operators.Operator` ([documentation](https://qiskit.org/documentation/stubs/qiskit.quantum_info.Operator.html?highlight=operator#qiskit.quantum_info.Operator)) so it works the same as `Operator.compose()` method. The same behavior is done with class `qiskit.opflow.operator_base.OperatorBase` ([documentation](https://qiskit.org/documentation/stubs/qiskit.opflow.OperatorBase.html#qiskit.opflow.OperatorBase)). ## Motivation When going through the Open Science Prize 2021 I encountered [problem](https://github.com/qiskit-community/open-science-prize-2021/issues/5). After investigation it turned out that `Operator` class doesn't have `@` overloading, so in order to fix the issue `compose()` or `np.matmul()` methods need to be used. As this is good solution it would be easier to use `@`, especially for reading the code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for mapping `Expr` values in DAG/QC converters ### What should we add? Once `Expr` values are valid in some `.condition` and `.target` attributes in `QuantumCircuit` instructions, they need to be supported through the `circuit_to_dag` and `dag_to_circuit` converters. Especially in `circuit_to_dag`, we must ensure that any implied classical dependencies between instructions are represented in the wires in the `DAGCircuit`. The work here will mostly be in ensuring that `DAGCircuit.apply_operation_back` has this handling. We should also ensure that `DAGCircuit.apply_operation_front` has the same handling. Depends on #10223 and #10224. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Going from numpy 1.14.5 to 1.15.0rc1 breaks loading a DLL using ctypes In our [Python API](https://github.com/ni/nimi-python) for accessing measurement hardware we allow the customer to retrieve their measurements in `numpy` arrays in case they want to do additional processing. When using `numpy` 1.14.5 or earlier, we are able to load our C DLL with no issue and make the appropriate calls using `ctypes`. When using `numpy` 1.15.0rc1, we get an error when `ctypes` tries to load the DLL saying \"[WinError 126] The specified module could not be found\". I am using `tox` to run tests so it is using `venv` and all I have to do is change the version of `numpy` and it will start working. This means the DLL is in the path as expected and all dependencies are also loadable. I have verified that `numpy` is the only installed package whose version is changing. I have verified that the path environment variable has the appropriate directory even in the failure case. I have verified that this happens on Python 2.7 and 3.6, both 32 bit and 64 bit. As far as I know we are using `ctypes` correctly. At this point I don't have any more ideas on what to look at. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add support for uploading table data via multipart/resumable requests See: - https://cloud.google.com/bigquery/loading-data-post-request#multipart - https://cloud.google.com/bigquery/loading-data-post-request#resumable Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Double check that fast_dev_run works correctly It should run a single validation and training batch and cover the full loop. Suggested by @adefazio Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: wrong or typo in signature for np.fromiter gen = (0 for _ in range(3) np.fromiter(iterable=gen,dtype='int') # fails np.fromiter(iter=gen,dtype='int') # works signature in docs and in core.multiarray declared as iterable np.__version__ Out[8]: '1.13.3' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Add multivariate normal pdf evalutation to jax.scipy It would be great to have a Multivariate gaussian pdf/logpdf implementation, similar to the univariate version in [jax.scipy.stats.norm](https://jax.readthedocs.io/en/latest/_modules/jax/scipy/stats/norm.html#logpdf). I am currently working with this hacky function: ``` @jit def multi_gauss_logpdf(x, mean, cov): \"\"\" Calculate the probability density of a sample from the multivariate normal. \"\"\" D = mean.shape[0] (sign, logdet) = np.linalg.slogdet(cov) p1 = D*np.log(2*np.pi) + logdet p2 = (x-mean).T @ np.linalg.inv(cov) @ (x-mean) return -1./2 * (p1 + p2) batch_logpdf = vmap(multi_gauss_logpdf, in_axes=(0, None, None)) ``` My `lax`/primitive knowledge is still fairly limited but I will try to put together a pr. Any recommendations how to speed things up? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %%time magic prevents assignment The `%%time` cell magic is preventing me from binding names. I found this in notebook code on Travis (py 3.6) and reproduced it locally (py 3.7) in notebook and in `ipython` at the terminal. It doesn't seem to apply to all cell magics: ``` Python 3.7.2 | packaged by conda-forge | (default, Mar 19 2019, 20:46:22) Type 'copyright', 'credits' or 'license' for more information IPython 7.4.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: %%time ...: foo = \"bar\" ...: ...: CPU times: user 3 µs, sys: 0 ns, total: 3 µs Wall time: 6.91 µs In [2]: foo --------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-2-f1d2d2f924e9> in <module> ----> 1 foo NameError: name 'foo' is not defined In [3]: %%prun ...: baz = \"qux\" ...: ...: 3 function calls in 0.000 seconds Ordered by: internal time ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 0.000 0.000 {built-in method builtins.exec} 1 0.000 0.000 0.000 0.000 <string>:2(<module>) 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} In [4]: baz Out[4]: 'qux' ``` Confirmed that 7.3.0 worked fine locally. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Latex barrier bugs There have been a number of attempts at fixing barriers in the latex drawer (https://github.com/Qiskit/qiskit-terra/pull/1727, https://github.com/Qiskit/qiskit-terra/pull/1534, https://github.com/Qiskit/qiskit-terra/pull/1361), but there are still bugs. ```python from qiskit import * qasm = \"\"\" OPENQASM 2.0; include \"qelib1.inc\"; qreg q[7]; cx q[1],q[6]; barrier q[1],q[4],q[5],q[6]; u3(1.8,-0.5,0.4) q[1]; cx q[0],q[1]; \"\"\" circ = QuantumCircuit.from_qasm_str(qasm) circ.draw(output='latex') ```  Bug 1: The barrier should only be on qubits 1, 4, 5, 6 -- but it is on qubits 1 to 4. Bug 2: It cuts through the U3 gate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Sympy 1.9 deprecates `expr_free_symbol`, used in `ParameterExpression` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: any - **Python version**: - **Operating system**: ### What is the current behavior? Sympy 1.9 has begun issuing deprecation warnings when accessing `expr_free_symbols`, which we do during visualisation. This breaks CI, and will be removed in a future version. ### Steps to reproduce the problem Run CI. ### What is the expected behavior? No deprecation warnings. ### Suggested solutions To get CI running again immediately, we can just pin Sympy to a lower version (see #7116). The full fix is to replace the usage with the new form (see #7117). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: compiler.has_argument doesn't work with clang-cl for warning flags **Describe the bug** The option `-Wimplicit-fallthrough=3` is unknown to clang-cl 12.0.1, and yet the `has_argument('-Wimplicit-fallthrough=3')` check passes, as can be seen [here](https://ci.appveyor.com/project/rizinorg/rizin/builds/43245228/job/x5rjqvh9bwub2a0k?fullLog=true#L62):  and [here](https://ci.appveyor.com/project/rizinorg/rizin/builds/43245228/job/x5rjqvh9bwub2a0k?fullLog=true#L34051):  The relevant `meson-log.txt` lines appear to be: ``` Compiler stdout: Compiler stderr: warning: unknown warning option '-Wimplicit-fallthrough=3'; did you mean '-Wimplicit-fallthrough'? [-Wunknown-warning-option] 1 warning generated. Compiler for C supports arguments -Wimplicit-fallthrough=3: YES ``` so the issue appears to be the same as for #755 except that the compiler involved is now clang-cl. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? native build * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) Windows Server 2019 * what Python version are you using e.g. 3.8.0 Python 3.8 * what `meson --version` 0.62.0 * what `ninja --version` if it's a Ninja build 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Legacy printing mode gives not-legacy result for array with negative value, value > 9 Numpy 1.13: ``` $ python -c 'import numpy; print(numpy.array([ -1. , 10]))' [ -1. 10.] ``` There is whitespace before the`-1`. Numpy 1.14: ``` $ python -c 'import numpy; print(numpy.array([ -1. , 10]))' [-1. 10.] $ python -c 'import numpy; numpy.set_printoptions(legacy=\"1.13\"); print(numpy.array([ -1. , 10]))' [-1. 10.] ``` No whitespace before the `-1`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Need to improve GCC OLD ABI COMPATIBILITY message A simple usability and quality of life improvement. It is better to copy and paste a command given to you, rather than manual editing of a file. [see patch](/Ignition/conan/commit/45a57617610abd3a5b4bfc76a5596468cbab23e0) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Regenerate Bigtable V2 protos (after the version landed in #1903). @sduskis reports: > There were some relatively minor changes in the v2 protos. Mostly the changes were in the comments. There were minor changes to rename fields from \"name\" to \"parent\" to better reflect the meaning of some of the proto elements. The latest version of the protos can be found in the official > google api repository at https://github.com/googleapis/googleapis/tree/master/google/bigtable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: user specified properties and/or where to store metadata (author, description) With version 1 files I have two comments at the beginning of the docker-compose file: ``` # author: Anthon van der Neut <a.van.der.neut@ruamel.eu> # description: mongo container ``` that I then extract in [`dc2service`](https://pypi.python.org/pypi/ruamel.dc2service) using `ruamel.yaml` and include this information into service file for Systemd/Upstart . Of course I could follow the YACF principle (Yet Another Configuration File) so often seen in python projects, but with 1.6.0 and the version 2.0 file format I could easily do: ``` version: '2' user-data: author: Anthon van der Neut <a.van.der.neut@ruamel.eu> description: mongo container services: ....... ``` Unfortunately `docker-compose` complains about `user-data` being an unexpected additional property. For the toplevel mapping in version 2, I propose we get one or more keys reserved for user specific data, with the only requirement being that the corresponding value is a valid YAML construct i.e. the whole file stays parsable YAML. This could be one key, with the recommendation that its corresponding value is a mapping (for flexibility), or alternatively docker-compose could ignore all toplevel keys that have a certain prefix (\"user-data-\") Something similar is e.g. done in container file formats like TIFF to allow inclusion of additional (vendor specific) information. That key's name should of course be something that is certainly not going to be used in docker-compose, so \"user-data\", \"non-dc-data\". The docker-compose developers could then always cherry-pick information, that they consider useful for other projects (hopefully like my author/description) and decide them to be inserted under some other property, or maybe even warrant their own toplevel property. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: cu1 and rzz do not display properly in text drawer when wide gate underneath <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.8 - **Operating system**: Ubuntu 18.04 ### What is the current behavior? cu1 and rzz display params multiple times in the text drawer when there is a wide gate underneath in the same layer. ### Steps to reproduce the problem ``` from qiskit import QuantumCircuit from numpy import pi qc = QuantumCircuit(5) qc.rzz(pi/2, 0, 1) qc.cu1(pi/2, 2, 3) qc.x(4, label='This is a really long X') print(qc) q_0: ─■───────────────────────── │zz(pi/2zz(pi/2zz(pi/2) q_1: ─■───────────────────────── q_2: ─────────■───────────────── │pi/pi/2 q_3: ─────────■───────────────── ┌─────────────────────────┐ q_4: ┤ This is a really long X ├ └─────────────────────────┘ ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Support for Xcode 13 Conan 1.40.1 does not support Xcode 13.0. To fix it, \"13.0\" must be added to the list of apple_clang versions. OS: macOS 11.6, Xcode: 13.0m, conan --version: 1.40.1, cc --version: \"Apple clang version 13.0.0 (clang-1300.0.29.3)\" - [x ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Update dependencies with IPtyhon dropping gui_banner, this mean that IPython master require ipykernel > master (future 4.2 or alike) we need to update dependency number in setup.py. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Fix symlinks not copied during export - [x] Refer to the issue that supports this Pull Request: fixes #3258 - [x] If the issue has missing info, explain the purpose/use case/pain/need that covers this Pull Request. - [x] I've read the [Contributing guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've followed the PEP8 style guides for Python code. - [ ] I've opened another PR in the Conan docs repo to the ``develop`` branch, documenting this one. Also adding a description of the changes in the ``changelog.rst`` file. https://github.com/conan-io/docs Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add CLI command for creating a project Would need to be in a new group and could look something like `prefect create project -n My_Project` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [Bug] conan export-pkg has seemingly all values from profile propagated with the exception of CONAN_CMAKE_GENERATOR When I want to export to local cache from a local source dir, I first run the setup commands and build my project ``` conan install . -if=build -pr=myprofile conan build . -sf=. -bf=build ``` then when I run *either* of these commands the wrong generator is used ``` conan export-pkg . user/channel -sf=. -bf=build -f conan export-pkg . user/channel -sf=. -bf=build -pr=myprofile -f ``` Looking at the `command` variable at line 195 in the cmake.py cmake helper class, the command given to cmake is exactly the same for both versions of `export-pkg` above. The cmake command value is how I expect it to be with the exception of that the generator given in the profile is not respected, but uses the default given in conan.conf. If no default in conan.conf is given it defaults back to MinGW Makefiles. A workaround is to set the correct generator as default in conan.conf. But this can only be temporary as projects sometimes includes C# so a mix of generators is to be used. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Loading FlaxHybridCLIP trained model ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.9.0.dev0 - Platform: Linux-5.4.0-1043-gcp-x86_64-with-glibc2.29 - Python version: 3.8.10 - PyTorch version (GPU?): 1.9.0+cu102 (False) - Tensorflow version (GPU?): 2.5.0 (False) - Flax version (CPU?/GPU?/TPU?): 0.3.4 (tpu) - Jax version: 0.2.16 - JaxLib version: 0.1.68 - Using GPU in script?: N/A - Using distributed or parallel set-up in script?: N/A Models: - FlaxHybridCLIP ## Information I am not sure about how to load a trained FlaxHybridCLIP model from a folder. We trained using [this](https://github.com/huggingface/transformers/tree/master/examples/research_projects/jax-projects/hybrid_clip). I tried: `FlaxHybridCLIP.from_text_vision_pretrained(PATH_TRAINED_MODEL, PATH_TRAINED_MODEL)`, but I got the following error: ```Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/home/vinid/transformers/examples/research_projects/jax-projects/hybrid_clip/modeling_hybrid_clip.py\", line 333, in from_text_vision_pretrained text_config = AutoConfig.from_pretrained(text_model_name_or_path) File \"/home/raphaelp/transformers/src/transformers/models/auto/configuration_auto.py\", line 452, in from_pretrained config_class = CONFIG_MAPPING[config_dict[\"model_type\"]] KeyError: 'hybrid-clip' ``` The folder (PATH_TRAINED_MODEL) contains the two following files: - `config.json` - `flax_model.msgpack` Thank you :) :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse naming issues <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> We have several naming issues in Pulse-frontend classes/modules/methods: - [ ] Inconsistency in Channel, PulseCommand, Schedule: PulseCommand -> Command? - [ ] common module -> remove and move contents to top-level? - [ ] Inconsistency in DriveInstruction applied to OutputChannel: OutputInstruction or rename OutputChannel? Rename both (to PulseInstruction and PulseChannel)? - [ ] channels module have more than channels, it's more like device module: pulse/channels -> pulse/device? (I guess we have more) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: lax.conv does not support float64 The lax package currently does not support float64 convolutions. This appears to be an explicit constraint and not a bug. https://github.com/google/jax/blob/master/jax/lax/lax.py#L1828 Feature request: allow convolutions with float64 -> float64 in full precision. TF supports this type of convolution, so I don't think there's anything inherent preventing this, but maybe it's something subtle. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Incorrect cmakedefine implementation **Describe the bug** the current cmakedefine implementation assumes that the definition name and value have to be the same e.g. `#cmakedefine VAR @VAR@` **To Reproduce** simply have any cmakedefine usage where the name and value mismatch e.g. `#cmakedefine const @HAVE_CONST@` (taken from SDL2 https://github.com/libsdl-org/SDL/blob/9d1dbd2ad86805c316cf4f2ee8ab2b361be18f4d/include/SDL_config.h.cmake#L34-L37) **Expected behavior** the value should be any definition value accepted by C This issue also affects muon, which is stricter about this and errors out. Muon issue report: https://todo.sr.ht/~lattis/muon/77 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pubsub 0.35.3 stop consuming messages - ConsumeBidirectionalStream exited RPC After an ~hour, the rpc connection is closed: ``` [2018-06-06 11:02:36,258 - INFO - Thread-14 - streaming_pull_manager] Observed recoverable stream error 504 Deadline Exceeded [2018-06-06 11:02:36,259 - INFO - Thread-ConsumeBidirectionalStream - streaming_pull_manager] Observed recoverable stream error 504 Deadline Exceeded [2018-06-06 11:02:36,260 - INFO - Thread-14 - streaming_pull_manager] Observed recoverable stream error 504 Deadline Exceeded [2018-06-06 11:02:36,260 - **ERROR - Thread-ConsumeBidirectionalStream - bidi] The bidirectional RPC unexpectedly exited. <google.api_core.grpc_helpers._StreamingResponseIterator object at 0x7fb758946090>** ``` I need to cancel and start the subscriber again. OS type and version - \"Debian GNU/Linux 8 (jessie)\" Version - Python 2.7.9 4. pip freeze | grep pubsub google-cloud-pubsub==0.35.3 Code example: ``` def subscriber_handler(message): path = message.attributes.get(\"type\") self.handler_function(path=path, body=message.data) message.ack() self.listening_subscriber = self.subscriber.subscribe(subscription_path, callback=subscriber_handler, flow_control=flow_control) ``` All the other info is the same as in https://github.com/GoogleCloudPlatform/google-cloud-python/issues/5325. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: MaskedArray with nested dtype and object elements cause AttributeError on access When I create a `MaskedArray` using a nested dtype which contains an `object` at the innermost level, trying to access it causes an _AttributeError: 'str' object has no attribute 'ndim'_. If I use `int` instead of `object`, the element access works fine. The issue seems to be caused by the assumption that `_fill_value` is of a numpy type and has an `ndim` attribute. This assumption is true for `numpy.int32` which would be used if `int` was specified inside the dtype. But for `object`, the `_fill_value` will be a just python `str` _'?'_, which has no attribute `ndim`. I propose to change the code line in question to ```python if hasattr(dout._fill_value, 'ndim') and dout._fill_value.ndim > 0: ``` ### Reproducing code example: ```python import numpy as np my_dtype = np.dtype([('b', [('c', object)], (1,))]) a = np.ma.masked_all((1,), my_dtype) print(a['b']['c']) ``` ### Error message: ``` Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"C:\\Python37\\lib\\site-packages\\numpy\\ma\\core.py\", line 3276, in __getitem__ if dout._fill_value.ndim > 0: AttributeError: 'str' object has no attribute 'ndim' ``` ### Numpy/Python version information: 1.18.1 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: mesonintrospect should give us access to project data I need to access the version/project_ name properties from a script and it appears that mesonintrospect doesn't let me get these. Is this supposed to be possible? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: supporting t5 for question answering # 🚀 Feature request Hi, this would be great and appreciated to support t5 model for run_qa.py script, currently this does not support it. ## Motivation T5 is the state of the art model, for which there are a lot of motivation for people in NLP community to use this model, specially it can handle multiple datasets. ## Your contribution <!-- Is there any way that you could help, e.g. by submitting a PR? Make sure to read the CONTRIBUTING.MD readme: https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.unicode aliased to np.compat.long It appears a bug was introduced in numpy when deprecating type aliases in #18230. The bug caused `np.unicode` to be aliased to `np.compat.long` which is an alias for `int`. This was quick to track down because of a typo in the deprecation message (unciode). https://github.com/numpy/numpy/blob/v1.20.0/numpy/__init__.py#L209-L212 ### Reproducing code example: ```python import numpy as np np.unicode(\"hello\") ``` ### Error message: ``` <stdin>:1: DeprecationWarning: `np.unciode` is a deprecated alias for `np.compat.unciode`. To silence this warning, use `np.compat.unciode` by itself. In the likely event your code does not need to work on Python 2 you can use the builtin `str` for which `np.compat.unciode` is itself an alias. Doing this will not modify any behaviour and is safe. If you specifically wanted the numpy scalar type, use `np.str_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations Traceback (most recent call last): File \"<stdin>\", line 1, in <module> ValueError: invalid literal for int() with base 10: 'hello' ``` ### NumPy/Python version information: ``` >>> import sys, numpy; print(numpy.__version__, sys.version) 1.20.0 3.8.2 (default, Nov 4 2020, 21:23:28) [Clang 12.0.0 (clang-1200.0.32.28)] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: File magic (%%file) does not work with paths beginning with tilde (e.g., ~/anaconda/stuff.txt) Found this quirk teaching a Software Carpentry class at LBL, wanted to jot down before I forgot it. I don't know if it's been resolved yet; this behavior occurred with IPython 0.13.1 in the notebook interface. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Improve conan_build_info command We want to leverage from the lock files feature and also from https://github.com/conan-io/conan/issues/5734 to generate a better build-info for Artifactory builds. The proposed commands are: - To incorporate to the `artifacts.properties` the build name and number: `conan_build_info start <build_name> <build_number>` - To remove from the `artifacts.properties` the build name and number: `conan_build_info stop` - To generate a build info json from a lockfile (and the local cache with #5734): `conan_build_info create “bili.json” --lockfile “conan.lock”` - To update a build info json with another one (typically different slave in CI): `conan_build_info update “bili2.json” “bili1.json”` - To publish the build info to Artifactory. The authentication process should be similar to the possibilities provided by the artifactory rest api: `conan_build_info publish “bili2.json” --url http://artifactory_url --user --password --apikey` **NOTE**: it is important to check if we can introduce the subcommands with a fallback to the old command to not break the previous usage. **NOTE2**: Test is the dependencies of a module need or not to push the build number and id as properties to be later promoted. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Unable to add a new user when logged using LDAP auth ### Discussed in https://github.com/apache/airflow/discussions/18290 <div type='discussions-op-text'> <sup>Originally posted by **pawsok** September 16, 2021</sup> ### Apache Airflow version 2.1.4 (latest released) ### Operating System Amazon Linux AMI 2018.03 ### Versions of Apache Airflow Providers _No response_ ### Deployment Other Docker-based deployment ### Deployment details - AWS ECS EC2 mode - RDS PostgreSQL for DB - LDAP authentication enabled ### What happened We upgraded Airflow from 2.0.1 to 2.1.3 and now when i log into Airflow (Admin role) using LDAP authentication and go to Security --> List Users i cannot see **add button** (\"plus\"). **Airflow 2.0.1** (our current version):  **Airflow 2.1.3:**  ### What you expected to happen Option to add a new user (using LDAP auth). ### How to reproduce 1. Upgrade to Airflow 2.1.3 2. Log in to Airflow as LDAP user type 3. Go to Security --> List Users ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) </div> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add support for logging in gcloud.storage Described here: https://developers.google.com/storage/docs/accesslogs Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Pretraining: batch size & document length ## Feature description I was just testing the `pretrain` command and ran out of memory ^^ ! Looking at the code, it seems that the `batch_size` is fixed to 3000. I also noticed that document with length greater than 500 token are pruned by default. I guess this are default parameters for a corpus of sentence / small text... But maybe we should let the user set these parameters ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Valid `google-resumable-media` versions conflict with Cloud Storage It looks like #9572 introduced a dependency conflict for `google-resumable-media` between the latest `google-cloud-storage` and `google-cloud-bigquery` releases. #### Environment details 1. Python 3.7 #### Steps to reproduce 1. `pip install google-cloud-storage` (latest release is `1.23.0`) 2.`pip install google-cloud-bigquery` (latest release is `1.21.0`) 3. Try to import both libraries in the same python #### Issue Today, `google-cloud-storage 1.23.0` was released. It depends on `google-resumable-media >= 0.5.0, < 0.6dev`. The current `google-cloud-bigquery` version, depends on `google-resumable-media >= 0.3.1, != 0.4.0, < 0.5.0dev` Therefore, the `setup.py` files for these two libraries will 2nd level dependency conflict when you attempt to `pip install`. This can be fixed by releasing a new `google-cloud-bigquery` version. (to pick up the changes in #9572) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Consider removing hard dependency on PyOpenSSL Authenticating service accounts with a JSON private key should not require installing PyOpenSSL. More specifically, when [`isinstance(credentials, service_account._ServiceAccountCredentials)`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/f577b3079333273f0be3393de4f3767853f95add/gcloud/storage/connection.py#L65) is `True`, PyOpenSSL is not required. Given that PyOpenSSL requires OpenSSL, minimizing the dependency is beneficial. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Conan 2.0 CLI: List command Develop the new `list` command for the Conan 2.0 CLI Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Minimum supported Python 3 version bump At some point we should update the minimum version of Python 3. Here's what the distros currently have: - Debian stable, 3.7 - Ubuntu Xenial, 3.5 - Ubuntu Bionic, 3.6 - RHEL 8, 3.6??? - SLES 15, I could not find out by googling Xenial is _probably_ old enough that we don't have to keep supporting it. 3.6 seems to be widely available, but is that so. Are there platforms where we'd need to support 3.5? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: contains() no longer works with lists of file objects **Describe the bug** With 0.59.0, `[].contains()` no longer works as expected with file objects **To Reproduce** foo.c: ``` ``` meson.build: ``` project('contains-bug', 'c', meson_version: '>= 0.59.0', ) l = [files('foo.c')] message(l.contains(files('foo.c'))) ``` **Expected behavior** This should print `Message: True` **system parameters** * plain native build * Fedora 33 * python 3.9.2 * meson 0.59.0 * ninja 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Windows Integrity Builds are Failing https://github.com/jupyterlab/jupyterlab/pull/8297 I enabled our Examples Checks to actually run but didn't notice that it broke our Windows Integrity builds. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Add async methods Is there a way to run multiple requests in parallel? It would be really nice to be able to execute requests asynchronously, e.g. ``` future = Query('MyKind').fetch_async() result = future.get_result() ``` [NDB](https://developers.google.com/appengine/docs/python/ndb/async) has a great support for async operations using an event loop. Is it something you guys might consider for future versions of the client? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Old version of MathJax imported with install_mathjax() If you run ``` from IPython.external.mathjax import install_mathjax install_mathjax() ``` then MathJax 2.4 is downloaded and installed. However, the current version of MathJax is 2.5. Line 138 of mathjax.py states: ``` def install_mathjax(tag='2.4.0', dest=default_dest, replace=False, file=None, extractor=extract_tar): ``` I suggest this should be updated to 2.5.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Document \"text\" vs. \"bytes\" values for Entities Docs need to explain clearly how users can ensure that the values they set onto entities get mapped as they expect: \"text\" values should be mapped to/from 'string_value' entries on the protobufs, and \"bytes\" values should be mapped to/from 'blob_value' entries. We are to have to educate folks that the native 'str' is \"bytes\" on Python2, but \"text\" on Python3, and mandate that they be explicit if they want to control how such values get stored. Document \"text\" vs. \"bytes\" values for Entities Docs need to explain clearly how users can ensure that the values they set onto entities get mapped as they expect: \"text\" values should be mapped to/from 'string_value' entries on the protobufs, and \"bytes\" values should be mapped to/from 'blob_value' entries. We are to have to educate folks that the native 'str' is \"bytes\" on Python2, but \"text\" on Python3, and mandate that they be explicit if they want to control how such values get stored. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: marginal_distribution raises for NumPy array indices ### Environment - **Qiskit Terra version**: 0.21 - **Python version**: 3.10 - **Operating system**: osx ### What is happening? `marginal_distribution` raises error when passes a NumPy array of indices: ```python marginal_distribution(counts, np.asarray([0, 2])) ``` --> 225 if indices is not None and (not indices or not set(indices).issubset(range(num_clbits))): 226 raise QiskitError(f\"indices must be in range [0, {num_clbits - 1}].\") 228 if isinstance(counts, Counts): ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all() ### How can we reproduce the issue? Try above ### What should happen? It should work for both lists and arrays. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inconsistency in drawing classical control in text drawer when cregbundle=False <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.0.dev0+b026000 - **Python version**: 3.7 - **Operating system**: ### What is the current behavior? The classical control is currently drawn in text drawer as a box with control value inside it when cregbundle=False. This is inconsistent with the other drawers in which the same is drawn as bullets. ### Steps to reproduce the problem We have the following for example: ``` python from qiskit import * q = QuantumRegister(2,'q') c = ClassicalRegister(2,'c') circ = QuantumCircuit(q,c) circ.h(0).c_if(c,2) ``` Text drawer draws this circuit as  while the latex drawer and mpl draws the same as   ### What is the expected behavior? For consistency, the classical control in text drawers should be drawn using open and closed bullets. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Typo in deberta_v2/__init__.py https://github.com/huggingface/transformers/blob/c503a1c15ec1b11e69a3eaaf06edfa87c05a2849/src/transformers/models/deberta_v2/__init__.py#L31 Should be '' DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST ''. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [python-requires] re-use scm variable for building from sources - Conan version: 1.7.1 - I'm using python_requires to re-use scm variable. - The library builds fine, but the final package which consumes the library does not. - This is because the scm variable is not expanded/processed while saving the conanfile for upload in local cache conanfile for MyBase: ``` scm = { \"type\" : \"git\", \"url\" : \"auto\", \"revision\" : \"auto\" } ``` conanfile for consumer library: ``` from conans import ConanFile, CMake, tools, python_requires base = python_requires(\"MyBase/1.7@demo/stable\") class MyPkgConanFile(base.MyBase): scm = base.scm ``` The same conanfile is saved in local cache, as opposed to the expanded values of scm variable. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: run not looking at depends_on I think that `docker-compose run <service>` should bring up the dependencies of that service, the same as `docker-compose up <service>` would. There is already the `--no-deps` flag for run, which implies that the default behavior is to bring up dependencies. If this is the intended behavior, then I am not seeing it. If I have a `docker-compose.yml` file like this: ``` yaml version: '2' services: web: image: postgres command: sh -c 'psql -h db -p 5432 -U postgres -d postgres -c \"\\list\"' entrypoint: /tmp/entrypoint.sh volumes: - ./entrypoint.sh:/tmp/entrypoint.sh depends_on: - db db: image: postgres ``` Then running `docker-compose run web` won't bring up the `db` container. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Opaque error message if npm is not installed In my deployment of jupyterlab+jupyterhub, I got this error message when I started to install extensions: ``` > '' pack @jupyterlab/geojson-extension expected str, bytes or os.PathLike object, not NoneType ``` This was a combination of two things: 1. `conda install jupyterlab` didn't install npm. Is this our intended behavior? 2. The error handling for a missing npm when a user runs a lab command requiring it is a bit opaque. Even if we don't require npm in the conda package, we should clean up that error message with something like: \"Building JupyterLab or installing JupyterLab extensions requires installing npm. If you are using conda, that can be done with `conda install nodejs`\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error converting QASM with a phase gate on it <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.15.2 - **Python version**: 3.7.8 - **Operating system**: Linux 4.15.0-117-generic (IQX Quantum Lab) ### What is the current behavior? When converting a QASM circuit using `QuantumCircuit.from_qasm_str`, if the QASM contains a [phase gate](https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/qasm/libs/qelib1.inc#L24) it fails during the ast to dag conversion with the next error: ``` AttributeError: 'UniversalUnitary' object has no attribute 'name' ``` ### Steps to reproduce the problem Run the next example: ``` from qiskit import QuantumCircuit qasm = \"\"\" OPENQASM 2.0; include \"qelib1.inc\"; qreg q[1]; p(0) q[0]; \"\"\" quantum_circuit = QuantumCircuit.from_qasm_str(qasm) ``` ### What is the expected behavior? To get a QuantumCircuit equal to the next one: ``` from qiskit import QuantumCircuit circuit = QuantumCircuit(1) circuit.p(0, 0) ``` ### Suggested solutions n/a Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Synthesis translation_method doesn't always respect basis_set <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: Master - **Python version**: 3.8 - **Operating system**: Any ### What is the current behavior? Transpiling a circuit with an XYX basis and setting the basis translation method to synthesis doesn't actually change the basis. ### Steps to reproduce the problem ``` import logging from qiskit import QuantumCircuit from qiskit.compiler import transpile from qiskit.compiler.transpile import CouplingMap logging.basicConfig(level='DEBUG') edge_list = [[0, 1], [0,2], [1,2]] cmap = CouplingMap(edge_list) qc = QuantumCircuit(3) qc.h(0) qc.h(1) qc.h(2) print(transpile(qc, coupling_map=cmap, basis_gates=['id', 'ry', 'rx', 'cx'], translation_method='synthesis')) ``` will return ``` ┌───┐ q_0 -> 0 ┤ H ├─────── ├───┤ q_1 -> 1 ┤ H ├─────── ├───┤ q_2 -> 2 ┤ H ├─────── └───┘ ``` ### What is the expected behavior? The hadamard gates get translated to Rx(pi) Ry(-pi/2) ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Partially missing training_step outputs in training_epoch_end **Learning Model:** the model consists of two branches: **teacher and student**. Two losses have been used to train two branches of the learning model using two optimizers. **ISSUE:** In the **`training_step`**, I produced two set of metrics outputs for teacher (_optimizer_idx=0_) and student (_optimizer_idx=1_) branches (teacher: `{loss,log:{acc, f1}}` and student: `{loss,log:{acc,f1,precision}}` ). But in the **`training_epoch_end`**, I only got the combined outputs for only student outputs (_optimizer_idx=1_). All the teacher outputs (_optimizer_idx=0_) are missing. I also see the training loop of PL and didn't observe any issue when the training loop tries to combine the **`training_step`** outputs. I am not sure what am I missing? - Version: 0.8.2.dev0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Sluggish response and unexplained hangs in QTConsole Stepes to reproduce: 1) plot a graphic, the plot appears and you get the prompt back immediately 3) quickly enter 1+<Enter> 4) there is a delay of 2-3 seconds in which everything stops, then you get the result. This didn't happen in (much?) older versions. I use `ipython qtconsole --pylab=inline` with git master 39ecc74. continues QTConsole regressions from #6726 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Implement suite-wide agent unit tests Add unit tests for all currently implemented agents and then add back to code cov Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Wrong linking order in module `pkgconfig` With the way `_process_libs` first appends to the `priv/pub_libs` and then returns `processed_libs` (which the calling code then also appends to those same lists), you effectively end up in a scenario where the library itself will typically be specified last, after all of its dependencies. Example: ``` Name: libplacebo Description: Reusable library for GPU-accelerated video/image rendering Version: 0.5.0 Requires: lcms2 >= 2.6, vulkan >= 1.0.42 Libs: -pthread -lm -lglslang -lHLSL -lOGLCompiler -lOSDependent -lSPIRV -lSPVRemapper -L${libdir} -lplacebo Cflags: -I${includedir} -pthread ``` This is the wrong way around, and results in a linking failure. The library must be specified first, *followed* by its dependencies. The easiest solution would be most likely to make `add_pub_libs`/`add_priv_libs` prepend instead of appending the result of `_process_libs`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Don't call ``package()`` twice. (new issue as requested by https://github.com/conan-io/conan/issues/4438#issuecomment-461341370) https://docs.conan.io/en/latest/reference/build_helpers/cmake.html#example shows the current best practice when using `cmake.install()` within the `package()` method is desired. This works quite nicely for in-source builds (as soon as #4438 is fixed). However, when following also cmake's best practice to build code out of source, results are sub optimal at the moment. In particular, using conan's `no_copy_source = True` recipe attribute causes that the `package()` method gets called twice which also leads to duplicated calls to `cmake.configure()` and `cmake.install()`. Any good approach to fix this would be highly appreciated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `run_command` target clash when invoked from subproject Repro steps: 1. Create some script file in project root. E.g. `echo.sh`. 2. Create a subproject. 3. Put the following line in both root and subproject's `meson.build`: `run_command(meson.source_root()/'echo.sh', '123')` 4. Invoke project setup with ninja backend (`meson setup _build`) Result: ``` Multiple producers for Ninja target \"../proj/echo.sh\". Please rename your targets. ``` The error is also triggered when the command is present in two subprojects (i.e. not present in root). It works properly when the command is invoked form the same `meson.build`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: vault: Allow custom CA bundle FR: Allow setting a custom CA bundle for the `vault` integration, similar to the `http_check` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Apply migrations in the proper order Currently, migrations are being applied in reverse order. They should be applied from the lowest version to the higher one, so each migration is applied on top of all the previous ones (probably related with this bug: https://github.com/conan-io/conan/issues/4866) ```python if old_version < Version(\"0.25\"): ... if old_version < Version(\"1.0\"): _migrate_lock_files(self.cache, self.out) if old_version < Version(\"1.12.0\"): migrate_plugins_to_hooks(self.cache) if old_version < Version(\"1.13.0\"): # MIGRATE LOCAL CACHE TO GENERATE MISSING METADATA.json _migrate_create_metadata(self.cache, self.out) if old_version < Version(\"1.14.0\"): migrate_config_install(self.cache) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Realtime ECS logging **Description** Currently when `ECSOperator` is run, the logs of the ECS task are fetched only when the task is done. That's not so convenient, especially when the task takes some good amount of time. In order to understand what's happening with the task, I need to go to Cloudwatch and search for the tasks logs. It would be good to have some parallel process that could fetch ECS task logs from Cloudwatch and make them visible in a realtime. **Are you willing to submit a PR?** I can try, but I need to be guided. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Submodules updated before revision checkout Conan version: 1.6.1 Platform/Settings: All Description: When specifying submodules to be updated after cloning from git with the `scm` attribute, the submodules are pulled from the state of the repo's current HEAD rather than the referenced revision. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: docs: Added missing cosine declaration - Added missing cosine declaration to code listing that already included imports for `dot` and `norm` function it uses. Signed-off-by: mr.Shu mr@shu.io --- @honnibal Thanks a ton for a great library! While reading the index document I kind of skipped the previous declarations of `cosine`. It seemed strange not to find them here since the imports were already in place. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ArchLinux meson cannot detect Qt Tools with pkg-config. **Describe the bug** ArchLinux meson cannot detect Qt Tools with pkg-config. **To Reproduce** Run ./run_project_tests.py --only frameworks/4 on ArchLinux **Expected behavior** Qt 6 Tools should be detectable. **system parameters** *Native *ArchLinux * Python 3.10.5 * master * ninja 1.11.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow passing in a Generator object for seed in QuantumVolume circuit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Allow `QuantumVolume` to be called with a generator object rather than only using a numerical seed. This is important for sharing RNG objects in applications using these circuits (such as in Ignis), and also internally in the QV circuit we can pass the RNG object to the `random_unitary` function which already accepts a generator for the seed kwarg. Example: to generate a list of quantum volume circuits from a single seed value: ```python seed = 101 rng = np.random.default_rng(seed) circs = [QuantumVolume(10, 10, seed=rng) for _ in range(20)] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.50.0 regression: Duplicated messages about \"Appending XXXFLAGS from environment\" ``` Appending CFLAGS from environment: '-O2 -g -pipe -Wall -Werror=format-security -Wp,-D_FORTIFY_SOURCE=2 -Wp,-D_GLIBCXX_ASSERTIONS -fexceptions -fstack-protector-strong -grecord-gcc-switches -specs=/usr/lib/rpm/redhat/redhat-hardened-cc1 -specs=/usr/lib/rpm/redhat/redhat-annobin-cc1 -m64 -mtune=generic -fasynchronous-unwind-tables -fstack-clash-protection -fcf-protection' Appending LDFLAGS from environment: '-Wl,-z,relro -Wl,--as-needed -Wl,-z,now -specs=/usr/lib/rpm/redhat/redhat-hardened-ld' Appending CFLAGS from environment: '-O2 -g -pipe -Wall -Werror=format-security -Wp,-D_FORTIFY_SOURCE=2 -Wp,-D_GLIBCXX_ASSERTIONS -fexceptions -fstack-protector-strong -grecord-gcc-switches -specs=/usr/lib/rpm/redhat/redhat-hardened-cc1 -specs=/usr/lib/rpm/redhat/redhat-annobin-cc1 -m64 -mtune=generic -fasynchronous-unwind-tables -fstack-clash-protection -fcf-protection' Appending LDFLAGS from environment: '-Wl,-z,relro -Wl,--as-needed -Wl,-z,now -specs=/usr/lib/rpm/redhat/redhat-hardened-ld' Native C compiler: cc (gcc 9.0.1 \"cc (GCC) 9.0.1 20190227 (Red Hat 9.0.1-0.8)\") Appending LDFLAGS from environment: '-Wl,-z,relro -Wl,--as-needed -Wl,-z,now -specs=/usr/lib/rpm/redhat/redhat-hardened-ld' Appending LDFLAGS from environment: '-Wl,-z,relro -Wl,--as-needed -Wl,-z,now -specs=/usr/lib/rpm/redhat/redhat-hardened-ld' Native Vala compiler: valac (valac 0.43.92) ``` This has happened to tracker. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Terminal token authentication broken ## Description When configuring jupyter server with token authentication, the terminal fails to connect. It appears that the latest service/terminal code ignores the `token` field passed in `ServerConnection.ISettings` when establishing the websocket connection. The url should look like: `wss://__my_hostname__/notebook/terminals/websocket/1?token=__my_token__` but is missing the `?token=__my_token__` part. I believe the faulty code is in [service/terminal/default.ts](https://github.com/jupyterlab/jupyterlab/blob/2bade97edadea865b294eb49c8d693d4261ca404/packages/services/src/terminal/default.ts#L261). The url is constructed without the token parameter (if specified), right before establishing the websocket connection. The package `@jupyterlab/services@4.2.0` used to work and properly form the url with the token in the query parameters, but I believe the latest refactoring from `TerminalSession` to `TerminalManager` broke it. ## Reproduce 1. Configure jupyter server to use token authentication 2. Open new terminal using `@jupyterlab/services@5.2.4` and `@jupyterlab/services@2.2.3`. An error appears in the console: ``` WebSocket connection to 'wss://__hostname__/notebook/terminals/websocket/1' failed: HTTP Authentication failed; no valid credentials available ``` Notice the token missing in the url parameters. ## Expected behavior Terminal connects to jupyter server and a prompt appears. ## Context - Operating System and version: Windows 10 - Browser and version: MS Edge 85.0.564.51 (Chromium version) - JupyterLab version: @jupyterlab/services@5.2.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Improve `CondaHTTPError` to include the response body ### Checklist - [X] I added a descriptive title - [X] I searched for other feature requests and couldn't find a duplicate (including also the ``type-feature`` tag) - [X] I confirmed that it's not related to another project (see the above section) ### What is the idea? When HTTP errors occur `conda` intercepts a number of cases with a hardcoded error message. We'd like to augment/replace these hardcoded messages with messages provided in the response so we can provide more targeted information. ### Why is this needed Provide more descriptive messaging for HTTP errors (e.g. 403 and 429) to explain why the user is experiencing those errors. ### What should happen? The server-provided message should be passed through as-is to the user. Here are some sample response bodies we'd want to provide: #### 403 ```json { \"reason\": \"NOT AUTHORIZED\", \"message\": \"Your IP address has been blocked due to...\" } ``` #### 429 ```json { \"reason\": \"TOO MANY REQUESTS\", \"message\": \"Your IP address has been throttled due to...\" } ``` ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add .definitions dict to MSBuild Helper like CMake helper has I came across a situation today where I wanted to pass a preprocessor definition to `MSBuild` helper but it is currently not supported. It is only supported to set msbuild `properties`. I understand why this functionality was not included by the `MSBuild` helper initially, but I believe that it's reasonable to add it now, and have the suggested implementation on how to do it. I will probably create a PR for this feature at some point if it's \"acceptable\" but nobody gets around to it before I do. I am fairly certain that the reason it's not implemented in the helper is that it's not natively supported by MSBuild. MSBuild CLI will not accept arbitrary preprocessor definitions and pass them to the compiler for you. The only \"supported\" solution is to use the `ForceImportBeforeCppTargets` feature, combined with a `.props` file, and do something like: `<PreprocessorDefinitions>_NEW_DEFINE;%(PreprocessorDefinitions)</PreprocessorDefinitions>` https://docs.microsoft.com/en-us/cpp/ide/working-with-project-properties?view=vs-2017 Conan is in a unique position to implement the requested because it already makes use of `ForceImportBeforeCppTargets`. So, this request would be to add the `definitions` member as a dict to the `MSBuild` helper just like CMakes, and implement it by simply injecting new preprocessor definition alongside the other variables that get injected. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: throw useful error when alias is invoked on solid output Currently If someone accidentally does ``` @pipeline def example(): my_solid().alias('rename_my_solid') # should be my_solid.alias('rename_my_solid')() ``` They get an error message that is pretty difficult to decipher. Since we control the object returned by solid invocation in composition functions, we could override `alias` and throw a good error message to help people find the issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: serve_logs.py should respect the logging config's task handler's base_log_folder value ### Apache Airflow version 2.2.5 ### What happened in a worker container, a flask app is spun up to serve task log files that is read by the webserver and rendered to the user in the UI. The log files cannot be read if you overwrite the task handler's base_log_folder value. (404 error) ie. in the airflow.cfg, the base_log_folder = `foo/bar/logs`, and the task handler uses `{base_log_folder}/dags` ### What you think should happen instead in https://github.com/apache/airflow/blob/main/airflow/utils/serve_logs.py#L33, it should read the logging config's task handler log location. ### How to reproduce use a custom logging config, override the task's base log folder. Run a dag and try to view logs in the ui, you will get a 404 ``` LOGGING_CONFIG[\"handlers\"].update( { \"task\": { \"class\": \"airflow.utils.log.file_task_handler.FileTaskHandler\", \"formatter\": \"airflow\", \"base_log_folder\": f\"{BASE_LOG_FOLDER}/dags\", \"filename_template\": FILENAME_TEMPLATE, \"filters\": [\"mask_secrets\"], }, } ``` ### Operating System ubuntu ### Versions of Apache Airflow Providers _No response_ ### Deployment Virtualenv installation ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Reload button on the clusters tab is not working I had a gazillion IPython profiles in my profile folder from a theme experiment that were all showing up on the `Clusters` tab. While the IPython server was running, I deleted all these profiles. When I now click on the reload icon, nothing happens. A web-browser reload also keeps showing the now non-existing profiles. Version: 2.2 Edit: After restarting the notebook server, the list of non-existing profiles was purged and only the existing profiles are shown. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Running summarization with default model fails. 4.27.0.dev0 ### System Info When runining examples/tensorflow/summarization/run_summarization.py as given in README, python run_summarization.py \\ --model_name_or_path facebook/bart-base \\ --dataset_name cnn_dailymail \\ --dataset_config \"3.0.0\" \\ --output_dir /tmp/tst-summarization \\ --per_device_train_batch_size 8 \\ --per_device_eval_batch_size 16 \\ --num_train_epochs 3 \\ --do_train \\ --do_eval it fails as below.  ### Who can help? _No response_ ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction 1. Copy script in README to a file 2. Run the script ### Expected behavior Should run without issues as it is example given in README Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Documentation Issue] gcloud.pubsub.message.Message isn't documented! Internal Username: ddopson@google Page Name: pubsub-subscription Release: 0.8.0 The documentation for the `pull` method says that it returns instances of `gcloud.pubsub.message.Message`. That type doesn't link anywhere and I can't find any documentation of the `Message` type. This makes it really hard to use the API. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Regression: link_whole does not propagate dependencies Bisected to commit c94c492089e7fecb56b7cc11ea76712a770f1e34 / #10699, /cc @dcbaker As an example test case, see https://github.com/linuxmint/xreader/ which builds a static library `builddir/cut-n-paste/totem-screensaver/libtotemscrsaver.a` that is linked into `shell/libshell.a` which is in turn linked into `shell/xreader`. libtotemscrsaver has a `dependency('x11')` and uses its symbols; no other code uses it directly. With the latest release of Meson, everything works. With the release candidate, a number of libraries are no longer linked to, such as /usr/lib/libX11.so. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebooks with filenames with accented characters (\"ã\", \"í\", etc.) don't open in 2.0 I'm using Python 2.7, Conda 3.4.0 and IPython 2.0 (on windows, with chrome). To reproduce the problem, create a notebook, change the name to include an accented character, close the notebook and try to reopen it. This worked before 2.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: zypper package tool is not detected correctly In the latest versions of opensuse. The newest versions of opensuse now report their distro.id() as \"opensuse-leap\", which breaks conan's detection of zypper. This patch fixes it for opensuse leap, opensuse tumbleweed and SLES (Issue opened to associate to PR #3368) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: What's the correct way to use add_prefix_space for the fast RoBERTa tokenizer in 3.0.0/3.0.1? The documentation says we should pass this flag to **the encoding methods**. https://github.com/huggingface/transformers/blob/58cca47c16149e43d1b516623d59e3c5d97f695e/src/transformers/tokenization_roberta.py#L259-L260 However, the encoding methods don't take such an argument, and passing it in actually causes an error: ``` File \"test.py\", line 127, in func self.tokenizer.encode(token, add_special_tokens=False, add_prefix_space=True) File \".../transformers/tokenization_utils_base.py\", line 1425, in encode **kwargs, File \".../transformers/tokenization_utils_base.py\", line 1737, in encode_plus **kwargs, File \".../transformers/tokenization_gpt2.py\", line 377, in _encode_plus return super()._encode_plus(*args, **kwargs) File \".../transformers/tokenization_utils_fast.py\", line 420, in _encode_plus **kwargs, File \".../transformers/tokenization_gpt2.py\", line 367, in _batch_encode_plus return super()._batch_encode_plus(*args, **kwargs) File \".../transformers/tokenization_utils_fast.py\", line 313, in _batch_encode_plus raise ValueError(f\"Keyword arguments {kwargs} not recognized.\") ValueError: Keyword arguments {'add_prefix_space': True} not recognized. ``` Then, I assumed that this documentation was a typo and we should pass this argument to `__init__`. But why is it default to `False` in `__init__`? Don't we pretty much always need to add a prefix space? Does `from_pretrained` set it to `True` automatically? If not, should we always do `AutoTokenizer.from_pretrained(..., use_prefix_space=True)`? https://github.com/huggingface/transformers/blob/58cca47c16149e43d1b516623d59e3c5d97f695e/src/transformers/tokenization_roberta.py#L299-L314 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `meson install` broken with Windows MSI installer After having installed meson via the MSI installer, I get this when trying to run `meson install` (or `ninja install`): ``` F:\\projects\\mesontest\\libfoo\\buildwin>meson install Traceback (most recent call last): File \"C:\\python\\lib\\site-packages\\cx_Freeze\\initscripts\\__startup__.py\", line 14, in run File \"C:\\python\\lib\\site-packages\\cx_Freeze\\initscripts\\Console.py\", line 26, in run File \"meson.py\", line 29, in <module> File \"mesonbuild\\mesonmain.py\", line 379, in main File \"mesonbuild\\mesonmain.py\", line 283, in run File \"mesonbuild\\minstall.py\", line 23, in <module> ImportError: cannot import name '__file__' ``` - the problem exists with `meson-0.47.1-32.msi`, also with `meson-0.47.0-32.msi` - works correctly with `meson-0.46.1-32.msi` - also works correctly when installing python and getting meson 0.47.1 via `pip3 install meson` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Method help popovers have become less useful in IPython 3.0.rc1 Forking from #7816 I've noticed that the help popover (i.e., what you get when you hit shit-TAB in side the text of a function call) now has a lot of information that is not very useful to the task of finding out the function signature for a method. I've particularly noticed this for Pandas Dataframes, though I assume the issue is more general than that. It's particularly annoying with DataFrames because the textual `__repr__` looks really bad, especially for large frames. (And also because I can never remember how to use their methods). Here's an example of what we used to get:  And here's what we get now:  (I should note that putting together this issue caused me to note how much more attractive I find the 3.0/Jupyter styling. Well done!) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Install of older python (revert) from newer yields error Build log at https://travis-ci.org/conda/conda-build/jobs/160031372 2.7 and 3.5 builds complete just fine - but they start with (approximately) the python version that they are using for the testing. Gist of the situation is that we start with a 3.5 installation, and then want to go back to a 3.4 installation for testing purposes. With conda 4.1.11, this works. For 4.2.6, it does not. I have not dug in further, but would be happy to do so. Install of older python (revert) from newer yields error Build log at https://travis-ci.org/conda/conda-build/jobs/160031372 2.7 and 3.5 builds complete just fine - but they start with (approximately) the python version that they are using for the testing. Gist of the situation is that we start with a 3.5 installation, and then want to go back to a 3.4 installation for testing purposes. With conda 4.1.11, this works. For 4.2.6, it does not. I have not dug in further, but would be happy to do so. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Wrong order of arguments to loss function in template example for finetuning Hi, I observed that the order for the loss function in the example for finetuning is switched. Instead of `self.loss(y_true, y_logits)` it should be `self.loss(y_logits, y_true)` Below is the exact location of the error: https://github.com/PyTorchLightning/pytorch-lightning/blob/bd49b07fbba09b1e7d8851ee5a1ffce3d5925e9e/pl_examples/domain_templates/computer_vision_fine_tuning.py#L246 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Hostname lost after rebuilding linked container Say I have 2 containers, one is linked to the other: ``` foo: image: php:5.6.10-apache links: - bar bar: image: php:5.6.10-apache ``` I can now start the containers, check for the container ID of `foo` and ping `bar` from `foo`: ``` $ docker-compose up -d Creating dct_bar_1... Creating dct_foo_1... $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 6ddb60dd97dd php:5.6.10-apache \"apache2-foreground\" 59 seconds ago Up 1 seconds 80/tcp dct_foo_1 809a937f3913 php:5.6.10-apache \"apache2-foreground\" 59 seconds ago Up 1 seconds 80/tcp dct_bar_1 $ docker exec -ti 6ddb6 ping bar PING bar (172.17.0.44): 56 data bytes 64 bytes from 172.17.0.44: icmp_seq=0 ttl=64 time=0.061 ms 64 bytes from 172.17.0.44: icmp_seq=1 ttl=64 time=0.059 ms ``` Now if i stop the containers, remove `bar` and run the containers again, the hostname of `bar` is no longer available in `foo`. I first have to also rebuild `foo`: ``` $ docker-compose stop Stopping dct_foo_1... done Stopping dct_bar_1... done $ docker-compose rm bar Going to remove dct_bar_1 Are you sure? [yN] y Removing dct_bar_1... done $ docker-compose up -d Creating dct_bar_1... Starting dct_foo_1... $ docker exec -ti 6ddb6 ping bar ping: unknown host ``` This is quite inconvenient as it means, I can not recreate any linked container without also recreating all containers where the removed one is linked to. ``` $ docker-compose --version docker-compose version: 1.4.0 $ docker --version Docker version 1.8.2, build 0a8c2e3 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Allow injecting custom fields into logger from prefect.context ## Current behavior In our system we pass trace_id from event source through to all systems to close so we can track end to end and correlate with performance traces and metrics. We put the trace_id into the prefect.context and use that to enrich traces and metrics, however the final part of the puzzle is to add to logs as well. I spoke to Dylan on slack, and he very kindly pointed me at this: https://github.com/PrefectHQ/prefect/blob/master/src/prefect/utilities/logging.py#L170 which does exactly what I need. However, so far as I can tell only a static list of context attributes are injected by default (from `PREFECT_LOG_RECORD_ATTRIBUTES`). I've found a way around this but it's super hacky: ``` prefect.utilities.prefect.utilities.logging.PREFECT_LOG_RECORD_ATTRIBUTES = ( PREFECT_LOG_RECORD_ATTRIBUTES + (\"trace_id\",) ) ``` ## Proposed behavior Would be great if this Tuple was a configurable list, possibly in the context object. I was thinking of a small patch to `_log_record_context_injector` that would look for a `prefect.context.additionally_injected_log_attributes` list and if found, include those values. If this seems like something you would merge I'd be happy to do a PR? ## Example If this list was configurable it would allow setting a custom logging format that includes these injected fields so that we have our trace_id in each log message. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Enhanced tools.vcvars_dict(...,only_diff=True) handling of lists To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Conan 1.5.1, Windows 7, Visual Studio 2017 tools.vcvars_dict seems to mostly exist to support `with tools.vcvars():`. However, this doesn't play nicely with any other packages offering additions to the the same environment variables (filter_known_paths offers a partial workaround for PATH), environment_append and env_info handle this use case nicely by supporting the idea that the dict value an be a list, and that this will be combined with the existing values using os.pathsep. So it would be nice if tools.vcvars_dict would, in only_diff=True, make use of this and split lists that vcvars modified by inserting additional entries at the front, rather than providing a blanket \"overwrite with this complete string\". e.g. https://github.com/conan-io/conan/blob/a8649076fa6bfeb6c0b7438832fd996e56d72ecf/conans/client/tools/win.py#L322-L323 could instead do something like (not tested) ```python oldvalue = os.environ.get(name_var) if only_diff else None if oldvalue and value.endswith(os.pathsep + oldvalue): new_env[name_var] = value[:-(len(oldvalue)+1)].split(os.pathsep) elif oldvalue != value: new_env[name_var] = value ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan on Mac can't recognize compiler correctly Hello, https://travis-ci.org/procxx/kepka/jobs/322618396 on the link you can see that Conan recognize compiler as gcc 4.2 on Travis, but it's not true. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Requests documentation 404s The docs builds all currently fail as the Requests documentation is not available at https://2.python-requests.org/en/v2.7.0/. It appears the new home is https://requests.kennethreitz.org/en/master/ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add support for XCode 11 (apple_clang: 11.0) Would be nice to have `apple_clang: version: \"11.0\"` in default `settings.yml` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gnome.mkenums_simple() installs the generated C source file The following snippet: ```meson enum_sources = gnome.mkenums_simple( 'dm-enums', install_header: true, install_dir: join_paths(get_option('includedir'), api_name), sources: installed_headers, ) ``` Will result in `dm-enums.c` being installed in the include directory: ``` Installing dmodel/dm-enums.c to /usr/include/dmodel-0/dm-enums.c Installing dmodel/dm-enums.h to /usr/include/dmodel-0/dm-enums.h ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add ability to keep retrying with a lock error The yum installer (IIRC) has a nice feature that it will keep trying every 10 seconds or so if there is a lock error. This could be useful for conda. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: isclose accepts bool inputs although the docs state it shouldn't ## Documentation The docstring of `numpy.isclose` currently states https://github.com/numpy/numpy/blob/623bc1fae1d47df24e7f1e29321d0c0ba2771ce0/numpy/core/numeric.py#L2314 but it happily accepts boolean tensors: ```python >>> a = np.array([True], dtype=np.bool_) >>> np.isclose(a, a) array([ True]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `Target.instruction_schedule_map().has_custom_gate()` always returns True ### Environment - **Qiskit Terra version**: 0.23.1 - **Python version**: 3.11 - **Operating system**: Linux ### What is happening? When using the `InstructionScheduleMap` returned from a Target object's (specifically from a FakeBackend object, but I think this occurs generally) `.instruction_schedule_map()` method the `.has_custom_gate()` method is always returning True. This wasn't the case pre-0.23.0 (and I expect means this is related to #8885 ). This leads to a transpiler performance regression because the transpiler thinks we need to evaluate pulse gates despite not having a custom calibration set. ### How can we reproduce the issue? ```python3 from qiskit.providers.fake_provider import FakeGeneva backend = FakeGeneva() instmap = backend.instruction_schedule_map assert not instmap.has_custom_gate() ``` ### What should happen? The above code snippet should not raise an assertion error because no custom gates are defined in the instruction schedule map. ### Any suggestions? I think this is being caused by a type mismatch and differing expectations between the `Target`/`BackendV2` path and the `InstructionScheduleMap` class. I originally thought this was just a case of a differing type being used in the target path post-#8885 to represent the default calibration from the defaults file now that we're lazy loading it. But looking at it a bit more closely the `InstructionScheduleMap`'s entries from the fake backend are all `ScheduleDef` which would be the same as a manually created `Schedule` object. I\"m not sure the best way to resolve this though. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: RecursionError or \"File name too long\" error when HF_HOME is set to a relative path ### System Info - `transformers` version: 4.31.0 - Platform: Linux-6.2.0-26-generic-x86_64-with-glibc2.35 - Python version: 3.9.5 - Huggingface_hub version: 0.16.4 - Safetensors version: 0.3.2 - Accelerate version: 0.21.0 - Accelerate config: not found - PyTorch version (GPU?): 1.12.1+cu113 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: <fill in> - Using distributed or parallel set-up in script?: <fill in> ### Who can help? @sgugger @LysandreJi ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction export HF_HOME=hfh or export HF_HOME=. Then execute below code ``` from pathlib import Path from transformers import pipeline print(Path(\"/home/test/hub\") / \"/home/test\") # = /home/test # OK print(Path(\"home/test/hub\") / \"home/test\") # = home/test/hub/home/test # BAD print(Path(\"hfh/mydir\") / \"hfh/\") # = hfh/mydir/hfh # BAD # See dynamic_module_utils.py -> create_dynamic_module() -> Line 62 pipe = pipeline(\"text-generation\", model=\"databricks/dolly-v2-3b\", trust_remote_code=True) pipe(\"Why the sky is blue?\") ``` Result with HF_HOME=hfh ``` OSError: [Errno 36] File name too long: 'hfh/modules/hfh/modules/hfh/modules/hfh/modules/hfh/modules/hfh/modules/... ``` Result with HF_HOME=. ``` RecursionError: maximum recursion depth exceeded while calling a Python object ``` ### Expected behavior pipeline should be executed Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] deploy generator broken with 1.25.0 ### Environment Details (include every applicable attribute) * Operating System+version: Ubuntu 20.04 * Compiler+version: any * Conan version: 1.25.0 * Python version: 3.8.2 ### Steps to reproduce (Include if Applicable) * mkdir /tmp/conan-paho-mqtt * conan install paho-mqtt-cpp/1.1@ -g deploy -o *:shared=True ### Logs (Executed commands with output) (Include/Attach if Applicable) ``` Configuration: [settings] arch=x86_64 arch_build=x86_64 build_type=Release compiler=gcc compiler.libcxx=libstdc++ compiler.version=9 os=Linux os_build=Linux [options] *:shared=True [build_requires] [env] Installing package: paho-mqtt-cpp/1.1 Requirements paho-mqtt-c/1.3.1 from 'conan-center' - Cache paho-mqtt-cpp/1.1 from 'conan-center' - Cache Packages paho-mqtt-c/1.3.1:bf0adb9a727594d902b6dc22b23c800d7707b38a - Cache paho-mqtt-cpp/1.1:698833d5e29368eb40ad7c3fd09f712da2722f78 - Cache Installing (downloading, building) binaries... paho-mqtt-c/1.3.1: Already installed! paho-mqtt-cpp/1.1: Already installed! ERROR: Generator deploy(file:deploy_manifest.txt) failed [Errno 2] No such file or directory: '/tmp/conan-paho-mqtt/paho-mqtt-cpp/lib/libpaho-mqttpp3.so.1' ERROR: [Errno 2] No such file or directory: '/tmp/conan-paho-mqtt/paho-mqtt-cpp/lib/libpaho-mqttpp3.so.1' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: update example visualizing_circuits <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? when the ascii drawer is in place update the `visualizing_circuits.py` example and show it using circuit.draw() as for me on a mac I cant user matplotlib with just python. Need to use the pythonw. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: include AssetSelection and AssetsDefinition in api doc Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Disable CI for documentation only changes Probably fail-fast approach can work. @jpakkane noted that in the past an attempt was made to implement this but coverage was broken because of this, so let's be careful this time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Batch (and Transaction) dataset_id should match that of Key / Query objects when added Proposed fix: Do not ask for `dataset_id` in the constructor and instead gather it from the keys and queries used in the transaction. This may require implementing #495 and **will** require removing the `self.begin()` [call](https://github.com/GoogleCloudPlatform/gcloud-python/blob/8faba35a266cd6280f125adf6035f902a07a26e4/gcloud/datastore/transaction.py#L246) from `Transaction.__enter__`. (Can't begin until a query or entity is encountered.) **Title** was: \"Transaction does not rollback correctly when multiple datasets involved\" --- Witness the following code: ``` python >>> from gcloud import datastore >>> cnxn = datastore.get_connection() >>> dataset1 = cnxn.dataset('PROJ1') >>> dataset2 = cnxn.dataset('PROJ2') >>> e1 = dataset1.entity('foo') >>> e2 = dataset2.entity('foo') >>> e1['bar'] = e2['bar'] = 0 >>> e1.save() <Entity[{'kind': u'foo', 'id': 5686683802533888L}] {'bar': 0}> >>> e2.save() <Entity[{'kind': u'foo', 'id': 5659313586569216L}] {'bar': 0}> >>> with dataset1.transaction(): ... e1.delete() ... e2.delete() ... >>> e1_still = dataset1.get_entity(e1.key()) >>> e1_still is None True >>> e2_still = dataset2.get_entity(e2.key()) >>> e2_still <Entity[{'kind': u'foo', 'id': 5659313586569216L}] {u'bar': 0L}> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda clean -t fails with FileNotFoundError ``` [root@localhost conda-recipes]# conda clean -t An unexpected error has occurred, please consider sending the following traceback to the conda GitHub issue tracker at: https://github.com/conda/conda/issues Include the output of the command 'conda info' in your report. Traceback (most recent call last): File \"/root/anaconda/bin/conda\", line 5, in <module> sys.exit(main()) File \"/home/aaronmeurer/conda/conda/cli/main.py\", line 202, in main args_func(args, p) File \"/home/aaronmeurer/conda/conda/cli/main.py\", line 207, in args_func args.func(args, p) File \"/home/aaronmeurer/conda/conda/cli/main_clean.py\", line 317, in execute pkgs_dir, rmlist, totalsize = find_tarballs() File \"/home/aaronmeurer/conda/conda/cli/main_clean.py\", line 108, in find_tarballs for fn in os.listdir(pkgs_dir): FileNotFoundError: [Errno 2] No such file or directory: '/root/.conda/envs/.pkgs' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Airflow doesn't re-use a secrets backend instance when loading configuration values ### Apache Airflow version main (development) ### What happened When airflow is loading its configuration, it creates a new secrets backend instance for each configuration backend it loads from secrets and then additionally creates a global secrets backend instance that is used in `ensure_secrets_loaded` which code outside of the configuration file uses. This can cause issues with the vault backend (and possibly others, not sure) since logging in to vault can be an expensive operation server-side and each instance of the vault secrets backend needs to re-login to use its internal client. ### What you think should happen instead Ideally, airflow would attempt to create a single secrets backend instance and re-use this. This can possibly be patched in the vault secrets backend, but instead I think updating the `configuration` module to cache the secrets backend would be preferable since it would then apply to any secrets backend. ### How to reproduce Use the hashicorp vault secrets backend and store some configuration in `X_secret` values. See that it logs in more than you'd expect. ### Operating System Ubuntu 18.04 ### Versions of Apache Airflow Providers ``` apache-airflow==2.3.0 apache-airflow-providers-hashicorp==2.2.0 hvac==0.11.2 ``` ### Deployment Official Apache Airflow Helm Chart ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython console ignores cursor_start and cursor_end on complete_reply messages Here is a minimal example using commit dbd30bf using Anaconda 3.4 64bit on Linux 17: ``` python from IPython.kernel.zmq.kernelbase import Kernel __version__ = '1' class TestKernel(Kernel): implementation = 'test_kernel' implementation_version = __version__ language = 'test' language_version = __version__ banner = '' def do_complete(self, code, cursor_pos): matches = [code[1:] + '_complete'] return {'matches': matches, 'cursor_start': 1, 'cursor_end': cursor_pos, 'metadata': dict(), 'status': 'ok'} def do_execute(self, code, silent, store_history=True, user_expressions=None, allow_stdin=False): return {'status': 'ok', 'execution_count': self.execution_count, 'payload': [], 'user_expressions': {}} if __name__ == '__main__': from IPython.kernel.zmq.kernelapp import IPKernelApp IPKernelApp.launch_instance(kernel_class=TestKernel) ``` In one terminal, launch this file as `python test_kernel.py`. In another tab, run `ipython console --existing ...`. At the prompt type `test<TAB>`. We expect to get `test_complete`, but instead we get `est_complete`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: add remaining --sbindir & Co. I think we still miss: * sbindir (/usr/sbin) * sharedstatedir (/var/lib) * infodir (/usr/share/info) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Warning expected for re-writing array to already open file Hello, I am using Numpy v1.14 on Mac OSX with Python 2.7. Consider the following snippet: ```python >>> f = open('test.npy', 'w') >>> a = [1,2] >>> np.save(f, np.asarray(a)) >>> aa = [1, 3] >>> np.save(f, np.asarray(aa)) # No effect of this >>> f.close() >>> ff = open('test.npy', 'r') >>> bb = np.load('test.npy') >>> bb np.array([1, 2]) # Expectation was np.array([1,3]) ``` I think there should be at least a warning on overwriting the already written and unclosed file. In the worst case, I think there should be a mention in the documentation. I believe this is an extreme boundary case. In general, this may not be the way one should use `np.save`. But when I designed my structure of the code and the classes, I simply assumed that this should work and after 3 hours of simulations, only the first iteration value was saved. Kindly look at it. Let me know if you need further information. Thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Running a script as part of project() broken 1b0048a7022a89f461cf4d01e7cdbf995bab70f5 ~~I noticed that cross compiling broke in master and bisected it back to this commit. I'm working on a fix now, but wanted to make sure that his was flagged so a release wasn't made with a serious regression.~~ Turns out the real regression is using a `run_command` as part of `project`. Still a problem for mesa though. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: lax.scatter batching (vmap) rule Follow-up from #246. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Y-gate gets transposed to 2x SX verses one X <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is the current behavior? ```python qc = QuantumCircuit(1) qc.y(0) transpile(qc,backend).draw() ``` gives: ``` global phase: -π/2 ┌────┐┌────┐┌───────┐ q_0 -> 0 ┤ √X ├┤ √X ├┤ RZ(π) ├ └────┘└────┘└───────┘ ``` which is twice as long in duration as directly using `x` since both `sx` and `x` have the same duration on the backend. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Perhaps `x` goes before `sx` in the basis gates? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: os.kill is not available in windows before python 2.7 As per the topic, the current celery implementation (>=2.3.0) crashes on windows using python 2.5 and 2.6, because it uses os.kill which is not available in windows before python 2.7 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PassManagerConfig.from_backend fails with AerSimulator ### Environment - **Qiskit Terra version**: 088f600be1914bfd2bc3c43d0a171ff08ccba9bf - **Python version**: 3.10.8 - **Operating system**: Fedora 36 - **Qiskit Aer version**: 0.11.2 ### What is happening? See repro. ### How can we reproduce the issue? ```python from qiskit.transpiler.passmanager_config import PassManagerConfig from qiskit_aer import AerSimulator backend = AerSimulator() pass_manager_config = PassManagerConfig.from_backend(backend) ``` ``` --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) Cell In [1], line 5 2 from qiskit_aer import AerSimulator 4 backend = AerSimulator() ----> 5 pass_manager_config = PassManagerConfig.from_backend(backend) File ~/projects/qiskit-terra/qiskit/transpiler/passmanager_config.py:139, in PassManagerConfig.from_backend(cls, backend, **pass_manager_options) 137 if backend_version < 2: 138 if hasattr(backend, \"defaults\"): --> 139 res.inst_map = backend.defaults().instruction_schedule_map 140 else: 141 res.inst_map = backend.instruction_schedule_map AttributeError: 'NoneType' object has no attribute 'instruction_schedule_map' ``` ### What should happen? It should work. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: fix README installation command and PyPI links The current PyPI install command, links, and images point to the wrong package. I suppose this might be due to the new auto-generated documentation platform in use. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: `unravel_index()` argument name `dims` is not consistent with other functions The [`unravel_index()`](https://docs.scipy.org/doc/numpy/reference/generated/numpy.unravel_index.html) function takes an argument named `dims` that corresponds to: > The **shape** of the array to use for unraveling `indices`. It seems like in most other places, this argument would be named `shape`, so I propose to rename it to match that convention, unless there is some special reason for this name to be different. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Qbs build helper It would be nice to have a Qbs build helper. Since Qbs has its own profiles it is not possible to just run the qbs command to build an application. When building a conan package with qbs first a qbs profile has to be created with the conan profile settings. Adding this manually to every conanfile or build pipeline definition is tedious. A Qbs build helper could setup qbs profiles automatically. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Remove unused parts of `auxlib` ### What is the idea? Remove unused submodules of `auxlib`. ### Why is this needed Continuing work of absorbing/refactoring `auxlib`. (See https://github.com/conda/conda/pull/11025) ### What should happen? Removal of unused submodules. ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: add emulator support **Is your feature request related to a problem? Please describe.** The library does not respect the `FIRESTORE_EMULATOR_HOST` environment variable thus it cannot be used with the emulator. **Describe the solution you'd like** Respect the `FIRESTORE_EMULATOR_HOST` environment variable and connect to the emulator when set. **Describe alternatives you've considered** None. If there are other ways to use the emulator with the library they are not documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: LLVM statically links on < 4.0, dynamically links on >= 4.0 *grumble* We need a fairly significant workaround to fix this (I'll write it). I just wanted to document this here so that if others ran into it they'd know. Basically in 4.0 LLVM added a --link-static and --link-shared option to llvm-config, and a default mode (on linux distros this seems to be shared on the distros tested (arch, fedora, debian)). Before that it was static linking from llvm-config, and you had to figure out where LLVM-x.y.so was located yourself if you wanted shared-linking. LLVM 5.0 also was the first version with symbol mangling, so static linking might be smarter for < 5.0 anyway. *grumble* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: LayoutLMv2 Model # 🌟 New model addition ## Model description LayoutLMv2 by pre-training text, layout and image in a multi-modal framework, where new model architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training stage, where cross-modality interaction is better learned. <!-- Important information --> ## Open source status * [ ] the model implementation is available: (give details) https://github.com/microsoft/unilm/tree/master/layoutlmv2 * [ ] the model weights are available: (give details) https://huggingface.co/microsoft/layoutlmv2-base-uncased/ * [ ] who are the authors: (mention them, if possible by @gh-username) @inproceedings{Xu2020LayoutLMv2MP, title = {LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding}, author = {Yang Xu and Yiheng Xu and Tengchao Lv and Lei Cui and Furu Wei and Guoxin Wang and Yijuan Lu and Dinei Florencio and Cha Zhang and Wanxiang Che and Min Zhang and Lidong Zhou}, booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) 2021}, year = {2021}, month = {August}, } Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: update pretty to use Python 3 style for sets In Python 3, `repr(set([1,2,3]))` is `{1,2,3}`, but pretty currently forces the output to be `set([1,2,3])`. We should probably use the set-literal format on Python 3, or just use it all the time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Support for clang 11 Hello Everyone, Is it possible to add in the default settings list the clang 11 (https://clang.llvm.org/docs/ReleaseNotes.html) ? The compiler is already being actively used from the https://conan.io/center/emsdk_installer/1.39.13 and for the moment I have to manually adapt my settings.yml ~~I think it used to work, but probably some changes with clang-apple removed the version ?! (no idea to be frank. I first noticed it a couple of weeks ago, when a ci job in one of my projects started failing)~~ (I think it is not valid. I notice in the logs that I was still using clang 10) Probably also related to: * https://github.com/conan-io/conan/issues/6910 - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Wrong output in take function I encountered an error when i use the numpy.take function. test : 2D array (20000x128) with double values P: integer vector 128 values in the range of [0...127] none are the same. if i execute the following code everything works fine and as intended, no error. `np.take(test, P, axis=1, mode='raise', out=test)` if i execute ` np.take(test, P, axis=1, mode='wrap', out=test) ` my output should be the same as in the other code, since i do not have any out-of-bounds indices. However, the output is different. Values are scrambled and appear multiple times although they are all different. if executed as `test = np.take(test, P, axis=1, mode='wrap') ` the output is correct. same for: mode = 'clip' numpy version 1.12.1 python version 2.7.13 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Rename `master` branch `main` ### Description You currently use the branch name `master` for this repository for historical reasons. However, the open source community has moved on from this, the GitHub default is now `main`, and `main` is 2-fewer letters to type :-) ### Guidance Renaming a branch will automatically update all open PRs, so this shouldn't be too disruptive as long as your dev community knows to update their local branches: https://github.com/github/renaming We've done it for several projects and it went very smoothly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: jlap: error with file:/// repositories ### Checklist - [X] I added a descriptive title - [X] I searched open reports and couldn't find a duplicate ### What happened? `--experimental=jlap` errors when pointed to a `file:///` repository containing `.jlap`: For example, `.condarc`: ``` channels: - file:///Users/dholth/prog/conda/repo experimental: [jlap] ``` In the `repo` folder, download `repodata.json`, `repodata.json.zst`, `repodata.jlap` into noarch/ and your arch (e.g. osx-arm64/) folders. A copy from defaults is fine for testing. Now try something like a `conda search` a few times until the second or third time where it would normally consult `.jlap` (which it only does after fetching `repodata.json`). An error appears since the \"pretend requests can talk to file\" system doesn't understand headers. ``` File \".../conda/gateways/repodata/jlap/fetch.py\", line 131, in request_jlap log.debug(\"request headers: %s\", pprint.pformat(response.request.headers)) AttributeError: 'NoneType' object has no attribute 'headers' ``` ### Conda Info Version 23.7.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Control order of list when calling `conda list` ### Checklist - [X] I added a descriptive title - [X] I searched open requests and couldn't find a duplicate ### What is the idea? Include an order control option for `conda list`. This can be something as `conda list --reverse` or `conda list --descending` or `conda list --desc` ### Why is this needed? I often have to deal with a package that starts with an `a`. When I check the installed packages in a terminal of a large environment (~500 packages) using `conda list` I see myself scrolling a loong way up. ### What should happen? Reverse the order of the list of installed packages. So instead of the following result: ```cmd # packages in environment at D:\\Software\\Miniconda3\\envs\\stable: # # Name Version Build Channel adagio 0.2.3 pypi_0 pypi affine 2.3.1 pyhd8ed1ab_0 conda-forge ... zlib-ng 2.0.6 h8ffe710_0 conda-forge zstd 1.5.2 h7755175_4 conda-forge (stable) D:\\Software> ``` You will get the following result: ```cmd # packages in environment at D:\\Software\\Miniconda3\\envs\\stable: # # Name Version Build Channel zlib-ng 2.0.6 h8ffe710_0 conda-forge zstd 1.5.2 h7755175_4 conda-forge ... adagio 0.2.3 pypi_0 pypi affine 2.3.1 pyhd8ed1ab_0 conda-forge (stable) D:\\Software> ``` ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Notify user if group_by_length won't be used @sgugger @stas00 (as suggested in [15196](https://github.com/huggingface/transformers/issues/15196#issuecomment-1024143208)) It is just a minor issue but it could prevent some head-scratching: Setting `group_by_length` to `True` during training has, as far as I can see, no effect if the provided dataset is a `torch.utils.data.IterableDataset`, as can be seen in this line: https://github.com/huggingface/transformers/blob/c4d1fd77fa52d72b66207c6002d3ec13cc36dca8/src/transformers/trainer.py#L646 Entering this branch will run the training without bucketing / grouping. Imo it would be best to raise an exception or, at the very least, print a warning message for the user. Grouping only happens in [`_get_train_sampler()`](https://github.com/huggingface/transformers/blob/c4d1fd77fa52d72b66207c6002d3ec13cc36dca8/src/transformers/trainer.py#L566:L628) which [is never reached](https://github.com/huggingface/transformers/blob/c4d1fd77fa52d72b66207c6002d3ec13cc36dca8/src/transformers/trainer.py#L646:L664) if said condition is true. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add ability to add and subtract operators on subsystems <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Add a `qargs` kwarg to `BaseOperator` `add` method so that a smaller operator can be added to larger one assuming identities on other subsystems (same as qargs for compose). As with issue #3872, also add support so that this can be done using the standard `+` `-` binary operators: ```python init = Operator.from_label('II') I = Operator.from_label('I') X = Operator.from_label('X') H = Operator.from_label('H') # Add this op = init + X([0]) - H([1]) # To be equivalent to this op = init + x.expand(I) - H.tensor(I) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Weird daylight savings time behavior with croniter As identified in a unit test in #325, cron seems to give an unexpected result during a DST transition. Thinking about DST is hard enough, let alone trying to figure out if this is a bug, so I've marked the test as `xfail` for now. It may be related to this issue: https://github.com/taichino/croniter/issues/116. If this *is* a bug, then we should probably be converting all cron dates to UTC when the schedule is created (in fact, this might not be a bad idea in general). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda install --rev is broken in 4.3 per https://github.com/ContinuumIO/anaconda-issues/issues/7855#issuecomment-357036226 Write downgrade integration tests In an integration test: 1. Create an environment with the current conda under test, but include an earlier version of conda in that environment. Probably something like conda create -n _test-env python=2.7 itsdangers conda=X.X 2. Subprocess to that conda, and make sure that conda can operate on that environment. CONDA_ROOT/envs/_test-env/bin/conda install -p CONDA_ROOT/envs/_test-env/bin/conda flask Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Federated bundle (for JLab>=3) and source bundle (for JLlab<3) in 1 pypi package For many python widget libraries, we put the js source tarball in `$prefix/share/jupyter/lab/extensions`. JLab 1 and 2 pick this up, and rebuild. For JLab 3, we want to put the Federated bundles into `$prefix/share/jupyter/labextensions`, e.g.: * https://github.com/glue-viz/bqplot-image-gl/pull/35 * https://github.com/bqplot/bqplot/pull/1222 However, if we want our new distributed python package to work for both JLab versions, not requiring a rebuild on 3, asking for a rebuild on 1 and 2. Is there a way to do this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Migrate elasticsearch client to 8.* (or latest 7.*) ### Body The eleasticsearch version we use is old (from 2021). It is eleasticsearch 7.* and since we are using elasticsearch-dsl, we cannot used elasticsearch 8 currently (first version of that was also released in 2021). We are currently limited to < 7.15.0 additionally to being limited to 7, because 7.15.0 breaks our tests as we found out when we released some of the dependencies as part of https://github.com/apache/airflow/pull/30067 We should migrate to a newer version of elasticsearch. There are two options: 1) Fix the tests and migrate to lates 7.* version - and bump to latest released 7* by fixing our tests (possible for short term). 2) Migreate to 8 version (better long term) ### Committer - [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Data Catalog: add sample for creating an entry group Entry Groups operations were added to Data Catalog's API and the client library supports them since 2019-10-23 (https://googleapis.dev/python/datacatalog/0.4.0/changelog.html#id1). Samples are now required, to update the official docs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Set k8s resource manager to only look for prefect identifier labeled resources ## Current behavior Currently the resource manager is greedy with what it chooses to clean up, taking every job in a set namespace. ## Proposed behavior Set the resource manager to only clean up jobs/pods with prefect identifier labels (which we already place on them when created) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Implement progress_bar_type support when bqstorage_client is used Follow-up to https://github.com/googleapis/google-cloud-python/pull/7552. We now support displaying a progress bar in `to_dataframe` when the tabledata.list API is used, but not when the `bqstorage_client` is used. The BigQuery Storage API is faster, but not instantaneous, so it would still be useful to display a progress bar. There are a couple of complications with this. * When the BigQuery Storage API is used, a threadpool is used to download query results. The progress bar should only be updated from a single thread, so the threadsafe queue should probably be used from the worker threads to send updates to the main thread that updates the progress bar. * `to_dataframe` in the BigQuery Storage API client only supports downloading a whole stream at once. The reader needs to be updated to provide a `pages` property to allow converting individual blocks to a pandas DataFrame. That way incremental updates can be sent. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Consolidate `bit_indices` as a circuit property I'm wondering if it makes sense to carry this around in the circuit object itself (maybe as a private). Pretty much anything that is going from a circuit to something else is now building this dict. _Originally posted by @mtreinish in https://github.com/Qiskit/qiskit-terra/pull/5504#discussion_r583153333_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: LDC can't parse RSP file issued by Meson **Describe the bug** When the command line length hits a threshold, it is converted to a RSP file. In this file, some of the arguments are quoted using python `shlex.quote`. `shlex.quote` happens to quote using single quotes `'` (at least on Windows). In my case, the RSP file contains among many other `'-L=/PDB:lib\\\\doptest.pdb'` and LDC fails to parse with `Error: unrecognized file extension pdb'`. (note the `'` in the file extension). LDC forwards expansion of RSP file directly to LLVM ([implementation](https://llvm.org/doxygen/CommandLine_8cpp_source.html#l00930)) So who's to blame here? `shlex` ? LLVM? Meson (for using shlex)? **To Reproduce** you may set `MESON_RSP_THRESHOLD` to a low value and compile a D project with LDC. **Expected behavior** No failure **system parameters** * plain native build * Windows 10 * Python 3.9.0 * Meson 0.57.1 * Ninja 1.10.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.sinc() documentation \"It works in 2-D as well\" looks misleading The [documentation](https://docs.scipy.org/doc/numpy/reference/generated/numpy.sinc.html#numpy.sinc) currently states: > It works in 2-D as well: > >>> x = np.linspace(-4, 4, 401) > >>> xx = np.outer(x, x) > >>> plt.imshow(np.sinc(xx)) This does not seem useful as it is computing np.sinc(x*y) over the domain [-4,4]*[-4,4]. In almost all cases, the desired generalization of np.sinc() to 2D is instead np.sinc(x)*np.sinc(y) [see [Wikipedia entry](https://en.wikipedia.org/wiki/Sinc_function#Higher_dimensions)]: xx, yy = np.meshgrid(np.linspace(-4, 4, 401), np.linspace(-4, 4, 401)) plt.imshow(np.sinc(xx) * np.sinc(yy), cmap='gray') Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Dependencies on python modules For mesa I need to check if the mako module is installed (and of the proper version) for the python version we're using (python2 at this point :/ ). I'm interested in adding the feature to meson, but I want to know whether the preferred implementation would be to writing a dependency type (maybe that took a python prog as an argument?), or to add a method to the python module (obviously for the latter we'd need a python2 module). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Stabilise state convergence In #1399, a basic version of state convergence was hidden behind the `--x-smart-recreate` flag. This should be promoted to a stable feature and become the default behaviour. A flag should be added to `up` to support the old behaviour where all containers are stopped and recreated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Exclude `test` as project name for `meson init`. **Describe the bug** Please see \"To Reproduce\" **To Reproduce** Just execute the following steps: ``` $ mkdir test; cd test $ meson init Using \"test\" (name of current directory) as project name. Using \"test\" (project name) as name of executable to build. Defaulting to generating a C language project. Sample project created. To build it run the following commands: meson setup builddir meson compile -C builddir $ meson setup builddir The Meson build system Version: 0.62.1 Source dir: /home/gerion/test Build dir: /home/gerion/test/builddir Build type: native build Project name: test Project version: 0.1 C compiler for the host machine: ccache cc (gcc 10.2.1 \"cc (Debian 10.2.1-6) 10.2.1 20210110\") C linker for the host machine: cc ld.bfd 2.35.2 Host machine cpu family: x86_64 Host machine cpu: x86_64 meson.build:5:0: ERROR: Target name 'test' is reserved for Meson's internal use. Please rename. A full log can be found at /home/gerion/test/builddir/meson-logs/meson-log.txt ``` **Expected behavior** `meson init` should rename the project if the folder is `test`. **system parameters** * what operating system: Debian 11 * what Python version are you using: 3.9.0 * what `meson --version`: 0.62.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: plot_histogram should return counts not probs for y-value ### What should we add? `plot_histogram` is returning a plot of probability vs. bit-string. However, this is not a true histogram that should be returning the discrete counts binned to the bit-string value. It would be nice to have `plot_histogram` return an actual histogram. This also comes into play when thinking about `Quasidistribution` objects that are actual distributions and may contain negative values (and also have integer keys). For these objects a histogram makes no sense, and thus they should have their own `plot_distribution` that returns probabilities and can better accommodate negative values. With two different plotting functions, returning the correct values, we can better handle things and allow only `Counts` to `plot_histogram`, and everything else to `plot_distribution` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: SabreSwap changes coupling map parameter in place <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.8 - **Operating system**: MacOS ### What is the current behavior? SabreSwap makes the coupling map symmetric \"in place\". This affects also SabreLayout indirectly. ### Steps to reproduce the problem ```python from qiskit import QuantumCircuit from qiskit.transpiler import PassManager, CouplingMap from qiskit.transpiler.passes import SabreSwap from qiskit.test.mock.backends import FakeTenerife coupling_map = CouplingMap(FakeTenerife().configuration().coupling_map) print(coupling_map) passmanager = PassManager(SabreSwap(coupling_map)) result = passmanager.run(QuantumCircuit(1)) print(coupling_map) ``` ``` [[1, 0], [2, 0], [2, 1], [3, 2], [3, 4], [4, 2]] [[1, 0], [2, 0], [2, 1], [3, 2], [3, 4], [4, 2], [0, 1], [0, 2], [1, 2], [2, 3], [4, 3], [2, 4]] ``` ### What is the expected behavior? Do not touch my coupling map! :) ### Suggested solutions Use a copy. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Transpiler pass for converting `c_if` to `if_test` ### What should we add? As developers, we want to transition away from `Instruction.condition` (via the `Instruction{,Set}.c_if` methods) to remove unnecessary state from `Instruction` subclasses. Part of the backwards compatibility for this support can be a transpiler pass that converts instructions with non-`None` conditions to instances `IfElseBlock`. This has two main benefits as a temporary measure: - we will have a path for converting old-style `Instruction` instances within the transpiler, without immediately needing to change the behaviour of `Instruction.c_if`, which is very hard to do within the deprecation policy. - the dynamic-circuits paths in the IBM provider prefer to have conditionals in this form, in order to more easily apply dynamic decoupling against blocks of instructions. The first point is the justification for why this is useful to be in Terra (albeit not yet in the preset pass managers - the rest of the support for `IfElseBlock` is too shallow right now), and the second point is why we want this sooner rather than later. Potential further work: complex conditionals (e.g. `custom_gate.c_if()`) are likely to be expanded by the basis translator into many conditional gates all with the same condition. Ideally these would be transformed by this pass _before_ basis translation so that they all appear in the same `IfElseBlock`, but right now the support for the control-flow operations in the rest of the transpiler (especially routing) is still being worked on. One could have a separate classical optimisation pass that runs during optimisation that collects runs of conditionals on the same condition into a single `IfElseBlock`. This might be moving Terra too far in the direction of classical optimisation, however, and may be better suited for other libraries. cc: @taalexander. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda 4.4 weird prompt addition in zsh Before conda 4.4 my prompt with zsh would look like this, when I'm in my conda env `stable`:  After the update to conda 4.4 (using the blog instructions), I have this:  Note the addition of '\\[\\]' that was added after the environment ID. How can I get rid of that? Using zsh 5.4.2 on macOS 10.12.6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Python extension_module does not install in site_packages In the *python* module documentation is claimed that `extension_module` install per default in `site_packages`: > `subdir`: By default, meson will install the extension module in the relevant top-level location for the python installation, eg `/usr/lib/site-packages`. When subdir is passed to this method, it will be appended to that location. This keyword argument is mutually exclusive with `install_dir` However, this does not work. When set `install: true` the modules are installed to `$prefix/lib64` on my system. One workaround is to specify the target like: ``` py3_mod = import('python') py3_inst = py3_mod.find_installation('python3') foo = py3_inst.extension_module('foo', <source_target>, install: true, subdir: get_option('prefix') + py3_inst.get_path('purelib'), dependencies: [py3_inst.dependency()] ) ``` It would be nice, if the subdir is set autotically to the `site-packages` folder. This bug is btw similar to #2859. However, this talks about the now deprecated *python3* module. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Can conan info get the package reference without the dependencies ? Using conan 1.6.0 It is pretty useful on our CI to get the package reference by doing a `conan info <path_to_recipe> -n None` and then extract the `Package/Version@PROJECT`. The fact is that we are only interested to get the package name and its version but the command resolves the dependencies but we don't need it and it can be time-consuming especially when the requirements are expressed in ranges (e.g `[^1.2.0]`) and the sub requirements as well. Is it possible to add another option like `--dont-check-dependencies` so they are not computed ? Another option for us is to grep the conanfile for `name =` and `version =` but it can be error prone in case where the name and/or the option is programmatically defined. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Python configuration via pkg-config may differ from that of found Python on path. It is fairly easy to have two Python installations on a system, only one of which reports to `pkg-config`. If another Python is earlier on the path, then `mod = import('python')` will find one Python, but `mod.find_installation().dependency()` will find another, because it first uses `pkg_config`, regardless of whether that matches the found Python. The consequence is that the code then compiles and links against a different Python to the one found. **To Reproduce** Install Python.org Python on Windows (no pkg-config files), to `c:\\Python39` (e.g. with `choco install python --version=3.9`). Install Msys2 gcc, that comes, by default, with a version of Python, along with `pkg-config` binary, and a `python3.pc` pkg-config configuration. Make sure `c:\\Python3.9` is earlier in the PATH. In that case, with this in `meson.build`: ``` py_mod = import('python') py_inst = py_mod.find_installation() py_dep = py_inst.dependency() ``` the `py_inst` will be the `c:\\Python39\\Python.exe` Python, but the `py_dep` variables will refer to the Msys2 Python. **Expected behavior** I think what should happen is that the `dependency()` call should confirm that the `pkg-config` variables do in fact refer to the `py_inst` Python, and if not, then `dependency` should use the `system` method to get dependency information. **system parameters** * Native build * Windows 10 * Python 3.9 * `meson --version` : 0.60.99 * `ninja --version` : 1.10.2.git.kitware.jobserver-1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Horovod with native 16 precision not working <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug <!-- A clear and concise description of what the bug is. --> ### To Reproduce Steps to reproduce the behavior: 1. using precision=16 with distributed_backend=horovod ``` Traceback (most recent call last): File \"/workspace/main_lightning.py\", line 500, in <module> main(hyperparams) File \"/workspace/main_lightning.py\", line 492, in main trainer.fit(model) File \"/usr/local/lib/python3.6/dist-packages/pytorch_lightning/trainer/states.py\", line 48, in wrapped_fn result = fn(self, *args, **kwargs) File \"/usr/local/lib/python3.6/dist-packages/pytorch_lightning/trainer/trainer.py\", line 1068, in fit results = self.horovod_train(model) File \"/usr/local/lib/python3.6/dist-packages/pytorch_lightning/trainer/distrib_parts.py\", line 213, in horovod_train model, optimizers = model.configure_apex(amp, model, self.optimizers, self.amp_level) File \"/usr/local/lib/python3.6/dist-packages/pytorch_lightning/core/lightning.py\", line 954, in configure_apex model, optimizers = amp.initialize(model, optimizers, opt_level=amp_level) ``` #### Code sample ``` trainer = Trainer( precision=16, gpus=1, distributed_backend=\"horovod\") ``` ### Environment - PyTorch Version: 1.6.0+cu101 - How you installed PyTorch: pip Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Ignore missing build directory if not building images Hello, We have a single Compose file that should be used for both building images and starting services. Images are built on one machine (manually or with CI/CD) and pushed to company's private Docker registry. Compose file snippet: ``` version: \"3.7\" services: standalone: build: context: build/wildfly/standalone ... ``` We want to be able to start the services with _docker-compose_ CLI on any other machine in our company, using the same Compose file, while pulling the previously built images from company's private Docker registry. Those other machines don't have access to the build files, only the Compose file. The problem is, when starting services with `up`, build path specified in the Compose file must exist, otherwise an error is thrown, even if building is not required or is explicitly turned off with `--no-build`. ``` docker-compose -f all-standalone-demo.yml up --no-build ERROR: build path /home/vpriscan/...../build/wildfly/standalone either does not exist, is not accessible, or is not a valid URL. ``` I propose that missing build directory is ignored when services being started don't require building the images, or alternatively if `--no-build` flag is present. Kind regards, Vedran Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Sympy backends need more testing <!--- Provide a general summary of the issue in the Title above --> The sympy backends were introduced by @liupibm in #217. In the interest of making all simulators behave similarly (and play nicely with the other changes made in #319), the sympy backends were also merged in the SDK. But they lack formal tests. ## Expected Behavior <!--- If you're describing a bug, tell us what should happen --> <!--- If you're suggesting a change/improvement, tell us how it should work --> Include tests in `test/python` ## Current Behavior <!--- If describing a bug, tell us what happens instead of the expected behavior --> <!--- If suggesting a change/improvement, explain the difference from current behavior --> ## Possible Solution <!--- Not obligatory, but suggest a fix/reason for the bug, --> <!--- or ideas how to implement the addition or change --> ## Steps to Reproduce (for bugs) <!--- Provide a link to a live example, or an unambiguous set of steps to --> <!--- reproduce this bug. Include code to reproduce, if relevant --> ## Context <!--- How has this issue affected you? What are you trying to accomplish? --> <!--- Providing context helps us come up with a solution that is most useful in the real world --> ## Your Environment <!--- Include as many relevant details about the environment you experienced the bug in --> * Version used: * Environment name and version (e.g. Python 3.6.1): * Operating System and version: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Add repr method for arbitrary mime-types We have `_repr_foo_` methods for a few common mime-types, but this mapping doesn't extend well to custom mime-types. I propose we add a new magic method that returns the full, formatted mime data, such as: ```python def _repr_mime_(self): \"\"\"Return mimetype-bundled representation(s) of me\"\"\" return { 'data': { 'application/vnd.tableschema.v1+json': {...}, 'text/html': '<div>...', 'metadata': {}, } ``` details: should this override or be in addition to existing methods if found? cc @rgbkrk Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Several GNU directory options are not available I see several [predefined directory options](https://github.com/mesonbuild/meson/blob/master/mesonbuild/coredata.py#L202), but several of the [GNU Coding Standard directories](https://www.gnu.org/prep/standards/html_node/Directory-Variables.html) are missing, notably `sysconfdir` being the main one. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Split Circuit Visualization Backends into separate modules <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Right now we have one giant module `qiskit.tools.visualization._circuit_visualization` which contains both the public methods and the implementations for 2 different backends (mpl and latex). As part of the circuit visualization cleanup we should create a separate module for each backend `qiskit.tools.visualization._latex` and `qiskit.tools.visualization._matplotlib`. This is how we set up the text/ascii backend already. After this happens we'll just have the public interfaces (mainly circuit_drawer() and it's helper functions) living in `qiskit.tools.visualization._circuit_visualization`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Make sure storage.bucket.Bucket.delete raises proper exceptions on failure From TODO: ``` python # TODO: Make sure the proper exceptions are raised. ``` See [`storage.bucket.Bucket.delete`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/bucket.py#L153) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 153) # TODO: Make sure the proper exceptions are raised. ``` Make sure storage.bucket.Bucket.delete raises proper exceptions on failure From TODO: ``` python # TODO: Make sure the proper exceptions are raised. ``` See [`storage.bucket.Bucket.delete`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/bucket.py#L153) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 153) # TODO: Make sure the proper exceptions are raised. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: styling prompt, {color.Normal} excepts version: ipython 0.12 With my prompt set to: `c.PromptManager.in_template = '{color.LightGreen} \\T {color.Normal}\\Y2 {color.LightGreen}\\$'` I get an `AttributeError: NoColors instance has no attribute 'Normal'` But I checked: ``` >>> from IPython.utils.coloransi import InputTermColors >>> InputTermColors.Normal # color has Normal, which is supposed to reset '\\x01\\x1b[0m\\x02' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: [mpl and latex circuit drawer] The box needs to extend over the classical registers as well when an instruction has classical parameters _Originally posted by @ajavadia in https://github.com/Qiskit/qiskit-terra/issues/2973#issuecomment-521635150_ > No mpl and latex also need to be fixed. The box needs to extend over the classical registers as well. But at least they draw something. I would say text is priority since that's the default drawer. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CMake translation handling macOS frameworks incorrectly I'm attempting to compile cURL as a subproject and getting linker errors for the final executable. The issue appears to be the following snippet in the final linker call: ``` /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX11.0.sdk/System/Library/Frameworks/CoreFoundation.framework /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX11.0.sdk/System/Library/Frameworks/Security.framework ``` This should instead just be `-framework CoreFoundation -framework Security`, and substituting appropriately causes the build to succeed. This appears to come from the generated meson files. In `subprojects/curl/meson.build`: ``` link_args : ['/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX11.0.sdk/System/Library/Frameworks/CoreFoundation.framework', '/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX11.0.sdk/System/Library/Frameworks/Security.framework', '/usr/local/lib/libssh2.dylib', '/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX11.0.sdk/usr/lib/libz.tbd'], ``` The equivalent CMake appears to just be something like: ``` find_library(COREFOUNDATION_FRAMEWORK \"CoreFoundation\") list(APPEND CURL_LIBS \"${COREFOUNDATION_FRAMEWORK}\") ``` I assume that macOS frameworks need to be special-cased for this to work. Meson version: 0.56.0 CMake version: 3.19.0 MacOS version: 11.0.1 How I'm invoking the CMake module: https://github.com/TypesettingTools/ffi-experiments/blob/3b9efd7a8b4e93386e0bcbe84acf33a7a9ef8615/meson.build#L16-L41 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Importing pyplot causes bouncing dock icon on mac This is illustrated by the following gif:  Importing pyplot in the normal python repl causes the python rocket icon to appear but not bounce distractingly. Importing it inside IPython causes the icon to bounce annoyingly for almost a minute. This is using a framework build of Python from Homebrew. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Branch `master` is failing <!-- commit 9ad54e15ddf7a689b639d0984a41867b84aef4b3@master --> Trying to build `master` at commit 9ad54e15ddf7a689b639d0984a41867b84aef4b3 failed. More info at: https://travis-ci.com/Qiskit/qiskit-terra/jobs/206584074 Branch `master` is failing <!-- commit 8f406d5a15c6aedd19d829541691a79489aa77bb@master --> Trying to build `master` at commit 8f406d5a15c6aedd19d829541691a79489aa77bb failed. More info at: https://travis-ci.com/Qiskit/qiskit-terra/jobs/206513297 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Transpiling `cp` into `['u', 'cx']` works; transpiling `cx` into `['u', 'cp']` doesn't <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: `0.18.0` - **Python version**: `Python 3.9.6` - **Operating system**: `Pop!_OS 21.04 x86_64` ### What is the current behavior? I am able to transpile a `cp` gate into using `['u', 'cx']` as basis gates, but I am unable to transpile a `cx` gate using `['u', 'cp']`. I want to be able to use `['u', 'cp']` as the transpilation target for more advanced circuits, but it does not work. Additionally, trying to transpile to `['u', 'crz']` also fails. ### Steps to reproduce the problem ``` from qiskit import QuantumCircuit, QuantumRegister from qiskit import transpile import numpy as np # works fine qr3 = QuantumRegister(2) qc3 = QuantumCircuit(qr3) qc3.cp(np.pi, qr3[0], qr3[1]) qc3 = transpile(qc3, basis_gates=['u', 'cx']) print(qc3) # fails to transpile qr1 = QuantumRegister(2) qc1 = QuantumCircuit(qr1) qc1.cx(qr1[0], qr1[1]) qc1 = transpile(qc1, basis_gates=['u', 'cp']) print(qc1) ``` ### What is the expected behavior? Transpilation should work in both directions, and `['u', 'cp']` should be a complete gate set. ### Suggested solutions I believe this is an issue with the way the transpiler runs; I don't understand all of the details of the transpiler to offer any useful suggestions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] MSYS2 is not properly detected as Windows While working on #2568 I tested conan with MSYS2. To my surprise, conan does not work out of the box in this environment. More specifically, the profile auto detection fails to detect the MSYS2 environment as `os=Windows` with `subsystem=msys2`. Instead, the following profile is generated: ~~~ [settings] os=MSYS_NT-10.0 os_build=MSYS_NT-10.0 arch=x86_64 arch_build=x86_64 compiler=gcc compiler.version=6 compiler.libcxx=libstdc++ build_type=Release [options] [build_requires] [env] ~~~ It seems like the reason for this behavior is that `platform.system()` is not returning the expected `Windows` but `MSYS_NT-10.0` instead. Interestingly, `sys.platform` is `msys`. Considering how often `platform.system() == \"Windows\"` is used within the conan codebase this makes me a little bit nervous... Best, Mario Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QPY fails to deserialize some `ControlledGate`s ### Environment - **Qiskit Terra version**: 0.20.1 - **Python version**: 3.8.12 - **Operating system**: Ubuntu 20.04.4 ### What is happening? QPY successfully serializes circuits containing instances of `ControlledGate`, but deserialization fails when `ControlledGate.__init__(...)` is called in `_read_instruction` with e.g.: ``` File \"<..>/qiskit/qpy/binary_io/circuits.py\", line 250, in _read_instruction gate = gate_class(*params) TypeError: __init__() missing 3 required positional arguments: 'name', 'num_qubits', and 'params' ``` ### How can we reproduce the issue? ``` from io import BytesIO from qiskit import qpy, QuantumCircuit from qiskit.circuit.library import DCXGate controlled_gate = DCXGate().control(1) # create instance of ControlledGate circuit = QuantumCircuit(3) circuit.append(controlled_gate, [0, 1, 2]) buf = BytesIO() qpy.dump(circuit, buf) # ok qpy.load(BytesIO(buf.getbuffer())) # TypeError: __init__() missing 3 required positional arguments: 'name', 'num_qubits', and 'params' ``` ### What should happen? `qpy.load()` should succeed ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Non-IPython kernel get passed --profile-dir Which (can) make them crash. - Either document it - remove it and deal with it. Proposal, special key like `{connexion_file}` so that it is not mandatory and not included by default. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: duplicate docstrings in numpy/core/_add_newdocs.py and numpy/core/multiarray.py ## Documentation When we transistioned to `__array_function__` we ended up with at least one duplicate docstring: in both [numpy/core/_add_newdocs.py](https://github.com/numpy/numpy/blob/v1.21.1/numpy/core/_add_newdocs.py#L3201) and [numpy/core/multiarray.py](https://github.com/numpy/numpy/blob/df6d2600c51502e1877aac563658d0616a75c5e5/numpy/core/multiarray.py#L737) there is a docstring for `dot`. It would be nice to go through and remove this and any other duplicates, I think the ones in `_add_newdocs.py` should be removed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [scm] deducing `url` with a windows path It looks like when `auto` is deduced for `url`, it has to be properly escaped for '\\\\', just in case if it happens to be a local (windows) path instead of a proper git url. I have scm section in my conanfile.py like the following ``` scm = { 'type': 'git', 'url': 'auto', 'revision': 'auto' } ``` I am getting the following error from our bamboo builds ``` [package]: Repo origin deduced by 'auto': file://C:\\bamboo\\xml-data\\build-dir\\_git-repositories-cache\\3da5a99bbc924e3c4d1788734921ce3e6554ac8c [snip] [package]: A new conanfile.py version was exported ERROR: Unable to load conanfile in [snip]\\export\\conanfile.py File \"<frozen importlib._bootstrap>\", line 684, in _load File \"<frozen importlib._bootstrap>\", line 665, in _load_unlocked File \"<frozen importlib._bootstrap_external>\", line 674, in exec_module File \"<frozen importlib._bootstrap_external>\", line 781, in get_code File \"<frozen importlib._bootstrap_external>\", line 741, in source_to_code File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed File \"[snip]\\export\\conanfile.py\", line 16 scm = {\"url\": \"file://C:\\bamboo\\xml-data\\build-dir\\_git-repositories-cache\\3da5a99bbc924e3c4d1788734921ce3e6554ac8c\", SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 16-17: truncated \\xXX escape ``` As it turns out, due to local bamboo git repo caching, I shouldn't use `auto` for `url` but conan should not fail due to windows paths in a deduced `url`. Of course if it didn't fail, I wouldn't have noticed this *issue* this easily, perhaps conan should give a warning or fail with a more descriptive message if the deduced `url` ends up being a local path instead of a proper git url. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose create Possibility to just create but not run containers. This would be a useful feature for systemd based startups. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Backend specific transpiler stages ### What should we add? Now that we have the `StagedPassManager` class this gives us flexibility in how we can compose and hook into the transpilation pipeline at specific points. The first piece of this is transpiler stage plugins which is being done in #8305 the other piece which is needed is a way for backends to add additional backend specific passes to the compilation pipeline. The idea being some passes are hardware specific and having a mechanism for a backend to provide it's own `PassManager` that will be run at fixed points in the compilation pipeline will enable backend authors to implement these hardware specific passes in a standardized way and when the compilation target is that backend it will run the pass manager at the appropriate point in the compilation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: error in download cli ## How to reproduce the behaviour <!-- Include a code example or the steps that led to the problem. Please try to be as specific as possible. --> python -m spacy download en results in an traceback ending in ``` data = url_read(url, verify=ssl_verify) TypeError: url_read() got an unexpected keyword argument 'verify' ``` something like this solves it ``` --- spacy/cli/download.py +++ spacy/cli/download.py @@ -71,7 +71,7 @@ def download(model, direct=False, insecure=False, ca_file=None): def get_json(url, desc, ssl_verify): try: - data = url_read(url, verify=ssl_verify) + data = url_read(url) ``` ## Your Environment <!-- Include details of your environment. If you're using spaCy 1.7+, you can also type `python -m spacy info --markdown` and copy-paste the result here.--> * Operating System: Linux * Python Version Used: 3.6 * spaCy Version Used: master * Environment Information: 💫 Improve \"spacy download\" and support for different installation prefixes Currently `spacy download` seems to struggle when Python is installed into a different prefix. See #1220 . Possible resolutions could include an argument to `spacy download`. Ideal resolution would be detecting the correct prefix, and installing there. If you work on this, please try to pay attention to cross-platform and cross-version support. Try to use the built-in `pkg_resources` module. The tools in `spacy.compat` might assist with this. Using `pathlib.Path` for file-system manipulation is also helpful. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: update paths/links according new org ## 🐛 Bug With moving to the PyTorchLightning org we need to update builds, badges and other related links... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: chord does nothing when the header is an empty list ## Checklist - [ x ] I have included the output of ``celery -A proj report`` in the issue. (if you are not able to do this, then at least specify the Celery version affected). Affected version: 4.1.0 - [ x ] I have verified that the issue exists against the `master` branch of Celery. ## Steps to reproduce Initiate the Celery configuration, and run the following code. ```py @celery.task() def add(a, b): return sum(a) + b print(chord([], add.s(3)).apply_async().get()) ``` ## Expected behavior Does not wait, executes the callback task, prints 3. ## Actual behavior Does nothing, the `get` call is stuck forever. I do not know if it's a bug, or a non-feature, but it should be at least documented. The use case behind this is we generate a list dynamically using Python's list comprehension `[my_task.s(i) for i in range(n)]`, the list is potentially empty. Another thing is the fact that the response sent to the callback is a list only if there is more than one element in the list is also counter intuitive and should be at best overridable. http://docs.celeryproject.org/en/latest/userguide/canvas.html#chords Thanks a lot in advance Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: RPATH removal breaks Xorg modules Trying to build xorg (from github.com/anholt/xserver, branch Meson; I used `meson --prefix=~/prefix/xorg -Dxorg=yes -Dxephyr=true -Dxwayland=yes -Dglamor=yes -Dxnest=no -Ddmx=false -Dxkb_dir=/usr/share/X11/xkb -Dxkb_output_dir=/var/lib/xkb/compiled -Dhal=no -Dsystemd_logind=yes build` to build) works just fine. But the installation fails, specifically in how the RPATH removal mangles the modules. With the default set of modules, dlopen() of modesetting_drv.so attempts to resolve a zero-length symbol: ``` [ 8270.883] (II) LoadModule: \"modesetting\" [ 8270.883] (II) Loading /home/daniels/prefix/xorg/lib64/xorg/modules/drivers/modesetting_drv.so [ 8270.884] (EE) Failed to load /home/daniels/prefix/xorg/lib64/xorg/modules/drivers/modesetting_drv.so: /home/daniels/prefix/xorg/lib64/xorg/modules/drivers/modesetting_drv.so: undefined symbol: [ 8270.884] (EE) Failed to load module \"modesetting\" (loader failed, 0) ``` Here is the file installed by `meson install`: https://static.fooishbar.org/tmp/modesetting_drv.so.broken And here is the original: https://static.fooishbar.org/tmp/modesetting_drv.so.working And, for completeness, the `chrpath -d` module, which also works fine: https://static.fooishbar.org/tmp/modesetting_drv.so.working.chrpath @aaronp24 and ajax worked out that the difference was Meson NULLing out the rpath, whereas `chrpath` deletes it entirely. NULLing it out breaks entirely, because modesetting has a symbol named `modesetting`. Its rpath is also `.../hw/xorg/driver/modesetting`. Thanks to the magic of read-only data sharing, the symbol definition points to the end of the rpath string, which we've just obliterated. Oops. Anyway, it looks like switching from `chrpath -r ''` to `chrpath -d` type semantics should fix it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: @jupyterlab/hub-extension in jupyterlab==3.0.0-rc.6 not appearing in the menus/commands Testing with `jupyterlab==3.0.0-rc.6` (we can't use 3.0.0-rc.11 atm because react 0.17 is incompatible with libraries used by some of our extensions), we're not finding the `Hub Control Panel` and cousins (any of the commands added in: https://github.com/jupyterlab/jupyterlab/blob/master/packages/hub-extension/src/index.ts) in the menus or the commands. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: support for scipy.stats.dirichlet Registering interest in having support for this distribution (specifically logpdf() and rvs()). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: debugger.py: pydb broken pydb support in IPython/core/debugger.py needs updating for the new configuration: line 41: ``` #We have to check this directly from sys.argv, config struct not yet available if '-pydb' in sys.argv: ``` but -pydb and --pydb are not accepted as a commandline argument for ipython Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Support for non-scalar np.repeat arguments. Hello, I noticed that jax.numpy.repeat does not support non-scalar repeats. ``` np.repeat(np.array([[1, 2, 3]]), np.array([2, 3, 1])) NotImplementedError Traceback (most recent call last) <ipython-input-120-c0c19bd58e3a> in <module>() ----> 1 np.repeat(np.array([[1, 2, 3]]), np.array([2, 3, 1])) google3/third_party/py/jax/numpy/lax_numpy.py in repeat(a, repeats, axis) 1539 if not isscalar(repeats): 1540 raise NotImplementedError( -> 1541 \"np.repeat implementation only supports scalar repeats\") 1542 if axis is None or isscalar(a): 1543 a = ravel(a) ``` The expected results with numpy: ``` array([1, 1, 2, 2, 2, 3]) ``` Note that the documentation indicates that this is supported: https://jax.readthedocs.io/en/latest/_autosummary/jax.numpy.repeat.html Is it possible to add support for this in jax, and/or is there a workaround? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Undefined references to UBSan when linking CUDA project with `b_sanitize=undefined` **Describe the bug** Hi, as a follow-up to https://github.com/mesonbuild/meson/issues/8337, I've noticed that when I enable UBSan for my project (`-Db_sanitize=undefined`), nvcc is fails to link the executables, producing lots of error about undefined references from libubsan. My current workaround is to add the followin snippet to meson.build: ``` if get_option('b_sanitize') == 'undefined' add_project_link_arguments('-lubsan', language: 'cuda') endif ``` This isn't sth that is a blocker for me or very problematic because the workaround is very simple, just giving you a heads up; @obilaniu would you care to take a look? **To Reproduce** Use the same project that was included with https://github.com/mesonbuild/meson/issues/8337, just add `-Db_sanitize=undefined` to `meson setup` invocation. **Expected behavior** Project linking without errors. **system parameters** * Native build * Ubuntu 18.04, gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0, Ubuntu packages: cuda-10-0, libboost-all-dev * Python 3.6.9 * meson 0.56.1 * ninja 1.8.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Operator() cannot simualte circuits with barrier it should, as they are just compiler directives. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: from_dict() should be able to handle complex numbers <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? .from_dict() will error out if (actual) complex numbers are present where complex numbers should be present. It's requiring that complex numbers be specified as lists when it should instead allow them to be specified as lists but also allow them to be complex numbers ### Steps to reproduce the problem See [these](https://github.com/Qiskit/qiskit-aer/pull/504) currently failing unit tests ``` qiskit.validation.exceptions.ModelValidationError: \"{'results': {0: {'data': {'unitary': {0: {0: ['(1+0j) cannot be parsed as a complex number.'] ... ``` ### What is the expected behavior? There's no reason for it to fail - when serializing things we should change complex to lists but '_deserialization' (from_dict) should be able to handle complex numbers (as well as the list format). ### Suggested solutions Don't throw an error if the thing we're trying to deserialize is already a complex number [here](https://github.com/Qiskit/qiskit-terra/blob/792e1b7f866b9f3685566341fa6b4b54d5ba33e9/qiskit/validation/fields/custom.py#L50) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: remove ghpages_documentation_deploy.sh <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? since all the documentation is now in qiskit/qiskit we should remove this script. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Resolve warning about renderedtifields query ### Body This warning is emitted when running a task instance, at least on mysql: ``` [2022-09-21, 05:22:56 UTC] {logging_mixin.py:117} WARNING - /home/airflow/.local/lib/python3.8/site-packages/airflow/models/renderedtifields.py:258 SAWarning: Coercing Subquery object into a select() for use in IN(); please pass a select() construct explicitly ``` Need to resolve. ### Committer - [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: vmap fails possibly due to internal mishandling of scalar ```python import jax import jax.numpy as np x = np.zeros([3,2], dtype=np.float32) y = np.zeros([3], dtype=np.float32) foo = jax.vmap(np.vdot, (1,None), 0) foo(x,y) ``` Gives `TypeError: transpose permutation isn't a permutation of operand dimensions, got permutation (1, 0) for operand shape (2L,).` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: QTConsole tooltip placement y-padding missing  with git master 5ef1976 Upper half is before and bottom is after fix. PR in a moment. Continuing QTC regression issues from https://github.com/ipython/ipython/issues/6726 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Vision raises TypeError: b'...' is not JSON serializable on Python 3 Simple reproducible case: ``` python import io import os from google.cloud import vision vision_client = vision.Client() file_name = os.path.join( os.path.dirname(__file__), 'resources/wakeupcat.jpg') with io.open(file_name, 'rb') as image_file: image = vision_client.image( content=image_file.read()) labels = image.detect_labels() print('Labels:') for label in labels: print(label.description) ``` works fine on Python 2, fails on Python 3. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: setp() issue in ipython notebook with figure references In IPython notebook, when I run `setp()` to change parameters of a figure created in another cell and accessed with its reference, an exception occurs ``` python --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-82-54a641ac28e1> in <module>() ----> 1 setp(axis.lines[0], linewidth=2) /home/amir/virtualenv/cr/local/lib/python2.7/site-packages/matplotlib/pyplot.pyc in setp(*args, **kwargs) 238 def setp(*args, **kwargs): 239 ret = _setp(*args, **kwargs) --> 240 draw_if_interactive() 241 return ret 242 /home/amir/virtualenv/cr/local/lib/python2.7/site-packages/IPython/zmq/pylab/backend_inline.py in draw_if_interactive() 123 # flush_figures() will act upon these values 124 --> 125 fig = Gcf.get_active().canvas.figure 126 127 # Hack: matplotlib FigureManager objects in interacive backends (at least AttributeError: 'NoneType' object has no attribute 'canvas' ``` Nevertheless, `setp()` successfully does its job but since IPython notebook by default closes the figures of previous cells the exception occurs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: storage.bucket.Bucket.copy_blob missing option to preserve ACL [Unlike](https://cloud.google.com/storage/docs/gsutil/commands/cp) `gsutil`. > Note that by default, the gsutil cp command does not copy the object ACL to the new object, and instead will use the default bucket ACL. You can override this behavior with the -p option. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumCircuit compose is throwing away calibrations <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master on commit 5be00b6626eb6ef902603b91e429bebd8563f3ae - **Python version**: 3.7.3 - **Operating system**: Ubuntu ### What is the current behavior? In quantum circuit compose we have `dest._calibrations.update(other.calibrations)`. A calibration looks like this: ``` defaultdict(dict, {'x': {((0,), (0.1, 30.0, 0.2)): Schedule((0, Play(Drag(duration=160, amp=(0.1+0j), sigma=30.0, beta=0.2), DriveChannel(0))), name=\"x\")}}) ``` Therefore, if we have multiple calibration for `x` each one for a different qubit `compose` will loose them. ### Steps to reproduce the problem A simple example suffices to see why this is the case ``` aa = {'a': {(0,): 'aa'}} bb = {'a': {(1,): 'bb'}} aa.update(bb) ``` results in `{'a': {(1,): 'bb'}}` i.e. the calibration for `(0, )` is no longer present. ### What is the expected behavior? In the simple example above we should have `{'a': {(0,): 'aa', (1,): 'bb'}}`. I.e. the expected behavior is that all calibration be carried over when using `compose`. ### Suggested solutions Replace `dest._calibrations.update(other.calibrations)` with something tailored to the structure of the calibrations dict. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Windows build broken https://dev.azure.com/elementl/dagster/_build/results?buildId=7627&view=logs&j=3108c3d6-f430-545a-6d06-0bbb96d639c3&t=652bead6-5c91-5891-e3ee-4a66fd4b0486 Blames to https://dagster.phacility.com/D3069 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: RTD build is broken Can look at this, leaving as note as reminder. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Typing % doesn't restrict autocompletion to just magics ## Steps to reproduce * Write `%` in the prompt * Hit \"Tab\" ## Expected result The autocompletion list presents the user with a choice of magics. ## Actual result Every name in the local namespace is present in the list, including locals, builtins, IPython-custom variables (`_`, for example) and all magics, but at the very end. ## System info Manjaro Linux, Python 3.9.4, IPython 7.22.0 (reproduces on IPython 8.0.0.dev) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Disabling/enabling remotes A feature request from user could be summarized as: - They have multiple remotes, 20+, that are defined and installed via ``conan config install`` - Developers need to login only to a few of them 1, 2... - The remotes that the user is not logged in should be skipped. After discussing it, the most common use case is that users would like to use those remotes, even if not logged-in, because anonymous read usage is common practice. So it doesn't seem a pattern that would be useful for other users. Furthermore, it would be coupling the auth process with the remote enabling process, seems not the best way. I think that the feature that could make sense and totally address this use case too is the one of enabling/disabling remotes: - Remotes can be ``conan remote disable <remote-name>`` or ``conan remote enable <remote-name>`` - Disabled remotes are NOT removed from the definition, that means that packages that were installed from that remote do not lose their tracking to that remote (removing a remote cleans from the metadata the original remote) - Disabled remotes are skipped when a package install is iterating remotes - An exception is raised if a package tries to reach that remote (like --update, or completing missing sources) This is a feature I have missed myself a few times, like disabling conan-center or bincrafters for doing experiments, and later needing to look up the remote to be able to set-up it again, and also playing with --insert to get the same order it was before. Plus it seems not very complex to implement. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: rpath contains paths to static libs Create a project with ninja backend and mirror layout: ```meson # subdir_1 my_st_lib = static_library('my_st_lib', ...) # subdir_2 my_sh_lib = shared_library('my_sh_lib', link_with: my_st_lib, ...) ``` `my_sh_lib`'s rpath will contain path to `subdir_1` (e.g. `$ORIGIN/../subdir_1`), which AFAIK is pointless. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Wandb Flatten Dict Wandb logger should flatten the dictionary of parameters before logging. Every other logger has the bellow pattern of code: ``` params = self._convert_params(params) params = self._flatten_dict(params) ``` ## 🐛 Bug Wandb logger does not flatten parameters resulting in dictionaries being logged to Wandb, which are not searchable causing for some loss of features in wandb. ### To Reproduce Run the cpu_template with wandb logger, and log a nested dictionary. ### Expected behavior Solution, just call ` params = self._flatten_dict(params)` this in the wandb logger. ### Environment * CUDA: - GPU: - available: False - version: None * Packages: - numpy: 1.18.5 - pyTorch_debug: False - pyTorch_version: 1.5.0 - pytorch-lightning: 0.8.4 - tensorboard: 2.2.2 - tqdm: 4.46.1 * System: - OS: Darwin - architecture: - 64bit - - processor: i386 - python: 3.7.7 - version: Darwin Kernel Version 19.4.0: Wed Mar 4 22:28:40 PST 2020; root:xnu-6153.101.6~15/RELEASE_X86_64 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Can the IPython directive use warnings for errors? Pandas would like to have a workflow where 1. the documentation build always completes to the end, even if there are warnings 2. the CI fails if there are any warnings. For regular sphinx things, this works with a combination of `-W error --keep-going`, which fails the job at the end of the build if there were any warnings. This doesn't work with exceptions in IPython blocks. Here's a small example ``` Welcome to test's documentation! ================================ .. ipython:: python 2 + 'a' The rest of the biuld .. ipython:: python 2 + 2 ``` And the relevant IPytyhon conf setting is `ipython_warning_is_error = False`. When I run ``` sphinx-build -W --keep-going \".\" _build/ ``` The entire document is built, but the exit code is `0`, when I'd like it to be `1`. I *hope* this is just because exceptions in IPython blocks are printed to stdout. On some basic testing, it looks like using `sphinx.util.logging` and `logger.warning` rather than `sys.stdout.write` will satisfy my needs. Are the IPython devs open to changing from `sys.stdout.write` to `logger.warning` for this? cc @tacaswell, and idea if this change would break matplotlib at all? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Lift version limitation for the PyJWT Currently Conan has version limitation for PyJWT like this: PyJWT>=1.4.0, <2.0.0 Popular frameworks, like PyGithub, are gradually lifting minimal PyJWT version to the 2.0+, and it becomes problematic to use conan together with the rest of the scripting. Situation is temporary resolvable using virtuenv, but python version switching is yet another dimension for human mistakes, especially for non-experts in python. It would be way easier if conan can be installed together with mainstream packages in a typical environment. Can PyJWT version limit be lifted to the 2.0+? - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: `conda package -w` is case dependent on Windows It should be case-insensitive, because windows filesystem is case insensitive. E.g., when I run from the environment root: `conda package -w Lib\\site-packages\\win32\\win32file.pyd` Ir finds the package, but if I run `conda package -w lib\\site-packages\\win32\\win32file.pyd` it will report nothing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Why do I need to do 2 imports for datastore transactions? What I see in the docs: ``` python >>> from gcloud import datastore >>> from gcloud.datastore.transaction import Transaction >>> datastore.set_defaults() >>> with Transaction(): ... datastore.put([entity1, entity2]) ``` What I want to do: ``` python >>> from gcloud import datastore >>> with datastore.Transaction() as t: ... t.put([entity1, entity2]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Stacktrace / traceback on `sudo docker-compose images` sudo docker-compose images Traceback (most recent call last): File \"/usr/bin/docker-compose\", line 11, in <module> load_entry_point('docker-compose==1.17.1', 'console_scripts', 'docker-compose')() File \"/usr/lib/python3.6/site-packages/compose/cli/main.py\", line 68, in main command() File \"/usr/lib/python3.6/site-packages/compose/cli/main.py\", line 121, in perform_command handler(command, command_options) File \"/usr/lib/python3.6/site-packages/compose/cli/main.py\", line 517, in images repo_tags = image_config['RepoTags'][0].rsplit(':', 1) IndexError: list index out of range Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] CMakeDeps generator: component and package with the same name Hi! During refactoring #8971 behavior of `tvalue` [macro](https://github.com/conan-io/conan/blob/80e99ca9a7d730e95adbc8bde5aa33da4f4fbb44/conan/tools/cmake/cmakedeps/templates/target_configuration.py#L35) was changed by adding some special case when `pkg_name` and `comp_name` are the same. It accidentally break this case, because `tvalue` macro is inlined in declaration of several variables (see [this](https://github.com/conan-io/conan/blob/80e99ca9a7d730e95adbc8bde5aa33da4f4fbb44/conan/tools/cmake/cmakedeps/templates/target_configuration.py#L98) for example). So these variables have one name (`{pkg_name}_{comp_name}_...`) during setting and the other name (`{comp_name}_...`) during using it in `set_property`. cc @lasote Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: TypeError on completions using version \"8.6.0\" I was using `IPCompleter.merge_completions = False` configuration, and after update to version `8.6.0` I got an error. I created a fresh virtual environment: ``` poetry init poetry add ipython ``` and still got the error: ``` Traceback (most recent call last): File \"/tmp/foobar/.venv/lib/python3.10/site-packages/IPython/terminal/ptutils.py\", line 122, in get_completions yield from self._get_completions(body, offset, cursor_position, self.ipy_completer) File \"/tmp/foobar/.venv/lib/python3.10/site-packages/IPython/terminal/ptutils.py\", line 138, in _get_completions for c in completions: File \"/tmp/foobar/.venv/lib/python3.10/site-packages/IPython/core/completer.py\", line 753, in _deduplicate_completions completions = list(completions) File \"/tmp/foobar/.venv/lib/python3.10/site-packages/IPython/core/completer.py\", line 2449, in completions for c in self._completions(text, offset, _timeout=self.jedi_compute_type_timeout/1000): File \"/tmp/foobar/.venv/lib/python3.10/site-packages/IPython/core/completer.py\", line 2499, in _completions results = self._complete( File \"/tmp/foobar/.venv/lib/python3.10/site-packages/IPython/core/completer.py\", line 2810, in _complete ) and len(result[\"completions\"]) TypeError: object of type 'filter' has no len() ``` In the [documentation](https://ipython.readthedocs.io/en/stable/config/options/terminal.html) I read that as of version `8.6.0`, setting `IPCompleter.merge_completions` to False is an alias for: `IPCompleter.suppress_competing_matchers = True`. I used the new option and the error still happens. After commented this line (to use the default value) the error stopped to happen. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: ERROR: for nginx 'NoneType' object has no attribute 'get' ``` ➜ projectname docker-compose -v docker-compose version 1.18.0, build 8dd22a9 ``` Having a strange problem when simply changing a volume's mount name. My configuration looks like this: ```yaml version: '3.4' services: cygnetise: image: someorg/projectname volumes: - type: volume source: projectname_client target: /app nginx: image: someorg/projectname-nginx ports: - target: 80 published: 8080 volumes: - type: volume source: projectname_client target: /mnt/projectname_client read_only: true volumes: projectname_client: projectname_admin: ``` If I change the nginx application's target location to ``` /home/app/projectname_client``` I get the following error: ``` ➜ projectname docker-compose -f docker-compose.local.yml up Recreating 12396073747d_projectname_nginx_1 ... projectname_projectname_1 is up-to-date ERROR: for 12396073747d_projectname_nginx_1 'NoneType' object has no attribute 'get' ERROR: for nginx 'NoneType' object has no attribute 'get' Traceback (most recent call last): File \"docker-compose\", line 6, in <module> File \"compose/cli/main.py\", line 71, in main File \"compose/cli/main.py\", line 124, in perform_command File \"compose/cli/main.py\", line 959, in up File \"compose/project.py\", line 479, in up File \"compose/parallel.py\", line 80, in parallel_execute AttributeError: 'NoneType' object has no attribute 'get' Failed to execute script docker-compose ``` Not sure why this would happen, and the error message doesn't really provide any useful pointers unfortunately. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `Stabilizer.expectation_value()` does not give the correct result ### Environment - **Qiskit Terra version**: 0.19.1 - **Python version**: 3.9.5 - **Operating system**: Win 10 ### What is happening? I wrote a script for generating random Clifford circuit with respect to certain layout. Then I convert it to `StabilizerState` and compute the expectation value of its stabilizers with `StabilizerState.expectation_value()`, which should be one. The stabilizers are obtained with `StabilizerState.clifford.to_dict()`. But some expectation values are zero, instead of one. ### How can we reproduce the issue? The following code can be used to reproduce the issue. ```python from qiskit.quantum_info import Pauli, random_clifford, StabilizerState from qiskit import QuantumCircuit from numpy.random import RandomState n_qubits = 3 circ = QuantumCircuit(n_qubits) compute_seed = RandomState(0).choice(10, size = (1, n_qubits)) for i in range(n_qubits): gate = random_clifford(1, compute_seed[0, i]) circ.compose(gate.to_circuit(), [i], inplace = True) print(circ) s = StabilizerState(circ) stab_gen = s.clifford.to_dict()[\"stabilizer\"] print(stab_gen) for i in range(n_qubits): print(s.expectation_value(Pauli(stab_gen[i]))) # should be 1 ``` The printed result of last line is ```python 1 1 0 ``` ### What should happen? The values should all be one. Actually, if we run the following code ```python stab_sim = Aer.get_backend(\"aer_simulator_stabilizer\") for i in range(3): circ.save_expectation_value(Pauli(stab_gen[i]), circ.qubits) result = execute(circ, stab_sim).result() print(result.data(circ)) circ.data.pop(-1) ``` Then, the printed results are all `{'expectation_value': 1.0}`. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DISCUSSION: Do we need ACL lazy loading? Is there a good reason for the [lazy](https://github.com/GoogleCloudPlatform/gcloud-python/blob/d51f29f39832d52a24b2b5dfdb4f882bf623f374/gcloud/storage/blob.py#L95-L99) loading [behavior](https://github.com/GoogleCloudPlatform/gcloud-python/blob/d51f29f39832d52a24b2b5dfdb4f882bf623f374/gcloud/storage/bucket.py#L127-L139), e.g. ``` python if self._acl is None: self._acl = ObjectACL(self) ``` This doesn't make any requests and just initializes a very lightweight object. I move to just create these in the constructor. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Cloud PR references Core See https://github.com/PrefectHQ/cloud/pull/1044 for more details Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: f2py: external functions declared in single line don't work External functions (e.g. #14919 or https://stackoverflow.com/questions/44073679/errors-when-using-a-fortran-call-back-function-in-f2py) do not generate correct headers in f2py if declared in F90 style. ### Reproducing code example: Version A: two lines for external ```fortran subroutine a(fcn) implicit none external fcn real(8) :: fcn real(8) :: x, y x = 0d0 y = fcn(x) end ``` Version B: one line for external ```fortran subroutine a(fcn) implicit none real(8), external :: fcn real(8) :: x, y x = 0d0 y = fcn(x) end ``` ### Output: Running `f2py source.f90 -h header.pyf` produces the following results. Version a correctly outputs a pyf header ```fortran ! -*- f90 -*- ! Note: the context of this file is case sensitive. python module a__user__routines interface a_user_interface function fcn(x) result (y) ! in external1.f90:a:unknown_interface real(kind=8) :: x real(kind=8) :: y end function fcn end interface a_user_interface end python module a__user__routines subroutine a(fcn) ! in external1.f90 use a__user__routines external fcn end subroutine a ! This file was auto-generated with f2py (version:2). ! See http://cens.ioc.ee/projects/f2py2e/ ``` Version B incorrectly produces a header without external function ```fortran ! -*- f90 -*- ! Note: the context of this file is case sensitive. subroutine b(fcn) ! in external2.f90 real(kind=8) :: fcn end subroutine b ! This file was auto-generated with f2py (version:2). ! See http://cens.ioc.ee/projects/f2py2e/ ``` ### NumPy/Python version information: 1.19.4 3.9.0 (default, Oct 27 2020, 14:15:17) [Clang 12.0.0 (clang-1200.0.32.21)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: firestore.CreateIfMissingOption should be replaced Paraphrased from @samtstern: It's still possible to do ```python city_ref.update({ u'capital': True }, firestore.CreateIfMissingOption(True)) ``` The other Firestore SDKs have removed this option and moved to an option on the `set()` operation called, `merge()`. For example, in the Android SDK: ```java db.collection(\"cities\").document(\"BJ\") .set(data, SetOptions.merge()); ``` The new semantics make it so that the `set()` operation (and `create()` which some SDKs offer) is the only operation which can make a new document. The `merge()` option means that the data will be deep merged into any existing document, rather than just obliterating and replacing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Trying to use a nonexistent pool fails silently Looking at the `pool_full()` method of `TaskInstance` (line 818 of models.py) -- if the TI has a pool specified but the pool doesn't exist in the database, it returns False (and the run continues). I think maybe if a pool was specified but doesn't exist, it should raise an error instead? After all, the point of a pool is to restrict execution and this behavior lets it go on (silently). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG? anything is allowed to cast to structured dtypes? I found while writing a ufunc that takes structured dtypes for its inputs that casting of essentially everything is allowed to a structured dtype, which is surprising. This is reflected in `can_cast`: ``` np.can_cast('f8', 'u1') # False np.can_cast('f8', '2u1') # True ``` I would have expected, at least for `safe`, that casting would only be allowed if the dtypes were the same (or, perhaps, that `can_cast` was applied recursively). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `Pauli('')` confusion ### Environment - **Qiskit Terra version**: 0.23.2 - **Python version**: 3.9.7 - **Operating system**: Linux ### What is happening? I find the following code example puzzling: ```python >>> from qiskit.quantum_info import Pauli >>> Pauli(\"X\")[[]] Pauli('') >>> Pauli('') Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/home/garrison/serverless/.direnv/python-3.9.7/lib/python3.9/site-packages/qiskit/quantum_info/operators/symplectic/pauli.py\", line 182, in __init__ base_z, base_x, base_phase = self._from_label(data) File \"/home/garrison/serverless/.direnv/python-3.9.7/lib/python3.9/site-packages/qiskit/quantum_info/operators/symplectic/pauli.py\", line 619, in _from_label raise QiskitError(f'Pauli string label \"{label}\" is not valid.') qiskit.exceptions.QiskitError: 'Pauli string label \"\" is not valid.' ``` The first REPL line allows me to construct an object whose `__repr__` is `Pauli('')`. However, if I try to instantiate `Pauli('')` directly, it fails. ### How can we reproduce the issue? Code snippet above. ### What should happen? Either both statements should fail, or both should be allowed. ### Any suggestions? I currently see no reason not to simply support `Pauli('')`, such that it works without raising an exception. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Two qubit KAK fails for CNOT input <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? ``` import numpy as np from qiskit.mapper.compiling import two_qubit_kak cx = np.array([ [1,0,0,0], [0,1,0,0], [0,0,0,1], [0,0,1,0] ]) two_qubit_kak(cx) ``` ``` ~/anaconda3/lib/python3.7/site-packages/qiskit_terra-0.8.0-py3.7-macosx-10.7-x86_64.egg/qiskit/mapper/compiling.py in euler_angles_1q(unitary_matrix) 41 # Find theta 42 if abs(U[0, 0]) > small: ---> 43 theta = 2 * math.acos(abs(U[0, 0])) 44 else: 45 theta = 2 * math.asin(abs(U[1, 0])) ValueError: math domain error ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions This may be fixed by moving to quaternions `qiskit.quantum_info.operators.quaternions` rather than Euler angles Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Update docs introduction Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Calling a jit'd function with or without kwarg name has different behavior Consider this example: ```python def foo(x, foo_power=10): # ... jit_foo = jax.jit(foo) jit_foo(x, foo_power=11) jit_foo(x, 11) ``` It would be reasonable to expect the two calls to jit_foo to have the same behavior/semantics. However, the first call with the kwarg name included will treat foo_power as a static arg, whereas the second call will treat it as a dynamic arg. This can cause errors if foo expects foo_power to be a compile-time constant (I ran into this jitting the fft method I'm working on). A workaround is to always include kwargs in the static_argnums argument to jit. We might wanna consider doing this automatically in jit to have more predictable behavior by default. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.datastore.connection should inherit from gcloud.connection The only [generic](https://github.com/dhermes/gcloud-python/blob/4c7fa75d7892e8b70281b722953f43f39711eea8/gcloud/connection.py#L28) [methods](https://github.com/dhermes/gcloud-python/blob/4c7fa75d7892e8b70281b722953f43f39711eea8/gcloud/connection.py#L32) in `gcloud.connection` are [identically](https://github.com/dhermes/gcloud-python/blob/4c7fa75d7892e8b70281b722953f43f39711eea8/gcloud/datastore/connection.py#L37) [defined](https://github.com/dhermes/gcloud-python/blob/4c7fa75d7892e8b70281b722953f43f39711eea8/gcloud/datastore/connection.py#L41) in `gcloud.datastore.connection`. I was adding a module docstring to `gcloud/connection.py` when I realized only one of our two implementations inherits from it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ninja/cmake issue when importing large subproject **Describe the bug** I am using meson to compile a complicated project. Part of this project involves sharing C++ source between my x86 spec PC and an ESP32 micro-controller. When I attempt to connect the ESP32 SDK's cmake project to my meson project as a subproject, ninja stops with error: `ERROR: Multiple producers for Ninja target \"subprojects/esp32/55ac3a2@@cm_mbedcrypto@sta/bignum.c.o\". Please rename your targets.` **To Reproduce** You'll need the ESP-IDF toolchain, setup guide here: https://docs.espressif.com/projects/esp-idf/en/latest/esp32/get-started/ I've created an example repo with a trivial ESP32 main implementation as an example here: https://github.com/Michael-Densberger/meson_esp32_issue_example **Expected behavior** I expected that the cmake subproject would build and I could use custom meson targets to interact with the idf.py wrapper that is used by the ESP-IDF toolchain to manage the micro-controller. Indeed, calling `idf.py flash monitor` from the subproject/esp32 dir results in a compiling and running binary on my ESP32 micro-controller. To clarify: 1. using cmake through the idf.py wrapper: works with no issues. 2. using cmake through meson results in: `ERROR: Multiple producers for Ninja target \"subprojects/esp32/55ac3a2@@cm_mbedcrypto@sta/bignum.c.o\". Please rename your targets.` **system parameters** * Native build * An as of this morning up-to-date Arch Linux * Python 3.8.2 * Meson 0.54.0 * Ninja 1.10.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: ELECTRA - some weights are not loaded ## Environment info - `transformers` version: 3.3.1 - Platform: Linux-4.15.0-118-generic-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.6.9 - PyTorch version (GPU?): 1.5.1 (True) - Tensorflow version (GPU?): 2.3.0 (True) - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help albert, bert, GPT2, XLM: @LysandreJik Model Cards: @julien-c ## Information Model I am using: ELECTRA I am getting a warning: > Some weights of the model checkpoint at google/electra-large-discriminator were not used when initializing ElectraModel: ['electra.embeddings_project.weight', 'electra.embeddings_project.bias'] > - This IS expected if you are initializing ElectraModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model). > - This IS NOT expected if you are initializing ElectraModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). when using the AutoModel.from_pretrained for google/electra-base-discriminator or google/electra-large-discriminator. There is no warning for google/electra-small-discriminator. The problem remains the same when directly using the ElectraModel.from_pretrained method. ## To reproduce ``` import transformers m=transformers.AutoModel.from_pretrained(\"google/electra-large-discriminator\") # or m=transformers.AutoModel.from_pretrained(\"google/electra-base-discriminator\") ``` ## Expected behavior no warning Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: boost dependency static libs require static: true (instead of missing) even when dynamic libs are absent **Describe the bug** I have a Boost instance that contains only static libraries. Until v 0.54.0, the boost dependency would find them without requiring me to specify `static: true`. **To Reproduce** Call a boost dependency for a module against a Boost installation without dynamic libraries. Don't use the `static` keyword. The dependency will fail to locate the static library. **Expected behavior** As long as I don't specify a static keyword, the boost dependency should first search for dynamic libraries, and then search for static libraries. If I don't care whether I match static or dynamic, I should be able to pick up static libraries if dynamic libs don't exist. If this expected behavior is wrong, then update the dependency documentation to describe the default behavior and rationale for when a dependency static keyword is missing. **system parameters** v 0.54.0, 0.54.1 Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: MAINT: ignore `.hypothesis/` <!-- Please be sure you are following the instructions in the dev guidelines http://www.numpy.org/devdocs/dev/development_workflow.html --> <!-- We'd appreciate it if your commit message is properly formatted http://www.numpy.org/devdocs/dev/development_workflow.html#writing-the-commit-message --> I ran the test using `np.test()`. Then the `.hypothesis` directory was created. This seems to a byproduct of the test. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Wrap target directory not checked No check is performed on the target directory for `wrap` files. Necessary `subdir()` checks are applied too late in process. Initial clone can lead to `out-of-tree` directory creation in arbitrary location. Large amounts of data may be downloaded to unusable location. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Restore level 1 layout/routing default to `SabreSwap` ### What should we add? Part of #9417. Depends on: - #9419 - #9421 In #8830 we had to revert optimisation level 1 to use its legacy behaviour of laying out with `DenseLayout` and routing with `StochasticSwap` if the circuit was a control-flow circuit, since the new default `SabreSwap` couldn't handle the control-flow. Once `SabreSwap` supports control-flow, we should remove this switching logic, and swap back to the preferred router. `SabreLayout` should be easier to upgrade to initial support of control-flow (especially since it'll technically already run, it'll just not have good output), if only the Python-space paths are upgraded. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery Python Client v0.28.0: num_rows, schema property of a Table returning None and empty list Hi, I am using the BigQuery Python client v0.28.0 Using the bigquery client to list all tables in a dataset using method `list_dataset_tables`, I get an iterator of table references in the dataset. When I try to access the `num_rows` and `schema` properties of the Table object it returns `None` and `[]`. But when I access the table using `client.get_table()` I am able to access both the num_rows and schema properties. I am confused since both the methods return a `google.cloud.bigquery.table.Table` object but are inconsistent. ``` for table in bqclient.list_dataset_tables(dataset_ref): print(table.num_rows) print(table.schema) ``` Returns None and [] ``` table = bqclient.get_table(table) print(table.num_rows) print(table.schema) ``` Returns the number of rows and list of schemaFields Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: some tokenizer(s) don't save the updated attributes ### System Info transformers version: 4.25.0.dev0 Torch version: 1.13.0+cpu Cuda available: False Cuda version: None CuDNN version: None Number of GPUs available: 0 ### Description For `GPT2Tokenizer(Fast)`, Set `tokenizer.model_max_length` to `128` (originally `1024`), save it then reload, will give `tokenizer.model_max_length` being `1024`. ### Reproduction ```python from transformers import GPT2Tokenizer, GPT2TokenizerFast tokenizer = GPT2TokenizerFast.from_pretrained(\"gpt2\") print(tokenizer.model_max_length) tokenizer.model_max_length = 128 print(tokenizer.model_max_length) tokenizer.save_pretrained(\"my-gpt2\") tokenizer_loaded = GPT2TokenizerFast.from_pretrained(\"my-gpt2\") print(tokenizer_loaded.model_max_length) ``` The output is ```bash 1024 128 1024 ``` ### Expected behavior `tokenizer_loaded.model_max_length` should be `128` in the above example. In general, the updated attribute(s) should be saved. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add KubernetesJobTask Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add API to selective refer to outputs of custom and build targets Continuation of #891 and #1178 where we discussed how best to allow people to selectively use a single output of a `custom_target`/`build_target` in another target. We will be able to selectively install targets once #1469 is merged, so this is all that's left. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: premake generator output 'conanbuildinfo.lua' consider rename `.lua` is not an extension unique to premake, but instead a lua script file. I am currently working on a generator for another build system which uses `.lua` files, and the problem is obvious. I suggest `conanbuildinfo.premake.lua`. That's the convention I'll be using for the new generator. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: regression with string escaping/formatting and cc.run() #3169 seems to have caused a regression with the GLib meson build, which does the following thing (simplified): ``` templ = ''' #include<stdio.h> int main(int argc, char **argv) { printf(\"%d\\n\", (int)@0@); return 0; }''' value_FOO = cc.run(templ.format('FOO'), name : 'FOO value').stdout().strip() ``` Let's ignore for now that this is not cross-compile friendly and should be using `cc.compute_int()` or such instead. Since the above commit 36aab0f4b2a05a1ae4c8603e57b4c3c684fe8ea8 this now fails with `Checking if \"POLLIN value\" runs: DID NOT COMPILE` The reason this fails to compile is because the code to be compiled is now (excerpt from log file): ``` Code: #include<stdio.h> int main(int argc, char **argv) { printf(\"%d \", (int)FOO); return 0; } Compiler stdout: Compiler stderr: /tmp/tmpguawnoj0/testfile.c: In function ‘main’: /tmp/tmpguawnoj0/testfile.c:5:10: warning: missing terminating \" character printf(\"%d ``` As you can see, the `\\n` in the multi-line string has been turned into an actual newline here. Before the commit, the code would have a backslash and an `n` character there instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan create in python API doesn't keep curdir With dev-conan version. If you run `api.create(...)` the `curdir` is changed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Missing tweedledum as required package <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.17.0 - **Python version**: 3.8.8 - **Operating system**: linux ### What is the current behavior? `qiskit.circuit.classicalfunction.BooleanExpression` fails with message that the `tweedledum` library is required. However, `tweedledum` is not listed a requirement for the `qiskit-terra` package. ### Steps to reproduce the problem Use API's that instantiate the `BooleanExpression` class. E.g. ``` from qiskit.circuit.library import PhaseOracle oracle = PhaseOracle('x & ~y') ``` Leads to error: ``` Traceback (most recent call last): File \"<ipython-input-97-28069418327a>\", line 3, in <module> oracle = PhaseOracle('x & ~y') # previous API: qiskit.aqua.components.oracles.LogicalExpressionOracle File \"/opt/conda/lib/python3.8/site-packages/qiskit/circuit/library/phase_oracle.py\", line 55, in __init__ expression = BooleanExpression(expression) File \"/opt/conda/lib/python3.8/site-packages/qiskit/circuit/classicalfunction/boolean_expression.py\", line 39, in __init__ raise MissingOptionalLibraryError( MissingOptionalLibraryError: \"The 'tweedledum' library is required to use 'BooleanExpression compiler'. You can install it with 'pip install tweedledum'.\" ``` ### What is the expected behavior? No error about missing library should happen. ### Suggested solutions Add `tweedledum` to `./requirements.txt`. Related to #5853 and #5830 where `tweedledum` is present in `./requirements-dev.txt`, but not added to `./requirements.txt` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: MPL drawer gates overlap if plot_barriers=False <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? There is a `cswap` gate under the column of Hadamards <img width=\"553\" alt=\"Screen Shot 2019-08-08 at 9 20 49 PM\" src=\"https://user-images.githubusercontent.com/1249193/62747443-6f45a380-ba22-11e9-996f-34f4acf186df.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add Working Directory # Enhancement When working with multiple projects, it would be really useful to have a --working-directory=\"/path/to/docker/compose/file\". Fix TopLevelCommand constructor to make use of all args Fixes #4855 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: recfromtext bytes delimiter I had existing code that uses BytesIO and a byte delimiter. It worked in <=1.13 and breaks after. The code works if the delimiter is switched to a string. All tests were performed with Python 3.6.5 from Anaconda. The failure can be reproduced using the excerpt below. Fails using 1.14.0, 1.14.1, and 1.14.2 ``` python -c \"import numpy as np; import io; print(np.version.version); data = np.recfromtxt(io.BytesIO(b'SPC:MW\\nNO:30\\nNO2:36'), delimiter=b':', dtype = ['S3', 'f4']); print(data)\" 1.14.2 Traceback (most recent call last): File \"<string>\", line 1, in <module> File \"/work/ROMO/anaconda3/envs/testnp113/lib/python3.6/site-packages/numpy/lib/npyio.py\", line 2230, in recfromtxt output = genfromtxt(fname, **kwargs) File \"/work/ROMO/anaconda3/envs/testnp113/lib/python3.6/site-packages/numpy/lib/npyio.py\", line 2116, in genfromtxt rows = np.array(data, dtype=[('', _) for _ in dtype_flat]) ValueError: could not assign tuple of length 1 to structure with 2 fields. ``` Passes with 1.13.3 ``` python -c \"import numpy as np; import io; print(np.version.version); data = np.recfromtxt(io.BytesIO(b'SPC:MW\\nNO:30\\nNO2:36'), delimiter=b':', dtype = ['S3', 'f4']); print(data)\" 1.13.3 [(b'SPC', nan) (b'NO', 30.) (b'NO2', 36.)] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: 'Table.insert_data()' fails when schema is not loaded I tried to insert data using the google cloud python client but seem to get rows where every field has a null value. I used the [code in the latest documentation](https://googlecloudplatform.github.io/google-cloud-python/stable/bigquery-usage.html). Using Debian 7.11 with Python 2.7.3 and google-cloud-python 0.20. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add target property to build Compose should support specifying target stage in the build definition. https://github.com/moby/moby/pull/32496 @dnephin Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Supporting mirrors in tools.get It would be handy if `tools.get()` could support mirrors to have fallback locations to try to download a file from if the first one fails. ### Problem My main use case for such a feature is currently linked to conan-center-index: the way to retrieve the sources today is to put link to the compressed sources in `conandata.yml`, and the `source()` method of the corresponding recipe generally consumes the data from the file as follows: ```cpp tools.get(**self.conan_data[\"sources\"][self.version]) ``` However today I need to build `sqlite3` with a specific configuration, but www.sqlite.org is down, which means that Conan fails to retrieve the sources and my whole build is kind of blocked. If `tools.get` supported mirrors it would be possible to add a list of mirrors to the `conandata.yml` to have other locations to retrieve the sources from when the first one fails. ### Solution While it would be possible to have `tools.get()` accept a list of URLs in `filename`, I believe that it might get users confused and think that it can retrieve a list of files from the given URLs, so it would probably more sensible to add a `mirrors` parameter accepting a list of URLs. Since YAML accept lists it means that a full list of mirrors could be forwarded directly from the `conandata.yml` file too. If `tools.get()` gets a `mirrors=` parameter, then it makes sense to mirror the feature and add it to `tools.download()` too. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Include a copy method for QuantumCircuit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? This code is often repeated a lot: ``` import copy qc_copy = copy.deepcopy(qc) ``` It would be nice if there was a `copy()` method for `QuantumCircuit` that did this for you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson can't find dependency via cmake Digging through the log files, I found out cmake failed with: ``` CMake Error at /usr/share/cmake-3.14/Modules/CheckIncludeFile.cmake:93 (try_compile): Unknown extension \".c\" for file [snip]/meson-private/cmake_prometheus-cpp/CMakeFiles/CMakeTmp/CheckIncludeFile.c try_compile() works only for enabled languages. Currently these are: C CXX See project() command to enable other languages. ``` Which is a really absurd error. Going into the mentioned directory then run cmake manually works. meson version is 0.51.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: numpy fft not yet implemented As a fairly fundamental operation I was surprised to find out this wasn't implemented. NotImplementedError: Numpy function <function fft at 0x7fdb56275510> not yet implemented In the short term is there a suggested workaround? I suppose I could use a full dft matrix. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Measures conditioned on register containing the target bit generate an invalid DAG When attempting to condition a `measure` on the register containing the target bit: ``` >>> qc = qk.QuantumCircuit(1,1) >>> qc.measure(0,0).c_if(qc.cregs[0],0) >>> qc.depth() 1 >>> qk.converters.circuit_to_dag(qc).depth() Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/dagcircuit/dagcircuit.py\", line 574, in depth raise DAGCircuitError(\"not a DAG\") qiskit.dagcircuit.exceptions.DAGCircuitError: 'not a DAG' ```  The drawer also has difficulty with them: ``` >>> qc = qk.QuantumCircuit(1,1) >>> qc.measure(0,0).c_if(qc.cregs[0],0) >>> print(qc) q_0: |0> c_0: 0 >>> qc = qk.QuantumCircuit(2,1) >>> qc.h([0,1]) >>> qc.measure(0,0) >>> qc.measure(1,0).c_if(qc.cregs[0], 0) >>> print(qc) ┌───┐┌─┐ q_0: |0>┤ H ├┤M├ ├───┤└╥┘ q_1: |0>┤ H ├─╫─ └───┘ ║ c_0: 0 ══════╩═ ``` Conditioning a `measure` on a separate register seems to work okay ``` >>> qr = qk.QuantumRegister(2) >>> cr1 = qk.ClassicalRegister(1) >>> cr2 = qk.ClassicalRegister(1) >>> qc = qk.QuantumCircuit(qr, cr1, cr2) >>> qc.h(qr) >>> qc.measure(qr[0], cr1[0]) >>> qc.measure(qr[1], cr2[0]).c_if(cr1, 0) >>> qc.depth() 3 >>> qk.converters.circuit_to_dag(qc).depth() 3 >>> print(qc) ┌───┐┌─┐ q3_0: |0>┤ H ├┤M├─────── ├───┤└╥┘ ┌─┐ q3_1: |0>┤ H ├─╫───┤M├── └───┘ ║ ┌─┴┴┴─┐ c2_0: 0 ══════╩═╡ = 0 ╞ └──║──┘ c3_0: 0 ═══════════╩═══ ```  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Allow PyYAML >= 5 The PyYAML team recently released version 5.1 of their lib to properly fix CVE-2017-18342 vulnerability. It would be great to add support for this version in docker-compose. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Add SLM metrics ### What does this PR do? <!-- A brief description of the change being made with this pull request. --> Add metrics about snapshot lifecycle management, available since 7.4.0 ### Motivation <!-- What inspired you to submit this pull request? --> Resolve #8178 ### Additional Notes <!-- Anything else we should know when reviewing? --> ``` elasticsearch.slm.snapshot_deletion_failures elasticsearch.slm.snapshots_deleted elasticsearch.slm.snapshots_failed elasticsearch.slm.snapshots_taken ``` ### Review checklist (to be filled by reviewers) - [ ] Feature or bugfix MUST have appropriate tests (unit, integration, e2e) - [ ] PR title must be written as a CHANGELOG entry [(see why)](https://github.com/DataDog/integrations-core/blob/master/CONTRIBUTING.md#pull-request-title) - [ ] Files changes must correspond to the primary purpose of the PR as described in the title (small unrelated changes should have their own PR) - [ ] PR must have `changelog/` and `integration/` labels attached Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPythonLexer test failure with pygments 2.1 Jenkins is showing us a test failure on Windows: https://jenkins.jupyter.org/job/windows-multi/_pyversion=3.5,label=windows/504/testReport/ It looks like `$HOME` is unexpectedly being split into two tokens. I suspect it's failing since pygments 2.1 was released. I see the same locally on Linux, but it's not failing on Travis (maybe we're not installing pygments so those tests are skipped?). @abalkin and @chebee7i have done the most signficant work on the lexer machinery. Any ideas? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Improve coverage of the documentation Currently, some public classes are not documented anywhere because we didn't create the corresponding doc pages. Those missing pages are: - Benchmark classes - Bert Japanese - Data collators If someone feels like working on one of those, please tag yourself with a comment on this issue. Once the objects are properly documented, they can be removed from the `SHOULD_BE_DOCUMENTED` constant in [this file](https://github.com/huggingface/transformers/blob/1310e1a758edc8e89ec363db76863c771fbeb1de/utils/check_repo.py#L374). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Schedules should support parameters <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Pulse schedules should support parameters that allow parameterization of the schedule outside of timing. This would allow `schedule` to consume the `Parameter`s of a `QuantumCircuit` and produce a `Schedule` containing these `Parameter`s which could later be fixed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Draw schedules with parameters <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Drawing `Schedule`s which utilize `Parameter`s raises an error. ### Steps to reproduce the problem ``` sched += Play(Gaussian(duration=128, sigma=10, amp=Parameter('amp')), DriveChannel(qubit)) sched.draw() ``` ### What is the expected behavior? Nice output, such as would be shown for quantum circuits with parameters. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Docs: is np.dtype.descr compatible with constructing a dtype? The [reference docs for dtype.descr](https://docs.scipy.org/doc/numpy/reference/generated/numpy.dtype.descr.html#numpy.dtype.descr) say: > Warning: This attribute exists specifically for `__array_interface__`, and is not a datatype description compatible with np.dtype. However, the [docs on constructing dtypes](https://docs.scipy.org/doc/numpy/reference/arrays.dtypes.html#specifying-and-constructing-data-types) describe `np.dtype()` accepting a list of 2- or 3-tuples, and explicitly say it's as used in `__array_interface__`. > `(field_name, field_dtype, field_shape), ...]` > > obj should be a list of fields where each field is described by a tuple of length 2 or 3. (Equivalent to the descr item in the `__array_interface__` attribute.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: regression: nuisance warning for g++ clang++ the solution is probably similar to #6050 #6053 as this problem was also introduced in b1b8a7a and symptom is almost identical, but for g++ instead of gfortran. A distinct symptom from #6050 is that I do see this on g++ 9.2.0 MSYS2 on Windows, but I don't see this on Ubuntu 18.04 g++ 7.4.0. Also, with clang++ 9.0.0 on Windows I get ``` WARNING: No include directory found parsing \"clang++ -xc++ -E -v -\" output ``` on any trivial Meson C++ project, meson.build ```meson project('blah', 'cpp') executable('foo', 'foo.cxx') ``` foo.cxx ```c++ int main(void) { return 0; } ``` on ```sh meson setup build ``` a lot of nuisance warnings are printed like: ``` WARNING: No include directory found parsing \"c++ -xc++ -E -v -\" output ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub: add ack_id property accessor to subscriber Message class Version: google-cloud-pubsub 0.35.4 This is a feature request to add a property accessor for ack_id in `google.cloud.pubsub_v1.subscriber.message.Message`. Currently the `_ack_id` field is 'private', and only gets used via the `ack()` method (plus other related methods). We find it useful to log the ack ID so that we can manually ack the ID using the Google Cloud SDK (`gcloud` command line interface). This helps us get out of situations where the message is stuck in a (virtually) infinite retry loop because of some error. We can just access the 'private' field, but it doesn't seem very nice to have to do that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Error on empty c.Session.key Adding `c.Session.key = ''` to the default (i.e. empty except for `c = get_config()`) `ipython_config.py` results in the following error when starting `ipython console`: ``` [ZMQTerminalIPythonApp] CRITICAL | Bad config encountered during initialization: [ZMQTerminalIPythonApp] CRITICAL | The 'key' trait of a Session instance must be a string, but a value of '' <class 'str'> was specified. ``` I [originally](https://github.com/gibiansky/IHaskell/issues/15) opened this issue on IHaskell, but it seems to be a problem with IPython itself. Some more info: ``` {'codename': 'Work in Progress', 'commit_hash': b'6fcfc4d', 'commit_source': 'repository', 'default_encoding': 'UTF-8', 'ipython_path': '/home/koomi/ipython/IPython', 'ipython_version': '2.0.0-dev', 'os_name': 'posix', 'platform': 'Linux-3.11.5-1-ARCH-x86_64-with-arch', 'sys_executable': '/usr/bin/python', 'sys_platform': 'linux', 'sys_version': '3.3.2 (default, Sep 6 2013, 09:30:10) \\n[GCC 4.8.1 20130725 (prerelease)]'} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: high-level documentation for __array_function__ missing This was noted in the tracking issue (gh-12028) but didn't have its own issue. I wanted to refer to these docs today and found them missing. Documentation is needed in two places: - [x] https://www.numpy.org/devdocs/reference/arrays.classes.html#special-attributes-and-methods - [x] https://www.numpy.org/devdocs/user/basics.subclassing.html A bigger-picture issue is that the subclassing doc nor other docs really discuss the issues with subclassing, and when it would be more appropriate to implement a duck array instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: MultiBerts in Huggingface # 🚀 Feature request It would be nice to have a script/converter of all the [multiberts](https://arxiv.org/pdf/2106.16163.pdf) checkpoints that were released about a month ago. It was [released](https://github.com/google-research/language/tree/master/language/multiberts) by Google, thus using tensorflow, and it would be nice to have it under the huggingface library/hub. <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> ## Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. --> These checkpoints may be useful to study training dynamics and hypotheses over multiple seeds that were used to train the model. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Fix/test pass overrides Fixes #909 I've added a test too, let me know if it's unnecessary. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Non-IPython kernel get passed --profile-dir Which (can) make them crash. - Either document it - remove it and deal with it. Proposal, special key like `{connexion_file}` so that it is not mandatory and not included by default. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: TypeError in bootstrap-tour.min.js Two minor issues: 1. When pressing `cursor left` in edit mode on current master I get: ``` TypeError: c is undefined ...ame+\"_\"+a,this._options.storage.removeItem(b),this._options.afterRemoveState(b))... ``` in `http://127.0.0.1:8889/static/components/bootstrap-tour/build/js/bootstrap-tour.min.js` 1. Also, `bootstrap-tour.min.css` isn't copied during installation (the .js file is). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Gates are not left justified in mpl circuit drawer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? There is always a space on the line between the qubit label and the first gate:  To reduce the width of the figure as much as possible, the gates should be drawn as far left as possible. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: [BUG] Exception on single task in group. ## Checklist ``` // I have included the output of ``celery -A proj report`` in the issue. // (if you are not able to do this, then at least specify the Celery // version affected). // // Doesn't make sense as it client-side issue. ``` - [x] I have verified that the issue exists against the `master` branch of Celery. ## Steps to reproduce On client send a group with single task in it ```python3.6 def fta_add_to_pool(applications_id: List[int]): return group( *[ app.signature('fta_tasks.add_to_pool', args=[application_id]) for application_id in applications_id ] ).apply_async().get() ``` ## Expected behavior I expected group to execute with a single task like there was no group. ## Actual behavior Exception: ``` File \"***/src/celery/celery/canvas.py\", line 976, in apply_async app = self.app File \"***/src/celery/celery/canvas.py\", line 1140, in app app = self.tasks[0].app File \"***/src/celery/celery/utils/functional.py\", line 213, in __getitem__ self.__consumed.append(next(self.__it)) TypeError: 'Signature' object is not an iterator``` ``` ## Comment It should be easy to fix but I'm not sure about celery typing and etc, so I decided to make the issue. https://github.com/celery/celery/blob/39d86e7dbe7f3a0a43e973910be880146de96fb7/celery/canvas.py#L948-L958 We just need to check if this single task is Task and not something else. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Standardize format of locations in warnings and errors for the benefit of IDEs In https://github.com/mesonbuild/meson/pull/2852#issuecomment-354570111, @QuLogic wrote: > We should make these more standard at some point. Something like `<file>:<line>: message`; I think editors know how to parse this sort of thing to go straight to the warning/error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: `jupyterlab extension list` outputs to stderr **Describe the bug** The bash command `jupyterlab extension list` outputs by default to stderr. **To Reproduce** Steps to reproduce the behavior: 1. Go to terminal 2. Type `jupyterlab extension list` 3. Confirm exit code with `echo $?`. This should be `0`, aka a-ok. 4. Type `jupyterlab extension list 1>stdout 2>stderr` 5. Check file content of `stdout` and `stderr`. `stdout` is empty, while `stderr` contains the regular output. **Expected behavior** `jupyterlab extension list` should output to `stdout`, not `stderr`. **Desktop (please complete the following information):** - OS: Ubuntu 18.04 - JupyterLab v.0.35.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Move gcloud.storage.iterator into gcloud's common package We'll need this for Cloud DNS in the ManagedZones.list method (https://developers.google.com/cloud-dns/api/v1beta1/managedZones/list) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Basic access authentification channels broken in 4.1.0 Previously it was possible to have a channel like: https://user:password@myserver.com or even have the user and password saved in `.netrc`. conda 4.1.0 and up ignore the credentials and give a 401 error (causing everything to break for users). ``` $ conda install conda=4.1.0 Using Anaconda Cloud api site https://api.anaconda.org Fetching package metadata ...........Error: HTTPError: 401 Client Error: Unauthorized for url:https://user:password@myserver.com ``` conda=4.1 no longer respects HTTP_PROXY My proxy variables are properly set: ``` $ set https_proxy HTTPS_PROXY=http://myproxy:8080 ``` `conda=4.0.8` successfully picks up my `%HTTPS_PROXY%` and installs `conda=4.1`: ``` $ conda install conda=4.1 Fetching package metadata: .......... Solving package specifications: ......... The following packages will be UPDATED: conda: 4.0.8-py27_0 defaults --> 4.1.0-py27_0 defaults ``` now trying to revert back to `conda=4.0`: ``` $ conda install conda=4.0 Fetching package metadata ......... Could not connect to https://repo.continuum.io/pkgs/free/win-64/ Connection error: HTTPSConnectionPool(host='repo.continuum.io', port=443): Max retries exceeded with url... ``` proxy settings no longer work. Configuring `proxy_servers` in `.condarc` restores connectivity. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Improve validation schema for list_or_dict fields Right now `extra_hosts` and `labels` use \"one of: object or array\", but no validation is done on the contents of the `object`. I think this can be improved by creating a schema for the object that uses `patternProperties`, so that it will fail if someone uses nested objects, or arrays within the object. ``` json { \"type\": \"object\", \"patternProperties\": {\"type\": \"string\"}, } ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: load_qasm example should use the quantumcircuit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Need to update the load_qasm with the new from file qasm load. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: backend_overview() returns deprecation warning <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.11.0 - **Python version**: 3.7 - **Operating system**: macOS 10.14.5 ### What is the current behavior? The following code returns a deprecation warning before listing a backend overview: ``` from qiskit.tools.monitor import backend_overview backend_overview() ``` ``` DeprecationWarning: IBMQ.backends() is being deprecated. Please use IBMQ.get_provider() to retrieve a provider and AccountProvider.backends() to find its backends. DeprecationWarning) ``` ### Steps to reproduce the problem Run `backend_overview()` ### What is the expected behavior? A backend overview with no deprecation warning because I didn't call `IBMQ.backends()` explicitly. The issue arises because `tools/monitor/backend_monitor.py` uses `IBMQ.backends()` in the function `get_unique_backends()` to get all the backends for which to show the overview. ### Suggested solutions Update `tools/monitor/backend_monitor.py` to account for providers. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Core: Make the Retry objects complete \"exactly\" at deadline In the [current implementation](https://github.com/googleapis/google-cloud-python/blob/58946321c7eb4059884eadd2a09cdd6b1d2604b6/api_core/google/api_core/retry.py#L193-L208), the Retry instances only check if the next delay (sleep period) happens before the deadline. If the next sleep period is long compared to the remaining time, the last retry can happen \"long\" after the specified deadline, which can be undesired in certain scenarios. As an API Core user I would like to have an option to mark the deadline as strict, making the Retry object to complete retrying (approximately) at the deadline, not beyond. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Filters should support properties with leading/trailing whitespaces in the name. `.filter('property with space =', 1)` or `.filter(' property with leading and trailing spaces =', 1)` should result in the properties names not losing the trailing/leading whitespaces. More context in https://github.com/GoogleCloudPlatform/gcloud-python/pull/294#discussion_r19435184 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Transpile Performance Regression <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: >=0.14.0 - **Python version**: Any - **Operating system**: Any ### What is the current behavior? https://github.com/Qiskit/qiskit-terra/commit/529a22b6 made some changes to how we reorder bits in stochastic swap and basic swap. These change slow down these passes about [2x slower for basic swap ](https://qiskit.github.io/qiskit/#mapping_passes.PassBenchmarks.time_basic_swap?machine=dedicated-benchmarking-softlayer-baremetal&os=Linux%204.15.0-46-generic&ram=16GB&p-n_qubits=5&p-depth=1024&commits=529a22b6)and [10-30% for stochastic swap](https://qiskit.github.io/qiskit/#mapping_passes.PassBenchmarks.time_stochastic_swap?machine=qiskit-benchmarking&os=Ubuntu%2018.04&ram=16%20GB&p-n_qubits=5&p-depth=1024&commits=529a22b6). You can also see the impact of stochastic swap for transpiles with the preset pass managers (because of stochastic swap) here: https://qiskit.github.io/qiskit/#transpiler_levels.TranspilerLevelBenchmarks.time_quantum_volume_transpile_50_x_20?machine=qiskit-benchmarking&os=Ubuntu%2018.04&ram=16%20GB&p-transpiler%20optimization%20level=1&commits=529a22b6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Support WHERE IN or WHERE ANY clause in DB-API BigQuery DB-API throws the following error when I pass parameters to the Cursor.execute() for WHERE IN or WHERE ANY clause. Any idea if it will be supported? ``` File \"/home/haibin/.local/share/virtualenvs/python-6nCS1ipk/lib/python3.6/site-packages/google/cloud/bigquery/dbapi/cursor.py\", line 159, in execute query_parameters = _helpers.to_query_parameters(parameters) File \"/home/haibin/.local/share/virtualenvs/python-6nCS1ipk/lib/python3.6/site-packages/google/cloud/bigquery/dbapi/_helpers.py\", line 117, in to_query_parameters return to_query_parameters_list(parameters) File \"/home/haibin/.local/share/virtualenvs/python-6nCS1ipk/lib/python3.6/site-packages/google/cloud/bigquery/dbapi/_helpers.py\", line 84, in to_query_parameters_list return [scalar_to_query_parameter(value) for value in parameters] File \"/home/haibin/.local/share/virtualenvs/python-6nCS1ipk/lib/python3.6/site-packages/google/cloud/bigquery/dbapi/_helpers.py\", line 84, in <listcomp> return [scalar_to_query_parameter(value) for value in parameters] File \"/home/haibin/.local/share/virtualenvs/python-6nCS1ipk/lib/python3.6/site-packages/google/cloud/bigquery/dbapi/_helpers.py\", line 69, in scalar_to_query_parameter name, value google.cloud.bigquery.dbapi.exceptions.ProgrammingError: encountered parameter None with value ['Apple.com', 'Coles'] of unexpected type ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda remove doesn't update environments.txt conda 4.4.6 I'm using `conda remove -p (envPath) --all -y`. The folder gets deleted but the environments.txt file is not updated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Example tester not catching errors **Describe the bug** The example tester isn't catching the console errors in the app example, which is missing a required extension. **To Reproduce** Steps to reproduce the behavior: 1. Go to 'examples/app' 2. Run `jlpm build` 3. Run `python main.py` 4. Note the console errors **Expected behavior** Console errors are caught in CI, example app works. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Pass experiment tags to MLFlowLogger **Is your feature request related to a problem? Please describe.** When using MLFlowLogger, I'm unable to easily set experiment tags, like username or run name. **Describe the solution you'd like** Add parameter `tags=None` which is passed to `MLFlowLogger`. Tags will be passed to `create_run` method **Describe alternatives you've considered** Manually hack logger, get experiment from it and set tag there If you don't see any drawbacks, I can make a PR Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: 💫 Raise error if user is running narrow unicode build ## Feature description Because v2.1 includes various changes to the regular expressions used in the tokenizer (including replacing `regex` with `re`), loading a model with a narrow unicode build of Python will fail with `sre_constants.error: bad character range`. See #3421 for details. spaCy should probably check `sys.maxunicode` on import and raise an error if it's `65535`, meaning the user is running a narrow build. (Even aside form spaCy, a narrow unicode build is pretty inconvenient when working with text in Python.) I've already added a section on this to the troubleshooting guide, so we can use text from that for the error message: https://spacy.io/usage#narrow-unicode Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: nbconvert incompatible with Windows? This is just speculation, but the way pathnames are defined in `IPython/nbconvert/exporters/exporter.py` looks like it will cause problems on windows systems. `os.path.join` should be used in favor of hard-coded paths. I don't have a windows machine to test this out on, though. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Allow passing extra arguments to gtkdoc-fixxref Extra arguments are typically used to let `gtkdoc-fixxref` fix the cross referenced symbols in the API reference being built with the symbols exported by installed API references. Having a `fixxref_args` similar to the existing `scan_args` and `html_args` would be enough to cover this use case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Document naming of CircuitInstruction and related classes ### What should we add? I asked @jakelishman why CircuitInstruction is named that way when it is not an Instruction, and why it has an attribute named `operation` which is actually an Instruction. He replied: >it’s because what’s currently called Instruction shouldn’t really be called that, but we can’t change it without breaking everything. So instead, the new interface definition for “something that can be added to QuantumCircuit is called Operation, and the container is CircuitInstruction to avoid the naming clash This should be publicly documented somewhere to mitigate user confusion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: b_sanitize=address requires b_lundef=false? If I don't specify `-Db_lundef=false` at the same time I specify `-Db_sanitize=address` I get linker errors when building shared objects. ``` CC=clang CXX=clang++ meson.py -Db_sanitize=address -Db_lundef=false --buildtype=debugoptimized build-clang-asan ``` This caught me by surprise and took a while to figure out why the linker was failing. Is it reasonable to automatically set `b_lundef` to false if `b_sanitize` is set to address (and possibly others)? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Fix callback signature on trainer.html ## 📚 Documentation According to [callbacks.html][1], `on_train_start` and `on_train_end` receive three arguments, but the callback example on [trainer.html][2] has only one: ``` from pytorch_lightning.callbacks import Callback class PrintCallback(Callback): def on_train_start(self): print(\"Training is started!\") def on_train_end(self): print(f\"Training is done. The logs are: {self.trainer.logs}\") ``` Also, it seems that `logs` doesn't exists anymore. Could you please confirm me? [1]: https://pytorch-lightning.readthedocs.io/en/stable/callbacks.html [2]: https://pytorch-lightning.readthedocs.io/en/stable/trainer.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Tensorboard logger logs to same directory when trial is pruned using hp_search and optuna ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.11.3 - Platform: Linux - Python version: 3.8.8 ### Who can help @sgugger ## Information I am running a hyperparameter search on various models using optuna on a modified GLUE task. Whenever optuna prunes a trial, the following trial is logged into the same logging directory and therefore doesn't show up in Tensorboard. As far as I can tell, the immediate easy fix would be to call the `on_train_end` callback when the trial is to be pruned. This would reset the tensorboard logger and has worked for me in testing. I'm not sure if it has any unwanted side effects, though. I've opened a Pull Request fixing the issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Hard to debug error ERROR: Expecting value: line 1 column 1 (char 0) Hi, first of all i want to congratulate you guys on this great project that is conan. I performed some conan copy to rename the owner of the package on custom packages that some have sources other get the sources from git and so on, they all are different but now i'm getting this anoying error when i try to do a conan install on some packages: ``` ERROR: Expecting value: line 1 column 1 (char 0) ``` The problem is that it is very hard to know what package is creating this error. I kind understand that the problem was that the conan copy does not copy sources or it seems... something like that i can't really explain, but doing the conan create again on the package seems to fix this... (when i find the package with error... but i got many and is hard to find the one in error or ones) It will be nice to add the package name on the error to easily find the package that is creating the problem (many package dependencies create this hard to find package in error) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Flaky test for NLLB-MoE Model ### System Info Environment: Circle CI test_torch image, defined [here](https://github.com/huggingface/transformers/blob/c15f937581048fa28f77794c4f6a257e14d272cb/.circleci/create_circleci_config.py#L211) ### Who can help? @ArthurZucker ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction The test `tests/models/nllb_moe/test_modeling_nllb_moe.py::NllbMoeModelTest::test_decoder_model_past_with_large_inputs` is flaky and occasionally fails. Note: the tolerance on the test is also very low. Error cannot be deterministically reproduced. The test passes when I run it locally. An example of a failed run: https://app.circleci.com/pipelines/github/huggingface/transformers/60931/workflows/4642cd50-8d8c-4a6b-bea9-b077ff7400cf/jobs/747651 This came from this run: https://github.com/huggingface/transformers/runs/12389736536 And this unrelated PR: https://github.com/huggingface/transformers/pull/21855 ### Expected behavior Tests pass on every run. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Display custom gate labels in circuit drawer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In the most recent version of Terra gate objects now support a custom label string (default None). If this string is set it would be good to display this in the circuit drawers. For example: ```python from qiskit import QuantumRegister, QuantumCircuit from qiskit.extensions import XGate, UnitaryGate qr = QuantumRegister(2) circ = QuantumCircuit(qr) circ.append(XGate(), [qr[0]]) circ.append(XGate(label='alt-X'), [qr[0]]) circ.append(UnitaryGate([[1, 0, 0, 0], [0, 0, 1j, 0], [0, 1j, 1, 0], [0, 0, 0, 1]], label=\"iswap\"), [qr[0], qr[1]]) print(circ) ``` currently shows: ``` ┌───┐┌───┐┌──────────┐ q1_0: |0>┤ X ├┤ X ├┤0 ├ └───┘└───┘│ unitary │ q1_1: |0>──────────┤1 ├ └──────────┘ ``` But with this change would ideally show: ``` ┌───┐┌───────┐┌────────┐ q1_0: |0>┤ X ├┤ alt-X ├┤0 ├ └───┘└───────┘│ iswap │ q1_1: |0>──────────────┤1 ├ └────────┘ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Faster Pegasus tokenizer tests Current test_tokenization_pegasus.py takes more than a minute to run because it uses a full size tokenizer [here](https://github.com/huggingface/transformers/blob/master/tests/test_tokenization_pegasus.py#L19) It should use \"fixtures/test_sentencepiece.model\" like `tests/test_tokenization_t5.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add support --device-cgroup-rule option Hello everyone! Almost one year ago `--device-cgroup-rule` was merged into main branch (https://github.com/moby/moby/pull/22563), but I cannot find any support for this option in latest docker-compose. 1. When will this option be added? 2. How can I use it now? Maybe some workaround for it? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: config does not handle unnamed volumes correct I do have several compose files. My goal is to combine them using \"docker-compose config\". The problem is, that docker-compose does not understand its own created file after that. Given a compose file with an unnamed volume ``` yml version: '2' services: test: image: ubuntu volumes: - /config ``` When running 'docker-compose config' Then the unnamed volume will be suffixed with \":rw\" Unnamed volumes are currently not allowed to be suffixed with \":rw\". This causes docker-compose to do not understand it's own format anymore. Error message is like ``` Creating composeconfig_test_1 ERROR: for test b'Invalid volume spec \"rw\": volumeabs: Invalid volume destination path: \\'rw\\' mount path must be absolute.' ERROR: Encountered errors while bringing up the project. ``` Once running docker-compose config again on that file, the volume will be again suffixed with \":rw\". Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [suggestion] Pass command to Runner as a sequence instead of string To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Conan-1.18.1 Conan's `Runner` class (and through it, `ConanFile`'s `run()` method) only support commands passed as strings. This forces users to correctly quote all arguments, which is a [frequent](https://github.com/conan-io/conan/pull/2555) [source](https://github.com/conan-io/conan/pull/1641) [of](https://github.com/conan-io/conan/issues/2185) [bugs](https://github.com/conan-io/conan/pull/2313) because problems only manifest when certain characters occur in option values or path names. What are people's thoughts on adding support for specifying the command as a sequence as an alternative to a string? The underlying Python call `subprocess.Popen()` already supports this, and `os.system()` can be replaced by `subprocess.run()` which does this as well. An `env` parameter will probably need to be added to support setting `DYLD_LIBRARY_PATH` in `ConanFile`'s `run()` method. It is possible to seamlessly support commands as both strings and sequences, so I expect this change to be fully backwards-compatible from the perspective of recipes. In my opinion, it would be a huge improvement to Conan's usability and safety. If there's any interest for this to go ahead, I'm more than willing to provide a PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Changing style in matplotlib circuit_drawer changes the circuit layout <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: current master - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? The output from the Matplotlib circuit drawer changes when the `style` kwarg is modified ### Steps to reproduce the problem `circuit_drawer(circ)` vs `circuit_drawer(circ,style=qx_color_scheme())`: (Here I show only the first pane of the circuit) <img width=\"964\" alt=\"screen shot 2018-09-25 at 5 44 48 am\" src=\"https://user-images.githubusercontent.com/1249193/46006709-298c2080-c086-11e8-9c62-f05c5a91153e.png\"> <img width=\"965\" alt=\"screen shot 2018-09-25 at 5 45 33 am\" src=\"https://user-images.githubusercontent.com/1249193/46006778-4de7fd00-c086-11e8-897d-433f48219b98.png\"> ### What is the expected behavior? I would assume that the style does not change the circuit layout in the figure. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: MAINT: Remove surviving and unused list comprehension from _polybase Lines 320 to 325 of `numpy/polynomial/_polybase.py` contains the following code: ``` # filter out uninteresting coefficients filtered_coeffs = [ (i, c) for i, c in enumerate(self.coef) # if not (c == 0) # handle NaN ] ``` A few things to note: 1) the comment no longer describes what the comprehension does 2) the conditional is commented out 3) resulting list is never used Looks like this is just some leftover code from a prior implementation that has caused no problems, as so has been overlooked. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython notebook not starting on winXP Hi, I am getting the following error when I try to start the Ipython notebook ``` Traceback (most recent call last): File \"C:\\Python26\\lib\\site-packages\\zmq\\eventloop\\ioloop.py\", line 354, in _run_callback callback() File \"C:\\Python26\\lib\\site-packages\\zmq\\eventloop\\stack_context.py\", line 133, in wrapped callback(*args, **kwargs) File \"C:\\Python26\\lib\\site-packages\\tornado-2.2-py2.6.egg\\tornado\\iostream.py\", line 304, in wrapper callback(*args) File \"C:\\Python26\\lib\\site-packages\\tornado-2.2-py2.6.egg\\tornado\\httpserver.py\", line 250, in _on_headers self.request_callback(self._request) File \"C:\\Python26\\lib\\site-packages\\tornado-2.2-py2.6.egg\\tornado\\web.py\", line 1362, in __call__ handler._execute(transforms, *args, **kwargs) TypeError: _execute() keywords must be strings ``` please note that I am using ZMQ version 2.1.7 Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Build API Tests Failing on Windows <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description We are currently skipping the build tests in `jupyterlab/tests/test_build_api.py` on Windows. We should reinstate them and fix the underlying error. <!--Describe the bug clearly and concisely. Include screenshots if possible--> ## Reproduce Uncomment the skipped tests and run CI on Windows. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: `overfit_pct` vs `train_percent_check` etc As far as I can make out, the (only?) purpose of `overfit_pct` is to overwrite the values of `train_percent_check`, `val_percent_check`, and `test_percent_check`. If that is the case, then I think we should - make the names more similar (e.g. `data_percent_check`) - move the positions of the arguments closer together (so that it suggests a relation) - update the docs to reflect that (I found the docs confusing) Also, the default value should not be `0.0` but `None`. Another option would be to drop it completely for the sake of simplification. Not sure. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: bug in dealing with data type at `one_qubit_decompose.py` ### Environment - **Qiskit Terra version**: `{'qiskit-terra': '0.23.0', 'qiskit-aer': '0.11.2', 'qiskit-ignis': '0.7.0', 'qiskit-ibmq-provider': '0.19.2', 'qiskit': '0.40.0', 'qiskit-nature': None, 'qiskit-finance': None, 'qiskit-optimization': None, 'qiskit-machine-learning': None}` - **Python version**: `python3.8` - **Operating system**: linux ### What is happening? I see error message as below: ``` \"/home/labuser/.virtualenvs/controller/lib/python3.8/site-packages/qiskit/quantum_info/synthesis/one_qubit_decompose.py\", line 242, in angles_and_phase return self._params(unitary) File \"/home/labuser/.virtualenvs/controller/lib/python3.8/site-packages/qiskit/quantum_info/synthesis/one_qubit_decompose.py\", line 265, in _params_u1x theta, phi, lam, phase = OneQubitEulerDecomposer._params_zyz(mat) TypeError: argument 'unitary': type mismatch: from=float64, to=complex128 ``` this was with input ``` [[ 0.70710678 0.70710678] [ 0.70710678 -0.70710678]] ``` ### How can we reproduce the issue? ``` from qiskit.quantum_info import OneQubitEulerDecomposer rzsxDecomposer = OneQubitEulerDecomposer('PSX') M=[[ 0.70710678, 0.70710678] , [ 0.70710678, -0.70710678]] (theta, phi, lam, gamma) = rzsxDecomposer.angles_and_phase(M) ``` The error can be resolved by manually casting M to complex; ``` from qiskit.quantum_info import OneQubitEulerDecomposer rzsxDecomposer = OneQubitEulerDecomposer('PSX') M=[[ 0.70710678, 0.70710678] , [ 0.70710678, -0.70710678]] (theta, phi, lam, gamma) = rzsxDecomposer.angles_and_phase(np.array(M).astype(complex)) ``` ### What should happen? flag the data type error ### Any suggestions? add wrapper before pass it to rust so that every variable we are passing is casted to complex Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Incorrect network name showed with --x-networking Started an application using https://github.com/arun-gupta/docker-images/blob/master/wildfly-mysql-javaee7/docker-compose.yml as: ``` console docker-compose --x-networking up -d Creating network \"wildflymysqljavaee7\" with driver \"None\" Creating wildflymysqljavaee7_mywildfly_1 Creating db ``` The message shows network is created with driver \"None\" but listing the network as `docker network ls` shows otherwise: ``` console > docker network ls NETWORK ID NAME DRIVER a3c9994d6134 none null 91537bec6510 host host b1770955e5aa wildflymysqljavaee7 bridge 6fda61934fbe bridge bridge ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [examples/pytorch/image-classification] why does it require `torch>=1.9.0` Why do we have these particular requirements at: https://github.com/huggingface/transformers/blob/b90096fe1424e1927e549b73b5db67341a0d27d0/examples/pytorch/image-classification/requirements.txt#L1-L2 I tested it and it works with pt-1.8.2 just fine. ``` RUN_SLOW=1 pyt examples/pytorch/test_examples.py -k test_run_image_classification ``` Let's not set a higher version requirement than it actually is needed. I propose to remove both entries altogether unless they are actually needed and if so tested with the lowest supported version. It's important in this particular case since HF Deepspeed integration tests are now included in the Deepspeeed CI which runs on pt-1.8 so I can't test HF image models on the Deepspeed side then. Thank you! @nateraw, @LysandreJik Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove MSBasisDecomposer from pass manager construction <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The MSBasisDecomposer pass and `ms_basis_swap` check in https://github.com/Qiskit/qiskit-terra/blob/41cf87c/qiskit/compiler/transpile.py#L290 were introduced as workarounds to support transpiling to devices with other basis gates. This is now supported directly by the transpiler, so these can be removed. The MSBasisDecomposer pass should be deprecated with a note re-directing to the BasisTranslator. `ms_basis_swap` can be removed directly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan install -u traceback When running `conan install -u` while no previous `conan install` was run (so e.g. no conan conanbuildinfo.cmake exists) I get the following traceback:  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Using docker-compose scale prevents --x-smart-recreate from skipping service Sample set-up - dispatcher - worker_a - worker_b ``` docker-compose up -d docker-compose scale worker_b=2 ``` Update code for worker_a, rebuild image (worker_b unaffected) ``` docker-compose up -d --x-smart-recreate > sample_dispatcher_1 is up-to-date > Recreating sample_worker_a_1... > Recreating sample_worker_b_1... > Recreating sample_worker_b_2... ``` Would expect worker_b instances to be left untouched. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Improve PyTorch examples for FP16 To get the full speed-up of FP16 training, every tensor passed through the model should have all its dimensions be a multiple of 8. In the new PyTorch examples, when using dynamic padding, the tensors are padded to the length of the biggest sentence of the batch, but that number is not necessarily a multiple of 8. The examples should be improved to pass along the option `pad_to_multiple_of=8` when `fp16` is True, if using a data collator that applies padding (or replace the `None` passed along to `Trainer` for `data_collator` by a `DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Provide a way to unset environment variables from conan I haven't found any way to unset environment variables in profiles and conan recipes. Tools module has `environment_append`, but it can only add or replace something, not delete. Empty value is not the same as unbound variable, so `environment_append({\"VAR\": \"\"})` does not work in some cases. `environment_append` could accept `None` values in a dictionary and unset the corresponding variables for them. For profiles I have no idea yet. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: retry in config, not in env-vars Changelog: omit Docs: omit Some cleaning and refactors after merging: https://github.com/conan-io/conan/pull/5174/files - Renamed Downloader, Uploader to FileDownloader, FileUploader, so they do not have the same name as the Conan Uploader - The ``retry`` variable is confusing actually is the total number of attempts. I have added +1 to it by default. - Passing ``retry`` and ``retry_wait`` as arguments, not env-vars - Minor pep8 fixes - The ``tools.download()`` still uses the env-vars, because it does not have access to the config An alternative solution that seemed cleaner initially was to add ``retry`` and ``retry_wait`` to ``ConanRequester``. It was way cleaner, but then it lost the possibility to replace ConanRequester by ``requests``, forcing some tests (like the RestApiTest) to wrap ``requests`` with a ``ConanRequester``. Would that be ok @lasote? What would you prefer? @tags: slow Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Wrong option printing regarding default values #3739 added a new feature to print options that are different from the default. However, this seems to never have worked or maybe I'm failing to understand how it is supposed to work. 1) Given a `meson.build` with `project('demo', 'c', default_options : ['b_pch=true'])` and configuring the project prints: `Option b_pch is: true [default: true]` 2) Given a `meson.build` without `default_options`, configuring with either `-Db_pch=false` or `-Db_pch=true` does not print anything. @NickeZ: since you implemented the initial patch, could you maybe chime in and tell me if this is expected behavior? What should actually be printed during configuration? - a) Options that are not the MESON default (either being overwritten by `default_options` or on the command line, or - b) Options that are not the PROJECT default and thus could have only been overwritten on the command line Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add detailed documentation for scheduler \"tuning\" parameters https://github.com/apache/airflow/pull/12139 added some new params to the scheduler -- we have \"cursory\" docs for them in the comments in the config file, but we should have a more details docs in the scheduler.rst page. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Provide a user-agent header for Conan (#3390) - [X] Refer to the issue that supports this Pull Request: Closes #3097 Docs: https://github.com/conan-io/docs/pull/700 This PR generates a user agent string that outputs the Conan client version and the Python version. This will allow us to track data for client version uptake, and data needed for assessing python version deprecation. Example: Conan/1.5.0 (Python 2.7.1) I have not implemented tests yet. I did do manual tests to confirm it achieves the desired result against Bintray, and when requesting a source tarball from places like source forge. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Latex drawer qubit index subscripts only apply to single character <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: Master - **Python version**: Any - **Operating system**: Any ### What is the current behavior? When drawing a circuit with >= 10 bits in a register the subscript is only applied to the first character in the index. For example:  The entire index should be included in the subscript, for example like:  ### Steps to reproduce the problem Visualize a circuit with >=10 bits in a register using the latex output. ### What is the expected behavior? The subscript applies to all characters in the index ### Suggested solutions Fix the bug (it's a one line fix) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: docstring for numpy.finfo.eps is incorrect The [docstring](https://github.com/numpy/numpy/blob/97c35365beda55c6dead8c50df785eb857f843f0/numpy/core/getlimits.py#L33-L36) for `numpy.finfo` currently defines the `eps` attribute as: > The smallest representable positive number such that 1.0 + eps != 1.0. [...] That definition is not correct, at least in the common case of the IEEE 754 binary formats. For example, with the IEEE 754 binary64 format under the usual round-ties-to-even rounding mode, the stated definition gives a value of `2**-53 + 2**-105` (approx. `1.1102230246251568e-16`), which is a little over half of the correct value of `2**-52` (approx `2.220446049250313e-16`). ``` In [36]: eps = 2**-53 + 2**-105 In [37]: eps Out[37]: 1.1102230246251568e-16 In [38]: 1.0 + eps != 1.0 Out[38]: True In [39]: 1.0 + np.nextafter(eps, -np.inf) != 1.0 Out[39]: False In [40]: np.finfo(float).eps Out[40]: 2.2204460492503131e-16 ``` Some possible rewordings: > The smallest positive number such that 1.0 + eps is representable. Or: > The difference between 1.0 and the smallest representable float larger than 1.0. Or it could be defined in terms of `nextafter` as: > The value of `np.nextafter(1.0, np.inf) - 1.0`. For comparison, section 5.2.4.2.2, paragraph 11 of the C99 standard defines the various `*_EPSILON` macros (`DBL_EPSILON`, `FLT_EPSILON`, ...) as: > the difference between 1 and the least value greater than 1 that is representable in the given floating point type, b<sup>1− p</sup> The docstring for `epsneg` is similarly incorrect. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] copy(ignore_case=False) under Windows <!-- Please don't forget to update the issue title. Include all applicable information to help us reproduce your problem. To help us debug your issue please explain: --> ### Environment Details (include every applicable attribute) * Operating System+version: Windows 10 * Conan version: 1.20.4 * Python version: 3.7.1 I would say `copy(ignore_case=False)` methods behavior under Windows is at least inconsistent with docs: > - **ignore_case** (Optional, Defaulted to False): If enabled, it will do a case-insensitive pattern matching. actually files case is effectively ignored regardless `ignore_case` value. That's due to https://github.com/conan-io/conan/blob/e5d142e61e9913b246c034a46d21c2d183ba0d35/conans/client/file_copier.py#L155 `fnmatch.filter` uses `fnmatch.fnmatch` that in turn involves `os.path.normcase()` doing case-insensitive filtering under Windows. What about ```python files_to_copy = [n for n in filenames if fnmatch.fnmatchcase(n, pattern)] ``` and replacing `fnmatch.fnmatch` with `fnmatch.fnmatchcase` everywhere? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Firestore] DocumentReference.path is missing. DocumentReference.path is missing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: plot_error_map fails ### Environment - **Qiskit Terra version**: 0.20 - **Python version**: 3.10 - **Operating system**: ```python backend = provider.backend.ibmq_kolkata plot_error_map(backend) ``` gives ``` ValueError: shape mismatch: objects cannot be broadcast to a single shape ``` ### What is happening? fails for some reason in the measurement bar plots ### How can we reproduce the issue? run above ### What should happen? works ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: to_categorical should go before get_num_classes in metrics/functional/classification.py https://github.com/PyTorchLightning/pytorch-lightning/blob/d18b9ef9d95ffd92591f767808cc497af5bd4e1c/pytorch_lightning/metrics/functional/classification.py#L174-L178 `to_categorical` should go before `get_num_classes`, since `get_num_classes` assumes `pred` has already been turned into categories (it is doing `int(pred.max().detach().item() + 1)`). Warnings are raised now and then with current code, for example: ``` UserWarning: You have set 10 number of classes if different from predicted (xx) and target (10) number of classes ``` If logits are passed in directly for metrics. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %run filename autocompletion \"The kernel heartbeat has been inactive ... \" error It only happens when I run it as an application, with \"Run in terminal\" unchecked. (When I run it in terminal, it does not happen) When I press tab to autocomplete during the input of the argument of the run magic command, for example: In [2]: %run 'work[TAB] ipython-qtconsole hangs for a while, and then gives me the following error: The kernel heartbeat has been inactive for 3.00 seconds. Do you want to restart the kernel? You may first want to check the network connection. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Cleanup extra logic that handle python <=3.3 https://github.com/ipython/ipython/pull/10833 dis most of that but there seem to be some logic still handling python 3.3 https://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/core/extensions.py#L17-L21 https://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/utils/openpy.py#L117-L121 https://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/utils/text.py#L512-L519 (3.4.2+) https://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/core/magics/execution.py#L145-L149 There are possibly other places, this should be relatively easy to fix for a new contributor. Each of these removal can be a separate PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Move ACL-related APIs for buckets/keys to the relevant ACL classes. See https://github.com/GoogleCloudPlatform/gcloud-python/pull/318#discussion_r19682468 and previous notes. Obsoletes #262. Move ACL-related APIs for buckets/keys to the relevant ACL classes. See https://github.com/GoogleCloudPlatform/gcloud-python/pull/318#discussion_r19682468 and previous notes. Obsoletes #262. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Duplicate param 'uid' in CeleryDaemonCommand # Checklist - [ x] I have checked the [issues list](https://github.com/celery/celery/issues?utf8=%E2%9C%93&q=is%3Aissue+label%3A%22Category%3A+Documentation%22+) for similar or identical bug reports. - [x ] I have checked the [pull requests list](https://github.com/celery/celery/pulls?q=is%3Apr+label%3A%22Category%3A+Documentation%22) for existing proposed fixes. - [ x] I have checked the [commit log](https://github.com/celery/celery/commits/master) to find out if the bug was already fixed in the master branch. - [ x] I have included all related issues and possible duplicate issues in this issue (If there are none, check this box anyway). ## Related Issues and Possible Duplicates #### Related Issues - None #### Possible Duplicates - None # Description CeleryDaemonCommand have duplicated CeleryOption for --uid which leads to all docs using it to have duplicated line (beat, multi, worker, etc). # Suggestions Remove the duplicate in CeleryDaemonCommand in celery/celery/bin/base.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Improve help for conan remove <ref_or_pattern> -p Related to #1467, #1314 `conan remove <ref_or_pattern> -p` command is allowed and displayed in the docs but the help does not state this clear ``` $ conan remove -h usage: conan remove [-h] [-b [BUILDS [BUILDS ...]]] [-f] [-l] [-o] [-p [PACKAGES [PACKAGES ...]]] [-q QUERY] [-r REMOTE] [-s] [-t] [pattern_or_reference] Removes packages or binaries matching pattern from local cache or remote. It can also be used to remove temporary source or build folders in the local conan cache. If no remote is specified, the removal will be done by default in the local conan cache. positional arguments: pattern_or_reference Pattern or package recipe reference, e.g., 'boost/*', 'MyPackage/1.2@user/channel' optional arguments: -h, --help show this help message and exit -b [BUILDS [BUILDS ...]], --builds [BUILDS [BUILDS ...]] By default, remove all the build folders or select one, specifying the package ID -f, --force Remove without requesting a confirmation -l, --locks Remove locks -o, --outdated Remove only outdated from recipe packages. This flag can only be used with a reference -p [PACKAGES [PACKAGES ...]], --packages [PACKAGES [PACKAGES ...]] Select package to remove specifying the package ID ``` Conan 1.17 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Merge `fields_schema_vx.json` and `service_schema_vx.json` Currently we split the config schema into two files, one for the \"top level\" configuration and the other for the service definition. We can actually put everything into the same file and still do multi-stage validation. 1. Move `#/definitions/service` into `fields_schema_vx.json` 2. Move `#/definitions/constraints` into `fields_schema_vx.json` (and rename it to service-constraints or something like that) 3. Rename `fields_schema_vx.json` to `config_schema_vx.json`, and remove `service_schema.json` 4. Create a new definition called something like `top-level-config` which contains the top level properties (`services`, `networks`, `volumes`, and `version`) with `type: object`, without any validation of the properties. 5. Move the current root schema properties into a new definitions, one for each type `networks`, `volumes`, `services`. 6. Change the top level schema to be `allOf: ['top-level-config', 'networks', 'volumes', 'services']` In the compose validation code we would never validate the root schema directly. First we validate against the `top-level-config` schema to make sure all the keys exist and are of the right type. Then as we validate each section we use the individual definitions. This allows us to raise an error which contains the name of the item (service name, volume name, etc) without having to guess at where the name is in within the schema. I think this should block #2089 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda confirmation prompt doesn't accept no When running `conda create` or another command and then choosing \"no\" at the prompt where it asks you to proceed, conda still goes ahead and performs the operation. Looks like this might have been introduced by #5203. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: TFBertModel ValueError: Tried to convert 'dims' to a tensor and failed. Error: Cannot convert a partially known TensorShape to a Tensor The code below was fine when transformers 2.1.1 but after I update to transformers 2.2.0 ``` model = TFBertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=5) model.summary() optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0) loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy') model.compile(optimizer=optimizer, loss=loss, metrics=[metric]) model_fit = model.fit(train_input_ids, train_label, batch_size=8, epochs=1, validation_data=(validation_input_ids, validation_label) ) ``` ``` ValueError: Tried to convert 'dims' to a tensor and failed. Error: Cannot convert a partially known TensorShape to a Tensor: (None, 512) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error when number of qubits is of type numpy.int64 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In `qiskit/validation/base.py`, function `check_types`: currently, if `n_qubits` or `memory_slots` are of type `numpy.int64`, then an error is triggered, because type `int` is expected. I find it too strict. Especially considering that if the number of qubits is originated in a `numpy` array, then its default type is `numpy.int64`. Terra can allow additional types, or convert the type internally. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Broadcast messages in Celery 4.0.1 + Django not worked for me ## Checklist - [x] I have included the output of ``celery -A proj report`` in the issue. (if you are not able to do this, then at least specify the Celery version affected). - [x] I have verified that the issue exists against the `master` branch of Celery. ## Steps to reproduce I'm using django 1.8 + Celery 4.0.1 + Kombu 4.0.1 + Redis as broker from kombu.common import Broadcast CELERY_QUEUE_BROADCAST = 'broadcast' CELERY_QUEUES = (Broadcast(queue=CELERY_QUEUE_BROADCAST), ) @task(ignore_result=True, queue=CELERY_QUEUE_BROADCAST) def broadcast_task(): print \"task runned\" started two workers celery -A proj worker -Q broadcast broadcast_task.delay() ## Expected behavior tasks are performed by each worker at same time ## Actual behavior tasks performed by one worker at same time also i placed my question on SO http://stackoverflow.com/questions/41639334/broadcast-messages-in-celery-4-x Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Update slackapiclient / slack_sdk to v3 Hello, Slack has released updates to its library and we can start using it for it. We especially like one change. > slack_sdk has no required dependencies. This means aiohttp is no longer automatically resolved. I've looked through the documentation and it doesn't look like a difficult task, but I think it's still worth testing. More info: https://slack.dev/python-slack-sdk/v3-migration/index.html#from-slackclient-2-x Best regards, Kamil Breguła Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %%time cell magic suppresses cell output The following code does not display the value of `x` when run. ``` %%time x = 10 x = x*2 x ``` Expected output includes the execution time and the value of `x`. Using the `%time` line magic seems to work, even for multi-line code. Additional info: ipython_version: 7.5.0 os_name: nt platform: Windows-10-10.0.17134-SP0 sys_platform': win32 sys_version: 3.7.3 [MSC v.1915 64 bit (AMD64)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Audit our warnings Our warnings should likely be audited to check the following (mostly for deprecation warnings): Warnings messages should try to mention: - Since which version something is deprecated. - Whether it currently has an effect (or not), and in both case by what it could (should?) be replaced. - a `stacklevel` value (except maybe at import time, in order to appear at in the right stackframe) That should be easy for someone to get into the code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: i0 changes the shape `numpy.i0` squeezes the input, as in an example of the document: ``` >>> np.i0([0.]) array(1.0) ``` This is different from `scipy.special`: ``` >>> special.i0([0.]) array([1.]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add a Getting started with Cloud Storage walk-through Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add data_interval_start and data_interval_end columns to DagRun table, and set them when creating DagRuns. Create a single DB Migration for the following: - [ ] Use `DagModel.schedule_interval` to calculate `DagRun.data_interval_start` and `DagRun.data_interval_end`. - [ ] Once`DagRun.data_interval_end` is calculated, use it's value as `DagRun.schedule_date` which will be a \"replacement\" for `DagRun.execution_date` as mentioned in [AIP-39](https://cwiki.apache.org/confluence/display/AIRFLOW/AIP-39+Richer+scheduler_interval#AIP39Richerscheduler_interval-RenameDagRun.execution_datetoschedule_date) (Keep `execution_date` - don't remove it for backwards compatibility.) Update template context to deprecate `execution_date` and add new \"interval\" properties As per the AIP, we want to deprecate some of the current variables in the template context, as well as add some new ones When one of these deprecated variables is accessed we want to issue a DeprecationWarning., Getting this to show up the location of the dag file may be hard, so we make to include the dag_id and task_id in the warning. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add dataloader arg to Trainer.test() ## 🚀 Feature <!-- A clear and concise description of the feature proposal --> It would be nice if you could use a model for inference using: `Trainer.test(model, test_dataloaders=test_loader)` ### Motivation This will match the calling structure for `Trainer.fit()` and allow for `test` to be called on any dataset multiple times <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too --> ### Pitch Here's a use case. After training a model using 5-fold cross-validation, you may want to stack the 5 checkpoints across multiple models, which will require a) out-of-fold (OOF) predictions and b) the 5 test predictions (which will be averaged). It would be cool if a & b could be generated as follows: ```python for f in folds: model1.load_from_checkpoint(f'path/to/model1_fold{f}.ckpt') trainer.test(model1, test_dataloaders=valid_loader) trainer.test(model1, test_dataloaders=test_loader) model2.load_from_checkpoint(f'path/to/model2_fold{f}.ckpt')) trainer.test(model2, test_dataloaders=valid_loader) trainer.test(model2, test_dataloaders=test_loader) ``` <!-- A clear and concise description of what you want to happen. --> ### Alternatives Maybe I'm misunderstanding how `test` works and there is an easier way? Or perhaps the best way to do this is to write an inference function as you would in pure PyTorch? <!-- A clear and concise description of any alternative solutions or features you've considered, if any. --> ### Additional context <!-- Add any other context or screenshots about the feature request here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inefficient 1Q sequences in -O3 ### Information - **Qiskit Terra version**: 0.17 - **Python version**: 3.7 - **Operating system**: macOS Catalina ### What is the current behavior? `synthesis(..., optimization_level=3, translation_method='synthesis')` emits programs with inefficient 1Q subsequences. ### Steps to reproduce the problem Supply any sufficiently complex circuit (e.g., a quantum volume circuit) to the synthesis routine with optimization level turned up. ### What is the expected behavior? Each 1Q subsequence should be efficient, e.g., should apply `sx` no more than twice. ### Suggested solutions The `_unroll` set of passes (`UnitarySynthesis` specifically) is un-doing some of the work of `_opt` (`Optimize1qDecompose` specifically). I think what’s happening is: * `ConsolidateBlocks` produces operation strings like `u q[0] q[1]; v q[1] q[2];`, where `u` and `v` are opaque two-qubit unitaries. * `UnitarySynthesis` subsequently throws single-qubit sequences onto `q[1]` after `u` and before `v`. * No one then merges + resynthesizes that pair of sequences. For an 8x8 quantum volume circuit, this pushes the depth up from ~340 to ~400 — a significant effect. Omitting `_unroll` entirely works fine for QV circuits targeting IBM devices, but the purpose of `_unroll` was to re-nativize any non-native output that `_opt` may have emitted. So long as we're concerned about that, we'll have to install a more delicate fix. For instance, we might run an analysis pass which checks for instructions outside of `basis_gates`, and only apply `_unroll` if any are found — though I'm not sure that this is sufficient logic. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: TypeError: savez() got multiple values for keyword argument 'file' savez consumes the 'file' parameter itself, thus the user can not save an array items named 'file'. This shall probably be documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Improper CMake generator string Currently, the generator string passed to CMake is formatted like this in cmake.py: `\"Visual Studio %s\" % self._settings.compiler.version`, which results in e.g. \"Visual Studio 14\". However, the correct string would be \"Visual Studio 14 2015\". For newer compiler versions, CMake supports the short version due to backward compatibility reasons, but when e.g. trying to use Visual Studio 2008, the generated string \"Visual Studio 9\" results in a CMake error (generator cannot be found), since it only supports the full string there (\"Visual Studio 9 2008\"). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Zero-shot classification pipeline truncation support Transformers 4.10.0 brought [a change](https://github.com/huggingface/transformers/pull/13299/files#diff-c5af53af9b08fb383b49d7a07c1a56c890198b5cd48adc97aeef753fe2e7d60dR91) that modified the default truncation strategy to TruncationStrategy.DO_NOT_TRUNCATE for the ZeroShotClassificationPipeline. That uncovered an issue in that the [ZeroShotClassificationPipeline](https://github.com/huggingface/transformers/blob/master/src/transformers/pipelines/zero_shot_classification.py#L217 ) doesn't appear to pass kwargs to the parent's call method. So even when calling the pipeline with truncation=True, it doesn't allow for truncation. Thank you for the assistance in advance, appreciate all the work you guys do. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Why beat.Schedle _when return this??? ## Steps to reproduce **https://github.com/celery/celery/blob/master/celery/beat.py#L261** ```python return (mktime(as_now.timetuple()) + as_now.microsecond / 1e6 + (adjust(next_time_to_run) or 0)) ``` What about the as_now timezone??? ## Expected behavior like this? ```python return (as_now.timestamp() + (adjust(next_time_to_run) or 0)) ``` But timestamp not support for python2.7? ```python return (mktime(as_now.utctimetuple()) + as_now.microsecond / 1e6 + (adjust(next_time_to_run) or 0)) ``` Or, tell me why wirte like this. This problem is found because of django-celery-beat.TzAwareCrontab not work as well. Beacause this schedule.now() return a time with timezone. ## Actual behavior Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: display_method of objects with custom __getattr__ Some objects such as pymongo collections implement a custom `__getattr__` method that always retursn an object. Then for the IPython display there is https://github.com/ipython/ipython/blob/master/IPython/core/displayhook.py#L245 which will call the `_ipython_display_` attribute returned by `__getattr__` and produce unpredictable behaviour; best case just an error, like: ``` TypeError: 'Collection' object is not callable. If you meant to call the '_ipython_display_' method on a 'Collection' object it is failing because no such method exists. ``` Probably can be considered a bug of pymongo, but may be worth considering to check for existence in `__dict__` rather than getattr. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Mistake in the BART doc & inconsistency between code & doc Version: Most recent in the Github repo. Model: BART. Description: https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/modeling_bart.py#L627 says to look at `modeling_bart._prepare_decoder_inputs` to modify the default behavior of the way `decoder_attention_mask` behaves by default, but there is no `_prepare_decoder_inputs` anywhere in the Huggingface Transformers repository. I guess it's an artifact from a previous version, and that the function is now called `_prepare_decoder_attention_mask`. However, this method doesn't seem to look at the values of the decoder inputs anywhere, so I don't think it does what the doc says, ie mask the pad tokens. Or is this done somewhere else? Thanks. ### Who can help? @patil-suraj ### Expected behavior ```shell Mask pad tokens by default in the decoder. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Minor dependency formatting glitch On Meson 0.47.2 I get Dependency GMock found: YES (prebuilt) On HEAD Meson I get Dependency GMock found: YES , prebuilt due to the system GMock missing a version specifier. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: UnicodeDecodeError - for environment variable with non-ascii character value ``` $ docker-compose --version docker-compose version: 1.3.2 CPython version: 2.7.9 OpenSSL version: OpenSSL 1.0.1e 11 Feb 2013 $ cat docker-compose.yml code: image: busybox $ docker-compose run -e FOO=bär code ls Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.main\", line 32, in main File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.docopt_command\", line 21, in sys_dispatch File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.command\", line 34, in dispatch File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.docopt_command\", line 24, in dispatch File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.command\", line 66, in perform_command File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.main\", line 342, in run File \"/code/build/docker-compose/out00-PYZ.pyz/compose.service\", line 225, in create_container File \"/code/build/docker-compose/out00-PYZ.pyz/compose.container\", line 38, in create File \"/code/build/docker-compose/out00-PYZ.pyz/docker.client\", line 237, in create_container File \"/code/build/docker-compose/out00-PYZ.pyz/docker.utils.utils\", line 528, in create_container_config UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 1: ordinal not in range(128) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: print colorful warnings for Vala warnings and errors The Vala compiler outputs colorful warnings and errors by default (since version 0.27.1) but Meson shows them only in black and white. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Support for custom directory for conan_server Currently conan_server only supports being deployed to a default location - `~/.conan_server/`. My suggestion is to let the user set a custom directory by adding command-line argument that will let the user set where the server config and data will be stored. As far as I see from the code it should be something that is rather easy to do, and I would like to open a PR to add the functionality. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub / Sub clients don't add scopes to passed-in credentials This was reported in https://github.com/GoogleCloudPlatform/google-auth-library-python/issues/225 but I have yet to confirm. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Drop `beta` from all usage of gRPC /cc @nathanielmanistaatgoogle Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Memory error when download very big packages `conan install node/6.1.0@silkedit/stable -s compiler=\"Visual Studio\" -s compiler.version=14` Downloader.download method keeps in memory too much data. ``` DEBUG :uploader_downloader.py[74]: <type 'exceptions.MemoryError'> [2016-09-23 15:15:02,983] DEBUG :uploader_downloader.py[75]: Traceback (most recent call last): File \"c:\\python27\\lib\\site-packages\\conans\\client\\rest\\uploader_downloader.py\", line 62, in download ret.extend(data) MemoryError ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Incorrect value for conanfile_directory when being packaged in the build method The problem is that the conanfile is read just once, the first time it is needed, from the \"export\" folder, and thus, the initial value for `ConanFile._conanfile_directory` is initialized to that value. Afterwards, when it is used in the `build()` method, it is still pointing to the \"export\" folder, not the current \"build\" folder, which has a copy of the \"export\" folder + possibly cloned or retrieved code with `source()` method. This feature is tested, but it passes just by chance, as reading the CMakeLists and code from the export folder also works in the examples, but there are many other cases in which it will fail. It can be possibly fixed by adding a setter and making conan set it to the correct folder when calling `build()`, but I will analyze if there are other possible interactions with this issue. cc/ @skizzay Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: Fix a missing precheck in create cluster component <!-- Reviewable:start --> This change is [<img src=\"https://reviewable.io/review_button.svg\" height=\"34\" align=\"absmiddle\" alt=\"Reviewable\"/>](https://reviewable.io/reviews/kubeflow/pipelines/1028) <!-- Reviewable:end --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: When updating a container definition with links: `ERROR: ... Conflict. The name ... is already in use by container ...` (1.7 regression) **What I do:** ``` docker-compose -f - up -d <<EOF rainbow: image: redis links: - red - green - blue red: image: redis green: image: redis blue: image: redis EOF docker-compose -f - up -d <<EOF rainbow: image: redis links: - red - green - blue red: image: redis green: image: redis blue: image: redis links: - cyan - navy cyan: image: redis navy: image: redis EOF ``` **What I expect:** Container `blue` is updated since in the 2nd version it has links to `cyan` and `navy` **What I see instead:** ``` ERROR: for cyan Conflict. The name \"/composebug_cyan_1\" is already in use by container 7841361683d7af4c53cac8c698a09a79cb16c8c21d83e9705ff3c36ed3dcc26e. You have to remove (or rename) that container to be able to reuse that name. ``` **Extra notes:** ``` $ docker-compose -v docker-compose version 1.7.0rc1, build 1ad8866 ``` This is The Weirdest Thing Ever. If I remove a container (e.g. `red`, `green`, or `navy`) everything works fine. If I rollback to Compose 1.6.2, all works correctly. If I bring up the 2nd stack directly (without going through the 1st stack) all works fine. This is executed on a single Engine, after wiping out all containers; running 1.11-rc3. I initially had the problem on a much bigger Compose file so I reduced it to the smallest thing that would still crash. To make it easy to tweak/test/etc, get this gist: https://gist.github.com/jpetazzo/6902757218d61ad7e2f4bc07ff40053c I'm stumped. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: bottom.QuantumCircuit.tensor(top. inplace=True) doubles ancillas on modified bottom ### Environment - **Qiskit Terra version**: 0.19.1 - **Python version**: 3.8.5 - **Operating system**: Win11x64 ### What is happening? Given QuantumCircuits \"bottom\" and \"top\", if \"bottom\" contains ancillas AND if performing bottom.tensor(top, inplace=True) then the modified \"bottom\" QuantumCircuit will have the ancilla entries doubled (with same name, so they are not visible in draw) in bottom.ancillas This does NOT happen if inplace=False ### How can we reproduce the issue? ```python bell = QuantumCircuit(2) bell.h(0) bell.cx(0, 1) c = QuantumCircuit(QuantumRegister(2), ClassicalRegister(2), AncillaRegister(2)) print(c.ancillas) # output: # [AncillaQubit(AncillaRegister(2, 'a8'), 0), # AncillaQubit(AncillaRegister(2, 'a8'), 1)] c.tensor(bell, inplace=True) print(c.ancillas) # output: # [AncillaQubit(AncillaRegister(2, 'a8'), 0), # AncillaQubit(AncillaRegister(2, 'a8'), 1), # AncillaQubit(AncillaRegister(2, 'a8'), 0), # AncillaQubit(AncillaRegister(2, 'a8'), 1)] ``` ### What should happen? Only the relevant ancillas should stay. ### Any suggestions? a related question: QuantumCircuit.qubits shows all qubits, including ancilla. Is that by design? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Improve instructions on pypi https://pypi.python.org/pypi/jupyterlab have minimal instruction > This is a very early pre-alpha developer preview. It is not ready for general usage yet. And there is no link to GitHub repository, it just point to jupyter.org, that does not link to here. I think that improving the readme on PyPI, and/org have a a page that describe what woudl be jupyterlab would be good. I thing that having the http://jupyter.org/jupyterlab/ page is great, though it might be a bit better suited for a branding page that match the jupyter.org theme, and can become just a normal tab, while the current page is a bit developper focused and can be scarry for \"normal\" users. Thoughts on both of these points ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Should the default revision mode be \"hash\"? Maybe it is a better default than the scm, it doesn't depend on external tools, not \"dirty/pristine\" issues... the scm mode with revisions could be the opt-in. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Is this realy a list or a Dict[str, int]? I think the docstring might be wrong because in the model json file it is stored as a dict. https://github.com/huggingface/transformers/blob/9bdce3a4f91c6d53873582b0210e61c92bba8fd3/src/transformers/configuration_utils.py#L117 See here for example: https://s3.amazonaws.com/models.huggingface.co/bert/oliverguhr/german-sentiment-bert/config.json Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Binder dev builds are broken slowing down review process Reviewing JupyterLab PRs slowed down as the Binder environment does not work currently: while the binder badge gets added, the installation no longer boots up, e.g. https://mybinder.org/v2/gh/fcollonval/jupyterlab/fix%2F13972-use-back-runmenu-in-toolbar?urlpath=lab or https://mybinder.org/v2/gh/andrii-i/jupyterlab/closing_tabs_w_kb?urlpath=lab results in: ``` Spawn failed: Server at [...] didn't respond in 30 seconds. ``` On gitter @bollwyvl suggested that this might be related to our `start` file: https://github.com/jupyterlab/jupyterlab/blob/master/binder/start Edit: Community Forum post: https://discourse.jupyter.org/t/how-to-debug-server-at-didnt-respond-in-30-seconds-error/18042 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: vision API manual detection documented but not implemented https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/docs/vision-usage.rst#manual-detection wah? https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/vision/google/cloud/vision/image.py#L88 documentation written by @daspecster https://github.com/GoogleCloudPlatform/google-cloud-python/commit/95a55c145bd2e16e80e34e180682932c8a16199a Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: limit fig log if i create a container with fig and let it run and produce lots and lots of logs, when i execute: ``` fig logs ``` for the first time it can take minutes to print all the logs (this is because I am running some development application in debug mode). I would like to have a feature like with tail, where I can specify the initial amount of lines say for example: ``` fig logs -n 1000 ``` which would print the last 1000 lines of the logs it could be either the last for each container or the total 1000, as long i can avoid the initial print of thousands of logs... that I am not interested in... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Fixed broken links based on location change. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Missing changelog entries ## Description of the issue This seems to be a repeat of #5871 . There's a version 1.23.2 on PyPI but the changelog was last updated for 1.23.0: https://github.com/docker/compose/blob/master/CHANGELOG.md This is not reassuring - both from an upgrade perspective (I want to be sure the new version won't need changes on my codebase) and security (is the new version legitimate?). ## Context information (for bug reports) N/A ## Steps to reproduce the issue 1. See new version on PyPI 2. Not see changelog entry ### Observed result Missing versions in changelog ### Expected result Every version in changelog ### Stacktrace / full error message N/A ## Additional information N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Visualizations with mapping is not represented correctly ## Description Below is a `flow` with `mapping` The results of the `map` are read into another function `munge_dfs` That `edge` is not defined in the visualization when using `flow_state` to visualize-- It is represented as some id. It makes reading the visualization confusing. And even more so with multiple maps in a flow  **However** visualizing the flow without running it outputs the expected visualization  ## Reproduction ``` from prefect import Flow, Parameter, Task, task, unmapped from prefect.tasks.control_flow import ifelse, merge @task def sum_list(num_list): return sum(num_list) @task def add_some_num(x, y): return x + y @task def multiply_num(x): return x*2 @task def handle_value_error(some_param): return some_param with Flow(\"map viz\") as map_viz: input_num = Parameter(\"input_num\", default=5) multiplied_num = multiply_num(input_num) is_ten = multiplied_num.is_equal(10) # Nums to map if input value equals 10 numbers = [1, 2, 3] added_nums = add_some_num.map( x = unmapped(input_num), y = numbers ) final_num = handle_value_error(input_num) ifelse( is_ten, added_nums, final_num ) summed_nums = sum_list(added_nums) final_num = merge(summed_nums, final_num) flow_state = map_viz.run() map_viz.visualize(flow_state=flow_state) ``` ## Environment *Any additional information about your environment* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: \"ZMQError: Interrupted system call\" from RichIPythonWidget I've included a RichIPythonWidget in an Qt application I'm working on. Initially, the IPython kernel starts up and the widget connects and works without problems. However, when the main program calls QFileDialog my RichIPythonWidget throws an error: ''' Exception in thread Thread-1: Traceback (most recent call last): File \"/usr/lib/python2.7/threading.py\", line 551, in __bootstrap_inner self.run() File \"/usr/local/lib/python2.7/dist-packages/IPython/zmq/heartbeat.py\", line 47, in run zmq.device(zmq.FORWARDER, self.socket, self.socket) File \"device.pyx\", line 55, in zmq.core.device.device (zmq/core/device.c:811) ZMQError: Interrupted system call Followed by continuous \"Kernel process is either remote or unspecified. Cannot restart.\" messages. ''' This may be related to #499 I'm using IPython 0.13 and pyzmq 2.2.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: commutative_cancellation removes repeated CX even though one is classically controlled ``` >> qc = qk.QuantumCircuit(3,2) >>> qc.h(0) <qiskit.circuit.instructionset.InstructionSet object at 0x12a19cc18> >>> qc.measure(0,0) <qiskit.circuit.instructionset.InstructionSet object at 0x12a19ccc0> >>> qc.cx(1,2) <qiskit.circuit.instructionset.InstructionSet object at 0x12a19ccf8> >>> qc.cx(1,2).c_if(qc.cregs[0], 0) <qiskit.circuit.instructionset.InstructionSet object at 0x12a19ccc0> >>> qc.measure([1,2],[0,1]) <qiskit.circuit.instructionset.InstructionSet object at 0x12a19ccf8> >>> print(qc) ┌───┐┌─┐ q_0: |0>┤ H ├┤M├───────────── └───┘└╥┘ ┌─┐ q_1: |0>──■───╫────■───┤M├─── ┌─┴─┐ ║ ┌─┴─┐ └╥┘┌─┐ q_2: |0>┤ X ├─╫──┤ X ├──╫─┤M├ └───┘ ║ └─┬─┘ ║ └╥┘ ║ ┌──┴──┐ ║ ║ c_0: 0 ══════╩═╡ ╞═╩══╬═ │ = 0 │ ║ c_1: 0 ════════╡ ╞════╩═ └─────┘ >>> print(qk.transpile(qc, optimization_level=2)) ┌───┐┌─┐ q_0: |0>┤ H ├┤M├─── └───┘└╥┘┌─┐ q_1: |0>──────╫─┤M├ ┌─┐ ║ └╥┘ q_2: |0>─┤M├──╫──╫─ └╥┘ ║ ║ c_0: 0 ══╬═══╩══╩═ ║ c_1: 0 ══╩════════ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Feature-extraction pipeline to return Tensor # 🚀 Feature request Actually, to code of the feature-extraction pipeline `transformers.pipelines.feature-extraction.FeatureExtractionPipeline l.82` return a `super().__call__(*args, **kwargs).tolist()` Which gives a list[float] (or list[list[float]] if list[str] in input) I guess it's to be framework agnostic, but we can specify `framework='pt'` in the pipeline config so I was expecting a `torch.tensor`. Could we add some logic to return tensors ? # Motivation Features will be used as input of other models, so keeping them as tensors (even better on GPU) would be profitable. Thanks in advance for the reply, Have a great day. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Drawing initialize disordered in mpl drawer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.12.0.dev0+6b6170a - **Python version**: 3.6 - **Operating system**: Ubuntu 18.04 ### What is the current behavior? The box of 'initialize' is disordered. It gets outside of the circuit and overlaps with other gates.  ### Steps to reproduce the problem ```from qiskit import * from math import pi, sqrt import numpy as np vec = np.array([sqrt(1/2), 0, 0, sqrt(1/2)]) qc = QuantumCircuit(2) qc.initialize(vec, [0,1]) qc.u3(0.12,pi/2,pi/4,0) qc.draw(output=\"mpl\") ``` ### What is the expected behavior? ### Suggested solutions Circuit marplot lib register and measurement on-top of each other <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? If the circuit goes over two frames the second frame if it is a measurement the register and the value are on top of each other -- see figure.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Update tests to use msvc setting Instead of Visual Studio Not necessary to migrate the whole test suite. Just add or update some tests to have better coverage of the new ``msvc`` compiler. There are already some tests that use it like ``test_locally_build_msvc_toolset()`` or ``test_toolchain_win_vs2017()``. The goal is to check relevant cases, like standard CMake build, and parameterize or add new tests. Only ``conan.tools`` new integrations Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] cmake_find_package_multi generator should not enforce that certain buildtypes are used. ### Environment Details (include every applicable attribute) * Conan version: 1.26.1 ### Steps to reproduce (Include if Applicable) I'm using cmake-conan but i'd assume this is preproduceable with other means too. CMakeLists.txt has: ```cmake set(CMAKE_CONFIGURATION_TYPES \"Debug;RelWithDebInfo\") conan_cmake_run( CONANFILE ${ROOT_CONANFILE} BASIC_SETUP UPDATE CMAKE_TARGETS CONFIGURATION_TYPES \"${CMAKE_CONFIGURATION_TYPES}\" GENERATORS \"cmake_find_package_multi\" ``` ### Logs (Executed commands with output) (Include/Attach if Applicable) ``` -- Conan: Loading conanbuildinfo_multi.cmake CMake Error at build/conanbuildinfo_multi.cmake:3488 (message): No conanbuildinfo_release.cmake, please install the Release conf first Call Stack (most recent call first): cmake/conan.cmake:464 (include) cmake/conan.cmake:507 (conan_load_buildinfo) CMakeLists.txt:27 (conan_cmake_run) ``` ### Afterthoughts For me, it it feels like that FATAL_ERROR messages are not really necessary, conanbuildinfo_$buildtype.cmake files are generated based upon what user provides and if release or debug is not on that list, they shouldnt be enforced to be present. In my usecase, this would actually save a minute from initial cmake run on 1gb network and cache on fast m2 ssd. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %%timeit should use minutes to format running time in long running cells I'm using `%%timeit -r1 -n1` to measure long running cells (30min+). Unfortunately `timeit` will only output seconds and if a cell run takes more than ten minutes it becomes cumbersome to read. It would be nice if `timeit`could gain a 'min' unit... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: cppstd in settings.yml was not updated when upgrading to 1.4 I've just upgraded to Conan 1.4 and `settings.yml.new` has this: cppstd: [None, 98, gnu98, 11, gnu11, 14, gnu14, 17, gnu17] I expected to see `20` and `gnu20` there. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Use of python_requires with enabled short_paths fails In Windows conan fails when a recipe uses `python_requires` and `short_paths = True` at the same time. To reproduce the issue, it's enough to just add `short_paths = True` into the consumer conanfile of the `python_requires` example. Conan will end with ``` ERROR: Error while trying to get recipe sources for pyreq/version@user/channel. No remote defined ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error with RZXCalibrationBuilder circuit being combined with other circuits <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**:0.17.0 - **Python version**:3.9.1 - **Operating system**:macOS Catalina ### What is the current behavior? When combining a regular QuantumCircuit with a calibrated circuit, the calibrated circuit information is lost and the default gate is used instead ### Steps to reproduce the problem from qiskit import IBMQ,QuantumCircuit,schedule,transpile from qiskit.transpiler import PassManager from qiskit.transpiler.passes import TemplateOptimization from qiskit.transpiler.passes.scheduling import RZXCalibrationBuilder, rzx_templates qc = QuantumCircuit(2) qc.rzx(0.1,0,1) pass_ = TemplateOptimization(**rzx_templates(['zz2'])) qc_cal = PassManager(pass_).run(qc) pass_ = RZXCalibrationBuilder(backend) qc_cal = PassManager(pass_).run(qc_cal) qc2 = QuantumCircuit(2) qc2 +=qc_cal print (schedule(transpile(qc,backend),backend).duration) print (schedule(transpile(qc_cal,backend),backend).duration) print (schedule(transpile(qc2,backend),backend).duration) ### What is the expected behavior? The scheduled circuit duration should be the same for all three schedules. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Gate cswap does not behave as expected <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit (Python SDK) version**: 0.5.6 - **Python version**: 3.6.5 - **Operating system**: Docker container based on Ubuntu 18.04, host Fedora 28 (Linux 4.17.4) ### What is the current behavior? The CSWAP gate behaves as a CCX gate ### Steps to reproduce the problem ```python q = QuantumRegister(3, 'q') c = ClassicalRegister(3, 'c') circuit = QuantumCircuit(q, c) circuit.h(q[0]) circuit.x(q[1]) circuit.cswap(q[0], q[1], q[2]) circuit.measure(q, c) job = execute(circuit, 'local_qasm_simulator') print(job.result().get_counts(circuit)) # {'010': 522, '111': 502} ``` ### What is the expected behavior? The output states of that code snippet should be `010` and `101`. ### Suggested solutions The issue seems to be [here](https://github.com/Qiskit/qiskit-terra/blob/909728c61d094eaf33a706d513e9a84a53370a5a/qiskit/extensions/standard/cswap.py#L24). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Subprocess launched in ddp have the wrong cwd when using hydra. <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug Details: https://github.com/PyTorchLightning/pytorch-lightning/pull/2639#issuecomment-663601262. I've talked to @omry about the issue and I will send out a fix soon. ### To Reproduce Please see the comment I posted above. ### Expected behavior The CWD for subprocesses should be the same as that of the parent, and relative paths should work. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: bucket.labels surprisingly returns a deepcopy I expected this to work: ```python bucket = storage_client.get_bucket(bucket_name) bucket.labels['example'] = 'label' bucket.patch() ``` Turns out `bucket.labels` returns a deepcopy, so I have to do this instead: ```python bucket = storage_client.get_bucket(bucket_name) labels = bucket.labels labels['example'] = 'label' bucket.labels = labels bucket.patch() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Post 0.8 deprecations <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? This issue keeps track of the items that have been marked as deprecated in **0.8+**, in order to remove them before 0.9: * [ ] visualization: `iplot_state()` * [x] converters: `circuits_to_qobj()` multiple args * [x] tools.compiler: `compile()` `config` arg * [ ] `qiskit/qiskiterror.py`: remove the file * [x] `tools.qcvv`: remove whole folder * [x] `qiskit.mapper.layout`: remove constructor from dict in favor of list Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add -ks as an alias for --keep-source You already have: `-kb` for `--keep-build` `-if` for `--install-folder` `-sf` for `--source-folder` `-bf` for `--build-folder` `-pf` for `--package-folder` Therefore, out of consistency, you should also have `-ks` for `--keep-source` Running conan 1.2.3 on Ubuntu 14.04. - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Re-generate library using asset/synth.py This PR was created by autosynth. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Improve TwoLocal and RealAmplitudes synthesis when entanglement='full' ### What should we add? When choosing a `TwoLocal` or `RealAmplitude` or `EfficientSU2` gate with `entanglement=full` on n-qubits (for VQE ansatz), then we get a circuit with a CX sub-circuit that contains `n*(n-1)/2` CX gates. However, we can re-write this circuit with only `n-1` CX gates with a linear connectivity (see a code example below). ``` from qiskit.circuit.library import * from qiskit.quantum_info import Operator n = 5 # print (RealAmplitudes(n, reps=1, insert_barriers=True).decompose()) # now note that the CX-subcircuit is in fact the same as this qc below qc = QuantumCircuit(n) for i in range(n): for j in range(i+1, n): qc.cx(i,j) # print (\"qc\", qc) mat = LinearFunction(qc).linear op = Operator(qc) qc1 = QuantumCircuit(n) for i in range(n-1): qc1.cx(n-i-2, n-i-1) # print (\"qc1\", qc1) mat1 = LinearFunction(qc).linear op1 = Operator(qc1) print((mat == mat1).all()) print (op == op1) ``` outputs: ``` True True ``` It will be good to update either `NLocal` or `TwoLocal` to consider this specific enhancement, as it seems that this is used in many applications. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug][triaging] shared_library_package_id() makes conan create call fail with empty error message <!-- Please don't forget to update the issue title. Include all applicable information to help us reproduce your problem. To help us debug your issue please explain: --> ### Environment Details * Operating System+version: macOS Catalina 10.15.4 * Compiler+version: apple-clang 10.0 * Conan version: 1.26.0 (error not exclusive to this version) * Python version: 3.7.7 ### Steps to reproduce The minimal code which displays the problem, along with more details and reproduction steps is uploaded [here](https://github.com/jbatnozic/conan-create-error-demo-2). Basically, the issue is that if you have a chain of dependencies which are by default static, except the top-level one which you want to build as shared, you have to call shared_library_package_id() in its package_id method so that all package IDs are generated properly. However, if any of the upstream dependencies are not available in cache and need to be built locally, package creation fails with an empty error message. ### Logs (Executed commands with output) [conan-log.txt](https://github.com/conan-io/conan/files/4845941/conan-log.txt) <!-- Your log content should be related to the bug description, it can be: - Conan command output - Server output (Artifactory, conan_server) --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add support for timeout parameter for load_image ### Feature request Add a parameter timeout to the `image_utils.py:load_image` function, which would enable setting the timeout for the requests call. This parameter should be plumbed in through all the ways to call that function (so add support for it in all the image related pipelines). Alternatively, you should add a `requests_params` parameter, which should be a dictionary, to enable passing any parameters to requests.get. ### Motivation When using requests, the default timeout is None, which means that the request will wait (hang) until the connection is closed. Some servers for whatever reason don't return anything, but also don't close the connection. It would be useful to be able to set a timeout for these cases. ### Your contribution I can contribute a PR for this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: AIP-56 - FAB AM - User's statistics view Move user's statistics view to FAB Auth manager Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: refactor airflow tests We should always be testing (and probably even expanding our tests) for the airflow compatibility layer. Right now, #246 introduces a new flag for `pytest` which optionally runs the airflow tests (which are very slow, around ~2min). We should: - refactor `AirFlow` to allow for using an already live airflow database - refactor the tests to rely on a single fixed airflow db instead of recreating one with each test - create a separate airflow CI job to run these tests so they don't slow down PRs too much Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Misaligned Tick Labels for state_plot_city ### What is the expected enhancement? At the moment, when plotting a statevector using state_plot_city, the assigned labels on the bottom axes are misaligned with the corresponding ticks. This is particularly apparent on the y-axis and when using a larger number of qubits (see below). ### Proposed Workaround Add horizontal and vertical alignments arguments to the calls of set_ticklabels() in state_plot_city. This aligns the labels on the x- and y-axes. The results are shown in comparison below for 2 and 4 qubits (before: left, after: right).   Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Transformer-XL: Remove unused/unnecessary Parameters # 🚀 Feature request <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> The used configuration parameters `tgt_len` and `ext_len` in the Transformer-XL implementation are not utilized in the source code. I would recommend removing those since the only confuse the users of the model(s). ## Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. --> As already mentioned, the unnecessary parameters are confusing and can be likely removed. The parameter `tgt_len` is determined for the input tensor anyway and `ext_len` was only an experimental feature (see [issue from the original repo](https://github.com/kimiyoung/transformer-xl/issues/9)). ## Your contribution <!-- Is there any way that you could help, e.g. by submitting a PR? Make sure to read the CONTRIBUTING.MD readme: https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md --> I am happy to contribute and open a PR with the requested changes if that's also in your interest? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Minor bug in celery utils time.py file There is a function named remaining in the celery.utils.time.py file. In that function, I think the statement start = start.replace(tzinfo=now.tzinfo) (line 211) has to be replaced with start = start.astimezone(now.tzinfo). I hope the expected working by using the statement (`start = start.replace(tzinfo=now.tzinfo)`) is to change the `start` variable's date and time according to the `now` variable's timezone. But the replace function in the above mentioned statement is just replacing the timezone of the `start` variable without changing the values of its date and time. I thought `astimezone` is the method required for our purpose (which converts the date and time in `start` variable to the given timezone argument). So, I think `start = start.replace(tzinfo=now.tzinfo)` must be changed to `start = start.astimezone(now.tzinfo)`. Please correct me incase I am wrong. Module versions: Python 3.5.2 celery==4.2.1 django-celery-beat==1.4.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: dependency got using find_library is not deduplicated for static library builds Simple test case attached. [Original issue found when porting DPDK project to meson, where we got errors due to too many parameters.] Setup: liba, which depends on libdl, and pthreads. Libb which depends on liba. App which depends on both liba and libb Shared build looks ok, no duplication seen with latest HEAD: ``` $ ninja -v -j1 <snip for brevity> [8/8] ccache cc -o app/app 'app/app@exe/app.c.o' -Wl,--no-undefined -Wl,--as-needed -Wl,--start-group liba/liba.so libb/libb.so -pthread -ldl -Wl,--end-group -ldl '-Wl,-rpath,$ORIGIN/../liba:$ORIGIN/../libb' -Wl,-rpath-link,/home/bruce/temp/meson-test/shared_build/liba:/home/bruce/temp/meson-test/shared_build/libb ``` Static library shows a large amount of duplication for -ldl, but not pthreads, despite both being listed as dependencies in the same places: ``` $ ninja -v -j1 <snip for brevity> [6/6] ccache cc -o app/app 'app/app@exe/app.c.o' -Wl,--no-undefined -Wl,--as-needed -Wl,--start-group liba/liba.a libb/libb.a -pthread -ldl -Wl,--end-group -ldl -ldl -ldl -ldl -ldl ``` [meson-test.zip](https://github.com/mesonbuild/meson/files/1194545/meson-test.zip) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: The value of `more_results` from storage.Connection.run_query should not be thrown away. I'm currently writing a regression test that checks for more items after a fetch with a limit set and this boolean would determine if the next fetch (at the final cursor) contains all the remaining results. As a side note, the Node [regression](https://github.com/GoogleCloudPlatform/gcloud-node/blob/029f3a52e05a3b59bd07f69d7d2032b7a61fe331/regression/datastore.js#L237) needlessly re-queries with a cursor which (should) point to the end of the kind. /cc @silvolu Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: error adding custom instruction to circuit reported by @chunfuchen: ```python from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit qr = QuantumRegister(2) cr = ClassicalRegister(2) qc = QuantumCircuit(qr, cr, name='inst') qc.x(qr[0]) qc.h(qr[1]) qc.measure(qr[0], cr[0]) qc.measure(qr[1], cr[1]) inst = qc.to_instruction() qc = QuantumCircuit(qr, cr, name='inst2') qc.append(inst, qr[:], cr[:]) ``` ``` >> TypeError: unhashable type: 'list' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Split ``QFI`` into ``QFI`` and ``QGT`` ### What should we add? The current QFI implementation doesn't properly reflect that the QFI is purely real, as the code allows to take also imaginary parts of it. Instead we should have a class for the quantum geometric tensor (QGT) that allows to take real, imaginary and real+imaginary parts and build the QFI on it, using `QFI = 4 * Re(QGT)`. In summary: ```python class QGT: def __init__(self, derivative_type=DerivativeType.COMPLEX): ... class LinCombQGT: ... class LinCombQFI: def __init__(self): self.qgt = LinCombQGT(derivative_type=DerivativeType.REAL) def run(self, ...): return 4 * self.qgt.run(...) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: SSH passwordless check with OpenSSH checks for the wrong thing The pattern passed to pexpect is '[Ppassword]:', which looks for any of those letters followed by ':', and not, as the intention seems to be, for 'Password:'. The correct pattern is '[Pp]assword:'. This is at IPython/external/ssh/tunnel.py:100. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Can no longer take powers of matrices with dtype object I am using numpy in python 3.6.5 where the code ``` >>> import numpy as np >>> M = np.matrix([[2,1],[1,1]], dtype=object) >>> M**3 ``` Runs fine in numpy 1.14.x but raises a `TypeError: Object arrays are not currently supported` in numpy 1.15.0. I looked in the 1.15.0 release notes but couldn't see anything about matrix multiplication / powers being depreciated for objects. Is there a way around this? Currently I need to make matrices of python integers in order to be able to support doing large powers without overflow. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Bug in LlamaTokenizer when `return_token_type_ids=True` ### System Info - `transformers` version: 4.29.0.dev0 - Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.31 - Python version: 3.10.10 - Huggingface_hub version: 0.13.4 - Safetensors version: not installed - PyTorch version (GPU?): 2.0.0 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: True - Using distributed or parallel set-up in script?: False ### Who can help? tokenizers: @ArthurZucker ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction When I use LLama's tokenizer and pass `return_token_type_ids=True`, I found that the length of the return value `token_type_ids` is different from `input_ids` and `attention_mask`. ```python In [2]: from transformers import AutoTokenizer In [3]: tok = AutoTokenizer.from_pretrained('/mnt/checkpoint/llama_7B_hf', use_fast=False) In [4]: inputs = 'I LOVE' In [5]: outputs = 'huggingface' In [6]: tok(inputs, outputs, return_token_type_ids=True) Out[6]: {'input_ids': [1, 306, 11247, 12064, 1, 298, 688, 3460, 2161], 'token_type_ids': [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]} In [7]: list(map(len, _.values())) Out[7]: [9, 10, 9] ``` ### Expected behavior ```python In [6]: tok(inputs, outputs, return_token_type_ids=True) Out[6]: {'input_ids': [1, 306, 11247, 12064, 1, 298, 688, 3460, 2161], 'token_type_ids': [0, 0, 0, 0, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]} In [7]: list(map(len, _.values())) Out[7]: [9, 9, 9] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Save notebooks with terminal newline (option) Maybe this feature already exists and I don't know it, in which case please clue me in. It would be nice to save iPython notebooks with a newline before EOF. As whitespace isn't significant in JSON, this should remain valid JSON. If there is some other reason that this shouldn't be standard, could we at least have an option perhaps in ~/.ipython somewhere? Thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Latex circuit drawer fails when barrier is present. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: latest master - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? Using `circuit_drawer` on a circuit with a barrier fails: ```python q = QuantumRegister(2, \"q\") qc = QuantumCircuit(q) qc.cx(q[0],q[1]) qc.barrier(q) circuit_drawer(qc) ``` giving the following log report: ``` <xymatrix ! Undefined control sequence. <recently read> \\barrier ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse schedule children should not be exposed to user <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The pulse schedule method should be hidden from users as this exposes the internal pulse schedule layout which may change in the future. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: creating network with defined ipam subnet is slow Whenever I define a subnet for a network, `docker-compose up` is really slow, and seems to wait for ± 15 seconds on creating the network. example config: ``` networks: default: ipam: config: - subnet: 172.17.0.0/28 ``` It doesn't matter what the network is called, or what the subnet actually is, and it doesn't conflict with anything. If I define multiple networks, creating each network takes about 15 seconds. PoC: https://github.com/ComaVN/docker-compose-network-slow ``` $ docker-compose --version docker-compose version 1.11.2, build dfed245 ``` ``` $ docker version Client: Version: 17.09.0-ce API version: 1.32 Go version: go1.8.3 Git commit: afdb6d4 Built: Tue Sep 26 22:42:18 2017 OS/Arch: linux/amd64 Server: Version: 17.09.0-ce API version: 1.32 (minimum version 1.12) Go version: go1.8.3 Git commit: afdb6d4 Built: Tue Sep 26 22:40:56 2017 OS/Arch: linux/amd64 Experimental: false ``` ``` $ lsb_release -a LSB Version: core-9.20160110ubuntu0.2-amd64:core-9.20160110ubuntu0.2-noarch:security-9.20160110ubuntu0.2-amd64:security-9.20160110ubuntu0.2-noarch Distributor ID: Ubuntu Description: Ubuntu 16.04.3 LTS Release: 16.04 Codename: xenial ``` docker-compose up should not allow -d and --timeout together As mentioned in #5310, --timeout on docker-compose is meant to be used for interactive mode so it doesn't make sense to use in combination with -d. If a user provides both options it should result in an error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: poor parallel performance with many jobs I've done some testing with parallel using the following code (after starting a default cluster with n=4): ``` from IPython.parallel import Client c = Client() import time def f(x): import time import random time.sleep(3 * random.random()) lview = c.load_balanced_view() t = time.time() j = lview.map(f, range(1000)) # Try also 10000 here. print time.time() - t ``` The results aren't encouraging. With 1000 tasks it takes a second to run the code above, and once it is submitted the cpu usage is negligible. However with 10000 tasks, the submission time becomes roughly one minute, but what's worse is that ipcontroller takes ~30% cpu now. As per suggestion by @minrk made at [StackOverflow](http://stackoverflow.com/questions/15669514/ipython-0-13-zmq-errors), I tried setting `c.TaskScheduler.hwm = 0` or 20 in ipcontroller_config.py. This doesn't seem to cause any visible change in submission time, but the cpu usage issue is cured with `hwm=0`. I believe that it is this performance slowdown that becomes a killer once I have a cluster with 200 engines and 4000 jobs in queue (I see ipcontroller take 100% cpu time and barely ever manage to submit jobs). Could it be tracked to the ipcontroller doing O(N_jobs) operations somewhere? PS. I have ipython 0.13.1rc2 from ubuntu 12.10 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: jupyterlab.browser_check broken by jupyter-server 2.0.2 <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue. Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description <!--Describe the bug clearly and concisely. Include screenshots if possible--> https://github.com/jupyter-server/jupyter_server/pull/1133 breaks `jupyterlab.browser_check` as the file to open is no longer written when the server is started with `open_browser = False` We gonna see plenty of CI error similar to https://github.com/jupyterlab/extension-cookiecutter-ts/pull/267/checks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Improve default selection for parallel macOS <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? As a follow up to #5324 we need to improve the default selection for parallel_map on OSX. In that PR we changed it to default to not be enabled for all macOS users, however this was probably a bit too conservative. We should improve the logic to find the problematic OS and Python version combinations and disable it by default on those platforms (and likely warn about it). In other cases we can leave the previous default and enable multiple processes by default. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `NinjaBackend.guess_external_link_dependencies` issues with LDFLAGS on Windows [`NinjaBackend.guess_external_link_dependencies`](https://github.com/mesonbuild/meson/blob/master/mesonbuild/backend/ninjabackend.py#L2384) assumes that `commands` will contain only canonical link args (`-L`, `-l`), but this is not always the case on Windows. In particular, when flags are coming from the environment (say from `LDFLAGS`), they are likely to be platform/compiler-specific (`/LIBPATH:`, `-LIBPATH:`); depending on whether it's `/LIBPATH:` or `-LIBPATH:`, `guess_external_link_dependencies` will either ignore the search path. or mangle it along the lines of `/LIBPATH:IBPATH:C:\\\\.conan\\\\dc6596\\\\1\\\\lib`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Generalize basis gate for Collect2qBlocks and ConsolidateBlocks let's open an issue for removing these hardcoded gates and generalizing them (and also the ones that are hardcoded in level 3 KAK). _Originally posted by @ajavadia in https://github.com/Qiskit/qiskit-terra/pull/4446_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Do not force 128-bit emulation for PCG64 I noticed that we are [forcing 128-bit arithmetic emulation](https://github.com/numpy/numpy/blob/master/numpy/random/setup.py#L61) even when it could be supported. I assume this was a temporary measure, but `pcg64.h` appears to not be written correctly without emulation for some reason. @bashtage @mattip Can you clarify? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Experiment versions should start with 000 for easier listing Instead of ```/dir/version_9``` it should be ```/dir/version_0009``` Suggested by @adefazio Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Batch being moved to gpu repeatedly with multiple optimizers and single gpu training If you have multiple optimizers, then transfer_batch_to_gpu winds up getting called once per opt_idx, and the batch is copied each time via copy.copy(batch) in training_forward. Why copy the batch when there is only a single gpu? By removing the copy.copy() my GAN model moves from 8.53it/s to 9.25it/s. Pretty significant speedup. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: ModelCheckpoint with custom filepath don't support training on multiple nodes ## 🐛 Bug When training on multiple nodes using `ModelCheckpoint` with custom `filepath`, it will raise `FileExistsError` caused by the following line of code: [model_checkpoint.py#L127](https://github.com/PyTorchLightning/pytorch-lightning/blob/97e6f35b34437c89d422bd440dca4a8d2c4d5a9f/pytorch_lightning/callbacks/model_checkpoint.py#L127). Maybe a try-except block is needed? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Jupyter Notebook: Stretched Bloch and Q-Spheres <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 14.2 - **Matplotlib version**: 3.3.0 - **Python version**: 3.7.7 - **Operating system**: macOS ### What is the current behavior? 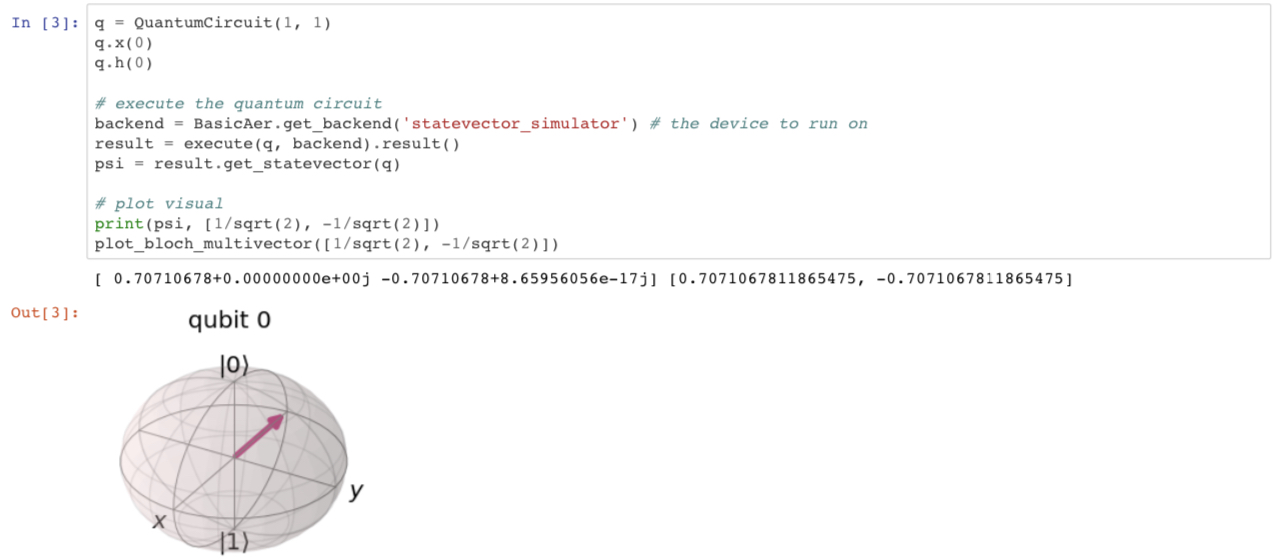 When I create a Bloch or Q-Sphere, the drawing displayed is horizontally stretched. ### Steps to reproduce the problem 1. Open a Jupyter Notebook 2. Type the following into a cell: ``` from numpy import sqrt from qiskit.visualization import plot_bloch_multivector plot_bloch_multivector([1/sqrt(2), 1/sqrt(2)]) ``` 3. Run the cell ### What is the expected behavior? I would expect the spheres to be shaped like spheres instead of ellipsoids. ### Suggested solutions Is it possible the backend (matplotlib?) needs to be updated? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: `trainer.on_gpu == True` for `gpus = 0` or `gpus=[]` **Describe the bug** `trainer.on_gpu == True` for `gpus = 0` or `gpus=[]` because of [this line](https://github.com/williamFalcon/pytorch-lightning/blob/master/pytorch_lightning/trainer/trainer.py#L135). When resuming from a checkpoint, the model is transfered to gpu at [this line](https://github.com/williamFalcon/pytorch-lightning/blob/9785a3e78e6c5b5ff2bde45d36f5e1165dbe16ab/pytorch_lightning/trainer/trainer_io.py#L171), even if `gpus=0` **Expected behavior** `gpus=0` should make training happen on CPU. I can make a PR for that, the fix is pretty simple, I think we can just replace `self.on_gpu = gpus is not None and torch.cuda.is_available()` by `self.on_gpu = True if (gpus and torch.cuda.is_available()) else False` Am I missing something? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Same widget does not update all interact. Cf [Stackoverflow](https://stackoverflow.com/questions/25945543/can-values-from-ipython-widgets-propagate-to-other-cells/25992790#25992790) having the same widget (say a Checkbox) shared by 2 interact, the value of the checkbox is updated across cell, but the interactived' function not call. Ex:  I clicked on first checkbox, second was highligted, but value did not changed from True to False. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: UnicodeDecodeError: 'ascii' codec can't decode byte 0xc5 in position 7: ordinal not in range(128) In `docker-compose.yml` I have something like that: ``` yaml app: environment: VARIABLE: ${VARIABLE} ``` When `VARIABLE` contains characters from Polish alphabet like `ą, ć, ę, ł, ń, ó, ś, ź, ż` it returns error: ``` Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"compose/cli/main.py\", line 56, in main File \"compose/cli/docopt_command.py\", line 23, in sys_dispatch File \"compose/cli/docopt_command.py\", line 26, in dispatch File \"compose/cli/main.py\", line 191, in perform_command File \"compose/cli/main.py\", line 657, in up File \"compose/project.py\", line 318, in up File \"compose/service.py\", line 370, in execute_convergence_plan File \"compose/service.py\", line 410, in recreate_container File \"compose/service.py\", line 258, in create_container File \"compose/service.py\", line 625, in _get_container_create_options File \"compose/service.py\", line 1031, in format_environment File \"compose/service.py\", line 1030, in format_env UnicodeDecodeError: 'ascii' codec can't decode byte 0xc5 in position 7: ordinal not in range(128) docker-compose returned -1 make: *** [run_compose_up] Error 255 ``` Is it possible that more than ASCII will be handled? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: del self.info.options.<option> in package_id() fails In [conan.io docs](http://docs.conan.io/en/latest/reference/conanfile/methods.html?highlight=deploy#self-info) I saw an example: ```python def package_id(self): del self.info.settings.compiler del self.info.options.shared ``` So I expected the following should work: ``` from conans import ConanFile class TestConan(ConanFile): name = \"Test\" version = \"0.0.1\" options = {\"opt\": [True, False]} default_options = \"opt=False\" def package(self): pass def package_info(self): del self.info.options.opt ``` But it does not: ``` conan create . dbely/testing ... Test/0.0.1@dbely/testing: Calling package() Test/0.0.1@dbely/testing: Package '5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9' created ERROR: Traceback (most recent call last): File \"c:\\python36\\lib\\site-packages\\conans\\errors.py\", line 24, in conanfile_exception_formatter yield File \"c:\\python36\\lib\\site-packages\\conans\\client\\installer.py\", line 473, in _call_package_info conanfile.package_info() File \"C:\\Users\\dbely\\.conan\\data\\Test\\0.0.1\\dbely\\testing\\export\\conanfile.py\", line 13, in package_info del self.info.options.opt AttributeError: opt ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Use Github Search repositories instead of getting all repos I noticed that the script uses the [`List organization repositories`](https://docs.github.com/en/rest/repos/repos#list-organization-repositories) endpoint. However, this command asks to recover all the repos (useless data) then to filter. It would be more relevant to use the [`Search repositories`](https://docs.github.com/en/rest/search#search-repositories) endpoint. A simple example would be : https://api.github.com/search/repositories?q=org:googleapis+python%20in:name We can of course improve, what do you think? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: random.logistic returns -inf If I call jax.random.logistic with key array([2308802225, 3876068305], dtype=uint32) and shape=(10000, 12), the sampled array contains -inf. I don't think this behavior is correct or at least it is not expected and causes downstream code that assumes finite floats to crash. I can work around this, but I think it's worth fixing. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: return_tensors and return_text in TextGenerationPipeline don't work or partially work ### System Info - transformers version: 4.24.0 - python version: 3.8.11 ### Who can help? Library: - Text generation: @patrickvonplaten, @Narsil, @gante - Pipelines: @Narsil Documentation: @sgugger, @stevhliu ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction 1. initialize TextGenerationPipeline, assume we call it `pipeline` below 2. run the following code snips: ```python results = pipeline(text_input, return_text=True, return_full_text=False, return_tensors=False)[0] ``` ```python results = pipeline(text_input, return_text=True, return_full_text=False, return_tensors=True)[0] ``` ```python results = pipeline(text_input, return_text=False, return_full_text=False, return_tensors=True)[0] ``` ```python results = pipeline(text_input, return_text=False, return_full_text=False, return_tensors=False)[0] ``` 3. all the four code snips return the same dict with only one key `generated_text` ### Expected behavior 1. when `return_text=True` and `return_tensors=False`, return a dict contains only one key `generated_text` 2. when `return_text=False` and `return_tensors=True`, return a dict contains only one key `generated_token_ids` 3. when `return_text=True` and `return_tensors=True`, return a dict contains both `generated_text` and `generated_token_ids` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: xcode 11's clang not recognized Xcode 11 beta 1 (e.g. on Mac OS 10.15) has changed its spots. The meson.build ``` project('simple', 'objc') ``` fails with ``` meson.build:1:0: ERROR: Unknown compiler(s): ['cc'] ``` in both oldish and latest meson. Fix easy, coming shortly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Replace flask_oauthlib with Authlib **Description** flask_oauthlib has been deprecated in favour of Authlib. It would be good if airflow starts using Authlib **Use case / motivation** FlaskAppBuilder is now using Authlib. Since FlaskAppBuilder is deeply integrated into Airflow, it will be good to also have this Authlib. Flask-oauthlib documentation recommends Authlib **Related Issues** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CMake build helper should prevent CMake from writing to the \"package registry\" To help us debug your issue please explain: - Conan version: 1.4.3 Use case is the following: * Recipe uses the CMake build helper * The `build()` method calls the `cmake.install()` instead of implementing the `package()` method * Somewhere in the CMake build scripts there is a call to `export(PACKAGE)` The call to export package will cause the \"cmake package registry\" to be written with an entry pointing to the current build directory. I've seen a scenario where this affects the results of CMake's `find_package()` even in projects that don't use conan at all, when invoked in the same machine where the conan package was built. It might better for the CMake build helper to define `CMAKE_EXPORT_NO_PACKAGE_REGISTRY` for convenience, which would prevent the local registry from being written at all (https://cmake.org/cmake/help/v3.11/variable/CMAKE_EXPORT_NO_PACKAGE_REGISTRY.html#variable:CMAKE_EXPORT_NO_PACKAGE_REGISTRY). I think it would make sense especially considering that with conan one might trigger builds for different settings/options on the same system, and to prevent package creation from altering the environment in anyway. I could contribute if this suggestion sounds reasonable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Inverted arguments order when calling 'conan install' Hi, while experimenting, I've seen that this fails: `conan install -o boost:shared=True --build missing ..` whereas this succeeds: `conan install -o boost:shared=True .. --build missing` This is unexpected, as the documentation states the very opposite, saying that the path should be last, after all options if any: ``` usage: conan install [-h] [-g GENERATOR] [-if INSTALL_FOLDER] [-m [MANIFESTS]] [-mi [MANIFESTS_INTERACTIVE]] [-v [VERIFY]] [--no-imports] [-u] [-pr PROFILE] [-r REMOTE] [-o OPTIONS] [-s SETTINGS] [-e ENV] [-b [BUILD [BUILD ...]]] path ``` I'm using conan 1.0.4 on Ubuntu 14.04. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: `conda list` doesn't have column headers The `conda list` command outputs 3 columns of data for which there are no column headers. The first appears to be `package name`, the second `version`, the third is possibly `feature+build number`? It would be great to have these headers added and could be done so in the already hash-prefixed lines so as not to upset filters/pipes relying on the package list format. Thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: New OrderedSet does not work with python 3.4 Here's a simple unit test: ``` diff --git a/run_unittests.py b/run_unittests.py index 1d80aac..1251517 100755 --- a/run_unittests.py +++ b/run_unittests.py @@ -24,7 +24,7 @@ from pathlib import PurePath import mesonbuild.compilers import mesonbuild.environment import mesonbuild.mesonlib -from mesonbuild.mesonlib import is_windows, is_osx, is_cygwin +from mesonbuild.mesonlib import is_windows, is_osx, is_cygwin, OrderedSet from mesonbuild.environment import Environment from mesonbuild.dependencies import PkgConfigDependency, ExternalProgram @@ -316,6 +316,10 @@ class InternalTests(unittest.TestCase): cmd = ['@OUTPUT@.out', 'ordinary', 'strings'] self.assertRaises(ME, substfunc, cmd, d) + def test_ordered_set(self): + oset = OrderedSet() + oset.update(['foo']) + class BasePlatformTests(unittest.TestCase): def setUp(self): ``` This fails with: ``` ====================================================================== ERROR: test_ordered_set (__main__.InternalTests) ---------------------------------------------------------------------- Traceback (most recent call last): File \"./run_unittests.py\", line 321, in test_ordered_set oset.update(['foo']) File \"/home/meh/devel/sandbox/meson/mesonbuild/mesonlib.py\", line 703, in update self[item] = True File \"/usr/lib64/python3.4/collections/__init__.py\", line 68, in __setitem__ self.__map[key] = link = Link() AttributeError: 'OrderedSet' object has no attribute '_OrderedDict__map' ``` My python version is 3.4.3. I'm a bit surprised at this OrderedSet implementation, I would suggest using something like: https://github.com/hotdoc/hotdoc/blob/master/hotdoc/utils/utils.py#L188 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Using [conf] block in profiles to skip running tests as part of build() The new [[conf] block](https://blog.conan.io/2021/01/27/New-conan-release-1-33.html) added to profiles in Conan 1.33 seems like a great addition that has been missing so far, so thanks a lot for adding this! I think it might be useful to allow users to skip running tests as part of the build. The official recommendation is to run tests as part of `build()` like this : ```python def build(self): cmake = CMake(self) cmake.configure() cmake.build() cmake.test() ``` Unfortunately, with larger test suites or tests that take long to run, it can get impractical when you just want to quickly perform a rebuild. Since we wanted to have an easy way of building without running tests, we are currently having our unit tests in test_package but this only works when your tests do not depend on any internal headers/APIs (and it also comes with other issues). Now with [conf] available, I'd like to give this a try: ```python def build(self): cmake = CMake(self) cmake.configure() cmake.build() if not self.conf[\"user:skip_tests\"]: cmake.test() ``` What might be a problem though: currently these conf values can only be set as part of a profile and not on the CLI. To be really useful for enabling/disabling tests, there would need to be a way to specify these conf values as parameters to `conan build`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Provide a way to install an empty directory Sometimes you need to create an empty directory (for third-party plugins, fonts, themes,…) as part of the software install. It does not seem currently possible. Maybe allow passing an empty subdir name to install_subdir to do the trick ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: test_order_of_l_arguments fails on Fedora Rawhide ```python ====================================================================== FAIL: test_order_of_l_arguments (__main__.LinuxlikeTests) ---------------------------------------------------------------------- Traceback (most recent call last): File \"run_unittests.py\", line 1772, in test_order_of_l_arguments self.assertLess(previous_index, current_index) AssertionError: 85 not less than 78 Stdout: The Meson build system Version: 0.41.0 Source dir: /builddir/build/BUILD/meson-0.41.0/test cases/unit/9 -L -l order Build dir: /tmp/tmpxs97a85i Build type: native build Project name: jonne Native c compiler: cc (gcc 7.1.1) Build machine cpu family: ppc64le Build machine cpu: ppc64le Found pkg-config: /usr/bin/pkg-config (1.3.7) Native dependency first found: YES 1.0.0 Native dependency second found: YES 1.0.0 Build targets in project: 1 ---------------------------------------------------------------------- Ran 53 tests in 39.639s FAILED (failures=1, skipped=7) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: Missing linspace import breaks concatenation funcs In #12057 the linspace is removed from the imports from `core` however this broke various concatenation code in SciPy. The AxesConcetananenantatotator (it's impossible to type) has a method call specifically for linspace and hence trips up. https://github.com/numpy/numpy/blob/872372bd56ccb5fe98faae8be7d14e4a8c69e037/numpy/lib/index_tricks.py#L349 There are other backwards incompatible changes for `hstack` and `column_stack` which were explicitly accepting generator expressions but now they don't. Xref : scipy/scipy#9405 ### Reproducing code example: The simplest would be ```python >>> import numpy as np >>> np.r_[0:36:100j] ``` ### Error message: ``` Traceback (most recent call last): File \"<ipython-input-62-500dc46d81ee>\", line 1, in <module> np.r_[0:5:10j] File \"c:\\...\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\numpy-1.16.0.dev0+872372b-py3.6-win-amd64.egg\\numpy\\lib\\index_tricks.py\", line 349, in __getitem__ newobj = function_base.linspace(start, stop, num=size) AttributeError: module 'numpy.lib.function_base' has no attribute 'linspace' ``` ### Numpy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> ``` 1.16.0.dev0+872372b 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: custom subdir installation not working I have a package that sets subdir to osx_1012-x86_64 - https://anaconda.org/msarahan/clang_osx-1012-x86_64 If I try to create a dummy environment with this package, I end up with PackageNotFound: ``` CONDA_SUBDIR=osx-1012-x84_64 conda create -n weee clang_osx-1012-x86_64 -c msarahan Fetching package metadata ............. Solving package specifications: PackageNotFoundError: Package missing in current osx-1012-x84_64 channels: - clang_osx-1012-x86_64 ``` I think I'm setting subdir correctly here, but please correct me if I'm not. Tested on current 4.3.x branch and 4.4.x branch. cc @mandeep Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Change default value for 'allow_softlinks' from True to False The `allow_softlinks` configuration parameter can be dangerous. Softlinks into prefixes directly from the package cache will often lead to environment corruption. It was an oversight that the default value for `allow_softlinks` is set to `True`. In conda 4.4, we should definitely change the default value to `False`. We should also consider it even for the next 4.3.x release. Change default value for 'allow_softlinks' from True to False The `allow_softlinks` configuration parameter can be dangerous. Softlinks into prefixes directly from the package cache will often lead to environment corruption. It was an oversight that the default value for `allow_softlinks` is set to `True`. In conda 4.4, we should definitely change the default value to `False`. We should also consider it even for the next 4.3.x release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Remove Python 3.4 support Opening this as an issue for tracking our decision here. - https://github.com/dask/distributed doesn't support Python 3.4, and this powers our main executor - https://devguide.python.org/#branchstatus Python 3.4's official EOL is in a few weeks - additionally, we constantly run into minor syntax errors / things we'd like to do that 3.4 prevents us from doing - our initial impression from our early partners is that this won't affect anyone Official decision: remove support for 3.4. This requires us to: - [ ] remove mentions of support from our documentation, possibly calling out our _lack_ of support - [ ] remove python 3.4 CI job - [ ] remove all pytest skip markers from our tests that concern python 3.4 - [ ] enjoy our new lives Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Timetable registration a la OperatorLinks Currently (as implemented in #17414), timetables are serialised by their classes’ full import path. This works most of the time, but not in some cases, including: * Nested in class or function * Declared directly in a DAG file without a valid import name (e.g. `12345.py`) It’s fundamentally impossible to fix some of the cases (e.g. function-local class declaration) due to how Python works, but by requiring the user to explicitly register the timetable class, we can at least expose that problem so users don’t attempt to do that. However, since the timetable actually would work a lot of times without any additional mechanism, I’m also wondering if we should _require_ registration. 1. Always require registration. A DAG using an unregistered timetable class fails to serialise. 2. Only require registration when the timetable class has wonky import path. “Normal” classes work out of the box without registering, and user sees a serialisation error asking for registration otherwise. 3. Don’t require registration. If a class cannot be correctly serialised, tell the user we can’t do it and the timetable must be declared another way. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: tokenizer of bert-base-uncased gives an incorrect split I found the following code gives an incorrect split `tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')` `text = \"[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]\"` `tokenized_text = tokenizer.tokenize(text)` `print(' '.join(tokenized_text))` > [ cl ##s ] who was jim henson ? [ sep ] jim henson was a puppet ##eer [ sep ] The correct one, based on the Quick tour example, seems to be > [CLS] who was jim henson ? [SEP] jim heson was a puppet ##eer [SEP] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigTable: row_data _validateChunk performance Looking at the performance graph for reading a large number (1000) of rows, each row having 10 cells in one column family, the validation of chunks takes a large percentage of time (>25%), as measured by cProfile. Areas for tuning are identified below. **Validation of timestamp_micros ordering** While a row is being read, a validation is made to make sure that cells for one qualifier are in timestamp_micros order (most recent first): ``` def _validate_chunk_row_in_progress(self, chunk): ... previous = self._previous_cell _raise_if(self._same_as_previous(chunk) and chunk.timestamp_micros <= previous.timestamp_micros) def _same_as_previous(self, chunk): previous = self._previous_cell return (chunk.row_key == previous.row_key and chunk.family_name == previous.family_name and chunk.qualifier == previous.qualifier and chunk.labels == previous.labels) ``` This validation may be extraneous because: 1. A RowFilter may have been applied - CellsColumnLimitFilter(1) - which will limit the result to the cell with the most recent timestamp. 2. There may only be one cell value for the qualifier. 3. The BigTable server may ALWAYS be providing the cells in timestamp order. Two possible tunings: 1. Remove the validation if the condition is unlikely to occur in the ReadRowResponse. 2. If the validation is kept, it could be performed only when qualifier cell lists with length > 1 are detected AFTER the chunks for the qualifier are consumed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: `GCSResultHandler` should be serializable Following the work begun in https://github.com/PrefectHQ/prefect/pull/578, the `GCSResultHandler` should be serializable as well; the only headache in implementing this is that `google.cloud` isn't currently a requirement for Prefect core, so writing this in a way that avoids `ImportError`s will be fun. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Tokenization in quickstart guide fails ## 🐛 Bug <!-- Important information --> The same issue as in #226 re-appears in transformers==2.2.1 (it works on 2.1!) I just encountered the same issue as @dhirajmadan1 with `transformers==2.2.1`. Is this expected somehow? I am following the quickstart guide: https://huggingface.co/transformers/quickstart.html ## To Reproduce Steps to reproduce the behavior: ``` tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') # Run an example text through this: text = \"[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]\" tokenized_text = tokenizer.tokenize(text) masked_index = 8 tokenized_text[masked_index] = '[MASK]' predicted_tokenized_sentence = ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]'] ``` ## Expected behavior This should not fail: ```assert tokenized_text == ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]']``` ## Environment * OS: Mac * Python version: 3.6 * PyTorch version: 1.3.1 * PyTorch Transformers version (or branch): 2.1 (latest-minor) * Using GPU no * Distributed of parallel setup no * Any other relevant information: ## Additional context <!-- Add any other context about the problem here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Utilities to set MSVC environment from conanfiles Not big issue, but something that handles the typical: vcvars = 'call \"%%vs140comntools%%../../VC/vcvarsall.bat\" %s' % param in conanfiles, for different MSVC versions, would be useful Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add support for ThinLTO when using Clang and LLD **Describe the bug** ThinLTO has significant improvements under the \"Full\" LTO path. It scales incredibly well from a memory consumption point of view and gives incremental and threaded linking to a project. ThinLTO has long been stable with other build systems also supporting it now. https://clang.llvm.org/docs/ThinLTO.html **To Reproduce** Easy enough to reproduce, `CC=clang CC_LD=lld meson -Db_lto=true <remaining options>` Meson will only set `-flto` for the compile args in this instance **Expected behavior** I expect meson to check which version of clang and lld is being used, and if it is above a certain version (ThinLTO was supported back with clang 3.9, but probably shouldn't be enabled there) then by default enable the thin lto option with `-flto=thin` Additionally a nice feature might be an option to set LTO flavour. This way people can still build with `-flto=full` for their final releases but keep thin around for their development and regression testing. `-Db_lto_flavor=full, -Db_lto_flavor=thin` **system parameters** * This isn't a cross-building problem * Linux at the very least effected, MacOS might matter as well, unsure if thinlto is supported under Windows * Python version doesn't matter * `git HEAD` for meson, checked the source tree and it isn't supporting thinlto * Ninja doesn't matter here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.51.0 `native: true`/`native: false` mixing warning doesn't account for safe conditional usage When building with meson-0.50.1 a lot of warnings are printed like: ``` WARNING: Target eolian_gen is used as a generator, but is built for the host machine. This means most cross builds will fail. You might want to set `native: true` instead to build it for the build machine. ``` However, all of our executables that are used as generators are guarded like this: ``` eolian_gen_bin = executable('eolian_gen', eolian_gen_src, dependencies: eolian, install: true, c_args : package_c_args, ) eolian_gen_path = eolian_gen_bin.full_path() if meson.is_cross_build() _eolian_gen_bin = find_program('eolian_gen', native : true) eolian_gen_path = _eolian_gen_bin.path() else _eolian_gen_bin = eolian_gen_bin eolian_gen_path = _eolian_gen_bin.full_path() endif eolian_gen = [_eolian_gen_bin, '-S'] ``` I did a cross compile to a unrunnable arch on my laptop to verify we have no problem there. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Unitaries equal to identity are not removed from circuit at optimization_level=3 ### Environment - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is happening? The following circuit is equal to the identity: ```python qr1 = QuantumRegister(3, 'state') qr2 = QuantumRegister(2, 'ancilla') cr = ClassicalRegister(2, 'c') qc2 = QuantumCircuit(qr1, qr2, cr) qc2.h(qr1[0]) qc2.cx(qr1[0], qr1[1]) qc2.cx(qr1[1], qr1[2]) qc2.cx(qr1[1], qr1[2]) qc2.cx(qr1[0], qr1[1]) qc2.h(qr1[0]) ``` At `optimization_level=2` one gets a empty circuit:  At `optimization_level=3` one does not:  What is left is a unitary that is equal to the identity (as it should be) but it is not removed from the circuit data. ### How can we reproduce the issue? Transpile above example ### What should happen? The circuit should be empty like at `optimization_level=2` ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `QuantumCircuit.compose` errors when `qubits` argument is `numpy.int64` instead of `int`. ### Environment - `qiskit-terra: '0.21.0': - `python: '3.9.12'`: - Ubuntu-20.04 windows subsystem for Linux running on Windows 10: - `numpy: 1.21.5` ### What is happening? `QuantumCircuit.compose()` errors when `qubits` argument is a list of `numpy.int64` instead of `int`. ### How can we reproduce the issue? ```python from qiskit import QuantumCircuit from qiskit.converters.circuit_to_dag import circuit_to_dag import numpy as np qc0 = QuantumCircuit(1) qc1 = QuantumCircuit(1) qc0.x(0) qc1.x(0) # First, let's try qubits = [0] (vanilla python `int`) qc_vanilla_int = qc0.compose(qc1, qubits=[0]) # `QuantumCircuit.compose` does not error even when the `qubits` argument is invalid, so we need to check the DAG circuit_to_dag(qc_vanilla_int) # does not error # Now let's try qubits = [np.int64(0)] qc_numpy_int = qc0.compose(qc1, qubits=[np.int64(0)]) #np.arange(0) does the same thing. circuit_to_dag(qc_numpy_int) #this one errors ``` Here is the error: ``` DAGCircuitError: \"(qu)bit 0 not found in OrderedDict([(Qubit(QuantumRegister(1, 'q'), 0), DAGOutNode(wire=Qubit(QuantumRegister(1, 'q'), 0)))])\" ``` ### What should happen? `qc0.compose` should return a `QuantumCircuit` object that can be converted to a DAG. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: `DebertaTokenizer` always assigns token type ID 0 ## Environment info - `transformers` version: 4.16.2 - Platform: Linux-5.15.13-051513-generic-x86_64-with-glibc2.34 - Python version: 3.9.7 - PyTorch version (GPU?): 1.9.0+cu111 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ### Who can help @LysandreJik ## Information Model I am using (Bert, XLNet ...): `microsoft/deberta-large` The problem arises when using: * [ ] the official example scripts: (give details below) * [x] my own modified scripts: (give details below) The tasks I am working on is: * [ ] an official GLUE/SQUaD task: (give the name) * [x] my own task or dataset: (give details below) ## To reproduce Steps to reproduce the behavior: Run this code: ```python from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained(\"microsoft/deberta-large\") print(tokenizer(\"Hello\", \"World\")) ``` It outputs: ``` {'input_ids': [1, 31414, 2, 10988, 2], 'token_type_ids': [0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1]} ``` Even though I put in two sequences, all `token_type_ids` are 0. ## Expected behavior The tokens from the second sequence should get type ID 1. `token_type_ids` should be `[0, 0, 0, 1, 1]`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: UnicodeDecodeError in 4.2 ``` Traceback (most recent call last): File \"/home/ec2-user/miniconda2/lib/python2.7/site-packages/conda/exceptions.py\", line 473, in conda_exception_handler return_value = func(*args, **kwargs) File \"/home/ec2-user/miniconda2/lib/python2.7/site-packages/conda/cli/main.py\", line 144, in _main exit_code = args.func(args, p) File \"/home/ec2-user/miniconda2/lib/python2.7/site-packages/conda/cli/main_install.py\", line 80, in execute install(args, parser, 'install') File \"/home/ec2-user/miniconda2/lib/python2.7/site-packages/conda/cli/install.py\", line 189, in install specs.extend(common.specs_from_url(fpath, json=context.json)) File \"/home/ec2-user/miniconda2/lib/python2.7/site-packages/conda/cli/common.py\", line 532, in specs_from_url (line, url)) File \"/home/ec2-user/miniconda2/lib/python2.7/site-packages/conda/exceptions.py\", line 350, in __init__ msg = 'Value error: %s' % message UnicodeDecodeError: 'ascii' codec can't decode byte 0x8b in position 18: ordinal not in range(128) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: benchmark() doesn't support same options as test() benchmark() doesn't support same options as test(), In particular, it is lacking 'protocol' and 'depends'. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Documentation: Impove CASE_DEFAULT documentation ### What should we add? From https://qiskit.org/documentation/stubs/qiskit.circuit.SwitchCaseOp.html: > The special value CASE_DEFAULT can be used to represent a default condition. But it doesn't explain how to import `CASE_DEFAULT` and there is no hyperlink. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `%save` does not understand `~/` E.g.: ``` In [62]: %save ~/remove_stale_branches.py 51 --------------------------------------------------------------------------- FileNotFoundError Traceback (most recent call last) <ipython-input-62-7439301d8c47> in <module> ----> 1 get_ipython().run_line_magic('save', '~/remove_stale_branches.py 51') ~/.pyenv/versions/3.9.1/lib/python3.9/site-packages/IPython/core/interactiveshell.py in InteractiveShell.run_line_magic(self, magic_name, line, _stack_depth) 2363 kwargs['local_ns'] = self.get_local_scope(stack_depth) 2364 with self.builtin_trap: -> 2365 result = fn(*args, **kwargs) 2366 return result <decorator-gen-36> in save(self, parameter_s) ~/.pyenv/versions/3.9.1/lib/python3.9/site-packages/IPython/core/magic.py in _method_magic_marker.<locals>.magic_deco.<locals>.<lambda>(f, *a, **k) 186 def magic_deco(arg): --> 187 call = lambda f, *a, **k: f(*a, **k) 189 if callable(arg): 190 # \"Naked\" decorator call (just @foo, no args) 191 func = arg ~/.pyenv/versions/3.9.1/lib/python3.9/site-packages/IPython/core/magics/code.py in CodeMagics.save(self, parameter_s) 235 print(e.args[0]) 236 return --> 237 with io.open(fname, mode, encoding=\"utf-8\") as f: 238 if not file_exists or not append: 239 f.write(\"# coding: utf-8\\n\") FileNotFoundError: [Errno 2] No such file or directory: '~/remove_stale_branches.py' ``` - [ ] Investigate where expansion should be made - [ ] Add tests - [ ] Check what other magics might suffer from this issue - [ ] Fix them too Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Graph View is empty when Operator has multiline string in args (v2.0) Airflow v2.0b3 Kubernetes v1.19.3 Discovered issue while testing KubernetesPodOperator (haven't tested with other operator). If I create a multiline string using \"\"\" \"\"\"\", add some variables inside (Jinja templating), then use this string as an argument to KubernetesPodOperator: - In Graph View DAG is not visible (just gray area where it should be a digraph); - in browser's web console i see the following error: `Uncaught TypeError: node is undefined preProcessGraph http://localhost:8080/static/dist/dagre-d3.min.js:103 preProcessGraph http://localhost:8080/static/dist/dagre-d3.min.js:103 fn http://localhost:8080/static/dist/dagre-d3.min.js:103 call http://localhost:8080/static/dist/d3.min.js:3 draw http://localhost:8080/graph?dag_id=mydag&execution_date=mydate expand_group http://localhost:8080/graph?dag_id=mydag&execution_date=mydate <anonymous> http://localhost:8080/graph?dag_id=mydag&execution_date=mydate` Tree view works without issues in this case. The DAG succeeds. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: 'auto' selection of histogram bins fails in some cases This is an odd corner case, but there are times using auto to select the number of bins gives only a single bin. from pylab import * data = zeros(1000) data[:100] = 10 np.histogram(data, bins='auto') Output is a single bin (array([1000]), array([ 0., 10.])) This must be the result of the sturges/fd estimators since (according to the documentation) auto just takes the max of these two. It seems like this should fall back to the default number of bins (10 I think), or perhaps sqrt. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Artifactory returns error on first login attemp In MacOS Mojave 10.14.6 Using Conan 1.19.1 and Artifactory CE 6.12.2: To reproduce: remove user and tokens `conan user -c ` Do anything with artifactory that requires login `conan upload * --all --force -c -r local` Enter user and password as requested, after that this error will appear: `ERROR: 400: Unsupported Conan v1 repository request for 'conan'. [Remote: local]` The second time trying to upload will work. To help us debug your issue please explain: - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make circuit.layout name descriptive #2736 added a `QuantumCircuit.layout` property and sets it with the layout determined during transpile. With the current naming, it is ambiguous as to where this property is generated, and whether or not it is user set-able. (e.g. demo code #2781 sets `circuit.layout` but this would be ignored if that circuit was passed to `transpile`.) We should add some documentation to the layout property, and consider making it read-only. We should also consider moving it to a location that better describes it's origin and purpose: e.g. `circuit.transpile_history.layout = { 'layout': Layout(...), 'source': 'DenseLayout'}` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda env create --url https://raw.githubusercontent.com/.../environment.yml I'm the maintainer for the datashader package, and I'm trying to streamline the process by which our users can set up an environment containing a bunch of libraries so that they can run our example scripts and notebooks. These libraries aren't dependencies of the main library, and so they aren't installed with the main `datashader` conda install, but we do want people to be able to get them all easily. For that reason, we provide an [environment file](https://raw.githubusercontent.com/bokeh/datashader/master/examples/environment.yml), but telling people to use that is complicated -- we either have to tell them to install datashader, then find the environment file wherever it ended up on their platform, or to go to the URL and download it using some platform-specific command or procedure, name it appropriately, then call it from the commandline. It would be vastly simpler for us our users if they could simply do the same command on all platforms to get the current environment: ``` conda env create --url https://raw.githubusercontent.com/bokeh/datashader/master/examples/environment.yml ``` Would that be feasible? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Release 'error_reporting-0.30.0' PR #5345 fixes the incompatibility of `0.29.1` with the current `logging-1.6.0` release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: cmd_def expression extraction should be replaced with math expression parser <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Pulse commands supplied by the backend may be parameterized with some expression that includes math performed on parameters of the form `P#`. Examples of valid strings are ``` P1 -(P1) cos(pi)*P1 1+1+P1 P1/P2 ... ``` Currently, parameters are extracted by first sanitizing the untrusted string supplied by backends to only math and then passing to Sympy parser for parameter extraction as [Sympy parsing is known to be unsafe due to its use of `eval`](https://docs.sympy.org/latest/modules/core.html). Sanitization is notoriously hard to implement correctly, and while it currently is mostly sufficient as the majority of backends are assumed to be trusted. Rather than using a sanitization + Sympy, a parser for the limited subset of math and expressions required should be implemented. This parser should output a Qiskit expression with parameters. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Output missing with container in TTY mode I'm trying to run several containers with TTY mode enabled (`tty: true` in config). When I enable TTY mode, commands such as `compose up` and `compose logs` do not show the container's output. However I can run `docker logs $cid` and the output shows up just fine. The output does show up when the container exits, but not until then. And when it does show up, the first several bytes of the stream are missing. For example: ``` hello: image: busybox command: sh -c 'echo hello world; sleep 2; echo done' tty: true ``` ``` # compose up Recreating code_hello_1... Attaching to code_hello_1 hello_1 | rld hello_1 | done code_hello_1 exited with code 0 Gracefully stopping... (press Ctrl+C again to force) ``` Both lines showed up at the exact same time instead of having a 2 second pause, and note that the `hello wo` is missing. This is using current master https://github.com/docker/compose/commit/43369cda9ce5f0fe4860c7160cfa6550d31e2417 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore: needs 'synth.py' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] self.cpp_info.name breaks pkg-config for some packages Defining self.cpp_info.name for a package changes (at least) two file names: cmake module `FindFOO` files, and pkg-config files. The problem is that in the wild, the name used for cmake module files and pkg-config files are not always identical, for example zlib has `FindZLIB`, but `zlib.pc`, and expat has `FindEXPAT` but `expat.pc`. recipes consuming these two packages via pkg-config are broken since these two recipes set `self.cpp_info.name` to uppercase, the workaround being to rename generated `ZLIB.pc` to `zlib.pc` and `EXPAT.pc` to `expat.pc`. If pkg-config files are always the lower-case version of corresponding `findFOO` cmake file, the simplest fix would be to modify pkg-config generator to use `self.cpp_info.name.lower()` instead of `self.cpp_info.name`. If not, a solution would be to make `self.cpp_info.name` a dictionary mapping generators to name. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Should DEFAULT_EXECUTOR be a class or an instance? Thought for @cicdw: Currently `DEFAULT_EXECUTOR` points to an executor class and is instantiated by a `FlowRunner` by calling `DEFAULT_EXECUTOR()`. Would it be cleaner to instantiate it in `__init__.py`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: QNX Neutrino support To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. there is some existing demand for QNX Neutrino support: https://github.com/conan-community/community/issues/78 https://github.com/conan-io/conan/issues/2970 add an official support for QNX Neutrino operation system. it means, at least, the following: - define new OS in `settings.yml` (name might be `QNX` or `Neutrino`) - define OS versions, at least `6.5`, `6.6`, `7.0` - define new compiler - `QCC`, and its versions (`4.2.2`, `5.4.0`) - add standard libraries for QNX/QCC: `gpp` (GNU C++), `cpp` (Dinkum C+) and its variations (like Embedded Dinkum C++, Dinkum Abridged C++, etc) - define GNU triplets for QNX cross-compiling (check `config.guess`) - add required changes to the CMake helper (see https://cmake.org/cmake/help/v3.1/manual/cmake-toolchains.7.html#id9) probably nice to have, but hard without access to the actual system - I doubt we will add it, as we mainly targeting cross-compiling from Windows/Linux/OSX to QNX, not running conan on QNX itself: - add detection for QNX OS and compiler /cc @jpovedano @Johnnyxy (as requestors) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add ability to compose operators on subsystems using binary operators <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The binary operator for compose `@` and dot `*` can currently only be used if operators have the same total dimensions. This feature is to add the ability to compose/dot operators on subsystems as if using the `qargs` kwarg for the `compose` and `dot` methods. Eg: ```python init = Operator.from_label('II') x = Operator.from_label('X') h = Operator.from_label('H') # Add this op = init @ x([0]) @ h([1]) # To be equivalent to this op = init.compose(x, qargs=[0]).compose(h, qargs=[1]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: text drawer cregbundle bug when instructions with classical wires ```python qr2 = QuantumRegister(2, 'qr') cr2 = ClassicalRegister(2, 'cr') inst = QuantumCircuit(qr2, cr2, name='name').to_instruction() circuit = QuantumCircuit(qr2, cr2) circuit.append(inst, qr2[:], cr2[:]) circuit.draw(cregbundle=False) ``` ``` ┌───────┐ qr_0: ┤0 ├ │ │ qr_1: ┤1 ├ │ name │ cr_0: ╡0 ╞ │ │ cr_1: ╡1 ╞ └───────┘ ``` but ```python circuit.draw(cregbundle=True) ``` ``` ValueError: max() arg is an empty sequence ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Downloading factory blob fails because media_link isn't available Creating a blob like this loads the blob's properties, so downloading works (if it exists) since the download_url is available: ``` python blob = client.bucket(bucket_name).get_blob(blob_name) blob.download_as_string() # works ``` But this doesn't load properties, so the download fails (even in the blob is valid): ``` python blob = client.bucket(bucket_name).blob(blob_name) # note .blob() instead of .get_blob() blob.download_as_string() # fail, no URI ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Matplotlib circuit drawer raises IndexError if there is no gate in QuantumCircuit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.7.3 - **Python version**: 3.6.8 - **Operating system**: macOS HighSierra ### What is the current behavior? If I try to draw a quantum circuit without any gate, the mpl drawer raises IndexError. The text drawer does not have this issue. ### Steps to reproduce the problem ``` # sample.py from qiskit import QuantumCircuit, QuantumRegister qr = QuantumRegister(1) qc = QuantumCircuit(qr) print(qc) qc.draw(filename='output.pdf', output='mpl') ``` ``` $ python sample.py q0_0: |0> Traceback (most recent call last): File \"c.py\", line 5, in <module> qc.draw(filename='output.pdf', output='mpl') File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/circuit/quantumcircuit.py\", line 353, in draw reverse_bits=reverse_bits) File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/tools/visualization/_circuit_visualization.py\", line 237, in circuit_drawer reverse_bits=reverse_bits) File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/tools/visualization/_circuit_visualization.py\", line 577, in _matplotlib_circuit_drawer return qcd.draw(filename) File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/tools/visualization/_matplotlib.py\", line 343, in draw self._draw_ops(verbose) File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/tools/visualization/_matplotlib.py\", line 466, in _draw_ops next_ops.pop(0) IndexError: pop from empty list ``` ### What is the expected behavior? No IndexError. ### Suggested solutions Check whether `next_ops` is empty or not. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: subproject() regression: cannot use subdirs any more It was really handy to allow `/` in `subproject()` for git submodules containing several tiny projects with a common purpose but no inter-dependencies. That way, there was no need to handle options (that the user can touch, which means you have to check them manually or the build could fail because the user disabled something needed) and I could just use the part I wanted. The fix for issue #2306 (6083eb29d0d5d81510a588dc64f5533ef58bb8e0) is quite overkill and prevents a really useful feature to me. Could we have a trade-off here? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: \"overridden\" is misspelled as \"overriden\" This affects a few places, but most notably user messages output by conan. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Old classes are not accessible via qiskit.extensions <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.14.0 - **Python version**: All - **Operating system**: Any ### What is the current behavior? Running ``` from qiskit.extensions import Cu3Gate ``` Raises an `ImportError` ``` Traceback (most recent call last): File \"<stdin>\", line 1, in <module> ImportError: cannot import name 'Cu3Gate' from 'qiskit.extensions' (/home/mtreinish/git/qiskit/qiskit/.tox/lint/lib/python3.8/site-packages/qiskit/extensions/__init__.py) ``` as do other classes which were deprecated as part of the 0.13.0 release cleanup. It worked fine on qiskit-terra 0.13.0 (also without a deprecation warning, which I thought it would raise). This is a big breakage and needs to be fixed in a quick 0.14.1 release. ### Steps to reproduce the problem ``` from qiskit.extensions import Cu3Gate ``` ### What is the expected behavior? This works, this is likely fallout from rushing through #4035 ### Suggested solutions Fix this Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Feature: model intra-package dependencies From https://github.com/conan-io/conan/issues/2382 This could help both to model system dependencies ``self.cpp_info.libs = [\"mylib\", \"pthread\"]``, and then some consumer can depend on pthread by other means, and the order mylib->pthread is not defined. It can be generalized for your own libs deps \"Mylib1\"->\"MyLib2\" inside the same package. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] 'conan info' to return the package revision Currently, the `conan info` command returns the recipe revision, but information about package revision is not available: ```json { \"revision\": \"a9d892fd37101b88578f17fbc04b9d60\", \"reference\": \"boost/1.70.0\", \"is_ref\": true, \"display_name\": \"boost/1.70.0\", \"id\": \"d45e2a7cc75163518ffbbda3fa886038ecaa8f54\", \"build_id\": null, \"remote\": { \"name\": \"conan-center\", \"url\": \"https://conan.bintray.com\" }, \"url\": \"https://github.com/conan-io/conan-center-index\", \"homepage\": \"https://www.boost.org\", \"license\": [ \"BSL-1.0\" ], \"description\": \"Boost provides free peer-reviewed portable C++ source libraries\", \"topics\": [ \"conan\", \"boost\", \"libraries\", \"cpp\" ], \"recipe\": \"Cache\", \"binary\": \"Cache\", \"binary_remote\": \"conan-center\", \"creation_date\": \"2020-08-31 13:15:59\", \"requires\": [ \"zlib/1.2.11\", \"bzip2/1.0.8\" ] }, ``` It should be easy to add and more convenient than running `conan search <ref>#<rrev>:<pid> --revisions` afterward. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Create `layout` stage (trivial, dense, sabre, noise_adaptive) plugin Create a plugin for the builtin layout stage methods. One particular oddity for this stage is it's not just the straight methods, but also a default method will be needed. The default stage will integrate vf2layout (and initial layout too for level 1). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Bug with jax.disable_jit (or lax.cond, or vmap?) Attempt at minimal reproducing example: ```python def fn(t): return jax.lax.cond(t > 0, 0, lambda x: 0, 0, lambda x: 1) fn = jax.vmap(fn) with jax.disable_jit(): outputs = fn(jnp.array([1])) ``` fails with ``` Encountered value: Traced<ShapedArray(bool[])>with<BatchTrace(level=11/0)> with val = DeviceArray([ True], dtype=bool) batch_dim = 0 ``` It does not fail without the `disable_jit()` and it does not fail without the `vmap` (input a scalar in that case). disable_jit extensions to control flow constructs break with vmap The extension of `jax.disable_jit()` context to the control flow elements (e.g. `while_loop`, `cond`) isn't correct in the presence of batch tracers for `vmap`. `while_loop` and `cond` are rewritten to use python control flow under this context, but conditional branching can't be evaluated on the batchtracers present when functions using these control flow constructs are inside a `vmap`. e.g. ```python def trivial_while(y): return lax.while_loop(lambda x: x < 10.0, lambda x: x + 1.0, y) # works: jax.vmap(trivial_while)(jnp.array([3.0,4.0])) # throws a ConcretizationTypeError: with jax.disable_jit(): jax.vmap(trivial_while)(jnp.array([3.0,4.0])) ``` likewise: ```python def trivial_cond(x): return lax.cond(x < 1.0, x, lambda x: x, x, lambda x: 2*x) # works jax.vmap(trivial_cond)(jnp.array([0.5,2.0])) # throws a ConcretizationTypeError: with jax.disable_jit(): jax.vmap(trivial_cond)(jnp.array([0.5,2.0])) ``` Perhaps the disabled_jit python implementations for these control flow constructs could peak at the tracer value's `val` field which I suspect will be populated in these use-cases? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add ability to sign URL from App Engine service account Can use the [App Identity](https://cloud.google.com/appengine/docs/python/appidentity/functions) API: ``` python from google.appengine.api.app_identity import sign_blob sign_blob(bytes_to_sign, deadline=deadline_seconds) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qpy not recognizing complex number as a parameter for Initialize <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.0 - **Python version**: - **Operating system**: ### What is the current behavior? When trying to serialize a QuantumCircuit using qpy, I got ``` ~/Documents/Q/Github/qiskit-terra/qiskit/circuit/qpy_serialization.py in _write_instruction(file_obj, instruction_tuple, custom_instructions, index_map) 722 size = len(data) 723 else: --> 724 raise TypeError( 725 f\"Invalid parameter type {instruction_tuple[0]} for gate {type(param)},\" 726 ) TypeError: Invalid parameter type <qiskit.extensions.quantum_initializer.initializer.Initialize object at 0x103fd6dc0> for gate <class 'complex'>, ``` ### Steps to reproduce the problem The circuit I used: ``` import io import numpy as np from qiskit.circuit import QuantumCircuit, qpy_serialization from qiskit.circuit.library import QFT from qiskit.quantum_info import Statevector k = 5 state = (1/np.sqrt(8))*np.array([np.exp(-1j*2*np.pi*k*(0)/8),np.exp(-1j*2*np.pi*k*(1)/8), np.exp(-1j*2*np.pi*k*(2)/8), np.exp(-1j*2*np.pi*k*3/8),np.exp(-1j*2*np.pi*k*4/8),np.exp(-1j*2*np.pi*k*5/8), np.exp(-1j*2*np.pi*k*6/8), np.exp(-1j*2*np.pi*k*7/8)]) qubits = 3 circuit = QuantumCircuit(qubits, qubits) circuit.initialize(state) circuit.append(QFT(qubits),range(qubits)) circuit.measure(range(qubits),range(qubits)) buffer = io.BytesIO() qpy_serialization.dump(circuit, buffer) ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: When kernel is missing, notebook fails to load Using master as of 0f92b92748b0dc07dd, I tried loading a notebook with a kernel I don't have configured (Python 3). Instead of getting the message indicating I should install it and at least being able to read the notebook, the popup said ``` Notebook failed to load The error was: TypeError: Cannot read property 'resources' of undefined ``` And the notebook didn't load at all. This is obviously a hard blocker for release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Do not allow fine tuning with sequence size larger than during training # 🚀 Feature request <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> ## Motivation I just wasted some hours chasing a problem see #10010 that I think could be avoided with the following simple solution: Do not allow `max_seq_length` to be higher than `max_position_embeddings`. Most models are built with 512 and, as such, this problem doesn't happen too often. It so happens that BERTweet was trained with 130. The code allows it to run with `max_seq_length` higher than 130 and it ends up with cryptic cuda errors down the pipe. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: custom_channels incorrect in 'conda config --show' Especially for anaconda channel, weird replacement happening. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan new template recipes A use case where a team is creating many packages for their own libraries, and the recipes are very similar, it is useful to have the possibility to use a pre-defined template for the ``conan new`` command. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: lax.scan has error when input array is not a jax array lax.scan raise an TypeError: 'JaxTuple' object does not support indexing incorrectly A simple repro can be found here ``` import collections from jax import lax import jax.numpy as np Point = collections.namedtuple('Point', 'x y') p0 = Point(x=np.array(1), y=np.array(2)) def plus_one(p, iter_idx): return Point(p.x+1, p.y+1), iter_idx point, _ = lax.scan(plus_one, p0, list(range(5))) print(point) ``` or in this colab https://colab.research.google.com/drive/1_jmdeIjfxJwUElNpwEbBR1gnAQDe8WbP Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: missing runtime vcruntime140.dll Hi thanks for your great project ! I installed **meson-0.42.1-32.msi** on a mostly clean 32-bit Windows 7, then on launching `meson --version` in a cmd, I get the \"missing runtime vcruntime140.dll \" pop-up. To fix it, I installed the [Microsoft Visual C++ 2015 Redistributable](https://www.microsoft.com/en-US/download/details.aspx?id=53587), this should probably be documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: WavLM paper points to UniSpeech ### System Info NA ### Who can help? @sgugger ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction https://github.com/huggingface/transformers/blob/e42587f596181396e1c4b63660abf0c736b10dae/src/transformers/models/wavlm/modeling_wavlm.py#L1060-L1063 https://arxiv.org/abs/2101.07597 is UniSpeech. WavLM should be https://arxiv.org/abs/2110.13900 instead. ### Expected behavior NA Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Qiskit transpiler cannot handle custom multi-qubit gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Because Qiskit is backend agnostic, we should be able to define custom multi qubit gate. What I want to do here is ```python qc = QuantumCircuit(3) qc.append(Gate('my_custom_3q_gate', 3, []), [0,1,2]) qc.h(0) qc.sdg(0) qc.y(1) ... qc.add_calibration('my_custom_3q_gate', (0,1,2), my_custom_3q_gate_schedule) qc = transpile(qc, backend, basis_gates=['u1', 'u2', 'u3', 'cx', 'my_custom_3q_gate']) sched = schedule(qc, backend) ``` But current transpiler passes don't allow to have 3q basis gates. I think this limits capability of Qiskit. https://github.com/Qiskit/qiskit-terra/blob/6646e681501deb8aac55cdc69a8a351ec058e989/qiskit/transpiler/preset_passmanagers/level0.py#L107 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Bug in mapping? <!--- Provide a general summary of the issue in the Title above --> Measurement results differ in compiling with/without coupling_map. ## Expected Behavior <!--- If you're describing a bug, tell us what should happen --> <!--- If you're suggesting a change/improvement, tell us how it should work --> With this QASM (`coupling_map=None`), expected measurement results are {'1001', '0001'} ``` OPENQASM 2.0; include \"qelib1.inc\"; qreg q[4]; creg c[4]; // -X-.----- // -Y-+-S-.- // -Z-.-T-+- // ---+-H--- x q[0]; y q[1]; z q[2]; cx q[0], q[1]; cx q[2], q[3]; s q[1]; t q[2]; h q[3]; cx q[1], q[2]; measure q[0] -> c[0]; measure q[1] -> c[1]; measure q[2] -> c[2]; measure q[3] -> c[3]; ``` ## Current Behavior <!--- If describing a bug, tell us what happens instead of the expected behavior --> <!--- If suggesting a change/improvement, explain the difference from current behavior --> {'0000', '1000'} are obtained with `coupling_map = {0: [2], 1: [2], 2: [3], 3: []}` ## Steps to Reproduce (for bugs) <!--- Provide a link to a live example, or an unambiguous set of steps to --> <!--- reproduce this bug. Include code to reproduce, if relevant --> ``` qp = QuantumProgram() qp.load_qasm_file('qasm_above.qasm', name='test2') coupling_map = {0: [2], 1: [2], 2: [3], 3: []} result1 = qp.execute([\"test2\"], backend=\"local_qasm_simulator\", coupling_map=coupling_map) print(result1.get_counts(\"test2\")) result2 = qp.execute([\"test2\"], backend=\"local_qasm_simulator\", coupling_map=None) print(result2.get_counts(\"test2\")) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Revisit importing dependencies from `IPython.external` `python3 -c \"import IPython; print(IPython.sys_info())\"` fails if executed in a directory which contains a subdirectory named \"path\": `Traceback (most recent call last): File \"<string>\", line 1, in <module> File \"/home/gert/.virtualenvs/ipython/lib/python3.3/site-packages/IPython/__init__.py\", line 43, in <module> from .config.loader import Config File \"/home/gert/.virtualenvs/ipython/lib/python3.3/site-packages/IPython/config/__init__.py\", line 16, in <module> from .application import * File \"/home/gert/.virtualenvs/ipython/lib/python3.3/site-packages/IPython/config/application.py\", line 31, in <module> from IPython.config.configurable import SingletonConfigurable File \"/home/gert/.virtualenvs/ipython/lib/python3.3/site-packages/IPython/config/configurable.py\", line 33, in <module> from IPython.utils.text import indent, wrap_paragraphs File \"/home/gert/.virtualenvs/ipython/lib/python3.3/site-packages/IPython/utils/text.py\", line 27, in <module> from IPython.external.path import path ImportError: cannot import name path` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan new command with template packages Template based generation of conan packages with \"test_package\" included for: - Header only libraries - Normal, with source. It should generate the skeleton of the package, including the test_package based on: - Package name, package version, user, channel (set default, can be changed later) - Header or source Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: GCSToBigQueryOperator no longer uses field_delimiter or time_partitioning ### Apache Airflow Provider(s) google ### Versions of Apache Airflow Providers google=8.5.0 ### Apache Airflow version 2.4.3 ### Operating System Debian GNU/Linux 11 (bullseye) ### Deployment Other Docker-based deployment ### Deployment details _No response_ ### What happened The newest version of the google providers no longer provides the `field_delimiter` or `time_partitioning` fields to the bq job configuration for the GCStoBQ transfers. Looking at the code it seems like this behavior was removed during the change to use deferrable operations ### What you think should happen instead These fields should continue to be provided ### How to reproduce _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [x] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose exec should support -u like docker-compose run does From the output of `docker-compose help run` ``` -u, --user=\"\" Run as specified username or uid ``` From the output of `docker-compose help exec` ``` --user USER Run the command as this user. ``` For symmetry reasons, `exec` should also support `-u`. The help messages should be identical, too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: install_headers ignores 'subdir:' if 'install_dir:' is set **Describe the bug** The install_headers function provides both `install_dir` and `subdir` parameters and documents that the `subdir` parameter is added to any `install_dir` parameter. However, the code ignores `subdir` when `install_dir` is specified. **To Reproduce** [install-header.zip](https://github.com/mesonbuild/meson/files/8165005/install-header.zip) **Expected behavior** The header file should be installed in install_dir / subdir **system parameters** * plain native build * Debian unstable * Python 3.9.10 * meson version 0.61.2 * ninja version 1.10.1 **Suggested Fix** Because existing meson will ignore subdir, I suggest that the documentation be changed to indicate that you cannot use both options at the same time and then make the code raise an error if they are both specified. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: docs: correct number of layers for various xlm models Hi, during some NER experiments I found out, that the number of reported layers in the documentation is different compared to the model configuration for some XLM models. This PR fixes the documentation :) Getting embedding from XLM in differnet languages ## ❓ Questions & Help Hi, I'm trying to get a cross-lingual embedding from the XLM model, but can't figure out how. In the project original github, you need to give the tokenizer the language of each of the tokens, but it doesn't seem the case here. Will appreciated any help on the matter :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: missing build script for highlight.js The highlight.js folder is missing tools/build.py required to build it from source. This is annoying for packaging so please add it, also in the 1.x branch. For debian the embedded yuicompressor is not needed as the packaged one can be used. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [suggestion] failure to auto-detect a compiler for the default profile should not report 'ERROR:' Conan outputs that there has been an error when no compiler is found during auto-detect: ``` conan profile new default --detect Profile created with detected settings: C:\\Jenkins\\workspace\\my_job\\.conan\\profiles\\default ERROR: Unable to find a working compiler ``` This happens often because my compiler is not installed on the machine - I am using a `build_requires` package for my cross-compiler toolchain and `conan config install ...` to get the profile which adds it. But I do still want to auto-detect to get the correct values for `os`, `arch`, etc. based on the build machine. I find this message misleading and developers often mistake this for the reason why jobs fail, rather than looking further down the build log... and it only becomes more confusing when creating a package which does not have a need for the `compiler` setting at all (for example, when packaging `build_requires`). I would like to see it re-worded or even removed. I guess any problems would become clear on `conan install` anyway. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: considering `pad_to_multiple_of` for run_mlm.py ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.3.3 - Platform: linux - Python version: 3.7 - PyTorch version (GPU?): 1.8 - Tensorflow version (GPU?): - - Using GPU in script?: - - Using distributed or parallel set-up in script?: - ### Who can help @sgugger, @patil-suraj ## Information I have seen in huggingface codes such as run_seq2seq.py that for the case of fp16, they pad to multiple of 8 like below, perhpas for efficiency purpose: ``` data_collator = DataCollatorForSeq2Seq( tokenizer, label_pad_token_id=label_pad_token_id, pad_to_multiple_of=8 if training_args.fp16 else None, ) ``` For run_mlm.py codes, the padding condition in case of fp16 is not considered, could it be a bug and possibly performance could get better in run_mlm.py if this was set? kindly appreciate having a look. thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Using docker-compose with multiple configuration files disables network_mode: \"host\" for services When using docker-compose (v1.6) with multiple configuration files with \"-f\" like the following: docker-compose -f docker-compose.yml -f preproduction.yml build docker-compose -f docker-compose.yml -f preproduction.yml up -d If services are using network_mode: \"host\" then this configuration is disabled (dropping to \"bridge\" mode) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Relocate mock backends from qiskit.test.mock to qiskit.mock or similar <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? From https://github.com/Qiskit/qiskit-terra/pull/3890#issuecomment-591655403 : now that the fake backends are useful beyond testing, they should be moved somewhere more visible and their usage should be documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Relaxing `PreTrainedModel` requirement in _save # 🚀 Feature request It's great to see that `Trainer` is becoming flexible. Each functions seems to be more self contained now making inheritance easier. I've experimented with many custom models. For instance, ``` class Model(nn.Module): def __init__(self, ..): self.encoder = AutoModel.from_pretrained(..) self.custom_modules = .. def forward(self, **kwargs): output = self.encoder(**kwargs) # some custom operations ``` Many users are required to create custom models if they just don't want simple `SequenceClassification` head. In all cases, I have to override `_save` method because of [this line](https://github.com/huggingface/transformers/blob/d822ab636b6a14ed50f7bca0797c1de42c19de61/src/transformers/trainer.py#L1097) which explicitly puts a restriction on `Trainer` to be used with models that inherit from `PreTrainedModel`. It would be good to relax this requirement and give a warning about not using `PreTrainedModel` instead. ## Your contribution I'll open a PR if I get approval. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: minor problem in error message for jax.experimental.optimizers.piecewise_constant Hi, I think there is a small problem with the error message for jax.experimental.optimizers.piecewise_constant. ```python def piecewise_constant(boundaries, values): boundaries = jnp.array(boundaries) values = jnp.array(values) if not boundaries.ndim == values.ndim == 1: raise ValueError(\"boundaries and values must be sequences\") if not boundaries.shape[0] == values.shape[0] - 1: raise ValueError(\"boundaries length must be one longer than values length\") ``` I think the last line should read \"boundaries length must be one less than values length\" or something along those lines. Cheers! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Transfer the CNOTDihedral Operator class from ignis to Terra quantum_info/Operators <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Transfer the `CNOTDihedral` Operator class from Ignis to Terra quantum_info/Operators, so that it can be useful not only to Randomized Benchmarking, but also to other applications. The code is currently located in: https://github.com/Qiskit/qiskit-ignis/blob/master/qiskit/ignis/verification/randomized_benchmarking/dihedral.py And the `CNOTDihedral` class already inherits from the abstract `BaseOperator` class. The following functions should be moved: - `CNOTDihedral` class should be moved to: https://github.com/Qiskit/qiskit-terra/tree/master/qiskit/quantum_info/operators - `decompose_cnotdihedral` should be moved to: https://github.com/Qiskit/qiskit-terra/tree/master/qiskit/quantum_info/synthesis - `random_cnotdihedral` should be moved to: https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/quantum_info/operators/random.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: multi-language documentation <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? I would like to remove all the multi-language documentation from this repository and add it to github.com/Qiskit/qiskit. I am not sure of the best way we do it and I let all discuss in that repository how we should do it. But we are not going to have documentation in the individual elements (only a readme about the element, contributing guidelines and other community files) @alfrisch could you take the lead on the German @rraymondhp could you take the lead on the Japanese @hanheepaik could you take the lead on the Korean @liupibm could you take the lead on the Chinese Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: L_BFGS_B maxiter and maxfun defaults should be swapped ### Environment Generic implementation bug, not about environment ### What is happening? Note that in qiskit.algorithms.optimizers.l_bfgs_b, we have the following defaults: ``` def __init__( self, maxfun: int = 1000, maxiter: int = 15000, ... ``` This is problematic since if maxfun is less than maxiter, the optimization will always get terminated by maxfun, since maxfun is always larger than maxiter (as calling from scipy library). Typically, one would get something like, depend on your option setting, ``` {'_x': (ignored here), '_fun': 942148.4943465312, '_jac': None, '_nfev': 12768, '_njev': 224, '_nit': 211} ``` Here, nit = 211 << nfev = 12768. Therefore I would think it is proper to have those two defaults swapped. It has been a while for me that I have to swap them manually each time. ### How can we reproduce the issue? The issue is about default values. ### What should happen? I suggest we set qiskit.algorithms.optimizers.l_bfgs_b to ``` def __init__( self, maxfun: int = 15000, maxiter: int = 1000, ... ``` ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Improve autocomplete UX Hi, IPython recently introduced hinted suggestions as input is being typed. The user can accept the suggestion by pressing END or RIGHT. Alternatively, the user can scroll through other prefix matches in the history by pressing UP (and DOWN). However, all these modes of navigation move the cursor to the end of the line. It is impossible to accept a prefix of a hinted suggestion. We would like to propose keeping the cursor in place and naturally supporting the cursor movement with the logic of “accept anything that is on the LHS of the cursor”. This would allow reusing long prefixes without the need to accept the entire line and make edits from its end. For example, suppose the history includes very.long.module.foo.func() very.long.module.bar.Baz() The user types the prefix “very.”. The hinted suggestion would be “long.module.bar.Baz()”. The user can now press: 1. RIGHT/CTRL-RIGHT to accept letters/words from the hinted completion. This would make it easier to type “very.long.module.bar.Zap()”. 2. END to accept the entire suggestion. 3. UP to replace the hinted suggestion with “long.module.foo.func()” (cursor stays in place). 4. BACKSPACE to delete last character and resume hinting from the new prefix (currently, it aborts hinting). 5. LEFT to accept the hint and move the cursor to the left. 6. New key binding to accept the suggestion but keep cursor in place. Thoughts? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Extracting permutation of classical registers from Quantum Circuit Hi, during routing/mapping passes input quantum registers could be permuted, the permutation logical -> physical qregs is saved in `quantum_circuit._layout` property and could be easily accessed by a user. Similarly, classical cregs also become permuted after routing/mapping: physical cregs->logical cregs. This permutation can be extracted when applying measure gates `quantum_circuit.measure_all()`. E.g. when two cregs (0 and 1) are permuted than the measure gates will look like: `measure qreg[0] creg[1];` `measure qreg[1] creg[0]`. However, _when measure gates are not applied_, there is still could be implicit permutation of cregs after mapping/routing pass. It seems that there is no simple way to access information about cregs permutation, which could be inconvenient in some cases. For example this information is necessary to check the equivalence of original and transpiled circuits. Is it possible to add this information as a property of QuantumCircuit object? Or there is some other way to access this information? Thanks a lot! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Provide a separate step for 2 step build systems such as CMake and AutoTools As discussed in #2470, it would be very helpful to have a separate step that would only call `configure()` function of `CMake` and `AutoToolsBuildEnvironment` because Conan passes useful information to them so calling them directly without Conan will probably configure them incorrectly and always calling `conan build` is very impractical. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: nbconvert --to slides --post server reveal.js redirection not working I am using ipython nbconvert to serve my notebooks as slides locally. When I run ipython nbconvert --to slides --post serve my-notebook.ipynb the slides are not rendered correctly. I have noticed in the log that a redirection is added to serve reveal.js: `[NbConvertApp] Redirecting reveal.js requests to https://cdn.jsdelivr.net/reveal.js/2.5.0` but https://cdn.jsdelivr.net/reveal.js/2.5.0 returns a 403 error. I have noticed that in the most recent version the file ipython/IPython/nbconvert/postprocessors/serve.py has the url updated to point to https://cdn.jsdelivr.net/reveal.js/2.6.2 -- this new url also returns a 403 error. --- Environment details: python -c \"import IPython; print(IPython.sys_info())\" {'commit_hash': '1c0eb68', 'commit_source': 'installation', 'default_encoding': 'UTF-8', 'ipython_path': '/Users/lm/anaconda/lib/python3.4/site-packages/IPython', 'ipython_version': '2.3.1', 'os_name': 'posix', 'platform': 'Darwin-14.1.0-x86_64-i386-64bit', 'sys_executable': '/Users/lm/anaconda/bin/python', 'sys_platform': 'darwin', 'sys_version': '3.4.2 |Anaconda 2.1.0 (x86_64)| (default, Oct 21 2014, ' '17:42:20) \\n' '[GCC 4.2.1 (Apple Inc. build 5577)]'} Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: GitPython in submodules Using GitPython in a submodule doesn't work. Python 2.7.6, GitPython 0.3.2 RC1 on Windows. I have a repository 'a' with a submodule 'b'. I do: ``` >>> repo = git.Repo('C:\\a\\b') >>> repo (git.Repo \"C:\\a\\.git\") >>> # (should be \"C:\\a\\.git\\modules\\b\") >>> repo.heads (... a's branches...) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add handling for `operational`, `faulty_{qubits,gates}` to `convert_to_target` ### What should we add? `convert_to_target` doesn't currently look at `operational` and `faulty_{qubits,gates}` fields. `Target` nominally has support for these by removing faulty gates from each qubit, but this needs to be done while constructing the `Target`. Handling these within `convert_to_target` would allow for compiling against backends with faulty qubits. (N.B. Executing jobs against these backends would still require an additional step of re-indexing compiled circuits to the original qubit indicies, but that may be eased by #9851 ). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Randomized testing failure on main <!-- commit 60c8bba11f7314e376ff2fd7e6f211bad11b702e@master --> Trying to build `master` at commit 60c8bba11f7314e376ff2fd7e6f211bad11b702e failed. More info at: https://travis-ci.com/Qiskit/qiskit-terra/jobs/208623536 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Better handling of linked packages @SylvainCorlay reported this while working on the ipywidgets upgrade. I'm going to come up with a repro, but the general idea is: - make an extension that depends on a published library - check out that library locally - bump the version number - run jupyter labextension link - change directories back to the extension - run jupyter labextension link At this point, jupyter lab complains that it cannot find a published version of the linked dependency. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Get Learning Rate SPSA & QNSPSA <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? For `SPSA` as well as `QNSPSA` you can set `learning_rate=None`. When calling the `.settings()` property of the optimizers after running the optimization, it will return `learning_rate=None` again. However, the effective `learning_rate` is actually [changed](https://github.com/Qiskit/qiskit-terra/blob/deebd5cce63601f5a6bb4aa762baedd9cb4876b3/qiskit/algorithms/optimizers/spsa.py#L501) by the `calibrate` function. Can `self.learning_rate` be updated accordingly? @Cryoris @des137 @mishmash Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: use import_module instead of __import__ Since Python 3.3 it is [_requested_ to use importlib.import_module instead of `__import__`](https://docs.python.org/3/library/importlib.html#importlib.__import__). The reason is not really given, but I guess there are reasons. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: paste into ipython stop working with vi mode this works well: ``` [ins] In [46]: In [41]: s = 'Abc Def Ghi' [ins] In [47]: ``` this does not work. ``` [ins] In [44]: [ins] In [41]: s = 'Abc Def Ghi' ...: ...: File \"<ipython-input-44-0af6a6a3f6c4>\", line 1 [ins] In [41]: s = 'Abc Def Ghi' ^ SyntaxError: invalid syntax ``` is it possible to configure ipython to also accept transcript under vi mode? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Make http timeouts configurable http://docs.python-requests.org/en/master/user/advanced/#timeouts Also set defaults to 2x current defaults. CC @quasiben Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `dependency('vulkan', version: ['>=1.X.X'])` fails on Windows **Describe the bug** `dependency('vulkan', version: ['>=1.3.0'])` fails on Windows if a version is specified. The Vulkan SDK is installed, and the environment variable (`VULKAN_SDK=C:\\VulkanSDK\\1.3.250.1`) is set. Edit: The same does work on Linux. **To Reproduce** Install a recent Vulkan SDK (>= 1.3.0) and use this meson.build: ```python project('test-project', 'cpp') # this does not work vulkan = dependency('vulkan', version: ['>=1.3.0']) # this does work # vulkan = dependency('vulkan') executable('test-project', ['main.cpp'], dependencies : [vulkan]) ``` **Expected behavior** Vulkan is detected correctly. **system parameters** * native build * Windows 11 * Python 3.9.13 * Meson 1.2.0 * Ninja 1.11.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Update the mock packages to Jupyter Packaging 0.9 https://github.com/jupyterlab/jupyterlab/pull/10096 updated to `jupyter-packaging~=0.9` for the main setup. But we should also update the mock packages used in tests, for example: https://github.com/jupyterlab/jupyterlab/blob/cf959fab54fe869a93547a04029da7d967830b94/jupyterlab/tests/mock_packages/test-hyphens/pyproject.toml#L2 Especially since the cookiecutter was also updated to `0.9`: https://github.com/jupyterlab/extension-cookiecutter-ts/blob/a80964880c0f1c3fda093d3f35a6400c193eaff8/%7B%7Bcookiecutter.python_name%7D%7D/pyproject.toml#L2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: add support for linux on s390/s390x https://en.wikipedia.org/wiki/Linux_on_z_Systems In our CI we are running \"normal\" Linux distributions like Ubuntu and Red Hat on s390/s390x. To publish and fetch packages, we would need support for s390 (31bit, yes, gcc will need -m31) and s390x (64bit). ``` >>> import platform >>> platform.system() 'Linux' >>> platform.machine() 's390x' >>> platform.processor() 's390x' >>> ``` `--build <pattern>` seems not to work When calling `conan help install` it states the following regarding the --build parameter: ``` --build=[pattern] Build always these packages from source, but never build the others. [...] 'pattern' is a fnmatch file pattern of a package name. ``` I would like to install a package and rebuild all of my own packages with it. All of my packages are within the `@monsdar/release` channel. The following seems not to work though: `conan install ... --build *monsdar*`. Conan gives me the message `ERROR: No package matching '*monsdar*' pattern`. Do I do something wrong? Or is this feature not working correctly? This happens with Conan 1.13.0 installed via Pip. Python 3.6.1 on a Windows 10 Professional with 64bit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: AIP-56 - FAB AM - Role views Move role related views to FAB Auth manager: - List roles - Edit role - Create role - View role Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Make `jupyter labextension` more verbose I think the following information would be really helpful to display in `jupyter labextension`: 1. The path to the module 2. If there is a warning (like the semver check failing from #1190), giving a list of the modules that failed it. 3. the necessary files check should display which files are missing 4. has entry could specify which of the conditions it is checking that is false. Basically, it would be very helpful to be explicit about exactly what files we are checking, and what is wrong with them. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Refactor and enhance Schedule traversal methods <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Enhance and refactor the traversal of schedules. 1. ScheduleComponent should have method `instructions` instead of `flatten` that returns an iterable for all instructions in schedule. 2. `flatten` should return a new schedule with all `instructions` in new schedule. This should be based in `pulse.ops`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Support for scipy.stats.norm.logcdf Hi there, Adding support for `scipy.stats.norm.logcdf` would be very useful to me (for probit in the likelihood). A workaround would be good too. I saw there is `erf`, but I could really do with a log version for numerical reasons. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Error while adding new tokens to GPT2 tokenizer A **NoneType Error** is encountered when I call `add_tokens()` to add new tokens to **GPT2 tokenizer** and the error is as following: ~~~~ File \".../pytorch_transformers/tokenization_utils.py\", line 311, in add_tokens if self.convert_tokens_to_ids(token) == self.convert_tokens_to_ids(self.unk_token): File \".../pytorch_transformers/tokenization_utils.py\", line 381, in convert_tokens_to_ids for token in tokens: TypeError: 'NoneType' object is not iterable ~~~~ The error comes from that it checks if the word id of a new `token` equals to that of the `unk_token` (as in tokenization_utils.py, line 311) but a **GPT2 tokenizer**'s `unk_token` is `None`. Therefore, the error happens when it tries iterating over `unk_token` in `convert_tokens_to_ids()` (as in tokenization_utils.py, line 381). I think we can solve it by either 1) changing the if-condition in line 311 and not checking the new token's equality to `unk_token` (I also don't quite understand the logic behind checking the equality here) or 2) dealing with `None` input in `convert_tokens_to_ids(self, tokens)`so it returns `[]` if `tokens is None`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Confusion about the meaning of the -L parameter with D compilers Hi! The dmd and ldc D compilers define the `-L` flag as \"pass the next command to the linker\", while gdc/gcc define it as \"set linker search path\". So I thought I was smart when translating a passed-in `-L` to a ldc/dmd compiler to `-L-L`, since this will make it work expected from a gcc compiler (= `-L` always sets the linker search path). Unfortunately it now turns out that many people use the `-L` flag as \"pass to linker\" and even use it in existing pkg-config files, which makes it really hard to change So, I wonder whether I should do some black magic to detect this in the DCompiler classes, or whether we could somehow utilize `get_linker_search_args()` to set linker search paths in a way all compilers understand, and make the to_native argument translation simply not-deal with an already existing `-L` flag (= have the compiler interpret it as it sees fit). Possible uses for `-L` for setting the linker search path is to search for local, precompiled shared or static libraries, e.g. `-Lpath/to/libraries -lfoo` (to find a `libfoo.a` or `libfoo.so` file which doesn't exist system-wide). For using `-L` directly, people use it to e.g. pass linker arguments to a compiler if they expect the compiler to be LDC/DMD. E.g. `-L-lfoo` to link against libfoo. I would prefer to just leave the `-L` flag alone in meson and utilize the `get_linker_search_args` command somehow to allow for a compiler-agnostic way to set linker search paths. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add license and license_family to MatchSpec for `conda search` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson.add_dist_script() in a subproject has MESON_PROJECT_DIST_ROOT == MESON_DIST_ROOT When project https://gitlab.gnome.org/GNOME/mm-common.git is a subproject, and meson.add_dist_script() calls a Python script, and that script reads the environment variable MESON_PROJECT_DIST_ROOT, it's equal to MESON_DIST_ROOT, except for the trailing slash. For instance it's <builddir>/meson-dist/libsigc++-3.0.7/. Should be <builddir>/meson-dist/libsigc++-3.0.7/subprojects/mm-common. I haven't seen this behaviour with other projects as subprojects. To reproduce the error: ``` git clone https://github.com/libsigcplusplus/libsigcplusplus.git cd libsigcplusplus meson --wrap-mode=forcefallback _build . cd _build meson configure -Dmm-common:use-network=true ninja meson dist --include-subprojects --no-tests ``` The dist script subprojects/mm-common/util/meson_aux/extra-dist-cmd.py does not do what it's supposed to do because MESON_PROJECT_DIST_ROOT points to the main project instead of subprojects/mm-common. In the tarball, subprojects/mm-common/ChangeLog should show the latest git commit, and there should be a subprojects/mm-common/doctags/libstdc++.tag file. meson.is_subproject() in mm-common's meson.build shows that mm-common is a subproject. I added some calls to print() in run_dist_scripts() in meson/mesonbuild/mdist.py. subprojects= {'mm-common': 'subprojects/mm-common'}. All dist scripts have d.subproject='', subdir='', even the one that belongs to subprojects/mm-common. I've tested with meson 0.60.3 and 0.61.99. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add support for referring to images by digest in docker-compose.yml Pulling by image digest is supported since docker 1.6.0 (https://github.com/docker/docker/pull/11109) ``` docker pull busybox@sha256:38a203e1986cf79639cfb9b2e1d6e773de84002feea2d4eb006b52004ee8502d ``` However putting an image digest for a service in `docker-compose.yml` leads to ``` Pulling busybox (busybox@sha256:38a203e1986cf79639cfb9b2e1d6e773de84002feea2d4eb006b52004ee8502d)... Invalid repository name (busybox@sha256), only [a-z0-9-_.] are allowed ``` Sample `docker-compose.yml` ``` service: image: busybox@sha256:38a203e1986cf79639cfb9b2e1d6e773de84002feea2d4eb006b52004ee8502d ``` ``` docker version Client version: 1.7.0 Client API version: 1.19 Go version (client): go1.4.2 Git commit (client): 0baf609 OS/Arch (client): darwin/amd64 Server version: 1.7.0 Server API version: 1.19 Go version (server): go1.4.2 Git commit (server): 0baf609 OS/Arch (server): linux/amd64 ``` ``` docker-compose --version docker-compose version: 1.3.1 CPython version: 2.7.9 OpenSSL version: OpenSSL 1.0.1j 15 Oct 2014 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Performance Regression Caused by Introduction of Bit Classes <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: Master - **Python version**: Any - **Operating system**: Any ### What is the current behavior? When #2414 was introduced it came with a sizeable performance regression in transpilation. This is best seen here: http://169.61.88.206/#quantum_volume.QuantumVolumeBenchmark.time_ibmq_backend_transpile?p-width=14&p-depth=34&commits=79c44e56 It is typically between ~1.2X and ~1.9X times slower to transpile circuits with #2414 applied. As a follow-on to: https://github.com/Qiskit/qiskit-terra/pull/2499#issuecomment-498268328 there is work to improve the performance introduced by #2414 in progress with #2529 and #2525, but it's not clear from those whether it will return to the prior performance or not. This issue is to track the progress to make sure we fix this prior to the next release. ### Suggested solutions Fix the performance regression. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Add support for differentiation of pseudoinverse Consider the following example: ```python def f(p): a = jnp.array([[0.,0.],[- p, 1.]]) * 1/ (1 + p**2) return jnp.linalg.pinv(a) jax.jacobian(f)(2.) Out[75]: DeviceArray([[nan, nan], [nan, nan]], dtype=float32) ``` So it returns `nan` values, whereas the correct values are ``` array( [[0., -1.], [ 0., 0.]]) ``` Oddly enough, jax is able to handle this function correctly: ```python def f2(p): a = jnp.array([[- p, 1.]]) * 1/ (1 + p**2) return jnp.linalg.pinv(a) In [77]: jax.jacobian(f)(2.) Out[77]: DeviceArray([[-0.99999976], [ 0. ]], dtype=float32) ``` Thoughts: 1. ~~f2 returns nd arrays and jax.jacobian seems not to handle those cases to well (probably should open another issue for that)~~ (this seems to be fixed in recent versions though) 2. There is a closed formula for the derivative of the pseudoinverse which uses the derivative of the original array: https://en.wikipedia.org/wiki/Moore%E2%80%93Penrose_inverse#Derivative Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: linspace floats I'm not sure if it's a bug or intended behavior, but may it make sense to obtain the same result in the two following linspace examples? ``` Python 2.7.9 (default, Mar 1 2015, 12:57:24) [GCC 4.9.2] on linux2 >>> import numpy >>> numpy.version.version '1.12.0.dev0+bd905a8' >>> numpy.linspace(2.0, 3.0, num=5) array([ 2. , 2.25, 2.5 , 2.75, 3. ]) >>> numpy.linspace(2.0, 3.0, 0.25) array([], dtype=float64) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: subdag doesn't work with LocalExecutor/SequentialExecutor I'm working with Airflow 1.6.2 on OSX; When running SubdagOperator using LocalExecutor/SequentialExecutor, it always hit the exception of \"DAG {sub_dag_name} could not be found in {dag_folder}'\", from https://github.com/airbnb/airflow/blob/master/airflow/bin/cli.py#L159 It looks to me that with LocalExecutor/SequentialExecutor, dags are not pickled, so when subdag operator uses backfill_job to execute subdag as a dag, it always tries to load the subdag from dag folder, which causes error because we hide the subdag using a factory method. (follow http://pythonhosted.org/airflow/concepts.html#subdags) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support project-provided lcovrc script for lcov coverage lcov has various options for excluding certain lines, directories and functions. In particular, I would like to be able to exclude certain function calls from branch coverage since they are assertions which it makes no sense to test. This uses the `lcov_excl_br_line` option ([example in GLib](https://gitlab.gnome.org/GNOME/glib/blob/master/.gitlab-ci/lcovrc)). Since that kind of configuration is quite highly project dependent, and needs to be repeated in all the `lcov` commands, I think it might make sense to allow the project to provide an `lcovrc` file which would get passed to all the `coverage.py` `lcov` commands using `--config-file path/to/lcovrc`. Failing that, it would be useful to be able to pass custom arguments to `lcov` so that projects could at least pass `--config-file` (or excl options) themselves. Add the function exclude_from_coverage() The function exclude_from_coverage() allow to pass a list of patterns to exclude them from the code coverage computation. I am not sure that this code is optimal, so feel free to come with remarks and things to fix in order to make it better. This patch is intended to fix issue #3287. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Incorrect Document Content in BlenderBot Tokenizer `The BlenderBot tokenizer has been trained to treat spaces like parts of the tokens (a bit like sentencepiece) so a word will be encoded differently whether it is at the beginning of the sentence (without space) or not.` However, the examples in BlenderBot Tokenizer (`BlenderbotTokenizer`) are the same: https://github.com/huggingface/transformers/blob/bd469c40659ce76c81f69c7726759d249b4aef49/src/transformers/models/blenderbot/tokenization_blenderbot.py#L105 The same issue also occurs in `BlenderbotTokenizerFast`: https://github.com/huggingface/transformers/blob/bd469c40659ce76c81f69c7726759d249b4aef49/src/transformers/models/blenderbot/tokenization_blenderbot_fast.py#L64 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: SIMD: The --cpu-baseline is not correctly configured in benchmark system. I'm trying to use the newest benchmark system to test the performance, but found out that the option is not working. here is the command that used for benchmarking. ``` python runtests.py --cpu-baseline=\"avx2\" --bench-compare master bench_linalg.Einsum.time_einsum_multiply ``` in this case, the macro `NPY_SIMD `should be 256 because my machine support `avx2 `intrinsics, but the actual value is 128, which is the default minimal settings. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Support for git describe --tags in tools.Git In our CI release flow, we'd like to number Conan packages based on a git tag applied in our repo. Right now if I apply a tag ```0.0.8```, then fetch that and and use ```git branch``` I see: ``` $ git branch * (HEAD detached at 0.0.8) ``` whereas if I use ```git describe --tags``` I see: ``` 0.0.8 ``` I'd like to be able to use ```0.0.8``` as the Conan package version. If I try using the example from https://docs.conan.io/en/latest/howtos/capture_version.html, namely: ``` return \"%s_%s\" % (git.get_branch(), git.get_revision()) ``` on that checked out tag I see: ``` E:\\DevelopBp\\mmaguir1\\src\\nx\\replicant>conan create . PORT/stable version[HEAD (no branch)_0dfb63c9c341536e528ef63f2e66746cf83c8539] ERROR: Value provided for package version, 'HEAD (no branch)_0dfb63c9c341536e528ef63f2e66746cf83c8539' (type Version), is too long. Valid names must contain at most 51 characters. ``` Alternatively, if there's some magic combination of the existing [Git tools](https://docs.conan.io/en/latest/reference/tools.html#tools-git) that will let me retrieve that tag name, that would be much appreciated! Related: https://github.com/conan-io/conan/issues/548 \"generating version from git\" https://github.com/conan-io/conan/issues/1764 \"Add Git helpers\" To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [v1.8.4 Windows Server 2012 git 2.12.1] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: versions after .5.2.1 do not print weights summary ubuntu 18.04.3lts, no virtual environment Model summary is not printed in versions .5.3, .5.3.1, and .5.3.2. trainer.weights_summary is set to 'full', but nothing is printed on screen. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Drop Python 2 Support? Given that IPython 6 is Python 3-only, JupyterHub is Python 3-only, and the fact that Notebook is scheduled be Python 3-only in its next release, it makes sense for this library to follow suit. From the IPython 6 [blog post](http://blog.jupyter.org/2017/04/19/release-of-ipython-6-0/): \"As the Jupyter protocol is language agnostic, it is perfectly possible to run Python 2 code in a Python 2 kernel using a Notebook Server running on Python 3. Especially since JupyterHub already requires Python 3, we envisage that the single-user notebook server will follow suit soon.\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Return errorcode 6 when settings are constrained to not support the current environment There are two approaches to restrict the environment a recipe is working for: [Constrain Settings and Options](https://docs.conan.io/en/latest/mastering/conditional.html?highlight=conaninvalidconfiguration#constrain-settings-and-options) When using the first approach and raising a `ConanInvalidConfiguration` Conan returns with errorcode 6. This could be further processed by scripts/CI perfectly. However the second approach with constraining the settings does not return with errorcode 6, but results in an [error](http://docs.conan.io/en/latest/faq/troubleshooting.html#error-invalid-setting) and errorcode 1 instead. Is there a reason why both return with different behaviour? It would be perfect if both would return with errorcode 6, so developers could use both methods and scripts/CI can react on that in the same way. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Some weights of AlbertModel were not initialized ['albert.embeddings.position_ids'] Hello! There seems to be a problem with the current code to load a pre-trained Albert model. This warning appears in any configuration of the Albert model: `Some weights of AlbertModel were not initialized from the model checkpoint at albert-base-v2 and are newly initialized: ['albert.embeddings.position_ids']` `You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.` I found this happens only when I install it from the source. Models load correctly (without warning) when installing the library with pip. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: GoogleCampaignManagerInsertReportOperator Fails when using Templated Reports The GoogleCampaignManagerInsertReportOperator fails with the following 400 error when attempting to insert a report rendered from a file template: > HttpError 400 when requesting https://www.googleapis.com/dfareporting/v3.3/userprofiles/*******/reports?alt=json returned \"Report type needs to be set.\" Appears the issue is that Jinja templates will always render as a String but the operator is expecting a Dictionary (representing the JSON object). Here's a sample call: ``` GoogleCampaignManagerInsertReportOperator( task_id=\"create_report\", gcp_conn_id=self.config.get(\"gcp_connection_id\"), profile_id=self.config.get(\"cm_profile_id\"), report=\"./resources/reports/cm_report.json\", params=report_params, dag=self.dag) ``` Relevant Code: https://github.com/apache/airflow/blob/096f5c5cba963b364ee75f6686d128cd4d34d66e/airflow/providers/google/marketing_platform/operators/campaign_manager.py#L287 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Wrong cpu detection for 'x86_64' windows In ‘x64 Native Tools Command Prompt for VS 2017’, the cpu detected by meson is 'x86' ? ``` shell ********************************************************************** ** Visual Studio 2017 Developer Command Prompt v15.9.16 ** Copyright (c) 2017 Microsoft Corporation ********************************************************************** [vcvarsall.bat] Environment initialized for: 'x64' ``` ```shell D:\\opt\\glib-2.62.2\\_build>meson .. --buildtype=release --prefix=\"D:\\opt\\glib\\\" The Meson build system Version: 0.52.0 Source dir: D:\\opt\\glib-2.62.2 Build dir: D:\\opt\\glib-2.62.2\\_build Build type: native build Project name: glib Project version: 2.62.2 C compiler for the host machine: cl (msvc 19.16.27034) C linker for the host machine: link 19.16.27034 C++ compiler for the host machine: cl (msvc 19.16.27034) C++ linker for the host machine: link 19.16.27034 Host machine cpu family: x86 Host machine cpu: x86 ``` And I tried in vs2013 , 2015, got the same result. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Language: typo (\"spech\") in Natural Language samples #### Environment details N/A #### Steps to reproduce N/A #### Code example Comments say \"Parts of spech\" instead of \"Parts of speech\" https://github.com/googleapis/google-cloud-python/blob/master/language/samples/v1/language_syntax_gcs.py#L67 https://github.com/googleapis/google-cloud-python/blob/master/language/samples/v1/language_syntax_text.py#L66 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Complex custom FindXXX.cmake example or generator? Conan manual explains [how to create a custom FindXXX.cmake file](http://docs.conan.io/en/latest/integrations/cmake/find_packages.html#creating-a-custom-findxxx-cmake-file). Basically it's ```cmake find_path(ZLIB_INCLUDE_DIR NAMES zlib.h PATHS ${CONAN_INCLUDE_DIRS_ZLIB}) find_library(ZLIB_LIBRARY NAMES ${CONAN_LIBS_ZLIB} PATHS ${CONAN_LIB_DIRS_ZLIB}) set(ZLIB_FOUND TRUE) set(ZLIB_INCLUDE_DIRS ${ZLIB_INCLUDE_DIR}) set(ZLIB_LIBRARIES ${ZLIB_LIBRARY}) mark_as_advanced(ZLIB_LIBRARY ZLIB_INCLUDE_DIR) ``` Unfortunately it only works for simple packages consisting of one lib file with no dependencies. If your package need to link multiple lib files you end up with something like [FindBoost.cmake](https://github.com/bincrafters/conan-cmake_findboost_modular/blob/stable/1.66.0/FindBoost.cmake) My question is: can we create something standard enough for that purpose? Maybe to add a function to `conans.tools` that will generate FindXXX.cmake using conan cpp_info/dep_cpp_info? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda 4.4 can fail to update packages For example, start with a fresh install of Anaconda3, and then `conda update anaconda-client` doesn't update, even though a new anaconda-client package exists. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Fix flatten option type hint for consistency For consistency with the rest of the signature (also the `Optional` import would need to be removed 🙂) ```suggestion flatten: bool | None = None, ``` _Originally posted by @Cryoris in https://github.com/Qiskit/qiskit-terra/pull/10269#discussion_r1269640303_ In #10269 the type hints added for the new flatten option were using `Optional[bool]` it should instead be `bool | None`. This should be fixed for the final 0.25.0 release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Compilations performed to instantiate lazy constants aren't cached [This compilation](https://github.com/google/jax/blob/master/jax/interpreters/xla.py#L895) isn't cached anywhere, so code like the following: ```python big_lazy_x = jnp.ones((jax.device_count(), 1e6)) for _ in range(100): _ = pmap(lambda x: x)(big_lazy_x) ``` will result in one compilation per device per step of the function that instantiates `big_lazy_x`. This should be fixed by the new lazy infra (#1668). jit does not respect backend type when the function has no arguments Example: ``` from jax.api import jit import jax.random as random def x(): return random.normal(random.PRNGKey(1), (2, 3)) x().device_buffer.device() jit(x)().device_buffer.device() jit(x, backend='cpu')().device_buffer.device() ``` All these output `GpuDevice(id=0)`, while the last one should be CPU. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Modify a copy of instruction instead of the same instance in circuit.data in QuantumCircuit.qasm() method. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In `QuantumCircuit.qasm()` method, when id is added to the instruction name to make it unique if it is the same as an existing instruction. See: https://github.com/Qiskit/qiskit-terra/blob/34b8079844fb19ee719015681184233afb4f9f72/qiskit/circuit/quantumcircuit.py#L1465-L1468 It currently modifies the circuit data directly, which is not ideal. We could just store a copy of the instruction where we modified the name instead of storing the same instance that lives in circuit.data. See comment here by @Cryoris: https://github.com/Qiskit/qiskit-terra/pull/5887#discussion_r664023701 Modify a copy of instruction instead of the same instance in circuit.data in QuantumCircuit.qasm() method. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In `QuantumCircuit.qasm()` method, when id is added to the instruction name to make it unique if it is the same as an existing instruction. See: https://github.com/Qiskit/qiskit-terra/blob/34b8079844fb19ee719015681184233afb4f9f72/qiskit/circuit/quantumcircuit.py#L1465-L1468 It currently modifies the circuit data directly, which is not ideal. We could just store a copy of the instruction where we modified the name instead of storing the same instance that lives in circuit.data. See comment here by @Cryoris: https://github.com/Qiskit/qiskit-terra/pull/5887#discussion_r664023701 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inconsistency in whether gates accept labels <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.19.dev - **Python version**: all - **Operating system**: all ### What is the current behavior? Not all defined `Gate` classes accept a label in their initialiser (e.g. `RXXGate`), and `QubitCircuit` is quite inconsistent on whether instruction methods accept a label: maybe about half (e.g. `QubitCircuit.x`) do, and about half (e.g. `QubitCircuit.h`) don't. ### Steps to reproduce the problem ```python >>> qc = QuantumCircuit(1) >>> qc.x(0, label=\"my_x\") <qiskit.circuit.instructionset.InstructionSet object at 0x7f9d60df81c0> >>> qc.h(0, label=\"my_h\") Traceback (most recent call last): File \"<stdin>\", line 1, in <module> TypeError: h() got an unexpected keyword argument 'label' ``` ```python >>> from qiskit.circuit.library import HGate, RZZGate >>> HGate(label=\"my_h\") <qiskit.circuit.library.standard_gates.h.HGate object at 0x7f9d90e77040> >>> RZZGate(0, label=\"my_rzz\") Traceback (most recent call last): File \"<stdin>\", line 1, in <module> TypeError: __init__() got an unexpected keyword argument 'label' ``` ### What is the expected behavior? Consistency. ### Suggested solutions Add the label kwarg everywhere. *edit*: this is a partial duplicate of #5098. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: oct2py v >= 0.3.1 doesn't need h5py anymore The octave magic docs/examples should update this information. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: set_custom_completer seems to be a no-op In [interactive_shell.py](https://github.com/ipython/ipython/blob/a2685d78f2403f84e6cb915ae11a4f6033ccc5f6/IPython/core/interactiveshell.py#L2034), `set_custom_completer` does self.Completer.matchers.insert(pos,newcomp) Looking at the source code of IPCompleter, though, [matchers](https://github.com/ipython/ipython/blob/eed56ba34aa3856b5726d60eedfe60a17e1c26c5/IPython/core/completer.py#L1114) seems to be a property returning an ephemeral list, so the insert is a no-op. To reproduce: import IPython def foo(*args, **kwargs): pass print(len(IPython.get_ipython().Completer.matchers)) IPython.get_ipython().set_custom_completer(foo, 0) print(len(IPython.get_ipython().Completer.matchers)) This should print the same number twice (in my version, 5, 5) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Swarm network can't use in docker-compose.yml I have two machines, In A, I crate the overlay network : `docker network create --driver overlay --attachable --subnet 172.40.0.0/16 docker3` In other machine, I want use it in the docker-compose.yml ``` networks: docker3: external: name: docker3 ``` and then I use command `docker-compose up -d` the result is ` ERROR: Network docker3 declared as external, but could not be found. Please create the network manually using docker network create docker3 and try again.` but I can use it in machines A, and use `docker run -d --net=docker3` in machines B Docker version 1.13.1 docker-compose version 1.11.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: DISCUSSION: Should dataset ID be set on datastore key? This question came up in the review in #282 while trying to define the \"correct\" behavior of `datastore.Key.__eq__`. The only remaining use of `Key._dataset_id` is in [`to_protobuf`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/b6d3e74a48e8554804ea3d33f53385bbbdb5c4b7/gcloud/datastore/key.py#L53) but #121 seems to indicate that the dataset ID is not needed on a `Key`. ISTM we should just remove `_dataset_id` from the `Key` class, even though it is returned in the protobuf after an entity is stored/retrieved. @pcostell WDYT? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: API Endpoints - Read-only - XCOM **Description** Hello We need to create several endpoints that perform basic read-only operations on **XCOM** . We need the following endpoints: - GET /dags/{dag_id}/taskInstances/{task_id}/{execution_date}/xcomValues - GET /dags/{dag_id}/taskInstances/{task_id}/{execution_date}/xcomValues/{key} For now, we focus only on read-only operations, but the others will also be implemented as the next step. Detailed information is available in the issue: https://github.com/apache/airflow/issues/8118 **Use case / motivation** N/A **Related Issues** N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: When auto_sceale_batch_size and auto_lr_find are both enabled, lr find is called with every batch search is this a bug or feature? I think lr find should be called after batch size search is done. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: boost library directory on Windows when binaries for more than one toolset version are installed On Windows I have installed the boost binaries for all combinations of architectures (32-bit/64-bit) and toolset versions (14.0/14.1) so in `C:\\Program Files\\boost\\boost_1_65_1` I have four library directories: - lib32-msvc-14.0 - lib32-msvc-14.1 - lib64-msvc-14.0 - lib64-msvc-14.1 when started in a x64 native tools command prompt for VS 2017, meson thinks it has found the Boost library directory as `C:\\Program Files\\boost\\boost_1_65_1\\lib64-msvc-14.0` whereas it should be `C:\\Program Files\\boost\\boost_1_65_1\\lib64-msvc-14.1` The [code](https://github.com/mesonbuild/meson/blob/master/mesonbuild/dependencies/misc.py#L256) is using globbing to find the first one, there is even a **FIXME** note; would it make sense to use [`compiler.c.get_toolset_version`](https://github.com/mesonbuild/meson/blob/master/mesonbuild/compilers/c.py#L1063) for that ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: NumPy 1.17 RC fails to compile with Intel C Compile 2016 <!-- Please describe the issue in detail here, and fill in the fields below --> Compiling NumPy 1.17.0rc2 sources with Intel C Compiler 2016, which does not yet implement `__builtin_cpu_supports(\"avx512f\")` fails with compilation error: ``` icc: numpy/core/src/umath/cpuid.c numpy/core/src/umath/cpuid.c(63): catastrophic error: invalid use of '__builtin_cpu_supports' compilation aborted for numpy/core/src/umath/cpuid.c (code 1) ``` Recent Intel C compiler (2019) proceeds just fine. There is config test to probe compiler for support of `__builtin_cpu_supports`, but the the test does not discriminate between supported arguments. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Incorrect documentation for CSWAP gate <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.17.0 - **Python version**: 3.8.8 - **Operating system**: Windows 8.1 ### What is the current behavior? The documentation for CSWAP gate incorrectly mentions it as a controlled-X gate. ### Steps to reproduce the problem See https://qiskit.org/documentation/stubs/qiskit.circuit.library.CSwapGate.html and here as well: https://qiskit.org/documentation/apidoc/circuit_library.html ### What is the expected behavior? The documentation should say that it is the controlled swap gate. ### Suggested solutions Update the appropriate docstring. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [docs] XLnet reference link bug in description of past_index Parameter of TrainingArguments XLnet reference link bug in description of past_index Parameter of TrainingArguments link to the doc: https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments **current description:** Some models like TransformerXL or **:doc`XLNet <../model_doc/xlnet>`** can make use of the past hidden states for their predictions. If this argument is set to a positive int, the Trainer will use the corresponding output (usually index 2) as the past state and feed it to the model at the next training step under the keyword argument mems. **expected description:** Some models like TransformerXL or **XLNet** can make use of the past hidden states for their predictions. If this argument is set to a positive int, the Trainer will use the corresponding output (usually index 2) as the past state and feed it to the model at the next training step under the keyword argument mems. ## Environment info Not required <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> ### Who can help @sgugger <!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @ If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**. Please tag fewer than 3 people. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Crash handler initialization is too aggressive We currently initialize the crash-handler first, before instantiating any classes. This means that any errors in startup will get a massive, largely meaningless, crash report, that obscures relevant information more than it helps. We should probably initialize the crash-handler _very last_, as part of the Application.start method, so that startup errors are raised as simple exceptions, rather than crashes. For instance, it's trivially easy to crash IPython right now, by simply giving invalid values for configurables: ``` ipython --colors=bananaphone ``` The crash report gives the incorrect impression that IPython has done something wrong. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Multiprocessing semantics in parallel.view.map I have a script that is executed using either - the builtin map - using multiprocessing map - IPython view.map. This is very convenient because I can easily debug and test scripts, as well as run the same script unchanged in different installations. However, the semantics of map is different. While in multiprocessing a generator is accepted, in IPython is not (fails when it tries to take the length of the generator). Insider multiprocessing, the following code converts a generator to a list: ``` if not hasattr(iterable, '__len__'): iterable = list(iterable) ``` I do not really like this behavior (`Explicit is better than implicit`), but having the same semantics is convenient. So, my questions are: 1.- Is it possible to have a `map` that does not require to know in advance the number of tasks? 2.- If not, what do you think about using the same semantics that `multiprocessing`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: print some message when installing that there is nothing to install ``` $ meson --prefix=/tmp/tmp The Meson build system Version: 0.34.0 Source dir: /home/zeenix/progs/meson Build dir: /home/zeenix/progs/meson/build Build type: native build Build machine cpu family: x86_64 Build machine cpu: x86_64 Project name: tutorial Native c compiler: ccache cc (gcc 6.2.1) Appending LDFLAGS from environment: '-L/jhbuild/lib ' Found pkg-config: /usr/bin/pkg-config (0.29) Native dependency gtk+-3.0 found: YES 3.22.1 Build targets in project: 1 [zeenix@zeelaptop build]$ ninja-build install -v [1/3] ccache cc '-Idemo@exe' '-fdiagnostics-color=always' '-I..' '-I.' '-pipe' '-Wall' '-Winvalid-pch' '-O0' '-g' '-pthread' '-I/jhbuild/include/gtk-3.0' '-I/jhbuild/include/at-spi2-atk/2.0' '-I/jhbuild/include/at-spi-2.0' '-I/jhbuild/include/gtk-3.0' '-I/jhbuild/include/gio-unix-2.0/' '-I/jhbuild/include/pango-1.0' '-I/jhbuild/include/harfbuzz' '-I/jhbuild/include/pango-1.0' '-I/jhbuild/include/atk-1.0' '-I/jhbuild/include/gdk-pixbuf-2.0' '-I/jhbuild/include/glib-2.0' '-I/jhbuild/lib/glib-2.0/include' '-I/usr/include/dbus-1.0' '-I/usr/lib64/dbus-1.0/include' '-I/usr/include/cairo' '-I/usr/include/pixman-1' '-I/usr/include/freetype2' '-I/usr/include/libpng16' '-I/usr/include/freetype2' '-I/usr/include/libdrm' '-I/usr/include/libpng16' '-MMD' '-MQ' 'demo@exe/main.c.o' '-MF' 'demo@exe/main.c.o.d' -o 'demo@exe/main.c.o' -c ../main.c [2/3] ccache cc -o demo 'demo@exe/main.c.o' '-Wl,--no-undefined' '-Wl,--as-needed' '-L/jhbuild/lib' '-L/jhbuild/lib' '-lgtk-3' '-lgdk-3' '-lpangocairo-1.0' '-lpango-1.0' '-latk-1.0' '-lcairo-gobject' '-lcairo' '-lgdk_pixbuf-2.0' '-lgio-2.0' '-lgobject-2.0' '-lglib-2.0' [2/3] '/usr/bin/python3' '/usr/bin/meson' '--internal' 'install' '/home/zeenix/progs/meson/build/meson-private/install.dat' [zeenix@zeelaptop build]$ ls /tmp/tmp/ ``` This doesn't help. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Compile and execute use a progress bar even if a single circuit is passed. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? The `compile` and `execute` functions make use of a progress bar for a single circuit. ### Steps to reproduce the problem ``` from qiskit import * from qiskit.tools.jupyter import TextProgressBar q = QuantumRegister(2) c = ClassicalRegister(2) qc = QuantumCircuit(q, c) qc.h(q[0]) qc.cx(q[0], q[1]) qc.measure(q, c) backend = Aer.get_backend('qasm_simulator') TextProgressBar() qobj = compile([qc], backend) ``` ### What is the expected behavior? A progress bar should not be used for a single circuit. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Visual studio default build project The first declared project in the visual studio solutions file is the \"start-up\" project, i.e. the default project. Should we have a `BUILD_ALL` project as the default project like cmake has? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: RFE: please provide color output in the tests listing With a long listing, it'd be nice to have the failing test name highlighted in red, and skipped test name highlighted in yellow, so it's easier to immediately see which tests were affected without looking at the result column. Also, this makes it easier to notice if anything failed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Upgrading JupyterLab to 0.34.1 causes crash on startup I tried to update the version of Jupyter Lab with conda, and after installing 0.34.1. the application does not start anymore, with the following error message appearing after any jupyter lab command: ``` >>> jupyter lab Traceback (most recent call last): File \"/Users/vilimstich/anaconda3/bin/jupyter-lab\", line 7, in <module> from jupyterlab.labapp import main File \"/Users/vilimstich/anaconda3/lib/python3.6/site-packages/jupyterlab/labapp.py\", line 32, in <module> app_version = get_app_version() File \"/Users/vilimstich/anaconda3/lib/python3.6/site-packages/jupyterlab/commands.py\", line 343, in get_app_version handler = _AppHandler(app_dir) File \"/Users/vilimstich/anaconda3/lib/python3.6/site-packages/jupyterlab/commands.py\", line 381, in __init__ self.info = self._get_app_info() File \"/Users/vilimstich/anaconda3/lib/python3.6/site-packages/jupyterlab/commands.py\", line 804, in _get_app_info info['extensions'] = extensions = self._get_extensions(core_data) File \"/Users/vilimstich/anaconda3/lib/python3.6/site-packages/jupyterlab/commands.py\", line 1068, in _get_extensions extensions = self._get_extensions_in_dir(self.sys_dir, core_data) File \"/Users/vilimstich/anaconda3/lib/python3.6/site-packages/jupyterlab/commands.py\", line 1094, in _get_extensions_in_dir url = data['repository'].get('url', '') AttributeError: 'str' object has no attribute 'get' ``` Reverting to 0.33.8 fixes the problem. I am running OS X. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ERROR: <ExternalLibrary libcrypto: True> is not a target. **Describe the bug** I get the error `ERROR: <ExternalLibrary libcrypto: True> is not a target.` when trying to setup the build directory for this simple project. **To Reproduce** meson.build ``` project('p', 'cpp') compiler = meson.get_compiler('cpp') libcrypto_dep = declare_dependency( include_directories: ['C:\\Qt\\Tools\\OpenSSL\\Win_x64\\include'], link_with: compiler.find_library('libcrypto', dirs: 'C:\\Qt\\Tools\\OpenSSL\\Win_x64\\lib')) executable('app', 'main.cpp', dependencies: [libcrypto_dep]) ``` main.cpp contains only an empty main() function. **Expected behavior** I think this should setup just fine, but maybe I am misunderstanding the declare_dependency() documentation or the error message?! **system parameters** * Native * Windows inside MSYS2 * Python: 3.10.6 * Meson: 0.63.1 * Ninja: 1.11.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [examples] should all examples support the predict stage? This is part of the ongoing effort to sync the example scripts. In https://github.com/huggingface/transformers/issues/10437#issuecomment-789090858 it was flagged that some scripts have test/predict, whereas others don't. Should we: A. have all scripts have train/eval/predict B. only have predict where it's desired @sgugger, @patil-suraj, @LysandreJik Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Take a look into normalizing the log levels of conan Currently, it's not clear whether verbose or notice/status is the default one, and if their order is correct. We should take a look into normalizing all the log levels to be consistent across Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Browser Check is Incorrectly Launching a Browser <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description https://github.com/jupyter-server/jupyter_server/pull/375 moved handling of the `open_browser` trait, which resulted in `python -m jupyterlab.browser_check` launching a visible browser instead of using the headless browser. <!--Describe the bug clearly and concisely. Include screenshots if possible--> ## Reproduce 1. `pip install jupyterlab==3.0.2` 2. `python -m jupyterlab.browser_check` 3. Notice that JupyterLab is launched in the browser <!--Describe step-by-step instructions to reproduce the behavior--> <!--Describe how you diagnosed the issue. See the guidelines at https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Expected behavior JupyterLab should not be launched in the browser <!--Describe what you expected to happen--> ## Context <!--Complete the following for context, and add any other relevant context--> - Operating System and version: - Browser and version: Version 87.0.4280.88 - JupyterLab version: 3.0.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: `AssertionError` with new `custom_jvp` for `jax.nn.relu` On this [commit](https://github.com/google/jax/commit/ca23be63fbaed20192cda5f921afe177ac8dcf4d) (currently just a few commits behind head, none of which look relevant), I'm finding that ```python import jax import jax.numpy as np import collections class F(collections.namedtuple(\"F\", [\"a\"])): def __call__(self, x): return jax.nn.relu(self.a) * x @jax.jit def g(f, x): return f(x) jax.grad(F(2.0))(0.) # works, returns DeviceArray(2., dtype=float32) jax.grad(g, argnums=(1,))(F(2.0), 0.) # AssertionError ``` hits an `AssertionError` on this line: https://github.com/google/jax/blob/1bb9aaa88c09a90a115c0304c05b0fc25932523b/jax/interpreters/partial_eval.py#L239 Commenting out the `@jax.jit` on `g` or replacing `jax.nn.relu(self.a)` with `np.maximum(self.a, 0)` both avoid the error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Setting environment variable on CLI raises exception when service has environment definition It looks like I can't set an environment variable in the fig.yml and on the console at the same time. fig version: `1.0.1` python version: `2.7 (homebrew)` OS: OSX `10.10.2` _fig.yml:_ ``` bliep: image: ubuntu:14.04 environment: - SECRET_KEY ``` _full output:_ ``` $ fig run -e BLA=bla bliep Traceback (most recent call last): File \"/usr/local/bin/fig\", line 9, in <module> load_entry_point('fig==1.0.1', 'console_scripts', 'fig')() File \"/usr/local/lib/python2.7/site-packages/fig/cli/main.py\", line 31, in main command.sys_dispatch() File \"/usr/local/lib/python2.7/site-packages/fig/cli/docopt_command.py\", line 21, in sys_dispatch self.dispatch(sys.argv[1:], None) File \"/usr/local/lib/python2.7/site-packages/fig/cli/command.py\", line 28, in dispatch super(Command, self).dispatch(*args, **kwargs) File \"/usr/local/lib/python2.7/site-packages/fig/cli/docopt_command.py\", line 24, in dispatch self.perform_command(*self.parse(argv, global_options)) File \"/usr/local/lib/python2.7/site-packages/fig/cli/command.py\", line 56, in perform_command handler(project, command_options) File \"/usr/local/lib/python2.7/site-packages/fig/cli/main.py\", line 312, in run service.options['environment'][k] = v TypeError: list indices must be integers, not unicode ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: MSBuild /bl flag for Binary Logging MSBuild has a command line flag to activate the output of a Binary Log that can replay builds to gather diagnostics on builds. I would be really useful to add this utility to the MSBuild helper. [MSBuild Binary Log Docs](https://github.com/Microsoft/msbuild/blob/master/documentation/wiki/Binary-Log.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: `additional_special_tokens` is replaced instead of being updated ### Reproduction ``` from transformers import T5Tokenizer from transformers.tokenization_utils import AddedToken tokenizer = T5Tokenizer.from_pretrained(\"t5-small\", extra_ids=0, additional_special_tokens=[\"new_token_1\"]) print(tokenizer.additional_special_tokens) print(tokenizer.added_tokens_encoder) tokenizer.add_special_tokens({\"additional_special_tokens\": [\"new_token_2\"]}) print(tokenizer.additional_special_tokens) print(tokenizer.added_tokens_encoder) tokenizer.add_special_tokens({\"additional_special_tokens\": [\"new_token_3\"]}) print(tokenizer.additional_special_tokens) print(tokenizer.added_tokens_encoder) ``` gives ``` ['new_token_1'] {'new_token_1': 32000} ['new_token_2'] {'new_token_1': 32000, 'new_token_2': 32001} ['new_token_3'] {'new_token_1': 32000, 'new_token_2': 32001, 'new_token_3': 32002} ``` ### Expected behavior We should get ['new_token_1', 'new_token_2', 'new_token_3'] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Logging: '_BaseEntry' missing fields added to 'LogEntry' in API [LogEntry](https://cloud.google.com/logging/docs/reference/v2/rest/v2/LogEntry) defines several additional fields which are dropped by [_BaseEntry](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/logging/google/cloud/logging/entries.py#L51) - [LogEntry](https://cloud.google.com/logging/docs/reference/v2/rest/v2/LogEntry) shows ``` \"receiveTimestamp\": string, \"traceSampled\": boolean, \"sourceLocation\": { object(LogEntrySourceLocation) }, ``` but those are not set on init of [entries.py](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/logging/google/cloud/logging/entries.py#L87) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conanfile.py is silently deleted by \"conan source\" Clone the test repo: ``` git clone https://github.com/db4/conan-scm_test.git ``` Execute ``` conan install . -if build conan source . -if build ``` The latter command silently removes `conanfile.py`. Why? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Shorten nox session names Suggestions: - `nox -s \"unit_tests(python_version='3.6')\"` becomes `nox -s \"unit(py='3.6')\"` - `nox -s \"system_tests(python_version='3.6')\"` becomes `nox -s \"system(py='3.6')\"` This is not important, but should be able to do in a few minutes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Print configuration in output for install/create I find it a bit tricky to debug and find the used settings, specially in traces of CI. And tracing back to a profile file, might still fail to see if some setting or option was overwritten in the command line. Maybe it would be useful to print it to output for these commands. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Resuming training from a checkpoint on Windows does not resume at the correct global_step ### Who can help Trainer: @sgugger ## Information I've noticed that resuming training from a checkpoint on Windows fails to start at the right global step (though learning rate, loss, etc continue from where the training left off). The same doesn't happen under macOS. ## Solution? I think the issue is in Trainer.train, specifically this line: `self.global_step = int(model_path.split(\"-\")[-1].split(\"/\")[0])` And it seems to work as expected by swapping `\"/\"` with `os.sep` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: fix deps cache always invalidated Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Use CTuple traitlet for Widget children Linked to #5199 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose does not pass environment variables true/false unchanged docker-compose does not pass environment variable 'true', 'false', 'yes', 'no' (without quotes) unchanged to the container. YML parser recognizes these values as a boolean and converts them to either True or False. This is confusing since environment variables are generally just a string. I would expect all values to be passed to the container exactly as defined in the yml file as if they were a string. Simple work around is to force them to be a string by quoting all environment variables. test.sh ``` echo $SHOW ``` docker-compose.yml ``` test: image: ubuntu environment: SHOW: true command: sh /tmp/test.sh volumes: - './test.sh:/tmp/test.sh' ``` Expected Output: ``` test_1 | true ``` Actual Output: ``` test_1 | True ``` ## Work Around: Put all environment variables in quotes to force it to behave as a string. ``` test: image: ubuntu environment: SHOW: 'true' command: sh /tmp/test.sh volumes: - './test.sh:/tmp/test.sh' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [nginx] Incorrectly reporting vts stats and nginxplus as gauge instead of rate The agent check code always uses gauge to report any number found in the vts/nginxplus json. Those numbers are in reality ever increasing total counters, wich makes the gauge useless in datadog. Some keys (for example the requests/sec) are correctly hard-coded as a rate metric. A recent commit also added for some keys a count variant, but this makes no sense as they are running totals and not counter values. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: KubeFlow Pipeline example notebook is half way updated for 0.1.4 The notebook: [KubeFlow Pipeline Using TFX OSS Components.ipynb](https://github.com/kubeflow/pipelines/blob/master/samples/notebooks/KubeFlow%20Pipeline%20Using%20TFX%20OSS%20Components.ipynb) is updated to have `.apply(gcp.use_gcp_secret('user-gcp-sa'))` to every container but all other content is written for 0.1.3-rc.2 release. To me, this notebook is the most useful reference for the pipeline creation and execution process and it is currently broken. Simply updating the `pip3 install kfp` to 0.1.4 do not fix the issues with that notebook. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Use of python_requires with enabled short_paths fails In Windows conan fails when a recipe uses `python_requires` and `short_paths = True` at the same time. To reproduce the issue, it's enough to just add `short_paths = True` into the consumer conanfile of the `python_requires` example. Conan will end with ``` ERROR: Error while trying to get recipe sources for pyreq/version@user/channel. No remote defined ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Attribute error on logical operations The following snippet: ```meson if true and true or true message('Works') endif ``` results in the following exception: AttributeError: 'AndNode' object has no attribute 'subdir' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ECRGate has wrong definition and doesn't implement RZX(pi/2) ### Environment - **Qiskit Terra version**: 0.22 - **Python version**: all - **Operating system**: all ### What is happening? The `ECRGate` documentation says it is supposed to implement a `RZX(pi.2)` gate, which as described in [Sheldon et al. PRA 2016](https://journals.aps.org/pra/abstract/10.1103/PhysRevA.93.060302) as the pulse sequence ``` ┌───────────┐┌───┐┌────────────┐┌───┐ q_0: ┤0 ├┤ X ├┤0 ├┤ X ├ │ Rzx(π/4) │└───┘│ Rzx(-π/4) │└───┘ q_1: ┤1 ├─────┤1 ├───── └───────────┘ └────────────┘ ``` However the current definition of `ECRGate` is missing the last X gate in its decompostion and is implemented as ``` ┌───────────┐┌───┐┌────────────┐ q_0: ┤0 ├┤ X ├┤0 ├ │ Rzx(π/4) │└───┘│ Rzx(-π/4) │ q_1: ┤1 ├─────┤1 ├ └───────────┘ └────────────┘ ``` which doesn't implement a `RZX(pi/2) = (II -1j * ZX)/sqrt(2)` gate, it instead implements the unitary `(IX - XY) /sqrt(2)` ### How can we reproduce the issue? ``` qi.SparsePauliOp.from_operator(ECRGate()) SparsePauliOp(['IX', 'XY'], coeffs=[ 0.70710678+0.j, -0.70710678+0.j]) ``` ### What should happen? If the ECR is supposed to be implemented as described in [Sheldon et al. PRA 2016](https://journals.aps.org/pra/abstract/10.1103/PhysRevA.93.060302) it should implement an RZXGate(pi/2). ### Any suggestions? To make it match the paper definition, one just needs to add the final X gate added to its decomposition definition and update its matrix definition Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qubit_lo_range and meas_lo_range are still in GHz in the configuration <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? The qubit and meas lo ranges are in Hz rather than GHz ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: fig can not start with tls env I have installed fig 1.0.0 on my mac, but I can not start fig now. My env: Boot2Docker 1.3 on Mac ➜ figtest env |grep DOCKER DOCKER_HOST=tcp://192.168.59.103:2376 DOCKER_CERT_PATH=/Users/linux_china/.boot2docker/certs/boot2docker-vm DOCKER_TLS_VERIFY=1 ➜ figtest fig up Traceback (most recent call last): File \"/usr/local/bin/fig\", line 8, in <module> load_entry_point('fig==1.0.0', 'console_scripts', 'fig')() File \"/Library/Python/2.7/site-packages/fig/cli/main.py\", line 31, in main command.sys_dispatch() File \"/Library/Python/2.7/site-packages/fig/cli/docopt_command.py\", line 21, in sys_dispatch self.dispatch(sys.argv[1:], None) File \"/Library/Python/2.7/site-packages/fig/cli/command.py\", line 28, in dispatch super(Command, self).dispatch(_args, *_kwargs) File \"/Library/Python/2.7/site-packages/fig/cli/docopt_command.py\", line 24, in dispatch self.perform_command(*self.parse(argv, global_options)) File \"/Library/Python/2.7/site-packages/fig/cli/command.py\", line 49, in perform_command verbose=options.get('--verbose')) File \"/Library/Python/2.7/site-packages/fig/cli/command.py\", line 78, in get_project self.get_client(verbose=verbose)) File \"/Library/Python/2.7/site-packages/fig/cli/command.py\", line 54, in get_client client = docker_client() File \"/Library/Python/2.7/site-packages/fig/cli/docker_client.py\", line 31, in docker_client ca_cert=ca_cert, TypeError: **init**() got an unexpected keyword argument 'assert_hostname' ➜ figtest Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: T5 has no module ```torch_xla``` when using T5 fine-tuned on SQUADv2 # 🐛 Bug ## Information I get this error: ``` ModuleNotFoundError: No module named 'torch_xla'``` Full error message: ``` 2 3 tokenizer = AutoTokenizer.from_pretrained(\"mrm8488/t5-base-finetuned-squadv2\") ----> 4 model = AutoModelWithLMHead.from_pretrained(\"mrm8488/t5-base-finetuned-squadv2\") 5 6 def get_answer(question, context): 1 frames /usr/local/lib/python3.6/dist-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs) 796 797 if hasattr(config, \"xla_device\") and config.xla_device: --> 798 import torch_xla.core.xla_model as xm 799 800 model = xm.send_cpu_data_to_device(model, xm.xla_device()) ModuleNotFoundError: No module named 'torch_xla' ``` ## To reproduce ```python from transformers import AutoModelWithLMHead, AutoTokenizer tokenizer = AutoTokenizer.from_pretrained(\"mrm8488/t5-base-finetuned-squadv2\") model = AutoModelWithLMHead.from_pretrained(\"mrm8488/t5-base-finetuned-squadv2\") def get_answer(question, context): input_text = \"question: %s context: %s </s>\" % (question, context) features = tokenizer([input_text], return_tensors='pt') output = model.generate(input_ids=features['input_ids'], attention_mask=features['attention_mask']) return tokenizer.decode(output[0]) context = \"Manuel have created RuPERTa-base with the support of HF-Transformers and Google\" question = \"Who has supported Manuel?\" get_answer(question, context) ``` I used this example code a few weeks ago and had no problem... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [BigQuery] Feature Request - An easy way to get a QueryResults from a QueryJob Problem: There isn't an easy way to fetch the row results of a `client.run_async_query(job_id, query)` call. I have to do some yucky stuff to get it to work in a sample I'm working on. ``` python client = bigquery.Client() query_job = client.run_async_query(str(uuid.uuid4()), query) query_job.use_legacy_sql = False query_job.begin() wait_for_job(query_job) query_results = bigquery.query.QueryResults('', client) query_results._properties['jobReference'] = { 'jobId': query_job.name, 'projectId': query_job.project } ``` Possible Solutions: - Modify constructor for QueryResults or add a class function to take an optional job object. - Add a method to QueryJob `get_query_results()` that does this same yuckiness (modifying the internal `_properties`) I'm sure there are other solutions, too, which is why I'm asking for input rather than going off and trying to fix right away. Reference: - QueryJob: [https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/bigquery/job.py#L933](https://github.com/GoogleCloudPlatform/gcloud-python/blob/6c49c54e94f79ef544ef75e6d7f2470f04656d3c/gcloud/bigquery/job.py#L933) - QueryResults: [https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/bigquery/query.py#L42](https://github.com/GoogleCloudPlatform/gcloud-python/blob/6c49c54e94f79ef544ef75e6d7f2470f04656d3c/gcloud/bigquery/query.py#L42) - Docs: https://raw.githubusercontent.com/GoogleCloudPlatform/gcloud-python/master/docs/bigquery-usage.rst Notice the async query does not show fetching row results. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Should Bucket.copy_blob be moved over to Blob? /cc @tseaver Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: [bug] remove frame introspection Currently breaking master, creating pickling errors. Instead saving params will have to be done explicitly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CMake generators including .cmake in builddirs Some packages like `Protoc` require to export some CMake macros. Typically these macros are declared in the `findXXX` script when calling `find_package`, but packages in the new conan-center index, read [#KB-H016](https://github.com/conan-io/conan-center-index/wiki/Error-Knowledge-Base), doesn't allow to export `findXXX` or `configXXX` files. So, there should be a way that a package like `protoc` can declare some macros to be reused by the consumers. For example when: - Calling `conan_basic_setup()` - Calling `find_package` and using a generated by conan find/module script. These `cmake` files to be imported should be located in a `build_dir` https://docs.conan.io/en/latest/reference/conanfile/attributes.html#cpp-info But I don't think we can import all of them automatically without breaking something, it should be or an opt-in mechanism in the recipe or a file name convention, like `conan_export*.cmake` or similar? We need to discuss it @memsharded @jgsogo @uilianries @SSE4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Compd should have command lines for all the compilers I didn't see another bug that quite matched this request, so hopefully it's not a dup :) What we need in Builder to improve our Vala support while running with the Meson build system is to get the compiler flags for `valac`. In particular, we're looking for those `--pkg gtk+-3.0 --pkg gio-2.0` type compiler flags. We need these to prime `libvala` so that we can get relevant auto-completion results. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: cannot load qasms containing delay e.g. ```c OPENQASM 2.0; include \"qelib1.inc\"; qreg q[4]; creg meas[4]; delay(172) q[1]; u3(1.955526,-3.9994262,1.5396532) q[1]; ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %%px? doesn't work, shows info for %px, general cell magic problem The px cell magic was implemented as a different function than the line magic. At first I thought this shouldn't work, but in fact it does. However, the introspection machinery gets completely confused, meaning that the %%px magic is much harder to use than it should, since users can't easily read its docstring. The problem is NOT in the magic itself, it's in the introspection code that didn't take this case into consideration. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Tries to write system files [`_get_config`](https://github.com/jupyterlab/jupyterlab/blob/f3c9838676eb7276069d04d4745d606d17307538/jupyterlab/commands.py#L222-L223) tries to write to [`_get_config_dir()`](https://github.com/jupyterlab/jupyterlab/blob/f3c9838676eb7276069d04d4745d606d17307538/jupyterlab/commands.py#L251-L252), which uses [`ENV_CONFIG_PATH`](https://github.com/jupyter/jupyter_core/blob/ebba39caec9e743f99d3ba8f6eb21c743dda99e0/jupyter_core/paths.py#L177), which isn’t a writable location. why don’t you use <code>[jupyter_config_path](https://github.com/jupyter/jupyter_core/blob/ebba39caec9e743f99d3ba8f6eb21c743dda99e0/jupyter_core/paths.py#L180)()[0]</code>? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Compose file version 3.2 is unsupported - v1.12.0-rc2 I'm trying to use the new Compose long syntax ports ``` version: '3.2' ... ports: - target: 50020 published: 50020 protocol: tcp mode: host - target: 50010 published: 50010 protocol: tcp mode: host ... ``` Getting following error on docker-compose build ``` ERROR: Version in \"./docker-compose.yml\" is unsupported. You might be seeing this error because you're using the wrong Compose file version. Either specify a supported version (\"2.0\", \"2.1\", \"3.0\", \"3.1\") and place your service definitions under the `services` key, or omit the `version` key and place your service definitions at the root of the file to use version 1. For more on the Compose file format versions, see https://docs.docker.com/compose/compose-file/ ``` Docker Compose version ``` docker-compose version 1.12.0-rc2, build 08dc2a4 docker-py version: 2.1.0 CPython version: 2.7.13 OpenSSL version: OpenSSL 1.0.1t 3 May 2016 ``` Docker version ``` Client: Version: 1.13.1 API version: 1.26 Go version: go1.7.5 Git commit: 092cba3 Built: Wed Feb 8 06:50:14 2017 OS/Arch: linux/amd64 Server: Version: 1.13.1 API version: 1.26 (minimum version 1.12) Go version: go1.7.5 Git commit: 092cba3 Built: Wed Feb 8 06:50:14 2017 OS/Arch: linux/amd64 Experimental: false ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: `jupyterlab` doesn't recognize `nodejs` and `npm` installations Hi, I'm having troubles installing the `jupyterlab_bokeh` extension. ``` $ jupyter labextension install jupyterlab_bokeh Errored, use --debug for full output: ValueError: Please install nodejs and npm before continuing installation. nodejs may be installed using conda or directly from the nodejs website. ``` I'm using a virtual environment (`pyenv` plus `pyenv-virtualenvwrapper`). I've tried to install the two packages first on my local OS (Ubuntu 16.04) and reinstalled `jupyterlab` but that didn't help. I've also tried to install both `nodejs` and `npm` via `pip` on the virtual enviroment, after having uninstalled the packages on my OS just to make sure they were not conflicting. Unfortunately, neither of the tentative succeeded. The weird thing is that if I type the `nodejs` command on my terminal, I can access a `nodejs` REPL. ``` bokeh==0.12.13 jupyter-client==5.2.1 jupyter-core==4.4.0 jupyterlab==0.31.1 jupyterlab-launcher==0.10.2 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: control_channels incorrect documentation in Pulse <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? From the [Pulse documentation](https://qiskit.org/documentation/apidoc/pulse.html#channels) on Channels, the method `control_channels(*qubits)` is defined as \"Return `AcquireChannel` for `qubit` on the active builder backend.\" I expect the correct definition to be \"Return `ControlChannel` for `qubit` on the active builder backend.\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Boost Python library detection is incompatible with Boost 1.67 and later In Boost 1.67, Boost changed their naming scheme for the shared libraries they compile for Boost Python. All libraries are now named according to the Python interpreter they were compiled against. From the [Boost 1.67.0 changelog](https://www.boost.org/users/history/version_1_67_0.html): ``` The library name now includes the version suffix of the Python version used to compile it. For example, a variant compiled with Python 2.7 will produce library names boost_python27 and boost_numpy27, etc.. Combined with a related fix in Boost.Build, this means that it is now possible to build variants for multiple Python versions in a single build process. ``` This breaks Meson's Boost Python detection since it looks for a shared library [named just boost_python with no suffix](https://github.com/mesonbuild/meson/blob/master/mesonbuild/dependencies/boost.py#L550). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: CLI: `airflow dags test { dag w/ schedule_interval=None } ` error: \"No run dates were found\" ### Apache Airflow version 2.2.0b2 (beta snapshot) ### Operating System ubuntu 20.04 ### Versions of Apache Airflow Providers n/a ### Deployment Virtualenv installation ### Deployment details pip install /path/to/airflow/src ### What happened Given any DAG initialized with: `schedule_interval=None` Run `airflow dags test mydagname $(date +%Y-%m-%d)` and get an error: ``` INFO - No run dates were found for the given dates and dag interval. ``` This behavior changed in https://github.com/apache/airflow/pull/15397, it used to trigger a backfill dagrun at the given date. ### What you expected to happen I expected a backfill dagrun with the given date, regardless of whether it fit into the `schedule_interval`. If AIP-39 made that an unrealistic expectation, then I'd hope for some way to define unscheduled dags which can still be tested from the command line (which, so far as I know, is the fastest way to iterate on a DAG.). As it is, I keep changing `schedule_interval` back and forth depending on whether I want to iterate via `astro dev start` (which tolerates `None` but does superfluous work if the dag is scheduled) or via `airflow dags test ...` (which doesn't tolerate `None`). ### How to reproduce Initialize a DAG with: `schedule_interval=None` and run it via `airflow dags test mydagname $(date +%Y-%m-%d)` ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: ShardedDeviceArray access should be threadsafe This used to be the case, but I broke it in https://github.com/google/jax/commit/07571ae4dd3fceee580aa49c4490f99ce7f6b6de here: https://github.com/google/jax/blob/master/jax/interpreters/pxla.py#L499 (self._npy_value may be accessed by another thread before it's populated). I'm planning to fix this today or Monday. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Mutable default value for `model_kwargs` in `pipeline` function https://github.com/huggingface/transformers/blob/a14d62b0b11e6cb0c64059606e4f8dbf78e40e41/src/transformers/pipelines/__init__.py#L311 Is this intentional? I noticed the default is an empty dict but inspecting the signature in an interactive session showed that the dictionary was mutated: ``` Signature: trf.pipeline( task: str, model: Optional = None, config: Union[str, transformers.configuration_utils.PretrainedConfig, NoneType] = None, tokenizer: Union[str, transformers.tokenization_utils.PreTrainedTokenizer, NoneType] = None, feature_extractor: Union[str, ForwardRef('SequenceFeatureExtractor'), NoneType] = None, framework: Optional[str] = None, revision: Optional[str] = None, use_fast: bool = True, use_auth_token: Union[bool, str, NoneType] = None, model_kwargs: Dict[str, Any] = {'use_auth_token': None}, **kwargs, ) -> transformers.pipelines.base.Pipeline ``` This can cause some headaches because the default value references the same dict object all the time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: polyfit reference: definition of 'residuals' Returns: residuals, rank, singular_values, rcond : Present only if full = True. Residuals of the least-squares fit... The 'residuals' returned is the sum of (the square of each residual) (i.e. one number in an array). It would be useful to actually return the array of all the residuals; if not that, then documentation should be changed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add option to reverse qubit order when drawing circuits <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Currently, qubits registers are displayed with their lower bits in the top; the flag would allow the order to be reversed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Cache-Control being set twice for no_cache_paths Whether browsers pick the first or last instance of a repeat header is ill defined. Some will pick the first (Firefox) and wind up caching custom.js practically forever (or until notebook server restart) and others will pick the latter and behave as intended.  PR with the fix in a moment. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Reenable jedi by default 8 months ago, in #11076, Jedi was disabled because an issue was still present that was in a new release “weeks later”. We should reenable it already! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Make shell completion DRYer and less hacky Thanks to @albers and @sdurrheimer, we now have both bash and zsh completion, which is fantastic. However, they (understandably) both do a lot of hacky stuff to read the YAML file without actually parsing YAML properly, and they both implement this separately. We could potentially add some commands/flags to Compose that would give them the information they need in a simple shell-parseable format. Going off a quick scan of the [bash script](https://github.com/docker/compose/blob/master/contrib/completion/bash/docker-compose), it looks like it'd be useful to be able to list: - [x] names of all services in the file - [ ] names of all services that have a given configuration option set - here, we'd even be able to evaluate `extends` to get the correct configuration, which I doubt would be any fun at all to implement in shell script - [ ] names of services that have at least one running container - [ ] names of services that have at least one stopped container Perhaps a `docker-compose services` command: ``` $ docker-compose services web redis $ docker-compose services --with-option=\"build\" web $ docker-compose services --with-running-container redis ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Updates to `nditer` docs? I was looking through the instructions on how to use `flags=['multi_index']` at https://docs.scipy.org/doc/numpy/reference/arrays.nditer.html#tracking-an-index-or-multi-index. The recommended way of doing ``` it = np.nditer(a, flags=['multi_index'], op_flags=['writeonly']) with it: while not it.finished: it[0] = it.multi_index[1] - it.multi_index[0] it.iternext() ``` seems a bit stilted and unpythonic, given that you can avoid iterating manually at all: ``` it = np.nditer(a, flags=['multi_index'], op_flags=['writeonly']) with it: for x in it: x[...] = it.multi_index[1] - it.multi_index[0] ``` This description appears for all versions at least up to 1.16.0. I agree that the alternative looping notation should be mentioned, perhaps in a section on \"Fine Grained Loop Control\" or \"Alternative Iteration Method\" or something similar, but it's not necessary to show the feature as the only way of iterating with an index. If my suggestion meets with a favorable response, I'd be happy to submit a patch. Or I can do that if you just want to see whatI had in mind. This issue is based on my answer to https://stackoverflow.com/q/54220875/2988730 Another item that came up in the same answer is that at least in version 1.12.0, `nditer` was not a context manager and did not have a close method. I propose adding some `since 1.1....` tags in a few places to document this explicitly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: x-smart-recreate crashes when modified image name/tag Just got this error with docker-compose 1.3.0rc2 : ``` $ docker-compose up --x-smart-recreate Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.main\", line 31, in main File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.docopt_command\", line 21, in sys_dispatch File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.command\", line 34, in dispatch File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.docopt_command\", line 24, in dispatch File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.command\", line 66, in perform_command File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.main\", line 469, in up File \"/code/build/docker-compose/out00-PYZ.pyz/compose.project\", line 221, in up File \"/code/build/docker-compose/out00-PYZ.pyz/compose.project\", line 261, in _get_convergence_plans File \"/code/build/docker-compose/out00-PYZ.pyz/compose.service\", line 285, in convergence_plan File \"/code/build/docker-compose/out00-PYZ.pyz/compose.service\", line 299, in _containers_have_diverged File \"/code/build/docker-compose/out00-PYZ.pyz/compose.service\", line 415, in config_hash File \"/code/build/docker-compose/out00-PYZ.pyz/compose.service\", line 420, in config_dict TypeError: 'NoneType' object has no attribute '__getitem__' ``` Resolved after `docker-compose pull` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Framechange instruction being converted to string with `as_dict` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Currently, frame change instructions are being converted to a string with as_dict. ### Steps to reproduce the problem Assemble a pulse qobj with a framechange instruction. call `qobj.as_dict()` and examine the `phase` parameter of the framechange instruction. ### What is the expected behavior? Phase parameter should be a float. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse drawer omits to plot specified channels when it is empty <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Pulse drawer omits to plot specified channels when it is empty. ### Steps to reproduce the problem ``` from qiskit.test.mock import FakeProvider import qiskit.pulse as pulse provider = FakeProvider() backend = provider.get_backend('fake_openpulse_2q') device = pulse.DeviceSpecification.create_from(backend) meas_pulse = pulse_lib.gaussian_square(duration=2000, amp=0.02, sigma=4, risefall=25, name='meas_pulse') acq_cmd=pulse.Acquire(duration=2000) sched = pulse.Schedule(name='gnd_q12') sched |= meas_pulse(device.q[0].measure) | acq_cmd(device.q, device.mem) << 100 sched.draw(channels_to_plot=[device.q[0].drive, device.q[0].measure], scaling=20.0, plot_range=(0, 200), plot_all=True) ``` The result omits to plot `d0` channel although it is specified in `channels_to_plot`. ### What is the expected behavior? All channels specified in `channels_to_plot` should be visualized. ### Suggested solutions qiskit.visualization.pulse.matplotlib.ScheduleDrawer._build_channels should receive `channels_to_plot`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Wrong logic in `batch_encode_plus()` # 🐛 Bug I'm trying to use `batch_encode_plus()` with already tokenized ID as input. So I have a `list of list of int` as input. For example : ```python x = [[0, 83, 313, 11, 10551, 2278, 16, 2183, 1958, 804, 7, 916, 11, 13933, 982, 4, 286, 68, 5046, 6, 37, 40, 3627, 231, 2697, 9, 1958, 11, 41, 36027, 27894, 1001, 21466, 424, 2233, 4, 2], [0, 20, 291, 212, 13989, 191, 3772, 42, 983, 4, 815, 34, 1714, 8617, 187, 63, 17692, 11, 8008, 4, 993, 864, 549, 1492, 2624, 5391, 9686, 8, 12291, 240, 7, 464, 4, 2]] ``` When I call `batch_encode_plus()` with this input, I receive `AssertionError` : ``` tokenizer.batch_encode_plus(x) # >>> line 1130, in batch_encode_plus # assert len(ids_or_pair_ids) == 2 ``` --- After reviewing the code, it seems there is an error in the logic. Here : https://github.com/huggingface/transformers/blob/b370cc7e99c5b8c7436154d4694c33b461ea0f08/src/transformers/tokenization_utils.py#L1128-L1137 since I gave only tokenized ID and not a tuple of tokenized ID (not a pair), the logic should bring me to the `else` clause. But instead, I enter the `if` clause, leading to the assertion error. **It's currently not possible to use `batch_encode_plus()` with already tokenized text / IDs** if the input is not a pair. --- I think this line : https://github.com/huggingface/transformers/blob/b370cc7e99c5b8c7436154d4694c33b461ea0f08/src/transformers/tokenization_utils.py#L1129 Should be changed to this : ```python if isinstance(ids_or_pair_ids, (list, tuple)) and len(ids_or_pair_ids) == 2: ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Schedule plot parameter `channels_to_plot` should be `channels` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The parameter `channels_to_plot` should be `channels` for `schedule.draw`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Pyinstaller has issues with signals There's a bunch of history in #1040 and #2055. We've tried multiple implementations of signal handlers, but each has their own set of issues, but **ONLY** when run from the frozen binary created by pyinstaller. It looks like there is a very old issue in pyinstaller around this: https://github.com/pyinstaller/pyinstaller/issues/208 These problems can manifest in three ways: - a `thread.error` when a signal interrupts a thread lock - the signal handlers being completely ignored and raising a `KeynoardInterupt` instead - the signal handlers being registered but the try/except to handle the except is skipped (this could be caused by the signal firing multiple times for a single `ctrl-c`, but I can't really verify that's what is happening) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: CoNLL2003 ner_tags order mismatch between the dataset from HF and the pretrained model @patrickvonplaten @dslim23 @dslim23 's pretrained models such as: https://huggingface.co/dslim/bert-base-NER have the following NER tag order baked in: `\"O\", \"B-MISC\", \"I-MISC\", \"B-PER\", \"I-PER\", \"B-ORG\", \"I-ORG\", \"B-LOC\", \"I-LOC\"` while the https://huggingface.co/datasets/conll2003 dataset has: `O (0), B-PER (1), I-PER (2), B-ORG (3), I-ORG (4) B-LOC (5), I-LOC (6) B-MISC (7), I-MISC (8)` The mismatch leads to defunct accuracy measurements out of the box for the pretrained NER models; try, for instance: `python examples/pytorch/token-classification/run_ner.py --model_name_or_path dslim/bert-base-NER --dataset_name conll2003 --output_dir /tmp/test-ner --do_eval` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud happybase port violates happybase license hello, happybase author here. the gcloud happybase port violates my software's license. i do not like this. the happybase license (mit+apache) is quite clear: > the above copyright notice and this permission notice shall be > included in all copies or substantial portions of the software. http://happybase.readthedocs.io/en/latest/license.html however, i don't see my name, the required notice, or even a small \"thanks\" or whatever, anywhere, neither in the gcloud docs, nor in the distributed software package itself. the happybase port that is distributed with hbase contains considerable amounts of code written by me (for instance the whole api, and the implementation of connection pooling and other features is the same). and even though various docstrings have been partially adapted, proper attribution is in order here as well. please fix this ASAP since this is NOT ok at all. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: error reporting still broken at 0.24 After updating to 0.24 to fix https://github.com/GoogleCloudPlatform/google-cloud-python/issues/3167 I'm still unable to report exceptions. Ubuntu xenial w/ Python 3.5.2 ```python client.report_exception(http_context=error_reporting.build_flask_context(flask.request)) ``` On google-cloud-error-reporting <0.23 the above line works fine. At 0.24 I get: ```python Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/cloud/error_reporting/client.py\", line 347, in report_exception Apr 1 15:52:51 user=user) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/cloud/error_reporting/client.py\", line 276, in _send_error_report Apr 1 15:52:51 self.report_errors_api.report_error_event(error_report) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/cloud/error_reporting/_gax.py\", line 75, in report_error_event Apr 1 15:52:51 ParseDict(error_report, error_report_payload) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/protobuf/json_format.py\", line 384, in ParseDict Apr 1 15:52:51 parser.ConvertMessage(js_dict, message) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/protobuf/json_format.py\", line 415, in ConvertMessage Apr 1 15:52:51 self._ConvertFieldValuePair(value, message) Apr 1 15:52:51 File \"/usr/local/lib/python3.5/dist-packages/google/protobuf/json_format.py\", line 501, in _ConvertFieldValuePair Apr 1 15:52:51 raise ParseError('Failed to parse {0} field: {1}'.format(name, e))\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CUDA can't build project with external dependencies When building a CUDA project the CUDA compiler/linker compiles and links only the CUDA code. To compiler and link the C/C++ code the CUDA compiler calls the system compiler and linker. Passing arguments through the CUDA compiler/linker to the system/linker is done by wrapping these arguments with special prefixes. Currently meson doesn't do this. Which means that the system linker doesn't get the '-L' and '-l' flags and linking fails. When CUDA encounters flags it doesn't support (and were meant for the system compiler linker) it bails. This basically means that com;piling CUDA projects with external dependencies is broken. I am preparing a pull request to fix this issue. This issue was opened just to make sure every thing is done by the book. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Classical bit string in strange format for real device. I have a three bit classical register and receive a 5 bit string as output. This always seems to include two bit that are always 0, but they aren't always in the same place. I cannot determine the logic behind it. I think it related to, but not exactly the same as, this issue https://github.com/IBM/qiskit-sdk-py/issues/2 More info can be found in my post to the QX community https://quantumexperience.ng.bluemix.net/qstage/#/community/question?questionId=3fde5ace6866eb41eba24fae2ce4dce3 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Volumes override doesn't work I have both docker-compose.yml and its override file. The essential part of the content is: docker-compose.yml: ``` version: \"3\" services: web: volumes: - \"../app:/var/www/drupal:ro\" ``` docker-compose.override.yml: ``` version: \"3\" services: web: volumes: - \"../app:/var/www/drupal:rw\" - \"./environments/local/data/composer:/home/developer/.composer:rw\" ``` For some reason the override for `../app` doesn't work - it is mounted in **ro** mode. But if comment out the second line (`- \"./environments/local/data/composer:/home/developer/.composer:rw\"`) all of a sudden it starts seeing the override and works correctly. I don't see any logic in this behavior. Any ideas? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: NLopt install instructions are outdated ### What should we add? The NLopt installation instructions here https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/algorithms/optimizers/nlopts/__init__.py are outdated and should be updated. I see NLopt is now on pypi (which it was not when that was originally written). We can probably reduce the install instructions to saying to use `pip install nlopt` but keep the nlopt links in case they are needed, This was originally noted here https://stackoverflow.com/questions/74218587/unable-to-install-nlopt-for-qiskit Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cross compilation presets I'm not sure this is a good idea, maybe Meson could be shipped with cross compilation presets on Linux distributions. For example on Fedora, there are mingw, arm(linux/none) compilers, etc. So while calling meson like this: ``` meson srcdir builddir --cross-file mingw32 ``` Meson could look into two path, the current one and and a global one like /etc/meson.d/. That may help new comers. The difficulties I see here are: - who provides this files Meson or the distribution? - when installing with pip One other solution would be to share them on github. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Regression in performance of samplers With jax versions > 0.1.24, random samplers are slow. I think that it is due to recent changes on how jit works with static_args/kwargs. A script to reproduce, ``` import time from jax import random t = time.time() random.normal(random.PRNGKey(0), shape=(1,)) print(time.time() - t) t = time.time() random.normal(random.PRNGKey(0), shape=(1,)) print(time.time() - t) ``` which returns `0.12923526763916016` and `0.12221717834472656`. However, if we wrap these samplers in some function, then it is fast. For example, ``` def f(): return random.normal(random.PRNGKey(0), shape=(1,)) t = time.time() f() print(time.time() - t) t = time.time() f() print(time.time() - t) ``` will return `0.12787413597106934` and `0.0010831356048583984`. I think that there is a small bug elsewhere which forces the sampler recompile. If this is an expected behaviour, then which function we should use to wrap these samplers to make it not recompiled? cc @neerajprad Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Move windows package cache and envs dirs back to '~/.conda' directory In conda 4.3, we moved the default writable user location for envs_dirs and pkgs_dirs from `%USERPROFILE%\\.conda` to `%USERPROFILE%\\AppData\\Local\\conda\\conda`. The reason for the change was to move conda towards more standards compliance. That change sometime collides with conda's concept of relocatable environments (i.e. environment root locations at any arbitrary file system path) and the standard [maximum path length restriction](https://docs.microsoft.com/en-us/windows/desktop/fileio/naming-a-file#maximum-path-length-limitation) of 260 characters. Consider transitioning user's package caches and new named envs directories back to `%USERPROFILE%\\.conda`. We will still need to keep knowledge of `%USERPROFILE%\\AppData\\Local\\conda\\conda`, but newly downloaded packages and newly created named envs can by default be located in `%USERPROFILE%\\.conda`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Setting `flow_run_id` in local runs breaks slack notifier #2868 made some additions to local runs so that targets/results could be templated properly both locally and in runs using a backend API. Setting `flow_run_id` on local runs here: https://github.com/PrefectHQ/prefect/blob/30c88b315c83748b114228703d42bfe3e7d6a763/src/prefect/core/flow.py#L964-L969 breaks the `slack_notifier` because it has an extra check for a `flow_run_id` in context. https://github.com/PrefectHQ/prefect/blob/30c88b315c83748b114228703d42bfe3e7d6a763/src/prefect/utilities/notifications/notifications.py#L151 I think this should be resolved by making the backend functionality of the slack notifier opt-in instead of default when a flow_run_id is present. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Documentation formatting is inconsistent There are some docstrings that are not consistently formatted and sometimes result in a supposedly unexpected format in the ipython.readthedocs.io An example: https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-env %env ----- Get, set, or list environment variables. Usage: %env: lists all environment variables/values %env var: get value for var %env var val: set value for var %env var=val: set value for var %env var=$val: set value for var, using python expansion if possible https://github.com/ipython/ipython/blob/223e783c447a773a497809646ca0d874ea10ceeb/IPython/core/magics/osm.py#L434-L449 For this case it would probably be best to use [field lists](https://www.sphinx-doc.org/en/master/usage/restructuredtext/basics.html#field-lists). It might pay off to do a systematic review of the docstring formatting. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Upcasting of attention computation for reliable pretraining of GPT-2 models # 🚀 Feature request In a recent [talk](https://youtu.be/AYPOzc50PHw?t=3662) about pretraining language models as part of the [Mistral](https://github.com/stanford-crfm/mistral/) project @siddk mentioned that in order to achieve stable pretraining a slight modification in the GPT-2 code is necessary. The issue is a numerical instability when training with mixed precision in the attention mechanism which can be solved by upcasting the attention computation (see [here](https://github.com/stanford-crfm/mistral/blob/53ebb290e55fe367dcaebb54ab63de4a137802db/src/models/mistral_gpt2.py#L324)). ## Motivation Enable reliable pretraining of GPT-2 models. ## Your contribution I can create a PR if adding this is an option. cc @thomwolf Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `QuantumCircuit._check_dup_param_spec` becomes slow for many gates reusing few parameters <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? When building a parameterized circuit where a large number of gates re-use a comparatively small number of parameters, `QuantumCircuit._check_dup_param_spec` becomes a performance bottleneck. For example, `circuit_construction.ParameterizedCircuitConstructionBench.time_build_parameterized_circuit` takes 90s to build a 131k gate circuit with 8 distinct parameters, vs. <5s to build a 131k gate circuit with anything more than 128 parameters: https://qiskit.github.io/qiskit/#circuit_construction.ParameterizedCircuitConstructionBench.time_build_parameterized_circuit?x-axis=number%20of%20params Since the structure of the `ParameterTable` is dict mapping `Parameter` instances to lists of `Instruction`s, each call to `_check_dup_param_spec` must walk the entire `Instruction` list to look for a match. One option would be to convert the list to a dict, which could be efficiently checked for membership. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] ps1 env files for Unix have wrong separators When making the PR for this change I forgot that Linux uses different separators in environment variables. This means the current setup still does something like ```$env:PATH=\"foo;bar\"``` instead of ```$env:PATH=foo:bar```. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Replace Airflow Slack Invite old link to short link Follow up to https://github.com/apache/airflow/pull/10034 https://apache-airflow-slack.herokuapp.com/ to https://s.apache.org/airflow-slack/ <!-- Thank you for contributing! Please make sure that your code changes are covered with tests. And in case of new features or big changes remember to adjust the documentation. Feel free to ping committers for the review! In case of existing issue, reference it using one of the following: closes: #ISSUE related: #ISSUE How to write a good git commit message: http://chris.beams.io/posts/git-commit/ --> --- **^ Add meaningful description above** Read the **[Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines)** for more information. In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda search --platform does not search other platforms The `--platform` argument of the `conda search` subcommand does not search for packages on other platforms. For example: ``` ~$ conda info Current conda install: platform : linux-64 conda version : 4.2.7 conda is private : False conda-env version : 4.2.7 conda-build version : 1.21.14+0.g4dfebe9.dirty python version : 3.5.2.final.0 requests version : 2.10.0 root environment : /home/jhelmus/anaconda (writable) default environment : /home/jhelmus/anaconda envs directories : /home/jhelmus/anaconda/envs package cache : /home/jhelmus/anaconda/pkgs channel URLs : https://repo.continuum.io/pkgs/free/linux-64/ https://repo.continuum.io/pkgs/free/noarch/ https://repo.continuum.io/pkgs/pro/linux-64/ https://repo.continuum.io/pkgs/pro/noarch/ https://conda.anaconda.org/conda-forge/linux-64/ https://conda.anaconda.org/conda-forge/noarch/ config file : /home/jhelmus/.condarc offline mode : False ~$ conda --version conda 4.2.7 ~$ conda search --platform win-64 gawk ~$ ``` Note that there is a gawk-3.1.6-0.tar.bz2 package in the [default win-64 repo](https://repo.continuum.io/pkgs/free/win-64/). This may be because the `get_index` function in the conda.api module takes a **platform** argument but this argument is not used in the function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: need a disassembler to replace qobj_to_circuits <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? We need a function `qiskit.compiler.disassemble()` that takes an assembled qobj and returns the components: ``` circuits, run_config, user_qobj_header = disassemble_qobj(qobj) ``` Currently we have a converter for this (`qobj_to_circuits`), but this is not really a conversion as the two entities are quite different. So this should be deprecated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ld.gold: fatal error: May not nest groups When cross compiling for Android, cc.find_library('iconv') gives me this error: ``` Command line: ccache aarch64-linux-android-gcc -L/home/xclaesse/programmation/cerbero/build/android-ndk-16/platforms/android-21/arch-arm64/usr/lib -L/home/xclaesse/programmation/cerbero/build/dist/android_arm64/lib /tmp/tmpmpem9ks6/testfile.c -pipe -D_FILE_OFFSET_BITS=64 -o /tmp/tmpmpem9ks6/output.exe -Wall -g -Os -isysroot /home/xclaesse/programmation/cerbero/build/android-ndk-16/sysroot -isystem /home/xclaesse/programmation/cerbero/build/dist/android_arm64/include -isystem /home/xclaesse/programmation/cerbero/build/android-ndk-16/sysroot/usr/include -isystem /home/xclaesse/programmation/cerbero/build/android-ndk-16/sysroot/usr/include/aarch64-linux-android -ffunction-sections -funwind-tables -fstack-protector -no-canonical-prefixes -fPIC -DANDROID -DPIC -D__ANDROID_API__=21 -Wa,--noexecstack -DNVALGRIND=1 -specs=/home/xclaesse/programmation/cerbero/build/sources/android_arm64/glib-2.56.0/_builddir/meson-gcc-specs-file.txt --sysroot /home/xclaesse/programmation/cerbero/build/android-ndk-16/platforms/android-21/arch-arm64 -fPIC -no-canonical-prefixes -Wl,-no-undefined -Wl,-z,noexecstack -Wl,-z,relro -Wl,-z,now -Wl,--gc-sections -Wl,-dynamic-linker,/system/bin/linker -fuse-ld=gold -O0 -Wl,--start-group -Wl,--start-group -liconv -Wl,--end-group -Wl,--end-group Code: int main(int argc, char **argv) { return 0; } Compiler stdout: Compiler stderr: /home/xclaesse/programmation/cerbero/build/android-ndk-16/toolchains/aarch64-linux-android-4.9/prebuilt/linux-x86_64/bin/../lib/gcc/aarch64-linux-android/4.9.x/../../../../aarch64-linux-android/bin/ld.gold: fatal error: May not nest groups collect2: error: ld returned 1 exit status meson.build:1532:6: ERROR: C library 'iconv' not found ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: consider adding poisson random variable generator Given the extensive list of random variables that can be generated by jax.random poisson sticks out as an important omission. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Check find_mode potential issue before 1.47 Hi @lasote! Sorry, have seen PR only now (when it has already merged :)). Here should be not `self.find_module_mode`, but something which depends on `values[find_mode.lower()]` from 191 line. Like `values[find_mode.values()] == \"MODULE\"` (or so) (doesn't matter what will be here for \"none\" find_mode). This is important for dependencies with different `cmake_file_name` and `cmake_module_file_name`. UPD: Not only here, but in `_get_dependency_filenames` too. _Originally posted by @alex-700 in https://github.com/conan-io/conan/pull/10917#discussion_r838721838_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: No more SQL Exception in 2.1.0 **Apache Airflow version**: 2.1.0 **Environment**: - self hosted docker-compose based stack **What happened**: Using JDBCOperator if the sql result in an error we got only ``` [2021-06-21 11:05:55,377] {local_task_job.py:151} INFO - Task exited with return code 1 ``` Before upgrading from 2.0.1 we got error details in logs: ``` jaydebeapi.DatabaseError: java.sql.SQLException:... [MapR][DrillJDBCDriver](500165) Query execution error. Details: VALIDATION ERROR:... ``` **What you expected to happen**: See `SQLException` in logs **How to reproduce it**: Perform a generic SQL task with broken SQL. **Anything else we need to know**: I think is somehow related to https://github.com/apache/airflow/commit/abcd48731303d9e141bdc94acc2db46d73ccbe12#diff-4fd3febb74d94b2953bf5e9b4a981b617949195f83d96f4a589c3078085959b7R202 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `backend.jobs()` does not show jobs from that particular backend <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: 0.5.7 - **Python version**: 3.7 - **Operating system**: MacOS ### Steps to reproduce the problem ```python from qiskit import * import Qconfig register(Qconfig.APItoken) backend_5 = get_backend('ibmq_5_tenerife') backend_16 = get_backend('ibmq_16_rueschlikon') jobs_5 = backend_5.jobs(limit=10) jobs_16 = backend_16.jobs(limit=10) for job in jobs_5: print(job.id) for job in jobs_16: print(job.id) ``` Both print the same set of jobs. ### What is the expected behavior? Different backends should report different jobs. `backend.jobs()` does not show jobs from that particular backend <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: 0.5.7 - **Python version**: 3.7 - **Operating system**: MacOS ### Steps to reproduce the problem ```python from qiskit import * import Qconfig register(Qconfig.APItoken) backend_5 = get_backend('ibmq_5_tenerife') backend_16 = get_backend('ibmq_16_rueschlikon') jobs_5 = backend_5.jobs(limit=10) jobs_16 = backend_16.jobs(limit=10) for job in jobs_5: print(job.id) for job in jobs_16: print(job.id) ``` Both print the same set of jobs. ### What is the expected behavior? Different backends should report different jobs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Call prepare_data once per node in DDP (torchelastic) # Before submitting - [ ] Was this discussed/approved via a Github issue? (no need for typos and docs improvements) - [ ] Did you read the [contributor guideline](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/.github/CONTRIBUTING.md), Pull Request section? - [ ] Did you make sure to update the docs? - [ ] Did you write any new necessary tests? - [ ] If you made a notable change (that affects users), did you update the [CHANGELOG](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/CHANGELOG.md)? <!-- For CHANGELOG separate each item in unreleased section by a blank line to reduce collisions --> ## What does this PR do? Slurm and elastic training create the training processes per node outside of the lightning context. This means that when the fit function calls prepare_data, the assumption that it's only being called on proc 0 is broken and it gets called for each process.. This fixes PyTorchLightning#1878 by calling prepare_data once per node, depending on the local rank. ## PR review Anyone in the community is free to review the PR once the tests have passed. If we didn't discuss your PR in Github issues there's a high chance it will not be merged. ## Did you have fun? Make sure you had fun coding 🙃 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: curry `vmap` We want to change the API to look more like `vmap(fun)` and `vmap(fun)(x, y)` instead of the current `vmap(fun, x, y)`. That makes it more consistent with the other main transformations (`jit` and `grad`, plus all the other autodiff ones) and seems to be more convenient given the experiences of @shoyer and @alexbw. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Investigate clock test failure https://circleci.com/gh/PrefectHQ/prefect/52671 ``` ================================== FAILURES =================================== _____________ TestCronClock.test_cron_clock_respects_microseconds _____________ self = <tests.schedules.test_clocks.TestCronClock object at 0x0000008C18CFE9C8> def test_cron_clock_respects_microseconds(self): every_day = \"0 0 * * *\" start_date = pendulum.datetime(2050, 1, 1, 0, 0, 0, 1) c = clocks.CronClock(every_day, start_date=start_date) > assert islice(c.events(), 1) == [pendulum.datetime(2050, 1, 2)] E AssertionError: assert [DateTime(205...ezone('UTC'))] == [DateTime(205...ezone('UTC'))] E At index 0 diff: DateTime(2050, 1, 1, 0, 0, 0, tzinfo=Timezone('UTC')) != DateTime(2050, 1, 2, 0, 0, 0, tzinfo=Timezone('UTC')) E Use -v to get the full diff tests\\schedules\\test_clocks.py:298: AssertionError ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: needs 'synth.py' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Cloud logging does not survive pickling Currently our cloud logs are sent to a Queue, which is then popped from in a background thread to be sent to cloud. If a TaskRunner is shipped off to a new dask worker, this queue doesn't survive and that TaskRunner fails to log. We should refactor to ensure that the log queues are freshly generated after unpickling of _all objects_ with loggers. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Pretty printing exceptions is broken ``` Python 3.2.2 (default, Oct 31 2011, 16:56:14) Type \"copyright\", \"credits\" or \"license\" for more information. IPython 0.12 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: ValueError('foo') Out[1]: ('foo') ``` I would have expected ``` Out[1]: ValueError('foo') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `initialize` and `Statevector` don't play nicely <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Aer version**: 0.5.1 - **Python version**: 3.7.3 - **Operating system**: OSX ### What is the current behavior? Using `initialize` in a circuit and then running with `Statevector` results in the error \"Cannot apply Instruction: reset\" ### Steps to reproduce the problem ``` import qiskit as qk import qiskit.quantum_info as qi from numpy import sqrt n = 2 ket0 = [1/sqrt(2),0,0,1/sqrt(2)] qc = qk.QuantumCircuit(n) qc.initialize(ket0,range(n)) ket_qi = qi.Statevector.from_instruction(qc) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QASM output of registerless Clbits and Qubits can shadow an existing name <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.19.dev - **Python version**: all - **Operating system**: all ### What is the current behavior? Unbound clbits and qubits are output in QASM into registers invariably called `regless`. This is a valid identifier for other registers, and the same name is emitted whether or not clashes exist, presumably because `QuantumCircuit` usually keeps names unique when the registers are added to the circuit, so there usually can't be a clash. ### Steps to reproduce the problem ```python >>> from qiskit.circuit import QuantumCircuit, ClassicalRegister, Clbit, Qubit >>> cr = ClassicalRegister(2, name='regless') >>> cb = Clbit() >>> qb = Qubit() >>> qc = QuantumCircuit(cr, [cb], [qb]) >>> print(qc.qasm()) OPENQASM 2.0; include \"qelib1.inc\"; creg regless[2]; qreg regless[1]; creg regless[1]; ``` A similar failure occurs with a `QuantumRegister(..., name=\"regless\")`. ### What is the expected behavior? The automatically generated `qreg regless[1]` and `creg regless[1]` should have unique names. ### Suggested solutions As far as I know there are no universally reserved names, but we can just generate a name like `_[cq]regless_<entropy>`, which should be good enough - by `<entropy>` I mostly just mean noise to prevent users from accidentally shadowing the name. `QuantumCircuit.qasm()` should (I've got to assume!) be deterministic, so the entropy could just be a string like `_qiskitprivate`, or if we really want to make sure users can't create a clash then ```python entropy = hash(tuple(register.name for registers in self.qregs + self.cregs)) ``` That seems like overkill to me, though. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: clang's linker doesn't like -pthread There is already #2118, but I'm not sure if this is the same issue. When I include `googletest` which requests `pthreads`, the compiler complains: ``` clang: warning: argument unused during compilation: '-pthread' [-Wunused-command-line-argument] ``` The command used to compile is: ``` c++ -o test/unittest/simpletest 'test/unittest/simpletest@exe/simpletest.cpp.o' 'test/unittest/simpletest@exe/.._.._subprojects_googletest-release-1.8.0_googletest_src_gtest-all.cc.o' 'test/unittest/simpletest@exe/.._.._subprojects_googletest-release-1.8.0_googletest_src_gtest_main.cc.o' src/mylib.a -pthread ``` and there are no duplicate entries of `-pthread`. Note that this is a super low priority issue (it's just a warning after all). See https://stackoverflow.com/a/19382663/585897 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Unintentional build downgrades in mixed feature settings Under certain limited circumstances involving features, `conda` unexpectedly downgrades to an earlier build of a package. The conditions are as follows: - The current version of a package `foo` has multiple builds with distinct build numbers. - Newer builds depend on a second package `bar`, while older builds do not. - Some of the valid choices for the `bar` dependency have features, and some do not. When those conditions are met, the command ``` conda create -n errtest foo ``` will select an older build of `foo`, without the `bar` dependency, instead of the latest build. (Contact me or @msarahan for a specific test case.) Currently, this is not occurring with conda 4.4. The reasons for this are not fully clear, because the bug has been located and exists in 4.3 and 4.4. Bug fix coming. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Allow user-defined generators to be used with conan install -g The ability to \"mix in\" generators when installing a package reference is a unique feature that I think could be improved by allowing the use of user-defined generators. The motivation for this comes from wanting to write a custom generator which would take any existing package and generate new file(s) from it at install time, similar to some of the built-in generators. Since this is restricted to built-in generators only, a new recipe would need to be created, maintained, and kept around for every package I wanted to use my custom generator with. I have a very simple implementation of this feature [here](https://github.com/cobalt77/conan/commit/e1947d58a7f9da78d6ddf24cdd81dca911cb2170). I added a new folder in the client cache called 'generators' which can contain user-defined generators. These can be installed using 'conan config install'. When 'conan install' is invoked with a package reference, user-defined generators from the generators folder are loaded and available to use with -g. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Allow IntSource for dagster_ssh remote_port Currently only allows explicit `int` set in the config YAML. The rest of my SFTP configs are provided via envvars, so it would be nice to allow IntSource for consistency https://github.com/dagster-io/dagster/blob/65caf7986b8d0a168c6943622ba55894c4a81055/python_modules/libraries/dagster-ssh/dagster_ssh/resources.py#L216 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Exception before prompting for password during ssh connection ### Setup Win 7 x64 ipython==0.12.1 paramiko==1.7.7.2 pyzmq==2.2.0 ### Issue I want to connect an IPython qtconsole on Windows to an IPython kernel on a remote linux box through ssh2. I made the following changes in `ipython_qtconsole_config.py`: ``` python #### Path to the ssh key to use for logging in to the ssh server. import os c.IPythonQtConsoleApp.sshkey = os.path.expanduser('~')+'\\\\.ssh\\\\id_dsa' ``` When I run `ipython qtconsole --IPythonQtConsoleApp.sshserver='user@hostname' --existing kernel-21449.json` I receive: ``` [IPythonQtConsoleApp] Could not setup tunnels Traceback (most recent call last): File \"C:\\Python27\\lib\\site-packages\\IPython\\frontend\\consoleapp.py\", line 289, in init_ssh newports = tunnel_to_kernel(info, self.sshserver, self.sshkey) File \"C:\\Python27\\lib\\site-packages\\IPython\\lib\\kernel.py\", line 248, in tunnel_to_kernel password = getpass(\"SSH Password for %s: \"%sshserver) File \"C:\\Python27\\lib\\getpass.py\", line 95, in win_getpass msvcrt.putch(c) TypeError: must be char, not unicode ``` For now, I edited IPython/lib/kernel.py:248 as a temporary workaround in the following way: ``` python password = getpass(\"SSH Password for %s: \"%sshserver.encode('ascii','ignore')) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Flax] Change all `shift_tokens_right` to numpy code shift labels right is called usually in the data collator and therefore should not be written in jax, but in numpy to not block the TPU. We should make sure that all Encoder-Decoder models have their `shift_tokens_right` implemented in numpy as it's faster. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Error passing 'fields' to pubsub GET API for subscription ``` $ tox -e regression --notest GLOB sdist-make: /home/tseaver/projects/agendaless/Google/src/gcloud-python/setup.py regression inst-nodeps: /home/tseaver/projects/agendaless/Google/src/gcloud-python/.tox/dist/gcloud-0.4.3.zip ___________________________________ summary ____________________________________ regression: skipped tests congratulations :) $ .tox/regression/bin/python regression/run_regression.py --package=pubsub test_create_subscription (pubsub.TestPubsub) ... ERROR test_create_topic (pubsub.TestPubsub) ... ok test_list_subscriptions (pubsub.TestPubsub) ... ok test_list_topics (pubsub.TestPubsub) ... ok test_message_pull_mode_e2e (pubsub.TestPubsub) ... ERROR ERROR: test_create_subscription (pubsub.TestPubsub) ---------------------------------------------------------------------- Traceback (most recent call last): File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/regression/pubsub.py\", line 74, in test_create_subscription self.assertFalse(subscription.exists()) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/.tox/regression/lib/python2.7/site-packages/gcloud/pubsub/subscription.py\", line 112, in exists query_params={'fields': 'name'}) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/.tox/regression/lib/python2.7/site-packages/gcloud/connection.py\", line 293, in api_request raise make_exception(response, content) gcloud.exceptions.BadRequest: 400 Invalid JSON payload received. Unknown name \"fields\": Cannot bind query parameter. ``` I omitted a similar failure in another test: both are for a call to `subscription.exists()` where the expected value is False. @dhermes this is the one I was working around in #794 @jgeewax maybe tag w/ \"google bug\"? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make interactive visualizations default for Jupyter <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The interactive visualizations contributed in PR #765 are much better than the static ones, and should be default when the environment is a Jupyter notebook. This is related to Epic #707 for providing better jupyter tools. Several issues must be solved first: - These visualizations need internet connection. Can we eliminate that? - The interface of the static and interactive visualizations are all the same, except for `plot_histogram` vs `iplot_histogram`. These should be made similar for consistency. But the interactive visualization is able to plot multiple histograms in one plot. - How \"heavy\" is it to run these interactive visualizations? I hear my laptop fan. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: expose no longer accepts port range in yaml config file docker-compose files stopped working after updating to docker-compose version 1.5.2 (from MacOS Docker Toolbox 1.9.1g). ``` Service 'xxx' configuration key 'expose' '0' is invalid: should be of the format 'PORT[/PROTOCOL]' ``` While the file contains: ``` expose: - \"8200-8219\" ``` Replacing the range by a single port \"resolves\" the issue, or reverting to docker-compose version: 1.5.1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: MatplotlibDeprecationWarning: The M attribute was deprecated in Matplotlib 3.4 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.16.4 - **Python version**: 3.8.8 - **Operating system**: Ubuntu Linux ### What is the current behavior? When running the Bloch sphere visualization function, the following warning message appears: ``` /opt/conda/lib/python3.8/site-packages/qiskit/visualization/bloch.py:69: MatplotlibDeprecationWarning: The M attribute was deprecated in Matplotlib 3.4 and will be removed two minor releases later. Use self.axes.M instead. x_s, y_s, _ = proj3d.proj_transform(xs3d, ys3d, zs3d, renderer.M) ``` ### Steps to reproduce the problem ```py from qiskit import QuantumCircuit from qiskit.quantum_info import Statevector from qiskit.visualization import plot_bloch_multivector qc = QuantumCircuit(1) state = Statevector.from_instruction(qc) plot_bloch_multivector(state) ``` ### What is the expected behavior? No warning message ### Suggested solutions Refactor mathplotlib related codes not to use deprecated feature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Auto Build is in Production Mode This should be configurable and default to development mode. jupyter lab build fails in webpack install I'm trying to install jupyter lab extensions in a clean linux box. I'm getting install errors which appear to occur because jupyter lab build is calling webpack and not webpack --dev so that the devdependencies are not getting installed warning ipysheet > css-loader > cssnano > postcss-merge-rules > caniuse-api > browserslist@1.7.7: Browserslist 2 could fail on reading Browserslist >3.0 config used in other tools. [2/4] Fetching packages... [###########################----------------------------------------] 419/1051[LabBuildApp] > node /usr/lib/python3.6/site-packages/jupyterlab/staging/yarn.js run build yarn run v1.9.4 $ webpack ✖ 「config」: An error occurred while trying to find a config file Did you forget to specify a --require? /usr/lib/node_modules/webpack-command/node_modules/@webpack-contrib/config-loader/lib/load.js:85 throw new LoadConfigError(e, configPath); ^ LoadConfigError: Cannot find module 'fs-extra' at Function.Module._resolveFilename (module.js:547:15) at Function.Module._load (module.js:474:25) at Module.require (module.js:596:17) at require (/usr/lib/node_modules/webpack-command/node_modules/v8-compile-cache/v8-compile-cache.js:159:20) at Object.<anonymous> (/usr/share/jupyter/lab/staging/webpack.config.js:7:10) at Module._compile (/usr/lib/node_modules/webpack-command/node_modules/v8-compile-cache/v8-compile-cache.js:178:30) at Object.Module._extensions..js (module.js:663:10) at Module.load (module.js:565:32) at tryModuleLoad (module.js:505:12) at Function.Module._load (module.js:497:3) error Command failed with exit code 1. info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Examples: label mapping for text classication tasks are not written into configuration Hi, I've shortly discussed this with @patrickvonplaten , and we came to the conclusion that the following scenario is a bug: When using the text classification for a GLUE task, no label mapping will be written into the configuration of the final fine-tuned model. This leads to an unesthetic \"label_0\" on the model hub, as it can be seen here:  One has to manually extend the `config.json`: ```json \"id2label\": { \"0\": \"NEGATIVE\", \"1\": \"POSITIVE\" }, \"label2id\": { \"NEGATIVE\": 0, \"POSITIVE\": 1 } ``` to get the following output:  The text classification examples should be extended, so that those label mappings are automatically added to the configuration file. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub: return type`future` is not `concurrent.futures.Future` https://github.com/googleapis/google-cloud-python/blob/8f63393a151a22018a3d03c7a35576da25ee17b3/pubsub/google/cloud/pubsub_v1/publisher/client.py#L170 Contrary to what's in the [reference](https://gcloud-python.readthedocs.io/en/latest/pubsub/publisher/api/client.html#google.cloud.pubsub_v1.publisher.client.Client.publish), the correct return type for `publish()` should be `google.cloud.pubsub_v1.publisher.futures.Future`. I didn't find a reference for it but only some reference for [`google.cloud.pubsub_v1.subscriber.futures.StreamingPullFuture`](https://google-cloud.readthedocs.io/en/latest/pubsub/subscriber/api/futures.html). People won't be able to use of Python's concurrent library's `wait()` method on `google.cloud.pubsub_v1.publisher.futures.Future`. But our doc implies they can because we say the return type is `concurrent.futures.Future`. ```Python from concurrent.futures import wait from google.cloud import pubsub_v1 publisher = pubsub_v1.PublisherClient() # future has type `google.cloud.pubsub_v1.publisher.futures.Future` future = publisher.publish('projects/{PROJECT_ID}/topics/{TOPIC_NAME}', data=b'rain') # wait(fs, timeout=None, return_when='ALL_COMPLETED') expects a sequence of `concurrent.futures.Future`. wait([future]) ``` Here is the error: ```Python Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/usr/lib/python3.5/concurrent/futures/_base.py\", line 257, in wait with _AcquireFutures(fs): File \"/usr/lib/python3.5/concurrent/futures/_base.py\", line 146, in __enter__ future._condition.acquire() AttributeError: 'Future' object has no attribute '_condition' ``` I tried in both Python 2 and 3. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Allow different cpp_info.name depending on the generator Something similar to `self.cpp_info.name['my_generator']` should work. Make it compatible with `cpp_info.name = 'name'` syntax Related to #5984 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: GPTNeo: importing model with padded vocab size should truncate wte ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: latest from `master` ### Who can help @LysandreJik ## Information Model I am using (Bert, XLNet ...): GPTNeo Script: https://github.com/huggingface/transformers/blob/master/src/transformers/models/gpt_neo/convert_gpt_neo_mesh_tf_to_pytorch.py Some GPTNeo models are trained with a vocab size greater than the actual used vocab size (i.e 50304 in config when the actual vocab size is 50257) where all tokens after the first i.e 50257 are unused. These models cannot currently be converted using the script because there is no way to cut the extra embeddings out of wte. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Transpiling 3+ qubit `UnitaryGate` circuits should work automatically <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? 3+ qubit unitary matrices can be transpiled to basis gates using the `isometry` instruction, however this is not used automatically if a circuit contains unitary gate instructions --- circuits with unitary gate instructions can currently only be transpiled if they are 1 or 2 qubits. The definition of the `UnitaryGate` class should be updated to unroll using an `isometry` instruction for 3+ qubits. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose: --quiet for builds ```sh $ docker -v Docker version 18.05.0-ce, build f150324 $ docker-compose -v docker-compose version 1.21.2, build a133471 ``` I want to silence the output of `docker-compose build` just like there is a `--quiet` command in `docker` if so, please display the full command required to get quiet builds. I guess one could just redirect standard out, but I'd rather not do this. Many thanks, Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: tools.vcvars() should be a no-op when not using windows and visual studio This way you can wrap all your code in: ``` with tools.vcvars(self.settings): CMake.build() ``` without having to care about what platform you are working with. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add Timeout State Suggestion: subclass `Failed` to create a `Timeout` state (or `TimedOut` state?). The nature of the failure is specific enough that this could be interesting to trap specifically. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: accept string values for non_argument_deps argument to asset decorator Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: A check_map analysis pass is needed <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In https://github.com/Qiskit/qiskit-terra/pull/1270#issuecomment-439951585 @ajavadia raised the need to have a pass to check if a circuit is compatible with a coupling map. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Cannot escape IPython.embed() when called repeatedly within function inside a for-loop I am running `foo.py` from the command line, and it includes a function has a for loop, inside of which is a function that has an IPython.embed() statement. This is to initialize an interpreter at that point within the function to have access to those local variables. However, when trying to escape from the embedded interpreter, it only opens a new interpreter (presumably up to k times for the for loop), effectively locking that terminal. It would be nice to have a command analogous to `ipdb`'s `q`, which immediately throws an exception and exits to the CLI in which `foo.py` was executed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.random.randint range must be valid `random.randint` doesn't check that `minval` < `maxval`. If it's not, you get surprising results. For example, `print(random.randint(random.PRNGKey(10003), (), 0, 0))` yields -1234647498. The best thing would be to throw an error message, but if that's not practical then it'd at least be nice to have the behavior be defined. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cannot use private Qt headers without hacks https://github.com/SirCmpwn/qtlayershell/blob/6315d292a72690391d207894f066a10becd1c8e6/qtlayershell/meson.build#L1-L10 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: package rev broke --build missing Environment: conan version 1.18.4 Cent OS 7 conan client + artifactory We recently turned on package revisions and set the package ID to `full_package_id`. Since we did that `conan install . --build missing` is not always able to build all missing packages ```bash $ conan install . --build missing Configuration: [settings] arch=x86_64 arch_build=x86_64 build_type=Release compiler=gcc compiler.libcxx=libstdc++11 compiler.version=7 os=Linux os_build=Linux qt_version=5 [options] [build_requires] [env] [... some packages are beeing built ...] GenericSU/0.3.5@deployment/stable: WARN: Can't find a 'GenericSU/0.3.5@deployment/stable' package for the specified settings, options and dependencies: - Settings: arch=x86_64, build_type=Release, compiler=gcc, compiler.libcxx=libstdc++11, compiler.version=7, os=Linux, qt_version=5 - Options: MccApi:coverage=False, MccApi:shared=True - Dependencies: Log4Qt/0.3.0@deployment/stable, MccApi/3.0.9@deployment/testing, Util/0.3.4@deployment/stable, AppFramework/0.3.5@deployment/stable, AppLauncher/0.3.4@deployment/stable - Package ID: Package_ID_unknown ERROR: Missing prebuilt package for 'GenericSU/0.3.5@deployment/stable' Try to build it from sources with \"--build GenericSU\" Or read \"http://docs.conan.io/en/latest/faq/troubleshooting.html#error-missing-prebuilt-package\" ``` However there is a package `GenericSU/0.3.5@deployment/stable`  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Fails to install under Jython 2.7 beta This is the error I get: ``` % pip install ipython-0.13.tar.gz Unpacking ./ipython-0.13.tar.gz Running setup.py egg_info for package from file:///home/aaditya/work/epsilon/installer/packages/ipython-0.13.tar.gz Unsupported operating system: java Complete output from command python setup.py egg_info: Unsupported operating system: java ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: activate on master is broken in OSX @msarahan I'm on master, and I get: ``` $ source activate koo path:usage: conda [-h] [-V] [--debug] command ... conda: error: argument command: invalid choice: '..changeps1' (choose from 'info', 'help', 'list', 'search', 'create', 'install', 'update', 'upgrade', 'remove', 'uninstall', 'run', 'config', 'init', 'clean', 'package', 'bundle') prepending /Users/ilan/python/envs/koo and /Users/ilan/python/envs/koo/cmd and /Users/ilan/python/envs/koo/bin to PATH -bash: awk: command not found -bash: dirname: command not found Traceback (most recent call last): File \"/Users/ilan/python/bin/conda\", line 4, in <module> from conda.cli.main import main File \"/Users/ilan/conda/conda/__init__.py\", line 19, in <module> __version__ = get_version(__file__, __name__) File \"/Users/ilan/python/lib/python2.7/site-packages/auxlib/packaging.py\", line 93, in get_version if is_git_repo(here): File \"/Users/ilan/python/lib/python2.7/site-packages/auxlib/packaging.py\", line 70, in is_git_repo return call(('git', 'rev-parse'), cwd=path) == 0 File \"/Users/ilan/python/lib/python2.7/subprocess.py\", line 522, in call return Popen(*popenargs, **kwargs).wait() File \"/Users/ilan/python/lib/python2.7/subprocess.py\", line 710, in __init__ errread, errwrite) File \"/Users/ilan/python/lib/python2.7/subprocess.py\", line 1335, in _execute_child raise child_exception ``` It is true that the new activate scripts depend on `awk` and `dirname`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Auto scale pulse drawings for given channels <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? There's a lot of unused space with default Schedule drawing. <img width=\"914\" alt=\"Screen Shot 2019-09-19 at 10 33 44 AM\" src=\"https://user-images.githubusercontent.com/10730254/65253650-fcbbef00-dac8-11e9-8020-480b7dae24ae.png\"> Changing the `scaling` option helps, but this still isn't great. We should try to automatically adjust the plotting range, or the scale, or at least not show negative values by default (it looks like the space for neg values leaves a large gap between channels, and I haven't seen it used) <img width=\"914\" alt=\"Screen Shot 2019-09-19 at 10 28 24 AM\" src=\"https://user-images.githubusercontent.com/10730254/65253795-41e02100-dac9-11e9-9f74-7e915d9c29ab.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Numpy 1.16.1 fails to run tests Newly released NumPy 1.16.1 built and installed from source fails to run tests: > python3 setup.py build > sudo python3 setup.py install ``` import numpy numpy.test('full') NumPy version 1.16.1 NumPy relaxed strides checking option: True ================================================================================================================== ERRORS =================================================================================================================== _____________________________________________________________________________________________ ERROR collecting core/_multiarray_module_test.py ______________________________________________________________________________________________ import file mismatch: imported module 'numpy.core._multiarray_module_test' has this __file__ attribute: /usr/local/lib/python3.6/dist-packages/numpy-1.16.1-py3.6-linux-x86_64.egg/numpy/core/_multiarray_module_test.cpython-36m-x86_64-linux-gnu.so which is not the same as the test file we want to collect: /usr/local/lib/python3.6/dist-packages/numpy-1.16.1-py3.6-linux-x86_64.egg/numpy/core/_multiarray_module_test.py HINT: remove __pycache__ / .pyc files and/or use a unique basename for your test file modules !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Interrupted: 1 errors during collection !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! 1 error in 4.18 seconds False ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Scheduler needs to respect MemSlots in QuantumCircuit Measures <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information Known bug from my PR https://github.com/Qiskit/qiskit-terra/pull/2650 ### What is the current behavior? When passing a circuit through the basic scheduler (`qiskit.scheduler.schedule`), the resulting `Schedule` will always measure qubit results into the `MemorySlot` which matches the qubit index. For example: ``` qc.measure(q[0], c[3]) ``` will measure qubit 0 into `MemorySlot(0)` rather than `MemorySlot(3)` -- it will use the default Acquire from the cmd_def which is probably something like `Acquire([0, 1], [MemSlot(0), MemSlot(1)])`. The correct behaviour is to use the classical reg from the instruction and then modify the `AcquireInstruction` from the `Schedule` returned by the `cmd_def`. It's unclear what we should do with the other qubits that are measured within the same `meas_map` group, if the user doesn't specify those other qubits to be measured. We need a follow up PR to handle this more carefully. The solution likely needs to update the helper function: `qiskit.scheduler.methods.basic.translate_gates_to_pulse_defs.get_measure_schedule` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions see above Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Use literal_eval for parsing configuration values ## Current behavior *Please describe how the feature works today* Currently, Prefect takes a [hardcoded stab](https://github.com/PrefectHQ/prefect/blob/master/src/prefect/configuration.py#L37) at converting strings to Python objects. We could replace this function with `ast.literal_eval()` and instantly gain a more flexible cast, including the ability to natively handle lists and dicts. ## Proposed behavior *Please describe your proposed change to the current behavior* Currently, setting `PREFECT__X__Y=\"['a', 'b', 3]\"` results in `prefect.config.x.y == \"['a', 'b', 3]\"`. This means some Prefect objects (thinking of environments, but also including the config itself) must re-parse config options. This is after we already make an attempt to coerce some values to known types. Replacing this with `ast.literal_eval()` would result in `prefect.config.x.y == ['a', 'b', 3]`. ## Example *Please give an example of how the enhancement would be useful* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit.library.graph_state needs testing The object `GraphState` (in `qiskit/circuit/library/graph_state.py`) needs testing. [No line is currently coveraged](https://coveralls.io/builds/30439931/source?filename=qiskit/circuit/library/graph_state.py). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: mypy --strict error when importing numpy.typing `mypy --strict` disables `implicit_reexport`. Consequently mypy throws an error when trying to import `ArrayLike` and `DTypeLike` from `numpy.typing`. ### Reproducing code example: ```python from numpy.typing import ArrayLike ``` ### Error message: ``` $ mypy --strict foo.py foo.py:1: error: Module 'numpy.typing' has no attribute 'ArrayLike' Found 1 error in 1 file (checked 1 source file) ``` ### NumPy/Python version information: ``` $ python -c 'import sys, numpy; print(numpy.__version__, sys.version)' 1.20.0rc2 3.8.6 (default, Dec 18 2020, 13:50:46) [GCC 10.2.0] $ mypy --version mypy 0.790 ``` ### Possible workarounds I guess that the reason why this happens is than `__all__` is not set when on `TYPE_CHECKING` mode: https://github.com/numpy/numpy/blob/af8e67c4fd368bae710b01f32611b10dfab02b61/numpy/typing/__init__.py#L156-L165 If setting `__all__` is not possible, a workaround might be to \"explicitly reexport\" the objects using something this: ``` python from ._array_like import ArrayLike as ArrayLike from ._dtype_like import DTypeLike as DTypeLike ``` It might also be possible to enable implicit reexports for this specific module using the numpy mypy plugin. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: PartitionMappings in public API and when non-partitioned assets depend on partitioned assets Fixes https://github.com/dagster-io/dagster/issues/8867 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Remove or limit table of content at the main Airflow doc page Table of content here : http://apache-airflow-docs.s3-website.eu-central-1.amazonaws.com/docs/apache-airflow/latest/index.html at the main page of \"apache-airflow\" documentation is huge and useless (especially that we have it in directory on the left). We should remove it or limit heavily (to 1st level only)  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: numpy scalars: should np.set_printoptions(legacy=True) in 0.14.dev reverts to 0.13 printing? This is another thing we bumped into our scikit-learn doctests using numpy dev. If this is easy for `np.set_printoptions(legacy=True)` to use pre-dragon4 printing it would make our life (and the life of other downstream projects bumping into the same problems with doctests) a bit easier when numpy 1.14 is released. I think the expected behaviour is that `np.set_printoptions(legacy=True)` does revert to pre-dragon4 format even with all its flaws. If this is not too costly in terms of maintenance, maybe it could be considered? Note we can work-around this issue with doctests ellipsis in scikit-learn. A snippet to illustrate what I mean in more details: ```py import numpy as np try: np.set_printoptions(legacy=True) except TypeError: pass i = 6 numpy_number = np.float64(1.) - i * 1e-17 print('str : ', numpy_number) print('repr : ', repr(numpy_number)) ``` Output on numpy master: ``` str : 0.9999999999999999 repr : 0.9999999999999999 ``` Output on numpy 1.13: ``` str : 1.0 repr : 0.99999999999999989 ``` When using `np.set_printoptions(legacy=True)` I would expect both output to match. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson-init can't detect vala-files Hello, I use meson init to create my mesonbuild files quickly, it works fine with \"Cs, c, cpp, java\" files, but does not work with Vala, I think the option has just been forgotten nothing of very serious ! it's still a bug ```No recognizable source files found. Run meson init in an empty directory to create a sample project.``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: latex drawer cannot draw custom gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently only the text drawer is able to do this. This capability is useful when defining hiearchical circuits. Also refer to #1939 for a discussion of how to draw these. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Boost not detected on Fedora 27 I installed `boost-devel` as well as `boost-static` using `dnf` on Fedora 27. I am including boost in a Meson project with ``` dep_boost = dependency('boost', modules : ['filesystem', 'system', 'asio']) ``` Which results in the following error messages: ``` WARNING: Invalid Boost modules: asio Dependency Boost (filesystem, system, asio) found: NO Meson encountered an error in file meson.build, line 69, column 0: Dependency \"boost\" not found ``` I also installed `boost-*`, which didn't help. Meson version is `0.44.0`. Works fine with `0.42.1`. To me this does not seem to be related to #2547 and #2564, my locale is English. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Implement i0e and i1e bessel functions These are useful for the von-Mises distribution on the unit circle. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: tools.which also returns dirs Hi, `tools.which` can returns a folder path if his basename match. For example, on Windows, it returns `C:\\Program Files (x86)\\Microsoft Visual Studio\\2017\\Community\\Common7\\IDE\\CommonExtensions\\Microsoft\\TeamFoundation\\Team Explorer\\Git` which is a directory. You can reproduce with: ```python import os from conans import tools tools.mkdir(\"C:\\Dev\") tools.mkdir(\"C:\\Dev\\Git\") with tools.environment_append({\"PATH\": \"C:\\Dev\\;\"+tools.get_env(\"PATH\")}): git = tools.which(\"git\") # returns \"C:\\Dev\\git\" print(os.path.isfile(git)) # Is False ``` I work with: * Conan 1.3.3 * Windows 10 1709 Thanks ! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: blob.acl.save_predefined() only works for private [From the documentation.](https://googlecloudplatform.github.io/gcloud-python/stable/storage-acl.html#gcloud.storage.acl.ACL.save_predefined) > Must be one of the keys in [_PREDEFINED_ACLS](https://github.com/tseaver/gcloud-python/blob/1a210341811aff3b4185f830b07e87b22c1ef73d/gcloud/storage/acl.py#L171) ``` Python _PREDEFINED_ACLS = frozenset([ \"private\", \"project-private\", \"public-read\", \"public-read-write\", \"authenticated-read\", \"bucket-owner-read\", \"bucket-owner-full-control\", ]) ``` Let's try. ``` Python >>> blob.acl.save_predefined('public-read') ... gcloud.exceptions.BadRequest: 400 Invalid string value: 'public-read'. Allowed values: [authenticatedread, bucketownerfullcontrol, bucketownerread, private, projectprivate, publicread] >>> blob.acl.save_predefined('publicread') ... ValueError: Invalid predefined ACL: publicread ``` Coincidentally, the [tests](https://github.com/tseaver/gcloud-python/blob/1a210341811aff3b4185f830b07e87b22c1ef73d/gcloud/storage/test_acl.py#L633) only try _private_. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Document format for Cloud Storage URIs used in BigQuery BigQuery APIs which load table data from (or extract it to) Cloud Storage blobs take URIs of the format, `gs://<bucket-name>/<object-name-or-glob>`. Ensure that the docstrings for those methods document the expected URI format. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [examples] replicate the new `--log_level` feature to all trainer-based pytorch examples https://github.com/huggingface/transformers/pull/12276 introduced a new `--log_level` feature, which now allows users to set their desired log level via CLI or TrainingArguments. `run_translation.py` was used as a \"model\" for other examples. Now we need to replicate this to all other Trainer-based examples under examples/pytorch/, the 3 changes are 1. importing datasets 2. using `training_args.get_node_log_level()` and setting log_level in 3 modules 3. replacing `datasets` object name with `raw_datasets`, since otherwise we have a conflict with `datasets` the module. and the relevant diff is [here](https://github.com/huggingface/transformers/pull/12276/files?file-filters%5B%5D=.py#diff-09777f56cee1060a535a72ce99a6c96cdb7f330c8cc3f9dcca442b3f7768237a) and of course since we don't quite have extensive tests for examples, you can just test with a staple cmd from the corresponding README.md with `--log_level=error` and check that almost all logs are gone. This is open to all. And thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Checkpoint naming broken ## 🐛 Bug I would like to be able to save checkpoints with custom names that include the value of my `val_loss`, ie. `path/epoch_2-val_loss_0.2.hdf5 `. The [documentation](https://pytorch-lightning.readthedocs.io/en/latest/pytorch_lightning.callbacks.html#pytorch_lightning.callbacks.ModelCheckpoint) for `ModelCheckpoint` suggests that this is possible using the `filepath` argument. This does not appear to be the case, since the [source code](https://github.com/PyTorchLightning/PyTorch-Lightning/blob/master/pytorch_lightning/callbacks/pt_callbacks.py#L247) calls `os.mkdirs(filepath)`. I have also tried using the `prefix` argument, but it doesn't seem to be possible to pass it a format string containing a variable. ## Expected behavior The documentation claims that `filepath='{epoch:02d}-{val_loss:.2f}.hdf5'` will save a checkpoint at `/path/epoch_2-val_loss_0.2.hdf5`. Instead, it saves a checkpoint at `{epoch:02d}-{val_loss:.2f}.hdf5/_ckpt_epoch_1.ckpt`. The issues in the documentation are two-fold: -- It suggests that `filepath` can contain the directory + name of the checkpoint, when it seems like it should only contain the directory specifying where to save. -- It suggests that it can 'contain named formatting options to be auto-filled', which also doesn't seem to be the case. Is it possible to achieve this functionality with the `prefix` argument instead? If so, how? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: client doesn't use connection file's 'location' in disambiguating 'interface' be9601be0603cd5de781c4f91b8fc6a3120c9839 seems to have changed client.py to stop using `location` in the call to `util.disambiguate_ip_address` (previously `util.disambiguate_url`). This means that if `interface`'s address is '*', the client tries to connect to localhost, which doesn't seem to me to be the correct behaviour. The fix appears to be as simple as ``` - addr = util.disambiguate_ip_address(addr) + addr = util.disambiguate_ip_address(addr, location) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [Supervisor] Can't use user & pass options when using socket On my Supervisor installation, I have no `[inet_http_server]` section, and yet I can do `supervisorctl -c supervisord.conf -u <user> -p <password>` **/etc/supervisor/supervisord.conf** ```ini [unix_http_server] file=/var/run/supervisor.sock [supervisord] ... [rpcinterface:supervisor] supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface [supervisorctl] serverurl=unix:///var/run/supervisor.sock ``` The code of the integration ignores the `user` & `pass` options when there is a `socket` option. https://github.com/DataDog/integrations-core/blob/5693dc717d4e41533aa693e2a87ad90f08a5985a/supervisord/datadog_checks/supervisord/supervisord.py#L164-L177 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Manual versioninig with semver for the first release of providers The first release can be manually versioned with 0.1.0 version for all packages. No automation is yet needed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Improve documentation of numpy.rint() ## Documentation The difference between `numpy.around()` and `numpy.rint()` is not clear. The doc says: https://numpy.org/doc/stable/reference/generated/numpy.around.html#numpy.around Evenly round to the given number of decimals. https://numpy.org/doc/stable/reference/generated/numpy.rint.html#numpy.rint Round elements of the array to the nearest integer. - `numpy.rint()` seems to also round to even, so the docstring would better be \"*Evenly* round elements of the array to the nearest integer.\" - It seems that `around()` is a more general function but for the default `decimals=0`, `numpy.around(a)` is equal to `numpy.rint(a)`. It would be good to mention that (or if it's different, what the difference is). Can somebody with more insight into this please comment? I'm happy to provide a PR with improved docs, once I understand this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose network ipam additional properties are not allowed Encounter this issue in the v1.12 & v1.11: ERROR: The Compose file './docker-compose.yml' is invalid because: networks.test.ipam value Additional properties are not allowed ('driver_opts' was unexpected) It has been resolved at docker-py: docker/docker-py#1165 networks part in docker-compose.yml: ```yml networks: internal: driver: bridge internal: true ipam: driver: default onlyoffice: driver: qnet ipam: driver: qnet driver_opts: iface: DEFAULT_NIC ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Logging: payload should be parsed as optional google-cloud-python requires a valid value for the `payload` field in a log entry. However, the proto shows its optional - [https://github.com/googleapis/googleapis/blob/master/google/logging/v2/log_entry.proto#L68](https://github.com/googleapis/googleapis/blob/master/google/logging/v2/log_entry.proto#L68) and i've verified i can emit a log entry w/ `payload=None` and simply the http_request value (this is used in logs groups) Looks like its checked for a value here * https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/logging/google/cloud/logging/entries.py#L128 ```python if logger is None: logger_name = logger_name_from_path(logger_fullname) logger = loggers[logger_fullname] = client.logger(logger_name) payload = resource[cls._PAYLOAD_KEY] insert_id = resource.get('insertId') timestamp = resource.get('timestamp') ``` * https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/logging/google/cloud/logging/_helpers.py#L47 ```python if 'textPayload' in resource: return TextEntry.from_api_repr(resource, client, loggers) elif 'jsonPayload' in resource: return StructEntry.from_api_repr(resource, client, loggers) elif 'protoPayload' in resource: return ProtobufEntry.from_api_repr(resource, client, loggers) raise ValueError('Cannot parse log entry resource.') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [workspace] Adding \"conan-project\" feature, to allow simultaneous edition of connected packages Everything in user space, linking in user space. How? Redirecting packages \"rootfolder\" to local folder, not to conan cache. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add in `model.generate` support to encoder outputs for flax models # 🚀 Feature request <!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. --> Add support to encoder outputs in `model.generate` for flax models (similar to Pytorch models). ## Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. --> With JAX, we need to pass a seed for each generation iteration. So when we want different samples, we may need to run the same function multiple times. For Encoder/Decoder models such as Bart, we could calculate the encoder outputs once and then directly pass them to the decoder, which could potentially save half of the computations (when encoder/decoder have same size). ## Your contribution <!-- Is there any way that you could help, e.g. by submitting a PR? Make sure to read the CONTRIBUTING.MD readme: https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md --> Not sure the best way to implement it but it seems that they typically come from `model._prepare_encoder_decoder_kwargs_for_generation` @patil-suraj @patrickvonplaten Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: use XDG_CACHE_HOME for cython objects cython magics fill a lot of object files into the ipython configuration directory usually located in XDG_CONFIG_HOME A better place for these would be the the XDG_CACHE_HOME as they in can be deleted and recreated easily. This is relevant for users with the HOME folder on a shared filesystem with a low quota, who set XDG_CACHE_HOME to a local folder to save space and better performance. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython console ignoring some stream messages? In JuliaLang/IJulia.jl#153, @cbecker commented that `ipython console` does not seem to get standard output (which is sent to the console via `stream` messages according to the message spec). I confirmed this: ``` $ ipython console --profile julia Python 2.7.1 (r271:86832, Jul 31 2011, 19:30:53) Type \"copyright\", \"credits\" or \"license\" for more information. IPython 1.1.0 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. IPython profile: julia Starting kernel event loops. In [1]: In [1]: ccall(:printf, Cint, (Ptr{Uint8},), \"Hello world!\\n\") Out[1]: 13 ``` It works (prints `\"Hello world!\"`) in both the `qtconsole` and `notebook` front-ends, so it seems like it may be a bug in the `console` front-end. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Use appropriate TaskInstance object related to TaskFail to get execution_date `TaskFail` instance has no execution_date attribute. Fetch execution_date from the relevant `TaskInstance` object to form the dictionary key tuple. closes: #22933 related: #22933 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: legacy 1.13 printing edge case: missing superfluous comma after ellipsis I think this is the last quirk that we found when running the scikit-learn doctests. After this one you will hopefully not hear from me for a while ;-). We have only one doctest affected by this and we can work around this easily by using `repr` instead of `print` or using doctest ellipsis. This edge case does break the `legacy='1.13'` promise so I thought I would let you know and then you can decide whether you want to fix it (i.e. match the buggy behaviour with `legacy='1.13'`) or not. I would completely understand if you just decided to close this issue ```py import numpy as np try: np.set_printoptions(legacy='1.13') except TypeError: pass print(np.arange(10000)) ``` Output numpy dev: ``` [ 0 1 2 ... 9997 9998 9999] ``` Ouput on 1.13.3 (note the additional comma after the ellipsis): ``` [ 0 1 2 ..., 9997 9998 9999] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add support for snowflake on the sql_sensor **Description** Enable the support for Snowflake on the SqlSensor. **Use case** Currently, the `SqlSensor` supports only the following connection types, - google_cloud_platform - jdbc - mssql - mysql - oracle - postgres - presto - sqlite - vertica At the moment, it doesn't have support for Snowflake. This ticket is to add support for Snowflake on the `SqlSensor`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add system tests for spanner datatypes Show inserting / reading all the datatypes supported by spanner, particularly: - Special-case floats (`nan`, `+inf`, `-inf`). - Arrays of all scalar types. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Link against custom targets For integration with custom toolchains and other such stuff. Basically if you put the output of custom_target to the `link_with` line of a build target it will: - add a dependency in the usual way - add the output file to the link line - assumes that this is enough to make it work, if not, then that is the build definition writer's developer's problem This can probably only be done reasonably for static libraries. Dependencies of dependencies also don't really work, because to do so would mean having to replicate Meson's entire dependency resolution chain for custom targets. I was going to do this today but am mostly been in bed suffering from the seasonal flu. Feel free to implement this if you wish. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: configure_file fails for files encoded with not utf-8 or ascii I'm working on wrapping a project (freeglut), and one of the files in the project that need to be configured (using configure_file) is encoded in ISO-8859, and contains an character that isn't compatible with utf-8. meson dies trying to configure said file. Here's the output: ``` Could not read input file /home/user/source/mesa-demos/subprojects/freeglut-3.0.0/freeglut.rc.in: 'utf-8' codec can't decode byte 0xa9 in position 740: invalid start byte ``` I don't know if this is a case really worth solving (how many projects use encodings other than ascii or utf-8?). Since it's just changing the encoding I've just copied the file into my wrap patch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: remove plot_state and iplot_state <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? These functions are not used anymore. We should remove them. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: savez fails on large array of objects I'm getting a RuntimeError \"File size unexpectedly exceeded ZIP64 limit\" when using `savez` to save a few arrays to a file, the largest of which is an array of matrices each with a different number of rows (so that the top level array's dtype is object). As best I can tell, the condition used by numpy internally to decide whether or not to pass `force_zip64=True` to the zipfile open is checking if any of the arrays to be put into the archive has nbytes greater than 2^30. My array of matrices reports nbytes less than 2^30 but in reality the total number of bytes exceeds this (it's about 1.7GB). I'm using python 3.6 and numpy 1.14.2 on Ubuntu 16.04. The following code produces the error: ```python test_data = np.asarray([np.random.rand(np.random.randint(50,100),4) for i in range(800000)]) np.savez('test', test_data=test_data) ``` whereas changing `np.random.randint(50,100)`->`75` produces no error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Floating widgets should be created at the point of code execution, not atop the page I tried running the example notebook `examples/Interactive Widgets/Variable Inspector.ipynb`, and the variable inspector is created atop the page, invisible to the user. You need to scroll back up to find it. This makes for pretty poor usabilit/discoverability. I think we should try to fix it before 3.0, if possible at all. But I don't know how much it would require a big overhaul of the scrolling model, which I know has been already the source of lots of grief. Perhaps @jdfreder has some thoughts here? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cpp_eh=none should set -fno-exceptions on non-MSVC compilers see title :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Feature Request: `docker-compose config` Command It would be pretty nice to have a `docker-compose validate` command that would validate the structure of the YAML file. The specific use case I have in mind is for CI pipelines. - Return true if valid YAML of Docker-Compose format - Return false otherwise Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Implement stratified resampling np.digitize in XLA Hi JAX team, I'm interested in implementing efficient stratified resampling in JAX. This is a technique for variance reduction in sequential monte carlo algorithms (see section 2.2.1 in Naesseth, Lindsten, and Schön \"Elements of Sequential Monte Carlo\"). The algorithm provided looks like this ```python # w.shape = (N, ) # x.shape = (N, ) # assert np.sum(w) = 1 def stratified_resampling(key, w, x) : N = w.shape[0] u = (np.arange(N) + jax.random.uniform(key, (N, )) / N bins = np.cumsum(w) return x[np.digitize(u, bins)] ``` although I'm also considering a version that doesn't actually do the shuffling in the last step (saving it for a \"decoding\" process later on which doesn't particularly need to be fast. The immediate issue is that `np.digitize` is not implemented in JAX. As it were, I don't actually need the gradient for it, but as it's in the hot path and defeats the tracer it's causing some real pain. Even more ideally, I'd like to have something like the interface to `jax.random.categorical` where I can just use unnormalized logits. How can I help implement at least tracing through `np.digitize`? Alternatively, is there a clever way of doing stratified resampling without using `np.digitize`? Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Restore testing of grpc under py27 Once grpc 0.13.1 releases with a fix for https://github.com/grpc/grpc/issues/5280. See: https://github.com/grpc/grpc/pull/5319#issuecomment-192412023 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Doc styling utils adds parasites new lines ## Environment info - `transformers` version: 4.2.0dev0 - Platform: Windows-10-10.0.18362-SP0 - Python version: 3.7.9 - PyTorch version (GPU?): 1.7.1 (False) - Tensorflow version (GPU?): 2.3.1 (False) - Using GPU in script?: Nope - Using distributed or parallel set-up in script?: Nope ### Who can help @sgugger ## Information Running the python util to style docs adds parasite new lines in every single docstring. See: ```bash $ python utils/style_doc.py src/transformers docs/source --max_len 119 --check_only Traceback (most recent call last): File \"utils/style_doc.py\", line 491, in <module> main(*args.files, max_len=args.max_len, check_only=args.check_only) File \"utils/style_doc.py\", line 479, in main raise ValueError(f\"{len(changed)} files should be restyled!\") ValueError: 345 files should be restyled! ``` See this commit for an example of what it does: https://github.com/huggingface/transformers/pull/9150/commits/b4dedd5ca25f043c66d12c774fa00a34c74dffb2 ## To reproduce Steps to reproduce the behavior: 1. Checkout and update master branch 2. run `python utils/style_doc.py src/transformers docs/source --max_len 119 --check-only` from transformers root Output: ```python Traceback (most recent call last): File \"utils/style_doc.py\", line 491, in <module> main(*args.files, max_len=args.max_len, check_only=args.check_only) File \"utils/style_doc.py\", line 479, in main raise ValueError(f\"{len(changed)} files should be restyled!\") ValueError: 345 files should be restyled! ``` It might have something to do with Windows or a particular setup of my machine because behavior cannot be reproduced by @patrickvonplaten. ## Expected behavior On master branch, documentation should not need to be restyled Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Consider using CMake's `include_guard()` in `conan_toolchain.cmake` Right now at the beginning of `conan_toolchain.cmake` `CMakeToolchain` generates: ```cmake # Avoid including toolchain file several times (bad if appending to variables like # CMAKE_CXX_FLAGS. See https://github.com/android/ndk/issues/323 if(CONAN_TOOLCHAIN_INCLUDED) return() endif() set(CONAN_TOOLCHAIN_INCLUDED TRUE) ``` When minimum version of CMake (3.10) will not be an issue anymore please consider using: https://cmake.org/cmake/help/latest/command/include_guard.html - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add `items()` method to `Options` ### What should we add? It would be nice if the `Options` class had a method to iterate over the entire set of options and return an iterator of all the fields and current values in the object. Right now the only way to do this is something like `options.__dict__.items()` which isn't a great user interface. So adding a dedicate method that returns an iterator of everything would be useful so we can replace all the places where users are using the `__dict__.items()` pattern (this will still be supported, but having a dedicated method will look cleaner if nothing else). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: StoreMagic.autorestore not working in 1.0.0 Since upgrading Ipython to version 1.0.0, the variables I have in `%store` don't seem to be loaded on startup, and have to be refreshed manually using `%store -r`. My `ipython_config.py` file contains the line: ``` c.StoreMagic.autorestore = True ``` but this doesn't seem to have any effect. My version info is: ``` {'codename': 'An Afternoon Hack', 'commit_hash': '02da31c', 'commit_source': 'installation', 'default_encoding': 'cp1252', 'ipython_path': 'C:\\\\Anaconda\\\\lib\\\\site-packages\\\\IPython', 'ipython_version': '1.0.0', 'os_name': 'nt', 'platform': 'Windows-7-6.1.7601-SP1', 'sys_executable': 'C:\\\\Anaconda\\\\pythonw.exe', 'sys_platform': 'win32', 'sys_version': '2.7.5 |Anaconda 1.6.2 (32-bit)| (default, Jul 1 2013, 12:41:55) [MSC v.1500 32 bit (Intel)]'} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: regression in 0.53. meson cannot handle CheckCXXSourceRuns.cmake Hi there, **Describe the bug** I'm trying to link with project that uses CMake and it checks supported CPU instructions via [CHECK_CXX_SOURCE_RUNS](https://cmake.org/cmake/help/v3.0/module/CheckCXXSourceRuns.html). Meson 0.52 were handling it without any problems, but 0.53 cannot. Here is cmake file that causes issue [CPUID.cmake](https://github.com/opencv/dldt/blob/2019/inference-engine/src/extension/cmake/CPUID.cmake) **To Reproduce** You should install that project and use this meson.build: ```meson project('mytestproject', ['c', 'cpp']) inference_engine_dep = dependency('InferenceEngine', version: '>=2.0.0', required: true, method : 'cmake', modules: ['IE::inference_engine']) ``` **Expected behavior** After running `meson build/` you must see following output: ```sh Run-time dependency inferenceengine (modules: IE::inference_engine) found: YES 2.1.0 ``` **system parameters** * This is just a plain native build * Operating system is Ubuntu 18.04 * Python version is 3.6.9 * meson version is 0.53.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Can't set measurements with len=1 NumPy array ### Environment - **Qiskit Terra version**: lastest - **Python version**: - **Operating system**: ### What is happening? This fails for len=1 arrays: ```python qc = QuantumCircuit(2, 1) qc.measure([0], np.array([0])) ``` ``` ~/mambaforge/envs/qiskit/lib/python3.8/site-packages/qiskit/circuit/quantumcircuit.py in _bit_argument_conversion(bit_representation, in_array) 1106 raise CircuitError(\"Index out of range.\") from ex 1107 except TypeError as ex: -> 1108 raise CircuitError( 1109 f\"Type error handling {bit_representation} ({type(bit_representation)})\" 1110 ) from ex CircuitError: \"Type error handling [0] (<class 'numpy.ndarray'>)\" ``` For length 2 or higher it works. Also works if cast to list. ### How can we reproduce the issue? See above ### What should happen? It should work for any length array ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: TypeError when setting up a build directory with LLVM linker **Describe the bug** https://gist.github.com/Akaricchi/23cde7c6782a150af568db920f17a5af **To Reproduce** Try to set up a build directory with the [llvm-mingw](https://github.com/mstorsjo/llvm-mingw) cross toolchain. Not sure if native compilation is affected. **Expected behavior** Successful generation of the build directory. **system parameters** * Cross build (windows i686 via llvm-mingw) * openSUSE Tumbleweed * Python 3.8.2 * meson 0.53.999 (b54e557a40497a0f9080e32cd0da91b2b59762cc) * ninja 1.10.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: expand_dims returns a view Hi, if we apply expand_dims to a numpy array 'a' : b = numpy.expand_dims(a, axis=0) the 'b' is not a new array, it will be a link to the objects 'a' is it correct behavior? if so, it should be noted in the manual thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ldconfig on install corrupts freebsd cache **Describe the bug** 2c3a68bc30cf and 6b7d43ebe0d7 make it so `ldconfig` is invoked after install. But it seems like thos corrupts the cache on FreeBSD (maybe other BSDs as well), and results in errors similar to: ld-elf.so.1: Shared object \"libreadline.so.8\" not found, required by \"bash\" when running executables after `ninja install`. Example full log: https://builds.sr.ht/~emersion/job/630186#task-tinywl Downstream discussion: https://gitlab.freedesktop.org/wlroots/wlroots/-/merge_requests/3349#note_1162574 cc @jbeich **To Reproduce** Run `ninja install` on freebsd. **Expected behavior** `ldconfig` cache isn't corrupted. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? no * what operating system: FreeBSD * what Python version are you using: N/A * what `meson --version`: 0.60.1 * what `ninja --version`: 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: should_bypass_proxies still an issue in 4.5.7 https://github.com/conda/conda/issues/7506#issuecomment-403811279 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: support graceful training cleanup after Keyboard Interrupt ## 🚀 Feature In the training loop, we should catch `KeyboardInterrupt` exceptions and enter a graceful termination (ie. run `on_training_end`, print profiler report, etc). ### Motivation Sometimes I'll train a model and just let it run until something interesting happens or my loss has converged. Exiting via \"Ctrl + C\" can be easier than waiting for \"EarlyStopping\" to trigger in some cases. However, I may still want certain things to occur (eg. printing out the profiler summary) after stopping training. Salesforce's AWD-LSTM has an example of this feature implemented [here](https://github.com/salesforce/awd-lstm-lm/blob/master/main.py#L287). ### Pitch Figure out what actions we want to run after a KeyboardInterrupt. Then adjust the training loop to catch this exception and ensure the aforementioned actions still run afterwards. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add synced batchnorm support https://pytorch.org/docs/stable/nn.html#torch.nn.SyncBatchNorm  @justusschock or @awaelchli interested? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: How can I skip healthchecks with Docker storage? ## Archived from the [Prefect Public Slack Community](https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU) **jeffbrainerd**: Hi Prefecters, I’m struggling with a peculiarity of Django, but I’m wondering if the problem is somewhat more general. The basic issue is that I need to initialize django before importing any ORM objects that many of my prefect tasks use. When Dask is running a task, I’m able to use an initialization hook to call that django function before the flow is deserialized with cloudpickle. The problem comes when building the prefect docker image -- the healthcheck fails during cloudpickle load. I’ve done some code spelunking and I can’t see an obvious way to override or provide a hook to the healthcheck script short of just hacking it (which I’m doing just to get it to pass). So I’m interested if there’s an existing workaround, or if this problem has come up before and if anyone else would benefit from some kind of mechanism for overriding, disabling or providing some kind of pre-run hook for the healthcheck script. Thanks all :pray: **chris**: Hey <@USBCBEJDV> - this is super interesting. First off, if you’d like to open an issue for a `ignore_healthchecks: bool` flag on `Docker` storage we’d be happy to get that in before the next release. Out of curiosity, is it too clunky to import the ORM objects _within_ the task definition (as opposed to the top of the file)? **jeremiah**: <@ULVA73B9P> archive “How can I skip healthchecks with Docker storage?” Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Releasedocs <!-- Thanks for contributing to JupyterLab! Please fill out the following items to submit a pull request. See the contributing guidelines for more information: https://github.com/jupyterlab/jupyterlab/blob/master/CONTRIBUTING.md --> ## Code changes Adds documentation for releases to reflect what actually happens during a release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: `conda activate` broken in fish shell (in `native_path_to_unix`) ### Checklist - [X] I added a descriptive title - [X] I searched open reports and couldn't find a duplicate ### What happened? `conda activate` fails. MSYS2, fish shell. It used to work just fine on that same system up until a month ago. Cause of error: `native_path_to_unix(paths)` is being called with an empty string in argument `paths` and can't handle it. As a workaround, I changed this code inside [`native_path_to_unix(paths)`](https://github.com/conda/conda/blob/26c74a12042bf035b76ed8186c3dddabd1f10606/conda/activate.py#L826): ``` if paths is None: return None ``` to that: ``` if not paths: # this will be true for both None and '' return '' ``` Additional info: the code fails on another place if `native_path_to_unix` returns `None`, that's why my workaround returns `''`. Does it make sense at all to return `None`? [ERROR_REPORT_native_path_to_unix.txt](https://github.com/conda/conda/files/11898703/ERROR_REPORT_native_path_to_unix.txt) ### Conda Info _No response_ ### Conda Config ```shell ==> C:\\Users\\theuser\\.condarc <== auto_activate_base: False channel_priority: strict channels: - conda-forge - defaults - intel ``` ### Conda list _No response_ ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Subscribe experimental doesn't appear to be retrying on retryable exceptions, also doesn't surface the error. Full context at https://github.com/GoogleCloudPlatform/google-cloud-python/issues/4841#issuecomment-386988007 downwards. gist with logs: https://gist.github.com/psalaberria002/e91956d94e82d706d65da7111a40ca24 Possible culprits: 1. `send()` and `recv()` expectedly error on `next(self.call)`, but if that was a *retryable* error that somehow re-bubbled, it would not trigger any callbacks. 2. `bidi` uses `rpc._wrapped` because `api_core` doesn't appropriately expose `add_done_callback`. This means that bidi unwraps all of the retry logic. This doesn't explain *why* retrying a perfectly normal looking error somehow still leads us to a broken stream, unless the newly opened stream also has an error. But it's unclear why that wouldn't happen when calling the initial RPC. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub: declaratively drop Python 3.4 support The README and the language classifiers in `setup.py` both only claim support for Python 3.5+ (and 2.7), but not Python 3.4. However, the `python_requires` in `setup.py` does not reflect that, and does not prevent installing the library in Python 3.4. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore transactions do not work without context manager [The docs](https://googlecloudplatform.github.io/gcloud-python/stable/datastore-transactions.html#gcloud.datastore.transaction.Transaction) state that you can use transactions without a context manager, but this is not exactly true because you need to resort to some private methods on `Client`: - [this file](https://gist.github.com/Bogdanp/a86192d1a2a37dd48df5ebdbb39a49d1#file-context-py-L20) uses the context manager and produces correct output - [this file](https://gist.github.com/Bogdanp/a86192d1a2a37dd48df5ebdbb39a49d1#file-failing-py-L20) uses transactions as described by the aforementioned docs and fails the assertion - [this file](https://gist.github.com/Bogdanp/a86192d1a2a37dd48df5ebdbb39a49d1#file-passing-py-L20) uses transactions along with calls to `client._push_batch` and `client._pop_batch` and produces correct output The issue is evident in [`Client.get_multi`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/client.py#L284) and [`Client.put_multi`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/client.py#L336) where `transaction` and `current` are `None` unless a `Batch` or `Transaction` has been pushed to the `_batch_stack` and the only time that happens is when you [`__enter__`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/batch.py#L273) a `Batch`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Change `conan new` to use dict in default options From: ``` options = {\"shared\": [True, False]} default_options = \"shared=False\" ``` To: ``` options = {\"shared\": [True, False]} default_options = {\"shared\": False} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Trigger for Mapped Task that resolves to \"failed\" only if more than x tasks fail For a particular mapped task, I may not expect 100% of the generated tasks to succeed. Further, I may not care if they don't. It would be great to have a trigger that allowed me to specify this. For example: ```python from prefect import task, Flow from prefect.triggers import some_failed @task(trigger=some_failed('>', 3)) def a_mapped_task(some_input): pass ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: run status sensors monitoring jobs in other repos allow run status sensors to monitor jobs in other repos https://dagster.slack.com/archives/C01U5LFUZJS/p1660586409688809 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Input parsing with %prun clobbers escapes Running this command, where `foo.csv` is a tab-separated file ``` In [3]: %prun -s cumulative table = read_table('foo.csv', sep=\"\\t\") ``` it blows up and I stepped up to the top level to see that `sep` has been passed as `t` and not `\\t` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Utility function to measure only a subset of qubits using OpenPulse ### What is the expected enhancement? Currently, measurement in OpenPulse is often done by getting the default measurement schedule from the `CmdDef`: ``` meas = cmd_def.get('measure', qubits=tuple(range(total_number_of_qubits))) ``` This isn't ideal because it will stimulate measurement on all qubits. More convenient would be to be able to do ``` schedule += measure_qubits(qubits_to_measure: List) ``` where `measure_qubits` is a utility function exposed within `pulse` and `qubits_to_measure` is a subset of all qubits. Only the qubits in `qubits_to_measure` will have a measurement pulse. All qubits will still have to be acquired according to the `meas_map`. The implementation may be similar to changes in the scheduler which have been started here: https://github.com/Qiskit/qiskit-terra/pull/3415 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] `conan_build_info --v2 publish` returns \"ERROR: 400: Bad Request\" Still having issues with the new `conan_build_info --v2` command. Publishing fails with \"ERROR: 400: Bad Request\". It seems that no trace messages are generated for this command so please let me know if you need any more info. ### Environment Details * Operating System+version: Windows 10 * Compiler+version: n/a * Conan version: 1.20.4 * Python version: 3.7.3 * Artifactory version: 6.12.1 * Python Packages: * requests 2.21.0 * six 1.12.0 ### Steps to reproduce run `conan_build_info --v2 publish buildinfo.json --url https://my_server.artifactory.cm.my_company.biz/artifactory --user <user> --password <password>` as per the [how-to](https://docs.conan.io/en/latest/howtos/generic_ci_artifactory.html#generating-build-info-from-lockfiles-information). ### Logs (Executed commands with output) - Conan command output: `ERROR: 400: Bad Request` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: i18n module doesn't help when merging back translations At the moment we have to do: custom_target('desktop-file', input: 'org.gnome.PowerStats.desktop.in', output: 'org.gnome.PowerStats.desktop', install: true, install_dir: join_paths(get_option('datadir'), 'applications'), command: [ msgfmt, '--desktop', '--template', '@INPUT@', '-d', podir, '-o', '@OUTPUT@' ]) Which is pretty horrific for something that's going to be super common for desktop applications. It's also the same issue for AppData files, GSettings schema and lots of other file types. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: genfromtxt won't unpack if dtype=None Not sure if this is a bug or a feature but if I use: ``` f_data = np.genfromtxt('file.dat', dtype=None, unpack=True) ``` where `file.dat` is a standard data file with several columns (ie: http://pastebin.com/ihEW2dxS) the result is not transposed as one would expect having set `unpack=True`. For example, the line `f_data = np.loadtxt('file.dat', unpack=True)` works as expected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add missing configuration properties to LoadJob There are several properties in the load job configuration that would be useful to expose in the LoadJob object. For example, `configuration.load.destinationTable` should be exposed as a TableReference property. Perhaps we should just expose a generic \"configuration\" property so that we get all of the properties and reflect the API resource? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add an option to the YAML file to specify an alternative signal to stop containers It would be great if we could specify a signal number in the `fig.yml` file. Fig would then use it with `docker kill -s SIGNAL` instead of `docker stop` when stopping a container. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Add a generator like class wrapping write_conanvcvars Create a public generator `VCVars()` class to wrap the `write_conanvcvars` command. After https://github.com/conan-io/conan/pull/9194 Change the conans/test/functional/toolchains/gnu/autotools/test_win_bash.py test Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Several statsd timers record seconds rather than milliseconds **Apache Airflow version**: 1.10.11 **What happened**: Statsd timers for 3 categories are reporting values 1000x off as the code passes seconds, rather rather than milliseconds (or a `timedelta()` instance) to [`StatsClient.timing()`](https://statsd.readthedocs.io/en/v3.3/reference.html#StatsClient.timing). **What you expected to happen**: The timings should be reported in milliseconds. **How to reproduce it**: Enable the `statsd` client and track reporting timings for: * `dag.loading-duration.*` (emitted from `models/dagbag.py`) * `dag.<dag_id>.<task_id>.duration` (emitted from `models/taskinstance.py`) * `dag_processing.last_duration.<filename>` (emitted from `utils/dag_processing.py`) and it's deprecated alias `dag_processing.last_runtime.*` **Anything else we need to know**: This was reported before, for the `dag_processing.last_*` stats, at https://issues.apache.org/jira/browse/AIRFLOW-6088. The accompanying pull request #6682, fixed 2 out of 3 of these, but only for Airflow 2.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: __file__ is not defined when file end with .ipy I named my IPython file.ipy I propose .ipy ? objections ? I feel ipython should not be confused with plain python! ``` echo \"#!/usr/bin/env ipython\" > test.ipy echo \"print __file__\" >> test.ipy cat test.ipy #!/usr/bin/env ipython print __file__ ``` ``` chmod +x test.ipy ./test.ipy > NameError: name '__file__' is not defined ipython test.ipy > NameError: name '__file__' is not defined ## run with plain python python test.ipy > ./test.ipy SUCCESS: ## rename file to be .py seems to solve the issue mv ./test.ipy ./test.py ipython test.ipy > ./test.py SUCCESS: ./test.py > ./test.py SUCCESS: ``` Should we not trust files with different endings... I have a feeling files not ending with .py are blacklisted to prevent issues with cgi or something... not to sure.. Perhaps it has something to do with the she-bang notation..? debian kubuntu 12.10 ``` ipython -v 0.12.1 ``` Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: set tolerance on isometry conversion <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Can the tolerance made to be user definable for setting the tolerance in the isometry to circuit conversion in https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/extensions/quantum_initializer/isometry.py Right now the tolerance is hard-coded to be 1e-10, but it would be useful for the user to be able to adjust this tolerance. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: confusing error message when boto is missing If one tries to install from an s3 channel (e.g., `conda install foo -c s3://bar/baz/conda`) while in an environment, this message shows up: `Error: boto is required for S3 channels. Please install it with: conda install boto`. Installing `boto` in the environment doesn't actually solve the problem, however, because `boto` has to be installed into the main set of packages (e.g., `source deactivate; conda install boto`). Perhaps a simple edit to the error message would address this. (e.g., `Error: boto is required for S3 channels. Please install it with: conda install boto. Make sure to run \"source deactivate\" if you are in an environment.`) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: run_command() with compiler object behind ccache fails. So say you have a compiler object `cc`: ``` cc = meson.get_compiler('c') ``` This compiler is a GCC behind ccache. `cc.get_id()` returns `gcc`, `cc.version()` returns the GCC version and other features seem to work well (`cc.compiles()` and whatnot). But `run_command()` seems to be run on ccache directly! For instance, try to run: `run_command(cc, '-v')` You won't get the output of `gcc -v` but the one of `ccache -v` (which is an invalid option, so `run_command(cc, '-v').returncode()` is 0, `stdout()` is empty and `stderr()` is ccache usage). P.S.: `run_command()` [docs](https://mesonbuild.com/Reference-manual.html#run_command) says explicitly it should work on a compiler object: > Runs the command specified in positional arguments. command can be a string, or the output of find_program(), files() or configure_file(), or a compiler object. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Running one-off containers does not work in 1.3, \"is already in use\" I used to run tests in docker by running one-off containers, but that is not possible in 1.3. When i try i says ``` $ docker-compose run backend npm test Conflict. The name \"app_backend_run_1\" is already in use by container e46cb8f520ad. You have to delete (or rename) that container to be able to reuse that name. ``` Same commando that I used before. I have tried running `docker-compose up` and also `docker-compose migrate-to-labels` How do you run one-off containers, like the docs propose https://github.com/docker/compose/blob/master/docs/cli.md#run Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Redis Tasks Using https://github.com/andymccurdy/redis-py let's add some tasks for communicating with Redis. These tasks should first connect to a Redis instance and then execute their respective commands. As a first pass (and to keep this minimal) let's add tasks for both `set` and `get` then branch out from there if there are more obvious basic commands we want to support. Other than those two we should also add a task for `execute_command` in which a task would take in a custom Redis command to execute against a db. - [ ] set - [ ] get - [ ] execute_command Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: extract_table does not check that the job config is an ExtractJobConfig See: https://github.com/GoogleCloudPlatform/python-docs-samples/issues/1281 bigquery_client = bigquery.Client() dataset_ref = bigquery_client.dataset(dataset_id) table_ref = dataset_ref.table(table_id) job_config = bigquery.LoadJobConfig() job_config.source_format = 'NEWLINE_DELIMITED_JSON' job = bigquery_client.extract_table(table_ref, destination, job_config=job_config) job.result() # Waits for job to complete print('Exported {}:{} to {}'.format( dataset_id, table_id, destination)) Fails with an error ``` google.api_core.exceptions.BadRequest: 400 Operation cannot be performed on a nested schema ``` Whereas it should fail because the `job_config` argument is a `LoadJobConfig`, not a `ExtractJobConfig`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Failed subproject dependency on systems without git shows \"Git program not found.\" **Describe the bug** On a system where builds happen in a sandbox with **no networking** with a subproject that's a git submodule the dependency will fail with ``` ERROR: Git program not found ``` which is highly confusing because it doesn't point to the exact issue at hand. **To Reproduce** I was building gnome-usage and the error pointed at this line https://gitlab.gnome.org/GNOME/gnome-usage/-/blob/master/meson.build#L22. The archive was not retrieved with submodules which was why meson was trying to call into `git`. **Expected behavior** An error that the submodule couldn't be retrieved would be much nicer. **system parameters** * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) NixOS * what Python version are you using e.g. 3.8.0 3.8.5 * what `meson --version` 0.55.1 * what `ninja --version` if it's a Ninja build 1.10.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove asserts from codebase ## Welcome contributor! Asserting is perfectly fine, there's nothing wrong with it, don't get me wrong :) ... but having said that, we do want to have a more grained control over our error control strategy. As an SDK we should have an homogeneous way of dealing with invalid states, so we want to change all: ```pythnon assert(condition_is_met?) ``` ... present in the code, with: ```python if condition_is_not_met: raise QISKitError('A meaningful error message goes here') ``` **W**A**R**N**I**N**G**: Use the correct exception in every situation. We have different kind of exceptions for some of the modules, like: `QasmError`, `SimulatorError`, `ResultError`, ... all of them inherit from QISKitError. We don't throw standard exceptions!! If unsure, use `QISKitError` or ask me ;) **W**A**R**N**I**N**G**: The only part of the code where `asserting` **is allowed** (and encouraged) is on tests, so don't change asserts there :) BTW, Happy New Year!! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] cmake_find_package generated file doesnt honor CONAN_CMAKE_SILENT_OUTPUT ### Environment Details (include every applicable attribute) * Operating System+version: not applicable * Compiler+version: not applicable * Conan version: everything released * Python version: not applicable ### Steps to reproduce (Include if Applicable) with cmake-conan at least when issuing following command: `cmake -GNinja -DCONAN_CMAKE_SILENT_OUTPUT $buildpath` and having cmake_find_package generator enabled in conanfile or passed in to conan_cmake_run(), generated Find$package.cmake has a single message() call. Since the bug is essentially here: https://github.com/conan-io/conan/blob/develop/conans/client/generators/cmake_find_package.py#L9 Same will most likely happen with calling `conan install` too.. When cmake 3.17 or never, these could be removed by filtering on the log level but that is not option for everybody. ### Logs (Executed commands with output) (Include/Attach if Applicable) Excessive output like this will be shown when generating build scripts: ```-- Conan: Using autogenerated FindXXX.cmake -- Conan: Using autogenerated FindYYY.cmake -- Conan: Using autogenerated FindZZZ.cmake ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: cu3 definition in qiskit/qasm/libs/qelib1.inc is inconsistent <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? have consistent cu3 definition. The cu3 defintion of the following file is not consistent with recent changes. https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/qasm/libs/qelib1.inc https://github.com/Qiskit/qiskit-terra/commit/02e4309104d28765d598e7aee7510d75e5d6467f ### Suggested solutions update the qelib1.inc to align cu3 definition Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Container List Fails I have a basic fig file with: ``` redis: image: dockerfile/redis ports: - \"6379:6379\" ``` and starting fig with `fig up -d` succeeds, however trying to list processes running throws the following error: ``` vagrant@docker:~$ fig ps Traceback (most recent call last): File \"/usr/local/bin/fig\", line 9, in <module> load_entry_point('fig==0.3.0', 'console_scripts', 'fig')() File \"/usr/local/lib/python2.7/dist-packages/fig/cli/main.py\", line 39, in main command.sys_dispatch() File \"/usr/local/lib/python2.7/dist-packages/fig/cli/docopt_command.py\", line 21, in sys_dispatch self.dispatch(sys.argv[1:], None) File \"/usr/local/lib/python2.7/dist-packages/fig/cli/command.py\", line 30, in dispatch super(Command, self).dispatch(*args, **kwargs) File \"/usr/local/lib/python2.7/dist-packages/fig/cli/docopt_command.py\", line 24, in dispatch self.perform_command(*self.parse(argv, global_options)) File \"/usr/local/lib/python2.7/dist-packages/fig/cli/command.py\", line 47, in perform_command return super(Command, self).perform_command(options, *args, **kwargs) File \"/usr/local/lib/python2.7/dist-packages/fig/cli/docopt_command.py\", line 27, in perform_command handler(command_options) File \"/usr/local/lib/python2.7/dist-packages/fig/cli/main.py\", line 158, in ps command = container.human_readable_command File \"/usr/local/lib/python2.7/dist-packages/fig/container.py\", line 89, in human_readable_command return ' '.join(self.dictionary['Config']['Cmd']) TypeError ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [DO NOT MERGE] Oslogin to pick up changes in the API or client library generator. This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/cloud/oslogin/artman_oslogin_v1.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:90f9d15e9bad675aeecd586725bce48f5667ffe7d5fc4d1e96d51ff34304815b Status: Image is up to date for googleapis/artman:latest synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/os-login-v1. synthtool > Replaced 'from google.cloud.oslogin.common import common_pb2' in google/cloud/oslogin_v1/proto/oslogin_pb2.py. synthtool > Replaced 'from google.cloud.oslogin.common import common_pb2' in google/cloud/oslogin_v1/proto/oslogin_pb2_grpc.py. synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Revisit iterators in storage.key, consider renaming for iterators not part of API See [note](https://github.com/GoogleCloudPlatform/gcloud-python/pull/241#discussion_r18805906) on #241 for more details. Revisit iterators in storage.key, consider renaming for iterators not part of API See [note](https://github.com/GoogleCloudPlatform/gcloud-python/pull/241#discussion_r18805906) on #241 for more details. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Client library should not try to validate sample rate The client library should allow validation of sample rate to occur on the server rather than trying to do it's own validation. Allowing the server to check errors means that we don't need to update the client if the server expands the range of sample rates that it supports. [https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/speech/google/cloud/speech/sample.py#L70][1] [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/speech/google/cloud/speech/sample.py#L70 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Drop api_core.gapic_v1.wrap_with_paging Prefer just inlining the wrapping logic in gapic clients. /cc @landrito Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Logging gives up too easily for non-JSON types Very possible that I'm missing a good reason why it has to be this way, but now with #1961 it's more apparent how many logging messages that seem innocuous cause issues for the current Cloud logging setup. For example, the following works fine with stdout: ``` logging.info(\"n = %d\", np.int64(2)) INFO:root:n = 2 ``` but shows up in Prefect Cloud as ``` CRITICAL Failed to write log with error: Object of type int64 is not JSON serializable ``` Same goes for anything of type `type` which is a pretty common thing to pass via `%s` in a debugging context. Any reason we can't let `logging` do whatever it normally would to coerce these values into a printable string and then ship that? cc @joshmeek Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: NumPy 1.17 RC fails to compile with Intel C Compile 2016 <!-- Please describe the issue in detail here, and fill in the fields below --> Compiling NumPy 1.17.0rc2 sources with Intel C Compiler 2016, which does not yet implement `__builtin_cpu_supports(\"avx512f\")` fails with compilation error: ``` icc: numpy/core/src/umath/cpuid.c numpy/core/src/umath/cpuid.c(63): catastrophic error: invalid use of '__builtin_cpu_supports' compilation aborted for numpy/core/src/umath/cpuid.c (code 1) ``` Recent Intel C compiler (2019) proceeds just fine. There is config test to probe compiler for support of `__builtin_cpu_supports`, but the the test does not discriminate between supported arguments. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Accessing conan trough a proxy In corperate environments it is frequently the case that internet connection must go trough a proxy server, sometimes even with authentication required. It would be good if conan would at least support the following proxy scenarios: 1. Access the internet trough a HTTP/HTTPS proxy without authentication 2. Access the internet trough a HTTP/HTTPS proxy with authentication required 3. Access the internet trough a SOCKSv5 proxy (this allows using SSH tunnels) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Boost rewrite breaks build Consider the following meson.build file ``` project('test_link', 'cpp', default_options : ['cpp_std=c++17']) boost_dep = dependency('boost', modules : ['system']) sources = files( 'main.cpp' ) a_out = executable('a.out', sources, dependencies : [boost_dep]) ``` (the file `main.cpp` can just contain `int main(){}`.) This no longer builds. The behavior was introduced with 08224dafcba1b694fb624553e7d84deb565aae22. The problem is that instead of `-lboost_system`, the file `/usr/lib/libboost_system.so.1.72.0` is passed as such to the linker: ``` [2/2] c++ -o a.out 'a.out@exe/main.cpp.o' -Wl,--as-needed -Wl,--no-undefined -Wl,--start-group /usr/lib/libboost_system.so.1.72.0 -Wl,--end-group FAILED: a.out c++ -o a.out 'a.out@exe/main.cpp.o' -Wl,--as-needed -Wl,--no-undefined -Wl,--start-group /usr/lib/libboost_system.so.1.72.0 -Wl,--end-group /usr/lib/gcc/x86_64-pc-linux-gnu/10.1.0/../../../../x86_64-pc-linux-gnu/bin/ld: error: /usr/lib/libboost_system.so.1.72.0: incompatible target collect2: error: ld returned 1 exit status ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Monitoring alias package is missing new service clients https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/monitoring/google/cloud/monitoring.py is missing the new clients added to https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/monitoring/google/cloud/monitoring_v3/__init__.py Should be a relatively easy fix. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: notebook kernel dies if started with invalid parameter current git head ipython notebook --no-brow after executing any cell in a notebook the kernel dies with ``` [IPKernelApp] Bad config encountered during initialization: [IPKernelApp] Unrecognized flag: ' --no-brow' ``` seems to be related to that the parameter is the start of a valid one, completely wrong parameters (correctly) prevent the notebook from starting at all. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: windows.compile_resources dependencies In the `meson.build` for X server, I want to write something like: ```meson convert = find_program('convert') ico = custom_target( 'xlogo-icon', command: [convert, '-background', 'transparent', '-trim', '-define', 'icon:auto-resize', '@INPUT@', '@OUTPUT@'], input: 'X.svg', output: 'X.ico', install: false, build_always: false, ) rsrc = windows.compile_resources( 'XWin.rc', # depend_files: ico, ??? # include_directories: ico.private_dir_include(), ??? ) ``` where `XWin.rc` contains an `ICON \"X.ico\"` line, and have correct dependencies exist. #3571 adds the depend_files: keyword, but that doesn't appear to permit a custom_target, currently There is also the problem that the directory that the custom target generates `X.ico` into needs to be added to the resource compiler's include directories: Not sure if that should be by giving the custom_target object a method to access that, or by having `compile_resources()` extract them from the dependencies... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: STORAGE: Which requests require a project? Grepping through the JSON discovery spec for `\"project\"` it only occurs in ``` storage.buckets.insert storage.buckets.list ``` yet we send it with every single request: ``` python def build_api_url(self, path, query_params=None, api_base_url=None, api_version=None, upload=False): ... query_params.update({'project': self.project}) ... ``` /cc @thobrla Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Adding `__repr__` method for the `DAGNode` object <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### Current Behaviour There does not exist any representation method for the `qiskit.dagcircuit.dagnode.DAGNode` object as of yet ### What is the expected behavior? Just like a `Qubit` object, a `DAGNode` should be more informative and allow a user to get a basic idea about the information it contains. ### Suggested changes A `__repr__` method for the `DAGNode` which displays basic attribute information like `qargs`, `cargs` and `type` for the `DAGNode` object Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Calling compile, transpile, or execute gives dep warning <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? Running `compile`, `transpile`, or `execute` gives depreciation warning: ```python from qiskit import * from qiskit.transpiler import transpile IBMQ.load_accounts() backend = IBMQ.get_backend('ibmqx4') q = QuantumRegister(2) c = ClassicalRegister(2) qc = QuantumCircuit(q, c) qc.h(q[0]) qc.cx(q[0], q[1]) qc.measure(q, c) compile(qc, backend) #transpile(qc, backend) #execute(qc, backend) ``` ```python /Users/paul/Desktop/Github_repos/qiskit-terra/qiskit/transpiler/passes/mapping/barrier_before_final_measurements.py:73: DeprecationWarning: Calling ancestors() with a node id is deprecated, use a DAGNode instead our_ancestors = barrier_layer.ancestors(new_barrier_id) ``` ### Steps to reproduce the problem This appears to be caused by #1815. ### What is the expected behavior? Our own code should not give depreciation warnings. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Checkpoint adding \"version_\" at the start of the logger name **To reproduce :** ```python logger = pl.loggers.TensorBoardLogger( save_dir='.', version='my_name' name='lightning_logs' ) trainer = pl.Trainer(logger=logger, log_gpu_memory='all', max_epochs=10) ``` **Giving as a result:** - /lightning_logs/my_name: Where is saved the logs - /lightning_logs/version_my_name : Where is saved the checkpoints **Possible Explanation:** It seems like the checkpoint saving add \"version_\" to the start of the name even if the name have been given as a parameter : https://github.com/PyTorchLightning/pytorch-lightning/blob/3e8f2d99a9951bfb5fc67a98614128317913be1d/pytorch_lightning/trainer/callback_config.py#L52-L57 Even if in the Tensorboard Logger if the name is provided there is no \"version_\" prefix : https://github.com/PyTorchLightning/pytorch-lightning/blob/8b82ce09039e75f3fcb77a987c964249e38def3b/pytorch_lightning/loggers/tensorboard.py#L81 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG or DOC: np.array dtype can be used to downcast data In the process of investigating the behaviour of `can_cast` for #13636 , I noticed that: ``` np.array([1000.], 'i1') # array([-24], dtype=int8) ``` i.e., casting is done unsafely. Yet the docstring suggests downcasting is not possible: ``` dtype : data-type, optional The desired data-type for the array. If not given, then the type will be determined as the minimum type required to hold the objects in the sequence. This argument can only be used to 'upcast' the array. For downcasting, use the .astype(t) method. ``` So, we should either ensure `array` behaves as documented, or document the actual behaviour. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: add group_name to AssetsDefinition.from_graph ### Issue from the [Dagster Slack](https://join.slack.com/t/dagster/shared_invite/enQtNjEyNjkzNTA2OTkzLTI0MzdlNjU0ODVhZjQyOTMyMGM1ZDUwZDQ1YjJmYjI3YzExZGViMDI1ZDlkNTY5OThmYWVlOWM1MWVjN2I3NjU) This issue was generated from the slack conversation at: https://dagster.slack.com/archives/C01U954MEER/p1655265200928469?thread_ts=1655265200.928469&cid=C01U954MEER --- ### Conversation excerpt U03BUAXQS4U: I'm using the new 'define assets from_graph' feature in 0.15.0. I can get it to work but I can't figure out how to add the created graph->asset to an asset group. It appears to get added do an asset group named 'default'. ```my_graph_asset = AssetsDefinition.from_graph(my_graph)``` graph doesn't have a group_name property, nor does from_graph(). In dagit I see my original asset group (my_asset_group) and another asset group named 'default'. my graph asset has upstream dependencies and I see the connections between my original group and the new one, so it works, but ideally I'd like to add the graph asset to the other asset group. is there a way to do this? thanks! U028M11QNDD: Hi there John. This is something we'll add within the next two releases, it was something we didn't quite have time to finish within 0.15.0. For now, one workaround you can do: ```AssetsDefinition.from_graph(my_graph).with_prefix_or_group(group_names_by_key={AssetKey(\"foo\"): \"group_name\"})``` U028M11QNDD: I'll make an issue so we can track this as well: U028M11QNDD: <@U018K0G2Y85> issue add group_name to AssetsDefinition.from_graph --- #### Message from the maintainers: Do you care about this too? Give it a :thumbsup:. We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow states in plot_histogram to be ordered by Hamming distance from target state <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Currently the bit strings using in `plot_histogram` can only be ordered as ascending or descending. However, it is informative to be able to order the bit strings in terms of some distance function from a target bit string. The Hamming distance is one such measure, and is useful to see the effects of gate and environmental noise on the system as measured by number of bit flips. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: api_core: Add metadata option to wrap_method To update GAPIC to use routing headers, `wrap_method` needs to accept more metadata than just the user agent. Example: ```python metadata = [ (b'x-google-request-params', b'name={}&book.read={}'.format(name, book.read))] self._create_book(request, retry=retry, timeout=timeout, metadata=metadata) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: Generate Admin V1 Client. Adding the Firestore Admin API Client will allow programmatic management of indexes, and export/import operations. * Artman config: [artman_firestore_v1.yaml](https://github.com/googleapis/googleapis/blob/master/google/firestore/admin/artman_firestore_v1.yaml) Feel free to ping me if any updates are needed for the artman file. b/129353554 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Runtime Performance Regression in `SabreLayout` ### Environment - **Qiskit Terra version**: 0.25.0 - **Python version**: 3.11 - **Operating system**: Linux ### What is happening? When running `SabreLayout` with 0.25.0 has a large performance regression between 0.24.x and 0.25.0 that is a function of the number of gates in the circuit. The rust computation of the swap map and initial layout is as fast as before, but when we iterate over that to rewrite the `DAGCircuit` using that output from rust the runtime performance is significantly slower. For more modestly sized circuits this isn't super noticeable , but as the number of instructions in a circuit increases this overhead can be significantly higher. ### How can we reproduce the issue? You can parse this qasm file from qasmbench: https://github.com/pnnl/QASMBench/blob/master/medium/bwt_n21/bwt_n21.qasm ```python from qiskit import transpile, QuantumCircuit from qiskit.providers.fake_provider import FakeCairoV2 import time import logging logging.basicConfig(level=\"INFO\") backend = FakeCairoV2() for filename in [\"bwt_n21.qasm\"]: start = time.time() qc = QuantumCircuit.from_qasm_file(filename) parse_stop = time.time() print(f\"parse {filename}: {parse_stop - start}\") tqc = transpile(qc, backend, optimization_level=1) stop = time.time() print(f\"{filename}: {stop - start}\") ``` ### What should happen? The performance should be roughly equivalent to qiskit-terra < 0.25.0. Looking at 0.24.2 the above example `SabreLayout` took `22515.55800 ms` and 0.23.0 took `18759.72962 ms`. But I've been too impatient to wait for 0.25.0 to finish after several minutes. ### Any suggestions? I expect the underlying issue stems from #10366 and specifically the rust<->python boundary doing unnecessary copies or conversions when we access data as we iterate over the circuit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Security file is not removed after shutdown by Ctrl+C or kill -INT I am using IPython 0.12 (Ubuntu 11.10, Python 2.7.2+). This is how to reproduce. I just open one new notebook after starting the server. ``` % ipython profile create test [ProfileCreate] Generating default config file: u'/home/takafumi/.config/ipython/p rofile_test/ipython_config.py' [ProfileCreate] Generating default config file: u'/home/takafumi/.config/ipython/p rofile_test/ipython_qtconsole_config.py' [ProfileCreate] Generating default config file: u'/home/takafumi/.config/ipython/p rofile_test/ipython_notebook_config.py' % ipython notebook --profile=test [NotebookApp] Using existing profile dir: u'/home/takafumi/.config/ipython/profile_test' [NotebookApp] The IPython Notebook is running at: http://127.0.0.1:8888 [NotebookApp] Use Control-C to stop this server and shut down all kernels. Created new window in existing browser session. [NotebookApp] Using MathJax from CDN [NotebookApp] Kernel started: 5946f2c5-4a2f-434f-8962-ef379d7969a0 [NotebookApp] Connecting to: tcp://127.0.0.1:42572 [NotebookApp] Connecting to: tcp://127.0.0.1:39724 [NotebookApp] Connecting to: tcp://127.0.0.1:54142 [IPKernelApp] To connect another client to this kernel, use: [IPKernelApp] --existing kernel-5946f2c5-4a2f-434f-8962-ef379d7969a0.json --profile test ^C % ls ~/.config/ipython/profile_test/security/ kernel-5946f2c5-4a2f-434f-8962-ef379d7969a0.json ``` BTW, is it safe to do `rm ~/.config/ipython/profile_*/security/*` when there is no IPython instance running? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: whos under pypy1.6 magic who command works, but 'whos' gives an error that has to do with numpy /IPython/core/magic.py in magic_whos(self, parameter_s) line 870 AttributeError: 'module' object has no attribute 'ndarray' This version of pypy has a trial version of numpy that only has 1d arrays, not ndarray. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: to_arrow() method similar to to_dataframe() Current there's a `to_dataframe()` method that returns a pandas `DataFrame` from a query. `DataFrame`s don't efficiently support array and struct values, but `pyarrow` provides efficient support for them: ```python In [11]: import pyarrow as pa In [13]: a = pa.array( ...: [ ...: {'a': [1, 2, 3]} ...: ], ...: pa.struct([pa.field('a', pa.list_(pa.int64()))]) ...: ) In [14]: a Out[14]: <pyarrow.lib.StructArray object at 0x7f55f8764b88> [ {'a': [1, 2, 3]} ] ``` A `to_arrow()` method will make it easier to efficiently support more complex types going forward in downstream libraries like [ibis](https://github.com/ibis-project/ibis). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for `Expr` values to `DAGCircuit.replace_block_with_op` ### What should we add? This may follow easily from the work in #10226, but at the very least this issue requires additional tests to be written to verify that the function is working as expected. Depends on #10223, #10224. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: A form of conan remote list that can be used with conan config install See https://github.com/conan-io/docs/issues/697 for further discussion/motivation, but basically the idea is that the output of `conan remote list` is not compatible with the format of `remotes.txt` expected for use with `conan config install`. It could be nice to have a modified version of `conan remote list` (@memsharded has suggested `conan remote list --raw`) so that ```bash conan remote list --raw > remotes.txt ``` can conveniently format a user's remotes for use in a packaged Conan client config. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Ability to provide sample conf JSON for a dag in trigger page **Description** In the trigger page, there is a text area to enter (optional) conf json. It would be great if a sample JSON can be provided programatically while defining DAG **Use case / motivation** This will improve usability of the UI that triggers a DAG Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CMake toolchain file does not define CMAKE_C*_COMPILER_ABI **Describe the bug** meson fails to find cmake dependencies on Linux with x32 ABI. It appears to be caused by toolchain file created by meson which contrary to CMake own mechanism does not set compiler's ABI ie CMAKE_C_COMPILER_ABI or CMAKE_CXX_COMPILER_ABI. and at the same time sets CMAKE_C*_COMPILER_FORCED. **To Reproduce** Any meson file with cmake dependency, however cmake file needs to be in /usr/libx32/cmake directory. **Expected behavior** cmake dependency should be found **system parameters** * Plain build * PLD Linux (arch x32) * Python 3.8.7 * meson 0.56.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Have RAG return generator cross-attentions when output_attentions=True # 🚀 Have RAG return generator cross-attentions when output_attentions=True This feature request is for the RAG code to be modified so that if `output_attentions=True`, it returns the generator's cross-attentions in addition to the attentions it already returns. ## Motivation I'm interested in extracting the generator's attentions from a RAG generator model. Currently, `transformers` allows you to extract the generator's encoder attentions and decoder attentions, but not it's cross attentions. For example, inside `modeling_rag.py`, the return objects such as [RetrievAugLMMarginOutput](https://github.com/huggingface/transformers/blob/master/src/transformers/models/rag/modeling_rag.py#L38), have fields for these other attentions, but not the cross-attentions. Because both T5 and BART can output cross-attentions, I think they could simply propagate up through the RAG code. Is there a reason this isn't already the case? Or could I do a PR to include the cross attentions along with the other attentions in the model output? ## Your contribution On my own fork of `transformers`, I've already added this feature and would happily submit a PR! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: records.fromfile - 64 bit incompatibility Hello, https://github.com/numpy/numpy/blob/983bbb5ed2495e034b437a0b58a69371d4dfed74/numpy/core/records.py#L796 Seems like unfortunately numpy.core.records.fromfile method uses 32 bit integers. Makes it impossible to read data larger than 4GB. Python 3.7.1 64 bit numpy 1.15.4 (numpy-1.15.4-cp37-none-win_amd64.whl) call: `raw_data = numpy.core.records.fromfile(io_input, shape=420453029, offset=0, formats='i4,u4,i4', names='t,k,n', byteorder='<')` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: 'load_table_from_dataframe' raises OSError with STRUCT / RECORD columns. pyarrow-0.14.0 pandas '0.24.2' windows 10 Hi, I am tring to load dataframe to big query that looks like that ``` uid_first agg_col 1001 [{'page_type': 1}, {'record_type': 1}, {'non_consectutive_home': 0}] ``` the agg_col is list of dicts I also tried dict Schema config: ``` schema = [ bigquery.SchemaField(\"uid_first\",\"STRING\",mode=\"NULLABLE\"), bigquery.SchemaField(\"agg_col\",\"RECORD\",mode=\"NULLABLE\",fields=[ bigquery.SchemaField(\"page_type\", \"INTEGER\", mode=\"NULLABLE\"), bigquery.SchemaField(\"record_type\", \"INTEGER\", mode=\"NULLABLE\"), bigquery.SchemaField(\"non_consectutive_home\", \"INTEGER\", mode=\"NULLABLE\")])] ``` load command ``` dataset_ref = client.dataset('dataset') table_ref = dataset_ref.table('table') table = bigquery.Table(table_ref,schema=schema) table = client.load_table_from_dataframe(dff, table).result() ``` The error message ``` Traceback (most recent call last): File \"<ipython-input-167-60a73e366976>\", line 4, in <module> table = client.load_table_from_dataframe(dff, table).result() File \"C:\\ProgramData\\Anaconda3\\envs\\p37\\lib\\site-packages\\google\\cloud\\bigquery\\client.py\", line 1546, in load_table_from_dataframe os.remove(tmppath) FileNotFoundError: [WinError 2] The system cannot find the file specified: 'C:\\\\Users\\\\ADMINI~1\\\\AppData\\\\Local\\\\Temp\\\\tmpcxotr6mb_job_5c94b06f.parquet' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: duplicate log messages Adding code ```python class DbgViewHandler(logging.Handler): def emit(self, record): print(\"DbgViewHandler: %s\" % record) logger = logging.getLogger(\"logging_test\") logger.setLevel(logging.DEBUG) logger.propagate = False stream_handler = logging.StreamHandler() stream_handler.setLevel(logging.WARNING) # all going to stderr dbgview = DbgViewHandler() # all going to stdout dbgview.setLevel(logging.DEBUG) logger.addHandler(dbgview) logger.addHandler(stream_handler) logger.info(\"Hello there\") logger.warn(\"Whoa there\") ``` To the bottom of conda/gateways/logging.py outputs too many copies of messages. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: CSPLayout is biased towards \"low\" qubits Take the following example: ```python from qiskit import QuantumCircuit qc = QuantumCircuit(3) qc.cz(0, 1) qc.cz(1, 2) qc.draw() ``` If this circuit is laid-out in a 5-qubit linear coupling map, using `CSPLayout`, the result is the following: ```python from qiskit.transpiler import CouplingMap from qiskit.converters import circuit_to_dag from qiskit.transpiler.passes import CSPLayout coupling_map = CouplingMap.from_line(5) dag = circuit_to_dag(qc) pass_ = CSPLayout(coupling_map) pass_.run(dag) print(pass_.property_set['layout']) ``` ``` Layout({0: Qubit(QuantumRegister(3, 'q'), 0), 1: Qubit(QuantumRegister(3, 'q'), 1), 2: Qubit(QuantumRegister(3, 'q'), 2)}) ``` Notice that there are other possible layout allocations besides the trivial one here. However, `CSPLayout` always choose this one, even when `CSPLayout(..., seed=...)` is set. ### What is the expected enhancement? I would expect a uniformly distribution of all possible allocations, controlled by the seed parameter. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: classical_function creates wrong circuits for some cases ### Information - **Qiskit Terra version**: master - **Python version**: 3.8 - **Operating system**: macOS Catalina ### What is the current behavior? `classical_function` creates wrong circuits for some cases. I confirmed at least two cases. ### Steps to reproduce the problem Case 1) ``` def expr1(x1: Int1, x2: Int1, x3: Int1) -> Int1: return x1 cf = classical_function(expr1) print(cf.synth()) q_0: ──■── │ q_1: ──┼── │ q_2: ──┼── ┌─┴─┐ q_3: ┤ X ├ └───┘ ``` Case 2) ``` def expr2(x1: Int1, x2: Int1, x3: Int1) -> Int1: return x1 or x2 or x3 cf = classical_function(expr2) print(cf.synth()) q_0: ──o──────────── │ q_1: ──o────o─────── │ │ q_2: ──■────■────■── ┌─┴─┐┌─┴─┐┌─┴─┐ q_3: ┤ X ├┤ X ├┤ X ├ └───┘└───┘└───┘ ``` ### What is the expected behavior? Case 1) The control bit of the CNOT gate should be the most bottom bit. As written in the [documentation](https://qiskit.org/documentation/apidoc/classicalfunction.html), following Qiskit’s little-endian bit ordering convention, the left-most bit (x1) is the most significant bit and the right-most bit (x3) is the least significant bit. The following code is an example for the correct bit ordering. ``` def expr3(x1: Int1, x2: Int1, x3: Int1) -> Int1: return not x1 and x2 and x3 cf = classical_function(expr3) print(cf.synth()) q_0: ──■── │ q_1: ──■── │ q_2: ──o── ┌─┴─┐ q_3: ┤ X ├ └───┘ ``` Case 2) The circuit does not represent `x1 or x2 or x3`. For example, when (x1, x2, x3) = (001), $q_3$ of the circuit does not become 1. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Going from numpy 1.14.5 to 1.15.0rc1 breaks loading a DLL using ctypes In our [Python API](https://github.com/ni/nimi-python) for accessing measurement hardware we allow the customer to retrieve their measurements in `numpy` arrays in case they want to do additional processing. When using `numpy` 1.14.5 or earlier, we are able to load our C DLL with no issue and make the appropriate calls using `ctypes`. When using `numpy` 1.15.0rc1, we get an error when `ctypes` tries to load the DLL saying \"[WinError 126] The specified module could not be found\". I am using `tox` to run tests so it is using `venv` and all I have to do is change the version of `numpy` and it will start working. This means the DLL is in the path as expected and all dependencies are also loadable. I have verified that `numpy` is the only installed package whose version is changing. I have verified that the path environment variable has the appropriate directory even in the failure case. I have verified that this happens on Python 2.7 and 3.6, both 32 bit and 64 bit. As far as I know we are using `ctypes` correctly. At this point I don't have any more ideas on what to look at. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support thin archives for static libraries that are not installed I have a project which generates several executables which (partially) share the same source files. Since each executable is first compiled in its own subdirectory, all these shared source files are recompiled for every executable. This is undesirable if I know that identical object files will be produced (that is, the compiler options are identical). Is there a way to specify the name of the build-subdirectory to avoid this repeated redundant compilation? I am aware that one could use static libraries to work around this problem, but besides being overkill this also has several disadvantages: It also has the overhead of building the library, and moreover, to support e.g. proper support for LTO it requires linker plugins etc. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: ma.average ignores masked weights The np.ma.average function ignores masked weights. Averaging a masked array with unmasked and masked weights incorrectly gives the same result. I am using numpy version 1.13.3, python 2.7.12. In previous versions of numpy (e.g. 1.11.0b3) ma.average did not exhibit this behavior. ``` import numpy as np import numpy.ma as ma x = np.ma.array(np.arange(9).reshape(3, 3), mask=[[1, 0, 0], [1, 0, 0], [0, 0, 0]]) w=ma.masked_array([31,28,31],mask=False) w2 = ma.masked_array([31,28,31],mask=[1,0,0]) ``` ``` np.ma.average(x, axis=0, weights=w, returned=True) (masked_array(data = [6.0 4.0 5.0], mask = [False False False], fill_value = 1e+20) , array([ 31., 90., 90.])) np.ma.average(x, axis=0, weights=w2, returned=True) (masked_array(data = [6.0 4.0 5.0], mask = [False False False], fill_value = 1e+20) , array([ 31., 90., 90.])) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Use WebSocket.ping to keep connections alive across proxies I am accessing a remote IPython Notebook and need to use a proxy (Squid/SOCKS) for internet access. As long as I am running cells everything works fine, but after one minute of inactivity the proxy seems to close the connection, resulting in the following Firefox console log: ``` The connection to wss://example.org/kernels/$uuid/shell was interrupted while the page was loading. @ https://example.org/static/js/kernel.js ``` The websocket connection is reestablished immediately (and interrupted again after one minute), but running cells does not work anymore until I manually restart the kernel. ``` ipython --version 0.13.1.rc2 ``` Sending any message via each websocket (shell+iopub) will avoid interruption. This is a quick and _dirty_ client side workaround: ``` from IPython.core.display import HTML HTML('''<script> var keepalive_timer; function keep_connection_alive() { IPython.notebook.kernel.execute(); keepalive_timer = setTimeout('keep_connection_alive()', 55000); } keep_connection_alive(); </script>''') ``` WebSocket has ping and pong frames for keep-alive, tornado has a ping() function to send such a frame. Could the ping function be called somewhere in the kernel code to keep alive connections even via proxy? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Add option to delete necessary files / directories when running conan config install An issue that I've run into is that restructuring the structure of Conan profiles in a shared Conan configuration via Git can fail when switching a file to a directory of the same name or vice versa. This pretty much fails without explanation, so the error message should probably be improved. Perhaps it would be best to make this default behavior, which wouldn't require anything special to ensure scheduled runs of `conan config install` don't break. Otherwise, there could be an option like `--force` which would all overwriting any conflicting directories / files. To reproduce this issue: 1. Create a git repository to share Conan configuration through `conan config install`. ``` mkdir conan-config cd conan-config mkdir profiles mkdir -p profiles/debug touch profiles/debug/address-sanitizer git init git add -A git commit -m \"Initial commit\" ``` 2. Install the repository using `conan config install`. ``` conan config install . ``` 3. Now re-organize such that a directory is now a file in the `conan-config` repository. ``` mv profiles/debug/address-sanitizer profiles/address-sanitizer rmdir profiles/debug touch profiles/debug git add -A git commit -m \"Restructure profiles\" ``` 4. Re-run `conan config install` to update the profiles. ``` conan config install Config install: /var/home/jordan/Projects/test/conan-config Copying file address-sanitizer to /var/home/jordan/.conan/profiles Copying file debug to /var/home/jordan/.conan/profiles ERROR: Failed conan config install: ``` Note the vague error message. - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: get_variable with a file object as default value: Argument of type File is not held by an ObjectHolder **Describe the bug** After updating Meson, I see this error in a previously working build: ``` build/analysis/vale/meson.build:24:0: ERROR: Argument build/analysis/vale/vale-styleguide/config/documentation.vale.ini of type File is not held by an ObjectHolder. This is a Meson bug and should be reported! ``` The file is being specified in this manner: ``` # Supply a style file, which will use this file instead of the default .vale.ini vale_config_file = get_variable('vale_config_file', files('vale-styleguide/config/documentation.vale.ini')) ``` The default variable option is being used - I'm not overriding it. The same is happening in a Doxygen module I use: ``` doxyfile_input = get_variable('doxyfile_input', files('Doxyfile.in')) ``` I tried moving the file object into another variable: ``` vale_default_config_file = files('vale-styleguide/config/documentation.vale.ini') vale_config_file = get_variable('vale_config_file', vale_default_config_file) ``` With teh same result - the error is reported on the `get_variable` line. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? **native** * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) **MacOS 10.15.7** * what Python version are you using e.g. 3.8.0 **Python 3.9.6** * what `meson --version` **0.59.0.rc1** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: clbit_labels should not contain null <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information The definition of `clbit_labels` was changed in #879 by @dcmckayibm. It used to be something like: ```[[\"c\", 2], [\"d\", 3]] ```, which assigns contiguous regions of memory to each register. Now it is like this, where single classical bits can be assigned to arbitrary locations of memory. ```[[\"c\", 1], [\"c\", 0], [\"d\", 0], [\"d\", 2], [\"d\", 1]]``` I agree with this change. However, the schema currently also allows something like this for `clbit_labels`. ```[[\"c\", 1], [\"c\", 0], [\"d\", 0], [\"d\", 2], [\"d\", 1], null, null]``` I don't think the schema should allow this. I want to have a convention that for each experiment, `memory_slots` defines the total amount of classical (slow) memory bits for that experiment, and `clbit_labels` have a 1-1 correspondence with those. It is fine for `qubit_labels` to have null, as the device can have more qubits than used for an experiment. But `clbit_labels` should just be as many classical bits as the experiment uses. By the way this information is important for Terra to be able to rebuild the original circuit registers in the Result. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Add setuptools to dagster/setup.py install_requires `setuptools` isn't a part of core Python, so when installing Dagster into an isolated environment by a package manager (e.g. PDM, poetry), it will not get picked up and installed as a dependency. Here's where it's throwing a `ModuleNotFoundError` when I try to run `dagster-cloud agent run`: https://github.com/dagster-io/dagster/blob/96a6762095eec173d9ec3a524dd64382d34f5ed7/python_modules/dagster/dagster/core/definitions/utils.py#L7 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add optional stdout logging for tasks ## Current behavior Currently, `print` statements or any other stdout is not treated in any special way. This has two consequences: - users who use `print` statements locally and can see the output are surprised when the output doesn't appear in the Cloud logs - print statements from third-party libraries that might be useful are not surfaced in cloud execution ## Proposed behavior We should introduce a new keyword argument on all Tasks `log_stdout` which defaults to `True`. When `True`, all standard out is converted to a DEBUG level log. When toggled to `False`, we will not redirect. This will capture richer information from task runs, but also allow for incredibly simple logging for our less advanced users: ```python @task def example(): print('hi') print('this is a test') print('of our emergency broadcast system') ``` will result in 3 debug logs. ## Example This is actually very simple with Python builtins: ```python import prefect from contextlib import redirect_stdout class RedirectToLog: def write(self, s): # avoids blank newlines if s.strip(): prefect.utilities.logging.prefect_logger.debug(s) to_debug_log = RedirectToLog() with redirect_stdout(to_debug_log): print('hi') print('this is a test') print('of our emergency broadcast system') ``` results in : ``` [2020-02-17 00:02:13,642] 4-- DEBUG - prefect | hi [2020-02-17 00:02:13,642] 4-- DEBUG - prefect | this is a test [2020-02-17 00:02:13,643] 4-- DEBUG - prefect | of our emergency broadcast system ``` **NOTE:** In our case, we want want to generate the redirect class on the fly so that it uses the task run specific logger in each case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Auto-suggestion (matching brackets code maybe ?) creates broken code even on trival statements This is in a fresh `python:latest` docker container where I installed the latest ipython version with pip. ``` Python 3.10.1 (main, Dec 21 2021, 09:01:08) [GCC 10.2.1 20210110] Type 'copyright', 'credits' or 'license' for more information IPython 8.0.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: foo = 'bar'' ``` I typed `foo = 'bar'` and it added a second single quote at the end, which is obviously invalid. The same happens with double quotes, so as much as I dislike this black integration, it seems unrelated since it happens at input time and not only when I run the code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook: Long delay before closing/server stop on Windows I'm on Windows with ipython 2.4.0 The console says \"Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).\". But doing so takes over a minute on my machine to actually exit! Just measured and it was 102 seconds. It's faster to just kill python.exe. Which is ugly and can't be the expected behavior. This is not new for me, but I couldn't find related issues, so what's up with that? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Compile Cython code to C++ Meson 0.59.0 introduced native support for [Cython](https://mesonbuild.com/Cython.html#cython). I am trying to compile an existing Cython project using Meson. The Cython code relies on functionality from the C++ standard library and therefore must be compiled to C++. I found some discussion on whether compilation from Cython to C++ can be supported in pull request #8706. Unfortunately, it remains unclear to me whether this functionality is already supported or not. Is it possible to compile `.pyx` files to `.cpp` files using Meson? Either by globally defining the target language in the `meson.build` file, or by adding the compiler directive `# distutils: language = c++` to the `.pyx` files. I tried the latter, but Meson still produces `.c` files. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.xla_computation ignores its static_argnums argument The implementation of jax.xla_computation completely ignores its static_argnums argument, which seems like an oversight. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Double-dash becomes en-dash in docs for \"cd\" magic The double-dash in [this line][line] gets rendered as an en-dash (Unicode U+2013) in [the docs][docs] for the `cd` magic. I don't know how to fix it, sorry, otherwise I'd submit a pull request :frowning_face: [line]: https://github.com/ipython/ipython/blob/86d24741188b0cedd78ab080d498e775ed0e5272/IPython/core/magics/osm.py#L317 [docs]: https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.scipy.ndimage.map_coordinates round half is different than scipy `jax.scipy.ndimage.map_coordinates` implements 'round half to even' when using nearest-neighbor interpolation and the coordinat values are exactly half (i.e. both 1.5 and 2.5 get rounded to 2). This is the default behavior for jax and ordinary numpy rounding (round, around, rint). However scipy.ndimage.map_coordinates appears to implement 'round half up'. The difference between jax and scipy is illustrated with the following commands. `>>> x = np.arange(10).astype(np.float32)` `>>> coords = [[3.5, 4.5, 5.5, 6.5, 7.5]]` `>>> jax.scipy.ndimage.map_coordinates(x, coords, order=0)` `DeviceArray([4., 4., 6., 6., 8.], dtype=float32)` `>>> scipy.ndimage.map_coordinates(x, coords, order=0)` `array([4., 5., 6., 7., 8.], dtype=float32)` Not sure which behavior is desired, but if the default numpy behavior is desired, the jax.scipy documentation should mention this. If the scipy behavior is desired, the rounding function at [https://github.com/google/jax/blob/7d157c71815e5386f2b449bac69ef9e3ab7e701f/jax/scipy/ndimage.py#L40](https://github.com/google/jax/blob/7d157c71815e5386f2b449bac69ef9e3ab7e701f/jax/scipy/ndimage.py#L40) should be changed to something like: `index = jnp.floor(coordinate + .5).astype(jnp.int32)` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Allow installation of output header (-H) for Vala library targets Currently it is unconditionally named after the library itself, but this is not always what people want. For instance in #890, @grindhold names the library `libhttpseverywhere-0.2`, but the header is called `libhttpseverywhere.h`. Found while investigating #890 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: add_project_arguments should ensure it is called before build targets only in the current project, not subprojects If a subproject is defined, and `add_project_arguments` is called after said subproject, then meson will error out with ``` Tried to set project arguments after a build target has been declared. This is not permitted. Please declare all project arguments before your targets. ``` This doesn't seem correct, as `add_project_arguments` differese from `add_global_arguments` specifcially in that it doesn't affect subprojects. Specfically this is annoying because it means that if a dependency needs to add define as an argument rather than as configuration_data that must be done before the subproject, making it impossible to use the fallback parameter. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Error differentiating QR decomposition This appears to be a bug but unfortunately I don't have time to delve into it. Below is a simple script to do gradient descent on a function involving a QR decomposition. It fails when I execute `training_gradient_fun` with `TypeError: No abstraction handler for type: <class 'jax.ad_util.Zero'>`. Ubuntu 16.04 python 3.6.6 jax 0.1.20 jaxlib 0.1.9 ``` import jax import jax.numpy as np import numpy as onp def loss(weights, inputs): q, r = np.linalg.qr(weights) a = np.matmul(q, weights) return np.mean(a ** 2) training_gradient_fun = jax.jit(jax.grad(loss)) inputs = onp.random.rand(5, 5) weights = onp.random.rand(5, 5) for i in range(100): weights -= 0.1 * training_gradient_fun(weights, inputs) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Don't pass ConanFileReference object to conan_api, pass string https://github.com/conan-io/conan/pull/5176/files introduces a ConanFileReference via the conan_api, please fix. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse and Schedule plots do not start at t0=0 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? As noted in https://github.com/Qiskit/qiskit-terra/pull/3418#pullrequestreview-313349295, the pulse and schedule plots do not start at t=0, nor do they finish at `t=t0+duration` ### Steps to reproduce the problem ```python import qiskit.pulse as pulse import qiskit.pulse.pulse_lib as pulse_lib sched = pulse.Schedule() sched += pulse_lib.constant(10, 1.0)(pulse.DriveChannel(1)) sched.draw(channels_to_plot=[pulse.DriveChannel(1)]) ``` ### What is the expected behavior? They should start and stop at t0(duration) ### Suggested solutions Any ideas @nkanazawa1989? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Filename completion with quotes in filename does not escape the quotes When completing filenames containing quotes those are completed verbatim, closing the string. The user has to go back in the string to escape the quotes manually. ``` $ touch /tmp/foo\\'bar $ ipython In [1]: open('/tmp/foo<TAB> # actual In [1]: open('/tmp/foo'bar # Expected: In [1]: open('/tmp/foo\\'bar ``` ```python {'commit_hash': '3a3686a', 'commit_source': 'repository', 'default_encoding': 'UTF-8', 'ipython_path': '/home/t-8ch/Projekte/ipython/IPython', 'ipython_version': '6.0.0.dev', 'os_name': 'posix', 'platform': 'Linux-4.8.10-1-ARCH-x86_64-with-arch', 'sys_executable': '/home/t-8ch/.local/share/virtualenvs/ipython/bin/python', 'sys_platform': 'linux', 'sys_version': '3.5.2 (default, Nov 7 2016, 11:31:36) \\n[GCC 6.2.1 20160830]'} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: make docs failing https://github.com/huggingface/transformers/blob/2a606f9974feb0f7578e6a638c7e5b548523ecb4/CONTRIBUTING.md?plain=1#L211-L221 ```bash make docs cd docs && make html SPHINXOPTS=\"-W -j 4\" Application error: config directory doesn't contain a conf.py file (source) make[1]: *** [html] Error 2 make: *** [docs] Error 2 ``` transformers version: master branch @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Can't call `conan upload --recipe-only` twice with backup sources enabled ### Steps to reproduce 1. Enable backup sources 2. Export a recipe that downloads file 3. Call conan upload only recipe for ref 4. Do it again, it fails due to KeyError Found while prepping for https://github.com/conan-io/conan-center-index/pull/18082 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: interactive -i mode doesn't work after exceptions since 4.1.1 Hi, I recently noticed that after upgrading from 4.0.3 to 4.1.1 (from anaconda), `-i` flag no longer drops to the interactive shell but quits after an exception. I downgraded to 4.0.3 and it is now working correctly. I searched on google but couldn't find a similar issue. Any ideas? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Remove deprecated `conda.install` ### What is the idea? Remove clearly deprecated code. ### Why is this needed This submodule was deprecated 4 years ago. ### What should happen? Remove `conda.install` and associated code that is no longer in use. ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Default value of UserFeatureOption is `enabled` instead of `auto` According to `meson --help`: ``` --auto-features {enabled,disabled,auto} Override value of all 'auto' features (default: auto). ``` However, in reality the default value is `enabled`. We should fix it to be `auto`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Check release is broken on main <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue. Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description <!--Describe the bug clearly and concisely. Include screenshots if possible--> Check release is broken on main The reason that the package on main are targeted 4.1.0 prereleases but the version have not been bumped. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: metrics.sklearns don't work with DDP: Tensors must be CUDA and dense ## 🐛 Bug Using sklearn-like metrics (from metrics.sklearns) works fine in DP mode, but results in the following error in DDP mode: `Tensors must be CUDA and dense` ### To Reproduce This colab notebook has a full example: https://colab.research.google.com/drive/1uxihs4pztF_qTN-gkO1QOaX0npzE_uSZ?usp=sharing Mentioning @justusschock Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add informative error message when the argument \"shots\" passed to the execute function is not of type int <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? execute(circuit, backend = Aer.get_backend('qasm_simulator), shots = \"1024\") doesn't give an informative error message (Issue number 842 in qiskit-aer). Add an informative error message. This isssue was posted in qiskit-aer which is a wrong place for it. Creating a new issue at qiskit-terra (which is relevant to it) and creating a pull request for a solution Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BLD: warning \"document not included in any toctree\" while building documentation When building documentation, there are many tens of warnings `WARNING: document isn't included in any toctree`. It seems to be from class attribute `autoattribute` generated documentation. This might be a numpydoc issue, but it does not occur when building scipy documentation. Any hints where to debug this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: make zmq-console and qtconsole monitor activity they did not initiate over at ivanov/vim-ipython#31, @pielgrzym pointed out that vim-ipython is able to monitor and display input and output for the kernel it is monitoring, regardless of what client initiated this activity, whereas activity initiated from vim-ipython is not reflected by these clients. This is not unique to vim-ipython, however. Both the qtconsole and console frontends currently ignore the messages that they did not initiate. In other words, if you have two qtconsoles connected to the same kernel, executing code from one of them will not affect the other one in any way. It would be nice for the qtconosle and console frontends to periodically check the relevant channels and make this activity visible. This would certainly be a good candidate for toggle-able behavior, since sometimes you really do want to ignore what other clients are doing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove Textbook reference from Phase Estimation docstring ## Description This line refers to the Qiskit Textbook as a reference for phase estimation. This page is no longer maintained and we should remove the reference https://github.com/Qiskit/qiskit-terra/blob/c8552f6b51a36aa432b21b0d31b88e212a104ca7/qiskit/circuit/library/phase_estimation.py#L46 CC: @abbycross, @lerongil, @javabster Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: `flow.run()` crashes on scheduled states in the far future ## Description *A clear description of the bug* `Paused` states default to setting a future run time in the far future; this exceeds the maximum argument that can be provided to `time.sleep()`. This crashes `flow.run()` when hitting a pause state. To be clear, Pausing and `flow.run()` aren't a great combo because there's not a way to provide a `Resume` state, but we can solve the crash. ## Expected Behavior Pausing really pauses, not crashes. ## Reproduction *A minimal example that exhibits the behavior.* ```python from prefect import task, Flow, triggers @task def task_1(): return 1 @task(trigger=triggers.manual_only) def add_one(x): return x + 1 with Flow(\"example\") as flow: t1 = task_1() t2 = add_one(x=t1) flow.run() # error ``` ## Environment *Any additional information about your environment* *Optionally run `prefect diagnostics` from the command line and paste the information here* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `c_if` fails when using indexing if there are no classical registers in the circuit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: main - **Python version**: any - **Operating system**: any ### What is the current behavior? All `c_if` statements immediately fail if there are no classical registers defined in the circuit, only loose bits, and one tries to specify the condition with an index. ### Steps to reproduce the problem ```python In [1]: from qiskit.circuit import QuantumCircuit, Clbit, Qubit ...: ...: qc = QuantumCircuit([Qubit(), Clbit()]) ...: qc.x(0).c_if(0, 0) --------------------------------------------------------------------------- UnboundLocalError Traceback (most recent call last) <ipython-input-1-efd3b9b41798> in <module> 2 3 qc = QuantumCircuit([Qubit(), Clbit()]) ----> 4 qc.x(0).c_if(0, 0) ~/code/qiskit/terra/qiskit/circuit/instructionset.py in c_if(self, classical, val) 65 if isinstance(classical, (Clbit, int)): 66 if isinstance(classical, int): ---> 67 classical = circuit_clbits[classical] 68 for creg in self.circuit_cregs: 69 if creg[:] == [classical]: UnboundLocalError: local variable 'circuit_clbits' referenced before assignment ``` ### What is the expected behavior? There should be no error, and it should select the correct bit as a condition. ### Suggested solutions A similar fix to #7246 will work here as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: cannot export to notebook with magic command in IPython 3.0.0 I was trying to export command history into a notebook with `%notebook -e $notebook_file`, and got the following error: <pre><code>/Users/w/python-venv/2.7/lib/python2.7/site-packages/IPython/core/magics/basic.pyc in notebook(self, s) 605 cells.append(v4.new_code_cell( 606 execution_count=execution_count, --> 607 source=source 608 )) 609 nb = v4.new_notebook(cells=cells) NameError: global name 'source' is not defined</pre></code> Had a quick look in the file `IPython/core/magics/basic.py`, and I guess the line `source=source` should be replaced by `source=input`? Here is the output of `python -c \"import IPython; print(IPython.sys_info())\"` on my system: <pre><code>{'commit_hash': u'f75fda4', 'commit_source': 'installation', 'default_encoding': 'UTF-8', 'ipython_path': '/Users/w/python-venv/2.7/lib/python2.7/site-packages/IPython', 'ipython_version': '3.0.0', 'os_name': 'posix', 'platform': 'Darwin-14.1.0-x86_64-i386-64bit', 'sys_executable': '/Users/w/python-venv/2.7/bin/python', 'sys_platform': 'darwin', 'sys_version': '2.7.6 (default, Sep 9 2014, 15:04:36) \\n[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.39)]'}</pre></code> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: 💫 Lemmatizer should apply rules on OOV words @juanmirocks points out in #327 that the lemmatizer fails on OOV words: ```python >>> nlp.vocab.morphology.lemmatizer(u'endosomes', 'noun', morphology={'number': 'plur'})set([u'endosomes']) >>> nlp.vocab.morphology.lemmatizer(u'chromosomes', 'noun', morphology={'number': 'plur'}) set([u'chromosome']) ``` Suggested patch to lemmatizer.py ```python oov_forms = [] for old, new in rules: if string.endswith(old): form = string[:len(string) - len(old)] + new if form in index or not form.isalpha(): forms.append(form) else: oov_forms.append(form) if not forms: forms.extend(oov_forms) ``` ## Your Environment <!-- Include details of your environment --> * Operating System: * Python Version Used: * spaCy Version Used: * Environment Information: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Bizarre removal of python Full report at https://ci.appveyor.com/project/ContinuumAnalytics/conda-build/build/1.0.163#L18 ``` Package plan for installation in environment C:\\Miniconda3-x64: The following packages will be downloaded: package | build ---------------------------|----------------- git-2.6.4 | 0 61.2 MB colorama-0.3.7 | py34_0 20 KB coverage-4.1 | py34_0 235 KB py-1.4.31 | py34_0 127 KB pytz-2016.4 | py34_0 171 KB six-1.10.0 | py34_0 17 KB clyent-1.2.2 | py34_0 15 KB pytest-2.9.2 | py34_0 283 KB python-dateutil-2.5.3 | py34_0 238 KB anaconda-client-1.4.0 | py34_0 156 KB pytest-cov-2.2.1 | py34_0 17 KB ------------------------------------------------------------ Total: 62.5 MB The following NEW packages will be INSTALLED: anaconda-client: 1.4.0-py34_0 clyent: 1.2.2-py34_0 colorama: 0.3.7-py34_0 coverage: 4.1-py34_0 git: 2.6.4-0 py: 1.4.31-py34_0 pytest: 2.9.2-py34_0 pytest-cov: 2.2.1-py34_0 python-dateutil: 2.5.3-py34_0 pytz: 2016.4-py34_0 six: 1.10.0-py34_0 The following packages will be REMOVED: python: 3.4.4-4 ``` CC @mcg1969 @kalefranz Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Use apitools for uploads/downloads [`uploads_test.py`](https://github.com/craigcitro/apitools/blob/master/samples/storage_sample/uploads_test.py) and [`downloads_test.py`](https://github.com/craigcitro/apitools/blob/master/samples/storage_sample/downloads_test.py) should provide good examples for it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Inconsistent convention for complex derivatives The convention for the handling of complex derivatives in JAX seems to be mixed. Consider the following two implementations of the abolute value function. ```py import jax.numpy as np from jax import grad def f(x): return np.abs(x) def g(x): return np.sqrt(np.real(x)**2 + np.imag(x)**2) df = grad(f) dg = grad(g) print('gradient by df: ',df(1.0+0.5j)) print('gradient by dg: ',dg(1.0+0.5j)) ``` The respective results differ by complex conjugation: ``` gradient by df: (0.8944272-0.4472136j) gradient by dg: (0.8944272+0.4472136j) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Uploading List of Files to Google Cloud Storage **Description** In the [current implementation](https://airflow.apache.org/docs/stable/_api/airflow/contrib/operators/file_to_gcs/index.html) of `FileToGoogleCloudStorageOperator`, a single file is inputted to be uploaded to Google Cloud Storage bucket. I'd like to implement functionality to allow input of a list of files, directory path or perhaps even a wildcard string (`/path/to/*.csv` for example). **Related Issues** Not that I can tell from searching, but there is this [stackoverflow question](https://stackoverflow.com/questions/58945050/uploading-local-directory-to-gcs-using-airflow) that @kaxil answered. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: pdb no longer works with airflow test command since 2.3.3 Converted back to issue as I've reproduced it and traced the issue back to https://github.com/apache/airflow/pull/24362 ### Discussed in https://github.com/apache/airflow/discussions/26352 <div type='discussions-op-text'> <sup>Originally posted by **GuruComposer** September 12, 2022</sup> ### Apache Airflow version 2.3.4 ### What happened I used to be able to use ipdb to debug DAGs by running `airflow tasks test <dag_name> <dag_id>`, and hitting an ipdb breakpoint (ipdb.set_trace()). This no longer works. I get a strange type error: ``` File \"/usr/local/lib/python3.9/bdb.py\", line 88, in trace_dispatch return self.dispatch_line(frame) File \"/usr/local/lib/python3.9/bdb.py\", line 112, in dispatch_line self.user_line(frame) File \"/usr/local/lib/python3.9/pdb.py\", line 262, in user_line self.interaction(frame, None) File \"/home/astro/.local/lib/python3.9/site-packages/IPython/core/debugger.py\", line 336, in interaction OldPdb.interaction(self, frame, traceback) File \"/usr/local/lib/python3.9/pdb.py\", line 357, in interaction self._cmdloop() File \"/usr/local/lib/python3.9/pdb.py\", line 322, in _cmdloop self.cmdloop() File \"/usr/local/lib/python3.9/cmd.py\", line 126, in cmdloop line = input(self.prompt) TypeError: an integer is required (got type NoneType)``` ### What you think should happen instead I should get the ipdb shell. ### How to reproduce 1. Add ipdb breakpoint anywhere in airflow task. import ipdb; ipdb.set_trace() 2. Run that task: Run `airflow tasks test <dag_name> <dag_id>`, and ### Operating System Debian GNU/Linux ### Versions of Apache Airflow Providers 2.3.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: AttributeError: 'str' object has no attribute '_credentials' Hi, I'm trying the example code and it's failing with the following exception: ``` >>> c = error_reporting.Client(project='<my-project-str>') >>> try: ... raise NameError ... except Exception: ... c.report_exception() ... Traceback (most recent call last): File \"<stdin>\", line 2, in <module> NameError During handling of the above exception, another exception occurred: Traceback (most recent call last): File \"<stdin>\", line 4, in <module> File \"/opt/python/3.6.0/lib/python3.6/site-packages/google/cloud/error_reporting/client.py\", line 348, in report_exception user=user) File \"/opt/python/3.6.0/lib/python3.6/site-packages/google/cloud/error_reporting/client.py\", line 277, in _send_error_report self.report_errors_api.report_error_event(error_report) File \"/opt/python/3.6.0/lib/python3.6/site-packages/google/cloud/error_reporting/client.py\", line 162, in report_errors_api self._report_errors_api = make_report_error_api(self._project) File \"/opt/python/3.6.0/lib/python3.6/site-packages/google/cloud/error_reporting/_gax.py\", line 39, in make_report_error_api client._credentials, AttributeError: 'str' object has no attribute '_credentials' ``` Reading the source, this seems like a rather obvious error: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/error_reporting/google/cloud/error_reporting/client.py#L162 `self._project` is a string and at https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/error_reporting/google/cloud/error_reporting/_gax.py#L29 it's treated like a client object. Is this not the case? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make ``VQE`` stateless ### Summary Make the `VQE` algorithm stateless. ### What is the expected enhancement All our algorithms are stateless, i.e. they don't store/depend on previous executions. The `VQE` still has methods that allow access to the last solved system, which should be strictly left to the results object. Furthermore the computation depends on an internal state being set, which should be changed to a procedural, stateless workflow. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: GCloudErrors (like NotFound) should show the URL that was referenced Saying \"the requested entity was not found\" is useful if you're working with one entity only... otherwise it's just sort of like saying \"something went wrong\". If we're able to figure out the URL that raised the error, we should include it in the exception (and the `__str__` version of the exception. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] missing CMakeUserPresets.json Conan 1.48.0 does not generate `CMakeUserPresets.json` if `conanfile.txt` used instead of `.py`. Probably this is duplicate of #11172. ### Environment Details * Operating System: linux * Conan version: 1.48.0 ### Steps to reproduce ``` cd \"$(mktemp -d)\" conan new hello/0.1 -m=cmake_exe rm conanfile.py echo -e \"[generators]\\nCMakeToolchain\" > conanfile.txt mkdir build (cd build && conan install ..) tree \"$(pwd)\" ``` ### Output ``` /tmp/tmp.6FdEpSMGTR ├── CMakeLists.txt ├── build │ ├── CMakePresets.json │ ├── conan.lock │ ├── conan_toolchain.cmake │ ├── conanbuildinfo.txt │ ├── conaninfo.txt │ └── graph_info.json ├── conanfile.txt ├── include │ └── hello.h ├── src │ ├── hello.cpp │ └── main.cpp └── test_package └── conanfile.py ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: BackfillJob eventually fails tasks when dependencies aren't met See https://github.com/airbnb/airflow/issues/1225#issuecomment-203153213 When dependencies are unmet, the command exists successfully (as in, without error or return code). The executor marks it as a success. But the task has no status, because it never ran. This triggers the \"airflow run command failed to report an error\" which eventually fails the task. This issue will be fixed as part of the resolution for #1225, this issue is for tracking it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: MPT ### Model description New LLM from MosaicML, 7B parameters. See: https://www.mosaicml.com/blog/mpt-7b ### Open source status - [X] The model implementation is available - [X] The model weights are available ### Provide useful links for the implementation https://huggingface.co/mosaicml/mpt-7b/tree/main The model is already implemented in a HF/T compatible way, but has multiple source files for its model implementation, some components that aren't used in this current model, and most importantly, dependencies that aren't normally included in HF (e.g. einops, flash_attn). Do the HF folks have a view on whether we would want to add those dependencies, or implement a vanilla version based only on existing requirements (in which case, it would arguably be easier to modify an existing LM implementation instead, rather than use MosaicML's implemenetation)? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] git clone for scm attribute fails in pyinstaller package Conan version 1.20.4 Original problem is that conan wrapped into pyinstaller package (which we use) fails to clone repository for recipe with `scm` attribute: ``` <...>: Configuring sources in /root/.conan/data/.../source <..>: Getting sources from url: 'ssh://git@bitbucket....' ERROR: Command 'git clone \"ssh://git@bitbucket...\" . ' returned non-zero exit status 128. ``` strace'ing showed that git fails to run because it uses libcrypto from conan (which is ancient) and can't find symbol. Apparently, conan doesn't restore `LD_LIBRARY_PATH` for `git clone` command. Similar problem was fixed long ago in #3036, but looking at `scm.py` / `run()` it has optional `_runner` which calls just `check_output` without restoring. If having `_runner` all the time is not an option, at least call to `check_output` should be wrapped into `pyinstaller_bundle_env_cleaned()` context manager. It would be nice to go through all calls to `Popen` and check whether they need to be wrapped into this context manager or maybe avoid direct usage of it and have an internal wrapper. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Alter signature of Client.set_flow_run_state ## Current behavior *Please describe how the feature works today* Currently, the `Client.set_flow_run_state(flow_run_id, state)` call always returns `None`. Unlike the task equivalent, which returns the new `State` object. All places where the client is calling this method are implicitly handling the state change by creating the new state, calling the method, then proceeding with that new state. ## Proposed behavior *Please describe your proposed change to the current behavior* The `set_flow_run_state` call should return the new `State` for a couple reasons. First, and most importantly, in order to extend the `Flow`'s options of states (instead of Pending -> Running -> Success / Failed), we need to be able to implement logic of listening to Cloud's response to the state change event. Secondly and less important, returning the new `State` for both the task and flow client calls would be nice for consistency reasons. ## Example *Please give an example of how the enhancement would be useful* While this feature itself won't change the current behavior, it will allow extension of Flow state control in the future! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Incorrect link in documentation There is an incorrect link at https://googlecloudplatform.github.io/google-cloud-python/latest/bigquery/dataset.html#google.cloud.bigquery.dataset.Dataset.delete. It links to https://cloud.google.com/bigquery/docs/reference/rest/v2/tables/delete, but it should link to https://cloud.google.com/bigquery/docs/reference/rest/v2/datasets/delete. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add DPT-hybrid ### Model description DPT-hybrid is used in Stable Diffusion 2.0's depth model and is also a nice depth estimation model in general. We already support [DPT](https://huggingface.co/docs/transformers/model_doc/dpt) - which is also the default model of our [depth estimation pipeline](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#transformers.DepthEstimationPipeline), but not DPT-hybrid. The latter uses ViT-hybrid as backbone. Hence, we first would need to add ViT-hybrid to the library. This model is very similar to a regular ViT, except that instead of patchifying an image and embedding each patch, this model uses a pre-trained ResNetv2 to embed the image before feeding the features to a Transformer encoder. This means that we first need to add ResNetv2 to the library. 😅 however that seems fairly doable, I'd recommend porting the one from timm: https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/resnetv2.py. ### Open source status - [X] The model implementation is available - [X] The model weights are available ### Provide useful links for the implementation DPT-hybrid is available here: https://github.com/isl-org/MiDaS Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Doc markdown formatting tweaks - [x] uniform spacing between **Args:**, **Returns:** and **Raises:** sections - [x] bad code indentation preservation in the main [`Task` docstring](https://prefect-docs.appspot.com/api/core/task.html) (the codeblock `with Flow()...`) - [ ] fix how class call signatures are formatted - [x] add docstrings for the various `.copy()` methods (Task, Flow) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: torch.compile() and FSDP/DDP wrappers are called in the wrong order. ### System Info transformers main branch ### Who can help? @sgugger ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction When training/fine-tuning a model, activate torch.compile() and FSDP with `torch_compile=True` and `fsdp=\"full_shard auto_wrap\"` as training arguments. The model is compiled before the FSDP wrapping, preventing optimizations on the backwards passes. According to the PyTorch docs, both DDP and FSDP wrappers have special optimizations that run with torch.compile() to ensure model training doesn't end up slower instead of faster (see [here](https://dev-discuss.pytorch.org/t/torchdynamo-update-11-making-fsdp-and-dynamo-work-together/1037)). ### Expected behavior Therefore, the model would need to be torch.compile()'d after being wrapped in either FSDP or DDP. Right now, in `src/transformers/trainer.py` that is not the case, with compile() being the first call in `_wrap_model()`. Before making a PR with the change, I figured I'd make this bug report to ensure nothing prevents that change from happening. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cross compiler ignored when build and host architectures are identical I'm trying to compile for Android x86_64 on Linux x86_64. Unfortunately, Meson selects the native compiler instead of the one provided by the cross-file. The setup is the same as described in #5097. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Environment for package() function differs when using conan create and conan export-pkg I'm trying to reuse my python code. For this I've made conan package named `ConanQMakeHelper`. I've made it just like in docks. Now I put this project as a dependency in `requires` varible of conanfile. And I use some functions from this package in `build()` and `package()` methods of third project. Both methods start `from qmakehelper import QMakeHelper`. Now if I use `conan create ...` all is OK. But I'm using CI. And in CI recipe on first stage I use `conan install ...` then `conan build ...` and in build method `qmakehelper` is visible. But on second CI stage I use `conan export-pkg`, and it fails and says that no `qmakehelper` found. The problem is that `os.environ['PYTHONPATH']` is empty in package method. `ConanQMakeHelper` is package name, `qmakehelper.py` is the python script file inside, `QMakeHelper` is a class in this file. ``` mkdir build_win cd build_win conan install .. -s build_type=Release --build=never -u conan build -bf . -sf .. .. cd .. conan export-pkg -bf build_win -if build_win . some/dev --force ``` Conan 1.1.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: SQLAlchemy engine configuration is not passed to FAB based UI SQLAlchemy engine configuration is not passed to FAB based UI. Faced this issue when running Airflow with MySQL metadata store with wait_timeout = 120. Webserver is failing with Internal Server Error due to \"[MySQL Server has gone away](https://docs.sqlalchemy.org/en/13/faq/connections.html#mysql-server-has-gone-away)\" error. Settings like `sql_alchemy_pool_recycle` and `sql_alchemy_pool_pre_ping` have no impact on FAB internal communication with MySQL. **Apache Airflow version**: 1.10.12 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.savetxt bug on structured array <!-- Please describe the issue in detail here, and fill in the fields below --> Saving numpy array subsampled by multi-field indexing fails. ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np x = np.array([(1,2,3),(4,5,6)], dtype=[('foo', 'i8'), ('bar', 'f4'), ('yee', 'f4')]) np.savetxt('out.txt', x[['foo', 'yee']]) ``` <!-- Remove these sections for a feature request --> ### Error message: TypeError: Mismatch between array dtype ('{'names':['foo','yee'], 'formats':['<i8','<f4'], 'offsets':[0,12], 'itemsize':16}') and format specifier ('%.18e %.18e %.18e') <!-- If you are reporting a segfault please include a GDB traceback, which you can generate by following https://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging --> <!-- Full error message, if any (starting from line Traceback: ...) --> ### Numpy/Python version information: ('1.16.2', '2.7.16 |Anaconda, Inc.| (default, Mar 14 2019, 21:00:58) \\n[GCC 7.3.0]') <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: confusing messages at downgrading When I willfully downgrade a package, confusing dialogs are given related to dependency conflicts, possibly because the same dialog/logging is used when an automatic downgrade requirement was being determined: ```bash (stable) └─❱❱❱ conda install pandas=0.19 +6295 8:05 ❰─┘ Fetching package metadata ........... Solving package specifications: .......... Package plan for installation in environment /Users/klay6683/miniconda3/envs/stable: The following packages will be DOWNGRADED due to dependency conflicts: pandas: 0.20.1-np112py36_0 conda-forge --> 0.19.2-np112py36_1 conda-forge Proceed ([y]/n)? ``` I think it would be preferable, that in the deliberate downgrade the messages should not say `due to dependency conflicts` and that this part is only added to the dialog when a dependency conflict was automatically found. version: 4.2.13 on macOS Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: CalibrationBuilder scales superlinearly <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? For a random circuit of equal width and depth the CalibrationBuilder pass scales like n_qubits^3 whereas one might expect scaling like n_qubits^2 if it was proportional to the number of gates. This slow down seems to be in retrieving the qubits associated with a dag node. This test was run without actual calibrations so only part of the pass code is actually profiled.   This is qiskit-terra version 0.19.0.dev0+637acc0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Inconsistent %matplotlib qt behavior Evaluating a cell beginning with the `%matplotlib qt` magic and immediately following with commands to [Mayavi](https://github.com/enthought/mayavi) cause the kernel to freeze. The Mayavi window opens correctly and responds to user input, but the cell never yields control back to the user. If instead, a cell containing `%matplotlib qt` in isolation is run, it returns without issue. Subsequently issuing Mayavi commands in a separate cell work as expected, returning immediately. [This notebook](http://nbviewer.ipython.org/gist/jabooth/8770104) gives a minimal demonstration of the problem, as well as some further diagnostic information. Note that the problem is confirmed to exist on OS X on a [recent master](https://github.com/ipython/ipython/commit/9b8c058d4ef1667b292fea5e5a365aa545da6112) and on Linux (thanks @fperez) Note that this bug only occurs the first time the `%matplotlib qt` command is executed - subsequent calls (e.g. after switching to `%matplotlib inline` and back to `%matplotlib qt` with commands immediately following in the qt enabled cell) work fine. ``` {'codename': 'Work in Progress', 'commit_hash': '9b8c058', 'commit_source': 'installation', 'default_encoding': 'UTF-8', 'ipython_path': '/usr/local/Cellar/python/2.7.5/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/IPython', 'ipython_version': '2.0.0-dev', 'os_name': 'posix', 'platform': 'Darwin-13.0.2-x86_64-i386-64bit', 'sys_executable': '/usr/local/Cellar/python/2.7.5/Frameworks/Python.framework/Versions/2.7/Resources/Python.app/Contents/MacOS/Python', 'sys_platform': 'darwin', 'sys_version': '2.7.5 (default, Oct 25 2013, 08:11:09) \\n[GCC 4.2.1 Compatible Apple LLVM 5.0 (clang-500.2.79)]'} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Utility rank_zero_only doesn't properly handle environment variable LOCAL_RANK ## 🐛 Bug The `LOCAL_RANK` environment variable can be a string. This causes checks in the rank_zero_only decorator to fail here: https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/utilities/distributed.py#L11 ### Expected behavior We should cast `LOCAL_RANK` to an int both in the rank_zero_only check as well as in the trainer here: https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/trainer/trainer.py#L385 Then the decorator works as we expected Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Qt5 modules should not always require uic Qt5 can be built without `uic` (if widgets are disable). This is quite common for embedded use-cases with QtQuick only applications. Currently meson fails because it always requires `uic`. I'm not sure what the correct fix is. Maybe handle this like `lrelease`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: `docker-compose config` strips quotes in environment values This is an issue if the value is a string `'Y'`, because the output `Y` is interpreted as a boolean. That fails validation in `docker stack deploy`. Take this (partial) source file: ``` version: '3.2' services: db: image: microsoft/mssql-server-windows-express environment: ACCEPT_EULA: 'Y' ``` `docker-compose config > docker-compose.stack.yml` renders a new file with the quotes removed in the service definition: ``` services: db: environment: ACCEPT_EULA: Y image: microsoft/mssql-server-windows-express version: '3.2' ``` If you try to deploy the generated file, you'll get an error: ``` services.db.environment.ACCEPT_EULA must be a string, number or null ``` There's no workaround that I can find using `>`, `|` or `!!str`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: DeprecationWarning: Using or importing the ABCs from 'collections' is deprecated ## Checklist - [x] I have included the output of ``celery -A proj report`` in the issue. (if you are not able to do this, then at least specify the Celery version affected). - [x] I have verified that the issue exists against the `master` branch of Celery. ## Steps to reproduce Run anything that uses `celery` under Python 3.7, verified against `celery==4.2.1` ## Expected behavior No `DeprecationWarning` should be seen ## Actual behavior ``` .../lib/python3.7/site-packages/celery/canvas.py:12 .../lib/python3.7/site-packages/celery/canvas.py:12: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableSequence, deque ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Bigquery: Missing Entity Type when reading dataset.access_entries When running the following code: ```python from google.cloud import bigquery gbq_client = bigquery.Client(project='project-name') dataset_ref = gbq_client.dataset(dataset_id='dataset1', project='project-name') dataset = gbq_client.get_dataset(dataset_ref=dataset_ref) print(len(dataset.access_entries)) ``` the following error will happen about 25% of the time: ```python Traceback (most recent call last): File \"iam.py\", line 5, in <module> print(len(dataset.access_entries)) File \"/usr/local/lib/python3.7/site-packages/google/cloud/bigquery/dataset.py\", line 376, in access_entries return [AccessEntry.from_api_repr(entry) for entry in entries] File \"/usr/local/lib/python3.7/site-packages/google/cloud/bigquery/dataset.py\", line 376, in <listcomp> return [AccessEntry.from_api_repr(entry) for entry in entries] File \"/usr/local/lib/python3.7/site-packages/google/cloud/bigquery/dataset.py\", line 183, in from_api_repr return cls(role, entity_type, entity_id) File \"/usr/local/lib/python3.7/site-packages/google/cloud/bigquery/dataset.py\", line 115, in __init__ raise ValueError(message) ValueError: Entity type 'iamMember' not among: domain, groupByEmail, specialGroup, userByEmail, view ``` It seems the Google API is returning a new 'iamMember' entity type that is not in the hard coded list of allowed entity types in [dataset.py](https://github.com/googleapis/google-cloud-python/blob/master/bigquery/google/cloud/bigquery/dataset.py) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [scm] --show-item not supported on older versions of subversion Thank you to @jgsogo for implementing SVN for the scm attribute. I've finally got the chance to try this new feature and discovered that my version of subversion (1.7.14 as supplied in RHEL 7) does not support --show-item for the svn info command. Unfortunately, this means I can't use this feature :sob: Can this be changed to something like: `svn info <other args> --xml` And the XML parsed? Bit like is suggested in #3653 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: [docs] clarify argument usage in op factory example ~\"nwe\" https://docs.dagster.io/concepts/ops-jobs-graphs/ops#op-factory~ ~bonus:~ update section for clarity https://dagster.slack.com/archives/C01U954MEER/p1643843874933099?thread_ts=1643843102.120129&cid=C01U954MEER Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Regression: array2string breaks for some subclasses EDIT: the below may not be complete; there seems to be other breakage for structured dtypes. The guard against infinite recursion in array2string done in #10544 causes problems for subclasses that count on user-defined formatters to have access to items of their own class; see https://github.com/astropy/astropy/issues/7214. In particular, astropy's `Angle` class assumed that inside array2print, any item selection would be done using its `__getitem__`, so that even scalars would be returned as array scalars with all the appropriate methods. This assumption broke by the introduction of an `asarray` in #10544. As noted in https://github.com/numpy/numpy/pull/10544#discussion_r170435274, it may be possible to solve this by doing `asarray` inside the numpy formatters, rather than upon entry in `array2print`. Here's a minimal testcase: ``` import numpy as np class DuckCounter(np.ndarray): def __getitem__(self, item): result = super(DuckCounter, self).__getitem__(item) if not isinstance(result, DuckCounter): result = result[...].view(DuckCounter) return result def to_string(self): # only on scalers in this example... return {0: 'zero', 1: 'one', 2: 'two'}.get(self.item(), 'many') def __str__(self): if self.shape == (): return self.to_string() else: return np.array2string(self, formatter={'all': lambda x: x.to_string()}) dc = np.arange(5).view(DuckCounter) print(dc) # [zero one two many many] ``` On numpy 1.14.1, this gives ``` AttributeError: 'numpy.int64' object has no attribute 'to_string' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Can't trigger startup code in Engines Newly launched ipcluster instances don't execute code from the variable c.IPEngineApp.startup_command . Min suggested that this is from the new forked Kernel implementation, which doesn't share the startup config. More context: http://mail.scipy.org/pipermail/ipython-user/2012-July/010769.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Deprecate adding Operators via plugins This is the companion issue to https://github.com/apache/airflow/issues/9498, but for adding a deprecation warning to 1.10.12 so we can remove it in Airflow 2.0 ``` from airflow.operators.my_plugin import MyOperator ``` can become ``` from my_plugin import MyOperator ``` In 1.10.12 we should issue a FutureDeprecationWarning in the plugin if it includes anything in `operators = []`, and additionally when anything imports from `airflow.operators.my_plugin` (this last part may already by happening. We should double check and confirm.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: _get_legacy_containers_iter() TypeError: argument of type 'NoneType' is not iterable I just upgraded from 1.1.0 to 1.3.2, and after dealing with the /tmp directory being mounted as noexec (issue #1339), I ran into another issue that I couldn't find in the backlog; ``` $ docker-compose up -d Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.main\", line 32, in main File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.docopt_command\", line 21, in sys_dispatch File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.command\", line 34, in dispatch File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.docopt_command\", line 24, in dispatch File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.command\", line 66, in perform_command File \"/code/build/docker-compose/out00-PYZ.pyz/compose.cli.main\", line 471, in up File \"/code/build/docker-compose/out00-PYZ.pyz/compose.project\", line 230, in up File \"/code/build/docker-compose/out00-PYZ.pyz/compose.service\", line 398, in remove_duplicate_containers File \"/code/build/docker-compose/out00-PYZ.pyz/compose.service\", line 405, in duplicate_containers File \"/code/build/docker-compose/out00-PYZ.pyz/compose.service\", line 112, in containers File \"/code/build/docker-compose/out00-PYZ.pyz/compose.legacy\", line 56, in check_for_legacy_containers File \"/code/build/docker-compose/out00-PYZ.pyz/compose.legacy\", line 138, in get_legacy_containers File \"/code/build/docker-compose/out00-PYZ.pyz/compose.legacy\", line 152, in _get_legacy_containers_iter TypeError: argument of type 'NoneType' is not iterable ``` Downgrading to 1.3.1 seems to alleviate this behavior. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: compose silently ignore stop_grace_period when extends or multiple compose files docker-compose version 1.16.1, build 6d1ac21 silently ignore the \"networks\" option when the service extends from another one. This version 3.3 docker-compose file : **test1.yml** ``` version: '3.3' services: node: stop_grace_period: 30s image: 'node' hostname: \"{{.Service.Name}}-{{.Task.Slot}}\" environment: - LOGSPOUT=ignore ports: - '9001:9001' command: node app/user/index.js ``` and **test2.yml** ``` version: '3.3' services: node: healthcheck: test: - CMD - curl - '-f' - 'http://localhost:9001/ping' interval: 30s timeout: 1s retries: 2 restart: unless-stopped stdin_open: true tty: true ``` the output of **docker-compose -f test1.yml -f test2.yml config** ``` services: node: command: node app/user/index.js environment: LOGSPOUT: ignore healthcheck: interval: 30s retries: 2 test: - CMD - curl - -f - http://localhost:9001/ping timeout: 1s hostname: '{{.Service.Name}}-{{.Task.Slot}}' image: node ports: - published: 9001 target: 9001 restart: unless-stopped stdin_open: true tty: true version: '3.3' ``` ***stop_grace_period is gone!!!*** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Release local agent as part of Prefect Core Rather than a separate repo, the local Agent should ship with Prefect Core, in order to minimize frictions to getting started with Prefect Cloud. For a user who had already set an auth token, connecting to the Prefect Cloud platform could be as easy as: ```bash prefect agent start ``` (or something) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Calling IBMQ.load_accounts() twice should give warning, not exception <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: latest master - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? Calling `IBMQ.load_accounts()` twice gives an Exception. However, in notebooks, it is common to just run multiple cells (or whole notebooks) repeatedly. Raising an exception breaks this convenient workflow. A similar issue, #673 , was raised and corrected, previously. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Make repeated calls to `IBMQ.load_accounts()` give a warning instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: [feature request] add support for numpy.linalg.svd and scipy.linalg.svd Hi, Considering there has been recent work going on w.r.t. improving the linalg modules with the addition of Cholesky and QR decompositions and solve methods, I would like to see SVD added to this list. I don’t mind working on this with some guidance from the developers, if they think this is worth adding. Thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: ProphetNetNgramAttention: Number of attention heads ## Information Model I am using (Bert, XLNet ...): ProphetNet The ProphetNet Ngram attention layer seem to refer to a wrong number of heads. The `ProphetNetNgramProphetNetSelfAttention` (seems to be a typo by the way, maybe `ProphetNetNgramSelfAttention` would be more appropriate?) is part of the decoder, and therefore I would expect it should contain a number of attention head equal to the configuration parameter `num_decoder_attention_heads `. However, when instantiated at https://github.com/huggingface/transformers/blob/02e05fb0a532e572b56ba75dad6ba3db625bbdeb/src/transformers/models/prophetnet/modeling_prophetnet.py#L759, it uses the property `num_attention_heads` that equals to the number of **encoder** attention heads. I assume that the correct value should be `config.num_decoder_attention_heads`. (Luckily?) no issue showed up in most models because pretrained models have the same number of encoder and decoder heads. Looking at the reference implementation, it does seem that the **decoder** number of attention heads is used for the Ngram attention (see https://github.com/microsoft/ProphetNet/blob/1d36bc5c4f334b0ed9b90fdf3a64785c174f5c45/GLGE_baselines/script/prophetnet/ngram_s2s_model.py#L586) ### Who can help @patrickvonplaten ? Again not sure since I do not see an owner for ProphetNet I would be happy to submit a small PR referencing to `config.num_decoder_attention_heads` rather than this property if you agree with this change Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [Active Directory] Entry point is using datadog_checks.ntp console script In the Active Directory integration's `setup.py` the entrypoint (for running without an agent) uses the datadog_checks.ntp console script. ``` # The entrypoint to run the check manually without an agent entry_points={ 'console_scripts': [ 'ntp=datadog_checks.ntp:main', ], }, ``` See: https://github.com/DataDog/integrations-core/blob/master/active_directory/setup.py#L124 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: \"conan user\" is broken in 1.20.0 17:52:59 alex@Totem:/ $ conan user -c WARN: Migration: Updating settings.yml WARN: **************************************** WARN: settings.yml is locally modified, can't be updated WARN: The new settings.yml has been stored in: /Users/alex/.conan/settings.yml.new WARN: **************************************** 17:53:04 alex@Totem:/ $ conan user -r REMOTE -p PASS USER ERROR: { \"errors\" : [ { \"status\" : 401, \"message\" : \"Authentication is required\" } ] }. [Remote: REMOTE] The exact same commands succeed after downgrading to 1.19.3. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Typing kwargs as dict can cause issues with type hinting systems Thanks to @retnikt for opening #7422. This issue is tracking that and will have an accompanying PR that more broadly fixes the issue. When typing Python code, the special *args and **kwargs params are typed based on their contents, not what they actually are (a tuple, and a dict) e.g. def foo(thing: int, *args: str): ... def bar(thing: int, *args: str, **kwargs: Union[int, float]): ... bar(-3, \"G\", spam=80, eggs=4.4) foo(44, \"abc\", \"xyz\") And in this case, the types are passed to a different func (Query.__init__) which has specific arguments, so it is best to not give **kwargs a type, or, better, copy the parameters of that function (but I haven't done this here). This also applies to Transaction. PS I know this is a stupidly minor change but it annoys me, having to write noinspection PyTypeChecker before every datastore query. 😄 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson not detecting dub packages with different compilers and arch Meson isn't accepting my DUB compiled libs, even though they were compiled using same tool. `> dub build daemonize ` ``` Building package daemonize in /home/ricardo/.dub/packages/daemonize-0.2.1/daemonize/ Performing \"debug\" build using /usr/bin/dmd for x86_64. daemonize 0.2.1: building configuration \"default\"... ``` `> meson build` ``` ... Found pkg-config: /usr/bin/pkg-config (1.6.0) Dependency gtkd-3 found: YES 3.8.5 Found DUB: /usr/bin/dub (DUB version 1.13.0, built on Jan 05 2019) ERROR: daemonize found but it wasn't compiled with dmd Dependency daemonize found: NO meson.build:20:0: ERROR: Dependency \"daemonize\" not found ``` Even though both commands report DMD being used as compiler, Meson still believes the library wasn't compiled with DMD. Tested with DMD and LDC. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add 'sysctl' option support PR https://github.com/docker/docker/pull/19265 merged 'sysctl' support into docker, but there seems to be no way to use this feature with docker-compose. Has anyone started work on such a feature? If not, I will attempt to patch docker-compose and create a PR. Are there any suggestions on how to implement it? I was thinking of starting with something similar to how the environment or cap_add options work. Support for `docker create --userns=host` Docker 1.11 has landed new feature to disable user namespaces per container when the daemon is running with global user namespace enabled. https://github.com/docker/docker/pull/20111 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Adding files to repository that is located directly in the root This is a weird scenario, but if you init git repo in the root directory(e.g. D:\\\\) and try to add a file using gitpython, it will throw a ValueError: ``` Absolute path `D:\\\\file` is not in git repository at `D:\\\\` ``` The reason for this is improper validation in _to_relative_path method located at git/index/base.py: ``` def _to_relative_path(self, path): \"\"\":return: Version of path relative to our git directory or raise ValueError if it is not within our git direcotory\"\"\" if not osp.isabs(path): return path if self.repo.bare: raise InvalidGitRepositoryError(\"require non-bare repository\") relative_path = path.replace(self.repo.working_tree_dir + os.sep, \"\") if relative_path == path: raise ValueError(\"Absolute path %r is not in git repository at %r\" % (path, self.repo.working_tree_dir)) return relative_path ``` I.e. when path is `/file` and working_tree_dir is `/`, relative_path stays equal to path, because `self.repo.working_tree + os.sep` is equal to `//`. The way to solve this is to simply use os.path.relpath methond. Please see pull-request attached. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Guide for Apache Druid operators **Description** Hello, A guide that describes how to use Apache Druid software operators would be useful. Other guides are available: https://airflow.readthedocs.io/en/latest/howto/operator/index.html Are you wondering how to start contributing to this project? Start by reading our [contributor guide](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst) Best regards, Kamil **Use case / motivation** N/A **Related Issues** Missing guides for Apache operators: Apache Cassandra: https://github.com/apache/airflow/issues/8189 Apache Druid: https://github.com/apache/airflow/issues/8199 Apache Hive: https://github.com/apache/airflow/issues/8191 Apache Livy: https://github.com/apache/airflow/issues/8192 Apache Pig: https://github.com/apache/airflow/issues/8193 Apache Pinot: https://github.com/apache/airflow/issues/8194 Apache Spark: https://github.com/apache/airflow/issues/8195 Apache Sqoop: https://github.com/apache/airflow/issues/8196 Hadoop Distributed File System (HDFS): https://github.com/apache/airflow/issues/8197 WebHDFS: https://github.com/apache/airflow/issues/8198 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Dynamical decoupling Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: einsum error with unicode input (regression in Numpy 1.14) This was working before Numpy 1.14 and now fails (on Python 2): ```python In [1]: from __future__ import unicode_literals ...: import numpy as np ...: np.einsum('...i,...i', [1,2,3], [2,3,4]) ...: --------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-1-dea65e271386> in <module>() 1 from __future__ import unicode_literals 2 import numpy as np ----> 3 np.einsum('...i,...i', [1,2,3], [2,3,4]) /home/conseil/miniconda3/envs/py2/lib/python2.7/site-packages/numpy/core/einsumfunc.pyc in einsum(*operands, **kwargs) 1085 # Build the contraction list and operand 1086 operands, contraction_list = einsum_path(*operands, optimize=optimize_arg, -> 1087 einsum_call=True) 1088 1089 handle_out = False /home/conseil/miniconda3/envs/py2/lib/python2.7/site-packages/numpy/core/einsumfunc.pyc in einsum_path(*operands, **kwargs) 686 687 # Python side parsing --> 688 input_subscripts, output_subscript, operands = _parse_einsum_input(operands) 689 subscripts = input_subscripts + '->' + output_subscript 690 /home/conseil/miniconda3/envs/py2/lib/python2.7/site-packages/numpy/core/einsumfunc.pyc in _parse_einsum_input(operands) 529 if char not in input_subscripts: 530 raise ValueError(\"Output character %s did not appear in the input\" --> 531 % char) 532 533 # Make sure number operands is equivalent to the number of terms ValueError: Output character e did not appear in the input ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Unauthenticated access with RBAC to URL has_dag_access results lose redirection <!-- **Apache Airflow version**: latest **Environment**: Linux - **Cloud provider or hardware configuration**: - **OS** (e.g. from /etc/os-release): - **Kernel** (e.g. `uname -a`): - **Install tools**: - **Others**: **What happened**: Unauthenticated access with RBAC to URL has_dag_access results lose redirection **What you expected to happen**: Redirection maintained, user can login and redirected to proper page Missing next URL parameter **How to reproduce it**: Setup airflow with RBAC Have a user who hasn't log in access a URL that uses decorator has_dag_access, i.e: http://localhost/graph?dag_id=dag_id User will be sent to login page, (note the next= argument that required to redirect to original page is gone) Login properly, user then will be sent to bad page If this is a UI bug, please provide a screenshot of the bug or a link to a youtube video of the bug in action Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error in evaluating Pauli-list style Hamiltonian tools.optimization.eval_hamiltonian() fails by error if hamiltonian is given as pauli list. ## Possible Solution I found an obvious invalid source format, so I'll fix it. ## Steps to Reproduce (for bugs) 1. Open qiskit-tutorial/4_application/quantum_chemistry.ipynb (latest stable branch) with qiskit-sdk-py (latest stable branch) 2. Just before the first definition of cost_function(), insert `H = pauli_list` 3. Run the notebook -> AttributeError: 'dict' object has no attribute 'conjugate' at line 344 ## Context Trying to understand tutorial more by running it with slightly modified parameters Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Count constructor crashes when data is empty <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.15.1 - **Python version**: 3.7.3 - **Operating system**: Mac OS Catalina 10.15.6 ### What is the current behavior? I simply ran a circuit which does not perform any measurements. On the returned results, `get_counts()` crashes because an empty dictionary is passed into the `Count` constructor and the constructor tries to iterate on the empty dictionary. I tried this on an older version, Terra 0.14.2, which instead of `Count` uses `postprocess.format_counts()`, which simply ignores the empty dictionary and returns an empty dictionary in this case. This did not crash. ### Steps to reproduce the problem Run any circuit without calling `measure()`, then try to apply `get_counts()` to the results. ### What is the expected behavior? `get_counts()` should return an empty dictionary (and not crash). ### Suggested solutions A simple check for an empty dictionary in the `Count` constructor would be sufficient, I think. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: serialization rules need to be extended <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? #1959 reintroduced the specialized methods for serializing different data types. However a couple were missed. ``` if isinstance(obj, numpy.ndarray): return cls._expand_item(obj.tolist()) if hasattr(obj, 'as_dict'): return obj.as_dict() ``` This is currently causing Aer master to fail. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Master is failing <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations Due to a [recent change in the IBMQuantumExperience library](https://github.com/Qiskit/qiskit-api-py/commit/d1bd8b7870cd50e4e5167b515009d8a6047e620b), we are experiencing failing tests. For a list of failing tests, see this Travis report: https://travis-ci.org/Qiskit/qiskit-terra/jobs/415922713 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: file:// URLs don't work anymore with conda 4.1.3 Conda 4.1.3 does not work anymore with **file://** URLs: ``` (E:\\Anaconda3) C:\\Windows\\system32>conda update --override-channels --channel file:///A:/pkgs/free --all Fetching package metadata ....Error: Could not find URL: file:///A:/pkgs/free/win-64/ ``` But `A:\\pkgs\\free\\win-64` really exists: ``` (E:\\Anaconda3) C:\\Windows\\system32>dir A:\\pkgs\\free\\win-64 Volume in drive A is Software Volume Serial Number is 4546-3CD9 Directory of A:\\pkgs\\free\\win-64 06/24/2016 12:31 AM <DIR> . 01/23/2016 06:27 PM <DIR> .. 06/24/2016 12:28 AM 259,605 repodata.json.bz2 07/07/2015 12:54 AM 85,764 argcomplete-0.9.0-py34_0.tar.bz2 ``` Before upgrading from 4.0.8-py35_0 everything worked fine. The same happened to the Linux version. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: google.cloud.language.syntax.Sentence is missing its \"sentiment\" property There are certain conditions where a sentence should have a sentiment. See https://cloud.google.com/natural-language/reference/rest/v1/Sentence Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython.core.debugger.Tracer tab-complete In the iPython 4.2.x series calling from IPython.core.debugger import Tracer; Tracer()() allows tab-completion .. This feature seems to have disappeared in iPython 5.x Thanks Carlos Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: [Content Gap] how to use create_databricks_job_solid and databricks_client ## What content is missing <!-- Help us to understand your request in context --> ## Type of the content <!-- Among the following items, pick a doc type that the content would most likely belong to - Tutorial - Main Concept: \"What is X in Dagster\" where X is a Dagster concept. - Integration Guide: \"How to use X in Dagster\" where X is a 3rd-party package/tool, e.g. dbt, Spark, etc - Best Practices Guide: \"How to do X in Dagster\" where X is usually a use case and can be addressed by incorporating multiple Dagster concepts at a time. - Deployment Guide: \"How to deploy Dagster to X\", e.g. Docker, K8S, GCP, etc - API Reference: e.g. docstring --> ## (Optional) Anything in particular you want the docs to cover <!-- Do you have exactly anything in mind you are looking for Examples: - Show how to test a partition set - Include a diagram to explain the relations between inputs and outputs --> ## (Optional) Target Date <!-- When do you want to have this by --> ## Writer's Guide - [Docs README](https://github.com/dagster-io/dagster/tree/master/docs) - Templates to follow: <fill by the docs team> - Examples for reference: <fill by the docs team> --- #### Message from the maintainers: Are you looking for the same documentation content? Give it a :thumbsup:. We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: vala: add support for generate Gir from valac valac has: `--gir=NAME-VERSION.gir GObject-Introspection repository file name` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Small typo in `conversation.py` docstring. ## Reproduction There is a small typographical error in the docstring for Conversation class in conversational.py. ```python class Conversation: \"\"\" Utility class containing a conversation and its history. This class is meant to be used as an input to the [`ConversationalPipeline`]. The conversation contains a number of utility function to manage the addition of new user input and generated model responses. A conversation needs to contain an unprocessed user input before being passed to the [`ConversationalPipeline`]. This user input is either created when the class is instantiated, or by calling `conversational_pipeline.append_response(\"input\")` after a conversation turn. ... ``` ## Proposed Solution This could be fixed by just rewriting this to: ```python class Conversation: \"\"\" Utility class containing a conversation and its history. This class is meant to be used as an input to the [`ConversationalPipeline`]. The conversation contains several utility functions to manage the addition of new user inputs and generated model responses. A conversation needs to contain an unprocessed user input before being passed to the [`ConversationalPipeline`]. This user input is either created when the class is instantiated, or by calling `conversational_pipeline.append_response(\"input\")` after a conversation turn. ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Only try updating outdated packages with update --all conda update --all tends to fail a lot because it requires that the whole environment become satisfiable, and without downgrading any packages. Perhaps a better solution would be to only try installing those packages that are known to be outdated. Another idea would be to relax the downgrade restriction, and just have it essentially \"reinstall\" the environment. This could lead to some surprises when it does downgrade things, but it would also reduce the number of unsatisfiable packages issues, as those seem to usually come from the version specification. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: planning: NVIDIA HPC SDK support Nvidia [released](https://developer.nvidia.com/hpc-sdk) a free-to-use HPC SDK that includes C, C++ and Fortran compilers, taking over from the legacy PGI-branded compilers. At first glance of the HPC SDK [user manual](https://docs.nvidia.com/hpc-sdk/index.html), the command line options look very similar to PGI compilers, but with compiler names ``` nvc nvc++ nvfortran ``` To implement these compilers, it might be worthwhile to refactor / update the \"PGI\" (non-user facing) branding inside Meson to \"NvidiaHPC\" or something similar so devs can find it, while not confusing with \"nvcc\" CUDA support. Prominent HPCs use PGI, and if the command line options are indeed identical or nearly so between legacy PGI and new Nvidia HPC SDK, it could be straightforward to use the same classes and method for the legacy PGI and new Nvidia branded compilers. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] can't specify c++20 with meson generator ### What is your suggestion? `/std:c++20` is supported by `cl` since [VS 2019 16.11](https://learn.microsoft.com/en-us/cpp/build/reference/std-specify-language-standard-version?view=msvc-160) : > The /std:c++20 option enables C++20 standard-specific features and behavior. Available starting in Visual Studio 2019 version 16.11 and clang-cl since [13](https://github.com/llvm/llvm-project/commit/a8f75d49). `c++latest` is far from ideal as it turns on 23 features (and generates a ton of deprecation warnings). An additional consideration is that only meson [1.0.1](https://github.com/mesonbuild/meson/pull/11221) supports `c++20` for `clang-cl`. So ultimately ``` _vs_cppstd_map = { '14': \"vc++14\", '17': \"vc++17\", '20': \"vc++latest\" } ``` is somewhat simplistic, as ideally it's a function of compiler, compiler version and meson version... But maybe a trivial change to `vc++20` is pragmatic? Thanks ### Have you read the CONTRIBUTING guide? - [X] I've read the CONTRIBUTING guide Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Update doc list indentation Currently _all_ lists in our docs have a particular padding / styling which has heavy indentation; this works well for API argument documentation, but not so much for generic markdown lists (see, e.g., the lists in https://docs.prefect.io/tutorials/airflow_migration.html#overview) We should be more nuanced in our application of this style. Doc images are not sized appropriately For example: https://docs.prefect.io/tutorials/triggers-and-references.html The image takes over the text. **cc**: @itsngansense Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: BUG: missing status graphics for dag_ids with periods Based on some experimentation, it looks like status circles on the main web server page don't appear for `dag_id`s that contain periods. Changing a dag_id from `test.dag` to `test_dag` was enough to make the circles reappear. Since I can see the dag_stats json is generated correctly, perhaps this is a problem with how d3 interprets the json? These are the circles I mean (note the missing middle row):  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Initialize instruction does not preserve global phase I create an `Initialize` instruction and pass it to the Aer statevector_simulator. But, the resulting amplitudes differ by a phase from the expected result. For example EDIT (08APR2021): A closer to minimal example is given in the comment following this one. EDIT (07APR2021): one line in this example has been edited to remove the dependence on aqua (which is deprecated) ```python from qiskit import Aer from qiskit.utils import QuantumInstance from qiskit.extensions import Initialize import numpy as np state_array = np.array([1j/np.sqrt(2), 0, 1j/np.sqrt(2), 0]) init = Initialize(state_array) init_circ = init.definition #init_circ.data = init_circ.data[2:3] qinstance = QuantumInstance(backend=Aer.get_backend(\"statevector_simulator\")) result = qinstance.execute(init_circ) state_array_out = result.get_statevector() ``` `state_array_out` differs from `state_array` by a factor of `i`. Uncommenting the line `init_circ.data = init_circ.data[2:3]` removes the qubit initializations, but does not change the result. The docstring for `Initialize` is ```python \"\"\"Complex amplitude initialization. Class that implements the (complex amplitude) initialization of some flexible collection of qubit registers (assuming the qubits are in the zero state). Note that Initialize is an Instruction and not a Gate since it contains a reset instruction, which is not unitary. \"\"\" ``` This doesn't explicitly say that a global phase is respected. But, I suppose it should be. I also wonder why \"assuming the qubits are in the zero state\" is included since reset instructions are inserted. (EDIT: The last point is addressed in #5190) ### Information - **Qiskit Terra version**: 348c75247 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Logging: needs 'synth.py' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %paste still bugs about IndentationError and says to use %paste ``` py In [8]: %paste sum([1, 2, 3, 4]) ## -- End pasted text -- IndentationError: unexpected indent If you want to paste code into IPython, try the %paste and %cpaste magic functions. ``` The IndentationError is legitimate, but it shouldn't tell me to use %paste when I already am. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: str() metadata for bucket and blob Surfaced by GCS team. The Cloud Storage library must stringify metadata sent in bucket and blob. Here's a known issue from not doing so: ```python from google.cloud import storage client = storage.Client(project=\"my-project\") my_bucket = client.get_bucket(\"my-bucket\") my_blob = my_bucket.get_blob(\"my-blob\") my_blob.metadata[\"bad\"] = float('nan') my_blob.patch() ``` `myblob.patch()` will send an unquoted `NaN`, which is a bug in the Cloud Storage API that the client should no longer depend on. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Support custom encryption keys Can we support custom encryption keys for files uploaded? Spec is here: https://cloud.google.com/compute/docs/disks/customer-supplied-encryption#top_of_page Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Let `bqstorage_client` authentication errors be raised in `to_dataframe` Now that I'm trying to write a tutorial on using the BigQuery Storage API to download query results, I've had a change of heart regarding whether `to_dataframe` should fall back to the `tabledata.list` API when there are authentication errors. Originally, I thought we should fallback on authentication errors, but now I see that it hides problems. Someone could have downloaded the right libraries but either don't have the right permissions or haven't enabled the API, but those errors will be swallowed. Instead, downloading large tables will be much slower than expected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose run should terminate container on SIGHUP When running `docker-compose run --rm $service $cmd`, the expectation is that the container will be terminated when docker-compose terminates. If docker-compose terminates due to SIGHUP (which can happen for example when docker-compose is run in a remote server and the ssh connection is terminated), it will leave the container running. It should stop and remove (if --rm was passed) the container. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: run_seq2seq.py doesn't work after enabling sortish sampler It gives an error saying **AttributeError: 'Dataset' object has no attribute 'make_sortish_sampler'**. Seems like something is wrong with the pipeline or versions. I install both transformers and datasets from the sources. [Exact line](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer_seq2seq.py#L46) ``` self.train_dataset.make_sortish_sampler( AttributeError: 'Dataset' object has no attribute 'make_sortish_sampler' ``` ## Environment info - `transformers` version: 4.3.0.dev0 - Platform: Linux-5.8.18-050818-generic-x86_64-with-glibc2.29 - Python version: 3.8.5 - PyTorch version (GPU?): 1.7.1+cu110 (True) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: <fill in> - Using distributed or parallel set-up in script?: <fill in> ### Who can help @LysandreJik @patrickvonplaten Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: mpl drawer cannot draw custom gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently only the text drawer is able to do this. This capability is useful when defining hiearchical circuits. Also refer to #1939 for a discussion of how to draw these. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Documentation Issue] Include doc for exclusion of GCE credentials for generate_signed_url Page Name: storage-blobs Release: 0.6.0 Since generate_signed_url parameter 'credentials' isn't supported currently by GCE, should include notice. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson output emits superfluous colon before `compiles:` Configuring systemd 249 prints: ``` The Meson build system Version: 0.59.2 Checking if \"-Werror=shadow with local shadowing\" compiles: YES ``` Configuring systemd 250 prints ``` The Meson build system Version: 0.61.1 Checking if \"-Werror=shadow with local shadowing\" : compiles: YES ``` The colon before `compiles` is superfluous. According to https://github.com/systemd/systemd/issues/22459 this is not caused by systemd, but by meson. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Only recreate containers whose configuration needs updating Currently, `docker-compose up` deletes and recreates every container, so as to make sure any changes to `docker-compose.yml` have been picked up. Instead, it should inspect container configuration to see if they _need_ recreating, and do the minimum necessary. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Generalize MLEngineStartTrainingJobOperator to custom images **Description** The operator is arguably unnecessarily limited to AI Platform’s standard images. The only change that is required to lift this constraint is making `package_uris` and `training_python_module` optional with default values `[]` and `None`, respectively. Then, using `master_config`, one can supply `imageUri` and run any image of choice. **Use case / motivation** This will open up for running arbitrary images on AI Platform. **Are you willing to submit a PR?** If the above sounds reasonable, I can open pull requests. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: TablesClient: predict does not work with Python list or dictionary The problematic line is at: https://github.com/googleapis/google-cloud-python/blob/bd5318aa5340fff19e38156b77d64d7db0e0e1c3/automl/google/cloud/automl_v1beta1/tables/tables_client.py#L402-L405 The expected type of the array/struct is google.protobuf.ListValue/google.protobuf.StructValue, not Python list/dictionary. The failure message is: ``` *** TypeError: Parameter to MergeFrom() must be instance of same class: expect ed google.protobuf.ListValue got list. ``` Preferably we should only support Python list/dictionary. Now for backwards compatibility, we should support list/dictionary/google.protobuf.ListValue/google.protobuf.StructValue Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Want a way to specify a dockerfile outside the context in the docker-compose dockerfile directive I've read several discussions about the security reasons why paths outside the context are not permitted. OK, but it seems to me that that should not apply to the dockerfile directive. After all, you can specify a dockerfile outside the context when using the docker build command itself, using -f. I'd like to be able to do the same thing in docker-compose, either relative to the context or relative to the dockerfile-compose.yml file. My goal is to put all the dockerfile-specific config in a subdirectory next to my context directory. I can do that with everything except the dockerfile itself. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Using generated files as qt resources fails with VS backend Seems that using 'File' as qresource argument is not supported. Usecase: including files generated at build time into resources, for example translations. ```meson cfg = configuration_data() #generate some files #set their paths into configuration rc_file = configure_file( configuration : cfg, input : 'test.qrc.in', output : 'test.qrc', ) processed = qt5_mod.preprocess( qresources : rc_file, ) ``` Tried to implement it. Get ninja error about no rule to make resulting rc file. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: BUG: AirflowException doesn't raise exception in SequentialExecutor or LocalExecutor Many bugs I've addressed recently share a symptom -- they all log an error that \"The airflow run command failed at reporting an error. This should not occur in normal circumstances.\" (from https://github.com/airbnb/airflow/blob/master/airflow/jobs.py#L808) Trying to reproduce. These are my notes... Sequence of events: 1. Use SequentialExecutor, as with `airflow test ...` 2. The SequentialExecutor runs the task airflow command with (https://github.com/airbnb/airflow/blob/master/airflow/executors/sequential_executor.py): ``` python try: sp = subprocess.Popen(command, shell=True) sp.wait() except Exception as e: self.change_state(key, State.FAILED) raise e self.change_state(key, State.SUCCESS) ``` 3. A task raises `AirflowException` **prior** to being executing - For example, the \"dag not found\" error raised by #1168 (prior to fix in #1196) due to SubDag errors 4. For some reason, the `AirflowException` is NOT caught by the executor's trap - **pretty sure this is the problem, still exploring** - don't we need to check `sp.returncode` rather than trapping errors? 5. The state gets changed to `success` 6. The task's state doesn't change 7. The \"normal circumstances\" error gets raised Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: renaming qiskit-terra <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? I want to get the name qiskit terra before we have too many references to qiskit-core. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: S3ResultHandler still failing on 0.10.0 ## Description We're still seeing https://github.com/PrefectHQ/prefect/issues/2204 after upgrading to `0.10.0`. We do see the code change from https://github.com/PrefectHQ/prefect/pull/2205 in the stack trace: ``` Unexpected error: AttributeError(\"'S3ResultHandler' object has no attribute '_client'\") Traceback (most recent call last): File \"/opt/conda/lib/python3.7/site-packages/prefect/engine/runner.py\", line 48, in inner new_state = method(self, state, *args, **kwargs) File \"/opt/conda/lib/python3.7/site-packages/prefect/engine/task_runner.py\", line 925, in get_task_run_state state._result.store_safe_value() File \"/opt/conda/lib/python3.7/site-packages/prefect/engine/result/base.py\", line 127, in store_safe_value value = self.result_handler.write(self.value) File \"/opt/conda/lib/python3.7/site-packages/prefect/engine/result_handlers/s3_result_handler.py\", line 114, in write self.client.upload_fileobj(stream, Bucket=self.bucket, Key=uri) File \"/opt/conda/lib/python3.7/site-packages/prefect/engine/result_handlers/s3_result_handler.py\", line 75, in client if not prefect.context.get(\"boto3client\") or not self._client: AttributeError: 'S3ResultHandler' object has no attribute '_client' ``` Just eyeballing it, maybe hasattr() will fix it, i.e. `if not prefect.context.get(\"boto3client\") or not hasattr(self, \"_client\"):` will fix it. ## Expected Behavior S3ResultHandler should checkpoint task outputs. ## Reproduction See previous issue. ## Environment We're running the Flow via Cloud with S3 storage. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Stack trace when trying to extend a nonexistent service ``` yaml web: image: busybox extends: service: foo ``` ``` $ docker-compose up -d Traceback (most recent call last): File \"/Users/aanand/.virtualenvs/docker-compose/bin/docker-compose\", line 9, in <module> load_entry_point('docker-compose==1.4.0.dev0', 'console_scripts', 'docker-compose')() File \"/Users/aanand/work/docker/compose/compose/cli/main.py\", line 39, in main command.sys_dispatch() File \"/Users/aanand/work/docker/compose/compose/cli/docopt_command.py\", line 21, in sys_dispatch self.dispatch(sys.argv[1:], None) File \"/Users/aanand/work/docker/compose/compose/cli/command.py\", line 27, in dispatch super(Command, self).dispatch(*args, **kwargs) File \"/Users/aanand/work/docker/compose/compose/cli/docopt_command.py\", line 24, in dispatch self.perform_command(*self.parse(argv, global_options)) File \"/Users/aanand/work/docker/compose/compose/cli/command.py\", line 57, in perform_command verbose=options.get('--verbose')) File \"/Users/aanand/work/docker/compose/compose/cli/command.py\", line 78, in get_project config.load(config_details), File \"/Users/aanand/work/docker/compose/compose/config/config.py\", line 132, in load service_dict = loader.make_service_dict(service_name, service_dict) File \"/Users/aanand/work/docker/compose/compose/config/config.py\", line 156, in make_service_dict service_dict = self.resolve_extends(service_dict) File \"/Users/aanand/work/docker/compose/compose/config/config.py\", line 183, in resolve_extends other_service_dict = other_config[extends_options['service']] KeyError: 'foo' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: tornado needs its own check Since tornado is a dependency for Notebook a check for it should be added to setupext/setupext.py and this check should be imported and called by by setupbase.py's check_for_dependencies Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.grad(has_aux=True) leaks identity tracers ``` def f(x): aux = dict(identity=x, p1=x+1) return x ** 2, aux jax.grad(f, has_aux=True)(3.) (DeviceArray(6., dtype=float32), {'identity': Traced<ConcreteArray(3.0, weak_type=True):JaxprTrace(level=0/0)>, 'p1': DeviceArray(4., dtype=float32)}) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Checkpoints cannot be loaded in non-pl env ~~## 🚀 Feature Add an option to save only `state_dict` for `ModelCheckpoint` callbacks~~ ## 🐛 Bug PL checkpoints cannot be loaded in non-pl envs ### Motivation To be able to move trained models and weights into pytorch only environments ### Additional context Currently when you do `torch.load()` on a pl generated checkpoint in an environment without pl, there is a pickling error. For my current use case I have to load the checkpoints in my training environment and save them again with only `state_dict` for the weights. See [reply below](https://github.com/PyTorchLightning/pytorch-lightning/issues/2653#issuecomment-681303007) for more info Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support docker exec command I've just learned about the new docker [exec](https://docs.docker.com/reference/commandline/cli/#exec) command. Wouldn't it be great to add it to fig ? I think it really makes sense with fig, as you could run `fig up` and then exec some commands (like a shell) to debug your running containers if something happen. Of course this is already possible by running `docker exec -it your_container cmd`, but I think that it wouldn't hurt to have `fig exec service cmd`. I'll try to give it a shot and submit a PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] CLI command to discover the cmake_find_package filename from the Conan package name? The `cmake_find_package` generator writes a Find Module file that defines a target in a namespace. Each of these three names (filename, namespace, target) are [configurable](https://github.com/conan-io/conan/issues/7254) in `cpp_info`. For example, ```python self.cpp_info.filename['cmake_find_package'] = 'BoostFile' self.cpp_info.names['cmake_find_package'] = 'BoostNamespace' self.cpp_info.name = 'BoostTarget' ``` will generate a file named `FindBoostFile.cmake` that is used like this: ```cmake find_package(BoostFile) target_link_libraries(${target} BoostNamespace::BoostTarget) ``` Is there a CLI command that can print out these values given a package reference? Something like ``` $ conan inspect -a cpp_info.names.cmake_find_package boost/1.73.0@ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Internationalization check is raising false positive I miss the point that the comment with the string code positions are part of the string used to generate the hash like: ``` #: packages/filebrowser-extension/src/index.ts:978 #: packages/mainmenu-extension/src/index.ts:526 msgid \"Shut Down Kernel\" msgstr \"\" ``` I'll push a PR to keep only the `msgid` and `msgctxt`. _Originally posted by @fcollonval in https://github.com/jupyterlab/jupyterlab/issues/11188#issuecomment-931307654_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add regression test for datastore keys (object names) with / separator See https://github.com/GoogleCloudPlatform/gcloud-python/pull/371#issuecomment-62659321 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Can an interrupted install leave locks inconsistent? I have seen conan installs fail with a message like this: ``` <name>/<version>@<channel> is locked by another concurrent conan process, wait... If not the case, quit, and do 'conan remove <name>/<version>@<channel> -f' ``` Trying to get to the root of this message I think I might have CTRL-C interrupted a previous installation, which in turn left the corresponding package lock file on disk. Then during another install attempt, the new process waited forever. I looked into the conan code and did not find try/finally logic with respect to the lock context managers. Does that mean I can end up in an inconsistent situation like described? Wouldn't it be preferrable to clean up locks also in such a situation? Semantically this would be correct I think, since the lock does not mean \"installed fine\", but simply \"no-one else is writing\". In case of CTRL-C this is in fact true, the process stopped writing, so the lock should be gone as well. Or did I get lost? :smiley: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: change Checkpoint callback's `save_best_only` to `save_top_k` **Is your feature request related to a problem? Please describe.** `save_best_only` is a special case of `save_top_k`. However, `save_tok_k` checkpoints can be used to create ensemble model during the test time. **Describe the solution you'd like** keep a dict of `{epoch: monitor}` of length `k`, and save new ckeckpoint that can enter this dict, remove the worst checkpoint. change Checkpoint callback's `save_best_only` to `save_top_k` **Is your feature request related to a problem? Please describe.** `save_best_only` is a special case of `save_top_k`. However, `save_tok_k` checkpoints can be used to create ensemble model during the test time. **Describe the solution you'd like** keep a dict of `{epoch: monitor}` of length `k`, and save new ckeckpoint that can enter this dict, remove the worst checkpoint. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Unexpected behavior encoding token_type_ids in GPT models # 🐛 Bug ## Information When `token_type_ids` are passed into the `GPT2Model` and subclasses, they're encoded using the `nn.Embedding` lookup table as the vocabulary ([line](https://github.com/huggingface/transformers/blob/3ae2e86baffc1fea8b8b93695fb5a10941fd63dc/src/transformers/modeling_gpt2.py#L477)). Because the token type ids output by `encode_plus()` are `{0,1}`, this seems to create unexpected behavior by using the same embedding vectors to represent both word-tokens 0 and 1 in the vocabulary and the very distinct token type ids. ## Expected Behavior Either: 1. instead of returning `token_type_ids` consisting of indices 0 and 1, extend the vocabulary by 2 and use those two ids as the `token_type_ids` in `encode_plus()`, or 2. addition of a separate `nn.Embedding` matrix for token_type_ids [here](https://github.com/huggingface/transformers/blob/3ae2e86baffc1fea8b8b93695fb5a10941fd63dc/src/transformers/modeling_gpt2.py#L352) (such as [in BERTModel](https://github.com/huggingface/transformers/blob/3ae2e86baffc1fea8b8b93695fb5a10941fd63dc/src/transformers/modeling_bert.py#L153)) 3. discourage or throw a warning when `token_type_ids` are passed to GPTModel instances Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython(3)Lexer fails to tokenize properly on source with magic functions Cross-issue from jupyter/nbconvert#105. The `IPython3Lexer` and `IPythonLexer` fail to properly tokenize on source with magic functions as seen in the example code below. ``` >>> from IPython.lib import lexers >>> lexer = lexers.IPython3Lexer() >>> fragment = \"%%time\\nfor i in range(5):\\nprint(n)\" >>> other_fragment = \"for i in range(5):\\nprint(n)\" >>> list(lexer.get_tokens(fragment)) [(Token.Operator, '%%'), (Token.Keyword, 'time'), (Token.Text, '\\nfor i in range(5):\\nprint(n)\\n')] >>> list(lexer.get_tokens(other_fragment)) [(Token.Keyword, 'for'), (Token.Text, ' '), (Token.Name, 'i'), (Token.Text, ' '), (Token.Operator.Word, 'in'), (Token.Text, ' '), (Token.Name.Builtin, 'range'), (Token.Punctuation, '('), (Token.Literal.Number.Integer, '5'), (Token.Punctuation, ')'), (Token.Punctuation, ':'), (Token.Text, '\\n'), (Token.Name.Builtin, 'print'), (Token.Punctuation, '('), (Token.Name, 'n'), (Token.Punctuation, ')'), (Token.Text, '\\n')] ``` The expected behavior is that the remaining part of the source (`for i in range(5): print(n)`) would be tokenized properly so that pygments can syntax highlight appropriately in `nbconvert`. Looking at the test suite, it appears there isn't actually a test case in `test_lexer.py` to test for this specific situation. I can take a stab at this. cc: @minrk Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose-help: add explanation about down :warning: I'm just creating this Issue to reference this at PR ## Description of the issue One could think just using `docker-compose down` already remove volumes, given it is listed like the other options at --help. ## Context information (for bug reports) **Output of `docker-compose version`** ``` docker-compose version 1.25.4, build 8d51620a docker-py version: 4.1.0 CPython version: 3.7.5 OpenSSL version: OpenSSL 1.1.1d 10 Sep 2019 ``` **Output of `docker version`** ``` Client: Docker Engine - Community Version: 19.03.8 API version: 1.40 Go version: go1.12.17 Git commit: afacb8b Built: Wed Mar 11 01:21:11 2020 OS/Arch: darwin/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.8 API version: 1.40 (minimum version 1.12) Go version: go1.12.17 Git commit: afacb8b Built: Wed Mar 11 01:29:16 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: v1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683 ``` **Output of `docker-compose config`** (Make sure to add the relevant `-f` and other flags) ``` There is no default config ``` ## Steps to reproduce the issue 1. Run `docker-compose --help` 2. See `down` description 3. Run `docker-compose down --help` 4. See `-v` description 5. Try to use `down` with and without `-v` ### Observed result Actually only passing -v you will remove volumes ### Expected result The main documentation to say it explicitly Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Firestore] List collection ids of a document How do I list subcollection ids of a document? Is it not yet implemented in the python firestore library? It's available for all other google cloud platform languages: [node](https://cloud.google.com/nodejs/docs/reference/firestore/0.14.x/DocumentReference#getCollections), [go](https://godoc.org/cloud.google.com/go/firestore#DocumentRef.Collections), [php](http://googlecloudplatform.github.io/google-cloud-php/#/docs/cloud-firestore/v0.11.0/firestore/documentreference?method=collections), [java](https://googlecloudplatform.github.io/google-cloud-java/google-cloud-clients/apidocs/index.html?com/google/cloud/firestore/package-summary.html), [ruby](http://googlecloudplatform.github.io/google-cloud-ruby/#/docs/google-cloud-firestore/v0.21.1/google/cloud/firestore/documentreference?method=cols-instance), [.NET](http://googlecloudplatform.github.io/google-cloud-dotnet/docs/Google.Cloud.Firestore/api/Google.Cloud.Firestore.DocumentReference.html#Google_Cloud_Firestore_DocumentReference_ListCollectionsAsync). There's no way that the python library is the only library that doesn't support this functionality, right? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Plotting bloch sphere using spherical coordinates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Functionality to accept Spherical coordinates as well as typical Cartesian for plot_bloch_vector function under state_visualization.py (https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/visualization/state_visualization.py) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Feature request conan.conf file To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x ] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. I have just been burnt by the same type of issue again.... a user was having connectivity issues with the Proxy devil. I looked at the conan.conf file and read right over the fact that the variable \"no_proxy\" was set, but what needed to be set was \"no_proxy_match\" Is it possible for conan to report: \"You have set the variable: 'XXXX' in the conan.conf file, but Conan does not understand that variable\" An error/warning message like that helps stupid people like me. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Refix gst building MR #737 broke building of gst. This is a regression. Unless we can come up with a fix to make both work, the MR should be reverted. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: AIP-56 - FAB AM - Logout Move the logout logic to the auth manager Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Wrong capitalization on bitgenerator MT19937 Wrong capitalization of MT19937 in default argument values of functions in numpy.random._pickle.py ### Reproducing code example: ```python import numpy as np np.random._pickle.__randomstate_ctor() # => error np.random._pickle.__randomstate_ctor('mt19937') # => error np.random._pickle.__randomstate_ctor('MT19937') # => works ``` ### Error message: *** ValueError: mt19937 is not a known BitGenerator module. ### Numpy/Python version information: 1.17.0 3.6.8 (default, Jan 14 2019, 11:02:34) [GCC 8.0.1 20180414 (experimental) [trunk revision 259383]] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Terra Tests Fail with Numpy 1.19.0 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: Master - **Python version**: Any - **Operating system**: Any ### What is the current behavior? Since the release of numpy 1.19.0 CI started failing on 2 tests: `test_qasm_2q_unitary` https://github.com/Qiskit/qiskit-terra/blob/master/test/python/circuit/test_unitary.py#L248-L271 and `test_pulse_limits: https://github.com/Qiskit/qiskit-terra/blob/master/test/python/pulse/test_pulse_lib.py#L60-L89 It's not clear if this is a bug in numpy or a usage bug in terra. If it's an iss This is being pinned in CI with https://github.com/Qiskit/qiskit-terra/pull/4599 ### Steps to reproduce the problem Run the tests with numpy 1.19.0 ### What is the expected behavior? The tests pass ### Suggested solutions Find the source of the bug, and fix or report it upstream Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Error message 'Subproject directory does not exist and can not be downloaded.' So I was a bit stupid and didn't read the documentation properly and I added a folder `submodules` to my source tree. It would be nice if Meson would check for the `subprojects` folder first, and if the error message would say instead: 'Directory \"subprojects\" not found in folder \"...\"'. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] conan download pkg/version@user/channel#randomrev downloads latest Latest 1.20, Windows 10, python 3.7 With revisions disable this doesn't fail (it should). And worse, it creates an entry with revision ``randomrev`` in the cache. Also, it seems that it is not possible to ``conan download`` a package with a given package revision. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [example scripts] disambiguate language specification API Currently in example scripts like `run_seq2seq.py` we have: 1. for t5 ``` --task translation_en_to_ro --source_prefix \"translate English to Romanian: \" ``` 2. Also these 2: ``` --target_lang ro_RO --source_lang en_XX ``` are used only for MBart and are ignored for other models. Which means that people will unknowingly try to use these two as well when they aren't need. The problem in both situations is that we provide error-prone API where a user wants to change the language and forgets that there is more than one of the same and changes only one of the sets of languages, but not the other, which leads to broken outcome. If such an error is made the specification supplied by the user becomes ambiguous, because one can't tell which of the multiple inputs takes precedence. Proposal: There should be only one way to input a set of languages and not multiple ways. Specifically: - in case 1, probably the easiest is to leave `--task translation_en_to_ro` and auto-generate `--source_prefix \"translate English to Romanian: \"` - in case 2, assert if `--target_lang` or `--source_lang` are passed and the model is not MBart. Thinking more about it, case 1 is a must to solve, because if a user misses `--source_prefix` or makes a typo in it - the train/eval won't fail, but will mysteriously produce really bad outcome. This is not user-friendly. @sgugger, @patrickvonplaten, @patil-suraj Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: pep8 is dead As of version 1.7.0, [`pep8`](https://pypi.python.org/pypi/pep8) is no longer getting releases, the tool is now called [`pycodestyle`](https://pypi.python.org/pypi/pycodestyle/). Visit https://github.com/PyCQA/pep8 to see the redirect. This means we haven't had any updates since January 12, 2016. Oops. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QASM conversion fails when a gate is conditioned on a individual bit of a classical register ### Environment - **Qiskit Terra version**: 0.21.2 - **Python version**: 3.7.7 - **Operating system**: Mac ### What is happening? A quantum circuit with a gate conditioned on a single bit value of a classical register cannot be converted to a QASM string. ### How can we reproduce the issue? ```python q = QuantumRegister(2, 'q') c = ClassicalRegister(2, 'c') qc = QuantumCircuit(q, c) qc.h(0) qc.cx(0, 1) qc.measure(0, 0) qc.x(1).c_if(c[0], 1) print(qc) qc.qasm() ``` /opt/miniconda3/lib/python3.7/site-packages/qiskit/circuit/instruction.py in _qasmif(self, string) 438 if self.condition is None: 439 return string --> 440 return \"if(%s==%d) \" % (self.condition[0].name, self.condition[1]) + string 441 442 def qasm(self): AttributeError: 'Clbit' object has no attribute 'name' ### What should happen? Expect to get a QASM string ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Generating with Flax fails when using padding ### System Info - `transformers` version: 4.25.1 - Platform: Linux-5.10.133+-x86_64-with-glibc2.27 - Python version: 3.8.15 - Huggingface_hub version: 0.11.1 - PyTorch version (GPU?): 1.13.0+cu116 (False) - Tensorflow version (GPU?): 2.9.2 (False) - Flax version (CPU?/GPU?/TPU?): 0.6.2 (cpu) - Jax version: 0.3.25 - JaxLib version: 0.3.25 - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help? @patil-suraj, @patrickvonplaten, @LysandreJik ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Generation with GPT-2 and OPT doesn't work when using padding token. Specifically, the issues are 1. In GPT-2, using builtin |endoftext| as pad token works with padding, but using customized token <|pad|> doesn't work, the generation only repeats `!`, e.g., `<|pad|> My cat is cute!!!!!!!!!!!!!!!`. 2. In GPT-2, despite pad_token_id is optional in generate() function, one has to provide pad_token_id=tokenizer.pad_token_id otherwise error. 3. In OPT, even using builtin <pad> token as padding token doesn't work, the generation only repeats `<s>`, e.g., `<pad></s>My cat is cute<s><s><s><s><s><s><s><s><s><s><s><s><s><s>`. The colab to reproduce the problems 1-3 is [here](https://colab.research.google.com/drive/1pcwTRU3snLjz8wTJx_Z5t4Z7IXnxHnDI?usp=sharing). A related issue to problem 2 is #18884. ### Expected behavior Expect the generation works with padding. E.g., `<pad></s>My cat is super cute and I love her so much. I love her so much. I love`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add default location to Client It is potentially quite cumbersome to pass in a `location` parameter to nearly every API request method. It would be nice to set a default `location` when you create a client to be used when creating datasets or jobs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add more agent API docs We should add more agent examples + descriptions of use at the top of each individual API reference page (https://docs.prefect.io/api/unreleased/agent/agent.html) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Ctrl-C on `docker-compose up` raises thread.error I get this intermittently (sometimes it does shutdown gracefully): ``` ^CGracefully stopping... (press Ctrl+C again to force) Stopping dailylead_db_1... Stopping dailylead_queue_1... Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/fig.cli.main\", line 39, in main File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/fig.cli.docopt_command\", line 21, in sys_dispatch File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/fig.cli.command\", line 30, in dispatch File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/fig.cli.docopt_command\", line 24, in dispatch File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/fig.cli.command\", line 47, in perform_command File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/fig.cli.docopt_command\", line 27, in perform_command File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/fig.cli.main\", line 316, in up File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/fig.cli.log_printer\", line 20, in run File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/fig.cli.multiplexer\", line 20, in loop File \"/Users/ben/fig/build/fig/out00-PYZ.pyz/Queue\", line 182, in get thread.error: release unlocked lock ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: WARNING: Unknown CPU family 'sparc', please report this Using meson/ninja for Buildroot [1] builds, e.g. with the provides sparc toolchain [2]. [1] https://buildroot.org/ [2] http://autobuild.buildroot.org/toolchains/tarballs/br-sparc-uclibc-2017.11-rc1.tar.bz2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Profile detect selects wrong default compiler on FreeBSD ### Environment details `conan profile detect` when both `gcc` and `clang` installed, `gcc` is selected, while `FreeBSD` actually uses `clang` as core/standard compiler. ### Steps to reproduce _No response_ ### Logs _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support for clang-tidy (or other linters) CMake has support for additional linting by clang-tidy: http://www.mariobadr.com/using-clang-tidy-with-cmake-36.html I was wondering if something like this could be done for Meson, so that header dependencies etc. still work. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: CUDA OOM when loading optimizer state dict ### System Info I am finetuning GPT NEO 1.3B with 1 GPU and 24GB VRAM. From scratch, model weights load and train fine with <1GB of memory to spare. When loading from checkpoint, I run into issues loading optimizer states. https://github.com/huggingface/transformers/blob/04bfac83b793b757e7b33188f88eebe21ac65ef7/src/transformers/trainer.py#L2434-L2436 If I hard-code `map_location ='cpu'`, the OOM goes away and I am able to resume training. After some reading, this was caused by the optimizer state dict being associated with 'gpu:0' at the time of checkpoint saving. I also found another ticket adding device logic to `map_location=self.args.device` in the first place due to CPU OOM for the PR author. I was wondering if the interface needs to be change in order to accommodate both use cases. ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction see above. Otherwise from using run_clm.py from the repo without deepspeed. ### Expected behavior Resume from checkpoint should fit in the same vram footprint as finetune from scratch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: GPT Neo for Sequence Classification Hi, Is there a way to use GPT Neo for classification tasks like BoolQ ? As 'OpenAI GPT2' integration of HF has 'GPT2ForSequenceClassification', is there a similar one for GPT Neo? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Dead links Using pytest-check-links: ``` C:\\dev\\jupyterlab [master ≡]> py.test --check-links -k .md . ============================= test session starts ============================= platform win32 -- Python 3.5.2, pytest-3.0.6, py-1.4.32, pluggy-0.4.0 rootdir: C:\\dev\\jupyterlab, inifile: pytest.ini plugins: tornado-0.4.5, timeout-1.2.0, cov-2.4.0, nbval-0.4.1, check-links-0.0.3.dev4 collected 121 items CONTRIBUTING.md .......F.. README.md ...................... RELEASE.md .. design\\about.md . tutorial\\adding_content.md ...F tutorial\\documents.md F......... tutorial\\examples.md .. tutorial\\labextensions.md F. tutorial\\notebook.md .................. tutorial\\patterns.md .. tutorial\\plugins.md ............... tutorial\\repo.md . tutorial\\virtualdom.md .. ================================== FAILURES =================================== ___ C:\\dev\\jupyterlab\\CONTRIBUTING.md: http://jupyter.github.io/jupyterlab/ ___ http://jupyter.github.io/jupyterlab/: HTTP Error 404: Not Found ________ C:\\dev\\jupyterlab\\tutorial\\adding_content.md: documents.html _________ documents.html: No such file: C:\\dev\\jupyterlab\\tutorial\\documents.html ____________ C:\\dev\\jupyterlab\\tutorial\\documents.md: plugins.html ____________ plugins.html: No such file: C:\\dev\\jupyterlab\\tutorial\\plugins.html __________ C:\\dev\\jupyterlab\\tutorial\\labextensions.md: plugins.html __________ plugins.html: No such file: C:\\dev\\jupyterlab\\tutorial\\plugins.html ============================= 30 tests deselected ============================= ============= 4 failed, 87 passed, 30 deselected in 40.90 seconds ============= ``` The last three are probably ok(?), but the first one is properly broken. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: show() blocks in pylab mode with ipython 0.10.1 After updating to ipython 0.10.1 on 64-bit Linux, I noticed that plotting commands no longer automatically display anything when ipython is started with the -pylab option. Moreover, the show() command now appears to block in pylab mode. I don't have any local ~/.matplotlib/matplotlibrc file installed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Silent error when calling datastore.put() on nonlist Repro instructions: ``` ent = datastore.Entity(key=datastore.Key('test',1)) datastore.put(ent) ``` Entity is not put in the datastore, and call completes successfully. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Backslash (\\) at the end of the line behavior different from default Python Quite often, I miss the Enter/Return key and press `\\`. In regular Python, I can enter two newlines, and the expression will be evaluated, like ``` py >>> 1\\ ... 1 ``` But in IPython, no amount of newlines will terminate it. And if I do finally terminate it by entering a `;`, the output is not printed (also different from Python). ``` py In [1]: 1\\ ...: ...: ...: ...: ...: ; In [2]: ``` ``` py >>> 1\\ ... ; 1 ``` Is this an intended feature caused by some more advanced multiline editing capabilities of IPython, or just a bug? Backslash (\\) at the end of the line behavior different from default Python Quite often, I miss the Enter/Return key and press `\\`. In regular Python, I can enter two newlines, and the expression will be evaluated, like ``` py >>> 1\\ ... 1 ``` But in IPython, no amount of newlines will terminate it. And if I do finally terminate it by entering a `;`, the output is not printed (also different from Python). ``` py In [1]: 1\\ ...: ...: ...: ...: ...: ; In [2]: ``` ``` py >>> 1\\ ... ; 1 ``` Is this an intended feature caused by some more advanced multiline editing capabilities of IPython, or just a bug? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: add includedir or dependencies to has_header I need to check if `boost/numeric/odeint/external/eigen/eigen_algebra.hpp` is there. Tried to debug: ``` cpp #include<boost/numeric/odeint/external/eigen/eigen_algebra.hpp> int someSymbolHereJustForFun; ``` /usr/include/boost/numeric/odeint/external/eigen/eigen_algebra.hpp:21:23: fatal error: Eigen/Dense: No such file or directory I also need pass `pkg-config --cflags eigen3` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython mangles unicode characters This occurs in IJulia, but I've checked the ZMQ message boundary so I think it probably happens somewhere between the browser and before it hits the kernel. When entering a high unicode character (such as U+1D712) it arrives at the kernel as ``` 6-element Array{Uint8,1}: 0xed 0xa0 0xb5 0xed 0xbc 0x92 ``` rather than the expected ``` 4-element Array{Uint8,1}: 0xf0 0x9d 0x9c 0x92 ``` . Now, in julia we do our best to retain invalid unicode data which gives the effect that if you print the above again it prints correctly in the browser. I assume somewhere in the software stack there's an encoding that's not quite UTF8, though it does convert back, so that's nice. I also checked that printing the proper UTF8 character shows up correctly in the browser. Now, this might be a browser issue, but I checked that it is set to UTF8 and it happens in Firefox and Safari as well and when I paste it out into a texteditor I get the proper UTF8 character. Let me know if there's anything I can do to help investigate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Two copies of is_context_provided in the code base ### Dagster version main ### What's the issue? There are two copies of `is_context_provided` in the codebase. One is there focused on type correctness in python_modules/dagster/dagster/_core/decorator_utils.py. However there is another one which actually inspects the name of the parameters to ensure that they are valid context names in `python_modules/dagster/dagster/_core/definitions/decorators/solid_decorator.py` These should be reconciled and have standardized behavior. If two functions are different, they should be named differently and documented. ### What did you expect to happen? _No response_ ### How to reproduce? _No response_ ### Deployment type None ### Deployment details _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: [1.15.0] Nested extends cause services to not be discovered It seems 1.15 re-introduced something that was fixed before in https://github.com/docker/compose/issues/2719 - Downgrading to 1.14 \"fixes\" this issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Bigtable Cluster.create() does not send location [Only][1] `serve_nodes` is used in the payload: ```python return messages_v2_pb2.CreateClusterRequest( parent=cluster._instance.name, cluster_id=cluster.cluster_id, cluster=data_v2_pb2.Cluster( serve_nodes=cluster.serve_nodes, ), ) ``` [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/08021bd85df19d073b33412dbd4ff4dbc8be008d/bigtable/google/cloud/bigtable/cluster.py#L51-L54 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: min_max log_gpu_memory option bug **Describe the bug** Setting `log_gpu_memory='min_max'` in `Trainer` leads to the following bug. ``` Traceback (most recent call last): File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/trainer.py\", line 347, in fit self.single_gpu_train(model) File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/dp_mixin.py\", line 79, in single_gpu_train self.run_pretrain_routine(model) File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/trainer.py\", line 467, in run_pretrain_routine self.train() File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/train_loop_mixin.py\", line 60, in train self.run_training_epoch() File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/train_loop_mixin.py\", line 126, in run_training_epoch self.log_metrics(batch_step_metrics, grad_norm_dic) File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/logging_mixin.py\", line 20, in log_metrics mem_map = memory.get_memory_profile(self.log_gpu_memory) File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/root_module/memory.py\", line 205, in get_memory_profile for k, v in memory_map: ValueError: too many values to unpack (expected 2) ``` **To Reproduce** On current master, execute the following. ``` trainer = Trainer( ... log_gpu_memory='min_max', ... ) trainer.fit(model) ``` **Expected behavior** Log the min/max utilization of gpu memory, as `min_max` option is documented. **Desktop (please complete the following information):** - OS: Ubuntu 18.04 - Version: Current master I am working on this issue. Will submit a PR soon. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Efficient implementation of exp(iHt) for an arbitrary hermitian matrix H <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Given a Hermitian matrix H and a time t, 1. Find a decomposition of H into H_1,H_2,...H_m such that H = H_1+...+H_m and such that we know the circuits for each exp(iH_j t) (e.g. a decomposition into 1-sparse matrices) 2. Approximate exp(iHt) via a Trotter/Suzuki product of the exp(iH_j t)'s At the moment the only possibility is via `qc.unitary((t*MatrixOp(H)).exp_i(),q)`, but this approach would kill the quantum advantage achieved by algorithms that run in polylog(N), where H is an NxN matrix. This enhancement is required for the HHL refactoring. References [1] Detailed explanation of the method: https://arxiv.org/pdf/quant-ph/0209131.pdf [2] An implementation of Step 1. from Qiskit Camp Asia 2019: https://github.com/martian17/qiskit-graph-coloring-hamiltonian Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Remove 'user_id', 'role_id' from User and Role in OpenAPI schema Would be good to remove the 'id' of both User and Role schemas from what is dumped in REST API endpoints. ID of User and Role table are sensitive data that would be fine to hide from the endpoints Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: GPT NeoX Input docstring includes token_type_ids but GPTNeoXModel does not have token_type_ids as an input to forward ### System Info n/a ### Who can help? @ArthurZucker @younesbelkada ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Go to https://huggingface.co/docs/transformers/main/en/model_doc/gpt_neox#transformers.GPTNeoXModel and see that forward does not include token_type_id but it is shown in the docstring ### Expected behavior Docstring should match forward Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: mapping from Euler angles to quaternions in mapper <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? To fix some of the mapper i going to change the 1q optimization from euler angles to quaternions and it should fix the mapper issues that keep getting brought up. This is a low priority as most times it works but the correct way to do it is quaternions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan lockfile keeps changing Every time I run `conan graph lock ...`, the lockfile is re-written. The core content hasn't changed, but hashes are regenerated and sometimes the order of the nodes changes. This makes it an awful pain to store that lockfile in the VCS repository. Am I doing something wrong? Is there a workflow change I need to make? An option that can be added to lock command? Is this a bug? - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: deepspeed typing Dict error ### System Info - `transformers` version: 4.32.0.dev0 - Platform: Linux-5.10.179-171.711.amzn2.x86_64-x86_64-with-glibc2.26 - Python version: 3.9.16 - Huggingface_hub version: 0.15.1 - Safetensors version: 0.3.1 - Accelerate version: 0.22.0.dev0 - Accelerate config: not found - PyTorch version (GPU?): 2.0.1+cu118 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: <fill in> - Using distributed or parallel set-up in script?: <fill in> ### Who can help? @sgugger ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Right now any command with `--deepspeed /path/to/json` will fail and throw the following error ``` --deepspeed: invalid Dict value ``` This is reported in https://github.com/huggingface/transformers/pull/24549#issuecomment-1613046347 but the merged fix https://github.com/huggingface/transformers/pull/24574 does not resolve this. In fact the `deepspeed: Union[str, Dict]` field in `training_args.py` still raise the error when the `deepspeed` is passed as the string. This seems to be a limitation of python dataclass. ### Expected behavior `deepspeed` flag should support string. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Compare compiler.cppstd version (#4943) Extends `conans.tools.Version` to support `settings.compiler.cppstd`: ``` def configure(self): if Version(self.settings.compiler.cppstd) < \"gnu17\": ... ``` `Version` from `model.version` was not affected. Changelog: Feature: Compare compiler.cppstd version (#4943) Docs: https://github.com/conan-io/docs/pull/1440 closes #4943 - [x] Refer to the issue that supports this Pull Request. - [x] If the issue has missing info, explain the purpose/use case/pain/need that covers this Pull Request. - [x] I've read the [Contributing guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've followed the PEP8 style guides for Python code. - [x] I've opened another PR in the Conan docs repo to the ``develop`` branch, documenting this one. <sup>**Note:** By default this PR will skip the slower tests and will use a limited set of python versions. Check [here](https://github.com/conan-io/conan/blob/develop/.github/PR_INCREASE_TESTING.md) how to increase the testing level by writing some tags in the current PR body text.</sup> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Change NewNotebook handler to use 30x redirect rewriting [the url for new notebooks](https://github.com/ipython/ipython/blob/master/IPython/frontend/html/notebook/static/js/savewidget.js#L127) seem to cause problem with jQuery tabs (#2206). I propose to change the NewNotebook handler to send a redirect 302 with the URL of the new notebook. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: NoPackagesFound does not work correctly for missing recursive dependencies Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Gamma sample gradients has incorrect dtype in x64 mode The following snippet of code fails in JAX: ``` import jax import jax.numpy as jnp import jax.random as jaxrand jax.config.update('jax_enable_x64', True) key = jaxrand.PRNGKey(0.) a = jnp.array(1., dtype=jnp.float32) b = jnp.array(3., dtype=jnp.float32) f = lambda x, y: jaxrand.gamma(key=key, a=x, dtype=jnp.float32) / y y, f_vjp = jax.vjp(f, a, b) ``` with ``` TypeError: body_fun output and input must have identical types, got (ShapedArray(float32[]), ShapedArray(float32[]), ShapedArray(float64[]), ShapedArray(bool[])) and (ShapedArray(float32[]), ShapedArray(float32[]), ShapedArray(float32[]), ShapedArray(bool[])) ``` Some dtype information is being lost along the way. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add support for gcd local development server Right now, there doesn't appear to be any support for the [datastore local development server gcd](https://cloud.google.com/datastore/docs/tools/devserver). For instance, the usage instructions tell you to set the dataset id in the environment variable `DATASTORE_DATASET` but gcloud-python doesn't appear to look for that in the `set_default_dataset_id()` function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: creating network with defined ipam subnet is slow Whenever I define a subnet for a network, `docker-compose up` is really slow, and seems to wait for ± 15 seconds on creating the network. example config: ``` networks: default: ipam: config: - subnet: 172.17.0.0/28 ``` It doesn't matter what the network is called, or what the subnet actually is, and it doesn't conflict with anything. If I define multiple networks, creating each network takes about 15 seconds. PoC: https://github.com/ComaVN/docker-compose-network-slow ``` $ docker-compose --version docker-compose version 1.11.2, build dfed245 ``` ``` $ docker version Client: Version: 17.09.0-ce API version: 1.32 Go version: go1.8.3 Git commit: afdb6d4 Built: Tue Sep 26 22:42:18 2017 OS/Arch: linux/amd64 Server: Version: 17.09.0-ce API version: 1.32 (minimum version 1.12) Go version: go1.8.3 Git commit: afdb6d4 Built: Tue Sep 26 22:40:56 2017 OS/Arch: linux/amd64 Experimental: false ``` ``` $ lsb_release -a LSB Version: core-9.20160110ubuntu0.2-amd64:core-9.20160110ubuntu0.2-noarch:security-9.20160110ubuntu0.2-amd64:security-9.20160110ubuntu0.2-noarch Distributor ID: Ubuntu Description: Ubuntu 16.04.3 LTS Release: 16.04 Codename: xenial ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support of Qt6 import Hi, Qt6 RC is out, it would be nice to add the support of this version to meson. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Extend iOS version in settings.yml Hi, could you please update settings for iOS? The newest version in settings.yml for iOS is 13.1. From [here](https://en.wikipedia.org/wiki/IOS_version_history) you can see that there are newer versions. I have to use 13.2 and this is not problem to edit locally my settings.yml, but if I do it all my clients have to do the same work. Br, Tomasz Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Implement PyTorch and/or TensorFlow sequence classification architectures for causal language models # 🚀 Feature request The architecture `GPT2ForSequenceClassification` was added in #7501 in PyTorch. It would be great to have it in TensorFlow (cf. issues #7622), but it would also be great to have it for other causal models: ~OpenAI GPT~, ~CTRL~ (PR opened @elk-cloner), ~TransfoXL~ (PR opened @spatil6) Below is a list of items to follow to make sure the integration of such an architecture is complete: - Implement `XXXForSequenceClassification` in `modeling_xxx.py` or `TFXXXForSequenceClassification` in `modeling_tf_xxx.py - Test that architecture in `tests/test_modeling_xxx.py` or `tests/test_modeling_tf_xxx.py` - Add that architecture to `__init__.py` and ` docs/source/model_doc/xxx.rst`. Taking a look at the code changes in #7501 would be a good start. A very good first issue to get acquainted with the library and its architectures! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Unpin tornado dependency #6123 rolled back our dependency on `notebook` due to some upstream issues with async kernel starts (or possibly tornado 6). We need to identify and fix these issues before making a release. Edit: we have resolved the immediate issue with notebook in 5.7.8, but issues with tornado 6 remain. Failing tests seen as passing In running tests, I see a few logs like: ``` @jupyterlab/test-docregistry: PASS src/mimedocument.spec.ts @jupyterlab/test-docregistry: ● Console @jupyterlab/test-docregistry: console.error ../../node_modules/@phosphor/signaling/lib/index.js:220 @jupyterlab/test-docregistry: AssertionError { @jupyterlab/test-docregistry: message: \"expected '' to equal 'bar'\", @jupyterlab/test-docregistry: showDiff: true, @jupyterlab/test-docregistry: actual: '', @jupyterlab/test-docregistry: expected: 'bar' } ``` I think what is going on is that a test like this: https://github.com/jupyterlab/jupyterlab/blob/c31b311fdc3503d67b843ef17b9d53e3bfdd2473/tests/test-docregistry/src/mimedocument.spec.ts#L115-L118 is actually failing, but the signal mechanism is catching the failure and printing the error to console, and the test as a whole is being seen as passing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pkgconfig add URL parameter Hello, I have tried to add URL to pkg.generate in: ``` python pkg = import('pkgconfig') libs = ... # the library/libraries users need to link against h = ['.', ...] # subdirectories of ${prefix}/${includedir} to add to header path pkg.generate(libraries : libs, subdirs : h, version : '1.0', name : 'libsimple', filebase : 'simple', description : 'A simple demo library.') ``` but there is error, so it seems that isn't supported yet ? Any help appreciated Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: Clarify that `np.array` can be 0-dimensional ## Documentation From the docstring of `np.array`, its only positional argument is: > An array, any object exposing the array interface, an object whose __array__ method returns an array, or any (nested) sequence. From such a description, it is surprising that one can do things like `np.array(1)` (I guess this is done to support 0D arrays). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Bug in np.eye. As suggested, it seems like np.eye broke at some point. To repro try, `np.allclose(onp.eye(N), np.eye(N))`. Upon closer inspection, it seems like this only kicks in at large N. Try e.g. 5000. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: gate dimension mismatch not detected <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? The following code should throw an error, because it's trying to append a 3 qubit initializer to 2 qubits. But it does not raise. ```python random_state = [ 1 / math.sqrt(4) * complex(0, 1), 1 / math.sqrt(8) * complex(1, 0), 0, 1 / math.sqrt(8) * complex(1, 0), 1 / math.sqrt(8) * complex(0, 1), 0, 1 / math.sqrt(4) * complex(1, 0), 1 / math.sqrt(8) * complex(1, 0)] qc = QuantumCircuit(qr) qc.initialize(random_state, qr[0:2]) ``` In stable this works as expected, so probably an issue with the recent append PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Tokenizer.encode documentation not correct # 🐛 Bug ## Information Model I am using Bert (bert-base-german-cased): Language I am using the model on German: The problem arises when using: * tokenizer of this model The tasks I am working on is: * encoding ## To reproduce Steps to reproduce the behavior: 1. lang_model = 'bert-base-german-cased' 2. tokenizer = BertTokenizer.from_pretrained(lang_model) 3. test_sentence = 'Das war gut' 4. tokenizer.encode(test_sentence) output: [3, 295, 185, 1522, 4] 5. tokenizer.convert_tokens_to_ids(tokenizer.tokenize(test_sentence)) output: [295, 185, 1522] ## Expected behavior According to the documentation of the encoding method in https://huggingface.co/transformers/main_classes/tokenizer.html these two outputs should be the same. The problem is, that the _encode_ method adds special tokens [CLS] and [SEP] at the beginning and the end. However, the transformation in line 5. does not. This is not a problem at all but one should consider correcting the online-documentation. That is, the hint **Same as doing self.convert_tokens_to_ids(self.tokenize(text))** in the encode method is misleading. Instead, one could also add, that these two commands are the same if _add_special_tokens_ is set _False_ in the _encode_ method. ## Environment info - `transformers` version: 2.8.0 - Platform: Windows 10 - Python version: 3.8.3 - PyTorch version (GPU?): 1.5.0+cpu - Tensorflow version (GPU?): None - Using GPU in script?:No - Using distributed or parallel set-up in script?:No Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Allow `python -m IPython` Is there any reason why we don't allow IPython to be run as a module as in `python -m IPython`? I'd expect the behavior to be the same as running `ipython.py` or the current: ``` sh $ python -m IPython.frontend.terminal.ipapp ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: local mathjax install doesn't work Hi, the command line provided in the popup when using mathjax offline doesn't work: from IPython.external import mathjax; mathjax.install_mathjax() the url is out of date: HTTPError: HTTP Error 500: Internal Server Error Downloading mathjax source from https://github.com/mathjax/MathJax/tarball/v2.2 x. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Improve an error message in qiskit.converters.circuit_to_gate() <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Let's assume we have `QuantumCircuit` object called `qc`, and one tries to convert it into a `Gate` object using `qiskit.converters.circuit_to_gate()`. If `qc` contains some instructions which cannot be converted into `Gate`, the following exception is raised ``` QiskitError: 'One or more instructions in this instruction cannot be converted to a gate' ``` My suggestion is to improve this error message and add some info about the particular instruction preventing the convertion from happening. I believe, something like the instruction name in the error message should be more helpfull, than the current general statement. Below is a code snippet (for a `qc` containing a measurement operation) which can be used to achieve the error mentioned above ``` from qiskit import QuantumCircuit from qiskit.converters import circuit_to_gate qc = QuantumCircuit(1, 1) qc.h(0) qc.measure(0, 0) gate = circuit_to_gate(qc) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add `ElectraForCausalLM` to enable constructing Electra-based `EncoderDecoderModel` # 🚀 Feature request Add `ElectraForCausalLM` model to enable constructing `EncoderDecoderModel` based on Electra. ## Motivation Currently, there are many encoder-only models, such as BERT or RoBERTA, which have already been supported for encoder-decoder settings. Even though Electra is pre-trained in a different fashion, I found out the fine-tuning an Electra2Electra model works as well. Also, there are publicly available checkpoints for a small configuration of the model and thus one can try to train a model which is an order of magnitude smaller than e.g. Bert2Bert or RoBERTa2RoBERTa. ## Your contribution I have already prepared an implementation for myself. If there's a desire to add this module I'll be happy to work on the PR. :] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: stdout/stderr should be flushed printing exception output...  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson claims Unknown compiler(s): ['c++', 'g++', 'clang++', 'pgc++', 'icpc'] This is kinda weird: I have a very small dummy meson.build which errors out with: > meson.build:7:0: ERROR: Unknown compiler(s): ['c++', 'g++', 'clang++', 'pgc++', 'icpc'] Whereas it's correct I don't have any of those compilers on my system, there is also no indication in my meson.build that this would be needed. The sample meson.build is: ``` project('sample', 'c', version: '1.0.0', meson_version: '>= 0.47', ) dep = dependency('doesnotexist', required: false) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: [notebook]user needs to press ctrl-c twice to stop notebook server should be put into terminal window See attached screenshot, \"Use Control-C to stop this server\" should be changed to \"Press Control-C twice to stop this server\". The document for this new feature was hidden in release notes of 3.0. It's not noticeable.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Firestore] Query.get returns incorrect type Query.get returns an Array of DocumentSnapshots, not a QuerySnapshot. QuerySnapshot are a requirement for Watch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: deprecate scalar conversions for rank>0 arrays Numpy allows for conversion of arrays into scalars if they are size-1, i.e., ```python float(numpy.array(1.0)) # 1.0 float(numpy.array([1.0])) # 1.0 float(numpy.array([[[[1.0]]]])) # 1.0 # TypeError: only size-1 arrays can be converted to Python scalars float(numpy.array([1.0, 1.0])) ``` I'm fine with rank-0 conversions, but I found that discrimination of conversion based on array size can easily lead to inconsistencies downstream. See, for example, https://github.com/sympy/sympy/issues/13924 where suddenly you have a different behavior of multiplication depending on the length of the input array. Moreover, this feature is actually redundant for rank>0 arrays since the value can simply be retrieved from the array via `x[0]`. When grepping for `\"converted to Python scalar\"` in the numpy sources, one finds that `numpy/lib/user_array.py` has ``` \"only rank-0 arrays can be converted to Python scalars.\" ``` which seems to be the more consistent solution. I would hence like to suggest to deprecate scalar conversion for rank>0 size-1 arrays. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: VQD `optimal_values` result field is incorrect VQD result object has these fields https://github.com/Qiskit/qiskit-terra/blob/c463b3c4741c7532494a583633d2798352fc828e/qiskit/algorithms/eigensolvers/vqd.py#L468-L470 the field `optimal_values` is incorrectly populated with points not values https://github.com/Qiskit/qiskit-terra/blob/c463b3c4741c7532494a583633d2798352fc828e/qiskit/algorithms/eigensolvers/vqd.py#L445-L451 This can be seen in [VQD tutorial](https://qiskit.org/documentation/tutorials/algorithms/04_vqd.html) where it says it will print 3 energy values, but instead it's 3 lists  See Qiskit/qiskit-tutorials#1471 which was to fix the deprecation and I had wondered why the change from using optimal_values as the output from what was checked in seemed fine. The above when its run from the latest VQD, as published out as html, is not though - so something changed since that was ran originally - hence this issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: alembic Logging ### Apache Airflow version 2.5.3 ### What happened When I call the airflow initdb function, it outputs these lines to the log INFO [alembic.runtime.migration] Context impl PostgresqlImpl. INFO [alembic.runtime.migration] Will assume transactional DDL. ### What you think should happen instead There should be a mechanism to disable these logs, or they should just be set to WARN by default ### How to reproduce Set up a new postgres connection and call: from airflow.utils.db import initdb initdb() ### Operating System MacOS ### Versions of Apache Airflow Providers _No response_ ### Deployment Virtualenv installation ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: plot_bloch_multivector should have most significant qubit on the left <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Since the standard ordering of qubits for a multiqubit state is most significant (left) to least significant (right), the multivector Bloch sphere output should respect the same order. For example, in the sample shown by the API documentation, qubit 1 should be on the left and qubit 0 on the right. https://qiskit.org/documentation/stubs/qiskit.visualization.plot_bloch_multivector.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: PRNG performance regression on XLA:GPU This is the public version of the internal bug b/140251596. We think the new way we lower `lax.while_loop` to the While HLO (where we generate a `Call` for convenience) caused a big performance regression for PRNGs on GPU. EDIT: it turns out that avoiding the `Call`s didn't help: it was a rolled vs unrolled loops thing, cf #1175. More commentary below and in #1269. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Consider allowing storage.bucket.Bucket.delete_key to silently fail if user requests it From TODO: ``` python # TODO: Should we accept a 'silent' param here to not raise an exception? ``` See [`storage.bucket.Bucket.delete_key`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/bucket.py#L158) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 158) # TODO: Should we accept a 'silent' param here to not raise an exception? ``` Consider allowing storage.bucket.Bucket.delete_key to silently fail if user requests it From TODO: ``` python # TODO: Should we accept a 'silent' param here to not raise an exception? ``` See [`storage.bucket.Bucket.delete_key`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/bucket.py#L158) for relevant code and #146 for some context. `git blame` output ``` b7f1b774 (JJ Geewax 2014-01-29 18:02:29 -0500 158) # TODO: Should we accept a 'silent' param here to not raise an exception? ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Proposal: Create new `ClientFailed` state This state will be a new `MetaState` which Tasks can enter into whenever `client.set_state` fails. This is designed specifically for the following situation: imagine a Flow with two tasks: Task A -> Task B. Task B has an `all_failed` trigger. Task A requests retries. Task A tries to run but an error is raised; Task A enters a Failed state first, but for _some reason_ Task A fails to set its state in Cloud. This produces an `ENDRUN` signal and Task A _ends in a `Failed` state_. Task B now sees this and runs successfully. I don't think this is intended behavior. If instead, a bad client call produced a `ClientFailed` meta state which: - is not considered finished - _wraps_ the previous state We could avoid the incorrect execution of Task B. **cc:** @jlowin Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: unique and NaN entries (Trac #1514) _Original ticket http://projects.scipy.org/numpy/ticket/1514 on 2010-06-18 by trac user rspringuel, assigned to unknown._ When unique operates on an array with multiple NaN entries its return includes a NaN for each entry that was NaN in the original array. Examples: a = random.randint(5,size=100).astype(float) > > > a[12] = nan #add a single nan entry > > > unique(a) > > > array([ 0., 1., 2., 3., 4., NaN]) > > > a[20] = nan #add a second > > > unique(a) > > > array([ 0., 1., 2., 3., 4., NaN, NaN]) > > > a[13] = nan > > > unique(a) #and a third > > > array([ 0., 1., 2., 3., 4., NaN, NaN, NaN]) This is probably due to the fact that x == y evaluates to False if both x and y are NaN. Unique needs to have \"or (isnan(x) and isnan(y))\" added to the conditional that checks for the presence of a value in the already identified values. I don't know were unique lives in numpy and couldn't find it when I went looking, so I can't make the change myself (or even be sure what the exact syntax of the conditional should be). Also, the following function can be used to patch over the behavior. def nanunique(x): a = numpy.unique(x) r = [] for i in a: if i in r or (numpy.isnan(i) and numpy.any(numpy.isnan(r))): continue else: r.append(i) return numpy.array(r) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: `sorted_return_tasks` should be implemented in `Flow.run` It's only for pretty printing and thus should be implemented in `Flow.run()`; having it implemented in `FlowRunner.run()` is causing weird bugs / requiring too much logic to be maintained Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Enable any ML experiment tracking framework People seem to have strong preferences for either using MLFlow, test-tube, polyaxon, etc... Let's just add generic support for whatever people want to use. I don't know if generic support is possible, but each can easily be supported individually. To make this work we'd need to: - change the logging to be non test-tube specific. Logging only happens in 2 places (train and validation completion). - Each call to log needs to be process-safe. Meaning when using distributed only rank=0 will log. - the experiment param in Trainer will need to be generalized (signature the same), to take any logger. I think that's all that's needed to add this support. Any suggestions and takers for working on this integration? @Borda @alok Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Extract 7z archives `conans.tools.unzip` supports `.zip` and `.tar.*`s as far as I can see. It would be nice if `.7z` would be supported also, as it usually compresses much better. Boost is 131 MB (`.zip`) vs 71 MB (`.7z`) for example (http://sourceforge.net/projects/boost/files/boost/1.60.0/). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Docker storage cannot locate Dockerfile with relative path on windows OS ## Description When calling `flow.register()` using a Docker storage configuration that uses a Dockerfile (and not a base Docker image) on windows OS, there is an APIError ``` Exception has occurred: APIError 500 Server Error: Internal Server Error (\"Cannot locate specified Dockerfile: .\\tmpp4mionwm\\Dockerfile\") File \"C:\\tmp\\prefect-bug\\demo.py\", line 24, in <module> flow.register() ``` After some digging, I observed that `prefect.environments.storage.docker._build_image()` creates a temporary directory that it uses for the Docker build context. However, Docker's `build()` function is unable to find this path. Pausing execution and updating the path to an absolute path resolves the issue.  ## Expected Behavior I expected the flow's storage to be built without error, and for the flow to be registered with the server. ## Reproduction ``` from prefect import task, Flow from prefect.environments.storage import Docker import prefect DOCKERFILE = \"\"\" FROM python:3.7 RUN echo \"hello\" \"\"\" with open('Dockerfile', 'w') as file: file.write(DOCKERFILE) @task def hello(): print('hello') with Flow('demo') as flow: task() flow.storage = Docker( dockerfile='Dockerfile' ) flow.register() ``` ## Environment Windows 10 operating system Prefect 10.1 { \"config_overrides\": { \"cloud\": { \"use_local_secrets\": true }, \"context\": { \"secrets\": false } }, \"env_vars\": [ \"PREFECT__CLOUD__USE_LOCAL_SECRETS\" ], \"system_information\": { \"platform\": \"Windows-10-10.0.17758-SP0\", \"prefect_version\": \"0.10.2\", \"python_version\": \"3.7.4\" } } Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Init signature gone for builtins #9335 seem to have broken some things in inspect, `Init signature` is sometime gone: ``` (rootenv)~/dev/ipython master$ ipython -c 'list?' Docstring: list() -> new empty list list(iterable) -> new list initialized from iterable's items Type: type (rootenv)~/dev/ipython master$ git checkout 4.2.0 ... (rootenv)~/dev/ipython (4.2.0)$ ipython -c 'list?' Init signature: list(self, /, *args, **kwargs) Docstring: list() -> new empty list list(iterable) -> new list initialized from iterable's items Type: type ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Auto suggestions cannot be completed when in the middle of multi-line input <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories. If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org. If you are unsure, it's ok to post here, though, there are few maintainer so you might not get a fast response. --> Completing an ipython 8 [autosuggestion](https://ipython.readthedocs.io/en/stable/whatsnew/version8.html#autosuggestions) by pressing `ctrl-f` or `ctrl-e` works perfectly for code on the final line of multi-line input (the following two screenshots show before and after pressing `ctrl-f` or `ctrl-e`): <img width=\"357\" alt=\"Screenshot 2023-03-12 at 14 09 48\" src=\"https://user-images.githubusercontent.com/19657652/224570634-fb856132-4b73-46b4-bdf0-576f9601633f.png\"> <img width=\"363\" alt=\"Screenshot 2023-03-12 at 14 10 00\" src=\"https://user-images.githubusercontent.com/19657652/224570647-40ccf5c1-00d6-4d5e-b965-691ca12ffe51.png\"> However pressing `ctrl-f` or `ctrl-e` fails when trying to complete the suggestion in the middle of multi-line input -- instead, the only thing that works is holding down right arrow until the suggestion is completed: <img width=\"361\" alt=\"Screenshot 2023-03-12 at 14 11 27\" src=\"https://user-images.githubusercontent.com/19657652/224570743-37756db5-989a-46d4-8447-bb23649d7309.png\"> Note this problem persists across different terminals (apple Terminal and iTerm2) and after disabling custom `bashrc` and `inputrc`. Is there any way suggestions can be completed with one keystroke in the middle of multi-line input? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Control wires are not correctly displayed @nkanazawa1989 noted: ### Summary - Bug fix for conditional gate when multiple classical registers are included. - Modify the appearance of classical-bit related gates to one in `latex_circuit_drawer`. ### Steps to reproduce The bug reported in Slack: e.g. ``` qreg = QuantumRegister(3, name='q') creg1 = ClassicalRegister(3, name='c1') creg2 = ClassicalRegister(2, name='c2') qc = QuantumCircuit(qreg, creg1, creg2) qc.measure(qreg, creg1) qc.x(qreg[0]).c_if(creg1, 3) ``` ### Expected behaviour The conditional only involves the classical register named `c1`. ### Current behaviour  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Incompatible Trainer.test() ## 🐛 Bug Trainer.test() stops on missing definitions of train & validation dataloaders methods. ### To Reproduce Steps to reproduce the behavior: - Define LightningModule without train & validation dataloaders - Train such model with data loaders provided to `Trainer.fit(...)` method - Load model from checkpoint and test it with `Trainer.test(...)` method test failes on : ~~~python 'No `train_dataloader()` method defined. Lightning `Trainer` expects as minimum a' pytorch_lightning.utilities.exceptions.MisconfigurationException: No `train_dataloader()` method defined. Lightning `Trainer` expects as minimum a `training_step()`, `training_dataloader()` and `configure_optimizers()` to be defined. ~~~ #### Code sample ~~~python test_data = data_loader(...) estimator = MyEstimator.load_from_checkpoint(checkpoint_path=CKPT_PATH) trainer = pl.Trainer(...) trainer.test(model=estimator, test_dataloaders=test_data) ~~~ ### Expected behaviour Run the test with provided test data loader, and do not stop on condition related to missing train & validation dataloaders which actually are not mandatory. ### Environment ~~~ * Packages: - numpy: 1.18.4 - pyTorch_debug: False - pyTorch_version: 1.5.0 - pytorch-lightning: 0.7.5 - tensorboard: 2.2.1 - tqdm: 4.46.0 * System: - OS: Linux - architecture: - 64bit - ELF - processor: - python: 3.8.2 - version: #1 SMP Wed, 29 Apr 2020 16:23:03 +0000 ~~~ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: UnicodeDecodeError when executing docker-compose up when running `docker-compose up` This error happens: ```Traceback (most recent call last): File \"bin/docker-compose\", line 6, in <module> File \"compose/cli/main.py\", line 68, in main File \"compose/cli/main.py\", line 121, in perform_command File \"contextlib.py\", line 35, in __exit__ File \"compose/cli/errors.py\", line 53, in handle_connection_errors File \"compose/cli/errors.py\", line 118, in get_conn_error_message File \"distutils/spawn.py\", line 220, in find_executable File \"posixpath.py\", line 73, in join UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 0: ordinal not in range(128) Failed to execute script docker-compose ``` Versions : `docker-compose version 1.17.1, build 6d101fb` `Docker version 17.09.0-ce, build afdb6d4` On `Ubuntu 16.04.3` locale ```LANG=en_US.UTF-8 LANGUAGE= LC_CTYPE=\"en_US.UTF-8\" LC_NUMERIC=en_US.UTF-8 LC_TIME=en_US.UTF-8 LC_COLLATE=\"en_US.UTF-8\" LC_MONETARY=en_US.UTF-8 LC_MESSAGES=\"en_US.UTF-8\" LC_PAPER=en_US.UTF-8 LC_NAME=en_US.UTF-8 LC_ADDRESS=en_US.UTF-8 LC_TELEPHONE=en_US.UTF-8 LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=en_US.UTF-8 LC_ALL= ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Long qubit name is not visible in latex drawer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.5 - **Operating system**: MacOS ### What is the current behavior? In a Jupyter notebook: ```python from qiskit import QuantumRegister, QuantumCircuit qr = QuantumRegister(4, 'looongname') circuit = QuantumCircuit(qr) circuit.h(qr) circuit.draw(output='latex') ``` <img width=\"537\" alt=\"Screen Shot 2019-07-12 at 3 13 11 PM\" src=\"https://user-images.githubusercontent.com/766693/61152884-95c1fe80-a4b7-11e9-8900-ab5307100741.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson does not report clang-tidy exit code if invoked \"manually (i.e. if run-clang-tidy(.py) is not in PATH) Meson does not report clang-tidy exit code if invoked \"manually (i.e. if run-clang-tidy(.py) is not in PATH). This is caused by ignoring the return value of `manual_clangformat()` in `clangformat()` within `mesonbuild/scripts/clangtidy.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `%save` magic does not work, just warns that `'' was not found in history` <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories. If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org. If you are unsure, it's ok to post here, though, there are few maintainer so you might not get a fast response. --> ```pycon In [1]: %save file.py '' was not found in history, as a file, url, nor in the user namespace. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Output of docker-compose stop looks kinda wierd I'm seeing this while doing stop. `michael@computer $ docker-compose stop` ``` Stopping my_foo_1... Stopping my_foo_1... done Stopping my_bar_1... Stopping my_nginx_1... Stopping my_bar_1... done Stopping my_bax_1... Stopping my_api_1... Stopping my_authserver_1... done Stopping my_content_1... Stopping my_nginx_1... done Stopping my_bax_1... done Stopping my_admin_1... Stopping my_mongo_1... Stopping my_search_1... Stopping my_cassandra_1... Stopping my_content_1... done Stopping my_postgres_1... Stopping my_qux_1... done Stopping my_dynamo_1... done Stopping my_search_1... done Stopping my_postgres_1... done Stopping my_cassandra_1... done Stopping my_mongo_1... done Stopping my_redisconsolidated_1... done michael@computer $ ``` Docker's output that displays while downloading an image in parallel is pretty awesome. Maybe we can do something like that? Best, Michael Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: JNI system dependency does not include FreeBSD **Describe the bug** When trying to use the JNI system dependency on FreeBSD, the following error appears: `Could not find a JDK platform include directory for your OS, please open an issue or provide a pull request.` This is related to the following list being limited to only Windows, Linux, Darwin and Solaris: https://github.com/mesonbuild/meson/blob/master/mesonbuild/dependencies/dev.py#L606-L622 **To Reproduce** As per code examination, merely trying to pull in the JNI system dependency should be a sufficient reproduction. **Expected behavior** Detecting the platform-dependent include directory on FreeBSD, whose name is `freebsd`. **system parameters** * FreeBSD 13.1 * Python 3.9.14 * Meson 0.62.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Docker Compose parses host paths for ENV substitution, but not container paths [This comment](https://github.com/docker/compose/issues/551#issuecomment-97411619) in #551 indicates that the following syntax should work for passing SSH_AUTH_SOCK into a container: ``` volumes: - $SSH_AUTH_SOCK:$SSH_AUTH_SOCK environment: - SSH_AUTH_SOCK ``` However, [resolve_host_path in config.py](https://github.com/docker/compose/blob/master/compose/config.py#L355) does exactly as it's named, it resolves the host path but not the container path. This means that the snippet pasted above results in a volume like this: `['/tmp/ssh-4NokVWqj63/agent.10499:$SSH_AUTH_SOCK']` Instead of resolve_host_paths/resolve_host_path, the functions should probably be resolve_path/resolve_paths and resolve both host and container paths. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.storage.bucket.Bucket.save_acl should clear existing ACL If an ACL is passed to 'save_acl', it should clear (or overwrite) any existing 'acl' attribute on the bucket, in addition to patching it server-side. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add fail message to dependency() to print if not found. If the dependency is not found I would like to print a message explaining where to obtain the library. something like: ``` zlib_dep = dependency('zlib', not_found_msg : '(http://www.gzip.org/zlib)') ``` Would output Dependency zlib found: NO (http://www.gzip.org/zlib) Also useful for libraries like freetype where the pkg-config version numbering is different to the release version. I would like to be able to print the release version required if the version check fails. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ?? is not coloring docstring anymore. Mike and I are on it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %%capture to grab rich display outputs we can currently grab standard out and standard error, but not the richer `display()` based things. This should be possible, and will make it possible to next magics like `%%capture %R` and grab the images generated by R Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: History navigation breaks in qtconsole I observe that, under some particular conditions, the behavior of the history navigation in the qtconsole breaks. Typically, if I type a letter, say 'a', and then press the up arrow key, IPython only shows the items in the history that start with that letter. However, under some conditions this behavior stop working. The phenomenon can be observed by typing the following in a qtconsole instance. (I am just showing what I type, not the IPython output): ``` a=1 'Enter' b=2 'Enter' b C-p C-a C-k a C-p ``` Here 'Enter' corresponds to pressing the enter key, and C-x corresponds to pressing Ctrl and the 'x' key. In this example, I expect that, after pressing C-p the last time, I should see 'a=1' in the prompt (that's what I see after doing this in a terminal IPython instance), however, I see 'b=2' in the prompt. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Problems with '%' in paths When using Jenkins with the github plugin branch names are automatically used to generate the workspace dir. If the branchname contains a slash, it is escaped by using '%2F'. This leads to problems when using conan inside this workspace dir: ```conan config set log.trace_file=\\\"/home_local/jenkins/workspace/3rdparty/yaml-cpp/recipe-release%2F0.6.1/conan_home/conan_log.log\\\"``` Error: File \"/opt/rmc-build-tools/any/conan/1.10.0/python/conans/client/command.py\", line 1428, in run method(args[0][1:]) File \"/opt/rmc-build-tools/any/conan/1.10.0/python/conans/client/command.py\", line 437, in config return self._conan.config_set(key, value) File \"/opt/rmc-build-tools/any/conan/1.10.0/python/conans/client/conan_api.py\", line 89, in wrapper return f(*args, **kwargs) File \"/opt/rmc-build-tools/any/conan/1.10.0/python/conans/client/conan_api.py\", line 554, in config_set config_parser.set_item(item, value) File \"/opt/rmc-build-tools/any/conan/1.10.0/python/conans/client/conf/__init__.py\", line 264, in set_item super(ConanClientConfigParser, self).set(section_name, key, value) File \"/opt/rmc-build-tools/osl42-x86_64/python3/default/lib/python3.6/configparser.py\", line 1193, in set super().set(section, option, value) File \"/opt/rmc-build-tools/osl42-x86_64/python3/default/lib/python3.6/configparser.py\", line 894, in set value) File \"/opt/rmc-build-tools/osl42-x86_64/python3/default/lib/python3.6/configparser.py\", line 402, in before_set \"position %d\" % (value, tmp_value.find('%'))) ValueError: invalid interpolation syntax in '\"/home_local/jenkins/workspace/3rdparty/yaml-cpp/recipe-release%2F0.6.1/conan_home/conan_log.log\"' at position 63 Conan version: 1.10.0 Jenkins version: 2.150.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Documentation mistake numpy.floor_divide The [floor_divide docs](https://docs.scipy.org/doc/numpy/reference/generated/numpy.floor_divide.html) claim that > Return the largest integer smaller or equal to the division of the inputs. It is equivalent to the Python // operator and pairs with the Python % (remainder), function so that b = a % b + b * (a // b) up to roundoff. However, the mathematical expression is equal to a, not equal to b. ### Reproducing code example: ``` a=9; b=2; a % b + b * (a // b) == a True ``` ### Numpy/Python version information: Numpy docs V1.16.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython profile locate should also work I know we have `ipython locate` and from it stems `ipython locate profile foo`, but this is awkward, because you get informed of the latter and want to use it when you look at `ipython profile --help` and it would make sense to have locating a profile work as a sub-command of profile. currently: `ipython locate profile foo` I want to: `ipython profile locate foo` , since we already have `ipython profile create` and `ipython profile list`. #1762 originally implemented `locate`, so pinging @minrk - like I always do :) Hi Min! :beers: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Image overflow in IPython Notebook 3 (beta) When my notebook converted from v3 to v4, running the code below, yielded the image below:   Additionally, the plot below, with dimensions (18,6) did not overflow in the previous version of the IPython Notebook:  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Tokenizer: UnboundLocalError with PaddingStrategy MAX_LENGTH ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 3.1.0 - Platform: macOS-10.15.7-x86_64-i386-64bit - Python version: 3.8.5 - PyTorch version (GPU?): 1.6.0 (False) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ### Who can help tokenizers: @mfuntowicz ## Information Model I am using: <transformers.tokenization_bert.BertTokenizer> The problem arises when using: * the official example scripts: using the `encode_plus` The tasks I am working on is: * Tokenizing ## To reproduce Steps to reproduce the behavior: 1. tokenizer = AutoTokenizer.from_pretrained(\"bert-base-cased\") 2. tokenizer.encode_plus(\"hello word\", max_length=128, padding=PaddingStrategy.MAX_LENGTH) <!-- If you have code snippets, error messages, stack traces please provide them here as well. Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.--> `UnboundLocalError: local variable 'padding_strategy' referenced before assignment` ## Expected behavior Return Tokenizer output Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Can we support the trace of ViT and Swin-Transformer based on torch.fx? # 🚀 Feature request Can we support the trace of ViT and Swin-Transformer based on torch.fx()? If not, what's the difficulty for that? ## Motivation ViT and Swin-Transformation is widely used in CV scenarios. Hope we could support the trace of torch.fx, so we can do the quantization based on the work. ## Your contribution I'm not sure right now. Currently I wanda whether we could support the ViT and Swin-Transformer. If not, the reason. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: env_file doesn't get extended https://github.com/vipconsult/dockerfiles docker-compose -f always-on-prod.yml --x-networking up -d this extends always-on.yml which on it side extends common.yml which has env_file: - env always-on-prod.yml defines its own env_file env_file: - env-prod the problem is that envs defined in the env-prod don't override the envs defined in common.yml I think this worked as expected before I upgraded from 1.5.0 Docker version 1.9.0, build 76d6bc9 docker-compose version: 1.6.0dev linux debian jessie Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Feature Request: generator.process() to allow 'extra_args' argument Hi Jussi, I have a generator for cuda's `nvcc` command and it's working OK. The issue is - sometimes an app needs to add custom args to `nvcc`. Would something like this be possible? ``` cuda_gen = generator(nvcc, output: '@BASENAME@.o', arguments: ['-c', '@INPUT@', '-o', '@OUTPUT@'], ) ``` ``` generated = cuda_gen.process('f1.cu', extra_args=['-Darg1', '-Darg2', '-foo-bar-arg3']) ``` Being about to pass extra args to the nvcc command would be ideal. The alternative is to create multiple generators.... not that huge of a deal, but breaks the DRY principle. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Modified during iteration in upgrade extension https://github.com/jupyterlab/jupyterlab/blob/0b46ba00f04f504d4e1da1399c9f97a46801518e/jupyterlab/upgrade_extension.py#L83-L86 We should take a copy of the items view to prevent this `for (key, value) in list(data[name].items())` Modified during iteration in upgrade extension https://github.com/jupyterlab/jupyterlab/blob/0b46ba00f04f504d4e1da1399c9f97a46801518e/jupyterlab/upgrade_extension.py#L83-L86 We should take a copy of the items view to prevent this `for (key, value) in list(data[name].items())` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: include generation in Blob repr. I added a comment here based on the `generation` addition to `storage` https://github.com/googleapis/google-cloud-python/pull/7444#issuecomment-485874643 I think it's worth adding an issue too - specifically because now `generation` defines a blob but isn't included in the repr. Meaning you can get confusing results like this: ```python blob <Blob: sixty-capital-temp, tests/test_357256/blob_645776> b2 = gcs.client(project).get_bucket(bucket).get_blob(blob.name) # recreate b2 <Blob: sixty-capital-temp, tests/test_357256/blob_645776> # same repr blob.exists() False b2.exists() True ``` ... but b2 & blob have the same repr! Prior to the latest release, both results would have been `True`. If generation were in the repr, this would be less confusing - e.g. I wouldn't have had to read the release notes to work out what was going on Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Automatically generated .gitignore / cvsignore / ? in the build directory As the build directory is a newly created directory, it could safely contain a `.gitignore` that ignores itself. I don't know how other vcs work, but meson may/should try to detect which vcs is used (by checking existence of .git ?) ``` # Meson generated .gitignore * ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Conditional Measurement is not conditional when exported to OpenQASM 3 ### Environment - **Qiskit Terra version**: main - **Python version**: 3.9 - **Operating system**: OSX ### What is happening? When exporting a circuit with a conditional measurement to OpenQASM 3 the measurement is not conditional. ### How can we reproduce the issue? ``` cr = ClassicalRegister(3) qr = QuantumRegister(3) qc = QuantumCircuit(qr, cr) # Prepare |011> qc.x(qr[:2]) # Measure \"001\" qc.measure(qr[0], cr[0]) # Conditionally measure \"011\", but the second bit is not reported # due to conditional measurement phase 1 limitations. The measurement # value is still available for runtime conditional executions. qc.measure(qr[1], cr[1]).c_if(cr[0], 1) # Conditionally prepare |111> based on the conditional measurement result qc.x(qr[2]).c_if(cr[1], 1) # Perform a final un-conditional measurement who's value will be determined # by the previous conditional measurement which is due to the usage of the gate # conditioned on the measurement result. qc.measure(qr[2], cr[2]) ``` Gives ``` OPENQASM 3; bit[3] c0; x $3; x $4; c0[0] = measure $3; c0[1] = measure $4; if (c0[1] == 1) { x $5; } c0[2] = measure $5; ``` ### What should happen? Should give ``` OPENQASM 3; bit[3] c0; x $3; x $4; c0[0] = measure $3; if (c0[1] == 1) { c0[1] = measure $4; } if (c0[1] == 1) { x $5; } c0[2] = measure $5; ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Building container fails after removing old image. I found this issue while working on a fix for issue #4337. By running the following sequence of commands on [this example repository](https://github.com/twelve17/dc-test): ``` git checkout tags/test2_run1 docker-compose build docker rmi --force dctest_service1 docker-compose build docker-compose up ``` Compose fails because the old image is never properly rebuilt from the old container: ``` WARNING: The Docker Engine you're using is running in swarm mode. Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node. To deploy your application across the swarm, use `docker stack deploy`. Recreating dctest_service1_1 ... error ERROR: for dctest_service1_1 no such image: sha256:bb41503c2e723478308998afc7df0886fac0811621b70d61b28ca36418a41bb7: No such image: sha256:bb41503c2e723478308998afc7df0886fac0811621b70d61b28ca36418a41bb7 ERROR: for service1 no such image: sha256:bb41503c2e723478308998afc7df0886fac0811621b70d61b28ca36418a41bb7: No such image: sha256:bb41503c2e723478308998afc7df0886fac0811621b70d61b28ca36418a41bb7 ERROR: Encountered errors while bringing up the project. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: text drawer should capitalize gate names The text drawer currently changes gate name capitalizations to capitalize the first letter. I think it should just rely on the gate name and not intervene. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow callables as optimizers in ``VQE`` ### What is the expected enhancement After #6382, allow callables with the same signature as `Optimizer.minimize` as `optimizer` in the VQE. This allows a much more flexible usage of the algorithm and get's rid of the overhead of implementing a new class each time users want to try their/other optimizers we don't yet have implemented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: add project parameter to `list_datasets`, `list_jobs` I think of a Client as corresponding to the \"billing project\" for BigQuery, but this should not restrict the client from listing datasets / jobs in other projects if its associated credentials have permissions to do so in those projects. https://github.com/ibis-project/ibis/pull/1428#discussion_r183066783 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub: publisher client's publish method does not expose retry settings https://github.com/googleapis/google-cloud-python/blob/a5af6acb85d8e1ed97e56ad7fc1cb0aefc524e61/pubsub/google/cloud/pubsub_v1/publisher/client.py#L166 Publish retry is supported in [Node.js](https://cloud.google.com/nodejs/docs/reference/pubsub/0.20.x/v1.PublisherClient#publish) and [Java](https://github.com/googleapis/google-cloud-java/blob/eb9fae59a236773a38c87dbce82206d4a267bf76/google-cloud-examples/src/main/java/com/google/cloud/examples/pubsub/snippets/PublisherSnippets.java#L107). It should be supported by Python too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Project inference is broken under Python 3.5.1 Project inference takes place in [_determine_default_project()](https://github.com/GoogleCloudPlatform/gcloud-python/blob/91be6938b26ba9198082f457ae37fba81b8f5ea0/gcloud/_helpers.py#L189), which hands off to [_compute_engine_id()](https://github.com/GoogleCloudPlatform/gcloud-python/blob/91be6938b26ba9198082f457ae37fba81b8f5ea0/gcloud/_helpers.py#L151). That returns the correct value -- but as `bytes`. The `Client` class checks if the project value is a `str` (using `six.string_types`) and raises an error because it is not (that code is [here](https://github.com/GoogleCloudPlatform/gcloud-python/blob/91be6938b26ba9198082f457ae37fba81b8f5ea0/gcloud/client.py#L144)). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pycodestyle update causing our lint to fail. From what I can tell, there are three new errors that pycodestyle is finding. E306: expected 1 blank line before a nested definition, found 0 ~E123: closing bracket does not match indentation of opening bracket's line~ ~E722: do not use bare except~ See: #2973 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Drawing a circuit with idle_wires=False causes the circuit to break in future draw/qpy events ### Environment - **Qiskit Terra version**: main - **Python version**: 3.9.1 - **Operating system**: OSX ### What is happening? When drawing a circuit with `circuit.draw(idle_wires=False)` the circuit is somehow mutated to fail on future drawing or qpy serialization events. ### How can we reproduce the issue? Using the circuit below. Message for QPY file. ```python from qiskit import qpy with open('test.qpy', 'wb') as fd: qpy.dump(transpiled_bit_code_circuit, fd) with open('test.qpy', 'rb') as fd: new_qc = qpy.load(fd)[0] new_qc.draw(idle_wires=False) new_qc.draw(idle_wires=False) ``` ### What should happen? Circuit should draw twice. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add support for batch requests in gcloud.storage Or wait for the new primitive client that simplifies this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: SynchronousExecutor for other dask schedulers For running many lightweight IO-bound tasks, I've been using a custom threaded executor I hacked together: ``` class ThreadedExecutor(SynchronousExecutor): \"\"\"Variant of built-in SynchronousExecutor that uses dask threaded scheduler.\"\"\" @contextmanager def start(self) -> Iterator: \"\"\" Context manager for initializing execution. Configures `dask` and yields the `dask.config` contextmanager. \"\"\" with dask.config.set(scheduler=\"threads\") as cfg: yield cfg def wait(self, futures: Any) -> Any: \"\"\" Resolves a `dask.delayed` object to its values. Blocks until the computation is complete. Args: - futures (Any): iterable of `dask.delayed` objects to compute Returns: - Any: an iterable of resolved futures \"\"\" with dask.config.set(scheduler=\"threads\"): return dask.compute(futures)[0] ``` I'm not sure this warrants its own executor in Prefect, but perhaps it could be a configurable parameter? Being able to easily swap out the sync/threaded/multiprocess/distributed schedulers is a huge plus of dask, and right now Prefect supports is capitalizing on some but not all of that flexibility. My own needs are already met by this little hack, just thought I'd contribute my $0.02. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Better vmap testing We should implement a test generator for checking batched primitives like the one we use for grad testing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: task.set_*stream should have more keyword arguments `Task.set_upstream` and `Task.set_downstream` were originally envisioned as methods for building up a Flow which does not pass data. `Task.set_dependencies` offers a richer API for specifying data passage between tasks. We should elevate all these methods to expose the full set of Prefect's features: - allow for the creation of keyed edges - allow for the creation of mapped edges We might need to think about whether `set_upstream` and `set_downstream` should have the same exact options - calls where the upstream task specifies a key on the downstream task like `t1.set_downstream(t2, key=\"y\")` feel unnatural. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan crash due to wrong function signature in migrations.py Installing Conan version 1.12.3 and running it (simply \"conan\" from the cmd line) results in crash. The error stems from wrong signature in function call in conans/client/migrations.py. On line 129, there is the following call `migrate_to_default_profile(conf_path, default_profile_path, output=self.out)` but the definition of `migrate_to_default_profile` on line 159 reads `def migrate_to_default_profile(conf_path, default_profile_path)` the call is incompatible with the signature. `output=self.out` should be removed since it is not used in `migrate_to_default_profile` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Stack trace when an override file is empty If I create an empty `docker-compose.override.yml` in a project, `docker-compose up` throws the following error: ``` Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"/compose/build/docker-compose/out00-PYZ.pyz/compose.cli.main\", line 53, in main File \"/compose/build/docker-compose/out00-PYZ.pyz/compose.cli.docopt_command\", line 23, in sys_dispatch File \"/compose/build/docker-compose/out00-PYZ.pyz/compose.cli.docopt_command\", line 26, in dispatch File \"/compose/build/docker-compose/out00-PYZ.pyz/compose.cli.main\", line 163, in perform_command File \"/compose/build/docker-compose/out00-PYZ.pyz/compose.cli.command\", line 54, in project_from_options File \"/compose/build/docker-compose/out00-PYZ.pyz/compose.cli.command\", line 90, in get_project File \"/compose/build/docker-compose/out00-PYZ.pyz/compose.config.config\", line 215, in load File \"/compose/build/docker-compose/out00-PYZ.pyz/compose.config.config\", line 205, in merge_services TypeError: 'NoneType' object is not iterable ``` We should instead show the same `Top level object needs to be a dictionary` error that you get if your `docker-compose.yml` file is empty. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [DO NOT MERGE] Language: pick up fixes to GAPIC generator. This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/cloud/language/artman_language_v1beta2.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:90f9d15e9bad675aeecd586725bce48f5667ffe7d5fc4d1e96d51ff34304815b Status: Image is up to date for googleapis/artman:latest synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/language-v1beta2. synthtool > Running generator for google/cloud/language/artman_language_v1.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:90f9d15e9bad675aeecd586725bce48f5667ffe7d5fc4d1e96d51ff34304815b Status: Image is up to date for googleapis/artman:latest synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/language-v1. synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: unparsable ninja.build generated from run_command with a multi-line string ```meson project('meson7' ,'c') run_target( 'update-rules', command : ['sh', '-c', ' python3 make-man-rules.py --meson']) ``` ``` ninja: error: build.ninja:64: expected '=', got lexing error python3$ make-man-rules.py$ --meson' ^ near here WARNING: Could not create compilation database. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: \"Unknown linker(s)\" failure because `ar --version` produces unexpected output Distro: OpenIndiana Hipster 2018.10 (powered by illumos) Compiler: gcc (OpenIndiana 6.4.0-OI-3) 6.4.0 Note that this is a Solaris fork. When running `meson` to configure the build it fails with this output: ``` meson.build:1:0: ERROR: Unknown linker(s): [['gcc-ar'], ['ar']] ``` The problem is that `ar --version` produces the following output which meson doesn't recognize: ``` ar: bad option: -- usage: ar -d[-SvV] archive file ... ar -m[-abiSvV] [posname] archive file ... ar -p[-vV][-sS] archive [file ...] ar -q[-cuvSV] [-abi] [posname] [file ...] ar -r[-cuvSV] [-abi] [posname] [file ...] ar -t[-vV][-sS] archive [file ...] ar -x[-vV][-sSCT] archive [file ...] ``` This diff fixes the problem: ``` diff --git a/mesonbuild/environment.py b/mesonbuild/environment.py index bf2cce93..da6bdb51 100644 --- a/mesonbuild/environment.py +++ b/mesonbuild/environment.py @@ -1217,6 +1217,8 @@ class Environment: return ArLinker(linker) if p.returncode == 1 and err.startswith('Usage'): # AIX return ArLinker(linker) + if p.returncode == 1 and err.startswith('ar: bad option: --'): # Solaris + return ArLinker(linker) self._handle_exceptions(popen_exceptions, linkers, 'linker') raise EnvironmentException('Unknown static linker \"%s\"' % ' '.join(linkers)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 consolidate metadata methods impl in storage.Key and storage.Bucket Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.50.0 regression: gnome test does not install gresource file As of 0.50.0, the `test cases/frameworks/7 gnome` project no longer installs the `simple-resources.gresource` file, causing the test to fail. Building the same project (from the 0.50.0 tarball) with meson 0.49.2 installs the file, as expected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qasm3 exporter wrong placement of `input` declaration ### Environment - **Qiskit Terra version**: 0.20.0 - **Python version**: 3.8.13 - **Operating system**: macOS Monterey 12.3.1 ### What is happening? When exporting parametrized `QuantumCircuit`s with custom gates to a QASM3 string, the exporter wrongly places the circuit's `input` declaration after the `gate` declarations, which is not according to the OpenQASM3.0 grammar - IO declarations should appear in the [header](https://github.com/Qiskit/openqasm/blob/c39eac9f5c87b80df9e8eaeced96cbf4b477e5d2/source/grammar/qasm3.g4#L12). ### How can we reproduce the issue? Run the following: ```python from qiskit import QuantumCircuit, qasm3 from qiskit.circuit import Parameter theta = Parameter(\"theta\") inner_qc = QuantumCircuit(1) inner_qc.rz(theta, 0) qc = QuantumCircuit(1) qc.append(inner_qc.to_gate(), range(1)) print(qasm3.dumps(qc)) ``` The resulting OpenQASM3.0 code is then: ```qasm OPENQASM 3; include \"stdgates.inc\"; gate circuit_21(theta) _gate_q_0 { rz(theta) _gate_q_0; } input float[64] theta; qubit[1] _all_qubits; let q = _all_qubits[0:0]; circuit_21(theta) q[0]; ``` ### What should happen? The expected output according to the grammar is: ```qasm OPENQASM 3; include \"stdgates.inc\"; input float[64] theta; gate circuit_21(theta) _gate_q_0 { rz(theta) _gate_q_0; } qubit[1] _all_qubits; let q = _all_qubits[0:0]; circuit_21(theta) q[0]; ``` ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Update to Language v1 ### What Update the hand-written code to Language v1, which was publicly announced yesterday (11/15). The new GAPIC code is in a [PR](https://github.com/googleapis/api-client-staging/pull/104), which will be published to PyPI as soon as its approved. ### Why Language v1beta1 has been replaced by v1 as of Tuesday 11/15. It has some additional features we want to support. This should be done soon, so that we can update the public documentation and samples to reference the `google-cloud-language` library. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Docs are unclear about behavior of `nonzero` on zero-dim arrays. <!-- Please describe the issue in detail here, and fill in the fields below --> From the docs, I would expect `nonzero` on a zero-dim array to return an empty tuple: > Returns a tuple of arrays, one for each dimension of a, containing the indices of the non-zero elements in that dimension. ### Reproducing code example: ```python >>> np.array(5).ndim 0 >>> len(np.array(5).nonzero()) 1 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Logging is not comprehensive with regard to %edit Python 3.4.3, Python 4.0.0. The IPython session copied to `ipython_session.py` in [this Gist](http://gist.github.com/horse-mans/b6691197932935b03fcf) produces the file `my_log.py`, also at that Gist. The first time `%edit` is run, the output line contains the complete contents of the file that was edited. If `%edit` is then called with a function argument, there is no output which contains the contents of the modifications. If a person in a session is constantly making changes/tweaking a function definition with the `%edit` command, even the most verbose logging session will never capture these modifications, making it difficult to retrace one's steps if they rely on session logs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: [AIRFLOW-726] Adding Vnomics to Airflow users Dear Airflow Maintainers, Please accept this PR that addresses the following issues: - https://issues.apache.org/jira/browse/AIRFLOW-726 Per Apache guidelines you need to create a [Jira issue](https://issues.apache.org/jira/browse/AIRFLOW/). Testing Done: - Unittests are required, if you do not include new unit tests please specify why you think this is not required. We like to improve our coverage so a non existing test is even a better reason to include one. Reminders for contributors (REQUIRED!): * Your PR's title must reference an issue on [Airflow's JIRA](https://issues.apache.org/jira/browse/AIRFLOW/). For example, a PR called \"[AIRFLOW-1] My Amazing PR\" would close JIRA issue #1. Please open a new issue if required! * For all PRs with UI changes, you must provide screenshots. If the UI changes are not obvious, either annotate the images or provide before/after screenshots. * Please squash your commits when possible and follow the [How to write a good git commit message](http://chris.beams.io/posts/git-commit/). Summarized as follows: 1. Separate subject from body with a blank line 2. Limit the subject line to 50 characters 3. Do not end the subject line with a period 4. Use the imperative mood in the subject line (add, not adding) 5. Wrap the body at 72 characters 6. Use the body to explain what and why vs. how Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Setting instruction duration in transpile seems to do nothing. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is the current behavior? ```python qc = QuantumCircuit(1) qc.x(0) qc.measure_all() trans_qc = transpile(qc, backend, instruction_durations=[('x', [0], 100000000000000)] ) ``` should take forever to run but it does not. ### Steps to reproduce the problem ### What is the expected behavior? I have not seen this feature before, but if it does what it says, https://qiskit.org/documentation/stubs/qiskit.compiler.transpile.html#qiskit-compiler-transpile I should be able to modify the duration of instructions. Perhaps this is for pulses only, and the documentation just does not spell this out? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: dependency() ignores required attribute when checked second or third time I believe this should fail at the meson configure stage: ``` foo_dep = dependency('foo-bar-xyz-12.3', required : false) bar_dep = dependency('foo-bar-xyz-12.3', required : true) ``` But it does not fail. Seems to re-use the previously-done dependency check and then ignore the required attribute. The real-world use case is more complicated of course, dependency is not required in one subproject but required in another. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow slicing of QuantumRegister and ClassicalRegister <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? It would be useful to be able to do the following: ```python q = QuantumRegister(5) circuit = QuantumCircuit(q) circuit.h(q[0]) # this is supported circuit.h(q) # this is supported circuit.h(q[1:3]) # this is not ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Compose build fails with \"Impossible to perform platform-targeted builds for API version < 1.35\" error ## Description of the issue docker-compose build fails with \"Impossible to perform platform-targeted builds for API version < 1.35\" error after updating to latest (edge) docker. ## Context information (for bug reports) ``` Output of \"docker-compose version\" ``` docker-compose version 1.21.0, build 5920eb08 docker-py version: 3.2.1 CPython version: 3.6.4 OpenSSL version: OpenSSL 1.0.2k 26 Jan 2017 ``` Output of \"docker version\" ``` Client: Version: 18.05.0-ce-rc1 API version: 1.37 Go version: go1.9.5 Git commit: 33f00ce Built: Thu Apr 26 00:57:53 2018 OS/Arch: windows/amd64 Experimental: false Orchestrator: swarm Server: Engine: Version: 18.05.0-ce-rc1 API version: 1.37 (minimum version 1.12) Go version: go1.10.1 Git commit: 33f00ce Built: Thu Apr 26 01:06:49 2018 OS/Arch: linux/amd64 Experimental: true ## Steps to reproduce the issue 1. Download latest docker edge for windows 2. Perform a simple docker-compose build 3. There is no step 3 ## Additional information Docker for windows. Started off on edge, switched to stable, error still present. Looks like it's related to this commit: https://github.com/docker/compose/commit/520f5d0fdece26862c622c33007775400a9b9000#diff-db70ffd20201b81c947f72fea35551d2. It thinks my version is < 1.35 but you can see above I'm on 1.37. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Scheduler adding unnecessary barriers ``` for i in range(2): circ.x([qr[i]]) circ.u1(np.pi, [qr[i]]) circ.x([qr[i]]) ``` if I do a code block like above it pushes the next qubit after the first when I schedule. For example <img width=\"744\" alt=\"image\" src=\"https://user-images.githubusercontent.com/32201347/68183260-dd3e3000-ff69-11e9-91b8-eb880c622a88.png\"> <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson crash: mesonbuild.mesonlib is not a package. The command ` meson configure . -Doptimization=0` crashes with a python stack trace: ``` Traceback (most recent call last): File \"/Users/john/.local/share/virtualenvs/etc-vauAPygS/lib/python3.10/site-packages/mesonbuild/mesonmain.py\", line 194, in run return options.run_func(options) File \"/Users/john/.local/share/virtualenvs/etc-vauAPygS/lib/python3.10/site-packages/mesonbuild/mconf.py\", line 300, in run c = Conf(builddir) File \"/Users/john/.local/share/virtualenvs/etc-vauAPygS/lib/python3.10/site-packages/mesonbuild/mconf.py\", line 72, in __init__ self.build = build.load(self.build_dir) File \"/Users/john/.local/share/virtualenvs/etc-vauAPygS/lib/python3.10/site-packages/mesonbuild/build.py\", line 2907, in load obj = pickle.load(f) ModuleNotFoundError: No module named 'mesonbuild.mesonlib.universal'; 'mesonbuild.mesonlib' is not a package ERROR: Unhandled python exception This is a Meson bug and should be reported! ``` Source is [cairo](https://gitlab.freedesktop.org/cairo/cairo/) at [commit 6dc5df6](https://gitlab.freedesktop.org/cairo/cairo/-/commit/c6dc5df61264be1bec2e622355b97c6c45d236fc). Native compilation on macOS 13.1beta with Xcode 14.1's toolchain. Python is a locally-compiled 3.10 in a pyenv-controlled virtenv, and meson-0.64.0 was just pulled from pypi with pip3. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Incompatible to import typing module with python prior to 3.5.2 For example `TYPE_CHECKING` is not provided in module `typing` for python version == 3.5.0 or 3.5.1. Suggest to use MYPY to resolve the issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: disabledExtensions are interpreted as strings and as regexes In https://github.com/jupyterlab/jupyterlab/blob/2bf9ba8a633117d68004e800a1e7b354860e1149/packages/coreutils/src/pageconfig.ts#L308-L310 and https://github.com/jupyterlab/jupyterlab/blob/2bf9ba8a633117d68004e800a1e7b354860e1149/packages/coreutils/src/pageconfig.ts#L317-L319, we see that a plugin is disabled (or deferred) if the string given in the corresponding config either matches exactly *or* is a regex that matches the plugin id. I think this is a mistake to conflate raw strings and strings that are meant to be interpreted as regexes. The simplicity we offer by treating the strings as raw strings that are compared exactly is illusionary since if that raw string contains a character special to regexes (like `.`), it would unintentionally match more. For example, if a package has two plugins `mypackage:my.plugin` and `mypackage:myAplugin`, you cannot disable `mypackage:my.plugin` as an exact string because it would also match `mypackage:myAplugin`. Also, if there is a plugin `mypackage:pluginA` and another extension `pluginA`, you cannot disable extension `pluginA` using an exact string without also disabling `mypackage:pluginA`. In general, I think the user should be explicit about which strings should be treated as raw strings that are matched exactly, and which strings should be treated as regexes. They do not have that capability in our current extension disable or defer configuration. (Caveat: I haven't tested these cases above yet - just reasoned through the logic in the code) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: implement iterating/collecting PauliSumOp coefficients <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> It would be useful to be able to iterate over, or return a list of coefficients in PauliSumOp. At present, one has to dig into the details to construct the coefficients for each term. In particular, it requires multiplying two numbers for each coeffcient. There are use cases, for instance when bounding the eigenvalues of the operators. For example, this gives a bound on the eigenvalues: ```python float(sum(abs(pauli_sum.primitive.coeffs)) * abs(pauli_sum.coeff)) ``` Abstracting access would be cleaner and resistant to implementation changes. Like this, if we want to return an numpy array ```python float(sum(abs(pauli_sum.coeffs))) ``` or this, if we return a list ```python sum(abs(c) for c in pauli_sum.coeffs) ``` This should be quite easy to implement. https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/opflow/primitive_ops/pauli_sum_op.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: repr change for arrays of size 1 even with np.set_printoptions(legacy=True) in numpy master In scikit-learn we have seen failures in doctests for a few days on our build using numpy-dev. This is one of them: ```py import numpy as np try: np.set_printoptions(legacy=True) except Exception: pass print(repr(np.array([0.]))) print(repr(np.array([[0.]]))) print(repr(np.array([1., 2., 3.]))) ``` With numpy master: ``` array([0.]) array([[0.]]) array([ 1., 2., 3.]) ``` With numpy 1.13 (note the space before the 0): ``` array([ 0.]) array([[ 0.]]) array([ 1., 2., 3.]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: storage: cannot set object properties Or at least I haven't figured out how. This is how the documentation suggests it may work. ``` Python >>> from gcloud import storage >>> bucket = storage.get_bucket('bucket', 'id') >>> key = storage.key.Key(bucket=bucket, name='dir/file.webp', ... properties={'contentType': 'image/webp'}) >>> key.upload_from_filename('dir/file.webp') ``` Success? ``` Python >>> key.properties['contentType'] 'image/webp' >>> key.content_type 'image/webp' ``` It's a lie unfortunately. (Also verified with `gsutil`). ``` Python >>> webp = bucket.get_key('dir/file.webp') >>> webp.properties['contentType'] u'application/unknown' >>> webp.content_type u'application/unknown' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: HTML lists seem to interfere with the QtConsole display Hi all, We are trying to use the awesome QtConsole with some custom HTML output of our objects. Some of these objects contains HTML lists. But when we display them the following happens.  Hopefully this is just an error in the way we are using the console, display objects, or HTML So we'd love to be corrected if that is the case. :) Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated Some of our tests print the numpy warning about using non-tuple sequence for indexing. For example, in tests/lax_numpy_indexing_test.py we use Ellipsis, None, slice, lists, all of which trigger this warning. Should we do something about this? Where in numpy this comes from: https://github.com/numpy/numpy/blob/3fcf144be4939a6a785dc80b75189c2e05d6bd22/numpy/core/src/multiarray/mapping.c#L313 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Differing ninja target behavior when accessing cmake subproject via sub_proj.target() method versus via __CMake_build dir **Describe the bug** I am importing a large cmake projectwith quite a few targets. If I attempt to use Meson to retrieve a cmake target from within the subproject and execute it, I get errors. If I use ninja directly on the __CMake_build dir I can run the same target with no issues. **To Reproduce** I've created a repo to showcase an example ESP/meson integrated project but at the moment it's serving as an example of the problem behavior: https://github.com/Michael-Densberger/meson_esp32 To produce the behavior I ran: `mkdir /opt/meson_esp32` `cd /opt/meson_esp32/` `git clone git@github.com:Michael-Densberger/meson_esp32.git .` `meson esp32/ build/ --cross-file=esp32/cross.txt` `ninja -C build/ flash_from_cmake_root` <- Works and flashes no problem. `ninja -C build/ flash` <- Build errors that vary. Note flash and flash_from_cmake_root are Meson `run_targets` that I defined in `meson.build` in the repo. **Expected behavior** The flash from the top level which is a `cmake.subproject` target would behave the same as the flash target in the lower level subproject `__CMake_build` folder. **system parameters** * Cross build. * Up-to-date Arch linux. * Python: 3.8.2 * Meson: 0.54.0 * Ninja: 1.10.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Test pass shouldn't require both test_step and test_end ## 🐛 Bug `trainer.test(...)` requires implementation of both `test_step` and `test_end`, but the warning says you only need to implement either or both. https://github.com/PyTorchLightning/pytorch-lightning/blob/56dddf970825b1ad2b598c9b9b23a8a77add8964/pytorch_lightning/trainer/evaluation_loop.py#L291 ### To Reproduce Run `.test()` on any `LightningModule` with only `test_step` or `test_end` implemented. #### Code sample ``` python import torch from torch.nn import functional as F from torch.utils.data import DataLoader from torchvision.datasets import MNIST import pytorch_lightning as pl class CoolSystem(pl.LightningModule): def __init__(self): super(CoolSystem, self).__init__() self.l1 = torch.nn.Linear(28 * 28, 10) def forward(self, x): return torch.relu(self.l1(x.view(x.size(0), -1))) def training_step(self, batch, batch_nb): x, y = batch y_hat = self.forward(x) loss = F.cross_entropy(y_hat, y) return {'loss': loss} def test_step(self, batch, batch_idx): x, y = batch y_hat = self.forward(x) return {'test_loss': F.cross_entropy(y_hat, y)} def configure_optimizers(self): return torch.optim.Adam(self.parameters(), lr=0.02) @pl.data_loader def train_dataloader(self): return DataLoader(MNIST('./', train=True, download=True), batch_size=32) @pl.data_loader def test_dataloader(self): return DataLoader(MNIST('./', train=False, download=True), batch_size=32) model = CoolSystem() trainer = pl.Trainer(max_epochs=2, val_percent_check=1) trainer.test(model) ``` ### Expected behaviour Test pass runs should run with either implemented or when at least `test_step` is. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Using 'type()' in qtconsole results in TypeError ipykernel-5.1.0 IPython-7.2.0 qtconsole-4.4.3 tornado-5.1.1 both Linux and Mac (Anaconda, version 2018.12, python 3.7) In qtconsole, trying to use 'type()' results in a TypeError. The error occurs immediately when entering 'type(', meaning as soon as I type the open-parenthesis character. Possibly some sort of completion error? Commenting out lines 863-868 of 'IPython/core/oinspect.py' removes the error. Traceback follows: ``` Traceback (most recent call last): File \"/Users/localuser/anaconda3/lib/python3.7/site-packages/ipykernel/kernelbase.py\", line 267, in dispatch_shell yield gen.maybe_future(handler(stream, idents, msg)) File \"/Users/localuser/anaconda3/lib/python3.7/site-packages/tornado/gen.py\", line 1133, in run value = future.result() File \"/Users/localuser/anaconda3/lib/python3.7/site-packages/tornado/gen.py\", line 326, in wrapper yielded = next(result) File \"/Users/localuser/anaconda3/lib/python3.7/site-packages/ipykernel/kernelbase.py\", line 593, in inspect_request content.get('detail_level', 0), File \"/Users/localuser/anaconda3/lib/python3.7/site-packages/ipykernel/ipkernel.py\", line 411, in do_inspect detail_level=detail_level File \"/Users/localuser/anaconda3/lib/python3.7/site-packages/IPython/core/interactiveshell.py\", line 1765, in object_inspect_mime detail_level=detail_level File \"/Users/localuser/anaconda3/lib/python3.7/site-packages/IPython/core/oinspect.py\", line 600, in _get_info info = self._info(obj, oname=oname, info=info, detail_level=detail_level) File \"/Users/localuser/anaconda3/lib/python3.7/site-packages/IPython/core/oinspect.py\", line 863, in _info names = [sub.__name__ for sub in obj.__subclasses__()] TypeError: descriptor '__subclasses__' of 'type' object needs an argument ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: database backend does not store children The [`Task`](https://github.com/celery/celery/blob/main/celery/backends/database/models.py#L20-L27) and [`TaskExtended`](https://github.com/celery/celery/blob/main/celery/backends/database/models.py#L57-L62) models for the `database` backend do not include `children`. This means that when using any `database` backend, [`AsyncResult.children`](https://github.com/celery/celery/blob/main/celery/result.py#L424) is always empty, even if a task does have children. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Incorrect tokenization of dash punctuation in Spanish In Spanish text, the conventions for using dashes and em-dashes as punctuation seems to be considerably different than in English. Spacy often does not tokenize the dash or em-dash as a separate token, instead keeping it attached to the closest word. For example, the Spanish sentence: —Yo me llamo... –murmuró el niño– Emilio Sánchez Pérez. English Translation: \"My name is...\", murmured the boy, \"Emilio Sanchez Perez.\" Here, the Spanish dash is used like a comma. The em-dash at the beginning of the sentence is used like a double quote. I believe that the fact that there is no space between the dash and word is throwing off the tokenizer. The Spanish sentence above is tokenized as: —Yo me llamo ... –murmuró el niño– Emilio Sánchez Pérez . I would expect the tokenization to be — Yo me llamo ... – murmuró el niño – Emilio Sánchez Pérez . ## Your Environment * **spaCy version:** 2.0.12 * **Platform:** Darwin-18.0.0-x86_64-i386-64bit * **Python version:** 3.7.0 * **Models:** de, es, en Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Expanding volumes source paths ## Description of the issue When volume defined with long syntax, its source paths which starts with `~` do not expand well as a paths started with `.` ## Context information (for bug reports) ``` docker-compose version 1.22.0, build f46880f ``` ``` version: \"3.4\" services: test: image: \"test:${DISTRO:-trusty}\" build: context: test/ args: { version: \"${DISTRO:-trusty}\" } volumes: - type: bind read_only: true source: ~/tmp/test1 target: /tmp/test1 - ~/tmp/test2:/tmp/test2:ro ``` ## Steps to reproduce the issue 1. Define volume with use of long syntax and set source started with `~` 2. `docker-compose up -d --force-recreate <service>` ### Observed result ``` Recreating test_test_1 ... error ERROR: for test_test_1 Cannot create container for service test: invalid mount config for type \"bind\": invalid mount path: '~/tmp/test1' mount path must be absolute ERROR: for test Cannot create container for service test: invalid mount config for type \"bind\": invalid mount path: '~/tmp/test1' mount path must be absolute ERROR: Encountered errors while bringing up the project. ``` ### Expected result ``` Recreating 48d9f6c670d9_test_test_1 ... done ``` ## Additional information `Ubuntu 18.04.1 LTS` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Bug concatenating large arrays on CPU On CPU, I get the following result when doing a concatenation of a large array with a smaller one ```python In [1]: import jax.numpy as np In [2]: a = np.concatenate((np.ones(1 << 32), np.array([2., 3., 4.]))) In [3]: a[-4:] Out[3]: DeviceArray([1., 1., 1., 1.], dtype=float32) ``` The result of the final line should be `[1., 2., 3., 4]`, not `[1., 1., 1., 1.]`. I've had a look at the implementation of jax.numpy.concatenate and it seems to delegate pretty directly to lax.concatenate, which is itself just a direct wrapper around the XLA op, so I wonder if this might be a bug in XLA. The result seems to be incorrect in the same way for other dtypes: ```python In [4]: a = np.concatenate((np.ones(1 << 32, 'float16'), np.array([2., 3., 4.], 'float16'))) In [5]: a[-4:] Out[5]: DeviceArray([1., 1., 1., 1.], dtype=float16) In [6]: a = np.concatenate((np.ones(1 << 32, 'uint16'), np.array([2., 3., 4.], 'uint16'))) In [7]: a[-4:] Out[7]: DeviceArray([1, 1, 1, 1], dtype=uint16) ``` I haven't had time to test whether this same issue exists on GPU or TPU. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Make context pickleable ## Current behavior In the following flow: ```python from prefect import context, Flow, task from prefect.engine.executors import DaskExecutor @task def extract(): \"\"\"Get a list of data\"\"\" return [1, 2, 3] @task def transform(data): \"\"\"Multiply the input by 10\"\"\" return [i * 10 for i in data] @task def load(data): \"\"\"Print the data to indicate it was received\"\"\" logger = context.get(\"logger\") logger.info(\"Here's your data: {}\".format(data)) with Flow(\"ETL\") as flow: e = extract() t = transform(e) l = load(t) executor = DaskExecutor(address=\"localhost:8786\" flow.run(executor=executor) ``` We will see the error `Unexpected error occured in FlowRunner: TypeError(\"can't pickle Context objects\")` because `context` is used as an attribute of `prefect`. This requires users to `import prefect` in their tasks in order to use context. ## Proposed behavior We could adjust the behavior so that context would be unpickled in the task and return `prefect.context` therefore avoiding this extra step of having to import prefect. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: new copyright header <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The following copyright needs to replace the old one in all the files: ```python # This code is part of Qiskit. # # (C) Copyright IBM 2017, XXXX. # # This code is licensed under the Apache License, Version 2.0. You may # obtain a copy of this license in the LICENSE.txt file in the root directory # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0. # # Any modifications or derivative works of this code must retain this # copyright notice, and modified files need to carry a notice indicating # that they have been altered from the originals. ``` where `XXXX` is the year of the file in question. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Minor typo in documentation for np.logical_and() <!-- Please describe the issue in detail here, and fill in the fields below --> The documentation for numpy.logical_and() has a minor typo. The 'return' field says > Boolean result of the logical OR operation applied to the elements of x1 and x2... Whereas it should say > Boolean result of the logical __AND__ operation applied to the elements of x1 and x2... (emphasis mine) ### Numpy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> [numpy v1.17 online documentation](https://docs.scipy.org/doc/numpy/reference/generated/numpy.logical_and.html) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Add a scaffold default config button For cases where you want to provide config in the launchpad, but you've provided all default values, in order to change config values away from the default, you have to manually type everything. Would be a lot more straightforward to just have a button that scaffolded defaults for you so that you could easily change the values you care about. This kind of works already if you use jobs, (we auto-fill default config for jobs) but only if you provide a top level config argument. From slack thread: https://dagster.slack.com/archives/C01U954MEER/p1674109975914069 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: load_table_from_dataframe should use a temporary file [load_table_from_dataframe](https://googleapis.github.io/google-cloud-python/latest/bigquery/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.load_table_from_dataframe) currently uses BytesIO when it serializes a pandas dataframe to parquet before uploading it via a load job. This is actually violating the contract for to_parquet, which requires a filepath. BytesIO happens to work when pyarrow is used but not with fastparquet. A more minor reason we may wish to serialize to disk is that dataframe can sometimes be quite large, so spilling to disk would be preferable to filling up memory. Note: the function should clean up after itself by removing the temp file after the load job completes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Can we have a project wide consensus on how to import the typing module? half of the code is structured like this: ```python import typing def foo(arg1: str, arg2: typing.List[str]) -> typing.Optional[str]: ... ``` The other half like this: ```python from typing import( this, that, some other things, and, more stuff, and even more stuff, ) def foo(art1: str, arg2: List[str]) -> Optional[str]: ... ``` Now, I *really* prefer the former. It avoids namspace pollution and minimizes git diffs because you don't have to worry about adding or removing things from the `from typing import(...)` lines. However, I'd really like to just have an agreement and convert all of the code to do the same thing so I can stop rebasing things and discover that a file has been changed from one form to the other in between. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan config install no longer works with 1.11.0 With conan v1.11.0: ``` conan config install http://rambo.local:8090/jenkins/job/microblink/job/conan-toolchains/job/master/lastSuccessfulBuild/artifact/android.zip Trying to download http://rambo.local:8090/jenkins/job/microblink/job/conan-toolchains/job/master/lastSuccessfulBuild/artifact/android.zip ERROR: Error downloading file http://rambo.local:8090/jenkins/job/microblink/job/conan-toolchains/job/master/lastSuccessfulBuild/artifact/android.zip: ''tuple' object has no attribute 'get'' ``` With conan v1.10.2 and earlier this works correctly. Our local CI server (that builds profile zips for company-wide use) is in local area network and does not use SSL (I guess #4158 could be related to breaking this behaviour). Are there any workarounds you could suggest? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Token substitution in YAML env file I have the following env file: ```yaml channels: - t/$ANACONDA_TOKEN/MYCHANNEL - conda-forge - anaconda dependencies: - python ==3.7.6 - myprivatepacakge ``` `ANACONDA_TOKEN` is correctly defined in my bash. But when I run the following, the token is not substituted: ```bash conda create -y -n test_env conda activate test_env conda env update -f test_env.yml ``` I got the following error: ```bash CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://conda.anaconda.org$anaconda_token/MYCHANNEL/linux-64/repodata.json> Elapsed: - ``` Note that if I substitute `$ANACONDA_TOKEN` by the real token, it works well. Is that a bug or just a not supported feature? Related PR: https://github.com/conda/conda/pull/7826 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: add_periodic_task function does not trigger the task ## Checklist * [x] I have included the output of ``celery -A proj report`` in the issue. (if you are not able to do this, then at least specify the Celery version affected). * [x] I have verified that the issue exists against the `master` branch of Celery. ## Steps to reproduce **tasks.py** ``` from celery import Celery celery = Celery('tasks', broker='pyamqp://guest@localhost//') @celery.task def add(x, y): return x + y @celery.on_after_configure.connect def add_periodic(): celery.add_periodic_task(10.0, add.s(2,3), name='add every 10') if __name__ == '__main__': add_periodic() ``` step 1: rabbitmq is up rabbitmq 1186 1 0 Nov12 ? 00:00:00 /bin/sh /usr/sbin/rabbitmq-server step2: execute tasks.py `python tasks.py ` step3: start beat worker `celery -A tasks -l info beat` celery beat v4.0.0 (latentcall) is starting. __ - ... __ - _ LocalTime -> 2016-11-12 17:37:58 Configuration -> . broker -> amqp://guest:**@localhost:5672// . loader -> celery.loaders.app.AppLoader . scheduler -> celery.beat.PersistentScheduler . db -> celerybeat-schedule . logfile -> [stderr]@%INFO . maxinterval -> 5.00 minutes (300s) [2016-11-12 17:37:58,912: INFO/MainProcess] beat: Starting... ## Expected behavior I expect the scheduler to trigger add() function every ten seconds. ## Actual behavior The add() function doesn't get triggered. I don't see any exception in the terminal. Do I miss anything? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: Query's cursor-related methods must not allow transforms Similar to #6699. The following conformance tests assert that `start_at`/`start_after`/`end_before`/`end_at` should raise an exception when passed one of `DELETE_FIELD`, `SERVER_TIMESTAMP`, `ArrayRemove`, or `ArrayUnion`: - `query-arrayremove-cursor.textproto` - `query-arrayunion-cursor.textproto` - `query-del-cursor.textproto` - `query-st-cursor.textproto` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: Avoid f-strings in `setup.py`? This is a very simple and small fix, but we should probably avoid Python version specific syntax in the main `setup.py` so that a nice the \"Python version >= 3.7 required.\" error message is given reliably. I may just do a fix, but if someone beats me to it, all the better :). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: activate symlink error when using source activate they get this symlink error > While trying to use the nfs installation with a user account that lacks the write permissions on the installation and the preconfigured environments, I'm getting an error: > > Cannot activate environment bash, not have write access to conda symlink > > Is this new, or I simply didn't notice the problem in the earlier versions? https://github.com/conda/conda/blob/4.1.x/conda/cli/activate.py#L158-L167 seems like its testing that it can create the symlink even if its already there, can anyone explain this functionality and why it would require permissions to write to the root environment? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Question: any chance to have a on_started handler in the Task class? It would be very handy to have an on_started call back in the Task class. In addition to after_return, on_failure, on_success and on_retry. Thoughts? Question: any chance to have a on_started handler in the Task class? It would be very handy to have an on_started call back in the Task class. In addition to after_return, on_failure, on_success and on_retry. Thoughts? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [skipped test] to fix https://github.com/huggingface/transformers/pull/12059 skipped failing: `tests/test_modeling_tapas.py::TapasUtilitiesTest::test_reduce_sum_vectorized` This issue is to track its resolution so that it won't be forgotten. @LysandreJik Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Remove Python2 **Is your feature request related to a problem? Please describe.** As January 1st approaches, support for \"Python 2\" gets to its end. By deprecating it we can free some machine/time on CI and maybe simplify our \"dependency matrix\" Note that this issue is not meant to be executed before the January 1st 2020. The early public issue is just to track it and talk/communicate about. **Describe the solution you'd like** - [ ] Remove py2 from the build matrix in Jenkins - [ ] Remove Python 2 from setup.py - [ ] Remove `six` from requirements.txt - [ ] Remove the announcement banner in README.md Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: PerceiverAudioPreprocessor: forward() missing 1 required positional argument: 'pos' The [`forward()` method implementation of `PerceiverAudioPreprocessor`](https://github.com/huggingface/transformers/blob/38cc35069c10d153e872162265288263bb7394b7/src/transformers/models/perceiver/modeling_perceiver.py#L3267) seems to be problematic because it has an extra required `pos` argument, whereas all other preprocessors do not (or it is optional). In fact, while it is passed to `_build_network_inputs()`, `pos` is not actually used in that method. Hence, I am not sure why it exists. Moreover, it breaks the default `PerceiverModel` operation, because that class assumes that there only one positional argument called `inputs` [when calling the preprocessor](https://github.com/huggingface/transformers/blob/38cc35069c10d153e872162265288263bb7394b7/src/transformers/models/perceiver/modeling_perceiver.py#L865). This seems to be a serious issue in my opinion because it crashes any instantiation of `PerceiverModel` with a `PerceiverAudioPreprocessor` as `input_preprocessor`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: warn_format_error no longer makes it clear that there was a problem formatting the output The recent changes to `warn_format_error` seem to have made it useless: one can no longer see the difference between a failed command and the failure to print the output. Currently, if formatting fails, `warn_format_error` shows the exception with traceback which looks indistinguishable to a normal traceback when a command failed. At the very least, the name `warn_format_error` no longer fits what it does. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cmake lexer/parser doesn't understand spaces I've been running into problems trying to build mesa on windows with llvm using the cmake finder for llvm. It turns out that having spaces in path names breaks the assumption of the cmake parser/lexer that spaces are always between the arguments of a function. Which isn't true because the replace tool doesn't add quotes around string values, so we'll need to try to figure that out ourselves. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: User_expression issues discoverd after question on list : in notebook, dooin this in js : ``` javascript IPython.notebook.kernel.execute('', {'execute_reply':function(data){console.log('data:',data)}}, {'user_expressions': {'foo':'a=1'} # interesting part }) ``` result in ``` ... foo: \"[ERROR] SyntaxError: invalid syntax (<string>, line 1)\" ... ``` in response. `1+1` does work, but more interesting things like `!ls`, `get_ipython().system(u'ls')` ... etc does not. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: More natural sorting of DAG runs in the grid view ### Apache Airflow version 2.3.2 ### What happened Dag with schedule to run once every hour. Dag was started manually at 12:44, lets call this run 1 At 13:00 the scheduled run started, lets call this run 2. It appears before run 1 in the grid view. See attached screenshot  ### What you think should happen instead Dags in grid view should appear in the order they are started. ### How to reproduce _No response_ ### Operating System Debian GNU/Linux 11 (bullseye) ### Versions of Apache Airflow Providers apache-airflow==2.3.2 apache-airflow-client==2.1.0 apache-airflow-providers-celery==3.0.0 apache-airflow-providers-cncf-kubernetes==4.0.2 apache-airflow-providers-docker==3.0.0 apache-airflow-providers-ftp==2.1.2 apache-airflow-providers-http==2.1.2 apache-airflow-providers-imap==2.2.3 apache-airflow-providers-postgres==5.0.0 apache-airflow-providers-sqlite==2.1.3 ### Deployment Other Docker-based deployment ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Settings friction review I've been experimenting with non-common settings for embedded devices and I've found a couple of issues: 1. We have to review why the CMake() build helper is raising in case it doesn't have compiler or architecture. It is very very uncomfortable to specify the settings and deleting them later for the package_id just to avoid the error. And it makes no sense. 2. If I install a `conanfile.txt` but without specifying `os` setting, it is crashing in the settings.py validate() method. Because somehow it has the os in the fields but not in the data. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `async with` doesn't allow newlines When writing a `with` statement, pressing enter goes onto a new line, rather than immediately running the code: ```py In [26]: with example: ...: do_1()[enter] ...: [<-pointer goes here] ``` However, when using `async with`, this does not apply to any lines except for the first after the colon: ```py In [26]: async with example: ...: do_1()[enter] [code is run] ``` (Tested in latest PyPI: `IPython.__version__ == \"7.23.1\"`) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Failed magic import appears not to throw error I'm trying to test that an ipython magic works inside of jupyter by doing this: `jupyter nbconvert --execute --to html tests/bigquery.ipynb`, where the `biquery.ipynb` notebook imports a magic called `%bigquery`. Currently, the `%bigquery` magic, which allows you to query Google's BigQuery service, is not importing due to a config problem. Unexpectedly, even though the output html says `ERROR:root:Line magic function %bigquery not found.`, the jupyter nbconvert command itself does not crash, even though it's supposed to if any exceptions arise. If it doesn't crash when it's supposed to, I can't reliably test whether the magic is in fact working. This appears to be the default ipython behavior. As @minrk put it in gitter: \"The error handling in magics is probably an IPython thing. For a long time, the only thing that mattered for IPython was what it looked like. But then Jupyter came around, and it now makes a difference whether an error was raised, or just 'reported' to output. This is the kind of thing that affects nbconvert's \"this failed\". But there are still a number of 'errors' that are caught and displayed as nicer errors than tracebacks, but now Jupyter frontends don't know that the cell failed.\" To reproduce the issue in ipython: ```python In [2]: import IPython In [3]: shell = IPython.core.interactiveshell.InteractiveShell.instance() In [4]: shell.run_cell('%bigquery') ERROR:root:Line magic function `%bigquery` not found. Out[4]: <ExecutionResult object at 7f27b7605e50, execution_count=None error_before_exec=None error_in_exec=None result=None> ``` Just wanted to flag this bug! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support for HTTP proxy configuration via config.json The docker CLI allows to configure proxy configuration via config.json in your .docker directory: https://github.com/docker/cli/pull/93 This proxy configuration is not used when running or building containers via docker-compose. This would have the advantage that you don't need to put any proxy related info in the docker-compose.yml. Then one could use the same docker-compose.yml for both environments (w/ and w/o proxies). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add quiet= and to_err= to job monitor to suppress or redirect status messages. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### Add quiet= and to_err= to job monitor to suppress or redirect status messages. If one captures output from a script, `qiskit.tools.monitor.job_monitor` (and its factor, `_text_checker`) spew extraneous info. Suppress with `quiet=True` or redirect to stderr with `to_err=True`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Sanitize env vars to remove secrets (e.g credentials for PROXY) For operations like `conda info -a` and error report uploads. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.dtype('d,L') -> NameError: name 'L' is not defined the title says it all. additional info: python: 2.7.9, numpy: 1.9.2, both from conda. other combinations not using 'L' seems to work fine. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add CCZ and CS gates to the circuit library and CNOTDihedral class ### What should we add? The `CCZ` gate is locally equivalent (up to 1-qubit gates) to the [CCXGate](https://qiskit.org/documentation/stubs/qiskit.circuit.library.CCXGate.html#qiskit.circuit.library.CCXGate) (Toffoli gate). The `CS` gate is locally equivalent (up to 1-qubit gates) to the [CSXGate](https://qiskit.org/documentation/stubs/qiskit.circuit.library.CSXGate.html#qiskit.circuit.library.CSXGate). First, it may be useful to add these two gates to the circuit library. Then, one can also add them to the [CNOTDihedral](https://qiskit.org/documentation/stubs/qiskit.quantum_info.CNOTDihedral.html#qiskit.quantum_info.CNOTDihedral) class, to obtain a better synthesis of CNOT-Dihedral circuits, using: https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/quantum_info/synthesis/cnotdihedral_decompose.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Misleading drawing format description in QuantumCircuit I find that the `matplotlib` in the possible output parameters for drawing a circuit is a bit misleading, see https://qiskit.org/documentation/stubs/qiskit.circuit.QuantumCircuit.draw.html. https://github.com/Qiskit/qiskit-terra/blob/56b0de6822dec3fe1d97c05f4a5ddf3c3f4d4174/qiskit/circuit/quantumcircuit.py#L1739 The actual argument for output is `mpl`. Following the docstring, a new user most likely will try `matplotlib` first. ### Suggestion Replace the line with ``` **mpl**: images with color rendered purely in Python using matplotlib. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: nbconvert: use r pygmentize backend when highlighting \"%%R\" cells It would be very nice to have R syntax highlighting on cells using the '%%R' magic when using nbconvert. Tested on: ``` json {'codename': 'An Afternoon Hack', 'commit_hash': '59d4731', 'commit_source': 'repository', 'default_encoding': 'UTF-8', 'ipython_path': '$HOME/ipython/IPython', 'ipython_version': '2.0.0-dev', 'os_name': 'posix', 'platform': 'Linux-3.9-0.bpo.1-amd64-x86_64-with-debian-7.1', 'sys_executable': '/usr/bin/python', 'sys_platform': 'linux2', 'sys_version': '2.7.3 (default, Jan 2 2013, 13:56:14) \\n[GCC 4.7.2]'} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: SpeechT5 cannot read numbers ### System Info transformers == 4.29.0 environment = Colab Python == 3.10.11 tensorflow == 2.12.0 torch == 2.0.1+cu118 torchaudio == 2.0.2+cu118 ### Who can help? @sanchit-gandhi ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction 1. Init a Transformer agent 2. Init a text which contains numbers. For example text = \"More than 10 people have been killed by Covid.\" 3. Call the agent for a text-to-speech (SpeechT5). For example, audio_translated = agent.run(\"Read out loud the text\", text=text) 4. Play the generated audio The audio blanks all the numbers/digits. I am suspecting SpeechT5 to behave wrongly as the code generated by the agent seems to be correct. Good luck :) ### Expected behavior The audio file should contain numbers/digits indicated in the text. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: IBMQjob Seed <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: master - **Python version**: 3.6.6 - **Operating system**: OSX ### What is the current behavior? [IBMQJob `_job_data` tries to directly access seed] (https://github.com/Qiskit/qiskit-terra/blob/37e4f3540e2fc1c9ab4b37c6cc5a449c82fb2391/qiskit/providers/ibmq/ibmqjob.py#L150). ### Steps to reproduce the problem ### What is the expected behaviour? It should not fail on pulse qobj's missing this seed. ### Suggested solutions `seed': old_qobj['circuits'][0]['config'].get('seed')` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Doc - expecting `push_to_hub` method for Tokenizers to be also in the Tokenizer class doc pages # 🚀 Doc request The gist is in the title. I was expecting the doc/docstring for the `push_to_hub` method for Tokenizers to be also in the Tokenizer class doc pages, e.g. on the main `Tokenizer` API landing page: https://huggingface.co/transformers/main_classes/tokenizer.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ImportError on Google Colab <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit version**: newest version - **Python version**: 3.7 - **Operating system**: - Platform: Google Colab ### What is the current behavior? After the update, the following pops up /usr/local/lib/python3.7/dist-packages/pennylane_qiskit/qiskit_device.py in <module>() 25 from qiskit import ClassicalRegister, QuantumCircuit, QuantumRegister 26 from qiskit import extensions as ex ---> 27 from qiskit.circuit.measure import measure 28 from qiskit.compiler import transpile 29 from qiskit.converters import circuit_to_dag, dag_to_circuit ImportError: cannot import name 'measure' from 'qiskit.circuit.measure' (/usr/local/lib/python3.7/dist-packages/qiskit/circuit/measure.py) The original code worked well before the update in 06/12/2021. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Diff::a_path is wrong for unicode characters The problem is slightly mentioned in #865. Let's consider the following example: ```shell git init foo cd ./foo echo a > a git add a git commit -a -m 'Add a' echo \"foo\" > špatně.txt git add špatně.txt git commit -a -m Add ``` ```python3 In [4]: Repo('.').commit().diff('HEAD~')[0].a_path Out[4]: '\"\\\\305\\\\241patn\\\\304\\\\233.txt\"' ``` Unless one uses `git config --global core.quotepath false`, the file name is quoted and I don't see a simple solution how to decode it to unicode? One can use `-z` option that can resolve the problem: ``` git diff HEAD~ --raw -z | cat :000000 100644 0000000 257cc56 Ašpatně.txt ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Docs no longer build <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? The index file in docs is pointing to `apidocs/terra` that does not exist, so the main docs do not get built. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `qiskit.test.decorators.enforce_subclasses_call` machinery is broken in 3.11.1 ### Environment - **Qiskit Terra version**: HEAD of main, currently `dd7f9390cf07` - **Python version**: 3.11.1 - **Operating system**: Both macOS and ubuntu, so far. ### What is happening? `import test.python` raises an error in 3.11.1, therefore tests do not run. @wshanks has indicated that it is working fine for him in 3.11.0 but not 3.11.1 (I don't have 3.11.0 installed). ``` Python 3.11.1 (v3.11.1:a7a450f84a, Dec 6 2022, 15:24:06) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin Type \"help\", \"copyright\", \"credits\" or \"license\" for more information. >>> import test.python Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/ihincks/ibm/qiskit-terra/test/__init__.py\", line 16, in <module> from qiskit.test.utils import generate_cases File \"/Users/ihincks/ibm/qiskit-terra/qiskit/test/__init__.py\", line 15, in <module> from .base import QiskitTestCase File \"/Users/ihincks/ibm/qiskit-terra/qiskit/test/base.py\", line 167, in <module> class QiskitTestCase(BaseQiskitTestCase): File \"/Users/ihincks/ibm/qiskit-terra/qiskit/utils/classtools.py\", line 117, in out retval = method(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^ TypeError: TestCase.__init_subclass__() missing 1 required positional argument: 'cls' ``` Or, see an example of this happening in CI: https://github.com/Qiskit/qiskit-experiments/actions/runs/3704009805/jobs/6281449337 ### How can we reproduce the issue? Run the tests or simply `import test.python` in Python 3.11.1. ### What should happen? This should not error. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Perform evaluation on HANS with Trainer (like GLUE example) Current [HANS](https://github.com/huggingface/transformers/tree/master/examples/adversarial) evaluation implementation is carried out in the old way. It'd be good to do it in the same manner as other examples are implemented now with the Trainer class. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Custom web socket host/port The issue is that the IPython notebook uses a fixed host name for web socket connections. This is fine in most cases, but some (PaaS) environments support web sockets only on specific ports. OpenShift, for example, [supports web sockets](https://www.openshift.com/blogs/paas-websockets) only on ports 8000 and 8443. I can't run the IPython server on that port because I'm running other web apps that also use web socket connections. It seems that in previous versions, the IPython notebook had an option `c.NotebookApp.websocket_host` that allowed users to override the web socket host url. This option would satisfy my needs, but appears to have been dropped in the current version (2.x). Was this a conscious decision? If not, can we bring back this option? I was able to solve this issue by modifying this [line](https://github.com/ipython/ipython/blob/2.x/IPython/html/static/services/kernels/js/kernel.js#L128) from ``` this.ws_host = location.protocol.replace('http', 'ws') + \"//\" + location.host; ``` to ``` this.ws_host = location.protocol.replace('http', 'ws') + \"//\" + location.host + \":8000\"; ``` This solution works well. I have nginx reverse proxy connections to /ipython/ to the ipython server backend running on an arbitrary port. Because I've manually added port `8000` to the `ws_host`, the web sockets function correctly on OpenShift. But it would nice to specify the port and host as a configuration parameter. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Trying to cancel a job just after initialization raises ### Steps to reproduce the problem 1. Create an `IBMQJob` by running a `qobj` in a backend. 2. Immediately after, call the `cancel()` method of the `IBMQJob` instance. ### What is the expected behaviour? Not throwing or, at least, not raising a gave exception but prevent the cancellation. ### What is the current behaviour? The method `cancel()` raises. ### Suggested solutions Detect if the job is still initializing and reject the cancellation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Console bug adds an extra quote on macOS Monterey <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories. If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org. If you are unsure, it's ok to post here, though, there are few maintainer so you might not get a fast response. --> I'm experiencing what seems to be a bug which adds an additional single quote. Here's what happens when I only write `x['odor']`, it becomes `x['odor']'`: [![console][1]][1] At first I thought I'm making a mistake but when it repeated multiple times in the same minute, by looking further I noticed an extra `'` being added. I don't know why this is happening besides, I want to change the default quote view from double to single quotes which for some reason changed in the following versions: * macOS Monterey `12.2.1` * ipython `8.0.1` installed using brew. [1]: https://i.stack.imgur.com/7rUlx.gif Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Simplify logic to resolve tasks stuck in queued despite stalled_task_timeout closes: #28120 closes: #21225 closes: #28943 Tasks occasionally get stuck in queued and aren't resolved by `stalled_task_timeout` (#28120). This PR moves the logic for handling stalled tasks to the scheduler and simplifies the logic by marking any task that has been queued for more than `scheduler.task_queued_timeout` as failed, allowing it to be retried if the task has available retries. This doesn't require an additional scheduler nor allow for the possibility of tasks to get stuck in an infinite loop of scheduled -> queued -> scheduled ... -> queued as exists in #28943. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Docs: Clarify stride for upcoming token classification pipeline I just tried out the upcoming `stride` option for token classification pipelines (#21771, very useful!) without being familiar with the non-standard use of `stride` in the underlying tokenizer settings. I think it would be helpful to also explain in the pipelines API documentation that the `stride` parameter sets the overlap and not the stride. I thought it was the stride and spent a while trying to figure out why the performance was so abysmal. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Jedi: Protect against crash on property access Jedi Completions object can raise on attribute access (eg `completion.type`). Completer.py ~ line 1520 should protect arount that: ``` for jm in jedi_matches: delta = len(jm.name_with_symbols) - len(jm.complete) try: yield Completion(start=offset - delta, end=offset, text=jm.name_with_symbols, type=jm.type, _origin='jedi') except Exception: print('crash with jm:',jm) ```` Reproducible with ``` ## foo.py def foo():pass ``` ``` In[1]: from foo import foo In[2] foo.__co<tab> ``` Log an error when debug is on would be a plus. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Prevent overriding dependency versions My situation is the following: - `PROJECT/0.2.0` -> `B/0.1.0`, `C/0.1.0`, `D/0.1.0` - `B/0.1.0` -> `D/0.1.0` - `C/0.1.0` -> `D/0.1.0` Until then, everything's fine. Now there's a new version of B that leads to the following: - `PROJECT/0.3.0` -> `B/0.2.0`, `C/0.1.0`, `D/0.1.0` - `B/0.2.0` -> `D/0.2.0` - `C/0.1.0` -> `D/0.1.0` I am defining `full_version_mode()` everywhere. If PROJECT did not depend on D, Conan would fail saying that the dependencies are incompatible. But if D happens to be a dependency of the project too, then it will override any dependencies' usage of D to its version. Is there a way to prevent this from happening and have it fail if there are any 2 versions of the same library that are different/incompatible? If I do not set `build=missing` it's ok for me because it will basically not find the `package_id` for the library with the overridden dependency. But I'd rather have it fail at the dependency graph analysis and re-enable the `build=missing` option. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [ ] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Unify codemirror highlight mode Assigning to myself, Need to unify the name of the variable that represent the default highlight mode for each cell type and mode the auto highlight methods as high as possible. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: [ENH] reverse order of operations when loading OpenQASM <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? When applying an operation to a quantum register in OpenQASM code, the operations get loaded in an order where the last qubit is first. It would be nice to have this reversed. Currently: ```python qasm = \"\"\"OPENQASM 2.0; include \"qelib1.inc\"; qreg q[3]; h q;\"\"\" from qiskit import QuantumCircuit circuit = QuantumCircuit.from_qasm_str(qasm) print(circuit.qasm()) ``` Yields H on q[2] first, then q[1], then q[0] ``` OPENQASM 2.0; include \"qelib1.inc\"; qreg q[3]; h q[2]; h q[1]; h q[0]; ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Graph View shows other relations than in DAG **Apache Airflow version**: master **Kubernetes version (if you are using kubernetes)** (use `kubectl version`): **Environment**: breeze **What happened**: This DAG ```python from airflow import models from airflow.operators.dummy_operator import DummyOperator from airflow.utils.dates import days_ago with models.DAG(\"test\", start_date=days_ago(1), schedule_interval=None,) as dag: t1 = DummyOperator(task_id=\"t1\") t2 = DummyOperator(task_id=\"t2\") t1 >> t2 ``` is rendering like that: <img width=\"1374\" alt=\"Screenshot 2020-08-27 at 19 59 41\" src=\"https://user-images.githubusercontent.com/9528307/91478403-11d7fb00-e8a0-11ea-91d0-d7d578bcb5a2.png\"> **What you expected to happen**: I expect to see same relations as defined in DAG file **How to reproduce it**: Render the example DAG from above. **Anything else we need to know**: I'm surprised by this bug 👀 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: can't require a function named `f` It took me a while to figure this one out: ``` python def f(x): return(x) @require(f): def g(y): return f(y) ``` gives: ``` --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-86-98a37b0c736a> in <module>() ----> 1 @require(f) 2 def g(y): 3 return f(y) 4 /usr/local/lib/python2.7/dist-packages/IPython/parallel/controller/dependency.pyc in require(*objects, **mapping) 133 for name, obj in mapping.items(): 134 mapping[name] = can(obj) --> 135 return depend(_require, *names, **mapping) 136 137 class Dependency(set): TypeError: __init__() got multiple values for keyword argument 'f' ``` I believe the cause is the use of `f` as a name in the constructor [here](https://github.com/ipython/ipython/blob/1934e25cb2fbaace740d97bc33ab45f01d1be962/IPython/parallel/controller/dependency.py#L43-L49). This seems like a bit of an arbitrary restriction; it may not be possible to get around having to forbid the use of _some_ function name, but at least we could maybe use something less likely to collide with users' things (`_f` maybe?). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Throw warning for changing val_loss Add warning to user that when changing val_loss to another keyword it will break checkpointing, early stopping, and other features relying on it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: AIP-56 - Create auth manager interface Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Applying labels to task groups shows a cycle in the graph view for the dag ### Apache Airflow version 2.2.2 ### Operating System Docker (debian:buster) ### Versions of Apache Airflow Providers N/A ### Deployment Astronomer ### Deployment details run airflow with this dag ```python3 with DAG( dag_id=\"label_bug_without_chain\" ) as dag: with TaskGroup(group_id=\"group1\") as taskgroup1: t1 = DummyOperator(task_id=\"dummy1\") t2 = DummyOperator(task_id=\"dummy2\") t3 = DummyOperator(task_id=\"dummy3\") t4 = DummyOperator(task_id=\"dummy4\") chain([Label(\"branch three\")], taskgroup1, t4,) ``` ### What happened expanded task views look like they have cycles <img width=\"896\" alt=\"Screen Shot 2021-11-22 at 2 33 49 PM\" src=\"https://user-images.githubusercontent.com/17841735/143083099-d250fd7e-963f-4b34-b544-405b51ee2859.png\"> ### What you expected to happen The task group shouldn't display as if it has loops in it. ### How to reproduce View the dag shown in the deployment details. ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Tracing a function that indexes into Numpy array gives a poor error message The following code fails on the last line ``` f = lambda i: jnp.zeros((3, 3))[i, :] g = lambda i: np.zeros((3, 3))[i, :] a = np.array([1, 2]) f(a) # Okay jax.jit(f)(a) # Okay g(a) # Okay jax.jit(g)(a) # Fail ``` with the standard error message ``` Tracer can't be used with raw numpy functions. You might have import numpy as np instead of import jax.numpy as np ``` The cause of the error is attempting to trace the `__getitem__` method of a raw numpy tensor. Normally \"Tracer can't be used ...\" errors are easy to spot because the offending call starts with `np.`, but this error is a bit more subtle and takes more time to track down. Also, binary operations that mix numpy and JAX arrays work fine, so it this is an exceptional case. Is there any way to improve this error message / detect this case? At the extreme end, could jax do without implementing the `__array__` method for implicit conversions (and replace with an explicit conversion method), to reduce the mental overhead associated with these conversions? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add forward and backward options to finite difference gradient ### What should we add? Currently, `FiniteDiffEstimatorGradient` and `FiniteDiffSamplerGradient` support only a central difference. A forward difference or backward difference require less circuit than the central difference, so they are faster. Also, there are cases that forward difference or backward difference can work better than central difference. https://en.wikipedia.org/wiki/Finite_difference Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: GPL question To help us debug your issue please explain: - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. I'm looking to recommend use of Conan in a large organization, and I'm doing due diligence on licensing Some concern has been raised over the way pylint is used. Could a version be cut which doesn't import pylint directly (i.e. invokes it out of process), or which doesn't depend on pylint at all? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support cpp_std=c++2a and cpp_std=gnu++2a The latest versions of both clang and gcc support these flags. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: In datastore.connection.Connection.save_entity, determine how to delete properties From TODO: ``` python # TODO: Is this the right method name? # TODO: How do you delete properties? Set them to None? ``` See [`datastore.connection.Connection.save_entity`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/connection.py#L321) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 321) # TODO: Is this the right method name? dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 322) # TODO: How do you delete properties? Set them to None? ``` In datastore.connection.Connection.save_entity, determine how to delete properties From TODO: ``` python # TODO: Is this the right method name? # TODO: How do you delete properties? Set them to None? ``` See [`datastore.connection.Connection.save_entity`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/datastore/connection.py#L321) for relevant code and #146 for some context. `git blame` output ``` dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 321) # TODO: Is this the right method name? dec0e7c6 (JJ Geewax 2014-01-28 15:15:40 -0500 322) # TODO: How do you delete properties? Set them to None? ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: source activate without arguments breaks source activate/deactivate commands Running `source activate` without any further arguments on Linux with the latest release makes it so that further activate/deactivate commands do not work. For example: ``` ihenriksen@ubuntu:~$ source activate prepending /home/ihenriksen/miniconda2/envs/bin to PATH ihenriksen@ubuntu:~$ source activate py27 bash: activate: No such file or directory ihenriksen@ubuntu:~$ source deactivate bash: deactivate: No such file or directory ihenriksen@ubuntu:~$ ``` This isn't at all a blocking issue for me, but it seems like something worth revisiting when we can. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: add visualization of open controlled gates [latex drawer] @ewinston says in https://github.com/Qiskit/qiskit-terra/issues/3864: > In PR #3739, open controlled gates were implemented. With that PR a new keyword argument was added to specify the control state, > > `XGate().control(3, ctrl_state=6)` > > This creates a 4 qubit gate where the first three qubits are controls and the fourth qubit is the target where the x-gate may be applied. A `ctrl_state` may alternatively be expressed as an integer string, > > `XGate().control(3, ctrl_state='110')` > > where it is more apparent which qubits are open and closed. In this case when q[0] is open and q[1] and q[2] are closed the x-gate will be applied to q[4]. As a reference https://github.com/Qiskit/qiskit-terra/pull/3867 implements open controlled gates for the text visualizer like this: ```python qr = QuantumRegister(4, 'q') circuit = QuantumCircuit(qr) circuit.append(U2Gate(pi, -5 * pi / 8).control(3, ctrl_state='100'), [qr[0], qr[3], qr[2], qr[1]]) circuit.draw('text') ``` ``` q_0: |0>────────o──────── ┌───────┴───────┐ q_1: |0>┤ U2(pi,-5pi/8) ├ └───────┬───────┘ q_2: |0>────────■──────── │ q_3: |0>────────o──────── ``` The current output for `circuit.draw('latex')` is: 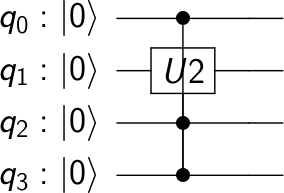 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Readlinelike display of options crashes ipython terminal. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Fix secret location with absolute paths With the following service: ``` db: container_name: db image: mysql:8.0 secrets: - source: mysql_init_sql target: /docker-entrypoint-initdb.d/init.sql ``` I would expect to find the `mysql_init_sql` secret as a file in `/docker-entrypoint-initdb.d/init.sql`. In the latest version of docker-compose this does not happen due to a bug and the secret is mounted incorrectly under `/run/secrets/docker-entrypoint-initdb.d/init.sql`. With this pull request the secrets are placed in the correct folder if the user specifies an absolute path in the `target` field Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Ninja include prefix wrong with italian version of Msvc 2015 Meson looks for the prefix to match the /showincludes directive for ninja using two colon ('Note: including file: d:\\MyDir\\include\\stdio.h') but the italian version of the visual studio compiler puts only one and writes 'Nota: file incluso d:\\MyDir\\include\\stdio.h' so meson matches the second colon after the drive, using as a prefix 'Nota: file incluso d:' (or similar, depends form where you installed things). The net result is that the include dependecies are not working correctly but only for a a limited number of file. For the italian part the fix is trivial, in ninjabackend.c, in detect_vs_dep_prefix(...): ```python if line.endswith('stdio.h'): # Match for italian version, with only one ':' if line.startswith('Nota: file incluso'): matchstr = 'Nota: file incluso' else: matchstr = ':'.join(line.split(':')[0:2]) + ':' with open(tempfilename, 'a') as binfile: ``` but maybe other languages have the same problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Please enable vmap(scan()) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ICL detection is too trivial It seems the presence of the string \"icl\" anywhere in the compiler name is enough to qualify as the ICL compiler. Consequently using a compiler named e.g. \"arm-particle-linux-gnueabi-gcc\" is not possible. ``` meson.build:21:0: ERROR: Unknown compiler(s): [['arm-particle-linux-gnueabi-gcc', '-mthumb', '-mfpu=neon-vfpv4', '-mfloat-abi=hard', '-mcpu=cortex-a7', '-fstack-protector-strong', '-D_FORTIFY_SOURCE=2', '-Wformat', '-Wformat-security', '-Werror=format-security', '--sysroot=/home/christian/embedded/yocto/raspi/build/tmp/work/cortexa7t2hf-neon-vfpv4-particle-linux-gnueabi/libdrm/2.4.99-r0/recipe-sysroot']] ``` A compiler named e.g. \"arm-partile-linux-gnueabi-gcc\" works as expected. Meson version: 0.51.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: Fix to ma.core for issue #15077 to correctly set min and max values for all float/complex dtypes Finding the max of a masked array with float16 or complex dtype returned inf due to the min and max values for these dtypes not being defined. These values are now set to +/- inf, the same as for float32, float64 and float128 dtypes. Fixes #15077 <!-- Please be sure you are following the instructions in the dev guidelines http://www.numpy.org/devdocs/dev/development_workflow.html --> <!-- We'd appreciate it if your commit message is properly formatted http://www.numpy.org/devdocs/dev/development_workflow.html#writing-the-commit-message --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: AWS Lambda Tasks We should include some tasks for interacting / invoking AWS Lambda functions inside our `src/prefect/tasks/aws/` submodule. We should probably include a few tasks: - [ ] Create a Lambda function - [ ] Invoke a Lambda function - [ ] List all Lambda functions? - [ ] Delete a Lambda function If there's an ability to return the value from an invoked lambda function, that could be useful in the \"invoke\" task (maybe as a toggle-able option). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Volume normalization in IPython.display.Audio should be optional I am manipulating audio using numpy with IPython Notebook and want to use IPython.display.Audio for listening to the numpy arrays. Unfortunately, auto-normalization tampers with the results. Example: ``` # Generate a sound import IPython import numpy as np framerate = 44100 t = np.linspace(0,5,framerate*5) tone = np.sin(2*np.pi*220*t) antitone = np.sin(2*np.pi*220*t + np.pi) IPython.display.Audio(tone+antitone, rate=framerate) ``` Adding a sin wav to itself shifted by 180 deg should give total silence. Instead, auto-normalization amplifies the floating point errors. The problem is in the IPython.lib.display.Audio _make_wav method, which always normalizes the numpy array(see 'scaled' variable). I think that we should have a normalize keyword argument, so that Audio can be used for audio analysis. Something like: ``` Audio(tone+antitone, rate=framerate, normalize=False) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make qiskit compatible with marshmallow >= 3 ### What is the expected enhancement? The qiskit package should work with `marshmallow` >= 0.3. Currently it only works with `marshmallow` < 0.3, which generates problems with other packages requiring a recent version of `marshmallow`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Google cloud storage needs requests >= 2.18.0 but the setup.py only requires >= 2.4.0 According to the requests [changelog](http://docs.python-requests.org/en/latest/community/updates/) the Response class was turned into a context manager only in version 2.18.0. However in google/resumable_media/requests/download.py line 62 (inside _write_to_stream) the code tries to use \"response\" as a context manager. Some digging reveals that this response makes its way from Client._http which is defined in google/cloud/client.py and gets the Response object from google/auth/transport/requests.py:AuthorizedSession. So... it definitely feels like something in here needs to require requests >= 2.18.0 (maybe all of them?). Thoughts? Detailed info: 1. OS type and version: N/A 2. Python version and virtual environment information: 2.7 but I don't think it matters. 3. google-cloud-python version: google-cloud-storage v 1.3.1 4. Stacktrace if available: below. 5. Steps to reproduce: Install a version of the requests library _less than 2.18.0_. Get some blob that exists. Try blob.download_as_string(). I personally re-pro'd this with version 2.10.0 to check. Note that the setup.py only requires 2.0.0 for storage and 2.4.0 for client, etc... -- PG. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Qt Console output spacing In IPython (=0.13) Qt Console, there seems to be a missing newline before the Out parameter in the first plot command after running `pylab`. See, for example `In [2]` and `Out[2]`: ``` Python 2.7.3 (default, Apr 20 2012, 22:39:59) Type \"copyright\", \"credits\" or \"license\" for more information. IPython 0.13 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. %guiref -> A brief reference about the graphical user interface. In [1]: pylab Welcome to pylab, a matplotlib-based Python environment [backend: TkAgg]. For more information, type 'help(pylab)'. In [2]: plot([1,2,3])Out[2]: [<matplotlib.lines.Line2D at 0x3e40210>] In [3]: plot([1,2,3]) Out[3]: [<matplotlib.lines.Line2D at 0x3e34d10>] In [4]: ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Conan config install list breaks if config file is missing The PR https://github.com/conan-io/conan/pull/7263 inserts a new feature, which breaks when conan cache is clear. ### Environment Details (include every applicable attribute) * Operating System+version: Linux * Compiler+version: Any * Conan version: 1.27.0-dev * Python version: 3.8.1 ### Steps to reproduce (Include if Applicable) 1) Set a new (empty) conan cache folder 2) Run `conan config install --list` ### Logs (Executed commands with output) (Include/Attach if Applicable) ``` export CONAN_USER_HOME=/tmp/conan conan config install --list Traceback (most recent call last): File \"/home/uilian/Development/conan/conan/venv/lib/python3.8/site-packages/conans/client/command.py\", line 2051, in run method(args[0][1:]) File \"/home/uilian/Development/conan/conan/venv/lib/python3.8/site-packages/conans/client/command.py\", line 608, in config configs = self._conan.config_install_list() File \"/home/uilian/Development/conan/conan/venv/lib/python3.8/site-packages/conans/client/conan_api.py\", line 94, in wrapper return f(api, *args, **kwargs) File \"/home/uilian/Development/conan/conan/venv/lib/python3.8/site-packages/conans/client/conan_api.py\", line 607, in config_install_list return json.loads(load(self.app.cache.config_install_file)) File \"/home/uilian/Development/conan/conan/venv/lib/python3.8/site-packages/conans/util/files.py\", line 218, in load with open(path, 'rb') as handle: FileNotFoundError: [Errno 2] No such file or directory: '/tmp/conan/.conan/config_install.json' ERROR: [Errno 2] No such file or directory: '/tmp/conan/.conan/config_install.json' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Type Hints for modeling_utils.py add [type hints](https://docs.python.org/3/library/typing.html) to the methods for better readability and autocomplete. If possible, check your work with an automated tool and tell us how you did it! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: MLFlow Logger Docs: MLFlowLogger has no attribute experiment Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [DO NOT MERGE] IoT: pick up fixes in GAPI generator. This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/cloud/iot/artman_cloudiot.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:90f9d15e9bad675aeecd586725bce48f5667ffe7d5fc4d1e96d51ff34304815b Status: Image is up to date for googleapis/artman:latest synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/iot-v1. synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Adding new Language class without modifying the core library code Will it be better if spaCy will provide a more extensive support for Language classes defined outside the library source code? According to the [documentation](http://spacy.io/usage/adding-languages) in order to add a new Language class properly you will need to **modify the library's code**. I think this reduces spaCy's flexibility/extensibility and adds some inconvenience in mantaining user defined Language classes. Currently if a Language class is defined outside spaCy it will work in some cases but in some cases including some CLI commands and getting noun_chunks it will fail probably because of relying on `util.get_lang_class()` function which only checks for language data within the spaCy library. In some cases like CLI commands it is not very difficult to create separate custom commands as a work-around but for core functionalities like noun_chunks generation ([_get_chunker](https://github.com/explosion/spaCy/blob/f29c3925eeba4b3720412f490bdd2b2991303b3c/spacy/tokens/doc.pyx#L71)) it seems there is no clear alternative. Are there other alternative to allow getting noun_chunks when using Language class defined outside spacy directory? Thank you very much for creating, sharing and mantaining spaCy. ## Info about spaCy * **spaCy version:** 2.0.5 * **Platform:** Linux-4.4.0-93-generic-x86_64-with-Ubuntu-14.04-trusty * **Python version:** 3.6.3 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: subproject('../../foo') escapes the current source directory and writes directories outside of the builddir I tried to use subproject() to depend on two projects outside of project folder with `subproject('../../foo')`. Everything went well with `--layout flat`, besides that meson still creates `subproject` directory tree with only empty directories in the build dir. Since I used `subproject('../../foo')` this result in empty directories being created outside of build dir. Are these empty subproject directories necessory? Or perhaps may be removed under `--layout flat`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Support `text-to-speech` in `pipeline` function and in Optimum ### Feature request SpeechT5 was recently added to Transformers: * **Blog post**: https://huggingface.co/blog/speecht5 * **Spaces demo**: https://huggingface.co/spaces/Matthijs/speecht5-tts-demo * **Models**: https://huggingface.co/mechanicalsea/speecht5-tts It would be great if `text-to-speech` could be supported across the Transformers stack. ### Motivation @xenova [bumped into this as an issue](https://github.com/xenova/transformers.js/issues/59) when trying to get SpeechT5 working in the browser (Transformers.js). ### Your contribution Probably unable to help with this at the moment. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: VS 2017 backend emits bad ProjectGuid value When I tried generating a VS 2017 solution, all generated *.vcxproj contained this: ``` <PropertyGroup Label=\"Globals\"> <ProjectGuid>64FCBDC2-8B6E-45D3-AEE0-DA999A2C7A64</ProjectGuid> </PropertyGroup> ``` Which then causes silent errors in visual studio 2017 IDE: project dont expand in solution explorer Reason - ProjectGuid value should contain brackets: `<ProjectGuid>{64FCBDC2-8B6E-45D3-AEE0-DA999A2C7A64}</ProjectGuid>` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Monitoring: where is CallOptions on monitoring API example? [OS] macOS Sierra 10.12.6 [Versions] - Python 3.6.1 ``` google-api-core==1.2.1 google-api-python-client==1.7.3 google-auth==1.5.0 google-auth-httplib2==0.0.3 google-cloud-monitoring==0.30.0 googleapis-common-protos==1.5.3 ``` ---- ## CallOptions class was not found! Hi. I'm new to GCP and Stackdriver. I wanted to use Google Kubernetes Engine and its auto scaling by custom metrics. Then, it is required to export the metrics to Stackdriver Monitoring, so I am trying to do it. But, After installing above-mentioned libraries, the example code on monitoring API README document failed. The pit hole is that `CallOptions` was not found, thus I've searched it in this repository and some other repositories. And finally, I couldn't find it... `CallOptions` is defined in gax.python, but the package is currently deprecated and moved to google-api-core. So I guess that also the dependency is currently corrupted or the some examples are out-of-date. Please tell me how handle this problem. _Thank you for the great package and platform._ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Raise exception with helpful error on Client pickle. Based on the discussion in #3191, raise an exception with a helpful error stating that `Client` classes are not pickleable. Note to self: We probably want this in GAX also. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Error on logging empty line to Cloudwatch **Apache Airflow version**: 2.0.1 **Environment**: - **Cloud provider or hardware configuration**: AWS **What happened**: I have Airflow with Cloudwatch-based remote logging running. I also have `BashOperator` that does, for example, `rsync` with invalid parameters, for example `rsync -av test test`. The output of the `rsync` error is formatted and contains empty line. Once that empty line is logged to the Cloudwatch, i receive an error: ``` 2021-04-06 19:29:22,318] /home/airflow/.local/lib/python3.6/site-packages/watchtower/__init__.py:154 WatchtowerWarning: Failed to deliver logs: Parameter validation failed: Invalid length for parameter logEvents[5].message, value: 0, valid range: 1-inf [2021-04-06 19:29:22,320] /home/airflow/.local/lib/python3.6/site-packages/watchtower/__init__.py:158 WatchtowerWarning: Failed to deliver logs: None ``` So basically empty lines can't be submitted to the Cloudwatch and as result the whole output of the process doesn't appear in logs. **What you expected to happen**: I expect to have an output of the bash command in logs. Empty lines can be skipped or replaced with something. **How to reproduce it**: For example: run `BashOperator` with `rsync` command that fails on Airflow with Cloudwatch-based remote logging. It could be any other command that produces empty line in the output. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Additional metrics for Elasticsearch Currently, the Elasticsearch in flight requests circuit breaker metrics are not captured. Can we add the following metrics? - breakers.in_flight_requests.tripped - breakers.in_flight_requests.overhead - breakers.in_flight_requests.estimated_size_in_bytes Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qpy changes names of `ControlledGate`s with non-default `ctrl_state` ### Environment - **Qiskit Terra version**: 0.22.1 - **Python version**: 3.8 - **Operating system**: Ubuntu 22.04.1 ### What is happening? qpy appends an extra `\"_o{ctrl_state}\"` to the name of `qiskit.circuit.ControlledGate` instances with non-default values for `ctrl_state` (so after one serialization+deserialization round the `gate.name` becomes `\"{name}_o{ctrl_state}_o{ctrl_state}\"`, and after a second round becomes `\"{name}_o{ctrl_state}_o{ctrl_state}_o{ctrl_state}\"`, etc) ### How can we reproduce the issue? ``` import qiskit import qiskit.qpy import io gate = qiskit.circuit.library.SGate().control(1, ctrl_state=\"0\") # create an instance of ControlledGate print(gate.name) # prints \"cs_o0\" circuit = qiskit.circuit.QuantumCircuit(2) circuit.append(gate, [0, 1]) print(circuit[0].operation.name) # prints \"cs_o0\" qiskit.qpy.dump(circuit, buf := io.BytesIO()) circuit = qiskit.qpy.load(io.BytesIO(buf.getbuffer()))[0] print(circuit[0].operation.name) # prints \"cs_o0_o0\" qiskit.qpy.dump(circuit, buf := io.BytesIO()) circuit = qiskit.qpy.load(io.BytesIO(buf.getbuffer()))[0] print(circuit[0].operation.name) # prints \"cs_o0_o0_o0\" ``` ### What should happen? every `print` statement above should print `\"cs_o0\"` ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: load_qasm_{file, string} converts `t` gate inappropriately ### Informations - **QISKit (Python SDK) version**: 0.5.3 - **Python version**: 3.6.5 - **Operating system**: macOS 10.13.5 ### What is the current behavior? `load_qasm_file` and `load_qasm_string` converts `t` gate into `tdg`. ### Steps to reproduce the problem Run the following script. ``` from qiskit.wrapper import load_qasm_string qasm_string=\"\"\" OPENQASM 2.0; include \"qelib1.inc\"; qreg q[1]; creg c[1]; t q[0]; \"\"\" circuit = load_qasm_string(qasm_string, name='tmp', basis_gates='t') print(circuit.qasm()) ``` The result is as follows. ``` OPENQASM 2.0; include \"qelib1.inc\"; qreg q[1]; creg c[1]; tdg q[0]; ``` ### What is the expected behavior? Do not change `t` gate. ### Suggested solutions I have no idea. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Switch back to a `/labconfig` directory cf https://github.com/jupyterlab/jupyterlab/pull/1555#issuecomment-276617756. Dictionaries are not deep-merged in a traitlets-based config, so we need to mirror the way `nbextensions` are handled. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Document headers argument At the moment there's no much information regarding headers argument for apply_async (and I think also applies to retry). I found out about this reading the changelog for version 3.1, but maybe it could be specified as an optional property for apply_async in the documentation. I can provide the PR for this if you want. Let me know if you agree. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Decompose does not propagate bound parameters ``` >>> import qiskit as qk >>> p = qk.circuit.Parameter('p') >>> qc = qk.QuantumCircuit(1) >>> qc.rx(p,0) <qiskit.circuit.instructionset.InstructionSet object at 0x1037b3668> >>> inst = qc.to_instruction() >>> qc2 = qk.QuantumCircuit(1) >>> qc2.append(inst, [0]) <qiskit.circuit.instructionset.InstructionSet object at 0x124066710> >>> print(qc2) ┌─────────────┐ q_0: |0>┤ Circuit0(p) ├ └─────────────┘ >>> print(qc2.bind_parameters({p: 0.5})) ┌───────────────┐ q_0: |0>┤ Circuit0(0.5) ├ └───────────────┘ >>> print(qc2.bind_parameters({p: 0.5}).decompose()) ┌───────┐ q_0: |0>┤ Rx(p) ├ └───────┘ ``` In the normal workflow, this isn't an issue since we decompose before we bind, but both forms should work. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Performance regression in parameter binding <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Since https://github.com/Qiskit/qiskit-terra/commit/296a745b the nightly benchmarks have flagged a regression in the benchmarks measure parameter binding. This appears quite severe as the number of parameters grow, for example: https://qiskit.github.io/qiskit/#circuit_construction.ParameterizedCircuitBindBench.time_bind_params?machine=dedicated-benchmarking-softlayer-baremetal&os=Linux%204.15.0-46-generic&ram=16GB&p-width=20&p-gates=2048&p-number%20of%20params=2048&commits=296a745b which is showing a 69.11x performance regression. ### Steps to reproduce the problem Bind parameters on a circuit, the benchmark code showing the regression is here: https://github.com/Qiskit/qiskit/blob/master/test/benchmarks/circuit_construction.py#L88-L102 ### What is the expected behavior? No performance regression ### Suggested solutions Fix the performance regression Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: CI: Rewrite `free_space` script in Python In our build/ci.yml (maybe other?) files we are using a \"free_space\" script that performs cleanup of the machine before running the tasks. This allows us to reclaim memory and disk space for our tasks. Example: https://github.com/apache/airflow/blob/eaa8ac72fc901de163b912a94dbe675045d2a009/.github/workflows/ci.yml#L334 This should be written in Python and our ci.yml and build.yml should be updated. We shoudl also be able to remove free_space script from the repo. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Make Qbs generator transitive Currently the Qbs generator creates Products for every required package. But it does not create [dependencies](https://doc.qt.io/qbs/qml-qbslanguageitems-depends.html) between the different required packages. This leads to two problems: * if you have a big project with many dependencies it cludders the project files * Qbs cannot track dependencies and may mess up the library order when linking - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add 'mongo_collection' to template_fields in MongoToS3Operator <!-- Welcome to Apache Airflow! For a smooth issue process, try to answer the following questions. Don't worry if they're not all applicable; just try to include what you can :-) If you need to include code snippets or logs, please put them in fenced code blocks. If they're super-long, please use the details tag like <details><summary>super-long log</summary> lots of stuff </details> Please delete these comment blocks before submitting the issue. --> **Description** <!-- A short description of your feature --> Make `MongoToS3Operator` `mongo_collection` parameter templated. **Use case / motivation** <!-- What do you want to happen? Rather than telling us how you might implement this solution, try to take a step back and describe what you are trying to achieve. --> This would allow for passing a templated mongo collection from other tasks, such as a mongo collection used as data destination by using `S3Hook`. For instance, we could use templated mongo collection to write data for different dates in different collections by using: `mycollection.{{ ds_nodash }}`. **Are you willing to submit a PR?** <!--- We accept contributions! --> Yes. **Related Issues** <!-- Is there currently another issue associated with this? --> N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Prefect Tasks do not seem to cache when invoked in a map Hi, Trying to get the Prefect cache to work for a mapped task. It seems like the tasks are correctly cached, but something about the function signature prevents the cache from correctly being recalled. New to prefect, so definitely may just be operator error... ``` from prefect import Flow, task from prefect.schedules import IntervalSchedule import pendulum from prefect.engine.cache_validators import all_inputs import time # Define flow run frequency refresh_schedule = IntervalSchedule( start_date=pendulum.parse(\"2019-01-01\"), interval=pendulum.duration(minutes=1) ) @task def a(): return [1,2] @task( cache_for=pendulum.duration(hours=1), cache_validator=all_inputs) def b(a): time.sleep(2.5) with Flow(\"test_flow\", schedule=refresh_schedule) as test_flow: z = a() b.map(a=z) test_flow.run() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Allow compatibility mode to be setup via environment variables or .env **Is your feature request related to a problem? Please describe.** The `--compatibility` option is only available as an option and I find myself obliged to add it everywhere on command line or in shell scripts when I do `up` or `run` commands. **Describe the solution you'd like** I would like to setup compatibility mode from my `.env` file. **Describe alternatives you've considered** The only alternative I've come up with is to use some script wrapper to docker-compose that prepend this option. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Incorrect output from jax.numpy.column_stack Using the CPU-only version of JAX (`jax 0.1.69`, `jaxlib 0.1.47`) in a fresh conda environment. ``` import numpy as np import jax.numpy as jp x = np.array([1., 1.]) y = np.array([2., 2.]) print(np.column_stack((x, y))) # [[1. 2.], [1. 2.]], expected print(jp.column_stack((x, y))) # [[1., 1., 2., 2.]], incorrect ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: export toposort for conda-build export toposort for conda-build Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: JSONBackend expects basis_gates as a list, receives a string As _openquantumcompiler.dag2json has been reintroduced by commit https://github.com/QISKit/qiskit-sdk-py/commit/77ffd963798e57b0f0650628048dd2ac19a30a16 it is not compatible with JSONBackend as it expects to get as argument a list of basis gates, not a comma separated string. A possible solution is to substitute https://github.com/QISKit/qiskit-sdk-py/blob/07b2485cb0c05d3649de83ece9be1c50c3aff979/qiskit/_openquantumcompiler.py#L36 by `` return DagUnroller(dag_circuit, JsonBackend(basis_gates.split(\",\")).execute()`` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Inspect shows version as None when using `set_version()` When using `set_version()` to version the package, `conan inspect` doesn't run the function, and as a result, prints \"None\". I would expect it to execute the function and include the version in the result out. ### Environment Details (include every applicable attribute) * Operating System+version: Windows 7 * Compiler+version: * Conan version: 1.21.0 * Python version: (via Conan Windows installer) ### Steps to reproduce (Include if Applicable) Create a new conanfile.py, replacing the version with: ```py def set_version(self) self.version = \"1.0\" ``` Then run `conan inspect . --attribute version`. ### Logs (Executed commands with output) (Include/Attach if Applicable) ``` $ conan inspect . --attribute version version: None ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: apex amp state dict ## 🐛 Bug https://github.com/PyTorchLightning/pytorch-lightning/blob/25ee51bc570503f331dceecc610d0eb355e22327/pytorch_lightning/trainer/training_io.py#L310 It seems for native amp support, the scalar state dict is saved. But for non native amp, the amp state dict is not saved? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: When retries are utilized and maximum retries exceeded the root cause is not shown in trace log ## Use Case <!-- Help us to understand your request in context --> When retries are being utilised by raising a RetryRequested exception and the retries are exhausted the run instance trace log only shows that the retries have been exceeded and the true cause of the error is not captured. The true cause of the error should be displayed in the trace log so that it is possible to understand the root cause of the failure. ## Ideas of Implementation <!-- Your ideal solution --> When raising the RetryRequested exception it should be possible to pass in the original exception and when the retries are exhausted the true exception (i.e. inner exception) should be included in the trace log. ## Additional Info <!-- (Optional)--> **True error example** 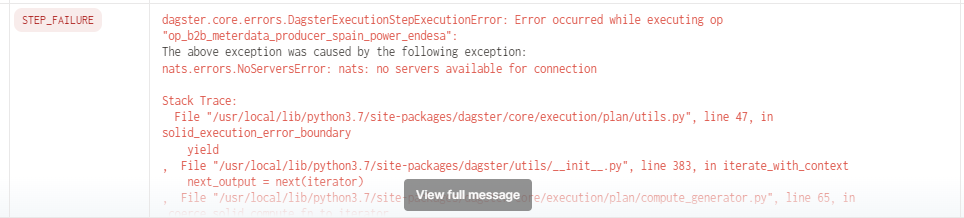 **Error shown when max retries exhausted** 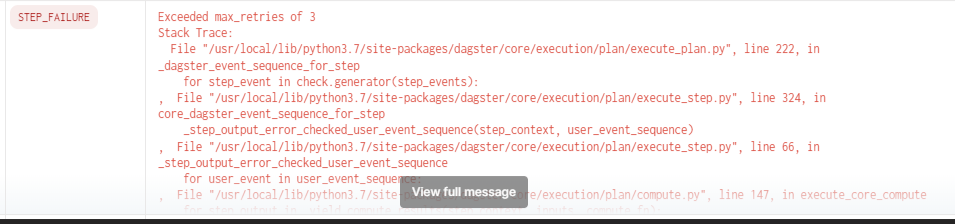 --- #### Message from the maintainers: Excited about this feature? Give it a :thumbsup:. We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Feature request: Show command line argument defaults # 🚀 Feature request When running with `--help`, show the default values for command line arguments. ## Motivation There are dozens of command line arguments. When I'm trying to figure out how to run a script, I often want to know what value is being used when I don't specify it. But running with `--help` doesn't show the default values unless it's explicitly written in the description (which is only for three of them for the example script I'm using). For example, `--evaluation_strategy` ``` --evaluation_strategy {no,steps,epoch} The evaluation strategy to use. ``` This ends up being a bit of a frustrating user experience. The two ways I currently use to find the value are: 1. Run the script again without `--help` and log all the arguments (done in the examples). This shows the assigned value, which will be the default if not passed. However, it doesn't show the description of what it does. 2. Go to the documentation. This will show the default value and a more thorough description, but requires opening a web browser and Googling to find the right page. In other Python projects, I use the `argparse.ArgumentDefaultsHelpFormatter`, which automatically displays default values in the `--help` message along with their descriptions. ```python parser = argparse.ArgumentParser( formatter_class=argparse.ArgumentDefaultsHelpFormatter ) ``` I wonder whether the Huggingface arguments could support the same feature? Many thanks for considering this! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Creating network - UnicodeDecodeError: 'ascii' codec can't decode byte 0xd0 in position 24: ordinal not in range(128) Hi, I have an issue while running docker-compose on Windows 10 with Russian language pack: > Creating network \"docker_default\" with the default driver > Traceback (most recent call last): > File \"logging__init__.py\", line 861, in emit > File \"logging__init__.py\", line 734, in format > File \"compose\\cli\\formatter.py\", line 48, in format > UnicodeDecodeError: 'ascii' codec can't decode byte 0xd0 in position 24: ordinal not in range(128) > Logged from file errors.py, line 71 I don't have any non-ascii characters on my docker-compose.yml, but suppose that something like network interface name may contain non-ascii characters. docker-compose --version > docker-compose version 1.8.1, build 004ddae docker-compose.yml > version: '2' > > services: > consul: > image: khaale/consul-nano > container_name: consul_agent > networks: > default: > aliases: > - consul-agent > awl-is: > image: khaale/awl-is > container_name: integration_service > links: > - consul Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Cannot upload packages in which file permission has changed Due to some workflows, developers often end up packaging up binaries that do not have write permission for `all`. When trying to fix these packages: 1. `conan download [SomeBadlyUploadedLibrary_REF]` 2. `chmod -R a+w $CONAN_USER_HOME/.conan/data/[SomeBadlyUploadedLibrary]/[Version]/[Uploader]/[Channel]/packages/*` 3. `conan upload --force -r our_remote [SomeBadlyUploadedLibrary_REF]` *Expected*: the packages are replaced in the conan server's repository. *Actual*: The upload step will check the hash of the package and decide that it matches so no uploading will take place. The impact of it, is that binaries, like shared libraries without write permission cannot be imported repeatedly into our build directory, which is, while can be corrected in the local cache, it is really annoying. Another way around is that to delete the package entirely from the remote repository, and upload it again and pray that no one is trying to pull that package right at that moment. This could be solved a number of ways: 1. Use the file permissions in the file hashes. Problematic might be between OSes. 2. (and this might be another issue all together): the import step should first clear out the previous import if there is one, and only then do the import really. This can also help to keep the build directory cleaner, in case requirements change. 3. The `--force` argument on upload should really *force* the upload, even if everything matching. This is a user experience issue: I expect this flag to work like it works in most commands and be absolutely forceful in whatever it is doing. I am happy to implement any or all of these, but I would like to have your opinion first. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Bump vendored `cpuinfo` version Let's file a ticket to upgrade or upstream the changes here to cpuinfo. _Originally posted by @jezdez in https://github.com/conda/conda/pull/11290#discussion_r826833053_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CMake translation missing Objective-C++ files in wxWidgets Attempting to build and link against wxWidgets on MacOS results in various linker errors. Looking up the symbols, they seem to be coming from the various objective-c++ `.mm` files in `src/osx/cocoa`. Compiling directly with CMake does seem to include those files. Unfortunately, I don't have a minimal repro handy. If that's needed, please let me know and I can try to make one. I've uploaded `meson.build`, `fileAPI.json` and `__CMake_build/cmake_trace.txt`, but if there's anything else I can provide I'd be happy to since this is blocking. [cmake_objcpp_bug_logs.zip](https://github.com/mesonbuild/meson/files/5742882/cmake_objcpp_bug_logs.zip) CMake module invocation: https://github.com/TypesettingTools/Aegisub/blob/meson-vs2019/meson.build#L125 System: MacOS 11.1 Python 3.9.1 Meson 0.56.0 CMake 3.19.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: JSON serialization should allow NaNs. In IPython's messaging machinery, the function `JSON.dumps` is called with the default value for the parameter `allow_nan`, that is `True`, causing the generated JSON to be invalid, and therefore causing parsing errors on the JavaScript side. (However, `JSON.loads` parses that invalid JSON, and therefore it is still fine for Python to Python communication.) The following code, to be run in the notebook triggers the error: ``` Python from IPython.kernel.comm import Comm from IPython.utils.traitlets import HasTraits, Instance class nanmsg(HasTraits): comm = Instance(Comm, kw=dict(target_name='nanmsg')) def __init__(self): self.comm.send([float('nan')]) nanmsg() ``` ``` JavaScript %%javascript var nanmsg = function (comm) { this.comm = comm; comm.on_msg($.proxy(this.handler, this)); }; nanmsg.prototype.handler = function (msg) { alert(msg); }; IPython.notebook.kernel.comm_manager.register_target('nanmsg', function (comm) { var f = new nanmsg(comm); console.log(f)}); ``` However, replacing `float('nan')` by `None` will not cause any JSON parsing error. All the calls to `JSON.dumps` should probably be done with `allow_nan=False`, which raises a ValueError when it encounters nans. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: PIN 16: Implement `Result` subtype mimicking `ConstantResultHandler` ## Use Case See PIN 16 (PR #2134) for background. This is a spin-off from #2141 for only one (special) handler, `ConstantResultHandler`, which has internal implications. ## Solution Implement a `Result` subclass for `ConstantResultHandler` that knows how to `.read`, `write`, and check if it `.exists` and operates properly for the same internal purposes as the current `ConstantResultHandler` does. ## Alternatives *Please describe any alternatives you've considered, even if you've dismissed them* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda env create gives confusing message if environment file does not exist Try executing `conda env create -f does_not_exist.txt`. The output I get is: ``` Using Anaconda API: https://api.anaconda.org SpecNotFound: Can't process without a name ``` That is not super useful or meaningful. I'd suggest it should say something obvious, like: ``` File not found: does_not_exist.txt ``` conda env create gives confusing message if environment file does not exist Try executing `conda env create -f does_not_exist.txt`. The output I get is: ``` Using Anaconda API: https://api.anaconda.org SpecNotFound: Can't process without a name ``` That is not super useful or meaningful. I'd suggest it should say something obvious, like: ``` File not found: does_not_exist.txt ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Swap project_name for project_id before things get out of hand... We need to be consistent with these names, and project_id is the appropriate argument name. If we don't fix this quickly, people may start depending on this as a kwarg and it will be a nightmare to fix.. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Improve \"Ninja does not support newlines in rules.\" diagnostic I made some changes to the AST Korn shell Meson config scripts and was surprised to see the `Ninja does not support newlines in rules.` error. I determined after a couple of hours of debugging it was due to a script, run via `run_command()`, that output a string containing a trailing newline. I didn't figure out what the problem was until I modified the `raise MesonException()` in *ninjabackend.py* to also show me the value of the `text` variable. Once I saw the problematic text string it was obvious what the problem was. Please consider always displaying the offending value of `text` in that error message. P.S., Thank you for the awesome build system. Switching AST Korn shell from its legacy Nmake build system to Meson has dramatically improved the build time (at least an order of magnitude) and has made it much easier to debug build failures -- this issue notwithstanding. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: links in docs, static code analysis and autocompletion in PyCharm are broken Due to docstrings formatted like this, static code analysis and autocomplete in PyCharm and the links in the [online Sphinx docs](https://googleapis.github.io/google-cloud-python/latest/firestore/client.html#google.cloud.firestore_v1beta1.client.Client.document) are broken: https://github.com/googleapis/google-cloud-python/blob/de0103cedaf9fb9f03ddca9be801ac64635d7b74/firestore/google/cloud/firestore_v1/client.py#L250-L252 This should result in the same short name with a working link in the Sphinx docs and would not kill autocomplete etc: ``` Returns: :class:`~google.cloud.firestore_v1.document.DocumentReference`: A reference to a document in a collection. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Provide a migration command or script for v1 to v2 Compose format We should provide a migration script or command for converting from the v1 format to the v2 format. We'll need to use a \"round trip\" yaml parser like https://pypi.python.org/pypi/ruamel.yaml I don't think we should change our yaml parser entirely, we can just use this library for the conversion and keep pyyaml for everything else. I think we can do something like this: 1. run the v1 config through `docker-compose config -q` to make sure it's valid 2. run the convertion 3. run the converted v2 config through `docker-compose config -q` again to make sure it's still valid. We could even compare the output from 1 and 3, and they should be the same. Doing it as a script would be easier (we don't have to go adding ruamel and all it's dependencies, which will increase the size of the binary for everyone), but a new command `migrate-to-v2` is possible. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Phishing protection: unit tests fail See [this Kokoro failure](https://source.cloud.google.com/results/invocations/a255dd66-093d-44b1-8173-cbe398ef3220/targets/cloud-devrel%2Fclient-libraries%2Fgoogle-cloud-python%2Fpresubmit%2Fphishingprotection/log), which I can reproduce locally: ```python _ ERROR collecting tests/unit/gapic/v1beta1/test_phishing_protection_service_client_v1beta1.py _ tests/unit/gapic/v1beta1/test_phishing_protection_service_client_v1beta1.py:21: in <module> from google.cloud import phishingprotection_v1beta1 google/cloud/phishingprotection_v1beta1/__init__.py:20: in <module> from google.cloud.phishingprotection_v1beta1.gapic import ( google/cloud/phishingprotection_v1beta1/gapic/phishing_protection_service_client.py:40: in <module> \"google-cloud-phishingprotection\" .nox/unit-3-6/lib/python3.6/site-packages/pkg_resources/__init__.py:481: in get_distribution dist = get_provider(dist) .nox/unit-3-6/lib/python3.6/site-packages/pkg_resources/__init__.py:357: in get_provider return working_set.find(moduleOrReq) or require(str(moduleOrReq))[0] .nox/unit-3-6/lib/python3.6/site-packages/pkg_resources/__init__.py:900: in require needed = self.resolve(parse_requirements(requirements)) .nox/unit-3-6/lib/python3.6/site-packages/pkg_resources/__init__.py:786: in resolve raise DistributionNotFound(req, requirers) E pkg_resources.DistributionNotFound: The 'google-cloud-phishingprotection' distribution was not found and is required by the application ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: einsum in numpy 1.15 is almost 30 times slower than numpy 1.14! <!-- Please describe the issue in detail here, and fill in the fields below --> einsum is significantly slower in numpy 1.15 (when compared to numpy 1.14). Could be related to [#11686](https://github.com/numpy/numpy/issues/11686). I am not sure... I am using python 3.7.0 in Arch Linux. I realize that 1.15 does bring some improvements to einsum in general; but, for this specific code, it is very slow! ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np import time print(np.version.version) b = np.random.random((5, 2)) t = np.random.random((5, 5, 2)) p = np.random.random((2, 5)) t1 = time.time() for _ in range(int(1e6)): out = np.einsum('ij,ixy,ji->xy', b, t, p) t2 = time.time() print(t2-t1) ``` <!-- Writing the output from my computer below --> ### Output 1: 1.15.0 129.36364936828613 ### Output 2: 1.14.5 4.071631908416748 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: ArrayQueryParameter.from_api_repr fails with STRUCT query parameter values I encountered a system test error on the `bigquery-b2` work when I modified some system tests to use QueryJob to pass in query parameters. The job resource that comes back cannot be parsed because of the query parameters in the query statistics. The resource which is show the problem is this one: RESOURCE = { 'parameterType': { 'type': 'ARRAY', 'arrayType': { 'type': 'STRUCT', 'structTypes': [ { 'name': 'name', 'type': {'type': 'STRING'}}, , { 'name': 'age', 'type': {'type': 'INT64'}, }, ], }, }, 'parameterValue': { 'arrayValues': [ { 'structValues': { 'name': {'value': 'Phred Phlyntstone'}, 'age': {'value': '32'}, }, }, { 'structValues': { 'name': { 'value': 'Bharney Rhubbyl', }, 'age': {'value': '31'}, }, }, ], }, } I'm currently investigating a fix. Will make a PR to `master` rather than `bigquery-b2` when ready because this issue will affect that branch too and I want a fix out possibly before Beta 2 is ready. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add BioGptForSequenceClassification # What does this PR do? Fixes #21530 ## Before submitting - [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case). - [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section? - [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case. - [x] Did you make sure to update the documentation with your changes? Here are the [documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation). - [x] Did you write any new necessary tests? ## Who can review? @NielsRogge Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] why isn't python requires updated with --update? To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. ``` Conan Version 1.12.2 Distributor ID: Ubuntu Description: Ubuntu 16.04.5 LTS Release: 16.04 Codename: xenial ``` I see from documentation at: https://docs.conan.io/en/latest/extending/python_requires.html That python_requires are not updated with --update `They are not automatically updated with the --update argument from remotes.` But why? Every time I update the python_requires I need to inform all users to clear their cache for those packages to be updated? Seems very cumbersome. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: latex_to_png fails on windows The `latex_to_png` command fails in the method `latex_to_png_dvipng`. The reason is the temporary file that is generated, contains a `~` in the path, which is not accepted by the latex command. The temporary file generated is ` 'C:\\\\Users\\\\EENDEB~1\\\\AppData\\\\Local\\\\Temp\\\\tmpxefqozm3\\\\tmp.tex'` The command that fails is: ``` subprocess.check_call( [\"latex\", \"-halt-on-error\", tmpfile, cwd=workdir, stdout=devnull, stderr=devnull) ``` Locally I can fix this by changing the command to ``` subprocess.check_call( [\"latex\", \"-halt-on-error\", os.path.split(tmpfile)[-1]], cwd=workdir, stdout=devnull, stderr=devnull) ``` (only the last part is required, since the `cwd` is also set). To make this work some other calls need to be modified as well <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories. If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org. If you are unsure, it's ok to post here, though, there are few maintainer so you might not get a fast response. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Printable dependency graph I have an idea for a feature add that I would be happy to implement if I knew that you would be open to incorporating it into the code base. Often while working on a big project with a lot of dependencies, it's nice to be able to see at a glance what the dependency tree looks like. The current way of seeing it via `conan info` is nice but hard to view mentally because it's just flat text. My idea would be to add something like `conan graph` which would generate a [dot](http://www.graphviz.org/content/dot-language) file that could be fed into a graph generator like [graphviz](http://www.graphviz.org/) or [mermaid](https://knsv.github.io/mermaid/). Thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: 1.10.0-rc1 docker compose doesn't work with slashes in .dockerignore file. With latest 1.10.0-rc1 docker compose, slash in .dockerignore cannot be recognized. It will have **below** errors with this .dockerginore file. ``` * !obj/Docker/publish/* !obj/Docker/empty/ ``` **Building webapplication1 Service 'webapplication1' failed to build: GetFileAttributesEx obj\\Docker\\empty\\: The system cannot find the path specified..** Note: slash works well in 1.9.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuantumCircuit.unitary doesn't accept single integer qargs <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master @ 251930a - **Python version**: 3.5 - **Operating system**: osx ### What is the current behavior? ``` >>> import qiskit as qk >>> qc = qk.QuantumCircuit(1) >>> qc.x(0) >>> qc.barrier(0) >>> qc.unitary([[0,1], [1,0]], 0) Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/extensions/unitary.py\", line 211, in unitary return self.append(UnitaryGate(obj, label=label), qubits, []) File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/circuit/quantumcircuit.py\", line 796, in append for (qarg, carg) in instruction.broadcast_arguments(expanded_qargs, expanded_cargs): File \"/Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/circuit/gate.py\", line 212, in broadcast_arguments 'The amount of qubit/clbit arguments does not match the gate expectation.') qiskit.circuit.exceptions.CircuitError: 'The amount of qubit/clbit arguments does not match the gate expectation.' >>> qc.unitary([[0,1], [1,0]], [0]) # This works ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: add timestamp metadata for tiebreaking conda-build 3 hashed packages Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: URLs with :: are OK and should not raise assertion errors For conda-build's perl skeleton generator, we can end up with URLs like: http://api.metacpan.org/v0/module/Test::More Unfortunately, conda prevents us from actually using those URLs: ``` File \"/Users/msarahan/miniconda2/lib/python2.7/site-packages/conda/fetch.py\", line 354, in download assert \"::\" not in str(url), url AssertionError: http://api.metacpan.org/v0/module/Test::More ``` Please partially revert https://github.com/conda/conda/commit/39605e01ccd05b5af5ebeceeacaafe652f4b32e4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: num_proc in dataloader affect F1 score in squad ### System Info transformers 4.18.0 (on CPU) python 3.9 ### Who can help? @sgugger ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction In the example question answering script, `cd examples/pytorch/question-answering/` Running the below two cmds will yield different F1 score report (even though their difference is just num workers in dataloader): 1. `python run_qa_no_trainer.py --model_name_or_path csarron/bert-base-uncased-squad-v1 --dataset_name squad --max_seq_length 384 --doc_stride 128 --num_train_epochs 0 --preprocessing_num_workers 1 --output_dir ~/tmp/debug_squad` 2. `python run_qa_no_trainer.py --model_name_or_path csarron/bert-base-uncased-squad-v1 --dataset_name squad --max_seq_length 384 --doc_stride 128 --num_train_epochs 0 --preprocessing_num_workers 4 --output_dir ~/tmp/debug_squad` ### Expected behavior 1. `Evaluation metrics: {'exact_match': 80.90823084200568, 'f1': 88.22754061399627}` 2. `Evaluation metrics: {'exact_match': 76.51844843897824, 'f1': 83.40809222646291}` They have different results on squad. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Provide a first-level `draw` function to depict circuits. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Commit bool in PostgresExecute can be misleading ## Current behavior PostgresExecute takes commit as a bool and the documentation says \"Set to True to commit a transaction, defaults to False\". This default to False only applies if you explicitly Begin a transaction in your query, otherwise the query commits automatically, ignoring the Commit Bool. ## Proposed behavior *Please describe your proposed change to the current behavior* Given there could be multiple configurations that change this behavior, creating a ticket to see if there is a preference on how this is fixed with documentation or implementation. ## Example *Please give an example of how the enhancement would be useful* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: remove usage of backports.shutil_get_terminal_size This is for pre-3.3 Python. Pretty easy it should only require deleting lines. Maybe a few need to be dedented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython 8 changes terminal cursor <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories. If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org. If you are unsure, it's ok to post here, though, there are few maintainer so you might not get a fast response. --> After starting IPython 8.0 and then returning to terminal, the cursor changes from block to I-Beam. Before:  After:  I need to call `reset` to get the cursor back to block. Setup: XFCE terminal + zsh + starship Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: System Package manager should not update package index if CONAN_SYSREQUIRES_MODE=verify Currently the SystemPackageManager.update() performs an update (which needs sudo rights!) if CONAN_SYSREQUIRES_MODE is anything else than \"disabled\". \"verify\" should also not update, I think. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Empty test suite list causes backtrace Specifying a test with an empty list of test suite names causes a backtrace: ``` test('name', executable, suite: []) ``` This is useful for consistency. Where a project has lots of tests and many (but not all) need suite names for filtering, it's more explicit to add a `suite: []` argument than just leaving it out. Example: 5 out of 10 tests need root permissions, so those tests have `suite: ['root']` while the others have `suite: []`. This currently triggers a backtrace: ``` $ meson test ... Traceback (most recent call last): File \"/usr/lib/python3.7/site-packages/mesonbuild/mesonmain.py\", line 122, in run return options.run_func(options) File \"/usr/lib/python3.7/site-packages/mesonbuild/mtest.py\", line 1005, in run return th.doit() File \"/usr/lib/python3.7/site-packages/mesonbuild/mtest.py\", line 756, in doit self.run_tests(tests) File \"/usr/lib/python3.7/site-packages/mesonbuild/mtest.py\", line 896, in run_tests visible_name = self.get_pretty_suite(test) File \"/usr/lib/python3.7/site-packages/mesonbuild/mtest.py\", line 875, in get_pretty_suite rv = TestHarness.split_suite_string(test.suite[0])[0] IndexError: list index out of range ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Error when downloading blobs with storage v1.1.0 See build log: https://www.google.com/url?q=https%3A%2F%2Ftravis-ci.org%2FGoogleCloudPlatform%2Fpython-docs-samples%2Fbuilds%2F226935178%23L786&sa=D&sntz=1&usg=AFQjCNG3mWBi07AXjvj70yKUdQ0pI4hJNw Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Kicking off runs via materialize button gives no way to set resource config The resources provided to assets may require config, but when kicking off runs via materialize, there is no way to edit the config that the materialization run will kick off with. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Default circuit names are not zero-based <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: latest - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? When creating a quantum circuit with no name, the default name is set to `circuitX`. Currently, `X` starts from `1` rather than `0`, and can cause some confusion when trying to index circuits by name. ### Steps to reproduce the problem ```python from qiskit import * q = QuantumRegister(2, \"q\") c = ClassicalRegister(2, \"c\") # Create measurement subcircuit qc = QuantumCircuit(q,c) qc.name ``` gives `'circuit1'` for the initial circuit created. It should be `'circuit0'` to coincide with the the indexing in Python. ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Failed healthcheck raises uncaught exception and kills execution. Just testing out the new healthcheck feature in config v2.1 and ensuring my containers start in order via the `depends_on` however, intermittently, I get an error like this: ```sh $ docker-compose up Creating network \"default\" with the default driver Creating rabbitmq_1 Creating redis_1 Creating s3_1 Creating database_1 Creating elasticsearch_1 Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"compose/cli/main.py\", line 64, in main File \"compose/cli/main.py\", line 116, in perform_command File \"compose/cli/main.py\", line 848, in up File \"compose/project.py\", line 410, in up File \"compose/parallel.py\", line 44, in parallel_execute File \"compose/parallel.py\", line 118, in parallel_execute_iter File \"compose/parallel.py\", line 175, in feed_queue File \"compose/parallel.py\", line 175, in <genexpr> File \"compose/service.py\", line 560, in <lambda> File \"compose/service.py\", line 920, in is_healthy compose.errors.HealthCheckFailed docker-compose returned -1 ``` This occurs when my database's healthcheck fails on startup. After doing some digging, it looks like exceptions raised in the [`is_healthy`](https://github.com/docker/compose/blob/bump-1.10.0-rc2/compose/service.py#L905-L921) method aren't being caught because they're called (as [`ready_check`](https://github.com/docker/compose/blob/bump-1.10.0-rc2/compose/parallel.py#L174)) outside the [`try..except` scope (inside `feed_queue`) in the `parralel_execute_iter` method](https://github.com/docker/compose/blob/bump-1.10.0-rc2/compose/parallel.py#L118-L126). Does that make sense? ``` $ docker --version Docker version 1.13.0-rc6, build 2f2d055 $ docker-compose --version docker-compose version 1.10.0-rc2, build fb241d0 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add example code block to `switch` docstring I recently realized I hadn't touched the `switch` code in a long time, and I would've really appreciated an example to work off of. Instead, I ended up looking at our tests which most users won't want to do. Relevant doc: https://docs.prefect.io/api/unreleased/tasks/control_flow.html#prefect-tasks-control-flow-conditional-switch Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Feature Request: More Initializers in stax Probably on a similar topic of #137, I think it would be better if stax had a few extra initializers for neural network layers, specifically glorot uniform, kalming/he normal and kalming/he uniform, as they are important in building deep neural networks with ReLU activation, as shown in [Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification ](https://arxiv.org/abs/1502.01852) and explored in [this medium post](https://towardsdatascience.com/hyper-parameters-in-action-part-ii-weight-initializers-35aee1a28404). logsoftmax has numerical issue Inside stax.py, `logsoftmax` doesn't use the trick of `softmax` where you can do x - x.max to make it more stable. ``` def logsoftmax(x, axis=-1): \"\"\"Apply log softmax to an array of logits, log-normalizing along an axis.\"\"\" return x - logsumexp(x, axis, keepdims=True) ``` ``` def softmax(x, axis=-1): \"\"\"Apply softmax to an array of logits, exponentiating and normalizing along an axis.\"\"\" unnormalized = np.exp(x - x.max(axis, keepdims=True)) return unnormalized / unnormalized.sum(axis, keepdims=True) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: numpy.percentile output is not sorted The output of `numpy.percentile` is not always sorted ### Reproducing code example: ```python import numpy as np q = np.arange(0, 1, 0.01) * 100 percentile = np.percentile(np.array([0, 1, 1, 2, 2, 3, 3 , 4, 5, 5, 1, 1, 9, 9 ,9, 8, 8, 7]) * 0.1, q) equals_sorted = np.sort(percentile) == percentile print(equals_sorted) assert equals_sorted.all() ``` ### Error message: [ True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True False False True True True True False True True True False] AssertionError Traceback (most recent call last) <ipython-input-63-2850fe4a4ce3> in <module> 1 q = np.percentile(np.array([0, 1, 1, 2, 2, 3, 3 , 4, 5, 5, 1, 1, 9, 9 ,9, 8, 8, 7]) * 0.1, np.arange(0, 1, 0.01) * 100) 2 equals_sorted = np.sort(q) == q ----> 3 assert equals_sorted.all() AssertionError: ### Numpy/Python version information: 1.17.2 3.6.8 (v3.6.8:3c6b436a57, Dec 24 2018, 02:04:31) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Update allowed gcc version in settings to 8.2 The current stable version of GCC is 8.2. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: intermittent bug in stochastic swap pass ```python qasm = \"\"\"OPENQASM 2.0; include \"qelib1.inc\"; qreg q[5]; creg c[5]; cx q[4],q[1]; u3(0.771421551875327*pi,1.93195729272833*pi,1.95526496079462*pi) q[2]; cx q[1],q[4]; cx q[3],q[2]; cx q[4],q[1]; u1(0.0680407993035097*pi) q[2]; u3(0.474906730130952*pi,0.679527728632899*pi,1.16361128456302*pi) q[1]; cx q[2],q[3]; cx q[1],q[0]; u3(0.479236620087447*pi,0,0) q[3]; u3(1.65884252662582*pi,0,0) q[1]; cx q[3],q[2]; cx q[0],q[1]; cx q[2],q[0]; cx q[1],q[0]; cx q[3],q[2]; cx q[0],q[1]; cx q[2],q[3]; cx q[1],q[0]; cx q[3],q[2]; cx q[0],q[4]; cx q[1],q[2]; measure q[4] -> c[4]; measure q[0] -> c[0]; measure q[1] -> c[1]; measure q[2] -> c[2]; measure q[3] -> c[3]; \"\"\" from qiskit import QuantumCircuit, execute, transpile, assemble, Aer from qiskit.transpiler import CouplingMap from qiskit.visualization import plot_histogram from qiskit.transpiler import passes from qiskit.transpiler import PassManager circ = QuantumCircuit().from_qasm_str(qasm) backend = Aer.get_backend('qasm_simulator') coupling_map = [[0, 1], [1, 0], [1, 2], [1, 3], [2, 1], [3, 1], [3, 4], [4, 3]] stochastic = passes.StochasticSwap(CouplingMap(coupling_map), seed=0) lookahead = passes.LookaheadSwap(CouplingMap(coupling_map)) basic = passes.BasicSwap(CouplingMap(coupling_map)) pm = PassManager(stochastic) new_circ = pm.run(circ) counts_cm = backend.run(assemble(new_circ,shots=10000)).result().get_counts() counts_no_cm = backend.run(assemble(circ,shots=10000)).result().get_counts() plot_histogram([counts_cm,counts_no_cm],legend=['coupling_map','no_coupling_map']) ``` 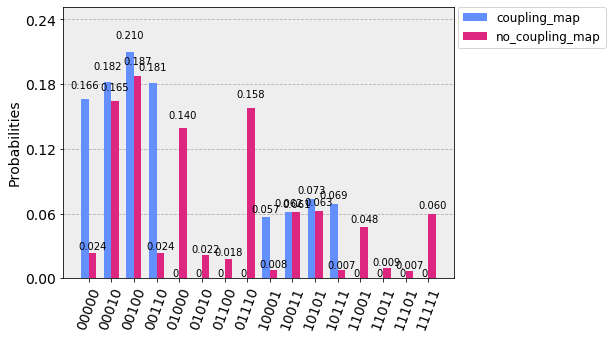 The circuit mapped to coupling map returns different counts vs. original circuit. This only occurs for some random seeds. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Remove duplicate test dependencies from nox session configuration The `system` and `snippets` nox session unnecessarily install `test_utils` twice, and this redundancy should be removed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson does not search CMake user package registry **Describe the bug** Users can install CMake packages into the user package registry (`$HOME/.cmake/packages` on Unix by default). CMake will check this directory for packages if a package isn't found on the system, but meson does not. **To Reproduce** The following works with plain CMake: ```bash $ mkdir -p ~/.cmake/packages/Foo $ echo \"$HOME/cmake/foo\" > ~/.cmake/packages/Foo/foo $ mkdir -p ~/cmake/foo $ touch ~/cmake/foo/FooConfig.cmake $ mkdir -p ~/cmake/bar $ cd ~/cmake/bar $ cat >CMakeLists.txt <<EOF project(bar) find_package(Foo REQUIRED) EOF $ cd ~/cmake/bar $ mkdir build $ cd build $ cmake .. ``` Now trying to use the `Foo` package from meson: ```bash $ mkdir ~/meson/bar $ cd ~/meson/bar $ cat > meson.build <<EOF project('bar', 'c') foo = dependency('Foo') EOF $ meson build ``` meson cannot find `Foo`. **Expected behavior** meson searches the CMake user package registry for CMake packages. **system parameters** * macOS Big Sur * Python 3.9.7 * meson 0.59.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Refactor CachedStates Currently, `CachedStates` are `Pending` subclasses that are stored as attributes of `Success` states. This makes it particularly difficult (expensive) to query for successes that have also been cached. A proposed refactor would make `Cached` (renamed from `CachedState`) subclasses of `Success`. When a task wants to be cached, it returns a `Cached` state which contains all the relevant result info. This is simple to query (\"give me the last cached state!\") and better maps onto the most common case: the cache is valid and the `Finished` state should be returned. If the cache turns out to be invalid, then the TaskRunner can trivially revert to a `Pending` state. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 'getpwuid(): uid not found: 1001' **Describe the bug** I am install dbus-python and this package require the meson. the install will raise an exception with 'getpwuid(): uid not found: 1001' **To Reproduce** Use an docker to install the dbus-python with the command. sudo pip3 install dbus-python==1.3.2 ``` INFO: autodetecting backend as ninja INFO: calculating backend command to run: /tmp/pip-build-env-v1swhhzx/overlay/bin/ninja Traceback (most recent call last): File \"/tmp/pip-build-env-v1swhhzx/overlay/lib/python3.9/site-packages/mesonbuild/mesonmain.py\", line 194, in run return options.run_func(options) File \"/tmp/pip-build-env-v1swhhzx/overlay/lib/python3.9/site-packages/mesonbuild/minstall.py\", line 823, in run if not rebuild_all(opts.wd, backend): File \"/tmp/pip-build-env-v1swhhzx/overlay/lib/python3.9/site-packages/mesonbuild/minstall.py\", line 803, in rebuild_all env, preexec_fn = drop_privileges() File \"/tmp/pip-build-env-v1swhhzx/overlay/lib/python3.9/site-packages/mesonbuild/minstall.py\", line 779, in drop_privileges homedir = pwd.getpwuid(int(orig_uid)).pw_dir KeyError: 'getpwuid(): uid not found: 1001' ``` **Expected behavior** install successful **system parameters** python 3.9.9 with meson 1.1.0 I check it successful yesterday. I guess it should be the new issue in 1.1.0 since it is a new release version. I found it with https://github.com/mesonbuild/meson/commit/ecb32bf457ed27b75c9b4386ca1acfbd4b63869e Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython console freezes for increasing no of seconds in %pylab mode launching ipython just in console with `ipython`. Am trying to reproduce bad editing (readline?) behavior now, looking at some functions, their help text etc. but it's all ok. Then launching `%pylab`. Typing in rubbish (like 'aoeuaoeaoeu') and can keep editing it without freezes. But from the moment I type in a function name that exists, like `dir()` it even gets stuck before printing the `()`. From now on the cursor gets stuck every 5 seconds or so and keeps stuck for 2-3 seconds at a time, but that number is increasing. Version abffd96eaa9c7 inside iTerm2 on Mac OSX. Python 2.7.8 from conda Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.rot90 support There is not provision of rotation of tensor in `lux_numpy.py` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Remove all deprecated items from BigQuery before GA Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: FlowRunner manages context cache wrongly ## Description AttributeError and different behavior of output caching between Flow.run and FlowRunner.run. ## Expected Behavior No AttributeError, same behavior and cached result reuse of FlowRunner.run after Flow.run. ## Reproduction ```python from datetime import timedelta import random from prefect import task, Flow from prefect.engine import FlowRunner from prefect.engine.cache_validators import duration_only @task(cache_for=timedelta(seconds=10), cache_validator=duration_only) def rand_inc(r, x): rand = random.randint(0, r) print(\"RAND\", rand) return rand + x with Flow(\"Cache\") as f: a1 = rand_inc(10, 0) # this fails: runner = FlowRunner(f) state1 = runner.run() # this would pass: #f.run() ``` Traceback: ``` Traceback (most recent call last): File \"/Users/dafcok/miniconda3/lib/python3.6/site-packages/prefect/engine/runner.py\", line 48, in inner new_state = method(self, state, *args, **kwargs) File \"~/miniconda3/lib/python3.6/site-packages/prefect/engine/task_runner.py\", line 631, in check_task_is_cached candidate_states = prefect.context.caches.get( AttributeError: 'Context' object has no attribute 'caches' ``` Moreover, if you `f.run()` once before `runner.run()`, cache validation always logs `Task 'rand_inc': can't use cache because it is now invalid`. ## Environment ``` { \"config_overrides\": {}, \"env_vars\": [], \"system_information\": { \"platform\": \"Darwin-19.0.0-x86_64-i386-64bit\", \"prefect_version\": \"0.10.4\", \"python_version\": \"3.6.8\" } } ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Neutrino OS version not updated The compiler was updated to match with the new QNX Neutrino release but I forgot to update the actual OS version Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Update backends, providers and authentication <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? After discussion, the mechanism for using backends, providers and authentication should undergo a revamp to conform to the agreed specification: * [x] implement the providers and authentication changes * [x] add new backend methods * [x] deprecate several top-level methods * [ ] update documentation (readme, sphinx, examples) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: SymPy tests fail in IPython 5b3 Run ``` ./bin/test ipython ``` from the SymPy repo with the IPython 5b3 beta installed. This is the test failure. ``` ______________________________________________________________________________________________________________________________________________________________ _________________________________________ sympy/interactive/tests/test_ipythonprinting.py:test_print_builtin_option __________________________________________ File \"/users/aaronmeurer/documents/python/sympy/sympy/sympy/interactive/tests/test_ipythonprinting.py\", line 66, in test_print_builtin_option raises(KeyError, lambda: app.user_ns['a'][0]['text/latex']) File \"/Users/aaronmeurer/Documents/Python/sympy/sympy/sympy/utilities/pytest.py\", line 81, in raises raise AssertionError(\"DID NOT RAISE\") AssertionError: DID NOT RAISE ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: `validation_step` progress bar output should be used When you're running validation steps your progress bar iter counter will increment once per `validation_step`. However, AFAICT there's no way to actually customize the progress_bar text during these validation_steps. For large validation sets, this makes it hard to know how far into validation you are, since the iter counter is the total steps. I am returning a dict from `validation_step` like: ``` def validation_step(self, batch, batch_nb): output = {'progress_bar': {'batch_nb': batch_nb}} return output ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: numpy.deprecate indentation question This code has two functions marked as deprecated with `numpy.deprecate`: ``` import numpy as np @np.deprecate(message=\"foo() is no longer supported.\") def foo(): \"\"\"This is foo. It doesn't do anything. \"\"\" return @np.deprecate(message=\"bar() is no longer supported.\") def bar(): \"\"\" This is bar. It does the same thing as foo(). \"\"\" return ``` The docstrings of `foo` and `bar` end up like this: ``` In [5]: print(foo.__doc__) `foo` is deprecated! foo() is no longer supported. This is foo. It doesn't do anything. In [6]: print(bar.__doc__) `bar` is deprecated! bar() is no longer supported. This is bar. It does the same thing as foo(). ``` Note that the indentation of the added deprecation text doesn't match the indentation of the original docstring. Is this intentional? It messes up the HTML documentation; see, for example, the online documentation for [`scipy.stats.itemfreq`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.itemfreq.html). That gray bar in front of what was originally the first line of the docstring (\"Return a 2-D array...\") shouldn't be there. A related issue was reported in https://github.com/numpy/numpy/issues/8058, which was closed by https://github.com/numpy/numpy/pull/8131. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook checkpoint time is displayed an hour out e.g. I see \"Last Checkpoint: Jun 03 09:49 (autosaved: Jun 03 10:49)\", having just saved it at 10:49 local time. The notification bubble when I hit save also showed 9:49 instead of 10:49. I don't know whether it's forcing the checkpoint time to UTC, or just somehow missing daylight saving time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Automatic docs I know it was proposed before and I tabled it but I think it's time to reconsider so docs can scale easier. Let's use whatever PyTorch uses and do documentation in the code (i assume that's how it's done?). Anyone want to take a stab at this? @Borda Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [Question] list header files in meson introspect Hi, i was wondering why meson don't list header files as source file in intro-targets ? And has meson a way to retreive headers ? (it's needed for completing QtCreator support of meson) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [frameworks: 15 llvm] fails with llvm/clang 14.0.0 As pointed out here: https://github.com/mesonbuild/meson/pull/10248#issuecomment-1092454817 The error I see in the logs (`check_source_compiles: C: needs to be enabled before use.`) suggest it is https://github.com/llvm/llvm-project/issues/53950 And indeed ```diff diff --git a/mesonbuild/dependencies/data/CMakeListsLLVM.txt b/mesonbuild/dependencies/data/CMakeListsLLVM.txt index 9d3e41234..4084597d3 100644 --- a/mesonbuild/dependencies/data/CMakeListsLLVM.txt +++ b/mesonbuild/dependencies/data/CMakeListsLLVM.txt @@ -2,6 +2,8 @@ cmake_minimum_required(VERSION ${CMAKE_MAJOR_VERSION}.${CMAKE_MINOR_VERSION}.${C set(PACKAGE_FOUND FALSE) +project(MesonTemp LANGUAGES C CXX) + while(TRUE) find_package(LLVM REQUIRED CONFIG QUIET) ``` seems to make it work here. I see that the generic CMakeLists file has some logic to inject the language, so I'm not sure if that should be extended or if the above patch is enough. based on the file history -> pinging @mensinda Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: BatchEncoding.to accepted types too restrictive ## Environment info - `transformers` version: 4.1.1 - Platform: Linux-4.14.81.bm.15-amd64-x86_64-with-debian-9.11 - Python version: 3.7.9 - PyTorch version (GPU?): 1.7.0 (True) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: yes - Using distributed or parallel set-up in script?: yes ### Who can help ## Information In `BatchEncoding.to`, the only accepted class types are `str` and `torch.device`. I think some libraries like pytorch-lightning call `.to` with the integer value for the GPU number, and HF complains about this when it is perfectly valid: ``` >>> x = torch.zeros(1) >>> x.to(0) tensor([0.], device='cuda:0') ``` ## Expected behavior Also allow int values in BatchEncoding.to Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Improve documentation for AlignMeasures and ValidatePulseGates transpiler passes <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In #6673 two new transpiler passes `AlignMeasures` and `ValidatePulseGates` were added. However, the documentation in these passes doesn't really describe anything about the passes, what they're used for, or how they are supposed to be used. Both only have a single line description about the pass (which basically mirrors the class name) and a comment about it being hardware aware. We should improve the documentation for these passes so it explains to users the purpose of the pass, what they can be used for, and how they're used. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [Feature request] Can we WARN when a user changes `user_home_short` to same as `path`? A colleague was working fine with Conan for weeks, then started getting the following error even for simple operations such as `conan search`: ``` C:\\Program Files (x86)\\Microsoft Visual Studio 14.0\\VC>conan search ERROR: Value provided for package version, '1' (type Version), is too short. Valid names must contain at least 2 characters. ``` I see similar https://github.com/conan-io/conan/issues/5606 -- is this the same issue? Windows Server 2012 R2, conan 1.16.1 To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Adding a backend_overview I think it is important to be able to view the backend status. I find myself writing this code lots ```python for backend in [IBMQ.backends(), Aer.backends()]: print(backend.status()) ``` and even this is not enough. I would like to be able to have a terminal or a section of my Juypiter (or even app) telling me continually the backend status. I would like to write something like ``` python backend_monitor([IBMQ, Aer,...]) ``` and this makes an output for me like ``` {'pending_jobs': 10, 'name': 'ibmqx4', 'operational': True} {'pending_jobs': 8, 'name': 'ibmqx5', 'operational': False} {'pending_jobs': 0, 'name': 'ibmqx2', 'operational': False} {'pending_jobs': 54, 'name': 'ibmq_16_melbourne', 'operational': True} {'pending_jobs': 0, 'name': 'ibmq_qasm_simulator', 'operational': True} {'name': 'qasm_simulator', 'operational': True, 'pending_jobs': 0} {'name': 'qasm_simulator_py', 'operational': True, 'pending_jobs': 0} {'name': 'statevector_simulator', 'operational': True, 'pending_jobs': 0} {'name': 'statevector_simulator_py', 'operational': True, 'pending_jobs': 0} {'name': 'unitary_simulator', 'operational': True, 'pending_jobs': 0} {'name': 'clifford_simulator', 'operational': True, 'pending_jobs': 0} ``` I think we need to add 'provider': 'IBMQ' (also add this to the spec) and \"status_msg\": \"This is a status message\" where the status_msg is set by the backend controller (down for maintence, retireded)... I think this should continue until I quit it, but this we can discuss more. Like the job_monitor it should live in wrapper or tools. I still need @delapuente to convince me what the difference is Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Support for Xcode 13.3 (currently in beta) Xcode 13.3 (still in beta) reports clang version as 13.1.6, so equivalent of #9642 is needed. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: BART summarization, tokenizer not working @patil-suraj When I am running pytorch/summarization, the logs are as below: ``` Adding AddedToken(content='<s>', single_word=False, lstrip=False, rstrip=False, normalized=True) to the vocabulary Adding AddedToken(content='</s>', single_word=False, lstrip=False, rstrip=False, normalized=True) to the vocabulary Adding AddedToken(content='<pad>', single_word=False, lstrip=False, rstrip=False, normalized=True) to the vocabulary Adding AddedToken(content='<mask>', single_word=False, lstrip=True, rstrip=False, normalized=True) to the vocabulary Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained. https://huggingface.co/facebook/bart-large-cnn/resolve/main/pytorch_model.bin not found in cache or force_download set to True, downloading to /home/sdiaoaa/.cache/huggingface/transformers/tmpama_iuh8 ``` But the embedding did not fit for the added tokens. The embedding is still [50264] but the token_ides ranges from [0, 50269] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: Fix mistake in documentation of `*.npy` header. The [documentation](https://docs.scipy.org/doc/numpy/neps/npy-format.html#format-specification-version-1-0) of the format contains the following paragraph: > \"The next HEADER_LEN bytes form the header data describing the array’s format. It is an ASCII string which contains a Python literal expression of a dictionary. It is terminated by a newline (‘n’) and padded with spaces (‘x20’) to make the total length of the magic string + 4 + HEADER_LEN be evenly divisible by **16** for alignment purposes.\" In the code comments (and in the actual format), padding is done such that the sum of the length of the magic string, 4, and the HEADER_LEN, is evenly divisible by **64**, not 16, as shown [here](https://github.com/numpy/numpy/blob/master/numpy/lib/format.py#L105): This has caused me some headache while writing a custom .npy serializer.. Also, the wording \"to make the total length of the magic string + 4 + HEADER_LEN\" is a little confusing, as it makes it seem that the amount being referenced is equal to `total length of magic string` + `4` + `HEADER_LEN` as opposed to total length of `magic string + 4 + HEADER_LEN`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: KubernetesPodOperator pod_template_file content doesn't support jinja airflow template variables KubernetesPodOperator pod_template_file content doesn't support jinja airflow template variables. pod_template_file is part of templated_fields list. https://github.com/apache/airflow/blob/master/airflow/providers/cncf/kubernetes/operators/kubernetes_pod.py#L165 template_fields: Iterable[str] = ( 'image', 'cmds', 'arguments', 'env_vars', 'labels', 'config_file', 'pod_template_file', ) But pod_template_file content is not supporting template variables. pod_template_file can be implemented the way SparkKubernetesOperator implemented using template_ext https://github.com/apache/airflow/blob/master/airflow/providers/cncf/kubernetes/operators/spark_kubernetes.py#L46 template_ext = ('yaml', 'yml', 'json') Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: No way to disable checkpoint callback With the recent change to provide a checkpoint callback by default, there's no way to disable checkpointing. Passing `checkpoint_callback=None` results in the default checkpointer being created. In `Trainer.__Init__`: ```python self.checkpoint_callback = checkpoint_callback if self.checkpoint_callback is None: if isinstance(logger, TestTubeLogger): ckpt_path = '{}/{}/{}'.format(self.default_save_path, self.logger.name, self.logger.version) else: ckpt_path = self.default_save_path self.checkpoint_callback = ModelCheckpoint( filepath=ckpt_path ) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Kernel start fails when using --browser argument repro steps: 1. Start ipython notebook with browser flag: - $ ipython notebook --browser firefox - Note that this successfully starts the notebook in firefox instead of the default browser 2. Open/create a notebook document 3. Wait for kernel to start What I expect to see: everything should just work :) What I see: A \"Kernel restarting\" dialog opens in the browser window for a little while, and finally switches to a \"Dead kernel\" dialog. The console log shows evidence of attempting to restart the kernel, ending with the following: [IPKernelApp] CRITICAL | Bad config encountered during initialization: [IPKernelApp] CRITICAL | Unrecognized flag: '--browser' 2014-04-11 15:58:30.172 [NotebookApp] WARNING | KernelRestarter: restart failed 2014-04-11 15:58:30.174 [NotebookApp] WARNING | Kernel 218d6d1f-0779-42b8-802f-5b3df58bc919 died, removing from map. ERROR:root:kernel 218d6d1f-0779-42b8-802f-5b3df58bc919 restarted failed! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add a blocking Delay instruction to pulse <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? We should add a new type of instruction `Delay` to pulse. This will be a blocking instruction that will occupy the timeslot for a given duration on the specified channel. This command should accept only duration and name as parameters. The command will be ignored at assembly time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `_log_format_changed()` missing 3 required positional arguments In `IPython.config.application`, the `_log_datefmt_changed` handler calls `_log_format_changed` but does not pass it the required arguments. My guess would be that this is the correct implementation: ``` def _log_datefmt_changed(self, name, old, new): self._log_format_changed(name, self.log_format, self.log_format) ``` However I am not really sure what the `name` parameter is for, so I might be wrong. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Fix anchors in URLs in external_config module In `external_config.py`, many links in docstrings point to non-existing HTML anchors, making them less convenient to open the page at the exact property/object the link points to. **Example:** The link to the `compression` property > https://cloud.google.com/bigquery/docs/reference/rest/v2/tables#externalDataConfiguration.compression should actually be > https://cloud.google.com/bigquery/docs/reference/rest/v2/tables#ExternalDataConfiguration.FIELDS.compression Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: service_run_+1 I have a two cronjob for `run` `php` service in same time. Only one `run` command execute correctly ``` Cannot create container for service php: Conflict. The container name \"/folder_php_run_1\" is already in use by container {hashhere}. You have to remove (or rename) that container to be able to reuse that name. Command exited with non-zero status 1 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] Is there a way to remove \"modified\" fields from lockfiles? <!-- What is your question? Please be as specific as possible! --> Hello, I'm playing with lockfiles right now, and my goal is to start a CI job, doing: * generating a `conan.lock` from the top-level recipe * rebuilding everything from the modified dependency up to the top-level recipe * pushing the lockfile to a repo, so that devs and further CI jobs can reuse it Problem is, the lockfile will contain `modified=built` fields, which make the lockfile unusable by further CI jobs. @memsharded told me that there was a previous `clean` command, that was removed earlier, reintroducing it might solve the problem. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Bug in text format of SabreSwap What is the file name(s) where you found the bug? File name: SabreSwap https://qiskit.org/documentation/apidoc/transpiler_passes.html#module-qiskit.transpiler.passes What is the current text that needs to be fixed? The mathematical expression for H_decay is overflown and out of the webpage margins. The absolute sign is missing? The link for 'SabreSwap()' https://qiskit.org/documentation/stubs/qiskit.transpiler.passes.SabreSwap.html#sabreswap Are there other related issues or pull requests about this bug? No. Does existing documentation need to be updated with new content? No Which files need to be updated? No  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: provide CONAN_CACHE_NO_LOCKS environment variable right now debugging conan (e.g. via PyCharm) is not very convenient, as stopping debugging causes strayed lock files, and it's necessary to run `conan remove --locks` each time before running. there is config setting `general.no_cache_locks`, but it's global, and affects regular conan execution. with environment variable, it's much more straightforward, as it can be easily specified in debugging target properties. To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cross compiler needs_exe_wrapper is ignored I tried to compile mesa with meson 0.51 with an x86_64 -> x86 cross compile, and it fails because one of our generators is host compiled, which will run just fine but meson asserts and dies instead. Looks pretty trivial, I'll fix it. Related to #5509 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Adjust `start_tasks` to include key tasks When a flow is run with `start_tasks`, we should add key tasks (`terminal_tasks`, `reference_tasks`) to the list of visited tasks. Otherwise, the FlowRunner will not have all available states when it performs its final state evaluation Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: vmap should check in_axes tree-prefix property, raise clear error Also we can probably improve the docstring's explanation of what tree prefixes are about. Thanks, @zhongwen ! Allow vmap to accept unbatchable arguments if they aren't mapped over I want to use vmap on functions that have some arguments which don't need to be mapped over. I can specify this using in_axes, but vmap doesn't allow this for some argument types. It seems to check if every argument is a valid type for batching, even if that argument is ignored due to in_axes. Can you remove this check for those arguments which won't be batched over? A simple example: ```Python from jax.api import vmap import jax.numpy as np def mymap(f, x): return f(x) vmap(mymap, in_axes=(None, 0))(np.sin, np.linspace(0, 1, 10)) ``` Fails with `TypeError: <type 'function'> is not a valid type for batching` This is a minor issue, because I could get around with with `partial` or by making closures, but that clutters up the code a bit. Better error messages for vmap dimensions This piece of code is incorrect since in_axes should be (0, 0) instead of (0, 1) def h(a, b): return np.sum(a) + np.sum(b) X = onp.random.randn(10, 4) U = onp.random.randn(10, 2) vmap(h, in_axes=(0, 1))(X, U) The current error message is: \"got inconsistent map dimension sizes: set([10, 2])\" I think the error message could describe the input shapes and mention which dimensions we are batching over. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [Bug] meson failed to compile with ubuntu 18.04 on launchpad build **Describe the bug** I was trying to build meson with ubuntu 18.04 on launchpad . But it is continuously failing to build. Always test error. For more details see the [launchpad build log](https://launchpad.net/~pipewire-debian/+archive/ubuntu/bionic-qt5125/+build/22357414/+files/buildlog_ubuntu-bionic-amd64.meson_0.60.0.r15.gc9e6afc-1~ubuntu18.04_BUILDING.txt.gz) I'd tried to build from release and from the latest branch 0.60 both are failing. I can successfully build the same with ubuntu >= 20.04 **Expected behavior** Test is failing. I think you can understand seeing the above mentioned launchpad build log properly. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? native build * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) ubuntu 18.04 * what Python version are you using e.g. 3.6.9 * what `meson --version` 0.58 * what `ninja --version` if it's a Ninja build 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: --update is not working with python-requires with version-ranges @memsharded This is still not functioning. `conan version 1.15.1` I'm using python requires in the manner described here: https://docs.conan.io/en/latest/extending/python_requires.html#python-requires-reusing-code-experimental I'm defining base ConanFile recipes, which works great! In my downstream conanfiles: ``` common = python_requires('ConanRecipes/[>=0.1.0-0, include_prerelease=True]@mh/testing') class ThisIsAPackage(common.BaseRecipe): ``` However, it still does not get updated with `--update` I have to remove the ConanRecipes locally to get latest version. `conan remove ConanRecipes* -f` Then it downloads the latest one. _Originally posted by @Mark-Hatch-Bose in https://github.com/conan-io/conan/issues/4650#issuecomment-497464305_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Opt-out of checkpointing on a single Task ## Current behavior With 0.9.0 Prefect Flows will begin aggressively checkpointing, taking a hint to enable or disable checkpointing based on the existence of a result handler. It may be desired to have select tasks to not checkpoint by specifying `@prefect.task(checkpointing=False)`, however, this option is now ignored. ## Proposed behavior Allow for select tasks to disable checkpointing with `@prefect.task(checkpointing=False)`. The Flow should continue to checkpoint all other tasks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Possibly wrong API documentation for BigBirdTokenizerFast - `transformers` version: v.4.9.0 ### Who can help Documentation: @sgugger ## Information At this URL: https://huggingface.co/transformers/model_doc/bigbird.html#transformers.BigBirdTokenizerFast The doc says, `bos_token (str, optional, defaults to \"[CLS]\")` and `eos_token (str, optional, defaults to \"[SEP]\")` but the actual code is: ``` def __init__( self, vocab_file=None, tokenizer_file=None, unk_token=\"<unk>\", bos_token=\"<s>\", eos_token=\"</s>\", pad_token=\"<pad>\", ``` May be the API document need a fix? the explanation seems already clear though, only default value of those params are wrong. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.devices returns only the devices from the default backend The documentation of jax.devices says that it returns all devices. This is not true in multi-backend setups, it returns only the devices from the default backend. This was confusing to me initially, and I also encountered this confusion in issue #2785 The simplest change would be to the documentation: if no `backend` is specified then only the devices on the default backend are returned (along with an explanation of what is the default backend). A better change may be though to say that it returns all devices, in the order of backend priority, such that `devices()[0]` is the same as now. This may break some code though. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.numpy.linalg ops missing GPU implementation I often hit messages like ```\"Singular value decomposition is only implemented on the CPU backend\"``` (https://github.com/google/jax/blob/27746b8c73f9ca9928da5da40b7382ae648a5f8d/jax/lax_linalg.py) for many `jax.numpy.linalg` ops. Examples I've hit so far are when calling: `jax.numpy.linalg.svd`; `jax.numpy.linalg.eigh`. It would be nice to be able to run on GPU. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Legacy 1.13 printing broken for 0d arrays Code to trigger the error: ```python >>> import numpy as np >>> np.__version__ '1.14.2' >>> np.array2string(np.array(1.0)) '1.' >>> np.set_printoptions(legacy='1.13') >>> np.array2string(np.array(1.0)) Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"[...]/numpy/core/arrayprint.py\", line 616, in array2string return style(a.item()) TypeError: object() takes no parameters ``` Same error with 1.14.1 and 1.14.0. Since `style` is just an alias for `np._NoValue` the code effectively calls (or instantiates, depending on the code version) `_NoValue(1.0)`, which is not valid. I saw that there was a recent change in `_globals.py` that makes `_NoValue` an instance instead of a class, but it has no `__call__`, so unless I'm missing something, it won't work either. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: resolve orphan process issues on Windows when terminating runs launched with the grpc run launcher Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Deprecation warnings in algorithms and opflow <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Doing a quick grep for `DeprecationWarning` in `qiskit/algorithms` and `qiskit/opflow` there are several places emitting deprecation warnings: - opflow/gradients/circuit_gradients/lin_comb.py - opflow/gradients/circuit_qfis/lin_comb_full.py - algorithms/optimizers/spsa.py - algorithms/optimizers/aqgd.py - algorithms/amplitude_amplifiers/grover.py - algorithms/optimizers/gsls.py Since these APIs are new in this namespace and in terra we should not be having an initial release with deprecations. The version in Aqua will have the deprecations and users will have to adapt there usage when they migration from aqua to the terra versions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Bug in run_classifier.py fp16 learning rate After the latest update, my learning rate of fp16 in run_classifier.py keeps increasing. https://github.com/huggingface/pytorch-pretrained-BERT/blob/2dee86319dbad575352358b8f2fb4129940e381a/examples/run_classifier.py#L857-L858 I think the right code is: lr_this_step = args.learning_rate * warmup_linear.get_lr(global_step, args.warmup_proportion). https://github.com/huggingface/pytorch-pretrained-BERT/blob/2dee86319dbad575352358b8f2fb4129940e381a/pytorch_pretrained_bert/optimization.py#L53-L62 In this function, the first argument should be step, and global_step/num_train_optimization_steps makes process calculated again and when input process to WarmupLinearSchedule, it would be too small to decrease https://github.com/huggingface/pytorch-pretrained-BERT/blob/2dee86319dbad575352358b8f2fb4129940e381a/pytorch_pretrained_bert/optimization.py#L162-L171 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Save/load hyperparameters with checkpoint Right now, test tube users can have `model.load_from_metrics`, but there's no equivalent functionality for users of other logging frameworks. I believe we discussed a while ago that this functionality should be decoupled from logggers. Proposal: * When hyperparameters are stored as an `argparse.Namespace` in the `hparams` property of the model (as already required to get automatic hyperparam logging), save these parameters as part of checkpoints. * Add a `load_from_checkpoint` classmethod to LightningModule that basically duplicates the functionality of `load_from_metrics`, but gets the hyperparameters from the checkpoint directly. I'm happy to send a PR if this proposal looks okay. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Usability improvements to Qt console Currently the Qt console is tricky to use with multiline cells recalled from history because it's very easy to go 'off the edge'. If the cursor reaches the top or bottom line and you do up/down once more, you jump to the next cell. When recalling history that's the desired behavior, but when you've already edited a cell, it's jarring to get bumped out of your editing context due to a single arrow movement. I don't know how easy/possible it would be to implement, but my idea is the following: the console should detect when a cell has been made 'dirty' by editing (any typing other than arrow movements, pasting, etc), then the behavior should change. At that point, the cell boundaries should become 'hard', preventing the cursor from exiting unless the person clears the cell. Basically, once the cell is being edited, it should feel like a little text editor that doesn't lose its content without some drastic action. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Did `numpy.version.short_version` disappear in version 1.21 RC ? I noticed the attribute `numpy.version.short_version` no more exists in the latest release candidate (1.21.0RC1) which has been pip-installed on linux-amd64 running python3.9 (binary wheel). This is breaking some build scripts downstream. I just wonder if it was foreseen to remove this attribute ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add support to log hparams and metrics to tensorboard? How can I log metrics (_e.g._ validation loss of best epoch) together with the set of hyperparameters? I have looked through the docs and through the code. It seems like an obvious thing, so maybe I'm just not getting it. Currently, the only way that I found was to extend the logger class: ```python class MyTensorBoardLogger(TensorBoardLogger): def __init__(self, *args, **kwargs): super(MyTensorBoardLogger, self).__init__(*args, **kwargs) def log_hyperparams(self, *args, **kwargs): pass @rank_zero_only def log_hyperparams_metrics(self, params: dict, metrics: dict) -> None: params = self._convert_params(params) exp, ssi, sei = hparams(params, metrics) writer = self.experiment._get_file_writer() writer.add_summary(exp) writer.add_summary(ssi) writer.add_summary(sei) # some alternative should be added self.tags.update(params) ``` And then I'm writing the hparams with metrics in a callback: ``` def on_train_end(self, trainer, module): module.logger.log_hyperparams_metrics(module.hparams, {'val_loss': self.best_val_loss}) ``` But that doesn't seem right. Is there a better way to write some metric together with the hparams as well? #### Environment - OS: Ubuntu18.04 - conda4.8.3 - pytorch-lightning==0.7.1 - torch==1.4.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Upgrade pylint <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Upgrade Pylint. Switching from pylint to flake8 are discussed another issue #1179. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: \"Tried to use subproject object as a dependency.\" erroneous message Given the following structure: ``` touch foo.c echo \"project('test', 'c') subdir('subdir') executable('foo', 'foo.c', dependencies: subdir_lib)\" > meson.build mkdir subdir touch subdir/lib.c echo \"subdir_lib = static_library('lib', 'lib.c')\" > subdir/meson.build meson build ``` Meson throws an exception: ``` Meson encountered an error in file meson.build, line 5, column 0: Tried to use subproject object as a dependency. You probably wanted to use a dependency declared in it instead. Access it by calling get_variable() on the subproject object. ``` But actually there is no subproject at all in this project, it confused me a lot to understand what was the actual problem which is I should not use a library as a dependency. All the stuff about `get_variable` is wrong and confusing in my opinion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: slim down progress bar default printing ## 🚀 Feature The progress bar is cluttered, too many prints by default. Let's remove some of them. ### Pitch Hi guys, I feel the progress bar contains some uninformative prints and leaves little space for user customization. This is the progress bar print before validation, with empty tqdm_dict (so no user addition to the progress bar metrics): ``` Epoch 1: 39%|███▉ | 343/875 [00:07<00:10, 48.46batch/s, batch_nb=342, gpu=0, loss=0.408, v_nb=18] ``` This is after a validation step where I add to the tqdm_dict validation accuracy and loss: ``` Epoch 2: 20%|█████████████████▏ | 171/875 [00:03<00:11, 58.99batch/s, batch_nb=170, gpu=0, loss=0.267, v_nb=21, val_acc=91.8, val_loss=0.278] ``` To avoid more clutter and make some room for user-defined metrics, I propose to **remove** the following outputs from the progress bar: - **batch_nb**: this is redundant, essentially the same number is printed on the left - **loss**: this is something always computed in the training step. If the user wants to show it, he just adds it to the tqdm_dict - **gpu**: this info is useless in single-gpu setting, and likely also in multi-gpu ones. - **v_nb**: This is the experiment version number, which is very convenient to know. Since it stays the same during the whole experiment, we could just print it by default before the training starts. Also, I propose to rename \"batch/s\" to tqdm default \"it/s\" to save a few extra characters. Pinging @tullie @Borda since this discussion almost started in #531 . Best, C Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: installed mode tests fail for non-root user on Solaris ``` ====================================================================== FAIL: test_installed_modes (__main__.LinuxlikeTests) ---------------------------------------------------------------------- Traceback (most recent call last): File \"run_unittests.py\", line 4579, in test_installed_modes self.assertEqual(want_mode, found_mode[1:]) AssertionError: 'rw------T' != 'rw-------' - rw------T ? ^ + rw------- ? ^ ``` ``` ====================================================================== FAIL: test_installed_modes_extended (__main__.LinuxlikeTests) ---------------------------------------------------------------------- Traceback (most recent call last): File \"run_unittests.py\", line 4650, in test_installed_modes_extended (fsobj, want_mode, found_mode))) AssertionError: '-r--r--r-T' != '-r--r--r--' - -r--r--r-T ? ^ + -r--r--r-- ? ^ : Expected file include/rootdir.h to have mode -r--r--r-T but found -r--r--r-- instead. ``` This appears to be because [Solaris chmod(2)](https://docs.oracle.com/cd/E88353_01/html/E37841/chmod-2.html) has an additional restriction: > If the process is not a privileged process and the file is not a direc- > tory, mode bit 01000 (S_ISVTX, the sticky bit) is cleared. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %paste + history From a user point of view, it seem like `%paste` should not store itself in IPython's history, but instead store the text that was pasted. It seems unlikely that a user will want to use history to get to paste again over get to the thing that was pasted.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: KeyError on second upload of a package without remote in registry When a package is uploaded to a remote, it gets associated to it in the registry. If the remote is removed from the registry (``conan remote remove``) and the package is uploaded to a different remote, Conan ends with an error and the name of the remote. The error turns to be a KeyError on a registry search of the remote url and verify_ssl in here: https://github.com/conan-io/conan/blob/a52dcdc87dd8146b661ed650da616b9fcd2371e3/conans/client/cache/remote_registry.py#L122 Here is a test reproducing the issue: ``` def upload_key_error_test(self): files = cpp_hello_conan_files(\"Hello0\", \"1.2.1\", build=False) server1 = TestServer([(\"*/*@*/*\", \"*\")], [(\"*/*@*/*\", \"*\")], users={\"lasote\": \"mypass\"}) server2 = TestServer([(\"*/*@*/*\", \"*\")], [(\"*/*@*/*\", \"*\")], users={\"lasote\": \"mypass\"}) servers = OrderedDict() servers[\"server1\"] = server1 servers[\"server2\"] = server2 client = TestClient(servers=servers) client.save(files) client.run(\"config set general.revisions_enabled=True\") client.run(\"create . user/testing\") client.run(\"user lasote -p mypass\") client.run(\"user lasote -p mypass -r server2\") client.run(\"upload Hello0/1.2.1@user/testing --all -r server1\") client.run(\"remove * --force\") client.run(\"install Hello0/1.2.1@user/testing -r server1\") client.run(\"remote remove server1\") client.run(\"upload Hello0/1.2.1@user/testing --all -r server2\") self.assertNotIn(\"ERROR: 'server1'\") ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: PROFILE_DIR with forward slashes hi there, I want to use the ```PROFILE_DIR``` variable in my profiles to access a path relative to the value of that variable. Now I do cross-compiling with a compiler that cannot parse backslashes. An example yaml like this: ```yaml [env] ABC=$PROFILE_DIR/path/abc ``` will result in a malformed path as the compiler tries to interpret the slashes as excape characters: compiler parsed: ... C:UsersNAME.conanprofiles/path/abc ... Would it be possible to provide an POSIX style path (like PROFILE_DIR_POSIX)? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Clean C++20 support for CMake 3.12+ CMake 3.12 is out there and officially supports C++20. So now you can use clean way to enable C++20 mode if CMake 3.12 or later is detected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: StochasticSwap bug <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: - **Python version**: 0.7.0 - **Operating system**: ### What is the current behavior? The stochastic swap mapper seems to create a non-equivalent circuit for the following case: ```python from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit from qiskit import BasicAer, execute from qiskit.transpiler import PassManager, transpile from qiskit.transpiler.passes import StochasticSwap from qiskit.mapper import CouplingMap coupling = [[0, 1], [1, 2], [2, 3], [3, 4], [4, 5], [5, 6]] qr = QuantumRegister(7, 'q') cr = ClassicalRegister(7, 'c') circuit = QuantumCircuit(qr, cr) circuit.h(qr[3]) circuit.cx(qr[0], qr[6]) circuit.cx(qr[6], qr[0]) circuit.cx(qr[0], qr[1]) circuit.cx(qr[3], qr[1]) circuit.cx(qr[3], qr[0]) circuit.measure(qr, cr) simulator = BasicAer.get_backend('qasm_simulator') coupling_map = CouplingMap(couplinglist=coupling) pass_manager = PassManager(StochasticSwap(coupling_map=coupling_map)) stochastic_circ = transpile(circuit, simulator, pass_manager=pass_manager) print(execute(circuit, simulator).result().get_counts()) print(execute(stochastic_circ, simulator).result().get_counts()) ``` ``` {'0000000': 488, '0001011': 536} {'0000000': 499, '0001001': 525} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: issue with i18n.merge_file I have the following rule: ``` i18n.merge_file( 'org.freedesktop.systemd1.policy', po_dir : po_dir, input : policy_in, output : 'org.freedesktop.systemd1.policy', install : true, install_dir : polkitpolicydir) ``` This fails like this: ``` FAILED: src/core/org.freedesktop.systemd1.policy 'msgfmt' '--xml' '--template' 'src/core/org.freedesktop.systemd1.policy.in' '-d' '/home/zbyszek/src/systemd/po' '-o' 'src/core/org.freedesktop.systemd1.policy' msgfmt: cannot locate ITS rules for src/core/org.freedesktop.systemd1.policy.in ``` I have no idea what \"ITS rules\" are ;( Doing it \"manually\" works: ``` policy_in = configure_file( input : 'org.freedesktop.systemd1.policy.in.in', output : 'org.freedesktop.systemd1.policy.in', configuration : substs) custom_target( 'org.freedesktop.systemd1.policy', input : policy_in, output : 'org.freedesktop.systemd1.policy', command : intltool_command, install : true, install_dir : polkitpolicydir) ``` I saw similar message in https://github.com/mesonbuild/meson/issues/1441#issuecomment-283585493, it might be related... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Bug in numpy_pad_and_concatenate https://github.com/huggingface/transformers/blob/77b862847b8069d57c0849ca012f48414c427d8e/src/transformers/trainer_pt_utils.py#L71 I believe this should be `np.concatenate((array1, array2), axis=0)` Bug in numpy_pad_and_concatenate https://github.com/huggingface/transformers/blob/77b862847b8069d57c0849ca012f48414c427d8e/src/transformers/trainer_pt_utils.py#L71 I believe this should be `np.concatenate((array1, array2), axis=0)` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: mesonintrospect --dependencies no longer works in 0.41.0 ``` Traceback (most recent call last): File \"/usr/bin/mesonintrospect\", line 20, in <module> sys.exit(mintro.run(sys.argv[1:])) File \"/usr/lib/python3.6/site-packages/mesonbuild/mintro.py\", line 245, in run list_deps(coredata) File \"/usr/lib/python3.6/site-packages/mesonbuild/mintro.py\", line 162, in list_deps if d.found(): AttributeError: 'tuple' object has no attribute 'found' ``` Broke with 8cf29bd288cb67008a42a5c9503042f975c04a43 in which CoreData.deps was changed to an OrderedDict? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Quickstart guide recommends np.set_printoptions(threshold=np.nan), which fails We should update [this guide](https://github.com/eric-wieser/numpy/blob/master/doc/source/user/quickstart.rst#printing-arrays) to use `sys.maxsize`. @mattip, I'm correct in assuming you prefer that to np.inf? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add the fast implementation of `BlenderbotTokenizer` # 🚀 Feature request As it is the case for other models' tokenizers, add the fast implementation of BlenderbotTokenizer. ## Motivation To have faster tokenization for Blenderbot models. (Also, the implementation should be pretty straightforward considering the similarity to the `RobertaTokenizer`/`RobertaTokenizerFast`.) ## Your contribution I would like to have a look at this and will be glad to add that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: SyntaxError: encoding declaration in Unicode string ``` In [1]: # -*- coding: utf-8 -*- File \"<ipython-input-1-df4697b9472e>\", line unknown SyntaxError: encoding declaration in Unicode string ``` In regular Python ``` py >>> # -*- coding: utf-8 -*- ... >>> ``` This came up `%paste`ing an example from http://numba.pydata.org/numba-doc/dev/examples.html#id1. This seems related to #1103. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: The PDF option for `--post` should work with lowercase Right now to get a PDF out of nbconvert you have to to ``` ipython nbconvert --to latex --post PDF foo.ipynb ``` Many users will try `pdf` instead and the error message is very confusing. We should just make it work with lowercase. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `FakePrague` list of supported operations is incorrect Looking at this list: ```python from qiskit.providers.fake_provider import FakePrague backend = FakePrague() list(zip(backend.operation_names, [type(x) for x in backend.operations])) ``` ```python [('id', qiskit.circuit.library.standard_gates.i.IGate), ('rz', qiskit.circuit.library.standard_gates.rz.RZGate), ('sx', qiskit.circuit.library.standard_gates.sx.SXGate), ('x', qiskit.circuit.library.standard_gates.x.XGate), ('cz', qiskit.circuit.gate.Gate), ('reset', qiskit.circuit.reset.Reset), ('measure', qiskit.circuit.measure.Measure), ('delay', qiskit.circuit.delay.Delay)] ``` you see that the entry for `cz` is not an instance of `CZGate`. This is apparently the origin of the bug referenced in #9935 #9937 #9982 . The gate with name `cz` in the list above is not recognized as a CZ gate when doing unitary synthesis here https://github.com/Qiskit/qiskit-terra/blob/971a203deb33bdc309b1467d00e39efc5eda8936/qiskit/transpiler/passes/synthesis/unitary_synthesis.py#L646 and here https://github.com/Qiskit/qiskit-terra/blob/971a203deb33bdc309b1467d00e39efc5eda8936/qiskit/transpiler/passes/synthesis/unitary_synthesis.py#L677 Furthermore: ```python In [37]: badcz = backend.operations[4] In [38]: badcz.definition # None In [39]: badcz.to_matrix() # Raises error CircuitError: \"to_matrix not defined for this <class 'qiskit.circuit.gate.Gate' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Build Quality of Life Improvements - We need to add the following to `webpack.config.js`: `optimization: minimizer: [new UglifyJsPlugin({ cache: process.platform !== \"win32\" })]`, to help avoid the path length restriction on Windows. I ran into this today on a machine where I don't have admin access to make a change to the registry. I was getting paths like the following: `node_modules\\\\\\\\.cache\\\\\\\\uglifyjs-webpack-plugin\\\\\\\\content-v2\\\\\\\\sha512\\\\\\\\f0\\\\\\\\d9\\\\\\\\41b44207c2fa7189a30f3b6aeb8e22585bd4b0a78f8de3894c218f5b16de8ff9e48f3e54f767f6f69f99b6ba0a41538dd5b163d436d72ceb0ba4f3d4fbd` - We should also consider making `dev_build` the default option for `jupyter lab build` (and `labextension install`), and only uglify when explicitly asked, to avoid taking up large amounts of CPU, RAM, and time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: `use_amp` is broken in 0.7.0 I see that `use_amp` is deprecated but since the Trainer still accepts it as an argument, I believe this is still a bug. The issue is that the [hook that deals with this](https://github.com/PyTorchLightning/pytorch-lightning/blob/3c2fd560aa4d31b4f48ee225b83361deec53d9c7/pytorch_lightning/core/hooks.py#L136-L143) specifically checks if `trainer.precision == 16`. However, the Trainer does not set `precision = 16` if `use_amp = True`. Proposed solution: if `use_amp` is passed in, set precision = 16 and raise a deprecation warning. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Clear-all on save option I sometimes forget to clear all before saving and checking the notebook into revision control, and it produces harder to read diffs and file sizes larger than I want to be commiting. Being able to set an option within a notebook to only save in cleared format would be very useful. Even nicer would be if it didn't clear the open notebook, just the saved version. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: Add extended documentation of '@' operator, @rgommers >Another idea, from the \"deprecate np.matrix\" discussion: add numpy documentation describing the preferred way to handle matrices, extolling the virtues of @, and move np.matrix documentation to a deprecated section. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: access to exe_wrapper from test scripts igt has some tests (in meson) that are shell scripts, but they need to invoke built binaries. So it needs some way to get at the exe_wrapper. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: bart-large-cnn ROUGE-L scores ## Environment info ### Who can help BART + Summarization @sshleifer ## Information Model I am using is BART. The problem arises when: verifying accuracy numbers of facebook/bart-large-cnn on CNN+Daily Mail. The paper reports R1, R2, RL of 44.16, 21.28, 40.90 but I can get only 44.05, 21.07, 30.62. I used [this](https://github.com/abisee/cnn-dailymail) to make my dataset. Is this expected? The tasks I am working on is: * CNN-Dm summarization task ## To reproduce Steps to reproduce the behavior: 1. Follow instructions to download dataset 2. Run with `python run_summarization.py --reference_path=data/cnn_dm/test.target data/cnn_dm/test.source results/test.log` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add timestamp to docs In a call I had today, it was suggested that it would be useful to add a timestamp to the docs, in addition to the link to the commit that generated them. Currently this only exists in the API reference. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Manually triggering a dagrun when already at max_active_runs leads to nothing being scheduled. If you have a DAG with `max_active_runs=1` and it is running some tasks, and then you manually trigger another run of this DAG, both runs end up not scheduling anything and you see this message over and over in the logs: ``` [2020-10-16 14:00:34,118] 2437572 {{airflow.jobs.scheduler_job.SchedulerJob scheduler_job.py:1657}} INFO - DAG scenario1_case2_01_1 already has 1 active runs, not queuing any more tasks ``` A longer term fix for this would be to introduce a \"queued\" state for DagRuns, and then when manually creating dag runs set it to queued, and only have the scheduler set DagRuns to running. That may or may not be less work than fixing the current mechanism. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Remove optimization to match `track_features` ### What happened? https://github.com/conda/conda/blob/main/conda/core/subdir_data.py#L154-L161 is code to match `track_features`, but it looks for the match against a nonexistent field `track`. This has been broken since at least 2017 https://github.com/conda/conda/commit/12669896ecaa7c853ea8028958c44ef86515402f#diff-ca5dabe5c431ae6f12bae85508e4f38520d264980ba10060eb882cdeff8fc5f4L120 And the SubdirData._track_features index doesn't split features by commas, instead, it creates one-letter features. Remove the index used for searching on track_features when the exact package name is not given '*[track_features=<name>]' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: \"import\" module completion on MacOSX \"import\" module completion doesn't work for some modules (e.g. sqlalchemy), because in site-packages directory these modules are archived .egg files. Version information: MacOS X Mountain Lion, python 2.7, ipython 0.13.1 Here is a quick patch: ``` patch --- IPython/core/completerlib.py 2012-10-21 03:30:53.000000000 +0300 +++ ../completerlib.py 2012-11-07 15:14:10.000000000 +0200 @@ -88,10 +88,13 @@ name, extension = os.path.splitext( path ) return import_re.match(path) and py3compat.isidentifier(name) - # Now find actual path matches for packages or modules - folder_list = [p for p in folder_list - if isfile(pjoin(path, p,'__init__.py')) - or is_importable_file(p) ] + if path.endswith('.egg') and isfile(path): + folder_list = set(p.split('/', 1)[0] for p in folder_list if is_importable_file and p.endswith('/__init__.py')) + else: + # Now find actual path matches for packages or modules + folder_list = [p for p in folder_list + if isfile(pjoin(path, p,'__init__.py')) + or is_importable_file(p) ] return [basename(p).split('.')[0] for p in folder_list] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: jupyter labextension uninstall deletes federated extensions <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description `jupyter labextension uninstall` deletes federated extensions, but federated extensions should not be managed by `jupyter labextension`, since they are managed by other package managers. ## Reproduce ``` conda create -y -n jlab-extension python nodejs conda activate jlab-extension pip install --pre jupyterlab pip install --pre jupyterlab_widgets ``` This installs the new federated extension for ipywidgets. We can see it in ``` jupyter labextension list ``` We can uninstall it with ``` jupyter labextension uninstall @jupyter-widgets/jupyterlab-manager ``` ## Expected behavior I expect `jupyter labextension list` to distinguish between federated and non-federated extensions, i.e., extensions installed by `labextension` and those that are not. I expect `jupyter labextension uninstall` to not uninstall federated extensions, since it is not responsible for managing their files and cannot install them. Essentially, by uninstalling by removing the appropriate share directory, you are deleting files installed by a python package without uninstalling the python package, messing things up. ## Context <!--Complete the following for context, and add any other relevant context--> - Operating System and version: macOS Catalina - JupyterLab version: JLab 3.0rc6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Set FSDP `transformer_layer_cls_to_wrap` to `model._no_split_modules` ? ### Feature request Currently, when training with FSDP, the Trainer expects to receive an `fsdp_config` argument specifying `fsdp_transformer_layer_cls_to_wrap`. https://github.com/huggingface/transformers/blob/66954ea25e342fd451c26ec1c295da0b8692086b/src/transformers/trainer.py#L1394-L1406 I am wondering if we can set this automatically, when the model has a `_no_split_modules` attribute, e.g. https://github.com/huggingface/transformers/blob/66954ea25e342fd451c26ec1c295da0b8692086b/src/transformers/models/opt/modeling_opt.py#L401 ### Motivation It would be a convenient feature to set this automatically. This argument is model-specific, but it might be nice to define training arguments independently of a specific model type. ### Your contribution Happy to help make a PR. Would be great if you can confirm whether this would be desirable or if I am misunderstanding something. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Epoch end checkpoint restarts previous epoch ## 🐛 Bug If restarting the training and reloading the model, the epoch that the checkpoint had just completed is restarted rather than beginning the next. ### Expected behavior When a checkpoint upon epoch end is saved, restarting it should resume its state and start the next epoch. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Comet PAPI Depreciated Use of the Comet API logger reports an unecessary depreciation warning relating to the use of comet_ml.papi, rather than the newer comet_ml.api. Example: `COMET WARNING: You have imported comet_ml.papi; this interface is deprecated. Please use comet_ml.api instead. For more information, see: https://www.comet.ml/docs/python-sdk/releases/#release-300` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan does not set define `CMAKE_SYSTEM_VERSION` when \"os.api_level\" specified Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: Instructions to run integrations tests fail on tox **Additional environment details (Operating System, Cloud provider, etc):** Ubuntu 14.04, Python 2.7.6 **Steps to reproduce the issue:** 1. Follow instructions at https://github.com/DataDog/integrations-core/blob/e3985fe43853f6ee3bb11e8d9d20a18ca12ae340/docs/dev/README.md 2. 3. **Describe the results you received:** ``` $ tox ERROR: No setup.py file found. The expected location is: /home/sday/src/DataDog/integrations-core/setup.py You can 1. Create one: https://packaging.python.org/tutorials/distributing-packages/#setup-py 2. Configure tox to avoid running sdist: http://tox.readthedocs.io/en/latest/example/general.html#avoiding-expensive-sdist ``` **Describe the results you expected:** Tests should run. **Additional information you deem important (e.g. issue happens only occasionally):** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Looks like we don't expose the `Dataset` class as datastore.Dataset? There are some docs that use the following syntax: ``` python >>> from gcloud import datastore >>> dataset = datastore.get_dataset('dataset-id') ``` I'm not sure if this is accurate, but either way, if we're following the convention of datastore/**init**.py, this should be: ``` python >>> from gcloud import datastore >>> dataset = datastore.Dataset('dataset-id') ``` However I don't see the import in `__init__.py`, so I'm guessing that neither of these work...? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: flags --name and --prefix should pick up env's .condarc file Right now probably picking up the `.condarc` of the active env, which is wrong when `--name` or `--prefix` flags are used for CIUR operations. Environment missing from list when created with `conda create -p` ### Environment - conda version: `4.3.14` though I've seen this issue in previous and newer versions as well. All installed through `Anaconda` installers. Tested upto `4.3.21` - Python version: `2.7` `3.5` `3.6`. I mean these as the main conda python version - Operating System: `Win7`, `Win8`, `Win10`. ### Details - Describe what you were trying to get done. Create and manage a conda environment created in a custom path. - What commands did you run to trigger this issue? If you can provide a [Minimal, Complete, and Verifiable example](http://stackoverflow.com/help/mcve) this will help us understand the issue. `conda create -p c:\\python27 python=2.7` - If there was a crash, please include the traceback here. When running: ``` conda create -p c:\\python27 python=2.7 conda env list ``` This returns the following list ``` # conda environments: # root * C:\\python36 ``` But when running ``` conda create -n py35 python=3.5 conda env list ``` This returns ``` # conda environments: # py35 C:\\python36\\envs\\py35 root * C:\\python36 ``` If I run `activate c:\\python27` the correct environment activates with no issue. Inside of `\\.conda\\environments.txt` it has ``` c:\\python27 C:\\python36\\envs\\py35 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: [AIRFLOW-XXX] airflow.models.DAG docstring mistake correction Make sure you have checked _all_ steps below. ### Jira - [ x ] My PR addresses the following [Airflow Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references them in the PR title. For example, \"\\[AIRFLOW-XXX\\] My Airflow PR\" - https://issues.apache.org/jira/browse/AIRFLOW-XXX - In case you are fixing a typo in the documentation you can prepend your commit with \\[AIRFLOW-XXX\\], code changes always need a Jira issue. ### Description - [ x ] Here are some details about my PR, including screenshots of any UI changes: ### Tests - [ x ] My PR adds the following unit tests __OR__ does not need testing for this extremely good reason: ### Commits - [ x ] My commits all reference Jira issues in their subject lines, and I have squashed multiple commits if they address the same issue. In addition, my commits follow the guidelines from \"[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)\": 1. Subject is separated from body by a blank line 1. Subject is limited to 50 characters (not including Jira issue reference) 1. Subject does not end with a period 1. Subject uses the imperative mood (\"add\", not \"adding\") 1. Body wraps at 72 characters 1. Body explains \"what\" and \"why\", not \"how\" ### Documentation - [ x ] In case of new functionality, my PR adds documentation that describes how to use it. - When adding new operators/hooks/sensors, the autoclass documentation generation needs to be added. ### Code Quality - [ x ] Passes `git diff upstream/master -u -- \"*.py\" | flake8 --diff` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Dataset list remembers old datasets ### Apache Airflow version main (development) ### What happened Here's a simple pair of dags linked by a dataset: ```python3 from datetime import datetime from airflow import Dataset from airflow.operators.empty import EmptyOperator from airflow.decorators import dag dataset = Dataset(\"dataset\") @dag(start_date=datetime(1970, 1, 1)) def upstream(): EmptyOperator(task_id=\"empty\", outlets=[dataset]) upstream() @dag(start_date=datetime(1970, 1, 1), schedule=[dataset]) def downstream(): EmptyOperator(task_id=\"empty\") downstream() ``` I let airflow parse this, then I made the following edit: ```python3 d̶a̶t̶a̶s̶e̶t̶ ̶=̶ ̶D̶a̶t̶a̶s̶e̶t̶(̶\"̶d̶a̶t̶a̶s̶e̶t̶\"̶)̶ dataset = Dataset(\"dataset1\") ``` I let airflow parse it again, then I made another edit: ```python3 d̶a̶t̶a̶s̶e̶t̶ ̶=̶ ̶D̶a̶t̶a̶s̶e̶t̶(̶\"̶d̶a̶t̶a̶s̶e̶t̶1̶\"̶)̶ dataset = Dataset(\"dataset2\") ``` Then I viewed the datasets page: <img width=\"675\" alt=\"Screen Shot 2022-09-14 at 12 07 08 AM\" src=\"https://user-images.githubusercontent.com/5834582/190073533-ebd4cb54-e080-4de5-9d95-9adf3c6c0a74.png\"> Notice that instead of updating the name of the dataset, as I intended, I ended up creating three datasets. ### What you think should happen instead If there are no dags which reference a dataset, it should not be shown in the dataset list ### How to reproduce update a dataset URI ### Operating System docker/debian ### Versions of Apache Airflow Providers n/a ### Deployment Astronomer ### Deployment details `astro dev start` ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan doesn't detect vswhere in the path If you install vswhere with choco, the tool is not in the paths Conan looks for. Conan should try to run it directly if `which` responds. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: 'Connection.lookup' can return 'missing' and 'deferred' results Do we need to support [those fields](https://github.com/GoogleCloudPlatform/google-cloud-datastore/blob/v1beta2-rev1-2.1.0/proto/datastore_v1.proto#L454-L457)? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: pass_manager_drawer requires filename to render <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? The `pass_manager_drawer` requires a filename in order to run. However this is not really a requirement of the code itself. Indeed, this works fine: ```python pass_manager_drawer(pm, '') ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Failures in Qbs The QbsProfile testing in https://github.com/conan-io/conan/blob/9ebc2e4282a35e4d29a7b697d71b85db45c31836/conans/test/unittests/tools/qbs/test_qbs_profile.py#L333 seems to have an incorrect indentation. So these tests are not running, when running, they throw: ``` self = <conans.test.unittests.tools.qbs.test_qbs_profile.QbsGenericTest testMethod=test_toolchain_content> @unittest.skipIf(six.PY2, \"Order of qbs output is defined only for PY3\") def test_toolchain_content(self): > self.assertEqual(qbs_toolchain.content, expected_content) test_qbs_profile.py:433: _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ self = <conan.tools.qbs.qbsprofile.QbsProfile object at 0x04D43A90> @property def content(self): context = { '_profile_values_from_setup': self._profile_values_from_setup, '_profile_values_from_env': self._profile_values_from_env, 'build_variant': self._build_variant, > 'architecture': self._architecture if not self._profile_values_from_setup[\"qbs.architecture\"] else None, 'optimization': self._optimization, 'sysroot': self._sysroot, 'position_independent_code': self._position_independent_code, 'cxx_language_version': self._cxx_language_version, 'target_platform': self._target_platform, 'runtime_library': self._runtime_library, } E KeyError: 'qbs.architecture' ..\\..\\..\\..\\..\\conan\\tools\\qbs\\qbsprofile.py:297: KeyError ``` Also please remove the print() in https://github.com/conan-io/conan/blob/9ebc2e4282a35e4d29a7b697d71b85db45c31836/conans/test/unittests/tools/qbs/test_qbs_profile.py#L318 cc @Psy-Kai Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Doc improvement suggestions: list () and tolist () are very different. numpy 1.15.4 python 3.7.1 I refer to this doc but I spent a lot of time discovering the following. https://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.tolist.html?highlight=tolist#numpy.ndarray.tolist ```python import numpy as np npA=np.uint32([1,2,3]) listA=list(npA) print(type(listA)) # <class 'list'> print(type(listA[0])) # <class 'numpy.uint32'> listA2 = npA.tolist() print(type(listA2)) # <class 'list'> print(type(listA2[0])) # <class 'int'> ``` I wanted to calculate numbers greater than 32bit integers, but I should have used tolist() only. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Passing host env var to run results in None value within container If you `run` a container and pass an env var from the host just like you'd do with `docker run -e ENV_VAR` the env var gets set to `None` inside the container that's started. Example commands: ``` export ENV_VAR='foo` docker-compose run -e ENV_VAR <servicename> ``` IMHO the expected behaviour is that it works the same as [`docker run`](https://docs.docker.com/engine/reference/run/#env-environment-variables), i.e. if you only pass the host's env var name it's value should be set inside the container. I couldn't find an issue or PR for this, but it's difficult to search for `env var` and `run`, so I might have missed it. This is somewhat related to #363 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: add support for other service account types Not just JWT certificate. Add __getitem__ support to connections and buckets Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Qt compile_resources stumbles on empty <file> element **Describe the bug** If a Qt resources file (.qrc) contains an empty <file> element, meson exits with an exception. ``` ... File \"/home/user/.local/lib/python3.10/site-packages/mesonbuild/modules/qt.py\", line 241, in _parse_qrc_deps if os.path.isabs(resource_path): File \"/usr/lib/python3.10/posixpath.py\", line 62, in isabs s = os.fspath(s) TypeError: expected str, bytes or os.PathLike object, not NoneType ``` **To Reproduce** meson.build ``` project('bug', 'cpp') qt = import('qt6') source = qt.compile_resources(sources: 'resource.qrc') executable('app', sources: source) ``` resource.qrc ``` <!DOCTYPE RCC> <RCC version=\"1.0\"> <qresource> <file></file> </qresource> </RCC> ``` **Expected behavior** An error message about the empty <file> element. This probably doesn't happen for static resources files like this, but for dynamic resource files going through `configure_file()` with some paths to generated files. And if any of those configuration_data fields is not set, the <file> element remains empty. In that case, a two page stacktrace doesn't really help. **system parameters** * Native build. * Ubuntu jammy * Python: 3.10.6 * Meson: 0.64.0 * Ninja: 1.10.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: bigquery.table.Table.upload_from_file() doesn't check the initial request response status If you try to add data to a table from a file without a schema: ``` python bigquery_client = bigquery.Client() dataset = bigquery_client.dataset(dataset_name) table = dataset.table(table_name) with open(source_file_name, 'rb') as source_file: job = table.upload_from_file( source_file, source_format='text/csv', rewind=True) job.begin() ``` This will fail with an opaque error: ``` Traceback (most recent call last): File \"load_data_from_file.py\", line 74, in <module> args.source_file_anme) File \"load_data_from_file.py\", line 40, in load_data_from_gcs source_file, source_format='text/csv', rewind=True) File \"/Users/jonwayne/workspace/python-docs-samples/bigquery/cloud-client/env/lib/python3.4/site-packages/gcloud/bigquery/table.py\", line 913, in upload_from_file return client.job_from_resource(json.loads(response_content)) File \"/Users/jonwayne/workspace/python-docs-samples/bigquery/cloud-client/env/lib/python3.4/site-packages/gcloud/bigquery/client.py\", line 119, in job_from_resource config = resource['configuration'] KeyError: 'configuration' ``` Inspection of the response from the initial upload request reveals the problem: ``` status: 400 body: { \"error\": { \"errors\": [ { \"domain\": \"global\", \"reason\": \"invalid\", \"message\": \"Empty schema specified for the load job. Please specify a schema that describes the data being loaded.\", ... ``` It seems we should check the response before constructing the job. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: ENH: `median` should not warn about invalid values The problem is that `median` would produce `RuntimeWarning` with the `Invalid value encountered in median for 2 results` message, while `mean` is silent about it. Why? ### Reproducing code example: ```python import numpy as np a = np.array([[1, 4, 3, np.nan], [2, 5, np.nan, 4]]) m = mean(a, axis=1) ``` ### Numpy/Python version information: ``` 1.15.4 3.7.1 (default, Oct 22 2018, 10:41:28) [GCC 8.2.1 20180831] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Proposal: docker-compose events There have been a few requests for supporting some form of \"hooks\" system within compose (#74, #1341). A feature which runs commands on the host would add a lot of complexity to compose and the compose configuration. Another option is to support these features by providing a way for external tools to run the command triggered by an event. [docker events](http://docs.docker.com/reference/api/docker_remote_api_v1.18/#monitor-dockers-events) provides an event stream of all docker events, but would still require filtering. `docker-compose events` could provide a similar interface by filtering the events returned by `/events` and return a stream of only the events related to the active compose project. The event stream could also include a new field `\"service\": <service_name>` in addition to the fields already provided by `/events` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Cloud Speech veneer should not throw an exception if there is more than one result. I believe this code in the veneer is incorrect because it throws if there is more than one result. https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/speech/google/cloud/speech/_gax.py#L263 As documented in the proto, the results contain a sequential list of transcription results corresponding to sequential portions of audio. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Description Field for Variables add text column to explain what the variable is used for same as https://github.com/apache/airflow/issues/10840 just for Variables. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Only log volume create message if a volume is created See https://github.com/docker/compose/pull/2883#issuecomment-190189471 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: toleration support for ContainerOp I have toleration set up in my cluster for my gpu nodes. how can I add that to my ContainerOp? ``` tolerations: - key: \"gpu\" operator: \"Equal\" value: \"run\" effect: \"NoSchedule\" ``` If it is not implemented can you guide me on how to implement it? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: i18n.gettext needs a set of defaults for GNOME projects In most projects this is going to be copy-pasted around: i18n.gettext(meson.project_name(), languages : langs, args: [ '--default-domain=' + meson.project_name(), '--from-code=UTF-8', '--add-comments', '--keyword=_', '--keyword=N_', '--keyword=C_:1c,2', '--keyword=NC_:1c,2', '--keyword=g_dcgettext:2', '--keyword=g_dngettext:2,3', '--keyword=g_dpgettext2:2c,3', '--flag=N_:1:pass-c-format', '--flag=C_:2:pass-c-format', '--flag=NC_:2:pass-c-format', '--flag=g_dngettext:2:pass-c-format', '--flag=g_strdup_printf:1:c-format', '--flag=g_string_printf:2:c-format', '--flag=g_string_append_printf:2:c-format', '--flag=g_error_new:3:c-format', '--flag=g_set_error:4:c-format', ]) The only thing that I can see needs to be configurable is the default-domain, the others could easily be simplified with a `type: 'gnome'` that would fill in the details and provide a single place to add new flags if/when we add new API that takes a vararg. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add CLI test Add test to catch behavior as in #1123 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: [Examples] The UNet model has some bugs <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug <!-- A clear and concise description of what the bug is. --> The UNet model definition has some bugs pertaining to bilinear interpolation. #### Code sample <!-- Ideally attach a minimal code sample to reproduce the decried issue. Minimal means having the shortest code but still preserving the bug. --> 1. https://github.com/PyTorchLightning/pytorch-lightning/blob/2950f669834506f8e5845b318b0f25d52d19e331/pl_examples/models/unet.py#L35-L37 In the code above, there seems to be a typo. The `bilinear` flag should be passed to the function `Up()`. It has instead been passed to the `.append()` method of the list. 2. https://github.com/PyTorchLightning/pytorch-lightning/blob/2950f669834506f8e5845b318b0f25d52d19e331/pl_examples/models/unet.py#L101-L104 The number of channels once the input passes through either one of these layers is different. For \"bilinear\", the number of channels remains the same, whereas they decrease to half if a `ConvTranspose2d` is used. This gives an error in the network's `.forward()` method. I wanted to directly use the model for some other application, but not sure how issue 2 should be solved. Maybe use a 1x1 convolution to reduce the channels to half? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ld: fatal: unrecognized option '--as-needed' on Solaris I'm using Meson 0.51 installed via pip. I followed the [Tutorial](https://mesonbuild.com/Tutorial.html). ``` $ cat meson.build project('tutorial', 'c') executable('demo', 'main.c') ``` ``` $ cat main.c #include<stdio.h> int main(int argc, char **argv) { printf(\"Hello there.\\n\"); return 0; } ``` ``` $ CC=\"gcc-6\" meson builddir The Meson build system Version: 0.51.0 Source dir: /export/home/vedranm/workspace/demo Build dir: /export/home/vedranm/workspace/demo/builddir Build type: native build Project name: tutorial Project version: undefined C compiler for the build machine: gcc-6 (gcc 6.5.0 \"gcc-6 (OpenIndiana 6.5.0-OI-1) 6.5.0\") C compiler for the host machine: gcc-6 (gcc 6.5.0 \"gcc-6 (OpenIndiana 6.5.0-OI-1) 6.5.0\") WARNING: Unknown CPU family 'i86pc', please report this at https://github.com/mesonbuild/meson/issues/new with theoutput of `uname -a` and `cat /proc/cpuinfo` Build machine cpu family: i86pc Build machine cpu: i86pc Build targets in project: 1 Found ninja-1.8.2 at /usr/bin/ninja ``` ``` $ cd builddir/ $ ninja [2/2] Linking target demo. FAILED: demo gcc-6 -o demo 'demo@exe/main.c.o' -Wl,--no-undefined -Wl,--as-needed ld: fatal: unrecognized option '--as-needed' ld: fatal: use the -z help option for usage information collect2: error: ld returned 1 exit status ninja: build stopped: subcommand failed. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.savetxt bug on structured array <!-- Please describe the issue in detail here, and fill in the fields below --> Saving numpy array subsampled by multi-field indexing fails. ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np x = np.array([(1,2,3),(4,5,6)], dtype=[('foo', 'i8'), ('bar', 'f4'), ('yee', 'f4')]) np.savetxt('out.txt', x[['foo', 'yee']]) ``` <!-- Remove these sections for a feature request --> ### Error message: TypeError: Mismatch between array dtype ('{'names':['foo','yee'], 'formats':['<i8','<f4'], 'offsets':[0,12], 'itemsize':16}') and format specifier ('%.18e %.18e %.18e') <!-- If you are reporting a segfault please include a GDB traceback, which you can generate by following https://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging --> <!-- Full error message, if any (starting from line Traceback: ...) --> ### Numpy/Python version information: ('1.16.2', '2.7.16 |Anaconda, Inc.| (default, Mar 14 2019, 21:00:58) \\n[GCC 7.3.0]') <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Perform evaluation on HANS with Trainer (like GLUE example) Current [HANS](https://github.com/huggingface/transformers/tree/master/examples/adversarial) evaluation implementation is carried out in the old way. It'd be good to do it in the same manner as other examples are implemented now with the Trainer class. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Flax port vision Transformer to flax Port the existing vision-transformer to flax. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Add callback method for on_save_checkpoint ## 🚀 Feature We should allow Callback objects to optionally persist state that can be reloaded from checkpoints. ### Motivation We already manually save the state for early stopping and model checkpoint callbacks. This refactor would eliminate callback-specific code in the Trainer and extend the ability to user-written callbacks. ### Pitch This callback would just return a state_dict which the Trainer could store. The only thing that I am unclear how we should handle is for other callbacks how we want to reinitialize the state. If we can expect that the same exact callbacks will be passed to the Trainer then it should be trivial. Or we could expect that you only pass in a single instance of each callback class (eg. callbacks=[CustomerLogger(), EarlyStopping(), ModelCheckpoint()] and not callbacks=[CustomerLogger(params_a), CustomerLogger(params_b), EarlyStopping(), ModelCheckpoint()] and just keep a mapping of callback class to state dicts. However, if the user passed multiple callback instances of the same class I'm not sure how we would want to handle that. I would recommend that we document the following constraints: - All objects in the dictionary must be pickle-able. - You cannot persist multiple instances of the same callback class. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: SabreLayout does not terminate in some cases ### Environment Qiskit version: master Python version: 3.8.8 OS: Mac OS 12.2 ### What is happening? SabreSwap gets stuck in some specific cases and does not make forward progress. ### How can we reproduce the issue? here's an example that runs indefinitely for me. Note that even though I run SabreLayout, internally it is calling SabreSwap and that's where it gets stuck. ```py from qiskit.circuit.library import QuantumVolume from qiskit.transpiler import PassManager, CouplingMap from qiskit.transpiler.passes import SabreLayout n = 30 coupling_map = CouplingMap.from_line(n) basis_gates=['cx', 'u'] qv = QuantumVolume(n, seed=983).decompose() pm = PassManager(SabreLayout(coupling_map, seed=1)) pm.run(qv) ``` ### What should happen? map the circuit and terminate ### Any suggestions? I think the SabreSwap algorithm has a way to score different swap options and to make forward progress, so not sure what's going on. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Permissions not preserved when uploading tar files The execute bit is not preserved when uploading the conan_export.tgz and conan_package.tgz. This makes it very difficult to use libraries which ship binaries used for configuration (e.g., llvm-config), since the execute bit will not be set. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Please cut a release of Cloud Asset Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `random_circuit` does not include mid-circuit measurements ### What should we add? `qiskit.circuit.utils.random_circuit` has a keyword argument `measure=False` that allows opt-in inclusion of an end-of-circuit measurement of all qubits: https://github.com/Qiskit/qiskit-terra/blob/ad7e609d10b02fd98090b0fac132113f329825b6/qiskit/circuit/random/utils.py#L50 It would be good to also be able to generalize this to be able to generate circuits which can additionally (and optionally) make of use mid-circuit measurement. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jit inside while_loop causes an error I'll help generate a repro tomorrow. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Cloud Spanner Client should prevent nested transactions Cloud Spanner does not support [nested transactions](https://en.wikipedia.org/wiki/Nested_transaction). But the client library does allow users to call `database.run_in_transaction` inside of the callback that is provided to an outer `database.run_in_transaction`. This is misleading since users might believe that this will behave like a nested transaction but in reality these will be two independent transactions. This is confusing and a source of bugs. Specifically the inner transaction might succeed while the outer might ABORT, in which case the callback will be rerun thus rerunning the inner transaction. We should prevent this from happening by detecting and raising an error if someone calls `database.run_in_transaction` inside the callback provided to `database.run_in_transaction`. Note that this needs to be done before Beta since this is a known breaking change. Also note that if we come across a use case where we do want to allow calling a nested `database.run_in_transaction`, we should be able to enable that in future without making a breaking change. cc @jgeewax @bjwatson Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: No module named sphinx.util.compat error using `IPython.sphinxext` with Sphinx pre1.7 master branch Trying out `IPython.sphinxext` 6.1.0 with ``Sphinx==1.7.dev20170617`` I get the following error on a Sphinx project: ``` Extension error: Could not import extension IPython.sphinxext.ipython_directive (exception: No module named 'sphinx.util.compat') ``` Indeed, the `sphinx.util.compat` is deprecated at 1.6 and will be [removed at Sphinx 1.7](https://github.com/sphinx-doc/sphinx/blob/3d5e0c5d7/CHANGES#L45). To reproduce, in a virtual env with IPython 6.1.0 run pip install git+https://github.com/sphinx-doc/sphinx and then ``` mkdir /tmp/IPython-test cd /tmp/IPython-test yes \"n\" | sphinx-quickstart --dot _ --project IPython-test --author \"Example\" -v 0 --release 0 --language en --suffix .rst --master index --makefile --batchfile . echo ' extensions = [ \"IPython.sphinxext.ipython_directive\", ] ' >> conf.py make html ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Loading from checkpoint without skipping requires the same number of GPUs ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.12.5 - Platform: Linux-4.4.0-210-generic-x86_64-with-glibc2.10 - Python version: 3.8.8 - PyTorch version (GPU?): 1.9.0a0+2ecb2c7 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed When changing the number of GPUs available, the trainer fails to load from the checkpoint that was trained with a different number of GPUs checkpoint. Note that this does not happen when the flag ignore_data_skip is used. The \"per_device_train_batch_size\" remains unchanged between runs. I use Trainer API The error looks like this: File \"/opt/conda/lib/python3.8/site-packages/transformers/trainer.py\", line 1298, in train self._load_rng_state(resume_from_checkpoint) File \"/opt/conda/lib/python3.8/site-packages/transformers/trainer.py\", line 1529, in _load_rng_state torch.cuda.random.set_rng_state_all(checkpoint_rng_state[\"cuda\"]) File \"/opt/conda/lib/python3.8/site-packages/torch/cuda/random.py\", line 73, in set_rng_state_all set_rng_state(state, i) File \"/opt/conda/lib/python3.8/site-packages/torch/cuda/random.py\", line 64, in set_rng_state _lazy_call(cb) File \"/opt/conda/lib/python3.8/site-packages/torch/cuda/__init__.py\", line 114, in _lazy_call callable() File \"/opt/conda/lib/python3.8/site-packages/torch/cuda/random.py\", line 61, in cb default_generator = torch.cuda.default_generators[idx] IndexError: tuple index out of range Thank you Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: dependencies: Undefined variable 'required' ``` python def get_variable(self, variable_name): p = subprocess.Popen([self.pkgbin, '--variable=%s' % variable_name, self.name], stdout=subprocess.PIPE, stderr=subprocess.PIPE) out = p.communicate()[0] if p.returncode != 0: if required: raise DependencyException('%s dependency %s not found.' % (type_string, self.name)) else: variable = out.decode().strip() mlog.debug('return of subprocess : %s' % variable) return variable ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add support for link-local IPs Engine issue: https://github.com/docker/docker/pull/23415 ~~Depends on: https://github.com/docker/docker-py/issues/1107~~ https://github.com/docker/docker-py/commit/986a14a152d20df6bb8622516ab2d18af73e5e20 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add m2m 100 multilingual translation model from FAIR Weights, code are available. + Fairseq Code: https://github.com/pytorch/fairseq/tree/master/examples/m2m_100?fbclid=IwAR304kICXsffdDMogK4MWf4D7Xeu_3Cbmgu8pBCU_jKcjijCuJfLK7CY9_I + Paper: https://arxiv.org/abs/2010.11125 + This model will not run on 1 V100 GPU, so model parallelism will be needed. + I would expect the state dict to be very similar to mBART, but not sure yet. + All I've done is download the state dict, run their command, and asked for help https://github.com/pytorch/fairseq/issues/2772#issuecomment-716152453 when it broke. Leaving this unassigned in case somebody else wants to take over. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Unable to use print_stats after %prun -r in notebook This applies to the notebook, I haven't tried this in plain ipython or the console: If I get a `pstats.Stats` object using `%prun -r` nothing shows up when I call `print_stats`. However, if I save to a file using `%prun -D` and then load the file using `pstats.Stats` calling `print_stats` works perfectly. I'm using a fresh install of IPython 0.13. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: update pretty to use Python 3 style for sets In Python 3, `repr(set([1,2,3]))` is `{1,2,3}`, but pretty currently forces the output to be `set([1,2,3])`. We should probably use the set-literal format on Python 3, or just use it all the time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Ensure the dev_env_setup.sh and installation guides reflect new module structures Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Raising of GitCommandError fails in archive function if stdout was a cStringIO object I tried to check out an archive for a not existing path from the repository and I expect a GitCommandError exception. I got following TypeError exception: \"Expected bytes or text, but got <cStringIO.StringO object at 0x7fabac6f97a0>\" I did following: fpt = StringIO() -- (used as a temporary storage for the tar archive) self._repository.archive(fpt, treeish=version_identifier, format=\"tar\", path=sub_path) -- (where sub_path points to an not existing path) The cause of the problem was, the Constructor of the GitCommandError could not handle the cStringIO object. (a normal file pointer may be faulty too). I suppose it should set its stdout variable to None in case of not handled types. Or it should be adjusted when raising the exception. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Make optional outputs opt-in Right now outputs are implicitly optional. That means if a user specifies multiple outputs and forgets to output it, it just continues execution and logs the fact that all outputs were not specific. This is really error prone and shouldn't be the default behavior. Instead we could make optionality an optional configuration option of an OutputDefinition. Right now where this condition is detected is simple_engine.py:82 ```py step_context.log.info( ( 'Not all inputs covered for {step}. Not executing. Output need for ' 'inputs {expected_outputs}' ).format(expected_outputs=expected_outputs, step=step.key) ) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Propagate arch argument to vcvars in MSBuild helper Coming from https://github.com/conan-io/conan-center-index/pull/719#discussion_r390337460 There is an arch override parameter in ``MSBuild.build()`` method, however, this is not propagated to the ``vcvars_command`` inside that same method. So the override in some cases is useless. I think the arch argument should be propagated to the vcvars as well. Related to #6428 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: rpath order of two subprojects is not deterministic This is related to issue #3922. In the attached testcase meson sometimes uses '-Wl,-rpath,$$ORIGIN/subprojects/sub1:$$ORIGIN/subprojects/sub2' and sometimes '-Wl,-rpath,$$ORIGIN/subprojects/sub2:$$ORIGIN/subprojects/sub1' [meson-test.zip](https://github.com/mesonbuild/meson/files/2217864/meson-test.zip) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Redis Client Reference Docs 404 Link from [Redis README](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/redis/README.rst) to API client reference documentation (https://googlecloudplatform.github.io/google-cloud-python/stable/redis/usage.html) does not resolve (404). Redis Client Reference Docs 404 Link from [Redis README](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/redis/README.rst) to API client reference documentation (https://googlecloudplatform.github.io/google-cloud-python/stable/redis/usage.html) does not resolve (404). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [example scripts] inconsistency around eval vs val * `val` == validation set (split) * `eval` == evaluation (mode) those two are orthogonal to each other - one is a split, another is a model's run mode. the trainer args and the scripts are inconsistent around when it's `val` and when it's `eval` in variable names and metrics. examples: * `eval_dataset` but `--validation_file` * `eval_*` metrics key for validation dataset - why the prediction is then `test_*` metric keys? * `data_args.max_val_samples` vs `eval_dataset` in the same line the 3 parallels: - `train` is easy - it's both the process and the split - `prediction` is almost never used in the scripts it's all `test` - var names and metrics and cl args - `eval` vs `val` vs `validation` is very inconsistent. when writing tests I'm never sure whether I'm looking up `eval_*` or `val_*` key. And one could run evaluation on the test dataset. Perhaps asking a question would help and then a consistent answer is obvious: Are metrics reporting stats on a split or a mode? A. split - rename all metrics keys to be `train|val|test` B. mode - rename all metrics keys to be `train|eval|predict` Thank you. @sgugger, @patil-suraj, @patrickvonplaten Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: pi_check cannot handle large values <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: ### What is the current behavior? When we bind a large value to a custom gate, the value appears as `-pi/0` in the drawer output. ### Steps to reproduce the problem ```python from qiskit.circuit import QuantumCircuit, Gate def my_gate(*args): return Gate('my_gate', num_qubits=1, params=list(args)) qc = QuantumCircuit(1) qc.append(my_gate(1e9), [0]) qc.draw() ``` output ``` ┌────────────────┐ q_0: ┤ my_gate(-pi/0) ├ └────────────────┘ ``` ### What is the expected behavior? The value will be shown in scientific notation such as `%.2e`. This is important to represent a custom pulse gate which has a parametrized modulation frequency. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] conan 2 list subcommands: -r and -c are not mutually exclusive In develop2 branch, in conan/cli/commands/list.py: ```py def _add_remotes_and_cache_options(subparser): remotes_group = subparser.add_mutually_exclusive_group() remotes_group.add_argument(\"-r\", \"--remote\", default=None, action=Extender, help=\"Remote names. Accepts wildcards\") subparser.add_argument(\"-c\", \"--cache\", action='store_true', help=\"Search in the local cache\") ``` Shouldn't the last line be remotes_group.add_argument instead? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: Text/link displayed after calling run_pipeline should be \"Run link\" not \"Job link\" Here: https://github.com/kubeflow/pipelines/blob/master/sdk/python/kfp/_client.py#L153 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Firestore] Add ARRAY_UNION, ARRAY_REMOVE ARRAY_CONTAINS FieldValues There is no support for FieldValue.arrayUnion()/FieldValue.arrayRemove() and no support for array-contains Queries. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: cookiecutter template for adding flax model # 🚀 Feature request Add cookiecutter template for adding flax model. ## Motivation There is no cookiecutter template for adding flax model. ## Your contribution I am trying to add a flax model (#12411), I think it's a good opportunity to create a template at the same time. Can I work on this? Any suggestions? @patil-suraj @patrickvonplaten Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [trainer] multi-node tweaks As I'm using Trainer in a multi-node setup, I will use this issue to post the things that could be improved for that type of env. 1. Repeated logging for non-rank-0 process rank-0 machine: I gathered all these that get repeated 16 times on a 16 nodes machine: ``` [INFO|trainer.py:1145] 2021-05-20 20:16:39,037 >> ***** Running training ***** [INFO|trainer.py:1146] 2021-05-20 20:16:39,037 >> Num examples = 1000 [INFO|trainer.py:1147] 2021-05-20 20:16:39,037 >> Num Epochs = 1 [INFO|trainer.py:1148] 2021-05-20 20:16:39,037 >> Instantaneous batch size per device = 4 [INFO|trainer.py:1149] 2021-05-20 20:16:39,037 >> Total train batch size (w. parallel, distributed & accumulation) = 256 [INFO|trainer.py:1150] 2021-05-20 20:16:39,037 >> Gradient Accumulation steps = 1 [INFO|trainer.py:1151] 2021-05-20 20:16:39,037 >> Total optimization steps = 4 100%|██████████| 4/4 [00:02<00:00, 1.95it/s][INFO|trainer.py:1341] 2021-05-20 20:16:41,214 >> {'train_runtime': 2.185, 'train_samples_per_second': 1.831, 'epoch': 1.0} Training completed. Do not forget to share your model on huggingface.co/models =) INFO:__main__:*** Evaluate *** [INFO|trainer.py:2115] 2021-05-20 20:16:41,690 >> ***** Running Evaluation ***** [INFO|trainer.py:2117] 2021-05-20 20:16:41,690 >> Num examples = 200 [INFO|trainer.py:2120] 2021-05-20 20:16:41,690 >> Batch size = 4 ``` Probably should check not only rank of the process, but also the rank of the machine, right? @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `FutureWarning` issued by `scikit-learn` in `opflow` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18+ - **Python version**: any - **Operating system**: any ### What is the current behavior? With the new(ish) `scikit-learn` version 1.0, there is a `FutureWarning` issued when using the `normalize` parameter of `LinearModel`, which `opflow` does when calculating gradients. This doesn't fail our tests (though perhaps it should), because `FutureWarning` doesn't count as a type of `DeprecationWarning`. ### Steps to reproduce the problem Run the test suite, especially `test.python.opflow.test_gradients.TestGradients.test_natural_gradient`. ### What is the expected behavior? No future warning. ### Suggested solutions Fix `opflow` to handle fitting with `StandardScaler` rather than the now-deprecated `normalize` parameter. This has existed for several minor releases of `scikit-learn`, so should be safe for us to do. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: pip is installing incompatible versions Current minimal example: ``` conda create -n break python=3.6 -y source activate break cd prefect/ # navigate to repo directory pip install . ``` and you'll see: ``` ... requests 2.20.1 has requirement idna<2.8,>=2.5, but you'll have idna 2.8 which is incompatible. ... ``` because apparently [pip doesn't have a dependency resolver](https://github.com/pypa/pip/issues/988). Moreover, because each CLI command runs through requirement dependency checks (can we turn this off?), our docker containers / installs are broken. `idna 2.8` was released [4 hours ago](https://pypi.org/project/idna/#history) as of this writing. **Possible fixes**: - We _could_ fix this immediately by including `idna<2.8` in our `requirements`, but this feels like a can of worms --> we shouldn't have to be responsible for dependencies that we don't explicitly rely on and this won't prevent it from happening again in the future - we could create `environment.yml` files and start using `conda` (which _does_ have a dependency resolver), but this creates some additional burden on us to: 1. we'd need to install miniconda in our docker containers and 2. we'd need some additional testing to make sure our `environment.yml` files stay up to date (integration tests could handle this piece well actually) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Ability to silence a cell in the notebook There are some functions in scipy that do not provide a way to silence them and they always pollute stdout with useless information. Usually I would just redirect `sys.stdout`, however this causes the notebook to hang. Can a magic `%noprint` be provided in order to silence the stdout? Or another option will be to have `toggle stdout` next to `toggle output` in the cell menu? What can be used as a workaround? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: \\001 and \\002 non-printable characters in docstrings can't be processed by latex Hello, While attempting to build the doc (`cd docs && make pdf`), the special characters at https://github.com/ipython/ipython/blob/e6432249582e05f438303ce73d082a0351bb383e/IPython/utils/coloransi.py#L77 cause the following error: ``` [...] [649] [650] [651] [652] [653] LaTeX Warning: Hyper reference `api/generated/IPython.testing.tools:IPython.testing.tools.AssertPrints' on page 654 undefined on input line 77077. [654] [655] [656] LaTeX Warning: Hyper reference `api/generated/IPython.utils.colorable:IPython.utils.colorable.Colorable' on page 657 undefined on input line 77444. [657] [658] ! Text line contains an invalid character. l.77706 This class is similar to TermColors, but the escapes are wrapped in ^^A ? ! Emergency stop. l.77706 This class is similar to TermColors, but the escapes are wrapped in ^^A ``` I tried editing them out of the coloransi.py source, but they remained in the sphinx-generated `ipython.tex` and still cause problems, so I'm a bit lost. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: A hundred or more pulse doc warnings being raised This are getting raised about a hundred or more times in the docs build: ``` <partial node>:: WARNING: toctree contains reference to document 'stubs/qiskit.pulse.pulse_lib.discrete' that doesn't have a title: no link will be generated <partial node>:: WARNING: toctree contains reference to document 'stubs/qiskit.pulse.channels' that doesn't have a title: no link will be generated ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Avoid saving tied weights with sharded checkpoints It seems that when sharding a checkpoint we untie weights which makes them take more space ```python import torch from transformers import GPT2LMHeadModel, GPT2Config config = GPT2Config() model = GPT2LMHeadModel(config) assert id(model.transformer.wte.weight) == id(model.lm_head.weight) model.save_pretrained(\"gpt2-tied-weights\") config.tie_word_embeddings = False model = GPT2LMHeadModel(config) assert id(model.transformer.wte.weight) != id(model.lm_head.weight) model.save_pretrained(\"gpt2-untied-weights\") config = GPT2Config() model = GPT2LMHeadModel(config) assert id(model.transformer.wte.weight) == id(model.lm_head.weight) model.save_pretrained(\"gpt2-tied-weights-sharded\", max_shard_size=\"100MB\") config.tie_word_embeddings = False model = GPT2LMHeadModel(config) assert id(model.transformer.wte.weight) != id(model.lm_head.weight) model.save_pretrained(\"gpt2-untied-weights-sharded\", max_shard_size=\"100MB\") ``` When checking the space taken by these checkpoints: ``` $ du -sh gpt2* 475M gpt2-tied-weights 622M gpt2-tied-weights-sharded # MUST BE 475M 622M gpt2-untied-weights 622M gpt2-untied-weights-sharded ``` cc @ArthurZucker @thomasw21 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: test failure in arg_split on windows arg_split has a failing test on windows. ``` ERROR: Ensure that argument lines are correctly split like in a shell. ---------------------------------------------------------------------- Traceback (most recent call last): File \"C:\\python\\ipydevel\\VENV\\py27\\lib\\site-packages\\nose\\case.py\", line 197, in runTest self.test(*self.arg) File \"C:\\python\\ipydevel\\VENV\\py27\\lib\\site-packages\\ipython-0.13.dev-py2.7.egg\\IPython\\testing\\decorators.py\", line 228, in skipper_func return f(*args, **kwargs) File \"C:\\python\\ipydevel\\VENV\\py27\\lib\\site-packages\\ipython-0.13.dev-py2.7.egg\\IPython\\utils\\tests\\test_process.py\",line 90, in test_arg_split_win32 nt.assert_equal(arg_split(argstr), argv) File \"C:\\python\\ipydevel\\VENV\\py27\\lib\\site-packages\\ipython-0.13.dev-py2.7.egg\\IPython\\utils\\_process_win32.py\", line 181, in arg_split result = [arg for arg in result_array_type.from_address(result_pointer)] TypeError: integer expected ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: tools.collect_libs() doesn't respect self.cpp_info.libdirs Fedora is putting 64bit libraries in `lib64/` not in `lib/`. The collect_libs tool should look out for an existing `lib64` directory to collect all libs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Testing with asset partition ranges ### What's the use case? Currently we can test a software defined asset that makes use of partition ranges, by creating an op context: `context = dagster.build_op_context(partition_key=\"2023-01-05\")` And then we can do `time_window = context.asset_partitions_time_window_for_output()` and it will work for the single day (because we can derive a time window from the key). However, there are some issues: - `asset_partitions_time_window_for_output()` is marked as deprecated on `OpExecutionContext` (but not `AssetExecutionContext`) - possibly related to https://github.com/dagster-io/dagster/issues/14871 and a missing `build_asset_context` function? - testing like this does not work with `context.partition_time_window` (` AttributeError: 'BoundOpExecutionContext' object has no attribute '_step_execution_context'. Did you mean: 'get_step_execution_context'?`) - Most importantly, we cannot test multiple days with this approach ### Ideas of implementation Being able to specify a date/time range in the `build_op_context` would be ideal. This might even need to be part of the upcoming `build_asset_context` (see https://github.com/dagster-io/dagster/issues/14871 again). ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: update --all broken in 4.4.0rc In 4.4.0rc an `update --all` wants to *remove* 90% of my packages. IMO an update should never remove any packages so the current behaviour seems pretty broken to me. ``` λ conda update --all Solving environment: done ## Package Plan ## environment location: C:\\Miniconda3 The following packages will be downloaded: package | build ---------------------------|----------------- openssl-1.0.2m | vc14_0 5.4 MB conda-forge The following packages will be REMOVED: _license: 1.1-py36_1 altair: 1.2.1-py_0 conda-forge anaconda-client: 1.6.5-py36hd36550c_0 https://repo.continuum.io/pkgs/main anaconda-navigator: 1.6.9-py36hc720852_0 https://repo.continuum.io/pkgs/main anaconda-project: 0.8.2-py36_0 conda-forge astroid: 1.5.3-py36h9d85297_0 https://repo.continuum.io/pkgs/main astropy: 2.0.2-py36h06391c4_4 https://repo.continuum.io/pkgs/main <snip> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gnome.generate_gir() should accept multiple libraries From `g-ir-scanner --help`: ``` -l LIBRARIES, --library=LIBRARIES libraries of this unit ``` Harfbuzz relies on this feature: https://github.com/harfbuzz/harfbuzz/blob/master/src/Makefile.am#L434-L437 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Better information on mismatch in dependency tree using conan v1.6.1 Consider following scenario: Monday: binary foo depends on potato and carrot in both versions 1.0.0 carrot depends on potato in version 1.0.0 potato does not depends on anything. All compiles fine. Tuesday: updating dependency in foo to potato 2.0.0 This leads to error like this: ``` Packages carrot/1.0.0@user/testing:1edc358bbd62390e309c027c1fcc23c7feea92d7 - Missing potato/2.0.0@user/testing:de9c231f84c85def9df09875e1785a1319fa8cb6 - Cache potato/2.0.0@user/testing: Already installed! carrot/1.0.0@user/testing: WARN: Can't find a 'carrot/1.0.0@user/testing' package for the specified options and settings: - Settings: arch=x86_64, build_type=Release, compiler=gcc, compiler.libcxx=libstdc++, compiler.version=4.8, os=Linux - Options: - Package ID: ... ERROR: Missing prebuilt package for 'carrot/1.0.0@user/testing' Try to build it from sources with \"--build carrot\" Or read \"http://docs.conan.io/en/latest/faq/troubleshooting.html#error-missing-prebuilt-package\" ``` Nowhere it hints to user that it is simply the issue of the carrot depending on the potato 1.0.0. One has to dig deeper by for example conan info to compare all the flags and the dependencies to find the issue. Maybe it would be possible for conan to compare the settings in the prebuilt ones, and get closest match, and inform why exactly that dependency cannot work? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Upgrade `pytest` We recently learned that the way Prefect uses `pytest` (specifically, some methods we call on markers in `conftest.py`) is incompatible with recent changes in `pytest >= 4.0`. Just to keep things up-to-date, we should investigate this and bump / adjust `pytest` accordingly in `dev-requirements.txt` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Aer CI failing due to error in BaseJob documentation. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: ### What is the current behavior? CI test are failing in Aer due sphinx errors in the inherited doc string from `BaseJob` in #3731 Since doc build warnings aren't treated as fatal in Terra this can lead to problems in other repos (like Aer) which have stricter CI checks on documentation. This will be an issue for any classes that are intended to be subclassed (ie BaseJob, BaseBackend, BaseProvider). ### Steps to reproduce the problem Run CI on qiskit-aer. Azure doc build fails with: ``` Warning, treated as error: /home/vsts/work/1/s/.tox/docs/lib/python3.7/site-packages/qiskit/providers/basejob.py:docstring of qiskit.providers.aer.AerJob.wait_for_final_state:7:Unexpected indentation. ERROR: InvocationError for command /home/vsts/work/1/s/.tox/docs/bin/sphinx-build -W -b html docs/ docs/_build/html -j auto (exited with code 2) ___________________________________ summary ____________________________________ ERROR: docs: commands failed ``` ### What is the expected behavior? No error. ### Suggested solutions Fix the doc string that is raising a warning. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: make test fails locally <!--- Provide a general summary of the issue in the Title above --> `make test` fails locally, possibly due to the configuration of hubs in the Qconfig. This has not been an issue with travis and submitted PRs. ## Steps to Reproduce (for bugs) <!--- Provide a link to a live example, or an unambiguous set of steps to --> <!--- reproduce this bug. Include code to reproduce, if relevant --> `python -m unittest -v test.python.test_api_ibmq.TestApiHub` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Backend based primitives are not serializable via dill ### Environment - **Qiskit Terra version**: 0.22 - **Python version**: 3.7 - **Operating system**: Any ### What is happening? Backend based primitives can't be saved via dill. Reference primitives can be loaded/saved. `QuantumInstance` is also serializable. This issue comes from Qiskit Machine Learning where quantum models can be saved to a file, then loaded to continue training or for inference on a real hardware. ### How can we reproduce the issue? Run a script ```python import dill from qiskit import Aer from qiskit.primitives import BackendSampler sampler = BackendSampler(Aer.get_backend(\"aer_simulator\")) with open(\"sampler.dill\", \"wb\") as f: dill.dump(sampler, f) with open(\"sampler.dill\", \"rb\") as f: sampler = dill.load(f) ``` ### What should happen? An exception is raised: ``` python __dill_primitives.py Traceback (most recent call last): File \"__dill_primitives.py\", line 10, in <module> sampler = dill.load(f) File \".../envs/dev-qml/lib/site-packages/dill/_dill.py\", line 313, in load return Unpickler(file, ignore=ignore, **kwds).load() File \".../envs/dev-qml/lib/site-packages/dill/_dill.py\", line 525, in load obj = StockUnpickler.load(self) TypeError: __new__() missing 1 required positional argument: 'backend' ``` ### Any suggestions? No exceptions must be raised. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Exception when running demo.initialize() ``` File \".../env/local/lib/python2.7/site-packages/gcloud/datastore/demo/__init__.py\", line 26, in initialize datastore.set_default_dataset_id(DATASET_ID) AttributeError: 'module' object has no attribute 'set_default_dataset_id' ``` When running with: ``` GCLOUD_TESTS_PROJECT_ID=X \\ GCLOUD_TESTS_DATASET_ID=X \\ GOOGLE_APPLICATION_CREDENTIALS=foobar.json \\ python -m gcloud.datastore.demo ``` on version 0.7.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Adding batch image processing to Vision API The amount of data that Vision can return can be pretty deep and processing more than one image at a time adds another level to that. Here's my proposed approach to work with multiple images with multiple feature types. ```python >>> images = client.batch() >>> for i in range(10): ... images.add_image(client.image(source_uri='gs://%s.jpg' % (i,))) >>> images.detect_faces() {'0.jpg': [], '1.jpg': [],} >>> >>> # With multiple feature types. >>> features = [Feature(FeatureTypes.FACE_DETECTION, 5), ... Feature(FeatureTypes.LOGO_DETECTION, 3)] >>> for i in range(10): ... image = client.image(source_uri='gs://%s.jpg' % (i,)) ... images.add_image(image=image, features=features) >>> images.detect() ``` With a context manager it could look something like this... ```python >>> features = [Feature(FeatureTypes.FACE_DETECTION, 5), ... Feature(FeatureTypes.LOGO_DETECTION, 3)] >>> with client.images() as images: ... for i in range(10): ... image = client.image(source_uri='gs://%s.jpg' % (i,)) ... images.add_image(image=image, features=features) ... results = images.detect() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: non-interactive transformers-cli upload? # 🚀 Feature request Currently, `transformers-cli upload` works only interactively due to its prompt: `Proceed? [Y/n]` After running the updated model conversion, I would like to be able to do: ``` cd data transformers-cli upload fsmt-wmt19-ru-en transformers-cli upload fsmt-wmt19-en-ru transformers-cli upload fsmt-wmt19-de-en transformers-cli upload fsmt-wmt19-en-de cd - ``` But this won't work: Would it be possible to add a `-y` override? Alternatively, would it be possible to give it all dirs to upload in one command? ``` transformers-cli upload fsmt-wmt19-ru-en fsmt-wmt19-en-ru fsmt-wmt19-de-en fsmt-wmt19-en-de ``` ## Motivation I have been re-uploading 4 x 1.1GB models on a relatively slow connection, and I have to be around to hit Y for each one of them, which is very counter-productive, as I have to go back and re-check whether each upload has been completed. I can probably code some shell expect script to feed it automatically, but this defeats the purpose. Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Allow setting port for postgres instance in `prefect server start` ## Use Case It's likely that there's already a postgres instance running on the default port. `prefect server start` should include an option for setting the port of its Postgres instance. ## Solution `prefect server start --postgres-port=5433` Investigate non-deterministic Python 3.6 scheduled parameter test failure https://circleci.com/gh/PrefectHQ/prefect/60188?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-checks-link ``` =================================== FAILURES =================================== _______ TestFlowRunMethod.test_flow_dot_run_passes_scheduled_parameters ________ self = <tests.core.test_flow.TestFlowRunMethod object at 0x7f97b853d8d0> def test_flow_dot_run_passes_scheduled_parameters(self): a = prefect.schedules.clocks.DatesClock( [pendulum.now(\"UTC\").add(seconds=0.1)], parameter_defaults=dict(x=1) ) b = prefect.schedules.clocks.DatesClock( [pendulum.now(\"UTC\").add(seconds=0.25)], parameter_defaults=dict(x=2) ) x = prefect.Parameter(\"x\", default=None, required=False) outputs = [] @prefect.task def whats_the_param(x): outputs.append(x) with Flow(\"test\", schedule=prefect.schedules.Schedule(clocks=[a, b])) as f: whats_the_param(x) f.run() > assert outputs == [1, 2] E assert [1] == [1, 2] E Right contains one more item: 2 E Full diff: E - [1] E + [1, 2] tests/core/test_flow.py:1620: AssertionError ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: NotebookProgressCallback doesn't work in databricks notebooks properly--should either be fixed or removed from trainer automatically if it is a databricks runtime https://github.com/huggingface/transformers/blob/71e602725b90f63f404109bae9f72cbdf755477b/src/transformers/utils/notebook.py#L269 Hey all, Using databricks for training, the default Trainer behavior will automatically add NotebookProgressCallback for databricks notebooks, but the databricks UI currently does not display the output properly. It just prints a bunch of text saying `<IPython.core.display.HTML object>` over and over. This is likely an issue on Databricks' end, so I recommend not adding this callback if the transformers library can detect it is a databricks runtime not a jupyter/google collab notebook. I think there should also be an easier way to delete specific callbacks--it took a long time to trace this issue and reading source code to figure out what the source cause is. I am circumventing the issue for now by popping the callback from the trainer callback handlers list but that is not a good pattern. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: TensorBoardLogger and ModelCheckpoint are not using the same folder by default ## 🐛 Bug (master branch) By default, the TensorBoardLogger writes logs into `lightning_logs/0` but ModelCheckpoint writes checkpoint into `lightning_logs/version_0`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: docs mentioning 'firestore.collection_group' are incorrect. #### Environment details # OS type and version Mac OSX 10.14.5 # Python version and virtual environment information: python 3.7.3 #google-cloud-<service> version: google-api-core 1.12.0 pypi_0 pypi google-auth 1.6.3 pypi_0 pypi google-cloud-core 1.0.2 pypi_0 pypi google-cloud-firestore 1.2.0 pypi_0 pypi googleapis-common-protos 1.6.0 #### Steps to reproduce 1. Created a collection with documents and sub-collections 2. Created a composite index for collection group queries 3. Cannot figure out how to do a collection group query that returns any results #### Code example ```python from google.cloud import firestore query = firestore.collection_group('mygroup') #directly from your docs ``` #### Stack trace ``` AttributeError: module 'google.cloud.firestore' has no attribute 'collection_group' ``` Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Small typo on real_amplitudes.py ### Environment - **Qiskit Terra version**: 0.43.1 (Qiskit version) - **Python version**: 3.10 - **Operating system**: MacOs Big Sur ### What is happening? Docstring of class in [real_amplitudes.py](https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/circuit/library/n_local/real_amplitudes.py) has repeated word \"of\" > ... The circuit consists of of alternating layers ... ### How can we reproduce the issue? NA. Docstring ### What should happen? Should erase one of the words \"of\" ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan download \"-p\" deprecation The same with `get` and `upload`, deprecate the `-p` in favor of full ref. Deprecate the '-p' argument in the 'download' and 'copy' cli As it is in `conan get...` and soon in `conan upload...`(#5224), it makes sense to deprecate the `-p` argument for `conan download...` and `conan copy...` too. ---- It still appears in the `conan remove...` but with an slightly different meaning 😞 ``` parser.add_argument('-p', '--packages', nargs=\"*\", action=Extender, help=\"Select package to remove specifying the package ID\") ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda env export error with setup.py develop packages conda 4.3.23, Anaconda 4.4.0 Environment export fails if there is a comma in the file path for the package. These paths are valid on Windows. See attached dump. [conda_export_error.txt](https://github.com/conda/conda/files/1208700/conda_export_error.txt) Fix is to change line 95 in ..\\conda_env\\pip_util.py to only split on the first comma: version, path = version.split(', ', 1) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow versioning to include git information if not using released version <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently there is no way to distinguish between the master branch dev version and a final release version. Currently, for example, they would both be labeled as `0.8.0`. It would be nice to have unreleased (dev) versions tagged with the git repo commit that they are pulled from. This is done, for example in SciPy and NumPy, and it quite easy to implement. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: deactivate sets `CONDA_PREFIX` to the wrong value. Deactivating an env. into which the new compilers have been installed leads to: ``` ERROR: This cross-compiler package contains no program /opt/conda/bin/x86_64-conda_cos6-linux-gnu-cc ``` This comes from [here](https://github.com/AnacondaRecipes/aggregate/blob/master/ctng-compilers-activation-feedstock/recipe/deactivate-gcc.sh#L58) It seems that `CONDA_PREFIX` has been set to the prefix of the new environment instead of that of the old environment. It doesn't seem to matter whether the legacy activate scripts or the conda shell function are used here, both exhibit the same problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Typo in docs? multi-label text classification The docs give an example of text classification on IMDB [here](https://spacy.io/usage/training#example-textcat). It says it's \"multi-label\", but this dataset is binary. So I'm not sure what you mean here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: ENH: added env vars I think these variables are useful for a multi user or root install of conda. ``` CONDA_ROOT CONDA_ENV_PATH CONDA_PACKAGE_CACHE ``` This PR adds them to config.py What is the equivalent to conda.config.Config in conda 1.7.1? We were using conda.config.Config in Wakari. In 1.7.1 it has disappeared. Ilan warned me that conda-api may not work, and he was right! It took a bit to figure out this was the problem I was having. Where can I find the equivalent functionality? wish: for auto proxy sites, process proxy.pac proxy.pac is javascript that tells the browser what proxy to use for a destination. it's possible to process that so that conda can communicate. it looks like pac files are being used for proxy mgt at larger corps. here is a pac parser that could be used https://code.google.com/p/pacparser/ <!--- @huboard:{\"order\":0.96875,\"custom_state\":\"\"} --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose config changes external: false to external: true ## Description of the issue In my `docker-compose.yml` I have `external: false` but `docker-compose config` gives me `external: true`. What is the reason for this change of value? My assumption was that this command just validates the file and performs only cosmetic changes. ## Context information (for bug reports) ``` docker-compose version 1.21.2, build a133471 docker-py version: 3.3.0 CPython version: 3.6.5 OpenSSL version: OpenSSL 1.0.1t 3 May 2016 ``` ``` Client: Version: 18.03.1-ce API version: 1.37 Go version: go1.9.5 Git commit: 9ee9f40 Built: Thu Apr 26 07:17:20 2018 OS/Arch: linux/amd64 Experimental: false Orchestrator: swarm Server: Engine: Version: 18.03.1-ce API version: 1.37 (minimum version 1.12) Go version: go1.9.5 Git commit: 9ee9f40 Built: Thu Apr 26 07:15:30 2018 OS/Arch: linux/amd64 Experimental: false ``` ## Steps to reproduce the issue ``` $> cat docker-compose.yml version: '3.4' volumes: test-volume: name: test-name external: false services: test-service: image: test-image $> docker-compose -f docker-compose.yml config services: test-service: image: test-image version: '3.4' volumes: test-volume: external: true name: test-name ``` ### Observed result `docker-compose config` yields `external: true` ### Expected result `external: false` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Populate `examples/` folders @joshmeek @jlowin please add to this list as much as you want: Examples we should have: - [x] example with state handler - [x] example which requires retry and succeeds on second run - [x] example with mapping - [x] example showing scheduling (possibly both cron and interval) - [x] example with a simple parameterized flow (running it multiple times gives multiple outputs due to the parameters) - [ ] an example of a cool flow that uses the imperative API These examples should be \"bite-sized\", and be ~3 tasks per Flow and easily readable. Updated w/ suggestions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Cannot take gradient of np.prod With the latest git version of jax, I get an error trying to `grad` a basic `np.prod` because some underlying `reduce` is not implemented. Perhaps this is a known limitation, but I could not find it in the documentation and it's what currently blocks me. Here is a minimal example: ``` import jax.numpy as np from jax import grad g = grad(lambda x: np.prod(x)) g(np.ones((10,8))) ``` > Traceback (most recent call last): > File \"/home/guy/jax/jax/interpreters/ad.py\", line 210, in process_primitive > jvp = primitive_jvps[primitive] > KeyError: reduce > ... > NotImplementedError: Forward-mode differentiation rule for 'reduce' not implemented > Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.take_along_axis gives wrong gradient The following repro script shows the issue: ``` import jax.numpy as np from jax import value_and_grad idx = np.repeat(np.arange(3), 10).reshape((30, 1)) def f(x): y = x * np.arange(3.).reshape((1, 3)) return np.take_along_axis(y, idx, -1).sum() def g(x): y = x * np.arange(3.).reshape((1, 3)) y = np.broadcast_to(y, (30, 3)) return np.take_along_axis(y, idx, -1).sum() print(value_and_grad(f)(1.)) # get 30, 0 print(value_and_grad(g)(1.)) # get 30, 30 ``` I think `(30, 30)` is the correct answer. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: jar install fails when strip enabled My C library has a java binding. When I try to install library with `strip` option enabled, it fails because of the jar target. The following output belongs to the test case `java/1 basic`, with `install` argument added to the jar target: ```sh $ DESTDIR=tmp ninja install [0/1] Installing files. Installing myprog.jar to tmp/usr/local/lib/x86_64-linux-gnu/myprog.jar Stripping target 'myprog.jar' Could not strip file. Stdout: Stderr: strip:tmp/usr/local/lib/x86_64-linux-gnu/myprog.jar: File format not recognized FAILED: install '/usr/bin/python3' '/usr/local/bin/meson' '--internal' 'install' '/home/fatih/git/meson/test cases/java/1 basic/build/meson-private/install.dat' ninja: build stopped: subcommand failed. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Core: Add timeout parameter to connection's api_request() method As a client library developer, I want to have an easy way of specifying the timeout at the transport level for HTTP requests. **Motivation:** If the transport layer makes an HTTP request that gets stalled, it can block the client. Any timeouts and retries on top of it cannot come into play, because the transport layer blocks them while waiting for the response without any timeout specified. One of the manifestations of the problem in the BigQuery client: https://github.com/googleapis/google-cloud-python/issues/7831 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: SyntaxWarning with Python 3.8 ``` >>> import sys, numpy; print(numpy.__version__, sys.version) C:\\Program Files\\Python38\\lib\\site-packages\\numpy\\ma\\core.py:4466: SyntaxWarning: \"is\" with a literal. Did you mean \"==\"? if self.shape is (): 1.16.4 3.8.0b2 (tags/v3.8.0b2:21dd01d, Jul 4 2019, 16:00:09) [MSC v.1916 64 bit (AMD64)] ``` [Python 3.8](https://docs.python.org/3.8/whatsnew/3.8.html): > now produces a [SyntaxWarning](https://docs.python.org/3.8/library/exceptions.html#SyntaxWarning) when identity checks (`is` and `is not`) are used with certain types of literals (e.g. strings, ints). These can often work by accident in CPython, but are not guaranteed by the language spec. The warning advises users to use equality tests (`==` and `!=`) instead. https://bugs.python.org/issue34850, https://github.com/python/cpython/pull/9642, https://github.com/python/cpython/commit/3bcbedc9f1471d957a30a90f9d1251516b422416 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Broken / incorrect links to REST API in reference docs Many of the BigQuery REST docs have moved, because internally we use a new code generator for the docs. Previously, all the resource details were on a single page, such as https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs. Now the docs are split up into smaller pages by resource, for example https://cloud.google.com/bigquery/docs/reference/rest/v2/JobReference. This issue was reported internally in issue 141542760 and 141917083. #### Steps to reproduce 1. Navigate to [BigQuery reference docs](https://googleapis.dev/python/bigquery/latest/reference.html). 2. Navigate to a class, such as [LoadJobConfig](https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.job.LoadJobConfig.html#google.cloud.bigquery.job.LoadJobConfig) 3. Click a link such as https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs#configuration.load.autodetect 4. Land on a page that does not include information about the desired resource property. #### Proposed solution 1. Identify all links to resources https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs, https://cloud.google.com/bigquery/docs/reference/rest/v2/datasets, https://cloud.google.com/bigquery/docs/reference/rest/v2/tables 2. Update links to point to new location of the relevant type. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: GPT-NEOX RuntimeError Hi, when I ran the model GPT-NEOX, I got the \"RuntimeError: batch1 dim 2 must match batch2 dim1\" in modeling_gpt_neox.py, line 212. So I tried to debugg and fix this problem, I found the code \"present = None if use_cache else (key, value)\" in modeling_gpt_neox.py, line 146. Is that logical wrong? and the correct coding should be \"present = None if not use_cache else (key, value)\" ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: AttributeError: 'Arrow3D' object has no attribute '_path2d' while plotting bloch vector I wrote the simple code from qiskit.visualization import plot_bloch_vector %matplotlib inline plot_bloch_vector([0,1,0], title=\"New Bloch Sphere\") taken from https://qiskit.org/documentation/stubs/qiskit.visualization.plot_bloch_vector.html I keep getting AttributeError: 'Arrow3D' object has no attribute '_path2d' in my jupyter notebook. I have {'qiskit-terra': '0.19.1', 'qiskit-aer': '0.10.1', 'qiskit-ignis': '0.7.0', 'qiskit-ibmq-provider': '0.18.3', 'qiskit-aqua': '0.9.4', 'qiskit': '0.34.0', 'qiskit-nature': None, 'qiskit-finance': None, 'qiskit-optimization': None, 'qiskit-machine-learning': None} My matplotlib version is 3.4.3 Can anyone provide a solution for this and let me know where I am going wrong. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Autocompletion of %colors No autocompletion is implemented for %colors currently. Arguably a low-priority item. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Adding NLLB-200 - MoE - 54.5B for no language left behind ### System Info Hello @LysandreJik, Thanks a lot for your work on no language left behind. Is there any plan to add the 54.4B Model? Kindest regards ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Improvement ### Expected behavior Improvement Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook tooltip has extra newlines. Make in less useful as it looses precious space with information. Proably due the the mimebundle refactor. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: API Endpoint - CRUD - Dag Runs Hello We need to create several endpoints that perform basic CRUD operations on **DAG Run**. We need the following endpoints: DELETE /dags/{dag_id}/dagRuns/{dag_run_id} PATCH /dags/{dag_id}/dagRuns/{dag_run_id} POST /dags/{dag_id}/dagRuns/{dag_run_id} It depends on https://github.com/apache/airflow/issues/8129 Detailed information is available in the issue: https://github.com/apache/airflow/issues/8118 LOVE, Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: MSVC __cplusplus fix used Visual Studio version rather than Visual C++ Compiler version **Describe the bug** A change was made to meson to specify /Zc:__cplusplus which makes MSVC correctly define __cplusplus to a meaningful value (see https://docs.microsoft.com/en-us/cpp/build/reference/zc-cplusplus?view=msvc-160), but the meson check whether to include it or not seems to be comparing against a Visual Studio version number rather than a Visual C++ compiler version number. See commit https://github.com/mesonbuild/meson/commit/04c728a126cc484cda21d21d672630d298cae9b8 ``` if version_compare(self.version, '>= 15.7') and '/Zc:__cplusplus' not in args: return args + ['/Zc:__cplusplus'] return args ``` The comparison should be something like the following, according to the version on this website https://walbourn.github.io/vs-2017-15-7-update ``` if version_compare(self.version, '>= 19.14.26428') and '/Zc:__cplusplus' not in args: return args + ['/Zc:__cplusplus'] return args ``` Visual Studio 2012 version is emitting the following complaint with each compilation unit: cl : Command line warning D9002 : ignoring unknown option '/Zc:__cplusplus' **To Reproduce** Any C++ project targeting Visual Studio 2012 exhibits the above behaviour. **Expected behavior** No warnings when building with versions of Visual Studio/C++ which don't support this. **system parameters** * Native * Windows 10 * Python 3.10.1 * `meson --version`: 0.63.0 * `ninja --version`: 1.10.2.git.kitware.jobserver-1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: local cache inconsistent after enabling short_paths in a recipe To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Conan Version 1.3.3 Windows 10 With a package in local cache whose recipe does NOT have `short_paths=True`, modify in normal development folder the recipe and set `short_paths=True` and run conan create. Folders in local cache become inconsistent showing both folders from previous conan create run and .conan_link files pointing to the short paths folders. This seems no not affect conan tool behavior when running commands and works well if `short_paths` is removed once again. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QNSPSA produces irreproducible results <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: qiskit-terra 0.17.0 - **Python version**: Python 3.7.3 - **Operating system**: MacOS Big Sur 11.6 ### What is the current behavior? Executing a `QNSPSA` optimization with the same random seed gives different results. We checked that the same optimization gives reproducible results with other optimizers such as `ADAM`. ### Steps to reproduce the problem Run an arbitrary optimization, e.g., VQE with QNSPSA, and compare the results. ### What is the expected behavior? The same results for the same seed. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Use make_singleuser_app when available Follow up to #8806. Once there is a release with https://github.com/jupyterhub/jupyterhub/pull/3128, prefer to use ` from jupyterhub.mixins import make_singleuser_app`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Make frozendict generic for type annotation Trying to make frozendict a generic that inherits dictionary causes linting issues. Seems related to this pylint issue: https://github.com/PyCQA/pylint/issues/2420 Things that I have tried: - `class frozendict(Dict[_KT, _VT], Generic[_KT, _VT]):` - `class frozendict(dict, Mapping[_KT, _VT]):` - `class frozendict(dict, Generic[_KT, _VT]):` errors it runs into: ``` dagster/core/log_manager.py:24:17: E1101: Instance of 'frozendict' has no 'keys' member (no-member) dagster/core/log_manager.py:24:62: E1101: Instance of 'frozendict' has no 'keys' member (no-member) dagster/core/log_manager.py:87:16: E1101: Instance of 'frozendict' has no 'get' member (no-member) dagster/core/log_manager.py:88:11: E1136: Value 'PYTHON_LOGGING_LEVELS_MAPPING' is unsubscriptable (unsubscriptable-object) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Potential Bug in DataFlowCreateJavaJobOperator ### Apache Airflow Provider(s) google ### Versions of Apache Airflow Providers _No response_ ### Apache Airflow version 2.2.3 ### Operating System mac ### Deployment Docker-Compose ### Deployment details _No response_ ### What happened Passing anything other than a GCS bucket path to the `jar` argument results in the job never being started on DataFlow. ### What you expected to happen Passing in a local path to a jar should result in a job starting on Data Flow. ### How to reproduce Create a task using the DataFlowCreateJavaJobOperator and pass in a non GCS path to the `jar` argument. ### Anything else It's probably an indentation error in this [file](https://github.com/apache/airflow/blob/17d3e78e1b4011267e81846b5d496769934a5bcc/airflow/providers/google/cloud/operators/dataflow.py#L413) starting on line 413. The code for starting the job is over indented and causes any non GCS path for the `jar` to be effectively ignored. ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Pub/Sub] Add a bare Subscriber factory to Client Current Pub / Sub API requires a topic to create a subscription. This is unnecessary and cumbersome. It is also not feasible for some use cases: some users will only be given a subscription resource name to work with and not know the topic. Current API: ```python from google.cloud import pubsub client = pubsub.Client() topic = client.topic(topic_name) subscription = topic.subscription(sub_name) ``` Target: ```python subscription = client.subscription(sub_name) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.datastore.key.Key.parent untested, undocumented, useless At the moment, it just raises `NotImplementedError`. I imagine that it is intended to return a new key whose path is the \"parent path\" of the current key. E.g.: ``` >>> from gcloud.datastore.key import Key >>> PATH = [{'kind': 'parent', 'id': 123}, {'kind': 'child', 'id': 456}] >>> child = Key(path=PATH) >>> parent = key.parent() >>> parent.path() == child.path[:-1] True ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: install_folder usage in CMakeDefinitionsBuilder can break custom generators To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. Conan 1.18 Windows 10 x86_64 Custom generator such as https://github.com/pepe82sh/ConanCmakeToolchainGenerator - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. #5021 moves install_folder outside the check for the generators. When we use a custom generator such as https://github.com/pepe82sh/ConanCmakeToolchainGenerator the CMakeDefinitionsBuilder cannot be used to get the cmake definitions. This results in: conanfile.txt: ERROR: Generator CmakeToolchain(file:conan_toolchain.cmake) failed 'ConanFile' object has no attribute 'install_folder' ERROR: 'ConanFile' object has no attribute 'install_folder' I'm not sure if this is the custom generator misusing CMakeDefininitionsBuilder, or the CMakeDefininitionsBuilder using install_folder when it should not. I think the functionality this custom generator brings are great and I am willing to have a look to fix this in a good way (on conan or CmakeToolchain), but for now I am clueless :-). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Decoding error when running a stored flow ``` Traceback (most recent call last): File \"<string>\", line 1, in <module> File \"/usr/local/lib/python3.6/site-packages/prefect/environments/execution/cloud/environment.py\", line 104, in run_flow flow = schema.load(json.load(f)) File \"/usr/local/lib/python3.6/json/__init__.py\", line 296, in load return loads(fp.read(), File \"/usr/local/lib/python3.6/codecs.py\", line 321, in decode (result, consumed) = self._buffer_decode(data, self.errors, final) UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte ``` Still investigating the issue Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: When a flow has no storage attached, the agent should mark the run as failed It appears that if the Agent picks up a run with no storage, it will mark it as submitted. This run will then exist in limbo forever, as it can never be run. The agent should put it in a failed state if it can recognize it'll never run. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] What does \"ERROR: There are 4 binaries with name libxml2\" mean? <!-- What is your question? Please be as specific as possible! --> Conan version: 1.20.2 I'm running into this error message when building our tree with most (but not all) of our profiles. There are many similar messages with different packages. I'm calling `conan create` with a lockfile to build the package. The message comes from here: https://github.com/conan-io/conan/blob/1.20.2/conans/model/graph_lock.py#L324 The wording \"binary\" is probably misleading here, but I assume this means that somehow there are multiple nodes in the dependency tree with the same name. We probably have overlap in the tree (i.e. not always just the minimal needed packages are required explicitly, sometimes things that are transitive deps of the top-level dependencies are also required explicitly). But we don't have name collisions in our packages. So what does this error mean exactly and what can I do to resolve it? --- - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Test package command failing when method requirements in test package's conanfile Creating a new package with \"conan new -t\", and editing the example to require the package in a requirements method: ``` class MyTestConan(ConanFile): settings = \"os\", \"compiler\", \"build_type\", \"arch\" # requires = \"prueba/0.1@%s/%s\" % (username, channel) generators = \"cmake\" def requirements(self): self.requires(\"prueba/%s@lasote/stable\" % os.environ.get(\"MY_VERSION_ENV\", \"0.1\")) ``` Output: `ERROR: Unable to retrieve first requirement of test conanfile.py` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: VS backend doesn't respect warning_level/--warnlevel All generated VS projects use `/W1` regardless of warning level. VisualStudioCPPCompiler correctly returns `'/W4'` for `get_warn_args('3')`, so it's clearly the backend that's failing to use it. I'm currently trying to trace the problem in order to create a pull request for it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: docstring typo/inconsistency: mention of an xml notebook format? The helptext for the `%notebook` magic mentions that you can save the notebook in an xml format, e.g. [here](https://github.com/ipython/ipython/blob/master/IPython/core/magics/basic.py#L557) and [here](https://github.com/ipython/ipython/blob/master/IPython/core/magics/basic.py#L564), but in [the code](https://github.com/ipython/ipython/blob/master/IPython/core/magics/basic.py#L602) it seems pretty clear that the xml format isn't allowed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Make links to documentation under help menu use configuration vars rather than hard coding <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue, but you can delete them once you've read them if you prefer! --> <!-- Thanks for thinking of a way to improve JupyterLab. If this solves a problem for you, then it probably solves that problem for lots of people! So the whole community will benefit from this request. Before creating a new feature request please search the issues for relevant feature requests. --> ### Problem Under the help menu, the links for Jupyterlab FAQ for instance, are all hardcoded in the compiled Javascript objects. when running Jupyter in an isolated environment, changing those URLs to point to locally hosted documentation involves lots of \"sed\" commands against the jupyter/lab/static directory, and the urls keep changing meaning the regexps keep having to be updated. (Is it /stable/ is it /latest/, etc...) If those URLs were instead in some kind of configuration file, even if as an option, that would make life much easier. ### Proposed Solution <!-- Provide a clear and concise description of a way to accomplish what you want. For example: * Add an option so that when [...] [...] will happen --> I am not sure where this would fit best. Could be a configuration setting you can change in the settings editor since you can apply overrides for those, could be in some hidden json file. Anything to make life easier going forward. Ideally the same solution would be leveraged by Notebookv7 but figured lab is where to get this discussion started. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Bigtable: valid range for RowSampleFilter is incorrect. This is a documentation bug, here: [https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/bigtable/google/cloud/bigtable/row_filters.py#L171][1] the documentation asserts that the valid range for a RowSampleFilter is `[0.0, 1.0]`. In fact, it is the open interval `(0.0, 1.0)`. The server rejects both `0.0` and `1.0`. [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/017714cf91a310caafc60181c044d7812c7226b7/bigtable/google/cloud/bigtable/row_filters.py#L171 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: wrong 'label2id' and 'id2label' in config when loading from pretrained # 🐛 Bug ## Information Model I am using (Bert, XLNet ...): Bert Language I am using the model on (English, Chinese ...): English The problem arises when using: * [ ] the official example scripts: (give details below) * [x] my own modified scripts: (give details below) The tasks I am working on is: * [ ] an official GLUE/SQUaD task: (give the name) * [x] my own task or dataset: (give details below) ## To reproduce Steps to reproduce the behavior: 1. ```python from transformers import BertConfig config = BertConfig.from_pretrained('bert-base-cased', num_labels=3) print(config.id2label) ``` 2. Prints: {0: 'LABEL_0', 1: 'LABEL_1'} <!-- If you have code snippets, error messages, stack traces please provide them here as well. Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.--> ## Expected behavior <!-- A clear and concise description of what you would expect to happen. --> prints {0: 'LABEL_0', 1: 'LABEL_1', 2: 'LABEL_2'} ## Environment info <!-- You can run the command `python transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 2.5.1 - Platform: Ubuntu 16.04 - Python version: 3.7.6 - PyTorch version (GPU?): 1.4.0 - Using GPU in script?: no - Using distributed or parallel set-up in script?: no Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: [qtconsole] %hist doesn't show anything in qtconsole I have built rc2 on Windows XP and while the qtconsole works fine for the most part, %hist does not show any history in the qtconsole. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: MAINT: _polybase __div__ method Line 420 - 422 of `numpy/polynomial/_polybase.py` has the following method: ``` def __div__(self, other): # set to __floordiv__, /, for now. return self.__floordiv__(other) ``` This implies the original author may have intended to come back and implement some other `__div__` method here. Is there a consensus on whether we would want to do that, remove the comment, or kick the can down the road? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Allow kernel specs to specify langauge specific help menu items Right now the link in our Help menu in the notebook are hard coded to Python specific things. Other kernels should be able to customize these links in the kernelspec JSON data and we should ship these links in our own kernel specs. This will allow us to point to Python 2/3 docs separately. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: dynamoDB result backend incorrect exception handling when table exists The following code https://github.com/celery/celery/blob/d0f5300691ca594f2311daf542aa63367622c027/celery/backends/dynamodb.py#L192 tries to create or get the table. In case the table exists and the role executing that code on AWS does not have the `CreateTable` permission, the raised exception is not the one expected by that particular line. Yet the table exists _and_ the exception is raised because the code tries to create it while lacking permissions. To reproduce: * celery 5.0.5 * create the result backend table and give the following permissions to the role executing celery on that table: ``` \"dynamodb:DescribeTable\", \"dynamodb:PutItem\", \"dynamodb:UpdateItem\", \"dynamodb:DeleteItem\", \"dynamodb:BatchWriteItem\", \"dynamodb:GetItem\", \"dynamodb:BatchGetItem\", \"dynamodb:Scan\", \"dynamodb:Query\", \"dynamodb:ConditionCheckItem\" ``` * remove the permission CreateTable from the role executing the code Possible solution: * handle the check of the table existence with another boto3 call such as [`describe_table`](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/dynamodb.html#DynamoDB.Client.describe_table) and then fall-back into the table creation * provide a configuration that, when indicated, assumes the existence of the table * handle that exception differently Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Improve coverage of the documentation Currently, some public classes are not documented anywhere because we didn't create the corresponding doc pages. Those missing pages are: - Benchmark classes - Bert Japanese - Data collators If someone feels like working on one of those, please tag yourself with a comment on this issue. Once the objects are properly documented, they can be removed from the `SHOULD_BE_DOCUMENTED` constant in [this file](https://github.com/huggingface/transformers/blob/1310e1a758edc8e89ec363db76863c771fbeb1de/utils/check_repo.py#L374). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: CLIP pooling is not compatible with adding new tokens ### System Info Feature request (Duplicate of #21029) For textual inversion in diffusers, we are adding tokens that have a higher token id than the eos token. So when we get clip embeddings for textual inv tokens, we need to change the pooling so it gets the eos token and not the arg max token. Motivation This is an issue that should be fixed as the clip embeddings won't work once we add more tokens to the tokenizer. This hasn't been a huge issue so far because most models use the hidden layers directly but [the new paper on SDXL](https://github.com/Stability-AI/generative-models/blob/main/assets/sdxl_report.pdf) also mentions using the pooled output now. @ArthurZucker @younesbelkada ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction 1. Add new token to tokenizer 2. Encode tokens with CLIPTextModel 3. Get pooled output ### Expected behavior Pooled output considers the added token ids vs eos id instead of argmax Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.datastore.key.Key.from_protobuf drops namespace Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: center labels on histogram <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? can we center the x labels on the histogram when plotting more than one data set. <img width=\"692\" alt=\"image\" src=\"https://user-images.githubusercontent.com/15731369/52830969-c6d10b00-30a0-11e9-926d-bc2b9042c1c7.png\"> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add missing parameter documentation for `KubernetesHook` and `KubernetesPodOperator` ### Body Currently the following modules are missing certain parameters in their docstrings. Because of this, these parameters are not captured in the [Python API docs for the Kubernetes provider](https://airflow.apache.org/docs/apache-airflow-providers-cncf-kubernetes/stable/_api/airflow/providers/cncf/kubernetes/index.html). - [ ] KubernetesHook: `in_cluster`, `config_file`, `cluster_context`, `client_configuration` - [ ] KubernetesPodOperator: `env_from`, `node_selectors`, `pod_runtime_info_envs`, `configmaps` ### Committer - [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Pylab banner shows up with first cell to execute If the notebook server is started with `--pylab=inline`, the first cell to be run shows the pylab banner (\"Welcome to pylab...\"). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Docker v1.13 init feature to use in docker compose It would be great to have the docker v1.13 init feature in Compose v3 so as to provision the containers with docker compose with an init process running as PID 1 inside the containers. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: load_table_from_dataframe fails on datetime64 column used for partitioning, saying it's an INTEGER Versions: ``` google-cloud-bigquery==1.19.0 ``` We were initially using 1.18.0 but I noticed #9044 was included in 1.19.0 so we tried that as well, but it made no difference. We're using a pandas dataframe read from parquet, example data would be ``` id status created_at execution_date 0 1 NEW 2018-09-12 09:24:31.291 2019-05-10 17:40:00 1 2 NEW 2018-09-12 09:26:45.890 2019-05-10 17:40:00 [628 rows x 4 columns] ``` `df.dtypes` shows: ``` id object status object created_at datetime64[ns] dataplatform_execution_date datetime64[ns] dtype: object ``` When trying to load this into BigQuery using `load_table_from_dataframe()` and setting the job config's `time_partitioning` to `bigquery.table.TimePartitioning(field=\"execution_date\")` we get the following error: ``` The field specified for time partitioning can only be of type TIMESTAMP or DATE. The type found is: INTEGER. ``` Which doesn't really make sense, since the field is clearly a `datetime64`. The job config shown in the console looks correct (ie it's set to partitioned by day and it's using the correct field). edit: It seems the cause for this is that Dataframe columns of type `datetime64` are being converted to type `INTEGER` instead of `DATE` (or `TIMESTAMP`? I'm not sure which one would be the correct type in BigQuery). edit2: Could it be this mapping is wrong and it should be `DATE` instead of `DATETIME`? https://github.com/googleapis/google-cloud-python/blob/dce13268e9bdf2df6a3c7a2df6db3b8a1bb51f75/bigquery/google/cloud/bigquery/_pandas_helpers.py#L55 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qiskit._util deprecation warning on `import qiskit` ``` Python 3.5.6 |Anaconda, Inc.| (default, Aug 26 2018, 16:30:03) [GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)] on darwin Type \"help\", \"copyright\", \"credits\" or \"license\" for more information. >>> import qiskit /Users/kevin.krsulichibm.com/q/qiskit-terra/qiskit/_util.py:18: DeprecationWarning: The qiskit._util module is deprecated and has been renamed qiskit.util. Please update your imports as qiskit._util will beremoved in Qiskit Terra 0.9. 'removed in Qiskit Terra 0.9.', DeprecationWarning) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add more useful header info on HTTP requests Most relevant place: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/9619004959def22ad2084691f382dc1cada46afd/core/google/cloud/_http.py#L177 May want to make this easier to use upstream /cc @lukesneeringer Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gdbus_codegen should return two different targets (.c, .h) With glib<2.56.2, gdbus_codegen() returns twice the same custom_target, with two outputs. A bug occurs when this return value is used for generate_gir(). The source list then contains twice the .c, and zero times the .h… Maybe gdbus_codegen() should return two custom_targets, with each one output (once the .c, once the .h). EDIT : Actually, after reading the source of generate_gir, I suppose the bug is there. ``` gir_filelist.write(os.path.join(state.environment.get_build_dir(), state.backend.get_target_dir(s), s.get_outputs()[0]) + '\\n') ``` Why only `s.get_outputs()[0]` ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: custom_target exe-wrapper data filename always changes on regen I have custom target with LONG command line (around 500 files at once) Simplified project: [classpath.zip](https://www.dropbox.com/s/nsh2y46e6opqrw1/classpath.zip) ``` project('avian', ['cpp']) subdir('classpath') javac = find_program('javac') classpath_classes = custom_target('classpath_classes', input: classpath_java_sources, output: 'classpath_classes', capture: true, command: [javac, '-encoding', 'UTF-8', '-source', '1.6', # JAVA_VERSION, '-target', '1.6', # JAVA_VERSION, '-d', meson.current_build_dir() + '/classpath', '-bootclasspath', meson.current_build_dir() + '/classpath', '@INPUT@' ], ) ``` Commands: ``` $ mkdir build $ meson build $ ninja -C build -d explain classpath_classes ``` Build success. Next time: ``` $ ninja -C build -d explain classpath_classes ninja: Entering directory `build' ninja: no work to do. ``` But: ``` $ touch meson.build $ ninja -C build -d explain classpath_classes ninja: Entering directory `build' ninja explain: output build.ninja older than most recent input ../meson.build (501180038 vs 501180064) [0/1] Regenerating build files The Meson build system Version: 0.36.0 Source dir: F:\\avian\\classpath Build dir: F:\\avian\\classpath\\build Build type: native build Project name: avian Native cpp compiler: c++ (gcc 6.2.0) Build machine cpu family: x86_64 Build machine cpu: x86_64 Program javac found: YES (C:\\Program Files\\Java\\jdk1.8.0_111\\bin\\javac.EXE) Build targets in project: 1 ninja explain: command line changed for classpath_classes ``` Where is command line changed? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: `manual_only` tasks won't run Currently, because we have stopped using `start_tasks` in the agent, `manual_only` triggers are _always_ called, preventing the tasks from running. `Resume` states should \"trigger\" (pun intended) a bypass of triggers. **cc**: @jlowin Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Make sure @property's are near constructor in methods See https://github.com/GoogleCloudPlatform/gcloud-python/pull/987/files#r35029989 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: difficult error to debug if ninja can't be found I updated ninja but forgot to `chmod +x` it and got this error. At first I had no clue what was happening until I remembered I updated `ninja`. ``` python3 ./ECS/meson/meson.py --prefix=/home/gitlab-runner/builds/15268147/0/dist-ecs --buildtype=debugoptimized build Traceback (most recent call last): File \"/home/gitlab-runner/builds/15268147/0/ECS/meson/mesonbuild/mesonmain.py\", line 283, in run app.generate() File \"/home/gitlab-runner/builds/15268147/0/ECS/meson/mesonbuild/mesonmain.py\", line 173, in generate g.generate(intr) File \"/home/gitlab-runner/builds/15268147/0/ECS/meson/mesonbuild/backend/ninjabackend.py\", line 203, in generate self.generate_ending(outfile) File \"/home/gitlab-runner/builds/15268147/0/ECS/meson/mesonbuild/backend/ninjabackend.py\", line 2094, in generate_ending ninja_command = environment.detect_ninja() File \"/home/gitlab-runner/builds/15268147/0/ECS/meson/mesonbuild/environment.py\", line 51, in detect_ninja p = subprocess.Popen([n, '--version'], stdout=subprocess.PIPE, stderr=subprocess.DEVNULL) File \"/usr/local/lib/python3.5/subprocess.py\", line 947, in __init__ restore_signals, start_new_session) File \"/usr/local/lib/python3.5/subprocess.py\", line 1551, in _execute_child raise child_exception_type(errno_num, err_msg) PermissionError: [Errno 13] Permission denied ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Control-C kills port forwarding ``` In [1]: from IPython.parallel import Client In [2]: c = Client() # this works as expected In [3]: <Control-C> SIGINT: Port forwarding stopped cleanly SIGINT: Port forwarding stopped cleanly SIGINT: Port forwarding stopped cleanly SIGINT: Port forwarding stopped cleanly SIGINT: Port forwarding stopped cleanly SIGINT: Port forwarding stopped cleanly KeyboardInterrupt ``` It seems that pressing Control-C at the prompt propagates to ssh, killing the tunnels. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: ValueError: For an array_value, subvalues must either all be indexed or all excluded from indexes. Getting `ValueError: For an array_value, subvalues must either all be indexed or all excluded from indexes.` error when querying entities with empty arrays. Edit: I tried getting around this with projection queries where possible but I need to modify the entities after fetching them, which you can't do with the results of a projection query. So this is a pretty big issue as there is no way around it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Logging system tests broken https://travis-ci.org/GoogleCloudPlatform/google-cloud-python/builds/205851892#L2768 ```python Traceback (most recent call last): File \"/home/travis/build/GoogleCloudPlatform/google-cloud-python/system_tests/logging_.py\", line 440, in test_update_sink self.assertFalse(sink.exists()) File \"/home/travis/build/GoogleCloudPlatform/google-cloud-python/.tox/system-tests/lib/python2.7/site-packages/google/cloud/logging/sink.py\", line 138, in exists client.sinks_api.sink_get(self.project, self.name) File \"/home/travis/build/GoogleCloudPlatform/google-cloud-python/.tox/system-tests/lib/python2.7/site-packages/google/cloud/logging/client.py\", line 134, in sinks_api self._sinks_api = make_gax_sinks_api(self) File \"/home/travis/build/GoogleCloudPlatform/google-cloud-python/.tox/system-tests/lib/python2.7/site-packages/google/cloud/logging/_gax.py\", line 573, in make_gax_sinks_api channel=channel, lib_name='gccl', lib_version=__version__) TypeError: __init__() got an unexpected keyword argument 'lib_name' ``` Preliminarily assigning to Luke. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Application._load_config_files log parameter default fails The files `examples/tests/embed/embed[1-3].py` are failing with an error like this: ``` Traceback (most recent call last): File \"embed1.py\", line 10, in <module> bar(f) File \"embed1.py\", line 8, in bar IPython.embed(banner1='check f in globals, foo in locals') File \"/home/takluyver/.local/lib/python3.3/site-packages/IPython/terminal/embed.py\", line 287, in embed config = load_default_config() File \"/home/takluyver/.local/lib/python3.3/site-packages/IPython/terminal/ipapp.py\", line 379, in load_default_config for cf in Application._load_config_files(\"ipython_config\", path=profile_dir): File \"/home/takluyver/.local/lib/python3.3/site-packages/IPython/config/application.py\", line 527, in _load_config_files log.debug(\"Loaded config file: %s\", loader.full_filename) AttributeError: 'NoneType' object has no attribute 'debug' ``` `_load_config_files` has a log parameter with a default of None. It should either be required, or it should do something sensible when it gets the default. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: GeneratedList as input of CustomTarget is broken with VS backends Can be seen in the `common\\113 generatorcustom` test: https://ci.appveyor.com/project/jpakkane/meson/build/1.0.925/job/p69h84wd9rtvkdns ``` Traceback (most recent call last): File \"C:\\projects\\meson\\mesonbuild\\mesonmain.py\", line 279, in run app.generate() File \"C:\\projects\\meson\\mesonbuild\\mesonmain.py\", line 169, in generate g.generate(intr) File \"C:\\projects\\meson\\mesonbuild\\backend\\vs2010backend.py\", line 168, in generate self.generate_solution(sln_filename, projlist) File \"C:\\projects\\meson\\mesonbuild\\backend\\vs2010backend.py\", line 233, in generate_solution all_deps = self.determine_deps(p) File \"C:\\projects\\meson\\mesonbuild\\backend\\vs2010backend.py\", line 203, in determine_deps all_deps[d.get_id()] = True AttributeError: 'GeneratedList' object has no attribute 'get_id' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: windows build broken with 0.52.0 We get a: ```meson.build:182:2: ERROR: Search directory \\usr\\local\\lib\\tensorflow_cc is not an absolute path.``` This is from: ```tf_tensorflow_lib = cc.find_library('libtensorflow_cc', dirs: tensorflow_libdir, required: false)``` and tensorflow_libdir is initialized through an array option with default value `['/usr/local/lib/tensorflow_cc/']`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: modeling_fnet.py config option https://github.com/huggingface/transformers/blob/b7d264be0d70d5309dbf24a6c7ebba1e073bdda5/src/transformers/models/fnet/modeling_fnet.py#L177 Should refer to config.tpu_short_seq_length Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: np.stack should support axis argument Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: __main__.py files not used in directory execution Take the following directory structure: ``` test_dir __main__.py ``` where `__main__.py` reads ``` python print(\"Hi\") ``` Using the standard `python` command, I can: ``` $ python3 test_dir Hi ``` Under `ipython`, this produces: ``` $ ipython3 test_dir [TerminalIPythonApp] WARNING | File not found: 'test_dir' ``` This feature was added in Python 2.5. I suspect this error is simply because `ipython` hasn't implemented this functionality yet, but I don't see any open issues. This feature is documented at https://docs.python.org/3/using/cmdline.html#interface-options. Is there a specific reason why `ipython` doesn't use [runpy.run_path](https://docs.python.org/3/library/runpy.html#runpy.run_path) for running scripts passed as arguments? If somebody could point me to a file in which I could patch this, I'd be happy to. I found [these lines](https://github.com/ipython/ipython/blob/master/IPython/core/interactiveshell.py#L2475-L2477) in `safe_execfile`, but `runpy.run_file` isn't entirely equivalent to `py3compat.execfile`, since it doesn't support the `locals` or `compiler` arguments. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: custom_target's build_always shouldn't imply build_by_default If you set `build_always` to `true` on a `custom_target` it will build it by default rather than explicit only. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Browser check is not failing when it should I noticed while working on https://github.com/jupyterlab/jupyterlab-module-federation/pull/22 that despite the chrome test failing, the job was succeeding. Pinning to 2.1.5 allowed the job to properly [fail](https://github.com/jupyterlab/jupyterlab-module-federation/pull/22/commits/903e26076e06f74c6fb80b1307dc715a373878dc). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CONAN_PRINT_RUN_COMMANDS=1 leads to TypeError exception under python 2.7 Consider the following test example: ```python from conans import ConanFile from io import StringIO import sys import traceback class TestConan(ConanFile): name = \"test\" version = \"0.0.1\" def package(self): output = StringIO() try: self.run(\"cd .\", output=output) except: traceback.print_tb(sys.exc_info()[2]) raise ``` Let's try to run `conan create` under python 2 & 3 with or without `CONAN_PRINT_RUN_COMMANDS=1` (I run python2 tests under lasote/conangcc5 docker image and python3 tests under Windows) Python3: `conan create . test/0.0.1@dbely/testing` - works `CONAN_PRINT_RUN_COMMANDS=1 conan create . test/0.0.1@dbely/testing` - works Python2: `conan create . test/0.0.1@dbely/testing` - works `CONAN_PRINT_RUN_COMMANDS=1 conan create . test/0.0.1@dbely/testing` - fails with ``` File \"/home/conan/.conan/data/test/0.0.1/dbely/testing/export/conanfile.py\", line 13, in package self.run(\"cd .\", output=output) File \"/usr/local/lib/python2.7/dist-packages/conans/model/conan_file.py\", line 252, in run retcode = self._runner(command, output, os.path.abspath(RUN_LOG_NAME), cwd) File \"/usr/local/lib/python2.7/dist-packages/conans/client/runner.py\", line 31, in __call__ stream_output.write(call_message) ERROR: test/0.0.1@dbely/testing: Error in package() method, line 13 self.run(\"cd .\", output=output) TypeError: unicode argument expected, got 'str' ``` Looks like a bug inside conan, isn't it? BTW, the way conan reports python exception (losing stack trace) is very misleading. I had to add `try/except` and `traceback.print_tb(sys.exc_info()[2])` to find out what was going on. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Python 3.6 regression for as_system() on cmake subproject dependency objects **Describe the bug** I need to change the include_type for cmake subproject dependencies to 'system'. Meson 0.54.3 using Python3.6 (Centos 7) this worked correctly. However after upgrading to Meson 0.55 I get a \"TypeError: cannot deepcopy this pattern object\" exception. If I upgrade to Python 3.7 this goes away. However, Meson is stated to be supported in Python 3.5+. **To Reproduce** meson.build ``` project('cmake_dep_regression','cpp') cmake = import('cmake') xerces_dep = cmake.subproject('xerces-c').dependency('xerces-c').as_system('system') exe1 = executable('main', ['main.cpp'], dependencies: [xerces_dep]) ``` main.cpp ``` #include <iostream> #include <cmMod.hpp> using namespace std; int main(void) { cmModClass obj(\"Hello\"); cout << obj.getStr() << endl; return 0; } ``` xerces-c.wrap ``` [wrap-git] url = https://github.com/apache/xerces-c.git revision = v3.2.2 ``` **Expected behavior** I expect the build to be successful (no traceback) and for the xerces header files to be -isystem included in the main.cpp compile step (see compile_commands.json). **system parameters** * Plain native build * CentOS 7.8 * Python 3.6.8 (fails) and Python 3.7.6 (works) * meson 0.55.0 * ninja 1.9.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: Wrong version in nightly wheels / pip 0.20.3 + python 3.9 Not sure if NumPy or pip is to blame but things are okay with pip 20.2.4: ``` $ python3.9 -m pip install --progress-bar off --upgrade \"pip!=20.3\" setuptools wheel ... Successfully installed pip-20.2.4 $ python3.9 -m pip install --progress-bar off --upgrade --pre --only-binary \":all:\" -i \"https://pypi.anaconda.org/scipy-wheels-nightly/simple\" numpy ... Successfully installed numpy-1.21.0.dev0+d0a457f ``` But broken with pip 20.3: ``` $ python3.9 -m pip install --progress-bar off --upgrade pip setuptools wheel ... Successfully installed pip-20.3 $ python3.9 -m pip install --progress-bar off --upgrade --pre --only-binary \":all:\" -i \"https://pypi.anaconda.org/scipy-wheels-nightly/simple\" numpy ... Collecting numpy Downloading https://pypi.anaconda.org/scipy-wheels-nightly/simple/numpy/1.21.0.dev0%2Bd0a457f/numpy-1.21.0.dev0%2B20201129040310_d0a457f-cp39-cp39-manylinux2010_x86_64.whl (15.4 MB) ERROR: Requested numpy from https://pypi.anaconda.org/scipy-wheels-nightly/simple/numpy/1.21.0.dev0%2Bd0a457f/numpy-1.21.0.dev0%2B20201129040310_d0a457f-cp39-cp39-manylinux2010_x86_64.whl has different version in metadata: '1.21.0.dev0+d0a457f' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Consider re-enabling GAX bundling for 'Topic.publish' ... once a fix is relased for https://github.com/googleapis/gax-python/issues/113 /cc @bjwatson, @geigerj. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [SCM] Inability to export (and create) when using the `scm` feature while the conanfile is in a subfolder (Working with conan 1.61 on both OS X and Windows) This issue is following the second part of the problem described in #3069. Our workflow relies on the *conanfile.py* `scm` feature for revision auto-deduction. We don't place said *conanfile.py* at the root of the repository, but at *conan/conanfile.py* instead. With this configuration, any attempt to run cd $gitrepo conan export conan/ com/develop Will fail with > ERROR: Not a git repository This seems to be because the folder containing the recipe is **not** the root of the repository (it does not contain the .git/ repository), yet its parent does. Is hosting the recipe in subfolders supported by conan? It seemed to work well for our use case, until this issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Improve error message on wrong value for settings attribute I had a wrong value for the settings attribute like: ``` settings = {\"os_build\": 'Linux', \"arch_build\": [\"x86\", \"x86_64\"]} ``` And the error message was very strange: ``` ERROR: /home/users/.../export/conanfile.py: Error while initializing settings. Invalid setting 'L' is not a valid 'os_build' value. Possible values are ['FreeBSD', 'Linux', 'Macos', 'SunOS', 'Windows', 'WindowsStore'] ``` It's not obvious at this point, what the problem was. After quite some digging, I found that the value for os_build is supposed to be a list. Maybe apply some schema checking at this point for a better error message. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Plotting a circuit with matplotlib interferes with global figure <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.0.dev0+98b4a1f - **Python version**: 3.8 - **Operating system**: Windows 10 ### What is the current behavior? Plotting a circuit diagram with matplotlib resizes the figure window ### Steps to reproduce the problem Here is a minimal example. We create a matplotlib window with a specified size and layout and we require qiskit to draw into the specified axis `ax2`. ``` import matplotlib.pyplot as plt from qiskit import QuantumCircuit Fig=plt.figure(1, figsize=(4,6)) plt.clf() ax1=Fig.add_subplot(1,2,1) ax2=Fig.add_subplot(1,2,2) ax1.plot([1,2,3], [4,7,4]) print(Fig.get_size_inches()) circ = QuantumCircuit(2, name='test') for ii in range(10): circ.h(1) circ.cz(0,1) circ.draw(ax=ax2, output='mpl') print(Fig.get_size_inches()) ``` After plotting the figure window has been resized. ### What is the expected behavior? Plotting on a specified axis should not interface with the other axis on a figure and the figure itself. ### Suggested solutions The problem is at this line: https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/visualization/matplotlib.py#L912 There the global figure properties are updated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Broadcasting of size-0 dimensions not implemented Numpy supports broadcasts with size-0 dimensions against size-1 dimensions: ``` onp.ones([0,1]) + onp.ones([1,128]) ``` produces: ``` array([], shape=(0, 128), dtype=float64) ``` However ``` to_device = jax.jit(lambda x:x) to_device(np.ones([0,1])) + to_device(np.ones([1,128])) ValueError: Incompatible shapes for broadcasting: ((0, 1), (1, 128)) ``` The broadcasting rule computes the output shape as ``` result_shape = onp.max(shapes, axis=0) ``` but it probably needs to be something like this: ``` min_shape = onp.min(shapes, axis=0) max_shape = onp.max(shapes, axis=0) result_shape = onp.where(min_shape == 0, 0, max_shape) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: PIN 16: Extend `Result` interface ## Use Case See PIN 16 (PR #2134) for background. This issue includes only extensions to the `Result` interface from the PIN that are independently deliverable from other issues. ## Solution Update the `Result` base class with the following init kwargs: - `validators: Iterable[Callable]` - `should_validate_result: bool` - `cache_for: datetime.timedelta` - `cache_validator: Callable` - `filename_template: str` and the following new methods: - `exists -> bool`, not implemented in the base class - ~`validate -> bool`, don't implement it yet~ (this will be added in #2144 to await ValidationFailed state in case we need it at that time) - `read`, not implemented in the base class - `write`, not implemented in the base class ## Alternatives Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Connect to Compute Engine instance by name Hello, It would be very helpful to have an operator that allows you to execute the SSH command on another virtual machine without the need to manage RSA keys and without the need to configure IP addresses. * The server should be specified by instance name and zone. * The key should be provided using the following methods (user selection): - [OSLogin](https://cloud.google.com/compute/docs/instances/managing-instance-access#gcloud_1) - [Project/instance metadata](https://cloud.google.com/compute/docs/instances/adding-removing-ssh-keys) - None - We should support tunnel the ssh connection through [the Cloud Identity-Aware Proxy](https://cloud.google.com/iap/docs/using-tcp-forwarding). Thanks to this, we will be able access to VM instances that do not have public IP addresses or do not permit direct access over the internet. - We should support Connect to instances using their internal IP addresses rather than their external IP addresses. Thanks to this, we will be able to connect from one instance to another on the same VPC network, over a VPN connection, or between two peered VPC networks. In brief. This should work similarly to the [gcloud compute ssh](https://cloud.google.com/sdk/gcloud/reference/compute/ssh ) command. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Agent shutdown can take up to 10 seconds ## Current behavior Today, when an agent is signaled to exit it can take up to 10 seconds to respond and shutdown. This is due to a canned sleep in a polling loop. ## Proposed behavior The agent should respond immediately to exit requests, especially when sleeping. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: dependency('foo', static: true) not working as expected Hi, When using `dependency('foo', static: true)` with pkg-config backend, meson is not trying to statically link the executable against that library Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: display.Image should allow manual setting of format even when a local file is given It appears that the `display.Image` class has some non-intuitive (and limiting) behavior for inferring the format of a locally-provided image. I would have _thought_ that supplying the `format` keyword would allow me to override whatever format the IPython machinery decided the local file was in. This is important for a use case where e.g. temporary files are used, as the file has _no_ extension, so you can't guess based on the filename. However, if I do something like: `IPython.display.Image(filename='/temp/somerandomfilename', format='jpg')` to my surprise, it does _not_ try to interpret the file as a JPEG, but rather says `ValueError: Cannot embed the '/temp/somerandomfilename' image format`. Is there a reason why this is the case, or could this be fixed? (See also astropy/astropy-tutorials#97 for the context that this was encountered) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: example_input_array dtype Currently assumed that example_input_array dtype to be equal to model dtype. This is not necessarily correct - e.g. if input is a vector of INT. https://github.com/PyTorchLightning/pytorch-lightning/blob/7dc58bd286b1e81ca4d293f05bddff5e93361020/pytorch_lightning/core/memory.py#L192 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Should ShapeDtypeStruct.size exist? `ShapeDtypeStruct` currently has `dtype` and `shape`. We could add numpy's `size` property via ``` class ShapeDtypeStruct(object): __slots__ = [\"shape\", \"dtype\"] def __init__(self, shape, dtype): self.shape = shape self.dtype = dtype @property def size(self): return np.prod(self.shape, dtype=int) ``` Do you want this patch? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: mean padding with np.pad may lead to different prepended and appended values The bug was posted [on the mailing list](https://mail.python.org/pipermail/numpy-discussion/2018-April/077961.html). It boils down to the fact that `np.mean` with mean padding recomputes the mean from the half-padded array for the append step. Mathematically this would be OK, but in case of finite precision and near-zero means the near-zero prepended values may bias the recomputed mean in a way that prepended and appended values are different. Stripped-down example: ``` >>> import numpy as np >>> a = np.array([-1, 2, -1]) + np.array([0, 1e-12, 0], dtype=np.float64) >>> a = np.pad(a, (1, 1), 'mean') >>> print(a) [ 3.33362967e-13 -1.00000000e+00 2.00000000e+00 -1.00000000e+00 3.33399974e-13] ``` As you can see, the first and the last values (both of which should be the mean) differ on the order of the machine epsilon. The prepended value is the true mean of the original array, the appended value is the mean where the prepended value is also taken into account. It was decided on the mailing list that [this is a bug](https://mail.python.org/pipermail/numpy-discussion/2018-April/077964.html). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: default EarlyStopping callback should not fail on missing val_loss data **Describe the bug** My training script failed overnight — this is the last thing I see in the logs before the instance shut down: ``` python3.7/site-packages/pytorch_lightning/callbacks/pt_callbacks.py:128: RuntimeWarning: Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: avg_val_loss_total,avg_val_jacc10,avg_val_ce RuntimeWarning) ``` It seems like we intended this to be a \"warning\" but it appears that it interrupted my training script. Do you think that's possible, or could it be something else? I had 2 training scripts running on 2 different instances last night and both shut down in this way, with this RuntimeWarning as the last line in the logs. Is it possible that the default EarlyStopping callback killed my script because I didn't log a `val_loss` tensor somewhere it could find it? To be clear, it is not my intention to use EarlyStopping at all, so I was quite surprised to wake up today and find my instance shut down and training interrupted, and no clear sign of a bug on my end. Did you intend this to interrupt the trainer? If so, how do we feel about changing that plan so that the default EarlyStopping callback has no effect when it can't find a `val_loss` metric? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Gates do not check if complex inputs passed in <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? This works: ```python from qiskit import * qc = QuantumCircuit(2, 2) qc.h(0) qc.rx(1+1j, 0) qc.cx(0, 1) qc.measure([0, 1], [0, 1]) qc.draw() ``` but it should not. It only gets caught later with: ``` TypeError: can't convert complex to float ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: [Metrics] SSIM ## 🚀 Feature Implement SSIM Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: [4.6.0] conda init powershell --all-users With the new `4.6.0rc1` `conda init powershell` puts the below config in your *user* `$PROFILE` ```powershell C:\\> $PROFILE C:\\Users\\dhirschfeld\\Documents\\WindowsPowerShell\\Microsoft.PowerShell_profile.ps1 C:\\> cat $PROFILE #region conda initialize # !! Contents within this block are managed by 'conda init' !! (& C:\\Miniconda3\\Scripts\\conda.exe shell.powershell hook) | Out-String | Invoke-Expression #endregion C:\\> ``` If you have an AllUsers install of Miniconda (e.g. in `C:\\Miniconda3`) it would be good to be able to initialize powershell for all users i.e. in the `$PROFILE.AllUsersAllHosts` ```powershell C:\\> $PROFILE.AllUsersAllHosts C:\\Windows\\System32\\WindowsPowerShell\\v1.0\\profile.ps1 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Add tab completion for `%config` Tab completion should be added for options for `%config`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Introduce the modular Transpiler ## Description Replace the current `compile()` function with a modular `Transpiler` that provides finer control over the steps involved and support for extending and customizing the pipeline, and reduce complexity overall. ## Checklist * [ ] Add the new `Transpiler` module files ## See also #413: previous issue with 0.5 planning Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: documentation of rollaxis Hi, On the web page https://docs.scipy.org/doc/numpy/reference/generated/numpy.rollaxis.html, where you document the rollaxis function, you first say: Roll the specified axis backwards, until it lies in a given position. then you write: start : int, optional The axis is rolled until it lies before this position. The default, 0, results in a “complete” roll. There seems to be a contradiction between \"lies in a given position\" and \"lies before this position\", or at least the wording is confusing. Also, it's not clear what a \"complete\" roll means. I would think that a complete roll meant a 360-degree roll, which would be equivalent to no roll at all, but I don't think that's what you mean here. As far as I can tell, \"lies in a given position\" is what the function really does. Thanks, Bruce Maggs ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> import numpy as np >>> a = np.ones((3,4,5,6)) >>> np.rollaxis(a, 3, 1).shape (3, 6, 4, 5) >>> np.rollaxis(a, 2).shape (5, 3, 4, 6) >>> np.rollaxis(a, 1, 4).shape (3, 5, 6, 4) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: fig ps should print service name Or group by service or something like that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: `storage.key.Key`: add direct support for additional resource fields The [Object API resource representation](https://cloud.google.com/storage/docs/json_api/v1/objects) defines a number of fields as \"writable\": - `acl[]` - `cacheControl` - `contentDisposition` - `contentEncoding` - `contentLanguage` - `contentType` - `crc32c` - `md5Hash` - `metadata{}` - `name` `Key.from_dict` currently captures them _all_ in the key's `metadata` attribute, but that name creates confusion with its `metadata` key (which stores application-defined key-value pairs). I think it would be cleaner to map each the non-user-defined fields onto separate attributes, and propagate them to the server via the [`insert`](https://cloud.google.com/storage/docs/json_api/v1/objects/insert), and [`patch`](https://cloud.google.com/storage/docs/json_api/v1/objects/patch) or [`update`](https://cloud.google.com/storage/docs/json_api/v1/objects/update) endpoints. `Key` should also expose read-only properties for the non-writable resource fields not already mapped, and which aren't constants: - `componentCount` - `etag` - `generation` - `id` - `mediaLink` - `metageneration` - `owner{}` - `selfLink` - `size` - `storageClass` - `timeDeleted` - `updated` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Allow to set execution_timeout default value in airflow.cfg ### Discussed in https://github.com/apache/airflow/discussions/18411 <div type='discussions-op-text'> <sup>Originally posted by **alexInhert** September 21, 2021</sup> ### Description Currently the default value of execution_timeout in base operator is None https://github.com/apache/airflow/blob/c686241f4ceb62d52e9bfa607822e4b7a3c76222/airflow/models/baseoperator.py#L502 This means that a task will run without limit till finished. ### Use case/motivation The problem is that there is no way to overwrite this default for all dags. This causes problems where we find that tasks run sometimes for 1 week!!! for no reason. They are just stuck. This mostly happens with tasks that submit work to some 3rd party resource. The 3rd party had some error and terminated but the Airflow task for some reason did not. This can be handled in cluster policy however it feels that cluster policy is more to enforce something but less about setting defaults values. ### Related issues _No response_ ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) </div> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.45.0 changes behavior of install_dir Given this code: ```meson configure_file( input: 'foo.in', output: 'foo.out', configuration: conf, install_dir: get_option('some-option') ? 'a-directory' : '', ) ``` In 0.44.1 `install_dir` being set to `''` meant do not install. In 0.45.0 this results in the destination being `$datadir/$project-name` for some reason. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: AutoTokenizer _batch_encode_plus method don't have add_prefix_space argument ### System Info ```shell - `transformers` version: 4.20.0.dev0 - Platform: macOS-12.3.1-arm64-arm-64bit - Python version: 3.8.12 - Huggingface_hub version: 0.6.0 - PyTorch version (GPU?): 1.11.0 (False) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ``` ### Who can help? @SaulLu @LysandreJik Hi, im just noticed that `AutoTokenizer._batch_encode_plus` method don't have `add_prefix_space` argument if I init it as `roberta-base` model. ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ```python tokenizer = transformers.AutoTokenizer.from_pretrained('roberta-base') input_ids = tokenizer('test string', add_prefix_space=True).data[\"input_ids\"] # Output: TypeError: _batch_encode_plus() got an unexpected keyword argument 'add_prefix_space' ``` ### Expected behavior ```shell tokenizer = transformers.AutoTokenizer.from_pretrained('roberta-base') input_ids = tokenizer('test string', add_prefix_space=True).data[\"input_ids\"] # Output: >>> input_ids [0, 1296, 6755, 2] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Remove Query dependency on Dataset and make dataset_id required in Query Use `dataset_id` instead and allow `connection` as optional argument on methods which interact with the network. ~~Need to finish #478 before this is possible to do in a user-friendly way.~~ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: In rmagic, images aren't always closed If a lot of R code is called which raises an RInterpreterError eventually I run into a 'too many open devices error' I fixed it by wrapping the code in a try/finally block to make sure that dev.off() gets called ``` python try: self.r('png(\"%s/Rplots%%03d.png\",%s)' % (tmpd.replace('\\\\', '/'), png_args)) text_output = '' try: if line_mode: for line in code.split(';'): text_result, result, visible = self.eval(line) text_output += text_result if text_result: # the last line printed something to the console so we won't return it return_output = False else: text_result, result, visible = self.eval(code) text_output += text_result if visible: old_writeconsole = ri.get_writeconsole() ri.set_writeconsole(self.write_console) ro.r.show(result) text_output += self.flush() ri.set_writeconsole(old_writeconsole) except RInterpreterError as e: print(e.stdout) if not e.stdout.endswith(e.err): print(e.err) rmtree(tmpd) return finally: self.r('dev.off()') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: auto_scale_batch_size not working with datamodule ## 🐛 Bug The `Trainer` expects the `LightningModule` to have `self.batch_size` (see `scale_batch_size()` in training_tricks.py). However, if one is using the new `LightningDataModule`, that should be the class with `self.batch_size` defined. ### To Reproduce ```python assert hasattr(lightning_data_module, \"batch_size\") trainer = Trainer(auto_scale_batch_size=True) trainer.fit(lightning_module, datamodule=lightning_data_module) ``` ```bash pytorch_lightning.utilities.exceptions.MisconfigurationException: Field batch_size not found in both `model` and `model.hparams` ``` ### Expected behavior `auto_scale_batch_size` should work using `LightningDataModule` ### Environment ``` * Packages: - numpy: 1.18.5 - pyTorch_debug: False - pyTorch_version: 1.6.0 - pytorch-lightning: 0.9.1rc1 - tensorboard: 2.2.0 - tqdm: 4.48.2 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Show pi in the text drawer as π <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Based on a discussion in #4931, there's interest in displaying pi in the text drawer as `π `instead of `pi`. ``` ┌─────────┐ ┌─────────┐ Change from q_0: ┤ RX(pij) ├ to q_0: ┤ RX(πj) ├ └─────────┘ └─────────┘ ``` To do this on all platforms requires completion of #4900 and modifying pi_check and 24 tests. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: np.copy does not work for nested np.arrays I have a created a np.array which consists of two other np.array which do not have the same size. If I want to copy the array with np.copy, both arrays are still linked together. By the use of copy.deepcopy() there is no such issue. ### Reproducing code example: ```python import numpy as np import copy as cp a = np.array([1, 2, 3]) b = np.array([[3, 4, 5], [2, 4, 7]]) c = np.array([a, b]) d = np.copy(c) e = cp.deepcopy(c) d[1][0, 2] = 10 e[1][0, 1] = 20 print('c = ', c) print('d = ', d) print('e = ', e) ``` Output: ```python c = [array([1, 2, 3]) array([[ 3, 4, 10], [ 2, 4, 7]])] d = [array([1, 2, 3]) array([[ 3, 4, 10], [ 2, 4, 7]])] e = [array([1, 2, 3]) array([[ 3, 20, 5], [ 2, 4, 7]])] ``` ### Numpy/Python version information: numpy version: 1.15.4 python version: 3.6.8 |Anaconda, Inc.| (default, Dec 30 2018, 18:50:55) [MSC v.1915 64 bit (AMD64)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: quit(keep_kernel=True) doesn't work I'm using IPython 3.1.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: GAX API hangs during (second) 'publish' /cc @bjwatson ``` python ====================================================================== ERROR: test_message_pull_mode_e2e (pubsub.TestPubsub) ---------------------------------------------------------------------- Traceback (most recent call last): File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/system_tests/pubsub.py\", line 157, in test_message_pull_mode_e2e topic.publish(MESSAGE_1, extra=EXTRA_1) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/gcloud/pubsub/topic.py\", line 246, in publish message_ids = api.topic_publish(self.full_name, [message_data]) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/gcloud/pubsub/_gax.py\", line 171, in topic_publish event.wait() AttributeError: 'exceptions.AttributeError' object has no attribute 'message_ids' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Components: POC components in the cmake generator After #6716 and #6717, we should be able to do a POC with the CMake generator and the usage of the \"smart targets\": Targets that depend only on the components needed (not the whole library. With the possibility of linking just with the needed components of other requirements depending on the implementation of #6717 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add Variable, Connection \"description\" fields available in the API ### Description I'd like to get the \"description\" field from the variable, and connection table available through the REST API for the calls: 1. /variables/{key} 2. /connections/{conn_id} ### Use case/motivation _No response_ ### Related issues _No response_ ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Exception raised when appending to a chain celery==3.1.20 django-redis==4.0.0 redis==2.10.5 websocket-client==0.35.0 Using the above versions of celery, redis and websocket. On production when I pass nearly 200 tasks to celery, the worker accepts only one task and then freezed and even not generated any error logs. It will not even process the current one. Although it works fine with 150 tasks. I have also gone through some solutions and suggestions but not be able to fix the issue. Am I using the correct versions of celery and redis in terms of compatibility? Is there any fix for this issue? Please let me know If I need to put some other details. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Allow mapped Task as input to another mapped task This dag ```python with DAG(dag_id=\"simple_mapping\", start_date=pendulum.DateTime(2022, 4, 6), catchup=True) as d3: @task(email='a@b.com') def add_one(x: int): return x + 1 two_three_four = add_one.expand(x=[1, 2, 3]) three_four_five = add_one.expand(x=two_three_four) ``` Fails with this error: ``` File \"/home/ash/code/airflow/airflow/airflow/models/taskinstance.py\", line 2239, in _record_task_map_for_downstreams raise UnmappableXComTypePushed(value) airflow.exceptions.UnmappableXComTypePushed: unmappable return type 'int' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Add documentation to the task_acks_on_failure_or_timeout setting # Description #4970 did not include the proper documentation for the setting. # Suggestions We should ensure to document it's behaviour before 4.3 GA. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: interactive=True has no effect with default drawer output ('text') <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? I think we either convert the text output to an image and make it pop out, or we clearly document that interactive only works when output is 'latex' or 'mpl'. Not the default 'text' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Documentation errors in base.py and test_docs.py revA..revB → revA...revB (three instead of two dots) [base.py, line 467](https://github.com/gitpython-developers/GitPython/blob/master/git/repo/base.py#L467) rorepo is a ~~a~~ Repo instance [test_docs.py, line 21](https://github.com/gitpython-developers/GitPython/blob/master/git/test/test_docs.py#L21) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"volumes_from: service\" fails silently if the service has no containers Example: ``` yaml foo: build: . volumes_from: - configs configs: build: ./configs volumes: - /etc/something ``` If I run ``` fig run foo ``` The volume is not mounted, without any warnings. This is because it tries to iterate over the containers for `configs`, and none exist yet, so it just skips it and continues. ``` fig up fig run foo ``` This works. I propose that if there is a `volumes_from` a service, and there are no containers for that services, it should at lease raise a warning, but possibly error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Schedule Call inlining has a bug <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: commit 3c979ebdacecbbd213757a8149bddc309bfa58c0 - **Python version**: 3.8.5 - **Operating system**: Ubuntu 20.04 ### What is the current behavior? Inlining the call instructions of a schedule does not remove all call instructions. ### Steps to reproduce the problem The following code should reproduce this behavior: ```python from qiskit.pulse.transforms import inline_subroutines from qiskit.circuit import Parameter import qiskit.pulse as pulse from qiskit.pulse import Drag, DriveChannel, Gaussian amp = Parameter(\"amp\") d0_ = DriveChannel(Parameter('ch0')) sigma = Parameter(\"σ\") with pulse.build(name=\"xp\") as xp: pulse.play(Gaussian(160, amp, sigma), d0_) with pulse.build(name=\"xp2\") as xp2: with pulse.align_sequential(): pulse.call(xp) print(xp2) print(inline_subroutines(xp2)) ``` The output is ``` ScheduleBlock(ScheduleBlock(Call(ScheduleBlock(Play(Gaussian(duration=160, amp=amp, sigma=σ), DriveChannel(ch0)), name=\"xp\", transform=AlignLeft()), name='call_xp'), name=\"block2\", transform=AlignSequential()), name=\"xp2\", transform=AlignLeft()) ScheduleBlock(ScheduleBlock(Call(ScheduleBlock(Play(Gaussian(duration=160, amp=amp, sigma=σ), DriveChannel(ch0)), name=\"xp\", transform=AlignLeft()), name='call_xp'), name=\"block2\", transform=AlignSequential()), name=\"xp2\", transform=AlignLeft()) ``` ### What is the expected behavior? All call instructions should have been removed by the inline. ### Suggested solutions There might be an issue with the inline function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: [Documentation Feedback] Please add example of passing extra arguments to the docs for dynamic mapping and collect From this Slack thread: https://dagster.slack.com/archives/C01U954MEER/p1638730392418700 It would be helpful to have this example: ```py @job def test(): mynumber = get_number() my_op_2().map(lambda x: another_op(a=x, b=mynumber)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: logging_epochs argument for TrainingArguments # 🚀 Feature request There is no `logging_epochs` argument in `TrainingArguments`. When someone wants to train with `EvaluationStrategy.EPOCH`, he/she wants to see the logs after each epoch. Currently it is not possible. ## Motivation Better logging for training ## Your contribution If I have time, I would like to add it. However, I am not available in a coming couple of weeks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: refactor conda/cli/activate.py to help menuinst Let menuinst not have to work about shellsdict in conda 4.3. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: console config not written assigning to @minrk who said: \"Oh jeez, I don't wanna fix that right now\". Marking it two-point-oh. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Allow keeping default save_dir in ModelCheckpointer ## Feature Make `filepath` argument of `ModelCheckpointer` optional. ### Motivation I'm pretty happy with all defaults of `ModelCheckpointer` except `save_top_k`. In case I want to override that parameter I have to write some awkward code related to figuring out the checkpointing path, which is normally only known at runtime: ```python DEFROOT = Path('/data/models/lightning') logger = WandbLogger(name=net.hparams.run_name, project=net.hparams.project, save_dir=str(DEFROOT)) logger.watch(net) _ = logger.experiment # create an experiment to determine version cp_template = str(DEFROOT / net.hparams.project / ('version_'+logger.version) / 'checkpoints' / '{epoch:04d}-{val_loss:.2f}-{other_metric:.2f}.pt') checkpointer = ModelCheckpoint( filepath=cp_template, save_top_k=10, verbose=True, monitor='val_loss', mode='min', ) trainer = Trainer( gpus=1, logger=logger, default_root_dir=DEFROOT, checkpoint_callback=checkpointer, **extra, ) trainer.fit(net) ``` It would be nice to have an option to allow Lightning to determine runtime-valued save location instead. Additionally, it would be nice to have an option to override checkpoint filename without overriding the whole save path. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Can't use None (anymore) in checkpoint_callback ## 🐛 Bug using None in checkpoint_callback now errors out ``` -- Process 0 terminated with the following error: Traceback (most recent call last): File \"/opt/conda/lib/python3.6/site-packages/torch/multiprocessing/spawn.py\", line 20, in _wrap fn(i, *args) File \"/opt/conda/lib/python3.6/site-packages/pytorch_lightning/trainer/distrib_data_parallel.py\", line 562, in ddp_train q.put(self.checkpoint_callback.best_model_path) AttributeError: 'NoneType' object has no attribute 'best_model_path' ``` ### To Reproduce `trainer = Trainer(checkpoint_callback=None)` Ran into this issue from upgrading to masters, was using masters from a few commits ago before Edit: `False` casuses the same error as well Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `auto_match` slow and hogs CPU in some cases To reproduce in IPython 8.2, paste `function_with_long_nameeee('arg`, and add the closing quotes at the end. The slowness increases when the prefix is longer (in this case dominated by the function name `function_with_long_nameeee`), so if you don't notice it, try increasing it). ## Steps to reproduce with docker 1. Build the image and start a container: ```sh build_oci_img() { docker build \"$@\" - <<EOF FROM python:3.8-slim RUN pip install ipython==8.2 EOF } build_oci_img docker run --rm --interactive --tty \"$(build_oci_img -q)\" ipython -i -c 'get_ipython().auto_match = True' ``` 2. Paste `function_with_long_nameeee('arg` and then type another `'` (single quote) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: min/max of empty arrays A similar issue was raised in #2670, however the edge case of (0, ) shape is still not covered. I can go around it with checking for non-zero length in an `if` statement, but it would be more practical if `np.min` could handle this, too. ``` In [24]: [np.min(param[x][1]) for x in fields] --------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-24-076aa74e3684> in <module>() ----> 1 [np.min(param[x][1]) for x in fields] /data/wts/pipeline64/python/lib/python2.6/site-packages/numpy/core/fromnumeric.pyc in amin(a, axis, out) 1893 except AttributeError: 1894 return _wrapit(a, 'min', axis, out) -> 1895 return amin(axis, out) 1896 1897 ValueError: zero-size array to minimum.reduce without identity In [25]: param[x] Out[25]: {1: array([], dtype=float64), 2: array([], dtype=float64), 3: array([], dtype=float64), 4: array([], dtype=float64)} In [26]: param[x][1].shape Out[26]: (0,) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Error when model checkpoint and no early stop **Describe the bug** When creating a `Trainer`, if we set a `checkpoint_callback=ModelCheckpoint(...)` and `early_stop_callback = False` we get an error at this [line](https://github.com/williamFalcon/pytorch-lightning/blob/master/pytorch_lightning/trainer/trainer_io.py#L157) here. **To Reproduce** Steps to reproduce the behavior: 1. Create a `ckpt = ModelCheckpoint(...)` 2. Create a `Trainer` 3. Setting `checkpoint_callback = ckpt` and `early_stop_callback=False` 4. See the error `AttributeError: 'NoneType' object has no attribute 'wait'` **Expected behavior** It should be possible to save the model without setting an EarlyStopping condition. Of course one could set an EarlyStopping with the max integer, but changing the condition from an `or` to an `and` solves the problem. **Desktop** - OS: Ubuntu 19.04 - Browser: Firefox Quantum - Version: 69.0.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: advi.py example is broken with jit advi.py example is broken with jit: @partial(jit, static_argnums=(0, 1, 2, 4)) If jit is removed, then It works. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: \"generator doesn't stop\" building harfbuzz in MSYS2/MinGW32 on Win7, but works on Win10 **Describe the bug** I'm using the [media-autobuild suite](https://github.com/m-ab-s/media-autobuild_suite/) (a set of batch and shell scripts which keeps an MSYS2 envirponment up-to-date before building software) to build several audio / video tools, up to an ffmpeg combining previously built libraries of different codecs. One of the used libraries is harfbuzz, which MABS builds using meson. This worked regularly, even a few weeks ago, but suddenly it started failing (possibly after an MSYS2 update) on one PC which still runs Windows 7, even after completely re-installing MSYS2 and MinGW, but works with the same set of host software on another PC running Windows 10. There are other projects (e.g. dav1d) which are still built successfully using meson. **To Reproduce** [logs.zip](https://github.com/mesonbuild/meson/files/5501015/logs.zip) collected by MABS, I added some possibly meson specific files (most interesting logs will be in harfbuzz-git/build-32bit). I am not able to produce a minimum source to reproduce this issue, because I am not a C/C++ developer, only a user of the media-autobuild suite. So I can only hope that the logs with the stack trace help to at least guess what may cause this issue, and to learn what it even means, to support the MABS team finding a possible solution. **Expected behavior** Prepare and run compilation, as it used to work a few weeks ago. **system parameters** * Windows 7 SP1 German, MSYS2/MinGW * Python 3.8.6-5 provided by MSYS2 * meson 0.56.0-1 provided by MSYS2 * ninja 1.10.1-1 provided by MSYS2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: `docker-compose restart` doesn't restart stopped containers I have a very simple `docker-compose.yml` file in `docker-restart` folder ``` yaml mysql: image: mysql environment: - \"MYSQL_ROOT_PASSWORD=root\" ubuntu: image: ubuntu:14.04 command: date ``` Now if I run the below set of commands ``` bash $ docker-compose up -d $ sleep 10 $ docker-compose restart dockerrestart_ubuntu_1 $ docker restart dockerrestart_ubuntu_1 $ docker-compose restart dockerrestart_ubuntu_1 $ docker restart dockerrestart_ubuntu_1 ``` If I check the logs, I would expect 5 date times, but only 3 appears, docker restart does restart and execute the container but docker-compose doesn't ``` bash $ docker logs dockerrestart_ubuntu_1 Thu Aug 6 07:01:12 UTC 2015 Thu Aug 6 07:02:32 UTC 2015 Thu Aug 6 07:03:14 UTC 2015 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Trainer Evaluates at each step (Not of epoch end) , indentation bug ## Environment info - `transformers` version: 3.2.0 - Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.6.9 - PyTorch version (GPU?): 1.6.0+cu101 (True) - Tensorflow version (GPU?): 2.3.0 (True) - Using GPU in script?: Yes - Using distributed or parallel set-up in script?: NA ### Who can help Trainer: @sgugger --> ## Information Model I am using (Bert, XLNet ...): BERT The problem arises when using: - [ ] the official example scripts: - [x] my own modified scripts: The tasks I am working on is: - [ ] an official GLUE/SQUaD task: - [x] my own task or dataset: Basic Single Sentence Classification Dataset loaded via a Dataset class ## To reproduce Steps to reproduce the behavior: 1. Use the trainer training function with `training_args.evaluation_strategy = EvaluationStrategy.EPOCH` ## Expected behavior Evaluation should happen after each epoch ends, but instead it happens after each step (batch). Indentation bug ## Suggested Fix Move the if condition on line https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py#L829 to before line https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py#L834 and remove 1 indentation block Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: double pylab greeting with c.InteractiveShellApp.pylab = \"tk\" in zmqconsole I added c.InteractiveShellApp.pylab = \"tk\" to my config to get pylab with the zmqconsole. you then get two pylab greetings when you start it: ``` ipython console Welcome to pylab, a matplotlib-based Python environment [backend: TkAgg]. For more information, type 'help(pylab)'. [IPKernelApp] To connect another client to this kernel, use: [IPKernelApp] --existing kernel-3395.json Welcome to pylab, a matplotlib-based Python environment [backend: TkAgg]. For more information, type 'help(pylab)'. ``` adding only c.TerminalIPythonApp.pylab = \"tk\" to the config will give you one greeting but pylab won't work which is a bit confusing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: ldconfig on install corrupts freebsd cache **Describe the bug** 2c3a68bc30cf and 6b7d43ebe0d7 make it so `ldconfig` is invoked after install. But it seems like thos corrupts the cache on FreeBSD (maybe other BSDs as well), and results in errors similar to: ld-elf.so.1: Shared object \"libreadline.so.8\" not found, required by \"bash\" when running executables after `ninja install`. Example full log: https://builds.sr.ht/~emersion/job/630186#task-tinywl Downstream discussion: https://gitlab.freedesktop.org/wlroots/wlroots/-/merge_requests/3349#note_1162574 cc @jbeich **To Reproduce** Run `ninja install` on freebsd. **Expected behavior** `ldconfig` cache isn't corrupted. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? no * what operating system: FreeBSD * what Python version are you using: N/A * what `meson --version`: 0.60.1 * what `ninja --version`: 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Mapped KubernetesPodOperater not rendering nested templates ### Apache Airflow version 2.3.3 ### What happened Nested values, such as `env_vars` for the `KubernetesPodOperater` are not being rendered when used as a dynamically mapped operator. Assuming the following: ```python op = KubernetesPodOperater.partial( env_vars=[k8s.V1EnvVar(name='AWS_ACCESS_KEY_ID', value='{{ var.value.aws_access_key_id }}')], # Other arguments ).expand(arguments=[[1], [2]]) ``` The *Rendered Template* results for `env_vars` should be: ``` (\"[{'name': 'AWS_ACCESS_KEY_ID', 'value': 'some-super-secret-value', 'value_from': None}]\") ``` Instead the actual *Rendered Template* results for `env_vars` are un-rendered: ``` (\"[{'name': 'AWS_ACCESS_KEY_ID', 'value': '{{ var.value.aws_access_key_id }}', 'value_from': None}]\") ``` This is probably caused by the fact that `MappedOperator` is not calling [`KubernetesPodOperater._render_nested_template_fields`](https://github.com/apache/airflow/blob/main/airflow/providers/cncf/kubernetes/operators/kubernetes_pod.py#L286). ### What you think should happen instead _No response_ ### How to reproduce _No response_ ### Operating System Ubuntu 18.04 ### Versions of Apache Airflow Providers _No response_ ### Deployment Other 3rd-party Helm chart ### Deployment details _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: from_pretrained() breaks with empty state_dict and model path as None ### System Info - `transformers` version: 4.26.1 - Platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35 - Python version: 3.10.6 - Huggingface_hub version: 0.12.0 - PyTorch version (GPU?): 1.12.1+cu116 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: Yes - Using distributed or parallel set-up in script?: No ### Who can help? @ArthurZucker @youne ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction To reproduce the behavior, you can run this snippet of code: ```py from transformers import GPTJConfig, AutoModelForCausalLM from collections import OrderedDict config = GPTJConfig( n_positions=128, n_embd=16, n_layer=2, n_head=2 ) AutoModelForCausalLM.from_pretrained( None, config=config, state_dict=OrderedDict() ) ``` ### Expected behavior The expected behavior from this is to allow a model to be initialized from scratch with an empty `state_dict` and `None` as the pretrained model. There is a [tool that I am working with](https://github.com/coreweave/tensorizer) that is broken due to a regression that was introduced around version 4.23.1. From the trace of running the reproduction code, a PR that handles the case when `resolved_archive_file` and the pretrained model path are `None` would fix this issue. It also seems that this issue is related: https://github.com/huggingface/transformers/issues/21526 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Move tests After the big split, we can move the tests to the individual `packages`. That way each test can be run from that package, or from the top level using `lerna run test`. We are hoisting dev dependencies, meaning that karma and mocha would only be installed at the root of the repo. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Stop calling ldconfig on `meson install` We've now had three different bugs around this, and it's slow when we don't need to call it, and it doesn't always yield the desired results anyway. I'd like to call for its removal in 0.61. I'm opening this, so we can generate some consensus in a single place. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: remove newline in repr of arrays with flexible datatype? Another one to think about while we are changing print output for 1.14: (see #9699) Flexible types have an extra newline before the datatype in the repr of the array: ```python >>> np.array(['hello']) array(['hello'], dtype='<U5') ``` Should we remove the newline? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: ConfigureEnvironment: 'libstdc++11' is not a valid 'settings.compiler.libcxx' value on OS X I've just updated to conan 0.8 with libcxx support and get this error: ``` python ## configure_environment.py ## # Append the definition for libcxx all_cpp_flags = copy.copy(self._deps_cpp_info.cppflags) if self.libcxx: tmp = \"-D_GLIBCXX_USE_CXX11_ABI=\" tmp += \"1\" if self.libcxx == \"libstdc++11\" else \"0\" # Exception occurs here all_cpp_flags.append(tmp) ``` for (os x default) apple-clang compiler: ``` apple-clang: version: [\"5.0\", \"5.1\", \"6.0\", \"6.1\", \"7.0\"] libcxx: [libstdc++, libc++] ``` on this (conanfile.py) code: ``` python env = ConfigureEnvironment(self.deps_cpp_info, self.settings) self.run(\"%s && ./configure --prefix=\\\"$PWD/install\\\" && make install\" % env.command_line) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Display task documentation when hovering on the task ### Description It would be great if task documentation wouldn't be hidden within the task instance page, but rather displayed when hovering over the task. ### Use case/motivation In complex DAGs, having access to this allows access to documentation with a few less clicks per task ### Related issues _No response_ ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Add a build:changed top level script Similar to #1952, it would check the modified time of `lib/` vs `src/`, and build if necessary. This allows us to only build the required packages after switching branches, and will be used in `setup.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Documenting keyboard shurtcuts IMHO it would be sensible if we can provide description to newly introduced keyboard shortcuts. Personally I hunted Google to learn about Ctrl+O, but there seem to be many other functions exposed with default shortcuts. Ctrl+S / Ctrl+R = `I-search` - seems to search some parts of history Ctrl+Space = `Selection mode` - already discussed as feature from modern emacs bindings ... Many other Ctrl+? bindings at least. So my suggestion is that we should provide reference to used bindings in documentation. At least just those exposed from PTK Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Very counter-intuitive \"Cross and native files must not be directories\" error Consider the following: ```c [0] [akari@navi] [master ← /home/akari/git/cosuzu/build] % ls -l total 0 drwxr-xr-x 6 akari users 122 Jul 12 07:39 native-gcc [0] [akari@navi] [master ← /home/akari/git/cosuzu/build] % file ~/.local/share/meson/cross/llvm-mingw-i686 /home/akari/.local/share/meson/cross/llvm-mingw-i686: ASCII text [0] [akari@navi] [master ← /home/akari/git/cosuzu/build] % meson --cross-file llvm-mingw-i686 ../ llvm-mingw-i686 ERROR: Cross and native files must not be directories [1] [akari@navi] [master ← /home/akari/git/cosuzu/build] % ls -l total 0 drwxr-xr-x 5 akari users 63 Jul 12 07:43 llvm-mingw-i686 drwxr-xr-x 6 akari users 122 Jul 12 07:39 native-gcc ``` Perhaps the cross/native file paths should be resolved *before* the build directory is created? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Replace `toolz` dependency with `cytoolz` This makes me all kind of uncomfortable since cytoolz is a separate pacakge and us using it this way is totally backwards. We should rely on it instead directly or remove our footprint using it. Probably larger than this PR though, so worth opening a ticket to look into it. _Originally posted by @jezdez in https://github.com/conda/conda/pull/11290#discussion_r826836808_ ### Tasks - [x] Do we need cytoolz/toolz anymore? - [x] If we need cytoolz/toolz, stop vendoring and make it a dependency - @kenodegard None of the third-party uses we have identified need cytoolz/toolz, replace with stdlib itertools or list-/dict-comprehension or arg unpacking - @kenodegard Conda itself will make cytoolz a dependency - [x] update default::conda feedstock - [x] update conda-forge::conda feedstock - [x] https://github.com/conda-incubator/conda-libmamba-solver/pull/45 - [x] https://github.com/conda/constructor/issues/523 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: \"?\" and expressions [tried with ipython 0.13.2, 1.0.0 and 1.1.0] Requesting information for a object returned by an expression (in the example below the object is stored in a `list`, and the expression is extracting an element from the list). Is this intended ? (When using only `?` in ipython, the documentation printed suggests that it should be working - the example given `{}.get?` is also not working). ``` In [1]: ?['a','b'][0] Object `` not found. ``` The following is working though: ``` In [2]: o = ['a','b'][0] In [3]: ?o Type: str String Form:a Length: 1 Docstring: str(object='') -> str str(bytes_or_buffer[, encoding[, errors]]) -> str Create a new string object from the given object. If encoding or errors is specified, then the object must expose a data buffer that will be decoded using the given encoding and error handler. Otherwise, returns the result of object.__str__() (if defined) or repr(object). encoding defaults to sys.getdefaultencoding(). errors defaults to 'strict'. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: id2lang in tokenization_xlm.py should be int, and removing hardcoding In https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_xlm.py#L78 we have: ``` \"id2lang\": {\"0\": \"de\", \"1\": \"en\"}, \"lang2id\": {\"de\": 0, \"en\": 1}, ``` and then: ``` lang2id (:obj:`Dict[str, int]`, `optional`, defaults to :obj:`None`): Dictionary mapping languages string identifiers to their IDs. id2lang (:obj:`Dict[int, str`, `optional`, defaults to :obj:`None`): ``` So it should be: ``` \"id2lang\": {0: \"de\", 1: \"en\"}, \"lang2id\": {\"de\": 0, \"en\": 1}, ``` All other entries need this change too. The problem hasn't been detected until now since they were used to only count the number of languages it seems. I need to pass src/tgt languages to the tokenizer I'm porting from fairseq, so I was looking at how to do that and `id2lang` seems to fit the purpose. But I actually need to look them up by `int` id, that's how I saw the problem. But I'm also not sure why do we need to hardcode the reversal, when it can be done in 1 line of code? Which would also remove this assertion code: ``` self.lang2id = lang2id self.id2lang = id2lang if lang2id is not None and id2lang is not None: assert len(lang2id) == len(id2lang) ``` Further we don't even need to hardcode the ids. Replace: ``` \"id2lang\": {0: \"de\", 1: \"en\"}, ``` with: ``` \"id2lang\": [\"de\", \"en\"] ``` So all we need is one of the two entries, and now generate the 2 lookup dicts on the fly. And since it's no longer `id2lang` semantically, probably renaming it to just `langs` would be more appropriate. I think I will use this approach regardless of the outcome of this issue. Thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Logout button handling not available when launching notebook app <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description Because this is handled currently in [LabApp](https://github.com/jupyterlab/jupyterlab/blob/a31a4cf625681524b44fe58847d8e253bd9e5650/jupyterlab/labapp.py#L493), it is not run when launching as `jupyter notebook`. We need to move the logic into `extension.py`. <!--Describe the bug clearly and concisely. Include screenshots if possible--> ## Reproduce 1. Launch as `jupyter notebook`. 2. Go to `/lab` 3. Open File menu 4. Note there is no logout button Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Copying `QuantumCircuit` fails after `circuit.remove_final_measurements()` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.17 - **Python version**: 3.8 - **Operating system**: MacOS ### What is the current behavior? Creating a `QuantumCircuit`, calling `circuit.remove_final_measurements()` and then copying the `circuit` fails with raising a `KeyError`. ### Steps to reproduce the problem ``` qc = QuantumCircuit(2) qc = qc.compose(RealAmplitudes(2)) qc.remove_final_measurements() qc.copy() ``` ### What is the expected behavior? Expected behavior would be to just get back a copy of the modified circuit. ### Suggested solutions Fix `remove_final_measurements()`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: i dont know what Tranier`s Dataset is. # ❓ Questions & Help <!-- The GitHub issue tracker is primarly intended for bugs, feature requests, new models and benchmarks, and migration questions. For all other questions, we direct you to the Hugging Face forum: https://discuss.huggingface.co/ . You can also try Stack Overflow (SO) where a whole community of PyTorch and Tensorflow enthusiast can help you out. In this case, make sure to tag your question with the right deep learning framework as well as the huggingface-transformers tag: https://stackoverflow.com/questions/tagged/huggingface-transformers --> ## Details <!-- Description of your issue -->   i thought its my customer dataset goes wrong, i dont konw what dataset it should return. the Trainer receive what dataset. <!-- You should first ask your question on the forum or SO, and only if you didn't get an answer ask it here on GitHub. --> **A link to original question on the forum/Stack Overflow**: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda update --name AssertionError ``` error: AssertionError() command: /Users/cpthgli/.anyenv/envs/pyenv/versions/default/bin/conda update --name --all --yes user_agent: conda/4.4.4 requests/2.18.4 CPython/3.6.4 Darwin/17.3.0 OSX/10.13.2 _messageid: -9223372036843525540 _messagetime: 1514462637935 / 2017-12-28 06:03:57 Traceback (most recent call last): File \"/Users/cpthgli/.anyenv/envs/pyenv/versions/anaconda3-5.0.1/lib/python3.6/site-packages/conda/exceptions.py\", line 724, in __call__ return func(*args, **kwargs) File \"/Users/cpthgli/.anyenv/envs/pyenv/versions/anaconda3-5.0.1/lib/python3.6/site-packages/conda/cli/main.py\", line 78, in _main exit_code = do_call(args, p) File \"/Users/cpthgli/.anyenv/envs/pyenv/versions/anaconda3-5.0.1/lib/python3.6/site-packages/conda/cli/conda_argparse.py\", line 75, in do_call exit_code = getattr(module, func_name)(args, parser) File \"/Users/cpthgli/.anyenv/envs/pyenv/versions/anaconda3-5.0.1/lib/python3.6/site-packages/conda/cli/main_update.py\", line 14, in execute install(args, parser, 'update') File \"/Users/cpthgli/.anyenv/envs/pyenv/versions/anaconda3-5.0.1/lib/python3.6/site-packages/conda/cli/install.py\", line 140, in install prefix = context.target_prefix File \"/Users/cpthgli/.anyenv/envs/pyenv/versions/anaconda3-5.0.1/lib/python3.6/site-packages/conda/base/context.py\", line 454, in target_prefix return determine_target_prefix(self) File \"/Users/cpthgli/.anyenv/envs/pyenv/versions/anaconda3-5.0.1/lib/python3.6/site-packages/conda/base/context.py\", line 974, in determine_target_prefix return locate_prefix_by_name(prefix_name) File \"/Users/cpthgli/.anyenv/envs/pyenv/versions/anaconda3-5.0.1/lib/python3.6/site-packages/conda/base/context.py\", line 923, in locate_prefix_by_name assert name AssertionError ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Allow arbitrary notebook filename extensions (... or allow custom handlers) I first described my use case in #7222, it has slightly changed since then. [GitHub repo here](https://github.com/rossant/ipymd). Basically I want to write technical documents/books in Markdown, and use the notebook UI to write/execute code. This brings the benefits of Markdown with the benefits of the notebook UI for interactive computing. When writing a book, I don't want to save/version-control the code outputs. I can always build a full document with the outputs eventually. Technically, I can achieve this by writing a custom `FileContentsManager`, and implementing my own serialization/deserialization process for notebooks (basically `nbcontents (dict) <==> markdown` converters). The only thing that doesn't work nicely for now is the file extension. Using `.ipynb` works, but it's probably not a good idea to use the same extension for two different file formats. When using `.md`, it looks like I cannot use the notebook UI because of the way handlers are implemented. AFAIU there's a `.ipynb` regex that redirects those paths to the notebook UI. For now, I could patch IPython myself, and ask users to clone my own fork/branch. I can see at least two solutions: - create a parameter with a list of file extensions that redirect to the notebook UI (basically changing the regex) - create a parameter with a list of extra handlers for the Web server What do you think? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Did `numpy.version.short_version` disappear in version 1.21 RC ? I noticed the attribute `numpy.version.short_version` no more exists in the latest release candidate (1.21.0RC1) which has been pip-installed on linux-amd64 running python3.9 (binary wheel). This is breaking some build scripts downstream. I just wonder if it was foreseen to remove this attribute ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Components: implement internal dependencies and link order resolution Coming from #5090 Use ``deps`` or ``require`` to indicate the list of components that a component depends on: ``` self.cpp_info.components[\"comp1\"].deps = [\"comp2\", \"comp3\"] ``` or prepare to model components depending on other components of a different library: ``` self.cpp_info.components[\"liba\"].requires = [\"::comp2\", \"other_lib::comp3\"] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: MSVC backend crashes when `c_pch` or `cpp_pch` is not an array https://github.com/mesonbuild/meson/blob/5626df46453e73b63827c4542aae36443fbd928b/mesonbuild/backend/vs2010backend.py#L864 ``` Traceback (most recent call last): File \"mesonbuild\\mesonmain.py\", line 352, in run File \"mesonbuild\\mesonmain.py\", line 147, in generate File \"mesonbuild\\mesonmain.py\", line 197, in _generate File \"mesonbuild\\backend\\vs2010backend.py\", line 161, in generate File \"mesonbuild\\backend\\vs2010backend.py\", line 311, in generate_projects File \"mesonbuild\\backend\\vs2010backend.py\", line 864, in gen_vcxproj IndexError: list index out of range ``` The PCH example from the manual is sufficient to reproduce this issue: http://mesonbuild.com/Precompiled-headers.html ```meson project('issue2833', 'c') sourcelist = files('main.c') executable('myexe', sources : sourcelist, c_pch : 'pch/myexe_pch.h') ``` Build with `meson --backend vs2017 builddir/`. --- _Side note:_ The Ninja backend is slightly more helpful. It tells you that MSVC expects `c_pch` and `cpp_pch` to be an array. ``` Traceback (most recent call last): File \"mesonbuild\\mesonmain.py\", line 352, in run File \"mesonbuild\\mesonmain.py\", line 147, in generate File \"mesonbuild\\mesonmain.py\", line 197, in _generate File \"mesonbuild\\backend\\ninjabackend.py\", line 210, in generate File \"mesonbuild\\backend\\ninjabackend.py\", line 362, in generate_target File \"mesonbuild\\backend\\ninjabackend.py\", line 2283, in generate_pch File \"mesonbuild\\backend\\ninjabackend.py\", line 2244, in generate_msvc_pch_command RuntimeError: MSVC requires one header and one source to produce precompiled headers. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Support TensoredMeasFitter in QuantumInstance <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently QuantumInstance supports as error mitigation input classes: `CompleteMeasFitter` and `TensoredMeasFitter`. However, its implementation is incomplete in `measurement_error_mitigation.py`: ``` if fitter_cls == CompleteMeasFitter: meas_calibs_circuits, state_labels = complete_meas_cal( qubit_list=range(len(qubit_list)), circlabel=circlabel ) elif fitter_cls == TensoredMeasFitter: # TODO support different calibration raise QiskitError(\"Does not support TensoredMeasFitter yet.\") else: raise QiskitError(\"Unknown fitter {}\".format(fitter_cls)) ``` Support should be added for `TensoredMeasFitter`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Prefect Docker Agent Continuously Launches Containers when using Concurrency Tags ## Description Hi everyone, I have been testing with concurrency tags and had a question about some behavior I am seeing with docker. It seems that after a task has been waiting (via concurrency tag limit) for 10 minutes, the prefect docker agent starts continuously spinning up new containers for that flow that is waiting to start. If I do a “docker ps” I could see 20 or more containers running for that flow. ## Expected Behavior While a flow is paused due to a concurrency tag limit, new docker containers are not continuously spun up by the agent. ## Reproduction It should be fairly simple to reproduce. 1. Create two flows that have tasks that take over 10 minutes to run. 2. Assign those long tasks to use the same concurrency tag. 3. Spin up one prefect docker agent to run the flows. 4. After 10 minutes check docker with \"docker ps\". ## Environment Prefect Version: 0.10.6 Docker Engine Version: 19.03.6-ce Storage Type: Docker OS: Replicated the issue on both Mac and Amazon Linux 2 Optionally run `prefect diagnostics` from the command line and paste the information here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 0.50.0 regression/feature: ERROR: Subdir keyword must not be an absolute path Mutter is failing to configure with following error: ``` cogl/cogl/meson.build:513:0: ERROR: Subdir keyword must not be an absolute path. ``` I just did not see this in release-notes. If this is intentional, please add entry in release notes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: [1.27.0_rc2] Version bump missing in setup.py (but advertised as a bugfix in change log) Hi! I noticed that the change log of 1.27.0_rc2 advertises `Fix float to bytes conversion via docker-py bump to 4.3.1` (see 45c6730e6464cb6e22439c558d3036647b301610) yet `setup.py` does not depend on that new version, see https://github.com/docker/compose/blob/45c6730e6464cb6e22439c558d3036647b301610/setup.py#L35 Is the bump missing in `setup.py`? Best, Sebastian Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Feature request: enable XLA PopulationCount op I think XLA has a PopulationCount op, listed [here](https://www.tensorflow.org/xla/operation_semantics#element-wise_unary_functions). Is it straightforward for JAX to expose it in lax.py? @hawkinsp I'm thinking you might be the right person to ask. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: make metric-comparison in ModelCheckpoint robust to NaN ## 🐛 Bug When the metric that is used in `ModelCheckpoint` reaches `NaN` in one epoch and then returns to a number in the following epoch, the model will not be saved as comparisons to `NaN` always return `False`. Here a screenshot from my training:  ### Expected behavior I think it would make sense to no save the model if the metric is `NaN`. ### Environment - PyTorch Version (e.g., 1.0): 1.2.0 - OS (e.g., Linux): Ubuntu 18.04 - How you installed PyTorch (`conda`, `pip`, source): pip - Python version: 3.7 - CUDA/cuDNN version: 10.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: calling .abort on AsyncMapResult results in traceback traceback says AsyncMapResult object has no attribute 'client' @fperez just ran into this doing a live demo, here's the TB: ``` python --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) /home/sgeadmin/<ipython-input-45-75c2b5e59cd8> in <module>() ----> 1 amr.abort() /software/python-2.7.1-release/lib/python2.7/site-packages/IPython/parallel/client/asyncresult.pyc in abort(self) 196 \"\"\"abort my tasks.\"\"\" 197 assert not self.ready(), \"Can't abort, I am already done!\" --> 198 return self.client.abort(self.msg_ids, targets=self._targets, block=True) 199 200 @property /software/python-2.7.1-release/lib/python2.7/site-packages/IPython/parallel/client/asyncresult.pyc in __getattr__(self, key) 239 except (error.TimeoutError, KeyError): 240 raise AttributeError(\"%r object has no attribute %r\"%( --> 241 self.__class__.__name__, key)) 242 243 # asynchronous iterator: AttributeError: 'AsyncMapResult' object has no attribute 'client' ``` Fernando said @minrk should be able to fix it before end of class :) (in an hour) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse DeviceSpecification to handle uchannels <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently `DeviceSpecification` cannot receive `u_channel_lo` from backend. It is not a list of `float` (see spec p.32), and LO is not configurable. Currently `device.q[0].control.lo_freq` cannot show any LO frequency information. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: [Requires Aer 0.2] BackendSchema list coupling_map as optional <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? The schemas in `qiskit.providers.model` list `coupling_map` as an optional field in the `backend.configuration` when it is in fact required. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: An unexpected error has occurred, please consider sending the following traceback to the conda GitHub issue tracker Hello. When trying to update anaconda recently via conda update anaconda, I received this error and was told to submit the issue here. This is the result from conda info. Traceback (most recent call last): File \"/Users/danielr/anaconda/bin/conda\", line 3, in <module> from conda.cli import main File \"/Users/danielr/anaconda/lib/python2.7/site-packages/conda/cli/**init**.py\", line 8, in <module> from conda.cli.main import main File \"/Users/danielr/anaconda/lib/python2.7/site-packages/conda/cli/main.py\", line 48, in <module> from conda.cli import main_create File \"/Users/danielr/anaconda/lib/python2.7/site-packages/conda/cli/main_create.py\", line 11, in <module> from conda.cli import common, install File \"/Users/danielr/anaconda/lib/python2.7/site-packages/conda/cli/install.py\", line 18, in <module> import conda.plan as plan File \"/Users/danielr/anaconda/lib/python2.7/site-packages/conda/plan.py\", line 22, in <module> from conda.fetch import fetch_pkg File \"/Users/danielr/anaconda/lib/python2.7/site-packages/conda/fetch.py\", line 24, in <module> from conda.connection import CondaSession, unparse_url, RETRIES File \"/Users/danielr/anaconda/lib/python2.7/site-packages/conda/connection.py\", line 22, in <module> import requests ImportError: No module named requests Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: ENH: Expose `bit_count` ufunc equivalent to the scalar methods Modern CPUs have a builtin [popcount](https://en.wikichip.org/wiki/population_count) instruction that counts the number of 1 bit in an unsigned integer. It would be great if numpy has a routine that exposes this operation. Both GCC and MSVC have builtin functions for this instruction. Possible usage: ```python >>> np.popcount(4) 1 >>> np.popcount(np.arange(5, dtype=np.uint)) array([0, 1, 1, 2, 1]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Linking with Clang 3.9 using LTO is broken by Meson 0.57 **Describe the bug** Clang 3.9 does not support `-flto-jobs` (added by #7820 / #8087). **To Reproduce** Use `clang-3.9` as the compiler for a build and enable LTO. The build fails when linking and clang is called with `-flto-jobs=0`, e.g.: ``` $ clang-3.9 -flto-jobs=0 clang: error: unknown argument: '-flto-jobs=0' clang: error: no input files ``` ``` $ clang-4.0 -flto-jobs=0 clang: error: no input files ``` **Expected behavior** Meson should not try to use `-flto-jobs` with Clang 3.9 **system parameters** * Ubuntu 18.04/20.04 * Python 3.8.10 * Meson 0.60.1 * Ninja 1.10.2.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: fixing timeout bug when timeout is not a multiple of wait time minor bug when checking for timeout Issue 29 - New Make.bat script to support operating with Windows <!--- Provide a general summary of your changes in the Title above --> Solves #29 ## Description <!--- Describe your changes in detail --> A new Make.bat script file has been created to support all the Makefile targets in Windows: ``` Make.bat run Make.bat test Make.bat profile Make.bat doc Make.bat clean ``` ## How Has This Been Tested? <!--- Please describe in detail how you tested your changes. --> <!--- Include details of your testing environment, and the tests you ran to --> <!--- see how your change affects other areas of the code, etc. --> All targets have been executed locally. There are problems with 'doc' target, because it invokes another Make.bat script file already present in the /doc sub-directory, that is malfunctioning. We will fix it in another issue. ## Screenshots (if appropriate): ## Types of changes <!--- What types of changes does your code introduce? Put an `x` in all the boxes that apply: --> - [ ] Bug fix (non-breaking change which fixes an issue) - [X] New feature (non-breaking change which adds functionality) - [ ] Breaking change (fix or feature that would cause existing functionality to change) ## Checklist: <!--- Go over all the following points, and put an `x` in all the boxes that apply. --> <!--- If you're unsure about any of these, don't hesitate to ask. We're here to help! --> - [ ] My code follows the code style of this project. - [ ] My change requires a change to the documentation. - [ ] I have updated the documentation accordingly. - [ ] I have read the **CONTRIBUTING** document. - [ ] I have added tests to cover my changes. - [X] All new and existing tests passed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: bloom add_prefix_space= True ### System Info Hi dear officer I use Bloom BloomTokenizerFast as a tokenizer. here is an issue. Version =4.28.0 when I use BloomTokenizerFast, I find the add_prefix_space= True is not useful. Here is the code. `tokenizer = BloomTokenizerFast.from_pretrained(\"bigscience/bloom\",add_prefix_space = True) print(tokenizer.add_prefix_space) print(tokenizer(\"Hello world\")[\"input_ids\"]) print(transformers.__version__) True [59414, 8876] 4.28.0 ` here is other code. `from transformers import BloomTokenizerFast tokenizer = BloomTokenizerFast.from_pretrained(\"bigscience/bloom\") print(tokenizer(\"Hello world\")[\"input_ids\"]) [59414, 8876] ` I don't know why they will encode the same result. please have a look! Thanks ### Who can help? @Arth ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction It should encode different results. since add_prefix_space= True. ### Expected behavior It should encode different results. since add_prefix_space= True. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: pdb completion menu not honouring prompt_toolkit style The menu colors look different when inside pdb (after %debug) than when outside it. In particular, neither of: ``` Token.Menu.Completions Token.Menu.Completions.Completion Token.Menu.Completions.Completion.Current Token.Menu.Completions.Meta Token.Menu.Completions.Meta.Current Token.Menu.Completions.MultiColumnMeta ``` is taken into account. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: result.get_memory() command We have many requests to have the random numbers streamed in memory. The basic idea is to get something to run like ``` backend = IBMQ.get_backend('name') backend.update_settings('memory'=True) job = backend.run(qobj) result = job.result() ``` then we go ``` outcomes = result.get_memory() ``` outcomes will be ``` ['010', '100', '111' ...] ``` - [ ] make sure the experiment can work with it @taalexander is doing this - [ ] pass the api - [ ] qiskit function exists to get_memory Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Don't allow passing parameters that don't exist `FlowRunner` raises an error if you run a flow and don't pass a required parameter, but it has no problem with users providing a parameter that doesn't exist. This should raise an error as well to avoid confusion. ```python f = Flow() f.run(parameters=dict(a=1)) # no error! ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Move pulse samplers into pulse_lib module <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Samplers are only used for constructing pulses. These should be moved within the pulse_lib module. I believe these are internal only for now and should be movable without using a shim. Thoughts @mtreinish? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: 1.3.0 regression: tools.save doesn't have \"append\" parameter For no obvious reason `conans.util.files.save` method was split into 2 methods: `save` and `save_append` with former not having `append` parameter and latter not being exported from `tools`. Since `tools.save` is in [the documentation](http://docs.conan.io/en/latest/reference/tools.html#tools-save) I consider it as a public API and suggest restore previous behavior. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Rename `CloudEnvironment` -> `DaskKubernetesEnvironment` Couple of changes here: 1. Rename the environment 2. Allow it to be slightly more customizable. A good first step is allowing the # of min/max workers to be specified Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Conan 2.0 build command no longer displays input profiles ### Environment details * Operating System+version: Debian 10 * Compiler+version: N/A * Conan version: 2.0 * Python version: N/A ### Steps to reproduce conan-2.0 build -pr:b tools.jinja -pr:h tools.jinja --name zlib --version 1.2.11 . ### Logs conan-2.0 build -pr:b tools.jinja -pr:h tools.jinja --name zlib --version 1.2.11 . ======== Computing dependency graph ======== Graph root conanfile.py (zlib/1.2.11): /tmp/tmp.E0yZBKFZqA/zlib/conanfile.py Build requirements cmake/3.25.2#3879379b09c6c62f34968ecd870c278f - Cache openssl/1.1.1t#48dbd82b8f9c47890074d82aafe302e1 - Cache ======== Computing necessary packages ======== Build requirements cmake/3.25.2#3879379b09c6c62f34968ecd870c278f:d51b94ec024af4a0f47ccf0400b7a0e260c30ff0#042b95eec03536ee7c6aea0e1157e2b9 - Cache openssl/1.1.1t#48dbd82b8f9c47890074d82aafe302e1:896855b1e3b5961bfcc08e699116d9ed588cac00#8a6a7d29ea2f08451c33f97867114fdc - Skip ======== Installing packages ======== Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: depends_on restarts dependent services when up is called I bring up two containers called master and slave where slave depends_on master. I destroy master. I then run `docker-compose up` and both slave and master are recreated even though nothing has changed about slave. ``` / $ docker-compose -v docker-compose version 1.7.0, build 0d7bf73 / $ docker -v Docker version 1.11.1, build 5604cbe ``` depends_on restarts dependent services when up is called I bring up two containers called master and slave where slave depends_on master. I destroy master. I then run `docker-compose up` and both slave and master are recreated even though nothing has changed about slave. ``` / $ docker-compose -v docker-compose version 1.7.0, build 0d7bf73 / $ docker -v Docker version 1.11.1, build 5604cbe ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: add option to build \".c\" or \".gresource\" out of gnome.compile_resources() It's not always needed to get `.c` + `.h`. Sometimes it's enough to get only `.c` or `.gresource. ``` (08:21:42 PM) ignatenkobrain: jpakkane: probably not, problem is that glib-compile-resources can generate `.c`, `.c + .h` or `.gresource` (08:21:57 PM) ignatenkobrain: I was thinking what's the best option to give user what exactly he wants (08:23:46 PM) jpakkane: No, that's too magic. Maybe something like have two methods, the current one and compile_gresource that produces a gresource file. Developers could the mix and match based on preference. (08:28:06 PM) ignatenkobrain: or having option: `output_mode` in (`source`, `header`, `sourceheader` (default), `gresource`), wdyt? (08:39:14 AM) TingPing: ignatenkobrain, i agree with simply adding another kwarg for it ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [Flax]Not able to Run Hugging Face GPT2 model for jax on TPU's Hi,Trying to do FlaxGPT2ForMultipleChoice.I am trying to run GPT2 using hugging face for TPU's.It is showing tuple out of index.But when i run it in CPU there is no such error.Even when i run a simple model without any code of mine it is also behaving the same in TPU.  This below example is for a basic model  To Reproduce This is the colab notebook: https://colab.research.google.com/drive/1h8CeTM5NUpHeS1oGHONX1YbwtGHf3nyU?usp=sharing Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: AutoTokenizer does not support XGLMTokenizer ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.17.0.dev (f380bf2b612e6030ef8bc8904b287d274f035e29) - Platform: Linux - Python version: 3.8 - PyTorch version (GPU?): 1.9.0 - Tensorflow version (GPU?): n/a - Using GPU in script?: Yes - Using distributed or parallel set-up in script?: ### Who can help @patil-suraj ## Information Model I am using (Bert, XLNet ...): XGLM The problem arises when using: * [ ] the official example scripts: (give details below) * [X] my own modified scripts: (give details below) The tasks I am working on is: * [ ] an official GLUE/SQUaD task: (give the name) * [X] my own task or dataset: (give details below) ## To reproduce Steps to reproduce the behavior: Just execute this piece of code: ``` from transformers import AutoTokenizer tokenizer=AutoTokenizer.from_pretrained(facebook/xglm-1.7B\") ``` ## Expected behavior tokenizer to be of class \"XGLMTokenizer\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Improved error message for overlapping pulses <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The current pulse overlap error message reads: `PulseError: 'Child schedules <Schedule 0>, <Schedule 1> overlap.'` For a user building pulse schedules, it would be nice for the error to give more information about how they overlapped, so the user could more easily debug their mistake. (For example, in my case, schedule 0 involved only qubit 0, and I thought schedule 1 involved only qubit 1, but I was actually measuring qubit 1 into mem slot 0, causing the conflict.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: optimize_1q_gates does not preserve circuit order Following #2000, the `Optimize1qGates` pass appends the 1q gate to the end of the DAG, rather than inserting it in place. e.g. ``` >>> import qiskit as qk >>> qr = qk.QuantumRegister(2) >>> qc = qk.QuantumCircuit(qr) >>> qc.u1(0.1, qr[0]) <qiskit.extensions.standard.u1.U1Gate object at 0x101c98128> >>> qc.u1(0.2, qr[0]) <qiskit.extensions.standard.u1.U1Gate object at 0x101c985f8> >>> qc.cx(qr[1],qr[0]) <qiskit.extensions.standard.cx.CnotGate object at 0x101c98208> >>> print(qc.draw()) ┌─────────┐┌─────────┐┌───┐ q0_0: |0>┤ U1(0.1) ├┤ U1(0.2) ├┤ X ├ └─────────┘└─────────┘└─┬─┘ q0_1: |0>────────────────────────■── >>> from qiskit.transpiler.passes import Optimize1qGates >>> from qiskit.converters import circuit_to_dag, dag_to_circuit >>> print(dag_to_circuit(Optimize1qGates().run(circuit_to_dag(qc))).draw()) ┌───┐┌─────────┐ q0_0: |0>┤ X ├┤ U1(0.3) ├ └─┬─┘└─────────┘ q0_1: |0>──■───────────── ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Networking doesn't work with Windows containers due to disconnecting containers from networks See @taylorb-microsoft's comment here: https://github.com/docker/compose/commit/313c584185f3999eb7a9ad0b7792a251b0afcbf8#commitcomment-16546187 Windows doesn't support disconnecting containers from networks and isn't going to any time soon. It seems like we should get better APIs for updating aliases on containers instead of doing this which feels like hack. This is blocking Compose working with Windows containers, I believe. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: `pre-commit` as part of the `build-system` seems super heavy From a downstream perspective, adding `pre-commit` as part of the `build-system` seems super heavy, as noted on https://github.com/conda-forge/jupyterlab-feedstock/pull/333 _Originally posted by @bollwyvl in https://github.com/jupyterlab/jupyterlab/issues/12279#issuecomment-1125035020_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: 'QueryResults.job' returns a new instance on each access. See second item of #1551. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: VS backends do not use b_pch When setting `b_pch=false`, a meson project (e.g. test case `common/13 pch`) compiles fine with VS, but fails with ninja. This assumes the project is set up in a way that it requires PCH in order to compile (because it does not add individual includes to source files). However, the correct behavior would be for VS to also fail, since it should be possible to toggle usage of PCH just by switching the `b_pch` option. If a project is set up incorrectly, VS should not make it compile magically. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Provide link aliases I'm trying to use fig to assemble our application and have run into a use case that I don't see supported at the moment: I need to have a service that has 2 links to the same container, like so: ``` links: - db:db - db:legacydb ``` The reason is that in some environments those are 2 different containers but in a dev environment they're set up as one. Is this something that is coming down the road for fig? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Optionally Skip Testing When Cross Building I am cross compiling libraries with test_packages which cannot be built for the target platform. Currently, this causes unnecessary build failures because the test_package build fails due to incompatibility with the platform. I would like to specify on the command line that test failures should not cause this build to fail because I know that these failures are false positives. While it can be argued that all code should always be tested for all platforms, doing so is not feasible in my case since it would require adding large amounts of platform specific code to the test_package and running the executable in an emulator. Currently, the simplest solution to this problem is to run `export` and `install` manually, but doing so is inconvenient and it's easy to forget to `export`. Adding more sophisticated options to each conanfile is perhaps more clean but requires additional work in each used package which may be maintained by third parties. To fix this issue, a simple `--no-test` flag should be added to `conan create`. *EDIT*: I just noticed that test_packages are only run for the current package, not those being built using `--build`. Originally, I detailed a system that allowed selectively disabling tests, but this fact greatly simplifies the issue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Missing activation Function I think the sigmoid / softmax activation function is missing here https://github.com/huggingface/transformers/blob/31ec2cb2badfbdd4c1ac9c6c9b8a74e974984206/src/transformers/models/roberta/modeling_tf_roberta.py#L1299 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Statevectors and unitaries should not be stored as lists of complex in Result class <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Currently the `Result` class stores statevectors and unitary matrices as lists and nested list of complex numbers, respectively. This however makes little sense as simulators use NumPy arrays, or c-aligned vectors that can directly be instantiated from NumPy arrays, internally. Thus the one starts with aligned data, makes a copy to lists in `Result` and then makes another copy of the data when doing `get_statevector()` or `get_unitary()` that returns a NumPy array. Why not just store the data as NumPy arrays in the `Results` to begin with? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Use `type(o)` instead of `o.__class__` in `ndb` See https://github.com/googleapis/google-cloud-python/pull/6487#discussion_r233600589 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.numpy.linspace() does not faithfully recover endpoints Example: ```python >>> import numpy as np >>> import jax.numpy as jnp >>> a, b = -2.3328583, 2.8459014 >>> np.linspace(a, b, 10)[-1] == b True >>> jnp.linspace(a, b, 10)[-1] == b DeviceArray(False, dtype=bool) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Allow max_chunk_size to be configurable [Here](https://github.com/gitpython-developers/GitPython/blob/cf8dc259fcc9c1397ea67cec3a6a4cb5816e3e68/git/cmd.py#L659) `max_chunk_size` will usually contain (depending on the platform) `8192`, which is a very high value for a chunk and won't trigger a `.write` (keep reading) until quite some output is printed to stdout. I propose to make that value configurable (maybe via an argument). My use case: I have the following class: class PipeIO(io.BytesIO): def __init__(self, cb): io.BytesIO.__init__(self) self.updater_cb = cb def write(self, b): buf = io.BytesIO.getbuffer(self).tobytes() progress = re.findall(\"(?<=\\()\\d+\\/\\d+(?=\\))\", buf.decode(\"utf-8\")) try: self.updater_cb(progress[-1]) except: pass return io.BytesIO.write(self, b) And I use it like this: stdout = PipeIO(self.my_updater_callback) self.repo.git.filter_branch(\"-f\", \"--env-filter\", s, output_stream = stdout) This will cause my callback to parse the content of the buffer every time [`.write`](https://github.com/gitpython-developers/GitPython/blob/cf8dc259fcc9c1397ea67cec3a6a4cb5816e3e68/git/util.py#L127) is called, which is very useful if I want to provide progress updates while running a long git command (like `filter-branch`). Possible solution: Make it possible to call raw commands with one extra argument: self.repo.git.filter_branch(\"-f\", \"--env-filter\", s, output_stream = stdout, max_chunk_size = 32) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Documentation for `QuantumCircuit.assign_parameters` seems to be wrong <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.17.4 - **Python version**: 3.9.4 - **Operating system**: MacOS 10.14.6 ### What is the current behavior? The description of the `QuantumCircuit.assign_parameters` method in the [docs](https://qiskit.org/documentation/stubs/qiskit.circuit.QuantumCircuit.html#qiskit.circuit.QuantumCircuit.assign_parameters), says that: > \"If an iterable, the elements are assigned to the existing parameters in the order they were inserted. \" but this does not seem to be the behaviour of the function. Instead, if you call `QuantumCircuit.parameters` the parameters seem to be returned in lexical order and passing an iterable assigns elements to the existing parameters in that order. The documentation does say that the order will be specified by `QuantumCircuit.parameters`: > \"You can call QuantumCircuit.parameters to check this order.\" But the comment about this being the order the parameters were inserted is misleading. ### Steps to reproduce the problem ```python from qiskit import QuantumCircuit from qiskit.circuit import Parameter circ = QuantumCircuit(4) for idx in range(12): circ.ry(Parameter('p'+f'{idx}'), idx%4) circ.draw() print(circ.parameters) circ2 = circ.assign_parameters([Parameter('q'+f'{idx}') for idx in range(12)]) circ2.draw() ``` The intended behaviour is to remap parameters so that 'p0 -> q0', 'p1 -> q1', 'p2 -> q2' etc. but because of the lexical ordering 'q2' instead replaces 'p10'. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: 1.20.0 output character error I recently upgraded to using version 1.20.0-rc2 and encountered this issue I'd never seen before. From the looks of it, it looks like it's an encoding issue... any other context needed? ``` Traceback (most recent call last): File \"bin/docker-compose\", line 6, in <module> File \"compose/cli/main.py\", line 71, in main File \"compose/cli/main.py\", line 127, in perform_command File \"compose/cli/main.py\", line 280, in build File \"compose/project.py\", line 372, in build File \"compose/service.py\", line 1003, in build File \"compose/progress_stream.py\", line 23, in stream_output File \"compose/progress_stream.py\", line 90, in print_output_event UnicodeEncodeError: 'ascii' codec can't encode character '\\u2013' in position 151: ordinal not in range(128) [96] Failed to execute script docker-compose Exited with code 255 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `ipython console` doesn't send a `shutdown_request` When shutting down in any method, `ipython console` does not send the `shutdown_request` message to the language kernel. According to the [documentation](http://ipython.org/ipython-doc/dev/development/messaging.html#kernel-shutdown), this should be sending the `shutdown_request` message. As a result, it's difficult in an external language kernel to detect when the kernel should shut down, and the kernel process just ends up hanging around in the background forever. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: UI Doesn't use all of Bootstrap theme css, Airflow 2.0 **Apache Airflow version**: 2.0.0 **Environment**: Ubuntu - **Cloud provider or hardware configuration**: - **OS** (e.g. from /etc/os-release): - **Kernel** (e.g. `uname -a`): - **Install tools**: - **Others**: **What happened**: Picked Cyborg.css in web_server config but background is still default  <!-- (please include exact error messages if you can) --> **What you expected to happen**: <!-- What do you think went wrong? --> **How to reproduce it**: <!--- As minimally and precisely as possible. Keep in mind we do not have access to your cluster or dags. If you are using kubernetes, please attempt to recreate the issue using minikube or kind. ## Install minikube/kind - Minikube https://minikube.sigs.k8s.io/docs/start/ - Kind https://kind.sigs.k8s.io/docs/user/quick-start/ If this is a UI bug, please provide a screenshot of the bug or a link to a youtube video of the bug in action You can include images using the .md style of  To record a screencast, mac users can use QuickTime and then create an unlisted youtube video with the resulting .mov file. ---> **Anything else we need to know**: <!-- How often does this problem occur? Once? Every time etc? Any relevant logs to include? Put them here in side a detail tag: <details><summary>x.log</summary> lots of stuff </details> --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: fPIC flag is on for MSYS2/Cygwin MSYS2 and Cygwin are Unix-like environments that run on Windows. This means that meson presumably assumes it is running under a Unix and turns on the -fPIC flag for C(++) shared libraries. However, since it is actually a windows system, a warning about the flag is generated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Complete the CMake variables for cpp_info.frameworks While integrating new changes in #5582, I realized some general variables are missing for frameworks. Currently, only the `CONAN_FRAMEWORK_<framework>` variable is generated, but there is no variable to iterate the global frameworks or the package's ones. These variables could be useful and should be added for completeness and consistency. - `CONAN_FRAMEWORKS`: GLobal variable with all the frameworks on the dependency graph. - `CONAN_FRAMEWORKS_<PKG-NAME>`: All frameworks of the package Additionally, check the tests that are checking the `CONAN_LIBS_<PKG-NAME>`, as this variable should only contain the package libraries but not the frameworks one. For example: https://github.com/conan-io/conan/pull/5582/files#diff-b50c3899bc268f45979432c9903b5539R343 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: pulse visualization does not truncate a command Suppose a schedule contains gates from 0 - 500 ns and readout from 500 - 2000 ns. When I use ``` sched.filter(time_ranges=[(0, 1000)]).draw() ``` I expect the schedule to be drawn up to 1000 ns. This means truncating, but showing, half of the readout. However currently it only draws up to 500 ns, because it does not want to truncate the readout. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson does not properly compute RUNPATH on a merged-usr system This was originally filed as https://github.com/systemd/systemd/issues/10430 Building systemd git master on a merged-/usr Debian sid system, results in broken test binaries. The RUNPATH is not properly set. After applying #4381, the test binaries are usable. But in case of ```/lib/x86_64-linux-gnu```, it shouldn't be added to RUNPATH at all, because this is a system library path. On a non-merged-/usr system, no such RUNPATH is added. It seems that the ```lib -> usr/lib``` symlink breaks the system library detection. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse amplitude representation in pulse library <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? From a calibration point of view, pulse amplitude is better to be represented in (`float` |amp|, `float` phase) rather than `complex` amp. Usually I tune pulse amplitude by amplitude sweep followed by error amplification, and then calibrate the phase separately. I often write wrapper function of one in the pulse library to convert (amp, phase) into complex value as an input, but changing the argument of those functions is more straightforward. Since they are public function, is it worth changing the interface? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Mime Renderer Simplification As noted in person with @gnestor and @ellisonbg last week: - We will create a separate package that has the [IRenderOptions](https://github.com/jupyterlab/jupyterlab/blob/3457b5d58a0b7496fb84608c7911bf5b6b99902b/packages/rendermime/src/rendermime.ts#L374) and [IWidgetFactoryOptions](https://github.com/jupyterlab/jupyterlab/blob/3457b5d58a0b7496fb84608c7911bf5b6b99902b/packages/docregistry/src/registry.ts#L771) interfaces. - A mime renderer \"plugin\" is one that consumes the render options and optionally provides widget factory options, exported as the default or as an array of defaults. - We enable in `package.json` as `jupyterlab: mimerenderer: true`. - We add a separate `renderTimeout` option that abstracts the `ActivityMonitor` handling for the renderer. - Plugins that are mimerenderers are automatically wrapped as application plugins. This enables the mime renderers to be as independent from the JupyterLab codebase as possible, ensuring long term compatibility as well as simplicity. @gnestor is working on a proof of concept. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: alias_target that depends on a run_target is quite broken While testing #9174, I tried to create the target I alluded to, there. In lib/libalpm/po/meson.build I added: ``` lib_mo = i18n.gettext(...) # this used to not be saved alias_target('regenerate-all-pot', lib_mo[1]) ``` In my build.ninja, I ended up with: ``` build regenerate-all-pot: phony | lib/libalpm/po/libalpm-pot ``` This is plainly wrong! It's reproducible with a simple meson.build ``` $ cat meson.build project('foo', 'c') subdir('in_subdir') $ cat in_subdir/meson.build r = run_target('run_a_target', command: ['echo', 'ran a target']) alias_target('aliased_run_a_target', r) ``` However, it is not reproducible in released meson at all, because instead I get: ``` in_subdir/meson.build:2:0: ERROR: Depends items must be build targets. ``` This seems like a regression from commit 982973f303e3d0431d9b79f89cdf2c8f1ee67bc0 which removed that error message and made it accept any build.Target -- which I then assumed should work while testing my PR... /cc @dcbaker I would actually sort of kind of like this to work properly as I'd like an alias_target that lets me run the i18n.gettext() pseudo-targets for multiple gettext domains in a single ninja invocation. Currently we have a 40-line shell script which spends most of its time trying to find the builddir. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Misleading error when from_pretrained fails, says there are flax weights when there aren't ### System Info ```shell - `transformers` version: 4.20.0.dev0 - Platform: Linux-5.14.0-1031-oem-x86_64-with-glibc2.17 - Python version: 3.8.12 - Huggingface_hub version: 0.4.0 - PyTorch version (GPU?): 1.10.0+cu102 (True) - Tensorflow version (GPU?): 2.9.0 (False) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ``` ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Tiny bug in the from_pretrained code that checks if flax weights are present. ``` from transformers import AutoModel, AutoConfig config = AutoConfig.from_pretrained(\"roberta-base\") model = AutoModel.from_pretrained(\"some_empty_dir\", config=config) ``` ### Expected behavior ```shell Should return: EnvironmentError( f\"Error no file named {WEIGHTS_NAME}, {TF2_WEIGHTS_NAME}, {TF_WEIGHTS_NAME + '.index'} or \" f\"{FLAX_WEIGHTS_NAME} found in directory {pretrained_model_name_or_path}.\" ) Instead returns: EnvironmentError( f\"Error no file named {WEIGHTS_NAME} found in directory {pretrained_model_name_or_path} but \" \"there is a file for Flax weights. Use `from_flax=True` to load this model from those \" \"weights.\" ) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Wrong urls in LabConfig `jupyterlab_server` renamed several of the urls the `LabApp` config, and some of those have not been updated in `jupyterlab`, leaving a few of the lab commands broken (particularly workspace importing and exporting). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `qiskit.tools.visualization_state_visualization` module fails to import <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: latest master - **Python version**: any - **Operating system**: any ### What is the current behavior? Since #1166 merged the api changed for the pauli_singles() function. However the `qiskit.tools.visualization_state_visualization` module still uses the old function and imports the function directly here: https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/tools/visualization/_state_visualization.py#L23 ### Steps to reproduce the problem import qiskit.tools.visualization_state_visualization ### What is the expected behavior? You can import the module and use all the functions in it. ### Suggested solutions Update the use of `pauli_singles` to the new api post #1166 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Fetching next batch of results using BigQuery's dbapi Currently, the maximum number of rows that you can get when iterating using `fetchmany`, `fetchall` or `fetchone` is limited by `arraysize`. I see that those methods are using iterator returned by `_query_data.fetch_data()` with `max_results` set to `arraysize` https://github.com/GoogleCloudPlatform/google-cloud-python/blob/36304f7448677cff2f89558ef87c374e904a0492/bigquery/google/cloud/bigquery/dbapi/cursor.py#L171-L172 However, shouldn't it automatically fetch the next page of results when we are finished iterating over the current batch of results? Otherwise, it makes it impossible to retrieve full results from the query without setting`arraysize` to an arbitrary large number. Here is what I've tried: ``` cursor.execute('SELECT * FROM dataset.table') while True: rows = cursor.fetchmany(5000) if not rows: break for row in rows: print(row) ``` ``` cursor.execute('SELECT * FROM dataset.table') row = cursor.fetchone() while row: print(row) row = cursor.fetchone() ``` I am using google-cloud-bigquery 0.26.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: compose config command parses the healthcheck.interval to int while stack deploy need string first, I defined the healthcheck section in compose file like this: ``` healthcheck: test: ... interval: 1m30s timeout: 10s retries: 3 ``` then I use `docker-compose config > compose.yml` to generate the whole compose file to be used by deploy. when I use `docker stack deploy -c compose.yml srv` to create the stack, error: ``` services.nginx.healthcheck.interval must be a string ``` maybe `docker-compose config` should parse the time into string? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Massive regression in performance of the ninja backend I noticed that despite the perf improvements in the interpreter run time that were achieved for 0.46, the configure time for gtk+ actually went up by a few seconds. So I added some profiling and found this: `intr.run()` time went from [25.2s](https://github.com/mesonbuild/meson/files/1943956/intr-0.45.1.log) to [13.8s](https://github.com/mesonbuild/meson/files/1943958/intr-0.47.0.dev1.log) `g.generate()` time went from [4.2s](https://github.com/mesonbuild/meson/files/1943959/generate-0.45.1.log) to [*20.6s*](https://github.com/mesonbuild/meson/files/1943960/generate-0.47.0.dev1.log) The above links are all profile stat dumps which can be parsed with the [pstats module](https://docs.python.org/3/library/profile.html#module-pstats). I haven't looked into the profiles properly yet. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Language modelling head has zero weights in pretrained TFMobileBertForMaskedLM ## Description The `TFMobileBertForMaskedLM` example returns all zero logits while `MobileBertForMaskedLM` example works fine. https://huggingface.co/transformers/model_doc/mobilebert.html#tfmobilebertformaskedlm I checked language modeling head weights for both models and found that TF pretrained model has zero weights. ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.3.0 - Platform: Google Colab - Python version: 3.6.9 - PyTorch version (GPU?): 1.7.0+cu101 - Tensorflow version (GPU?): 2.4.1 - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help @jplu @patrickvonplaten ## Information Model I am using (Bert, XLNet ...): TFMobileBertForMaskedLM The problem arises when using: - [x] the official example scripts: (give details below) ## To reproduce ``` from transformers import MobileBertForMaskedLM from transformers import TFMobileBertForMaskedLM # PyTorch model = MobileBertForMaskedLM.from_pretrained('google/mobilebert-uncased') print(list(model.cls.parameters())[0]) # Parameter containing: # tensor([-7.2946, -7.4302, -7.5401, ..., -7.4850, -7.4503, -2.7798], # requires_grad=True) # TensorFlow model = TFMobileBertForMaskedLM.from_pretrained('google/mobilebert-uncased') print(model.layers[1].get_weights()[0]) # array([0., 0., 0., ..., 0., 0., 0.], dtype=float32) ``` ## Expected behavior Language modeling head for TFMobileBertForMaskedLM should have the same weights as of MobileBertForMaskedLM Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Tokenization not working using v2.1 ## How to reproduce the behaviour I found a bug where tokenization is completely not working with version 2.1.0a10 on python 2.7. I have reproduced this on three of my machines. ``` $ conda create -n py27_spacy2 python=2.7 $ source activate py27_spacy2 $ pip install -U spacy-nightly $ python -m spacy download en_core_web_sm $ python -c \"import spacy; nlp=spacy.load('en_core_web_sm'); doc=nlp(u'hello world'); print ','.join([t.text for t in doc])\" h,e,ll,o,w,o,r,l,d ``` ## Your Environment * Operating System: Ubuntu * Python Version Used: 2.7 * spaCy Version Used: 2.1.0a10 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Doc broken / Link broken * The readme link \"Lightning module\" is broken: https://pytorch-lightning.readthedocs.io/en/latest/LightningModule/RequiredTrainerInterface/ * The source link in documentation goes nowhere: https://pytorch-lightning.readthedocs.io/en/latest/logging.html click on source goes to https://github.com/PyTorchLightning/PyTorch-Lightning/blob/pytorch_lightning/logging.py It is really confusing and worrying for news comer like me who expect a simple and easy to plug api well documented and maintained. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Traceback on Qt console exit Start the Qt console, and then type `exit` to exit it (closing it from the frontend doesn't exhibit the bug). I see this message, repeated twice: ``` Traceback (most recent call last): File \"/home/takluyver/.local/lib/python3.4/site-packages/IPython/qt/console/frontend_widget.py\", line 812, in _document_contents_change self._call_tip() File \"/home/takluyver/.local/lib/python3.4/site-packages/IPython/qt/console/frontend_widget.py\", line 724, in _call_tip msg_id = self.kernel_client.inspect(code, cursor_pos) File \"/home/takluyver/.local/lib/python3.4/site-packages/IPython/kernel/channels.py\", line 326, in inspect self._queue_send(msg) File \"/home/takluyver/.local/lib/python3.4/site-packages/IPython/kernel/channels.py\", line 171, in _queue_send self.ioloop.add_callback(thread_send) File \"/usr/lib/python3/dist-packages/tornado/ioloop.py\", line 732, in add_callback raise RuntimeError(\"IOLoop is closing\") RuntimeError: IOLoop is closing If you suspect this is an IPython bug, please report it at: https://github.com/ipython/ipython/issues or send an email to the mailing list at ipython-dev@scipy.org You can print a more detailed traceback right now with \"%tb\", or use \"%debug\" to interactively debug it. Extra-detailed tracebacks for bug-reporting purposes can be enabled via: c.Application.verbose_crash=True ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Wrong Tooltip with shift-tab @andram opened jupyter/notebook#520 at 2015-10-01 10:09:29 UTC If a notebook cell starts with a multiline string, then shift-tab gets confused and shows the wrong tooltips for following lines. For example consider a cell containing the following 5 lines: ``` \"\"\" Docstring \"\"\" max() min() ``` now position the cursor inside the brackets of max(). Expected behaviour is that the docstring for `max` is shown. Actual behaviour is that the docstring for min is shown. (see attached screenshot for current github version of jupyter notebook)  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython swallows exceptions in repr ### IPython console behavior ``` Python In [1]: class Foo(object): ...: def __repr__(self): ...: raise Exception() ...: In [2]: Foo() Out[2]: <repr(<__main__.Foo at 0x7f50f6bb69d0>) failed: Exception: > ``` ### Normal Python repl behavior ``` Python >>> class Foo(object): ... def __repr__(self): ... raise Exception() ... >>> Foo() Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"<stdin>\", line 3, in __repr__ Exception ``` In some cases (particularly the case that I'm dealing with), it'd be nice for IPython to allow this exception to bubble up to the user, rather than just printing it out. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Local filesystem channel fails with conda 4.6 ## Current Behavior After updating to conda 4.6.1, using a local channel with for example `conda search -c file:///some/path '*'` fails with an `UnavailableInvalidChannel` error, while it worked as expected with conda 4.5.12. ### Steps to Reproduce ``` $ tree /opt/conda/conda-bld /opt/conda/conda-bld └── noarch └── mypkg-1.0.0-py_0.tar.bz2 $ conda index /opt/conda/conda-bld $ conda search -c file:///opt/conda/conda-bld '*' UnavailableInvalidChannel: The channel is not accessible or is invalid. channel name: opt/conda/conda-bld channel url: file:///opt/conda/conda-bld error code: 404 You will need to adjust your conda configuration to proceed. Use `conda config --show channels` to view your configuration's current state, and use `conda config --show-sources` to view config file locations. As of conda 4.3, a valid channel must contain a `noarch/repodata.json` and associated `noarch/repodata.json.bz2` file, even if `noarch/repodata.json` is empty. Use `conda index /opt/conda/conda-bld`, or create `noarch/repodata.json` and associated `noarch/repodata.json.bz2`. ``` When switching back to conda 4.5.12 it works as expected: ``` $ conda install -y conda==4.5.12 $ conda search -c file:///opt/conda/conda-bld '*' Loading channels: done # Name Version Build Channel mypkg 1.0.0 py_0 conda-bld ``` ## Expected Behavior The local channel should be used successfully as with conda 4.5.12. ## Environment Information conda: 4.5.12 conda-build: 3.17.8 python: 3.7.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: RFE: Give Commit objects a replace method that returns new Commit with modified attributes The `datetime` objects produced by Python's `datetime` module are immutable, much like `Commit` objects. The `datetime` module provides a convenient `replace` function that returns a new object based on an old with one or more attributes replaced. E.g, I can write: ``` >>> d = datetime.datetime.now() >>> d.replace(hour=0, minute=0, second=0) datetime.datetime(2021, 2, 15, 0, 0, 0, 318021) ``` I would like to see the same api on `Commit` objects, so that one could write: ``` >>> newcommit = oldcommit.replace(message='This is a test', author='Cookie Monster') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Proposal: New field to define ordered start and stop Original implementation is #686 Now that networks don't require you to define service dependencies we could provide a new field to define an order, allowing applications to start and stop containers in a specific order. The advantage to a new field (and not re-using an existing one), is that it allows applications that don't need an order to start and stop everything in parallel. Order would only be applied explicitly if the user wants it. This does not address healthchecking and the problems described in #374, but it's a prerequisite of any solution to that problem. It does solve issues like #2619 (and maybe others?). Current proposal is to name the field `depends_on` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Text drawer option vertically_compressed is not exposed into higher drawing APIs _Originally posted by @1ucian0 in https://github.com/Qiskit/qiskit-terra/pull/2480#issuecomment-494994853_ The text drawer has an option to enable and disable vertical compression: `vertically_compressed`. However, this option is not exposed by `circuit_drawer` or `QuantumCircuit.draw`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Support storing results in a specific schema of a PostgreSQL database I'm using celery in a PostgreSQL environment where I only have a single database. So I use the \"schema\" idiom to keep non-strongly-related data apart. That's why I'd like to be able to store the celery task results in a different schema than the default \"public\" one. Source code modification would take place in `backends/database/models.py`, both the Task & TaskSet tables and their related Sequence. Plus of course adding a configuration hook to specify the schema name. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: \"Failed to parse JSON: No active field found\" when using load_table_from_json() On Mac (Python 3.7.4 & google-cloud-bigquery==1.19.0) I'm using the following code: ``` from google.cloud import bigquery test_ndjson = '{\"name\": \"bob\"}' client = bigquery.Client() table_ref = client.dataset('my_ds').table('test') job_config = bigquery.LoadJobConfig() job_config.write_disposition = bigquery.WriteDisposition.WRITE_TRUNCATE job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON job_config.autodetect = True job = client.load_table_from_json(test_ndjson, table_ref, job_config=job_config) job.result() # Waits for table load to complete. ``` I get: > google.api_core.exceptions.BadRequest: 400 Error while reading data, error message: Failed to parse JSON: No active field found.; ParsedString returned false When I do exactly the same thing using the bq command it works as expected: ``` echo '{\"name\": \"bob\"}' > data.json bq load --apilog '' --source_format=NEWLINE_DELIMITED_JSON --autodetect=True myproject\\:my_ds.test ./data.json ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Websecurityscanner: needs 'synth.py' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] 2.0 Remove \"imports\" and \"deploy\" mechanism We think that the imports use cases can be solved with other mechanisms: `imports()` method: 1. Import a tool from a dependency to run it, like cmake: Superseded by virtual environments. 2. Import shared libraries to run something in the build method. Superseded by virtual environments, and also broken because if you want to build a package locally you want to import the artifacts at \"generate\" time, not just before calling \"build()\" 3. Import any asset from dependencies necessary for building (same case 2) **Both could be done using the new `copy` tool and iterating the dependencies. Include a POC to see how it could look (access to bindirs, libdirs...) and maybe propose some tool to help?** `imports()` command: 1. Bring some things to the local directory, shared, or tools or whatever. But we were missing the very requested feature of installing the packages from the dependencies in a local directory but pointing the generators to these local folders, so you can distribute all as a zip (*1) `deploy()` method Kind of mixed-use case where you also can copy files from the package itself. **We will try to implement something in the direction of (\\*1) in a different issue** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: python -m transformers.onnx --model=Helsinki-NLP/opus-mt-en-zh onnx/ ### System Info transformers:4.22.2 python3.8.4 win10 raise ValueError( ValueError: Outputs values doesn't match between reference model and ONNX exported model: Got max absolute difference of: 2.8133392333984375e-05 ### Who can help? _No response_ ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction python -m transformers.onnx --model=Helsinki-NLP/opus-mt-en-zh onnx/ ### Expected behavior Export onnx and translate through onnx https://www.kaggle.com/code/catchlife/translate-opt Custom export has incorrect translation results Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Rename `themeDir` to `themePath` For theme extensions, it appears that `themeDir` package.json property was changed to `themePath`. However, there are still some references to `themeDir` in [commands.py](https://github.com/jupyterlab/jupyterlab/blob/73c33aa2225fb8b2fe86be1e5e35f91b958a7057/jupyterlab/commands.py): https://github.com/jupyterlab/jupyterlab/search?utf8=%E2%9C%93&q=themedir&type= This is probably a bug and those references should probably be replaced with `themePath`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Registers copied by reference <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.13.0 - **Python version**: 3.7.5 - **Operating system**: MacOS Catalina ### What is the current behavior? The registers in the circuit are copied via reference. Modifying the registers in the copied circuit changes the original circuit. Note that this causes Aqua algorithms such as the VQE to fail, if passed a quantum circuit and run on the QASM simulator. This happens because the Algorithm may add a classical register called `'c'` to a copy of the Ansatz wavefunction multiple times, but since the original circuit is modified, the adding fails as a register called `'c'` already exists. ### Steps to reproduce the problem ```python circuit = QuantumCircuit(1) circuit.x(0) copied = circuit.copy() copied.add_register(ClassicalRegister(1, name='c')) print(circuit.cregs) ``` produces ``` [ClassicalRegister(1, 'c')] ``` ### What is the expected behavior? Copy `qregs` and `cregs`. ### Suggested solutions ```python # L1176 in quantumcircuit.py cpy = copy.copy(self) cpy.qregs = self.qregs.copy() cpy.cregs = self.cregs.copy() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: NaT and extended sort order https://docs.scipy.org/doc/numpy-1.15.0/reference/generated/numpy.sort.html#numpy.sort describes how `np.nan` is handled for floating point data. `NaT` and datetime data are not mentioned. ### Reproducing code example: In the following, `NaN` is sorted to the end, while `NaT` is sorted to the start. ```python In [32]: arr = np.array([np.nan, 1, 2, 3]) In [33]: arr.sort(); arr Out[33]: array([ 1., 2., 3., nan]) In [34]: dtarr = np.array(['NaT', 1, 2, 3], dtype='datetime64[ns]') In [35]: dtarr.sort(); dtarr Out[35]: array([ 'NaT', '1970-01-01T00:00:00.000000001', '1970-01-01T00:00:00.000000002', '1970-01-01T00:00:00.000000003'], dtype='datetime64[ns]') ``` So my question: is NaT sorting to the start a bug or deliberate? If it's deliberate, I could add a section to the docs noting that. ### Numpy/Python version information: 1.16.0.dev0+9cc9f01 3.7.1 (default, Nov 6 2018, 18:45:35) [Clang 10.0.0 (clang-1000.11.45.5)] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Do not use --no-undefined and --as-needed with lld cross-compiling for windows When cross-compiling and linking with lld + mingw for Windows, meson links with `--no-undefined` and `--as-needed`, both of these are not supported. Meson should either try if those flags are accepted by the linker before trying to use those or the defaults need adjustment for the case of lld when cross compiling for windows. (This can be easily worked around by disabling the flags, so this is not a urgent issue but should eventually be solved.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Certain Fortran targets are always considered out of date **Describe the bug** In some situations ninja re-builds Fortran targets that do not need to get rebuild. **To Reproduce** ``` $ cd \"test cases/fortran/3 module procedure\" $ meson setup build $ ninja -C build ninja: Entering directory `build' [3/3] Linking target use_syntax $ ninja -C build ninja: Entering directory `build' ninja: no work to do. $ touch use_syntax.f90 $ ninja -C build/ ninja: Entering directory `build/' [2/2] Linking target use_syntax $ ninja -C build/ ninja: Entering directory `build/' [2/2] Linking target use_syntax $ ninja -C build/ ninja: Entering directory `build/' [2/2] Linking target use_syntax ``` **Expected behavior** Executing ninja twice should give \"ninja: no work to do.\" **system parameters** * Native Build * Arch Linux * Python 3.10.10 * meson 1.0.1 * ninja 1.11.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Unable to `python_requires_extend` a package with a '.' in the name ### Environment Details (include every applicable attribute) * Operating System+version: Windows 10 * Conan version: 1.25.1 * Python version: 3.8.1 ### Steps to reproduce (Include if Applicable) - Create a package with a '.' in the name (E.g. my.package/1.2.3) - Create a recipe for another package with ``` python_requires = 'my.package/1.2.3' python_requires_extend = 'my.package.MyPackage' ``` - Receive the error ERROR: too many values to unpack (expected 2) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Timezone calculations in app.now() are incorrect From `celery/app/base.py` ``` def now(self): \"\"\"Return the current time and date as a datetime.\"\"\" from datetime import datetime return datetime.utcnow().replace(tzinfo=self.timezone) ``` This is just semantically wrong. This takes the UTC timezone-aware time and replaces the timezone, _without actually ensuring it's the same point in time_. So 9 AM UTC becomes 9 AM JTC, even though 9 AM UTC is 6 PM JTC The \"proper\" way of doing this is `self.timezone.normalize(datetime.utcnow())` This bug breaks things like `crontab` for celery beat, for example, since the schedules get shifted around. And it's the wrong time too Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Postgres Tasks Using https://github.com/psycopg/psycopg2 let's add some tasks for working with a postgres database. The main function that we should add is `execute` which takes in an arbitrary SQL string to execute against a db. On immediate appearance the `ExecuteTask` (or whatever it becomes called) should take in a db host, db name, user, pass, SQL string, data tuple, and optional commit param. http://initd.org/psycopg/docs/cursor.html?highlight=execute#cursor.execute There are other functions such as `fetchone`, `fetchmany`, `rowcount`, etc... that may only be _slightly_ useful and we should use this issue as a means to debate what we think is important. (http://initd.org/psycopg/docs/cursor.html) cc @jlowin for your psycopg2 expertise Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Move ssh out of external and into lib This module does not belong in external - it cannot be replaced by an external system module. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Built-in automatic \"conan config install\" The most common request for a \"global init hook\", as proposed in: https://github.com/conan-io/conan/pull/6434 https://github.com/conan-io/conan/issues/6423 Is to achieve the automatic call to ``conan config install`` periodically by developers when they use Conan. Implementing it in hooks has several challenges, so we want to implement this as a built-in feature: - It uses conan.conf to define a minimal interval of time (hours, minutes, days?) between consecutive calls to ``conan config install``, to avoid doing one call per command, which would be very time consuming and annoying - Conan ``command.py`` can read the conf, compare the current time, with the latest time stored in the cache (as its own file, or as the \"touch\" time of version.txt, if that is robust), and if the time elapsed is greater than the configured one, it will be calling \"conan config install\" via the ``conan_api.py`` - ``conan config install`` doesn't require arguments, it knows how to repeat latest config-installs. - Make sure to reset the relevant bits, probably a completely new ConanApp. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: CI: shippable builds numpy twice The Shippable CI currently appears to build Numpy twice: first in `pip install` and then in `runtests.py`. As it's the slowest CI (no parallel jobs), it might make sense to try to avoid building twice (maybe add `-n` to runtest call and `-v` to pip so the build log gets shown?). https://github.com/numpy/numpy/blob/a8aa162c7097d8aa4edd6e555f01d7f0a248e1ad/shippable.yml#L45-L52 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Inability to set many=True during schema binding ### Information `@bind_schema` decorator does not allow passing extra parameters with the schema like `many=True` which results in inability to deserialize a collection of objects. - **Qiskit Terra version**: 0.8.2 - **Python version**: 3.7.3 - **Operating system**: Darwin Kernel Version 18.7.0 ### What is the current behavior? Any payload with collections gets rejected by model validation. ### Steps to reproduce the problem Let's define a simple schema and a corresponding model: ``` from qiskit.validation import BaseSchema, BaseModel, bind_schema from qiskit.validation.fields import String class TestSchema(BaseSchema): test = String(required=True) @bind_schema(TestSchema) class TestModel(BaseModel): def __init__(self, test, **kwargs): self.test = test ``` Then try to deserialize a payload with a collection: ``` from qiskit.validation import ModelValidationError from test.ibmqtestcase import IBMQTestCase class Test(IBMQTestCase): def test_schema(self): payload = [{'test': 'abc'}] try: result = TestModel.from_dict(payload) except ModelValidationError: self.fail('Could not deserialize the payload') self.assertTrue(isinstance(result, list)) ``` ### What is the expected behavior? Ability to pass `many = True` during schema binding, and the payload to be deserialized successfully into a list of `TestModel` objects. ### Suggested solutions Add `**kwargs` parameters to `@bind_schema` and parse them accordingly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda-env appears to lack support for path-based environments I am trying to use `conda env` with AEN where all the conda environments are path-based (not name-based), however I cannot figure out how to do `conda env attach` or `conda env export` since, so far as I can tell, conda-env only works with name-based conda environments. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Opflow gives wrong results calculating probabilities <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.17.0 - **Python version**: 3.8.3 - **Operating system**: Windows 10 Enterprise 64-bit ### What is the current behavior? Opflow yields wrong results when calculating probabilities such as in the example below. As seen there, the results are always correct when converting into matrix form or (not shown below) when using a quantum circuit in place of `phi`. ### Steps to reproduce the problem ```python from qiskit.opflow import Zero, One, Z, I, StateFn phi = 0.5*((One + Zero)^2) ZeroOp = ((Z + I)/2) OneOp = ((I - Z)/2) h1 = OneOp ^ I h2 = OneOp^(OneOp+ZeroOp) # OneOp + ZeroOp == I h2a = OneOp^OneOp h2b = OneOp^ZeroOp print((~StateFn(h1)@phi).eval()) print((~StateFn(h2)@phi).eval()) print((~StateFn(h2a)@phi).eval()) print((~StateFn(h2b)@phi).eval()) print((~StateFn(h2a + h2b)@phi).eval()) print((~StateFn(h2a)@phi).eval() + (~StateFn(h2b)@phi).eval()) print('---') print(h1.to_matrix() @ phi.to_matrix() @ phi.to_matrix()) print(h2.to_matrix() @ phi.to_matrix() @ phi.to_matrix()) print(h2a.to_matrix() @ phi.to_matrix() @ phi.to_matrix()) print(h2b.to_matrix() @ phi.to_matrix() @ phi.to_matrix()) (0.5+0j) # correct (-0.25+0j) # wrong (0.25+0j) # correct 0j # wrong (-0.25+0j) # wrong (0.25+0j) # wrong --- (0.5+0j) # correct (0.5+0j) # correct (0.25+0j) # correct (0.25+0j) # correct ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Allow None as subsettings in settings.yml They shouldn't need definition in command line or profiles, should be like a None value in a list of possible values in settings.yml ``` Linux: distro: None: Ubuntu: Yocto: version: [\"sumo\", \"rocko\"] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gst-plugins-base fails on MacOS due to -fobjc-arc check gst-plugins-base fails on MacOS with the following error: ``` Compiler for Objective-C supports arguments -fobjc-arc: NO gst-libs/gst/gl/meson.build:683:4: ERROR: Problem encountered: ARC is required for building ``` This happens because of this check: https://gitlab.freedesktop.org/boxerab/gst-plugins-bad/commit/38c3d4ca7b8e562e1396b902bb6dea07155ed3aa Digging into the logs, the failure is: ``` Working directory: /Users/jenkins/jhbuild/checkout/gst-plugins-base-1.16.2/build/meson-private/tmpicamerlo Command line: cc -L/Users/jenkins/DCV_JHBUILD/inst/lib /Users/jenkins/jhbuild/checkout/gst-plugins-base-1.16.2/build/meson-private/tmpicamerlo/testfile.m -o /Users/jenkins/jhbuild/checkout/gst-plugins-base-1.16.2/build/meson-private/tmpicamerlo/output.obj -pipe -c -O0 -Werror=unknown-warning-option -Werror=unused-command-line-argument -Werror=ignored-optimization-argument -fobjc-arc Code: int i; Compiler stdout: Compiler stderr: clang: error: argument unused during compilation: '-L/Users/jenkins/DCV_JHBUILD/inst/lib' [-Werror,-Wunused-command-line-argument] Compiler for Objective-C supports arguments -fobjc-arc: NO gst-libs/gst/gl/meson.build:683:4: ERROR: Problem encountered: ARC is required for building ``` So, basically it seems to fail because there are LDFLAGS in the env (which are set by jhbuild in this case). Should meson be able to sanitize the env for these kind of checks? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Update Docker healthcheck to include result handlers There are certain situations that we can catch prior to deployment that would result in a Flow not behaving as expected. In particular, if a user tries to deploy a Flow which: - has a task with retry settings - that task also has a keyed upstream edge - the upstream task has no result handler Then retries will fail to work in Cloud. Because this situation can be inferred apriori we should raise an informative error during the Docker health check. Similarly, if a user has tasks with `checkpoint=True` that don't have corresponding result handlers, we should raise an error. Note that if the Flow itself has a result handler (but the Task does not), then all of this is OK because the Flow's should be the fallback. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Update the content of the Markdown generator The content that the Markdown generator is creating is very outdated. It should show how to use the new generators (`CMakeToolchain`, `CMakeDeps`, `MSBuildToolchain`, etc). There is a proposal [here](https://docs.google.com/document/d/1PbUUXVHB73Ht3YrmBxndboKMrw-_EXU_o8J8DKeWhWQ/). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: Missing Affinity for Containerop **What happened:** currently we are missing function to setup the affinity for containerop. Am gonna create a PR to support that shortly Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Setting environment variable on CLI raises exception when service has environment definition It looks like I can't set an environment variable in the fig.yml and on the console at the same time. fig version: `1.0.1` python version: `2.7 (homebrew)` OS: OSX `10.10.2` _fig.yml:_ ``` bliep: image: ubuntu:14.04 environment: - SECRET_KEY ``` _full output:_ ``` $ fig run -e BLA=bla bliep Traceback (most recent call last): File \"/usr/local/bin/fig\", line 9, in <module> load_entry_point('fig==1.0.1', 'console_scripts', 'fig')() File \"/usr/local/lib/python2.7/site-packages/fig/cli/main.py\", line 31, in main command.sys_dispatch() File \"/usr/local/lib/python2.7/site-packages/fig/cli/docopt_command.py\", line 21, in sys_dispatch self.dispatch(sys.argv[1:], None) File \"/usr/local/lib/python2.7/site-packages/fig/cli/command.py\", line 28, in dispatch super(Command, self).dispatch(*args, **kwargs) File \"/usr/local/lib/python2.7/site-packages/fig/cli/docopt_command.py\", line 24, in dispatch self.perform_command(*self.parse(argv, global_options)) File \"/usr/local/lib/python2.7/site-packages/fig/cli/command.py\", line 56, in perform_command handler(project, command_options) File \"/usr/local/lib/python2.7/site-packages/fig/cli/main.py\", line 312, in run service.options['environment'][k] = v TypeError: list indices must be integers, not unicode ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: pyin messages should have execution_count @ivanov keeps bugging me about this one but never opens an Issue for it when I ask, so I'll just assign it to him ;) It does hightly the issue that has been raised in the past that our message spec may want to be versioned somehow, and folding that versioning into the spec itself (presumably as a field in the header). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Add details about contributing to the library Specifically, we need to point out that anyone contributing needs to sign the appropriate CLA. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Mistake in documentation of numpy.gradient Under \"Notes\" the second line in the second equation should read \\\\beta h_{d}-\\\\gamma h_{s}=1 \\\\\\\\ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: parallel.Client() not using profile that notebook was run with? I just updated some code that was using 0.13.1 to 1.1, and I noticed that even though I started the notebooks with a profile, when I did `rc = parallel.Client()` it looked in my default directory for the json connection files not the profile used to start the notebook. I had to specifically pass a profile keyword. Feature or bug? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Test case/situation for mapping Consider: ```python with Flow(): inputs = Parameter('inputs') transform_map = transform.map(inputs) # this version of load is mapped load_map = load.map(transform_map) # this version of load is \"reduced\" load_reduce = load(transform_map) ``` Let's say the input has 10 items, and the 10th one has a problem (for whatever reason) and that mapped task is either `Failed` or `Skipped`. I'm confident that `load_map` works just fine -- 9 of the items process their transformed inputs, and the last one responds to its trigger appropriately. I'm not sure what to expect as the input to `load_reduce` though. Is it a list of the 9 items that did process? 10 items and one is None? Should its trigger function be applied to each of the mapped states? What is the behavior of mapping over an empty list? I'm not sure if this is well-defined at the moment. My first reaction is to return a single `Success(result=[])` state. However, that would be at odds with the expectation that a \"mapped\" task returns a list of states. Second effort - a list `[Success(result=None)]` -- but that's indistinguishable from a task that was mapped over a single result and returned a result of `None`, so it's not possible for it also to represent a map over an empty input. @cicdw defer to your intuition here. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CFLAGS and friends leak into cross environment Haven't had time to write a test-case for this yet, but just filing here so this doesn't slip through the cracks once I finish porting Frida to Meson. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: purge_results with jobid crashing - looking for insight ipython 1.1.0 in anaconda on osx mavericks i used to have the following line which appeared to work fine till recently: ``` client.purge_results(self.taskmap[taskid]) ``` however, i'm getting the following error now: ``` AssertionError: Can't purge a client with outstanding tasks! ``` and i see the assertion statement that raises this. however i don't see any docs on what causes this error and how best to fix this. my intent with this was to clear that specific job out of existence as far as ipython was concerned. i've retrieved the results, i don't want any aspect of the job to take up memory anywhere (i send thousands of jobs to the client and at least initially when we implemented this - the memory was increasing as more jobs ran). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: We need win module and a method win.compile_resources() VC compile resource to COFF with 2 tools - 'RC', 'CVTRES'. > Compiling resource files using the Win32 SDK requires three separate tools: the first tool you use is > the RC compiler, which turns your .RC file into a .RES file; you then use the CVTRES tool to convert > the .RES file into an object file; and finally, you link the object file to the program executable using > LINK32. > https://msdn.microsoft.com/en-us/library/cc194805.aspx > > You can specify a .res file when linking a program. The .res file is created by the resource compiler > (RC). LINK automatically converts .res files to COFF. The CVTRES.exe tool must be in the same > directory as LINK.exe or in a directory specified in the PATH environment variable. > https://msdn.microsoft.com/en-us/library/kcz8ck35.aspx But mingw have some other tool 'windres.exe' which combinate 'RC.exe' and 'CVTRES.exe' in one executable. http://www.mingw.org/wiki/MS_resource_compiler Can we have some functional for easier compiling resource with vc compiler ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Cannot create container for service (invalid port specification) with 1.12.0-rc1 I could reproduce it with: ``` Version 17.03.0-ce-mac1 (15606) Channel: nightly 8303314087 docker-compose version: 1.12.0-rc1 ``` **test.yml** ```yml version: '2' services: a: image: nginx ports: - 80 b: extends: service: a ``` **Result** ``` $ docker-compose -f test.yml up -d Creating test_a_1 Creating test_b_1 ERROR: for b Cannot create container for service b: invalid port specification: \"_ServicePort(target='80', published=None, protocol=None, mode=None, external_ip=None)\" ERROR: Encountered errors while bringing up the project. ``` **Expected result** ``` $ docker-compose -f test.yml up -d Creating test_a_1 Creating test_b_1 ``` If I don't extend from service a, and simply copypaste everything down, it works fine. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Similar packages in pkgs/main and pkgs/free are considered the same package If `pkgs/main` and `pkgs/free` contain a package with the same subdir, name, version, build_number and build [conda considers](https://github.com/conda/conda/blob/4.6.6/conda/models/records.py#L253-L266) these packages identical and will not respect the sub-channel priority (main > free). A good example of this is the blas=1.0=mkl packages for the linux-64 platform. Additionally packages in `pkgs/free` and `pkg/main` with the [same name, version and build](https://github.com/conda/conda/blob/4.6.6/conda/models/records.py#L272-L273) will be considered by the [solver](https://github.com/conda/conda/blob/4.6.6/conda/resolve.py#L612-L620) to be the same even if they have a different build_number. This occurs with the blas=1.0=openblas packages for the linux-ppc64le platform which makes them un-installable. cf: #8301 #8236 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson 0.51 breaks Mesa build Configuring Mesa (https://gitlab.freedesktop.org/mesa/mesa) with meson 0.51 causes `ninja` to regenerate the build files in an infinite loop. Mesa was configured like this, which works fine in earlier meson version: ``` meson \"$build_dir\" \\ --strip \\ -D buildtype=release \\ -D prefix=\"$install_dir\" \\ -D b_lto=true \\ -D b_ndebug=true \\ -D platforms=drm,x11 \\ -D dri-drivers= \\ -D gallium-drivers= \\ -D vulkan-drivers=amd \\ -D gles1=false \\ -D gles2=false \\ -D opengl=false \\ -D valgrind=false ``` This was tested on Arch Linux, which just recently updated meson to 0.51. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Uninformative error message when trying to install using python<3.6 Because `setup.py` (lines [182](https://github.com/numpy/numpy/blob/master/setup.py#L182), [191](https://github.com/numpy/numpy/blob/master/setup.py#L191)) uses f-strings introduced in python 3.6, anyone using lower version of python would get a syntax error message. The [code checking if version>=3.6](https://github.com/numpy/numpy/blob/master/setup.py#L29) and producing an informative error message for the user would not be executed. Possible solutions include but are not limited to: 1. Putting the f-strings in try-catch block, e.g. ``` try: eval(\"raise ValueError(f'Submodule {p} missing')\") except SyntaxError: raise RuntimeError('Support for f-strings required') ``` 2. Removing f-strings and using \"traditional\" string formatting methods for backward compatibility AFAIK using `from __future__ import` would be troublesome here https://stackoverflow.com/questions/42097052/can-i-import-pythons-3-6s-formatted-string-literals-f-strings-into-older-3-x If a decision is made to address this non-critical issue and change `setup.py` in any way, I will be glad to submit a PR. ### Reproducing code example: e.g. `python setup.py build_ext -i` ### Error message: ``` File \"setup.py\", line 182 raise ValueError(f'Submodule {p} missing') ^ SyntaxError: invalid syntax ``` ### Numpy/Python version information: `1.16.3 3.5.2` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Bigtable: ConditionalRow not passing parameters to CheckAndMutateRowRequest Since `google-cloud-bigtable>=0.30.0`, the `commit()` function of `ConditionalRow` seems to be completely broken: - values for `true_mutations`, `false_mutations` and `predicate_filter / self._filter.to_pb()` exist in `ConditionalRow`, but are not passed to `data_client.check_and_mutate_row()` - the return value `resp` is a single `google.cloud.bigtable_v2.types.CheckAndMutateRowResponse`, which doesn't support indexing https://github.com/googleapis/google-cloud-python/blob/b34a859cc8915cb7e6b6ca6ec7cca40e203c5832/bigtable/google/cloud/bigtable/row.py#L521-L525 Both changes were part of the huge #5178 commit: https://github.com/googleapis/google-cloud-python/commit/86102c959c6852d6b02c2fe3ddeea946a003bee6#diff-0320c7c7abd68618413e8879c6269554R536 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Runtimeconfig: Update time fails to parse OS: Linux (Debian 4.9.65) Python: 3.5.3 / 2.7.13 Version: google-cloud-runtimeconfig==0.28.0, google-cloud==0.32.0 Steps to reproduce: 1. Using gcloud, set a runtimeconfig variable. 2. In Python, load that variable 3. Try to access its update_time property. ```pycon >>> from google.cloud import runtimeconfig >>> client = runtimeconfig.Client() >>> config = client.config('testconfig') >>> var = config.get_variable('foo') >>> var.update_time Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/redacted/lib/python3.5/site-packages/google/cloud/runtimeconfig/variable.py\", line 160, in update_time value = _rfc3339_to_datetime(value) File \"/redacted/lib/python3.5/site-packages/google/cloud/_helpers.py\", line 274, in _rfc3339_to_datetime dt_str, _RFC3339_MICROS).replace(tzinfo=UTC) File \"/usr/lib/python3.5/_strptime.py\", line 510, in _strptime_datetime tt, fraction = _strptime(data_string, format) File \"/usr/lib/python3.5/_strptime.py\", line 343, in _strptime (data_string, format)) ValueError: time data '2018-01-22T21:39:44.095040522Z' does not match format '%Y-%m-%dT%H:%M:%S.%fZ' >>> var._properties {'text': '43', 'updateTime': '2018-01-22T21:39:44.095040522Z'} ``` Observation: The `%f` format accepts microseconds, not fractions of arbitrary precision. That means six digits at most, but I see nine in the data. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: [feature request] Factory default for extension attributes ## Feature description As usual with Python, mutable defaults are a big no-no for extension attributes, since they are shared by all instances, which leads to subtle and ~~quick to anger~~ hard to root out bugs (see e.g. #2581). The documentation mentions that pitfall, but doesn't offer a convenient solution: if I want to keep a static list of interesting spans in my document in a `Doc._.interesting`, it is not clear where the getter and setter that I am supposed to use for this property should store the state. (From what I understand, it should probably be somewhere in `Doc.user_data`, but I have not found a lot of doc on that either) I propose a `factory` argument to `set_extension` that would be called the first time that the value for the corresponding extension property is retrieved for a given instance (as `collections.defaultdict` does), so one could just write ```python spacy.tokens.Doc.set_extension('interesting', factory=list) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qobj_to_circuits/disassemble doesn't work for conditionals <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: Master - **Python version**: any - **Operating system**: any ### What is the current behavior? When trying to run `disassemble()` (or `qobj_to_circuits()`) on a qobj that includes conditionals for instructions this isn't handled properly. This was listed as a todo in the code doing the conversion: https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/compiler/disassembler.py#L17 but it has yet to be handled. ### Steps to reproduce the problem Build a qobj with experiments that include a conditional and then run disassemble or qobj_to_circuits on it. ### What is the expected behavior? The conditional is reflected in the output circuit. ### Suggested solutions Add the missing conditional support. (Likely after #2147 merges) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson install and VisualStudio backend There is no `meson-private/install.dat` for VS backend. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [FlaxBert] Non-broadcastable attention mask in batched forward-pass ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: - Platform: Linux - Python version: 3.8 - JAX version: - jax==0.2.6 - jaxlib==0.1.57+cuda110 - flax==0.2.2 - PyTorch version (GPU?): n/a - Tensorflow version (GPU?): n/a - Using GPU in script?: **yes** (cuda 11.0) - Using distributed or parallel set-up in script?: **no** ### Who can help @mfuntowicz @avital @LysandreJik ## Information I ran the script from the recent Twitter [post](https://twitter.com/huggingface/status/1331255460033400834):  The only thing I changed was that I fed in multiple sentences: ```python from transformers import FlaxBertModel, BertTokenizerFast, TensorType tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased') model = FlaxBertModel.from_pretrained('bert-base-cased') # apply_fn = jax.jit(model.model.apply) sentences = [\"this is an example sentence\", \"this is another\", \"and a third one\"] encodings = tokenizer(sentences, return_tensors=TensorType.JAX, padding=True, truncation=True) tokens, pooled = model(**encodings) ``` > ValueError: Incompatible shapes for broadcasting: ((3, 12, 7, 7), (1, 1, 3, 7)) See full stack trace: https://pastebin.com/sPUSjGVi Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: tokenizer truncation_side is not set up with from_pretrained call ## Environment info - `transformers` version: 4.16.1 ### Who can help Library: - Tokenizers: @SaulLu - Pipelines: @Narsil ## Information Model I am using (Bert, XLNet ...): **GPT2Tokenizer** The problem arises when using: * [ ] the official example scripts: (give details below) * [x] my own modified scripts: (give details below) The tasks I am working on is: * [ ] an official GLUE/SQUaD task: (give the name) * [x] my own task or dataset: (give details below) ## To reproduce ``` tokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\", truncation_side=\"left\") print(tokenizer.truncation_side) ``` ``` right ``` ## Expected behavior ``` left ``` ## Possible solution I believe the problem is in the missing part at `tokenization_utils_base.py` (just like the one for the padding side at https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_utils_base.py#L1457-L1462) ``` # Truncation side is right by default and overridden in subclasses. If specified in the kwargs, it is changed. self.truncation_side = kwargs.pop(\"truncation_side\", self.truncation_side) assert self.truncation_side in [ \"right\", \"left\", ], f\"Truncation side should be selected between 'right' and 'left', current value: {self.truncation_side}\" ``` Feel free to add this solution if it is good enough without writing tests, as I don't have transformers dev environment ready for PR right now. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Traitlets: allow_none default value for trait types For a number of trait types the default value for `allow_none` is `True`, such as `Enum`, `Dict`, `List`, `Instance`. It probably makes sense for `Type`, but as explicit is often better than implicit, could be interesting to change this before traitlets are separated out. This would be a divergence with respect to the `traits` library though. (still I think that given the popularity of IPython, traitlets are much more used). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: dagster_databricks Automatically Set Dagster Cloud Environment Variables ### What's the use case? When submitting a job to databricks, it would be nice to automatically set environment variables that are not sensitive but are required for the dagster project code to load, in particular, environment variables normally set by Dagster Cloud automatically. ### Ideas of implementation Based off of: https://github.com/dagster-io/dagster/pull/8685/files It should be possible to check if Dagster Cloud env vars are set, and if they are, add them to this list dict that gets set in databricks, the equivalent of a user manually adding: ``` \"env_variables\": { \"DAGSTER_CLOUD_IS_BRANCH_DEPLOYMENT\": os.getenv(\"DAGSTER_CLOUD_IS_BRANCH_DEPLOYMENT\", \"\"), \"DAGSTER_CLOUD_DEPLOYMENT_NAME\": os.getenv(\"DAGSTER_CLOUD_DEPLOYMENT_NAME\", \"\") }, ``` ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qpy roundtrip for FourierChecking fails with TypeError: DiagonalGate.__init__() takes 2 positional arguments but 5 were given ### Environment - **Qiskit Terra version**: 0.24.1 - **Python version**: 3.10 - **Operating system**: NixOS 23.11 ### What is happening? This is likely because the named gate (`DiagonalGate`) is not explicitly supported in the gates in the following code branch: https://github.com/Qiskit/qiskit-terra/blob/e9f8b7c50968501e019d0cb426676ac606eb5a10/qiskit/qpy/binary_io/circuits.py#L282-L289 ### How can we reproduce the issue? ```python import io from qiskit import qpy import qiskit.circuit.library as qcl def encode(qc): with io.BytesIO() as f: qpy.dump(qc, f) # Rewind back to the beginning of the \"file\". f.seek(0) serialized = f.read() return serialized def decode(data): with io.BytesIO(data) as f: circuits = qpy.load(f) return circuits[0] # Works decode(encode(qcl.QFT(3))) # Doesn't work decode(encode(qcl.FourierChecking([1, -1, -1, -1], [1, 1, -1, -1]))) ``` ### What should happen? The error message should have said that the `DiagonalGate` is not supported when it is not covered by the if-else checks in the `_read_instruction`. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Draw barrier in `latex_drawer` ### What is the current behavior? Right now the barriers are not drawn with latex. We want them to be drawn for `barrier`, `noise`, `save`, `load`, and `snapshot` instructions at that depth. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: v1beta3 and emulator use The docs in this link do not make it clear on how to use the library against the local emulator, with out any creds needed. https://cloud.google.com/datastore/docs/datastore-api-tutorial The service object can be instantiated without creds for emulator use: c = datastore.Client(project='test', http=httplib2.Http()) The lib I assume requires the latest version of the emulator to work, it should be noted somewhere in the docs too, I did a \"gcloud components install gcd-emulator\" to get the latest version. Lastly, with all the above in place, the lib does not work with the emulator, it calls a url that the emulator does not recognise and therefore complains. I had to make this adjustment to have the lib and emulator working together: Change https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/datastore/connection.py line 49 from: API_URL_TEMPLATE = ('{api_base}/{api_version}/projects' to: API_URL_TEMPLATE = ('{api_base}/datastore/{api_version}/projects' With this change, the library and latest emulator worked together without creds, as expected. I am not sure if this is a general issue with the lib, or if I am using it incorrectly to need this, or if the emulator is the issue and it should be fixed there? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: AutoML Tables: Passing client_info produces a a TypeError #### Environment details 1. Linux. 2. python 3.7 3. Latest google-cloud-python master branch #### Steps to reproduce 1. Initializing the automl tables client with a client_info parameter throws a TypeError due to it being passed twice to the underlying clients. #### Code example client = automl_v1beta1.TablesClient(client_info=client_info) A more thorough example in this PR (where we have to make an exception of setting the ClientInfo due to the error): https://github.com/Kaggle/docker-python/pull/671/files. #### Stack trace ``` TypeError: type object got multiple values for keyword argument 'client_info'. ``` It should be a pretty easy fix, putting together the PR now :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [DO NOT MERGE] Websecurityscanner: order-of-enums only synth This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/cloud/websecurityscanner/artman_websecurityscanner_v1alpha.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:229601142daed005bf56fbaa21a02cf7aa0b261b57677d38306f8013e536de7a Status: Image is up to date for googleapis/artman:latest synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/websecurityscanner-v1alpha. synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Autocompletion with Init-Signatures of C extension classes I don't quite get the autocompletion to work with C extension classes. These classes have a Signature (at least since python 3.4 by utilizing `__text_signature__`) but it seems IPython cannot autocomplete the parameters in `__text_signature__`. For example: ``` >>> import pickle >>> import inspect >>> inspect.Signature.from_callable(pickle.Pickler) <Signature (file, protocol=None, fix_imports=True)> ``` Note that the signature is saved as `__text_signature__`-attribute on ``pickle.Pickle``. I would expect that after printing`pickle.Pickler(` and then hitting TAB it would show: ``` file= protocol= fix_imports= # other stuff ``` but it doesn't. Classes seem to be special in this regard - IPython is definitly able to get the parameters for functions and methods! It just doesn't work for classes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan remove --query removes binaries without exact match ```python def remove_query_test(self): test_server = TestServer(users={\"lasote\": \"password\"}) # exported users and passwords servers = {\"default\": test_server} client = TestClient(servers=servers, users={\"default\": [(\"lasote\", \"password\")]}) conanfile = \"\"\"from conans import ConanFile class Test(ConanFile): settings = \"os\" \"\"\" client.save({\"conanfile.py\": conanfile}) client.run(\"create . Test/0.1@lasote/testing -s os=Windows\") client.run(\"create . Test/0.1@lasote/testing -s os=Linux\") client.save({\"conanfile.py\": conanfile.replace(\"settings\", \"pass #\")}) client.run(\"create . Test2/0.1@lasote/testing\") client.run(\"upload * --all --confirm\") client.run(\"remove Test/0.1@lasote/testing -q=os=Windows -f -r=default\") client.run(\"search Test/0.1@lasote/testing -r=default\") self.assertNotIn(\"os: Windows\", client.out) self.assertIn(\"os: Linux\", client.out) # THIS REMOVAL IS BUGGY client.run(\"remove Test2/0.1@lasote/testing -q=os=Windows -f -r=default\") client.run(\"search Test2/0.1@lasote/testing -r=default\") self.assertIn(\"Package_ID: 5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9\", client.out) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: ❓ Summarization example : Why no shuffling ? # ❓ Questions & Help Usually, when loading using Dataloader, data is shuffled for the training set. But in the case of the summarization example, data is not shuffled for training set : https://github.com/huggingface/transformers/blob/1dc9b3c7847269961458c059ad8ad443b26bf60d/examples/summarization/bart/finetune.py#L105-L108 --- **Why data is not shuffled ?** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add TAP tests support It would be very useful if meson would support the TAP protocol for tests, that would make it easy to write tests that do not have to be split up into individual binaries. I could not find anything about that in the documentation, so I am quite sure this is not supported currently. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Trainer callback breaks old code https://github.com/huggingface/transformers/blob/ba4bbd92bcb55febbfa06aaa1551738388ec7eb0/src/transformers/trainer_callback.py#L438-L447 Currently it depends on the fact that evaluate() will first call `self.prediction_loop` https://github.com/huggingface/transformers/blob/ba4bbd92bcb55febbfa06aaa1551738388ec7eb0/src/transformers/trainer.py#L1181 which will then call `.callback_handler.on_prediction_step ` https://github.com/huggingface/transformers/blob/ba4bbd92bcb55febbfa06aaa1551738388ec7eb0/src/transformers/trainer.py#L1270 But in my old code (3.1.0), I subclass Trainer and overwrite evaluate(), without calling self.prediction_loop. And results in this error: ``` self.prediction_bar.close() AttributeError: 'NoneType' object has no attribute 'close' ``` I propose we add `on_predict_begin` and `on_predict_end`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [d] empty include directory when using include_directories('.') in meson.source_root() **Describe the bug** In my D project I need to always have the root source dir as an include-directory. Thus I did ``` project_dep = declare_dependency( include_directories: ['.'], ) ``` and use it like this: ``` bix_lib = library( 'bix', ['bix.d'], dependencies: [ project_dep] ) ``` But I get the following error using ldc: ``` ldc2 -I=ex/mod/libbx.so.p -I=ex/mod -I=../ex/mod -I= -I=.. -I=subprojects -I=../subprojects -enable-color -wi -g -d-debug -relocation-model=pic -makedeps=ex/libbx.so.p/bx.d.o.deps -of=ex/libbx.so.p/bx.d.o -c ../ex/bx.d Error: Expected argument to '-I' ``` **To Reproduce** Attached a tar ball reproducing the issue for me. [meson_issue.tar.gz](https://github.com/mesonbuild/meson/files/7153466/meson_issue.tar.gz) **Expected behavior** -I=. instead of -I= **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? plain native * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) linux (arch) * what Python version are you using e.g. 3.8.0 python 3.9.6 * what `meson --version` meson --version 0.58.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [Java/JAR] Cannot bundle resources files **Describe the bug** One cannot bundle resources files (images, audio, properties or other arbitrary files) in a JAR via Meson’s `jar()` function **To Reproduce** ```meson project('java-project', 'java', version : '0.1') jar('project', 'com.example.Main.java', 'com.example.icon.png') ``` **Expected behavior** Any resource file would be included in the JAR file as-is **system parameters** * Native build * CentOS 7 * Python 3.6.8 * Meson 0.55.1 * Ninja 1.10.2 Ping @tristan957 as asked :-) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Production image has only amazon and google providers installed When \"production\" image is prepared for, only amazon and google providers are installed from sources. **Apache Airflow version**: master **What you expected to happen**: All providers should be installed **How to reproduce it**: ``` ./breeze --production-image --python 3.6 ``` Then: ``` ./breeze --production-image --python 3.6 shell bash ``` then ``` ls -la ~/.local/lib/python3.6/site-packages/airflow/providers/ amazon google ``` UPDATE: They are not even installed: ``` . ./amazon ./amazon/aws ./amazon/aws/hooks ./amazon/aws/hooks/batch_waiters.json ./google ./google/cloud ./google/cloud/example_dags ./google/cloud/example_dags/example_bigquery_query.sql ./google/cloud/example_dags/example_cloud_build.yaml ./google/cloud/example_dags/example_spanner.sql ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Celery can't send error email when task has non-ascii arguments There is the issue with celery 3.1.18, python 3.4 and tasks with non-ascii string arguments. When task raises exception and CELERY_SEND_TASK_ERROR_EMAILS set to True, celery couldn't send mail because email.mime.MimeText instance raises UnicodeDecodeError('ascii', ...). Exception is raised [here](https://github.com/celery/celery/blob/dffb61c4d99f1ce5817be267104e9810e88391ee/celery/utils/mail.py#L56). Looks like Message constructor has charset argument with 'us-ascii' as default value, and it can't be changed without editing celery source code. When charset changed to 'utf-8', bug disappears. Example app: ``` python from celery import Celery app = Celery('app') app.conf.CELERY_SEND_TASK_ERROR_EMAILS = True app.conf.ADMINS = ( ('Admin', 'test@example.com'), ) @app.task def test(arg): raise Exception() test.delay('Щ') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: in SDA keys, only allow characters that can be included in definition names I.e. no slashes, etc. We already effectively do this, because we convert the keys to an op name. However, we should document it and raise a clearer error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Sampling issue of Qasm simulator at BasicAer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: the master branch - **Python version**: 3.7 - **Operating system**: macOS 10.14 ### What is the current behavior? Produce the correct measurement result ### Steps to reproduce the problem ```python from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister from qiskit import BasicAer, Aer, execute basicaer = BasicAer.get_backend('qasm_simulator') aer = Aer.get_backend('qasm_simulator') qr = QuantumRegister(2) cr = ClassicalRegister(1) qc = QuantumCircuit(qr, cr) qc.h(qr[0]) qc.x(qr[1]) qc.measure(qr[1], cr[0]) basicaer_result = execute(qc, backend=basicaer).result().get_counts() aer_result = execute(qc, backend=aer).result().get_counts() print(basicaer_result) print(aer_result) ``` ### What is the expected behavior? the results should be `{'1': 1024}` but BasicAer returns wrong results. ### Suggested solutions No idea but it is related to the PR #2735 since before this PR, basic aer works correctly. Furthermore, if all quantum registers are measured, the basic aer works okay. It seems that this issue only happened when only a part of quantum registers are measured. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Ability to disable log prefixes **Describe the solution you'd like** A flag like `--disable-log-prefix` to remove the log prefixes.  I have implemented my own log prefixes into the services I am running. Thus the log prefixes by docker compose are redundant. **Describe alternatives you've considered** For now I am using [this](https://stackoverflow.com/a/58467189/8586803) workaround, which works surprisingly good. ``` docker-compose up --no-color 2>&1 | sed 's/^[^ ]* *| //' ``` But it has one problem: `CTRL + C` will not stop the containers. (any ideas why?) **Additional context** I am not familiar with the docker compose source code, but it seems as if this is a relatively simple change around here: https://github.com/docker/compose/blob/9c5351cf27d10a7b8078496fb21a37929b6687cb/compose/cli/log_printer.py#L29 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow inheritance of QuantumRegister and ClassicalRegister Attempting to inherit from QuantumRegister or ClassicalRegister currently causes type errors in `instruction.py`'s constructor. There may be other areas that require updates to make this functionality viable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub: mistake in publisher client example It should have been `from google.cloud.pubsub_v1 import PublisherClient` in this line: https://github.com/googleapis/google-cloud-python/blob/23a3204770f68a56dba12d1a37058398773f3daf/pubsub/google/cloud/pubsub_v1/publisher/client.py#L156 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Expose load_state_dict strict=False ## 🚀 Feature In contrastive learning, we normally train a representation learning backbone then adding the classifier. Sometimes, I wish to play with different classifiers. It would be best to have ```strict=False``` exposed to make the model still load with a user's permission. ```python model = TransferLearningModel.load_from_checkpoint(ckpt_path, strict=False) ``` The implementation is intuitive but an extremely useful feature in my case. Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: text visualizer should not use transpiler(format='json') We are going to remove the option `format='json'` from the transpiler (see #1129). For that, we need to move the visualizers into the function `get_instractions` introduced in PR #1187. The function `_text_circuit_drawer` calls `transpile_dag(dag_circuit, basis_gates=basis, format='json')`. This needs to be removed in favor of `_utils.get_instructions(dag)`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: install.package_cache() broken with cache directory does not exist I just ran into this bug when building a package with `conda-build`. Before building the package, I cleaned out removed the cache directory `pkgs`. The trachback is as follows: ``` Traceback (most recent call last): File \"/home/ilan/minonda/bin/conda-build\", line 6, in <module> exec(compile(open(__file__).read(), __file__, 'exec')) File \"/home/ilan/conda-build/bin/conda-build\", line 5, in <module> sys.exit(main()) File \"/home/ilan/conda-build/conda_build/main_build.py\", line 140, in main args_func(args, p) File \"/home/ilan/conda-build/conda_build/main_build.py\", line 380, in args_func args.func(args, p) File \"/home/ilan/conda-build/conda_build/main_build.py\", line 367, in execute build.test(m) File \"/home/ilan/conda-build/conda_build/build.py\", line 613, in test rm_pkgs_cache(m.dist()) File \"/home/ilan/conda-build/conda_build/build.py\", line 386, in rm_pkgs_cache plan.execute_plan(rmplan) File \"/home/ilan/conda/conda/plan.py\", line 583, in execute_plan inst.execute_instructions(plan, index, verbose) File \"/home/ilan/conda/conda/instructions.py\", line 133, in execute_instructions cmd(state, arg) File \"/home/ilan/conda/conda/instructions.py\", line 65, in RM_FETCHED_CMD install.rm_fetched(arg) File \"/home/ilan/conda/conda/install.py\", line 749, in rm_fetched rec = package_cache().get(dist) File \"/home/ilan/conda/conda/install.py\", line 692, in package_cache for fn in os.listdir(pdir): OSError: [Errno 2] No such file or directory: '/home/ilan/minonda/pkgs' ``` The problem is that https://github.com/conda/conda/blob/master/conda/install.py#L692 assumes that the directory already exists, which might not be the case. CC @mcg1969 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: CI Linux usage is broken <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue. Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description <!--Describe the bug clearly and concisely. Include screenshots if possible--> The following error is emitted: ``` Error: Cannot find module '/home/runner/work/jupyterlab/jupyterlab/jupyterlab/examples/federated/core_package/package.json' ``` ## Root cause The error comes from https://github.com/jupyterlab/jupyterlab/blob/74405d37ad156d8bdc0e7c36f199abc1eb642c1f/jupyterlab/federated_labextensions.py#L215 The `ext_path` is not correct to resolve relative path `core_path` as it is defined relative to the command execution directory not the extension directory. I have no clue why it works before. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: The tools in qiskit/tools/apps/ need more testing The files under `qiskit/tools/apps/` are poorly covered by the current testsuite. (see #221) file | statements | missing | coverage -- | -- | -- | -- qiskit/tools/apps/fermion.py | 173 | 173 | 0% qiskit/tools/apps/optimization.py | 240 | 171 | 29% It would be great to have more tests to cover the methods and functions in these files. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: `ifelse` should behave like a ternary expression Currently, our conditional `ifelse` operator just sets dependencies in a particular way, but always returns `None`. It would feel much more natural if it returned a task object whose value at runtime behaved like a standard `x = condition ? if_true : if_false` expression Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Avoid needing to change the owner of staging files Use `shutil.copy` instead of `shutil.copy2` for the staging files because we still get permission bit setting without attempting to change the user, which can be problematic. We must also remove the `static/` directory since `shutil.copytree` also uses `copystat()`. cf https://docs.python.org/2/library/shutil.html#shutil.copy. cc @athornton Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: quantum_info.Kraus: Possible redundant documentation In the `Kraus` class of `quantum_info` module, the current [documentation](https://qiskit.org/documentation/stubs/qiskit.quantum_info.Kraus.html) is as follows: 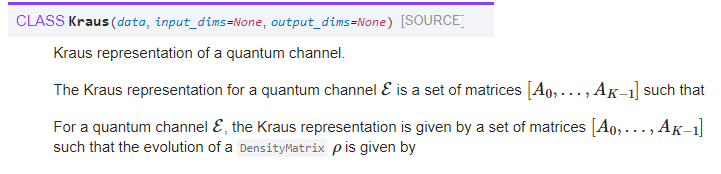 I believe the 2nd line, 'The Kraus representation for a quantum channel $\\mathcal{E}$ is a set of matrices $[A_0, ... A_{K-1}]$ such that' can be removed, as it does not convey much information, and the next line 'For a quantum channel...' conveys the required information quite completely. If removing the line is not acceptable, perhaps at the least the two lines can be combined (and the dangling 'such that' removed). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Scheduler should be supported in execute pipeline <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? It should be configurable to schedule your circuit into pulses during execute. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add an equiv method to the StabilizerState class ### What should we add? Add an `equiv` method to the `StabilizerState` class, that checks if the generating sets of two stabilizer states generate the same stabilizer group. This can be done as follows: The first step would be to check that each stabilizer from the first set commutes with each stabilizer from the second set. If no, the two sets give rise to different stabilizer states. If yes, compute the expected value of each stabilizer from the first set on the stabilizer state determined by the second set. The two stabilizer states coincide iff the expected value is +1 for each stabilizer. See also: https://github.com/Qiskit/qiskit-terra/pull/5907#discussion_r628484220 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: VS 2017 in combination with v140 toolset does not work any longer Hi @lasote, @memsharded and @jgsogo , at least since Conan 1.15 the combination Visual Studio 2017 and toolset v140 does not work any longer. But it worked in older versions (like 1.11.2) and sadly we need exactly this combination due to many, many, many ... existing v140 packages and VS2017 installations in our company. It can be easily fixed by changing conans/client/generators/cmake_common.py at lines 356-357 to the following: ``` # 1900-1919 = VS 15.0 (v140 and v141 toolsets) (CONAN_COMPILER_VERSION STREQUAL \"15\" AND NOT((MSVC_VERSION GREATER_EQUAL 1900) AND (MSVC_VERSION LESS 1920))) OR ``` Our used profile: ``` [build_requires] [settings] os=Windows arch=x86_64 compiler=Visual Studio compiler.version=15 compiler.toolset=v140 build_type=Release arch_build=x86_64 os_build=Windows [options] [env] ``` Thanks in advance. Best Aalmann Edit: compiler.version fixed Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Remove datastore.Dataset class The replacement will be handled by a string when dataset ID is explicitly needed (which will only be for power users). Some functionality will be moved to `key.Key` and the rest to the `connection` module as free functions. In order to make use easier, they will also have versions in `__init__` which can use a default / implicit connection. Steps to complete: - [x] Make `set_default_connection` similar to [`set_default_dataset`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/b79d8624950b3b205de20f527488dde7aa8c8cd8/gcloud/datastore/__init__.py#L61) (#478) - [x] Remove ~~`query()`,~~ `entity()`, and `transaction()` methods from `Dataset`, replace their use elsewhere. (#479) - [x] Move `Dataset.get_entity` to `Key` (will impact elsewhere, e.g. `Entity.reload`) (#480) - [x] Move ~~`save()` and `delete()` methods~~ `delete()` method from `Entity` to `Key` (#481) - [x] Move `allocate_ids()` method from `Dataset` to ~~`connection`~~ `__init__` module as free function (#482) - [x] Move `get_entities()` method from `Dataset` to ~~`connection`~~ `__init__` module as free function (#483) - [x] Fix ~~#484, #485, #486~~ - Lots to do to re-make `Entity`, `Query`, and `Transaction` to not depend on `Dataset` - [x] Remove all remnants of `Dataset` (e.g. `set_default_dataset`, `Entity._must_dataset`, and `_implicit_environ._DatastoreBase`) - [x] Update stale documentation **NOTE**: Don't close until `cyclic-import` in #480 is resolved. See https://docs.google.com/document/d/1xKw8Tz6lfN5uOcv0my4uUgFSeDoRzwCLho2UGlBpqDU/edit for more. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add C++2a standard GCC 8 was released a few days ago and added some useful C++2a features such as `std::endian`. I really want to migrate all my Conan packages to `-std=c++2a`. I think `2a` and `gnu2a` should be added to `cppstd` and then be renamed to `20` and `gnu20` after the publication. This would require support for aliases so packages' hashes won't be changed but we still have several years to develop this feature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Query.fetch() w/o limit returns different results than w/ large limit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Unify on- and off- schedule run pipelines Currently, `flow.run()` has two logic branches: - if a flow doesn't have a schedule, we create a flowrunner and call it's run() method. - if a flow does have a schedule, we call the `_run_on_schedule` method which does a number of additional logic. I would like to combine these into a single branch, because having two different pipelines leads to the potential for different behaviors depending on how you're running a flow (an issue that plagues Airflow). For example in #1429 I realized that tasks results are returned when running on schedule, but not returned when running off schedule. A solution would be to simply create a \"one-off\" schedule and call `_run_on_schedule()` no matter what, with the caveat that the schedule would need to be removed so it didn't overwrite the original flow schedule. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [examples] replicate the new `--log_level` feature to all trainer-based pytorch examples https://github.com/huggingface/transformers/pull/12276 introduced a new `--log_level` feature, which now allows users to set their desired log level via CLI or TrainingArguments. `run_translation.py` was used as a \"model\" for other examples. Now we need to replicate this to all other Trainer-based examples under examples/pytorch/, the 3 changes are 1. importing datasets 2. using `training_args.get_node_log_level()` and setting log_level in 3 modules 3. replacing `datasets` object name with `raw_datasets`, since otherwise we have a conflict with `datasets` the module. and the relevant diff is [here](https://github.com/huggingface/transformers/pull/12276/files?file-filters%5B%5D=.py#diff-09777f56cee1060a535a72ce99a6c96cdb7f330c8cc3f9dcca442b3f7768237a) and of course since we don't quite have extensive tests for examples, you can just test with a staple cmd from the corresponding README.md with `--log_level=error` and check that almost all logs are gone. This is open to all. And thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gnome.generate_gir(): need ability to set environment variables when calling g-ir-scanner I need to set some environment variables so that when g-ir-scanner calls gst_init() no GStreamer plugins from the install prefix (or anywhere really) get loaded, amongst other things. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: General: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working I'm getting this deprecation warning when running pytests on my app that uses Google Storage. #### Environment details Arch Linux Python 3.7.1 google-api-core==1.5.1 google-auth==1.5.1 google-cloud-core==0.28.1 google-cloud-storage==1.13.0 google-resumable-media==0.3.1 googleapis-common-protos==1.5.5 pytest==3.9.1 #### Steps to reproduce 1. Create file `test.py`. 2. Add line `from google.protobuf.pyext import _message` to it. 3. Run `pytest test.py` (to install pytest first `pip install pytest==3.9.1`) 4. Pytest will print the following: `test.py:1: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from google.protobuf.pyext import _message` In my tests this warning comes from: `google/protobuf/internal/api_implementation.py:154` Couldn't reproduce in shell, but pytest somehow catches this while running tests. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Request to add project_license() method to the meson object Hi, In the `meson` builtin object, we have `project_version()` but not `project_license()`, which would be handy for, say, auto-generation of manifest files or similar. It would be useful to add this. if I get some time, I'll add this myself, but I thought I'd mention it in any case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Check query's run status using property, not attribute Split out from #3001, where @amirshavit reported: > The run method checks if `self._job is not None`: to prevent a double invocation. It should however run that check with `self.job` instead (no underscore), as `self._job` is only set if you previously used `self.job`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Move Transaction tomb-stoning up to Batch and use commit_request directly See #1341 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Make test_tube optional **Is your feature request related to a problem? Please describe.** `test_tube` is only needed when using `TestTubeLogger`, thus it should not be an install requirement like `mlflow`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add tests for CLI project / no project logic As of `0.10.0` some of the CLI commands now make the project name specification optional due to the API differences between Core's server and Cloud. Tests should be added for this behavior ``` # when using Cloud prefect get flows -n my-flow -p my-project # when using the server prefect get flows -n my-flow ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Suggestion: adding a helper for darwin host Hi, I was wondering if a helper could be added in `tools` to detect if the `os` setting is targeting a darwin platform. Here is my use-case: ```python if self.settings.os in [\"Macos\", \"iOS\", \"watchOS\", \"tvOS\"]: # ... # What I have in mind if tools.darwin_platform(self.settings.os): # ... ``` This is not a big deal, but I'm too lazy to type it in every recipe :D Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Opt-in global full_version instead of semver for package_id Consider adding an opt-in mechanism using the conan.conf to change the global behavior of the package_id method to default all packages (only default, not override if they have fine adjustments) so we can change the default `semver` to default `full_version`, that would be the default in Conan 2.0 Probably we should consider the default being configurable => `full_package_id`, `full_version`... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add debug logs in to_dataframe / to_arrow When debugging performance issues with `to_dataframe` and `to_arrow`, it would be really helpful to know: * If `tabledata.list` or the BQ Storage API is being used and why. * If the BQ Storage API is used, the full session ID would be really useful, as it would help the backend team investigate problems from their end. Since these are debugging lines, they should be written at the debug logging level. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Support fairseq encoder-normalize-before in RoBERTa ### Feature request Support Fairseq's `--encoder-normalize-before` variation of transformer-based models, (particularly RoBERTa, not sure how many it applies to) that \"apply layernorm before each encoder block\". See: https://fairseq.readthedocs.io/en/v0.7.0/models.html ### Motivation There currently exist unofficial hacks of Huggingface's transformer model at https://github.com/princeton-nlp/dinkytrain which uses `--encoder-normalize-before` with fairseq and then applies a series of hacks to make it work with Huggingface's transformer library. See in particular [their custom version of RoBERTa](https://github.com/princeton-nlp/DinkyTrain/blob/main/huggingface/modeling_roberta_prelayernorm.py) which is a hack of Huggingface's RoBERTa implementation and depends on several internal components. The weights for these hacked models are currently distributed on https://huggingface.co/princeton-nlp but are not actually compatible with the official transformer library. (https://arxiv.org/abs/2202.08005 is the related paper). It would be great to implement feature parity for `--encoder-normalize-before` in Huggingface's transformer such that these hacks can be prevented. Note that I have not affiliation with fairseq, the https://github.com/princeton-nlp/DinkyTrain authors, nor the https://arxiv.org/abs/2202.08005 authors. ### Your contribution I'm happy to contribute a PR for RoBERTa that adds feature parity for the `--encoder-normalize-before` fairseq flag. Note that I have no affiliation with fairseq nor the https://github.com/princeton-nlp/DinkyTrain authors. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: documentation: no easy way to find version number I want to report errors, but cannot easyily tell which version of jax I am using. Apparently executing 'pip freeze' from the command line tells me jax==0.1.18 jaxlib==0.1.7 but perhaps there should be a __version__ attribute in the module? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add upgrade error message for unsupported repodata_version Going back to the 4.3.x branch, add an exception that gets raised if a field `repodata_version` exists with a value that's greater than 1. Add upgrade error message for unsupported repodata_version Going back to the 4.3.x branch, add an exception that gets raised if a field `repodata_version` exists with a value that's greater than 1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: FakeBackendV2 runs noise-less simulation if not touching `target` in advance ### Environment - **Qiskit Terra version**: main branch - **Python version**: 3.8 - **Operating system**: Mac ### What is happening? `FakeBackendV2.run` invokes noise-less simulation if it is called before touching `target` (more precisely, if it is called before the internal `_target` object is populated). ### How can we reproduce the issue? Run the following code. ``` from qiskit.circuit import QuantumCircuit from qiskit.providers.fake_provider.backends import FakeManilaV2 circ = QuantumCircuit(2, 2) circ.cx(0, 1) circ.measure([0, 1], [0, 1]) result = FakeManilaV2().run(circ).result() counts = result.get_counts() print(counts) # -> {'00': 1024} (noise-less result) ``` ### What should happen? Noisy simulation should be run if `qiskit_aer` is installed (as like FakeBackend V1). ### Any suggestions? [This line](https://github.com/Qiskit/qiskit-terra/blob/4a857f61146fb185878abd8634524941d71f1f6b/qiskit/providers/fake_provider/fake_backend.py#L124) should be replaced with `if self.target:` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Transparent background for inline plots in IPython notebook Is there any way of setting transparent background for inline plots in IPython notebook? Currently it seems to be always white, which in my opinion doesn't look good with customized notebook backgrounds. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: why does conan detect gcc 1 ? This is running in a docker linux container, clang 6 is installed. gcc is not. ```bash `[openssl] $ sh -c \"conan create -s build_type=Debug -s compiler=clang -s compiler.libcxx=libstdc++11 -s compiler.version=6.0 . turboit/openssl \" OpenSSL/1.0.2o@turboit/openssl: Exporting package recipe Linter warnings WARN: Linter. Line 101: Anomalous backslash in string: '\\$'. String constant might be missing an r prefix. WARN: Linter. Line 101: Anomalous backslash in string: '\\$'. String constant might be missing an r prefix. WARN: Linter. Line 101: Anomalous backslash in string: '\\$'. String constant might be missing an r prefix. WARN: Linter. Line 101: Anomalous backslash in string: '\\$'. String constant might be missing an r prefix. WARN: Linter. Line 102: Anomalous backslash in string: '\\$'. String constant might be missing an r prefix. WARN: Linter. Line 102: Anomalous backslash in string: '\\$'. String constant might be missing an r prefix. OpenSSL/1.0.2o@turboit/openssl: A new conanfile.py version was exported OpenSSL/1.0.2o@turboit/openssl: Folder: /root/workspace/conan/openssl@tmp/conan.tmp6052754136315568067/.conan/data/OpenSSL/1.0.2o/turboit/openssl/export Auto detecting your dev setup to initialize the default profile (/root/workspace/conan/openssl@tmp/conan.tmp6052754136315568067/.conan/profiles/default) Found gcc 1 Found clang 6.0 Default settings os=Linux os_build=Linux arch=x86_64 arch_build=x86_64 compiler=gcc compiler.version=1 compiler.libcxx=libstdc++ build_type=Release *** You can change them in /root/workspace/conan/openssl@tmp/conan.tmp6052754136315568067/.conan/profiles/default *** *** Or override with -s compiler='other' -s ...s*** ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature+bug] conan.tools.gnu.autotools.Autotools can only configure in root source folder Some times, configure scripts can be found in subdirectories. Right now, `ConanFile.source_folder` is hard coded at https://github.com/conan-io/conan/blob/916cb10b99ed92d319cd0719462708ee0501ecd4/conan/tools/gnu/autotools.py#L25 It would be VERY useful to be able to change this. ### Environment Details (include every applicable attribute) * Operating System+version: all * Compiler+version: all * Conan version: 1.39.0 * Python version: 3.9.6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Feature: Dict traitlet klass attribute for values Just like `List`, `Dict` traitlet type could have an optional `klass` attribute, that would be a traitlet instance enforcing validation of values of the dict. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Compatibility check for extensions not working <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description It seems that the compatibility check for versions is not working, when it at least should give a warning. ## Reproduce <!--Describe step-by-step instructions to reproduce the behavior--> ``` conda create -n jlabversion notebook nodejs conda activate jlabversion pip install --pre jupyterlab==2.0.0a0 ``` Now try installing the widgets extension. ``` jupyter labextension install @jupyter-widgets/jupyterlab-manager ``` I think because of the yarn resolutions, it no longer fails to install. This is good (in that we can test the widgets extension in an alpha version easily) and bad (there should be at least *some* warning that we are installing into a jlab where the versions conflict with what is requested). <!--Describe how you diagnosed the issue. See the guidelines at https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Expected behavior I think the version compatibility check should at least warn if we are installing into a jlab prerelease where the eventual non-prerelease would conflict, and it should error out and not let you install the incompatible extension if jlab is not a prerelease version. In this case, I would expect a warning that the extension is not compatible with the eventual release, but we are letting you install anyway, and I would expect installing into 2.0 final release would fail. ## Context <!--Complete the following for context, and add any other relevant context--> - Operating System and version: macOS 10.14.6 - Browser and version: N/A - JupyterLab version: 2.0.0a0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Don't include upstream_failed in the 'active task instances' test in the scheduler **Apache Airflow version**: 2.0.0a1 **What happened**: On my dev environment I have a lot of DAG runs with failed tasks, where the *downstream* task instances then have been set to `upstream_failed`. The scheduler is now refusing to schedule more instances for such DAGs. The scheduler looks for such task instances that are not in the `State.finished` set: https://github.com/apache/airflow/blob/db3fe0926bb75008311eed804052c90bfa912424/airflow/jobs/scheduler_job.py#L1482-L1488 However, `State.finished` is currently not a proper inverse of *running* states, it only includes success, failed, and skipped: https://github.com/apache/airflow/blob/db3fe0926bb75008311eed804052c90bfa912424/airflow/utils/state.py#L110-L114 What is missing is the task instance `upstream_failed` state, so currently my log is being filled (very rapidly) with: ``` [2020-10-18 13:22:18,503] {{scheduler_job.py:1658}} INFO - DAG test_dag already has 26 active runs, not queuing any more tasks ``` Those 26 'active runs' are simply dag runs that failed and have 'upstream_failed' task instances. Either `upstream_failed` should be added to `State.finished`, or the Scheduler task instance test should explicitly take that state into account. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Display relative time in event logs **User reported in slack:** > Just want to suggest that it would be a nice feature if the user could switch from timestamp to relative time in structured event logs in run view, so here in the screenshot below first event time would be 00:00:00.000 and other will be related to it. It would simplify estimating time delta between some events > often look to the timestamp to check where are slow parts of a job (relative time use case) and sometimes when some event occurs to match some other events in external services (timestamp use case) so timestamp on hover is looking more preferable option for me  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Remove build.{,cross_}compilers https://github.com/mesonbuild/meson/pull/4755 made those fields alias `coredata`'s. But that complicates copying logic in an ad-hoc way. I don't think the complexity is worth the shorthand; it would be better to just remove those fields, and the copying special case, from `build` and use `build.environment.coredata.{,cross_}compilers` everywhere. Not sure if we have any \"new contributor\" or \"easy\" tag, but this is a straightforward refactor, albeit one that will take a few test runs and greps to catch everything. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Import connections/variables from a file Hello, We have a new local file system secret backend that allows us to load connections and variables from files. We support 3 file formats: YAML, JSON, ENV. https://airflow.readthedocs.io/en/latest/howto/use-alternative-secrets-backend.html#local-filesystem-secrets-backend https://github.com/apache/airflow/blob/master/airflow/secrets/local_filesystem.py I think we can use the same code to create new commands for the CLI that allow us o import connections or variables. Best regards, Kamil Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Fig does not exit if container stops before attaching When running fig up, if a container stops before attaching it seems like Fig will only attach to the containers that are left running. The output from the stopped container is also not displayed. ``` $ cat > fig.yml web: build: ubuntu command: echo hello world db: image: postgres:9.1 $ fig up Creating example_web_1... Creating example_db_1... Attaching to example_db_1 db_1 | The files belonging to this database system will be owned by user \"postgres\". db_1 | This user must also own the server process. ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Addsibling script is broken in master Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Implement Topic.subscription factory See #910 I tried to implement in 1f80e368d45da5036e4f753d25f48a47fd758160 but was not able to make the `pylint` god happy about the cyclic import. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: storemagic needs to use self.shell As reported [on the mailing list](http://mail.scipy.org/pipermail/ipython-user/2012-July/010551.html) ``` AttributeError Traceback (most recent call last) <ipython-input-3-6795157a19c8> in <module>() ----> 1 get_ipython().magic(u'store') C:\\Python26\\ArcGIS10.0\\lib\\site-packages\\IPython\\core\\interactiveshell.pyc in magic(self, arg_s) 2159 magic_name, _, magic_arg_s = arg_s.partition(' ') 2160 magic_name = magic_name.lstrip(prefilter.ESC_MAGIC) -> 2161 return self.run_line_magic(magic_name, magic_arg_s) 2162 2163 #------------------------------------------------------------------------- C:\\Python26\\ArcGIS10.0\\lib\\site-packages\\IPython\\core\\interactiveshell.pyc in run_line_magic(self, magic_name, line) 2085 args.append(sys._getframe(stack_depth).f_locals) 2086 with self.builtin_trap: -> 2087 result = fn(*args) 2088 return result 2089 C:\\Python26\\ArcGIS10.0\\lib\\site-packages\\IPython\\extensions\\storemagic.pyc in store(self, parameter_s) C:\\Python26\\ArcGIS10.0\\lib\\site-packages\\IPython\\core\\magic.pyc in <lambda>(f, *a, **k) 189 # but it's overkill for just that one bit of state. 190 def magic_deco(arg): --> 191 call = lambda f, *a, **k: f(*a, **k) 192 193 if callable(arg): C:\\Python26\\ArcGIS10.0\\lib\\site-packages\\IPython\\extensions\\storemagic.pyc in store(self, parameter_s) 141 # run without arguments -> list variables & values 142 elif not args: --> 143 vars = self.db.keys('autorestore/*') 144 vars.sort( 145 if vars: AttributeError: 'StoreMagics' object has no attribute 'db' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Use callable in utils.functional.head_from_fun After the discussion in #3952, we should investigate whether an improvement can be applied using the builtin `callable` instead of `hasattr(fun, '__call__')`. https://docs.python.org/2/library/functions.html#callable Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Use better naming conventions for deployed tasks/jobs ## Current behavior e.g. the Fargate agent creates tasks called `prefect-task` and the FargateTaskEnvironment created tasks called `prefect-task`. These should be better named ## Proposed behavior Come up with better names for the intermediate tasks/jobs and those which actually run the flow ## Example N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Search query `compiler.libcxx` seems broken When adding `compiler.libcxx=libstdc++` to my search query it never matches any packages: ``` tru@xps ~/Code/Plex/plex-conan$ conan search -r plex zlib/1.2.8@plex/stable -q \"os=Linux\" Existing packages for recipe zlib/1.2.8@plex/stable: Package_ID: 2f48fd86f2c789d46ce8ba025775628e47b36354 [options] shared: False [settings] arch: x86_64 build_type: Release compiler: gcc compiler.libcxx: libstdc++11 compiler.version: 6.2 os: Linux [requires] plexconantool/1.0@plex/stable:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 outdated from recipe: False Package_ID: 60c8d7f7b9f3a84a70cc433b2769f5324f190d5f [options] shared: False [settings] arch: x86_64 build_type: Release compiler: gcc compiler.libcxx: libstdc++ compiler.version: 6.2 os: Linux [requires] plexconantool/1.0@plex/stable:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 outdated from recipe: False Package_ID: 74110c4f5bcaa8e2e9536ddbb6057226e2c675af [options] shared: False [settings] arch: x86_64 build_type: Release compiler: gcc compiler.libcxx: libstdc++ compiler.version: 5.4 os: Linux [requires] plexconantool/1.0@plex/stable:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 outdated from recipe: False ``` ``` tru@xps ~/Code/Plex/plex-conan$ conan search -r plex zlib/1.2.8@plex/stable -q \"compiler.libcxx=libstdc++11\" There are no packages for reference 'zlib/1.2.8@plex/stable' matching the query 'compiler.libcxx=libstdc++11' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Unable to fig build a github repo / works with docker build Using `docker build` I can pull and build an image directly from Github, for example: `docker build -t java https://github.com/StrictlyBusiness/docker-java8.git` When I try to do the same using `fig build` and the following `fig.yml`: ``` webapp: build: https://github.com/StrictlyBusiness/docker-java8.git ``` it shows `Building webapp...` then after ~40 seconds, it shows just a single closing bracket `)`. For example: ``` $ fig build Building webapp... ) ``` I haven't found a way to get any more details on what's happening behind the scenes in fig to know why it's failing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qiskit.pulse module and underlying functionality needs documentation. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Implement `np.select` It appears that JAX has not implemented `np.select`. One can work around this by using `lax.select`, but it doesn't implement numpy's broadcasting semantics, so it's not quite as nice. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Dead link to optuna.create_study under hyperparamter_search in Trainer I noticed the hyperlink to the documentation of optuna's create_study under ```kwargs``` in the ```hyperparameter_search``` method of Trainer is outdated. https://huggingface.co/transformers/main_classes/trainer.html ### Who can help Documentation: @sgugger New URL (I'm guessing): https://optuna.readthedocs.io/en/stable/reference/generated/optuna.study.create_study.html Old (currently used): https://optuna.readthedocs.io/en/stable/reference/alias_generated/optuna.create_study.html#optuna.create_study Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: default network I'm not sure I'm reading correctly, but it seems like compose is choosing `bridge` by default as default network driver : https://github.com/docker/compose/blob/master/compose/project.py#L86 We should let the daemon decide instead, same as this PR https://github.com/docker/docker/pull/17504 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Left over U1 gates at optimization level 2 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? ```python import numpy as np from qiskit import * qc = QuantumCircuit(3) qc.h(0) qc.h(1) qc.cp(np.pi/8,0,1) qc.cp(np.pi/4,0,2) trans_qc = transpile(qc, basis_gates=['id', 'rz', 'sx', 'x', 'cx'], optimization_level=2) trans_qc.draw() ``` gives ``` global phase: -26.4090132442392 ┌─────────┐┌────┐┌────────────┐ » q_0: ┤ RZ(π/2) ├┤ √X ├┤ U1(11π/16) ├──■──────────────────■────────────────■──» ├─────────┤├────┤└┬─────────┬─┘┌─┴─┐┌────────────┐┌─┴─┐┌──────────┐ │ » q_1: ┤ RZ(π/2) ├┤ √X ├─┤ RZ(π/2) ├──┤ X ├┤ RZ(6.0868) ├┤ X ├┤ RZ(π/16) ├──┼──» └─────────┘└────┘ └─────────┘ └───┘└────────────┘└───┘└──────────┘┌─┴─┐» q_2: ───────────────────────────────────────────────────────────────────┤ X ├» └───┘» « «q_0: ───────────────■───────────── « │ «q_1: ───────────────┼───────────── « ┌───────────┐┌─┴─┐┌─────────┐ «q_2: ┤ RZ(15π/8) ├┤ X ├┤ RZ(π/8) ├ « └───────────┘└───┘└─────────┘ ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: f2py fails to generate Fortran modules on Numpy 1.16.0 <!-- Please describe the issue in detail here, and fill in the fields below --> On Numpy 1.16.0, `f2py` fails to generate Fortran modules: ``` error: f2py target file '/tmp/tmpnke02j8i/src.linux-x86_64-3.6/test_f2py.c' not generated ``` Tested on Ubuntu 1.16 and macOS 1.14.2 both with Python 3.6. This appears to be a new bug as there are no issue with Numpy 1.15.4 or lower. ### Reproducing code example: Create `test_f2py.f90` and `test_f2py.py` and add the following lines: - `test_f2py.f90` ``` program test_f2py end program test_f2py ``` - `test_f2py.py` ``` import numpy.f2py as f2py with open('test_f2py.f90', 'rb') as fid: source = fid.read() f2py.compile(source , modulename='test_f2py', extension='.f90') ``` Run `test_f2py.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: apply_operation_back API in dag should change to be consistent with add_qreg and add_creg Recently, the API for `DAGCircuit.add_qreg` and `DAGCircuit.add_creg` changed to be called with an object instead of a tuple (see #1189). `apply_operation_back` should also change in the same direction to be consistent. DAG apply_operation_front has bugs <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Applying gates to the front of the dag is done with `dag.apply_operation_dag()`. However it currently does not produce the expected result. This function is not used anywhere now, only `apply_operation_back()` is used, which works fine. But this function should be fixed nonetheless. ### Steps to reproduce the problem If I create this dag:  Then do this: ``` dag.apply_operation_front(Reset(qubit0)) dag.apply_operation_front(Reset(qubit1)) ``` I get this:  ### What is the expected behavior? The \"op\" nodes (blue) should occur between the \"in\" nodes (green) and the \"out\" nodes (red) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add AIX to default_settings_yml Add AIX to os in default settings.yml. Add AIX to default_settings_yml Add AIX to os in default settings.yml. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC The docstring of numpy.equal is misleading The [docstring of numpy.equal](https://www.numpy.org/devdocs/reference/generated/numpy.equal.html#numpy-equal) says that the input arrays should be of the same shape. I think this is wrong as broadcasting will be used and no error is returned if you use two input arrays with different shapes. Besides the second example does not compare two arrays. ```python >>> np.equal(1, np.ones(1)) array([ True]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: HfArgumentParser support yaml parser ### Feature request HfArgumentParser now supports for parsing dict and json files, will it be possible to support for parsing the widely used yaml files? ### Motivation I think using yaml is a good way to record arguments. ### Your contribution Not yet. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Modify param printing to show top level modules only Add a model summary option that just shows the number of parameters for the top level modules. - Set pd.options.display.float_format = ’{:,}’.for- mat so it uses comma separators. - Also summarize the number of parameters like 1,000,234 to 1M. - use 1k, 1M, 1B, 1T, etc... Suggested by @adefazio Specifically, change: ```python Trainer(print_weights_summary=True) ``` To: ```python # default Trainer(weights_summary='full') # second option Trainer(weights_summary='top') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Trace: docs have bad url for \"Library Documentation\" https://googlecloudplatform.github.io/google-cloud-python/latest/trace/starting.html is linked to from the root of the latest trace docs. This page doesn't seem to exist. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Build errors are scary  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Make docker server fungible ## Use Case I'd like to be able to keep data saved in the docker postgres database across docker restarts. At the moment, a persistent docker volume is not created on the host and any data like ETL registrations and previous runs is lost when docker restarts. ## Solution Either always create a docker volume in the docker-compose.yml, or add an option in the cli to create a docker volume. ## Alternatives I've considered maybe a snapshot mechanism from within the prefect service but adding the docker volume seems like the easiest approach. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [ux] [bug] Improve error raised when 'settings.yml' cannot be parsed If the file `settings.yml` is invalid, Conan raises an ugly error with all the traceback. --- How to reproduce: * Edit `settings.yml` and make it an invalid YAML * Run something like `conan create ....`: ``` ⇒ conan create dep1 Traceback (most recent call last): File \"/Users/jgsogo/dev/conan/conan/conans/client/command.py\", line 1911, in run method(args[0][1:]) File \"/Users/jgsogo/dev/conan/conan/conans/client/command.py\", line 355, in create lockfile=args.lockfile) .... lots of traceback ... yaml.scanner.ScannerError: while scanning a simple key in \"<unicode string>\", line 14, column 1: os dasf:ffs ^ could not find expected ':' in \"<unicode string>\", line 15, column 12: Windows: ^ ERROR: while scanning a simple key in \"<unicode string>\", line 14, column 1: os dasf:ffs ^ could not find expected ':' in \"<unicode string>\", line 15, column 12: Windows: ^ ``` --- I would expect something easier like: `File 'settings.yml' has invalid YAML format/ cannot be parsed / error reading....` and, if possible, add the information with the line and column. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: script magic error message loop this script magic worked in 0.13.2: ``` %%script python /tmp/test.py ``` now it gives this error: ``` %%script (with double %) expects code beneath it. Did you mean %script ``` if I use that I get: ``` Line magic function %script not found, ... did you mean %%script? ``` what I'm doing is probably wrong (I guess I should use !python file.py) but %%script should not recommend %script if that does not exist. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Issue with pl.Trainer.from_argparse_args(...) <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug <!-- A clear and concise description of what the bug is. --> ### To Reproduce Steps to reproduce the behavior: 1. Use `parser = pl.Trainer.add_argparse_args(parser)` 2. Run `python main.py --overfit_batches 1` 3. The training runs over the whole dataset instead of running on a single batch <!-- If you have a code sample, error messages, stack traces, please provide it here as well -->  #### Code sample <!-- Ideally attach a minimal code sample to reproduce the decried issue. Minimal means having the shortest code but still preserving the bug. --> ### Expected behavior Only one batch should have run. <!-- A clear and concise description of what you expected to happen. --> ### Environment * CUDA: - GPU: - Tesla P100-PCIE-16GB - available: True - version: 10.1 * Packages: - numpy: 1.18.5 - pyTorch_debug: False - pyTorch_version: 1.6.0+cu101 - pytorch-lightning: 0.8.5 - tensorboard: 2.3.0 - tqdm: 4.41.1 * System: - OS: Linux - architecture: - 64bit - - processor: x86_64 - python: 3.6.9 - version: #1 SMP Thu Jul 23 08:00:38 PDT 2020 ### Additional context <!-- Add any other context about the problem here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Inconsistency in how compose handles empty environment variables If you want to use the value of an environment variable that is available in the host you can: ``` bash $ HOST_ENV=value docker run -e HOST_ENV ubuntu:14.04 env PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=acb280b6edd9 HOST_ENV=value HOME=/root ``` But, if the variable is not defined in the host, then it also doesn't get created in the container: ``` bash $ docker run -e HOST_ENV ubuntu:14.04 env PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=29a464f43ecb HOME=/root ``` But, given the following `docker-compose.yml`: ``` yaml banana: image: ubuntu:14.04 command: env environment: HOST_ENV: ``` We get an empty variable: ``` bash $ docker-compose run banana PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=9841adaf229b TERM=xterm HOST_ENV= HOME=/root ``` Should this be considered a bug? I would expect the same behavior from both tools. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Specify that exit code -9 is due to RAM Related to https://github.com/apache/airflow/issues/9655 It would be nice to add a message when you get this error with some info, like 'This probably is because a lack of RAM' or something like that. I have found the code where the -9 is assigned but have no idea how to add a logging message. self.process = None if self._rc is None: # Something else reaped it before we had a chance, so let's just \"guess\" at an error code. self._rc = -9 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: tools.environment_append raises if tries to unset variable which was never set after #4224, I may use the following code, for instance, to ensure variable is not set: ``` with environment_append({'CONAN_BASH_PATH': None}): pass ``` however, it raises if `CONAN_BASH_PATH` is not set (prior to the environment_append invocation): ``` Traceback (most recent call last): File \"C:\\bincrafters\\conan\\conans\\test\\unittests\\client\\tools\\os_info\\osinfo_test.py\", line 39, in test_windows with environment_append(new_env): File \"c:\\users\\sse4\\appdata\\local\\programs\\python\\python36\\lib\\contextlib.py\", line 81, in __enter__ return next(self.gen) File \"C:\\bincrafters\\conan\\conans\\client\\tools\\env.py\", line 57, in environment_append os.environ.pop(var) File \"c:\\users\\sse4\\appdata\\local\\programs\\python\\python36\\lib\\_collections_abc.py\", line 795, in pop value = self[key] File \"c:\\users\\sse4\\appdata\\local\\programs\\python\\python36\\lib\\os.py\", line 669, in __getitem__ raise KeyError(key) from None KeyError: 'CONAN_BASH_PATH' ``` I would expect `tools.environment_append` to be no op in such case, otherwise, it requires additional logic to workaround this behavior. To help us debug your issue please explain: - [ ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [ ] I've specified the Conan version, operating system version and any tool that can be relevant. - [ ] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan prioritizes indirect dependency over direct dependency I'm having the following component tree: * LibConsumer uses LibCore/1.0.0+abc@user/channel * MyComp uses LibConsumer and LibCore/1.0.0+xyz@user/channel conanfile.py in MyComp: ``` ... def requirements(self): self.requires( \"LibConsumer/1.0.0@user/channel\") #indirectly uses LibCore/1.0.0+abc@user/channel self.requires( \"LibCore/1.0.0+xyz@user/channel\") ... ``` When running a `conan install` on MyComp Conan resolves LibCore to `LibCore/1.0.0+abc@user/channel`. This is probably due to LibConsumer being first in the list of requires and the SemVer of both LibCore packages not being different. When I swap the requires-statement to the following Conan resolves LibCore to `LibCore/1.0.0+xyz@user/channel`: ``` ... def requirements(self): self.requires( \"LibCore/1.0.0+xyz@user/channel\") self.requires( \"LibConsumer/1.0.0@user/channel\") ... ``` I would have expected Conan to always prefer the direct dependencies over the indirect dependencies, thus always resolving to `LibCore/1.0.0+xyz@user/channel` because it has explicitly been named. I know that there isn't a difference between from a SemVer viewpoint, but there could be reasons why someone put the one over the other into the conanfile. Is there a way to enforce using the direct deps over the indirect ones? Should this be changed by default? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: DAGCircuit Documentation types outdated <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information The documentation of DAGCircuit still references tuples instead of the QuantumRegisters as input type for wires and qargs. This does not work any more. - **Qiskit Terra version**: 0.8.2 - **Python version**: 3.7.4 - **Operating system**: macOS 10.14 ### What is the current behavior? An excerpt from the current documentation: ``` def apply_operation_back(self, op, qargs=None, cargs=None, condition=None): \"\"\"Apply an operation to the output of the circuit. Args: op (Instruction): the operation associated with the DAG node qargs (list[tuple]): qubits that op will be applied to cargs (list[tuple]): cbits that op will be applied to condition (tuple or None): optional condition (ClassicalRegister, int) Returns: DAGNode: the current max node Raises: DAGCircuitError: if a leaf node is connected to multiple outputs \"\"\" ``` which lists tuples as expected type. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: what are the restrictions for initial_layout? Getting deeper in https://github.com/Qiskit/qiskit-terra/issues/4757 a conversation about \"valid\" `initial_layout`s popped up. There is a need to answer two questions: - What are the restrictions to set `initial_layout`? - Which component should validate `initial_layout`? The example can be is the following, where `initial_layout` is *bigger* than the circuit: ```python from qiskit import QuantumCircuit, transpile from qiskit.test.mock import FakeTenerife circuit = QuantumCircuit(3) circuit.h(1) transpiled = transpile(circuit, backend=FakeTenerife(), initial_layout=list(range(5))) ``` Should this be accepted? If yes, why does layout (wrongly) [validate the size of the layout](https://github.com/Qiskit/qiskit-terra/blob/10ac1ecd2aa9b7a25e9735ff30339650d0e9b040/qiskit/transpiler/layout.py#L291) in the `from_intlist` static method? If no, why does [`Layout` accept physical qubits pointing to `None` ](https://github.com/Qiskit/qiskit-terra/blob/10ac1ecd2aa9b7a25e9735ff30339650d0e9b040/test/python/transpiler/test_layout.py#L341)? The intermediate solution is allow any `Layout` and `transpile` should do the check before creating the layout. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add Video Vision Transformer # 🌟 New model addition ## Model description The ViViT is a transformer based model similar to Vision Transformer but operating on videos. In their paper, the authors present 4 types of possible architecture, and 2 are considered successful (unfactorised and factorised encoder models). Paper available at https://arxiv.org/abs/2103.15691. The original research uses flax, and mentions usage of weights from large pretrained image models (ViT). I currently have an implementation of model 1, analogous to existing ViTModel. I have also written a flax-to-pytorch weights conversion (to use weights from the original repo) and I have written the adaptation of ViT-based weights to ViViT weights (based on the methodology in the paper). ## Open source status * [ ] the model implementation is available: Original implementation in Scenic (flax) https://github.com/google-research/scenic/tree/main/scenic/projects/vivit * [ ] the model weights are available: Flax checkpoints and TF SavedModel present here https://github.com/google-research/scenic/blob/main/scenic/projects/vivit/README.md * [ ] who are the authors: Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid @MostafaDehghani @anuragarnab Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython.utils.columnize sometime wrong... ``` python In [1]: import IPython.utils.text as ut ...: len(ut.columnize(['x'*40,'x'*40],displaywidth=80).split('\\n')[0]) Out[1]: 82 # should be < 80 ``` two 40 letters words separated by 2 char could not enter on a 80 char line. should be 2 times 40(+separator size maybe) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Pipeline image-to-text task and Bitsandbytes error ### System Info Python 3.10.6 Transformers 4.30.0 Bitsandbytes 0.39.1 Windows / Linux ### Who can help? @nar ### Information - [X] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction Using an 4 or 8bit quantised model such as: https://huggingface.co/Mediocreatmybest/blip2-opt-2.7b_8bit ### Expected behavior The Pipeline image processor to detect the model is running with a 4 or 8bit model with bitsandbytes. I apologise if this should be a feature request or if it’s a bug, I couldn’t find any examples of what I was trying to do. When running through the pipeline examples from the hugging face website, if I try using an 8bit model, the model seems to be detected correctly and casts it to 8bit, but the Processor doesn’t seem to follow suit and runs at its default, throwing an error that they both should be set at the same floating point. I’ve uploaded a few models set at 8bit to save on size and memory, as BLIP2 is pretty heavy, using it on consumer devices is oviously challenging. The models I’ve uploaded to HuggingFace are: Mediocreatmybest/blip2-opt-2.7b_8bit Mediocreatmybest/blip2-opt-6.7b_8bit Mediocreatmybest/blip2-flan-t5-xxl_8bit I can get them working with regular methods, but as I’m a beginner it’s obviously challenging. Thanks again for all the great work! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: How should environments be loaded in Cloud? Currently, environments are loaded via marshmallow deserialization here: https://github.com/PrefectHQ/prefect/blob/master/src/prefect/cli/execute.py#L66-L67 This works great, except that it prevents users from implementing custom execution environments. Because this CLI typically runs inside a docker container containing the Flow bytecode, we could load that, etc. but then we're taking over the responsibilities of `environment.execute()`, which IMO means we have a leaky abstraction somewhere. Our ideal solution to this problem should support: - custom user environments - the (future) ability to specify environments on a per-flow-run basis - labels on custom environments should be readable on the Cloud-side through the marshmallow deserialization process Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for `Expr` to `DAGCircuit.substitute_node` Very similar to #10379, although there may be issues in cases where the `condition`/`target` wires aren't included in the `DAGOpNode`'s `cargs`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Control-flow builders fail to recognise registers in nested `switch` statements ### Environment - **Qiskit Terra version**: 0.24.1 - **Python version**: 3.10 - **Operating system**: macOS ### What is happening? The control-flow builder interfaces can fail to notice registers that appear only in a `SwitchCaseOp.target` nested in one of their scopes, and consequently don't build this register into the block. ### How can we reproduce the issue? ```python from qiskit.circuit import QuantumCircuit, QuantumRegister, ClassicalRegister qr = QuantumRegister(3) cr1 = ClassicalRegister(2, \"c1\") cr2 = ClassicalRegister(2, \"c2\") test = QuantumCircuit(qr, cr1, cr2) with test.switch(cr1) as case_outer, case_outer(0): with test.switch(cr2) as case_inner, case_inner(False): test.x(0) # Fails. assert cr2 in test.data[0].operation.blocks[0].cregs ``` ### What should happen? `cr2` should be present in the outer switch's case block, because it's used by the inner switch. ### Any suggestions? _No response_ Add support for using `Expr` values in the control-flow builder interface ### What should we add? While #10224 is satisfied by opening up the typing of the manual-construction forms of the relevant control-flow operations, this is not the preferred manner for users to construct these. The control-flow builder interface (`with qc.if_test(...)`, etc) should have support for the `condition` or `target` as appropriate being an `Expr` value. This involves modifying the internal trackers and classical-resource resolvers in `QuantumCircuit` and the builder blocks to understand how to visit `Expr` types to find all used resources within them. Depends on #10224. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: model.setup and model.on_fit_start not working self.model not yet set so `self.is_function_implemented('on_fit_start')` and `self.is_function_implemented('setup')` in `trainer.fit` will both always return false. Resolve by checking if model instead of self has the relevant function, e.g. `if callable(getattr(model, f_name, None)): model.f_name()` relevant lines: https://github.com/PyTorchLightning/pytorch-lightning/blob/f8c10fbff03240bf76896bc78def2118ad4fe141/pytorch_lightning/trainer/trainer.py#L851 https://github.com/PyTorchLightning/pytorch-lightning/blob/f8c10fbff03240bf76896bc78def2118ad4fe141/pytorch_lightning/trainer/trainer.py#L855 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: labextension install fails when read-only template yarn.lock is copied into staging directory ## Description `jupyter labextension install myextension --app-dir=./myapp` fails with ``` error An unexpected error occurred: \"EACCES: permission denied, open '/nix/store/lg2kmn1i3wj0473q0i6vbjbqhvrg5yky-jupyterlab-extended/staging/yarn.lock'\" ``` when the template `yarn.lock` file that is included in the base jupyterlab package is readonly. In this case, it seems to be copied over to `./myapp` when the staging directory is populated without setting the appropriate access rights: https://github.com/jupyterlab/jupyterlab/blob/172e664aa66d8c9be89960c575d24dc4051e7bb9/jupyterlab/commands.py#L1181 This naturally occurs when installing jupyterlab with Nix, where the base install has to be immutable to ensure reproducibility. A simple fix would be to set write access on the copied `yarn.lock` in the staging directory. ## Reproduce (I can only give approximate steps for a standard conda or pip install because I am using nix to install jupyterlab) 1. install jupyter lab and find the `staging` directory. 2. set `chmod -w yarn.lock` inside of the staging directory 3. go to a temporary directory somewhere else 4. run `jupyter labextension install <<anyextension>> --app-dir=. --debug` ## Expected behavior Jupyterlab with the extension is built successfully in `app-dir`. ## Context - Operating System and version: Ubuntu 16.04, Nix package manager - JupyterLab version: 1.2.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Store verify-ssl option in conan.conf after conan config install Only the custom user args are stored in conan.conf, and it would make sense to store the verify-ssl argument too, to make ``conan config install`` complete. cc/ @danimtb Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: jlap: add previous footer, checksum to logs to debug fetch hiccups ### Checklist - [X] I added a descriptive title - [X] I searched open requests and couldn't find a duplicate ### What is the idea? When using the `--experimental=jlap` feature, the debug logs show \"Checksum OK\" if the patch was able to be partially dowloaded, and \"Checksum Not OK\" if the running checksum plus the new lines don't match up with the trailing checksum. Then conda overwrites the `.state.json` required to reproduce the checksum mismatch. Instead, conda should log the old footer and running checksum or `iv` to be able to reproduce and debug the mismatch. Since we truncate the patch files after they get too large, it is normal to sometimes get a checksum mismatch. But it seems like these happen more often than that. Attaching this issue to a refactor that cleans up the new feature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Cannot take gradient of function using linspace I've found I will get an exception \"Tracer can't be used with raw numpy function\" when I use linspace where one of the arguments to linspace is a parameter which needs to be differentiated with respect to. Here is a MWE that shows the problem ``` import jax.numpy as jnp import jax def testlinspace(x, *args): #does not work out = jnp.linspace(x[0],x[1],50) #linspace depends on parameters out = x[2]*jnp.square(out) out = jnp.sum(out) return out def testlinspace2(x, *args): #works out = jnp.linspace(1.,50.,50) #linspace is just some array of numbers out = x[2]*jnp.square(out)+x[0]*x[1] out = jnp.sum(out) return out x = [2.,3.,1.5] testobj = testlinspace(x) testgrad = jax.grad(testlinspace) testobj2 = testlinspace2(x) testgrad2 = jax.grad(testlinspace2) print(testgrad(x)) #throws exception, note gradient using finite differences is DeviceArray([174.48979293, 200.51020897, 316.83673001]) print(testgrad2(x)) #works, gives DeviceArray([ 149.99968698, 99.99930626, 42924.99943404]) ``` So the problem is you can't do something like jax.numpy.linspace(x[0],10,50) because the linspace is depending on the parameters 'x' being reverse-mode differentiated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Explore Upgrading Python K8s library We're currently bound by 10.0 https://github.com/kubernetes-client/python/releases/tag/v11.0.0a1\\ **cc:** @joshmeek Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Clang 6.0 implications in cppstd flags We have added to the `settings.yml` clang 6.0, but we have to review the `cppstd` flags and `package_id` to adjust it correctly and knowing the default one of the compiler to keep the compatibility of packages that do not specify the `cppstd` setting. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Transformer Vit-MAE hard coded image channels ### Feature request Although the config file for the model accepts number of input channels, the class methods patchify and unpatchify use hard coded 3 channel image input. It should use num_channels argument of the config. https://github.com/huggingface/transformers/blob/a727db62f4f4e5cb15020fa5efa86ae559324616/src/transformers/models/vit_mae/modeling_vit_mae.py#L899 ### Motivation With this feature, VIT MAE model will be able to run on gray scale images as well ### Your contribution I already fixed it in my code, but I haven't tested it thoroughly Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add annotation to circuit_drawer() for snapshot instructions <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? PR #1021 added support for drawing a barrier line to the circuit drawer for the` snapshot` instruction. However, to make the visualizations for the snapshot instruction more useful we should add a label above the barrier line drawn. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: add circuit diagrams to source code when some claim about a circuit is made ### What is the expected enhancement? when reading source code that is related to some circuits, it is often useful to be able to see the circuit. examples are transpiler tests (which claim two pre-/post-transpile circuits are equivalent), and circuit equivalence libraries. Examples of files that have this already: https://github.com/Qiskit/qiskit-terra/blob/main/test/python/transpiler/test_dynamical_decoupling.py https://github.com/Qiskit/qiskit-terra/blob/main/test/python/transpiler/test_instruction_alignments.py Examples of files that do not but could benefit: https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/circuit/library/standard_gates/equivalence_library.py https://github.com/Qiskit/qiskit-terra/blob/main/test/python/transpiler/test_hoare_opt.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Refreshing tokens via GraphQL has the wrong input type ## Description *A clear description of the bug* The GraphQL mutation issued to refresh an auth token has the wrong input type; I believe it should be `refresh_token_input` but it's just `refresh_token`. The change happened [here](https://github.com/PrefectHQ/prefect/commit/cdd7ea745ba95fec0286ebfb2b80454adbc80137#diff-4a014f9fa1d03a95b5f41c18553bfea0R472). This results in a 400 error when calling `Client._refresh_access_token()` with a USER-scoped token. ## Expected Behavior *What did you expect to happen instead?* The token would be refreshed without error. ## Reproduction *A minimal example that exhibits the behavior.* ``` import prefect c = prefect.Client(api_token=<USER TOKEN>) c.login_to_tenant(<TENANT>) c._refresh_access_token() # error ``` ## Environment *Any additional information about your environment* *Optionally run `prefect diagnostics` from the command line and paste the information here* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Problems accessing Variables properties using Cloud SDK, I'm able to construct a Configs resource, a Variables resource in it and set a text value but, when I try to access these properties through Cloud Client Libraries for Python, I'm unable to get the values: ``` gcloud beta runtime-config configs variables get-value my-variable \\ --config-name=${CONFIG} \\ --project=${PROJECT} ``` Returns: ``` my-value ``` ``` gcloud beta runtime-config configs variables describe my-variable \\ --config-name=${CONFIG} \\ --project=${PROJECT} ``` Returns: ``` atomicName: projects/$PROJECT/configs/$NAME/variables/my-variable name: my-variable text: my-value updateTime: '2017-08-29T15:03:26.359064036Z' ``` And: ```python from google.cloud import runtimeconfig client = runtimeconfig.Client() config = client.config(CONFIG) print (config.exists()) print(config.get_variable(VARIABLE).exists()) print(config.get_variable(VARIABLE).full_name) ``` Returns: ``` True True projects/$PROJECT/configs/$NAME/variables/$VARIABLE ``` But: ``` print(config.get_variable(VARIABLE).state) print(config.get_variable(VARIABLE).value) ``` Returns: ``` None None ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Visual Studio 2015 support While playing around with #429 I noticed that there are a few subtle differences between how Visual Studio 2010 and 2015 handle project / solution files. I want to bring in vs2015 support for meson and discuss the best way for doing this. Should I add it as a separate backend (sharing most of the code in a super class, of course) like CMake does or just control the version with backend options, once I implemented those? I feel like a separate backend is cleaner. BTW: Is there any reason why meson started with vs2010 in the first place and did not use vs2015 right away? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CMake helper should handle fPIC like Autotools helper is doing To help us debug your issue please explain: - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Conan version 1.0.4 If fPIC is an options in the recipe. Enable/Disable it depending on the compiler should be managed by CMake helper like autotools helper is doing. Usually this check is needed. ```python def build(self): cmake = CMake(self) ... if self.options.fPIC and self.settings.compiler != \"Visual Studio\": cmake.definitions[\"CMAKE_CXX_FLAGS\"] = \"-fPIC\" cmake.definitions[\"CMAKE_C_FLAGS\"] = \"-fPIC\" ``` Example with autotools helper: ``` from conans import ConanFile, AutoToolsBuildEnvironment class ExampleConan(ConanFile): ... def build(self): env_build = AutoToolsBuildEnvironment(self) env_build.fpic = True env_build.libs.append(\"pthread\") env_build.defines.append(\"NEW_DEFINE=23\") env_build.configure() env_build.make() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Scientific notation in QASM output causes export to other platform to fail ### Environment - **Qiskit version**: {'qiskit-terra': '0.24.0', 'qiskit-aer': '0.12.0', 'qiskit-ignis': '0.7.1', 'qiskit-ibmq-provider': '0.20.2', 'qiskit': '0.43.0', 'qiskit-nature': None, 'qiskit-finance': None, 'qiskit-optimization': None, 'qiskit-machine-learning': None} - **Python version**: 3.10.6 - **Operating system**: Linux Mint ### What is happening? Exporting a circuit with small rotation gates through circuit.qasm() results in scientific notation being used. This causes issues when importing the QASM code into another quantum computing platform. ### How can we reproduce the issue? ``` from qiskit import QuantumCircuit qc = QuantumCircuit(1) qc.rx(0.00001, 0) print(qc.qasm()) ``` output: ``` OPENQASM 2.0; include \"qelib1.inc\"; qreg q[1]; creg meas[1]; rx(1e-05) q[0]; barrier q[0]; measure q[0] -> meas[0]; ``` ### What should happen? output: ``` OPENQASM 2.0; include \"qelib1.inc\"; qreg q[1]; creg meas[1]; rx(0.00001) q[0]; barrier q[0]; measure q[0] -> meas[0]; ``` ### Any suggestions? The conversion from float to string happens in `pi_check`. The call is `pi_check(0.00001, output=\"qasm\", eps=1e-12)` and returns `'1e-05'`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: docs: transaction doesn't have property succeeded The docs still mention the `succeeded` property on transactions run with `with` even though it has been removed in ed0762b9531bc68f7a9e90835a0f0fbb75ddf383. It's not clear to me how to check for a successful transaction now. I suspect it throws an exception otherwise, which mirrors `ndb` behaviour, but I still check for `_status == 3` just in case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [nginx] NGINX Plus extended status API depreciated; Integration needs to use Plus API instead NGINX R13 was just released and it replaces the Extended Status API with the NGINX Plus API. [See Announcement](https://www.nginx.com/blog/nginx-plus-r13-released/) A future version of NGINX Plus will drop support for the Extended Status API. They are promising at least 6 months before they do so. The Datadog integration for NGINX Plus depends on the Extended Status API (http status module). https://github.com/DataDog/integrations-core/tree/master/nginx ### Extended Status API Deprecated The previous on-the-fly reconfiguration and extended status APIs are now deprecated. The deprecated APIs will continue to be shipped with NGINX Plus for a minimum of 6 months, alongside the new NGINX Plus API. After this period, the old APIs will be removed in a subsequent release of NGINX Plus. ### NGINX Plus API NGINX Plus R13 includes a new API that is unified under one single endpoint. Previous versions of NGINX Plus included separate upstream_conf and extended status APIs. The new API combines the functionality of both, and also includes a new Key-Value Store module which brings a variety of use cases for on-the-fly reconfiguration (discussed in the next section). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: frozen setup: permission denied for default ipython_dir Ipython's embedded shell is creating its configuration directory in `../.ipython` in frozen setups. When the directory is not writeable (such as if the frozen code was in `c:/Program\\ Files/app/`, then `c:/Program\\ Files/.ipython` fails to be created by non-admin), ipython fails with `WindowsError`. This case should be handled more gracefully - e.g. by doing without configuration directory. A workaround is to set IPYTHONDIR to something writeable (in my case, `expanduser('~/.ipython')`) before constructing the embedded shell. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: Provide credential-free access to public-access buckets Per the [GCS authentication doc](https://cloud.google.com/storage/docs/authentication): > Objects are anonymously accessible if the `allUsers` group has `READ` permission. Add support for such access to the storage client. Two strategies seem possible: - Add a classmethod factory to the `Client` class which bypasses inferring credentials from the user environment. - Add a custom `AnonymousCredentials` singleton which can be passed to the `Client` constructor. We don't need to enforce any limits on the access to buckets / objects retrieved from the \"anonymous\" client: the back-end will return `UNAUTHORIZED`. System tests can use the `gcp-public-data-landsat` bucket, if desired (hopefully CI throttling won't be an issue). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: API Endpoint - CRUD - DAG Hello We need to create several endpoints that perform basic CRUD operations on **DAG**. We need the following endpoints: - PATCH /dags/{dag_id} It depends on https://github.com/apache/airflow/issues/8128 Detailed information is available in the issue: https://github.com/apache/airflow/issues/8118 LOVE, Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: MAINT: remove numpy/tools/test-installed-numpy.py ? Looking at Matti's modifications in #13482, I don't see a good reason to keep `test-installed-numpy.py` if we are going to continue using `runtests.py`. Both have separate parsers to accomplish similar things, but `runtests.py` is more developed / actively used while `test-installed-numpy.py` still has discussion of nose / python 2.4, and Matti's proposed change there adds `-n` option which does something different in `runtests.py`. `runtests.py -n` will test installed NumPy instead of rebuilding, so seems like redundancy / maintenance burden we don't need moving forward Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Make installation of system packages in system_requirements() optional Feature request: It would be nice if it would be possible to disable installation of system packages in `system_requirements()`. An environment variable, e.g. `CONAN_DISABLE_SYSREQUIRES`, would be handy. In general this would be helpful when testing packages in environments without sudo-rights where required packages are preinstalled. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: host zlib is found using a cross file. **Describe the bug** When using a cross file which is not setting pkg_config_libdir, meson find the host version of zlib with ``` MESON build-cross --cross-file=path_to/my-cross-file.txt ``` **To Reproduce** Meson file: ``` project('hellomeson', 'c') cc = meson.get_compiler('c') libz_dep = dependency('zlib', required : false) if not libz_dep.found() warning('unable to find libz') endif executable('hello-meson', 'src/hello.c') ``` Cross file: ``` [host_machine] system = 'linux' cpu_family = 'aarch64' cpu = 'arm64' endian = 'little' [properties] c_args = [] cpp_args = [] objc_args = [] objcpp_args = [] c_link_args = [] cpp_link_args = [] objc_link_args = [] objcpp_link_args = [] pkg_config_libdir = ['__unknown_sysroot__'] [binaries] c = ['aarch64-linux-gnu-gcc'] cpp = ['aarch64-linux-gnu-g++'] ar = ['aarch64-linux-gnu-ar'] pkgconfig = 'pkg-config' strip = ['aarch64-linux-gnu-strip'] ``` **Expected behavior** To not find any zlib or at least not the one from my host and then use it.. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? cross build * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) Ubuntu 18.04 * what Python version are you using e.g. 3.8.0 3.6.9 * what `meson --version` master * what `ninja --version` if it's a Ninja build 1.8.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] Getting 'settings.compiler.libcxx' value not defined in a --pure-c project <!-- What is your question? Please be as specific as possible! --> - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Even though I've created a new package with the flag `--pure-c`, which conanfile.py template configures the deletion of the field `self.settings.compiler.libcxx`, the command conan create still fails with the error `ERROR: : 'settings.compiler.libcxx' value not defined`. Am I doing something wrong? Is that a bug? Here are the commands: ``` conan new myproj/1.2.3 --test --pure-c ``` ``` # generated conanfile.py def configure(self): del self.settings.compiler.libcxx ``` ``` conan create . user/testing -s compiler=clang -s compiler.version=10 Exporting package recipe myproj/1.2.3@user/testing: A new conanfile.py version was exported myproj/1.2.3@user/testing: Folder: /home/myuser/.conan/data/myproj/1.2.3/user/testing/export myproj/1.2.3@user/testing: Exported revision: 71b84694e77a8c54b51a1f797a31116a Configuration: [settings] arch=x86_64 arch_build=x86_64 build_type=Release compiler=clang compiler.version=10 os=Linux os_build=Linux [options] [build_requires] [env] ERROR: : 'settings.compiler.libcxx' value not defined ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: ResultHandlers should be called in TaskRunner pipeline steps Another PIN 2 issue (https://github.com/PrefectHQ/prefect/pull/570). Instead of delegating out result handling to state serializers (as is currently implemented), result handling should take place inside a TaskRunner pipeline step (and failures should raise `ENDRUN`s accordingly). Note that: - output result handling should only take place if `cache_for` is provided on a task - input result handling should use `state.metadata` (https://github.com/PrefectHQ/prefect/issues/573) to determine the correct result handler to use for caching _each individual input_ `JSONResultHandler` for handling small data There are certain situations in which a user might want to place small bits of _raw_ data into the database (strings, simple numbers, etc.). To provide a route to doing this, we should implement a `JSONResultHandler` which simply returns `json.dumps` for an object. Note this handler needs to be serializable (https://github.com/PrefectHQ/prefect/issues/572) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: GCC ABI compatibility warning always points to default profile Steps to reproduce: ``` $ conan --version # not the latest, but the issue is still present in master Conan version 1.12.1 $ conan profile new --detect gcc Found gcc 8.2 gcc>=5, using the major as version Found clang 7.0 ************************* WARNING: GCC OLD ABI COMPATIBILITY *********************** Conan detected a GCC version > 5 but has adjusted the 'compiler.libcxx' setting to 'libstdc++' for backwards compatibility. Your compiler is likely using the new CXX11 ABI by default (libstdc++11). If you want Conan to use the new ABI, edit the default profile at: ~/.conan/profiles/default adjusting 'compiler.libcxx=libstdc++11' ************************************************************************************ ``` This is misleading, because I did not create a `default` profile, but rather a profile named `gcc`. I suppose the warning in [this line](https://github.com/conan-io/conan/blob/dac7447838d95361676c43cb055e202556092be6/conans/client/conf/detect.py#L151) and two lines up should be changed to use the actual name of the profile being created. Perhaps a bit of an edge case because most folks will use only one profile, but still. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: `install_data()` default destination directory in subprojects The default `install_dir` for `install_data()` is documented to be `{datadir}/{projectname}` thus I would expect the following calls to install in the same directory: ``` install_data('foo') install_data('bar', install_dir: get_option('datadir') / meson.project_name()) ``` However, when the following snippet appears in a Meson project installed as subproject, they do not. The default `install_dir` is derived from the parent project name. I've verified this with the current git master. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `jupyter-execute` displayed in docs The `.. jupyter-execute` command is erroneously displayed in the [docs](https://qiskit.org/documentation/stubs/qiskit.circuit.QuantumCircuit.initialize.html?highlight=initialize#qiskit.circuit.QuantumCircuit.initialize).  **Source Code** https://github.com/Qiskit/qiskit-terra/blob/fe8ab43f1218d6997458fb3bf4011045f40932b0/qiskit/extensions/quantum_initializer/initializer.py#L163 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Could we have support for scipy.stats.logistic? In #324 we got support for `logit` and `expit` from `scipy.special`. This provides all the building blocks to also support `scipy.stats.logistic` (in particular, it’s members `cdf`, `pdf`, `ppf`, `logcdf` and `logpdf`). Having this would enable doing maximum-likelihood estimation of logistic regression using `scipy.optimize`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Documentation Unclear: \"If the property is not set locally, returns None.\" The [Google Storage Blob documentation](https://googlecloudplatform.github.io/google-cloud-python/latest/storage/blobs.html) says that almost all properties return the value `None` if the \"property is not set locally.\" However, there is no documentation explaining how properties are set/unset locally or when that occurs. This is confusing, there should be a preamble explaining when local Blob properties are set locally. ### Motivation I ran into this because I started seeing some of these values return `None` in my project in unexpected circumstances (there may be another bug there), but when I went to the documentation, it did not shed much light on why or when these properties should be returning `None`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: DeprecationWarnings should be visible by default in interactive usage DeprecationWarning and PendingDeprecationWarning are invisible by default. The rationale for this is that they are only useful to people who are writing code, so they should not be shown to end-users who are merely running code. If someone is typing stuff into the interactive REPL or a notebook, though, and the code they type uses some deprecated functionality, then we should actually show them this warning. We know that the author is sitting right there. And they're probably going to take whatever they tested interactively and move it into a more permanent form and ugh. This problem is particularly acute for packages that are primarily used through the interactive prompt, like numpy. I'm really tired of getting bugs like this: numpy/numpy#5919 The solution is simple: when entering interactive mode, IPython should do something like: ``` warnings.filterwarnings(\"default\", category=DeprecationWarning, module=\"__main__\") warnings.filterwarnings(\"default\", category=PendingDeprecationWarning, module=\"__main__\") ``` This means \"for any `DeprecationWarning` or `PendingDeprecation` warning which is caused by code running in the module with name `\"__main__\"`, use the `\"default\"` handler (which means: display once per line of code that triggered it). (Confusingly, the default handler for these warning messages is not `\"default\"`, but `\"ignore\"`. So overriding the default with `\"default\"` produces a non-default outcome.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: install_data() doesn't accept files() object ``` ... plugins = files('example-c.plugin', 'example-python.plugin') install_data(plugins, install_dir : plugin_path) ... ``` ``` Meson encountered an error in file libdnf/plugins/meson.build, line 3, column 0: Arguments must be strings. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Tutorial broken link to Plugins Page The \"Plugins\" link on this page: http://jupyterlab-tutorial.readthedocs.io/en/latest/labextensions.html is broken, missing .html in the end I believe. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: AuthorizationError when watching logs from CLI When running with `prefect run cloud --logs`, after a few minutes I see the following error: ``` prefect.utilities.exceptions.AuthorizationError: [{'message': 'AuthenticationError', 'locations': [], 'path': ['flow_run'], 'extensions': {'code': 'UNAUTHENTICATED'}}] ``` The run itself succeeds but the logs stop at that point, so I guess the token is initially valid but just expires...? cc @joshmeek @cicdw Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: ufunc doc not in html build ? It seem the docstring of \"ufunc\" is not in the html build of the docs: ``` In [5]: from numpy import ufunc In [6]: 'whole array' in ufunc.__doc__ Out[6]: True ``` If I grep the html build for \"whole array\" there is no results... ufunc doc is set in `numpy/core/_add_newdocs.py`, like other things so there is no reason for it not to be built, it likely miss a entry in generated API ? Am I really bad at searching ? Or maybe that's on purpose. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Switch from imgmath to mathjax For html doc builds we currently need to have LaTeX installed, which in general is a pain. In the Gitpod setup this also bloats the Docker image. `sphinx.ext.imgmath` needs LaTeX, `sphinx.ext.mathjax` does not. Older discussion in gh-11753. And from https://github.com/numpy/numpy/pull/18822#issuecomment-824331826: >> It was needed for `sphinx.ext.imgmath` to work without warnings. From my understanding, the `:math:` directives would not display anything without latex + dvisvgm. >> >> (scipy uses `sphinx.ext.mathjax` so it does not run into this issue) > Ah thanks, that makes perfect sense now. The SciPy setup works fine, and I think is actually preferable given that we can avoid LaTeX: - discussion on moving from `mathjax` to `imgmath`: https://github.com/scipy/scipy/pull/7358 - PR to bundle `mathjax` instead: https://github.com/scipy/scipy/pull/7376 - Pandas and scikit-learn use `mathjax` as well, but have limitations for viewing rendered math offline. I think the SciPy approach is preferred here. _Proposal: let's switch to `mathjax` and use https://github.com/scipy/scipy-mathjax as a submodule._ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Test metrics is not being reported to TensorBoard since 0.7.2 <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug <!-- A clear and concise description of what the bug is. --> ### To Reproduce Steps to reproduce the behavior: https://colab.research.google.com/drive/1fM6xL140u9pU0vcmJf6qKzHwczjcMpcF <!-- If you have a code sample, error messages, stack traces, please provide it here as well --> #### Code sample <!-- Ideally attach a minimal code sample to reproduce the decried issue. Minimal means having the shortest code but still preserving the bug. --> Please see the colab above. ### Expected behavior <!-- A clear and concise description of what you expected to happen. --> The test metrics should be reported. ### Environment The Colab environment: ``` cuda: GPU: available: False version: 10.1 packages: numpy: 1.18.2 pyTorch_debug: False pyTorch_version: 1.4.0 pytorch-lightning: 0.7.2 tensorboard: 2.2.0 tqdm: 4.38.0 system: OS: Linux architecture: 64bit processor: x86_64 python: 3.6.9 version: #1 SMP Wed Feb 19 05:26:34 PST 2020 ``` ### Additional context Regression from 0.7.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: get_variable() fallback does not work with arrays This fails with `Items of foreach loop is not an array`: ``` arr = get_variable('does_not_exist', []) foreach i : arr error('Should not be reached!') endforeach ``` also ``` arr = get_variable('does_not_exist', ['a']) foreach i : arr endforeach ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Build error when using target.extract_all_objects() when target has header sources An issue has been discovered while working on PR #2711: > ninja: error: 'gio/gio-2.0@sha/meson-generated_.._gnetworking.h.o', needed by 'gio/libgio-2.0.a', missing and no known rule to make it According to @nirbheek it is a bug in extract_all_objects(): > I've seen this bug before elsewhere. It's because when figuring out the list of sources to use in extract_all_objects(), we don't skip over headers. See the sources classification in backends/ninjabackend.py:NinjaBackend.generate_target(). Specifically, look at how we handle the contents oftarget_sources and generated_sources. > >This file classification needs to be factored out and probably moved to the BuildTarget object so it can also be used by extract_all_objects(). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: CouplingMap doesn't document it creates (and requires) a graph with contiguous qubit ids ### Information - **Qiskit Terra version**: `qiskit-terra==0.18.1` - **Python version**: `3.7.3` - **Operating system**: `macOS Mojave` ### What is the current behavior? transpiler CouplingMap method fails to recognize that the graph with edges `(0, 1), (1, 4)` is connected. ### Steps to reproduce the problem ``` import networkx as nx from qiskit.transpiler import CouplingMap edges = [(0, 1), (1, 4)] subg_coupling = CouplingMap(edges) print(subg_coupling.get_edges()) print(subg_coupling.is_connected()) print(nx.is_connected(nx.Graph(edges))) ``` ### What is the expected behavior? The CouplingMap is_connected() method returns False, while the networkx method returns True. ### Suggested solutions One option is to use the `networkx` is_connected() method instead of the `retworkx` method. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan user command show which users are authenticated cc / @Aalmann PRobably use JSon output to it too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add Optional \"Name\" to Agents - in init - in CLI `--name` and the logger name will adjust accordingly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Kernel/Interrupt Kernel does not terminate stuck subprocesses in the notebook When a subprocess is run from the notebook, if it gets stuck the kernel will get locked waiting for it. Selecting Kernel/Interrupt from the menu does not terminate the subprocess, but rather leaves the kernel in an unstable, \"partially locked\" state, where other cells do not execute. The only resolution is to restart the kernel. This occurred for me on Windows - I do not know if it also happens on Unix. To demonstrate, start a notebook and enter !python in a cell. The process will lock as it is waiting for interactive input. As there is no way to provide that input, the kernel must be restarted to continue. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: I can‘t stop a task by its task_id [2018-12-02 23:53:58,955: INFO/MainProcess] Received task: tasks.add[bb1fe102-c1f9-4361-9370-1129900c0d52] [2018-12-02 23:54:02,479: INFO/MainProcess] Terminating bb1fe102-c1f9-4361-9370-1129900c0d52 (Signals.SIGTERM) [2018-12-02 23:54:02,490: ERROR/MainProcess] pidbox command error: NotImplementedError(\"<class 'celery.concurrency.eventlet.TaskPool'> does not implement kill_job\",) Traceback (most recent call last): File \"d:\\envs\\aidcs\\lib\\site-packages\\kombu\\pidbox.py\", line 101, in dispatch reply = handle(method, arguments) File \"d:\\envs\\aidcs\\lib\\site-packages\\kombu\\pidbox.py\", line 122, in handle_cast return self.handle(method, arguments) File \"d:\\envs\\aidcs\\lib\\site-packages\\kombu\\pidbox.py\", line 116, in handle return self.handlers[method](self.state, **arguments) File \"d:\\envs\\aidcs\\lib\\site-packages\\celery\\worker\\control.py\", line 163, in revoke request.terminate(state.consumer.pool, signal=signum) File \"d:\\envs\\aidcs\\lib\\site-packages\\celery\\worker\\request.py\", line 249, in terminate pool.terminate_job(self.worker_pid, signal) File \"d:\\envs\\aidcs\\lib\\site-packages\\celery\\concurrency\\base.py\", line 115, in terminate_job '{0} does not implement kill_job'.format(type(self))) NotImplementedError: <class 'celery.concurrency.eventlet.TaskPool'> does not implement kill_job [2018-12-02 23:55:38,956: INFO/MainProcess] Task tasks.add[bb1fe102-c1f9-4361-9370-1129900c0d52] succeeded in 100.0s: 8 this is my main code: from celery.app.control import Control from tasks import add, app myControl=Control(app) myControl.revoke(task_id=\"b11729b0-6272-4527-af9d-dc24c0ad492d\", terminate=True) finally,if i want to look at the state of the task only by task_id (just like above), how . Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Matplotlib circuit drawer returns NoneType rather than PIL.Image <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? The matplotlib circuit drawer returns a NoneType rather than the `PIL.Image` as stated in the docstring for `circuit_drawer` and `matplotlib_circuit_drawer`. Thus, you can do nothing with the output. For example, it would be nice to grab the output and use it in a matplotlib `subplots` or the like and group circuits in a single figure. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: storage's delete_bucket method should take a \"force\" parameter deleting even a full bucket This would just be a shortcut for: ``` if force: for key in bucket: key.delete() ``` If people just want to kill a bucket, we shouldn't make it more complicated to do this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: SCM fails in Windows if remote URL is a local path with backslash if the git clone of the repo is done with forward slash, all is ok, but if done with backslash, as would do automatically if from a python script, the SCM replacement in the conan recipe will have backslash and the conanfile.py will fail to parse Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Text circuit drawer raises ValueError if an empty circuit is given <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.7.3 - **Python version**: 3.6.8 - **Operating system**: macOS HighSierra ### What is the current behavior? If I try to draw an empty circuit with the text drawer, it raises ValueError. ### Steps to reproduce the problem ``` # sample.py from qiskit import QuantumCircuit qc = QuantumCircuit() print(qc) ``` ``` $ python sample.py Traceback (most recent call last): File \"c.py\", line 3, in <module> print(qc) File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/circuit/quantumcircuit.py\", line 83, in __str__ return str(self.draw(output='text')) File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/tools/visualization/_text.py\", line 413, in __str__ return self.single_string() File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/tools/visualization/_text.py\", line 438, in single_string return \"\\n\".join(self.lines()) File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/tools/visualization/_text.py\", line 472, in lines layers = self.build_layers() File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/tools/visualization/_text.py\", line 672, in build_layers layers.append(InputWire.fillup_layer(self.wire_names(with_initial_value=True))) File \"/Users/ima/envs/vqe2/lib/python3.6/site-packages/qiskit/tools/visualization/_text.py\", line 394, in fillup_layer longest = max([len(name) for name in names]) ValueError: max() arg is an empty sequence ``` ### What is the expected behavior? No ValueError. ### Suggested solutions Check whether `names` is empty or not. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan Server 1.10 is broken #### Description Hi! I'm trying to start conan server but seems like is broken. $ conan_server > Traceback (most recent call last): > File \"/opt/miniconda3/bin/conan_server\", line 7, in <module> > from conans.conan_server import run > File \"/opt/miniconda3/lib/python3.6/site-packages/conans/conan_server.py\", line 1, in <module> > from conans.server.server_launcher import main > File \"/opt/miniconda3/lib/python3.6/site-packages/conans/server/server_launcher.py\", line 53, in <module> > launcher = ServerLauncher() > File \"/opt/miniconda3/lib/python3.6/site-packages/conans/server/server_launcher.py\", line 47, in __init__ server_capabilities, only_v1=False) > TypeError: __init__() got an unexpected keyword argument 'only_v1' #### Environment Conan Versions: 1.10 Python version: 3.6, 3.7 OS: Linux Ubuntu 18.04 #### Steps to reproduce pip3 install conan==1.10.0 conan_server or using Conan Docker Tools: BUILD_CONAN_SERVER_IMAGE=1 python build.py docker run -t -p 9300:9300 --name conan_server conanio/conan_server:latest - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] SystemPackageTool installed() method is missing According to [conan-io/docs](https://github.com/conan-io/docs/blame/18d6adbf56a55a7d9185a12aa707b5fe161b35e9/reference/conanfile/methods.rst#L642), [docs.conan.io](https://docs.conan.io/en/latest/reference/conanfile/methods.html#systempackagetool) SystemPackageTool should have a public `installed(package_name)` method. Instead, only a protected `_installed(packages)` is provided (see [here](https://github.com/conan-io/conan/blob/develop/conans/client/tools/system_pm.py#L146)). ### Environment Details (include every applicable attribute) * Operating System+version: Ubuntu 18.04.3 LTS * Compiler+version: no applicable * Conan version: 1.20.5 * Python version: 3.6.9 ### Steps to reproduce (Include if Applicable) Try to use `SystemPackageTool.installed(package_name)` ### Logs (Executed commands with output) (Include/Attach if Applicable) ` ERROR: while executing system_requirements(): 'SystemPackageTool' object has no attribute 'installed'` and if `_installed` is used: ``` Linter warnings WARN: Linter. Line 25: Access to a protected member _installed of a client class ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: GAX API hangs during (second) 'publish' /cc @bjwatson ``` python ====================================================================== ERROR: test_message_pull_mode_e2e (pubsub.TestPubsub) ---------------------------------------------------------------------- Traceback (most recent call last): File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/system_tests/pubsub.py\", line 157, in test_message_pull_mode_e2e topic.publish(MESSAGE_1, extra=EXTRA_1) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/gcloud/pubsub/topic.py\", line 246, in publish message_ids = api.topic_publish(self.full_name, [message_data]) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/gcloud/pubsub/_gax.py\", line 171, in topic_publish event.wait() AttributeError: 'exceptions.AttributeError' object has no attribute 'message_ids' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Respect service_healthy in docker-compose run <!-- Welcome to the docker-compose issue tracker! Before creating an issue, please heed the following: --> ## Description of the issue `docker-compose run` and `docker-compose up` demonstrate different behaviour when it comes to `condition: service_healthy`. `up` correctly waits for all the dependencies to be healthy while `run` only creates dependencies without waiting for them to be healthy (effectively disregarding the `condition`). Personally, I would consider this a bug since this is a rather unexpected inconsistent behaviour. ## Context information (for bug reports) Relevant issues with examples of this: - [docker-compose run: healthcheck not detecting if one of the services failed to start](https://github.com/docker/compose/issues/4420) - [run dont do condition: service_healthy](https://github.com/docker/compose/issues/4952) - [Healthcheck dependency not respected during one-off command (run)](https://github.com/docker/compose/issues/4369) ## Steps to reproduce the issue 1. `docker-compose run` a service that declares a `condition: service_healthy` dependency ### Observed result `docker-compose` only creates a container for the dependency and doesn't wait for the health-check to pass. ### Expected result `docker-compose` creates a container for the dependency and waits for the health-check to pass - demonstrating the same behaviour as `docker-compose up`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add pulse builder \"macro\" decorator <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? I have found a decorator of this form very useful for constructing pulse experiments from functions. I suggest `macro` to represent a python function with an activated builder context that will be called and evaluated during program construction. I propose that we reserve `function` for support of pulse functions which will be analyzed and compiled as a function in the pulse IR with a signature, to then be loaded and evaluated in the hardware. ```python import functools from qiskit.pulse import builder # decorator for pulse builder function def macro(func): @functools.wraps(func) def inst_map_wrapper(*args, **kwargs): builder_ = builder._active_builder() # activate the pulse builder before calling the function with pulse.build(builder_.backend) as built: output = func(*args, **kwargs) builder_.call_schedule(built) return output return inst_map_wrapper @macro def nested(a): pulse.play(pulse.Gaussian(100, a, 20), pulse.drive_channel(0)) return a*2 @macro def test(): pulse.play(pulse.Constant(100, 1.0), pulse.drive_channel(0)) output = nested(0.5) print(output) with pulse.build(backend=backend) as sched: print(builder._active_builder()) test() sched.draw() ``` We should add this to the standard pulse builder library, document, rename what needs to be to be clearer and test. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Weird behavior of --update I have a bunch of remotes defined in my Conan configuration. We'll call them A, B and C. They are defined in the same order so remote A should be used first, then B, then C. Now I continuously upload new versions for the package `Pkg/x.x.x.x@sick/dev` to remote C. These are required by a consumer application using `requires = \"Pkg/[*]@sick/dev\"`. I would have expected that a call to `conan install .. --update` in the consumer's build directory queries all of the remotes for new versions. However, that doesn't seem to be the case. It always resolves to the last installed version in the local cache. I have to explicitly add a `-r C` to the install command to make it fetch the most recent version from the remote. With `--update` Conan emits the message `%s versions not found in remotes` (sic). It seems that the corresponding line in the Conan sources is also missing the format expression. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: ndarrays pickled on 1.16.0 cannot be loaded in previous versions As reported in #12825 in [these](https://github.com/numpy/numpy/issues/12825#issuecomment-456561919) [comments](https://github.com/numpy/numpy/issues/12825#issuecomment-456566648). Should change the module for backward compatibility Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: API reference: increase font size of \"methods\" back to standard size As identified by @cicdw API reference: increase font size of \"methods\" back to standard size As identified by @cicdw Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Add profile_name variable to profile rendering ### What is your suggestion? Feature request: Please add `profile_name` variable into profile templates - this will help a lot for the use case with large number of profiles. In our use case, we have dozens of profiles that have pattern-style names like `<os>_<compiler>_<version>_<arch>`. Since profile name can be parsed, it's easy to script profile generation. Here is what we have right now: We have dozens of profiles where each profile (`.jinja` file) has the same code with the only difference in profile name, for example **windows_msvc_v1933_x86.jinja**: ```jinja {% from '_profile_generator.jinja' import generate with context %} {{ generate(\"windows_msvc_v1933_x86\") }} ``` Here is the profile generator **_profile_generator.jinja** (a bit simplified): ```jinja {% macro generate(profile_name) %} {% set os, compiler, compiler_version, arch = profile_name.split('_') %} include(fragments/os/{{ os }}) include(fragments/compiler/{{ compiler }}_{{ compiler_version }}) include(fragments/arch/{{ arch }}) {% endmacro %} ``` As soon as `profile_name` variable is available, we can make all `<os>_<compiler>_<version>_<arch>.jinja` files to be symlinks to a profile generator that can parse global `profile_name` variable and include corresponding fragments. The benefit would be in removing of the maintenance burden of slightly different content of `.jinja` files. ### Have you read the CONTRIBUTING guide? - [X] I've read the CONTRIBUTING guide Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: marginal_counts does not act on memory field ### Environment - **Qiskit Terra version**: 0.20 - **Python version**: 3.8 - **Operating system**: Windows 10 ### What is happening? The `marginal_counts` method acts on a `Result` by marginalizing the counts in the `ExperimentResultData` object. It does act on the `counts` field, but not in the `memory` field. ### How can we reproduce the issue? A minimal example: ``` from qiskit.circuit import QuantumCircuit from qiskit import Aer from qiskit.result import marginal_counts b=Aer.get_backend('qasm_simulator') qc=QuantumCircuit(2) qc.h(0) qc.h(1) qc.measure_all() result=b.run([qc], shots=50, memory=True).result() print(result.results[0].data) marginal_result=marginal_counts(result, indices=[1] ) data=marginal_result.results[0].data print(data) ``` The results in the fields `counts` and `memory` from `data` are not consistent. ### What should happen? The memory field should be updated by the `marginal_counts` method. (or as a fallback: the `memory` field should be made empty) ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: backend.view_jobs() Many times we want to be able to view the jobs we have ran and save on the cloud. In the spec, we defined a backend.jobs() method which returns job objects. The problem is if this returns a job object then service that requires the job to be deleted after it has been called it removes it from the cloud. Since the use case is just to have a way of checking on all my jobs ``` for ran_job in backend.jobs(limit=5): print(str(ran_job.job_id()) + \" \" + str(ran_job.status())) ``` ``` 5bba0ceb1a814c003cbfdda2 JobStatus.CANCELLED 5bba0c3d5d72db004c6e1867 JobStatus.DONE 5bba0c3dc6992500552f155c JobStatus.DONE 5bb9b0f19458ec0044ab4954 JobStatus.DONE 5bb9abd60b99f20045d26437 JobStatus.DONE ``` I suggest that we change this to ``` backend.view_jobs() ``` Are there any other things that should be displayed. I think something like a message to add that is human readable if an error occuers. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: PyTorch (with GPU) Trainer leaks CPU memory on Google Colab ## Environment info - `transformers` version: 3.1.0 - Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.6.9 - PyTorch version (GPU?): 1.6.0+cu101 (True) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: Yes - Using distributed or parallel set-up in script?: No ### Who can help Trainer: @sgugger ## Information Model I am using `RoBERTaForMaskedLM`: ` config = RobertaConfig( vocab_size=32_000, max_position_embeddings=256+2, num_attention_heads=12, num_hidden_layers=6, type_vocab_size=1, ) ` The problem arises when using: * [ ] [my own modified scripts](https://colab.research.google.com/drive/1bVv6V9IIhTNXvWbpUvQyPyRpK3LOgFfz?usp=sharing): I am trying to follow the official blog tutorial on training a language model from scratch. I have made a few changes from the official script (using Marathi OSCAR corpus, changed model config, and vocabulary size, and am fetching the sentences in the dataset on the fly The tasks I am working on is: * [ ] my own task or dataset: Masked Language Modelling with RoBERTa on Marathi Oscar Corpus ## To reproduce Steps to reproduce the behavior: 1. Run this [colab notebook](https://colab.research.google.com/drive/1bVv6V9IIhTNXvWbpUvQyPyRpK3LOgFfz?usp=sharing). ## Expected behavior The RAM consumption starts rising towards the end of the first epoch, ultimately crashing the entire session due to full memory consumption (12.72GB of Colab RAM) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jvp of np.sum fails in shape assertion when jit'ed The following piece of code, which computes the jvp of the `(reduce_)sum` operation, fails with `AssertionError: (3, 2, 2) != (3,)` when the sum is jit'ed. It computes without problems and gives the expected result when the `sum` operation is not jit'ed. The assertion is thrown from the `_reduce_sum_shape_rule` (lax.py, line 3017) which appears to be only called during actual evaluation of the `f_jvp` function when jit'ed. ``` import jax import jax.numpy as np T = np.array([[1., 2.], [3., 4.], [5., 6.]]) x = np.array([1, 2, 3]) mysum = jax.jit(np.sum) # this doesn't work when jit'ed y, f_jvp = jax.linearize(mysum, x) Z = f_jvp(T) # this doesn't work either when jit'ed # y, Z = jax.jvp(mysum, (x, ), (T, )) print(y) print(Z) ``` Unfortunately, I haven't been able to work out a fix for this on my own so far due to the many layers of abstraction and indirections in between and would be grateful if someone could push me the right way on this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Fix prefix data cache with rm_rf for conda-build on windows As reported by @mingwandroid: conda-build uses rd on Windows to remove the prefix before calling `rm_rf`, so we need conda to forget about the installed packages. Fix prefix data cache with rm_rf for conda-build on windows As reported by @mingwandroid: conda-build uses rd on Windows to remove the prefix before calling `rm_rf`, so we need conda to forget about the installed packages. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Creating a virtual environment starting with '.' (dot/period) Hi, Is there any way to create a virtual environment that starts with a '.' (dot/period)? I am running a program that searches for virtual python environments in a specific dot-prefixed folder name. The developers for that software use `virtualenv` for their environment, but I would like to keep using conda and was wondering if there is a workaround for this. Cheers Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Memory-related spec changes for 0.7 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? After recent discussion, the specs needs further tweaks before 0.7: * `BackendConfiguration`: * `BackendConfiguration.memory` (boolean): new **required** field, indicates if the backend supports `memory` * `BackendConfiguration.max_shots` (int): new **required** field, contains the maximum number of shots supported * `Qobj`: * `config.memory` (boolean): new **optional** field, indicates if the job is going to use `memory` This changes need to be reflected as well in #1047, for tracking purposes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [Conan 2.0] Remove old migrations I think it is safe to assume that Conan 2.0 doesn't need to run migrations from older (rather than latest 1.X at the moment of 2.0 GA) Conan version. So all migrations can be removed (and their tests) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: AutoToolsBuildEnvironment adds unknown options to MSVC To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. certain projects (e.g. ffmpeg) use auto-tools style builds for Visual Studio as well. as for conan 1.0.2, using the **AutoToolsBuildEnvironment** helper, MSVC receives unrecognized options: ``` cl : Command line warning D9002 : ignoring unknown option '-m64' cl : Command line warning D9002 : ignoring unknown option '-g' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: C++11 and -isystem Hello ! I am doing some tests with conan, CMake and Corss Compilation for ARM (with a custom CMake toolchain) under linux. The thing is my code uses some C++11 header only library which is also a conan package. With that configuration, I am getting this kind of error messages with gcc : ``` error: template with C linkage ``` After some investigation, I found that conan defined include paths as following : ``` -isystem /package/include/path ``` And if I replace that by : ``` -I/package/include/path ``` Everything compiles without any problem. So my question is : what is the point of using \"-isystem\" instead of \"-I\" ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Assigned pulse parameter is not converted into complex value. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? This crashes execution because `ParameterExpression` is not JSON serializable. ### Steps to reproduce the problem ```python from qiskit import pulse, circuit amp = circuit.Parameter(\"amp\") with pulse.build() as sched: pulse.play( pulse.Drag(160, 1j * amp, 40, 0.1), pulse.DriveChannel(0) ) sched.assign_parameters({amp: 0.5}, inplace=True) sched.instructions[0][1].pulse.amp # ParameterExpression(0.5*I) ``` ### What is the expected behavior? Assigned value should be converted into complex. ### Suggested solutions Current format logic doesn't recognize `*I` as complex value. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: einsum broadcast regression (with optimize=True) In numpy 1.13.3, it was possible to execute the following snippet without errors, while in 1.14.0 this happens: ```python In [1]: import numpy as np In [2]: a = np.ones((10,2)) In [3]: b = np.ones((1,2)) In [4]: np.einsum('t...i,ti->t...', a, b) Traceback (most recent call last): File \"<ipython-input-4-fa62d1d882f9>\", line 1, in <module> np.einsum('t...i,ti->t...', a, b) File \"/usr/local/lib/python2.7/dist-packages/numpy/core/einsumfunc.py\", line 1087, in einsum einsum_call=True) File \"/usr/local/lib/python2.7/dist-packages/numpy/core/einsumfunc.py\", line 710, in einsum_path \"not match previous terms.\", char, tnum) ValueError: (\"Size of label '%s' for operand %d does not match previous terms.\", 't', 1) ``` However `optimize=False` solves the problem: ```python In [5]: np.einsum('t...i,ti->t...', a, b, optimize=False) Out[5]: array([2., 2., 2., 2., 2., 2., 2., 2., 2., 2.]) ``` Is this intended behavior and the user is now responsible to explicitly disable optimization or is this a bug? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: fixing timeout bug when timeout is not a multiple of wait time minor bug when checking for timeout Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [build system] [MSBuild] msbuild: generate props file with dependent libraries list for linking conan-1.4.5 If I understand correctly Conan now passes LIB environment variable as dependent libraries search path, and generates props file include directories and other compiler flags. (btw documentation is totally unclear about this, so I had to dig to the Conan sources a lot) What Conan doesn't do is generation of a list of libraries to link with. So it's supposed Visual Studio project file already has valid names of libraries what unfortunately is not always true. What I suggest is to add an option to generate the libraries list as well. So a maintainer of a package can use something like replace_in_file to remove known invalid libraries names from a project file and let Conan do its business with linking. Usually it's not an issue when VS files are also maintained by the same maintainer, otherwise it is. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: postfix integration should not require sudo to root Reading the source code to integrations-core/postfix/check.py I note that it does a sudo to root to run the find command. This is noted in the docs / comments : > WARNING: the user that dd-agent runs as must have sudo access for the 'find' command > -- > | sudo access is not required when running dd-agent as root (not recommended) > | > | example /etc/sudoers entry: > | dd-agent ALL=(ALL) NOPASSWD:/usr/bin/find /var/spool/postfix* -type f root should not be required here - postfix user should be sufficient. That would be combined with a '-u postfix' on line 64's sudo command to allow this to work. This is a concern because find has a -exec parameter and your command list has a wildcard in it - this could be used to run arbitrary commands as root if the dd-agent user is compromised. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Infinite loop when using ipdb on ipython 7.13+ I use pytest with appium and when I use ipdb.set_trace() I'm stuck in a loop: ``` Exception in thread Thread-21249: Traceback (most recent call last): File \"/usr/local/Cellar/python/3.7.6_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py\", line 926, in _bootstrap_inner self.run() File \"/usr/local/Cellar/python/3.7.6_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py\", line 870, in run self._target(*self._args, **self._kwargs) File \"/Users/vverdeil/workspace/venv/testenv/lib/python3.7/site-packages/IPython/terminal/debugger.py\", line 102, in in_thread line = self.pt_app.prompt() File \"/Users/vverdeil/workspace/venv/testenv/lib/python3.7/site-packages/prompt_toolkit/shortcuts/prompt.py\", line 986, in prompt return self.app.run() File \"/Users/vverdeil/workspace/venv/testenv/lib/python3.7/site-packages/prompt_toolkit/application/application.py\", line 788, in run return get_event_loop().run_until_complete(self.run_async(pre_run=pre_run)) File \"/usr/local/Cellar/python/3.7.6_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/asyncio/events.py\", line 644, in get_event_loop % threading.current_thread().name) RuntimeError: There is no current event loop in thread 'Thread-21249'. ``` As you can see I reached thread 21249 before managing to kill the process. With the same code it works as expected on ipython 7.12, so I guess is it linked to https://github.com/ipython/ipython/pull/12141/ Am I the only one having this bug? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Reconnect with password In case you have a public notebook you will most certainly want to use a password (BTW. why is this not using HTTP basic auth?) When your notebook server wents down/you do a manual restart you get a reconnect question, though this fails on notebooks with passwords, obviously. Can we just trigger a normal F5 in this case? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: llvm broken on windows with static linking I bisected to dd2c44cdf6f8ed8a969d0666cafb08aaf78a919d, so this is a regression between 0.50 and 0.51, and should be resolved before 0.51 is realeased. I'm actively working on this, but wanted to have a tracker bug. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"up --build\" does not use updated image if containers already exist I have a project with containers already created but stopped. When I do `up --build`, it just starts the containers and doesn't recreate them: ``` $ docker-compose up --build Building web ... Removing intermediate container d2dbcf581064 Successfully built ebe1c55658cd Starting charingcross_db_1 Starting charingcross_web_1 ... ``` Running a second time builds twice, but recreates it successfully: ``` $ docker-compose up -d Building web ... Removing intermediate container 47aa1ff5fd24 Successfully built 2f73f4815ea1 Starting charingcross_db_1 Recreating charingcross_web_1 Building web ... Successfully built 2f73f4815ea1 Attaching to charingcross_db_1, charingcross_web_1 ... ``` Compose 1.7.0rc1 / Engine 1.11.0rc3 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: dev install on windows fails After cloning `npm install` appears to work but `pip install -e .` fails due to apparently not recognising npm even though it is on the path. ``` λ pip install -e . Obtaining file:///C:/dev/code/jupyterlab Complete output from command python setup.py egg_info: setup.py entered running egg_info running jsdeps C:\\Python\\envs\\py-dev\\lib\\distutils\\dist.py:261: UserWarning: Unknown distribution option: 'License' warnings.warn(msg) `npm` unavailable. If you're running this command using sudo, make sure `npm` is available to sudo Installing extension build dependencies with npm. This may take a while... rebuilding js and css failed missing files: ['C:\\\\dev\\\\code\\\\jupyterlab\\\\jupyterlab\\\\build\\\\bundle.js'] error: [WinError 2] The system cannot find the file specified ---------------------------------------- Command \"python setup.py egg_info\" failed with error code 1 in C:\\dev\\code\\jupyterlab\\ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Improve docs surrounding \"Cloud\" tasks in the library ## Current behavior *Please describe how the feature works today* As it stands today, docs surrounding our \"Cloud\" tasks in the library are a bit contradictory, sometimes specifying that they rely on Cloud, sometimes saying they can be used with Cloud or Server. Additionally, they're filed under the \"Cloud\" category. ## Proposed behavior *Please describe your proposed change to the current behavior* At a minimum, it's worth cleaning up the docs to help users use the `FlowRunTask`. It's probably also worth renaming the Cloud category of tasks in the library-- maybe \"orchestration\" or \"Prefect orchestration?\" ## Example *Please give an example of how the enhancement would be useful* Improving the docs would remove ambiguity surrounding the use of this task. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: logs doesn't exit if the container is already stopped Related to #1858 (cc @aanand, @mnowster since this just came up) If we attach the log printer to a container that has already exited, it never gets the \"end of log\" condition and `docker-compose logs` doesn't exist (the same is true for `up`). In a way, this is related to the problem described in #1115, where logs for containers created by scale are not picked up. I think we can fix both of those issues by adjusting the way we find containers to log. Instead of sending in a list of containers, we can do something like this: 1. start a thread which tails events (related to #1510) 2. when it receives a \"create\" event that matches the service name we want to print logs for, create a new thread to consume logs for that container 3. (in the case of `up`) start the containers 4. proceed with log tailing until all containers have exited (which will change the exit condition as well I think) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: test fsmt finetuning Would be interested to know whether this works with finetune.py. Just add your tiny guy to https://github.com/huggingface/transformers/blob/master/examples/seq2seq/test_seq2seq_examples.py#L378 and edit l382 to set task='translation'. If it doesn't pass, we can investigate, but I expect it to pass. Happy for either of us to take this one @stas00 (this is behind tiny fsmt in the queue, but writing it down so I don't forget.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: string templated fields are not rendered literally **Apache Airflow version**: 2.0.1 **Kubernetes version (if you are using kubernetes)** (use `kubectl version`): n/a **Environment**: - **Cloud provider or hardware configuration**: - **OS** (e.g. from /etc/os-release): redhat 7.9 - **Kernel** (e.g. `uname -a`): 3.10.0-1160.11.1.el7.x86_64 - **Install tools**: pip - **Others**: **What happened**: Given the following code ``` SSHOperator(task_id='dummy', command='''\\ for i in 1..100 do echo $i echo $i $i echo $i $i $i done ''') ``` The `command` field is rendered as: ``` '\\n\\nfor i in 1..100\\ndo\\necho $i\\necho $i $i\\necho $i $i $i\\ndone\\n' ``` **What you expected to happen**: I expect to see ``` for i in 1..100 do echo $i echo $i $i echo $i $i $i done ``` **How to reproduce it**: **Anything else we need to know**: This is because the following line renders templated fields using the `pformat` function. https://github.com/apache/airflow/blob/35c9a902929b79cf7cf53ac5b90c3565dddb97dc/airflow/www/views.py#L926-L928 I suggest we should render strings as is. ```diff if renderer in renderers: html_dict[template_field] = renderers[renderer](content) else: html_dict[template_field] = Markup(\"<pre><code>{}</pre></code>\").format( pformat(content) + content if isinstance(content, str) else pformat(content) ) # noqa ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Bigtable: cleanup and warnings about support for backwards compatible features that will be discontinued. Remove unused [variable](https://github.com/googleapis/google-cloud-python/blob/master/bigtable/google/cloud/bigtable/instance.py#L33). Add `DeprecationWarnings` for backwards compatible features that should/will go away. - `table.yield_rows()` - `location_id`, `serve_nodes` and `default_storage_type` parameters in `instance.create()` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: @graph composition breaks input type checks Execution plan code assumes all input types were the same across composition layers / input mappings. This is no longer true with `@graph` and has resulted in input check using the wrong types, grabbing the type def from the top of the mapping chain instead of the `@op` . related to #7109 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Celery fails to convert tasks w/o kwargs from protocol v1 to v2 InvalidTaskError is being raised when there's no kwargs present in the message. There's actually a test (https://github.com/celery/celery/blob/master/t/unit/worker/test_strategy.py#L33-L36) ensuring that an`InvalidTaskError` is raised in case there's no kwargs in the task. This is not what used to happen in v1. Docs also say the following for kwargs: ``` Dictionary of keyword arguments. Will be an empty dictionary if not provided. ``` as you can see in http://docs.celeryproject.org/en/latest/internals/protocol.html#id8 I can open a PR if you guys think this rule should really be removed. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: remove spurious print statement from parallel annoted functions ``` my_view.map(lambda x : x + 1, range(4)) ``` versus ``` @my_view.parallel() def testMap(x): return x[0] + 1 testMap(range(100)) ``` the second one prints out an annoying ``` in sync results <function ParallelFunction.__call__ at 0x7fb058110950> ``` Presumably left over from debugging? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Initial layout is not honoured when coupling_map is present <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: 0.8.0 - **Python version**: 3.6.6 - **Operating system**: OSX ### What is the current behavior? When `coupling_map` is present in `transpile` it overwrites `initial_layout`. ### Steps to reproduce the problem Transpile a circuit with both a `coupling_map` and `initial_layout` ### What is the expected behavior? `initial_layout` should be honoured if `coupling_map` is present. ### Suggested solutions https://github.com/Qiskit/qiskit-terra/blob/1a9229d51c98253e4875b54a522d80c52aa404ce/qiskit/transpiler/_transpiler.py#L104-L119 Should be modified to `if coupling_map and initial_layout is None:` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Use of shell=True could lead to shell injection File: pytorch_lightning/trainer/training_io.py Line Number: 227-233 Relevant Code: ` # find job id job_id = os.environ['SLURM_JOB_ID'] cmd = 'scontrol requeue {}'.format(job_id) # requeue job log.info(f'requeing job {job_id}...') result = call(cmd, shell=True)` From [here](https://docs.python.org/2/library/subprocess.html), \"Executing shell commands that incorporate unsanitized input from an untrusted source makes a program vulnerable to shell injection, a serious security flaw which can result in arbitrary command execution. For this reason, the use of shell=True is strongly discouraged in cases where the command string is constructed from external input...shell=False disables all shell based features, but does not suffer from this vulnerability\" Meaning anything that can set the SLURM_JOB_ID environment variable can perform code execution. The documentation also describes why you might need/want shell=True, \"This can be useful if you are using Python primarily for the enhanced control flow it offers over most system shells and still want convenient access to other shell features such as shell pipes, filename wildcards, environment variable expansion, and expansion of ~ to a user’s home directory.\" Looking at the code above, it doesn't look like we need any of these features and we can switch to shell=False with no change in functionality while gaining the security benefits of shell=False. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Not able to use gcloud credential helpers with docker-compose build --pull Hey, We are seeing strange behaviour with compose and default cred helpers when pulling as part of a build. Both our image, and our base image are in a private gcloud repo. We do `gcloud auth configure-docker` to configure docker to give us this config: ``` { \"credHelpers\": { \"gcr.io\": \"gcloud\", \"us.gcr.io\": \"gcloud\", \"eu.gcr.io\": \"gcloud\", \"asia.gcr.io\": \"gcloud\", \"staging-k8s.gcr.io\": \"gcloud\" } } ``` Which allows us to pull private images, eg: ``` bash-4.2$ docker pull eu.gcr.io/at-artefacts/platform-base-nodejs Using default tag: latest latest: Pulling from at-artefacts/platform-base-nodejs Digest: sha256:ca558cb49a6fd2e0f178e4016c30638ed722328608bfb87fdc389c76a9c9af03 Status: Image is up to date for eu.gcr.io/at-artefacts/platform-base-nodejs:latest ``` We have this compose file: ``` version: '3.2' services: app: image: \"eu.gcr.io/at-artefacts/platform-base-nodejs:${IMAGE_TAG:-latest}\" restart: always build: context: . dockerfile: Dockerfile args: GO_DEPENDENCY_LABEL_BASE_CENTOS: \"${GO_DEPENDENCY_LABEL_BASE_CENTOS:-latest}\" ``` And a `docker-compose pull` doesn't give any output, but it does pull the image. ``` bash-4.2$ docker-compose pull Pulling app ... done ``` But, a build with `--pull` in it fails: ``` bash-4.2$ docker-compose build --pull --compress app Building app Step 1/8 : FROM eu.gcr.io/at-artefacts/platform-base-centos:latest ERROR: Service 'app' failed to build: unauthorized: You don't have the needed permissions to perform this operation, and you may have invalid credentials. To authenticate your request, follow the steps in: https://cloud.google.com/container-registry/docs/advanced-authentication ``` Any ideas? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: `GCSToLocalFilesystemOperator` unnecessarily downloads objects when it checks object size `GCSToLocalFilesystemOperator` in `airflow/providers/google/cloud/transfers/gcs_to_local.py` checks the file size if `store_to_xcom_key` is `True`. https://github.com/apache/airflow/blob/b40dffa08547b610162f8cacfa75847f3c4ca364/airflow/providers/google/cloud/transfers/gcs_to_local.py#L137-L142 How it checks size is to download the object as `bytes` then check the size. This unnecessarily downloads the objects. `google.cloud.storage.blob.Blob` itself already has a `size` property ([documentation reference](https://googleapis.dev/python/storage/1.30.0/blobs.html#google.cloud.storage.blob.Blob.size)), and it should be used instead. In extreme cases, if the object is big size, it adds unnecessary burden on the instance resources. A new method, `object_size()`, can be added to `GCSHook`, then this can be addressed in `GCSToLocalFilesystemOperator`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add Flow and Task identifying information to LogRecords ## Current behavior - All log entries have the default [LogRecord attributes](https://docs.python.org/3/library/logging.html#logrecord-objects)... - There is no universally identifiable flow slug ## Proposed behavior ...It would be useful to attach Core-specific information to log entries: - `task_name` & `task_slug`: available only on entries emitted from Tasks and TaskRunners - `flow_name` & `flow_slug`: available only on entries emitted from Flows and FlowRunners The addition of the `flow_slug` makes is possible to uniquely identify flows other than by name. ## Example One can now take a single stream of log entries during a local flow run and separate it by entity without parsing the `LogRecord.msg` field (which is unreliable). This makes is possible to build richer feedback interfaces for filtering, organizing, and otherwise selectively manipulating log entries. Here is an example CLI interface that would be made possible by theses features:  (Given the following flow): ```python from utils import seed, random_data import prefect @prefect.task def extract(): return seed.get() @prefect.task def transform(seed): logger = prefect.context.get(\"logger\") data = [] for x in range(10): c_data = random_data(seed) logger.info(\"debug info: {}\".format(c_data)) data.append(c_data) return data @prefect.task def load(data): # do something with the data.... pass with prefect.Flow(\"ETL\") as flow: e = extract() t = transform(e) load(t) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Improper kwarg forwarding for np.mean Steps to reproduce ``` import jax.numpy as np import numpy as onp x = lax.add(np.eye(3), 0.) onp.mean(x) ``` Traceback: ``` --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-91-45d207ceb919> in <module>() 1 x = lax.add(np.eye(3), 0.) ----> 2 onp.mean(x) ~/anaconda/lib/python3.5/site-packages/numpy/core/fromnumeric.py in mean(a, axis, dtype, out, keepdims) 2915 pass 2916 else: -> 2917 return mean(axis=axis, dtype=dtype, out=out, **kwargs) 2918 2919 return _methods._mean(a, axis=axis, dtype=dtype, TypeError: mean() got an unexpected keyword argument 'out' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Support for numpy.take_along_axis Requesting support for [this Numpy primitive](https://docs.scipy.org/doc/numpy-1.15.0/reference/generated/numpy.take_along_axis.html#numpy.take_along_axis). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Access a job's payload through `job.qobj()` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? One often wants to know the `job.qobj()` associated with a job as well (right now you can only get `job.result()` for previous jobs). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: EventMetadata.asset and EventMetadata.piepline_run are not parsed correctly ## Summary Creating an asset materialization with `EventMetadata.asset` or `EventMetadata.piepline_run` in the metadata produces the following error: ``` dagster.core.errors.DagsterInvalidEventMetadata: Could not resolve the metadata value for \"...\" to a known type. Consider wrapping the value with the appropriate EventMetadata type. ``` ## Reproduction ``` from dagster import AssetMaterialization, AssetKey, EventMetadata, Output, solid, pipeline from dagster import execute_pipeline @solid def parent(context): value = 0 yield AssetMaterialization( asset_key=AssetKey([\"parent\"]), metadata={\"pipeline_run\": EventMetadata.pipeline_run(context.run_id), \"value\":value}, ) yield Output(value) @solid def child(inp): value = inp+1 yield AssetMaterialization( asset_key=AssetKey([\"parent\", \"child\"]), metadata={\"lineage\": EventMetadata.asset(asset_key=AssetKey([\"parent\"])), \"value\":value}, ) yield Output(value) @solid def grandchild(inp): value = inp+1 yield AssetMaterialization( asset_key=AssetKey([\"parent\", \"child\", \"grandchild\"]), metadata={\"lineage\": EventMetadata.asset(asset_key=AssetKey([\"parent\", \"child\"])), \"value\":value}, ) yield Output(value) @pipeline def lineage_pipeline(): init = parent() add_one = child(init) add_two = grandchild(add_one) execute_pipeline(lineage_pipeline) ``` ## Additional Info about Your Environment Dagster version: 0.12.7 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add common usage explanations and code examples to qiskit.visualization module level API reference page. ### What should we add? As part of the new Qiskit Documentation content restructuring, we are deprecating [Qiskit Visualizations tutorial](https://qiskit.org/documentation/tutorials/circuits/2_plotting_data_in_qiskit.html) and moving the content to API reference: https://github.com/Qiskit/qiskit-tutorials/issues/1436 @Guillermo-Mijares-Vilarino have improved the code examples and explanations for a few ploting functions. But we still need to add usage explanations and code examples that are common to most (if not all) plotting functions, such as `title`, `figsize`, `color` `ax` to the [module level API page](https://qiskit.org/documentation/apidoc/visualization.html) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: transpile not available from import * <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? The `transpile` function is still not available using `from qiskit import *`. The previous issue #2178 was closed assuming that this was fixed, but it is not. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: throw an error (or warning) when an array is silently broadcast to higher dimension Feature request submitted based on in person discussion with @mattjj . Silent overly-generous broadcasting of arrays often masks bugs. (It might make sense for the behavior -- error, warn, silent, where silent corresponds to numpy behavior -- to be controlled by a global variable.) e.g., I believe the following should result in an error or warning: ``` a = np.arange(5) # shape (5,) b = np.zeros((5,5)) # shape (5,5) c = a + b # should throw an error, since a and b have different numbers of dimensions ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Partially missing training_step outputs in training_epoch_end **Learning Model:** the model consists of two branches: **teacher and student**. Two losses have been used to train two branches of the learning model using two optimizers. **ISSUE:** In the **`training_step`**, I produced two set of metrics outputs for teacher (_optimizer_idx=0_) and student (_optimizer_idx=1_) branches (teacher: `{loss,log:{acc, f1}}` and student: `{loss,log:{acc,f1,precision}}` ). But in the **`training_epoch_end`**, I only got the combined outputs for only student outputs (_optimizer_idx=1_). All the teacher outputs (_optimizer_idx=0_) are missing. I also see the training loop of PL and didn't observe any issue when the training loop tries to combine the **`training_step`** outputs. I am not sure what am I missing? - Version: 0.8.2.dev0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Timeout is ambiguous in SSHHook and SSHOperator In SSHHook the timeout argument of the constructor is used to set a connection timeout. This is fine. But in SSHOperator the timeout argument of the constructor is used for *both* the timeout of the SSHHook *and* the timeout of the command itself (see paramiko's ssh client exec_command use of the timeout parameter). This ambiguous use of the same parameter is very dirty. I see two ways to clean the behaviour: 1. Let the SSHHook constructor be the only way to handle the connection timeout (thus, if one wants a specific timeout they should explicitely build a hook to be passed to the operator using the operator's constructor). 2. Split the timeout argument in SSHOperator into two arguments conn_timeout and cmd_timeout for example. The choice between 1 and 2 depends on how frequently people are supposed to want to change the connection timeout. If it is something very frequent. then go for 2. if not go for 1. BR and thanks for the code! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: RFC: Add a generic variable getter method for dependencies We now have 4 different kinds of dependencies, cmake, pkg-config, config-tool, and declare_dependency. pkg-config and config-tool have a method that allow getting arbitrary variables, cmake might but I haven't looked closely. Some dependencies can be found multiple ways (cmake or config-tool for example). Because of that it would be nice to have a generic getter method, such as ```meson dep = dependency('dep') use_thing = dep.get_variable(cmake : 'CMakeVariable', pkg-config : 'pkg-config-variable', config-tool : 'config-tool-argument') ``` Which would be implemented such that each kind of dependency would respect the proper keyword. @jpakkane, opinions? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: DbApiHook: add chunksize to get_pandas_df parameters **Description** The method \"get_pandas_df\" should be extended by the parameter \"chunksize\". **Use case / motivation** For the case that very large amounts of data are read, the \"chunksize\" is a good way to reduce the size of individual queries. **Links** https://github.com/apache/airflow/blob/f4faed6eea70e34da60edcb555fffc9099d3214a/airflow/hooks/dbapi_hook.py#L123 https://github.com/pandas-dev/pandas/blob/0.25.x/pandas/io/sql.py#L344 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Python error on introspect on meson.build file Some introspect methods work on unconfigured builds, but for the other I gets a Python exception. ``` $ meson introspect --dependencies meson.build Traceback (most recent call last): File \"/usr/lib/python3.7/site-packages/mesonbuild/mesonmain.py\", line 122, in run return options.run_func(options) File \"/usr/lib/python3.7/site-packages/mesonbuild/mintro.py\", line 405, in run return print_results(options, results, indent) File \"/usr/lib/python3.7/site-packages/mesonbuild/mintro.py\", line 374, in print_results print(json.dumps(results[0][1], indent=indent)) File \"/usr/lib64/python3.7/json/__init__.py\", line 238, in dumps **kw).encode(obj) File \"/usr/lib64/python3.7/json/encoder.py\", line 201, in encode chunks = list(chunks) File \"/usr/lib64/python3.7/json/encoder.py\", line 429, in _iterencode yield from _iterencode_list(o, _current_indent_level) File \"/usr/lib64/python3.7/json/encoder.py\", line 325, in _iterencode_list yield from chunks File \"/usr/lib64/python3.7/json/encoder.py\", line 405, in _iterencode_dict yield from chunks File \"/usr/lib64/python3.7/json/encoder.py\", line 438, in _iterencode o = _default(o) File \"/usr/lib64/python3.7/json/encoder.py\", line 179, in default raise TypeError(f'Object of type {o.__class__.__name__} ' TypeError: Object of type FunctionNode is not JSON serializable ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: All agents should accept additional env vars for flow \"jobs\" Right now, agents set a pre-defined list of environment variables on all flow run jobs which configure Core to run a certain way and talk to Prefect Cloud. We should open this up a little and allow for users to specify a dictionary of environment variables at agent start time via both `__init__` as well as CLI flags. This would allow for security / sensitive configurations to be set much more seamlessly and securely. E.g., if I want to start a Docker agent which grants S3 access to all of its flow runs, it can set AWS creds on each container job and that doesn't need to be persisted as either a Secret or in code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add annotation option support to gnome.gdbus_codegen gdbus-codegen has an option to inject D-Bus annotations into the given XML files. The option works as follows: `--annotate ELEMENT KEY VALUE` This is the example at [GNOME's developer's corner](https://developer.gnome.org/gio/stable/gdbus-codegen.html): ` gdbus-codegen --c-namespace MyApp \\ --generate-c-code myapp-generated \\ --annotate \"org.project.InterfaceName\" org.gtk.GDBus.C.Name MyFrobnicator \\ --annotate \"org.project.InterfaceName:Property\" bar bat \\ --annotate \"org.project.InterfaceName.Method()\" org.freedesktop.DBus.Deprecated true \\ --annotate \"org.project.InterfaceName.Method()[arg_name]\" snake hiss \\ --annotate \"org.project.InterfaceName::Signal\" cat meow \\ --annotate \"org.project.InterfaceName::Signal[arg_name]\" dog wuff \\ myapp-dbus-interfaces.xml ` I have found it when porting [gnome-control-center](https://git.gnome.org/browse/gnome-control-center/tree/panels/user-accounts/Makefile.am?h=wip/inigomartinez/meson#n79). I tried to use a [custom_target as a workaround](https://git.gnome.org/browse/gnome-control-center/tree/panels/user-accounts/meson.build?h=wip/inigomartinez/meson#n122), but it doesn't work. The main problem seems to be the \"multivalue\" option. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Handle booleans in environment/labels/extra_hosts We've been warning when a boolean value is used in these fields because things like `y`, `yes`, `on`, `off`, are all converted to `True`, which is often not the intent of the user. The warning says we're going to make it an error in the next release, so we should do that. I think our options are: 1. make it an error 2. violate the yaml spec, and only accept `True`, and `False` as booleans, and treat everything else as a string. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: removing upper bound for markupsafe ### Description Per discussion and guidance from #19753, opening this issue and PR https://github.com/apache/airflow/pull/19760 for review. Based on if all the tests pass, this could be reviewed further. ### Use case/motivation Currently Jinja2 upper bound is jinja2>=2.10.1,<4 at https://github.com/apache/airflow/blob/main/setup.cfg#L121 as part of #16595 Jinja2 seems to require MarkupSafe>=2.0 at https://github.com/pallets/jinja/blob/main/setup.py#L6 as part of pallets/jinja@e2f673e Based on this, is it feasible to consider updating upper bound in airflow for markupsafe>=1.1.1, <2.0 to allow 2.0 at https://github.com/apache/airflow/blob/main/setup.cfg#L126 ? ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Removing credentials from 'url' for SCM doesn't play well with SSH git repository hosting - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. conan 1.12+, previous used version was 1.11 Once upon a time there was a pull request #4207 that changed URLs like `ssh://git@a.b.c.d:port/GROUP/repo.git` to `ssh://a.b.c.d:port/GROUP/repo.git` (i.e. without username) for SCM attribute. Recently I updated to conan 1.18.5 and got a problem. I'm pulling sources from a GitLab instance via SSH (I can't change it now to HTTP) and GitLab (I think git hosting services too) doesn't accept SSH connections without username. So what options do I have now? - Every user of package have to execute `git config --global url.ssh://git@a.b.c.d:port.insteadOf ssh://a.b.c.d:port`, i.e. add config to rewrite URL. It doesn't scale well. - Every package developer must hardcode username 'git' in the scm attribute i.e. ```scm = { \"type\": \"git\", \"username\": \"git\", \"url\": \"auto\", \"revision\": \"auto\", } ``` It doesn't scale too and what if someone wants to use HTTPS and his name is not `git`? For me as a user of conan it looks like a regression. Could you suggest a scalable workaround or fix this issue? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Problem: when building a package the http auth credentials are lost in 4.4.2 This is most likely introduced by 4.4.2 - has not existed before! We are using channels that have http auth enabled. Our channel urls look like this: `https://user:password@host.com/path/to/channel/`. Conda in all versions works fine with this. After updating to conda 4.4.2, our conda-build calls fail with: ``` conda.exceptions.CondaHTTPError: HTTP 401 UNAUTHORIZED for url https://host.com/path/to/channel/ ``` Downgrading to 4.4.1 resolves the problem. We saw this error on all platforms (win/linux). There are two interesting observations: - conda still works with auth, just the conda-build process does not - the error message indicates, that the credentials get lost. When a _wrong_ password is specified, then the credentials are usually printed alongside: `conda.exceptions.CondaHTTPError: HTTP 401 UNAUTHORIZED for url https://user:wrong_password@host.com/path/to/channel/`. That leaves the impression that the auth info get lost/dropped somewhere @kalefranz @msarahan I'm not 100% sure whether this is a conda or conda-build bug - but i think its introduced by conda 4.4.2... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Support running validation every fixed number of examples **Is your feature request related to a problem? Please describe.** For IterableDataset, we may not know the length of the dataset in advance. Running validation every X examples would be helpful. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Changing register size can corrupt circuit structures. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.15.0.dev0+63449c4 - **Python version**: Python 3.7.7 - **Operating system**: MacOs 10.15.3 ### What is the current behavior? If a register size is changed using the register \"size\" attribute and the size is smaller than the original, the system is left in an inconsistent state as there may be instructions using one of the bits past the bit index. If the size is larger, a new bit is not added so errors occur if one attempts to use the \"new\" bit. As well, any system or application code using registers or bits as keys to a map becomes inconsistent because the hash changes. ### Steps to reproduce the problem reg = QuantumRegister(2) reg.size = 3 qc = QuantumCircuit(reg) qc.h(2) # fails because the bit was not added: list index out of range reg = QuantumRegister(3) qc = QuantumCircuit(reg) qc.h(2) reg.size=2 print(qc) # fails because qubit is not available: qubit 2 not found ### What is the expected behavior? Register size should be read-only. ### Suggested solutions Register size should be made read-only because changing it changes the hash values for the register and its bits, prohibiting their use as keys for structures such as sets and maps, which would be invalidated as soon as the size changes. Probably the 'name' attribute should also be made read-only as changing that also changes the hash and potentially invalidates keyed structures. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Barrier API documentation is not informative ### What should we add? A Google search for \"[qiskit barrier](https://google.com/search?q=qiskit+barrier)\" leads one to [its entry in the API reference](https://qiskit.org/documentation/stubs/qiskit.circuit.library.Barrier.html) as the first hit. Unfortunately, this page contains only a circular definition, and does not even explain what a barrier does: > Barrier instruction. > > Create new barrier instruction. There is a much more useful description by @chriseclectic on StackExchange, with tens of upvotes. I believe a similar explanation should be incorporated into the `Barrier` docstring(s). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan create not deleting cached sources with scm capture Repository with the `conanfile.py`, scm to auto: In the local project: `conan create . user/channel` `>> Change CMakeLists.txt <<` `conan create . user/channel` **Result**: Conan create is keeping the local cache source folder, so the change in the CMakeLists.txt is not used. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: error on click in dag-dependencies - airflow 2.1 Python version: 3.7.9 Airflow version: 2.1.0 Traceback (most recent call last): File \"/usr/local/lib/python3.7/site-packages/flask/app.py\", line 2447, in wsgi_app response = self.full_dispatch_request() File \"/usr/local/lib/python3.7/site-packages/flask/app.py\", line 1952, in full_dispatch_request rv = self.handle_user_exception(e) File \"/usr/local/lib/python3.7/site-packages/flask/app.py\", line 1821, in handle_user_exception reraise(exc_type, exc_value, tb) File \"/usr/local/lib/python3.7/site-packages/flask/_compat.py\", line 39, in reraise raise value File \"/usr/local/lib/python3.7/site-packages/flask/app.py\", line 1950, in full_dispatch_request rv = self.dispatch_request() File \"/usr/local/lib/python3.7/site-packages/flask/app.py\", line 1936, in dispatch_request return self.view_functions[rule.endpoint](**req.view_args) File \"/usr/local/lib/python3.7/site-packages/airflow/www/auth.py\", line 34, in decorated return func(*args, **kwargs) File \"/usr/local/lib/python3.7/site-packages/airflow/www/decorators.py\", line 97, in view_func return f(*args, **kwargs) File \"/usr/local/lib/python3.7/site-packages/airflow/www/decorators.py\", line 60, in wrapper return f(*args, **kwargs) File \"/usr/local/lib/python3.7/site-packages/airflow/www/views.py\", line 4003, in list if SerializedDagModel.get_max_last_updated_datetime() > self.last_refresh: TypeError: '>' not supported between instances of 'NoneType' and 'datetime.datetime' **What you expected to happen**: See the dags dependencies **What do you think went wrong?** It's happen only if I don't have any dag yet. **How to reproduce it**: With any dag created click in menu -> browser -> dag-dependencies <!--- Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: .condarc: disallow Disallow does not work for --clone. If you add packages to the disallow list, you can still clone them from the root env. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: parameterized circuits raise exception at optimization_level>=2 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? When a parameterized circuit is passed to the compiler with optimization_level>=2 one gets the exception > ParameterExpression with unbound parameters ({Parameter(x)}) cannot be cast to a float. This seems to be due to the commutation analysis pass attempting to convert the rx to a matrix. ### Steps to reproduce the problem ``` qc = QuantumCircuit(1) theta = qiskit.circuit.parameter('theta') qc.rx(theta, 0) qc,x(0) qiskit.compiler.transpile(qc, optimization_level=3) ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Storage] make_public() and public_url() don't describe how they work/when they work. Documentation for `make_public()` and `public_url()` don't describe how they work/when they work. Specifically `make_public()` uses ACLs to make the object public and `public_url()` only works when the object has necessary permissions granted to all users in the form of `ACL` or a project/bucket has an IAM policy assigning `allUsers` the role `roles/storage.objectViewer`. Users should stay away from project-level IAM policies with allUsers roles/storage.objectViewer` that would not be good. (noting this down as I don't want to forget it.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Don't draw pulse Schedule name by default when plotting <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Pulse schedule names are currently being drawn by default. Most names are useless as they are automatically generated. Names should be drawn as an optional flag. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Can't build projects dynamically linked to boost.log Since this change: https://github.com/mesonbuild/meson/blob/7c68fe80083fd72a100998578417b223e3704af5/mesonbuild/dependencies/boost.py#L791 I can't compile anymore some applications dynamically linked to boost.log: ``` /usr/include/boost169/boost/log/detail/config.hpp:225: error: \"BOOST_LOG_DLL\" redefined [-Werror] # define BOOST_LOG_DLL <command-line>: note: this is the location of the previous definition ``` I think that `-DBOOST_LOG_DLL` should not specified (see https://www.boost.org/doc/libs/1_72_0/libs/log/doc/html/log/rationale/namespace_mangling.html) but only `-DBOOST_LOG_DYN_LINK=1` Tested with boost from 1.69 to 1.72 on CentOS and MacOS. If you confirm that `-DBOOST_LOG_DLL` can be removed I can provide a PR, just let me know . Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Simple dynamic circuits raise RuntimeWarning ### Environment - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is happening? The following code gives a warning on MPL drawing ```python qc = QuantumCircuit(1, 1) qc.measure(0, 0) with qc.if_test((0, True)): qc.x(0) qc.draw('mpl') ``` RuntimeWarning: Cregbundle set to False since an instruction needs to refer to individual classical wire self._get_layer_widths() ### How can we reproduce the issue? run above ### What should happen? no warning should happen ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Support DAGS folder being in different location on scheduler and worker. **Description** Dags folder in celery workers can be kept at different location as kept in Airflow scheduler node. Airflow task run can use dag full file path based on airflow home configuration on their node given dag file relative path to dags folder. **Use case / motivation** Currently scheduler uses absolute path for dags file to schedule task in task run command (`-sd` arg). This command makes hard to keep dags folder at different locations in celery workers which may be running in different environment. So using Airflow with celery with cross environment setup is difficult. This feature will help to keep dags folder at any location at worker nodes and tasks command can be configured for dag file path using home configuration. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Split one token into several ## Feature description We now have a feature to merge tokens into one, implemented in the retokenizer. We're lacking the reverse feature: split one token into several. An API exist in _retokenize, but is not implemented yet. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose failed if is in path what contains dir starting on `_` ## Description of the issue docker-compose failed if is in path what contains dir starting on `_` ## Context information (for bug reports) can run docker-compose build if `docker-compose.yml` is in `_docker` dir as in before version getting ERROR: invalid reference format when I rename dir `_docker` to `docker` everything run good ``` docker-compose version 1.21.1, build 5a3f1a3 docker-py version: 3.3.0 CPython version: 3.6.4 OpenSSL version: OpenSSL 1.0.2o 27 Mar 2018 ``` ``` Client: Version: 18.03.1-ce API version: 1.37 Go version: go1.9.5 Git commit: 9ee9f40 Built: Thu Apr 26 07:13:02 2018 OS/Arch: darwin/amd64 Experimental: false Orchestrator: swarm Server: Engine: Version: 18.03.1-ce API version: 1.37 (minimum version 1.12) Go version: go1.9.5 Git commit: 9ee9f40 Built: Thu Apr 26 07:22:38 2018 OS/Arch: linux/amd64 Experimental: true ``` ## Steps to reproduce the issue 1. move docker-compose.yml (contains service: build: .... ) to _docker dir 2. run docker-compose build ## Additional information Docker for Mac: version: 18.03.1-ce-mac65 (dd2831d4b7421cf559a0881cc7a5fdebeb8c2b98) macOS: version 10.13.4 (build: 17E202) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Installer package is missing conan.tools.scm When creating a PyInstaller package conan.tools.scm is missing. When using the generated executable this error message is shown when the conanfile.py uses conan.tools.scm: ``` Error loading conanfile at 'conanfile.py': Unable to load conanfile in /xxx/conanfile.py File \"<frozen importlib._bootstrap>\", line 719, in _load File \"<frozen importlib._bootstrap>\", line 688, in _load_unlocked File \"<frozen importlib._bootstrap_external>\", line 883, in exec_module File \"<frozen importlib._bootstrap>\", line 241, in _call_with_frames_removed File \"/xxx/conanfile.py\", line 8, in <module> from conan.tools.scm import Git ModuleNotFoundError: No module named 'conan.tools.scm' ``` I will provide a fix. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Changing kernels quickly leaks fds and crashes the notebook If you open a notebook and then rapidly change between different kernels a couple of things happen: - The main server process leaks fds and eventually runs out (quickly on OS X). - The notebook IU will alter on websocket connection failures. - The terminal will log the following: ``` [E 15:11:06.765 tornado.application] Uncaught exception in /api/kernels/4920106a-3f6c-42ac-96fb-6d6520372225/shell Traceback (most recent call last): File \"/Users/bgranger/anaconda/lib/python2.7/site-packages/tornado/websocket.py\", line 322, in wrapper return callback(*args, **kwargs) File \"/Users/bgranger/github/ipython/ipython/IPython/html/services/kernels/handlers.py\", line 149, in on_message self.session.send(self.zmq_stream, msg) File \"/Users/bgranger/github/ipython/ipython/IPython/kernel/zmq/session.py\", line 658, in send stream.send_multipart(to_send, copy=copy) AttributeError: 'NoneType' object has no attribute 'send_multipart' ``` My guess is that the issue is caused by changing kernels before the previous kernel was fully running. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Submodule._to_relative_path trims start of path when super repo is directly the root of a Windows Drive Given a repository say at `D:` Create a submodule at `D:\\submodule_path` `Submodule._to_relative_path` will return `ubmodule_path` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Would be nice if conda config --get channels listed the channels in priority order As far as I can tell it currently lists them in reverse order. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Document pmap on pytrees The pmap documentation does not mention how it can be used on pytrees or what it is supposed to do when pytrees are involved. For example, code like what is pasted below in Trax seems to do things on pytrees. ``` @functools.partial(backend.pmap, axis_name='batch') def mapped_predict(x, params, state, rng): return model_predict(x, params=params, state=state, rng=rng) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda info always shows 'unknown' for admin indicator on Windows Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: credentials failed for qiskit ver 0.6.1 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: 0.6.1 - **Python version**: 3.7.0 - **Operating system**:MAC OSX 10.13.6 ### What is the current behavior? After I acquired fresh token from https://quantumexperience.ng.bluemix.net/qx/account/advanced IBMQ.load_accounts() fails. ### Steps to reproduce the problem ``` from qiskit import IBMQ myToken='b6abe11442c9a...' IBMQ.save_account(myToken) IBMQ.load_accounts() ``` Results with ``` Traceback (most recent call last): File \"/anaconda3/lib/python3.7/site-packages/qiskit/backends/ibmq/ibmqsingleprovider.py\", line 71, in _authenticate credentials.verify) File \"/anaconda3/lib/python3.7/site-packages/IBMQuantumExperience/IBMQuantumExperience.py\", line 478, in __init__ self.req = _Request(token, config=config, verify=verify) File \"/anaconda3/lib/python3.7/site-packages/IBMQuantumExperience/IBMQuantumExperience.py\", line 253, in __init__ ntlm_credentials=self.ntlm_credentials) File \"/anaconda3/lib/python3.7/site-packages/IBMQuantumExperience/IBMQuantumExperience.py\", line 95, in __init__ self.obtain_token(config=self.config) File \"/anaconda3/lib/python3.7/site-packages/IBMQuantumExperience/IBMQuantumExperience.py\", line 159, in obtain_token raise CredentialsError('error during login: %s' % error_message) IBMQuantumExperience.IBMQuantumExperience.CredentialsError: error during login: Wrong user or password, check your credentials. ``` ### What is the expected behavior? Would be better if IBMQ.load_accounts() accepted me. All worked well w/ ver 0.5. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: line_length in text drawer needs a default <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? Large circuits are scrambled when using the text-based circuit drawer.  vs <img width=\"824\" alt=\"screen shot 2018-11-01 at 6 16 35 pm\" src=\"https://user-images.githubusercontent.com/1249193/47883114-48f33780-de02-11e8-9c5d-9448bf45364c.png\"> ### Steps to reproduce the problem Make a large circuit and draw it. ### What is the expected behavior? ### Suggested solutions Have the text-based circuit wrap according to the size of the terminal or Jupyter notebook cell width, and split like the Matplotlib version does. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 32 bit warning with Xcode backend on Catalina <img width=\"1512\" alt=\"Screen Shot 2019-10-11 at 6 54 30 PM\" src=\"https://user-images.githubusercontent.com/10180857/66689367-9144e780-ec58-11e9-83b3-9d9a523cd883.png\"> Using a simple project with a single main.c ```c #include <stdio.h> int main(int argc, char **argv) { printf(\"Hello there.\\n\"); return 0; } ``` ```python project('c', 'c') executable('main', 'main.c') ``` I ran `meson --backend xcode xcode` and then opened the Xcode project in Xcode and got the error in the screenshot. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose exec issue Im not sure why/what is going wrong with this, but Im trying to refactor some docker exec commands I use to docker-compose exec so I don't have to rely on grep name workaround for dynamic container names. example OLD docker exec command I use is - ``` docker exec -i $(docker ps --format {{.Names}} | grep db) mysql -u dev -pDEVPASSWORD dev_db < latest.sql ``` An example docker-compose exec command that IS working is - ``` docker-compose exec -T db mysql -u dev -pDEVPASSWORD -Bse \"create database dev_db;\" ``` But when I try to execute the standard mysql import nothing happens - ``` docker-compose exec -T db mysql -u dev -pDEVPASSWORD dev_db < latest.sql ``` It just hangs. thing only things that show in the mysql.log for the last command is the rolling - ``` 170104 19:50:37 82 Connect dev@localhost as anonymous on dev_db 82 Query select @@version_comment limit 1 ``` thoughts? ideas? Am I missing something? Happy to provide any more info or run any tests that may help diagnose if this even is an issue. thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [TF Longformer] Add Multiple Choice, Seq Classification Model # 🚀 Feature request `modeling_longformer.py` has the classes `LongformerForSequenceClassification`, `LongformerForMultipleChoice` and `LongformerForTokenClassification` which are not present in `modeling_tf_longformer.py` at the moment. Those classes should be equally added to `modeling_tf_longformer.py`. ## Motivation The pretrained weights for TFLongformer are available so that these classes could be used for finetuning. ## Your contribution This issue is a good first issue because it is not too complicated to add these models. One should take a look at `modeling_tf_roberta.py` to see how these models are implemented for `TFRoberta` and implement them analogous for `TFLongformer`. Please make sure that the docstring is correct and that test are added for each class (again Roberta can serve as an example here, check out `test_modeling_tf_roberta.py`). I am happy to guide interested community contributors through the PR and help them get it merged. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Result.utils.marginal_counts returns inconsistent creg structure for multiple cregs <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master @ d26f273d - **Python version**: 3.6 - **Operating system**: osx ### Steps to reproduce the problem ```python from qiskit import * qr_data = QuantumRegister(3, 'qr_data') qr_anc = QuantumRegister(2, 'qr_anc') cr_data = ClassicalRegister(3, 'cr_data') cr_anc = ClassicalRegister(2, 'cr_anc') qc = QuantumCircuit(qr_data, qr_anc, cr_data, cr_anc) qc.x(qr_data) qc.measure(qr_data, cr_data) qc.measure(qr_anc, cr_anc) qc.draw('mpl') ```  ```python result = execute(qc, Aer.get_backend('qasm_simulator')).result() result.get_counts() ``` ``` {'00 111': 1024} ``` ```python from qiskit.result.utils import marginal_counts marginal_counts(result, [0, 1, 2]).get_counts() ``` ``` {'11 1': 1024} ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: backend overview and plot_gate_map show matplotlib warning <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.5 - **Operating system**: mac Matplotlib version 3.0.3 ### What is the current behavior? > /Users/kevin.krsulichibm.com/q/qiskit-terra/lib/python3.5/site-packages/matplotlib/figure.py:2369: UserWarning: This figure includes Axes that are not compatible with tight_layout, so results might be incorrect. warnings.warn(\"This figure includes Axes that are not compatible \" <img width=\"1141\" alt=\"image\" src=\"https://user-images.githubusercontent.com/2241698/65148384-12a8b180-d9ee-11e9-8260-1ade309f5842.png\"> <img width=\"1119\" alt=\"image\" src=\"https://user-images.githubusercontent.com/2241698/65149025-58b24500-d9ef-11e9-975c-224fa2eadd6c.png\"> Only occurs on the first call, so recalling the function will clear the warning ### Steps to reproduce the problem ``` %matplotlib inline import matplotlib.pyplot as plt import qiskit.tools.jupyter qk.IBMQ.load_account() ibmq_open_provider = qk.IBMQ.get_provider( hub = 'ibm-q', group = 'open', project = 'main' ) %qiskit_backend_overview from qiskit.visualization import plot_gate_map plot_gate_map(ibmq_open_provider.get_backend('ibmqx2')) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: result.get_counts() should return all counts if called with no arg <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? `job.result().get_counts()` should return a list of all the counts available when there are multiple circuits in a job. This allows, for example, doing: ``` plot_histogram(result.get_counts()) ``` verses having to explicitly write out the counts indexing by hand, or in a loop using `len(job.result().results)` and appending to a new list. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `to_instruction()` of a loop-body circuit fails if the loop-body has `if_test` with `clbit` condition. ### Environment - **Qiskit Terra version**: main (f85cd87247be95572d28f038ac19b2bab7636346) - **Python version**: Any - **Operating system**: Any ### What is happening? `UnboundLocalError` is thrown when a loop-body circuit calls `to_instruction()`. ``` File \"error.py\", line 14, in <module> loop_body.to_instruction() File \"site-packages/qiskit/circuit/quantumcircuit.py\", line 1482, in to_instruction return circuit_to_instruction(self, parameter_map, label=label) File \"site-packages/qiskit/converters/circuit_to_instruction.py\", line 123, in circuit_to_instruction rule[0].condition = (c[idx + list(cond_reg).index(reg)], val) UnboundLocalError: local variable 'cond_reg' referenced before assignment ``` The loop-body has `if_test` and its test expression is a tuple of `Clbit` and a value. If the tuple consists of `ClassicalRegister` and a value, this error does not occur. ### How can we reproduce the issue? ``` from qiskit import QuantumCircuit from qiskit.circuit import QuantumRegister, ClassicalRegister qreg = QuantumRegister(4) creg = ClassicalRegister(1) circ = QuantumCircuit(qreg, creg) with circ.for_loop(range(1)): with circ.if_test((circ.clbits[0], 0)): circ.h(0) for_loop_inst, _, _ = circ._data[0] loop_body = for_loop_inst.params[2] loop_body.to_instruction() ``` ### What should happen? No error. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Removing a service causes \"up\" to fail Run this app: ``` web: image: nginx links: - redis redis: image: redis ``` Now change to this: ``` web: image: nginx ``` and then: ``` $ docker-compose up Starting composedemo_web_1... Cannot start container 757b1fb7911f12a2cb06a22c7de192da687f5042daf6a4db30d76a487f71f94a: Cannot link to a non running container: /composedemo_redis_1 AS /composedemo_web_1/composedemo_redis_1 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add support for `Expr` values to `DAGCircuit.compose` ### What should we add? Similar to #10226 and #10227, we need support for mapping `Expr` values in `DAGCircuit.compose`. A lot of the work will likely be quite similar to those two issues. Depends on #10223 and #10224. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Raise exceptions instead of using assertions for control flow https://github.com/huggingface/transformers/blob/546dc24e0883e5e9f5eb06ec8060e3e6ccc5f6d7/src/transformers/models/gpt2/modeling_gpt2.py#L698 Assertions can't be relied upon for control flow because they can be disabled, as per the following: ```shell $ python --help usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ... ... -O : remove assert and __debug__-dependent statements; add .opt-1 before .pyc extension; also PYTHONOPTIMIZE=x ... ``` From my understanding, this is why mypy has no qualms about using them to narrow types because you can turn them off at runtime and so they incur zero cost. Would you be open to me changing these assertions to other appropriate exceptions as I encounter them? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: reduce client caching of results The current parallel code doesn't _need_ to store much in memory. But it does, particularly in the Client. We cache results for convenience in the Client's `results` and `metadata` dicts. This data is readily reproducible from the the Hub, so discarding it beyond a certain point shouldn't be an issue. To easily run your client out of memory, simply echo a large array a number of times: ``` python A = np.zeros(1024*1024) for i in range(100): rc[0].apply_sync(lambda x:x, A) ``` And bam, you have 100 copies of A in memory. We should figure out a sensible scheme for purging old results, so the client doesn't grow too much during data-intensive tasks. One thing we could do is have AsyncResult objects _remove_ results from the Client's result dict when they are retrieved. It's true that it's possible to have multiple AsyncResults pointing to the same message, but it's not likely, and shouldn't come up in normal use. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: custom_target() doesn't accept SharedLibrary as command argument When using a library as command argument, you get a RuntimeError: is of unknown type <class 'mesonbuild.build.SharedLibrary'> ``` lib = library('foo', sources) abidw = find_program('abidw') custom_target('abi', output : 'libfoo.abi', command : [abidw, lib] ) ``` That seems enough: ```diff diff --git a/mesonbuild/backend/backends.py b/mesonbuild/backend/backends.py index 687b12265..b220bc730 100644 --- a/mesonbuild/backend/backends.py +++ b/mesonbuild/backend/backends.py @@ -960,7 +960,7 @@ class Backend: # Evaluate the command list cmd = [] for i in target.command: - if isinstance(i, build.Executable): + if isinstance(i, (build.SharedLibrary, build.SharedModule, build.Executable)): cmd += self.exe_object_to_cmd_array(i) continue elif isinstance(i, build.CustomTarget): ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Can't open task log from Gantt view ### Apache Airflow version 2.2.1 ### Operating System Linux 5.4.149-73.259.amzn2.x86_64 ### Versions of Apache Airflow Providers default for 2.2.1 ### Deployment Other 3rd-party Helm chart ### Deployment details aws eks using own-developed helm chart ### What happened When trying to open log from gantt view - receiving an exception ``` File \"/home/airflow/.local/lib/python3.9/site-packages/pendulum/parsing/__init__.py\", line 177, in _parse_common return date(year, month, day) ValueError: year 0 is out of range ``` due to incorrect query parameter push: no value for `execution_date` pushed ``` /log?dag_id=report_generator_daily&task_id=check_quints_earnings&execution_date= ``` ### What you expected to happen Logs should be available ### How to reproduce Open dag's `gantt` chart click on task ribbon click on `log` observe an error ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Hoare optimizer fails for some circuits ### Environment - **Qiskit Terra version**: 0.19.0.dev0+a603740 - **Python version**: 3.8.5 - **Operating system**: Linux ### What is happening? Certain simple circuits fail raising a ValueError in `_multigate_opt` when trying to remove a node from its self.gatecache. I came across this when running random circuits through the pass and failures seem to occur when there are repeated gates at the beginning or end of the circuit. ### How can we reproduce the issue? ```python from qiskit import QuantumCircuit from qiskit.converters import circuit_to_dag import qiskit.transpiler.passes.optimization.hoare_opt as hoare qc = QuantumCircuit(1) qc.h(0) qc.h(0) qc.h(0) qc.rx(0.1, 0) hoare.HoareOptimizer().run(circuit_to_dag(qc)) ``` ### What should happen? Shouldn't get an exception. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Internal error when embedding app Celery 3.1.13 and 3.1.16 (latest release as of this writing) I'm wrapping the celery app inside a utility class, which constructs the app and the worker: ``` python self.celery = celery.Celery() self.worker = self.celery.WorkController(pool_cls='solo', queues=[self.queue_name]) self.celery.task(self._receive_callback, name=self.callback_task_name) ``` The utility class has a start() method which starts the worker like this: ``` python t = threading.Thread(target=self.worker.start) # Starting the worker in a daemonic thread so that it doesn't keep the process # alive when the main thread exits t.setDaemon(True) t.start() ``` When the embedded app receives the task it crashes with the following traceback: ``` python CRITICAL:celery.worker.job:Task [my_task_name][cfe87fb7-373d-4082-a72c-0f44d265cc9f] INTERNAL ERROR: AttributeError(\"'NoneType' object has no attribute 'loader'\",) Traceback (most recent call last): File \"/virtualenvdir/lib/python2.7/site-packages/celery/app/trace.py\", line 333, in trace_task task.__trace__ = build_tracer(task.name, task, **opts) File \"/virtualenvdir/lib/python2.7/site-packages/celery/app/trace.py\", line 160, in build_tracer loader = loader or app.loader AttributeError: 'NoneType' object has no attribute 'loader' ``` I printed the stack trace from the exception handler in celery.app.trace.trace_task right before report_internal error is called and the error seems to be triggered in _trace_task_ret: ``` python def _trace_task_ret(name, uuid, args, kwargs, request={}, app=None, **opts): return trace_task((app or current_app).tasks[name], uuid, args, kwargs, request, app=app, **opts) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Update `DotDict` docstring We should update the `DotDict` class docstring to clearly articulate what can / can't be accessed via `.`: - only valid python identifiers (no numbers, etc.) - no dunders `__X` gets converted to `_DotDict__X` via mangling Changelog doesn't update in doc builds Looking at #297 I realize that our formatted docs Changelog doesn't update (we use a static file); we should start updating this as we do the `README.md` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython 3.0 breaks compatibility with emacs-ipython-notebook Some more details in millejoh/emacs-ipython-notebook#4, but essentially emacs-ipython-notebook currently supports the REST protocol described in IPEP 16 and not IPEP 27. My primary concern is in supporting both IPython 2.0 and 3.0 as 3.0 adoption probably won't be instantaneous. Is there a cross-version API for querying the version of IPython notebook? I am probably missing something obvious. Any other suggestions on how to support two different REST APIs (actually three, but I'm not planning on supporting IPython versions earlier than 2.0) in emacs-ipython-notebook greatly welcomed. Also please permit me some old man grumbling for a moment - you guys are going to stick with the API specified in IPEP27 from now on, right? Or at least try in the future to make sure any changes are backwards-compatible? Chasing API's is certainly helping me learn a fair amount about IPython and ein, but it isn't exactly the most productive use of time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error in doc string for `QuantumCircuit.assign_parameters` In the following \"True\" should be replaced by \"False\" https://github.com/Qiskit/qiskit-terra/blob/33e7448a22ccb74c3e2a288c242a1da411ab195e/qiskit/circuit/quantumcircuit.py#L2147-L2149 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 33e7448 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: __linux virtual package <!-- Hi! Read this; it's important. This is an issue tracker for conda -- the package manager. File feature requests for conda here, as well as bug reports about something conda has messed up. Anaconda Community Code of Conduct: https://www.anaconda.com/community-code-of-conduct/ If your issue is a feature request for: * a specific conda package from Anaconda ('defaults' channel): ==> file at https://github.com/ContinuumIO/anaconda-issues * a specific conda package from conda-forge: ==> file at the corresponding feedstock under https://github.com/conda-forge * repo.anaconda.com access and service: ==> file at https://github.com/ContinuumIO/anaconda-issues * anaconda.org access and service: ==> file at https://anaconda.org/contact/report * commands under 'conda build': ==> file at https://github.com/conda/conda-build * commands under 'conda env': ==> please file it here! * all other conda commands that start with 'conda': ==> please file it here! --> Hi, currently, there are `__unix` and` __linux` virtual packages. It would be nice to have one for Linux a well. Based on #10214 I would assume this to be something along the lines of: ```python if is_linux: rec = _make_virtual_package('__linux') index[rec] = rec ``` Happy to create the PR but just wanted to check first if that'd be the correct approach? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Unify conversion of datetime <--> timestamp strings Use a shared formatting string for the \"RFC 3339 w/ microseconds\" format, and centralize conversion of datetimes to strings and back (w/ `pytz.utc` zone). See: - https://github.com/GoogleCloudPlatform/gcloud-python/pull/816#discussion_r28172973 - https://github.com/GoogleCloudPlatform/gcloud-python/pull/816#discussion_r28173336 - https://github.com/GoogleCloudPlatform/gcloud-python/pull/816#discussion_r28180427 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: DAG visualization dependence on graphviz is not mentioned <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: latest - **Python version**: 3.7 - **Operating system**: OSX ### What is the current behavior? Calling `dag_drawer(dag)` gives the error: ```python InvocationException: GraphViz's executables not found ``` indicating that `GraphViz` is a requirement for this function, but it is not listed anywhere. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: flow.visualize() fails on windows A simple flow.visualize() command fails when running on Windows. Looks like it's due to the way that windows creates tempfiles (see this thread: https://stackoverflow.com/questions/23212435/permission-denied-to-write-to-my-temporary-file) Traceback (most recent call last): File \"C:\\Dev\\source\\python\\prefecttesting\\dostuff.py\", line 34, in <module> flow.visualize() File \"C:\\Dev\\source\\python\\prefecttesting\\venv\\lib\\site-packages\\prefect\\core\\flow.py\", line 1106, in visualize graph.render(tmp.name, view=True) File \"C:\\Dev\\source\\python\\prefecttesting\\venv\\lib\\site-packages\\graphviz\\files.py\", line 183, in render filepath = self.save(filename, directory) File \"C:\\Dev\\source\\python\\prefecttesting\\venv\\lib\\site-packages\\graphviz\\files.py\", line 155, in save with io.open(filepath, 'w', encoding=self.encoding) as fd: PermissionError: [Errno 13] Permission denied: 'c:\\\\dev\\\\temp\\\\tmpn3cczj0a' Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Change QuantumCircuit method input arg names <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Make the following changes for the qubit naming conventions used in `QuantumCircuit` methods: `ctl -> control_qubit` `tgt -> target_qubit` `q -> qubit` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Improve AutoToolsBuildEnvironment target triple Currently AutoToolsBuildEnvironment's `configure` ignores `os_target`, `arch_target` settings, even if `target=None`. The documentation says: > target (Optional, Defaulted to None): To specify a value for the parameter --target. If None it will try to detect the value if cross-building is detected according to the settings. If False, it will not use this argument at all. Currently it requires `arg` to be passed in with `--target=<target_triple>`. In my situation we are not cross building, but we are making cross compiler tools (build==host, target different). In my opinion the only thing that makes sense is to propagate `os_target` and `arch_target` to the relevant triple or None when target triple is irrelevant. [see patch](/Ignition/conan/commit/fd4d0eb6774e8e0137ec9a6d5550750b746b8762) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Better support for handling block diagonal matrices Dear JAX team, Thanks for the amazing work with JAX! I'm currently doing some work which would really benefit from support for handling block diagonal matrices. In particular, I would like to assemble matrices using something like `scipy.linalg.block_diag` (https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.linalg.block_diag.html). It would also be nice to be able to split them again, but that's a bit awkward in numpy too and I think could be done using slicing. I've been able to work around this for now using kronecker products, but it's not very neat. Would this be hard to add? Could give it a go too if it's not too hard and there's a rough plan (maybe scatter would be one way to go?). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Right arrow broken in 8.12.1 The -> arrow doesn't work. When I press the <- arrow to go back and edit the current command, Ipython ignores it. I don't think my explanation is very clear, so here is an example. If I type: ``` In [1]: print(A ``` And realise I forgot to open the quotes, I go back, ``` In [1]: print(\"|A ``` Now I am stuck, and cannot \"hop\" over A. I can keep moving backwards, though. Pressing `end` does work. I have replicated it in an empty virtualenv under both Python 3.9 and 3.10. The problem disappears downgrading to Ipython 8.12.0. I am using Fedora Linux, with Qterminal 1.1.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Big query TIMESTAMP field off by factor of 1000 Using master branch. In BigQuery TIMESTAMP fields are off by a factor of 1000 when using fetch_data. See my in-line comment - https://github.com/GoogleCloudPlatform/gcloud-python/commit/41e64395661a31af8352fb2358e5c95ff5437830#diff-c56e349a3e511bfabb4e8dfcfe686bc8R739 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %save magic fails in clients without stdin if file already exists `%save` fails in the nb/qtconsole if a file already exists, because it tries to ask the user interactively and this produces a `StdinNotImplementedError`. We should in that case capture the exception, print instead a message and offer a -f option to support forced writes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Nested flow control for Passmanagers <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Skimming through the pass manager code and reading the documentation (which is quite lacking) for building pass managers I do not see an option to nest flow control. The `FlowController` class is only attached to a set of passes which makes it impossible to apply an additional flow controller on a subset of those passes. For example the use case I have in mind is to have a condition in a do while loop, for example something like: ```python while not fixed_point: pass_a() pass_b() check_pass() if not check_pass_result: pass_d() pass_e() pass_f() ``` which at least I couldn't find a way to represent in the current pass manager structure. It would be very useful as we make the pass manager more sophisticated to have nested flow control like this. If I just missed it we should improve the documentation around this (which honestly we need regardless). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %guiref in qtconsole broken With the latest git master, %guiref gives the following error in qtconsole: ``` In [1]: %guiref --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-1-abc9b6d653cc> in <module>() ----> 1 get_ipython().magic(u'guiref') /Users/takimoto/Library/Python/2.7/lib/python/site-packages/IPython/core/interactiveshell.pyc in magic(self, arg_s) 2238 magic_name, _, magic_arg_s = arg_s.partition(' ') 2239 magic_name = magic_name.lstrip(prefilter.ESC_MAGIC) -> 2240 return self.run_line_magic(magic_name, magic_arg_s) 2241 2242 #------------------------------------------------------------------------- /Users/takimoto/Library/Python/2.7/lib/python/site-packages/IPython/core/interactiveshell.pyc in run_line_magic(self, magic_name, line) 2159 kwargs['local_ns'] = sys._getframe(stack_depth).f_locals 2160 with self.builtin_trap: -> 2161 result = fn(*args,**kwargs) 2162 return result 2163 /Users/takimoto/Library/Python/2.7/lib/python/site-packages/IPython/core/usage.pyc in page_guiref(arg_s) 567 \"\"\"Show a basic reference about the GUI Console.\"\"\" 568 from IPython.core import page --> 569 page.page(gui_reference, auto_html=True) 570 TypeError: page() got an unexpected keyword argument 'auto_html' ``` See #5902 for my system info. May be related with the commit 095e73ab7386af077968a3bb6c28e5d88d9abe60 ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: do_lower_case not saved/loaded correctly for Tokenizers ## Environment info - `transformers` version: 3.4.0 - Platform: Linux-5.4.0-52-generic-x86_64-with-debian-buster-sid - Python version: 3.7.6 - PyTorch version (GPU?): 1.5.1 (False) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help @mfuntowicz ## Information The `do_lower_case` property of BertTokenizer is not correctly restored after saving / loading. ## To reproduce ```python from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\") print(tokenizer.do_lower_case) tokenizer.save_pretrained(\"debug_tokenizer\") tokenizer_loaded = BertTokenizer.from_pretrained(\"debug_tokenizer\") print(tokenizer_loaded.do_lower_case) ``` returns ``` False True ``` ## Expected behavior Same object attributes after saving / loading Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Remove references to `return_tasks` in docs As identified by @ntaylorwss, some of the docs and tutorials reference the `return_tasks` kwarg that was removed in #693, and will need updating before the next release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: add -w--workdir= option to docker-compose run Same as docker Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: on 64 bit host, cross compilation install libraries in \"lib64\" instead of \"lib\" I use a x86_64 machine to cross compile for a 32bit mips platform. My \"cross_file.txt\" is: ```ini c = '/opt/br_mips-2013.11/usr/bin/mips-linux-gcc' cpp = '/opt/br_mips-2013.11/usr/bin/mips-linux-g++' ar = '/opt/br_mips-2013.11/usr/bin/mips-linux-ar' strip = '/opt/br_mips-2013.11/usr/bin/mips-linux-strip' [host_machine] system = 'linux' cpu_family = 'mips' cpu = 'mips' endian = 'big' ``` Unfortunately when i run the \"ninja install\" target the libraries are installed in the \"lib64\" directory instead of the \"lib\" directory. I've checked the \"meson_install.py\" script but i didn't found any reference to the lib directory, what is the correct source file to check? Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Here maybe a bug, when we load staged checkpoint https://github.com/huggingface/transformers/blob/40d98ebf50c4662bcd6dce6395bbed0b2142ea52/src/transformers/trainer.py#L458 I met this bug when I used the setting below: global_steps = 2748 len(train_dataloader) = 27484 gradient_accumulation_steps = 4 In the original code, \"steps_trained_in_current_epoch\" will be 2748 ! BUT this variable should be 2748*4 = 10,992 the code I suggested is below: ``` epochs_trained = (self.global_step * self.args.gradient_accumulation_steps) // len(train_dataloader) steps_trained_in_current_epoch = (self.global_step * self.args.gradient_accumulation_steps) % len(train_dataloader) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Attempt to `create schema if not exists ...` crashes flow when connector role lacks permissions to create schemas in the database ### Dagster version 1.1.21 ### What's the issue? The snowflake connector tries `create schema if not exists ...` prior to materializing a DataFrame as a Snowflake table. This causes flows to crash when the Snowflake role assigned to the connector lacks privileges to create schemas in the database. It is related to this pull request: https://github.com/dagster-io/dagster/pull/11764 ### What did you expect to happen? Check whether a schema exists before trying to create it, but do so in a way that will not return an error from Snowflake when the connector's role lacks privileges to create schemas. ### How to reproduce? Use a role with access to a schema but that lacks privileges to create a new schema. ### Deployment type Docker Compose ### Deployment details _No response_ ### Additional information This is a dagster-breaking bug for me and I will not be able to upgrade to a new version until it is addressed. ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gnome yelp: install fails with symlink_media if icon exists already Running `ninja install` twice will error out with gnome.yelp(): ```nstalling /tmp/nettool/help/ca/network-connectivity.page to /tmp/prefix/share/help/ca/gnome-nettool/network-connectivity.page Symlinking /tmp/prefix/share/help/ca/gnome-nettool/figures/gnome-nettool-trail.png to /tmp/prefix/share/help/C/gnome-nettool/figures/gnome-nettool-trail.png. Traceback (most recent call last): File \"/home/tpm/Devel/meson/meson.py\", line 37, in <module> sys.exit(main()) File \"/home/tpm/Devel/meson/meson.py\", line 34, in main return mesonmain.run(launcher, sys.argv[1:]) File \"/home/tpm/Devel/meson/mesonbuild/mesonmain.py\", line 269, in run sys.exit(run_script_command(args[1:])) File \"/home/tpm/Devel/meson/mesonbuild/mesonmain.py\", line 257, in run_script_command return cmdfunc(cmdargs) File \"/home/tpm/Devel/meson/mesonbuild/scripts/yelphelper.py\", line 114, in run destdir, options.project_id, options.symlinks) File \"/home/tpm/Devel/meson/mesonbuild/scripts/yelphelper.py\", line 82, in install_help os.symlink(srcfile, outfile) FileExistsError: [Errno 17] File exists: '/tmp/prefix/share/help/C/gnome-nettool/figures/gnome-nettool-trail.png' -> '/tmp/prefix/share/help/ca/gnome-nettool/figures/gnome-nettool-trail.png' Failed to run install script '/usr/bin/python3 /home/tpm/Devel/meson/meson.py --internal yelphelper install --subdir=help --id=gnome-nettool --installdir=share/help --sources=index.page@@introduction.page@@ip-information.page@@network-connectivity.page --symlinks=true --media=figures/gnome-nettool-trail.png@@figures/gnome-nettool.png --langs=ca@@cs@@da@@de@@el@@en_GB@@es@@fr@@hu@@ko@@oc@@pa@@pl@@pt_BR@@ru@@sv@@uk@@vi@@zh_CN' FAILED: install ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: jupyter labextension uninstall deletes federated extensions <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description `jupyter labextension uninstall` deletes federated extensions, but federated extensions should not be managed by `jupyter labextension`, since they are managed by other package managers. ## Reproduce ``` conda create -y -n jlab-extension python nodejs conda activate jlab-extension pip install --pre jupyterlab pip install --pre jupyterlab_widgets ``` This installs the new federated extension for ipywidgets. We can see it in ``` jupyter labextension list ``` We can uninstall it with ``` jupyter labextension uninstall @jupyter-widgets/jupyterlab-manager ``` ## Expected behavior I expect `jupyter labextension list` to distinguish between federated and non-federated extensions, i.e., extensions installed by `labextension` and those that are not. I expect `jupyter labextension uninstall` to not uninstall federated extensions, since it is not responsible for managing their files and cannot install them. Essentially, by uninstalling by removing the appropriate share directory, you are deleting files installed by a python package without uninstalling the python package, messing things up. ## Context <!--Complete the following for context, and add any other relevant context--> - Operating System and version: macOS Catalina - JupyterLab version: JLab 3.0rc6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Wishlist: Remove hard dependency on ctypes `IPython.lib.inputhook` has a hard dependency on `ctypes`. Recently I've been working with Python on a machine without ctypes. I was able to get a basic IPython terminal by commenting out much of the file. Obviously this means I won't have any `%gui` magic abilities, but that's not a problem in my situation. Perhaps instead of this hard dependency we should consider refactoring the class so that InputHookManager was a pluggable configuration option? Would this be a realistic project? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: non-conda-installed python packages can have missing version information When reading up metadata out of site-packages, non-conda-installed python packages can sometime be missing version information. When this is the case, we should default to a hard-codes `0.0.0` version. I believe this behavior is consistent with python’s own `python setup.py —version` when no version is actually given in the `setup()` function. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Bug in DDP, but not DP modes. Pytorch 1.5 ``` In [3]: pytorch_lightning.__version__ Out[3]: '0.7.5rc1' ``` In DP everything works. In DDP fails with: ``` File \"/home/vladimir/anaconda3/envs/solaris/lib/python3.7/multiprocessing/popen_fork.py\", line 20, in __init__ self._launch(process_obj) File \"/home/vladimir/anaconda3/envs/solaris/lib/python3.7/multiprocessing/popen_spawn_posix.py\", line 47, in _launch reduction.dump(process_obj, fp) File \"/home/vladimir/anaconda3/envs/solaris/lib/python3.7/multiprocessing/reduction.py\", line 60, in dump ForkingPickler(file, protocol).dump(obj) _pickle.PicklingError: Can't pickle <class 'torch._C._VariableFunctions'>: it's not the same object as torch._C._VariableFunctions ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Update MultiRegional and Regional to Standard Previously, we implemented the concept of \"Location Type\" to move the concept of bucket location away from storage class. It is no longer considered correct to use \"MultiRegional\" or \"Regional\" as a storage class, instead those should be location types. As such, we need to update every instance of the \"MultiRegional\" and \"Regional\" storage in samples, library documentation, and tests to use \"Standard\" instead--Standard is a correct storage class. Note that \"MultiRegional\" and \"Regional\" should only be replaced with \"Standard\" in cases where they are used a storage class. If they're used as a location type, that's fine and doesn't need to be replaced. https://github.com/googleapis/google-cloud-python/blob/ae2e7058e402c4c963bc4991af7cd5f2b2801cc9/storage/tests/unit/test_bucket.py https://github.com/googleapis/google-cloud-python/blob/ccac1e1a95bbdc85c001c96ad359dcec50f3e407/storage/tests/unit/test_blob.py#L3040 https://github.com/googleapis/google-cloud-python/blob/ae2e7058e402c4c963bc4991af7cd5f2b2801cc9/storage/tests/unit/test_bucket.py#L55 https://github.com/GoogleCloudPlatform/python-docs-samples/blob/03e47889042b52ebb2610c5ba19a23bebb39a497/notebooks/rendered/storage-command-line-tool.md#L73 https://github.com/GoogleCloudPlatform/python-docs-samples/blob/03e47889042b52ebb2610c5ba19a23bebb39a497/notebooks/tutorials/storage/Storage%20command-line%20tool.ipynb#L141 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: pauli.evolve() needs a major speedup ### What should we add? @aeddins-ibm found that `pauli.evolve()` can be quite slow, and we can get substantial performance improvement from using private methods for special cases. Since `pauli.evolve()` is the main entry-point / user-interface, it should be fast. There are probably some simple things that can be done to dramatically speed it up. But it needs some profiling to see what's causing the slowdown. Here's a code that shows `pauli.evolve()` is 10,000x slower than calling `_evolve_cx()` on individual instructions. Some of this is expected since CX is a special case of clifford. But a) we should have faster ways of dealing with special cases of self-adjoint cliffords and b) is there some other overhead from validation/type-checking? ```py from qiskit import QuantumCircuit from qiskit.quantum_info.operators.symplectic.base_pauli import _evolve_cx from qiskit.quantum_info import Clifford, Pauli, PauliList, random_pauli_list, SparsePauliOp import time n = 65 paulis_per_instance = 100 instances = 100 qc = QuantumCircuit(n) qc.cx(range(n-1),range(1,n)) cliff = Clifford(qc) result1 = random_pauli_list(n, paulis_per_instance*instances) result2 = result1.copy() start = time.time() result1 = result1.evolve(cliff,frame='s') print('time using evolve:',time.time()-start) start = time.time() for gate in qc.data: _evolve_cx(result2, gate[1][0]._index, gate[1][1]._index) print('time using _evolve_cx:',time.time()-start) print('same answer?',result1 == result2) ``` ```py time using evolve: 33.13418793678284 time using _evolve_cx: 0.0023658275604248047 same answer? True ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson unconditionally generates deprecated compiler option '/Gm' for vs2017 /Gm has been deprecated and produces warning: `cl : Command line warning D9035: option 'Gm' has been deprecated and will be removed in a future release` at least since VS 15.9 and is known to be working incorrectly, more info [here](https://docs.microsoft.com/en-us/cpp/build/reference/gm-enable-minimal-rebuild?view=vs-2017) and [here](https://developercommunity.visualstudio.com/content/problem/99877/vs2017-1532-c-minimalrebuild-incorrectly-skips-com.html). Meson sets it [unconditionally](https://github.com/mesonbuild/meson/blob/master/mesonbuild/backend/vs2010backend.py#L948), and I failed to find a workaround, adding '/Gm-' doesn't help. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PassManager.passes() needs a drawer _For context, originally posted by @jaygambetta in https://github.com/Qiskit/qiskit-terra/issues/2179#issuecomment-489385917_ >I also think I should be able to draw a pass manager > >```pm.draw()``` > >and it make a flow diagram of all the passes I have in my pass manager with the inputs going into them Via #2079, `PassManager.passes()` returns structure with the passes and flow control in a pass manager instance. A drawer should take that structure and make flow diagram based on it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ``ScipyOptimizer`` options are overriden by default values <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: 3.7.9 - **Operating system**: macOS ### What is the current behavior? The `ScipyOptimizer`s allow two ways to specify settings of an optimizer: * directly as named arguments (e.g. `L_BFGS_B(maxiter=10)`) * via an `options` argument (e.g. `L_BFGS_B(options={\"maxiter\": 10})`) However using the second method via `options`, does not actually set the options since they are overriden by the default value. ### Steps to reproduce the problem ```python from qiskit.algorithms.optimizers import L_BFGS_B opt = L_BFGS_B(options={\"maxiter\": 2}) print(opt._options) ``` prints ``` {'maxiter': 15000, 'maxfun': 1000, 'ftol': 2.220446049250313e-15, 'iprint': -1, 'eps': 1e-08} ``` ### What is the expected behavior & suggested solution I think it would be cleaner to not have the `options` in the initializer and let the user just use named arguments. We could still keep `_options` under the hood in the `SciPyOptimizer`, just not expose it. Alternatively we could make sure all named arguments are `None` by default and then only set the value in the options if they are not none. However that is a bit cumbersome and less nice to read in the docs, so I think just removing `options` from the initializer would be cleaner. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: self.run() regression: mishandles output in 1.30.1 vs. 1.29.1 I have a recipe which in the deploy() function has this code: class Buf: def __init__(self): self.buf = [] def write(self, data): self.buf.append(data) def getData(self): return \"\".join((str(x) for x in self.buf)).strip() myBuf = Buf() self.run('\"python\" -c \"import sys;sys.stdout.write(\\'\\\\n\\'.join((sys.exec_prefix,' 'str(sys.version_info[0]), str(sys.version_info[1]))))\"', output = myBuf) data = myBuf.getData().replace(\"\\r\", \"\").split('\\n') assert len(data) == 3 This code worked fine, in agreement with the published documentation in version 1.29.1 on Ubuntu 18.04. In version 1.30.1 the run() command fails because with the error message: **\"Buf has no attribute _stream\"**. The documentation: https://docs.conan.io/en/latest/reference/conanfile/other.html#output-and-running Specifies that the only requirement for the value of the output argument is that it has a write method. \"You can pass **any stream that accepts a write method** like a six.StringIO()\" As far as I know a stream is not required to have a private member named stream. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: system_requirements files not shared between host/docker I have an application depends on a library libA. libA's recipe has a system_requirements() method which installs a system library. libA's artifact is stored remotely. When I built the applications, it failed to find the system library installed by the libA's recipe. Is system_requirements() transitive? If so, how to specify in the conanfile.txt or conanfile.py of application? By the way, I don't want to build libA from source. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Multi-Directory notebooks overwrite each other's checkpoints IPython version: 71ff8f9523e438402f696104be44e90394bbf429 (after 2.0) Even though I haven't seen any open issue about this yet, I believe it might be already known, given that it is mentioned here: https://github.com/ipython/ipython/wiki/IPEP-16%3A-Notebook-multi-directory-dashboard-and-URL-mapping#create-a-checkpoint In brief, the problem is that notebooks that have the same name will write/read the same checkpoint file, regardless of the notebooks' path. Example: Notebooks `/test.ipynb` and `/some_path/test.ipynb` will both have their checkpoint file named `test-checkpoint.ipynb` directly under `.ipynb_checkpoints`. The consequence of this is that if two or more notebooks located in different subdirectories happen to have the same name they will overwrite each other's checkpoints. A potential solution could be to save the checkpoints in subdirectories as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: VideoMAE with `num_channels!=3` needs a small fix ## Issue The VideoMAE model doesn't work for non-RGB videos (when `num_channels!=3`). I believe this is caused by the harcoded image-net means and stds in the following lines: https://github.com/huggingface/transformers/blob/d51e7c7e8265d69db506828dce77eb4ef9b72157/src/transformers/models/videomae/modeling_videomae.py#L824L826 ## Code to Reproduce ``` import torch from transformers import VideoMAEConfig, VideoMAEForPreTraining NUM_CHANNELS = 1 config = VideoMAEConfig(num_channels=NUM_CHANNELS) model = VideoMAEForPreTraining(config) pixel_values = torch.rand(1, 16, NUM_CHANNELS, 224, 224) num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2 seq_length = (model.config.num_frames // model.config.tubelet_size) * num_patches_per_frame bool_masked_pos = torch.randint(0, 2, (1, seq_length)).bool() outputs = model(pixel_values, bool_masked_pos=bool_masked_pos) loss = outputs.loss ``` This produces the following error: ```File \".../lib/python3.10/site-packages/torch/functional.py\", line 74, in broadcast_tensors return _VF.broadcast_tensors(tensors) # type: ignore[attr-defined] RuntimeError: The size of tensor a (512) must match the size of tensor b (1536) at non-singleton dimension 2``` Setting NUM_CHANNELS = 3 works fine. ## Potential Fix Since we don't have a `_DEFAULT_MEAN/STD` for non-RGB images, we can just replace `frames=pixel_values` and disallow `norm_pix_loss=False` if `num_channels!=3`. With this modification, the code works on my machine. I am willing to fix and submit a PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: mpl circuit drawer requires excessive load time <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: Main - **Python version**: 3.8 - **Operating system**: Ubuntu ### What is the current behavior? When a text width calculation method was first added to the mpl circuit drawer, the method was called whenever it was needed. This has caused excessive load times due to repetitive method calls for medium to large circuits (100-1000+ gates), especially for gates with parameters. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Caching the text widths will eliminate the repetitive calls. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: [DataModule] Datamodule setup in docs shows non-existent stage arg <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug <!-- A clear and concise description of what the bug is. --> ### To Reproduce [Colab Minimal code](https://colab.research.google.com/drive/1nzVh8xeEGLOJvSZ0Ih7WccNHgI1gDzaD?usp=sharing) <!-- If you have a code sample, error messages, stack traces, please provide it here as well --> ### Expected behavior DataModule should call `prepare_data` and `setup` ### Environment - Colab ### Additional context PL Version: 0.9.0rc3 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Cannot close last figure window After updating ipython to 5.0 (from macports), I cannot close last figure window (neither with button in window bar, nor with 'close()'). The mouse cursor becomes spinning wheel inside the window, but I can still type command in the terminal window. However, if I type clf(), the figure window closes and a new one appears. This happens only when there is only one figure window remaining. Here's my system (OS X El Capitan, with python/ipython etc. installed via macports) : ``` [~] $ python -c \"import IPython; print(IPython.sys_info())\" {'commit_hash': u'<not found>', 'commit_source': '(none found)', 'default_encoding': 'UTF-8', 'ipython_path': '/opt/local/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/IPython', 'ipython_version': '5.0.0', 'os_name': 'posix', 'platform': 'Darwin-15.5.0-x86_64-i386-64bit', 'sys_executable': '/opt/local/Library/Frameworks/Python.framework/Versions/2.7/Resources/Python.app/Contents/MacOS/Python', 'sys_platform': 'darwin', 'sys_version': '2.7.12 (default, Jun 29 2016, 12:52:38) \\n[GCC 4.2.1 Compatible Apple LLVM 7.0.2 (clang-700.1.81)]'} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Avoid pydot for graphviz based visualization ### What is the expected enhancement? The current releases of pydot has a compatibility issue with it's upstream dependency pyparsing causing parsing errors that introduce empty nodes into visualizations (see: https://github.com/pydot/pydot/issues/280). For example: https://qiskit.org/documentation/stable/0.34/stubs/qiskit.visualization.dag_drawer.html#qiskit.visualization.dag_drawer This raises a question why do we need to be using pydot for graphviz based visualizations at all? We're just using it as a library to call `subprocess` on graphviz for us and not leveraging the parsing or dot file building capabilities of pydot (with the exception of the pass manager drawer but this is easy to refactor). Instead of using pydot in qiskit we have two alternative options available we either can replace the pydot usage with a direct subprocess call to graphviz, or we can leverage retworkx's built in graphviz visualization function: https://qiskit.org/documentation/retworkx/apiref/retworkx.visualization.graphviz_draw.html#retworkx.visualization.graphviz_draw If we use the retworkx function we can remove a lot of boilerplate code to deal with i/o and image objects too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: [Enhancement] Add axis-less flip for 1d arrays I suggest autoflipping 1d arrays without specifying axis: ``` python a = np.array([1, 2, 3]) b = np.flip(a) ``` instead of `b = np.flip(a, 0)` `fliplr` doesn't work in this case, and `flip` can easily check input's `ndim`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] New AutotoolsDeps customization The `AutotoolsDeps` generator should precalculate things in the constructor to allow the user to modify them before calling the `generate()` method. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Feature request: fast conda env update for satisfied dependencies I would love a mode for `conda env update -f environment.yml` that functions a bit more like `pip install -r requirements.txt` in terms of dong less unneeded work. In particular, I would like it to avoid updating packages that don't need updating, and ideally avoid talking to the index at all if the environment.yml is already satisfied. I think `update_dependencies: False` does *part* of this, but it doesn't apply to explicitly listed dependencies. In general, there appears to be no available operation to say \"Given this environment.yml, make the fewest possible changes to satisfy its specification.\" My particular goals: 1. `conda env update` with an already satisfied environment.yml should install no packages, make no network requests, and in general complete as fast as possible. 2. if spec is partially satisfied, do not update packages that already satisfy their requirement, unless it is required to satisfy the packages that will be installed I would like this behavior for `conda install` as well, such that I could call `conda install notebook` and it would only perform any actions if notebook is not up to date. Are there existing combinations of flags that accomplish some or all of this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add `map:` prefix to tasks in `Flow.visualize()` For more clarity into which tasks are mapped, which aren't Add `map:` prefix to tasks in `Flow.visualize()` For more clarity into which tasks are mapped, which aren't Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: most requirements skipped with conan 1.5 when some are private We have a conan setup that, when called with conan 1.4.5 or earlier, generates a visual studio property sheet with all our requirements. When called with 1.5, however, only one (Flow) of the requirements is included by the property sheet. The conanfile.py that is used to generate the property sheet has a requirements field that looks like `requires = Flow.dependencies + ('Flow/'+Flow.Flow.version + \"@velo3d/stable\",)` where flow dependencies is a tuple like `dependencies = ('foo/1.2.3@velo3d/thirdparty',...` and the requires field on Flow looks like ``` requires = dependencies + ( ('X/b64300d87-5@velo3d/stable', 'private'), ('Y/d41fca23204-3@velo3d/stable', 'private'), ('Z/bcdf4b4f51a-2@velo3d/stable', 'private'), ('W/b155f94-1@velo3d/stable', 'private'), ('U/2d139f800c8-1@velo3d/stable', 'private')) ``` Going back to 1.4.5 or replacing Flow requires with ``` requires = dependencies + ( 'X/b64300d87-5@velo3d/stable', 'Y/d41fca23204-3@velo3d/stable', 'Z/bcdf4b4f51a-2@velo3d/stable', 'W/b155f94-1@velo3d/stable', 'U/2d139f800c8-1@velo3d/stable') ``` fixes the problem. Any ideas? Thanks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Use new Sessions API for Consoles #1160 introduced a temporary workaround for dealing with consoles. Once we have https://github.com/jupyterlab/services/pull/237, we can use the session name and type as discriminators. cf https://github.com/jupyter/notebook/pull/1359 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: Typo in `numpy.polydiv` https://github.com/numpy/numpy/blob/92ebe1e9a6aeb47a881a1226b08218175776f9ea/numpy/lib/polynomial.py#L959 The typo in this line causes wrong return types in cases when `v` is `poly1d` fix to be: `truepoly = (isinstance(u, poly1d) or isinstance(v, poly1d))` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Doc styling utils adds parasites new lines ## Environment info - `transformers` version: 4.2.0dev0 - Platform: Windows-10-10.0.18362-SP0 - Python version: 3.7.9 - PyTorch version (GPU?): 1.7.1 (False) - Tensorflow version (GPU?): 2.3.1 (False) - Using GPU in script?: Nope - Using distributed or parallel set-up in script?: Nope ### Who can help @sgugger ## Information Running the python util to style docs adds parasite new lines in every single docstring. See: ```bash $ python utils/style_doc.py src/transformers docs/source --max_len 119 --check_only Traceback (most recent call last): File \"utils/style_doc.py\", line 491, in <module> main(*args.files, max_len=args.max_len, check_only=args.check_only) File \"utils/style_doc.py\", line 479, in main raise ValueError(f\"{len(changed)} files should be restyled!\") ValueError: 345 files should be restyled! ``` See this commit for an example of what it does: https://github.com/huggingface/transformers/pull/9150/commits/b4dedd5ca25f043c66d12c774fa00a34c74dffb2 ## To reproduce Steps to reproduce the behavior: 1. Checkout and update master branch 2. run `python utils/style_doc.py src/transformers docs/source --max_len 119 --check-only` from transformers root Output: ```python Traceback (most recent call last): File \"utils/style_doc.py\", line 491, in <module> main(*args.files, max_len=args.max_len, check_only=args.check_only) File \"utils/style_doc.py\", line 479, in main raise ValueError(f\"{len(changed)} files should be restyled!\") ValueError: 345 files should be restyled! ``` It might have something to do with Windows or a particular setup of my machine because behavior cannot be reproduced by @patrickvonplaten. ## Expected behavior On master branch, documentation should not need to be restyled Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Create `scheduling` stage (alap, asap) plugins Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Better warning for windows users when using %run After working on #10079, I thought it would be better to give windows users an explanation as to why they are receiving that error. Currently it just shows them a standard error with code that looks odd, but works on *nix systems: `ERROR:root:File \"'../test.py'.py\" not found.` I added a `warn` call to try to help: ``` warn('For Windows, use double quotes to wrap a filename: %run \"mypath\\\\myfile.py\"') ERROR:root:File `\"'../test.py'.py\"` not found. ``` I hopped that this would point them into the right direction. Especially if they are new users. I am not sure if using a `warn()` is the best way to handle this, so let me know any thoughts. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython console freezes for increasing no of seconds in %pylab mode launching ipython just in console with `ipython`. Am trying to reproduce bad editing (readline?) behavior now, looking at some functions, their help text etc. but it's all ok. Then launching `%pylab`. Typing in rubbish (like 'aoeuaoeaoeu') and can keep editing it without freezes. But from the moment I type in a function name that exists, like `dir()` it even gets stuck before printing the `()`. From now on the cursor gets stuck every 5 seconds or so and keeps stuck for 2-3 seconds at a time, but that number is increasing. Version abffd96eaa9c7 inside iTerm2 on Mac OSX. Python 2.7.8 from conda Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Remote code is loaded from `main` even when revision is provided ### System Info When specifying a branch to load a model with remote code as follows fails because there is no modeling file on `main`. Is this a bug or the expected behaviour? ### Who can help? The one and only _**@sgugger**_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ```python model = transformers.AutoModelForCausalLM.from_pretrained(\"bigcode/santacoder-fast-inference\", revision=\"main_custom\", trust_remote_code=True) ``` The following error shows that the code file is attempted to be loaded from `main` instead of `main_custom` (where a modeling file is present: ```bash Could not locate the configuration_gpt_bigcode.py inside bigcode/santacoder-fast-inference. Traceback (most recent call last): File \"/work/arjunguha-research-group/arjun/venvs/bigcode/lib/python3.8/site-packages/huggingface_hub/utils/_errors.py\", line 264, in hf_raise_for_status response.raise_for_status() File \"/shared/centos7/python/3.8.1/lib/python3.8/site-packages/requests/models.py\", line 940, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/bigcode/santacoder-fast-inference/resolve/main/configuration_gpt_bigcode.py ``` ### Expected behavior Loading without error. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: OverflowError execption in handlers.py Please see https://github.com/facebook/tornado/issues/713 IPython uses the same code fragment and creates an OverflowError when trying to load a sketch using procesing.js. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: AIP-56 - Move sync-perm command It has been brought up by Jarek in this [discussion](https://github.com/apache/airflow/discussions/32187#discussioncomment-6323078). I dont have much context on it but it seems we need to move this command as well as part of the AIP-56 work Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `ls` magic alias to `ls -F --color` I have many different profiles used in linux. I use one profile when my terminal does not support any color. Is there any option to control the `ls` aliases so that it uses `ls -F` instead of `ls -F --color`? I already used `c.InteractiveShell.colors = 'NoColor'` but it does not affect the `ls` alias Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: unary + does not work in jax ``` >>> import jax >>> +jax.numpy.asarray([1,2,3]) /Users/lukasheinrich/Code/excursiondev/excvenv/lib/python3.6/site-packages/jax/lib/xla_bridge.py:119: UserWarning: No GPU/TPU found, falling back to CPU. warnings.warn('No GPU/TPU found, falling back to CPU.') Traceback (most recent call last): File \"<stdin>\", line 1, in <module> TypeError: bad operand type for unary +: 'DeviceArray' ``` while in numpy it works ``` >>> import numpy >>> +numpy.asarray([1,2,3]) array([1, 2, 3]) ``` a similar issue appear for the `-` operator Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: describe CLI command outputs dictionary instead of json ## Current behavior Currently commands like `prefect describe flow ...` outputs a string representation of a Python dictionary ## Proposed behavior Output parsable JSON instead of a dictionary ## Example Docs show output similar to: ``` $ prefect describe flows --name my-flow { \"name\": \"my-flow\", \"version\": 1, \"project\": { \"name\": \"Demo\" }, \"created\": \"2019-07-25T14:23:21.704585+00:00\", \"description\": null, \"parameters\": [], \"archived\": false, \"storage\": { \"type\": \"Docker\", \"flows\": { \"my-flow\": \"/root/.prefect/my-flow.prefect\" }, \"image_tag\": \"9b444406-355b-4d32-832e-77ddc21d2073\", \"image_name\": \"my-flow\", \"__version__\": \"0.6.0\", \"registry_url\": \"gcr.io/my-registry/\", \"prefect_version\": \"master\" }, \"environment\": { \"type\": \"RemoteEnvironment\", \"executor\": \"prefect.engine.executors.SynchronousExecutor\", \"__version__\": \"0.6.1\", \"executor_kwargs\": {} } } ``` It should mimc that behavior Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: redundant params in base gate and controlled gate In parameterized `ControlledGate`s like CU1, there are separate parameters associated with the ControlledGate and its base_gate. These should be references to each other, otherwise can lead to inconsistencies. ```python from qiskit import * circuit = QuantumCircuit(2) circuit.cu1(0.1, 0, 1) circuit[0][0].base_gate.params >> [0.1] circuit[0][1].params >> [0.1] circuit[0][0].base_gate.params = [0.2] circuit[0][0].base_gate.params >> [0.2] circuit[0][1].params # this has not updated, while the base has updated >> [0.1] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Testing sensors is not compatible with Definitions ### Dagster version 1.2.3 ### What's the issue? I am writing tests of a multi-asset sensor. I need to give it a context. [The docs](https://docs.dagster.io/concepts/partitions-schedules-sensors/asset-sensors#multi-asset-sensors) tell me to use [build_multi_asset_sensor_context](https://docs.dagster.io/_apidocs/schedules-sensors#dagster.build_multi_asset_sensor_context). That function has a required argument of 'repository_def: RepositoryDefinition`. So to use it, I *must* provide a repository_def. But I don't have a repository definition, since I'm using Definitions. A different page in the docs (the [one for Repositories](https://docs.dagster.io/concepts/repositories-workspaces/repositories#repositories)) has an admonition on the top: > In 1.1.6, we introduced [Definitions](https://docs.dagster.io/_apidocs/definitions#dagster.Definitions), which replaces repositories. While repositories will continue to work, we recommend migrating to Definitions If Definitions are preferred, I think build_multi_asset_sensor_context should accept them. ### What did you expect to happen? Maybe the docs should be consistent in their recommendation, or explain how to work with either system by providing conversion tools, or maybe the build_multi_asset_sensor_context function should accept a Definitions. ### How to reproduce? n/a ### Deployment type None ### Deployment details _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: scm.subfolder support only one level of subfolders (not foo/baz/bar) conan v1.6.1, Windows 10, Python 3.6 I'm moving our codebase to conan packages and encountered following error. I have to specify not single directory in `scm.subfolder` attribute, but multiple ones: ```python scm = { \"type\": \"git\", \"subfolder\": \"foo/baz/bar\", \"url\": \"auto\", \"revision\": \"auto\", } ``` The reason is that I shouldn't change paths in `#include` directives today and I will update paths in the future. With such recipe conan fails to build missing packages, i.e. `conan install . --build missing` fails with an strange error: `FileNotFoundError: [WinError 3] The system cannot find the path specified: 'C:\\\\.conan2\\\\gk8g1phl\\\\1\\\\foo\\\\baz\\bar` I think that source of this problem is this line: https://github.com/conan-io/conan/blob/develop/conans/client/tools/scm.py#L20 Could you call `os.makedirs` instead of `os.mkdir`? - [*] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [*] I've specified the Conan version, operating system version and any tool that can be relevant. - [*] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: removing tool.qi.qi.py We need to decide what lives in there and what can go else where. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rename `SamplePulse` to `Waveform` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Let's deprecate the name `SamplePulse` and rename it as `Waveform`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda 4.4 has no difference between 'conda install' and 'conda update' That is, `conda update` installs packages, even if the package isn't already in the environment. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Implement TensorboardLogger Implement a simple Tensorboard logger. No more external dependencies for basic logging! Only question on this one is how to deal with the fact that `SummaryWriter.add_hparams` wasn't added until torch 1.3.0. Right now, I just throw a warning and skip writting hparams to Tensorboard. The only other thing I can think of would be to write the hparams to a text file in the same directory as the TB logs. Closes #588 Closes #265 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: FIXME in `numpy/__init__.py` related to `numpy.lib` imports There is a FIXME comment in `numpy/__init__.py` that doesn't seem to have a corresponding issue on GitHub, at least not one that I noticed with a cursory search of the issues. https://github.com/numpy/numpy/blob/eb167a3fe540780f397a14817f54a95333fbcc6c/numpy/__init__.py#L140-L145 There is additional code in `numpy/__init__.py` related to this FIXME: https://github.com/numpy/numpy/blob/eb167a3fe540780f397a14817f54a95333fbcc6c/numpy/__init__.py#L178-L184 My intent is getting this into the issue tracker so that it can be discussed/documented and synced up with the code comments. If there is an existing issue that I missed, I'd recommend updating the comment in `numpy/__init__.py` to point there. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: load_module will be removed in Python 3.12 Several of our scripts call `spec.loader.load_module()`. Although this mostly affects standalone utils scripts, it's also called at the top level of `processing_utils.py`, which will be executed by all `Processor` classes. `load_module()` has been deprecated for a while and will be fully deleted in Python 3.12, which is entering beta soon. We need to replace this code or the library will not be usable in Py3.12. I can investigate and try to find a suitable replacement when I have time, but if anyone is more familiar with that code and can think of an obvious replacement that achieves the same goal, let me know! cc @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Error reporting accessing client.project instead of client._project. [Originally](https://github.com/GoogleCloudPlatform/google-cloud-python/issues/2687#issuecomment-286703711) from @DizzeePascall. When running the examples from the documentation, I get the following error: ``` Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/home/laurence/miniconda3/envs/sonalytic/lib/python3.5/site-packages/google/cloud/error_reporting/client.py\", line 320, in report report_location=report_location) File \"/home/laurence/miniconda3/envs/sonalytic/lib/python3.5/site-packages/google/cloud/error_reporting/client.py\", line 277, in _send_error_report self.report_errors_api.report_error_event(error_report) File \"/home/laurence/miniconda3/envs/sonalytic/lib/python3.5/site-packages/google/cloud/error_reporting/client.py\", line 162, in report_errors_api self._report_errors_api = make_report_error_api(self) File \"/home/laurence/miniconda3/envs/sonalytic/lib/python3.5/site-packages/google/cloud/error_reporting/_gax.py\", line 44, in make_report_error_api return _ErrorReportingGaxApi(gax_client, client.project) AttributeError: 'Client' object has no attribute 'project' ``` Disabling GRPC via the `GOOGLE_CLOUD_DISABLE_GRPC` environment variable fixes this. I'm running on an Ubuntu 14.04 compute instance with python 3.5.3 and version 023.1 of the google-cloud-error-reporting project Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add support for tmpfs In the latest release candidate for 1.6.0 the --tmpfs options is not available. Is it possible to add this to the service definition via some other mechanism. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: depend_files in subdir looks in parent Not sure if this is by design, but if I have a subdir with the files `foo.in` and `file`, and: ~~~Meson # meson.build subdir(src) # src/meson.build custom_target('foo', build_by_default : true, depend_files : 'file', input : 'foo.in', output : 'foo.out', command : [ ... ] ) ~~~ then building fails with > ninja: error: '../file', needed by 'src/foo.out', missing and no known rule to make it whereas if I use `files('file')` instead of `'file'` it works. If I put `file` in the parent folder it also builds. I kind of assumed that referring to `'file'` inside the build file of the subdir would just work, like referring to `'foo.in'` does. depend_files in subdir looks in parent Not sure if this is by design, but if I have a subdir with the files `foo.in` and `file`, and: ~~~Meson # meson.build subdir(src) # src/meson.build custom_target('foo', build_by_default : true, depend_files : 'file', input : 'foo.in', output : 'foo.out', command : [ ... ] ) ~~~ then building fails with > ninja: error: '../file', needed by 'src/foo.out', missing and no known rule to make it whereas if I use `files('file')` instead of `'file'` it works. If I put `file` in the parent folder it also builds. I kind of assumed that referring to `'file'` inside the build file of the subdir would just work, like referring to `'foo.in'` does. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `%matplotlib` + qt5 Support for qt5 was just merged into matplotlib master (https://github.com/matplotlib/matplotlib/pull/3072), however due to the way that `pylabtools` deals with parsing the backend the `%matplotlib` magic does not work correctly with the `Qt5Agg` backend. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: poly1d coefficients appear to be immutable In some older versions of numpy, it was possible to change the coefficients of a `poly1d` object. Now it seems not possible. According to https://github.com/numpy/numpy/issues/9385 I believe the coefficients should still be mutable. ### Reproducing code example: ```python import numpy as np import numpy p = numpy.poly1d((1,1)) print(p) p.c[0]=0 print(p) ``` Both print statements print `array([1, 1])`. ### Numpy/Python version information: I am using numpy version 1.16.2. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: yelp support To make it easy to port GNOME modules from autotools to meson, it'll be nice to have some convenience from meson for building/installing user help pages. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Add support for `np.trace` Goal is to use `@jit` on a function containing a call `np.trace(..)`. My rudimentary attempt to implement via indexing also fails ```python from jax import numpy from jax.api import jit import numpy as onp @jit def trace(A): return np.trace(A) # Exception: Numpy function <function trace at 0x7f89bee1eb90> not yet implemented @jit def trace(A): idx = onp.diag_indices(len(A)) diag = A[idx] # TypeError: No abstraction handler for type: <type 'tuple'> return np.sum(diag) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Deferred TI's `next_method` and `next_kwargs` not cleared on retries ### Apache Airflow version main (development) ### Operating System macOS 11.5.2 ### Versions of Apache Airflow Providers _No response_ ### Deployment Virtualenv installation ### Deployment details _No response_ ### What happened If your first try fails and you have retries enabled, the subsequent tries skip right to the final `next_method(**next_kwargs)` instead of starting with `execute` again. ### What you expected to happen Like we reset things like start date, we should wipe `next_method` and `next_kwargs` so we can retry the task from the beginning. ### How to reproduce _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: more scan jacrev/jacfwd bugs This is a follow up of #711 (different error from #757): ``` python import unittest import numpy as onp import jax.numpy as np import functools import jax from jax.config import config; config.update(\"jax_enable_x64\", True) from jax.experimental import optimizers from jax.test_util import check_grads def harmonic_bond(conf, params): return np.sum(conf * params) opt_init, opt_update, get_params = optimizers.sgd(5e-2) x0 = onp.array([0.5], dtype=onp.float64) params = onp.array([0.3], dtype=onp.float64) def minimize_structure(test_params): energy_fn = functools.partial(harmonic_bond, params=test_params) grad_fn = jax.grad(energy_fn, argnums=(0,)) opt_state = opt_init(x0) # use lax.scan, way faster compilation times. def apply_carry(carry, _): i, x = carry g = grad_fn(get_params(x))[0] new_state = opt_update(i, g, x) new_carry = (i+1, new_state) return new_carry, _ carry_final, _ = jax.lax.scan(apply_carry, (0, opt_state), np.zeros((75, 0))) trip, opt_final = carry_final assert trip == 75 return opt_final initial_params = 0.5 minimize_structure(initial_params) def loss(test_params): opt_final = minimize_structure(test_params) return 1.0 - get_params(opt_final)[0] loss_opt_init, loss_opt_update, loss_get_params = optimizers.sgd(5e-2) jax.grad(loss, argnums=(0,))(initial_params) # okay jax.jacrev(loss, argnums=(0,))(initial_params) # AttributeError: 'JaxTuple' object has no attribute 'broadcast' jax.jacfwd(loss, argnums=(0,))(initial_params) # TypeError: <class 'tuple'> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: OptimizeSwapBeforeMeasure removes classically conditioned SwapGate <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? From https://travis-ci.com/github/Qiskit/qiskit-terra/jobs/495770351#L997: ``` >>> qc = qk.QuantumCircuit.from_qasm_str(''' OPENQASM 2.0; include \"qelib1.inc\"; qreg q3134[2]; creg c137[1]; cx q3134[1],q3134[0]; h q3134[1]; if(c137==1) swap q3134[1],q3134[0]; measure q3134[1] -> c137[0]; ''') >>> qc.draw() ┌───┐ q3134_0: ┤ X ├────────X────── └─┬─┘┌───┐ │ ┌─┐ q3134_1: ──■──┤ H ├───X───┤M├ └───┘┌──╨──┐└╥┘ c137: 1/══════════╡ = 1 ╞═╩═ └─────┘ 0 >>> qk.transpile(qc, optimization_level=3).draw() ┌───┐ ┌─┐ q3134_0: ┤ X ├─────┤M├ └─┬─┘┌───┐└╥┘ q3134_1: ──■──┤ H ├─╫─ └───┘ ║ c137: 1/═══════════╩═ 0 ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Warn or error out when targets try to link_with: shared modules On osx shared modules are NOT getting -install arguments, (there seems to be a reason for this). But when creating the .symol files, we rely on finding a LC_ID_DYLIB. Which will read to a crash. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: polyval turns masked array into array (Trac #1884) _Original ticket http://projects.scipy.org/numpy/ticket/1884 on 2011-06-28 by trac user mauro, assigned to @pierregm._ When using a masked array as input for polyval, then the return is an array. I think it should be a masked array again (or at least document it that it is not). The fix seems easy, remove the line x = NX.asarray(x) from np.lib.polyval. But presumably that line is there for a reason... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: CmdDef should have a simpler representation <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The current `CmdDef`'s, `repr` is based on its underlying dictionary. This quickly becomes complicated. Perhaps something like `CmdDef(commands=['u1','u2','u3','measure','cx'], qubits=[0,1,2,3])` is simpler to take in at a quick glance. cmd_def.get error messaging <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the current behavior? `CMdDef.get` error messaging returns a standard error. For example ``` cmd_def.get('u3', qubits=(1, 0), P0=2*np.pi, P1=0., P2=np.pi) ``` returns ``` 'Command u3 for qubits (1, 0) is not present in CmdDef' ``` because `'u3'` is not a two-qubit gate (wrong user input). ### What is the expected enhancement? A more informative error message could suggest that `'u3'` is present but that the `qubits` argument is wrong. Potentially, the error message could suggest the correct qubits format. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Value \"gnu89\" (of type \"string\") for combo option \"C language standard to use\" is not one of the choices. Possible choices are (as string): \"none\", \"c89\", \"c99\", \"c11\", \"c17\", \"gnu99\", \"gnu11\". Building glib2 2.62.6 with meson 0.59.1 fails: ``` Value \"gnu89\" (of type \"string\") for combo option \"C language standard to use\" is not one of the choices. Possible choices are (as string): \"none\", \"c89\", \"c99\", \"c11\", \"c17\", \"gnu99\", \"gnu11\". ``` With meson 0.58.1 there was no such error. See https://trac.macports.org/ticket/63462 In #8766 gnu99 and gnu11 were added to the list of possible choices but for some reason gnu89 was not added? Could you add it, please? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: improve config line magic check for MissUpperCasing and add additional info if there is a case insensitive match on clas if line of the form %config Class.value return the value of the trait instead of just throwing bad usage --- Yes the code is ugly, I'll reread it when I'll be backs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Store checksum of downloaded (and uploaded) packages Store in the ``metadata.json`` the checksum of the files actually downloaded or uploaded to the servers. We need this data to generate the _build information_ without querying the server again. For Artifactory, the required properties would be ``actual_md5`` and ``actual_sha1``. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: set MASTER_PORT automatically when using DDP, use must set a manual MASTER_PORT. However, we should automatically set one. The problem is that we can't choose a random one as each process might generate a different solution. Instead, I propose to use the SLURM JOB ID as the seed to k possible ports. Then every process can deterministically generate the same sequence of ports. With that list, the root node can init NCCL connection making its way down the list until a port is open. However, if we choose the length of the job id to use correctly we may potentially not run into collisions and won't need to iterate a list of potential ports. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Allow custom_target outputs to be directories Currently we allow this, but that directory can then not be installed: ``` Traceback (most recent call last): File \"/home/nirbheek/projects/repositories/github/meson.git/meson.py\", line 25, in <module> sys.exit(mesonmain.run(launcher, sys.argv[1:])) File \"/home/nirbheek/projects/repositories/github/meson.git/mesonbuild/mesonmain.py\", line 242, in run sys.exit(run_script_command(args[1:])) File \"/home/nirbheek/projects/repositories/github/meson.git/mesonbuild/mesonmain.py\", line 232, in run_script_command return cmdfunc(cmdargs) File \"/home/nirbheek/projects/repositories/github/meson.git/mesonbuild/scripts/meson_install.py\", line 251, in run do_install(datafilename) File \"/home/nirbheek/projects/repositories/github/meson.git/mesonbuild/scripts/meson_install.py\", line 54, in do_install install_targets(d) File \"/home/nirbheek/projects/repositories/github/meson.git/mesonbuild/scripts/meson_install.py\", line 205, in install_targets do_copy(fname, outname) File \"/home/nirbheek/projects/repositories/github/meson.git/mesonbuild/scripts/meson_install.py\", line 36, in do_copy shutil.copyfile(from_file, to_file) File \"/usr/lib64/python3.5/shutil.py\", line 114, in copyfile with open(src, 'rb') as fsrc: IsADirectoryError: [Errno 21] Is a directory: 'devhelp' FAILED: install ``` I can't think of a reason to not allow this. Found while investigating #890 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Check CMakeToolchain template variable names homogeneity Currently in the CMakeToolchain we have some variables that are passed to the templates that are uppercase, like `CMAKE_OSX_ARCHITECTURES`, others that are lowercase like `cmake_system_processor`... We should decide a unique criteria for this. This is important because we have mechanism in CMakeToolchain that you can inject different values for the variables inside the blocks' templates like this: ```python # modify one or more variables of the context def generate(self): tc = CMakeToolchain(conanfile) # block.values is the context dictionary build_type = tc.blocks[\"generic_system\"].values[\"build_type\"] tc.blocks[\"generic_system\"].values[\"build_type\"] = \"Super\" + build_type # modify the whole context values def generate(self): tc = CMakeToolchain(conanfile) tc.blocks[\"generic_system\"].values = {\"build_type\": \"SuperRelease\"} ``` So changing in the Conan codebase `build_type` to other name tomorrow will break users... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Feature-extraction pipeline to return Tensor # 🚀 Feature request Actually, to code of the feature-extraction pipeline `transformers.pipelines.feature-extraction.FeatureExtractionPipeline l.82` return a `super().__call__(*args, **kwargs).tolist()` Which gives a list[float] (or list[list[float]] if list[str] in input) I guess it's to be framework agnostic, but we can specify `framework='pt'` in the pipeline config so I was expecting a `torch.tensor`. Could we add some logic to return tensors ? # Motivation Features will be used as input of other models, so keeping them as tensors (even better on GPU) would be profitable. Thanks in advance for the reply, Have a great day. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add flag to build environment.yml without build strings https://gitter.im/conda/conda?at=59ef54ebe44c43700a70e9a4 https://twitter.com/drvinceknight/status/922837449092542464?ref_src=twsrc%5Etfw > Due to hashes of packages being introduced in `envinronment.yml` I'm getting all sorts of issues with building envs from file. (Very new problem) test.py error \"prefix is not writeable\" While attempting to use \"pyinstaller\" to create a standalone conda-index executable, the resulting binary failed in “conda/gateways/disk/test.py” prefix_is_writable because that method assumes the prefix is a python root directory, and in the case of the standalone, the “prefix” is the executable’s current directory. If I add append sys.executable to the end of the “find_first_existing” call parameter list, then it worked as expected. Of course, this particular writability check seems unnecessary for conda-index, because the only writing is to the target, not the conda-meta directory. Any change that would allow the creation of a standalone conda-index is appreciated. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Template path initialization doesn't handle unicode strings We package IPython as a .par file and for some reason this makes the `_template_path` a unicode string. Unfortunately, this breaks `template_path` initialization in 3.x since that only checks for ascii strings (https://github.com/ipython/ipython/blob/8b0eef4cb37a85b8a35784f82799352188d90ca3/IPython/html/notebookapp.py#L157). The line should instead check whether `_template_path` is not a list. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: make sure conda 4.4 has soft-pinning for python https://github.com/conda/conda/issues/6164#issuecomment-336733311 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [Vala] can't compile files that have the same name but are on different directories When a project has two files with the same name in multiple directories, meson claims that it has `Multiple producers for Ninja target` Here is a branch that adds the required test case https://github.com/tintou/meson/commit/960bf0e921d59d301b29e19596d1b398628d4324 I believe that the issue is located in [`./mesonbuild/backend/ninjabackend.py` line 1136](https://github.com/mesonbuild/meson/blob/master/mesonbuild/backend/ninjabackend.py#L1136) but I have no idea how can I fix this. Thanks in advance Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Make PubSub publisher's batch interfaces private In preparation for GA, we're going to hide some interfaces that users don't need at the moment. We can always make these public in a future minor release. Please make the following items private: 1. https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/pubsub/google/cloud/pubsub_v1/publisher/batch (rename the whole module to `_batch`). 2. https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/pubsub/google/cloud/pubsub_v1/publisher/client.py#L46 (make the argument private or remove it outright) 3. https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/pubsub/google/cloud/pubsub_v1/publisher/client.py#L105 Make the method private. Make PubSub publisher's batch interfaces private In preparation for GA, we're going to hide some interfaces that users don't need at the moment. We can always make these public in a future minor release. Please make the following items private: 1. https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/pubsub/google/cloud/pubsub_v1/publisher/batch (rename the whole module to `_batch`). 2. https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/pubsub/google/cloud/pubsub_v1/publisher/client.py#L46 (make the argument private or remove it outright) 3. https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/pubsub/google/cloud/pubsub_v1/publisher/client.py#L105 Make the method private. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rename or remove aquaerror exception class <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The aqua error exception class was included as part of #5422 which was a migration of common utils from aqua to terra (in support of future migration, mainly opflow and algorithms). As part of that migration an aqua error exception class was migrated which was used as a common base exception class for exceptions raised from aqua. This no longer applies since the hierarchy has been flattened and it all just lives in qiskit now. Before we release this exception class should either be removed or renamed to better reflect the new structure, and how it's used. I'm thinking we probably should have a base opflow exception and a base algorithms exception class instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [Zookeeper] metadata.csv is missing many metrics emitted by the check Per the [`check.py` docstring](https://github.com/jeffwidman/integrations-core/blob/patch-2/zk/check.py#L10-L15): Duplicate information is being reported by both `mntr` and `stat` to keep backwards compatability. Example: `stat` reports: zookeeper.latency.avg `mntr` reports: zookeeper.avg.latency If available, make use of the data reported by `mntr` not `stat`. The duplicate `stat` reports are only kept for backward compatability. I noticed this in our Datadog account because we have multiple zookeeper installations so I see both metrics myself... Yet in the zookeeper check's `metadata.csv`, I only see the `stat` metrics, not the `mntr` metrics... for example, the `zookeeper.avg.latency` is missing. Since these metrics are missing from `metadata.csv`, are they billed as custom metrics rather than standard metrics? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Calculate Number of memoryslots required based on input schedules if not set. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? At qobj assembly time the number of `memory_slots` required should be calculated from the input schedules if it is not set. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Killing Search ! It appears we're changing direction on the Cloud Search API (it was Alpha, so no surprise here). Let's chop it from the library..... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Loading Qiskit with no internet results in a ConnectionError <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### What is the current behavior? Loading Qiskit with no Internet results in a `ConnectionError`. ### Steps to reproduce the problem Run Qiskit without Internet connection. ### What is the expected behavior? Qiskit prompt no error at all. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Cannot copy a pulse enabled backend configuration <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? Doing `copy.deepcopy(provider.backends.ibmq_almaden.configuration())` fails with the error: TypeError: __init__() missing 10 required positional arguments: 'n_uchannels', 'u_channel_lo', 'meas_levels', 'qubit_lo_range', 'meas_lo_range', 'dt', 'dtm', 'rep_times', 'meas_kernels', and 'discriminators' Non-pulse enabled backends work fine. e.g. ```python copy.deepcopy(provider.backends.ibmq_vigo.configuration()) ``` QasmBackendConfiguration(backend_name='ibmq_vigo', backend_version='1.0.2', basis_gates=['u1', 'u2', 'u3', 'cx', 'id'], conditional=False, coupling_map=[[0, 1], [1, 0], [1, 2], [1, 3], [2, 1], [3, 1], [3, 4], [4, 3]], gates=[GateConfig(id, [], gate id q { U(0,0,0) q; }, [[0], [1], [2], [3], [4]]), GateConfig(u1, ['lambda'], gate u1(lambda) q { U(0,0,lambda) q; }, [[0], [1], [2], [3], [4]]), GateConfig(u2, ['phi', 'lambda'], gate u2(phi,lambda) q { U(pi/2,phi,lambda) q; }, [[0], [1], [2], [3], [4]]), GateConfig(u3, ['theta', 'phi', 'lambda'], gate u3(theta,phi,lambda) q { U(theta,phi,lambda) q; }, [[0], [1], [2], [3], [4]]), GateConfig(cx, [], gate cx q1,q2 { CX q1,q2; }, [[0, 1], [1, 0], [1, 2], [1, 3], [2, 1], [3, 1], [3, 4], [4, 3]])], local=False, max_shots=8192, memory=True, n_qubits=5, open_pulse=False, simulator=False) ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: completion should favor displaying the actually completed part of the string rather than the prefix One screenshot says it all.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Also update progress_bar in training_epoch_end ## 🚀 Feature [PR 1357](https://github.com/PyTorchLightning/pytorch-lightning/pull/1357) implements training_epoch_end to log metrics. The comments in the issue suggest that it should behave like validation_epoch_end, but the PR only replicates the callbacks and metric logging. This feature would add updates to the progress bar as well. ### Motivation Motivation is for the same usecase as having a progress bar. While tensorboard or any other logger is a great resource to have. It is painful to set up in environments like slurm where you can only submit jobs and possibly cannot forward ports or set up the logging. ### Pitch The changes should only entail adding an update to tqdm [here](https://github.com/PyTorchLightning/pytorch-lightning/blob/b2707c9b2ebeac03f19a3939df9432ac8859d894/pytorch_lightning/trainer/training_loop.py#L503) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: State handler errors are not logged well Example: ```python from prefect import task, Flow def handler(*args, **kwargs): raise SyntaxError(\"unique informative message\") @task(state_handlers=[handler]) def my_task(): pass f = Flow(\"reproducible-example\", tasks=[my_task]) f.run() # INFO - prefect.FlowRunner | Beginning Flow run for 'reproducible-example' # INFO - prefect.FlowRunner | Starting flow run. # DEBUG - prefect.FlowRunner | Flow 'reproducible-example': Handling state change from Scheduled to Running # INFO - prefect.TaskRunner | Task 'my_task': Starting task run... # DEBUG - prefect.TaskRunner | Task 'my_task': Handling state change from Pending to Running # INFO - prefect.TaskRunner | Task 'my_task': finished task run for task with final state: 'Failed' # INFO - prefect.FlowRunner | Flow run FAILED: some reference tasks failed. # DEBUG - prefect.FlowRunner | Flow 'reproducible-example': Handling state change from Running to Failed ``` We should see an `ERROR` log displaying a repr of the exception that was thrown inside the state handler. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Start menu shortcuts not created in Python 3 Apparently this is because of the lack of a post_install script included by setup3.py (Reported by Christoph Gohlke on the mailing list) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Typo in XCLIP model ### System Info transformers version 4.25.1 ### Who can help? @NielsRogge @ydshieh There's a typo/mismatch for the xclip model pretrained config archive map between https://github.com/huggingface/transformers/blob/main/src/transformers/models/auto/configuration_auto.py#L333 and. https://github.com/huggingface/transformers/blob/main/src/transformers/models/x_clip/configuration_x_clip.py#L27 notice in the first example, there is underscore between X and CLIP whereas in the second example, there isn't. This leads to an error when initializing automodel ` huggingface_models = list(ALL_PRETRAINED_CONFIG_ARCHIVE_MAP.keys()) File \"/usr/local/lib/python3.8/dist-packages/transformers/models/auto/configuration_auto.py\", line 612, in keys self._initialize() File \"/usr/local/lib/python3.8/dist-packages/transformers/models/auto/configuration_auto.py\", line 602, in _initialize mapping = getattr(module, map_name) File \"/usr/local/lib/python3.8/dist-packages/transformers/utils/import_utils.py\", line 1086, in __getattr__ raise AttributeError(f\"module {self.__name__} has no attribute {name}\") AttributeError: module transformers.models.x_clip has no attribute X_CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP` ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction 1. from transformers import ALL_PRETRAINED_CONFIG_ARCHIVE_MAP 2. huggingface_models = list(ALL_PRETRAINED_CONFIG_ARCHIVE_MAP.keys()) ### Expected behavior Expect no errors to be raised Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Statevector and DensityMatrix expectation value ignores qargs for Pauli ops <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.17.0 - **Python version**: - **Operating system**: ### What is the current behavior? The `expectation_value` method of `Statevector` and `DensityMatrix` returns the incorrect value for a Pauli or SparsePauliOp operator if non-trivial qargs are used. ### Steps to reproduce the problem Compare the expectation value for a `Pauli` op to `Pauli.to_matrix()` computed via the `Operator` method. ### What is the expected behavior? The operator and Pauli methods should be equal for equivalent operators. ### Suggested solutions This is because the qargs are not used in the internal pauli expval function Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Remove codepath for Python < 3.6 This issue is in priority for new for new contributors; even if you are a new contributor lease fix only one of the places linked to below; to leave a chance for someone else to contribute. We dropped Python 3.5 a few minutes ago : https://github.com/ipython/ipython/pull/11937 There is likely a number of place that use codepath only for Python 3.5 and below: ``` tools/gen_latex_symbols.py 14:if sys.version_info[0] < 3: IPython/core/async_helpers.py 102: if sys.version_info >= (3,8): 133: if sys.version_info < (3, 7): 152: if sys.version_info > (3, 8): IPython/core/interactiveshell.py 119:if sys.version_info > (3,6): 169:if sys.version_info > (3, 5): 2248: if sys.version_info >(3,5): IPython/lib/pretty.py 102:DICT_IS_ORDERED = sys.version_info >= (3, 6) IPython/terminal/interactiveshell.py 418: if sys.version_info >= (3, 6): IPython/testing/iptest.py 116: In [3]: test_for('sys', (2,6), callback=lambda sys: sys.version_info) IPython/extensions/tests/test_autoreload.py 143: @skipif(sys.version_info < (3, 6)) IPython/lib/tests/test_display.py 52: if sys.version_info >= (3, 6): IPython/core/tests/test_async_helpers.py 17:if sys.version_info > (3, 5): 204: sys.version_info >= (3, 6), IPython/core/tests/test_completer.py 474: if sys.version_info > (3, 4): ``` Some of these can be cleaned up either because they are always True or False now. If you are a new contributor and look to make one of your first contribution; try to find one of these place in the IPython codebase (line number may have shifted a bit); understand what it does, and try to clean it up to make the code base simpler. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Remove __iter__ and __contains__ from Connection in storage @tseaver WDYT? This is part of a movement towards making `Connection` more of a background / low-level / raw interface (like it is for datastore). What's more ``` python for bucket in connection.get_all_buckets(): ... ``` seems much more clear than ``` python for bucket in connection: ... ``` We could potentially make up for `__contains__` by adding a `Bucket.exists` method / property. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Cannot use URL as build context According to https://docs.docker.com/compose/compose-file/#/context it should be possible to use URL to a git repository for build context, but I am having no luck docker-py version: 1.8.1 CPython version: 2.7.9 OpenSSL version: OpenSSL 1.0.1e 11 Feb 2013 docker-compose.yml ``` version: '2' services: test: build: context: https://github.com/docker/compose.git ``` docker-compose build ``` Building test Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"compose/cli/main.py\", line 58, in main File \"compose/cli/main.py\", line 109, in perform_command File \"compose/cli/main.py\", line 215, in build File \"compose/project.py\", line 300, in build File \"compose/service.py\", line 719, in build File \".tox/py27/lib/python2.7/site-packages/docker/api/build.py\", line 104, in build File \".tox/py27/lib/python2.7/site-packages/docker/utils/decorators.py\", line 46, in inner AttributeError: 'NoneType' object has no attribute 'update' docker-compose returned -1 ``` Unable to pull private images when using credentials helper I'm using the secretservice credentials helper with docker 1.11.2 and docker-compose 1.8.0-rc1. If I try to run `docker-compose up`, it fails to pull private images from our gitlab registry. --verbose says: ``` docker.auth.auth.resolve_authconfig: No entry found docker.api.image.pull: No auth config found ``` Pulling the image manually using docker pull works. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: API Endpoint - Config **Description** Hello, We need an endpoint that allows us to **read** the current Airflow configuration. - GET /config More details about API Endpoints: https://github.com/apache/airflow/issues/8118 **Use case / motivation** N/A **Related Issues** N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: --alt-hint flag no longer used; remove it from CLI API https://github.com/conda/conda/pull/5427#issue-231367721 > I couldn't figure out what `--alt-hint` did, so I looked at the source code only to find that it doesn't do anything. Now I'm removing the option so no one else wastes their time the same way. --alt-hint flag no longer used; remove it from CLI API https://github.com/conda/conda/pull/5427#issue-231367721 > I couldn't figure out what `--alt-hint` did, so I looked at the source code only to find that it doesn't do anything. Now I'm removing the option so no one else wastes their time the same way. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Deprecation warnings are reversed **Describe the bug** When I use `python3` module with min_version where it was not deprecated yet, I get deprecation warning and a “feature too new” warning: ``` DEPRECATION: Project targeting '>= 0.47' but tried to use feature deprecated since '0.48.0': python3 module Build targets in project: 0 WARNING: Project specifies a minimum meson_version '>= 0.47' but uses features which were added in newer versions: * 0.48.0: {'python3 module'} WARNING: Deprecated features used: * 0.48.0: {'python3 module'} ``` When I bump the min_version to 0.48 both warnings disappear. **To Reproduce** ``` project('almanah', 'c', meson_version: '>= 0.47') python3 = import('python3') python = python3.find_python().path() ``` **Expected behavior** * Do not show deprecation warning with min_version < 48 * Show deprecation warning with min_version ≥ 48 * Never show “feature too new” warning. **system parameters** * native build * NixOS * Python 3.7.7 * Meson 0.54.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: array_split incorrect behavior with array size bigger MAX_INT32 `numpy.array_split()` produces empty last chunk in case of original array size is bigger than MAX_INT32. ### Reproducing code example: **NOT OK**: ``` import numpy as np test = np.random.rand(1 << 31, 1) for chunk in np.array_split(test, 2): print(chunk.shape) >>>(1073741824, 1) >>>(0, 1) ``` **NOT OK**: ``` import numpy as np test = np.random.rand(1 << 31, 1) for chunk in np.array_split(test, 3): print(chunk.shape) >>>(715827883, 1) >>>(715827883, 1) >>>(0, 1) ``` **OK**: ``` import numpy as np test = np.random.rand(1 << 30, 1) for chunk in np.array_split(test, 2): print(chunk.shape) >>>(536870912, 1) >>>(536870912, 1) ``` **OK**: ``` import numpy as np test = np.random.rand((1 << 31) - 1, 1) for chunk in np.array_split(test, 2): print(chunk.shape) >>>(1073741824, 1) >>>(1073741823, 1) ``` ### Numpy/Python version information: ``` numpy.__version__ >>> 1.14.4 sys.version >>> 3.5.2 |Continuum Analytics, Inc.| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)] ``` 112 GB of RAM to exclude the problem with the memory lack. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: vs_module_defs ignored when cross-compiling to Windows with clang `gen_vs_module_defs_args` [checks if the compiler type is `GCC_CYGWIN` or `GCC_MINGW` to decide whether or not to pass the def file along](https://github.com/mesonbuild/meson/blob/807981889f0cbecf165d0dc8bfb1e980adac58d8/mesonbuild/compilers/compilers.py#L1485), which results in it dropping it on the floor when the compiler type is `CLANG_MINGW`. It seems like there are a few other places where there are similar checks, which probably also breaks c_winlibs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ExecutePreprocessor should run from the notebook's directory If you run `nbconvert` from the command line with the `--execute` flag, but are not in the same directory as the notebook, then the notebook won't run successfully if it depends on external files because the kernel will have been started in the cwd rather than the notebook's directory. So probably `ExecutePreprocessor` should chdir to the notebook's directory first, then chdir back to the original directory. I'll make a PR for this later today. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: add short option for \"--use-index-cache\" `--use-index-cache` makes search and info much faster, but it's a lot of characters to type. Could you add a short equivalent? To propose something: it could be a capital C like in yum/dnf: ``` -C, --cacheonly Run entirely from system cache, don't update the cache and use it even in case it is expired. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: run_target Permission Denied error should be clearer Minimal example - [folder.zip](https://github.com/mesonbuild/meson/files/1530489/folder.zip) I ran - `mkdir build && cd build && meson .. && ninja` and everything works. Now I run - `ninja myscript` and it throws errors - ``` [0/1] Running external command myscript. Traceback (most recent call last): File \"/usr/bin/meson\", line 37, in <module> sys.exit(main()) File \"/usr/bin/meson\", line 34, in main return mesonmain.run(sys.argv[1:], launcher) File \"/usr/lib/python3.6/site-packages/mesonbuild/mesonmain.py\", line 311, in run sys.exit(run_script_command(args[1:])) File \"/usr/lib/python3.6/site-packages/mesonbuild/mesonmain.py\", line 278, in run_script_command return cmdfunc(cmdargs) File \"/usr/lib/python3.6/site-packages/mesonbuild/scripts/commandrunner.py\", line 60, in run pc = run_command(src_dir, build_dir, subdir, meson_command, command, arguments) File \"/usr/lib/python3.6/site-packages/mesonbuild/scripts/commandrunner.py\", line 39, in run_command return subprocess.Popen(command_array, env=child_env, cwd=cwd) File \"/usr/lib/python3.6/subprocess.py\", line 709, in __init__ restore_signals, start_new_session) File \"/usr/lib/python3.6/subprocess.py\", line 1344, in _execute_child raise child_exception_type(errno_num, err_msg, err_filename) PermissionError: [Errno 13] Permission denied: '/home/agauniyal/temp/scripts/script.sh' FAILED: meson-myscript /usr/bin/python /usr/bin/meson --internal commandrunner /home/agauniyal/temp/ /home/agauniyal/temp/build '' /usr/bin/python /usr/bin/meson /home/agauniyal/temp/scripts/script.sh ninja: build stopped: subcommand failed. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Empty args list results in unhelpful error Having the Dockerfile ``` Dockerfile FROM scratch ``` and the `docker-compose.yml` file ``` yml version: \"2\" services: web: build: context: . args: ``` Gives me the following error on any docker-compose command (`config`, `build`) ``` Traceback (most recent call last): File \"<string>\", line 3, in <module> File \"/code/compose/cli/main.py\", line 55, in main File \"/code/compose/cli/docopt_command.py\", line 23, in sys_dispatch File \"/code/compose/cli/docopt_command.py\", line 26, in dispatch File \"/code/compose/cli/main.py\", line 169, in perform_command File \"/code/compose/cli/main.py\", line 210, in config File \"/code/compose/config/config.py\", line 288, in load File \"/code/compose/config/config.py\", line 397, in process_config_file File \"/code/compose/config/validation.py\", line 371, in validate_against_fields_schema File \"/code/compose/config/validation.py\", line 412, in _validate_against_schema File \"/code/compose/config/validation.py\", line 362, in process_errors File \"/code/compose/config/validation.py\", line 362, in <genexpr> File \"/code/compose/config/validation.py\", line 360, in format_error_message File \"/code/compose/config/validation.py\", line 248, in handle_generic_service_error File \"/code/compose/config/validation.py\", line 328, in _parse_oneof_validator File \"/code/compose/config/validation.py\", line 303, in _parse_valid_types_from_validator File \"/code/compose/config/validation.py\", line 188, in anglicize_validator TypeError: coercing to Unicode: need string or buffer, dict found docker-compose returned -1 ``` Using `docker-compose version 1.6.0, build d99cad6` on Ubuntu 15.10. I see the empty dictionary is a stupid mistake, it came up when I commented out all the arguments, but would it be possible to provide a helpful error message here? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: MPL drawer does not support controlled gates ### Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: MacOS ### What is the current behavior? The matplotlib drawer does not print controlled gates correctly. ### Steps to reproduce the problem ``` qr = QuantumRegister(3, 'q') circuit = QuantumCircuit(qr) circuit.append(HGate().control(2), [qr[0], qr[1], qr[2]]) circuit.draw('mpl') ```  ### What is the expected behavior? Something along the text drawer: ``` q_0: |0>──■── │ q_1: |0>──■── ┌─┴─┐ q_2: |0>┤ H ├ └───┘ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [QUESTION] Check validity of `setup.py` in build H/T to http://inre.dundeemt.com/2014-05-17/pypi-setup-py-keeping-a-dry-long_description/ (I was Googling around for DRY in `setup.py`) ``` python setup.py check --restructuredtext --strict ``` --- For example, running it on the post #2442 version gives: ``` $ python setup.py check --restructuredtext --strict running check warning: check: Duplicate implicit target name: \"contributing\". warning: check: Duplicate implicit target name: \"license\". error: Please correct your package. ``` because we have sections named license and contributing as well as links with those names. This could be fixed via ``` diff diff --git a/README.rst b/README.rst index 715368b..bbf0f72 100644 --- a/README.rst +++ b/README.rst @@ -96,16 +96,16 @@ Contributing Contributions to this library are always welcome and highly encouraged. -See `CONTRIBUTING`_ for more information on how to get started. +`See CONTRIBUTING`_ for more information on how to get started. -.. _CONTRIBUTING: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/CONTRIBUTING.rst +.. _See CONTRIBUTING: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/CONTRIBUTING.rst License ------- -Apache 2.0 - See `LICENSE`_ for more information. +Apache 2.0 - `See LICENSE`_ for more information. -.. _LICENSE: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/LICENSE +.. _See LICENSE: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/LICENSE .. |build| image:: https://travis-ci.org/GoogleCloudPlatform/google-cloud-python.svg?branch=master :target: https://travis-ci.org/GoogleCloudPlatform/google-cloud-python ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question][bug] XcodeDeps with custom configuration does not behave as expected ### What is your question? Hi, I'm trying to understand the example from the [XcodeDeps tutorial with custom configurations](https://docs.conan.io/2/reference/tools/apple/xcodedeps.html#custom-configurations). I've added the `conanfile.py` from the example and ran ``` > conan profile show Host profile: [settings] arch=armv8 build_type=Release compiler=apple-clang compiler.cppstd=gnu20 compiler.libcxx=libc++ compiler.version=14 os=Macos Build profile: [settings] arch=armv8 build_type=Release compiler=apple-clang compiler.cppstd=gnu20 compiler.libcxx=libc++ compiler.version=14 os=Macos > conan install . --output-folder=build --build=missing -o 'shared=True' ``` I was expecting that the config specifier in the resulting xcconfig files would now reflect the adapted configuration name, e.g. `ReleaseShared` - I thought that was the whole point. But when I look inside the resulting `conan_zlib_zlib_release_arm64.xcconfig` then it's just `HEADER_SEARCH_PATHS_zlib_zlib[config=Release][arch=arm64][sdk=macosx*] ...`. Is my understanding wrong? We have several differently named Debug and Release configurations, e.g. \"Release with asserts\" and for that I need an xcconfig for all of them. ### Have you read the CONTRIBUTING guide? - [X] I've read the CONTRIBUTING guide Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gdbus_codegen should return two different targets (.c, .h) With glib<2.56.2, gdbus_codegen() returns twice the same custom_target, with two outputs. A bug occurs when this return value is used for generate_gir(). The source list then contains twice the .c, and zero times the .h… Maybe gdbus_codegen() should return two custom_targets, with each one output (once the .c, once the .h). EDIT : Actually, after reading the source of generate_gir, I suppose the bug is there. ``` gir_filelist.write(os.path.join(state.environment.get_build_dir(), state.backend.get_target_dir(s), s.get_outputs()[0]) + '\\n') ``` Why only `s.get_outputs()[0]` ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] How to not include some libs in conanbuildinfo.props Conan version 1.19.0 I have a dependency on boost (boost/1.71.0@conan/stable). I'm using the visual_studio generator with VS2017 This adds *all* of the boost libs to conanbuildinfo.props which causes my build to fail. I don't completely understand why this used to be OK with 1.68 and now fails with that too after moving my cache to a different drive (perhaps it was due to installing vs2019 alongside vs2017). But regardless it would be good if I could either cherrypick which libs to include or remove specific ones from the list. For example I don't want to include any of the stacktrace libs which result in duplicate symbols. I can't figure out how to do it. If I specify any of the 'without_xxx' options then it rebuilds the whole of the boost dependency which I would rather avoid - I just want to control which libs it puts in the vs props file! I was trying to see if there was some place I could remove them from deps_cpp_info but it doesn't look like there is a place to put that (i.e. an event just before the generators are run). Perhaps overriding the generator could do the trick but it seems like that would be a bit of a sledgehammer and not all that clean. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson dies with a TypeError if project version number is an integer instead of a string **Describe the bug** If I mistakenly specify the project version number as an integer rather than a string, Meson prints a few pages of stack trace rather than a useful error message. The last lines of the traceback are: ``` File \"/home/james/src/ubuntu/meson/mesonbuild/interpreter.py\", line 3216, in func_project mlog.log('Project version:', mlog.bold(self.project_version)) File \"/home/james/src/ubuntu/meson/mesonbuild/mlog.py\", line 225, in log arr = process_markup(args, True) File \"/home/james/src/ubuntu/meson/mesonbuild/mlog.py\", line 178, in process_markup arr.append(arg.get_text(keep)) File \"/home/james/src/ubuntu/meson/mesonbuild/mlog.py\", line 128, in get_text text = self.code + self.text + AnsiDecorator.plain_code TypeError: can only concatenate str (not \"int\") to str ``` **To Reproduce** I can trigger this with the following trivial build file: ``` project('foo', 'C', version: 42) ``` **Expected behavior** I would expect Meson to either error out telling me that the version number must be a string, or to actually accept the integer version number. It would probably be more consistent to reject such projects, since that's effectively the current behaviour with the TypeError. **system parameters** * Ubuntu 20.04 * Python 3.8.5 * Meson 0.56.99 (from git at revision 8992729). * Ninja 1.10.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Reduce number of selinuxenabled and restorecon calls Currently, when installing headers, meson will execute `selinuxenabled` for each header, and if enabled, call `restorecon` to alter the selinux context. This has a fairly high overhead at install time. If I make a dummy `selinuxenabled` shell script that just does `exit 1`, the time to install Builder's header files goes from a couple of seconds down to imperceptible. There seems to be a couple of strategies to improve the performance here, and mix-n-match as appropriate. * Use /usr/bin/install when available to install files instead of Python's copy_file(). This would probably gain some optimizations they do there for faster copies (not a big deal) but also allow for the `-Z --context=ctx` option. * Cache the result of `selinuxenabled` * Cache the location of `which restorecon` to avoid traversing `$PATH` for each `execve()`. * Coalesce `restorecon` calls. It's not clear to me if these can be coalesced into a single call, or per-directory. `man restorecon` does imply that you can call it with multiple files at least. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: Bug: Dataset not found in US I'm getting an error while running the BigQuery kfp component to export some data from BQ to GCS. It says: `google.api_core.exceptions.NotFound: 404 Not found: xxx was not found in location US` which is correct, because the dataset is in EU, but I couldn't find any way to change the default behaviour of looking for datasets in the US. On our regular codebase we specify the location on the BigQuery client initialisation, but the code here just uses the default: https://github.com/danicat/pipelines/blob/master/component_sdk/python/kfp_component/google/bigquery/_query.py It is a one line change in the code, but I don't know how to rebuild the ml-pipeline container. The developer guide doesn't mention how to do it (but it does explain how to build containers for other components of the solution). Please help! :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Suboptimal logging from `import('python').find_installation()` The output from `import('python').find_installation('python')` when `python` is not found is confusing. The following `meson.python` ``` project('test') py = find_program('python3.12', required: false) py = import('python').find_installation('python3.12') ``` results in this output: ``` Program python3.12 found: NO Program nonexistingprogram found: NO meson.build:5:22: ERROR: python3.12 not found ``` Where `Program python3.12 found: NO` comes from the `find_program()` call and `Program nonexistingprogram found: NO` comes from the `find_installation()` call. I think that `nonexistingprogram` would be better replaced with something more descriptive. This is on macOS with Meson 1.1.0. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Mutating list while iterating https://github.com/PrefectHQ/prefect/blob/8c886b64df8e264791ec1d0e401cbbd6c4719af5/src/prefect/agent/local/agent.py#L75-L77 It's a no-no to mutate the list while iterating. Indeed, in my tests, a loop like this fails to examine the _next_ item in the list, so it's actually not working as intended. For instance: ``` x = [0,1,2,3,4,5,6,7,8] for idx, y in enumerate(x): print(idx, y) if y == 3: z = x.pop(idx) print(idx, y) ``` yields this output; note that the `4` element in the list is never examined. ``` 0 0 0 0 1 1 1 1 2 2 2 2 3 3 3 3 4 5 4 5 5 6 5 6 6 7 6 7 7 8 7 8 ``` To be fair this is somewhat harmless, because the process will likely be examined in the next heartbeat call, or in the worst case after all of the processes earlier in the list are completed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC/BUG: np.sum supports generators, unlike the other reduction helpers ```python >>> np.sum(a for a in range(10)) 45 >>> np.prod(a for a in range(10)) <generator object <genexpr> at 0x0000023BAF7ED1A8> ``` Generators are not considered `array_like`, so the result for `sum` does not match the documentation. Introduced in a13aad3ac33b629f3e696b4d4d5dbf4b5605d567 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Flipping of gate direction in Transpiler for CZ gate ### What should we add? The current version of the transpiler raises the following error when attempting to set the basis gate of a backend as `cz` ` 'Flipping of gate direction is only supported for CX, ECR, and RZX at this time, not cz.' ` As far as I'm aware and through my own testing flipping of a CZ should be easy to implement as it's \"flip\" produces the same unitary operator. There is no direct identity needed. If this could get added that would be great! I would have done this via a pull request myself but it seems \"too easy\" of a solution that I must be missing something. The Qiskit file that would need changing. https://github.com/Qiskit/qiskit-terra/blob/1312624309526812eb62b97e0d47699d46649a25/qiskit/transpiler/passes/utils/gate_direction.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Cap batch size by number of training samples when using auto_scale_batch_size <!-- ### Common bugs: 1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). 2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) --> ## 🐛 Bug The batch size finder sets an unrealistically high batch size if all samples of the training dataset fit into one batch. ``` ... Batch size 8388608 succeeded, trying batch size 16777216 Batch size 16777216 succeeded, trying batch size 33554432 Batch size 33554432 succeeded, trying batch size 67108864 Finished batch size finder, will continue with full run using batch size 67108864 ``` ### To Reproduce Steps to reproduce the behavior: 1. Run [Mnist Example](https://colab.research.google.com/drive/1F_RNcHzTfFuQf-LeKvSlud6x7jXYkG31#scrollTo=HOk9c4_35FKg) with `auto_scale_batch_size=True` (one needs to remove hardcoded batch size and set `self.batch_size`). ### Expected behavior Batch size search space should not be larger than number of available training samples. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: The \"get_statevector\" and \"get_unitary\" methods of the result objects of statevector and unitary simulators seem to ignore the \"decimals\" parameter ### Informations - **Qiskit version**: 0.20.1 - **Python version**: The one on the Jupyter server of the IBM Q Experience - **Operating system**: The one on the Jupyter server of the IBM Q Experience ### What is the current behavior? The \"get_statevector\" and \"get_unitary\" methods of the result objects of statevector and unitary simulators seem to ignore the \"decimals\" parameter ### Steps to reproduce the problem %matplotlib inline # Importing standard Qiskit libraries and configuring account from qiskit import QuantumCircuit, execute, Aer, IBMQ from qiskit.compiler import transpile, assemble from qiskit.tools.jupyter import * from qiskit.visualization import * # Loading your IBM Q account(s) provider = IBMQ.load_account() circ = QuantumCircuit(1,1) circ.h(0) backend = Aer.get_backend('statevector_simulator') job = execute(circ, backend) result = job.result() outputstate = result.get_statevector(circ, decimals=3) print(outputstate) outputstate = result.get_statevector(circ, decimals=1) print(outputstate) outputstate = result.get_statevector(circ) print(outputstate) ***** Something similar happens with the get_unitary method when the unitary simulator is used ### What is the expected behavior? The number of decimals of the outputstate should be the one used as parameter ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add support for Cloud Storage Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython Notebook Server URL now requires \"tree\" at the end of the URL? (version 2.2) I've been using a bookmark to go visit my IPython notebook server so I was surprise to get a 404 Server Not Found message after I upgraded to version 2.2. So after some trial and error, I found out I needed to add \"tree\" to the end of the URL. Was this documented somewhere? I was going to maybe mention this as an issue at their Github site. I did look at the docs, but no where does it mention that you now have to add \"tree\" at the end of the URL. Anyone else notice this or is it just me? Does the documentation need to be updated to reflect this? Thanks in advance. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Expose stable flag on XLA sort XLA's sort HLOs have an \"is_stable\" attribute, which defaults to false; in practice, the sort used on CPU is stable but the one on GPU isn't. This means that e.g. this code will fail on GPU: ```python x = onp.array([5, 1, 2, 6, 5, -2, 2, 0, 0, 1, 0, 4]) assert jnp.argsort(x) == onp.argsort(x) ``` and #2760 won't match NumPy behavior (ties to earliest) either. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: windows msvc cross-compilation linker arguments are wrong for sanity-check given a cross-file: `` [binaries] c = 'C:\\\\\\\\Program Files (x86)\\\\\\\\Microsoft Visual Studio\\\\\\\\2017\\\\\\\\Professional\\\\\\\\VC\\\\\\\\Tools\\\\\\\\MSVC\\\\\\\\14.11.25503\\\\\\\\bin\\\\\\\\Hostx64\\\\\\\\x86\\\\\\\\cl' [properties] c_link_args = ['/LIBPATH:C:\\\\\\\\Program Files (x86)\\\\\\\\Microsoft Visual Studio\\\\\\\\2017\\\\\\\\Professional\\\\\\\\VC\\\\\\\\Tools\\\\\\\\MSVC\\\\\\\\14.11.25503\\\\\\\\lib\\\\\\\\x86', '/LIBPATH:C:\\\\\\\\Program Files (x86)\\\\\\\\Windows Kits\\\\\\\\NETFXSDK\\\\\\\\4.6.1\\\\\\\\lib\\\\\\\\um\\\\\\\\x86', '/LIBPATH:C:\\\\\\\\Program Files (x86)\\\\\\\\Windows Kits\\\\\\\\10\\\\\\\\lib\\\\\\\\10.0.16299.0\\\\\\\\ucrt\\\\\\\\x86', '/LIBPATH:C:\\\\\\\\Program Files (x86)\\\\\\\\Windows Kits\\\\\\\\10\\\\\\\\lib\\\\\\\\10.0.16299.0\\\\\\\\um\\\\\\\\x86', '/MACHINE:X86'] `` it tries to run cl.exe sanity-check.c with linker arguments which are not recognized (linker arguments must be prefixed with /link and passed after all other options and source files) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Support IterableDatasets for validation and test, not just train set [blocked by #953] ## 🚀 Feature Currently Lightning supports `IterableDatasets` only in the training set (see [code](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/trainer/data_loading.py#L177)). This makes them second-class citizens compared to the map-style datasets, and supporting them seems a low hanging fruit. ### Motivation This enables having larger test sets that may not fit into a machine's memory (they could be very large in production settings, or of modest size running in a student's cheap laptop). Moreover, datasets are usually generated together (eg train, val, test can come from the same process). It is very likely that the same process has the same signature, so you may end up having IterableDatasets even when their size may not deem it strictly necessary. ### Pitch <!-- A clear and concise description of what you want to happen. --> Changing a few lines of code by bringing in the checks we are doing for training should be enough unless I'm missing something. ### Additional context <!-- Add any other context or screenshots about the feature request here. --> Are there any gotchas that make this harder than it looks? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: db+ string in result backend but not metadata secret ### Official Helm Chart version 1.1.0 (latest released) ### Apache Airflow version 2.1.3 (latest released) ### Kubernetes Version 1.21 ### Helm Chart configuration data: metadataSecretName: \"airflow-metadata\" resultBackendSecretName: \"airflow-result-backend\" ### Docker Image customisations _No response_ ### What happened If we only supply 1 secret with ``` connection: postgresql://airflow:password@postgres.rds:5432/airflow?sslmode=disable ``` To use for both metadata and resultBackendConnection then we end up with a connection error because resultBackendConnection expects the string to be formatted like ``` connection: db+postgresql://airflow:password@postgres.rds:5432/airflow?sslmode=disable ``` from what i can tell ### What you expected to happen I'd expect to be able to use the same secret for both using the same format if they are using the same connection. ### How to reproduce Make a secret structured like above to look like the metadataConnection auto-generated secret. use that same secret for the result backend. deploy. ### Anything else Occurs always. To get around currently we make 2 secrets one with just the db+ prepended. ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Replace QiskitError in qiskit/circuit/* with CircuitError Following the suggestion in https://github.com/Qiskit/qiskit-terra/issues/601#issuecomment-471257119 Also #3203 needs `CircuitError`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Remove support for API_KEY in translation See #2731 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Replace `config.output_attentions` parameter with function argument `output_attentions` # 🚀 Feature request Currently the user has to decide whether the model should output the attentions when she/he creates the config of a model: config.output_attentions = True/False. It would be nice if the user can decide this when calling the models `forward()` / `call()` with a flag `output_attentions`. This should be done for all TF and PT models that can output attentions. A very similar recent change was done for the variable `config.output_past` -> see PR:#3734 ## Motivation The user has more flexibility when the hidden states should be output or not. ## Your contribution If someone feels like contributing to the library, this would be a great first PR. I'm very happy to guide the contributor through the PR! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: TranspilerAccessError should be deprecated in favor of TranspilerError Following the suggestion in https://github.com/Qiskit/qiskit-terra/issues/601#issuecomment-471257119 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: no tab completion in terminal when using debugger @Carreau I chatted with Brian Granger, who said I should bring this to your attention. OS: Mac OS 10.10.5 python -V: Python 3.5.2 : Anaconda custom (x86_64) ipython --version : 5.0.0 source of ipython: conda-forge build When I am in the ipython terminal and using the debugger, tab completion does not work (i.e., I just get a tab). This happened in the version of IPython I had before installing this a few minutes ago, so I wonder if it's something wrong with the conda-forge build? I'm at Scipy, so if someone wants a demo of the problem, I'm happy to do that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: python extension_module should not link to python library on macOS and Linux Continuing from https://gitlab.gnome.org/GNOME/pygobject/issues/253#note_307567 `python.extension_module()` needs to be passed `python_dep` explicitly, which makes sense because meson can't always know what python the project wants to use, but it should not explicitly link to the Python `so` or `dylib` (but it should link to the `dll`) since it's a `shared_module()`. Currently projects need to use `python_dep.partial_dependency(compile_args: true)` on non-Windows platforms, but we should handle this automatically. CCing @MathieuDuponchelle @tschoonj Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: `docker-compose rm` on windows waits for y/N answer before the question is shown. When I do a **docker-compose rm** it just shows a new empty line and then nothing. By trial and error I found out that the \"Are you sure?\" question doesn't display but it waits for input. Look at the flow below... ``` $ docker-compose rm y Removing afdriftmysql_phpmyadmin_1 ... done Removing afdriftmysql_db_1 ... done Going to remove afdriftmysql_phpmyadmin_1, afdriftmysql_db_1 Are you sure? [yN] ``` I would expect the question to be asked before having to answer it. - Windows 7 Pro x64 - docker-toolbox 1.10.0 - git 2.6.2 x64 from git-scm.com Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG?: 1.14 printing requires gc run to clean up all references to printed array Dear NumPy devs, one of our NumPy integration doctests in Cython has been failing on travis for a couple of weeks. I checked the changelog of CPython and Cython from the time when it started, but neither showed anything remotely related. However, the failing travis nodes use NumPy 1.14, and since there were PyPy related changes in that release, I suspect that this could be the cause. I only see the failures in Py3.5+, and they started in the CPython-dev integration test runs for py3.6-dev and py3.7-dev on travis, however those are built (NumPy is pre-installed in them). Here's an example of a [failing run](https://travis-ci.org/cython/cython/builds/342548198). The now failing [test](https://github.com/cython/cython/blob/2e1066dcfc1c4ccbfaa0babf3cbe9f58640431fd/tests/memoryview/numpy_memoryview.pyx#L415-L423) is simply this: ``` cdef int[:, :] array = create_array((4, 5), mode=\"c\", use_callback=True) print(np.asarray(array)[::2, ::2]) ``` Meaning, there is a buffer provider (not NumPy), we take a Cython memory view from it, and then wrap that with `numpy.asarray()` to print it. The difference is when the buffer provider will be deallocated. Previously, it was cleaned up immediately at function exit (and we print a confirmation in a cleanup callback when that happens). With the new NumPy version, it is no longer cleaned up immediately, but only at the next GC run. I added a conditional GC call to the test to trigger that and keep the test from failing (we didn't need a GC run before), but I thought I'd at least bring this change to your attention, in case it's unintentional. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Chaining configure_file() can cause ninja to go in an infinite loop ```meson cfg1 = configure_file( ... ) cfg2 = configure_file( input: cfg1, ... ) ``` Currently this is not possible, because cfg1 is saved in builddir and absolute path of the cfg1 File object is trashed - https://github.com/mesonbuild/meson/blob/7882549f860730dda43fcc825b5beb75b0209410/mesonbuild/interpreter.py#L2338, thus cfg2 is looking for cfg1 in the sourcedir. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: ENH: Implement `np.floating.as_integer_ratio` To match the builtin `float.as_integer_ratio` This would allow conversion from `longdouble` to `Decimal`, and to `Fraction` if https://bugs.python.org/issue28716 is resolved Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: MPL circuit drawer shifts creg if n_qubits=n_clbits=1 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.9 - **Python version**: - **Operating system**: ### What is the current behavior? <img width=\"158\" alt=\"Screen Shot 2019-08-24 at 6 53 44 AM\" src=\"https://user-images.githubusercontent.com/1249193/63636348-26a20300-c63c-11e9-959c-0bb5758b97ff.png\"> ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Flow should serialize its environment no matter what Currently, `flow.serialize()` only serializes its environment if `build=True`. I _believe_ this is a vestige of old environment behavior and can be updated so the behavior is consistent. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson emits incorrect warning when uninstalled_variables keyword is added to pkgconfig generator Meson incorrectly emits warning messages `WARNING: Passed invalid keyword argument \"uninstalled_variables\".` `WARNING: This will become a hard error in the future.` when the uninstalled_variables keyword is added to a pkgconfig.generate() statement. The variables are correctly added to the uninstalled .pc file. meson version 0.57.1 ubuntu 20.04 LTS Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: Unexpected pad value when padding an uint64 array This seems to be an edge case, nevertheless I wanted to report this behavior. Especially because I find it kind of interesting. ### Description When padding an array of dtype uint64 there are some cases when mode \"constant\" doesn't append with the correct value but instead pads with 0. **Code to reproduce** ```python >>> offset = 1024 >>> pad_value = np.uint64(-1024) >>> x = np.zeros(5, dtype=np.uint64) - offset >>> np.pad(x, 1, mode=\"constant\", constant_values=pad_value) array([ 0, 18446744073709551615, 18446744073709551615, 18446744073709551615, 18446744073709551615, 18446744073709551615, 0], dtype=uint64) ``` **Expected Result** ```python array([18446744073709551615, 18446744073709551615, 18446744073709551615, 18446744073709551615, 18446744073709551615, 18446744073709551615, 18446744073709551615], dtype=uint64) ``` There are some interesting observations to be made: - This only happens for uint64 (uint32, uint16 and below are fine). - This behavior is only visible if `offset` is in [1, 1024] and the argument of `np.uint64` in `pad_value` is in [-1, -1024]. - `np.pad(x, 1, mode=\"minimum\")` (or `maximum`) works fine, regardless of `offset`. ### Platform, versions, etc. NumPy: 1.14.2 Operating system: Manjaro 17.1.7, x86_64 Linux 4.14.36-1-MANJARO Python version: 3.6.5 (Anaconda, [GCC 7.2.0] on linux) I hope this is reproduce-able and not a weird quirk of my setup. Feel free to ask for further diagnostics if you can think of any. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: COMPOSE_HTTP_TIMEOUT is set but incorrect value is print when timeout is reached I set COMPOSE_HTTP_TIMEOUT to 300, but when it times out the error message says: ``` An HTTP request took too long to complete. Retry with --verbose to obtain debug information. If you encounter this issue regularly because of slow network conditions, consider setting COMPOSE_HTTP_TIMEOUT to a higher value (current value: 60). ``` I looked at the source on master and it appears to still be using the const HTTP_TIMEOUT in the message. This is: Docker version 1.11.2, build b9f10c9 docker-compose version 1.7.1, build 0a9ab35 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Versioning the format of the lockfile? @memsharded I think we should add a field to a generated lockfile with the version, for example \"0.1\". I'm not thinking about making Conan compatible with older lockfiles necessarily, but it might be useful to: - Fail accordingly if the format is not supported. - Maybe other tools (I'm thinking about jfrog-cli and build-info, if maybe it could leverage from the lockfiles for a better build-info), but they will need to know the input format-version. (Very preliminary thoughts) This is pretty speculative but I think it is real enough and cheap to introduce just a field. WDYT? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Request] Verify User Project methods comments are not ambiguous General Request: Verify that the comments are clear for methods which accept User Project with and without Requester Pays. Here's a distinction between Requester Pays and User Project: User Project: Is a request metadata field that is used to assign Storage operational costs to a specified project. Requester Pays: Is a bucket-level metadata field that is used to enforce the use of the User Project metadata field to assign operational costs when an operation is made on a Bucket and its objects. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: `FeaturesManager.get_model_from_feature` should be a staticmethod ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.17.0 - Platform: Linux (Pop!_OS) - Python version: 3.9.6 - PyTorch version (GPU?): 1.9.0+cu111 - Tensorflow version (GPU?): / - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help @michaelbenayoun who committed #14358 ## Information Type error for Pylance in VsCode:  ## Fix https://github.com/huggingface/transformers/blob/77321481247787c97568c3b9f64b19e22351bab8/src/transformers/onnx/features.py#L336-L345 I believe the above function should have the `@staticmethod` decorator. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: prioritize channels within multi-channels Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Latex drawer leaves too much space at end of circuit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.9.0 - **Python version**: 3.7.4 - **Operating system**: Windows 10 [18362] ### What is the current behavior? The latex drawer draws too much \"empty circuit\" after the last gate. It's already visible on a small circuit:  But the larger the circuit, the more noticeable it gets:  ### Steps to reproduce the problem Draw any circuit using the latex drawer. ### What is the expected behavior? Draw the circuit shorter after the last gate. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Error when trying to read the `conanfile.txt` In our Jenkins-system, jenkins created a projectdirectory, that contains an \"@\". After we generated the conanfile.txt, we cannot run conan, cause it doesn't find the \"@ folder=True\" at the end of the line. The conanfile.txt parser, splits at the first \"@\" and when we habe an \"@\" in our directory name, the parsing fails. Example: /home/jenkins/workspace/conan_test@2/conanfile.txt ``` [generators] cmake [requires] OpenSSL/1.1.1@conan/stable [options] OpenSSL:shared=True OpenSSL:no_zlib=True [imports] \"., LICENSE -> /home/jenkins/workspace/conan_test@2/install/licenses @ folder=True\" lib, * -> /home/jenkins/workspace/conan_test@2/g/install/lib bin, * -> /home/jenkins/workspace/conan_test@2/install/bin include, * -> /home/jenkins/workspace/conan_test@2/install/include ``` Run conan install: `conan install . -g cmake -s build_type=Debug -s os=Linux -s arch=x86_64 -s compiler=gcc -s compiler.version=7 -s compiler.libcxx=libstdc++11 --build=missing` Error: ERROR: Invalid imports line: \"., LICENSE -> /home/jenkins/workspace/conan_test@2/install/licenses @ folder=True\" EX: OpenCV/lib, * -> ./lib Invalid imports. Unknown argument 2install/licenses @ folder Code with error: /conans/client/loader_txt.py: https://github.com/conan-io/conan/blob/ab15630bf0675eb2b787b4aaad8f79a53b3580f6/conans/client/loader_txt.py#L75 Possible Solution: Split it at the last \"@\" if possible or ignore things, that are inside `\"` or `'`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] `check_min_cppstd` should specifically report on an unknown compiler The `check_min_cppstd` works, or is intended to work, with default compilers. But it should handle unknown compilers that could be added by users. Right now it doesn't handle the `None` value returned by the `deduced_cppstd` and proceeds to compare it. Should probably throw a specialized error? https://github.com/conan-io/conan/blob/develop/conans/client/tools/settings.py#L51 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Win 10: Update to conda 4.4.4 breaks python path I updated to conda 4.4.4 recently, and now when I open a new \"Anaconda Prompt\" the first thing that is displayed is: `'python' is not recognized as an internal or external command, operable program or batch file.` At this point, I can start Python just fine. However, if I activate and then deactivate another environment, I can't use Python from the command prompt anymore. I get the same error message as above. I've tried rolling back the conda update with revisions, but that broke my installation. (The package pycosat does not get uninstalled properly, which seemed to break my conda install.) Not sure if this matters, but the text in parentheses before the path has changed. Before the update, It would read as the path to my Anaconda installation. In conda 4.4.4, it reads as `(base)`. This may be intended for this update, but I just thought I would share. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `Register.name_format` inaccessible as class property during deprecation ### Environment - **Qiskit Terra version**: 0.23.0 - **Python version**: 3.10 - **Operating system**: macOS ### What is happening? There used to be some class data `Register.name_format`, which is a regex for testing for valid OQ2 identifiers (ignoring keywords). It's now deprecated as the naming restrictions on registers were relaxed in #9100, but the deprecation is done wrong - it's no longer usable as a class attribute, only an instance one. ### How can we reproduce the issue? ```python from qiskit import ClassicalRegister ClassicalRegister.name_format.match(\"valid_name\") ``` gives ``` --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-5-8200813a2299> in <module> 1 from qiskit import ClassicalRegister 2 ----> 3 ClassicalRegister.name_format.match(\"valid_name\") AttributeError: 'property' object has no attribute 'match' ``` ### What should happen? In older Terras, `Register.name_format` was a `re.Pattern` accessible from the class. It's not much use to need an _instance_ of `Register` to get the valid name formats to pass to its constructor. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Core: rename x-goog-header-params -> x-goog-request-params Typo causing problems with Tasks API. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Load more history into readline buffer at startup I'm curious why, at startup in core/interactiveshell.py, the readline history is populated with a hard coded value of only 1000 (instead of, say, the configuration parameter history_length) history entries. I've personally wished I had more history. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: DeviceTuple constant handler doesn't work (and is untested) From @fehiepsi in [this comment](https://github.com/google/jax/issues/804#issuecomment-500169961). ```python def f(x): return jit(lax.fori_loop, static_argnums=(2,))(0, 10, lambda *args: args[1], x) jit(f)(1.) ``` ``` TypeError: No constant handler for type: <class 'jaxlib.xla_extension.XlaOp'> ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Bump Click to <9.0 ## Use Case Currently, Dagster depends on Click <8.0 as a result of https://github.com/dagster-io/dagster/commit/dadf6d5c8d16f679e1b0ad720f93a1686bdcffeb. Would it be possible to bump the maximum supported Click version? The rest of my monorepo depends on `click==8.0.1`, so I currently cannot integrate Dagster into it. ## Ideas of Implementation Bump the maximum supported version. --- #### Message from the maintainers: Excited about this feature? Give it a :thumbsup:. We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support fig.yml and show a deprecation warning Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Argument <InternalDependency null: True> of type InternalDependency is not held by an ObjectHolder. **Describe the bug** meson ( as of commit 84b371c6451344f032d2c6f550c2711ec0776ca8 ) applied to the efl lib ( https://git.enlightenment.org/core/efl.git , commit ID 4ab074c4685e842dae4404fdbdb4fabef4e4b758 ), results in the mentioned error Argument <InternalDependency null: True> of type InternalDependency is not held by an ObjectHolder. The build is performed in the Linux environment of ChromeOS. The bug is NOT present in Meson 0.58.1. **To Reproduce** See above. **Expected behavior** No internal error happens. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? no * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) Linux, ChromeOS, derived from Debian 10.10 * what Python version are you using e.g. 3.8.0: python is present in several versions, it is unclear, which one meson will use. python points to version 2.7.16, python3 points to version 3.7.3 * what `meson --version` : what: command not found * meson --version : 0.58.999 * what `ninja --version` if it's a Ninja build: what: command not found * ninja --version : 1.10.2.git Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: want install_data() variant that allows installing file under a different name Sometimes one needs to install a file (data), but under a different name than it exists in the source tree, e.g. install `foo.bar.win32` as `foo.bar`. We can currently hack around that with `configure_file()` and an empty configuration, but would be nice if there was an official way too. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Add bindirs to pkgconfig generator ### What is your suggestion? pkg-config generator is useful to use conan dependencies in meson build system, especially on Windows. However, meson has no way of knowing where the DLL files are located, since the linkage is done on the import libraries. Providing a `bindir` variable to the generated .pc file would allow meson (an possibly other systems) to query pkg-config for the location of the shared library binaries. ### Have you read the CONTRIBUTING guide? - [X] I've read the CONTRIBUTING guide Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Improve output messages for parallel uploads Now that the [parallel uploads feature](https://github.com/conan-io/conan/pull/5856) is going to be merged we could improve the output information little bit: - The text of the uploaded files should contain to which packages they belong. - For uploads using cmake.conan or CI the output is a few lines of blank text, which reads weird. We could improve those messages. - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Deprecate and cleaned publish_display_data's and DisplayPublisher/publish \"source\" parameter It's been unused and deprecated for years. 1) It should emit a warning when parameter is passed in. 2) the deprecation should say since when it's deprecated. Once this is done, we can think of removing it in a couple of years. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Forward the OS X version to CMake helper Following PR #3091 , there is now an optional `os.version` setting for OS X. Following [this comment](https://github.com/conan-io/conan/issues/2534#issuecomment-399117915) from @lasote, we plan to use it as the minimum osx version (the `-mmacosx-version-min` compiler flag). CMake makes a provision for that thanks to the [`CMAKE_OSX_DEPLOYMENT_TARGET`](https://cmake.org/cmake/help/latest/variable/CMAKE_OSX_DEPLOYMENT_TARGET.html). Should `os.version` be automatically used by the CMake helper, like many other settings are implicitly used to define some CMake variables? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Define policy for conan vs user ConanFile attributes and methods To reduce possible future collisions when things are added to conan. E.g.: - Use \"_myattribute\" for user defined attributes. Conan reserves all public members - Use \"__myattribute\" for user defined atributes. (What happens for inheritance via python_requires?) - Etc. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: please bring back app example It was removed in #2795... and I think it worked in the commit that Steve pointed to in a comment on that PR, but it does not work with the last published version of the packages on npm. I know there are server-side settings which weren't working with this example, but all of those should be optional. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Chaining ACL grants on Storage does not work. So from what I can tell [this](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/ce6756fbe3633c74fd742567654565147628f4ba/storage/google/cloud/storage/acl.py#L56) doesn't work. Example: ```python acl.all().grant_read().revoke_write() ``` None of the grant methods return an object to chain to. See: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/486163e5378897961bc3cf367062c8b10cf7ce3e/storage/google/cloud/storage/acl.py#L148-L170 Should I just take this out of the docs? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: make user config should create default User configurability may be unclear to the user, so I think `prefect make-user-config` should give the user more guidance about their options than an empty file I propose that it should copy the defaults to the user config location However, I could just as easily see doing both of the following, instead of this PR-- 1) adding a note to the `prefect make-user-config` part of the docs (docs/guide/core_concepts) about where to find the default file 2) adding \"the default configuration is located at src/prefect/config.toml\" to the auto-generated settings file Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Use jinja2 templates for editable layouts Syntax in editable layouts are currently using placeholders like ``{settings.build_type}`` to make some conditional logic regarding folder paths. We knew it has some limitations specially with placeholder like ``{options.shared}``, that will replace the value with a ``True``/``False`` instead of a useful value. We evaluated the following: - Inline evaluation of python code - Evaluation of field headers like ``[includedirs#settings.build_type==True]`` - Python syntax in *layout.py* implementing a ``package_info()`` - Jinja2 templating And decided that jinja2 is a fairly common orthogonal language used in a lot of tools, syntax is well documented and contemplates many conditional scenarios. Also this should be quite easy to implement. The information available in this jinja2 templates should be ``options`` and ``settings``. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: difference in source highlighting between 5.3 and 6.0rc1 using %colors Linux The following screenshot shows the difference in source highlighting between the two versions of IPython (note the difference in version between left and right):  The \"null\" profile is just an empty, freshly created profile. Arch Linux, pip-installed ipython. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Report warnings for conflicting versions of build_requires and regular requires It is possible that: - A -> (build_requires) -> B -> C1.0 - A -> (requires) -> C2.0 A ``deps_cpp_info`` will be collecting information from two different versions of C, C2.0 and C1.0 that are conflicting, one might overwrite the other in ``deps_cpp_info``. The build_requires one (in this case, the C1.0 one) is the one that is getting selected (applied latest). At least, it should output a warning of this conflict. cc/ @dodoent Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: validate field paths passed to 'Query.{select,where,order_by}` The following conformance tests assert that passing field paths with invalid path elements to `Query.select` / `Query.where` / `Query.order_by` should raise an exception: - `query-invalid-path-select.textproto` - `query-invalid-path-where.textproto` - `query-invalid-path-order.textproto` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Bug in scheduler if circuit is empty <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? A bug was found in the scheduler if the circuit is empty. The fix is here in my pulse builder PR. This should be fixed, and tests in master and a backport made. https://github.com/Qiskit/qiskit-terra/blob/40fe25df33f89432e2829a8fdb37f968c602106f/qiskit/scheduler/methods/basic.py#L121 ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add sysctl option support when creating service Closes #3765 Signed-off-by: Jari Takkala jtakkala@gmail.com Add 'sysctl' option support PR https://github.com/docker/docker/pull/19265 merged 'sysctl' support into docker, but there seems to be no way to use this feature with docker-compose. Has anyone started work on such a feature? If not, I will attempt to patch docker-compose and create a PR. Are there any suggestions on how to implement it? I was thinking of starting with something similar to how the environment or cap_add options work. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: better message for unsupported nbformat Currently, when opening a notebook that is newer than the current format (just change the nbformat to 4 in an existing notebook to test), the user gets the following message in the notebook UI: > An error occurred while loading this notebook. Most likely this notebook is in a newer format than is supported by this version of IPython. This version can load notebook formats v3 or earlier. And this message is logged in the nbserver: > WARNING:root:500 GET /notebooks/8291848e-ba50-407d-88a3-5480e60d700e?_=1334382692585 (127.0.0.1): Unreadable JSON notebook. The message for an unsupported nb version should be clear and concise, and distinguishable from any _other_ arbitrary failure to load, e.g. from corrupted JSON. In particular, it should report the actual nbformat version of the notebook that is failing to open, so users can more easily find what version of IPython they need. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] 1.8.0 introduces a misleading warning in tools.collect_libs() After updating to 1.8.0 today (thank you for such frequent releases 👍 ), I noticed several warnings when `conan install`ing recipes that depends on our custom boost recipe. ``` boost/1.67@com/stable: WARN: Library 'boost_atomic' already found in a previous 'conanfile.cpp_info.libdirs' folder boost/1.67@com/stable: WARN: Library 'boost_chrono' already found in a previous 'conanfile.cpp_info.libdirs' folder ... ``` Which corresponds to the following addition to the source: https://github.com/conan-io/conan/blob/a20c0f5ca432192596af6b34eccf56c1f5e20904/conans/client/tools/files.py#L308-L310 We see the intention here, but in our situation this message is misleading: it would imply there are several `conanfile.cpp_info.libdirs`, although there is actually only one element in this collection. The message is in fact triggered because in this single `conanfile.cpp_info.libdirs` directory, each library is present with two different extensions (static and dynamic libraries). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Spelling: s/obselete/obsolete `core/google/cloud/obselete.py` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: What should be done about non-atomicity of Table.counter_set() See #1541 for discussion. There is a [note](https://github.com/wbolster/happybase/blob/9cbd718c10a3089f234f1eac1236b631e1f8e7cd/happybase/table.py#L531-L534) from the HappyBase source code > Note that application code should _never_ store a incremented or decremented counter value directly; use the atomic `Table.counter_inc` and `Table.counter_dec` methods for that. and we just went one step further and just made `Table.counter_set()` a not implemented method (it raises `NotImplementedError` when called). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.around uses an inexact algorithm, not mentioned in docstring I came across this from [this discussion](https://news.ycombinator.com/item?id=20818662) of how CPython rounds floating point values to decimal places in `round()`. The two examples below show what CPython does (correct), and the last two what numpy does with a fast but inexact strategy: ```python >>> round(56294995342131.5, 2) 56294995342131.5 >>> round(56294995342131.5, 3) 56294995342131.5 >>> np.round(56294995342131.5, 2) 56294995342131.5 >>> np.round(56294995342131.5, 3) 56294995342131.51 ``` I don't see any past issue for this, and the `around` code and docstring seems to have been last touched over 11 years ago, since the last commit is the copy-n-paste from numeric. The `np.around` docstring does contain the cryptic remark that \"Results may also be surprising due to the inexact representation of decimal fractions in the IEEE floating point standard [1]_ and errors introduced when scaling by powers of ten.\" If it is indeed the case that there is no \"fast\" algorithm for decimal rounding, I think the docstring should at least be elaborated to make clear what approximation is being made. Eg, that we compute `np.true_divide(x*10**d, 10**d)`, which has floating point error, instead of a more accurate BigInt computation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Expose config-hash checking I'm writing a tool that uses docker-compose and it needs to tell the user whether they need to 'up' a service. To do this, I have reproduced the config-hash so I can check if the config has been changed, but the method of doing this changes between docker-compose versions, so it would be handy to be able to ask docker-compose whether it thinks the config has changed directly, without performing any other actions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: FillMaskPipeline very slow when provided with a large `targets` ## Environment info <!-- You can run the command `transformers-cli env` and copy-and-paste its output below. Don't forget to fill out the missing fields in that output! --> - `transformers` version: 4.6.1 - Platform: Linux-5.4.0-67-generic-x86_64-with-glibc2.10 - Python version: 3.8.5 - PyTorch version (GPU?): 1.8.1 (False) - Tensorflow version (GPU?): N/A - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help @LysandreJik @Narsil ## Information The model I am using: `ethanyt/guwenbert-base`, with a `RoBERTa` model and a `BertTokenizerFast` tokenizer. ## To reproduce Steps to reproduce the behavior: 1. Initialize a `fill-mask` pipeline with the model and the tokenizer mentioned above 2. Call it with any sentence and a large `targets` (with a length of ~10k single words) ## Problem The call would be much slower than a similar call without a `targets` argument. A call without a `targets` argument costs ~0.1s, while a call with a `targets` argument costs ~0.3s. The following code is present in `src/transformers/pipelines/fill_mask.py`: ```python class FillMaskPipeline(Pipeline): # ... def __call__(self, *args, targets=None, top_k: Optional[int] = None, **kwargs): # ... if targets is not None: # ... targets_proc = [] for target in targets: target_enc = self.tokenizer.tokenize(target) # ... targets_proc.append(target_enc[0]) ``` This function iterates through targets, rather than sending it directly to `tokenize`, which does not utilize the batch processing optimization of `TokenizerFast`s, hence the slow speed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.scipy.linalg routines segfault on Mac OS X on scipy 1.2.1 or later but not scipy 1.1.0 I'm not exactly sure *why* this happens, being unfamiliar with the internal architecture, but on MacOS with Python 3.6.8, the following code segfaults if scipy 1.2.1 is installed (the version that comes by default when you `pip install jax jaxlib`): ```python import jax.random as random import jax.scipy.linalg as linalg key = random.PRNGKey(42) # For some reason, matrices smaller than (50, 50) or so do not trigger segfaults X = random.normal(key, (500, 500)) A = X @ X.T # Drawn from standard Wishart distribution linalg.cholesky(A) print(\"Success!\") ``` Output: ``` $ python -W ignore test.py zsh: bus error python -W ignore test.py ``` If I roll back to Scipy 1.1.0, everything works: ``` $ python -W ignore test.py Success! ``` This is a great project by the way--thanks for working on it! Edit: after further digging, I found the following in the the Scipy 1.2 release notes: > scipy.linalg.lapack now exposes the LAPACK routines using the Rectangular Full Packed storage (RFP) for upper triangular, lower triangular, symmetric, or Hermitian matrices; the upper trapezoidal fat matrix RZ decomposition routines are now available as well. Perhaps this has something to do with it? Even more edits: yet more digging has revealed scipy/scipy#9751, which hints that this might be caused by a specific (old) version of XCode. I will report back once XCode is upgraded. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Move start_task_ids from FlowRunner to Environment In order to facilitate passing `start_tasks` from external systems, we added a `start_task_ids` argument to `FlowRunner.run()`, which essentially dynamically creates the appropriate `start_tasks` argument. This means an external system (or command line) can use start_tasks without loading a Python Task and passing it to the FlowRunner. This logic is really only used by `Environments`, which are the canonical way of interacting with flows from a remote system. I propose that it should therefore move to `Environment.run()` and leave `FlowRunner.run()` a cleaner API. While this would be nominally a breaking change, it would have no breaking impact based on any current use of Prefect. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ControlFlow context manager places \"composed\" elements outside scope ### Environment - **Qiskit Terra version**: 0.21.0rc1-45 - **Python version**: 3.10 - **Operating system**: Linux ### What is happening? When using the `compose` method within a ControlFlow context builder the composed element is inserted at the top level scope. ### How can we reproduce the issue? ```python from qiskit.circuit.library.standard_gates.x import CCXGate qreg = QuantumRegister(3) creg = ClassicalRegister(3) circ = QuantumCircuit(qreg, creg) with circ.for_loop(range(3)): circ.x(qreg) circ.compose(CCXGate().definition, inplace=True) print(circ) ``` yields, ``` ┌───┐ ┌───────────┐ q0_0: ───────────────────■─────────────────────■────■───┤ T ├───■──┤0 ├ │ ┌───┐ │ ┌─┴─┐┌┴───┴┐┌─┴─┐│ │ q0_1: ───────■───────────┼─────────■───┤ T ├───┼──┤ X ├┤ Tdg ├┤ X ├┤1 For_loop ├ ┌───┐┌─┴─┐┌─────┐┌─┴─┐┌───┐┌─┴─┐┌┴───┴┐┌─┴─┐├───┤└┬───┬┘└───┘│ │ q0_2: ┤ H ├┤ X ├┤ Tdg ├┤ X ├┤ T ├┤ X ├┤ Tdg ├┤ X ├┤ T ├─┤ H ├──────┤2 ├ └───┘└───┘└─────┘└───┘└───┘└───┘└─────┘└───┘└───┘ └───┘ └───────────┘ c0: 3/══════════════════════════════════════════════════════════════════════════ ``` ### What should happen? The composed circuit should appear inside the `for-loop` as an appended instruction currently does. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Don't warn about unused variables when compiling C code generated by the Vala compiler The Vala compiler tends to generate unused variables. So when compiling Vala code with Meson I get a lot of warnings from the C compiler that do not look nice and clutter the output. You might argue that this is a bug of the Vala compiler but I don't think so. I agree that in hand-written code unused variables are something bad but for a compiler that outputs C code eliminating unused variables is an additional step that might not be worth it because the C compiler will eliminate them anyway. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Announcements from custom ATOM feed are not displayed in front-end ## Description I'm looking to show custom announcements in Jupyterlab using a custom ATOM feed. I start a lab instance (3.6.2) using the command - `jupyter lab --LabApp.news_url=\"<foo>\"` where foo is the url to a xml file containing a ATOM feed generated through [feedgen](https://feedgen.kiesow.be/). However, I do not see the custom announcements show up in the UI -  My notification settings look like this -  Note - I **do not want** to have official Jupyter news, I'm looking to use the Announcements framework to provide custom announcements. I toggled the options related to official Jupyter news to check if they have any effect and they did not. ## Context - Browser and version: Chrome 102 - JupyterLab version: 3.6.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: dagit should politely offer to find a port if the one it expects it taken ```Something is already running at port 8000 ✔ Would you like to run the app at another port instead? … no``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Missing operator - CloudVisionReferenceImageCreateOperator Hello, We miss the operator for method delete_reference_image to hook CloudVisionHook. All other methods probably have matching operators. This is important to me because the hook method refers to this operator in docstring. https://github.com/apache/airflow/blob/1d36b0303b8632fce6de78ca4e782ae26ee06fea/airflow/providers/google/cloud/hooks/vision.py#L428 Best regards, Kamil Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rewrite Faster Amplitude Estimator with primitives. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pthread function checking can't replicate a cmake check. Hullo. Sorry if this question has been answered or if the proper way to do it is obvious and I'm blind. I'm working on porting/creating a wrap for [openal-soft](https://github.com/kcat/openal-soft), getting pretty far into it, but I'm having trouble replicating the following cmake snippet: ```cmake CHECK_LIBRARY_EXISTS(pthread pthread_create \"\" HAVE_LIBPTHREAD) IF(HAVE_LIBPTHREAD) SET(EXTRA_LIBS pthread ${EXTRA_LIBS}) ENDIF() ``` I've tried the following: ```meson thread_dep = dependency('threads', required : false) cc.has_function('pthread_create') cc.has_function('pthread_create', dependencies : thread_dep) cc.has_function('pthread_create', dependencies : thread_dep, prefix : '#include <pthread.h>') ``` Also, there is an odd snippet I've ran into in this same project which is like so: ```cmake CHECK_SYMBOL_EXISTS(pthread_setname_np \"pthread.h;pthread_np.h\" HAVE_PTHREAD_SETNAME_NP) ``` Perhaps cc.has_header_symbol should be able to take an array of header strings? Seems some systems may require two headers to access certain functions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Text-based circuit drawer output is scrambled in notebook unless print is called. <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? ```python from qiskit import * from qiskit.tools.visualization import circuit_drawer q = QuantumRegister(5) qc = QuantumCircuit(q) qc.ccx(q[1], q[2], q[3]) qc.ccx(q[0], q[2], q[4]) qc.x(q[4]) qc.x(q[3]) circuit_drawer(qc, output='text') ``` ' \\nq1_0: |0>────────────■───────\\n │ \\nq1_1: |0>──■─────────┼───────\\n │ │ \\nq1_2: |0>──■─────────■───────\\n ┌─┴─┐┌───┐ │ \\nq1_3: |0>┤ X ├┤ X ├──┼───────\\n └───┘└───┘┌─┴─┐┌───┐\\nq1_4: |0>──────────┤ X ├┤ X ├\\n └───┘└───┘' ### Steps to reproduce the problem The output is messed up unless calling `print(circuit_drawer(qc, output='text'))`. Therefore it is not a drop in replacement for the other methods which work fine in a notebook. ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: qtconsole: ValueError('close_fds is not supported on Windows platforms if you redirect stdin/stdout/stderr',) Line 308 in IPython/kernel/connect.py should be changed to ``` return Popen([sys.executable, '-c', cmd, '--existing', cf] + argv, stdout=PIPE, stderr=PIPE, close_fds=sys.platform != \"win32\", ``` to account for this ValueError on windows. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Circuit drawers should indicate which gates have been overloaded with pulse gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The circuit drawers will have some indication whether or not a gate has been replaced with a custom pulse gate (\"calibration\")/. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: os.getcwd() FileNotFoundError ``` error: FileNotFoundError(2, 'No such file or directory') command: /root/anaconda3/bin/conda shell.posix deactivate user_agent: conda/4.4.4 requests/2.18.4 CPython/3.6.3 Linux/4.13.0-kali1-amd64 kali/2017.3 glibc/2.25 _messageid: -9223372036844975611 _messagetime: 1514233339489 / 2017-12-25 14:22:19 Traceback (most recent call last): File \"/root/anaconda3/lib/python3.6/site-packages/conda/cli/main.py\", line 110, in main from ..activate import main as activator_main File \"/root/anaconda3/lib/python3.6/site-packages/conda/activate.py\", line 12, in <module> context.__init__() # oOn import, context does not include SEARCH_PATH. This line fixes that. File \"/root/anaconda3/lib/python3.6/site-packages/conda/base/context.py\", line 214, in __init__ argparse_args=argparse_args) File \"/root/anaconda3/lib/python3.6/site-packages/conda/common/configuration.py\", line 723, in __init__ self._set_search_path(search_path) File \"/root/anaconda3/lib/python3.6/site-packages/conda/common/configuration.py\", line 729, in _set_search_path self._set_raw_data(load_file_configs(search_path)) File \"/root/anaconda3/lib/python3.6/site-packages/conda/common/configuration.py\", line 366, in load_file_configs expanded_paths = tuple(expand(path) for path in search_path) File \"/root/anaconda3/lib/python3.6/site-packages/conda/common/configuration.py\", line 366, in <genexpr> expanded_paths = tuple(expand(path) for path in search_path) File \"/root/anaconda3/lib/python3.6/site-packages/conda/common/path.py\", line 49, in expand return abspath(expanduser(expandvars(path))) File \"/root/anaconda3/lib/python3.6/posixpath.py\", line 374, in abspath cwd = os.getcwd() FileNotFoundError: [Errno 2] No such file or directory ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Write More Idioms We should write some more idioms: - [x] how to define conditional logic using the [new conditional api](https://github.com/PrefectHQ/prefect/pull/2443) and the \"old\" way - [x] how to use `target`s (0.11.0+) - [x] how to configure notifications (three options: write a downstream task, state handler, cloud hook) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Support conan info --json for all outputs, and support stdout I'm not sure why --json is only supported when --build-order is also passed, but we would like all outputs from `conan info` to support output as `json`. Our primary reason is that we'll often be calling `conan info` in order to pass the information to another step in our automation. If it's JSON, we can then parse the information more easily, and get nice access to the fields in the result like: info_result.package_folder. As it stands, we have to have custom parsing for the output format. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Use sensible versioning system for Compose file format As we've added more and more versions in recent months, our version checking has grown out of hand, requiring frequent, tedious updates across the code several times in a single release cycle. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: latex_source visualizer should not use transpiler(format='json') We are going to remove the option `format='json'` from the transpiler (see #1129). For that, we need to move the visualizers into the function `get_instractions` introduced in PR #1187. The function `_generate_latex_source` calls `transpile_dag(dag_circuit, basis_gates=basis, format='json')`. This needs to be removed in favor of `_utils.get_instructions(dag)`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: setup.py: Install scripts without extensions on UNIX-like platforms Because of issue #394 , meson install scripts as `xxx.py` , but in linux, install script with a extension name is no a good practice. And change the installed script name also break some package depend on meson. Could you deal with it for different platform? thx. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Support airflowignore for plugins Hello, Airflow has a mechanism to ignore files before they are automatically loaded by Airflow using a .airflowignore file. A .airflowignore file specifies the directories or files in DAG_FOLDER that Airflow should intentionally ignore. > For example, you can prepare a .airflowignore file with contents > ``` > project_a > tenant_[\\d] > ``` > Then files like project_a_dag_1.py, TESTING_project_a.py, tenant_1.py, project_a/dag_1.py, and tenant_1/dag_1.py in your DAG_FOLDER would be ignored (If a directory’s name matches any of the patterns, this directory and all its subfolders would not be scanned by Airflow at all. This improves efficiency of DAG finding). More information: https://airflow.readthedocs.io/en/latest/concepts.html?highlight=airflowignore It would be helpful to make a similar feature available to plugins. This improves the efficiency of plugins finding. If anyone is interested in this, I am willing to provide all the necessary tips and information. Are you wondering how to start contributing to this project? Start by reading our [contributor guide](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst) Cheers Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Check version consistency for extends directives See: https://github.com/docker/compose/pull/2421#discussion_r47576562 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: configure_file not working with vs and layout=flat **Describe the bug** On a toy project following [the manual](https://mesonbuild.com/Configuration.html#a-full-example), using layout=flat on vs backend fails because the include path is incorrect. **To Reproduce** [meson_layout_flat.zip](https://github.com/mesonbuild/meson/files/5996320/meson_layout_flat.zip) meson build --backend=vs --layout=flat **Expected behavior** compilation will fail with 'projconfig.h' : No such file or directory while it compiles with meson build --backend=vs **system parameters** * native build * windows 7 64bits * Python 3.8.7 * `meson --version` = 0.56.2 * `ninja --version` = 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Firestore] WriteBatch doesn't return instance so you cannot chain. The WriteBatch methods don’t return the WriteBatch instances for chaining. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] conan remove does not find recipe Hi there, I tried to delete every version of a recipe in a certain user/channel but Conan stopped working with the error that it could not find the recipe: ``` conan remove cygwin_installer/*@user/channel ERROR: Recipe not found: 'cygwin_installer/*@user/channel' ``` But when I modify the recipe name and append an asterix it works: ``` conan remove cygwin_installer*/*@user/channel Are you sure you want to delete from 'cygwin_installer/2.9.0@user/channel' (yes/no): ``` Is this intentional? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: rename file got diff with change_type: R100 when I renamed file A to B like this ```bash $ git mv A B $ git status On branch master Changes to be committed: (use \"git reset HEAD <file>...\" to unstage) modified: .gitmodules renamed: A -> B modified: Cprogramming ``` but using gitpython in ipython3 I got this: ```python In [135]: repo.commit('HEAD~2').diff(repo.head.commit) Out[135]: [<git.diff.Diff at 0x7fc52ab13730>, <git.diff.Diff at 0x7fc529943c80>, <git.diff.Diff at 0x7fc529943d90>, <git.diff.Diff at 0x7fc52994ec80>] In [136]: repo.commit('HEAD~2').diff(repo.head.commit)[2].b_path Out[136]: 'Cprogramming' In [137]: repo.commit('HEAD~2').diff(repo.head.commit)[1].b_path Out[137]: 'B' In [138]: repo.commit('HEAD~2').diff(repo.head.commit)[1].change_type Out[138]: 'R100' ``` is that normal or something went wrong? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Phased XX - YY interaction gate ### What should we add? Gate for phased XX-YY interaction. This gate has the same exact definition as [XYGate](https://github.com/Qiskit/qiskit-terra/blob/517265c26e91baac44a690fafe1f473ad89d70b2/qiskit/circuit/library/standard_gates/xy.py) but with XX-YY instead of XX+YY. It is equivalent up to two single-qubit X rotations, but the reason to have it as a separate gate is that those extra single-qubit gates aren't necessary for the decomposition. The decomposition can be obtained from the XYGate decomposition by tweaking some signs in the gate angles. An external reference for this gate is https://arxiv.org/abs/1208.1287. I'm happy to contribute this gate if this proposal is accepted and the name agreed upon. I suggest PhasedXXMinusYYGate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add cli command to create network Creating docker networks is not a thread safe operation, so running `docker-compose up` twice in parallell will create two networks with the same name, which leads to the services being partitioned in different networks. See https://github.com/moby/moby/issues/20648 Since creating services in parallell is a pretty big performance gain it would be awesome if it was possible to create the default network manually, before running `docker-compose up`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan search <pattern> --revisions I miss a list of references but with the current revision in the local cache. Why? Even having the revisions enabled, the \"install\" traces ~~don't show which RREV is being used~~ (edit: there is a trace P1/1.0@conan/stable: Downloaded recipe revision c9da69cad5ccb88452fa1c6ed3db54b2) but still would be practical. If you have missing packages and you want to \"debug\" why first you need to know at first sight the resolved revisions for the recipes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: 'test_bpo_set_unset_preserves_acls' no longer sees expected 'BadRequest'. From [this Kokoro job](https://source.cloud.google.com/results/invocations/2691ce70-20dd-4f90-ad95-d483b80b4ec2/targets/cloud-devrel%2Fclient-libraries%2Fgoogle-cloud-python%2Fpresubmit%2Fstorage/log): ```python ____________ TestIAMConfiguration.test_bpo_set_unset_preserves_acls ____________ self = <tests.system.TestIAMConfiguration testMethod=test_bpo_set_unset_preserves_acls> def test_bpo_set_unset_preserves_acls(self): new_bucket_name = \"bpo-acls\" + unique_resource_id(\"-\") self.assertRaises( exceptions.NotFound, Config.CLIENT.get_bucket, new_bucket_name ) bucket = retry_429(Config.CLIENT.create_bucket)(new_bucket_name) self.case_buckets_to_delete.append(new_bucket_name) blob_name = \"my-blob.txt\" blob = bucket.blob(blob_name) payload = b\"DEADBEEF\" blob.upload_from_string(payload) # Preserve ACLs before setting BPO bucket_acl_before = list(bucket.acl) blob_acl_before = list(bucket.acl) # Set BPO bucket.iam_configuration.bucket_policy_only_enabled = True bucket.patch() # While BPO is set, cannot get / set ACLs with self.assertRaises(exceptions.BadRequest): > bucket.acl.reload() E AssertionError: BadRequest not raised tests/system.py:1709: AssertionError ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Phosphor shim is not fully functional The phosphor [shim](https://github.com/jupyterlab/jupyterlab/blob/master/buildutils/src/webpack.config.base.ts#L66) relies on a local `@lumino` package being installed. We probably need some more advanced logic to install `lumino` if we detect that `@phosphor` packages are installed. cc @jasongrout Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: LGTM alerts . I notice that there are still a fair number LGTM alerts, many of which look pretty simple. I wonder if they would be a good source of issues for the next NumPy sprint? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: nbconvert markdown issues Markdown converter is set to show html output as the richest repr, but does not show it. and add extra $$ around latex one. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Jupyterlab 1.1.0 not compatible with Python 3.5 due to f-string usage? <!-- Welcome! Before creating a new issue: * Search for relevant issues * Follow the issue reporting guidelines: https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html --> ## Description Jupyterlab 1.1.0 hits a `SyntaxError` when run on Python 3.5.2 (Ubuntu 16.04 Python 3 via apt): ``` Traceback (most recent call last): File \"/usr/local/bin/jupyter-lab\", line 6, in <module> from jupyterlab.labapp import main File \"/usr/local/lib/python3.5/dist-packages/jupyterlab/labapp.py\", line 22, in <module> from .commands import ( File \"/usr/local/lib/python3.5/dist-packages/jupyterlab/commands.py\", line 557 self.logger.info(f'Building jupyterlab assets ({command})') ^ SyntaxError: invalid syntax ``` This appears to be due to the use of an f-string in one of the modules, which will only work in Python 3.6+: [commands.py](https://github.com/jupyterlab/jupyterlab/blame/v1.1.0/jupyterlab/commands.py#L557). According to the [changelog](https://jupyterlab.readthedocs.io/en/stable/getting_started/changelog.html#v1-1-0), JupyterLab v1.1.0 should still support 3.5+. ## Context - Operating System and version: Ubuntu 16.04 LTS - Browser and version: Firefox 68.0.2 - JupyterLab version: 1.1.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython pyqt 4.10 incompatibilty, QTextBlockUserData ipython qtconsole seems to be incompatible with pytqt 4.10, if you type in a line you get this ``` if 1: print 1 Traceback (most recent call last): File \"/usr/lib/python2.7/dist-packages/IPython/frontend/qt/console/frontend_widget.py\", line 59, in highlightBlock super(FrontendHighlighter, self).highlightBlock(string) File \"/usr/lib/python2.7/dist-packages/IPython/frontend/qt/console/pygments_highlighter.py\", line 109, in highlightBlock self._lexer._saved_state_stack = prev_data.syntax_stack AttributeError: 'QTextBlockUserData' object has no attribute 'syntax_stack' ``` this needs to be fixed in two places, pyqt needs an update (currently available as snapshot) and ipython needs a fix in pygments_highlighter.py ``` self._document = QtGui.QTextDocument() ``` ...to... ``` self._document = self.document() ``` see: http://www.riverbankcomputing.com/pipermail/pyqt/2013-March/032512.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Return parametric pulse names <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In pusle command definition with parametric pulses, the name of pulse becomes `parametric_pulse` and we cannot infer what is being played, ie pulse drawer. The QobjInstruction of `y90p` pulse looks like ``` PulseQobjInstruction(name=\"parametric_pulse\", t0=0, ch=\"d0\", pulse_shape=\"drag\", parameters={'amp': (0.00023655993186320415+0.09826971941800593j), 'beta': 0.91118629367975, 'duration': 160, 'sigma': 40}) ``` but it is hard to know original pulse name from this information. To tell Qiskit what the pulse entry is, we need to add `label` to Schema so that backend can send pulse default object with proper pulse names. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add Agent Label to prefect.context.config ## Current behavior From within a task, basic info about an Agent is available via `prefect.context.config`: ``` {'cloud': {'agent': {'level': 'INFO', 'name': 'agent', 'resource_manager': <Box: {'loop_interval': 60}>}, ``` ## Proposed behavior If running multiple Agents (with [Environment Labels](https://docs.prefect.io/cloud/agent/overview.html#labels)), having access to the label setting for the Agent that kicked off execution would be useful. ## Example A Flow that monitors a k8s/Dask cluster could include the environment label in its alerts, e.g. \"Found 100 nodes running in the *staging* environment\" where `staging` was the label the Agent was started with. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: 'meson test' fails to run on Python 3.12 **Describe the bug** Meson fails to run on Python 3.12 due to reliance on the implicit instantiation of the asyncio mainloop that was deprecated in Python 3.10. It has now been removed. Additional details in [this Fedora bug](https://bugzilla.redhat.com/show_bug.cgi?id=2155490) and [this Python upstream issue](https://github.com/python/cpython/issues/93453). **To Reproduce** * Install python 3.12 alpha. * Run `meson test` in any project that supports it **Expected behavior** Tests should run **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? * Native * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) * Experienced on Fedora Rawhide (38), but likely present on any Linux with Python 3.12 * what Python version are you using e.g. 3.8.0 * Python 3.12 * what `meson --version` * Meson 0.64.1 * what `ninja --version` if it's a Ninja build * Ninja 1.5.8.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: SciPy.weave broken in IPython notebook/ qtconsole # Problem Compiling and running of compiled scipy.weave code is not possible with IPython notebook and IPython console. However, it works with standalone, plain IPython. # Minimal Example http://projects.scipy.org/scipy/browser/trunk/Lib/weave/examples/array3d.py?rev=1558 # Error ## compiling code find the traceback here: http://pastebin.com/FdSadJtV final error: AttributeError: 'OutStream' object has no attribute 'fileno' ## executing code For both notebook and qtconsole, the output is printed in the terminal that was used to start them. # tested version ## failure in ipython 0.13.1 scipy '0.11.0' numpy '1.7.0' ## working in ### compilation Apparently it is working with numpy 1.6.0. I did not test it by myself, but that was a response on IRC. It was there also reproduced using numpy 1.7.0. I could compile it in an virtualenv using numpy 1.6 using the notebook. (Still trying to get the qtconsole to run so that I can test that) ### output Even with numpy 1.6 the output is directed to the terminal that was used to start the IPython kernel Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: Document public bucket property **Is your feature request related to a problem? Please describe.** I have a Blob object and I want to know what Bucket it belongs to. **Describe the solution you'd like** Convert `Blob.bucket` into a real `@property` so that it can be documented. It should be a read-only property, as the bucket it part of the identifier for the blob, so seems best if it's immutable. **Describe alternatives you've considered** You could put `bucket` in the docstring for the `Blob` class, but this is less discoverable than a true property. **Additional context** Discovered in review of https://github.com/googleapis/google-cloud-python/pull/8424. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add options to make conan inspect more machine friendly I would like to make `conan inspect` more machine friendly. Here are two things that would help me: Add an option where the label will not be included on the attribute. For example, currently if you run ``` $ conan inspect . -a name name: service-common ``` Then a script would have to parse the actual name from the output. I would like to have an option that would remove the label, like: ``` $ conan inspect . --no-label -a name service-common ``` Also, I'd like a way to have the JSON output sent to stdout. For example: ``` $ conan inspect . -j - {\"name\": \"service-common\", \"version\": null, \"url\": \"http://bitbucket-idb:7990/scm/deal/falcon.git\", \"homepage\": null, \"license\": \"Copyright (c) 2018 Tradeweb\", \"author\": null, \"description\": \"Falcon Base Service common library\", \"topics\": null, \"generators\": [\"cmake\"], \"exports\": [], \"exports_sources\": [], \"short_paths\": false, \"apply_env\": true, \"build_policy\": null} ``` Thanks, Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython.display.Image crash if passed invalid bytes Used in notebook test suite for testing not tested in IPython. ``` Image(\"iVBORw0KGgoAAAANSUhEUgAAAAEAAAABAQMAAAAl21bKAAAAA1BMVEUAAACnej3aAAAAAWJLR0QAiAUdSAAAAAlwSFlzAAALEwAACxMBAJqcGAAAAAd0SU1FB94BCRQnOqNu0b4AAAAKSURBVAjXY2AAAAACAAHiIbwzAAAAAElFTkSuQmCC\") ``` ``` --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-4-871bd9636d0c> in <module>() ----> 1 Image(b\"iVBORw0KGgoAAAANSUhEUgAAAAEAAAABAQMAAAAl21bKAAAAA1BMVEUAAACnej3aAAAAAWJLR0QAiAUdSAAAAAlwSFlzAAALEwAACxMBAJqcGAAAAAd0SU1FB94BCRQnOqNu0b4AAAAKSURBVAjXY2AAAAACAAHiIbwzAAAAAElFTkSuQmCC\".encode()) /Users/bussonniermatthias/anaconda3/lib/python3.5/site-packages/IPython/core/display.py in __init__(self, data, url, filename, format, embed, width, height, retina, unconfined, metadata) 732 format = self._FMT_JPEG 733 --> 734 if format.lower() == 'jpg': 735 # jpg->jpeg 736 format = self._FMT_JPEG AttributeError: 'NoneType' object has no attribute 'lower' ``` Probably a bad logic to detect the format if `data` is `bytes`, we likely also need a Python2 special case Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: API Endpoint - CRUD - Pool Hello We need to create several endpoints that perform basic CRUD operations on **Pools**. We need the following endpoints: POST /pools DELETE /pools/{pool_name} PATCH /pools/{pool_name} Detailed information is available in the issue: https://github.com/apache/airflow/issues/8118 LOVE, Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: How to specify Memory & CPU limit in version 3 I am unable to specify CPU & memory for services specified in version 3 . With version 2 it works fine with \"mem_limit\" & \"cpu_shares\" parameters under the services . But it fails while using version 3 , putting them under deploy section doesn't seem worthy unless i am using swarm mode . Can somebody help ? version: \"3\" services: node: build: context: . dockerfile: ./docker-build/Dockerfile.node restart: always environment: - VIRTUAL_HOST=localhost volumes: - logs:/app/out/ expose: - 8083 command: [\"npm\",\"start\"] cap_drop: - NET_ADMIN - SYS_ADMIN Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: AutoML: Tables client importing data with 'pandas_dataframe' fails. #### Problem: Client: automl_v1beta1 Class: TablesClient Method: import_data When using pandas_dataframe argument when specifying data to import to automl tables, get: \"google.api_core.exceptions.GoogleAPICallError: None Invalid column names: \" error. I believe #### Environment details: os: windows python version: 3.5 google-cloud-automl==0.7.0 google==2.0.2 google-api-core==1.14.3 #### Code Example: ``` import pandas as pd from google.cloud import automl_v1beta1 client = automl_v1beta1.TablesClient(project=<my_project>, region=<my_region>) d = client.create_dataset(dataset_display_name=<ds_display_name) data_df = pd.DataFrame({'a':[1,2,3], 'b':[4,5,6]}) response = client.import_data(dataset=d, pandas_dataframe=data_df) def callback(operation_future): result = operation_future.result() response.add_done_callback(callback) ``` #### Stack trace `Error while executing Future callback. Traceback (most recent call last): File \"/home/jupyter/.local/lib/python3.5/site-packages/google/api_core/future/_helpers.py\", line 37, in safe_invoke_callback return callback(*args, **kwargs) File \"<ipython-input-41-d646f4ce2c0e>\", line 6, in callback result = operation_future.result() File \"/home/jupyter/.local/lib/python3.5/site-packages/google/api_core/future/polling.py\", line 127, in result raise self._exception google.api_core.exceptions.GoogleAPICallError: None Invalid column names: ` #### hypothesis: it seems to be treating the dataframe index as a column in the import, and if this is not specified, will trigger the invalid column name error. If I set the index to one of the columns, it works. Suggest leaving index out of import by default, and maybe optionally include index during import with keyword argument. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose fails reporting \"Duplicate bind mount /var/lib/mysql\" \"docker-compose up\" fails reporting \"Duplicate bind mount /var/lib/mysql\" while trying to mount \"/var/lib/mysql\" as host volume for mysql or percona image. > $ docker-compose up > Removing db_db_1... > Recreating ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_ce40d9fe7e_db_db_1... > Duplicate bind mount /var/lib/mysql docker-compose.yml > db: > image: mysql > environment: > MYSQL_ROOT_PASSWORD: root > volumes: > -./data/:/var/lib/mysql/ Running on OSX 10.9.5 with Boot2Docker-cli version: v1.7.1 (Git commit: 8fdc6f5), Docker version 1.7.1, build 786b29d, docker-compose version: 1.3.3. Is there any way to fix this issue? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Possible to suppress \"to activate this environment...\" message on env update? I don't see a switch that would allow me to turn this message off: `# # To activate this environment, use: # > activate soq1 # # To deactivate this environment, use: # > deactivate soq1 # # * for power-users using bash, you must source #` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Duplicated matplotlib figures when running ipykernel 6 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.1 - **Python version**: 3.7.8 - **Operating system**: Linux ### What is the current behavior? When running ipykernel >= 6.0.0 (latest at the time of writing is `ipykernel==6.0.3`) on Jupyter Notebooks (also in Jupyter Lab) displaying any matplotlib figure using Qiskit (a Quantum Circuit or a visualization of an output) the output is displayed twice. This doesn't seem to happen when running an example of matplotlib in the same notebook. <details> <summary>Notebook example with the issue, running ipykernel 6.0.3</summary> <img src=\"https://user-images.githubusercontent.com/5927888/128843518-617ce18f-0629-4f94-8763-5346661e5b95.png\"> </details> <details> <summary>Same notebook example without issues, running ipykernel 5</summary> <img src=\"https://user-images.githubusercontent.com/5927888/128843473-5d77f098-1f11-4e14-8d8b-c0d397fc8535.png\"> </details> ### Steps to reproduce the problem - On a fresh Jupyter Notebooks environment (you can try an [online environment](https://jupyter.org/try)) install the latest ipykernel by running `pip install ipykernel==6.0.3` - Build a QuantumCircuit and draw it using `.draw('mpl')` - See the circuit figure duplicated ### What is the expected behavior? To display the figures only once. ### Suggested solutions N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson cmake method issue **Describe the bug** Meson is failing to import multiple dependencies such as protobuf, the problem was also occuring with cpprestsdk **To Reproduce** ``` project('App', 'cpp') gtkmmdep = dependency('gtkmm-3.0') protobufdep = dependency('protobuf') executable('Application', 'src/app.cpp', dependencies : [gtkmmdep, protobufdep], cpp_pch : 'pch/App_pch.h') ``` **Current output**: ``` [0/1] Regenerating build files. The Meson build system Version: 0.55.0 Source dir: /home/xxx/Documents/Developpement/App Build dir: /home/xxx/Documents/Developpement/App/builddir Build type: native build Project name: App Project version: undefined C++ compiler for the host machine: c++ (gcc 10.1.1 \"c++ (GCC) 10.1.1 20200507 (Red Hat 10.1.1-1)\") C++ linker for the host machine: c++ ld.bfd 2.34-3 Host machine cpu family: x86_64 Host machine cpu: x86_64 Found pkg-config: /usr/bin/pkg-config (1.6.3) Found CMake: /usr/local/bin/cmake (3.18.20200725) ../meson.build:3:0: ERROR: CMake: set() requires at least one argument CMake TRACE: /home/infrandomness/sdk/grpc/lib64/cmake/protobuf/protobuf-config-version.cmake:7 set(['', '']) ``` **Expected behavior** Meson succeeding at setting protobuf as a dependency and producing a binary with it **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? Just a plain native build * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) Fedora 32 5.7.9-200.fc32.x86_64 * what Python version are you using e.g. 3.8.0 Python 3.8.3 * what `meson --version` 0.55.0 * what `ninja --version` if it's a Ninja build 1.10.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Control.revoke can be get list of task ids <!-- Please fill this template entirely and do not erase parts of it. We reserve the right to close without a response bug reports which are incomplete. --> # Checklist <!-- To check an item on the list replace [ ] with [x]. --> - [x] I have checked the [issues list](https://github.com/celery/celery/issues?utf8=%E2%9C%93&q=is%3Aissue+label%3A%22Category%3A+Documentation%22+) for similar or identical bug reports. - [x] I have checked the [pull requests list](https://github.com/celery/celery/pulls?q=is%3Apr+label%3A%22Category%3A+Documentation%22) for existing proposed fixes. - [x] I have checked the [commit log](https://github.com/celery/celery/commits/master) to find out if the bug was already fixed in the master branch. - [x] I have included all related issues and possible duplicate issues in this issue (If there are none, check this box anyway). ## Related Issues and Possible Duplicates <!-- Please make sure to search and mention any related issues or possible duplicates to this issue as requested by the checklist above. This may or may not include issues in other repositories that the Celery project maintains or other repositories that are dependencies of Celery. If you don't know how to mention issues, please refer to Github's documentation on the subject: https://help.github.com/en/articles/autolinked-references-and-urls#issues-and-pull-requests --> #### Related Issues - None #### Possible Duplicates - None # Description <!-- Please describe what's missing or incorrect about our documentation. Include links and/or screenshots which will aid us to resolve the issue. --> The existing documentation does not show the option to send some tasks ids # Suggestions <!-- Please provide us suggestions for how to fix the documentation --> Update the document Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] The VirtualBuildEnv and VirtualRunEnv never clean the deactivate script Quoted from https://github.com/conan-io/conan/issues/10979#issuecomment-1091155807 > You are right, in .bat it doesn't happen because it has: > ``` > echo @echo off > \"{deactivate_file}\" > echo echo Restoring environment >> \"{deactivate_file}\" > ``` > So the first line removes the previous content of the file. Why this wouldn't be enough to do the same for .sh? That would be simple and remove the issue, wouldn't it? We would be happy to have this simple thing for shell being fixed. It's really weird to have multiple prints of `Restoring environment` and unset while activating/deactivating the VirtualBuildEnv and/or VirtualRunEnv sequentially multiple time. That would align the behavior with Windows. ### Environment Details (include every applicable attribute) * Operating System+version: Ubuntu 18.04 * Conan version: 1.53.0 * Python version: 3.6.9 ### Steps to reproduce (Include if Applicable) See https://github.com/conan-io/conan/issues/10979#issue-1193563400 ### Logs (Executed commands with output) (Include/Attach if Applicable) See https://github.com/conan-io/conan/issues/10979#issue-1193563400 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Quantum cost of template substitution ### What is the expected enhancement? Template substitution allows users to identify sub-circuits in a quantum circuit and replace them with equivalent quantum circuits with a lower implementation cost. For example `CNOT(0,1) CNOT(0,1)` is equivalent to the identity `I`. Since the implementation cost of `I` is lower than two CNOT gates this replacement makes sense. Currently, the implementation cost of a quantum circuit is evaluated in `TemplateSubstitution._quantum_cost(self, left, right)` in `template_substitution.py`. `_quantum_cost` evaluates the cost using a hard coded `cost_dict` instance. The user should be able to add/remove/modify elements from this dictionary as it is architecture dependent and the user may also whish to add his own gates to it. `cost_dict` should therefore be an attribute of the `TemplateSubstitution` class that users can access when creating template matching transpiler passes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CMake helper to get CTest to output on failure I'd like to be able to configure my `conanfile.py` so that I can invoke `ctest --output-on-failure` in some fashion. After chatting with on cpplang.slack.com, it was noted that it doesn't look like this is currently possible, and so I'll need to invoke this manually. Is such a feature on the roadmap, and if not, could it please be added in a future release? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Getting an x64 build with VS2019, but expecting an x86 build I'm trying to get my project ready for VS2019, but I'm getting an x64 build where I used to get an x86 build in VS2017. I noticed VS2019 support hasn't been announced in the changelog, so apologies if I'm reporting on an unfinished feature! Tools I'm using: Conan 1.13.1 CMake 3.14.0 Visual Studio Community 2019 16.0.0 RC.2 Visual Studio Community 2017 15.9.9 Windows 10 1809 64-bit Steps to reproduce: git clone https://gitlab.com/ssrobins/conan-sdl2.git cd conan-sdl2 build_windows.bat Notice that when the CMake output shows the selected compiler it shows Hostx86/x86/cl.exe, as expected. Open build_windows.bat in a text editor and change: compiler.version=15 To: compiler.version=16 Re-run build_windows.bat. CMake output shows Hostx64/x64/cl.exe as the compiler. Make sure you have a finished sdl2 lib build so the lib is ready for the next step. Now try to build a program using the sdl2 VS2019 lib in your local cache: git clone https://gitlab.com/ssrobins/sdl2-example.git cd sdl2-example Open build_windows.bat in a text editor and change: compiler.version=15 To: compiler.version=16 Also, change the cmake command from this: cmake -G \"Visual Studio 15 2017\" .. || goto :error To this: cmake -G \"Visual Studio 16 2019\" -A Win32 .. || goto :error Run build_windows.bat. I get linker errors because it's trying to link the 32-bit program with the 64-bit sdl2 lib. I think the removal of architecture from the CMake generator name in favor of a separate -A parameter might be causing the problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: RFE: add `install_create_dir` target Not sure about the name... Related to #1602, but for empty directories. `install_mode` should set the mode. Motivation: - no need to manipulate $DESTDIR manually - uninstallation - easy way to set access mode Another option would be to extend `install_data` to support an empty file list (e.g. `[]` as the positional arg), and add `install_dir_mode` option. That's probably better than adding another install function. Provide a way to install an empty directory Sometimes you need to create an empty directory (for third-party plugins, fonts, themes,…) as part of the software install. It does not seem currently possible. Maybe allow passing an empty subdir name to install_subdir to do the trick ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Error in computing number of connected components using qc.num_connected_components() <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.0.dev0+27e96cb - **Python version**: 3.7 ### What is the current behavior? When we try to use `qc.num_connected_components()` on a circuit involving `c_if()`, in some cases, the function outputs `0` as the number of connected components. However, this is not possible since there has to be at least one component, the whole circuit itself. ### Steps to reproduce the problem The error comes up when the circuit involves two or more gates with `c_if()`. For instance the following code gives an output `0` which is incorrect ```python q = QuantumRegister(2) c = ClassicalRegister(2) qc = QuantumCircuit(q,c) qc.h(0).c_if(c,0) qc.h(1).c_if(c,1) qc.num_connected_components() ``` while for the circuit in the code below the function outputs `2` which is correct. ```python q = QuantumRegister(2) c = ClassicalRegister(2) qc = QuantumCircuit(q,c) qc.h(0).c_if(c,0) qc.h(1) qc.num_connected_components() ``` The function seems to have passed the test because there is just a single test in which the test circuit contains just a single gate that is classical conditioned while the error shows up in circuits with more than one classically conditioned gates. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Gather information about transitive python_requires for graph output [Here it is](https://github.com/conan-io/conan/pull/3957/files#diff-c1d8c5f67c39ed424586c4102d74afc2R712) a test for a complex dependency graph.  Its output is the following: ``` project/1.0@jgsogo/test: Installing package Requirements project/1.0@jgsogo/test from local cache - Cache Python requires python_requires2/1.0@jgsogo/test python_requires22/1.0@jgsogo/test Packages project/1.0@jgsogo/test:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 - Build ``` and it should contain inside the _Python requires_ section the references `python_requires11/1.0@jgsogo/test`, `python_requires0/1.0@jgsogo/test` and `python_requires1/1.0@jgsogo/test`, which are the _transitive python_requires_: ``` Python requires python_requires11/1.0@jgsogo/test python_requires0/1.0@jgsogo/test python_requires22/1.0@jgsogo/test python_requires1/1.0@jgsogo/test python_requires2/1.0@jgsogo/test ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: einsum broadcast regression (with optimize=True) In numpy 1.13.3, it was possible to execute the following snippet without errors, while in 1.14.0 this happens: ```python In [1]: import numpy as np In [2]: a = np.ones((10,2)) In [3]: b = np.ones((1,2)) In [4]: np.einsum('t...i,ti->t...', a, b) Traceback (most recent call last): File \"<ipython-input-4-fa62d1d882f9>\", line 1, in <module> np.einsum('t...i,ti->t...', a, b) File \"/usr/local/lib/python2.7/dist-packages/numpy/core/einsumfunc.py\", line 1087, in einsum einsum_call=True) File \"/usr/local/lib/python2.7/dist-packages/numpy/core/einsumfunc.py\", line 710, in einsum_path \"not match previous terms.\", char, tnum) ValueError: (\"Size of label '%s' for operand %d does not match previous terms.\", 't', 1) ``` However `optimize=False` solves the problem: ```python In [5]: np.einsum('t...i,ti->t...', a, b, optimize=False) Out[5]: array([2., 2., 2., 2., 2., 2., 2., 2., 2., 2.]) ``` Is this intended behavior and the user is now responsible to explicitly disable optimization or is this a bug? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Github repo builds not working on windows ## Description of the issue https://github.com/docker/compose/commit/96a49a02534d5bd58f8adcbd4148076d463afea9#r31367442 This breaks url builds. Eg. if you want to build from a github repo in docker compose on windows. A fix would be to change the if check to check for urls: ``` if IS_WINDOWS_PLATFORM and not path.startswith(WINDOWS_LONGPATH_PREFIX) and not \"://\" in path: path = WINDOWS_LONGPATH_PREFIX + os.path.normpath(path) ``` A more sophisticated way of checking for urls would perhaps be needed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: 'Bucket'/'Blob' do not support 'user_project' during 'update' Whether due to oversight, or because the `buckets.update` / `objects.update` APIs weren't allowing it during implementation, the `update` methods (implemented in `_helpers._PropertyMixin`) don't pass their object's `user_project` (if set). See #3474. See also the `buckets.update` and `objects.update` method descriptions in the [discovery doc](https://www.googleapis.com/discovery/v1/apis/storage/v1/rest), which clearly show that `userProject` should be allowed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: sdl2 does not build with the \"vs\" backend SDL2 fails to build with the following error ``` > meson compile -C build INFO: autodetecting backend as vs2022 INFO: calculating backend command to run: msbuild \"ABC\\build\\ABC.sln\" -maxCpuCount -verbosity:minimal MSBuild version 17.5.0+6f08c67f3 for .NET Framework SDL_windows_main.c ABC\\subprojects\\SDL2-2.26.0\\include\\SDL_config.h(58,1): fatal error C1189: #error: Wrong SDL_config.h, check your include path? [ABC\\build\\subprojects\\SDL2-2.26.0\\5f2ac02@@sdl2main@sta.vcxproj] ``` when the `vs` backend is used. It compiles fine with the `ninja` backend. As far as I can tell the reason is that the include directories are passed to the compiler in different order: * with `vs`: `..\\..\\..\\subprojects\\SDL2-2.26.0\\include;include;` * with `ninja`: `\"-Isubprojects\\SDL2-2.26.0\\include\" \"-I..\\subprojects\\SDL2-2.26.0\\include\"` (I think it's a bit hard to understand what's going on because they are different relative paths, but the order is swapped.) So the `SDL_config.h` that has the `#error` is found first with the `vs` backend. Removing or renaming the file makes it build OK (as far as I have tested). Could this be a `meson` issue? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pkg_config_path argument gives warnings if PKG_CONFIG_PATH environment contains duplicates Somewhere between Meson 0.50.1 and 0.51.0, a spurious DEPRECATION warning began appearing if the `PKG_CONFIG_PATH` environment variable happens to have duplicate directories, which is safe: ``` The Meson build system Version: 0.51.0 Source dir: /Meson/test cases/common/99 threads Build dir: /Meson/test cases/common/99 threads/build Build type: native build DEPRECATION: Duplicated values in array option is deprecated. This will become a hard error in the future. Project name: threads Project version: undefined C compiler for the build machine: cc (gcc 7.4.0 \"cc (SUSE Linux) 7.4.0\") C++ compiler for the build machine: c++ (gcc 7.4.0 \"c++ (SUSE Linux) 7.4.0\") C compiler for the host machine: cc (gcc 7.4.0 \"cc (SUSE Linux) 7.4.0\") C++ compiler for the host machine: c++ (gcc 7.4.0 \"c++ (SUSE Linux) 7.4.0\") Build machine cpu family: x86_64 Build machine cpu: x86_64 Run-time dependency threads found: YES Build targets in project: 2 Found ninja-1.8.2 at /usr/bin/ninja [4/4] Linking target cppthreadprog. ``` See [this message](https://github.com/mesonbuild/meson/pull/5681#issuecomment-516050525) by @dcbaker. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Setting lifecycle rules totally undocumented It took me quite a while to figure out how to set lifecycle rules. If you look at the code, it's undocumented: ``` @lifecycle_rules.setter def lifecycle_rules(self, rules): self._patch_property('lifecycle', {'rule': rules}) ``` I found [some tests for this](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/090c5d583da82daabf05c52e8f72b858a0bb09c2/storage/unit_tests/test_bucket.py#L588-L596), but even those don't seem to use the `lifecycle_rules` method. Not having a documented method for doing this is very frustrating since this is supposed to be a library that supports all of the features. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Forward slashes in channel names breaks channel notice cache ### Checklist - [X] I added a descriptive title - [X] I searched open reports and couldn't find a duplicate ### What happened? When a channel name has forward slashes, this creates an illegal file name for our cache entries and causes errors like the following: https://github.com/napari/packaging/runs/7519992448?check_suite_focus=true We need to make sure that we are properly sanitizing channel names so that they contain no illegal characters. This needs to be true for \"unix\" like operating systems as well as Windows. This Stack Overflow post is a good starting point for listing these characters: https://stackoverflow.com/questions/1976007/what-characters-are-forbidden-in-windows-and-linux-directory-names ### Conda Info _No response_ ### Conda Config _No response_ ### Conda list _No response_ ### Additional Context First reported by @jaimergp (thank you!) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Allow for try/except imports for custom code ### Feature request When uploading a model with custom code, I wanted to try and use Flash Attention in one of the modules. However, to get around a case where people might use it on CPU, I added `try/except` block for the import. However, I get an error when downloading locally like `This modeling file requires the following packages that were not found in your environment` which seems to come from [this file](https://github.com/huggingface/transformers/blob/main/src/transformers/dynamic_module_utils.py#L112). ### Motivation I want to be able to write custom model code that allows for optional imports if possible (like FlashAttention) ### Your contribution I could try a crack at a PR? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: MSBuild should allow \"do not adjust PlatformToolset\" with an argument Hey, In https://github.com/conan-io/conan/pull/4250 the default behavior of VisualStudio's toolset selection was changed to compile the whole solution using the same toolset (the `/p:PlatformToolset` is always set - see discussion here https://github.com/conan-io/conan/pull/4250#pullrequestreview-193994771). This change prevents using two different toolsets in the same solution. In my case building a driver using the `WindowsKernelModeDriver10.0` (which is not even a valid option right now) toolset and user mode library using the `v141` toolset. I will be happy to write the code if this behavior change is accepted. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Allow for documentation versioning Relevant but not necessary for us to do this ourselves: https://github.com/vuejs/vuepress/issues/857 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Ctrl + M + L does not toggle line numbering in htmlnotebook Hi All, In the development version, the combination given int the title does not toggle the line numbering in a code cell. It switches on the line numbers, but then those cannot be switched off. This is different in the stable version, and I believe, that is the intended behaviour. Cheers, Zoltán Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Revise the documentation TOC subsection handling <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? An issue raised during #1254: > Also Is it possible in the template to show the subsection when that section is viewed. The new fancy design currently does not show subsections in the left-side TOC pane (except for the autodocs). Ideally it should show the subsections, allowing collapsing with sensible defaults and usability. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Is tab supposed to work in the ultratb prompt ? I really love ultratb and I probably overuse it (instead of logging and running I often raise) When I press tab I get a tab char inserted into the ipdb REPL. Is tab supposed to work in ultratb or does tab completion require `prompt_toolkit`? Maybe it is not working on my machine or maybe it is working as it is supposed to--not sure. If it is not supposed to work would it make sense to supply TerminalPdb instead of debugger.Pdb ? Maybe that could be exposed as a kwargs option... ``` Python 3.9.10 (main, Jan 17 2022, 00:00:00) import IPython @>>> IPython.version_info (8, 0, 1, '') kitty 0.21.2 created by Kovid Goyal fish, version 3.3.1 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Is there some way to set a CDN url to host the static fiels I've asked a few times on gitter but didn't get an answer. I can see that the jupyterlab_server can take a public_url which can be a CDN url [1], but I can't for the life of me figure out how to set it, in jupyter_notebook_config.py, or other. Is there some straight forward way to get jupyterlab to host the javascript, css and images files from a CDN, its for speed as I deploy lab servers for a lot of users? [1] https://github.com/jupyterlab/jupyterlab_server/blob/master/jupyterlab_server/handlers.py#L113 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Earlystopping should use a key not in progress_bar or log Make early stopping use any of the keys not used in progress_bar or log (see #330) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add `idempotency_key` argument to Client `client.create_flow_run` should have an `idempotency_key` argument to better expose that piece of functionality Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Build in regression test case retries Add in one retry for network failures to reduce (eliminate?) flaky / intermittent failures. For example https://travis-ci.org/GoogleCloudPlatform/gcloud-python/builds/46346592 after #509 failed on code that didn't even change in the PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Get Sink By Name I think there should be an easier way to get a sink by name. Currently you have to create it with a filter and destination and then do a reload. It would make more sense to me if filter/destination were optional, so you could just create it by name and then do a reload() to pull it in. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Spurious `Error: cannot import name 'load_qasm_file` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations When importing qiskit from current master, an error is printed, even if the function can actually be imported and used correctly. - **Qiskit Terra version**: master 83085edb374a3e26175bfc408ea293fdfb76aeb4 - **Python version**: - **Operating system**: ### What is the current behavior? ``` In [1]: import qiskit Error: cannot import name 'load_qasm_file' In [2]: qiskit.load_qasm_file Out[2]: <function qiskit.wrapper._wrapper.load_qasm_file(qasm_file, name=None, basis_gates='id,u0,u1,u2,u3,x,y,z,h,s,sdg,t,tdg,rx,ry,rz,cx,cy,cz,ch,crz,cu1,cu3,swap,ccx,cswap')> ``` ### Suggested solutions This seems to be related to the order of imports in `qiskit/__init__.py` introduced in #874, which rippled back silently after #885 . The error message is printed during the import of `circuit_drawer`, as it tries to import `qiskit.load_qasm_string`, which is not available by that time. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Update trigger functions to use `TriggerFailed` Once #44 / #59 are merged, trigger functions should raise `TriggerFailed` instead of `Failed`. Moreover, triggers should probably never just return False -- originally that was done to allow triggers to indicate that they didn't have enough information to determine if they would run or not (for example, an `all_success` trigger that was passed 2 `Success` states and 1 `Pending`) but now that all states must be finished before being passed to a trigger, triggers should always be able to either pass or raise a signal. Update trigger functions to use `TriggerFailed` Once #44 / #59 are merged, trigger functions should raise `TriggerFailed` instead of `Failed`. Moreover, triggers should probably never just return False -- originally that was done to allow triggers to indicate that they didn't have enough information to determine if they would run or not (for example, an `all_success` trigger that was passed 2 `Success` states and 1 `Pending`) but now that all states must be finished before being passed to a trigger, triggers should always be able to either pass or raise a signal. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Accepting torch device objects in the Pipeline init ### Feature request Currently Pipeline init only takes an integer as a device argument in the constructor. It would make it a little easier to interface with and integrate with existing code if it also took a pytorch device object. ### Motivation It's frustrating not be to be able to use the model.device/self.device object when instantiating the pipeline object ### Your contribution I feel like I could do this and I'm happy to take a whack, but I haven't contributed to Transformers yet Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: GAN example: Only one backward() call? In the PyTorch GAN tutorial [https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html](https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html) there are two backward() calls for the discriminator. How do you ensure this with your structure, where backward() gets called after the training step? Best, Alain Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: 'conda update --all' causes \"'python' is not recognized as an internal or external command\" repro steps: 1. fresh install of latest version of miniconda 2. `conda update --all` and yes to all questions 3. restart 'Anaconda Prompt' and you will see ``` 'python' is not recognized as an internal or external command, operable program or batch file. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] Upload fails with multiple remotes in the same command When uploading several packages at once (without specifying a remote) and some packages are uploaded to different remotes, the command will fail. The bug appears to be due to reusing a closed thread pool in the loop in CmdUploader.upload() in uploader.py. Once thread pools are closed they can't be reused, so any iterations after the first will cause an error. ### Environment Details (include every applicable attribute) * Operating System+version: RHEL 7.6 * Conan version: Tested with 1.29.0 and 1.30.dev0 (develop) * Python version: 3.8.5 ### Steps to reproduce (Include if Applicable) 1. Set up two remotes 2. Create 2 recipes and add_ref one recipe to each remote 4. Upload using `conan upload \"*\" --all` ### Logs (Executed commands with output) (Include/Attach if Applicable) I can't get the logs off my machine, but the stack trace looks like this: command.py:2103 command.py:1477 conan_api.py:94 conan_api.py:965 uploader.py:109 pool.py:364 pool.py:473 pool.py:350 ValueError: Pool not running Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: new clang version 10.0.0 is not supported (settings.compiler.version) conan version: 1.4.4 clang version: 10.0.0 I've used the following pipeline in Jenkins : https://github.com/jfrog/project-examples/blob/master/jenkins-examples/pipeline-examples/conan-example/Jenkinsfile If failed with the following output: (/var/folders/3h/fkh389zj34s7hl6xdpjd1hn0bc436s/T/conan5921226174563491616/.conan/profiles/default) Found apple-clang 0.0 Default settings os=Macos os_build=Macos arch=x86_64 arch_build=x86_64 compiler=apple-clang compiler.version=0.0 compiler.libcxx=libc++ build_type=Release *** You can change them in /var/folders/3h/fkh389zj34s7hl6xdpjd1hn0bc436s/T/conan5921226174563491616/.conan/profiles/default *** *** Or override with -s compiler='other' -s ...s*** **ERROR: Invalid setting '0.0' is not a valid 'settings.compiler.version' value. Possible values are ['5.0', '5.1', '6.0', '6.1', '7.0', '7.3', '8.0', '8.1', '9.0', '9.1']** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: part of PR #1606 (loadpy -> load) erased by magic refactoring. Nothing serious. Just will hate to reapply some changes in the correct files. This mainly makes docs inconsistent Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add `clustering_fields` property to TableListItem API reference: https://cloud.google.com/bigquery/docs/reference/rest/v2/tables/list The property `clustering.fields[]` now appears in the API results for `list_tables()`. In the `Table` class, this property is exposed as [Table.clustering_fields](https://googleapis.github.io/google-cloud-python/latest/bigquery/generated/google.cloud.bigquery.table.Table.html#google.cloud.bigquery.table.Table.clustering_fields). A similar property needs to appear on TableListItem. Related: https://github.com/googleapis/google-cloud-python/issues/5117 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: clang-format: Also format header files Currently the code ```python suffixes = set(lang_suffixes['c']).union(set(lang_suffixes['cpp'])) ``` in `mesonbuild/scripts/clangformat.py` just takes all `*.c` and `*.cpp` files and formats them but ignores all `*.h` (or `*.hpp`) files in the source. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add retry + timeout to Airflow db check ### Description In my company usage of Airflow, developmental instances of Airflow run on containerized PostgreSQL that are spawned at the same time the Airflow container is spawned. Before the Airflow container runs its initialization scripts, it needs to make sure that the PostgreSQL instance can be reached, for which `airflow db check` is a great option. However, there is a non-deterministic race condition between the PSQL container and Airflow containers (not sure which will each readiness first and by how much), calling the `airflow db check` command once is not sufficient, and implementing a retry-timeout in shell script is feasible but unpleasant. It would be great if the `airflow db check` command can take two additional optional arguments: `--retry` and `--retry-delay` (just like with `curl`) so that the database connection can be checked repeatedly for up to a specified number of times. This command should exit with `0` exit code if any of the retries succeeds, and `1` if all of the retries failed. ### Use case/motivation _No response_ ### Related issues _No response_ ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: unexpected behaviour of np.broadcast_to As detected during discussions at https://github.com/google/jax/pull/1515, `np.broadcast_to(np.ones((2, 3)), (1, 3)).shape` should raise an error instead of returning `(1, 2, 3)`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: load_qasm_file and load_qasm_string should be part of circuits <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? The load_qasm_* should be part of the circuit object and not in the wrapper ```circuit(qasm_file)``` or ```circuit.load(qasm_file)``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: AttributeError: 'list' object has no attribute 'items' <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.71 - **Python version**: 3.7.3 - **Operating system**: windows 10 ### What is the current behavior? When running the example code teleport.py, I got the following error: File \"…\\Python3.7.3\\lib\\site-packages\\qiskit\\mapper\\_mapping.py\", line 397, in swap_mapper for k, v in initial_layout.items()} AttributeError: 'list' object has no attribute 'items' ### Steps to reproduce the problem run the code in the most currently installed terra: examples/python/teleport.py, ### What is the expected behavior? Should not have such error. ### Suggested solutions debug if the definition and usage of object initial_layout is consistent in: ..\\Python3.7.3\\lib\\site-packages\\qiskit\\mapper\\_mapping.py Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add Opflow Migration Guide ### What should we add? To follow through with our plan to deprecate `qiskit.opflow`, we need a clear migration guide, and most likely a new documentation sub-section called ``migrations`` (@1ucian0). I am currently working on this guide on a fork of the documentation repo, and will open a PR once the content is complete. In the meantime, you can track the progress of the current WIP document [here](https://github.com/ElePT/qiskit_sphinx_theme/blob/opflow-migration/docs/migrations/opflow_operator_logic.rst). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: fix docs formatting ## 📚 Documentation At this moment the docs raise about 140 warnings which may cause some issues in documentation. To build the docs locally follow these steps: ```bash cd docs pip install -r requirements.txt make html ``` Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: [Docs] Wrong name in DynamicalDecoupling deprecation message? ### Environment - **Qiskit Terra version**: online docs ### What is happening? https://qiskit.org/documentation/stubs/qiskit.transpiler.passes.DynamicalDecoupling.html Deprecation message says to use `DynamicalDecouplingPadding`: <img width=\"845\" alt=\"image\" src=\"https://github.com/Qiskit/qiskit-terra/assets/60495383/ca061bc6-3c67-4aae-be8a-f27537e0565b\"> But the actual name seems to be `PadDynamicalDecoupling`: https://qiskit.org/documentation/stubs/qiskit.transpiler.passes.PadDynamicalDecoupling.html <img width=\"787\" alt=\"image\" src=\"https://github.com/Qiskit/qiskit-terra/assets/60495383/1187e22f-5729-4c19-be6a-49ba6711c571\"> ### How can we reproduce the issue? Read deprecation message here: https://qiskit.org/documentation/stubs/qiskit.transpiler.passes.DynamicalDecoupling.html ### What should happen? Deprecation message should probably direct users to `PadDynamicalDecoupling` if that's the correct replacement to use. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Passing files() in run_target() assumes working directory is the build root I was a bit surprised when `files('foo.txt')` from a subdir returned a path like `'../common/MDP1/foo.txt'` This made using `foo` defined as `foo = files('foo.txt')` almost useless. Is this expected? (I tried using it from the root dir. I changed it to `foo = join_paths(meson.current_source_dir(), 'foo.txt')` and am now good but just wanted to share my experience. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: How to deal with the re-implementation of numpy functions depending of C functions? As per title, is there / what is the procedure to re-implement numpy functions that depend on C functions, e.g. [`numpy.nonzero`](https://github.com/numpy/numpy/blob/v1.17.0/numpy/core/fromnumeric.py#L1759-L1849), depending on [`PyObject_NonZero`](https://github.com/numpy/numpy/blob/4b1cd4e118e543260cbe9c7fba51a1de37e03618/numpy/core/src/multiarray/item_selection.c#L2215-L2475)? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.storage.connection.Connection.api_request defaults path to None, but doesn't handle it https://github.com/GoogleCloudPlatform/gcloud-python/blob/master/gcloud/storage/connection.py#L165 If the 'path' argument is not passed, the generated URI is nonsensical. We should either default to a sensible path ('/'), or else test for None and do something reasonable. As an alternative, we could just make 'path' a required argument (as it is for 'build_api_url'). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Move bytes signing code upstream into oauth2client Code was last modified: https://github.com/GoogleCloudPlatform/gcloud-python/pull/1338 Both `PyCrypto` and `pyOpenSSL` versions could be supported there as well as pure Python. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ls broken after merge of #1089 After the merge of #1089 ls in the qtconsole prints blank lines and not the contents of the dir. On ubuntu 11.10 using python2.7 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: undefined f if vmap applied to lu.WrappedFun In `vmap`, `f` is not be defined whenever the if condition is false: https://github.com/google/jax/blob/f8eda9bb645a1ed489f08be57bae380bbcf5fa0c/jax/api.py#L414-L420 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Filename completion when run script with %run When I type `~/` and press `Tab`, it completes with files in my home directory. Works also when a script runs `input`. _But_ when I want to run a script with args, the tab completion only works with directories, not files. Ex: `%run my_script ~` press Tab will expend: `/home/me/dir1 /home/me/dir2` but not: `/home/me/dir1 /home/me/dir2 /home/me/file` Is it possible tu have the file completion just like in a shell? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Basic pulse scheduler <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The Pulse API will supply a pulse `scheduler`, which in conjunction with the `CommandDefinition` (#1918) will allow compilation of `QuantumCircuit`s to a `PulseSchedule` (#1919). See #1713 for more information. For v0.8 a simple pulse scheduler will naively compile a `QuantumCircuit` to a `PulseSchedule`. v0.9 will include a more advanced scheduler that utilizes a PassManager. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Cannot inspect callable that raise in __bool__ The following should not raise. ``` python class NoBoolCall: def __call__(self): pass def __bool__(self): raise NotImplementedError('Must be implemented') b = NoBoolCall() b? ``` Likely in `oinspect.py`: ``` 835: if callable_obj: ``` Should be `if callable_obj is not None`, though i'm not sure. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add BackendV2 mocked backends ### What is the expected enhancement? The mock backends in `qiskit/test/mock/backends` are built using snapshots of IBM Quantum's devices. Right now they're built using `BackendV1` (and `BaseBackend` for the legacy backend classes). To start fully testing the `BackendV2` interface we should add variants of these fake backend classes using `BackendV2`. We shouldn't replace the `BackendV1` objects since it's useful to exercise both versions of the interface while both are supported. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] default_options are typed to unicode <!-- Please don't forget to update the issue title. Include all applicable information to help us reproduce your problem. To help us debug your issue please explain: --> ### Environment Details (include every applicable attribute) * Operating System+version: solaris intel or solaris ultrasparc (any version) * Compiler+version: gcc 4.8.5 * Conan version: 1.21.0 * Python version: 2.7.16 (Deprecation, but an issue to upgrade in our environment) ### Steps to reproduce (Include if Applicable) when setting the following default options as: ```python default_options=(\"SOME_OPT=%s\" % (os.environ[\"SOME_OPT\"])) ``` It causes the value reaching the conan_file.py create_options to be unicode, causing an exception You can fix this by changing line 26 on model/conan_file.py from ```python elif isinstance(default_options, str) ``` to be ```python elif isinstance(default_options, (str, unicode)) ``` Would be much appriciated and a quick fix :) Thanks, Ofir Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: run_circuits is using a hardcoded sleep when checking job status ### Environment - **Qiskit Terra version**: `main` branch - **Python version**: n/a - **Operating system**: n/a ### What is happening? The qiskit `run_circuits` utility is using a hard-coded sleep when it waits to check the job status here https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/utils/run_circuits.py#L219. ### How can we reproduce the issue? _The issue has to do with using a hard-coded value when there is a configured value that can be used instead._ ### What should happen? The code should instead use `qjob_config[\"wait\"]` which comes from the `QuantumInstance` [constructor](https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/utils/quantum_instance.py#L168) and which can be made available to the code in run_circuits. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: deactivate bug @kevinzzz007 your issue reported in #4275 is different than what #4275 is reporting. I've created a new issue here. > I have a similar problem, I created an env with a name that does not start with an underscore, first I can successfully activate this env, but when I type source deactivate when inside the env, I get an error as the following /Users/MyName/anaconda3/envs/EnvName/bin/deactivate:81: no such file or directory: /Users/MyName/anaconda3/envs/EnvName/bin/python, I looked at the /Users/MyName/anaconda3/envs/EnvName/bin directory and there is no python file in this directory, and after I typed the source deactivate command, my command prompt seems to be back to normal, but then the command prompt can't recognize simple commands like ls... > my conda version is 4.3.4 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add a pad method to pulse schedule <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? With the introduction of a delay instruction (#2846) we should add a method `pad` (or another name) which will take a pulse schedule and return a new schedule with delays inserted in all available timeslots. This will allow one to fix the behaviour of a given schedule by preventing additional pulses to be inserted and allow easier scheduling. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: LaTeX Barriers are not centered between gates and measures on all columns <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: latest master - **Python version**: 3.7 - **Operating system**: linux ### What is the current behavior? @nonhermitian example in issue #938 shows a circuit with a barrier being drawn with a measure after a gate but the barrier is not centered for the gate and measure on q0_15:  The barrier is being drawn from q0_0 (because the \\barrier command in latex draws the barrier line down from the topmost bit) and the default horizontal offset is used because there is no measure immediately after the gate on that bit. This ends up being incorrect on q0_15 because because there is a measure immediately after the gate on that bit which moves the center line between those 2 boxes to the left. ### Steps to reproduce the problem Draw a circuit with a measure right after a gate on a bit covered by the barrier, but is not the bit where \\barrier will be written in the latex. ### What is the expected behavior? The barrier line should centered between gates and measures on all bits covered by a barrier, not just the topmost bit (where the \\barrier call is made from in the latex) ### Suggested solutions We need to adjust the check in the latex circuit drawer that looks for a measure directly after a gate on a bit to check all bits being covered by the barrier, not just the bit Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: TensoredOp's to_matrix() returns a wrong value if coeff is not 1 ### Environment - **Qiskit Terra version**: 0.22.4 - **Python version**: 3.10.4 - **Operating system**: Ubuntu 20.04.5 LTS ### What is happening? `TensoredOp`'s `to_matrix()` returns a wrong value if coeff is not 1. ### How can we reproduce the issue? Run the following code: ``` from qiskit.opflow import Plus, Zero print((0.5 * (Plus ^ Zero)).to_matrix()) ``` Then, the following will be printed: ``` [0.1767767+0.j 0. +0.j 0.1767767+0.j 0. +0.j] ``` ### What should happen? The following should be printed: ``` [0.35355339+0.j, 0. +0.j, 0.35355339+0.j, 0. +0.j] ``` ### Any suggestions? I think this problem is related to #9283. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: One off containers no longer link to themselves Regression since 0.3.2. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Update jsonschema dependency **Is your feature request related to a problem? Please describe.** I'm trying to install [poetry](https://github.com/sdispater/poetry) and `docker-compose` in a virtualenv but since they depend on different [jsonschema](https://github.com/Julian/jsonschema/blob/master/CHANGELOG.rst) major versions they become incompatible when running together in the venv. - `poetry`: [`>=3, <4`](https://github.com/sdispater/poetry/blob/master/pyproject.toml#L30) - `docker-compose`: [`>=2.5.1, <3`](https://github.com/docker/compose/blob/master/setup.py#L42) **Describe the solution you'd like** `docker-compose` to update its `jsonschema` dependency to `>=3, <4`. **Describe alternatives you've considered** I could just put the two in different venvs. I'm lazy and just want all my tools available in a single venv so I don't have to hop around so much. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Key name w/ slash quoted twice during upload The fix for #354 in #364 mistakenly quotes the `Key.name` when adding it the the `query_params` for the upload API call, but those params are already going to be quoted inside `Connection.make_api_request` (by way of `urllib.urlencode`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [examples] add --max_train_samples --max_val_samples --max_test_samples cl args to all scripts As a part of an effort to make all examples have the same look and feel this issue requests to sync the support for these 3 cl args in `run_seq2seq.py`: ``` --max_train_samples 5 --max_val_samples 5 --max_test_samples 5 ``` into: 1. all other `examples/*/run_*.py` 2. `templates/adding_a_new_example_script` Part B. the metrics should be now updated to include the actual number of samples that were run. here is an example for train: https://github.com/huggingface/transformers/blob/f52a15897b46ffa40af5c96d3726f0e18e91879b/examples/seq2seq/run_seq2seq.py#L586-L590 and the same for eval/test. I'd say this can probable refactored too. Let me check with Sylvain. The way it's currently used is to limit the number of dataset entries w/o needing to change the dataset, example: ``` run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir --do_eval --do_predict --do_train \\ --evaluation_strategy=steps --predict_with_generate --task summarization --dataset_name xsum \\ --max_train_samples 60 --max_val_samples 10 --n_test 10 ``` All the code that currently takes care of it can be found inside https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_seq2seq.py This issue is open to anybody in the community who would like to tackle it. Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Suggestion: 'undeprecate' extensions I can't think of a single reason why it is deprecated. Python package management is really bad to rely on pip, packing small personal customization extensions is a massive overkill and can lead to potential pip conflicts in the future and publishing it is a horrendous waste of time (and might not even be possible in some cases). Extensions folder was perfect for very simple personal extensions and now using it constantly shows warnings that can't be disabled. Startup scripts aren't a good alternative because they clutter globals space and trying to do something without putting anything into globals leads to extremely ugly code in startup scripts. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: PIN 16: Implement `Result.validate` ## Use Case ~Blocked by #2143 and #2139~. See [PIN 16](https://github.com/PrefectHQ/prefect/pull/2134) for background. ## Solution Implement `Result.validate` such that - if `Result.run_validators=True` - all `Result.validators` are called on the result value - if any fail, raise ValidationFailed signal to trigger ValidationFailed state (*see alternative) - if all succeed, return True (*see alternative) ## Alternatives *Please describe any alternatives you've considered, even if you've dismissed them* - *I may be misrepresenting the intended method signature; if this method will be called by a TaskRunner method, we may want to receive `False` instead of a raise a ValidationFailed signal to allow the TaskRunner method to construct the ValidationFailed state and return it as part of the pipeline a la https://github.com/PrefectHQ/prefect/blob/66703e5f0a2d0d035d4d48af013b87d24a7a2a56/src/prefect/engine/task_runner.py#L957-L964 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: --use-local flag not working in 4.4.0 For some time I've been doing this: ``` conda build --old-build-string --python 2.7 conda install taxcalc=0.0.0 --use-local --yes ``` But that `conda install` command now fails under conda 4.4.0 and 4.4.1. I have been able to work around this problem by doing this: ``` conda build --old-build-string --python 2.7 conda install --offline ~/anaconda/conda-bld/osx-64/taxcalc-0.0.0-py27_0.tar.bz2 ``` Why does my old code fail under conda 4.4.0 and conda 4.4.1? The failure is that it says it cannot find the package, but it is where it has always been built: `~/anaconda/conda-bld/osx-64/taxcalc-0.0.0-py27_0.tar.bz2` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: ReduceLROnPlateau scheduler type check ## 🐛 Bug Incorrect type check for scheduler of class ReduceLROnPlateau. https://github.com/PyTorchLightning/pytorch-lightning/blob/bc01b9ac1c0ddf503f83755c00d5541a2679e5b4/pytorch_lightning/trainer/trainer.py#L713 I believe, this check: `isinstance(scheduler, optim.lr_scheduler.ReduceLROnPlateau)` must look like this: `isinstance(scheduler['scheduler'], optim.lr_scheduler.ReduceLROnPlateau)` ### To Reproduce Steps to reproduce the behavior: 1. Create a scheduler of type `optim.lr_scheduler.ReduceLROnPlateau` in the `configure_optimizers` method of a `LightningModule` class. 2. Return an optimizer and scheduler from this method. Place them in lists: `return [optimizer], [scheduler]`. 2. Execute the `trainer.fit(module)`. 3. Put a break-point here: https://github.com/PyTorchLightning/pytorch-lightning/blob/bc01b9ac1c0ddf503f83755c00d5541a2679e5b4/pytorch_lightning/trainer/trainer.py#L712 4. Make sure that the condition is never True. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Implement PyTorch and/or TensorFlow sequence classification architectures for causal language models # 🚀 Feature request The architecture `GPT2ForSequenceClassification` was added in #7501 in PyTorch. It would be great to have it in TensorFlow (cf. issues #7622), but it would also be great to have it for other causal models: ~OpenAI GPT~, ~CTRL~ (PR opened @elk-cloner), ~TransfoXL~ (PR opened @spatil6) Below is a list of items to follow to make sure the integration of such an architecture is complete: - Implement `XXXForSequenceClassification` in `modeling_xxx.py` or `TFXXXForSequenceClassification` in `modeling_tf_xxx.py - Test that architecture in `tests/test_modeling_xxx.py` or `tests/test_modeling_tf_xxx.py` - Add that architecture to `__init__.py` and ` docs/source/model_doc/xxx.rst`. Taking a look at the code changes in #7501 would be a good start. A very good first issue to get acquainted with the library and its architectures! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add standard Docker CLI flags for remote Daemon config? It'd be pretty nice to be able to run commands like you can with the regular docker client, so I don't have to always inject stuff into the shell environment. For example: ``` $ docker-compose $(docker-machine config default) up -d web ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CMake subproject with MSVC generate many warnings D9025 I use the CMake subproject in a project with cl-compiler and the ninja build system. The meson automatically puts the **/ZI** argument, but when parsing a subproject, it puts the **/Zi** argument. This causes many warnings D9025. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: build_always: false does not match the 0.46.1 behaviour Specifying `build_always: false` and `build_by_default: true` on the same target seems to suppress the later. Targets declared as such are therefore never built unless something depends on them (but if you are using `build_by_default`, then chances are nothing does). ~~I suspect it also affects `build_always_stale: true` in the same way, but I have not tested that yet.~~ `build_always` must have lower priority than the other two for compatibility with older Meson releases. In addition, please don't be too trigger happy with deprecation warnings. As it stands, it is impossible to avoid the warning in meson git without also breaking compatibility with every current stable release, even if this bug is fixed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: base_url and static path Static path in template does not use the base_project_url. Which seem to work, but tornado is still serving static resources in `/static/` instead of `/$base_url/static` I will promote this to high as this prevent running ipython in parallel with other webapp. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: TypeError: <class 'jax.ad_util.Zero'> is not a valid Jax type when I combine custom_jvp and lax.scan Hi all I have a difficult bug which I don't understand. It started appearing when I defined my custom gradients with `custom_jvp` (in forward mode), before, I did it in reverse mode with `custom_gradient`. I'm up-to-date on the master branch, as of this writing. `TypeError: <class 'jax.ad_util.Zero'> is not a valid Jax type` I've tried to make a simple code snippet to reproduce it, but it's still rather complex because the bug, as far as I can tell, only appears when I combine different things. I've tried lots of combinations, and so far I've seen the bug appear only when: 1) I define the gradient with `custom_jvp` 2) The custom gradient depends on `dA` (`A` does not depend on `theta`, I think it's got something to do with this) 3) I use `lax.scan` (the bug disappears when I use a python loop) 4) `theta` is used as below, directly in `step` (this is not breaking the 'pure function' requirement, right?) ```python import jax import jax.numpy as np @jax.custom_jvp def f(A, b): return A @ b def f_jvp(primals, tangents): A, b = primals dA, db = tangents z = f(A, b) dz = dA @ db return z, dz f.defjvp(f_jvp) def experiment(theta): def step(q, _): z = f(np.eye(3), np.ones(3) * theta) q += z[0] return q, q q = 0. q, _ = jax.lax.scan(step, q, None, 4) return q experiment_grad = jax.grad(experiment) g = experiment_grad(1.) print(g) ``` Thanks for the help! Rembert Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: IAM policy should return an empty set of the bindings do not exist https://github.com/GoogleCloudPlatform/google-cloud-python/blob/bd9fdfba07fac63a91847628613928a569250c0f/core/google/cloud/iam.py#L71 Should return an empty set if no bindings are set for that role. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [-e] Define cli syntax for packages in editable mode I'm working in a new feature: **install packages in editable mode.** ([branch](https://github.com/conan-io/conan/projects/1)) This feature should implement _the same_ behavior as the Python one: `pip install -e .` that makes the package in the working copy available system wide so you can use it from the sources you are editing. In Conan we would like to allow the user to install a package (a full reference) in editable mode, so every recipe making use of it will use the recipe, includes, binaries,... from the working copy. This simplifies the workflow when dealing with several interdependent libraries at the same time. Changes in a package will be taken into account in the dependent one without calling any Conan command (of course, build/link is still needed to compile and update `.lib` or `.bin` files). Ideas: ``` $ conan editable <path_to_conanfile.py> package/version@user/channel $ conan install -e <path_to_conanfile.py> package/version@user/channel ``` but I want feedback from every @conan-io/barbarians and @conan-io/community-leaders, and everyone interested, to design a new command or use an existing one. We should also think about how this new option/command interferes with existing ones. With the first implementation, I will provide a working example and explain what the package has to satisfy in order to allow _editable mode_. 💪 Thanks for your feedback. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: AssertionError: If you see this error, please let us know by opening an issue at... Hi there! Just ran into ``` AssertionError: If you see this error, please let us know by opening an issue at https://github.com/google/jax/issues since we thought this was unreachable! ``` so I thought I better do as i was told! I am trying to implement an ML algorithm, and when jit tracing a function I get the error above. The issue was that i used a good old numpy randint inside the loss function, and when replacing that with a jax.random randint the error went away. AssertionError: If you see this error, please let us know by opening an issue at... Hi there! Just ran into ``` AssertionError: If you see this error, please let us know by opening an issue at https://github.com/google/jax/issues since we thought this was unreachable! ``` so I thought I better do as i was told! I am trying to implement an ML algorithm, and when jit tracing a function I get the error above. The issue was that i used a good old numpy randint inside the loss function, and when replacing that with a jax.random randint the error went away. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: CORS access_control_allow_origin header never returned ### Apache Airflow version 2.2.2 (latest released) ### What happened To fix CORS problem added the [access_control_allow_headers](https://airflow.apache.org/docs/apache-airflow/stable/configurations-ref.html#access-control-allow-headers), [access_control_allow_methods](https://airflow.apache.org/docs/apache-airflow/stable/configurations-ref.html#access-control-allow-methods), [access_control_allow_origins](https://airflow.apache.org/docs/apache-airflow/stable/configurations-ref.html#access-control-allow-origins) variables to the 2.2.2 docker-compose file provided in documentation. Both header, and methods returns with the correct value, but origins never does. ### What you expected to happen The CORS response returning with provided origin header value. ### How to reproduce Download the latest docker-compose from documentation add the following lines: `AIRFLOW__API__ACCESS_CONTROL_ALLOW_HEADERS: 'content-type, origin, authorization, accept'` `AIRFLOW__API__ACCESS_CONTROL_ALLOW_METHODS: 'GET, POST, OPTIONS, DELETE'` `AIRFLOW__API__ACCESS_CONTROL_ALLOW_ORIGINS: '*'` run and call with a CORS preflight ### Operating System Windows 11 ### Versions of Apache Airflow Providers _No response_ ### Deployment Docker-Compose ### Deployment details _No response_ ### Anything else It's repeatable regardless of ORIGINS value. There was a name change on this variable that's possibly not handled. On 2.1.4 the same works without problems. ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Audit nbconvert HTML output The HTML output of nbconvert should exactly match that of the live notebook. We need to do a careful diff of these two to make sure the tags and attributes match. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Need an REST API or/and Airflow CLI to fetch last parsed time of a given DAG ### Description We need to access the time at which a given DAG was parsed last. Airflow Version : 2.2.2 and above. ### Use case/motivation End users want to run a given DAG post applying the changes they have done on them. This would mean that the DAG should be parsed post the edits done to it. Right now the last parsed time is available by accessing the airflow database only. Querying the database directly is not the best solution to the problem. Ideally airflow should be exposing APIs that end users can consume that can help provide the last parsed time for a given DAG. ### Related issues Not Aware. ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: GitCommand errors are stringifying bytes in 3.1.15 The 3.1.15 release changed at least how `git.exc.GitCommandError` Errors are being generated. I have tested with `stderr`, but am guessing the same would be true for `stdout`. Previously `git.exc.GitCommandError.stderr` was a string of the error with bytes decoded, now the error is a string with bytes stringified. repo.git.rebase Error: * 3.1.14-stderr = `\"\\n stderr: 'fatal: invalid upstream 'invalid_branch''\"` * 3.1.15-stderr = `'\\n stderr: \\'b\"fatal: invalid upstream \\'invalid_branch\\'\"\\''` remote.push Error: * 3.1.14-stderr = `\"\\n stderr: 'error: src refspec invalid_branch does not match any\\nerror: failed to push some refs to 'git@gitservice.com:project/repo.git''\"` * 3.1.15-stderr = `'\\n stderr: \\'b\"error: src refspec invalid_branch does not match any\\\\nerror: failed to push some refs to \\'git@gitservice.com:project/repo.git\\'\"\\''` Steps to reproduce: ``` import git exception = git.exc.CommandError(command=\"git rebase invalid_branch\".split(), stderr=b\"abc\") exception.stderr ``` Steps to reproduce from code ``` import git path_to_repo = \"my_project\" repo = git.Repo(path_to_repo) local_branch = \"invalid_branch\" remote_branch = local_branch # Generate Error for Rebase try: repo.git.rebase(refspec=f\"{remote_branch})\" except Exception as err: print(err.stderr) # Generate Error for Push try: repo.remotes[0].push(f\"{local_branch}:{remote_branch}\") except Exception as err: print(err.stderr) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Quoted defines are not correctly generated in Conan premake To help us debug your issue please explain: - [X] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Conan version 1.14.4 macOs : 10.14.3 When including libraries or flags containing quote, the generated conanbuildinfo.premake.lua contains invalid data. For example, if a recipe includes : ```self.cpp_info.exelinkflags.extend([ '-framework \"Chromium Embedded Framework\"'])``` the following code is generated : ```\"-framework \"Chromium Embedded Framework\"\" ``` I have a fix located at firefalcom/conan@01dd9849630fd9e8884ea15ff8e9c262514baa0d It simply escapes the '''\"''', generating ```\"-framework \\\"Chromium Embedded Framework\\\"\" ``` I can make a pull request if the fix is ok for you Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Support jupyterlab_server 1.0 We cleaned up the server in https://github.com/jupyterlab/jupyterlab_server/pull/70 in preparation for its 1.0 release. We need to update ourselves accordingly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `C3SXGate` inconsistent with `SXGate` <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.18.3 - **Python version**: any - **Operating system**: any ### What is the current behavior? The definition of `C3SXGate()` is currently equivalent to `SXdgGate.control(3)`, but its name and its base gate definition indicate it should be equivalent to `SXgate.control(3)`. ### Steps to reproduce the problem ```python In [1]: from qiskit.circuit.library import SXGate, SXdgGate, C3SXGate ...: from qiskit.quantum_info import Operator ...: import numpy as np ...: ...: ( ...: np.linalg.norm(Operator(SXGate().control(3)) - Operator(C3SXGate())), ...: np.linalg.norm(Operator(SXdgGate().control(3)) - Operator(C3SXGate())), ...: ) Out[1]: (1.9999999999999984, 6.088839805355096e-15) ``` ### What is the expected behavior? `C3SXGate` should be consistent with `SXGate().control(3)`. ### Suggested solutions Swap the negatives of the angles in `C3SXGate.definition`. There's a fair amount more to do as well to ensure consistency - checking the equivalence library, QASM definitions, etc. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: multi-gpu training triggers CUDA out of memory error Hi - I am running into issues when going from single to multi-gpu training. Specifically, if I switch the line `pl.Trainer(gpus=1, precision=16, distributed_backend='ddp')` to `pl.Trainer(gpus=4, precision=16, distributed_backend='ddp')` I get the dreaded CUDA out of memory error. Is there any reason why the parallelism causes the GPU to receive more data? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Improve documentation of ipcontroller and possible BUG I tried to follow the documentation to setup a simple cluster with one host acting as controller (Ubuntu) and a second host running several ipengine (Windows7). There is a misleading command in the doc. To launch the controller the doc says in \"General consideration\": ``` ipcontroller --ip=* ``` and in \"Using the ipcontroller and ipengine commands\" ``` ipcontroller --ip=192.168.1.16 ``` (and BTW there is no mention anymore to the \\* syntax). However the command that worked for me is: ``` ipcontroller --ip='*' --location=192.168.1.64 ``` where location is the ip address of the host running the controller. Without location, the ipengine JSON file doesn't have the proper ip address (it has 127.0.0.1 instead). On a related note, the doc also states to use the following command to retrieve the local ip address in ipcontroller_config.py: ``` import socket ex_ip = socket.gethostbyname_ex(socket.gethostname())[-1][0] ``` but running this command on Ubuntu 12.04 returns 127.0.0.1, which is wrong. This maybe the reason why the ipcontroller command fails without the --location flag. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: The tools in qiskit/tools/qi/ need more testing The files under `qiskit/tools/qi/` are partially covered by the current testsuite. (see #221) file | statements | missing | coverage -- | -- | -- | -- qiskit/tools/qi/qi.py | 207 | 99 | 52% qiskit/tools/qi/pauli.py | 155 | 38 | 75% It would be great to have more tests to cover the methods and functions in these files. Specially `qiskit/tools/qi/qi.py`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cross compilation, static libraries and ranlib In Arch Linux it seems that we have to manually run ranlib to be able to use static libraries compiled using meson here you can find the meson wrapper (after 0.48 release we can finally remove the wine hack, thanks for fixing!) https://aur.archlinux.org/cgit/aur.git/tree/meson-mingw-wrapper?h=mingw-w64-meson and the cross file https://aur.archlinux.org/cgit/aur.git/tree/toolchain-mingw.meson?h=mingw-w64-meson as you can see ranlib is defined, but we have to manually run ranlib to be able to use the static libraries, for example: https://aur.archlinux.org/cgit/aur.git/tree/PKGBUILD?h=mingw-w64-glib2#n62 isn't meson supposed to do this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: seaborn library requirement breaks Terra <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.11.0 - **Python version**: 3.6.7 - **Operating system**: Ubuntu 16.04.6 LTS ### What is the current behavior? Aqua travis is failing due to missing library \"seaborn\": ile \"/tmp/qiskit-terra-master/qiskit/execute.py\", line 24, in <module> from qiskit.compiler import transpile, assemble File \"/tmp/qiskit-terra-master/qiskit/compiler/__init__.py\", line 35, in <module> from .transpile import transpile File \"/tmp/qiskit-terra-master/qiskit/compiler/transpile.py\", line 19, in <module> from qiskit.transpiler import Layout, CouplingMap File \"/tmp/qiskit-terra-master/qiskit/transpiler/__init__.py\", line 69, in <module> from .passmanager import PassManager File \"/tmp/qiskit-terra-master/qiskit/transpiler/passmanager.py\", line 19, in <module> from qiskit.visualization import pass_manager_drawer File \"/tmp/qiskit-terra-master/qiskit/visualization/__init__.py\", line 107, in <module> from .gate_map import plot_gate_map, plot_circuit_layout, plot_error_map File \"/tmp/qiskit-terra-master/qiskit/visualization/gate_map.py\", line 24, in <module> import seaborn as sns ModuleNotFoundError: No module named 'seaborn' ### Steps to reproduce the problem Just add the statement: \"from qiskit.execute import execute\" ### What is the expected behavior? Seaborn should not be required since it is part of optional visualization feature ### Suggested solutions Do not throw exception if seaborn is not present. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Debug linking of renderer extensions ``` git clone https://github.com/gnestor/jupyter-renderers.git cd jupyter-renderers git checkout rendermime-refactor npm install npm run build jupyter labextension link packages/geojson-extension ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Sabre swap mapper dominated by data copy <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? Running Sabre on a QV circuit over 20 qubits shows that data copying is the current bottleneck: Abbreviated profile: ``` 9631133 function calls (8921864 primitive calls) in 4.184 seconds Ordered by: internal time ncalls tottime percall cumtime percall filename:lineno(function) 497066/663 0.492 0.000 1.516 0.002 copy.py:132(deepcopy) 44375/860 0.312 0.000 1.499 0.002 copy.py:220(_deepcopy_tuple) 389939 0.232 0.000 0.326 0.000 layout.py:97(__getitem__) 191092 0.179 0.000 0.511 0.000 sabre_swap.py:326(<genexpr>) 55118/10740 0.160 0.000 1.537 0.000 copy.py:269(_reconstruct) 1312882 0.112 0.000 0.112 0.000 bit.py:73(__hash__) 1032203 0.107 0.000 0.108 0.000 {method 'get' of 'dict' objects} 44177/660 0.090 0.000 1.497 0.002 copy.py:237(_deepcopy_dict) ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Can't pass environment variables to Git.execute This is needed for commands like `git-commit` and `git-commit-tree` in order to be able to specify author and committer information. While `git-commit` does provide the `--author` and `--date` to specify author information, there are no options for specifying committer information, and `git-commit-tree` is wholly dependent on environment variables. For instance, the following code fails with `TypeError: type object got multiple values for keyword argument 'env'`. ``` def pipe_of(string): import os if type(string) is str: string = bytes(string, 'utf-8') r,w = os.pipe() os.write(w, string) os.close(w) return r git = Repo('/path/ro/repo').git blob = git.execute(['git', 'hash-object', '-w', '--stdin'], istream=pipe_of(\"my data\")) tree = git.execute(['git', 'mktree'], istream=pipe_of(\"100644 blob {}\\tmy-file\\n\".format(blob))) commit = git.execute(['git', 'commit-tree', tree], istream=None, env={ 'GIT_AUTHOR_NAME':'Author Name', 'GIT_AUTHOR_EMAIL':'author@example.com', 'GIT_AUTHOR_DATE':'1400000000+0000', 'GIT_COMMITTER_NAME':'Comitter Name', 'GIT_COMMITTER_EMAIL':'committer@example.com', 'GIT_COMMITTER_DATE':'1500000000+0000', }) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.in1d bug on the object array The `np.in1d` method (Numpy 1.19.1, Python 3.8.3) makes some errors on the irregular-object array: **Case 1:** ```python np.in1d([(1,), 2], [(1,), 2]) ``` The output should be `[True, True]` but it says: ### Error message: ```python array([False, True]) ``` **Case 2:** ```python np.in1d([(1,), (2,)], [(1,), 2]) ``` The output should be `[True, False]` but it says: ### Error message: ```python array([True, True]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qpy import of circuit with StatePreparation fails ### Environment - **Qiskit Terra version**: 0.21.0 - **Python version**: 3.8.9 - **Operating system**: macOS (M1) - Qiskit version 0.37.0 ### What is happening? When reimporting a simple circuit containing a StatePreparation with `qiskit.qpy`, one gets the error `qiskit.exceptions.QiskitError: 'The num_qubits parameter to StatePreparation should only be used when params is an integer'`. ### How can we reproduce the issue? Minimal example: ``` #!/usr/bin/python3 import qiskit import qiskit.qpy print(qiskit.__qiskit_version__) qc = qiskit.QuantumCircuit(1) qc.prepare_state([0,1], [0]) with open(\"tmp.qpy\", \"wb\") as file: qiskit.qpy.dump(qc, file) with open(\"tmp.qpy\", \"rb\") as file: new_qc = qiskit.qpy.load(file) #qiskit.exceptions.QiskitError: 'The num_qubits parameter to StatePreparation should only be used when params is an integer' ``` ### What should happen? Reimporting a circuit with qiskit.qpy should be possible. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: GCS test failures for 'headers' Was: https://github.com/GoogleCloudPlatform/google-resumable-media-python/issues/41 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Template Module missing save_hyperparameters() / has unused args ## 📚 Documentation / Examples The main example is missing the current hparams best-practice outlined in: https://pytorch-lightning.readthedocs.io/en/latest/hyperparameters.html This means in the current example there is no automatic tensorboard logging of hparams which is insanely useful. It also includes ` optimizer_name: str = 'adam'` which is not actually used in `configure_optimizers()` since the optimizer is hard-coded to adam. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Wish: add ability to use local patch files It is impossible to use cmake projects if they placed not in root directory of subproject. For example look into LLVM project repository: https://github.com/llvm/llvm-project/ Each of its subdir is cmake projects but it is impossible to use them from Meson if llvm-project will be wrapped as subproject. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add support for ui_extra_arguments to qt5 Just like https://github.com/mesonbuild/meson/pull/2529 adds moc_extra_arguments, ui_extra_arguments would be useful to override translator function (hello gettext/i18n). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Method validate_parameter() of GaussianSquare raises PulseError if you call it on a created pulse ### Environment - **Qiskit Terra version**: 0.19.2 - **Python version**: 3.10 - **Operating system**: MacOS ### What is happening? The validate_parameter() method of the GaussianSquare pulse will raise an error if you call it after the pulse is created. This happen because the `width` and the `risefall_sigma_ratio` are both set. ### How can we reproduce the issue? ```python import qiskit.pulse as ps # For any given acceptable pulse it will raise an error. out_pulse = ps.GaussianSquare(100, 0.3+0.3j, 2, 10). # Or any other param, that is not the focus. out_pulse.validate_parameters() ``` ### What should happen? After looking at the source code, I figured this was an internal function that is called before the pulse if completed. It should be expected that you can't call this function for any given pulse (Drag or Gaussian too for exemple.) Perhaps raise a different error in this case (the case of having a completed pulse.) ### Any suggestions? Perhaps two solutions that are both equivalent, one that I don't really know what it represent to change the name of this particular function. - Make this function private. - Document the function to explain that it is not client-side code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda list FileNotFoundError ``` \"command\": \"/Users/hideki/anaconda/bin/conda list\" \"user_agent\": \"conda/4.4.3 requests/2.14.2 CPython/3.5.2 Darwin/16.7.0 OSX/10.12.6\" Traceback (most recent call last): File \\\"/Users/hideki/anaconda/lib/python3.5/site-packages/conda/exceptions.py\\\", line 722, in __call__ return func(*args, **kwargs) File \\\"/Users/hideki/anaconda/lib/python3.5/site-packages/conda/cli/main.py\\\", line 78, in _main exit_code = do_call(args, p) File \\\"/Users/hideki/anaconda/lib/python3.5/site-packages/conda/cli/conda_argparse.py\\\", line 75, in do_call exit_code = getattr(module, func_name)(args, parser) File \\\"/Users/hideki/anaconda/lib/python3.5/site-packages/conda/cli/main_list.py\\\", line 150, in execute show_channel_urls=context.show_channel_urls) File \\\"/Users/hideki/anaconda/lib/python3.5/site-packages/conda/cli/main_list.py\\\", line 85, in print_packages other_python = get_egg_info(prefix) File \\\"/Users/hideki/anaconda/lib/python3.5/site-packages/conda/egg_info.py\\\", line 86, in get_egg_info for path in get_egg_info_files(join(prefix, sp_dir)): File \\\"/Users/hideki/anaconda/lib/python3.5/site-packages/conda/egg_info.py\\\", line 35, in get_egg_info_files for egg in get_egg_info_files(reader.readline().strip()): File \\\"/Users/hideki/anaconda/lib/python3.5/site-packages/conda/egg_info.py\\\", line 32, in get_egg_info_files for fn in os.listdir(sp_dir): FileNotFoundError: [Errno 2] No such file or directory: '/Users/hideki/darkflow' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Support control flow ops in QASM3 exporter ### What is the expected enhancement? The QASM3 exporter is presently unaware of any of the op types in `qiskit.circuit.controlflow`, and will attempt to export them as opaque gates. It should be able to recognize them, and export the matching QASM3 control flow statements. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: Make HTTP-Method in signed url in upper case (and validate) 1. Specify the API at the beginning of the title (for example, \"BigQuery: ...\") General, Core, and Other are also allowed as types ✅ 2. OS type and version I use the Storage lib inside a `Cloud Function` (Python Beta runntime) 3. Python version and virtual environment information `python --version` 3.7 4. google-cloud-python version `pip show google-cloud`, `pip show google-<service>` or `pip freeze` 1.12.0 5. Stacktrace if available ❌ 6. Steps to reproduce ❌ 7. Code example 👇 Hey guys 👋 currently I experiment a little bit with the Cloud Storage library inside a Cloud Function. For testing I want to make an already uploaded file available via `Blob#generate_signed_url`. The thing is - it works. I have no issues. But Yesterday I spend at least 6 hours for testing it because the `method` in the `generated_signed_url` needs to be in uppercase. Meaning the following does **not** work: ```python blob.generate_signed_url(timedelta(minutes=5), \"get\") ``` but **this** works: ```python blob.generate_signed_url(timedelta(minutes=5), \"GET\") ``` After a quick look into your code I found out that you \"just put\" the string into the generated URL. Without validating if that is a valid HTTP-Method! https://github.com/GoogleCloudPlatform/google-cloud-python/blob/81bc5ef11d1918580f41e9f8ee2c9be2529b1169/storage/google/cloud/storage/_signing.py#L189 I would recommend (or request with this issue 🙃 ) to either: * Check if the given string is a valid HTTP-Method (POST, GET, PUT etc.) **and** make the string to uppercase! * Or better (but leads to breaking changes (maybe 😃)) make an ENUM of it and only allow to put an enum-value into the method. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson configuring runs os.walk() over the entire source directory **Describe the bug** Running `meson --reconfigure` will os.walk() the entire source directory to find meson.build and meson_options.txt files. This can take a long time and is unnecessary: the result of this is only used for `meson introspect`. **To Reproduce** Place a really big directory tree in any Meson project, notice that this makes `meson --reconfigure` take much longer **Expected behavior** Meson should not use os.walk() and should only read files that were referenced by the build. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? native * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.): macOS 10.14.6 * what Python version are you using e.g. 3.8.0: 3.7.0 * what `meson --version`: 0.52.0 * what `ninja --version` if it's a Ninja build: 1.9.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storage: blob.update_storage_class() does not work for large files [`Blob.update_storage_class()`](https://googleapis.github.io/google-cloud-python/latest/_modules/google/cloud/storage/blob.html#Blob.update_storage_class) does not work the same as [`Blob.rewrite()`](https://googleapis.github.io/google-cloud-python/latest/_modules/google/cloud/storage/blob.html#Blob.rewrite) despite sharing a common underlying API. When multiple API calls are required to complete the rewrite operation, `Blob.update_storage_class()` will fail after the first call. `Blob.update_storage_class()` assumes that `api_response['resource']` exists. However, according to the [docs](https://cloud.google.com/storage/docs/json_api/v1/objects/rewrite#response), this is only true when the operation completes on the first operation. Instead, I think that `Blob.update_storage_class()` should just leverage the logic in `Blob.rewrite()`, which handles this case already. I will also look to see how `gsutil` implements this. #### Stack trace ``` Traceback (most recent call last): File \"rehost.py\", line 31, in <module> blob.update_storage_class('COLDLINE') File \"/var/lib/mysql/.local/lib/python2.7/site-packages/google/cloud/storage/blob.py\", line 1497, in update_storage_class self._set_properties(api_response['resource']) KeyError: 'resource' Command exited with non-zero status 1 ``` #### Implementation - [x] Re-implement `Blob.update_storage_class()` as a wrapper around `Blob.rewrite()` - [x] Update any `Blob.update_storage_class()` tests - [x] Manually test new implementation with a large file #### References How `gsutil` handles looping through a rewrite operation - https://github.com/GoogleCloudPlatform/gsutil/blob/704781b250314791dda08191a7472d1a72da2c6c/gslib/gcs_json_api.py#L1477-L1526 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda only updates itself in the root environment I was listening to a presentation about conda a couple of days ago where it was mentioned that conda aggressively auto-updates itself. Aggressive auto-updates can be problematic, because they can result in the quick spread of a buggy release that is no longer able to update itself, which has happened to me and co-workers in the past. But in general they are a good thing, because they can help make sure that the installed user base is (a) not using outdated versions where problems were fixed long ago, and (b) are using a similar set of versions so that we don't have to reason about the effects of all possible version combinations. However, the main benefits of aggressively auto-updating only accrue if all or nearly all installations auto-update, which does not appear to be the case. Right now, it looks to me like auto-updates happen only when people regularly use the root environment. In my own workflows, I haven't installed anything in the root environment in many months; I always work on one of a number of more specialized environments instead. I didn't even realize this until recently, when I ran into a bug fixed several months ago in conda, and which I expected not to apply to me. I eventually fixed it by switching to the root environment and running ``conda update conda``, which was fine, but it was not at all clear that this would be needed. I imagine other users who don't use the root environment may encounter similar issues. I don't think conda is installed in any environment other than root, but maybe the other environments could warn on a ``conda install`` command if conda itself is more than a month or so out of date? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: DLL import lib placed in subdirectory despite --layout=flat When I build this [example project](https://github.com/melak47/repro) with ``` meson target --layout=flat cd target ninja -v ``` I get: ``` [1/5] c++ @meson-out/repro@exe/src_main.cpp.obj.rsp [2/5] c++ @meson-out/foo@sha/src_foo.cpp.obj.rsp [3/5] c++ @meson-out/libfoo.dll.rsp [4/5] \"c:\\python36\\python.exe\" \"C:\\Python36\\Scripts\\meson.py\" --internal symbolextractor meson-out/libfoo.dll meson-out/foo@sha/meson-out/libfoo.dll.symbols [5/5] c++ @meson-out/repro.exe.rsp FAILED: meson-out/repro.exe c++ @meson-out/repro.exe.rsp c++: error: meson-out\\libfoo.dll.a: No such file or directory ninja: build stopped: subcommand failed. ``` The `libfoo.dll` target is defined in the `vendor/foo` subdirectory. `libfoo.dll` is correctly put into the `target/meson-out` directory, but `libfoo.dll.a` is put into `target/vendor/foo` (as with `--layout=mirror`): ``` . ├── meson-private │ ... ├── meson-out │ ├── libfoo.dll │ ├── foo@sha │ │ ├── src_foo.cpp.obj │ │ └── meson-out │ │ └── libfoo.dll.symbols │ ├── repro@exe │ │ └── src_main.cpp.obj │ └── repro.exe.rsp ├── build.ninja ├── vendor │ └── foo │ └── libfoo.dll.a ├── meson-logs │ └── meson-log.txt └── compile_commands.json ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: PubSub: Publisher Futures result TimeOutError documentation is not matched with the code PubSub: Publisher Futures Result TimeOutError Environment: Python 3.6.9 * [Documentation](https://googleapis.dev/python/pubsub/latest/publisher/api/futures.html): `TimeoutError – If the request times out.` The link is point to `https://python.readthedocs.io/en/latest/library/exceptions.html#TimeoutError` * [Code](https://github.com/googleapis/google-cloud-python/blob/master/pubsub/google/cloud/pubsub_v1/exceptions.py): The TimeOutError used is `concurrent.futures.TimeoutError` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: target_compile_definitions from import cmake project not working correctly I try to use this cmake library https://github.com/felixguendling/cista In CmakeLists line: target_compile_definitions(cista INTERFACE CISTA_${CISTA_HASH}=1) passed to the compiler incorrectly. On the cmake site https://cmake.org/cmake/help/latest/command/target_compile_definitions.html says that prefix -D not required, but meson doesn’t think so and pass to compiler two definitions at once: CISTA_FNV1A=1 -DCISTA_FNV1A=1 - ??? Change line to target_compile_definitions(cista INTERFACE -DCISTA_${CISTA_HASH}=1) fix this problem. But there is another library that does similar things and everything works fine: target_compile_definitions(spdlog PUBLIC SPDLOG_COMPILED_LIB) I think the problem is with INTERFACE or with parameter = 1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: [FR] support batching rule for `while` Currently, `vmap` seems do not support a function which involves `lax.while_loop`. For example, the following script will throw `NotImplementedError: Batching rule for 'while' not implemented`: ``` import jax.numpy as np from jax import jit, lax, vmap @jit def f(x): return lax.while_loop(lambda x: x <= 0, lambda x: x + 1, x) g = vmap(f) y = g(np.arange(3.)) ``` In case it is complicated to support `while_loop` for `vmap`, then could someone let me know other alternatives? I know some other alternatives from *gufuncs* tutorial such as using `onp.vectorize` or python for loop but they are slow. To make `g` fast, can I write `f` in C/Cython code and use vmap with it? Or should I write the whole `g` in C/Cython code? I have little experience with C/Cython but will try to learn if that is the only option. I just want to use `g` as a primitive function and will define `jvp_rule` for it separately. Thank you for any help in advance! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Dag disappears when DAG tag is longer than 100 char limit ### Apache Airflow version 2.2.5 ### What happened We added new DAG tags to a couple of our DAGs. In the case when the tag was longer than the 100 character limit the DAG was not showing in the UI and wasn't scheduled. It was however possible to reach it by typing in the URL to the DAG. Usually when DAGs are broken there will be an error message in the UI, but this problem did not render any error message. This problem occurred to one of our templated DAGs. Only one DAG broke and it was the one with a DAG tag which was too long. When we fixed the length, the DAG was scheduled and was visible in the UI again. ### What you think should happen instead Exclude the dag if it is over the 100 character limit or show an error message in the UI. ### How to reproduce Add a DAG tag which is longer than 100 characters. ### Operating System Ubuntu ### Versions of Apache Airflow Providers _No response_ ### Deployment Other 3rd-party Helm chart ### Deployment details Running Airflow in Kubernetes. Syncing DAGs from S3 with https://tech.scribd.com/blog/2020/breaking-up-the-dag-repo.html ### Anything else _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Propose to save new model before deleting previous ones in ModelCheckpointing ## 🚀 Feature <!-- A clear and concise description of the feature proposal --> In an edge case, the trainer deleted previous model and then was killed because of system error before successfully saving new model. Thus all the models were lost. I understand specifying save_top_k > 1 helps, and saving before deleting leads to larger disk consumption. But it might be good to provide an option for this? ### Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too --> ### Pitch <!-- A clear and concise description of what you want to happen. --> in the worst case, you have two but never none... ### Alternatives <!-- A clear and concise description of any alternative solutions or features you've considered, if any. --> ### Additional context <!-- Add any other context or screenshots about the feature request here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: multiple find_program() output with add_install_script() I use add_install_script() multiple times and it searching for program every time. ``` Program ln found: YES (/usr/bin/ln) Program ln found: YES (/usr/bin/ln) Program ln found: YES (/usr/bin/ln) Program ln found: YES (/usr/bin/ln) Program ln found: YES (/usr/bin/ln) Program ln found: YES (/usr/bin/ln) Program ln found: YES (/usr/bin/ln) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Collect object / bucket updates in batch See https://github.com/GoogleCloudPlatform/gcloud-python/pull/349/files#r19983607 By sending a `PATCH` request every time a property is set, we may make an application unnecessarily slow. We should work to make this simple and intuitive to users. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Capturing stdout and stderr from %run seems not to work When trying to capture stdout out from %run when using %%capture cell magic, the output of %run is still streamed to the cell. This is also true when the %%capture magic is substituded for the older solution, provided on stack overflow a few years ago by minrk: http://stackoverflow.com/questions/14571090/ipython-redirecting-output-of-a-python-script-to-a-file-like-bash Will provide a minimum working example shortly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add build dir before source dir in include directories When adding a directory to the list of included directories, we currently add both the source and build directory, but we should put the build directory before the source directory. This is particularly important for people who ship Meson alongside a build system that builds in-tree such as Autotools. We will accidentally pick up headers from the Autotools build over the one we just built with Meson. This is very commonly hit by people, and is a blocker for GStreamer shipping meson build files in the tarball releases. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: #7858 breaks IterableDataset with __len__ in Trainer https://github.com/huggingface/transformers/blob/08f534d2da47875a4b7eb1c125cfa7f0f3b79642/src/transformers/trainer.py#L381-L382 This used to be (before #7858) ```python if isinstance(self.train_dataset, torch.utils.data.IterableDataset): ``` I am using IterableDataset with __len__ in Trainer. This change makes it return a sampler and results in an error later. `ValueError: DataLoader with IterableDataset: expected unspecified sampler option, but got sampler=<torch.utils.data.sampler.RandomSampler object at 0x7fa32c57b340>` Maybe change to this? ```python if (isinstance(self.train_dataset, torch.utils.data.IterableDataset) or not isinstance(self.train_dataset, collections.abc.Sized)): ``` @j-rossi-nl @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [apache] fix metric collection ### What does this PR do? This collects the correct data for `apache.net.bytes_per_s` and `apache.net.request_per_s`. https://www.datadoghq.com/blog/collect-apache-performance-metrics https://wiki.opennms.org/wiki/Monitoring_Apache_with_the_HTTP_collector https://httpd.apache.org/docs/current/mod/mod_status.html ### Motivation Customer encountered bug Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support for samurai (alternate ninja implementation) I'm the author of [samurai](https://github.com/michaelforney/samurai), an alternative implementation of ninja, and I'd like to see what it would take to get meson to support it. It looks like the relevant code is here: https://github.com/mesonbuild/meson/blob/cb597adb0170a4818a4950ca9a4fe3f6d5a6c9d2/mesonbuild/environment.py#L106-L119 samurai doesn't support the `--version` option, and I am hesitant to add it for several reasons. However, it seems to me that meson shouldn't need to be doing this probing at all. The version is already checked by ninja itself using `ninja_required_version` in `build.ninja`, and if the user does not have it installed, they simply won't be able to start the build. As far as I can tell, meson needs to know the ninja command for three purposes: 1. To support `ninja clean` as an alternative to `ninja -t clean`. 2. To support `ninja meson-scan-build` as an alternative to `scan-build ninja`. 3. To generate a compilation database during `build.ninja` generation. Additionally, the version in `detect_ninja` is only used in one place in `run_tests.py`, presumably to make sure it supports `-w dupbuild=err`. However, earlier ninja versions will just fail because of an unsupported option. One way to support samurai as well as any other future implementations would be to make a failure in `detect_ninja` just a warning, and in this case just omit a `clean` target. A failure in `ninja -t compdb` is already just a warning, so that could just be skipped if meson can't figure out the ninja command. Would this be acceptable? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Use private docker repository with K8S operator and XCOM sidecar container **Use private docker repository with K8S operator and XCOM sidecar container** An extra parameter to KubernetesPodOperator: docker_repository, this allows to specify the repository where the sidecar container is located **My company force docker proxy usage for K8S** I need to use my company docker repository, images that are not proxifed by the company docker repository are not allowed Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Pretty printing PyPy dicts not as \"dictproxy\" I'm using IPython pretty printer in my plugin for running doctests with a custom representation printer. It actually works fine in CPython, but it prints all PyPy dicts as proxies. In CPython 2.7.12 a dict isn't a dictproxy, and it's well known that they appear with curly brackets: ``` python In [1]: {\"this\": 1, \"is\": \"a\", \"test\": None} Out[1]: {'is': 'a', 'test': None, 'this': 1} In [2]: import types In [3]: types.DictProxyType is dict Out[3]: False ``` But in PyPy 5.3.1 (Python 2.7.10), a dict appears as a dictproxy, and these types are actually the same w.r.t. the types module: ``` python In [1]: {\"this\": 1, \"is\": \"a\", \"test\": None} Out[1]: <dictproxy {'is': 'a', 'test': None, 'this': 1}> In [2]: import types In [3]: types.DictProxyType is dict Out[3]: True In [4]: dict.__name__ Out[4]: 'dict' In [5]: repr(_1) Out[5]: \"{'this': 1, 'is': 'a', 'test': None}\" ``` The last outputs suggests that the assignment to `_type_pprinters[types.DictProxyType]` in IPython.lib.pretty replaces the dict printer. Shouldn't that assignment be done with the setdefault method instead? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Show Conan version in HTML files When Conan generates a HTML file (`search --table`, `info --graph`), the version which generated that file is not assigned there. It can be useful for the follow cases: * When a new feature is present and the result is different from the previous, so people can distinguish that is outdated * When comparing HTML (e.g. 1.24 output x 1.25). Well we have JSON output for it, but let's say you and your co-worker are reading the HTML at same time * When CI provides a table to indicate the current packages (like internal scripts). Some possible preview (the version is before the table):  - [ X ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Backward pass of gather needlessly allocates global memory When using a gather-type operation in the forward pass for word embeddings, the backward pass pre-allocates a constant all-zero matrix that is the same size as the embedding matrix. My current fix is: ``` --- a/jax/lax/lax.py +++ b/jax/lax/lax.py @@ -2692,7 +2692,9 @@ def _gather_transpose_rule(t, operand, s assert operand is None if t is ad_util.zero: return [ad_util.zero, ad_util.zero] - zeros = broadcast(_const(t, 0), operand_shape) + zeros = full(operand_shape, 0, dtype=t.dtype) scatter_dnums = ScatterDimensionNumbers( update_window_dims=dimension_numbers.offset_dims, inserted_window_dims=dimension_numbers.collapsed_slice_dims, ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove ScheduleComponent class <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Now that the object model has developed more clearly for pulse it is clear that the `ScheduleComponent` class is no longer necessary. We should remove this and settle on having both a `Schedule` and `Instruction` as distinct entities. A type may be defined `ScheduleComponent = Union[Schedule, Instruction]` if it is useful. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Change backend status from AVAILABLE to OPERATIONAL ### What is the expected enhancement? The new name is more accurate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add warnings when environment variables change and wont be honored We only honor most environment variables in `meson setup`, and not in `meson configure` or ninja, with #4931 that extends to pkg-config as well. We really should have a warning when we detect that those environment variables have changed and wont be honored, at least for `meson configure`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [question] Is new cmake_layout compatible with cpp_info.components ? Hi, I've been using CMakeToolchain for a while with the CMake build helper that comes with it. But after updating today I saw that `CMake` build helper does not accept a `build_folder` parameter anymore. Looking at why it happened I arrived at https://github.com/conan-io/conan/pull/8554/files#diff-d72013a45b00a0adf06f4536d6a8c8844461e51b72911937d63e6dda9a3d440aR64 this means that the new way of providing the folder topology is via `def layout(self)` right? My first move was to employ the new `cmake_layout` utility, but I was unable to create a package if this one used `self.cpp_info.components` ``` ERROR: ConanException: say/0.1 package_info(): self.cpp_info.components cannot be used with self.cpp_info global values at the same time ``` Conanfile example: ``` from conans import ConanFile, CMake from conan.tools.layout import cmake_layout, LayoutPackager class Pkg(ConanFile): name = \"say\" version = \"0.1\" settings = \"os\", \"compiler\", \"arch\", \"build_type\" generators = \"cmake\" exports_sources = \"src/*\" def layout(self): cmake_layout(self) def build(self): cmake = CMake(self) cmake.configure() cmake.build() def package(self): LayoutPackager(self).package() def package_info(self): self.cpp_info.components[\"say\"].libs = [\"say\"] ``` So, I am doing something wrong? Is this intended or just a bug/missing feature? Thanks! - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: bizarre repr of empty dtype I doubt anyone is using this, but multiple parts of this repr are bizarre: ``` >>> np.zeros(10, np.dtype([])) array([), ), ), ), ), ), ), ), ), )], dtype='[]') ``` Thankfully not a 1.14 regression - was there in 1.13 too Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: CELERY_RESULT_SERIALIZER = 'json' breaks Exception marshaling Setting `CELERY_RESULT_SERIALIZER = json` and raising an exception in the worker leads to this: ``` /path/to/lib/python2.7/site-packages/celery/result.py in get(self, timeout, propagate, interval, no_ack, follow_parents, EXCEPTION_STATES, PROPAGATE_STATES) 173 status = meta['status'] 174 if status in PROPAGATE_STATES and propagate: --> 175 raise meta['result'] 176 return meta['result'] 177 wait = get # deprecated alias to :meth:`get`. TypeError: exceptions must be old-style classes or derived from BaseException, not dict ``` where the contents of `meta['result']` are (in my case): ``` {u'exc_message': u'unknown keys: nam', u'exc_type': u'ValueError'} ``` so it _looks_ like celery could convert the dict to a real exception before raising, but it does not currently. Changing back to `pickle` works as expected. bug can be reproduced with the following: ``` python # jsonresults.py from celery.app.base import Celery CELERY_RESULT_SERIALIZER = 'json' CELERY_RESULT_BACKEND = 'amqp' app = Celery(config_source=__name__) @app.task def hello(): raise ValueError('go away') ``` worker: ``` # python -m celery --app=jsonresults:app worker ``` caller: ``` python import jsonresults jsonresults.hello.delay().get() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda 4.4 + zsh: conda:shift:1: shift count must be <= $# With conda 4.4.0rc1 and zsh, calling the new conda shell function with no arguments results in ``` $ conda conda:shift:1: shift count must be <= $# usage: conda [-h] [-V] command ... conda: error: argument command: invalid choice: '' (choose from 'clean', 'config', 'create', 'help', 'info', 'install', 'list', 'package', 'remove', 'uninstall', 'search', 'update', 'upgrade') ``` It's mostly an esthetic point but it would be nice if the shell error message (shift count) was not shown. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: STORAGE: _patch_properties is never called with more than one key in the dict Should we just accept the key and value? Should we rename to `_patch_property`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: QTConsole completion still broken #6726 made things better, but there is still breakage, tested on git master c829e58f ``` python np.<tab> # works x=np.<tab> # works ``` but ``` python In [3]: from collections import namedtuple ...: np.<tab> # nope ...: s=np.<tab> # nope ``` doesn't trigger completion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [examples/text-classification] `do_predict` for the test set of local datasets # 🚀 Feature request It seems that `run_glue.py` has the train set and the validation set management for local CSV/JSON files, but it doesn't have args for managing the test set of the local datasets. https://github.com/huggingface/transformers/blob/7a9f1b5c99e9a5d1772649d029acdf5160419239/examples/text-classification/run_glue.py#L90-L95 I think the script is intended to be used not only for the train/validation but the test, as `glue` tasks test sets are downloaded as shown in https://huggingface.co/docs/datasets/loading_datasets.html#selecting-a-configuration. It has the `--do_predict` option for the test sets. If there is no particular reason for not having the ability to read the test set in the local dataset, would it be ok for me to add the feature? Or is there some intention behind this implementation? ## Motivation I'd like to train, validate, and test my own local dataset. ## Your contribution I think some modifications like the below may help to add the feature. ``` python test_file: Optional[str] = field( default=None, metadata={\"help\": \"A csv or a json file containing the test data.\"} ) ``` ``` python datasets = load_dataset( \"csv\", data_files={\"train\": data_args.train_file, \"validation\": data_args.validation_file, \"test\": data_args.test_file} ) ``` ``` python # if data_args.task_name is not None: # test_dataset = datasets[\"test_matched\" if data_args.task_name == \"mnli\" else \"test\"] test_dataset = datasets[\"test_matched\" if data_args.task_name == \"mnli\" else \"test\"] ``` Thank you in advance. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: add 'labels' properties to job and job config classes See the [API ref](https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs#configuration.labels) - Each job config class should have a writable `labels` property, taking / returning a mapping, `{str: str}`. - Each job class should have a read-only `lables` property, returning a mapping, `{str: str}`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [suggestion] Add PYTHONPATH to virtualrunenv Adding PYTHONPATH would make it sufficient to activate a virtualrunenv to use python modules in conan packages that also have dynamic library dependencies. Without PYTHONPATH (as it is now) both a virtualrunenv and virtualenv needs to be activated for such python modules to work. I would like to contribute to this feature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [DO NOT MERGE] Trace: pick up fixes to GAPIC generator. This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/devtools/cloudtrace/artman_cloudtrace_v1.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:90f9d15e9bad675aeecd586725bce48f5667ffe7d5fc4d1e96d51ff34304815b Status: Image is up to date for googleapis/artman:latest synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/trace-v1. synthtool > Replaced 'from google.devtools.cloudtrace_v1.proto import ' in google/cloud/trace_v1/proto/trace_pb2_grpc.py. synthtool > Running generator for google/devtools/cloudtrace/artman_cloudtrace_v2.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:90f9d15e9bad675aeecd586725bce48f5667ffe7d5fc4d1e96d51ff34304815b Status: Image is up to date for googleapis/artman:latest synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/trace-v2. synthtool > Replaced 'from google.devtools.cloudtrace_v2.proto import ' in google/cloud/trace_v2/proto/tracing_pb2_grpc.py. synthtool > Replaced 'from google.devtools.cloudtrace_v2.proto import ' in google/cloud/trace_v2/proto/tracing_pb2.py. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/trace_v2/proto/trace_pb2.py. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/trace_v2/proto/tracing_pb2.py. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/trace_v1/proto/trace_pb2.py. synthtool > No replacements made in google/cloud/trace_v1/gapic/trace_service_client.py for pattern :: , maybe replacement is not longer needed? synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: migrate_to_labels or --migrate-to-labels? #1356 introduced some uncertainty about how to convert containers to the new format. The help message says > `migrate_to_labels` Recreate containers to add labels The error message is > If you'd like compose to use this container, please run `docker-compose --migrate-to-labels` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython 5.3.0 debug mode breakpoint issue Hi IPython Team, I recently upgraded Python to version 2.7.8 (from 2.6.6) and IPython to version 5.3.0. I noticed that when using the magic command (%run -d) in IPython, subsequent runs of a program seem to fail with a \"KeyError\", apparently due to the debugger's failure to clear breakpoints from previous runs of the program. I attached a sample of output from one such failed run (see below), where a breakpoint that had been set at line 56 in a previous call caused the program to crash, though in the current call, only one breakpoint at line 70 is requested. For the time being, I've downgraded to IPython version 4.2.0, which seems to work as expected. Cheers, Taylor [ipython_error.txt](https://github.com/ipython/ipython/files/1004089/ipython_error.txt) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: ability to set default job / table / dataset configs in client class The [location](https://github.com/GoogleCloudPlatform/google-cloud-python/issues/5148) is considered a global parameter (by the the BigQuery engineering team and the `bq` command-line tool), and we are tracking the feature to set a default location at https://github.com/GoogleCloudPlatform/google-cloud-python/issues/5148. There are other non-global properties where it would be useful to set a user-configurable default. For example: - Labels on jobs. It could be useful to set default labels so that folks can track more easily which jobs are getting run by which application. - `use_legacy_sql` on QueryJobConfig. Right now this defaults to standard SQL syntax, but some people might prefer to use legacy SQL for existing queries. - The `destination_encryption_configuration` in jobs and the `encryption_configuration` in tables. Maybe this one actually makes sense as a global parameter, but it's not considered on in the `bq` command-line tool. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Make it easier to import average_data <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Should be able to import `qiskit.quantum_info.analysis.average.average_data` directly from `qiskit.quantum_info` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Initialize should be composed of Resets + StatePreparation <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? In #6236, we discussed the possibility of a StatePreparation class with no resets and a separate Initialize that uses resets + state-preparation. There is a related issue in #1896. I raised the possibility to remove the resets in #6236 because an alternative to go from a state | a> to a state | b> is to apply the inverse of initialize |a> followed by initialize |b>. Another example of initialization without resets is a controlled initialization as in arXiv:1703.10793. In these cases, a gate StatePreparation should be used instead of an instruction Initialize with resets. The discussion in #1896 does not address these cases. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Dlang: -Dbuildtype=minsize invokes -Os instead of -Oz for LDC `-Dbuildtype=minsize` invokes `-Os` instead of `--Oz` for LDC As result compiler produces binaries about 10% larger. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? Cross build * what `meson --version` Current ~master Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Where are the allowed log entry protobuf types documented? The [`LogEntry` API docs](https://cloud.google.com/logging/docs/api/ref_v2beta1/rest/v2beta1/LogEntry#FIELDS.proto_payload) say: ``` The log entry payload, represented as a protocol buffer. You can only use protoPayload values that belong to a set of approved types. An object containing fields of an arbitrary type. An additional field \"@type\" contains a URI identifying the type. Example: { \"id\": 1234, \"@type\": \"types.example.com/standard/id\" }. ``` Where are the allowed protobuf types documented, and the corresponding URIs? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Errors during interact display at the terminal, not anywhere in the notebook If an error is raised by calling a function from an interact widget (or presumably from any widget update), the traceback appears in the terminal where the server was started, not anywhere in the notebook interface. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: CMAKE_SKIP_INSTALL_RPATH is not set on macOS Hi, According to the docs `conan_basic_setup()` sets `CMAKE_SKIP_RPATH 1` on macOS. However, `otool -L my_installed_lib.dylib` gives the following output: >@rpath/libmy_installed_lib.dylib (compatibility version 0.0.0, current version 0.0.0) Whereas the one in the build folder doesn't have the `@rpath/` prefix. Is this intended? I'm kind of a n00b with rpaths. EDIT: setting `cmake.definitions[\"CMAKE_SKIP_INSTALL_RPATH\"] = \"ON\"` in my recipe fixes the issue. EDIT2: that's weird though, the CMake doc says that CMAKE_SKIP_RPATH includes CMAKE_SKIP_INSTALL_RPATH... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Script (e.g. Bash) magics doesn't have an error on status code I ran into a use-case where I wanted to call a small bash script magic in a notebook, but couldn't halt execution easily based on exit status. ======= Cell 1 ======= ``` %%bash not_a_valid_command ``` ======= Cell 2 ======= ``` print(\"I don't want to run this if the bash command didn't return status code 0\") ``` It seems like the [script magics](https://ipython.readthedocs.io/en/stable/interactive/magics.html) and the [code](https://github.com/ipython/ipython/blob/ec3d1a11bf26a0962cb2cf55ba263b12ac023183/IPython/core/magics/script.py#L63) don't have any options to inform the subprocess to error on non-zero status code. This would be nice to be configurable and/or defaulted. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [Commands] Return package_id from export_pkg **Conan version:** 1.7.4 **Python version:** 3.7 I am using the conan api to export a package and upload it. For example: ```python from conans.client.conan_api import Conan conan, _, _ = Conan.factory() package = 'package' version = '0.1.0' user = 'chrahunt' channel = 'develop' conan.export_pkg( 'conanfile.py', package, channel, user=user, version=version, package_folder='dist') conan.upload( pattern=f'{package}/{version}@{user}/{channel}', all_packages=True, remote_name='artifactory') ``` I would like to upload ONLY the package that was exported to the local cache in the call to `export_pkg`. If `export_pkg` could return the package reference then I think it would help a lot. A similar request was made and fulfilled in #1985 for `conan create` (which I think can be closed actually). ---- To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Eliminating display of intermediate stages in progress bars Migrated from https://github.com/ipython/nbconvert/issues/185 Original author @fonnesbeck --- When working with notebooks that use code that generates visual outputs such as progress bars, displaying them either in nbviewer or as an export format (e.g. latex) results in the intermediate outputs from such components are printed, taking up a huge amount of document space. These need to be manually deleted in order for the document to be usable. Here is what it looks like:  [Here's an example notebook with this behavior](http://nbviewer.ipython.org/urls/raw.github.com/pymc-devs/pymc/glm/pymc/examples/GLM.ipynb) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Support (non-legacy) SQL nested data types `STRUCT<t>` and `ARRAY<t>` seem to be the types. See #2342. h/t to @c0b for filing. --- From #2585: [Sample app that reproduces this](https://github.com/GoogleCloudPlatform/python-docs-samples/blob/176f161cae3d4f01b01456a6e403faf6645414a1/bigquery/cloud-client/simple_app.py) Stacktrace: ``` python Traceback (most recent call last): File \"simple_app.py\", line 57, in <module> query_shakespeare() File \"simple_app.py\", line 47, in query_shakespeare page_token=page_token) File \"lib/python2.7/site-packages/google/cloud/bigquery/query.py\", line 401, in fetch_data rows_data = _rows_from_json(response.get('rows', ()), self.schema) File \"lib/python2.7/site-packages/google/cloud/bigquery/_helpers.py\", line 98, in _rows_from_json for item in cell['v']]) File \"lib/python2.7/site-packages/google/cloud/bigquery/_helpers.py\", line 61, in _record_from_json for subfield, cell in zip(field.fields, value['f']): KeyError: 'f' ``` --- Stepping into the debugger: ``` python ipdb> value {u'v': {u'f': [{u'v': u'hamlet'}, {u'v': u'5318'}]}} ipdb> field.__dict__ {'field_type': u'RECORD', 'description': None, 'name': u'title', 'fields': [<google.cloud.bigquery.schema.SchemaField object at 0x7f4ba9227550>, <google.cloud.bigquery.schema.SchemaField object at 0x7f4ba9227690>], 'mode': u'REPEATED'} ``` (Added by @dhermes) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pub/Sub: Send modify_ack_deadline requests in chunks Currently leaser is limited in total number of messages (<2000?) which is a problem for use cases with many small messages. Same issue was solved in nodejs library here: https://github.com/googleapis/nodejs-pubsub/pull/65 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Sphinx automodule only documents tasks if undoc-members is set Reopening from #4584. Sphinx autodoc picks up tasks automatically (e.g. without explicitly adding `.. autotask:: name.of.task`) only if the `undoc-members` option is set. This is demonstrated by removing the `undoc-members` flag from the default autodoc flags in the unit test from #4583. The reason is that the task class and task instance have exactly the same docstring, which trips [this conditional in sphinx](https://github.com/sphinx-doc/sphinx/blob/v1.7.1/sphinx/ext/autodoc/__init__.py#L606-L613), which is intended to suppress repetition of the docstring of a class when documenting an instance of that class. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Template substitution with parameters can result in unbound templates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: on commit 287dc80e17ad302be1fb9d79150e35cba131d083 - **Python version**: 3.7.9 - **Operating system**: Ubuntu ### What is the current behavior? Template substitution where templates have parameters sometimes causes errors. When parameters are present the template substitution first performs a soft match and then solves a system of equations in `_attempt_bind` to determine if the match is valid. When the whole template is matched this results in a temporary template where all parameters have been bound. For incomplete matches occurring before `_attempt_bind` the temporary template may still have parameters in it. This causes the template substitution to crash as we cannot invert circuits with parameters. ### Steps to reproduce the problem Perform template matching with a template with parameters that does not result in a complete match. ### What is the expected behavior? The code should not crash and furthermore should not use temporary templates after `_attempt_bind` that still have parameters. ### Suggested solutions Augment the already existing function `_remove_impossible` to exclude the temporary templates produced by `_attempt_bind` that have parameters. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Compose isn't supposed to support 'credential_spec' key in V3.3 Hi guys, I'm using `docker run security-opt \"credentialspec...` without any issues but when I try to use it in docker-compose yaml file, I get the following warning: `WARNING: Some services (wcm) use the 'credential_spec' key, which will be ignored. Compose does not support 'credential_spec' configuration - use `docker stack deploy` to deploy to a swarm.` Did I miss something in the [documentation](https://docs.docker.com/compose/compose-file/#credential_spec)? ``` Client: Version: 17.06.2-ee-6 API version: 1.30 Go version: go1.8.3 Git commit: e75fdb8 Built: Mon Nov 27 22:46:09 2017 OS/Arch: windows/amd64 Server: Version: 17.06.2-ee-6 API version: 1.30 (minimum version 1.24) Go version: go1.8.3 Git commit: e75fdb8 Built: Mon Nov 27 22:55:16 2017 OS/Arch: windows/amd64 Experimental: false ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: --env-file option This option has been discussed in a [couple](https://github.com/docker/compose/issues/4841#issuecomment-345242740) of [tickets](https://github.com/docker/compose/issues/745) but never had a ticket for itself. One should be able to execute `docker-compose up --env-file=.env.test` (perhaps multiple env files) to override the usage of `.env` file. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: ModelCheckpoint wipes out current directory @williamFalcon I think this is what you were seeing in #389. If we let the `Trainer` create the default `ModelCheckpoint` callback and don't use `TestTubeLogger`, the prefix ends up being set to the current directory. Then, when `ModelCheckpoint` tries to clean up previous checkpoints, it wipes out everything in the current directory. Relevant bits of code: * `default_save_path` set to `os.getcwd()`: https://github.com/williamFalcon/pytorch-lightning/blob/master/pytorch_lightning/trainer/trainer.py#L151 * `ModelCheckpoint` falls back to `default_save_path`: https://github.com/williamFalcon/pytorch-lightning/blob/master/pytorch_lightning/trainer/trainer.py#L280 ( `ModelCheckpoint` blows away pre-existing files in checkpoint directory: https://github.com/williamFalcon/pytorch-lightning/blob/master/pytorch_lightning/callbacks/pt_callbacks.py#L216 The most obvious fix is to provide a better default checkpoint prefix, but there would still be a lurking footgun for a user who sets `default_save_path` incorrectly. Should we maybe insist that the checkpoint directory not exist before training starts, or that it be empty? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `'NoneType' object has no attribute 'metadata'` when trying to serialize custom gate on `qiskit-terra==0.21.2` when it used to work on `qiskit-terra==0.21.1` ### Environment - **Qiskit Terra version**: 0.21.2 - **Python version**: 3.8.13 - **Operating system**: Ubuntu ### What is happening? Qsikit errors out when trying to serial a circuit which contains a custom gate, when it used to work before on `qiskit-terra==0.21.1` ### How can we reproduce the issue? Run ```python import io from typing import Optional, Union import numpy as np import qiskit from qiskit.circuit.library import XGate from qiskit.qpy import dump class CustomCXGate(qiskit.circuit.ControlledGate): def __init__( self, label: Optional[str] = None, ctrl_state: Optional[Union[str, int]] = None ) -> None: super().__init__( \"cx\", 2, [], label, num_ctrl_qubits=1, ctrl_state=ctrl_state, base_gate=XGate() ) def _define(self) -> None: qc = qiskit.QuantumCircuit(2, name=self.name) qc.cx(0, 1) self.definition = qc def __array__(self, dtype: Optional[type] = None) -> np.ndarray: mat = qiskit.circuit._utils._compute_control_matrix( self.base_gate.to_matrix(), self.num_ctrl_qubits, ctrl_state=self.ctrl_state ) return np.asarray(mat, dtype=dtype) circuit = qiskit.QuantumCircuit(2) circuit.append(CustomCXGate(),[0, 1]) buf = io.BytesIO() dump(circuit, buf) ``` This will throw an error ``` circuit.metadata, separators=(\",\", \":\"), cls=metadata_serializer AttributeError: 'NoneType' object has no attribute 'metadata' ``` ### What should happen? The above snippet should run with no errors. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: & escaped to & in tex ? Reported on list. Hi all (most probably Matthias), This is the first time I have had to use nbconvert, and I have noticed that the ampersand symbol used in the eqnarray environment to align equations is not replaced properly in the latex output. In the latex file I still have &=& (which can't be compiled by latex), while in the JSON file I have the correct form, &=&. Is this a known issue? If so, what is the magic fix? Cheers, Zoltán ping @jdfreder Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: has_function fails to detect missing dependencies with CFLAGS=-O1 GStreamer uses `cc.has_function('backtrace', prefix : '#include <execinfo.h>')` to check whether it can use backtrace-related functions. Using these functions doesn't require linking extra libraries on GNU/Linux, but it is required to link with `-lexecinfo` on FreeBSD. Therefore, I have to write a meson alternative to autoconf `AC_SEARCH_LIBS` macro. I implemented it with this patch: https://bugzilla-attachments.gnome.org/attachment.cgi?id=339827 However, this only worked with `CFLAGS=-O0`: ``` Has header \"execinfo.h\": YES Checking for function \"backtrace\": NO # without -lexecinfo Library execinfo found: YES Checking for function \"backtrace\": YES # with -lexecinfo ``` If I set `CFLAGS=-O1` in the environment, the first `has_function` test didn't fail and caused undefined reference error when linking `libgstreamer-1.0.so`: ``` Has header \"execinfo.h\": YES Checking for function \"backtrace\": YES # without -lexecinfo ... [99/442] Linking target gst/libgstreamer-1.0.so.0.1100.0 FAILED: gst/libgstreamer-1.0.so.0.1100.0 gst/gstreamer-1.0@sha/gstinfo.c.o: In function `generate_backtrace_trace': gst/gstinfo.c:2707: undefined reference to `backtrace_symbols' clang++: error: linker command failed with exit code 1 (use -v to see invocation) ``` I tested it on FreeBSD 11.0 with clang 3.8.0 and binutils 2.27. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [zookeeper] bytes_received and bytes_sent metrics do not represent bytes The `zookeeper.bytes_received` and `zookeeper.bytes_sent` metrics are misnamed. The data for these metrics is collected from the ZK `stat` command, which prints `Received` and `Sent` fields. But these fields represent [packets received and sent](https://github.com/apache/zookeeper/blob/ec20c5434cc8a334b3fd25e27d26dccf4793c8f3/src/java/main/org/apache/zookeeper/server/ServerStats.java#L109-L110), not bytes. This in turn means that the DD ZK dashboard is wrong when it displays the data in a widget named *Bytes sent/received/outstanding per second*. In addition, both metrics are being submitted as `gauge` types. In reality they are [monotonic counts](https://github.com/apache/zookeeper/blob/ec20c5434cc8a334b3fd25e27d26dccf4793c8f3/src/java/main/org/apache/zookeeper/server/ServerStats.java#L141-L146), except they are not truly monotonic as they can be reset using the ZK `srst` command and they will reset if the ZK server is restarted. It appears that the developers of the ZK dashboard where aware of the wrong metric type applied to `zookeeper.bytes_received` and `zookeeper.bytes_sent`, as the dashboard uses the `per_second` function to convert the \"gauges\" into rates. As an aside, the ZK dashboard mistakenly displays the `zookeeper.bytes_outstanding` metric in the same widget as the `zookeeper.bytes_received` and `zookeeper.bytes_sent` metrics. Even if those two metrics did refer to received and sent bytes displaying `zookeeper.bytes_outstanding` with them would be an error. As the [comment in the collector](https://github.com/DataDog/integrations-core/blob/master/zk/check.py#L330-L331) notes, that metric refers to outstanding requests, not outstanding bytes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: 'NoneType' object has no attribute 'lower' while training on TPU ## 🐛 Bug distributed_backend is not set to 'tpu' which breaks it here: line https://github.com/PyTorchLightning/pytorch-lightning/blob/2c935d048e69a2890889dea768ecceb0252cf321/pytorch_lightning/trainer/distrib_data_parallel.py#L412 distributed_backend has to be explicitly specified in Trainer params to have it working which is misleading from the docs: https://pytorch-lightning.readthedocs.io/en/latest/tpu.html#distributed-backend-with-tpu ### To Reproduce Steps to reproduce the behavior: https://www.kaggle.com/lezwon/lightning-mnist-tpu ### Expected behavior Should automatically set `distributed_backend` and train successfully. ### Additional context Related to : https://github.com/PyTorchLightning/pytorch-lightning/issues/2698#issuecomment-671665202 https://github.com/PyTorchLightning/pytorch-lightning/issues/2812#issuecomment-668659590 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Merging logging-stdlib-handling-feature into master @tseaver @dhermes @jgeewax tell me what needs to be done. The feature branch approach is not really working either. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Pulse meas_level=2 result doesn't conduct zero padding <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Experimental result with `meas_level=2` doesn't conduct zero padding. ### Steps to reproduce the problem ``` result.get_counts(0) ``` it may return ``` {'1000010000': 1, '10000000010000000011': 1, '10000010010010': 1, '1000000100': 1, '1000011': 1, '10011': 4, '10000100': 1, '10000000010010': 2, '100000': 1, '100000000': 5, '10100': 1, '10000100001000000010': ... ``` ### What is the expected behavior? the result bit streams should have the same length (length of `memory_slots`). ### Suggested solutions `qiskit.result` sees `QobjExperimentalHeader` to find `memory_slots`. https://github.com/Qiskit/qiskit-terra/blob/f54f02d151ed9b671e45da13cf20d22ccbb2d28d/qiskit/result/result.py#L135-L140 `memory_slots` should be added to the `QobjExperimentalHeader`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] JSON output for `conan config home` The command `conan config home` returns the directory where the config resides. Within our CI we use this to clean up before doing `conan config install ...`. Right now we parse the output of that command, but this could be errorprone as outputs sometimes change or are extended with additional information. This feature request ist about adding a `--json` parameter like all the other commands have. - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Make pinned packages optional/constrained dependencies In the conda 4.3 feature branch, make the `get_pinned_specs()` function in `conda/plan.py` return `MatchSpec` objects with the `optional=True` flag. Make sure (by writing extra unit tests) that the `conda.cli.common.spec_from_line()` function is both working correctly and being used correctly. Package pinning configuration was recently implemented within condarc files via https://github.com/conda/conda/pull/4921/files. Reviewing that PR would be a good place to start. Make pinned packages optional/constrained dependencies In the conda 4.3 feature branch, make the `get_pinned_specs()` function in `conda/plan.py` return `MatchSpec` objects with the `optional=True` flag. Make sure (by writing extra unit tests) that the `conda.cli.common.spec_from_line()` function is both working correctly and being used correctly. Package pinning configuration was recently implemented within condarc files via https://github.com/conda/conda/pull/4921/files. Reviewing that PR would be a good place to start. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Remove location parameter from query code samples The `location` parameter can sometimes confuse new BigQuery developers. Previously it could not be autodetected in regional endpoints, but now autodetection works pretty well. Let's remove this parameter from all (or most if we happen to have a code sample specifically for specifying location) query samples. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: 💫 Merge conllu converters into one function I was just updating the `spacy convert` command and docs and noticed that the converters are currently a bit messy. We might be able to eliminate some code duplication and make them a bit nicer overall. It'd be nice if we could merge the `conll` converters (or at least `conll`/`conllu` and `conllubio`) into a single script. (That said, we do have to accept that they'll always be kinda hacky, simply because the formats we're dealing with aren't always 100% consistent. There are several variations of the `.conll` format alone that we need to handle). ### Resources * `spacy.cli.converters`: https://github.com/explosion/spaCy/tree/develop/spacy/cli/converters * #2525: original PR and motivation for the `conllubio` converter ### FYI: Future plans 1. Change converters to create and return `Doc` objects instead of JSON objects. This means that the new `Doc.to_json` object will be the single source of truth for the JSON format and we don't end up with arbitrary data transformation logic all over the place. 2. Update the training data format to a more straightforward JSONL format. See #2928. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: -Dcmake_prefix_path does not work for CMake subprojects This works for both CMake dependencies and CMake subprojects: ``` $ export CMAKE_PREFIX_PATH=<somedir> $ meson <builddir> ``` And this works for CMake dependencies only: ``` meson -Dcmake_prefix_path=<somedir> <builddir> ``` I think it should be mentioned in the docs to avoid confusion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: `seed_generator` would casue tensorflow gpu memory growth immediately https://github.com/huggingface/transformers/blob/7cced021fa8ddc59f0f77384300760d34545394e/src/transformers/generation_tf_utils.py#L349 In transformers version >=4.18.0, import something from `generation_tf_utils.py` would casue gpu memory growth immediately if I don't set env `TF_FORCE_GPU_ALLOW_GROWTH=true` before importing modules from this file. And I locate the problem at this line. Making attr `seed_generator` lazy loaded could solve this. ``` # ... class TFGenerationMixin: \"\"\" A class containing all of the functions supporting generation, to be used as a mixin in [`TFPreTrainedModel`]. \"\"\" # seed_generator = tf.random.Generator.from_non_deterministic_state() _seed_generator = None @property def seed_generator(self): if self._seed_generator is None: self._seed_generator = tf.random.Generator.from_non_deterministic_state() return self._seed_generator # ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Support Azure OpenAI in transformer agents ### Feature request Support it by setting the openai properties. ``` python openai.api_type = \"azure\" openai.api_version = \"2023-03-15-preview\" openai.api_base = \"https://THE_NAME.openai.azure.com/\" openai.api_key = \"AZURE_OPENAI_API_KEY\" # response = openai.Completion.create(engine=\"xxxx\", ...) ``` ### Motivation Azure OpenAI is also used by a lot of people. It would be great to support it in the transformer agents. ### Your contribution I may contribute to test it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Airflow logging secrets masker assumes dict_key is type `str` **Apache Airflow version**: 2.1.0 **What happened**: Airflow logging assume dict_key is type `str` ``` logging.info(\"Dictionary where key is int type: %s\", modified_table_mapping) File \"/usr/lib64/python3.6/logging/__init__.py\", line 1902, in info root.info(msg, *args, **kwargs) File \"/usr/lib64/python3.6/logging/__init__.py\", line 1308, in info self._log(INFO, msg, args, **kwargs) File \"/usr/lib64/python3.6/logging/__init__.py\", line 1444, in _log self.handle(record) File \"/usr/lib64/python3.6/logging/__init__.py\", line 1453, in handle if (not self.disabled) and self.filter(record): File \"/usr/lib64/python3.6/logging/__init__.py\", line 720, in filter result = f.filter(record) File \"/bb/bin/airflow_env/lib/python3.6/site-packages/airflow/utils/log/secrets_masker.py\", line 157, in filter record.__dict__[k] = self.redact(v) File \"/bb/bin/airflow_env/lib/python3.6/site-packages/airflow/utils/log/secrets_masker.py\", line 193, in redact return {dict_key: self.redact(subval, dict_key) for dict_key, subval in item.items()} File \"/bb/bin/airflow_env/lib/python3.6/site-packages/airflow/utils/log/secrets_masker.py\", line 193, in <dictcomp> return {dict_key: self.redact(subval, dict_key) for dict_key, subval in item.items()} File \"/bb/bin/airflow_env/lib/python3.6/site-packages/airflow/utils/log/secrets_masker.py\", line 189, in redact if name and should_hide_value_for_key(name): File \"/bb/bin/airflow_env/lib/python3.6/site-packages/airflow/utils/log/secrets_masker.py\", line 74, in should_hide_value_for_key name = name.strip().lower() AttributeError: 'int' object has no attribute 'strip' ``` **How to reproduce it**: Define a dictionary where the type of keys is `int` and print it in any Airflow tasks. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Fargate Task Environment ## Use Case Currently when using AWS Fargate the only supported environment is the Remote Environment with a specific set of configuration. We want to have an environment which allows users of the Fargate Agent to deploy their flows using a completely custom Fargate task. ## Solution Create an environment which takes in a Fargate task definition ## Alternatives N/A Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore: add 'client_info' argument to client ctor. Overlooked in #7825. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: modeling_swin.py img_mask doesn't have expected torch dtype ### System Info ```shell transformers: master branch ``` ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction How to repro: Run Swin Transformer with NVIDIA mixed precision apex amp opt_level=O2. The problem is at this line: https://github.com/huggingface/transformers/blob/main/src/transformers/models/swin/modeling_swin.py#L600, it creates img_mask as float32 type, which will conflict other types (float16) when mixed precision O2 is used. One way to fix is shown below: ``` - def get_attn_mask(self, height, width): + def get_attn_mask(self, height, width, dtype): if self.shift_size > 0: # calculate attention mask for SW-MSA - img_mask = torch.zeros((1, height, width, 1)) + img_mask = torch.zeros((1, height, width, 1), dtype=dtype) height_slices = ( slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), @@ -641,7 +641,7 @@ class SwinLayer(nn.Module): # partition windows hidden_states_windows = window_partition(shifted_hidden_states, self.window_size) hidden_states_windows = hidden_states_windows.view(-1, self.window_size * self.window_size, channels) - attn_mask = self.get_attn_mask(height_pad, width_pad) + attn_mask = self.get_attn_mask(height_pad, width_pad, dtype=hidden_states.dtype) ``` ### Expected behavior ```shell the img_mask tensor should be created with the same type of hidden_states. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda docs time out in main branch ### Checklist - [X] I added a descriptive title - [X] I searched open reports and couldn't find a duplicate ### What happened? This leads to a 404 on https://docs.conda.io/projects/conda/en/latest/ and is probably related to https://github.com/conda/conda/commit/d7ec1562cc0e87b8304c5eca080b1c850e9475f7 and #12416. ### Conda Info _No response_ ### Conda Config _No response_ ### Conda list _No response_ ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: `.view` no longer works on field selections of structured arrays See [this SO question](https://stackoverflow.com/questions/48267058/using-np-view-with-changes-to-structured-arrays-in-numpy-1-14): ```python >>> some_data = np.array([('foo', 3.5, 2.15), ('bar', 2.8, 5.3), ('baz', 1.2, 3.7)], dtype=[('col1', '<U20'), ('A', '<f8'), ('B', '<f8')]) >>> ab = some_data[['A', 'B']] ``` ```python >>> np.__version__ '1.13.3' >>> ab.dtype dtype([('A', '<f8'), ('B', '<f8')]) >>> ab.view(('<f8', 2)) FutureWarning: Numpy has detected that you may be viewing or writing to an array returned by selecting multiple fields in a structured array. This code may break in numpy 1.13 because this will return a view instead of a copy -- see release notes for details. array([[ 3.5 , 2.15], [ 2.8 , 5.3 ], [ 1.2 , 3.7 ]]) ``` vs ```python >>> np.__version__ '1.15.0.dev...' >>> ab.dtype dtype({'names':['A','B'], 'formats':['<f8','<f8'], 'offsets':[80,88], 'itemsize':96}) >>> ab.view(('<f8', 2)) ValueError: Changing the dtype to a subarray type is only supported if the total itemsize is unchanged ``` Since we now return a view rather than a copy from `arr[fields]`, we end up with a dtype with padding. This prevents `.view` being called, even though the memory layout is sufficient to allow it Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Run tests with CPU mode when on CPU+GPU version I have built the package with ``` python build/build.py --enable_march_native --enable_mkl_dnn --enable_cuda pip install -e build pip install -e . ``` I think this should build a CPU + GPU version. When I tried to run `pytest -n 2 tests examples -W ignore`, some of the tests failed. It appeared to me that some of the functions are only support in CPU mode. I also tried `JAX_ENABLE_X64=1 JAX_NUM_GENERATED_CASES=100 pytest -n auto tests` and `JAX_ENABLE_X64=0 JAX_NUM_GENERATED_CASES=100 pytest -n auto tests`, but neither of them worked. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: tab auto-completion fails if there is no space ``` python In [1]: import numpy as np In [2]: x=np.[tab] --> no auto-completion In [2]: x= np.[tab] --> ok ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Inference with a Dataset using pipeline in a tokenclassification job causes a ValueError(\"At least one input is required.\") I can see that TokenClassificationPipeline was initialized in \"transformers.pipelines.__init__.py\", but when a dataset was used as inputs, it will first parse arguments using \"_inputs, offset_mappings = self._args_parser(inputs, **kwargs)\" , where a dataset is not allowed. If a list[str]-like object was used as inputs, the arguments parsing code can pass, but Pipeline's __call__ method called next will print a warning info (\"You seem to be using the pipelines sequentially on GPU. In order to maximize efficiency please use a dataset\"). So, would anybody show me how to use a pipeline with GPU more efficiently? Thanks a lot. ## Environment info - `transformers` version: 4.12.3 - Platform: Ubuntu 20.04.3 LTS - Python version: 3.8 - PyTorch version (GPU?): GPU - Tensorflow version (GPU?): 2.6 - Using GPU in script?: Yes - Using distributed or parallel set-up in script?: No ### Who can help @Narsil @LysandreJik ## Information Model I am using : Bert The tasks I am working on is: * [x] an official GLUE/SQUaD task: ner ## To reproduce Steps to reproduce the behavior: 1. initialize a pipeline: nlp = pipeline('ner',model=model,tokenizer=tokenizer,device=0) 2. define a torch Dataset and initialize an user object of this self defined Dataset 3. call pipeline and pass the dataset to it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Keep original docstring from @task decorated function ## Current behavior When decorating a function with `@task`, the original docstring of the function is lost. ## Proposed behavior Original docstring is kept. Looking at the wrapper [`prefect.utilities.tasks.task`](https://github.com/PrefectHQ/prefect/blob/c1686091731144bbc0fab367e78b93221fccf28b/src/prefect/utilities/tasks.py#L152-L202), I thinks this should be do-able with [`functools.wraps`](https://docs.python.org/3/library/functools.html#functools.wraps), although I am not exactly sure what change needs to be made. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Duplicated libraries in the build order returned by conan info Using conan 1.6.0 on ubuntu 16.04. Here is the dependency graph :  And the output returned by `conan info` (I added the notation \"(Private)\" when it is the case) : [conan_info.txt](https://github.com/conan-io/conan/files/2222887/conan_info.txt) When calling `conan info`with the `-bo` options to get what we have to rebuild in our graph, it outputs the following : Command: `conan info . -bo Concepts/1.0.0@common/stable -bo PackageG/0.1.0@common/stable` Returns: `[Concepts/1.0.0@common/stable, Concepts/1.0.0@common/stable, Concepts/1.0.0@common/stable], [Math/0.3.0@common/stable, Math/0.3.0@common/stable, Math/0.3.0@common/stable], [PackageC/0.0.1@common/stable, PackageG/0.1.0@common/stable, PackageN/1.0.0@common/stable]` As you can see, some packages are duplicated, hence in our CI theses packages are built multiple times unnecessarily. If needed, I can provide the recipes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: VQE property setter method updates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? I noticed during the development of this PR (https://github.com/Qiskit/qiskit-nature/pull/380) that the VQE algorithm does not expose all of its attributes via property setters. In particular the following initializer arguments do not have property setters: - `include_custom` - `max_evals_grouped` - `callback` - `sort_parameters_by_name` Furthermore, the reversion to default behavior when passing `None` to any of the initializer arguments cannot be achieved via the property setters. E.g. it would be great to have the following: ```python vqe = VQE(optimizer=SPSA()) # vqe has non-default SPSA optimizer vqe.optimizer = None # vqe now falls back to default SLSQP optimizer ``` The current behavior simply sets the internal optimizer object to `None` resulting in subsequent errors. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Allow python config to be passed into lab extensions JupyterHub and Flexx have already expressed need to add items to the `lab.html` `jupyter-config-data`. We should add an optional `_jupyter_labextension_config` function that returns a dictionary of values to add to that data. cc @almarklein @danielballan @minrk Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Can't use `-Dsubproject:option` format for `default_library` Running `meson -Dgstreamer:default_library=static` yields: ``` |WARNING: In subproject gstreamer: Unknown options: \"gstreamer:default_library\" ``` I thought this already worked. @xclaesse, any ideas? :) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Questionable choice for the greek codepoints in IPython.core.latex_symbols The `IPython.core.latex_symbols` seems to contain odd choices for the greek letters. To make an example, the codepoint for epsilon is `GREEK LUNATE EPSILON SYMBOL` instead of the more obvious `GREEK SMALL LETTER EPSILON`. To check this, just run ```python >>> import unicodedata >>> from IPython.core.latex_symbols import latex_symbols >>> unicodedata.name(latex_symbols['\\epsilon']) 'GREEK LUNATE EPSILON SYMBOL' >>> unicodedata.name('ε') 'GREEK SMALL LETTER EPSILON' ``` If I'm not wrong, the *lunate* version appeared in Unicode 3.1.0 (March, 2001), while the more common codepoint is in Unicode 1.1.0 (June, 1993). LaTeX symbols seems to be autogenerated from Julia's one via the `/tools/gen_latex_symbols.py` so the issue probably derives from Julia code. Is there a reason for this choice? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Spanner: IndexError: pop from empty list when merge_array ``` return merger(lhs, rhs, type_) File \".../google/cloud/spanner_v1/streamed.py\", line 259, in _merge_array first = rhs.pop(0) IndexError: pop from empty list ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Logging] Move the code path of calling get_gae_labels() to emit() Related with #3359. To make it easier to set the labels in each request without explicitly calling `handler.get_gae_labels()` or calling `client.setup_logging()` inside the request which causes a lot overhead, it's better to move the code path of getting the gae labels to the `emit()` function in the logging handler. And change the `AppEngineHandler` to extend the `logging.StreamHandler` directly instead of extending the `CloudLoggingHandler`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: User configs shouldn't be entirely copied into Containers User configs will tend to have things like local secrets that I don't think should be copied into Docker Containers. We should have an explicit list of what we need to pull from user configs. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigTable: Make read deadlines modifiable The 0.31 bigtable client does a good job of retrying read requests, but the retry parameters are fixed (in `google/cloud/bigtable/row_data.py:408`). The defaults are fine for most uses, but not always, e.g. during long-running scans that really Must Work. (e.g., when doing a backup of an entire bigtable, which is where I ran into this) It would be very helpful to give `table.read_rows` a retry argument analogous to `table.mutate_rows`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QAOA does not update the operator when calling construct_circuit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Optimization version**: The one on the IBM Quantum Experience - **Python version**: The one on the IBM Quantum Experience - **Operating system**: The one on the IBM Quantum Experience ### What is the current behavior? If you call construct_circuit with two different operators, the second time the operator is not updated and the operator of the first call is used instead. ### Steps to reproduce the problem from qiskit.algorithms import QAOA from qiskit.opflow.primitive_ops import PauliOp from qiskit.quantum_info import Pauli from qiskit import Aer op = PauliOp(Pauli(\"ZZ\")) qaoa = QAOA() qaoa.construct_circuit([0,0],op)[0].draw(output=\"text\") op = PauliOp(Pauli(\"IZ\")) qaoa.construct_circuit([0,0],op)[0].draw(output=\"text\") ### What is the expected behavior? The second call to construct_circuit should update the operator and return the correct circuit ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Allow users to specify p12/json credentials file From the conversation in #621 > What is the process to specify the keyfile path? That is, I know my keys are at \"/creds.json\" or \"/key.p12\" (pick whichever you want) and don't want to use the environment variable stuff... > - @jgeewax ... > It does not exist ATM. > - @dhermes We need to make sure that people can still be explicit. So the goal of this bug is to make sure people can specify a path to either a `.p12` file or a `.json` file with credentials, and use all the services with those credentials... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: add jax.numpy.einsum_path Requested by @murphyk. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Is MergeFrom used by accident (instead of CopyFrom) in bigtable.Table.create? See [source][1]. As an example of why `MergeFrom` instead of `CopyFrom` can be a bug: ```python >>> from google.protobuf.timestamp_pb2 import Timestamp >>> from google.cloud.bigtable._generated.bigtable_instance_admin_pb2 import ( ... CreateInstanceMetadata) >>> >>> metadata1 = CreateInstanceMetadata(request_time=Timestamp(nanos=100)) >>> metadata2 = CreateInstanceMetadata(request_time=Timestamp(nanos=100)) >>> t = Timestamp(seconds=1000) >>> metadata1 request_time { nanos: 100 } >>> metadata2 request_time { nanos: 100 } >>> t seconds: 1000 >>> >>> metadata1.request_time.MergeFrom(t) >>> metadata2.request_time.CopyFrom(t) >>> >>> metadata1 request_time { seconds: 1000 nanos: 100 } >>> metadata2 request_time { seconds: 1000 } ``` [1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/2d81f88454724f0a672b453c994413c3cf1110c7/bigtable/google/cloud/bigtable/table.py#L184 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: config install with a git repository fails when the temporary directory is not empty To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. with conan 1.16.0, I sometimes get the following messages on our ci server: ``` conan config install git@repos.local:Conan/conan-config.git Trying to clone repo: git@repos.local:Conan/conan-config.git ERROR: Can't clone repo: The destination folder '/Users/Jenkins/Library/Caches/conan/1.16.0/.conan/tmp_config_install' is not empty, specify a branch to checkout (not a tag or commit) or specify a 'subfolder' attribute in the 'scm' ``` This happen when one of our devs cancelled (even if they have been told not to) a previous ci job while conan is running, leaving the directory. I would suggest to use a random generated temporary directory, or to simply overwrite the directory content. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.lax.{scan, map} break when supplied with an empty array Hey all, with 0.1.59 I'm seeing an error with both `map` and `scan`, where they can't handle an empty list: ```python jax.lax.map(lambda x: x * x, np.array([])) jax.lax.scan(lambda i, j: (i, j), np.array([]), np.array([])) ``` Both result in this error: ``` TypeError: slice slice_sizes must be less than or equal to operand shape, got slice_sizes (1,) for operand shape (0,). ``` This has been my workaround, though there is surely something more elegant and more correct: ```python def safe_map(f, xs): if xs.shape[0] == 0: return xs else: return jax.lax.map(f, xs) ``` Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Bug in revisions: Create json output doesn't return the revision From a server with revisions, I install a package that is stored with revisions using the json output: `conan install <ref> -r remote --json file.json` Apparently, the \"id\" field of the json (recipe and packages) doesn't contain the revision, and it should. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: How to properly fix random seed with pytorch lightning? #### What is your question? Hello guys I wonder how to fix seed to get reproducibility of my experiments Right now I'm using this function before the start of the training ``` def seed_everything(seed=42): random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False ``` But it doesn't work. I run training in DDP mode if it is somehow important. Thanks in advance! #### What's your environment? - OS: Ubuntu 18.04 - Packaging: pip - Version: 0.7.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Small typo in documentation of TokenClassificationPipeline ### System Info https://github.com/huggingface/transformers/blob/v4.23.1/src/transformers/pipelines/token_classification.py#L176 ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Open the documentation https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.TokenClassificationPipeline.__call__ > word (str) — The token/word classified. This is obtained by decoding the selected tokens. If you want to have the exact string in the original sentence, use start and stop. ### Expected behavior I'm quite sure it should be \"`start` and `end`\" Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"Invalid repository name\" error message alerts about the wrong service name This is close to [issue 1012](https://github.com/docker/compose/issues/1012) and its likes. I tried the below `docker-compose.yml` file ``` yaml version: '2' services: test_app: build: . depends_on: - mongo mong\\o: image: mongo ``` in which I intentionally had a slash in the `mongo` service name. But the error message I got when I run `docker-compose ps` in the same directory was ``` bash ERROR: The Compose file './docker-compose.yml' is invalid because: Invalid service name 'test_app' - only [a-zA-Z0-9\\._\\-] characters are allowed ``` wrongly referencing `test_app` instead of `mong\\o` My docker-compose version is: `docker-compose version 1.7.1, build 0a9ab35` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: QuasiDistribution returned by BackendSampler has incorrect shots ### Environment - **Qiskit Terra version**: 07e0a2fc79bada7c1fbf0594f4ad33934f70b7e - **Python version**: 3.10.8 - **Operating system**: Arch Linux ### What is happening? See title. ### How can we reproduce the issue? ```python from qiskit.circuit import QuantumCircuit from qiskit.primitives import BackendSampler from qiskit.providers.fake_provider import FakeLagos circuit = QuantumCircuit(2) circuit.measure_all() backend = FakeLagos() sampler = BackendSampler(backend) result = sampler.run(circuit, shots=100).result() quasis = result.quasi_dists[0] print(quasis.shots) ``` ``` None ``` ### What should happen? It should print \"100\", not \"None\". ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Deprecation warning from Jedi xref https://github.com/pandas-dev/pandas/pull/31323 and https://github.com/pandas-dev/pandas/issues/31342 It looks like there is a deprecation warning in Ipython once starting to use the latest jedi version (0.16.0) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Rename a remote - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. conan 1.1.0 Currently, the only way to rename a remote is to remove it, and then add it with a new name. - This breaks existing reference-remote-associations. - The old name must be known. Solutions could be - `conan remote rename old_name new_name` - `conan remote add remote_name remote_url --rename` - `conan remote add remote_name remote_url --force` I would prefer the last solution. It always works, no matter if there is an existing remote. See also https://github.com/conan-io/conan-package-tools/issues/156#issuecomment-373639997 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: `fig ps` empty after scaling, docker stop'ing a container, and scaling again To recreate: 1. `fig up -d` 2. `fig ps` # everything's running 3. `fig scale foo=2` 4. `docker stop my_foo_1` 5. `fig scale foo=2` # restarts my_foo_1 6. `fig ps` # empty and fig commands don't work until you stop & rm all containers with docker Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose should warn on duplicate mount points ## Description of the issue The following configuration produces an error from docker-compose: ```yaml version: '3' services: webserver: image: nginx volumes: - /tmp/foo:/tmp/foo - /tmp/foo:/tmp/foo ``` ``` ERROR: The Compose file './docker-compose.yml' is invalid because: services.webserver.volumes value ['/tmp/foo:/tmp/foo', '/tmp/foo:/tmp/foo'] has non-unique elements ``` However, the following variants do not: ```yaml version: '3' services: webserver: image: nginx volumes: - /tmp/foo:/tmp/foo - /tmp/foo:/tmp/foo:rw ``` ```yaml version: '3' services: webserver: image: nginx volumes: - /x:/y - /z:/y ``` Whilst it's easy to spot in simple cases like this, we've been tripped up by this in large configurations, where we assume `docker-compose config` would error on invalid configurations. ## Context information (for bug reports) ``` Output of \"docker-compose version\" docker-compose version 1.21.0, build 5920eb0 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Attempting to interrupt the kernel while autocomplete is thinking crashes the runtime Backstory: we've added some custom completers, some of which do things that amount to making a network request (say to find out the potential arguments to a function). Sometimes, this can be slow, and users are tempted to interrupt their kernel. Doing so then crashes the kernel. Here's a really goofy repro: ``` def bad_completer(*args, **kwargs): import time time.sleep(10) return ['houses'] get_ipython().set_hook('complete_command', bad_completer, re_key='%%file') %%file <TAB> ``` and then interrupt while you're waiting. A naive fix would be to simply catch any exception [here](https://github.com/ipython/ipython/blob/268a37740656a2cfb033e6803e2459fdf4ece516/IPython/core/completer.py#L1703), but I'm not sure if that should happen in a more central place. In particular, if a user does interrupt a completer, do we want to continue with the next one, or cancel completion completely? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Multiple warnings when accessing backend <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? <img width=\"1025\" alt=\"Screen Shot 2019-10-31 at 9 32 41 AM\" src=\"https://user-images.githubusercontent.com/1249193/67951233-816a5480-fbc1-11e9-8644-6b9df9b40f80.png\"> ### Steps to reproduce the problem Load up a backend in Jupyter. ### What is the expected behavior? No warnings ### Suggested solutions I am not sure why `dt` has been changed to seconds. Given the GHz freq. that we use, the natural timescales are nanosec. This was already a bit funky given that we do T1 and T2 in microsec. So now we have three different timescales for our parameters. As a side note, the natural timescale for the simulator is nanosec. I am not sure how this affects that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add DocumentQuestionAnswering pipeline # What does this PR do? This PR extends VisualQuestionAnsweringPipeline to accept `words` and `boxes` as input, passes them into the tokenizer/model (along with the question), and post-processes their `QuestionAnsweringModelOutput` response. Fixes #18380 ## Before submitting - [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case). - [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section? - [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case. - [ ] Did you make sure to update the documentation with your changes? Here are the [documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation). - [ ] Did you write any new necessary tests? ## Who can review? @Narsil Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Trainer.predict multiple progress bars ### System Info - `transformers` version: 4.21.0.dev0 - Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic - Python version: 3.7.13 - Huggingface_hub version: 0.8.1 - PyTorch version (GPU?): 1.11.0+cu113 (False) - Tensorflow version (GPU?): 2.8.2 (False) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ### Who can help? @sgugger ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction ``` model = AutoModelForSequenceClassification.from_pretrained(\"bert-base-uncased\") trainer = Trainer(model) trainer.predict([{\"input_ids\": torch.zeros(20).long()} for _ in range(48)]) # [6/6 00:03] trainer.predict([{\"input_ids\": torch.zeros(20).long()} for _ in range(96)]) # [6/6 00:12] despite having more examples ``` ### Expected behavior Two progress bars, one of length 6 and the other of length 12. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Assigment to np.ma.masked_array ignores mask in index Assignments like a[a>=3] = 5 dont handle masked elements in condition/index properly: ### Reproducing code example: ```python >>> import numpy as np >>> import numpy.ma as ma >>> a = ma.array([1, 2, 3, 4], mask=[1, 0, 1, 0]) >>> a masked_array(data=[--, 2, --, 4], mask=[ True, False, True, False], fill_value=999999) >>> c = a>=3 >>> c masked_array(data=[--, False, --, True], mask=[ True, False, True, False], fill_value=999999) >>> c.data array([False, False, True, True]) >>> a[c] = 5 >>> a masked_array(data=[--, 2, 5, 5], mask=[ True, False, False, False], fill_value=999999) EXPECTED: masked_array(data=[--, 2, --, 5], mask=[ True, False, True, False], fill_value=999999) ``` 3 is masked, so it shouldn't be overwritten. This works as a workaround: ```python >>> a = ma.array([1, 2, 3, 4], mask=[1, 0, 1, 0]) >>> c = a>=3 >>> a[~c.mask & c.data] = 5 >>> a masked_array(data=[--, 2, --, 5], mask=[ True, False, True, False], fill_value=999999) ``` ### Error message: None. ### NumPy/Python version information: 1.20.2 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)] numpy-1.20.2-cp38-cp38-win_amd64.whl Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Get input and output descriptions from docstrings optionally Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Using docker-compose scale prevents --x-smart-recreate from skipping service Sample set-up - dispatcher - worker_a - worker_b ``` docker-compose up -d docker-compose scale worker_b=2 ``` Update code for worker_a, rebuild image (worker_b unaffected) ``` docker-compose up -d --x-smart-recreate > sample_dispatcher_1 is up-to-date > Recreating sample_worker_a_1... > Recreating sample_worker_b_1... > Recreating sample_worker_b_2... ``` Would expect worker_b instances to be left untouched. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Move output_names into TranspileConfig Follow up items from https://github.com/Qiskit/qiskit-terra/pull/2789#pullrequestreview-269057207 - `output_names` should move into `TranspileConfig`, and its parsing should be split out similar to the other arguments to `transpile` - `transpile` should raise if passed an `output_names` that's not a `str` or a `list` - Update docstring to include that `output_names` is strictly 1-to-1 or n-to-n (unlike other transpile args that will do 1-to-n broadcasting.) - Rename `output_names` to `output_name` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [Enhancement] make conanbuildinfo.cmake silent Hello there, I have browsed through similar requests / issues where the user wants to control the amount of output. This time it is about the generated CMake file. The \"Library ... found: <awful long path and filename here>\" message appears many many times in my CMake output and it comes from conanbuildinfo.cmake. Can we please suppress certain outputs like the above one? ideally, conan install would look like: conan install <arguments> -g cmake -quiet_cmake_files there are also warnings that might be acceptable under certain circumstances. Eg. we deploy precompiled packages with compiler = gcc. If someone compiles the product with Clang, we will get a compiler mismatch warning (or the warning that we disabled the check). The product compiles and the linker can link everything fine. So in this case we don't need the warning. So please consider allowing us to make the CMake script silent! Thanks Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose build leaves dangling containers on fail With this Dockerfile ``` dockerfile FROM busybox RUN exit 1 ``` and docker-compose.yml ``` yml service: build: . ``` Running ``` bash docker-compose build service ``` will fail because of the \"RUN exit 1\" and will leave in intermediate container there (which is completely unusable and useless). There is an option for docker called --force-rm which fixes this but I see no option in compose for this. Could there be one added? Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Allow interactive mode on Windows Sort-of related to: - https://github.com/docker/compose/issues/3096 - https://github.com/docker/compose/issues/2836 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Bug in pretty printing The code in `IPython.lib.pretty.RepresentationPrinter.pretty` has a bug: it fails to look in the class `__dict__`s of the classes in the MRO. Fixes this is pretty easy: ``` --- pretty.py.orig 2012-07-11 15:38:34.000000000 +0200 +++ pretty.py 2012-07-11 15:32:05.000000000 +0200 @@ -354,7 +354,7 @@ # Some objects automatically create any requested # attribute. Try to ignore most of them by checking for # callability. - if '_repr_pretty_' in obj_class.__dict__: + if '_repr_pretty_' in cls.__dict__: meth = obj_class._repr_pretty_ if isinstance(meth, collections.Callable): return meth(obj, self, cycle) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Keybord shortcut Documentation page does not render. At least not on RTD, it works for me locally. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: DAGCircuit Remove node When modifying a DAGCircuit it is not easily possible to remove a specific node from the circuit. There exists a protected method `_remove_op_node` which does what I want to do. Is there a reason why this method needs to be protected? ## Expected Behavior There should exist a way to remove a specific node from a DAGCircuit that does not use protected methods. ## Current Behavior The only way currently is to either modify `multi_graph` directly (and risk breaking changes) or ignore the protected status and use `_remove_op_node` anyway (my choice currently). ## Possible Solution Simple fix: Make the method public. Complex fix: Rework the API for interacting with DAGCircuit. Currently, I am required to inspect `multi_graph` directly for many things that I wish to do with a DAGCircuit. I do not think this should be intended, since `multi_graph` encodes some fairly opaque internal state. ## Context I am trying to transform a DAGCircuit for the [QISKit developer challenge](https://qx-awards.mybluemix.net/#qiskitDeveloperChallengeAward) to conform to a given hardware architecture. I do that by removing op nodes from the given DAGCircuit and building a DAGCircuit that conforms to the architecture. ## Your Environment * Version used: qiskit 0.4.8 * Environment name and version (e.g. Python 3.6.1): python 3.6.4 * Operating System and version: macOS 10.13 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Subsecond timeouts not respected This is currently a (passing) unit test in `test_flow_runner.py`: ```python @pytest.mark.parametrize(\"executor\", [\"local\", \"mthread\", \"sync\"], indirect=True) def test_flow_runner_handles_timeouts(executor): sleeper = SlowTask(timeout=datetime.timedelta(seconds=1)) with Flow() as flow: res = sleeper(3) state = FlowRunner(flow=flow).run(return_tasks=[res], executor=executor) assert state.is_failed() assert isinstance(state.result[res], TimedOut) assert \"timed out\" in state.result[res].message assert isinstance(state.result[res].result, TimeoutError) ``` However, if you change the SlowTask timeout to `datetime.timedelta(seconds=0.5)`, the test fails. I'm not immediately sure why, though it looks like the timeout isn't being raised (the task finishes successfully) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Auto-initialize submodules in subprojects/ directory as if it had a wrap file The auto-init will only happen when a `subproject()` or `dependency(... fallback:)` call is encountered, just like a .wrap project. Also we need to add an FAQ entry on how wraps actually work. A lot of people misunderstand them and think they will always fetch from the network. Filing a bug about all this so I don't forget. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Optimization on SCM ('scm_folder.txt' pointing to local folder) could lead to unexpected package When the SCM feature is used, there is an optimization to avoid the git commands `git commit`, `git push` in order to test new sources for `conan create` command: Conan creates a file 'scm_folder.txt' inside the cache that stores the path to the local sources and copies them from it instead of cloning the repository. This optimization also applies for `conan install <...> --build=ref/v1@user/channel`, so this command will copy the sources from the local folder in order to build `ref` (but those sources could correspond to a different version, package,... to the one supposed to be at the moment when the recipe was created in the cache). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: flake8 error on master branch, file compose/bundle.py When trying to run the test suite on master branch the pre-commit hook fails with an flake8 error: ``` $ script/test/default Flake8...................................................................Failed hookid: flake8 compose/bundle.py:124:5: E722 do not use bare except' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Configure Kubernetes run launcher image pull policy in separate field ## Summary In the case where user deployments are enabled, users should still be able to configure the pull policy of the run launcher. ## Reproduction See the conversation [here](https://dagster.slack.com/archives/C01U954MEER/p1630618208199900?thread_ts=1630177344.082400&cid=C01U954MEER). ## Dagit UI/UX Issue Screenshots <!-- (Optional) --> ## Additional Info about Your Environment <!-- (Optional) --> --- #### Message from the maintainers: Impacted by this bug? Give it a 👍. We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: [bug] using `lax.cond` with partial effect function gives TypeError In the master branch, the following script shows the error ```sh TypeError: could not merge true_fun and false_fun output pvals: ((ShapedArray(int32[]), None), JaxTuple(*,0)) and ((ShapedArray(int32[]),ShapedArray(int32[])), JaxTuple(*,*)). ``` ``` lax.cond(True, (0, 0), lambda x: (x[0], 0), (1, 1), lambda x: x) ``` While these versions works well: ``` lax.cond(True, (0, 0), lambda x: (0, 0), (1, 1), lambda x: x) ``` or ``` lax.cond(True, (0, 0), lambda x: (x[0], x[1]), (1, 1), lambda x: x) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: List command doesn't work in ipdb debugger the first time When starting a debug session, if the very first command issued is `l` (`list`), it doesn't work. Once at least one statement has been executed, then it's OK: ``` In [1]: run -d -b50 ~/scratch/error.py Breakpoint 1 at /home/fperez/scratch/error.py:50 NOTE: Enter 'c' at the ipdb> prompt to start your script. > <string>(1)<module>() ipdb> l ipdb> n > /home/fperez/scratch/error.py(50)main() 49 size = 6 1--> 50 reps = 5 51 import pdb; pdb.set_trace() ipdb> l 45 result[:] = arange(size)*step + start 46 47 def main(): 48 #print 'hi' 49 size = 6 1--> 50 reps = 5 51 import pdb; pdb.set_trace() 52 print 'reps:',reps 53 array_normal = [0]*size 54 t0=time.clock() 55 for i in xrange(reps): # <<<<< ERROR (fork instead of for) ipdb> ``` There's likely a file cache loading that isn't happening at the start, which we need to do. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Issue with viewing a schematic for example flow ## Archived from the [Prefect Public Slack Community](https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU) **louisguitton93**: hi everyone, I'm trying to visualise in the UI the spacy_nlp.py DAG from the examples. I can see the DAG for etl.py just fine. I'm wondering what I'm doing wrong. Code to reproduce ``` git clone --depth 1 <https://github.com/PrefectHQ/prefect.git> cd prefect/examples sed -i '' 's/flow.run/flow.register/g' etl.py sed -i '' 's/flow.run/flow.register/g' spacy_nlp.py prefect server start python etl.py python spacy_nlp.py ``` **jeremiah**: Hi Louis, I’m having trouble replicating the setup — however, prior to running `python spacy_nlp.py` i had to run `python -m spacy download en_core_web_sm` in order to make the model available; otherwise the last step had an error. After that, `python spacy_nlp.py` ran and I see: **louisguitton93**: that's right. I see it too, and it runs fine with an agent. However I can't see the Schematic (that's what I meant sorry if I wasn't clear) <http://localhost:8080/flow/xxxx-flow-id-xxxx?schematic=> **jeremiah**: Ah, my apologies for misunderstanding - yes that IS an issue and thanks for raising it, I see it too. I’m sure <@UN6FTLFAS> will get to the bottom of it. I guess one of these tasks must be unexpectedly missing a property. **jeremiah**: <@ULVA73B9P> archive “Issue with viewing a schematic for example flow” Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: np.prod and np.product behave differently on duck-typed arrays ```python >>> class CanProd(object): ... def prod(self, axis, dtype, out): return \"prod\" >>> np.product(CanProd()) <__main__.CanProd object at 0x0000023BAF7B29E8> >>> np.prod(CanProd()) 'prod' ``` We should probably deprecate one of these, or simply make them identical. The docs already claim they are the same Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Specifying gates to decompose fails ### Environment - **Qiskit Terra version**: e4e4646f18d6e7d5dae0bc5308bcb5f5c9aa206d - **Python version**: 3.9.7 - **Operating system**: RHEL 8.6 ### What is happening? See title. ### How can we reproduce the issue? ```python from qiskit import QuantumCircuit from qiskit.circuit.library import XGate, XXPlusYYGate circuit = QuantumCircuit(2) circuit.append(XGate(), [0]) circuit.append(XXPlusYYGate(0.1), [0, 1]) decomposed = circuit.decompose(gates_to_decompose=XXPlusYYGate) decomposed.draw() ``` Output: ``` ┌───┐┌─────────────────┐ q_0: ┤ X ├┤0 ├ └───┘│ {XX+YY}(0.1,0) │ q_1: ─────┤1 ├ └─────────────────┘ ``` ### What should happen? The specified gates should be decomposed. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: datastore: No way to exclude_from_indexes new properties on updated entities When loading an `Entity` from the datastore and updating it, there is no way to exclude new attributes from being indexed, since the only public API for setting `exclude_from_indexes` is on the `Entity` constructor. To work around this, I am currently setting `entity._exclude_from_indexes = (...)` in my code, which is not a \"public\" API. Example: ```python client = google.cloud.datastore.Client() key = client.key('SomeEntityKey') entity = google.cloud.datastore.Entity(key, exclude_from_indexes=('foo', 'bar')) entity['foo'] = 'foo' print 'entity.exclude_from_indexes:', entity.exclude_from_indexes client.put(entity) entity2 = client.get(entity.key) print 'entity2.exclude_from_indexes:', entity2.exclude_from_indexes entity2['bar'] = 'bar' client.put(entity2) ``` Output: ``` entity.exclude_from_indexes: frozenset(['foo', 'bar']) entity2.exclude_from_indexes: frozenset([u'foo']) ``` This is actually \"expected\" based on how the Datastore works, however, in the code sample above, there should be some way for me to put the entity back, without copying it into a brand new `Entity`. Tested using: * Mac OS X 10.11.6 * Python 2.7.10 * The following Google packages: ``` gapic-google-cloud-datastore-v1==0.15.3 google-auth==1.0.1 google-auth-httplib2==0.0.2 google-cloud-core==0.24.1 google-cloud-datastore==1.0.0 google-cloud-storage==1.1.1 google-gax==0.15.13 google-resumable-media==0.0.2 googleapis-common-protos==1.5.2 proto-google-cloud-datastore-v1==0.90.4 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: DeBERTa Fast Tokenizer Hi, I am interested in using the DeBERTa model that was recently implemented here and incorporating it into [FARM](https://github.com/deepset-ai/FARM) so that it can also be used in open-domain QA settings through [Haystack](https://github.com/deepset-ai/haystack). Just wondering why there's only a Slow Tokenizer implemented for DeBERTa and wondering if there are plans to create the Fast Tokenizer too. Thanks in advance! Hi @stefan-it! Wondering if you might have any insight on this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: add boto3 to conda's s3 adapter Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Bug in Timeslot Ordering <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? A bug in the ordering of timeslots has led to a problem with `ch_stop_time` this was not caught as timeslot tests were deleted with the old implementation and the `Schedule` method didn't have any `ch_stop_time` tests directly. ### Steps to reproduce the problem ```python def test_ch_stop_time(self): reference_sched = Schedule() reference_sched = reference_sched.insert( 10, Delay(10, DriveChannel(0))) reference_sched = reference_sched.insert( 10, ShiftPhase(0.1, DriveChannel(0))) self.assertEqual( reference_sched.timeslots[DriveChannel(0)], [(10, 10,), (10, 20)]) self.assertEqual(reference_sched.duration, 20) self.assertEqual(reference_sched.ch_stop_time(DriveChannel(0)), 20) ``` ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Vision \"manual\" system tests are broken https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/2591 ``` nox > Session system_tests(python_version='3.6') successful. :) nox > Running session system_tests_manual_layer(python_version='2.7') nox > virtualenv /var/code/gcp/.nox/system_tests_manual_layer-python_version-2-7 -p python2.7 nox > chdir /var/code/gcp/vision nox > pip install --upgrade pytest ../core/ ../storage/ nox > pip install --upgrade ../test_utils/ nox > pip install --upgrade -e . nox > py.test --quiet tests/system_old.py ............FFF................ =================================== FAILURES =================================== _______________ TestVisionClientLabel.test_detect_labels_content _______________ Traceback (most recent call last): File \"/var/code/gcp/vision/tests/system_old.py\", line 368, in test_detect_labels_content self._assert_label(label) File \"/var/code/gcp/vision/tests/system_old.py\", line 357, in _assert_label self.assertIn(label.description, self.DESCRIPTIONS) File \"/usr/local/lib/python2.7/unittest/case.py\", line 803, in assertIn self.fail(self._formatMessage(msg, standardMsg)) File \"/usr/local/lib/python2.7/unittest/case.py\", line 410, in fail raise self.failureException(msg) AssertionError: u'motor vehicle' not found in ('car', 'vehicle', 'land vehicle', 'automotive design', 'wheel', 'automobile make', 'luxury vehicle', 'sports car', 'performance car', 'automotive exterior') ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Optimize1qGatesSimpleCommutation scales superlinearly <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The transpiler pass Optimize1qGatesSimpleCommutation scales as the ~4th power in the number of qubits for a random circuit of equal width and depth.   This is qiskit-terra 0.19.0.dev0+637acc0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: scp checking for existence of directories: directory names are incorrect Commit d02d22204f9445ad3634b150ac5dc8a360b05c95 is supposed to ensure that SSHlaunchers check that destination directories exist when copying files between hosts (see issue #3411). However there is a bug where the hostname (or ip address) of the destination machine is included in the directory name by mistake. The offending code is: ``` python check_output(self.ssh_cmd + self.ssh_args + \\ [self.location, 'mkdir', '-p', '--', remote_dir] ) ``` The problem is that `remote_dir` includes the hostname (or ip) of the destination machine, so for example a directory that should be created on the destination machine at: ``` ~/.ipython/profile_ssh/security ``` will instead be created at: ``` ~/<DESTINATION HOSTNAME>/.ipython/profile_ssh/security ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Trainer.fit() crashes if no checkpoint callback is provided I hope it's okay that I keep posting issues... Now that I can circumvent the github installation issues, I pulled in the latests master and let my simple CoolModel demo code run. But now calling trainer.fit() crashes with: > AttributeError Traceback (most recent call last) <ipython-input-3-4ff64ec6323b> in <module> 21 ) 22 ---> 23 trainer.fit(model) 24 # exp.close() > /opt/miniconda3/envs/dev_pytorch_lightning36/lib/python3.6/site-packages/pytorch_lightning/models/trainer.py in fit(self, model) 494 self.optimizers, self.lr_schedulers = self.optimizers 495 --> 496 self.__run_pretrain_routine(model) 497 498 # return 1 when finished > /opt/miniconda3/envs/dev_pytorch_lightning36/lib/python3.6/site-packages/pytorch_lightning/models/trainer.py in __run_pretrain_routine(self, model) 680 681 # restore training and model before hpc call --> 682 self.restore_state_if_existing_checkpoint() 683 684 # enable cluster checkpointing > /opt/miniconda3/envs/dev_pytorch_lightning36/lib/python3.6/site-packages/pytorch_lightning/models/trainer.py in restore_state_if_existing_checkpoint(self) 261 262 # find last epoch --> 263 checkpoints = os.listdir(self.checkpoint_callback.filepath) 264 for name in checkpoints: 265 # ignore hpc ckpts > AttributeError: 'NoneType' object has no attribute 'filepath' Looking at the code, it appears to happen because I did not provide a checkpoint callback and it tries to access it in `restore_state_if_existing_checkpoint` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson 0.56.0 feature qt5.compile_translations(qt5.compile_translations:...) does not work according to the changelog https://github.com/mesonbuild/meson/blob/master/docs/markdown/Release-notes-for-0.56.0.md#qt5-compile_translations-now-supports-qresource-preprocessing for 0.56.0 there should be the ability to write ```cpp qt5.compile_translations(qresource: 'i18n.qrc') ``` the `i18n.qrc` looks like: ``` <RCC> <qresource> <file>de.ts</file> </qresource> </RCC> ``` however, when running meson it results in the following error: ``` ERROR: qt.compile_translations: qresource can only contain ts files, found de.ts ``` whiiiich is a contradiction. In my opinion there is a bug along these lines. meson should compile from `ts` to `qm` and not vice-versa. https://github.com/mesonbuild/meson/blob/d4eec9664bb96a093b92c3e1f565806686ea0ccb/mesonbuild/modules/qt.py#L236 There seem to be no tests about this. Am I getting something wrong? Thx for your time! By the way, thx for this great tool! :laughing: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Chipped figure in matplotlib for a plain quantum circuit <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.16.1 - **Python version**: 3.8.6 - **Operating system**: Artix Linux ### What is the current behavior? When drawing a plain quantum circuit (just initializing the quantum and classical registers without implementing any gates), the figure rendered in matplotlib renders chipped text. Testing this with a previous release of terra (I used 0.15.1), the text appears fine without any chipping whatsoever. ### Steps to reproduce the problem ```python from qiskit import * qr = QuantumRegister(2) cr = ClassicalRegister(3) qc = QuantumCircuit(qr,cr) qc.draw('mpl') ``` *With current release (0.16.1)*:  *With a previous release (0.15.1)*:  ### What is the expected behavior? The expected behaviour is to draw the circuit without any text chipping and draw the circuit as implemented in version 0.15.1. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Remove int_asbuffer On python 3, `int_asbuffer`: * Checks to see if dereferencing the address would segfault * Throws `NotImplementedError` if not I don't think it is worth keeping around. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker run working directory option Please add an option in fig.yml to mount the working directory like with `docker run -w /path/to/workdir <image> <command>`, which is also specified in a Dockerfile with: ``` WORKDIR /path/to/workdir ``` Something like this in fig.yml: ``` web: - image: my-image - command: my-command - workdir: /path/on/container ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [meson 0.56] Cannot handle spaces in [binaries] paths / string index out of range in ninjabackend.py **Describe the bug** ``` Traceback (most recent call last): File \"E:\\vcpkg_cache\\downloads\\tools\\meson\\meson-0.56.0\\mesonbuild\\mesonmain.py\", line 140, in run return options.run_func(options) File \"E:\\vcpkg_cache\\downloads\\tools\\meson\\meson-0.56.0\\mesonbuild\\msetup.py\", line 253, in run app.generate() File \"E:\\vcpkg_cache\\downloads\\tools\\meson\\meson-0.56.0\\mesonbuild\\msetup.py\", line 161, in generate self._generate(env) File \"E:\\vcpkg_cache\\downloads\\tools\\meson\\meson-0.56.0\\mesonbuild\\msetup.py\", line 223, in _generate intr.backend.generate() File \"E:\\vcpkg_cache\\downloads\\tools\\meson\\meson-0.56.0\\mesonbuild\\backend\\ninjabackend.py\", line 533, in generate self.write_rules(outfile) File \"E:\\vcpkg_cache\\downloads\\tools\\meson\\meson-0.56.0\\mesonbuild\\backend\\ninjabackend.py\", line 1122, in write_rules b.count_rule_references() File \"E:\\vcpkg_cache\\downloads\\tools\\meson\\meson-0.56.0\\mesonbuild\\backend\\ninjabackend.py\", line 342, in count_rule_references if self._should_use_rspfile(): File \"E:\\vcpkg_cache\\downloads\\tools\\meson\\meson-0.56.0\\mesonbuild\\backend\\ninjabackend.py\", line 336, in _should_use_rspfile return self.rule.length_estimate(infilenames, File \"E:\\vcpkg_cache\\downloads\\tools\\meson\\meson-0.56.0\\mesonbuild\\backend\\ninjabackend.py\", line 273, in length_estimate if chunk[1] == '{': IndexError: string index out of range ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda remove --dry-run actually removes the package Is there anything set around here: https://github.com/conda/conda/blob/ded940c3fa845bbb86b3492e4a7c883c1bcec10b/conda/cli/main_remove.py#L196 to actually exit before removing the package if --dry-run is set but --json is not? I'm just running 3.11.0 and haven't grabbed and functionally tested master to see if this is still a problem. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Bart encoder with add_final_layer_norm https://github.com/huggingface/transformers/blob/91cb95461e438dc57555c4f57f8ce95a56328036/src/transformers/modeling_bart.py#L305 I feel like it should be self.layer_norm = LayerNorm(config.d_model) if config.add_final_layer_norm else None as in the BartDecoder. https://github.com/huggingface/transformers/blob/91cb95461e438dc57555c4f57f8ce95a56328036/src/transformers/modeling_bart.py#L486 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: AssertionError on completion on 5.0.0b2 Constantly reproducible AssertionError on completion. How to reproduce: - start ipython - type `import collect` - press Tab key - press Enter Additional info: - prompt_toolkit 1.0.0 (from PyPI) - ipython 5.0.0b2 (from PyPI) - [Crash_report_ipython.txt](https://github.com/ipython/ipython/files/304616/Crash_report_ipython.txt) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `PauliOp.adjoint()` does not return correct value ### Environment - **Qiskit Terra version**: 0.24.0.dev0+e981b7e - **Python version**: 3.8.16 - **Operating system**: Linux ### What is happening? `PauliOp.adjoint()` does not return a correct answer like `SparsePauliOp.adjoint()` does. ### How can we reproduce the issue? ```python from qiskit.opflow.primitive_ops import PauliOp from qiskit.quantum_info import Pauli, SparsePauliOp sparse_pauli_op = SparsePauliOp([\"iX\"], [3.0]) expected = SparsePauliOp([\"-iX\"], [3.0]) assert sparse_pauli_op.adjoint() == expected # this is OK pauli_op = PauliOp(Pauli(\"X\"), coeff=3j) expected = PauliOp(Pauli(\"X\"), coeff=-3j) assert pauli_op.adjoint() == expected # this is also OK pauli_op = PauliOp(Pauli(\"iX\"), coeff=3) expected = PauliOp(Pauli(\"-iX\"), coeff=3) assert pauli_op.adjoint() == expected # returns AssertionError ``` ### What should happen? The code above should not return `AssertionError`. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: BasicSwap cannot handle move_measurements.qasm In the process to understand #1575, I noticed that `BasicSwap` also fails with that example (in which `move_measurements.qasm` tries to be mapped). I managed to extract a minimal example: ``` coupling = CouplingMap([[0, 1], [1, 2]]) qr0 = QuantumRegister(1, 'q0') qr1 = QuantumRegister(1, 'q1') qr2 = QuantumRegister(1, 'q2') circuit = QuantumCircuit(qr0, qr1, qr2) circuit.cx(qr1[0], qr2[0]) dag = circuit_to_dag(circuit) layout = Layout([(qr1, 0), (qr0, 0), (qr2, 0)]) pass_ = BasicSwap(coupling, initial_layout=layout) after = pass_.run(dag) ``` This fails with `qiskit.dagcircuit.exceptions.DAGCircuitError: 'invalid wire mapping key q2[0]'`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Example config code uses invalid 'output_attention' rather than 'output_attentions' Looks like documentation only bug. `output_attention` used rather than `output_attentions`. Occurs in multiple places in repo. Maybe linked to #2985 ## Environment info - `transformers` version: 3.1.0 - Platform: Darwin-19.6.0-x86_64-i386-64bit - Python version: 3.7.4 - PyTorch version (GPU?): 1.5.1 (False) - Tensorflow version (GPU?): not installed (NA) - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help documentation: @sgugger ## Information Model I am using (Bert, XLNet ...): The problem arises when using: * [x] the official example scripts: (give details below) * [ ] my own modified scripts: (give details below) The tasks I am working on is: * [ ] an official GLUE/SQUaD task: (give the name) * [x] my own task or dataset: (give details below) ## To reproduce Steps to reproduce the behavior: From docs L4-L5 of AutoConfig example: [docs](https://huggingface.co/transformers/model_doc/auto.html#transformers.AutoConfig) or [code](https://github.com/huggingface/transformers/blob/master/src/transformers/configuration_auto.py#L264) ```python config = AutoConfig.from_pretrained('bert-base-uncased', output_attention=True, foo=False) assert config.output_attention == True ``` causes: ``` AttributeError: 'BertConfig' object has no attribute 'output_attention' ``` ## Expected behavior The assertion given in documentation passes. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: BUILD upgrade to isort v5 The contributing guide says > Right now, we need an unreleased version of isort to avoid a bug: However, it looks like the linked PR has been incorporated into the latest version of isort. I could submit a PR to address this if it would be welcome Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Compiler options with colons in them are not passed correctly The Microsoft compiler has many options that include colons. These are not handled correctly when they get included in the ninja.build file. For instance, if you try to pass the ```/Zc:wchar_t``` compiler option, it shows up in the build.ninja file as ```\"/Zc$:wchar_t\"``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: etcd leader check uses unsupported endpoint The etcd integration currently uses the `/v3alpha/maintenance/status` endpoint when determining whether the instance it's checking is the leader: https://github.com/DataDog/integrations-core/blame/7ab36d84f116ccbdef71ed12b84e81462ca38113/etcd/datadog_checks/etcd/etcd.py#L127 However, this endpoint has been graduated to `/v3/...`, so trying to access the `/v3alpha/...` endpoint returns a 404 on etcd 3.4. This results in the leader tag not getting added. I think this check should be updated to use the `/v3/...` endpoint, since that is available on 3.4.0 (https://github.com/hexfusion/etcd/blob/v3.4.0/Documentation/dev-guide/apispec/swagger/rpc.swagger.json#L1045) and above. Per etcd's docs on suported versions (https://etcd.io/docs/v3.5/op-guide/versioning/), because 3.5 is the current version, 3.4 is still maintained, but anything below is no longer maintained. Also, the oldest maintained version of kubernetes (1.25) is using etcd 3.5 (https://github.com/kubernetes/kubernetes/pull/110033). I'd be happy to make a PR for this change! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: coupling_map.subgraph() creates extra nodes Trying to get a subgraph of this coupling map: ```py from qiskit.test.mock import FakeMumbai from retworkx.visualization import mpl_draw backend = FakeMumbai() cmap = CouplingMap(backend.configuration().coupling_map) mpl_draw(cmap.graph) ``` <img width=\"418\" alt=\"image\" src=\"https://user-images.githubusercontent.com/8622381/125465693-39b6c29f-bf4e-4399-8fac-7fa82acd0a50.png\"> If I use retworkx directly to get the subgraph on 9 nodes, it gives me this which is correct I think: ```py mpl_draw(cmap.graph.subgraph([0, 1, 4, 7, 10, 12, 15, 18, 17])) ```  But if I do the same using the CouplingMap API I get this. There are incorrect nodes added here: ```py cmap.subgraph([0, 1, 4, 7, 10, 12, 15, 18, 17]).draw() ```  @mtreinish says this is due to a difference in how networkx and retworkx implement `.subgraph()`. But I like the retworkx output because it numbers nodes as 0-k, and that is consistent with how coupling maps in qiskit are numbered (i.e. no \"holes\"). So I think something just needs to change here to remove the extra nodes. If we provide an option to keep the original node numberings, I'd be fine with that, but I'm not sure whether Qiskit can actually work with such a coupling map object. The best route I see is to remap the node numbers in the same order (smallest to 0, largest to k). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose down shouldn't abort if resources have already been deleted Running `docker-compose down` a second time should be a no-op, but it complains about the network having already been removed: ``` console $ docker-compose down Stopping app_web_1 ... done Stopping app_redis_1 ... done Removing app_web_1 ... done Removing app_redis_1 ... done Removing network app_default $ docker-compose down Removing network app_default ERROR: network app_default not found ``` The same thing happens with volumes if you pass `-v`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Could I convert lightning module to onnx? Thanks! ## 🚀 Feature pytorch Lightning works very good, but I cannot find any comments or examples to guide my convert to onnx from a pretrained lightning model, doesn't lightning module only use for researching purpose, without support of onnx cross platform? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Storing embedded entity, it's ignoring exclude_from_indexes from embedded I'm trying to have a embedded entity with a field that is larger than 1500bytes. I add that field to the exclude_from_indexes key of the embedded entity. When I try and save the parent Entity it tells me the field is bigger than 1500bytes. If I save the embedded entity independently, it works. Is exclude_from_indexes ignored on embedded entity? ``` client = datastore.Client(dataset_id=projectID) record_key = client.key('Record', my_id) record_entity = datastore.Entity(record_key) embedded_key = client.key('Data', another_id) embedded_entity = datastore.Entity(key=embedded_key,exclude_from_indexes=('big_field',)) embedded_entity['field1']='1234' embedded_entity['big_field']='large string bigger than 1500bytes' record_entity['RandomFieldName']=embedded_entity client.put(record_entity) #Error: gcloud.exceptions.BadRequest: 400 The value of property "big_field" is longer than 1500 bytes. client.put(embedded_entity) #No Error ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Re-run system_requirements() I am using the following scenario: - I am running builds of our software on CI (Jenkins) which rely on some Conan packages - The packages feature `system_requirements()` to install some system packages - The builds run inside Docker container - The Docker container mount a volume to which all Conan data is cached between CI builds (to save bandwidth and speed things up in general) This is what happens: - The first CI build is fine - Conan package is not installed - it gets downloaded - `system_requirements()` install system packages inside the Docker container - whole build runs fine - On subsequent builds it fails - Conan package is already installed (because it is inside the mounted volume) - Conan does not invoke `system_requirements()` - System packages are missing in the Docker container - the build fails Is there any way to re-run `system_requirements()` for an already installed package? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython 7.6 problem with %%time In IPython 7.6, the `%%time` magic is messing with the workspace. Looks like the last variable is never assigned in the workspace. This is a pretty serious error. IPython 7.5.0 worked fine, so I assume it's related to https://github.com/ipython/ipython/pull/11716/. Also works fine when there's exactly one statement inside the cell. ``` In [1]: %%time a = 1 b = 2 c = 3 ``` Wall time: 0 ns ``` In [2]: a, b, c ``` ``` --------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-2-6fd489e9d195> in <module> ----> 1 a, b, c NameError: name 'c' is not defined ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit without gates cannot be drew on latex ### Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: MacOS ### Steps to reproduce the problem ```python from qiskit import * qc = QuantumCircuit(2) qc.draw('latex') ``` ``` IndexError: list index out of range ``` ### What is the expected behavior? Same as other drawers: ```python qc.draw('text') ``` ``` q_0: q_1: ``` ```python qc.draw('mpl') ```  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Create `optimization` stage (there is a different PM for each optimization level) plugins Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipython-qtconsole script isn't installed for Python 2.x Please see bug https://bugs.gentoo.org/show_bug.cgi?id=407823 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Implement indexed updates that mix basic and advanced indexing I'm trying to update certain rows of a matrix with corresponding gradients. I tried \"index_add\" and it raised NotImplementedError for _scattter_update error for now. This is crucial for my use case where weight matrix selection is data-dependent. ```new_weights = index_add(weights, ops.index[neuron_indices + context_values, :], - learning_rate * gradient)``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: ⚠ Better warning/ handling for CTC models in ASR pipeline ### System Info - `transformers` version: 4.31.0 - Platform: Linux-5.15.109+-x86_64-with-glibc2.35 - Python version: 3.10.12 - Huggingface_hub version: 0.16.4 - Safetensors version: 0.3.1 - Accelerate version: not installed - Accelerate config: not found - PyTorch version (GPU?): 2.0.1+cu118 (False) - Tensorflow version (GPU?): 2.12.0 (False) - Flax version (CPU?/GPU?/TPU?): 0.7.0 (cpu) - Jax version: 0.4.13 - JaxLib version: 0.4.13 - Using GPU in script?: No - Using distributed or parallel set-up in script?: No ### Who can help? @sanchit-gandhi @arth ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Created an independent colab to demostrate the issue: https://github.com/Vaibhavs10/scratchpad/blob/main/transformers_asr_pipeline_inconsistencies.ipynb The ASR pipeline behaviour should be consistent across `CTC` and `Seq2Seq` models. ### Expected behavior Either `CTC` models should default to `return_timestamps=\"word\"` when passed with `return_timestamps=True` or we should pass a more intuitive error message. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Rescale layer in whisper processor ### Feature request Whisper processor does not currently rescale to the expected [-1, 1) that it requires. ### Motivation Consistency between model processor layers. ### Your contribution - Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: variable substitution in docker-compose.yml: empty default value is not supported Docker-Compose version 1.16.1, build `6d1ac21`. In my `docker-compose.yml` I am using an environment variable, which, if unset, must default to an empty value: ``` version: '3.3' services: test: image: alpine:latest command: echo \"'${TEST:-}'\" ``` Running this setup ends up with the following error: ``` $ TEST=test docker-compose up ERROR: Invalid interpolation format for \"command\" option in service \"test\": \"echo ${TEST:-}\" ``` Adding a space after 'minus' works around this issue: ``` $ sed -e 's/:-/:- /' docker-compose.yml | TEST=test docker-compose -f - up Recreating test_test_1 ... Recreating test_test_1 ... done Attaching to test_test_1 test_1 | 'test' test_test_1 exited with code 0 ``` But having an empty default should also work from my perspective. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: K8s Agent references old prefect docker image name ## Description Whenever the kubernetes agent creates a job, it references our old docker image naming conventions in at least on place [here](https://github.com/PrefectHQ/prefect/blob/d204261c6f9856dbfd7442a194de91c4be768e7f/src/prefect/agent/kubernetes/agent.py#L198). We should audit all such references and update them for our new naming scheme, which can be inferred from our `circleci/config.yml` file [here](https://github.com/PrefectHQ/prefect/blob/master/.circleci/config.yml#L296-L324) **cc:** @joshmeek Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add automatic best model loading to Trainer # What does this PR do? This PR cleans up a bit the part that saves the training state inside `Trainer` and adds an API that can track which was the best model during any of the evaluation phases to load it back at the end. When fine-tuning a model on a dataset that can easily overfit the model, it's quite common to have the last model not be the best one (in terms of metrics). This PR adds a `TrainingArgument` named `load_best_model_at_end` that triggers the following behavior: - `save_steps` gets ignored and the model is saved every time there is an evaluation (determined by `evaluation_strategy` and `eval_steps`) - It keeps track in a `TrainerState` of when the best model was encountered (that state is saved along the checkpoints so it can work with resuming a training) - The best model is determined by the new `TrainingArgument`s `metric_for_best_model` (defaults to the loss) and `greater_is_better` (default to False for the loss, True otherwise). - The best model is loaded once the training is finished. In passing I've added some tests of the saving API in Trainer and made sure it can handle both `PreTrainedModel` and regular `nn.Module` (a feature asked in #6901). Both are now tested in the CI, as is the new API. Fixes #6901 Those newly introduced arguments and APIs can then be leveraged to have early stopping supported in `Trainer`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Solving the LD issue I think we (I) made a mistake with LD cross/native ld. We've caused a lot of regressions and our use of LD differs from what autotools does, which is confusing. I wonder if the best solutions is to (if IIRC) match autotools and go to a CCLD, CXXLD, etc environment variable, and remove LD. We could CCLD would only apply the C compiler, CXXLD would only apply to the C++ compiler, etc. If we want to go this route it would be a backwards incompatible change, and I'd like to land it for 0.53.1, with apologies. My plan would be that CCLD would work the same way the LD currently does, that is, if the C compiler is GCC like then the linker would be invoked with `$CC -fuse-ld=$CCLD`, for msvc it would be invoked as a binary, say `lld-link.exe`. Is my understanding of autotools correct, and does this plan make sense? Are we willing to make a backwards incompatible change after the release? Related #6413, #6431 @eli-schwartz, @jpakkane, @textshell (I think there was someone else on IRC who had opinions about this) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Catch another case with non-optional outputs See error message at simple_engine.py:76 When the previous outputs are not optional this should throw ``` step_context.log.info( ( 'Not all inputs covered for {step}. Not executing. Output need for ' 'inputs {expected_outputs}' ).format(expected_outputs=expected_outputs, step=step.key) ) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Issue with TrainingArguments docs. Hi Team, This is a minor issue but on this [link](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments), the default optimizer mentioned is Adam in the docs. However, the `Trainer` uses AdamW by default. This is slightly misleading. Thanks, Gunjan Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Provide more informative error message upon incompatible extensions being found Currently, when incompatible extensions are found, the error message given to the user is something like:  For any user who's not intimately familiar with where extensions get installed, this isn't very useful as they won't know where to go. If we can provide the location on disk of the problematic extensions, at least the user can try to take some remediations on their own. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Enum input for meas_return to assembler is being converted incorrectly <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? Enum input to the assembler is being converted incorrectly to a string. ### Steps to reproduce the problem ```python qobj = assemble(pulse.Schedule(), backend) backend.run(qobj) ``` ### What is the expected behavior? ### Suggested solutions Convert enum to a string preemptively. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: trainer.save_model load error reference code : https://github.com/bhadreshpsavani/UnderstandingNLP/blob/master/go_emotion_of_transformers_multilabel_text_classification_v2.ipynb ---- ----> 6 save_model ='./model/emotion' ----> 7 trainer.save_model(save_model) ----> 8 load_model = AutoModel.from_pretrained(save_model) 4 frames [/usr/local/lib/python3.8/dist-packages/transformers/configuration_utils.py](https://localhost:8080/#) in __init__(self, **kwargs) 315 f\"{self.id2label}. The number of labels wil be overwritten to {self.num_labels}.\" 316 ) --> 317 print(id2label) 318 self.id2label = dict((int(key), value) for key, value in self.id2label.items()) 319 # Keys are always strings in JSON so convert ids to int here. AttributeError: 'list' object has no attribute 'items' --- After fine-tuning the emotion classification model with 28 classes, I learned and saved it through trainer() , but the model is not loaded. can someone help? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Wrong std for implicitly complex input <!-- Please describe the issue in detail here, and fill in the fields below --> Standart deviation formula could give unexpected result (e.g. imaginary values) when input is implicitly complex. ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np a = np.array([None, 0]) a[0] = 1j b = np.array([1j, 0]) print(f'res={np.std(a)}, dtype={a.dtype}') # gives imaginary std print(f'res={np.std(b)}, dtype={b.dtype}') ``` <!-- Remove these sections for a feature request --> ### Error message: <!-- If you are reporting a segfault please include a GDB traceback, which you can generate by following https://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging --> <!-- Full error message, if any (starting from line Traceback: ...) --> ### Numpy/Python version information: numpy 1.16.2 python 3.7 <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> res=0.5j, dtype=object res=0.5, dtype=complex128 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Automate language matters check Please take a look at the last commit only. It is based on #9174 --- Make sure to mark the boxes below before creating PR: [x] - [x] Description above provides context of the change - [x] Unit tests coverage for changes (not needed for documentation changes) - [x] Target Github ISSUE in description if exists - [x] Commits follow \"[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)\" - [x] Relevant documentation is updated including usage instructions. - [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: None value and default value in options - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. conan v1.6.1, Windows I know that the value `None` has a special meening in options. I think the exact meening is not fully documented (see also https://github.com/conan-io/conan/issues/2780#issuecomment-383234689). In the following example the behaviour seems inconsistent: ```python class libaconan(ConanFile): name = \"liba\" version = \"1.0\" options = {\"opt\": [None, \"a\"]} default_options = \"opt=a\" def configure(self): print(\"opt =\", self.options.opt) ``` - `conan install liba/1.0@user/testing` prints `opt = a` - `conan install liba/1.0@user/testing -o opt=a` prints `opt = a` - `conan install liba/1.0@user/testing -o opt=None` prints `opt = None` (!) But with libb consuming liba: ```python class libbconan(ConanFile): name = \"libb\" version = \"1.0\" requires = \"liba/1.0@user/testing\" ``` - `conan install libb/1.0@user/testing` prints `opt = a`. - `conan install libb/1.0@user/testing -o liba:opt=a` prints `opt = a`. - `conan install libb/1.0@user/testing -o liba:opt=None` prints `opt = a`. (!) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan inspect should not fail on missing attribute Conan 1.9.1 I'm trying to get list of direct dependencies for the recipe and when I run `conan inspect -a build_requires` on a recipe without `build_requires` it just fails because `AttributeError` is fatal. I think this behavior is inconvenient as I don't know in advance which attributes are present and if I specify multiple custom attributes, whole command fails. I suggest that missing attributes should be translated to missing keys in the resulting dictionary (effectively ignoring `AttributeError` in `ConanAPIV1.inspect()` instead of converting it to `ConanException`). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: [CMake] subproject panic when including non \"C:\\\" libraries **Describe the bug** CMake subprojects will panic when trying to include libraries not installed to the `C:` drive **To Reproduce** build a CMake subproject, make sure it has a dependency not on the `C:` drive. Discovery of bug included building `LibKF5Attica` as a subproject, with `QT5` as a dependency on drive `D:`. Native CMake build completed successfully with this setup. **Expected behavior** Build the subproject. **system parameters** native build Windows 10 (Current latest patch KB4538461) python version 3.7.1 meson version 0.54.1 ninja Not Applicable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Update Storage after #9915, incompatible change. Currently unit and system tests for storage are failing due to a change introduced by #9915 ``` headers[CLIENT_INFO_HEADER] = self.user_agent headers[\"User-Agent\"] = self.user_agent return self._do_request( > method, url, headers, data, target_object, timeout=timeout ) E TypeError: _do_request() got an unexpected keyword argument 'timeout' ``` Unit Tests: `29 failed, 681 passed, 2 skipped in 14.05s` Update minimum versions for core/api core in storage to ``` \"google-auth >= 1.9.0, < 2.0dev\", \"google-api-core >= 1.15.0, < 2.0dev\", \"google-cloud-core >= 1.1.0, < 2.0dev\" ``` Rerun tests and adjust to account for timeout param. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: scm get ignore files crashing By an unknown cause, the `excluded_files` function (Conan 1.8.4) during the call to `git check-ignore` is raising a `FileNotFoundError`. Investigate when it can happen. Maybe the `self.folder`? Apparently calling manually it works. But anyway it would be better to just print a warning and ignore the failure, because this is only an optimization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qc.count_ops() should return the operations sorted from high to low by number of occurances <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? `count_ops` should use a ordered dict with the order set by the number of times the gate is used in the circuit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: pubsub: The publisher client API page is empty The documentation page is empty. https://googlecloudplatform.github.io/google-cloud-python/latest/pubsub/publisher/api/client.html However, the subscriber page is working. https://googlecloudplatform.github.io/google-cloud-python/latest/pubsub/subscriber/api/client.html Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: JAX with GPU support requires jaxlib version 0.1.26 I've got an issue. So, I followed the installation instructions here:  Then I run the following line in `JupyterLab`: ```python import jax.numpy as jnp ``` And that produces the following error: ```python ValueError: jaxlib is version 0.1.23, but this version of jax requires version 0.1.26. ``` I went back and changed the second last line to: ```bash pip install --upgrade $BASE_URL/$CUDA_VERSION/jaxlib-0.1.26-$PYTHON_VERSION-none-$PLATFORM.whl ``` Tried running. But, was denied.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: bump repodata pickle version in 4.3.x Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose does not have a way to override tls version at the commandline Using compose, if I set COMPOSE_TLS_VERSION DOCKER_TLS_VERIFY DOCKER_CERT_PATH docker-compose works fine and gives me no errors. If I decide to use command line argument instead of these environment variables, I have no way to set which version of TLS I want to use. For servers that do not support TLS version 1, I get the following errors: ERROR: SSL error: [SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:590) Setting the COMPOSE_TLS_VERSION environment variable and using compose with TLS arguments doesn't seem to work. Compose seems to ignore it if TLS cmdline options are used. --- docker-compose binary version 1.9.0 and 1.11.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Remove ParameterTable import From QFT.inverse <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Following https://github.com/Qiskit/qiskit-terra/pull/4319#discussion_r417599735 : > @mtreinish 1 hour ago Member > > Is there a reason this is a run time import? > @kdk > kdk 1 hour ago Author Member > > Only because it's a bit of hack (qft shouldn't have to manage it's own parameter table). Looking now though, this could be avoided if we set inverted.data = [] instead of inverted._data = []. I'll take care of that. @kdk kdk 1 hour ago Author Member > > Never mind, inverted.data = [] fails with AttributeError: can't set attribute. Maybe because BlueprintCircuit overrides the data property but not also the setter? @Cryoris Cryoris 44 minutes ago • Member > > super()._invalidate() > self._data = [] > > should work I think, the blueprint circuit resets the parameter table upon _invalidate. (Then also the _invalidate method of QFT can be removed). > >Actually, on a second look, the inverse method should probably be added to the BlueprintCircuit to do this inversion. Then inverse would return a BlueprintCircuit instead of a QuantumCircuit. But we can do this after the release, this is not crucial for the functionality. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: API Core PyType fails intermittently/changing errors https://github.com/googleapis/google-cloud-python/pull/6769 Copying from #6769 and @rchen152 > @crwilcox It looks like what's happening is that pytype is somehow finding multiple files named path_template.py (and timeout.py and grpc_helpers.py - the error probably differs because it varies which file pytype discovers first). The other thing I noticed is that the file count in the status message (\"Analyzing 53 sources with 0 dependencies\") differs from the one I see (28 sources). Any idea why there might be two copies of some source files? > > EDIT: if there are two files with the same name in different directories, this may be google/pytype#198. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: small improvement to DAGCircuit.replace_block_with_op() ### What should we add? Short version: - Add the line `return new_node` to the end of `DAGCircuit.replace_block_with_op()`. Details: `DAGCircuit.replace_block_with_op(block, op, ...)` internally creates a `new_node` containing `op`, and replaces the `block` of DAG nodes by this `new_node`. I think `replace_block_with_op()` should return `new_node`. (Currently there is no `return` statement). This change would be in line with the behavior of `DAGCircuit.substitute_node()`, which does return its internal `new_node`. Otherwise, the user does not know the node_id or even the name of the new node, so finding the new node for further manipulations is difficult. (All I can think of is to look along one of the wires for the one node in the new DAG that wasn't in the old DAG... obviously this is cumbersome.) Since the function already has `new_node` available internally, seems like we may as well `return` it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: transfer_to_batch_gpu returns null when input has primitives **Describe the bug** when passing a batch such as: ```python batch = list(tensor, tensor, [0,1,2]) ``` the list of ints won't be returned correctly **Additional context** Fix should add a return of the item it no condition matches Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose run should terminate container on SIGHUP When running `docker-compose run --rm $service $cmd`, the expectation is that the container will be terminated when docker-compose terminates. If docker-compose terminates due to SIGHUP (which can happen for example when docker-compose is run in a remote server and the ssh connection is terminated), it will leave the container running. It should stop and remove (if --rm was passed) the container. docker-compose run should terminate container on SIGHUP When running `docker-compose run --rm $service $cmd`, the expectation is that the container will be terminated when docker-compose terminates. If docker-compose terminates due to SIGHUP (which can happen for example when docker-compose is run in a remote server and the ssh connection is terminated), it will leave the container running. It should stop and remove (if --rm was passed) the container. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Create `translation` stage (translator, synthesis, unroller) plugins Create transpiler stage plugins and export them in the qiskit-terra metadata (similar to how the routing stage is done now) for the translation stage. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Create RSS Tasks for Task Library Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: MLM training for DeBERTa not supported: configuration class is missing When I ran the example script run_mlm.py to fine tune the pretrained deberta model on a customized dataset, I got the following error. The same command worked for roberta-base. The command: python run_mlm.py --model_name_or_path 'microsoft/deberta-base' --train_file slogans/train.txt --validation_file slogans/test.txt --do_train --do_eval --per_device_train_batch_size 64 --per_device_eval_batch_size 64 --learning_rate 1e-3 --num_train_epochs 10 --output_dir /home/jovyan/share2/xiaolin/models/mlm/temp --save_steps 5000 --logging_steps 100 The terminal error: Traceback (most recent call last): File \"run_mlm.py\", line 409, in <module> main() File \"run_mlm.py\", line 264, in main cache_dir=model_args.cache_dir, File \"/home/jovyan/.local/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py\", line 1093, in from_pretrained config.__class__, cls.__name__, \", \".join(c.__name__ for c in MODEL_FOR_MASKED_LM_MAPPING.keys()) ValueError: Unrecognized configuration class <class 'transformers.models.deberta.configuration_deberta.DebertaConfig'> for this kind of AutoModel: AutoModelForMaskedLM. Model type should be one of LayoutLMConfig, DistilBertConfig, AlbertConfig, BartConfig, CamembertConfig, XLMRobertaConfig, LongformerConfig, RobertaConfig, SqueezeBertConfig, BertConfig, MobileBertConfig, FlaubertConfig, XLMConfig, ElectraConfig, ReformerConfig, FunnelConfig, MPNetConfig, TapasConfig. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: basis translation method based on unitary synthesis As a follow-up to https://github.com/Qiskit/qiskit-terra/pull/4446, we should have another method for basis translation that relies on `OneQubitEulerDecomposer` and `TwoQubitBasisDecomposer`. There are some advantages to this, the main one being that the decompositions are algorithmic and can cover a wider range of basis. For example if someone comes up with some esoteric two-qubit gate as the native gate, this code will handle it whereas the EquivalenceLibrary is only as good as its populated content. This has to be done after all 3+ qubit gates are decomposed. Then I think a sequence of 1-qubit and 2-qubit block collection passes followed by invoking those synthesizers will do the job. It remains to be seen which basis translation method works best and it's something we will need to benchmark. But this empowers us to do so. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Operator(circuit) does not return the correct unitary <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information -Qiskit Terra version: 0.8.1 -Python version: 3.7.2 -Operating system: MacOS Mojave ### What is the current behavior? The data stored in Operator(circuit).data (with Operator imported from qiskit.quantum_info ) seems not to correspond to the right unitary for certain circuits. ### Steps to reproduce the problem Choose the following circuit: qasm = 'OPENQASM 2.0;' qasm += 'include \"qelib1.inc\";' qasm += 'qreg q[3];' qasm += 'creg c[3];' qasm += 'rx(3.141592653589793) q[2];' qasm += 'ry(0.294524311274043) q[2];' qasm += 'cx q[0],q[2];' qasm += 'ry(-0.0981747704246810) q[2];' qasm += 'cx q[1],q[2];' qasm += 'ry(0.0981747704246810) q[2];' qasm += 'cx q[0],q[2];' qasm += 'ry(-3.141592653589793) q[2];' circuit = QuantumCircuit.from_qasm_str(qasm) One finds a different result [than the one found by(Operator(circuit).data] using the unitary_simulator: simulator = BasicAer.get_backend('unitary_simulator') result = execute(circuit, simulator).result() unitary = result.get_unitary(circuit) matrix_equal(Operator(circuit).data, unitary, ignore_phase=True) The last line returns False. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Update context / config docs - config is now in context - users shouldn't directly modify config; always use context Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: refactor `bigquery_query_params_*` code samples to pass `query_parameters` to `QueryJobConfig` constructor **Is your feature request related to a problem? Please describe.** The code samples for using query parameters are a bit hard to follow because they create several temporary variables. https://github.com/googleapis/google-cloud-python/blob/518931bb306ed7cb78ce76323fbde289fbc15338/bigquery/docs/snippets.py#L1868-L1873 The code samples are still in `snippets.py`. Ideally these samples would be moved to the `samples/` directory. The code samples supply a `location` argument for queries, even though this can now be autodetected for queries in all regions. **Describe the solution you'd like** A clear and concise description of what you want to happen. - [ ] Move any `bigquery_query_params_...` samples to the `samples/` directory. - [ ] Remove the `location` argument from the `query()` method in the moved code samples - [ ] Use the `query_parameters` argument in the constructor to `QueryJobConfig` (added in https://github.com/googleapis/google-cloud-python/pull/6397). ```python job_config = bigquery.QueryJobConfig( query_parameters=[ bigquery.ScalarQueryParameter(\"corpus\", \"STRING\", \"romeoandjuliet\"), bigquery.ScalarQueryParameter(\"min_word_count\", \"INT64\", 250), ], ) ``` **Describe alternatives you've considered** A clear and concise description of any alternative solutions or features you've considered. N/A **Additional context** Add any other context or screenshots about the feature request here. Reported by customer in internal issue 143862711. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Regression in installing symlinked source files as regular files After https://github.com/mesonbuild/meson/issues/3914 systemd installation has regressed. The source tree has: ./units/basic.target (not installed) ./test/basic.target -> ../units/basic.target In test/meson.build it does: install_data(file, install_dir : testsdir + '/testdata/' + subdir) To install ./test/basic.target into ./usr/lib/systemd/tests/testdata/basic.target Previously with v0.47 and earlier, installation of ./test/basic.target into /usr/lib/systemd/tests/testdata/basic.target would result in a regular text file. Now with master it results in /usr/lib/systemd/tests/testdata/basic.target being a dangling symlink to a non-existant '../units/basic.target' I believe this is a regression and a change of behavior. It is slightly unexpected that a resolvable source file, started to be copied as a broken dangling symlink. Especially since install_symlink is not used.... Is this an upstream bug or feature? How should this be fixed in meson or in my meson.build? And to be backwards/forwards compatible with older and the upcoming meson versions.... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the kubeflow/pipelines codebase. Here's the problem: cmle training component should output job_dir.txt It should output the file regardless user provides jodDir or not, otherwise argo will fail. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Changes to files outside source dir do not trigger reconfigure In my Meson script, I read some configuration files that affect the build. If the config file is in the source dir, all is fine. However, if I'm reading a config file that is in the build dir, weird things happen. When the build dir is inside the source dir (I tested in `build` subdirectory), meson generates dependencies as expected and when config files change Meson is re-run automatically. However, when build dir is a sibling of the source dir, those same dependencies are _not_ generated and `ninja` ignores changes to those files. Here is a short test example: ```meson project( 'meson test', [ 'c', 'cpp' ], ) conf_file = files(meson.build_root() / '_testcfg') run_command('cat', conf_file) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Proposal: Support for creating volume and network with label options I have ran into a situation where I need to get networks and volumes created by a given compose project. I think it could be done by adding a label to the networks and volumes defined in the compose file and then I could query the networks and volumes by a label filter through docker api. But when I check the schema definition at **compose/config/config_schema_v2.0.json**, I found it's not supported by compose. Would it be better if creating volume and network with label options is supported? I could do this if this feature is reasonable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support --net value in fig.yml It should be possible to decide between one of available values for --net argument in run command (bridge, hoste, etc.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Cannot roll back with 'conda install --revision' ``` error: AttributeError(\"'dict' object has no attribute 'get_pfe'\",) command: C:\\Program Files\\Anaconda3\\Scripts\\conda install --revision 4 user_agent: conda/4.4.4 requests/2.18.4 CPython/3.5.2 Windows/8.1 Windows/6.3.9600 _messageid: -9223372036843575560 _messagetime: 1514442489595 / 2017-12-28 00:28:09 Traceback (most recent call last): File \"C:\\Program Files\\Anaconda3\\lib\\site-packages\\conda\\exceptions.py\", line 724, in __call__ return func(*args, **kwargs) File \"C:\\Program Files\\Anaconda3\\lib\\site-packages\\conda\\cli\\main.py\", line 78, in _main exit_code = do_call(args, p) File \"C:\\Program Files\\Anaconda3\\lib\\site-packages\\conda\\cli\\conda_argparse.py\", line 75, in do_call exit_code = getattr(module, func_name)(args, parser) File \"C:\\Program Files\\Anaconda3\\lib\\site-packages\\conda\\cli\\main_install.py\", line 11, in execute install(args, parser, 'install') File \"C:\\Program Files\\Anaconda3\\lib\\site-packages\\conda\\cli\\install.py\", line 232, in install progressive_fetch_extract = unlink_link_transaction.get_pfe() AttributeError: 'dict' object has no attribute 'get_pfe' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Numpy failing to install with python3.5 The new release of numpy fails to install when using python3.5. It seems clear the problem is the use of f string formatting in the setup.py file that is only supported in python 3.6 and higher. ### Reproducing code example: ``` docker run python:3.5.2-alpine pip install numpy==1.19.0rc1 ``` <!-- Remove these sections for a feature request --> ### Error message: File \"/tmp/pip-build-gg798dty/numpy/setup.py\", line 182 raise ValueError(f'Submodule {p} missing') ^ SyntaxError: invalid syntax ### Numpy/Python version information: Fails installing `numpy==1.19.0rc1` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: setting default_channels from CLI raises NotImplementedError Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Exception when constructing a Repo() from a pathlib.Path ``` python Traceback (most recent call last): File \"venv/bin/gridtied\", line 11, in <module> load_entry_point('gridtied', 'console_scripts', 'gridtied')() File \"/home/epc/g/20/grid-tied/venv/lib/python3.6/site-packages/click/core.py\", line 722, in __call__ return self.main(*args, **kwargs) File \"/home/epc/g/20/grid-tied/venv/lib/python3.6/site-packages/click/core.py\", line 697, in main rv = self.invoke(ctx) File \"/home/epc/g/20/grid-tied/venv/lib/python3.6/site-packages/click/core.py\", line 1066, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File \"/home/epc/g/20/grid-tied/venv/lib/python3.6/site-packages/click/core.py\", line 895, in invoke return ctx.invoke(self.callback, **ctx.params) File \"/home/epc/g/20/grid-tied/venv/lib/python3.6/site-packages/click/core.py\", line 535, in invoke return callback(*args, **kwargs) File \"/home/epc/g/20/grid-tied/python/gridtied/package.py\", line 59, in cli commit(), File \"/home/epc/g/20/grid-tied/python/gridtied/package.py\", line 35, in commit repo = git.Repo(gridtied.project_root) File \"/home/epc/g/20/grid-tied/venv/lib/python3.6/site-packages/git/repo/base.py\", line 119, in __init__ if expand_vars and (\"%\" in epath or \"$\" in epath): TypeError: argument of type 'PosixPath' is not iterable ``` https://github.com/gitpython-developers/GitPython/blob/master/git/repo/base.py#L119 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Tons of warnings on use of TransfoXLModel. masked_fill_ input dtype torch.uint8 should be changed to torch.bool ## 🕑 Usage of deprecated behaviour Using example from documentation web page: https://huggingface.co/pytorch-transformers/model_doc/transformerxl.html#pytorch_transformers.TransfoXLModel ``` import torch from pytorch_transformers import * tokenizer = TransfoXLTokenizer.from_pretrained('transfo-xl-wt103') model = TransfoXLModel.from_pretrained('transfo-xl-wt103') input_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is cute\")).unsqueeze(0) outputs = model(input_ids) last_hidden_states, mems = outputs[:2] ``` Get tons of same warnings: > /pytorch/aten/src/ATen/native/LegacyDefinitions.cpp:14: UserWarning: masked_fill_ received a mask with dtype torch.uint8, this behavior is now deprecated,please use a mask with dtype torch.bool instead.  Created #1120 to fix it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: plot_histogram sort by value there's a `sort` argument in `plot_histogram()` which sorts according to the keys. But it would be useful to be able to sort according to the values (i.e. height of bars). Like put the most likely outcomes first and so on. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Revisions: Manage non-pristine state in repo to capture the revision What to do during the export if the SCM folder contains not committed changes? Mark in metadata as \"dirty\" and forbid upload? What if we enable `scm_mode` to `hash` but still using `scm` feature? #4413 What if we don't use `scm` feature but revisions? Looks like it has to be marked as `dirty` both if we use the `scm_mode` as revisions mode and/or if we use the `scm` feature. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add support for Funnel-Transformer # 🌟 New model addition ## Model description The recently introduced Funnel-Transformer architecture and models would be a great feature for Transformers: >Funnel-Transformer is a new self-attention model that gradually compresses the sequence of hidden states to a shorter one and hence reduces the computation cost. More importantly, by re-investing the saved FLOPs from length reduction in constructing a deeper or wider model, Funnel-Transformer usually has a higher capacity given the same FLOPs. In addition, with a decoder, Funnel-Transformer is able to recover the token-level deep representation for each token from the reduced hidden sequence, which enables standard pretraining. The paper can be found [here](https://arxiv.org/abs/2006.03236). ## Open source status * [x] the model implementation is available: [official GitHub repo](https://github.com/laiguokun/Funnel-Transformer) * [x] the model weights are available: [Google Cloud Bucket](https://github.com/laiguokun/Funnel-Transformer/blob/master/download_all_ckpts.sh) * [x] who are the authors: @zihangdai and @laiguokun Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Download command switch to just download the recipe. Hi guys, congrats on getting 1.0 out! I think it might be useful to add a command switch for the download command to only download the conanfile.py. I have a use case where I need to re-host some packages locally on our own conan_server, when I do a search and download using conan it downloads all of the package folders for a package. To save on time and bandwidth it would be useful to just download the recipe and build the packages our devs will use ourselves. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: wxWidgets dependency: static option not working ## Description The option to link the dependency static is not working for wxWidgets. However, I've found a little hack to make it work, but I guess that's something that should be fixed. ## Expected behaviour: if the dependency is declared as: ``` wxDep = dependency('wxwidgets', version : '>=3.0.0', required : true, static : true, modules : ['std', 'stc']) ``` The application should built with static linking of the wxWidgets-modules. ## What happens: The application builds successful, but is not linked static. ## Temporary workarond I've found a workaround, by doing this: ``` add_project_link_arguments('--static', language : ['c', 'cpp']) #This is needed to also link other libraries static wxDep = dependency('wxwidgets', version : '>=3.0.0', required : true, modules : ['--static', 'std', 'stc']) ``` This way, it's build with fully static linking. Build command used: ``` meson setup build_win --default-library=static && ninja -C build_win ``` Systeminfo: Windows 10, MSYS2/mingw64 subsystem Meson Version: 0.53, installed within MSYS2 I'll attach the Testproject, so you can reproduce this (Includes buildfiles and logs). [wxTest.zip](https://github.com/mesonbuild/meson/files/4142792/wxTest.zip) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Qasms with composite gates don't load Here is the qasm string 'OPENQASM 2.0;\\ninclude \"qelib1.inc\";\\ngate r q { h q; s q; h q; s q; }\\ngate rinv q {sdg q; h q; sdg q; h q; }\\ngate sinv q {s q; z q;}\\nqreg q[3];\\ncreg c[3];\\nrinv q[0];\\ncx q[1], q[2];\\nr q[1];\\nrinv q[2];\\ncx q[0], q[2];\\nrinv q[0];\\nr q[2];\\ncx q[0], q[1];\\nrinv q[1];\\ny q[0];\\nbarrier q[0], q[1], q[2];\\nr q[1];\\ncx q[0], q[1];\\nrinv q[2];\\nr q[0];\\ncx q[0], q[2];\\nr q[2];\\nrinv q[1];\\ncx q[1], q[2];\\nr q[0];\\nx q[0];\\nz q[1];\\nmeasure q[0] -> c[0];\\nmeasure q[1] -> c[1];\\nmeasure q[2] -> c[2];' If I run `from_qasm_str` I get `QiskitError: 'unknown operation for ast node name rinv'` ### Informations - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Outdated conda notification does not respect `-q` arg The notify_outdated_conda warning checks only `if context.notify_outdated_conda`, but I think it should check `if context.notify_outdated_conda and not context.quiet`. If I specify the `-q` flag, I don't want to see this warning. Outdated conda notification does not respect `-q` arg The notify_outdated_conda warning checks only `if context.notify_outdated_conda`, but I think it should check `if context.notify_outdated_conda and not context.quiet`. If I specify the `-q` flag, I don't want to see this warning. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Disable default sigmoid function for single label classification Inference API # 🚀 Feature request Allow people to disable the default sigmoid function in TextClassificationPipeline (maybe via model cards?). ## Motivation When we use the sequence classification model (e.g. RobertaForSequenceClassification) for regression tasks, the output may have different ranges other than [0,1], it would be better to allow configurations for the sigmoid function in TextClassificationPipeline. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Missing implicit dependency to generated code **Describe the bug** When using the result of `custom_target` as source to a build target, an implicit dependency (or order-only dependency?) should be added to each object file to ensure that the generated code is built before the other sources, because the other sources may depend on the generated code. **To Reproduce** Try to build the project https://github.com/rtbo/meson-dep-test (meson.build copied hereafter). Compilation of `lib.d` races with compilation of `generated.d` and cannot find module `generated`. If I manually add `generated.o` as implicit dependency of `lib.o` in `ninja.build`, everything is file. ```meson project('meson-dep-test', 'd') generator = executable('generator', 'generator.d') generated = custom_target('generated', capture: true, output: 'generated.d', input: 'input.txt', command: [ generator, '@INPUT@' ] ) lib = static_library('lib', generated, 'lib.d', include_directories: include_directories('.'), ) ``` **Expected behavior** Reliable build without race **system parameters** Arch Linux meson master branch (0.62.99) Python 3.10.4 Ninja 1.11.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: c_std and cpp_std are not honored when compiling Objective-C/C++ files ``` $ echo 'int main(void){return 0;}' > x.m $ cat > meson.build project('test', 'objc', default_options: ['c_std=c99']) executable('testexe', 'x.m') ``` If you set this up and build with `ninja -v`, you'll see ``` [1/2] cc -Itestexe@exe -I. -I.. -pipe -Wall -Winvalid-pch -g -MD -MQ 'testexe@exe/x.m.o' -MF 'testexe@exe/x.m.o.d' -o 'testexe@exe/x.m.o' -c ../x.m ``` Notice how the c99 flag is not properly applied. I see `objc_args` was a thing, but changing to `objc_std` does not fix it. The same happens with `cpp_std` and Objective-C++. This is causing build errors for me as I'm using C++11-only features. (And that project also uses `add_language()` to add `objc` and `objcpp` on macOS only.) Currently using meson 0.50.1 (through MacPorts) on macOS Sierra with Xcode 9.2. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Release 'datastore 1.7.0' Major changes are: - Add support for Python 3.7. - Drop support for Python 3.4. - Bugfix: query offsets (#4675). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Tests for flags fail on clang with -Weverything -Werror due to missing variable declarations Setting C/CXXFLAGS to \"-Weverything -Werror\" causes checks for compiler flags (e.g., `cc.has_argument('-fopenmp-simd')`) to always fail because the test Meson uses to check the flag uses an undeclared variable, which triggers clang's `-Wmissing-variable-declarations` diagnostic. I'm not sure when -Wmissing-variable-declarations was added to clang, but it is definitiely included in 10.0. I can't imagine you need any help reproducing this, but if you do you can use [SIMDe](https://github.com/nemequ/simde). Here is the relevant output from meson-logs/meson-log.txt: ``` Running compile: Working directory: /home/nemequ/local/src/simde/build/meson-private/tmpfvjq1jts Command line: clang /home/nemequ/local/src/simde/build/meson-private/tmpfvjq1jts/testfile.c -o /home/nemequ/local/src/simde/build/meson-private/tmpfvjq1jts/output.obj -pipe -c -Weverything -Werror -D_FILE_OFFSET_BITS=64 -O0 -Werror=unknown-warning-option -Werror=unused-command-line-argument -Werror=ignored-optimization-argument -fopenmp-simd Code: int i; Compiler stdout: Compiler stderr: /home/nemequ/local/src/simde/build/meson-private/tmpfvjq1jts/testfile.c:1:5: error: no previous extern declaration for non-static variable 'i' [-Werror,-Wmissing-variable-declarations] int i; ^ /home/nemequ/local/src/simde/build/meson-private/tmpfvjq1jts/testfile.c:1:1: note: declare 'static' if the variable is not intended to be used outside of this translation unit int i; ^ 1 error generated. Compiler for C supports arguments -fopenmp-simd: NO ``` Note that `-Wc++98-compat-pedantic` is also triggered by the missing newline, which causes checks for OpenMP to fail. I suspect that this is the same root issue, and that is just the C++ manifestation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: UI time zone not used in Gantt charts tooltips **Apache Airflow version**: v2.0.0.dev0 **Kubernetes version (if you are using kubernetes)** (use `kubectl version`): - **Environment**: Docker - **Cloud provider or hardware configuration**: - - **OS** (e.g. from /etc/os-release): Debian GNU/Linux 10 (buster) - **Kernel** (e.g. `uname -a`): Linux 6dac905dd519 4.19.76-linuxkit #1 SMP Thu Oct 17 19:31:58 UTC 2019 x86_64 GNU/Linux - **Install tools**: Airflow Breeze (image: apache/airflow:master-python3.6-ci) - **Others**: - **What happened**: Gantt charts seem to always use UTC for displaying task start/end dates, but use local time for time axis, regardless of the time zone set in UI (see screens below: my local time zone is CEST). <img width=\"815\" alt=\"Zrzut ekranu 2020-04-8 o 09 18 50\" src=\"https://user-images.githubusercontent.com/34898234/78764706-3c73f680-7987-11ea-925b-e394ac329298.png\"> <img width=\"840\" alt=\"Zrzut ekranu 2020-04-8 o 09 17 17\" src=\"https://user-images.githubusercontent.com/34898234/78764752-4eee3000-7987-11ea-957b-338376d1bf41.png\"> <img width=\"925\" alt=\"Zrzut ekranu 2020-04-8 o 10 58 09\" src=\"https://user-images.githubusercontent.com/34898234/78765233-01be8e00-7988-11ea-8215-9179102cb390.png\"> **What you expected to happen**: Time zone of the time axis and task start/end dates should be the same - probably the time zone specified in the UI should be used. **How to reproduce it**: Simply go to Gantt chart of any Dag Run and try changing the time zone in the UI to see that neither the time axis nor task start/end dates reflect the change. You can also change the local time on your workstation and refresh the page with Gantt chart to see that time axis changed to reflect the new time zone. **Anything else we need to know**: - Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: link to SciPy's multidimensional interpolation functions <!-- Please describe the issue in detail here, and fill in the fields below --> ### Reproducing code example: np.interp currently requires its `fp` argument to be one-dimensional. An obvious generalization would be to allow interpolation of `R->R^n` functions, by allowing `fp` to have shape (..., len(x)) (or (len(x), ...) -- whichever is consistent with e.g. polyfit). Obviously the shapes of `left` and `right` should be adjusted accordingly. Thoughts? ### Numpy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> ``` 1.17.0 3.7.3 (default, Mar 27 2019, 22:11:17) [GCC 7.3.0] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [general] Documentation on page_size is very minimal. The explanation of page_size is extremely limited. Example from the [logging API:](https://github.com/googleapis/google-cloud-python/blob/master/logging/google/cloud/logging/client.py#L185) `maximum number of entries to return, If not passed, defaults to a value set by the API.` If you're familiar with gRPC then this makes sense, but for newcomers this is extremely limited information. Simple wording change can make a lot of difference here IMHO. Looking at [this example](https://googleapis.github.io/google-cloud-java/google-cloud-clients/apidocs/com/google/cloud/spanner/Options.html#pageSize-int-) from the Cloud Spanner Javadocs shows a slight change, but makes it easier to understand: `Specifying this will cause the list operations to fetch at most this many records in a page.` On a semi-related note, having usage examples would also clarify the usage a lot, but this can be said for all methods in the whole python library. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: make python examples using_qiskit* and other examples run as a test <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? Since the using_qiskit are to be use case examples we need to make them part of the tests. We would have found out that job.done was used and I'm hoping user did note make examples based on this when we make this release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Some state visualizations have illegible parts when using a non-default matplotlib style <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.14.0 - **Python version**: 3.8.2 - **Operating system**: Manjaro ### What is the current behavior? Some state visualizations are illegible when using a non-default matplotlib style. ### Steps to reproduce the problem In Jupyter: ```python import matplotlib.pyplot as plt plt.style.use(\"dark_background\") ``` Then run the example code in [`plot_state_qsphere`'s documentation](https://qiskit.org/documentation/stubs/qiskit.visualization.plot_state_qsphere.html).  Some other [\"Counts and State Visualizations\"](https://qiskit.org/documentation/apidoc/visualization.html#counts-and-state-visualizations) functions are affected. Testing with their example code produces the following issues: * `plot_bloch_vector`: x, y, \\ket{0}, \\ket{1} labels invisible * `plot_bloch_multivector`: same as `plot_bloch_vector` * `plot_state_qsphere`: sphere is invisible; the word \"Phase\" in the center of the phase legend is invisible Note that in testing these, you will want to configure Jupyter to use a dark page background (as otherwise white text may be printed on Jupyter's default white background). JupyterLab's dark theme is one possible option. ### What is the expected behavior? Colors should dynamically change based on the current style. ### Suggested solutions Change colors dynamically based on the current style. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: S3KeySensor wildcard_match only matching key prefixes instead of full patterns ### Apache Airflow Provider(s) amazon ### Versions of Apache Airflow Providers 3.4.0 ### Apache Airflow version 2.3.2 (latest released) ### Operating System Debian GNU/Linux 10 ### Deployment Docker-Compose ### Deployment details _No response_ ### What happened For patterns like \"*.zip\" the S3KeySensor succeeds for all files, does not take full pattern into account i.e. the \".zip\" part). Bug introduced in https://github.com/apache/airflow/pull/22737 ### What you think should happen instead Full pattern match as in version 3.3.0 (in S3KeySensor poke()): ``` ... if self.wildcard_match: return self.get_hook().check_for_wildcard_key(self.bucket_key, self.bucket_name) ... ``` alternatively the files obtained by `files = self.get_hook().get_file_metadata(prefix, bucket_name)` which only match the prefix should be further filtered. ### How to reproduce create a DAG with a key sensor task containing wildcard and suffix, e.g. the following task should succeed only if any ZIP-files are available in \"my-bucket\", but succeeds for all instead: `S3KeySensor(task_id=\"wait_for_file\", bucket_name=\"my-bucket\", bucket_key=\"*.zip\", wildcard_match=True)` ### Anything else Not directly part of this issue but at the same time I would suggest to include additional file attributes in method _check_key, e.g. the actual key of the files. This way more filters, e.g. exclude specific keys, could be implemented by using the check_fn. ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Move tools.qi to a folder quantum_info Move tools.qi to a foder quantum_info. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: How to install transformers with pytorch only? ## ❓ Questions & Help Hi! Pytorch1.0 is installed and I'm installing the transformers with pip, everything is fine. But when I try: ``` import torch from transformers import BertModel ``` then, an error occurred: ``` Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/home/pc/miniconda3/lib/python3.7/site-packages/transformers/__init__.py\", line 20, in <module> from .file_utils import (TRANSFORMERS_CACHE, PYTORCH_TRANSFORMERS_CACHE, PYTORCH_PRETRAINED_BERT_CACHE, File \"/home/pc/miniconda3/lib/python3.7/site-packages/transformers/file_utils.py\", line 30, in <module> assert int(tf.__version__[0]) >= 2 AttributeError: module 'tensorflow' has no attribute '__version__' ``` It seems like it cannot work unless both the tensorflow and pytorch have been installed, is that right? And is there a way to run transformers with pytorch only? (I don't want to install tensorflow) Thanks in advance! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: think a bit about namespaces We don't think carefully enough about namespaces and imports, and we really should for anything that would reasonably be imported by code outside IPython (API consumers or interactive user code). Some current bad examples: ``` python from IPython.config.loader import Config # should be accessible as from IPython.config import Config ``` - display classes are split between core.display and lib.display (YouTube being the only one defined in lib). The divide made some sense from a code boundary standpoint, but APIs shouldn't expose this kind of thing. There should be a single import where all of these are defined. - The relationship of embedding and config/namespace initialization is still a mess. I cringe every time I have to tell someone to `from IPython.frontend.terminal.embed import InteractiveShellEmbed`. Four levels deep is simply too much for a public API like this. - `IPython.parallel` is meant to be the entire API namespace for the parallel stuff, but some (not all!) decorators are not pulled from parallel.util into top-level parallel. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Remove pkgs/pro from defaults in conda 4.6 For the release for conda 4.6.0, remove `https://repo.anaconda.com/pkgs/pro` from the default value for `defaults`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: gnome.generate_gir() is failing with address sanitizer. Compiling fwupd with: meson .. -Db_sanitize=address ...completes until it gets to the `g-ir-scanner` calls. This returns: [1/4] 'Generating Fwupd-1.0.gir with a custom command.' FAILED: libfwupd/Fwupd-1.0.gir '/usr/bin/g-ir-scanner' '../libfwupd/fwupd-client.c' '../libfwupd/fwupd-enums.c' '../libfwupd/fwupd-enums.h' '../libfwupd/fwupd-error.c' '../libfwupd/fwupd-remote.c' '../libfwupd/fwupd-result.c' '-I/usr/include/gobject-introspection-1.0' '-I/usr/include/glib-2.0' '-I/usr/lib64/glib-2.0/include' '-pthread' '--no-libtool' '--namespace=Fwupd' '--nsversion=1.0' '--warn-all' '--output' 'libfwupd/Fwupd-1.0.gir' '-I/home/hughsie/Code/fwupd/libfwupd' '-I/home/hughsie/Code/fwupd/build/libfwupd' '-I./libfwupd/..' '-I../libfwupd/..' '--include=GObject-2.0' '--cflags-begin' '-fstack-protector-strong' '-Wwrite-strings' '--cflags-end' '--symbol-prefix=fwupd' '--identifier-prefix=Fwupd' '--pkg-export=fwupd' '..' '-I/usr/include/gio-unix-2.0/' '-I/usr/include/glib-2.0' '-I/usr/lib64/glib-2.0/include' '-pthread' '-I/usr/include/libsoup-2.4' '-I/usr/include/libxml2' '-L/home/hughsie/Code/fwupd/build/libfwupd' '--extra-library=gio-2.0' '--extra-library=gobject-2.0' '--extra-library=glib-2.0' '--extra-library=soup-2.4' '--library' 'fwupd' ==6599==ASan runtime does not come first in initial library list; you should either link runtime to your application or manually preload it with LD_PRELOAD. Command '[u'/home/hughsie/Code/fwupd/build/tmp-introspectKke532/Fwupd-1.0', u'--introspect-dump=/home/hughsie/Code/fwupd/build/tmp-introspectKke532/functions.txt,/home/hughsie/Code/fwupd/build/tmp-introspectKke532/dump.xml']' returned non-zero exit status 1 I think the gnome module needs to remove the address sanitization flags before passing them to `/usr/bin/g-ir-scanner` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Batching broken for non-monoidal reducers repro: >>> import jax.numpy as np >>> from jax import vmap >>> vmap(np.any)(np.array([[True, False], [False, False]])) jax/lib/xla_bridge.py:138: UserWarning: No GPU found, falling back to CPU. warnings.warn('No GPU found, falling back to CPU.') Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"jax/api.py\", line 149, in batched_fun out_flat = batching.batch(flat_fun, in_flat, in_axes_, out_axes) File \"jax/interpreters/batching.py\", line 43, in batch out_val, out_dim = batch_transform(fun).call_wrapped(in_vals, in_dims) File \"jax/linear_util.py\", line 85, in call_wrapped ans = self.f(*args, **self.kwargs) File \"jax/numpy/lax_numpy.py\", line 607, in reduction result = lax.reduce(a, _reduction_init_val(a, init_val), op, dims) File \"jax/lax.py\", line 260, in reduce dimensions=tuple(dimensions)) File \"jax/core.py\", line 74, in bind out_tracer = top_trace.process_primitive(self, tracers, kwargs) File \"jax/interpreters/batching.py\", line 119, in process_primitive val_out, dim_out = batched_primitive(vals_in, dims_in, **params) TypeError: reducer_batcher() takes exactly 4 arguments (3 given) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: OpenAIGPTModel raises exception with `afn=\"Relu\"` ### System Info - `transformers` version: 4.30.2 - Platform: Linux-5.4.0-148-generic-x86_64-with-glibc2.31 - Python version: 3.9.16 - Huggingface_hub version: 0.16.4 - Safetensors version: 0.3.1 - PyTorch version (GPU?): 2.0.1+cu117 (True) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: no - Using distributed or parallel set-up in script?: no ### Who can help? @ArthurZucker @younesbelkada ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction ```python from transformers.models.openai import OpenAIGPTConfig, OpenAIGPTModel OpenAIGPTModel(OpenAIGPTConfig(n_vocab=1, n_embed=1, afn=\"relu\"))(torch.eye(1, dtype=int)) # raises: # AttributeError: 'ReLU' object has no attribute 'size' ``` ### Expected behavior I would expect no error to be raised and the calculation to be performed. For example, the following code behaves as expected: ```python OpenAIGPTModel(OpenAIGPTConfig(n_vocab=1, n_embed=1, afn=\"gelu\"))(torch.eye(1, dtype=int)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: .hgtags included in dist archive **Describe the bug** When running `ninja dist` the resulting `tar.xz` includes the `.hgtags` files that distros (namely debian) will mark as a packaging error. **To Reproduce** Run `ninja dist` on a mercurial repository that has at least 1 tag. **Expected behavior** That the archive does not have the `.hgtags` file in it. I just did an `hg archive` and unfortunately saw that `.hgtags` was there as well. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? Native * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) Linux, Debian Unstable * what Python version are you using e.g. 3.8.0: 3.7.6 * what `meson --version`: 0.53.1 * what `ninja --version` if it's a Ninja build: 1.9.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose version should show git hash It would be nice if `docker-compose --version` showed also the Git SHA which the \"binary\" was compiled with. Having some struggles with compiling Compose, I wanted to verify that I was in fact using the correct version. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: commit requires author to be Actor, not string Documentation is wrong about the author parameter: it has to be an Actor, not a string. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Allow colors for container log messages to be specified in docker-compose.yml When debugging a particular group of containers run with `docker-compose`, one becomes very familiar with looking for messages reported from a certain color. However, every once in a while these colors unpredictably change. It would be nice if the RGB code could be specified for each container in the `docker-compose.yml` file, to ensure the colors are always what I expect. Including @nweston, whose brought this idea to my attention. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: scatter/gather fail with targets='all' ``` python dview = rc.direct_view(targets='all') dview.scatter('x', range(16)) ``` gives: ``` TypeError: 'a' not valid str target, must be 'all' ``` Because it is trying to scatter across targets `['a', 'l', 'l']`. Fix coming... Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qc.qasm() does not create valid QASM when \"qreg\" or \"creg\" are register names <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.7 - **Operating system**: MacOS ### What is the current behavior? If you set the name of circuit register as `qreg` or `creg` in your QASM, then the parser fails. ### Steps to reproduce the problem In general, ny name is allow for registers ```python from qiskit import * qr = QuantumRegister(1,'qreg') cr = ClassicalRegister(1,'creg') qc = QuantumCircuit(qr, cr) print(qc.qasm()) ``` ``` OPENQASM 2.0; include \"qelib1.inc\"; qreg qreg[1]; creg creg[1]; ``` However, the parse seems not supporting `qreg` or `creg` as names: ```python QuantumCircuit.from_qasm_str(qc.qasm()) ``` ``` QasmError: \"Expected an ID, received 'qreg'\" ``` ### What is the expected behavior? I'm not fully sure if `qreg` and `creg` are reserved words in the specification. If so, It should not be allowed to do `ClassicalRegister(1,'creg')` (or, alternatively, change the name when `qc.qasm()`, with a warning). Otherwise, the parser needs to be fixed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: rzz gate <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.7.2 - **Python version**: 3.6.6 - **Operating system**: Windows 10 ### What is the current behavior? rzz gate appears to give incorrect results ### Steps to reproduce the problem rzz gate rule defined in https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/extensions/standard/rzz.py ``` CnotGate(q[0], q[1]), U1Gate(self.params[0], q[0]), CnotGate(q[0], q[1]) ``` ### What is the expected behavior? I think it should be ``` CnotGate(q[0], q[1]), U1Gate(self.params[0], q[1]), CnotGate(q[0], q[1]) ``` the u1 phase should be on the target instead of control ### Suggested solutions modify rzz gate definition to give the right behavior. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: PassManager should record execution time for each pass <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? The `PassManager` should record the execution time for each pass that it runs, and this information should be easily retrievable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Support gcc 7.4 in settings.yml Conan: 1.19.1 gcc 7.4 is the current system compiler on [Ubuntu 18.04 Bionic](https://packages.ubuntu.com/bionic/gcc) but is not \"supported\" by conan at the moment out of the box. Considering that Bionic is even a LTS versions I think it is important to add this gcc versions to conan's default `settings.yml`. For reference, gcc 7.4 was apparently already (released in [December 2018](https://gcc.gnu.org/gcc-7/)). Best, Mario Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: non-zero exit status not returned when error happens with `-c` This should return an exit status of 1 IIUIC ```bash $ ipython -c \"import blah\" Using matplotlib backend: Qt5Agg --------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) <ipython-input-1-253b2e59e51a> in <module>() ----> 1 import blah ModuleNotFoundError: No module named 'blah' $ echo $? 0 ``` This works for the normal python interpreter ```bash $ python -c \"import blah\" Traceback (most recent call last): File \"<string>\", line 1, in <module> ModuleNotFoundError: No module named 'blah' $ echo $? 1 ``` and if you use a file instead of `-c` ```bash $ echo \"import blah\" > test.py $ ipython test.py Using matplotlib backend: Qt5Agg --------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) ~/Desktop/civis-jupyter-notebook/test.py in <module>() ----> 1 import blah ModuleNotFoundError: No module named 'blah' $ echo $? 1 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: [dagster-bigquery-pandas] investigate usage of load_table_from_dataframe and to_dataframe instead of pandas_gbq ### What's the use case? bigquery provides an out of box `load_table_from_dataframe` and `to_dataframe` methods that we could use instead of pandas_gbq. Would need to investigate that these methods will be drop-in replacements. For example, based on api docs it is unclear is load_table_from_dataframe will append or overwrite an existing table https://cloud.google.com/python/docs/reference/bigquery/latest/google.cloud.bigquery.client.Client#google_cloud_bigquery_client_Client_load_table_from_dataframe https://cloud.google.com/bigquery/docs/samples/bigquery-load-table-dataframe https://cloud.google.com/bigquery/docs/samples/bigquery-list-rows-dataframe this would also allow custom LoadJobConfig https://cloud.google.com/python/docs/reference/bigquery/latest/google.cloud.bigquery.job.LoadJobConfig ### Ideas of implementation _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: For loop support in python interpreter of Transformer agent ### Feature request Hello, I would like to add for loop support in https://github.com/huggingface/transformers/blame/c2393cad085e3875ee2206d917d46d15e50602a3/src/transformers/tools/python_interpreter.py Any idea about how to implement this? ### Motivation For loop is quite common in generated code. Usually it will not cause infinite loop. ### Your contribution An additional 'elif' for 'ast.For' before the 'else' will be nice: https://github.com/huggingface/transformers/blame/c2393cad085e3875ee2206d917d46d15e50602a3/src/transformers/tools/python_interpreter.py#L132 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: flake8 error on master branch, file compose/bundle.py When trying to run the test suite on master branch the pre-commit hook fails with an flake8 error: ``` $ script/test/default Flake8...................................................................Failed hookid: flake8 compose/bundle.py:124:5: E722 do not use bare except' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Default DOMWidget Padding should be 0px, and Button styling issue @jdfreder  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose config doesn't print ':' when first port is 0 From @lawrencepit in docker/for-mac#1824: We have this docker-compose.yml file: ``` version: '2' services: test: image: test container_name: test ports: - 0:80 ``` Then: ``` $ docker-compose --file docker-compose-test.yml config services: test: container_name: test image: test ports: - 080/tcp version: '2.0' ``` Expected result: The output should be: ``` ports: - 0:80/tcp ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Change default value for 'allow_softlinks' from True to False The `allow_softlinks` configuration parameter can be dangerous. Softlinks into prefixes directly from the package cache will often lead to environment corruption. It was an oversight that the default value for `allow_softlinks` is set to `True`. In conda 4.4, we should definitely change the default value to `False`. We should also consider it even for the next 4.3.x release. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: MAINT: exec_command() cleanup With the impending demise of `exec_command()` related to #11824, there will soon only be unit tests that call this function in our code base even though it will no longer be used. The unit tests are in `numpy/distutils/tests/test_exec_command.py` -- will we want to remove the tests that specifically call `exec_command()`? I assume we won't want to unit test the standard library stuff we've replaced `exec_command()` with. Also, do we need a deprecation marker of some sort on `exec_command()` before removing it? I'm not sure how public-facing / used it is; maybe I need to check that deprecation policy NEP again! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: num_training_batches rounds down, causing 0 batches count ## 🐛 Bug self.num_training_batches is defined using int [here](https://github.com/williamFalcon/pytorch-lightning/blob/ca73b70d15bc8db3f57c1fd2d3bf152e6e1d7c4e/pytorch_lightning/trainer/data_loading.py#L52), which rounds it down to 0 when a small training_percent_check or overfit_pct is used, even though at least 1 batch is still processed. This does not cause any errors in \"vanilla\" lightning, but crashes any user code that uses the number of batches in a division (for example to get an average of some quantity over batches). ### To Reproduce Steps to reproduce the behavior: Set the training percentage to a small enough percentage that the number of examples is smaller than the batch size for a given dataset. This would require a very simple fix, either to use `math.ceil()` or `max(1, self.num_training_batches)`, depending of how the quantity is expected to behave in the rest of the code. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: No module named 'transformers' after installing from source ### System Info Ubuntu 22.04 in Windwos WSL 2. ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction I just followed the doc [here](https://huggingface.co/docs/transformers/installation#install-from-source). However, error occured as below: ``` wu@DESKTOP-COM:~/llama.cpp/transformers$ python Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] on linux Type \"help\", \"copyright\", \"credits\" or \"license\" for more information. >>> import transformers Traceback (most recent call last): File \"<stdin>\", line 1, in <module> ModuleNotFoundError: No module named 'transformers' ``` ### Expected behavior No error occured. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: SyntaxWarning with Python 3.8 ``` >>> import sys, numpy; print(numpy.__version__, sys.version) C:\\Program Files\\Python38\\lib\\site-packages\\numpy\\ma\\core.py:4466: SyntaxWarning: \"is\" with a literal. Did you mean \"==\"? if self.shape is (): 1.16.4 3.8.0b2 (tags/v3.8.0b2:21dd01d, Jul 4 2019, 16:00:09) [MSC v.1916 64 bit (AMD64)] ``` [Python 3.8](https://docs.python.org/3.8/whatsnew/3.8.html): > now produces a [SyntaxWarning](https://docs.python.org/3.8/library/exceptions.html#SyntaxWarning) when identity checks (`is` and `is not`) are used with certain types of literals (e.g. strings, ints). These can often work by accident in CPython, but are not guaranteed by the language spec. The warning advises users to use equality tests (`==` and `!=`) instead. https://bugs.python.org/issue34850, https://github.com/python/cpython/pull/9642, https://github.com/python/cpython/commit/3bcbedc9f1471d957a30a90f9d1251516b422416 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: [dagster-bigquery] add `timeout` configuration ### What's the use case? ability to configure `timeout` for all of the bigquery client methods ### Ideas of implementation _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Gates do not check if complex inputs passed in <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: - **Operating system**: ### What is the current behavior? This works: ```python from qiskit import * qc = QuantumCircuit(2, 2) qc.h(0) qc.rx(1+1j, 0) qc.cx(0, 1) qc.measure([0, 1], [0, 1]) qc.draw() ``` but it should not. It only gets caught later with: ``` TypeError: can't convert complex to float ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: sizeof compiler check should #include after {prefix} Else, things like `#define _GNU_SOURCE` do not get applied to it. https://github.com/systemd/casync/pull/160#issuecomment-406201718 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: storage: Switch to JSON API v1 Google Cloud Storage v1beta2 is deprecated and will be shut down in a couple of months. Please upgrade to v1: https://developers.google.com/storage/docs/json_api/release_notes#april302014 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: Add timeout parameter to all Client and Job methods where applicable The upcoming fix for #7831 will add a `timeout` parameter to the `QueryJob.done()` method. As this is not the only public method that can get stuck at the transport layer, we need to add an option to specify a timeout to these methods, too. **Update:** This excludes the `load_table_from_file()` method and methods depending on it. These will be handled separately in #10005. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Conan install ignores top-level hooks To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. I'm using Conan version 1.11.2 on Windows 10. While trying out the new \"hooks\" feature I had problems installing them using \"conan install\". I did the following: * Create a folder with the following folder structure ``` myconfig ├── hooks │ ├── my-hook.py │ └── conan.conf ``` * Call `conan config install myconfig` I would expect, that the \"my-hook.py\" will be copied in to the \".conan/hooks\" directory. Instead, nothing is copied. I noticed, that it works, if the hook is in a subfolder, i.e. a structure like ``` myconfig ├── hooks │ ├── my-hook │ |---- my-hook.py └── conan.conf ``` is copied properly. Did I miss something? Is it now *required* to use subfolders in the hooks directory? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: preprocessing_num_workers missing in run_summarization_no_trainer Hello, I find that in script: https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization_no_trainer.py The `preprocessing_num_workers` does not exist. It just appears in the arguments, but does not take effect in dataset map operations. So is it intentionally missing ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: VQE should batch per default ### What should we add? The VQE is most commonly used with SPSA or gradient descent, which require 2 or (up to) 2 * `num_parameters` circuit evaluations per iterations, respectively. Since the new execution model is shifting from using the runtime VQE program to the primitive-based VQE in Terra, we should also enable batching as many circuits per default as possible. Otherwise the standard usage of the VQE will be much slower than necessary (~2 or 2 * `num_parameters` to slow 😅). This is something the runtime VQE also did, maybe we can use the same defaults? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Docker-compose start strange behviour when containers are not available When I use `docker-compose start ` before a `docker-compose up` I obtain the following result: ``` Starting mongo ... done Starting elasticsearch ... done Starting transporter ... done Starting pdf ... done Starting back ... done Starting front ... done ERROR: No containers to start ``` This behaviour is pretty strange as the output is contradictory it says that it start all containers but the errors say the opposite. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: casting parametric parameters into int in addition to floats <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit version**: 0.20.0 - **Python version**: 3.8.5 - **Operating system**: OSX ### What is the current behavior? When trying to bind an integer for a circuit.Parameter() into a qiskit.pulse.library.Waveform(), the parameter needs to be casted into a float, then into an integer before it can be bound. references: https://qiskit.org/documentation/tutorials/pulse/6_pulse_scheduler.html ### Steps to reproduce the problem def gs_pulse(duration): duration = int(float(duration)) # hacky solution needed ATM... TODO? return qiskit.pulse.library.GaussianSquare(duration,0.5,64,64) def random_2q_gate(x): sched = qiskit.pulse.Schedule() sched = sched.insert(0,Play(gs_pulse(x), DriveChannel(1))) return sched my_random_2q_gate = ParameterizedSchedule(random_2q_gate, parameters=['x']) ### What is the expected behavior? binding a parameter should maintain the datatype through to the parameterExpression ### Suggested solutions Talk to @lcapelluto , @taalexander , or #4940 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: typify for str + NoneType is wrong https://github.com/conda/conda/pull/5107#issuecomment-296356913 It still seems to me as if `typify()` is doing something wrong: ```python >>> from conda._vendor.auxlib.configuration import typify >>> typify('false', str) 'false' >>> typify('false', (str, type(None))) 'False' ``` Why should addition of type `None` introduce such a change? The code flow is: ```python elif not (type_hint - (STRING_TYPES_SET | {NoneType})): value = typify_str_no_hint(text_type(value)) return None if value is None else text_type(value) ``` I wonder why not just return `text_type(value)`? Why call `typify_str_no_hint`? typify for str + NoneType is wrong https://github.com/conda/conda/pull/5107#issuecomment-296356913 It still seems to me as if `typify()` is doing something wrong: ```python >>> from conda._vendor.auxlib.configuration import typify >>> typify('false', str) 'false' >>> typify('false', (str, type(None))) 'False' ``` Why should addition of type `None` introduce such a change? The code flow is: ```python elif not (type_hint - (STRING_TYPES_SET | {NoneType})): value = typify_str_no_hint(text_type(value)) return None if value is None else text_type(value) ``` I wonder why not just return `text_type(value)`? Why call `typify_str_no_hint`? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Possible DST issue? I just noticed a crontab task setup to run at 12:00 today for some reason ran at at both 11:00 and then again at 12:00. I've checked the server date and time and it does seem to have made the switch to winter time last night so i'm not sure if this was a fluke or really related to the DST but i don't see any other reason for it to run the task twice... My crontab setup, for this particular task, looks like this: ``` from celery.schedules import crontab CELERYBEAT_SCHEDULE = { 'event_suggestions': { 'task': 'events.event_suggestions', 'schedule': crontab(hour=12, minute=0, day_of_week=1) } } ``` Versions are: celery==3.0.24 django-celery==3.0.23 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Add autodetect arg in BQCreateExternalTable Operator ### Apache Airflow Provider(s) google ### Versions of Apache Airflow Providers _No response_ ### Apache Airflow version 2.2.4 (latest released) ### Operating System macOS Monterey ### Deployment Virtualenv installation ### Deployment details _No response_ ### What happened Autodetect parameter is missing in the create_external_table function in BQCreateExternalTableOperator because of which one cannot create external tables if schema files are missing See function on line 1140 in this [file](https://github.com/apache/airflow/blob/main/airflow/providers/google/cloud/operators/bigquery.py) ### What you expected to happen If autodetect argument is passed to the create_external_table function then one can create external tables without mentioning the schema for a CSV file leveraging the automatic detection functionality provided by the big query ### How to reproduce Simply call BigQueryCreateExternalTableOperator in the dag without mentioning schema_fields or schema_object ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Spanner ignores provided credentials when executing a query. (This bug is re-posted from an e-mail I received yesterday.) ---------------------- We are using python spanner client libraries, and I have a credentials issue in executing a sql query. Seems like executing a sql ignores the provided credentials to the client and just try to use the default credentials. The code looks like: ```python spanner_client = spanner.Client(credentials=credentials, project=project_id) instance = spanner_client.instance(instance_id) database = instance.database(database_id) database.execute_sql(stmt) ``` Debugging the code for a bit, I found out that eventually the code [will try to create a session](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/spanner/google/cloud/spanner/session.py#L97) and it will [try to get the spanner API client](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/spanner/google/cloud//spanner/database.py#L157). When this object created, credentials is not passed and hence it's `None`, and hence the SpannerClient is trying to get the default credentials and fails in my case because I do not have default creds. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: VS 2017 backend emits bad WindowsTargetPlatformVersion value When I tried generating a VS 2017 solution, the generated app.vcxproj contained this: ``` <WindowsTargetPlatformVersion>10.0.14393.0\\</WindowsTargetPlatformVersion> ``` Which then causes errors in other `.targets` files attempting to do a numeric comparison against that. This value is probably taken straight from one of these environment variables: ``` WindowsSDKLibVersion=10.0.14393.0\\ WindowsSDKVersion=10.0.14393.0\\ ``` The trailing backslash is a bit suspect, but may be there intentionally so it can be concatenated to ``` WindowsSdkDir=C:\\Program Files (x86)\\Windows Kits\\10\\ ``` directly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: LocalDaskExecutor with \"processes\" scheduler runs some tasks twice ## Description I noticed that when running a Flow containing mapped tasks via the `LocalDaskExecutor(scheduler=\"processes\")` some of the tasks in the flow run twice, and in worst case scenario the whole pipeline runs twice. With all the other executor setups (e.g. `DaskExecutor` or just using `threads` scheduler in the `LocalDaskExecutor`( the pipeline runs correctly. ## Expected Behavior The execution of the same pipeline should be the same across different executors. ## Reproduction I was only able to create this simple example which shows that one of the tasks ran twice. However, the original pipeline that has a similar structure runs all its tasks twice, every time. ```[Python] @task def check_files(): print(\"CHECKING FILES\") return True @task def load_files(checked): return [1,2] @task def process_files(f): return f @task def agg(f): return sum(f) with Flow(\"EvalPipeline\") as flow: checked = check_files() files = load_files(checked) processed = process_files.map(files) summary = agg(processed) state = flow.run( executor=LocalDaskExecutor(scheduler=\"processes\", num_workers=1) ) ``` Output:  ## Environment * prefect==0.12.6 * dask==2.15.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Slow BERT Tokenizer adds UNK when calling tokenize() Hi! I've run into an inconsistency between the base tokenizer docstring and the slow BERT tokenizer. Specifically, when calling `tokenizer.encode()`, the `[UNK]` token is inserted for unknown tokens, even though the [docstring](https://github.com/huggingface/transformers/blob/v4.0.1/src/transformers/tokenization_utils_base.py#L2026) says that such tokens should be unchanged. Here's how I'm calling the tokenizer: ```python tokenizer = BertTokenizer.from_pretrained( save_dir, do_lower_case=False, strip_accents=False, tokenize_chinese_chars=True ) sentence = \"RINDIRIZZA Ġwann Marija Vianney\" print(tokenizer.tokenize(sentence)) ``` and the output is ``` ['RI', '##ND', '##IR', '##I', '##Z', '##ZA', '[UNK]', 'Marija', 'Via', '##nne', '##y'] ``` (notice the `[UNK]` in the middle). So, it seems that this particular slow tokenizer isn't following the docstring. Is this expected? If not, is there a way to prevent replacement of unknown tokens? I wanted to use the slow BERT tokenizer over the fast one for exactly this reason, and it'd be great if there's a way to make this work. I'm using `transformers` v4.0.1, but it looks like this docstring hasn't changed between [`master`](https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_utils_base.py#L2027) and `4.0.1`. Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: TensorBoardLogger creates another tfevents file. ## 🐛 Bug TensorBoardLogger creates another tfevents file when fit() is running. It seems that no metrics are logged in the redundant file, but it will be shown in TensorBoard as a `run`. I don't do anything about loggers in my LightningModules. **Expected file structure:** ``` | |- save_dir | |- name | |- version_0 | |- events.out.tfevents.1579833025.ip-xxx-xxx-xxx-xxx.17584.0 | |- meta_tags.csv |- train.py ``` **Observed file structure:** ``` | |- save_dir | |- name | |- version_0 | |- 1579833032 | |- events.out.tfevents.1579833032.ip-xxx-xxx-xxx-xxx.17584.1 | |- events.out.tfevents.1579833025.ip-xxx-xxx-xxx-xxx.17584.0 | |- meta_tags.csv |- train.py ``` ### To Reproduce / Code sample Basic training step of PyTorch Lightning: ```python # define a logger logger = TensorBoardLogger( save_dir='runs', name=args.model ) # define callbacks ckpt_path = Path(logger.experiment.log_dir) / 'ckpts' checkpoint_callback = ModelCheckpoint(filepath=ckpt_path) # instantiate trainer trainer = Trainer( logger=logger, checkpoint_callback=checkpoint_callback, gpus=args.gpus ) # define a model model = CoolModel(args) # start training! trainer.fit(model) ``` ### Environment - PyTorch Lightning Version (e.g., 1.0): `0.6.0` - PyTorch Version (e.g., 1.0): `1.3.1` - OS (e.g., Linux): `Ubuntu 16.04 LTS` - How you installed PyTorch (`conda`, `pip`, source): `pip` - Build command you used (if compiling from source): - Python version: `3.7.4` - CUDA/cuDNN version: `10.1` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: list_subscriptions does not work properly `list_subscriptions()` works but `list_subscriptions(topic_name = 'topic_name')` does not work properly ``` python >>> from gcloud import pubsub >>> client = pubsub.Client(project = 'my_project') >>> client.list_subscriptions(topic_name = 'my_topic') Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/usr/local/lib/python2.7/dist-packages/gcloud/pubsub/client.py\", line 131, in list_subscriptions for resource in resp['subscriptions']] File \"/usr/local/lib/python2.7/dist-packages/gcloud/pubsub/subscription.py\", line 68, in from_api_repr topic_path = resource['topic'] TypeError: string indices must be integers ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: pastebin magic does not work: github requires authentication to create gists Github now [requires authentication](https://developer.github.com/v3/gists/#authentication) to create gists: > You can read public gists anonymously, but you must be signed into GitHub to create gists. `%pastebin` does not work anymore and returns 401: HTTPError: HTTP Error 401: Unauthorized Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Create Docker Tasks for Task Library Add initial tasks to the task library relating to Docker. - Containers: create, kill, logs, exec - Images: list, pull, push, remove, tag, build Any other tasks are more than welcome. These are just the initial ones I feel are most important / commonly used Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: conan download only respects the first repository in remotes.txt Scenario: I want to download a package from an Artifactory repository called 'conan-local' with the following command `conan download package/version@user/channel` But the package gets downloaded only if the repository which contains the package is the first in the list of remotes in registry.txt. registry.txt: ``` conan-local http://... other-repo http://... ``` If the repository which contains the package is not the first in the list of remotes, the following error occurs: `ERROR: 'package/version@user/channel' not found in remote` registry.txt: ``` other-repo http://... conan-local http://... ``` I think there is also a mistake in the documentation for the conan download command: \"Only if a *reference* is specified, it will download all packages from the specified remote. Otherwise, it will search sequentially in the configured remotes.\" should be: \"Only if a **remote** is specified, it will download all packages from the specified remote. Otherwise, it will search sequentially in the configured remotes.\" Tested with Conan 1.5.0 + Conan 1.6.0 using Python 3.6.5 running in Windows 7 and Ubuntu 14.04 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda install from tarball error? Running into this issue when trying to install directly from a tarball. ``` Traceback (most recent call last): File \"/usr/local/bin/conda2\", line 6, in <module> sys.exit(main()) An unexpected error has occurred, please consider sending the following traceback to the conda GitHub issue tracker at: https://github.com/conda/conda/issues Include the output of the command 'conda info' in your report. File \"/opt/conda2/lib/python2.7/site-packages/conda/cli/main.py\", line 120, in main exit_code = args_func(args, p) File \"/opt/conda2/lib/python2.7/site-packages/conda/cli/main.py\", line 130, in args_func exit_code = args.func(args, p) File \"/opt/conda2/lib/python2.7/site-packages/conda/cli/main_install.py\", line 69, in execute install(args, parser, 'install') File \"/opt/conda2/lib/python2.7/site-packages/conda/cli/install.py\", line 196, in install explicit(args.packages, prefix, verbose=not args.quiet) File \"/opt/conda2/lib/python2.7/site-packages/conda/misc.py\", line 79, in explicit is_file = schannel.startswith('file:') and schannel.endswith('/') UnboundLocalError: local variable 'schannel' referenced before assignment ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: docs: Document buildtarget.get_id() [skip ci] Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Latex tab completions leave extra backslash in terminal console In `ipython console`: ``` \\alp<TAB> -> \\\\alpha \\alpha<TAB> -> \\α ``` In both cases, there's a backslash left over that shouldn't be there. It works in the notebook and the Qt console. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Ability to specify step for logged metrics ## 🚀 Feature Add option to specify `step` for logged metrics ### Motivation After calculating some metric on n-th epoch I'd like to put corresponding mark (`n`) on x-axis. As I see in the source code, there's no obvious way to do this. Instead something like `n * num_batches` will be shown, like in the figure where the loss is calculated after each epoch.  ### Pitch I'd love to see `0,1,2,...` ticks on x-axis. My proposal is to allow user to add `step` key in `log` dict, if this key is presented, corresponding value would be used in x-axis. I can make a PR if you agree with this idea. ### Alternatives It would be interesting to know how this could be achieved in other way. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: minor issues in modeling_clip.py While working on the PR [Add TFCLIPModel](https://github.com/huggingface/transformers/pull/13967), I observed a few minor issues in [modeling_clip.py](https://github.com/huggingface/transformers/blob/master/src/transformers/models/clip/modeling_clip.py): 1. Miss `@dataclass` decorators before https://github.com/huggingface/transformers/blob/d5b82bb70c2e8c4b184a6f2a7d1c91d7fd156956/src/transformers/models/clip/modeling_clip.py#L74 This causes `None` elements included in the tuple form. 2. typo in `CLIPVisionTransformer.pre_layrnorm` https://github.com/huggingface/transformers/blob/d5b82bb70c2e8c4b184a6f2a7d1c91d7fd156956/src/transformers/models/clip/modeling_clip.py#L738 3. In https://github.com/huggingface/transformers/blob/d5b82bb70c2e8c4b184a6f2a7d1c91d7fd156956/src/transformers/models/clip/modeling_clip.py#L291 - `layer_head_mask` not in the arguments - shape of `hidden_states` is incorrect, I think 4. https://github.com/huggingface/transformers/blob/d5b82bb70c2e8c4b184a6f2a7d1c91d7fd156956/src/transformers/models/clip/modeling_clip.py#L500 I am not sure why there is `embed_tokens` here. 5. https://github.com/huggingface/transformers/blob/d5b82bb70c2e8c4b184a6f2a7d1c91d7fd156956/src/transformers/models/clip/modeling_clip.py#L520 Here `inputs_embeds` is a required argument instead of being `optional`. 6. There are a few places `model(...)` in `test_modeling_clip.py` without being inside `with torch.no_grad():`. ## Who can help @patil-suraj Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Prefix-dependent types for sysconfdir, etc, do not work with default_options: in project() Specifically, [this](http://mesonbuild.com/Release-notes-for-0-44-0.html#prefixdependent-defaults-for-sysconfdir-localstatedir-and-sharedstatedir) does not work: ```meson project('testprefix', 'c', default_options: ['prefix=/usr']) ``` ```console $ meson _build $ meson configure _build ... Directories: Option Current Value Description ------ ------------- ----------- prefix /usr Installation prefix. ... sysconfdir etc Sysconf data directory. localstatedir /var/local Localstate data directory. sharedstatedir /var/local/lib Architecture-independent data directory. ... ``` However, passing `--prefix=/usr` works as expected. Reported by @williamh on IRC. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Rewrite QAOA with primitives. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Linker error while building gtkdoc I'm trying to make GStreamer modules build with meson inside Cerbero. When it builds gtkdoc I get this error: ``` Error in gtkdoc helper script: 'gtkdoc-scangobj' failed with status 1 ld: unrecognized option '-Wl,-rpath,/home/xclaesse/programmation/cerbero/build/sources/linux_x86_64/gst-transcoder-1.9/cerbero-build-dir/' ld: use the --help option for usage information Linking of scanner failed: ``` The exact command line that produce that error is: ``` gtkdoc-scangobj --types=/home/xclaesse/programmation/cerbero/build/sources/linux_x86_64/gst-transcoder-1.9/cerbero-build-dir/docs/libs/gst-transcoder.types --module=gst-transcoder --cflags=\"-I/home/xclaesse/programmation/cerbero/build/sources/linux_x86_64/gst-transcoder-1.9/cerbero-build-dir/gst-libs -I/home/xclaesse/programmation/cerbero/build/sources/linux_x86_64/gst-transcoder-1.9/gst-libs -I/home/xclaesse/programmation/cerbero/build/dist/linux_x86_64/include/glib-2.0 -I/home/xclaesse/programmation/cerbero/build/dist/linux_x86_64/lib/glib-2.0/include -pthread -I/home/xclaesse/programmation/cerbero/build/dist/linux_x86_64/include/gstreamer-1.0\" --ldflags=\"-L/home/xclaesse/programmation/cerbero/build/sources/linux_x86_64/gst-transcoder-1.9/cerbero-build-dir/ -Wl,-rpath,/home/xclaesse/programmation/cerbero/build/sources/linux_x86_64/gst-transcoder-1.9/cerbero-build-dir/ -lgsttranscoder-1.0 -L/home/xclaesse/programmation/cerbero/build/dist/linux_x86_64/lib -lglib-2.0 -lgobject-2.0 -lgstreamer-1.0 -lgstpbutils-1.0\" ``` GStreamer's gtkdoc seems to build fine with meson when using gst-build, so I don't understand what's the difference when ran inside cerbero env. Any clue? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Please support Verify=False option for tools.get() as is currently supported for tools.download() To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [1.8.4] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Automatically check if modules are left out of the API docs See [previous comment](https://github.com/GoogleCloudPlatform/gcloud-python/issues/707#issuecomment-78552001) for context. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Replace /bin/bash with /usr/bin/env bash Currently `conda` hardcodes `#!/bin/bash`. If instead `#!/usr/bin/env bash` would be used, then the version of the current environment would be used. I'm attempting to package `conda` at the moment for an OS where `#!/bin/bash` is unavailable, but `#!/usr/bin/env bash` does work. The same by the way applies to some of the packages offered via `conda`. Edit: I can understand if such change wouldn't be made since there might be distributions where exactly that option isn't available. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPythonConsoleLexer fails with python2 and pygments 2.5 As of pygments 2.5, `PythonLexer` [now](https://pygments.org/docs/changelog/) is an alias for `Python3Lexer`. iPython still uses `PythonLexer` for the python2 case: https://github.com/ipython/ipython/blob/a6082c6ff799e4ec30ad24afbfc5f1550185934d/IPython/lib/lexers.py#L79 It should explicitly use `Python2Lexer` instead. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: text drawer should be enhanced for multi-qubit gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? 1. If I have a two-qubit box/gate and want to apply it to non-adjacent gates, the text drawer raises the following error: ```python VisualizationError: 'Text visualizaer does know how to build a gate with multiplebits when they are not adjacent to each other' ``` We just need to indicate/mark those wires that the gate is acting upon, and then it will be clear. 2. This raises another issue. The order of wires can be different when the gate is applied, so the drawer should reflect that. So I think we should show something like this: ``` ┌─────────┐┌─────────┐ q3_0: |0>┤0 ├┤1 ├ │ My_gate ││ │ q3_1: |0>┤1 ├┤ My_gate ├ └─────────┘│ │ q3_2: |0>───────────┤0 ├ └─────────┘ ``` Here, \"my_gate\" is a two-qubit gate, with some internal definition. It has been added to the circuit like this: ```python circuit.append(my_gate, [q[0], q[1]]) circuit.append(my_gate, [q[2], q[0]]) ``` Note: this code is possible in PR #1816 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: `NameError` if conda-content-trust fails to import ### Checklist - [X] I added a descriptive title - [X] I searched open reports and couldn't find a duplicate ### What happened? When importing conda-content-trust (e.g. because of #12736) it can't import `SignatureError`, leading to a `NameError` exception: from https://github.com/conda/conda/actions/runs/5110614066/jobs/9323820330?pr=12707#step:8:68: ``` ../../../miniconda3/envs/conda-test-env/lib/python3.9/importlib/__init__.py:127: in import_module return _bootstrap._gcd_import(name[level:], package, level) tests/trust/test_signature_verification.py:14: in <module> from conda.trust.signature_verification import SignatureError, _SignatureVerification E ImportError: cannot import name 'SignatureError' from 'conda.trust.signature_verification' (/Users/runner/work/conda/conda/conda/trust/signature_verification.py) ``` The example here is breaking because of a separate issue with conda-content-trust on conda-forge (as it's incompatible with cryptography>=41). And https://github.com/conda-forge/conda-forge-repodata-patches-feedstock/pull/462 hasn't been merged yet. ### Conda Info ```shell - ``` ### Conda Config ```shell - ``` ### Conda list ```shell - ``` ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: jax.numpy.arange() doesn't match numpy.arange() for fractional values Example: ```python In [1]: import jax.numpy as jnp In [2]: import numpy as np In [3]: jnp.arange(2.5) Out[3]: DeviceArray([0., 1.], dtype=float32) In [4]: np.arange(2.5) Out[4]: array([0., 1., 2.]) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: boolean indexing support The `README` mentions boolean index slices `a[idx]` in relation to jit-able functions as something to avoid, but currently it seems they do not work in jax at all ``` >>> import jax.numpy as np >>> a = np.array([1,2,3]) >>> a[[True,False,False]] ``` raises `IndexError: Indexing mode not yet supported. Open a feature request!` is this expected? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pubsub.list_topics fails when there are no topics [Offending line](https://github.com/GoogleCloudPlatform/gcloud-python/blob/0910f9979a45af8cc2826dd4c6ff38d9efa5ccec/gcloud/pubsub/client.py#L80). Reproduce via: ``` python client = pubsub.Client() >>> client.list_topics() Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"gcloud/pubsub/client.py\", line 80, in list_topics for resource in resp['topics']] KeyError: 'topics' ``` @tseaver ISTM we should locate all instances where we assume a key is present and just protect against this. The time between releases behooves us to be \"protective\" of users. (I realize that we've usually done it this way based on documented outputs.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: pymongo refuses backend/mongodb.py default settings `self.options.setdefault('max_pool_size', self.max_pool_size)` `self.options.setdefault('auto_start_request', False)` These lines are refusing from `pymongo` and gives `ConfigurationError` exception. By the way pymongo version is 3.0 and for use mongodb as backend i have to remove that lines from mongodb.py. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Progress bar broken  ``` C:\\Users\\Korijn\\dev\\myproject>conda info Current conda install: platform : win-64 conda version : 4.2.7 conda is private : False conda-env version : 4.2.7 conda-build version : 2.0.1 python version : 3.5.1.final.0 requests version : 2.9.1 root environment : C:\\Users\\Korijn\\Miniconda3 (writable) default environment : C:\\Users\\Korijn\\Miniconda3 envs directories : C:\\Users\\Korijn\\Miniconda3\\envs package cache : C:\\Users\\Korijn\\Miniconda3\\pkgs channel URLs : https://repo.continuum.io/pkgs/free/win-64/ https://repo.continuum.io/pkgs/free/noarch/ https://repo.continuum.io/pkgs/pro/win-64/ https://repo.continuum.io/pkgs/pro/noarch/ https://repo.continuum.io/pkgs/msys2/win-64/ https://repo.continuum.io/pkgs/msys2/noarch/ config file : C:\\Users\\Korijn\\.condarc offline mode : False ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ParametereExpression.__eq__ doesn't gracefully convert numeric types <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? `__eq__` in python conventionally considers objects equal if they are semantically equivalent, even if their types differ. ``` >>> 2 == 2 True >>> 2.0 == 2.0 True >>> 2 == 2.0 True ``` Same for Sympy: ``` >>> import sympy as sp >>> sp.Integer(2) == sp.Integer(2) True >>> sp.Float('2.0', precision=53) == sp.Float(2.0, precision=54) True >>> sp.Integer(2) == sp.Float('2.0', precision=53) True ``` But `ParameterExpression.__eq__` breaks this convention. ``` >>> import qiskit as qk >>> theta = qk.circuit.Parameter('theta') >>> theta * 2 == theta * 2 True >>> theta * 2.0 == theta * 2.0 True >>> theta * 2 == theta * 2.0 False ``` Currently, at https://github.com/Qiskit/qiskit-terra/blob/44462a8b13ea6c2cce0f9c7345c26c15fb0d4ce3/qiskit/circuit/parameterexpression.py#L389 , we compare `srepr(self._symbol_expr) == srepr(other._symbol_expr)` as strings. (`srepr` of the examples above would look like `Mul(Integer(2), Symbol('th'))` for `theta * 2` and `Mul(Float('2.0', precision=53), Symbol('th'))` for `theta * 2.0`. Instead, we should walk the sympy expression tree (following https://docs.sympy.org/latest/tutorial/manipulation.html#recursing-through-an-expression-tree ) and rely on sympy's built in `__eq__`. (The original motivation for using `srepr` instead of directly comparing `._symbol_expr` isn't clear from the current code, so that may be another option worth investigating.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Schedule padding passes don't respect target's instruction constraints ### Environment - **Qiskit Terra version**: 0.23.0 and main (0.24.0) - **Python version**: 3.10 - **Operating system**: Linux ### What is happening? The transpiler scheduling padding passes do not respect the instruction constraints in a `Target`. If running on a backend which doesn't support certain operations on qubits the padding passes will potentially insert invalid operations at the end of a `transpile()` call. The simplest example of this is if you use the built in `scheduling_method` kwarg for `transpile()` on a backend which doesn't support `delay` then the output of the transpiler will not be valid. ### How can we reproduce the issue? Run the padding passes on a target that doesn't support the padding operations on some (or all qubits). ### What should happen? The padding passes should only run on qubits that the padding operations are supported on that qubit. If not we should skip padding that operation. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Firestore: passing empty list to 'Query.select' implies '__name__' The `query-select-empty.textproto` conformance test mandates this behavior. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Meson doesn't handle 'link_args' correctly for non-gnu D compilers Sample config ``` project('test-project', 'd') libabc_dep = dependency('libabc') test_exe = executable('test', 'app.d', #d_args: ['-I/usr/include', '-L/usr/lib'], dependencies: libabc_dep ) ``` When compiling the `test_exe` target, the compiler fails to add the arguments specified in the pkgconfig (usually, `-I/usr/include` and `-L/usr/lib`). If I add the right arguments to `d_args`, as shown in the commented code, it works. I have only tried to link dependencies provided by pkgconfig. I also tried compiling with both LDC and DMD, same result. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [Discussion] oauth2client credentials in a post-oauth2client world. We recently switched `core` to use [`google-auth`](https://google-auth.readthedocs.io) in #2639 and completely removed support for `oauth2client`. It is possible that some users are explicitly passing `oauth2client` credentials into `Client` constructors, e.g.: ```python credentials = oauth2client.contrib.gce.AppAppsertionCredentials() storage_client = storage.Client(credentials=credentials) ``` After `google-cloud-core==0.22.0` is released this code will no longer work. Only credentials from `google-auth` will work. There is a potential that we could break some user code and there may be some valid reasons for sticking with oauth2client in the near-term (user credentials and storage, for example). `google-auth` offers a way to [`convert`](https://github.com/GoogleCloudPlatform/google-auth-library-python/blob/443df66cb6e7960205c1d2108e67220d27408efe/google/auth/_oauth2client.py#L136) credentials: ```python import google.auth._oauth2client new_credentials = google.auth._oauth2client.convert(old_credentials) ``` We have two options: 1. Tell users who still want to use oauth2client to use `google.auth._oauth2client` to convert their credentials. 2. Add code in our `Client` base class to automatically convert credentials and issue a warning. I strongly prefer (1) so that we do not prolong oauth2client's lifetime and so that we can more quickly free ourselves to switch http libraries. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Local Lab Extension Workflow A couple of things I have seen in practice with using local extensions: - Forgetting to `npm install` before `jupyter labextension install .`. - Forgetting to `npm run build` before `jupyter labextension install .`. This one can result in the cryptic error of the form: ```javascript WARNING in ./build/index.out.js Module not found: Error: Can't resolve '@jupyterlab/github/' in '/usr/share/jupyter/lab/staging/build' @ ./build/index.out.js 639:25-55 ``` We should run `npm install` in a local folder if it doesn't have a `node_modules`, and encourage the use of a `prepack` script. The `prepack` script is run on `npm pack` and `yarn pack`. I will add the `prepack` script to the cookie cutter. The command is also run on `npm publish` and `yarn publish`, so it can be used instead of the `prepublish`/`prepare`/`prepublishOnly` scripts if appropriate. cc @ian-r-rose @jasongrout Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Exception message as a string is still being unpacked Here: https://github.com/celery/celery/blob/master/celery/backends/base.py#L282 Following code: ``` exc_msg = 'SHOULDBETOGETHER' print(*exc_msg if isinstance(exc_msg, tuple) else exc_msg) ``` results in: ``` S H O U L D B E T O G E T H E R ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: dist failure with relative submodule paths **Describe the bug** dist fails with git submodules using relative paths. **To Reproduce** The entire tree is at https://gitlab.freedesktop.org/xdg/shared-mime-info/-/tree/40db4c7adba8a5cc586e24f5b4b5aff0b2a81bcc, see .gitlab-ci.yml there for how it's built in CI. The xdgmime submodule is defined as `../xdgmime.git` CI failure log is at https://gitlab.freedesktop.org/xdg/shared-mime-info/-/jobs/6403481 -- essentially it seems meson is trying to checkout the submodule from a directory relative to the main project working dir, whereas it should treat relative submodule path as relative to the superproject's default remote repo; https://git-scm.com/docs/git-submodule#Documentation/git-submodule.txt-add-bltbranchgt-f--force--nameltnamegt--referenceltrepositorygt--depthltdepthgt--ltrepositorygtltpathgt **Expected behavior** Working submodule checkout during dist. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) * what Python version are you using e.g. 3.8.0 * what `meson --version` * what `ninja --version` if it's a Ninja build Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: If AutoAck pull returns empty then exception raised on context exit If the subscription pull returns 0 messages in the __enter__ method in the AutoAck class then on __exit__ the acknowledge call raises an exception on the HTTP call: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/pubsub-0.22.0/pubsub/google/cloud/pubsub/subscription.py#L512 Currently the way a deal with this is to wrap the context manager in try/except or override __exit__ to check for an empty list. The former is messy and the latter can just be fixed at source. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda raises bogus NotWritableError exception for a bogus attempt to chown to root This isn't a dupe (well it is a dupe of #7109) but the issue still persists. #7180 fixed the problem in one section of code, but the same problematic snippet is present here: https://github.com/conda/conda/blob/master/conda/gateways/disk/update.py#L121 conda raises bogus NotWritableError exception for a bogus attempt to chown to root This isn't a dupe (well it is a dupe of #7109) but the issue still persists. #7180 fixed the problem in one section of code, but the same problematic snippet is present here: https://github.com/conda/conda/blob/master/conda/gateways/disk/update.py#L121 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Pubsub: How to flush unsent messages on program exit? I have set caching configuration which may cache some messages and messages are not sent to pubsub yet. Is there a `flush` method when I want to exit the program. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Fig should say \"you probably need to run docker-osx shell\" if docker-osx exists and it can't connect to Docker Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Use of `ravel` in `intersect1d` breaks compatibility with xarray See https://github.com/pydata/xarray/issues/2371 ### Numpy/Python version information: ``` 1.15.0 3.6.6 |Anaconda, Inc.| (default, Jun 28 2018, 17:14:51) [GCC 7.2.0] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Message being acknowledged on WorkerLostError when CELERY_ACKS_LATE=True When using celery v3.0.24, with `CELERY_ACKS_LATE = True` , if the OOM killer kills the celery worker, then the worker acknowledges the message. As per [this](https://github.com/celery/celery/commit/e810420c) commit. The `exc_info.internal` comes in as `false`, which means it is not a internal error, due to which the message is acknowledged. The desirable behaviour, in such a case would be to not acknowledge the message (and be able to know, whether its a OOM error), so that some other worker can pick it up. As a workaround, I've commented out the [code](https://github.com/siddharth96/celery/commit/427695d1b23034dadda85fd7a48f7367831be4fa), where celery acknowledges the message, because in such a case, message will be lost. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: transformers does not detect Tensorflow when installing tensorflow-cpu package ### System Info This issue was introduced in transformers 4.30.x. Output of pip list (partial): ``` tensorflow-cpu 2.12.0 tensorflow-estimator 2.12.0 tensorflow-intel 2.12.0 tensorflow-io-gcs-filesystem 0.31.0 transformers 4.30.1 ``` ### Who can help? _No response_ ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction Manifests itself like this: ``` None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used. ImportError while loading <REDACTED> from transformers import file_utils, modeling_tf_outputs, modeling_tf_utils .venv\\lib\\site-packages\\transformers\\modeling_tf_utils.py:42: in <module> from .generation import GenerationConfig, TFGenerationMixin E ImportError: cannot import name 'TFGenerationMixin' from 'transformers.generation' (<REDACTED>) ``` ### Expected behavior No errors, Tensorflow detected. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Py3: Commands with subarguments do and say nothing if no params are entered Run: `conan editable`, `conan config`, `conan remote`, `conan profile`, `conan workspace`... In general all the commands with sub arguments. They should show the help. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Quantum info Operator does not work with delay operations <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is the current behavior? Trying to convert a circuit with delays to `Operator` gives: QiskitError: 'Cannot apply Instruction: delay' ### Steps to reproduce the problem ### What is the expected behavior? Since delays do nothing with respect to the Unitary operator I would expect this to work. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Make the conda install table easier to read The table of what packages will be installed and removed is hard to read. For one thing, it's hard to tell easily what packages are not removed but just upgraded or downgraded. Also, the \"link\" terminology is confusing. A suggestion by @jklowden: ``` $ conda update conda Updating Anaconda environment at /usr/local/anaconda The following packages will be downloaded: conda-2.2.3-py27_0.tar.bz2 [http://repo.continuum.io/pkgs/free/osx-64/] The following packages will be upgraded: Old version Replace with ------------------------- ------------------------- conda-1.4.4 conda-2.2.3 ``` > or, if you really want the build (I don't, it's not meaningful to the user) ``` package Old version New version ------------ ------------------ ------------------ conda 1.4.4, py27_0 2.2.3, py27_0 ``` I think the build is meaningful as it tells you what Python version is being used. It also tells you if you are using mkl. And also some people might use the build string to put other information which may be useful to users. <!--- @huboard:{\"order\":3.3142282405143226e-49,\"custom_state\":\"\"} --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add a flag forbidding upload if recipe was changed Hello, I'm using Conan 1.0.4. It would be useful to have an option in `conan upload` to prevent uploading packages if there is already a package with the same reference upstream **AND** the recipe was modified. That way we could enforce that a new binary package will not break existing ones (e.g. by modifying the recipe without changing the `package_id`). - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipcluster bug in clean_logs flag Setting clean_logs=True when using the IPClusterEngines application doesn't remove the log files. The offending line is at parallel/apps/ipclusterapp.py line 404 in IPClusterEngines.start_logging() which looks like this: ``` if re.match(r'ip(engine|controller)z-\\d+\\.(log|err|out)',f): ``` The 'z' after controller) should be removed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Unable to install package from anaconda.org Despite successfully logging in, I am unable to install a package from anaconda.org. Why do I need to be \"authorized\" to install from a public repo? Here's a session: > (anaconda) src% conda install -c pydanny cookiecutter > Fetching package metadata ... > > CondaHTTPError: HTTP 401 UNAUTHORIZED for url <https://conda.anaconda.org/pydanny/linux-64/repodata.json> > Elapsed: 00:00.186933 > CF-RAY: 34f70e302ebd099a-ORD > > The remote server has indicated you are using invalid credentials for this channel. > > If the remote site is anaconda.org or follows the Anaconda Server API, you > will need to > (a) login to the site with `anaconda login`, or > (b) provide conda with a valid token directly. > > Further configuration help can be found at <https://conda.io/docs/config.html>. > > > > (anaconda) src% anaconda login > Using Anaconda API: https://api.anaconda.org > Username: smontanaro > smontanaro's Password: > login successful > (anaconda) src% conda install -c pydanny cookiecutter > Fetching package metadata ... > > CondaHTTPError: HTTP 401 UNAUTHORIZED for url <https://conda.anaconda.org/t/sm-1bb26830-27a7-4652-a4df-f47d9426aaf1/pydanny/linux-64/repodata.json> > Elapsed: 00:00.189228 > CF-RAY: 34f7135bfaa52597-ORD > > The remote server has indicated you are using invalid credentials for this channel. > > If the remote site is anaconda.org or follows the Anaconda Server API, you > will need to > (a) login to the site with `anaconda login`, or > (b) provide conda with a valid token directly. > > Further configuration help can be found at <https://conda.io/docs/config.html>. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Failed to install connan 1.8.2 on ubuntu16.04 I'm installing as ``` pip --no-cache-dir install conan conan_package_tools ``` As the time of installing, the latest version was 1.8.2. And, the output logs: ``` Installing collected packages: PyJWT, colorama, patch, monotonic, fasteners, node-semver, distro, isort, wrapt, lazy-object-proxy, typed-ast, astroid, mccabe, pylint, deprecation, t qdm, bottle, pluginbase, conan, idna, tabulate, conan-package-tools Running setup.py install for patch: started Running setup.py install for patch: finished with status 'done' Running setup.py install for wrapt: started Running setup.py install for wrapt: finished with status 'done' Found existing installation: tqdm 4.26.0 Uninstalling tqdm-4.26.0: Successfully uninstalled tqdm-4.26.0 Rolling back uninstall of tqdm Could not install packages due to an EnvironmentError: [Errno 2] No such file or directory: '/usr/local/man/man1' ``` I switched the installing to version 1.7.4, and everything was good. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Hashing a tokenizer using the 🤗 nlp lib is not deterministic In the `nlp` library it is common to use a tokenizer on a dataset. The library takes care of caching the results, so that if you run the tokenization twice, it will reuse the previous results. To make the caching work, we compute a hash of the tokenizer. However the `unique_no_split_tokens` attribute of tokenizers is not deterministic, and it makes the hashing return different hashes for the same tokenizer over different sessions. `unique_no_split_tokens` can be a list like `['[CLS]', '[MASK]', '[PAD]', '[SEP]', '[UNK]']` for example. But it happens that re-loading a tokenizer in another session shuffles the tokens in the list. For example this code doesn't always return the same output over different sessions: ```python from transformers import AutoTokenizer model_name = \"distilbert-base-uncased-finetuned-sst-2-english\" tokenizer = AutoTokenizer.from_pretrained(model_name) print(tokenizer.unique_no_split_tokens) ``` Reproduce on google colab: https://colab.research.google.com/drive/1nyskaLavcTCkXibZBlYX71bkG476uSzz?usp=sharing Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: cmake_find_package generator does not produce CONAN_RES_DIRS_ variables In my package recipe, I do the following: ```py exports_sources = \"res/*\" def package(self): self.copy(\"*\", dst=\"res\", src=\"res\") def package_info(self): self.cpp_info.resdirs = ['res'] ``` In the resulting package, the resource files are present, but for projects that consume this package via the cmake_find_package generator, the generated Findx.cmake file does not contain any CONAN_RES_DIRS_ variables, which was confirmed by another user in the Conan slack. I also checked the normal cmake generator and it seems to have the correct behaviour. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Unexpected behavior with `tags` contextmanager Example: ```python from prefect import task, tags, Flow @task def say_hi(name): pass with Flow() as f: c = say_hi(\"chris\") with tags(\"example\"): a = say_hi(\"alice\") b = say_hi(\"bob\") ``` What is `c.tags`? Answer: `{'example'}`, because `tags` is a set, and `task.copy()` keeps a reference to the same set. Unexpected behavior with `tags` contextmanager Example: ```python from prefect import task, tags, Flow @task def say_hi(name): pass with Flow() as f: c = say_hi(\"chris\") with tags(\"example\"): a = say_hi(\"alice\") b = say_hi(\"bob\") ``` What is `c.tags`? Answer: `{'example'}`, because `tags` is a set, and `task.copy()` keeps a reference to the same set. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Allow setting of custom attributes during retokenization ## Feature description <!-- Please describe the feature: Which area of the library is it related to? What specific solution would you like? --> Perhaps I am just missing something, but I don't seem to be able to set custom attributes on a merged token during retokenization (using the new 2.1.x Retokenizer class). with doc.retokenize() as retokenizer: retokenizer.merge(span, attrs={ ... }) I can set any of the attributes listed in the Token documentation, but I am unable to do that for custom attributes. If there is a special syntax for setting custom attributes already, it should be documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add Agent Logging for Platform Roadblocks ## Use Case e.g. ``` 2019-09-11 20:06:34,237 - agent - INFO - Found 1 flow run(s) to submit for execution. 2019-09-11 20:06:34,545 - agent - ERROR - (403) Reason: Forbidden HTTP response headers: HTTPHeaderDict({'Audit-Id': '8775dbb3-ad97-43b6-9f0a-144b95f5b43b', 'Content-Type': 'application/json', 'X-Content-Type-Options': 'nosniff', 'Date': 'Wed, 11 Sep 2019 20:06:34 GMT', 'Content-Length': '309'}) HTTP response body: {\"kind\":\"Status\",\"apiVersion\":\"v1\",\"metadata\":{},\"status\":\"Failure\",\"message\":\"jobs.batch is forbidden: User \\\"system:serviceaccount:my-space:default\\\" cannot create resource \\\"jobs\\\" in API group \\\"batch\\\" in the namespace \\\"my-space\\\"\",\"reason\":\"Forbidden\",\"details\":{\"group\":\"batch\",\"kind\":\"jobs\"},\"code\":403} ``` We want to notify users of potential platform issues. ^ in this one the agent didn't have permission to create jobs in its namespace (RBAC wasn't properly configured). ## Solution While we can't force permissions we can elevate this was a warning to users through the flow run logs. ## Alternatives Another option is to feed into the agent heartbeat issue #1373 where instead of becoming a flow run log it could be reflected in the agents dashboard. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Standard sampling library <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected enhancement? A library of standard `Sampler` (#1934) strategies should be provided for users that transform a continuous function of `t` into a `FunctionPulse`. Pulses: - [x] `left` - [x] `right` - [x] `mid_point` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Opflow Evolutions don't work on PauliSumOp <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? The evolution converters in Opflow do a typecheck for a `SummedOp` and break if passed `PauliSumOp`. This is a problem because we implicitly return a `PauliSumOp` for expressions that used to be a `SummedOp`, e.g for `X + Z`. ### Steps to reproduce the problem ```python from qiskit.opflow import Suzuki operator = (X ^ X ^ I) + (Z ^ Z ^ I) evo = Suzuki() evolution = evo.convert(operator) # breaks, type is PauliSumOp evolution = evo.convert(operator.to_pauli_op()) # works, type is SummedOp ``` ### What is the expected behavior? Allow passing `PauliSumOp` to the evolutions. Opflow Evolutions don't work on PauliSumOp <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? The evolution converters in Opflow do a typecheck for a `SummedOp` and break if passed `PauliSumOp`. This is a problem because we implicitly return a `PauliSumOp` for expressions that used to be a `SummedOp`, e.g for `X + Z`. ### Steps to reproduce the problem ```python from qiskit.opflow import Suzuki operator = (X ^ X ^ I) + (Z ^ Z ^ I) evo = Suzuki() evolution = evo.convert(operator) # breaks, type is PauliSumOp evolution = evo.convert(operator.to_pauli_op()) # works, type is SummedOp ``` ### What is the expected behavior? Allow passing `PauliSumOp` to the evolutions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: LDFLAGS get passed to valac during sanity check See: https://github.com/mesonbuild/meson/issues/5086#issuecomment-478881890 and later comments. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qpy_serialization causes some QuantumCircuit objects to have their parameters re-ordered ### Environment - **qiskit-terra 0.18 or 0.19**: - **Python 3.9**: - **MacOS**: ### What is happening? QuantumCircuits with parameters associated with Parameter\u0010Vectors generally have their parameters re-ordered upon serialization/deserialization. This is because qpy_serialization interprets the elements of ParameterVectors as Parameters, rather than ParameterVectorElements, which leads to the parameters being re-ordered according to their ascii name values. ### How can we reproduce the issue? ``` import json from qiskit import QuantumCircuit from qiskit.circuit import ParameterVector from qiskit.providers.ibmq.runtime.utils import RuntimeEncoder, RuntimeDecoder qc = QuantumCircuit(11) # Vectors of data and trainable parameters input_params = ParameterVector(\"x_par\", 11) user_params = ParameterVector(\"θ_par\", 11) # Create an initial rotation layer of trainable parameters for i, param in enumerate(user_params): qc.ry(param, qc.qubits[i]) # Create a circuit representation of the data group for i, param in enumerate(input_params): qc.rz(param, qc.qubits[i]) # Serialize/deserialize circuit to demonstrate parameter re-ordering qc_serial = json.dumps(qc, cls=RuntimeEncoder) qc_deserial = json.loads(qc_serial, cls=RuntimeDecoder) # Print the parameter ordering discrepancies for i, unserialized_param in enumerate(qc.parameters): if qc_deserial.parameters[i].name != unserialized_param.name: print(f\"{qc_deserial.parameters[i].name} != {unserialized_param.name}\") ``` ### What should happen? I believe qpy serialization should maintain the underlying parameter ordering of the input. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Legacy 1.13 printing broken for 0d arrays Code to trigger the error: ```python >>> import numpy as np >>> np.__version__ '1.14.2' >>> np.array2string(np.array(1.0)) '1.' >>> np.set_printoptions(legacy='1.13') >>> np.array2string(np.array(1.0)) Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"[...]/numpy/core/arrayprint.py\", line 616, in array2string return style(a.item()) TypeError: object() takes no parameters ``` Same error with 1.14.1 and 1.14.0. Since `style` is just an alias for `np._NoValue` the code effectively calls (or instantiates, depending on the code version) `_NoValue(1.0)`, which is not valid. I saw that there was a recent change in `_globals.py` that makes `_NoValue` an instance instead of a class, but it has no `__call__`, so unless I'm missing something, it won't work either. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: execute/transpile with optimization_level=0 runs default_pass_manager `optimization_level=0` does not work in `execute()` and `transpile()`, and runs `default_pass_manager` (if `coupling_map` is specified) instead of `level_0_pass_manager`. ### Steps to reproduce the problem ``` from qiskit import QuantumCircuit, QuantumRegister, QiskitError from qiskit.compiler import transpile from qiskit.transpiler import CouplingMap q = QuantumRegister(2) qc = QuantumCircuit(q) qc.cx(q[0], q[1]) qc.cx(q[0], q[1]) coupling = CouplingMap([[0, 1]]) compiled = transpile(qc, coupling_map=CouplingMap([[0, 1]]), optimization_level=0) print(compiled) ``` results in no gates, i.e. two CNOTs are cancelled out. ``` q_0: |0> q_1: |0> ``` ### What is the expected behavior? It should return ``` q0_0: |0>──■────■── ┌─┴─┐┌─┴─┐ q0_1: |0>┤ X ├┤ X ├ └───┘└───┘ ``` (No optimization for level 0) ### Suggested solutions In `transpile_circuit.py`, ``` elif transpile_config.optimization_level: ``` -> ``` elif transpile_config.optimization_level is not None: ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Celery does not consider authSource on mongodb backend URLs Version: Celery 4.0.2 (from looking at the changes since then it seems there is no change addressing this issue here: https://github.com/celery/celery/commits/master/celery/backends/mongodb.py ) (Edit) Confirmed with the following versions as well: amqp==2.2.2 billiard==3.5.0.3 celery==4.1.0 kombu==4.1.0 pymongo==3.6.0 Celery Report software -> celery:4.0.2 (latentcall) kombu:4.0.2 py:2.7.8 billiard:3.5.0.3 py-amqp:2.2.1 platform -> system:Linux arch:64bit, ELF imp:CPython loader -> celery.loaders.default.Loader settings -> transport:amqp results:disabled ## Steps to reproduce Give Celery a Backend URL pointing to a MongoDB instance with authentication and username/password (user/pwd set on the Admin DB by default) in the format: mongodb://user:pass@your-server/your_db?authSource=admin (Please see http://api.mongodb.com/python/current/examples/authentication.html#default-database-and-authsource and http://api.mongodb.com/python/current/api/pymongo/mongo_client.html?highlight=authsource ) ## Expected behavior Celery authenticates the user in the admin database (this is the same as passing --authenticationDatabase to the mongo client or the same url to MongoClient) ## Actual behavior Celery tries to authenticate the user on the your_db database (failing to authenticate) ## Workaround (not recommended) Change the db on the URL to /admin (this db shouldn't be used to store arbitrary data normally) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Implement monitored resource for logging client Log entries can have a monitored resource associated with them as of v2 of the logging API. * entries.write documentation: https://cloud.google.com/logging/docs/reference/v2/rest/v2/entries/write * MonitoredResource reference: https://cloud.google.com/logging/docs/reference/v2/rest/v2/MonitoredResource * Existing tiny resource class in monitoring: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/monitoring/google/cloud/monitoring/resource.py#L159 Essentially, the `_BaseEntry` class should be extend to accept a `resource`. Helper methods such as `log_text` and `log_struct` should likely be extended to accept the resource as well. This'll need to work with http and gax. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Cell magics fail to switch the language To reproduce, create a notebook with a cell like this: ``` %%sh a=${HOME} echo $a ``` Select File / Print Preview. Observe the red boxes around `$`'s. ``` html .. <span class=\"n\">a</span> <span class=\"o\">=</span> <span class=\"err\">$</span> <span class=\"p\">{</span> <span class=\"n\">HOME</span> <span class=\"p\">}</span> .. ``` I am using Python 3.4.2 and IPython 3.0.0-dev. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Azure no longer passes on 32 bit linux. See https://dev.azure.com/numpy/numpy/_build/results?buildId=3152. Probably related to the failing PR #13336. @mattip Could you take a look? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Output widget broken Caused by the grand asynchronous movement of 2014. Specifically, the asynchronous code in the comm that calls back the user registered message handling function. The output assumes (now incorrectly) that the widget custom messages are received by the front-end in the same order as the stdout/display messages. @takluyver @jasongrout :horse: Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add IPv6-support for `extra_hosts` the `extra_hosts` option doesn't support IPv6 yet. since the host is seperated from the ip with a colon, how would Compose expect the ip to be given? ``` extra_hosts: - host:1111:2222:3333:4444:5555:6666:7777:8888 ``` or ``` extra_hosts: - host:[1111:2222:3333:4444:5555:6666:7777:8888] ``` or any different? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.clip: change in precedence between minimum and maximum when maximum < minimum Greetings! First, thanks to the NumPy community for your efforts. Second, In NumPy 1.16.5 I observe the following: ```python >>> import numpy as np >>> np.clip(2, 3, 0) 3 ``` In NumPy 1.17.4, I get a different result: ```python >>> import numpy as np >>> np.clip(2, 3, 0) 0 ``` I see that the difference has to do with which constraint gets precedence. Was this an intentional change in precedence then? ### Reproducing code example: ```python import numpy as np assert np.clip(2, 3, 0), 3 ``` ### Numpy/Python version information: ```python >>> import sys, numpy; print(numpy.__version__, sys.version) 1.17.4 3.7.4 (default, Dec 3 2019, 11:37:16) [GCC 5.4.0 20160609] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Importing ABC directly from collections has been deprecated and will be removed in Python 3.10 ## Description Importing ABC directly from collections has been deprecated and will be removed in Python 3.10. ## Expected Behavior Use collections.abc instead ## Reproduction ```python src/prefect/core/flow.py 184: if state_handlers and not isinstance(state_handlers, collections.Sequence): src/prefect/core/task.py 255: if state_handlers and not isinstance(state_handlers, collections.Sequence): src/prefect/engine/runner.py 86: state_handlers, collections.Sequence ``` ## Environment Python 3.8 on Ubuntu Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Default message function in dagster-msteams results in a truncated message ### Dagster version dagster, version 1.0.13 ### What's the issue? Text from the default message function in the dagster-msteams package is truncated by teams. See the image below.  ### What did you expect to happen? The default message function should demonstrate a best-practice - i.e., a message that displays correctly in Teams. ### How to reproduce? Send any Teams alert to an Incoming Webhook from dagster-msteams. ### Deployment type Dagster Cloud ### Deployment details Dagster Cloud Serverless ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Addition of Swin Transformer for Computer Vision # 🌟 Addition Swin Transformer ## Model description Swin Transformer (the name Swin stands for Shifted window) is initially described in arxiv, which capably serves as a general-purpose backbone for computer vision. It is basically a hierarchical Transformer whose representation is computed with shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. Swin Transformer achieves strong performance on COCO object detection (58.7 box AP and 51.1 masks AP on test-dev) and ADE20K semantic segmentation (53.5 mIoU on Val), surpassing previous models by a large margin. ## Open source status * [x] the model implementation is available: https://github.com/microsoft/Swin-Transformer * [x] the model weights are available: https://github.com/microsoft/Swin-Transformer * [x] who are the authors: [Swin Transformer](https://arxiv.org/pdf/2103.14030.pdf) ## Possible Task Support: Opensource Version Supports below tasks * Image Classification * Object Detection * Instance Segmentation * Semantic Segmentation * Video Recognition Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: `Image()` signature/doc improvements The `Image` call has proved to be remarkably popular, but its signature is a bit awkward. - The most common usage I've seen from looking at many notebooks is to call it with a filename, but that's the third positional argument, forcing the vast majority of usage to be done with `Image(filename=...)`, instead of simply `Image(...)`. - The data argument accepts raw data, a url or a filename, but the signature only mentions urls and data. I think we should change the signature and dosctring to take simply a url/filename as the first argument, which could be called `pathspec` or `location`. For backwards compatibility we can continue accepting the keywords `filename` and `url`, but both aren't necessary. The much less common usage of calling it with raw data can be relegated to be called with `data = ...`, though it's worth considering for backwards compatibility auto-detection of raw data if the argument is say longer than 10kbytes or so. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Create a conda command to write default config values and info to condarc It would be nice to have a way to materialize the whole spectrum of configuration options for conda in the user condarc (if empty). `conda config --write-defaults` I guess this could also be used for other locations `conda config --write-defaults --sytem` Something like:  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: No way to pass max_length/max_new_tokens to generate for image-to-text pipeline ### System Info Transformers 4.23.1 ### Who can help? @narsil ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ```python from transformers import pipeline nlp = pipeline(\"image-to-text\") nlp(\"image.jpg\", max_length=20) ``` Results in ``` transformers/generation_utils.py:1301: UserWarning: Neither `max_length` nor `max_new_tokens` has been set ``` ### Expected behavior No warning or a way to disable the warning. This warning is also raised with the `automatic-speech-recognition` pipeline when using the OpenAI Whisper model. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cross definitions files \"inherit\" When writing a new cross-compilation definition but very resemblant to another one, we need to rewrite the whole file. Could a `based_on` or `inherit` tag be added to the files to minimize the definitions duplication ? Moreover, could `meson --cross-file` take multiple files ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose run fails to set up link aliases in Windows interactive mode https://github.com/docker/for-win/issues/278 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the explosion/spaCy codebase. Here's the problem: Error should be raised if you try to set conflicting doc.ents ## How to reproduce the behaviour ```python import spacy from spacy.tokens import Span nlp = spacy.load('en_core_web_sm') doc = nlp(u\"Louisiana Office of Conservation\") print(doc.ents[0], doc.ents[0].label_) entity = Span(doc, 0, 1, label=391L) print(entity, entity.label_) doc.ents = list(doc.ents) + [entity] print(doc.ents[0], doc.ents[0].label_) ``` ## Output: `(Louisiana Office of Conservation, u'ORG')` `(Louisiana, u'MONEY')` `(Louisiana Office of Conservation, u'MONEY')` ## Expected Behaviour: I was expecting MONEY entity to override the ORG entity and end offset of MONEY should have been used after merging. Please let me know if I got this wrong. ## Your Environment * Operating System:Windows 7 * Python Version Used: 2.7.12 * spaCy Version Used: 2.0.7 * Environment Information: None Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the DataDog/integrations-core codebase. Here's the problem: [sqlserver] Add 'recovery model' tag to database metrics Add the `recovery_model_desc` column from `sys.databases` to `SqlBaseStats` as a tag. This would be a useful addition to be able to filter off of for alerts, and since the data is already being queried it should be a minor update. https://github.com/DataDog/integrations-core/blob/01b9aaa746ca94f0b233b41b357cc61b58f3f7ae/sqlserver/datadog_checks/sqlserver/metrics.py#L687-L715 Happy to make the PR if the suggestion is accepted. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Rename CMAKE_SHARED_LINK_FLAGS I couldn't find any CMake documentation for CMAKE_SHARED_LINK_FLAGS which shows up when generating conanbuildinfo.cmake. Is this a typo that should be [CMAKE_SHARED_LINKER_FLAGS](https://cmake.org/cmake/help/v3.0/variable/CMAKE_SHARED_LINKER_FLAGS.html)? I'm not currently conan with CMake myself, so I haven't tested if it causes any errors at the moment. Patching sources tool This has been reported a few times, at least 2 publicly: - @mcraveiro: https://github.com/conan-io/conan/issues/56 - @Klaim: http://boost.2283326.n4.nabble.com/Feedback-boost-conan-binary-packages-td4682377.html I think this is a common use-case, maybe some helpers can be done to ease this task. Delete source folder after conan export command If you export a modified conanfile.py, maybe adding sources, etc, the source folder which is created from a copy of the \"export\" folder + executing the conanfile.py `source()` method is not deleted. If not deleted, build uses the old source folder. Thus, the user has to remember to `conan remove` the local storage before each `conan export` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Is the logic for datastore.Entity.save() correct? I think we may need to rework the structure a bit. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Visual Build tools doesn't include devenv So, we need a way, as consumers, to specify that we don't want to upgrade the sln projects. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Databricks hook: Retry also on HTTP Status 429 - rate limit exceeded ### Apache Airflow Provider(s) databricks ### Versions of Apache Airflow Providers 2.2.0 ### Apache Airflow version 2.2.3 (latest released) ### Operating System Any ### Deployment Other ### Deployment details _No response_ ### What happened Operations aren't retried when Databricks API returns HTTP Status 429 - rate limit exceeded ### What you expected to happen the operation should retry ### How to reproduce this happens when you have multiple calls to API, especially when it happens outside of Airflow ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Run tests on Python 3.10 ### Checklist - [X] I added a descriptive title - [X] I searched for other feature requests and couldn't find a duplicate (including also the ``type-feature`` tag) - [X] I confirmed that it's not related to another project (see the above section) ### What is the idea? Now that Python 3.10 is out we should be testing Conda regularly on it. ### Why is this needed _No response_ ### What should happen? _No response_ ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Blob.upload_from_file doesn't work for file-like objects without size parameter When using `StringIO`, `io.BytesIO` or other file-like objects (such as Flask/werkzeug's file upload object), trying to upload via `Blob.upload_from_file` doesn't work because it attempts to find the size of the object using `os.stat` throwing a `AttributeError: StringIO instance has no attribute 'fileno'`. Passing in the size manually fixes this, but imo this inconsistency shouldn't burden the user as there are other ways than fileno to determine the size of a StringIO or io.BytesIO instance (`seek`, `tell`). At any rate, the error message could be more helpful. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `assemble_schedules` breaks with default arguments <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master - **Python version**: 3.6.8 - **Operating system**: MacOS 10.14 ### What is the current behavior? The `assemble_schedules` function uses the kwarg `run_config=None` by default, which breaks the function when trying to construct a dictionary from `None`. ### Steps to reproduce the problem ``` from qiskit import IBMQ from qiskit.compiler import assemble from qiskit.assembler import assemble_schedules from qiskit.pulse import functional_pulse from qiskit import pulse IBMQ.load_accounts() backend_name = 'ibmq_poughkeepsie' backend = IBMQ.get_backend(backend_name) device = pulse.DeviceSpecification.create_from(backend) @functional_pulse def simple_square_pulse(duration): return [1/10] * duration rabi_pulse = simple_square_pulse(duration=30) schedule = pulse.Schedule(name='Simple square pulse') schedule.insert(0, rabi_pulse(device.q[0].drive)) assemble_schedules([schedule]) ``` ### What is the expected behavior? A valid qobj should be returned. ### Suggested solutions The arg `run_config` should not be optional. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Handle \"unsupported callables\" for task arg introspection Follow up from https://github.com/PrefectHQ/prefect/pull/897#discussion_r272286805 Builtin functions and functions like `np.dot` are \"unsupported callables\" because `inspect` can't determine their signature, which means we can't build arguments automatically. For example, this fails: ```pytyon prefect.task(np.dot)(x, y) ``` Currently, functions like this need to be nested in a pure-Python function: ```python @task def mydot(x, y): return np.dot(x, y) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Using clang-cl with libraries compiled with Visual Studio doesn't work Conan version: 1.18.1 OS Name: Windows 10 Version: 1903 OS build: 18362.418 Visual Studio 2019 Version 16.3.3 When using clang-cl I want to use libraries that were compiled with Visual Studio since they are binary compatible and building most libraries with clang-cl is basically impossible right now(but thats another issue). I made a little proof of concept of what I'm trying to do [here](https://github.com/munoah/clang-cl-poc). Since it uses conan_cmake your default profile should look something like this: ``` [settings] os_build=Windows arch=x86_64 arch_build=x86_64 compiler=Visual Studio compiler.version=16 build_type=Release ``` In Visual Studio go to Open -> CMake and select the CMakeLists.txt Everything works as expected in the x64-Debug Configuration, however when I switch to x64-Clang-Debug I get: ``` CMake Error at out/build/x64-Clang-Debug/conanbuildinfo.cmake:642 (message): Incorrect 'Visual Studio'. Toolset specifies compiler as 'MSVC' but CMake detected 'Clang' ``` I can `set(CONAN_DISABLE_CHECK_COMPILER TRUE)` to disable the whole function, but disabling sanity checks is not nice. The check that the specified toolset uses the same compiler as the project seems a bit counterproductive, clang-cl and cl are binary compatible (and i guess the check further down is the same problem, maybe someone wants to compile my code with gcc, but the libraries with clang for performance reasons) My fix for this would be reverting https://github.com/conan-io/conan/issues/2285, but that would presumably break toolchains, but these seem to work different in vs19 anyways Relates Issues: https://github.com/conan-io/conan/issues/1839 https://github.com/conan-io/conan/issues/2285 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Launching navigator via prompt warnings appear _From @RidaZubair on May 24, 2017 9:47_ **OS:** Windows **Anaconda: 4.4.0** **Actual:** On launching navigator via prompt following warning appears on prompt  _Copied from original issue: ContinuumIO/navigator#1189_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `FakePrague` list of supported operations is incorrect Looking at this list: ```python from qiskit.providers.fake_provider import FakePrague backend = FakePrague() list(zip(backend.operation_names, [type(x) for x in backend.operations])) ``` ```python [('id', qiskit.circuit.library.standard_gates.i.IGate), ('rz', qiskit.circuit.library.standard_gates.rz.RZGate), ('sx', qiskit.circuit.library.standard_gates.sx.SXGate), ('x', qiskit.circuit.library.standard_gates.x.XGate), ('cz', qiskit.circuit.gate.Gate), ('reset', qiskit.circuit.reset.Reset), ('measure', qiskit.circuit.measure.Measure), ('delay', qiskit.circuit.delay.Delay)] ``` you see that the entry for `cz` is not an instance of `CZGate`. This is apparently the origin of the bug referenced in #9935 #9937 #9982 . The gate with name `cz` in the list above is not recognized as a CZ gate when doing unitary synthesis here https://github.com/Qiskit/qiskit-terra/blob/971a203deb33bdc309b1467d00e39efc5eda8936/qiskit/transpiler/passes/synthesis/unitary_synthesis.py#L646 and here https://github.com/Qiskit/qiskit-terra/blob/971a203deb33bdc309b1467d00e39efc5eda8936/qiskit/transpiler/passes/synthesis/unitary_synthesis.py#L677 Furthermore: ```python In [37]: badcz = backend.operations[4] In [38]: badcz.definition # None In [39]: badcz.to_matrix() # Raises error CircuitError: \"to_matrix not defined for this <class 'qiskit.circuit.gate.Gate' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: In storage.Key.get_acl, account for very long list of ACLs From TODO: ``` python # TODO: This might be a VERY long list. Use the specific API endpoint. ``` See [`gcloud.storage.Key.get_acl`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/key.py#L388) for relevant code and #146 for some context. In storage.Key.get_acl, account for very long list of ACLs From TODO: ``` python # TODO: This might be a VERY long list. Use the specific API endpoint. ``` See [`gcloud.storage.Key.get_acl`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/key.py#L388) for relevant code and #146 for some context. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Unable to cross build glib [my-meson-cross-file.txt](https://github.com/mesonbuild/meson/files/4275963/my-meson-cross-file.txt) **Describe the bug** The configure step fails during the configuration of glib: ``` File \"/home/scerveau/DEV/EXTERNAL/meson/mesonbuild/modules/pkgconfig.py\", line 71, in _check_generated_pc_deprecation location=obj.generated_pc_warn[1]) File \"/home/scerveau/DEV/EXTERNAL/meson/mesonbuild/mlog.py\", line 279, in deprecation return _log_error('deprecation', *args, **kwargs, is_error=True) File \"/home/scerveau/DEV/EXTERNAL/meson/mesonbuild/mlog.py\", line 253, in _log_error if location is not None: AttributeError: 'types.SimpleNamespace' object has no attribute 'filename' ``` **To Reproduce** Checkout gst-build and try to cross build with the given cross-file attached [my-meson-cross-file.txt](https://github.com/mesonbuild/meson/files/4275967/my-meson-cross-file.txt) **Expected behavior** To finish the configuration step without failing **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? yes * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) Ubuntu 18.04 * what Python version are you using e.g. 3.8.0 3.6.9 * what `meson --version` master b190a20a * what `ninja --version` if it's a Ninja build 1.8.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [fairscale] rng states saving fails in an extended multi-gpu test @sgugger, following up on the RNG states PR ``` RUN_SLOW=1 pytest tests/extended/test_trainer_ext.py::TestTrainerExt::test_run_seq2seq_fully_sharded_ddp_fp16 -sv ``` fails on multi-gpu scheduled CI: ``` File \"/__w/transformers/transformers/examples/pytorch/translation/run_translation.py\", line 589, in <module> main() File \"/__w/transformers/transformers/examples/pytorch/translation/run_translation.py\", line 522, in main train_result = trainer.train(resume_from_checkpoint=checkpoint) File \"/__w/transformers/transformers/src/transformers/trainer.py\", line 1316, in train self._maybe_log_save_evaluate(tr_loss, model, trial, epoch) File \"/__w/transformers/transformers/src/transformers/trainer.py\", line 1397, in _maybe_log_save_evaluate self._save_checkpoint(model, trial, metrics=metrics) File \"/__w/transformers/transformers/src/transformers/trainer.py\", line 1534, in _save_checkpoint stderr: Saving model checkpoint to /tmp/tmpb6tfhvqb/checkpoint-1 torch.save(rng_states, os.path.join(output_dir, f\"rng_state_{local_rank}.pth\")) File \"/opt/conda/lib/python3.8/site-packages/torch/serialization.py\", line 369, in save with _open_file_like(f, 'wb') as opened_file: File \"/opt/conda/lib/python3.8/site-packages/torch/serialization.py\", line 230, in _open_file_like return _open_file(name_or_buffer, mode) File \"/opt/conda/lib/python3.8/site-packages/torch/serialization.py\", line 211, in __init__ super(_open_file, self).__init__(open(name, mode)) stderr: FileNotFoundError: [Errno 2] No such file or directory: '/tmp/tmpb6tfhvqb/checkpoint-1/rng_state_1.pth' ``` https://github.com/huggingface/transformers/runs/2514006341?check_suite_focus=true Oddly enough it works fine for me if I try it locally. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Datastore Key's reference is missing location identifier in app argument in to_legacy_urlsafe() @dhermes I put this as a new issue because I thought people might have a problem with this too. Please feel free to edit/remove this issue if it is not appropriate to put it here. I was running `pip install --upgrade google-cloud-datastore` to get latest version that has the `key.to_legacy_urlsafe()` implemented in [#3491](https://github.com/GoogleCloudPlatform/google-cloud-python/pull/3491). I tested the method and I found out that the urlsafe generated from the method is still not the same as datastore's urlsafe. I have implemented my own function to generate the urlsafe key before the update was released and so far it worked properly for me (I can share my code if anybody wants). So I compared my function with the to_legacy_urlsafe and I found the problem: ``` reference = _app_engine_key_pb2.Reference( app=self.project, path=_to_legacy_path(self._path), # Avoid the copy. name_space=self.namespace, ) ``` In the app argument, the location identifier is missing unlike in my function where I concatenated the \"s~\" at the beginning of the string. I think this is the cause of the problem why it was not getting the urlsafe correct, although I don't understand why it needs the location identifier in front of the project name in the first place. Do you think I should send a PR to fix this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Linkage errors due to malformed ninja script Using meson to build my project generates a ninja file that fails to link at the final stage. Downgrading to version `0.47.2-1` fixes the problem. Upon further investigation it seems the culprit is this line in my ninja file: `LINK_ARGS = -L=-L-L/usr/lib// -L=-L-lgtkd-3 -L=-L-ldl` It looked odd that the arguments had the `-L` argument duplicated. And in fact, removing the extra argument allowed ninja to successfully link my project: `LINK_ARGS = -L=-L/usr/lib// -L=-lgtkd-3 -L=-ldl` @FFY00 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: add a utility for creating table schema metadata for a Pandas dataframe Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Output for semicolon-terminated lines with comments cf https://github.com/JuliaLang/IJulia.jl/issues/109 The output of a semicolon-terminated line with comment is not suppressed in IPython. ``` b = 1 b; # foo ``` give `Out[13]: 1` ``` b = 1 b; ``` does not. Havent found such and issue on our tracker. @takluyver you are the best with the input machinery and coroutines; Thoughts ? (Because of the comment @stevengj in sus-cited issue, marking as prio-high, but won't mind if priority decreased later, or not fixed) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose log should show the Volume creation Hello, when you create a network in docker-compose, you can see it in the log when the creation is done `Creating network \"contrib_default\" with the default driver` However, it's not the same for Volume. I expect something like: `Creating Volume \"contrib_clair-data\" with the default driver` ``` 🐳 〔default〕➜ contrib git:(develop) docker-compose up -d Creating network \"contrib_default\" with the default driver Creating clair Creating hyperclair_dev Creating registry Creating auth Creating hyperclair 🐳 〔default〕➜ contrib git:(develop) docker volume ls DRIVER VOLUME NAME local 90f7961046a7b545199d0e7cd739b25286d764bc6ee2c763bd6eb0147606e25b local 11e10cfd723ad02c5136a14c61187854f7d5c2d02a8c0f6b37cd3ad41aec2e53 local 174022a4616e81395c5feb80a567e456c042a9d3984c7212193035e5182d1a40 local 46f40889b0bc99419650a6b098ebbf2717c742cdf9be961401559815af71a672 local c6fd2336d72eef540a2e8e996f2c67043386eea7c163e37b0f5a261a0f511749 local 36a85ac92bfcc150dcc594f0a6a3327925af342f2aab840a9b6f7a900ca5e015 local contrib_clair-data local 2a88aad1fc5bc27dd87ddb207c47c20bd9dc9d7a5e2af5370047fd0ca483eb4c local 78c6a7f594cfcf5d856311426786d762928bd675eba1dc5791f3b54c65ad7d41 local 5a207163e75caa3e48fb69663de6ca4b37c06db6d570ff10e24eb36182b4de58 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Error 500 while saving IPython notebook Hi, I've created a notebook using IPython master and Python 3.3, then opened and changed it in 'ipython notebook' using IPython master and Python 2.7. Now I can't save changes because IPython raises the following exception: ``` Traceback (most recent call last): File \"/Users/kmike/envs/scraping/lib/python2.7/site-packages/tornado/web.py\", line 1077, in _execute *self.path_args, **self.path_kwargs) File \"/Users/kmike/envs/scraping/lib/python2.7/site-packages/tornado/web.py\", line 1892, in wrapper return method(self, *args, **kwargs) File \"/Users/kmike/envs/scraping/lib/python2.7/site-packages/IPython/frontend/html/notebook/handlers.py\", line 672, in put nbm.save_notebook(notebook_id, self.request.body, name=name, format=format) File \"/Users/kmike/envs/scraping/lib/python2.7/site-packages/IPython/frontend/html/notebook/nbmanager.py\", line 168, in save_notebook self.write_notebook_object(nb, notebook_id) File \"/Users/kmike/envs/scraping/lib/python2.7/site-packages/IPython/frontend/html/notebook/filenbmanager.py\", line 175, in write_notebook_object old_checkpoints = self.list_checkpoints(notebook_id) File \"/Users/kmike/envs/scraping/lib/python2.7/site-packages/IPython/frontend/html/notebook/filenbmanager.py\", line 313, in list_checkpoints path = self.get_checkpoint_path(notebook_id, checkpoint_id) File \"/Users/kmike/envs/scraping/lib/python2.7/site-packages/IPython/frontend/html/notebook/filenbmanager.py\", line 277, in get_checkpoint_path return self.get_checkpoint_path_by_name(name, checkpoint_id) File \"/Users/kmike/envs/scraping/lib/python2.7/site-packages/IPython/frontend/html/notebook/filenbmanager.py\", line 269, in get_checkpoint_path_by_name ext=self.filename_ext, UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-8: ordinal not in range(128) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Memory explosion when jitting dynamic_slice The [following example][1] explodes in memory usage when calling the jitted functions. The culprit seems to be the dynamic_slice. It happens calling with or without the GPU. Incidentally, it is also rather slow (twice slower than the plain Python version), so I welcome comments if there is a jax-friendlier way to rewrite it, but perhaps that is what jit should do? My system: Fedora 29, 31 GB RAM jax 0.1.36 jaxlib 0.1.16, installed from the googleapis wheel. CUDA 10.0 Nvidia driver 430.14. [1]: https://gist.github.com/Dapid/b33919674f6a3cd9839473bfd2821e28 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: TrainingArguments does not support `mps` device (Mac M1 GPU) ### System Info - `transformers` version: 4.21.0.dev0 - Platform: macOS-12.4-arm64-arm-64bit - Python version: 3.8.9 - Huggingface_hub version: 0.8.1 - PyTorch version (GPU?): 1.12.0 (False) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: yes - Using distributed or parallel set-up in script?: no ### Who can help? @sgugger ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction ```bash export TASK_NAME=wnli python run_glue.py \\ --model_name_or_path bert-base-cased \\ --task_name $TASK_NAME \\ --do_train \\ --do_eval \\ --max_seq_length 128 \\ --per_device_train_batch_size 32 \\ --learning_rate 2e-5 \\ --num_train_epochs 3 \\ --output_dir /tmp/$TASK_NAME/ ``` ### Expected behavior When running the `Trainer.train` on a machine with an MPS GPU, it still just uses the CPU. I expected it to use the MPS GPU. This is supported by `torch` in the newest version 1.12.0, and we can check if the MPS GPU is available using `torch.backends.mps.is_available()`. It seems like the issue lies in the [`TrainingArguments._setup_devices` method](https://github.com/huggingface/transformers/blob/49cd736a288a315d741e5c337790effa4c9fa689/src/transformers/training_args.py#L1266), which doesn't appear to allow for the case where `device = \"mps\"`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: CMake subproject sandbox violation **Describe the bug** Meson seems to be hitting a sandbox violation when using a CMake subproject. Offending CMake code: https://github.com/mongodb/mongo-c-driver/blob/master/src/libbson/CMakeLists.txt#L122=. Log: https://github.com/hse-project/hse/runs/7198083520?check_suite_focus=true#step%3A12%3A360= **To Reproduce** Use mongo-c-driver as a subproject. You can clone hse-project/hse and -Dwrap_mode=forcefallback. **Expected behavior** Not hit a sandbox violation using the cmake module. **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? no * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.) fc36 * what Python version are you using 3.10.5 * what `meson --version` 0.63.0 * what `ninja --version` if it's a Ninja build 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Blob.download_to_file() downloads to RAM instead Hello, Blob.download_to_file() with no chunk size set causes the file to be pulled entirely into RAM before starting to write it to the supplied file object. This is due to google/resumable_media/download.py's \"sans I/O\" approach. I can work around it by setting the chunk size parameter, however this changes both what I am billed for (multiple GETs rather than a single GET) and application's latency profile to paper over an obvious deficiency in the client library, so if you don't consider this a design flaw then at least consider it a performance bug. Either way, I've lost 24 hours of data due to an OOM triggered by this, the docstring should at a minimum be updated to warn the user that the library cares more about some trend from last week than doing what you'd expect the simplest possible HTTP client talking to Gcloud could have done in the early 90s. Apologies for the angst, but I'm leaving it in here, because you really need to know how disappointing it is to have a crash of this sort caused by a library function so conceptually simple. pip freeze: ```` gapic-google-cloud-pubsub-v1==0.15.4 gapic-google-cloud-speech-v1==0.15.3 google-api-python-client==1.6.2 google-auth==1.0.1 google-auth-httplib2==0.0.2 google-cloud-core==0.25.0 google-cloud-language==0.25.0 google-cloud-pubsub==0.26.0 google-cloud-speech==0.25.1 google-cloud-storage==1.1.1 google-cloud-translate==0.24.0 google-gax==0.15.13 google-resumable-media==0.0.2 googleapis-common-protos==1.5.2 grpc-google-iam-v1==0.11.1 proto-google-cloud-pubsub-v1==0.15.4 proto-google-cloud-speech-v1==0.15.3 ```` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Expose versionGroupId in flow deployment Currently, when deploying Flows from Core using the standard documented method you are forced to use the versioning mechanism of Cloud (which is by name / project). Cloud actually has a built-in versioning mechanism which is much more flexible, allowing users to provide a `versionGroupId` with each flow deploy. We should expose this input in `flow.deploy` and `client.deploy` and document it accordingly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: MongoDB backend does not support mongodb+srv:// URL's ## Checklist https://github.com/celery/celery/blob/master/celery/backends/mongodb.py#L143-L146 ## Steps to reproduce Set the MongoDB URL to one like: ```mongodb+srv://mongo.private.corp.example.com/celery?ssl=false``` ## Expected behavior This works. ## Actual behavior This fails because the URL parsing does not match on `mongodb+srv://` instead trying to match `mongodb://` only. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Shouldn't gcloud.dataset.transaction.Transaction rollback on error exit from context manager? If the application raises inside a 'with transaction:' block, the transaction should be rolled back, rather than blindlin committed. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: TFAlbertMainLayer cannot be imported from the transformers library. Unlike the TFBertMainLayer class which can be imported from transformers, TFAlbertMainLayer cannot be imported. Locally I made the changes to init.py: Import TFAlbertMainLayer from modeling_tf_albert Similar to tensorflow version, pytorch version should also be implemented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: add file_to_run=file.ipynb capability to the notebook over at ipython/nbconvert#13, @Krastanov requested the ability to re-run all cells in a notebook before doing a conversion. @Krastanov said: > Is there a way to evaluate all cells of a notebook before we use nbconvert? > > Why: > I am writing a script that will convert our example notebooks to some static form to be part of the documentation. But many of > the examples contain plots, which take too much space to be kept in git so we are keeping only the unevaluated notebooks in the tree. However we want to generate documentation containing these images, so we must generate them somehow? I suggested this can legitimately live in the `ipython notebook` entry point (hence this enhancement request), but can also see the advantages of having that functionality in the (forthcoming) `ipython nbconvert` This would be the equivalent of clicking on \"Run All\" under the \"Cell\" menu of a notebook and saving it, without needing a web browser. This is somewhat similar to, but different from #945. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Add docs for `Result` / `NoResult` We need to both add the classes to the API docs + add a concept doc for these objects. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ccz drawing inconsistency A cz gate is being draw like this: ``` qr = QuantumRegister(2, 'q') circuit = QuantumCircuit(qr) circuit.append(ZGate().control(1), [qr[0], qr[1]]) circuit.draw() ``` ``` q_0: |0>─■─ │ q_1: |0>─■─ ```   A ccz gate is being draw like this: ``` qr = QuantumRegister(3, 'q') circuit = QuantumCircuit(qr) circuit.append(ZGate().control(2), [qr[0], qr[1], qr[2]]) circuit.draw('text') ``` ``` q_0: |0>──■── │ q_1: |0>──■── ┌─┴─┐ q_2: |0>┤ Z ├ └───┘ ```   I thinks they all should be something like this: ``` q_0: |0>──■── │ q_1: |0>──■── │ q_2: |0>──■── ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Support training multiple models in parallel on each TPU core. ## 🚀 Feature While training a model using K-Fold method, it would be beneficial to train each model parallelly on a separate TPU core. There should be a feature by which we can assign a model training process to a particular TPU core. Similar to `gpus=[0,2]` ### Motivation I came across this [kernel](https://www.kaggle.com/abhishek/super-duper-fast-pytorch-tpu-kernel) by Abhishek Thakur, wherein he trains multiple ROBERT models in parallel on each TPU core. It trained the model fast by utilizing all cores. I have tried doing the same with Lightning but realized I cant select a TPU core with it. ### Pitch Not very clear about it. Maybe inbuilt support for KFold method wherein the dataset is split accordingly and a model is trained on each TPU code in a Kfold manner. Or just the support to select a core and train on it. e.g `tpus=[1]` ### Additional context Kernel by Abhishek Thakur: https://www.kaggle.com/abhishek/super-duper-fast-pytorch-tpu-kernel Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %paste + history From a user point of view, it seem like `%paste` should not store itself in IPython's history, but instead store the text that was pasted. It seems unlikely that a user will want to use history to get to paste again over get to the thing that was pasted.  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Remove deprecated `conda.compat` ### What is the idea? Remove clearly deprecated code. ### Why is this needed This submodule was deprecated 4 years ago. ### What should happen? Remove `conda.compat` and associated code that is no longer in use. ### Additional Context _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `QuantumCircuit.qasm` can output invalid gate names <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.19dev @ 6b08154 - **Python version**: any - **Operating system**: any ### What is the current behavior? `Instruction` instances can be given any Python string as a name. If the name is not of a known gate, the QASM 2 dumper will create a `gate <name> { ... }` block to describe it, and use `Instruction.name` verbatim. If the name contains invalid characters for a QASM 2 identifier, they will be reproduced immediately. ### Steps to reproduce the problem There's currently a bug in `QuantumCircuit.qasm` when working with `UnitaryGate` (#7051) which will throw a type error earlier, but in principle ```python import qiskit qv = qiskit.circuit.library.QuantumVolume(2) print(qv.qasm()) ``` _would_ produce something like ```text OPENQASM 2.0; include \"qelib1.inc\"; gate su4_755 q0,q1 { <truncated> } gate su4_747 q0,q1 { <truncated> } gate quantum_volume_[2,2,257] q0,q1 { su4_755 q0,q1; su4_747 q1,q0; } // ^^^^^^^^^^^^^^^^^^^^^^^^ error qreg q[2]; quantum_volume_[2,2,257] q[0],q[1]; ``` ### What is the expected behavior? Output identifiers should be valid. ### Suggested solutions Either we only allow `Instruction.name` to be valid QASM identifiers, or we escape invalid characters when outputting the identifiers. Using escapes (e.g. just replacing all invalid characters by an underscore) is probably the best, because it'll be the easiest to work with when we have QASM 2 and 3 outputters - QASM 3 is far less restrictive in what's an allowed identifier, and we're more likely then to be in a position when users are giving us their own names. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Failing lax_numpy_indexing_test.py tests on Python 3.7 `python tests/lax_numpy_indexing_test.py --num_generated_cases=1` on Python 3.7 (fresh Anaconda install on a macOS). Numpy version 1.15.4. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Fargate agent kwarg literal parse can also raise SyntaxError ## Description If a kwarg is passed to the Fargate agent such as `taskRoleArn='arn:aws:iam::543216789012:role/Dev'` the literal eval will raise a `SyntaxError` instead of the currently handled `ValueError`. ## Expected Behavior I expect all kwargs to be properly parsed if they need to be, otherwise pass. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Deprecate Mirror The mirror option for downloading is now deprecated due to the switching to Git LFS and removal of Tuna. https://github.com/tuna/issues/issues/937 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Figure out the right level of abstraction for iterators. (From #2545) We need to determine how users will interact with our iterators and what level of abstraction is expected. Right now @dhermes has implemented an iterator that iterates through items but exposes page information by setting state on the iterator itself. ``` python iterator = MyIterator(...) for item in iterator: print(item) print(iterator.page) print(iterator.next_page_token) ``` I'm not the biggest fan of this for two reasons: it combines the `iterable` and the `iterator` interfaces, it merges the item-level and page-level abstractions. In my opinion, we should work at well-defined abstraction levels and keep the `iterable` and `iterator` separate. The first level is the page level: ``` python iterator = MyIterator(...) # You could also specify arguments to pages, such as page_token for page in iterator.pages(): print(page.number) print(page.items) print(page.next_page_token) ``` The second level yields items but also page context: ``` python for item, current_page in iterator.items_by_page(): print(item) print(page.number) print(page.next_page_token) ``` The final level yields only items and completely abstracts away the concept of pages: ``` python for item in iterator.items(): print(item) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Can create a delay gate with negative time <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is the current behavior? It is possible to make this: ``` ┌───┐┌──────────────────┐ ░ ┌─┐ q_0: ┤ X ├┤ DELAY(-1000[dt]) ├─░─┤M├ └───┘└──────────────────┘ ░ └╥┘ meas: 1/═════════════════════════════╩═ 0 ``` ### Steps to reproduce the problem ### What is the expected behavior? Negative times should be caught. It does however work on IBM HW but gives odd results. ### Suggested solutions A simple if and raise would likely solve this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Output widget issues. Widget outputs not stored in notebook format anymore. Example of beating frequency does not work the same for 2 reasons : 1 - `<audio controls=\\\"controls\\\" >` not in ipynb anymore. 2 - `f1, f2 = v.children`raise as `v` has 3 childrens: `f1`, `f2` and `out`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: package command does not use modified environment `conan build` command runs in a modified environment that among other things has a `PATH` variable that includes dependencies' binary directories. This functionality supports using tools as build requirements, for example having a build system as a build requirement. The `conan package` command seems not to run in an environment modified in a similar way, as the command fails if the necessary tool is installed via Conan and not through external methods. This can be reproduced using a very simple example: ```python # conanfile.py from conans import ConanFile, CMake class MyConan(ConanFile): build_requires = \"cmake_installer/3.13.0@conan/stable\" def build(self): cmake = CMake(self) cmake.configure() cmake.build() def package(self): cmake = CMake(self) cmake.install() ``` ```cmake # CMakeLists.txt cmake_minimum_required(VERSION 3.12.0) project(ConanTest) install(CODE \"message(\\\"installing...\\\")\") ``` Inside the project directory run ```shell $ conan install . --build mssing $ conan build . $ conan package . ``` The `conan build` command will succeed, but `conan package` will fail, unless there is a `cmake` executable installed in system. I've tested this on Conan 1.11.1 - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: exports not copied when inheriting from another package with python_requires I tried inheriting from the `bzip2/1.0.6@conan/stable` package. I wanted to generate an additional file at the end of the build. So here's what I did: ``` import conans base = conans.python_requires('bzip2/1.0.6@conan/stable') class Bzip2QiToolchain(base.Bzip2Conan): def build(self): print(\"Calling parent class\") super(Bzip2QiToolchain, self).build() self.generate_metadata() def generate_metadata(self): pass ``` The problem here is that the bzip2 package has a `CMakeLists.txt` listed in its exports, that it copies using: `shutil.move(\"CMakeLists.txt\", \"%s/CMakeLists.txt\" % self.zip_folder_name)` The problem is that the source `CMakeLists.txt` it want to copy doesn't exist, so the copy fails. Using Conan 1.7.3 on Linux. - [X] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [X] I've specified the Conan version, operating system version and any tool that can be relevant. - [X] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: triu/tril behavior on N-D arrays with N > 2 From the docs it is unclear that `triu` and `tril` work on N-D arrays with N > 2. However this does seem to work. So it would be good to explain this and provide an example. <details> ```python In [1]: import numpy as np In [2]: a = np.arange(3 * 4 * 5).reshape(3, 4, 5); a Out[2]: array([[[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14], [15, 16, 17, 18, 19]], [[20, 21, 22, 23, 24], [25, 26, 27, 28, 29], [30, 31, 32, 33, 34], [35, 36, 37, 38, 39]], [[40, 41, 42, 43, 44], [45, 46, 47, 48, 49], [50, 51, 52, 53, 54], [55, 56, 57, 58, 59]]]) In [3]: np.triu(a) Out[3]: array([[[ 0, 1, 2, 3, 4], [ 0, 6, 7, 8, 9], [ 0, 0, 12, 13, 14], [ 0, 0, 0, 18, 19]], [[20, 21, 22, 23, 24], [ 0, 26, 27, 28, 29], [ 0, 0, 32, 33, 34], [ 0, 0, 0, 38, 39]], [[40, 41, 42, 43, 44], [ 0, 46, 47, 48, 49], [ 0, 0, 52, 53, 54], [ 0, 0, 0, 58, 59]]]) In [4]: np.tril(a) Out[4]: array([[[ 0, 0, 0, 0, 0], [ 5, 6, 0, 0, 0], [10, 11, 12, 0, 0], [15, 16, 17, 18, 0]], [[20, 0, 0, 0, 0], [25, 26, 0, 0, 0], [30, 31, 32, 0, 0], [35, 36, 37, 38, 0]], [[40, 0, 0, 0, 0], [45, 46, 0, 0, 0], [50, 51, 52, 0, 0], [55, 56, 57, 58, 0]]]) ``` </details> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: add page_size parameter for list_rows and use in DB-API for arraysize With https://github.com/GoogleCloudPlatform/google-cloud-python/pull/4144 the arraysize parameter no longer affects how much data the library actually requests from the API. We should add a `page_size` parameter to `Client.list_rows` and use that parameter in the DB-API implementation. See also: https://github.com/GoogleCloudPlatform/google-cloud-python/issues/4134 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Latex visualizer confuses the qubits when measurement ### Informations - **Qiskit Terra version**: master ### What is the current behavior? The following code generates the following image: ```Python q = QuantumRegister(3, 'q') c = ClassicalRegister(1, 'c') circ_py = QuantumCircuit(q, c) circ_py.measure(q[0], c[0]) circ_py.z(q[1]).c_if(c, 1) circ_py.draw(output='latex').show() ```  ### What is the expected behavior? The measurement should be on `q_0`, not on `q_2` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Handle KeyboardInterrupt during training ## 🚀 Feature It should be possible to examine the stack if the training is interrupted manually. ### Motivation In my case, the program hangs at some point and I have to cancel it manually. Because Lightning catches KeyboardInterrupt, I don't get to know where the program was hanging. ### Alternatives 1. **Re-raise KeyboardInterrupt.** This would break the current behavior. This could be made configurable. 2. **Save result of `sys.exc_info()` for later examination.** This could introduce memory issues like memory leaks or circular references. 3. **Call a handler.** The users could then call `sys.exc_info()` in the handler. This would make memory issues less likely. I will prepare a pull request for the third option. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Add a way for Meson to find “curses” generically Add a way for Meson to find `curses` generically. There are definitely different names for `curses` library but what about a generic `curses_dep = dependency(‘curses’)` for finding the correct `curses` libraries like what Meson does with threads. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Allow linux like paths in volume source on Windows I would expect the following two docker-compose files to work exactly the same but they do not. The first one works with **C:/** but the second one with just **/** does not. In most other places in docker like Dockerfiles, Linux like paths can be used with no issues. # Works: ``` version: '3.3' services: arch.samples.containers: volumes: - type: bind source: ${ArchSamplesContainersConfigPath-C:/etc/Arch.Samples.Containers} target: /etc/Arch.Samples.Containers read_only: true volume: nocopy: true ``` # Does not work: ``` version: '3.3' services: arch.samples.containers: volumes: - type: bind source: ${ArchSamplesContainersConfigPath-/etc/Arch.Samples.Containers} target: /etc/Arch.Samples.Containers read_only: true volume: nocopy: true ``` Fails with \"Cannot create container for service arch.samples.containers: invalid mount config for type \"bind\": bind source path does not exist\" Docker Version: Client: Version: 18.02.0-ce API version: 1.36 Go version: go1.9.3 Git commit: fc4de44 Built: Wed Feb 7 21:12:53 2018 OS/Arch: windows/amd64 Experimental: true Orchestrator: kubernetes Server: Engine: Version: 18.02.0-ce API version: 1.36 (minimum version 1.12) Go version: go1.9.3 Git commit: fc4de44 Built: Wed Feb 7 21:20:15 2018 OS/Arch: linux/amd64 Experimental: true docker-compose version 1.19.0, build 9e633ef3 docker-py version: 2.7.0 CPython version: 2.7.14 OpenSSL version: OpenSSL 1.0.2k 26 Jan 2017 Windows Version: Windows 10 Build 17107.rs4_release.180220-1350 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: ndarrays pickled on 1.16.0 cannot be loaded in previous versions As reported in #12825 in [these](https://github.com/numpy/numpy/issues/12825#issuecomment-456561919) [comments](https://github.com/numpy/numpy/issues/12825#issuecomment-456566648). Should change the module for backward compatibility Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Using IterableDatasets without __len__ for Training Calling `fit(model, trainloader, evalloader)` internally calls `enforce_datamodule_dataloader_override`. This function has the if statement `if (train_dataloader or val_dataloaders) and datamodule:`. https://github.com/PyTorchLightning/pytorch-lightning/blob/2c935d048e69a2890889dea768ecceb0252cf321/pytorch_lightning/trainer/configuration_validator.py#L13 This is similar to the PR #1560, the problem is that the `if(dl)` translates to `if(bool(dl))`, but there's no dataloader.__bool__ so bool() uses dataloader.__len__ > 0. But... dataloader.__len__ uses IterableDataset.__len__ for IterableDatasets for which __len__ is undefined. The fix is also the same, the `if dl` should be replaced by `if dl is not None`. I will open a PR fixing this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Provide Checksum header on all uploads To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. We should provide an X-Checksum header (preferably SHA2) on ALL uploads so that artifactory can check for corruption of a binary on upload. Currently we only do it during checksum deploy, so we're not taking advantage of the corruption protection in artifactory. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Dtype.base attribute not documented dtype instances have a `base` attribute that, I think, is meant to be the \"base dtype\" for subarrays. It is, however, not documented, leading to hesitation with and confusion about its use. See https://stackoverflow.com/questions/52476601/purpose-status-of-the-attribute-numpy-dtype-base and https://github.com/astropy/astropy/pull/8353#issuecomment-454945823 My sense is that it is useful and should just be documented properly. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Raise more meaningful messages from GraphInfo parsing Changelog: omit Docs: omit Related to #4443, add more meaningful errors related to `graph_info.json` parsing. The output for the linked issue would have been: ```bash ⇒ conan info . ERROR: Error parsing GraphInfo from file '/Users/jgsogo/dev/conan/issues/tmp2/graph_info.json': Error related to GraphInfo text content: Required node 'root' is not present ``` @lasote I'm not sure if I should open this PR against `develop` or against a minor `1.12.1`. closes #4443 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Need a dag visualizer <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? A dag visualizer is important for developing transpiler passes. It should be easy to use like the circuit visualizer. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: options in cross/native files cannot store capitals `ConfigParser.configparser` by default stores all keys in sections as lower case strings. We need to change that. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Include profile dir custom.css in nbconvert HTML output Suggested by @ksmith13 in #4902 , we should include `custom.css` from the user's profile directory in nbconvert HTML output, _at least_ for the print preview / download as in the live notebook. It's not practical to have to copy `custom.css` into every folder in which you want print preview and download as to work. This could be a quick fix, if we decide the behavior of nbconvert --to html should match that of download as and print preview; else, we may need to add a parameter to the nbconvert web API used by the notebook. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Add height and width parameters to core.display.Video I'm viewing some videos in a notebook. The videos are larger than the width of my notebook so I can't see the entire frame unless I scroll left and right. I would like to specify a height and width so I can view the entire frame at once. I think it'd be pretty cool if it could resize automatically, but I'd be happy with the ability to set the height and width. I can post some pictures if it helps. ``` ipython --version 6.5.0 jupyter lab --version 0.34.12 ``` I've been doing this work around: ``` HTML( '<video controls width=500>' '<source src=\"video.mp4\" type=\"video/mp4\"/>' '</video>' ) ``` It seems like a simple PR, I could make it if you all like this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: migrate-to-labels is missing full help entry ``` $ docker-compose help migrate-to-labels No such command: migrate-to-labels Commands: build Build or rebuild services help Get help on a command kill Kill containers logs View output from containers port Print the public port for a port binding ps List containers pull Pulls service images restart Restart services rm Remove stopped containers run Run a one-off command scale Set number of containers for a service start Start services stop Stop services up Create and start containers migrate-to-labels Recreate containers to add labels ``` docker-compose==1.3.0, installed via pip Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: HTML vs Iframe I was again the witness of people miss-using HTML to display IFrames, and having issues. Could we detect in HTML the usage of `<iframe>....</iframe>` and warn user that there is an iframe object ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: %magic doesn't work ``` In [48]: %magic --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-48-99e14b2858dd> in <module>() ----> 1 get_ipython().magic(u'magic') /Users/aaronmeurer/Documents/ipython/IPython/core/interactiveshell.pyc in magic(self, arg_s) 2180 magic_name, _, magic_arg_s = arg_s.partition(' ') 2181 magic_name = magic_name.lstrip(prefilter.ESC_MAGIC) -> 2182 return self.run_line_magic(magic_name, magic_arg_s) 2183 2184 #------------------------------------------------------------------------- /Users/aaronmeurer/Documents/ipython/IPython/core/interactiveshell.pyc in run_line_magic(self, magic_name, line) 2101 kwargs['local_ns'] = sys._getframe(stack_depth).f_locals 2102 with self.builtin_trap: -> 2103 result = fn(*args,**kwargs) 2104 return result 2105 /Users/aaronmeurer/Documents/ipython/IPython/core/magics/basic.pyc in magic(self, parameter_s) /Users/aaronmeurer/Documents/ipython/IPython/core/magic.pyc in <lambda>(f, *a, **k) 190 # but it's overkill for just that one bit of state. 191 def magic_deco(arg): --> 192 call = lambda f, *a, **k: f(*a, **k) 193 194 if callable(arg): /Users/aaronmeurer/Documents/ipython/IPython/core/magics/basic.pyc in magic(self, parameter_s) 272 magic_docs, 273 \"Summary of magic functions (from %slsmagic):\" % magic_escapes['line'], --> 274 self._lsmagic(), 275 ] 276 page.page('\\n'.join(out)) AttributeError: 'BasicMagics' object has no attribute '_lsmagic' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: fix higher-order rev-mode lax.index_take test failures With the new-and-more-thorough `check_grads`, we started getting some failures in higher-order tests of `lax.index_take`. See commented-out line in lax_test.py's testIndexTake. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Support expanded port syntax See https://github.com/docker/docker/pull/30476 ```yaml version: \"3.1\" services: nginx: image: nginx ports: - mode: host target: 80 published: 9005 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add KDE Neon to the with_apt list To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. The issue is very simple, KDE neon is missing from the list of operating systems that support apt. https://github.com/conan-io/conan/blob/85a41a2a502290879721c3e585672df292a1359b/conans/client/tools/oss.py#L122 For this OS the distro.id() function returns 'neon'. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Virtualenv generator prepends duplicated values in env vars from profile With a *conanfile.txt* empty and a profile with: ``` [env] PREPEND_VAR = ['kk','pp'] ``` Commands: ``` $ conan install . -g virtualenv ``` In activate.sh there is: ``` PREPEND_VAR=\"kk\":\"pp\":\"kk\":\"pp\" ``` and in *activate.bat* you alaso have: ``` SET PREPEND_VAR=kk;pp;kk;pp ``` So at least variables that should be pretended are applied twice. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Unable bind parameters in global phase <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: master @ c3b2d7ac - **Python version**: 3.7.9 - **Operating system**: macOS Big Sur ### What is the current behavior? If the global phase of a circuit contains a parameter it can currently not be bound: ```python >>> from qiskit.circuit import QuantumCircuit, Parameter >>> x = Parameter('x') >>> circuit = QuantumCircuit(1, global_phase=x) >>> circuit.bind_parameters({x: 2}).draw() Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/jul/Qiskit/qiskit-terra/qiskit/circuit/quantumcircuit.py\", line 1912, in bind_parameters return self.assign_parameters(value_dict) File \"/Users/jul/Qiskit/qiskit-terra/qiskit/circuit/quantumcircuit.py\", line 1886, in assign_parameters ', '.join(map(str, params_not_in_circuit)))) qiskit.circuit.exceptions.CircuitError: 'Cannot bind parameters (x) not present in the circuit.' ``` The above bug might be due to #5648, since the low-level `_assign_parameter` seems to support global phase binding. Also, they are not listed when calling `circuit.parameters`: ```python >>> from qiskit.circuit import QuantumCircuit, Parameter >>> from qiskit.opflow import StateFn >>> x = Parameter('x') >>> circuit = QuantumCircuit(1, global_phase=x) >>> circuit.parameters set() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Loading facebook/regnet-y-040 FeatureExtractor fails mysteriously unless pillow is installed ### System Info ```shell I'm running transformers installed directly from `ee393c0`. ``` ### Who can help? @NielsRogge @sgugger ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction import transformers feature_extractor = transformers.AutoFeatureExtractor.from_pretrained(\"facebook/regnet-y-040\") If I don't have pillow installed, the second line fails with: AttributeError: module transformers.models.convnext has no attribute ConvNextFeatureExtractor If I then run `pip install pillow`, everything works as expected. ### Expected behavior ```shell The feature extractor should be loaded successfully. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: fix text circuit drawer for unitary gates <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? exception is raised (TypeError) when attempting to draw circuit with unitary matrix gate. ### Steps to reproduce the problem print circuit with unitary gate ### What is the expected behavior? Draw a box with \"unitary\". Don't need to try displaying matrix. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Warning when using cmake.install() for packaging To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. I'm using conan version 1.4.4, running on Windows 10 I have a simple conanfile.py, which contains mostly: def configure_cmake(self): cmake = CMake(self) cmake.configure() return cmake def build(self): cmake = self.configure_cmake() cmake.build() def package(self): cmake = self.configure_cmake() cmake.install() Note that cmake.install is used to copy files into the package folder. This method is documented at https://docs.conan.io/en/latest/reference/build_helpers/cmake.html. I invoke conan like this: conan export conanfile.py MyUser/MyChannel conan install MyPackage/MyVersion@MyUser/MyChannel --build I get a warning MyPackage/MyVersion@MyUser/MyChannel: WARN: No files copied from build folder! However, the package folder does actually contain my files. The warning is incorrect. Is there some way for me to suppress it? I generally don't allow any warnings or errors in my build process. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: under Windows, \"ipython3 nbconvert \"C:/blabla/first_try.ipynb\" --to latex --post PDF\" POST processing action fails because of a bad parameter Hello, The \"one single step\" option to create a \".pdf\" from a .ipynb\" fails on my windows python3 pc Nbconvert apparently tries compile \".TEX\" result with \"pdflatex .\\first_try.tex\" ==> It generates a bad behaviour of pdflatex, which picks \"pdfTex\" option instead of \"PdfLatex\". The working option, on my Windows PC and when I do it by hand, is not to put the \".\\\" \"pdflatex first_try.tex\" UPDATE : replacing \".\\\" per \"./\" seems also to be a solution. \"pdflatex ./first_try.tex\" Hint to the problem comes from here http://tex.stackexchange.com/questions/78178/miktex-how-to-run-pdflatex-from-cmd-prompt-on-windows-7-compared-to-windows-xp Details below. Sheers *\\* instruction *\\* ipython3 nbconvert \"C:/blabla/first_try.ipynb\" --to latex --post PDF\" **\\* (start of the output ) *** C:\\Users\\parent\\Desktop\\winpython\\WinPython-32bit-3.3.2.1rc1\\python-3.3.2>ipytho n3 nbconvert \"C:/blabla//first_try.ipynb\" --to latex --po st PDF [NbConvertApp] Using existing profile dir: 'C:\\Users\\parent\\Desktop\\winpytho n\\WinPython-32bit-3.3.2.1rc1\\settings\\.ipython\\profile_default' [NbConvertApp] Converting notebook C:/blabla/first_try.ipynb to latex [NbConvertApp] Support files will be in first_try_files\\ [NbConvertApp] Loaded template latex_article.tplx [NbConvertApp] Writing 53680 bytes to .\\first_try.tex [NbConvertApp] Building PDF: `pdflatex .\\first_try.tex` This is pdfTeX, Version 3.1415926-2.4-1.40.13 (TeX Live 2012/W32TeX) restricted \\write18 enabled. entering extended mode ! Undefined control sequence. <_> .\\first _try.tex ? *_\\* (end of the output ) *** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: clang 6.x warning when using precompiled header input with .h extension If my precompiled header ends with \".h\", clang assumes the input type is `c-header`, but since Clang is being invoked as `clang++` it knows it needs to treat it as a `c++-header`, but it complains about it: ``` clang-6.0: warning: treating 'c-header' input as 'c++-header' when in C++ mode, this behavior is deprecated [-Wdeprecated] ``` It looks like meson needs to be adding `-x c++-header` to the compile command for the precompiled header, since it already does know the what language the precompiled header is for anyway. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: `np.asarray` defaults to `order='K'`, not `'C'`, as docstring suggests ## Documentation Docstring for `np.asarray` states that the `order` keyword argument defaults to `'C'`. However, the default behavior corresponds to `'K'`. This stems directly from the fact that the implementation of `np.asarray` simply passes its arguments to `np.array` whose docstring clearly states that the default `order='K'`. https://numpy.org/doc/stable/reference/generated/numpy.asarray.html https://numpy.org/doc/stable/reference/generated/numpy.array.html I suggest that the current behavior should be preserved - it is likely that users expect `np.asarray` to copy data only if absolutely necessary. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: fig up and fig run should start dependencies when you specify a specific service `web` links to `db`. ``` $ fig up web $ fig run web ./manage.py shell ``` These things should start the `db` service. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: [helm] dagit command overrides ## Use Case To be able to for example, set `--path-prefix` in the `dagit` invocation to allow it to be hosted on a non `/` path Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [runtimeconfig] typo: \"config.get_variable(...)\" https://github.com/GoogleCloudPlatform/google-cloud-python/blob/bee32c0ae68b1e6cf224f9017c758a8e31e8be83/runtimeconfig/google/cloud/runtimeconfig/config.py#L190 [runtimeconfig] Should be \"client.config(...)\" not \"client.get_config(...) https://github.com/GoogleCloudPlatform/google-cloud-python/blob/bee32c0ae68b1e6cf224f9017c758a8e31e8be83/runtimeconfig/google/cloud/runtimeconfig/config.py#L189 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: dtype repr of subclasses of np.void throw an exception This one is on me, I think, in #10602. I wasn't aware this was legal: ```python >>> np.__version__ '1.13.3' >>> class Custom(np.void): pass >>> np.dtype(Custom) dtype('V') ``` ```python >>> np.__version__ '1.16.0.dev0+7af8e10' >>> class Custom(np.void): pass >>> np.dtype(Custom) RuntimeError: Internal error: NumPy dtype unrecognized type number ``` Not sure if this affects 1.15.0 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: deploy options dropped running docker-compose config I'm having a strange problem running `docker-compose config` on a project. I use the `config` command to combine multiple Compose files together for deployment using `docker stack deploy --compose-file …`. For some reason, when I run `config` on this project, Docker Compose is dropping the `deploy` options on the services. [monitoring.zip](https://github.com/docker/compose/files/790739/monitoring.zip) The monitoring project consists of three Compose files, specified in `.env`. Running `docker-compose config` in this directory produces a config with the `deploy` options missing. I'm using Docker Compose 1.11.1. ``` → monitoring git:(monitoring-stack) ✗ docker-compose --version docker-compose version 1.11.1, build 7c5d5e4 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Upgrading version to 0.6.0. Using last release PR (#813) as a template. consolidate metadata methods impl in storage.Key and storage.Bucket Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Qtconsole Unicode repr mojibake IPython 3.1.0 Qtconsole under Python 2.7.9 (win32): ``` python In [1]: import pandas In [2]: pandas.DataFrame({'spam': [u'sp\\xe4m']}) Out[2]: spam 0 späm ``` As opposed to the plain IPython shell: ``` python In [2]: pandas.DataFrame({'spam': [u'sp\\xe4m']}) Out[2]: spam 0 späm ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Job executing problem on RBPi with Raspbian Stretch in _parallel.py ### Informations - **Qiskit Terra version**: 0.6.1 - **Python version**: 3.6 - **Operating system**: Raspbian Stretch ### What is the current behavior? When trying to execute job on my Raspberry Pi B I get following error in _parallel.py: \"... _parallel.py\", line 109, in parallel_map if platform.system() != 'Windows' and num_processes > 1 \\ TypeError: '>' not supported between instances of 'NoneType' and 'int' From what I understand initialization of num_processes (or rather it's default value - CPU_COUNT = local_hardware_info()['cpus']) is a problem on selected os. ### Steps to reproduce the problem Try to execute a job on Raspbian Stretch on RBPi. ### What is the expected behavior? The job gets executed. ### Suggested solutions Check if num_processes is an initialized int before comparison. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Avoid text \"failed\" when solving environment fails I recommend avoiding the term \"failed\" when we try `current_repodata.json` and then fall back to `repodata.json`. I wonder if this might be better replaced with \"failed. Retrying\" or something similar that says \"we're going to try something else now instead\" ``` (base) mrocklin@dgx15:~$ conda install cudatoolkit Collecting package metadata (current_repodata.json): done Solving environment: failed # <<<------ this might scare users Collecting package metadata (repodata.json): done Solving environment: / ``` Just a thought, please ignore if this isn't appropriate. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: make REVOKES_MAX and REVOKE_EXPIRES configurable Values of REVOKE_EXPIRES and REVOKES_MAX in worker/state.py are hardcoded. This should be configurable. Some of us really needed to change this. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Calling `synth(registerless=False)` on a classical function synth labels the qubits wrongly ### Environment - **Qiskit Terra version**: 0.23.0.dev0+dcd7bea - **Python version**: 3.9 ### What is happening? In https://github.com/Qiskit/qiskit-terra/pull/9337#discussion_r1067055542 @Cryoris noticed that `classical_function` synthesis labels the qubits in the reversed order. ### How can we reproduce the issue? : ```python from qiskit.circuit.classicalfunction import classical_function from qiskit.circuit.classicalfunction.types import Int1 @classical_function def grover_oracle(a: Int1, b: Int1, c: Int1) -> Int1: return (a and b and not c) quantum_circuit = grover_oracle.synth(registerless=False) print(quantum_circuit.draw()) ``` ``` c: ──■── │ b: ──■── │ a: ──o── ┌─┴─┐ return: ┤ X ├ └───┘ ``` ### What should happen? in that example, the open control is on `c`, not on `a`. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Validation every epoch with non-finite dataloader ## 🚀 Feature <!-- A clear and concise description of the feature proposal --> Providing a way to do validation every epoch with non-finite (`__len__` not implemented) dataloaders. ### Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too --> Doing validation every epoch is a natural choice, and with finite dataloader you can do it easily by setting `val_check_interval=1.0`. However, with non-finite dataloader you cannot set `val_check_interval` to be float. There's no simple way to work around it yet. ### Pitch <!-- A clear and concise description of what you want to happen. --> There can be several way to make it happen. One solution on top of my head is to let `val_check_interval` to be `None`. if it is none, just do the validation according to the number of `check_val_every_n_epoch` at the end of every epoch. ### Alternatives <!-- A clear and concise description of any alternative solutions or features you've considered, if any. --> Alternatively, you can let the user set `val_check_interval` to be 1.0 even with non-finite dataloaders. Anything below 1.0 would be invalid but only 1.0 can be valid. If it is 1.0 then do the validation according to the number of `check_val_every_n_epoch` at the end of every epoch. ### Additional context <!-- Add any other context or screenshots about the feature request here. --> Not all dataloaders without `__len__` implemented are infinite dataloaders. Some just cannot decide length in advance. With these dataloaders the concept of 'epoch' is still valid. Pytorch-lightning needs to serve this kind of dataloaders better. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: DOC: add proper docstrings and documentation to refguide-check `tools/refguide-check.py` needs work documenting the functions. xref gh-14732. This file is not shipped with NumPy and does not appear on the numpy.org website, but still should be properly documented. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Add helper for Windows on `jupyter labextension develop` symlink is not allowed by default on Windows. So that line will failed https://github.com/jupyterlab/jupyterlab/blob/136d2ec216ebfc429a696e6ee75fee5f8ead73e2/jupyterlab/federated_labextensions.py#L113 But on Windows 10 with Python >= 3.8, users can activate the developer mode to allow them. https://docs.python.org/3/library/os.html#os.symlink https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development What about updating the documentation to point that out and maybe catch the OSError to print a more user friendly error in such case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Purging the \".trash\" folder. OS: Windows. When updating an environment, a snapshot of the environment get stored in the ```[miniconda]\\pkgs\\.trash``` Is there a way to clean up this trash directory with a ```conda``` command? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: New in NumPy 1.14: failures in PyTables In the following snippet: ```python import numpy as np data_proper = [(456, b'dbe', 1.2), (2, b'ded', 1.3)] data_improper = [[456, b'dbe', 1.2], [2, b'ded', 1.3]] descr = [('f0', '<i4'), ('f1', 'S3'), ('f2', '<f8')] dtype = np.dtype((np.record, descr)) np.array(data_improper, dtype=dtype) ``` Execution of the last line in 1.13 used to raise: ``` TypeError: a bytes-like object is required, not 'int' ``` which allowed the logic in [numpy/core/records.py#L676](https://github.com/numpy/numpy/blob/master/numpy/core/records.py#L676) to recover and reinterpret the line as `np.array(data_proper, dtype=dtype)`. The trouble is that in NumPy 1.14 ``` ValueError: invalid literal for int() with base 10: b'dbe' ``` is being raised instead, which results in the failure. This is a gist of the issue behind numerous test failures in pyTables when used with NumPy 1.14. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Batching rule for 'gather' not implemented Here is a minimal example to reproduce the error. ``` import jax import jax.numpy as np a = np.ones((3, 3)) def f(a): inds = np.arange(a.shape[0]) return a[inds] jax.vmap(f)(a) ``` `NotImplementedError: Batching rule for 'index_take' not implemented` So if you want to use `vmap`, the only form of indexing you can do is scalar indexing. Am I interpreting this correctly? For me that's a huge limitation. I would try to implement the batch rule but I think it will be complicated and I have a workaround: `np.stack([a[ind] for ind in inds])` instead of `a[inds]`. With an ideal JIT compiler those two would be equivalent, but my guess is that the performance of this workaround is not optimal. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Backend monitor displays incorrect information <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - master - any - any ### What is the current behavior? Qubit anharmonicities, in GHz, appear in the Readout Properties column of the Backend Monitor generated by the code in https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/tools/jupyter/backend_monitor.py. This is true at least for backends that are currently reporting anharmonicities, which may not be all of them yet, but will be soon. ### Steps to reproduce the problem In a Jupyter notebook, type `provider.get_backend('ibmq_montreal')` Observe issue as below:  ### What is the expected behavior? Readout properties column should show readout properties ### Suggested solutions -Fix the code near line 282 of the mentioned file to not hard-code the array indices of different qubit properties in the qubit_data array. -Consider adding a column for anharmonicity to the table (or not). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Facing memory issue while loading the bigquery table data through python. Hi, while trying to fetch the data of 1.8 M rows from Bigquery to local machine, we are getting Memory Error. Import pandas_gbq as pgbq df= pgbq.read_gbq(sql, dialect) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: [DO NOT MERGE] Container: new 'parent'/'name' arguments (non-breaking), timeouts, docstring updates via synth. This PR was generated using Autosynth. :rainbow: Here's the log from Synthtool: ``` synthtool > Cloning googleapis. synthtool > Running generator for google/container/artman_container_v1.yaml. synthtool > Ensuring dependencies. synthtool > Pulling artman image. latest: Pulling from googleapis/artman Digest: sha256:229601142daed005bf56fbaa21a02cf7aa0b261b57677d38306f8013e536de7a Status: Image is up to date for googleapis/artman:latest synthtool > Generated code into /home/kbuilder/.cache/synthtool/googleapis/artman-genfiles/python/container-v1. synthtool > Replaced '(^.*$\\\\n)*' in google/cloud/container_v1/proto/cluster_service_pb2.py. synthtool > Cleaned up 0 temporary directories. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: optimization_level=3 triggers error in unrolling _Originally posted by @itoko in https://github.com/Qiskit/qiskit-terra/issues/2339#issuecomment-490103445_ The follow input triggers and an issue in the unroller. ```python from qiskit import QuantumCircuit, QuantumRegister, QiskitError from qiskit.compiler import transpile from qiskit.transpiler import CouplingMap q = QuantumRegister(2) qc = QuantumCircuit(q) qc.cx(q[0], q[1]) qc.cx(q[0], q[1]) coupling = CouplingMap([[0, 1]]) compiled = transpile(qc, coupling_map=CouplingMap([[0, 1]]), optimization_level=3) print(compiled) ``` ``` QiskitError: \"Cannot unroll the circuit to the given basis, ['cx', 'cx']. No rule to expand instruction U.\" ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: UnicodeDecodeError in bash_operator.py Hi, I see a lot of these errors when running `airflow backfill` : ``` Traceback (most recent call last): File \"/usr/lib/python2.7/logging/__init__.py\", line 851, in emit msg = self.format(record) File \"/usr/lib/python2.7/logging/__init__.py\", line 724, in format return fmt.format(record) File \"/usr/lib/python2.7/logging/__init__.py\", line 467, in format s = self._fmt % record.__dict__ UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 13: ordinal not in range(128) Logged from file bash_operator.py, line 72 ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Invalid formatting of libdir/includedir in pkg_config generator [bug] Version: conan-1.2.3 OS: Linux https://github.com/conan-io/conan/blob/ac25c8994878706bac23efd009ae74bc294c1add/conans/client/generators/pkg_config.py#L28-L36 `pkg_config` generator doesn't check if libdir or includedir are absolute paths which leads to the following (invalid) `.pc` being generated for `boost_math/1.66.0@bincrafters/stable`: ``` prefix=/home/user/.conan/data/boost_math/1.66.0/bincrafters/stable/package/937af278b1c9d86290dddaf1322dc99fb7d75862 libdir=${prefix}//home/user/.conan/data/boost_level8group/1.66.0/bincrafters/stable/package/afc149253b16bde7d64e527e0dbfa27b203330c8/math/lib includedir=${prefix}//home/user/.conan/data/boost_level8group/1.66.0/bincrafters/stable/package/afc149253b16bde7d64e527e0dbfa27b203330c8/math/include ... ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Error when fine tuning GPT2 on GPU An error occur when training with `run_language_modeling.py` file (Ubuntu 18, pytorch with cuda compiled), while the error does not occur on Macbook without the GPU ``` File \"train.py\", line 283, in <module> main() File \"train.py\", line 247, in main trainer.train(model_path=model_path) File \"/home/antonio/anaconda3/lib/python3.7/site-packages/transformers/trainer.py\", line 518, in train for step, inputs in enumerate(epoch_iterator): File \"/home/antonio/anaconda3/lib/python3.7/site-packages/tqdm/_tqdm.py\", line 1017, in __iter__ for obj in iterable: File \"/home/antonio/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py\", line 346, in __next__ data = self._dataset_fetcher.fetch(index) # may raise StopIteration File \"/home/antonio/anaconda3/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py\", line 47, in fetch return self.collate_fn(data) File \"/home/antonio/anaconda3/lib/python3.7/site-packages/transformers/data/data_collator.py\", line 90, in __call__ labels[labels == self.tokenizer.pad_token_id] = -100 TypeError: eq() received an invalid combination of arguments - got (NoneType), but expected one of: * (Tensor other) didn't match because some of the arguments have invalid types: (NoneType) * (Number other) didn't match because some of the arguments have invalid types: (NoneType) ``` Command and arguments used to run: ```bash python train.py \\ --output_dir ckpts/prova \\ --model_type=gpt2 \\ --model_name_or_path=gpt2 \\ --do_train \\ --train_data_file data.train \\ --num_train_epochs 1 \\ --per_device_train_batch_size 1 \\ --gradient_accumulation_steps 1 \\ --save_steps 200 ``` Any idea on how to solve this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Broken link in Documentation ### System Info @sgugger Where I started https://huggingface.co/docs/transformers/v4.26.1/en/main_classes/text_generation#transformers.GenerationMixin.contrastive_search What doesnt exist https://huggingface.co/docs/transformers/v4.26.1/en/main_classes/generation_strategies https://huggingface.co/docs/transformers/main/en/main_classes/generation_strategies ### Who can help? _No response_ ### Information - [ ] The official example scripts - [ ] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction Go to the links above ### Expected behavior The pages would exist. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: SIGINT handler returns 0, should return non-zero Can you return a non-zero exit code when SIGINT is passed in? I don't think it's normal for a program to return 0 when ctrl+c is pressed. I don't know the SIGBREAK signal, but perhaps the same applies there as well. https://github.com/conan-io/conan/blob/develop/conans/client/command.py#L1216 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Relax version constraint for azure-storage packages in dagster-azure ## Use Case In our team we make heavy use of apache arrow for reading / writing parquet files. We want to implement some io_managers, using arrow to read data from ADLS storage. For this we [need](https://arrow.apache.org/docs/python/filesystems.html#using-fsspec-compatible-filesystems) to use [adlfs](https://github.com/dask/adlfs/), which requires `azure-storage-blob>=12.5`, while `dagster-azure` only allows `12.3.*`. ## Ideas of Implementation Relax version constraint in dagster-azure package. ## Additional Info We tested dagster-azure locally with different versions of both azure storage packages required, and have encountered no issues. --- #### Message from the maintainers: Excited about this feature? Give it a :thumbsup:. We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: How to use jax.hessian? I'm using this snippet from the README ``` from jax import jit, jacfwd, jacrev def hessian(fun): return jit(jacfwd(jacrev(fun))) ``` combined with the \"getting started with pytorch data loaders\" colab. How do I compute and use the hessian of this neural network? So far I have tried: 1. Naive: `hessian_loss = hessian(loss)(params, x, y)` (`TypeError: jacfwd() takes 2 positional arguments but 4 were given`) 2. Naive2: `hessian_loss = hessian(loss)((params, x, y))` (takes a long time with a small network and then returns `AttributeError: 'PyLeaf' object has no attribute 'node_type'`) 3. FromTheTests: `hessian_loss = hessian(lambda params_: loss(params_, x, y)(params)` (`AttributeError: 'PyLeaf' object has no attribute 'node_type'`) All I really need is to compute the eigenvalues and eigenvectors of this Hessian. Note: `repr(params) = [(DeviceArray{float32[10,784]}, DeviceArray{float32[10]})]` Some ideas that I have: 1. Should I re-write the code to use only flat arrays? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Gates that can be added with their own QuantumCircuit method don't have a link to it in their Circuit Library pages The gates that can be added with their own `QuantumCircuit` method, don't have any link to it in their [Circuit Library](https://qiskit.org/documentation/apidoc/circuit_library.html) page. For example, in the `UGate` [library page](https://qiskit.org/documentation/stubs/qiskit.circuit.library.UGate.html#qiskit.circuit.library.UGate) there is no reference to the `QuantumCircuit.u` [page](https://qiskit.org/documentation/stable/0.35/stubs/qiskit.circuit.QuantumCircuit.u.html). I think they should be added so users can add those gates to their circuits more easily. - [x] UGate - [x] PhaseGate - [x] IGate - [x] XGate - [x] YGate - [x] ZGate - [x] HGate - [x] SGate - [x] SdgGate - [x] TGate - [x] TdgGate - [x] SXGate - [x] SXdgGate - [x] CSXGate - [x] RGate - [x] RXGate - [x] RYGate - [x] RZGate - [x] CXGate - [x] CYGate - [x] CZGate - [x] CHGate - [x] CRXGate - [x] CRYGate - [x] CRZGate - [x] CPhaseGate - [x] CUGate - [x] SWAPGate - [x] CCXGate - [x] RCCXGate - [x] RC3XGate - [x] MCXGate - [x] CSWAPGate - [x] iSWAPGate - [x] DCXGate - [x] ECRGate - [x] RXXGate - [x] RYYGate - [x] RZZGate - [x] RZXGate Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: --gpus flag with add_argparse_args bug ## 🐛 Bug When using ``` parser = Trainer.add_argparse_args(parser) args = parser.parse_args() trainer = Trainer.from_argparse_args(args) ``` if the user does not provide the --gpus flag, the code allocates some memory on the GPU and reports GPU available: True, used: True but does not use this GPU. This issue has been discovered in bolts: 1. https://github.com/PyTorchLightning/pytorch-lightning-bolts/issues/35 2. https://github.com/PyTorchLightning/pytorch-lightning-bolts/issues/124 ### To Reproduce Steps to reproduce the behavior: Use the following method to create the trainer object ``` parser = Trainer.add_argparse_args(parser) args = parser.parse_args() trainer = Trainer.from_argparse_args(args) ``` and don't pass the --gpus flag. ### Expected behavior If --gpus flag is not provided in the script call, then Lightning should report GPU available: True, used: False with a warning, and not allocate any memory on the GPU. This way, the user can set the --gpus flag if they have missed out on it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Error in PackageNotFoundError Commit https://github.com/conda/conda/commit/bb3e54d8a8be3a51de0601206faf20d82b3f0dbb broke PackageNotFoundError for v4.3.14 Expected: ```bash (root) [root@4cd1258efdd1 ~]$ conda install perl Fetching package metadata ......... PackageNotFoundError: Package not found: '' Package missing in current linux-64 channels: - perl Close matches found; did you mean one of these? perl: petl You can search for packages on anaconda.org with anaconda search -t conda perl You may need to install the anaconda-client command line client with conda install anaconda-client ``` What actually happens: ```bash (root) [root@4cd1258efdd1 ~]$ conda update conda -y Fetching package metadata ......... Solving package specifications: . Package plan for installation in environment /conda: The following packages will be UPDATED: conda: 4.3.11-py27_0 --> 4.3.14-py27_0 conda-4.3.14-p 100% |###################################################################################################################################################################| Time: 0:00:00 6.61 MB/s (root) [root@4cd1258efdd1 ~]$ conda install perl Fetching package metadata ......... PackageNotFoundError: Package not found: Conda could not find ' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: concatenate fails when axis = None when running documentation example I'm getting a error: ``` import jax.numpy as np a = np.array([[1, 2], [3, 4]]) b = np.array([[5, 6]]) np.concatenate((a, b), axis=None) ``` Error: ``` --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-37-28d5f29078d3> in <module>() 5 np.concatenate((a, b.T), axis=1) 6 ----> 7 np.concatenate((a, b), axis=None) 8 1 frames /usr/local/lib/python3.6/dist-packages/jax/numpy/lax_numpy.py in concatenate(arrays, axis) 1996 if ndim(arrays[0]) == 0: 1997 raise ValueError(\"Zero-dimensional arrays cannot be concatenated.\") -> 1998 axis = _canonicalize_axis(axis, ndim(arrays[0])) 1999 arrays = _promote_dtypes(*arrays) 2000 # lax.concatenate can be slow to compile for wide concatenations, so form a /usr/local/lib/python3.6/dist-packages/jax/lax/lax.py in _canonicalize_axis(axis, num_dims) 5490 def _canonicalize_axis(axis, num_dims): 5491 \"\"\"Canonicalize an axis in [-num_dims, num_dims) to [0, num_dims).\"\"\" -> 5492 axis = operator.index(axis) 5493 if not -num_dims <= axis < num_dims: 5494 raise ValueError( TypeError: 'NoneType' object cannot be interpreted as an integer ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IOStream IP address configurable Hi, I am running in an environment where I can not bind to 127.0.0.1 ... possible to make this configurable? https://github.com/ipython/ipython/blob/master/IPython/kernel/zmq/iostream.py#L68 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Notebook: Changing base_project_url results in failed WebSockets call Setting `base_project_url` within ipython_notebook_config.py results in failed websockets calls, as the websocket url is not updated with the `base_project_url` prefix. I believe the issue is a result of line 135 in kernel.js. ``` this.ws_host = parsed.protocol + \"//\" + parsed.host; ``` Which is then used to construct the WebSocket connection. Existing notebooks can be properly viewed after ignoring the modal complaining about the lack of a websocket connection. System info: ``` {'codename': 'Work in Progress', 'commit_hash': '5258b9e', 'commit_source': 'installation', 'default_encoding': 'UTF-8', 'ipython_path': '/home/ipython/.virtualenvs/ipython/local/lib/python2.7/site-packages/IPython', 'ipython_version': '2.0.0-dev', 'os_name': 'posix', 'platform': 'Linux-3.5.0-45-generic-i686-with-Ubuntu-12.04-precise', 'sys_executable': '/home/ipython/.virtualenvs/ipython/bin/python', 'sys_platform': 'linux2', 'sys_version': '2.7.3 (default, Sep 26 2013, 20:08:41) \\n[GCC 4.6.3]'} ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Opflow fails ((Z^I)@(X^X))@(Plus^Plus), but works with Aqua operators opflow With Aqua and Terra latest versions from main branches: Here is what I find. Using Aqua operators, just looking at the first part as we see a difference that helps understand the final failure ``` >>> ((Z^I)@(X^X)) PauliOp(Pauli('YX'), coeff=1j) ``` using Terra opflow ``` >>> ((Z^I)@(X^X)) PauliOp(Pauli('iYX'), coeff=1.0) ``` Now Aqua - adding the `@(Plus^Plus)` to the expression to complete it as per the failure ``` >>> ((Z^I)@(X^X))@(Plus^Plus) CircuitStateFn(<qiskit.circuit.quantumcircuit.QuantumCircuit object at 0x7fbb1947ada0>, coeff=1j, is_measurement=False) ``` where using Terra opflow it fails ``` qiskit/opflow/primitive_ops/pauli_op.py\", line 323, in to_circuit gate = PAULI_GATE_MAPPING[pauli_str] KeyError: 'i' ``` this is in some to_circuit logic where the i is not managed since it seems to only expect X,Y,Z I in the mapping and in mapping each element it goes wrong. In Aqua it was just XY with the i being part of coeff. Now it moved to iXY and the to_circuit fails. As originally reported on Qiskit Slack aqua channel here https://qiskit.slack.com/archives/CB6C24TPB/p1623208786231500 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Validate the format of `expose` The other day I expend some hours trying to investigate why my docker container was not exposing some ports. And understanding that was a docker problem, and not an app problem. In dockerfile there is **expose** to say the ports, but **ports** in docker-compose. Ok, there is a change. But why cannot say that \"warning, expose syntax is not valid in docker-compose, you meant ports?\" or something like this? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: dns.zone.ManagedZone does not update dns_name during reload When calling `ManagedZone.reload`, the zone's `dns_name` is not updated from the returned response. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: ``CVaRMeasurement`` does not check ``PauliSumOp``s efficiently for diagonality ### Environment - **Qiskit Terra version**: main @ fe5acd4d1 - **Python version**: 3.7 - **Operating system**: macOS ### What is happening? The CVaR measurement is only defined for diagonal observables and the code checks that. It tries to do that efficiently (meaning w/o a conversion to a matrix) but that didn't cover the case for `PauliSumOp`s. Luckily, there's a check in place that raises an error if a large operator is converted to a matrix so this expensive calculation doesn't happen silently. This issue was seen with the Qiskit QAOA Runtime since there CVaR expectation makes sense to use _and_ we have large qubit numbers. ### How can we reproduce the issue? ```python from qiskit.opflow import PauliSumOp, CVaRMeasurement op = PauliSumOp.from_list([(\"Z\" * 30, 1)]) _ = CVaRMeasurement(op) ``` ### What should happen? `PauliSumOp`s should be checked efficiently. ### Any suggestions? See upcoming PR Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: EagerResult doesn't seem to poplate name Sometimes I run my tasks with `CELERY_TASK_ALWAYS_EAGER` to aid debugging, it seems like the `name` property of EagerResult isn't populated, which makes this sort of investigation more tricky. I have some code I use to list my tasks in a django app, and part of this is to grab the task name. When running eagerly, the EagerResult task status is SUCCESS, so I would have expected `name` to be available at this point. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: extract_all_objects malfunctions with respect to vala files `extract_all_objects` seems to malfunction when used on Vala projects. The extracted objects use the naming scheme of `object.vala.o`, while the generated ninja files are `object.c.o`. Attempting to use extracted objects with vala builds therefore fails. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: [qtconsole] %hist doesn't show anything in qtconsole I have built rc2 on Windows XP and while the qtconsole works fine for the most part, %hist does not show any history in the qtconsole. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add BackendV2 support for `transpiler._parse_inst_map()` ### What should we add? BackendV2 has removed `defaults` attribute from backend and `transpiler._parse_inst_map()` needs to be updated to support BackendV2. https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/compiler/transpiler.py#L666-L676 ```python def _parse_inst_map(inst_map, backend, num_circuits): # try getting inst_map from user, else backend if inst_map is None: if hasattr(backend, \"defaults\"): inst_map = getattr(backend.defaults(), \"instruction_schedule_map\", None) # inst_maps could be None, or single entry if inst_map is None or isinstance(inst_map, InstructionScheduleMap): inst_map = [inst_map] * num_circuits return inst_map ``` This was discovered in #7643. Created as a issue with separate PR to follow by @mtreinish https://github.com/Qiskit/qiskit-terra/pull/7643/files/474e529c55e8198493512a02c4df52966ad83063#r823983767 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: python string encoding woes The crux of the matter is (with print debugging): 'ascii' codec can't decode byte 0xc3 in position 91: ordinal not in range(128) Meson encountered an error in file subprojects/gst-plugins-base/gst-libs/gst/pbutils/meson.build, line 20, column 0: Could not read input file /home/matt/Projects/gst/gst-all/subprojects/gst-plugins-base/gst-libs/gst/pbutils/gstpluginsbaseversion.h.in. The 91st character in that file is a ü. The only difference between this build and all my previous builds is that I'm attempting to build over an ssh connection here. I've worked around it for now by using codecs.open(, 'utf-8') instead of plain open() but this still begs the question, what are we going to do about this (and any other string encoding issue)? We can replace all the instances of open() with codecs.open() which should cover the majority of use cases however there are probably some files that won't work with a utf-8 encoding. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: StopIteration Error when running beam search for squad 2.0 I'm using `huggingface/transformers-pytorch-gpu:4.3.0` on Ubuntu DGX1 server with 8 V100 GPUs. `NVIDIA-SMI 418.126.02 Driver Version: 418.126.02 CUDA Version: 10.1` When running the step in `examples/question_answering/README.md` for beam search for squad 2.0 ``` python run_qa_beam_search.py \\ --model_name_or_path xlnet-large-cased \\ --dataset_name squad_v2 \\ --do_train \\ --do_eval \\ --version_2_with_negative \\ --learning_rate 3e-5 \\ --num_train_epochs 4 \\ --max_seq_length 384 \\ --doc_stride 128 \\ --output_dir ./wwm_cased_finetuned_squad/ \\ --per_device_eval_batch_size=2 \\ --per_device_train_batch_size=2 \\ --save_steps 5000 ``` Error ``` StopIteration: Caught StopIteration in replica 0 on device 0. Original Traceback (most recent call last): File \"/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/parallel_apply.py\", line 61, in _worker output = module(*input, **kwargs) File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py\", line 727, in _call_impl result = self.forward(*input, **kwargs) File \"/usr/local/lib/python3.6/dist-packages/transformers/models/xlnet/modeling_xlnet.py\", line 1978, in forward start_logits = self.start_logits(hidden_states, p_mask=p_mask) File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py\", line 727, in _call_impl result = self.forward(*input, **kwargs) File \"/usr/local/lib/python3.6/dist-packages/transformers/modeling_utils.py\", line 1241, in forward if next(self.parameters()).dtype == torch.float16: StopIteration ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: The celery document has a mistake about crontab ## about crontab the document in this link about crontab simple. http://docs.celeryproject.org/en/master/userguide/periodic-tasks.html **crontab(0, 0, day_of_month='2-30/3')** Execute on every even numbered day. shuld be **crontab(0, 0, day_of_month='2-30/2')** Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Make new conditional API compatible with the imperative API ## Current behavior *Please describe how the feature works today* In #2443, @jcrist added a new conditional API to Prefect, which is 💯. However, at this moment, it can only be used with the functional API (as it [requires](https://github.com/PrefectHQ/prefect/blob/12662a3a821b52dca0c0d39ced1bbbbba0674a85/src/prefect/tasks/control_flow/case.py#L87) a `flow` in the Prefect context). ## Proposed behavior *Please describe your proposed change to the current behavior* The check for `case` in context currently [takes place](https://github.com/PrefectHQ/prefect/blob/12662a3a821b52dca0c0d39ced1bbbbba0674a85/src/prefect/core/task.py#L463) in `Task.bind()`, which is called by the functional API but not common imperative patterns like `Task.set_upstream()`, `Task.set_downstream()`, `Task.set_dependencies()`, `Flow.add_task()`, or `Flow.set_dependencies()`. I believe `Flow.add_task()` is the lowest-level API (called by all the others mentioned above) and consequently might be an opportune place to move the check for `case` in context. This way, adding a task to a flow while in a conditional block would automatically add it to the `case` class as well. Since the flow is (obviously) available when `Flow.add_task()` is called, it can be used inside the `case` context manager when calling `bind()` and `set_upstream()`. I think this would enable the following imperative syntax, while still using the existing case context managers: ``` Switch = Task() A = Task() B = Task() C = Task() f = Flow('imperative flow') switch = Switch() f.add_task(switch) with case(switch, 'foo'): f.add_task(A()) with case(switch, 'bar'): b = B() c = C() c.set_upstream(b, flow=f) ``` ## Example *Please give an example of how the enhancement would be useful* Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: No such file or directory: 'C:\\\\Program Files\\\\Meson\\\\mesonbuild\\\\scripts\\\\python_info.py' ### Discussed in https://github.com/mesonbuild/meson/discussions/11688 <div type='discussions-op-text'> <sup>Originally posted by **KyrietS** April 15, 2023</sup> Hi, I tried compiling Cairo but when I ran `meson setup build/` I got an error: ``` meson.build:111:27: ERROR: <PythonExternalProgram 'python3' -> ['C:\\\\Program Files\\\\Meson\\\\meson.exe', 'runpython']> is not a valid python or it is missing distutils ``` Inside `build/meson-logs/meson-log.txt` I can see: ``` Program stderr: Traceback (most recent call last): File \"mesonbuild\\mesonmain.py\", line 194, in run File \"mesonbuild\\mesonmain.py\", line 149, in run_runpython_command File \"runpy.py\", line 288, in run_path File \"runpy.py\", line 252, in _get_code_from_file FileNotFoundError: [Errno 2] No such file or directory: 'C:\\\\Program Files\\\\Meson\\\\mesonbuild\\\\scripts\\\\python_info.py' ``` My specs: * Windows 11 * Python 3.11.3 * Meson 1.1.0 </div> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Trainer should run the test loop with the best weights when ModelCheckpoint is used ## 🚀 Feature <!-- A clear and concise description of the feature proposal --> ### Motivation <!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too --> I noticed that even when `ModelCheckpoint` is used, `Trainer` by default runs the test loop with the last weights, not the best weights saved by `ModelCheckpoint`. I believe the sensible default here is to run the test loop with the best weights saved by `ModelCheckpoint`. ### Pitch <!-- A clear and concise description of what you want to happen. --> Now that `ModelCheckpoint` has a pointer to the best weights, `Trainer` can replace the last weights with the best weights before running the test loop automatically. ### Alternatives <!-- A clear and concise description of any alternative solutions or features you've considered, if any. --> Possibly, this could be another option to `Trainer`. I don't like this as much b/c this is the behavior most users would expect. ### Additional context <!-- Add any other context or screenshots about the feature request here. --> Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Improvement of `core.magic_arguments` example Currently, there is only a [very raw example](https://ipython.readthedocs.io/en/stable/api/generated/IPython.core.magic_arguments.html?highlight=%40magic_arguments.argumen#module-IPython.core.magic_arguments ) of using `magic_arguments` with custom cell magic. Therefore, I have the idea to add a second, more fleshed out example that might help people to easier understand and use cell magic arguments:  Here is the code: ```py from IPython.core import magic_arguments from IPython.core.magic import register_cell_magic @magic_arguments.magic_arguments() @magic_arguments.argument( \"--option\", help=(\"Add an option here\"), ) @magic_arguments.argument( \"--style\", default=None, help=(\"Add some style arguments\"), ) @register_cell_magic def my_cell_magic(line, cell): \"\"\"Cool cell magic\"\"\" args = magic_arguments.parse_argstring(my_cell_magic, line) print(args.style) print(args.option) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Ability to customize `Received task` message - [X] I have checked the [issues list](https://github.com/celery/celery/issues?q=is%3Aissue+label%3A%22Issue+Type%3A+Enhancement%22+-label%3A%22Category%3A+Documentation%22) for similar or identical enhancement to an existing feature. - [X] I have checked the [pull requests list](https://github.com/celery/celery/pulls?q=is%3Apr+label%3A%22Issue+Type%3A+Enhancement%22+-label%3A%22Category%3A+Documentation%22) for existing proposed enhancements. - [X] I have checked the [commit log](https://github.com/celery/celery/commits/master) to find out if the if the same enhancement was already implemented in the master branch. - [X] I have included all related issues and possible duplicate issues in this issue (If there are none, check this box anyway). ## Related Issues and Possible Duplicates #### Related Issues - None #### Possible Duplicates - None # Brief Summary Currently `LOG_SUCCESS` and friends allows customizing the messages, but `Received task` is fixed. It would be good for this to be customizable and include the same values in `extra` (i.e. use `celery.app.trace.info` rather than `logging.info`). I was thinking something like this: ``` info('Received task: %s', { 'name': req.name, 'id': req.id, }) ``` # Design ## Architectural Considerations Should be a non-breaking change that only adds a customization point ## Proposed Behavior Add `LOG_RECEIVED` so it can be customized as well ## Proposed UI/UX N/A ## Diagrams N/A ## Alternatives None that I can think of Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: documentation build broken in head commit 0c0c1a161c84109 broke the documentation build: ``` HOME=$PWD/build PYTHONPATH=$PWD make -C docs html ... File \"/usr/lib/python2.7/dist-packages/sphinx/util/__init__.py\", line 201, in get_module_source loader = getattr(mod, '__loader__', None) File \"/home/jtaylor/Packages/ipython/ipython/IPython/frontend.py\", line 68, in __getattr__ raise ImportError('No module named %s' % obj) ImportError: No module named __loader__ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Add JSON output options to install and create `--json` option for `conda create` and `conda install` would be nice for the sake of `conda_api` module. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: meson test -C builddir does not chdir before running tests This means that if there are tests that need to be passed filesystem arguments they will fail, since those arguments will be relative builddir. This is rather suprising since `ninja -C builddir` does chdir before running tests (since ninja does the chdir). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Rename and fix overfit_pct, val_percent_check and test_percent_check Fixes #1668 Fixes #1920 Fixes #830 ## Overfit - Removes `overfit_pct` - Adds `overfit_batches` which can be a float (%) or int (steps) - overfit now makes sure train, test and val splits are all the train step - sets shuffle=False in the train set ## limit_xxx_batches - removes `train_percent_check` and `val_percent_check` - replaces with `limit_train_batches` and `limit_val_batches` which can also be int (steps) or percent (float) ## docs + tests - adds tests to verify - updates docs @tullie these flag names make sense? ### TODO: also replace train_percent_check with limit_train_batches Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: ConfigureEnvironment overwrites flags instead of augmenting C/CPPFLAGS mainly. Consider also the possibility to add UI so the user could add easily their own flags to the ConfigureEnvironment. Initially reported by @tru Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: \"fig run\" should support port forwarding Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: gcloud.storage.iterator.KeyDataIterator chunking is off-by-one 'get_headers' computes the \"Range:\" header as '_bytes_written' - '_bytes_written + CHUNK_SIZE': https://github.com/GoogleCloudPlatform/gcloud-python/blob/1f2aaf3606802f4f02eeb30e22e1082ef7f4594e/gcloud/storage/iterator.py#L215 and the '_bytes_written' gets updated to bump by the size of the chunk the server returns. Consider the initial read, assuming a CHUNK_SIZE of 100: Range: bytes=0-100 Note that, per RFC2616. this will return up to 101 bytes (both bytes-position values are inclusive): http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.35.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Add a stabilizer_state to qiskit.quantum_info.states <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? Add a `stabilizer_state.py` to `qiskit.quantum_info.states` It should be a new class `StabilizerState` which is a `QuantumState` subclass based on the `Clifford` object, with further abstract methods for reset, measure, probabilities etc. (similar to Aer stabilizer simulator). I would like to be assigned on this issue - Thanks! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Migrate to pubsub API to v1 See https://github.com/GoogleCloudPlatform/gcloud-node/issues/699 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: CORS documentation missing setter https://googlecloudplatform.github.io/gcloud-python/stable/storage-buckets.html#gcloud.storage.bucket.Bucket.cors > Retrieve CORS policies configured for this bucket. It doesn't mention that it can also be set. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `GlobalPhaseGate` generates an error when trying to generate `Statevector` ### Environment - **Qiskit Terra version**: 0.24.0rc1 - **Python version**: 3.10 - **Operating system**: MacOS Monterrey ### What is happening? `Statevector` class generates a `tuple index out of range` error when a quantum circuit includes an instance of the recently-added `GlobalPhaseGate`. ### How can we reproduce the issue? ```python from math import pi from qiskit import QuantumCircuit from qiskit.circuit.library import GlobalPhaseGate from qiskit.quantum_info import Statevector qc = QuantumCircuit(1) qc.append(GlobalPhaseGate(pi/2)) print(Statevector(qc)) ``` ### What should happen? The issue seems to be related to how the operator used to evolve the initial state is being generated. This operator uses the instruction `.to_matrix()` method, which for the `GlobalPhaseGate` results in a matrix of shape (1,1), which is basically an array containing the global phase being added. For example: ```python >>> from qiskit.circuit.library import GlobalPhaseGate >>> from math import pi >>> GlobalPhaseGate(pi/3).to_matrix() array([[0.5+0.8660254j]]) ``` For this to work correctly, the operator needs to be a diagonal matrix with the global phase value of shape (2^n_qubits, 2^n_qubits) instead of just the value itself. ### Any suggestions? I would volunteer to help with this, but if I am not mistaken, the `to_matrix()` method is inherited from the `Gate` class, so I can't think of an easy solution other than treating `GlobalPhaseGate` as a special case. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Remove `--allow-insecure-ssl` flag This flag became a no-op warning in 1.4. So there have been two full releases which warned about this deprecated flag. I think we can drop it as part of the 1.6 release. What do you think? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Implement new file-based storage types We should introduce a new storage class for storing flows on GitHub as python scripts. In addition, we should introduce a new kwarg on all storage classes specifying whether the flow is stored as bytes or as a python file. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] \"conan install\" detects the wrong compiler version with gcc 10 and fails I am trying to upgrade one of my projects to use gcc 10 so I can use some C++20 features, but I ran into some issues with Conan not wanting to cooperate with the newer gcc version. See this question for my initial findings: https://github.com/conan-io/conan/issues/6538 It turns out that even after I add \"10\" as a valid compiler version in \"~/.conan/settings.yml\" the \"conan install\" command still looks for the wrong version and fails saying that \"1\" is not a valid version. As a temporary workaround I am able to add \"1\" to the list of versions in \"~/.conan/settings.yml\" but there's definitely something wrong going on here. Once I add \"1\" it works. ### Environment Details (include every applicable attribute) * Operating System+version: Ubuntu 19.1.0 * Compiler+version: gcc 10.0.1 * Conan version: 1.22.1 * Python version: 2.7.17 ### Steps to reproduce (Include if Applicable) 1. Try to use Conan with a project that uses gcc 10 as the compiler. (currently to use gcc 10 it must be built from source here https://github.com/gcc-mirror/gcc) 2. Add version \"10\" as a valid compiler in \"~/.conan/settings.yml\" 3. Attempt to do \"conan install\" for the project (it will fail saying version \"1\" is not valid) ``` ERROR: Invalid setting '1' is not a valid 'settings.compiler.version' value. Possible values are ['10', '4.1', '4.4', '4.5', '4.6', '4.7', '4.8', '4.9', '5', '5.1', '5.2', '5.3', '5.4', '5.5', '6', '6.1', '6.2', '6.3', '6.4', '7', '7.1', '7.2', '7.3', '7.4', '8', '8.1', '8.2', '8.3', '9', '9.1', '9.2'] ``` 4. Add version \"1\" to the list (even though this seems totally wrong) 5. Try again -- \"conan install\" will work. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Parameter assignment has a bug <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: commit c06f50c028638161153909e10fcefe7c4f2eef06 of master. - **Python version**: 3.7.3 - **Operating system**: Ubuntu ### What is the current behavior? Assigning a parameter to another parameter in the circuit overwrites the `_parameter_table` when there already is an entry. ### Steps to reproduce the problem The following code illustrates the problem: ``` a = Parameter('a') b = Parameter('b') qc1 = QuantumCircuit(1) qc1.rx(a, 0) qc1.ry(b, 0) print(qc1._parameter_table) qc1.assign_parameters({a: -b}, inplace=True) print(qc1._parameter_table) ``` The first print statement yields: ``` ParameterTable({ Parameter(a): [(<qiskit.[...].RXGate object at 0x7ff79fcc6668>, 0)], Parameter(b): [(<qiskit.[...].RYGate object at 0x7ff79fcc66d8>, 0)] }) ``` And the second print statement gives ``` ParameterTable({ Parameter(b): [(<qiskit.[...].RXGate object at 0x7ff79fcc6668>, 0)] }) ``` ### What is the expected behavior? We should see the `RYGate` in the second print output under `Parameter(b)`. ### Suggested solutions The issue appears to be in `QuantumCircuit._assign_parameter(self, parameter, value)` at the lines ``` if isinstance(value, ParameterExpression): entry = self._parameter_table.pop(parameter) for new_parameter in value.parameters: self._parameter_table[new_parameter] = entry ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Some Models do not support gradient checkpointing Thanks for this wonderful library. I found some models do not support gradient_checkpointing, which I believe is a very important feature. For example, ElectraModel: ElectraConfig has no gradient_checkpointing option but ElectraModel will use gradient_checkpointing if config.gradient_checkpointing = True DistillBERT: DistillBertConfig has no gradient_checkpointing option and DistillBertModel does not support gradient_checkpointing. I assume all transformer-based models should be able to support gradient_checkpointing. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [docs] TFRobertaModel example: last_hidden_states -> last_hidden_state This is a documentation error on the currently deployed version of https://huggingface.co/transformers/ ### Who can help examples/distillation: @VictorSanh documentation: @sgugger ## Information Model I am using: TFRoberta The problem arises when using: * [x] the official example scripts ## To reproduce Steps to reproduce the behavior: 1. View the code example at https://huggingface.co/transformers/model_doc/roberta.html#tfrobertamodel 2. `last_hidden_states = outputs.last_hidden_states` should be `last_hidden_states = outputs.last_hidden_state` The current incorrect spelling will yield an error. I apologize that I was not able to find that line in the repo, otherwise I would submit a PR. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add progress bars to improve UX A progress bar will indicate the user that something is running and he must wait until completion. Some operations in Conan can take a long time (uploading, unzipping,...) and the user can Ctrl+Break it if there is no feedback. We may develop/reuse a progress bar component (even for parallel jobs) that could be used anywhere inside Conan. This component may replace also existing code. Here it is a list with the places where a progress bar can fit (list updated with comments): Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: gatefacecolor key has no effect on circuit diagrams ### Information - **Qiskit Terra version**: 0.9.0 - **Python version**: 3.7.4 - **Operating system**: Ubuntu 18.04.3 ### What is the current behavior? When plotting circuit diagrams, the `gatefacecolor` key has no effect. ### Steps to reproduce the problem ```python from qiskit import QuantumRegister, QuantumCircuit, ClassicalRegister qr = QuantumRegister(3) cr = ClassicalRegister(1) qc1 = QuantumCircuit(qr) qc1.x(qr[1]) qc1.h(range(3)) qc1.cx(qr[1], qr[2]) qc1.cx(qr[0], qr[1]) style = {'gatefacecolor': '#hhhhhh'} qc1.draw(output='mpl', style=style).show() ``` Produces this image:  The same image is produced using any hex colour code or by removing the gatefacecolor key. ### What is the expected behavior? The gate faces should be white in this example. ### Suggested solutions A suggested solution was to use `style=False`, which overrides the default styling and produces a black and white diagram. However, this would not allow the use of other desired style keys such as `'usepiformat': 'true'`. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: result.get_ran_qasm() not working ### What is the current behavior? `Result.get_ran_qasm()` seem to be broken due to PR #501. That's because the Result datastructure no longer has a copy of the qobj json inside it. We should see how/if this can be fixed with the recent introduction of Qobj class. ### Steps to reproduce the problem ```python from qiskit import * q = QuantumRegister(3) c = ClassicalRegister(3) circ = QuantumCircuit(q, c) circ.ccx(q[0], q[1], q[2]) print(circ.qasm()) result = execute(circ, 'local_qasm_simulator').result() result.get_ran_qasm(circ.name) # does not return an answer ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] SCM username value is ignored Conan ignores `username` SCM attribute. For file: ```python from conans import ConanFile class TestRecipe(ConanFile): name = 'test-recipe' version = '0.1' scm = { 'type': 'git', 'url': 'ssh://github.com/conan-io/conan.git', 'username': 'test-user', } ``` When cloning git repository, `test-user` is not used, but current logged-in user is used instead: ```bash test-recipe/0.1: SCM: Getting sources from url: 'ssh://github.com/conan-io/conan.git' ERROR: Command 'git -c http.sslVerify=true clone \"ssh://github.com/conan-io/conan.git\" . ' returned non-zero exit status 128. Cloning into '.'... seva@github.com: Permission denied (publickey). ``` (conan.git repository is used just as example). ### Environment Details Conan version: 1.31.0 Python version: 3.8.4, 3.7.3 ### Steps to reproduce - Create conanfile recipe (example is attached). - run 'conan create .' in it's directory. Conanfile and example output: [username-bug.zip](https://github.com/conan-io/conan/files/5492773/username-bug.zip) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Add InvalidConfigurationException to be raised in Conanfile.configure() Copy here the issue discussed at conan-package-tools https://github.com/conan-io/conan-package-tools/issues/146: > Motivation.- Protobuf package has an issue with windows/shared configuration so we have to disable it and prevent CI to run those jobs in order to get a green badge. > > What to ask for.- I think that it would be useful to have a conan.errors.InvalidConfigurationException (better name?) to be raised from configure() method in recipes instead of the generic ConanException (as it is suggested here). This way users will get the proper information when running conan, but projects like conan-package-tools can catch this specific exception, handle it and mark the job in CI as successful. > > This way we don't need to tweak build.py files to avoid running certain configurations, so we move forwards to a even more standarized (unneeded) file. Will require to add the exception type and document it ([here](https://docs.conan.io/en/latest/uploading_packages/bintray/conan_center_guide.html#recipe-quality)), I think that Conan's internals won't be affected by it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Control() method of UnitaryGate does not pass num_ctrl_bits and ctrl_state to ControlledGate <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: 0.13 - **Python version**: 3.8 - **Operating system**: Ubuntu 18.04 ### What is the current behavior? In the control() method for UnitaryGate, the call to ControlledGate does not include the num_ctrl_bits or ctrl_state. ### Steps to reproduce the problem ``` from qiskit import * from qiskit.extensions import UnitaryGate import numpy as np c=QuantumCircuit(3) op = np.matrix([[1,0],[0,-1]]) r=UnitaryGate(op, label='rt') re=r.control(2, ctrl_state='10') c.append(re, [0,1,2]) c.draw('text') ``` produces this output. ``` q_0: ───■─── ┌─┴┼──┐ q_1: ┤0 │ ├ │ rt │ q_2: ┤1 ├ └─────┘ ``` ### What is the expected behavior? ``` q_0: ──o─── │ q_1: ──■─── ┌─┴──┐ q_2: ┤ rt ├ └────┘ ``` ### Suggested solutions Add num_ctrl_bits and ctrl_state to the ControlledGate call. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: ipcluster --version Display: ``` 0.0 ``` While ipengine and ipcontroller display the right version (0.13.2 and master). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: plot_error_map fails ### Environment - **Qiskit Terra version**: 0.20 - **Python version**: 3.10 - **Operating system**: ```python backend = provider.backend.ibmq_kolkata plot_error_map(backend) ``` gives ``` ValueError: shape mismatch: objects cannot be broadcast to a single shape ``` ### What is happening? fails for some reason in the measurement bar plots ### How can we reproduce the issue? run above ### What should happen? works ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [feature] Add Conan package name and version to visual studio generator prop file <!-- What is your suggestion? Please be as specific as possible! --> Can we get the feature to add `CONAN_PACKAGE_NAME` and `CONAN_PACKAGE_VERSION` to the visual studio generator prop file? Currently, Conan does support adding package name and version through CMake generator. The feature I am talking about is mentioned [here](https://github.com/conan-io/conan/blob/c923c692fb14dd3ad0a66bab308b4a59f6a037dc/conans/client/generators/cmake_common.py#L71-L73) for CMake generator - [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md). Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: activate.d scripts not run on windows if prefix contains unicode activate.d scripts are not run on windows if the path contains unicode characters. A test for this is to create environments with and without unicode characters with the `_test_set_env_in_activate_d` package in the `jjhelmus` channel. When activated the `TEST_VAR` variable should be set to \"1\". In environments with unicode characters running the activate.d script fails because of an invalid path in the activation script. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: add option to globally disable jit for better debugging (Relates to #196) It's harder to debug jitted functions than non-jitted functions, since it's essentially impossible to introspect their intermediate state. One option is to comment out the jit decorator, but then you have to remember to put it back when you're done debugging. It'd be nice to have a mechanism (maybe a context manager?) to globally disable jitting for debugging purposes; once bugs are fixed, you don't have to reinsert all of your @jit statements. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Objects of files() may be ambiguous When files are specified using files(), their subdirectories aren't added as a prefix to their object file names, and all are output to the same output directory. As a result, if two different subdirectories have files with the same name, a conflict will follow. For example, the following fails with `Multiple producers for Ninja target \"a.out@exe/file.c.o\". Please rename your targets.`: ```sh #!/bin/sh mkdir -p dir1 dir2 echo \"int main() { return 0; }\" > dir1/file.c echo \"sources += files('file.c')\" > dir1/meson.build touch dir2/file.c echo \"sources += files('file.c')\" > dir2/meson.build cat >meson.build <<EOF project('proj', 'c') sources = [] subdir('dir1') subdir('dir2') executable('a.out', sources: sources) EOF meson build ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [trainer] add distributed_env to TrainingArguments As discussed in https://github.com/huggingface/transformers/pull/8823 it's not simple to check whether the downstream code is running under distributed mode or not (currently requires checking `self.args.local_rank != -1` which is far from obvious. So we were discussing about adding a flag like `distributed_env` so that the downstream code could do a much simpler intuitive check. I'm not sure whether we need just True/False for ddp or whether we also need to have another flag if we are under DP as well? @sgugger Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: New GPT2 tokenizer no longer encodes Unicode characters properly in Python 3 In commit 5afa497cbfc53c679a9b22997b6312fad57ee2f8, you changed `token.encode('utf-8')` to simply `token`. This would make the code compatible with Python 2, but now it breaks in Python 3. You'll get a KeyError when you try to encode a Unicode character that requires more than 1 byte in UTF-8 encoding. For example, this raises a KeyError in Python 3: ```python from pytorch_pretrained_bert.tokenization_gpt2 import GPT2Tokenizer tokenizer = GPT2Tokenizer.from_pretrained('gpt2') tokenizer.encode('你') ``` I think what you want to do is: ```python if sys.version_info[0] == 2: token = ''.join(self.byte_encoder[ord(b)] for b in token) else: token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8')) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Inconsistent casting of floats with jit compilation. ``` def mul(R, c): return R * c R = np.array([1, 2, 3], dtype=np.float32) c = 0.1 print(mul(R, c).dtype) # Evaluates to np.float32 as expected. print(jit(mul)(R, c).dtype) # Evaluates to np.float64. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Bug in masked array boolean comparison in Numpy 1.15.3 An issue was introduced in Numpy 1.15.3 compared to Numpy 1.15.2 which results in comparisons of masked arrays crashing (this has broken some functionality over at astropy - e.g. https://github.com/astropy/astropy/issues/7943) This is likely due to https://github.com/numpy/numpy/pull/12237 ### Reproducing code example: **Expected (Numpy 1.15.2)** ```python >>> (np.ma.array(['A', 'B', 'C'], fill_value='N') == 'A') | (np.ma.array(['A', 'B', 'C'], fill_value='N') == 'A') masked_array(data=[ True, False, False], mask=False, fill_value='N') ``` (arguably this was wrong too since fill_value should have been a bool, but at least it didn't crash) **Actual (Numpy 1.15.3)**: ```python >>> (np.ma.array(['A', 'B', 'C'], fill_value='N') == 'A') | (np.ma.array(['A', 'B', 'C'], fill_value='N') == 'A') Traceback (most recent call last): File \"<stdin>\", line 1, in <module> File \"/Users/tom/miniconda3/envs/np1153/lib/python3.6/site-packages/numpy/ma/core.py\", line 3016, in __array_finalize__ self._fill_value = _check_fill_value(self._fill_value, self.dtype) File \"/Users/tom/miniconda3/envs/np1153/lib/python3.6/site-packages/numpy/ma/core.py\", line 476, in _check_fill_value fill_value = np.array(fill_value, copy=False, dtype=ndtype) ValueError: invalid literal for int() with base 10: 'N' ``` ### Numpy/Python version information: Python 3.6, Numpy 1.15.3 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Explicitly construct C3X and C4X in MCXGrayCode <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: latest GitHub code - **Python version**: N/A - **Operating system**: N/A ### What is the current behavior? The docstring of the `MCXGate` constructor says \"creates an explicit CX, CCX, C3X or C4X instance or a generic MCX gate\", however it explicitly creates CX and CCX only. ### Steps to reproduce the problem N/A ### What is the expected behavior? Create C3X and C4X gates explicitly as well. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: gradients through np.where when one of branches is nan, #347 except with arctan2 I have come across an issue that I think is almost identical to #347, except with arctan2. Here's a repro: ``` def test(a): b = np.arctan2(a,a) print(b) temp = np.array([0.,1.,0.]) c = np.where(temp>0.5,0.,b) print(c) return np.sum(c) aa = np.array([3.,0.,-5.]) print(test(aa)) print(grad(test)(aa)) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Unnecessary copying of read-only arrays negates benefit of BLAS saxpy BLAS saxpy provides a substantial improvement over the native numpy equivalent but any improvement is lost when _input_ x is marked read-only: ### Reproduction ```python import scipy.linalg.blas, numpy as np, mkl mkl.set_num_threads(1) size = 100*1000**2 y = np.zeros(size, dtype=np.float32) x = np.ones_like(y) a = 0.1 # blas: 10 loops, best of 3: 75.3 ms per loop scipy.linalg.blas.saxpy(x, y, a=a) # numpy: 1 loop, best of 3: 202 ms per loop y += x * a ``` However when x is read-only saxpy is no faster than numpy as f2py makes a copy of x: ```python x.setflags(write=False) # blas: 1 loop, best of 3: 210 ms per loop scipy.linalg.blas.saxpy(x, y, a=a) # numpy: 1 loop, best of 3: 206 ms per loop y += x * a ``` ### Root cause The copy is made as this test of layout order fails for read-only arrays: https://github.com/numpy/numpy/blob/master/numpy/f2py/src/fortranobject.c#L737. The test is calling: ```c #define PyArray_ISFARRAY(m) PyArray_FLAGSWAP(m, NPY_ARRAY_FARRAY) ``` But those flags test for a writable arrays: ```c #define NPY_ARRAY_BEHAVED (NPY_ARRAY_ALIGNED | NPY_ARRAY_WRITEABLE) ... #define NPY_ARRAY_FARRAY (NPY_ARRAY_F_CONTIGUOUS | NPY_ARRAY_BEHAVED) ``` Arguments marked intent(in) should instead check array flags against NPY_ARRAY_FARRAY_RO to avoid this unnecessary copy: ```c #define NPY_ARRAY_FARRAY_RO (NPY_ARRAY_F_CONTIGUOUS | NPY_ARRAY_ALIGNED) ``` [1] x is readonly in our use-case as we wrap a network buffer using np.frombuffer(str). It's no longer possible to force this writable due to change https://github.com/numpy/numpy/pull/11739. ### Numpy/Python version information: numpy 1.16.5 python 3.7.5 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Multiple package ID compatibility model There are some frictions while declaring compatibility between packages: - In one hand, you can declare with the package_id that a package, for example, gcc8 is compatible with gcc7. That causes that both of them will have the same package_id - On the other hand you really want to distinguish between packages from gcc8 and gcc7. POC here: https://github.com/conan-io/conan/pull/5837 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: Can't clear all upstream tasks when DAG Serialization is enabled **Apache Airflow version**: 1.10.10 **To Reproduce** Steps to reproduce the behavior with Astronomer Image: 1. Enable DAG Serialization (Put `AIRFLOW__CORE__STORE_SERIALIZED_DAGS=True` Once the Webserver boots up, run any DAG 1. Once the DAG completes execution, click on the task that has few upstream tasks in Graph View 1. One the **Task Instance Modal**, select **Upstream** -> click on **Clear**. You will see a list of tasks but that would not have all the upstream tasks. **Screenshots**  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BUG: exp and log cast float16 to float32 <!-- Please describe the issue in detail here, and fill in the fields below --> After #13134 is merged, `np.exp` and `np.log` return float32 arrays for float16 inputs. Is the change intended? I could not find docs for it (https://www.numpy.org/devdocs/reference/generated/numpy.exp.html), while it is documented that `np.sum` casts ints to the default platform integer. ### Reproducing code example: <!-- A short code example that reproduces the problem/missing feature. It should be self-contained, i.e., possible to run as-is via 'python myproblem.py' --> ```python import numpy as np print(np.exp(np.array([1, 2], np.float16)).dtype) # => float32 print(np.log(np.array([1, 2], np.float16)).dtype) # => float32 ``` <!-- Remove these sections for a feature request --> <!-- ### Error message: --> <!-- If you are reporting a segfault please include a GDB traceback, which you can generate by following https://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging --> <!-- Full error message, if any (starting from line Traceback: ...) --> ### Numpy/Python version information: <!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' --> ``` 1.17.0.dev0+64b3e67 3.7.1 (default, Nov 6 2018, 21:02:07) [Clang 10.0.0 (clang-1000.10.44.4)] ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Port Datastore onto GAPIC ### What Port the gRPC code path for Datastore onto GAPIC. The package is available [here](https://pypi.python.org/pypi/gapic-google-cloud-datastore-v1). ### Why This is not a beta-blocker, since there already is gRPC code for Datastore, but it is preferred. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Issues with the JSON created by conan create Conan version: 1.2.0 Command: `conan create --json ./foo.json . myteam/unstable` The generated JSON does not separate the dependency packages of the built project, from the built package. This makes it difficult to parse. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Allow inheritance of QuantumRegister and ClassicalRegister Attempting to inherit from QuantumRegister or ClassicalRegister currently causes type errors in `instruction.py`'s constructor. There may be other areas that require updates to make this functionality viable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: GraphState circuit depth excedingly high using optimization_levels 2 & 3 <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: latest - **Python version**: - **Operating system**: ### What is the current behavior? The following graph state fits exactly on the device (72 CX), but `optimization_level` 2 or 3 transpiles it to ~950 CX gates: ```python backend = pro.get_backend('ibmq_manhattan') config = backend.configuration() rows = [x[0] for x in config.coupling_map] cols = [x[1] for x in config.coupling_map] A = np.zeros((65, 65)) A[rows, cols] = 1 qc = qiskit.circuit.library.GraphState(A) qc.measure_all() trans_qc = transpile(qc, backend, optimization_level=3) ``` ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: 'BertForSequenceClassification' is not defined 'DUMMY_INPUTS' is not defined transformers-2.1.1 https://github.com/huggingface/transformers#quick-tour-tf-20-training-and-pytorch-interoperability i just copied and paste and run the code. it showed ``` NameError: name 'BertForSequenceClassification' is not defined ``` i can't even ``` from transformers import BertForSequenceClassification ``` ``` --------------------------------------------------------------------------- ImportError Traceback (most recent call last) <ipython-input-27-7a027f32a339> in <module> ----> 1 from transformers import BertForSequenceClassification ImportError: cannot import name 'BertForSequenceClassification' from 'transformers' ``` 'BertForSequenceClassification' is not defined 'DUMMY_INPUTS' is not defined transformers-2.1.1 https://github.com/huggingface/transformers#quick-tour-tf-20-training-and-pytorch-interoperability i just copied and paste and run the code. it showed ``` NameError: name 'BertForSequenceClassification' is not defined ``` i can't even ``` from transformers import BertForSequenceClassification ``` ``` --------------------------------------------------------------------------- ImportError Traceback (most recent call last) <ipython-input-27-7a027f32a339> in <module> ----> 1 from transformers import BertForSequenceClassification ImportError: cannot import name 'BertForSequenceClassification' from 'transformers' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Support a query over an external data source / federated data source Bigquery supports running queries over csv files, but I don't see this option in this bigquery api. See https://cloud.google.com/bigquery/external-data-sources and https://cloud.google.com/bigquery/external-data-cloud-storage I see example for reading csv files into a table, but I would rather not have to manage creating and deleting temporary tables. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: D: -D flag gets ignored with ldc2 **Describe the bug** When building with ldc2, `-D`, `-Dd`, or `-Df` flags are not parsed (these flags are related to documentation). It seems to be introduced by [this PR](https://github.com/mesonbuild/meson/commit/efea48788ab29c45a83f6a50d39fd7d0689f5f0e) that ignores every `-D*` flag. **To Reproduce** Use ldc2 compiler with `-D` as global argument. **Expected behavior** Documentation is generated as well as binaries. **system parameters** * `python3 --version` --> ` Python 3.9.2` * what `meson --version` --> `0.62.99` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: Eager mode hides serialization side-effects Running a task in eager mode doesn't pass the arguments through serialization, and therefore hides some of its side-effects. For example, calling a celery task in eager mode with UUID arguments, will leave them as UUIDs, whereas passing them through serialization (with eager mode switched off) converts them to strings. This hid a bunch of bugs in our application code. Do you agree it would be more reasonable to pass the arguments through the serialization backends, even in eager mode, to have a more consistently behaving API? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Autocall fails if first function argument begins with \"-\" or \"+ Original Launchpad bug 315706: https://bugs.launchpad.net/ipython/+bug/315706 Reported by: dmuders (Dirk Muders). Auto parentheses fail if the first argument of a function begins with \"-\" or \"+\". Thus these examples fail: ``` %autocall 2 def f(a): print a f -1 f +1 ``` The reason is the re_exclude_auto in prefilter.py which reads ``` re_exclude_auto = re.compile(r'^[,&^\\|\\*/\\+-]' r'|^is |^not |^in |^and |^or ') ``` in v0.9.1. It appears that this line had been changed at some point after v0.6.2 to also catch operators. However, \"-\" and \"+\" can be used with numbers as shown above. Changing the line to ``` re_exclude_auto = re.compile(r'^[,&^\\|\\*/]' r'|^is |^not |^in |^and |^or ') ``` fixes the problem but I do not know if something else was intended by adding \"+-\". If so, then this would need to be caught in a different way. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: `circuit.draw(idle_wires=False)` should ignore barrier There is an option to the circuit drawers for not plotting qubits that are idle - this is useful for visualizing small circuits that happen to be embedded on large devices. However a barrier on a qubit is seen as a sign of non-idleness. I think barriers should just be ignored as they are not operations. And barriers on all device qubits gets inserted by the transpiler, so it makes this option useless until the drawer can ignore it. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: 🔥[Community Event] Doc Tests Sprint - Configuration files🔥 This sprint is similar to #16292 - but for model **configuration files**, i.e. `configuration_[model_name].py`. For example, `src/transformers/models/bert/configuration_bert.py` # The expected changes The changes we expect could be find #19485: 1. **Change the import order of the model and configuration classes** 2. **Add `(with random weights)` in the comment before model initialization line** 3. **Add `configuration_[model_name].py` to `utils/documentation_tests.txt`** (respecting the order) Please do step 3. only after **Running the doctest and make sure all tests pass** (see below) 🙏 # How to run doctests Suppose you are working on `src/transformers/models/bert/configuration_bert.py`. The steps to run the test are: 0. **Stage your changes** ```bash git add src/transformers/models/bert/configuration_bert.py ``` 1. **Prepare the files to be tested** ```python python utils/prepare_for_doc_test.py src ``` or if you prefer to be more specific ```python python utils/prepare_for_doc_test.py src/transformers/models/bert/configuration_bert.py ``` This will change some files (doc-testing needs to add additional lines that we don't include in the doc source files). 2. **Launch the test:** ```python python -m pytest --doctest-modules src/transformers/models/bert/configuration_bert.py -sv --doctest-continue-on-failure ``` 3. **Cleanup git status** ```bash git checkout -- . ``` to clean up the changes in step 1. # Ready (or not)? If all tests pass, you can commit, push and open a PR 🔥 🚀 , otherwise iterate the above steps 💯 ! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Document Storage.Blob setter for metadata Hi! Based on other methods that have a getter and setter for example [bucket.cors](https://googlecloudplatform.github.io/google-cloud-python/stable/storage/buckets.html#google.cloud.storage.bucket.Bucket.cors). I have a request to document the metadata setter found [here](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/ffd7cca2c1bbcf71b753913eab4d95ec0ca04f8a/storage/google/cloud/storage/blob.py#L1408) to documentation found [here]( https://googlecloudplatform.github.io/google-cloud-python/stable/storage/blobs.html#google.cloud.storage.blob.Blob.metadata). Thank you! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Run full validation epoch before training ## ❓ Questions and Help #### What is your question? How can I manually trigger a full validation step before training? I want to compute and log the validation metrics before I start the training (ideally also updating the progress bar dictionary). The reason why I want to do this is that I am fine-tuning a pre-trained model, and I want to check the performances before training. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the dagster-io/dagster codebase. Here's the problem: Maximum recursion depth exceeded when non partitioned asset depends on asset with self dependency ### Dagster version 1.1.9 ### What's the issue? The following asset setup: ```py @asset( partitions_def=HourlyPartitionsDefinition(start_date=\"2023-01-01-00:00\"), ins={ \"hourly_depends_on_past\": AssetIn( partition_mapping=TimeWindowPartitionMapping(start_offset=-1, end_offset=-1) ) } ) def hourly_depends_on_past(hourly_depends_on_past): time.sleep(3) return 1 @asset def non_partitioned(hourly_depends_on_past): time.sleep(30) return 1 ``` Produces the following error message in the dagit UI when loaded: ``` Operation name: AssetGraphLiveQuery Message: maximum recursion depth exceeded Path: [\"assetNodes\",1,\"projectedLogicalVersion\"] Locations: [{\"line\":41,\"column\":3}] ``` ### What did you expect to happen? Expected the two assets to be able to not produce an error when viewing in Dagit ### How to reproduce? _No response_ ### Deployment type Local ### Deployment details _No response_ ### Additional information _No response_ ### Message from the maintainers Impacted by this issue? Give it a 👍! We factor engagement into prioritization. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Raise error if no RUNNER token is provided to agent ## Description If an agent is started without a token (e.g. `prefect agent start` without `--token`) it will default to using the `cloud.agent.auth_token` (RUNNER) in config https://github.com/PrefectHQ/prefect/blob/master/src/prefect/agent/agent.py#L39. If that is not set then an empty string is passed into the Client initialization and in the case of a provided empty token it defaults to `cloud.auth_token` (USER) token https://github.com/PrefectHQ/prefect/blob/master/src/prefect/client/client.py#L86. This was allowing the state to be updated to `Submitted` in cloud but upon creating the job the RUNNER token was once again asked for https://github.com/PrefectHQ/prefect/blob/master/src/prefect/agent/local/agent.py#L82 in populating the config for the job. This was throwing a `Malformed Authorization header` because the header that was provided was an empty Bearer. ## Expected Behavior The agent should raise an error on start if it does not have a RUNNER token. ## Reproduction Run the Local Agent without a token and run a flow :) ## Environment N/A cc @bnaul @cicdw Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Removed compiled_circuit_qasm from QobjExperimentalHeader <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? After #1629 when all the backends are Qobj 1.0 compatible we need to remove compiled_circuit_qasm from the header. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Serialize methods and closures IPython+Pickle can't serialize class methods. ``` Python >>> from IPython.parallel import Client >>> view = Client()[:] >>> view.map(str.split, ['hello world', 'foo bar']) PicklingError: Can't pickle <type 'method_descriptor'>: attribute lookup __builtin__.method_descriptor failed ``` IPython+Pickle can't serialze closures ``` Python /home/mrocklin/Software/anaconda/lib/python2.7/site-packages/IPython/utils/codeutil.pyc in reduce_code(co) 32 def reduce_code(co): 33 if co.co_freevars or co.co_cellvars: ---> 34 raise ValueError(\"Sorry, cannot pickle code objects with closures\") 35 args = [co.co_argcount, co.co_nlocals, co.co_stacksize, 36 co.co_flags, co.co_code, co.co_consts, co.co_names, ValueError: Sorry, cannot pickle code objects with closures ``` The `dill` project (CC @mmckerns) _can_ serialize code in both of these cases. Is there a way to leverage `dill` here? One somewhat hacky option would be to fall back on `pickle` rather than `cPickle` in case of failure. Dill is able to register its serialization routines with the pure Python implementation. ``` Python In [1]: import pickle In [2]: pickle.dumps(str.split) TypeError: can't pickle method_descriptor objects In [3]: import dill In [4]: pickle.dumps(str.split) # Note: still using pickle interface Out[4]: 'cdill.dill\\n_getattr\\np0\\n(cdill.dill\\n_load_type\\np1\\n(S\\'StringType\\'\\np2\\ntp3\\nRp4\\nS\\'split\\'\\np5\\nS\"<method \\'split\\' of \\'str\\' objects>\"\\np6\\ntp7\\nRp8\\n.' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Add ability to use isolation with build In Windows there is no way to build a container that requires specification of the isolation option. If the default isolation is process(which is the default for docker), and I want to build an image based on a downlevel container then the build needs to get passed isolation=hyperv . I see two options. 1. Have build inherit the isolation setting from the service. 2. Add isolation into the build args. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: BLD: Regression: improper double quotes appear in rpath (linux) ### Steps to reproduce the problem: I've observed a regression on RH7 when installing numpy (currently v1.16.0) with ```bash pip install numpy --force-reinstall --ignore-installed --no-binary :all: ``` Until now I had no problem with python 3.6.5 (and previous) and with earlier versions of numpy (v1.14.3), now I observe the following issue (python 3.7.2, and even python 3.6.5) with numpy 1.16.0. I fill `~/site.cfg` with information where to find lapack and blas libraries ```ini [lapack] lapack_libs = lapack language = gfortran library_dirs = /some/path/rh7/lapack/3.6.1/lib runtime_library_dirs = /some/path/rh7/lapack/3.6.1/lib [blas] blas_libs = blas,cblas language = gfortran library_dirs = /some/path/rh7/lapack/3.6.1/lib runtime_library_dirs = /some/path/rh7/lapack/3.6.1/lib ``` ### Observed problem: When I run `ldd` on the produced `numpy/linalg/lapack_lite.cpython-*m-x86_64-linux-gnu.so`, `liblapack.so`, `libblas.so` and `libblas.so` aren't found. When I ask `readelf -d numpy/linalg/lapack_lite.cpython-*m-x86_64-linux-gnu.so | grep rpath`, I see ``` 0x000000000000000f (RPATH) Library rpath: [\"/some/path/rh7/lapack/3.6.1/lib\"] ``` instead of ``` 0x000000000000000f (RPATH) Library rpath: [/some/path/rh7/lapack/3.6.1/lib] ``` that I had with previous versions of numpy. Removing the double-quotes with `chrpath` fixes the issue. ### Numpy/Python version information: Numpy 1.16.0 (according to `pip -v`) Python 1.6.5 and 1.7.2 No trouble with Numpy 1.14.3 (and earlier versions) and Python 1.6.5 (and earlier versions) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: mintro: AttributeError: 'str' object has no attribute 'subdir' Running this in [Mesa](/mesa3d/mesa) breaks meson: ``` $ meson -v 0.44.0 $ meson introspect --target-files egd_tables.h@cus Traceback (most recent call last): File \"/usr/bin/meson\", line 37, in <module> sys.exit(main()) File \"/usr/bin/meson\", line 34, in main return mesonmain.run(sys.argv[1:], launcher) File \"/usr/lib/python3.6/site-packages/mesonbuild/mesonmain.py\", line 297, in run return mintro.run(remaining_args) File \"/usr/lib/python3.6/site-packages/mesonbuild/mintro.py\", line 236, in run list_target_files(options.target_files, coredata, builddata) File \"/usr/lib/python3.6/site-packages/mesonbuild/mintro.py\", line 118, in list_target_files sources = [os.path.join(i.subdir, i.fname) for i in sources] File \"/usr/lib/python3.6/site-packages/mesonbuild/mintro.py\", line 118, in <listcomp> sources = [os.path.join(i.subdir, i.fname) for i in sources] AttributeError: 'str' object has no attribute 'subdir' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: group_texts function produces batches with length shorter than block_size ### System Info - `transformers` version: 4.28.1 - Platform: Linux-3.10.0-1160.76.1.el7.x86_64-x86_64-with-glibc2.17 - Python version: 3.10.0 - Huggingface_hub version: 0.14.1 - Safetensors version: not installed - PyTorch version (GPU?): 1.12.1+cu102 (False) - Tensorflow version (GPU?): not installed (NA) - Flax version (CPU?/GPU?/TPU?): not installed (NA) - Jax version: not installed - JaxLib version: not installed - Using GPU in script?: Yes - Using distributed or parallel set-up in script?: No ### Who can help? _No response_ ### Information - [X] The official example scripts - [ ] My own modified scripts ### Tasks - [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below) ### Reproduction There's a bug in the PyTorch language_modeling examples: for example: [run_clm.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py) The `group_texts` function is supposed to group the data into batches of equal sizes to `block_size`, and to ignore the small remainder chunk. There's a bug and instead, it inserts the last batch with a smaller size, which creates an error, as the model takes in data with equal sequence length. ## Error: ValueError: expected sequence of length 128 at dim 1 (got 94) ### Expected behavior The expected behavior is for the function to return data with equal sequence lengths for all batches. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Wrong help description for profile parameter in conan profile To help us debug your issue please explain: - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Conan version 1.0.3 In: ``` $ conan profile show -h usage: conan profile show [-h] profile positional arguments: profile name of the profile optional arguments: -h, --help show this help message and exit ``` The profile parameter could be a path to a profile instead of just a name of the profile in the deafult profile folder. Fix help message for all profile sub-commands that can accept a profile path as profile argument. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Cannot build ipython 4.0.3 with setuptools 18.2 I was just updating [a bunch of Python packages](https://github.com/NixOS/nixpkgs/pull/12552) for Nix, when I get the following error when building ipython 4.0.3: ``` error in ipython setup command: Invalid environment marker: sys_platform == \"darwin\" and platform_python_implementation == \"CPython\" ``` Now I'm not familiar with these markers but I can imagine it is related to the pip 8.0.2 update. The error occurs with all Python versions. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Please support array_contains in queries `array_contains` is supported in most other languages (Python and Ruby are holdouts) : https://firebase.google.com/docs/firestore/query-data/queries#array_membership Is there a timeframe for when this might become available for Python? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: 'install_folder' attribute is not always set To reproduce, take https://github.com/memsharded/conan-hello example with one addition: ```python def package(self): print(\"self.source_folder:\", self.source_folder) print(\"self.build_folder:\", self.build_folder) print(\"self.install_folder:\", self.install_folder) ... ``` now package it: ``` conan create . dbely/testing ``` everything goes well, with the output ``` Hello/0.1@dbely/testing: Calling package() self.source_folder: C:\\Users\\dbely\\.conan\\data\\Hello\\0.1\\dbely\\testing\\build\\6cc50b139b9c3d27b3e9042d5f5372d327b3a9f7 self.build_folder: C:\\Users\\dbely\\.conan\\data\\Hello\\0.1\\dbely\\testing\\build\\6cc50b139b9c3d27b3e9042d5f5372d327b3a9f7 self.install_folder: C:\\Users\\dbely\\.conan\\data\\Hello\\0.1\\dbely\\testing\\build\\6cc50b139b9c3d27b3e9042d5f5372d327b3a9f7 ``` Now do it step by step: ``` conan source . conan install . conan build . conan package . ``` All the commands succeed except the last one: ``` PROJECT: Calling package() self.source_folder: C:\\Users\\dbely\\conan\\conan-hello.git self.build_folder: C:\\Users\\dbely\\conan\\conan-hello.git ERROR: Hello/0.1@PROJECT: Error in package() method, line 21 print(\"self.install_folder:\", self.install_folder) AttributeError: 'HelloConan' object has no attribute 'install_folder' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: '_implicit_environ.compute_engine_id()' may raise I just saw this while running tests: ``` ERROR: test_set_explicit_None_wo_env_var_set (gcloud.datastore.test___init__.Test_set_default_dataset_id) ---------------------------------------------------------------------- Traceback (most recent call last): File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/gcloud/datastore/test___init__.py\", line 71, in test_set_explicit_None_wo_env_var_set self._callFUT(None) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/gcloud/datastore/test___init__.py\", line 31, in _callFUT return set_default_dataset_id(dataset_id=dataset_id) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/gcloud/datastore/__init__.py\", line 91, in set_default_dataset_id dataset_id = _implicit_environ.compute_engine_id() File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/gcloud/datastore/_implicit_environ.py\", line 73, in compute_engine_id response, content = http.request(uri, method='GET', headers=headers) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/.tox/cover/lib/python2.7/site-packages/httplib2/__init__.py\", line 1593, in request (response, content) = self._request(conn, authority, uri, request_uri, method, body, headers, redirections, cachekey) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/.tox/cover/lib/python2.7/site-packages/httplib2/__init__.py\", line 1335, in _request (response, content) = self._conn_request(conn, request_uri, method, body, headers) File \"/home/tseaver/projects/agendaless/Google/src/gcloud-python/.tox/cover/lib/python2.7/site-packages/httplib2/__init__.py\", line 1291, in _conn_request response = conn.getresponse() File \"/opt/Python-2.7.9/lib/python2.7/httplib.py\", line 1061, in getresponse raise ResponseNotReady() ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Review Android variables and document the new libcxx The purpose of this issue is to create a new PR with the small revisions on PR #4538: - Rename `CONAN_CMAKE_ANDROID_NDK_HOME` to `CONAN_CMAKE_ANDROID_NDK` to follow the same name as in CMake: https://cmake.org/cmake/help/v3.7/manual/cmake-toolchains.7.html#cross-compiling-for-android - Check if `CMAKE_SYSTEM_NAME` is Android before adjusting anything. - Move code setting CMake vairables to ``def _cmake_cross_build_defines()`` - Remove unneeded imports - Document settings of libcxx: ``c++_shared``, ``c++_static`` - Document ``CONAN_CMAKE_ANDROID_NDK`` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: BigQuery: jobs created with run_async_query() and run with begin() ignores flag dry_run=True The aim is to be able to dry run the queries to check how much it would cost us before we actually proceed with it. Hopefully we will be able to use it as a safety mechanism. I hope I am not misunderstanding the availability of the `dry_run` parameter as [listed on the docs](https://googlecloudplatform.github.io/google-cloud-python/stable/bigquery-job.html#google.cloud.bigquery.job.QueryJob.dry_run). I have set it, and it appears on the configs, **but it runs anyway**. 1. Ubuntu 14.04 2. Python 2.7.6 3. google-cloud-python version ``` google-api-python-client==1.5.5 google-auth==0.5.0 google-auth-httplib2==0.0.2 google-cloud-bigquery==0.22.0 google-cloud-core==0.22.1 google-cloud-storage==0.22.0 googleapis-common-protos==1.5.0 ``` 4. Stacktrace if available NIL 5. Steps to reproduce - create job with run_async_query() - set job.dry_run = True - run it with job.begin() - examine job when it is done 6. Code example ``` job = client.run_async_query(JOB_NAME, QUERY_STRING) job.dry_run = True job.begin() print job.__dict__ ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Early Stopping kicks in at min_epochs + 2 instead of min_epochs ### Describe the bug I was working on a fix for #524 and found that early stopping starts to kick in at epoch 3 despite min_epochs = 1. #### To Reproduce run basic_examples/gpu_template.py and log the callback calls every epoch. #### Expected behavior When setting min_epochs=n (counting from 1), we should evaluate early stopping at the end of epoch n. #### Proposed fix: I propose to change [this](https://github.com/williamFalcon/pytorch-lightning/blob/58cc6e13b9999161a526b83063c983750e6553b1/pytorch_lightning/trainer/training_loop.py#L322) line in the training loop: `met_min_epochs = epoch > self.min_epochs` to `met_min_epochs = epoch >= self.min_epochs - 1` - Why the \"-1\"? The `epoch` variable in the training loop starts at 0, but the Trainer argument `min_epochs` starts counting at 1. - Why the \">=\"? The early stop check is done at the end of each epoch, hence the `epoch` counter will be = to `min_epochs` after `min_epochs` have passed. Desktop (please complete the following information): - OS: Linux - Version: master Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Default arguments of clm example are confusing I was having a look at the `run_clm.py` script and which new arguments are available to push to the hub. ```sh python transformers\\examples\\pytorch\\language-modeling\\run_clm.py -h ``` I see the following options (note the True defaults for all): ``` --no_keep_linebreaks Whether to keep line breaks when using TXT files or not. (default: True) --keep_linebreaks [KEEP_LINEBREAKS] Whether to keep line breaks when using TXT files or not. (default: True) --no_dataloader_pin_memory Whether or not to pin memory for DataLoader. (default: True) --dataloader_pin_memory [DATALOADER_PIN_MEMORY] Whether or not to pin memory for DataLoader. (default: True) --no_skip_memory_metrics Whether or not to skip adding of memory profiler reports to metrics. (default: True) --skip_memory_metrics [SKIP_MEMORY_METRICS] Whether or not to skip adding of memory profiler reports to metrics. (default: True) ``` From this, I cannot figure out what the default behaviour is or what I should change to become the expected behavior. I do not know what the use case is for this but it seems much better to only keep one of each option. If one the two for each option is deprecated, then that could be added in the description too. I'm on current master (4.12 dev). ### Who can help @sgugger, @patil-suraj Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: add lax.pswapaxes pxla translation Needed by @thenerdstation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: Python 3.5 failing with AttributeError: module 'os' has no attribute 'PathLike' This morning our builds started to fail as soon we moved to 3.1.15. I seems that 3.1.15 makes use of os.PathLike that was introduced in python 3.6. From README.md seems that Python 3.5 is still supported. ``` REQUIREMENTS GitPython needs the git executable to be installed on the system and available in your PATH for most operations. If it is not in your PATH, you can help GitPython find it by setting the GIT_PYTHON_GIT_EXECUTABLE=<path/to/git> environment variable. Git (1.7.x or newer) Python >= 3.5 ``` ``` class os.PathLike An abstract base class for objects representing a file system path, e.g. pathlib.PurePath. New in version 3.6. ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: np.histogram erroneously emit warning when density=False As seen in https://travis-ci.org/ejeschke/ginga/jobs/395720074 . The actual code in Ginga calling histogram is: ```python # get image histogram hist, bins = numpy.histogram(some_array, hashsize, density=False) ``` Note that `normed` was not used. However, it caused this warning in Numpy ~~dev~~ prerelease: ```python else: if normed is not None: # 2018-06-13, numpy 1.15.0 (this was not noisily deprecated in 1.6) warnings.warn( \"Passing normed=False is deprecated, and has no effect. \" \"Consider passing the density argument instead.\", > DeprecationWarning, stacklevel=2) E DeprecationWarning: Passing normed=False is deprecated, and has no effect. Consider passing the density argument instead. ``` I think this is caused by #11352 . When `density=False`, it goes into the logic block that forces `normed=False`, which resulted in it going into this logic block in `np.histogram()`: ```python else: if normed is not None: ... ``` cc @ejeschke Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: hidden exception during job submission <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? If the API encounters an exception during job submission before a job is actually submitted to the server IBMQJob._future.result() returns None but self._future_captured_exception is not raised. Instead 'error' is checked for in None which raises a different exception and hides the root one inside IBMQuantumExperience. ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions raise self._future_captured_exception for this case Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the apache/airflow codebase. Here's the problem: BigQueryGetDataOperator does not support passing project_id ### Apache Airflow Provider(s) google ### Versions of Apache Airflow Providers apache-airflow-providers-google==8.3.0 ### Apache Airflow version 2.3.2 ### Operating System MacOS ### Deployment Other ### Deployment details _No response_ ### What happened Can not actively pass project_id as an argument when using `BigQueryGetDataOperator`. This operator internally fallbacks into `default` project id. ### What you think should happen instead Should let developers pass project_id when needed ### How to reproduce _No response_ ### Anything else _No response_ ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: prune unused names from parallel.error <del>The error classes defined in parallel.error have no real reason to be defined separately from the core, and their presence elsewhere can cause shenanigans to be required if they are used in core, as in #2043.</del> parallel.error is a leftover from the old kernel code, and should probably be aggressively pruned of unused exception classes <del>when they are merged into core.error</del>. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Documentation for inputs to an Estimator instance disagree with implementation ### Environment - **Qiskit Terra version**: 0.37.1 ### What is happening? The documentation in [BaseEstimator](https://github.com/Qiskit/qiskit-terra/blob/c318725d679b0eb3aa8874fb9755fa0567c5e94b/qiskit/primitives/base_estimator.py#L114) says that when calling an instance four arguments are supplied. The third and fourth are parameters and parameter values. But the implementation and the example are different. They take only three arguments. Parameter values are passed, but not parameters. Instead, in the call method, the parameters are retrieved from the circuit. The above is in the file for `BaseEstimator`, but the doc string and example contained therein refer to `Estimator`. It appears online in the API reference section. ### How can we reproduce the issue? Read the source ### What should happen? Documented interface should agree with implementation. ### Any suggestions? _No response_ Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: set_tracking_branch fails quietly when .git/config contains an include I have git-branchless setup in this repository and for the longest time I was confounded, why `set_tracking_branch` did not work (anymore). Turns out, git-branchless adds an `[include]` section to the `.git/config` file and this causes GitPython to quietly skip writing the config changes back that are necessary for `set_tracking_branch` to have any effect. Could we maybe set `merge_includes=False` for the config_writer; at least in the Head class? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: [GPT-J] where expected condition to be a boolean tensor, but got a tensor with dtype Half ### System Info - `transformers` version: 4.28.1 - Platform: Linux-5.10.147+-x86_64-with-glibc2.31 - Python version: 3.10.11 - Huggingface_hub version: 0.14.1 - Safetensors version: not installed - PyTorch version (GPU?): 2.0.0+cu118 (True) - Tensorflow version (GPU?): 2.12.0 (True) - Flax version (CPU?/GPU?/TPU?): 0.6.9 (gpu) - Jax version: 0.4.8 - JaxLib version: 0.4.7 - Using GPU in script?: yes - Using distributed or parallel set-up in script?: no ### Who can help? @younesbelkada ### Information - [ ] The official example scripts - [X] My own modified scripts ### Tasks - [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below) ### Reproduction Collab example - [Link](https://colab.research.google.com/drive/1D689vHxZk5Bov5piIXOQ62t3M_cim4dr?usp=sharing) ### Expected behavior I expected some output generated from the model Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: cc.has_header assumes header can be included by itself Not all headers can be included directly; sometimes they require a specific define, and especially on Windows a lot of headers (such as `GL/wglext.h`) require including `windows.h`. We should allow specifying a prefix to verify the usability of a header. This might also be useful for people who want to detect the correct prefixes necessary to make a header usable. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Enable Publish from Windows We should support publishing from a Windows machine. We ran into https://bugs.python.org/issue31226 when trying to publish 1.0.0. For dev_mode, we should have a `clean:node` command that removes all node_modules. This should be called before trying to create the `sdist` if on Windows: https://github.com/jupyterlab/jupyterlab/blob/e2fd4c8841a7393f9131fb6b6e8252864a8bd351/buildutils/src/publish.ts#L53. We can refactor the logic [here](https://github.com/jupyterlab/jupyterlab/blob/master/clean.py#L8) used for `clean:slate` into a node module that also calls `rmdir` in a child_process. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker run --isolation parameter not available `docker run` has a parameter [--isolation](https://docs.docker.com/engine/reference/commandline/run/#/specify-isolation-technology-for-container-isolation) that can be used to set additional isolation modes when running Docker containers. For example, `docker run --isolation=hyperv` is commonly used on Windows with Hyper-V. Given that most of the other run options are already supported such as `security_opt` and `privileged`, I think it makes sense that `isolation` should be there too. Here's an example of how I would like to use it in docker-compose.yml: ``` none version: '2' services: sql: image: windowsservercore tty: true stdin_open: true # isolation: 'hyperv' web: image: windowsservercore tty: true stdin_open: true # isolation: 'hyperv' networks: default: external: name: nat ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: docker-compose fails if using secrets file ## Environment ``` $ docker --version Docker version 1.13.1, build 092cba3 $ docker-compose --version docker-compose version 1.11.1, build 7c5d5e4 ``` ## Steps to reproduce ``` $ ls docker-compose.yml my_file_secret.txt $ cat my_file_secret.txt This is a file secret. $ cat docker-compose.yml version: '3.1' services: a: image: tutum/hello-world b: image: tutum/hello-world secrets: - my_file_secret secrets: my_file_secret: file: my_file_secret.txt ``` ``` $ docker-compose up Traceback (most recent call last): File \"docker-compose\", line 3, in <module> File \"compose/cli/main.py\", line 88, in main File \"compose/cli/main.py\", line 137, in perform_command File \"compose/cli/command.py\", line 36, in project_from_options File \"compose/cli/command.py\", line 115, in get_project File \"compose/project.py\", line 110, in from_config File \"compose/project.py\", line 566, in get_secrets AttributeError: 'str' object has no attribute 'source' Failed to execute script docker-compose ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Extra return line in environment.py Just a little error. :cat2: There's an extra return in: https://github.com/mesonbuild/meson/blob/5d9a1558c2e1041b1149fca6b2bceba447b6823e/mesonbuild/environment.py#L761-L766 Which is a duplicate of the return in the if block directly above: https://github.com/mesonbuild/meson/blob/5d9a1558c2e1041b1149fca6b2bceba447b6823e/mesonbuild/environment.py#L752-L760 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Basis gate decomposition success depends on knowing internal implimentation details ### What should we add? Consider the following simple circuit: ```python qc = QuantumCircuit(1) qc.y(0) ``` I should be able to decompose this into the following: ``` ┌────────┐┌───┐ q: ┤ Rz(-π) ├┤ X ├ └────────┘└───┘ ``` However, using the `rz` and `x` basis in the transpiler fails: ```python transpile(qc, basis_gates=['rz', 'x']) ``` ``` Unable to translate the operations in the circuit: ['y'] to the backend's (or manually specified) target basis: ['reset', 'delay', 'x', 'snapshot', 'rz', 'barrier', 'measure'] ``` In order to work around this, I one needs to know about the internals of how the gate equivalence works. Namely that adding an `sx` gate that is used as an intermediary will yield the correct decomposition, and the above circuit: ```python transpile(qc, basis_gates=['rz', 'sx', 'x']) ``` It would be nice if the success of the decomposition did not rely on understanding internal implementation issues. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the jupyterlab/jupyterlab codebase. Here's the problem: Disabling Plugins only works on one at a time ```bash $ jupyter labextension list JupyterLab v0.28.11 Known labextensions: app dir: /Users/ssilvester/anaconda/share/jupyter/lab @jupyter-widgets/jupyterlab-manager @jupyter-widgets/jupyterlab-manager v0.29.3 enabled OK @jupyterlab/google-drive @jupyterlab/google-drive v0.7.0 enabled OK $ jupyter labextension disable @jupyter-widgets/jupyterlab-manager $ jupyter labextension list JupyterLab v0.28.11 Known labextensions: app dir: /Users/ssilvester/anaconda/share/jupyter/lab @jupyter-widgets/jupyterlab-manager @jupyter-widgets/jupyterlab-manager v0.29.3 disabled OK @jupyterlab/google-drive @jupyterlab/google-drive v0.7.0 enabled OK $ jupyter labextension disable @jupyterlab/google-drive $ jupyter labextension list JupyterLab v0.28.11 Known labextensions: app dir: /Users/ssilvester/anaconda/share/jupyter/lab @jupyter-widgets/jupyterlab-manager @jupyter-widgets/jupyterlab-manager v0.29.3 enabled OK @jupyterlab/google-drive @jupyterlab/google-drive v0.7.0 disabled OK ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: can't use parallel.Reference in view.map This is due to the more conservative serialization not walking down into containers for canning/uncanning. Works: ``` view.apply_sync(lambda x:x, parallel.Reference('a')) ``` Doesn't work: ``` view.map_sync(lambda x:x, [parallel.Reference('a')]) ``` Or, for that matter: ``` view.apply_sync(lambda x:x, [parallel.Reference('a')]) ``` for the same reason: because the _list itself_ is canned, and not its contents. I think I can rework things a little bit so that it will dive exactly one level down, which would catch this case, and any other first-level containers of special objects, while still avoiding arbitrary inspection of nested containers. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: datastore.get() requires a list See http://googlecloudplatform.github.io/gcloud-python/ The snippet is: ``` python from gcloud import datastore datastore.set_defaults() product_key = datastore.Key('Product', 123) print datastore.get([product_key]) ``` I'd expect it to be: ``` python from gcloud import datastore product_key = datastore.Key('Product', 123) product = datastore.get(product_key) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: updated %quickref to show short-hand for %sc and %sx I updated the %quickref to show the ! and !! short-hand for %sc and %sx to make it more obvious, otherwise people may not realize there is a short-hand unless they look deeper into the documentation. Also, I edited the original one-line description to be shorter (but hopefully still grammatically correct) so that it will fit properly within 80-column output. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: remove the folder wrappers (post 0.7) <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? After 0.7 we don't this folder anymore. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: display_* not respected if _repr_mimebundle_ defined. See https://github.com/ipython/ipython/pull/10496#issuecomment-300641192  Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: qobj_to_circuits not using the compiled qasm in the qobj header <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? ### Steps to reproduce the problem ### What is the expected behavior? ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: repo.continuum.io is transitioning to repo.anaconda.com There is currently no plan to stop service at repo.continuum.io. However, at some point in the distant future, repo.continuum.io might redirect to repo.anaconda.com. This issue tracks the change for the `defaults` channel urls from repo.continuum.io to repo.anaconda.com. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: Customizing hparams after loading checkpoint ## ❓ Questions and Help ### Before asking: 1. search the issues. 2. search the docs. #### What is your question? I'm wondering what the best practice for loading a model with different hparams than what is stored in the checkpoint? I realize I could just load the model and set them afterwards e.g.: ``` model = model.load_from_checkpoint(args.checkpoint_file) # Load model # Set hparams etc.. model.hparams.arg1 = 0.0 model.hparams.arg2 = 1.0 ``` But the problem is that my model __init__ function depends on the hparams arg1 and arg2 so they're set too late. I could also do ``` checkpoint = torch.load(args.checkpoint_file) checkpoint['hparams']['arg1'] = 0.0 checkpoint['hparams']['arg2'] = 1.0 model = model._load_state_dict(checkpoint) ``` The problem here is that i'm using the protected function _load_state_dict. Is there another way of solving this that i've missed? Or could we consider making _load_state_dict public? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Add documentation on how to delete a property from a datastore entity Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Source link in doc of `printoptions` goes to contextlib The source link in [the documentation of the new `printoptions` context manager](https://docs.scipy.org/doc/numpy/reference/generated/numpy.printoptions.html?highlight=printoption) has the wrong link target: it goes to the invalid ``` http://github.com/anaconda3/lib/python3.6/contextlib.py#L281-L311 ``` Seems like an issue with the link auto-generation machinery, maybe even with other decorated functions? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: python3.3: Type error when launching SGE cluster in IPython notebook IPython13.2: Launching a cluster configured for SGE use caused a type error stating that you cannot apply a regular expression to a byte sequence (that apparently was the result of some shell level command). Unfortunately, the exact message got lost. Workaround: Change ib/python3.3/site-packages/ipython-0.13.2-py3.3.egg/IPython/parallel/apps/launcher.py a follows: def parse_job_id(self, output): \"\"\"Take the output of the submit command and return the job id.\"\"\" output=output.decode('UTF8') ... I guess that python3.3 issues like these lurk in many places where the result of a shell command (usually a byte string) is combined somehow with a python3.3 (unicode) string. Georg Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: replace param with params in the code <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. --> ### What is the expected behavior? There are many places in the code where it has a variable param which we should replace with params. This issue just notes that we should change this. This is a follow on from #1634 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: conda info --json and package lookup If you set the `--json` flag for `conda info` when searching for packages, you sometimes get nothing: ``` bash $ conda info numpy=1.11.0=py35_0 Fetching package metadata: .... numpy 1.11.0 py35_0 ------------------- file name : numpy-1.11.0-py35_0.tar.bz2 name : numpy version : 1.11.0 build number: 0 build string: py35_0 channel : defaults size : 6.1 MB date : 2016-03-28 license : BSD md5 : 1900998c19c5e310687013f95374bba2 installed environments: dependencies: mkl 11.3.1 python 3.5* $ conda info --json numpy=1.11.0=py35_0 {} ``` Things work fine for `conda info --json numpy`, so it's something with the spec format. conda info: ``` platform : linux-64 conda version : 4.0.5 conda-build version : not installed python version : 2.7.11.final.0 requests version : 2.9.1 root environment : /opt/conda (writable) default environment : /opt/conda envs directories : /opt/conda/envs package cache : /opt/conda/pkgs channel URLs : https://repo.continuum.io/pkgs/free/linux-64/ https://repo.continuum.io/pkgs/free/noarch/ https://repo.continuum.io/pkgs/pro/linux-64/ https://repo.continuum.io/pkgs/pro/noarch/ config file : None is foreign system : False ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: Non interactive mode also prevents prompt from `conan user` The new non interactive mode also prevents the prompt from `conan user <name> -p`. This is not what is specified in the documentation. (And also not what was originally implemented.) I hope the prompt can be re-enabled for this particular case. If not, the documentation should be changed. Oh, and a purely cosmetic remark: the non interactive error only appears after the prompt has been displayed. Using Conan 1.2 on Windows 7. - [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md). - [x] I've specified the Conan version, operating system version and any tool that can be relevant. - [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Include MathJax by default or access the CDN over a secure connection IPython Notebook loads MathJax over an insecure connection by default. Code running within the IPython Notebook can, by design, execute code on the user's system. This leaves users vulnerable to MITM attacks. Possible fixes (that I can think of): - Always access the MathJax CDN over a secure connection (it support HTTPS). - Custom loader which verifies the code against a local checksum (this would protect against a compromised CDN, but has some obvious disadvantages like complexity or the need to maintain a list of checksums). - Ship local MathJax sources (undesirable because it's ~43MB?). Related: CVE-2014-3429 / https://github.com/ipython/ipython/pull/4845 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Include \"execution_time\" or \"execution_date\" in context For flow runs, both local and cloud runs should include \"execution_time\" (or something similarly named) into context. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the numpy/numpy codebase. Here's the problem: Copy and deepcopy of np.ma.masked returns np.ma.array() I would expect that copy or deepcopy of `np.ma.masked` would give me the same object, but this doesn't appear to be the case: ``` In [9]: copy.deepcopy(np.ma.masked) Out[9]: masked_array(data=--, mask=True, fill_value=1e+20, dtype=float64) In [10]: copy.copy(np.ma.masked) Out[10]: masked_array(data=--, mask=True, fill_value=1e+20, dtype=float64) In [11]: type(copy.deepcopy(np.ma.masked)) Out[11]: numpy.ma.core.MaskedArray In [12]: type(np.ma.masked) Out[12]: numpy.ma.core.MaskedConstant In [13]: np.__version__ Out[13]: '1.14.2' ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: AvgPool does only work as global average pooling ```python3 from jax.experimental import stax import jax.numpy as np init_fn, apply_fun = stax.AvgPool((2, 2), strides=(2, 2)) output_shape, params = init_fn((-1, 32, 32, 3)) print(output_shape) print(params) apply_fun(params, np.zeros((100, 32, 32, 3))) ``` This should work but instead it fails with this error: ``` (-1, 16, 16, 3) () Traceback (most recent call last): File \"minimal_example.py\", line 9, in <module> apply_fun(params, np.zeros((100, 32, 32, 3))) File \"/gpfs01/bethge/home/jrauber/PhD/063_jax/jax/jax/experimental/stax.py\", line 172, in apply_fun return rescale(out, inputs) if rescale else out File \"/gpfs01/bethge/home/jrauber/PhD/063_jax/jax/jax/experimental/stax.py\", line 183, in rescale return outputs / window_sizes File \"/gpfs01/bethge/home/jrauber/PhD/063_jax/jax/jax/numpy/lax_numpy.py\", line 350, in true_divide x1, x2 = _promote_shapes(x1, x2) File \"/gpfs01/bethge/home/jrauber/PhD/063_jax/jax/jax/numpy/lax_numpy.py\", line 134, in _promote_shapes nd = len(_broadcast_shapes(*shapes)) File \"/gpfs01/bethge/home/jrauber/PhD/063_jax/jax/jax/util.py\", line 161, in memoized_fun ans = cache[key] = fun(*args, **kwargs) File \"/gpfs01/bethge/home/jrauber/PhD/063_jax/jax/jax/numpy/lax_numpy.py\", line 151, in _broadcast_shapes .format(tuple(map(tuple, shapes)))) ValueError: Incompatible shapes for broadcasting: ((100, 16, 16, 3), (1, 1, 16, 16)) ``` Note that it also doesn't work if stride is 1. The only case in which `AvgPool` works seems to be if stride is 1 and the pooling size is identical to the input size (i.e. global average pooling). `MaxPool` seems to work fine. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Support \"cpp_std=c++20\" for Windows Visual Studio backend **Describe the bug** Since [Visual Studio 2019 v16.11](https://docs.microsoft.com/en-us/cpp/build/reference/std-specify-language-standard-version?view=msvc-160#c-standards-support), it supports C++20 standard. However, when using \"cpp_std=c++20\", I get error: Value \"c++20\" (of type \"string\") for combo option \"C++ language standard to use\" is not one of the choices. Possible choices are (as string): \"none\", \"c++11\", \"vc++11\", \"c++14\", \"c++latest\", \"vc++latest\", \"vc++14\", \"c++17\", \"vc++17\". **To Reproduce** meson.build: ``` project( 'my_project', 'cpp', default_options : ['cpp_std=c++latest'] ) ``` **Expected behavior** `meson builddir` should complete without error **system parameters** * Is this a [cross build](https://mesonbuild.com/Cross-compilation.html) or just a plain native build (for the same computer)? No * what operating system (e.g. MacOS Catalina, Windows 10, CentOS 8.0, Ubuntu 18.04, etc.): Windows 10 * what Python version are you using e.g. 3.8.0: 3.9.7 * what `meson --version`: 0.59.1 * what `ninja --version` if it's a Ninja build: 1.10.2 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add Swin2SR ### Model description Swin2SR is a Swinv2-based model for image super resolution and compression. ### Open source status - [X] The model implementation is available - [X] The model weights are available ### Provide useful links for the implementation https://github.com/mv-lab/swin2sr Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: IPython 5.0 deprecates but still uses utils.io.IOStream Resulting in unavoidable self-referencing deprecation warnings. We should either remove/limit the warnings, or actually stop using them. io.IOStream is deprecated in 5.0, but is still used in a few places: - [Terminal]InteractiveShell.init_io - testing.globalipapp Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: python dependency causes warnings when compiling with msvc Hi, When compiling with msvc on windows, the python dependency emits a warning about a macro redefinition, starting with 1.0.2: https://cirrus-ci.com/task/6721555284099072?logs=build#L1512 ``` [04:38:28.590] [1498/2168] Compiling C object src/pl/plpython/plpython3.dll.p/plpy_elog.c.obj [04:38:28.590] C:\\python\\Include\\pyconfig.h(117): warning C4005: 'MS_WIN64': macro redefinition [04:38:28.590] src/pl/plpython/plpython3.dll.p/meson_pch-c.c: note: see previous definition of 'MS_WIN64' ``` This is due to 91c336449561a68f5624692d3c894f2345e466a2 / 81a8c488f007e842e83aa16ba941877250430a15 (in the 1.0 branch). Even before 3.12 pyconfig.h defined MS_WIN64, just only when using msvc: https://github.com/python/cpython/blob/aae91fa63c65745c4118eafca0088447d87e65b0/PC/pyconfig.h#L104-L114 Seems that either this needs to be restricted to !msvc, or needs to check if MS_WIN64 is defined by pyconfig.h? CC: @eli-schwartz Regards, Andres Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: bfloat16 support Add support for `bfloat16`. Bfloat16 is supported by XLA and valuable on TPUs in particular. There is a numpy `bfloat16` extension in the TF source tree that we can leverage: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/lib/core/bfloat16.cc (although it supports a fairly limited set of operations.) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Compiler base options ('b_lundef', 'b_asneeded', etc) are not always valid for the cross-compiler Have `-Wl,--no-undefined` and `-Wl,--as-needed` any meaning when cross-comliling? In case of cross-compilation linker can't check for this correctly, I'm wrong? I'm asking because cross-compiler to macosx ([osxcross](https://github.com/tpoechtrager/osxcross)) does not support these options, and I'm unsure is this bug of that toolchain, or bug of meson? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Performance regression in unrolling and circuit_to_instruction <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: Master - **Python version**: any - **Operating system**: Any ### What is the current behavior? Since #4622 unrolling during transpilation and the `circuit_to_instruction()` have regressed in run time performance. The benchmarking machine shows this pretty clearly: https://qiskit.github.io/qiskit/#passes.PassBenchmarks.time_unroller?machine=dedicated-benchmarking-softlayer-baremetal&os=Linux%204.15.0-46-generic&ram=16GB&p-n_qubits=14&p-depth=1024&commits=e265409a https://qiskit.github.io/qiskit/#passes.PassBenchmarks.time_unroll_3q_or_more?machine=qiskit-benchmarking&os=Ubuntu%2018.04&ram=16%20GB&p-n_qubits=20&p-depth=1024&commits=e265409a https://qiskit.github.io/qiskit/#converters.ConverterBenchmarks.time_circuit_to_instruction?machine=dedicated-benchmarking-softlayer-baremetal&os=Linux%204.15.0-46-generic&ram=16GB&p-n_qubits=5&p-depth=8192&commits=e265409a ### Steps to reproduce the problem Run any of the affected functions. ### What is the expected behavior? There is no performance regression ### Suggested solutions Fix the performance issue introduced. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: circuit.measure_all() and circuit.remove_final_measures() It is a very common occurrence that a user wants to get the ideal statevector for a circuit, but also send it to a device to get counts. I'm seeing a lot of functions around (Ignis for example) that generate instances of `qc` and `qc_m` for these cases. I think the QuantumCircuit class should have a simple method (`circuit.measure_all()`) that measures all qubits. (This would add a new ClassicalRegister to the circuit). We probably also want a `measure_active()` to measure only non-idle qubits, because in some cases we don't want all the extra 0s that get measured. In addition we may also consider a `circuit.remove_final_measurements()` that does the opposite. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: Pyside2 5.15 seems to break --gui qt on mac Just a heads up, I think pyside2 5.15.0 may be breaking IPython GUI event loop integration. ``` conda create -n test python=3.8 conda activate test pip install ipython pyside2==5.15 ipython --gui qt # cannot type anything into the interpreter! pip install pyside==5.14.2 ipython --gui qt # works again ``` tested on two different macs: 10.15.4 and 10.13.6 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the docker/compose codebase. Here's the problem: Pressing ctrl-C twice to force kill no longer works It used to do this: ``` ^CGracefully stopping... (press Ctrl+C again to force) Stopping composedemo_web_1... ^CKilling composedemo_web_1... Killing composedemo_redis_1... ``` This now doesn't seem to work: ``` ^CGracefully stopping... (press Ctrl+C again to force) composedemo_web_1: Stopping... composedemo_redis_1: Stopped ^C^C^C^C^C^C^C^C^C^C% ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conan-io/conan codebase. Here's the problem: [bug] 'cmake' generator does not set INTERFACE_LINK_DIRECTORIES ### Environment Details (include every applicable attribute) * Conan version: 1.46.0 ### Steps to reproduce (Include if Applicable) The error surfaced when trying to consume `boost` with option `magic_autolink=True`. This option causes the link library list to be empty. Instead the boost headers include `#pragma comment` statements to select the libraries to link against. For this approach to work the libraries need to be found by the compiler. Here are the locations for both cmake generators ([cmake](https://github.com/conan-io/conan/blob/e98a7590b544e738fdb927678d34821ccb78ad78/conans/client/generators/cmake_common.py#L166) and [cmake_find_package](https://github.com/conan-io/conan/blob/8f7ac4306cdf7fc4536728b07457b20895be0023/conans/client/generators/cmake_find_package.py#L179)). The latter correctly sets the `INTERFACE_LINK_DIRECTORIES` variable while the former is missing that part. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Lightning-AI/lightning codebase. Here's the problem: CI: Add type checking Related to #855 add type check in CI Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: Cuda Tests fail when werror=true When building a project containing cuda code, if the default_options are set to have werror=true, the build fails with ```sh File \"/usr/local/lib/python3.6/dist-packages/meson-0.49.999-py3.6.egg/mesonbuild/backend/backends.py\", line 569, in generate_basic_compiler_args commands += compiler.get_werror_args() AttributeError: 'CudaCompiler' object has no attribute 'get_werror_args' ``` This can be seen in the tests, particularly `test cases/cuda/1 simple` I am running off `627d0d1f3e`. Thank you. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the celery/celery codebase. Here's the problem: test_retry_kwargs_can_be_empty fails on pypy3 From https://travis-ci.org/celery/celery/jobs/151613800: ``` ====================================================================== ERROR: test_retry_kwargs_can_be_empty (celery.tests.tasks.test_tasks.test_task_retries) ---------------------------------------------------------------------- Traceback (most recent call last): File \"/home/travis/build/celery/celery/celery/tests/tasks/test_tasks.py\", line 178, in test_retry_kwargs_can_be_empty self.retry_task_mockapply.retry(args=[4, 4], kwargs=None) File \"/home/travis/build/celery/celery/celery/app/task.py\", line 611, in retry raise_with_context(exc or Retry('Task can be retried', None)) File \"/home/travis/build/celery/celery/celery/utils/serialization.py\", line 255, in raise_with_context _raise_with_context(exc, exc_info[1]) File \"<string>\", line 1, in _raise_with_context TypeError: exception causes must derive from BaseException, not NoneType ``` https://github.com/celery/celery/blob/5031d6f27862001d3e3bc5a2dacf1185c933f2c9/celery/tests/tasks/test_tasks.py#L169 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: License header for qiskit/tools/apps/optimization.py <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Informations After merging #724, the license header for `qiskit/tools/apps/optimization.py` has been reverted to \"old\" one - was this on purpose? @ajavadia , @nonhermitian can you comment and take action if appropiate? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: kernel crash when showing tooltip (?) I originally posted this as a pandas bug, but realized this must be on the IPython side. More details are at https://github.com/pydata/pandas/issues/960 Basic repro on IPython 0.12 with pandas 0.7.1 or 0.7.2 is ``` import pandas pandas.DataFrame.reindex( ``` kernel crashes when you open the parenthesis on reindex. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the mesonbuild/meson codebase. Here's the problem: pkgconfig: `dataonly` files should be installed in `datadir`/pkgconfig **Describe the bug** Since `dataonly` pkg-config files are architecture-independent they [should](https://refspecs.linuxfoundation.org/FHS_3.0/fhs/ch04s11.html) get installed in `datadir`/pkgconfig, and not `libdir`/pkgconfig **To Reproduce** ```meson project('dataonly.pc') import('pkgconfig').generate( name: 'dataonly', dataonly: true, description: 'Should be in $prefix/share/pkgconfig' ) ``` ```sh $ tree install_prefix install_prefix └── lib └── x86_64-linux-gnu └── pkgconfig └── dataonly.pc ``` **Expected behavior** The .pc file should get installed in $prefix/share/pkgconfig **system parameters** * Build type: native * OS: Debian Testing * Python version: 3.9.10 * Meson version: 0.61.1 * Ninja version: 1.10.1 Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: CmdDef unittest has wrong argument <!-- ⚠️ If you do not respect this template, your issue will be closed --> <!-- ⚠️ Make sure to browse the opened and closed issues --> ### Information - **Qiskit Terra version**: - **Python version**: - **Operating system**: ### What is the current behavior? cmd_def test specifies a string value `'0'` instead of int/float/complex value for a parameter. https://github.com/Qiskit/qiskit-terra/blob/7f01b8bae8fa05de47e9eb4dcaa5a0154df2bd72/test/python/pulse/test_cmd_def.py#L86 ### Steps to reproduce the problem ### What is the expected behavior? argument should be int, float or complex. ### Suggested solutions Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the gitpython-developers/GitPython codebase. Here's the problem: repo.index.diff(\"HEAD\", create_patch=True) always empty I am using GitPython v2.1.11 with Python 3.6. My git version is 2.17.1. I see inconsistent behavior of the diff method of a repo index if create_patch option set to True. I am running the following script in a git repository with staged and unstaged changes. ```python from git import Repo repo = Repo(\".\") print(repo.index.diff(\"HEAD\")) print(repo.index.diff(\"HEAD\", create_patch=True)) # Problem here print(repo.index.diff(None)) print(repo.index.diff(None, create_patch=True)) ``` But it prints: ``` [<git.diff.Diff object at 0x7fd54c328678>, <git.diff.Diff object at 0x7fd549e405e8>, <git.diff.Diff object at 0x7fd54c328558>] [] [<git.diff.Diff object at 0x7fd54c328678>] [<git.diff.Diff object at 0x7fd54c328678>] ``` Somehow, the diff is empty if I set `create_patch` to True and the first argument to anything but `None`. Do you know why it happens ? Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: Use cached_inputs whenever available Right now, I believe cached_inputs are only used if: 1) a state with `cached_inputs` is provided to the `FlowRunner` 2) AND the task is set as a `start_task` OR 3) a state with `cached_inputs` is loaded from cloud and specially-handled. I propose that the pipeline step which currently creates the `task_inputs` dict should be adjusted to use any `cached_inputs` found on the task's current [pending] state. This would be regardless of whether the task was a `start_task` or not, and remove the need for any special casing elsewhere Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the ipython/ipython codebase. Here's the problem: curious behavior on Ijulia on IPython3.0b1 on windows Hi, Trying `Pkg.`+`<Tab>` on a cell of a IJulia notebook, I can select `build` in the dropdown window, but when I validate it, only `build`remains in my cell (instead of `Pkg.build`) (on Firefox as on Chrome) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: Implement vmap/batching support for LU decomposition I'm trying to solve linear equations Ax = b with vmap: ```python import jax.numpy as np import jax.random as random from jax import vmap key = random.PRNGKey(0) A = random.normal(key, shape=(100, 2, 2)) x = random.normal(key, shape=(100, 2)) b = vmap(lambda A, x: A @ x)(A, x) # works! shape (100, 2) x_hat = vmap(lambda A, x: np.linalg.solve(A, x))(A, x) ``` Here, using `np.linalg.solve` results in the following error message: ``` NotImplementedError: Batching rule for 'lu' not implemented ``` Opening this issue to request batching support for LU decomposition. Thanks in advance! Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the conda/conda codebase. Here's the problem: Conda should automatically add binstar tokens to urls if the user is logged in to binstar @asmeurer here is an example code snippet to detect if a user is logged in. ``` from binstar_client.utils import get_binstar bs = get_binstar() print bs.token if bs.token: print \"You are logged in to binstar. Your token is\", bs.token ``` Also, as a side consideration with the new on-site installs of binstar. The user may not be logged into https://binstar.org. To check this you can do: ``` bs.domain == 'https://api.binstar.org' ``` For our on-site clients, you may want to use this domain as the base url for shorthand binstar channels. The following would be great for on-site binstar clients. When a user does `conda config --add channels my_channel` The binstar url should be the onsite binstar IP address, not binstar.org This can be done with the code snippet: ``` binstar_url_prefix = bs.domain.replace('api', 'conda') ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the PrefectHQ/prefect codebase. Here's the problem: flow.update(flow) doesn't maintain mapped edges ``` from prefect import task, Flow, Parameter @task def add_one(x): return x + 1 @task def printit(p): print(p) with Flow(\"Test Flow\") as test_flow: test_list = Parameter(\"test_list\") add_one_list = add_one.map(test_list) printit(add_one_list) with Flow(\"Second Test\") as second_test_flow: second_test_flow.update(test_flow) test_flow.run(test_list=[1, 2, 3]) second_test_flow.run(test_list=[1, 2, 3]) ``` In this example, the `second_test_flow.run` will fail with the following error in the `add_one` task: ``` Unexpected error: TypeError('can only concatenate list (not \"int\") to list') ``` Is this the intended effect? If not, it should be fixable by updating `add_edge` call in `Flow.update` [here](https://github.com/PrefectHQ/prefect/blob/cfb186a4e6fb387e610d35cb530d10f4032f2da2/src/prefect/core/flow.py#L547-L552) to: ``` self.add_edge( upstream_task=edge.upstream_task, downstream_task=edge.downstream_task, key=edge.key, mapped=edge.mapped, validate=validate, ) ``` Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Avoid deleting blob when it's renamed to itself An issue was encountered where the new name for a blob was expected to differ from the existing name and the object was being deleted as a result of the copy-then-delete strategy. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the googleapis/google-cloud-python codebase. Here's the problem: Job.type is referenced throughout bigquery-usage but is not implemented From #1397 /cc @ollikaven Job.job_id is populated before job creation in bigquery-usage The [`job_id`](https://github.com/GoogleCloudPlatform/gcloud-python/blob/ffe5869aa7c31bd82483e4d52adacbf83cf0fd69/gcloud/bigquery/job.py#L150-L156) property uses the `_properties` returned from the server. It seems the original intent was a `uuid.uuid4()` on instance creation. Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the google/jax codebase. Here's the problem: bug in shape-checking rules for the case of fori_loop The following three loops should all give the same results but the lax.fori_loop throws an error. Could be related to #1681 import jax.numpy as np from jax.lax import fori_loop as fori_loop_jax def fori_loop_python(lower, upper, body_fun, init_val): val = init_val for i in range(lower, upper): val = body_fun(i, val) return val def body_fun(i,arr): a,b = arr return a-b[i]*b[i+1], b s = np.ones([10,10]) r = s.shape[1]-1 E = 0 for i in range(r): E -= s[:, i] * s[:, i + 1] print(E) E, _ = fori_loop_python(0, s.shape[0]-1, body_fun, (0,s)) print(E) E, _ = fori_loop_jax(0, r, body_fun, (0,s))[0] print(E) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the Qiskit/qiskit codebase. Here's the problem: Quantum shannon decomposition failing for some inputs ### Environment - **Qiskit Terra version**: 0.42.1 - **Python version**: 3.10.8 ### What is happening? qs_decomposition in [qsd.py](https://github.com/Qiskit/qiskit-terra/blob/main/qiskit/quantum_info/synthesis/qsd.py) throws an error for some examples, seemingly due to a bug in the code ### How can we reproduce the issue? ``` from qiskit.quantum_info.synthesis.qsd import qs_decomposition qs_decomposition(np.array([[0,1],[1,0]])) ``` Output: ``` Traceback (most recent call last): Cell In[14], line 3 qs_decomposition(np.array([[0,1],[1,0]])) File /opt/conda/lib/python3.10/site-packages/qiskit/quantum_info/synthesis/qsd.py:122 in qs_decomposition return _apply_a2(circ) File /opt/conda/lib/python3.10/site-packages/qiskit/quantum_info/synthesis/qsd.py:253 in _apply_a2 qc3 = two_qubit_decompose.two_qubit_cnot_decompose(mat2) UnboundLocalError: local variable 'mat2' referenced before assignment Use %tb to get the full traceback. ``` Alternatively, ``` qs_decomposition(qiskit.quantum_info.random_unitary(4).to_matrix()) ``` Giving the same error ### What should happen? We should still be able to produce a decomposed circuit from these examples ### Any suggestions? This seems to occur when line 233 of qsd.py in the function ‘_apply_a2()’ does not transpile to include any of the ‘qsd2q’ gate type for an instance. To fix this add something such as the following before the loop on line 242: ``` if not ind2q: return ccirc ``` Additionally should add a test for this kind of case to the [test](https://github.com/Qiskit/qiskit-terra/blob/main/test/python/quantum_info/test_synthesis.py) Can you help me debug this systematically and explain your reasoning?"}]}
|
|||
|
|
{"conversation": [{"role": "system", "content": "You are an expert software debugging assistant. Help debug issues by analyzing problems systematically and providing clear, step-by-step reasoning."}, {"role": "user", "content": "I'm having an issue with the huggingface/transformers codebase. Here's the problem: Add warning message if model uses `input_ids` that include padding tokens, but no `attention_mask` is provided. ## **First good issue** A current error is that a user forwards a batched tensor of `input_ids` that include a padding token, e.g. ```input_ids = torch.tensor([[\"hello\", \"this\", \"is\", \"a\", \"long\", \"string\"], [\"hello\", \"<pad>\", \"<pad>\", \"<pad>\", \"<pad>\"]]``` In this case, the `attention_mask` should be provided as well. Otherwise the output hidden_states will be incorrectly computed. This is quite a common silent error IMO. With @LysandreJik @sgugger, we have decided to not **automatically** create the `attention_mask` that masks out the padding tokens in this case because of the reasons explains here: https://github.com/huggingface/transformers/issues/15479#issuecomment-1066639938 . However as pointed out in https://github.com/huggingface/transformers/issues/15479, we should IMO at least displa a warning since this error happens a lot IMO. As a first good issue, one could add such a warning to the BertModel in a first case which would go something like: ```py if attention_mask is not None and (input_ids == pad_token_id).any(): logger.warn(\"display nice warning here....\") ``` What do you think @sgugger @LysandreJik ? Can you help me debug this systematically and explain your reasoning?"}]}
|